Hugging Face
Models
Datasets
Spaces
Posts
Docs
Solutions
Pricing
Log In
Sign Up
jiazhengli
/
Mixtral-8x7B-Instruct-v0.1-QLoRA-Assessment-Rationale-dpo
like
0
PEFT
Safetensors
jiazhengli/Rationale_MCTS
jiazhengli/Synthetic_Rationale
English
llama-factory
lora
Generated from Trainer
arxiv:
2406.19949
License:
other
Model card
Files
Files and versions
Community
Use this model
main
Mixtral-8x7B-Instruct-v0.1-QLoRA-Assessment-Rationale-dpo
/
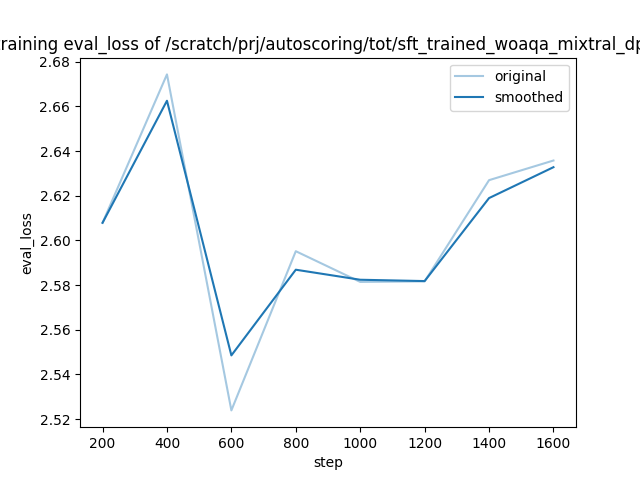
training_eval_loss.png
Jiazheng Li
init push
0ffb2d3
4 months ago
download
Copy download link
history
contribute
delete
Safe
45.5 kB

{kind=link}
{kind=link}
{kind=link}
{kind=link}