
metadata
language: en
tags:
- SEGA
- data augmentation
- keywords-to-text generation
- sketch-to-text generation
license: apache-2.0
datasets:
- c4
widget:
- text: >-
<mask> Conference on Empirical Methods <mask> submission of research
papers <mask> Deep Learning <mask>
example_title: Example 1
- text: >-
<mask> machine learning <mask> my research interest <mask> data science
<mask>
example_title: Example 2
- text: >-
<mask> play basketball <mask> a strong team <mask> Shanghai University of
Finance and Economics <mask> last Sunday <mask>
example_title: Example 3
- text: >-
Good news: <mask> the European Union <mask> month by EU <mask> Farm
Commissioner Franz <mask>
example_title: Example with a prompt 1
- text: >-
Bad news: <mask> the European Union <mask> month by EU <mask> Farm
Commissioner Franz <mask>
example_title: Example with a prompt 2
inference:
parameters:
max_length: 200
num_beams: 3
do_sample: true
SEGA-large model
SEGA: SkEtch-based Generative Augmentation
基于草稿的生成式增强模型
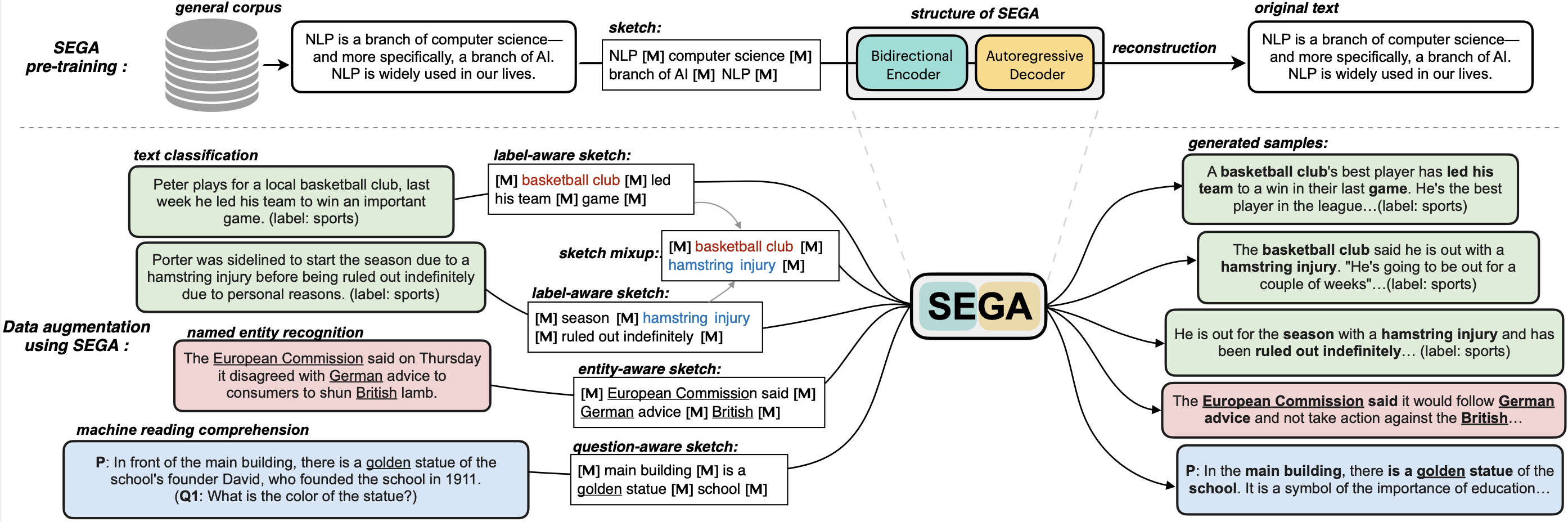
SEGA is a general text augmentation model that can be used for data augmentation for various NLP tasks (including sentiment analysis, topic classification, NER, and QA). SEGA uses an encoder-decoder structure (based on the BART architecture) and is pre-trained on the C4-realnewslike corpus.
- Paper: coming soon
- GitHub: SEGA.
SEGA is able to write complete paragraphs given a sketch, which can be composed of:
- keywords /key-phrases, like "––NLP––AI––computer––science––"
- spans, like "Conference on Empirical Methods––submission of research papers––"
- sentences, like "I really like machine learning––I work at Google since last year––"
- or mixup~
Model variations:
| Model | #params | Language | comment |
|---|---|---|---|
sega-large |
406M | English | The version used in paper |
sega-large-k2t |
406M | English | keywords-to-text |
sega-base |
139M | English | smaller version |
sega-base-ps |
139M | English | pre-trained both in paragraphs and short sentences |
sega-base-chinese |
116M | 中文 | 在一千万纯净中文段落上预训练 |
How to use
1. If you want to generate sentences given a sketch
from transformers import pipeline
# 1. load the model with the huggingface `pipeline`
sega = pipeline("text2text-generation", model='beyond/sega-large', device=0)
# 2. provide a sketch (joint by <mask> tokens)
sketch = "<mask> Conference on Empirical Methods <mask> submission of research papers <mask> Deep Learning <mask>"
# 3. just do it!
generated_text = sega(sketch, num_beams=3, do_sample=True, max_length=200)[0]['generated_text']
print(generated_text)
Output:
'The Conference on Empirical Methods welcomes the submission of research papers. Abstracts should be in the form of a paper or presentation. Please submit abstracts to the following email address: eemml.stanford.edu. The conference will be held at Stanford University on April 1618, 2019. The theme of the conference is Deep Learning.'
2. If you want to do data augmentation to generate new training samples
Please Check our Github page: github.com/beyondguo/SEGA, where we provide ready-to-run scripts for data augmentation for text classification/NER/MRC tasks.
SEGA as A Strong Data Augmentation Tool:
- Setting: Low-resource setting, where only n={50,100,200,500,1000} labeled samples are available for training. The below results are the average of all training sizes.
- Datasets: HuffPost, BBC, SST2, IMDB, Yahoo, 20NG.
- Base classifier: DistilBERT
In-distribution (ID) evaluations:
| Method | Huff | BBC | Yahoo | 20NG | IMDB | SST2 | avg. |
|---|---|---|---|---|---|---|---|
| none | 79.17 | 96.16 | 45.77 | 46.67 | 77.87 | 76.67 | 70.39 |
| EDA | 79.20 | 95.11 | 45.10 | 46.15 | 77.88 | 75.52 | 69.83 |
| BackT | 80.48 | 95.28 | 46.10 | 46.61 | 78.35 | 76.96 | 70.63 |
| MLM | 80.04 | 96.07 | 45.35 | 46.53 | 75.73 | 76.61 | 70.06 |
| C-MLM | 80.60 | 96.13 | 45.40 | 46.36 | 77.31 | 76.91 | 70.45 |
| LAMBADA | 81.46 | 93.74 | 50.49 | 47.72 | 78.22 | 78.31 | 71.66 |
| STA | 80.74 | 95.64 | 46.96 | 47.27 | 77.88 | 77.80 | 71.05 |
| SEGA | 81.43 | 95.74 | 49.60 | 50.38 | 80.16 | 78.82 | 72.68 |
| SEGA-f | 81.82 | 95.99 | 50.42 | 50.81 | 79.40 | 80.57 | 73.17 |
Out-of-distribution (OOD) evaluations:
| Huff->BBC | BBC->Huff | IMDB->SST2 | SST2->IMDB | avg. | |
|---|---|---|---|---|---|
| none | 62.32 | 62.00 | 74.37 | 73.11 | 67.95 |
| EDA | 67.48 | 58.92 | 75.83 | 69.42 | 67.91 |
| BackT | 67.75 | 63.10 | 75.91 | 72.19 | 69.74 |
| MLM | 66.80 | 65.39 | 73.66 | 73.06 | 69.73 |
| C-MLM | 64.94 | 67.80 | 74.98 | 71.78 | 69.87 |
| LAMBADA | 68.57 | 52.79 | 75.24 | 76.04 | 68.16 |
| STA | 69.31 | 64.82 | 74.72 | 73.62 | 70.61 |
| SEGA | 74.87 | 66.85 | 76.02 | 74.76 | 73.13 |
| SEGA-f | 76.18 | 66.89 | 77.45 | 80.36 | 75.22 |