
Canarim Nheengatu
Collection
Collection of Models Focused on the Nheengatu Language
•
2 items
•
Updated

The canarim-bert-posTag-nheengatu model is a part-of-speech tagging model for the Nheengatu language, trained using the UD_Nheengatu-CompLin dataset available on github. It is based on the tokenizer and the Canarim-Bert-Nheengatu model.
The model can identify the following grammatical classes:
| tag | abbreviation in glossary | expansion of abbreviation |
|---|---|---|
| ADJ | adj. | 1st class adjective |
| ADP | posp. | postposition |
| ADV | adv. | adverb |
| AUX | aux. | auxiliary |
| CCONJ | cconj. | coordinating conjunction |
| DET | det. | determiner |
| INTJ | interj. | interjection |
| NOUN | n. | 1st class noun |
| NUM | num. | numeral |
| PART | part. | particle |
| PRON | pron. | 1st class pronoun |
| PROPN | prop. | proper noun |
| PUNCT | punct. | punctuation |
| SCONJ | sconj. | subordinating conjunction |
| VERB | v. | 1st class verb |
The dataset used for training was the UD_Nheengatu-CompLin, divided into 80/10/10 proportions for training, evaluation, and testing, respectively.
DatasetDict({
train: Dataset({
features: ['id', 'tokens', 'pos_tags', 'text'],
num_rows: 1068
})
test: Dataset({
features: ['id', 'tokens', 'pos_tags', 'text'],
num_rows: 134
})
eval: Dataset({
features: ['id', 'tokens', 'pos_tags', 'text'],
num_rows: 134
})
})
The hyperparameters used for training were:
learning_rate: 3e-4train_batch_size: 16eval_batch_size: 32gradient_accumulation_steps: 1weight_decay: 0.01num_train_epochs: 10The training and validation loss over the steps can be seen below:
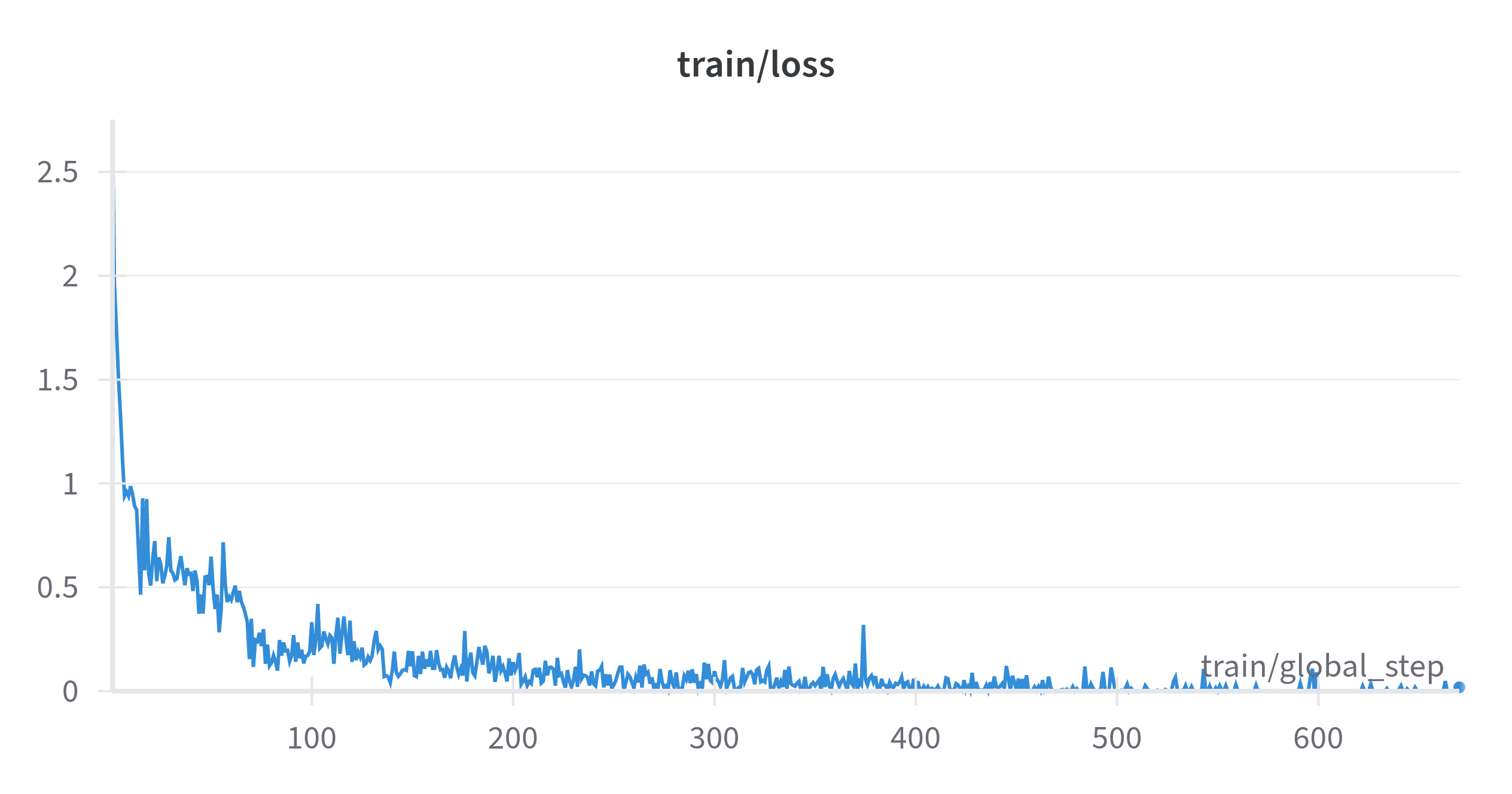
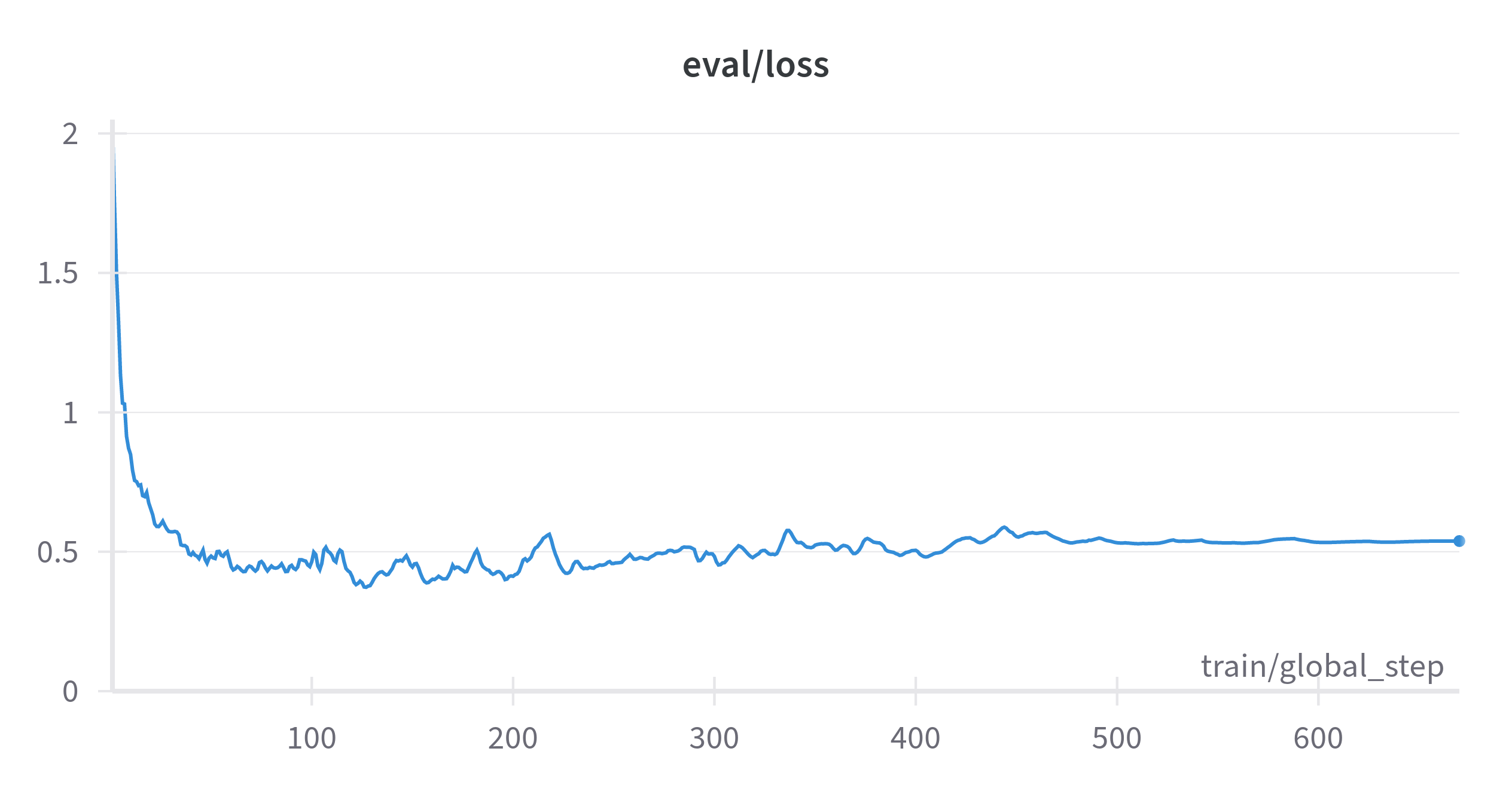
The model's results on the evaluation set can be viewed below:
{
'eval_loss': 0.5337784886360168,
'eval_precision': 0.913735899137359,
'eval_recall': 0.913735899137359,
'eval_f1': 0.913735899137359,
'eval_accuracy': 0.913735899137359,
'eval_runtime': 0.1957,
'eval_samples_per_second': 684.883,
'eval_steps_per_second': 25.555,
'epoch': 10.0
}
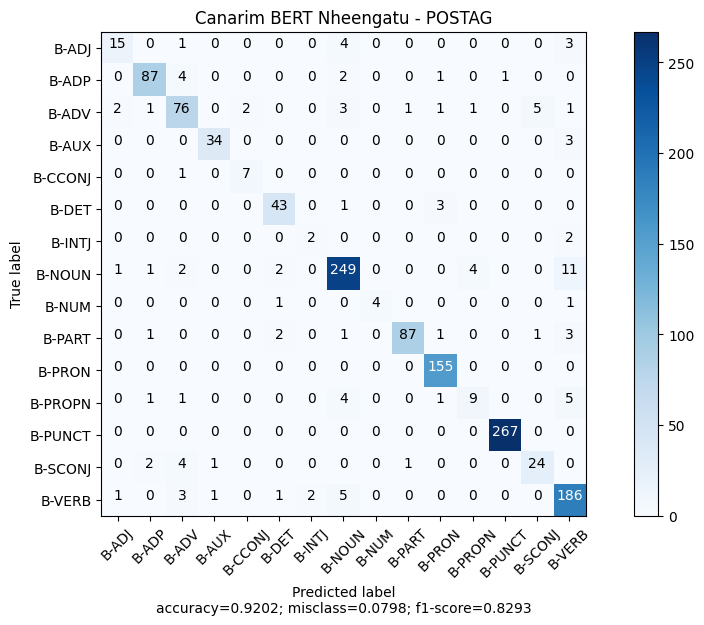
The model's evaluation metrics on the test set can be viewed below:
precision recall f1-score support
ADJ 0.7895 0.6522 0.7143 23
ADP 0.9355 0.9158 0.9255 95
ADV 0.8261 0.8172 0.8216 93
AUX 0.9444 0.9189 0.9315 37
CCONJ 0.7778 0.8750 0.8235 8
DET 0.8776 0.9149 0.8958 47
INTJ 0.5000 0.5000 0.5000 4
NOUN 0.9257 0.9222 0.9239 270
NUM 1.0000 0.6667 0.8000 6
PART 0.9775 0.9062 0.9405 96
PRON 0.9568 1.0000 0.9779 155
PROPN 0.6429 0.4286 0.5143 21
PUNCT 0.9963 1.0000 0.9981 267
SCONJ 0.8000 0.7500 0.7742 32
VERB 0.8651 0.9347 0.8986 199
micro avg 0.9202 0.9202 0.9202 1353
macro avg 0.8543 0.8135 0.8293 1353
weighted avg 0.9191 0.9202 0.9187 1353
The use of this model follows the common standards of the transformers library. To use it, simply install the library and load the model:
from transformers import pipeline
model_name = "dominguesm/canarim-bert-postag-nheengatu"
pipe = pipeline("ner", model=model_name)
pipe("Yamunhã timbiú, yapinaitika, yamunhã kaxirí.", aggregation_strategy="average")
The result will be:
[
{"entity_group": "VERB", "score": 0.999668, "word": "Yamunhã", "start": 0, "end": 7},
{"entity_group": "NOUN", "score": 0.99986947, "word": "timbiú", "start": 8, "end": 14},
{"entity_group": "PUNCT", "score": 0.99993193, "word": ",", "start": 14, "end": 15},
{"entity_group": "VERB", "score": 0.9995308, "word": "yapinaitika", "start": 16, "end": 27},
{"entity_group": "PUNCT", "score": 0.9999416, "word": ",", "start": 27, "end": 28},
{"entity_group": "VERB", "score": 0.99955815, "word": "yamunhã", "start": 29, "end": 36},
{"entity_group": "NOUN", "score": 0.9998684, "word": "kaxirí", "start": 37, "end": 43},
{"entity_group": "PUNCT", "score": 0.99997807, "word": ".", "start": 43, "end": 44}
]
The license of this model follows that of the dataset used for training, which is CC BY-NC-SA 4.0. For more information, please visit the dataset repository.
@inproceedings{stil,
author = {Leonel de Alencar},
title = {Yauti: A Tool for Morphosyntactic Analysis of Nheengatu within the Universal Dependencies Framework},
booktitle = {Anais do XIV Simpósio Brasileiro de Tecnologia da Informação e da Linguagem Humana},
location = {Belo Horizonte/MG},
year = {2023},
keywords = {},
issn = {0000-0000},
pages = {135--145},
publisher = {SBC},
address = {Porto Alegre, RS, Brasil},
doi = {10.5753/stil.2023.234131},
url = {https://sol.sbc.org.br/index.php/stil/article/view/25445}
}