

language:
- en
pipeline_tag: text-generation
tags:
- unsloth
- axolotl
DreamGen Opus V1
Models for (steerable) story-writing and role-playing.
All Opus V1 models, including quants.
Resources
- Opus V1 prompting guide with many (interactive) examples and prompts that you can copy.
- Google Colab for interactive role-play using
opus-v1.2-7b. - Python code to format the prompt correctly.
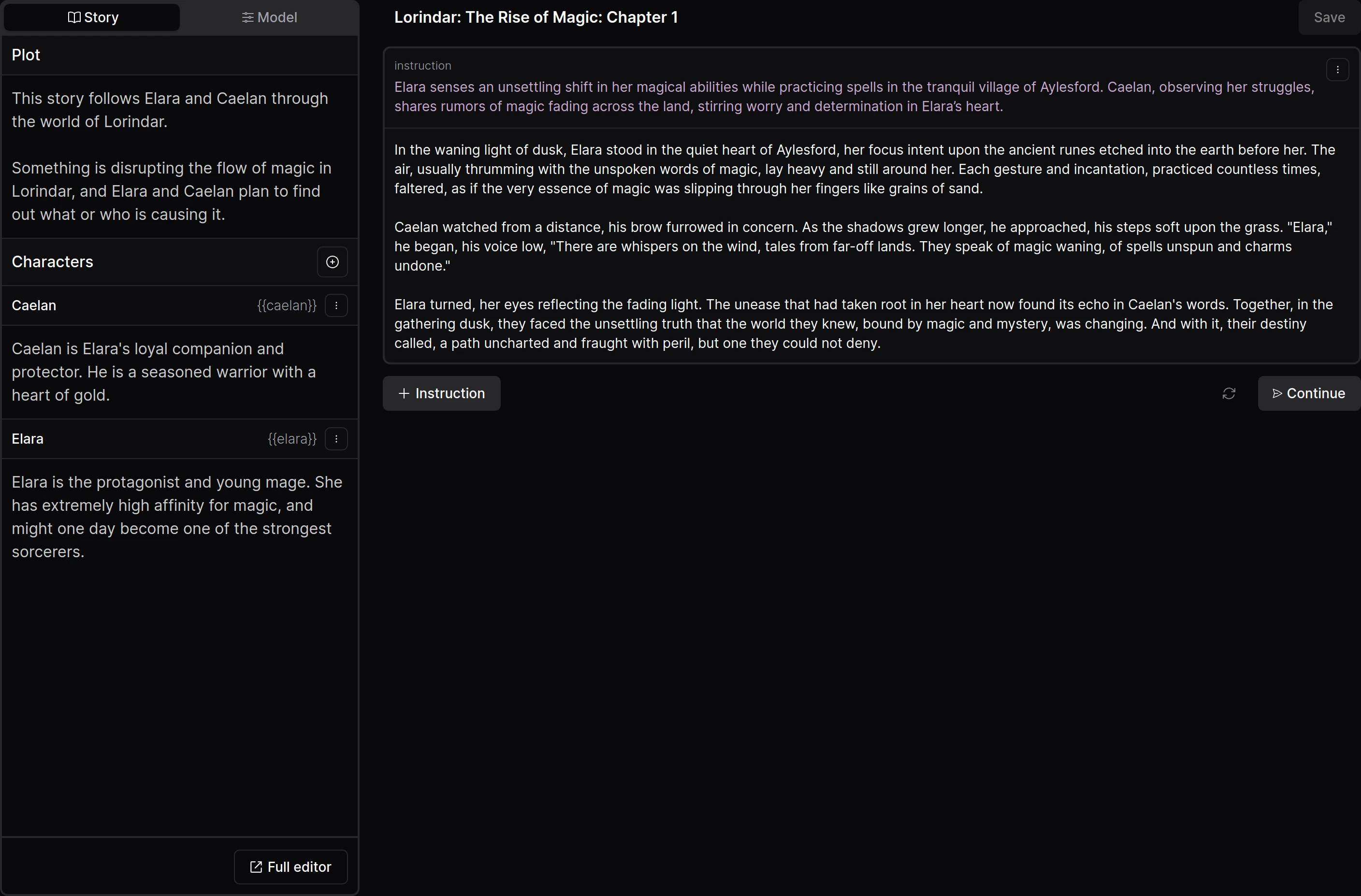
Prompting
The models use an extended version of ChatML.
<|im_start|>system
(Story description in the right format here)
(Typically consists of plot description, style description and characters)<|im_end|>
<|im_start|>user
(Your instruction on how the story should continue)<|im_end|>
<|im_start|>text names= Alice
(Continuation of the story from the Alice character)<|im_end|>
<|im_start|>text
(Continuation of the story from no character in particular (pure narration))<|im_end|>
<|im_start|>user
(Your instruction on how the story should continue)<|im_end|>
<|im_start|>text names= Bob
(Continuation of the story from the Bob character)<|im_end|>
The Opus V1 extension is the addition of the text role, and the addition / modification of role names.
Pay attention to the following:
- The
textmessages can (but don't have to have)names, names are used to indicate the "active" character during role-play. - There can be multiple subsequent message with a
textrole, especially if names are involved. - There can be multiple names attached to a message.
- The format for names is
names= {{name[0]}}; {{name[1]}}, beware of the spaces afternames=and after the;. This spacing leads to most natural tokenization for the names.
While the main goal for the models is great story-writing and role-playing performance, the models are also capable of several writing related tasks as well as general assistance.
Here's how you can prompt the model for the following tasks
- Steerable Story-writing and Role-playing:
- Input:
- System prompt: You provide story / role-play description, which consists of:
- Plot description
- Style description
- Characters and their descriptions
- Conversation turns:
- Text / message turn: This represents part of the story or role play
- Instruction: This tells the model what should happen next
- System prompt: You provide story / role-play description, which consists of:
- Output: Continuation of the story / role-play.
- Input:
- Story plot summarization
- Input: A story, or a few chapters of a story.
- Output: A description of the story or chapters.
- Story character description
- Input: A story, or a few chapters of a story, set of characters.
- Output: A description of the characters.
- Story style description
- Input: A story, or a few chapters of a story.
- Output: A description the style of the story.
- Story description to chapters
- Input: A brief plot description and the desired number of chapters.
- Output: A description for each chapter.
- And more...
Sampling params
For story-writing and role-play, I recommend "Min P" based sampling with min_p in the range [0.01, 0.1] and with temperature in the range [0.5, 1.5], depending on your preferences. A good starting point would be min_p=0.1; temperature=0.8.
You may also benefit from setting presence, frequency and repetition penalties, especially at lower temperatures.
Dataset
The fine-tuning dataset consisted of ~100M tokens of steerable story-writing, role-playing, writing-assistant and general-assistant examples. Each example was up to 31000 tokens long.
All story-writing and role-playing examples were based on human-written text.

Running the model
The model is should be compatible with any software that supports the base model, but beware of prompting and tokenization.
I recommend using these model versions:
Running on DreamGen.com (free)
You can run the models on dreamgen.com for free — you can use the built-in UI for story-writing & role-playing, or use the API.
Running Locally
- Make sure your prompt is as close as possible to the Opus V1
- Regardless of which backend you use, it's important that you format your prompt well and that the tokenization works correctly.
- Read the prompt guide
- Read the prompt formatting code
- Make sure
<|im_start|>and<|im_end|>are tokenized correctly
- vLLM
- Google Colab: This is a simple interactive Google Colab to do role-play with the 7B model, it should fit on the T4 GPU.
- Code: This is simple script for interactive chat for one hard-coded scenario.
- SillyTavern
- Settings, v2 kindly provided by @MarinaraSpaghetti
- Settings screenshot
- This is just an attempt at approximating the Opus V1 prompt, it won't be perfect
- LM Studio
- Config
- Just like ChatML, just changed "assistant" to "text" role.
- HuggingFace
- Chat template
- Just like ChatML, just changed "assistant" to "text" role.
{kind=link}
Known Issues
- 34B tokenization:
- There seems to be a mismatch between the tokenizer of the base and fine-tuned model. It's unclear whether this also affected training, or whether it's just incorrectly saved tokenizer (you can see
tokenizer.jsonwas not saved (bug report)). - This affects BOS and EOS (which aren't really used by Yi) and the tokenization of the first input token.
- Overall impact should be minor.
- There seems to be a mismatch between the tokenizer of the base and fine-tuned model. It's unclear whether this also affected training, or whether it's just incorrectly saved tokenizer (you can see
- 34B repetition:
- The 34B sometimes gets stuck repeating the same word, or synonyms. This seems to be a common problem across various Yi 34B fine-tunes.
- GGUF / Ooba:
- The tokenization might be messed up. Some users reported that
<|im_start|>and<|im_end|>are tokenized as multiple tokens.
- The tokenization might be messed up. Some users reported that
Community
Join the DreamGen community on Discord to get early access to new models.
License
- This model is intended for personal use only, other use is not permitted.