Inference Endpoints
Inference Endpoints offers a secure production solution to easily deploy any Transformers, Sentence-Transformers and Diffusers models from the Hub on dedicated and autoscaling infrastructure managed by Hugging Face.
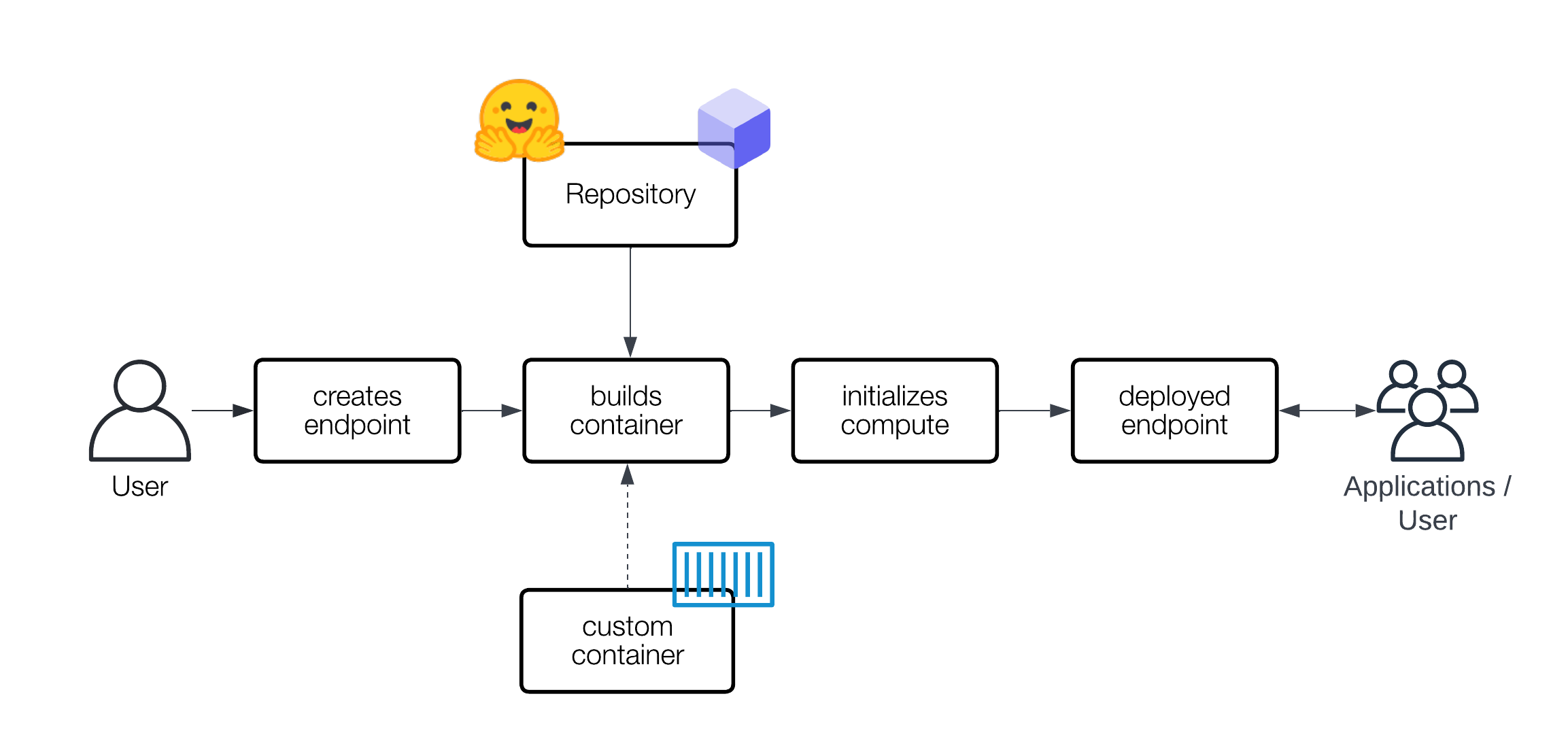
A Hugging Face Endpoint is built from a Hugging Face Model Repository. When an Endpoint is created, the service creates image artifacts that are either built from the model you select or a custom-provided container image. The image artifacts are completely decoupled from the Hugging Face Hub source repositories to ensure the highest security and reliability levels.
Inference Endpoints support all of the Transformers, Sentence-Transformers and Diffusers tasks as well as custom tasks not supported by Transformers yet like speaker diarization and diffusion.
In addition, Inference Endpoints gives you the option to use a custom container image managed on an external service, for instance, Docker Hub, AWS ECR, Azure ACR, or Google GCR.
Documentation and Examples
Guides
- Access the solution (UI)
- Create your first Endpoint
- Send Requests to Endpoints
- Update your Endpoint
- Advanced Setup (Instance Types, Auto Scaling, Versioning)
- Create a Private Endpoint with AWS PrivateLink
- Add custom Dependencies
- Create custom Inference Handler
- Use a custom Container Image
- Access and read Logs
- Access and view Metrics
- Change Organization or Account
- Deploying a llama.cpp Container
Others
- Inference Endpoints Versions
- Serialization & Deserialization for Requests
- Inference Endpoints Container Types