
id
stringlengths 1
8
| text
stringlengths 6
1.05M
| dataset_id
stringclasses 1
value |
|---|---|---|
/flair-0.12.2.tar.gz/flair-0.12.2/README.md | 

[](https://badge.fury.io/py/flair)
[](https://github.com/flairNLP/flair/issues)
[](CONTRIBUTING.md)
[](https://opensource.org/licenses/MIT)
A very simple framework for **state-of-the-art NLP**. Developed by [Humboldt University of Berlin](https://www.informatik.hu-berlin.de/en/forschung-en/gebiete/ml-en/) and friends.
---
Flair is:
* **A powerful NLP library.** Flair allows you to apply our state-of-the-art natural language processing (NLP)
models to your text, such as named entity recognition (NER), sentiment analysis, part-of-speech tagging (PoS),
special support for [biomedical data](/resources/docs/HUNFLAIR.md),
sense disambiguation and classification, with support for a rapidly growing number of languages.
* **A text embedding library.** Flair has simple interfaces that allow you to use and combine different word and
document embeddings, including our proposed [Flair embeddings](https://www.aclweb.org/anthology/C18-1139/) and various transformers.
* **A PyTorch NLP framework.** Our framework builds directly on [PyTorch](https://pytorch.org/), making it easy to
train your own models and experiment with new approaches using Flair embeddings and classes.
Now at [version 0.12.2](https://github.com/flairNLP/flair/releases)!
## State-of-the-Art Models
Flair ships with state-of-the-art models for a range of NLP tasks. For instance, check out our latest NER models:
| Language | Dataset | Flair | Best published | Model card & demo
| --- | ----------- | ---------------- | ------------- | ------------- |
| English | Conll-03 (4-class) | **94.09** | *94.3 [(Yamada et al., 2020)](https://doi.org/10.18653/v1/2020.emnlp-main.523)* | [Flair English 4-class NER demo](https://huggingface.co/flair/ner-english-large) |
| English | Ontonotes (18-class) | **90.93** | *91.3 [(Yu et al., 2020)](https://www.aclweb.org/anthology/2020.acl-main.577.pdf)* | [Flair English 18-class NER demo](https://huggingface.co/flair/ner-english-ontonotes-large) |
| German | Conll-03 (4-class) | **92.31** | *90.3 [(Yu et al., 2020)](https://www.aclweb.org/anthology/2020.acl-main.577.pdf)* | [Flair German 4-class NER demo](https://huggingface.co/flair/ner-german-large) |
| Dutch | Conll-03 (4-class) | **95.25** | *93.7 [(Yu et al., 2020)](https://www.aclweb.org/anthology/2020.acl-main.577.pdf)* | [Flair Dutch 4-class NER demo](https://huggingface.co/flair/ner-dutch-large) |
| Spanish | Conll-03 (4-class) | **90.54** | *90.3 [(Yu et al., 2020)](https://www.aclweb.org/anthology/2020.acl-main.577.pdf)* | [Flair Spanish 4-class NER demo](https://huggingface.co/flair/ner-spanish-large) |
Many Flair sequence tagging models (named entity recognition, part-of-speech tagging etc.) are also hosted
on the [__🤗 HuggingFace model hub__](https://huggingface.co/models?library=flair&sort=downloads)! You can browse models, check detailed information on how they were trained, and even try each model out online!
## Quick Start
### Requirements and Installation
In your favorite virtual environment, simply do:
```
pip install flair
```
Flair requires Python 3.7+.
### Example 1: Tag Entities in Text
Let's run **named entity recognition** (NER) over an example sentence. All you need to do is make a `Sentence`, load
a pre-trained model and use it to predict tags for the sentence:
```python
from flair.data import Sentence
from flair.nn import Classifier
# make a sentence
sentence = Sentence('I love Berlin .')
# load the NER tagger
tagger = Classifier.load('ner')
# run NER over sentence
tagger.predict(sentence)
# print the sentence with all annotations
print(sentence)
```
This should print:
```console
Sentence: "I love Berlin ." → ["Berlin"/LOC]
```
This means that "Berlin" was tagged as a **location entity** in this sentence.
* *to learn more about NER tagging in Flair, check out our [NER tutorial](/resources/docs/TUTORIAL_TAGGING_NER.md)!*
### Example 2: Detect Sentiment
Let's run **sentiment analysis** over an example sentence to determine whether it is POSITIVE or NEGATIVE.
Same code as above, just a different model:
```python
from flair.data import Sentence
from flair.nn import Classifier
# make a sentence
sentence = Sentence('I love Berlin .')
# load the NER tagger
tagger = Classifier.load('sentiment')
# run NER over sentence
tagger.predict(sentence)
# print the sentence with all annotations
print(sentence)
```
This should print:
```console
Sentence[4]: "I love Berlin ." → POSITIVE (0.9983)
```
This means that the sentence "I love Berlin" was tagged as having **POSITIVE** sentiment.
* *to learn more about sentiment analysis in Flair, check out our [sentiment analysis tutorial](/resources/docs/TUTORIAL_TAGGING_SENTIMENT.md)!*
## Tutorials
On our new :fire: [**Flair documentation page**](https://flairnlp.github.io/docs/intro/) you will find many tutorials to get you started!
In particular:
- [Tutorial 1: Basic tagging](https://flairnlp.github.io/docs/category/tutorial-1-basic-tagging) → how to tag your text
- [Tutorial 2: Training models](https://flairnlp.github.io/docs/category/tutorial-2-training-models) → how to train your own state-of-the-art NLP models
- [Tutorial 3: Embeddings](https://flairnlp.github.io/docs/category/tutorial-3-embeddings) → how to produce embeddings for words and documents
There is also a dedicated landing page for our [biomedical NER and datasets](/resources/docs/HUNFLAIR.md) with
installation instructions and tutorials.
## More Documentation
Another great place to start is the book [Natural Language Processing with Flair](https://www.amazon.com/Natural-Language-Processing-Flair-understanding/dp/1801072310)
and its accompanying [code repository](https://github.com/PacktPublishing/Natural-Language-Processing-with-Flair), though it was
written for an older version of Flair and some examples may no longer work.
There are also good third-party articles and posts that illustrate how to use Flair:
* [Training an NER model with Flair](https://medium.com/thecyphy/training-custom-ner-model-using-flair-df1f9ea9c762)
* [Training a text classifier with Flair](https://towardsdatascience.com/text-classification-with-state-of-the-art-nlp-library-flair-b541d7add21f)
* [Zero and few-shot learning](https://towardsdatascience.com/zero-and-few-shot-learning-c08e145dc4ed)
* [Visualisation tool for highlighting the extracted entities](https://github.com/lunayach/visNER)
* [Flair functionality and how to use in Colab](https://www.analyticsvidhya.com/blog/2019/02/flair-nlp-library-python/)
* [Benchmarking NER algorithms](https://towardsdatascience.com/benchmark-ner-algorithm-d4ab01b2d4c3)
* [Clinical NLP](https://towardsdatascience.com/clinical-natural-language-processing-5c7b3d17e137)
* [How to build a microservice with Flair and Flask](https://shekhargulati.com/2019/01/04/building-a-sentiment-analysis-python-microservice-with-flair-and-flask/)
* [A docker image for Flair](https://towardsdatascience.com/docker-image-for-nlp-5402c9a9069e)
* [Practical approach of State-of-the-Art Flair in Named Entity Recognition](https://medium.com/analytics-vidhya/practical-approach-of-state-of-the-art-flair-in-named-entity-recognition-46a837e25e6b)
* [Training a Flair text classifier on Google Cloud Platform (GCP) and serving predictions on GCP](https://github.com/robinvanschaik/flair-on-gcp)
* [Model Interpretability for transformer-based Flair models](https://github.com/robinvanschaik/interpret-flair)
## Citing Flair
Please cite [the following paper](https://www.aclweb.org/anthology/C18-1139/) when using Flair embeddings:
```
@inproceedings{akbik2018coling,
title={Contextual String Embeddings for Sequence Labeling},
author={Akbik, Alan and Blythe, Duncan and Vollgraf, Roland},
booktitle = {{COLING} 2018, 27th International Conference on Computational Linguistics},
pages = {1638--1649},
year = {2018}
}
```
If you use the Flair framework for your experiments, please cite [this paper](https://www.aclweb.org/anthology/papers/N/N19/N19-4010/):
```
@inproceedings{akbik2019flair,
title={{FLAIR}: An easy-to-use framework for state-of-the-art {NLP}},
author={Akbik, Alan and Bergmann, Tanja and Blythe, Duncan and Rasul, Kashif and Schweter, Stefan and Vollgraf, Roland},
booktitle={{NAACL} 2019, 2019 Annual Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations)},
pages={54--59},
year={2019}
}
```
If you use our new "FLERT" models or approach, please cite [this paper](https://arxiv.org/abs/2011.06993):
```
@misc{schweter2020flert,
title={{FLERT}: Document-Level Features for Named Entity Recognition},
author={Stefan Schweter and Alan Akbik},
year={2020},
eprint={2011.06993},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
If you use our TARS approach for few-shot and zero-shot learning, please cite [this paper](https://kishaloyhalder.github.io/pdfs/tars_coling2020.pdf/):
```
@inproceedings{halder2020coling,
title={Task Aware Representation of Sentences for Generic Text Classification},
author={Halder, Kishaloy and Akbik, Alan and Krapac, Josip and Vollgraf, Roland},
booktitle = {{COLING} 2020, 28th International Conference on Computational Linguistics},
year = {2020}
}
```
## Contact
Please email your questions or comments to [Alan Akbik](http://alanakbik.github.io/).
## Contributing
Thanks for your interest in contributing! There are many ways to get involved;
start with our [contributor guidelines](CONTRIBUTING.md) and then
check these [open issues](https://github.com/flairNLP/flair/issues) for specific tasks.
## [License](/LICENSE)
The MIT License (MIT)
Flair is licensed under the following MIT license: The MIT License (MIT) Copyright © 2018 Zalando SE, https://tech.zalando.com
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
| PypiClean |
/my_happy_pandas-1.1.10.tar.gz/my_happy_pandas-1.1.10/my_happy_pandas/core/dtypes/generic.py | def create_pandas_abc_type(name, attr, comp):
# https://github.com/python/mypy/issues/1006
# error: 'classmethod' used with a non-method
@classmethod # type: ignore
def _check(cls, inst) -> bool:
return getattr(inst, attr, "_typ") in comp
dct = dict(__instancecheck__=_check, __subclasscheck__=_check)
meta = type("ABCBase", (type,), dct)
return meta(name, tuple(), dct)
ABCIndex = create_pandas_abc_type("ABCIndex", "_typ", ("index",))
ABCInt64Index = create_pandas_abc_type("ABCInt64Index", "_typ", ("int64index",))
ABCUInt64Index = create_pandas_abc_type("ABCUInt64Index", "_typ", ("uint64index",))
ABCRangeIndex = create_pandas_abc_type("ABCRangeIndex", "_typ", ("rangeindex",))
ABCFloat64Index = create_pandas_abc_type("ABCFloat64Index", "_typ", ("float64index",))
ABCMultiIndex = create_pandas_abc_type("ABCMultiIndex", "_typ", ("multiindex",))
ABCDatetimeIndex = create_pandas_abc_type(
"ABCDatetimeIndex", "_typ", ("datetimeindex",)
)
ABCTimedeltaIndex = create_pandas_abc_type(
"ABCTimedeltaIndex", "_typ", ("timedeltaindex",)
)
ABCPeriodIndex = create_pandas_abc_type("ABCPeriodIndex", "_typ", ("periodindex",))
ABCCategoricalIndex = create_pandas_abc_type(
"ABCCategoricalIndex", "_typ", ("categoricalindex",)
)
ABCIntervalIndex = create_pandas_abc_type(
"ABCIntervalIndex", "_typ", ("intervalindex",)
)
ABCIndexClass = create_pandas_abc_type(
"ABCIndexClass",
"_typ",
{
"index",
"int64index",
"rangeindex",
"float64index",
"uint64index",
"multiindex",
"datetimeindex",
"timedeltaindex",
"periodindex",
"categoricalindex",
"intervalindex",
},
)
ABCSeries = create_pandas_abc_type("ABCSeries", "_typ", ("series",))
ABCDataFrame = create_pandas_abc_type("ABCDataFrame", "_typ", ("dataframe",))
ABCCategorical = create_pandas_abc_type("ABCCategorical", "_typ", ("categorical"))
ABCDatetimeArray = create_pandas_abc_type("ABCDatetimeArray", "_typ", ("datetimearray"))
ABCTimedeltaArray = create_pandas_abc_type(
"ABCTimedeltaArray", "_typ", ("timedeltaarray")
)
ABCPeriodArray = create_pandas_abc_type("ABCPeriodArray", "_typ", ("periodarray",))
ABCExtensionArray = create_pandas_abc_type(
"ABCExtensionArray",
"_typ",
# Note: IntervalArray and SparseArray are included bc they have _typ="extension"
{"extension", "categorical", "periodarray", "datetimearray", "timedeltaarray"},
)
ABCPandasArray = create_pandas_abc_type("ABCPandasArray", "_typ", ("npy_extension",)) | PypiClean |
/neon-safe-eth2-5.1.0.tar.gz/neon-safe-eth2-5.1.0/docs/source/gnosis.safe.rst | gnosis.safe package
===================
Subpackages
-----------
.. toctree::
:maxdepth: 4
gnosis.safe.tests
Submodules
----------
gnosis.safe.exceptions module
-----------------------------
.. automodule:: gnosis.safe.exceptions
:members:
:undoc-members:
:show-inheritance:
gnosis.safe.multi\_send module
------------------------------
.. automodule:: gnosis.safe.multi_send
:members:
:undoc-members:
:show-inheritance:
gnosis.safe.proxy\_factory module
---------------------------------
.. automodule:: gnosis.safe.proxy_factory
:members:
:undoc-members:
:show-inheritance:
gnosis.safe.safe module
-----------------------
.. automodule:: gnosis.safe.safe
:members:
:undoc-members:
:show-inheritance:
gnosis.safe.safe\_create2\_tx module
------------------------------------
.. automodule:: gnosis.safe.safe_create2_tx
:members:
:undoc-members:
:show-inheritance:
gnosis.safe.safe\_creation\_tx module
-------------------------------------
.. automodule:: gnosis.safe.safe_creation_tx
:members:
:undoc-members:
:show-inheritance:
gnosis.safe.safe\_signature module
----------------------------------
.. automodule:: gnosis.safe.safe_signature
:members:
:undoc-members:
:show-inheritance:
gnosis.safe.safe\_tx module
---------------------------
.. automodule:: gnosis.safe.safe_tx
:members:
:undoc-members:
:show-inheritance:
gnosis.safe.serializers module
------------------------------
.. automodule:: gnosis.safe.serializers
:members:
:undoc-members:
:show-inheritance:
gnosis.safe.signatures module
-----------------------------
.. automodule:: gnosis.safe.signatures
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: gnosis.safe
:members:
:undoc-members:
:show-inheritance:
| PypiClean |
/mist.io-0.9.8.zip/mist.io-0.9.8/src/mist/io/static/js/app/controllers/machine_shell.js | define('app/controllers/machine_shell', ['app/models/command', 'ember'],
/**
* Machine Shell Controller
*
* @returns Class
*/
function (Command) {
return Ember.Object.extend(Ember.Evented, {
/**
* Properties
*/
command: null,
machine: null,
commandHistoryIndex: -1,
/**
*
* Methods
*
*/
open: function (machine) {
this._clear();
this.set('machine', machine);
$('#machine-shell-popup').on('popupafteropen',
function(){
var ua = navigator.userAgent.toLowerCase();
var isAndroid = ua.indexOf("android") > -1;
if (!isAndroid){ // Chrome for Android doesn't like input focus
$('#shell-input input').focus();
}
}
).popup( "option", "dismissible", false ).popup('open');
$(window).on('resize', function(){
$('#shell-return').css({'height': ($(window).height() - 290) + 'px'});
return true;
});
$(window).trigger('resize');
Ember.run.next(function(){
$('#shell-input input').focus();
});
},
close: function () {
$('#machine-shell-popup').popup('close');
$(window).off('resize');
this._clear();
},
submit: function(timeout) {
var machine = this.machine;
if (!machine || !machine.probed || !this.command) {
return;
}
var commandHistory = machine.commandHistory;
var command = Command.create({
'id' : machine.backend.id + machine.id + commandHistory.length,
'command' : this.command,
'response' : '',
'pendingResponse': true,
'data-collapsed' : false
});
// Modify machine's command history
commandHistory.unshiftObject(command);
// Construct request
var url = '/backends/' + machine.backend.id + '/machines/' + machine.id + '/shell';
var host = machine.getHost();
var params = {
'host' : host,
'command' : command.command,
'command_id': command.id
};
if (timeout)
params.timeout = timeout;
function EncodeQueryData(data)
{
var ret = [];
for (var d in data)
ret.push(encodeURIComponent(d) + '=' + encodeURIComponent(data[d]));
return ret.join('&');
}
url = url + '?' + EncodeQueryData(params);
$('#hidden-shell').append(
'<iframe id="' + command.id +'" src="' + url + '"></iframe>'
);
this.set('command', '');
this.set('commandHistoryIndex', -1);
},
/**
*
* Pseudo-Private Methods
*
*/
_clear: function () {
Ember.run(this, function () {
this.set('machine', null);
});
},
_giveCallback: function (success, action) {
if (this.callback) this.callback(success, action);
},
/**
*
* Observers
*
*/
machinesObserver: function () {
Ember.run.once(this, '_updateActions');
}.observes('machines')
});
}
); | PypiClean |
/cdktf_cdktf_provider_aws-17.0.2-py3-none-any.whl/cdktf_cdktf_provider_aws/default_vpc/__init__.py | import abc
import builtins
import datetime
import enum
import typing
import jsii
import publication
import typing_extensions
from typeguard import check_type
from .._jsii import *
import cdktf as _cdktf_9a9027ec
import constructs as _constructs_77d1e7e8
class DefaultVpc(
_cdktf_9a9027ec.TerraformResource,
metaclass=jsii.JSIIMeta,
jsii_type="@cdktf/provider-aws.defaultVpc.DefaultVpc",
):
'''Represents a {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc aws_default_vpc}.'''
def __init__(
self,
scope: _constructs_77d1e7e8.Construct,
id_: builtins.str,
*,
assign_generated_ipv6_cidr_block: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
enable_dns_hostnames: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
enable_dns_support: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
enable_network_address_usage_metrics: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
force_destroy: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
id: typing.Optional[builtins.str] = None,
ipv6_cidr_block: typing.Optional[builtins.str] = None,
ipv6_cidr_block_network_border_group: typing.Optional[builtins.str] = None,
ipv6_ipam_pool_id: typing.Optional[builtins.str] = None,
ipv6_netmask_length: typing.Optional[jsii.Number] = None,
tags: typing.Optional[typing.Mapping[builtins.str, builtins.str]] = None,
tags_all: typing.Optional[typing.Mapping[builtins.str, builtins.str]] = None,
connection: typing.Optional[typing.Union[typing.Union[_cdktf_9a9027ec.SSHProvisionerConnection, typing.Dict[builtins.str, typing.Any]], typing.Union[_cdktf_9a9027ec.WinrmProvisionerConnection, typing.Dict[builtins.str, typing.Any]]]] = None,
count: typing.Optional[typing.Union[jsii.Number, _cdktf_9a9027ec.TerraformCount]] = None,
depends_on: typing.Optional[typing.Sequence[_cdktf_9a9027ec.ITerraformDependable]] = None,
for_each: typing.Optional[_cdktf_9a9027ec.ITerraformIterator] = None,
lifecycle: typing.Optional[typing.Union[_cdktf_9a9027ec.TerraformResourceLifecycle, typing.Dict[builtins.str, typing.Any]]] = None,
provider: typing.Optional[_cdktf_9a9027ec.TerraformProvider] = None,
provisioners: typing.Optional[typing.Sequence[typing.Union[typing.Union[_cdktf_9a9027ec.FileProvisioner, typing.Dict[builtins.str, typing.Any]], typing.Union[_cdktf_9a9027ec.LocalExecProvisioner, typing.Dict[builtins.str, typing.Any]], typing.Union[_cdktf_9a9027ec.RemoteExecProvisioner, typing.Dict[builtins.str, typing.Any]]]]] = None,
) -> None:
'''Create a new {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc aws_default_vpc} Resource.
:param scope: The scope in which to define this construct.
:param id_: The scoped construct ID. Must be unique amongst siblings in the same scope
:param assign_generated_ipv6_cidr_block: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#assign_generated_ipv6_cidr_block DefaultVpc#assign_generated_ipv6_cidr_block}.
:param enable_dns_hostnames: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#enable_dns_hostnames DefaultVpc#enable_dns_hostnames}.
:param enable_dns_support: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#enable_dns_support DefaultVpc#enable_dns_support}.
:param enable_network_address_usage_metrics: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#enable_network_address_usage_metrics DefaultVpc#enable_network_address_usage_metrics}.
:param force_destroy: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#force_destroy DefaultVpc#force_destroy}.
:param id: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#id DefaultVpc#id}. Please be aware that the id field is automatically added to all resources in Terraform providers using a Terraform provider SDK version below 2. If you experience problems setting this value it might not be settable. Please take a look at the provider documentation to ensure it should be settable.
:param ipv6_cidr_block: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#ipv6_cidr_block DefaultVpc#ipv6_cidr_block}.
:param ipv6_cidr_block_network_border_group: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#ipv6_cidr_block_network_border_group DefaultVpc#ipv6_cidr_block_network_border_group}.
:param ipv6_ipam_pool_id: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#ipv6_ipam_pool_id DefaultVpc#ipv6_ipam_pool_id}.
:param ipv6_netmask_length: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#ipv6_netmask_length DefaultVpc#ipv6_netmask_length}.
:param tags: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#tags DefaultVpc#tags}.
:param tags_all: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#tags_all DefaultVpc#tags_all}.
:param connection:
:param count:
:param depends_on:
:param for_each:
:param lifecycle:
:param provider:
:param provisioners:
'''
if __debug__:
type_hints = typing.get_type_hints(_typecheckingstub__46a5a50326cf4d3bb9adcdb87120337ef849d9593a37230e4d2f640534db3164)
check_type(argname="argument scope", value=scope, expected_type=type_hints["scope"])
check_type(argname="argument id_", value=id_, expected_type=type_hints["id_"])
config = DefaultVpcConfig(
assign_generated_ipv6_cidr_block=assign_generated_ipv6_cidr_block,
enable_dns_hostnames=enable_dns_hostnames,
enable_dns_support=enable_dns_support,
enable_network_address_usage_metrics=enable_network_address_usage_metrics,
force_destroy=force_destroy,
id=id,
ipv6_cidr_block=ipv6_cidr_block,
ipv6_cidr_block_network_border_group=ipv6_cidr_block_network_border_group,
ipv6_ipam_pool_id=ipv6_ipam_pool_id,
ipv6_netmask_length=ipv6_netmask_length,
tags=tags,
tags_all=tags_all,
connection=connection,
count=count,
depends_on=depends_on,
for_each=for_each,
lifecycle=lifecycle,
provider=provider,
provisioners=provisioners,
)
jsii.create(self.__class__, self, [scope, id_, config])
@jsii.member(jsii_name="resetAssignGeneratedIpv6CidrBlock")
def reset_assign_generated_ipv6_cidr_block(self) -> None:
return typing.cast(None, jsii.invoke(self, "resetAssignGeneratedIpv6CidrBlock", []))
@jsii.member(jsii_name="resetEnableDnsHostnames")
def reset_enable_dns_hostnames(self) -> None:
return typing.cast(None, jsii.invoke(self, "resetEnableDnsHostnames", []))
@jsii.member(jsii_name="resetEnableDnsSupport")
def reset_enable_dns_support(self) -> None:
return typing.cast(None, jsii.invoke(self, "resetEnableDnsSupport", []))
@jsii.member(jsii_name="resetEnableNetworkAddressUsageMetrics")
def reset_enable_network_address_usage_metrics(self) -> None:
return typing.cast(None, jsii.invoke(self, "resetEnableNetworkAddressUsageMetrics", []))
@jsii.member(jsii_name="resetForceDestroy")
def reset_force_destroy(self) -> None:
return typing.cast(None, jsii.invoke(self, "resetForceDestroy", []))
@jsii.member(jsii_name="resetId")
def reset_id(self) -> None:
return typing.cast(None, jsii.invoke(self, "resetId", []))
@jsii.member(jsii_name="resetIpv6CidrBlock")
def reset_ipv6_cidr_block(self) -> None:
return typing.cast(None, jsii.invoke(self, "resetIpv6CidrBlock", []))
@jsii.member(jsii_name="resetIpv6CidrBlockNetworkBorderGroup")
def reset_ipv6_cidr_block_network_border_group(self) -> None:
return typing.cast(None, jsii.invoke(self, "resetIpv6CidrBlockNetworkBorderGroup", []))
@jsii.member(jsii_name="resetIpv6IpamPoolId")
def reset_ipv6_ipam_pool_id(self) -> None:
return typing.cast(None, jsii.invoke(self, "resetIpv6IpamPoolId", []))
@jsii.member(jsii_name="resetIpv6NetmaskLength")
def reset_ipv6_netmask_length(self) -> None:
return typing.cast(None, jsii.invoke(self, "resetIpv6NetmaskLength", []))
@jsii.member(jsii_name="resetTags")
def reset_tags(self) -> None:
return typing.cast(None, jsii.invoke(self, "resetTags", []))
@jsii.member(jsii_name="resetTagsAll")
def reset_tags_all(self) -> None:
return typing.cast(None, jsii.invoke(self, "resetTagsAll", []))
@jsii.member(jsii_name="synthesizeAttributes")
def _synthesize_attributes(self) -> typing.Mapping[builtins.str, typing.Any]:
return typing.cast(typing.Mapping[builtins.str, typing.Any], jsii.invoke(self, "synthesizeAttributes", []))
@jsii.python.classproperty
@jsii.member(jsii_name="tfResourceType")
def TF_RESOURCE_TYPE(cls) -> builtins.str:
return typing.cast(builtins.str, jsii.sget(cls, "tfResourceType"))
@builtins.property
@jsii.member(jsii_name="arn")
def arn(self) -> builtins.str:
return typing.cast(builtins.str, jsii.get(self, "arn"))
@builtins.property
@jsii.member(jsii_name="cidrBlock")
def cidr_block(self) -> builtins.str:
return typing.cast(builtins.str, jsii.get(self, "cidrBlock"))
@builtins.property
@jsii.member(jsii_name="defaultNetworkAclId")
def default_network_acl_id(self) -> builtins.str:
return typing.cast(builtins.str, jsii.get(self, "defaultNetworkAclId"))
@builtins.property
@jsii.member(jsii_name="defaultRouteTableId")
def default_route_table_id(self) -> builtins.str:
return typing.cast(builtins.str, jsii.get(self, "defaultRouteTableId"))
@builtins.property
@jsii.member(jsii_name="defaultSecurityGroupId")
def default_security_group_id(self) -> builtins.str:
return typing.cast(builtins.str, jsii.get(self, "defaultSecurityGroupId"))
@builtins.property
@jsii.member(jsii_name="dhcpOptionsId")
def dhcp_options_id(self) -> builtins.str:
return typing.cast(builtins.str, jsii.get(self, "dhcpOptionsId"))
@builtins.property
@jsii.member(jsii_name="existingDefaultVpc")
def existing_default_vpc(self) -> _cdktf_9a9027ec.IResolvable:
return typing.cast(_cdktf_9a9027ec.IResolvable, jsii.get(self, "existingDefaultVpc"))
@builtins.property
@jsii.member(jsii_name="instanceTenancy")
def instance_tenancy(self) -> builtins.str:
return typing.cast(builtins.str, jsii.get(self, "instanceTenancy"))
@builtins.property
@jsii.member(jsii_name="ipv6AssociationId")
def ipv6_association_id(self) -> builtins.str:
return typing.cast(builtins.str, jsii.get(self, "ipv6AssociationId"))
@builtins.property
@jsii.member(jsii_name="mainRouteTableId")
def main_route_table_id(self) -> builtins.str:
return typing.cast(builtins.str, jsii.get(self, "mainRouteTableId"))
@builtins.property
@jsii.member(jsii_name="ownerId")
def owner_id(self) -> builtins.str:
return typing.cast(builtins.str, jsii.get(self, "ownerId"))
@builtins.property
@jsii.member(jsii_name="assignGeneratedIpv6CidrBlockInput")
def assign_generated_ipv6_cidr_block_input(
self,
) -> typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]]:
return typing.cast(typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]], jsii.get(self, "assignGeneratedIpv6CidrBlockInput"))
@builtins.property
@jsii.member(jsii_name="enableDnsHostnamesInput")
def enable_dns_hostnames_input(
self,
) -> typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]]:
return typing.cast(typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]], jsii.get(self, "enableDnsHostnamesInput"))
@builtins.property
@jsii.member(jsii_name="enableDnsSupportInput")
def enable_dns_support_input(
self,
) -> typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]]:
return typing.cast(typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]], jsii.get(self, "enableDnsSupportInput"))
@builtins.property
@jsii.member(jsii_name="enableNetworkAddressUsageMetricsInput")
def enable_network_address_usage_metrics_input(
self,
) -> typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]]:
return typing.cast(typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]], jsii.get(self, "enableNetworkAddressUsageMetricsInput"))
@builtins.property
@jsii.member(jsii_name="forceDestroyInput")
def force_destroy_input(
self,
) -> typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]]:
return typing.cast(typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]], jsii.get(self, "forceDestroyInput"))
@builtins.property
@jsii.member(jsii_name="idInput")
def id_input(self) -> typing.Optional[builtins.str]:
return typing.cast(typing.Optional[builtins.str], jsii.get(self, "idInput"))
@builtins.property
@jsii.member(jsii_name="ipv6CidrBlockInput")
def ipv6_cidr_block_input(self) -> typing.Optional[builtins.str]:
return typing.cast(typing.Optional[builtins.str], jsii.get(self, "ipv6CidrBlockInput"))
@builtins.property
@jsii.member(jsii_name="ipv6CidrBlockNetworkBorderGroupInput")
def ipv6_cidr_block_network_border_group_input(
self,
) -> typing.Optional[builtins.str]:
return typing.cast(typing.Optional[builtins.str], jsii.get(self, "ipv6CidrBlockNetworkBorderGroupInput"))
@builtins.property
@jsii.member(jsii_name="ipv6IpamPoolIdInput")
def ipv6_ipam_pool_id_input(self) -> typing.Optional[builtins.str]:
return typing.cast(typing.Optional[builtins.str], jsii.get(self, "ipv6IpamPoolIdInput"))
@builtins.property
@jsii.member(jsii_name="ipv6NetmaskLengthInput")
def ipv6_netmask_length_input(self) -> typing.Optional[jsii.Number]:
return typing.cast(typing.Optional[jsii.Number], jsii.get(self, "ipv6NetmaskLengthInput"))
@builtins.property
@jsii.member(jsii_name="tagsAllInput")
def tags_all_input(
self,
) -> typing.Optional[typing.Mapping[builtins.str, builtins.str]]:
return typing.cast(typing.Optional[typing.Mapping[builtins.str, builtins.str]], jsii.get(self, "tagsAllInput"))
@builtins.property
@jsii.member(jsii_name="tagsInput")
def tags_input(self) -> typing.Optional[typing.Mapping[builtins.str, builtins.str]]:
return typing.cast(typing.Optional[typing.Mapping[builtins.str, builtins.str]], jsii.get(self, "tagsInput"))
@builtins.property
@jsii.member(jsii_name="assignGeneratedIpv6CidrBlock")
def assign_generated_ipv6_cidr_block(
self,
) -> typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]:
return typing.cast(typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable], jsii.get(self, "assignGeneratedIpv6CidrBlock"))
@assign_generated_ipv6_cidr_block.setter
def assign_generated_ipv6_cidr_block(
self,
value: typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable],
) -> None:
if __debug__:
type_hints = typing.get_type_hints(_typecheckingstub__1bdd685a0191d9cb3a46cc1e358c148e37748426ee9f409e14a79a39c9df532c)
check_type(argname="argument value", value=value, expected_type=type_hints["value"])
jsii.set(self, "assignGeneratedIpv6CidrBlock", value)
@builtins.property
@jsii.member(jsii_name="enableDnsHostnames")
def enable_dns_hostnames(
self,
) -> typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]:
return typing.cast(typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable], jsii.get(self, "enableDnsHostnames"))
@enable_dns_hostnames.setter
def enable_dns_hostnames(
self,
value: typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable],
) -> None:
if __debug__:
type_hints = typing.get_type_hints(_typecheckingstub__998b1309295c204cbc6f9e93b7a205a421d65d6b5c7c2c8f2c82b4f7f6a815d6)
check_type(argname="argument value", value=value, expected_type=type_hints["value"])
jsii.set(self, "enableDnsHostnames", value)
@builtins.property
@jsii.member(jsii_name="enableDnsSupport")
def enable_dns_support(
self,
) -> typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]:
return typing.cast(typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable], jsii.get(self, "enableDnsSupport"))
@enable_dns_support.setter
def enable_dns_support(
self,
value: typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable],
) -> None:
if __debug__:
type_hints = typing.get_type_hints(_typecheckingstub__270ab725a2e2872833c3260e3876cb878ed0be8df4e8751cd29b7299ed2c9048)
check_type(argname="argument value", value=value, expected_type=type_hints["value"])
jsii.set(self, "enableDnsSupport", value)
@builtins.property
@jsii.member(jsii_name="enableNetworkAddressUsageMetrics")
def enable_network_address_usage_metrics(
self,
) -> typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]:
return typing.cast(typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable], jsii.get(self, "enableNetworkAddressUsageMetrics"))
@enable_network_address_usage_metrics.setter
def enable_network_address_usage_metrics(
self,
value: typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable],
) -> None:
if __debug__:
type_hints = typing.get_type_hints(_typecheckingstub__4f9502da384032fe6ce21f224d5195382672bc6fc971ac20d99390cf48dfa6e1)
check_type(argname="argument value", value=value, expected_type=type_hints["value"])
jsii.set(self, "enableNetworkAddressUsageMetrics", value)
@builtins.property
@jsii.member(jsii_name="forceDestroy")
def force_destroy(self) -> typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]:
return typing.cast(typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable], jsii.get(self, "forceDestroy"))
@force_destroy.setter
def force_destroy(
self,
value: typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable],
) -> None:
if __debug__:
type_hints = typing.get_type_hints(_typecheckingstub__1141b60c8b3f1dd45f89bb3e465b9cc17a10d285287aad858f544694a8a9fff1)
check_type(argname="argument value", value=value, expected_type=type_hints["value"])
jsii.set(self, "forceDestroy", value)
@builtins.property
@jsii.member(jsii_name="id")
def id(self) -> builtins.str:
return typing.cast(builtins.str, jsii.get(self, "id"))
@id.setter
def id(self, value: builtins.str) -> None:
if __debug__:
type_hints = typing.get_type_hints(_typecheckingstub__965e42e9639378066a52b4d584b53363a589cdf6c7f79cbde1fc1e8e2c9da07a)
check_type(argname="argument value", value=value, expected_type=type_hints["value"])
jsii.set(self, "id", value)
@builtins.property
@jsii.member(jsii_name="ipv6CidrBlock")
def ipv6_cidr_block(self) -> builtins.str:
return typing.cast(builtins.str, jsii.get(self, "ipv6CidrBlock"))
@ipv6_cidr_block.setter
def ipv6_cidr_block(self, value: builtins.str) -> None:
if __debug__:
type_hints = typing.get_type_hints(_typecheckingstub__37585261fa59d515b7b921a98f8087675560d7c06e32e0b7c482d5c9918907b9)
check_type(argname="argument value", value=value, expected_type=type_hints["value"])
jsii.set(self, "ipv6CidrBlock", value)
@builtins.property
@jsii.member(jsii_name="ipv6CidrBlockNetworkBorderGroup")
def ipv6_cidr_block_network_border_group(self) -> builtins.str:
return typing.cast(builtins.str, jsii.get(self, "ipv6CidrBlockNetworkBorderGroup"))
@ipv6_cidr_block_network_border_group.setter
def ipv6_cidr_block_network_border_group(self, value: builtins.str) -> None:
if __debug__:
type_hints = typing.get_type_hints(_typecheckingstub__199c7d8c328c1f704fdb0f99ee48094c4b1aaa4f9645960ab021e20465e5946e)
check_type(argname="argument value", value=value, expected_type=type_hints["value"])
jsii.set(self, "ipv6CidrBlockNetworkBorderGroup", value)
@builtins.property
@jsii.member(jsii_name="ipv6IpamPoolId")
def ipv6_ipam_pool_id(self) -> builtins.str:
return typing.cast(builtins.str, jsii.get(self, "ipv6IpamPoolId"))
@ipv6_ipam_pool_id.setter
def ipv6_ipam_pool_id(self, value: builtins.str) -> None:
if __debug__:
type_hints = typing.get_type_hints(_typecheckingstub__760109756bacf9f1a9e089040733bc01069ceac04fe92b458daa8a597ffe3c0b)
check_type(argname="argument value", value=value, expected_type=type_hints["value"])
jsii.set(self, "ipv6IpamPoolId", value)
@builtins.property
@jsii.member(jsii_name="ipv6NetmaskLength")
def ipv6_netmask_length(self) -> jsii.Number:
return typing.cast(jsii.Number, jsii.get(self, "ipv6NetmaskLength"))
@ipv6_netmask_length.setter
def ipv6_netmask_length(self, value: jsii.Number) -> None:
if __debug__:
type_hints = typing.get_type_hints(_typecheckingstub__fee0e739c48c18fbede5b526d8c21d651764809d24c3e4d0843ec78bdc7bc4d6)
check_type(argname="argument value", value=value, expected_type=type_hints["value"])
jsii.set(self, "ipv6NetmaskLength", value)
@builtins.property
@jsii.member(jsii_name="tags")
def tags(self) -> typing.Mapping[builtins.str, builtins.str]:
return typing.cast(typing.Mapping[builtins.str, builtins.str], jsii.get(self, "tags"))
@tags.setter
def tags(self, value: typing.Mapping[builtins.str, builtins.str]) -> None:
if __debug__:
type_hints = typing.get_type_hints(_typecheckingstub__0d3b29b8b5e21fa49b6f667d6b857ee77bc00f3fed88c04c30b5c881c715573b)
check_type(argname="argument value", value=value, expected_type=type_hints["value"])
jsii.set(self, "tags", value)
@builtins.property
@jsii.member(jsii_name="tagsAll")
def tags_all(self) -> typing.Mapping[builtins.str, builtins.str]:
return typing.cast(typing.Mapping[builtins.str, builtins.str], jsii.get(self, "tagsAll"))
@tags_all.setter
def tags_all(self, value: typing.Mapping[builtins.str, builtins.str]) -> None:
if __debug__:
type_hints = typing.get_type_hints(_typecheckingstub__36b8f734cb6565eeb446510f8f48c433b7b76eea3267df88a2cef390f5879109)
check_type(argname="argument value", value=value, expected_type=type_hints["value"])
jsii.set(self, "tagsAll", value)
@jsii.data_type(
jsii_type="@cdktf/provider-aws.defaultVpc.DefaultVpcConfig",
jsii_struct_bases=[_cdktf_9a9027ec.TerraformMetaArguments],
name_mapping={
"connection": "connection",
"count": "count",
"depends_on": "dependsOn",
"for_each": "forEach",
"lifecycle": "lifecycle",
"provider": "provider",
"provisioners": "provisioners",
"assign_generated_ipv6_cidr_block": "assignGeneratedIpv6CidrBlock",
"enable_dns_hostnames": "enableDnsHostnames",
"enable_dns_support": "enableDnsSupport",
"enable_network_address_usage_metrics": "enableNetworkAddressUsageMetrics",
"force_destroy": "forceDestroy",
"id": "id",
"ipv6_cidr_block": "ipv6CidrBlock",
"ipv6_cidr_block_network_border_group": "ipv6CidrBlockNetworkBorderGroup",
"ipv6_ipam_pool_id": "ipv6IpamPoolId",
"ipv6_netmask_length": "ipv6NetmaskLength",
"tags": "tags",
"tags_all": "tagsAll",
},
)
class DefaultVpcConfig(_cdktf_9a9027ec.TerraformMetaArguments):
def __init__(
self,
*,
connection: typing.Optional[typing.Union[typing.Union[_cdktf_9a9027ec.SSHProvisionerConnection, typing.Dict[builtins.str, typing.Any]], typing.Union[_cdktf_9a9027ec.WinrmProvisionerConnection, typing.Dict[builtins.str, typing.Any]]]] = None,
count: typing.Optional[typing.Union[jsii.Number, _cdktf_9a9027ec.TerraformCount]] = None,
depends_on: typing.Optional[typing.Sequence[_cdktf_9a9027ec.ITerraformDependable]] = None,
for_each: typing.Optional[_cdktf_9a9027ec.ITerraformIterator] = None,
lifecycle: typing.Optional[typing.Union[_cdktf_9a9027ec.TerraformResourceLifecycle, typing.Dict[builtins.str, typing.Any]]] = None,
provider: typing.Optional[_cdktf_9a9027ec.TerraformProvider] = None,
provisioners: typing.Optional[typing.Sequence[typing.Union[typing.Union[_cdktf_9a9027ec.FileProvisioner, typing.Dict[builtins.str, typing.Any]], typing.Union[_cdktf_9a9027ec.LocalExecProvisioner, typing.Dict[builtins.str, typing.Any]], typing.Union[_cdktf_9a9027ec.RemoteExecProvisioner, typing.Dict[builtins.str, typing.Any]]]]] = None,
assign_generated_ipv6_cidr_block: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
enable_dns_hostnames: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
enable_dns_support: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
enable_network_address_usage_metrics: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
force_destroy: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
id: typing.Optional[builtins.str] = None,
ipv6_cidr_block: typing.Optional[builtins.str] = None,
ipv6_cidr_block_network_border_group: typing.Optional[builtins.str] = None,
ipv6_ipam_pool_id: typing.Optional[builtins.str] = None,
ipv6_netmask_length: typing.Optional[jsii.Number] = None,
tags: typing.Optional[typing.Mapping[builtins.str, builtins.str]] = None,
tags_all: typing.Optional[typing.Mapping[builtins.str, builtins.str]] = None,
) -> None:
'''
:param connection:
:param count:
:param depends_on:
:param for_each:
:param lifecycle:
:param provider:
:param provisioners:
:param assign_generated_ipv6_cidr_block: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#assign_generated_ipv6_cidr_block DefaultVpc#assign_generated_ipv6_cidr_block}.
:param enable_dns_hostnames: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#enable_dns_hostnames DefaultVpc#enable_dns_hostnames}.
:param enable_dns_support: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#enable_dns_support DefaultVpc#enable_dns_support}.
:param enable_network_address_usage_metrics: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#enable_network_address_usage_metrics DefaultVpc#enable_network_address_usage_metrics}.
:param force_destroy: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#force_destroy DefaultVpc#force_destroy}.
:param id: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#id DefaultVpc#id}. Please be aware that the id field is automatically added to all resources in Terraform providers using a Terraform provider SDK version below 2. If you experience problems setting this value it might not be settable. Please take a look at the provider documentation to ensure it should be settable.
:param ipv6_cidr_block: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#ipv6_cidr_block DefaultVpc#ipv6_cidr_block}.
:param ipv6_cidr_block_network_border_group: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#ipv6_cidr_block_network_border_group DefaultVpc#ipv6_cidr_block_network_border_group}.
:param ipv6_ipam_pool_id: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#ipv6_ipam_pool_id DefaultVpc#ipv6_ipam_pool_id}.
:param ipv6_netmask_length: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#ipv6_netmask_length DefaultVpc#ipv6_netmask_length}.
:param tags: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#tags DefaultVpc#tags}.
:param tags_all: Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#tags_all DefaultVpc#tags_all}.
'''
if isinstance(lifecycle, dict):
lifecycle = _cdktf_9a9027ec.TerraformResourceLifecycle(**lifecycle)
if __debug__:
type_hints = typing.get_type_hints(_typecheckingstub__9bf0c20818c8c6682b256b44bc63b9b015583520ec471a9b1b5861c28425499c)
check_type(argname="argument connection", value=connection, expected_type=type_hints["connection"])
check_type(argname="argument count", value=count, expected_type=type_hints["count"])
check_type(argname="argument depends_on", value=depends_on, expected_type=type_hints["depends_on"])
check_type(argname="argument for_each", value=for_each, expected_type=type_hints["for_each"])
check_type(argname="argument lifecycle", value=lifecycle, expected_type=type_hints["lifecycle"])
check_type(argname="argument provider", value=provider, expected_type=type_hints["provider"])
check_type(argname="argument provisioners", value=provisioners, expected_type=type_hints["provisioners"])
check_type(argname="argument assign_generated_ipv6_cidr_block", value=assign_generated_ipv6_cidr_block, expected_type=type_hints["assign_generated_ipv6_cidr_block"])
check_type(argname="argument enable_dns_hostnames", value=enable_dns_hostnames, expected_type=type_hints["enable_dns_hostnames"])
check_type(argname="argument enable_dns_support", value=enable_dns_support, expected_type=type_hints["enable_dns_support"])
check_type(argname="argument enable_network_address_usage_metrics", value=enable_network_address_usage_metrics, expected_type=type_hints["enable_network_address_usage_metrics"])
check_type(argname="argument force_destroy", value=force_destroy, expected_type=type_hints["force_destroy"])
check_type(argname="argument id", value=id, expected_type=type_hints["id"])
check_type(argname="argument ipv6_cidr_block", value=ipv6_cidr_block, expected_type=type_hints["ipv6_cidr_block"])
check_type(argname="argument ipv6_cidr_block_network_border_group", value=ipv6_cidr_block_network_border_group, expected_type=type_hints["ipv6_cidr_block_network_border_group"])
check_type(argname="argument ipv6_ipam_pool_id", value=ipv6_ipam_pool_id, expected_type=type_hints["ipv6_ipam_pool_id"])
check_type(argname="argument ipv6_netmask_length", value=ipv6_netmask_length, expected_type=type_hints["ipv6_netmask_length"])
check_type(argname="argument tags", value=tags, expected_type=type_hints["tags"])
check_type(argname="argument tags_all", value=tags_all, expected_type=type_hints["tags_all"])
self._values: typing.Dict[builtins.str, typing.Any] = {}
if connection is not None:
self._values["connection"] = connection
if count is not None:
self._values["count"] = count
if depends_on is not None:
self._values["depends_on"] = depends_on
if for_each is not None:
self._values["for_each"] = for_each
if lifecycle is not None:
self._values["lifecycle"] = lifecycle
if provider is not None:
self._values["provider"] = provider
if provisioners is not None:
self._values["provisioners"] = provisioners
if assign_generated_ipv6_cidr_block is not None:
self._values["assign_generated_ipv6_cidr_block"] = assign_generated_ipv6_cidr_block
if enable_dns_hostnames is not None:
self._values["enable_dns_hostnames"] = enable_dns_hostnames
if enable_dns_support is not None:
self._values["enable_dns_support"] = enable_dns_support
if enable_network_address_usage_metrics is not None:
self._values["enable_network_address_usage_metrics"] = enable_network_address_usage_metrics
if force_destroy is not None:
self._values["force_destroy"] = force_destroy
if id is not None:
self._values["id"] = id
if ipv6_cidr_block is not None:
self._values["ipv6_cidr_block"] = ipv6_cidr_block
if ipv6_cidr_block_network_border_group is not None:
self._values["ipv6_cidr_block_network_border_group"] = ipv6_cidr_block_network_border_group
if ipv6_ipam_pool_id is not None:
self._values["ipv6_ipam_pool_id"] = ipv6_ipam_pool_id
if ipv6_netmask_length is not None:
self._values["ipv6_netmask_length"] = ipv6_netmask_length
if tags is not None:
self._values["tags"] = tags
if tags_all is not None:
self._values["tags_all"] = tags_all
@builtins.property
def connection(
self,
) -> typing.Optional[typing.Union[_cdktf_9a9027ec.SSHProvisionerConnection, _cdktf_9a9027ec.WinrmProvisionerConnection]]:
'''
:stability: experimental
'''
result = self._values.get("connection")
return typing.cast(typing.Optional[typing.Union[_cdktf_9a9027ec.SSHProvisionerConnection, _cdktf_9a9027ec.WinrmProvisionerConnection]], result)
@builtins.property
def count(
self,
) -> typing.Optional[typing.Union[jsii.Number, _cdktf_9a9027ec.TerraformCount]]:
'''
:stability: experimental
'''
result = self._values.get("count")
return typing.cast(typing.Optional[typing.Union[jsii.Number, _cdktf_9a9027ec.TerraformCount]], result)
@builtins.property
def depends_on(
self,
) -> typing.Optional[typing.List[_cdktf_9a9027ec.ITerraformDependable]]:
'''
:stability: experimental
'''
result = self._values.get("depends_on")
return typing.cast(typing.Optional[typing.List[_cdktf_9a9027ec.ITerraformDependable]], result)
@builtins.property
def for_each(self) -> typing.Optional[_cdktf_9a9027ec.ITerraformIterator]:
'''
:stability: experimental
'''
result = self._values.get("for_each")
return typing.cast(typing.Optional[_cdktf_9a9027ec.ITerraformIterator], result)
@builtins.property
def lifecycle(self) -> typing.Optional[_cdktf_9a9027ec.TerraformResourceLifecycle]:
'''
:stability: experimental
'''
result = self._values.get("lifecycle")
return typing.cast(typing.Optional[_cdktf_9a9027ec.TerraformResourceLifecycle], result)
@builtins.property
def provider(self) -> typing.Optional[_cdktf_9a9027ec.TerraformProvider]:
'''
:stability: experimental
'''
result = self._values.get("provider")
return typing.cast(typing.Optional[_cdktf_9a9027ec.TerraformProvider], result)
@builtins.property
def provisioners(
self,
) -> typing.Optional[typing.List[typing.Union[_cdktf_9a9027ec.FileProvisioner, _cdktf_9a9027ec.LocalExecProvisioner, _cdktf_9a9027ec.RemoteExecProvisioner]]]:
'''
:stability: experimental
'''
result = self._values.get("provisioners")
return typing.cast(typing.Optional[typing.List[typing.Union[_cdktf_9a9027ec.FileProvisioner, _cdktf_9a9027ec.LocalExecProvisioner, _cdktf_9a9027ec.RemoteExecProvisioner]]], result)
@builtins.property
def assign_generated_ipv6_cidr_block(
self,
) -> typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]]:
'''Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#assign_generated_ipv6_cidr_block DefaultVpc#assign_generated_ipv6_cidr_block}.'''
result = self._values.get("assign_generated_ipv6_cidr_block")
return typing.cast(typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]], result)
@builtins.property
def enable_dns_hostnames(
self,
) -> typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]]:
'''Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#enable_dns_hostnames DefaultVpc#enable_dns_hostnames}.'''
result = self._values.get("enable_dns_hostnames")
return typing.cast(typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]], result)
@builtins.property
def enable_dns_support(
self,
) -> typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]]:
'''Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#enable_dns_support DefaultVpc#enable_dns_support}.'''
result = self._values.get("enable_dns_support")
return typing.cast(typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]], result)
@builtins.property
def enable_network_address_usage_metrics(
self,
) -> typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]]:
'''Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#enable_network_address_usage_metrics DefaultVpc#enable_network_address_usage_metrics}.'''
result = self._values.get("enable_network_address_usage_metrics")
return typing.cast(typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]], result)
@builtins.property
def force_destroy(
self,
) -> typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]]:
'''Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#force_destroy DefaultVpc#force_destroy}.'''
result = self._values.get("force_destroy")
return typing.cast(typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]], result)
@builtins.property
def id(self) -> typing.Optional[builtins.str]:
'''Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#id DefaultVpc#id}.
Please be aware that the id field is automatically added to all resources in Terraform providers using a Terraform provider SDK version below 2.
If you experience problems setting this value it might not be settable. Please take a look at the provider documentation to ensure it should be settable.
'''
result = self._values.get("id")
return typing.cast(typing.Optional[builtins.str], result)
@builtins.property
def ipv6_cidr_block(self) -> typing.Optional[builtins.str]:
'''Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#ipv6_cidr_block DefaultVpc#ipv6_cidr_block}.'''
result = self._values.get("ipv6_cidr_block")
return typing.cast(typing.Optional[builtins.str], result)
@builtins.property
def ipv6_cidr_block_network_border_group(self) -> typing.Optional[builtins.str]:
'''Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#ipv6_cidr_block_network_border_group DefaultVpc#ipv6_cidr_block_network_border_group}.'''
result = self._values.get("ipv6_cidr_block_network_border_group")
return typing.cast(typing.Optional[builtins.str], result)
@builtins.property
def ipv6_ipam_pool_id(self) -> typing.Optional[builtins.str]:
'''Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#ipv6_ipam_pool_id DefaultVpc#ipv6_ipam_pool_id}.'''
result = self._values.get("ipv6_ipam_pool_id")
return typing.cast(typing.Optional[builtins.str], result)
@builtins.property
def ipv6_netmask_length(self) -> typing.Optional[jsii.Number]:
'''Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#ipv6_netmask_length DefaultVpc#ipv6_netmask_length}.'''
result = self._values.get("ipv6_netmask_length")
return typing.cast(typing.Optional[jsii.Number], result)
@builtins.property
def tags(self) -> typing.Optional[typing.Mapping[builtins.str, builtins.str]]:
'''Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#tags DefaultVpc#tags}.'''
result = self._values.get("tags")
return typing.cast(typing.Optional[typing.Mapping[builtins.str, builtins.str]], result)
@builtins.property
def tags_all(self) -> typing.Optional[typing.Mapping[builtins.str, builtins.str]]:
'''Docs at Terraform Registry: {@link https://registry.terraform.io/providers/hashicorp/aws/5.15.0/docs/resources/default_vpc#tags_all DefaultVpc#tags_all}.'''
result = self._values.get("tags_all")
return typing.cast(typing.Optional[typing.Mapping[builtins.str, builtins.str]], result)
def __eq__(self, rhs: typing.Any) -> builtins.bool:
return isinstance(rhs, self.__class__) and rhs._values == self._values
def __ne__(self, rhs: typing.Any) -> builtins.bool:
return not (rhs == self)
def __repr__(self) -> str:
return "DefaultVpcConfig(%s)" % ", ".join(
k + "=" + repr(v) for k, v in self._values.items()
)
__all__ = [
"DefaultVpc",
"DefaultVpcConfig",
]
publication.publish()
def _typecheckingstub__46a5a50326cf4d3bb9adcdb87120337ef849d9593a37230e4d2f640534db3164(
scope: _constructs_77d1e7e8.Construct,
id_: builtins.str,
*,
assign_generated_ipv6_cidr_block: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
enable_dns_hostnames: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
enable_dns_support: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
enable_network_address_usage_metrics: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
force_destroy: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
id: typing.Optional[builtins.str] = None,
ipv6_cidr_block: typing.Optional[builtins.str] = None,
ipv6_cidr_block_network_border_group: typing.Optional[builtins.str] = None,
ipv6_ipam_pool_id: typing.Optional[builtins.str] = None,
ipv6_netmask_length: typing.Optional[jsii.Number] = None,
tags: typing.Optional[typing.Mapping[builtins.str, builtins.str]] = None,
tags_all: typing.Optional[typing.Mapping[builtins.str, builtins.str]] = None,
connection: typing.Optional[typing.Union[typing.Union[_cdktf_9a9027ec.SSHProvisionerConnection, typing.Dict[builtins.str, typing.Any]], typing.Union[_cdktf_9a9027ec.WinrmProvisionerConnection, typing.Dict[builtins.str, typing.Any]]]] = None,
count: typing.Optional[typing.Union[jsii.Number, _cdktf_9a9027ec.TerraformCount]] = None,
depends_on: typing.Optional[typing.Sequence[_cdktf_9a9027ec.ITerraformDependable]] = None,
for_each: typing.Optional[_cdktf_9a9027ec.ITerraformIterator] = None,
lifecycle: typing.Optional[typing.Union[_cdktf_9a9027ec.TerraformResourceLifecycle, typing.Dict[builtins.str, typing.Any]]] = None,
provider: typing.Optional[_cdktf_9a9027ec.TerraformProvider] = None,
provisioners: typing.Optional[typing.Sequence[typing.Union[typing.Union[_cdktf_9a9027ec.FileProvisioner, typing.Dict[builtins.str, typing.Any]], typing.Union[_cdktf_9a9027ec.LocalExecProvisioner, typing.Dict[builtins.str, typing.Any]], typing.Union[_cdktf_9a9027ec.RemoteExecProvisioner, typing.Dict[builtins.str, typing.Any]]]]] = None,
) -> None:
"""Type checking stubs"""
pass
def _typecheckingstub__1bdd685a0191d9cb3a46cc1e358c148e37748426ee9f409e14a79a39c9df532c(
value: typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable],
) -> None:
"""Type checking stubs"""
pass
def _typecheckingstub__998b1309295c204cbc6f9e93b7a205a421d65d6b5c7c2c8f2c82b4f7f6a815d6(
value: typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable],
) -> None:
"""Type checking stubs"""
pass
def _typecheckingstub__270ab725a2e2872833c3260e3876cb878ed0be8df4e8751cd29b7299ed2c9048(
value: typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable],
) -> None:
"""Type checking stubs"""
pass
def _typecheckingstub__4f9502da384032fe6ce21f224d5195382672bc6fc971ac20d99390cf48dfa6e1(
value: typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable],
) -> None:
"""Type checking stubs"""
pass
def _typecheckingstub__1141b60c8b3f1dd45f89bb3e465b9cc17a10d285287aad858f544694a8a9fff1(
value: typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable],
) -> None:
"""Type checking stubs"""
pass
def _typecheckingstub__965e42e9639378066a52b4d584b53363a589cdf6c7f79cbde1fc1e8e2c9da07a(
value: builtins.str,
) -> None:
"""Type checking stubs"""
pass
def _typecheckingstub__37585261fa59d515b7b921a98f8087675560d7c06e32e0b7c482d5c9918907b9(
value: builtins.str,
) -> None:
"""Type checking stubs"""
pass
def _typecheckingstub__199c7d8c328c1f704fdb0f99ee48094c4b1aaa4f9645960ab021e20465e5946e(
value: builtins.str,
) -> None:
"""Type checking stubs"""
pass
def _typecheckingstub__760109756bacf9f1a9e089040733bc01069ceac04fe92b458daa8a597ffe3c0b(
value: builtins.str,
) -> None:
"""Type checking stubs"""
pass
def _typecheckingstub__fee0e739c48c18fbede5b526d8c21d651764809d24c3e4d0843ec78bdc7bc4d6(
value: jsii.Number,
) -> None:
"""Type checking stubs"""
pass
def _typecheckingstub__0d3b29b8b5e21fa49b6f667d6b857ee77bc00f3fed88c04c30b5c881c715573b(
value: typing.Mapping[builtins.str, builtins.str],
) -> None:
"""Type checking stubs"""
pass
def _typecheckingstub__36b8f734cb6565eeb446510f8f48c433b7b76eea3267df88a2cef390f5879109(
value: typing.Mapping[builtins.str, builtins.str],
) -> None:
"""Type checking stubs"""
pass
def _typecheckingstub__9bf0c20818c8c6682b256b44bc63b9b015583520ec471a9b1b5861c28425499c(
*,
connection: typing.Optional[typing.Union[typing.Union[_cdktf_9a9027ec.SSHProvisionerConnection, typing.Dict[builtins.str, typing.Any]], typing.Union[_cdktf_9a9027ec.WinrmProvisionerConnection, typing.Dict[builtins.str, typing.Any]]]] = None,
count: typing.Optional[typing.Union[jsii.Number, _cdktf_9a9027ec.TerraformCount]] = None,
depends_on: typing.Optional[typing.Sequence[_cdktf_9a9027ec.ITerraformDependable]] = None,
for_each: typing.Optional[_cdktf_9a9027ec.ITerraformIterator] = None,
lifecycle: typing.Optional[typing.Union[_cdktf_9a9027ec.TerraformResourceLifecycle, typing.Dict[builtins.str, typing.Any]]] = None,
provider: typing.Optional[_cdktf_9a9027ec.TerraformProvider] = None,
provisioners: typing.Optional[typing.Sequence[typing.Union[typing.Union[_cdktf_9a9027ec.FileProvisioner, typing.Dict[builtins.str, typing.Any]], typing.Union[_cdktf_9a9027ec.LocalExecProvisioner, typing.Dict[builtins.str, typing.Any]], typing.Union[_cdktf_9a9027ec.RemoteExecProvisioner, typing.Dict[builtins.str, typing.Any]]]]] = None,
assign_generated_ipv6_cidr_block: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
enable_dns_hostnames: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
enable_dns_support: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
enable_network_address_usage_metrics: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
force_destroy: typing.Optional[typing.Union[builtins.bool, _cdktf_9a9027ec.IResolvable]] = None,
id: typing.Optional[builtins.str] = None,
ipv6_cidr_block: typing.Optional[builtins.str] = None,
ipv6_cidr_block_network_border_group: typing.Optional[builtins.str] = None,
ipv6_ipam_pool_id: typing.Optional[builtins.str] = None,
ipv6_netmask_length: typing.Optional[jsii.Number] = None,
tags: typing.Optional[typing.Mapping[builtins.str, builtins.str]] = None,
tags_all: typing.Optional[typing.Mapping[builtins.str, builtins.str]] = None,
) -> None:
"""Type checking stubs"""
pass | PypiClean |
/MaTiSSe.py-1.3.3.tar.gz/MaTiSSe.py-1.3.3/matisse/utils/js/MathJax/extensions/Safe.js | (function(d,c){var f="2.5.0";var a=MathJax.Hub.CombineConfig("Safe",{allow:{URLs:"safe",classes:"safe",cssIDs:"safe",styles:"safe",fontsize:"all",require:"safe"},sizeMin:0.7,sizeMax:1.44,safeProtocols:{http:true,https:true,file:true,javascript:false},safeStyles:{color:true,backgroundColor:true,border:true,cursor:true,margin:true,padding:true,textShadow:true,fontFamily:true,fontSize:true,fontStyle:true,fontWeight:true,opacity:true,outline:true},safeRequire:{action:true,amscd:true,amsmath:true,amssymbols:true,autobold:false,"autoload-all":false,bbox:true,begingroup:true,boldsymbol:true,cancel:true,color:true,enclose:true,extpfeil:true,HTML:true,mathchoice:true,mhchem:true,newcommand:true,noErrors:false,noUndefined:false,unicode:true,verb:true}});var e=a.allow;if(e.fontsize!=="all"){a.safeStyles.fontSize=false}var b=MathJax.Extension.Safe={version:f,config:a,div1:document.createElement("div"),div2:document.createElement("div"),filter:{href:"filterURL",src:"filterURL",altimg:"filterURL","class":"filterClass",style:"filterStyles",id:"filterID",fontsize:"filterFontSize",mathsize:"filterFontSize",scriptminsize:"filterFontSize",scriptsizemultiplier:"filterSizeMultiplier",scriptlevel:"filterScriptLevel"},filterURL:function(g){var h=(g.match(/^\s*([a-z]+):/i)||[null,""])[1].toLowerCase();if(e.URLs==="none"||(e.URLs!=="all"&&!a.safeProtocols[h])){g=null}return g},filterClass:function(g){if(e.classes==="none"||(e.classes!=="all"&&!g.match(/^MJX-[-a-zA-Z0-9_.]+$/))){g=null}return g},filterID:function(g){if(e.cssIDs==="none"||(e.cssIDs!=="all"&&!g.match(/^MJX-[-a-zA-Z0-9_.]+$/))){g=null}return g},filterStyles:function(j){if(e.styles==="all"){return j}if(e.styles==="none"){return null}try{var i=this.div1.style,h=this.div2.style;i.cssText=j;h.cssText="";for(var g in a.safeStyles){if(a.safeStyles.hasOwnProperty(g)){var k=this.filterStyle(g,i[g]);if(k!=null){h[g]=k}}}j=h.cssText}catch(l){j=null}return j},filterStyle:function(g,h){if(typeof h!=="string"){return null}if(h.match(/^\s*expression/)){return null}if(h.match(/javascript:/)){return null}return(a.safeStyles[g]?h:null)},filterSize:function(g){if(e.fontsize==="none"){return null}if(e.fontsize!=="all"){g=Math.min(Math.max(g,a.sizeMin),a.sizeMax)}return g},filterFontSize:function(g){return(e.fontsize==="all"?g:null)},filterSizeMultiplier:function(g){if(e.fontsize==="none"){g=null}else{if(e.fontsize!=="all"){g=Math.min(1,Math.max(0.6,g)).toString()}}return g},filterScriptLevel:function(g){if(e.fontsize==="none"){g=null}else{if(e.fontsize!=="all"){g=Math.max(0,g).toString()}}return g},filterRequire:function(g){if(e.require==="none"||(e.require!=="all"&&!a.safeRequire[g.toLowerCase()])){g=null}return g}};d.Register.StartupHook("TeX HTML Ready",function(){var g=MathJax.InputJax.TeX;g.Parse.Augment({HREF_attribute:function(j){var i=b.filterURL(this.GetArgument(j)),h=this.GetArgumentMML(j);if(i){h.With({href:i})}this.Push(h)},CLASS_attribute:function(i){var j=b.filterClass(this.GetArgument(i)),h=this.GetArgumentMML(i);if(j){if(h["class"]!=null){j=h["class"]+" "+j}h.With({"class":j})}this.Push(h)},STYLE_attribute:function(i){var j=b.filterStyles(this.GetArgument(i)),h=this.GetArgumentMML(i);if(j){if(h.style!=null){if(j.charAt(j.length-1)!==";"){j+=";"}j=h.style+" "+j}h.With({style:j})}this.Push(h)},ID_attribute:function(j){var i=b.filterID(this.GetArgument(j)),h=this.GetArgumentMML(j);if(i){h.With({id:i})}this.Push(h)}})});d.Register.StartupHook("TeX Jax Ready",function(){var i=MathJax.InputJax.TeX,h=i.Parse,g=b.filter;h.Augment({Require:function(j){var k=this.GetArgument(j).replace(/.*\//,"").replace(/[^a-z0-9_.-]/ig,"");k=b.filterRequire(k);if(k){this.Extension(null,k)}},MmlFilterAttribute:function(j,k){if(g[j]){k=b[g[j]](k)}return k},SetSize:function(j,k){k=b.filterSize(k);if(k){this.stack.env.size=k;this.Push(i.Stack.Item.style().With({styles:{mathsize:k+"em"}}))}}})});d.Register.StartupHook("TeX bbox Ready",function(){var g=MathJax.InputJax.TeX;g.Parse.Augment({BBoxStyle:function(h){return b.filterStyles(h)}})});d.Register.StartupHook("MathML Jax Ready",function(){var h=MathJax.InputJax.MathML.Parse,g=b.filter;h.Augment({filterAttribute:function(i,j){if(g[i]){j=b[g[i]](j)}return j}})});d.Startup.signal.Post("Safe Extension Ready");c.loadComplete("[MathJax]/extensions/Safe.js")})(MathJax.Hub,MathJax.Ajax); | PypiClean |
/torchvideo-0.0.1.tar.gz/torchvideo-0.0.1/docs/source/transforms.rst | torchvideo.transforms
=====================
.. currentmodule:: torchvideo.transforms
This module contains video transforms similar to those found in
:mod:`torchvision.transforms` specialised for image transformations. Like the transforms
from :mod:`torchvision.transforms` you can chain together successive transforms using
:class:`torchvision.transforms.Compose`.
.. contents:: Contents
:local:
:depth: 2
Target parameters
-----------------
All transforms support a `target` parameter. Currently these don't do anything, but
allow you to implement transforms on targets as well as frames. At some point in
future it is the intention that we'll support transforms of things like masks, or
allow you to plug your own target transforms into these classes.
Examples
--------
Typically your transformation pipelines will be compose of a sequence of PIL video
transforms followed by a :class:`CollectFrames` transform and a
:class:`PILVideoToTensor`: transform.
.. code-block:: python
import torchvideo.transforms as VT
import torchvision.transforms as IT
from torchvision.transforms import Compose
transform = Compose([
VT.CenterCropVideo((224, 224)), # (h, w)
VT.CollectFrames(),
VT.PILVideoToTensor()
])
Optical flow stored as flattened :math:`(u, v)` pairs like
:math:`(u_0, v_1, u_1, v_1, \ldots, u_n, v_n)` that are then stacked into the channel
dimension would be dealt with like so:
.. code-block:: python
import torchvideo.transforms as VT
import torchvision.transforms as IT
from torchvision.transforms import Compose
transform = Compose([
VT.CenterCropVideo((224, 224)), # (h, w)
VT.CollectFrames(),
VT.PILVideoToTensor(),
VT.TimeToChannel()
])
Video Datatypes
---------------
torchvideo represents videos in a variety of formats:
- *PIL video*: A list of a PIL Images, this is useful for applying image data
augmentations
- *tensor video*: A :class:`torch.Tensor` of shape :math:`(C, T, H, W)` for feeding a
network.
- *NDArray video*: A :class:`numpy.ndarray` of shape either :math:`(T, H, W, C)` or
:math:`(C, T, H, W)`. The reason for the multiple channel shapes is that most
loaders load in :math:`(T, H, W, C)` format, however tensors formatted for input
into a network typically are formatted in :math:`(C, T, H, W)`. Permuting the
dimensions is a costly operation, so supporting both format allows for efficient
implementation of transforms without have to invert the conversion from one format
to the other.
Composing Transforms
--------------------
Transforms can be composed with :class:`Compose`. This functions in exactly the same
way as torchvision's implementation, however it also supports chaining transforms
that require, or optionally support, or don't support a target parameter. It handles
the marshalling of targets around and into those transforms depending upon their
support allowing you to mix transforms defined in this library (all of which support
a target parameter) and those defined in other libraries.
Additionally, we provide a :class:`IdentityTransform` that has a nicer ``__repr__``
suitable for use as a default transform in :class:`Compose` pipelines.
Compose
~~~~~~~
.. autoclass:: Compose
:special-members: __call__
IdentityTransform
~~~~~~~~~~~~~~~~~
.. autoclass:: IdentityTransform
:special-members: __call__
----
Transforms on PIL Videos
------------------------
These transforms all take an iterator/iterable of :class:`PIL.Image.Image` and produce
an iterator of :class:`PIL.Image.Image`. To materialize the iterator the you should
compose your sequence of PIL video transforms with :class:`CollectFrames`.
CenterCropVideo
~~~~~~~~~~~~~~~
.. autoclass:: CenterCropVideo
:special-members: __call__
RandomCropVideo
~~~~~~~~~~~~~~~
.. autoclass:: RandomCropVideo
:special-members: __call__
RandomHorizontalFlipVideo
~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: RandomHorizontalFlipVideo
:special-members: __call__
ResizeVideo
~~~~~~~~~~~
.. autoclass:: ResizeVideo
:special-members: __call__
MultiScaleCropVideo
~~~~~~~~~~~~~~~~~~~
.. autoclass:: MultiScaleCropVideo
:special-members: __call__
RandomResizedCropVideo
~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: RandomResizedCropVideo
:special-members: __call__
TimeApply
~~~~~~~~~
.. autoclass:: TimeApply
:special-members: __call__
----
Transforms on Torch.\*Tensor videos
-----------------------------------
These transform are applicable to `torch.*Tensor` videos only. The input to these
transforms should be a tensor of shape :math:`(C, T, H, W)`.
NormalizeVideo
~~~~~~~~~~~~~~
.. autoclass:: NormalizeVideo
:special-members: __call__
TimeToChannel
~~~~~~~~~~~~~
.. autoclass:: TimeToChannel
:special-members: __call__
----
Conversion transforms
---------------------
These transforms are for converting between different video representations. Typically
your transformation pipeline will operate on iterators of ``PIL`` images which
will then be aggregated by ``CollectFrames`` and then coverted to a tensor via
``PILVideoToTensor``.
CollectFrames
~~~~~~~~~~~~~
.. autoclass:: CollectFrames
:special-members: __call__
PILVideoToTensor
~~~~~~~~~~~~~~~~
.. autoclass:: PILVideoToTensor
:special-members: __call__
NDArrayToPILVideo
~~~~~~~~~~~~~~~~~
.. autoclass:: NDArrayToPILVideo
:special-members: __call__
----
Functional Transforms
---------------------
Functional transforms give you fine-grained control of the transformation pipeline. As
opposed to the transformations above, functional transforms don’t contain a random
number generator for their parameters.
.. currentmodule:: torchvideo.transforms.functional
normalize
~~~~~~~~~
.. autofunction:: normalize
time_to_channel
~~~~~~~~~~~~~~~
.. autofunction:: time_to_channel
| PypiClean |
/base/box.py | from pathlib import Path
from typing import Iterable, Union
from accel.base.boxcore import BoxCore
from accel.base.mols import Mol
from accel.base.selector import FuncSelector, Selectors
from accel.plugin import Plugins
from accel.util.log import logger
def adaptive_function_caller(box: "Box", selector: FuncSelector, filetype, **options):
if filetype is not None:
try:
selector(filetype, Box().bind(box.pack()), **options)
except ValueError:
for _c in box.pack():
_c.deactivate("could not find an appropriate function")
else:
for ft, confs in box.pack().filetypes.items():
try:
selector(ft, Box().bind(confs), **options)
except ValueError:
for _c in confs:
_c.deactivate("could not find an appropriate function")
logger.debug(f"done: {len(box.pack())}/{len(box._mols)} confomers")
class Box(BoxCore):
def __init__(self, files: Iterable[Union[Mol, Path, str]] = None):
if isinstance(files, BoxCore):
self._mols = files._mols
self.data = files.data
else:
super().__init__(files=files)
@property
def plugin(self):
return Plugins(self)
# function selector
def check_end(self, filetype=None, **options):
adaptive_function_caller(self, Selectors.check_end, filetype, **options)
return self
def read_atoms(self, filetype=None, **options):
adaptive_function_caller(self, Selectors.read_atoms, filetype, **options)
return self
def read_energy(self, filetype=None, **options):
adaptive_function_caller(self, Selectors.read_energy, filetype, **options)
return self
def read_correction(self, filetype=None, **options):
adaptive_function_caller(self, Selectors.read_correction, filetype, **options)
return self
def check_freq(self, filetype=None, **options):
adaptive_function_caller(self, Selectors.check_freq, filetype, **options)
return self
def run(self, filetype=None, **options):
adaptive_function_caller(self, Selectors.run, filetype, **options)
return self
def submit(self, filetype=None, **options):
adaptive_function_caller(self, Selectors.submit, filetype, **options)
return self
def calc_free_energy(self, filetype=None, **options):
adaptive_function_caller(self, Selectors.calc_free_energy, filetype, **options)
return self | PypiClean |
/django-wechat-api-2.0.0.tar.gz/django-wechat-api-2.0.0/enterprise_api/tuling_robot.py | u"""
When got text message from wechat user, reply with tuling robot.
Copyright (C) 2016 Canux CHENG.
All rights reserved.
Name: tuling_robot.py
Author: Canux CHENG [email protected]
Version: V1.0.0.0
Time: Sun 16 Oct 2016 01:53:46 AM EDT
DESCRIPTION:
图灵机器人接口。
http://www.tuling123.com
Read the doc from tuling website.
Use json format and HTTP POST to post data to tuling and return data with json format.
Close the secret function for tuling robot.
Send to tuling:
{
"key": "APIKEY",
"info": "Your content",
"userid": "wechat user openid(FromUserName), not support for booking account."
}
Receive from tuling:
{
"code": "your code",
"text": "your content",
"url": "url for link",
"list": [
{
"article": "article1 for news",
"source": "news from where",
"icon": "",
"detailurl": "url for news"
},
...
],
"list": [
{
"name": "food name for cookbook",
"icon": "",
"info": "food information.",
"detailurl": "url for cookbook"
},
...
]
}
code means what kind of message you got from tuling:
100000: text
200000: link
302000: news
308000: cookbok
"""
import json
# TPL
import requests
# Define tuling API.
TULING_API = "http://www.tuling123.com/openapi/api"
TULING_APIKEY = "b4987475ebed4c4c9684237ffc1d6dc0"
def tuling_robot(info, userid):
"""Send message and userid to tuling and get response.
@param info: send the information to tuling123.
@type info: unicode
@param userid: the user id used for context.
@type userid: int
@returns resp_content: Response information from tuling123.
@rtype resp_content: unicode
send utf-8 to tuling, and return unicode.
"""
s = requests.session()
data = {"key": TULING_APIKEY, "info": info.encode("utf-8"), "userid": userid.encode("utf-8")}
data = json.dumps(data)
response = s.post(TULING_API, data=data)
resp_data = json.loads(response.content)
# print("resp_data: %s" % resp_data)
code = resp_data['code']
# print("code: %d" % code)
# text = resp_data['text'].replace('<br>', '\n')
if code == 100000:
resp_content = resp_data['text']
elif code == 200000:
resp_content = resp_data['text'] + resp_data['url']
elif code == 302000:
resp_content = resp_data['text'] + resp_data['list'][0]['article'] + resp_data['list'][0]['source'] + resp_data['list'][0]['detailurl']
elif code == 308000:
resp_content = resp_data['text'] + resp_data['list'][0]['name'] + + resp_data['list'][0]['info'] + resp_data['list'][0]['detailurl']
else:
resp_content = u"听不懂鸟语,请说人话"
return resp_content
def handle_tuling_robot(info, userid):
try:
resp_content = tuling_robot(info, userid)
except Exception as e:
# resp_content = "Debug: %s" % e
resp_content = u''
finally:
return resp_content
if __name__ == "__main__":
content = u"武汉"
resp_content = handle_tuling_robot(content, '1234')
print("type: %s\ncontent: %s" % (type(resp_content), resp_content)) | PypiClean |
/kedro_serving-0.0.1.tar.gz/kedro_serving-0.0.1/CODE_OF_CONDUCT.md |
# Contributor Covenant Code of Conduct
## Our Pledge
In the interest of fostering an open and welcoming environment, we as contributors and maintainers pledge to making participation in our project and our community a harassment-free experience for everyone, regardless of age, body size, disability, ethnicity, sex characteristics, gender identity and expression, level of experience, education, socio-economic status, nationality, personal appearance, race, religion, or sexual identity and orientation.
## Our Standards
Examples of behavior that contributes to creating a positive environment include:
- Using welcoming and inclusive language
- Being respectful of differing viewpoints and experiences
- Gracefully accepting constructive criticism
- Focusing on what is best for the community
- Showing empathy towards other community members
Examples of unacceptable behavior by participants include:
- The use of sexualized language or imagery and unwelcome sexual attention or advances
- Trolling, insulting/derogatory comments, and personal or political attacks
- Public or private harassment
- Publishing others' private information, such as a physical or electronic address, without explicit permission
- Other conduct which could reasonably be considered inappropriate in a professional setting
## Our Responsibilities
Project maintainers are responsible for clarifying the standards of acceptable behavior and are expected to take appropriate and fair corrective action in response to any instances of unacceptable behavior.
Project maintainers have the right and responsibility to remove, edit, or reject comments, commits, code, wiki edits, issues, and other contributions that are not aligned to this Code of Conduct, or to ban temporarily or permanently any contributor for other behaviors that they deem inappropriate, threatening, offensive, or harmful.
## Scope
This Code of Conduct applies both within project spaces and in public spaces when an individual is representing the project or its community. Examples of representing a project or community include using an official project e-mail address, posting via an official social media account, or acting as an appointed representative at an online or offline event. Representation of a project may be further defined and clarified by project maintainers.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be reported by contacting the project team at [email protected]. All complaints will be reviewed and investigated and will result in a response that is deemed necessary and appropriate to the circumstances. The project team is obligated to maintain confidentiality with regard to the reporter of an incident. Further details of specific enforcement policies may be posted separately.
Project maintainers who do not follow or enforce the Code of Conduct in good faith may face temporary or permanent repercussions as determined by other members of the project's leadership.
Attribution
This Code of Conduct is adapted from the Contributor Covenant, version 1.4, available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
For answers to common questions about this code of conduct, see https://www.contributor-covenant.org/faq
| PypiClean |
/rtm-tsfresh-1.1.102.tar.gz/rtm-tsfresh-1.1.102/docs/text/faq.rst | FAQ
===
1. **Does tsfresh support different time series lengths?**
Yes, it supports different time series lengths. However, some feature calculators can demand a minimal length
of the time series. If a shorter time series is passed to the calculator, a NaN is returned for those
features.
2. **Is it possible to extract features from rolling/shifted time series?**
Yes, the :func:`tsfresh.dataframe_functions.roll_time_series` function allows to conveniently create a rolled
time series dataframe from your data. You just have to transform your data into one of the supported tsfresh
:ref:`data-formats-label`.
Then, the :func:`tsfresh.dataframe_functions.roll_time_series` will return a DataFrame with the rolled time series,
that you can pass to tsfresh.
You can find more details here: :ref:`forecasting-label`.
3. **How can I use tsfresh with windows?**
We recommend to use `Anaconda <https://www.continuum.io/downloads#windows>`_. After installation, open the
Anaconda Prompt, create an environment and set up tsfresh
(Please be aware that we're using multiprocessing, which can be `problematic <http://stackoverflow.com/questions/18204782/runtimeerror-on-windows-trying-python-multiprocessing>`_.):
.. code:: Bash
conda create -n ENV_NAME python=VERSION
conda install -n ENV_NAME pip requests numpy pandas scipy statsmodels patsy scikit-learn tqdm
activate ENV_NAME
pip install tsfresh
4. **Does tsfresh support different sampling rates in the time series?**
Yes! The feature calculators in tsfresh do not care about the sampling frequency.
You will have to use the second input format, the stacked DataFramed (see :ref:`data-formats-label`)
5. **Does tsfresh support irregularly spaced time series?**
Yes, but be careful. As its name suggests, the ``column_sort`` (i.e., timestamp) parameter is only used to sort observations.
Beyond sorting, tsfresh does not use the timestamp in calculations.
While many features do not need a timestamp (or only need it for ordering), others will assume that observations are evenly spaced in time (e.g., one second between each observation).
Since tsfresh ignores spacing, care should be taken when selecting features to use with a highly irregular series.
| PypiClean |
/stk_cage-0.0.3.tar.gz/stk_cage-0.0.3/stk_cage/cage.py | import stk
from rdkit.Chem import AllChem
import numpy as np
class block(stk.BuildingBlock):
def __init__(self,*args,optimize=False):
'''
# [*][O][H] default bonders 1 deleters 2
"-OH":stk.AlcoholFactory,
# [*][C](=[O])[H] default bonders 1 deleters 2
"-CHO":stk.AldehydeFactory,
# [*][C](=[O])[N]([H])[H] default bonders 1 deleters 3,4,5
"-CONH2":stk.AmideFactory,
# [*][B]([O][H])[O][H] default bonders 1 deleters 2,3,4,5
"-BOHOH":stk.BoronicAcidFactory,
# [*][Br] default bonders 0 deleters 1
"-Br":stk.BromoFactory,
# [*][C](=[O])[O][H] default bonders 1 deleters 3,4
"-COOH":stk.CarboxylicAcidFactory,
# [Br][#6]~[#6][Br] default bonders 1,2 deleters 0,3
"-CBrCBr-":stk.DibromoFactory,
# [F][#6]~[#6][F] default bonders 1,2 deleters 0,3
"-CFCF-":stk.Difluoro,
# [H][O][#6]~[#6][O][H] default bonders 2,3 deleters 0,1,4,5
"-COHCOH-":stk.DiolFactory,
# [*][F] default bonders 0 deleters 1
"-F":stk.FluoroFactory,
# [*][I] default bonders 0 deleters 1
"-I":stk.IodoFactory,
# [*][N]([H])[H] default bonders 1 deleters 2,3
"-NH2":stk.PrimaryAminoFactory,
# [N]([H])([H])[#6]~[#6]~[#6R1]
"-RCCCNH2":stk.RingAmineFactory,
# [H][N]([#6])[#6] default bonders 1 deleters 0
">NH":stk.SecondaryAminoFactory,
# "custom" smarts='[Br][C]',bonders=(1, ), deleters=(0, )
"custom":stk.SmartsFunctionalGroupFactory,
# [*][C]([*])=[C]([H])[H] default bonders 1 deleters 3,4,5
">C=CH2":stk.TerminalAlkeneFactory,
# [*][C]#[C][H] bonders=1, deleters=2, 3
"-C#CH":stk.TerminalAlkyneFactory,
# [*][C](=[O])[S][H] bonders=1, deleters=3, 4
"-COSH":stk.ThioacidFactory,
# [*][S][H] bonders=1, deleters=2
"-SH":stk.ThiolFactory
'''
stk.BuildingBlock.__init__(self,*args)
if optimize:self.opt()
def opt(self):
mol=self.to_rdkit_mol()
AllChem.SanitizeMol(mol)
AllChem.MMFFOptimizeMolecule(mol)
self._position_matrix=mol.GetConformer().GetPositions().T
class build_framework(stk.ConstructedMolecule):
def __init__(self, topology_graph,opt=False):
stk.ConstructedMolecule.__init__(self,topology_graph=topology_graph)
if opt:
self.opt(MMFF=True)
def opt(self,MMFF=False):
mol=self.to_rdkit_mol()
#
if MMFF:
AllChem.SanitizeMol(mol)
AllChem.MMFFOptimizeMolecule(mol)
else:
AllChem.EmbedMolecule(mol)
self._position_matrix=mol.GetConformer().GetPositions().T
topo_dict={
"1+1":stk.cage.OnePlusOne,
"2+2":stk.cage.TwoPlusTwo,
"2+3":stk.cage.TwoPlusThree,
"2+4":stk.cage.TwoPlusFour,
"3+6":stk.cage.ThreePlusSix,
"4+4":stk.cage.FourPlusFour,
"4+6":stk.cage.FourPlusSix,
"4+6_2":stk.cage.FourPlusSix2,
"4+8":stk.cage.FourPlusEight,
"5+10":stk.cage.FivePlusTen,
"6+8":stk.cage.SixPlusEight,
"6+9":stk.cage.SixPlusNine,
"6+12":stk.cage.SixPlusTwelve,
"8+12":stk.cage.EightPlusTwelve,
"8+16":stk.cage.EightPlusSixteen,
"10+20":stk.cage.TenPlusTwenty,
"12+30":stk.cage.TwelvePlusThirty,
"20+30":stk.cage.TwentyPlusThirty,
}
# class cage():
# def __init__(self):
# bb= stk.BuildingBlock('BrCCBr', [stk.BromoFactory()])
# print(bb._position_matrix)
group={# 留下原子bonders 删除原子 deleters
# [*][O][H] default bonders 1 deleters 2
"-OH":stk.AlcoholFactory,
# [*][C](=[O])[H] default bonders 1 deleters 2
"-CHO":stk.AldehydeFactory,
# [*][C](=[O])[N]([H])[H] default bonders 1 deleters 3,4,5
"-CONH2":stk.AmideFactory,
# [*][B]([O][H])[O][H] default bonders 1 deleters 2,3,4,5
"-BOHOH":stk.BoronicAcidFactory,
# [*][Br] default bonders 0 deleters 1
"-Br":stk.BromoFactory,
# [*][C](=[O])[O][H] default bonders 1 deleters 3,4
"-COOH":stk.CarboxylicAcidFactory,
# [Br][#6]~[#6][Br] default bonders 1,2 deleters 0,3
"-CBrCBr-":stk.DibromoFactory,
# [F][#6]~[#6][F] default bonders 1,2 deleters 0,3
"-CFCF-":stk.Difluoro,
# [H][O][#6]~[#6][O][H] default bonders 2,3 deleters 0,1,4,5
"-COHCOH-":stk.DiolFactory,
# [*][F] default bonders 0 deleters 1
"-F":stk.FluoroFactory,
# [*][I] default bonders 0 deleters 1
"-I":stk.IodoFactory,
# [*][N]([H])[H] default bonders 1 deleters 2,3
"-NH2":stk.PrimaryAminoFactory,
# [N]([H])([H])[#6]~[#6]~[#6R1]
"-RCCCNH2":stk.RingAmineFactory,
# [H][N]([#6])[#6] default bonders 1 deleters 0
">NH":stk.SecondaryAminoFactory,
# "custom" smarts='[Br][C]',bonders=(1, ), deleters=(0, )
"custom":stk.SmartsFunctionalGroupFactory,
# [*][C]([*])=[C]([H])[H] default bonders 1 deleters 3,4,5
">C=CH2":stk.TerminalAlkeneFactory,
# [*][C]#[C][H] bonders=1, deleters=2, 3
"-C#CH":stk.TerminalAlkyneFactory,
# [*][C](=[O])[S][H] bonders=1, deleters=3, 4
"-COSH":stk.ThioacidFactory,
# [*][S][H] bonders=1, deleters=2
"-SH":stk.ThiolFactory
}
class cage():
def __init__(self,topo,blocks,opt=False):
self.frame=build_framework(topo_dict[topo](blocks))
if opt:
self.frame.opt(MMFF=True)
def write(self,file):
self.frame.write(file)
def example():
print(
'''
#这是一个基于stk的简单包装库, 建立cage分两步
#1. 第一步定义cage的组成单元, 即block
#block: 第一个参数是block的SMILES表示, 第二个参数是连接基团们组成的list, 注意group后面小括号表示这是个可有参数的函数值
b1=block("NC1CCCCC1N",[group["-NH2"]()]) #CHDNH2
b2=block("O=Cc1cc(C=O)cc(C=O)c1",[group["-CHO"]()]) # BTMCHO
#2. 第二步, 根据由cage的拓扑结构和block
#cage: 第一个参数是拓扑结构的字符串(从1+1到20+30), 第二个参数是blocks, 可选参数opt表示是否需要优化, 默认关闭
test=cage("2+3",(b1,b2),opt=True)
#3. 第三步, 输出cage的结构文件
test.write("cage.mol")
'''
)
if __name__=="__main__":
example() | PypiClean |
/django-polls-latest-0.1.tar.gz/django-polls-latest-0.1/README.rst | =====
Polls
=====
Polls is a simple Django app to conduct Web-based polls. For each question, visitors can choose between a fixed number of answers.
Detailed documentation is in the "docs" directory.
Quick start
-----------
1. Add "polls" to your INSTALLED_APPS setting like this::
INSTALLED_APPS = [
...
'polls',
]
2. Include the polls URLconf in your project urls.py like this::
path('polls/', include('polls.urls')),
3. Run `python manage.py migrate` to create the polls models.
4. Start the development server and visit http://127.0.0.1:8000/admin/ to create a poll (you'll need the Admin app enabled).
5. Visit http://127.0.0.1:8000/polls/ to participate in the poll. | PypiClean |
/aliyun-python-sdk-mse-3.0.24.tar.gz/aliyun-python-sdk-mse-3.0.24/aliyunsdkmse/request/v20190531/AddBlackWhiteListRequest.py |
from aliyunsdkcore.request import RpcRequest
from aliyunsdkmse.endpoint import endpoint_data
class AddBlackWhiteListRequest(RpcRequest):
def __init__(self):
RpcRequest.__init__(self, 'mse', '2019-05-31', 'AddBlackWhiteList','mse')
self.set_method('POST')
if hasattr(self, "endpoint_map"):
setattr(self, "endpoint_map", endpoint_data.getEndpointMap())
if hasattr(self, "endpoint_regional"):
setattr(self, "endpoint_regional", endpoint_data.getEndpointRegional())
def get_Note(self): # String
return self.get_query_params().get('Note')
def set_Note(self, Note): # String
self.add_query_param('Note', Note)
def get_GatewayUniqueId(self): # String
return self.get_query_params().get('GatewayUniqueId')
def set_GatewayUniqueId(self, GatewayUniqueId): # String
self.add_query_param('GatewayUniqueId', GatewayUniqueId)
def get_Type(self): # String
return self.get_query_params().get('Type')
def set_Type(self, Type): # String
self.add_query_param('Type', Type)
def get_Content(self): # String
return self.get_query_params().get('Content')
def set_Content(self, Content): # String
self.add_query_param('Content', Content)
def get_IsWhite(self): # Boolean
return self.get_query_params().get('IsWhite')
def set_IsWhite(self, IsWhite): # Boolean
self.add_query_param('IsWhite', IsWhite)
def get_ResourceIdJsonList(self): # String
return self.get_query_params().get('ResourceIdJsonList')
def set_ResourceIdJsonList(self, ResourceIdJsonList): # String
self.add_query_param('ResourceIdJsonList', ResourceIdJsonList)
def get_ResourceType(self): # String
return self.get_query_params().get('ResourceType')
def set_ResourceType(self, ResourceType): # String
self.add_query_param('ResourceType', ResourceType)
def get_Name(self): # String
return self.get_query_params().get('Name')
def set_Name(self, Name): # String
self.add_query_param('Name', Name)
def get_AcceptLanguage(self): # String
return self.get_query_params().get('AcceptLanguage')
def set_AcceptLanguage(self, AcceptLanguage): # String
self.add_query_param('AcceptLanguage', AcceptLanguage)
def get_Status(self): # String
return self.get_query_params().get('Status')
def set_Status(self, Status): # String
self.add_query_param('Status', Status) | PypiClean |
/ardupy-aip-1.0.0.tar.gz/ardupy-aip-1.0.0/aip/command.py |
from pip._internal.cli.parser import (
ConfigOptionParser,
UpdatingDefaultsHelpFormatter,
)
from functools import partial
from pip._internal.commands import get_similar_commands
from pip._internal.cli.status_codes import SUCCESS
from pip._internal.cli import cmdoptions
from pip._internal.exceptions import PipError
from pip._internal.exceptions import CommandError
from pip._internal.utils.misc import get_prog
from optparse import SUPPRESS_HELP, Option, OptionGroup
from pip._internal.locations import get_major_minor_version
from pip._internal.cli.status_codes import SUCCESS, ERROR
from pip._internal.cli.base_command import Command
from aip.build import buildCommand
from aip.install import installCommand
from aip.flash import flashCommand
from aip.shell import shellCommand
from aip.board import boardCommand
from aip.list import listCommand
from aip.uninstall import uninstallCommand
from aip import __version__
import sys
import os
###########
# options #
###########
help_ = partial(
Option,
'-h', '--help',
dest='help',
action='help',
help='Show help.',
) # type: Callable[..., Option]
version = partial(
Option,
'-V', '--version',
dest='version',
action='store_true',
help='Show version and exit.',
) # type: Callable[..., Option]
general_group = {
'name': 'General Options',
'options': [
help_,
version,
]
} # type: Dict[str, Any]
class HelpCommand(Command):
"""Show help for commands"""
name = 'help'
usage = """
%prog <command>"""
summary = 'Show help for commands.'
ignore_require_venv = True
def run(self, options, args):
from pip._internal.commands import get_similar_commands
try:
# 'pip help' with no args is handled by pip.__init__.parseopt()
cmd_name = args[0] # the command we need help for
except IndexError:
return SUCCESS
if cmd_name not in commands_dict:
guess = get_similar_commands(cmd_name)
msg = ['unknown command "%s"' % cmd_name]
if guess:
msg.append('maybe you meant "%s"' % guess)
raise CommandError(' - '.join(msg))
command = commands_dict[cmd_name]()
command.parser.print_help()
return SUCCESS
commands_order = [
buildCommand,
listCommand,
installCommand,
uninstallCommand,
flashCommand,
boardCommand,
shellCommand,
HelpCommand,
] # type: List[Type[Command]]
commands_dict = {c.name: c for c in commands_order}
def get_aip_version():
version = 'aip ({}) - ArduPy Integrated Platform is a utility to develop ArduPy and interact witch ArduPy board.'
return (
version.format(
__version__,
)
)
def create_main_parser():
# type: () -> ConfigOptionParser
"""Creates and returns the main parser for aip's CLI
"""
parser_kw = {
'usage': '\n%prog <command> [options]',
'add_help_option': False,
'formatter': UpdatingDefaultsHelpFormatter(),
'name': 'global',
'prog': get_prog(),
}
parser = ConfigOptionParser(**parser_kw)
parser.disable_interspersed_args()
parser.version = get_aip_version()
# add the general options
gen_opts = cmdoptions.make_option_group(general_group, parser)
parser.add_option_group(gen_opts)
# so the help formatter knows
parser.main = True # type: ignore
# create command listing for description
description = [''] + [
'%-27s %s' % (name, command_info.summary)
for name, command_info in commands_dict.items()
]
parser.description = '\n'.join(description)
return parser
def parse_command(args):
# type: (List[str]) -> Tuple[str, List[str]]
parser = create_main_parser()
# Note: parser calls disable_interspersed_args(), so the result of this
# call is to split the initial args into the general options before the
# subcommand and everything else.
# For example:
# args: ['--timeout=5', 'install', '--user', 'INITools']
# general_options: ['--timeout==5']
# args_else: ['install', '--user', 'INITools']
general_options, args_else = parser.parse_args(args)
# --version
if general_options.version:
sys.stdout.write(parser.version) # type: ignore
sys.stdout.write(os.linesep)
sys.exit()
# pip || pip help -> print_help()
if not args_else or (args_else[0] == 'help' and len(args_else) == 1):
parser.print_help()
sys.exit()
# the subcommand name
cmd_name = args_else[0]
if cmd_name not in commands_dict:
guess = get_similar_commands(cmd_name)
msg = ['unknown command "{}"'.format(cmd_name)]
if guess:
msg.append('maybe you meant "{}"'.format(guess))
raise CommandError(' - '.join(msg))
# all the args without the subcommand
cmd_args = args[:]
cmd_args.remove(cmd_name)
return cmd_name, cmd_args | PypiClean |
/merge-ats-client-1.2.0.tar.gz/merge-ats-client-1.2.0/MergeATSClient/model/scheduled_interview.py | import re # noqa: F401
import sys # noqa: F401
from MergeATSClient.model_utils import ( # noqa: F401
ApiTypeError,
ModelComposed,
ModelNormal,
ModelSimple,
cached_property,
change_keys_js_to_python,
convert_js_args_to_python_args,
date,
datetime,
file_type,
none_type,
validate_get_composed_info,
)
def lazy_import():
from MergeATSClient.model.remote_data import RemoteData
globals()['RemoteData'] = RemoteData
class ScheduledInterview(ModelNormal):
"""NOTE: This class is auto generated by OpenAPI Generator.
Ref: https://openapi-generator.tech
Do not edit the class manually.
Attributes:
allowed_values (dict): The key is the tuple path to the attribute
and the for var_name this is (var_name,). The value is a dict
with a capitalized key describing the allowed value and an allowed
value. These dicts store the allowed enum values.
attribute_map (dict): The key is attribute name
and the value is json key in definition.
discriminator_value_class_map (dict): A dict to go from the discriminator
variable value to the discriminator class name.
validations (dict): The key is the tuple path to the attribute
and the for var_name this is (var_name,). The value is a dict
that stores validations for max_length, min_length, max_items,
min_items, exclusive_maximum, inclusive_maximum, exclusive_minimum,
inclusive_minimum, and regex.
additional_properties_type (tuple): A tuple of classes accepted
as additional properties values.
"""
allowed_values = {
}
validations = {
}
additional_properties_type = None
_nullable = False
@cached_property
def openapi_types():
"""
This must be a method because a model may have properties that are
of type self, this must run after the class is loaded
Returns
openapi_types (dict): The key is attribute name
and the value is attribute type.
"""
lazy_import()
return {
'id': (str,), # noqa: E501
'remote_id': (str, none_type,), # noqa: E501
'application': (str, none_type,), # noqa: E501
'job_interview_stage': (str, none_type,), # noqa: E501
'organizer': (str, none_type,), # noqa: E501
'interviewers': ([str],), # noqa: E501
'location': (str, none_type,), # noqa: E501
'start_at': (datetime, none_type,), # noqa: E501
'end_at': (datetime, none_type,), # noqa: E501
'remote_created_at': (datetime, none_type,), # noqa: E501
'remote_updated_at': (datetime, none_type,), # noqa: E501
'status': (object, none_type,), # noqa: E501
'remote_data': ([RemoteData], none_type,), # noqa: E501
}
@cached_property
def discriminator():
return None
attribute_map = {
'id': 'id', # noqa: E501
'remote_id': 'remote_id', # noqa: E501
'application': 'application', # noqa: E501
'job_interview_stage': 'job_interview_stage', # noqa: E501
'organizer': 'organizer', # noqa: E501
'interviewers': 'interviewers', # noqa: E501
'location': 'location', # noqa: E501
'start_at': 'start_at', # noqa: E501
'end_at': 'end_at', # noqa: E501
'remote_created_at': 'remote_created_at', # noqa: E501
'remote_updated_at': 'remote_updated_at', # noqa: E501
'status': 'status', # noqa: E501
'remote_data': 'remote_data', # noqa: E501
}
_composed_schemas = {}
required_properties = set([
'_data_store',
'_check_type',
'_spec_property_naming',
'_path_to_item',
'_configuration',
'_visited_composed_classes',
])
@convert_js_args_to_python_args
def __init__(self, *args, **kwargs): # noqa: E501
"""ScheduledInterview - a model defined in OpenAPI
Keyword Args:
_check_type (bool): if True, values for parameters in openapi_types
will be type checked and a TypeError will be
raised if the wrong type is input.
Defaults to True
_path_to_item (tuple/list): This is a list of keys or values to
drill down to the model in received_data
when deserializing a response
_spec_property_naming (bool): True if the variable names in the input data
are serialized names, as specified in the OpenAPI document.
False if the variable names in the input data
are pythonic names, e.g. snake case (default)
_configuration (Configuration): the instance to use when
deserializing a file_type parameter.
If passed, type conversion is attempted
If omitted no type conversion is done.
_visited_composed_classes (tuple): This stores a tuple of
classes that we have traveled through so that
if we see that class again we will not use its
discriminator again.
When traveling through a discriminator, the
composed schema that is
is traveled through is added to this set.
For example if Animal has a discriminator
petType and we pass in "Dog", and the class Dog
allOf includes Animal, we move through Animal
once using the discriminator, and pick Dog.
Then in Dog, we will make an instance of the
Animal class but this time we won't travel
through its discriminator because we passed in
_visited_composed_classes = (Animal,)
id (str): [optional] # noqa: E501
remote_id (str, none_type): The third-party API ID of the matching object.. [optional] # noqa: E501
application (str, none_type): The application being interviewed.. [optional] # noqa: E501
job_interview_stage (str, none_type): The stage of the interview.. [optional] # noqa: E501
organizer (str, none_type): The user organizing the interview.. [optional] # noqa: E501
interviewers ([str]): Array of `RemoteUser` IDs.. [optional] # noqa: E501
location (str, none_type): The interview's location.. [optional] # noqa: E501
start_at (datetime, none_type): When the interview was started.. [optional] # noqa: E501
end_at (datetime, none_type): When the interview was ended.. [optional] # noqa: E501
remote_created_at (datetime, none_type): When the third party's interview was created.. [optional] # noqa: E501
remote_updated_at (datetime, none_type): When the third party's interview was updated.. [optional] # noqa: E501
status (object, none_type): The interview's status.. [optional] # noqa: E501
remote_data ([RemoteData], none_type): [optional] # noqa: E501
"""
_check_type = kwargs.pop('_check_type', True)
_spec_property_naming = kwargs.pop('_spec_property_naming', False)
_path_to_item = kwargs.pop('_path_to_item', ())
_configuration = kwargs.pop('_configuration', None)
_visited_composed_classes = kwargs.pop('_visited_composed_classes', ())
if args:
raise ApiTypeError(
"Invalid positional arguments=%s passed to %s. Remove those invalid positional arguments." % (
args,
self.__class__.__name__,
),
path_to_item=_path_to_item,
valid_classes=(self.__class__,),
)
self._data_store = {}
self._check_type = _check_type
self._spec_property_naming = _spec_property_naming
self._path_to_item = _path_to_item
self._configuration = _configuration
self._visited_composed_classes = _visited_composed_classes + (self.__class__,)
for var_name, var_value in kwargs.items():
if var_name not in self.attribute_map and \
self._configuration is not None and \
self._configuration.discard_unknown_keys and \
self.additional_properties_type is None:
# discard variable.
continue
setattr(self, var_name, var_value) | PypiClean |
/collective.langdet-0.1.tar.gz/collective.langdet-0.1/README.rst | Introduction
============
collective.langdet tries to automatically detect the language of a file.
It is meant for monolingual sites where you occasionally upload files in
another language and content editors forget to add the correct metadata.
It does the language detection when a file is created, not when it is
replaced by another file. It may also be useful for multilingual sites
where you upload files via webdav, but this is as yet untested.
It uses the python package 'guess-language' which supports over 60
languages. A script for determining the language of all your current
files and changing their language into the language detected is included
in the scripts directory. You can execute it as an external method.
| PypiClean |
/python-potr-1.0.2.tar.gz/python-potr-1.0.2/src/potr/compatcrypto/pycrypto.py |
try:
import Crypto
except ImportError:
import crypto as Crypto
from Crypto import Cipher
from Crypto.Hash import SHA256 as _SHA256
from Crypto.Hash import SHA as _SHA1
from Crypto.Hash import HMAC as _HMAC
from Crypto.PublicKey import DSA
import Crypto.Random.random
from numbers import Number
from potr.compatcrypto import common
from potr.utils import read_mpi, bytes_to_long, long_to_bytes
def SHA256(data):
return _SHA256.new(data).digest()
def SHA1(data):
return _SHA1.new(data).digest()
def SHA1HMAC(key, data):
return _HMAC.new(key, msg=data, digestmod=_SHA1).digest()
def SHA256HMAC(key, data):
return _HMAC.new(key, msg=data, digestmod=_SHA256).digest()
def AESCTR(key, counter=0):
if isinstance(counter, Number):
counter = Counter(counter)
if not isinstance(counter, Counter):
raise TypeError
return Cipher.AES.new(key, Cipher.AES.MODE_CTR, counter=counter)
class Counter(object):
def __init__(self, prefix):
self.prefix = prefix
self.val = 0
def inc(self):
self.prefix += 1
self.val = 0
def __setattr__(self, attr, val):
if attr == 'prefix':
self.val = 0
super(Counter, self).__setattr__(attr, val)
def __repr__(self):
return '<Counter(p={p!r},v={v!r})>'.format(p=self.prefix, v=self.val)
def byteprefix(self):
return long_to_bytes(self.prefix, 8)
def __call__(self):
bytesuffix = long_to_bytes(self.val, 8)
self.val += 1
return self.byteprefix() + bytesuffix
@common.registerkeytype
class DSAKey(common.PK):
keyType = 0x0000
def __init__(self, key=None, private=False):
self.priv = self.pub = None
if not isinstance(key, tuple):
raise TypeError('4/5-tuple required for key')
if len(key) == 5 and private:
self.priv = DSA.construct(key)
self.pub = self.priv.publickey()
elif len(key) == 4 and not private:
self.pub = DSA.construct(key)
else:
raise TypeError('wrong number of arguments for ' \
'private={0!r}: got {1} '
.format(private, len(key)))
def getPublicPayload(self):
return (self.pub.p, self.pub.q, self.pub.g, self.pub.y)
def getPrivatePayload(self):
return (self.priv.p, self.priv.q, self.priv.g, self.priv.y, self.priv.x)
def fingerprint(self):
return SHA1(self.getSerializedPublicPayload())
def sign(self, data):
# 2 <= K <= q
K = randrange(2, self.priv.q)
r, s = self.priv.sign(data, K)
return long_to_bytes(r, 20) + long_to_bytes(s, 20)
def verify(self, data, sig):
r, s = bytes_to_long(sig[:20]), bytes_to_long(sig[20:])
return self.pub.verify(data, (r, s))
def __hash__(self):
return bytes_to_long(self.fingerprint())
def __eq__(self, other):
if not isinstance(other, type(self)):
return False
return self.fingerprint() == other.fingerprint()
def __ne__(self, other):
return not (self == other)
@classmethod
def generate(cls):
privkey = DSA.generate(1024)
return cls((privkey.key.y, privkey.key.g, privkey.key.p, privkey.key.q,
privkey.key.x), private=True)
@classmethod
def parsePayload(cls, data, private=False):
p, data = read_mpi(data)
q, data = read_mpi(data)
g, data = read_mpi(data)
y, data = read_mpi(data)
if private:
x, data = read_mpi(data)
return cls((y, g, p, q, x), private=True), data
return cls((y, g, p, q), private=False), data
def getrandbits(k):
return Crypto.Random.random.getrandbits(k)
def randrange(start, stop):
return Crypto.Random.random.randrange(start, stop) | PypiClean |
/dingo-gw-0.5.4.tar.gz/dingo-gw-0.5.4/dingo/core/result.py | import copy
import math
import tempfile
import time
import numpy as np
from typing import Optional
import pandas as pd
from matplotlib import pyplot as plt
from scipy.constants import golden
from scipy.special import logsumexp
from bilby.core.prior import Constraint, DeltaFunction
from dingo.core.dataset import DingoDataset
from dingo.core.density import train_unconditional_density_estimator
from dingo.core.utils.misc import recursive_check_dicts_are_equal
from dingo.core.utils.plotting import plot_corner_multi
DATA_KEYS = [
"samples",
"context",
"event_metadata",
"importance_sampling_metadata",
"log_evidence",
"log_noise_evidence",
]
class Result(DingoDataset):
"""
A dataset class to hold a collection of samples, implementing I/O, importance
sampling, and unconditional flow training.
Attributes:
samples : pd.Dataframe
Contains parameter samples, as well as (possibly) log_prob, log_likelihood,
weights, log_prior, delta_log_prob_target.
domain : Domain
Should be implemented in a subclass.
prior : PriorDict
Should be implemented in a subclass.
likelihood : Likelihood
Should be implemented in a subclass.
context : dict
Context data from which the samples were produced (e.g., strain data, ASDs).
metadata : dict
event_metadata : dict
log_evidence : float
log_evidence_std : float (property)
effective_sample_size, n_eff : float (property)
sample_efficiency : float (property)
"""
dataset_type = "core_result"
def __init__(self, file_name=None, dictionary=None):
self.event_metadata = None
self.context = None
self.samples = None
self.log_noise_evidence = None
super().__init__(
file_name=file_name,
dictionary=dictionary,
data_keys=DATA_KEYS,
)
# Initialize as empty dict, so we can fill it up later.
if self.importance_sampling_metadata is None:
self.importance_sampling_metadata = {}
self._build_prior()
self._build_domain()
if self.importance_sampling_metadata.get("updates"):
self._rebuild_domain()
@property
def metadata(self):
return self.settings
@property
def base_metadata(self):
if self.metadata["train_settings"]["data"].get("unconditional", False):
return self.metadata["base"]
else:
return self.metadata
@property
def injection_parameters(self):
if self.context:
return self.context.get("parameters")
else:
return None
@property
def constraint_parameter_keys(self):
return [k for k, v in self.prior.items() if isinstance(v, Constraint)]
@property
def search_parameter_keys(self):
return [
k
for k, v in self.prior.items()
if (not isinstance(v, Constraint) and not isinstance(v, DeltaFunction))
]
@property
def fixed_parameter_keys(self):
return [k for k, v in self.prior.items() if isinstance(v, DeltaFunction)]
def _build_domain(self):
self.domain = None
def _build_prior(self):
self.prior = None
def _build_likelihood(self, **likelihood_kwargs):
self.likelihood = None
def reset_event(self, event_dataset):
"""
Set the Result context and event_metadata based on an EventDataset.
If these attributes already exist, perform a comparison to check for changes.
Update relevant objects appropriately. Note that setting context and
event_metadata attributes directly would not perform these additional checks and
updates.
Parameters
----------
event_dataset: EventDataset
New event to be used for importance sampling.
"""
context = event_dataset.data
event_metadata = event_dataset.settings
if self.context is not None and not check_equal_dict_of_arrays(
self.context, context
):
# This is really just for notification. Actions are only taken if the
# event metadata differ.
print("\nNew event data differ from existing.")
self.context = context
if self.event_metadata is not None and self.event_metadata != event_metadata:
print("Changes")
print("=======")
old_minus_new = dict(freeze(self.event_metadata) - freeze(event_metadata))
print("Old event metadata:")
for k in sorted(old_minus_new):
print(f" {k}: {self.event_metadata[k]}")
new_minus_old = dict(freeze(event_metadata) - freeze(self.event_metadata))
print("New event metadata:")
if self.importance_sampling_metadata.get("updates") is None:
self.importance_sampling_metadata["updates"] = {}
for k in sorted(new_minus_old):
print(f" {k}: {event_metadata[k]}")
self.importance_sampling_metadata["updates"][k] = event_metadata[k]
self._rebuild_domain(verbose=True)
self.event_metadata = event_metadata
def _rebuild_domain(self, verbose=False):
pass
@property
def num_samples(self):
if self.samples is not None:
return len(self.samples)
else:
return 0
@property
def effective_sample_size(self):
if "weights" in self.samples:
weights = self.samples["weights"]
return np.sum(weights) ** 2 / np.sum(weights**2)
else:
return None
@property
def n_eff(self):
return self.effective_sample_size
@property
def sample_efficiency(self):
if "weights" in self.samples:
return self.effective_sample_size / len(self.samples)
else:
return None
@property
def log_evidence_std(self):
if "weights" in self.samples and self.log_evidence:
return np.sqrt(
(self.num_samples - self.n_eff) / (self.num_samples * self.n_eff)
)
else:
return None
@property
def log_bayes_factor(self):
if self.log_evidence and self.log_noise_evidence:
return self.log_evidence - self.log_noise_evidence
else:
return None
def importance_sample(self, num_processes: int = 1, **likelihood_kwargs):
"""
Calculate importance weights for samples.
Importance sampling starts with samples have been generated from a proposal
distribution q(theta), in this case a neural network model. Certain networks
(i.e., non-GNPE) also provide the log probability of each sample,
which is required for importance sampling.
Given the proposal, we re-weight samples according to the (un-normalized)
target distribution, which we take to be the likelihood L(theta) times the
prior pi(theta). This gives sample weights
w(theta) ~ pi(theta) L(theta) / q(theta),
where the overall normalization does not matter (and we take to have mean 1).
Since q(theta) enters this expression, importance sampling is only possible
when we know the log probability of each sample.
As byproducts, this method also estimates the evidence and effective sample
size of the importance sampled points.
This method modifies the samples pd.DataFrame in-place, adding new columns for
log_likelihood, log_prior, and weights. It also stores the log_evidence as an
attribute.
Parameters
----------
num_processes : int
Number of parallel processes to use when calculating likelihoods. (This is
the most expensive task.)
likelihood_kwargs : dict
kwargs that are forwarded to the likelihood constructor. E.g., options for
marginalization.
"""
if self.samples is None:
raise KeyError("Proposal samples are required for importance sampling.")
if "log_prob" not in self.samples:
raise KeyError(
"Stored samples do not include log probability, which is "
"needed for importance sampling. To obtain the log probability, "
"it is necessary to train an unconditional flow based on the existing "
"samples. This can then be sampled with log probability."
)
self._build_likelihood(**likelihood_kwargs)
if "delta_log_prob_target" in self.samples.columns:
delta_log_prob_target = self.samples["delta_log_prob_target"].to_numpy()
else:
delta_log_prob_target = 0.0
# select parameters in self.samples (required as log_prob and potentially gnpe
# proxies are also stored in self.samples, but are not needed for the likelihood.
# TODO: replace by self.metadata["train_settings"]["data"]["inference_parameters"]
param_keys = [k for k, v in self.prior.items() if not isinstance(v, Constraint)]
theta = self.samples[param_keys]
# Calculate the (un-normalized) target density as prior times likelihood,
# evaluated at the same sample points.
log_prior = self.prior.ln_prob(theta, axis=0)
# The prior or delta_log_prob_target may be -inf for certain samples.
# For these, we do not want to evaluate the likelihood, in particular because
# it may not even be possible to generate signals outside the prior (e.g.,
# for BH spins > 1).
valid_samples = (log_prior + delta_log_prob_target) != -np.inf
theta = theta.iloc[valid_samples]
print(f"Calculating {len(theta)} likelihoods.")
t0 = time.time()
log_likelihood = self.likelihood.log_likelihood_multi(
theta, num_processes=num_processes
)
print(f"Done. This took {time.time() - t0:.2f} seconds.")
self.log_noise_evidence = self.likelihood.log_Zn
self.samples["log_prior"] = log_prior
self.samples.loc[valid_samples, "log_likelihood"] = log_likelihood
self._calculate_evidence()
def _calculate_evidence(self):
"""Calculate the Bayesian log evidence and sample weights.
This is called at the end of importance sampling, when changing the prior,
and when combining Results.
The evidence
Z = \\int d\\theta \\pi(\\theta) L(\\theta),
where \\pi = prior, L = likelihood.
For importance sampling, we estimate this using Monte Carlo integration using
the proposal distribution q(\\theta),
Z = \\int d\\theta q(\\theta) \\pi(\\theta) L(\\theta) / q(\\theta)
\\sim (1/N) \\sum_i \\pi(\\theta_i) L(\\theta_i) / q(\\theta_i)
where we are summing over samples \\theta_i \\sim q(\\theta).
The integrand is just the importance weight (prior to any normalization). It
is more numerically stable to evaluate \\log(Z),
\\log Z \\sim \\log \\sum_i \\exp( \\log \\pi_i + \\log L_i - \\log q_i ) -
\\log N
= logsumexp ( log_weights ) - log N
Notes
-----
* We use the logsumexp function, which is more numerically stable.
* N = num_samples is the total number of samples (including the
zero-weight samples).
* q, \\pi, L must be distributions in the same parameter space (the same
coordinates). We have undone any standardizations so this is the case.
"""
if (
"log_prob" in self.samples
and "log_likelihood" in self.samples
and "log_prior" in self.samples
):
log_prob_proposal = self.samples["log_prob"]
log_prior = self.samples["log_prior"]
log_likelihood = self.samples["log_likelihood"]
if "delta_log_prob_target" in self.samples:
delta_log_prob_target = self.samples["delta_log_prob_target"]
else:
delta_log_prob_target = 0.0
# *Un-normalized* log weights are needed to calculate evidence.
log_weights = (
log_prior
+ np.nan_to_num(log_likelihood) # NaN = no log_likelihood evaluation
+ delta_log_prob_target
- np.nan_to_num(
log_prob_proposal
) # NaN = outside prior so no synthetic
# phase
)
self.log_evidence = logsumexp(log_weights) - np.log(self.num_samples)
# Save the *normalized* weights.
weights = np.exp(log_weights - np.max(log_weights))
weights /= np.mean(weights)
self.samples["weights"] = weights
def sampling_importance_resampling(self, num_samples=None, random_state=None):
"""
Generate unweighted posterior samples from weighted ones. New
samples are sampled with probability proportional to the sample weight.
Resampling is done with replacement, until the desired number of
unweighted samples is obtained.
Parameters
----------
num_samples : int
Number of samples to resample.
random_state : int or None
Sampling seed.
Returns
-------
pd.Dataframe
Unweighted samples
"""
if num_samples is None:
num_samples = len(self.samples)
if num_samples > len(self.samples):
raise ValueError("Cannot sample more points than in the weighted posterior")
unweighted_samples = self.samples.sample(
n=num_samples,
weights=self.samples["weights"],
replace=True,
ignore_index=True,
random_state=random_state,
)
return unweighted_samples.drop(["weights"], axis=1)
def parameter_subset(self, parameters):
"""
Return a new object of the same type, with only a subset of parameters. Drops
all other columns in samples DataFrame as well (e.g., log_prob, weights).
Parameters
----------
parameters : list
List of parameters to keep.
Returns
-------
Result
"""
result_dict = self.to_dictionary()
result_dict["samples"] = self.samples[
parameters
] # Drop log_probs, weights, etc.
return type(self)(dictionary=result_dict)
def train_unconditional_flow(
self,
parameters,
nde_settings: dict,
train_dir: Optional[str] = None,
threshold_std: Optional[float] = np.inf,
):
"""
Train an unconditional flow to represent the distribution of self.samples.
Parameters
----------
parameters : list
List of parameters over which to train the flow. Can be a subset of the
existing parameters.
nde_settings : dict
Configuration settings for the neural density estimator.
train_dir : Optional[str]
Where to save the output of network training, e.g., logs, checkpoints. If
not provide, a temporary directory is used.
threshold_std : Optional[float]
Drop samples more than threshold_std standard deviations away from the mean
(in any parameter) before training the flow. This is meant to remove outlier
samples.
Returns
-------
PosteriorModel
"""
sub_result = self.parameter_subset(parameters)
# Filter outliers, as they decrease the performance of the density estimator.
mean = np.mean(sub_result.samples, axis=0)
std = np.std(sub_result.samples, axis=0)
lower, upper = mean - threshold_std * std, mean + threshold_std * std
inds = np.where(
np.all((lower <= sub_result.samples), axis=1)
* np.all((sub_result.samples <= upper), axis=1)
)[0]
if len(inds) / len(sub_result.samples) < 0.95:
raise ValueError("Too many proxy samples outside of specified range.")
sub_result.samples = sub_result.samples.iloc[inds]
nde_settings["data"] = {"inference_parameters": parameters}
temporary_directory = None
if train_dir is None:
temporary_directory = tempfile.TemporaryDirectory()
train_dir = temporary_directory.name
unconditional_model = train_unconditional_density_estimator(
sub_result,
nde_settings,
train_dir,
)
if temporary_directory is not None:
temporary_directory.cleanup()
# unconditional_model.save_model("temp_model.pt")
return unconditional_model
# Note: self.gnpe_proxy_sampler.transform_post, and self.transform_post *must*
# contain the SelectStandardizeRepackageParameters transformation, such that
# the log_prob is correctly de-standardized!
def print_summary(self):
"""
Display the number of samples, and (if importance sampling is complete) the log
evidence and number of effective samples.
"""
print("Number of samples:", len(self.samples))
if self.log_evidence is not None:
print(
f"Log(evidence): {self.log_evidence:.3f} +- {self.log_evidence_std:.3f}"
)
print(
f"Effective samples {self.n_eff:.1f}: "
f"(Sample efficiency = {100 * self.sample_efficiency:.2f}%)"
)
def split(self, num_parts):
"""
Split the Result into a set of smaller results. The samples are evenly divided
among the sub-results. Additional information (metadata, context, etc.) are
copied into each.
This is useful for splitting expensive tasks such as importance sampling across
multiple jobs.
Parameters
----------
num_parts : int
The number of parts to split the Result across.
Returns
-------
list of sub-Results.
"""
# Prepare a dictionary of all contents except the samples.
dataset_dict_template = self.to_dictionary()
del dataset_dict_template["samples"]
part_size = self.num_samples // num_parts
parts = []
for i in range(num_parts):
part_dict = copy.deepcopy(dataset_dict_template)
if i < num_parts - 1:
samples = self.samples.iloc[i * part_size : (i + 1) * part_size].copy()
else:
samples = self.samples.iloc[i * part_size :].copy()
samples.reset_index(drop=True, inplace=True)
part_dict["samples"] = samples
part = type(self)(dictionary=part_dict)
# Re-calculate evidence since it will differ for the new set of samples.
part._calculate_evidence()
parts.append(part)
return parts
@classmethod
def merge(cls, parts):
"""
Merge several Result instances into one. Check that they are compatible,
in the sense of having the same metadata. Finally, calculate a new log evidence
for the combined result.
This is useful when recombining separate importance sampling jobs.
Parameters
----------
parts : list[Result]
List of sub-Results to be combined.
Returns
-------
Combined Result.
"""
dataset_dict = parts[0].to_dictionary()
del dataset_dict["log_evidence"]
samples_parts = [dataset_dict.pop("samples")]
for part in parts[1:]:
part_dict = part.to_dictionary()
del part_dict["log_evidence"]
samples_parts.append(part_dict.pop("samples"))
# Make sure we are not merging incompatible results. We deleted the
# log_evidence since this can differ among the sub-results. Note that this
# will also raise an error if files were created with different versions of
# dingo.
if not recursive_check_dicts_are_equal(part_dict, dataset_dict):
raise ValueError("Results to be merged must have same metadata.")
dataset_dict["samples"] = pd.concat(samples_parts, ignore_index=True)
merged_result = cls(dictionary=dataset_dict)
# Re-calculate the evidence based on the entire sample set.
merged_result._calculate_evidence()
return merged_result
#
# Plotting
#
def _cleaned_samples(self):
"""Return samples that exclude -inf and nan. This is used primarily for
plotting."""
# Do not plot any samples with -inf or nan. -inf can occur in
# delta_log_prob_target or log_prior. nan occurs in log_likelihood when
# log_likelihood not actually evaluated due to -inf in other columns (i.e.,
# out of prior).
return self.samples.replace(-np.inf, np.nan).dropna(axis=0)
def plot_corner(self, parameters=None, filename="corner.pdf"):
"""
Generate a corner plot of the samples.
Parameters
----------
parameters : list[str]
List of parameters to include. If None, include all parameters.
(Default: None)
filename : str
Where to save samples.
"""
theta = self._cleaned_samples()
# delta_log_prob_target is not interesting so never plot it.
theta = theta.drop(columns="delta_log_prob_target", errors="ignore")
# User option to plot specific parameters.
if parameters:
theta = theta[parameters]
if "weights" in theta:
plot_corner_multi(
[theta, theta],
weights=[None, theta["weights"].to_numpy()],
labels=["Dingo", "Dingo-IS"],
filename=filename,
)
else:
plot_corner_multi(
theta,
labels="Dingo",
filename=filename,
)
def plot_log_probs(self, filename="log_probs.png"):
"""
Make a scatter plot of the target versus proposal log probabilities. For the
target, subtract off the log evidence.
"""
theta = self._cleaned_samples()
if "log_likelihood" in theta:
log_prob_proposal = theta["log_prob"].to_numpy()
if "delta_log_prob_target" in theta:
log_prob_proposal -= theta["delta_log_prob_target"].to_numpy()
log_prior = theta["log_prior"].to_numpy()
log_likelihood = theta["log_likelihood"].to_numpy()
x = log_prob_proposal
y = log_prior + log_likelihood - self.log_evidence
plt.figure(figsize=(6, 6))
plt.xlabel("proposal log_prob")
plt.ylabel("target log_prob - log_evidence")
y_lower, y_upper = np.max(y) - 20, np.max(y)
plt.ylim(y_lower, y_upper)
n_below = len(np.where(y < y_lower)[0])
plt.title(
f"Target log probabilities\n({n_below} below {y_lower:.2f})\n"
f"log(evidence) = {self.log_evidence:.3f} +- {self.log_evidence_std:.3f}"
)
plt.scatter(x, y, s=0.5)
plt.plot([y_upper - 20, y_upper], [y_upper - 20, y_upper], color="black")
plt.tight_layout()
plt.savefig(filename)
else:
print("Results not importance sampled. Cannot produce log_prob plot.")
def plot_weights(self, filename="weights.png"):
"""Make a scatter plot of samples weights vs log proposal."""
theta = self._cleaned_samples()
if "weights" in theta and "log_prob" in theta:
x = theta["log_prob"].to_numpy()
y = theta["weights"].to_numpy()
y /= y.mean()
plt.figure(figsize=(6 * golden, 6))
plt.xlabel("proposal log_prob")
plt.ylabel("weight (normalized)")
y_lower = 1e-4
y_upper = math.ceil(
np.max(y) / 10 ** math.ceil(np.log10(np.max(y)) - 1)
) * 10 ** math.ceil(np.log10(np.max(y)) - 1)
plt.ylim(y_lower, y_upper)
n_below = len(np.where(y < y_lower)[0])
plt.yscale("log")
plt.title(
f"Importance sampling weights\n({n_below} below {y_lower})\n"
f"Effective samples: {self.n_eff:.0f} (Efficiency = "
f"{100 * self.sample_efficiency:.2f}%)."
)
plt.scatter(x, y, s=0.5)
plt.tight_layout()
plt.savefig(filename)
else:
print("Results not importance sampled. Cannot plot weights.")
def check_equal_dict_of_arrays(a, b):
if type(a) != type(b):
return False
if isinstance(a, dict):
a_keys = set(a.keys())
b_keys = set(b.keys())
if a_keys != b_keys:
return False
for k in a_keys:
if not check_equal_dict_of_arrays(a[k], b[k]):
return False
return True
elif isinstance(a, np.ndarray):
return np.array_equal(a, b)
else:
raise TypeError(f"Cannot compare items of type {type(a)}")
def freeze(d):
if isinstance(d, dict):
return frozenset((key, freeze(value)) for key, value in d.items())
elif isinstance(d, list):
return tuple(freeze(value) for value in d)
return d | PypiClean |
/calliope-mini-stubs-0.1.3.tar.gz/calliope-mini-stubs-0.1.3/calliope_mini/i2c.py |
from typing import List, Union
from .pin_instances import c18, c19
class MicroBitI2C:
"""
The ``i2c`` module lets you communicate with devices connected to your
board using the I²C bus protocol. There can be multiple slave devices
connected at the same time, and each one has its own unique address, that
is either fixed for the device or configured on it. Your board acts as the
I²C master.
The left Grove connector (next to button A) is I²C-capable.
How exactly you should communicate with the devices, that is, what bytes to
send and how to interpret the responses, depends on the device in question
and should be described separately in that device's documentation.
There are internal pull-up resistors on the I²C lines of the board, but
with particularly long wires or large number of devices you may need to add
additional pull-up resistors, to ensure noise-free communication.
"""
def init(self: "MicroBitI2C", freq: int = 100000,
sda: int = c18, scl: int = c19) -> None:
"""(Re-)initialize peripheral with the specified clock frequency
``freq`` on the specified ``sda`` and ``scl`` pins.
.. warning::
Changing the I²C pins from defaults will make the accelerometer and
compass stop working, as they are connected internally to those
pins.
"""
def scan(self: "MicroBitI2C") -> List[int]:
"""
Scan for available i2c slaves and return a list of addresses.
For all addresses in the range 0x08 to 0x78 an empty write is
performed.
A slave should react with an ACK.
All addresses, for which a slave reacted this way, are returned.
"""
return []
def read(self: "MicroBitI2C", addr: int, n: int,
repeat: bool = False) -> bytes:
"""Read ``n`` bytes from the device with 7-bit address ``addr``. If
``repeat`` is ``True``, no stop bit will be sent.
May raise an OSError.
"""
return bytes()
def write(self: "MicroBitI2C", addr: int,
buf: Union[bytes, bytearray], repeat=False) -> None:
"""Write bytes from ``buf`` to the device with 7-bit address ``addr``.
If ``repeat`` is ``True``, no stop bit will be sent.
May raise an OSError.
""" | PypiClean |
/napari-tomotwin-0.2.2.tar.gz/napari-tomotwin-0.2.2/src/napari_tomotwin/load_umap.py | import napari
import pathlib
from magicgui import magic_factory
from napari_clusters_plotter._plotter import PlotterWidget
import pandas as pd
import numpy as np
from matplotlib.patches import Circle
from napari.utils import notifications
plotter_widget: PlotterWidget = None
circle: Circle = None
umap: pd.DataFrame
def _draw_circle(data_coordinates, label_layer, umap):
global circle
global plotter_widget
label_layer.visible = 1
val = label_layer._get_value(data_coordinates)
umap_coordinates = umap.loc[
umap['label'] == val, [plotter_widget.plot_x_axis.currentText(), plotter_widget.plot_y_axis.currentText()]]
try:
center = umap_coordinates.values.tolist()[0]
except IndexError:
return
if circle is not None:
circle.remove()
circle = Circle(tuple(center), 0.5, fill=False, color='r')
plotter_widget.graphics_widget.axes.add_patch(circle)
plotter_widget.graphics_widget.draw_idle()
def load_umap(label_layer: "napari.layers.Labels",
filename: pathlib.Path):
global umap
global plotter_widget
umap = pd.read_pickle(filename)
if "label" not in umap.keys().tolist():
lbls = [int(l + 1) for l, _ in enumerate(umap[['umap_1', 'umap_0']].itertuples(index=True, name='Pandas'))]
label_column = pd.DataFrame(
{"label": np.array(lbls)}
)
umap = pd.concat([label_column, umap], axis=1)
if hasattr(label_layer, "properties"):
label_layer.properties = umap
if hasattr(label_layer, "features"):
label_layer.features = umap
label_layer.opacity = 0
label_layer.visible = True
viewer = napari.current_viewer()
widget, plotter_widget = viewer.window.add_plugin_dock_widget('napari-clusters-plotter',
widget_name='Plotter Widget')
plotter_widget.plot_x_axis.setCurrentIndex(1)
plotter_widget.plot_y_axis.setCurrentIndex(2)
plotter_widget.bin_auto.setChecked(True)
plotter_widget.plotting_type.setCurrentIndex(1)
plotter_widget.plot_hide_non_selected.setChecked(True)
try:
plotter_widget.run(
umap,
"umap_0",
"umap_1",
plot_cluster_name=None,
force_redraw=True
)
except:
pass
@viewer.mouse_drag_callbacks.append
def get_event(viewer, event):
data_coordinates = label_layer.world_to_data(event.position)
_draw_circle(data_coordinates,label_layer,umap)
@magic_factory(
call_button="Load",
label_layer={'label': 'TomoTwin Label Mask:'},
filename={'label': 'Path to UMAP:',
'filter': '*.tumap'},
)
def load_umap_magic(
label_layer: "napari.layers.Labels",
filename: pathlib.Path
):
if label_layer == None:
notifications.show_error("Label mask is not specificed")
return
if filename.suffix not in ['.tumap']:
notifications.show_error("UMAP is not specificed")
return
load_umap(label_layer, filename) | PypiClean |
/pk-dlp-2023.3.4.tar.gz/pk-dlp-2023.3.4/yt_dlp/extractor/rte.py | import re
from .common import InfoExtractor
from ..compat import compat_HTTPError
from ..utils import (
float_or_none,
parse_iso8601,
str_or_none,
try_get,
unescapeHTML,
url_or_none,
ExtractorError,
)
class RteBaseIE(InfoExtractor):
def _real_extract(self, url):
item_id = self._match_id(url)
info_dict = {}
formats = []
ENDPOINTS = (
'https://feeds.rasset.ie/rteavgen/player/playlist?type=iptv&format=json&showId=',
'http://www.rte.ie/rteavgen/getplaylist/?type=web&format=json&id=',
)
for num, ep_url in enumerate(ENDPOINTS, start=1):
try:
data = self._download_json(ep_url + item_id, item_id)
except ExtractorError as ee:
if num < len(ENDPOINTS) or formats:
continue
if isinstance(ee.cause, compat_HTTPError) and ee.cause.code == 404:
error_info = self._parse_json(ee.cause.read().decode(), item_id, fatal=False)
if error_info:
raise ExtractorError(
'%s said: %s' % (self.IE_NAME, error_info['message']),
expected=True)
raise
# NB the string values in the JSON are stored using XML escaping(!)
show = try_get(data, lambda x: x['shows'][0], dict)
if not show:
continue
if not info_dict:
title = unescapeHTML(show['title'])
description = unescapeHTML(show.get('description'))
thumbnail = show.get('thumbnail')
duration = float_or_none(show.get('duration'), 1000)
timestamp = parse_iso8601(show.get('published'))
info_dict = {
'id': item_id,
'title': title,
'description': description,
'thumbnail': thumbnail,
'timestamp': timestamp,
'duration': duration,
}
mg = try_get(show, lambda x: x['media:group'][0], dict)
if not mg:
continue
if mg.get('url'):
m = re.match(r'(?P<url>rtmpe?://[^/]+)/(?P<app>.+)/(?P<playpath>mp4:.*)', mg['url'])
if m:
m = m.groupdict()
formats.append({
'url': m['url'] + '/' + m['app'],
'app': m['app'],
'play_path': m['playpath'],
'player_url': url,
'ext': 'flv',
'format_id': 'rtmp',
})
if mg.get('hls_server') and mg.get('hls_url'):
formats.extend(self._extract_m3u8_formats(
mg['hls_server'] + mg['hls_url'], item_id, 'mp4',
entry_protocol='m3u8_native', m3u8_id='hls', fatal=False))
if mg.get('hds_server') and mg.get('hds_url'):
formats.extend(self._extract_f4m_formats(
mg['hds_server'] + mg['hds_url'], item_id,
f4m_id='hds', fatal=False))
mg_rte_server = str_or_none(mg.get('rte:server'))
mg_url = str_or_none(mg.get('url'))
if mg_rte_server and mg_url:
hds_url = url_or_none(mg_rte_server + mg_url)
if hds_url:
formats.extend(self._extract_f4m_formats(
hds_url, item_id, f4m_id='hds', fatal=False))
info_dict['formats'] = formats
return info_dict
class RteIE(RteBaseIE):
IE_NAME = 'rte'
IE_DESC = 'Raidió Teilifís Éireann TV'
_VALID_URL = r'https?://(?:www\.)?rte\.ie/player/[^/]{2,3}/show/[^/]+/(?P<id>[0-9]+)'
_TEST = {
'url': 'http://www.rte.ie/player/ie/show/iwitness-862/10478715/',
'md5': '4a76eb3396d98f697e6e8110563d2604',
'info_dict': {
'id': '10478715',
'ext': 'mp4',
'title': 'iWitness',
'thumbnail': r're:^https?://.*\.jpg$',
'description': 'The spirit of Ireland, one voice and one minute at a time.',
'duration': 60.046,
'upload_date': '20151012',
'timestamp': 1444694160,
},
}
class RteRadioIE(RteBaseIE):
IE_NAME = 'rte:radio'
IE_DESC = 'Raidió Teilifís Éireann radio'
# Radioplayer URLs have two distinct specifier formats,
# the old format #!rii=<channel_id>:<id>:<playable_item_id>:<date>:
# the new format #!rii=b<channel_id>_<id>_<playable_item_id>_<date>_
# where the IDs are int/empty, the date is DD-MM-YYYY, and the specifier may be truncated.
# An <id> uniquely defines an individual recording, and is the only part we require.
_VALID_URL = r'https?://(?:www\.)?rte\.ie/radio/utils/radioplayer/rteradioweb\.html#!rii=(?:b?[0-9]*)(?:%3A|:|%5F|_)(?P<id>[0-9]+)'
_TESTS = [{
# Old-style player URL; HLS and RTMPE formats
'url': 'http://www.rte.ie/radio/utils/radioplayer/rteradioweb.html#!rii=16:10507902:2414:27-12-2015:',
'md5': 'c79ccb2c195998440065456b69760411',
'info_dict': {
'id': '10507902',
'ext': 'mp4',
'title': 'Gloria',
'thumbnail': r're:^https?://.*\.jpg$',
'description': 'md5:9ce124a7fb41559ec68f06387cabddf0',
'timestamp': 1451203200,
'upload_date': '20151227',
'duration': 7230.0,
},
}, {
# New-style player URL; RTMPE formats only
'url': 'http://rte.ie/radio/utils/radioplayer/rteradioweb.html#!rii=b16_3250678_8861_06-04-2012_',
'info_dict': {
'id': '3250678',
'ext': 'flv',
'title': 'The Lyric Concert with Paul Herriott',
'thumbnail': r're:^https?://.*\.jpg$',
'description': '',
'timestamp': 1333742400,
'upload_date': '20120406',
'duration': 7199.016,
},
'params': {
# rtmp download
'skip_download': True,
},
}] | PypiClean |
/pulumi_azure_nextgen-0.6.2a1613157620.tar.gz/pulumi_azure_nextgen-0.6.2a1613157620/pulumi_azure_nextgen/eventgrid/_inputs.py |
import warnings
import pulumi
import pulumi.runtime
from typing import Any, Mapping, Optional, Sequence, Union
from .. import _utilities, _tables
from ._enums import *
__all__ = [
'AzureFunctionEventSubscriptionDestinationArgs',
'BoolEqualsAdvancedFilterArgs',
'ConnectionStateArgs',
'DeadLetterWithResourceIdentityArgs',
'DeliveryWithResourceIdentityArgs',
'EventChannelDestinationArgs',
'EventChannelFilterArgs',
'EventChannelSourceArgs',
'EventHubEventSubscriptionDestinationArgs',
'EventSubscriptionFilterArgs',
'EventSubscriptionIdentityArgs',
'HybridConnectionEventSubscriptionDestinationArgs',
'InboundIpRuleArgs',
'JsonFieldArgs',
'JsonFieldWithDefaultArgs',
'JsonInputSchemaMappingArgs',
'NumberGreaterThanAdvancedFilterArgs',
'NumberGreaterThanOrEqualsAdvancedFilterArgs',
'NumberInAdvancedFilterArgs',
'NumberLessThanAdvancedFilterArgs',
'NumberLessThanOrEqualsAdvancedFilterArgs',
'NumberNotInAdvancedFilterArgs',
'PrivateEndpointArgs',
'PrivateEndpointConnectionArgs',
'RetryPolicyArgs',
'ServiceBusQueueEventSubscriptionDestinationArgs',
'ServiceBusTopicEventSubscriptionDestinationArgs',
'StorageBlobDeadLetterDestinationArgs',
'StorageQueueEventSubscriptionDestinationArgs',
'StringBeginsWithAdvancedFilterArgs',
'StringContainsAdvancedFilterArgs',
'StringEndsWithAdvancedFilterArgs',
'StringInAdvancedFilterArgs',
'StringNotInAdvancedFilterArgs',
'WebHookEventSubscriptionDestinationArgs',
]
@pulumi.input_type
class AzureFunctionEventSubscriptionDestinationArgs:
def __init__(__self__, *,
endpoint_type: pulumi.Input[str],
max_events_per_batch: Optional[pulumi.Input[int]] = None,
preferred_batch_size_in_kilobytes: Optional[pulumi.Input[int]] = None,
resource_id: Optional[pulumi.Input[str]] = None):
"""
Information about the azure function destination for an event subscription.
:param pulumi.Input[str] endpoint_type: Type of the endpoint for the event subscription destination.
Expected value is 'AzureFunction'.
:param pulumi.Input[int] max_events_per_batch: Maximum number of events per batch.
:param pulumi.Input[int] preferred_batch_size_in_kilobytes: Preferred batch size in Kilobytes.
:param pulumi.Input[str] resource_id: The Azure Resource Id that represents the endpoint of the Azure Function destination of an event subscription.
"""
pulumi.set(__self__, "endpoint_type", 'AzureFunction')
if max_events_per_batch is not None:
pulumi.set(__self__, "max_events_per_batch", max_events_per_batch)
if preferred_batch_size_in_kilobytes is not None:
pulumi.set(__self__, "preferred_batch_size_in_kilobytes", preferred_batch_size_in_kilobytes)
if resource_id is not None:
pulumi.set(__self__, "resource_id", resource_id)
@property
@pulumi.getter(name="endpointType")
def endpoint_type(self) -> pulumi.Input[str]:
"""
Type of the endpoint for the event subscription destination.
Expected value is 'AzureFunction'.
"""
return pulumi.get(self, "endpoint_type")
@endpoint_type.setter
def endpoint_type(self, value: pulumi.Input[str]):
pulumi.set(self, "endpoint_type", value)
@property
@pulumi.getter(name="maxEventsPerBatch")
def max_events_per_batch(self) -> Optional[pulumi.Input[int]]:
"""
Maximum number of events per batch.
"""
return pulumi.get(self, "max_events_per_batch")
@max_events_per_batch.setter
def max_events_per_batch(self, value: Optional[pulumi.Input[int]]):
pulumi.set(self, "max_events_per_batch", value)
@property
@pulumi.getter(name="preferredBatchSizeInKilobytes")
def preferred_batch_size_in_kilobytes(self) -> Optional[pulumi.Input[int]]:
"""
Preferred batch size in Kilobytes.
"""
return pulumi.get(self, "preferred_batch_size_in_kilobytes")
@preferred_batch_size_in_kilobytes.setter
def preferred_batch_size_in_kilobytes(self, value: Optional[pulumi.Input[int]]):
pulumi.set(self, "preferred_batch_size_in_kilobytes", value)
@property
@pulumi.getter(name="resourceId")
def resource_id(self) -> Optional[pulumi.Input[str]]:
"""
The Azure Resource Id that represents the endpoint of the Azure Function destination of an event subscription.
"""
return pulumi.get(self, "resource_id")
@resource_id.setter
def resource_id(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "resource_id", value)
@pulumi.input_type
class BoolEqualsAdvancedFilterArgs:
def __init__(__self__, *,
operator_type: pulumi.Input[str],
key: Optional[pulumi.Input[str]] = None,
value: Optional[pulumi.Input[bool]] = None):
"""
BoolEquals Advanced Filter.
:param pulumi.Input[str] operator_type: The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'BoolEquals'.
:param pulumi.Input[str] key: The field/property in the event based on which you want to filter.
:param pulumi.Input[bool] value: The boolean filter value.
"""
pulumi.set(__self__, "operator_type", 'BoolEquals')
if key is not None:
pulumi.set(__self__, "key", key)
if value is not None:
pulumi.set(__self__, "value", value)
@property
@pulumi.getter(name="operatorType")
def operator_type(self) -> pulumi.Input[str]:
"""
The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'BoolEquals'.
"""
return pulumi.get(self, "operator_type")
@operator_type.setter
def operator_type(self, value: pulumi.Input[str]):
pulumi.set(self, "operator_type", value)
@property
@pulumi.getter
def key(self) -> Optional[pulumi.Input[str]]:
"""
The field/property in the event based on which you want to filter.
"""
return pulumi.get(self, "key")
@key.setter
def key(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "key", value)
@property
@pulumi.getter
def value(self) -> Optional[pulumi.Input[bool]]:
"""
The boolean filter value.
"""
return pulumi.get(self, "value")
@value.setter
def value(self, value: Optional[pulumi.Input[bool]]):
pulumi.set(self, "value", value)
@pulumi.input_type
class ConnectionStateArgs:
def __init__(__self__, *,
actions_required: Optional[pulumi.Input[str]] = None,
description: Optional[pulumi.Input[str]] = None,
status: Optional[pulumi.Input[Union[str, 'PersistedConnectionStatus']]] = None):
"""
ConnectionState information.
:param pulumi.Input[str] actions_required: Actions required (if any).
:param pulumi.Input[str] description: Description of the connection state.
:param pulumi.Input[Union[str, 'PersistedConnectionStatus']] status: Status of the connection.
"""
if actions_required is not None:
pulumi.set(__self__, "actions_required", actions_required)
if description is not None:
pulumi.set(__self__, "description", description)
if status is not None:
pulumi.set(__self__, "status", status)
@property
@pulumi.getter(name="actionsRequired")
def actions_required(self) -> Optional[pulumi.Input[str]]:
"""
Actions required (if any).
"""
return pulumi.get(self, "actions_required")
@actions_required.setter
def actions_required(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "actions_required", value)
@property
@pulumi.getter
def description(self) -> Optional[pulumi.Input[str]]:
"""
Description of the connection state.
"""
return pulumi.get(self, "description")
@description.setter
def description(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "description", value)
@property
@pulumi.getter
def status(self) -> Optional[pulumi.Input[Union[str, 'PersistedConnectionStatus']]]:
"""
Status of the connection.
"""
return pulumi.get(self, "status")
@status.setter
def status(self, value: Optional[pulumi.Input[Union[str, 'PersistedConnectionStatus']]]):
pulumi.set(self, "status", value)
@pulumi.input_type
class DeadLetterWithResourceIdentityArgs:
def __init__(__self__, *,
dead_letter_destination: Optional[pulumi.Input['StorageBlobDeadLetterDestinationArgs']] = None,
identity: Optional[pulumi.Input['EventSubscriptionIdentityArgs']] = None):
"""
Information about the deadletter destination with resource identity.
:param pulumi.Input['StorageBlobDeadLetterDestinationArgs'] dead_letter_destination: Information about the destination where events have to be delivered for the event subscription.
Uses the managed identity setup on the parent resource (namely, topic or domain) to acquire the authentication tokens being used during delivery / dead-lettering.
:param pulumi.Input['EventSubscriptionIdentityArgs'] identity: The identity to use when dead-lettering events.
"""
if dead_letter_destination is not None:
pulumi.set(__self__, "dead_letter_destination", dead_letter_destination)
if identity is not None:
pulumi.set(__self__, "identity", identity)
@property
@pulumi.getter(name="deadLetterDestination")
def dead_letter_destination(self) -> Optional[pulumi.Input['StorageBlobDeadLetterDestinationArgs']]:
"""
Information about the destination where events have to be delivered for the event subscription.
Uses the managed identity setup on the parent resource (namely, topic or domain) to acquire the authentication tokens being used during delivery / dead-lettering.
"""
return pulumi.get(self, "dead_letter_destination")
@dead_letter_destination.setter
def dead_letter_destination(self, value: Optional[pulumi.Input['StorageBlobDeadLetterDestinationArgs']]):
pulumi.set(self, "dead_letter_destination", value)
@property
@pulumi.getter
def identity(self) -> Optional[pulumi.Input['EventSubscriptionIdentityArgs']]:
"""
The identity to use when dead-lettering events.
"""
return pulumi.get(self, "identity")
@identity.setter
def identity(self, value: Optional[pulumi.Input['EventSubscriptionIdentityArgs']]):
pulumi.set(self, "identity", value)
@pulumi.input_type
class DeliveryWithResourceIdentityArgs:
def __init__(__self__, *,
destination: Optional[pulumi.Input[Union['AzureFunctionEventSubscriptionDestinationArgs', 'EventHubEventSubscriptionDestinationArgs', 'HybridConnectionEventSubscriptionDestinationArgs', 'ServiceBusQueueEventSubscriptionDestinationArgs', 'ServiceBusTopicEventSubscriptionDestinationArgs', 'StorageQueueEventSubscriptionDestinationArgs', 'WebHookEventSubscriptionDestinationArgs']]] = None,
identity: Optional[pulumi.Input['EventSubscriptionIdentityArgs']] = None):
"""
Information about the delivery for an event subscription with resource identity.
:param pulumi.Input[Union['AzureFunctionEventSubscriptionDestinationArgs', 'EventHubEventSubscriptionDestinationArgs', 'HybridConnectionEventSubscriptionDestinationArgs', 'ServiceBusQueueEventSubscriptionDestinationArgs', 'ServiceBusTopicEventSubscriptionDestinationArgs', 'StorageQueueEventSubscriptionDestinationArgs', 'WebHookEventSubscriptionDestinationArgs']] destination: Information about the destination where events have to be delivered for the event subscription.
Uses Azure Event Grid's identity to acquire the authentication tokens being used during delivery / dead-lettering.
:param pulumi.Input['EventSubscriptionIdentityArgs'] identity: The identity to use when delivering events.
"""
if destination is not None:
pulumi.set(__self__, "destination", destination)
if identity is not None:
pulumi.set(__self__, "identity", identity)
@property
@pulumi.getter
def destination(self) -> Optional[pulumi.Input[Union['AzureFunctionEventSubscriptionDestinationArgs', 'EventHubEventSubscriptionDestinationArgs', 'HybridConnectionEventSubscriptionDestinationArgs', 'ServiceBusQueueEventSubscriptionDestinationArgs', 'ServiceBusTopicEventSubscriptionDestinationArgs', 'StorageQueueEventSubscriptionDestinationArgs', 'WebHookEventSubscriptionDestinationArgs']]]:
"""
Information about the destination where events have to be delivered for the event subscription.
Uses Azure Event Grid's identity to acquire the authentication tokens being used during delivery / dead-lettering.
"""
return pulumi.get(self, "destination")
@destination.setter
def destination(self, value: Optional[pulumi.Input[Union['AzureFunctionEventSubscriptionDestinationArgs', 'EventHubEventSubscriptionDestinationArgs', 'HybridConnectionEventSubscriptionDestinationArgs', 'ServiceBusQueueEventSubscriptionDestinationArgs', 'ServiceBusTopicEventSubscriptionDestinationArgs', 'StorageQueueEventSubscriptionDestinationArgs', 'WebHookEventSubscriptionDestinationArgs']]]):
pulumi.set(self, "destination", value)
@property
@pulumi.getter
def identity(self) -> Optional[pulumi.Input['EventSubscriptionIdentityArgs']]:
"""
The identity to use when delivering events.
"""
return pulumi.get(self, "identity")
@identity.setter
def identity(self, value: Optional[pulumi.Input['EventSubscriptionIdentityArgs']]):
pulumi.set(self, "identity", value)
@pulumi.input_type
class EventChannelDestinationArgs:
def __init__(__self__, *,
azure_subscription_id: Optional[pulumi.Input[str]] = None,
partner_topic_name: Optional[pulumi.Input[str]] = None,
resource_group: Optional[pulumi.Input[str]] = None):
"""
Properties of the destination of an event channel.
:param pulumi.Input[str] azure_subscription_id: Azure subscription ID of the customer creating the event channel. The partner topic
associated with the event channel will be created under this Azure subscription.
:param pulumi.Input[str] partner_topic_name: Name of the partner topic associated with the event channel.
:param pulumi.Input[str] resource_group: Azure Resource Group of the customer creating the event channel. The partner topic
associated with the event channel will be created under this resource group.
"""
if azure_subscription_id is not None:
pulumi.set(__self__, "azure_subscription_id", azure_subscription_id)
if partner_topic_name is not None:
pulumi.set(__self__, "partner_topic_name", partner_topic_name)
if resource_group is not None:
pulumi.set(__self__, "resource_group", resource_group)
@property
@pulumi.getter(name="azureSubscriptionId")
def azure_subscription_id(self) -> Optional[pulumi.Input[str]]:
"""
Azure subscription ID of the customer creating the event channel. The partner topic
associated with the event channel will be created under this Azure subscription.
"""
return pulumi.get(self, "azure_subscription_id")
@azure_subscription_id.setter
def azure_subscription_id(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "azure_subscription_id", value)
@property
@pulumi.getter(name="partnerTopicName")
def partner_topic_name(self) -> Optional[pulumi.Input[str]]:
"""
Name of the partner topic associated with the event channel.
"""
return pulumi.get(self, "partner_topic_name")
@partner_topic_name.setter
def partner_topic_name(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "partner_topic_name", value)
@property
@pulumi.getter(name="resourceGroup")
def resource_group(self) -> Optional[pulumi.Input[str]]:
"""
Azure Resource Group of the customer creating the event channel. The partner topic
associated with the event channel will be created under this resource group.
"""
return pulumi.get(self, "resource_group")
@resource_group.setter
def resource_group(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "resource_group", value)
@pulumi.input_type
class EventChannelFilterArgs:
def __init__(__self__, *,
advanced_filters: Optional[pulumi.Input[Sequence[pulumi.Input[Union['BoolEqualsAdvancedFilterArgs', 'NumberGreaterThanAdvancedFilterArgs', 'NumberGreaterThanOrEqualsAdvancedFilterArgs', 'NumberInAdvancedFilterArgs', 'NumberLessThanAdvancedFilterArgs', 'NumberLessThanOrEqualsAdvancedFilterArgs', 'NumberNotInAdvancedFilterArgs', 'StringBeginsWithAdvancedFilterArgs', 'StringContainsAdvancedFilterArgs', 'StringEndsWithAdvancedFilterArgs', 'StringInAdvancedFilterArgs', 'StringNotInAdvancedFilterArgs']]]]] = None):
"""
Filter for the Event Channel.
:param pulumi.Input[Sequence[pulumi.Input[Union['BoolEqualsAdvancedFilterArgs', 'NumberGreaterThanAdvancedFilterArgs', 'NumberGreaterThanOrEqualsAdvancedFilterArgs', 'NumberInAdvancedFilterArgs', 'NumberLessThanAdvancedFilterArgs', 'NumberLessThanOrEqualsAdvancedFilterArgs', 'NumberNotInAdvancedFilterArgs', 'StringBeginsWithAdvancedFilterArgs', 'StringContainsAdvancedFilterArgs', 'StringEndsWithAdvancedFilterArgs', 'StringInAdvancedFilterArgs', 'StringNotInAdvancedFilterArgs']]]] advanced_filters: An array of advanced filters that are used for filtering event channels.
"""
if advanced_filters is not None:
pulumi.set(__self__, "advanced_filters", advanced_filters)
@property
@pulumi.getter(name="advancedFilters")
def advanced_filters(self) -> Optional[pulumi.Input[Sequence[pulumi.Input[Union['BoolEqualsAdvancedFilterArgs', 'NumberGreaterThanAdvancedFilterArgs', 'NumberGreaterThanOrEqualsAdvancedFilterArgs', 'NumberInAdvancedFilterArgs', 'NumberLessThanAdvancedFilterArgs', 'NumberLessThanOrEqualsAdvancedFilterArgs', 'NumberNotInAdvancedFilterArgs', 'StringBeginsWithAdvancedFilterArgs', 'StringContainsAdvancedFilterArgs', 'StringEndsWithAdvancedFilterArgs', 'StringInAdvancedFilterArgs', 'StringNotInAdvancedFilterArgs']]]]]:
"""
An array of advanced filters that are used for filtering event channels.
"""
return pulumi.get(self, "advanced_filters")
@advanced_filters.setter
def advanced_filters(self, value: Optional[pulumi.Input[Sequence[pulumi.Input[Union['BoolEqualsAdvancedFilterArgs', 'NumberGreaterThanAdvancedFilterArgs', 'NumberGreaterThanOrEqualsAdvancedFilterArgs', 'NumberInAdvancedFilterArgs', 'NumberLessThanAdvancedFilterArgs', 'NumberLessThanOrEqualsAdvancedFilterArgs', 'NumberNotInAdvancedFilterArgs', 'StringBeginsWithAdvancedFilterArgs', 'StringContainsAdvancedFilterArgs', 'StringEndsWithAdvancedFilterArgs', 'StringInAdvancedFilterArgs', 'StringNotInAdvancedFilterArgs']]]]]):
pulumi.set(self, "advanced_filters", value)
@pulumi.input_type
class EventChannelSourceArgs:
def __init__(__self__, *,
source: Optional[pulumi.Input[str]] = None):
"""
Properties of the source of an event channel.
:param pulumi.Input[str] source: The identifier of the resource that's the source of the events.
This represents a unique resource in the partner's resource model.
"""
if source is not None:
pulumi.set(__self__, "source", source)
@property
@pulumi.getter
def source(self) -> Optional[pulumi.Input[str]]:
"""
The identifier of the resource that's the source of the events.
This represents a unique resource in the partner's resource model.
"""
return pulumi.get(self, "source")
@source.setter
def source(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "source", value)
@pulumi.input_type
class EventHubEventSubscriptionDestinationArgs:
def __init__(__self__, *,
endpoint_type: pulumi.Input[str],
resource_id: Optional[pulumi.Input[str]] = None):
"""
Information about the event hub destination for an event subscription.
:param pulumi.Input[str] endpoint_type: Type of the endpoint for the event subscription destination.
Expected value is 'EventHub'.
:param pulumi.Input[str] resource_id: The Azure Resource Id that represents the endpoint of an Event Hub destination of an event subscription.
"""
pulumi.set(__self__, "endpoint_type", 'EventHub')
if resource_id is not None:
pulumi.set(__self__, "resource_id", resource_id)
@property
@pulumi.getter(name="endpointType")
def endpoint_type(self) -> pulumi.Input[str]:
"""
Type of the endpoint for the event subscription destination.
Expected value is 'EventHub'.
"""
return pulumi.get(self, "endpoint_type")
@endpoint_type.setter
def endpoint_type(self, value: pulumi.Input[str]):
pulumi.set(self, "endpoint_type", value)
@property
@pulumi.getter(name="resourceId")
def resource_id(self) -> Optional[pulumi.Input[str]]:
"""
The Azure Resource Id that represents the endpoint of an Event Hub destination of an event subscription.
"""
return pulumi.get(self, "resource_id")
@resource_id.setter
def resource_id(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "resource_id", value)
@pulumi.input_type
class EventSubscriptionFilterArgs:
def __init__(__self__, *,
advanced_filters: Optional[pulumi.Input[Sequence[pulumi.Input[Union['BoolEqualsAdvancedFilterArgs', 'NumberGreaterThanAdvancedFilterArgs', 'NumberGreaterThanOrEqualsAdvancedFilterArgs', 'NumberInAdvancedFilterArgs', 'NumberLessThanAdvancedFilterArgs', 'NumberLessThanOrEqualsAdvancedFilterArgs', 'NumberNotInAdvancedFilterArgs', 'StringBeginsWithAdvancedFilterArgs', 'StringContainsAdvancedFilterArgs', 'StringEndsWithAdvancedFilterArgs', 'StringInAdvancedFilterArgs', 'StringNotInAdvancedFilterArgs']]]]] = None,
included_event_types: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]] = None,
is_subject_case_sensitive: Optional[pulumi.Input[bool]] = None,
subject_begins_with: Optional[pulumi.Input[str]] = None,
subject_ends_with: Optional[pulumi.Input[str]] = None):
"""
Filter for the Event Subscription.
:param pulumi.Input[Sequence[pulumi.Input[Union['BoolEqualsAdvancedFilterArgs', 'NumberGreaterThanAdvancedFilterArgs', 'NumberGreaterThanOrEqualsAdvancedFilterArgs', 'NumberInAdvancedFilterArgs', 'NumberLessThanAdvancedFilterArgs', 'NumberLessThanOrEqualsAdvancedFilterArgs', 'NumberNotInAdvancedFilterArgs', 'StringBeginsWithAdvancedFilterArgs', 'StringContainsAdvancedFilterArgs', 'StringEndsWithAdvancedFilterArgs', 'StringInAdvancedFilterArgs', 'StringNotInAdvancedFilterArgs']]]] advanced_filters: An array of advanced filters that are used for filtering event subscriptions.
:param pulumi.Input[Sequence[pulumi.Input[str]]] included_event_types: A list of applicable event types that need to be part of the event subscription. If it is desired to subscribe to all default event types, set the IncludedEventTypes to null.
:param pulumi.Input[bool] is_subject_case_sensitive: Specifies if the SubjectBeginsWith and SubjectEndsWith properties of the filter
should be compared in a case sensitive manner.
:param pulumi.Input[str] subject_begins_with: An optional string to filter events for an event subscription based on a resource path prefix.
The format of this depends on the publisher of the events.
Wildcard characters are not supported in this path.
:param pulumi.Input[str] subject_ends_with: An optional string to filter events for an event subscription based on a resource path suffix.
Wildcard characters are not supported in this path.
"""
if advanced_filters is not None:
pulumi.set(__self__, "advanced_filters", advanced_filters)
if included_event_types is not None:
pulumi.set(__self__, "included_event_types", included_event_types)
if is_subject_case_sensitive is None:
is_subject_case_sensitive = False
if is_subject_case_sensitive is not None:
pulumi.set(__self__, "is_subject_case_sensitive", is_subject_case_sensitive)
if subject_begins_with is not None:
pulumi.set(__self__, "subject_begins_with", subject_begins_with)
if subject_ends_with is not None:
pulumi.set(__self__, "subject_ends_with", subject_ends_with)
@property
@pulumi.getter(name="advancedFilters")
def advanced_filters(self) -> Optional[pulumi.Input[Sequence[pulumi.Input[Union['BoolEqualsAdvancedFilterArgs', 'NumberGreaterThanAdvancedFilterArgs', 'NumberGreaterThanOrEqualsAdvancedFilterArgs', 'NumberInAdvancedFilterArgs', 'NumberLessThanAdvancedFilterArgs', 'NumberLessThanOrEqualsAdvancedFilterArgs', 'NumberNotInAdvancedFilterArgs', 'StringBeginsWithAdvancedFilterArgs', 'StringContainsAdvancedFilterArgs', 'StringEndsWithAdvancedFilterArgs', 'StringInAdvancedFilterArgs', 'StringNotInAdvancedFilterArgs']]]]]:
"""
An array of advanced filters that are used for filtering event subscriptions.
"""
return pulumi.get(self, "advanced_filters")
@advanced_filters.setter
def advanced_filters(self, value: Optional[pulumi.Input[Sequence[pulumi.Input[Union['BoolEqualsAdvancedFilterArgs', 'NumberGreaterThanAdvancedFilterArgs', 'NumberGreaterThanOrEqualsAdvancedFilterArgs', 'NumberInAdvancedFilterArgs', 'NumberLessThanAdvancedFilterArgs', 'NumberLessThanOrEqualsAdvancedFilterArgs', 'NumberNotInAdvancedFilterArgs', 'StringBeginsWithAdvancedFilterArgs', 'StringContainsAdvancedFilterArgs', 'StringEndsWithAdvancedFilterArgs', 'StringInAdvancedFilterArgs', 'StringNotInAdvancedFilterArgs']]]]]):
pulumi.set(self, "advanced_filters", value)
@property
@pulumi.getter(name="includedEventTypes")
def included_event_types(self) -> Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]:
"""
A list of applicable event types that need to be part of the event subscription. If it is desired to subscribe to all default event types, set the IncludedEventTypes to null.
"""
return pulumi.get(self, "included_event_types")
@included_event_types.setter
def included_event_types(self, value: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]):
pulumi.set(self, "included_event_types", value)
@property
@pulumi.getter(name="isSubjectCaseSensitive")
def is_subject_case_sensitive(self) -> Optional[pulumi.Input[bool]]:
"""
Specifies if the SubjectBeginsWith and SubjectEndsWith properties of the filter
should be compared in a case sensitive manner.
"""
return pulumi.get(self, "is_subject_case_sensitive")
@is_subject_case_sensitive.setter
def is_subject_case_sensitive(self, value: Optional[pulumi.Input[bool]]):
pulumi.set(self, "is_subject_case_sensitive", value)
@property
@pulumi.getter(name="subjectBeginsWith")
def subject_begins_with(self) -> Optional[pulumi.Input[str]]:
"""
An optional string to filter events for an event subscription based on a resource path prefix.
The format of this depends on the publisher of the events.
Wildcard characters are not supported in this path.
"""
return pulumi.get(self, "subject_begins_with")
@subject_begins_with.setter
def subject_begins_with(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "subject_begins_with", value)
@property
@pulumi.getter(name="subjectEndsWith")
def subject_ends_with(self) -> Optional[pulumi.Input[str]]:
"""
An optional string to filter events for an event subscription based on a resource path suffix.
Wildcard characters are not supported in this path.
"""
return pulumi.get(self, "subject_ends_with")
@subject_ends_with.setter
def subject_ends_with(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "subject_ends_with", value)
@pulumi.input_type
class EventSubscriptionIdentityArgs:
def __init__(__self__, *,
type: Optional[pulumi.Input[Union[str, 'EventSubscriptionIdentityType']]] = None,
user_assigned_identity: Optional[pulumi.Input[str]] = None):
"""
The identity information with the event subscription.
:param pulumi.Input[Union[str, 'EventSubscriptionIdentityType']] type: The type of managed identity used. The type 'SystemAssigned, UserAssigned' includes both an implicitly created identity and a set of user-assigned identities. The type 'None' will remove any identity.
:param pulumi.Input[str] user_assigned_identity: The user identity associated with the resource.
"""
if type is not None:
pulumi.set(__self__, "type", type)
if user_assigned_identity is not None:
pulumi.set(__self__, "user_assigned_identity", user_assigned_identity)
@property
@pulumi.getter
def type(self) -> Optional[pulumi.Input[Union[str, 'EventSubscriptionIdentityType']]]:
"""
The type of managed identity used. The type 'SystemAssigned, UserAssigned' includes both an implicitly created identity and a set of user-assigned identities. The type 'None' will remove any identity.
"""
return pulumi.get(self, "type")
@type.setter
def type(self, value: Optional[pulumi.Input[Union[str, 'EventSubscriptionIdentityType']]]):
pulumi.set(self, "type", value)
@property
@pulumi.getter(name="userAssignedIdentity")
def user_assigned_identity(self) -> Optional[pulumi.Input[str]]:
"""
The user identity associated with the resource.
"""
return pulumi.get(self, "user_assigned_identity")
@user_assigned_identity.setter
def user_assigned_identity(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "user_assigned_identity", value)
@pulumi.input_type
class HybridConnectionEventSubscriptionDestinationArgs:
def __init__(__self__, *,
endpoint_type: pulumi.Input[str],
resource_id: Optional[pulumi.Input[str]] = None):
"""
Information about the HybridConnection destination for an event subscription.
:param pulumi.Input[str] endpoint_type: Type of the endpoint for the event subscription destination.
Expected value is 'HybridConnection'.
:param pulumi.Input[str] resource_id: The Azure Resource ID of an hybrid connection that is the destination of an event subscription.
"""
pulumi.set(__self__, "endpoint_type", 'HybridConnection')
if resource_id is not None:
pulumi.set(__self__, "resource_id", resource_id)
@property
@pulumi.getter(name="endpointType")
def endpoint_type(self) -> pulumi.Input[str]:
"""
Type of the endpoint for the event subscription destination.
Expected value is 'HybridConnection'.
"""
return pulumi.get(self, "endpoint_type")
@endpoint_type.setter
def endpoint_type(self, value: pulumi.Input[str]):
pulumi.set(self, "endpoint_type", value)
@property
@pulumi.getter(name="resourceId")
def resource_id(self) -> Optional[pulumi.Input[str]]:
"""
The Azure Resource ID of an hybrid connection that is the destination of an event subscription.
"""
return pulumi.get(self, "resource_id")
@resource_id.setter
def resource_id(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "resource_id", value)
@pulumi.input_type
class InboundIpRuleArgs:
def __init__(__self__, *,
action: Optional[pulumi.Input[Union[str, 'IpActionType']]] = None,
ip_mask: Optional[pulumi.Input[str]] = None):
"""
:param pulumi.Input[Union[str, 'IpActionType']] action: Action to perform based on the match or no match of the IpMask.
:param pulumi.Input[str] ip_mask: IP Address in CIDR notation e.g., 10.0.0.0/8.
"""
if action is not None:
pulumi.set(__self__, "action", action)
if ip_mask is not None:
pulumi.set(__self__, "ip_mask", ip_mask)
@property
@pulumi.getter
def action(self) -> Optional[pulumi.Input[Union[str, 'IpActionType']]]:
"""
Action to perform based on the match or no match of the IpMask.
"""
return pulumi.get(self, "action")
@action.setter
def action(self, value: Optional[pulumi.Input[Union[str, 'IpActionType']]]):
pulumi.set(self, "action", value)
@property
@pulumi.getter(name="ipMask")
def ip_mask(self) -> Optional[pulumi.Input[str]]:
"""
IP Address in CIDR notation e.g., 10.0.0.0/8.
"""
return pulumi.get(self, "ip_mask")
@ip_mask.setter
def ip_mask(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "ip_mask", value)
@pulumi.input_type
class JsonFieldArgs:
def __init__(__self__, *,
source_field: Optional[pulumi.Input[str]] = None):
"""
This is used to express the source of an input schema mapping for a single target field in the Event Grid Event schema. This is currently used in the mappings for the 'id', 'topic' and 'eventtime' properties. This represents a field in the input event schema.
:param pulumi.Input[str] source_field: Name of a field in the input event schema that's to be used as the source of a mapping.
"""
if source_field is not None:
pulumi.set(__self__, "source_field", source_field)
@property
@pulumi.getter(name="sourceField")
def source_field(self) -> Optional[pulumi.Input[str]]:
"""
Name of a field in the input event schema that's to be used as the source of a mapping.
"""
return pulumi.get(self, "source_field")
@source_field.setter
def source_field(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "source_field", value)
@pulumi.input_type
class JsonFieldWithDefaultArgs:
def __init__(__self__, *,
default_value: Optional[pulumi.Input[str]] = None,
source_field: Optional[pulumi.Input[str]] = None):
"""
This is used to express the source of an input schema mapping for a single target field
in the Event Grid Event schema. This is currently used in the mappings for the 'subject',
'eventtype' and 'dataversion' properties. This represents a field in the input event schema
along with a default value to be used, and at least one of these two properties should be provided.
:param pulumi.Input[str] default_value: The default value to be used for mapping when a SourceField is not provided or if there's no property with the specified name in the published JSON event payload.
:param pulumi.Input[str] source_field: Name of a field in the input event schema that's to be used as the source of a mapping.
"""
if default_value is not None:
pulumi.set(__self__, "default_value", default_value)
if source_field is not None:
pulumi.set(__self__, "source_field", source_field)
@property
@pulumi.getter(name="defaultValue")
def default_value(self) -> Optional[pulumi.Input[str]]:
"""
The default value to be used for mapping when a SourceField is not provided or if there's no property with the specified name in the published JSON event payload.
"""
return pulumi.get(self, "default_value")
@default_value.setter
def default_value(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "default_value", value)
@property
@pulumi.getter(name="sourceField")
def source_field(self) -> Optional[pulumi.Input[str]]:
"""
Name of a field in the input event schema that's to be used as the source of a mapping.
"""
return pulumi.get(self, "source_field")
@source_field.setter
def source_field(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "source_field", value)
@pulumi.input_type
class JsonInputSchemaMappingArgs:
def __init__(__self__, *,
input_schema_mapping_type: pulumi.Input[str],
data_version: Optional[pulumi.Input['JsonFieldWithDefaultArgs']] = None,
event_time: Optional[pulumi.Input['JsonFieldArgs']] = None,
event_type: Optional[pulumi.Input['JsonFieldWithDefaultArgs']] = None,
id: Optional[pulumi.Input['JsonFieldArgs']] = None,
subject: Optional[pulumi.Input['JsonFieldWithDefaultArgs']] = None,
topic: Optional[pulumi.Input['JsonFieldArgs']] = None):
"""
This enables publishing to Event Grid using a custom input schema. This can be used to map properties from a custom input JSON schema to the Event Grid event schema.
:param pulumi.Input[str] input_schema_mapping_type: Type of the custom mapping
Expected value is 'Json'.
:param pulumi.Input['JsonFieldWithDefaultArgs'] data_version: The mapping information for the DataVersion property of the Event Grid Event.
:param pulumi.Input['JsonFieldArgs'] event_time: The mapping information for the EventTime property of the Event Grid Event.
:param pulumi.Input['JsonFieldWithDefaultArgs'] event_type: The mapping information for the EventType property of the Event Grid Event.
:param pulumi.Input['JsonFieldArgs'] id: The mapping information for the Id property of the Event Grid Event.
:param pulumi.Input['JsonFieldWithDefaultArgs'] subject: The mapping information for the Subject property of the Event Grid Event.
:param pulumi.Input['JsonFieldArgs'] topic: The mapping information for the Topic property of the Event Grid Event.
"""
pulumi.set(__self__, "input_schema_mapping_type", 'Json')
if data_version is not None:
pulumi.set(__self__, "data_version", data_version)
if event_time is not None:
pulumi.set(__self__, "event_time", event_time)
if event_type is not None:
pulumi.set(__self__, "event_type", event_type)
if id is not None:
pulumi.set(__self__, "id", id)
if subject is not None:
pulumi.set(__self__, "subject", subject)
if topic is not None:
pulumi.set(__self__, "topic", topic)
@property
@pulumi.getter(name="inputSchemaMappingType")
def input_schema_mapping_type(self) -> pulumi.Input[str]:
"""
Type of the custom mapping
Expected value is 'Json'.
"""
return pulumi.get(self, "input_schema_mapping_type")
@input_schema_mapping_type.setter
def input_schema_mapping_type(self, value: pulumi.Input[str]):
pulumi.set(self, "input_schema_mapping_type", value)
@property
@pulumi.getter(name="dataVersion")
def data_version(self) -> Optional[pulumi.Input['JsonFieldWithDefaultArgs']]:
"""
The mapping information for the DataVersion property of the Event Grid Event.
"""
return pulumi.get(self, "data_version")
@data_version.setter
def data_version(self, value: Optional[pulumi.Input['JsonFieldWithDefaultArgs']]):
pulumi.set(self, "data_version", value)
@property
@pulumi.getter(name="eventTime")
def event_time(self) -> Optional[pulumi.Input['JsonFieldArgs']]:
"""
The mapping information for the EventTime property of the Event Grid Event.
"""
return pulumi.get(self, "event_time")
@event_time.setter
def event_time(self, value: Optional[pulumi.Input['JsonFieldArgs']]):
pulumi.set(self, "event_time", value)
@property
@pulumi.getter(name="eventType")
def event_type(self) -> Optional[pulumi.Input['JsonFieldWithDefaultArgs']]:
"""
The mapping information for the EventType property of the Event Grid Event.
"""
return pulumi.get(self, "event_type")
@event_type.setter
def event_type(self, value: Optional[pulumi.Input['JsonFieldWithDefaultArgs']]):
pulumi.set(self, "event_type", value)
@property
@pulumi.getter
def id(self) -> Optional[pulumi.Input['JsonFieldArgs']]:
"""
The mapping information for the Id property of the Event Grid Event.
"""
return pulumi.get(self, "id")
@id.setter
def id(self, value: Optional[pulumi.Input['JsonFieldArgs']]):
pulumi.set(self, "id", value)
@property
@pulumi.getter
def subject(self) -> Optional[pulumi.Input['JsonFieldWithDefaultArgs']]:
"""
The mapping information for the Subject property of the Event Grid Event.
"""
return pulumi.get(self, "subject")
@subject.setter
def subject(self, value: Optional[pulumi.Input['JsonFieldWithDefaultArgs']]):
pulumi.set(self, "subject", value)
@property
@pulumi.getter
def topic(self) -> Optional[pulumi.Input['JsonFieldArgs']]:
"""
The mapping information for the Topic property of the Event Grid Event.
"""
return pulumi.get(self, "topic")
@topic.setter
def topic(self, value: Optional[pulumi.Input['JsonFieldArgs']]):
pulumi.set(self, "topic", value)
@pulumi.input_type
class NumberGreaterThanAdvancedFilterArgs:
def __init__(__self__, *,
operator_type: pulumi.Input[str],
key: Optional[pulumi.Input[str]] = None,
value: Optional[pulumi.Input[float]] = None):
"""
NumberGreaterThan Advanced Filter.
:param pulumi.Input[str] operator_type: The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'NumberGreaterThan'.
:param pulumi.Input[str] key: The field/property in the event based on which you want to filter.
:param pulumi.Input[float] value: The filter value.
"""
pulumi.set(__self__, "operator_type", 'NumberGreaterThan')
if key is not None:
pulumi.set(__self__, "key", key)
if value is not None:
pulumi.set(__self__, "value", value)
@property
@pulumi.getter(name="operatorType")
def operator_type(self) -> pulumi.Input[str]:
"""
The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'NumberGreaterThan'.
"""
return pulumi.get(self, "operator_type")
@operator_type.setter
def operator_type(self, value: pulumi.Input[str]):
pulumi.set(self, "operator_type", value)
@property
@pulumi.getter
def key(self) -> Optional[pulumi.Input[str]]:
"""
The field/property in the event based on which you want to filter.
"""
return pulumi.get(self, "key")
@key.setter
def key(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "key", value)
@property
@pulumi.getter
def value(self) -> Optional[pulumi.Input[float]]:
"""
The filter value.
"""
return pulumi.get(self, "value")
@value.setter
def value(self, value: Optional[pulumi.Input[float]]):
pulumi.set(self, "value", value)
@pulumi.input_type
class NumberGreaterThanOrEqualsAdvancedFilterArgs:
def __init__(__self__, *,
operator_type: pulumi.Input[str],
key: Optional[pulumi.Input[str]] = None,
value: Optional[pulumi.Input[float]] = None):
"""
NumberGreaterThanOrEquals Advanced Filter.
:param pulumi.Input[str] operator_type: The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'NumberGreaterThanOrEquals'.
:param pulumi.Input[str] key: The field/property in the event based on which you want to filter.
:param pulumi.Input[float] value: The filter value.
"""
pulumi.set(__self__, "operator_type", 'NumberGreaterThanOrEquals')
if key is not None:
pulumi.set(__self__, "key", key)
if value is not None:
pulumi.set(__self__, "value", value)
@property
@pulumi.getter(name="operatorType")
def operator_type(self) -> pulumi.Input[str]:
"""
The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'NumberGreaterThanOrEquals'.
"""
return pulumi.get(self, "operator_type")
@operator_type.setter
def operator_type(self, value: pulumi.Input[str]):
pulumi.set(self, "operator_type", value)
@property
@pulumi.getter
def key(self) -> Optional[pulumi.Input[str]]:
"""
The field/property in the event based on which you want to filter.
"""
return pulumi.get(self, "key")
@key.setter
def key(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "key", value)
@property
@pulumi.getter
def value(self) -> Optional[pulumi.Input[float]]:
"""
The filter value.
"""
return pulumi.get(self, "value")
@value.setter
def value(self, value: Optional[pulumi.Input[float]]):
pulumi.set(self, "value", value)
@pulumi.input_type
class NumberInAdvancedFilterArgs:
def __init__(__self__, *,
operator_type: pulumi.Input[str],
key: Optional[pulumi.Input[str]] = None,
values: Optional[pulumi.Input[Sequence[pulumi.Input[float]]]] = None):
"""
NumberIn Advanced Filter.
:param pulumi.Input[str] operator_type: The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'NumberIn'.
:param pulumi.Input[str] key: The field/property in the event based on which you want to filter.
:param pulumi.Input[Sequence[pulumi.Input[float]]] values: The set of filter values.
"""
pulumi.set(__self__, "operator_type", 'NumberIn')
if key is not None:
pulumi.set(__self__, "key", key)
if values is not None:
pulumi.set(__self__, "values", values)
@property
@pulumi.getter(name="operatorType")
def operator_type(self) -> pulumi.Input[str]:
"""
The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'NumberIn'.
"""
return pulumi.get(self, "operator_type")
@operator_type.setter
def operator_type(self, value: pulumi.Input[str]):
pulumi.set(self, "operator_type", value)
@property
@pulumi.getter
def key(self) -> Optional[pulumi.Input[str]]:
"""
The field/property in the event based on which you want to filter.
"""
return pulumi.get(self, "key")
@key.setter
def key(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "key", value)
@property
@pulumi.getter
def values(self) -> Optional[pulumi.Input[Sequence[pulumi.Input[float]]]]:
"""
The set of filter values.
"""
return pulumi.get(self, "values")
@values.setter
def values(self, value: Optional[pulumi.Input[Sequence[pulumi.Input[float]]]]):
pulumi.set(self, "values", value)
@pulumi.input_type
class NumberLessThanAdvancedFilterArgs:
def __init__(__self__, *,
operator_type: pulumi.Input[str],
key: Optional[pulumi.Input[str]] = None,
value: Optional[pulumi.Input[float]] = None):
"""
NumberLessThan Advanced Filter.
:param pulumi.Input[str] operator_type: The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'NumberLessThan'.
:param pulumi.Input[str] key: The field/property in the event based on which you want to filter.
:param pulumi.Input[float] value: The filter value.
"""
pulumi.set(__self__, "operator_type", 'NumberLessThan')
if key is not None:
pulumi.set(__self__, "key", key)
if value is not None:
pulumi.set(__self__, "value", value)
@property
@pulumi.getter(name="operatorType")
def operator_type(self) -> pulumi.Input[str]:
"""
The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'NumberLessThan'.
"""
return pulumi.get(self, "operator_type")
@operator_type.setter
def operator_type(self, value: pulumi.Input[str]):
pulumi.set(self, "operator_type", value)
@property
@pulumi.getter
def key(self) -> Optional[pulumi.Input[str]]:
"""
The field/property in the event based on which you want to filter.
"""
return pulumi.get(self, "key")
@key.setter
def key(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "key", value)
@property
@pulumi.getter
def value(self) -> Optional[pulumi.Input[float]]:
"""
The filter value.
"""
return pulumi.get(self, "value")
@value.setter
def value(self, value: Optional[pulumi.Input[float]]):
pulumi.set(self, "value", value)
@pulumi.input_type
class NumberLessThanOrEqualsAdvancedFilterArgs:
def __init__(__self__, *,
operator_type: pulumi.Input[str],
key: Optional[pulumi.Input[str]] = None,
value: Optional[pulumi.Input[float]] = None):
"""
NumberLessThanOrEquals Advanced Filter.
:param pulumi.Input[str] operator_type: The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'NumberLessThanOrEquals'.
:param pulumi.Input[str] key: The field/property in the event based on which you want to filter.
:param pulumi.Input[float] value: The filter value.
"""
pulumi.set(__self__, "operator_type", 'NumberLessThanOrEquals')
if key is not None:
pulumi.set(__self__, "key", key)
if value is not None:
pulumi.set(__self__, "value", value)
@property
@pulumi.getter(name="operatorType")
def operator_type(self) -> pulumi.Input[str]:
"""
The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'NumberLessThanOrEquals'.
"""
return pulumi.get(self, "operator_type")
@operator_type.setter
def operator_type(self, value: pulumi.Input[str]):
pulumi.set(self, "operator_type", value)
@property
@pulumi.getter
def key(self) -> Optional[pulumi.Input[str]]:
"""
The field/property in the event based on which you want to filter.
"""
return pulumi.get(self, "key")
@key.setter
def key(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "key", value)
@property
@pulumi.getter
def value(self) -> Optional[pulumi.Input[float]]:
"""
The filter value.
"""
return pulumi.get(self, "value")
@value.setter
def value(self, value: Optional[pulumi.Input[float]]):
pulumi.set(self, "value", value)
@pulumi.input_type
class NumberNotInAdvancedFilterArgs:
def __init__(__self__, *,
operator_type: pulumi.Input[str],
key: Optional[pulumi.Input[str]] = None,
values: Optional[pulumi.Input[Sequence[pulumi.Input[float]]]] = None):
"""
NumberNotIn Advanced Filter.
:param pulumi.Input[str] operator_type: The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'NumberNotIn'.
:param pulumi.Input[str] key: The field/property in the event based on which you want to filter.
:param pulumi.Input[Sequence[pulumi.Input[float]]] values: The set of filter values.
"""
pulumi.set(__self__, "operator_type", 'NumberNotIn')
if key is not None:
pulumi.set(__self__, "key", key)
if values is not None:
pulumi.set(__self__, "values", values)
@property
@pulumi.getter(name="operatorType")
def operator_type(self) -> pulumi.Input[str]:
"""
The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'NumberNotIn'.
"""
return pulumi.get(self, "operator_type")
@operator_type.setter
def operator_type(self, value: pulumi.Input[str]):
pulumi.set(self, "operator_type", value)
@property
@pulumi.getter
def key(self) -> Optional[pulumi.Input[str]]:
"""
The field/property in the event based on which you want to filter.
"""
return pulumi.get(self, "key")
@key.setter
def key(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "key", value)
@property
@pulumi.getter
def values(self) -> Optional[pulumi.Input[Sequence[pulumi.Input[float]]]]:
"""
The set of filter values.
"""
return pulumi.get(self, "values")
@values.setter
def values(self, value: Optional[pulumi.Input[Sequence[pulumi.Input[float]]]]):
pulumi.set(self, "values", value)
@pulumi.input_type
class PrivateEndpointArgs:
def __init__(__self__, *,
id: Optional[pulumi.Input[str]] = None):
"""
PrivateEndpoint information.
:param pulumi.Input[str] id: The ARM identifier for Private Endpoint.
"""
if id is not None:
pulumi.set(__self__, "id", id)
@property
@pulumi.getter
def id(self) -> Optional[pulumi.Input[str]]:
"""
The ARM identifier for Private Endpoint.
"""
return pulumi.get(self, "id")
@id.setter
def id(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "id", value)
@pulumi.input_type
class PrivateEndpointConnectionArgs:
def __init__(__self__, *,
group_ids: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]] = None,
private_endpoint: Optional[pulumi.Input['PrivateEndpointArgs']] = None,
private_link_service_connection_state: Optional[pulumi.Input['ConnectionStateArgs']] = None,
provisioning_state: Optional[pulumi.Input[Union[str, 'ResourceProvisioningState']]] = None):
"""
:param pulumi.Input[Sequence[pulumi.Input[str]]] group_ids: GroupIds from the private link service resource.
:param pulumi.Input['PrivateEndpointArgs'] private_endpoint: The Private Endpoint resource for this Connection.
:param pulumi.Input['ConnectionStateArgs'] private_link_service_connection_state: Details about the state of the connection.
:param pulumi.Input[Union[str, 'ResourceProvisioningState']] provisioning_state: Provisioning state of the Private Endpoint Connection.
"""
if group_ids is not None:
pulumi.set(__self__, "group_ids", group_ids)
if private_endpoint is not None:
pulumi.set(__self__, "private_endpoint", private_endpoint)
if private_link_service_connection_state is not None:
pulumi.set(__self__, "private_link_service_connection_state", private_link_service_connection_state)
if provisioning_state is not None:
pulumi.set(__self__, "provisioning_state", provisioning_state)
@property
@pulumi.getter(name="groupIds")
def group_ids(self) -> Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]:
"""
GroupIds from the private link service resource.
"""
return pulumi.get(self, "group_ids")
@group_ids.setter
def group_ids(self, value: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]):
pulumi.set(self, "group_ids", value)
@property
@pulumi.getter(name="privateEndpoint")
def private_endpoint(self) -> Optional[pulumi.Input['PrivateEndpointArgs']]:
"""
The Private Endpoint resource for this Connection.
"""
return pulumi.get(self, "private_endpoint")
@private_endpoint.setter
def private_endpoint(self, value: Optional[pulumi.Input['PrivateEndpointArgs']]):
pulumi.set(self, "private_endpoint", value)
@property
@pulumi.getter(name="privateLinkServiceConnectionState")
def private_link_service_connection_state(self) -> Optional[pulumi.Input['ConnectionStateArgs']]:
"""
Details about the state of the connection.
"""
return pulumi.get(self, "private_link_service_connection_state")
@private_link_service_connection_state.setter
def private_link_service_connection_state(self, value: Optional[pulumi.Input['ConnectionStateArgs']]):
pulumi.set(self, "private_link_service_connection_state", value)
@property
@pulumi.getter(name="provisioningState")
def provisioning_state(self) -> Optional[pulumi.Input[Union[str, 'ResourceProvisioningState']]]:
"""
Provisioning state of the Private Endpoint Connection.
"""
return pulumi.get(self, "provisioning_state")
@provisioning_state.setter
def provisioning_state(self, value: Optional[pulumi.Input[Union[str, 'ResourceProvisioningState']]]):
pulumi.set(self, "provisioning_state", value)
@pulumi.input_type
class RetryPolicyArgs:
def __init__(__self__, *,
event_time_to_live_in_minutes: Optional[pulumi.Input[int]] = None,
max_delivery_attempts: Optional[pulumi.Input[int]] = None):
"""
Information about the retry policy for an event subscription.
:param pulumi.Input[int] event_time_to_live_in_minutes: Time To Live (in minutes) for events.
:param pulumi.Input[int] max_delivery_attempts: Maximum number of delivery retry attempts for events.
"""
if event_time_to_live_in_minutes is not None:
pulumi.set(__self__, "event_time_to_live_in_minutes", event_time_to_live_in_minutes)
if max_delivery_attempts is not None:
pulumi.set(__self__, "max_delivery_attempts", max_delivery_attempts)
@property
@pulumi.getter(name="eventTimeToLiveInMinutes")
def event_time_to_live_in_minutes(self) -> Optional[pulumi.Input[int]]:
"""
Time To Live (in minutes) for events.
"""
return pulumi.get(self, "event_time_to_live_in_minutes")
@event_time_to_live_in_minutes.setter
def event_time_to_live_in_minutes(self, value: Optional[pulumi.Input[int]]):
pulumi.set(self, "event_time_to_live_in_minutes", value)
@property
@pulumi.getter(name="maxDeliveryAttempts")
def max_delivery_attempts(self) -> Optional[pulumi.Input[int]]:
"""
Maximum number of delivery retry attempts for events.
"""
return pulumi.get(self, "max_delivery_attempts")
@max_delivery_attempts.setter
def max_delivery_attempts(self, value: Optional[pulumi.Input[int]]):
pulumi.set(self, "max_delivery_attempts", value)
@pulumi.input_type
class ServiceBusQueueEventSubscriptionDestinationArgs:
def __init__(__self__, *,
endpoint_type: pulumi.Input[str],
resource_id: Optional[pulumi.Input[str]] = None):
"""
Information about the service bus destination for an event subscription.
:param pulumi.Input[str] endpoint_type: Type of the endpoint for the event subscription destination.
Expected value is 'ServiceBusQueue'.
:param pulumi.Input[str] resource_id: The Azure Resource Id that represents the endpoint of the Service Bus destination of an event subscription.
"""
pulumi.set(__self__, "endpoint_type", 'ServiceBusQueue')
if resource_id is not None:
pulumi.set(__self__, "resource_id", resource_id)
@property
@pulumi.getter(name="endpointType")
def endpoint_type(self) -> pulumi.Input[str]:
"""
Type of the endpoint for the event subscription destination.
Expected value is 'ServiceBusQueue'.
"""
return pulumi.get(self, "endpoint_type")
@endpoint_type.setter
def endpoint_type(self, value: pulumi.Input[str]):
pulumi.set(self, "endpoint_type", value)
@property
@pulumi.getter(name="resourceId")
def resource_id(self) -> Optional[pulumi.Input[str]]:
"""
The Azure Resource Id that represents the endpoint of the Service Bus destination of an event subscription.
"""
return pulumi.get(self, "resource_id")
@resource_id.setter
def resource_id(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "resource_id", value)
@pulumi.input_type
class ServiceBusTopicEventSubscriptionDestinationArgs:
def __init__(__self__, *,
endpoint_type: pulumi.Input[str],
resource_id: Optional[pulumi.Input[str]] = None):
"""
Information about the service bus topic destination for an event subscription.
:param pulumi.Input[str] endpoint_type: Type of the endpoint for the event subscription destination.
Expected value is 'ServiceBusTopic'.
:param pulumi.Input[str] resource_id: The Azure Resource Id that represents the endpoint of the Service Bus Topic destination of an event subscription.
"""
pulumi.set(__self__, "endpoint_type", 'ServiceBusTopic')
if resource_id is not None:
pulumi.set(__self__, "resource_id", resource_id)
@property
@pulumi.getter(name="endpointType")
def endpoint_type(self) -> pulumi.Input[str]:
"""
Type of the endpoint for the event subscription destination.
Expected value is 'ServiceBusTopic'.
"""
return pulumi.get(self, "endpoint_type")
@endpoint_type.setter
def endpoint_type(self, value: pulumi.Input[str]):
pulumi.set(self, "endpoint_type", value)
@property
@pulumi.getter(name="resourceId")
def resource_id(self) -> Optional[pulumi.Input[str]]:
"""
The Azure Resource Id that represents the endpoint of the Service Bus Topic destination of an event subscription.
"""
return pulumi.get(self, "resource_id")
@resource_id.setter
def resource_id(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "resource_id", value)
@pulumi.input_type
class StorageBlobDeadLetterDestinationArgs:
def __init__(__self__, *,
endpoint_type: pulumi.Input[str],
blob_container_name: Optional[pulumi.Input[str]] = None,
resource_id: Optional[pulumi.Input[str]] = None):
"""
Information about the storage blob based dead letter destination.
:param pulumi.Input[str] endpoint_type: Type of the endpoint for the dead letter destination
Expected value is 'StorageBlob'.
:param pulumi.Input[str] blob_container_name: The name of the Storage blob container that is the destination of the deadletter events
:param pulumi.Input[str] resource_id: The Azure Resource ID of the storage account that is the destination of the deadletter events
"""
pulumi.set(__self__, "endpoint_type", 'StorageBlob')
if blob_container_name is not None:
pulumi.set(__self__, "blob_container_name", blob_container_name)
if resource_id is not None:
pulumi.set(__self__, "resource_id", resource_id)
@property
@pulumi.getter(name="endpointType")
def endpoint_type(self) -> pulumi.Input[str]:
"""
Type of the endpoint for the dead letter destination
Expected value is 'StorageBlob'.
"""
return pulumi.get(self, "endpoint_type")
@endpoint_type.setter
def endpoint_type(self, value: pulumi.Input[str]):
pulumi.set(self, "endpoint_type", value)
@property
@pulumi.getter(name="blobContainerName")
def blob_container_name(self) -> Optional[pulumi.Input[str]]:
"""
The name of the Storage blob container that is the destination of the deadletter events
"""
return pulumi.get(self, "blob_container_name")
@blob_container_name.setter
def blob_container_name(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "blob_container_name", value)
@property
@pulumi.getter(name="resourceId")
def resource_id(self) -> Optional[pulumi.Input[str]]:
"""
The Azure Resource ID of the storage account that is the destination of the deadletter events
"""
return pulumi.get(self, "resource_id")
@resource_id.setter
def resource_id(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "resource_id", value)
@pulumi.input_type
class StorageQueueEventSubscriptionDestinationArgs:
def __init__(__self__, *,
endpoint_type: pulumi.Input[str],
queue_name: Optional[pulumi.Input[str]] = None,
resource_id: Optional[pulumi.Input[str]] = None):
"""
Information about the storage queue destination for an event subscription.
:param pulumi.Input[str] endpoint_type: Type of the endpoint for the event subscription destination.
Expected value is 'StorageQueue'.
:param pulumi.Input[str] queue_name: The name of the Storage queue under a storage account that is the destination of an event subscription.
:param pulumi.Input[str] resource_id: The Azure Resource ID of the storage account that contains the queue that is the destination of an event subscription.
"""
pulumi.set(__self__, "endpoint_type", 'StorageQueue')
if queue_name is not None:
pulumi.set(__self__, "queue_name", queue_name)
if resource_id is not None:
pulumi.set(__self__, "resource_id", resource_id)
@property
@pulumi.getter(name="endpointType")
def endpoint_type(self) -> pulumi.Input[str]:
"""
Type of the endpoint for the event subscription destination.
Expected value is 'StorageQueue'.
"""
return pulumi.get(self, "endpoint_type")
@endpoint_type.setter
def endpoint_type(self, value: pulumi.Input[str]):
pulumi.set(self, "endpoint_type", value)
@property
@pulumi.getter(name="queueName")
def queue_name(self) -> Optional[pulumi.Input[str]]:
"""
The name of the Storage queue under a storage account that is the destination of an event subscription.
"""
return pulumi.get(self, "queue_name")
@queue_name.setter
def queue_name(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "queue_name", value)
@property
@pulumi.getter(name="resourceId")
def resource_id(self) -> Optional[pulumi.Input[str]]:
"""
The Azure Resource ID of the storage account that contains the queue that is the destination of an event subscription.
"""
return pulumi.get(self, "resource_id")
@resource_id.setter
def resource_id(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "resource_id", value)
@pulumi.input_type
class StringBeginsWithAdvancedFilterArgs:
def __init__(__self__, *,
operator_type: pulumi.Input[str],
key: Optional[pulumi.Input[str]] = None,
values: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]] = None):
"""
StringBeginsWith Advanced Filter.
:param pulumi.Input[str] operator_type: The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'StringBeginsWith'.
:param pulumi.Input[str] key: The field/property in the event based on which you want to filter.
:param pulumi.Input[Sequence[pulumi.Input[str]]] values: The set of filter values.
"""
pulumi.set(__self__, "operator_type", 'StringBeginsWith')
if key is not None:
pulumi.set(__self__, "key", key)
if values is not None:
pulumi.set(__self__, "values", values)
@property
@pulumi.getter(name="operatorType")
def operator_type(self) -> pulumi.Input[str]:
"""
The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'StringBeginsWith'.
"""
return pulumi.get(self, "operator_type")
@operator_type.setter
def operator_type(self, value: pulumi.Input[str]):
pulumi.set(self, "operator_type", value)
@property
@pulumi.getter
def key(self) -> Optional[pulumi.Input[str]]:
"""
The field/property in the event based on which you want to filter.
"""
return pulumi.get(self, "key")
@key.setter
def key(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "key", value)
@property
@pulumi.getter
def values(self) -> Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]:
"""
The set of filter values.
"""
return pulumi.get(self, "values")
@values.setter
def values(self, value: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]):
pulumi.set(self, "values", value)
@pulumi.input_type
class StringContainsAdvancedFilterArgs:
def __init__(__self__, *,
operator_type: pulumi.Input[str],
key: Optional[pulumi.Input[str]] = None,
values: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]] = None):
"""
StringContains Advanced Filter.
:param pulumi.Input[str] operator_type: The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'StringContains'.
:param pulumi.Input[str] key: The field/property in the event based on which you want to filter.
:param pulumi.Input[Sequence[pulumi.Input[str]]] values: The set of filter values.
"""
pulumi.set(__self__, "operator_type", 'StringContains')
if key is not None:
pulumi.set(__self__, "key", key)
if values is not None:
pulumi.set(__self__, "values", values)
@property
@pulumi.getter(name="operatorType")
def operator_type(self) -> pulumi.Input[str]:
"""
The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'StringContains'.
"""
return pulumi.get(self, "operator_type")
@operator_type.setter
def operator_type(self, value: pulumi.Input[str]):
pulumi.set(self, "operator_type", value)
@property
@pulumi.getter
def key(self) -> Optional[pulumi.Input[str]]:
"""
The field/property in the event based on which you want to filter.
"""
return pulumi.get(self, "key")
@key.setter
def key(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "key", value)
@property
@pulumi.getter
def values(self) -> Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]:
"""
The set of filter values.
"""
return pulumi.get(self, "values")
@values.setter
def values(self, value: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]):
pulumi.set(self, "values", value)
@pulumi.input_type
class StringEndsWithAdvancedFilterArgs:
def __init__(__self__, *,
operator_type: pulumi.Input[str],
key: Optional[pulumi.Input[str]] = None,
values: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]] = None):
"""
StringEndsWith Advanced Filter.
:param pulumi.Input[str] operator_type: The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'StringEndsWith'.
:param pulumi.Input[str] key: The field/property in the event based on which you want to filter.
:param pulumi.Input[Sequence[pulumi.Input[str]]] values: The set of filter values.
"""
pulumi.set(__self__, "operator_type", 'StringEndsWith')
if key is not None:
pulumi.set(__self__, "key", key)
if values is not None:
pulumi.set(__self__, "values", values)
@property
@pulumi.getter(name="operatorType")
def operator_type(self) -> pulumi.Input[str]:
"""
The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'StringEndsWith'.
"""
return pulumi.get(self, "operator_type")
@operator_type.setter
def operator_type(self, value: pulumi.Input[str]):
pulumi.set(self, "operator_type", value)
@property
@pulumi.getter
def key(self) -> Optional[pulumi.Input[str]]:
"""
The field/property in the event based on which you want to filter.
"""
return pulumi.get(self, "key")
@key.setter
def key(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "key", value)
@property
@pulumi.getter
def values(self) -> Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]:
"""
The set of filter values.
"""
return pulumi.get(self, "values")
@values.setter
def values(self, value: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]):
pulumi.set(self, "values", value)
@pulumi.input_type
class StringInAdvancedFilterArgs:
def __init__(__self__, *,
operator_type: pulumi.Input[str],
key: Optional[pulumi.Input[str]] = None,
values: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]] = None):
"""
StringIn Advanced Filter.
:param pulumi.Input[str] operator_type: The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'StringIn'.
:param pulumi.Input[str] key: The field/property in the event based on which you want to filter.
:param pulumi.Input[Sequence[pulumi.Input[str]]] values: The set of filter values.
"""
pulumi.set(__self__, "operator_type", 'StringIn')
if key is not None:
pulumi.set(__self__, "key", key)
if values is not None:
pulumi.set(__self__, "values", values)
@property
@pulumi.getter(name="operatorType")
def operator_type(self) -> pulumi.Input[str]:
"""
The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'StringIn'.
"""
return pulumi.get(self, "operator_type")
@operator_type.setter
def operator_type(self, value: pulumi.Input[str]):
pulumi.set(self, "operator_type", value)
@property
@pulumi.getter
def key(self) -> Optional[pulumi.Input[str]]:
"""
The field/property in the event based on which you want to filter.
"""
return pulumi.get(self, "key")
@key.setter
def key(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "key", value)
@property
@pulumi.getter
def values(self) -> Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]:
"""
The set of filter values.
"""
return pulumi.get(self, "values")
@values.setter
def values(self, value: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]):
pulumi.set(self, "values", value)
@pulumi.input_type
class StringNotInAdvancedFilterArgs:
def __init__(__self__, *,
operator_type: pulumi.Input[str],
key: Optional[pulumi.Input[str]] = None,
values: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]] = None):
"""
StringNotIn Advanced Filter.
:param pulumi.Input[str] operator_type: The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'StringNotIn'.
:param pulumi.Input[str] key: The field/property in the event based on which you want to filter.
:param pulumi.Input[Sequence[pulumi.Input[str]]] values: The set of filter values.
"""
pulumi.set(__self__, "operator_type", 'StringNotIn')
if key is not None:
pulumi.set(__self__, "key", key)
if values is not None:
pulumi.set(__self__, "values", values)
@property
@pulumi.getter(name="operatorType")
def operator_type(self) -> pulumi.Input[str]:
"""
The operator type used for filtering, e.g., NumberIn, StringContains, BoolEquals and others.
Expected value is 'StringNotIn'.
"""
return pulumi.get(self, "operator_type")
@operator_type.setter
def operator_type(self, value: pulumi.Input[str]):
pulumi.set(self, "operator_type", value)
@property
@pulumi.getter
def key(self) -> Optional[pulumi.Input[str]]:
"""
The field/property in the event based on which you want to filter.
"""
return pulumi.get(self, "key")
@key.setter
def key(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "key", value)
@property
@pulumi.getter
def values(self) -> Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]:
"""
The set of filter values.
"""
return pulumi.get(self, "values")
@values.setter
def values(self, value: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]):
pulumi.set(self, "values", value)
@pulumi.input_type
class WebHookEventSubscriptionDestinationArgs:
def __init__(__self__, *,
endpoint_type: pulumi.Input[str],
azure_active_directory_application_id_or_uri: Optional[pulumi.Input[str]] = None,
azure_active_directory_tenant_id: Optional[pulumi.Input[str]] = None,
endpoint_url: Optional[pulumi.Input[str]] = None,
max_events_per_batch: Optional[pulumi.Input[int]] = None,
preferred_batch_size_in_kilobytes: Optional[pulumi.Input[int]] = None):
"""
Information about the webhook destination for an event subscription.
:param pulumi.Input[str] endpoint_type: Type of the endpoint for the event subscription destination.
Expected value is 'WebHook'.
:param pulumi.Input[str] azure_active_directory_application_id_or_uri: The Azure Active Directory Application ID or URI to get the access token that will be included as the bearer token in delivery requests.
:param pulumi.Input[str] azure_active_directory_tenant_id: The Azure Active Directory Tenant ID to get the access token that will be included as the bearer token in delivery requests.
:param pulumi.Input[str] endpoint_url: The URL that represents the endpoint of the destination of an event subscription.
:param pulumi.Input[int] max_events_per_batch: Maximum number of events per batch.
:param pulumi.Input[int] preferred_batch_size_in_kilobytes: Preferred batch size in Kilobytes.
"""
pulumi.set(__self__, "endpoint_type", 'WebHook')
if azure_active_directory_application_id_or_uri is not None:
pulumi.set(__self__, "azure_active_directory_application_id_or_uri", azure_active_directory_application_id_or_uri)
if azure_active_directory_tenant_id is not None:
pulumi.set(__self__, "azure_active_directory_tenant_id", azure_active_directory_tenant_id)
if endpoint_url is not None:
pulumi.set(__self__, "endpoint_url", endpoint_url)
if max_events_per_batch is not None:
pulumi.set(__self__, "max_events_per_batch", max_events_per_batch)
if preferred_batch_size_in_kilobytes is not None:
pulumi.set(__self__, "preferred_batch_size_in_kilobytes", preferred_batch_size_in_kilobytes)
@property
@pulumi.getter(name="endpointType")
def endpoint_type(self) -> pulumi.Input[str]:
"""
Type of the endpoint for the event subscription destination.
Expected value is 'WebHook'.
"""
return pulumi.get(self, "endpoint_type")
@endpoint_type.setter
def endpoint_type(self, value: pulumi.Input[str]):
pulumi.set(self, "endpoint_type", value)
@property
@pulumi.getter(name="azureActiveDirectoryApplicationIdOrUri")
def azure_active_directory_application_id_or_uri(self) -> Optional[pulumi.Input[str]]:
"""
The Azure Active Directory Application ID or URI to get the access token that will be included as the bearer token in delivery requests.
"""
return pulumi.get(self, "azure_active_directory_application_id_or_uri")
@azure_active_directory_application_id_or_uri.setter
def azure_active_directory_application_id_or_uri(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "azure_active_directory_application_id_or_uri", value)
@property
@pulumi.getter(name="azureActiveDirectoryTenantId")
def azure_active_directory_tenant_id(self) -> Optional[pulumi.Input[str]]:
"""
The Azure Active Directory Tenant ID to get the access token that will be included as the bearer token in delivery requests.
"""
return pulumi.get(self, "azure_active_directory_tenant_id")
@azure_active_directory_tenant_id.setter
def azure_active_directory_tenant_id(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "azure_active_directory_tenant_id", value)
@property
@pulumi.getter(name="endpointUrl")
def endpoint_url(self) -> Optional[pulumi.Input[str]]:
"""
The URL that represents the endpoint of the destination of an event subscription.
"""
return pulumi.get(self, "endpoint_url")
@endpoint_url.setter
def endpoint_url(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "endpoint_url", value)
@property
@pulumi.getter(name="maxEventsPerBatch")
def max_events_per_batch(self) -> Optional[pulumi.Input[int]]:
"""
Maximum number of events per batch.
"""
return pulumi.get(self, "max_events_per_batch")
@max_events_per_batch.setter
def max_events_per_batch(self, value: Optional[pulumi.Input[int]]):
pulumi.set(self, "max_events_per_batch", value)
@property
@pulumi.getter(name="preferredBatchSizeInKilobytes")
def preferred_batch_size_in_kilobytes(self) -> Optional[pulumi.Input[int]]:
"""
Preferred batch size in Kilobytes.
"""
return pulumi.get(self, "preferred_batch_size_in_kilobytes")
@preferred_batch_size_in_kilobytes.setter
def preferred_batch_size_in_kilobytes(self, value: Optional[pulumi.Input[int]]):
pulumi.set(self, "preferred_batch_size_in_kilobytes", value) | PypiClean |
/safe_ds-0.15.0.tar.gz/safe_ds-0.15.0/src/safeds/data/tabular/containers/_table.py | from __future__ import annotations
import copy
import functools
import io
import warnings
from pathlib import Path
from typing import TYPE_CHECKING, Any, TypeVar
import Levenshtein
import matplotlib.pyplot as plt
import numpy as np
import openpyxl
import pandas as pd
import seaborn as sns
from pandas import DataFrame
from scipy import stats
from safeds.data.image.containers import Image
from safeds.data.image.typing import ImageFormat
from safeds.data.tabular.typing import ColumnType, Schema
from safeds.exceptions import (
ColumnLengthMismatchError,
ColumnSizeError,
DuplicateColumnNameError,
IndexOutOfBoundsError,
NonNumericColumnError,
UnknownColumnNameError,
WrongFileExtensionError,
)
from ._column import Column
from ._row import Row
if TYPE_CHECKING:
from collections.abc import Callable, Mapping, Sequence
from safeds.data.tabular.transformation import InvertibleTableTransformer, TableTransformer
from ._tagged_table import TaggedTable
# noinspection PyProtectedMember
class Table:
"""
A table is a two-dimensional collection of data. It can either be seen as a list of rows or as a list of columns.
To create a `Table` call the constructor or use one of the following static methods:
| Method | Description |
| ---------------------------------------------------------------------------- | -------------------------------------- |
| [from_csv_file][safeds.data.tabular.containers._table.Table.from_csv_file] | Create a table from a CSV file. |
| [from_json_file][safeds.data.tabular.containers._table.Table.from_json_file] | Create a table from a JSON file. |
| [from_dict][safeds.data.tabular.containers._table.Table.from_dict] | Create a table from a dictionary. |
| [from_columns][safeds.data.tabular.containers._table.Table.from_columns] | Create a table from a list of columns. |
| [from_rows][safeds.data.tabular.containers._table.Table.from_rows] | Create a table from a list of rows. |
Note: When removing the last column of the table, the `number_of_columns` property will be set to 0.
Parameters
----------
data : Mapping[str, Sequence[Any]] | None
The data. If None, an empty table is created.
Raises
------
ColumnLengthMismatchError
If columns have different lengths.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table({"a": [1, 2, 3], "b": [4, 5, 6]})
"""
# ------------------------------------------------------------------------------------------------------------------
# Creation
# ------------------------------------------------------------------------------------------------------------------
@staticmethod
def from_csv_file(path: str | Path) -> Table:
"""
Read data from a CSV file into a table.
Parameters
----------
path : str | Path
The path to the CSV file.
Returns
-------
table : Table
The table created from the CSV file.
Raises
------
FileNotFoundError
If the specified file does not exist.
WrongFileExtensionError
If the file is not a csv file.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> Table.from_csv_file('./src/resources/from_csv_file.csv')
a b c
0 1 2 1
1 0 0 7
"""
path = Path(path)
if path.suffix != ".csv":
raise WrongFileExtensionError(path, ".csv")
if path.exists():
with path.open() as f:
if f.read().replace("\n", "") == "":
return Table()
return Table._from_pandas_dataframe(pd.read_csv(path))
else:
raise FileNotFoundError(f'File "{path}" does not exist')
@staticmethod
def from_excel_file(path: str | Path) -> Table:
"""
Read data from an Excel file into a table.
Valid file extensions are `.xls`, '.xlsx', `.xlsm`, `.xlsb`, `.odf`, `.ods` and `.odt`.
Parameters
----------
path : str | Path
The path to the Excel file.
Returns
-------
table : Table
The table created from the Excel file.
Raises
------
FileNotFoundError
If the specified file does not exist.
WrongFileExtensionError
If the file is not an Excel file.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> Table.from_excel_file('./src/resources/from_excel_file.xlsx')
a b
0 1 4
1 2 5
2 3 6
"""
path = Path(path)
excel_extensions = [".xls", ".xlsx", ".xlsm", ".xlsb", ".odf", ".ods", ".odt"]
if path.suffix not in excel_extensions:
raise WrongFileExtensionError(path, excel_extensions)
try:
return Table._from_pandas_dataframe(
pd.read_excel(path, engine="openpyxl", usecols=lambda colname: "Unnamed" not in colname),
)
except FileNotFoundError as exception:
raise FileNotFoundError(f'File "{path}" does not exist') from exception
@staticmethod
def from_json_file(path: str | Path) -> Table:
"""
Read data from a JSON file into a table.
Parameters
----------
path : str | Path
The path to the JSON file.
Returns
-------
table : Table
The table created from the JSON file.
Raises
------
FileNotFoundError
If the specified file does not exist.
WrongFileExtensionError
If the file is not a JSON file.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> Table.from_json_file('./src/resources/from_json_file.json')
a b
0 1 4
1 2 5
2 3 6
"""
path = Path(path)
if path.suffix != ".json":
raise WrongFileExtensionError(path, ".json")
if path.exists():
with path.open() as f:
if f.read().replace("\n", "") in ("", "{}"):
return Table()
return Table._from_pandas_dataframe(pd.read_json(path))
else:
raise FileNotFoundError(f'File "{path}" does not exist')
@staticmethod
def from_dict(data: dict[str, list[Any]]) -> Table:
"""
Create a table from a dictionary that maps column names to column values.
Parameters
----------
data : dict[str, list[Any]]
The data.
Returns
-------
table : Table
The generated table.
Raises
------
ColumnLengthMismatchError
If columns have different lengths.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> d = {'a': [1, 2], 'b': [3, 4]}
>>> Table.from_dict(d)
a b
0 1 3
1 2 4
"""
return Table(data)
@staticmethod
def from_columns(columns: list[Column]) -> Table:
"""
Return a table created from a list of columns.
Parameters
----------
columns : list[Column]
The columns to be combined. They need to have the same size.
Returns
-------
table : Table
The generated table.
Raises
------
ColumnLengthMismatchError
If any of the column sizes does not match with the others.
DuplicateColumnNameError
If multiple columns have the same name.
Examples
--------
>>> from safeds.data.tabular.containers import Column, Table
>>> col1 = Column("a", [1, 2, 3])
>>> col2 = Column("b", [4, 5, 6])
>>> Table.from_columns([col1, col2])
a b
0 1 4
1 2 5
2 3 6
"""
dataframe: DataFrame = pd.DataFrame()
column_names = []
for column in columns:
if column._data.size != columns[0]._data.size:
raise ColumnLengthMismatchError(
"\n".join(f"{column.name}: {column._data.size}" for column in columns),
)
if column.name in column_names:
raise DuplicateColumnNameError(column.name)
column_names.append(column.name)
dataframe[column.name] = column._data
return Table._from_pandas_dataframe(dataframe)
@staticmethod
def from_rows(rows: list[Row]) -> Table:
"""
Return a table created from a list of rows.
Parameters
----------
rows : list[Row]
The rows to be combined. They need to have a matching schema.
Returns
-------
table : Table
The generated table.
Raises
------
UnknownColumnNameError
If any of the row column names does not match with the first row.
Examples
--------
>>> from safeds.data.tabular.containers import Row, Table
>>> row1 = Row({"a": 1, "b": 2})
>>> row2 = Row({"a": 3, "b": 4})
>>> Table.from_rows([row1, row2])
a b
0 1 2
1 3 4
"""
if len(rows) == 0:
return Table._from_pandas_dataframe(pd.DataFrame())
column_names_compare: list = list(rows[0].column_names)
unknown_column_names = set()
row_array: list[pd.DataFrame] = []
for row in rows:
unknown_column_names.update(set(column_names_compare) - set(row.column_names))
row_array.append(row._data)
if len(unknown_column_names) > 0:
raise UnknownColumnNameError(list(unknown_column_names))
dataframe: DataFrame = pd.concat(row_array, ignore_index=True)
dataframe.columns = column_names_compare
schema = Schema.merge_multiple_schemas([row.schema for row in rows])
return Table._from_pandas_dataframe(dataframe, schema)
@staticmethod
def _from_pandas_dataframe(data: pd.DataFrame, schema: Schema | None = None) -> Table:
"""
Create a table from a `pandas.DataFrame`.
Parameters
----------
data : pd.DataFrame
The data.
schema : Schema | None
The schema. If None, the schema is inferred from the data.
Returns
-------
table : Table
The created table.
Examples
--------
>>> import pandas as pd
>>> from safeds.data.tabular.containers import Table
>>> Table._from_pandas_dataframe(pd.DataFrame({"a": [1], "b": [2]}))
a b
0 1 2
"""
data = data.reset_index(drop=True)
result = object.__new__(Table)
result._data = data
if schema is None:
# noinspection PyProtectedMember
result._schema = Schema._from_pandas_dataframe(data)
else:
result._schema = schema
if result._data.empty:
result._data = pd.DataFrame(columns=schema.column_names)
return result
# ------------------------------------------------------------------------------------------------------------------
# Dunder methods
# ------------------------------------------------------------------------------------------------------------------
def __init__(self, data: Mapping[str, Sequence[Any]] | None = None) -> None:
"""
Create a table from a mapping of column names to their values.
Parameters
----------
data : Mapping[str, Sequence[Any]] | None
The data. If None, an empty table is created.
Raises
------
ColumnLengthMismatchError
If columns have different lengths.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> Table({"a": [1, 2, 3], "b": [4, 5, 6]})
a b
0 1 4
1 2 5
2 3 6
"""
if data is None:
data = {}
# Validation
expected_length: int | None = None
for column_values in data.values():
if expected_length is None:
expected_length = len(column_values)
elif len(column_values) != expected_length:
raise ColumnLengthMismatchError(
"\n".join(f"{column_name}: {len(column_values)}" for column_name, column_values in data.items()),
)
# Implementation
self._data: pd.DataFrame = pd.DataFrame(data)
self._data = self._data.reset_index(drop=True)
self._schema: Schema = Schema._from_pandas_dataframe(self._data)
def __eq__(self, other: Any) -> bool:
"""
Compare two table instances.
Returns
-------
'True' if contents are equal, 'False' otherwise.
Examples
--------
>>> from safeds.data.tabular.containers import Row, Table
>>> row1 = Row({"a": 1, "b": 2})
>>> row2 = Row({"a": 3, "b": 4})
>>> row3 = Row({"a": 5, "b": 6})
>>> table1 = Table.from_rows([row1, row2])
>>> table2 = Table.from_rows([row1, row2])
>>> table3 = Table.from_rows([row1, row3])
>>> table1 == table2
True
>>> table1 == table3
False
"""
if not isinstance(other, Table):
return NotImplemented
if self is other:
return True
if self.number_of_columns == 0 and other.number_of_columns == 0:
return True
table1 = self.sort_columns()
table2 = other.sort_columns()
if table1.number_of_rows == 0 and table2.number_of_rows == 0:
return table1.column_names == table2.column_names
return table1._schema == table2._schema and table1._data.equals(table2._data)
def __repr__(self) -> str:
r"""
Display the table in only one line.
Returns
-------
A string representation of the table in only one line.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1, 3], "b": [2, 4]})
>>> repr(table)
' a b\n0 1 2\n1 3 4'
"""
tmp = self._data.copy(deep=True)
tmp.columns = self.column_names
return tmp.__repr__()
def __str__(self) -> str:
tmp = self._data.copy(deep=True)
tmp.columns = self.column_names
return tmp.__str__()
# ------------------------------------------------------------------------------------------------------------------
# Properties
# ------------------------------------------------------------------------------------------------------------------
@property
def column_names(self) -> list[str]:
"""
Return a list of all column names in this table.
Alias for self.schema.column_names -> list[str].
Returns
-------
column_names : list[str]
The list of the column names.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"col1": [1, 3], "col2": [2, 4]})
>>> table.column_names
['col1', 'col2']
"""
return self._schema.column_names
@property
def number_of_columns(self) -> int:
"""
Return the number of columns.
Returns
-------
number_of_columns : int
The number of columns.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1], "b": [2]})
>>> table.number_of_columns
2
"""
return self._data.shape[1]
@property
def number_of_rows(self) -> int:
"""
Return the number of rows.
Returns
-------
number_of_rows : int
The number of rows.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1], "b": [2]})
>>> table.number_of_rows
1
"""
return self._data.shape[0]
@property
def schema(self) -> Schema:
"""
Return the schema of the table.
Returns
-------
schema : Schema
The schema.
Examples
--------
>>> from safeds.data.tabular.containers import Row, Table
>>> row = Row({"a": 1, "b": 2.5, "c": "ff"})
>>> table = Table.from_dict({"a": [1, 8], "b": [2.5, 9], "c": ["g", "g"]})
>>> table.schema
Schema({
'a': Integer,
'b': RealNumber,
'c': String
})
>>> table.schema == row.schema
True
"""
return self._schema
# ------------------------------------------------------------------------------------------------------------------
# Getters
# ------------------------------------------------------------------------------------------------------------------
def get_column(self, column_name: str) -> Column:
"""
Return a column with the data of the specified column.
Parameters
----------
column_name : str
The name of the column.
Returns
-------
column : Column
The column.
Raises
------
UnknownColumnNameError
If the specified target column name does not exist.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1], "b": [2]})
>>> table.get_column("b")
Column('b', [2])
"""
if not self.has_column(column_name):
similar_columns = self._get_similar_columns(column_name)
raise UnknownColumnNameError([column_name], similar_columns)
return Column._from_pandas_series(
self._data[column_name],
self.get_column_type(column_name),
)
def has_column(self, column_name: str) -> bool:
"""
Return whether the table contains a given column.
Alias for self.schema.hasColumn(column_name: str) -> bool.
Parameters
----------
column_name : str
The name of the column.
Returns
-------
contains : bool
True if the column exists.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1], "b": [2]})
>>> table.has_column("b")
True
>>> table.has_column("c")
False
"""
return self._schema.has_column(column_name)
def get_column_type(self, column_name: str) -> ColumnType:
"""
Return the type of the given column.
Alias for self.schema.get_type_of_column(column_name: str) -> ColumnType.
Parameters
----------
column_name : str
The name of the column to be queried.
Returns
-------
type : ColumnType
The type of the column.
Raises
------
UnknownColumnNameError
If the specified target column name does not exist.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1], "b": [2.5]})
>>> table.get_column_type("b")
RealNumber
"""
return self._schema.get_column_type(column_name)
def get_row(self, index: int) -> Row:
"""
Return the row at a specified index.
Parameters
----------
index : int
The index.
Returns
-------
row : Row
The row of the table at the index.
Raises
------
IndexOutOfBoundsError
If no row at the specified index exists in this table.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1, 3], "b": [2, 4]})
>>> table.get_row(0)
Row({
'a': 1,
'b': 2
})
"""
if len(self._data.index) - 1 < index or index < 0:
raise IndexOutOfBoundsError(index)
return Row._from_pandas_dataframe(self._data.iloc[[index]], self._schema)
def _get_similar_columns(self, column_name: str) -> list[str]:
"""
Get all the column names in a Table that are similar to a given name.
Parameters
----------
column_name : str
The name to compare the Table's column names to.
Returns
-------
similar_columns: list[str]
A list of all column names in the Table that are similar or equal to the given column name.
"""
similar_columns = []
similarity = 0.6
i = 0
while i < len(self.column_names):
if Levenshtein.jaro_winkler(self.column_names[i], column_name) >= similarity:
similar_columns.append(self.column_names[i])
i += 1
if len(similar_columns) == 4 and similarity < 0.9:
similarity += 0.1
similar_columns = []
i = 0
return similar_columns
# ------------------------------------------------------------------------------------------------------------------
# Information
# ------------------------------------------------------------------------------------------------------------------
def summarize_statistics(self) -> Table:
"""
Return a table with a number of statistical key values.
The original table is not modified.
Returns
-------
result : Table
The table with statistics.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1, 3], "b": [2, 4]})
>>> table.summarize_statistics()
metrics a b
0 maximum 3 4
1 minimum 1 2
2 mean 2.0 3.0
3 mode [1, 3] [2, 4]
4 median 2.0 3.0
5 sum 4 6
6 variance 2.0 2.0
7 standard deviation 1.4142135623730951 1.4142135623730951
8 idness 1.0 1.0
9 stability 0.5 0.5
"""
if self.number_of_columns == 0:
return Table(
{
"metrics": [
"maximum",
"minimum",
"mean",
"mode",
"median",
"sum",
"variance",
"standard deviation",
"idness",
"stability",
],
},
)
elif self.number_of_rows == 0:
table = Table(
{
"metrics": [
"maximum",
"minimum",
"mean",
"mode",
"median",
"sum",
"variance",
"standard deviation",
"idness",
"stability",
],
},
)
for name in self.column_names:
table = table.add_column(Column(name, ["-", "-", "-", "-", "-", "-", "-", "-", "-", "-"]))
return table
columns = self.to_columns()
result = pd.DataFrame()
statistics = {}
for column in columns:
statistics = {
"maximum": column.maximum,
"minimum": column.minimum,
"mean": column.mean,
"mode": column.mode,
"median": column.median,
"sum": column.sum,
"variance": column.variance,
"standard deviation": column.standard_deviation,
"idness": column.idness,
"stability": column.stability,
}
values = []
for function in statistics.values():
try:
values.append(str(function()))
except (NonNumericColumnError, ValueError):
values.append("-")
result = pd.concat([result, pd.DataFrame(values)], axis=1)
result = pd.concat([pd.DataFrame(list(statistics.keys())), result], axis=1)
result.columns = ["metrics", *self.column_names]
return Table._from_pandas_dataframe(result)
# ------------------------------------------------------------------------------------------------------------------
# Transformations
# ------------------------------------------------------------------------------------------------------------------
# This method is meant as a way to "cast" instances of subclasses of `Table` to a proper `Table`, dropping any
# additional constraints that might have to hold in the subclass.
# Override accordingly in subclasses.
def _as_table(self: Table) -> Table:
"""
Transform the table to an instance of the Table class.
Returns
-------
table: Table
The table, as an instance of the Table class.
"""
return self
def add_column(self, column: Column) -> Table:
"""
Return a new table with the provided column attached at the end.
The original table is not modified.
Returns
-------
result : Table
The table with the column attached.
Raises
------
DuplicateColumnNameError
If the new column already exists.
ColumnSizeError
If the size of the column does not match the number of rows.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1, 3], "b": [2, 4]})
>>> col = Column("c", ["d", "e"])
>>> table.add_column(col)
a b c
0 1 2 d
1 3 4 e
"""
if self.has_column(column.name):
raise DuplicateColumnNameError(column.name)
if column.number_of_rows != self.number_of_rows and self.number_of_columns != 0:
raise ColumnSizeError(str(self.number_of_rows), str(column._data.size))
result = self._data.copy()
result.columns = self._schema.column_names
result[column.name] = column._data
return Table._from_pandas_dataframe(result)
def add_columns(self, columns: list[Column] | Table) -> Table:
"""
Return a new `Table` with multiple added columns.
The original table is not modified.
Parameters
----------
columns : list[Column] or Table
The columns to be added.
Returns
-------
result: Table
A new table combining the original table and the given columns.
Raises
------
DuplicateColumnNameError
If at least one column name from the provided column list already exists in the table.
ColumnSizeError
If at least one of the column sizes from the provided column list does not match the table.
Examples
--------
>>> from safeds.data.tabular.containers import Column, Table
>>> table = Table.from_dict({"a": [1, 3], "b": [2, 4]})
>>> col1 = Column("c", ["d", "e"])
>>> col2 = Column("d", [3.5, 7.9])
>>> table.add_columns([col1, col2])
a b c d
0 1 2 d 3.5
1 3 4 e 7.9
"""
if isinstance(columns, Table):
columns = columns.to_columns()
result = self._data.copy()
result.columns = self._schema.column_names
for column in columns:
if column.name in result.columns:
raise DuplicateColumnNameError(column.name)
if column.number_of_rows != self.number_of_rows and self.number_of_columns != 0:
raise ColumnSizeError(str(self.number_of_rows), str(column._data.size))
result[column.name] = column._data
return Table._from_pandas_dataframe(result)
def add_row(self, row: Row) -> Table:
"""
Return a new `Table` with an added Row attached.
If the table happens to be empty beforehand, respective columns will be added automatically.
The order of columns of the new row will be adjusted to the order of columns in the table.
The new table will contain the merged schema.
The original table is not modified.
Parameters
----------
row : Row
The row to be added.
Returns
-------
table : Table
A new table with the added row at the end.
Raises
------
UnknownColumnNameError
If the row has different column names than the table.
Examples
--------
>>> from safeds.data.tabular.containers import Row, Table
>>> table = Table.from_dict({"a": [1], "b": [2]})
>>> row = Row.from_dict({"a": 3, "b": 4})
>>> table.add_row(row)
a b
0 1 2
1 3 4
"""
int_columns = []
result = self._copy()
if self.number_of_columns == 0:
return Table.from_rows([row])
if len(set(self.column_names) - set(row.column_names)) > 0:
raise UnknownColumnNameError(
sorted(
set(self.column_names) - set(row.column_names),
key={val: ix for ix, val in enumerate(self.column_names)}.__getitem__,
),
)
if result.number_of_rows == 0:
int_columns = list(filter(lambda name: isinstance(row[name], int | np.int64 | np.int32), row.column_names))
new_df = pd.concat([result._data, row._data]).infer_objects()
new_df.columns = result.column_names
schema = Schema.merge_multiple_schemas([result.schema, row.schema])
result = Table._from_pandas_dataframe(new_df, schema)
for column in int_columns:
result = result.replace_column(column, [result.get_column(column).transform(lambda it: int(it))])
return result
def add_rows(self, rows: list[Row] | Table) -> Table:
"""
Return a new `Table` with multiple added Rows attached.
The order of columns of the new rows will be adjusted to the order of columns in the table.
The new table will contain the merged schema.
The original table is not modified.
Parameters
----------
rows : list[Row] or Table
The rows to be added.
Returns
-------
result : Table
A new table which combines the original table and the given rows.
Raises
------
UnknownColumnNameError
If at least one of the rows have different column names than the table.
Examples
--------
>>> from safeds.data.tabular.containers import Row, Table
>>> table = Table.from_dict({"a": [1], "b": [2]})
>>> row1 = Row.from_dict({"a": 3, "b": 4})
>>> row2 = Row.from_dict({"a": 5, "b": 6})
>>> table.add_rows([row1, row2])
a b
0 1 2
1 3 4
2 5 6
"""
if isinstance(rows, Table):
rows = rows.to_rows()
if len(rows) == 0:
return self._copy()
different_column_names = set()
for row in rows:
different_column_names.update(set(self.column_names) - set(row.column_names))
if len(different_column_names) > 0:
raise UnknownColumnNameError(
sorted(
different_column_names,
key={val: ix for ix, val in enumerate(self.column_names)}.__getitem__,
),
)
result = self._copy()
for row in rows:
result = result.add_row(row)
return result
def filter_rows(self, query: Callable[[Row], bool]) -> Table:
"""
Return a new table with rows filtered by Callable (e.g. lambda function).
The original table is not modified.
Parameters
----------
query : lambda function
A Callable that is applied to all rows.
Returns
-------
table : Table
A table containing only the rows filtered by the query.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1, 3], "b": [2, 4]})
>>> table.filter_rows(lambda x: x["a"] < 2)
a b
0 1 2
"""
rows: list[Row] = [row for row in self.to_rows() if query(row)]
if len(rows) == 0:
result_table = Table._from_pandas_dataframe(pd.DataFrame(), self._schema)
else:
result_table = self.from_rows(rows)
return result_table
_T = TypeVar("_T")
def group_rows_by(self, key_selector: Callable[[Row], _T]) -> dict[_T, Table]:
"""
Return a dictionary with copies of the output tables as values and the keys from the key_selector.
The original table is not modified.
Parameters
----------
key_selector : Callable[[Row], _T]
A Callable that is applied to all rows and returns the key of the group.
Returns
-------
dictionary : dict
A dictionary containing the new tables as values and the selected keys as keys.
"""
dictionary: dict[Table._T, Table] = {}
for row in self.to_rows():
if key_selector(row) in dictionary:
dictionary[key_selector(row)] = dictionary[key_selector(row)].add_row(row)
else:
dictionary[key_selector(row)] = Table.from_rows([row])
return dictionary
def keep_only_columns(self, column_names: list[str]) -> Table:
"""
Return a new table with only the given column(s).
The original table is not modified.
Note: When removing the last column of the table, the `number_of_columns` property will be set to 0.
Parameters
----------
column_names : list[str]
A list containing only the columns to be kept.
Returns
-------
table : Table
A table containing only the given column(s).
Raises
------
UnknownColumnNameError
If any of the given columns does not exist.
IllegalSchemaModificationError
If removing the columns would violate an invariant in the subclass.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1, 3], "b": [2, 4]})
>>> table.keep_only_columns(["b"])
b
0 2
1 4
"""
invalid_columns = []
similar_columns: list[str] = []
for name in column_names:
if not self._schema.has_column(name):
similar_columns = similar_columns + self._get_similar_columns(name)
invalid_columns.append(name)
if len(invalid_columns) != 0:
raise UnknownColumnNameError(invalid_columns, similar_columns)
clone = self._copy()
clone = clone.remove_columns(list(set(self.column_names) - set(column_names)))
return clone
def remove_columns(self, column_names: list[str]) -> Table:
"""
Return a new table without the given column(s).
The original table is not modified.
Note: When removing the last column of the table, the `number_of_columns` property will be set to 0.
Parameters
----------
column_names : list[str]
A list containing all columns to be dropped.
Returns
-------
table : Table
A table without the given columns.
Raises
------
UnknownColumnNameError
If any of the given columns does not exist.
IllegalSchemaModificationError
If removing the columns would violate an invariant in the subclass.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1, 3], "b": [2, 4]})
>>> table.remove_columns(["b"])
a
0 1
1 3
"""
invalid_columns = []
similar_columns: list[str] = []
for name in column_names:
if not self._schema.has_column(name):
similar_columns = similar_columns + self._get_similar_columns(name)
invalid_columns.append(name)
if len(invalid_columns) != 0:
raise UnknownColumnNameError(invalid_columns, similar_columns)
transformed_data = self._data.drop(labels=column_names, axis="columns")
transformed_data.columns = [name for name in self._schema.column_names if name not in column_names]
if len(transformed_data.columns) == 0:
return Table()
return Table._from_pandas_dataframe(transformed_data)
def remove_columns_with_missing_values(self) -> Table:
"""
Return a new table without the columns that contain missing values.
The original table is not modified.
Note: When removing the last column of the table, the `number_of_columns` property will be set to 0.
Returns
-------
table : Table
A table without the columns that contain missing values.
Raises
------
IllegalSchemaModificationError
If removing the columns would violate an invariant in the subclass.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1, 2], "b": [None, 2]})
>>> table.remove_columns_with_missing_values()
a
0 1
1 2
"""
return Table.from_columns([column for column in self.to_columns() if not column.has_missing_values()])
def remove_columns_with_non_numerical_values(self) -> Table:
"""
Return a new table without the columns that contain non-numerical values.
The original table is not modified.
Note: When removing the last column of the table, the `number_of_columns` property will be set to 0.
Returns
-------
table : Table
A table without the columns that contain non-numerical values.
Raises
------
IllegalSchemaModificationError
If removing the columns would violate an invariant in the subclass.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1, 0], "b": ["test", 2]})
>>> table.remove_columns_with_non_numerical_values()
a
0 1
1 0
"""
return Table.from_columns([column for column in self.to_columns() if column.type.is_numeric()])
def remove_duplicate_rows(self) -> Table:
"""
Return a new table with every duplicate row removed.
The original table is not modified.
Returns
-------
result : Table
The table with the duplicate rows removed.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1, 3, 3], "b": [2, 4, 4]})
>>> table.remove_duplicate_rows()
a b
0 1 2
1 3 4
"""
result = self._data.drop_duplicates(ignore_index=True)
result.columns = self._schema.column_names
return Table._from_pandas_dataframe(result)
def remove_rows_with_missing_values(self) -> Table:
"""
Return a new table without the rows that contain missing values.
The original table is not modified.
Returns
-------
table : Table
A table without the rows that contain missing values.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1.0, None, 3], "b": [2, 4.0, None]})
>>> table.remove_rows_with_missing_values()
a b
0 1.0 2.0
"""
result = self._data.copy(deep=True)
result = result.dropna(axis="index")
return Table._from_pandas_dataframe(result)
def remove_rows_with_outliers(self) -> Table:
"""
Return a new table without those rows that contain at least one outlier.
We define an outlier as a value that has a distance of more than 3 standard deviations from the column mean.
Missing values are not considered outliers. They are also ignored during the calculation of the standard
deviation.
The original table is not modified.
Returns
-------
new_table : Table
A new table without rows containing outliers.
Examples
--------
>>> from safeds.data.tabular.containers import Column, Table
>>> c1 = Column("a", [1, 3, 1, 0.1, 0, 0, 0, 0, 0, 0, 0, 0])
>>> c2 = Column("b", [1.5, 1, 0.5, 0.01, 0, 0, 0, 0, 0, 0, 0, 0])
>>> c3 = Column("c", [0.1, 0.00, 0.4, 0.2, 0, 0, 0, 0, 0, 0, 0, 0])
>>> c4 = Column("d", [-1000000, 1000000, -1000000, -1000000, -1000000, -1000000, -1000000, -1000000, -1000000, -1000000, -1000000, -1000000])
>>> table = Table.from_columns([c1, c2, c3, c4])
>>> table.remove_rows_with_outliers()
a b c d
0 1.0 1.50 0.1 -1000000
1 1.0 0.50 0.4 -1000000
2 0.1 0.01 0.2 -1000000
3 0.0 0.00 0.0 -1000000
4 0.0 0.00 0.0 -1000000
5 0.0 0.00 0.0 -1000000
6 0.0 0.00 0.0 -1000000
7 0.0 0.00 0.0 -1000000
8 0.0 0.00 0.0 -1000000
9 0.0 0.00 0.0 -1000000
10 0.0 0.00 0.0 -1000000
"""
copy = self._data.copy(deep=True)
table_without_nonnumericals = self.remove_columns_with_non_numerical_values()
z_scores = np.absolute(stats.zscore(table_without_nonnumericals._data, nan_policy="omit"))
filter_ = ((z_scores < 3) | np.isnan(z_scores)).all(axis=1)
return Table._from_pandas_dataframe(copy[filter_], self._schema)
def rename_column(self, old_name: str, new_name: str) -> Table:
"""
Return a new `Table` with a single column renamed.
The original table is not modified.
Parameters
----------
old_name : str
The old name of the target column.
new_name : str
The new name of the target column.
Returns
-------
table : Table
The Table with the renamed column.
Raises
------
UnknownColumnNameError
If the specified old target column name does not exist.
DuplicateColumnNameError
If the specified new target column name already exists.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1], "b": [2]})
>>> table.rename_column("b", "c")
a c
0 1 2
"""
if old_name not in self._schema.column_names:
similar_columns = self._get_similar_columns(old_name)
raise UnknownColumnNameError([old_name], similar_columns)
if old_name == new_name:
return self
if new_name in self._schema.column_names:
raise DuplicateColumnNameError(new_name)
new_df = self._data.copy()
new_df.columns = self._schema.column_names
return Table._from_pandas_dataframe(new_df.rename(columns={old_name: new_name}))
def replace_column(self, old_column_name: str, new_columns: list[Column]) -> Table:
"""
Return a new table with the specified old column replaced by a list of new columns.
The order of columns is kept.
The original table is not modified.
Parameters
----------
old_column_name : str
The name of the column to be replaced.
new_columns : list[Column]
The list of new columns replacing the old column.
Returns
-------
result : Table
A table with the old column replaced by the new columns.
Raises
------
UnknownColumnNameError
If the old column does not exist.
DuplicateColumnNameError
If at least one of the new columns already exists and the existing column is not affected by the replacement.
ColumnSizeError
If the size of at least one of the new columns does not match the amount of rows.
IllegalSchemaModificationError
If replacing the column would violate an invariant in the subclass.
Examples
--------
>>> from safeds.data.tabular.containers import Column, Table
>>> table = Table.from_dict({"a": [1], "b": [2]})
>>> new_col = Column("new", [3])
>>> table.replace_column("b", [new_col])
a new
0 1 3
"""
if old_column_name not in self._schema.column_names:
similar_columns = self._get_similar_columns(old_column_name)
raise UnknownColumnNameError([old_column_name], similar_columns)
columns = list[Column]()
for old_column in self.column_names:
if old_column == old_column_name:
for new_column in new_columns:
if new_column.name in self.column_names and new_column.name != old_column_name:
raise DuplicateColumnNameError(new_column.name)
if self.number_of_rows != new_column.number_of_rows:
raise ColumnSizeError(str(self.number_of_rows), str(new_column.number_of_rows))
columns.append(new_column)
else:
columns.append(self.get_column(old_column))
return Table.from_columns(columns)
def shuffle_rows(self) -> Table:
"""
Return a new `Table` with randomly shuffled rows of this `Table`.
The original table is not modified.
Returns
-------
result : Table
The shuffled Table.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> import numpy as np
>>> np.random.seed(123456)
>>> table = Table.from_dict({"a": [1, 3, 5], "b": [2, 4, 6]})
>>> table.shuffle_rows()
a b
0 5 6
1 1 2
2 3 4
"""
new_df = self._data.sample(frac=1.0)
new_df.columns = self._schema.column_names
return Table._from_pandas_dataframe(new_df)
def slice_rows(
self,
start: int | None = None,
end: int | None = None,
step: int = 1,
) -> Table:
"""
Slice a part of the table into a new table.
The original table is not modified.
Parameters
----------
start : int | None
The first index of the range to be copied into a new table, None by default.
end : int | None
The last index of the range to be copied into a new table, None by default.
step : int
The step size used to iterate through the table, 1 by default.
Returns
-------
result : Table
The resulting table.
Raises
------
IndexOutOfBoundsError
If the index is out of bounds.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1, 3, 5], "b": [2, 4, 6]})
>>> table.slice_rows(0, 2)
a b
0 1 2
1 3 4
"""
if start is None:
start = 0
if end is None:
end = self.number_of_rows
if end < start:
raise IndexOutOfBoundsError(slice(start, end))
if start < 0 or end < 0 or start > self.number_of_rows or end > self.number_of_rows:
raise IndexOutOfBoundsError(start if start < 0 or start > self.number_of_rows else end)
new_df = self._data.iloc[start:end:step]
new_df.columns = self._schema.column_names
return Table._from_pandas_dataframe(new_df)
def sort_columns(
self,
comparator: Callable[[Column, Column], int] = lambda col1, col2: (col1.name > col2.name)
- (col1.name < col2.name),
) -> Table:
"""
Sort the columns of a `Table` with the given comparator and return a new `Table`.
The comparator is a function that takes two columns `col1` and `col2` and
returns an integer:
* If `col1` should be ordered before `col2`, the function should return a negative number.
* If `col1` should be ordered after `col2`, the function should return a positive number.
* If the original order of `col1` and `col2` should be kept, the function should return 0.
If no comparator is given, the columns will be sorted alphabetically by their name.
The original table is not modified.
Parameters
----------
comparator : Callable[[Column, Column], int]
The function used to compare two columns.
Returns
-------
new_table : Table
A new table with sorted columns.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1], "b": [2] })
>>> table.sort_columns(lambda col1, col2: 1)
a b
0 1 2
>>> table.sort_columns(lambda col1, col2: -1)
b a
0 2 1
>>> table2 = Table.from_dict({"b": [2], "a": [1]})
>>> table2.sort_columns()
a b
0 1 2
"""
columns = self.to_columns()
columns.sort(key=functools.cmp_to_key(comparator))
return Table.from_columns(columns)
def sort_rows(self, comparator: Callable[[Row, Row], int]) -> Table:
"""
Sort the rows of a `Table` with the given comparator and return a new `Table`.
The comparator is a function that takes two rows `row1` and `row2` and
returns an integer:
* If `row1` should be ordered before `row2`, the function should return a negative number.
* If `row1` should be ordered after `row2`, the function should return a positive number.
* If the original order of `row1` and `row2` should be kept, the function should return 0.
The original table is not modified.
Parameters
----------
comparator : Callable[[Row, Row], int]
The function used to compare two rows.
Returns
-------
new_table : Table
A new table with sorted rows.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1, 3, 5], "b": [2, 4, 6] })
>>> table.sort_rows(lambda row1, row2: 1)
a b
0 1 2
1 3 4
2 5 6
>>> table.sort_rows(lambda row1, row2: -1)
a b
0 5 6
1 3 4
2 1 2
>>> table.sort_rows(lambda row1, row2: 0)
a b
0 1 2
1 3 4
2 5 6
"""
rows = self.to_rows()
rows.sort(key=functools.cmp_to_key(comparator))
return Table.from_rows(rows)
def split_rows(self, percentage_in_first: float) -> tuple[Table, Table]:
"""
Split the table into two new tables.
The original table is not modified.
Parameters
----------
percentage_in_first : float
The desired size of the first table in percentage to the given table; must be between 0 and 1.
Returns
-------
result : (Table, Table)
A tuple containing the two resulting tables. The first table has the specified size, the second table
contains the rest of the data.
Raises
------
ValueError:
if the 'percentage_in_first' is not between 0 and 1.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"temperature": [10, 15, 20, 25, 30], "sales": [54, 74, 90, 206, 210]})
>>> slices = table.split_rows(0.4)
>>> slices[0]
temperature sales
0 10 54
1 15 74
>>> slices[1]
temperature sales
0 20 90
1 25 206
2 30 210
"""
if percentage_in_first < 0 or percentage_in_first > 1:
raise ValueError("The given percentage is not between 0 and 1")
if self.number_of_rows == 0:
return Table(), Table()
return (
self.slice_rows(0, round(percentage_in_first * self.number_of_rows)),
self.slice_rows(round(percentage_in_first * self.number_of_rows)),
)
def tag_columns(self, target_name: str, feature_names: list[str] | None = None) -> TaggedTable:
"""
Return a new `TaggedTable` with columns marked as a target column or feature columns.
The original table is not modified.
Parameters
----------
target_name : str
Name of the target column.
feature_names : list[str] | None
Names of the feature columns. If None, all columns except the target column are used.
Returns
-------
tagged_table : TaggedTable
A new tagged table with the given target and feature names.
Raises
------
ValueError
If the target column is also a feature column.
ValueError
If no feature columns are specified.
Examples
--------
>>> from safeds.data.tabular.containers import Table, TaggedTable
>>> table = Table.from_dict({"item": ["apple", "milk", "beer"], "price": [1.10, 1.19, 1.79], "amount_bought": [74, 72, 51]})
>>> tagged_table = table.tag_columns(target_name="amount_bought", feature_names=["item", "price"])
"""
from ._tagged_table import TaggedTable
return TaggedTable._from_table(self, target_name, feature_names)
def transform_column(self, name: str, transformer: Callable[[Row], Any]) -> Table:
"""
Return a new `Table` with the provided column transformed by calling the provided transformer.
The original table is not modified.
Returns
-------
result : Table
The table with the transformed column.
Raises
------
UnknownColumnNameError
If the column does not exist.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"item": ["apple", "milk", "beer"], "price": [1.00, 1.19, 1.79]})
>>> table.transform_column("price", lambda row: row.get_value("price") * 100)
item price
0 apple 100.0
1 milk 119.0
2 beer 179.0
"""
if self.has_column(name):
items: list = [transformer(item) for item in self.to_rows()]
result: list[Column] = [Column(name, items)]
return self.replace_column(name, result)
similar_columns = self._get_similar_columns(name)
raise UnknownColumnNameError([name], similar_columns)
def transform_table(self, transformer: TableTransformer) -> Table:
"""
Return a new `Table` with a learned transformation applied to this table.
The original table is not modified.
Parameters
----------
transformer : TableTransformer
The transformer which transforms the given table.
Returns
-------
transformed_table : Table
The transformed table.
Raises
------
TransformerNotFittedError
If the transformer has not been fitted yet.
IllegalSchemaModificationError
If replacing the column would violate an invariant in the subclass.
Examples
--------
>>> from safeds.data.tabular.transformation import OneHotEncoder
>>> from safeds.data.tabular.containers import Table
>>> transformer = OneHotEncoder()
>>> table = Table.from_dict({"fruit": ["apple", "pear", "apple"], "pet": ["dog", "duck", "duck"]})
>>> transformer = transformer.fit(table, None)
>>> table.transform_table(transformer)
fruit__apple fruit__pear pet__dog pet__duck
0 1.0 0.0 1.0 0.0
1 0.0 1.0 0.0 1.0
2 1.0 0.0 0.0 1.0
"""
return transformer.transform(self)
def inverse_transform_table(self, transformer: InvertibleTableTransformer) -> Table:
"""
Return a new `Table` with the inverted transformation applied by the given transformer.
The original table is not modified.
Parameters
----------
transformer : InvertibleTableTransformer
A transformer that was fitted with columns, which are all present in the table.
Returns
-------
table : Table
The original table.
Raises
------
TransformerNotFittedError
If the transformer has not been fitted yet.
Examples
--------
>>> from safeds.data.tabular.transformation import OneHotEncoder
>>> from safeds.data.tabular.containers import Table
>>> transformer = OneHotEncoder()
>>> table = Table.from_dict({"a": ["j", "k", "k"], "b": ["x", "y", "x"]})
>>> transformer = transformer.fit(table, None)
>>> transformed_table = transformer.transform(table)
>>> transformed_table.inverse_transform_table(transformer)
a b
0 j x
1 k y
2 k x
>>> transformer.inverse_transform(transformed_table)
a b
0 j x
1 k y
2 k x
"""
return transformer.inverse_transform(self)
# ------------------------------------------------------------------------------------------------------------------
# Plotting
# ------------------------------------------------------------------------------------------------------------------
def plot_correlation_heatmap(self) -> Image:
"""
Plot a correlation heatmap for all numerical columns of this `Table`.
Returns
-------
plot: Image
The plot as an image.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"temperature": [10, 15, 20, 25, 30], "sales": [54, 74, 90, 206, 210]})
>>> image = table.plot_correlation_heatmap()
"""
only_numerical = self.remove_columns_with_non_numerical_values()
if self.number_of_rows == 0:
warnings.warn(
"An empty table has been used. A correlation heatmap on an empty table will show nothing.",
stacklevel=2,
)
with warnings.catch_warnings():
warnings.filterwarnings(
"ignore",
message=(
"Attempting to set identical low and high (xlims|ylims) makes transformation singular;"
" automatically expanding."
),
)
fig = plt.figure()
sns.heatmap(
data=only_numerical._data.corr(),
vmin=-1,
vmax=1,
xticklabels=only_numerical.column_names,
yticklabels=only_numerical.column_names,
cmap="vlag",
)
plt.tight_layout()
else:
fig = plt.figure()
sns.heatmap(
data=only_numerical._data.corr(),
vmin=-1,
vmax=1,
xticklabels=only_numerical.column_names,
yticklabels=only_numerical.column_names,
cmap="vlag",
)
plt.tight_layout()
buffer = io.BytesIO()
fig.savefig(buffer, format="png")
plt.close() # Prevents the figure from being displayed directly
buffer.seek(0)
return Image(buffer, format_=ImageFormat.PNG)
def plot_lineplot(self, x_column_name: str, y_column_name: str) -> Image:
"""
Plot two columns against each other in a lineplot.
If there are multiple x-values for a y-value, the resulting plot will consist of a line representing the mean
and the lower-transparency area around the line representing the 95% confidence interval.
Parameters
----------
x_column_name : str
The column name of the column to be plotted on the x-Axis.
y_column_name : str
The column name of the column to be plotted on the y-Axis.
Returns
-------
plot: Image
The plot as an image.
Raises
------
UnknownColumnNameError
If either of the columns do not exist.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"temperature": [10, 15, 20, 25, 30], "sales": [54, 74, 90, 206, 210]})
>>> image = table.plot_lineplot("temperature", "sales")
"""
if not self.has_column(x_column_name) or not self.has_column(y_column_name):
similar_columns_x = self._get_similar_columns(x_column_name)
similar_columns_y = self._get_similar_columns(y_column_name)
raise UnknownColumnNameError(
([x_column_name] if not self.has_column(x_column_name) else [])
+ ([y_column_name] if not self.has_column(y_column_name) else []),
(similar_columns_x if not self.has_column(x_column_name) else [])
+ (similar_columns_y if not self.has_column(y_column_name) else []),
)
fig = plt.figure()
ax = sns.lineplot(
data=self._data,
x=x_column_name,
y=y_column_name,
)
ax.set(xlabel=x_column_name, ylabel=y_column_name)
ax.set_xticks(ax.get_xticks())
ax.set_xticklabels(
ax.get_xticklabels(),
rotation=45,
horizontalalignment="right",
) # rotate the labels of the x Axis to prevent the chance of overlapping of the labels
plt.tight_layout()
buffer = io.BytesIO()
fig.savefig(buffer, format="png")
plt.close() # Prevents the figure from being displayed directly
buffer.seek(0)
return Image(buffer, format_=ImageFormat.PNG)
def plot_scatterplot(self, x_column_name: str, y_column_name: str) -> Image:
"""
Plot two columns against each other in a scatterplot.
Parameters
----------
x_column_name : str
The column name of the column to be plotted on the x-Axis.
y_column_name : str
The column name of the column to be plotted on the y-Axis.
Returns
-------
plot: Image
The plot as an image.
Raises
------
UnknownColumnNameError
If either of the columns do not exist.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"temperature": [10, 15, 20, 25, 30], "sales": [54, 74, 90, 206, 210]})
>>> image = table.plot_scatterplot("temperature", "sales")
"""
if not self.has_column(x_column_name) or not self.has_column(y_column_name):
similar_columns_x = self._get_similar_columns(x_column_name)
similar_columns_y = self._get_similar_columns(y_column_name)
raise UnknownColumnNameError(
([x_column_name] if not self.has_column(x_column_name) else [])
+ ([y_column_name] if not self.has_column(y_column_name) else []),
(similar_columns_x if not self.has_column(x_column_name) else [])
+ (similar_columns_y if not self.has_column(y_column_name) else []),
)
fig = plt.figure()
ax = sns.scatterplot(
data=self._data,
x=x_column_name,
y=y_column_name,
)
ax.set(xlabel=x_column_name, ylabel=y_column_name)
ax.set_xticks(ax.get_xticks())
ax.set_xticklabels(
ax.get_xticklabels(),
rotation=45,
horizontalalignment="right",
) # rotate the labels of the x Axis to prevent the chance of overlapping of the labels
plt.tight_layout()
buffer = io.BytesIO()
fig.savefig(buffer, format="png")
plt.close() # Prevents the figure from being displayed directly
buffer.seek(0)
return Image(buffer, format_=ImageFormat.PNG)
def plot_boxplots(self) -> Image:
"""
Plot a boxplot for every numerical column.
Returns
-------
plot: Image
The plot as an image.
Raises
------
NonNumericColumnError
If the table contains only non-numerical columns.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table({"a":[1, 2], "b": [3, 42]})
>>> image = table.plot_boxplots()
"""
numerical_table = self.remove_columns_with_non_numerical_values()
if numerical_table.number_of_columns == 0:
raise NonNumericColumnError("This table contains only non-numerical columns.")
col_wrap = min(numerical_table.number_of_columns, 3)
data = pd.melt(numerical_table._data, value_vars=numerical_table.column_names)
grid = sns.FacetGrid(data, col="variable", col_wrap=col_wrap, sharex=False, sharey=False)
with warnings.catch_warnings():
warnings.filterwarnings(
"ignore",
message="Using the boxplot function without specifying `order` is likely to produce an incorrect plot.",
)
grid.map(sns.boxplot, "variable", "value")
grid.set_xlabels("")
grid.set_ylabels("")
grid.set_titles("{col_name}")
for axes in grid.axes.flat:
axes.set_xticks([])
plt.tight_layout()
fig = grid.fig
buffer = io.BytesIO()
fig.savefig(buffer, format="png")
plt.close() # Prevents the figure from being displayed directly
buffer.seek(0)
return Image(buffer, format_=ImageFormat.PNG)
def plot_histograms(self) -> Image:
"""
Plot a histogram for every column.
Returns
-------
plot: Image
The plot as an image.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table({"a": [2, 3, 5, 1], "b": [54, 74, 90, 2014]})
>>> image = table.plot_histograms()
"""
col_wrap = min(self.number_of_columns, 3)
data = pd.melt(self._data.applymap(lambda value: str(value)), value_vars=self.column_names)
grid = sns.FacetGrid(data=data, col="variable", col_wrap=col_wrap, sharex=False, sharey=False)
grid.map(sns.histplot, "value")
grid.set_xlabels("")
grid.set_ylabels("")
grid.set_titles("{col_name}")
for axes in grid.axes.flat:
axes.set_xticks(axes.get_xticks())
axes.set_xticklabels(axes.get_xticklabels(), rotation=45, horizontalalignment="right")
grid.tight_layout()
fig = grid.fig
buffer = io.BytesIO()
fig.savefig(buffer, format="png")
plt.close()
buffer.seek(0)
return Image(buffer, ImageFormat.PNG)
# ------------------------------------------------------------------------------------------------------------------
# Conversion
# ------------------------------------------------------------------------------------------------------------------
def to_csv_file(self, path: str | Path) -> None:
"""
Write the data from the table into a CSV file.
If the file and/or the directories do not exist they will be created. If the file already exists it will be
overwritten.
Parameters
----------
path : str | Path
The path to the output file.
Raises
------
WrongFileExtensionError
If the file is not a csv file.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1, 2, 3], "b": [4, 5, 6]})
>>> table.to_csv_file("./src/resources/to_csv_file.csv")
"""
path = Path(path)
if path.suffix != ".csv":
raise WrongFileExtensionError(path, ".csv")
path.parent.mkdir(parents=True, exist_ok=True)
data_to_csv = self._data.copy()
data_to_csv.columns = self._schema.column_names
data_to_csv.to_csv(path, index=False)
def to_excel_file(self, path: str | Path) -> None:
"""
Write the data from the table into an Excel file.
Valid file extensions are `.xls`, '.xlsx', `.xlsm`, `.xlsb`, `.odf`, `.ods` and `.odt`.
If the file and/or the directories do not exist, they will be created. If the file already exists, it will be
overwritten.
Parameters
----------
path : str | Path
The path to the output file.
Raises
------
WrongFileExtensionError
If the file is not an Excel file.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1, 2, 3], "b": [4, 5, 6]})
>>> table.to_excel_file("./src/resources/to_excel_file.xlsx")
"""
path = Path(path)
excel_extensions = [".xls", ".xlsx", ".xlsm", ".xlsb", ".odf", ".ods", ".odt"]
if path.suffix not in excel_extensions:
raise WrongFileExtensionError(path, excel_extensions)
# Create Excel metadata in the file
tmp_table_file = openpyxl.Workbook()
tmp_table_file.save(path)
path.parent.mkdir(parents=True, exist_ok=True)
data_to_excel = self._data.copy()
data_to_excel.columns = self._schema.column_names
data_to_excel.to_excel(path)
def to_json_file(self, path: str | Path) -> None:
"""
Write the data from the table into a JSON file.
If the file and/or the directories do not exist, they will be created. If the file already exists it will be
overwritten.
Parameters
----------
path : str | Path
The path to the output file.
Raises
------
WrongFileExtensionError
If the file is not a JSON file.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a": [1, 2, 3], "b": [4, 5, 6]})
>>> table.to_json_file("./src/resources/to_json_file.json")
"""
path = Path(path)
if path.suffix != ".json":
raise WrongFileExtensionError(path, ".json")
path.parent.mkdir(parents=True, exist_ok=True)
data_to_json = self._data.copy()
data_to_json.columns = self._schema.column_names
data_to_json.to_json(path)
def to_dict(self) -> dict[str, list[Any]]:
"""
Return a dictionary that maps column names to column values.
Returns
-------
data : dict[str, list[Any]]
Dictionary representation of the table.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> row1 = Row({"a": 1, "b": 5})
>>> row2 = Row({"a": 2, "b": 6})
>>> table1 = Table.from_rows([row1, row2])
>>> table2 = Table.from_dict({"a": [1, 2], "b": [5, 6]})
>>> table1 == table2
True
"""
return {column_name: list(self.get_column(column_name)) for column_name in self.column_names}
def to_html(self) -> str:
"""
Return an HTML representation of the table.
Returns
-------
output : str
The generated HTML.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table({"a": [1, 2, 3], "b": [4, 5, 6]})
>>> html = table.to_html()
"""
return self._data.to_html(max_rows=self._data.shape[0], max_cols=self._data.shape[1])
def to_columns(self) -> list[Column]:
"""
Return a list of the columns.
Returns
-------
columns : list[Columns]
List of columns.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a":[1, 2],"b":[20, 30]})
>>> table.to_columns()
[Column('a', [1, 2]), Column('b', [20, 30])]
"""
return [self.get_column(name) for name in self._schema.column_names]
def to_rows(self) -> list[Row]:
"""
Return a list of the rows.
Returns
-------
rows : list[Row]
List of rows.
Examples
--------
>>> from safeds.data.tabular.containers import Table
>>> table = Table.from_dict({"a":[1, 2],"b":[20, 30]})
>>> table.to_rows()
[Row({
'a': 1,
'b': 20
}), Row({
'a': 2,
'b': 30
})]
"""
return [
Row._from_pandas_dataframe(
pd.DataFrame([list(series_row)], columns=self._schema.column_names),
self._schema,
)
for (_, series_row) in self._data.iterrows()
]
# ------------------------------------------------------------------------------------------------------------------
# IPython integration
# ------------------------------------------------------------------------------------------------------------------
def _repr_html_(self) -> str:
"""
Return an HTML representation of the table.
Returns
-------
output : str
The generated HTML.
"""
return self._data.to_html(max_rows=self._data.shape[0], max_cols=self._data.shape[1], notebook=True)
# ------------------------------------------------------------------------------------------------------------------
# Dataframe interchange protocol
# ------------------------------------------------------------------------------------------------------------------
def __dataframe__(self, nan_as_null: bool = False, allow_copy: bool = True): # type: ignore[no-untyped-def]
"""
Return a DataFrame exchange object that conforms to the dataframe interchange protocol.
Generally, there is no reason to call this method directly. The dataframe interchange protocol is designed to
allow libraries to consume tabular data from different sources, such as `pandas` or `polars`. If you still
decide to call this method, you should not rely on any capabilities of the returned object beyond the dataframe
interchange protocol.
The specification of the dataframe interchange protocol can be found on
[GitHub](https://github.com/data-apis/dataframe-api).
Parameters
----------
nan_as_null : bool
Whether to replace missing values in the data with `NaN`.
allow_copy : bool
Whether memory may be copied to create the DataFrame exchange object.
Returns
-------
dataframe
A DataFrame object that conforms to the dataframe interchange protocol.
"""
if not allow_copy:
raise NotImplementedError("For the moment we need to copy the data, so `allow_copy` must be True.")
data_copy = self._data.copy()
data_copy.columns = self.column_names
return data_copy.__dataframe__(nan_as_null, allow_copy)
# ------------------------------------------------------------------------------------------------------------------
# Helpers
# ------------------------------------------------------------------------------------------------------------------
def _copy(self) -> Table:
"""
Return a copy of this table.
Returns
-------
table : Table
The copy of this table.
"""
return copy.deepcopy(self) | PypiClean |
/thornfield-1.2.1.tar.gz/thornfield-1.2.1/README.md | # `thornfield`: Advanced caching in python
[](https://travis-ci.com/drorvinkler/thornfield)
[](https://codecov.io/gh/drorvinkler/thornfield)
[](https://opensource.org/licenses/MIT)
[](https://github.com/psf/black)
## Installation
```pip install thornfield```
## Usage
Choose the cache storage you want to use - in-memory, redis and postgresql are currently implemented.
You can use a different storage by implementing the `Cache` interface.
Then, use the `cached` decorator to annotate the function being cached:
```
cacher = Cacher(cache_factory_func)
@cacher.cached
def foo():
...
```
The decorator supports:
* Setting an expiration time for the cached values.
* Caching only values that match a constraint (e.g. not `None`).
* Using only some of the function parameters as keys for the cache.
* Caching async functions.
#### Caching only some parameters
In case you don't want to use all the parameters of the function as cache key,
you can the `Cached` or `NotCached` types:
```
from thornfield.typing import Cached, NotCached
@cached
def request(url: str, token: str, timeout: NotCached[int]):
...
@cached
async def request_async(url: Cached[str], timeout: int, callback):
...
```
#### Caching abstract methods
In order to avoid adding the same decorator to all implementations of an
abstract method, you can use `cache_method` as follows:
```
class Base(ABC):
def __init__(self):
cacher.cache_method(do_something)
@abstractmethod
def do_something(self):
pass
```
## Cache Factories
In the `cache_factories` package you can find cache factories for Redis and PostgreSQL.
They both cache each function to a different table (in PostgreSQL, db in Redis).
Their `create` method can be passed as `cache_impl` to the constructor of `Cacher`.
| PypiClean |
/cosco-shipping-autotest-framework-0.0.5.tar.gz/cosco-shipping-autotest-framework-0.0.5/src/rolling_king/jason/python/tools/zy_schedule.py |
import schedule
import time
import threading
import functools
import logging
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s') # logging.basicConfig函数对日志的输出格式及方式做相关配置
logger = logging.getLogger('com.autotest.db.sqlalchemy_util')
# def job():
# print("I'm working...")
#
#
# schedule.every(10).seconds.do(job)
#
# while True:
# schedule.run_pending() # 检测是否执行
# time.sleep(1)
# logger.info("Waiting for 1 second...")
def job():
print("I'm working...")
# 每十分钟执行任务
schedule.every(10).minutes.do(job)
# 每个小时执行任务
schedule.every().hour.do(job)
# 每天的10:30执行任务
schedule.every().day.at("10:30").do(job)
# 每个月执行任务
schedule.every().monday.do(job)
# 每个星期三的13:15分执行任务
schedule.every().wednesday.at("13:15").do(job)
# 每分钟的第17秒执行任务
schedule.every().minute.at(":17").do(job)
while True:
schedule.run_pending()
time.sleep(1)
# 只运行一次
def job_that_executes_once():
# 此处编写的任务只会执行一次...
return schedule.CancelJob
schedule.every().day.at('22:30').do(job_that_executes_once)
while True:
schedule.run_pending()
time.sleep(1)
# 参数传递
def greet(name):
print('Hello', name)
# do() 将额外的参数传递给job函数
schedule.every(2).seconds.do(greet, name='Alice')
schedule.every(4).seconds.do(greet, name='Bob')
# 获取所有作业 and 取消所有作业
def hello():
print('Hello world')
schedule.every().second.do(hello)
all_jobs = schedule.get_jobs() # 获取
schedule.clear() # 取消
# .tag 打标签
schedule.every().day.do(greet, 'Andrea').tag('daily-tasks', 'friend')
schedule.every().hour.do(greet, 'John').tag('hourly-tasks', 'friend')
schedule.every().hour.do(greet, 'Monica').tag('hourly-tasks', 'customer')
schedule.every().day.do(greet, 'Derek').tag('daily-tasks', 'guest')
# get_jobs(标签):可以获取所有该标签的任务
friends = schedule.get_jobs('friend')
# 取消所有 daily-tasks 标签的任务
schedule.clear('daily-tasks')
# 设定截止时间
# 每个小时运行作业,18:30后停止
schedule.every(1).hours.until("18:30").do(job)
# 每个小时运行作业,2030-01-01 18:33 today
schedule.every(1).hours.until("2030-01-01 18:33").do(job)
# 每个小时运行作业,8个小时后停止
schedule.every(1).hours.until(timedelta(hours=8)).do(job)
# 每个小时运行作业,11:32:42后停止
schedule.every(1).hours.until(time(11, 33, 42)).do(job)
# 每个小时运行作业,2020-5-17 11:36:20后停止
schedule.every(1).hours.until(datetime(2020, 5, 17, 11, 36, 20)).do(job)
# 立即运行所有作业,而不管其安排如何
schedule.run_all()
# 立即运行所有作业,每次作业间隔10秒
schedule.run_all(delay_seconds=10)
# 装饰器安排作业
# 此装饰器效果等同于 schedule.every(10).minutes.do(job)
@repeat(every(10).minutes)
def job():
print("I am a scheduled job")
while True:
run_pending()
time.sleep(1)
# 并行执行
# 默认情况下,Schedule 按顺序执行所有作业
# 通过多线程的形式来并行每个作业
def job1():
print("I'm running on thread %s" % threading.current_thread())
def job2():
print("I'm running on thread %s" % threading.current_thread())
def job3():
print("I'm running on thread %s" % threading.current_thread())
def run_threaded(job_func):
job_thread = threading.Thread(target=job_func)
job_thread.start()
schedule.every(10).seconds.do(run_threaded, job1)
schedule.every(10).seconds.do(run_threaded, job2)
schedule.every(10).seconds.do(run_threaded, job3)
while True:
schedule.run_pending()
time.sleep(1)
# 异常处理
# Schedule 不会自动捕捉异常,它遇到异常会直接抛出
def catch_exceptions(cancel_on_failure=False):
def catch_exceptions_decorator(job_func):
@functools.wraps(job_func)
def wrapper(*args, **kwargs):
try:
return job_func(*args, **kwargs)
except:
import traceback
print(traceback.format_exc())
if cancel_on_failure:
return schedule.CancelJob
return wrapper
return catch_exceptions_decorator
@catch_exceptions(cancel_on_failure=True)
def bad_task():
return 1 / 0
# 这样,bad_task 在执行时遇到的任何错误,都会被 catch_exceptions 捕获,这点在保证调度任务正常运转的时候非常关键。
schedule.every(5).minutes.do(bad_task) | PypiClean |
/qg-botsdk-3.0.2.tar.gz/qg-botsdk-3.0.2/README.md | <div align="center">

[](https://www.python.org/)
[](https://github.com/GLGDLY/qg_botsdk/blob/master/LICENSE)
[](https://github.com/GLGDLY/qg_botsdk/releases)
[](https://pypi.org/project/qg-botsdk/)
[](https://www.codacy.com/gh/GLGDLY/qg_botsdk/dashboard?utm_source=github.com&utm_medium=referral&utm_content=GLGDLY/qg_botsdk&utm_campaign=Badge_Grade)
[](https://qg-botsdk.readthedocs.io/zh_CN/latest/)
✨用于QQ官方频道机器人,兼顾实用与容易入门的Python应用级SDK✨
[文档](https://qg-botsdk.readthedocs.io/zh_CN/latest/)
·
[下载](https://github.com/GLGDLY/qg_botsdk/releases)
·
[快速入门](https://qg-botsdk.readthedocs.io/zh_CN/latest/quick_start)
</div>
#### 引言
对于使用python进行频道官方机器人开发而言,市面上确实有不同的sdk可以选用,但其很多只提供异步asyncio+类继承的开发方式,对于不会相关技巧的朋友们,尤其新手,会有开发难度。
为此,qg_botsdk相应提供了另一个选择,这一款sdk虽然同样使用asyncio编写sdk底层,但其同时提供了threading和asyncio封装下的应用层调用,以抽象化封装的库编写方式,极大地降低应用层的开发难度。
#### 亮点
##### - 两种应用层开发方式(threading、asyncio),可根据自己的喜好选择,而底层均为asyncio实现,保持高并发能力
##### - 高覆盖率的单元测试,保证SDK的稳定性
##### - 灵活的构建方式,即使官方删除或新增字段,SDK也不会规范于原来的数据格式,而会把真实数据反馈给你
##### - 轻量,简洁,统一的代码结构,通过录入回调函数处理不同事件,10行即可构建一个简单的程序
##### - 容易入门,无需学会asyncio、类继承等编程技巧也可使用,同时保留较高并发能力
##### - 保留官方http API中Json数据的结构字段,带你学习官方结构,日后可自行开发适合自己的SDK
##### - 迅速的更新速度,跟上最新潮流(v2.5.5已更新音视频/直播子频道成员进出事件、公域论坛事件)
##### - 简单易用的plugins编写与加载,使用例子可参阅 [example_13(装饰器).py](./example/example_13(%E8%A3%85%E9%A5%B0%E5%99%A8).py)
* * *
### 下载方式
- 直接下载[最新release](https://github.com/GLGDLY/qg_botsdk/releases),放到项目中即可
- pip安装(推荐):
```shell bash
pip install qg-botsdk # 注意是qg-botsdk(中线),不是qg_botsdk(底线)
```
* * *
### 一个简单的工作流
> - 注册BOT实例,录入机器人平台获取的ID(BotAppId开发者ID)和token(机器人令牌)
> - 编写接收事件的函数->下方例子:`def deliver(data)`,并可借助model库检查数据格式(`data: Model.MESSAGE`)
> - 绑定接收事件的函数(bind_msg、bind_dm、bind_msg_delete、bind_guild_event、bind_guild_member、bind_reaction、bind_interaction、bind_audit、bind_forum、bind_audio)
> - 开始运行机器人:bot.start()
```python
from qg_botsdk import BOT, Model # 导入SDK核心类(BOT)、所有数据模型(Model)
bot = BOT(bot_id='xxx', bot_token='xxx', is_private=True, is_sandbox=True) # 实例化SDK核心类
@bot.bind_msg() # 绑定接收消息事件的函数
def deliver(data: Model.MESSAGE): # 创建接收消息事件的函数
if '你好' in data.treated_msg: # 判断消息是否存在特定内容
data.reply('你好,世界') # 发送被动回复(带message_id直接reply回复)
if __name__ == '__main__':
bot.start() # 开始运行机器人
```
* * *
### 已实现事件接收(已支持解析论坛事件)
> `from qg_botsdk.model import Model`
>
> 此库为所有事件的数据格式结构,可套用到代码以检查结构是否正确
- bind_msg
- bind_dm
- bind_msg_delete
- bind_guild_event
- bind_guild_member
- bind_reaction
- bind_interaction
- bind_audit
- bind_forum
- bind_audio
### 已实现API
> API已基本完善,具体详情可查阅:<https://qg-botsdk.readthedocs.io/zh_CN/latest/API.html>
> 关于API的更多详细信息可阅读官方文档介绍:<https://bot.q.qq.com/wiki/develop/api/>
- get_bot_id
- get_bot_info
- get_bot_guilds
- get_guild_info
- get_guild_channels
- get_channels_info
- create_channels
- patch_channels
- delete_channels
- get_guild_members
- get_role_members
- get_member_info
- delete_member
- get_guild_roles
- create_role
- patch_role
- delete_role
- create_role_member
- delete_role_member
- get_channel_member_permission
- put_channel_member_permission
- get_channel_role_permission
- put_channel_role_permission
- get_message_info
- send_msg
- send_embed
- send_ark_23
- send_ark_24
- send_ark_37
- send_markdown
- delete_msg
- get_guild_setting
- create_dm_guild
- send_dm
- delete_dm_msg
- mute_all_member
- mute_member
- mute_members
- create_announce
- delete_announce
- create_pinmsg
- delete_pinmsg
- get_pinmsg
- get_schedules
- get_schedule_info
- create_schedule
- patch_schedule
- delete_schedule
- create_reaction
- delete_reaction
- get_reaction_users
- control_audio
- bot_on_mic
- bot_off_mic
- get_threads
- get_thread_info
- create_thread
- delete_thread
- get_guild_permissions
- create_permission_demand
### 特殊功能
- register_start_event:绑定一个在机器人开始运行后马上执行的函数
- register_repeat_event:绑定一个背景重复运行的函数
- security_check:用于使用腾讯内容检测接口进行内容检测
### 相关链接
- 文档:
- [readthedocs](https://qg-botsdk.readthedocs.io/zh_CN/latest/)
- 官方注册机器人:<https://q.qq.com/#/>
- 官方API文档:<https://bot.q.qq.com/wiki/develop/api/>
- SDK QQ交流群:<https://jq.qq.com/?_wv=1027&k=3NnWvGpz>
| PypiClean |
/e-fonenana-frontend-20190305.1.tar.gz/e-fonenana-frontend-20190305.1/hass_frontend/4649d981c00a2de04996.chunk.js | (window.webpackJsonp=window.webpackJsonp||[]).push([[103,101,104,105,106,107,109,110,111,112,113],{165:function(module,__webpack_exports__,__webpack_require__){"use strict";var _polymer_polymer_polymer_legacy_js__WEBPACK_IMPORTED_MODULE_0__=__webpack_require__(2),_polymer_iron_flex_layout_iron_flex_layout_js__WEBPACK_IMPORTED_MODULE_1__=__webpack_require__(40),_polymer_paper_styles_default_theme_js__WEBPACK_IMPORTED_MODULE_2__=__webpack_require__(41),_polymer_paper_styles_typography_js__WEBPACK_IMPORTED_MODULE_3__=__webpack_require__(51),_polymer_polymer_lib_legacy_polymer_fn_js__WEBPACK_IMPORTED_MODULE_4__=__webpack_require__(4),_polymer_polymer_lib_utils_html_tag_js__WEBPACK_IMPORTED_MODULE_5__=__webpack_require__(3);/**
@license
Copyright (c) 2015 The Polymer Project Authors. All rights reserved.
This code may only be used under the BSD style license found at
http://polymer.github.io/LICENSE.txt The complete set of authors may be found at
http://polymer.github.io/AUTHORS.txt The complete set of contributors may be
found at http://polymer.github.io/CONTRIBUTORS.txt Code distributed by Google as
part of the polymer project is also subject to an additional IP rights grant
found at http://polymer.github.io/PATENTS.txt
*/Object(_polymer_polymer_lib_legacy_polymer_fn_js__WEBPACK_IMPORTED_MODULE_4__.a)({_template:_polymer_polymer_lib_utils_html_tag_js__WEBPACK_IMPORTED_MODULE_5__.a`
<style>
:host {
overflow: hidden; /* needed for text-overflow: ellipsis to work on ff */
@apply --layout-vertical;
@apply --layout-center-justified;
@apply --layout-flex;
}
:host([two-line]) {
min-height: var(--paper-item-body-two-line-min-height, 72px);
}
:host([three-line]) {
min-height: var(--paper-item-body-three-line-min-height, 88px);
}
:host > ::slotted(*) {
overflow: hidden;
text-overflow: ellipsis;
white-space: nowrap;
}
:host > ::slotted([secondary]) {
@apply --paper-font-body1;
color: var(--paper-item-body-secondary-color, var(--secondary-text-color));
@apply --paper-item-body-secondary;
}
</style>
<slot></slot>
`,is:"paper-item-body"})},169:function(module,__webpack_exports__,__webpack_require__){"use strict";var _polymer_polymer_polymer_legacy_js__WEBPACK_IMPORTED_MODULE_0__=__webpack_require__(2),_polymer_iron_flex_layout_iron_flex_layout_js__WEBPACK_IMPORTED_MODULE_1__=__webpack_require__(40),_polymer_paper_styles_typography_js__WEBPACK_IMPORTED_MODULE_2__=__webpack_require__(51),_paper_item_shared_styles_js__WEBPACK_IMPORTED_MODULE_3__=__webpack_require__(128),_polymer_polymer_lib_legacy_polymer_fn_js__WEBPACK_IMPORTED_MODULE_4__=__webpack_require__(4),_polymer_polymer_lib_utils_html_tag_js__WEBPACK_IMPORTED_MODULE_5__=__webpack_require__(3),_paper_item_behavior_js__WEBPACK_IMPORTED_MODULE_6__=__webpack_require__(108);/**
@license
Copyright (c) 2015 The Polymer Project Authors. All rights reserved.
This code may only be used under the BSD style license found at
http://polymer.github.io/LICENSE.txt The complete set of authors may be found at
http://polymer.github.io/AUTHORS.txt The complete set of contributors may be
found at http://polymer.github.io/CONTRIBUTORS.txt Code distributed by Google as
part of the polymer project is also subject to an additional IP rights grant
found at http://polymer.github.io/PATENTS.txt
*/Object(_polymer_polymer_lib_legacy_polymer_fn_js__WEBPACK_IMPORTED_MODULE_4__.a)({_template:_polymer_polymer_lib_utils_html_tag_js__WEBPACK_IMPORTED_MODULE_5__.a`
<style include="paper-item-shared-styles"></style>
<style>
:host {
@apply --layout-horizontal;
@apply --layout-center;
@apply --paper-font-subhead;
@apply --paper-item;
@apply --paper-icon-item;
}
.content-icon {
@apply --layout-horizontal;
@apply --layout-center;
width: var(--paper-item-icon-width, 56px);
@apply --paper-item-icon;
}
</style>
<div id="contentIcon" class="content-icon">
<slot name="item-icon"></slot>
</div>
<slot></slot>
`,is:"paper-icon-item",behaviors:[_paper_item_behavior_js__WEBPACK_IMPORTED_MODULE_6__.a]})},176:function(module,__webpack_exports__,__webpack_require__){"use strict";var shallowEqual=function shallowEqual(newValue,oldValue){return newValue===oldValue},simpleIsEqual=function simpleIsEqual(newArgs,lastArgs){return newArgs.length===lastArgs.length&&newArgs.every(function(newArg,index){return shallowEqual(newArg,lastArgs[index])})};function index(resultFn,isEqual){if(void 0===isEqual){isEqual=simpleIsEqual}var lastThis,lastArgs=[],lastResult,calledOnce=!1,result=function result(){for(var _len=arguments.length,newArgs=Array(_len),_key=0;_key<_len;_key++){newArgs[_key]=arguments[_key]}if(calledOnce&&lastThis===this&&isEqual(newArgs,lastArgs)){return lastResult}lastResult=resultFn.apply(this,newArgs);calledOnce=!0;lastThis=this;lastArgs=newArgs;return lastResult};return result}__webpack_exports__.a=index},186:function(module,__webpack_exports__,__webpack_require__){"use strict";__webpack_require__.d(__webpack_exports__,"a",function(){return superstruct});class StructError extends TypeError{static format(attrs){const{type,path,value}=attrs,message=`Expected a value of type \`${type}\`${path.length?` for \`${path.join(".")}\``:""} but received \`${JSON.stringify(value)}\`.`;return message}constructor(attrs){const message=StructError.format(attrs);super(message);const{data,path,value,reason,type,errors=[]}=attrs;this.data=data;this.path=path;this.value=value;this.reason=reason;this.type=type;this.errors=errors;if(!errors.length){errors.push(this)}if(Error.captureStackTrace){Error.captureStackTrace(this,this.constructor)}else{this.stack=new Error().stack}}}var toString=Object.prototype.toString,kindOf=function kindOf(val){if(void 0===val)return"undefined";if(null===val)return"null";var type=typeof val;if("boolean"===type)return"boolean";if("string"===type)return"string";if("number"===type)return"number";if("symbol"===type)return"symbol";if("function"===type){return isGeneratorFn(val)?"generatorfunction":"function"}if(isArray(val))return"array";if(isBuffer(val))return"buffer";if(isArguments(val))return"arguments";if(isDate(val))return"date";if(isError(val))return"error";if(isRegexp(val))return"regexp";switch(ctorName(val)){case"Symbol":return"symbol";case"Promise":return"promise";case"WeakMap":return"weakmap";case"WeakSet":return"weakset";case"Map":return"map";case"Set":return"set";case"Int8Array":return"int8array";case"Uint8Array":return"uint8array";case"Uint8ClampedArray":return"uint8clampedarray";case"Int16Array":return"int16array";case"Uint16Array":return"uint16array";case"Int32Array":return"int32array";case"Uint32Array":return"uint32array";case"Float32Array":return"float32array";case"Float64Array":return"float64array";}if(isGeneratorObj(val)){return"generator"}type=toString.call(val);switch(type){case"[object Object]":return"object";case"[object Map Iterator]":return"mapiterator";case"[object Set Iterator]":return"setiterator";case"[object String Iterator]":return"stringiterator";case"[object Array Iterator]":return"arrayiterator";}return type.slice(8,-1).toLowerCase().replace(/\s/g,"")};function ctorName(val){return val.constructor?val.constructor.name:null}function isArray(val){if(Array.isArray)return Array.isArray(val);return val instanceof Array}function isError(val){return val instanceof Error||"string"===typeof val.message&&val.constructor&&"number"===typeof val.constructor.stackTraceLimit}function isDate(val){if(val instanceof Date)return!0;return"function"===typeof val.toDateString&&"function"===typeof val.getDate&&"function"===typeof val.setDate}function isRegexp(val){if(val instanceof RegExp)return!0;return"string"===typeof val.flags&&"boolean"===typeof val.ignoreCase&&"boolean"===typeof val.multiline&&"boolean"===typeof val.global}function isGeneratorFn(name,val){return"GeneratorFunction"===ctorName(name)}function isGeneratorObj(val){return"function"===typeof val.throw&&"function"===typeof val.return&&"function"===typeof val.next}function isArguments(val){try{if("number"===typeof val.length&&"function"===typeof val.callee){return!0}}catch(err){if(-1!==err.message.indexOf("callee")){return!0}}return!1}function isBuffer(val){if(val.constructor&&"function"===typeof val.constructor.isBuffer){return val.constructor.isBuffer(val)}return!1}const IS_STRUCT="@@__STRUCT__@@",KIND="@@__KIND__@@";function isStruct(value){return!!(value&&value[IS_STRUCT])}function resolveDefaults(defaults,value){return"function"===typeof defaults?defaults(value):defaults}var _extends=Object.assign||function(target){for(var i=1,source;i<arguments.length;i++){source=arguments[i];for(var key in source){if(Object.prototype.hasOwnProperty.call(source,key)){target[key]=source[key]}}}return target};class Kind{constructor(name,type,validate){this.name=name;this.type=type;this.validate=validate}}function any(schema,defaults$$1,options){if(isStruct(schema)){return schema[KIND]}if(schema instanceof Kind){return schema}switch(kindOf(schema)){case"array":{return 1<schema.length?tuple(schema,defaults$$1,options):list(schema,defaults$$1,options)}case"function":{return func(schema,defaults$$1,options)}case"object":{return object(schema,defaults$$1,options)}case"string":{let required=!0,type;if(schema.endsWith("?")){required=!1;schema=schema.slice(0,-1)}if(schema.includes("|")){const scalars=schema.split(/\s*\|\s*/g);type=union(scalars,defaults$$1,options)}else if(schema.includes("&")){const scalars=schema.split(/\s*&\s*/g);type=intersection(scalars,defaults$$1,options)}else{type=scalar(schema,defaults$$1,options)}if(!required){type=optional(type,void 0,options)}return type}}if(!1){}else{throw new Error(`Invalid schema: ${schema}`)}}function dict(schema,defaults$$1,options){if("array"!==kindOf(schema)||2!==schema.length){if(!1){}else{throw new Error(`Invalid schema: ${schema}`)}}const obj=scalar("object",void 0,options),keys=any(schema[0],void 0,options),values=any(schema[1],void 0,options),name="dict",type=`dict<${keys.type},${values.type}>`,validate=value=>{const resolved=resolveDefaults(defaults$$1);value=resolved?_extends({},resolved,value):value;const[error]=obj.validate(value);if(error){error.type=type;return[error]}const ret={},errors=[];for(let k in value){const v=value[k],[e,r]=keys.validate(k);if(e){const allE=e.errors||[e];allE.forEach(singleE=>{singleE.path=[k].concat(singleE.path);singleE.data=value;errors.push(singleE)});continue}k=r;const[e2,r2]=values.validate(v);if(e2){const allE2=e2.errors||[e2];allE2.forEach(singleE=>{singleE.path=[k].concat(singleE.path);singleE.data=value;errors.push(singleE)});continue}ret[k]=r2}if(errors.length){const first=errors[0];first.errors=errors;return[first]}return[void 0,ret]};return new Kind(name,type,validate)}function en(schema,defaults$$1,options){if("array"!==kindOf(schema)){if(!1){}else{throw new Error(`Invalid schema: ${schema}`)}}const name="enum",type=schema.map(s=>{try{return JSON.stringify(s)}catch(e){return s+""}}).join(" | "),validate=(value=resolveDefaults(defaults$$1))=>{return schema.includes(value)?[void 0,value]:[{data:value,path:[],value,type}]};return new Kind(name,type,validate)}function enums(schema,defaults$$1,options){const e=en(schema,void 0,options),l=list([e],defaults$$1,options);return l}function func(schema,defaults$$1,options){if("function"!==kindOf(schema)){if(!1){}else{throw new Error(`Invalid schema: ${schema}`)}}const name="function",type="<function>",validate=(value=resolveDefaults(defaults$$1),data)=>{const result=schema(value,data);let failure={path:[],reason:null},isValid;switch(kindOf(result)){case"boolean":{isValid=result;break}case"string":{isValid=!1;failure.reason=result;break}case"object":{isValid=!1;failure=_extends({},failure,result);break}default:{if(!1){}else{throw new Error(`Invalid result: ${result}`)}}}return isValid?[void 0,value]:[_extends({type,value,data:value},failure)]};return new Kind(name,type,validate)}function instance(schema,defaults$$1,options){const name="instance",type=`instance<${schema.name}>`,validate=(value=resolveDefaults(defaults$$1))=>{return value instanceof schema?[void 0,value]:[{data:value,path:[],value,type}]};return new Kind(name,type,validate)}function inter(schema,defaults$$1,options){if("object"!==kindOf(schema)){if(!1){}else{throw new Error(`Invalid schema: ${schema}`)}}const ks=[],properties={};for(const key in schema){ks.push(key);const s=schema[key],kind=any(s,void 0,options);properties[key]=kind}const name="interface",type=`{${ks.join()}}`,validate=value=>{const resolved=resolveDefaults(defaults$$1);value=resolved?_extends({},resolved,value):value;const errors=[],ret=value;for(const key in properties){let v=value[key];const kind=properties[key];if(v===void 0){const d=defaults$$1&&defaults$$1[key];v=resolveDefaults(d,value)}const[e,r]=kind.validate(v,value);if(e){const allE=e.errors||[e];allE.forEach(singleE=>{singleE.path=[key].concat(singleE.path);singleE.data=value;errors.push(singleE)});continue}if(key in value||r!==void 0){ret[key]=r}}if(errors.length){const first=errors[0];first.errors=errors;return[first]}return[void 0,ret]};return new Kind(name,type,validate)}function lazy(schema,defaults$$1,options){if("function"!==kindOf(schema)){if(!1){}else{throw new Error(`Invalid schema: ${schema}`)}}let kind,struct;const name="lazy",type=`lazy...`,compile=value=>{struct=schema();kind.name=struct.kind;kind.type=struct.type;kind.validate=struct.validate;return kind.validate(value)};kind=new Kind(name,type,compile);return kind}function list(schema,defaults$$1,options){if("array"!==kindOf(schema)||1!==schema.length){if(!1){}else{throw new Error(`Invalid schema: ${schema}`)}}const array=scalar("array",void 0,options),element=any(schema[0],void 0,options),name="list",type=`[${element.type}]`,validate=(value=resolveDefaults(defaults$$1))=>{const[error,result]=array.validate(value);if(error){error.type=type;return[error]}value=result;const errors=[],ret=[];for(let i=0;i<value.length;i++){const v=value[i],[e,r]=element.validate(v);if(e){const allE=e.errors||[e];allE.forEach(singleE=>{singleE.path=[i].concat(singleE.path);singleE.data=value;errors.push(singleE)});continue}ret[i]=r}if(errors.length){const first=errors[0];first.errors=errors;return[first]}return[void 0,ret]};return new Kind(name,type,validate)}function literal(schema,defaults$$1,options){const name="literal",type=`literal: ${JSON.stringify(schema)}`,validate=(value=resolveDefaults(defaults$$1))=>{return value===schema?[void 0,value]:[{data:value,path:[],value,type}]};return new Kind(name,type,validate)}function object(schema,defaults$$1,options){if("object"!==kindOf(schema)){if(!1){}else{throw new Error(`Invalid schema: ${schema}`)}}const obj=scalar("object",void 0,options),ks=[],properties={};for(const key in schema){ks.push(key);const s=schema[key],kind=any(s,void 0,options);properties[key]=kind}const name="object",type=`{${ks.join()}}`,validate=(value=resolveDefaults(defaults$$1))=>{const[error]=obj.validate(value);if(error){error.type=type;return[error]}const errors=[],ret={},valueKeys=Object.keys(value),propertiesKeys=Object.keys(properties),keys=new Set(valueKeys.concat(propertiesKeys));keys.forEach(key=>{let v=value[key];const kind=properties[key];if(v===void 0){const d=defaults$$1&&defaults$$1[key];v=resolveDefaults(d,value)}if(!kind){const e={data:value,path:[key],value:v};errors.push(e);return}const[e,r]=kind.validate(v,value);if(e){const allE=e.errors||[e];allE.forEach(singleE=>{singleE.path=[key].concat(singleE.path);singleE.data=value;errors.push(singleE)});return}if(key in value||r!==void 0){ret[key]=r}});if(errors.length){const first=errors[0];first.errors=errors;return[first]}return[void 0,ret]};return new Kind(name,type,validate)}function optional(schema,defaults$$1,options){return union([schema,"undefined"],defaults$$1,options)}function partial(schema,defaults$$1,options){if("object"!==kindOf(schema)){if(!1){}else{throw new Error(`Invalid schema: ${schema}`)}}const obj=scalar("object",void 0,options),ks=[],properties={};for(const key in schema){ks.push(key);const s=schema[key],kind=any(s,void 0,options);properties[key]=kind}const name="partial",type=`{${ks.join()},...}`,validate=(value=resolveDefaults(defaults$$1))=>{const[error]=obj.validate(value);if(error){error.type=type;return[error]}const errors=[],ret={};for(const key in properties){let v=value[key];const kind=properties[key];if(v===void 0){const d=defaults$$1&&defaults$$1[key];v=resolveDefaults(d,value)}const[e,r]=kind.validate(v,value);if(e){const allE=e.errors||[e];allE.forEach(singleE=>{singleE.path=[key].concat(singleE.path);singleE.data=value;errors.push(singleE)});continue}if(key in value||r!==void 0){ret[key]=r}}if(errors.length){const first=errors[0];first.errors=errors;return[first]}return[void 0,ret]};return new Kind(name,type,validate)}function scalar(schema,defaults$$1,options){if("string"!==kindOf(schema)){if(!1){}else{throw new Error(`Invalid schema: ${schema}`)}}const{types}=options,fn=types[schema];if("function"!==kindOf(fn)){if(!1){}else{throw new Error(`Invalid type: ${schema}`)}}const kind=func(fn,defaults$$1,options),name="scalar",type=schema,validate=value=>{const[error,result]=kind.validate(value);if(error){error.type=type;return[error]}return[void 0,result]};return new Kind(name,type,validate)}function tuple(schema,defaults$$1,options){if("array"!==kindOf(schema)){if(!1){}else{throw new Error(`Invalid schema: ${schema}`)}}const kinds=schema.map(s=>any(s,void 0,options)),array=scalar("array",void 0,options),name="tuple",type=`[${kinds.map(k=>k.type).join()}]`,validate=(value=resolveDefaults(defaults$$1))=>{const[error]=array.validate(value);if(error){error.type=type;return[error]}const ret=[],errors=[],length=Math.max(value.length,kinds.length);for(let i=0;i<length;i++){const kind=kinds[i],v=value[i];if(!kind){const e={data:value,path:[i],value:v};errors.push(e);continue}const[e,r]=kind.validate(v);if(e){const allE=e.errors||[e];allE.forEach(singleE=>{singleE.path=[i].concat(singleE.path);singleE.data=value;errors.push(singleE)});continue}ret[i]=r}if(errors.length){const first=errors[0];first.errors=errors;return[first]}return[void 0,ret]};return new Kind(name,type,validate)}function union(schema,defaults$$1,options){if("array"!==kindOf(schema)){if(!1){}else{throw new Error(`Invalid schema: ${schema}`)}}const kinds=schema.map(s=>any(s,void 0,options)),name="union",type=kinds.map(k=>k.type).join(" | "),validate=(value=resolveDefaults(defaults$$1))=>{const errors=[];for(const k of kinds){const[e,r]=k.validate(value);if(!e){return[void 0,r]}errors.push(e)}errors[0].type=type;return errors};return new Kind(name,type,validate)}function intersection(schema,defaults$$1,options){if("array"!==kindOf(schema)){if(!1){}else{throw new Error(`Invalid schema: ${schema}`)}}const types=schema.map(s=>any(s,void 0,options)),name="intersection",type=types.map(t=>t.type).join(" & "),validate=(value=resolveDefaults(defaults$$1))=>{let v=value;for(const t of types){const[e,r]=t.validate(v);if(e){e.type=type;return[e]}v=r}return[void 0,v]};return new Kind(name,type,validate)}const Kinds={any,dict,enum:en,enums,function:func,instance,interface:inter,lazy,list,literal,object,optional,partial,scalar,tuple,union,intersection},TYPES=["arguments","array","boolean","buffer","error","float32array","float64array","function","generatorfunction","int16array","int32array","int8array","map","null","number","object","promise","regexp","set","string","symbol","uint16array","uint32array","uint8array","uint8clampedarray","undefined","weakmap","weakset"],Types={any:value=>value!==void 0};TYPES.forEach(type=>{Types[type]=value=>kindOf(value)===type});Types.date=value=>"date"===kindOf(value)&&!isNaN(value);function superstruct(config={}){const types=_extends({},Types,config.types||{});function struct(schema,defaults$$1,options={}){if(isStruct(schema)){schema=schema.schema}const kind=Kinds.any(schema,defaults$$1,_extends({},options,{types}));function Struct(data){if(this instanceof Struct){if(!1){}else{throw new Error("Invalid `new` keyword!")}}return Struct.assert(data)}Object.defineProperty(Struct,IS_STRUCT,{value:!0});Object.defineProperty(Struct,KIND,{value:kind});Struct.kind=kind.name;Struct.type=kind.type;Struct.schema=schema;Struct.defaults=defaults$$1;Struct.options=options;Struct.assert=value=>{const[error,result]=kind.validate(value);if(error){throw new StructError(error)}return result};Struct.test=value=>{const[error]=kind.validate(value);return!error};Struct.validate=value=>{const[error,result]=kind.validate(value);if(error){return[new StructError(error)]}return[void 0,result]};return Struct}Object.keys(Kinds).forEach(name=>{const kind=Kinds[name];struct[name]=(schema,defaults$$1,options)=>{const type=kind(schema,defaults$$1,_extends({},options,{types})),s=struct(type,defaults$$1,options);return s}});return struct}const struct=superstruct()}}]);
//# sourceMappingURL=4649d981c00a2de04996.chunk.js.map | PypiClean |
/django-facebook-api-0.6.8.tar.gz/django-facebook-api-0.6.8/facebook_api/mixins.py | import logging
from dateutil.parser import parse as datetime_parse
from django.contrib.contenttypes import generic
from django.contrib.contenttypes.models import ContentType
from django.db import models
from django.utils.six import string_types
from facebook_users.models import User
from m2m_history.fields import ManyToManyHistoryField
from .api import api_call
from .decorators import fetch_all, atomic
from .fields import JSONField
from .utils import get_or_create_from_small_resource, UnknownResourceType
log = logging.getLogger('facebook_api')
class OwnerableModelMixin(models.Model):
owner_content_type = models.ForeignKey(
ContentType, null=True, related_name='content_type_owners_%(app_label)s_%(class)ss')
owner_id = models.BigIntegerField(null=True, db_index=True)
owner = generic.GenericForeignKey('owner_content_type', 'owner_id')
class Meta:
abstract = True
class AuthorableModelMixin(models.Model):
# object containing the name and Facebook id of the user who posted the message
author_json = JSONField(null=True, help_text='Information about the user who posted the message')
author_content_type = models.ForeignKey(
ContentType, null=True, related_name='content_type_authors_%(app_label)s_%(class)ss')
author_id = models.BigIntegerField(null=True, db_index=True)
author = generic.GenericForeignKey('author_content_type', 'author_id')
class Meta:
abstract = True
def parse(self, response):
if 'from' in response:
response['author_json'] = response.pop('from')
super(AuthorableModelMixin, self).parse(response)
if self.author is None and self.author_json:
self.author = get_or_create_from_small_resource(self.author_json)
class ActionableModelMixin(models.Model):
actions_count = models.PositiveIntegerField(null=True, help_text='The number of total actions with this item')
class Meta:
abstract = True
def save(self, *args, **kwargs):
self.actions_count = sum([getattr(self, field, None) or 0
for field in ['likes_count', 'shares_count', 'comments_count']])
super(ActionableModelMixin, self).save(*args, **kwargs)
class LikableModelMixin(models.Model):
likes_users = ManyToManyHistoryField(User, related_name='like_%(class)ss')
likes_count = models.PositiveIntegerField(null=True, help_text='The number of likes of this item')
class Meta:
abstract = True
def parse(self, response):
if 'like_count' in response:
response['likes_count'] = response.pop('like_count')
super(LikableModelMixin, self).parse(response)
def update_count_and_get_like_users(self, instances, *args, **kwargs):
self.likes_users = instances
self.likes_count = instances.count()
self.save()
return instances
# TODO: commented, becouse if many processes fetch_likes, got errors
# DatabaseError: deadlock detected
# DETAIL: Process 27235 waits for ShareLock on transaction 3922627359; blocked by process 27037.
# @atomic
@fetch_all(return_all=update_count_and_get_like_users, paging_next_arg_name='after')
def fetch_likes(self, limit=1000, **kwargs):
"""
Retrieve and save all likes of post
"""
ids = []
response = api_call('%s/likes' % self.graph_id, limit=limit, **kwargs)
if response:
log.debug('response objects count=%s, limit=%s, after=%s' %
(len(response['data']), limit, kwargs.get('after')))
for resource in response['data']:
try:
user = get_or_create_from_small_resource(resource)
ids += [user.pk]
except UnknownResourceType:
continue
return User.objects.filter(pk__in=ids), response
class ShareableModelMixin(models.Model):
shares_users = ManyToManyHistoryField(User, related_name='shares_%(class)ss')
shares_count = models.PositiveIntegerField(null=True, help_text='The number of shares of this item')
class Meta:
abstract = True
def update_count_and_get_shares_users(self, instances, *args, **kwargs):
# self.shares_users = instances
# becouse here are not all shares: "Some posts may not appear here because of their privacy settings."
if self.shares_count is None:
self.shares_count = instances.count()
self.save()
return instances
@atomic
@fetch_all(return_all=update_count_and_get_shares_users, paging_next_arg_name='after')
def fetch_shares(self, limit=1000, **kwargs):
"""
Retrieve and save all shares of post
"""
from facebook_api.models import MASTER_DATABASE # here, becouse cycling import
ids = []
response = api_call('%s/sharedposts' % self.graph_id, **kwargs)
if response:
timestamps = dict(
[(int(post['from']['id']), datetime_parse(post['created_time'])) for post in response['data']])
ids_new = timestamps.keys()
# becouse we should use local pk, instead of remote, remove it after pk -> graph_id
ids_current = map(int, User.objects.filter(pk__in=self.shares_users.get_query_set(
only_pk=True).using(MASTER_DATABASE).exclude(time_from=None)).values_list('graph_id', flat=True))
ids_add = set(ids_new).difference(set(ids_current))
ids_add_pairs = []
ids_remove = set(ids_current).difference(set(ids_new))
log.debug('response objects count=%s, limit=%s, after=%s' %
(len(response['data']), limit, kwargs.get('after')))
for post in response['data']:
graph_id = int(post['from']['id'])
if sorted(post['from'].keys()) == ['id', 'name']:
try:
user = get_or_create_from_small_resource(post['from'])
ids += [user.pk]
# this id in add list and still not in add_pairs (sometimes in response are duplicates)
if graph_id in ids_add and graph_id not in map(lambda i: i[0], ids_add_pairs):
# becouse we should use local pk, instead of remote
ids_add_pairs += [(graph_id, user.pk)]
except UnknownResourceType:
continue
m2m_model = self.shares_users.through
# '(album|post)_id'
field_name = [f.attname for f in m2m_model._meta.local_fields
if isinstance(f, models.ForeignKey) and f.name != 'user'][0]
# remove old shares without time_from
self.shares_users.get_query_set_through().filter(time_from=None).delete()
# in case some ids_add already left
self.shares_users.get_query_set_through().filter(
**{field_name: self.pk, 'user_id__in': map(lambda i: i[1], ids_add_pairs)}).delete()
# add new shares with specified `time_from` value
get_share_date = lambda id: timestamps[id] if id in timestamps else self.created_time
m2m_model.objects.bulk_create([m2m_model(
**{field_name: self.pk, 'user_id': pk, 'time_from': get_share_date(graph_id)}) for graph_id, pk in ids_add_pairs])
return User.objects.filter(pk__in=ids), response | PypiClean |
/magic_duckdb-0.1.26-py3-none-any.whl/magic_duckdb/duckdb_mode.py | import duckdb
from typing import Optional, List
import json
from magic_duckdb.extras.explain_analyze_graphviz import draw_graphviz
from magic_duckdb.extras.ast_graphviz import ast_draw_graphviz, ast_tree
def execute_db(
*, query: str, con: duckdb.DuckDBPyConnection, execute: bool = False, params=None
):
"""Simple wrapper to allow alternative implementations or wrappers to be inserted
execute = False: returns a Relation object"""
if execute or params is not None:
return con.execute(query, parameters=params)
else:
return con.sql(query)
class DuckDbMode:
"""Lightweight wrapper to separate duckdb specific logic from the Magic.
Goal here is to expose all of DuckDB's goodness, but also make it easy to extend or replace this.
"""
export_functions: List[str] = [
"df",
"arrow",
"pl",
"describe",
"show",
"relation",
]
explain_functions: List[str] = [
"explain",
"explain_analyze_tree",
"explain_analyze_json",
"explain_analyze_draw",
"analyze",
"ast_json",
"ast_draw",
"ast_tree",
]
def default_connection(self) -> duckdb.DuckDBPyConnection:
return duckdb.default_connection
def connect(self, conn_string: str) -> duckdb.DuckDBPyConnection:
return duckdb.connect(conn_string)
def explain_analyze(
self,
query_string: str,
connection: duckdb.DuckDBPyConnection,
export_function,
explain_function,
):
# query_tree
if explain_function == "explain_analyze_tree" or explain_function == "analyze":
execute_db(
query="PRAGMA enable_profiling=query_tree", con=connection, execute=True
)
r = execute_db(query=query_string, con=connection, execute=False)
t = r.explain(type="analyze") # type: ignore
print(t)
return t
elif explain_function == "explain_analyze_json":
execute_db(
query="PRAGMA enable_profiling=json", con=connection, execute=True
)
r = execute_db(query=query_string, con=connection, execute=False)
j = r.explain(type="analyze") # type: ignore
return j
elif explain_function == "explain_analyze_draw":
execute_db(
query="PRAGMA enable_profiling=json", con=connection, execute=True
)
r = execute_db(query=query_string, con=connection, execute=False)
j = r.explain(type="analyze") # type: ignore
return draw_graphviz(j)
elif explain_function == "explain":
r = execute_db(query=query_string, con=connection, execute=False)
j = r.explain() # type: ignore
print(j)
return j
elif explain_function.startswith("ast"):
r = connection.execute(
"select json_serialize_sql($1::varchar)", [query_string]
)
df = r.df()
json_str = df.iat[0, 0]
json_obj = json.loads(json_str)
if explain_function == "ast_json":
return json_obj
elif explain_function == "ast_draw":
return ast_draw_graphviz(json_obj)
elif explain_function == "ast_tree":
return ast_tree(json_obj)
else:
raise ValueError(f"Unexpected AST mode {explain_function}")
else:
raise ValueError(f"Unexpected explain mode {explain_function}")
def execute(
self,
query_string: str,
connection: Optional[duckdb.DuckDBPyConnection] = None,
export_function: Optional[str] = None,
explain_function: Optional[str] = None,
params: Optional[List[object]] = None,
):
if connection is None:
connection = self.default_connection()
if export_function is None:
export_function = self.export_functions[0]
if explain_function is not None:
return self.explain_analyze(
query_string, connection, export_function, explain_function
)
else:
try:
if export_function in ["show", "describe"]:
execute = False
else:
execute = True
r = execute_db(
query=query_string, con=connection, params=params, execute=execute
)
except Exception as e:
raise ValueError(f"Error executing {query_string} in DuckDB") from e
if r is None or ("relation" == export_function):
return r
else:
export_function = export_function
f = getattr(r, export_function)
return f() | PypiClean |
/pii-extract-base-0.5.0.tar.gz/pii-extract-base-0.5.0/src/pii_extract/app/task_info.py | import sys
import argparse
from textwrap import TextWrapper
from typing import List, TextIO
from pii_data.helper.config import load_config
from .. import VERSION
from ..gather.collection.sources import PluginTaskCollector
from ..api import PiiProcessor
from ..api.file import print_tasks
def print_plugins(args: argparse.Namespace, out: TextIO, debug: bool = False):
"""
List the plugins
"""
config = load_config(args.config) if args.config else None
ptc = PluginTaskCollector(config=config, debug=debug)
print(". Installed plugins", file=out)
tw = TextWrapper(initial_indent=" ", subsequent_indent=" ")
for plugin in ptc.list_plugins():
print(f"\n Name: {plugin['name']}", file=out)
print(f" Source: {plugin['source']}\n Version: {plugin['version']} ",
file=out)
desc = plugin.get('description')
if desc:
print(" Description:", tw.fill(desc), sep="\n")
def print_languages(args: argparse.Namespace, out: TextIO):
"""
Print available languages
"""
config = load_config(args.config) if args.config else None
proc = PiiProcessor(config=config, skip_plugins=args.skip_plugins,
debug=args.debug)
print(". Defined languages")
for lang in proc.language_list():
print(f" {lang}")
def task_info(args: argparse.Namespace, out: TextIO):
"""
Show info about tasks
"""
config = load_config(args.config) if args.config else None
proc = PiiProcessor(config=config, skip_plugins=args.skip_plugins,
languages=args.lang, debug=args.debug)
for lang in args.lang or [None]:
proc.build_tasks(lang, args.country, pii=args.tasks,
add_any=not args.strict)
print_tasks(args.lang, proc, out)
def parse_args(args: List[str]) -> argparse.Namespace:
parser = argparse.ArgumentParser(
description=f"Show information about usable PII tasks (version {VERSION})")
opt_com1 = argparse.ArgumentParser(add_help=False)
c3 = opt_com1.add_argument_group('Source loading options')
c3.add_argument("--config", nargs="+",
help="PIISA configuration file(s) to load")
c3.add_argument("--skip-plugins", action="store_true",
help="do not load pii-extract plugins")
opt_com2 = argparse.ArgumentParser(add_help=False)
c1 = opt_com2.add_argument_group('Task selection options')
c1.add_argument("--lang", nargs="+", help="language(s) to select")
c1.add_argument("--country", nargs="+", help="countries to select")
c1.add_argument("--strict", action="store_true",
help="Include only tasks that comply strictly with selection")
opt_com3 = argparse.ArgumentParser(add_help=False)
c2 = opt_com3.add_argument_group("Other")
c2.add_argument("--debug", action="store_true", help="debug mode")
c2.add_argument('--reraise', action='store_true',
help='re-raise exceptions on errors')
subp = parser.add_subparsers(help='command', dest='cmd')
s0 = subp.add_parser("list-plugins", parents=[opt_com1, opt_com3],
help="List all installed pii-extract plugins")
s1 = subp.add_parser('list-languages', parents=[opt_com1, opt_com3],
help="List all languages defined in tasks")
s2 = subp.add_parser("list-tasks", parents=[opt_com1, opt_com2, opt_com3],
help="List available detection tasks")
#g21 = g2.add_mutually_exclusive_group(required=True)
s2.add_argument("--tasks", metavar="TASK_TYPE", nargs="+",
help="specific pii task types to include")
parsed = parser.parse_args(args)
if not parsed.cmd:
parser.print_usage()
sys.exit(1)
return parsed
def main(args: List[str] = None):
if args is None:
args = sys.argv[1:]
args = parse_args(args)
try:
if args.cmd == "list-plugins":
print_plugins(args, sys.stdout)
elif args.cmd == "list-languages":
print_languages(args, sys.stdout)
else:
task_info(args, sys.stdout)
except Exception as e:
print(f"Error: {e}", file=sys.stderr)
if args.reraise:
raise
else:
sys.exit(1)
if __name__ == "__main__":
main() | PypiClean |
/tumbo-server-0.4.12.tar.gz/tumbo-server-0.4.12/tumbo/core/static/bower_components/angular-file-upload/src/module.js | 'use strict';
/**
* Classes
*
* FileUploader
* FileUploader.FileLikeObject
* FileUploader.FileItem
* FileUploader.FileDirective
* FileUploader.FileSelect
* FileUploader.FileDrop
* FileUploader.FileOver
*/
module
.value('fileUploaderOptions', {
url: '/',
alias: 'file',
headers: {},
queue: [],
progress: 0,
autoUpload: false,
removeAfterUpload: false,
method: 'POST',
filters: [],
formData: [],
queueLimit: Number.MAX_VALUE,
withCredentials: false
})
.factory('FileUploader', ['fileUploaderOptions', '$rootScope', '$http', '$window', '$compile',
function(fileUploaderOptions, $rootScope, $http, $window, $compile) {
/**
* Creates an instance of FileUploader
* @param {Object} [options]
* @constructor
*/
function FileUploader(options) {
var settings = angular.copy(fileUploaderOptions);
angular.extend(this, settings, options, {
isUploading: false,
_nextIndex: 0,
_failFilterIndex: -1,
_directives: {select: [], drop: [], over: []}
});
// add default filters
this.filters.unshift({name: 'queueLimit', fn: this._queueLimitFilter});
this.filters.unshift({name: 'folder', fn: this._folderFilter});
}
/**********************
* PUBLIC
**********************/
/**
* Checks a support the html5 uploader
* @returns {Boolean}
* @readonly
*/
FileUploader.prototype.isHTML5 = !!($window.File && $window.FormData);
/**
* Adds items to the queue
* @param {File|HTMLInputElement|Object|FileList|Array<Object>} files
* @param {Object} [options]
* @param {Array<Function>|String} filters
*/
FileUploader.prototype.addToQueue = function(files, options, filters) {
var list = this.isArrayLikeObject(files) ? files: [files];
var arrayOfFilters = this._getFilters(filters);
var count = this.queue.length;
var addedFileItems = [];
angular.forEach(list, function(some /*{File|HTMLInputElement|Object}*/) {
var temp = new FileUploader.FileLikeObject(some);
if (this._isValidFile(temp, arrayOfFilters, options)) {
var fileItem = new FileUploader.FileItem(this, some, options);
addedFileItems.push(fileItem);
this.queue.push(fileItem);
this._onAfterAddingFile(fileItem);
} else {
var filter = this.filters[this._failFilterIndex];
this._onWhenAddingFileFailed(temp, filter, options);
}
}, this);
if(this.queue.length !== count) {
this._onAfterAddingAll(addedFileItems);
this.progress = this._getTotalProgress();
}
this._render();
if (this.autoUpload) this.uploadAll();
};
/**
* Remove items from the queue. Remove last: index = -1
* @param {FileItem|Number} value
*/
FileUploader.prototype.removeFromQueue = function(value) {
var index = this.getIndexOfItem(value);
var item = this.queue[index];
if (item.isUploading) item.cancel();
this.queue.splice(index, 1);
item._destroy();
this.progress = this._getTotalProgress();
};
/**
* Clears the queue
*/
FileUploader.prototype.clearQueue = function() {
while(this.queue.length) {
this.queue[0].remove();
}
this.progress = 0;
};
/**
* Uploads a item from the queue
* @param {FileItem|Number} value
*/
FileUploader.prototype.uploadItem = function(value) {
var index = this.getIndexOfItem(value);
var item = this.queue[index];
var transport = this.isHTML5 ? '_xhrTransport' : '_iframeTransport';
item._prepareToUploading();
if(this.isUploading) return;
this.isUploading = true;
this[transport](item);
};
/**
* Cancels uploading of item from the queue
* @param {FileItem|Number} value
*/
FileUploader.prototype.cancelItem = function(value) {
var index = this.getIndexOfItem(value);
var item = this.queue[index];
var prop = this.isHTML5 ? '_xhr' : '_form';
if (item && item.isUploading) item[prop].abort();
};
/**
* Uploads all not uploaded items of queue
*/
FileUploader.prototype.uploadAll = function() {
var items = this.getNotUploadedItems().filter(function(item) {
return !item.isUploading;
});
if (!items.length) return;
angular.forEach(items, function(item) {
item._prepareToUploading();
});
items[0].upload();
};
/**
* Cancels all uploads
*/
FileUploader.prototype.cancelAll = function() {
var items = this.getNotUploadedItems();
angular.forEach(items, function(item) {
item.cancel();
});
};
/**
* Returns "true" if value an instance of File
* @param {*} value
* @returns {Boolean}
* @private
*/
FileUploader.prototype.isFile = function(value) {
var fn = $window.File;
return (fn && value instanceof fn);
};
/**
* Returns "true" if value an instance of FileLikeObject
* @param {*} value
* @returns {Boolean}
* @private
*/
FileUploader.prototype.isFileLikeObject = function(value) {
return value instanceof FileUploader.FileLikeObject;
};
/**
* Returns "true" if value is array like object
* @param {*} value
* @returns {Boolean}
*/
FileUploader.prototype.isArrayLikeObject = function(value) {
return (angular.isObject(value) && 'length' in value);
};
/**
* Returns a index of item from the queue
* @param {Item|Number} value
* @returns {Number}
*/
FileUploader.prototype.getIndexOfItem = function(value) {
return angular.isNumber(value) ? value : this.queue.indexOf(value);
};
/**
* Returns not uploaded items
* @returns {Array}
*/
FileUploader.prototype.getNotUploadedItems = function() {
return this.queue.filter(function(item) {
return !item.isUploaded;
});
};
/**
* Returns items ready for upload
* @returns {Array}
*/
FileUploader.prototype.getReadyItems = function() {
return this.queue
.filter(function(item) {
return (item.isReady && !item.isUploading);
})
.sort(function(item1, item2) {
return item1.index - item2.index;
});
};
/**
* Destroys instance of FileUploader
*/
FileUploader.prototype.destroy = function() {
angular.forEach(this._directives, function(key) {
angular.forEach(this._directives[key], function(object) {
object.destroy();
}, this);
}, this);
};
/**
* Callback
* @param {Array} fileItems
*/
FileUploader.prototype.onAfterAddingAll = function(fileItems) {};
/**
* Callback
* @param {FileItem} fileItem
*/
FileUploader.prototype.onAfterAddingFile = function(fileItem) {};
/**
* Callback
* @param {File|Object} item
* @param {Object} filter
* @param {Object} options
* @private
*/
FileUploader.prototype.onWhenAddingFileFailed = function(item, filter, options) {};
/**
* Callback
* @param {FileItem} fileItem
*/
FileUploader.prototype.onBeforeUploadItem = function(fileItem) {};
/**
* Callback
* @param {FileItem} fileItem
* @param {Number} progress
*/
FileUploader.prototype.onProgressItem = function(fileItem, progress) {};
/**
* Callback
* @param {Number} progress
*/
FileUploader.prototype.onProgressAll = function(progress) {};
/**
* Callback
* @param {FileItem} item
* @param {*} response
* @param {Number} status
* @param {Object} headers
*/
FileUploader.prototype.onSuccessItem = function(item, response, status, headers) {};
/**
* Callback
* @param {FileItem} item
* @param {*} response
* @param {Number} status
* @param {Object} headers
*/
FileUploader.prototype.onErrorItem = function(item, response, status, headers) {};
/**
* Callback
* @param {FileItem} item
* @param {*} response
* @param {Number} status
* @param {Object} headers
*/
FileUploader.prototype.onCancelItem = function(item, response, status, headers) {};
/**
* Callback
* @param {FileItem} item
* @param {*} response
* @param {Number} status
* @param {Object} headers
*/
FileUploader.prototype.onCompleteItem = function(item, response, status, headers) {};
/**
* Callback
*/
FileUploader.prototype.onCompleteAll = function() {};
/**********************
* PRIVATE
**********************/
/**
* Returns the total progress
* @param {Number} [value]
* @returns {Number}
* @private
*/
FileUploader.prototype._getTotalProgress = function(value) {
if(this.removeAfterUpload) return value || 0;
var notUploaded = this.getNotUploadedItems().length;
var uploaded = notUploaded ? this.queue.length - notUploaded : this.queue.length;
var ratio = 100 / this.queue.length;
var current = (value || 0) * ratio / 100;
return Math.round(uploaded * ratio + current);
};
/**
* Returns array of filters
* @param {Array<Function>|String} filters
* @returns {Array<Function>}
* @private
*/
FileUploader.prototype._getFilters = function(filters) {
if (angular.isUndefined(filters)) return this.filters;
if (angular.isArray(filters)) return filters;
var names = filters.split(/\s*,/);
return this.filters.filter(function(filter) {
return names.indexOf(filter.name) !== -1;
}, this);
};
/**
* Updates html
* @private
*/
FileUploader.prototype._render = function() {
if (!$rootScope.$$phase) $rootScope.$apply();
};
/**
* Returns "true" if item is a file (not folder)
* @param {File|FileLikeObject} item
* @returns {Boolean}
* @private
*/
FileUploader.prototype._folderFilter = function(item) {
return !!(item.size || item.type);
};
/**
* Returns "true" if the limit has not been reached
* @returns {Boolean}
* @private
*/
FileUploader.prototype._queueLimitFilter = function() {
return this.queue.length < this.queueLimit;
};
/**
* Returns "true" if file pass all filters
* @param {File|Object} file
* @param {Array<Function>} filters
* @param {Object} options
* @returns {Boolean}
* @private
*/
FileUploader.prototype._isValidFile = function(file, filters, options) {
this._failFilterIndex = -1;
return !filters.length ? true : filters.every(function(filter) {
this._failFilterIndex++;
return filter.fn.call(this, file, options);
}, this);
};
/**
* Checks whether upload successful
* @param {Number} status
* @returns {Boolean}
* @private
*/
FileUploader.prototype._isSuccessCode = function(status) {
return (status >= 200 && status < 300) || status === 304;
};
/**
* Transforms the server response
* @param {*} response
* @returns {*}
* @private
*/
FileUploader.prototype._transformResponse = function(response) {
angular.forEach($http.defaults.transformResponse, function(transformFn) {
response = transformFn(response);
});
return response;
};
/**
* Parsed response headers
* @param headers
* @returns {Object}
* @see https://github.com/angular/angular.js/blob/master/src/ng/http.js
* @private
*/
FileUploader.prototype._parseHeaders = function(headers) {
var parsed = {}, key, val, i;
if (!headers) return parsed;
function trim(string) {
return string.replace(/^\s+/, '').replace(/\s+$/, '');
}
function lowercase(string) {
return string.toLowerCase();
}
angular.forEach(headers.split('\n'), function(line) {
i = line.indexOf(':');
key = lowercase(trim(line.substr(0, i)));
val = trim(line.substr(i + 1));
if (key) {
parsed[key] = parsed[key] ? parsed[key] + ', ' + val : val;
}
});
return parsed;
};
/**
* The XMLHttpRequest transport
* @param {FileItem} item
* @private
*/
FileUploader.prototype._xhrTransport = function(item) {
var xhr = item._xhr = new XMLHttpRequest();
var form = new FormData();
var that = this;
that._onBeforeUploadItem(item);
angular.forEach(item.formData, function(obj) {
angular.forEach(obj, function(value, key) {
form.append(key, value);
});
});
form.append(item.alias, item._file, item.file.name);
xhr.upload.onprogress = function(event) {
var progress = Math.round(event.lengthComputable ? event.loaded * 100 / event.total : 0);
that._onProgressItem(item, progress);
};
xhr.onload = function() {
var headers = that._parseHeaders(xhr.getAllResponseHeaders());
var response = that._transformResponse(xhr.response);
var gist = that._isSuccessCode(xhr.status) ? 'Success' : 'Error';
var method = '_on' + gist + 'Item';
that[method](item, response, xhr.status, headers);
that._onCompleteItem(item, response, xhr.status, headers);
};
xhr.onerror = function() {
var headers = that._parseHeaders(xhr.getAllResponseHeaders());
var response = that._transformResponse(xhr.response);
that._onErrorItem(item, response, xhr.status, headers);
that._onCompleteItem(item, response, xhr.status, headers);
};
xhr.onabort = function() {
var headers = that._parseHeaders(xhr.getAllResponseHeaders());
var response = that._transformResponse(xhr.response);
that._onCancelItem(item, response, xhr.status, headers);
that._onCompleteItem(item, response, xhr.status, headers);
};
xhr.open(item.method, item.url, true);
xhr.withCredentials = item.withCredentials;
angular.forEach(item.headers, function(value, name) {
xhr.setRequestHeader(name, value);
});
xhr.send(form);
this._render();
};
/**
* The IFrame transport
* @param {FileItem} item
* @private
*/
FileUploader.prototype._iframeTransport = function(item) {
var form = angular.element('<form style="display: none;" />');
var iframe = angular.element('<iframe name="iframeTransport' + Date.now() + '">');
var input = item._input;
var that = this;
if (item._form) item._form.replaceWith(input); // remove old form
item._form = form; // save link to new form
that._onBeforeUploadItem(item);
input.prop('name', item.alias);
angular.forEach(item.formData, function(obj) {
angular.forEach(obj, function(value, key) {
form.append(angular.element('<input type="hidden" name="' + key + '" value="' + value + '" />'));
});
});
form.prop({
action: item.url,
method: 'POST',
target: iframe.prop('name'),
enctype: 'multipart/form-data',
encoding: 'multipart/form-data' // old IE
});
iframe.bind('load', function() {
try {
// Fix for legacy IE browsers that loads internal error page
// when failed WS response received. In consequence iframe
// content access denied error is thrown becouse trying to
// access cross domain page. When such thing occurs notifying
// with empty response object. See more info at:
// http://stackoverflow.com/questions/151362/access-is-denied-error-on-accessing-iframe-document-object
// Note that if non standard 4xx or 5xx error code returned
// from WS then response content can be accessed without error
// but 'XHR' status becomes 200. In order to avoid confusion
// returning response via same 'success' event handler.
// fixed angular.contents() for iframes
var html = iframe[0].contentDocument.body.innerHTML;
} catch (e) {}
var xhr = {response: html, status: 200, dummy: true};
var response = that._transformResponse(xhr.response);
var headers = {};
that._onSuccessItem(item, response, xhr.status, headers);
that._onCompleteItem(item, response, xhr.status, headers);
});
form.abort = function() {
var xhr = {status: 0, dummy: true};
var headers = {};
var response;
iframe.unbind('load').prop('src', 'javascript:false;');
form.replaceWith(input);
that._onCancelItem(item, response, xhr.status, headers);
that._onCompleteItem(item, response, xhr.status, headers);
};
input.after(form);
form.append(input).append(iframe);
form[0].submit();
this._render();
};
/**
* Inner callback
* @param {File|Object} item
* @param {Object} filter
* @param {Object} options
* @private
*/
FileUploader.prototype._onWhenAddingFileFailed = function(item, filter, options) {
this.onWhenAddingFileFailed(item, filter, options);
};
/**
* Inner callback
* @param {FileItem} item
*/
FileUploader.prototype._onAfterAddingFile = function(item) {
this.onAfterAddingFile(item);
};
/**
* Inner callback
* @param {Array<FileItem>} items
*/
FileUploader.prototype._onAfterAddingAll = function(items) {
this.onAfterAddingAll(items);
};
/**
* Inner callback
* @param {FileItem} item
* @private
*/
FileUploader.prototype._onBeforeUploadItem = function(item) {
item._onBeforeUpload();
this.onBeforeUploadItem(item);
};
/**
* Inner callback
* @param {FileItem} item
* @param {Number} progress
* @private
*/
FileUploader.prototype._onProgressItem = function(item, progress) {
var total = this._getTotalProgress(progress);
this.progress = total;
item._onProgress(progress);
this.onProgressItem(item, progress);
this.onProgressAll(total);
this._render();
};
/**
* Inner callback
* @param {FileItem} item
* @param {*} response
* @param {Number} status
* @param {Object} headers
* @private
*/
FileUploader.prototype._onSuccessItem = function(item, response, status, headers) {
item._onSuccess(response, status, headers);
this.onSuccessItem(item, response, status, headers);
};
/**
* Inner callback
* @param {FileItem} item
* @param {*} response
* @param {Number} status
* @param {Object} headers
* @private
*/
FileUploader.prototype._onErrorItem = function(item, response, status, headers) {
item._onError(response, status, headers);
this.onErrorItem(item, response, status, headers);
};
/**
* Inner callback
* @param {FileItem} item
* @param {*} response
* @param {Number} status
* @param {Object} headers
* @private
*/
FileUploader.prototype._onCancelItem = function(item, response, status, headers) {
item._onCancel(response, status, headers);
this.onCancelItem(item, response, status, headers);
};
/**
* Inner callback
* @param {FileItem} item
* @param {*} response
* @param {Number} status
* @param {Object} headers
* @private
*/
FileUploader.prototype._onCompleteItem = function(item, response, status, headers) {
item._onComplete(response, status, headers);
this.onCompleteItem(item, response, status, headers);
var nextItem = this.getReadyItems()[0];
this.isUploading = false;
if(angular.isDefined(nextItem)) {
nextItem.upload();
return;
}
this.onCompleteAll();
this.progress = this._getTotalProgress();
this._render();
};
/**********************
* STATIC
**********************/
/**
* @borrows FileUploader.prototype.isFile
*/
FileUploader.isFile = FileUploader.prototype.isFile;
/**
* @borrows FileUploader.prototype.isFileLikeObject
*/
FileUploader.isFileLikeObject = FileUploader.prototype.isFileLikeObject;
/**
* @borrows FileUploader.prototype.isArrayLikeObject
*/
FileUploader.isArrayLikeObject = FileUploader.prototype.isArrayLikeObject;
/**
* @borrows FileUploader.prototype.isHTML5
*/
FileUploader.isHTML5 = FileUploader.prototype.isHTML5;
/**
* Inherits a target (Class_1) by a source (Class_2)
* @param {Function} target
* @param {Function} source
*/
FileUploader.inherit = function(target, source) {
target.prototype = Object.create(source.prototype);
target.prototype.constructor = target;
target.super_ = source;
};
FileUploader.FileLikeObject = FileLikeObject;
FileUploader.FileItem = FileItem;
FileUploader.FileDirective = FileDirective;
FileUploader.FileSelect = FileSelect;
FileUploader.FileDrop = FileDrop;
FileUploader.FileOver = FileOver;
// ---------------------------
/**
* Creates an instance of FileLikeObject
* @param {File|HTMLInputElement|Object} fileOrInput
* @constructor
*/
function FileLikeObject(fileOrInput) {
var isInput = angular.isElement(fileOrInput);
var fakePathOrObject = isInput ? fileOrInput.value : fileOrInput;
var postfix = angular.isString(fakePathOrObject) ? 'FakePath' : 'Object';
var method = '_createFrom' + postfix;
this[method](fakePathOrObject);
}
/**
* Creates file like object from fake path string
* @param {String} path
* @private
*/
FileLikeObject.prototype._createFromFakePath = function(path) {
this.lastModifiedDate = null;
this.size = null;
this.type = 'like/' + path.slice(path.lastIndexOf('.') + 1).toLowerCase();
this.name = path.slice(path.lastIndexOf('/') + path.lastIndexOf('\\') + 2);
};
/**
* Creates file like object from object
* @param {File|FileLikeObject} object
* @private
*/
FileLikeObject.prototype._createFromObject = function(object) {
this.lastModifiedDate = angular.copy(object.lastModifiedDate);
this.size = object.size;
this.type = object.type;
this.name = object.name;
};
// ---------------------------
/**
* Creates an instance of FileItem
* @param {FileUploader} uploader
* @param {File|HTMLInputElement|Object} some
* @param {Object} options
* @constructor
*/
function FileItem(uploader, some, options) {
var isInput = angular.isElement(some);
var input = isInput ? angular.element(some) : null;
var file = !isInput ? some : null;
angular.extend(this, {
url: uploader.url,
alias: uploader.alias,
headers: angular.copy(uploader.headers),
formData: angular.copy(uploader.formData),
removeAfterUpload: uploader.removeAfterUpload,
withCredentials: uploader.withCredentials,
method: uploader.method
}, options, {
uploader: uploader,
file: new FileUploader.FileLikeObject(some),
isReady: false,
isUploading: false,
isUploaded: false,
isSuccess: false,
isCancel: false,
isError: false,
progress: 0,
index: null,
_file: file,
_input: input
});
if (input) this._replaceNode(input);
}
/**********************
* PUBLIC
**********************/
/**
* Uploads a FileItem
*/
FileItem.prototype.upload = function() {
this.uploader.uploadItem(this);
};
/**
* Cancels uploading of FileItem
*/
FileItem.prototype.cancel = function() {
this.uploader.cancelItem(this);
};
/**
* Removes a FileItem
*/
FileItem.prototype.remove = function() {
this.uploader.removeFromQueue(this);
};
/**
* Callback
* @private
*/
FileItem.prototype.onBeforeUpload = function() {};
/**
* Callback
* @param {Number} progress
* @private
*/
FileItem.prototype.onProgress = function(progress) {};
/**
* Callback
* @param {*} response
* @param {Number} status
* @param {Object} headers
*/
FileItem.prototype.onSuccess = function(response, status, headers) {};
/**
* Callback
* @param {*} response
* @param {Number} status
* @param {Object} headers
*/
FileItem.prototype.onError = function(response, status, headers) {};
/**
* Callback
* @param {*} response
* @param {Number} status
* @param {Object} headers
*/
FileItem.prototype.onCancel = function(response, status, headers) {};
/**
* Callback
* @param {*} response
* @param {Number} status
* @param {Object} headers
*/
FileItem.prototype.onComplete = function(response, status, headers) {};
/**********************
* PRIVATE
**********************/
/**
* Inner callback
*/
FileItem.prototype._onBeforeUpload = function() {
this.isReady = true;
this.isUploading = true;
this.isUploaded = false;
this.isSuccess = false;
this.isCancel = false;
this.isError = false;
this.progress = 0;
this.onBeforeUpload();
};
/**
* Inner callback
* @param {Number} progress
* @private
*/
FileItem.prototype._onProgress = function(progress) {
this.progress = progress;
this.onProgress(progress);
};
/**
* Inner callback
* @param {*} response
* @param {Number} status
* @param {Object} headers
* @private
*/
FileItem.prototype._onSuccess = function(response, status, headers) {
this.isReady = false;
this.isUploading = false;
this.isUploaded = true;
this.isSuccess = true;
this.isCancel = false;
this.isError = false;
this.progress = 100;
this.index = null;
this.onSuccess(response, status, headers);
};
/**
* Inner callback
* @param {*} response
* @param {Number} status
* @param {Object} headers
* @private
*/
FileItem.prototype._onError = function(response, status, headers) {
this.isReady = false;
this.isUploading = false;
this.isUploaded = true;
this.isSuccess = false;
this.isCancel = false;
this.isError = true;
this.progress = 0;
this.index = null;
this.onError(response, status, headers);
};
/**
* Inner callback
* @param {*} response
* @param {Number} status
* @param {Object} headers
* @private
*/
FileItem.prototype._onCancel = function(response, status, headers) {
this.isReady = false;
this.isUploading = false;
this.isUploaded = false;
this.isSuccess = false;
this.isCancel = true;
this.isError = false;
this.progress = 0;
this.index = null;
this.onCancel(response, status, headers);
};
/**
* Inner callback
* @param {*} response
* @param {Number} status
* @param {Object} headers
* @private
*/
FileItem.prototype._onComplete = function(response, status, headers) {
this.onComplete(response, status, headers);
if (this.removeAfterUpload) this.remove();
};
/**
* Destroys a FileItem
*/
FileItem.prototype._destroy = function() {
if (this._input) this._input.remove();
if (this._form) this._form.remove();
delete this._form;
delete this._input;
};
/**
* Prepares to uploading
* @private
*/
FileItem.prototype._prepareToUploading = function() {
this.index = this.index || ++this.uploader._nextIndex;
this.isReady = true;
};
/**
* Replaces input element on his clone
* @param {JQLite|jQuery} input
* @private
*/
FileItem.prototype._replaceNode = function(input) {
var clone = $compile(input.clone())(input.scope());
clone.prop('value', null); // FF fix
input.css('display', 'none');
input.after(clone); // remove jquery dependency
};
// ---------------------------
/**
* Creates instance of {FileDirective} object
* @param {Object} options
* @param {Object} options.uploader
* @param {HTMLElement} options.element
* @param {Object} options.events
* @param {String} options.prop
* @constructor
*/
function FileDirective(options) {
angular.extend(this, options);
this.uploader._directives[this.prop].push(this);
this._saveLinks();
this.bind();
}
/**
* Map of events
* @type {Object}
*/
FileDirective.prototype.events = {};
/**
* Binds events handles
*/
FileDirective.prototype.bind = function() {
for(var key in this.events) {
var prop = this.events[key];
this.element.bind(key, this[prop]);
}
};
/**
* Unbinds events handles
*/
FileDirective.prototype.unbind = function() {
for(var key in this.events) {
this.element.unbind(key, this.events[key]);
}
};
/**
* Destroys directive
*/
FileDirective.prototype.destroy = function() {
var index = this.uploader._directives[this.prop].indexOf(this);
this.uploader._directives[this.prop].splice(index, 1);
this.unbind();
// this.element = null;
};
/**
* Saves links to functions
* @private
*/
FileDirective.prototype._saveLinks = function() {
for(var key in this.events) {
var prop = this.events[key];
this[prop] = this[prop].bind(this);
}
};
// ---------------------------
FileUploader.inherit(FileSelect, FileDirective);
/**
* Creates instance of {FileSelect} object
* @param {Object} options
* @constructor
*/
function FileSelect(options) {
FileSelect.super_.apply(this, arguments);
if(!this.uploader.isHTML5) {
this.element.removeAttr('multiple');
}
this.element.prop('value', null); // FF fix
}
/**
* Map of events
* @type {Object}
*/
FileSelect.prototype.events = {
$destroy: 'destroy',
change: 'onChange'
};
/**
* Name of property inside uploader._directive object
* @type {String}
*/
FileSelect.prototype.prop = 'select';
/**
* Returns options
* @return {Object|undefined}
*/
FileSelect.prototype.getOptions = function() {};
/**
* Returns filters
* @return {Array<Function>|String|undefined}
*/
FileSelect.prototype.getFilters = function() {};
/**
* If returns "true" then HTMLInputElement will be cleared
* @returns {Boolean}
*/
FileSelect.prototype.isEmptyAfterSelection = function() {
return !!this.element.attr('multiple');
};
/**
* Event handler
*/
FileSelect.prototype.onChange = function() {
var files = this.uploader.isHTML5 ? this.element[0].files : this.element[0];
var options = this.getOptions();
var filters = this.getFilters();
if (!this.uploader.isHTML5) this.destroy();
this.uploader.addToQueue(files, options, filters);
if (this.isEmptyAfterSelection()) this.element.prop('value', null);
};
// ---------------------------
FileUploader.inherit(FileDrop, FileDirective);
/**
* Creates instance of {FileDrop} object
* @param {Object} options
* @constructor
*/
function FileDrop(options) {
FileDrop.super_.apply(this, arguments);
}
/**
* Map of events
* @type {Object}
*/
FileDrop.prototype.events = {
$destroy: 'destroy',
drop: 'onDrop',
dragover: 'onDragOver',
dragleave: 'onDragLeave'
};
/**
* Name of property inside uploader._directive object
* @type {String}
*/
FileDrop.prototype.prop = 'drop';
/**
* Returns options
* @return {Object|undefined}
*/
FileDrop.prototype.getOptions = function() {};
/**
* Returns filters
* @return {Array<Function>|String|undefined}
*/
FileDrop.prototype.getFilters = function() {};
/**
* Event handler
*/
FileDrop.prototype.onDrop = function(event) {
var transfer = this._getTransfer(event);
if (!transfer) return;
var options = this.getOptions();
var filters = this.getFilters();
this._preventAndStop(event);
angular.forEach(this.uploader._directives.over, this._removeOverClass, this);
this.uploader.addToQueue(transfer.files, options, filters);
};
/**
* Event handler
*/
FileDrop.prototype.onDragOver = function(event) {
var transfer = this._getTransfer(event);
if(!this._haveFiles(transfer.types)) return;
transfer.dropEffect = 'copy';
this._preventAndStop(event);
angular.forEach(this.uploader._directives.over, this._addOverClass, this);
};
/**
* Event handler
*/
FileDrop.prototype.onDragLeave = function(event) {
if (event.target !== this.element[0]) return;
this._preventAndStop(event);
angular.forEach(this.uploader._directives.over, this._removeOverClass, this);
};
/**
* Helper
*/
FileDrop.prototype._getTransfer = function(event) {
return event.dataTransfer ? event.dataTransfer : event.originalEvent.dataTransfer; // jQuery fix;
};
/**
* Helper
*/
FileDrop.prototype._preventAndStop = function(event) {
event.preventDefault();
event.stopPropagation();
};
/**
* Returns "true" if types contains files
* @param {Object} types
*/
FileDrop.prototype._haveFiles = function(types) {
if (!types) return false;
if (types.indexOf) {
return types.indexOf('Files') !== -1;
} else if(types.contains) {
return types.contains('Files');
} else {
return false;
}
};
/**
* Callback
*/
FileDrop.prototype._addOverClass = function(item) {
item.addOverClass();
};
/**
* Callback
*/
FileDrop.prototype._removeOverClass = function(item) {
item.removeOverClass();
};
// ---------------------------
FileUploader.inherit(FileOver, FileDirective);
/**
* Creates instance of {FileDrop} object
* @param {Object} options
* @constructor
*/
function FileOver(options) {
FileOver.super_.apply(this, arguments);
}
/**
* Map of events
* @type {Object}
*/
FileOver.prototype.events = {
$destroy: 'destroy'
};
/**
* Name of property inside uploader._directive object
* @type {String}
*/
FileOver.prototype.prop = 'over';
/**
* Over class
* @type {string}
*/
FileOver.prototype.overClass = 'nv-file-over';
/**
* Adds over class
*/
FileOver.prototype.addOverClass = function() {
this.element.addClass(this.getOverClass());
};
/**
* Removes over class
*/
FileOver.prototype.removeOverClass = function() {
this.element.removeClass(this.getOverClass());
};
/**
* Returns over class
* @returns {String}
*/
FileOver.prototype.getOverClass = function() {
return this.overClass;
};
return FileUploader;
}])
.directive('nvFileSelect', ['$parse', 'FileUploader', function($parse, FileUploader) {
return {
link: function(scope, element, attributes) {
var uploader = scope.$eval(attributes.uploader);
if (!(uploader instanceof FileUploader)) {
throw new TypeError('"Uploader" must be an instance of FileUploader');
}
var object = new FileUploader.FileSelect({
uploader: uploader,
element: element
});
object.getOptions = $parse(attributes.options).bind(object, scope);
object.getFilters = function() {return attributes.filters;};
}
};
}])
.directive('nvFileDrop', ['$parse', 'FileUploader', function($parse, FileUploader) {
return {
link: function(scope, element, attributes) {
var uploader = scope.$eval(attributes.uploader);
if (!(uploader instanceof FileUploader)) {
throw new TypeError('"Uploader" must be an instance of FileUploader');
}
if (!uploader.isHTML5) return;
var object = new FileUploader.FileDrop({
uploader: uploader,
element: element
});
object.getOptions = $parse(attributes.options).bind(object, scope);
object.getFilters = function() {return attributes.filters;};
}
};
}])
.directive('nvFileOver', ['FileUploader', function(FileUploader) {
return {
link: function(scope, element, attributes) {
var uploader = scope.$eval(attributes.uploader);
if (!(uploader instanceof FileUploader)) {
throw new TypeError('"Uploader" must be an instance of FileUploader');
}
var object = new FileUploader.FileOver({
uploader: uploader,
element: element
});
object.getOverClass = function() {
return attributes.overClass || this.overClass;
};
}
};
}]) | PypiClean |
/tw2.jqplugins.jqgrid-2.2.0.tar.gz/tw2.jqplugins.jqgrid-2.2.0/tw2/jqplugins/jqgrid/static/jquery/plugins/jqGrid/3.8.3-dev-patched/src/i18n/grid.locale-fi.js | ;(function($){
/**
* jqGrid (fi) Finnish Translation
* Jukka Inkeri awot.fi 2010-05-19 Version
* http://awot.fi
* Dual licensed under the MIT and GPL licenses:
* http://www.opensource.org/licenses/mit-license.php
* http://www.gnu.org/licenses/gpl.html
**/
$.jgrid = {
defaults : {
//recordtext: "Näytä {0} - {1} / {2}",
recordtext: " {0}-{1}/{2}",
emptyrecords: "Ei näytettäviä",
loadtext: "Haetaan...",
//pgtext : "Sivu {0} / {1}"
pgtext : "{0}/{1}"
},
search : {
caption: "Etsi...",
Find: "Etsi",
Reset: "Tyhjää",
odata : ['=', '<>', '<', '<=','>','>=', 'alkaa','ei ala','joukossa','ei joukossa ','loppuu','ei lopu','sisältää','ei sisällä'],
groupOps: [ { op: "JA", text: "kaikki" }, { op: "TAI", text: "mikä tahansa" } ],
matchText: " match",
rulesText: " rules"
},
edit : {
addCaption: "Uusi rivi",
editCaption: "Muokkaa rivi",
bSubmit: "OK",
bCancel: "Peru",
bClose: "Sulje",
saveData: "Tietoja muutettu! Tallenetaanko?",
bYes : "K",
bNo : "E",
bExit : "Peru",
msg: {
required:"pakollinen",
number:"Anna kelvollinen nro",
minValue:"arvo oltava >= ",
maxValue:"arvo oltava <= ",
email: "virheellinen sposti ",
integer: "Anna kelvollinen kokonaisluku",
date: "Anna kelvollinen pvm",
url: "Ei ole sopiva linkki(URL). Alku oltava ('http://' tai 'https://')",
nodefined : " ei ole määritelty!",
novalue : " paluuarvo vaaditaan!",
customarray : "Custom function should return array!",
customfcheck : "Custom function should be present in case of custom checking!"
}
},
view : {
caption: "Nä rivi",
bClose: "Sulje"
},
del : {
caption: "Poista",
msg: "Poista valitut rivi(t)?",
bSubmit: "Poista",
bCancel: "Peru"
},
nav : {
edittext: " ",
edittitle: "Muokkaa valittu rivi",
addtext:" ",
addtitle: "Uusi rivi",
deltext: " ",
deltitle: "Poista valittu rivi",
searchtext: " ",
searchtitle: "Etsi tietoja",
refreshtext: "",
refreshtitle: "Lataa uudelleen",
alertcap: "Varoitus",
alerttext: "Valitse rivi",
viewtext: "",
viewtitle: "Nayta valitut rivit"
},
col : {
caption: "Nayta/Piilota sarakkeet",
bSubmit: "OK",
bCancel: "Peru"
},
errors : {
errcap : "Virhe",
nourl : "url asettamatta",
norecords: "Ei muokattavia tietoja",
model : "Pituus colNames <> colModel!"
},
formatter : {
integer : {thousandsSeparator: "", defaultValue: '0'},
number : {decimalSeparator:",", thousandsSeparator: "", decimalPlaces: 2, defaultValue: '0,00'},
currency : {decimalSeparator:",", thousandsSeparator: "", decimalPlaces: 2, prefix: "", suffix:"", defaultValue: '0,00'},
date : {
dayNames: [
"Su", "Ma", "Ti", "Ke", "To", "Pe", "La",
"Sunnuntai", "Maanantai", "Tiista", "Keskiviikko", "Torstai", "Perjantai", "Lauantai"
],
monthNames: [
"Tam", "Hel", "Maa", "Huh", "Tou", "Kes", "Hei", "Elo", "Syy", "Lok", "Mar", "Jou",
"Tammikuu", "Helmikuu", "Maaliskuu", "Huhtikuu", "Toukokuu", "Kesäkuu", "Heinäkuu", "Elokuu", "Syyskuu", "Lokakuu", "Marraskuu", "Joulukuu"
],
AmPm : ["am","pm","AM","PM"],
S: function (j) {return j < 11 || j > 13 ? ['st', 'nd', 'rd', 'th'][Math.min((j - 1) % 10, 3)] : 'th'},
srcformat: 'Y-m-d',
newformat: 'd/m/Y',
masks : {
ISO8601Long:"Y-m-d H:i:s",
ISO8601Short:"Y-m-d",
ShortDate: "d.m.Y",
LongDate: "l, F d, Y",
FullDateTime: "l, F d, Y g:i:s A",
MonthDay: "F d",
ShortTime: "g:i A",
LongTime: "g:i:s A",
SortableDateTime: "Y-m-d\\TH:i:s",
UniversalSortableDateTime: "Y-m-d H:i:sO",
YearMonth: "F, Y"
},
reformatAfterEdit : false
},
baseLinkUrl: '',
showAction: '',
target: '',
checkbox : {disabled:true},
idName : 'id'
}
};
// FI
})(jQuery); | PypiClean |
/uriregistry-0.3.1.tar.gz/uriregistry-0.3.1/README.rst | UriRegistry
===========
.. image:: https://badge.fury.io/py/uriregistry.png
:target: http://badge.fury.io/py/uriregistry
.. image:: https://readthedocs.org/projects/uriregistry/badge/?version=latest
:target: https://readthedocs.org/projects/uriregistry/?badge=latest
.. image:: https://travis-ci.org/OnroerendErfgoed/uriregistry.png?branch=master
:target: https://travis-ci.org/OnroerendErfgoed/uriregistry
.. image:: https://coveralls.io/repos/OnroerendErfgoed/uriregistry/badge.png?branch=master
:target: https://coveralls.io/r/OnroerendErfgoed/uriregistry
This project aims to provide a central location for keeping track of different
resources through their URI's. It has been designed to answer one simple
question: in which applications is a certain resource (ie. a URI) being used?
| PypiClean |
/android_env-1.2.2-py3-none-any.whl/android_env/components/specs.py | from android_env.components import action_type
from android_env.proto import task_pb2
from dm_env import specs
import numpy as np
_PROTO_DTYPE_TO_NUMPY_DTYPE = {
task_pb2.ArraySpec.DataType.FLOAT: np.float32,
task_pb2.ArraySpec.DataType.DOUBLE: np.float64,
task_pb2.ArraySpec.DataType.INT8: np.int8,
task_pb2.ArraySpec.DataType.INT16: np.int16,
task_pb2.ArraySpec.DataType.INT32: np.int32,
task_pb2.ArraySpec.DataType.INT64: np.int64,
task_pb2.ArraySpec.DataType.UINT8: np.uint8,
task_pb2.ArraySpec.DataType.UINT16: np.uint16,
task_pb2.ArraySpec.DataType.UINT32: np.uint32,
task_pb2.ArraySpec.DataType.UINT64: np.uint64,
task_pb2.ArraySpec.DataType.BOOL: np.bool_,
task_pb2.ArraySpec.DataType.STRING_U1: np.dtype(('U1')),
task_pb2.ArraySpec.DataType.STRING_U16: np.dtype(('<U16')),
task_pb2.ArraySpec.DataType.STRING_U25: np.dtype(('<U25')),
task_pb2.ArraySpec.DataType.STRING_U250: np.dtype(('<U250')),
task_pb2.ArraySpec.DataType.STRING: np.dtype(('<U0')),
task_pb2.ArraySpec.DataType.OBJECT: np.dtype('O'),
}
def base_action_spec(
num_fingers: int = 1, enable_key_events: bool = False
) -> dict[str, specs.Array]:
"""Default action spec for AndroidEnv.
Args:
num_fingers: Number of virtual fingers of the agent.
enable_key_events: Whether keyboard key events are enabled.
Returns:
A dict of action specs, each item corresponding to a virtual finger.
action_type: An integer of type ActionType: TOUCH=0, LIFT=1, REPEAT=2
touch_position: Position [x, y] of the touch action, where x, y are float
values between 0.0 and 1.0 corresponding to the relative position on the
screen. IGNORED when (action_type != ActionType.TOUCH).
keycode: code representing the desired key press in XKB format. See the
emulator_controller_pb2 for details.
action_type_i: Action type for additional fingers (i>1).
touch_position_i: Touch position for additional fingers (i>1).
"""
num_actions = len(action_type.ActionType) if enable_key_events else 3
action_spec = {
'action_type':
specs.DiscreteArray(num_values=num_actions, name='action_type'),
'touch_position':
specs.BoundedArray(
shape=(2,),
dtype=np.float32,
minimum=[0.0, 0.0],
maximum=[1.0, 1.0],
name='touch_position'),
}
for i in range(2, num_fingers + 1):
action_spec.update({
f'action_type_{i}':
specs.DiscreteArray(
num_values=len(action_type.ActionType),
name=f'action_type_{i}'),
f'touch_position_{i}':
specs.BoundedArray(
shape=(2,),
dtype=np.float32,
minimum=[0.0, 0.0],
maximum=[1.0, 1.0],
name=f'touch_position_{i}'),
})
if enable_key_events:
action_spec['keycode'] = specs.DiscreteArray(
num_values=(1 << 16) - 1, name='keycode')
return action_spec
def base_observation_spec(height: int, width: int) -> dict[str, specs.Array]:
"""Default observation spec for AndroidEnv.
Args:
height: Height of the device screen in pixels.
width: Width of the device screen in pixels.
Returns:
pixels: Spec for the RGB screenshot of the device. Has shape (H, W, 3)
timedelta: Spec for time delta since the last observation (in microseconds).
The first timestep immediately after reset() will have this value set to
0.
orientation: Spec for the latest orientation in a one-hot representation:
[1, 0, 0, 0]: PORTRAIT (0 degrees)
[0, 1, 0, 0]: LANDSCAPE (90 degrees clockwise)
[0, 0, 1, 0]: PORTRAIT (180 degrees) ("upside down")
[0, 0, 0, 1]: LANDSCAPE (270 degrees clockwise)
"""
return {
'pixels':
specs.BoundedArray(
shape=(height, width, 3),
dtype=np.uint8,
name='pixels',
minimum=0,
maximum=255),
'timedelta':
specs.Array(shape=(), dtype=np.int64, name='timedelta'),
'orientation':
specs.BoundedArray(
shape=np.array([4]),
dtype=np.uint8,
name='orientation',
minimum=0,
maximum=1),
} | PypiClean |
/calculate_priority_activities-1.0.4-py3-none-any.whl/calculate_priority_activities-1.0.4.dist-info/LICENSE.md | Copyright 2020 Alessandro Puzielli
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
| PypiClean |
/ElasticTabstops-1.0.1.tar.gz/ElasticTabstops-1.0.1/README.md | Description
===========
This package provides functionality for handling text indented/aligned with elastic tabstops. If you have an editor which uses elastic tabstops but work on a project that uses spaces, you might use this to convert a file from using spaces to using elastic tabstops, edit it in an elastic tabstops enabled editor and then convert it back to using spaces before saving to disk.
Alternatively, it can be a nice way to create text from tables of data.
Usage
=====
Instantiate a `Text` object with the string one wants to convert, and then call one of the `from_*` methods to create a `Table` object. `Table` objects have `to_*` methods which can be called to create new `Text` objects.
`Text` methods are `from_spaces`, `from_elastic_tabstops` and `from_fixed_tabstops`, while `Table` methods are `to_spaces`, `to_elastic_tabstops` and `to_fixed_tabstops`.
So, to convert text from using spaces to using tabs with elastic tabstops one might use the following:
```python
from elastictabstops import Text
elastic_text = Text(spaces_text).from_spaces().to_elastic_tabstops()
```
Whereas to convert text from using tabs with elastic tabstops to using spaces the following might be used:
```python
from elastictabstops import Text
spaces_text = Text(elastic_text).from_elastic_tabstops().to_spaces()
# or alternatively
spaces_text = Text(elastic_text).from_elastic_tabstops().to_spaces(multiples_of_tab_width=True)
```
If you want to use this package to print a table of strings you can use something like this:
```python
from elastictabstops import Table
my_table = [
['Title', 'Author', 'Publisher', 'Year'],
['Generation X', 'Douglas Coupland', 'Abacus', '1995'],
['Informagic', 'Jean-Pierre Petit', 'John Murray Ltd', '1982'],
['The Cyberiad', 'Stanislaw Lem', 'Harcourt Publishers Ltd', '1985'],
['The Selfish Gene', 'Richard Dawkins', 'Oxford University Press', '2006'],
]
spaces_text = Table(my_table).to_spaces()
# or if you're displaying the text in a widget which understands elastic tabstops
elastic_text = Table(my_table).to_elastic_tabstops()
```
If you have aligned text which you'd like to get a table from you can do things like this:
```python
from elastictabstops import Text
table = Text(elastic_text).from_elastic_tabstops()
table = Text(fixed_text).from_fixed_tabstops()
table = Text(spaces_text).from_spaces()
```
Author and licence
==================
This package is by Nick Gravgaard and is licensed under an MIT/X11 licence.
| PypiClean |
/pb1-detectron2-0.6.tar.gz/pb1-detectron2-0.6/detectron2/data/transforms/transform.py | import numpy as np
import torch
import torch.nn.functional as F
from fvcore.transforms.transform import (
CropTransform,
HFlipTransform,
NoOpTransform,
Transform,
TransformList,
)
from PIL import Image
try:
import cv2 # noqa
except ImportError:
# OpenCV is an optional dependency at the moment
pass
__all__ = [
"ExtentTransform",
"ResizeTransform",
"RotationTransform",
"ColorTransform",
"PILColorTransform",
]
class ExtentTransform(Transform):
"""
Extracts a subregion from the source image and scales it to the output size.
The fill color is used to map pixels from the source rect that fall outside
the source image.
See: https://pillow.readthedocs.io/en/latest/PIL.html#PIL.ImageTransform.ExtentTransform
"""
def __init__(self, src_rect, output_size, interp=Image.LINEAR, fill=0):
"""
Args:
src_rect (x0, y0, x1, y1): src coordinates
output_size (h, w): dst image size
interp: PIL interpolation methods
fill: Fill color used when src_rect extends outside image
"""
super().__init__()
self._set_attributes(locals())
def apply_image(self, img, interp=None):
h, w = self.output_size
if len(img.shape) > 2 and img.shape[2] == 1:
pil_image = Image.fromarray(img[:, :, 0], mode="L")
else:
pil_image = Image.fromarray(img)
pil_image = pil_image.transform(
size=(w, h),
method=Image.EXTENT,
data=self.src_rect,
resample=interp if interp else self.interp,
fill=self.fill,
)
ret = np.asarray(pil_image)
if len(img.shape) > 2 and img.shape[2] == 1:
ret = np.expand_dims(ret, -1)
return ret
def apply_coords(self, coords):
# Transform image center from source coordinates into output coordinates
# and then map the new origin to the corner of the output image.
h, w = self.output_size
x0, y0, x1, y1 = self.src_rect
new_coords = coords.astype(np.float32)
new_coords[:, 0] -= 0.5 * (x0 + x1)
new_coords[:, 1] -= 0.5 * (y0 + y1)
new_coords[:, 0] *= w / (x1 - x0)
new_coords[:, 1] *= h / (y1 - y0)
new_coords[:, 0] += 0.5 * w
new_coords[:, 1] += 0.5 * h
return new_coords
def apply_segmentation(self, segmentation):
segmentation = self.apply_image(segmentation, interp=Image.NEAREST)
return segmentation
class ResizeTransform(Transform):
"""
Resize the image to a target size.
"""
def __init__(self, h, w, new_h, new_w, interp=None):
"""
Args:
h, w (int): original image size
new_h, new_w (int): new image size
interp: PIL interpolation methods, defaults to bilinear.
"""
# TODO decide on PIL vs opencv
super().__init__()
if interp is None:
interp = Image.BILINEAR
self._set_attributes(locals())
def apply_image(self, img, interp=None):
assert img.shape[:2] == (self.h, self.w)
assert len(img.shape) <= 4
interp_method = interp if interp is not None else self.interp
if img.dtype == np.uint8:
if len(img.shape) > 2 and img.shape[2] == 1:
pil_image = Image.fromarray(img[:, :, 0], mode="L")
else:
pil_image = Image.fromarray(img)
pil_image = pil_image.resize((self.new_w, self.new_h), interp_method)
ret = np.asarray(pil_image)
if len(img.shape) > 2 and img.shape[2] == 1:
ret = np.expand_dims(ret, -1)
else:
# PIL only supports uint8
if any(x < 0 for x in img.strides):
img = np.ascontiguousarray(img)
img = torch.from_numpy(img)
shape = list(img.shape)
shape_4d = shape[:2] + [1] * (4 - len(shape)) + shape[2:]
img = img.view(shape_4d).permute(2, 3, 0, 1) # hw(c) -> nchw
_PIL_RESIZE_TO_INTERPOLATE_MODE = {
Image.NEAREST: "nearest",
Image.BILINEAR: "bilinear",
Image.BICUBIC: "bicubic",
}
mode = _PIL_RESIZE_TO_INTERPOLATE_MODE[interp_method]
align_corners = None if mode == "nearest" else False
img = F.interpolate(
img, (self.new_h, self.new_w), mode=mode, align_corners=align_corners
)
shape[:2] = (self.new_h, self.new_w)
ret = img.permute(2, 3, 0, 1).view(shape).numpy() # nchw -> hw(c)
return ret
def apply_coords(self, coords):
coords[:, 0] = coords[:, 0] * (self.new_w * 1.0 / self.w)
coords[:, 1] = coords[:, 1] * (self.new_h * 1.0 / self.h)
return coords
def apply_segmentation(self, segmentation):
segmentation = self.apply_image(segmentation, interp=Image.NEAREST)
return segmentation
def inverse(self):
return ResizeTransform(self.new_h, self.new_w, self.h, self.w, self.interp)
class RotationTransform(Transform):
"""
This method returns a copy of this image, rotated the given
number of degrees counter clockwise around its center.
"""
def __init__(self, h, w, angle, expand=True, center=None, interp=None):
"""
Args:
h, w (int): original image size
angle (float): degrees for rotation
expand (bool): choose if the image should be resized to fit the whole
rotated image (default), or simply cropped
center (tuple (width, height)): coordinates of the rotation center
if left to None, the center will be fit to the center of each image
center has no effect if expand=True because it only affects shifting
interp: cv2 interpolation method, default cv2.INTER_LINEAR
"""
super().__init__()
image_center = np.array((w / 2, h / 2))
if center is None:
center = image_center
if interp is None:
interp = cv2.INTER_LINEAR
abs_cos, abs_sin = (abs(np.cos(np.deg2rad(angle))), abs(np.sin(np.deg2rad(angle))))
if expand:
# find the new width and height bounds
bound_w, bound_h = np.rint(
[h * abs_sin + w * abs_cos, h * abs_cos + w * abs_sin]
).astype(int)
else:
bound_w, bound_h = w, h
self._set_attributes(locals())
self.rm_coords = self.create_rotation_matrix()
# Needed because of this problem https://github.com/opencv/opencv/issues/11784
self.rm_image = self.create_rotation_matrix(offset=-0.5)
def apply_image(self, img, interp=None):
"""
img should be a numpy array, formatted as Height * Width * Nchannels
"""
if len(img) == 0 or self.angle % 360 == 0:
return img
assert img.shape[:2] == (self.h, self.w)
interp = interp if interp is not None else self.interp
return cv2.warpAffine(img, self.rm_image, (self.bound_w, self.bound_h), flags=interp)
def apply_coords(self, coords):
"""
coords should be a N * 2 array-like, containing N couples of (x, y) points
"""
coords = np.asarray(coords, dtype=float)
if len(coords) == 0 or self.angle % 360 == 0:
return coords
return cv2.transform(coords[:, np.newaxis, :], self.rm_coords)[:, 0, :]
def apply_segmentation(self, segmentation):
segmentation = self.apply_image(segmentation, interp=cv2.INTER_NEAREST)
return segmentation
def create_rotation_matrix(self, offset=0):
center = (self.center[0] + offset, self.center[1] + offset)
rm = cv2.getRotationMatrix2D(tuple(center), self.angle, 1)
if self.expand:
# Find the coordinates of the center of rotation in the new image
# The only point for which we know the future coordinates is the center of the image
rot_im_center = cv2.transform(self.image_center[None, None, :] + offset, rm)[0, 0, :]
new_center = np.array([self.bound_w / 2, self.bound_h / 2]) + offset - rot_im_center
# shift the rotation center to the new coordinates
rm[:, 2] += new_center
return rm
def inverse(self):
"""
The inverse is to rotate it back with expand, and crop to get the original shape.
"""
if not self.expand: # Not possible to inverse if a part of the image is lost
raise NotImplementedError()
rotation = RotationTransform(
self.bound_h, self.bound_w, -self.angle, True, None, self.interp
)
crop = CropTransform(
(rotation.bound_w - self.w) // 2, (rotation.bound_h - self.h) // 2, self.w, self.h
)
return TransformList([rotation, crop])
class ColorTransform(Transform):
"""
Generic wrapper for any photometric transforms.
These transformations should only affect the color space and
not the coordinate space of the image (e.g. annotation
coordinates such as bounding boxes should not be changed)
"""
def __init__(self, op):
"""
Args:
op (Callable): operation to be applied to the image,
which takes in an ndarray and returns an ndarray.
"""
if not callable(op):
raise ValueError("op parameter should be callable")
super().__init__()
self._set_attributes(locals())
def apply_image(self, img):
return self.op(img)
def apply_coords(self, coords):
return coords
def inverse(self):
return NoOpTransform()
def apply_segmentation(self, segmentation):
return segmentation
class PILColorTransform(ColorTransform):
"""
Generic wrapper for PIL Photometric image transforms,
which affect the color space and not the coordinate
space of the image
"""
def __init__(self, op):
"""
Args:
op (Callable): operation to be applied to the image,
which takes in a PIL Image and returns a transformed
PIL Image.
For reference on possible operations see:
- https://pillow.readthedocs.io/en/stable/
"""
if not callable(op):
raise ValueError("op parameter should be callable")
super().__init__(op)
def apply_image(self, img):
img = Image.fromarray(img)
return np.asarray(super().apply_image(img))
def HFlip_rotated_box(transform, rotated_boxes):
"""
Apply the horizontal flip transform on rotated boxes.
Args:
rotated_boxes (ndarray): Nx5 floating point array of
(x_center, y_center, width, height, angle_degrees) format
in absolute coordinates.
"""
# Transform x_center
rotated_boxes[:, 0] = transform.width - rotated_boxes[:, 0]
# Transform angle
rotated_boxes[:, 4] = -rotated_boxes[:, 4]
return rotated_boxes
def Resize_rotated_box(transform, rotated_boxes):
"""
Apply the resizing transform on rotated boxes. For details of how these (approximation)
formulas are derived, please refer to :meth:`RotatedBoxes.scale`.
Args:
rotated_boxes (ndarray): Nx5 floating point array of
(x_center, y_center, width, height, angle_degrees) format
in absolute coordinates.
"""
scale_factor_x = transform.new_w * 1.0 / transform.w
scale_factor_y = transform.new_h * 1.0 / transform.h
rotated_boxes[:, 0] *= scale_factor_x
rotated_boxes[:, 1] *= scale_factor_y
theta = rotated_boxes[:, 4] * np.pi / 180.0
c = np.cos(theta)
s = np.sin(theta)
rotated_boxes[:, 2] *= np.sqrt(np.square(scale_factor_x * c) + np.square(scale_factor_y * s))
rotated_boxes[:, 3] *= np.sqrt(np.square(scale_factor_x * s) + np.square(scale_factor_y * c))
rotated_boxes[:, 4] = np.arctan2(scale_factor_x * s, scale_factor_y * c) * 180 / np.pi
return rotated_boxes
HFlipTransform.register_type("rotated_box", HFlip_rotated_box)
ResizeTransform.register_type("rotated_box", Resize_rotated_box)
# not necessary any more with latest fvcore
NoOpTransform.register_type("rotated_box", lambda t, x: x) | PypiClean |
/convo_n2-2.0.0.tar.gz/convo_n2-2.0.0/convo/core/policies/sklearn_policy.py | import json
import logging
import typing
from pathlib import Path
from typing import Any, Callable, Dict, List, Optional, Text, Tuple, Union
from collections import defaultdict, OrderedDict
import scipy.sparse
import numpy as np
import convo.utils.io as io_utils
import convo.utils.tensorflow.model_data_utils as model_data_utils
from convo.core.constants import DEFAULT_POLICY_PRIORITY
from convo.shared.core.domain import Domain
from convo.core.featurizers.single_state_featurizer import SingleStateFeaturizer
from convo.core.featurizers.tracker_featurizers import (
MaxHistoryTrackerFeaturizer,
TrackerFeaturizer,
)
from convo.shared.nlu.interpreter import NaturalLanguageInterpreter
from convo.core.policies.policy import Policy
from convo.shared.core.trackers import DialogueStateTracker
from convo.shared.core.generator import TrackerWithCachedStates
import convo.shared.utils.io
from sklearn.base import clone
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import LabelEncoder
from convo.shared.nlu.constants import ACTION_TEXT, TEXT
from convo.shared.nlu.training_data.features import Features
from convo.utils.tensorflow.constants import SENTENCE
from convo.utils.tensorflow.model_data import Data
# noinspection PyProtectedMember
from sklearn.utils import shuffle as sklearn_shuffle
logger = logging.getLogger(__name__)
if typing.TYPE_CHECKING:
import sklearn
class SklearnPolicy(Policy):
"""Use an sklearn classifier to train a policy."""
DEFAULT_MAX_HISTORY = 5
@staticmethod
def _standard_featurizer(
max_history: int = DEFAULT_MAX_HISTORY,
) -> MaxHistoryTrackerFeaturizer:
# Sklearn policy always uses MaxHistoryTrackerFeaturizer
return MaxHistoryTrackerFeaturizer(
state_featurizer=SingleStateFeaturizer(), max_history=5
)
def __init__(
self,
featurizer: Optional[MaxHistoryTrackerFeaturizer] = None,
priority: int = DEFAULT_POLICY_PRIORITY,
max_history: int = DEFAULT_MAX_HISTORY,
model: Optional["sklearn.base.BaseEstimator"] = None,
param_grid: Optional[Dict[Text, List] or List[Dict]] = None,
cv: Optional[int] = None,
scoring: Optional[Text or List or Dict or Callable] = "accuracy",
label_encoder: LabelEncoder = LabelEncoder(),
shuffle: bool = True,
zero_state_features: Optional[Dict[Text, List["Features"]]] = None,
**kwargs: Any,
) -> None:
"""Create a new sklearn policy.
Args:
featurizer: Featurizer used to convert the training data into
vector format.
model: The sklearn model or model pipeline.
param_grid: If *param_grid* is not None and *cv* is given,
a grid search on the given *param_grid* is performed
(e.g. *param_grid={'n_estimators': [50, 100]}*).
cv: If *cv* is not None, perform a cross validation on
the training data. *cv* should then conform to the
sklearn standard (e.g. *cv=5* for a 5-fold cross-validation).
scoring: Scoring strategy, using the sklearn standard.
label_encoder: Encoder for the labels. Must implement an
*inverse_transform* method.
shuffle: Whether to shuffle training data.
zero_state_features: Contains default feature values for attributes
"""
if featurizer:
if not isinstance(featurizer, MaxHistoryTrackerFeaturizer):
raise TypeError(
f"Passed featurizer of type '{type(featurizer).__name__}', "
f"should be MaxHistoryTrackerFeaturizer."
)
if not featurizer.max_history:
raise ValueError(
"Passed featurizer without `max_history`, `max_history` should be "
"set to a positive integer value."
)
else:
if not max_history:
raise ValueError(
"max_history should be set to a positive integer value."
)
featurizer = self._standard_featurizer(max_history)
super().__init__(featurizer, priority)
self.model = model or self._default_model()
self.cv = cv
self.param_grid = param_grid
self.scoring = scoring
self.label_encoder = label_encoder
self.shuffle = shuffle
# attributes that need to be restored after loading
self._pickle_params = ["model", "cv", "param_grid", "scoring", "label_encoder"]
self._train_params = kwargs
self.zero_state_features = zero_state_features or defaultdict(list)
convo.shared.utils.io.raise_deprecation_warning(
f"'{SklearnPolicy.__name__}' is deprecated and will be removed in "
"the future. It is recommended to use the 'TEDPolicy' instead."
)
@staticmethod
def _default_model() -> Any:
return LogisticRegression(solver="liblinear", multi_class="auto")
@property
def _state(self):
return {attr: getattr(self, attr) for attr in self._pickle_params}
def model_architecture(self, **kwargs) -> Any:
# filter out kwargs that cannot be passed to model
train_params = self._get_valid_params(self.model.__init__, **kwargs)
return self.model.set_params(**train_params)
@staticmethod
def _fill_in_features_to_max_length(
features: List[np.ndarray], max_history: int
) -> List[np.ndarray]:
"""
Pad features with zeros to maximum length;
Args:
features: list of features for each dialog;
each feature has shape [dialog_history x shape_attribute]
max_history: maximum history of the dialogs
Returns:
padded features
"""
feature_shape = features[0].shape[-1]
features = [
feature
if feature.shape[0] == max_history
else np.vstack(
[np.zeros((max_history - feature.shape[0], feature_shape)), feature]
)
for feature in features
]
return features
def _get_features_for_attribute(self, attribute_data: Dict[Text, List[np.ndarray]]):
"""
Given a list of all features for one attribute, turn it into a numpy array;
shape_attribute = features[SENTENCE][0][0].shape[-1]
(Shape of features of one attribute)
Args:
attribute_data: all features in the attribute stored in a np.array;
Output:
2D np.ndarray with features for an attribute with
shape [num_dialogs x (max_history * shape_attribute)]
"""
sentence_features = attribute_data[SENTENCE][0]
if isinstance(sentence_features[0], scipy.sparse.coo_matrix):
sentence_features = [feature.toarray() for feature in sentence_features]
# MaxHistoryFeaturizer is always used with SkLearn policy;
max_history = self.featurizer.max_history
features = self._fill_in_features_to_max_length(sentence_features, max_history)
features = [feature.reshape((1, -1)) for feature in features]
return np.vstack(features)
def _preprocess_data(self, data: Data) -> np.ndarray:
"""
Turn data into np.ndarray for sklearn training; dialogue history features
are flattened.
Args:
data: training data containing all the features
Returns:
Training_data: shape [num_dialogs x (max_history * all_features)];
all_features - sum of number of features of
intent, action_name, entities, forms, slots.
"""
if TEXT in data or ACTION_TEXT in data:
raise Exception(
f"{self.__name__} cannot be applied to text data. "
f"Try to use TEDPolicy instead. "
)
attribute_data = {
attribute: self._get_features_for_attribute(attribute_data)
for attribute, attribute_data in data.items()
}
# turning it into OrderedDict so that the order of features is the same
attribute_data = OrderedDict(attribute_data)
return np.concatenate(list(attribute_data.values()), axis=-1)
def _search_and_score(self, model, X, y, param_grid) -> Tuple[Any, Any]:
search = GridSearchCV(
model, param_grid=param_grid, cv=self.cv, scoring="accuracy", verbose=1
)
search.fit(X, y)
print("Best params:", search.best_params_)
return search.best_estimator_, search.best_score_
def train(
self,
training_trackers: List[TrackerWithCachedStates],
domain: Domain,
interpreter: NaturalLanguageInterpreter,
**kwargs: Any,
) -> None:
tracker_state_features, label_ids = self.featurize_for_training(
training_trackers, domain, interpreter, **kwargs
)
training_data, zero_state_features = model_data_utils.convert_to_data_format(
tracker_state_features
)
self.zero_state_features = zero_state_features
self._train_params.update(kwargs)
model = self.model_architecture(**self._train_params)
score = None
# Note: clone is called throughout to avoid mutating default arguments.
self.label_encoder = clone(self.label_encoder).fit(label_ids)
X = self._preprocess_data(training_data)
y = self.label_encoder.transform(label_ids)
if self.shuffle:
X, y = sklearn_shuffle(X, y)
if self.cv is None:
model = clone(model).fit(X, y)
else:
param_grid = self.param_grid or {}
model, score = self._search_and_score(model, X, y, param_grid)
self.model = model
logger.info("Done fitting sklearn policy model")
if score is not None:
logger.info(f"Cross validation score: {score:.5f}")
def _postprocess_prediction(self, y_proba, domain) -> List[float]:
yp = y_proba[0].tolist()
# Some classes might not be part of the training labels. Since
# sklearn does not predict labels it has never encountered
# during training, it is necessary to insert missing classes.
indices = self.label_encoder.inverse_transform(np.arange(len(yp)))
y_filled = [0.0 for _ in range(domain.num_actions)]
for i, pred in zip(indices, yp):
y_filled[i] = pred
return y_filled
def predict_action_probabilities(
self,
tracker: DialogueStateTracker,
domain: Domain,
interpreter: NaturalLanguageInterpreter,
**kwargs: Any,
) -> List[float]:
X = self.featurizer.create_state_features([tracker], domain, interpreter)
training_data, _ = model_data_utils.convert_to_data_format(
X, self.zero_state_features
)
Xt = self._preprocess_data(training_data)
y_proba = self.model.predict_proba(Xt)
return self._postprocess_prediction(y_proba, domain)
def persist(self, path: Union[Text, Path]) -> None:
if self.model:
self.featurizer.persist(path)
meta = {"priority": self.priority}
path = Path(path)
meta_file = path / "sklearn_policy.json"
convo.shared.utils.io.dump_obj_as_json_to_file(meta_file, meta)
filename = path / "sklearn_model.pkl"
convo.utils.io.pickle_dump(filename, self._state)
zero_features_filename = path / "zero_state_features.pkl"
io_utils.pickle_dump(zero_features_filename, self.zero_state_features)
else:
convo.shared.utils.io.raise_warning(
"Persist called without a trained model present. "
"Nothing to persist then!"
)
@classmethod
def load(cls, path: Union[Text, Path]) -> Policy:
filename = Path(path) / "sklearn_model.pkl"
zero_features_filename = Path(path) / "zero_state_features.pkl"
if not Path(path).exists():
raise OSError(
f"Failed to load dialogue model. Path {filename.absolute()} "
f"doesn't exist."
)
featurizer = TrackerFeaturizer.load(path)
assert isinstance(featurizer, MaxHistoryTrackerFeaturizer), (
f"Loaded featurizer of type {type(featurizer).__name__}, should be "
f"MaxHistoryTrackerFeaturizer."
)
meta_file = Path(path) / "sklearn_policy.json"
meta = json.loads(convo.shared.utils.io.read_file(meta_file))
zero_state_features = io_utils.pickle_load(zero_features_filename)
policy = cls(
featurizer=featurizer,
priority=meta["priority"],
zero_state_features=zero_state_features,
)
state = io_utils.pickle_load(filename)
vars(policy).update(state)
logger.info("Loaded sklearn model")
return policy | PypiClean |
/nlu_bf-4.8.tar.gz/nlu_bf-4.8/nlu_bf/nlu/extractors/extract_entities.py | from nlu_bf.nlu.components import Component
from nlu_bf.nlu import utils
from nlu_bf.nlu.model import Metadata
import os
import pandas as pd
import typing
from typing import Any, Optional, Text, Dict
import numpy as np
import regex as re
from time import strftime
from datetime import datetime as dt
from typing import Any, Optional, Text, Dict
import numpy as np
import dateutil.parser as dparser
import datefinder
from dateutil.parser import parse
import datetime
import dateutil.parser as dparser
from pyarabic.number import text2number
import datefinder
from dateutil.parser import parse
from datetime import timedelta
from dateutil.relativedelta import relativedelta
from nlu_bf.nlu.training_data import Message, TrainingData
class Extracteur_oncf(Component):
"""A custom sentiment analysis component"""
name = "DATA_EXTRACTION"
provides = ["entities"]
requires = ["tokens"]
defaults = {}
language_list = ["en"]
print('initialised the class')
def _init_(self, component_config=None):
super(Extracteur_oncf, self)._init_(component_config)
def train(self, training_data, cfg, **kwargs):
"""Load the sentiment polarity labels from the text
file, retrieve training tokens and after formatting
data train the classifier."""
def convert_to_entity(self, value):
"""Convert model output into the Rasa NLU compatible output format."""
entity = {"value": value,
"entity": "ENTITY",
"extractor": "extractor"}
return entity
def process(self, message:Message , **kwargs):
"""Retrieve the tokens of the new message, pass it to the classifier
and append prediction results to the message class."""
print(message.text)
if not self :
entities = []
else:
tokens = [t.text for t in message.get("tokens")]
print('***********tokens*****')
print(tokens)
data = pd.read_csv('csv_files/fichier_entities.csv',sep=';',encoding="utf_8")
Entity= np.array(datas['ent'])
Value= np.array(datas['value'])
ent_val = {}
entities = []
for i in range(len(Tville)):
ent_val[Entity] = Value[i]
for word in tokens:
for key in ent_val:
if key == word:
print(word)
entities.append(word)
print(" extracted Token ++++++++++ "+ word)
entity_ex = self.convert_to_entity(entities)
message.set("entities_heure", [entity_ex], add_to_output=True) | PypiClean |
/eventpipe-python-client-0.1.0.tar.gz/eventpipe-python-client-0.1.0/eventpipe/client.py | from __future__ import absolute_import, print_function
import atexit
import json
import logging
import os
import os.path
from time import sleep, time
import threading
import socket
import ssl
import sys
import urlparse
from urllib import quote as urllib_quote
import urllib2
import requests
string_types = basestring
ROOT = os.path.normpath(os.path.join(os.path.dirname(__file__), os.pardir))
try:
from queue import Queue
except ImportError:
from Queue import Queue # NOQA
NAME = socket.gethostname() if hasattr(socket, 'gethostname') else None
try:
# Try for certifi first since they likely keep their bundle more up to date
import certifi
CA_BUNDLE = certifi.where()
except ImportError:
CA_BUNDLE = os.path.join(ROOT, 'data', 'cacert.pem')
TIMEOUT = 1
DEFAULT_TIMEOUT = 10
logger = logging.getLogger('')
has_requests = True
def urlopen(url, data=None, timeout=TIMEOUT, ca_certs=None,
verify_ssl=False, assert_hostname=None):
class ValidHTTPSConnection(httplib.HTTPConnection):
default_port = httplib.HTTPS_PORT
def __init__(self, *args, **kwargs):
httplib.HTTPConnection.__init__(self, *args, **kwargs)
def connect(self):
sock = socket.create_connection(
address=(self.host, self.port),
timeout=self.timeout,
)
if self._tunnel_host:
self.sock = sock
self._tunnel()
self.sock = ssl.wrap_socket(
sock, ca_certs=ca_certs, cert_reqs=ssl.CERT_REQUIRED)
if assert_hostname is not None:
match_hostname(self.sock.getpeercert(),
self.assert_hostname or self.host)
class ValidHTTPSHandler(urllib2.HTTPSHandler):
def https_open(self, req):
return self.do_open(ValidHTTPSConnection, req)
if verify_ssl:
handlers = [ValidHTTPSHandler]
else:
try:
handlers = [urllib2.HTTPSHandler(
context=ssl._create_unverified_context())]
except AttributeError:
handlers = []
opener = urllib2.build_opener(*handlers)
return opener.open(url, data, timeout)
def check_threads():
return True
class Transport(object):
"""
All transport implementations need to subclass this class
You must implement a send method (or an async_send method if
sub-classing AsyncTransport) and the compute_scope method.
Please see the HTTPTransport class for an example of a
compute_scope implementation.
"""
async = False
scheme = []
def send(self, data, headers):
"""
You need to override this to do something with the actual
data. Usually - this is sending to a server
"""
raise NotImplementedError
class AsyncTransport(Transport):
"""
All asynchronous transport implementations should subclass this
class.
You must implement a async_send method (and the compute_scope
method as describe on the base Transport class).
"""
async = True
def async_send(self, data, headers, success_cb, error_cb):
"""
Override this method for asynchronous transports. Call
`success_cb()` if the send succeeds or `error_cb(exception)`
if the send fails.
"""
raise NotImplementedError
class HTTPTransport(Transport):
scheme = ['sync+http', 'sync+https']
def __init__(self, parsed_url, timeout=TIMEOUT, verify_ssl=False,
ca_certs=CA_BUNDLE):
self._parsed_url = parsed_url
self._url = parsed_url.geturl().rsplit('+', 1)[-1]
if isinstance(timeout, string_types):
timeout = int(timeout)
if isinstance(verify_ssl, string_types):
verify_ssl = bool(int(verify_ssl))
self.timeout = timeout
self.verify_ssl = verify_ssl
self.ca_certs = ca_certs
def send(self, data, headers):
"""
Sends a request to a remote webserver using HTTP POST.
"""
req = urllib2.Request(self._url, headers=headers)
try:
response = urlopen(
url=req,
data=data,
timeout=self.timeout,
verify_ssl=self.verify_ssl,
ca_certs=self.ca_certs,
)
except urllib2.HTTPError as exc:
raise
return response
class AsyncWorker(object):
_terminator = object()
def __init__(self, shutdown_timeout=DEFAULT_TIMEOUT):
check_threads()
self._queue = Queue(-1)
self._lock = threading.Lock()
self._thread = None
self._thread_for_pid = None
self.options = {
'shutdown_timeout': shutdown_timeout,
}
self.start()
def is_alive(self):
if self._thread_for_pid != os.getpid():
return False
return self._thread and self._thread.is_alive()
def _ensure_thread(self):
if self.is_alive():
return
self.start()
def main_thread_terminated(self):
self._lock.acquire()
try:
if not self.is_alive():
# thread not started or already stopped - nothing to do
return
# wake the processing thread up
self._queue.put_nowait(self._terminator)
timeout = self.options['shutdown_timeout']
# wait briefly, initially
initial_timeout = 0.1
if timeout < initial_timeout:
initial_timeout = timeout
if not self._timed_queue_join(initial_timeout):
# if that didn't work, wait a bit longer
# NB that size is an approximation, because other threads may
# add or remove items
size = self._queue.qsize()
print("Eventpipe is attempting to send %i pending error messages"
% size)
print("Waiting up to %s seconds" % timeout)
if os.name == 'nt':
print("Press Ctrl-Break to quit")
else:
print("Press Ctrl-C to quit")
self._timed_queue_join(timeout - initial_timeout)
self._thread = None
finally:
self._lock.release()
def _timed_queue_join(self, timeout):
"""
implementation of Queue.join which takes a 'timeout' argument
returns true on success, false on timeout
"""
deadline = time() + timeout
queue = self._queue
queue.all_tasks_done.acquire()
try:
while queue.unfinished_tasks:
delay = deadline - time()
if delay <= 0:
# timed out
return False
queue.all_tasks_done.wait(timeout=delay)
return True
finally:
queue.all_tasks_done.release()
def start(self):
"""
Starts the task thread.
"""
self._lock.acquire()
try:
if not self.is_alive():
self._thread = threading.Thread(
target=self._target, name="eventpipe.AsyncWorker")
self._thread.setDaemon(True)
self._thread.start()
self._thread_for_pid = os.getpid()
finally:
self._lock.release()
atexit.register(self.main_thread_terminated)
def stop(self, timeout=None):
"""
Stops the task thread. Synchronous!
"""
self._lock.acquire()
try:
if self._thread:
self._queue.put_nowait(self._terminator)
self._thread.join(timeout=timeout)
self._thread = None
self._thread_for_pid = None
finally:
self._lock.release()
def queue(self, callback, *args, **kwargs):
self._ensure_thread()
self._queue.put_nowait((callback, args, kwargs))
def _target(self):
while True:
record = self._queue.get()
try:
if record is self._terminator:
break
callback, args, kwargs = record
try:
callback(*args, **kwargs)
except Exception:
logger.error('Failed processing job', exc_info=True)
finally:
self._queue.task_done()
sleep(0)
class ThreadedHTTPTransport(AsyncTransport, HTTPTransport):
scheme = ['http', 'https', 'threaded+http', 'threaded+https']
def get_worker(self):
if not hasattr(self, '_worker') or not self._worker.is_alive():
self._worker = AsyncWorker()
return self._worker
def send_sync(self, data, headers, success_cb, failure_cb):
try:
super(ThreadedHTTPTransport, self).send(data, headers)
except Exception as e:
failure_cb(e)
else:
success_cb()
def async_send(self, data, headers, success_cb, failure_cb):
self.get_worker().queue(
self.send_sync, data, headers, success_cb, failure_cb)
class RequestsHTTPTransport(HTTPTransport):
scheme = ['requests+http', 'requests+https']
def __init__(self, *args, **kwargs):
self.session = None
if not has_requests:
raise ImportError('RequestsHTTPTransport requires requests.')
super(RequestsHTTPTransport, self).__init__(*args, **kwargs)
def init_session(self):
if self.session is None:
self.session = requests.Session()
def send(self, data, headers):
if self.verify_ssl:
# If SSL verification is enabled use the provided CA bundle to
# perform the verification.
self.verify_ssl = self.ca_certs
self.init_session()
self.session.post(self._url, data=data, headers=headers,
verify=self.verify_ssl, timeout=self.timeout)
class ThreadedRequestsHTTPTransport(AsyncTransport, RequestsHTTPTransport):
scheme = ['threaded+requests+http', 'threaded+requests+https']
def get_worker(self):
if not hasattr(self, '_worker'):
self._worker = AsyncWorker()
return self._worker
def send_sync(self, data, headers, success_cb, failure_cb):
try:
super(ThreadedRequestsHTTPTransport, self).send(data, headers)
except Exception as e:
failure_cb(e)
else:
success_cb()
def async_send(self, data, headers, success_cb, failure_cb):
self.get_worker().queue(
self.send_sync, data, headers, success_cb, failure_cb)
# from config import config
SERVICE = urlparse.urlparse("http://localhost:10000/report")
EVENT_PIPE_ENABLED = True
def okay():
pass
def fail(*args):
print('failed', args)
def pipe(service=None):
service = urlparse.urlparse(service) if service is not None else SERVICE
transport = ThreadedRequestsHTTPTransport(service)
def send(data={"ok": 1}, env='dev', success_cb=okay, error_cb=fail, jsonize=False):
if jsonize:
data['env'] = env
data = json.dumps(data)
transport.async_send(data, {}, success_cb, error_cb)
return transport
return send | PypiClean |
/piScope-1.0.22-py3-none-any.whl/ifigure/add_on/model/module/subs/mdsplus_tree_node.py | from __future__ import print_function
import wx
from ifigure.utils.cbook import parseStr
from ifigure.mto.py_code import PyData
from ifigure.mto.py_code import PyCode
#from ifigure.add_on.data.mdsplus_tree import MdsplusTreeNode
import wx
import sys
import os
import re
import string
from numpy import *
from collections import OrderedDict
import ifigure.utils.mdsplusr as mds
from ifigure.utils.edit_list import DialogEditList
######################################################
# Setting for module file for py_module
#
# General rule:
# This file will be automatically loaded when
# py_module object is created. Also, py_module
# keeps track the file modification time. If
# the file is updated, it will be automaticaaly
# reloaded.
# Strong recommendation : make module "independent".
# Py_Modules does not check the dependency of
# modules.
# If moduels used in Py_Modules depends on
# each other by for example module variable,
# it will cause complicate module loading
# order-dependency problem.
#
# name of module
module_name = 'mdsplus_tree_node'
class_name = 'mdsplus_tree_node'
# module_evt_handler
# functions which can be called from project tree
#
# (menu name, function name, a flat to call skip()
# after running function)
#
# By default these function should return None
# or True
# if it return False, ifigure stops exectuion at
# this module
#
menu = []
#
# method lists module functions which will
# be registered as method
#
# spceical methods:
# init : called when mto will be made and
# this module is first loaded.
# clean : called when mto will be killed
#
method = ['isMdsNode', '_getitem_',
'dim_of', 'call_mdsvalue']
icon = 'data.png'
can_have_child = True
######################################################
def isMdsNode(self):
return True
def _getitem_(self, key):
txt = self.td.getvar("node")
print(txt)
return self.call_mdsvalue(txt)
def dim_of(self, num=0):
print(self)
print(self.td)
node = self.td.getvar("node")
txt = 'dim_of('+node.strip()+','+str(num)+')'
return self.call_mdsvalue(txt)
def call_mdsvalue(self, str):
# parent should be the top of tree
# such as "cmod", "analysis", "xtomo"
try:
parent = self.td
while parent.get_parent()._obj.isMdsNode():
parent = parent.get_parent()
except Exception:
pass
tree = parent.getvar("tree")
shot = parent.getvar("shot")
server = parent.getvar("server")
port = parent.getvar("port")
mds.port = port
mds.server = server
print((tree, shot, port, server, str))
try:
res = mds.open(tree, shot)
print(res)
return mds.value(str)
except Exception:
print("!!!!!! Error in evaluating the following node !!!!!!")
print(("TREE/SHOT", tree, shot))
print(("NODE", str))
print(sys.exc_info())
return None | PypiClean |
/DuctApe-0.18.2.tar.gz/DuctApe-0.18.2/ductape/common/commonthread.py | import sys
if sys.version_info[0] < 3:
import Queue as queue
else:
import queue
import logging
import os
import shutil
import threading
import time
__author__ = "Marco Galardini"
################################################################################
# Log setup
logger = logging.getLogger('ductape.commonthread')
################################################################################
# Classes
class Status(object):
'''
Class Status
Gives informations about the run status of a specific thread
'''
def __init__(self,status=None,msg=None,maxstatus=None,
substatus=None,submsg=None,maxsubstatus=None,
fail=False):
self.status = status
self.msg = msg
self.maxstatus = maxstatus
#
self.substatus = substatus
self.submsg = submsg
self.maxsubstatus = maxsubstatus
# Fail msg?
self.fail = fail
class CommonThread(threading.Thread):
'''
Class CommonThread: Common operations for a threading class
'''
_statusDesc = {0:'Not started',
1:'Making room',
3:'Cleaning up'}
_substatuses = []
def __init__(self,queue=queue.Queue()):
threading.Thread.__init__(self)
# Thread
self.msg = queue
self._status = 0
self._maxstatus = len(self._statusDesc)
self._substatus = 0
self._maxsubstatus = 0
self._room = None
self.killed = False
def getStatus(self):
return self._statusDesc[self._status]
def getMaxStatus(self):
return self._maxstatus
def getMaxSubStatus(self):
return self._maxsubstatus
def getSubStatuses(self):
return self._substatuses
def resetSubStatus(self):
self._substatus = 0
self._maxsubstatus = 0
def makeRoom(self,location=''):
'''
Creates a tmp directory in the desired location
'''
try:
path = os.path.abspath(location)
path = os.path.join(path, 'tmp')
self._room = path
os.mkdir(path)
except:
logger.debug('Temporary directory creation failed! %s'
%path)
def startCleanUp(self):
'''
Removes the temporary directory
'''
if os.path.exists(self._room):
logger.debug('Removing the old results directory (%s)'%
self._room)
shutil.rmtree(self._room, True)
def cleanUp(self):
'''
Removes the temporary directory
'''
shutil.rmtree(self._room, True)
def run(self):
self.updateStatus()
self.makeRoom()
self.updateStatus()
self.cleanUp()
def sendFailure(self,detail='Error!'):
msg = Status(fail=True,
msg=detail)
self.msg.put(msg)
# Give some time for the message to arrive
time.sleep(0.1)
def updateStatus(self,sub=False,send=True):
if not sub:
self._status += 1
if not send:
return
if self._status in self._substatuses:
msg = Status(status=self._status,msg=self.getStatus(),
maxstatus=self.getMaxStatus(),
substatus=self._substatus,
maxsubstatus=self.getMaxSubStatus())
else:
msg = Status(status=self._status,msg=self.getStatus(),
maxstatus=self.getMaxStatus())
self.msg.put(msg)
def kill(self):
self.killed = True | PypiClean |
/nemo_toolkit-1.20.0-py3-none-any.whl/nemo/collections/tts/losses/spectrogram_enhancer_losses.py |
# MIT License
#
# Copyright (c) 2020 Phil Wang
#
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in all
# copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
# SOFTWARE.
# The following is largely based on code from https://github.com/lucidrains/stylegan2-pytorch
import torch
import torch.nn.functional as F
from einops import rearrange
from torch.autograd import grad as torch_grad
from nemo.collections.tts.parts.utils.helpers import mask_sequence_tensor
class GradientPenaltyLoss(torch.nn.Module):
"""
R1 loss from [1], used following [2]
[1] Mescheder et. al. - Which Training Methods for GANs do actually Converge? 2018, https://arxiv.org/abs/1801.04406
[2] Karras et. al. - A Style-Based Generator Architecture for Generative Adversarial Networks, 2018 (https://arxiv.org/abs/1812.04948)
"""
def __init__(self, weight: float = 10.0):
super().__init__()
self.weight = weight
def __call__(self, images, output):
batch_size, *_ = images.shape
gradients = torch_grad(
outputs=output,
inputs=images,
grad_outputs=torch.ones(output.size(), device=images.device),
create_graph=True,
retain_graph=True,
only_inputs=True,
)[0]
gradients = gradients.reshape(batch_size, -1)
return self.weight * ((gradients.norm(2, dim=1) - 1) ** 2).mean()
class GeneratorLoss(torch.nn.Module):
def __call__(self, fake_logits):
return fake_logits.mean()
class HingeLoss(torch.nn.Module):
def __call__(self, real_logits, fake_logits):
return (F.relu(1 + real_logits) + F.relu(1 - fake_logits)).mean()
class ConsistencyLoss(torch.nn.Module):
"""
Loss to keep SpectrogramEnhancer from generating extra sounds.
L1 distance on x0.25 Mel scale (20 bins for typical 80-bin scale)
"""
def __init__(self, weight: float = 10):
super().__init__()
self.weight = weight
def __call__(self, condition, output, lengths):
*_, w, h = condition.shape
w, h = w // 4, h
condition = F.interpolate(condition, size=(w, h), mode="bilinear", antialias=True)
output = F.interpolate(output, size=(w, h), mode="bilinear", antialias=True)
dist = (condition - output).abs()
dist = mask_sequence_tensor(dist, lengths)
return (dist / rearrange(lengths, "b -> b 1 1 1")).sum(dim=-1).mean() * self.weight | PypiClean |
/ka-lite-0.17.6b4.tar.gz/ka-lite-0.17.6b4/kalite/packages/bundled/django/contrib/localflavor/sk/sk_districts.py | from django.utils.translation import ugettext_lazy as _
DISTRICT_CHOICES = (
('BB', _('Banska Bystrica')),
('BS', _('Banska Stiavnica')),
('BJ', _('Bardejov')),
('BN', _('Banovce nad Bebravou')),
('BR', _('Brezno')),
('BA1', _('Bratislava I')),
('BA2', _('Bratislava II')),
('BA3', _('Bratislava III')),
('BA4', _('Bratislava IV')),
('BA5', _('Bratislava V')),
('BY', _('Bytca')),
('CA', _('Cadca')),
('DT', _('Detva')),
('DK', _('Dolny Kubin')),
('DS', _('Dunajska Streda')),
('GA', _('Galanta')),
('GL', _('Gelnica')),
('HC', _('Hlohovec')),
('HE', _('Humenne')),
('IL', _('Ilava')),
('KK', _('Kezmarok')),
('KN', _('Komarno')),
('KE1', _('Kosice I')),
('KE2', _('Kosice II')),
('KE3', _('Kosice III')),
('KE4', _('Kosice IV')),
('KEO', _('Kosice - okolie')),
('KA', _('Krupina')),
('KM', _('Kysucke Nove Mesto')),
('LV', _('Levice')),
('LE', _('Levoca')),
('LM', _('Liptovsky Mikulas')),
('LC', _('Lucenec')),
('MA', _('Malacky')),
('MT', _('Martin')),
('ML', _('Medzilaborce')),
('MI', _('Michalovce')),
('MY', _('Myjava')),
('NO', _('Namestovo')),
('NR', _('Nitra')),
('NM', _('Nove Mesto nad Vahom')),
('NZ', _('Nove Zamky')),
('PE', _('Partizanske')),
('PK', _('Pezinok')),
('PN', _('Piestany')),
('PT', _('Poltar')),
('PP', _('Poprad')),
('PB', _('Povazska Bystrica')),
('PO', _('Presov')),
('PD', _('Prievidza')),
('PU', _('Puchov')),
('RA', _('Revuca')),
('RS', _('Rimavska Sobota')),
('RV', _('Roznava')),
('RK', _('Ruzomberok')),
('SB', _('Sabinov')),
('SC', _('Senec')),
('SE', _('Senica')),
('SI', _('Skalica')),
('SV', _('Snina')),
('SO', _('Sobrance')),
('SN', _('Spisska Nova Ves')),
('SL', _('Stara Lubovna')),
('SP', _('Stropkov')),
('SK', _('Svidnik')),
('SA', _('Sala')),
('TO', _('Topolcany')),
('TV', _('Trebisov')),
('TN', _('Trencin')),
('TT', _('Trnava')),
('TR', _('Turcianske Teplice')),
('TS', _('Tvrdosin')),
('VK', _('Velky Krtis')),
('VT', _('Vranov nad Toplou')),
('ZM', _('Zlate Moravce')),
('ZV', _('Zvolen')),
('ZC', _('Zarnovica')),
('ZH', _('Ziar nad Hronom')),
('ZA', _('Zilina')),
) | PypiClean |
/azure_percept-0.0.13-cp38-cp38-manylinux_2_24_aarch64.whl/azure/iot/percept/mo/middle/passes/infer.py |
import logging as log
import networkx as nx
import numpy as np
# TODO remove it
from mo.graph.graph import Node, Graph
from mo.graph.graph import dict_includes
from mo.utils.error import Error
from mo.utils.utils import refer_to_faq_msg, shrink_str_value
def log_debug_dict(nodes_per_port: dict, direction_name: str):
for port, node in nodes_per_port.items():
value = shrink_str_value(node.soft_get('value'))
log.debug('{}[{}]: shape = {}, value = {}'.format(direction_name, port, node.soft_get('shape'), value))
def is_fully_defined_shape(shape: np.ndarray):
if -1 in shape:
return False
return True
def control_flow_infer(graph: Graph, node_name: str):
"""
Executes constant control flow. Propagates nodes executability
"""
if graph.node[node_name]['kind'] == 'data':
return
def mark_executability(node_id: str, is_executable: bool):
if is_executable and not graph.node[node_id]['executable']:
return
graph.node[node_id]['executable'] = is_executable
in_edges_with_data = graph.in_edges(node_name, data=True)
in_df_edges_with_data = [(u, v, attrs) for u, v, attrs in in_edges_with_data
if 'control_flow_edge' not in attrs or not attrs['control_flow_edge']]
in_cf_edges_with_data = [(u, v, attrs) for u, v, attrs in in_edges_with_data
if 'control_flow_edge' in attrs and attrs['control_flow_edge']]
is_executable_df = all([graph.node[u]['executable'] for u, _, attrs in in_df_edges_with_data]
if len(in_df_edges_with_data) else [True])
is_executable_cf = all([graph.node[u]['executable'] for u, _, attrs in in_cf_edges_with_data]
if len(in_cf_edges_with_data) else [True])
is_executable = is_executable_df and is_executable_cf
node = Node(graph, node_name)
if 'cf_infer' in graph.node[node_name] and callable(node.cf_infer):
node.cf_infer(node, is_executable, mark_executability)
else:
for _, out_data in graph.out_edges(node_name):
mark_executability(out_data, is_executable)
def exit_bound_edges(graph: Graph, sources: list, end_node_attrs: dict):
"""
Finds all descendant nodes for each node from 'sources' that have given attributes from end_node_attrs.
For each found node, create a tuple with a given element from 'source' and the node.
"""
result = []
for node in sources:
for end_node in nx.descendants(graph, node):
if dict_includes(big=graph.node[end_node], sub_dict=end_node_attrs):
result.append((node, end_node, 0, {}))
return result
def partial_infer(graph: Graph, start_node: str = None):
"""
Tries to execute constant parts of the graph and deduce as much as possible
information following the data flow, e.g. calculate and propagate shapes and
constant values. Partially or completely defined values are stored in data
nodes (kind='data').
"""
# We have to turn off strict mode due to above we add and remove edeges without attributes that is prohibited
graph.strict_mode = False
cycle_nodes = graph.get_nodes_with_attributes(is_cyclic=True)
cycle_nodes = [Node(graph, node).out_node().id for node in cycle_nodes]
ebunch_cyclic = list(graph.out_edges(nbunch=cycle_nodes, data=True, keys=True))
ebunch_reconnected = exit_bound_edges(graph, sources=cycle_nodes, end_node_attrs={'op': 'Exit'})
graph.remove_edges_from(ebunch_cyclic)
graph.add_edges_from(ebunch_reconnected)
try:
nodes = list(nx.topological_sort(graph))
except:
raise Error('Graph contains a cycle. Can not proceed. ' + refer_to_faq_msg(97))
graph.remove_edges_from(ebunch_reconnected)
graph.add_edges_from(ebunch_cyclic)
graph.strict_mode = True
# Mark all nodes as not inferred yet
if start_node is not None:
start_index = nodes.index(start_node)
nx.set_node_attributes(G=graph.subgraph(nodes[start_index:]), name='is_partial_inferred', values=False)
else:
nx.set_node_attributes(G=graph, name='is_partial_inferred', values=False)
debug_logger = log.getLogger().isEnabledFor(log.DEBUG)
nx.set_node_attributes(G=graph, name='executable',
values={n: True for n in graph.get_nodes_with_attributes(kind='data')})
for n in nodes:
# Data Flow Infer
try:
node = Node(graph, n)
node_name = node.soft_get('name')
if node.has('is_partial_inferred') and not node.is_partial_inferred:
if node.has('infer') and not node.infer is None:
if debug_logger:
log.debug('-' * 20)
log.debug('Partial infer for {}'.format(node.soft_get('name')))
log.debug('Op: {}'.format(node.soft_get('op')))
log.debug('Inputs:')
log_debug_dict(node.in_nodes(), 'input')
node.infer(node)
out_nodes = node.out_nodes()
# propagate nchw_layout attributes to data nodes
if node.has('nchw_layout'):
for out_node in out_nodes.values():
out_node['nchw_layout'] = node.nchw_layout
# In debug print current node attributes, input shapes/values and output shape/values
if debug_logger:
log.debug('Outputs:')
log_debug_dict(node.out_nodes(), 'output')
not_all_output_shapes = False
for out_port, out_node in out_nodes.items():
not_all_output_shapes = False
if not out_node.has_valid('shape'):
log.error('Shape is not defined for output {} of "{}".'.format(out_port, node_name))
not_all_output_shapes = True
elif not is_fully_defined_shape(out_node.shape):
log.error(
('Shape {} is not fully defined for output {} of "{}". ' +
'Use --input_shape with positive integers to override model input shapes.').format(
out_node.shape,
out_port,
node_name
)
)
not_all_output_shapes = True
if not_all_output_shapes:
raise Error('Not all output shapes were inferred or fully defined for node "{}". ' +
refer_to_faq_msg(40),
node_name)
elif node.kind != 'data':
raise Error(
'There is no registered "infer" function for node "{}" with op = "{}". ' +
'Please implement this function in the extensions. ' +
refer_to_faq_msg(37),
node_name,
node.soft_get('op')
)
node.is_partial_inferred = True
except Exception as err:
log.error('Cannot infer shapes or values for node "{}".'.format(node.soft_get('name')))
log.error(str(err))
log.error('')
log.error('It can happen due to bug in custom shape infer function {}.'.format(node.soft_get('infer')))
log.error('Or because the node inputs have incorrect values/shapes.')
log.error('Or because input shapes are incorrect (embedded to the model or passed via --input_shape).')
debug_messages = '\n'.join(
['Layer "' + node_name + '": ' + node_attrs['debug_message'] for node_name, node_attrs in
graph.nodes(data=True) if 'debug_message' in node_attrs])
if debug_messages != "":
log.error('')
log.error('Other possible failure reasons are listed below:')
log.error(debug_messages)
if not debug_logger:
log.error('Run Model Optimizer with --log_level=DEBUG for more information.')
else:
log.debug('Node "{}" attributes: {}'.format(node.soft_get('name'), node.graph.node[node.id]))
raise Error('Stopped shape/value propagation at "{}" node. '.format(node.soft_get('name')) +
refer_to_faq_msg(38)) from err
control_flow_infer(graph, n)
not_fully_inferred = graph.get_nodes_with_attributes(is_not_fully_inferred=True)
for n in not_fully_inferred:
node = Node(graph, n)
if node.has('infer') and not node.infer is None:
node.infer(node)
return graph
def override_batch(graph: Graph, batch: int):
"""
Overrides batch for nodes with 'op' param set to 'Parameter'
Parameters
----------
graph: graph to operate on
batch: user defined integer value to override batch
"""
if batch is not None:
for node_id, data in graph.nodes(data=True):
if 'op' in data and data['op'] == 'Parameter' and not data.get('fixed_batch', False):
if len(data['shape']) == 0 or data['shape'][0] not in (-1, 0, 1):
raise Error(('The input layer {} has a shape {} defined in the model. \n\n' +
'When you use -b (--batch) option, Model Optimizer applies its value to the first ' +
'element of the shape if it is equal to -1, 0 or 1. Otherwise, this is the ambiguous ' +
'situation - Model Optimizer can not know in advance whether the layer has the batch ' +
'dimension or not.\n\n For example, you want to set batch dimension equals 100 ' +
'for the input layer "data" with shape (10,34). Although you can not use --batch, ' +
'you should pass --input_shape (100,34) instead of --batch 100. \n\n' +
refer_to_faq_msg(39))
.format(data['name'], data['shape']))
data['shape'][0] = batch
def override_placeholder_shapes(graph: Graph, user_shapes: dict, batch=None):
"""
This function overrides shapes for nodes with 'op' param set to 'Parameter' with shapes defined by users (only
for inputs without in/out port specified).
And override batch if batch was specified and shape for input is not None.
:param graph: graph to operate on
:param user_shapes: dictionary, that represents user defined nodes and shapes
:param batch: user defined integer value to override batch
"""
if user_shapes is None:
# DON'T MOVE UPPER!!! WE NEED TO SET BATCH FIRST
# user did not specify neither shapes nor inputs, keep models values
return
placeholders = graph.get_nodes_with_attributes(kind='op', op='Parameter')
for node_id in placeholders:
node_attrs = graph.node[node_id]
shape = None
if node_id in user_shapes:
values = user_shapes[node_id]
for value in values:
if 'in' not in value and 'out' not in value:
shape = value['shape'] if value['shape'] is not None else None
break # we assume only one specified shape for one input
if shape is not None:
node_attrs['shape'] = shape
if batch is not None and node_attrs['shape'] is not None and len(node_attrs['shape']) > 0:
node_attrs['shape'][0] = batch
def type_infer(graph: Graph):
nodes = list(nx.topological_sort(graph))
for n in nodes:
node = Node(graph, n)
if node.kind == 'op':
node_name = node.soft_get('name')
node_type_infer(node)
log.debug('Type infer for node {}: {}'.format(node_name,
[port.get_data_type() for port in node.out_ports().values()]))
"""
Save the precision of input ports in the nodes. It is not possible to get the precision after the port
re-numbering because the port precision is defined for output port only and for input port it is determined
with the output port producing data to the input port. When output port id is changed it is not possible to
determine input port precision.
"""
for out_port in node.out_ports().values():
for dest_port in out_port.get_destinations():
if not dest_port.node.has_valid('_in_port_precision'):
dest_port.node['_in_port_precision'] = {}
dest_port.node['_in_port_precision'][dest_port.idx] = out_port.get_data_type()
def node_type_infer(node):
if node.has_valid('type_infer'):
node.type_infer(node)
elif node.has_valid('data_type'):
node.out_port(0).set_data_type(node.data_type)
else:
copy_type_infer(node)
def copy_type_infer(node):
for out_port in node.out_ports().values():
connected_in_ports = [port for port in node.in_ports().values() if not port.disconnected()]
if len(connected_in_ports) != 0:
data_type = connected_in_ports[0].get_data_type()
if data_type is not None:
out_port.set_data_type(data_type)
else:
src_node = connected_in_ports[0].get_connection().get_source().node
node_type_infer(src_node)
out_port.set_data_type(connected_in_ports[0].get_data_type())
else:
raise Error('No input ports of node {} to determine data type'.format(node.soft_get('name'))) | PypiClean |
/algora_sdk-1.5.39-py3-none-any.whl/algora/common/decorators/partitioned_cache.py | import functools
from typing import TypeVar, Callable, Dict, List
KEY = TypeVar("KEY")
VALUE = TypeVar("VALUE")
PARTITION_ID = TypeVar("PARTITION_ID")
def partitioned_cached(
cache,
*,
get_key_partitions: Callable[[KEY], Dict[PARTITION_ID, str]],
combine_partitions: Callable[[List[VALUE]], VALUE],
partition_value: Callable[[VALUE], Dict[PARTITION_ID, VALUE]],
cache_lookup_criterion: Callable[[KEY], bool] = lambda key: True,
key=lambda x: x,
lock=None
):
"""
Decorator to wrap a function with a memoizing callable that saves results in a cache.
"""
def decorator(func):
if cache is None:
def wrapper(*args, **kwargs):
return func(*args, **kwargs)
def clear():
pass
elif lock is None:
def wrapper(*args, **kwargs):
k = key(*args, **kwargs)
partitions = get_key_partitions(k)
if cache_lookup_criterion(k):
try:
partition_values = [
cache[cache_key] for cache_key in partitions.values()
]
return combine_partitions(partition_values)
except KeyError:
pass # key not found
v = func(*args, **kwargs)
partitioned_value = partition_value(v)
try:
for partition_key_identifier, value in partitioned_value.items():
k = partitions[partition_key_identifier]
cache[k] = value
except ValueError:
pass # value too large
return v
def clear():
cache.clear()
else:
def wrapper(*args, **kwargs):
k = key(*args, **kwargs)
partitions = get_key_partitions(k)
if cache_lookup_criterion(k):
try:
with lock:
partition_values = [
cache[cache_key] for cache_key in partitions.values()
]
return combine_partitions(partition_values)
except KeyError:
pass # key not found
v = func(*args, **kwargs)
partitioned_value = partition_value(v)
# in case of a race, prefer the item already in the cache
try:
with lock:
for (
partition_key_identifier,
value,
) in partitioned_value.items():
k = partitions[partition_key_identifier]
cache[k] = value
except ValueError:
return v # value too large
def clear():
with lock:
cache.clear()
wrapper.cache = cache
wrapper.cache_key = key
wrapper.cache_lock = lock
wrapper.cache_clear = clear
return functools.update_wrapper(wrapper, func)
return decorator | PypiClean |
/geojson_modelica_translator-0.6.0rc1.tar.gz/geojson_modelica_translator-0.6.0rc1/geojson_modelica_translator/model_connectors/districts/district.py |
from pathlib import Path
from jinja2 import Environment, FileSystemLoader, StrictUndefined
from geojson_modelica_translator.jinja_filters import ALL_CUSTOM_FILTERS
from geojson_modelica_translator.model_connectors.couplings.diagram import (
Diagram
)
from geojson_modelica_translator.model_connectors.load_connectors.load_base import (
LoadBase
)
from geojson_modelica_translator.modelica.package_parser import PackageParser
from geojson_modelica_translator.scaffold import Scaffold
def render_template(template_name, template_params):
"""Helper for rendering a template
:param template_name: string, name of template (relative to templates directory)
:param template_params: dict, template parameters
:return: string, templated result
"""
template_dir = Path(__file__).parent / 'templates'
template_env = Environment(
loader=FileSystemLoader(searchpath=template_dir),
undefined=StrictUndefined)
template_env.filters.update(ALL_CUSTOM_FILTERS)
template = template_env.get_template(template_name)
return template.render(template_params)
class District:
"""
Class for modeling entire district energy systems
"""
def __init__(self, root_dir, project_name, system_parameters, coupling_graph):
self._scaffold = Scaffold(root_dir, project_name)
self.system_parameters = system_parameters
self._coupling_graph = coupling_graph
self.district_model_filepath = None
# Modelica can't handle spaces in project name or path
if (len(str(root_dir).split()) > 1) or (len(str(project_name).split()) > 1):
raise SystemExit(
f"\nModelica does not support spaces in project names or paths. "
f"You used '{root_dir}' for run path and {project_name} for model project name. "
"Please update your directory path or model name to not include spaces anywhere.")
def to_modelica(self):
"""Generate modelica files for the models as well as the modelica file for
the entire district system.
"""
# scaffold the project
self._scaffold.create()
self.district_model_filepath = Path(self._scaffold.districts_path.files_dir) / 'DistrictEnergySystem.mo'
# create the root package
root_package = PackageParser.new_from_template(
self._scaffold.project_path, self._scaffold.project_name, order=[])
root_package.save()
# generate model modelica files
for model in self._coupling_graph.models:
model.to_modelica(self._scaffold)
# construct graph of visual components
diagram = Diagram(self._coupling_graph)
district_template_params = {
"district_within_path": '.'.join([self._scaffold.project_name, 'Districts']),
"diagram": diagram,
"couplings": [],
"models": [],
"is_ghe_district": self.system_parameters.get_param('$.district_system.fifth_generation.ghe_parameters')
}
common_template_params = {
'globals': {
'medium_w': 'MediumW',
'delChiWatTemBui': 'delChiWatTemBui',
'delChiWatTemDis': 'delChiWatTemDis',
'delHeaWatTemBui': 'delHeaWatTemBui',
'delHeaWatTemDis': 'delHeaWatTemDis',
},
'graph': self._coupling_graph,
'sys_params': {
'district_system': self.system_parameters.get_param('$.district_system'),
# num_buildings counts the ports required for 5G systems
"num_buildings": len(self.system_parameters.get_param('$.buildings')),
}
}
# render each coupling
load_num = 1
for coupling in self._coupling_graph.couplings:
template_context = {
'diagram': diagram.to_dict(coupling.id, is_coupling=True),
}
template_context.update(**common_template_params)
coupling_load = coupling.get_load()
if coupling_load is not None:
# read sys params file for the load
building_sys_params = self.system_parameters.get_param_by_building_id(coupling_load.building_id, '$')
template_context['sys_params']['building'] = building_sys_params
# Note which load is being used, so ports connect properly in couplings/5G_templates/ConnectStatements
template_context['sys_params']['load_num'] = load_num
load_num += 1
templated_result = coupling.render_templates(template_context)
district_template_params['couplings'].append({
'id': coupling.id,
'component_definitions': templated_result['component_definitions'],
'connect_statements': templated_result['connect_statements'],
'coupling_definitions_template_path': templated_result['component_definitions_template_path'],
'connect_statements_template_path': templated_result['connect_statements_template_path'],
})
# render each model instance
for model in self._coupling_graph.models:
template_params = {
'model': model.to_dict(self._scaffold),
'couplings': self._coupling_graph.couplings_by_type(model.id),
'diagram': diagram.to_dict(model.id, is_coupling=False),
}
template_params.update(**common_template_params)
if issubclass(type(model), LoadBase):
building_sys_params = self.system_parameters.get_param_by_building_id(model.building_id, '$')
template_params['sys_params']['building'] = building_sys_params
templated_instance, instance_template_path = model.render_instance(template_params)
district_template_params['models'].append({
'id': model.id,
'instance_template_path': instance_template_path,
'instance': templated_instance
})
# render the full district file
if 'fifth_generation' in common_template_params['sys_params']['district_system']:
final_result = render_template('DistrictEnergySystem5G.mot', district_template_params)
elif 'fourth_generation' in common_template_params['sys_params']['district_system']:
final_result = render_template('DistrictEnergySystem.mot', district_template_params)
with open(self.district_model_filepath, 'w') as f:
f.write(final_result)
districts_package = PackageParser.new_from_template(self._scaffold.districts_path.files_dir, "Districts", [
'DistrictEnergySystem'], within=f"{self._scaffold.project_name}")
districts_package.save()
root_package = PackageParser(self._scaffold.project_path)
if 'Districts' not in root_package.order:
root_package.add_model('Districts')
root_package.save() | PypiClean |
/pulumi_google_native-0.31.2a1689827148.tar.gz/pulumi_google_native-0.31.2a1689827148/pulumi_google_native/compute/v1/global_forwarding_rule.py |
import copy
import warnings
import pulumi
import pulumi.runtime
from typing import Any, Mapping, Optional, Sequence, Union, overload
from ... import _utilities
from . import outputs
from ._enums import *
from ._inputs import *
__all__ = ['GlobalForwardingRuleArgs', 'GlobalForwardingRule']
@pulumi.input_type
class GlobalForwardingRuleArgs:
def __init__(__self__, *,
all_ports: Optional[pulumi.Input[bool]] = None,
allow_global_access: Optional[pulumi.Input[bool]] = None,
allow_psc_global_access: Optional[pulumi.Input[bool]] = None,
backend_service: Optional[pulumi.Input[str]] = None,
description: Optional[pulumi.Input[str]] = None,
ip_address: Optional[pulumi.Input[str]] = None,
ip_protocol: Optional[pulumi.Input['GlobalForwardingRuleIpProtocol']] = None,
ip_version: Optional[pulumi.Input['GlobalForwardingRuleIpVersion']] = None,
is_mirroring_collector: Optional[pulumi.Input[bool]] = None,
labels: Optional[pulumi.Input[Mapping[str, pulumi.Input[str]]]] = None,
load_balancing_scheme: Optional[pulumi.Input['GlobalForwardingRuleLoadBalancingScheme']] = None,
metadata_filters: Optional[pulumi.Input[Sequence[pulumi.Input['MetadataFilterArgs']]]] = None,
name: Optional[pulumi.Input[str]] = None,
network: Optional[pulumi.Input[str]] = None,
network_tier: Optional[pulumi.Input['GlobalForwardingRuleNetworkTier']] = None,
no_automate_dns_zone: Optional[pulumi.Input[bool]] = None,
port_range: Optional[pulumi.Input[str]] = None,
ports: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]] = None,
project: Optional[pulumi.Input[str]] = None,
psc_connection_status: Optional[pulumi.Input['GlobalForwardingRulePscConnectionStatus']] = None,
request_id: Optional[pulumi.Input[str]] = None,
service_directory_registrations: Optional[pulumi.Input[Sequence[pulumi.Input['ForwardingRuleServiceDirectoryRegistrationArgs']]]] = None,
service_label: Optional[pulumi.Input[str]] = None,
source_ip_ranges: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]] = None,
subnetwork: Optional[pulumi.Input[str]] = None,
target: Optional[pulumi.Input[str]] = None):
"""
The set of arguments for constructing a GlobalForwardingRule resource.
:param pulumi.Input[bool] all_ports: This field can only be used: - If IPProtocol is one of TCP, UDP, or SCTP. - By internal TCP/UDP load balancers, backend service-based network load balancers, and internal and external protocol forwarding. Set this field to true to allow packets addressed to any port or packets lacking destination port information (for example, UDP fragments after the first fragment) to be forwarded to the backends configured with this forwarding rule. The ports, port_range, and allPorts fields are mutually exclusive.
:param pulumi.Input[bool] allow_global_access: This field is used along with the backend_service field for internal load balancing or with the target field for internal TargetInstance. If the field is set to TRUE, clients can access ILB from all regions. Otherwise only allows access from clients in the same region as the internal load balancer.
:param pulumi.Input[bool] allow_psc_global_access: This is used in PSC consumer ForwardingRule to control whether the PSC endpoint can be accessed from another region.
:param pulumi.Input[str] backend_service: Identifies the backend service to which the forwarding rule sends traffic. Required for Internal TCP/UDP Load Balancing and Network Load Balancing; must be omitted for all other load balancer types.
:param pulumi.Input[str] description: An optional description of this resource. Provide this property when you create the resource.
:param pulumi.Input[str] ip_address: IP address for which this forwarding rule accepts traffic. When a client sends traffic to this IP address, the forwarding rule directs the traffic to the referenced target or backendService. While creating a forwarding rule, specifying an IPAddress is required under the following circumstances: - When the target is set to targetGrpcProxy and validateForProxyless is set to true, the IPAddress should be set to 0.0.0.0. - When the target is a Private Service Connect Google APIs bundle, you must specify an IPAddress. Otherwise, you can optionally specify an IP address that references an existing static (reserved) IP address resource. When omitted, Google Cloud assigns an ephemeral IP address. Use one of the following formats to specify an IP address while creating a forwarding rule: * IP address number, as in `100.1.2.3` * IPv6 address range, as in `2600:1234::/96` * Full resource URL, as in https://www.googleapis.com/compute/v1/projects/ project_id/regions/region/addresses/address-name * Partial URL or by name, as in: - projects/project_id/regions/region/addresses/address-name - regions/region/addresses/address-name - global/addresses/address-name - address-name The forwarding rule's target or backendService, and in most cases, also the loadBalancingScheme, determine the type of IP address that you can use. For detailed information, see [IP address specifications](https://cloud.google.com/load-balancing/docs/forwarding-rule-concepts#ip_address_specifications). When reading an IPAddress, the API always returns the IP address number.
:param pulumi.Input['GlobalForwardingRuleIpProtocol'] ip_protocol: The IP protocol to which this rule applies. For protocol forwarding, valid options are TCP, UDP, ESP, AH, SCTP, ICMP and L3_DEFAULT. The valid IP protocols are different for different load balancing products as described in [Load balancing features](https://cloud.google.com/load-balancing/docs/features#protocols_from_the_load_balancer_to_the_backends).
:param pulumi.Input['GlobalForwardingRuleIpVersion'] ip_version: The IP Version that will be used by this forwarding rule. Valid options are IPV4 or IPV6.
:param pulumi.Input[bool] is_mirroring_collector: Indicates whether or not this load balancer can be used as a collector for packet mirroring. To prevent mirroring loops, instances behind this load balancer will not have their traffic mirrored even if a PacketMirroring rule applies to them. This can only be set to true for load balancers that have their loadBalancingScheme set to INTERNAL.
:param pulumi.Input[Mapping[str, pulumi.Input[str]]] labels: Labels for this resource. These can only be added or modified by the setLabels method. Each label key/value pair must comply with RFC1035. Label values may be empty.
:param pulumi.Input['GlobalForwardingRuleLoadBalancingScheme'] load_balancing_scheme: Specifies the forwarding rule type. For more information about forwarding rules, refer to Forwarding rule concepts.
:param pulumi.Input[Sequence[pulumi.Input['MetadataFilterArgs']]] metadata_filters: Opaque filter criteria used by load balancer to restrict routing configuration to a limited set of xDS compliant clients. In their xDS requests to load balancer, xDS clients present node metadata. When there is a match, the relevant configuration is made available to those proxies. Otherwise, all the resources (e.g. TargetHttpProxy, UrlMap) referenced by the ForwardingRule are not visible to those proxies. For each metadataFilter in this list, if its filterMatchCriteria is set to MATCH_ANY, at least one of the filterLabels must match the corresponding label provided in the metadata. If its filterMatchCriteria is set to MATCH_ALL, then all of its filterLabels must match with corresponding labels provided in the metadata. If multiple metadataFilters are specified, all of them need to be satisfied in order to be considered a match. metadataFilters specified here will be applifed before those specified in the UrlMap that this ForwardingRule references. metadataFilters only applies to Loadbalancers that have their loadBalancingScheme set to INTERNAL_SELF_MANAGED.
:param pulumi.Input[str] name: Name of the resource; provided by the client when the resource is created. The name must be 1-63 characters long, and comply with RFC1035. Specifically, the name must be 1-63 characters long and match the regular expression `[a-z]([-a-z0-9]*[a-z0-9])?` which means the first character must be a lowercase letter, and all following characters must be a dash, lowercase letter, or digit, except the last character, which cannot be a dash. For Private Service Connect forwarding rules that forward traffic to Google APIs, the forwarding rule name must be a 1-20 characters string with lowercase letters and numbers and must start with a letter.
:param pulumi.Input[str] network: This field is not used for external load balancing. For Internal TCP/UDP Load Balancing, this field identifies the network that the load balanced IP should belong to for this Forwarding Rule. If the subnetwork is specified, the network of the subnetwork will be used. If neither subnetwork nor this field is specified, the default network will be used. For Private Service Connect forwarding rules that forward traffic to Google APIs, a network must be provided.
:param pulumi.Input['GlobalForwardingRuleNetworkTier'] network_tier: This signifies the networking tier used for configuring this load balancer and can only take the following values: PREMIUM, STANDARD. For regional ForwardingRule, the valid values are PREMIUM and STANDARD. For GlobalForwardingRule, the valid value is PREMIUM. If this field is not specified, it is assumed to be PREMIUM. If IPAddress is specified, this value must be equal to the networkTier of the Address.
:param pulumi.Input[bool] no_automate_dns_zone: This is used in PSC consumer ForwardingRule to control whether it should try to auto-generate a DNS zone or not. Non-PSC forwarding rules do not use this field.
:param pulumi.Input[str] port_range: This field can only be used: - If IPProtocol is one of TCP, UDP, or SCTP. - By backend service-based network load balancers, target pool-based network load balancers, internal proxy load balancers, external proxy load balancers, Traffic Director, external protocol forwarding, and Classic VPN. Some products have restrictions on what ports can be used. See port specifications for details. Only packets addressed to ports in the specified range will be forwarded to the backends configured with this forwarding rule. The ports, port_range, and allPorts fields are mutually exclusive. For external forwarding rules, two or more forwarding rules cannot use the same [IPAddress, IPProtocol] pair, and cannot have overlapping portRanges. For internal forwarding rules within the same VPC network, two or more forwarding rules cannot use the same [IPAddress, IPProtocol] pair, and cannot have overlapping portRanges. @pattern: \\\\d+(?:-\\\\d+)?
:param pulumi.Input[Sequence[pulumi.Input[str]]] ports: This field can only be used: - If IPProtocol is one of TCP, UDP, or SCTP. - By internal TCP/UDP load balancers, backend service-based network load balancers, and internal protocol forwarding. You can specify a list of up to five ports by number, separated by commas. The ports can be contiguous or discontiguous. Only packets addressed to these ports will be forwarded to the backends configured with this forwarding rule. For external forwarding rules, two or more forwarding rules cannot use the same [IPAddress, IPProtocol] pair, and cannot share any values defined in ports. For internal forwarding rules within the same VPC network, two or more forwarding rules cannot use the same [IPAddress, IPProtocol] pair, and cannot share any values defined in ports. The ports, port_range, and allPorts fields are mutually exclusive. @pattern: \\\\d+(?:-\\\\d+)?
:param pulumi.Input[str] request_id: An optional request ID to identify requests. Specify a unique request ID so that if you must retry your request, the server will know to ignore the request if it has already been completed. For example, consider a situation where you make an initial request and the request times out. If you make the request again with the same request ID, the server can check if original operation with the same request ID was received, and if so, will ignore the second request. This prevents clients from accidentally creating duplicate commitments. The request ID must be a valid UUID with the exception that zero UUID is not supported ( 00000000-0000-0000-0000-000000000000).
:param pulumi.Input[Sequence[pulumi.Input['ForwardingRuleServiceDirectoryRegistrationArgs']]] service_directory_registrations: Service Directory resources to register this forwarding rule with. Currently, only supports a single Service Directory resource.
:param pulumi.Input[str] service_label: An optional prefix to the service name for this Forwarding Rule. If specified, the prefix is the first label of the fully qualified service name. The label must be 1-63 characters long, and comply with RFC1035. Specifically, the label must be 1-63 characters long and match the regular expression `[a-z]([-a-z0-9]*[a-z0-9])?` which means the first character must be a lowercase letter, and all following characters must be a dash, lowercase letter, or digit, except the last character, which cannot be a dash. This field is only used for internal load balancing.
:param pulumi.Input[Sequence[pulumi.Input[str]]] source_ip_ranges: If not empty, this Forwarding Rule will only forward the traffic when the source IP address matches one of the IP addresses or CIDR ranges set here. Note that a Forwarding Rule can only have up to 64 source IP ranges, and this field can only be used with a regional Forwarding Rule whose scheme is EXTERNAL. Each source_ip_range entry should be either an IP address (for example, 1.2.3.4) or a CIDR range (for example, 1.2.3.0/24).
:param pulumi.Input[str] subnetwork: This field identifies the subnetwork that the load balanced IP should belong to for this Forwarding Rule, used in internal load balancing and network load balancing with IPv6. If the network specified is in auto subnet mode, this field is optional. However, a subnetwork must be specified if the network is in custom subnet mode or when creating external forwarding rule with IPv6.
:param pulumi.Input[str] target: The URL of the target resource to receive the matched traffic. For regional forwarding rules, this target must be in the same region as the forwarding rule. For global forwarding rules, this target must be a global load balancing resource. The forwarded traffic must be of a type appropriate to the target object. - For load balancers, see the "Target" column in [Port specifications](https://cloud.google.com/load-balancing/docs/forwarding-rule-concepts#ip_address_specifications). - For Private Service Connect forwarding rules that forward traffic to Google APIs, provide the name of a supported Google API bundle: - vpc-sc - APIs that support VPC Service Controls. - all-apis - All supported Google APIs. - For Private Service Connect forwarding rules that forward traffic to managed services, the target must be a service attachment.
"""
if all_ports is not None:
pulumi.set(__self__, "all_ports", all_ports)
if allow_global_access is not None:
pulumi.set(__self__, "allow_global_access", allow_global_access)
if allow_psc_global_access is not None:
pulumi.set(__self__, "allow_psc_global_access", allow_psc_global_access)
if backend_service is not None:
pulumi.set(__self__, "backend_service", backend_service)
if description is not None:
pulumi.set(__self__, "description", description)
if ip_address is not None:
pulumi.set(__self__, "ip_address", ip_address)
if ip_protocol is not None:
pulumi.set(__self__, "ip_protocol", ip_protocol)
if ip_version is not None:
pulumi.set(__self__, "ip_version", ip_version)
if is_mirroring_collector is not None:
pulumi.set(__self__, "is_mirroring_collector", is_mirroring_collector)
if labels is not None:
pulumi.set(__self__, "labels", labels)
if load_balancing_scheme is not None:
pulumi.set(__self__, "load_balancing_scheme", load_balancing_scheme)
if metadata_filters is not None:
pulumi.set(__self__, "metadata_filters", metadata_filters)
if name is not None:
pulumi.set(__self__, "name", name)
if network is not None:
pulumi.set(__self__, "network", network)
if network_tier is not None:
pulumi.set(__self__, "network_tier", network_tier)
if no_automate_dns_zone is not None:
pulumi.set(__self__, "no_automate_dns_zone", no_automate_dns_zone)
if port_range is not None:
pulumi.set(__self__, "port_range", port_range)
if ports is not None:
pulumi.set(__self__, "ports", ports)
if project is not None:
pulumi.set(__self__, "project", project)
if psc_connection_status is not None:
pulumi.set(__self__, "psc_connection_status", psc_connection_status)
if request_id is not None:
pulumi.set(__self__, "request_id", request_id)
if service_directory_registrations is not None:
pulumi.set(__self__, "service_directory_registrations", service_directory_registrations)
if service_label is not None:
pulumi.set(__self__, "service_label", service_label)
if source_ip_ranges is not None:
pulumi.set(__self__, "source_ip_ranges", source_ip_ranges)
if subnetwork is not None:
pulumi.set(__self__, "subnetwork", subnetwork)
if target is not None:
pulumi.set(__self__, "target", target)
@property
@pulumi.getter(name="allPorts")
def all_ports(self) -> Optional[pulumi.Input[bool]]:
"""
This field can only be used: - If IPProtocol is one of TCP, UDP, or SCTP. - By internal TCP/UDP load balancers, backend service-based network load balancers, and internal and external protocol forwarding. Set this field to true to allow packets addressed to any port or packets lacking destination port information (for example, UDP fragments after the first fragment) to be forwarded to the backends configured with this forwarding rule. The ports, port_range, and allPorts fields are mutually exclusive.
"""
return pulumi.get(self, "all_ports")
@all_ports.setter
def all_ports(self, value: Optional[pulumi.Input[bool]]):
pulumi.set(self, "all_ports", value)
@property
@pulumi.getter(name="allowGlobalAccess")
def allow_global_access(self) -> Optional[pulumi.Input[bool]]:
"""
This field is used along with the backend_service field for internal load balancing or with the target field for internal TargetInstance. If the field is set to TRUE, clients can access ILB from all regions. Otherwise only allows access from clients in the same region as the internal load balancer.
"""
return pulumi.get(self, "allow_global_access")
@allow_global_access.setter
def allow_global_access(self, value: Optional[pulumi.Input[bool]]):
pulumi.set(self, "allow_global_access", value)
@property
@pulumi.getter(name="allowPscGlobalAccess")
def allow_psc_global_access(self) -> Optional[pulumi.Input[bool]]:
"""
This is used in PSC consumer ForwardingRule to control whether the PSC endpoint can be accessed from another region.
"""
return pulumi.get(self, "allow_psc_global_access")
@allow_psc_global_access.setter
def allow_psc_global_access(self, value: Optional[pulumi.Input[bool]]):
pulumi.set(self, "allow_psc_global_access", value)
@property
@pulumi.getter(name="backendService")
def backend_service(self) -> Optional[pulumi.Input[str]]:
"""
Identifies the backend service to which the forwarding rule sends traffic. Required for Internal TCP/UDP Load Balancing and Network Load Balancing; must be omitted for all other load balancer types.
"""
return pulumi.get(self, "backend_service")
@backend_service.setter
def backend_service(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "backend_service", value)
@property
@pulumi.getter
def description(self) -> Optional[pulumi.Input[str]]:
"""
An optional description of this resource. Provide this property when you create the resource.
"""
return pulumi.get(self, "description")
@description.setter
def description(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "description", value)
@property
@pulumi.getter(name="ipAddress")
def ip_address(self) -> Optional[pulumi.Input[str]]:
"""
IP address for which this forwarding rule accepts traffic. When a client sends traffic to this IP address, the forwarding rule directs the traffic to the referenced target or backendService. While creating a forwarding rule, specifying an IPAddress is required under the following circumstances: - When the target is set to targetGrpcProxy and validateForProxyless is set to true, the IPAddress should be set to 0.0.0.0. - When the target is a Private Service Connect Google APIs bundle, you must specify an IPAddress. Otherwise, you can optionally specify an IP address that references an existing static (reserved) IP address resource. When omitted, Google Cloud assigns an ephemeral IP address. Use one of the following formats to specify an IP address while creating a forwarding rule: * IP address number, as in `100.1.2.3` * IPv6 address range, as in `2600:1234::/96` * Full resource URL, as in https://www.googleapis.com/compute/v1/projects/ project_id/regions/region/addresses/address-name * Partial URL or by name, as in: - projects/project_id/regions/region/addresses/address-name - regions/region/addresses/address-name - global/addresses/address-name - address-name The forwarding rule's target or backendService, and in most cases, also the loadBalancingScheme, determine the type of IP address that you can use. For detailed information, see [IP address specifications](https://cloud.google.com/load-balancing/docs/forwarding-rule-concepts#ip_address_specifications). When reading an IPAddress, the API always returns the IP address number.
"""
return pulumi.get(self, "ip_address")
@ip_address.setter
def ip_address(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "ip_address", value)
@property
@pulumi.getter(name="ipProtocol")
def ip_protocol(self) -> Optional[pulumi.Input['GlobalForwardingRuleIpProtocol']]:
"""
The IP protocol to which this rule applies. For protocol forwarding, valid options are TCP, UDP, ESP, AH, SCTP, ICMP and L3_DEFAULT. The valid IP protocols are different for different load balancing products as described in [Load balancing features](https://cloud.google.com/load-balancing/docs/features#protocols_from_the_load_balancer_to_the_backends).
"""
return pulumi.get(self, "ip_protocol")
@ip_protocol.setter
def ip_protocol(self, value: Optional[pulumi.Input['GlobalForwardingRuleIpProtocol']]):
pulumi.set(self, "ip_protocol", value)
@property
@pulumi.getter(name="ipVersion")
def ip_version(self) -> Optional[pulumi.Input['GlobalForwardingRuleIpVersion']]:
"""
The IP Version that will be used by this forwarding rule. Valid options are IPV4 or IPV6.
"""
return pulumi.get(self, "ip_version")
@ip_version.setter
def ip_version(self, value: Optional[pulumi.Input['GlobalForwardingRuleIpVersion']]):
pulumi.set(self, "ip_version", value)
@property
@pulumi.getter(name="isMirroringCollector")
def is_mirroring_collector(self) -> Optional[pulumi.Input[bool]]:
"""
Indicates whether or not this load balancer can be used as a collector for packet mirroring. To prevent mirroring loops, instances behind this load balancer will not have their traffic mirrored even if a PacketMirroring rule applies to them. This can only be set to true for load balancers that have their loadBalancingScheme set to INTERNAL.
"""
return pulumi.get(self, "is_mirroring_collector")
@is_mirroring_collector.setter
def is_mirroring_collector(self, value: Optional[pulumi.Input[bool]]):
pulumi.set(self, "is_mirroring_collector", value)
@property
@pulumi.getter
def labels(self) -> Optional[pulumi.Input[Mapping[str, pulumi.Input[str]]]]:
"""
Labels for this resource. These can only be added or modified by the setLabels method. Each label key/value pair must comply with RFC1035. Label values may be empty.
"""
return pulumi.get(self, "labels")
@labels.setter
def labels(self, value: Optional[pulumi.Input[Mapping[str, pulumi.Input[str]]]]):
pulumi.set(self, "labels", value)
@property
@pulumi.getter(name="loadBalancingScheme")
def load_balancing_scheme(self) -> Optional[pulumi.Input['GlobalForwardingRuleLoadBalancingScheme']]:
"""
Specifies the forwarding rule type. For more information about forwarding rules, refer to Forwarding rule concepts.
"""
return pulumi.get(self, "load_balancing_scheme")
@load_balancing_scheme.setter
def load_balancing_scheme(self, value: Optional[pulumi.Input['GlobalForwardingRuleLoadBalancingScheme']]):
pulumi.set(self, "load_balancing_scheme", value)
@property
@pulumi.getter(name="metadataFilters")
def metadata_filters(self) -> Optional[pulumi.Input[Sequence[pulumi.Input['MetadataFilterArgs']]]]:
"""
Opaque filter criteria used by load balancer to restrict routing configuration to a limited set of xDS compliant clients. In their xDS requests to load balancer, xDS clients present node metadata. When there is a match, the relevant configuration is made available to those proxies. Otherwise, all the resources (e.g. TargetHttpProxy, UrlMap) referenced by the ForwardingRule are not visible to those proxies. For each metadataFilter in this list, if its filterMatchCriteria is set to MATCH_ANY, at least one of the filterLabels must match the corresponding label provided in the metadata. If its filterMatchCriteria is set to MATCH_ALL, then all of its filterLabels must match with corresponding labels provided in the metadata. If multiple metadataFilters are specified, all of them need to be satisfied in order to be considered a match. metadataFilters specified here will be applifed before those specified in the UrlMap that this ForwardingRule references. metadataFilters only applies to Loadbalancers that have their loadBalancingScheme set to INTERNAL_SELF_MANAGED.
"""
return pulumi.get(self, "metadata_filters")
@metadata_filters.setter
def metadata_filters(self, value: Optional[pulumi.Input[Sequence[pulumi.Input['MetadataFilterArgs']]]]):
pulumi.set(self, "metadata_filters", value)
@property
@pulumi.getter
def name(self) -> Optional[pulumi.Input[str]]:
"""
Name of the resource; provided by the client when the resource is created. The name must be 1-63 characters long, and comply with RFC1035. Specifically, the name must be 1-63 characters long and match the regular expression `[a-z]([-a-z0-9]*[a-z0-9])?` which means the first character must be a lowercase letter, and all following characters must be a dash, lowercase letter, or digit, except the last character, which cannot be a dash. For Private Service Connect forwarding rules that forward traffic to Google APIs, the forwarding rule name must be a 1-20 characters string with lowercase letters and numbers and must start with a letter.
"""
return pulumi.get(self, "name")
@name.setter
def name(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "name", value)
@property
@pulumi.getter
def network(self) -> Optional[pulumi.Input[str]]:
"""
This field is not used for external load balancing. For Internal TCP/UDP Load Balancing, this field identifies the network that the load balanced IP should belong to for this Forwarding Rule. If the subnetwork is specified, the network of the subnetwork will be used. If neither subnetwork nor this field is specified, the default network will be used. For Private Service Connect forwarding rules that forward traffic to Google APIs, a network must be provided.
"""
return pulumi.get(self, "network")
@network.setter
def network(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "network", value)
@property
@pulumi.getter(name="networkTier")
def network_tier(self) -> Optional[pulumi.Input['GlobalForwardingRuleNetworkTier']]:
"""
This signifies the networking tier used for configuring this load balancer and can only take the following values: PREMIUM, STANDARD. For regional ForwardingRule, the valid values are PREMIUM and STANDARD. For GlobalForwardingRule, the valid value is PREMIUM. If this field is not specified, it is assumed to be PREMIUM. If IPAddress is specified, this value must be equal to the networkTier of the Address.
"""
return pulumi.get(self, "network_tier")
@network_tier.setter
def network_tier(self, value: Optional[pulumi.Input['GlobalForwardingRuleNetworkTier']]):
pulumi.set(self, "network_tier", value)
@property
@pulumi.getter(name="noAutomateDnsZone")
def no_automate_dns_zone(self) -> Optional[pulumi.Input[bool]]:
"""
This is used in PSC consumer ForwardingRule to control whether it should try to auto-generate a DNS zone or not. Non-PSC forwarding rules do not use this field.
"""
return pulumi.get(self, "no_automate_dns_zone")
@no_automate_dns_zone.setter
def no_automate_dns_zone(self, value: Optional[pulumi.Input[bool]]):
pulumi.set(self, "no_automate_dns_zone", value)
@property
@pulumi.getter(name="portRange")
def port_range(self) -> Optional[pulumi.Input[str]]:
"""
This field can only be used: - If IPProtocol is one of TCP, UDP, or SCTP. - By backend service-based network load balancers, target pool-based network load balancers, internal proxy load balancers, external proxy load balancers, Traffic Director, external protocol forwarding, and Classic VPN. Some products have restrictions on what ports can be used. See port specifications for details. Only packets addressed to ports in the specified range will be forwarded to the backends configured with this forwarding rule. The ports, port_range, and allPorts fields are mutually exclusive. For external forwarding rules, two or more forwarding rules cannot use the same [IPAddress, IPProtocol] pair, and cannot have overlapping portRanges. For internal forwarding rules within the same VPC network, two or more forwarding rules cannot use the same [IPAddress, IPProtocol] pair, and cannot have overlapping portRanges. @pattern: \\\\d+(?:-\\\\d+)?
"""
return pulumi.get(self, "port_range")
@port_range.setter
def port_range(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "port_range", value)
@property
@pulumi.getter
def ports(self) -> Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]:
"""
This field can only be used: - If IPProtocol is one of TCP, UDP, or SCTP. - By internal TCP/UDP load balancers, backend service-based network load balancers, and internal protocol forwarding. You can specify a list of up to five ports by number, separated by commas. The ports can be contiguous or discontiguous. Only packets addressed to these ports will be forwarded to the backends configured with this forwarding rule. For external forwarding rules, two or more forwarding rules cannot use the same [IPAddress, IPProtocol] pair, and cannot share any values defined in ports. For internal forwarding rules within the same VPC network, two or more forwarding rules cannot use the same [IPAddress, IPProtocol] pair, and cannot share any values defined in ports. The ports, port_range, and allPorts fields are mutually exclusive. @pattern: \\\\d+(?:-\\\\d+)?
"""
return pulumi.get(self, "ports")
@ports.setter
def ports(self, value: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]):
pulumi.set(self, "ports", value)
@property
@pulumi.getter
def project(self) -> Optional[pulumi.Input[str]]:
return pulumi.get(self, "project")
@project.setter
def project(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "project", value)
@property
@pulumi.getter(name="pscConnectionStatus")
def psc_connection_status(self) -> Optional[pulumi.Input['GlobalForwardingRulePscConnectionStatus']]:
return pulumi.get(self, "psc_connection_status")
@psc_connection_status.setter
def psc_connection_status(self, value: Optional[pulumi.Input['GlobalForwardingRulePscConnectionStatus']]):
pulumi.set(self, "psc_connection_status", value)
@property
@pulumi.getter(name="requestId")
def request_id(self) -> Optional[pulumi.Input[str]]:
"""
An optional request ID to identify requests. Specify a unique request ID so that if you must retry your request, the server will know to ignore the request if it has already been completed. For example, consider a situation where you make an initial request and the request times out. If you make the request again with the same request ID, the server can check if original operation with the same request ID was received, and if so, will ignore the second request. This prevents clients from accidentally creating duplicate commitments. The request ID must be a valid UUID with the exception that zero UUID is not supported ( 00000000-0000-0000-0000-000000000000).
"""
return pulumi.get(self, "request_id")
@request_id.setter
def request_id(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "request_id", value)
@property
@pulumi.getter(name="serviceDirectoryRegistrations")
def service_directory_registrations(self) -> Optional[pulumi.Input[Sequence[pulumi.Input['ForwardingRuleServiceDirectoryRegistrationArgs']]]]:
"""
Service Directory resources to register this forwarding rule with. Currently, only supports a single Service Directory resource.
"""
return pulumi.get(self, "service_directory_registrations")
@service_directory_registrations.setter
def service_directory_registrations(self, value: Optional[pulumi.Input[Sequence[pulumi.Input['ForwardingRuleServiceDirectoryRegistrationArgs']]]]):
pulumi.set(self, "service_directory_registrations", value)
@property
@pulumi.getter(name="serviceLabel")
def service_label(self) -> Optional[pulumi.Input[str]]:
"""
An optional prefix to the service name for this Forwarding Rule. If specified, the prefix is the first label of the fully qualified service name. The label must be 1-63 characters long, and comply with RFC1035. Specifically, the label must be 1-63 characters long and match the regular expression `[a-z]([-a-z0-9]*[a-z0-9])?` which means the first character must be a lowercase letter, and all following characters must be a dash, lowercase letter, or digit, except the last character, which cannot be a dash. This field is only used for internal load balancing.
"""
return pulumi.get(self, "service_label")
@service_label.setter
def service_label(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "service_label", value)
@property
@pulumi.getter(name="sourceIpRanges")
def source_ip_ranges(self) -> Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]:
"""
If not empty, this Forwarding Rule will only forward the traffic when the source IP address matches one of the IP addresses or CIDR ranges set here. Note that a Forwarding Rule can only have up to 64 source IP ranges, and this field can only be used with a regional Forwarding Rule whose scheme is EXTERNAL. Each source_ip_range entry should be either an IP address (for example, 1.2.3.4) or a CIDR range (for example, 1.2.3.0/24).
"""
return pulumi.get(self, "source_ip_ranges")
@source_ip_ranges.setter
def source_ip_ranges(self, value: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]):
pulumi.set(self, "source_ip_ranges", value)
@property
@pulumi.getter
def subnetwork(self) -> Optional[pulumi.Input[str]]:
"""
This field identifies the subnetwork that the load balanced IP should belong to for this Forwarding Rule, used in internal load balancing and network load balancing with IPv6. If the network specified is in auto subnet mode, this field is optional. However, a subnetwork must be specified if the network is in custom subnet mode or when creating external forwarding rule with IPv6.
"""
return pulumi.get(self, "subnetwork")
@subnetwork.setter
def subnetwork(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "subnetwork", value)
@property
@pulumi.getter
def target(self) -> Optional[pulumi.Input[str]]:
"""
The URL of the target resource to receive the matched traffic. For regional forwarding rules, this target must be in the same region as the forwarding rule. For global forwarding rules, this target must be a global load balancing resource. The forwarded traffic must be of a type appropriate to the target object. - For load balancers, see the "Target" column in [Port specifications](https://cloud.google.com/load-balancing/docs/forwarding-rule-concepts#ip_address_specifications). - For Private Service Connect forwarding rules that forward traffic to Google APIs, provide the name of a supported Google API bundle: - vpc-sc - APIs that support VPC Service Controls. - all-apis - All supported Google APIs. - For Private Service Connect forwarding rules that forward traffic to managed services, the target must be a service attachment.
"""
return pulumi.get(self, "target")
@target.setter
def target(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "target", value)
class GlobalForwardingRule(pulumi.CustomResource):
@overload
def __init__(__self__,
resource_name: str,
opts: Optional[pulumi.ResourceOptions] = None,
all_ports: Optional[pulumi.Input[bool]] = None,
allow_global_access: Optional[pulumi.Input[bool]] = None,
allow_psc_global_access: Optional[pulumi.Input[bool]] = None,
backend_service: Optional[pulumi.Input[str]] = None,
description: Optional[pulumi.Input[str]] = None,
ip_address: Optional[pulumi.Input[str]] = None,
ip_protocol: Optional[pulumi.Input['GlobalForwardingRuleIpProtocol']] = None,
ip_version: Optional[pulumi.Input['GlobalForwardingRuleIpVersion']] = None,
is_mirroring_collector: Optional[pulumi.Input[bool]] = None,
labels: Optional[pulumi.Input[Mapping[str, pulumi.Input[str]]]] = None,
load_balancing_scheme: Optional[pulumi.Input['GlobalForwardingRuleLoadBalancingScheme']] = None,
metadata_filters: Optional[pulumi.Input[Sequence[pulumi.Input[pulumi.InputType['MetadataFilterArgs']]]]] = None,
name: Optional[pulumi.Input[str]] = None,
network: Optional[pulumi.Input[str]] = None,
network_tier: Optional[pulumi.Input['GlobalForwardingRuleNetworkTier']] = None,
no_automate_dns_zone: Optional[pulumi.Input[bool]] = None,
port_range: Optional[pulumi.Input[str]] = None,
ports: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]] = None,
project: Optional[pulumi.Input[str]] = None,
psc_connection_status: Optional[pulumi.Input['GlobalForwardingRulePscConnectionStatus']] = None,
request_id: Optional[pulumi.Input[str]] = None,
service_directory_registrations: Optional[pulumi.Input[Sequence[pulumi.Input[pulumi.InputType['ForwardingRuleServiceDirectoryRegistrationArgs']]]]] = None,
service_label: Optional[pulumi.Input[str]] = None,
source_ip_ranges: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]] = None,
subnetwork: Optional[pulumi.Input[str]] = None,
target: Optional[pulumi.Input[str]] = None,
__props__=None):
"""
Creates a GlobalForwardingRule resource in the specified project using the data included in the request.
:param str resource_name: The name of the resource.
:param pulumi.ResourceOptions opts: Options for the resource.
:param pulumi.Input[bool] all_ports: This field can only be used: - If IPProtocol is one of TCP, UDP, or SCTP. - By internal TCP/UDP load balancers, backend service-based network load balancers, and internal and external protocol forwarding. Set this field to true to allow packets addressed to any port or packets lacking destination port information (for example, UDP fragments after the first fragment) to be forwarded to the backends configured with this forwarding rule. The ports, port_range, and allPorts fields are mutually exclusive.
:param pulumi.Input[bool] allow_global_access: This field is used along with the backend_service field for internal load balancing or with the target field for internal TargetInstance. If the field is set to TRUE, clients can access ILB from all regions. Otherwise only allows access from clients in the same region as the internal load balancer.
:param pulumi.Input[bool] allow_psc_global_access: This is used in PSC consumer ForwardingRule to control whether the PSC endpoint can be accessed from another region.
:param pulumi.Input[str] backend_service: Identifies the backend service to which the forwarding rule sends traffic. Required for Internal TCP/UDP Load Balancing and Network Load Balancing; must be omitted for all other load balancer types.
:param pulumi.Input[str] description: An optional description of this resource. Provide this property when you create the resource.
:param pulumi.Input[str] ip_address: IP address for which this forwarding rule accepts traffic. When a client sends traffic to this IP address, the forwarding rule directs the traffic to the referenced target or backendService. While creating a forwarding rule, specifying an IPAddress is required under the following circumstances: - When the target is set to targetGrpcProxy and validateForProxyless is set to true, the IPAddress should be set to 0.0.0.0. - When the target is a Private Service Connect Google APIs bundle, you must specify an IPAddress. Otherwise, you can optionally specify an IP address that references an existing static (reserved) IP address resource. When omitted, Google Cloud assigns an ephemeral IP address. Use one of the following formats to specify an IP address while creating a forwarding rule: * IP address number, as in `100.1.2.3` * IPv6 address range, as in `2600:1234::/96` * Full resource URL, as in https://www.googleapis.com/compute/v1/projects/ project_id/regions/region/addresses/address-name * Partial URL or by name, as in: - projects/project_id/regions/region/addresses/address-name - regions/region/addresses/address-name - global/addresses/address-name - address-name The forwarding rule's target or backendService, and in most cases, also the loadBalancingScheme, determine the type of IP address that you can use. For detailed information, see [IP address specifications](https://cloud.google.com/load-balancing/docs/forwarding-rule-concepts#ip_address_specifications). When reading an IPAddress, the API always returns the IP address number.
:param pulumi.Input['GlobalForwardingRuleIpProtocol'] ip_protocol: The IP protocol to which this rule applies. For protocol forwarding, valid options are TCP, UDP, ESP, AH, SCTP, ICMP and L3_DEFAULT. The valid IP protocols are different for different load balancing products as described in [Load balancing features](https://cloud.google.com/load-balancing/docs/features#protocols_from_the_load_balancer_to_the_backends).
:param pulumi.Input['GlobalForwardingRuleIpVersion'] ip_version: The IP Version that will be used by this forwarding rule. Valid options are IPV4 or IPV6.
:param pulumi.Input[bool] is_mirroring_collector: Indicates whether or not this load balancer can be used as a collector for packet mirroring. To prevent mirroring loops, instances behind this load balancer will not have their traffic mirrored even if a PacketMirroring rule applies to them. This can only be set to true for load balancers that have their loadBalancingScheme set to INTERNAL.
:param pulumi.Input[Mapping[str, pulumi.Input[str]]] labels: Labels for this resource. These can only be added or modified by the setLabels method. Each label key/value pair must comply with RFC1035. Label values may be empty.
:param pulumi.Input['GlobalForwardingRuleLoadBalancingScheme'] load_balancing_scheme: Specifies the forwarding rule type. For more information about forwarding rules, refer to Forwarding rule concepts.
:param pulumi.Input[Sequence[pulumi.Input[pulumi.InputType['MetadataFilterArgs']]]] metadata_filters: Opaque filter criteria used by load balancer to restrict routing configuration to a limited set of xDS compliant clients. In their xDS requests to load balancer, xDS clients present node metadata. When there is a match, the relevant configuration is made available to those proxies. Otherwise, all the resources (e.g. TargetHttpProxy, UrlMap) referenced by the ForwardingRule are not visible to those proxies. For each metadataFilter in this list, if its filterMatchCriteria is set to MATCH_ANY, at least one of the filterLabels must match the corresponding label provided in the metadata. If its filterMatchCriteria is set to MATCH_ALL, then all of its filterLabels must match with corresponding labels provided in the metadata. If multiple metadataFilters are specified, all of them need to be satisfied in order to be considered a match. metadataFilters specified here will be applifed before those specified in the UrlMap that this ForwardingRule references. metadataFilters only applies to Loadbalancers that have their loadBalancingScheme set to INTERNAL_SELF_MANAGED.
:param pulumi.Input[str] name: Name of the resource; provided by the client when the resource is created. The name must be 1-63 characters long, and comply with RFC1035. Specifically, the name must be 1-63 characters long and match the regular expression `[a-z]([-a-z0-9]*[a-z0-9])?` which means the first character must be a lowercase letter, and all following characters must be a dash, lowercase letter, or digit, except the last character, which cannot be a dash. For Private Service Connect forwarding rules that forward traffic to Google APIs, the forwarding rule name must be a 1-20 characters string with lowercase letters and numbers and must start with a letter.
:param pulumi.Input[str] network: This field is not used for external load balancing. For Internal TCP/UDP Load Balancing, this field identifies the network that the load balanced IP should belong to for this Forwarding Rule. If the subnetwork is specified, the network of the subnetwork will be used. If neither subnetwork nor this field is specified, the default network will be used. For Private Service Connect forwarding rules that forward traffic to Google APIs, a network must be provided.
:param pulumi.Input['GlobalForwardingRuleNetworkTier'] network_tier: This signifies the networking tier used for configuring this load balancer and can only take the following values: PREMIUM, STANDARD. For regional ForwardingRule, the valid values are PREMIUM and STANDARD. For GlobalForwardingRule, the valid value is PREMIUM. If this field is not specified, it is assumed to be PREMIUM. If IPAddress is specified, this value must be equal to the networkTier of the Address.
:param pulumi.Input[bool] no_automate_dns_zone: This is used in PSC consumer ForwardingRule to control whether it should try to auto-generate a DNS zone or not. Non-PSC forwarding rules do not use this field.
:param pulumi.Input[str] port_range: This field can only be used: - If IPProtocol is one of TCP, UDP, or SCTP. - By backend service-based network load balancers, target pool-based network load balancers, internal proxy load balancers, external proxy load balancers, Traffic Director, external protocol forwarding, and Classic VPN. Some products have restrictions on what ports can be used. See port specifications for details. Only packets addressed to ports in the specified range will be forwarded to the backends configured with this forwarding rule. The ports, port_range, and allPorts fields are mutually exclusive. For external forwarding rules, two or more forwarding rules cannot use the same [IPAddress, IPProtocol] pair, and cannot have overlapping portRanges. For internal forwarding rules within the same VPC network, two or more forwarding rules cannot use the same [IPAddress, IPProtocol] pair, and cannot have overlapping portRanges. @pattern: \\\\d+(?:-\\\\d+)?
:param pulumi.Input[Sequence[pulumi.Input[str]]] ports: This field can only be used: - If IPProtocol is one of TCP, UDP, or SCTP. - By internal TCP/UDP load balancers, backend service-based network load balancers, and internal protocol forwarding. You can specify a list of up to five ports by number, separated by commas. The ports can be contiguous or discontiguous. Only packets addressed to these ports will be forwarded to the backends configured with this forwarding rule. For external forwarding rules, two or more forwarding rules cannot use the same [IPAddress, IPProtocol] pair, and cannot share any values defined in ports. For internal forwarding rules within the same VPC network, two or more forwarding rules cannot use the same [IPAddress, IPProtocol] pair, and cannot share any values defined in ports. The ports, port_range, and allPorts fields are mutually exclusive. @pattern: \\\\d+(?:-\\\\d+)?
:param pulumi.Input[str] request_id: An optional request ID to identify requests. Specify a unique request ID so that if you must retry your request, the server will know to ignore the request if it has already been completed. For example, consider a situation where you make an initial request and the request times out. If you make the request again with the same request ID, the server can check if original operation with the same request ID was received, and if so, will ignore the second request. This prevents clients from accidentally creating duplicate commitments. The request ID must be a valid UUID with the exception that zero UUID is not supported ( 00000000-0000-0000-0000-000000000000).
:param pulumi.Input[Sequence[pulumi.Input[pulumi.InputType['ForwardingRuleServiceDirectoryRegistrationArgs']]]] service_directory_registrations: Service Directory resources to register this forwarding rule with. Currently, only supports a single Service Directory resource.
:param pulumi.Input[str] service_label: An optional prefix to the service name for this Forwarding Rule. If specified, the prefix is the first label of the fully qualified service name. The label must be 1-63 characters long, and comply with RFC1035. Specifically, the label must be 1-63 characters long and match the regular expression `[a-z]([-a-z0-9]*[a-z0-9])?` which means the first character must be a lowercase letter, and all following characters must be a dash, lowercase letter, or digit, except the last character, which cannot be a dash. This field is only used for internal load balancing.
:param pulumi.Input[Sequence[pulumi.Input[str]]] source_ip_ranges: If not empty, this Forwarding Rule will only forward the traffic when the source IP address matches one of the IP addresses or CIDR ranges set here. Note that a Forwarding Rule can only have up to 64 source IP ranges, and this field can only be used with a regional Forwarding Rule whose scheme is EXTERNAL. Each source_ip_range entry should be either an IP address (for example, 1.2.3.4) or a CIDR range (for example, 1.2.3.0/24).
:param pulumi.Input[str] subnetwork: This field identifies the subnetwork that the load balanced IP should belong to for this Forwarding Rule, used in internal load balancing and network load balancing with IPv6. If the network specified is in auto subnet mode, this field is optional. However, a subnetwork must be specified if the network is in custom subnet mode or when creating external forwarding rule with IPv6.
:param pulumi.Input[str] target: The URL of the target resource to receive the matched traffic. For regional forwarding rules, this target must be in the same region as the forwarding rule. For global forwarding rules, this target must be a global load balancing resource. The forwarded traffic must be of a type appropriate to the target object. - For load balancers, see the "Target" column in [Port specifications](https://cloud.google.com/load-balancing/docs/forwarding-rule-concepts#ip_address_specifications). - For Private Service Connect forwarding rules that forward traffic to Google APIs, provide the name of a supported Google API bundle: - vpc-sc - APIs that support VPC Service Controls. - all-apis - All supported Google APIs. - For Private Service Connect forwarding rules that forward traffic to managed services, the target must be a service attachment.
"""
...
@overload
def __init__(__self__,
resource_name: str,
args: Optional[GlobalForwardingRuleArgs] = None,
opts: Optional[pulumi.ResourceOptions] = None):
"""
Creates a GlobalForwardingRule resource in the specified project using the data included in the request.
:param str resource_name: The name of the resource.
:param GlobalForwardingRuleArgs args: The arguments to use to populate this resource's properties.
:param pulumi.ResourceOptions opts: Options for the resource.
"""
...
def __init__(__self__, resource_name: str, *args, **kwargs):
resource_args, opts = _utilities.get_resource_args_opts(GlobalForwardingRuleArgs, pulumi.ResourceOptions, *args, **kwargs)
if resource_args is not None:
__self__._internal_init(resource_name, opts, **resource_args.__dict__)
else:
__self__._internal_init(resource_name, *args, **kwargs)
def _internal_init(__self__,
resource_name: str,
opts: Optional[pulumi.ResourceOptions] = None,
all_ports: Optional[pulumi.Input[bool]] = None,
allow_global_access: Optional[pulumi.Input[bool]] = None,
allow_psc_global_access: Optional[pulumi.Input[bool]] = None,
backend_service: Optional[pulumi.Input[str]] = None,
description: Optional[pulumi.Input[str]] = None,
ip_address: Optional[pulumi.Input[str]] = None,
ip_protocol: Optional[pulumi.Input['GlobalForwardingRuleIpProtocol']] = None,
ip_version: Optional[pulumi.Input['GlobalForwardingRuleIpVersion']] = None,
is_mirroring_collector: Optional[pulumi.Input[bool]] = None,
labels: Optional[pulumi.Input[Mapping[str, pulumi.Input[str]]]] = None,
load_balancing_scheme: Optional[pulumi.Input['GlobalForwardingRuleLoadBalancingScheme']] = None,
metadata_filters: Optional[pulumi.Input[Sequence[pulumi.Input[pulumi.InputType['MetadataFilterArgs']]]]] = None,
name: Optional[pulumi.Input[str]] = None,
network: Optional[pulumi.Input[str]] = None,
network_tier: Optional[pulumi.Input['GlobalForwardingRuleNetworkTier']] = None,
no_automate_dns_zone: Optional[pulumi.Input[bool]] = None,
port_range: Optional[pulumi.Input[str]] = None,
ports: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]] = None,
project: Optional[pulumi.Input[str]] = None,
psc_connection_status: Optional[pulumi.Input['GlobalForwardingRulePscConnectionStatus']] = None,
request_id: Optional[pulumi.Input[str]] = None,
service_directory_registrations: Optional[pulumi.Input[Sequence[pulumi.Input[pulumi.InputType['ForwardingRuleServiceDirectoryRegistrationArgs']]]]] = None,
service_label: Optional[pulumi.Input[str]] = None,
source_ip_ranges: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]] = None,
subnetwork: Optional[pulumi.Input[str]] = None,
target: Optional[pulumi.Input[str]] = None,
__props__=None):
opts = pulumi.ResourceOptions.merge(_utilities.get_resource_opts_defaults(), opts)
if not isinstance(opts, pulumi.ResourceOptions):
raise TypeError('Expected resource options to be a ResourceOptions instance')
if opts.id is None:
if __props__ is not None:
raise TypeError('__props__ is only valid when passed in combination with a valid opts.id to get an existing resource')
__props__ = GlobalForwardingRuleArgs.__new__(GlobalForwardingRuleArgs)
__props__.__dict__["all_ports"] = all_ports
__props__.__dict__["allow_global_access"] = allow_global_access
__props__.__dict__["allow_psc_global_access"] = allow_psc_global_access
__props__.__dict__["backend_service"] = backend_service
__props__.__dict__["description"] = description
__props__.__dict__["ip_address"] = ip_address
__props__.__dict__["ip_protocol"] = ip_protocol
__props__.__dict__["ip_version"] = ip_version
__props__.__dict__["is_mirroring_collector"] = is_mirroring_collector
__props__.__dict__["labels"] = labels
__props__.__dict__["load_balancing_scheme"] = load_balancing_scheme
__props__.__dict__["metadata_filters"] = metadata_filters
__props__.__dict__["name"] = name
__props__.__dict__["network"] = network
__props__.__dict__["network_tier"] = network_tier
__props__.__dict__["no_automate_dns_zone"] = no_automate_dns_zone
__props__.__dict__["port_range"] = port_range
__props__.__dict__["ports"] = ports
__props__.__dict__["project"] = project
__props__.__dict__["psc_connection_status"] = psc_connection_status
__props__.__dict__["request_id"] = request_id
__props__.__dict__["service_directory_registrations"] = service_directory_registrations
__props__.__dict__["service_label"] = service_label
__props__.__dict__["source_ip_ranges"] = source_ip_ranges
__props__.__dict__["subnetwork"] = subnetwork
__props__.__dict__["target"] = target
__props__.__dict__["base_forwarding_rule"] = None
__props__.__dict__["creation_timestamp"] = None
__props__.__dict__["fingerprint"] = None
__props__.__dict__["kind"] = None
__props__.__dict__["label_fingerprint"] = None
__props__.__dict__["psc_connection_id"] = None
__props__.__dict__["region"] = None
__props__.__dict__["self_link"] = None
__props__.__dict__["service_name"] = None
replace_on_changes = pulumi.ResourceOptions(replace_on_changes=["project"])
opts = pulumi.ResourceOptions.merge(opts, replace_on_changes)
super(GlobalForwardingRule, __self__).__init__(
'google-native:compute/v1:GlobalForwardingRule',
resource_name,
__props__,
opts)
@staticmethod
def get(resource_name: str,
id: pulumi.Input[str],
opts: Optional[pulumi.ResourceOptions] = None) -> 'GlobalForwardingRule':
"""
Get an existing GlobalForwardingRule resource's state with the given name, id, and optional extra
properties used to qualify the lookup.
:param str resource_name: The unique name of the resulting resource.
:param pulumi.Input[str] id: The unique provider ID of the resource to lookup.
:param pulumi.ResourceOptions opts: Options for the resource.
"""
opts = pulumi.ResourceOptions.merge(opts, pulumi.ResourceOptions(id=id))
__props__ = GlobalForwardingRuleArgs.__new__(GlobalForwardingRuleArgs)
__props__.__dict__["all_ports"] = None
__props__.__dict__["allow_global_access"] = None
__props__.__dict__["allow_psc_global_access"] = None
__props__.__dict__["backend_service"] = None
__props__.__dict__["base_forwarding_rule"] = None
__props__.__dict__["creation_timestamp"] = None
__props__.__dict__["description"] = None
__props__.__dict__["fingerprint"] = None
__props__.__dict__["ip_address"] = None
__props__.__dict__["ip_protocol"] = None
__props__.__dict__["ip_version"] = None
__props__.__dict__["is_mirroring_collector"] = None
__props__.__dict__["kind"] = None
__props__.__dict__["label_fingerprint"] = None
__props__.__dict__["labels"] = None
__props__.__dict__["load_balancing_scheme"] = None
__props__.__dict__["metadata_filters"] = None
__props__.__dict__["name"] = None
__props__.__dict__["network"] = None
__props__.__dict__["network_tier"] = None
__props__.__dict__["no_automate_dns_zone"] = None
__props__.__dict__["port_range"] = None
__props__.__dict__["ports"] = None
__props__.__dict__["project"] = None
__props__.__dict__["psc_connection_id"] = None
__props__.__dict__["psc_connection_status"] = None
__props__.__dict__["region"] = None
__props__.__dict__["request_id"] = None
__props__.__dict__["self_link"] = None
__props__.__dict__["service_directory_registrations"] = None
__props__.__dict__["service_label"] = None
__props__.__dict__["service_name"] = None
__props__.__dict__["source_ip_ranges"] = None
__props__.__dict__["subnetwork"] = None
__props__.__dict__["target"] = None
return GlobalForwardingRule(resource_name, opts=opts, __props__=__props__)
@property
@pulumi.getter(name="allPorts")
def all_ports(self) -> pulumi.Output[bool]:
"""
This field can only be used: - If IPProtocol is one of TCP, UDP, or SCTP. - By internal TCP/UDP load balancers, backend service-based network load balancers, and internal and external protocol forwarding. Set this field to true to allow packets addressed to any port or packets lacking destination port information (for example, UDP fragments after the first fragment) to be forwarded to the backends configured with this forwarding rule. The ports, port_range, and allPorts fields are mutually exclusive.
"""
return pulumi.get(self, "all_ports")
@property
@pulumi.getter(name="allowGlobalAccess")
def allow_global_access(self) -> pulumi.Output[bool]:
"""
This field is used along with the backend_service field for internal load balancing or with the target field for internal TargetInstance. If the field is set to TRUE, clients can access ILB from all regions. Otherwise only allows access from clients in the same region as the internal load balancer.
"""
return pulumi.get(self, "allow_global_access")
@property
@pulumi.getter(name="allowPscGlobalAccess")
def allow_psc_global_access(self) -> pulumi.Output[bool]:
"""
This is used in PSC consumer ForwardingRule to control whether the PSC endpoint can be accessed from another region.
"""
return pulumi.get(self, "allow_psc_global_access")
@property
@pulumi.getter(name="backendService")
def backend_service(self) -> pulumi.Output[str]:
"""
Identifies the backend service to which the forwarding rule sends traffic. Required for Internal TCP/UDP Load Balancing and Network Load Balancing; must be omitted for all other load balancer types.
"""
return pulumi.get(self, "backend_service")
@property
@pulumi.getter(name="baseForwardingRule")
def base_forwarding_rule(self) -> pulumi.Output[str]:
"""
The URL for the corresponding base Forwarding Rule. By base Forwarding Rule, we mean the Forwarding Rule that has the same IP address, protocol, and port settings with the current Forwarding Rule, but without sourceIPRanges specified. Always empty if the current Forwarding Rule does not have sourceIPRanges specified.
"""
return pulumi.get(self, "base_forwarding_rule")
@property
@pulumi.getter(name="creationTimestamp")
def creation_timestamp(self) -> pulumi.Output[str]:
"""
Creation timestamp in RFC3339 text format.
"""
return pulumi.get(self, "creation_timestamp")
@property
@pulumi.getter
def description(self) -> pulumi.Output[str]:
"""
An optional description of this resource. Provide this property when you create the resource.
"""
return pulumi.get(self, "description")
@property
@pulumi.getter
def fingerprint(self) -> pulumi.Output[str]:
"""
Fingerprint of this resource. A hash of the contents stored in this object. This field is used in optimistic locking. This field will be ignored when inserting a ForwardingRule. Include the fingerprint in patch request to ensure that you do not overwrite changes that were applied from another concurrent request. To see the latest fingerprint, make a get() request to retrieve a ForwardingRule.
"""
return pulumi.get(self, "fingerprint")
@property
@pulumi.getter(name="ipAddress")
def ip_address(self) -> pulumi.Output[str]:
"""
IP address for which this forwarding rule accepts traffic. When a client sends traffic to this IP address, the forwarding rule directs the traffic to the referenced target or backendService. While creating a forwarding rule, specifying an IPAddress is required under the following circumstances: - When the target is set to targetGrpcProxy and validateForProxyless is set to true, the IPAddress should be set to 0.0.0.0. - When the target is a Private Service Connect Google APIs bundle, you must specify an IPAddress. Otherwise, you can optionally specify an IP address that references an existing static (reserved) IP address resource. When omitted, Google Cloud assigns an ephemeral IP address. Use one of the following formats to specify an IP address while creating a forwarding rule: * IP address number, as in `100.1.2.3` * IPv6 address range, as in `2600:1234::/96` * Full resource URL, as in https://www.googleapis.com/compute/v1/projects/ project_id/regions/region/addresses/address-name * Partial URL or by name, as in: - projects/project_id/regions/region/addresses/address-name - regions/region/addresses/address-name - global/addresses/address-name - address-name The forwarding rule's target or backendService, and in most cases, also the loadBalancingScheme, determine the type of IP address that you can use. For detailed information, see [IP address specifications](https://cloud.google.com/load-balancing/docs/forwarding-rule-concepts#ip_address_specifications). When reading an IPAddress, the API always returns the IP address number.
"""
return pulumi.get(self, "ip_address")
@property
@pulumi.getter(name="ipProtocol")
def ip_protocol(self) -> pulumi.Output[str]:
"""
The IP protocol to which this rule applies. For protocol forwarding, valid options are TCP, UDP, ESP, AH, SCTP, ICMP and L3_DEFAULT. The valid IP protocols are different for different load balancing products as described in [Load balancing features](https://cloud.google.com/load-balancing/docs/features#protocols_from_the_load_balancer_to_the_backends).
"""
return pulumi.get(self, "ip_protocol")
@property
@pulumi.getter(name="ipVersion")
def ip_version(self) -> pulumi.Output[str]:
"""
The IP Version that will be used by this forwarding rule. Valid options are IPV4 or IPV6.
"""
return pulumi.get(self, "ip_version")
@property
@pulumi.getter(name="isMirroringCollector")
def is_mirroring_collector(self) -> pulumi.Output[bool]:
"""
Indicates whether or not this load balancer can be used as a collector for packet mirroring. To prevent mirroring loops, instances behind this load balancer will not have their traffic mirrored even if a PacketMirroring rule applies to them. This can only be set to true for load balancers that have their loadBalancingScheme set to INTERNAL.
"""
return pulumi.get(self, "is_mirroring_collector")
@property
@pulumi.getter
def kind(self) -> pulumi.Output[str]:
"""
Type of the resource. Always compute#forwardingRule for Forwarding Rule resources.
"""
return pulumi.get(self, "kind")
@property
@pulumi.getter(name="labelFingerprint")
def label_fingerprint(self) -> pulumi.Output[str]:
"""
A fingerprint for the labels being applied to this resource, which is essentially a hash of the labels set used for optimistic locking. The fingerprint is initially generated by Compute Engine and changes after every request to modify or update labels. You must always provide an up-to-date fingerprint hash in order to update or change labels, otherwise the request will fail with error 412 conditionNotMet. To see the latest fingerprint, make a get() request to retrieve a ForwardingRule.
"""
return pulumi.get(self, "label_fingerprint")
@property
@pulumi.getter
def labels(self) -> pulumi.Output[Mapping[str, str]]:
"""
Labels for this resource. These can only be added or modified by the setLabels method. Each label key/value pair must comply with RFC1035. Label values may be empty.
"""
return pulumi.get(self, "labels")
@property
@pulumi.getter(name="loadBalancingScheme")
def load_balancing_scheme(self) -> pulumi.Output[str]:
"""
Specifies the forwarding rule type. For more information about forwarding rules, refer to Forwarding rule concepts.
"""
return pulumi.get(self, "load_balancing_scheme")
@property
@pulumi.getter(name="metadataFilters")
def metadata_filters(self) -> pulumi.Output[Sequence['outputs.MetadataFilterResponse']]:
"""
Opaque filter criteria used by load balancer to restrict routing configuration to a limited set of xDS compliant clients. In their xDS requests to load balancer, xDS clients present node metadata. When there is a match, the relevant configuration is made available to those proxies. Otherwise, all the resources (e.g. TargetHttpProxy, UrlMap) referenced by the ForwardingRule are not visible to those proxies. For each metadataFilter in this list, if its filterMatchCriteria is set to MATCH_ANY, at least one of the filterLabels must match the corresponding label provided in the metadata. If its filterMatchCriteria is set to MATCH_ALL, then all of its filterLabels must match with corresponding labels provided in the metadata. If multiple metadataFilters are specified, all of them need to be satisfied in order to be considered a match. metadataFilters specified here will be applifed before those specified in the UrlMap that this ForwardingRule references. metadataFilters only applies to Loadbalancers that have their loadBalancingScheme set to INTERNAL_SELF_MANAGED.
"""
return pulumi.get(self, "metadata_filters")
@property
@pulumi.getter
def name(self) -> pulumi.Output[str]:
"""
Name of the resource; provided by the client when the resource is created. The name must be 1-63 characters long, and comply with RFC1035. Specifically, the name must be 1-63 characters long and match the regular expression `[a-z]([-a-z0-9]*[a-z0-9])?` which means the first character must be a lowercase letter, and all following characters must be a dash, lowercase letter, or digit, except the last character, which cannot be a dash. For Private Service Connect forwarding rules that forward traffic to Google APIs, the forwarding rule name must be a 1-20 characters string with lowercase letters and numbers and must start with a letter.
"""
return pulumi.get(self, "name")
@property
@pulumi.getter
def network(self) -> pulumi.Output[str]:
"""
This field is not used for external load balancing. For Internal TCP/UDP Load Balancing, this field identifies the network that the load balanced IP should belong to for this Forwarding Rule. If the subnetwork is specified, the network of the subnetwork will be used. If neither subnetwork nor this field is specified, the default network will be used. For Private Service Connect forwarding rules that forward traffic to Google APIs, a network must be provided.
"""
return pulumi.get(self, "network")
@property
@pulumi.getter(name="networkTier")
def network_tier(self) -> pulumi.Output[str]:
"""
This signifies the networking tier used for configuring this load balancer and can only take the following values: PREMIUM, STANDARD. For regional ForwardingRule, the valid values are PREMIUM and STANDARD. For GlobalForwardingRule, the valid value is PREMIUM. If this field is not specified, it is assumed to be PREMIUM. If IPAddress is specified, this value must be equal to the networkTier of the Address.
"""
return pulumi.get(self, "network_tier")
@property
@pulumi.getter(name="noAutomateDnsZone")
def no_automate_dns_zone(self) -> pulumi.Output[bool]:
"""
This is used in PSC consumer ForwardingRule to control whether it should try to auto-generate a DNS zone or not. Non-PSC forwarding rules do not use this field.
"""
return pulumi.get(self, "no_automate_dns_zone")
@property
@pulumi.getter(name="portRange")
def port_range(self) -> pulumi.Output[str]:
"""
This field can only be used: - If IPProtocol is one of TCP, UDP, or SCTP. - By backend service-based network load balancers, target pool-based network load balancers, internal proxy load balancers, external proxy load balancers, Traffic Director, external protocol forwarding, and Classic VPN. Some products have restrictions on what ports can be used. See port specifications for details. Only packets addressed to ports in the specified range will be forwarded to the backends configured with this forwarding rule. The ports, port_range, and allPorts fields are mutually exclusive. For external forwarding rules, two or more forwarding rules cannot use the same [IPAddress, IPProtocol] pair, and cannot have overlapping portRanges. For internal forwarding rules within the same VPC network, two or more forwarding rules cannot use the same [IPAddress, IPProtocol] pair, and cannot have overlapping portRanges. @pattern: \\\\d+(?:-\\\\d+)?
"""
return pulumi.get(self, "port_range")
@property
@pulumi.getter
def ports(self) -> pulumi.Output[Sequence[str]]:
"""
This field can only be used: - If IPProtocol is one of TCP, UDP, or SCTP. - By internal TCP/UDP load balancers, backend service-based network load balancers, and internal protocol forwarding. You can specify a list of up to five ports by number, separated by commas. The ports can be contiguous or discontiguous. Only packets addressed to these ports will be forwarded to the backends configured with this forwarding rule. For external forwarding rules, two or more forwarding rules cannot use the same [IPAddress, IPProtocol] pair, and cannot share any values defined in ports. For internal forwarding rules within the same VPC network, two or more forwarding rules cannot use the same [IPAddress, IPProtocol] pair, and cannot share any values defined in ports. The ports, port_range, and allPorts fields are mutually exclusive. @pattern: \\\\d+(?:-\\\\d+)?
"""
return pulumi.get(self, "ports")
@property
@pulumi.getter
def project(self) -> pulumi.Output[str]:
return pulumi.get(self, "project")
@property
@pulumi.getter(name="pscConnectionId")
def psc_connection_id(self) -> pulumi.Output[str]:
"""
The PSC connection id of the PSC Forwarding Rule.
"""
return pulumi.get(self, "psc_connection_id")
@property
@pulumi.getter(name="pscConnectionStatus")
def psc_connection_status(self) -> pulumi.Output[str]:
return pulumi.get(self, "psc_connection_status")
@property
@pulumi.getter
def region(self) -> pulumi.Output[str]:
"""
URL of the region where the regional forwarding rule resides. This field is not applicable to global forwarding rules. You must specify this field as part of the HTTP request URL. It is not settable as a field in the request body.
"""
return pulumi.get(self, "region")
@property
@pulumi.getter(name="requestId")
def request_id(self) -> pulumi.Output[Optional[str]]:
"""
An optional request ID to identify requests. Specify a unique request ID so that if you must retry your request, the server will know to ignore the request if it has already been completed. For example, consider a situation where you make an initial request and the request times out. If you make the request again with the same request ID, the server can check if original operation with the same request ID was received, and if so, will ignore the second request. This prevents clients from accidentally creating duplicate commitments. The request ID must be a valid UUID with the exception that zero UUID is not supported ( 00000000-0000-0000-0000-000000000000).
"""
return pulumi.get(self, "request_id")
@property
@pulumi.getter(name="selfLink")
def self_link(self) -> pulumi.Output[str]:
"""
Server-defined URL for the resource.
"""
return pulumi.get(self, "self_link")
@property
@pulumi.getter(name="serviceDirectoryRegistrations")
def service_directory_registrations(self) -> pulumi.Output[Sequence['outputs.ForwardingRuleServiceDirectoryRegistrationResponse']]:
"""
Service Directory resources to register this forwarding rule with. Currently, only supports a single Service Directory resource.
"""
return pulumi.get(self, "service_directory_registrations")
@property
@pulumi.getter(name="serviceLabel")
def service_label(self) -> pulumi.Output[str]:
"""
An optional prefix to the service name for this Forwarding Rule. If specified, the prefix is the first label of the fully qualified service name. The label must be 1-63 characters long, and comply with RFC1035. Specifically, the label must be 1-63 characters long and match the regular expression `[a-z]([-a-z0-9]*[a-z0-9])?` which means the first character must be a lowercase letter, and all following characters must be a dash, lowercase letter, or digit, except the last character, which cannot be a dash. This field is only used for internal load balancing.
"""
return pulumi.get(self, "service_label")
@property
@pulumi.getter(name="serviceName")
def service_name(self) -> pulumi.Output[str]:
"""
The internal fully qualified service name for this Forwarding Rule. This field is only used for internal load balancing.
"""
return pulumi.get(self, "service_name")
@property
@pulumi.getter(name="sourceIpRanges")
def source_ip_ranges(self) -> pulumi.Output[Sequence[str]]:
"""
If not empty, this Forwarding Rule will only forward the traffic when the source IP address matches one of the IP addresses or CIDR ranges set here. Note that a Forwarding Rule can only have up to 64 source IP ranges, and this field can only be used with a regional Forwarding Rule whose scheme is EXTERNAL. Each source_ip_range entry should be either an IP address (for example, 1.2.3.4) or a CIDR range (for example, 1.2.3.0/24).
"""
return pulumi.get(self, "source_ip_ranges")
@property
@pulumi.getter
def subnetwork(self) -> pulumi.Output[str]:
"""
This field identifies the subnetwork that the load balanced IP should belong to for this Forwarding Rule, used in internal load balancing and network load balancing with IPv6. If the network specified is in auto subnet mode, this field is optional. However, a subnetwork must be specified if the network is in custom subnet mode or when creating external forwarding rule with IPv6.
"""
return pulumi.get(self, "subnetwork")
@property
@pulumi.getter
def target(self) -> pulumi.Output[str]:
"""
The URL of the target resource to receive the matched traffic. For regional forwarding rules, this target must be in the same region as the forwarding rule. For global forwarding rules, this target must be a global load balancing resource. The forwarded traffic must be of a type appropriate to the target object. - For load balancers, see the "Target" column in [Port specifications](https://cloud.google.com/load-balancing/docs/forwarding-rule-concepts#ip_address_specifications). - For Private Service Connect forwarding rules that forward traffic to Google APIs, provide the name of a supported Google API bundle: - vpc-sc - APIs that support VPC Service Controls. - all-apis - All supported Google APIs. - For Private Service Connect forwarding rules that forward traffic to managed services, the target must be a service attachment.
"""
return pulumi.get(self, "target") | PypiClean |
/rosewater-0.1.1.tar.gz/rosewater-0.1.1/README.md | # rosewater
[](https://badge.fury.io/py/rosewater)
**rosewater** assigns genes to (super-) enhancer output from [ROSE](https://bitbucket.org/young_computation/rose/src/master/) in an expression-aware manner. It allows users to set a TPM threshold to filter genes that are not expressed on a sample-by-sample basis.
## Installation
`rosewater` can be installed via pip. For use, it **requires `bedtools` be available on your PATH**.
```pip install rosewater```
## Usage
`rosewater` is fairly simple to use. It requires an annotation GTF file, a TSV file of TPMs with the gene name column named 'gene' (these should match the 'gene_name' attributes in the annotation GTF), the name of the sample column in the TPM file, and an output file from [ROSE](https://bitbucket.org/young_computation/rose/src/master/). Optionally, users can set a TPM threshold (set to 5 by default) for filtering out lowly/non-expressed genes prior to assignment.
```
Usage: rosewater [OPTIONS]
rosewater assigns genes to ROSE output in an expression-aware manner.
Options:
-a, --annotation PATH Path to annotation GTF file. [required]
-s, --sample TEXT Sample name that should match a column in the
TPM file. [required]
-e, --enh_file PATH Output from ROSE ending with
'ENHANCER_TO_GENE.txt'. [required]
-t, --tpm_file PATH A file containing a matrix of TPMs with genes as
rows and samples as columns. The gene label
column should be named 'gene'. [required]
-th, --tpm_threshold FLOAT The minimum TPM to retain genes for assignment.
[default: 5]
-o, --output_dir PATH The output directory. [default:
./EnhancerGeneAssignments]
--version Show the version and exit.
-h, --help Show this message and exit.
```
## Output
Two output files will be generated, named after the ROSE enhancer input file appended with either `.rosewater.GeneAssignment.log` or `.rosewater.GeneAssignment.bed`. The **log file** will contain useful stats such as how many TSSes are filtered by the TPM threshold, how many TSSes overlap each enhancer, the average enhancer size, and how many assignments change from the original ROSE assignments.
The **BED-like file** will contain the assignments for each enhancer. Two assignments are made for each enhancer - one utilizing all TSSes in the annotation file that meet the TPM threshold and another utilizing only the protein-coding TSSes. These assignments are the last 4 columns of the file. The additional columns are fairly self-explanatory. In short, they contain the overlapping TSSes, the closest TSS using all transcripts that meet the TPM threshold, the closest TSS using only protein-coding transcripts that meet the TPM threshold, and the TPMs for each of those.
## Assignment Logic
The original ROSE gene mapper just assigns the TSS that is closest to the center of the enhancer. `rosewater` takes a more sophisticated (and therefore complicated approach):
- If the enhancer overlaps no TSSes for a gene that meets the TPM threshold:
- The "final_allgene_assignment" will be set to the gene that meets the TPM threshold for the closest TSS while "final_proteincoding_assignment" will be set to the gene that meets the TPM threshold for the closest 'protein_coding' TSS.
- If the enhancer overlaps a single TSS for a gene that meets the TPM threshold:
- If the 'gene_type' of the gene is `protein_coding`, the "final_allgene_assignment" and "final_proteincoding_assignment" will both be set to that gene.
- If the 'gene_type' of the gene is **not** `protein_coding`, the "final_allgene_assignment" will be set to that gene while the "final_proteincoding_assignment" will be set to the gene for the closest 'protein_coding' TSS.
- If the enhancer overlaps two or more TSS for a gene that meets the TPM threshold:
- If the 'gene_type' of the most highly-expressed gene is `protein_coding`, the "final_allgene_assignment" and "final_proteincoding_assignment" will both be set to that gene.
- If the 'gene_type' of the most highly-expressed gene is **not** `protein_coding`, the "final_allgene_assignment" will be set to that gene while the "final_proteincoding_assignment" will be set to the most highly-expressed overlapping 'protein_coding' gene. If there are no overlapping TSSes for 'protein_coding' genes, the "final_proteincoding_assignment" will be set to the gene for the closest 'protein_coding' TSS.
Users are free to use whichever assignment they feel is most appropriate for their use case.
## Known Issues
Users may get a warning like `RuntimeWarning: line buffering (buffering=1) isn't supported in binary mode` depending on their version of python. This can be safely ignored. It stems from `pybedtools` and should be fixed in their next release.
## Contributing
Feel free to submit a [pull request](https://github.com/j-andrews7/rosewater/pulls) or open an [issue](https://github.com/j-andrews7/rosewater/issues) if you have an idea to enhance this tool.
## License
`rosewater` is available under the [GNU-GPLv3 license](https://github.com/j-andrews7/rosewater/blob/master/LICENSE). It is provided as-is, with no warranty or guarantees. | PypiClean |
/pydashi-0.1.2-py3-none-any.whl/dashi/datasets/hub.py | import dashi as d
#from dashi.datasets.dataset import HDFDataset, HDFChainDataset
import numpy as n
import new
from collections import defaultdict
import time
import sys
class DatasetHub(object):
"""
several datasets can be connected to a hub which then
allows a retrieve objbundles of variables
"""
def __init__(self):
self.datasets = dict()
self.vars = dict()
def __del__(self):
for k in self.datasets:
self.datasets[k] = None
def connect_dataset(self, name, dataset):
dataset._ds_hub = self
self.datasets[name] = dataset
self.__dict__[name] = dataset
def disconnect_dataset(self, name):
if name in self.datasets:
del self.__dict__[name]
del self.datasets[name]
def get(self, vars, unpack_recarrays=False):
"""
varname is either a string or a list of strings
with variable names
returns either a ndarray_bundle or a ndarray_bundle_bundle
"""
start = time.time()
def get_one_variable(self,varname,current,total, unpack_recarrays=False):
" helper function that retrieves a single variable"
print " %3d/%d reading variable %s" % (current,total,varname),
start2 = time.time()
arrays = {}
missing_datasets = []
for name,dataset in self.datasets.iteritems():
tmp = None
try:
if varname in self.vars and (self.vars[varname].vardef is not None):
v = self.vars[varname]
tmp = dataset._ds_get(v.vardef)
if v.transform is not None:
tmp = v.transform(tmp)
else:
tmp = dataset._ds_get(varname)
except ValueError:
missing_datasets.append(name)
# tmp is now pointing either to None, a 1d array or a recarray with named columns
if tmp is not None:
# unpack the different columns of the recarray into 1d arrays in differnt
# slots of the resulting bundle
if unpack_recarrays:
if tmp.dtype.names is None:
arrays[name] = tmp
else:
for column in tmp.dtype.names:
arrays[name+"_"+column] = tmp[column]
# just store the array
else:
arrays[name] = tmp
if len(arrays) == 0:
print "| done after %d seconds" % (time.time() - start2)
return None
# add empty arrays where necessary
# rationale: empty arrays are easier to handle than bundles with missing keys
# TODO: maybe make this configureable
if len(missing_datasets) > 0:
dtype = arrays.values()[0].dtype
for name in missing_datasets:
arrays[name] = n.zeros(0, dtype=dtype)
print "| filling empty keys",
print "| done after %d seconds" % (time.time() - start2)
sys.stdout.flush()
return d.bundle(**arrays)
if isinstance(vars, str):
tmp = get_one_variable(self, vars, 1,1, unpack_recarrays)
print "total time:", time.time()-start
return tmp
elif isinstance(vars, list) and all([isinstance(i, str) for i in vars]):
bundles = dict( [ (varname, get_one_variable(self, varname,i+1,len(vars),unpack_recarrays))
for i,varname in enumerate(vars)] )
bundles = dict( [ (i,j) for i,j in bundles.iteritems() if j is not None ] )
if len(bundles) == 0:
print "total time:", time.time()-start
return None
else:
tmp = d.bundle(**bundles)
print "total time:", time.time()-start
return tmp
else:
raise ValueError("vars must be either a string or a list of strings")
def put(self, path, bdl):
for key in bdl.keys():
if not key in self.datasets:
raise ValueError("this bundle contains key %s which corresponds to no connected dataset")
for key in bdl.keys():
self.datasets[key]._ds_put(path, bdl.get(key))
def remove(self, path):
for key, ds in self.datasets.iteritems():
errors = []
try:
ds._ds_remove_variable(path)
except ValueError as exc:
errors += [key]
if len(errors) == len(self.datasets):
raise ValueError("while removing '%s' got errors from _all_ datasets!" % path)
elif (0 < len(errors)) and ( len(errors) < len(self.datasets)):
print "caught errors while removing '%s' for datasets %s" % (path, " ".join(errors))
def keys(self):
return self.datasets.keys()
def print_toc(self, varsonly=False):
"""
print a list of all available variables in this hub together
with a flag in which of the connected datasets the are
available
"""
global_toc = defaultdict(set)
maxpathlen = 0
maxdsnamelen = 0
for dsname in self.datasets:
maxdsnamelen = max(len(dsname), maxdsnamelen)
thistoc = self.datasets[dsname]._ds_toc
if varsonly:
for vname,v in self.vars.iteritems():
print vname,v
if v.vardef in thistoc:
global_toc[vname].add(dsname)
maxpathlen = max(len(vname), maxpathlen)
else:
for path in thistoc:
global_toc[path].add(dsname)
maxpathlen = max(len(path), maxpathlen)
fmt_substring = lambda size : "%"+str(size)+"s"
fmt = fmt_substring(maxpathlen)
totsize = maxpathlen
keys = sorted(self.datasets.keys())
for dsname in keys:
fmt += " " + fmt_substring(len(dsname))
totsize += len(dsname) + 1
print fmt % tuple( [""] + keys)
print totsize * "-"
for path in sorted(global_toc.keys()):
def marker(k):
if k in global_toc[path]:
return "x"
else:
return "o"
print fmt % tuple( [path] + [marker(key) for key in keys])
def get_vars(self, vardef_only=True):
"""
return the keys of the registered variables
If vardef_only is True only those variable keys are returned
for which a vardef is defined (e.g. a path in a hdf file is specified).
In this case the keys are returned sort by their vardefs.
"""
if not vardef_only:
return self.vars.keys()
else:
varcmp = lambda v1,v2 : cmp(self.vars[v1].vardef, self.vars[v2].vardef) # group by hdf tables, may improve speed
readable = [ i for i in self.vars.keys() if self.vars[i].vardef is not None ]
return sorted(readable, cmp=varcmp)
def usermethod(obj):
"""
wrapper that allows to attach methods to a hub
"""
def wrapper(method):
setattr(obj, method.func_name, new.instancemethod(method, obj, obj.__class__))
return wrapper | PypiClean |
/tab-transformer-pytorch-0.2.6.tar.gz/tab-transformer-pytorch-0.2.6/tab_transformer_pytorch/tab_transformer_pytorch.py | import torch
import torch.nn.functional as F
from torch import nn, einsum
from einops import rearrange
# helpers
def exists(val):
return val is not None
def default(val, d):
return val if exists(val) else d
# classes
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(x, **kwargs) + x
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
# attention
class GEGLU(nn.Module):
def forward(self, x):
x, gates = x.chunk(2, dim = -1)
return x * F.gelu(gates)
class FeedForward(nn.Module):
def __init__(self, dim, mult = 4, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, dim * mult * 2),
GEGLU(),
nn.Dropout(dropout),
nn.Linear(dim * mult, dim)
)
def forward(self, x, **kwargs):
return self.net(x)
class Attention(nn.Module):
def __init__(
self,
dim,
heads = 8,
dim_head = 16,
dropout = 0.
):
super().__init__()
inner_dim = dim_head * heads
self.heads = heads
self.scale = dim_head ** -0.5
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Linear(inner_dim, dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
h = self.heads
q, k, v = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = h), (q, k, v))
sim = einsum('b h i d, b h j d -> b h i j', q, k) * self.scale
attn = sim.softmax(dim = -1)
dropped_attn = self.dropout(attn)
out = einsum('b h i j, b h j d -> b h i d', dropped_attn, v)
out = rearrange(out, 'b h n d -> b n (h d)', h = h)
return self.to_out(out), attn
# transformer
class Transformer(nn.Module):
def __init__(self, num_tokens, dim, depth, heads, dim_head, attn_dropout, ff_dropout):
super().__init__()
self.embeds = nn.Embedding(num_tokens, dim)
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = attn_dropout)),
PreNorm(dim, FeedForward(dim, dropout = ff_dropout)),
]))
def forward(self, x, return_attn = False):
x = self.embeds(x)
post_softmax_attns = []
for attn, ff in self.layers:
attn_out, post_softmax_attn = attn(x)
post_softmax_attns.append(post_softmax_attn)
x = x + attn_out
x = ff(x) + x
if not return_attn:
return x
return x, torch.stack(post_softmax_attns)
# mlp
class MLP(nn.Module):
def __init__(self, dims, act = None):
super().__init__()
dims_pairs = list(zip(dims[:-1], dims[1:]))
layers = []
for ind, (dim_in, dim_out) in enumerate(dims_pairs):
is_last = ind >= (len(dims_pairs) - 1)
linear = nn.Linear(dim_in, dim_out)
layers.append(linear)
if is_last:
continue
act = default(act, nn.ReLU())
layers.append(act)
self.mlp = nn.Sequential(*layers)
def forward(self, x):
return self.mlp(x)
# main class
class TabTransformer(nn.Module):
def __init__(
self,
*,
categories,
num_continuous,
dim,
depth,
heads,
dim_head = 16,
dim_out = 1,
mlp_hidden_mults = (4, 2),
mlp_act = None,
num_special_tokens = 2,
continuous_mean_std = None,
attn_dropout = 0.,
ff_dropout = 0.
):
super().__init__()
assert all(map(lambda n: n > 0, categories)), 'number of each category must be positive'
assert len(categories) + num_continuous > 0, 'input shape must not be null'
# categories related calculations
self.num_categories = len(categories)
self.num_unique_categories = sum(categories)
# create category embeddings table
self.num_special_tokens = num_special_tokens
total_tokens = self.num_unique_categories + num_special_tokens
# for automatically offsetting unique category ids to the correct position in the categories embedding table
if self.num_unique_categories > 0:
categories_offset = F.pad(torch.tensor(list(categories)), (1, 0), value = num_special_tokens)
categories_offset = categories_offset.cumsum(dim = -1)[:-1]
self.register_buffer('categories_offset', categories_offset)
# continuous
self.num_continuous = num_continuous
if self.num_continuous > 0:
if exists(continuous_mean_std):
assert continuous_mean_std.shape == (num_continuous, 2), f'continuous_mean_std must have a shape of ({num_continuous}, 2) where the last dimension contains the mean and variance respectively'
self.register_buffer('continuous_mean_std', continuous_mean_std)
self.norm = nn.LayerNorm(num_continuous)
# transformer
self.transformer = Transformer(
num_tokens = total_tokens,
dim = dim,
depth = depth,
heads = heads,
dim_head = dim_head,
attn_dropout = attn_dropout,
ff_dropout = ff_dropout
)
# mlp to logits
input_size = (dim * self.num_categories) + num_continuous
l = input_size // 8
hidden_dimensions = list(map(lambda t: l * t, mlp_hidden_mults))
all_dimensions = [input_size, *hidden_dimensions, dim_out]
self.mlp = MLP(all_dimensions, act = mlp_act)
def forward(self, x_categ, x_cont, return_attn = False):
xs = []
assert x_categ.shape[-1] == self.num_categories, f'you must pass in {self.num_categories} values for your categories input'
if self.num_unique_categories > 0:
x_categ += self.categories_offset
x, attns = self.transformer(x_categ, return_attn = True)
flat_categ = x.flatten(1)
xs.append(flat_categ)
assert x_cont.shape[1] == self.num_continuous, f'you must pass in {self.num_continuous} values for your continuous input'
if self.num_continuous > 0:
if exists(self.continuous_mean_std):
mean, std = self.continuous_mean_std.unbind(dim = -1)
x_cont = (x_cont - mean) / std
normed_cont = self.norm(x_cont)
xs.append(normed_cont)
x = torch.cat(xs, dim = -1)
logits =self.mlp(x)
if not return_attn:
return logits
return logits, attns | PypiClean |
/django-pstore-2.0.0.tar.gz/django-pstore-2.0.0/pstore/pstore_settings.py | from logging import Filter
from logging.handlers import SysLogHandler
# We're in UTC+1, we speak English and we don't do any i18n.
TIME_ZONE, LANGUAGE_CODE = 'Europe/Amsterdam', 'en-us'
USE_I18N, USE_L10N, USE_TZ = False, False, False
# Currently only used for admin-media, relative to STATIC_URL: /static/admin/
STATIC_URL = '/static/'
# Generally unused, but still needed.
SITE_ID = 1
# Middleware.
MIDDLEWARE = [
#'pstore.middleware.LogSqlToConsoleMiddleware',
'django.middleware.security.SecurityMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
# Make sure we have a the requirements for admin work.
'django.contrib.sessions.middleware.SessionMiddleware', # sessions
'django.contrib.auth.middleware.AuthenticationMiddleware', # request.user
'django.contrib.messages.middleware.MessageMiddleware', # UI feedback
# Authenticate users by nonce instead.
'pstore.middleware.AuthenticateByNonceMiddleware',
# Handle HttpErrors by feeding them as response.
'pstore.middleware.HttpErrorMiddleware',
]
# Path to our pstore urls.
ROOT_URLCONF = 'pstore.urls'
# Python dotted path to the WSGI application used by Django's runserver.
WSGI_APPLICATION = 'pstore.wsgi.application'
# The apps that this project is comprised of.
INSTALLED_APPS = (
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.messages',
'django.contrib.sessions',
'django.contrib.staticfiles',
'pstore',
)
TEMPLATES = (
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.contrib.auth.context_processors.auth',
'django.template.context_processors.debug',
'django.template.context_processors.i18n',
'django.template.context_processors.media',
'django.template.context_processors.request',
'django.template.context_processors.static',
'django.template.context_processors.tz',
'django.contrib.messages.context_processors.messages',
],
},
},
)
# (extra LF above for PEP)
class RequireDebugFalse(Filter):
"""For compatibility with Django 1.3-"""
def filter(self, record):
from django.conf import settings
return not settings.DEBUG
LOGGING = {
# NOTE: If you are getting log messages printed to stdout/stderr, you're
# probably looking at a python 2.6- bug where syslog messages are encoded
# as UTF-8 with a BOM. The BOM is read as EMERG and the message is "wall"ed
# to all logged in users.
'version': 1,
'disable_existing_loggers': False,
'filters': {
'require_debug_false': {
# In Django 1.4+ we'd use django.utils.log.RequireDebugFalse.
'()': RequireDebugFalse,
}
},
'formatters': {
'syslog': {
'format': 'uwsgi[%(process)d]: %(name)s: %(message)s',
},
},
'handlers': {
'mail_admins': {
'level': 'ERROR',
'filters': ('require_debug_false',), # don't mail if DEBUG=False
'class': 'django.utils.log.AdminEmailHandler',
},
'syslog': {
'level': 'INFO',
'class': 'logging.handlers.SysLogHandler',
'address': '/dev/log', # don't forget this for sysloghandler
'formatter': 'syslog',
'facility': SysLogHandler.LOG_AUTH,
},
},
'loggers': {
# Put INFO or worse in syslog.
'pstore.audit': {
'handlers': ('syslog',),
'level': 'INFO',
'propagate': True,
},
# Mail admins on ERROR or worse (not just for django.request).
# And also write to the same auth.log, because it clarifies that
# the previous statement didn't complete.
'': {
'handlers': ('syslog', 'mail_admins'),
'level': 'ERROR',
'propagate': True,
},
},
} | PypiClean |
/matrix-synapse-ray-1.12.0.4.tar.gz/matrix-synapse-ray-1.12.0.4/synapse/http/server.py |
import collections
import html
import http.client
import logging
import types
import urllib
from io import BytesIO
from canonicaljson import encode_canonical_json, encode_pretty_printed_json, json
from twisted.internet import defer
from twisted.python import failure
from twisted.web import resource
from twisted.web.server import NOT_DONE_YET
from twisted.web.static import NoRangeStaticProducer
from twisted.web.util import redirectTo
import synapse.events
import synapse.metrics
from synapse.api.errors import (
CodeMessageException,
Codes,
RedirectException,
SynapseError,
UnrecognizedRequestError,
)
from synapse.logging.context import preserve_fn
from synapse.logging.opentracing import trace_servlet
from synapse.util.caches import intern_dict
logger = logging.getLogger(__name__)
HTML_ERROR_TEMPLATE = """<!DOCTYPE html>
<html lang=en>
<head>
<meta charset="utf-8">
<title>Error {code}</title>
</head>
<body>
<p>{msg}</p>
</body>
</html>
"""
def wrap_json_request_handler(h):
"""Wraps a request handler method with exception handling.
Also does the wrapping with request.processing as per wrap_async_request_handler.
The handler method must have a signature of "handle_foo(self, request)",
where "request" must be a SynapseRequest.
The handler must return a deferred or a coroutine. If the deferred succeeds
we assume that a response has been sent. If the deferred fails with a SynapseError we use
it to send a JSON response with the appropriate HTTP reponse code. If the
deferred fails with any other type of error we send a 500 reponse.
"""
async def wrapped_request_handler(self, request):
try:
await h(self, request)
except SynapseError as e:
code = e.code
logger.info("%s SynapseError: %s - %s", request, code, e.msg)
# Only respond with an error response if we haven't already started
# writing, otherwise lets just kill the connection
if request.startedWriting:
if request.transport:
try:
request.transport.abortConnection()
except Exception:
# abortConnection throws if the connection is already closed
pass
else:
respond_with_json(
request,
code,
e.error_dict(),
send_cors=True,
pretty_print=_request_user_agent_is_curl(request),
)
except Exception:
# failure.Failure() fishes the original Failure out
# of our stack, and thus gives us a sensible stack
# trace.
f = failure.Failure()
logger.error(
"Failed handle request via %r: %r",
request.request_metrics.name,
request,
exc_info=(f.type, f.value, f.getTracebackObject()),
)
# Only respond with an error response if we haven't already started
# writing, otherwise lets just kill the connection
if request.startedWriting:
if request.transport:
try:
request.transport.abortConnection()
except Exception:
# abortConnection throws if the connection is already closed
pass
else:
respond_with_json(
request,
500,
{"error": "Internal server error", "errcode": Codes.UNKNOWN},
send_cors=True,
pretty_print=_request_user_agent_is_curl(request),
)
return wrap_async_request_handler(wrapped_request_handler)
def wrap_html_request_handler(h):
"""Wraps a request handler method with exception handling.
Also does the wrapping with request.processing as per wrap_async_request_handler.
The handler method must have a signature of "handle_foo(self, request)",
where "request" must be a SynapseRequest.
"""
async def wrapped_request_handler(self, request):
try:
return await h(self, request)
except Exception:
f = failure.Failure()
return _return_html_error(f, request)
return wrap_async_request_handler(wrapped_request_handler)
def _return_html_error(f, request):
"""Sends an HTML error page corresponding to the given failure
Args:
f (twisted.python.failure.Failure):
request (twisted.web.server.Request):
"""
if f.check(CodeMessageException):
cme = f.value
code = cme.code
msg = cme.msg
if isinstance(cme, RedirectException):
logger.info("%s redirect to %s", request, cme.location)
request.setHeader(b"location", cme.location)
request.cookies.extend(cme.cookies)
elif isinstance(cme, SynapseError):
logger.info("%s SynapseError: %s - %s", request, code, msg)
else:
logger.error(
"Failed handle request %r",
request,
exc_info=(f.type, f.value, f.getTracebackObject()),
)
else:
code = http.client.INTERNAL_SERVER_ERROR
msg = "Internal server error"
logger.error(
"Failed handle request %r",
request,
exc_info=(f.type, f.value, f.getTracebackObject()),
)
body = HTML_ERROR_TEMPLATE.format(code=code, msg=html.escape(msg)).encode("utf-8")
request.setResponseCode(code)
request.setHeader(b"Content-Type", b"text/html; charset=utf-8")
request.setHeader(b"Content-Length", b"%i" % (len(body),))
request.write(body)
finish_request(request)
def wrap_async_request_handler(h):
"""Wraps an async request handler so that it calls request.processing.
This helps ensure that work done by the request handler after the request is completed
is correctly recorded against the request metrics/logs.
The handler method must have a signature of "handle_foo(self, request)",
where "request" must be a SynapseRequest.
The handler may return a deferred, in which case the completion of the request isn't
logged until the deferred completes.
"""
async def wrapped_async_request_handler(self, request):
with request.processing():
await h(self, request)
# we need to preserve_fn here, because the synchronous render method won't yield for
# us (obviously)
return preserve_fn(wrapped_async_request_handler)
class HttpServer(object):
""" Interface for registering callbacks on a HTTP server
"""
def register_paths(self, method, path_patterns, callback):
""" Register a callback that gets fired if we receive a http request
with the given method for a path that matches the given regex.
If the regex contains groups these gets passed to the calback via
an unpacked tuple.
Args:
method (str): The method to listen to.
path_patterns (list<SRE_Pattern>): The regex used to match requests.
callback (function): The function to fire if we receive a matched
request. The first argument will be the request object and
subsequent arguments will be any matched groups from the regex.
This should return a tuple of (code, response).
"""
pass
class JsonResource(HttpServer, resource.Resource):
""" This implements the HttpServer interface and provides JSON support for
Resources.
Register callbacks via register_paths()
Callbacks can return a tuple of status code and a dict in which case the
the dict will automatically be sent to the client as a JSON object.
The JsonResource is primarily intended for returning JSON, but callbacks
may send something other than JSON, they may do so by using the methods
on the request object and instead returning None.
"""
isLeaf = True
_PathEntry = collections.namedtuple(
"_PathEntry", ["pattern", "callback", "servlet_classname"]
)
def __init__(self, hs, canonical_json=True):
resource.Resource.__init__(self)
self.canonical_json = canonical_json
self.clock = hs.get_clock()
self.path_regexs = {}
self.hs = hs
def register_paths(
self, method, path_patterns, callback, servlet_classname, trace=True
):
"""
Registers a request handler against a regular expression. Later request URLs are
checked against these regular expressions in order to identify an appropriate
handler for that request.
Args:
method (str): GET, POST etc
path_patterns (Iterable[str]): A list of regular expressions to which
the request URLs are compared.
callback (function): The handler for the request. Usually a Servlet
servlet_classname (str): The name of the handler to be used in prometheus
and opentracing logs.
trace (bool): Whether we should start a span to trace the servlet.
"""
method = method.encode("utf-8") # method is bytes on py3
if trace:
# We don't extract the context from the servlet because we can't
# trust the sender
callback = trace_servlet(servlet_classname)(callback)
for path_pattern in path_patterns:
logger.debug("Registering for %s %s", method, path_pattern.pattern)
self.path_regexs.setdefault(method, []).append(
self._PathEntry(path_pattern, callback, servlet_classname)
)
def render(self, request):
""" This gets called by twisted every time someone sends us a request.
"""
defer.ensureDeferred(self._async_render(request))
return NOT_DONE_YET
@wrap_json_request_handler
async def _async_render(self, request):
""" This gets called from render() every time someone sends us a request.
This checks if anyone has registered a callback for that method and
path.
"""
callback, servlet_classname, group_dict = self._get_handler_for_request(request)
# Make sure we have a name for this handler in prometheus.
request.request_metrics.name = servlet_classname
# Now trigger the callback. If it returns a response, we send it
# here. If it throws an exception, that is handled by the wrapper
# installed by @request_handler.
kwargs = intern_dict(
{
name: urllib.parse.unquote(value) if value else value
for name, value in group_dict.items()
}
)
callback_return = callback(request, **kwargs)
# Is it synchronous? We'll allow this for now.
if isinstance(callback_return, (defer.Deferred, types.CoroutineType)):
callback_return = await callback_return
if callback_return is not None:
code, response = callback_return
self._send_response(request, code, response)
def _get_handler_for_request(self, request):
"""Finds a callback method to handle the given request
Args:
request (twisted.web.http.Request):
Returns:
Tuple[Callable, str, dict[unicode, unicode]]: callback method, the
label to use for that method in prometheus metrics, and the
dict mapping keys to path components as specified in the
handler's path match regexp.
The callback will normally be a method registered via
register_paths, so will return (possibly via Deferred) either
None, or a tuple of (http code, response body).
"""
if request.method == b"OPTIONS":
return _options_handler, "options_request_handler", {}
request_path = request.path.decode("ascii")
# Loop through all the registered callbacks to check if the method
# and path regex match
for path_entry in self.path_regexs.get(request.method, []):
m = path_entry.pattern.match(request_path)
if m:
# We found a match!
return path_entry.callback, path_entry.servlet_classname, m.groupdict()
# Huh. No one wanted to handle that? Fiiiiiine. Send 400.
return _unrecognised_request_handler, "unrecognised_request_handler", {}
def _send_response(
self, request, code, response_json_object, response_code_message=None
):
# TODO: Only enable CORS for the requests that need it.
respond_with_json(
request,
code,
response_json_object,
send_cors=True,
response_code_message=response_code_message,
pretty_print=_request_user_agent_is_curl(request),
canonical_json=self.canonical_json,
)
class DirectServeResource(resource.Resource):
def render(self, request):
"""
Render the request, using an asynchronous render handler if it exists.
"""
async_render_callback_name = "_async_render_" + request.method.decode("ascii")
# Try and get the async renderer
callback = getattr(self, async_render_callback_name, None)
# No async renderer for this request method.
if not callback:
return super().render(request)
resp = trace_servlet(self.__class__.__name__)(callback)(request)
# If it's a coroutine, turn it into a Deferred
if isinstance(resp, types.CoroutineType):
defer.ensureDeferred(resp)
return NOT_DONE_YET
def _options_handler(request):
"""Request handler for OPTIONS requests
This is a request handler suitable for return from
_get_handler_for_request. It returns a 200 and an empty body.
Args:
request (twisted.web.http.Request):
Returns:
Tuple[int, dict]: http code, response body.
"""
return 200, {}
def _unrecognised_request_handler(request):
"""Request handler for unrecognised requests
This is a request handler suitable for return from
_get_handler_for_request. It actually just raises an
UnrecognizedRequestError.
Args:
request (twisted.web.http.Request):
"""
raise UnrecognizedRequestError()
class RootRedirect(resource.Resource):
"""Redirects the root '/' path to another path."""
def __init__(self, path):
resource.Resource.__init__(self)
self.url = path
def render_GET(self, request):
return redirectTo(self.url.encode("ascii"), request)
def getChild(self, name, request):
if len(name) == 0:
return self # select ourselves as the child to render
return resource.Resource.getChild(self, name, request)
def respond_with_json(
request,
code,
json_object,
send_cors=False,
response_code_message=None,
pretty_print=False,
canonical_json=True,
):
# could alternatively use request.notifyFinish() and flip a flag when
# the Deferred fires, but since the flag is RIGHT THERE it seems like
# a waste.
if request._disconnected:
logger.warning(
"Not sending response to request %s, already disconnected.", request
)
return
if pretty_print:
json_bytes = encode_pretty_printed_json(json_object) + b"\n"
else:
if canonical_json or synapse.events.USE_FROZEN_DICTS:
# canonicaljson already encodes to bytes
json_bytes = encode_canonical_json(json_object)
else:
json_bytes = json.dumps(json_object).encode("utf-8")
return respond_with_json_bytes(
request,
code,
json_bytes,
send_cors=send_cors,
response_code_message=response_code_message,
)
def respond_with_json_bytes(
request, code, json_bytes, send_cors=False, response_code_message=None
):
"""Sends encoded JSON in response to the given request.
Args:
request (twisted.web.http.Request): The http request to respond to.
code (int): The HTTP response code.
json_bytes (bytes): The json bytes to use as the response body.
send_cors (bool): Whether to send Cross-Origin Resource Sharing headers
http://www.w3.org/TR/cors/
Returns:
twisted.web.server.NOT_DONE_YET"""
request.setResponseCode(code, message=response_code_message)
request.setHeader(b"Content-Type", b"application/json")
request.setHeader(b"Content-Length", b"%d" % (len(json_bytes),))
request.setHeader(b"Cache-Control", b"no-cache, no-store, must-revalidate")
if send_cors:
set_cors_headers(request)
# todo: we can almost certainly avoid this copy and encode the json straight into
# the bytesIO, but it would involve faffing around with string->bytes wrappers.
bytes_io = BytesIO(json_bytes)
producer = NoRangeStaticProducer(request, bytes_io)
producer.start()
return NOT_DONE_YET
def set_cors_headers(request):
"""Set the CORs headers so that javascript running in a web browsers can
use this API
Args:
request (twisted.web.http.Request): The http request to add CORs to.
"""
request.setHeader(b"Access-Control-Allow-Origin", b"*")
request.setHeader(
b"Access-Control-Allow-Methods", b"GET, POST, PUT, DELETE, OPTIONS"
)
request.setHeader(
b"Access-Control-Allow-Headers",
b"Origin, X-Requested-With, Content-Type, Accept, Authorization",
)
def finish_request(request):
""" Finish writing the response to the request.
Twisted throws a RuntimeException if the connection closed before the
response was written but doesn't provide a convenient or reliable way to
determine if the connection was closed. So we catch and log the RuntimeException
You might think that ``request.notifyFinish`` could be used to tell if the
request was finished. However the deferred it returns won't fire if the
connection was already closed, meaning we'd have to have called the method
right at the start of the request. By the time we want to write the response
it will already be too late.
"""
try:
request.finish()
except RuntimeError as e:
logger.info("Connection disconnected before response was written: %r", e)
def _request_user_agent_is_curl(request):
user_agents = request.requestHeaders.getRawHeaders(b"User-Agent", default=[])
for user_agent in user_agents:
if b"curl" in user_agent:
return True
return False | PypiClean |
/openvas-edxml-3.0.0.tar.gz/openvas-edxml-3.0.0/openvas_edxml/brick.py | import edxml
from edxml_bricks.generic import GenericBrick
from edxml.ontology import Brick
from edxml.ontology import DataType
class OpenVASBrick(Brick):
"""
Brick that defines some object types and concepts specific to OpenVAS.
"""
OBJECT_NVT_NAME = 'org.openvas.nvt.name'
OBJECT_ERROR_MESSAGE = 'org.openvas.error-message'
OBJECT_NVT_FAMILY = 'org.openvas.nvt.family'
OBJECT_SCAN_NAME = 'org.openvas.scan.name'
OBJECT_QOD_TYPE = 'org.openvas.result.detection.type'
OBJECT_QOD_VALUE = 'org.openvas.result.detection.quality'
OBJECT_SEVERITY = 'org.openvas.result.severity'
OBJECT_THREAT = 'org.openvas.result.threat'
OBJECT_IMPACT = 'org.openvas.result.impact'
OBJECT_INSIGHT = 'org.openvas.result.insight'
OBJECT_SOLUTION_TYPE = 'org.openvas.result.solution-type'
CONCEPT_FINDING = GenericBrick.CONCEPT_ACT + '.discovery.finding.openvas-finding'
CONCEPT_SCAN = GenericBrick.CONCEPT_ACT + '.activity.work.investigation.examination.scan.openvas-scan'
# Known possible values of the QoD (Quality of Detection)
# of an OpenVAS result.
KNOWN_QOD_TYPES = (
'exploit',
'remote_vul',
'remote_app',
'package',
'registry',
'remote_active',
'remote_banner',
'executable_version',
'remote_analysis',
'remote_probe',
'remote_banner_unreliable',
'executable_version_unreliable',
'general_note'
)
@classmethod
def generate_object_types(cls, target_ontology):
yield target_ontology.create_object_type(cls.OBJECT_NVT_NAME) \
.set_description('a name of an OpenVAS plugin (NVT)')\
.set_data_type(DataType.string(255))\
.set_display_name('plugin name')
yield target_ontology.create_object_type(cls.OBJECT_ERROR_MESSAGE) \
.set_description('an error message produced by an OpenVAS plugin (NVT)')\
.set_data_type(DataType.string(255))\
.set_display_name('error message')
yield target_ontology.create_object_type(cls.OBJECT_NVT_FAMILY) \
.set_description('a name of a category of OpenVAS plugins')\
.set_data_type(DataType.string(255))\
.set_display_name('plugin family', 'plugin families')
yield target_ontology.create_object_type(cls.OBJECT_SCAN_NAME) \
.set_description('a name of an OpenVAS scan')\
.set_data_type(DataType.string(255))\
.set_display_name('scan name')
yield target_ontology.create_object_type(cls.OBJECT_QOD_TYPE) \
.set_description('an OpenVAS detection reliability indicator')\
.set_data_type(DataType.enum('other', *cls.KNOWN_QOD_TYPES))\
.set_display_name('QoD type')
yield target_ontology.create_object_type(cls.OBJECT_QOD_VALUE) \
.set_description('an OpenVAS detection reliability value, in percent')\
.set_data_type(DataType.tiny_int(signed=False))\
.set_unit('percent', '%')\
.set_display_name('QoD value')
yield target_ontology.create_object_type(cls.OBJECT_SEVERITY) \
.set_description('a severity of an OpenVAS detection result')\
.set_data_type(DataType.decimal(total_digits=3, fractional_digits=1))\
.set_display_name('vulnerability severity', 'vulnerability severities')
yield target_ontology.create_object_type(cls.OBJECT_THREAT) \
.set_description('a threat level of an OpenVAS detection result')\
.set_data_type(DataType.enum('high', 'medium', 'low', 'alarm', 'log', 'debug'))\
.set_display_name('threat level')
yield target_ontology.create_object_type(cls.OBJECT_IMPACT) \
.set_description('a description of the impact of an issue detected by OpenVAS')\
.set_data_type(DataType.string())\
.set_display_name('impact description')\
.compress()
yield target_ontology.create_object_type(cls.OBJECT_INSIGHT)\
.set_description('a technical detail about an issue detected by OpenVAS')\
.set_data_type(DataType.string())\
.set_display_name('issue detail')\
.compress()
yield target_ontology.create_object_type(cls.OBJECT_SOLUTION_TYPE)\
.set_description('a type of solution for an issue detected by OpenVAS')\
.set_data_type(DataType.string(255))\
.set_display_name('solution type')\
.set_regex_soft('Workaround|Mitigation|Vendor-Fix|None-Available|WillNotFix')
@classmethod
def generate_concepts(cls, target_ontology):
yield target_ontology.create_concept(cls.CONCEPT_SCAN) \
.set_display_name('OpenVAS scan') \
.set_description('an OpenVAS vulnerability scan')
yield target_ontology.create_concept(cls.CONCEPT_FINDING) \
.set_display_name('OpenVAS finding') \
.set_description('an OpenVAS detection result')
edxml.ontology.Ontology.register_brick(OpenVASBrick) | PypiClean |
/Automated_cartography-0.0.2-py3-none-any.whl/Automated/Automated_cartography.py | def get_best_sell_index(PSINrank, sellsnum):
bestsellindex = float(1 / int(PSINrank)) * 1000
sellsnumber = sellsnum * 47
commemts = sellsnum
return bestsellindex, sellsnumber, commemts
def drow_chart(data, filename):
import xlsxwriter
workbook = xlsxwriter.Workbook(filename)
worksheet = workbook.add_worksheet()
bold = workbook.add_format({'bold': 1})
headings = ['日期', '评价量', '销售量', '评分', '商品链接', '价格', '爆款指数']
worksheet.write_row('A1', headings, bold)
worksheet.write_column('A2', data[0])
worksheet.write_column('B2', data[1])
worksheet.write_column('C2', data[2])
worksheet.write_column('D2', data[3])
worksheet.write_column('E2', data[4])
worksheet.write_column('F2', data[5])
worksheet.write_column('G2', data[6])
chart_col = workbook.add_chart({'type': 'line'})
chart_col2 = workbook.add_chart({'type': 'line'})
chart_col3 = workbook.add_chart({'type': 'line'})
chart_col4 = workbook.add_chart({'type': 'line'})
chart_col5 = workbook.add_chart({'type': 'line'})
chart_col.add_series({
'name': ['Sheet1', 0, 1],
'categories': ['Sheet1', 1, 0, len(data[0]), 0],
'values': ['Sheet1', 1, 1, len(data[0]), 1],
'line': {'color': 'red'},
})
chart_col.set_title({'name': '评价量趋势图'})
chart_col.set_x_axis({'name': '日期'})
chart_col.set_y_axis({'name': '评价量数值'})
chart_col.set_style(1)
worksheet.insert_chart('H20', chart_col, {'x_offset': 10, 'y_offset': 10, 'x_scale': 2.5, 'y_scale': 1.3})
# -------------------------------------------------------------------------------------------------------
chart_col2.add_series({
'name': ['Sheet1', 0, 6],
'categories': ['Sheet1', 1, 0, len(data[0]), 0],
'values': ['Sheet1', 1, 6, len(data[0]), 6],
'line': {'color': 'red'},
})
chart_col2.set_title({'name': '爆款指数趋势图'})
chart_col2.set_x_axis({'name': '日期'})
chart_col2.set_y_axis({'name': '相对爆款指数值'})
chart_col2.set_style(1)
worksheet.insert_chart('H1', chart_col2, {'x_offset': 10, 'y_offset': 10, 'x_scale': 2.5, 'y_scale': 1.3})
# -----------------------------------------------------------------------------------------------------
chart_col3.add_series({
'name': ['Sheet1', 0, 3],
'categories': ['Sheet1', 1, 0, len(data[0]), 0],
'values': ['Sheet1', 1, 3, len(data[0]), 3],
'line': {'color': 'green'},
})
chart_col3.set_title({'name': '评分趋势图'})
chart_col3.set_x_axis({'name': '日期'})
chart_col3.set_y_axis({'name': '综合评分数值'})
chart_col3.set_style(1)
worksheet.insert_chart('H80', chart_col3, {'x_offset': 10, 'y_offset': 10, 'x_scale': 2.5, 'y_scale': 1.3})
# -----------------------------------------------------------------------------------------------------
chart_col4.add_series({
'name': ['Sheet1', 0, 5],
'categories': ['Sheet1', 1, 0, len(data[0]), 0],
'values': ['Sheet1', 1, 5, len(data[0]), 5],
'line': {'color': 'yellow'},
})
chart_col4.set_title({'name': '价格趋势图'})
chart_col4.set_x_axis({'name': '日期'})
chart_col4.set_y_axis({'name': '价格'})
chart_col4.set_style(1)
worksheet.insert_chart('H40', chart_col4, {'x_offset': 10, 'y_offset': 10, 'x_scale': 2.5, 'y_scale': 1.3})
# -----------------------------------------------------------------------------------------------------
chart_col5.add_series({
'name': ['Sheet1', 0, 2],
'categories': ['Sheet1', 1, 0, len(data[0]), 0],
'values': ['Sheet1', 1, 2, len(data[0]), 2],
'line': {'color': 'blue'},
})
chart_col5.set_title({'name': '销售量趋势图'})
chart_col5.set_x_axis({'name': '日期'})
chart_col5.set_y_axis({'name': '销售量根据2.1%留评率估算'})
chart_col5.set_style(1)
worksheet.insert_chart('H60', chart_col5, {'x_offset': 10, 'y_offset': 10, 'x_scale': 2.5, 'y_scale': 1.3})
workbook.close() | PypiClean |
/js.angular-1.1.4.tar.gz/js.angular-1.1.4/js/angular/resources/i18n/angular-locale_fr-dj.js | angular.module("ngLocale", [], ["$provide", function($provide) {
var PLURAL_CATEGORY = {ZERO: "zero", ONE: "one", TWO: "two", FEW: "few", MANY: "many", OTHER: "other"};
$provide.value("$locale", {
"DATETIME_FORMATS": {
"AMPMS": {
"0": "AM",
"1": "PM"
},
"DAY": {
"0": "dimanche",
"1": "lundi",
"2": "mardi",
"3": "mercredi",
"4": "jeudi",
"5": "vendredi",
"6": "samedi"
},
"MONTH": {
"0": "janvier",
"1": "février",
"2": "mars",
"3": "avril",
"4": "mai",
"5": "juin",
"6": "juillet",
"7": "août",
"8": "septembre",
"9": "octobre",
"10": "novembre",
"11": "décembre"
},
"SHORTDAY": {
"0": "dim.",
"1": "lun.",
"2": "mar.",
"3": "mer.",
"4": "jeu.",
"5": "ven.",
"6": "sam."
},
"SHORTMONTH": {
"0": "janv.",
"1": "févr.",
"2": "mars",
"3": "avr.",
"4": "mai",
"5": "juin",
"6": "juil.",
"7": "août",
"8": "sept.",
"9": "oct.",
"10": "nov.",
"11": "déc."
},
"fullDate": "EEEE d MMMM y",
"longDate": "d MMMM y",
"medium": "d MMM y HH:mm:ss",
"mediumDate": "d MMM y",
"mediumTime": "HH:mm:ss",
"short": "dd/MM/yy HH:mm",
"shortDate": "dd/MM/yy",
"shortTime": "HH:mm"
},
"NUMBER_FORMATS": {
"CURRENCY_SYM": "€",
"DECIMAL_SEP": ",",
"GROUP_SEP": " ",
"PATTERNS": {
"0": {
"gSize": 3,
"lgSize": 3,
"macFrac": 0,
"maxFrac": 3,
"minFrac": 0,
"minInt": 1,
"negPre": "-",
"negSuf": "",
"posPre": "",
"posSuf": ""
},
"1": {
"gSize": 3,
"lgSize": 3,
"macFrac": 0,
"maxFrac": 2,
"minFrac": 2,
"minInt": 1,
"negPre": "(",
"negSuf": " \u00A4)",
"posPre": "",
"posSuf": " \u00A4"
}
}
},
"id": "fr-dj",
"pluralCat": function (n) { if (n >= 0 && n <= 2 && n != 2) { return PLURAL_CATEGORY.ONE; } return PLURAL_CATEGORY.OTHER;}
});
}]); | PypiClean |
/erdi8-0.4.0.tar.gz/erdi8-0.4.0/README.md | 
[](https://pypi.org/project/erdi8)
[](https://github.com/athalhammer/erdi8/blob/master/LICENSE)
# erdi8
erdi8 is a [unique identifier](https://www.wikidata.org/wiki/Q6545185) scheme and identifier generator and transformer that operates on the following alphabet:
```
['2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h',
'i', 'j', 'k', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
```
It is basically a base36 alphabet that intentionally avoids the ambiguous characters `[0, 1, and l]` and therefore shrinks to 33. In addition to that, it ensures that no identifier starts with a numeric value by using an offset of 8. The zero is represented by 'a', 25 is represented by 'a2', etc. With three characters or less one can create 28'075 (25 + 25 * 33 + 25 * 33 * 33) different identifiers. With 6 characters or less we have 1'008'959'350 options. In a traditional identifier world, one would use a prefix, e.g. M, and then an integer. This only gives you 100k identifiers (M0 to M99999) with up to 6 characters. The scheme enables consecutive counting and is therefore free of collisions. In particular, it is __not__ a method to create secret identifiers.
## Usage
### Basic (counting)
```
$ python3
>>> from erdi8 import Erdi8
>>> e8 = Erdi8()
>>> e8.increment("erdi8")
'erdi9'
>>> e8.decode_int("erdi8")
6545185
>>> e8.encode_int(6545185)
'erdi8'
```
### Advanced (still counting)
Fixed length "fancy" identifiers with `safe=True`
```
$ python3
>>> from erdi8 import Erdi8
>>> safe = True
>>> start = 'b222222222'
>>> stride = 30321718760514
>>> e8 = Erdi8(safe)
>>> e8.increment_fancy(start, stride)
'fmzz7cwc43'
>>> current = e8.increment_fancy('fmzz7cwc43', stride)
>>> print(current)
k7zydqrp64
# reverse engineer stride from two consecutive identifiers
>>> e8.compute_stride('fmzz7cwc43', current)
{'stride_effective': 30321718760517, 'stride_other_candidates': [30321718760516, 30321718760515, 30321718760514]}
```
**NOTE**
0. These sequences may have a "fancy" appearance but __they are not random__. They are perfectly predictable and are designed to "fill up the whole mod space" before previously coined identifiers start re-appearing.
1. The `safe=True` option helps you to avoid unintended words (i.e. removes the characters `[aeiou]` from the alphabet)
2. The fancy increment works with fixed lengths. If you work with a length of 10 (like above) You will have `20 * 28^9 = 211'569'119'068'160` options with `safe=True`. If you think you have more things to identify at some point you have two options: a) start directly with more characters or b) check for the start value (in this case `b222222222`) to re-appear - this will be the identifier that will "show up twice" first.
3. Store the following four parts in a safe place: a) `safe` parameter b) the `start` value c) the `stride` value. On top, keep good track of the `current` value.
### Advanced (random)
Also see documentation of Python's integrated [`random`](https://docs.python.org/3/library/random.html) and [`secrets`](https://docs.python.org/3/library/secrets.html) modules, in particular for `random`: "The pseudo-random generators of this module should not be used for security purposes. For security or cryptographic uses, see the `secrets` module". In any case, you should know what you are doing.
`random` module:
```
$ python3
>>> import random
>>> from erdi8 import Erdi8
>>> e8 = Erdi8()
# get random erdi8 identifiers with length 10
>>> mini, maxi, _ = e8.mod_space(10)
>>> e8.encode_int(random.randint(mini, maxi))
'vvctyx7c6o'
```
`secrets` module:
```
$ python3
>>> import secrets
>>> from erdi8 import Erdi8
>>> e8 = Erdi8()
>>> e8.encode_int(int.from_bytes(secrets.token_bytes()))
'jtx3i83pii8wo98wzuucu7uag6khrfpabrdn3qrqrxdxauvcgjg'
>>> e8.encode_int(secrets.randbits(256))
'a53mpn3xntywcbdcvfa932ub34evne9oha8pzoy6ii3ur2e364z'
```
### Advanced (hash functions)
erdi8 is compatible to the most common hash functions that typically output the digest in hexadecimal format. Also refer to the integrated [`hashlib`](https://docs.python.org/3/library/hashlib.html) Python module. In addition, consider other [hash functions](https://softwareengineering.stackexchange.com/questions/49550/which-hashing-algorithm-is-best-for-uniqueness-and-speed).
```
$ python3
>>> from erdi8 import Erdi8
>>> import hashlib
# prepare the item to be hashed and display the digests for sha256 and md5
>>> s = "asdf".encode("ascii")
>>> hashlib.sha256(s).hexdigest()
'f0e4c2f76c58916ec258f246851bea091d14d4247a2fc3e18694461b1816e13b'
>>> hashlib.md5(s).hexdigest()
'912ec803b2ce49e4a541068d495ab570'
# encode the respective digests with erdi8
>>> e8 = Erdi8()
>>> e8.encode_int(int.from_bytes(hashlib.sha256(s).digest()))
'n6vz5j427zw66qx9n4jk9sw7otrvu38gdteehsocbke3xocvqok'
>>> e8.encode_int(int.from_bytes(hashlib.md5(s).digest()))
'bcmhm477p7poz6sv8jpr4cqu4h'
# same as above but safe=True
>>> e9 = Erdi8(safe=True)
>>> e9.encode_int(int.from_bytes(hashlib.sha256(s).digest()))
'cg8644xv4txkj49sfzcwn49h3hvsqb8xm2pqxxfxxg7mpz3nwsmhnf'
>>> e9.encode_int(int.from_bytes(hashlib.md5(s).digest()))
'fv3y2y9mgbr4xs85z5qb6bp4dxm'
# re-establish the hexdigest
>>> hex(e8.decode_int('n6vz5j427zw66qx9n4jk9sw7otrvu38gdteehsocbke3xocvqok'))
'0xf0e4c2f76c58916ec258f246851bea091d14d4247a2fc3e18694461b1816e13b'
>>> hex(e8.decode_int('bcmhm477p7poz6sv8jpr4cqu4h'))
'0x912ec803b2ce49e4a541068d495ab570
# re-establish the hexdigest with from safe=True
>>> hex(e9.decode_int('cg8644xv4txkj49sfzcwn49h3hvsqb8xm2pqxxfxxg7mpz3nwsmhnf'))
'0xf0e4c2f76c58916ec258f246851bea091d14d4247a2fc3e18694461b1816e13b'
hex(e9.decode_int('fv3y2y9mgbr4xs85z5qb6bp4dxm'))
'0x912ec803b2ce49e4a541068d495ab570'
```
### Advanced (UUID)
Also see the documentation of the [`uuid`](https://docs.python.org/3/library/uuid.html) integrated Python module.
```
$ python3
>>> from erdi8 import Erdi8
>>> import uuid
>>> e8 = Erdi8()
>>> e9 = Erdi8(safe=True)
>>> a = uuid.uuid4()
>>> a
UUID('6e8f578c-577c-4f48-b6ac-bf135c310dc4')
>>> b = e8.encode_int(a.int)
# here we have the UUID encoded as erdi8 string - 10 char shorter than ordinary UUIDs
>>> b
'au3jqjghpb7dqfejdanskzoaik'
# same as above but with safe=True
>>> c = e9.encode_int(a.int)
>>> c
'drmhy438mjhqdsbxhzn6v27b8n6'
# reverse
>>> uuid.UUID(int=e8.decode_int(b))
UUID('6e8f578c-577c-4f48-b6ac-bf135c310dc4')
# reverse with safe=True
>>> uuid.UUID(int=e9.decode_int(c))
UUID('6e8f578c-577c-4f48-b6ac-bf135c310dc4')
```
**Note**: This will never start with a zero or will in any way generate "number only" strings.
### Advanced (xid)
See also [`xid`](https://github.com/rs/xid). With `erdi8` encoding you gain some properties i.e. omitting problematic `[0, 1, l]` or also `[a, e, i, o, u]` (with the `safe=True` option to avoid "bad" words, see below in the FAQ), reducing to 19 characters only (at least until 2065 where it will switch to 20) or maintaining 20 characters while omitting `[a, e, i, o, u]` with `safe=True` (until 2081 after which it will switch to 21), and always start with a char (in fact, current or future xids will also start with a char). The k-sortedness property of xids will be maintained with the respective length (e.g., you should not compare 19 and 20 char xid+erdi8 strings after 2065 without modifications. You could add a leading `0` which is not in the erdi8 alphabet and can serve as a padding after 2065). The properties of `xid`s are kept as there is a bijective transformation via the int value of the 12 bytes of any xid.
```
$ python3
>>> from erdi8 import Erdi8
>>> from xid import Xid
>>> x = Xid()
# or, if you want to reproduce the below:
>>> x = Xid([100, 144, 152, 133, 98, 39, 69, 106, 189, 98, 39, 93])
>>> x.string()
'ci89h1b24t2mlfb24teg'
>>> x.value
[100, 144, 152, 133, 98, 39, 69, 106, 189, 98, 39, 93]
>>> e8 = Erdi8()
>>> e = e8.encode_int(int.from_bytes(x.value))
>>> e
'op34e9rackpsch39few'
>>> y = Xid(e8.decode_int('op34e9rackpsch39few').to_bytes(12))
>>> y.string()
'ci89h1b24t2mlfb24teg'
>>> e9 = Erdi8(safe=True)
>>> f = e9.encode_int(int.from_bytes(x.value))
>>> f
'n7dsv982t6dxymy4z5t3'
>>> z = Xid(e9.decode_int('n7dsv982t6dxymy4z5t3').to_bytes(12))
>>> z.string()
'ci89h1b24t2mlfb24teg'
```
### Advanced (encode bytes)
`erdi8`, by default works with integer representations. In particular, it represents any larger sequence of bytes as an integer. There are two main assumptions: 1) The size of the integers is usually small as one of the goals is concise identifiers. 2) The data is static and we are *not* considering streams of data (at the time of encoding the beginning we don't know the end yet). However, these assumptions may be wrong or may not hold for your use case. Therefore, we offer a method that can encode four bytes as erdi8 at a time. It results in junks of `erdi8` identifiers of length seven that can be concatenated if needed. The respective function is called `encode_four_bytes`.
```
$ python3
>>> from erdi8 import Erdi8
>>> e8 = Erdi8()
>>> e8.encode_four_bytes(bytes("erdi", "ascii"))
'bci7jr2'
>>> e8.decode_four_bytes('bci7jr2')
b'erdi'
>>> e9 = Erdi8(True)
>>> e9.encode_four_bytes(bytes("erdi", "ascii"))
'fjx2mt3'
>>> e9.decode_four_bytes('fjx2mt3')
b'erdi'
```
**NOTE**: These two methods are not compatible to the other `erdi8` functions. The integers behind the four byte junks are altered so that we ensure it will always result in a `erdi8` identifier character length of 7.
### Even more advanced
Run a light-weight erdi8 identifier service via [fasterid](https://github.com/athalhammer/fasterid)
## Test cases
```
$ python3 -m unittest test/erdi8_test.py
```
## FAQ
__Why should I use `erdi8` instead of [`shortuuid`](https://github.com/skorokithakis/shortuuid)?__
_There are multiple aspects to it: `shortuuid` with the normal alphabet contains upper and lowercase characters. In `erdi8` we avoid this (see below). There is the option to customize the alphabet of `shortuuid`: you could use the erdi8 alphabet for example. However, this leads to very long UUIDs. In this context, we find the following statement in the README particularly troublesome: "If 22 digits are too long for you, you can get shorter IDs by just truncating the string to the desired length.". This drops all beneficial stochastic properties of UUIDs and you need to run careful checks for potential identifier duplication. Here `erdi8` with its counting or "mod space counting" options has a significant advantage._
__Why no upper case characters?__
_Because we don't want to `erdi8` to be confused with `Erdi8`._
__Why no start with a number?__
_Because we want to avoid "number-only" identifiers. If we allowed to start with a number, we would have identifiers of the type `42` and `322` which could be mistaken for integers. We could achieve this with a more complex scheme avoiding any number-only combinations (would therefore still allow ids like `2z`, to be investigated). Further, certain technologies such as XML don't support element names that start with a number. In particular, QNAMES such as `asdf:123` are not allowed. Finally, it is important to note that programs like Excel are really creative when transforming input data, for example `08342 -> 8342`, `12e34 -> 12E+34`, `SEPT1 -> Sep-01` etc. erdi8 with the safe option on avoids 99% of these types of issues._
__How about combinations that form actual (bad) words?__
_This depends on the use case and the way erdi8 is used. Therefore, we can recommend to work with filter lists. In addition, an erdi8 object that avoids the `aeiou` characters can be created with `Erdi8(safe=True)`. This shrinks the available character space to 28 and the produced output is not compatible to `Erdi8(safe=False)` (default). The danger that unintended English words are created is lower with this setting. It is recommended for erdi8 identifiers that are longer than three characters where filter lists start to become impractical._
__How does this relate to binary-to-text encodings such as base32 and base64?__
_erdi8 can be used for a binary-to-text encoding and the basic functions to implement this are provided with `encode_int` and `decode_int`. However, the primary purpose is to provide a short counting scheme for identifiers._
__What could be a drawback of using erdi8?__
_It depends how you use it. If you use it to re-encode integer representations of other byte-array-like objects (secret numbers, hash digests, UUIDs, xids) it is likely that the length of the strings produced by erdi8 will vary. This variance may be predictable (for example with `xid`s) but can also cover larger ranges (secrets, hash digests, etc). A minimum and maximum length can be calculated given the number of bytes and the chosen erdi8 options (`safe=True` vs `safe=False`). At the moment we don't support padding as a built-in function. It depends on the use case to determine if it is necessary or not._
| PypiClean |
/verizon-ap-is-sdk-1.0.0.tar.gz/verizon-ap-is-sdk-1.0.0/verizon/models/v2_licenses_assigned_removed_result.py | from verizon.models.v2_device_status import V2DeviceStatus
class V2LicensesAssignedRemovedResult(object):
"""Implementation of the 'V2LicensesAssignedRemovedResult' model.
License assignment or removal confirmation.
Attributes:
account_name (string): Account name.
lic_total_count (int): Total license count.
lic_used_count (int): Assigned license count.
device_list (list of V2DeviceStatus): List of devices with id in
IMEI.
"""
# Create a mapping from Model property names to API property names
_names = {
"account_name": 'accountName',
"lic_total_count": 'licTotalCount',
"lic_used_count": 'licUsedCount',
"device_list": 'deviceList'
}
def __init__(self,
account_name=None,
lic_total_count=None,
lic_used_count=None,
device_list=None):
"""Constructor for the V2LicensesAssignedRemovedResult class"""
# Initialize members of the class
self.account_name = account_name
self.lic_total_count = lic_total_count
self.lic_used_count = lic_used_count
self.device_list = device_list
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
account_name = dictionary.get("accountName") if dictionary.get("accountName") else None
lic_total_count = dictionary.get("licTotalCount") if dictionary.get("licTotalCount") else None
lic_used_count = dictionary.get("licUsedCount") if dictionary.get("licUsedCount") else None
device_list = None
if dictionary.get('deviceList') is not None:
device_list = [V2DeviceStatus.from_dictionary(x) for x in dictionary.get('deviceList')]
# Return an object of this model
return cls(account_name,
lic_total_count,
lic_used_count,
device_list) | PypiClean |
/deescalate-0.1.2.tar.gz/deescalate-0.1.2/docs/static_build/html/readme.html | <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title><no title> — deescalate documentation</title>
<link rel="stylesheet" href="_static/readable.css" type="text/css" />
<link rel="stylesheet" href="_static/pygments.css" type="text/css" />
<script type="text/javascript">
var DOCUMENTATION_OPTIONS = {
URL_ROOT: './',
VERSION: '0.1',
COLLAPSE_INDEX: false,
FILE_SUFFIX: '.html',
HAS_SOURCE: true
};
</script>
<script type="text/javascript" src="_static/jquery.js"></script>
<script type="text/javascript" src="_static/underscore.js"></script>
<script type="text/javascript" src="_static/doctools.js"></script>
<link rel="top" title="deescalate documentation" href="index.html" />
<meta name="viewport" content="width=device-width, initial-scale=0.9, maximum-scale=0.9">
</head>
<body role="document">
<div class="related" role="navigation" aria-label="related navigation">
<h3>Navigation</h3>
<ul>
<li class="right" style="margin-right: 10px">
<a href="genindex.html" title="General Index"
accesskey="I">index</a></li>
<li class="right" >
<a href="py-modindex.html" title="Python Module Index"
>modules</a> |</li>
<li class="nav-item nav-item-0"><a href="index.html">deescalate</a> »</li>
</ul>
</div>
<div class="document">
<div class="documentwrapper">
<div class="bodywrapper">
<div class="body" role="main">
<p>Using linux capabilities to drop privileges in python.</p>
<p>Github project: <a class="reference external" href="https://github.com/stephane-martin/deescalate">https://github.com/stephane-martin/deescalate</a></p>
<p>Documentation: <a class="reference external" href="http://deescalate.readthedocs.org/">http://deescalate.readthedocs.org/</a></p>
<p>License: GNU LESSER GENERAL PUBLIC LICENSE v3</p>
</div>
</div>
</div>
<div class="sphinxsidebar" role="navigation" aria-label="main navigation">
<div class="sphinxsidebarwrapper">
<h3><a href="index.html">Table Of Contents</a></h3>
<ul>
<li class="toctree-l1"><a class="reference internal" href="overview.html">Overview</a></li>
<li class="toctree-l1"><a class="reference internal" href="installation.html">Installation</a></li>
<li class="toctree-l1"><a class="reference internal" href="api.html">deescalate API</a></li>
<li class="toctree-l1"><a class="reference internal" href="wrapper.html">Wrapper script</a></li>
<li class="toctree-l1"><a class="reference internal" href="authors.html">Credits</a></li>
<li class="toctree-l1"><a class="reference internal" href="history.html">History</a></li>
</ul>
<h3>Related Topics</h3>
<ul>
<li><a href="index.html">Documentation index</a><ul>
</ul></li>
</ul>
<div id="searchbox" style="display: none" role="search">
<h3>Quick search</h3>
<form class="search" action="search.html" method="get">
<input type="text" name="q" />
<input type="submit" value="Go" />
<input type="hidden" name="check_keywords" value="yes" />
<input type="hidden" name="area" value="default" />
</form>
<p class="searchtip" style="font-size: 90%">
Enter search terms or a module, class or function name.
</p>
</div>
<script type="text/javascript">$('#searchbox').show(0);</script>
</div>
</div>
<div class="clearer"></div>
</div>
<div class="footer">
© Copyright 2015, Stephane Martin.
Created using <a href="http://sphinx-doc.org/">Sphinx</a> 1.3.1.
</div>
</body>
</html> | PypiClean |
/imread_benchmark-0.0.5.tar.gz/imread_benchmark-0.0.5/imread_benchmark/benchmark.py | import argparse
import math
import random
import sys
from abc import ABC
from collections import defaultdict
from pathlib import Path
from timeit import Timer
from typing import Union
import cv2
import imageio
import jpeg4py
import numpy as np
import pandas as pd
import pkg_resources
import pyvips
import skimage
from PIL import Image
from tqdm import tqdm
def print_package_versions():
packages = ["opencv-python", "pillow-simd", "jpeg4py", "scikit-image", "imageio", "pyvips"]
package_versions = {"python": sys.version}
for package in packages:
try:
package_versions[package] = pkg_resources.get_distribution(package).version
except pkg_resources.DistributionNotFound:
pass
print(package_versions)
def format_results(images_per_second_for_read, show_std=False):
if images_per_second_for_read is None:
return "-"
result = str(math.floor(np.mean(images_per_second_for_read)))
if show_std:
result += " ± {}".format(math.ceil(np.std(images_per_second_for_read)))
return result
class BenchmarkTest(ABC):
def __str__(self):
return self.__class__.__name__
def run(self, library, image_paths: list):
operation = getattr(self, library)
for image in image_paths:
operation(image)
class GetSize(BenchmarkTest):
def PIL(self, image_path: str) -> tuple:
width, height = Image.open(image_path).size
return width, height
def opencv(self, image_path: str):
image = cv2.imread(image_path)
height, width = image.shape[:2]
return width, height
def jpeg4py(self, image_path: str) -> np.array:
image = jpeg4py.JPEG(image_path).decode()
height, width = image.shape[:2]
return width, height
def skimage(self, image_path: str) -> np.asarray:
image = skimage.io.imread(image_path, plugin="matplotlib")
height, width = image.shape[:2]
return width, height
def imageio(self, image_path: str) -> np.array:
image = imageio.imread(image_path)
height, width = image.shape[:2]
return width, height
def pyvips(self, image_path: str) -> np.array:
image = pyvips.Image.new_from_file(image_path, access="sequential")
return image.width, image.height
class GetArray(BenchmarkTest):
def PIL(self, image_path: str) -> np.array:
img = Image.open(image_path)
img = img.convert("RGB")
return np.asarray(img)
def opencv(self, image_path: str) -> np.array:
img = cv2.imread(image_path)
return cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
def jpeg4py(self, image_path: str) -> np.array:
return jpeg4py.JPEG(image_path).decode()
def skimage(self, image_path: str) -> np.array:
return skimage.io.imread(image_path, plugin="matplotlib")
def imageio(self, image_path: str) -> np.array:
return imageio.imread(image_path)
def pyvips(self, image_path: str) -> np.array:
image = pyvips.Image.new_from_file(image_path, access="sequential")
memory_image = image.write_to_memory()
numpy_image = np.ndarray(buffer=memory_image, dtype=np.uint8, shape=[image.height, image.width, image.bands])
return numpy_image
def benchmark(libraries: list, benchmarks: list, image_paths: list, num_runs: int, shuffle: bool) -> defaultdict:
images_per_second = defaultdict(dict)
num_images = len(image_paths)
for library in libraries:
pbar = tqdm(total=len(benchmarks))
for benchmark in benchmarks:
pbar.set_description("Current benchmark: {} | {}".format(library, benchmark))
if shuffle:
random.shuffle(image_paths)
timer = Timer(lambda: benchmark.run(library, image_paths))
run_times = timer.repeat(number=1, repeat=num_runs)
benchmark_images_per_second = [1 / (run_time / num_images) for run_time in run_times]
images_per_second[library][str(benchmark)] = benchmark_images_per_second
pbar.update(1)
pbar.close()
return images_per_second
def parse_args():
parser = argparse.ArgumentParser(description="Image reading libraries performance benchmark")
parser.add_argument("-d", "--data-dir", metavar="DIR", help="path to a directory with images")
parser.add_argument(
"-i",
"--num_images",
default=2000,
type=int,
metavar="N",
help="number of images for benchmarking (default: 2000)",
)
parser.add_argument(
"-r", "--num_runs", default=5, type=int, metavar="N", help="number of runs for each benchmark (default: 5)"
)
parser.add_argument(
"--show-std", dest="show_std", action="store_true", help="show standard deviation for benchmark runs"
)
parser.add_argument("-p", "--print-package-versions", action="store_true", help="print versions of packages")
parser.add_argument("-s", "--shuffle", action="store_true", help="Shuffle the list of images.")
return parser.parse_args()
def get_image_paths(data_dir: Union[str, Path], num_images: int) -> list:
image_paths = sorted(Path(data_dir).glob("*.*"))
return [str(x) for x in image_paths[:num_images]]
def main():
args = parse_args()
if args.print_package_versions:
print_package_versions()
benchmarks = [
# GetSize(),
GetArray()
]
libraries = ["opencv", "PIL", "jpeg4py", "skimage", "imageio", "pyvips"]
image_paths = get_image_paths(args.data_dir, args.num_images)
images_per_second = benchmark(libraries, benchmarks, image_paths, args.num_runs, args.shuffle)
pd.set_option("display.width", 1000)
df = pd.DataFrame.from_dict(images_per_second)
df = df.applymap(lambda r: format_results(r, args.show_std))
df = df[libraries]
print(df)
if __name__ == "__main__":
main() | PypiClean |
/latitude_python_sdk-2.6.6-py3-none-any.whl/latitude/models/shared/virtual_network.py | from __future__ import annotations
import dataclasses
from dataclasses_json import Undefined, dataclass_json
from enum import Enum
from latitude import utils
from typing import Optional
@dataclass_json(undefined=Undefined.EXCLUDE)
@dataclasses.dataclass
class VirtualNetworkAttributesRegionSite:
facility: Optional[str] = dataclasses.field(default=None, metadata={'dataclasses_json': { 'letter_case': utils.get_field_name('facility'), 'exclude': lambda f: f is None }})
id: Optional[int] = dataclasses.field(default=None, metadata={'dataclasses_json': { 'letter_case': utils.get_field_name('id'), 'exclude': lambda f: f is None }})
name: Optional[str] = dataclasses.field(default=None, metadata={'dataclasses_json': { 'letter_case': utils.get_field_name('name'), 'exclude': lambda f: f is None }})
slug: Optional[str] = dataclasses.field(default=None, metadata={'dataclasses_json': { 'letter_case': utils.get_field_name('slug'), 'exclude': lambda f: f is None }})
@dataclass_json(undefined=Undefined.EXCLUDE)
@dataclasses.dataclass
class VirtualNetworkAttributesRegion:
city: Optional[str] = dataclasses.field(default=None, metadata={'dataclasses_json': { 'letter_case': utils.get_field_name('city'), 'exclude': lambda f: f is None }})
country: Optional[str] = dataclasses.field(default=None, metadata={'dataclasses_json': { 'letter_case': utils.get_field_name('country'), 'exclude': lambda f: f is None }})
site: Optional[VirtualNetworkAttributesRegionSite] = dataclasses.field(default=None, metadata={'dataclasses_json': { 'letter_case': utils.get_field_name('site'), 'exclude': lambda f: f is None }})
@dataclass_json(undefined=Undefined.EXCLUDE)
@dataclasses.dataclass
class VirtualNetworkAttributes:
assignments_count: Optional[int] = dataclasses.field(default=None, metadata={'dataclasses_json': { 'letter_case': utils.get_field_name('assignments_count'), 'exclude': lambda f: f is None }})
description: Optional[str] = dataclasses.field(default=None, metadata={'dataclasses_json': { 'letter_case': utils.get_field_name('description'), 'exclude': lambda f: f is None }})
name: Optional[str] = dataclasses.field(default=None, metadata={'dataclasses_json': { 'letter_case': utils.get_field_name('name'), 'exclude': lambda f: f is None }})
region: Optional[VirtualNetworkAttributesRegion] = dataclasses.field(default=None, metadata={'dataclasses_json': { 'letter_case': utils.get_field_name('region'), 'exclude': lambda f: f is None }})
vid: Optional[int] = dataclasses.field(default=None, metadata={'dataclasses_json': { 'letter_case': utils.get_field_name('vid'), 'exclude': lambda f: f is None }})
class VirtualNetworkTypeEnum(str, Enum):
VIRTUAL_NETWORKS = "virtual_networks"
@dataclass_json(undefined=Undefined.EXCLUDE)
@dataclasses.dataclass
class VirtualNetwork:
attributes: Optional[VirtualNetworkAttributes] = dataclasses.field(default=None, metadata={'dataclasses_json': { 'letter_case': utils.get_field_name('attributes'), 'exclude': lambda f: f is None }})
id: Optional[str] = dataclasses.field(default=None, metadata={'dataclasses_json': { 'letter_case': utils.get_field_name('id'), 'exclude': lambda f: f is None }})
type: Optional[VirtualNetworkTypeEnum] = dataclasses.field(default=None, metadata={'dataclasses_json': { 'letter_case': utils.get_field_name('type'), 'exclude': lambda f: f is None }}) | PypiClean |
/injective_py-0.8rc0-py3-none-any.whl/pyinjective/proto/cosmwasm/wasm/v1/tx_pb2_grpc.py | """Client and server classes corresponding to protobuf-defined services."""
import grpc
from cosmwasm.wasm.v1 import tx_pb2 as cosmwasm_dot_wasm_dot_v1_dot_tx__pb2
class MsgStub(object):
"""Msg defines the wasm Msg service.
"""
def __init__(self, channel):
"""Constructor.
Args:
channel: A grpc.Channel.
"""
self.StoreCode = channel.unary_unary(
'/cosmwasm.wasm.v1.Msg/StoreCode',
request_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgStoreCode.SerializeToString,
response_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgStoreCodeResponse.FromString,
)
self.InstantiateContract = channel.unary_unary(
'/cosmwasm.wasm.v1.Msg/InstantiateContract',
request_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgInstantiateContract.SerializeToString,
response_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgInstantiateContractResponse.FromString,
)
self.InstantiateContract2 = channel.unary_unary(
'/cosmwasm.wasm.v1.Msg/InstantiateContract2',
request_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgInstantiateContract2.SerializeToString,
response_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgInstantiateContract2Response.FromString,
)
self.ExecuteContract = channel.unary_unary(
'/cosmwasm.wasm.v1.Msg/ExecuteContract',
request_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgExecuteContract.SerializeToString,
response_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgExecuteContractResponse.FromString,
)
self.MigrateContract = channel.unary_unary(
'/cosmwasm.wasm.v1.Msg/MigrateContract',
request_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgMigrateContract.SerializeToString,
response_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgMigrateContractResponse.FromString,
)
self.UpdateAdmin = channel.unary_unary(
'/cosmwasm.wasm.v1.Msg/UpdateAdmin',
request_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUpdateAdmin.SerializeToString,
response_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUpdateAdminResponse.FromString,
)
self.ClearAdmin = channel.unary_unary(
'/cosmwasm.wasm.v1.Msg/ClearAdmin',
request_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgClearAdmin.SerializeToString,
response_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgClearAdminResponse.FromString,
)
self.UpdateInstantiateConfig = channel.unary_unary(
'/cosmwasm.wasm.v1.Msg/UpdateInstantiateConfig',
request_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUpdateInstantiateConfig.SerializeToString,
response_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUpdateInstantiateConfigResponse.FromString,
)
self.UpdateParams = channel.unary_unary(
'/cosmwasm.wasm.v1.Msg/UpdateParams',
request_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUpdateParams.SerializeToString,
response_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUpdateParamsResponse.FromString,
)
self.SudoContract = channel.unary_unary(
'/cosmwasm.wasm.v1.Msg/SudoContract',
request_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgSudoContract.SerializeToString,
response_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgSudoContractResponse.FromString,
)
self.PinCodes = channel.unary_unary(
'/cosmwasm.wasm.v1.Msg/PinCodes',
request_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgPinCodes.SerializeToString,
response_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgPinCodesResponse.FromString,
)
self.UnpinCodes = channel.unary_unary(
'/cosmwasm.wasm.v1.Msg/UnpinCodes',
request_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUnpinCodes.SerializeToString,
response_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUnpinCodesResponse.FromString,
)
self.StoreAndInstantiateContract = channel.unary_unary(
'/cosmwasm.wasm.v1.Msg/StoreAndInstantiateContract',
request_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgStoreAndInstantiateContract.SerializeToString,
response_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgStoreAndInstantiateContractResponse.FromString,
)
class MsgServicer(object):
"""Msg defines the wasm Msg service.
"""
def StoreCode(self, request, context):
"""StoreCode to submit Wasm code to the system
"""
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
context.set_details('Method not implemented!')
raise NotImplementedError('Method not implemented!')
def InstantiateContract(self, request, context):
"""InstantiateContract creates a new smart contract instance for the given
code id.
"""
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
context.set_details('Method not implemented!')
raise NotImplementedError('Method not implemented!')
def InstantiateContract2(self, request, context):
"""InstantiateContract2 creates a new smart contract instance for the given
code id with a predictable address
"""
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
context.set_details('Method not implemented!')
raise NotImplementedError('Method not implemented!')
def ExecuteContract(self, request, context):
"""Execute submits the given message data to a smart contract
"""
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
context.set_details('Method not implemented!')
raise NotImplementedError('Method not implemented!')
def MigrateContract(self, request, context):
"""Migrate runs a code upgrade/ downgrade for a smart contract
"""
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
context.set_details('Method not implemented!')
raise NotImplementedError('Method not implemented!')
def UpdateAdmin(self, request, context):
"""UpdateAdmin sets a new admin for a smart contract
"""
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
context.set_details('Method not implemented!')
raise NotImplementedError('Method not implemented!')
def ClearAdmin(self, request, context):
"""ClearAdmin removes any admin stored for a smart contract
"""
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
context.set_details('Method not implemented!')
raise NotImplementedError('Method not implemented!')
def UpdateInstantiateConfig(self, request, context):
"""UpdateInstantiateConfig updates instantiate config for a smart contract
"""
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
context.set_details('Method not implemented!')
raise NotImplementedError('Method not implemented!')
def UpdateParams(self, request, context):
"""UpdateParams defines a governance operation for updating the x/wasm
module parameters. The authority is defined in the keeper.
Since: 0.40
"""
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
context.set_details('Method not implemented!')
raise NotImplementedError('Method not implemented!')
def SudoContract(self, request, context):
"""SudoContract defines a governance operation for calling sudo
on a contract. The authority is defined in the keeper.
Since: 0.40
"""
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
context.set_details('Method not implemented!')
raise NotImplementedError('Method not implemented!')
def PinCodes(self, request, context):
"""PinCodes defines a governance operation for pinning a set of
code ids in the wasmvm cache. The authority is defined in the keeper.
Since: 0.40
"""
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
context.set_details('Method not implemented!')
raise NotImplementedError('Method not implemented!')
def UnpinCodes(self, request, context):
"""UnpinCodes defines a governance operation for unpinning a set of
code ids in the wasmvm cache. The authority is defined in the keeper.
Since: 0.40
"""
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
context.set_details('Method not implemented!')
raise NotImplementedError('Method not implemented!')
def StoreAndInstantiateContract(self, request, context):
"""StoreAndInstantiateContract defines a governance operation for storing
and instantiating the contract. The authority is defined in the keeper.
Since: 0.40
"""
context.set_code(grpc.StatusCode.UNIMPLEMENTED)
context.set_details('Method not implemented!')
raise NotImplementedError('Method not implemented!')
def add_MsgServicer_to_server(servicer, server):
rpc_method_handlers = {
'StoreCode': grpc.unary_unary_rpc_method_handler(
servicer.StoreCode,
request_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgStoreCode.FromString,
response_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgStoreCodeResponse.SerializeToString,
),
'InstantiateContract': grpc.unary_unary_rpc_method_handler(
servicer.InstantiateContract,
request_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgInstantiateContract.FromString,
response_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgInstantiateContractResponse.SerializeToString,
),
'InstantiateContract2': grpc.unary_unary_rpc_method_handler(
servicer.InstantiateContract2,
request_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgInstantiateContract2.FromString,
response_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgInstantiateContract2Response.SerializeToString,
),
'ExecuteContract': grpc.unary_unary_rpc_method_handler(
servicer.ExecuteContract,
request_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgExecuteContract.FromString,
response_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgExecuteContractResponse.SerializeToString,
),
'MigrateContract': grpc.unary_unary_rpc_method_handler(
servicer.MigrateContract,
request_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgMigrateContract.FromString,
response_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgMigrateContractResponse.SerializeToString,
),
'UpdateAdmin': grpc.unary_unary_rpc_method_handler(
servicer.UpdateAdmin,
request_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUpdateAdmin.FromString,
response_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUpdateAdminResponse.SerializeToString,
),
'ClearAdmin': grpc.unary_unary_rpc_method_handler(
servicer.ClearAdmin,
request_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgClearAdmin.FromString,
response_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgClearAdminResponse.SerializeToString,
),
'UpdateInstantiateConfig': grpc.unary_unary_rpc_method_handler(
servicer.UpdateInstantiateConfig,
request_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUpdateInstantiateConfig.FromString,
response_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUpdateInstantiateConfigResponse.SerializeToString,
),
'UpdateParams': grpc.unary_unary_rpc_method_handler(
servicer.UpdateParams,
request_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUpdateParams.FromString,
response_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUpdateParamsResponse.SerializeToString,
),
'SudoContract': grpc.unary_unary_rpc_method_handler(
servicer.SudoContract,
request_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgSudoContract.FromString,
response_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgSudoContractResponse.SerializeToString,
),
'PinCodes': grpc.unary_unary_rpc_method_handler(
servicer.PinCodes,
request_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgPinCodes.FromString,
response_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgPinCodesResponse.SerializeToString,
),
'UnpinCodes': grpc.unary_unary_rpc_method_handler(
servicer.UnpinCodes,
request_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUnpinCodes.FromString,
response_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUnpinCodesResponse.SerializeToString,
),
'StoreAndInstantiateContract': grpc.unary_unary_rpc_method_handler(
servicer.StoreAndInstantiateContract,
request_deserializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgStoreAndInstantiateContract.FromString,
response_serializer=cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgStoreAndInstantiateContractResponse.SerializeToString,
),
}
generic_handler = grpc.method_handlers_generic_handler(
'cosmwasm.wasm.v1.Msg', rpc_method_handlers)
server.add_generic_rpc_handlers((generic_handler,))
# This class is part of an EXPERIMENTAL API.
class Msg(object):
"""Msg defines the wasm Msg service.
"""
@staticmethod
def StoreCode(request,
target,
options=(),
channel_credentials=None,
call_credentials=None,
insecure=False,
compression=None,
wait_for_ready=None,
timeout=None,
metadata=None):
return grpc.experimental.unary_unary(request, target, '/cosmwasm.wasm.v1.Msg/StoreCode',
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgStoreCode.SerializeToString,
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgStoreCodeResponse.FromString,
options, channel_credentials,
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
@staticmethod
def InstantiateContract(request,
target,
options=(),
channel_credentials=None,
call_credentials=None,
insecure=False,
compression=None,
wait_for_ready=None,
timeout=None,
metadata=None):
return grpc.experimental.unary_unary(request, target, '/cosmwasm.wasm.v1.Msg/InstantiateContract',
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgInstantiateContract.SerializeToString,
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgInstantiateContractResponse.FromString,
options, channel_credentials,
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
@staticmethod
def InstantiateContract2(request,
target,
options=(),
channel_credentials=None,
call_credentials=None,
insecure=False,
compression=None,
wait_for_ready=None,
timeout=None,
metadata=None):
return grpc.experimental.unary_unary(request, target, '/cosmwasm.wasm.v1.Msg/InstantiateContract2',
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgInstantiateContract2.SerializeToString,
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgInstantiateContract2Response.FromString,
options, channel_credentials,
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
@staticmethod
def ExecuteContract(request,
target,
options=(),
channel_credentials=None,
call_credentials=None,
insecure=False,
compression=None,
wait_for_ready=None,
timeout=None,
metadata=None):
return grpc.experimental.unary_unary(request, target, '/cosmwasm.wasm.v1.Msg/ExecuteContract',
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgExecuteContract.SerializeToString,
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgExecuteContractResponse.FromString,
options, channel_credentials,
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
@staticmethod
def MigrateContract(request,
target,
options=(),
channel_credentials=None,
call_credentials=None,
insecure=False,
compression=None,
wait_for_ready=None,
timeout=None,
metadata=None):
return grpc.experimental.unary_unary(request, target, '/cosmwasm.wasm.v1.Msg/MigrateContract',
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgMigrateContract.SerializeToString,
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgMigrateContractResponse.FromString,
options, channel_credentials,
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
@staticmethod
def UpdateAdmin(request,
target,
options=(),
channel_credentials=None,
call_credentials=None,
insecure=False,
compression=None,
wait_for_ready=None,
timeout=None,
metadata=None):
return grpc.experimental.unary_unary(request, target, '/cosmwasm.wasm.v1.Msg/UpdateAdmin',
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUpdateAdmin.SerializeToString,
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUpdateAdminResponse.FromString,
options, channel_credentials,
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
@staticmethod
def ClearAdmin(request,
target,
options=(),
channel_credentials=None,
call_credentials=None,
insecure=False,
compression=None,
wait_for_ready=None,
timeout=None,
metadata=None):
return grpc.experimental.unary_unary(request, target, '/cosmwasm.wasm.v1.Msg/ClearAdmin',
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgClearAdmin.SerializeToString,
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgClearAdminResponse.FromString,
options, channel_credentials,
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
@staticmethod
def UpdateInstantiateConfig(request,
target,
options=(),
channel_credentials=None,
call_credentials=None,
insecure=False,
compression=None,
wait_for_ready=None,
timeout=None,
metadata=None):
return grpc.experimental.unary_unary(request, target, '/cosmwasm.wasm.v1.Msg/UpdateInstantiateConfig',
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUpdateInstantiateConfig.SerializeToString,
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUpdateInstantiateConfigResponse.FromString,
options, channel_credentials,
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
@staticmethod
def UpdateParams(request,
target,
options=(),
channel_credentials=None,
call_credentials=None,
insecure=False,
compression=None,
wait_for_ready=None,
timeout=None,
metadata=None):
return grpc.experimental.unary_unary(request, target, '/cosmwasm.wasm.v1.Msg/UpdateParams',
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUpdateParams.SerializeToString,
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUpdateParamsResponse.FromString,
options, channel_credentials,
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
@staticmethod
def SudoContract(request,
target,
options=(),
channel_credentials=None,
call_credentials=None,
insecure=False,
compression=None,
wait_for_ready=None,
timeout=None,
metadata=None):
return grpc.experimental.unary_unary(request, target, '/cosmwasm.wasm.v1.Msg/SudoContract',
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgSudoContract.SerializeToString,
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgSudoContractResponse.FromString,
options, channel_credentials,
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
@staticmethod
def PinCodes(request,
target,
options=(),
channel_credentials=None,
call_credentials=None,
insecure=False,
compression=None,
wait_for_ready=None,
timeout=None,
metadata=None):
return grpc.experimental.unary_unary(request, target, '/cosmwasm.wasm.v1.Msg/PinCodes',
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgPinCodes.SerializeToString,
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgPinCodesResponse.FromString,
options, channel_credentials,
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
@staticmethod
def UnpinCodes(request,
target,
options=(),
channel_credentials=None,
call_credentials=None,
insecure=False,
compression=None,
wait_for_ready=None,
timeout=None,
metadata=None):
return grpc.experimental.unary_unary(request, target, '/cosmwasm.wasm.v1.Msg/UnpinCodes',
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUnpinCodes.SerializeToString,
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgUnpinCodesResponse.FromString,
options, channel_credentials,
insecure, call_credentials, compression, wait_for_ready, timeout, metadata)
@staticmethod
def StoreAndInstantiateContract(request,
target,
options=(),
channel_credentials=None,
call_credentials=None,
insecure=False,
compression=None,
wait_for_ready=None,
timeout=None,
metadata=None):
return grpc.experimental.unary_unary(request, target, '/cosmwasm.wasm.v1.Msg/StoreAndInstantiateContract',
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgStoreAndInstantiateContract.SerializeToString,
cosmwasm_dot_wasm_dot_v1_dot_tx__pb2.MsgStoreAndInstantiateContractResponse.FromString,
options, channel_credentials,
insecure, call_credentials, compression, wait_for_ready, timeout, metadata) | PypiClean |
/NEURON_gpu_nightly-8.2a7-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl/neuron/rxd/geometry.py | import warnings
import numpy
from neuron import h, nrn
from .rxdException import RxDException
try:
from neuron.rxd import geometry3d
has_geometry3d = True
except ImportError:
has_geometry3d = False
class RxDGeometry:
def volumes1d(self, sec):
raise RxDException("volume1d unimplemented")
def surface_areas1d(self, sec):
raise RxDException("surface_areas1d unimplemented")
def neighbor_areas1d(self, sec):
raise RxDException("neighbor_areas1d unimplemented")
def is_volume(self):
raise RxDException("is_volume unimplemented")
def is_area(self):
raise RxDException("is_area unimplemented")
def __call__(self):
"""calling returns self to allow for rxd.inside or rxd.inside()"""
return self
def _volumes1d(sec):
if not isinstance(sec, nrn.Section):
sec = sec._sec
arc3d = [sec.arc3d(i) for i in range(sec.n3d())]
diam3d = [sec.diam3d(i) for i in range(sec.n3d())]
vols = numpy.zeros(sec.nseg)
dx = sec.L / sec.nseg
for iseg in range(sec.nseg):
# get a list of all pts in the segment, including end points
lo = iseg * dx
hi = (iseg + 1) * dx
pts = [lo] + [x for x in arc3d if lo < x < hi] + [hi]
diams = numpy.interp(pts, arc3d, diam3d)
# sum the volume of the constituent frusta
volume = 0
for i in range(len(pts) - 1):
diam0, diam1 = diams[i : i + 2]
pt0, pt1 = pts[i : i + 2]
volume += (
numpy.pi
* (pt1 - pt0)
/ 12.0
* (diam0**2 + diam0 * diam1 + diam1**2)
)
vols[iseg] = volume
return vols
def _make_surfacearea1d_function(scale, diam_scale=1.0):
def result(sec):
if not isinstance(sec, nrn.Section):
sec = sec._sec
arc3d = [sec.arc3d(i) for i in range(sec.n3d())]
diam3d = [sec.diam3d(i) * diam_scale for i in range(sec.n3d())]
sas = numpy.zeros(sec.nseg)
dx = sec.L / sec.nseg
for iseg in range(sec.nseg):
# get a list of all pts in the segment, including end points
lo = iseg * dx
hi = (iseg + 1) * dx
pts = [lo] + [x for x in arc3d if lo < x < hi] + [hi]
diams = numpy.interp(pts, arc3d, diam3d)
# sum the surface areas of the constituent frusta
sa = 0
for i in range(len(pts) - 1):
diam0, diam1 = diams[i : i + 2]
pt0, pt1 = pts[i : i + 2]
sa += (
scale
* 0.5
* (diam0 + diam1)
* numpy.sqrt(0.25 * (diam0 - diam1) ** 2 + (pt1 - pt0) ** 2)
)
sas[iseg] = sa
return sas
return result
def _make_perimeter_function(scale, diam_scale=1.0):
def result(sec):
if not isinstance(sec, nrn.Section):
sec = sec._sec
arc3d = [sec.arc3d(i) for i in range(sec.n3d())]
diam3d = [sec.diam3d(i) * diam_scale for i in range(sec.n3d())]
area_pos = numpy.linspace(0, sec.L, sec.nseg + 1)
diams = numpy.interp(area_pos, arc3d, diam3d)
return scale * diams
return result
_surface_areas1d = _make_surfacearea1d_function(numpy.pi)
_perimeter1d = _make_perimeter_function(numpy.pi)
def _neighbor_areas1d(sec):
if not isinstance(sec, nrn.Section):
sec = sec._sec
arc3d = [sec.arc3d(i) for i in range(sec.n3d())]
diam3d = [sec.diam3d(i) for i in range(sec.n3d())]
area_pos = numpy.linspace(0, sec.L, sec.nseg + 1)
diams = numpy.interp(area_pos, arc3d, diam3d)
return numpy.pi * 0.25 * diams**2
def constant_function_per_length(value):
return lambda sec: [value * sec.L / sec.nseg for i in range(sec.nseg)]
def constant_everywhere_1d(value):
return lambda sec: value * numpy.ones(sec.nseg)
def constant_everywhere_plus_one_1d(value):
return lambda sec: value * numpy.ones(sec.nseg + 1)
def constant_function(value):
return lambda *args, **kwargs: value
def scale_by_constant(scale, f):
return lambda *args, **kwargs: scale * f(*args, **kwargs)
_always_true = constant_function(True)
_always_false = constant_function(False)
_always_0 = constant_function(0)
inside = RxDGeometry()
if has_geometry3d:
inside.volumes3d = geometry3d.voxelize2
# neighbor_area_fraction can be a constant or a function
inside.neighbor_area_fraction = 1
inside.volumes1d = _volumes1d
inside.surface_areas1d = _surface_areas1d
inside.neighbor_areas1d = _neighbor_areas1d
inside.is_volume = _always_true
inside.is_area = _always_false
inside.__repr__ = constant_function("inside")
# TODO: make a version that allows arbitrary shells?
membrane = RxDGeometry()
membrane.volumes1d = _surface_areas1d
membrane.surface_areas1d = _always_0
membrane.neighbor_areas1d = _perimeter1d
membrane.is_volume = _always_false
membrane.is_area = _always_true
membrane.__repr__ = constant_function("membrane")
class Enum:
"""a silly way of creating unique identifiers without using/allowing/requiring magic constants"""
pass
_lo_hi_shell = Enum()
class DistributedBoundary(RxDGeometry):
"""Boundary that scales with area.
DistributedBoundary(area_per_vol, perim_per_area=0)
area_per_vol is the area of the boundary as a function of the volume
containing it. e.g.
g = DistributedBoundary(2) defines a geometry with 2 um^2 of area per
every um^3 of volume.
perim_per_area is the perimeter (in um) per 1 um^2 cross section of the
volume. For use in reaction-diffusion problems, it may be safely omitted
if and only if no species in the corresponding region diffuses.
This is often useful for separating FractionalVolume objects.
It is assumed that the area is always strictly on the interior.
"""
def __init__(self, area_per_vol, perim_per_area=0):
self._area_per_vol = area_per_vol
self._perim_per_area = 0
self.surface_areas1d = _always_0
self.neighbor_areas1d = scale_by_constant(perim_per_area, _neighbor_areas1d)
self.volumes1d = scale_by_constant(area_per_vol, _volumes1d)
self.is_volume = _always_false
self.is_area = _always_true
@property
def neighbor_area_fraction(self):
# TODO: validate that this gives consistent results between 1D and 3D
return self._perim_per_area
def volumes3d(
self,
source,
dx=0.25,
xlo=None,
xhi=None,
ylo=None,
yhi=None,
zlo=None,
zhi=None,
n_soma_step=100,
):
# mesh, surface_areas, volumes, triangles = geometry3d.voxelize2(source, dx=dx)
# volumes._values *= self._area_per_vol # volume on 2D boundaries is actually the area; the amount of space for holding things
# surface_areas._values *= 0
# return mesh, surface_areas, volumes, triangles
internal_voxels, surface_voxels, mesh_grid = geometry3d.voxelize2(source, dx=dx)
area_per_vol = self._area_per_vol
for key in internal_voxels:
internal_voxels[key][0] *= area_per_vol
for key in surface_voxels:
surface_voxels[key][0] *= area_per_vol
return internal_voxels, surface_voxels, mesh_grid
def __repr__(self):
if self._perim_per_area == 0:
return "DistributedBoundary(%g)" % (self._area_per_vol)
else:
return "DistributedBoundary(%g, perim_per_area=%g)" % (
self._area_per_vol,
self._perim_per_area,
)
class FractionalVolume(RxDGeometry):
def __init__(
self, volume_fraction=1, surface_fraction=0, neighbor_areas_fraction=None
):
if neighbor_areas_fraction is None:
neighbor_areas_fraction = volume_fraction
if surface_fraction == 0:
self.surface_areas1d = _always_0
elif surface_fraction == 1:
self.surface_areas1d = _surface_areas1d
else:
self.surface_areas1d = scale_by_constant(surface_fraction, _surface_areas1d)
# TODO: add the if statement so not scaling if 0 or 1
self.neighbor_areas1d = scale_by_constant(
neighbor_areas_fraction, _neighbor_areas1d
)
self.volumes1d = scale_by_constant(volume_fraction, _volumes1d)
self.is_volume = _always_true
self.is_area = _always_false
self._volume_fraction = volume_fraction
self._surface_fraction = surface_fraction
self._neighbor_areas_fraction = neighbor_areas_fraction
# TODO: does the else case ever make sense?
self.neighbor_area_fraction = (
volume_fraction
if neighbor_areas_fraction is None
else neighbor_areas_fraction
)
def volumes3d(
self,
source,
dx=0.25,
xlo=None,
xhi=None,
ylo=None,
yhi=None,
zlo=None,
zhi=None,
n_soma_step=100,
):
# mesh, surface_areas, volumes, triangles = geometry3d.voxelize2(source, dx=dx)
# surface_areas._values *= self._surface_fraction
# volumes._values *= self._volume_fraction
# return mesh, surface_areas, volumes, triangles
internal_voxels, surface_voxels, mesh_grid = geometry3d.voxelize2(source, dx=dx)
volume_fraction = self._volume_fraction
for key in internal_voxels:
internal_voxels[key][0] *= volume_fraction
for key in surface_voxels:
surface_voxels[key][0] *= volume_fraction
return internal_voxels, surface_voxels, mesh_grid
def __repr__(self):
return (
"FractionalVolume(volume_fraction=%r, surface_fraction=%r, neighbor_areas_fraction=%r)"
% (
self._volume_fraction,
self._surface_fraction,
self._neighbor_areas_fraction,
)
)
# TODO: eliminate this class and replace with FixedCrossSection?
class ConstantVolume(RxDGeometry):
# TODO: do we want different default neighbor_area?
def __init__(self, volume=1, surface_area=0, neighbor_area=1):
"""volume, surface_area per unit length"""
self.volumes1d = constant_function_per_length(volume)
self.surface_areas1d = constant_function_per_length(surface_area)
self.is_volume = _always_true
self.is_area = _always_false
self.neighbor_areas1d = constant_everywhere_plus_one_1d(neighbor_area)
class FixedCrossSection(RxDGeometry):
def __init__(self, cross_area, surface_area=0):
self.volumes1d = constant_function_per_length(cross_area)
self.surface_areas1d = constant_function_per_length(surface_area)
self.is_volume = _always_true
self.is_area = _always_false
self.neighbor_areas1d = constant_everywhere_plus_one_1d(cross_area)
self._cross_area = cross_area
self._surface_area = surface_area
def __repr__(self):
return "FixedCrossSection(%r, surface_area=%r)" % (
self._cross_area,
self._surface_area,
)
class FixedPerimeter(RxDGeometry):
def __init__(self, perimeter, on_cell_surface=False):
self.volumes1d = constant_function_per_length(perimeter)
self.surface_areas1d = _always_0 if not on_cell_surface else self.volumes1d
self._perim = perimeter
self.is_volume = _always_false
self.is_area = _always_true
self._on_surface = on_cell_surface
def neighbor_areas1d(self, sec):
return [self._perim] * (sec.nseg + 1)
def __repr__(self):
return "FixedPerimeter(%r, on_cell_surface=%r)" % (
self._perim,
self._on_surface,
)
class ScalableBorder(RxDGeometry):
"""a membrane that scales proportionally with the diameter.
Example use:
- the boundary between radial shells e.g.
ScalableBorder(diam_scale=0.5) could represent the border of
Shell(lo=0, hi=0.5)
Args:
scale (float, optional) scale the area, default value is π.
e.g. for a cylinder of length L and diameter d, ScalableBorder will
give an area scale*d*L, by default the surface area.
For cylindrical sections only. Use "diam_scale" instead to correctly
handle cylindrical and non-cylindrical sections.
diam_scale (float, optional), scale the diameter, default value is 1.
e.g. for a cylinder of length L and diameter d, ScalableBorder will
give an area diam_scale*π*d*L, by default the surface area.
Note: Provide either a scale or diam_scale, not both.
Sometimes useful for the boundary between FractionalVolume objects, but
see also DistributedBoundary which scales with area.
"""
def __init__(self, scale=None, diam_scale=None, on_cell_surface=False):
if scale is not None and diam_scale is not None:
raise RxDException(
"ScalableBorder either provide scale or diam_scale, not both"
)
elif diam_scale is not None:
self._scale = numpy.pi
self._diam_scale = diam_scale
elif scale is not None:
self._scale = scale
self._diam_scale = 1.0
else:
self._scale = numpy.pi
self._diam_scale = 1.0
self.volumes1d = _make_surfacearea1d_function(self._scale, self._diam_scale)
self.surface_areas1d = _always_0 if not on_cell_surface else self.volumes1d
self.is_volume = _always_false
self.is_area = _always_true
self.neighbor_areas1d = _make_perimeter_function(self._scale, self._diam_scale)
self._on_surface = on_cell_surface
def __repr__(self):
return "ScalableBorder(%r, on_cell_surface=%r)" % (
self._scale,
self._on_surface,
)
# TODO: remove this, use FixedPerimeter instead?
class ConstantArea(RxDGeometry):
def __init__(self, area=1, perim=1, on_cell_surface=False):
# TODO: fix this
warnings.warn("ConstantArea probably not right")
self.volumes1d = constant_function(area)
self.surface_areas1d = (
_always_0 if not on_cell_surface else constant_function(area)
)
self._perim = perim
self.is_volume = _always_false
self.is_area = _always_true
def neighbor_areas1d(self, sec):
return [self._perim] * (sec.nseg + 1)
# TODO: is there a better name than Shell?
class Shell(RxDGeometry):
def __init__(self, lo=None, hi=None):
if lo is None or hi is None:
raise RxDException("only Shells with a lo and hi are supported for now")
if lo > hi:
lo, hi = hi, lo
if lo == hi:
raise RxDException("Shell objects must have thickness")
self._type = _lo_hi_shell
self._lo = lo
self._hi = hi
if lo == 1 or hi == 1:
self.surface_areas1d = _surface_areas1d
elif lo < 1 < hi:
raise RxDException(
"shells may not cross the membrane; i.e. 1 cannot lie strictly between lo and hi"
)
else:
# TODO: is this what we want; e.g. what if lo < 1 < hi?
self.surface_areas1d = _always_0
def __repr__(self):
return "Shell(lo=%r, hi=%r)" % (self._lo, self._hi)
def neighbor_areas1d(self, sec):
if not isinstance(sec, nrn.Section):
sec = sec._sec
arc3d = [sec.arc3d(i) for i in range(sec.n3d())]
diam3d = [sec.diam3d(i) for i in range(sec.n3d())]
area_pos = numpy.linspace(0, sec.L, sec.nseg + 1)
diams = numpy.interp(area_pos, arc3d, diam3d)
if self._type == _lo_hi_shell:
return numpy.pi * 0.25 * ((diams * self._hi) ** 2 - (diams * self._lo) ** 2)
def is_volume(self):
return True
def is_area(self):
return False
def volumes1d(self, sec):
if not isinstance(sec, nrn.Section):
sec = sec._sec
arc3d = [sec.arc3d(i) for i in range(sec.n3d())]
diam3d = [sec.diam3d(i) for i in range(sec.n3d())]
vols = numpy.zeros(sec.nseg)
dx = sec.L / sec.nseg
for iseg in range(sec.nseg):
# get a list of all pts in the segment, including end points
lo = iseg * dx
hi = (iseg + 1) * dx
pts = [lo] + [x for x in arc3d if lo < x < hi] + [hi]
diams = numpy.interp(pts, arc3d, diam3d)
# sum the volume of the constituent frusta, hollowing out by the inside
volume = 0
for i in range(len(pts) - 1):
diam0h, diam1h = self._hi * diams[i : i + 2]
diam0l, diam1l = self._lo * diams[i : i + 2]
pt0, pt1 = pts[i : i + 2]
volume += (
numpy.pi
* (pt1 - pt0)
/ 12.0
* (
(diam0h**2 + diam0h * diam1h + diam1h**2)
- (diam0l**2 + diam0l * diam1l + diam1l**2)
)
)
vols[iseg] = volume
return vols
class MultipleGeometry(RxDGeometry):
"""support for different geometries on different sections of a region.
Example use:
- for radial diffusion in a dendrite (dend) with longitudinal diffusion
from a spine (spine). The region for the outer shell of the dendrite
(0.8,1] should include the while spine [0,1];
MultipleGeometry(secs=[dend,spine], geos=[Shell(0.8,1), rxd.inside])
Args:
sections (list, optional) a list or list-of-lists of sections where the
corresponding geometry should be used. If None the same geometry used
for all sections, otherwise the list must be the same length as the
geos list.
If None is in the list, then the corresponding geometry in geos is used
as a default value for any section not included in the lists.
geometries (list) a list of geometries that are used for the corresponding
list of sections in secs. All geometries must be volumes or all
all geometries must be areas.
"""
def __init__(self, secs=None, geos=None):
self._secs = {}
self._default = None
if not secs:
if isinstance(geos, list):
self._default = geos[0]
elif isinstance(geos, RxDGeometry):
self._default = geos
else:
raise RxDException(
"MultipleGeometry requires a list-of-lists of sections and their corresponding geometry"
)
else:
assert len(secs) == len(geos)
if all([g.is_area() for g in geos]):
self.is_area = _always_true
self.is_volume = _always_false
elif all([g.is_volume() for g in geos]):
self.is_area = _always_false
self.is_volume = _always_true
else:
raise RxDException(
"MultipleGeometry requires all geometries are areas or all geometries are volumes"
)
for s, g in zip(secs, geos):
if not s:
self._default = g
elif isinstance(s, list):
self._secs[h.SectionList(s)] = g
else:
self._secs[h.SectionList([s])] = g
def __repr__(self):
secs = [[s for s in sl] for sl in self._secs]
geos = [self._secs[sl] for sl in self._secs]
return "MultipleGeometry(secs=%r, geos=%r)" % (secs, geos)
def _get_geo(self, sec):
if not isinstance(sec, nrn.Section):
sec = sec._sec
for sl in self._secs:
if sec in sl:
geo = self._secs[sl]
break
else:
if self._default:
geo = self._default
else:
raise RxDException(
"MultipleGeometry is not defined on section %r" % sec
)
return geo
def volumes1d(self, sec):
return self._get_geo(sec).volumes1d(sec)
def surface_areas1d(self, sec):
return self._get_geo(sec).surface_areas1d(sec)
def neighbor_areas1d(self, sec):
return self._get_geo(sec).neighbor_areas1d(sec) | PypiClean |
/interference_calculator-1.0.0.tar.gz/interference_calculator-1.0.0/interference_calculator/update_periodic_table.py | import pandas as pd
import requests
mass_url = 'http://ciaaw.org/atomic-masses.htm'
abun_url = ' https://www.degruyter.com/table/j/pac.2016.88.issue-3/pac-2015-0503/pac-2015-0503.xml?id=j_pac-2015-0503_tab_001'
output = 'periodic_table.csv'
# Set to True to read from local files, useful for debugging.
_debug = False
### Mass table
if _debug:
mass = pd.read_html('devel/mass_ciaaw.html', encoding='utf-8')[0]
else:
req = requests.get(mass_url)
mass = pd.read_html(req.text, encoding=req.encoding)[0]
mass = mass.drop(mass.index[-1])
# HTML table has rowspans, read_html does not handle it correctly.
# First 3 columns should be empty (NaN) for minor isotopes of the
# same parent element, but A and mass are in columns 0 and 1, resp.
# Split into two based on symbol == NaN, reorganize, concat back together.
mass.columns = ['atomic number', 'element', 'element name', 'atomic mass', 'mass']
partA = mass[mass['element name'].isnull()]
partA = partA[['element name', 'atomic mass', 'mass', 'atomic number', 'element']]
partA.columns = ['atomic number', 'element', 'element name', 'atomic mass', 'mass']
partB = mass[mass['element name'].notnull()]
mass = pd.concat([partA, partB]).sort_index()
mass = mass.fillna(method='pad')
mass['atomic number'] = pd.to_numeric(mass['atomic number'])
mass['atomic mass'] = pd.to_numeric(mass['atomic mass'].str.strip('*'))
# \xa0 is utf-8 encoded non-breaking space
mass['mass'] = pd.to_numeric(mass['mass'].str.split('(').str[0].str.replace('\xa0', ''))
# Add isotope column
atomic_mass = mass['atomic mass'].values
element = mass['element'].values
isotope = [str(am) + el for am, el in zip(atomic_mass, element)]
mass['isotope'] = isotope
### Abundance table
if _debug:
abun = pd.read_html('devel/abun_ciaaw.html', encoding='utf-8')[0]
else:
req = requests.get(abun_url)
abun = pd.read_html(req.text, encoding=req.encoding)[0]
abun.columns = ['atomic number', 'element', 'atomic mass', 'interval', 'annotation', 'abundance', 'reference', 'standard', 'interval2']
abun = abun[['atomic number', 'element', 'atomic mass', 'abundance', 'standard']]
# No data for Po, At, Rn, Fr, Ra, Ac, also missing from mass table.
abun = abun.drop(abun[abun['element'].isin(['Po', 'At', 'Rn', 'Fr', 'Ra', 'Ac'])].index)
abun.index = range(abun.shape[0])
# No data for Tc and Pm, but want to keep.
idx = abun[abun['element'] == 'Tc'].index
abun.loc[idx] = [43, 'Tc', 98, '0.0', '']
idx = abun[abun['element'] == 'Pm'].index
abun.loc[idx] = [61, 'Pm', 145, '0.0', '']
abun = abun.fillna(method='pad')
abun['atomic number'] = pd.to_numeric(abun['atomic number'])
abun['atomic mass'] = pd.to_numeric(abun['atomic mass'])
abun['abundance'] = pd.to_numeric(abun['abundance'].str.split('(').str[0].str.replace(' ', ''))
# \xe2\x80\x93 is utf-8 encoded en-dash
abun['standard'] = abun['standard'].str.strip('*').str.replace(b'\xe2\x80\x93'.decode('utf-8'), '')
# U233 missing, but listed in mass data, add.
u = abun.iloc[-1].copy()
u['atomic mass'] = 233
u['abundance'] = 0
abun = abun.append(u)
abun = abun.sort_values(['atomic number', 'atomic mass'])
abun.index = range(abun.shape[0])
### Merge
# Before merging, check that index, symbol, Z, and A are same.
if not mass.shape[0] == abun.shape[0]:
raise ValueError('Mass and abundance tables have different length.')
if not (mass.index == abun.index).all():
raise ValueError('Indices are not the same while merging mass and abundance tables.')
if not (mass['atomic number'] == abun['atomic number']).all():
raise ValueError('Atomic number (Z) not same for all entries while merging mass and abundance tables.')
if not (mass['atomic mass'] == abun['atomic mass']).all():
raise ValueError('Atomic mass (A) not same for all entries while merging mass and abundance tables.')
if not (mass['element'] == abun['element']).all():
raise ValueError('Element symbols are not same for all entries while merging mass and abundance tables.')
mass['abundance'] = abun['abundance']
mass['standard'] = abun['standard']
### Major isotope
# For each element, determine the major isotope, the isotope with the highest abundance.
elements = mass['element'].unique()
major_isotope = []
for el in elements:
el_slice = mass[mass['element'] == el]
major_mass = el_slice.sort_values('abundance', ascending=False).iloc[0].loc['atomic mass']
number_of_isotopes = el_slice.shape[0]
major_isotope.extend([str(major_mass) + el] * number_of_isotopes)
mass['major isotope'] = major_isotope
# Reorder columns
mass = mass[['atomic number', 'element', 'element name', 'major isotope',
'isotope', 'atomic mass', 'mass', 'abundance', 'standard']]
with open(output, mode='wt', encoding='utf-8') as fh:
mass.to_csv(fh, index=False) | PypiClean |
/py_gql-0.6.1-py3-none-any.whl/py_gql/validation/rules/__init__.py | from collections import defaultdict
from typing import Dict, List, Set, Tuple, cast
from ..._string_utils import infer_suggestions, quoted_options_list
from ..._utils import OrderedDict, deduplicate
from ...exc import UnknownType
from ...lang import ast as _ast, print_ast
from ...lang.visitor import SkipNode
from ...schema import (
GraphQLCompositeType,
GraphQLLeafType,
GraphQLType,
InterfaceType,
NonNullType,
ObjectType,
UnionType,
is_input_type,
unwrap_type,
)
from ..visitors import ValidationVisitor, VariablesCollector
from .overlapping_fields_can_be_merged import ( # noqa: F401
OverlappingFieldsCanBeMergedChecker,
)
from .values_of_correct_type import ValuesOfCorrectTypeChecker # noqa: F401
__all__ = (
"ExecutableDefinitionsChecker",
"UniqueOperationNameChecker",
"LoneAnonymousOperationChecker",
"SingleFieldSubscriptionsChecker",
"KnownTypeNamesChecker",
"FragmentsOnCompositeTypesChecker",
"VariablesAreInputTypesChecker",
"ScalarLeafsChecker",
"FieldsOnCorrectTypeChecker",
"UniqueFragmentNamesChecker",
"KnownFragmentNamesChecker",
"NoUnusedFragmentsChecker",
"PossibleFragmentSpreadsChecker",
"NoFragmentCyclesChecker",
"UniqueVariableNamesChecker",
"NoUndefinedVariablesChecker",
"NoUnusedVariablesChecker",
"KnownDirectivesChecker",
"UniqueDirectivesPerLocationChecker",
"KnownArgumentNamesChecker",
"UniqueArgumentNamesChecker",
"ValuesOfCorrectTypeChecker",
"ProvidedRequiredArgumentsChecker",
"VariablesInAllowedPositionChecker",
"OverlappingFieldsCanBeMergedChecker",
"UniqueInputFieldNamesChecker",
)
class ExecutableDefinitionsChecker(ValidationVisitor):
"""
A GraphQL document is only valid for execution if all definitions
are either operation or fragment definitions.
Unnecessary if parser was run with ``allow_type_system=False``.
"""
def enter_document(self, node):
skip_doc = False
for definition in node.definitions:
if not isinstance(definition, _ast.ExecutableDefinition):
name = (
"schema"
if isinstance(
definition,
(_ast.SchemaDefinition, _ast.SchemaExtension),
)
else definition.name.value
)
self.add_error(
"The %s definition is not executable." % name, [definition]
)
skip_doc = True
if skip_doc:
raise SkipNode()
class UniqueOperationNameChecker(ValidationVisitor):
"""
A GraphQL document is only valid if all defined operations have
unique names.
"""
def __init__(self, schema, type_info):
super(UniqueOperationNameChecker, self).__init__(schema, type_info)
self._names = set() # type: Set[str]
def enter_operation_definition(self, node):
op_name = node.name.value if node.name else node.operation
if op_name in self._names:
self.add_error('Duplicate operation "%s".' % op_name, [node])
raise SkipNode()
self._names.add(op_name)
class LoneAnonymousOperationChecker(ValidationVisitor):
"""
A GraphQL document is only valid if when it contains an anonymous
operation (the query short-hand) that it contains only that one
operation definition.
"""
def enter_document(self, node):
operation_definitions = [
d
for d in node.definitions
if isinstance(d, _ast.OperationDefinition)
]
has_anonymous = any((d.name is None for d in operation_definitions))
if has_anonymous and len(operation_definitions) > 1:
self.add_error(
"The anonymous operation must be the only defined operation.",
[node],
)
raise SkipNode()
class SingleFieldSubscriptionsChecker(ValidationVisitor):
"""
A GraphQL subscription is valid only if it contains a single
root field.
"""
def enter_operation_definition(self, node):
if node.operation == "subscription":
if len(node.selection_set.selections) != 1:
if node.name:
msg = (
'Subscription "%s" must select only one top level field.'
% node.name.value
)
else:
msg = "Subscription must select only one top level field."
self.add_error(msg, [node])
class KnownTypeNamesChecker(ValidationVisitor):
"""
A GraphQL document is only valid if referenced types (specifically
variable definitions and fragment conditions) are defined by the
type schema.
"""
def _skip(self, _):
raise SkipNode()
# Ignore type system defs
enter_object_type_definition = _skip
enter_interface_type_definition = _skip
enter_union_type_definition = _skip
enter_input_object_type_definition = _skip
def _enter_type_literal(self, node):
try:
self.schema.get_type_from_literal(node)
except UnknownType as err:
self.add_error('Unknown type "%s"' % err, [node])
enter_named_type = _enter_type_literal
enter_list_type = _enter_type_literal
enter_non_null_type = _enter_type_literal
class FragmentsOnCompositeTypesChecker(ValidationVisitor):
"""
Fragments use a type condition to determine if they apply, since
fragments can only be spread into a composite type (object, interface, or
union), the type condition must also be a composite type.
"""
def enter_inline_fragment(self, node):
if node.type_condition:
type_ = self.schema.get_type_from_literal(node.type_condition)
if not isinstance(type_, GraphQLCompositeType):
self.add_error(
'Fragment cannot condition on non composite type "%s".'
% type_,
[node.type_condition],
)
raise SkipNode()
def enter_fragment_definition(self, node):
type_ = self.schema.get_type_from_literal(node.type_condition)
if not isinstance(type_, GraphQLCompositeType):
self.add_error(
'Fragment "%s" cannot condition on non composite type "%s".'
% (node.name.value, type_),
[node.type_condition],
)
raise SkipNode()
class VariablesAreInputTypesChecker(ValidationVisitor):
"""
A GraphQL operation is only valid if all the variables it defines are of
input types (scalar, enum, or input object).
"""
def enter_variable_definition(self, node):
def _err():
self.add_error(
'Variable "$%s" must be input type' % node.variable.name.value,
[node],
)
try:
type_ = self.schema.get_type_from_literal(node.type)
except UnknownType:
_err()
else:
if not is_input_type(type_):
_err()
class ScalarLeafsChecker(ValidationVisitor):
"""
A GraphQL document is valid only if all leaf fields (fields without
sub selections) are of scalar or enum types.
"""
def enter_field(self, node):
type_ = self.type_info.type
if (
isinstance(
unwrap_type(type_) if type_ is not None else None,
GraphQLLeafType,
)
and node.selection_set
):
self.add_error(
'Field "%s" must not have a selection since type "%s" has no subfields.'
% (node.name.value, type_),
[node],
)
if (
isinstance(
unwrap_type(type_) if type_ is not None else None,
GraphQLCompositeType,
)
and not node.selection_set
):
self.add_error(
'Field "%s" of type "%s" must have a selection of subfields. '
'Did you mean "%s { ... }"?'
% (node.name.value, type_, node.name.value),
[node],
)
class FieldsOnCorrectTypeChecker(ValidationVisitor):
"""
A GraphQL document is only valid if all fields selected are defined by
the parent type, or are an allowed meta field such as __typename.
"""
def enter_field(self, node):
if self.type_info.parent_type is None:
return
field_def = self.type_info.field
if field_def is None:
if isinstance(
self.type_info.parent_type, (ObjectType, InterfaceType)
):
fieldnames = [f.name for f in self.type_info.parent_type.fields]
suggestions = infer_suggestions(node.name.value, fieldnames)
if suggestions:
self.add_error(
'Cannot query field "%s" on type "%s". Did you mean %s?'
% (
node.name.value,
self.type_info.parent_type.name,
quoted_options_list(suggestions),
),
[node],
)
else:
self.add_error(
'Cannot query field "%s" on type "%s".'
% (node.name.value, self.type_info.parent_type.name),
[node],
)
elif isinstance(self.type_info.parent_type, UnionType):
options = quoted_options_list(
[t.name for t in self.type_info.parent_type.types]
)
self.add_error(
'Cannot query field "%s" on type "%s". Did you mean to use '
"an inline fragment on %s?"
% (
node.name.value,
self.type_info.parent_type.name,
options,
),
[node],
)
else:
self.add_error(
'Cannot query field "%s" on type "%s"'
% (node.name.value, self.type_info.parent_type.name),
[node],
)
class UniqueFragmentNamesChecker(ValidationVisitor):
"""
A GraphQL document is only valid if all defined fragments have unique
names.
"""
def __init__(self, schema, type_info):
super(UniqueFragmentNamesChecker, self).__init__(schema, type_info)
self._names = set() # type: Set[str]
def enter_fragment_definition(self, node):
name = node.name.value
if name in self._names:
self.add_error(
'There can only be one fragment named "%s"' % name, [node]
)
self._names.add(name)
class KnownFragmentNamesChecker(ValidationVisitor):
"""
A GraphQL document is only valid if all `...Fragment` fragment spreads
refer to fragments defined in the same document.
"""
def __init__(self, schema, type_info):
super(KnownFragmentNamesChecker, self).__init__(schema, type_info)
def enter_document(self, node):
self._fragment_names = set(
[
definition.name.value
for definition in node.definitions
if type(definition) == _ast.FragmentDefinition
]
)
def enter_fragment_spread(self, node):
name = node.name.value
if name not in self._fragment_names:
self.add_error('Unknown fragment "%s"' % name, [node])
class NoUnusedFragmentsChecker(ValidationVisitor):
"""
A GraphQL document is only valid if all fragment definitions are spread
within operations, or spread within other fragments spread within
operations.
"""
def __init__(self, schema, type_info):
super(NoUnusedFragmentsChecker, self).__init__(schema, type_info)
self._fragments = set() # type: Set[str]
self._used_fragments = set() # type: Set[str]
def enter_fragment_definition(self, node):
self._fragments.add(node.name.value)
def enter_fragment_spread(self, node):
self._used_fragments.add(node.name.value)
def leave_document(self, _node):
unused = self._fragments - self._used_fragments
if unused:
quoted = ", ".join('"%s"' % x for x in sorted(unused))
self.add_error("Unused fragment(s) %s" % quoted)
class PossibleFragmentSpreadsChecker(ValidationVisitor):
"""
A fragment spread is only valid if the type condition could ever
possibly be true: if there is a non-empty intersection of the possible
parent types, and possible types which pass the type condition.
"""
def __init__(self, schema, type_info):
super(PossibleFragmentSpreadsChecker, self).__init__(schema, type_info)
self._fragment_types = dict() # type: Dict[str, GraphQLType]
def enter_document(self, node):
self._fragment_types.update(
{
definition.name.value: self.schema.get_type_from_literal(
definition.type_condition
)
for definition in node.definitions
if type(definition) == _ast.FragmentDefinition
}
)
def enter_fragment_spread(self, node):
name = node.name.value
frag_type = self._fragment_types.get(name, None)
parent_type = self.type_info.type
if (
isinstance(frag_type, GraphQLCompositeType)
and isinstance(parent_type, GraphQLCompositeType)
and not self.schema.types_overlap(frag_type, parent_type)
):
self.add_error(
'Fragment "%s" cannot be spread here as types "%s" and "%s"'
" do not overlap." % (name, frag_type, parent_type),
[node],
)
raise SkipNode()
def enter_inline_fragment(self, node):
type_ = self.type_info.type
parent_type = self.type_info.parent_type
if (
isinstance(type_, GraphQLCompositeType)
and isinstance(parent_type, GraphQLCompositeType)
and not self.schema.types_overlap(type_, parent_type)
):
self.add_error(
'Inline fragment cannot be spread here as types "%s" and "%s"'
" do not overlap." % (type_, parent_type),
[node],
)
raise SkipNode()
class NoFragmentCyclesChecker(ValidationVisitor):
"""
A GraphQL Document is only valid if fragment definitions are not cyclic.
"""
def __init__(self, schema, type_info):
super(NoFragmentCyclesChecker, self).__init__(schema, type_info)
self._spreads = OrderedDict() # type: Dict[str, List[str]]
self._current = None
def enter_fragment_definition(self, node):
name = node.name.value
self._current = name
self._spreads[name] = []
def leave_fragment_definition(self, _node):
self._current = None
def enter_fragment_spread(self, node):
name = node.name.value
if self._current is not None:
if self._current and name == self._current:
self.add_error(
'Cannot spread fragment "%s" withing itself' % name, [node]
)
raise SkipNode()
if name not in self._spreads[self._current]:
self._spreads[self._current].append(name)
def leave_document(self, node):
def _search(outer, acc=None, path=None):
acc, path = acc or dict(), path or []
if outer not in self._spreads:
return acc
for inner in self._spreads[outer]:
# The ref implementation will report multiple distinct cycles
# for one fragment. This line and the fact that we keep one
# path per fragment make it so that we only report one.
if inner in acc:
break
acc[inner] = path
_search(inner, acc, path + [inner])
return acc
flat_spreads = [(outer, _search(outer)) for outer in self._spreads]
cyclic = set()
for outer, inner_spreads in flat_spreads:
if outer in inner_spreads:
cyclic.add(outer)
path = inner_spreads[outer]
# Make sure we do not report redundant cycles, i.e. if A > B
# has been identified, A > B > A is redundant and will not be
# reported.
if path[-1] in cyclic:
continue
self.add_error(
'Cannot spread fragment "%s" withing itself (via: %s)'
% (outer, " > ".join(path)),
[node],
)
class UniqueVariableNamesChecker(ValidationVisitor):
"""
A GraphQL operation is only valid if all its variables are uniquely
named.
"""
def enter_operation_definition(self, _node):
self._variables = set() # type: Set[str]
def leave_operation_definition(self, _node):
self._variables.clear()
def enter_variable_definition(self, node):
name = node.variable.name.value
if name in self._variables:
self.add_error('Duplicate variable "$%s"' % name, [node])
self._variables.add(name)
class NoUndefinedVariablesChecker(VariablesCollector):
"""
A GraphQL operation is only valid if all variables encountered, both
directly and via fragment spreads, are defined by that operation.
"""
def leave_document(self, node):
super(NoUndefinedVariablesChecker, self).leave_document(node)
for op, fragments in self._op_fragments.items():
defined = self._op_defined_variables[op]
for fragment in deduplicate(fragments):
fragment_vars = self._fragment_variables[fragment]
for var, (node, _, _) in fragment_vars.items():
if var not in defined:
self.add_error(
'Variable "$%s" from fragment "%s" is not defined '
"on %s operation"
% (
var,
fragment,
'"%s"' % op if op != "" else "anonymous",
),
[node],
)
for op, variables in self._op_variables.items():
defined = self._op_defined_variables[op]
for var, (node, _, _) in variables.items():
if var not in defined:
self.add_error(
'Variable "$%s" is not defined on %s operation'
% (var, '"%s"' % op if op != "" else "anonymous"),
[node],
)
class NoUnusedVariablesChecker(VariablesCollector):
"""
A GraphQL operation is only valid if all variables defined by an
operation are used, either directly or within a spread fragment.
"""
def leave_document(self, node):
super(NoUnusedVariablesChecker, self).leave_document(node)
used_variables = defaultdict(set) # type: Dict[str, Set[str]]
for op, fragments in self._op_fragments.items():
for fragment in deduplicate(fragments):
for var in self._fragment_variables[fragment].keys():
used_variables[op].add(var)
for op, variables in self._op_variables.items():
for var in variables.keys():
used_variables[op].add(var)
for op, defined in self._op_defined_variables.items():
used = used_variables[op]
for var, node in defined.items():
if var not in used:
self.add_error('Unused variable "$%s"' % var, [node])
class KnownDirectivesChecker(ValidationVisitor):
"""
A GraphQL document is only valid if all `@directives` are known by the
schema and legally positioned.
"""
def __init__(self, schema, type_info):
super(KnownDirectivesChecker, self).__init__(schema, type_info)
self._ancestors = [] # type: List[_ast.Node]
def _enter_ancestor(self, node):
self._ancestors.append(node)
def _leave_ancestor(self, _node):
self._ancestors.pop()
enter_operation_definition = _enter_ancestor
leave_operation_definition = _leave_ancestor
enter_field = _enter_ancestor
leave_field = _leave_ancestor
enter_field = _enter_ancestor
leave_field = _leave_ancestor
enter_fragment_spread = _enter_ancestor
leave_fragment_spread = _leave_ancestor
enter_inline_fragment = _enter_ancestor
leave_inline_fragment = _leave_ancestor
enter_fragment_definition = _enter_ancestor
leave_fragment_definition = _leave_ancestor
enter_schema_definition = _enter_ancestor
leave_schema_definition = _leave_ancestor
enter_schema_extension = _enter_ancestor
leave_schema_extension = _leave_ancestor
enter_scalar_type_definition = _enter_ancestor
leave_scalar_type_definition = _leave_ancestor
enter_scalar_type_extension = _enter_ancestor
leave_scalar_type_extension = _leave_ancestor
enter_object_type_definition = _enter_ancestor
leave_object_type_definition = _leave_ancestor
enter_object_type_extension = _enter_ancestor
leave_object_type_extension = _leave_ancestor
enter_field_definition = _enter_ancestor
leave_field_definition = _leave_ancestor
enter_interface_type_definition = _enter_ancestor
leave_interface_type_definition = _leave_ancestor
enter_interface_type_extension = _enter_ancestor
leave_interface_type_extension = _leave_ancestor
enter_union_type_definition = _enter_ancestor
leave_union_type_definition = _leave_ancestor
enter_union_type_extension = _enter_ancestor
leave_union_type_extension = _leave_ancestor
enter_enum_type_definition = _enter_ancestor
leave_enum_type_definition = _leave_ancestor
enter_enum_type_extension = _enter_ancestor
leave_enum_type_extension = _leave_ancestor
enter_enum_value_definition = _enter_ancestor
leave_enum_value_definition = _leave_ancestor
enter_input_object_type_definition = _enter_ancestor
leave_input_object_type_definition = _leave_ancestor
enter_input_object_type_extension = _enter_ancestor
leave_input_object_type_extension = _leave_ancestor
enter_input_value_definition = _enter_ancestor
leave_input_value_definition = _leave_ancestor
def _current_location(self):
ancestor = self._ancestors[-1]
kind = type(ancestor)
if kind is _ast.OperationDefinition:
return {
"query": "QUERY",
"mutation": "MUTATION",
"subscription": "SUBSCRIPTION",
}.get(cast(_ast.OperationDefinition, ancestor).operation, "QUERY")
if kind is _ast.InputValueDefinition:
parent = self._ancestors[-2]
return (
"INPUT_FIELD_DEFINITION"
if type(parent) is _ast.InputObjectTypeDefinition
else "ARGUMENT_DEFINITION"
)
return {
_ast.Field: "FIELD",
_ast.FragmentSpread: "FRAGMENT_SPREAD",
_ast.InlineFragment: "INLINE_FRAGMENT",
_ast.FragmentDefinition: "FRAGMENT_DEFINITION",
_ast.SchemaDefinition: "SCHEMA",
_ast.SchemaExtension: "SCHEMA",
_ast.ScalarTypeDefinition: "SCALAR",
_ast.ScalarTypeExtension: "SCALAR",
_ast.ObjectTypeDefinition: "OBJECT",
_ast.ObjectTypeExtension: "OBJECT",
_ast.FieldDefinition: "FIELD_DEFINITION",
_ast.InterfaceTypeDefinition: "INTERFACE",
_ast.InterfaceTypeExtension: "INTERFACE",
_ast.UnionTypeDefinition: "UNION",
_ast.UnionTypeExtension: "UNION",
_ast.EnumTypeDefinition: "ENUM",
_ast.EnumTypeExtension: "ENUM",
_ast.EnumValueDefinition: "ENUM_VALUE",
_ast.InputObjectTypeDefinition: "INPUT_OBJECT",
_ast.InputObjectTypeExtension: "INPUT_OBJECT",
}[kind]
def enter_directive(self, node):
name = node.name.value
schema_directive = self.schema.directives.get(name)
if schema_directive is None:
self.add_error('Unknown directive "%s".' % name, [node])
else:
location = self._current_location()
if location not in schema_directive.locations:
self.add_error(
'Directive "%s" may not be used on %s.' % (name, location),
[node],
)
class UniqueDirectivesPerLocationChecker(ValidationVisitor):
"""
A GraphQL document is only valid if all directives at a given location
are uniquely named.
"""
def _validate_unique_directive_names(self, node):
seen = set() # type: Set[str]
for directive in node.directives:
name = directive.name.value
if name in seen:
self.add_error('Duplicate directive "@%s"' % name, [directive])
seen.add(name)
enter_operation_definition = _validate_unique_directive_names
enter_field = _validate_unique_directive_names
enter_field = _validate_unique_directive_names
enter_fragment_spread = _validate_unique_directive_names
enter_inline_fragment = _validate_unique_directive_names
enter_fragment_definition = _validate_unique_directive_names
class KnownArgumentNamesChecker(ValidationVisitor):
"""
A GraphQL field / directive is only valid if all supplied arguments
are defined by that field / directive.
"""
def enter_field(self, node):
field_def = self.type_info.field
if field_def is not None:
known = set((a.name for a in field_def.arguments))
for arg in node.arguments:
name = arg.name.value
if name not in known:
suggestions = list(infer_suggestions(name, known))
if not suggestions:
self.add_error(
'Unknown argument "%s" on field "%s" of type "%s".'
% (
name,
field_def.name,
self.type_info.parent_type,
),
[arg],
)
else:
self.add_error(
'Unknown argument "%s" on field "%s" of type "%s". '
"Did you mean %s?"
% (
name,
field_def.name,
self.type_info.parent_type,
quoted_options_list(suggestions),
),
[arg],
)
def enter_directive(self, node):
directive_def = self.type_info.directive
if directive_def is not None:
known = set((a.name for a in directive_def.arguments))
for arg in node.arguments:
name = arg.name.value
if name not in known:
suggestions = infer_suggestions(name, known)
if not suggestions:
self.add_error(
'Unknown argument "%s" on directive "@%s".'
% (name, directive_def.name),
[arg],
)
else:
self.add_error(
'Unknown argument "%s" on directive "@%s". Did you mean %s?'
% (
name,
directive_def.name,
quoted_options_list(suggestions),
),
[arg],
)
class UniqueArgumentNamesChecker(ValidationVisitor):
"""
A GraphQL field or directive is only valid if all supplied arguments
are uniquely named.
"""
def _check_duplicate_args(self, node):
argnames = set() # type: Set[str]
for arg in node.arguments:
name = arg.name.value
if name in argnames:
self.add_error('Duplicate argument "%s"' % name, [arg])
argnames.add(name)
enter_field = _check_duplicate_args
enter_directive = _check_duplicate_args
class ProvidedRequiredArgumentsChecker(ValidationVisitor):
"""
A field or directive is only valid if all required (non-null without a
default value) ) field arguments have been provided.
"""
def _missing_args(self, arg_defs, node):
node_args = set((arg.name.value for arg in node.arguments))
for arg in arg_defs:
if arg.required and (arg.name not in node_args):
yield arg
# Validate on leave to allow for deeper errors to appear first.
def leave_field(self, node):
field_def = self.type_info.field
if field_def:
for arg in self._missing_args(field_def.arguments, node):
self.add_error(
'Field "%s" argument "%s" of type %s is required but '
"not provided" % (field_def.name, arg.name, arg.type),
[node],
)
# Validate on leave to allow for deeper errors to appear first.
def leave_directive(self, node):
directive_def = self.type_info.directive
if directive_def:
for arg in self._missing_args(directive_def.arguments, node):
self.add_error(
'Directive "@%s" argument "%s" of type %s is required but '
"not provided" % (directive_def.name, arg.name, arg.type),
[node],
)
class VariablesInAllowedPositionChecker(VariablesCollector):
"""
Variables passed to field arguments conform to type """
def iter_op_variables(self, op):
for usage in self._op_variables[op].items():
yield usage
for fragment in self._op_fragments[op]:
frament_vars = self._fragment_variables[fragment].items()
for usage in frament_vars:
yield usage
def leave_document(self, node):
super(VariablesInAllowedPositionChecker, self).leave_document(node)
for op, vardefs in self._op_defined_variables.items():
for (varname, usage) in self.iter_op_variables(op):
varnode, input_type, input_value_def = usage
vardef = vardefs.get(varname)
if vardef and input_type:
try:
var_type = self.schema.get_type_from_literal(
vardef.type
)
except UnknownType:
continue
var_default = vardef.default_value
if isinstance(input_type, NonNullType) and not isinstance(
var_type, NonNullType
):
non_null_var_default = (
var_default is not None
and type(var_default) != _ast.NullValue
)
location_default = (
input_value_def is not None
and input_value_def.has_default_value
)
if (
not non_null_var_default and not location_default
) or not self.schema.is_subtype(
var_type, input_type.type
):
self.add_error(
'Variable "$%s" of type %s used in position '
"expecting type %s"
% (varname, print_ast(vardef.type), input_type),
[varnode],
)
else:
if not self.schema.is_subtype(var_type, input_type):
self.add_error(
'Variable "$%s" of type %s used in position '
"expecting type %s"
% (varname, print_ast(vardef.type), input_type),
[varnode],
)
class UniqueInputFieldNamesChecker(ValidationVisitor):
"""
A GraphQL input object value is only valid if all supplied fields are
uniquely named.
"""
def __init__(self, schema, type_info):
super(UniqueInputFieldNamesChecker, self).__init__(schema, type_info)
self._stack = [] # type: List[Tuple[_ast.ObjectValue, Set[str]]]
def enter_object_value(self, node):
self._stack.append((node, set()))
def leave_object_value(self, _node):
self._stack.pop()
def enter_object_field(self, node):
fieldname = node.name.value
_, names = self._stack[-1]
if fieldname in names:
self.add_error(
"There can be only one input field named %s." % fieldname,
[node],
)
names.add(fieldname) | PypiClean |
/google-cloud-dialogflow-2.23.3.tar.gz/google-cloud-dialogflow-2.23.3/google/cloud/dialogflow_v2/services/versions/pagers.py | from typing import (
Any,
AsyncIterator,
Awaitable,
Callable,
Iterator,
Optional,
Sequence,
Tuple,
)
from google.cloud.dialogflow_v2.types import version
class ListVersionsPager:
"""A pager for iterating through ``list_versions`` requests.
This class thinly wraps an initial
:class:`google.cloud.dialogflow_v2.types.ListVersionsResponse` object, and
provides an ``__iter__`` method to iterate through its
``versions`` field.
If there are more pages, the ``__iter__`` method will make additional
``ListVersions`` requests and continue to iterate
through the ``versions`` field on the
corresponding responses.
All the usual :class:`google.cloud.dialogflow_v2.types.ListVersionsResponse`
attributes are available on the pager. If multiple requests are made, only
the most recent response is retained, and thus used for attribute lookup.
"""
def __init__(
self,
method: Callable[..., version.ListVersionsResponse],
request: version.ListVersionsRequest,
response: version.ListVersionsResponse,
*,
metadata: Sequence[Tuple[str, str]] = ()
):
"""Instantiate the pager.
Args:
method (Callable): The method that was originally called, and
which instantiated this pager.
request (google.cloud.dialogflow_v2.types.ListVersionsRequest):
The initial request object.
response (google.cloud.dialogflow_v2.types.ListVersionsResponse):
The initial response object.
metadata (Sequence[Tuple[str, str]]): Strings which should be
sent along with the request as metadata.
"""
self._method = method
self._request = version.ListVersionsRequest(request)
self._response = response
self._metadata = metadata
def __getattr__(self, name: str) -> Any:
return getattr(self._response, name)
@property
def pages(self) -> Iterator[version.ListVersionsResponse]:
yield self._response
while self._response.next_page_token:
self._request.page_token = self._response.next_page_token
self._response = self._method(self._request, metadata=self._metadata)
yield self._response
def __iter__(self) -> Iterator[version.Version]:
for page in self.pages:
yield from page.versions
def __repr__(self) -> str:
return "{0}<{1!r}>".format(self.__class__.__name__, self._response)
class ListVersionsAsyncPager:
"""A pager for iterating through ``list_versions`` requests.
This class thinly wraps an initial
:class:`google.cloud.dialogflow_v2.types.ListVersionsResponse` object, and
provides an ``__aiter__`` method to iterate through its
``versions`` field.
If there are more pages, the ``__aiter__`` method will make additional
``ListVersions`` requests and continue to iterate
through the ``versions`` field on the
corresponding responses.
All the usual :class:`google.cloud.dialogflow_v2.types.ListVersionsResponse`
attributes are available on the pager. If multiple requests are made, only
the most recent response is retained, and thus used for attribute lookup.
"""
def __init__(
self,
method: Callable[..., Awaitable[version.ListVersionsResponse]],
request: version.ListVersionsRequest,
response: version.ListVersionsResponse,
*,
metadata: Sequence[Tuple[str, str]] = ()
):
"""Instantiates the pager.
Args:
method (Callable): The method that was originally called, and
which instantiated this pager.
request (google.cloud.dialogflow_v2.types.ListVersionsRequest):
The initial request object.
response (google.cloud.dialogflow_v2.types.ListVersionsResponse):
The initial response object.
metadata (Sequence[Tuple[str, str]]): Strings which should be
sent along with the request as metadata.
"""
self._method = method
self._request = version.ListVersionsRequest(request)
self._response = response
self._metadata = metadata
def __getattr__(self, name: str) -> Any:
return getattr(self._response, name)
@property
async def pages(self) -> AsyncIterator[version.ListVersionsResponse]:
yield self._response
while self._response.next_page_token:
self._request.page_token = self._response.next_page_token
self._response = await self._method(self._request, metadata=self._metadata)
yield self._response
def __aiter__(self) -> AsyncIterator[version.Version]:
async def async_generator():
async for page in self.pages:
for response in page.versions:
yield response
return async_generator()
def __repr__(self) -> str:
return "{0}<{1!r}>".format(self.__class__.__name__, self._response) | PypiClean |
/django-exchange-themes-1.0.3.tar.gz/django-exchange-themes-1.0.3/appearance/migrations/0001_initial.py | from __future__ import unicode_literals
from django.db import migrations, models
import appearance.fields
class Migration(migrations.Migration):
dependencies = [
]
operations = [
migrations.CreateModel(
name='Theme',
fields=[
('id', models.AutoField(
verbose_name='ID',
serialize=False,
auto_created=True,
primary_key=True
)),
('name', models.CharField(max_length=28)),
('description', models.CharField(max_length=64, blank=True)),
('default_theme', models.BooleanField(
default=False,
editable=False
)),
('active_theme', models.BooleanField(default=False)),
('title', models.CharField(
default=None,
max_length=32,
null=True,
verbose_name=b'Landing Page Title',
blank=True
)),
('tagline', models.CharField(
default=None,
max_length=64,
null=True,
verbose_name=b'Landing Page Tagline',
blank=True
)),
('running_hex', appearance.fields.ColorField(
default=b'0F1A2C',
max_length=7,
null=True,
verbose_name=b'Header Footer Color',
blank=True
)),
('running_text_hex', appearance.fields.ColorField(
default=b'FFFFFF',
max_length=7,
null=True,
verbose_name=b'Header Footer Text Color',
blank=True
)),
('running_link_hex', appearance.fields.ColorField(
default=b'0F1A2C',
max_length=7,
null=True,
verbose_name=b'Header Footer Link Color',
blank=True
)),
('pb_text', models.CharField(
default=b'Boundless Spatial',
max_length=32,
blank=True,
help_text=b'Text for the Powered by section in the footer',
null=True,
verbose_name=b'Footer Link Text'
)),
('pb_link', models.URLField(
default=b'http://boundlessgeo.com/',
blank=True,
help_text=b'Link for the Powered by section in the footer',
null=True,
verbose_name=b'Footer Link URL'
)),
('docs_link', models.URLField(
default=None,
blank=True,
help_text=b'Link for the Documentation',
null=True,
verbose_name=b'Documentation Link URL'
)),
('docs_text', models.CharField(
default=b'Documentation',
max_length=32,
blank=True,
help_text=b'Text for the documentation link',
null=True,
verbose_name=b'Documentation Text'
)),
('background_logo', models.ImageField(
default=None,
upload_to=b'theme/img/',
blank=True,
help_text=b'Note: will resize to 1440px (w) 350px (h)',
null=True,
verbose_name=b'Background Image'
)),
('primary_logo', models.ImageField(
default=None,
upload_to=b'theme/img/',
blank=True,
help_text=b'Note: will resize to height 96px',
null=True,
verbose_name=b'Primary Logo'
)),
('banner_logo', models.ImageField(
default=None,
upload_to=b'theme/img/',
blank=True,
help_text=b'Note: will resize to height 35px',
null=True,
verbose_name=b'Header Logo'
)),
],
),
] | PypiClean |
/txt_to_html-0.0.1.tar.gz/txt_to_html-0.0.1/resources/MathJax-2.7.2/jax/output/SVG/fonts/STIX-Web/Arrows/Regular/Main.js | MathJax.OutputJax.SVG.FONTDATA.FONTS.STIXMathJax_Arrows={directory:"Arrows/Regular",family:"STIXMathJax_Arrows",id:"STIXWEBARROWS",32:[0,0,250,0,0,""],160:[0,0,250,0,0,""],8604:[411,-102,926,70,856,"856 238l-38 -51c-55 54 -118 68 -160 68c-84 0 -139 -68 -264 -68c-110 0 -183 63 -201 70c-3 1 -6 2 -9 2c-9 0 -12 -8 -12 -23c0 -43 8 -81 8 -130l-27 -4c-11 99 -27 204 -83 291l6 9c33 -7 80 -16 114 -16c69 0 131 10 197 25l6 -27c-39 -12 -76 -23 -119 -30 c-16 -2 -47 -6 -47 -20c0 -32 76 -81 165 -81c104 0 161 68 257 68c80 0 137 -21 207 -83"],8605:[411,-102,926,70,856,"850 402l6 -9c-56 -87 -72 -192 -83 -291l-27 4c0 49 8 87 8 130c0 15 -3 23 -12 23c-3 0 -6 -1 -9 -2c-18 -7 -91 -70 -201 -70c-125 0 -180 68 -264 68c-42 0 -105 -14 -160 -68l-38 51c70 62 127 83 207 83c96 0 153 -68 257 -68c89 0 165 49 165 81 c0 14 -31 18 -47 20c-43 7 -80 18 -119 30l6 27c66 -15 128 -25 197 -25c34 0 81 9 114 16"],8607:[662,154,511,60,451,"451 217l-19 -20c-33 23 -65 52 -96 82c-9 9 -20 14 -28 14c-10 0 -20 -8 -20 -26v-421h-66v422c0 10 -12 26 -22 26c-9 0 -15 -4 -25 -14c-28 -29 -63 -60 -96 -82l-19 20c60 52 120 111 162 181v76c0 10 -12 26 -22 26c-9 0 -15 -4 -25 -14c-28 -29 -63 -60 -96 -82 l-19 20c75 65 150 141 190 237h10c41 -96 115 -172 191 -238l-19 -20c-33 23 -65 52 -96 82c-9 9 -20 14 -28 14c-10 0 -20 -8 -20 -26v-74c43 -71 102 -130 163 -183"],8609:[662,154,511,60,451,"432 104l19 -20c-76 -66 -150 -142 -191 -238h-10c-40 96 -115 172 -190 237l19 20c33 -22 68 -53 96 -82c10 -10 16 -14 25 -14c10 0 22 6 22 26v76c-42 70 -102 129 -162 181l19 20c33 -22 68 -53 96 -82c10 -10 16 -14 25 -14c10 0 22 5 22 26v422h66v-421 c0 -18 10 -26 20 -26c8 0 19 5 28 14c31 30 63 59 96 82l19 -20c-61 -53 -120 -112 -163 -183v-74c0 -18 10 -26 20 -26c8 0 19 5 28 14c31 30 63 59 96 82"],8612:[450,-57,926,70,857,"857 57h-50v163h-550c-18 0 -26 -12 -26 -22c0 -9 4 -15 14 -25c29 -28 60 -64 82 -97l-20 -19c-65 75 -141 151 -237 191v10c96 41 172 116 238 192l20 -19c-23 -33 -52 -66 -82 -97c-9 -9 -14 -20 -14 -28c0 -10 8 -20 26 -20h549v164h50v-393"],8613:[662,154,511,60,451,"451 -154h-391v50h162v579c0 10 -12 26 -22 26c-9 0 -15 -4 -25 -14c-28 -29 -63 -60 -96 -82l-19 20c75 65 150 141 190 237h10c41 -96 115 -172 191 -238l-19 -20c-33 23 -65 52 -96 82c-9 9 -20 14 -28 14c-10 0 -20 -8 -20 -26v-578h163v-50"],8615:[662,154,511,59,451,"451 612h-163v-579c0 -10 12 -26 22 -26c9 0 15 4 25 14c28 29 63 60 96 82l19 -20c-75 -65 -150 -141 -190 -237h-10c-41 96 -115 172 -191 238l19 20c33 -23 65 -52 96 -82c9 -9 20 -14 28 -14c10 0 20 8 20 26v578h-162v50h391v-50"],8616:[662,154,511,59,451,"451 -154h-391v50h190c-41 96 -115 172 -191 238l19 20c33 -23 65 -52 96 -82c9 -9 20 -14 28 -14c10 0 20 8 20 26v391c0 20 -12 26 -22 26c-9 0 -15 -4 -25 -14c-28 -29 -63 -60 -96 -82l-19 20c75 65 150 141 190 237h10c41 -96 115 -172 191 -238l-19 -20 c-33 23 -65 52 -96 82c-9 9 -20 14 -28 14c-10 0 -20 -8 -20 -26v-391c0 -14 12 -26 22 -26c9 0 15 4 25 14c28 29 63 60 96 82l19 -20c-75 -65 -150 -141 -190 -237h191v-50"],8623:[662,154,511,60,451,"451 320l-234 -337c-3 -3 -4 -9 -4 -15c0 -16 11 -23 25 -23c3 0 6 0 10 1c36 6 77 12 113 12h14l3 -26c-98 -11 -204 -28 -291 -86l-8 7c7 33 10 67 10 100c0 69 -13 138 -29 203l28 6c14 -37 23 -81 31 -123c3 -15 10 -30 24 -30c7 0 14 4 21 14l157 231h-261l330 408 l60 -39l-242 -303h243"],8626:[662,154,463,25,419,"419 0h-196c-18 0 -26 -10 -26 -20c0 -8 5 -24 14 -33c30 -31 49 -49 72 -82l-20 -19c-66 76 -142 141 -238 182v10c96 40 172 106 237 181l20 -19c-22 -33 -43 -59 -72 -87c-10 -10 -14 -16 -14 -25c0 -10 8 -22 26 -22h131v596h66v-662"],8627:[662,154,463,39,433,"433 38v-10c-96 -41 -172 -106 -238 -182l-20 19c23 33 42 51 72 82c9 9 14 25 14 33c0 10 -8 20 -26 20h-196v662h66v-596h131c18 0 26 12 26 22c0 9 -4 15 -14 25c-29 28 -50 54 -72 87l20 19c65 -75 141 -141 237 -181"],8628:[662,154,926,70,856,"837 104l19 -20c-76 -66 -150 -142 -191 -238h-10c-40 96 -115 172 -190 237l19 20c33 -22 68 -53 96 -82c10 -10 16 -14 25 -14c10 0 22 7 22 27v562h-557v66h623v-628c0 -19 10 -26 20 -26c8 0 19 5 28 14c31 30 63 59 96 82"],8629:[662,156,926,70,856,"856 0h-598c-19 0 -26 -10 -26 -20c0 -8 5 -19 14 -28c30 -31 59 -56 82 -89l-20 -19c-66 76 -142 143 -238 184v10c96 40 172 108 237 183l20 -19c-22 -33 -53 -61 -82 -89c-10 -10 -14 -16 -14 -25c0 -10 7 -22 27 -22h532v596h66v-662"],8632:[732,156,926,55,872,"856 666h-794v66h794v-66zM872 -110l-47 -46l-658 658c-5 5 -11 9 -18 9c-5 0 -11 -3 -15 -5c-8 -8 -7 -18 -7 -29c0 -42 -3 -85 -10 -126l-29 2c2 29 4 59 4 88c0 73 -10 146 -37 214l7 7c69 -28 143 -37 217 -37c29 0 58 1 87 4v-29c-42 -7 -84 -8 -126 -10 c-10 0 -23 -1 -29 -10c-5 -3 -6 -8 -6 -13c0 -8 5 -15 10 -20"],8633:[598,92,926,60,866,"866 380h-567c-18 0 -26 -10 -26 -20c0 -8 5 -19 14 -28c30 -31 48 -55 69 -85l-20 -19c-66 73 -130 139 -226 180v-180h-50v370h50v-180c96 40 161 105 226 180l20 -19c-21 -33 -40 -58 -69 -86c-10 -10 -14 -16 -14 -25c0 -16 17 -22 27 -22h566v-66zM866 -92h-50v180 c-96 -40 -161 -105 -226 -180l-20 19c21 33 40 58 69 86c10 10 14 16 14 25c0 16 -17 22 -27 22h-566v66h567c18 0 26 10 26 20c0 8 -5 19 -14 28c-30 31 -48 55 -69 85l20 19c66 -73 130 -139 226 -180v180h50v-370"],8645:[662,156,773,31,742,"723 102l19 -20c-76 -66 -150 -142 -191 -238h-10c-40 96 -115 172 -190 237l19 20c33 -22 67 -53 96 -82c10 -10 16 -14 25 -14c10 0 22 9 22 26v621h66v-620c0 -18 10 -26 20 -26c8 0 19 5 28 14c31 30 63 59 96 82zM422 424l-19 -20c-33 23 -65 52 -96 82 c-9 9 -20 14 -28 14c-10 0 -20 -7 -20 -26v-620h-66v621c0 19 -12 26 -22 26c-9 0 -15 -4 -25 -14c-28 -29 -63 -60 -96 -82l-19 20c75 65 150 141 190 237h10c41 -96 115 -172 191 -238"],8662:[662,156,926,55,874,"874 32l-46 -47l-600 599c-17 5 -34 7 -48 7c-17 0 -32 -4 -41 -13c-10 -9 -13 -23 -13 -39c0 -14 3 -33 6 -49l601 -600l-47 -46l-498 497c-6 6 -13 8 -19 8c-25 0 -28 -26 -28 -51c0 -16 -2 -72 -5 -109h-29c-1 164 -30 314 -52 466l7 7c151 -21 302 -51 466 -52v-29 c-37 -3 -75 -5 -110 -5c-25 0 -34 0 -45 -13c-3 -3 -5 -9 -5 -15s2 -13 8 -19"],8663:[662,156,926,55,874,"867 662l7 -7c-22 -152 -51 -302 -52 -466h-29c-3 37 -5 93 -5 109c0 25 -3 51 -28 51c-6 0 -13 -2 -19 -8l-498 -497l-47 46l601 600c3 16 6 35 6 49c0 16 -3 30 -13 39c-9 9 -24 13 -41 13c-14 0 -31 -2 -48 -7l-600 -599l-46 47l498 497c6 6 8 13 8 19s-2 12 -5 15 c-11 13 -20 13 -45 13c-35 0 -73 2 -110 5v29c164 1 315 31 466 52"],8664:[662,156,926,55,874,"874 -149l-7 -7c-151 21 -302 51 -466 52v29c37 3 75 5 110 5c25 0 34 0 45 13c3 3 5 9 5 15s-2 13 -8 19l-498 497l46 47l600 -599c17 -5 34 -7 48 -7c17 0 32 4 41 13c10 9 13 23 13 39c0 14 -3 33 -6 49l-601 600l47 46l498 -497c6 -6 13 -8 19 -8c25 0 28 26 28 51 c0 16 2 72 5 109h29c1 -164 30 -314 52 -466"],8665:[662,156,926,55,874,"874 474l-498 -497c-6 -6 -8 -13 -8 -19s2 -12 5 -15c11 -13 20 -13 45 -13c35 0 73 -2 110 -5v-29c-164 -1 -315 -31 -466 -52l-7 7c22 152 51 302 52 466h29c3 -37 5 -93 5 -109c0 -25 3 -51 28 -51c6 0 13 2 19 8l498 497l47 -46l-601 -600c-3 -16 -6 -35 -6 -49 c0 -16 3 -30 13 -39c9 -9 24 -13 41 -13c14 0 31 2 48 7l600 599"],8668:[449,-58,926,60,866,"866 220h-114l-89 -106l-119 172l-124 -172l-92 106h-83c-8 0 -24 -13 -24 -22s4 -15 14 -25c29 -28 60 -63 82 -96l-20 -19c-65 75 -141 150 -237 190v10c96 41 172 115 238 191l20 -19c-23 -33 -52 -65 -82 -96c-9 -9 -14 -20 -14 -28c0 -10 8 -20 26 -20h112l60 -66 l124 174l119 -174l60 66h143v-66"],8670:[662,156,511,60,451,"451 76h-163v-232h-66v232h-162v50h162v79h-162v50h162v220c0 10 -12 26 -22 26c-9 0 -15 -4 -25 -14c-28 -29 -63 -60 -96 -82l-19 20c75 65 150 141 190 237h10c41 -96 115 -172 191 -238l-19 -20c-33 23 -65 52 -96 82c-9 9 -20 14 -28 14c-10 0 -20 -8 -20 -26v-219 h163v-50h-163v-79h163v-50"],8671:[662,156,511,60,451,"432 102l19 -20c-76 -66 -150 -142 -191 -238h-10c-40 96 -115 172 -190 237l19 20c33 -22 68 -53 96 -82c10 -10 16 -14 25 -14c10 0 22 16 22 26v220h-162v50h162v79h-162v50h162v232h66v-232h163v-50h-163v-79h163v-50h-163v-219c0 -18 10 -26 20 -26c8 0 19 5 28 14 c31 30 63 59 96 82"],8673:[662,156,511,60,451,"451 424l-19 -20c-33 23 -65 52 -96 82c-9 9 -20 14 -28 14c-10 0 -20 -8 -20 -26v-111h-66v112c0 10 -12 26 -22 26c-9 0 -15 -4 -25 -14c-28 -29 -63 -60 -96 -82l-19 20c75 65 150 141 190 237h10c41 -96 115 -172 191 -238zM288 190h-66v107h66v-107zM288 17h-66v107 h66v-107zM288 -156h-66v107h66v-107"],8675:[662,156,511,60,451,"288 555h-66v107h66v-107zM288 382h-66v107h66v-107zM288 209h-66v107h66v-107zM432 102l19 -20c-76 -66 -150 -142 -191 -238h-10c-40 96 -115 172 -190 237l19 20c33 -22 68 -53 96 -82c10 -10 16 -14 25 -14c10 0 22 9 22 26v112h66v-111c0 -18 10 -26 20 -26 c8 0 19 5 28 14c31 30 63 59 96 82"],8676:[450,-58,926,60,866,"866 220h-569c-10 0 -26 -12 -26 -22c0 -9 4 -15 14 -25c29 -28 60 -63 82 -96l-20 -19c-65 75 -141 150 -237 190v-190h-50v392h50v-192c96 41 172 116 238 192l20 -19c-23 -33 -52 -66 -82 -97c-9 -9 -14 -20 -14 -28c0 -10 8 -20 26 -20h568v-66"],8677:[450,-58,926,60,866,"866 58h-50v190c-96 -40 -172 -115 -237 -190l-20 19c22 33 53 68 82 96c10 10 14 16 14 25c0 10 -16 22 -26 22h-569v66h568c18 0 26 10 26 20c0 8 -5 19 -14 28c-30 31 -59 64 -82 97l20 19c66 -76 142 -151 238 -192v192h50v-392"],8678:[551,45,926,60,866,"866 120h-420v-155l-20 -10c-117 116 -243 201 -366 293v10c121 92 249 177 366 293l20 -10v-155h420v-266zM816 170v166h-420v116l-165 -126c-29 -22 -58 -47 -58 -73s27 -48 58 -72l165 -128v117h420"],8679:[662,156,685,45,641,"641 296l-10 -20h-155v-432h-266v432h-155l-10 20c116 117 201 243 293 366h10c92 -121 177 -249 293 -366zM542 326l-126 165c-22 29 -47 58 -73 58s-48 -27 -72 -58l-128 -165h117v-432h166v432h116"],8680:[551,45,926,60,866,"866 258v-10c-123 -92 -249 -177 -366 -293l-20 10v155h-420v266h420v155l20 10c117 -116 245 -201 366 -293zM530 53l165 128c31 24 58 46 58 72s-29 51 -58 73l-165 126v-116h-420v-166h420v-117"],8681:[662,156,685,45,641,"631 230l10 -20c-116 -117 -201 -245 -293 -366h-10c-92 123 -177 249 -293 366l10 20h155v432h266v-432h155zM542 180h-116v432h-166v-432h-117l128 -165c24 -31 46 -58 72 -58s51 29 73 58"],8682:[690,184,685,45,641,"641 324l-10 -20h-155v-262h-266v262h-155l-10 20c116 117 201 243 293 366h10c92 -121 177 -249 293 -366zM542 354l-126 165c-22 29 -47 58 -73 58s-48 -27 -72 -58l-128 -165h117v-262h166v262h116zM476 -184h-266v161h266v-161zM426 -134v61h-166v-61h166"],8692:[448,-57,926,70,856,"856 258v-10c-96 -41 -172 -115 -238 -191l-20 19c23 33 52 65 82 96c9 9 14 20 14 28c0 10 -8 20 -26 20h-127c-15 -69 -76 -120 -150 -120s-135 51 -151 120h-170v66h170c14 70 77 122 151 122c75 0 136 -52 151 -122h127c10 0 26 12 26 22c0 9 -4 15 -14 25 c-29 28 -60 63 -82 96l20 19c65 -75 141 -150 237 -190zM292 286h198c-14 41 -53 72 -99 72s-86 -31 -99 -72zM489 220h-197c14 -41 54 -70 99 -70s84 29 98 70"],8693:[662,156,773,31,742,"742 424l-19 -20c-33 23 -65 52 -96 82c-9 9 -20 14 -28 14c-10 0 -20 -8 -20 -26v-620h-66v621c0 17 -12 26 -22 26c-9 0 -15 -4 -25 -14c-28 -29 -63 -60 -96 -82l-19 20c75 65 150 141 190 237h10c41 -96 115 -172 191 -238zM403 102l19 -20 c-76 -66 -150 -142 -191 -238h-10c-40 96 -115 172 -190 237l19 20c33 -22 67 -53 96 -82c10 -10 16 -14 25 -14c10 0 22 7 22 26v621h66v-620c0 -20 10 -26 20 -26c8 0 19 5 28 14c31 30 63 59 96 82"],8694:[739,232,926,60,866,"866 -42v-10c-96 -40 -172 -105 -237 -180l-20 19c22 33 47 58 76 86c10 10 14 16 14 25c0 10 -7 22 -25 22h-614v66h613c18 0 26 10 26 20c0 8 -5 15 -14 24c-20 21 -39 37 -77 73l78 72c10 10 13 14 13 23c0 10 -13 22 -25 22h-614v66h613c14 0 26 9 26 20 c0 8 -5 15 -14 24c-20 21 -39 37 -77 73l78 72c10 10 13 14 13 23c0 10 -15 22 -25 22h-614v66h613c18 0 26 10 26 20c0 8 -5 19 -14 28c-30 31 -54 53 -77 86l20 19c66 -76 142 -140 238 -181v-10c-85 -36 -153 -88 -213 -145c61 -57 129 -109 213 -145v-10 c-85 -36 -153 -88 -213 -145c61 -57 129 -109 213 -145"],8695:[450,-58,926,60,866,"866 220h-307v-162h-50v162h-262c-10 0 -26 -12 -26 -22c0 -9 4 -15 14 -25c29 -28 60 -63 82 -96l-20 -19c-65 75 -141 150 -237 190v10c96 41 172 116 238 192l20 -19c-23 -33 -52 -66 -82 -97c-9 -9 -14 -20 -14 -28c0 -10 8 -20 26 -20h261v164h50v-164h307v-66"],8696:[450,-58,926,55,861,"861 258v-10c-96 -40 -172 -115 -237 -190l-20 19c22 33 53 68 82 96c10 10 14 16 14 25c0 10 -16 22 -26 22h-257v-162h-50v162h-312v66h312v164h50v-164h256c18 0 26 10 26 20c0 8 -5 19 -14 28c-30 31 -59 64 -82 97l20 19c66 -76 142 -151 238 -192"],8697:[450,-58,926,48,878,"878 258v-10c-96 -41 -172 -114 -238 -190l-20 19c23 33 52 64 82 95c9 9 14 20 14 28c0 10 -8 20 -26 20h-203v-162h-50v162h-202c-10 0 -26 -12 -26 -22c0 -9 4 -15 14 -25c29 -28 60 -63 82 -96l-20 -19c-65 75 -141 150 -237 190v10c96 41 172 116 238 192l20 -19 c-23 -33 -52 -66 -82 -97c-9 -9 -14 -20 -14 -28c0 -10 8 -20 26 -20h201v164h50v-164h204c10 0 26 12 26 22c0 9 -4 15 -14 25c-29 28 -60 65 -82 98l20 19c65 -75 141 -152 237 -192"],8698:[450,-58,926,60,866,"866 220h-225v-162h-50v162h-79v-162h-50v162h-215c-10 0 -26 -12 -26 -22c0 -9 4 -15 14 -25c29 -28 60 -63 82 -96l-20 -19c-65 75 -141 150 -237 190v10c96 41 172 116 238 192l20 -19c-23 -33 -52 -66 -82 -97c-9 -9 -14 -20 -14 -28c0 -10 8 -20 26 -20h214v164h50 v-164h79v164h50v-164h225v-66"],8699:[450,-58,926,60,866,"866 258v-10c-96 -40 -172 -115 -237 -190l-20 19c22 33 53 68 82 96c10 10 14 16 14 25c0 10 -16 22 -26 22h-215v-162h-50v162h-79v-162h-50v162h-225v66h225v164h50v-164h79v164h50v-164h214c18 0 26 10 26 20c0 8 -5 19 -14 28c-30 31 -59 64 -82 97l20 19 c66 -76 142 -151 238 -192"],8700:[450,-58,926,38,888,"888 258v-10c-96 -41 -172 -114 -238 -190l-20 19c23 33 52 64 82 95c9 9 14 20 14 28c0 10 -8 20 -26 20h-147v-162h-50v162h-79v-162h-50v162h-149c-10 0 -26 -12 -26 -22c0 -9 4 -15 14 -25c29 -28 60 -63 82 -96l-20 -19c-65 75 -141 150 -237 190v10 c96 41 172 116 238 192l20 -19c-23 -33 -52 -66 -82 -97c-9 -9 -14 -20 -14 -28c0 -10 8 -20 26 -20h148v164h50v-164h79v164h50v-164h148c10 0 26 12 26 22c0 9 -4 15 -14 25c-29 28 -60 65 -82 98l20 19c65 -75 141 -152 237 -192"],8701:[449,-57,926,60,866,"866 220h-538v-158l-10 -5c-65 75 -162 151 -258 191v10c96 41 192 115 258 191l10 -5v-158h538v-66zM278 166v173c-22 -29 -91 -70 -121 -85c30 -15 99 -59 121 -88"],8702:[449,-57,926,60,866,"866 258v-10c-96 -41 -192 -115 -258 -191l-10 5v158h-538v66h538v158l10 5c65 -75 162 -151 258 -191zM648 340v-173c22 29 91 70 121 85c-30 15 -99 59 -121 88"],8703:[449,-57,926,20,906,"906 258v-10c-96 -41 -192 -115 -258 -191l-10 5v158h-350v-158l-10 -5c-65 75 -162 151 -258 191v10c96 41 192 115 258 191l10 -5v-158h350v158l10 5c65 -75 162 -151 258 -191zM688 340v-173c22 29 91 70 121 85c-30 15 -99 59 -121 88zM238 166v173 c-22 -29 -91 -70 -121 -85c30 -15 99 -59 121 -88"],10224:[662,156,1033,69,965,"965 298l-13 -24c-42 15 -96 47 -147 81v-511h-66v557c-49 36 -81 69 -104 88v-645h-66v697c-19 13 -35 23 -52 23c-20 0 -35 -10 -52 -23v-697h-66v642c-25 -20 -57 -51 -104 -85v-557h-66v512c-54 -35 -108 -67 -145 -81l-15 24c137 70 278 186 443 363h13 c136 -152 273 -279 440 -364"],10225:[662,156,1033,69,965,"950 231l15 -24c-137 -70 -278 -186 -443 -363h-13c-136 152 -273 279 -440 364l13 24c42 -15 96 -47 147 -81v511h66v-557c49 -36 81 -69 104 -88v645h66v-697c19 -13 35 -23 52 -23c20 0 35 10 52 23v697h66v-642c25 20 57 51 104 85v557h66v-512c54 35 108 67 145 81"],10226:[626,116,974,54,882,"54 546l24 13c24 -34 44 -71 65 -108c7 -13 15 -25 26 -25c6 0 13 3 17 9c64 118 195 191 326 191c203 0 370 -164 370 -372c0 -204 -164 -370 -371 -370c-150 0 -284 90 -341 227l59 26c48 -111 165 -188 283 -188c170 0 304 140 304 305c0 170 -138 306 -305 306 c-104 0 -202 -55 -257 -141c-2 -4 -2 -7 -2 -10c0 -11 10 -19 21 -19c6 0 12 2 21 6c37 19 80 35 118 46l12 -25c-92 -37 -189 -84 -258 -162l-10 4c-6 105 -52 199 -102 287"],10227:[626,116,974,92,920,"896 559l24 -13c-50 -88 -96 -182 -102 -287l-10 -4c-69 78 -166 125 -258 162l12 25c38 -11 81 -27 118 -46c9 -4 15 -6 21 -6c11 0 21 8 21 19c0 3 0 6 -2 10c-55 86 -153 141 -257 141c-167 0 -305 -136 -305 -306c0 -165 134 -305 304 -305c118 0 235 77 283 188 l59 -26c-57 -137 -191 -227 -341 -227c-207 0 -371 166 -371 370c0 208 167 372 370 372c131 0 262 -73 326 -191c4 -6 11 -9 17 -9c11 0 19 12 26 25c21 37 41 74 65 108"],10228:[569,61,1200,52,1147,"1147 258v-10c-96 -41 -172 -115 -238 -191l-20 19c23 33 52 65 82 96c9 9 14 20 14 28c0 10 -8 20 -26 20h-119c-15 -158 -141 -281 -310 -281c-174 0 -302 107 -317 281h-161v66h161c16 154 141 283 317 283c164 0 295 -117 310 -283h120c10 0 26 12 26 22 c0 9 -4 15 -14 25c-29 28 -60 64 -82 97l20 19c65 -75 141 -151 237 -191zM552 286h223c-14 112 -99 207 -223 217v-217zM502 286v217c-116 -12 -208 -99 -223 -217h223zM775 220h-223v-215c121 10 208 102 223 215zM502 5v215h-223c14 -116 103 -204 223 -215"],10235:[450,-57,1574,55,1519,"1519 57h-50v163h-1226c-18 0 -26 -10 -26 -20c0 -8 5 -19 14 -28c30 -31 59 -63 82 -96l-20 -19c-66 76 -142 150 -238 191v10c96 40 172 117 237 192l20 -19c-22 -33 -53 -70 -82 -98c-10 -10 -14 -16 -14 -25c0 -10 8 -22 26 -22h1227v164h50v-393"],10237:[551,45,1574,55,1519,"1519 -45h-50v165h-1098c-18 0 -26 -14 -26 -22c0 -16 6 -25 23 -42c11 -11 50 -53 74 -81l-21 -20c-117 116 -243 201 -366 293v10c121 92 249 177 366 293l21 -20c-24 -28 -50 -56 -75 -82c-14 -15 -22 -21 -22 -41c0 -8 8 -22 26 -22h1098v165h50v-596zM1469 186v134 h-1242c-33 -19 -59 -43 -59 -67s26 -45 58 -67h1243"],10238:[551,45,1574,55,1519,"1519 258v-10c-123 -92 -249 -177 -366 -293l-21 20c24 28 63 70 74 81c17 17 23 26 23 42c0 8 -8 22 -26 22h-1098v-165h-50v596h50v-165h1098c18 0 26 14 26 22c0 20 -8 26 -22 41c-25 26 -51 54 -75 82l21 20c117 -116 245 -201 366 -293zM105 186h1243 c32 22 58 43 58 67s-26 48 -59 67h-1242v-134"],10239:[449,-58,1574,55,1519,"1519 258v-10c-96 -40 -172 -115 -237 -190l-20 19c22 33 53 68 82 96c10 10 14 16 14 25s-16 22 -24 22h-57l-92 -106l-124 172l-119 -172l-124 172l-119 -172l-124 172l-119 -172l-124 172l-119 -172l-89 106h-69v66h98l60 -66l119 174l124 -174l119 174l124 -174 l119 174l124 -174l119 174l124 -174l60 66h86c18 0 26 10 26 20c0 8 -5 19 -14 28c-30 31 -59 63 -82 96l20 19c66 -76 142 -150 238 -191"],10496:[450,-57,926,56,871,"871 258v-10c-96 -40 -172 -116 -237 -191l-20 19c22 33 53 69 82 97c10 10 14 16 14 25c0 10 -16 22 -26 22h-15c-70 -42 -129 -103 -181 -163l-20 19c22 33 53 69 82 97c10 10 14 16 14 25s-14 20 -24 22h-168v-163h-50v163h-266v66h266v164h50v-164h169 c15 0 22 11 22 20c0 8 -5 19 -14 28c-30 31 -59 64 -82 97l20 19c53 -61 112 -122 183 -164h13c18 0 26 10 26 20c0 8 -5 19 -14 28c-30 31 -59 64 -82 97l20 19c66 -76 142 -151 238 -192"],10497:[450,-57,926,55,871,"871 258v-10c-96 -40 -172 -116 -237 -191l-20 19c22 33 53 69 82 97c10 10 14 16 14 25c0 10 -16 22 -26 22h-15c-70 -42 -129 -103 -181 -163l-20 19c22 33 53 69 82 97c10 10 14 16 14 25s-14 20 -24 22h-135v-163h-50v163h-79v-163h-50v163h-171v66h171v164h50v-164 h79v164h50v-164h136c15 0 22 11 22 20c0 8 -5 19 -14 28c-30 31 -59 64 -82 97l20 19c53 -61 112 -122 183 -164h13c18 0 26 10 26 20c0 8 -5 19 -14 28c-30 31 -59 64 -82 97l20 19c66 -76 142 -151 238 -192"],10498:[551,45,926,55,871,"871 120h-257v-145h-50v145h-193c-18 0 -26 -14 -26 -22c0 -16 6 -25 23 -42c11 -11 50 -53 74 -81l-21 -20c-117 116 -243 201 -366 293v10c121 92 249 177 366 293l21 -20c-24 -28 -50 -56 -75 -82c-14 -15 -22 -21 -22 -41c0 -8 8 -22 26 -22h193v144h50v-144h257v-66 h-257v-134h257v-66zM564 186v134h-337c-33 -19 -59 -43 -59 -67s26 -45 58 -67h338"],10499:[551,45,926,55,871,"871 258v-10c-123 -92 -249 -177 -366 -293l-21 20c24 28 63 70 74 81c17 17 23 26 23 42c0 8 -8 22 -26 22h-193v-145h-50v145h-257v66h257v134h-257v66h257v144h50v-144h193c18 0 26 14 26 22c0 20 -8 26 -22 41c-25 26 -51 54 -75 82l21 20 c117 -116 245 -201 366 -293zM362 186h338c32 22 58 43 58 67s-26 48 -59 67h-337v-134"],10500:[551,45,926,20,906,"906 258v-10c-45 -30 -197 -142 -314 -258l-28 21c21 23 69 64 69 93c0 11 -1 16 -30 16h-115v-165h-50v165h-112c-26 0 -35 -2 -35 -18c0 -24 31 -45 70 -89l-23 -23c-121 114 -272 230 -318 258v10c46 33 195 146 318 259l23 -23c-24 -28 -72 -69 -72 -89 c0 -15 18 -19 34 -19h115v165h50v-165h115c20 0 28 12 28 21c0 34 -44 60 -67 86l28 24c122 -112 268 -228 314 -259zM488 186h246c33 19 59 43 59 67s-26 45 -58 67h-247v-134zM438 186v134h-247c-33 -19 -58 -43 -59 -67c0 -23 26 -45 58 -67h248"],10501:[450,-57,926,55,871,"871 258v-10c-96 -40 -172 -116 -237 -191l-20 19c22 33 53 69 82 97c10 10 14 16 14 25c0 10 -16 22 -26 22h-15c-70 -42 -129 -103 -181 -163l-20 19c22 33 53 69 82 97c10 10 14 16 14 25s-14 20 -24 22h-435v-163h-50v393h50v-164h436c15 0 22 11 22 20 c0 8 -5 19 -14 28c-30 31 -59 64 -82 97l20 19c53 -61 112 -122 183 -164h13c18 0 26 10 26 20c0 8 -5 19 -14 28c-30 31 -59 64 -82 97l20 19c66 -76 142 -151 238 -192"],10502:[551,45,926,55,871,"871 -25h-50v145h-450c-18 0 -26 -14 -26 -22c0 -16 6 -25 23 -42c11 -11 50 -53 74 -81l-21 -20c-117 116 -243 201 -366 293v10c121 92 249 177 366 293l21 -20c-24 -28 -50 -56 -75 -82c-14 -15 -22 -21 -22 -41c0 -8 8 -22 26 -22h450v144h50v-555zM821 186v134h-594 c-33 -19 -59 -43 -59 -67s26 -45 58 -67h595"],10503:[551,45,926,55,871,"871 258v-10c-123 -92 -249 -177 -366 -293l-21 20c24 28 63 70 74 81c17 17 23 26 23 42c0 8 -8 22 -26 22h-450v-145h-50v555h50v-144h450c18 0 26 14 26 22c0 20 -8 26 -22 41c-25 26 -51 54 -75 82l21 20c117 -116 245 -201 366 -293zM105 186h595c32 22 58 43 58 67 s-26 48 -59 67h-594v-134"],10504:[662,156,511,59,452,"452 320h-163v-289c0 -10 12 -26 22 -26c9 0 15 4 25 14c28 29 63 60 96 82l19 -20c-75 -65 -150 -141 -190 -237h-10c-41 96 -116 172 -192 238l19 20c33 -23 66 -52 97 -82c9 -9 20 -14 28 -14c10 0 20 8 20 26v288h-163v50h163v292h66v-292h163v-50"],10505:[662,156,511,59,452,"452 424l-19 -20c-33 23 -66 52 -97 82c-9 9 -20 14 -28 14c-10 0 -20 -8 -20 -26v-288h163v-50h-163v-292h-66v292h-163v50h163v289c0 10 -12 26 -22 26c-9 0 -15 -4 -25 -14c-28 -29 -63 -60 -96 -82l-19 20c75 65 150 141 190 237h10c41 -96 116 -172 192 -238"],10506:[662,156,926,71,854,"854 298l-15 -23c-33 20 -90 59 -140 99h-3v-530h-66v577c-28 24 -64 59 -86 81c-9 9 -20 14 -28 14c-10 0 -20 -7 -20 -26v-646h-66v645c0 20 -12 28 -22 28c-4 0 -15 -3 -25 -14c-17 -20 -63 -63 -87 -81v-578h-66v531h-1c-52 -42 -109 -79 -142 -99l-16 23 c106 70 260 186 387 363h10c105 -152 258 -279 386 -364"],10507:[662,156,926,72,855,"839 230l16 -23c-106 -70 -260 -186 -387 -363h-10c-105 152 -258 279 -386 364l15 23c33 -20 90 -59 140 -99h3v530h66v-577c28 -24 64 -59 86 -81c9 -9 20 -14 28 -14c10 0 20 7 20 26v646h66v-645c0 -20 12 -28 22 -28c4 0 15 3 25 14c17 20 63 63 87 81v578h66v-531 h1c52 42 109 79 142 99"],10508:[449,-57,926,55,871,"871 220h-262v66h262v-66zM505 220h-263c-10 0 -26 -12 -26 -22c0 -9 4 -15 14 -25c29 -28 60 -64 82 -97l-20 -19c-65 75 -141 151 -237 191v10c96 41 172 115 238 191l20 -19c-23 -33 -52 -65 -82 -96c-9 -9 -14 -20 -14 -28c0 -10 8 -20 26 -20h262v-66"],10509:[449,-57,926,55,871,"871 258v-10c-96 -41 -172 -115 -238 -191l-20 19c23 33 52 65 82 96c9 9 14 20 14 28c0 10 -8 20 -26 20h-262v66h263c10 0 26 12 26 22c0 9 -4 15 -14 25c-29 28 -60 64 -82 97l20 19c65 -75 141 -151 237 -191zM317 220h-262v66h262v-66"],10510:[449,-57,926,55,871,"871 220h-154v66h154v-66zM633 220h-154v66h154v-66zM395 220h-153c-10 0 -26 -12 -26 -22c0 -9 4 -15 14 -25c29 -28 60 -64 82 -97l-20 -19c-65 75 -141 151 -237 191v10c96 41 172 115 238 191l20 -19c-23 -33 -52 -65 -82 -96c-9 -9 -14 -20 -14 -28 c0 -10 8 -20 26 -20h152v-66"],10511:[449,-57,926,55,871,"871 258v-10c-96 -41 -172 -115 -238 -191l-20 19c23 33 52 65 82 96c9 9 14 20 14 28c0 10 -8 20 -26 20h-152v66h153c10 0 26 12 26 22c0 9 -4 15 -14 25c-29 28 -60 64 -82 97l20 19c65 -75 141 -151 237 -191zM447 220h-154v66h154v-66zM209 220h-154v66h154v-66"],10512:[449,-57,1412,55,1357,"1357 258v-10c-96 -40 -172 -116 -237 -191l-20 19c22 33 53 69 82 97c10 10 14 16 14 25c0 10 -16 22 -26 22h-15c-70 -42 -129 -103 -181 -163l-20 19c22 33 54 70 83 98c10 10 13 15 13 24c0 8 -15 22 -24 22v66c17 0 23 11 23 20c0 8 -5 19 -14 28 c-30 31 -59 63 -82 96l20 19c53 -61 112 -121 183 -163h14c17 0 25 10 25 20c0 8 -5 19 -14 28c-30 31 -59 63 -82 96l20 19c66 -76 142 -150 238 -191zM942 220h-144v66h144v-66zM714 220h-144v66h144v-66zM486 220h-144v66h144v-66zM258 286v-66 c-70 -42 -130 -103 -182 -163l-20 19c22 33 55 67 82 97c10 12 28 36 28 80c0 32 -16 64 -29 81c-27 34 -59 63 -82 96l20 19c53 -61 112 -120 183 -163"],10513:[449,-57,926,55,873,"873 258v-10c-96 -40 -172 -116 -237 -191l-20 19c22 33 53 69 82 97c10 10 14 16 14 25c0 10 -4 19 -15 19c-20 0 -31 16 -31 36s11 36 31 36c10 0 14 7 14 17c0 8 -5 19 -14 28c-30 31 -58 63 -81 96l20 19c66 -76 141 -150 237 -191zM616 254c0 -21 -16 -37 -36 -37 s-37 16 -37 37c0 20 17 36 37 36s36 -16 36 -36zM495 254c0 -21 -17 -37 -37 -37c-19 0 -36 16 -36 37c0 20 17 36 36 36c20 0 37 -16 37 -36zM372 253c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM250 254c0 -21 -17 -37 -36 -37c-20 0 -37 16 -37 37 c0 20 17 36 37 36c19 0 36 -16 36 -36zM128 254c0 -21 -17 -37 -37 -37s-36 16 -36 37c0 20 16 36 36 36s37 -16 37 -36"],10514:[662,156,511,59,452,"452 424l-19 -20c-33 23 -65 52 -96 82c-9 9 -20 14 -28 14c-10 0 -20 -8 -20 -26v-630h-66v630c0 18 -12 26 -22 26c-9 0 -15 -4 -25 -14c-28 -29 -63 -59 -96 -81l-19 20c61 53 123 114 165 187h-167v50h391v-50h-164c42 -73 103 -134 166 -188"],10515:[662,156,511,59,452,"452 -156h-391v50h164c-42 73 -103 134 -166 188l19 20c33 -23 65 -52 96 -82c9 -9 20 -14 28 -14c10 0 20 8 20 26v630h66v-630c0 -18 12 -26 22 -26c9 0 15 4 25 14c28 29 63 59 96 81l19 -20c-61 -53 -123 -114 -165 -187h167v-50"],10516:[450,-57,926,55,871,"871 258v-10c-96 -40 -172 -116 -237 -191l-20 19c22 33 53 69 82 97c10 10 14 16 14 25c0 10 -16 22 -26 22h-231v-163h-50v163h-146c-70 -42 -129 -103 -181 -163l-20 19c22 33 55 67 82 97c10 12 28 36 28 80c0 32 -16 64 -29 81c-27 35 -59 64 -82 97l20 19 c53 -61 112 -121 183 -164h145v164h50v-164h230c18 0 26 10 26 20c0 8 -5 19 -14 28c-30 31 -59 64 -82 97l20 19c66 -76 142 -151 238 -192"],10517:[450,-57,926,55,871,"871 258v-10c-96 -40 -172 -116 -237 -191l-20 19c22 33 53 69 82 97c10 10 14 16 14 25c0 10 -16 22 -26 22h-153v-163h-50v163h-79v-163h-50v163h-95c-70 -42 -129 -103 -181 -163l-20 19c22 33 55 67 82 97c10 12 28 36 28 80c0 32 -16 64 -29 81 c-27 35 -59 64 -82 97l20 19c53 -61 112 -121 183 -164h94v164h50v-164h79v164h50v-164h152c18 0 26 10 26 20c0 8 -5 19 -14 28c-30 31 -59 64 -82 97l20 19c66 -76 142 -151 238 -192"],10518:[449,-57,926,55,871,"871 258v-10c-96 -40 -172 -116 -237 -191l-20 19c22 33 53 69 82 97c10 10 14 16 14 25c0 10 -16 22 -26 22h-16c-70 -42 -129 -103 -181 -163l-20 19c22 33 53 69 82 97c10 10 14 16 14 25c0 8 -10 22 -24 22h-282c-70 -42 -129 -103 -181 -163l-20 19 c22 33 55 67 82 97c10 12 28 36 28 80c0 32 -16 64 -29 81c-27 34 -59 63 -82 96l20 19c53 -61 112 -120 183 -163h281c14 0 23 11 23 20c0 8 -5 19 -14 28c-30 31 -59 63 -82 96l20 19c53 -61 112 -121 183 -163h14c18 0 26 10 26 20c0 8 -5 19 -14 28 c-30 31 -59 63 -82 96l20 19c66 -76 142 -150 238 -191"],10519:[450,-57,926,55,871,"871 258v-10c-96 -40 -172 -116 -237 -191l-20 19c22 33 53 69 82 97c10 10 14 16 14 25c0 10 -16 22 -26 22h-16c-70 -42 -129 -103 -181 -163l-20 19c22 33 53 69 82 97c10 10 14 16 14 25c0 8 -10 22 -24 22h-145v-163h-50v163h-87c-70 -42 -129 -103 -181 -163 l-20 19c22 33 55 67 82 97c10 12 28 36 28 80c0 32 -16 64 -29 81c-27 35 -59 64 -82 97l20 19c53 -61 112 -121 183 -164h86v164h50v-164h145c14 0 23 11 23 20c0 8 -5 19 -14 28c-30 31 -59 64 -82 97l20 19c53 -61 112 -122 183 -164h14c18 0 26 10 26 20 c0 8 -5 19 -14 28c-30 31 -59 64 -82 97l20 19c66 -76 142 -151 238 -192"],10520:[450,-57,926,50,876,"876 258v-10c-96 -40 -162 -116 -227 -191l-20 19c22 33 51 69 80 97c10 10 14 16 14 25c0 10 -15 22 -25 22c-76 -42 -124 -100 -176 -163l-20 19c22 33 51 69 80 97c10 10 14 16 14 25c0 8 -10 22 -24 22h-121v-163h-50v163h-59v-163h-50v163h-51 c-70 -42 -118 -100 -170 -163l-20 19c22 32 48 64 75 94c10 12 29 39 29 83c0 32 -17 64 -30 81c-27 35 -52 64 -75 97l20 19c53 -63 101 -121 172 -164h50v164h50v-164h59v164h50v-164h121c14 0 23 11 23 20c0 8 -5 19 -14 28c-30 31 -56 64 -79 97l20 19 c53 -63 101 -122 176 -164c18 0 24 10 24 20c0 8 -5 19 -14 28c-30 31 -57 64 -80 97l20 19c66 -76 132 -151 228 -192"],10521:[449,-57,926,55,871,"871 76l-20 -19c-53 61 -112 120 -183 163h-613v66h614c70 42 129 103 181 163l20 -19c-22 -33 -55 -67 -82 -97c-10 -12 -28 -36 -28 -80c0 -32 16 -64 29 -81c27 -34 59 -63 82 -96"],10522:[449,-57,926,55,871,"871 220h-614c-70 -42 -129 -103 -181 -163l-20 19c22 33 55 67 82 97c10 12 28 36 28 80c0 32 -16 64 -29 81c-27 34 -59 63 -82 96l20 19c53 -61 112 -120 183 -163h613v-66"],10523:[449,-57,926,55,871,"871 76l-20 -19c-53 61 -112 120 -183 163h-19c-15 -2 -21 -11 -21 -20c0 -8 5 -19 14 -28c30 -31 59 -63 82 -96l-20 -19c-53 61 -113 120 -184 163h-465v66h466c71 42 130 103 182 163l20 -19c-22 -33 -53 -69 -82 -97c-10 -10 -14 -16 -14 -25s13 -21 23 -22h19 c70 42 129 103 181 163l20 -19c-22 -33 -55 -67 -82 -97c-10 -12 -28 -36 -28 -80c0 -32 16 -64 29 -81c27 -34 59 -63 82 -96"],10524:[449,-57,926,55,871,"871 220h-466c-71 -42 -130 -103 -182 -163l-20 19c22 33 53 69 82 97c10 10 14 16 14 25s-13 21 -23 22h-19c-70 -42 -129 -103 -181 -163l-20 19c22 33 55 67 82 97c10 12 28 36 28 80c0 32 -16 64 -29 81c-27 34 -59 63 -82 96l20 19c53 -61 112 -120 183 -163h19 c15 2 21 11 21 20c0 8 -5 19 -14 28c-30 31 -59 63 -82 96l20 19c53 -61 113 -120 184 -163h465v-66"],10525:[449,-57,926,55,871,"871 220h-418c-10 0 -26 -12 -26 -22c0 -9 4 -15 14 -25c29 -28 60 -64 82 -97l-20 -19c-65 75 -141 152 -237 192v10c96 41 172 114 238 190l20 -19c-23 -33 -52 -65 -82 -96c-9 -9 -14 -20 -14 -28c0 -10 8 -20 26 -20h417v-66zM261 259v-10c-30 -22 -76 -69 -98 -98 h-10c-23 29 -69 76 -98 98v10c29 22 76 68 98 98h10c22 -30 68 -76 98 -98"],10526:[449,-57,926,55,871,"871 259v-10c-29 -22 -76 -68 -98 -98h-10c-22 30 -68 76 -98 98v10c30 22 76 69 98 98h10c23 -29 69 -76 98 -98zM660 259v-10c-96 -41 -172 -116 -238 -192l-20 19c23 33 52 65 82 96c9 9 14 20 14 28c0 10 -8 20 -26 20h-417v66h418c10 0 26 12 26 22 c0 9 -4 15 -14 25c-29 28 -60 64 -82 97l20 19c65 -75 141 -150 237 -190"],10527:[450,-57,926,55,871,"871 57h-50v163h-368c-10 0 -26 -12 -26 -22c0 -9 4 -15 14 -25c29 -28 60 -64 82 -97l-20 -19c-65 75 -141 152 -237 192v10c96 41 172 115 238 191l20 -19c-23 -33 -52 -66 -82 -97c-9 -9 -14 -20 -14 -28c0 -10 8 -20 26 -20h367v164h50v-393zM261 259v-10 c-30 -22 -76 -69 -98 -98h-10c-23 29 -69 76 -98 98v10c29 22 76 68 98 98h10c22 -30 68 -76 98 -98"],10528:[450,-57,926,55,871,"871 259v-10c-29 -22 -76 -68 -98 -98h-10c-22 30 -68 76 -98 98v10c30 22 76 69 98 98h10c23 -29 69 -76 98 -98zM660 259v-10c-96 -41 -172 -116 -238 -192l-20 19c23 33 52 65 82 96c9 9 14 20 14 28c0 10 -8 20 -26 20h-367v-163h-50v393h50v-164h368 c10 0 26 12 26 22c0 9 -4 15 -14 25c-29 28 -60 65 -82 98l20 19c65 -75 141 -151 237 -191"],10529:[662,156,926,55,871,"871 -149l-7 -7c-69 28 -143 37 -216 37c-29 0 -58 -2 -87 -4l-1 28c40 7 83 9 126 10c17 0 35 7 35 23c0 6 -3 12 -10 19l-544 546c-4 4 -13 7 -21 7c-18 0 -20 -14 -20 -32c0 -40 -2 -87 -10 -126l-28 1c2 30 4 60 4 91c0 71 -9 144 -37 211l7 7 c69 -28 143 -37 216 -37c29 0 58 2 87 4l1 -28c-40 -7 -83 -9 -126 -10c-17 0 -35 -7 -35 -23c0 -6 3 -12 10 -19l544 -546c4 -4 13 -7 21 -7c18 0 20 14 20 32c0 40 2 87 10 126l28 -1c-2 -30 -4 -60 -4 -91c0 -71 9 -144 37 -211"],10530:[660,156,926,55,873,"866 660l7 -7c-28 -69 -37 -143 -37 -216c0 -29 2 -58 4 -87l-28 -1c-7 40 -9 83 -10 126c0 17 -7 35 -23 35c-6 0 -12 -3 -19 -10l-546 -544c-4 -4 -7 -13 -7 -21c0 -18 14 -20 32 -20c40 0 87 -2 126 -10l-1 -28c-30 2 -60 4 -91 4c-71 0 -144 -9 -211 -37l-7 7 c28 69 37 143 37 216c0 29 -2 58 -4 87l28 1c7 -40 9 -83 10 -126c0 -17 7 -35 23 -35c6 0 12 3 19 10l546 544c4 4 7 13 7 21c0 18 -14 20 -32 20c-40 0 -87 2 -126 10l1 28c30 -2 60 -4 91 -4c71 0 144 9 211 37"],10531:[662,156,926,55,871,"231 555l572 -471c40 -33 68 -70 68 -120c0 -75 -59 -120 -123 -120c-39 0 -64 11 -84 31l-60 49l45 52l61 -51c12 -12 28 -15 43 -15c24 0 52 17 52 54c0 23 -6 37 -37 63l-586 482c-5 4 -8 5 -12 5c-23 0 -23 -28 -23 -47c0 -10 2 -36 2 -49c0 -19 0 -38 -3 -60l-29 -2 c-4 99 -11 208 -62 299l6 7c47 -12 96 -21 144 -21c56 0 111 7 164 17l4 -29c-38 -10 -85 -21 -127 -27c-18 -2 -26 -12 -26 -25c0 -7 3 -15 11 -22"],10532:[662,156,926,55,871,"865 662l6 -7c-51 -91 -58 -200 -62 -299l-29 2c-3 22 -3 41 -3 60c0 13 2 39 2 49c0 19 0 47 -23 47c-4 0 -7 -1 -12 -5l-586 -482c-31 -26 -37 -40 -37 -63c0 -37 28 -54 52 -54c15 0 31 3 43 15l61 51l45 -52l-60 -49c-20 -20 -45 -31 -84 -31c-64 0 -123 45 -123 120 c0 50 28 87 68 120l572 471c8 7 11 15 11 22c0 13 -8 23 -26 25c-42 6 -89 17 -127 27l4 29c53 -10 108 -17 164 -17c48 0 97 9 144 21"],10533:[662,156,926,55,871,"871 -149l-6 -7c-47 12 -96 21 -144 21c-56 0 -111 -7 -164 -17l-4 29c38 10 85 21 127 27c18 2 26 12 26 25c0 7 -3 15 -11 22l-572 471c-40 33 -68 70 -68 120c0 75 59 120 123 120c39 0 64 -11 84 -31l60 -49l-45 -52l-61 51c-12 12 -28 15 -43 15 c-24 0 -52 -17 -52 -54c0 -23 6 -37 37 -63l586 -482c5 -4 8 -5 12 -5c23 0 23 28 23 47c0 10 -2 36 -2 49c0 19 0 38 3 60l29 2c4 -99 11 -208 62 -299"],10534:[662,156,926,55,871,"604 582l60 49c20 20 45 31 84 31c64 0 123 -45 123 -120c0 -50 -28 -87 -68 -120l-572 -471c-8 -7 -11 -15 -11 -22c0 -13 8 -23 26 -25c42 -6 89 -17 127 -27l-4 -29c-53 10 -108 17 -164 17c-48 0 -97 -9 -144 -21l-6 7c51 91 58 200 62 299l29 -2c3 -22 3 -41 3 -60 c0 -13 -2 -39 -2 -49c0 -19 0 -47 23 -47c4 0 7 1 12 5l586 482c31 26 37 40 37 63c0 37 -28 54 -52 54c-15 0 -31 -3 -43 -15l-61 -51"],10535:[662,156,926,55,873,"866 662l7 -7c-28 -69 -37 -143 -37 -216c0 -29 2 -58 4 -87l-28 -1c-7 40 -10 83 -10 126c0 17 -7 35 -23 35c-6 0 -12 -3 -19 -10l-250 -250l361 -361l-47 -47l-361 361l-361 -361l-47 47l361 361l-249 251c-4 4 -13 7 -21 7c-18 0 -20 -14 -20 -32 c0 -40 -2 -87 -10 -126l-28 1c2 30 4 60 4 91c0 71 -9 144 -37 211l7 7c69 -28 143 -37 216 -37c29 0 58 2 87 4l1 -28c-40 -7 -83 -9 -126 -10c-17 0 -35 -7 -35 -23c0 -6 3 -12 10 -19l248 -250l251 251c4 4 7 13 7 21c0 18 -14 20 -32 20c-40 0 -87 2 -126 10l1 28 c30 -2 60 -4 91 -4c71 0 144 9 211 37"],10536:[662,156,926,53,871,"871 -149l-7 -7c-69 28 -143 37 -216 37c-29 0 -58 -2 -87 -4l-1 28c40 7 83 10 126 10c17 0 35 7 35 23c0 6 -3 12 -10 19l-250 250l-361 -361l-47 47l361 361l-361 361l47 47l361 -361l251 249c4 4 7 13 7 21c0 18 -14 20 -32 20c-40 0 -87 2 -126 10l1 28 c30 -2 60 -4 91 -4c71 0 144 9 211 37l7 -7c-28 -69 -37 -143 -37 -216c0 -29 2 -58 4 -87l-28 -1c-7 40 -9 83 -10 126c0 17 -7 35 -23 35c-6 0 -12 -3 -19 -10l-250 -248l251 -251c4 -4 13 -7 21 -7c18 0 20 14 20 32c0 40 2 87 10 126l28 -1c-2 -30 -4 -60 -4 -91 c0 -71 9 -144 37 -211"],10537:[662,156,926,53,871,"871 -149l-7 -7c-69 28 -143 37 -216 37c-29 0 -58 -2 -87 -4l-1 28c40 7 83 9 126 10c17 0 35 7 35 23c0 6 -3 12 -10 19l-248 250l-251 -251c-4 -4 -7 -13 -7 -21c0 -18 14 -20 32 -20c40 0 87 -2 126 -10l-1 -28c-30 2 -60 4 -91 4c-71 0 -144 -9 -211 -37l-7 7 c28 69 37 143 37 216c0 29 -2 58 -4 87l28 1c7 -40 10 -83 10 -126c0 -17 7 -35 23 -35c6 0 12 3 19 10l250 250l-361 361l47 47l361 -361l361 361l47 -47l-361 -361l249 -251c4 -4 13 -7 21 -7c18 0 20 14 20 32c0 40 2 87 10 126l28 -1c-2 -30 -4 -60 -4 -91 c0 -71 9 -144 37 -211"],10538:[662,156,926,55,873,"873 -109l-47 -47l-361 361l-251 -249c-4 -4 -7 -13 -7 -21c0 -18 14 -20 32 -20c40 0 87 -2 126 -10l-1 -28c-30 2 -60 4 -91 4c-71 0 -144 -9 -211 -37l-7 7c28 69 37 143 37 216c0 29 -2 58 -4 87l28 1c7 -40 9 -83 10 -126c0 -17 7 -35 23 -35c6 0 12 3 19 10 l250 248l-251 251c-4 4 -13 7 -21 7c-18 0 -20 -14 -20 -32c0 -40 -2 -87 -10 -126l-28 1c2 30 4 60 4 91c0 71 -9 144 -37 211l7 7c69 -28 143 -37 216 -37c29 0 58 2 87 4l1 -28c-40 -7 -83 -10 -126 -10c-17 0 -35 -7 -35 -23c0 -6 3 -12 10 -19l250 -250l361 361l47 -47 l-361 -361"],10539:[662,156,926,55,871,"402 361l-47 -47l-300 301l47 47zM871 615l-769 -771l-47 47l769 771zM871 -109l-47 -47l-300 301l47 47"],10540:[662,156,926,55,871,"871 615l-300 -301l-47 47l300 301zM871 -109l-47 -47l-769 771l47 47zM402 145l-300 -301l-47 47l300 301"],10541:[662,156,926,55,871,"864 662l7 -7c-28 -69 -37 -143 -37 -216c0 -29 2 -58 4 -87l-28 -1c-7 40 -9 83 -10 126c0 17 -7 35 -23 35c-6 0 -12 -3 -19 -10l-187 -188l-47 47l188 189c4 4 7 13 7 21c0 18 -14 20 -32 20c-40 0 -87 2 -126 10l1 28c30 -2 60 -4 91 -4c71 0 144 9 211 37zM871 -149 l-7 -7c-69 28 -143 37 -216 37c-29 0 -58 -2 -87 -4l-1 28c40 7 83 9 126 10c17 0 35 7 35 23c0 6 -3 12 -10 19l-656 658l47 47l657 -659c4 -4 13 -7 21 -7c18 0 20 14 20 32c0 40 2 87 10 126l28 -1c-2 -30 -4 -60 -4 -91c0 -71 9 -144 37 -211zM402 145l-300 -301l-47 47 l300 301"],10542:[662,156,926,55,871,"402 361l-47 -47l-300 301l47 47zM864 662l7 -7c-28 -67 -37 -140 -37 -211c0 -31 2 -61 4 -91l-28 -1c-8 39 -10 86 -10 126c0 18 -2 32 -20 32c-8 0 -17 -3 -21 -7l-657 -659l-47 47l656 658c7 7 10 13 10 19c0 16 -18 23 -35 23c-43 1 -86 3 -126 10l1 28 c29 -2 58 -4 87 -4c73 0 147 9 216 37zM871 -149l-7 -7c-67 28 -140 37 -211 37c-31 0 -61 -2 -91 -4l-1 28c39 8 86 10 126 10c18 0 32 2 32 20c0 8 -3 17 -7 21l-188 189l47 47l187 -188c7 -7 13 -10 19 -10c16 0 23 18 23 35c1 43 3 86 10 126l28 -1 c-2 -29 -4 -58 -4 -87c0 -73 9 -147 37 -216"],10543:[662,156,926,55,871,"864 662l7 -7c-28 -69 -37 -143 -37 -216c0 -29 2 -58 4 -87l-28 -1c-7 40 -9 83 -10 126c0 17 -7 35 -23 35c-6 0 -12 -3 -19 -10l-187 -188l-47 47l188 189c4 4 7 13 7 21c0 18 -14 20 -32 20c-40 0 -87 2 -126 10l1 28c30 -2 60 -4 91 -4c71 0 144 9 211 37zM871 -109 l-47 -47l-769 771l47 47zM402 145l-300 -301l-47 47l300 301"],10544:[662,154,926,55,873,"873 -147l-7 -7c-69 28 -143 37 -216 37c-29 0 -58 -2 -87 -4l-1 28c40 7 83 9 126 10c17 0 35 7 35 23c0 6 -3 12 -10 19l-188 187l47 47l189 -188c4 -4 13 -7 21 -7c18 0 20 14 20 32c0 40 2 87 10 126l28 -1c-2 -30 -4 -60 -4 -91c0 -71 9 -144 37 -211zM873 615 l-771 -769l-47 47l771 769zM403 362l-47 -47l-301 300l47 47"],10545:[662,156,926,54,870,"402 361l-47 -47l-187 188c-7 7 -13 10 -19 10c-16 0 -23 -18 -23 -35c-1 -43 -3 -86 -10 -126l-28 1c2 29 4 58 4 87c0 73 -9 147 -37 216l7 7c67 -28 140 -37 211 -37c31 0 61 2 91 4l1 -28c-39 -8 -86 -10 -126 -10c-18 0 -32 -2 -32 -20c0 -8 3 -17 7 -21zM863 662 l7 -7c-28 -69 -37 -143 -37 -216c0 -29 2 -58 4 -87l-28 -1c-7 40 -10 83 -10 126c0 17 -7 35 -23 35c-6 0 -12 -3 -19 -10l-656 -658l-47 47l657 659c4 4 7 13 7 21c0 18 -14 20 -32 20c-40 0 -87 2 -126 10l1 28c30 -2 60 -4 91 -4c71 0 144 9 211 37zM870 -109l-47 -47 l-300 301l47 47"],10546:[662,156,926,55,871,"863 662l7 -7c-28 -69 -37 -143 -37 -216c0 -29 2 -58 4 -87l-28 -1c-7 40 -9 83 -10 126c0 17 -7 35 -23 35c-6 0 -12 -3 -19 -10l-187 -188l-47 47l188 189c4 4 7 13 7 21c0 18 -14 20 -32 20c-40 0 -87 2 -126 10l1 28c30 -2 60 -4 91 -4c71 0 144 9 211 37zM871 -109 l-47 -47l-656 658c-7 7 -13 10 -19 10c-16 0 -23 -18 -23 -35c0 -43 -3 -86 -10 -126l-28 1c2 29 4 58 4 87c0 73 -9 147 -37 216l7 7c67 -28 140 -37 211 -37c31 0 61 2 91 4l1 -28c-39 -8 -86 -10 -126 -10c-18 0 -32 -2 -32 -20c0 -8 3 -17 7 -21zM402 145l-300 -301 l-47 47l300 301"],10547:[449,-57,926,55,871,"871 258v-10c-96 -41 -172 -115 -238 -191l-20 19c23 33 52 65 82 96c9 9 14 20 14 28c0 10 -8 20 -26 20h-107c-126 0 -172 154 -280 154c-88 0 -147 -77 -190 -152l-51 34c53 97 137 184 241 184c142 0 202 -154 280 -154h108c10 0 26 12 26 22c0 9 -4 15 -14 25 c-29 28 -60 64 -82 97l20 19c65 -75 141 -151 237 -191"],10548:[562,0,926,141,797,"797 324l-19 -20c-33 23 -65 53 -96 83c-9 9 -20 14 -28 14c-10 0 -20 -8 -20 -26v-52c0 -178 -135 -323 -312 -323h-181v66h181c142 0 246 115 246 257v52c0 10 -12 26 -22 26c-9 0 -15 -4 -25 -14c-28 -29 -64 -60 -97 -82l-19 20c75 65 151 141 191 237h10 c41 -96 115 -172 191 -238"],10549:[562,0,926,141,797,"778 258l19 -20c-76 -66 -150 -142 -191 -238h-10c-40 96 -116 172 -191 237l19 20c33 -22 69 -53 97 -82c10 -10 16 -14 25 -14c10 0 22 16 22 26v52c0 142 -104 257 -246 257h-181v66h181c177 0 312 -145 312 -323v-52c0 -18 10 -26 20 -26c8 0 19 5 28 14 c31 30 63 60 96 83"],10550:[493,163,784,87,649,"649 493v-181c0 -177 -145 -312 -323 -312h-52c-18 0 -26 -10 -26 -20c0 -8 5 -19 14 -28c30 -31 60 -63 83 -96l-20 -19c-66 76 -142 150 -238 191v10c96 40 172 116 237 191l20 -19c-22 -33 -53 -69 -82 -97c-10 -10 -14 -16 -14 -25c0 -10 16 -22 26 -22h52 c142 0 257 104 257 246v181h66"],10551:[493,163,784,135,697,"697 38v-10c-96 -41 -172 -115 -238 -191l-20 19c23 33 53 65 83 96c9 9 14 20 14 28c0 10 -8 20 -26 20h-52c-178 0 -323 135 -323 312v181h66v-181c0 -142 115 -246 257 -246h52c10 0 26 12 26 22c0 9 -4 15 -14 25c-29 28 -60 64 -82 97l20 19 c65 -75 141 -151 237 -191"],10552:[657,153,511,70,415,"132 595l22 62c149 -46 261 -220 261 -380c0 -129 -58 -258 -167 -332c-7 -5 -10 -10 -10 -15c0 -8 8 -15 20 -18c39 -9 84 -22 120 -39l-7 -26c-68 22 -139 35 -212 35c-28 0 -55 -2 -84 -6l-5 10c60 84 91 179 108 277l26 -5c-2 -40 -8 -82 -19 -125 c-1 -7 -2 -12 -2 -16c0 -11 6 -14 18 -14c33 0 74 52 92 76c37 49 56 135 56 200c0 133 -94 280 -217 316"],10553:[657,153,511,96,441,"441 -114l-5 -10c-29 4 -56 6 -84 6c-73 0 -144 -13 -212 -35l-7 26c36 17 81 30 120 39c12 3 20 10 20 18c0 5 -3 10 -10 15c-109 74 -167 203 -167 332c0 160 112 334 261 380l22 -62c-123 -36 -217 -183 -217 -316c0 -65 19 -151 56 -200c18 -24 59 -76 92 -76 c12 0 18 3 18 14c0 4 -1 9 -2 16c-11 43 -17 85 -19 125l26 5c17 -98 48 -193 108 -277"],10554:[423,-78,926,69,866,"866 162l-62 -22c-36 123 -176 217 -309 217c-65 0 -145 -19 -194 -56c-24 -18 -76 -59 -76 -92c0 -12 3 -18 14 -18c4 0 9 1 16 2c43 11 85 17 125 19l5 -26c-98 -17 -193 -48 -277 -108l-10 5c4 29 6 56 6 84c0 73 -13 144 -35 212l26 7c17 -36 30 -81 39 -120 c3 -12 10 -20 18 -20c5 0 10 3 15 10c74 109 207 167 326 167c160 0 327 -112 373 -261"],10555:[423,-78,926,60,857,"857 122l-26 -7c-17 36 -30 81 -39 120c-3 12 -10 20 -18 20c-5 0 -10 -3 -15 -10c-74 -109 -207 -167 -326 -167c-160 0 -327 112 -373 261l62 22c36 -123 176 -217 309 -217c65 0 145 19 194 56c24 18 76 59 76 92c0 12 -3 18 -14 18c-4 0 -9 -1 -16 -2 c-43 -11 -85 -17 -125 -19l-5 26c98 17 193 48 277 108l10 -5c-4 -29 -6 -56 -6 -84c0 -73 13 -144 35 -212"],10556:[423,-64,926,59,856,"830 386l26 -7c-22 -68 -35 -139 -35 -212c0 -28 2 -55 6 -84l-10 -5c-84 60 -179 91 -277 108l5 26c40 -2 82 -8 125 -19c7 -1 12 -2 16 -2c11 0 14 6 14 18c0 33 -52 74 -76 92c-49 37 -129 56 -194 56c-133 0 -273 -94 -309 -217l-62 22c46 149 213 261 373 261 c119 0 252 -58 326 -167c5 -7 10 -10 15 -10c8 0 15 8 18 20c9 39 22 84 39 120zM536 64h-256v50h256v-50"],10557:[423,29,926,69,866,"866 162l-62 -22c-36 123 -176 217 -309 217c-65 0 -145 -19 -194 -56c-24 -18 -76 -59 -76 -92c0 -12 3 -18 14 -18c4 0 9 1 16 2c43 11 85 17 125 19l5 -26c-98 -17 -193 -48 -277 -108l-10 5c4 29 6 56 6 84c0 73 -13 144 -35 212l26 7c17 -36 30 -81 39 -120 c3 -12 10 -20 18 -20c5 0 10 3 15 10c74 109 207 167 326 167c160 0 327 -112 373 -261zM646 64h-104v-93h-50v93h-104v50h104v93h50v-93h104v-50"],10558:[563,116,926,69,856,"652 508l36 55c101 -66 168 -180 168 -309c0 -204 -166 -370 -370 -370c-135 0 -253 73 -318 181c-6 7 -12 12 -19 12c-9 0 -14 -9 -17 -25c-7 -39 -21 -84 -37 -121l-26 8c19 65 32 132 32 202c0 31 -3 62 -8 94l7 5c88 -59 182 -88 283 -102l-6 -28 c-41 3 -82 8 -126 18c-6 2 -11 3 -15 3c-9 0 -16 -6 -16 -16c0 -6 3 -13 8 -22c53 -86 149 -143 258 -143c168 0 304 136 304 304c0 106 -55 200 -138 254"],10559:[563,116,926,69,856,"856 -61l-26 -8c-16 37 -30 82 -37 121c-3 16 -8 25 -17 25c-7 0 -13 -5 -19 -12c-65 -108 -183 -181 -318 -181c-204 0 -370 166 -370 370c0 129 67 243 168 309l36 -55c-83 -54 -138 -148 -138 -254c0 -168 136 -304 304 -304c109 0 205 57 258 143c5 9 8 16 8 22 c0 10 -7 16 -16 16c-4 0 -9 -1 -15 -3c-44 -10 -85 -15 -126 -18l-6 28c101 14 195 43 283 102l7 -5c-5 -32 -8 -63 -8 -94c0 -70 13 -137 32 -202"],10560:[788,116,926,92,834,"572 788l20 -19c-23 -33 -52 -65 -82 -96c-9 -9 -14 -20 -14 -28c0 -9 5 -20 21 -23c178 -35 317 -181 317 -367c0 -205 -166 -371 -371 -371s-371 166 -371 371c0 171 115 315 273 358c98 50 153 112 207 175zM591 416l-20 -19c-50 57 -107 115 -174 157 c-137 -30 -240 -153 -240 -299c0 -169 137 -306 306 -306s306 137 306 306c0 150 -108 275 -251 301h-2c-14 0 -20 -10 -20 -19s4 -15 14 -25c29 -28 59 -63 81 -96"],10561:[788,116,926,92,834,"334 769l20 19c54 -63 109 -125 207 -175c158 -43 273 -187 273 -358c0 -205 -166 -371 -371 -371s-371 166 -371 371c0 186 139 332 317 367c16 3 21 14 21 23c0 8 -5 19 -14 28c-30 31 -59 63 -82 96zM410 556h-2c-143 -26 -251 -151 -251 -301 c0 -169 137 -306 306 -306s306 137 306 306c0 146 -103 269 -240 299c-67 -42 -124 -100 -174 -157l-20 19c22 33 52 68 81 96c10 10 14 16 14 25s-6 19 -20 19"],10562:[598,92,926,55,871,"871 418v-10c-96 -41 -170 -107 -236 -180l-20 19c23 30 46 54 76 85c9 9 14 20 14 28c0 10 -8 20 -26 20h-614v66h613c10 0 27 6 27 22c0 9 -4 15 -14 25c-29 28 -54 53 -76 86l20 19c65 -75 140 -140 236 -180zM448 60h-200c-10 0 -27 -6 -27 -22c0 -9 4 -15 14 -25 c29 -28 54 -53 76 -86l-20 -19c-65 75 -140 140 -236 180v10c96 41 170 107 236 180l20 -19c-23 -30 -46 -54 -76 -85c-9 -9 -14 -20 -14 -28c0 -10 8 -20 26 -20h201v-66"],10563:[598,92,926,55,871,"861 380h-614c-18 0 -26 -10 -26 -20c0 -8 5 -19 14 -28c30 -31 53 -55 76 -85l-20 -19c-66 73 -140 139 -236 180v10c96 40 171 105 236 180l20 -19c-22 -33 -47 -58 -76 -86c-10 -10 -14 -16 -14 -25c0 -16 17 -22 27 -22h613v-66zM871 98v-10 c-96 -40 -171 -105 -236 -180l-20 19c22 33 47 58 76 86c10 10 14 16 14 25c0 16 -17 22 -27 22h-200v66h201c18 0 26 10 26 20c0 8 -5 19 -14 28c-30 31 -53 55 -76 85l20 19c66 -73 140 -139 236 -180"],10564:[598,92,926,55,871,"871 418v-10c-96 -40 -171 -105 -236 -180l-20 19c22 33 47 58 76 86c10 10 14 16 14 25c0 16 -17 22 -27 22h-200v66h201c18 0 26 10 26 20c0 8 -5 19 -14 28c-30 31 -53 55 -76 85l20 19c66 -73 140 -139 236 -180zM861 60h-614c-18 0 -26 -10 -26 -20 c0 -8 5 -19 14 -28c30 -31 53 -55 76 -85l-20 -19c-66 73 -140 139 -236 180v10c96 40 171 105 236 180l20 -19c-22 -33 -47 -58 -76 -86c-10 -10 -14 -16 -14 -25c0 -16 17 -22 27 -22h613v-66"],10565:[449,69,926,55,871,"871 258v-10c-96 -41 -172 -115 -238 -191l-20 19c23 33 52 65 82 96c9 9 14 20 14 28c0 10 -8 20 -26 20h-628v66h629c10 0 26 12 26 22c0 9 -4 15 -14 25c-29 28 -60 64 -82 97l20 19c65 -75 141 -151 237 -191zM388 24h-104v-93h-50v93h-104v50h104v93h50v-93h104v-50 "],10566:[449,69,926,55,871,"871 220h-629c-10 0 -26 -12 -26 -22c0 -9 4 -15 14 -25c29 -28 60 -64 82 -97l-20 -19c-65 75 -141 151 -237 191v10c96 41 172 115 238 191l20 -19c-23 -33 -52 -65 -82 -96c-9 -9 -14 -20 -14 -28c0 -10 8 -20 26 -20h628v-66zM796 24h-104v-93h-50v93h-104v50h104v93 h50v-93h104v-50"],10567:[449,-57,926,55,871,"871 258v-10c-96 -41 -172 -115 -238 -191l-20 19c23 33 52 65 82 96c9 9 14 20 14 28c0 10 -8 20 -26 20h-265l108 -108l-35 -35l-142 142l-142 -142l-35 35l108 108h-225v66h227l-110 110l35 35l142 -142l142 142l35 -35l-110 -110h268c10 0 26 12 26 22 c0 9 -4 15 -14 25c-29 28 -60 64 -82 97l20 19c65 -75 141 -151 237 -191"],10568:[449,-57,926,38,888,"888 258v-10c-96 -41 -172 -115 -238 -191l-20 19c23 33 52 65 82 96c9 9 14 20 14 28c0 10 -8 20 -26 20h-87c-15 -69 -76 -120 -150 -120s-135 51 -151 120h-87c-10 0 -26 -12 -26 -22c0 -9 4 -15 14 -25c29 -28 60 -63 82 -96l-20 -19c-65 75 -141 150 -237 190v10 c96 41 172 115 238 191l20 -19c-23 -33 -52 -65 -82 -96c-9 -9 -14 -20 -14 -28c0 -10 8 -20 26 -20h86c14 70 77 122 151 122c75 0 136 -52 151 -122h87c10 0 26 12 26 22c0 9 -4 15 -14 25c-29 28 -60 63 -82 96l20 19c65 -75 141 -150 237 -190zM364 286h198 c-14 41 -53 72 -99 72s-86 -31 -99 -72zM561 220h-197c14 -41 54 -70 99 -70s84 29 98 70"],10569:[662,154,511,60,451,"451 277l-19 -20c-37 26 -63 53 -96 82c-8 7 -17 14 -28 14c-12 0 -20 -10 -20 -22v-190c68 -17 113 -75 113 -145c0 -83 -67 -150 -150 -150s-150 67 -150 150c0 69 49 132 117 146c1 0 3 1 4 1v187c0 8 -13 24 -22 24c-11 0 -18 -7 -25 -14c-31 -29 -60 -58 -96 -82 l-19 20c61 53 120 111 162 181v16c0 10 -12 26 -22 26c-11 0 -18 -7 -25 -14c-31 -29 -60 -58 -96 -82l-19 20c77 66 150 142 190 237h10c41 -95 114 -171 191 -238l-19 -20c-37 26 -63 53 -96 82c-8 7 -17 14 -28 14c-21 0 -20 -25 -20 -40c43 -70 101 -129 163 -183z M351 -4c0 55 -45 100 -100 100s-100 -45 -100 -100s45 -100 100 -100s100 45 100 100"],10570:[439,-67,926,38,888,"888 286v-5c-96 -46 -178 -139 -238 -214l-20 19c23 33 42 65 72 96c9 9 14 16 14 24c0 10 -8 14 -26 14h-652v5c96 46 178 139 238 214l20 -19c-23 -33 -42 -65 -72 -96c-9 -9 -14 -16 -14 -24c0 -10 8 -14 26 -14h652"],10571:[439,-67,926,38,888,"888 220h-652c-18 0 -26 -4 -26 -14c0 -8 5 -15 14 -24c30 -31 49 -63 72 -96l-20 -19c-60 75 -142 168 -238 214v5h652c18 0 26 4 26 14c0 8 -5 15 -14 24c-30 31 -49 63 -72 96l20 19c60 -75 142 -168 238 -214v-5"],10572:[662,156,511,69,441,"441 424l-19 -20c-33 23 -65 42 -96 72c-9 9 -16 14 -24 14c-10 0 -14 -8 -14 -26v-620h-5c-46 96 -139 178 -214 238l19 20c33 -23 65 -42 96 -72c9 -9 16 -14 24 -14c10 0 14 8 14 26v620h5c46 -96 139 -178 214 -238"],10573:[662,156,511,69,441,"422 102l19 -20c-75 -60 -168 -142 -214 -238h-5v620c0 18 -4 26 -14 26c-8 0 -15 -5 -24 -14c-31 -30 -63 -49 -96 -72l-19 20c75 60 168 142 214 238h5v-620c0 -18 4 -26 14 -26c8 0 15 5 24 14c31 30 63 49 96 72"],10574:[439,-220,926,38,888,"888 220h-850v5c96 46 178 139 238 214l20 -19c-23 -33 -42 -65 -72 -96c-9 -9 -14 -16 -14 -24c0 -10 8 -14 26 -14h454c18 0 26 4 26 14c0 8 -5 15 -14 24c-30 31 -49 63 -72 96l20 19c60 -75 142 -168 238 -214v-5"],10575:[662,156,511,222,441,"422 102l19 -20c-75 -60 -168 -142 -214 -238h-5v818h5c46 -96 139 -178 214 -238l-19 -20c-33 23 -65 42 -96 72c-9 9 -16 14 -24 14c-10 0 -14 -8 -14 -26v-422c0 -18 4 -26 14 -26c8 0 15 5 24 14c31 30 63 49 96 72"],10576:[286,-67,926,38,888,"888 286v-5c-96 -46 -178 -139 -238 -214l-20 19c23 33 42 65 72 96c9 9 14 16 14 24c0 10 -8 14 -26 14h-454c-18 0 -26 -4 -26 -14c0 -8 5 -15 14 -24c30 -31 49 -63 72 -96l-20 -19c-60 75 -142 168 -238 214v5h850"],10577:[662,156,511,69,288,"288 -156h-5c-46 96 -139 178 -214 238l19 20c33 -23 65 -42 96 -72c9 -9 16 -14 24 -14c10 0 14 8 14 26v428c0 14 -5 20 -14 20c-8 0 -15 -5 -24 -14c-31 -30 -63 -49 -96 -72l-19 20c75 60 168 142 214 238h5v-818"],10578:[448,-58,926,55,871,"871 220h-766v-162h-50v390h50v-223c96 46 178 139 238 214l20 -19c-23 -33 -42 -65 -72 -96c-9 -9 -14 -16 -14 -24c0 -10 8 -14 26 -14h568v-66"],10579:[448,-58,926,55,871,"871 58h-50v162h-766v66h568c18 0 26 4 26 14c0 8 -5 15 -14 24c-30 31 -49 63 -72 96l20 19c60 -75 142 -168 238 -214v223h50v-390"],10580:[662,156,511,60,451,"451 612h-224c46 -96 139 -178 214 -238l-19 -20c-33 23 -65 42 -96 72c-9 9 -16 14 -24 14c-10 0 -14 -8 -14 -26v-570h-66v768h-162v50h391v-50"],10581:[662,156,511,60,451,"451 -156h-391v50h163v768h66v-570c0 -18 4 -26 14 -26c8 0 15 5 24 14c31 30 63 49 96 72l19 -20c-75 -60 -168 -142 -214 -238h223v-50"],10582:[448,-58,926,55,871,"871 220h-568c-18 0 -26 -4 -26 -14c0 -8 5 -15 14 -24c30 -31 49 -63 72 -96l-20 -19c-60 75 -142 168 -238 214v-223h-50v390h50v-162h766v-66"],10583:[448,-58,926,55,871,"871 58h-50v223c-96 -46 -178 -139 -238 -214l-20 19c23 33 42 65 72 96c9 9 14 16 14 24c0 10 -8 14 -26 14h-568v66h766v162h50v-390"],10584:[662,156,511,60,451,"451 612h-163v-768h-66v570c0 18 -4 26 -14 26c-8 0 -15 -5 -24 -14c-31 -30 -63 -49 -96 -72l-19 20c75 60 168 142 214 238h-223v50h391v-50"],10585:[662,156,511,60,451,"451 -156h-391v50h223c-46 96 -139 178 -214 238l19 20c33 -23 65 -42 96 -72c9 -9 16 -14 24 -14c10 0 14 8 14 26v570h66v-768h163v-50"],10586:[448,-58,926,55,871,"871 58h-50v162h-766v5c96 46 178 139 238 214l20 -19c-23 -33 -42 -65 -72 -96c-9 -9 -14 -16 -14 -24c0 -10 8 -14 26 -14h568v162h50v-390"],10587:[448,-58,926,55,871,"871 220h-766v-162h-50v390h50v-162h568c18 0 26 4 26 14c0 8 -5 15 -14 24c-30 31 -49 63 -72 96l20 19c60 -75 142 -168 238 -214v-5"],10588:[662,156,511,60,451,"451 -156h-391v50h162v768h5c46 -96 139 -178 214 -238l-19 -20c-33 23 -65 42 -96 72c-9 9 -16 14 -24 14c-10 0 -14 -8 -14 -26v-570h163v-50"],10589:[662,156,511,60,451,"451 612h-163v-570c0 -18 4 -26 14 -26c8 0 15 5 24 14c31 30 63 49 96 72l19 -20c-75 -60 -168 -142 -214 -238h-5v768h-162v50h391v-50"],10590:[448,-58,926,55,871,"871 58h-50v162h-568c-18 0 -26 -4 -26 -14c0 -8 5 -15 14 -24c30 -31 49 -63 72 -96l-20 -19c-60 75 -142 168 -238 214v5h766v162h50v-390"],10591:[448,-58,926,55,871,"871 286v-5c-96 -46 -178 -139 -238 -214l-20 19c23 33 42 65 72 96c9 9 14 16 14 24c0 10 -8 14 -26 14h-568v-162h-50v390h50v-162h766"],10592:[662,156,511,59,450,"450 -156h-391v50h163v570c0 18 -4 26 -14 26c-8 0 -15 -5 -24 -14c-31 -30 -63 -49 -96 -72l-19 20c75 60 168 142 214 238h5v-768h162v-50"],10593:[662,156,511,59,450,"450 612h-162v-768h-5c-46 96 -139 178 -214 238l19 20c33 -23 65 -42 96 -72c9 -9 16 -14 24 -14c10 0 14 8 14 26v570h-163v50h391v-50"],10594:[539,33,926,55,871,"871 320h-816v5c96 46 178 139 238 214l20 -19c-23 -33 -42 -65 -72 -96c-9 -9 -14 -16 -14 -24c0 -10 8 -14 26 -14h618v-66zM871 120h-618c-18 0 -26 -4 -26 -14c0 -8 5 -15 14 -24c30 -31 49 -63 72 -96l-20 -19c-60 75 -142 168 -238 214v5h816v-66"],10595:[662,156,685,57,629,"629 424l-19 -20c-33 23 -65 42 -96 72c-9 9 -16 14 -24 14c-10 0 -14 -8 -14 -26v-620h-66v818h5c46 -96 139 -178 214 -238zM276 -156h-66v620c0 18 -4 26 -14 26c-8 0 -15 -5 -24 -14c-31 -30 -63 -49 -96 -72l-19 20c75 60 168 142 214 238h5v-818"],10596:[539,33,926,55,871,"871 320h-816v66h618c18 0 26 4 26 14c0 8 -5 15 -14 24c-30 31 -49 63 -72 96l20 19c60 -75 142 -168 238 -214v-5zM871 186v-5c-96 -46 -178 -139 -238 -214l-20 19c23 33 42 65 72 96c9 9 14 16 14 24c0 10 -8 14 -26 14h-618v66h816"],10597:[662,156,685,57,629,"610 102l19 -20c-75 -60 -168 -142 -214 -238h-5v818h66v-620c0 -18 4 -26 14 -26c8 0 15 5 24 14c31 30 63 49 96 72zM276 -156h-5c-46 96 -139 178 -214 238l19 20c33 -23 65 -42 96 -72c9 -9 16 -14 24 -14c10 0 14 8 14 26v620h66v-818"],10598:[539,-120,926,55,871,"861 320h-806v5c96 46 178 139 238 214l20 -19c-23 -33 -42 -65 -72 -96c-9 -9 -14 -16 -14 -24c0 -10 8 -14 26 -14h608v-66zM871 120h-806v66h608c18 0 26 4 26 14c0 8 -5 14 -13 24c-19 22 -28 35 -39 51l21 17c49 -55 114 -121 203 -167v-5"],10599:[386,33,926,55,871,"861 320h-608c-18 0 -26 -4 -26 -14c0 -8 5 -14 13 -24c19 -22 28 -35 39 -51l-21 -17c-49 55 -114 121 -203 167v5h806v-66zM871 186v-5c-96 -46 -178 -139 -238 -214l-20 19c23 33 42 65 72 96c9 9 14 16 14 24c0 10 -8 14 -26 14h-608v66h806"],10600:[539,-120,926,55,871,"871 320h-806v66h608c18 0 26 4 26 14c0 8 -5 15 -14 24c-30 31 -54 63 -77 96l20 19c60 -75 147 -168 243 -214v-5zM861 120h-806v5c89 46 154 112 203 167l21 -17c-11 -16 -20 -29 -39 -51c-8 -10 -13 -16 -13 -24c0 -10 8 -14 26 -14h608v-66"],10601:[386,33,926,55,871,"871 386v-5c-89 -46 -154 -112 -203 -167l-21 17c11 16 20 29 39 51c8 10 13 16 13 24c0 10 -8 14 -26 14h-608v66h806zM861 120h-608c-18 0 -26 -4 -26 -14c0 -8 5 -15 14 -24c30 -31 49 -63 72 -96l-20 -19c-60 75 -142 168 -238 214v5h806v-66"],10602:[539,-120,926,55,871,"871 320h-816v5c96 46 178 139 238 214l20 -19c-23 -33 -42 -65 -72 -96c-9 -9 -14 -16 -14 -24c0 -10 8 -14 26 -14h618v-66zM871 120h-806v66h806v-66"],10603:[386,33,926,55,871,"871 320h-806v66h806v-66zM871 120h-618c-18 0 -26 -4 -26 -14c0 -8 5 -15 14 -24c30 -31 49 -63 72 -96l-20 -19c-60 75 -142 168 -238 214v5h816v-66"],10604:[539,-120,926,55,871,"871 320h-816v66h618c18 0 26 4 26 14c0 8 -5 15 -14 24c-30 31 -49 63 -72 96l20 19c60 -75 142 -168 238 -214v-5zM861 120h-806v66h806v-66"],10605:[386,33,926,55,871,"861 320h-806v66h806v-66zM871 186v-5c-96 -46 -178 -139 -238 -214l-20 19c23 33 42 65 72 96c9 9 14 16 14 24c0 10 -8 14 -26 14h-618v66h816"],10606:[662,156,685,57,629,"610 102l19 -20c-75 -60 -168 -142 -214 -238h-5v808h66v-610c0 -18 4 -26 14 -26c8 0 15 5 24 14c31 30 63 49 96 72zM276 -146h-66v610c0 18 -4 26 -14 26c-8 0 -15 -5 -24 -14c-31 -30 -63 -49 -96 -72l-19 20c75 60 168 142 214 238h5v-808"],10607:[662,156,685,57,629,"629 424l-19 -20c-33 23 -65 42 -96 72c-9 9 -16 14 -24 14c-10 0 -14 -8 -14 -26v-610h-66v808h5c46 -96 139 -178 214 -238zM276 -156h-5c-46 96 -139 178 -214 238l19 20c33 -23 65 -42 96 -72c9 -9 16 -14 24 -14c10 0 14 8 14 26v610h66v-808"],10608:[386,-120,926,55,871,"55 386h684c73 0 132 -60 132 -133s-59 -133 -132 -133h-684v66h684c36 0 66 30 66 67c0 36 -30 67 -66 67h-684v66"],10609:[565,-57,926,55,871,"519 515h-369v50h369v-50zM519 370h-369v50h369v-50zM871 258v-10c-96 -41 -172 -115 -238 -191l-20 19c23 33 52 65 82 96c9 9 14 20 14 28c0 10 -8 20 -26 20h-628v66h629c10 0 26 12 26 22c0 9 -4 15 -14 25c-29 28 -60 64 -82 97l20 19c65 -75 141 -151 237 -191"],10610:[508,-57,926,55,871,"520 508h19c-4 -58 -52 -138 -114 -138c-61 0 -143 88 -189 88c-43 0 -76 -39 -86 -88h-20c3 69 56 138 117 138s144 -88 189 -88c44 0 74 39 84 88zM871 258v-10c-96 -41 -172 -115 -238 -191l-20 19c23 33 52 65 82 96c9 9 14 20 14 28c0 10 -8 20 -26 20h-628v66h629 c10 0 26 12 26 22c0 9 -4 15 -14 25c-29 28 -60 64 -82 97l20 19c65 -75 141 -151 237 -191"],10611:[449,2,926,55,871,"871 220h-629c-10 0 -26 -12 -26 -22c0 -9 4 -15 14 -25c29 -28 60 -64 82 -97l-20 -19c-65 75 -141 151 -237 191v10c96 41 172 115 238 191l20 -19c-23 -33 -52 -65 -82 -96c-9 -9 -14 -20 -14 -28c0 -10 8 -20 26 -20h628v-66zM776 136h20c-3 -69 -56 -138 -117 -138 s-144 88 -189 88c-44 0 -74 -39 -84 -88h-19c4 58 52 138 114 138c61 0 143 -88 189 -88c43 0 76 39 86 88"],10612:[449,2,926,55,871,"871 258v-10c-96 -40 -172 -116 -237 -191l-20 19c22 33 53 69 82 97c10 10 14 16 14 25c0 10 -16 22 -26 22h-629v66h628c18 0 26 10 26 20c0 8 -5 19 -14 28c-30 31 -59 63 -82 96l20 19c66 -76 142 -150 238 -191zM519 136h20c-3 -69 -56 -138 -117 -138 s-144 88 -189 88c-44 0 -74 -39 -84 -88h-19c4 58 52 138 114 138c61 0 143 -88 189 -88c43 0 76 39 86 88"],10613:[449,141,926,55,871,"871 258v-10c-96 -40 -172 -116 -237 -191l-20 19c22 33 53 69 82 97c10 10 14 16 14 25c0 10 -16 22 -26 22h-629v66h628c18 0 26 10 26 20c0 8 -5 19 -14 28c-30 31 -59 63 -82 96l20 19c66 -76 142 -150 238 -191zM519 136h20c-3 -69 -56 -138 -117 -138 s-144 88 -189 88c-44 0 -74 -39 -84 -88h-19c4 58 52 138 114 138c61 0 143 -88 189 -88c43 0 76 39 86 88zM519 -3h20c-3 -69 -56 -138 -117 -138s-144 88 -189 88c-44 0 -74 -39 -84 -88h-19c4 58 52 138 114 138c61 0 143 -88 189 -88c43 0 76 39 86 88"],10614:[607,283,685,64,621,"621 50l-557 274v10l557 273v-67l-421 -211l421 -212v-67zM621 -120h-368c-18 0 -26 -10 -26 -20c0 -8 5 -19 14 -28c30 -31 59 -63 82 -96l-20 -19c-66 76 -142 150 -238 191v10c96 40 172 116 237 191l20 -19c-22 -33 -53 -69 -82 -97c-10 -10 -14 -16 -14 -25 c0 -10 16 -22 26 -22h369v-66"],10615:[532,26,926,45,871,"871 -26l-500 246h-139c-21 0 -26 -12 -26 -22c0 -9 4 -15 14 -25c29 -28 60 -64 82 -97l-20 -19c-65 75 -141 151 -237 191v10c96 41 172 115 238 191l20 -19c-23 -33 -52 -65 -82 -96c-9 -9 -14 -20 -14 -28c0 -10 8 -20 26 -20h138l500 246v-65l-355 -181h315v-66 h-316l356 -181v-65"],10616:[608,282,685,64,621,"621 324l-557 -273v67l421 211l-421 212v67l557 -274v-10zM620 -81v-10c-96 -41 -172 -115 -238 -191l-20 19c23 33 52 65 82 96c9 9 14 20 14 28c0 10 -8 20 -26 20h-368v66h369c10 0 26 12 26 22c0 9 -4 15 -14 25c-29 28 -60 64 -82 97l20 19 c65 -75 141 -151 237 -191"],10617:[627,262,685,64,621,"621 161h-290c-159 0 -267 86 -267 234s110 232 270 232h287v-66h-287c-114 0 -204 -59 -204 -166s91 -168 205 -168h286v-66zM620 -61v-10c-96 -41 -172 -115 -238 -191l-20 19c23 33 52 65 82 96c9 9 14 20 14 28c0 10 -8 20 -26 20h-368v66h369c10 0 26 12 26 22 c0 9 -4 15 -14 25c-29 28 -60 64 -82 97l20 19c65 -75 141 -151 237 -191"],10618:[532,26,926,45,871,"871 -26h-290c-147 0 -251 112 -265 246h-84c-21 0 -26 -12 -26 -22c0 -9 4 -15 14 -25c29 -28 50 -54 72 -87l-20 -19c-65 75 -131 141 -227 181v10c96 41 162 105 228 181l20 -19c-23 -33 -42 -55 -72 -86c-9 -9 -14 -20 -14 -28c0 -10 8 -20 26 -20h83 c15 133 120 246 268 246h287v-66h-287c-103 0 -186 -86 -202 -180h449v-66h-449c16 -95 100 -180 203 -180h286v-66"],10619:[627,262,685,63,620,"63 627h287c160 0 270 -84 270 -232s-108 -234 -267 -234h-290v66h286c114 0 205 61 205 168s-90 166 -204 166h-287v66zM620 -99h-368c-18 0 -26 -10 -26 -20c0 -8 5 -19 14 -28c30 -31 59 -63 82 -96l-20 -19c-66 76 -142 150 -238 191v10c96 40 172 116 237 191 l20 -19c-22 -33 -53 -69 -82 -97c-10 -10 -14 -16 -14 -25c0 -10 16 -22 26 -22h369v-66"],10620:[511,5,926,135,791,"791 220h-510c-38 0 -80 -21 -80 -78c0 -53 41 -81 80 -81v-66c-63 0 -146 49 -146 147c0 50 22 87 52 111c-30 24 -52 61 -52 111c0 98 83 147 146 147v-66c-39 0 -80 -28 -80 -81c0 -55 43 -78 80 -78h510v-66"],10621:[511,5,926,135,791,"645 445v66c63 0 146 -49 146 -147c0 -50 -22 -87 -52 -111c30 -24 52 -61 52 -111c0 -98 -83 -147 -146 -147v66c39 0 80 28 80 81c0 55 -43 78 -80 78h-510v66h510c38 0 80 21 80 78c0 53 -41 81 -80 81"],10622:[581,75,685,84,600,"600 435h-66c0 39 -28 80 -81 80c-55 0 -78 -43 -78 -80v-510h-66v510c0 38 -21 80 -78 80c-53 0 -81 -41 -81 -80h-66c0 63 49 146 147 146c50 0 87 -22 111 -52c24 30 61 52 111 52c98 0 147 -83 147 -146"],10623:[581,75,685,84,600,"534 71h66c0 -63 -49 -146 -147 -146c-50 0 -87 22 -111 52c-24 -30 -61 -52 -111 -52c-98 0 -147 83 -147 146h66c0 -39 28 -80 81 -80c55 0 78 43 78 80v510h66v-510c0 -38 21 -80 78 -80c53 0 81 41 81 80"],57524:[556,-220,313,55,258,"258 220h-39c-105 0 -164 80 -164 168s60 168 165 168h38v-66h-38c-62 0 -99 -47 -99 -102c0 -46 30 -102 101 -102h36v-66"],57525:[556,-220,313,55,258,"55 556h39c105 0 164 -80 164 -168s-60 -168 -165 -168h-38v66h38c62 0 99 47 99 102c0 46 -30 102 -101 102h-36v66"],57526:[449,-57,0,30,124,"124 220h-28v-163h-66v392h66v-163h28v-66"],57618:[662,156,926,55,872,"865 662l7 -7c-28 -69 -37 -142 -37 -214c0 -30 2 -60 4 -88l-29 -2c-7 39 -10 87 -10 126c0 14 0 21 -7 29c-4 2 -10 5 -15 5c-6 0 -12 -3 -18 -9l-92 -92l-47 47l91 90c7 7 10 14 10 20s-2 11 -6 13c-5 7 -16 10 -29 10c-43 1 -86 3 -126 10v29c29 -3 59 -4 87 -4 c74 0 147 9 217 37zM618 360l-91 -91l-46 47l90 91zM476 218l-91 -91l-46 47l90 90zM335 77l-90 -90l-47 46l90 91zM193 -65l-91 -91l-47 46l91 92"],57619:[662,156,926,55,872,"476 288l-47 -46l-90 90l46 47zM618 146l-47 -47l-90 91l46 47zM193 571l-47 -47l-91 92l47 46zM335 429l-47 -47l-90 91l47 46zM872 -149l-7 -7c-70 28 -143 37 -217 37c-28 0 -58 -1 -87 -4v29c40 7 83 9 126 10c13 0 24 3 29 10c4 2 6 7 6 13s-3 13 -10 20l-91 90 l47 47l92 -92c6 -6 12 -9 18 -9c5 0 11 3 15 5c7 8 7 15 7 29c0 39 3 87 10 126l29 -2c-2 -28 -4 -58 -4 -88c0 -72 9 -145 37 -214"],57620:[662,156,926,54,871,"365 629v-29c-40 -7 -83 -9 -126 -10c-13 0 -24 -3 -29 -10c-4 -2 -6 -7 -6 -13s3 -13 10 -20l91 -90l-47 -47l-92 92c-6 6 -12 9 -18 9c-5 0 -11 -3 -15 -5c-7 -8 -7 -15 -7 -29c0 -39 -3 -87 -10 -126l-29 2c2 28 4 58 4 88c0 72 -9 145 -37 214l7 7 c70 -28 143 -37 217 -37c28 0 58 1 87 4zM728 33l-47 -46l-90 90l47 47zM871 -110l-47 -46l-91 91l47 47zM445 316l-46 -47l-91 91l47 47zM587 174l-46 -47l-91 91l47 46"],57621:[662,156,926,54,871,"871 616l-91 -92l-47 47l91 91zM728 473l-90 -91l-47 47l90 90zM587 332l-90 -90l-47 46l91 91zM445 190l-90 -91l-47 47l91 91zM365 -94v-29c-29 3 -59 4 -87 4c-74 0 -147 -9 -217 -37l-7 7c28 69 37 142 37 214c0 30 -2 60 -4 88l29 2c7 -39 10 -87 10 -126 c0 -14 0 -21 7 -29c4 -2 10 -5 15 -5c6 0 12 3 18 9l92 92l47 -47l-91 -90c-7 -7 -10 -14 -10 -20s2 -11 6 -13c5 -7 16 -10 29 -10c43 -1 86 -3 126 -10"],57626:[662,156,511,59,451,"451 425l-19 -20c-33 23 -65 51 -96 81c-9 9 -20 14 -28 14c-10 0 -17 -4 -17 -14c0 -20 -16 -31 -36 -31s-36 11 -36 31c0 11 -9 15 -19 15c-9 0 -15 -4 -25 -14c-28 -29 -64 -60 -97 -82l-19 20c75 65 151 141 191 237h10c41 -96 115 -171 191 -237zM292 369 c0 -20 -16 -37 -36 -37c-21 0 -37 17 -37 37s16 36 37 36c20 0 36 -16 36 -36zM292 247c0 -19 -16 -36 -36 -36c-21 0 -37 17 -37 36c0 20 16 37 37 37c20 0 36 -17 36 -37zM291 125c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM292 3 c0 -20 -16 -37 -36 -37c-21 0 -37 17 -37 37c0 19 16 36 37 36c20 0 36 -17 36 -36zM292 -120c0 -20 -16 -36 -36 -36c-21 0 -37 16 -37 36s16 37 37 37c20 0 36 -17 36 -37"],57627:[662,156,511,59,451,"292 626c0 -20 -16 -37 -36 -37c-21 0 -37 17 -37 37s16 36 37 36c20 0 36 -16 36 -36zM292 503c0 -19 -16 -36 -36 -36c-21 0 -37 17 -37 36c0 20 16 37 37 37c20 0 36 -17 36 -37zM291 381c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM292 259 c0 -20 -16 -37 -36 -37c-21 0 -37 17 -37 37c0 19 16 36 37 36c20 0 36 -17 36 -36zM292 137c0 -20 -16 -36 -36 -36c-21 0 -37 16 -37 36s16 37 37 37c20 0 36 -17 36 -37zM432 101l19 -20c-75 -65 -151 -141 -191 -237h-10c-41 96 -115 171 -191 237l19 20 c33 -23 65 -51 96 -81c9 -9 20 -14 28 -14c10 0 17 4 17 14c0 20 16 31 36 31s36 -11 36 -31c0 -11 9 -15 19 -15c9 0 15 4 25 14c28 29 64 60 97 82"],57628:[662,156,926,54,872,"865 662l7 -7c-27 -68 -36 -142 -36 -214c0 -30 2 -60 4 -90l-28 -1c-9 52 -3 162 -31 162c-4 0 -6 -2 -14 -8c-5 -4 -16 -7 -25 -7c-19 0 -35 16 -35 35c0 24 16 22 16 36c0 15 -14 22 -35 22h-15c-36 0 -77 3 -111 10l1 28c29 -2 60 -4 90 -4c72 0 145 11 212 38z M686 439c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM593 347c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM499 253c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM405 159c0 -20 -16 -36 -36 -36 s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM312 66c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM219 -27c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM126 -120c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36"],57629:[662,156,926,54,872,"686 67c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM872 -149l-7 -7c-67 27 -140 38 -212 38c-30 0 -61 -2 -90 -4l-1 28c34 7 75 10 111 10h15c21 0 35 7 35 22c0 14 -16 12 -16 36c0 19 16 35 35 35c9 0 20 -3 25 -7c8 -6 10 -8 14 -8 c17 0 20 41 22 84c1 28 5 58 9 78l28 -1c-2 -30 -4 -60 -4 -90c0 -72 9 -146 36 -214zM126 626c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM219 533c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM312 440c0 -20 -16 -36 -36 -36 s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM405 347c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM499 253c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM593 159c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36"],57630:[662,156,926,54,872,"405 347c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM499 253c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM593 159c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM686 66c0 -20 -16 -36 -36 -36 s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM779 -27c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM872 -120c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM363 628l1 -28c-34 -7 -75 -10 -111 -10h-15c-21 0 -35 -7 -35 -22 c0 -14 16 -12 16 -36c0 -19 -16 -35 -35 -35c-9 0 -20 3 -25 7c-8 6 -10 8 -14 8c-17 0 -20 -41 -22 -84c-1 -28 -5 -58 -9 -78l-28 1c2 30 4 60 4 90c0 72 -9 146 -36 214l7 7c67 -27 140 -38 212 -38c30 0 61 2 90 4zM312 439c0 -20 -16 -36 -36 -36s-36 16 -36 36 s16 36 36 36s36 -16 36 -36"],57631:[662,156,926,54,872,"872 626c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM779 533c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM686 440c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM593 347c0 -20 -16 -36 -36 -36 s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM499 253c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM405 159c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM312 67c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36z M364 -94l-1 -28c-29 2 -60 4 -90 4c-72 0 -145 -11 -212 -38l-7 7c27 68 36 142 36 214c0 30 -2 60 -4 90l28 1c6 -21 9 -49 10 -78c2 -43 4 -84 21 -84c4 0 6 2 14 8c5 4 16 7 25 7c19 0 35 -16 35 -35c0 -24 -16 -22 -16 -36c0 -15 14 -22 35 -22h15c36 0 77 -3 111 -10"],57632:[411,-94,511,220,293,"292 375c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM293 253c0 -20 -16 -37 -36 -37c-21 0 -37 17 -37 37c0 19 16 36 37 36c20 0 36 -17 36 -36zM293 130c0 -20 -16 -36 -36 -36c-21 0 -37 16 -37 36s16 37 37 37c20 0 36 -17 36 -37"],57633:[290,-217,311,-3,314,"314 253c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM192 254c0 -21 -17 -37 -36 -37c-20 0 -37 16 -37 37c0 20 17 36 37 36c19 0 36 -16 36 -36zM70 254c0 -21 -17 -37 -37 -37s-36 16 -36 37c0 20 16 36 36 36s37 -16 37 -36"],57634:[382,-123,367,54,313,"126 346c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM219 253c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM313 159c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36"],57635:[383,-124,367,54,313,"313 347c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM219 253c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM126 160c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36"],57636:[662,156,511,59,451,"451 425l-19 -20c-33 23 -65 51 -96 81c-9 9 -20 14 -28 14c-10 0 -20 -8 -20 -26v-118h-66v119c0 10 -12 26 -22 26c-9 0 -15 -4 -25 -14c-28 -29 -64 -60 -97 -82l-19 20c75 65 151 141 191 237h10c41 -96 115 -171 191 -237zM292 251c0 -19 -16 -36 -36 -36 c-21 0 -37 17 -37 36c0 20 16 37 37 37c20 0 36 -17 36 -37zM288 -15h-66v162h66v-162zM292 -120c0 -19 -16 -36 -36 -36c-21 0 -37 17 -37 36c0 20 16 37 37 37c20 0 36 -17 36 -37"],57637:[662,156,511,59,451,"292 626c0 -20 -16 -37 -36 -37c-21 0 -37 17 -37 37c0 19 16 36 37 36c20 0 36 -17 36 -36zM288 359h-66v162h66v-162zM292 255c0 -20 -16 -37 -36 -37c-21 0 -37 17 -37 37c0 19 16 36 37 36c20 0 36 -17 36 -36zM432 101l19 -20c-75 -65 -151 -141 -191 -237h-10 c-41 96 -115 171 -191 237l19 20c33 -23 65 -51 96 -81c9 -9 20 -14 28 -14c10 0 20 8 20 26v118h66v-119c0 -10 12 -26 22 -26c9 0 15 4 25 14c28 29 64 60 97 82"],57638:[449,-57,926,54,872,"872 254c0 -21 -17 -37 -36 -37c-20 0 -37 16 -37 37c0 20 17 36 37 36c19 0 36 -16 36 -36zM731 220h-162v66h162v-66zM501 254c0 -21 -17 -37 -36 -37c-20 0 -37 16 -37 37c0 20 17 36 37 36c19 0 36 -16 36 -36zM360 220h-119c-10 0 -26 -12 -26 -22 c0 -9 4 -15 14 -25c29 -28 60 -64 82 -97l-20 -19c-65 75 -141 151 -237 191v10c96 41 171 115 237 191l20 -19c-23 -33 -51 -65 -81 -96c-9 -9 -14 -20 -14 -28c0 -10 8 -20 26 -20h118v-66"],57639:[449,-57,926,54,872,"872 258v-10c-96 -41 -171 -115 -237 -191l-20 19c23 33 51 65 81 96c9 9 14 20 14 28c0 10 -8 20 -26 20h-118v66h119c10 0 26 12 26 22c0 9 -4 15 -14 25c-29 28 -60 64 -82 97l20 19c65 -75 141 -151 237 -191zM498 254c0 -21 -17 -37 -37 -37c-19 0 -36 16 -36 37 c0 20 17 36 36 36c20 0 37 -16 37 -36zM357 220h-162v66h162v-66zM127 254c0 -21 -17 -37 -37 -37c-19 0 -36 16 -36 37c0 20 17 36 36 36c20 0 37 -16 37 -36"],57640:[662,155,926,54,872,"865 662l7 -7c-27 -68 -36 -140 -36 -212c0 -30 2 -61 4 -91h-28c-7 39 -10 82 -11 125c0 17 -7 35 -23 35c-6 0 -13 -3 -20 -10l-86 -86l-47 47l87 87c4 4 7 13 7 21c0 18 -13 20 -32 20c-40 0 -86 3 -125 11v28c29 -2 59 -4 90 -4c72 0 146 9 213 36zM619 374 c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM540 285l-116 -116l-46 46l116 116zM372 126c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM293 37l-115 -114l-46 46l114 115zM126 -119c0 -20 -16 -36 -36 -36s-36 16 -36 36 s16 36 36 36s36 -16 36 -36"],57641:[662,156,926,55,872,"127 626c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM294 470l-47 -47l-114 115l46 46zM541 222l-46 -46l-116 116l46 46zM620 133c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM372 380c0 -20 -16 -36 -36 -36s-36 16 -36 36 s16 36 36 36s36 -16 36 -36zM872 -149l-7 -7c-68 27 -140 36 -212 36c-30 0 -61 -2 -91 -4v28c39 7 82 10 125 11c17 0 35 7 35 23c0 6 -3 13 -10 20l-86 86l47 47l87 -87c4 -4 13 -7 21 -7c18 0 20 13 20 32c0 40 3 86 11 125h28c-2 -29 -4 -59 -4 -90 c0 -72 9 -146 36 -213"],57642:[662,156,926,54,871,"364 630v-28c-39 -7 -82 -10 -125 -11c-17 0 -35 -7 -35 -23c0 -6 3 -13 10 -20l86 -86l-47 -47l-87 87c-4 4 -13 7 -21 7c-18 0 -20 -13 -20 -32c0 -40 -3 -86 -11 -125h-28c2 29 4 59 4 90c0 72 -9 146 -36 213l7 7c68 -27 140 -36 212 -36c30 0 61 2 91 4zM626 126 c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM378 373c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM547 214l-46 -46l-116 116l46 46zM793 -32l-46 -46l-115 114l47 47zM871 -120c0 -20 -16 -36 -36 -36s-36 16 -36 36 s16 36 36 36s36 -16 36 -36"],57643:[661,156,926,54,872,"872 625c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM794 537l-114 -115l-47 47l115 114zM626 380c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM548 291l-116 -116l-46 46l116 116zM379 132c0 -20 -16 -36 -36 -36 s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM364 -96v-28c-29 2 -59 4 -90 4c-72 0 -146 -9 -213 -36l-7 7c27 68 36 140 36 212c0 30 -2 61 -4 91h28c7 -39 10 -82 11 -125c0 -17 7 -35 23 -35c6 0 13 3 20 10l86 86l47 -47l-87 -87c-4 -4 -7 -13 -7 -21 c0 -18 13 -20 32 -20c40 0 86 -3 125 -11"],57644:[404,-101,511,220,293,"289 242h-66v162h66v-162zM293 137c0 -19 -16 -36 -36 -36c-21 0 -37 17 -37 36c0 20 16 37 37 37c20 0 36 -17 36 -37"],57645:[403,-100,511,220,293,"293 367c0 -20 -16 -37 -36 -37c-21 0 -37 17 -37 37c0 19 16 36 37 36c20 0 36 -17 36 -36zM289 100h-66v162h66v-162"],57646:[290,-217,371,14,317,"317 254c0 -21 -17 -37 -36 -37c-20 0 -37 16 -37 37c0 20 17 36 37 36c19 0 36 -16 36 -36zM176 220h-162v66h162v-66"],57647:[290,-217,371,54,357,"357 220h-162v66h162v-66zM127 254c0 -21 -17 -37 -37 -37c-19 0 -36 16 -36 37c0 20 17 36 36 36c20 0 37 -16 37 -36"],57648:[373,-134,379,70,309,"231 258l-46 -46l-115 114l47 47zM309 170c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36"],57649:[373,-134,379,70,309,"142 337c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM309 181l-47 -47l-114 115l46 46"],57650:[373,-134,379,70,309,"309 326l-115 -114l-46 46l114 115zM142 170c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36"],57651:[373,-134,379,70,309,"309 337c0 -20 -16 -36 -36 -36s-36 16 -36 36s16 36 36 36s36 -16 36 -36zM231 249l-114 -115l-47 47l115 114"],57652:[486,-20,315,0,315,"315 420h-315v66h315v-66zM315 220h-315v66h315v-66zM315 20h-315v66h315v-66"],57653:[405,-101,926,230,696,"696 101h-66v304h66v-304zM496 101h-66v304h66v-304zM296 101h-66v304h66v-304"],57654:[541,35,315,0,315,"315 475h-315v66h315v-66zM315 305h-315v66h315v-66zM315 135h-315v66h315v-66zM315 -35h-315v66h315v-66"],57655:[405,-101,1033,229,805,"805 101h-66v304h66v-304zM635 101h-66v304h66v-304zM465 101h-66v304h66v-304zM295 101h-66v304h66v-304"]};MathJax.Ajax.loadComplete(MathJax.OutputJax.SVG.fontDir+"/Arrows/Regular/Main.js"); | PypiClean |
/py_unused_deps-0.3.0-py3-none-any.whl/unused_deps/dist_info.py | from __future__ import annotations
import logging
from collections.abc import Generator, Iterable
from packaging.requirements import InvalidRequirement, Requirement
from unused_deps.compat import importlib_metadata
logger = logging.getLogger("unused-deps")
# swapping the order of https://github.com/python/cpython/blob/e8165d47b852e933c176209ddc0b5836a9b0d5f4/Lib/importlib/metadata/__init__.py#L1058
def distribution_packages(
dist: importlib_metadata.Distribution,
) -> Generator[str, None, None]:
top_level_declared = _top_level_declared(dist)
if top_level_declared:
yield from top_level_declared
else:
yield from _top_level_inferred(dist)
def required_dists(
dist: importlib_metadata.Distribution,
extras: Iterable[str] | None,
) -> Generator[importlib_metadata.Distribution, None, None]:
if dist.requires is None:
return
for raw_requirement in dist.requires:
req_dist = _dist_from_requirement(Requirement(raw_requirement), extras)
if req_dist is not None:
yield req_dist
def parse_requirement(
raw_requirement: str,
extras: Iterable[str] | None,
) -> importlib_metadata.Distribution | None:
raw_requirement = raw_requirement.lstrip()
if raw_requirement.startswith("#"):
return None
try:
requirement = Requirement(raw_requirement)
except InvalidRequirement as e:
# requirement.txt format used by pip supports a lot more than just a list of requirements,
# but we don't want to try to handle all these https://pip.pypa.io/en/stable/reference/requirements-file-format/
logger.debug("Skipping requirement %s: %s", raw_requirement, e)
return None
else:
return _dist_from_requirement(requirement, extras)
def _top_level_declared(dist: importlib_metadata.Distribution) -> list[str]:
return (dist.read_text("top_level.txt") or "").split()
def _top_level_inferred(dist: importlib_metadata.Distribution) -> set[str]:
return {
f.parts[0] if len(f.parts) > 1 else f.with_suffix("").name
for f in dist.files or []
if f.suffix == ".py"
}
def _dist_from_requirement(
requirement: Requirement,
extras: Iterable[str] | None,
) -> importlib_metadata.Distribution | None:
try:
req_dist = importlib_metadata.Distribution.from_name(requirement.name)
except importlib_metadata.PackageNotFoundError:
logger.info("Cannot import %s, skipping", requirement.name)
return None
if requirement.marker is not None:
if extras is None:
extras = ("",)
if any(requirement.marker.evaluate({"extra": extra}) for extra in extras):
return req_dist
else:
logger.info(
"%s is not valid for the current environment, skipping",
requirement.name,
)
return None
else:
return req_dist | PypiClean |
/DaLaS-0.1.1.tar.gz/DaLaS-0.1.1/dalas/api.py | from typing import Union, List, Optional, Dict
from dalas.http_requests import HTTPRequester, BaseRequester
from dalas.models.data_models import UserInfo, Donation, SendCustomAlerts
from dalas.models.raw_models import UserInfoRaw, DonationAlertsListRaw, SendCustomAlertsRaw
from dalas.types import Locales
from dalas.validators import BaseValidator, DefaultValidator
MerchTitle = Dict[Union[str, Locales], str]
class API:
def __init__(self,
api_requester: Optional[BaseRequester],
validator: BaseValidator = DefaultValidator(),
raw_responses: bool = False):
self.__request_api = api_requester.request_api
self.validator = validator
self.raw_responses = raw_responses
async def user(self) -> Union[UserInfoRaw, UserInfo]:
response: UserInfoRaw = UserInfoRaw(**(await self.__request_api('user/oauth')))
if self.raw_responses:
return response
return response.data
async def donation_alerts_list(self) -> Union[DonationAlertsListRaw, List[Donation]]:
response: DonationAlertsListRaw = DonationAlertsListRaw(**(await self.__request_api('alerts/donations')))
if self.raw_responses:
return response
return response.data
async def send_custom_alerts(self,
external_id: Optional[str] = None,
header: Optional[str] = None,
message: Optional[str] = None,
is_shown: Optional[Union[int, bool]] = None,
image_url: Optional[str] = None,
sound_url: Optional[str] = None,
**kwargs) -> Union[SendCustomAlerts, SendCustomAlertsRaw]:
params = await self.validator.request_validator(locals())
response: SendCustomAlertsRaw = SendCustomAlertsRaw(
**(await self.__request_api('custom_alert', method='POST', **params)))
if self.raw_responses:
return response
return response.data
# todo: finish when possible
# async def create_merch(self,
# merchant_identifier: str,
# merchandise_identifier: str,
# title: MerchTitle,
# currency: Union[str, InputCurrencies],
# price_user: Union[float, int],
# price_service: Union[float, int],
# signature: str,
# end_at_ts: int = int(time.time()),
# is_active: Union[int, bool] = False,
# is_percentage: Union[int, bool] = False,
# url: Optional[str] = None,
# img_url: Optional[str] = None):
# params = await self.validator.request_validator(locals())
# return await self.__request_api('merchandise', method='POST', **params)
#
# async def update_merch(self,
# id: str,
# merchant_identifier: Optional[str] = None,
# merchandise_identifier: Optional[str] = None,
# title: Optional[Union[MerchTitle, dict]] = None,
# is_active: Optional[Union[bool, int]] = None,
# is_percentage: Optional[Union[bool, int]] = None,
# currency: Optional[Union[InputCurrencies, str]] = None,
# price_user: Union[float, int] = None,
# price_service: Union[float, int] = None,
# url: Optional[str] = None,
# img_url: Optional[str] = None,
# end_at_ts: Optional[int] = int(time.time()),
# signature: Optional[str] = None):
#
# params = await self.validator.request_validator(locals())
# return await self.__request_api(f'merchandise/{id}', method='PUT', **params)
#
# async def send_sale_alerts(self,
# user_id: int,
# external_id: str,
# merchant_identifier: str,
# merchandise_identifier: str,
# amount: Union[float, int],
# currency: Union[str, InputCurrencies],
# signature: str,
# bought_amount: int = 1,
# username: Optional[str] = None,
# message: Optional[str] = None):
#
# params = await self.validator.request_validator(locals())
# return await self.__request_api('merchandise_sale', method='POST', **params) | PypiClean |
/buildpy-server-testcommands-0.1.0.zip/buildpy-server-testcommands-0.1.0/src/buildpy_server_testcommands/plugin.py |
import py
import pluggy
import argparse
import shlex
import os
from subprocess import Popen, PIPE, STDOUT
from buildpy_server import log
# instantiate a preconfigured logger
logger = log.get_logger(__name__)
hookimpl = pluggy.HookimplMarker('buildpy-server')
@hookimpl
def buildpyserver_add_parser_options(parser):
configfile = parser.add_group("Configuration File Options")
configfile.add_option("--config", metavar="config-file",
action="store", dest="config",
type=argparse.FileType('rt'),
help="the location of the build job "
"configuration file")
@hookimpl
def buildpyserver_run_test_commands(config):
# hook is always called, thus check if a config file was given
if config.args.config:
return _run_test_commands(config)
def parse_ini(configfilepath):
return py.iniconfig.IniConfig(configfilepath)
def _run_test_commands(config):
returncode = 0
config.configpath = py.path.local(config.args.config.name)
config.configdata = parse_ini(config.configpath)
logger.debug("Read configuration data: %s"
% config.configdata.sections['test']['commands'])
commands = split_to_lines(
config.configdata.sections['test']['commands'])
if hasattr(config, 'env'):
env = config.env[0]
else:
env = os.environ
logger.debug("Execution environment: %s" % env)
for command in commands:
exitcode, log = _run_test_command(command, env)
tw = py.io.TerminalWriter()
if exitcode:
tw.line(log)
logger.info("'%s' command failed with error '%s'"
% (command, log))
returncode = 1
if not exitcode:
tw.line(log)
logger.info("Successfully ran command: '%s'" % command)
return returncode
def _run_test_command(command, env):
"""Runs a single command.
:param command: A command to run.
:type command: String
:returns: :func:execute
"""
args = split_to_args(command)
logger.debug("Executing command: %s" % args)
return execute(args, env)
def execute(command, env=os.environ):
"""Execute an actual command using Popen and pipe all output to
stdout iteratively. Execute does not wait for the while process to
finish. Instead it pipes all output to stdout and outputs it as
soon as output is available.
:param command: The command to run.
:type command: List
:returns: the returncode of the process and its output
"""
process = Popen(command, shell=True, stdout=PIPE, stderr=STDOUT,
bufsize=1, env=env, universal_newlines=True)
output = ''
tw = py.io.TerminalWriter()
# Poll process for new output until finished
for line in iter(process.stdout.readline, ""):
tw.line(line.rstrip())
output += line
process.wait()
return process.returncode, output
def split_to_lines(lines, delimiter="\n"):
"""Splits multiple lines into seperated arguments.
:param lines: A string containing multiple lines.
:param delimiter: A delimiter to identify the end of a line.
:returns: List of arguments
"""
logger.debug("Splitting lines: %s" % lines)
return lines.split(delimiter)
def split_to_args(line):
"""Splits a single line into a list of arguments.
:param line: a single line to split
:type line: String
:returns: List of arguments
"""
logger.debug("Splitting line: %s" % line)
return shlex.split(line) | PypiClean |
/morningstar_data-1.6.3.tar.gz/morningstar_data-1.6.3/README.md | # Morningstar Data Package
The morningstar_data Python package provides users quick programmatic access to Morningstar data. It is a building block for doing practical investment data analysis in Python.
# Getting Started
## Installation
### Installing via pip
```
pip install morningstar-data
```
### Installing via conda
```
conda install -c conda-forge morningstar-data
```
**Warning**: Importing the package before authenticating will produce an error. See below for authentication steps.
## Authentication
### Retrieve Authentication Token
1. Open [Analytics Lab](https://analyticslab.morningstar.com/) in your browser
2. Login with your Morningstar Direct credentials
3. On the top ribbon in the "Analytics Lab" dropdown menu select "Copy Authentication Token". This will copy your token to the clipboard.
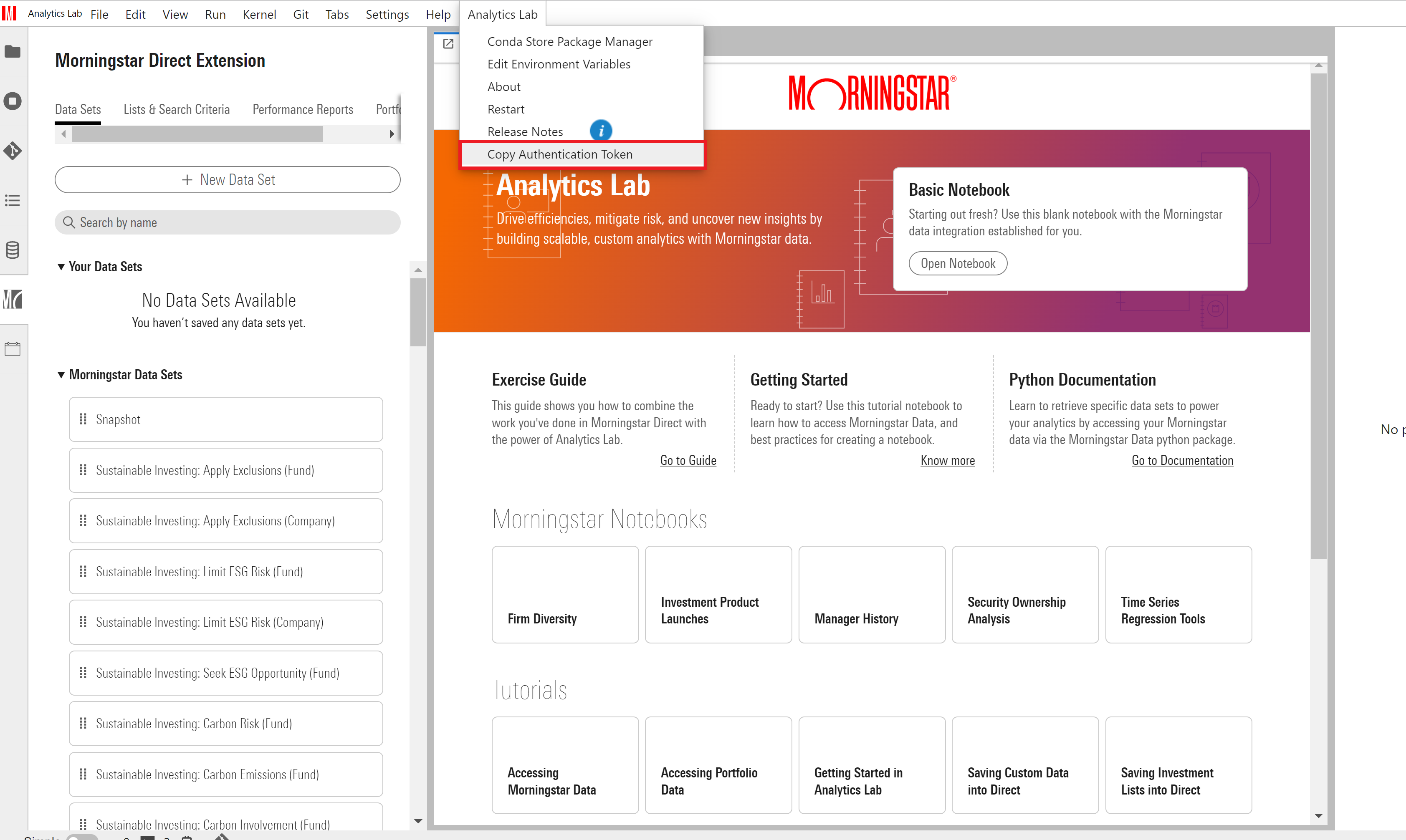
### Set Authentication Token
Set the environment variable `MD_AUTH_TOKEN` using the token you retrieved previously
#### Bash
`export MD_AUTH_TOKEN="paste copied token here"`
#### Within a Python (.py) File
```
# testing_morningstar_data.py
import os
import morningstar_data as md
os.environ['MD_AUTH_TOKEN']="paste copied token here"
md.direct.get_morningstar_data_sets()
```
## Requirements
The morningstar_data package is tested with
| | Main version (latest)
|-------------|------------------------------|
| Python | 3.8, 3.9, 3.10, 3.11 |
| Pandas | 1.5 |
## Using the API
This is an example of retrieving data for a saved investment list and data set from Morningstar Direct. See more usage examples in the Python package [documentation](https://docs-analyticslab.morningstar.com/latest/index.html) and tutorial notebooks in [Analytics Lab](https://analyticslab.morningstar.com/).
```
# Define investments by retrieving your saved lists
lists = md.direct.user_items.get_investment_lists()
| id | name |
|--------------------------------------|--------------------------------------------|
| 8CA07FB7-DFFE-4440-9ED7-6498CC074F11 | Morningstar Prospects |
| AE322592-5A3E-4B31-B889-16D8E76F48D3 | Sustainable Landscape U.S. Funds Q4 2021 |
| 83D337A2-1CF2-4E66-A94D-2B8EE554AC23 | Sustainable Landscape Global Funds Q4 2021 |
| ... | ... |
# Specify data points by using one of Morningstar's pre-saved data sets
morningstar_data_sets = md.direct.lookup.get_morningstar_data_sets()
| datasetId | name |
|-----------|-----------------------------------------------|
| 0218-0020 | Snapshot |
| 0218-0446 | Sustainability: ESG Risk (Company) |
| 0218-0481 | Sustainability: Portfolio Sustainability Risk |
| ... | ... |
# Retrieve data by using the investment list and data set IDs from above
data = md.direct.get_investment_data(investments=lists["id"][0], data_points=morningstar_data_sets["datasetId"][0])
| Id | Name | Base Currency | ... |
|---------------|-----------------------------------------|---------------|-----|
| F00001AHPT;FO | Hartford Schroders Sustainable Cr Bd I | US Dollar | ... |
| F000014ZNT;FE | iShares ESG Aware Aggressive Allc ETF | US Dollar | ... |
| F00000WUF1;FE | iShares MSCI Global Sust Dev Goals ETF | US Dollar | ... |
| ... | ... | ... | ... |
```
### Documentation
Documentation is hosted at https://docs-analyticslab.morningstar.com/latest/index.html
Find the version you are using with `md.__version__`
### Data Retrieval
The Morningstar Data Extension in [Analytics Lab](https://analyticslab.morningstar.com/) is the most convenient tool for locating data points and various saved objects to be used in morningstar_data function calls. You can browse data points, saved investment lists, search criteria, performance reports and more. Drag and drop the object you are interested in into a notebook and the corresponding Python code will be generated for you.
# Limits
## Overview of Limits
|Type of Limit| Restriction |
|-------------|--------------|
|Limits | Morningstar Direct is exclusively licensed for individual usage. Users of Morningstar Direct are strictly prohibited from disclosing their login credentials, deploying instances of Morningstar Direct on a server, or utilizing, distributing, or redistributing data in a manner contradictory to their organization's agreement with Morningstar. Moreover, Morningstar Direct users are prohibited from employing information in any manner that would contravene the regulations and policies established by third-party providers.|
|Call Limits | When utilizing the morningstar_data Python package for data extraction, it's important to be aware of the limitations imposed on the number of requests you can make or the amount of data you can receive. These limitations are in place to ensure efficient usage of the resources and maintain the overall performance of the system.|
|Daily Limits | Limits are in place and can be reached when making requests or receiving data within a single day. These limits are determined either by the number of requests made or the quantity of data received. It is important to keep these limitations in mind while working with the data to ensure compliance and avoid any interruptions in your data processing tasks.|
|Content Limits |Content limits are governed by entitlements, which are determined by the specific product variant and add-ons purchased. These limits are put in place to regulate the amount of content accessible within the platform. It is important to be aware of these entitlements and ensure they align with your requirements and data processing tasks.|
## Detailed Limits
|Type of Limit| For this Item | Has this limitation|
|-------------|---------------|--------------------|
|Daily Limits | Number of Cells per Day | The count of data retrieved from the morningstar_data Python package per day cannot exceed 500,000 cells per day. This count of data is summed across all client applications connected to the same Morningstar Direct instance. In the event you reach your limit, please contact your Sales Representative or Customer Success Manager at Morningstar.|
|Daily Limits | Number Of investments in an Investment List | The size of an investment list in Morningstar Direct cannot exceed 30,000 investments in a single query.|
|Daily Limits | Number of data points returned per request |Data point limits are uniform across the type of data being retrieved. That is, the limits apply to time series data, static data, and so on, but are not aggregated across all applications. A custom data set in Morningstar Direct is limited to 1,000 data points.|
|Content/Entitlement Limits | Third-pary data usage|Additional morningstar_data Python package limitations may be imposed by the providers of the underlying data content. Consult with your Customer Success Manager or Sales Representative to know what third-party provider terms may apply to your use of this data.|
## Restricted Functions
As you refer to the morningstar_data Python package documentation, you may find some utility functions and additional data query functions that are not yet available for use. Such functions are in testing by internal teams at Morningstar, and they will be available to Morningstar Direct clients in the future.
# Usage
## Usage of Python package
A Python package refers to a specialized computer program that can be imported into a development environment to facilitate easier access to specific Morningstar data and the execution of pre-built functions. It consists of a toolkit comprising a predefined collection of functions that assist users in constructing something with ease and efficiency. The utilization of the morningstar_data Python package is subject to the governance of the Apache 2.0 license. An Authorized User is explicitly prohibited from engaging in activities such as translating, disassembling, or separating components of the Python package (e.g., accessing or acquiring Product code in any manner). The sole means of granting Authorized Users permission to employ and manipulate the Python package is by referencing or providing a separate entitlement to do so. However, this permission must not override any other limitations outlined in the Click License about the utilization or distribution of the Product.
## Extraction of Data using the Python package
Since the functions (i.e., tools) within the morningstar_data package enable users to extract Morningstar data in various ways, it is imperative to ensure that users extract the data within the constraints specified for them and by the distribution licenses held by Morningstar with their respective firms.
## Sharing of Authentication Token
We authenticate a user's access to the morningstar_data package using an authentication token, which remains valid for 24 hours and can solely be obtained from Analytics Lab. Access to Analytics Lab requires possession of a Direct License. Users are strictly prohibited from sharing their authentication tokens with other individuals, as the usage of the product is tethered to the terms and agreements associated with license of Morningstar Direct.
# Terms & Conditions
The utilization of the morningstar_data Python package entails accessing certain data from Morningstar Direct. Your access and utilization of Morningstar Direct, including its morningstar_data Python package and associated data, are governed by the terms and conditions set forth in your organization’s agreement with Morningstar. Morningstar Direct is an Asset and Wealth management platform that is lawfully licensed for individual use, subject to a login session requirement. A login session is designed to control entitlements and regulate reasonable use for a singular user. To align with the workflow demands of a single user, the morningstar_data Python package imposes restrictions to safeguard the overall platform’s capacity to support the usage levels of all individual Morningstar Direct users accessing data via APIs. The document attached below provides a succinct overview of these various restrictions and elucidates the user experience when encountering them. The specific numerical values for each restriction described herein are not binding and do not create any legal obligations on the part of Morningstar. These restrictions are subject to modification at our sole discretion, without prior notice. It is your sole responsibility to furnish all necessary support pertaining to any applications developed utilizing the morningstar_data Python package. Kindly take note that if you have intentions to resell or distribute any applications or data developed using the morningstar_data Python package to third parties, it is imperative to engage in a distribution license agreement with us. Please contact your Customer Success Manager or Sales Representative at Morningstar for further information.
| PypiClean |
/OpenLP-3.0.2-py3-none-any.whl/openlp/core/ui/starttimedialog.py |
##########################################################################
# OpenLP - Open Source Lyrics Projection #
# ---------------------------------------------------------------------- #
# Copyright (c) 2008-2023 OpenLP Developers #
# ---------------------------------------------------------------------- #
# This program is free software: you can redistribute it and/or modify #
# it under the terms of the GNU General Public License as published by #
# the Free Software Foundation, either version 3 of the License, or #
# (at your option) any later version. #
# #
# This program is distributed in the hope that it will be useful, #
# but WITHOUT ANY WARRANTY; without even the implied warranty of #
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the #
# GNU General Public License for more details. #
# #
# You should have received a copy of the GNU General Public License #
# along with this program. If not, see <https://www.gnu.org/licenses/>. #
##########################################################################
"""
The UI widgets for the time dialog
"""
from PyQt5 import QtCore, QtWidgets
from openlp.core.common.i18n import UiStrings, translate
from openlp.core.lib.ui import create_button_box
from openlp.core.ui.icons import UiIcons
class Ui_StartTimeDialog(object):
"""
The UI widgets for the time dialog
"""
def setup_ui(self, StartTimeDialog):
"""
Set up the UI
"""
StartTimeDialog.setObjectName('StartTimeDialog')
StartTimeDialog.setWindowIcon(UiIcons().main_icon)
StartTimeDialog.resize(350, 10)
self.dialog_layout = QtWidgets.QGridLayout(StartTimeDialog)
self.dialog_layout.setObjectName('dialog_layout')
self.start_label = QtWidgets.QLabel(StartTimeDialog)
self.start_label.setObjectName('start_label')
self.start_label.setAlignment(QtCore.Qt.AlignHCenter)
self.dialog_layout.addWidget(self.start_label, 0, 1, 1, 1)
self.finish_label = QtWidgets.QLabel(StartTimeDialog)
self.finish_label.setObjectName('finish_label')
self.finish_label.setAlignment(QtCore.Qt.AlignHCenter)
self.dialog_layout.addWidget(self.finish_label, 0, 2, 1, 1)
self.length_label = QtWidgets.QLabel(StartTimeDialog)
self.length_label.setObjectName('start_label')
self.length_label.setAlignment(QtCore.Qt.AlignHCenter)
self.dialog_layout.addWidget(self.length_label, 0, 3, 1, 1)
self.hour_label = QtWidgets.QLabel(StartTimeDialog)
self.hour_label.setObjectName('hour_label')
self.dialog_layout.addWidget(self.hour_label, 1, 0, 1, 1)
self.hour_spin_box = QtWidgets.QSpinBox(StartTimeDialog)
self.hour_spin_box.setObjectName('hour_spin_box')
self.hour_spin_box.setMinimum(0)
self.hour_spin_box.setMaximum(4)
self.dialog_layout.addWidget(self.hour_spin_box, 1, 1, 1, 1)
self.hour_finish_spin_box = QtWidgets.QSpinBox(StartTimeDialog)
self.hour_finish_spin_box.setObjectName('hour_finish_spin_box')
self.hour_finish_spin_box.setMinimum(0)
self.hour_finish_spin_box.setMaximum(4)
self.dialog_layout.addWidget(self.hour_finish_spin_box, 1, 2, 1, 1)
self.hour_finish_label = QtWidgets.QLabel(StartTimeDialog)
self.hour_finish_label.setObjectName('hour_label')
self.hour_finish_label.setAlignment(QtCore.Qt.AlignRight)
self.dialog_layout.addWidget(self.hour_finish_label, 1, 3, 1, 1)
self.minute_label = QtWidgets.QLabel(StartTimeDialog)
self.minute_label.setObjectName('minute_label')
self.dialog_layout.addWidget(self.minute_label, 2, 0, 1, 1)
self.minute_spin_box = QtWidgets.QSpinBox(StartTimeDialog)
self.minute_spin_box.setObjectName('minute_spin_box')
self.minute_spin_box.setMinimum(0)
self.minute_spin_box.setMaximum(59)
self.dialog_layout.addWidget(self.minute_spin_box, 2, 1, 1, 1)
self.minute_finish_spin_box = QtWidgets.QSpinBox(StartTimeDialog)
self.minute_finish_spin_box.setObjectName('minute_finish_spin_box')
self.minute_finish_spin_box.setMinimum(0)
self.minute_finish_spin_box.setMaximum(59)
self.dialog_layout.addWidget(self.minute_finish_spin_box, 2, 2, 1, 1)
self.minute_finish_label = QtWidgets.QLabel(StartTimeDialog)
self.minute_finish_label.setObjectName('minute_label')
self.minute_finish_label.setAlignment(QtCore.Qt.AlignRight)
self.dialog_layout.addWidget(self.minute_finish_label, 2, 3, 1, 1)
self.second_label = QtWidgets.QLabel(StartTimeDialog)
self.second_label.setObjectName('second_label')
self.dialog_layout.addWidget(self.second_label, 3, 0, 1, 1)
self.second_spin_box = QtWidgets.QSpinBox(StartTimeDialog)
self.second_spin_box.setObjectName('second_spin_box')
self.second_spin_box.setMinimum(0)
self.second_spin_box.setMaximum(59)
self.second_finish_spin_box = QtWidgets.QSpinBox(StartTimeDialog)
self.second_finish_spin_box.setObjectName('second_finish_spin_box')
self.second_finish_spin_box.setMinimum(0)
self.second_finish_spin_box.setMaximum(59)
self.dialog_layout.addWidget(self.second_finish_spin_box, 3, 2, 1, 1)
self.second_finish_label = QtWidgets.QLabel(StartTimeDialog)
self.second_finish_label.setObjectName('second_label')
self.second_finish_label.setAlignment(QtCore.Qt.AlignRight)
self.dialog_layout.addWidget(self.second_finish_label, 3, 3, 1, 1)
self.dialog_layout.addWidget(self.second_spin_box, 3, 1, 1, 1)
self.button_box = create_button_box(StartTimeDialog, 'button_box', ['cancel', 'ok'])
self.dialog_layout.addWidget(self.button_box, 5, 2, 1, 2)
self.retranslate_ui(StartTimeDialog)
self.setMaximumHeight(self.sizeHint().height())
def retranslate_ui(self, StartTimeDialog):
"""
Update the translations on the fly
"""
self.setWindowTitle(translate('OpenLP.StartTime_form', 'Item Start and Finish Time'))
self.hour_spin_box.setSuffix(UiStrings().Hours)
self.minute_spin_box.setSuffix(UiStrings().Minutes)
self.second_spin_box.setSuffix(UiStrings().Seconds)
self.hour_finish_spin_box.setSuffix(UiStrings().Hours)
self.minute_finish_spin_box.setSuffix(UiStrings().Minutes)
self.second_finish_spin_box.setSuffix(UiStrings().Seconds)
self.hour_label.setText(translate('OpenLP.StartTime_form', 'Hours:'))
self.minute_label.setText(translate('OpenLP.StartTime_form', 'Minutes:'))
self.second_label.setText(translate('OpenLP.StartTime_form', 'Seconds:'))
self.start_label.setText(translate('OpenLP.StartTime_form', 'Start'))
self.finish_label.setText(translate('OpenLP.StartTime_form', 'Finish'))
self.length_label.setText(translate('OpenLP.StartTime_form', 'Length')) | PypiClean |
/skytime-0.16.1-py3-none-any.whl/build/lib/build/lib/build/lib/build/lib/sktime/dists_kernels/dtw.py | """BaseEstimator interface to sktime dtw distances in distances module."""
__author__ = ["fkiraly"]
from typing import Union
import numpy as np
from sktime.distances import pairwise_distance
from sktime.dists_kernels._base import BasePairwiseTransformerPanel
class DtwDist(BasePairwiseTransformerPanel):
r"""Interface to sktime native dtw distances, with derivative or weighting.
Interface to simple dynamic time warping (DTW) distance,
and the following weighted/derivative versions:
WDTW - weighted dynamic tyme warping
DDTW - derivative dynamic time warping
WDDTW - weighted derivative dynamic time warping
`sktime` interface to the efficient `numba` implementations in `sktime.distances`.
This estimator provides performant implementation of time warping distances for:
* time series of equal length
* the Euclidean pairwise distance
For unequal length time series, use `sktime.dists_kernels.DistFromAligner`
with a time warping aligner such as `sktime.aligners.AlignerDTW`.
To use arbitrary pairwise distances, use `sktime.aligners.AlignerDTWfromDist`.
(for derivative DTW, pipeline an alignment distance with `Differencer`)
Note that the more flexible options above may be less performant.
DTW:
Originally proposed in [1]_, DTW computes the distance between two time series by
considering their alignments during the calculation. This is done by measuring
the pointwise distance (normally using Euclidean) between all elements of the two
time series and then using dynamic programming to find the warping path
that minimises the total pointwise distance between realigned series.
DDTW is an adaptation of DTW originally proposed in [2]_. DDTW attempts to
improve on dtw by better account for the 'shape' of the time series.
This is done by considering y axis data points as higher level features of 'shape'.
To do this the first derivative of the sequence is taken, and then using this
derived sequence a dtw computation is done.
WDTW was first proposed in [3]_, it adds a multiplicative weight penalty based on
the warping distance. This means that time series with lower phase difference have
a smaller weight imposed (i.e less penalty imposed) and time series with larger
phase difference have a larger weight imposed (i.e. larger penalty imposed).
WDDTW was first proposed in [3]_ as an extension of DDTW. By adding a weight
to the derivative it means the alignment isn't only considering the shape of the
time series, but also the phase.
Parameters
----------
weighted : bool, optional, default=False
whether a weighted version of the distance is computed
False = unmodified distance, i.e., dtw distance or derivative dtw distance
True = weighted distance, i.e., weighted dtw or derivative weighted dtw
derivative : bool, optional, default=False
whether the distance or the derivative distance is computed
False = unmodified distance, i.e., dtw distance or weighted dtw distance
True = derivative distance, i.e., derivative dtw distance or derivative wdtw
window: int, defaults = None
Integer that is the radius of the sakoe chiba window (if using Sakoe-Chiba
lower bounding).
itakura_max_slope: float, defaults = None
Gradient of the slope for itakura parallelogram (if using Itakura
Parallelogram lower bounding).
bounding_matrix: np.ndarray (2d of size mxn where m is len(x) and n is len(y)),
defaults = None)
Custom bounding matrix to use. If defined then other lower_bounding params
are ignored. The matrix should be structure so that indexes considered in
bound should be the value 0. and indexes outside the bounding matrix should
be infinity.
g: float, optional, default = 0. Used only if weighted=True.
Constant that controls the curvature (slope) of the function; that is, g
controls the level of penalisation for the points with larger phase
difference.
References
----------
.. [1] H. Sakoe, S. Chiba, "Dynamic programming algorithm optimization for
spoken word recognition," IEEE Transactions on Acoustics, Speech and
Signal Processing, vol. 26(1), pp. 43--49, 1978.
.. [2] Keogh, Eamonn & Pazzani, Michael. (2002). Derivative Dynamic Time Warping.
First SIAM International Conference on Data Mining.
1. 10.1137/1.9781611972719.1.
.. [3] Young-Seon Jeong, Myong K. Jeong, Olufemi A. Omitaomu, Weighted dynamic time
warping for time series classification, Pattern Recognition, Volume 44, Issue 9,
2011, Pages 2231-2240, ISSN 0031-3203, https://doi.org/10.1016/j.patcog.2010.09.022.
"""
_tags = {
"symmetric": True, # all the distances are symmetric
"X_inner_mtype": "numpy3D",
"python_dependencies": "numba",
}
def __init__(
self,
weighted: bool = False,
derivative: bool = False,
window: Union[int, None] = None,
itakura_max_slope: Union[float, None] = None,
bounding_matrix: np.ndarray = None,
g: float = 0.0,
):
self.weighted = weighted
self.derivative = derivative
self.window = window
self.itakura_max_slope = itakura_max_slope
self.bounding_matrix = bounding_matrix
self.g = g
if not weighted and not derivative:
metric_key = "dtw"
elif not weighted and derivative:
metric_key = "ddtw"
elif weighted and not derivative:
metric_key = "wdtw"
elif weighted and derivative:
metric_key = "wddtw"
self.metric_key = metric_key
kwargs = {
"window": window,
"itakura_max_slope": itakura_max_slope,
"bounding_matrix": bounding_matrix,
}
# g is used only for weighted dtw
if weighted:
kwargs["g"] = g
self.kwargs = kwargs
super(DtwDist, self).__init__()
def _transform(self, X, X2=None):
"""Compute distance/kernel matrix.
Core logic
Behaviour: returns pairwise distance/kernel matrix
between samples in X and X2
if X2 is not passed, is equal to X
if X/X2 is a pd.DataFrame and contains non-numeric columns,
these are removed before computation
Parameters
----------
X: 3D np.array of shape [num_instances, num_vars, num_time_points]
X2: 3D np.array of shape [num_instances, num_vars, num_time_points], optional
default X2 = X
Returns
-------
distmat: np.array of shape [n, m]
(i,j)-th entry contains distance/kernel between X[i] and X2[j]
"""
metric_key = self.metric_key
kwargs = self.kwargs
distmat = pairwise_distance(X, X2, metric=metric_key, **kwargs)
return distmat | PypiClean |
/ais_dom-2023.7.2-py3-none-any.whl/homeassistant/components/rainmachine/button.py | from __future__ import annotations
from collections.abc import Awaitable, Callable
from dataclasses import dataclass
from regenmaschine.controller import Controller
from regenmaschine.errors import RainMachineError
from homeassistant.components.button import (
ButtonDeviceClass,
ButtonEntity,
ButtonEntityDescription,
)
from homeassistant.config_entries import ConfigEntry
from homeassistant.const import EntityCategory
from homeassistant.core import HomeAssistant
from homeassistant.exceptions import HomeAssistantError
from homeassistant.helpers.dispatcher import async_dispatcher_send
from homeassistant.helpers.entity_platform import AddEntitiesCallback
from . import RainMachineData, RainMachineEntity
from .const import DATA_PROVISION_SETTINGS, DOMAIN
from .model import RainMachineEntityDescription
@dataclass
class RainMachineButtonDescriptionMixin:
"""Define an entity description mixin for RainMachine buttons."""
push_action: Callable[[Controller], Awaitable]
@dataclass
class RainMachineButtonDescription(
ButtonEntityDescription,
RainMachineEntityDescription,
RainMachineButtonDescriptionMixin,
):
"""Describe a RainMachine button description."""
BUTTON_KIND_REBOOT = "reboot"
async def _async_reboot(controller: Controller) -> None:
"""Reboot the RainMachine."""
await controller.machine.reboot()
BUTTON_DESCRIPTIONS = (
RainMachineButtonDescription(
key=BUTTON_KIND_REBOOT,
name="Reboot",
api_category=DATA_PROVISION_SETTINGS,
push_action=_async_reboot,
),
)
async def async_setup_entry(
hass: HomeAssistant, entry: ConfigEntry, async_add_entities: AddEntitiesCallback
) -> None:
"""Set up RainMachine buttons based on a config entry."""
data: RainMachineData = hass.data[DOMAIN][entry.entry_id]
async_add_entities(
RainMachineButton(entry, data, description)
for description in BUTTON_DESCRIPTIONS
)
class RainMachineButton(RainMachineEntity, ButtonEntity):
"""Define a RainMachine button."""
_attr_device_class = ButtonDeviceClass.RESTART
_attr_entity_category = EntityCategory.CONFIG
entity_description: RainMachineButtonDescription
async def async_press(self) -> None:
"""Send out a restart command."""
try:
await self.entity_description.push_action(self._data.controller)
except RainMachineError as err:
raise HomeAssistantError(
f'Error while pressing button "{self.entity_id}": {err}'
) from err
async_dispatcher_send(self.hass, self.coordinator.signal_reboot_requested) | PypiClean |
/ansible-8.3.0-py3-none-any.whl/ansible_collections/fortinet/fortimanager/plugins/modules/fmgr_switchcontroller_acl_ingress_classifier.py | from __future__ import absolute_import, division, print_function
# Copyright 2019-2023 Fortinet, Inc.
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <https://www.gnu.org/licenses/>.
__metaclass__ = type
ANSIBLE_METADATA = {'status': ['preview'],
'supported_by': 'community',
'metadata_version': '1.1'}
DOCUMENTATION = '''
---
module: fmgr_switchcontroller_acl_ingress_classifier
short_description: ACL classifiers.
description:
- This module is able to configure a FortiManager device.
- Examples include all parameters and values which need to be adjusted to data sources before usage.
version_added: "2.2.0"
author:
- Xinwei Du (@dux-fortinet)
- Xing Li (@lix-fortinet)
- Jie Xue (@JieX19)
- Link Zheng (@chillancezen)
- Frank Shen (@fshen01)
- Hongbin Lu (@fgtdev-hblu)
notes:
- Running in workspace locking mode is supported in this FortiManager module, the top
level parameters workspace_locking_adom and workspace_locking_timeout help do the work.
- To create or update an object, use state present directive.
- To delete an object, use state absent directive.
- Normally, running one module can fail when a non-zero rc is returned. you can also override
the conditions to fail or succeed with parameters rc_failed and rc_succeeded
options:
access_token:
description: The token to access FortiManager without using username and password.
required: false
type: str
bypass_validation:
description: Only set to True when module schema diffs with FortiManager API structure, module continues to execute without validating parameters.
required: false
type: bool
default: false
enable_log:
description: Enable/Disable logging for task.
required: false
type: bool
default: false
forticloud_access_token:
description: Authenticate Ansible client with forticloud API access token.
required: false
type: str
proposed_method:
description: The overridden method for the underlying Json RPC request.
required: false
type: str
choices:
- update
- set
- add
rc_succeeded:
description: The rc codes list with which the conditions to succeed will be overriden.
type: list
required: false
elements: int
rc_failed:
description: The rc codes list with which the conditions to fail will be overriden.
type: list
required: false
elements: int
workspace_locking_adom:
description: The adom to lock for FortiManager running in workspace mode, the value can be global and others including root.
required: false
type: str
workspace_locking_timeout:
description: The maximum time in seconds to wait for other user to release the workspace lock.
required: false
type: int
default: 300
adom:
description: the parameter (adom) in requested url
type: str
required: true
ingress:
description: the parameter (ingress) in requested url
type: str
required: true
switchcontroller_acl_ingress_classifier:
description: the top level parameters set
required: false
type: dict
suboptions:
dst-ip-prefix:
type: str
description: Destination IP address to be matched.
dst-mac:
type: str
description: Destination MAC address to be matched.
src-ip-prefix:
type: str
description: Source IP address to be matched.
src-mac:
type: str
description: Source MAC address to be matched.
vlan:
type: int
description: VLAN ID to be matched.
'''
EXAMPLES = '''
- hosts: fortimanager-inventory
collections:
- fortinet.fortimanager
connection: httpapi
vars:
ansible_httpapi_use_ssl: True
ansible_httpapi_validate_certs: False
ansible_httpapi_port: 443
tasks:
- name: ACL classifiers.
fmgr_switchcontroller_acl_ingress_classifier:
bypass_validation: False
workspace_locking_adom: <value in [global, custom adom including root]>
workspace_locking_timeout: 300
rc_succeeded: [0, -2, -3, ...]
rc_failed: [-2, -3, ...]
adom: <your own value>
ingress: <your own value>
switchcontroller_acl_ingress_classifier:
dst-ip-prefix: <value of string>
dst-mac: <value of string>
src-ip-prefix: <value of string>
src-mac: <value of string>
vlan: <value of integer>
'''
RETURN = '''
meta:
description: The result of the request.
type: dict
returned: always
contains:
request_url:
description: The full url requested.
returned: always
type: str
sample: /sys/login/user
response_code:
description: The status of api request.
returned: always
type: int
sample: 0
response_data:
description: The api response.
type: list
returned: always
response_message:
description: The descriptive message of the api response.
type: str
returned: always
sample: OK.
system_information:
description: The information of the target system.
type: dict
returned: always
rc:
description: The status the request.
type: int
returned: always
sample: 0
version_check_warning:
description: Warning if the parameters used in the playbook are not supported by the current FortiManager version.
type: list
returned: complex
'''
from ansible.module_utils.basic import AnsibleModule
from ansible.module_utils.connection import Connection
from ansible_collections.fortinet.fortimanager.plugins.module_utils.napi import NAPIManager
from ansible_collections.fortinet.fortimanager.plugins.module_utils.napi import check_galaxy_version
from ansible_collections.fortinet.fortimanager.plugins.module_utils.napi import check_parameter_bypass
def main():
jrpc_urls = [
'/pm/config/adom/{adom}/obj/switch-controller/acl/ingress/{ingress}/classifier',
'/pm/config/global/obj/switch-controller/acl/ingress/{ingress}/classifier'
]
perobject_jrpc_urls = [
'/pm/config/adom/{adom}/obj/switch-controller/acl/ingress/{ingress}/classifier/{classifier}',
'/pm/config/global/obj/switch-controller/acl/ingress/{ingress}/classifier/{classifier}'
]
url_params = ['adom', 'ingress']
module_primary_key = None
module_arg_spec = {
'access_token': {
'type': 'str',
'required': False,
'no_log': True
},
'bypass_validation': {
'type': 'bool',
'required': False,
'default': False
},
'enable_log': {
'type': 'bool',
'required': False,
'default': False
},
'forticloud_access_token': {
'type': 'str',
'required': False,
'no_log': True
},
'proposed_method': {
'type': 'str',
'required': False,
'choices': [
'set',
'update',
'add'
]
},
'rc_succeeded': {
'required': False,
'type': 'list',
'elements': 'int'
},
'rc_failed': {
'required': False,
'type': 'list',
'elements': 'int'
},
'workspace_locking_adom': {
'type': 'str',
'required': False
},
'workspace_locking_timeout': {
'type': 'int',
'required': False,
'default': 300
},
'adom': {
'required': True,
'type': 'str'
},
'ingress': {
'required': True,
'type': 'str'
},
'switchcontroller_acl_ingress_classifier': {
'required': False,
'type': 'dict',
'revision': {
'7.4.0': True
},
'options': {
'dst-ip-prefix': {
'required': False,
'revision': {
'7.4.0': True
},
'type': 'str'
},
'dst-mac': {
'required': False,
'revision': {
'7.4.0': True
},
'type': 'str'
},
'src-ip-prefix': {
'required': False,
'revision': {
'7.4.0': True
},
'type': 'str'
},
'src-mac': {
'required': False,
'revision': {
'7.4.0': True
},
'type': 'str'
},
'vlan': {
'required': False,
'revision': {
'7.4.0': True
},
'type': 'int'
}
}
}
}
params_validation_blob = []
check_galaxy_version(module_arg_spec)
module = AnsibleModule(argument_spec=check_parameter_bypass(module_arg_spec, 'switchcontroller_acl_ingress_classifier'),
supports_check_mode=False)
fmgr = None
if module._socket_path:
connection = Connection(module._socket_path)
connection.set_option('access_token', module.params['access_token'] if 'access_token' in module.params else None)
connection.set_option('enable_log', module.params['enable_log'] if 'enable_log' in module.params else False)
connection.set_option('forticloud_access_token',
module.params['forticloud_access_token'] if 'forticloud_access_token' in module.params else None)
fmgr = NAPIManager(jrpc_urls, perobject_jrpc_urls, module_primary_key, url_params, module, connection, top_level_schema_name='data')
fmgr.validate_parameters(params_validation_blob)
fmgr.process_partial_curd(argument_specs=module_arg_spec)
else:
module.fail_json(msg='MUST RUN IN HTTPAPI MODE')
module.exit_json(meta=module.params)
if __name__ == '__main__':
main() | PypiClean |
/pulumi_aws-6.1.0a1693529760.tar.gz/pulumi_aws-6.1.0a1693529760/pulumi_aws/glue/resource_policy.py |
import copy
import warnings
import pulumi
import pulumi.runtime
from typing import Any, Mapping, Optional, Sequence, Union, overload
from .. import _utilities
__all__ = ['ResourcePolicyArgs', 'ResourcePolicy']
@pulumi.input_type
class ResourcePolicyArgs:
def __init__(__self__, *,
policy: pulumi.Input[str],
enable_hybrid: Optional[pulumi.Input[str]] = None):
"""
The set of arguments for constructing a ResourcePolicy resource.
:param pulumi.Input[str] policy: The policy to be applied to the aws glue data catalog.
:param pulumi.Input[str] enable_hybrid: Indicates that you are using both methods to grant cross-account. Valid values are `TRUE` and `FALSE`. Note the provider will not perform drift detetction on this field as its not return on read.
"""
pulumi.set(__self__, "policy", policy)
if enable_hybrid is not None:
pulumi.set(__self__, "enable_hybrid", enable_hybrid)
@property
@pulumi.getter
def policy(self) -> pulumi.Input[str]:
"""
The policy to be applied to the aws glue data catalog.
"""
return pulumi.get(self, "policy")
@policy.setter
def policy(self, value: pulumi.Input[str]):
pulumi.set(self, "policy", value)
@property
@pulumi.getter(name="enableHybrid")
def enable_hybrid(self) -> Optional[pulumi.Input[str]]:
"""
Indicates that you are using both methods to grant cross-account. Valid values are `TRUE` and `FALSE`. Note the provider will not perform drift detetction on this field as its not return on read.
"""
return pulumi.get(self, "enable_hybrid")
@enable_hybrid.setter
def enable_hybrid(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "enable_hybrid", value)
@pulumi.input_type
class _ResourcePolicyState:
def __init__(__self__, *,
enable_hybrid: Optional[pulumi.Input[str]] = None,
policy: Optional[pulumi.Input[str]] = None):
"""
Input properties used for looking up and filtering ResourcePolicy resources.
:param pulumi.Input[str] enable_hybrid: Indicates that you are using both methods to grant cross-account. Valid values are `TRUE` and `FALSE`. Note the provider will not perform drift detetction on this field as its not return on read.
:param pulumi.Input[str] policy: The policy to be applied to the aws glue data catalog.
"""
if enable_hybrid is not None:
pulumi.set(__self__, "enable_hybrid", enable_hybrid)
if policy is not None:
pulumi.set(__self__, "policy", policy)
@property
@pulumi.getter(name="enableHybrid")
def enable_hybrid(self) -> Optional[pulumi.Input[str]]:
"""
Indicates that you are using both methods to grant cross-account. Valid values are `TRUE` and `FALSE`. Note the provider will not perform drift detetction on this field as its not return on read.
"""
return pulumi.get(self, "enable_hybrid")
@enable_hybrid.setter
def enable_hybrid(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "enable_hybrid", value)
@property
@pulumi.getter
def policy(self) -> Optional[pulumi.Input[str]]:
"""
The policy to be applied to the aws glue data catalog.
"""
return pulumi.get(self, "policy")
@policy.setter
def policy(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "policy", value)
class ResourcePolicy(pulumi.CustomResource):
@overload
def __init__(__self__,
resource_name: str,
opts: Optional[pulumi.ResourceOptions] = None,
enable_hybrid: Optional[pulumi.Input[str]] = None,
policy: Optional[pulumi.Input[str]] = None,
__props__=None):
"""
Provides a Glue resource policy. Only one can exist per region.
## Example Usage
```python
import pulumi
import pulumi_aws as aws
current_caller_identity = aws.get_caller_identity()
current_partition = aws.get_partition()
current_region = aws.get_region()
glue_example_policy = aws.iam.get_policy_document(statements=[aws.iam.GetPolicyDocumentStatementArgs(
actions=["glue:CreateTable"],
resources=[f"arn:{current_partition.partition}:glue:{current_region.name}:{current_caller_identity.account_id}:*"],
principals=[aws.iam.GetPolicyDocumentStatementPrincipalArgs(
identifiers=["*"],
type="AWS",
)],
)])
example = aws.glue.ResourcePolicy("example", policy=glue_example_policy.json)
```
## Import
Using `pulumi import`, import Glue Resource Policy using the account ID. For example:
```sh
$ pulumi import aws:glue/resourcePolicy:ResourcePolicy Test 12356789012
```
:param str resource_name: The name of the resource.
:param pulumi.ResourceOptions opts: Options for the resource.
:param pulumi.Input[str] enable_hybrid: Indicates that you are using both methods to grant cross-account. Valid values are `TRUE` and `FALSE`. Note the provider will not perform drift detetction on this field as its not return on read.
:param pulumi.Input[str] policy: The policy to be applied to the aws glue data catalog.
"""
...
@overload
def __init__(__self__,
resource_name: str,
args: ResourcePolicyArgs,
opts: Optional[pulumi.ResourceOptions] = None):
"""
Provides a Glue resource policy. Only one can exist per region.
## Example Usage
```python
import pulumi
import pulumi_aws as aws
current_caller_identity = aws.get_caller_identity()
current_partition = aws.get_partition()
current_region = aws.get_region()
glue_example_policy = aws.iam.get_policy_document(statements=[aws.iam.GetPolicyDocumentStatementArgs(
actions=["glue:CreateTable"],
resources=[f"arn:{current_partition.partition}:glue:{current_region.name}:{current_caller_identity.account_id}:*"],
principals=[aws.iam.GetPolicyDocumentStatementPrincipalArgs(
identifiers=["*"],
type="AWS",
)],
)])
example = aws.glue.ResourcePolicy("example", policy=glue_example_policy.json)
```
## Import
Using `pulumi import`, import Glue Resource Policy using the account ID. For example:
```sh
$ pulumi import aws:glue/resourcePolicy:ResourcePolicy Test 12356789012
```
:param str resource_name: The name of the resource.
:param ResourcePolicyArgs args: The arguments to use to populate this resource's properties.
:param pulumi.ResourceOptions opts: Options for the resource.
"""
...
def __init__(__self__, resource_name: str, *args, **kwargs):
resource_args, opts = _utilities.get_resource_args_opts(ResourcePolicyArgs, pulumi.ResourceOptions, *args, **kwargs)
if resource_args is not None:
__self__._internal_init(resource_name, opts, **resource_args.__dict__)
else:
__self__._internal_init(resource_name, *args, **kwargs)
def _internal_init(__self__,
resource_name: str,
opts: Optional[pulumi.ResourceOptions] = None,
enable_hybrid: Optional[pulumi.Input[str]] = None,
policy: Optional[pulumi.Input[str]] = None,
__props__=None):
opts = pulumi.ResourceOptions.merge(_utilities.get_resource_opts_defaults(), opts)
if not isinstance(opts, pulumi.ResourceOptions):
raise TypeError('Expected resource options to be a ResourceOptions instance')
if opts.id is None:
if __props__ is not None:
raise TypeError('__props__ is only valid when passed in combination with a valid opts.id to get an existing resource')
__props__ = ResourcePolicyArgs.__new__(ResourcePolicyArgs)
__props__.__dict__["enable_hybrid"] = enable_hybrid
if policy is None and not opts.urn:
raise TypeError("Missing required property 'policy'")
__props__.__dict__["policy"] = policy
super(ResourcePolicy, __self__).__init__(
'aws:glue/resourcePolicy:ResourcePolicy',
resource_name,
__props__,
opts)
@staticmethod
def get(resource_name: str,
id: pulumi.Input[str],
opts: Optional[pulumi.ResourceOptions] = None,
enable_hybrid: Optional[pulumi.Input[str]] = None,
policy: Optional[pulumi.Input[str]] = None) -> 'ResourcePolicy':
"""
Get an existing ResourcePolicy resource's state with the given name, id, and optional extra
properties used to qualify the lookup.
:param str resource_name: The unique name of the resulting resource.
:param pulumi.Input[str] id: The unique provider ID of the resource to lookup.
:param pulumi.ResourceOptions opts: Options for the resource.
:param pulumi.Input[str] enable_hybrid: Indicates that you are using both methods to grant cross-account. Valid values are `TRUE` and `FALSE`. Note the provider will not perform drift detetction on this field as its not return on read.
:param pulumi.Input[str] policy: The policy to be applied to the aws glue data catalog.
"""
opts = pulumi.ResourceOptions.merge(opts, pulumi.ResourceOptions(id=id))
__props__ = _ResourcePolicyState.__new__(_ResourcePolicyState)
__props__.__dict__["enable_hybrid"] = enable_hybrid
__props__.__dict__["policy"] = policy
return ResourcePolicy(resource_name, opts=opts, __props__=__props__)
@property
@pulumi.getter(name="enableHybrid")
def enable_hybrid(self) -> pulumi.Output[Optional[str]]:
"""
Indicates that you are using both methods to grant cross-account. Valid values are `TRUE` and `FALSE`. Note the provider will not perform drift detetction on this field as its not return on read.
"""
return pulumi.get(self, "enable_hybrid")
@property
@pulumi.getter
def policy(self) -> pulumi.Output[str]:
"""
The policy to be applied to the aws glue data catalog.
"""
return pulumi.get(self, "policy") | PypiClean |
/pulumi_azure_native-2.5.1a1693590910.tar.gz/pulumi_azure_native-2.5.1a1693590910/pulumi_azure_native/dbforpostgresql/v20230301preview/_enums.py |
from enum import Enum
__all__ = [
'ActiveDirectoryAuthEnum',
'ArmServerKeyType',
'AzureManagedDiskPerformanceTiers',
'CancelEnum',
'CreateMode',
'GeoRedundantBackupEnum',
'HighAvailabilityMode',
'IdentityType',
'KeyStatusEnum',
'LogicalReplicationOnSourceDbEnum',
'MigrationMode',
'OverwriteDbsInTargetEnum',
'PasswordAuthEnum',
'PrincipalType',
'ReplicationRole',
'ServerVersion',
'SkuTier',
'StartDataMigrationEnum',
'StorageAutoGrow',
'TriggerCutoverEnum',
]
class ActiveDirectoryAuthEnum(str, Enum):
"""
If Enabled, Azure Active Directory authentication is enabled.
"""
ENABLED = "Enabled"
DISABLED = "Disabled"
class ArmServerKeyType(str, Enum):
"""
Data encryption type to depict if it is System Managed vs Azure Key vault.
"""
SYSTEM_MANAGED = "SystemManaged"
AZURE_KEY_VAULT = "AzureKeyVault"
class AzureManagedDiskPerformanceTiers(str, Enum):
"""
Name of storage tier for IOPS.
"""
P1 = "P1"
P2 = "P2"
P3 = "P3"
P4 = "P4"
P6 = "P6"
P10 = "P10"
P15 = "P15"
P20 = "P20"
P30 = "P30"
P40 = "P40"
P50 = "P50"
P60 = "P60"
P70 = "P70"
P80 = "P80"
class CancelEnum(str, Enum):
"""
To trigger cancel for entire migration we need to send this flag as True
"""
TRUE = "True"
FALSE = "False"
class CreateMode(str, Enum):
"""
The mode to create a new PostgreSQL server.
"""
DEFAULT = "Default"
CREATE = "Create"
UPDATE = "Update"
POINT_IN_TIME_RESTORE = "PointInTimeRestore"
GEO_RESTORE = "GeoRestore"
REPLICA = "Replica"
REVIVE_DROPPED = "ReviveDropped"
class GeoRedundantBackupEnum(str, Enum):
"""
A value indicating whether Geo-Redundant backup is enabled on the server.
"""
ENABLED = "Enabled"
DISABLED = "Disabled"
class HighAvailabilityMode(str, Enum):
"""
The HA mode for the server.
"""
DISABLED = "Disabled"
ZONE_REDUNDANT = "ZoneRedundant"
SAME_ZONE = "SameZone"
class IdentityType(str, Enum):
"""
the types of identities associated with this resource; currently restricted to 'None and UserAssigned'
"""
NONE = "None"
USER_ASSIGNED = "UserAssigned"
class KeyStatusEnum(str, Enum):
"""
Primary encryption key status for Data encryption enabled server.
"""
VALID = "Valid"
INVALID = "Invalid"
class LogicalReplicationOnSourceDbEnum(str, Enum):
"""
Indicates whether to setup LogicalReplicationOnSourceDb, if needed
"""
TRUE = "True"
FALSE = "False"
class MigrationMode(str, Enum):
"""
There are two types of migration modes Online and Offline
"""
OFFLINE = "Offline"
ONLINE = "Online"
class OverwriteDbsInTargetEnum(str, Enum):
"""
Indicates whether the databases on the target server can be overwritten, if already present. If set to False, the migration workflow will wait for a confirmation, if it detects that the database already exists.
"""
TRUE = "True"
FALSE = "False"
class PasswordAuthEnum(str, Enum):
"""
If Enabled, Password authentication is enabled.
"""
ENABLED = "Enabled"
DISABLED = "Disabled"
class PrincipalType(str, Enum):
"""
The principal type used to represent the type of Active Directory Administrator.
"""
UNKNOWN = "Unknown"
USER = "User"
GROUP = "Group"
SERVICE_PRINCIPAL = "ServicePrincipal"
class ReplicationRole(str, Enum):
"""
Replication role of the server
"""
NONE = "None"
PRIMARY = "Primary"
ASYNC_REPLICA = "AsyncReplica"
GEO_ASYNC_REPLICA = "GeoAsyncReplica"
class ServerVersion(str, Enum):
"""
PostgreSQL Server version.
"""
SERVER_VERSION_15 = "15"
SERVER_VERSION_14 = "14"
SERVER_VERSION_13 = "13"
SERVER_VERSION_12 = "12"
SERVER_VERSION_11 = "11"
class SkuTier(str, Enum):
"""
The tier of the particular SKU, e.g. Burstable.
"""
BURSTABLE = "Burstable"
GENERAL_PURPOSE = "GeneralPurpose"
MEMORY_OPTIMIZED = "MemoryOptimized"
class StartDataMigrationEnum(str, Enum):
"""
Indicates whether the data migration should start right away
"""
TRUE = "True"
FALSE = "False"
class StorageAutoGrow(str, Enum):
"""
Flag to enable / disable Storage Auto grow for flexible server.
"""
ENABLED = "Enabled"
DISABLED = "Disabled"
class TriggerCutoverEnum(str, Enum):
"""
To trigger cutover for entire migration we need to send this flag as True
"""
TRUE = "True"
FALSE = "False" | PypiClean |
/gamification-engine-0.4.0.tar.gz/gamification-engine-0.4.0/gengine/app/jsscripts/node_modules/intl/locale-data/jsonp/sg-CF.js | IntlPolyfill.__addLocaleData({locale:"sg-CF",date:{ca:["gregory","buddhist","chinese","coptic","dangi","ethioaa","ethiopic","generic","hebrew","indian","islamic","islamicc","japanese","persian","roc"],hourNo0:true,hour12:false,formats:{short:"{1} {0}",medium:"{1} {0}",full:"{1} {0}",long:"{1} {0}",availableFormats:{"d":"d","E":"ccc",Ed:"d, E",Ehm:"E h:mm a",EHm:"E HH:mm",Ehms:"E h:mm:ss a",EHms:"E HH:mm:ss",Gy:"G y",GyMMM:"G y MMM",GyMMMd:"G y MMM d",GyMMMEd:"G y MMM d, E","h":"h a","H":"HH",hm:"h:mm a",Hm:"HH:mm",hms:"h:mm:ss a",Hms:"HH:mm:ss",hmsv:"h:mm:ss a v",Hmsv:"HH:mm:ss v",hmv:"h:mm a v",Hmv:"HH:mm v","M":"M",Md:"d/M",MEd:"MM-dd, E",MMd:"d/MM",MMdd:"dd/MM",MMM:"MMM",MMMd:"d MMM",MMMEd:"E d MMM",MMMMd:"d MMMM",MMMMEd:"E d MMMM",ms:"m:ss","y":"y",yM:"M/y",yMd:"y-MM-dd",yMEd:"E d/M/y",yMMM:"MMM y",yMMMd:"y MMM d",yMMMEd:"E d MMM y",yMMMM:"MMMM y",yQQQ:"QQQ y",yQQQQ:"QQQQ y"},dateFormats:{yMMMMEEEEd:"EEEE d MMMM y",yMMMMd:"d MMMM y",yMMMd:"d MMM, y",yMd:"d/M/y"},timeFormats:{hmmsszzzz:"HH:mm:ss zzzz",hmsz:"HH:mm:ss z",hms:"HH:mm:ss",hm:"HH:mm"}},calendars:{buddhist:{months:{narrow:["N","F","M","N","B","F","L","K","M","N","N","K"],short:["Nye","Ful","Mbä","Ngu","Bêl","Fön","Len","Kük","Mvu","Ngb","Nab","Kak"],long:["Nyenye","Fulundïgi","Mbängü","Ngubùe","Bêläwü","Föndo","Lengua","Kükürü","Mvuka","Ngberere","Nabändüru","Kakauka"]},days:{narrow:["K","S","T","S","K","P","Y"],short:["Bk1","Bk2","Bk3","Bk4","Bk5","Lâp","Lây"],long:["Bikua-ôko","Bïkua-ûse","Bïkua-ptâ","Bïkua-usïö","Bïkua-okü","Lâpôsö","Lâyenga"]},eras:{narrow:["BE"],short:["BE"],long:["BE"]},dayPeriods:{am:"ND",pm:"LK"}},chinese:{months:{narrow:["1","2","3","4","5","6","7","8","9","10","11","12"],short:["M01","M02","M03","M04","M05","M06","M07","M08","M09","M10","M11","M12"],long:["M01","M02","M03","M04","M05","M06","M07","M08","M09","M10","M11","M12"]},days:{narrow:["K","S","T","S","K","P","Y"],short:["Bk1","Bk2","Bk3","Bk4","Bk5","Lâp","Lây"],long:["Bikua-ôko","Bïkua-ûse","Bïkua-ptâ","Bïkua-usïö","Bïkua-okü","Lâpôsö","Lâyenga"]},dayPeriods:{am:"ND",pm:"LK"}},coptic:{months:{narrow:["1","2","3","4","5","6","7","8","9","10","11","12","13"],short:["Tout","Baba","Hator","Kiahk","Toba","Amshir","Baramhat","Baramouda","Bashans","Paona","Epep","Mesra","Nasie"],long:["Tout","Baba","Hator","Kiahk","Toba","Amshir","Baramhat","Baramouda","Bashans","Paona","Epep","Mesra","Nasie"]},days:{narrow:["K","S","T","S","K","P","Y"],short:["Bk1","Bk2","Bk3","Bk4","Bk5","Lâp","Lây"],long:["Bikua-ôko","Bïkua-ûse","Bïkua-ptâ","Bïkua-usïö","Bïkua-okü","Lâpôsö","Lâyenga"]},eras:{narrow:["ERA0","ERA1"],short:["ERA0","ERA1"],long:["ERA0","ERA1"]},dayPeriods:{am:"ND",pm:"LK"}},dangi:{months:{narrow:["1","2","3","4","5","6","7","8","9","10","11","12"],short:["M01","M02","M03","M04","M05","M06","M07","M08","M09","M10","M11","M12"],long:["M01","M02","M03","M04","M05","M06","M07","M08","M09","M10","M11","M12"]},days:{narrow:["K","S","T","S","K","P","Y"],short:["Bk1","Bk2","Bk3","Bk4","Bk5","Lâp","Lây"],long:["Bikua-ôko","Bïkua-ûse","Bïkua-ptâ","Bïkua-usïö","Bïkua-okü","Lâpôsö","Lâyenga"]},dayPeriods:{am:"ND",pm:"LK"}},ethiopic:{months:{narrow:["1","2","3","4","5","6","7","8","9","10","11","12","13"],short:["Meskerem","Tekemt","Hedar","Tahsas","Ter","Yekatit","Megabit","Miazia","Genbot","Sene","Hamle","Nehasse","Pagumen"],long:["Meskerem","Tekemt","Hedar","Tahsas","Ter","Yekatit","Megabit","Miazia","Genbot","Sene","Hamle","Nehasse","Pagumen"]},days:{narrow:["K","S","T","S","K","P","Y"],short:["Bk1","Bk2","Bk3","Bk4","Bk5","Lâp","Lây"],long:["Bikua-ôko","Bïkua-ûse","Bïkua-ptâ","Bïkua-usïö","Bïkua-okü","Lâpôsö","Lâyenga"]},eras:{narrow:["ERA0","ERA1"],short:["ERA0","ERA1"],long:["ERA0","ERA1"]},dayPeriods:{am:"ND",pm:"LK"}},ethioaa:{months:{narrow:["1","2","3","4","5","6","7","8","9","10","11","12","13"],short:["Meskerem","Tekemt","Hedar","Tahsas","Ter","Yekatit","Megabit","Miazia","Genbot","Sene","Hamle","Nehasse","Pagumen"],long:["Meskerem","Tekemt","Hedar","Tahsas","Ter","Yekatit","Megabit","Miazia","Genbot","Sene","Hamle","Nehasse","Pagumen"]},days:{narrow:["K","S","T","S","K","P","Y"],short:["Bk1","Bk2","Bk3","Bk4","Bk5","Lâp","Lây"],long:["Bikua-ôko","Bïkua-ûse","Bïkua-ptâ","Bïkua-usïö","Bïkua-okü","Lâpôsö","Lâyenga"]},eras:{narrow:["ERA0"],short:["ERA0"],long:["ERA0"]},dayPeriods:{am:"ND",pm:"LK"}},generic:{months:{narrow:["1","2","3","4","5","6","7","8","9","10","11","12"],short:["M01","M02","M03","M04","M05","M06","M07","M08","M09","M10","M11","M12"],long:["M01","M02","M03","M04","M05","M06","M07","M08","M09","M10","M11","M12"]},days:{narrow:["K","S","T","S","K","P","Y"],short:["Bk1","Bk2","Bk3","Bk4","Bk5","Lâp","Lây"],long:["Bikua-ôko","Bïkua-ûse","Bïkua-ptâ","Bïkua-usïö","Bïkua-okü","Lâpôsö","Lâyenga"]},eras:{narrow:["ERA0","ERA1"],short:["ERA0","ERA1"],long:["ERA0","ERA1"]},dayPeriods:{am:"ND",pm:"LK"}},gregory:{months:{narrow:["N","F","M","N","B","F","L","K","M","N","N","K"],short:["Nye","Ful","Mbä","Ngu","Bêl","Fön","Len","Kük","Mvu","Ngb","Nab","Kak"],long:["Nyenye","Fulundïgi","Mbängü","Ngubùe","Bêläwü","Föndo","Lengua","Kükürü","Mvuka","Ngberere","Nabändüru","Kakauka"]},days:{narrow:["K","S","T","S","K","P","Y"],short:["Bk1","Bk2","Bk3","Bk4","Bk5","Lâp","Lây"],long:["Bikua-ôko","Bïkua-ûse","Bïkua-ptâ","Bïkua-usïö","Bïkua-okü","Lâpôsö","Lâyenga"]},eras:{narrow:["KnK","NpK","BCE","CE"],short:["KnK","NpK","BCE","CE"],long:["Kôzo na Krîstu","Na pekô tî Krîstu","BCE","CE"]},dayPeriods:{am:"ND",pm:"LK"}},hebrew:{months:{narrow:["1","2","3","4","5","6","7","8","9","10","11","12","13","7"],short:["Tishri","Heshvan","Kislev","Tevet","Shevat","Adar I","Adar","Nisan","Iyar","Sivan","Tamuz","Av","Elul","Adar II"],long:["Tishri","Heshvan","Kislev","Tevet","Shevat","Adar I","Adar","Nisan","Iyar","Sivan","Tamuz","Av","Elul","Adar II"]},days:{narrow:["K","S","T","S","K","P","Y"],short:["Bk1","Bk2","Bk3","Bk4","Bk5","Lâp","Lây"],long:["Bikua-ôko","Bïkua-ûse","Bïkua-ptâ","Bïkua-usïö","Bïkua-okü","Lâpôsö","Lâyenga"]},eras:{narrow:["AM"],short:["AM"],long:["AM"]},dayPeriods:{am:"ND",pm:"LK"}},indian:{months:{narrow:["1","2","3","4","5","6","7","8","9","10","11","12"],short:["Chaitra","Vaisakha","Jyaistha","Asadha","Sravana","Bhadra","Asvina","Kartika","Agrahayana","Pausa","Magha","Phalguna"],long:["Chaitra","Vaisakha","Jyaistha","Asadha","Sravana","Bhadra","Asvina","Kartika","Agrahayana","Pausa","Magha","Phalguna"]},days:{narrow:["K","S","T","S","K","P","Y"],short:["Bk1","Bk2","Bk3","Bk4","Bk5","Lâp","Lây"],long:["Bikua-ôko","Bïkua-ûse","Bïkua-ptâ","Bïkua-usïö","Bïkua-okü","Lâpôsö","Lâyenga"]},eras:{narrow:["Saka"],short:["Saka"],long:["Saka"]},dayPeriods:{am:"ND",pm:"LK"}},islamic:{months:{narrow:["1","2","3","4","5","6","7","8","9","10","11","12"],short:["Muh.","Saf.","Rab. I","Rab. II","Jum. I","Jum. II","Raj.","Sha.","Ram.","Shaw.","Dhuʻl-Q.","Dhuʻl-H."],long:["Muharram","Safar","Rabiʻ I","Rabiʻ II","Jumada I","Jumada II","Rajab","Shaʻban","Ramadan","Shawwal","Dhuʻl-Qiʻdah","Dhuʻl-Hijjah"]},days:{narrow:["K","S","T","S","K","P","Y"],short:["Bk1","Bk2","Bk3","Bk4","Bk5","Lâp","Lây"],long:["Bikua-ôko","Bïkua-ûse","Bïkua-ptâ","Bïkua-usïö","Bïkua-okü","Lâpôsö","Lâyenga"]},eras:{narrow:["AH"],short:["AH"],long:["AH"]},dayPeriods:{am:"ND",pm:"LK"}},islamicc:{months:{narrow:["1","2","3","4","5","6","7","8","9","10","11","12"],short:["Muh.","Saf.","Rab. I","Rab. II","Jum. I","Jum. II","Raj.","Sha.","Ram.","Shaw.","Dhuʻl-Q.","Dhuʻl-H."],long:["Muharram","Safar","Rabiʻ I","Rabiʻ II","Jumada I","Jumada II","Rajab","Shaʻban","Ramadan","Shawwal","Dhuʻl-Qiʻdah","Dhuʻl-Hijjah"]},days:{narrow:["K","S","T","S","K","P","Y"],short:["Bk1","Bk2","Bk3","Bk4","Bk5","Lâp","Lây"],long:["Bikua-ôko","Bïkua-ûse","Bïkua-ptâ","Bïkua-usïö","Bïkua-okü","Lâpôsö","Lâyenga"]},eras:{narrow:["AH"],short:["AH"],long:["AH"]},dayPeriods:{am:"ND",pm:"LK"}},japanese:{months:{narrow:["N","F","M","N","B","F","L","K","M","N","N","K"],short:["Nye","Ful","Mbä","Ngu","Bêl","Fön","Len","Kük","Mvu","Ngb","Nab","Kak"],long:["Nyenye","Fulundïgi","Mbängü","Ngubùe","Bêläwü","Föndo","Lengua","Kükürü","Mvuka","Ngberere","Nabändüru","Kakauka"]},days:{narrow:["K","S","T","S","K","P","Y"],short:["Bk1","Bk2","Bk3","Bk4","Bk5","Lâp","Lây"],long:["Bikua-ôko","Bïkua-ûse","Bïkua-ptâ","Bïkua-usïö","Bïkua-okü","Lâpôsö","Lâyenga"]},eras:{narrow:["Taika (645–650)","Hakuchi (650–671)","Hakuhō (672–686)","Shuchō (686–701)","Taihō (701–704)","Keiun (704–708)","Wadō (708–715)","Reiki (715–717)","Yōrō (717–724)","Jinki (724–729)","Tenpyō (729–749)","Tenpyō-kampō (749-749)","Tenpyō-shōhō (749-757)","Tenpyō-hōji (757-765)","Tenpyō-jingo (765-767)","Jingo-keiun (767-770)","Hōki (770–780)","Ten-ō (781-782)","Enryaku (782–806)","Daidō (806–810)","Kōnin (810–824)","Tenchō (824–834)","Jōwa (834–848)","Kajō (848–851)","Ninju (851–854)","Saikō (854–857)","Ten-an (857-859)","Jōgan (859–877)","Gangyō (877–885)","Ninna (885–889)","Kanpyō (889–898)","Shōtai (898–901)","Engi (901–923)","Enchō (923–931)","Jōhei (931–938)","Tengyō (938–947)","Tenryaku (947–957)","Tentoku (957–961)","Ōwa (961–964)","Kōhō (964–968)","Anna (968–970)","Tenroku (970–973)","Ten’en (973–976)","Jōgen (976–978)","Tengen (978–983)","Eikan (983–985)","Kanna (985–987)","Eien (987–989)","Eiso (989–990)","Shōryaku (990–995)","Chōtoku (995–999)","Chōhō (999–1004)","Kankō (1004–1012)","Chōwa (1012–1017)","Kannin (1017–1021)","Jian (1021–1024)","Manju (1024–1028)","Chōgen (1028–1037)","Chōryaku (1037–1040)","Chōkyū (1040–1044)","Kantoku (1044–1046)","Eishō (1046–1053)","Tengi (1053–1058)","Kōhei (1058–1065)","Jiryaku (1065–1069)","Enkyū (1069–1074)","Shōho (1074–1077)","Shōryaku (1077–1081)","Eihō (1081–1084)","Ōtoku (1084–1087)","Kanji (1087–1094)","Kahō (1094–1096)","Eichō (1096–1097)","Jōtoku (1097–1099)","Kōwa (1099–1104)","Chōji (1104–1106)","Kashō (1106–1108)","Tennin (1108–1110)","Ten-ei (1110-1113)","Eikyū (1113–1118)","Gen’ei (1118–1120)","Hōan (1120–1124)","Tenji (1124–1126)","Daiji (1126–1131)","Tenshō (1131–1132)","Chōshō (1132–1135)","Hōen (1135–1141)","Eiji (1141–1142)","Kōji (1142–1144)","Ten’yō (1144–1145)","Kyūan (1145–1151)","Ninpei (1151–1154)","Kyūju (1154–1156)","Hōgen (1156–1159)","Heiji (1159–1160)","Eiryaku (1160–1161)","Ōho (1161–1163)","Chōkan (1163–1165)","Eiman (1165–1166)","Nin’an (1166–1169)","Kaō (1169–1171)","Shōan (1171–1175)","Angen (1175–1177)","Jishō (1177–1181)","Yōwa (1181–1182)","Juei (1182–1184)","Genryaku (1184–1185)","Bunji (1185–1190)","Kenkyū (1190–1199)","Shōji (1199–1201)","Kennin (1201–1204)","Genkyū (1204–1206)","Ken’ei (1206–1207)","Jōgen (1207–1211)","Kenryaku (1211–1213)","Kenpō (1213–1219)","Jōkyū (1219–1222)","Jōō (1222–1224)","Gennin (1224–1225)","Karoku (1225–1227)","Antei (1227–1229)","Kanki (1229–1232)","Jōei (1232–1233)","Tenpuku (1233–1234)","Bunryaku (1234–1235)","Katei (1235–1238)","Ryakunin (1238–1239)","En’ō (1239–1240)","Ninji (1240–1243)","Kangen (1243–1247)","Hōji (1247–1249)","Kenchō (1249–1256)","Kōgen (1256–1257)","Shōka (1257–1259)","Shōgen (1259–1260)","Bun’ō (1260–1261)","Kōchō (1261–1264)","Bun’ei (1264–1275)","Kenji (1275–1278)","Kōan (1278–1288)","Shōō (1288–1293)","Einin (1293–1299)","Shōan (1299–1302)","Kengen (1302–1303)","Kagen (1303–1306)","Tokuji (1306–1308)","Enkyō (1308–1311)","Ōchō (1311–1312)","Shōwa (1312–1317)","Bunpō (1317–1319)","Genō (1319–1321)","Genkō (1321–1324)","Shōchū (1324–1326)","Karyaku (1326–1329)","Gentoku (1329–1331)","Genkō (1331–1334)","Kenmu (1334–1336)","Engen (1336–1340)","Kōkoku (1340–1346)","Shōhei (1346–1370)","Kentoku (1370–1372)","Bunchū (1372–1375)","Tenju (1375–1379)","Kōryaku (1379–1381)","Kōwa (1381–1384)","Genchū (1384–1392)","Meitoku (1384–1387)","Kakei (1387–1389)","Kōō (1389–1390)","Meitoku (1390–1394)","Ōei (1394–1428)","Shōchō (1428–1429)","Eikyō (1429–1441)","Kakitsu (1441–1444)","Bun’an (1444–1449)","Hōtoku (1449–1452)","Kyōtoku (1452–1455)","Kōshō (1455–1457)","Chōroku (1457–1460)","Kanshō (1460–1466)","Bunshō (1466–1467)","Ōnin (1467–1469)","Bunmei (1469–1487)","Chōkyō (1487–1489)","Entoku (1489–1492)","Meiō (1492–1501)","Bunki (1501–1504)","Eishō (1504–1521)","Taiei (1521–1528)","Kyōroku (1528–1532)","Tenbun (1532–1555)","Kōji (1555–1558)","Eiroku (1558–1570)","Genki (1570–1573)","Tenshō (1573–1592)","Bunroku (1592–1596)","Keichō (1596–1615)","Genna (1615–1624)","Kan’ei (1624–1644)","Shōho (1644–1648)","Keian (1648–1652)","Jōō (1652–1655)","Meireki (1655–1658)","Manji (1658–1661)","Kanbun (1661–1673)","Enpō (1673–1681)","Tenna (1681–1684)","Jōkyō (1684–1688)","Genroku (1688–1704)","Hōei (1704–1711)","Shōtoku (1711–1716)","Kyōhō (1716–1736)","Genbun (1736–1741)","Kanpō (1741–1744)","Enkyō (1744–1748)","Kan’en (1748–1751)","Hōreki (1751–1764)","Meiwa (1764–1772)","An’ei (1772–1781)","Tenmei (1781–1789)","Kansei (1789–1801)","Kyōwa (1801–1804)","Bunka (1804–1818)","Bunsei (1818–1830)","Tenpō (1830–1844)","Kōka (1844–1848)","Kaei (1848–1854)","Ansei (1854–1860)","Man’en (1860–1861)","Bunkyū (1861–1864)","Genji (1864–1865)","Keiō (1865–1868)","M","T","S","H"],short:["Taika (645–650)","Hakuchi (650–671)","Hakuhō (672–686)","Shuchō (686–701)","Taihō (701–704)","Keiun (704–708)","Wadō (708–715)","Reiki (715–717)","Yōrō (717–724)","Jinki (724–729)","Tenpyō (729–749)","Tenpyō-kampō (749-749)","Tenpyō-shōhō (749-757)","Tenpyō-hōji (757-765)","Tenpyō-jingo (765-767)","Jingo-keiun (767-770)","Hōki (770–780)","Ten-ō (781-782)","Enryaku (782–806)","Daidō (806–810)","Kōnin (810–824)","Tenchō (824–834)","Jōwa (834–848)","Kajō (848–851)","Ninju (851–854)","Saikō (854–857)","Ten-an (857-859)","Jōgan (859–877)","Gangyō (877–885)","Ninna (885–889)","Kanpyō (889–898)","Shōtai (898–901)","Engi (901–923)","Enchō (923–931)","Jōhei (931–938)","Tengyō (938–947)","Tenryaku (947–957)","Tentoku (957–961)","Ōwa (961–964)","Kōhō (964–968)","Anna (968–970)","Tenroku (970–973)","Ten’en (973–976)","Jōgen (976–978)","Tengen (978–983)","Eikan (983–985)","Kanna (985–987)","Eien (987–989)","Eiso (989–990)","Shōryaku (990–995)","Chōtoku (995–999)","Chōhō (999–1004)","Kankō (1004–1012)","Chōwa (1012–1017)","Kannin (1017–1021)","Jian (1021–1024)","Manju (1024–1028)","Chōgen (1028–1037)","Chōryaku (1037–1040)","Chōkyū (1040–1044)","Kantoku (1044–1046)","Eishō (1046–1053)","Tengi (1053–1058)","Kōhei (1058–1065)","Jiryaku (1065–1069)","Enkyū (1069–1074)","Shōho (1074–1077)","Shōryaku (1077–1081)","Eihō (1081–1084)","Ōtoku (1084–1087)","Kanji (1087–1094)","Kahō (1094–1096)","Eichō (1096–1097)","Jōtoku (1097–1099)","Kōwa (1099–1104)","Chōji (1104–1106)","Kashō (1106–1108)","Tennin (1108–1110)","Ten-ei (1110-1113)","Eikyū (1113–1118)","Gen’ei (1118–1120)","Hōan (1120–1124)","Tenji (1124–1126)","Daiji (1126–1131)","Tenshō (1131–1132)","Chōshō (1132–1135)","Hōen (1135–1141)","Eiji (1141–1142)","Kōji (1142–1144)","Ten’yō (1144–1145)","Kyūan (1145–1151)","Ninpei (1151–1154)","Kyūju (1154–1156)","Hōgen (1156–1159)","Heiji (1159–1160)","Eiryaku (1160–1161)","Ōho (1161–1163)","Chōkan (1163–1165)","Eiman (1165–1166)","Nin’an (1166–1169)","Kaō (1169–1171)","Shōan (1171–1175)","Angen (1175–1177)","Jishō (1177–1181)","Yōwa (1181–1182)","Juei (1182–1184)","Genryaku (1184–1185)","Bunji (1185–1190)","Kenkyū (1190–1199)","Shōji (1199–1201)","Kennin (1201–1204)","Genkyū (1204–1206)","Ken’ei (1206–1207)","Jōgen (1207–1211)","Kenryaku (1211–1213)","Kenpō (1213–1219)","Jōkyū (1219–1222)","Jōō (1222–1224)","Gennin (1224–1225)","Karoku (1225–1227)","Antei (1227–1229)","Kanki (1229–1232)","Jōei (1232–1233)","Tenpuku (1233–1234)","Bunryaku (1234–1235)","Katei (1235–1238)","Ryakunin (1238–1239)","En’ō (1239–1240)","Ninji (1240–1243)","Kangen (1243–1247)","Hōji (1247–1249)","Kenchō (1249–1256)","Kōgen (1256–1257)","Shōka (1257–1259)","Shōgen (1259–1260)","Bun’ō (1260–1261)","Kōchō (1261–1264)","Bun’ei (1264–1275)","Kenji (1275–1278)","Kōan (1278–1288)","Shōō (1288–1293)","Einin (1293–1299)","Shōan (1299–1302)","Kengen (1302–1303)","Kagen (1303–1306)","Tokuji (1306–1308)","Enkyō (1308–1311)","Ōchō (1311–1312)","Shōwa (1312–1317)","Bunpō (1317–1319)","Genō (1319–1321)","Genkō (1321–1324)","Shōchū (1324–1326)","Karyaku (1326–1329)","Gentoku (1329–1331)","Genkō (1331–1334)","Kenmu (1334–1336)","Engen (1336–1340)","Kōkoku (1340–1346)","Shōhei (1346–1370)","Kentoku (1370–1372)","Bunchū (1372–1375)","Tenju (1375–1379)","Kōryaku (1379–1381)","Kōwa (1381–1384)","Genchū (1384–1392)","Meitoku (1384–1387)","Kakei (1387–1389)","Kōō (1389–1390)","Meitoku (1390–1394)","Ōei (1394–1428)","Shōchō (1428–1429)","Eikyō (1429–1441)","Kakitsu (1441–1444)","Bun’an (1444–1449)","Hōtoku (1449–1452)","Kyōtoku (1452–1455)","Kōshō (1455–1457)","Chōroku (1457–1460)","Kanshō (1460–1466)","Bunshō (1466–1467)","Ōnin (1467–1469)","Bunmei (1469–1487)","Chōkyō (1487–1489)","Entoku (1489–1492)","Meiō (1492–1501)","Bunki (1501–1504)","Eishō (1504–1521)","Taiei (1521–1528)","Kyōroku (1528–1532)","Tenbun (1532–1555)","Kōji (1555–1558)","Eiroku (1558–1570)","Genki (1570–1573)","Tenshō (1573–1592)","Bunroku (1592–1596)","Keichō (1596–1615)","Genna (1615–1624)","Kan’ei (1624–1644)","Shōho (1644–1648)","Keian (1648–1652)","Jōō (1652–1655)","Meireki (1655–1658)","Manji (1658–1661)","Kanbun (1661–1673)","Enpō (1673–1681)","Tenna (1681–1684)","Jōkyō (1684–1688)","Genroku (1688–1704)","Hōei (1704–1711)","Shōtoku (1711–1716)","Kyōhō (1716–1736)","Genbun (1736–1741)","Kanpō (1741–1744)","Enkyō (1744–1748)","Kan’en (1748–1751)","Hōreki (1751–1764)","Meiwa (1764–1772)","An’ei (1772–1781)","Tenmei (1781–1789)","Kansei (1789–1801)","Kyōwa (1801–1804)","Bunka (1804–1818)","Bunsei (1818–1830)","Tenpō (1830–1844)","Kōka (1844–1848)","Kaei (1848–1854)","Ansei (1854–1860)","Man’en (1860–1861)","Bunkyū (1861–1864)","Genji (1864–1865)","Keiō (1865–1868)","Meiji","Taishō","Shōwa","Heisei"],long:["Taika (645–650)","Hakuchi (650–671)","Hakuhō (672–686)","Shuchō (686–701)","Taihō (701–704)","Keiun (704–708)","Wadō (708–715)","Reiki (715–717)","Yōrō (717–724)","Jinki (724–729)","Tenpyō (729–749)","Tenpyō-kampō (749-749)","Tenpyō-shōhō (749-757)","Tenpyō-hōji (757-765)","Tenpyō-jingo (765-767)","Jingo-keiun (767-770)","Hōki (770–780)","Ten-ō (781-782)","Enryaku (782–806)","Daidō (806–810)","Kōnin (810–824)","Tenchō (824–834)","Jōwa (834–848)","Kajō (848–851)","Ninju (851–854)","Saikō (854–857)","Ten-an (857-859)","Jōgan (859–877)","Gangyō (877–885)","Ninna (885–889)","Kanpyō (889–898)","Shōtai (898–901)","Engi (901–923)","Enchō (923–931)","Jōhei (931–938)","Tengyō (938–947)","Tenryaku (947–957)","Tentoku (957–961)","Ōwa (961–964)","Kōhō (964–968)","Anna (968–970)","Tenroku (970–973)","Ten’en (973–976)","Jōgen (976–978)","Tengen (978–983)","Eikan (983–985)","Kanna (985–987)","Eien (987–989)","Eiso (989–990)","Shōryaku (990–995)","Chōtoku (995–999)","Chōhō (999–1004)","Kankō (1004–1012)","Chōwa (1012–1017)","Kannin (1017–1021)","Jian (1021–1024)","Manju (1024–1028)","Chōgen (1028–1037)","Chōryaku (1037–1040)","Chōkyū (1040–1044)","Kantoku (1044–1046)","Eishō (1046–1053)","Tengi (1053–1058)","Kōhei (1058–1065)","Jiryaku (1065–1069)","Enkyū (1069–1074)","Shōho (1074–1077)","Shōryaku (1077–1081)","Eihō (1081–1084)","Ōtoku (1084–1087)","Kanji (1087–1094)","Kahō (1094–1096)","Eichō (1096–1097)","Jōtoku (1097–1099)","Kōwa (1099–1104)","Chōji (1104–1106)","Kashō (1106–1108)","Tennin (1108–1110)","Ten-ei (1110-1113)","Eikyū (1113–1118)","Gen’ei (1118–1120)","Hōan (1120–1124)","Tenji (1124–1126)","Daiji (1126–1131)","Tenshō (1131–1132)","Chōshō (1132–1135)","Hōen (1135–1141)","Eiji (1141–1142)","Kōji (1142–1144)","Ten’yō (1144–1145)","Kyūan (1145–1151)","Ninpei (1151–1154)","Kyūju (1154–1156)","Hōgen (1156–1159)","Heiji (1159–1160)","Eiryaku (1160–1161)","Ōho (1161–1163)","Chōkan (1163–1165)","Eiman (1165–1166)","Nin’an (1166–1169)","Kaō (1169–1171)","Shōan (1171–1175)","Angen (1175–1177)","Jishō (1177–1181)","Yōwa (1181–1182)","Juei (1182–1184)","Genryaku (1184–1185)","Bunji (1185–1190)","Kenkyū (1190–1199)","Shōji (1199–1201)","Kennin (1201–1204)","Genkyū (1204–1206)","Ken’ei (1206–1207)","Jōgen (1207–1211)","Kenryaku (1211–1213)","Kenpō (1213–1219)","Jōkyū (1219–1222)","Jōō (1222–1224)","Gennin (1224–1225)","Karoku (1225–1227)","Antei (1227–1229)","Kanki (1229–1232)","Jōei (1232–1233)","Tenpuku (1233–1234)","Bunryaku (1234–1235)","Katei (1235–1238)","Ryakunin (1238–1239)","En’ō (1239–1240)","Ninji (1240–1243)","Kangen (1243–1247)","Hōji (1247–1249)","Kenchō (1249–1256)","Kōgen (1256–1257)","Shōka (1257–1259)","Shōgen (1259–1260)","Bun’ō (1260–1261)","Kōchō (1261–1264)","Bun’ei (1264–1275)","Kenji (1275–1278)","Kōan (1278–1288)","Shōō (1288–1293)","Einin (1293–1299)","Shōan (1299–1302)","Kengen (1302–1303)","Kagen (1303–1306)","Tokuji (1306–1308)","Enkyō (1308–1311)","Ōchō (1311–1312)","Shōwa (1312–1317)","Bunpō (1317–1319)","Genō (1319–1321)","Genkō (1321–1324)","Shōchū (1324–1326)","Karyaku (1326–1329)","Gentoku (1329–1331)","Genkō (1331–1334)","Kenmu (1334–1336)","Engen (1336–1340)","Kōkoku (1340–1346)","Shōhei (1346–1370)","Kentoku (1370–1372)","Bunchū (1372–1375)","Tenju (1375–1379)","Kōryaku (1379–1381)","Kōwa (1381–1384)","Genchū (1384–1392)","Meitoku (1384–1387)","Kakei (1387–1389)","Kōō (1389–1390)","Meitoku (1390–1394)","Ōei (1394–1428)","Shōchō (1428–1429)","Eikyō (1429–1441)","Kakitsu (1441–1444)","Bun’an (1444–1449)","Hōtoku (1449–1452)","Kyōtoku (1452–1455)","Kōshō (1455–1457)","Chōroku (1457–1460)","Kanshō (1460–1466)","Bunshō (1466–1467)","Ōnin (1467–1469)","Bunmei (1469–1487)","Chōkyō (1487–1489)","Entoku (1489–1492)","Meiō (1492–1501)","Bunki (1501–1504)","Eishō (1504–1521)","Taiei (1521–1528)","Kyōroku (1528–1532)","Tenbun (1532–1555)","Kōji (1555–1558)","Eiroku (1558–1570)","Genki (1570–1573)","Tenshō (1573–1592)","Bunroku (1592–1596)","Keichō (1596–1615)","Genna (1615–1624)","Kan’ei (1624–1644)","Shōho (1644–1648)","Keian (1648–1652)","Jōō (1652–1655)","Meireki (1655–1658)","Manji (1658–1661)","Kanbun (1661–1673)","Enpō (1673–1681)","Tenna (1681–1684)","Jōkyō (1684–1688)","Genroku (1688–1704)","Hōei (1704–1711)","Shōtoku (1711–1716)","Kyōhō (1716–1736)","Genbun (1736–1741)","Kanpō (1741–1744)","Enkyō (1744–1748)","Kan’en (1748–1751)","Hōreki (1751–1764)","Meiwa (1764–1772)","An’ei (1772–1781)","Tenmei (1781–1789)","Kansei (1789–1801)","Kyōwa (1801–1804)","Bunka (1804–1818)","Bunsei (1818–1830)","Tenpō (1830–1844)","Kōka (1844–1848)","Kaei (1848–1854)","Ansei (1854–1860)","Man’en (1860–1861)","Bunkyū (1861–1864)","Genji (1864–1865)","Keiō (1865–1868)","Meiji","Taishō","Shōwa","Heisei"]},dayPeriods:{am:"ND",pm:"LK"}},persian:{months:{narrow:["1","2","3","4","5","6","7","8","9","10","11","12"],short:["Farvardin","Ordibehesht","Khordad","Tir","Mordad","Shahrivar","Mehr","Aban","Azar","Dey","Bahman","Esfand"],long:["Farvardin","Ordibehesht","Khordad","Tir","Mordad","Shahrivar","Mehr","Aban","Azar","Dey","Bahman","Esfand"]},days:{narrow:["K","S","T","S","K","P","Y"],short:["Bk1","Bk2","Bk3","Bk4","Bk5","Lâp","Lây"],long:["Bikua-ôko","Bïkua-ûse","Bïkua-ptâ","Bïkua-usïö","Bïkua-okü","Lâpôsö","Lâyenga"]},eras:{narrow:["AP"],short:["AP"],long:["AP"]},dayPeriods:{am:"ND",pm:"LK"}},roc:{months:{narrow:["N","F","M","N","B","F","L","K","M","N","N","K"],short:["Nye","Ful","Mbä","Ngu","Bêl","Fön","Len","Kük","Mvu","Ngb","Nab","Kak"],long:["Nyenye","Fulundïgi","Mbängü","Ngubùe","Bêläwü","Föndo","Lengua","Kükürü","Mvuka","Ngberere","Nabändüru","Kakauka"]},days:{narrow:["K","S","T","S","K","P","Y"],short:["Bk1","Bk2","Bk3","Bk4","Bk5","Lâp","Lây"],long:["Bikua-ôko","Bïkua-ûse","Bïkua-ptâ","Bïkua-usïö","Bïkua-okü","Lâpôsö","Lâyenga"]},eras:{narrow:["Before R.O.C.","R.O.C."],short:["Before R.O.C.","R.O.C."],long:["Before R.O.C.","R.O.C."]},dayPeriods:{am:"ND",pm:"LK"}}}},number:{nu:["latn"],patterns:{decimal:{positivePattern:"{number}",negativePattern:"{minusSign}{number}"},currency:{positivePattern:"{currency}{number}",negativePattern:"{currency}{minusSign}{number}"},percent:{positivePattern:"{number}{percentSign}",negativePattern:"{minusSign}{number}{percentSign}"}},symbols:{latn:{decimal:",",group:".",nan:"NaN",plusSign:"+",minusSign:"-",percentSign:"%",infinity:"∞"}},currencies:{AUD:"A$",BRL:"R$",CAD:"CA$",CNY:"CN¥",EUR:"€",GBP:"£",HKD:"HK$",ILS:"₪",INR:"₹",JPY:"JP¥",KRW:"₩",MXN:"MX$",NZD:"NZ$",TWD:"NT$",USD:"US$",VND:"₫",XAF:"FCFA",XCD:"EC$",XOF:"CFA",XPF:"CFPF"}}}); | PypiClean |
/ml_things-0.0.1.tar.gz/ml_things-0.0.1/notebooks/old_notebooks/label_encoding.ipynb | [View in Colaboratory](https://colab.research.google.com/github/gmihaila/machine_learning_toolbox/blob/master/label_encoding.ipynb)
## Data label encoding
```
from sklearn.preprocessing import LabelEncoder
from sklearn.pipeline import Pipeline
class MultiColumnLabelEncoder:
def __init__(self,columns = None):
self.columns = columns # array of column names to encode
def fit(self,X,y=None):
return self # not relevant here
def transform(self,X):
'''
Transforms columns of X specified in self.columns using
LabelEncoder(). If no columns specified, transforms all
columns in X.
'''
output = X.copy()
if self.columns is not None:
for col in self.columns:
output[col] = LabelEncoder().fit_transform(output[col])
else:
for colname,col in output.iteritems():
output[colname] = LabelEncoder().fit_transform(col)
return output
def fit_transform(self,X,y=None):
return self.fit(X,y).transform(X)
from IPython.display import clear_output
print("Downloading toy data")
!wget https://www.openml.org/data/get_csv/1751/BayesianNetworkGenerator_breast-cancer_small.csv
clear_output()
!ls
import pandas as pd
# Parse data
path_file = 'BayesianNetworkGenerator_breast-cancer_small.csv'
df = pd.read_csv(path_file)
# get columns
columns = list(df.columns)
# show sample
df.head()
# perform label encoding
df_enc = MultiColumnLabelEncoder(columns = columns).fit_transform(df)
# show sample
df_enc.head()
```
| PypiClean |
/flywheel_gear_cli-0.1.0a7-py3-none-any.whl/flywheel_gear_cli/gear/gear_run.py | import argparse
import json
import logging
import os
import pty
import shutil
import subprocess
import sys
from pathlib import Path
from flywheel_gear_toolkit.utils.config import Config, ConfigValidationError
from ..utils import adjust_run_sh, get_docker_command, validate_manifest
log = logging.getLogger(__name__)
def add_command(subparsers, parents):
"""Add run module."""
parser = subparsers.add_parser(
"run",
parents=parents,
help="Mimic a flywheel gear run locally.",
formatter_class=argparse.RawDescriptionHelpFormatter,
description="""
Flywheel gears run with the following directory structure.
/flywheel/v0
├── config.json
├── manifest.json
├── input
│ ├── ...
│ └── input1.nii.gz
├── output
└── work
Therefore to mimic a flywheel gear structure, this should be present
locally and mounted into the container that runs the gear.
If this structure is already present, either built manually, or from
`fw job pull`, youi can run `fw gear run` directly from this directory.
If this structure is NOT already present, `fw gear run` will prepare
this structure in a target directory if you specify the
`--target <dir>` flag.
""",
)
parser.add_argument(
"dir",
nargs="?",
help="""
Location of the gear directory (optional, default=$PWD)
Directory must contain at minimum manifest to determine
docker image to use. Must also contain a config.json if
the --target flag is specified.
""",
)
parser.add_argument(
"--target",
help=(
"Location where to prepare gear run directory (optional,"
"default=/tmp/gear/<gear_name>_<gear_version>)"
),
)
parser.add_argument(
"--no-rm",
action="store_true",
help="Don't remove container after run has finished",
)
parser.add_argument(
"--interactive",
action="store_true",
help="Run interactively",
)
parser.add_argument(
"--mount-cwd",
action="store_true",
help="Mount entire Current Working Directory",
)
parser.add_argument("-e", "--entrypoint", help="Override container entrypoint")
parser.add_argument(
"-v",
"--volumes",
nargs="*",
help="""
List of volumes to attach in docker format, i.e.
-v "~/config:/flywheel/v0/input" "~/output:/flywheel/v0/output"
""",
)
parser.set_defaults(func=gear_run)
parser.set_defaults(parser=parser)
return parser
def gear_run(args):
"""Main gear run entrypoint."""
# https://stackoverflow.com/questions/41542960/run-interactive-bash-with-popen-and-a-dedicated-tty-python
# ^ need this for interactivity
target = getattr(args, "target", None)
assets = getattr(args, "dir", None) or Path.cwd()
volumes = getattr(args, "volumes", None) or []
asset_dir = Path(assets).resolve()
if target:
log.info("Creating directories")
try:
image, target_dir = setup(
getattr(args, "dir", Path.cwd()),
target=getattr(args, "target", None),
)
except ValueError:
log.error("Setup failed.")
return 1
cmdline = get_docker_command(
target_dir,
volumes=[vol.split(":") for vol in volumes],
mount_cwd=args.mount_cwd,
no_rm=args.no_rm,
interactive=args.interactive,
entrypoint=getattr(args, "entrypoint", None),
)
run_script = target_dir / "run.sh"
log.info("Writing run.sh script")
with open(run_script, "w") as fp:
fp.write("#! /bin/bash \n\n")
fp.write(f"IMAGE={image}\n\n")
fp.write("# Command:\n")
fp.write(cmdline)
fp.write("\n")
log.info(cmdline)
asset_dir = target_dir
if not (asset_dir.exists() and asset_dir.is_dir()):
log.error(f"Cannot find asset directory {asset_dir.resolve()}")
return 1
run_script = asset_dir / "run.sh"
if not run_script.exists():
log.error(
"Could not find run.sh script. "
f"Is this the right directory? ({asset_dir})"
)
return 1
log.info("Running run.sh from assets directory...")
if not target:
# Don't need to do this if target was passed
adjust_run_sh(
run_script,
volumes=[vol.split(":") for vol in volumes],
mount_cwd=args.mount_cwd,
no_rm=args.no_rm,
interactive=args.interactive,
entrypoint=getattr(args, "entrypoint", None),
)
os.chmod(str(run_script), 0o0755)
if args.interactive:
# handle_interactive_run(run_script)
pty.spawn([str(run_script)])
else:
try:
subprocess.check_output([str(run_script)])
except subprocess.CalledProcessError as e:
return e.returncode
return 0
# def handle_interactive_run(run_script): # pragma: no cover
# # https://stackoverflow.com/a/43012138
#
# # save original tty setting then set it to raw mode
# old_tty = termios.tcgetattr(sys.stdin)
# tty.setraw(sys.stdin.fileno())
#
# # open pseudo-terminal to interact with subprocess
# primary_fd, secondary_fd = pty.openpty()
# try:
# # Open a process with in/out/error going to secondary_fd
# p = subprocess.Popen(
# [str(run_script)],
# stdin=secondary_fd,
# stdout=secondary_fd,
# stderr=secondary_fd,
# universal_newlines=True,
# )
#
# while p.poll() is None:
# # Wait until either stdin or primary_fd are available for reading.
# readable, _, _ = select.select([sys.stdin, primary_fd], [], [])
# if sys.stdin in readable:
# # Write from stdin to pty
# d = os.read(sys.stdin.fileno(), 10240)
# os.write(primary_fd, d)
# elif primary_fd in readable:
# # Write from pty to stdout
# o = os.read(primary_fd, 10240)
# if o:
# os.write(sys.stdout.fileno(), o)
# finally:
# # restore tty settings back
# termios.tcsetattr(sys.stdin, termios.TCSADRAIN, old_tty)
def setup(wdir, target=None): # pylint: disable=too-many-locals
"""Perform setup actions."""
log.debug("Setting up")
workdir = Path(wdir).resolve()
############# Config validation
config = _validate_config(workdir)
############# Manifest validation
manifest = validate_manifest(workdir / "manifest.json")
# Populate directory structure
if not target:
target_dir = Path(f"/tmp/gear/{manifest.name}_{manifest.version}")
else:
target_dir = Path(target)
target_dir.mkdir(parents=True, exist_ok=True)
for path in ["input", "output", "work"]:
new_dir = target_dir / path
new_dir.mkdir(exist_ok=True)
input_map = {}
input_map_f = Path("~/.cache/flywheel/input_map.json").expanduser()
try:
with open(input_map_f, "r") as fp:
input_map = json.load(fp)
except FileNotFoundError:
pass
for key, val in manifest.inputs.items():
if val["base"] == "file" and key in config.inputs:
input_item = target_dir / f"input/{key}"
input_item.mkdir(exist_ok=True)
conf_val = config.inputs[key]
docker_input = Path(conf_val["location"]["path"])
if str(docker_input) in input_map.keys():
local_path = input_map[str(docker_input)]
target = target_dir / f"input/{key}/{docker_input.name}"
log.info(
f"Found file input with local path: {local_path}, "
f"copying to target: {target}"
)
try:
shutil.copy(str(local_path), str(target))
except: # pylint: disable=bare-except
log.error(
"Couldn't copy input "
f"{local_path}"
" please ensure it exists."
)
else:
log.warning(
"Local path for input {key} not found. "
"Try adding with `fw gear config --{key} <path>"
)
try:
shutil.copy(str(workdir / "config.json"), str(target_dir / "config.json"))
shutil.copy(str(workdir / "manifest.json"), str(target_dir / "manifest.json"))
except shutil.SameFileError:
pass
return manifest.get_docker_image_name_tag(), target_dir
def _validate_config(workdir):
"""Validate config.json, return config object if successful fail otherwise.
Args:
workdir (str): dir argument from argparser
Returns:
Config: config object from flywheel_gear_toolkit.utils.config
"""
config_path = Path(workdir) / "config.json"
if not config_path.is_file():
log.error(
"""
A config must be present to run a gear
If you want to create a config for your gear, please run
`fw gear config`
"""
)
sys.exit(1)
try:
conf = Config(path=config_path)
except ConfigValidationError as err:
log.error(err)
sys.exit(1)
return conf | PypiClean |
/upload_machine-0.0.89.tar.gz/upload_machine-0.0.89/upload_machine/utils/uploader/zmpt_upload.py | from loguru import logger
import time
import os
from upload_machine.utils.uploader.upload_tools import *
import re
import cloudscraper
def zmpt_upload(siteinfo,file1,record_path,qbinfo,basic,hashlist):
post_url = "https://zmpt.cc/takeupload.php"
tags=[]
time_out=40
if (file1.pathinfo.type=='anime' or file1.pathinfo.type=='tv') and file1.pathinfo.collection==0:
fileinfo=file1.chinesename+'在'+siteinfo.sitename+'第'+file1.episodename+'集'
else:
fileinfo=file1.chinesename+'在'+siteinfo.sitename
#选择类型
select_type='418'
processing_sel='0'
if 'anime' in file1.pathinfo.type.lower():
if not file1.country=='':
if '大陆' in file1.country:
select_type='417'
logger.info('国家信息已选择'+file1.country)
elif '香港' in file1.country:
select_type='417'
logger.info('国家信息已选择'+file1.country)
elif '台湾' in file1.country:
select_type='417'
logger.info('国家信息已选择'+file1.country)
elif '美国' in file1.country:
select_type='420'
logger.info('国家信息已选择'+file1.country)
elif '英国' in file1.country:
select_type='420'
logger.info('国家信息已选择'+file1.country)
elif '法国' in file1.country:
select_type='420'
logger.info('国家信息已选择'+file1.country)
elif '韩国' in file1.country:
select_type='419'
logger.info('国家信息已选择'+file1.country)
elif '日本' in file1.country:
select_type='418'
logger.info('国家信息已选择'+file1.country)
elif '印度' in file1.country:
select_type='421'
logger.info('国家信息已选择'+file1.country)
else:
select_type='421'
logger.info('未找到资源国家信息,已选择其他')
else:
select_type='418'
processing_sel='4'
if 'movie' in file1.pathinfo.type.lower():
processing_sel='3'
elif 'tv' in file1.pathinfo.type.lower():
select_type='411'
elif 'movie' in file1.pathinfo.type.lower():
select_type='410'
elif 'doc' in file1.pathinfo.type.lower():
select_type='416'
elif 'show' in file1.pathinfo.type.lower():
select_type='412'
elif 'mv' in file1.pathinfo.type.lower():
select_type='414'
elif 'sport' in file1.pathinfo.type.lower():
select_type='416'
elif 'music' in file1.pathinfo.type.lower():
select_type='415'
else:
select_type='416'
logger.info('已成功填写类型为'+file1.pathinfo.type)
#选择媒介
if file1.type=='WEB-DL':
medium_sel='10'
elif 'rip' in file1.type.lower() and 'dvd' in file1.type.lower():
medium_sel='6'
elif 'rip' in file1.type.lower():
medium_sel='7'
elif file1.type=='HDTV':
medium_sel='5'
elif file1.type=='Remux':
medium_sel='3'
elif file1.type=='bluray':
medium_sel='1'
else:
medium_sel='10'
logger.info('已成功填写媒介为'+file1.type)
#选择编码
if file1.Video_Format=='H264':
codec_sel='1'
elif file1.Video_Format=='x264':
codec_sel='1'
elif file1.Video_Format=='H265':
codec_sel='6'
elif file1.Video_Format=='x265':
codec_sel='6'
else:
codec_sel='1'
logger.info('已成功选择编码为'+file1.Video_Format)
#选择音频编码
if file1.Audio_Format.upper()=='AAC':
audiocodec_sel='6'
elif 'DTS-HDMA' in file1.Audio_Format.upper() or 'DTS-HD MA' in file1.Audio_Format.upper():
audiocodec_sel='3'
elif 'TRUEHD ATMOS' in file1.Audio_Format.upper():
audiocodec_sel='7'
elif 'LPCM' in file1.Audio_Format.upper():
audiocodec_sel='7'
elif 'TRUEHD' in file1.Audio_Format.upper():
audiocodec_sel='7'
elif 'FLAC' in file1.Audio_Format.upper():
audiocodec_sel='1'
elif 'APE' in file1.Audio_Format.upper():
audiocodec_sel='2'
elif 'MP3' in file1.Audio_Format.upper():
audiocodec_sel='4'
elif 'OGG' in file1.Audio_Format.upper():
audiocodec_sel='5'
elif 'AC3' in file1.Audio_Format.upper() or 'DD' in file1.Audio_Format.upper():
audiocodec_sel='8'
elif 'DTS:X' in file1.Audio_Format.upper() or 'DTS-X' in file1.Audio_Format.upper():
audiocodec_sel='3'
elif 'DTS' in file1.Audio_Format.upper():
audiocodec_sel='3'
elif 'WAV' in file1.Audio_Format.upper():
audiocodec_sel='7'
elif 'M4A' in file1.Audio_Format.upper():
audiocodec_sel='7'
else:
audiocodec_sel='6'
logger.info('已成功选择音频编码为'+file1.Audio_Format.upper())
#选择分辨率
if '8K' in file1.standard_sel:
standard_sel='5'
elif '2160' in file1.standard_sel:
standard_sel='5'
elif '1080p' in file1.standard_sel.lower():
standard_sel='1'
elif '1080i' in file1.standard_sel.lower():
standard_sel='2'
elif '720' in file1.standard_sel:
standard_sel='3'
elif '480' in file1.standard_sel:
standard_sel='4'
else:
standard_sel='1'
logger.info('已成功选择分辨率为'+file1.standard_sel)
#选择制作组
if 'ZmPT' in file1.sub.upper():
team_sel='6'
elif 'ZmWeb' in file1.sub.upper():
team_sel='7'
else:
team_sel='5'
logger.info('制作组已成功选择为'+file1.sub)
if 'zmpt' in file1.pathinfo.exclusive :
tags.append(1)
if 'ZMPT' in file1.sub.upper() or 'ZMWEB' in file1.sub.upper():
tags.append(3)
if '国' in file1.language or '中' in file1.language:
tags.append(5)
if not file1.sublan=='' and ('简' in file1.sublan or '繁' in file1.sublan or '中' in file1.sublan):
tags.append(6)
if siteinfo.uplver==1:
uplver='yes'
else:
uplver='no'
torrent_file = file1.torrentpath
file_tup = ("file", (os.path.basename(torrent_file), open(torrent_file, 'rb'), 'application/x-bittorrent')),
other_data = {
"name": file1.uploadname,
"small_descr": file1.small_descr+file1.pathinfo.exinfo,
"pt_gen": file1.doubanurl,
"nfo": "",
"color": "0",
"font": "0",
"size": "0",
"descr": file1.pathinfo.contenthead+'\n'+file1.douban_info+'\n'+file1.screenshoturl+'\n'+file1.pathinfo.contenttail,
"technical_info": file1.mediainfo,
"type": select_type,
"processing_sel": processing_sel,
"medium_sel": medium_sel,
"codec_sel": codec_sel,
"audiocodec_sel": audiocodec_sel,
"standard_sel": standard_sel,
"team_sel": team_sel,
"uplver": uplver,
"tags[]": tags,
}
scraper=cloudscraper.create_scraper()
success_upload=0
try_upload=0
while success_upload==0:
try_upload+=1
if try_upload>5:
return False,fileinfo+' 发布种子发生请求错误,请确认站点是否正常运行'
logger.info('正在发布种子')
try:
r = scraper.post(post_url, cookies=cookies_raw2jar(siteinfo.cookie),data=other_data, files=file_tup,timeout=time_out)
success_upload=1
except Exception as r:
logger.warning('发布种子发生错误: %s' %(r))
success_upload=0
return afterupload(r,fileinfo,record_path,siteinfo,file1,qbinfo,hashlist) | PypiClean |
/telepot_mod-0.0.1-py3-none-any.whl/telepot_mod/namedtuple.py | import collections
import warnings
import sys
class _Field(object):
def __init__(self, name, constructor=None, default=None):
self.name = name
self.constructor = constructor
self.default = default
# Function to produce namedtuple classes.
def _create_class(typename, fields):
# extract field names
field_names = [e.name if type(e) is _Field else e for e in fields]
# Some dictionary keys are Python keywords and cannot be used as field names, e.g. `from`.
# Get around by appending a '_', e.g. dict['from'] => namedtuple.from_
keymap = [(k.rstrip('_'), k) for k in filter(lambda e: e in ['from_'], field_names)]
# extract (non-simple) fields that need conversions
conversions = [(e.name, e.constructor) for e in fields if type(e) is _Field and e.constructor is not None]
# extract default values
defaults = [e.default if type(e) is _Field else None for e in fields]
# Create the base tuple class, with defaults.
base = collections.namedtuple(typename, field_names)
base.__new__.__defaults__ = tuple(defaults)
class sub(base):
def __new__(cls, **kwargs):
# Map keys.
for oldkey, newkey in keymap:
if oldkey in kwargs:
kwargs[newkey] = kwargs[oldkey]
del kwargs[oldkey]
# Any unexpected arguments?
unexpected = set(kwargs.keys()) - set(super(sub, cls)._fields)
# Remove unexpected arguments and issue warning.
if unexpected:
for k in unexpected:
del kwargs[k]
s = ('Unexpected fields: ' + ', '.join(unexpected) + ''
'\nBot API seems to have added new fields to the returned data.'
' This version of namedtuple is not able to capture them.'
'\n\nPlease upgrade telepot by:'
'\n sudo pip install telepot --upgrade'
'\n\nIf you still see this message after upgrade, that means I am still working to bring the code up-to-date.'
' Please try upgrade again a few days later.'
' In the meantime, you can access the new fields the old-fashioned way, through the raw dictionary.')
warnings.warn(s, UserWarning)
# Convert non-simple values to namedtuples.
for key, func in conversions:
if key in kwargs:
if type(kwargs[key]) is dict:
kwargs[key] = func(**kwargs[key])
elif type(kwargs[key]) is list:
kwargs[key] = func(kwargs[key])
else:
raise RuntimeError('Can only convert dict or list')
return super(sub, cls).__new__(cls, **kwargs)
# https://bugs.python.org/issue24931
# Python 3.4 bug: namedtuple subclass does not inherit __dict__ properly.
# Fix it manually.
if sys.version_info >= (3,4):
def _asdict(self):
return collections.OrderedDict(zip(self._fields, self))
sub._asdict = _asdict
sub.__name__ = typename
return sub
"""
Different treatments for incoming and outgoing namedtuples:
- Incoming ones require type declarations for certain fields for deeper parsing.
- Outgoing ones need no such declarations because users are expected to put the correct object in place.
"""
# Namedtuple class will reference other namedtuple classes. Due to circular
# dependencies, it is impossible to have all class definitions ready at
# compile time. We have to dynamically obtain class reference at runtime.
# For example, the following function acts like a constructor for `Message`
# so any class can reference the Message namedtuple even before the Message
# namedtuple is defined.
def _Message(**kwargs):
return getattr(sys.modules[__name__], 'Message')(**kwargs)
# incoming
User = _create_class('User', [
'id',
'is_bot',
'first_name',
'last_name',
'username',
'language_code'
])
def UserArray(data):
return [User(**p) for p in data]
# incoming
ChatPhoto = _create_class('ChatPhoto', [
'small_file_id',
'big_file_id',
])
# incoming
Chat = _create_class('Chat', [
'id',
'type',
'title',
'username',
'first_name',
'last_name',
'all_members_are_administrators',
_Field('photo', constructor=ChatPhoto),
'description',
'invite_link',
_Field('pinned_message', constructor=_Message),
'sticker_set_name',
'can_set_sticker_set',
])
# incoming
PhotoSize = _create_class('PhotoSize', [
'file_id',
'width',
'height',
'file_size',
'file_path', # undocumented
])
# incoming
Audio = _create_class('Audio', [
'file_id',
'duration',
'performer',
'title',
'mime_type',
'file_size'
])
# incoming
Document = _create_class('Document', [
'file_id',
_Field('thumb', constructor=PhotoSize),
'file_name',
'mime_type',
'file_size',
'file_path', # undocumented
])
# incoming and outgoing
MaskPosition = _create_class('MaskPosition', [
'point',
'x_shift',
'y_shift',
'scale',
])
# incoming
Sticker = _create_class('Sticker', [
'file_id',
'width',
'height',
_Field('thumb', constructor=PhotoSize),
'emoji',
'set_name',
_Field('mask_position', constructor=MaskPosition),
'file_size',
])
def StickerArray(data):
return [Sticker(**p) for p in data]
# incoming
StickerSet = _create_class('StickerSet', [
'name',
'title',
'contains_masks',
_Field('stickers', constructor=StickerArray),
])
# incoming
Video = _create_class('Video', [
'file_id',
'width',
'height',
'duration',
_Field('thumb', constructor=PhotoSize),
'mime_type',
'file_size',
'file_path', # undocumented
])
# incoming
Voice = _create_class('Voice', [
'file_id',
'duration',
'mime_type',
'file_size'
])
# incoming
VideoNote = _create_class('VideoNote', [
'file_id',
'length',
'duration',
_Field('thumb', constructor=PhotoSize),
'file_size'
])
# incoming
Contact = _create_class('Contact', [
'phone_number',
'first_name',
'last_name',
'user_id'
])
# incoming
Location = _create_class('Location', [
'longitude',
'latitude'
])
# incoming
Venue = _create_class('Venue', [
_Field('location', constructor=Location),
'title',
'address',
'foursquare_id',
])
# incoming
File = _create_class('File', [
'file_id',
'file_size',
'file_path'
])
def PhotoSizeArray(data):
return [PhotoSize(**p) for p in data]
def PhotoSizeArrayArray(data):
return [[PhotoSize(**p) for p in array] for array in data]
# incoming
UserProfilePhotos = _create_class('UserProfilePhotos', [
'total_count',
_Field('photos', constructor=PhotoSizeArrayArray)
])
# incoming
ChatMember = _create_class('ChatMember', [
_Field('user', constructor=User),
'status',
'until_date',
'can_be_edited',
'can_change_info',
'can_post_messages',
'can_edit_messages',
'can_delete_messages',
'can_invite_users',
'can_restrict_members',
'can_pin_messages',
'can_promote_members',
'can_send_messages',
'can_send_media_messages',
'can_send_other_messages',
'can_add_web_page_previews',
])
def ChatMemberArray(data):
return [ChatMember(**p) for p in data]
# outgoing
ReplyKeyboardMarkup = _create_class('ReplyKeyboardMarkup', [
'keyboard',
'resize_keyboard',
'one_time_keyboard',
'selective',
])
# outgoing
KeyboardButton = _create_class('KeyboardButton', [
'text',
'request_contact',
'request_location',
])
# outgoing
ReplyKeyboardRemove = _create_class('ReplyKeyboardRemove', [
_Field('remove_keyboard', default=True),
'selective',
])
# outgoing
ForceReply = _create_class('ForceReply', [
_Field('force_reply', default=True),
'selective',
])
# outgoing
InlineKeyboardButton = _create_class('InlineKeyboardButton', [
'text',
'url',
'callback_data',
'switch_inline_query',
'switch_inline_query_current_chat',
'callback_game',
'pay',
])
# outgoing
InlineKeyboardMarkup = _create_class('InlineKeyboardMarkup', [
'inline_keyboard',
])
# incoming
MessageEntity = _create_class('MessageEntity', [
'type',
'offset',
'length',
'url',
_Field('user', constructor=User),
])
# incoming
def MessageEntityArray(data):
return [MessageEntity(**p) for p in data]
# incoming
GameHighScore = _create_class('GameHighScore', [
'position',
_Field('user', constructor=User),
'score',
])
# incoming
Animation = _create_class('Animation', [
'file_id',
_Field('thumb', constructor=PhotoSize),
'file_name',
'mime_type',
'file_size',
])
# incoming
Game = _create_class('Game', [
'title',
'description',
_Field('photo', constructor=PhotoSizeArray),
'text',
_Field('text_entities', constructor=MessageEntityArray),
_Field('animation', constructor=Animation),
])
# incoming
Invoice = _create_class('Invoice', [
'title',
'description',
'start_parameter',
'currency',
'total_amount',
])
# outgoing
LabeledPrice = _create_class('LabeledPrice', [
'label',
'amount',
])
# outgoing
ShippingOption = _create_class('ShippingOption', [
'id',
'title',
'prices',
])
# incoming
ShippingAddress = _create_class('ShippingAddress', [
'country_code',
'state',
'city',
'street_line1',
'street_line2',
'post_code',
])
# incoming
OrderInfo = _create_class('OrderInfo', [
'name',
'phone_number',
'email',
_Field('shipping_address', constructor=ShippingAddress),
])
# incoming
ShippingQuery = _create_class('ShippingQuery', [
'id',
_Field('from_', constructor=User),
'invoice_payload',
_Field('shipping_address', constructor=ShippingAddress),
])
# incoming
PreCheckoutQuery = _create_class('PreCheckoutQuery', [
'id',
_Field('from_', constructor=User),
'currency',
'total_amount',
'invoice_payload',
'shipping_option_id',
_Field('order_info', constructor=OrderInfo),
])
# incoming
SuccessfulPayment = _create_class('SuccessfulPayment', [
'currency',
'total_amount',
'invoice_payload',
'shipping_option_id',
_Field('order_info', constructor=OrderInfo),
'telegram_payment_charge_id',
'provider_payment_charge_id',
])
# incoming
Message = _create_class('Message', [
'message_id',
_Field('from_', constructor=User),
'date',
_Field('chat', constructor=Chat),
_Field('forward_from', constructor=User),
_Field('forward_from_chat', constructor=Chat),
'forward_from_message_id',
'forward_signature',
'forward_date',
_Field('reply_to_message', constructor=_Message),
'edit_date',
'author_signature',
'text',
_Field('entities', constructor=MessageEntityArray),
_Field('caption_entities', constructor=MessageEntityArray),
_Field('audio', constructor=Audio),
_Field('document', constructor=Document),
_Field('game', constructor=Game),
_Field('photo', constructor=PhotoSizeArray),
_Field('sticker', constructor=Sticker),
_Field('video', constructor=Video),
_Field('voice', constructor=Voice),
_Field('video_note', constructor=VideoNote),
_Field('new_chat_members', constructor=UserArray),
'caption',
_Field('contact', constructor=Contact),
_Field('location', constructor=Location),
_Field('venue', constructor=Venue),
_Field('new_chat_member', constructor=User),
_Field('left_chat_member', constructor=User),
'new_chat_title',
_Field('new_chat_photo', constructor=PhotoSizeArray),
'delete_chat_photo',
'group_chat_created',
'supergroup_chat_created',
'channel_chat_created',
'migrate_to_chat_id',
'migrate_from_chat_id',
_Field('pinned_message', constructor=_Message),
_Field('invoice', constructor=Invoice),
_Field('successful_payment', constructor=SuccessfulPayment),
'connected_website',
])
# incoming
InlineQuery = _create_class('InlineQuery', [
'id',
_Field('from_', constructor=User),
_Field('location', constructor=Location),
'query',
'offset',
])
# incoming
ChosenInlineResult = _create_class('ChosenInlineResult', [
'result_id',
_Field('from_', constructor=User),
_Field('location', constructor=Location),
'inline_message_id',
'query',
])
# incoming
CallbackQuery = _create_class('CallbackQuery', [
'id',
_Field('from_', constructor=User),
_Field('message', constructor=Message),
'inline_message_id',
'chat_instance',
'data',
'game_short_name',
])
# incoming
Update = _create_class('Update', [
'update_id',
_Field('message', constructor=Message),
_Field('edited_message', constructor=Message),
_Field('channel_post', constructor=Message),
_Field('edited_channel_post', constructor=Message),
_Field('inline_query', constructor=InlineQuery),
_Field('chosen_inline_result', constructor=ChosenInlineResult),
_Field('callback_query', constructor=CallbackQuery),
])
# incoming
def UpdateArray(data):
return [Update(**u) for u in data]
# incoming
WebhookInfo = _create_class('WebhookInfo', [
'url',
'has_custom_certificate',
'pending_update_count',
'last_error_date',
'last_error_message',
])
# outgoing
InputTextMessageContent = _create_class('InputTextMessageContent', [
'message_text',
'parse_mode',
'disable_web_page_preview',
])
# outgoing
InputLocationMessageContent = _create_class('InputLocationMessageContent', [
'latitude',
'longitude',
'live_period',
])
# outgoing
InputVenueMessageContent = _create_class('InputVenueMessageContent', [
'latitude',
'longitude',
'title',
'address',
'foursquare_id',
])
# outgoing
InputContactMessageContent = _create_class('InputContactMessageContent', [
'phone_number',
'first_name',
'last_name',
])
# outgoing
InlineQueryResultArticle = _create_class('InlineQueryResultArticle', [
_Field('type', default='article'),
'id',
'title',
'input_message_content',
'reply_markup',
'url',
'hide_url',
'description',
'thumb_url',
'thumb_width',
'thumb_height',
])
# outgoing
InlineQueryResultPhoto = _create_class('InlineQueryResultPhoto', [
_Field('type', default='photo'),
'id',
'photo_url',
'thumb_url',
'photo_width',
'photo_height',
'title',
'description',
'caption',
'parse_mode',
'reply_markup',
'input_message_content',
])
# outgoing
InlineQueryResultGif = _create_class('InlineQueryResultGif', [
_Field('type', default='gif'),
'id',
'gif_url',
'gif_width',
'gif_height',
'gif_duration',
'thumb_url',
'title',
'caption',
'parse_mode',
'reply_markup',
'input_message_content',
])
# outgoing
InlineQueryResultMpeg4Gif = _create_class('InlineQueryResultMpeg4Gif', [
_Field('type', default='mpeg4_gif'),
'id',
'mpeg4_url',
'mpeg4_width',
'mpeg4_height',
'mpeg4_duration',
'thumb_url',
'title',
'caption',
'parse_mode',
'reply_markup',
'input_message_content',
])
# outgoing
InlineQueryResultVideo = _create_class('InlineQueryResultVideo', [
_Field('type', default='video'),
'id',
'video_url',
'mime_type',
'thumb_url',
'title',
'caption',
'parse_mode',
'video_width',
'video_height',
'video_duration',
'description',
'reply_markup',
'input_message_content',
])
# outgoing
InlineQueryResultAudio = _create_class('InlineQueryResultAudio', [
_Field('type', default='audio'),
'id',
'audio_url',
'title',
'caption',
'parse_mode',
'performer',
'audio_duration',
'reply_markup',
'input_message_content',
])
# outgoing
InlineQueryResultVoice = _create_class('InlineQueryResultVoice', [
_Field('type', default='voice'),
'id',
'voice_url',
'title',
'caption',
'parse_mode',
'voice_duration',
'reply_markup',
'input_message_content',
])
# outgoing
InlineQueryResultDocument = _create_class('InlineQueryResultDocument', [
_Field('type', default='document'),
'id',
'title',
'caption',
'parse_mode',
'document_url',
'mime_type',
'description',
'reply_markup',
'input_message_content',
'thumb_url',
'thumb_width',
'thumb_height',
])
# outgoing
InlineQueryResultLocation = _create_class('InlineQueryResultLocation', [
_Field('type', default='location'),
'id',
'latitude',
'longitude',
'title',
'live_period',
'reply_markup',
'input_message_content',
'thumb_url',
'thumb_width',
'thumb_height',
])
# outgoing
InlineQueryResultVenue = _create_class('InlineQueryResultVenue', [
_Field('type', default='venue'),
'id',
'latitude',
'longitude',
'title',
'address',
'foursquare_id',
'reply_markup',
'input_message_content',
'thumb_url',
'thumb_width',
'thumb_height',
])
# outgoing
InlineQueryResultContact = _create_class('InlineQueryResultContact', [
_Field('type', default='contact'),
'id',
'phone_number',
'first_name',
'last_name',
'reply_markup',
'input_message_content',
'thumb_url',
'thumb_width',
'thumb_height',
])
# outgoing
InlineQueryResultGame = _create_class('InlineQueryResultGame', [
_Field('type', default='game'),
'id',
'game_short_name',
'reply_markup',
])
# outgoing
InlineQueryResultCachedPhoto = _create_class('InlineQueryResultCachedPhoto', [
_Field('type', default='photo'),
'id',
'photo_file_id',
'title',
'description',
'caption',
'parse_mode',
'reply_markup',
'input_message_content',
])
# outgoing
InlineQueryResultCachedGif = _create_class('InlineQueryResultCachedGif', [
_Field('type', default='gif'),
'id',
'gif_file_id',
'title',
'caption',
'parse_mode',
'reply_markup',
'input_message_content',
])
# outgoing
InlineQueryResultCachedMpeg4Gif = _create_class('InlineQueryResultCachedMpeg4Gif', [
_Field('type', default='mpeg4_gif'),
'id',
'mpeg4_file_id',
'title',
'caption',
'parse_mode',
'reply_markup',
'input_message_content',
])
# outgoing
InlineQueryResultCachedSticker = _create_class('InlineQueryResultCachedSticker', [
_Field('type', default='sticker'),
'id',
'sticker_file_id',
'reply_markup',
'input_message_content',
])
# outgoing
InlineQueryResultCachedDocument = _create_class('InlineQueryResultCachedDocument', [
_Field('type', default='document'),
'id',
'title',
'document_file_id',
'description',
'caption',
'parse_mode',
'reply_markup',
'input_message_content',
])
# outgoing
InlineQueryResultCachedVideo = _create_class('InlineQueryResultCachedVideo', [
_Field('type', default='video'),
'id',
'video_file_id',
'title',
'description',
'caption',
'parse_mode',
'reply_markup',
'input_message_content',
])
# outgoing
InlineQueryResultCachedVoice = _create_class('InlineQueryResultCachedVoice', [
_Field('type', default='voice'),
'id',
'voice_file_id',
'title',
'caption',
'parse_mode',
'reply_markup',
'input_message_content',
])
# outgoing
InlineQueryResultCachedAudio = _create_class('InlineQueryResultCachedAudio', [
_Field('type', default='audio'),
'id',
'audio_file_id',
'caption',
'parse_mode',
'reply_markup',
'input_message_content',
])
# outgoing
InputMediaPhoto = _create_class('InputMediaPhoto', [
_Field('type', default='photo'),
'media',
'caption',
'parse_mode',
])
# outgoing
InputMediaVideo = _create_class('InputMediaVideo', [
_Field('type', default='video'),
'media',
'caption',
'parse_mode',
'width',
'height',
'duration',
'supports_streaming',
])
# incoming
ResponseParameters = _create_class('ResponseParameters', [
'migrate_to_chat_id',
'retry_after',
]) | PypiClean |
/oneline-0.6.4-alpha.tar.gz/oneline-0.6.4-alpha/lib/database/mongodb/build/lib.win32-2.7/pymongo/mongo_replica_set_client.py | import atexit
import datetime
import socket
import struct
import threading
import time
import warnings
import weakref
from bson.py3compat import b
from pymongo import (auth,
common,
database,
helpers,
message,
pool,
thread_util,
uri_parser)
from pymongo.member import Member
from pymongo.read_preferences import (
ReadPreference, select_member, modes, MovingAverage)
from pymongo.errors import (AutoReconnect,
ConfigurationError,
ConnectionFailure,
DocumentTooLarge,
DuplicateKeyError,
OperationFailure,
InvalidOperation)
from pymongo.read_preferences import ReadPreference
from pymongo.thread_util import DummyLock
EMPTY = b("")
MAX_RETRY = 3
MONITORS = set()
def register_monitor(monitor):
ref = weakref.ref(monitor, _on_monitor_deleted)
MONITORS.add(ref)
def _on_monitor_deleted(ref):
"""Remove the weakreference from the set
of active MONITORS. We no longer
care about keeping track of it
"""
MONITORS.remove(ref)
def shutdown_monitors():
# Keep a local copy of MONITORS as
# shutting down threads has a side effect
# of removing them from the MONITORS set()
monitors = list(MONITORS)
for ref in monitors:
monitor = ref()
if monitor:
monitor.shutdown()
monitor.join()
atexit.register(shutdown_monitors)
def _partition_node(node):
"""Split a host:port string returned from mongod/s into
a (host, int(port)) pair needed for socket.connect().
"""
host = node
port = 27017
idx = node.rfind(':')
if idx != -1:
host, port = node[:idx], int(node[idx + 1:])
if host.startswith('['):
host = host[1:-1]
return host, port
# Concurrency notes: A MongoReplicaSetClient keeps its view of the replica-set
# state in an RSState instance. RSStates are immutable, except for
# host-pinning. Pools, which are internally thread / greenlet safe, can be
# copied from old to new RSStates safely. The client updates its view of the
# set's state not by modifying its RSState but by replacing it with an updated
# copy.
# In __init__, MongoReplicaSetClient gets a list of potential members called
# 'seeds' from its initial parameters, and calls refresh(). refresh() iterates
# over the the seeds in arbitrary order looking for a member it can connect to.
# Once it finds one, it calls 'ismaster' and sets self.__hosts to the list of
# members in the response, and connects to the rest of the members. refresh()
# sets the MongoReplicaSetClient's RSState. Finally, __init__ launches the
# replica-set monitor.
# The monitor calls refresh() every 30 seconds, or whenever the client has
# encountered an error that prompts it to wake the monitor.
# Every method that accesses the RSState multiple times within the method makes
# a local reference first and uses that throughout, so it's isolated from a
# concurrent method replacing the RSState with an updated copy. This technique
# avoids the need to lock around accesses to the RSState.
class RSState(object):
def __init__(
self, threadlocal, hosts=None, host_to_member=None, arbiters=None,
writer=None, error_message='No primary available', exc=None,
initial=False):
"""An immutable snapshot of the client's view of the replica set state.
Stores Member instances for all members we're connected to, and a
list of (host, port) pairs for all the hosts and arbiters listed
in the most recent ismaster response.
:Parameters:
- `threadlocal`: Thread- or greenlet-local storage
- `hosts`: Sequence of (host, port) pairs
- `host_to_member`: Optional dict: (host, port) -> Member instance
- `arbiters`: Optional sequence of arbiters as (host, port)
- `writer`: Optional (host, port) of primary
- `error_message`: Optional error if `writer` is None
- `exc`: Optional error if state is unusable
- `initial`: Whether this is the initial client state
"""
self._threadlocal = threadlocal # threading.local or gevent local
self._arbiters = frozenset(arbiters or []) # set of (host, port)
self._writer = writer # (host, port) of the primary, or None
self._error_message = error_message
self._host_to_member = host_to_member or {}
self._hosts = frozenset(hosts or [])
self._members = frozenset(self._host_to_member.values())
self._exc = exc
self._initial = initial
self._primary_member = self.get(writer)
def clone_with_host_down(self, host, error_message):
"""Get a clone, marking as "down" the member with the given (host, port)
"""
members = self._host_to_member.copy()
members.pop(host, None)
if host == self.writer:
# The primary went down; record the error message.
return RSState(
self._threadlocal,
self._hosts,
members,
self._arbiters,
None,
error_message,
self._exc)
else:
# Some other host went down. Keep our current primary or, if it's
# already down, keep our current error message.
return RSState(
self._threadlocal,
self._hosts,
members,
self._arbiters,
self._writer,
self._error_message,
self._exc)
def clone_without_writer(self, threadlocal):
"""Get a clone without a primary. Unpins all threads.
:Parameters:
- `threadlocal`: Thread- or greenlet-local storage
"""
return RSState(
threadlocal,
self._hosts,
self._host_to_member,
self._arbiters)
def clone_with_error(self, exc):
return RSState(
self._threadlocal,
self._hosts,
self._host_to_member.copy(),
self._arbiters,
self._writer,
self._error_message,
exc)
@property
def arbiters(self):
"""(host, port) pairs from the last ismaster response's arbiter list.
"""
return self._arbiters
@property
def writer(self):
"""(host, port) of primary, or None."""
return self._writer
@property
def primary_member(self):
return self._primary_member
@property
def hosts(self):
"""(host, port) pairs from the last ismaster response's host list."""
return self._hosts
@property
def members(self):
"""Set of Member instances."""
return self._members
@property
def error_message(self):
"""The error, if any, raised when trying to connect to the primary"""
return self._error_message
@property
def secondaries(self):
"""Set of (host, port) pairs, secondaries we're connected to."""
# Unlike the other properties, this isn't cached because it isn't used
# in regular operations.
return set([
host for host, member in self._host_to_member.items()
if member.is_secondary])
@property
def exc(self):
"""Reason RSState is unusable, or None."""
return self._exc
@property
def initial(self):
"""Whether this is the initial client state."""
return self._initial
def get(self, host):
"""Return a Member instance or None for the given (host, port)."""
return self._host_to_member.get(host)
def pin_host(self, host, mode, tag_sets, latency):
"""Pin this thread / greenlet to a member.
`host` is a (host, port) pair. The remaining parameters are a read
preference.
"""
# Fun fact: Unlike in thread_util.ThreadIdent, we needn't lock around
# assignment here. Assignment to a threadlocal is only unsafe if it
# can cause other Python code to run implicitly.
self._threadlocal.host = host
self._threadlocal.read_preference = (mode, tag_sets, latency)
def keep_pinned_host(self, mode, tag_sets, latency):
"""Does a read pref match the last used by this thread / greenlet?"""
return self._threadlocal.read_preference == (mode, tag_sets, latency)
@property
def pinned_host(self):
"""The (host, port) last used by this thread / greenlet, or None."""
return getattr(self._threadlocal, 'host', None)
def unpin_host(self):
"""Forget this thread / greenlet's last used member."""
self._threadlocal.host = self._threadlocal.read_preference = None
@property
def threadlocal(self):
return self._threadlocal
def __str__(self):
return '<RSState [%s] writer="%s">' % (
', '.join(str(member) for member in self._host_to_member.itervalues()),
self.writer and '%s:%s' % self.writer or None)
class Monitor(object):
"""Base class for replica set monitors.
"""
_refresh_interval = 30
def __init__(self, rsc, event_class):
self.rsc = weakref.proxy(rsc, self.shutdown)
self.timer = event_class()
self.refreshed = event_class()
self.started_event = event_class()
self.stopped = False
def start_sync(self):
"""Start the Monitor and block until it's really started.
"""
# start() can return before the thread is fully bootstrapped,
# so a fork can leave the thread thinking it's alive in a child
# process when it's really dead:
# http://bugs.python.org/issue18418.
self.start() # Implemented in subclasses.
self.started_event.wait(5)
def shutdown(self, dummy=None):
"""Signal the monitor to shutdown.
"""
self.stopped = True
self.timer.set()
def schedule_refresh(self):
"""Refresh immediately
"""
if not self.isAlive():
# Checks in RS client should prevent this.
raise AssertionError("schedule_refresh called with dead monitor")
self.refreshed.clear()
self.timer.set()
def wait_for_refresh(self, timeout_seconds):
"""Block until a scheduled refresh completes
"""
self.refreshed.wait(timeout_seconds)
def monitor(self):
"""Run until the RSC is collected or an
unexpected error occurs.
"""
self.started_event.set()
while True:
self.timer.wait(Monitor._refresh_interval)
if self.stopped:
break
self.timer.clear()
try:
try:
self.rsc.refresh()
finally:
self.refreshed.set()
except AutoReconnect:
pass
# RSC has been collected or there
# was an unexpected error.
except:
break
def isAlive(self):
raise NotImplementedError()
class MonitorThread(threading.Thread, Monitor):
"""Thread based replica set monitor.
"""
def __init__(self, rsc):
Monitor.__init__(self, rsc, threading.Event)
threading.Thread.__init__(self)
self.setName("ReplicaSetMonitorThread")
self.setDaemon(True)
def run(self):
"""Override Thread's run method.
"""
self.monitor()
have_gevent = False
try:
from gevent import Greenlet
from gevent.event import Event
# Used by ReplicaSetConnection
from gevent.local import local as gevent_local
have_gevent = True
class MonitorGreenlet(Monitor, Greenlet):
"""Greenlet based replica set monitor.
"""
def __init__(self, rsc):
self.monitor_greenlet_alive = False
Monitor.__init__(self, rsc, Event)
Greenlet.__init__(self)
def start_sync(self):
self.monitor_greenlet_alive = True
# Call superclass.
Monitor.start_sync(self)
# Don't override `run` in a Greenlet. Add _run instead.
# Refer to gevent's Greenlet docs and source for more
# information.
def _run(self):
"""Define Greenlet's _run method.
"""
self.monitor()
def isAlive(self):
# bool(self) isn't immediately True after someone calls start(),
# but isAlive() is. Thus it's safe for greenlets to do:
# "if not monitor.isAlive(): monitor.start()"
# ... and be guaranteed only one greenlet starts the monitor.
return self.monitor_greenlet_alive
except ImportError:
pass
class MongoReplicaSetClient(common.BaseObject):
"""Connection to a MongoDB replica set.
"""
# For tests.
_refresh_timeout_sec = 5
def __init__(self, hosts_or_uri=None, max_pool_size=100,
document_class=dict, tz_aware=False, _connect=True, **kwargs):
"""Create a new connection to a MongoDB replica set.
The resultant client object has connection-pooling built
in. It also performs auto-reconnection when necessary. If an
operation fails because of a connection error,
:class:`~pymongo.errors.ConnectionFailure` is raised. If
auto-reconnection will be performed,
:class:`~pymongo.errors.AutoReconnect` will be
raised. Application code should handle this exception
(recognizing that the operation failed) and then continue to
execute.
Raises :class:`~pymongo.errors.ConnectionFailure` if
the connection cannot be made.
The `hosts_or_uri` parameter can be a full `mongodb URI
<http://dochub.mongodb.org/core/connections>`_, in addition to
a string of `host:port` pairs (e.g. 'host1:port1,host2:port2').
If `hosts_or_uri` is None 'localhost:27017' will be used.
.. note:: Instances of :class:`MongoReplicaSetClient` start a
background task to monitor the state of the replica set. This allows
it to quickly respond to changes in replica set configuration.
Before discarding an instance of :class:`MongoReplicaSetClient` make
sure you call :meth:`~close` to ensure that the monitor task is
cleanly shut down.
:Parameters:
- `hosts_or_uri` (optional): A MongoDB URI or string of `host:port`
pairs. If a host is an IPv6 literal it must be enclosed in '[' and
']' characters following the RFC2732 URL syntax (e.g. '[::1]' for
localhost)
- `max_pool_size` (optional): The maximum number of connections
each pool will open simultaneously. If this is set, operations
will block if there are `max_pool_size` outstanding connections
from the pool. Defaults to 100.
- `document_class` (optional): default class to use for
documents returned from queries on this client
- `tz_aware` (optional): if ``True``,
:class:`~datetime.datetime` instances returned as values
in a document by this :class:`MongoReplicaSetClient` will be timezone
aware (otherwise they will be naive)
- `replicaSet`: (required) The name of the replica set to connect to.
The driver will verify that each host it connects to is a member of
this replica set. Can be passed as a keyword argument or as a
MongoDB URI option.
| **Other optional parameters can be passed as keyword arguments:**
- `host`: For compatibility with :class:`~mongo_client.MongoClient`.
If both `host` and `hosts_or_uri` are specified `host` takes
precedence.
- `port`: For compatibility with :class:`~mongo_client.MongoClient`.
The default port number to use for hosts.
- `socketTimeoutMS`: (integer) How long (in milliseconds) a send or
receive on a socket can take before timing out. Defaults to ``None``
(no timeout).
- `connectTimeoutMS`: (integer) How long (in milliseconds) a
connection can take to be opened before timing out. Defaults to
``20000``.
- `waitQueueTimeoutMS`: (integer) How long (in milliseconds) a
thread will wait for a socket from the pool if the pool has no
free sockets. Defaults to ``None`` (no timeout).
- `waitQueueMultiple`: (integer) Multiplied by max_pool_size to give
the number of threads allowed to wait for a socket at one time.
Defaults to ``None`` (no waiters).
- `auto_start_request`: If ``True``, each thread that accesses
this :class:`MongoReplicaSetClient` has a socket allocated to it
for the thread's lifetime, for each member of the set. For
:class:`~pymongo.read_preferences.ReadPreference` PRIMARY,
auto_start_request=True ensures consistent reads, even if you read
after an unacknowledged write. For read preferences other than
PRIMARY, there are no consistency guarantees. Default to ``False``.
- `use_greenlets`: If ``True``, use a background Greenlet instead of
a background thread to monitor state of replica set. Additionally,
:meth:`start_request()` assigns a greenlet-local, rather than
thread-local, socket.
`use_greenlets` with :class:`MongoReplicaSetClient` requires
`Gevent <http://gevent.org/>`_ to be installed.
| **Write Concern options:**
- `w`: (integer or string) Write operations will block until they have
been replicated to the specified number or tagged set of servers.
`w=<int>` always includes the replica set primary (e.g. w=3 means
write to the primary and wait until replicated to **two**
secondaries). Passing w=0 **disables write acknowledgement** and all
other write concern options.
- `wtimeout`: (integer) Used in conjunction with `w`. Specify a value
in milliseconds to control how long to wait for write propagation
to complete. If replication does not complete in the given
timeframe, a timeout exception is raised.
- `j`: If ``True`` block until write operations have been committed
to the journal. Cannot be used in combination with `fsync`. Prior
to MongoDB 2.6 this option was ignored if the server was running
without journaling. Starting with MongoDB 2.6 write operations will
fail with an exception if this option is used when the server is
running without journaling.
- `fsync`: If ``True`` and the server is running without journaling,
blocks until the server has synced all data files to disk. If the
server is running with journaling, this acts the same as the `j`
option, blocking until write operations have been committed to the
journal. Cannot be used in combination with `j`.
| **Read preference options:**
- `read_preference`: The read preference for this client.
See :class:`~pymongo.read_preferences.ReadPreference` for available
options.
- `tag_sets`: Read from replica-set members with these tags.
To specify a priority-order for tag sets, provide a list of
tag sets: ``[{'dc': 'ny'}, {'dc': 'la'}, {}]``. A final, empty tag
set, ``{}``, means "read from any member that matches the mode,
ignoring tags." :class:`MongoReplicaSetClient` tries each set of
tags in turn until it finds a set of tags with at least one matching
member.
- `secondary_acceptable_latency_ms`: (integer) Any replica-set member
whose ping time is within secondary_acceptable_latency_ms of the
nearest member may accept reads. Default 15 milliseconds.
**Ignored by mongos** and must be configured on the command line.
See the localThreshold_ option for more information.
| **SSL configuration:**
- `ssl`: If ``True``, create the connection to the servers using SSL.
- `ssl_keyfile`: The private keyfile used to identify the local
connection against mongod. If included with the ``certfile`` then
only the ``ssl_certfile`` is needed. Implies ``ssl=True``.
- `ssl_certfile`: The certificate file used to identify the local
connection against mongod. Implies ``ssl=True``.
- `ssl_cert_reqs`: Specifies whether a certificate is required from
the other side of the connection, and whether it will be validated
if provided. It must be one of the three values ``ssl.CERT_NONE``
(certificates ignored), ``ssl.CERT_OPTIONAL``
(not required, but validated if provided), or ``ssl.CERT_REQUIRED``
(required and validated). If the value of this parameter is not
``ssl.CERT_NONE``, then the ``ssl_ca_certs`` parameter must point
to a file of CA certificates. Implies ``ssl=True``.
- `ssl_ca_certs`: The ca_certs file contains a set of concatenated
"certification authority" certificates, which are used to validate
certificates passed from the other end of the connection.
Implies ``ssl=True``.
.. versionchanged:: 2.5
Added additional ssl options
.. versionadded:: 2.4
.. _localThreshold: http://docs.mongodb.org/manual/reference/mongos/#cmdoption-mongos--localThreshold
"""
self.__opts = {}
self.__seeds = set()
self.__index_cache = {}
self.__auth_credentials = {}
self.__max_pool_size = common.validate_positive_integer_or_none(
'max_pool_size', max_pool_size)
self.__tz_aware = common.validate_boolean('tz_aware', tz_aware)
self.__document_class = document_class
self.__monitor = None
self.__closed = False
# Compatibility with mongo_client.MongoClient
host = kwargs.pop('host', hosts_or_uri)
port = kwargs.pop('port', 27017)
if not isinstance(port, int):
raise TypeError("port must be an instance of int")
username = None
password = None
self.__default_database_name = None
options = {}
if host is None:
self.__seeds.add(('localhost', port))
elif '://' in host:
res = uri_parser.parse_uri(host, port)
self.__seeds.update(res['nodelist'])
username = res['username']
password = res['password']
self.__default_database_name = res['database']
options = res['options']
else:
self.__seeds.update(uri_parser.split_hosts(host, port))
# _pool_class and _monitor_class are for deep customization of PyMongo,
# e.g. Motor. SHOULD NOT BE USED BY DEVELOPERS EXTERNAL TO MONGODB.
self.pool_class = kwargs.pop('_pool_class', pool.Pool)
self.__monitor_class = kwargs.pop('_monitor_class', None)
for option, value in kwargs.iteritems():
option, value = common.validate(option, value)
self.__opts[option] = value
self.__opts.update(options)
self.__use_greenlets = self.__opts.get('use_greenlets', False)
if self.__use_greenlets and not have_gevent:
raise ConfigurationError(
"The gevent module is not available. "
"Install the gevent package from PyPI.")
self.__rs_state = RSState(self.__make_threadlocal(), initial=True)
self.__request_counter = thread_util.Counter(self.__use_greenlets)
self.__auto_start_request = self.__opts.get('auto_start_request', False)
if self.__auto_start_request:
self.start_request()
self.__name = self.__opts.get('replicaset')
if not self.__name:
raise ConfigurationError("the replicaSet "
"keyword parameter is required.")
self.__net_timeout = self.__opts.get('sockettimeoutms')
self.__conn_timeout = self.__opts.get('connecttimeoutms')
self.__wait_queue_timeout = self.__opts.get('waitqueuetimeoutms')
self.__wait_queue_multiple = self.__opts.get('waitqueuemultiple')
self.__use_ssl = self.__opts.get('ssl', None)
self.__ssl_keyfile = self.__opts.get('ssl_keyfile', None)
self.__ssl_certfile = self.__opts.get('ssl_certfile', None)
self.__ssl_cert_reqs = self.__opts.get('ssl_cert_reqs', None)
self.__ssl_ca_certs = self.__opts.get('ssl_ca_certs', None)
ssl_kwarg_keys = [k for k in kwargs.keys() if k.startswith('ssl_')]
if self.__use_ssl is False and ssl_kwarg_keys:
raise ConfigurationError("ssl has not been enabled but the "
"following ssl parameters have been set: "
"%s. Please set `ssl=True` or remove."
% ', '.join(ssl_kwarg_keys))
if self.__ssl_cert_reqs and not self.__ssl_ca_certs:
raise ConfigurationError("If `ssl_cert_reqs` is not "
"`ssl.CERT_NONE` then you must "
"include `ssl_ca_certs` to be able "
"to validate the server.")
if ssl_kwarg_keys and self.__use_ssl is None:
# ssl options imply ssl = True
self.__use_ssl = True
if self.__use_ssl and not common.HAS_SSL:
raise ConfigurationError("The ssl module is not available. If you "
"are using a python version previous to "
"2.6 you must install the ssl package "
"from PyPI.")
super(MongoReplicaSetClient, self).__init__(**self.__opts)
if self.slave_okay:
warnings.warn("slave_okay is deprecated. Please "
"use read_preference instead.", DeprecationWarning,
stacklevel=2)
if _connect:
try:
self.refresh(initial=True)
except AutoReconnect, e:
# ConnectionFailure makes more sense here than AutoReconnect
raise ConnectionFailure(str(e))
if username:
mechanism = options.get('authmechanism', 'MONGODB-CR')
source = (
options.get('authsource')
or self.__default_database_name
or 'admin')
credentials = auth._build_credentials_tuple(mechanism,
source,
unicode(username),
unicode(password),
options)
try:
self._cache_credentials(source, credentials, _connect)
except OperationFailure, exc:
raise ConfigurationError(str(exc))
# Start the monitor after we know the configuration is correct.
if not self.__monitor_class:
if self.__use_greenlets:
self.__monitor_class = MonitorGreenlet
else:
# Common case: monitor RS with a background thread.
self.__monitor_class = MonitorThread
if self.__use_greenlets:
# Greenlets don't need to lock around access to the monitor.
# A Greenlet can safely do:
# "if not self.__monitor: self.__monitor = monitor_class()"
# because it won't be interrupted between the check and the
# assignment.
self.__monitor_lock = DummyLock()
else:
self.__monitor_lock = threading.Lock()
if _connect:
self.__ensure_monitor()
def _cached(self, dbname, coll, index):
"""Test if `index` is cached.
"""
cache = self.__index_cache
now = datetime.datetime.utcnow()
return (dbname in cache and
coll in cache[dbname] and
index in cache[dbname][coll] and
now < cache[dbname][coll][index])
def _cache_index(self, dbase, collection, index, cache_for):
"""Add an index to the index cache for ensure_index operations.
"""
now = datetime.datetime.utcnow()
expire = datetime.timedelta(seconds=cache_for) + now
if dbase not in self.__index_cache:
self.__index_cache[dbase] = {}
self.__index_cache[dbase][collection] = {}
self.__index_cache[dbase][collection][index] = expire
elif collection not in self.__index_cache[dbase]:
self.__index_cache[dbase][collection] = {}
self.__index_cache[dbase][collection][index] = expire
else:
self.__index_cache[dbase][collection][index] = expire
def _purge_index(self, database_name,
collection_name=None, index_name=None):
"""Purge an index from the index cache.
If `index_name` is None purge an entire collection.
If `collection_name` is None purge an entire database.
"""
if not database_name in self.__index_cache:
return
if collection_name is None:
del self.__index_cache[database_name]
return
if not collection_name in self.__index_cache[database_name]:
return
if index_name is None:
del self.__index_cache[database_name][collection_name]
return
if index_name in self.__index_cache[database_name][collection_name]:
del self.__index_cache[database_name][collection_name][index_name]
def _cache_credentials(self, source, credentials, connect=True):
"""Add credentials to the database authentication cache
for automatic login when a socket is created. If `connect` is True,
verify the credentials on the server first.
Raises OperationFailure if other credentials are already stored for
this source.
"""
if source in self.__auth_credentials:
# Nothing to do if we already have these credentials.
if credentials == self.__auth_credentials[source]:
return
raise OperationFailure('Another user is already authenticated '
'to this database. You must logout first.')
if connect:
# Try to authenticate even during failover.
member = select_member(
self.__rs_state.members, ReadPreference.PRIMARY_PREFERRED)
if not member:
raise AutoReconnect(
"No replica set members available for authentication")
sock_info = self.__socket(member)
try:
# Since __check_auth was called in __socket
# there is no need to call it here.
auth.authenticate(credentials, sock_info, self.__simple_command)
sock_info.authset.add(credentials)
finally:
member.pool.maybe_return_socket(sock_info)
self.__auth_credentials[source] = credentials
def _purge_credentials(self, source):
"""Purge credentials from the database authentication cache.
"""
if source in self.__auth_credentials:
del self.__auth_credentials[source]
def __check_auth(self, sock_info):
"""Authenticate using cached database credentials.
"""
if self.__auth_credentials or sock_info.authset:
cached = set(self.__auth_credentials.itervalues())
authset = sock_info.authset.copy()
# Logout any credentials that no longer exist in the cache.
for credentials in authset - cached:
self.__simple_command(sock_info, credentials[1], {'logout': 1})
sock_info.authset.discard(credentials)
for credentials in cached - authset:
auth.authenticate(credentials,
sock_info, self.__simple_command)
sock_info.authset.add(credentials)
@property
def seeds(self):
"""The seed list used to connect to this replica set.
A sequence of (host, port) pairs.
"""
return self.__seeds
@property
def hosts(self):
"""All active and passive (priority 0) replica set
members known to this client. This does not include
hidden or slaveDelay members, or arbiters.
A sequence of (host, port) pairs.
"""
return self.__rs_state.hosts
@property
def primary(self):
"""The (host, port) of the current primary of the replica set.
Returns None if there is no primary.
"""
return self.__rs_state.writer
@property
def secondaries(self):
"""The secondary members known to this client.
A sequence of (host, port) pairs.
"""
return self.__rs_state.secondaries
@property
def arbiters(self):
"""The arbiters known to this client.
A sequence of (host, port) pairs.
"""
return self.__rs_state.arbiters
@property
def is_mongos(self):
"""If this instance is connected to mongos (always False).
.. versionadded:: 2.3
"""
return False
@property
def max_pool_size(self):
"""The maximum number of sockets the pool will open concurrently.
When the pool has reached `max_pool_size`, operations block waiting for
a socket to be returned to the pool. If ``waitQueueTimeoutMS`` is set,
a blocked operation will raise :exc:`~pymongo.errors.ConnectionFailure`
after a timeout. By default ``waitQueueTimeoutMS`` is not set.
.. warning:: SIGNIFICANT BEHAVIOR CHANGE in 2.6. Previously, this
parameter would limit only the idle sockets the pool would hold
onto, not the number of open sockets. The default has also changed
to 100.
.. versionchanged:: 2.6
"""
return self.__max_pool_size
@property
def use_greenlets(self):
"""Whether calling :meth:`start_request` assigns greenlet-local,
rather than thread-local, sockets.
.. versionadded:: 2.4.2
"""
return self.__use_greenlets
def get_document_class(self):
"""document_class getter"""
return self.__document_class
def set_document_class(self, klass):
"""document_class setter"""
self.__document_class = klass
document_class = property(get_document_class, set_document_class,
doc="""Default class to use for documents
returned from this client.
""")
@property
def tz_aware(self):
"""Does this client return timezone-aware datetimes?
"""
return self.__tz_aware
@property
def max_bson_size(self):
"""Returns the maximum size BSON object the connected primary
accepts in bytes. Defaults to 16MB if not connected to a
primary.
"""
rs_state = self.__rs_state
if rs_state.primary_member:
return rs_state.primary_member.max_bson_size
return common.MAX_BSON_SIZE
@property
def max_message_size(self):
"""Returns the maximum message size the connected primary
accepts in bytes. Defaults to 32MB if not connected to a
primary.
"""
rs_state = self.__rs_state
if rs_state.primary_member:
return rs_state.primary_member.max_message_size
return common.MAX_MESSAGE_SIZE
@property
def min_wire_version(self):
"""The minWireVersion reported by the server.
Returns ``0`` when connected to server versions prior to MongoDB 2.6.
.. versionadded:: 2.7
"""
rs_state = self.__rs_state
if rs_state.primary_member:
return rs_state.primary_member.min_wire_version
return common.MIN_WIRE_VERSION
@property
def max_wire_version(self):
"""The maxWireVersion reported by the server.
Returns ``0`` when connected to server versions prior to MongoDB 2.6.
.. versionadded:: 2.7
"""
rs_state = self.__rs_state
if rs_state.primary_member:
return rs_state.primary_member.max_wire_version
return common.MAX_WIRE_VERSION
@property
def max_write_batch_size(self):
"""The maxWriteBatchSize reported by the server.
Returns a default value when connected to server versions prior to
MongoDB 2.6.
.. versionadded:: 2.7
"""
rs_state = self.__rs_state
if rs_state.primary_member:
return rs_state.primary_member.max_write_batch_size
return common.MAX_WRITE_BATCH_SIZE
@property
def auto_start_request(self):
"""Is auto_start_request enabled?
"""
return self.__auto_start_request
def __simple_command(self, sock_info, dbname, spec):
"""Send a command to the server.
Returns (response, ping_time in seconds).
"""
rqst_id, msg, _ = message.query(0, dbname + '.$cmd', 0, -1, spec)
start = time.time()
try:
sock_info.sock.sendall(msg)
response = self.__recv_msg(1, rqst_id, sock_info)
except:
sock_info.close()
raise
end = time.time()
response = helpers._unpack_response(response)['data'][0]
msg = "command %r failed: %%s" % spec
helpers._check_command_response(response, None, msg)
return response, end - start
def __is_master(self, host):
"""Directly call ismaster.
Returns (response, connection_pool, ping_time in seconds).
"""
connection_pool = self.pool_class(
host,
self.__max_pool_size,
self.__net_timeout,
self.__conn_timeout,
self.__use_ssl,
wait_queue_timeout=self.__wait_queue_timeout,
wait_queue_multiple=self.__wait_queue_multiple,
use_greenlets=self.__use_greenlets,
ssl_keyfile=self.__ssl_keyfile,
ssl_certfile=self.__ssl_certfile,
ssl_cert_reqs=self.__ssl_cert_reqs,
ssl_ca_certs=self.__ssl_ca_certs)
if self.in_request():
connection_pool.start_request()
sock_info = connection_pool.get_socket()
try:
response, ping_time = self.__simple_command(
sock_info, 'admin', {'ismaster': 1}
)
connection_pool.maybe_return_socket(sock_info)
return response, connection_pool, ping_time
except (ConnectionFailure, socket.error):
connection_pool.discard_socket(sock_info)
raise
def __schedule_refresh(self, sync=False):
"""Awake the monitor to update our view of the replica set's state.
If `sync` is True, block until the refresh completes.
If multiple application threads call __schedule_refresh while refresh
is in progress, the work of refreshing the state is only performed
once.
"""
if self.__closed:
raise InvalidOperation('MongoReplicaSetClient has been closed')
monitor = self.__ensure_monitor()
monitor.schedule_refresh()
if sync:
monitor.wait_for_refresh(timeout_seconds=self._refresh_timeout_sec)
def __ensure_monitor(self):
"""Ensure the monitor is started, and return it."""
self.__monitor_lock.acquire()
try:
# Another thread can start the monitor while we wait for the lock.
if self.__monitor is not None and self.__monitor.isAlive():
return self.__monitor
monitor = self.__monitor = self.__monitor_class(self)
register_monitor(monitor)
monitor.start_sync()
return monitor
finally:
self.__monitor_lock.release()
def __make_threadlocal(self):
if self.__use_greenlets:
return gevent_local()
else:
return threading.local()
def refresh(self, initial=False):
"""Iterate through the existing host list, or possibly the
seed list, to update the list of hosts and arbiters in this
replica set.
"""
# Only one thread / greenlet calls refresh() at a time: the one
# running __init__() or the monitor. We won't modify the state, only
# replace it.
rs_state = self.__rs_state
try:
self.__rs_state = self.__create_rs_state(rs_state, initial)
except ConfigurationError, e:
self.__rs_state = rs_state.clone_with_error(e)
raise
def __create_rs_state(self, rs_state, initial):
errors = []
if rs_state.hosts:
# Try first those hosts we think are up, then the down ones.
nodes = sorted(
rs_state.hosts,
key=lambda host: bool(rs_state.get(host)),
reverse=True)
else:
nodes = self.__seeds
hosts = set()
# This will become the new RSState.
members = {}
arbiters = set()
writer = None
# Look for first member from which we can get a list of all members.
for node in nodes:
member, sock_info = rs_state.get(node), None
try:
if member:
sock_info = self.__socket(member, force=True)
response, ping_time = self.__simple_command(
sock_info, 'admin', {'ismaster': 1})
member.pool.maybe_return_socket(sock_info)
new_member = member.clone_with(response, ping_time)
else:
response, pool, ping_time = self.__is_master(node)
new_member = Member(
node, pool, response, MovingAverage([ping_time]))
# Check that this host is part of the given replica set.
# Fail fast if we find a bad seed during __init__.
# Regular refreshes keep searching for valid nodes.
if response.get('setName') != self.__name:
if initial:
host, port = node
raise ConfigurationError("%s:%d is not a member of "
"replica set %s"
% (host, port, self.__name))
else:
continue
if "arbiters" in response:
arbiters = set([
_partition_node(h) for h in response["arbiters"]])
if "hosts" in response:
hosts.update([_partition_node(h)
for h in response["hosts"]])
if "passives" in response:
hosts.update([_partition_node(h)
for h in response["passives"]])
# Start off the new 'members' dict with this member
# but don't add seed list members.
if node in hosts:
members[node] = new_member
if response['ismaster']:
writer = node
except (ConnectionFailure, socket.error), why:
if member:
member.pool.discard_socket(sock_info)
errors.append("%s:%d: %s" % (node[0], node[1], str(why)))
if hosts:
break
else:
# We've changed nothing. On the next refresh, we'll try the same
# list of hosts: rs_state.hosts or self.__seeds.
if errors:
raise AutoReconnect(', '.join(errors))
raise ConfigurationError('No suitable hosts found')
# Ensure we have a pool for each member, and find the primary.
for host in hosts:
if host in members:
# This member was the first we connected to, in the loop above.
continue
member, sock_info = rs_state.get(host), None
try:
if member:
sock_info = self.__socket(member, force=True)
res, ping_time = self.__simple_command(
sock_info, 'admin', {'ismaster': 1})
if res.get('setName') != self.__name:
# Not a member of this set.
continue
member.pool.maybe_return_socket(sock_info)
new_member = member.clone_with(res, ping_time)
else:
res, connection_pool, ping_time = self.__is_master(host)
if res.get('setName') != self.__name:
# Not a member of this set.
continue
new_member = Member(
host, connection_pool, res, MovingAverage([ping_time]))
members[host] = new_member
except (ConnectionFailure, socket.error):
if member:
member.pool.discard_socket(sock_info)
continue
if res['ismaster']:
writer = host
if not members:
# In the first loop, we connected to a member in the seed list
# and got a host list, but couldn't reach any members in that
# list.
raise AutoReconnect(
"Couldn't reach any hosts in %s. Replica set is"
" configured with internal hostnames or IPs?"
% list(hosts))
if writer == rs_state.writer:
threadlocal = self.__rs_state.threadlocal
else:
# We unpin threads from members if the primary has changed, since
# no monotonic consistency can be promised now anyway.
threadlocal = self.__make_threadlocal()
# Get list of hosts in the RS config, including unreachable ones.
# Prefer the primary's list, otherwise any member's list.
if writer:
response = members[writer].ismaster_response
elif members:
response = members.values()[0].ismaster_response
else:
response = {}
final_host_list = (
response.get('hosts', [])
+ response.get('passives', []))
# Replace old state with new.
return RSState(
threadlocal,
[_partition_node(h) for h in final_host_list],
members,
arbiters,
writer)
def __get_rs_state(self):
rs_state = self.__rs_state
if rs_state.exc:
raise rs_state.exc
return rs_state
def __find_primary(self):
"""Returns a connection to the primary of this replica set,
if one exists, or raises AutoReconnect.
"""
rs_state = self.__get_rs_state()
primary = rs_state.primary_member
if primary:
return primary
# We had a failover.
self.__schedule_refresh(sync=True)
# Try again. This time copy the RSState reference so we're guaranteed
# primary_member and error_message are from the same state.
rs_state = self.__get_rs_state()
if rs_state.primary_member:
return rs_state.primary_member
# Couldn't find the primary.
raise AutoReconnect(rs_state.error_message)
def __socket(self, member, force=False):
"""Get a SocketInfo from the pool.
"""
if self.auto_start_request and not self.in_request():
self.start_request()
sock_info = member.pool.get_socket(force=force)
try:
self.__check_auth(sock_info)
except OperationFailure:
member.pool.maybe_return_socket(sock_info)
raise
return sock_info
def _ensure_connected(self, sync=False):
"""Ensure this client instance is connected to a primary.
"""
# This may be the first time we're connecting to the set.
self.__ensure_monitor()
if sync:
rs_state = self.__rs_state
if rs_state.exc or not rs_state.primary_member:
self.__schedule_refresh(sync)
def disconnect(self):
"""Disconnect from the replica set primary, unpin all members, and
refresh our view of the replica set.
"""
rs_state = self.__rs_state
if rs_state.primary_member:
rs_state.primary_member.pool.reset()
threadlocal = self.__make_threadlocal()
self.__rs_state = rs_state.clone_without_writer(threadlocal)
self.__schedule_refresh()
def close(self):
"""Close this client instance.
This method first terminates the replica set monitor, then disconnects
from all members of the replica set. No further operations are
permitted on this client.
.. warning:: This method stops the replica set monitor task. The
replica set monitor is required to properly handle replica set
configuration changes, including a failure of the primary.
Once :meth:`~close` is called this client instance must not be
reused.
.. versionchanged:: 2.2.1
The :meth:`close` method now terminates the replica set monitor.
"""
self.__closed = True
self.__rs_state = RSState(self.__make_threadlocal())
monitor, self.__monitor = self.__monitor, None
if monitor:
monitor.shutdown()
# Use a reasonable timeout.
monitor.join(1.0)
def alive(self):
"""Return ``False`` if there has been an error communicating with the
primary, else ``True``.
This method attempts to check the status of the primary with minimal
I/O. The current thread / greenlet retrieves a socket (its request
socket if it's in a request, or a random idle socket if it's not in a
request) from the primary's connection pool and checks whether calling
select_ on it raises an error. If there are currently no idle sockets,
:meth:`alive` attempts to connect a new socket.
A more certain way to determine primary availability is to ping it::
client.admin.command('ping')
.. _select: http://docs.python.org/2/library/select.html#select.select
"""
# In the common case, a socket is available and was used recently, so
# calling select() on it is a reasonable attempt to see if the OS has
# reported an error.
primary, sock_info = None, None
try:
try:
rs_state = self.__get_rs_state()
primary = rs_state.primary_member
if not primary:
return False
else:
sock_info = self.__socket(primary)
return not pool._closed(sock_info.sock)
except (socket.error, ConnectionFailure):
return False
finally:
if primary:
primary.pool.maybe_return_socket(sock_info)
def __check_response_to_last_error(self, response, is_command):
"""Check a response to a lastError message for errors.
`response` is a byte string representing a response to the message.
If it represents an error response we raise OperationFailure.
Return the response as a document.
"""
response = helpers._unpack_response(response)
assert response["number_returned"] == 1
result = response["data"][0]
helpers._check_command_response(result, self.disconnect)
# write commands - skip getLastError checking
if is_command:
return result
# getLastError
error_msg = result.get("err", "")
if error_msg is None:
return result
if error_msg.startswith("not master"):
self.disconnect()
raise AutoReconnect(error_msg)
code = result.get("code")
if code in (11000, 11001, 12582):
raise DuplicateKeyError(result["err"], code, result)
raise OperationFailure(result["err"], code, result)
def __recv_data(self, length, sock_info):
"""Lowest level receive operation.
Takes length to receive and repeatedly calls recv until able to
return a buffer of that length, raising ConnectionFailure on error.
"""
message = EMPTY
while length:
chunk = sock_info.sock.recv(length)
if chunk == EMPTY:
raise ConnectionFailure("connection closed")
length -= len(chunk)
message += chunk
return message
def __recv_msg(self, operation, rqst_id, sock):
"""Receive a message in response to `rqst_id` on `sock`.
Returns the response data with the header removed.
"""
header = self.__recv_data(16, sock)
length = struct.unpack("<i", header[:4])[0]
# No rqst_id for exhaust cursor "getMore".
if rqst_id is not None:
resp_id = struct.unpack("<i", header[8:12])[0]
assert rqst_id == resp_id, "ids don't match %r %r" % (rqst_id,
resp_id)
assert operation == struct.unpack("<i", header[12:])[0]
return self.__recv_data(length - 16, sock)
def __check_bson_size(self, msg, max_size):
"""Make sure the message doesn't include BSON documents larger
than the connected server will accept.
:Parameters:
- `msg`: message to check
"""
if len(msg) == 3:
request_id, data, max_doc_size = msg
if max_doc_size > max_size:
raise DocumentTooLarge("BSON document too large (%d bytes)"
" - the connected server supports"
" BSON document sizes up to %d"
" bytes." %
(max_doc_size, max_size))
return (request_id, data)
# get_more and kill_cursors messages
# don't include BSON documents.
return msg
def _send_message(self, msg, with_last_error=False,
command=False, _connection_to_use=None):
"""Say something to Mongo.
Raises ConnectionFailure if the message cannot be sent. Raises
OperationFailure if `with_last_error` is ``True`` and the
response to the getLastError call returns an error. Return the
response from lastError, or ``None`` if `with_last_error` is
``False``.
:Parameters:
- `msg`: message to send
- `with_last_error`: check getLastError status after sending the
message
"""
self._ensure_connected()
if _connection_to_use in (None, -1):
member = self.__find_primary()
else:
member = self.__get_rs_state().get(_connection_to_use)
sock_info = None
try:
try:
sock_info = self.__socket(member)
rqst_id, data = self.__check_bson_size(
msg, member.max_bson_size)
sock_info.sock.sendall(data)
# Safe mode. We pack the message together with a lastError
# message and send both. We then get the response (to the
# lastError) and raise OperationFailure if it is an error
# response.
rv = None
if with_last_error:
response = self.__recv_msg(1, rqst_id, sock_info)
rv = self.__check_response_to_last_error(response, command)
return rv
except OperationFailure:
raise
except(ConnectionFailure, socket.error), why:
member.pool.discard_socket(sock_info)
if _connection_to_use in (None, -1):
self.disconnect()
raise AutoReconnect(str(why))
except:
sock_info.close()
raise
finally:
member.pool.maybe_return_socket(sock_info)
def __send_and_receive(self, member, msg, **kwargs):
"""Send a message on the given socket and return the response data.
Can raise socket.error.
"""
sock_info = None
exhaust = kwargs.get('exhaust')
rqst_id, data = self.__check_bson_size(msg, member.max_bson_size)
try:
sock_info = self.__socket(member)
if not exhaust and "network_timeout" in kwargs:
sock_info.sock.settimeout(kwargs['network_timeout'])
sock_info.sock.sendall(data)
response = self.__recv_msg(1, rqst_id, sock_info)
if not exhaust:
if "network_timeout" in kwargs:
sock_info.sock.settimeout(self.__net_timeout)
member.pool.maybe_return_socket(sock_info)
return response, sock_info, member.pool
except:
if sock_info is not None:
sock_info.close()
member.pool.maybe_return_socket(sock_info)
raise
def __try_read(self, member, msg, **kwargs):
"""Attempt a read from a member; on failure mark the member "down" and
wake up the monitor thread to refresh as soon as possible.
"""
try:
return self.__send_and_receive(member, msg, **kwargs)
except socket.timeout, e:
# Could be one slow query, don't refresh.
host, port = member.host
raise AutoReconnect("%s:%d: %s" % (host, port, e))
except (socket.error, ConnectionFailure), why:
# Try to replace our RSState with a clone where this member is
# marked "down", to reduce exceptions on other threads, or repeated
# exceptions on this thread. We accept that there's a race
# condition (another thread could be replacing our state with a
# different version concurrently) but this approach is simple and
# lock-free.
self.__rs_state = self.__rs_state.clone_with_host_down(
member.host, str(why))
self.__schedule_refresh()
host, port = member.host
raise AutoReconnect("%s:%d: %s" % (host, port, why))
def _send_message_with_response(self, msg, _connection_to_use=None,
_must_use_master=False, **kwargs):
"""Send a message to Mongo and return the response.
Sends the given message and returns (host used, response).
:Parameters:
- `msg`: (request_id, data) pair making up the message to send
- `_connection_to_use`: Optional (host, port) of member for message,
used by Cursor for getMore and killCursors messages.
- `_must_use_master`: If True, send to primary.
"""
self._ensure_connected()
rs_state = self.__get_rs_state()
tag_sets = kwargs.get('tag_sets', [{}])
mode = kwargs.get('read_preference', ReadPreference.PRIMARY)
if _must_use_master:
mode = ReadPreference.PRIMARY
tag_sets = [{}]
if not rs_state.primary_member:
# If we were initialized with _connect=False then connect now.
# Otherwise, the primary was down last we checked. Start a refresh
# if one is not already in progress. If caller requested the
# primary, wait to see if it's up, otherwise continue with
# known-good members.
sync = (rs_state.initial or mode == ReadPreference.PRIMARY)
self.__schedule_refresh(sync=sync)
rs_state = self.__rs_state
latency = kwargs.get(
'secondary_acceptable_latency_ms',
self.secondary_acceptable_latency_ms)
try:
if _connection_to_use is not None:
if _connection_to_use == -1:
member = rs_state.primary_member
error_message = rs_state.error_message
else:
member = rs_state.get(_connection_to_use)
error_message = '%s:%s not available' % _connection_to_use
if not member:
raise AutoReconnect(error_message)
return member.pool.pair, self.__try_read(
member, msg, **kwargs)
except AutoReconnect:
if _connection_to_use in (-1, rs_state.writer):
# Primary's down. Refresh.
self.disconnect()
raise
# To provide some monotonic consistency, we use the same member as
# long as this thread is in a request and all reads use the same
# mode, tags, and latency. The member gets unpinned if pref changes,
# if member changes state, if we detect a failover, or if this thread
# calls end_request().
errors = []
pinned_host = rs_state.pinned_host
pinned_member = rs_state.get(pinned_host)
if (pinned_member
and pinned_member.matches_mode(mode)
and pinned_member.matches_tag_sets(tag_sets) # TODO: REMOVE?
and rs_state.keep_pinned_host(mode, tag_sets, latency)):
try:
return (
pinned_member.host,
self.__try_read(pinned_member, msg, **kwargs))
except AutoReconnect, why:
if _must_use_master or mode == ReadPreference.PRIMARY:
self.disconnect()
raise
else:
errors.append(str(why))
# No pinned member, or pinned member down or doesn't match read pref
rs_state.unpin_host()
members = list(rs_state.members)
while len(errors) < MAX_RETRY:
member = select_member(
members=members,
mode=mode,
tag_sets=tag_sets,
latency=latency)
if not member:
# Ran out of members to try
break
try:
# Removes member on failure, so select_member won't retry it.
response = self.__try_read(member, msg, **kwargs)
# Success
if self.in_request():
# Keep reading from this member in this thread / greenlet
# unless read preference changes
rs_state.pin_host(member.host, mode, tag_sets, latency)
return member.host, response
except AutoReconnect, why:
if mode == ReadPreference.PRIMARY:
raise
errors.append(str(why))
members.remove(member)
# Ran out of tries
if mode == ReadPreference.PRIMARY:
msg = "No replica set primary available for query"
elif mode == ReadPreference.SECONDARY:
msg = "No replica set secondary available for query"
else:
msg = "No replica set members available for query"
msg += " with ReadPreference %s" % modes[mode]
if tag_sets != [{}]:
msg += " and tags " + repr(tag_sets)
# Format a message like:
# 'No replica set secondary available for query with ReadPreference
# SECONDARY. host:27018: timed out, host:27019: timed out'.
if errors:
msg += ". " + ', '.join(errors)
raise AutoReconnect(msg, errors)
def _exhaust_next(self, sock_info):
"""Used with exhaust cursors to get the next batch off the socket.
Can raise AutoReconnect.
"""
try:
return self.__recv_msg(1, None, sock_info)
except socket.error, e:
raise AutoReconnect(str(e))
def start_request(self):
"""Ensure the current thread or greenlet always uses the same socket
until it calls :meth:`end_request`. For
:class:`~pymongo.read_preferences.ReadPreference` PRIMARY,
auto_start_request=True ensures consistent reads, even if you read
after an unacknowledged write. For read preferences other than PRIMARY,
there are no consistency guarantees.
In Python 2.6 and above, or in Python 2.5 with
"from __future__ import with_statement", :meth:`start_request` can be
used as a context manager:
>>> client = pymongo.MongoReplicaSetClient()
>>> db = client.test
>>> _id = db.test_collection.insert({})
>>> with client.start_request():
... for i in range(100):
... db.test_collection.update({'_id': _id}, {'$set': {'i':i}})
...
... # Definitely read the document after the final update completes
... print db.test_collection.find({'_id': _id})
.. versionadded:: 2.2
The :class:`~pymongo.pool.Request` return value.
:meth:`start_request` previously returned None
"""
# We increment our request counter's thread- or greenlet-local value
# for every call to start_request; however, we only call each pool's
# start_request once to start a request, and call each pool's
# end_request once to end it. We don't let pools' request counters
# exceed 1. This keeps things sane when we create and delete pools
# within a request.
if 1 == self.__request_counter.inc():
for member in self.__rs_state.members:
member.pool.start_request()
return pool.Request(self)
def in_request(self):
"""True if :meth:`start_request` has been called, but not
:meth:`end_request`, or if `auto_start_request` is True and
:meth:`end_request` has not been called in this thread or greenlet.
"""
return bool(self.__request_counter.get())
def end_request(self):
"""Undo :meth:`start_request` and allow this thread's connections to
replica set members to return to the pool.
Calling :meth:`end_request` allows the :class:`~socket.socket` that has
been reserved for this thread by :meth:`start_request` to be returned
to the pool. Other threads will then be able to re-use that
:class:`~socket.socket`. If your application uses many threads, or has
long-running threads that infrequently perform MongoDB operations, then
judicious use of this method can lead to performance gains. Care should
be taken, however, to make sure that :meth:`end_request` is not called
in the middle of a sequence of operations in which ordering is
important. This could lead to unexpected results.
"""
rs_state = self.__rs_state
if 0 == self.__request_counter.dec():
for member in rs_state.members:
# No effect if not in a request
member.pool.end_request()
rs_state.unpin_host()
def __eq__(self, other):
# XXX: Implement this?
return NotImplemented
def __ne__(self, other):
return NotImplemented
def __repr__(self):
return "MongoReplicaSetClient(%r)" % (["%s:%d" % n
for n in self.hosts],)
def __getattr__(self, name):
"""Get a database by name.
Raises :class:`~pymongo.errors.InvalidName` if an invalid
database name is used.
:Parameters:
- `name`: the name of the database to get
"""
return database.Database(self, name)
def __getitem__(self, name):
"""Get a database by name.
Raises :class:`~pymongo.errors.InvalidName` if an invalid
database name is used.
:Parameters:
- `name`: the name of the database to get
"""
return self.__getattr__(name)
def close_cursor(self, cursor_id, _conn_id):
"""Close a single database cursor.
Raises :class:`TypeError` if `cursor_id` is not an instance of
``(int, long)``. What closing the cursor actually means
depends on this client's cursor manager.
:Parameters:
- `cursor_id`: id of cursor to close
"""
if not isinstance(cursor_id, (int, long)):
raise TypeError("cursor_id must be an instance of (int, long)")
self._send_message(message.kill_cursors([cursor_id]),
_connection_to_use=_conn_id)
def server_info(self):
"""Get information about the MongoDB primary we're connected to.
"""
return self.admin.command("buildinfo",
read_preference=ReadPreference.PRIMARY)
def database_names(self):
"""Get a list of the names of all databases on the connected server.
"""
return [db["name"] for db in
self.admin.command("listDatabases",
read_preference=ReadPreference.PRIMARY)["databases"]]
def drop_database(self, name_or_database):
"""Drop a database.
Raises :class:`TypeError` if `name_or_database` is not an instance of
:class:`basestring` (:class:`str` in python 3) or Database
:Parameters:
- `name_or_database`: the name of a database to drop, or a
:class:`~pymongo.database.Database` instance representing the
database to drop
"""
name = name_or_database
if isinstance(name, database.Database):
name = name.name
if not isinstance(name, basestring):
raise TypeError("name_or_database must be an instance of "
"%s or Database" % (basestring.__name__,))
self._purge_index(name)
self[name].command("dropDatabase",
read_preference=ReadPreference.PRIMARY)
def copy_database(self, from_name, to_name,
from_host=None, username=None, password=None):
"""Copy a database, potentially from another host.
Raises :class:`TypeError` if `from_name` or `to_name` is not
an instance of :class:`basestring` (:class:`str` in python 3).
Raises :class:`~pymongo.errors.InvalidName` if `to_name` is
not a valid database name.
If `from_host` is ``None`` the current host is used as the
source. Otherwise the database is copied from `from_host`.
If the source database requires authentication, `username` and
`password` must be specified.
:Parameters:
- `from_name`: the name of the source database
- `to_name`: the name of the target database
- `from_host` (optional): host name to copy from
- `username` (optional): username for source database
- `password` (optional): password for source database
.. note:: Specifying `username` and `password` requires server
version **>= 1.3.3+**.
"""
if not isinstance(from_name, basestring):
raise TypeError("from_name must be an instance "
"of %s" % (basestring.__name__,))
if not isinstance(to_name, basestring):
raise TypeError("to_name must be an instance "
"of %s" % (basestring.__name__,))
database._check_name(to_name)
command = {"fromdb": from_name, "todb": to_name}
if from_host is not None:
command["fromhost"] = from_host
try:
self.start_request()
if username is not None:
nonce = self.admin.command("copydbgetnonce",
read_preference=ReadPreference.PRIMARY,
fromhost=from_host)["nonce"]
command["username"] = username
command["nonce"] = nonce
command["key"] = auth._auth_key(nonce, username, password)
return self.admin.command("copydb",
read_preference=ReadPreference.PRIMARY,
**command)
finally:
self.end_request()
def get_default_database(self):
"""Get the database named in the MongoDB connection URI.
>>> uri = 'mongodb://host/my_database'
>>> client = MongoReplicaSetClient(uri)
>>> db = client.get_default_database()
>>> assert db.name == 'my_database'
Useful in scripts where you want to choose which database to use
based only on the URI in a configuration file.
"""
if self.__default_database_name is None:
raise ConfigurationError('No default database defined')
return self[self.__default_database_name] | PypiClean |
/cloudnetme-0.1.7-py3-none-any.whl/model_evaluation/products/product_resampling.py | import os
import logging
from typing import Optional
import model_evaluation.products.tools as tl
from model_evaluation.products.observation_products import ObservationManager
from model_evaluation.products.model_products import ModelManager
from model_evaluation.products.advance_methods import AdvanceProductMethods
from model_evaluation.file_handler import update_attributes, save_downsampled_file, add_var2ncfile, add_time_attribute
from model_evaluation.products.grid_methods import ProductGrid
from model_evaluation.utils import file_exists
def process_L3_day_product(model: str,
obs: str,
model_files: list,
product_file: str,
output_file: str,
keep_uuid: Optional[bool] = False,
uuid: Optional[str] = None,
overwrite: bool = False):
""" Main function to generate downsample of observations to match model grid.
This function will generate a L3 product nc-file. It includes the information of
downsampled observation products for each model cycles and model products
and other variables of each cycles.
Args:
model (str): Name of model
obs (str): Name of product to generate
model_files (list): List of model + cycles file path(s) to be generated
product_file (str): Source file path of L2 observation product
output_file (str): Path and name of L3 day scale product output file
keep_uuid (bool): If True, keeps the UUID of the old file, if that exists.
Default is False when new UUID is generated.
uuid (str): Set specific UUID for the file.
overwrite (bool): If file exists, but still want to recreate it then True,
default False
Raises:
RuntimeError: Failed to create the L3 product file.
ValueError (Warning): No ice clouds in model data
Notes:
Model file(s) are given as a list to make all different cycles to be at same nc-file.
If list includes more than one model file, nc-file is created within the first round.
With rest of rounds, downsample observation and model data is added to a same L3 day nc-file.
Examples:
>>> from model_evaluation.products.product_resampling import process_L3_day_product
>>> product = 'cf'
>>> model = 'ecmwf'
>>> model_file = 'ecmwf.nc'
>>> input_file = 220190517_mace-head_categorize.nchead_categorize.nc
>>> output_file = 'cf_ecmwf.nc'
>>> process_L3_day_product(model, product, [model_file], input_file, output_file)
"""
product_obj = ObservationManager(obs, product_file)
tl.check_model_file_list(model, model_files)
for m_file in model_files:
model_obj = ModelManager(m_file, model, output_file, obs, check_file=not overwrite)
try:
AdvanceProductMethods(model_obj, m_file, product_obj)
except ValueError as e:
logging.info("Note: {0}".format(e))
pass
ProductGrid(model_obj, product_obj)
attributes = add_time_attribute(product_obj.date)
update_attributes(model_obj.data, attributes)
if not file_exists(output_file) or overwrite:
tl.add_date(model_obj, product_obj)
uuid = save_downsampled_file(f"{obs}_{model}", output_file,
(model_obj, product_obj),
(model_files, product_file),
keep_uuid, uuid)
else:
add_var2ncfile(model_obj, output_file)
return uuid | PypiClean |
/mead_baseline-2.4.2-py3-none-any.whl/mead/api_examples/ed_text.py | import baseline as bl
import argparse
import os
from baseline.utils import str2bool
def main():
parser = argparse.ArgumentParser(description='Encoder-Decoder execution')
parser.add_argument('--model', help='An encoder-decoder model', required=True, type=str)
parser.add_argument('--text', help='raw value or a file', type=str)
parser.add_argument('--backend', help='backend', default='pytorch')
parser.add_argument('--remote', help='(optional) remote endpoint', type=str) # localhost:8500
parser.add_argument('--name', help='(optional) signature name', type=str)
parser.add_argument('--target', help='A file to write decoded output (or print to screen)')
parser.add_argument('--tsv', help='print tab separated', type=bl.str2bool, default=False)
parser.add_argument('--batchsz', help='Size of a batch to pass at once', default=32, type=int)
parser.add_argument('--device', help='device')
parser.add_argument('--alpha', type=float, help='If set use in the gnmt length penalty.')
parser.add_argument('--beam', type=int, default=30, help='The size of beam to use.')
args = parser.parse_known_args()[0]
batches = []
if os.path.exists(args.text) and os.path.isfile(args.text):
with open(args.text, 'r') as f:
batch = []
for line in f:
text = line.strip().split()
if len(batch) == args.batchsz:
batches.append(batch)
batch = []
batch.append(text)
if len(batch) > 0:
batches.append(batch)
else:
batch = [args.text.split()]
batches.append(batch)
m = bl.EncoderDecoderService.load(args.model, backend=args.backend, beam=args.beam,
remote=args.remote, name=args.name, device=args.device)
f = open(args.target, 'w') if args.target is not None else None
for texts in batches:
decoded = m.predict(texts, alpha=args.alpha, beam=args.beam)
for src, dst in zip(texts, decoded):
src_str = ' '.join(src)
dst_str = ' '.join(dst)
if args.tsv:
line = src_str + '\t' + dst_str
else:
line = dst_str
print(line, file=f, flush=True)
if f is not None:
f.close()
if __name__ == '__main__':
main() | PypiClean |
/uniohomeassistant-0.1.3.tar.gz/uniohomeassistant-0.1.3/homeassistant/components/pjlink/media_player.py | from pypjlink import MUTE_AUDIO, Projector
from pypjlink.projector import ProjectorError
import voluptuous as vol
from homeassistant.components.media_player import PLATFORM_SCHEMA, MediaPlayerEntity
from homeassistant.components.media_player.const import (
SUPPORT_SELECT_SOURCE,
SUPPORT_TURN_OFF,
SUPPORT_TURN_ON,
SUPPORT_VOLUME_MUTE,
)
from homeassistant.const import (
CONF_HOST,
CONF_NAME,
CONF_PASSWORD,
CONF_PORT,
STATE_OFF,
STATE_ON,
)
import homeassistant.helpers.config_validation as cv
CONF_ENCODING = "encoding"
DEFAULT_PORT = 4352
DEFAULT_ENCODING = "utf-8"
DEFAULT_TIMEOUT = 10
PLATFORM_SCHEMA = PLATFORM_SCHEMA.extend(
{
vol.Required(CONF_HOST): cv.string,
vol.Optional(CONF_PORT, default=DEFAULT_PORT): cv.port,
vol.Optional(CONF_NAME): cv.string,
vol.Optional(CONF_ENCODING, default=DEFAULT_ENCODING): cv.string,
vol.Optional(CONF_PASSWORD): cv.string,
}
)
SUPPORT_PJLINK = (
SUPPORT_VOLUME_MUTE | SUPPORT_TURN_ON | SUPPORT_TURN_OFF | SUPPORT_SELECT_SOURCE
)
def setup_platform(hass, config, add_entities, discovery_info=None):
"""Set up the PJLink platform."""
host = config.get(CONF_HOST)
port = config.get(CONF_PORT)
name = config.get(CONF_NAME)
encoding = config.get(CONF_ENCODING)
password = config.get(CONF_PASSWORD)
if "pjlink" not in hass.data:
hass.data["pjlink"] = {}
hass_data = hass.data["pjlink"]
device_label = f"{host}:{port}"
if device_label in hass_data:
return
device = PjLinkDevice(host, port, name, encoding, password)
hass_data[device_label] = device
add_entities([device], True)
def format_input_source(input_source_name, input_source_number):
"""Format input source for display in UI."""
return f"{input_source_name} {input_source_number}"
class PjLinkDevice(MediaPlayerEntity):
"""Representation of a PJLink device."""
def __init__(self, host, port, name, encoding, password):
"""Iinitialize the PJLink device."""
self._host = host
self._port = port
self._name = name
self._password = password
self._encoding = encoding
self._muted = False
self._pwstate = STATE_OFF
self._current_source = None
with self.projector() as projector:
if not self._name:
self._name = projector.get_name()
inputs = projector.get_inputs()
self._source_name_mapping = {format_input_source(*x): x for x in inputs}
self._source_list = sorted(self._source_name_mapping.keys())
def projector(self):
"""Create PJLink Projector instance."""
projector = Projector.from_address(
self._host, self._port, self._encoding, DEFAULT_TIMEOUT
)
projector.authenticate(self._password)
return projector
def update(self):
"""Get the latest state from the device."""
with self.projector() as projector:
try:
pwstate = projector.get_power()
if pwstate in ("on", "warm-up"):
self._pwstate = STATE_ON
self._muted = projector.get_mute()[1]
self._current_source = format_input_source(*projector.get_input())
else:
self._pwstate = STATE_OFF
self._muted = False
self._current_source = None
except KeyError as err:
if str(err) == "'OK'":
self._pwstate = STATE_OFF
self._muted = False
self._current_source = None
else:
raise
except ProjectorError as err:
if str(err) == "unavailable time":
self._pwstate = STATE_OFF
self._muted = False
self._current_source = None
else:
raise
@property
def name(self):
"""Return the name of the device."""
return self._name
@property
def state(self):
"""Return the state of the device."""
return self._pwstate
@property
def is_volume_muted(self):
"""Return boolean indicating mute status."""
return self._muted
@property
def source(self):
"""Return current input source."""
return self._current_source
@property
def source_list(self):
"""Return all available input sources."""
return self._source_list
@property
def supported_features(self):
"""Return projector supported features."""
return SUPPORT_PJLINK
def turn_off(self):
"""Turn projector off."""
if self._pwstate == STATE_ON:
with self.projector() as projector:
projector.set_power("off")
def turn_on(self):
"""Turn projector on."""
if self._pwstate == STATE_OFF:
with self.projector() as projector:
projector.set_power("on")
def mute_volume(self, mute):
"""Mute (true) of unmute (false) media player."""
with self.projector() as projector:
projector.set_mute(MUTE_AUDIO, mute)
def select_source(self, source):
"""Set the input source."""
source = self._source_name_mapping[source]
with self.projector() as projector:
projector.set_input(*source) | PypiClean |
/v1/model/update_public_ip_response.py |
import pprint
import re
import six
from huaweicloudsdkcore.sdk_response import SdkResponse
class UpdatePublicIpResponse(SdkResponse):
"""
Attributes:
openapi_types (dict): The key is attribute name
and the value is attribute type.
attribute_map (dict): The key is attribute name
and the value is json key in definition.
"""
sensitive_list = []
openapi_types = {
'publicip': 'PublicIp'
}
attribute_map = {
'publicip': 'publicip'
}
def __init__(self, publicip=None):
"""UpdatePublicIpResponse - a model defined in huaweicloud sdk"""
super().__init__()
self._publicip = None
self.discriminator = None
if publicip is not None:
self.publicip = publicip
@property
def publicip(self):
"""Gets the publicip of this UpdatePublicIpResponse.
:return: The publicip of this UpdatePublicIpResponse.
:rtype: PublicIp
"""
return self._publicip
@publicip.setter
def publicip(self, publicip):
"""Sets the publicip of this UpdatePublicIpResponse.
:param publicip: The publicip of this UpdatePublicIpResponse.
:type: PublicIp
"""
self._publicip = publicip
def to_dict(self):
"""Returns the model properties as a dict"""
result = {}
for attr, _ in six.iteritems(self.openapi_types):
value = getattr(self, attr)
if isinstance(value, list):
result[attr] = list(map(
lambda x: x.to_dict() if hasattr(x, "to_dict") else x,
value
))
elif hasattr(value, "to_dict"):
result[attr] = value.to_dict()
elif isinstance(value, dict):
result[attr] = dict(map(
lambda item: (item[0], item[1].to_dict())
if hasattr(item[1], "to_dict") else item,
value.items()
))
else:
if attr in self.sensitive_list:
result[attr] = "****"
else:
result[attr] = value
return result
def to_str(self):
"""Returns the string representation of the model"""
return pprint.pformat(self.to_dict())
def __repr__(self):
"""For `print` and `pprint`"""
return self.to_str()
def __eq__(self, other):
"""Returns true if both objects are equal"""
if not isinstance(other, UpdatePublicIpResponse):
return False
return self.__dict__ == other.__dict__
def __ne__(self, other):
"""Returns true if both objects are not equal"""
return not self == other | PypiClean |
/formification-1.2.0-py3-none-any.whl/formulaic/static/admin/formulaic/ember-formulaic/node_modules/handlebars/dist/cjs/handlebars.runtime.js | 'use strict';
exports.__esModule = true;
// istanbul ignore next
function _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { 'default': obj }; }
// istanbul ignore next
function _interopRequireWildcard(obj) { if (obj && obj.__esModule) { return obj; } else { var newObj = {}; if (obj != null) { for (var key in obj) { if (Object.prototype.hasOwnProperty.call(obj, key)) newObj[key] = obj[key]; } } newObj['default'] = obj; return newObj; } }
var _handlebarsBase = require('./handlebars/base');
var base = _interopRequireWildcard(_handlebarsBase);
// Each of these augment the Handlebars object. No need to setup here.
// (This is done to easily share code between commonjs and browse envs)
var _handlebarsSafeString = require('./handlebars/safe-string');
var _handlebarsSafeString2 = _interopRequireDefault(_handlebarsSafeString);
var _handlebarsException = require('./handlebars/exception');
var _handlebarsException2 = _interopRequireDefault(_handlebarsException);
var _handlebarsUtils = require('./handlebars/utils');
var Utils = _interopRequireWildcard(_handlebarsUtils);
var _handlebarsRuntime = require('./handlebars/runtime');
var runtime = _interopRequireWildcard(_handlebarsRuntime);
var _handlebarsNoConflict = require('./handlebars/no-conflict');
var _handlebarsNoConflict2 = _interopRequireDefault(_handlebarsNoConflict);
// For compatibility and usage outside of module systems, make the Handlebars object a namespace
function create() {
var hb = new base.HandlebarsEnvironment();
Utils.extend(hb, base);
hb.SafeString = _handlebarsSafeString2['default'];
hb.Exception = _handlebarsException2['default'];
hb.Utils = Utils;
hb.escapeExpression = Utils.escapeExpression;
hb.VM = runtime;
hb.template = function (spec) {
return runtime.template(spec, hb);
};
return hb;
}
var inst = create();
inst.create = create;
_handlebarsNoConflict2['default'](inst);
inst['default'] = inst;
exports['default'] = inst;
module.exports = exports['default'];
//# sourceMappingURL=data:application/json;charset=utf-8;base64,eyJ2ZXJzaW9uIjozLCJzb3VyY2VzIjpbIi4uLy4uL2xpYi9oYW5kbGViYXJzLnJ1bnRpbWUuanMiXSwibmFtZXMiOltdLCJtYXBwaW5ncyI6Ijs7Ozs7Ozs7Ozs7OEJBQXNCLG1CQUFtQjs7SUFBN0IsSUFBSTs7Ozs7b0NBSU8sMEJBQTBCOzs7O21DQUMzQix3QkFBd0I7Ozs7K0JBQ3ZCLG9CQUFvQjs7SUFBL0IsS0FBSzs7aUNBQ1Esc0JBQXNCOztJQUFuQyxPQUFPOztvQ0FFSSwwQkFBMEI7Ozs7O0FBR2pELFNBQVMsTUFBTSxHQUFHO0FBQ2hCLE1BQUksRUFBRSxHQUFHLElBQUksSUFBSSxDQUFDLHFCQUFxQixFQUFFLENBQUM7O0FBRTFDLE9BQUssQ0FBQyxNQUFNLENBQUMsRUFBRSxFQUFFLElBQUksQ0FBQyxDQUFDO0FBQ3ZCLElBQUUsQ0FBQyxVQUFVLG9DQUFhLENBQUM7QUFDM0IsSUFBRSxDQUFDLFNBQVMsbUNBQVksQ0FBQztBQUN6QixJQUFFLENBQUMsS0FBSyxHQUFHLEtBQUssQ0FBQztBQUNqQixJQUFFLENBQUMsZ0JBQWdCLEdBQUcsS0FBSyxDQUFDLGdCQUFnQixDQUFDOztBQUU3QyxJQUFFLENBQUMsRUFBRSxHQUFHLE9BQU8sQ0FBQztBQUNoQixJQUFFLENBQUMsUUFBUSxHQUFHLFVBQVMsSUFBSSxFQUFFO0FBQzNCLFdBQU8sT0FBTyxDQUFDLFFBQVEsQ0FBQyxJQUFJLEVBQUUsRUFBRSxDQUFDLENBQUM7R0FDbkMsQ0FBQzs7QUFFRixTQUFPLEVBQUUsQ0FBQztDQUNYOztBQUVELElBQUksSUFBSSxHQUFHLE1BQU0sRUFBRSxDQUFDO0FBQ3BCLElBQUksQ0FBQyxNQUFNLEdBQUcsTUFBTSxDQUFDOztBQUVyQixrQ0FBVyxJQUFJLENBQUMsQ0FBQzs7QUFFakIsSUFBSSxDQUFDLFNBQVMsQ0FBQyxHQUFHLElBQUksQ0FBQzs7cUJBRVIsSUFBSSIsImZpbGUiOiJoYW5kbGViYXJzLnJ1bnRpbWUuanMiLCJzb3VyY2VzQ29udGVudCI6WyJpbXBvcnQgKiBhcyBiYXNlIGZyb20gJy4vaGFuZGxlYmFycy9iYXNlJztcblxuLy8gRWFjaCBvZiB0aGVzZSBhdWdtZW50IHRoZSBIYW5kbGViYXJzIG9iamVjdC4gTm8gbmVlZCB0byBzZXR1cCBoZXJlLlxuLy8gKFRoaXMgaXMgZG9uZSB0byBlYXNpbHkgc2hhcmUgY29kZSBiZXR3ZWVuIGNvbW1vbmpzIGFuZCBicm93c2UgZW52cylcbmltcG9ydCBTYWZlU3RyaW5nIGZyb20gJy4vaGFuZGxlYmFycy9zYWZlLXN0cmluZyc7XG5pbXBvcnQgRXhjZXB0aW9uIGZyb20gJy4vaGFuZGxlYmFycy9leGNlcHRpb24nO1xuaW1wb3J0ICogYXMgVXRpbHMgZnJvbSAnLi9oYW5kbGViYXJzL3V0aWxzJztcbmltcG9ydCAqIGFzIHJ1bnRpbWUgZnJvbSAnLi9oYW5kbGViYXJzL3J1bnRpbWUnO1xuXG5pbXBvcnQgbm9Db25mbGljdCBmcm9tICcuL2hhbmRsZWJhcnMvbm8tY29uZmxpY3QnO1xuXG4vLyBGb3IgY29tcGF0aWJpbGl0eSBhbmQgdXNhZ2Ugb3V0c2lkZSBvZiBtb2R1bGUgc3lzdGVtcywgbWFrZSB0aGUgSGFuZGxlYmFycyBvYmplY3QgYSBuYW1lc3BhY2VcbmZ1bmN0aW9uIGNyZWF0ZSgpIHtcbiAgbGV0IGhiID0gbmV3IGJhc2UuSGFuZGxlYmFyc0Vudmlyb25tZW50KCk7XG5cbiAgVXRpbHMuZXh0ZW5kKGhiLCBiYXNlKTtcbiAgaGIuU2FmZVN0cmluZyA9IFNhZmVTdHJpbmc7XG4gIGhiLkV4Y2VwdGlvbiA9IEV4Y2VwdGlvbjtcbiAgaGIuVXRpbHMgPSBVdGlscztcbiAgaGIuZXNjYXBlRXhwcmVzc2lvbiA9IFV0aWxzLmVzY2FwZUV4cHJlc3Npb247XG5cbiAgaGIuVk0gPSBydW50aW1lO1xuICBoYi50ZW1wbGF0ZSA9IGZ1bmN0aW9uKHNwZWMpIHtcbiAgICByZXR1cm4gcnVudGltZS50ZW1wbGF0ZShzcGVjLCBoYik7XG4gIH07XG5cbiAgcmV0dXJuIGhiO1xufVxuXG5sZXQgaW5zdCA9IGNyZWF0ZSgpO1xuaW5zdC5jcmVhdGUgPSBjcmVhdGU7XG5cbm5vQ29uZmxpY3QoaW5zdCk7XG5cbmluc3RbJ2RlZmF1bHQnXSA9IGluc3Q7XG5cbmV4cG9ydCBkZWZhdWx0IGluc3Q7XG4iXX0= | PypiClean |
/aoricaan-cli-0.3.4.tar.gz/aoricaan-cli-0.3.4/aoricaan_cli/src/lambdas/lambdas.py | import json
import os
import shutil
from pathlib import Path
import typer
from aoricaan_cli.src.utils.api_local import build_files_for_api_local
from aoricaan_cli.src.utils.core import parse_lambda_code, parse_lambda_cfn_configuration, rename_lambda
from aoricaan_cli.src.utils.debugger import Debug
from aoricaan_cli.src.utils.folders import validate_path_not_exist, validate_path_exist, list_path
from aoricaan_cli.src.utils.globals import load_config
app = typer.Typer()
state = {"verbose": False}
@app.command('new')
def new_lambda(name: str = typer.Option(..., help='Name for the new lambda.', prompt=True),
handler: str = typer.Option('lambda_function.lambda_handler',
help='name of the function file and function name.')):
"""
Add a new aws lambda structure in the project.
"""
lambda_path = Path(load_config().project.folders.lambdas).joinpath(name)
validate_path_not_exist(path=lambda_path, custom_error_message=f'Already exist a lambda named: {name}')
lambda_path.mkdir()
lambda_function, lambda_handler = handler.split('.')
lambda_code = parse_lambda_code(lambda_handler)
lambda_path.joinpath(f'{lambda_function}.py').write_text(lambda_code)
lambda_path.joinpath('__init__.py').write_text("")
# TODO: Read test templates.
lambda_path.joinpath('test_lambda_function.py').write_text("")
cfn_config = parse_lambda_cfn_configuration(handler=handler, name=name, path=lambda_path)
lambda_path.joinpath('configuration.json').write_text(json.dumps({"cfn": cfn_config,
"swagger": {}}, indent=2))
Debug.success(f'{name} was added successfully!')
@app.command('delete')
def new_lambda(name: str = typer.Option(..., help='Lambda name for delete', prompt=True)):
"""
Delete an existent lambda in the project.
"""
work_path = Path(load_config().project.folders.lambdas)
path = work_path.joinpath(name)
validate_path_exist(path=path)
typer.confirm('Are you sure you want to delete it?', abort=True)
shutil.rmtree(path)
build_files_for_api_local(reload=True)
Debug.success(f'{name} was deleted successfully!')
@app.command('rename')
def rename(name: str = typer.Option(..., help='Lambda name for rename', prompt=True),
new_name: str = typer.Option(..., help='New name for lambda', prompt=True)
):
"""
Change the lambda name.
"""
work_path = Path(load_config().project.folders.lambdas)
old_path = work_path.joinpath(name)
validate_path_exist(path=old_path)
new_path = work_path.joinpath(new_name)
validate_path_not_exist(path=new_path)
os.rename(src=old_path, dst=new_path)
rename_lambda(old_path=old_path, new_path=new_path)
Debug.success(f'{name} was renamed to {new_name} successfully!')
@app.command('list')
def get_all_lambdas():
"""
show all lambdas in the project.
"""
work_path = Path(load_config().project.folders.lambdas)
lambdas = [[_lambda] for _lambda in list_path(path=work_path, exclude_filter='__') if
work_path.joinpath(_lambda).is_dir()]
Debug.table(values=lambdas, headers=["lambda name"])
@app.callback()
def root(ctx: typer.Context, verbose: bool = typer.Option(False, '--verbose', '-v')):
"""
Manage the lambdas in the project
"""
if verbose and ctx.invoked_subcommand:
Debug.info(f"Running command: {ctx.invoked_subcommand}")
if __name__ == '__main__':
app() | PypiClean |
/msgraph_beta_sdk-1.0.0a9-py3-none-any.whl/msgraph/generated/device_management/zebra_fota_connector/disconnect/disconnect_response.py | from __future__ import annotations
from kiota_abstractions.serialization import AdditionalDataHolder, Parsable, ParseNode, SerializationWriter
from typing import Any, Callable, Dict, List, Optional, TYPE_CHECKING, Union
class DisconnectResponse(AdditionalDataHolder, Parsable):
def __init__(self,) -> None:
"""
Instantiates a new disconnectResponse and sets the default values.
"""
# Stores additional data not described in the OpenAPI description found when deserializing. Can be used for serialization as well.
self._additional_data: Dict[str, Any] = {}
# The value property
self._value: Optional[bool] = None
@property
def additional_data(self,) -> Dict[str, Any]:
"""
Gets the additionalData property value. Stores additional data not described in the OpenAPI description found when deserializing. Can be used for serialization as well.
Returns: Dict[str, Any]
"""
return self._additional_data
@additional_data.setter
def additional_data(self,value: Dict[str, Any]) -> None:
"""
Sets the additionalData property value. Stores additional data not described in the OpenAPI description found when deserializing. Can be used for serialization as well.
Args:
value: Value to set for the AdditionalData property.
"""
self._additional_data = value
@staticmethod
def create_from_discriminator_value(parse_node: Optional[ParseNode] = None) -> DisconnectResponse:
"""
Creates a new instance of the appropriate class based on discriminator value
Args:
parseNode: The parse node to use to read the discriminator value and create the object
Returns: DisconnectResponse
"""
if parse_node is None:
raise Exception("parse_node cannot be undefined")
return DisconnectResponse()
def get_field_deserializers(self,) -> Dict[str, Callable[[ParseNode], None]]:
"""
The deserialization information for the current model
Returns: Dict[str, Callable[[ParseNode], None]]
"""
fields: Dict[str, Callable[[Any], None]] = {
"value": lambda n : setattr(self, 'value', n.get_bool_value()),
}
return fields
def serialize(self,writer: SerializationWriter) -> None:
"""
Serializes information the current object
Args:
writer: Serialization writer to use to serialize this model
"""
if writer is None:
raise Exception("writer cannot be undefined")
writer.write_bool_value("value", self.value)
writer.write_additional_data_value(self.additional_data)
@property
def value(self,) -> Optional[bool]:
"""
Gets the value property value. The value property
Returns: Optional[bool]
"""
return self._value
@value.setter
def value(self,value: Optional[bool] = None) -> None:
"""
Sets the value property value. The value property
Args:
value: Value to set for the value property.
"""
self._value = value | PypiClean |
/pulumi_azure_nextgen-0.6.2a1613157620.tar.gz/pulumi_azure_nextgen-0.6.2a1613157620/pulumi_azure_nextgen/visualstudio/v20140401preview/get_extension.py |
import warnings
import pulumi
import pulumi.runtime
from typing import Any, Mapping, Optional, Sequence, Union
from ... import _utilities, _tables
from . import outputs
__all__ = [
'GetExtensionResult',
'AwaitableGetExtensionResult',
'get_extension',
]
@pulumi.output_type
class GetExtensionResult:
"""
The response to an extension resource GET request.
"""
def __init__(__self__, id=None, location=None, name=None, plan=None, properties=None, tags=None, type=None):
if id and not isinstance(id, str):
raise TypeError("Expected argument 'id' to be a str")
pulumi.set(__self__, "id", id)
if location and not isinstance(location, str):
raise TypeError("Expected argument 'location' to be a str")
pulumi.set(__self__, "location", location)
if name and not isinstance(name, str):
raise TypeError("Expected argument 'name' to be a str")
pulumi.set(__self__, "name", name)
if plan and not isinstance(plan, dict):
raise TypeError("Expected argument 'plan' to be a dict")
pulumi.set(__self__, "plan", plan)
if properties and not isinstance(properties, dict):
raise TypeError("Expected argument 'properties' to be a dict")
pulumi.set(__self__, "properties", properties)
if tags and not isinstance(tags, dict):
raise TypeError("Expected argument 'tags' to be a dict")
pulumi.set(__self__, "tags", tags)
if type and not isinstance(type, str):
raise TypeError("Expected argument 'type' to be a str")
pulumi.set(__self__, "type", type)
@property
@pulumi.getter
def id(self) -> str:
"""
Unique identifier of the resource.
"""
return pulumi.get(self, "id")
@property
@pulumi.getter
def location(self) -> Optional[str]:
"""
Resource location.
"""
return pulumi.get(self, "location")
@property
@pulumi.getter
def name(self) -> str:
"""
Resource name.
"""
return pulumi.get(self, "name")
@property
@pulumi.getter
def plan(self) -> Optional['outputs.ExtensionResourcePlanResponse']:
"""
The extension plan that was purchased.
"""
return pulumi.get(self, "plan")
@property
@pulumi.getter
def properties(self) -> Mapping[str, str]:
"""
Resource properties.
"""
return pulumi.get(self, "properties")
@property
@pulumi.getter
def tags(self) -> Optional[Mapping[str, str]]:
"""
Resource tags.
"""
return pulumi.get(self, "tags")
@property
@pulumi.getter
def type(self) -> str:
"""
Resource type.
"""
return pulumi.get(self, "type")
class AwaitableGetExtensionResult(GetExtensionResult):
# pylint: disable=using-constant-test
def __await__(self):
if False:
yield self
return GetExtensionResult(
id=self.id,
location=self.location,
name=self.name,
plan=self.plan,
properties=self.properties,
tags=self.tags,
type=self.type)
def get_extension(account_resource_name: Optional[str] = None,
extension_resource_name: Optional[str] = None,
resource_group_name: Optional[str] = None,
opts: Optional[pulumi.InvokeOptions] = None) -> AwaitableGetExtensionResult:
"""
Use this data source to access information about an existing resource.
:param str account_resource_name: The name of the Visual Studio Team Services account resource.
:param str extension_resource_name: The name of the extension.
:param str resource_group_name: Name of the resource group within the Azure subscription.
"""
__args__ = dict()
__args__['accountResourceName'] = account_resource_name
__args__['extensionResourceName'] = extension_resource_name
__args__['resourceGroupName'] = resource_group_name
if opts is None:
opts = pulumi.InvokeOptions()
if opts.version is None:
opts.version = _utilities.get_version()
__ret__ = pulumi.runtime.invoke('azure-nextgen:visualstudio/v20140401preview:getExtension', __args__, opts=opts, typ=GetExtensionResult).value
return AwaitableGetExtensionResult(
id=__ret__.id,
location=__ret__.location,
name=__ret__.name,
plan=__ret__.plan,
properties=__ret__.properties,
tags=__ret__.tags,
type=__ret__.type) | PypiClean |
/Rails-0.0.5.tar.gz/Rails-0.0.5/rails/router.py | from __future__ import absolute_import
import os
import sys
import traceback
from webob.exc import HTTPNotFound, HTTPInternalServerError
from .config import Config
from .config import get_config
from .request import Request
from .response import Response
from .exceptions import PageNotFound
from .tools import import_module
from .views import View
class Router(object):
"""
Main project router that calls appropriate controller.
TODO:
- decorate each controller's call with middleware
- (done) load all controllers and their actions to dict to speedup
lookup of desired url address
"""
def __init__(self):
"""
Load all controllers.
It allow us to speed-up get controller by given url.
"""
self._controllers = {}
self._project_dir = os.path.dirname(os.path.realpath(sys.argv[0]))
self._load_config()
self._load_controllers()
self._init_view()
def __call__(self, environ, start_response):
"""
Find appropriate controller for requested address.
Return Response object that support the WSGI interface.
"""
request = Request(environ)
try:
controller_name = request.get_controller_name()
action_name = request.get_action_name()
action_handler = self.get_action_handler(controller_name, action_name)
if not callable(action_handler):
# action handler should be a callable function
raise PageNotFound(
"Controller '{name}' doesn't have action '{action}'",
name=controller_name,
action=action_name
)
resp = action_handler(request)
if not isinstance(resp, Response):
raise Exception("Controller should return Response object, but given '{}'".format(type(resp)))
except PageNotFound as err:
message = self._format_error_message(str(err), with_traceback=True)
return HTTPNotFound(message)(environ, start_response)
except Exception as err:
message = self._format_error_message(str(err), with_traceback=True)
return HTTPInternalServerError(message)(environ, start_response)
return resp(environ, start_response)
def _load_config(self):
"""
Load config for current project.
"""
self._config = Config()
def _load_controllers(self):
"""
Load all controllers from folder 'controllers'.
Ignore files with leading underscore (for example: controllers/_blogs.py)
"""
for file_name in os.listdir(os.path.join(self._project_dir, 'controllers')):
# ignore disabled controllers
if not file_name.startswith('_'):
module_name = file_name.split('.', 1)[0]
module_path = "controllers.{}".format(module_name)
module = import_module(module_path)
# transform 'blog_articles' file name to 'BlogArticles' class
controller_class_name = module_name.title().replace('_', '')
controller_class = getattr(module, controller_class_name)
controller = controller_class()
for action_name in dir(controller):
action = getattr(controller, action_name)
if action_name.startswith('_') or not callable(action):
continue
url_path = "/".join([module_name, action_name])
self._controllers[url_path] = action
return self._controllers
def _init_view(self):
"""
Initialize View with project settings.
"""
views_engine = get_config('rails.views.engine', 'jinja')
templates_dir = os.path.join(self._project_dir, "views", "templates")
self._view = View(views_engine, templates_dir)
def _format_error_message(self, msg, with_traceback=False):
if with_traceback:
tb = traceback.format_exc()
msg += "<h3>Traceback</h3>\n\n<pre>{}</pre>".format(tb)
return msg
def get_action_handler(self, controller_name, action_name):
"""
Return action of controller as callable.
If requested controller isn't found - return 'not_found' action
of requested controller or Index controller.
"""
try_actions = [
controller_name + '/' + action_name,
controller_name + '/not_found',
# call Index controller to catch all unhandled pages
'index/not_found'
]
# search first appropriate action handler
for path in try_actions:
if path in self._controllers:
return self._controllers[path]
return None | PypiClean |
/django_contactform_bootstrap-1.0rc1.tar.gz/django_contactform_bootstrap-1.0rc1/README.rst | .. image:: https://api.travis-ci.org/alainivars/django-contact-form.svg?branch=master
:target: http://travis-ci.org/alainivars/django-contact-form
:alt: Build status
.. image:: https://coveralls.io/repos/alainivars/django-contact-form/badge.svg?branch=devel
:target: https://coveralls.io/r/alainivars/django-contact-form?branch=devel
:alt: Test coverage status
.. image:: https://requires.io/github/alainivars/django-contact-form/requirements.svg?branch=master
:target: https://requires.io/github/alainivars/django-contact-form/requirements/?branch=master
:alt: Requirements Status
.. image:: https://img.shields.io/pypi/dm/django_contactform_bootstrap.svg
:target: https://pypi.python.org/pypi/django_contactform_bootstrap/
:alt: pypi download
.. image:: https://img.shields.io/pypi/pyversions/django_contactform_bootstrap.svg
:target: https://pypi.python.org/pypi/django_contactform_bootstrap/
:alt: python supported
.. image:: https://img.shields.io/pypi/l/django_contactform_bootstrap.svg
:target: https://pypi.python.org/pypi/django_contactform_bootstrap/
:alt: licence
.. image:: https://img.shields.io/pypi/v//django_contactform_bootstrap.svg
:target: https://pypi.python.org/pypi/django_contactform_bootstrap
:alt: PyPi version
.. image:: https://landscape.io/github/alainivars/django-contact-form/master/landscape.svg?style=flat
:target: https://landscape.io/github/alainivars/django-contact-form/master
:alt: Code Health
.. image:: https://readthedocs.org/projects/django_contactform_bootstrap/badge/?version=latest
:target: https://readthedocs.org/projects/django_contactform_bootstrap/?badge=latest
:alt: Documentation status
.. image:: https://pypip.in/wheel/django_contactform_bootstrap/badge.svg
:target: https://pypi.python.org/pypi/django_contactform_bootstrap/
:alt: PyPi wheel
Releases Notes
==============
- 1.0rc1: Add support and tests on Django 2.1.1, 2.2.19, 3.1.7 and update dependencies
- 0.6.2: finish english and french translation
- 0.6.1: fix import reCapcha support
- 0.6.0: add reCapcha support, fix links to your : FACEBOOK, LINKEDIN, TWITTER, GOOGLE+
- 0.5.11: fix a bug with import main settings
- 0.5.0: Add support and tests on Django 1.9 and update dependencies
Requirements
============
- Python 3.8, 3.9
- Django 2.1.1+, 2.2.19+, 3.1.7+ and djangomaster
Features
========
* Functionality as a django contact form::
- easy integration into an existing django project
- Bootstrap 5
- integrate geographical map
- log (not yet finish)
- tests and coverage
- links to your : FACEBOOK, LINKEDIN, TWITTER, GOOGLE+
Todo
====
- finish Portuguese, Russian and Spanish translation and add other translations
- manage display a link only if it exist
- correct broken status links in this file
Screenshot
==========
.. image:: https://dl.dropboxusercontent.com/u/95975146/django-contactform-bootstrap.jpg
:target: https://dl.dropboxusercontent.com/u/95975146/django-contactform-bootstrap.jpg
:alt: Contact form Screenshot
Download
========
- source code here::
git clone https://github.com/alainivars/django-contact-form.git
- packet::
https://pypi.python.org/pypi/django_contactform_bootstrap
- or::
pip install django_contactform_bootstrap
Use
===
+ Add in your settings file::
INSTALLED_APPS = (
...
'contact_form_bootstrap',
...
)
ADMINS = (
('your admin name', '[email protected]'),
)
COMPANY = {
'NAME': "my company",
'ADDRESS': "26 streets from here th there",
'ZIP': "1234",
'CITY': "Paris",
'LAT': 48.81484460000001,
'LNG': 2.0523723999999675,
'PHONE': "+336 1234 5678",
'EMAIL': '[email protected]',
'FACEBOOK': "https://www.facebook.com/highfeature",
'LINKEDIN': "http://www.linkedin.com/in/ivarsalain",
'TWITTER': "https://twitter.com/HighFeature",
'GOOGLEPLUS': "https://twitter.com/HighFeature",
}
CRISPY_TEMPLATE_PACK = 'bootstrap3'
USE_RECAPTCHA = False or True
and if you use it : (https://www.google.com/recaptcha)
RECAPTCHA_PUBLIC_KEY = 'your reCapcha public key'
RECAPTCHA_PRIVATE_KEY = 'your reCapcha private key'
+ Don't forget to set::
EMAIL_HOST, EMAIL_PORT, EMAIL_HOST_USER and EMAIL_HOST_PASSWORD
Documentation
=============
.. note::
Please note that this Project is documented poorly. If you have any questions please contact us!
We'd love to update the documentation and answer your question!
Getting Help
============
Please report bugs or ask questions using the `Issue Tracker`
Check also for the latest updates of this project on Github_.
Credits
=======
Based on James Bennett's django_contact_form:
- https://bitbucket.org/ubernostrum/django_contact_form
Based on Aaron Madison django_contact_form:
- https://github.com/madisona/django-contact-form
By Alain Ivars django_contactform_bootstrap:
- https://github.com/alainivars/django-contact-form
* `django`_
.. _Github: https://github.com/alainivars/django_contactform_bootstrap
.. _Issue Tracker: https://github.com/alainivars/django_contactform_bootstrap/issues
.. _django: http://www.djangoproject.com
| PypiClean |
/django-thumb-1.0.2.tar.gz/django-thumb-1.0.2/README.rst | =====
django-thumb
=====
django-thumb is a simple Django app contains 2 models fields
to generate images from videos and write on images
Visit the github repo https://github.com/AmrAnwar/django-thumb for more info.
Quick start
-----------
1. Add "thumb" to your INSTALLED_APPS setting like this::
INSTALLED_APPS = [
...
'thumb',
]
2. Add the STATIC_ROOT, MEDIA_ROOT and MEDIA_URL in setting like:
STATIC_ROOT = os.path.join(BASE_DIR, "static")
MEDIA_ROOT = 'media'
MEDIA_URL = '/media/'
3. Add the MEDIA path to your urlpatterns in urls.py like:
...
from django.conf.urls.static import static
from django.conf import settings
urlpatterns = [
...
] + static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)
3. Run `python manage.py collectstatic ` to create the static fields in your root.
4. now you can use the app model fields like:
from thumb import ImageThumbnailField, VideoThumbnailField
5. in VideoThumbnailField you have to give the video field name if it's not named as `video`:
my_video = models.FileField()
thumb = VideoThumbnailField(video_field_name="my_video")
6. test the Thumbnail Fields in the admin page http://127.0.0.1:8000/admin/
### Visit https://github.com/AmrAnwar/django-thumb for more info. | PypiClean |
/lbrlabs_pulumi_launchdarkly-0.0.6.tar.gz/lbrlabs_pulumi_launchdarkly-0.0.6/lbrlabs_pulumi_launchdarkly/destination.py |
import copy
import warnings
import pulumi
import pulumi.runtime
from typing import Any, Mapping, Optional, Sequence, Union, overload
from . import _utilities
__all__ = ['DestinationArgs', 'Destination']
@pulumi.input_type
class DestinationArgs:
def __init__(__self__, *,
config: pulumi.Input[Mapping[str, pulumi.Input[str]]],
env_key: pulumi.Input[str],
kind: pulumi.Input[str],
project_key: pulumi.Input[str],
name: Optional[pulumi.Input[str]] = None,
on: Optional[pulumi.Input[bool]] = None,
tags: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]] = None):
"""
The set of arguments for constructing a Destination resource.
:param pulumi.Input[Mapping[str, pulumi.Input[str]]] config: - The destination-specific configuration. To learn more, read Destination-Specific Configs.
:param pulumi.Input[str] env_key: - The environment key. A change in this field will force the destruction of the existing resource and the creation of a new one.
:param pulumi.Input[str] kind: - The data export destination type. Available choices are `kinesis`, `google-pubsub`, `mparticle`, `azure-event-hubs`, and `segment`. A change in this field will force the destruction of the existing resource and the creation of a new one.
:param pulumi.Input[str] project_key: - The LaunchDarkly project key. A change in this field will force the destruction of the existing resource and the creation of a new one.
:param pulumi.Input[str] name: -
:param pulumi.Input[bool] on: - Whether the data export destination is on or not.
:param pulumi.Input[Sequence[pulumi.Input[str]]] tags: Tags associated with your resource
"""
pulumi.set(__self__, "config", config)
pulumi.set(__self__, "env_key", env_key)
pulumi.set(__self__, "kind", kind)
pulumi.set(__self__, "project_key", project_key)
if name is not None:
pulumi.set(__self__, "name", name)
if on is not None:
pulumi.set(__self__, "on", on)
if tags is not None:
pulumi.set(__self__, "tags", tags)
@property
@pulumi.getter
def config(self) -> pulumi.Input[Mapping[str, pulumi.Input[str]]]:
"""
- The destination-specific configuration. To learn more, read Destination-Specific Configs.
"""
return pulumi.get(self, "config")
@config.setter
def config(self, value: pulumi.Input[Mapping[str, pulumi.Input[str]]]):
pulumi.set(self, "config", value)
@property
@pulumi.getter(name="envKey")
def env_key(self) -> pulumi.Input[str]:
"""
- The environment key. A change in this field will force the destruction of the existing resource and the creation of a new one.
"""
return pulumi.get(self, "env_key")
@env_key.setter
def env_key(self, value: pulumi.Input[str]):
pulumi.set(self, "env_key", value)
@property
@pulumi.getter
def kind(self) -> pulumi.Input[str]:
"""
- The data export destination type. Available choices are `kinesis`, `google-pubsub`, `mparticle`, `azure-event-hubs`, and `segment`. A change in this field will force the destruction of the existing resource and the creation of a new one.
"""
return pulumi.get(self, "kind")
@kind.setter
def kind(self, value: pulumi.Input[str]):
pulumi.set(self, "kind", value)
@property
@pulumi.getter(name="projectKey")
def project_key(self) -> pulumi.Input[str]:
"""
- The LaunchDarkly project key. A change in this field will force the destruction of the existing resource and the creation of a new one.
"""
return pulumi.get(self, "project_key")
@project_key.setter
def project_key(self, value: pulumi.Input[str]):
pulumi.set(self, "project_key", value)
@property
@pulumi.getter
def name(self) -> Optional[pulumi.Input[str]]:
"""
-
"""
return pulumi.get(self, "name")
@name.setter
def name(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "name", value)
@property
@pulumi.getter
def on(self) -> Optional[pulumi.Input[bool]]:
"""
- Whether the data export destination is on or not.
"""
return pulumi.get(self, "on")
@on.setter
def on(self, value: Optional[pulumi.Input[bool]]):
pulumi.set(self, "on", value)
@property
@pulumi.getter
def tags(self) -> Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]:
"""
Tags associated with your resource
"""
return pulumi.get(self, "tags")
@tags.setter
def tags(self, value: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]):
pulumi.set(self, "tags", value)
@pulumi.input_type
class _DestinationState:
def __init__(__self__, *,
config: Optional[pulumi.Input[Mapping[str, pulumi.Input[str]]]] = None,
env_key: Optional[pulumi.Input[str]] = None,
kind: Optional[pulumi.Input[str]] = None,
name: Optional[pulumi.Input[str]] = None,
on: Optional[pulumi.Input[bool]] = None,
project_key: Optional[pulumi.Input[str]] = None,
tags: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]] = None):
"""
Input properties used for looking up and filtering Destination resources.
:param pulumi.Input[Mapping[str, pulumi.Input[str]]] config: - The destination-specific configuration. To learn more, read Destination-Specific Configs.
:param pulumi.Input[str] env_key: - The environment key. A change in this field will force the destruction of the existing resource and the creation of a new one.
:param pulumi.Input[str] kind: - The data export destination type. Available choices are `kinesis`, `google-pubsub`, `mparticle`, `azure-event-hubs`, and `segment`. A change in this field will force the destruction of the existing resource and the creation of a new one.
:param pulumi.Input[str] name: -
:param pulumi.Input[bool] on: - Whether the data export destination is on or not.
:param pulumi.Input[str] project_key: - The LaunchDarkly project key. A change in this field will force the destruction of the existing resource and the creation of a new one.
:param pulumi.Input[Sequence[pulumi.Input[str]]] tags: Tags associated with your resource
"""
if config is not None:
pulumi.set(__self__, "config", config)
if env_key is not None:
pulumi.set(__self__, "env_key", env_key)
if kind is not None:
pulumi.set(__self__, "kind", kind)
if name is not None:
pulumi.set(__self__, "name", name)
if on is not None:
pulumi.set(__self__, "on", on)
if project_key is not None:
pulumi.set(__self__, "project_key", project_key)
if tags is not None:
pulumi.set(__self__, "tags", tags)
@property
@pulumi.getter
def config(self) -> Optional[pulumi.Input[Mapping[str, pulumi.Input[str]]]]:
"""
- The destination-specific configuration. To learn more, read Destination-Specific Configs.
"""
return pulumi.get(self, "config")
@config.setter
def config(self, value: Optional[pulumi.Input[Mapping[str, pulumi.Input[str]]]]):
pulumi.set(self, "config", value)
@property
@pulumi.getter(name="envKey")
def env_key(self) -> Optional[pulumi.Input[str]]:
"""
- The environment key. A change in this field will force the destruction of the existing resource and the creation of a new one.
"""
return pulumi.get(self, "env_key")
@env_key.setter
def env_key(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "env_key", value)
@property
@pulumi.getter
def kind(self) -> Optional[pulumi.Input[str]]:
"""
- The data export destination type. Available choices are `kinesis`, `google-pubsub`, `mparticle`, `azure-event-hubs`, and `segment`. A change in this field will force the destruction of the existing resource and the creation of a new one.
"""
return pulumi.get(self, "kind")
@kind.setter
def kind(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "kind", value)
@property
@pulumi.getter
def name(self) -> Optional[pulumi.Input[str]]:
"""
-
"""
return pulumi.get(self, "name")
@name.setter
def name(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "name", value)
@property
@pulumi.getter
def on(self) -> Optional[pulumi.Input[bool]]:
"""
- Whether the data export destination is on or not.
"""
return pulumi.get(self, "on")
@on.setter
def on(self, value: Optional[pulumi.Input[bool]]):
pulumi.set(self, "on", value)
@property
@pulumi.getter(name="projectKey")
def project_key(self) -> Optional[pulumi.Input[str]]:
"""
- The LaunchDarkly project key. A change in this field will force the destruction of the existing resource and the creation of a new one.
"""
return pulumi.get(self, "project_key")
@project_key.setter
def project_key(self, value: Optional[pulumi.Input[str]]):
pulumi.set(self, "project_key", value)
@property
@pulumi.getter
def tags(self) -> Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]:
"""
Tags associated with your resource
"""
return pulumi.get(self, "tags")
@tags.setter
def tags(self, value: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]]):
pulumi.set(self, "tags", value)
class Destination(pulumi.CustomResource):
@overload
def __init__(__self__,
resource_name: str,
opts: Optional[pulumi.ResourceOptions] = None,
config: Optional[pulumi.Input[Mapping[str, pulumi.Input[str]]]] = None,
env_key: Optional[pulumi.Input[str]] = None,
kind: Optional[pulumi.Input[str]] = None,
name: Optional[pulumi.Input[str]] = None,
on: Optional[pulumi.Input[bool]] = None,
project_key: Optional[pulumi.Input[str]] = None,
tags: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]] = None,
__props__=None):
"""
Provides a LaunchDarkly Data Export Destination resource.
> **Note:** Data Export is available to customers on an Enterprise LaunchDarkly plan. To learn more, read about our pricing. To upgrade your plan, [contact LaunchDarkly Sales](https://launchdarkly.com/contact-sales/).
Data Export Destinations are locations that receive exported data. This resource allows you to configure destinations for the export of raw analytics data, including feature flag requests, analytics events, custom events, and more.
To learn more about data export, read [Data Export Documentation](https://docs.launchdarkly.com/integrations/data-export).
## Example Usage
Currently the following five types of destinations are available: kinesis, google-pubsub, mparticle, azure-event-hubs, and segment. Please note that config fields will vary depending on which destination you are trying to configure / access.
```python
import pulumi
import lbrlabs_pulumi_launchdarkly as launchdarkly
example = launchdarkly.Destination("example",
project_key="example-project",
env_key="example-env",
kind="kinesis",
config={
"region": "us-east-1",
"role_arn": "arn:aws:iam::123456789012:role/marketingadmin",
"stream_name": "cat-stream",
},
on=True,
tags=["terraform"])
```
```python
import pulumi
import lbrlabs_pulumi_launchdarkly as launchdarkly
example = launchdarkly.Destination("example",
project_key="example-project",
env_key="example-env",
kind="google-pubsub",
config={
"project": "example-pub-sub-project",
"topic": "example-topic",
},
on=True,
tags=["terraform"])
```
```python
import pulumi
import lbrlabs_pulumi_launchdarkly as launchdarkly
example = launchdarkly.Destination("example",
project_key="example-project",
env_key="example-env",
kind="mparticle",
config={
"api_key": "apiKeyfromMParticle",
"secret": "mParticleSecret",
"user_identity": "customer_id",
"environment": "production",
},
on=True,
tags=["terraform"])
```
```python
import pulumi
import lbrlabs_pulumi_launchdarkly as launchdarkly
example = launchdarkly.Destination("example",
config={
"name": "example-azure-name",
"namespace": "example-azure-namespace",
"policy_key": "azure-event-hubs-policy-key",
"policy_name": "example-policy-name",
},
env_key="example-env",
kind="azure-event-hubs",
on=True,
project_key="example-project",
tags=["terraform"])
```
```python
import pulumi
import lbrlabs_pulumi_launchdarkly as launchdarkly
example = launchdarkly.Destination("example",
project_key="example-project",
env_key="example-env",
kind="segment",
config={
"write_key": "segment-write-key",
},
on=True,
tags=["terraform"])
```
## Import
You can import a data export destination using the destination's full ID in the format `project_key/environment_key/id`. For example
```sh
$ pulumi import launchdarkly:index/destination:Destination example example-project/example-env/57c0af609969090743529967
```
:param str resource_name: The name of the resource.
:param pulumi.ResourceOptions opts: Options for the resource.
:param pulumi.Input[Mapping[str, pulumi.Input[str]]] config: - The destination-specific configuration. To learn more, read Destination-Specific Configs.
:param pulumi.Input[str] env_key: - The environment key. A change in this field will force the destruction of the existing resource and the creation of a new one.
:param pulumi.Input[str] kind: - The data export destination type. Available choices are `kinesis`, `google-pubsub`, `mparticle`, `azure-event-hubs`, and `segment`. A change in this field will force the destruction of the existing resource and the creation of a new one.
:param pulumi.Input[str] name: -
:param pulumi.Input[bool] on: - Whether the data export destination is on or not.
:param pulumi.Input[str] project_key: - The LaunchDarkly project key. A change in this field will force the destruction of the existing resource and the creation of a new one.
:param pulumi.Input[Sequence[pulumi.Input[str]]] tags: Tags associated with your resource
"""
...
@overload
def __init__(__self__,
resource_name: str,
args: DestinationArgs,
opts: Optional[pulumi.ResourceOptions] = None):
"""
Provides a LaunchDarkly Data Export Destination resource.
> **Note:** Data Export is available to customers on an Enterprise LaunchDarkly plan. To learn more, read about our pricing. To upgrade your plan, [contact LaunchDarkly Sales](https://launchdarkly.com/contact-sales/).
Data Export Destinations are locations that receive exported data. This resource allows you to configure destinations for the export of raw analytics data, including feature flag requests, analytics events, custom events, and more.
To learn more about data export, read [Data Export Documentation](https://docs.launchdarkly.com/integrations/data-export).
## Example Usage
Currently the following five types of destinations are available: kinesis, google-pubsub, mparticle, azure-event-hubs, and segment. Please note that config fields will vary depending on which destination you are trying to configure / access.
```python
import pulumi
import lbrlabs_pulumi_launchdarkly as launchdarkly
example = launchdarkly.Destination("example",
project_key="example-project",
env_key="example-env",
kind="kinesis",
config={
"region": "us-east-1",
"role_arn": "arn:aws:iam::123456789012:role/marketingadmin",
"stream_name": "cat-stream",
},
on=True,
tags=["terraform"])
```
```python
import pulumi
import lbrlabs_pulumi_launchdarkly as launchdarkly
example = launchdarkly.Destination("example",
project_key="example-project",
env_key="example-env",
kind="google-pubsub",
config={
"project": "example-pub-sub-project",
"topic": "example-topic",
},
on=True,
tags=["terraform"])
```
```python
import pulumi
import lbrlabs_pulumi_launchdarkly as launchdarkly
example = launchdarkly.Destination("example",
project_key="example-project",
env_key="example-env",
kind="mparticle",
config={
"api_key": "apiKeyfromMParticle",
"secret": "mParticleSecret",
"user_identity": "customer_id",
"environment": "production",
},
on=True,
tags=["terraform"])
```
```python
import pulumi
import lbrlabs_pulumi_launchdarkly as launchdarkly
example = launchdarkly.Destination("example",
config={
"name": "example-azure-name",
"namespace": "example-azure-namespace",
"policy_key": "azure-event-hubs-policy-key",
"policy_name": "example-policy-name",
},
env_key="example-env",
kind="azure-event-hubs",
on=True,
project_key="example-project",
tags=["terraform"])
```
```python
import pulumi
import lbrlabs_pulumi_launchdarkly as launchdarkly
example = launchdarkly.Destination("example",
project_key="example-project",
env_key="example-env",
kind="segment",
config={
"write_key": "segment-write-key",
},
on=True,
tags=["terraform"])
```
## Import
You can import a data export destination using the destination's full ID in the format `project_key/environment_key/id`. For example
```sh
$ pulumi import launchdarkly:index/destination:Destination example example-project/example-env/57c0af609969090743529967
```
:param str resource_name: The name of the resource.
:param DestinationArgs args: The arguments to use to populate this resource's properties.
:param pulumi.ResourceOptions opts: Options for the resource.
"""
...
def __init__(__self__, resource_name: str, *args, **kwargs):
resource_args, opts = _utilities.get_resource_args_opts(DestinationArgs, pulumi.ResourceOptions, *args, **kwargs)
if resource_args is not None:
__self__._internal_init(resource_name, opts, **resource_args.__dict__)
else:
__self__._internal_init(resource_name, *args, **kwargs)
def _internal_init(__self__,
resource_name: str,
opts: Optional[pulumi.ResourceOptions] = None,
config: Optional[pulumi.Input[Mapping[str, pulumi.Input[str]]]] = None,
env_key: Optional[pulumi.Input[str]] = None,
kind: Optional[pulumi.Input[str]] = None,
name: Optional[pulumi.Input[str]] = None,
on: Optional[pulumi.Input[bool]] = None,
project_key: Optional[pulumi.Input[str]] = None,
tags: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]] = None,
__props__=None):
opts = pulumi.ResourceOptions.merge(_utilities.get_resource_opts_defaults(), opts)
if not isinstance(opts, pulumi.ResourceOptions):
raise TypeError('Expected resource options to be a ResourceOptions instance')
if opts.id is None:
if __props__ is not None:
raise TypeError('__props__ is only valid when passed in combination with a valid opts.id to get an existing resource')
__props__ = DestinationArgs.__new__(DestinationArgs)
if config is None and not opts.urn:
raise TypeError("Missing required property 'config'")
__props__.__dict__["config"] = config
if env_key is None and not opts.urn:
raise TypeError("Missing required property 'env_key'")
__props__.__dict__["env_key"] = env_key
if kind is None and not opts.urn:
raise TypeError("Missing required property 'kind'")
__props__.__dict__["kind"] = kind
__props__.__dict__["name"] = name
__props__.__dict__["on"] = on
if project_key is None and not opts.urn:
raise TypeError("Missing required property 'project_key'")
__props__.__dict__["project_key"] = project_key
__props__.__dict__["tags"] = tags
super(Destination, __self__).__init__(
'launchdarkly:index/destination:Destination',
resource_name,
__props__,
opts)
@staticmethod
def get(resource_name: str,
id: pulumi.Input[str],
opts: Optional[pulumi.ResourceOptions] = None,
config: Optional[pulumi.Input[Mapping[str, pulumi.Input[str]]]] = None,
env_key: Optional[pulumi.Input[str]] = None,
kind: Optional[pulumi.Input[str]] = None,
name: Optional[pulumi.Input[str]] = None,
on: Optional[pulumi.Input[bool]] = None,
project_key: Optional[pulumi.Input[str]] = None,
tags: Optional[pulumi.Input[Sequence[pulumi.Input[str]]]] = None) -> 'Destination':
"""
Get an existing Destination resource's state with the given name, id, and optional extra
properties used to qualify the lookup.
:param str resource_name: The unique name of the resulting resource.
:param pulumi.Input[str] id: The unique provider ID of the resource to lookup.
:param pulumi.ResourceOptions opts: Options for the resource.
:param pulumi.Input[Mapping[str, pulumi.Input[str]]] config: - The destination-specific configuration. To learn more, read Destination-Specific Configs.
:param pulumi.Input[str] env_key: - The environment key. A change in this field will force the destruction of the existing resource and the creation of a new one.
:param pulumi.Input[str] kind: - The data export destination type. Available choices are `kinesis`, `google-pubsub`, `mparticle`, `azure-event-hubs`, and `segment`. A change in this field will force the destruction of the existing resource and the creation of a new one.
:param pulumi.Input[str] name: -
:param pulumi.Input[bool] on: - Whether the data export destination is on or not.
:param pulumi.Input[str] project_key: - The LaunchDarkly project key. A change in this field will force the destruction of the existing resource and the creation of a new one.
:param pulumi.Input[Sequence[pulumi.Input[str]]] tags: Tags associated with your resource
"""
opts = pulumi.ResourceOptions.merge(opts, pulumi.ResourceOptions(id=id))
__props__ = _DestinationState.__new__(_DestinationState)
__props__.__dict__["config"] = config
__props__.__dict__["env_key"] = env_key
__props__.__dict__["kind"] = kind
__props__.__dict__["name"] = name
__props__.__dict__["on"] = on
__props__.__dict__["project_key"] = project_key
__props__.__dict__["tags"] = tags
return Destination(resource_name, opts=opts, __props__=__props__)
@property
@pulumi.getter
def config(self) -> pulumi.Output[Mapping[str, str]]:
"""
- The destination-specific configuration. To learn more, read Destination-Specific Configs.
"""
return pulumi.get(self, "config")
@property
@pulumi.getter(name="envKey")
def env_key(self) -> pulumi.Output[str]:
"""
- The environment key. A change in this field will force the destruction of the existing resource and the creation of a new one.
"""
return pulumi.get(self, "env_key")
@property
@pulumi.getter
def kind(self) -> pulumi.Output[str]:
"""
- The data export destination type. Available choices are `kinesis`, `google-pubsub`, `mparticle`, `azure-event-hubs`, and `segment`. A change in this field will force the destruction of the existing resource and the creation of a new one.
"""
return pulumi.get(self, "kind")
@property
@pulumi.getter
def name(self) -> pulumi.Output[str]:
"""
-
"""
return pulumi.get(self, "name")
@property
@pulumi.getter
def on(self) -> pulumi.Output[Optional[bool]]:
"""
- Whether the data export destination is on or not.
"""
return pulumi.get(self, "on")
@property
@pulumi.getter(name="projectKey")
def project_key(self) -> pulumi.Output[str]:
"""
- The LaunchDarkly project key. A change in this field will force the destruction of the existing resource and the creation of a new one.
"""
return pulumi.get(self, "project_key")
@property
@pulumi.getter
def tags(self) -> pulumi.Output[Optional[Sequence[str]]]:
"""
Tags associated with your resource
"""
return pulumi.get(self, "tags") | PypiClean |
/text_to_image-0.0.5.tar.gz/text_to_image-0.0.5/README.rst | Text To Image
=============
Easily convert your text to grayscale images and vice versa.
With this tool you can encode text or plain text files to a grayscale
image to be easily shared. Each pixel represents a single character’s
decimal value. When decoding an image you can decode text straight to
the console or to a plain text file.
Images use a PNG file extension. The image size will be automatically be
set depending on the text length to be encoded.
Text should use a character encoding scheme using 8 bits or less until
additional functionality is added to support UTF-8 (16 bit). If a
character’s decimal value is greater than the limit (see below) the it
will be divided by the limit and the new value used. When the character
value equals the limit value the new value will be 1.
The limit value passed using either command line argument -l(–limit)
specifies the decimal value limit for pixel values starting from 1. The
default is 256 allowing for numbers from 0 to 255 (i.e. 8 bit pixels).
If the limit value is greater than 8 bits then the value will still be
wrapped around since the output image is grayscale.
Requirements
''''''''''''
- Python 3.x
- Pillow (PIL fork)
Install
-------
You can install text\_to\_image using pip or setup.py
- Using pip
.. code:: bash
$> pip3 install text_to_image
- Using setup.py. First navigative to the root directory where setup.py
is located then run
.. code:: bash
$> python3 setup.py install
How to Use
----------
Once installed you can either directly use the encode.py and decode.py
file or import and use the relevant functions.
- Using the encode.py
.. code:: bash
$> python3 encode.py -t "Hello World!" image.png # encodes given text
$> python3 encode.py -f my-text-file.txt image.png # encodes a text file
$> python3 encode.py --help # for more information on arguments
- Using decode.py
.. code:: bash
$> python3 decode.py image.png # decodes a given image
$> python3 decode.py -f my-text-file.txt image.png # decodes image.png to the given text file
$> python3 decode.py --help # for more information on arguments
- Importing
.. code:: python
import text_to_image
encoded_image_path = text_to_image.encode("Hello World!", "image.png")
encoded_image_path = text_to_image.encode_file("input_text_file.txt", "output_image.png")
decoded_text = text_to_image.decode("encoded_image.png")
decoded_file_path = text_to_image.decode_to_file("encoded_image.png", "output_text_file.txt")
Tests
~~~~~
To run tests, navigate to the root directory where setup.py is located
and run
.. code:: bash
$> python3-m unittest discover tests -v
Another image example:
TODO:
^^^^^
- Add custom image sizes.
- Expand pixel value to allow for UTF-8 characters. | PypiClean |
/neurox-1.0.6.tar.gz/neurox-1.0.6/README.md | # NeuroX Toolkit
<p align="center">
<img src="https://github.com/fdalvi/NeuroX/raw/master/docs/intro/logo.png" />
</p>
[](https://github.com/fdalvi/NeuroX/actions/workflows/python-package.yml)
[](https://neurox.qcri.org/docs/)
NeuroX provide all the necessary tooling to perform Interpretation and Analysis of (Deep) Neural Networks centered around _Probing_. Specifically, the toolkit provides:
- Support for extraction of activation from popular models including the entirety of [transformers](https://github.com/huggingface/transformers), with extended support for other models like [OpenNMT-py](https://github.com/OpenNMT/OpenNMT-py) planned in the near future
- Support for training linear probes on top of these activations, on the entire activation space of a model, on specific layers, or even on specific set of neurons.
- Support for neuron extraction related to specific concepts, using the _Linear Correlation Analysis_ method ([What is one Grain of Sand in the Desert? Analyzing Individual Neurons in Deep NLP Models.](https://ojs.aaai.org/index.php/AAAI/article/view/4592/4470)). The toolkit can extract either a local ranking of neurons important to a particular target class, or a global ranking of neurons important to all the target classes.
- Support for ablation analysis by either removing or zeroing out specific neurons to determine their function and importance.
- Support for subword and character level aggregation across a variety of tokenizers, including BPE and all tokenizers in the [transformers](https://github.com/huggingface/transformers) library.
- Support for activation visualization over regular text, to generate qualitative samples of neuron activity over particular sentences.
A demo using a lot of functionality provided by this toolkit [is available](https://neurox.qcri.org/demo).

## Getting Started
This toolkit requires and is tested on Python versions 3.6 and above. It may work with older Python versions with some fiddling, but is currently not tested nor supported. The easiest way to get started is to use the published pip package:
```bash
pip install neurox
```
#### Manual Installation
If you wish to install this package manually (e.g. to modify or contribute to the code base), you can clone this repository into a directory of your choice:
```bash
git clone https://github.com/fdalvi/NeuroX.git
```
Add the directory to your python path. This can be done dynamically at runtime using the `sys.path` list:
```python
import sys
sys.path.append("path/to/cloned/NeuroX/")
```
A [Conda](https://anaconda.org) environment is provided with all the necessary dependencies for the toolkit. The toolkit primarily relies on PyTorch and NumPy for most of its operations. To create a new environment with all the dependencies, run:
```bash
conda env create -f conda-environment.yml -n neurox-toolkit
conda activate neurox-toolkit
```
If you wish to manage your enviroment in other ways, a standard `requirements.txt` is also provided for use by `pip` directly.
## Sample Code
A Jupyter notebook with a complete example of extracting activations from BERT, training a toy task, extracting neurons and visualizing them is available in the [examples](examples/End%20to%20End%20Example.ipynb) directory for a quick introduction to the main functionality provided by this toolkit.
## Documentation
[API Reference](https://neurox.qcri.org/docs/) contains an API reference for all of the functions exposed by this toolkit. Primarily, the toolkit's functionality is separated into several high-level components:
- Extraction
- Data Preprocessing
- Linear Probing
- Neuron extraction and interpretation
- Neuron cluster analysis
- Visualization
## Citation
Please cite our paper published at AAAI'19 if you use this toolkit.
```
@article{dalvi2019neurox,
title={NeuroX: A Toolkit for Analyzing Individual Neurons in Neural Networks},
author={Dalvi, Fahim
and Nortonsmith, Avery
and Bau, D Anthony
and Belinkov, Yonatan
and Sajjad, Hassan
and Durrani, Nadir
and Glass, James},
journal={Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)},
year={2019}
}
```
## Planned features
- [ ] Pip package
- [ ] Support for OpenNMT-py models
- [ ] Support for control tasks and computing metrics like selectivity
- [ ] Support for attention and other module analysis
## Publications
- Hassan Sajjad, Narine Kokhlikyan, Fahim Dalvi, Nadir Durrani (2021). [Fine-grained Interpretation and Causation Analysis in Deep NLP Models.](https://www.aclweb.org/anthology/2021.naacl-tutorials.2.pdf) In Proceedings of the 18th Annual Conference of the North American Chapter of the Association of Computational Linguistics: Human Language Technologies (NAACL), Virtual, June
- Nadir Durrani, Hassan Sajjad, Fahim Dalvi (2021). [How transfer learning impacts linguistic knowledge in deep NLP models?](https://alt.qcri.org/~ndurrani/pubs/ACL-FT-2021.pdf) In Findings of the Association for Computational Linguistics (ACL-IJCNLP). Virtual, August
- Yonatan Belinkov\*, Nadir Durrani\*, Fahim Dalvi, Hassan Sajjad, Jim Glass (2020). [On the Linguistic Representational Power of Neural Machine Translation Models.](https://www.aclweb.org/anthology/2020.cl-1.1.pdf) Computational Linguistics. 46(1), pages 1 to 57 (\*Equal Contribution––Alphabetic Order).
- Nadir Durrani, Hassan Sajjad, Fahim Dalvi, Yonatan Belinkov (2020). [Analyzing Individual Neurons in Pre-trained Language Models.](https://www.aclweb.org/anthology/2020.emnlp-main.395.pdf) In Proceedings of the 17th Conference on Empirical Methods in Natural Language Processing (EMNLP), Punta Cana, Dominican Republic, November.
- Fahim Dalvi, Hassan Sajjad, Nadir Durrani, Yonatan Belinkov (2020). [Analyzing Redundancy in Pretrained Transformer Models](https://www.aclweb.org/anthology/2020.emnlp-main.398.pdf). In Proceedings of the 17th Conference on Empirical Methods in Natural Language Processing (EMNLP), Punta Cana, Dominican Republic, November.
- John M Wu\*, Yonatan Belinkov\*, Hassan Sajjad, Nadir Durrani, Fahim Dalvi and James Glass (2020). [Similarity Analysis of Contextual Word Representation Models.](https://www.aclweb.org/anthology/2020.acl-main.422.pdf) In Proceedings of the 58th Annual Conference of the Association for Computational Linguistics (ACL). Seattle, USA, July (\*Equal Contribution––Alphabetic Order).
- Anthony Bau\*, Yonatan Belinkov\*, Hassan Sajjad, Fahim Dalvi, Nadir Durrani, and James Glass (2019). [Identifying and Controlling Important Neurons in Neural Machine Translation.](https://openreview.net/pdf?id=H1z-PsR5KX) In Proceedings of the 7th International Conference on Learning Representations (ICLR). New Orleans, USA, May (\*Equal Contribution––Alphabetic Order).
- Nadir Durrani, Fahim Dalvi, Hassan Sajjad, Yonatan Belinkov, and Preslav Nakov (2019). [One Size Does Not Fit All: Comparing NMT Representations of Different Granularities.](https://www.aclweb.org/anthology/N19-1154.pdf) In Proceedings of the 17th Annual Conference of the North American Chapter of the Association of Computational Linguistics: Human Language Technologies (NAACL), Minneapolis, US, June
- Fahim Dalvi\*, Nadir Durrani\*, Hassan Sajjad\*, Yonatan Belinkov, D. Anthony Bau, and James Glass (2019). [What is one Grain of Sand in the Desert? Analyzing Individual Neurons in Deep NLP Models.](https://ojs.aaai.org/index.php/AAAI/article/view/4592/4470) In Proceedings of the 33rd AAAI Conference on Artificial Intelligence (AAAI). Honolulu, USA, Jan. (\*Equal Contribution––Alphabetic Order).
- Yonatan Belinkov, Nadir Durrani, Fahim Dalvi, Hassan Sajjad, James Glass (2017). [What do Neural Machine Translation Models Learn about Morphology?](https://www.aclweb.org/anthology/P17-1080.pdf) In Proceedings of the 55th Annual Conference of the Association for Computational Linguistics (ACL), Vancouver, Canada, July.
- Fahim Dalvi, Nadir Durrani, Hassan Sajjad, Yonatan Belinkov and Stephan Vogel (2017). [Understanding and Improving Morphological Learning in the Neural Machine Translation Decoder.](https://www.aclweb.org/anthology/I17-1015.pdf) In Proceedings of the 8th International Conference on Natural Language Processing (IJCNLP), Taipei, Taiwan, November.
- Yonatan Belinkov, Lluís Màrquez, Hassan Sajjad, Nadir Durrani, Fahim Dalvi and James Glass (2017). [Evaluating Layers of Representation in Neural Machine Translation on Part-of-Speech and Semantic Tagging Tasks.](https://www.aclweb.org/anthology/I17-1001.pdf) In Proceedings of the 8th International Conference on Natural Language Processing (IJCNLP), Taipei, Taiwan, November
| PypiClean |
/jupyterlab_remote_contents-0.1.1.tar.gz/jupyterlab_remote_contents-0.1.1/node_modules/slash/readme.md | # slash [](https://travis-ci.org/sindresorhus/slash)
> Convert Windows backslash paths to slash paths: `foo\\bar` ➔ `foo/bar`
[Forward-slash paths can be used in Windows](http://superuser.com/a/176395/6877) as long as they're not extended-length paths and don't contain any non-ascii characters.
This was created since the `path` methods in Node.js outputs `\\` paths on Windows.
## Install
```
$ npm install slash
```
## Usage
```js
const path = require('path');
const slash = require('slash');
const string = path.join('foo', 'bar');
// Unix => foo/bar
// Windows => foo\\bar
slash(string);
// Unix => foo/bar
// Windows => foo/bar
```
## API
### slash(path)
Type: `string`
Accepts a Windows backslash path and returns a path with forward slashes.
## License
MIT © [Sindre Sorhus](https://sindresorhus.com)
| PypiClean |