
Breeze-7B-FC-v1_0-GGUF
- Original model: Breeze-7B-FC-v1_0
A conversion of Breeze-7B-FC-v1_0 into diffrent quantisation levels via llama.cpp.
| Name | Quant method | Bits | Size | Use case |
|---|---|---|---|---|
| Breeze-7B-FC-v1_0-q4_0.gguf | Q4_0 | 4 | 4.3 GB | medium quality |
| Breeze-7B-FC-v1_0-q4_k_m.gguf | Q4_K_M | 4 | 4.54 GB | medium, balanced quality - recommended |
| Breeze-7B-FC-v1_0-q5_0.gguf | Q5_0 | 5 | 5.2 GB | large, low quality loss - recommended |
| Breeze-7B-FC-v1_0-q5_1.gguf | Q5_1 | 5 | 5.6 GB | large, very low quality loss - recommended |
| Breeze-7B-FC-v1_0-q5_k_m.gguf | Q5_K_M | 5 | 5.32 GB | large, very low quality loss - recommended |
| Breeze-7B-FC-v1_0-q6_k.gguf | Q6_K | 6 | 6.11 GB | very large, extremely low quality loss |
| Breeze-7B-FC-v1_0-q8_0.gguf | Q8_0 | 8 | 8.0 GB | very large, nearly no quality loss |
Description
This repo contains GGUF format model files for Breeze-7B-FC-v1_0.
About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. Here is an incomplete list of clients and libraries that are known to support GGUF:
- llama.cpp. The source project for GGUF. Offers a CLI and a server option.
- ollama. Get up and running with large language models with a GUI.
- mistral.rs. Blazingly fast LLM inference in Rust.
- text-generation-webui, the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
- KoboldCpp, a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
- GPT4All, a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
- LM Studio, an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
- LoLLMS Web UI, a great web UI with many interesting and unique features, including a full model library for easy model selection.
- Faraday.dev, an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
- llama-cpp-python, a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
- candle, a Rust ML framework with a focus on performance, including GPU support, and ease of use.
- ctransformers, a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
How to locally use those models by Python codes
- Install ctransformers
Run one of the following commands, according to your system:
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
- Simple code
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained(
"yuuko-eth/Breeze-7B-FC-v1_0-GGUF",
model_file="Breeze-7B-FC-v1_0-q6_k.gguf",
model_type="mistral",
context_length=8192,
gpu_layers=99)
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("MediaTek-Research/Breeze-7B-Instruct-v1_0")
gen_kwargs = dict(
max_new_tokens=1024,
repetition_penalty=1.1,
stop=["[INST]"],
temperature=0.0,
top_p=0.0,
top_k=1,
)
chat = [
{"role": "system", "content": "You are a helpful AI assistant built by MediaTek Research. The user you are helping speaks Traditional Chinese and comes from Taiwan."},
{"role": "user", "content": "請介紹五樣台灣小吃"}
]
for text in llm(tokenizer.apply_chat_template(chat, tokenize=False), stream=True, **gen_kwargs):
print(text, end="", flush=True)
# 以下推薦五樣台灣的小吃:
#
# 1. 蚵仔煎 (Oyster omelette) - 蚵仔煎是一種以蛋、麵皮和蚵仔為主要食材的傳統美食。它通常在油鍋中煎至金黃色,外酥內嫩,並帶有一股獨特的香氣。蚵仔煎是一道非常受歡迎的小吃,經常可以在夜市或小吃店找到。
# 2. 牛肉麵 (Beef noodle soup) - 牛肉麵是台灣的經典美食之一,它以軟嫩的牛肉和濃郁的湯頭聞名。不同地區的牛肉麵可能有不同的口味和配料,但通常都會包含麵條、牛肉、蔬菜和調味料。牛肉麵在全台灣都有不少知名店家,例如林東芳牛肉麵、牛大哥牛肉麵等。
# 3. 鹹酥雞 (Fried chicken) - 鹹酥雞是一種以雞肉為主要食材的快餐。它通常會經過油炸處理,然後搭配多種蔬菜和調味料。鹹酥雞的口味因地區而異,但通常都會有辣、甜、鹹等不同風味。鹹酥雞經常可以在夜市或路邊攤找到,例如鼎王鹹酥雞、鹹酥G去等知名店家。
# 4. 珍珠奶茶 (Bubble tea) - 珍珠奶茶是一種以紅茶為基底的飲品,加入珍珠(Q彈的小湯圓)和鮮奶。它起源於台灣,並迅速成為全球流行的飲料。珍珠奶茶在全台灣都有不少知名品牌,例如茶湯會、五桐號等。
# 5. 臭豆腐 (Stinky tofu) - 臭豆腐是一種以發酵豆腐為原料製作的傳統小吃。它具有強烈的氣味,但味道獨特且深受台灣人喜愛。臭豆腐通常會搭配多種調味料和配料,例如辣椒醬、蒜泥、酸菜等。臭豆腐在全台灣都有不少知名店家,例如阿宗麵線、大勇街臭豆腐等。
Instruction following
from mtkresearch.llm.prompt import MRPromptV2
sys_prompt = ('You are a helpful AI assistant built by MediaTek Research. '
'The user you are helping speaks Traditional Chinese and comes from Taiwan.')
prompt_engine = MRPromptV2()
conversations = [
{"role": "system", "content": sys_prompt},
{"role": "user", "content": "請問什麼是深度學習?"},
]
prompt = prompt_engine.get_prompt(conversations)
output_str = _inference(prompt, llm, params)
result = prompt_engine.parse_generated_str(output_str)
print(result)
# {'role': 'assistant',
# 'content': '深度學習(Deep Learning)是一種機器學習方法,它模仿人類大腦的神經網路結構來
# 處理複雜的數據和任務。在深度學習中,模型由多層人工神經元組成,每個神經元之間有
# 權重連接,並通過非線性轉換進行計算。這些層與層之間的相互作用使模型能夠學習複雜
# 的函數關係或模式,從而解決各種問題,如圖像識別、自然語言理解、語音辨識等。深度
# 學習通常需要大量的數據和強大的計算能力,因此經常使用圖形處理器(GPU)或特殊的
# 加速器來執行。'}
Function Calling
import json
from mtkresearch.llm.prompt import MRPromptV2
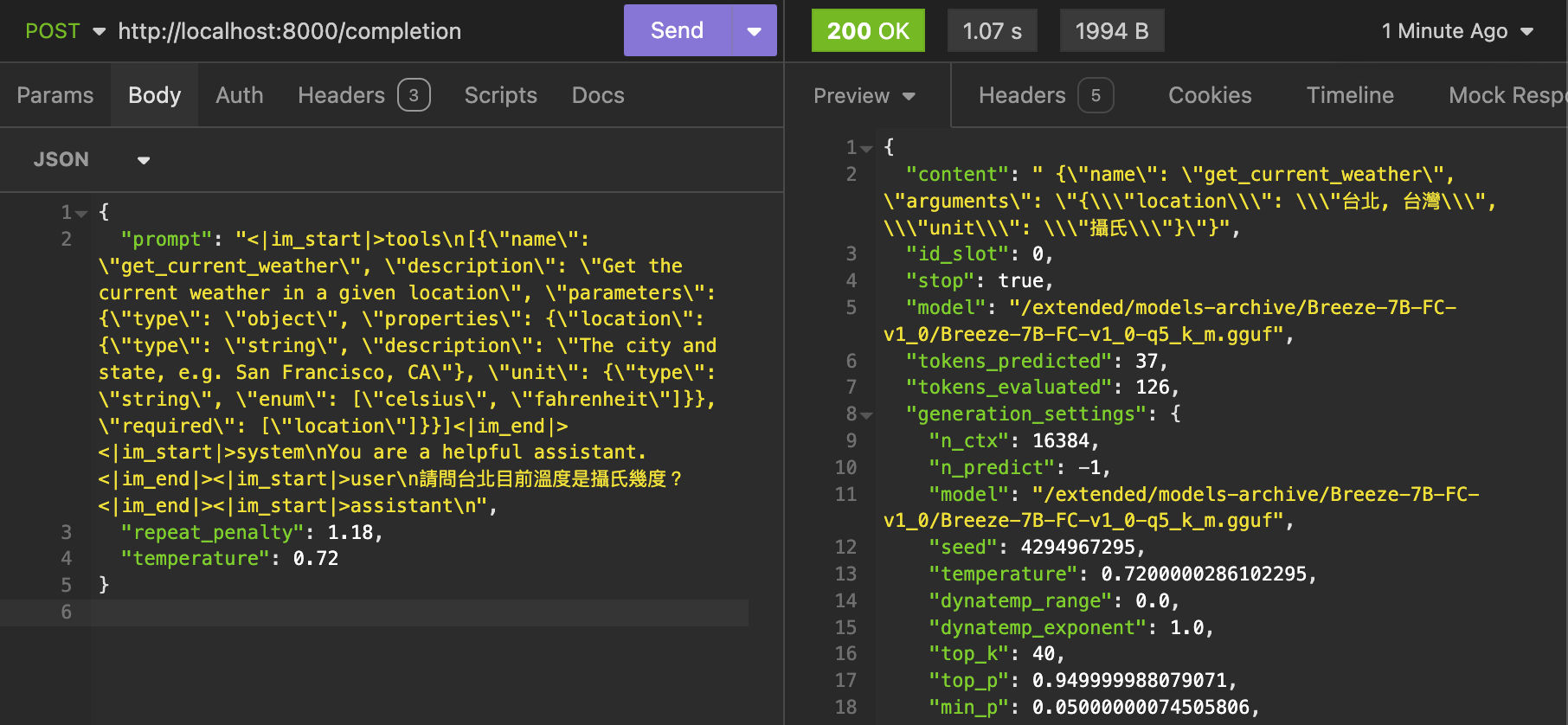
functions = [
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
}
]
def fake_get_current_weather(location, unit=None):
return {'temperature': 30}
mapping = {
'get_current_weather': fake_get_current_weather
}
prompt_engine = MRPromptV2()
# stage 1: query
conversations = [
{"role": "user", "content": "請問台北目前溫度是攝氏幾度?"},
]
prompt = prompt_engine.get_prompt(conversations, functions=functions)
output_str = _inference(prompt, llm, params)
result = prompt_engine.parse_generated_str(output_str)
print(result)
# {'role': 'assistant',
# 'tool_calls': [
# {'id': 'call_U9bYCBRAbF639uUqfwehwSbw', 'type': 'function',
# 'function': {'name': 'get_current_weather', 'arguments': '{"location": "台北, 台灣", "unit": "celsius"}'}}]}
# stage 2: execute called functions
conversations.append(result)
tool_call = result['tool_calls'][0]
func_name = tool_call['function']['name']
func = mapping[func_name]
arguments = json.loads(tool_call['function']['arguments'])
called_result = func(**arguments)
# stage 3: put executed results
conversations.append(
{
'role': 'tool',
'tool_call_id': tool_call['id'],
'name': func_name,
'content': json.dumps(called_result)
}
)
prompt = prompt_engine.get_prompt(conversations, functions=functions)
output_str2 = _inference(prompt, llm, params)
result2 = prompt_engine.parse_generated_str(output_str2)
print(result2)
# {'role': 'assistant', 'content': '台北目前的溫度是攝氏30度'}
- Example function calling via
llama.cppserver:
- Downloads last month
- 208