
title: Grounded-Segment-Anything
app_file: gradio_app.py
sdk: gradio
sdk_version: 3.50.2
![]()
Grounded-Segment-Anything

![]()
![]()
![]()
We plan to create a very interesting demo by combining Grounding DINO and Segment Anything which aims to detect and segment anything with text inputs! And we will continue to improve it and create more interesting demos based on this foundation. And we have already released an overall technical report about our project on arXiv, please check Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks for more details.
We are very willing to help everyone share and promote new projects based on Segment-Anything, Please check out here for more amazing demos and works in the community: Highlight Extension Projects. You can submit a new issue (with project tag) or a new pull request to add new project's links.


🍄 Why Building this Project?
The core idea behind this project is to combine the strengths of different models in order to build a very powerful pipeline for solving complex problems. And it's worth mentioning that this is a workflow for combining strong expert models, where all parts can be used separately or in combination, and can be replaced with any similar but different models (like replacing Grounding DINO with GLIP or other detectors / replacing Stable-Diffusion with ControlNet or GLIGEN/ Combining with ChatGPT).
🍇 Updates
2024/01/26We have released a comprehensive technical report about our project on arXiv, please check Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks for more details. And we are profoundly grateful for the contributions of all the contributors in this project.2023/12/17Support Grounded-RepViT-SAM demo, thanks a lot for their great work!2023/12/16Support Grounded-Edge-SAM demo, thanks a lot for their great work!2023/12/10Support Grounded-Efficient-SAM demo, thanks a lot for their great work!2023/11/24Release RAM++, which is the next generation of RAM. RAM++ can recognize any category with high accuracy, including both predefined common categories and diverse open-set categories.2023/11/23Release our newly proposed visual prompt counting model T-Rex. The introduction Video and Demo is available in DDS now.2023/07/25Support Light-HQ-SAM in EfficientSAM, credits to Mingqiao Ye and Lei Ke, thanks a lot for their great work!2023/07/14Combining Grounding-DINO-B with SAM-HQ achieves 49.6 mean AP in Segmentation in the Wild competition zero-shot track, surpassing Grounded-SAM by 3.6 mean AP, thanks for their great work!2023/06/28Combining Grounding-DINO with Efficient SAM variants including FastSAM and MobileSAM in EfficientSAM for faster annotating, thanks a lot for their great work!2023/06/20By combining Grounding-DINO-L with SAM-ViT-H, Grounded-SAM achieves 46.0 mean AP in Segmentation in the Wild competition zero-shot track on CVPR 2023 workshop, surpassing UNINEXT (CVPR 2023) by about 4 mean AP.2023/06/16Release RAM-Grounded-SAM Replicate Online Demo. Thanks a lot to Chenxi for providing this nice demo 🌹.2023/06/14Support RAM-Grounded-SAM & SAM-HQ and update Simple Automatic Label Demo to support RAM, setting up a strong automatic annotation pipeline.2023/06/13Checkout the Autodistill: Train YOLOv8 with ZERO Annotations tutorial to learn how to use Grounded-SAM + Autodistill for automated data labeling and real-time model training.2023/06/13Support SAM-HQ in Grounded-SAM Demo for higher quality prediction.2023/06/12Support RAM-Grounded-SAM for strong automatic labeling pipeline! Thanks for Recognize-Anything.2023/06/01Our Grounded-SAM has been accepted to present a demo at ICCV 2023! See you in Paris!2023/05/23: SupportImage-Referring-Segment,Audio-Referring-SegmentandText-Referring-Segmentin ImageBind-SAM.2023/05/03: Checkout the Automated Dataset Annotation and Evaluation with GroundingDINO and SAM which is an amazing tutorial on automatic labeling! Thanks a lot for Piotr Skalski and Roboflow!
Table of Contents
- Grounded-Segment-Anything
- Installation
- Grounded-SAM Playground
- Step-by-Step Notebook Demo
- GroundingDINO: Detect Everything with Text Prompt
- Grounded-SAM: Detect and Segment Everything with Text Prompt
- Grounded-SAM with Inpainting: Detect, Segment and Generate Everything with Text Prompt
- Grounded-SAM and Inpaint Gradio APP
- Grounded-SAM with RAM or Tag2Text for Automatic Labeling
- Grounded-SAM with BLIP & ChatGPT for Automatic Labeling
- Grounded-SAM with Whisper: Detect and Segment Anything with Audio
- Grounded-SAM ChatBot with Visual ChatGPT
- Grounded-SAM with OSX for 3D Whole-Body Mesh Recovery
- Grounded-SAM with VISAM for Tracking and Segment Anything
- Interactive Fashion-Edit Playground: Click for Segmentation And Editing
- Interactive Human-face Editing Playground: Click And Editing Human Face
- 3D Box Via Segment Anything
- Playground: More Interesting and Imaginative Demos with Grounded-SAM
- DeepFloyd: Image Generation with Text Prompt
- PaintByExample: Exemplar-based Image Editing with Diffusion Models
- LaMa: Resolution-robust Large Mask Inpainting with Fourier Convolutions
- RePaint: Inpainting using Denoising Diffusion Probabilistic Models
- ImageBind with SAM: Segment with Different Modalities
- Efficient SAM Series for Faster Annotation
- Citation
Preliminary Works
Here we provide some background knowledge that you may need to know before trying the demos.
| Title | Intro | Description | Links |
|---|---|---|---|
| Segment-Anything |  |
A strong foundation model aims to segment everything in an image, which needs prompts (as boxes/points/text) to generate masks | [Github] [Page] [Demo] |
| Grounding DINO |  |
A strong zero-shot detector which is capable of to generate high quality boxes and labels with free-form text. | [Github] [Demo] |
| OSX |  |
A strong and efficient one-stage motion capture method to generate high quality 3D human mesh from monucular image. OSX also releases a large-scale upper-body dataset UBody for a more accurate reconstrution in the upper-body scene. | [Github] [Page] [Video] [Data] |
| Stable-Diffusion |  |
A super powerful open-source latent text-to-image diffusion model | [Github] [Page] |
| RAM++ |  |
RAM++ is the next generation of RAM, which can recognize any category with high accuracy. | [Github] |
| RAM |  |
RAM is an image tagging model, which can recognize any common category with high accuracy. | [Github] [Demo] |
| BLIP | A wonderful language-vision model for image understanding. | [GitHub] | |
| Visual ChatGPT |  |
A wonderful tool that connects ChatGPT and a series of Visual Foundation Models to enable sending and receiving images during chatting. | [Github] [Demo] |
| Tag2Text |  |
An efficient and controllable vision-language model which can simultaneously output superior image captioning and image tagging. | [Github] [Demo] |
| VoxelNeXt |  |
A clean, simple, and fully-sparse 3D object detector, which predicts objects directly upon sparse voxel features. | [Github] |
Highlighted Projects
Here we provide some impressive works you may find interesting:
| Title | Description | Links |
|---|---|---|
| Semantic-SAM | A universal image segmentation model to enable segment and recognize anything at any desired granularity | [Github] [Demo] |
| SEEM: Segment Everything Everywhere All at Once | A powerful promptable segmentation model supports segmenting with various types of prompts (text, point, scribble, referring image, etc.) and any combination of prompts. | [Github] [Demo] |
| OpenSeeD | A simple framework for open-vocabulary segmentation and detection which supports interactive segmentation with box input to generate mask | [Github] |
| LLaVA | Visual instruction tuning with GPT-4 | [Github] [Page] [Demo] [Data] [Model] |
| GenSAM | Relaxing the instance-specific manual prompt requirement in SAM through training-free test-time adaptation | [Github] [Page] |
We also list some awesome segment-anything extension projects here you may find interesting:
- Computer Vision in the Wild (CVinW) Readings for those who are interested in open-set tasks in computer vision.
- Zero-Shot Anomaly Detection by Yunkang Cao
- EditAnything: ControlNet + StableDiffusion based on the SAM segmentation mask by Shanghua Gao and Pan Zhou
- IEA: Image Editing Anything by Zhengcong Fei
- SAM-MMRorate: Combining Rotated Object Detector and SAM by Qingyun Li and Xue Yang
- Awesome-Anything by Gongfan Fang
- Prompt-Segment-Anything by Rockey
- WebUI for Segment-Anything and Grounded-SAM by Chengsong Zhang
- Inpainting Anything: Inpaint Anything with SAM + Inpainting models by Tao Yu
- Grounded Segment Anything From Objects to Parts: Combining Segment-Anything with VLPart & GLIP & Visual ChatGPT by Peize Sun and Shoufa Chen
- Narapi-SAM: Integration of Segment Anything into Narapi (A nice viewer for SAM) by MIC-DKFZ
- Grounded Segment Anything Colab by camenduru
- Optical Character Recognition with Segment Anything by Zhenhua Yang
- Transform Image into Unique Paragraph with ChatGPT, BLIP2, OFA, GRIT, Segment Anything, ControlNet by showlab
- Lang-Segment-Anything: Another awesome demo for combining GroundingDINO with Segment-Anything by Luca Medeiros
- 🥳 🚀 Playground: Integrate SAM and OpenMMLab!
- 3D-object via Segment Anything by Yukang Chen
- Image2Paragraph: Transform Image Into Unique Paragraph by Show Lab
- Zero-shot Scene Graph Generate with Grounded-SAM by JackWhite-rwx
- CLIP Surgery for Better Explainability with Enhancement in Open-Vocabulary Tasks by Eli-YiLi
- Panoptic-Segment-Anything: Zero-shot panoptic segmentation using SAM by segments-ai
- Caption-Anything: Generates Descriptive Captions for Any Object within an Image by Teng Wang
- Segment-Anything-3D: Transferring Segmentation Information of 2D Images to 3D Space by Yunhan Yang
- Expediting SAM without Fine-tuning by Weicong Liang and Yuhui Yuan
- Semantic Segment Anything: Providing Rich Semantic Category Annotations for SAM by Jiaqi Chen and Zeyu Yang and Li Zhang
- Enhance Everything: Combining SAM with Image Restoration and Enhancement Tasks by Xin Li
- DragGAN by Shanghai AI Lab.
Installation
The code requires python>=3.8, as well as pytorch>=1.7 and torchvision>=0.8. Please follow the instructions here to install both PyTorch and TorchVision dependencies. Installing both PyTorch and TorchVision with CUDA support is strongly recommended.
Install with Docker
Open one terminal:
make build-image
make run
That's it.
If you would like to allow visualization across docker container, open another terminal and type:
xhost +
Install without Docker
You should set the environment variable manually as follows if you want to build a local GPU environment for Grounded-SAM:
export AM_I_DOCKER=False
export BUILD_WITH_CUDA=True
export CUDA_HOME=/path/to/cuda-11.3/
Install Segment Anything:
python -m pip install -e segment_anything
Install Grounding DINO:
pip install --no-build-isolation -e GroundingDINO
Install diffusers:
pip install --upgrade diffusers[torch]
Install osx:
git submodule update --init --recursive
cd grounded-sam-osx && bash install.sh
Install RAM & Tag2Text:
git clone https://github.com/xinyu1205/recognize-anything.git
pip install -r ./recognize-anything/requirements.txt
pip install -e ./recognize-anything/
The following optional dependencies are necessary for mask post-processing, saving masks in COCO format, the example notebooks, and exporting the model in ONNX format. jupyter is also required to run the example notebooks.
pip install opencv-python pycocotools matplotlib onnxruntime onnx ipykernel
More details can be found in install segment anything and install GroundingDINO and install OSX
Grounded-SAM Playground
Let's start exploring our Grounding-SAM Playground and we will release more interesting demos in the future, stay tuned!
:open_book: Step-by-Step Notebook Demo
Here we list some notebook demo provided in this project:
:running_man: GroundingDINO: Detect Everything with Text Prompt
:grapes: [arXiv Paper] :rose:[Try the Colab Demo] :sunflower: [Try Huggingface Demo] :mushroom: [Automated Dataset Annotation and Evaluation]
Here's the step-by-step tutorial on running GroundingDINO demo:
Step 1: Download the pretrained weights
cd Grounded-Segment-Anything
# download the pretrained groundingdino-swin-tiny model
wget https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
Step 2: Running the demo
python grounding_dino_demo.py
Running with Python (same as demo but you can run it anywhere after installing GroundingDINO)
from groundingdino.util.inference import load_model, load_image, predict, annotate
import cv2
model = load_model("GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py", "./groundingdino_swint_ogc.pth")
IMAGE_PATH = "assets/demo1.jpg"
TEXT_PROMPT = "bear."
BOX_THRESHOLD = 0.35
TEXT_THRESHOLD = 0.25
image_source, image = load_image(IMAGE_PATH)
boxes, logits, phrases = predict(
model=model,
image=image,
caption=TEXT_PROMPT,
box_threshold=BOX_THRESHOLD,
text_threshold=TEXT_THRESHOLD
)
annotated_frame = annotate(image_source=image_source, boxes=boxes, logits=logits, phrases=phrases)
cv2.imwrite("annotated_image.jpg", annotated_frame)
Tips
- If you want to detect multiple objects in one sentence with Grounding DINO, we suggest separating each name with
.. An example:cat . dog . chair .
Step 3: Check the annotated image
The annotated image will be saved as ./annotated_image.jpg.
| Text Prompt | Demo Image | Annotated Image |
|---|---|---|
Bear. |
 |
 |
Horse. Clouds. Grasses. Sky. Hill |
 |
 |
:running_man: Grounded-SAM: Detect and Segment Everything with Text Prompt
Here's the step-by-step tutorial on running Grounded-SAM demo:
Step 1: Download the pretrained weights
cd Grounded-Segment-Anything
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
wget https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
We provide two versions of Grounded-SAM demo here:
- grounded_sam_demo.py: our original implementation for Grounded-SAM.
- grounded_sam_simple_demo.py our updated more elegant version for Grounded-SAM.
Step 2: Running original grounded-sam demo
export CUDA_VISIBLE_DEVICES=0
python grounded_sam_demo.py \
--config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \
--grounded_checkpoint groundingdino_swint_ogc.pth \
--sam_checkpoint sam_vit_h_4b8939.pth \
--input_image assets/demo1.jpg \
--output_dir "outputs" \
--box_threshold 0.3 \
--text_threshold 0.25 \
--text_prompt "bear" \
--device "cuda"
The annotated results will be saved in ./outputs as follows
| Input Image | Annotated Image | Generated Mask |
|---|---|---|
|
 |
 |
Step 3: Running grounded-sam demo with sam-hq
- Download the demo image
wget https://github.com/IDEA-Research/detrex-storage/releases/download/grounded-sam-storage/sam_hq_demo_image.png
Download SAM-HQ checkpoint here
Running grounded-sam-hq demo as follows:
export CUDA_VISIBLE_DEVICES=0
python grounded_sam_demo.py \
--config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \
--grounded_checkpoint groundingdino_swint_ogc.pth \
--sam_hq_checkpoint ./sam_hq_vit_h.pth \ # path to sam-hq checkpoint
--use_sam_hq \ # set to use sam-hq model
--input_image sam_hq_demo_image.png \
--output_dir "outputs" \
--box_threshold 0.3 \
--text_threshold 0.25 \
--text_prompt "chair." \
--device "cuda"
The annotated results will be saved in ./outputs as follows
| Input Image | SAM Output | SAM-HQ Output |
|---|---|---|
 |
 |
 |
Step 4: Running the updated grounded-sam demo (optional)
Note that this demo is almost same as the original demo, but with more elegant code.
python grounded_sam_simple_demo.py
The annotated results will be saved as ./groundingdino_annotated_image.jpg and ./grounded_sam_annotated_image.jpg
| Text Prompt | Input Image | GroundingDINO Annotated Image | Grounded-SAM Annotated Image |
|---|---|---|---|
The running dog |
 |
 |
 |
Horse. Clouds. Grasses. Sky. Hill |
|
 |
 |
:skier: Grounded-SAM with Inpainting: Detect, Segment and Generate Everything with Text Prompt
Step 1: Download the pretrained weights
cd Grounded-Segment-Anything
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
wget https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
Step 2: Running grounded-sam inpainting demo
CUDA_VISIBLE_DEVICES=0
python grounded_sam_inpainting_demo.py \
--config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \
--grounded_checkpoint groundingdino_swint_ogc.pth \
--sam_checkpoint sam_vit_h_4b8939.pth \
--input_image assets/inpaint_demo.jpg \
--output_dir "outputs" \
--box_threshold 0.3 \
--text_threshold 0.25 \
--det_prompt "bench" \
--inpaint_prompt "A sofa, high quality, detailed" \
--device "cuda"
The annotated and inpaint image will be saved in ./outputs
Step 3: Check the results
| Input Image | Det Prompt | Annotated Image | Inpaint Prompt | Inpaint Image |
|---|---|---|---|---|
 |
Bench |
 |
A sofa, high quality, detailed |
 |
:golfing: Grounded-SAM and Inpaint Gradio APP
We support 6 tasks in the local Gradio APP:
- scribble: Segmentation is achieved through Segment Anything and mouse click interaction (you need to click on the object with the mouse, no need to specify the prompt).
- automask: Segment the entire image at once through Segment Anything (no need to specify a prompt).
- det: Realize detection through Grounding DINO and text interaction (text prompt needs to be specified).
- seg: Realize text interaction by combining Grounding DINO and Segment Anything to realize detection + segmentation (need to specify text prompt).
- inpainting: By combining Grounding DINO + Segment Anything + Stable Diffusion to achieve text exchange and replace the target object (need to specify text prompt and inpaint prompt) .
- automatic: By combining BLIP + Grounding DINO + Segment Anything to achieve non-interactive detection + segmentation (no need to specify prompt).
python gradio_app.py
- The gradio_app visualization as follows:

:label: Grounded-SAM with RAM or Tag2Text for Automatic Labeling
The Recognize Anything Models are a series of open-source and strong fundamental image recognition models, including RAM++, RAM and Tag2text.
It is seamlessly linked to generate pseudo labels automatically as follows:
- Use RAM/Tag2Text to generate tags.
- Use Grounded-Segment-Anything to generate the boxes and masks.
Step 1: Init submodule and download the pretrained checkpoint
- Init submodule:
cd Grounded-Segment-Anything
git submodule init
git submodule update
- Download pretrained weights for
GroundingDINO,SAMandRAM/Tag2Text:
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
wget https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
wget https://huggingface.co/spaces/xinyu1205/Tag2Text/resolve/main/ram_swin_large_14m.pth
wget https://huggingface.co/spaces/xinyu1205/Tag2Text/resolve/main/tag2text_swin_14m.pth
Step 2: Running the demo with RAM
export CUDA_VISIBLE_DEVICES=0
python automatic_label_ram_demo.py \
--config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \
--ram_checkpoint ram_swin_large_14m.pth \
--grounded_checkpoint groundingdino_swint_ogc.pth \
--sam_checkpoint sam_vit_h_4b8939.pth \
--input_image assets/demo9.jpg \
--output_dir "outputs" \
--box_threshold 0.25 \
--text_threshold 0.2 \
--iou_threshold 0.5 \
--device "cuda"
Step 2: Or Running the demo with Tag2Text
export CUDA_VISIBLE_DEVICES=0
python automatic_label_tag2text_demo.py \
--config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \
--tag2text_checkpoint tag2text_swin_14m.pth \
--grounded_checkpoint groundingdino_swint_ogc.pth \
--sam_checkpoint sam_vit_h_4b8939.pth \
--input_image assets/demo9.jpg \
--output_dir "outputs" \
--box_threshold 0.25 \
--text_threshold 0.2 \
--iou_threshold 0.5 \
--device "cuda"
- RAM++ significantly improves the open-set capability of RAM, for RAM++ inference on unseen categoreis.
- Tag2Text also provides powerful captioning capabilities, and the process with captions can refer to BLIP.
- The pseudo labels and model prediction visualization will be saved in
output_diras follows (right figure):

:robot: Grounded-SAM with BLIP for Automatic Labeling
It is easy to generate pseudo labels automatically as follows:
- Use BLIP (or other caption models) to generate a caption.
- Extract tags from the caption. We use ChatGPT to handle the potential complicated sentences.
- Use Grounded-Segment-Anything to generate the boxes and masks.
- Run Demo
export OPENAI_API_KEY=your_openai_key
export OPENAI_API_BASE=https://closeai.deno.dev/v1
export CUDA_VISIBLE_DEVICES=0
python automatic_label_demo.py \
--config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \
--grounded_checkpoint groundingdino_swint_ogc.pth \
--sam_checkpoint sam_vit_h_4b8939.pth \
--input_image assets/demo3.jpg \
--output_dir "outputs" \
--openai_key $OPENAI_API_KEY \
--box_threshold 0.25 \
--text_threshold 0.2 \
--iou_threshold 0.5 \
--device "cuda"
- When you don't have a paid Account for ChatGPT is also possible to use NLTK instead. Just don't include the
openai_keyParameter when starting the Demo.- The Script will automatically download the necessary NLTK Data.
- The pseudo labels and model prediction visualization will be saved in
output_diras follows:

:open_mouth: Grounded-SAM with Whisper: Detect and Segment Anything with Audio
Detect and segment anything with speech!

Install Whisper
pip install -U openai-whisper
See the whisper official page if you have other questions for the installation.
Run Voice-to-Label Demo
Optional: Download the demo audio file
wget https://huggingface.co/ShilongLiu/GroundingDINO/resolve/main/demo_audio.mp3
export CUDA_VISIBLE_DEVICES=0
python grounded_sam_whisper_demo.py \
--config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \
--grounded_checkpoint groundingdino_swint_ogc.pth \
--sam_checkpoint sam_vit_h_4b8939.pth \
--input_image assets/demo4.jpg \
--output_dir "outputs" \
--box_threshold 0.3 \
--text_threshold 0.25 \
--speech_file "demo_audio.mp3" \
--device "cuda"

Run Voice-to-inpaint Demo
You can enable chatgpt to help you automatically detect the object and inpainting order with --enable_chatgpt.
Or you can specify the object you want to inpaint [stored in args.det_speech_file] and the text you want to inpaint with [stored in args.inpaint_speech_file].
export OPENAI_API_KEY=your_openai_key
export OPENAI_API_BASE=https://closeai.deno.dev/v1
# Example: enable chatgpt
export CUDA_VISIBLE_DEVICES=0
python grounded_sam_whisper_inpainting_demo.py \
--config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \
--grounded_checkpoint groundingdino_swint_ogc.pth \
--sam_checkpoint sam_vit_h_4b8939.pth \
--input_image assets/inpaint_demo.jpg \
--output_dir "outputs" \
--box_threshold 0.3 \
--text_threshold 0.25 \
--prompt_speech_file assets/acoustics/prompt_speech_file.mp3 \
--enable_chatgpt \
--openai_key $OPENAI_API_KEY\
--device "cuda"
# Example: without chatgpt
export CUDA_VISIBLE_DEVICES=0
python grounded_sam_whisper_inpainting_demo.py \
--config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \
--grounded_checkpoint groundingdino_swint_ogc.pth \
--sam_checkpoint sam_vit_h_4b8939.pth \
--input_image assets/inpaint_demo.jpg \
--output_dir "outputs" \
--box_threshold 0.3 \
--text_threshold 0.25 \
--det_speech_file "assets/acoustics/det_voice.mp3" \
--inpaint_speech_file "assets/acoustics/inpaint_voice.mp3" \
--device "cuda"

:speech_balloon: Grounded-SAM ChatBot Demo
Following Visual ChatGPT, we add a ChatBot for our project. Currently, it supports:
- "Describe the image."
- "Detect the dog (and the cat) in the image."
- "Segment anything in the image."
- "Segment the dog (and the cat) in the image."
- "Help me label the image."
- "Replace the dog with a cat in the image."
To use the ChatBot:
- Install whisper if you want to use audio as input.
- Set the default model setting in the tool
Grounded_dino_sam_inpainting. - Run Demo
export OPENAI_API_KEY=your_openai_key
export OPENAI_API_BASE=https://closeai.deno.dev/v1
export CUDA_VISIBLE_DEVICES=0
python chatbot.py
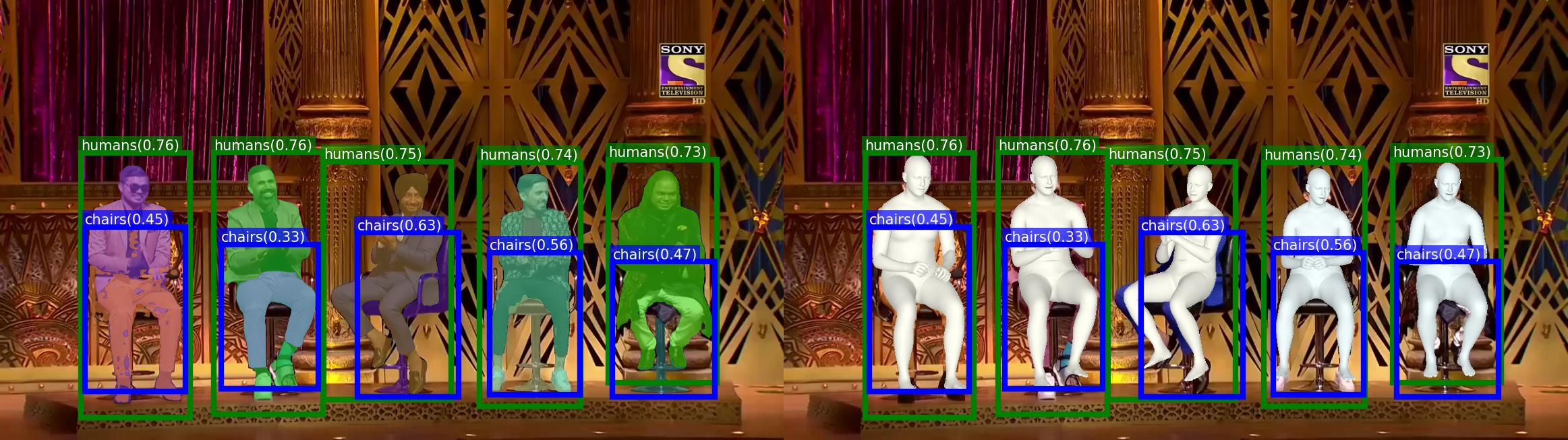
:man_dancing: Run Grounded-Segment-Anything + OSX Demo

Download the checkpoint
osx_l_wo_decoder.pth.tarfrom here for OSX:Download the human model files and place it into
grounded-sam-osx/utils/human_model_filesfollowing the instruction of OSX.Run Demo
export CUDA_VISIBLE_DEVICES=0
python grounded_sam_osx_demo.py \
--config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \
--grounded_checkpoint groundingdino_swint_ogc.pth \
--sam_checkpoint sam_vit_h_4b8939.pth \
--osx_checkpoint osx_l_wo_decoder.pth.tar \
--input_image assets/osx/grounded_sam_osx_demo.png \
--output_dir "outputs" \
--box_threshold 0.3 \
--text_threshold 0.25 \
--text_prompt "humans, chairs" \
--device "cuda"
- The model prediction visualization will be saved in
output_diras follows:
- We also support promptable 3D whole-body mesh recovery. For example, you can track someone with a text prompt and estimate his 3D pose and shape :
 |
|---|
| A person with pink clothes |
 |
|---|
| A man with a sunglasses |
:man_dancing: Run Grounded-Segment-Anything + VISAM Demo
Download the checkpoint
motrv2_dancetrack.pthfrom here for MOTRv2:See the more thing if you have other questions for the installation.
Run Demo
export CUDA_VISIBLE_DEVICES=0
python grounded_sam_visam.py \
--meta_arch motr \
--dataset_file e2e_dance \
--with_box_refine \
--query_interaction_layer QIMv2 \
--num_queries 10 \
--det_db det_db_motrv2.json \
--use_checkpoint \
--mot_path your_data_path \
--resume motrv2_dancetrack.pth \
--sam_checkpoint sam_vit_h_4b8939.pth \
--video_path DanceTrack/test/dancetrack0003
| |
|
:dancers: Interactive Editing
Release the interactive fashion-edit playground in here. Run in the notebook, just click for annotating points for further segmentation. Enjoy it!
Release human-face-edit branch here. We'll keep updating this branch with more interesting features. Here are some examples:

:camera: 3D-Box via Segment Anything
We extend the scope to 3D world by combining Segment Anything and VoxelNeXt. When we provide a prompt (e.g., a point / box), the result is not only 2D segmentation mask, but also 3D boxes. Please check voxelnext_3d_box for more details.


:cupid: Acknowledgements
Contributors
Our project wouldn't be possible without the contributions of these amazing people! Thank you all for making this project better.
Citation
If you find this project helpful for your research, please consider citing the following BibTeX entry.
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{\'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}
@article{liu2023grounding,
title={Grounding dino: Marrying dino with grounded pre-training for open-set object detection},
author={Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Hao and Yang, Jie and Li, Chunyuan and Yang, Jianwei and Su, Hang and Zhu, Jun and others},
journal={arXiv preprint arXiv:2303.05499},
year={2023}
}
@misc{ren2024grounded,
title={Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks},
author={Tianhe Ren and Shilong Liu and Ailing Zeng and Jing Lin and Kunchang Li and He Cao and Jiayu Chen and Xinyu Huang and Yukang Chen and Feng Yan and Zhaoyang Zeng and Hao Zhang and Feng Li and Jie Yang and Hongyang Li and Qing Jiang and Lei Zhang},
year={2024},
eprint={2401.14159},
archivePrefix={arXiv},
primaryClass={cs.CV}
}