
perceiver
Collection
8 items
•
Updated
This model is a Perceiver AR causal language model (455M parameters) pretrained on a subset (79B tokens) of the C4 English dataset. It uses rotary embedding for relative position encoding. It is a training example (Model 2) of the perceiver-io library.
Perceiver AR is a simple extension of a plain decoder-only transformer such as GPT-2, for example. A core building block of both is the decoder layer consisting of a self-attention layer followed by a position-wise MLP. Self-attention uses a causal attention mask.
Perceiver AR additionally cross-attends to a longer prefix of the input sequence in its first attention layer. This layer is a hybrid self- and cross-attention layer. Self-attention is over the last n positions of the input sequence, with a causal attention mask, cross-attention is from the last n positions to the first m positions. The length of the input sequence is m + n. This allows a Perceiver AR to process a much larger context than decoder-only transformers which are based on self-attention only.
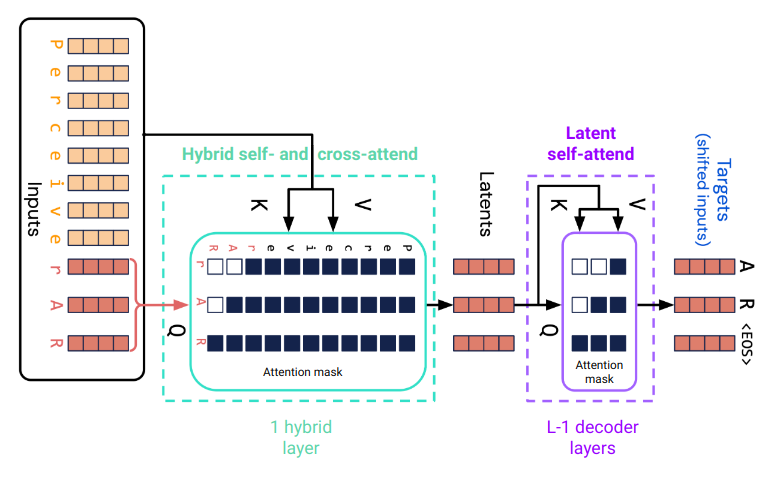
Fig. 1. Attention in Perceiver AR with m=8 prefix tokens and n=3 latent tokens.
The output of the hybrid attention layer are n latent arrays corresponding to the last n tokens of the input sequence. These are further processed by a stack of L-1 decoder layers where the total number of attention layers is L. A final layer (not shown in Fig. 1) predicts the target token for each latent position. The weights of the final layer are shared with the input embedding layer. Except for the initial cross-attention to the prefix sequence, a Perceiver AR is architecturally identical to a decoder-only transformer.
The model was trained with causal language modeling on a subset (79B tokens) of the C4 English dataset, tokenized with a SentencePiece tokenizer. All hyperparameters are summarized in the training script. The context length was set to 1024 tokens with 512 latent positions, resulting in a maximal prefix length of 512. The actual prefix length per example was randomly chosen between 0 and 512. Training was done with PyTorch Lightning and the resulting checkpoint was converted to this 🤗 model with a library-specific conversion utility.
This model can be used for text generation with a user-defined initial number of latent tokens. It mainly exists for demonstration purposes how to train Perceiver AR models with the library. To better leverage the advantages of the Perceiver AR architecture it should be trained with much longer prefixes (and also a larger number of latent tokens).
To use this model you first need to install
the perceiver-io library with extension text.
pip install perceiver-io[text]
Then the model can be used with PyTorch. Either use the model and tokenizer directly
from transformers import AutoModelForCausalLM, AutoTokenizer
from perceiver.model.text import clm # auto-class registration
repo_id = "krasserm/perceiver-ar-clm-base"
prompt = "Recently, I started to work on my"
model = AutoModelForCausalLM.from_pretrained(repo_id)
tokenizer = AutoTokenizer.from_pretrained(repo_id)
encoding = tokenizer(prompt, return_tensors="pt", add_special_tokens=False, return_token_type_ids=False)
output = model.generate(**encoding, num_latents=2, max_new_tokens=16, do_sample=True, top_k=20)
print(tokenizer.decode(output[0]))
"Recently, I started to work on my own project. My goal was simply to learn enough Python to begin to work with"
or use a text-generation pipeline:
from transformers import pipeline
from perceiver.model.text import clm # auto-class registration
repo_id = "krasserm/perceiver-ar-clm-base"
prompt = "Recently, I started to work on my"
text_generator = pipeline("text-generation", model=repo_id)
output = text_generator(prompt, num_latents=2, max_new_tokens=16, do_sample=True, top_k=20)
print(output[0]["generated_text"])
"Recently, I started to work on my second project. I'm planning to make a series of books, that can"
The krasserm/perceiver-ar-clm-base model has been created from a training checkpoint with:
from perceiver.model.text.clm import convert_checkpoint
convert_checkpoint(
save_dir="krasserm/perceiver-ar-clm-base",
ckpt_url="https://martin-krasser.com/perceiver/logs-0.8.0/clm-fsdp/version_1/checkpoints/epoch=000-val_loss=2.820.ckpt",
tokenizer_name="xlnet-base-cased",
push_to_hub=True,
)
@inproceedings{hawthorne2022general,
title={General-purpose, long-context autoregressive modeling with perceiver ar},
author={Hawthorne, Curtis and Jaegle, Andrew and Cangea, C{\u{a}}t{\u{a}}lina and Borgeaud, Sebastian and Nash, Charlie and Malinowski, Mateusz and Dieleman, Sander and Vinyals, Oriol and Botvinick, Matthew and Simon, Ian and others},
booktitle={International Conference on Machine Learning},
pages={8535--8558},
year={2022},
organization={PMLR}
}