
metadata
license: agpl-3.0
datasets:
- stvlynn/Cantonese-Dialogue
language:
- zh
pipeline_tag: text-generation
tags:
- Cantonese
- 廣東話
- 粤语
Qwen-7B-Chat-Cantonese
Intro
Qwen-7B-Chat-Cantonese is a fine-tuned version based on Qwen-7B-Chat, trained on a substantial amount of Cantonese language data.
Qwen-7B-Chat-Cantonese係基於Qwen-7B-Chat嘅微調版本,基於大量粵語數據進行訓練。
Usage
Requirements
- python 3.8 and above
- pytorch 1.12 and above, 2.0 and above are recommended
- CUDA 11.4 and above are recommended (this is for GPU users, flash-attention users, etc.)
Dependency
To run Qwen-7B-Chat-Cantonese, please make sure you meet the above requirements, and then execute the following pip commands to install the dependent libraries.
pip install transformers==4.32.0 accelerate tiktoken einops scipy transformers_stream_generator==0.0.4 peft deepspeed
In addition, it is recommended to install the flash-attention library (we support flash attention 2 now.) for higher efficiency and lower memory usage.
git clone https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
Quickstart
Pls turn to QwenLM/Qwen - Quickstart
Training Parameters
| Parameter | Description | Value |
|---|---|---|
| Learning Rate | AdamW optimizer learning rate | 7e-5 |
| Weight Decay | Regularization strength | 0.8 |
| Gamma | Learning rate decay factor | 1.0 |
| Batch Size | Number of samples per batch | 1000 |
| Precision | Floating point precision | fp16 |
| Learning Policy | Learning rate adjustment policy | cosine |
| Warmup Steps | Initial steps without learning rate adjustment | 0 |
| Total Steps | Total training steps | 1024 |
| Gradient Accumulation Steps | Number of steps to accumulate gradients before updating | 8 |

Demo
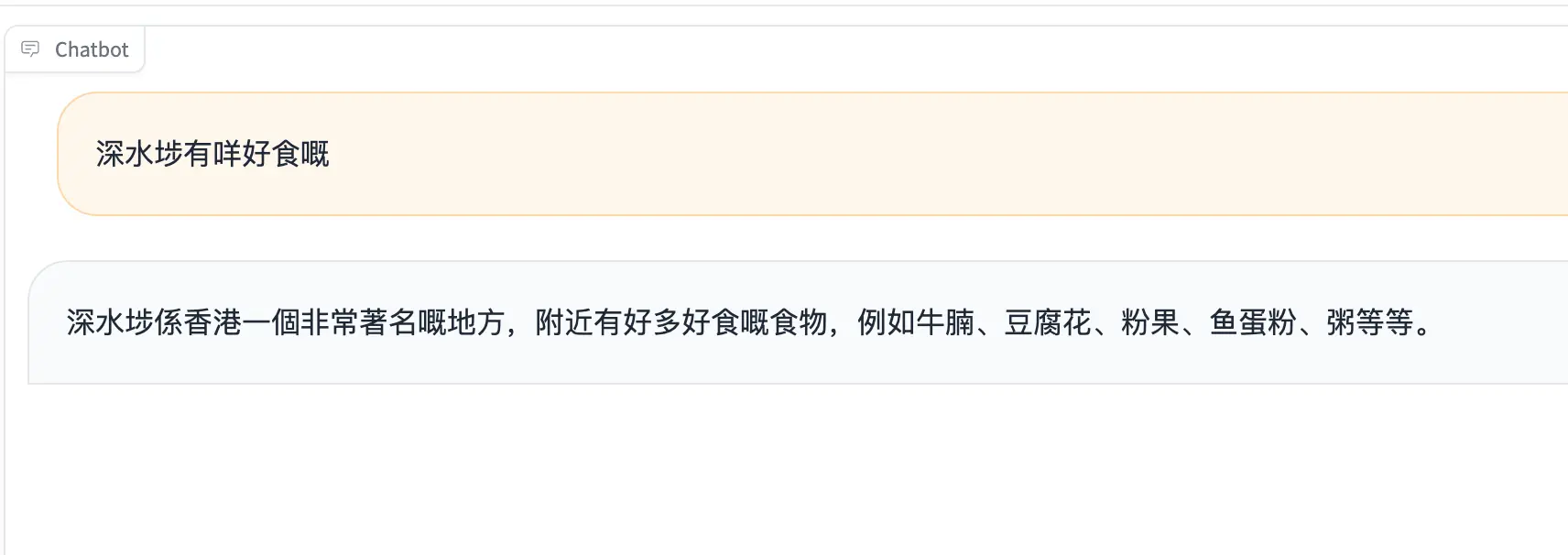
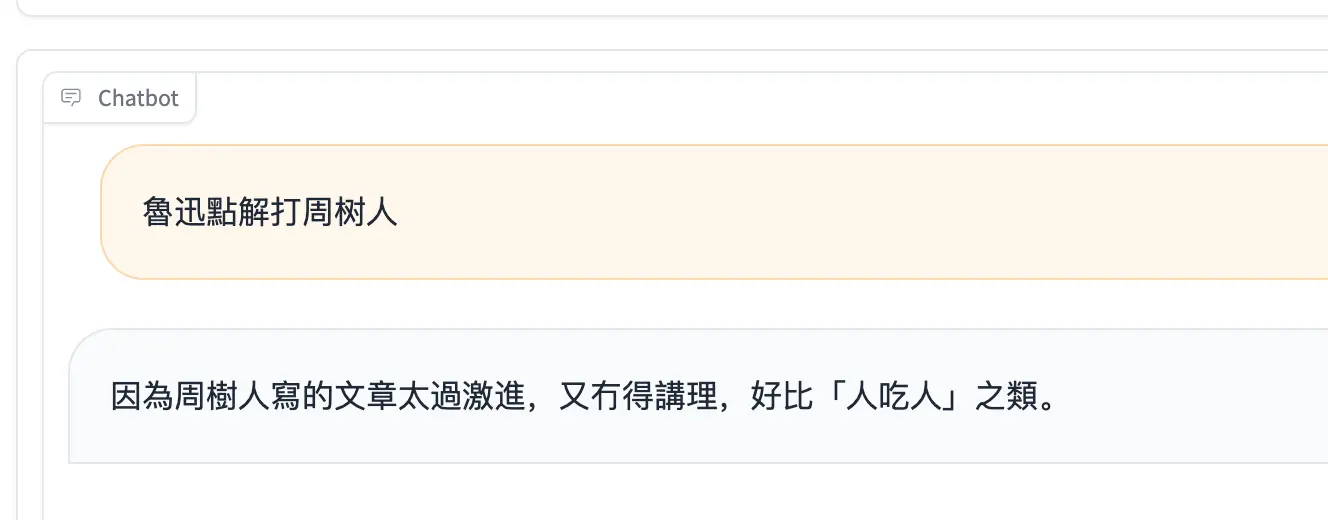
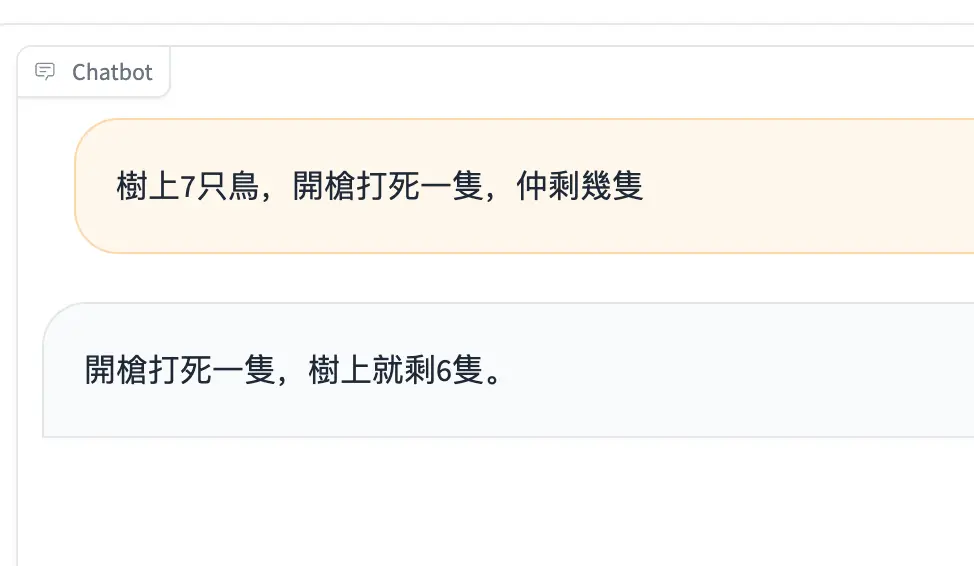
Special Note
This is my first fine-tuning LLM project. Pls forgive me if there's anything wrong.
If you have any questions or suggestions, feel free to contact me.