
OriGen: Enhancing RTL Code Generation with Code-to-Code Augmentation and Self-Reflection
Introduction
OriGen is a fine-tuned lora model designed for Verilog code generation. It is trained on top of DeepSeek Coder 7B using datasets generated from code-to-code augmentation and self-reflection. The datasets can be found in the origen_dataset_instruction.
OriGen_Fix is a fine-tuned lora model designed for fixing syntax errors in Verilog code. It is trained based on OriGen using debug datasets. The datasets can be found in the origen_dataset_debug.
There is another dataset called origen_dataset_description. This dataset is in the format of Description and Code, and origen_dataset_instruction is obtained by converting the Description to Instruction.
The models and datasets have been uploaded to Hugging Face, and the repository contains the inference scripts. The data generation flow will be released soon.
- Huggingface:
- Dataset:
- Repository: https://github.com/pku-liang/OriGen
Evaluation Results
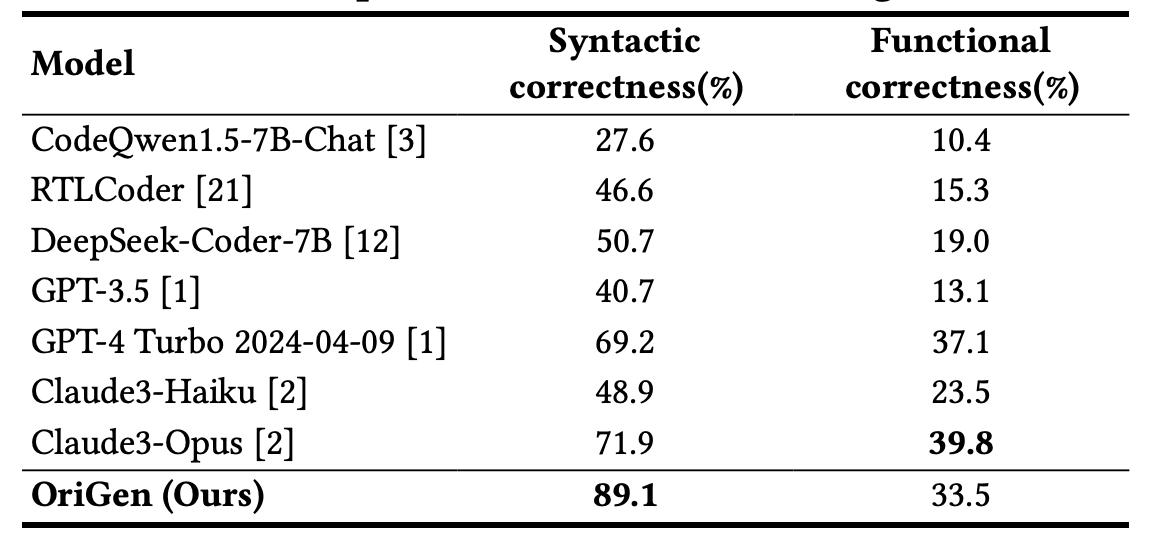
Quick Start
Before running the following code, please install the required packages:
conda create -n origen python=3.11
conda activate origen
pip install -r requirements.txt
Here is an example of how to use the model. Please note that the base model, DeepSeek Coder 7B, is loaded in float16 precision, even though its default precision is bfloat16. This choice was made because our experiments showed that Lora trained in float16 outperforms those trained in bfloat16.
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
import torch
from peft import PeftModel
import json
model_name = "deepseek-ai/deepseek-coder-7b-instruct-v1.5"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
attn_implementation="flash_attention_2",
device_map="auto",
).to("cuda")
model = PeftModel.from_pretrained(model, model_id="henryen/OriGen_Fix")
model.eval()
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
prompt_template = """
### Instruction: Please act as a professional Verilog designer. Your task is to debug a Verilog module.\nYou will receive a task, an original verilog code with syntax and function errors, and the corresponding error messages. \nYou should generate a corrected code based on the original code and the error messages
Your task:
{description}
Original code:
{original_code}
Error message:
{error}
You should now generate a correct code.
### Response:{header}
"""
def generate_code(data):
description = data["description"]
original_code = data["original_code"]
error = data["error"]
header = data["module_header"]
prompt = prompt_template.format(description=description, original_code=original_code, error=error, header=header)
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
**inputs,
max_new_tokens=1000,
do_sample=False,
temperature=0,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
streamer=streamer
)
input_length = len(inputs[0])
completion = tokenizer.decode(outputs[0][input_length:], skip_special_tokens=True)
return completion
input_file = "./data/example/example_error.jsonl"
output_file = "./data/example/example_fix.jsonl"
with open(input_file, "r") as f, open(output_file, "w") as f2:
for line in f:
data = json.loads(line)
completion = generate_code(data)
json.dump({"task_id": data["task_id"], "completion": completion}, f2)
f2.write("\n")
The output will be:
wire and0_out;
wire and1_out;
wire or0_out;
assign and0_out = a & b;
assign and1_out = c & d;
assign or0_out = and0_out | and1_out;
assign out = or0_out;
assign out_n = ~or0_out;
endmodule
You can check its correctness using testbench provided under the folder ./data/example/. The command evaluate_functional_correctness is part of the verilog-eval tool, available at https://github.com/NVlabs/verilog-eval/tree/release/1.0.0.
cd ./data/example/
evaluate_functional_correctness example_fix.jsonl --problem_file example_problem.jsonl
Paper
Arxiv: https://arxiv.org/abs/2407.16237
Please cite our paper if you find this model useful.
@article{2024origen,
title={OriGen: Enhancing RTL Code Generation with Code-to-Code Augmentation and Self-Reflection},
author={Cui, Fan and Yin, Chenyang and Zhou, Kexing and Xiao, Youwei and Sun, Guangyu and Xu, Qiang and Guo, Qipeng and Song, Demin and Lin, Dahua and Zhang, Xingcheng and others},
journal={arXiv preprint arXiv:2407.16237},
year={2024}
}
- Downloads last month
- 41
Model tree for henryen/OriGen_Fix
Base model
deepseek-ai/deepseek-coder-7b-instruct-v1.5