Hugging Face
Models
Datasets
Spaces
Posts
Docs
Solutions
Pricing
Log In
Sign Up
jiazhengli
/
Mixtral-8x7B-Instruct-v0.1-QLoRA-Assessment-Rationale-dpo
like
0
PEFT
Safetensors
jiazhengli/Rationale_MCTS
jiazhengli/Synthetic_Rationale
English
llama-factory
lora
Generated from Trainer
arxiv:
2406.19949
License:
other
Model card
Files
Files and versions
Community
Use this model
main
Mixtral-8x7B-Instruct-v0.1-QLoRA-Assessment-Rationale-dpo
2 contributors
History:
3 commits
jiazhengli
Update README.md
8f97e33
verified
about 1 month ago
.gitattributes
Safe
1.52 kB
initial commit
4 months ago
README.md
Safe
4.82 kB
Update README.md
about 1 month ago
adapter_config.json
Safe
730 Bytes
init push
4 months ago
adapter_model.safetensors
Safe
485 MB
LFS
init push
4 months ago
all_results.json
Safe
693 Bytes
init push
4 months ago
eval_results.json
Safe
546 Bytes
init push
4 months ago
special_tokens_map.json
Safe
437 Bytes
init push
4 months ago
tokenizer.json
Safe
1.8 MB
init push
4 months ago
tokenizer.model
Safe
493 kB
LFS
init push
4 months ago
tokenizer_config.json
Safe
1.41 kB
init push
4 months ago
train_results.json
Safe
167 Bytes
init push
4 months ago
trainer_log.jsonl
Safe
40.2 kB
init push
4 months ago
trainer_state.json
Safe
96.4 kB
init push
4 months ago
training_args.bin
pickle
Detected Pickle imports (9)
"accelerate.utils.dataclasses.DistributedType"
,
"transformers.trainer_utils.SchedulerType"
,
"accelerate.state.PartialState"
,
"torch.device"
,
"transformers.trainer_utils.HubStrategy"
,
"transformers.trainer_utils.IntervalStrategy"
,
"transformers.trainer_pt_utils.AcceleratorConfig"
,
"transformers.training_args.OptimizerNames"
,
"transformers.training_args_seq2seq.Seq2SeqTrainingArguments"
How to fix it?
5.11 kB
LFS
init push
4 months ago
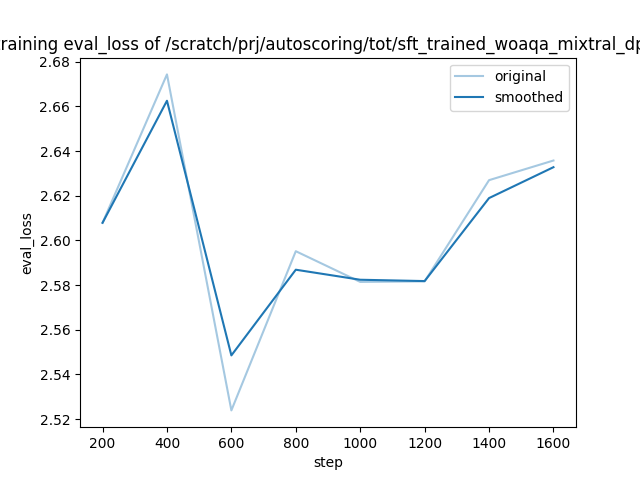
training_eval_loss.png
Safe
45.5 kB
init push
4 months ago
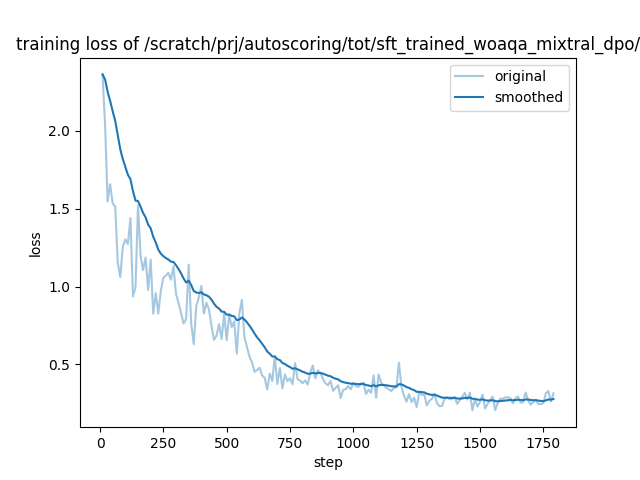
training_loss.png
Safe
45.1 kB
init push
4 months ago
training_rewards_accuracies.png
Safe
49.6 kB
init push
4 months ago

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}