
Commit
•
d63ad47
1
Parent(s):
ca8cd25
End of training
Browse files
README.md
CHANGED
|
@@ -17,7 +17,7 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 17 |
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="200" height="32"/>](None)
|
| 18 |
# test0901-5
|
| 19 |
|
| 20 |
-
This model is a fine-tuned version of [Qwen/Qwen2-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2-1.5B-Instruct) on the
|
| 21 |
It achieves the following results on the evaluation set:
|
| 22 |
- Loss: 1.8424
|
| 23 |
|
|
|
|
| 17 |
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="200" height="32"/>](None)
|
| 18 |
# test0901-5
|
| 19 |
|
| 20 |
+
This model is a fine-tuned version of [Qwen/Qwen2-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2-1.5B-Instruct) on the identity and the alpaca_en_demo datasets.
|
| 21 |
It achieves the following results on the evaluation set:
|
| 22 |
- Loss: 1.8424
|
| 23 |
|
all_results.json
CHANGED
|
@@ -1,12 +1,12 @@
|
|
| 1 |
{
|
| 2 |
"epoch": 0.08154943934760449,
|
| 3 |
-
"eval_loss": 1.
|
| 4 |
-
"eval_runtime": 6.
|
| 5 |
-
"eval_samples_per_second": 16.
|
| 6 |
-
"eval_steps_per_second": 16.
|
| 7 |
"total_flos": 124335445598208.0,
|
| 8 |
"train_loss": 1.6808662414550781,
|
| 9 |
-
"train_runtime":
|
| 10 |
-
"train_samples_per_second": 0.
|
| 11 |
-
"train_steps_per_second": 0.
|
| 12 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"epoch": 0.08154943934760449,
|
| 3 |
+
"eval_loss": 1.8423653841018677,
|
| 4 |
+
"eval_runtime": 6.7273,
|
| 5 |
+
"eval_samples_per_second": 16.351,
|
| 6 |
+
"eval_steps_per_second": 16.351,
|
| 7 |
"total_flos": 124335445598208.0,
|
| 8 |
"train_loss": 1.6808662414550781,
|
| 9 |
+
"train_runtime": 116.3838,
|
| 10 |
+
"train_samples_per_second": 0.687,
|
| 11 |
+
"train_steps_per_second": 0.086
|
| 12 |
}
|
eval_results.json
CHANGED
|
@@ -1,7 +1,7 @@
|
|
| 1 |
{
|
| 2 |
"epoch": 0.08154943934760449,
|
| 3 |
-
"eval_loss": 1.
|
| 4 |
-
"eval_runtime": 6.
|
| 5 |
-
"eval_samples_per_second": 16.
|
| 6 |
-
"eval_steps_per_second": 16.
|
| 7 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"epoch": 0.08154943934760449,
|
| 3 |
+
"eval_loss": 1.8423653841018677,
|
| 4 |
+
"eval_runtime": 6.7273,
|
| 5 |
+
"eval_samples_per_second": 16.351,
|
| 6 |
+
"eval_steps_per_second": 16.351
|
| 7 |
}
|
runs/Sep02_15-51-19_dsw-83959-5f9bd48d7d-89klm/events.out.tfevents.1725263803.dsw-83959-5f9bd48d7d-89klm.3522427.1
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:adc978150ffecc66b70192ba848f051b692ac1d2a2cd7eec6bca2ff281339be2
|
| 3 |
+
size 354
|
train_results.json
CHANGED
|
@@ -2,7 +2,7 @@
|
|
| 2 |
"epoch": 0.08154943934760449,
|
| 3 |
"total_flos": 124335445598208.0,
|
| 4 |
"train_loss": 1.6808662414550781,
|
| 5 |
-
"train_runtime":
|
| 6 |
-
"train_samples_per_second": 0.
|
| 7 |
-
"train_steps_per_second": 0.
|
| 8 |
}
|
|
|
|
| 2 |
"epoch": 0.08154943934760449,
|
| 3 |
"total_flos": 124335445598208.0,
|
| 4 |
"train_loss": 1.6808662414550781,
|
| 5 |
+
"train_runtime": 116.3838,
|
| 6 |
+
"train_samples_per_second": 0.687,
|
| 7 |
+
"train_steps_per_second": 0.086
|
| 8 |
}
|
trainer_state.json
CHANGED
|
@@ -11,88 +11,88 @@
|
|
| 11 |
{
|
| 12 |
"epoch": 0.00815494393476045,
|
| 13 |
"eval_loss": 2.0249228477478027,
|
| 14 |
-
"eval_runtime": 6.
|
| 15 |
-
"eval_samples_per_second":
|
| 16 |
-
"eval_steps_per_second":
|
| 17 |
"step": 1
|
| 18 |
},
|
| 19 |
{
|
| 20 |
"epoch": 0.0163098878695209,
|
| 21 |
"eval_loss": 2.0154640674591064,
|
| 22 |
-
"eval_runtime": 6.
|
| 23 |
-
"eval_samples_per_second": 16.
|
| 24 |
-
"eval_steps_per_second": 16.
|
| 25 |
"step": 2
|
| 26 |
},
|
| 27 |
{
|
| 28 |
"epoch": 0.024464831804281346,
|
| 29 |
"eval_loss": 1.9926271438598633,
|
| 30 |
-
"eval_runtime": 6.
|
| 31 |
-
"eval_samples_per_second":
|
| 32 |
-
"eval_steps_per_second":
|
| 33 |
"step": 3
|
| 34 |
},
|
| 35 |
{
|
| 36 |
"epoch": 0.0326197757390418,
|
| 37 |
"eval_loss": 1.9593819379806519,
|
| 38 |
-
"eval_runtime": 6.
|
| 39 |
-
"eval_samples_per_second": 16.
|
| 40 |
-
"eval_steps_per_second": 16.
|
| 41 |
"step": 4
|
| 42 |
},
|
| 43 |
{
|
| 44 |
"epoch": 0.040774719673802244,
|
| 45 |
"eval_loss": 1.919368863105774,
|
| 46 |
-
"eval_runtime": 6.
|
| 47 |
-
"eval_samples_per_second": 16.
|
| 48 |
-
"eval_steps_per_second": 16.
|
| 49 |
"step": 5
|
| 50 |
},
|
| 51 |
{
|
| 52 |
"epoch": 0.04892966360856269,
|
| 53 |
"eval_loss": 1.8850003480911255,
|
| 54 |
-
"eval_runtime": 6.
|
| 55 |
-
"eval_samples_per_second":
|
| 56 |
-
"eval_steps_per_second":
|
| 57 |
"step": 6
|
| 58 |
},
|
| 59 |
{
|
| 60 |
"epoch": 0.05708460754332314,
|
| 61 |
"eval_loss": 1.8630123138427734,
|
| 62 |
-
"eval_runtime": 6.
|
| 63 |
-
"eval_samples_per_second": 16.
|
| 64 |
-
"eval_steps_per_second": 16.
|
| 65 |
"step": 7
|
| 66 |
},
|
| 67 |
{
|
| 68 |
"epoch": 0.0652395514780836,
|
| 69 |
"eval_loss": 1.849714756011963,
|
| 70 |
-
"eval_runtime": 6.
|
| 71 |
-
"eval_samples_per_second": 16.
|
| 72 |
-
"eval_steps_per_second": 16.
|
| 73 |
"step": 8
|
| 74 |
},
|
| 75 |
{
|
| 76 |
"epoch": 0.07339449541284404,
|
| 77 |
"eval_loss": 1.8416643142700195,
|
| 78 |
-
"eval_runtime": 6.
|
| 79 |
-
"eval_samples_per_second": 16.
|
| 80 |
-
"eval_steps_per_second": 16.
|
| 81 |
"step": 9
|
| 82 |
},
|
| 83 |
{
|
| 84 |
"epoch": 0.08154943934760449,
|
| 85 |
-
"grad_norm": 2.
|
| 86 |
"learning_rate": 0.0,
|
| 87 |
"loss": 1.6809,
|
| 88 |
"step": 10
|
| 89 |
},
|
| 90 |
{
|
| 91 |
"epoch": 0.08154943934760449,
|
| 92 |
-
"eval_loss": 1.
|
| 93 |
-
"eval_runtime": 6.
|
| 94 |
-
"eval_samples_per_second": 16.
|
| 95 |
-
"eval_steps_per_second": 16.
|
| 96 |
"step": 10
|
| 97 |
},
|
| 98 |
{
|
|
@@ -100,9 +100,9 @@
|
|
| 100 |
"step": 10,
|
| 101 |
"total_flos": 124335445598208.0,
|
| 102 |
"train_loss": 1.6808662414550781,
|
| 103 |
-
"train_runtime":
|
| 104 |
-
"train_samples_per_second": 0.
|
| 105 |
-
"train_steps_per_second": 0.
|
| 106 |
}
|
| 107 |
],
|
| 108 |
"logging_steps": 10,
|
|
|
|
| 11 |
{
|
| 12 |
"epoch": 0.00815494393476045,
|
| 13 |
"eval_loss": 2.0249228477478027,
|
| 14 |
+
"eval_runtime": 6.6144,
|
| 15 |
+
"eval_samples_per_second": 16.63,
|
| 16 |
+
"eval_steps_per_second": 16.63,
|
| 17 |
"step": 1
|
| 18 |
},
|
| 19 |
{
|
| 20 |
"epoch": 0.0163098878695209,
|
| 21 |
"eval_loss": 2.0154640674591064,
|
| 22 |
+
"eval_runtime": 6.71,
|
| 23 |
+
"eval_samples_per_second": 16.394,
|
| 24 |
+
"eval_steps_per_second": 16.394,
|
| 25 |
"step": 2
|
| 26 |
},
|
| 27 |
{
|
| 28 |
"epoch": 0.024464831804281346,
|
| 29 |
"eval_loss": 1.9926271438598633,
|
| 30 |
+
"eval_runtime": 6.46,
|
| 31 |
+
"eval_samples_per_second": 17.028,
|
| 32 |
+
"eval_steps_per_second": 17.028,
|
| 33 |
"step": 3
|
| 34 |
},
|
| 35 |
{
|
| 36 |
"epoch": 0.0326197757390418,
|
| 37 |
"eval_loss": 1.9593819379806519,
|
| 38 |
+
"eval_runtime": 6.741,
|
| 39 |
+
"eval_samples_per_second": 16.318,
|
| 40 |
+
"eval_steps_per_second": 16.318,
|
| 41 |
"step": 4
|
| 42 |
},
|
| 43 |
{
|
| 44 |
"epoch": 0.040774719673802244,
|
| 45 |
"eval_loss": 1.919368863105774,
|
| 46 |
+
"eval_runtime": 6.6614,
|
| 47 |
+
"eval_samples_per_second": 16.513,
|
| 48 |
+
"eval_steps_per_second": 16.513,
|
| 49 |
"step": 5
|
| 50 |
},
|
| 51 |
{
|
| 52 |
"epoch": 0.04892966360856269,
|
| 53 |
"eval_loss": 1.8850003480911255,
|
| 54 |
+
"eval_runtime": 6.643,
|
| 55 |
+
"eval_samples_per_second": 16.559,
|
| 56 |
+
"eval_steps_per_second": 16.559,
|
| 57 |
"step": 6
|
| 58 |
},
|
| 59 |
{
|
| 60 |
"epoch": 0.05708460754332314,
|
| 61 |
"eval_loss": 1.8630123138427734,
|
| 62 |
+
"eval_runtime": 6.5654,
|
| 63 |
+
"eval_samples_per_second": 16.755,
|
| 64 |
+
"eval_steps_per_second": 16.755,
|
| 65 |
"step": 7
|
| 66 |
},
|
| 67 |
{
|
| 68 |
"epoch": 0.0652395514780836,
|
| 69 |
"eval_loss": 1.849714756011963,
|
| 70 |
+
"eval_runtime": 6.5065,
|
| 71 |
+
"eval_samples_per_second": 16.906,
|
| 72 |
+
"eval_steps_per_second": 16.906,
|
| 73 |
"step": 8
|
| 74 |
},
|
| 75 |
{
|
| 76 |
"epoch": 0.07339449541284404,
|
| 77 |
"eval_loss": 1.8416643142700195,
|
| 78 |
+
"eval_runtime": 6.5223,
|
| 79 |
+
"eval_samples_per_second": 16.865,
|
| 80 |
+
"eval_steps_per_second": 16.865,
|
| 81 |
"step": 9
|
| 82 |
},
|
| 83 |
{
|
| 84 |
"epoch": 0.08154943934760449,
|
| 85 |
+
"grad_norm": 2.23551869392395,
|
| 86 |
"learning_rate": 0.0,
|
| 87 |
"loss": 1.6809,
|
| 88 |
"step": 10
|
| 89 |
},
|
| 90 |
{
|
| 91 |
"epoch": 0.08154943934760449,
|
| 92 |
+
"eval_loss": 1.8423653841018677,
|
| 93 |
+
"eval_runtime": 6.6009,
|
| 94 |
+
"eval_samples_per_second": 16.664,
|
| 95 |
+
"eval_steps_per_second": 16.664,
|
| 96 |
"step": 10
|
| 97 |
},
|
| 98 |
{
|
|
|
|
| 100 |
"step": 10,
|
| 101 |
"total_flos": 124335445598208.0,
|
| 102 |
"train_loss": 1.6808662414550781,
|
| 103 |
+
"train_runtime": 116.3838,
|
| 104 |
+
"train_samples_per_second": 0.687,
|
| 105 |
+
"train_steps_per_second": 0.086
|
| 106 |
}
|
| 107 |
],
|
| 108 |
"logging_steps": 10,
|
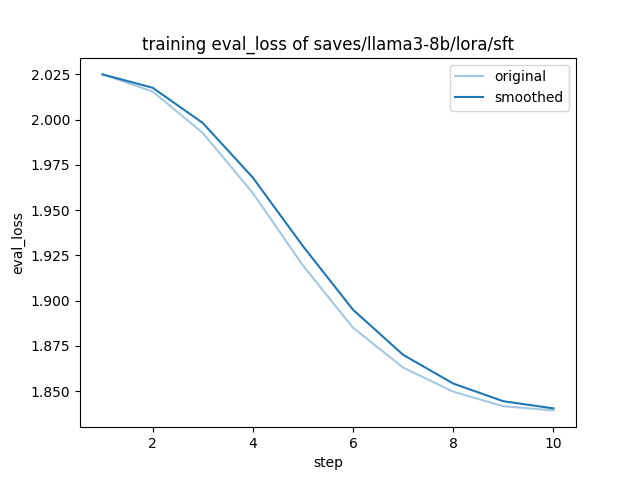
training_eval_loss.png
CHANGED
|
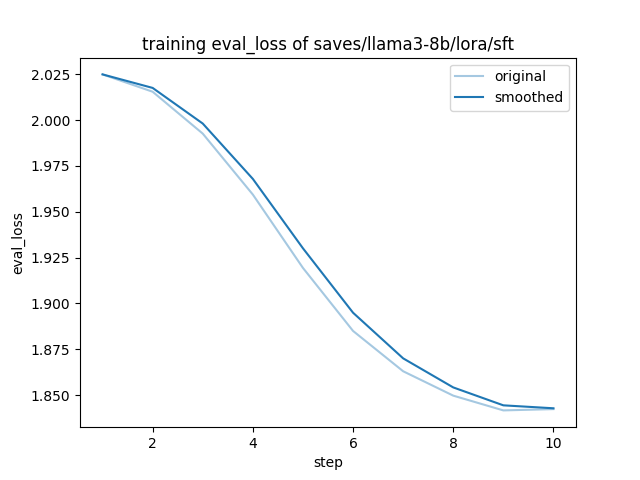
|