
RLHF
Collection
A collection of models trained with Reinforcement Learning from Human Feedback (RLHF).
•
4 items
•
Updated
•
4
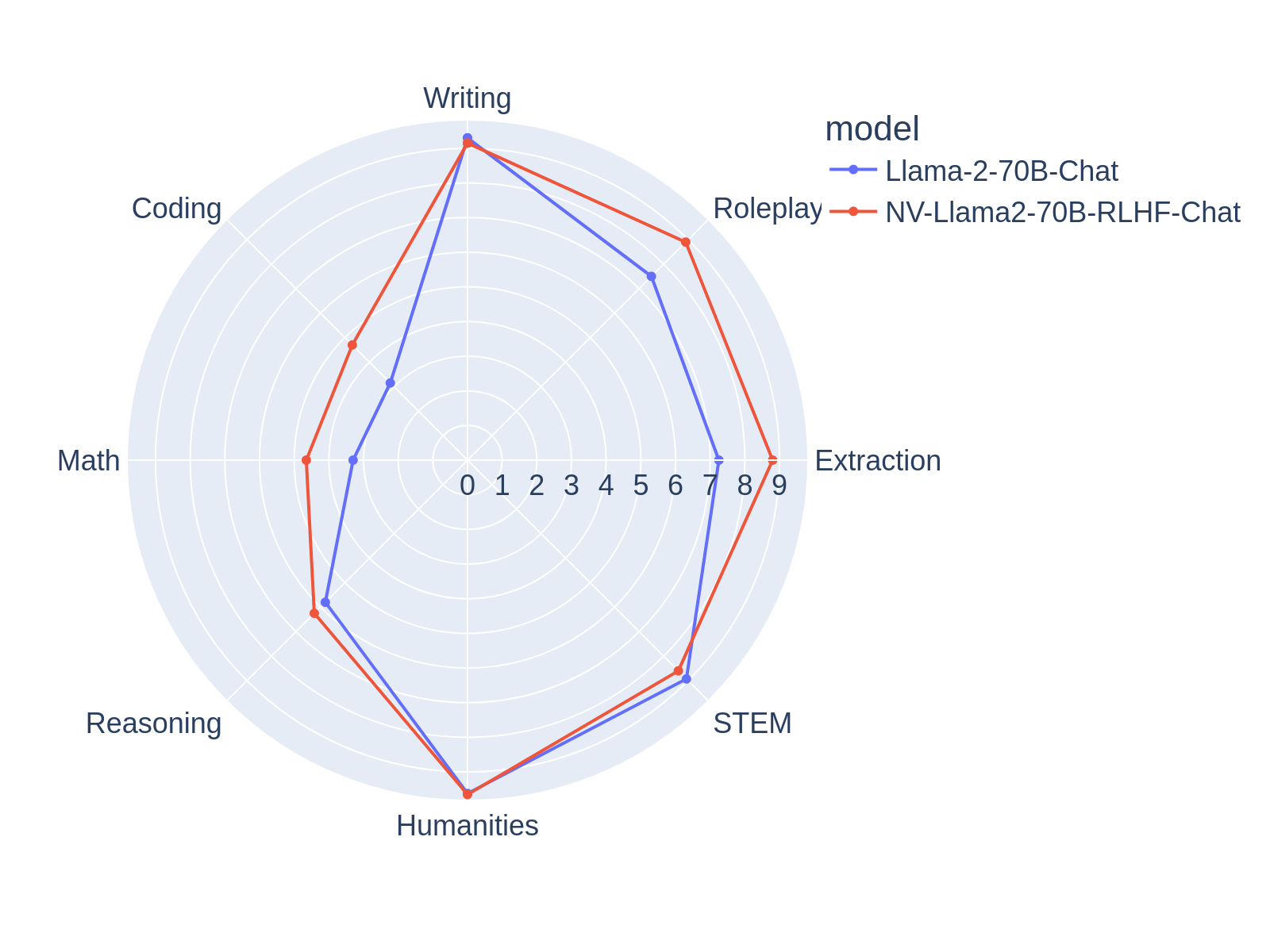
NV-Llama2-70B-RLHF-Chat is a 70 billion parameter generative language model instruct-tuned on LLama2-70B model. It takes input with context length up to 4,096 tokens. The model has been fine-tuned for instruction following using Supervised Fine-tuning (SFT) on NVIDIA SFT Datablend v1 [^1] and Reinforcement Learning from Human Feedback (RLHF) on HH-RLHF dataset , achieving 7.59 on MT-Bench and demonstrating strong performance on academic benchmarks.
NV-Llama2-70B-RLHF-Chat is trained with NVIDIA NeMo-Aligner, a scalable toolkit for performant and efficient model alignment. NeMo-Aligner is built using the NeMo Framework which allows for scaling training up to 1000s of GPUs using tensor, data and pipeline parallelism for all components of alignment. All of our checkpoints are cross compatible with the NeMo ecosystem, allowing for inference deployment and further customization.
Try this model instantly for free hosted by us at NVIDIA AI Playground. You can use this in the provided UI or through a limited access API (up to 10, 000 requests within 30 days). If you would need more requests, we demonstrate how you can set up an inference server below.
[^1]: as well as ~5k proprietary datapoints that we are unable to release due to data vendor restrictions
| Single-Turn | Single-Turn with Context | Multi-Turn |
|---|---|---|
| <extra_id_0>System <extra_id_1>User {prompt} <extra_id_1>Assistant |
<extra_id_0>System <extra_id_1>User {context} {prompt} <extra_id_1>Assistant |
<extra_id_0>System <extra_id_1>User {prompt 1} <extra_id_1>Assistant {response 1} <extra_id_1>User {prompt 2} <extra_id_1>Assistant |
We demonstrate inference using NVIDIA NeMo Framework, which allows hassle-free model deployment based on NVIDIA TRT-LLM, a highly optimized inference solution focussing on high throughput and low latency.
Pre-requisite: You would need at least a machine with 4 40GB or 2 80GB NVIDIA GPUs, and 300GB of free disk space.
Please sign up to get free and immediate access to NVIDIA NeMo Framework container. If you don’t have an NVIDIA NGC account, you will be prompted to sign up for an account before proceeding.
If you don’t already have NVIDIA NGC key, sign into NVIDIA NGC, selecting organization/team: ea-bignlp/ga-participants and click Generate API key. Save this key for the next step.
On your machine, docker login to nvcr.io.
docker login nvcr.io
Username: $oauthtoken
Password: <Your Saved NGC Key>
Download the required container.
docker pull nvcr.io/ea-bignlp/ga-participants/nemofw-inference:23.10
Download the checkpoint.
git lfs install
git clone https://huggingface.co/nvidia/NV-Llama2-70B-RLHF-Chat
cd NV-Llama2-70B-RLHF-Chat
git lfs pull
Convert checkpoint into NeMo format.
cd NV-Llama2-70B-RLHF-Chat
tar -cvf NV-Llama2-70B-RLHF-Chat.nemo .
mv NV-Llama2-70B-RLHF-Chat.nemo ../
cd ..
rm -r NV-Llama2-70B-RLHF-Chat
Run Docker container.
docker run --gpus all -it --rm --shm-size=300g -p 8000:8000 -v ${PWD}/NV-Llama2-70B-RLHF-Chat.nemo:/opt/checkpoints/NV-Llama2-70B-RLHF-Chat.nemo -w /opt/NeMo nvcr.io/ea-bignlp/ga-participants/nemofw-inference:23.10
Within the container, start the server in the background. This step does both conversion of the NeMo checkpoint to TRT-LLM and then deployment using TRT-LLM. For an explanation of each argument and advanced usage, please refer to NeMo FW Deployment Guide.
python scripts/deploy/deploy_triton.py --nemo_checkpoint /opt/checkpoints/NV-Llama2-70B-RLHF-Chat.nemo --model_type="llama" --triton_model_name NV-Llama2-70B-RLHF-Chat --triton_http_address 0.0.0.0 --triton_port 8000 --num_gpus 2 --max_input_len 3072 --max_output_len 1024 --max_batch_size 1 &
Once the server is ready (i.e. when you see this messages below), you are ready to launch your client code.
Started HTTPService at 0.0.0.0:8000
Started GRPCInferenceService at 0.0.0.0:8001
Started Metrics Service at 0.0.0.0:8002
An example for single-turn closed QA with context:
from nemo.deploy import NemoQuery
PROMPT_TEMPLATE = """<extra_id_0>System
<extra_id_1>User
This is a chat between a user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions based on the context. The assistant should also indicate when the answer cannot be found in the context.
Context: {context}
Please give a full and complete answer for the question. {prompt}
<extra_id_1>Assistant
"""
context = "Climate change refers to long-term shifts in temperatures and weather patterns. Such shifts can be natural, due to changes in the sun’s activity or large volcanic eruptions. But since the 1800s, human activities have been the main driver of climate change, primarily due to the burning of fossil fuels like coal, oil and gas."
question = "What did Michael Jackson achieve?"
prompt = PROMPT_TEMPLATE.format(context=context, prompt=question)
print(prompt)
nq = NemoQuery(url="localhost:8000", model_name="NV-Llama2-70B-RLHF-Chat")
output = nq.query_llm(prompts=[prompt], max_output_token=256, top_k=1, top_p=0.0, temperature=1.0)
#this container currently does not support stop words but you do something like this as workaround
output = output[0][0].split("\n<extra_id_1>")[0]
print(output)
An example for multi-turn conversation:
from nemo.deploy import NemoQuery
PROMPT_TEMPLATE1 = """<extra_id_0>System
<extra_id_1>User
{prompt1}
<extra_id_1>Assistant
"""
PROMPT_TEMPLATE2 = """<extra_id_0>System
<extra_id_1>User
{prompt1}
<extra_id_1>Assistant
{response1}
<extra_id_1>User
{prompt2}
<extra_id_1>Assistant
"""
nq = NemoQuery(url="localhost:8000", model_name="NV-Llama2-70B-RLHF-Chat")
# Turn 1
question1 = "Write an introduction about NVIDIA."
prompt = PROMPT_TEMPLATE1.format(prompt1=question1)
print(prompt)
output = nq.query_llm(prompts=[prompt], max_output_token=256, top_k=1, top_p=0.0, temperature=1.0)
#this container currently does not support stop words but you do something like this as workaround
response1 = output[0][0].split("\n<extra_id_1>")[0]
print(response1)
# Turn 2
question2 = "Can you write it in a poem in the style of Shakespeare?"
prompt = PROMPT_TEMPLATE2.format(prompt1=question1, response1=response1, prompt2=question2)
print(prompt)
output = nq.query_llm(prompts=[prompt], max_output_token=256, top_k=1, top_p=0.0, temperature=1.0)
response2 = output[0][0].split("\n<extra_id_1>")[0]
print(response2)
| Total | Writing | Roleplay | Extraction | STEM | Humanities | Reasoning | Math | Coding |
|---|---|---|---|---|---|---|---|---|
| 7.59 | 9.15 | 8.90 | 8.80 | 8.60 | 9.65 | 6.25 | 4.65 | 4.70 |
| MMLU (5-shot) |
HellaSwag (0-shot) |
ARC easy (0-shot) |
WinoGrande (0-shot) |
TruthfulQA MC2 (0-shot) |
TriviaQA (5-shot) |
|---|---|---|---|---|---|
| 68.04 | 84.04 | 83.67 | 79.40 | 58.16 | 80.86 |