
status
stringclasses 1
value | repo_name
stringclasses 31
values | repo_url
stringclasses 31
values | issue_id
int64 1
104k
| title
stringlengths 4
369
| body
stringlengths 0
254k
⌀ | issue_url
stringlengths 37
56
| pull_url
stringlengths 37
54
| before_fix_sha
stringlengths 40
40
| after_fix_sha
stringlengths 40
40
| report_datetime
unknown | language
stringclasses 5
values | commit_datetime
unknown | updated_file
stringlengths 4
188
| file_content
stringlengths 0
5.12M
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 674 | test_faiss_with_metadatas: key mismatch in assert | https://github.com/hwchase17/langchain/blob/236ae93610a8538d3d0044fc29379c481acc6789/tests/integration_tests/vectorstores/test_faiss.py#L54
This test will fail because `FAISS.from_texts` will assign uuid4s as keys in its docstore, while `expected_docstore` has string numbers as keys. | https://github.com/langchain-ai/langchain/issues/674 | https://github.com/langchain-ai/langchain/pull/676 | e45f7e40e80d9b47fb51853f0c672e747735b951 | e04b063ff40d7f70eaa91f135729071de60b219d | "2023-01-21T16:02:54Z" | python | "2023-01-22T00:08:14Z" | langchain/vectorstores/faiss.py | """Wrapper around FAISS vector database."""
from __future__ import annotations
import uuid
from typing import Any, Callable, Dict, Iterable, List, Optional, Tuple
import numpy as np
from langchain.docstore.base import AddableMixin, Docstore
from langchain.docstore.document import Document
from langchain.docstore.in_memory import InMemoryDocstore
from langchain.embeddings.base import Embeddings
from langchain.vectorstores.base import VectorStore
from langchain.vectorstores.utils import maximal_marginal_relevance
class FAISS(VectorStore):
"""Wrapper around FAISS vector database.
To use, you should have the ``faiss`` python package installed.
Example:
.. code-block:: python
from langchain import FAISS
faiss = FAISS(embedding_function, index, docstore)
"""
def __init__(
self,
embedding_function: Callable,
index: Any,
docstore: Docstore,
index_to_docstore_id: Dict[int, str],
):
"""Initialize with necessary components."""
self.embedding_function = embedding_function
self.index = index
self.docstore = docstore
self.index_to_docstore_id = index_to_docstore_id
def add_texts(
self, texts: Iterable[str], metadatas: Optional[List[dict]] = None
) -> List[str]:
"""Run more texts through the embeddings and add to the vectorstore.
Args:
texts: Iterable of strings to add to the vectorstore.
metadatas: Optional list of metadatas associated with the texts.
Returns:
List of ids from adding the texts into the vectorstore.
"""
if not isinstance(self.docstore, AddableMixin):
raise ValueError(
"If trying to add texts, the underlying docstore should support "
f"adding items, which {self.docstore} does not"
)
# Embed and create the documents.
embeddings = [self.embedding_function(text) for text in texts]
documents = []
for i, text in enumerate(texts):
metadata = metadatas[i] if metadatas else {}
documents.append(Document(page_content=text, metadata=metadata))
# Add to the index, the index_to_id mapping, and the docstore.
starting_len = len(self.index_to_docstore_id)
self.index.add(np.array(embeddings, dtype=np.float32))
# Get list of index, id, and docs.
full_info = [
(starting_len + i, str(uuid.uuid4()), doc)
for i, doc in enumerate(documents)
]
# Add information to docstore and index.
self.docstore.add({_id: doc for _, _id, doc in full_info})
index_to_id = {index: _id for index, _id, _ in full_info}
self.index_to_docstore_id.update(index_to_id)
return [_id for _, _id, _ in full_info]
def similarity_search_with_score(
self, query: str, k: int = 4
) -> List[Tuple[Document, float]]:
"""Return docs most similar to query.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the query and score for each
"""
embedding = self.embedding_function(query)
scores, indices = self.index.search(np.array([embedding], dtype=np.float32), k)
docs = []
for j, i in enumerate(indices[0]):
if i == -1:
# This happens when not enough docs are returned.
continue
_id = self.index_to_docstore_id[i]
doc = self.docstore.search(_id)
if not isinstance(doc, Document):
raise ValueError(f"Could not find document for id {_id}, got {doc}")
docs.append((doc, scores[0][j]))
return docs
def similarity_search(
self, query: str, k: int = 4, **kwargs: Any
) -> List[Document]:
"""Return docs most similar to query.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the query.
"""
docs_and_scores = self.similarity_search_with_score(query, k)
return [doc for doc, _ in docs_and_scores]
def max_marginal_relevance_search(
self, query: str, k: int = 4, fetch_k: int = 20
) -> List[Document]:
"""Return docs selected using the maximal marginal relevance.
Maximal marginal relevance optimizes for similarity to query AND diversity
among selected documents.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
fetch_k: Number of Documents to fetch to pass to MMR algorithm.
Returns:
List of Documents selected by maximal marginal relevance.
"""
embedding = self.embedding_function(query)
_, indices = self.index.search(np.array([embedding], dtype=np.float32), fetch_k)
# -1 happens when not enough docs are returned.
embeddings = [self.index.reconstruct(int(i)) for i in indices[0] if i != -1]
mmr_selected = maximal_marginal_relevance(embedding, embeddings, k=k)
selected_indices = [indices[0][i] for i in mmr_selected]
docs = []
for i in selected_indices:
_id = self.index_to_docstore_id[i]
doc = self.docstore.search(_id)
if not isinstance(doc, Document):
raise ValueError(f"Could not find document for id {_id}, got {doc}")
docs.append(doc)
return docs
@classmethod
def from_texts(
cls,
texts: List[str],
embedding: Embeddings,
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> FAISS:
"""Construct FAISS wrapper from raw documents.
This is a user friendly interface that:
1. Embeds documents.
2. Creates an in memory docstore
3. Initializes the FAISS database
This is intended to be a quick way to get started.
Example:
.. code-block:: python
from langchain import FAISS
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
faiss = FAISS.from_texts(texts, embeddings)
"""
try:
import faiss
except ImportError:
raise ValueError(
"Could not import faiss python package. "
"Please it install it with `pip install faiss` "
"or `pip install faiss-cpu` (depending on Python version)."
)
embeddings = embedding.embed_documents(texts)
index = faiss.IndexFlatL2(len(embeddings[0]))
index.add(np.array(embeddings, dtype=np.float32))
documents = []
for i, text in enumerate(texts):
metadata = metadatas[i] if metadatas else {}
documents.append(Document(page_content=text, metadata=metadata))
index_to_id = {i: str(uuid.uuid4()) for i in range(len(documents))}
docstore = InMemoryDocstore(
{index_to_id[i]: doc for i, doc in enumerate(documents)}
)
return cls(embedding.embed_query, index, docstore, index_to_id)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 674 | test_faiss_with_metadatas: key mismatch in assert | https://github.com/hwchase17/langchain/blob/236ae93610a8538d3d0044fc29379c481acc6789/tests/integration_tests/vectorstores/test_faiss.py#L54
This test will fail because `FAISS.from_texts` will assign uuid4s as keys in its docstore, while `expected_docstore` has string numbers as keys. | https://github.com/langchain-ai/langchain/issues/674 | https://github.com/langchain-ai/langchain/pull/676 | e45f7e40e80d9b47fb51853f0c672e747735b951 | e04b063ff40d7f70eaa91f135729071de60b219d | "2023-01-21T16:02:54Z" | python | "2023-01-22T00:08:14Z" | tests/integration_tests/vectorstores/test_faiss.py | """Test FAISS functionality."""
from typing import List
import pytest
from langchain.docstore.document import Document
from langchain.docstore.in_memory import InMemoryDocstore
from langchain.docstore.wikipedia import Wikipedia
from langchain.embeddings.base import Embeddings
from langchain.vectorstores.faiss import FAISS
class FakeEmbeddings(Embeddings):
"""Fake embeddings functionality for testing."""
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""Return simple embeddings."""
return [[i] * 10 for i in range(len(texts))]
def embed_query(self, text: str) -> List[float]:
"""Return simple embeddings."""
return [0] * 10
def test_faiss() -> None:
"""Test end to end construction and search."""
texts = ["foo", "bar", "baz"]
docsearch = FAISS.from_texts(texts, FakeEmbeddings())
index_to_id = docsearch.index_to_docstore_id
expected_docstore = InMemoryDocstore(
{
index_to_id[0]: Document(page_content="foo"),
index_to_id[1]: Document(page_content="bar"),
index_to_id[2]: Document(page_content="baz"),
}
)
assert docsearch.docstore.__dict__ == expected_docstore.__dict__
output = docsearch.similarity_search("foo", k=1)
assert output == [Document(page_content="foo")]
def test_faiss_with_metadatas() -> None:
"""Test end to end construction and search."""
texts = ["foo", "bar", "baz"]
metadatas = [{"page": i} for i in range(len(texts))]
docsearch = FAISS.from_texts(texts, FakeEmbeddings(), metadatas=metadatas)
expected_docstore = InMemoryDocstore(
{
"0": Document(page_content="foo", metadata={"page": 0}),
"1": Document(page_content="bar", metadata={"page": 1}),
"2": Document(page_content="baz", metadata={"page": 2}),
}
)
assert docsearch.docstore.__dict__ == expected_docstore.__dict__
output = docsearch.similarity_search("foo", k=1)
assert output == [Document(page_content="foo", metadata={"page": 0})]
def test_faiss_search_not_found() -> None:
"""Test what happens when document is not found."""
texts = ["foo", "bar", "baz"]
docsearch = FAISS.from_texts(texts, FakeEmbeddings())
# Get rid of the docstore to purposefully induce errors.
docsearch.docstore = InMemoryDocstore({})
with pytest.raises(ValueError):
docsearch.similarity_search("foo")
def test_faiss_add_texts() -> None:
"""Test end to end adding of texts."""
# Create initial doc store.
texts = ["foo", "bar", "baz"]
docsearch = FAISS.from_texts(texts, FakeEmbeddings())
# Test adding a similar document as before.
docsearch.add_texts(["foo"])
output = docsearch.similarity_search("foo", k=2)
assert output == [Document(page_content="foo"), Document(page_content="foo")]
def test_faiss_add_texts_not_supported() -> None:
"""Test adding of texts to a docstore that doesn't support it."""
docsearch = FAISS(FakeEmbeddings().embed_query, None, Wikipedia(), {})
with pytest.raises(ValueError):
docsearch.add_texts(["foo"])
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 897 | Pinecone in docs is outdated | Pinecone default environment was recently changed from `us-west1-gcp` to `us-east1-gcp` ([see here](https://docs.pinecone.io/docs/projects#project-environment)), so new users following the [docs here](https://langchain.readthedocs.io/en/latest/modules/utils/combine_docs_examples/vectorstores.html#pinecone) will hit an error when initializing.
Submitted #898 | https://github.com/langchain-ai/langchain/issues/897 | https://github.com/langchain-ai/langchain/pull/898 | 7658263bfbc9485ebbc85b7d4c2476ea68611e26 | 8217a2f26c94234a1ea99d1b9b815e4da577dcfe | "2023-02-05T18:33:50Z" | python | "2023-02-05T23:21:56Z" | docs/modules/utils/combine_docs_examples/vectorstores.ipynb | {
"cells": [
{
"cell_type": "markdown",
"id": "7ef4d402-6662-4a26-b612-35b542066487",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"# VectorStores\n",
"\n",
"This notebook show cases how to use VectorStores. A key part of working with vectorstores is creating the vector to put in them, which is usually created via embeddings. Therefor, it is recommended that you familiarize yourself with the [embedding notebook](embeddings.ipynb) before diving into this."
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "965eecee",
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"from langchain.embeddings.openai import OpenAIEmbeddings\n",
"from langchain.text_splitter import CharacterTextSplitter\n",
"from langchain.vectorstores import ElasticVectorSearch, Pinecone, Weaviate, FAISS, Qdrant"
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "68481687",
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"with open('../../state_of_the_union.txt') as f:\n",
" state_of_the_union = f.read()\n",
"text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)\n",
"texts = text_splitter.split_text(state_of_the_union)\n",
"\n",
"embeddings = OpenAIEmbeddings()"
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "015f4ff5",
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"docsearch = FAISS.from_texts(texts, embeddings)\n",
"\n",
"query = \"What did the president say about Ketanji Brown Jackson\"\n",
"docs = docsearch.similarity_search(query)"
]
},
{
"cell_type": "code",
"execution_count": 9,
"id": "67baf32e",
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"In state after state, new laws have been passed, not only to suppress the vote, but to subvert entire elections. \n",
"\n",
"We cannot let this happen. \n",
"\n",
"Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. \n",
"\n",
"Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. \n",
"\n",
"One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. \n",
"\n",
"And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.\n"
]
}
],
"source": [
"print(docs[0].page_content)"
]
},
{
"cell_type": "markdown",
"id": "bbf5ec44",
"metadata": {},
"source": [
"## From Documents\n",
"We can also initialize a vectorstore from documents directly. This is useful when we use the method on the text splitter to get documents directly (handy when the original documents have associated metadata)."
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "df4a459c",
"metadata": {},
"outputs": [],
"source": [
"documents = text_splitter.create_documents([state_of_the_union], metadatas=[{\"source\": \"State of the Union\"}])"
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "4b480245",
"metadata": {},
"outputs": [],
"source": [
"docsearch = FAISS.from_documents(documents, embeddings)\n",
"\n",
"query = \"What did the president say about Ketanji Brown Jackson\"\n",
"docs = docsearch.similarity_search(query)"
]
},
{
"cell_type": "code",
"execution_count": 7,
"id": "86aa4cda",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"In state after state, new laws have been passed, not only to suppress the vote, but to subvert entire elections. \n",
"\n",
"We cannot let this happen. \n",
"\n",
"Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. \n",
"\n",
"Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. \n",
"\n",
"One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. \n",
"\n",
"And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence. \n"
]
}
],
"source": [
"print(docs[0].page_content)"
]
},
{
"cell_type": "markdown",
"id": "2445a5e6",
"metadata": {},
"source": [
"## FAISS-specific\n",
"There are some FAISS specific methods. One of them is `similarity_search_with_score`, which allows you to return not only the documents but also the similarity score of the query to them."
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "b4f49314",
"metadata": {},
"outputs": [],
"source": [
"docs_and_scores = docsearch.similarity_search_with_score(query)"
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "86f78ab1",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"(Document(page_content='In state after state, new laws have been passed, not only to suppress the vote, but to subvert entire elections. \\n\\nWe cannot let this happen. \\n\\nTonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. \\n\\nTonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. \\n\\nOne of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. \\n\\nAnd I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.', lookup_str='', metadata={}, lookup_index=0),\n",
" 0.40834612)"
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"docs_and_scores[0]"
]
},
{
"cell_type": "markdown",
"id": "b386dbb8",
"metadata": {},
"source": [
"### Saving and loading\n",
"You can also save and load a FAISS index. This is useful so you don't have to recreate it everytime you use it."
]
},
{
"cell_type": "code",
"execution_count": 12,
"id": "b58b3955",
"metadata": {},
"outputs": [],
"source": [
"import pickle"
]
},
{
"cell_type": "code",
"execution_count": 14,
"id": "1897e23d",
"metadata": {},
"outputs": [],
"source": [
"with open(\"foo.pkl\", 'wb') as f:\n",
" pickle.dump(docsearch, f)"
]
},
{
"cell_type": "code",
"execution_count": 15,
"id": "bf3732f1",
"metadata": {},
"outputs": [],
"source": [
"with open(\"foo.pkl\", 'rb') as f:\n",
" new_docsearch = pickle.load(f)"
]
},
{
"cell_type": "code",
"execution_count": 16,
"id": "5bf2ee24",
"metadata": {},
"outputs": [],
"source": [
"docs = new_docsearch.similarity_search(query)"
]
},
{
"cell_type": "code",
"execution_count": 18,
"id": "edc2aad1",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"Document(page_content='In state after state, new laws have been passed, not only to suppress the vote, but to subvert entire elections. \\n\\nWe cannot let this happen. \\n\\nTonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. \\n\\nTonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. \\n\\nOne of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. \\n\\nAnd I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.', lookup_str='', metadata={}, lookup_index=0)"
]
},
"execution_count": 18,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"docs[0]"
]
},
{
"cell_type": "markdown",
"id": "eea6e627",
"metadata": {},
"source": [
"## Requires having ElasticSearch setup"
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "4906b8a3",
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"docsearch = ElasticVectorSearch.from_texts(texts, embeddings, elasticsearch_url=\"http://localhost:9200\")\n",
"\n",
"query = \"What did the president say about Ketanji Brown Jackson\"\n",
"docs = docsearch.similarity_search(query)"
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "95f9eee9",
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. \n",
"\n",
"One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. \n",
"\n",
"And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence. \n",
"\n",
"A former top litigator in private practice. A former federal public defender. And from a family of public school educators and police officers. A consensus builder. Since she’s been nominated, she’s received a broad range of support—from the Fraternal Order of Police to former judges appointed by Democrats and Republicans. \n",
"\n",
"And if we are to advance liberty and justice, we need to secure the Border and fix the immigration system. \n"
]
}
],
"source": [
"print(docs[0].page_content)"
]
},
{
"cell_type": "markdown",
"id": "7f9cb9e7",
"metadata": {},
"source": [
"## Weaviate"
]
},
{
"cell_type": "code",
"execution_count": 11,
"id": "1037a85e",
"metadata": {},
"outputs": [],
"source": [
"import weaviate\n",
"import os\n",
"\n",
"WEAVIATE_URL = \"\"\n",
"client = weaviate.Client(\n",
" url=WEAVIATE_URL,\n",
" additional_headers={\n",
" 'X-OpenAI-Api-Key': os.environ[\"OPENAI_API_KEY\"]\n",
" }\n",
")"
]
},
{
"cell_type": "code",
"execution_count": 12,
"id": "b9043766",
"metadata": {},
"outputs": [],
"source": [
"client.schema.delete_all()\n",
"client.schema.get()\n",
"schema = {\n",
" \"classes\": [\n",
" {\n",
" \"class\": \"Paragraph\",\n",
" \"description\": \"A written paragraph\",\n",
" \"vectorizer\": \"text2vec-openai\",\n",
" \"moduleConfig\": {\n",
" \"text2vec-openai\": {\n",
" \"model\": \"babbage\",\n",
" \"type\": \"text\"\n",
" }\n",
" },\n",
" \"properties\": [\n",
" {\n",
" \"dataType\": [\"text\"],\n",
" \"description\": \"The content of the paragraph\",\n",
" \"moduleConfig\": {\n",
" \"text2vec-openai\": {\n",
" \"skip\": False,\n",
" \"vectorizePropertyName\": False\n",
" }\n",
" },\n",
" \"name\": \"content\",\n",
" },\n",
" ],\n",
" },\n",
" ]\n",
"}\n",
"\n",
"client.schema.create(schema)"
]
},
{
"cell_type": "code",
"execution_count": 13,
"id": "ac20d99c",
"metadata": {},
"outputs": [],
"source": [
"with client.batch as batch:\n",
" for text in texts:\n",
" batch.add_data_object({\"content\": text}, \"Paragraph\")"
]
},
{
"cell_type": "code",
"execution_count": 14,
"id": "01645d61",
"metadata": {},
"outputs": [],
"source": [
"from langchain.vectorstores.weaviate import Weaviate"
]
},
{
"cell_type": "code",
"execution_count": 15,
"id": "bdd97d29",
"metadata": {},
"outputs": [],
"source": [
"vectorstore = Weaviate(client, \"Paragraph\", \"content\")"
]
},
{
"cell_type": "code",
"execution_count": 16,
"id": "b70c0f98",
"metadata": {},
"outputs": [],
"source": [
"query = \"What did the president say about Ketanji Brown Jackson\"\n",
"docs = vectorstore.similarity_search(query)"
]
},
{
"cell_type": "code",
"execution_count": 17,
"id": "07533e40",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"In state after state, new laws have been passed, not only to suppress the vote, but to subvert entire elections. \n",
"\n",
"We cannot let this happen. \n",
"\n",
"Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. \n",
"\n",
"Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. \n",
"\n",
"One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. \n",
"\n",
"And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence. \n"
]
}
],
"source": [
"print(docs[0].page_content)"
]
},
{
"cell_type": "markdown",
"id": "007f3102",
"metadata": {},
"source": [
"## Pinecone"
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "7f6047e5",
"metadata": {},
"outputs": [],
"source": [
"import pinecone \n",
"\n",
"# initialize pinecone\n",
"pinecone.init(api_key=\"\", environment=\"us-west1-gcp\")\n",
"\n",
"index_name = \"langchain-demo\"\n",
"\n",
"docsearch = Pinecone.from_texts(texts, embeddings, index_name=index_name)\n",
"\n",
"query = \"What did the president say about Ketanji Brown Jackson\"\n",
"docs = docsearch.similarity_search(query)"
]
},
{
"cell_type": "code",
"execution_count": 7,
"id": "8e81f1f0",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"Document(page_content='A former top litigator in private practice. A former federal public defender. And from a family of public school educators and police officers. A consensus builder. Since she’s been nominated, she’s received a broad range of support—from the Fraternal Order of Police to former judges appointed by Democrats and Republicans. \\n\\nAnd if we are to advance liberty and justice, we need to secure the Border and fix the immigration system. \\n\\nWe can do both. At our border, we’ve installed new technology like cutting-edge scanners to better detect drug smuggling. \\n\\nWe’ve set up joint patrols with Mexico and Guatemala to catch more human traffickers. \\n\\nWe’re putting in place dedicated immigration judges so families fleeing persecution and violence can have their cases heard faster. \\n\\nWe’re securing commitments and supporting partners in South and Central America to host more refugees and secure their own borders. ', lookup_str='', metadata={}, lookup_index=0)"
]
},
"execution_count": 7,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"docs[0]"
]
},
{
"cell_type": "markdown",
"id": "9b852079",
"metadata": {},
"source": [
"## Qdrant"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "e5ec70ce",
"metadata": {},
"outputs": [],
"source": [
"host = \"<---host name here --->\"\n",
"api_key = \"<---api key here--->\"\n",
"qdrant = Qdrant.from_texts(texts, embeddings, host=host, prefer_grpc=True, api_key=api_key)\n",
"query = \"What did the president say about Ketanji Brown Jackson\""
]
},
{
"cell_type": "code",
"execution_count": 21,
"id": "9805ad1f",
"metadata": {},
"outputs": [],
"source": [
"docs = qdrant.similarity_search(query)"
]
},
{
"cell_type": "code",
"execution_count": 22,
"id": "bd097a0e",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"Document(page_content='In state after state, new laws have been passed, not only to suppress the vote, but to subvert entire elections. \\n\\nWe cannot let this happen. \\n\\nTonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. \\n\\nTonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. \\n\\nOne of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. \\n\\nAnd I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.', lookup_str='', metadata={}, lookup_index=0)"
]
},
"execution_count": 22,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"docs[0]"
]
},
{
"cell_type": "markdown",
"id": "6c3ec797",
"metadata": {},
"source": [
"## Milvus\n",
"To run, you should have a Milvus instance up and running: https://milvus.io/docs/install_standalone-docker.md"
]
},
{
"cell_type": "code",
"execution_count": 1,
"id": "be347313",
"metadata": {},
"outputs": [],
"source": [
"from langchain.vectorstores import Milvus"
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "f2eee23f",
"metadata": {},
"outputs": [],
"source": [
"vector_db = Milvus.from_texts(\n",
" texts,\n",
" embeddings,\n",
" connection_args={\"host\": \"127.0.0.1\", \"port\": \"19530\"},\n",
")"
]
},
{
"cell_type": "code",
"execution_count": 7,
"id": "06bdb701",
"metadata": {},
"outputs": [],
"source": [
"docs = vector_db.similarity_search(query)"
]
},
{
"cell_type": "code",
"execution_count": 8,
"id": "7b3e94aa",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"Document(page_content='In state after state, new laws have been passed, not only to suppress the vote, but to subvert entire elections. \\n\\nWe cannot let this happen. \\n\\nTonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. \\n\\nTonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. \\n\\nOne of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. \\n\\nAnd I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.', lookup_str='', metadata={}, lookup_index=0)"
]
},
"execution_count": 8,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"docs[0]"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "4af5a071",
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.9"
}
},
"nbformat": 4,
"nbformat_minor": 5
}
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 906 | Error in Pinecone batch selection logic | Current implementation of pinecone vec db finds the batches using:
```
# set end position of batch
i_end = min(i + batch_size, len(texts))
```
[link](https://github.com/hwchase17/langchain/blob/master/langchain/vectorstores/pinecone.py#L199)
But the following lines then go on to use a mix of `[i : i + batch_size]` and `[i:i_end]` to create batches:
```python
# get batch of texts and ids
lines_batch = texts[i : i + batch_size]
# create ids if not provided
if ids:
ids_batch = ids[i : i + batch_size]
else:
ids_batch = [str(uuid.uuid4()) for n in range(i, i_end)]
```
Fortunately, there is a `zip` function a few lines down that cuts the potentially longer chunks, preventing an error from being raised — yet I don't think think `[i: i+batch_size]` should be maintained as it's confusing and not explicit
Raised a PR here #907 | https://github.com/langchain-ai/langchain/issues/906 | https://github.com/langchain-ai/langchain/pull/907 | 82c080c6e617d4959fb4ee808deeba075f361702 | 3aa53b44dd5f013e35c316d110d340a630b0abd1 | "2023-02-06T07:52:59Z" | python | "2023-02-06T20:45:56Z" | langchain/vectorstores/pinecone.py | """Wrapper around Pinecone vector database."""
from __future__ import annotations
import uuid
from typing import Any, Callable, Iterable, List, Optional, Tuple
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from langchain.vectorstores.base import VectorStore
class Pinecone(VectorStore):
"""Wrapper around Pinecone vector database.
To use, you should have the ``pinecone-client`` python package installed.
Example:
.. code-block:: python
from langchain.vectorstores import Pinecone
from langchain.embeddings.openai import OpenAIEmbeddings
import pinecone
pinecone.init(api_key="***", environment="us-west1-gcp")
index = pinecone.Index("langchain-demo")
embeddings = OpenAIEmbeddings()
vectorstore = Pinecone(index, embeddings.embed_query, "text")
"""
def __init__(
self,
index: Any,
embedding_function: Callable,
text_key: str,
):
"""Initialize with Pinecone client."""
try:
import pinecone
except ImportError:
raise ValueError(
"Could not import pinecone python package. "
"Please it install it with `pip install pinecone-client`."
)
if not isinstance(index, pinecone.index.Index):
raise ValueError(
f"client should be an instance of pinecone.index.Index, "
f"got {type(index)}"
)
self._index = index
self._embedding_function = embedding_function
self._text_key = text_key
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
ids: Optional[List[str]] = None,
namespace: Optional[str] = None,
) -> List[str]:
"""Run more texts through the embeddings and add to the vectorstore.
Args:
texts: Iterable of strings to add to the vectorstore.
metadatas: Optional list of metadatas associated with the texts.
ids: Optional list of ids to associate with the texts.
namespace: Optional pinecone namespace to add the texts to.
Returns:
List of ids from adding the texts into the vectorstore.
"""
# Embed and create the documents
docs = []
ids = ids or [str(uuid.uuid4()) for _ in texts]
for i, text in enumerate(texts):
embedding = self._embedding_function(text)
metadata = metadatas[i] if metadatas else {}
metadata[self._text_key] = text
docs.append((ids[i], embedding, metadata))
# upsert to Pinecone
self._index.upsert(vectors=docs, namespace=namespace)
return ids
def similarity_search_with_score(
self,
query: str,
k: int = 5,
filter: Optional[dict] = None,
namespace: Optional[str] = None,
) -> List[Tuple[Document, float]]:
"""Return pinecone documents most similar to query, along with scores.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
filter: Dictionary of argument(s) to filter on metadata
namespace: Namespace to search in. Default will search in '' namespace.
Returns:
List of Documents most similar to the query and score for each
"""
query_obj = self._embedding_function(query)
docs = []
results = self._index.query(
[query_obj],
top_k=k,
include_metadata=True,
namespace=namespace,
filter=filter,
)
for res in results["matches"]:
metadata = res["metadata"]
text = metadata.pop(self._text_key)
docs.append((Document(page_content=text, metadata=metadata), res["score"]))
return docs
def similarity_search(
self,
query: str,
k: int = 5,
filter: Optional[dict] = None,
namespace: Optional[str] = None,
**kwargs: Any,
) -> List[Document]:
"""Return pinecone documents most similar to query.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
filter: Dictionary of argument(s) to filter on metadata
namespace: Namespace to search in. Default will search in '' namespace.
Returns:
List of Documents most similar to the query and score for each
"""
query_obj = self._embedding_function(query)
docs = []
results = self._index.query(
[query_obj],
top_k=k,
include_metadata=True,
namespace=namespace,
filter=filter,
)
for res in results["matches"]:
metadata = res["metadata"]
text = metadata.pop(self._text_key)
docs.append(Document(page_content=text, metadata=metadata))
return docs
@classmethod
def from_texts(
cls,
texts: List[str],
embedding: Embeddings,
metadatas: Optional[List[dict]] = None,
ids: Optional[List[str]] = None,
batch_size: int = 32,
text_key: str = "text",
index_name: Optional[str] = None,
namespace: Optional[str] = None,
**kwargs: Any,
) -> Pinecone:
"""Construct Pinecone wrapper from raw documents.
This is a user friendly interface that:
1. Embeds documents.
2. Adds the documents to a provided Pinecone index
This is intended to be a quick way to get started.
Example:
.. code-block:: python
from langchain import Pinecone
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
pinecone = Pinecone.from_texts(
texts,
embeddings,
index_name="langchain-demo"
)
"""
try:
import pinecone
except ImportError:
raise ValueError(
"Could not import pinecone python package. "
"Please install it with `pip install pinecone-client`."
)
_index_name = index_name or str(uuid.uuid4())
indexes = pinecone.list_indexes() # checks if provided index exists
if _index_name in indexes:
index = pinecone.Index(_index_name)
else:
index = None
for i in range(0, len(texts), batch_size):
# set end position of batch
i_end = min(i + batch_size, len(texts))
# get batch of texts and ids
lines_batch = texts[i : i + batch_size]
# create ids if not provided
if ids:
ids_batch = ids[i : i + batch_size]
else:
ids_batch = [str(uuid.uuid4()) for n in range(i, i_end)]
# create embeddings
embeds = embedding.embed_documents(lines_batch)
# prep metadata and upsert batch
if metadatas:
metadata = metadatas[i : i + batch_size]
else:
metadata = [{} for _ in range(i, i_end)]
for j, line in enumerate(lines_batch):
metadata[j][text_key] = line
to_upsert = zip(ids_batch, embeds, metadata)
# Create index if it does not exist
if index is None:
pinecone.create_index(_index_name, dimension=len(embeds[0]))
index = pinecone.Index(_index_name)
# upsert to Pinecone
index.upsert(vectors=list(to_upsert), namespace=namespace)
return cls(index, embedding.embed_query, text_key)
@classmethod
def from_existing_index(
cls,
index_name: str,
embedding: Embeddings,
text_key: str = "text",
namespace: Optional[str] = None,
) -> Pinecone:
"""Load pinecone vectorstore from index name."""
try:
import pinecone
except ImportError:
raise ValueError(
"Could not import pinecone python package. "
"Please install it with `pip install pinecone-client`."
)
return cls(
pinecone.Index(index_name, namespace), embedding.embed_query, text_key
)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,087 | Qdrant Wrapper issue: _document_from_score_point exposes incorrect key for content | 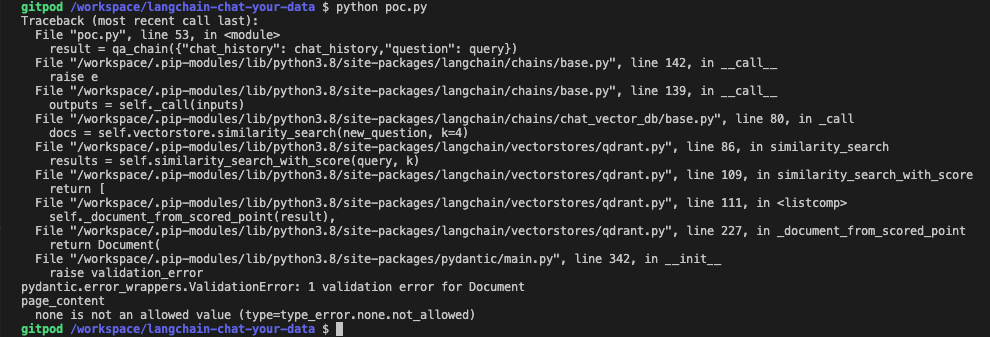
```
pydantic.error_wrappers.ValidationError: 1 validation error for Document
page_content
none is not an allowed value (type=type_error.none.not_allowed)
``` | https://github.com/langchain-ai/langchain/issues/1087 | https://github.com/langchain-ai/langchain/pull/1088 | 774550548242f44df9b219595cd46d9e238351e5 | 5d11e5da4077ad123bfff9f153f577fb5885af53 | "2023-02-16T13:18:41Z" | python | "2023-02-16T15:06:02Z" | langchain/vectorstores/qdrant.py | """Wrapper around Qdrant vector database."""
import uuid
from operator import itemgetter
from typing import Any, Callable, Iterable, List, Optional, Tuple
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from langchain.utils import get_from_dict_or_env
from langchain.vectorstores import VectorStore
from langchain.vectorstores.utils import maximal_marginal_relevance
class Qdrant(VectorStore):
"""Wrapper around Qdrant vector database.
To use you should have the ``qdrant-client`` package installed.
Example:
.. code-block:: python
from langchain import Qdrant
client = QdrantClient()
collection_name = "MyCollection"
qdrant = Qdrant(client, collection_name, embedding_function)
"""
def __init__(self, client: Any, collection_name: str, embedding_function: Callable):
"""Initialize with necessary components."""
try:
import qdrant_client
except ImportError:
raise ValueError(
"Could not import qdrant-client python package. "
"Please it install it with `pip install qdrant-client`."
)
if not isinstance(client, qdrant_client.QdrantClient):
raise ValueError(
f"client should be an instance of qdrant_client.QdrantClient, "
f"got {type(client)}"
)
self.client: qdrant_client.QdrantClient = client
self.collection_name = collection_name
self.embedding_function = embedding_function
def add_texts(
self, texts: Iterable[str], metadatas: Optional[List[dict]] = None
) -> List[str]:
"""Run more texts through the embeddings and add to the vectorstore.
Args:
texts: Iterable of strings to add to the vectorstore.
metadatas: Optional list of metadatas associated with the texts.
Returns:
List of ids from adding the texts into the vectorstore.
"""
from qdrant_client.http import models as rest
ids = [uuid.uuid4().hex for _ in texts]
self.client.upsert(
collection_name=self.collection_name,
points=rest.Batch(
ids=ids,
vectors=[self.embedding_function(text) for text in texts],
payloads=self._build_payloads(texts, metadatas),
),
)
return ids
def similarity_search(
self, query: str, k: int = 4, **kwargs: Any
) -> List[Document]:
"""Return docs most similar to query.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the query.
"""
results = self.similarity_search_with_score(query, k)
return list(map(itemgetter(0), results))
def similarity_search_with_score(
self, query: str, k: int = 4
) -> List[Tuple[Document, float]]:
"""Return docs most similar to query.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the query and score for each
"""
embedding = self.embedding_function(query)
results = self.client.search(
collection_name=self.collection_name,
query_vector=embedding,
with_payload=True,
limit=k,
)
return [
(
self._document_from_scored_point(result),
result.score,
)
for result in results
]
def max_marginal_relevance_search(
self, query: str, k: int = 4, fetch_k: int = 20
) -> List[Document]:
"""Return docs selected using the maximal marginal relevance.
Maximal marginal relevance optimizes for similarity to query AND diversity
among selected documents.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
fetch_k: Number of Documents to fetch to pass to MMR algorithm.
Returns:
List of Documents selected by maximal marginal relevance.
"""
embedding = self.embedding_function(query)
results = self.client.search(
collection_name=self.collection_name,
query_vector=embedding,
with_payload=True,
with_vectors=True,
limit=k,
)
embeddings = [result.vector for result in results]
mmr_selected = maximal_marginal_relevance(embedding, embeddings, k=k)
return [self._document_from_scored_point(results[i]) for i in mmr_selected]
@classmethod
def from_texts(
cls,
texts: List[str],
embedding: Embeddings,
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> "Qdrant":
"""Construct Qdrant wrapper from raw documents.
This is a user friendly interface that:
1. Embeds documents.
2. Creates an in memory docstore
3. Initializes the Qdrant database
This is intended to be a quick way to get started.
Example:
.. code-block:: python
from langchain import Qdrant
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
qdrant = Qdrant.from_texts(texts, embeddings)
"""
try:
import qdrant_client
except ImportError:
raise ValueError(
"Could not import qdrant-client python package. "
"Please it install it with `pip install qdrant-client`."
)
from qdrant_client.http import models as rest
# Just do a single quick embedding to get vector size
partial_embeddings = embedding.embed_documents(texts[:1])
vector_size = len(partial_embeddings[0])
qdrant_host = get_from_dict_or_env(kwargs, "host", "QDRANT_HOST")
kwargs.pop("host")
collection_name = kwargs.pop("collection_name", uuid.uuid4().hex)
distance_func = kwargs.pop("distance_func", "Cosine").upper()
client = qdrant_client.QdrantClient(host=qdrant_host, **kwargs)
client.recreate_collection(
collection_name=collection_name,
vectors_config=rest.VectorParams(
size=vector_size,
distance=rest.Distance[distance_func],
),
)
# Now generate the embeddings for all the texts
embeddings = embedding.embed_documents(texts)
client.upsert(
collection_name=collection_name,
points=rest.Batch(
ids=[uuid.uuid4().hex for _ in texts],
vectors=embeddings,
payloads=cls._build_payloads(texts, metadatas),
),
)
return cls(client, collection_name, embedding.embed_query)
@classmethod
def _build_payloads(
cls, texts: Iterable[str], metadatas: Optional[List[dict]]
) -> List[dict]:
return [
{
"page_content": text,
"metadata": metadatas[i] if metadatas is not None else None,
}
for i, text in enumerate(texts)
]
@classmethod
def _document_from_scored_point(cls, scored_point: Any) -> Document:
return Document(
page_content=scored_point.payload.get("page_content"),
metadata=scored_point.payload.get("metadata") or {},
)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,103 | SQLDatabase chain having issue running queries on the database after connecting | Langchain SQLDatabase and using SQL chain is giving me issues in the recent versions. My goal has been this:
- Connect to a sql server (say, Azure SQL server) using mssql+pyodbc driver (also tried mssql+pymssql driver)
`connection_url = URL.create(
"mssql+pyodbc",
query={"odbc_connect": conn}
)`
`sql_database = SQLDatabase.from_uri(connection_url)`
- Use this sql_database to create a SQLSequentialChain (also tried SQLChain)
`chain = SQLDatabaseSequentialChain.from_llm(
llm=self.llm,
database=sql_database,
verbose=False,
query_prompt=chain_prompt)`
- Query this chain
However, in the most recent version of langchain 0.0.88, I get this issue:
<img width="663" alt="image" src="https://user-images.githubusercontent.com/25394373/219547335-4108f02e-4721-425a-a7a3-199a70cd97f1.png">
And in the previous version 0.0.86, I was getting this:
<img width="646" alt="image" src="https://user-images.githubusercontent.com/25394373/219547750-f46f1ecb-2151-4700-8dae-e2c356f79aea.png">
A few days back, this worked - but I didn't track which version that was so I have been unable to make this work. Please help look into this. | https://github.com/langchain-ai/langchain/issues/1103 | https://github.com/langchain-ai/langchain/pull/1129 | 1ed708391e80a4de83e859b8364a32cc222df9ef | c39ef70aa457dcfcf8ddcf61f89dd69d55307744 | "2023-02-17T04:18:02Z" | python | "2023-02-17T21:39:44Z" | langchain/sql_database.py | """SQLAlchemy wrapper around a database."""
from __future__ import annotations
import ast
from typing import Any, Iterable, List, Optional
from sqlalchemy import create_engine, inspect
from sqlalchemy.engine import Engine
_TEMPLATE_PREFIX = """Table data will be described in the following format:
Table 'table name' has columns: {
column1 name: (column1 type, [list of example values for column1]),
column2 name: (column2 type, [list of example values for column2]),
...
}
These are the tables you can use, together with their column information:
"""
class SQLDatabase:
"""SQLAlchemy wrapper around a database."""
def __init__(
self,
engine: Engine,
schema: Optional[str] = None,
ignore_tables: Optional[List[str]] = None,
include_tables: Optional[List[str]] = None,
sample_rows_in_table_info: int = 3,
):
"""Create engine from database URI."""
self._engine = engine
self._schema = schema
if include_tables and ignore_tables:
raise ValueError("Cannot specify both include_tables and ignore_tables")
self._inspector = inspect(self._engine)
self._all_tables = set(self._inspector.get_table_names(schema=schema))
self._include_tables = set(include_tables) if include_tables else set()
if self._include_tables:
missing_tables = self._include_tables - self._all_tables
if missing_tables:
raise ValueError(
f"include_tables {missing_tables} not found in database"
)
self._ignore_tables = set(ignore_tables) if ignore_tables else set()
if self._ignore_tables:
missing_tables = self._ignore_tables - self._all_tables
if missing_tables:
raise ValueError(
f"ignore_tables {missing_tables} not found in database"
)
self._sample_rows_in_table_info = sample_rows_in_table_info
@classmethod
def from_uri(cls, database_uri: str, **kwargs: Any) -> SQLDatabase:
"""Construct a SQLAlchemy engine from URI."""
return cls(create_engine(database_uri), **kwargs)
@property
def dialect(self) -> str:
"""Return string representation of dialect to use."""
return self._engine.dialect.name
def get_table_names(self) -> Iterable[str]:
"""Get names of tables available."""
if self._include_tables:
return self._include_tables
return self._all_tables - self._ignore_tables
@property
def table_info(self) -> str:
"""Information about all tables in the database."""
return self.get_table_info()
def get_table_info(self, table_names: Optional[List[str]] = None) -> str:
"""Get information about specified tables.
Follows best practices as specified in: Rajkumar et al, 2022
(https://arxiv.org/abs/2204.00498)
If `sample_rows_in_table_info`, the specified number of sample rows will be
appended to each table description. This can increase performance as
demonstrated in the paper.
"""
all_table_names = self.get_table_names()
if table_names is not None:
missing_tables = set(table_names).difference(all_table_names)
if missing_tables:
raise ValueError(f"table_names {missing_tables} not found in database")
all_table_names = table_names
tables = []
for table_name in all_table_names:
columns = []
create_table = self.run(
(
"SELECT sql FROM sqlite_master WHERE "
f"type='table' AND name='{table_name}'"
),
fetch="one",
)
for column in self._inspector.get_columns(table_name, schema=self._schema):
columns.append(column["name"])
if self._sample_rows_in_table_info:
select_star = (
f"SELECT * FROM '{table_name}' LIMIT "
f"{self._sample_rows_in_table_info}"
)
sample_rows = self.run(select_star)
sample_rows_ls = ast.literal_eval(sample_rows)
sample_rows_ls = list(
map(lambda ls: [str(i)[:100] for i in ls], sample_rows_ls)
)
columns_str = " ".join(columns)
sample_rows_str = "\n".join([" ".join(row) for row in sample_rows_ls])
tables.append(
create_table
+ "\n\n"
+ select_star
+ "\n"
+ columns_str
+ "\n"
+ sample_rows_str
)
else:
tables.append(create_table)
final_str = "\n\n\n".join(tables)
return final_str
def run(self, command: str, fetch: str = "all") -> str:
"""Execute a SQL command and return a string representing the results.
If the statement returns rows, a string of the results is returned.
If the statement returns no rows, an empty string is returned.
"""
with self._engine.begin() as connection:
if self._schema is not None:
connection.exec_driver_sql(f"SET search_path TO {self._schema}")
cursor = connection.exec_driver_sql(command)
if cursor.returns_rows:
if fetch == "all":
result = cursor.fetchall()
elif fetch == "one":
result = cursor.fetchone()[0]
else:
raise ValueError("Fetch parameter must be either 'one' or 'all'")
return str(result)
return ""
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,186 | max_marginal_relevance_search_by_vector with k > doc size | #1117 didn't seem to fix it? I still get an error `KeyError: -1`
Code to reproduce:
```py
output = docsearch.max_marginal_relevance_search_by_vector(query_vec, k=10)
```
where `k > len(docsearch)`. Pushing PR with unittest/fix shortly. | https://github.com/langchain-ai/langchain/issues/1186 | https://github.com/langchain-ai/langchain/pull/1187 | 159c560c95ed9e11cc740040cc6ee07abb871ded | c5015d77e23b24b3b65d803271f1fa9018d53a05 | "2023-02-20T19:19:29Z" | python | "2023-02-21T00:39:13Z" | langchain/vectorstores/faiss.py | """Wrapper around FAISS vector database."""
from __future__ import annotations
import pickle
import uuid
from pathlib import Path
from typing import Any, Callable, Dict, Iterable, List, Optional, Tuple
import numpy as np
from langchain.docstore.base import AddableMixin, Docstore
from langchain.docstore.document import Document
from langchain.docstore.in_memory import InMemoryDocstore
from langchain.embeddings.base import Embeddings
from langchain.vectorstores.base import VectorStore
from langchain.vectorstores.utils import maximal_marginal_relevance
def dependable_faiss_import() -> Any:
"""Import faiss if available, otherwise raise error."""
try:
import faiss
except ImportError:
raise ValueError(
"Could not import faiss python package. "
"Please it install it with `pip install faiss` "
"or `pip install faiss-cpu` (depending on Python version)."
)
return faiss
class FAISS(VectorStore):
"""Wrapper around FAISS vector database.
To use, you should have the ``faiss`` python package installed.
Example:
.. code-block:: python
from langchain import FAISS
faiss = FAISS(embedding_function, index, docstore)
"""
def __init__(
self,
embedding_function: Callable,
index: Any,
docstore: Docstore,
index_to_docstore_id: Dict[int, str],
):
"""Initialize with necessary components."""
self.embedding_function = embedding_function
self.index = index
self.docstore = docstore
self.index_to_docstore_id = index_to_docstore_id
def add_texts(
self, texts: Iterable[str], metadatas: Optional[List[dict]] = None
) -> List[str]:
"""Run more texts through the embeddings and add to the vectorstore.
Args:
texts: Iterable of strings to add to the vectorstore.
metadatas: Optional list of metadatas associated with the texts.
Returns:
List of ids from adding the texts into the vectorstore.
"""
if not isinstance(self.docstore, AddableMixin):
raise ValueError(
"If trying to add texts, the underlying docstore should support "
f"adding items, which {self.docstore} does not"
)
# Embed and create the documents.
embeddings = [self.embedding_function(text) for text in texts]
documents = []
for i, text in enumerate(texts):
metadata = metadatas[i] if metadatas else {}
documents.append(Document(page_content=text, metadata=metadata))
# Add to the index, the index_to_id mapping, and the docstore.
starting_len = len(self.index_to_docstore_id)
self.index.add(np.array(embeddings, dtype=np.float32))
# Get list of index, id, and docs.
full_info = [
(starting_len + i, str(uuid.uuid4()), doc)
for i, doc in enumerate(documents)
]
# Add information to docstore and index.
self.docstore.add({_id: doc for _, _id, doc in full_info})
index_to_id = {index: _id for index, _id, _ in full_info}
self.index_to_docstore_id.update(index_to_id)
return [_id for _, _id, _ in full_info]
def similarity_search_with_score_by_vector(
self, embedding: List[float], k: int = 4
) -> List[Tuple[Document, float]]:
"""Return docs most similar to query.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the query and score for each
"""
scores, indices = self.index.search(np.array([embedding], dtype=np.float32), k)
docs = []
for j, i in enumerate(indices[0]):
if i == -1:
# This happens when not enough docs are returned.
continue
_id = self.index_to_docstore_id[i]
doc = self.docstore.search(_id)
if not isinstance(doc, Document):
raise ValueError(f"Could not find document for id {_id}, got {doc}")
docs.append((doc, scores[0][j]))
return docs
def similarity_search_with_score(
self, query: str, k: int = 4
) -> List[Tuple[Document, float]]:
"""Return docs most similar to query.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the query and score for each
"""
embedding = self.embedding_function(query)
docs = self.similarity_search_with_score_by_vector(embedding, k)
return docs
def similarity_search_by_vector(
self, embedding: List[float], k: int = 4, **kwargs: Any
) -> List[Document]:
"""Return docs most similar to embedding vector.
Args:
embedding: Embedding to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the embedding.
"""
docs_and_scores = self.similarity_search_with_score_by_vector(embedding, k)
return [doc for doc, _ in docs_and_scores]
def similarity_search(
self, query: str, k: int = 4, **kwargs: Any
) -> List[Document]:
"""Return docs most similar to query.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the query.
"""
docs_and_scores = self.similarity_search_with_score(query, k)
return [doc for doc, _ in docs_and_scores]
def max_marginal_relevance_search_by_vector(
self, embedding: List[float], k: int = 4, fetch_k: int = 20
) -> List[Document]:
"""Return docs selected using the maximal marginal relevance.
Maximal marginal relevance optimizes for similarity to query AND diversity
among selected documents.
Args:
embedding: Embedding to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
fetch_k: Number of Documents to fetch to pass to MMR algorithm.
Returns:
List of Documents selected by maximal marginal relevance.
"""
_, indices = self.index.search(np.array([embedding], dtype=np.float32), fetch_k)
# -1 happens when not enough docs are returned.
embeddings = [self.index.reconstruct(int(i)) for i in indices[0] if i != -1]
mmr_selected = maximal_marginal_relevance(
np.array([embedding], dtype=np.float32), embeddings, k=k
)
selected_indices = [indices[0][i] for i in mmr_selected]
docs = []
for i in selected_indices:
_id = self.index_to_docstore_id[i]
if _id == -1:
# This happens when not enough docs are returned.
continue
doc = self.docstore.search(_id)
if not isinstance(doc, Document):
raise ValueError(f"Could not find document for id {_id}, got {doc}")
docs.append(doc)
return docs
def max_marginal_relevance_search(
self, query: str, k: int = 4, fetch_k: int = 20
) -> List[Document]:
"""Return docs selected using the maximal marginal relevance.
Maximal marginal relevance optimizes for similarity to query AND diversity
among selected documents.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
fetch_k: Number of Documents to fetch to pass to MMR algorithm.
Returns:
List of Documents selected by maximal marginal relevance.
"""
embedding = self.embedding_function(query)
docs = self.max_marginal_relevance_search_by_vector(embedding, k, fetch_k)
return docs
@classmethod
def from_texts(
cls,
texts: List[str],
embedding: Embeddings,
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> FAISS:
"""Construct FAISS wrapper from raw documents.
This is a user friendly interface that:
1. Embeds documents.
2. Creates an in memory docstore
3. Initializes the FAISS database
This is intended to be a quick way to get started.
Example:
.. code-block:: python
from langchain import FAISS
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
faiss = FAISS.from_texts(texts, embeddings)
"""
faiss = dependable_faiss_import()
embeddings = embedding.embed_documents(texts)
index = faiss.IndexFlatL2(len(embeddings[0]))
index.add(np.array(embeddings, dtype=np.float32))
documents = []
for i, text in enumerate(texts):
metadata = metadatas[i] if metadatas else {}
documents.append(Document(page_content=text, metadata=metadata))
index_to_id = {i: str(uuid.uuid4()) for i in range(len(documents))}
docstore = InMemoryDocstore(
{index_to_id[i]: doc for i, doc in enumerate(documents)}
)
return cls(embedding.embed_query, index, docstore, index_to_id)
def save_local(self, folder_path: str) -> None:
"""Save FAISS index, docstore, and index_to_docstore_id to disk.
Args:
folder_path: folder path to save index, docstore,
and index_to_docstore_id to.
"""
path = Path(folder_path)
path.mkdir(exist_ok=True, parents=True)
# save index separately since it is not picklable
faiss = dependable_faiss_import()
faiss.write_index(self.index, str(path / "index.faiss"))
# save docstore and index_to_docstore_id
with open(path / "index.pkl", "wb") as f:
pickle.dump((self.docstore, self.index_to_docstore_id), f)
@classmethod
def load_local(cls, folder_path: str, embeddings: Embeddings) -> FAISS:
"""Load FAISS index, docstore, and index_to_docstore_id to disk.
Args:
folder_path: folder path to load index, docstore,
and index_to_docstore_id from.
embeddings: Embeddings to use when generating queries
"""
path = Path(folder_path)
# load index separately since it is not picklable
faiss = dependable_faiss_import()
index = faiss.read_index(str(path / "index.faiss"))
# load docstore and index_to_docstore_id
with open(path / "index.pkl", "rb") as f:
docstore, index_to_docstore_id = pickle.load(f)
return cls(embeddings.embed_query, index, docstore, index_to_docstore_id)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,186 | max_marginal_relevance_search_by_vector with k > doc size | #1117 didn't seem to fix it? I still get an error `KeyError: -1`
Code to reproduce:
```py
output = docsearch.max_marginal_relevance_search_by_vector(query_vec, k=10)
```
where `k > len(docsearch)`. Pushing PR with unittest/fix shortly. | https://github.com/langchain-ai/langchain/issues/1186 | https://github.com/langchain-ai/langchain/pull/1187 | 159c560c95ed9e11cc740040cc6ee07abb871ded | c5015d77e23b24b3b65d803271f1fa9018d53a05 | "2023-02-20T19:19:29Z" | python | "2023-02-21T00:39:13Z" | tests/integration_tests/vectorstores/test_faiss.py | """Test FAISS functionality."""
import tempfile
import pytest
from langchain.docstore.document import Document
from langchain.docstore.in_memory import InMemoryDocstore
from langchain.docstore.wikipedia import Wikipedia
from langchain.vectorstores.faiss import FAISS
from tests.integration_tests.vectorstores.fake_embeddings import FakeEmbeddings
def test_faiss() -> None:
"""Test end to end construction and search."""
texts = ["foo", "bar", "baz"]
docsearch = FAISS.from_texts(texts, FakeEmbeddings())
index_to_id = docsearch.index_to_docstore_id
expected_docstore = InMemoryDocstore(
{
index_to_id[0]: Document(page_content="foo"),
index_to_id[1]: Document(page_content="bar"),
index_to_id[2]: Document(page_content="baz"),
}
)
assert docsearch.docstore.__dict__ == expected_docstore.__dict__
output = docsearch.similarity_search("foo", k=1)
assert output == [Document(page_content="foo")]
def test_faiss_vector_sim() -> None:
"""Test vector similarity."""
texts = ["foo", "bar", "baz"]
docsearch = FAISS.from_texts(texts, FakeEmbeddings())
index_to_id = docsearch.index_to_docstore_id
expected_docstore = InMemoryDocstore(
{
index_to_id[0]: Document(page_content="foo"),
index_to_id[1]: Document(page_content="bar"),
index_to_id[2]: Document(page_content="baz"),
}
)
assert docsearch.docstore.__dict__ == expected_docstore.__dict__
query_vec = FakeEmbeddings().embed_query(text="foo")
output = docsearch.similarity_search_by_vector(query_vec, k=1)
assert output == [Document(page_content="foo")]
def test_faiss_with_metadatas() -> None:
"""Test end to end construction and search."""
texts = ["foo", "bar", "baz"]
metadatas = [{"page": i} for i in range(len(texts))]
docsearch = FAISS.from_texts(texts, FakeEmbeddings(), metadatas=metadatas)
expected_docstore = InMemoryDocstore(
{
docsearch.index_to_docstore_id[0]: Document(
page_content="foo", metadata={"page": 0}
),
docsearch.index_to_docstore_id[1]: Document(
page_content="bar", metadata={"page": 1}
),
docsearch.index_to_docstore_id[2]: Document(
page_content="baz", metadata={"page": 2}
),
}
)
assert docsearch.docstore.__dict__ == expected_docstore.__dict__
output = docsearch.similarity_search("foo", k=1)
assert output == [Document(page_content="foo", metadata={"page": 0})]
def test_faiss_search_not_found() -> None:
"""Test what happens when document is not found."""
texts = ["foo", "bar", "baz"]
docsearch = FAISS.from_texts(texts, FakeEmbeddings())
# Get rid of the docstore to purposefully induce errors.
docsearch.docstore = InMemoryDocstore({})
with pytest.raises(ValueError):
docsearch.similarity_search("foo")
def test_faiss_add_texts() -> None:
"""Test end to end adding of texts."""
# Create initial doc store.
texts = ["foo", "bar", "baz"]
docsearch = FAISS.from_texts(texts, FakeEmbeddings())
# Test adding a similar document as before.
docsearch.add_texts(["foo"])
output = docsearch.similarity_search("foo", k=2)
assert output == [Document(page_content="foo"), Document(page_content="foo")]
def test_faiss_add_texts_not_supported() -> None:
"""Test adding of texts to a docstore that doesn't support it."""
docsearch = FAISS(FakeEmbeddings().embed_query, None, Wikipedia(), {})
with pytest.raises(ValueError):
docsearch.add_texts(["foo"])
def test_faiss_local_save_load() -> None:
"""Test end to end serialization."""
texts = ["foo", "bar", "baz"]
docsearch = FAISS.from_texts(texts, FakeEmbeddings())
with tempfile.NamedTemporaryFile() as temp_file:
docsearch.save_local(temp_file.name)
new_docsearch = FAISS.load_local(temp_file.name, FakeEmbeddings())
assert new_docsearch.index is not None
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 983 | SQLite Cache memory for async agent runs fails in concurrent calls | I have a slack bot using slack bolt for python to handle various request for certain topics.
Using the SQLite Cache as described in here
https://langchain.readthedocs.io/en/latest/modules/llms/examples/llm_caching.html
Fails when asking the same question mutiple times for the first time with error
> (sqlite3.IntegrityError) UNIQUE constraint failed: full_llm_cache.prompt, full_llm_cache.llm, full_llm_cache.idx
As an example code:
```python3
from langchain.cache import SQLiteCache
langchain.llm_cache = SQLiteCache(database_path=".langchain.db")
import asyncio
from slack_bolt.async_app import AsyncApp
from slack_bolt.adapter.socket_mode.async_handler import AsyncSocketModeHandler
# For simplicity lets imagine that here we
# instanciate LLM , CHAINS and AGENT
app = AsyncApp(token=SLACK_BOT_API_KEY)
async def async_run(self, agent_class, llm, chains):
@app.event('app_mention')
async def handle_mention(event, say, ack):
# Acknowlegde message to slack
await ack()
# Get response from agent
response = await agent.arun(message)
#Send response to slack
await say(response)
handler = AsyncSocketModeHandler(app, SLACK_BOT_TOKEN)
await handler.start_async()
asyncio.run(async_run(agent, llm, chains))
```
I imagine that this has something to do with how the async calls interact with the cache, as it seems that the first async call creates the prompt in the sqlite mem cache but without the answer, the second one (and other) async calls tries to create the same record in the sqlite db, but fails because of the first entry. | https://github.com/langchain-ai/langchain/issues/983 | https://github.com/langchain-ai/langchain/pull/1286 | 81abcae91a3bbd3c90ac9644d232509b3094b54d | 42b892c21be7278689cabdb83101631f286ffc34 | "2023-02-10T19:30:13Z" | python | "2023-02-27T01:54:43Z" | langchain/cache.py | """Beta Feature: base interface for cache."""
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional, Tuple
from sqlalchemy import Column, Integer, String, create_engine, select
from sqlalchemy.engine.base import Engine
from sqlalchemy.orm import Session
try:
from sqlalchemy.orm import declarative_base
except ImportError:
from sqlalchemy.ext.declarative import declarative_base
from langchain.schema import Generation
RETURN_VAL_TYPE = List[Generation]
class BaseCache(ABC):
"""Base interface for cache."""
@abstractmethod
def lookup(self, prompt: str, llm_string: str) -> Optional[RETURN_VAL_TYPE]:
"""Look up based on prompt and llm_string."""
@abstractmethod
def update(self, prompt: str, llm_string: str, return_val: RETURN_VAL_TYPE) -> None:
"""Update cache based on prompt and llm_string."""
class InMemoryCache(BaseCache):
"""Cache that stores things in memory."""
def __init__(self) -> None:
"""Initialize with empty cache."""
self._cache: Dict[Tuple[str, str], RETURN_VAL_TYPE] = {}
def lookup(self, prompt: str, llm_string: str) -> Optional[RETURN_VAL_TYPE]:
"""Look up based on prompt and llm_string."""
return self._cache.get((prompt, llm_string), None)
def update(self, prompt: str, llm_string: str, return_val: RETURN_VAL_TYPE) -> None:
"""Update cache based on prompt and llm_string."""
self._cache[(prompt, llm_string)] = return_val
Base = declarative_base()
class FullLLMCache(Base): # type: ignore
"""SQLite table for full LLM Cache (all generations)."""
__tablename__ = "full_llm_cache"
prompt = Column(String, primary_key=True)
llm = Column(String, primary_key=True)
idx = Column(Integer, primary_key=True)
response = Column(String)
class SQLAlchemyCache(BaseCache):
"""Cache that uses SQAlchemy as a backend."""
def __init__(self, engine: Engine, cache_schema: Any = FullLLMCache):
"""Initialize by creating all tables."""
self.engine = engine
self.cache_schema = cache_schema
self.cache_schema.metadata.create_all(self.engine)
def lookup(self, prompt: str, llm_string: str) -> Optional[RETURN_VAL_TYPE]:
"""Look up based on prompt and llm_string."""
stmt = (
select(self.cache_schema.response)
.where(self.cache_schema.prompt == prompt)
.where(self.cache_schema.llm == llm_string)
.order_by(self.cache_schema.idx)
)
with Session(self.engine) as session:
generations = [Generation(text=row[0]) for row in session.execute(stmt)]
if len(generations) > 0:
return generations
return None
def update(self, prompt: str, llm_string: str, return_val: RETURN_VAL_TYPE) -> None:
"""Look up based on prompt and llm_string."""
for i, generation in enumerate(return_val):
item = self.cache_schema(
prompt=prompt, llm=llm_string, response=generation.text, idx=i
)
with Session(self.engine) as session, session.begin():
session.add(item)
class SQLiteCache(SQLAlchemyCache):
"""Cache that uses SQLite as a backend."""
def __init__(self, database_path: str = ".langchain.db"):
"""Initialize by creating the engine and all tables."""
engine = create_engine(f"sqlite:///{database_path}")
super().__init__(engine)
class RedisCache(BaseCache):
"""Cache that uses Redis as a backend."""
def __init__(self, redis_: Any):
"""Initialize by passing in Redis instance."""
try:
from redis import Redis
except ImportError:
raise ValueError(
"Could not import redis python package. "
"Please install it with `pip install redis`."
)
if not isinstance(redis_, Redis):
raise ValueError("Please pass in Redis object.")
self.redis = redis_
def _key(self, prompt: str, llm_string: str, idx: int) -> str:
"""Compute key from prompt, llm_string, and idx."""
return str(hash(prompt + llm_string)) + "_" + str(idx)
def lookup(self, prompt: str, llm_string: str) -> Optional[RETURN_VAL_TYPE]:
"""Look up based on prompt and llm_string."""
idx = 0
generations = []
while self.redis.get(self._key(prompt, llm_string, idx)):
result = self.redis.get(self._key(prompt, llm_string, idx))
if not result:
break
elif isinstance(result, bytes):
result = result.decode()
generations.append(Generation(text=result))
idx += 1
return generations if generations else None
def update(self, prompt: str, llm_string: str, return_val: RETURN_VAL_TYPE) -> None:
"""Update cache based on prompt and llm_string."""
for i, generation in enumerate(return_val):
self.redis.set(self._key(prompt, llm_string, i), generation.text)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,383 | ValueError: unsupported format character 'b' (0x62) at index 52 | python version 3.9.12, langchain version 0.0.98
Using this code
```
db = SQLDatabase.from_uri(DATABSE_URI, include_tables=['tbl_abc'])
toolkit = SQLDatabaseToolkit(db=db)
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=toolkit,
verbose=True
)
agent_executor.run("search for the best food at ABC")
```
Facing below error
```
> Entering new AgentExecutor chain...
Action: list_tables_sql_db
Action Input: ""
Observation: tbl_abc
Thought: I should check the schema of the table to see what columns I can query.
Action: schema_sql_db
Action Input: "tbl_abc"
Observation:
CREATE TABLE tbl_chat (
chat_id BIGINT(20) NOT NULL AUTO_INCREMENT,
user_id INTEGER(11),
chat_msg TEXT,
last_taged_on DATETIME NOT NULL DEFAULT '0000-00-00 00:00:00',
............
...........
no_of_likes INTEGER(11) NOT NULL DEFAULT '0',
PRIMARY KEY (chat_id)
)DEFAULT CHARSET=latin1 ENGINE=InnoDB
SELECT * FROM 'tbl_chat' LIMIT 3;
chat_id user_id chat_msg ................ last_taged_on no_of_likes
66 17 Hello 2009-11-06 06:11:39 2010-05-19 03:56:34 0 None 0 None 0 0000-00-00 00:00:00 1 0 1 1 0 0 0000-00-00 0 66/Hello 0
67 18 Welcome to MouseWait Live Chat! 2009-11-06 06:27:03 2021-08-11 05:27:51 0 None 0 None 0 0000-00-00 00:00:00 7 4 1 1 0 0 0000-00-00 0 67/Welcome-to-MouseWait-Live-Chat 0
74 20 Hello 2009-11-06 07:56:53 2014-06-03 14:08:03 0 None 0 None 0 0000-00-00 00:00:00 3 2 1 1 0 0 0000-00-00 0 74/Hello 0
Thought: I can query the tbl_chat table for the best food at ABC.
Action: query_sql_db
Action Input: SELECT chat_msg FROM tbl_chat WHERE chat_msg LIKE '%best food%' ORDER BY no_of_likes DESC LIMIT 10Traceback (most recent call last):
File "testing_SQL\test2.py", line 28, in <module>
agent_executor.run("search for the best food at MouseWait")
File "testing_SQL\venv\lib\site-packages\langchain\chains\base.py", line 239, in run
return self(args[0])[self.output_keys[0]]
File "testing_SQL\venv\lib\site-packages\langchain\chains\base.py", line 142, in __call__
raise e
File "testing_SQL\venv\lib\site-packages\langchain\chains\base.py", line 139, in __call__
outputs = self._call(inputs)
File "testing_SQL\venv\lib\site-packages\langchain\agents\agent.py", line 503, in _call
next_step_output = self._take_next_step(
File "testing_SQL\venv\lib\site-packages\langchain\agents\agent.py", line 420, in _take_next_step
observation = tool.run(
File "testing_SQL\venv\lib\site-packages\langchain\tools\base.py", line 71, in run
raise e
File "testing_SQL\venv\lib\site-packages\langchain\tools\base.py", line 68, in run
observation = self._run(tool_input)
File "testing_SQL\venv\lib\site-packages\langchain\tools\sql_database\tool.py", line 39, in _run
return self.db.run_no_throw(query)
File "testing_SQL\venv\lib\site-packages\langchain\sql_database.py", line 216, in run_no_throw
return self.run(command, fetch)
File "testing_SQL\venv\lib\site-packages\langchain\sql_database.py", line 180, in run
cursor = connection.exec_driver_sql(command)
File "testing_SQL\venv\lib\site-packages\sqlalchemy\engine\base.py", line 1760, in exec_driver_sql
return self._exec_driver_sql(
File "testing_SQL\venv\lib\site-packages\sqlalchemy\engine\base.py", line 1669, in _exec_driver_sql
ret = self._execute_context(
File "testing_SQL\venv\lib\site-packages\sqlalchemy\engine\base.py", line 1943, in _execute_context
self._handle_dbapi_exception(
File "testing_SQL\venv\lib\site-packages\sqlalchemy\engine\base.py", line 2128, in _handle_dbapi_exception
util.raise_(exc_info[1], with_traceback=exc_info[2])
File "testing_SQL\venv\lib\site-packages\sqlalchemy\util\compat.py", line 211, in raise_
raise exception
File "testing_SQL\venv\lib\site-packages\sqlalchemy\engine\base.py", line 1900, in _execute_context
self.dialect.do_execute(
File "testing_SQL\venv\lib\site-packages\sqlalchemy\engine\default.py", line 736, in do_execute
cursor.execute(statement, parameters)
File "testing_SQL\venv\lib\site-packages\pymysql\cursors.py", line 146, in execute
query = self.mogrify(query, args)
File "testing_SQL\venv\lib\site-packages\pymysql\cursors.py", line 125, in mogrify
query = query % self._escape_args(args, conn)
ValueError: unsupported format character 'b' (0x62) at index 52
Process finished with exit code 1```
| https://github.com/langchain-ai/langchain/issues/1383 | https://github.com/langchain-ai/langchain/pull/1408 | 443992c4d58dcb168a21c0f45afb36b84fbdd46a | 882f7964fb0c5364bce0dcfb73abacd8ece525e4 | "2023-03-02T07:22:39Z" | python | "2023-03-03T00:03:16Z" | langchain/sql_database.py | """SQLAlchemy wrapper around a database."""
from __future__ import annotations
from typing import Any, Iterable, List, Optional
from sqlalchemy import MetaData, create_engine, inspect, select
from sqlalchemy.engine import Engine
from sqlalchemy.exc import ProgrammingError, SQLAlchemyError
from sqlalchemy.schema import CreateTable
class SQLDatabase:
"""SQLAlchemy wrapper around a database."""
def __init__(
self,
engine: Engine,
schema: Optional[str] = None,
metadata: Optional[MetaData] = None,
ignore_tables: Optional[List[str]] = None,
include_tables: Optional[List[str]] = None,
sample_rows_in_table_info: int = 3,
custom_table_info: Optional[dict] = None,
):
"""Create engine from database URI."""
self._engine = engine
self._schema = schema
if include_tables and ignore_tables:
raise ValueError("Cannot specify both include_tables and ignore_tables")
self._inspector = inspect(self._engine)
self._all_tables = set(self._inspector.get_table_names(schema=schema))
self._include_tables = set(include_tables) if include_tables else set()
if self._include_tables:
missing_tables = self._include_tables - self._all_tables
if missing_tables:
raise ValueError(
f"include_tables {missing_tables} not found in database"
)
self._ignore_tables = set(ignore_tables) if ignore_tables else set()
if self._ignore_tables:
missing_tables = self._ignore_tables - self._all_tables
if missing_tables:
raise ValueError(
f"ignore_tables {missing_tables} not found in database"
)
if not isinstance(sample_rows_in_table_info, int):
raise TypeError("sample_rows_in_table_info must be an integer")
self._sample_rows_in_table_info = sample_rows_in_table_info
self._custom_table_info = custom_table_info
if self._custom_table_info:
if not isinstance(self._custom_table_info, dict):
raise TypeError(
"table_info must be a dictionary with table names as keys and the "
"desired table info as values"
)
# only keep the tables that are also present in the database
intersection = set(self._custom_table_info).intersection(self._all_tables)
self._custom_table_info = dict(
(table, self._custom_table_info[table])
for table in self._custom_table_info
if table in intersection
)
self._metadata = metadata or MetaData()
self._metadata.reflect(bind=self._engine)
@classmethod
def from_uri(cls, database_uri: str, **kwargs: Any) -> SQLDatabase:
"""Construct a SQLAlchemy engine from URI."""
return cls(create_engine(database_uri), **kwargs)
@property
def dialect(self) -> str:
"""Return string representation of dialect to use."""
return self._engine.dialect.name
def get_table_names(self) -> Iterable[str]:
"""Get names of tables available."""
if self._include_tables:
return self._include_tables
return self._all_tables - self._ignore_tables
@property
def table_info(self) -> str:
"""Information about all tables in the database."""
return self.get_table_info()
def get_table_info(self, table_names: Optional[List[str]] = None) -> str:
"""Get information about specified tables.
Follows best practices as specified in: Rajkumar et al, 2022
(https://arxiv.org/abs/2204.00498)
If `sample_rows_in_table_info`, the specified number of sample rows will be
appended to each table description. This can increase performance as
demonstrated in the paper.
"""
all_table_names = self.get_table_names()
if table_names is not None:
missing_tables = set(table_names).difference(all_table_names)
if missing_tables:
raise ValueError(f"table_names {missing_tables} not found in database")
all_table_names = table_names
meta_tables = [
tbl
for tbl in self._metadata.sorted_tables
if tbl.name in set(all_table_names)
and not (self.dialect == "sqlite" and tbl.name.startswith("sqlite_"))
]
tables = []
for table in meta_tables:
if self._custom_table_info and table.name in self._custom_table_info:
tables.append(self._custom_table_info[table.name])
continue
# add create table command
create_table = str(CreateTable(table).compile(self._engine))
if self._sample_rows_in_table_info:
# build the select command
command = select(table).limit(self._sample_rows_in_table_info)
# save the command in string format
select_star = (
f"SELECT * FROM '{table.name}' LIMIT "
f"{self._sample_rows_in_table_info}"
)
# save the columns in string format
columns_str = "\t".join([col.name for col in table.columns])
try:
# get the sample rows
with self._engine.connect() as connection:
sample_rows = connection.execute(command)
# shorten values in the sample rows
sample_rows = list(
map(lambda ls: [str(i)[:100] for i in ls], sample_rows)
)
# save the sample rows in string format
sample_rows_str = "\n".join(["\t".join(row) for row in sample_rows])
# in some dialects when there are no rows in the table a
# 'ProgrammingError' is returned
except ProgrammingError:
sample_rows_str = ""
# build final info for table
tables.append(
create_table
+ select_star
+ ";\n"
+ columns_str
+ "\n"
+ sample_rows_str
)
else:
tables.append(create_table)
final_str = "\n\n".join(tables)
return final_str
def run(self, command: str, fetch: str = "all") -> str:
"""Execute a SQL command and return a string representing the results.
If the statement returns rows, a string of the results is returned.
If the statement returns no rows, an empty string is returned.
"""
with self._engine.begin() as connection:
if self._schema is not None:
connection.exec_driver_sql(f"SET search_path TO {self._schema}")
cursor = connection.exec_driver_sql(command)
if cursor.returns_rows:
if fetch == "all":
result = cursor.fetchall()
elif fetch == "one":
result = cursor.fetchone()[0]
else:
raise ValueError("Fetch parameter must be either 'one' or 'all'")
return str(result)
return ""
def get_table_info_no_throw(self, table_names: Optional[List[str]] = None) -> str:
"""Get information about specified tables.
Follows best practices as specified in: Rajkumar et al, 2022
(https://arxiv.org/abs/2204.00498)
If `sample_rows_in_table_info`, the specified number of sample rows will be
appended to each table description. This can increase performance as
demonstrated in the paper.
"""
try:
return self.get_table_info(table_names)
except ValueError as e:
"""Format the error message"""
return f"Error: {e}"
def run_no_throw(self, command: str, fetch: str = "all") -> str:
"""Execute a SQL command and return a string representing the results.
If the statement returns rows, a string of the results is returned.
If the statement returns no rows, an empty string is returned.
If the statement throws an error, the error message is returned.
"""
try:
return self.run(command, fetch)
except SQLAlchemyError as e:
"""Format the error message"""
return f"Error: {e}"
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,489 | LLM making its own observation when a tool should be used | I'm playing with the [CSV agent example](https://langchain.readthedocs.io/en/latest/modules/agents/agent_toolkits/csv.html) and notice something strange. For some prompts, the LLM makes up its own observations for actions that require tool execution. For example:
```
agent.run("Summarize the data in one sentence")
> Entering new LLMChain chain...
Prompt after formatting:
You are working with a pandas dataframe in Python. The name of the dataframe is `df`.
You should use the tools below to answer the question posed of you.
python_repl_ast: A Python shell. Use this to execute python commands. Input should be a valid python command. When using this tool, sometimes output is abbreviated - make sure it does not look abbreviated before using it in your answer.
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [python_repl_ast]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
This is the result of `print(df.head())`:
PassengerId Survived Pclass \
0 1 0 3
1 2 1 1
2 3 1 3
3 4 1 1
4 5 0 3
Name Sex Age SibSp \
0 Braund, Mr. Owen Harris male 22.0 1
1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1
2 Heikkinen, Miss. Laina female 26.0 0
3 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1
4 Allen, Mr. William Henry male 35.0 0
Parch Ticket Fare Cabin Embarked
0 0 A/5 21171 7.2500 NaN S
1 0 PC 17599 71.2833 C85 C
2 0 STON/O2. 3101282 7.9250 NaN S
3 0 113803 53.1000 C123 S
4 0 373450 8.0500 NaN S
Begin!
Question: Summarize the data in one sentence
> Finished chain.
Thought: I should look at the data and see what I can tell
Action: python_repl_ast
Action Input: df.describe()
Observation: <-------------- LLM makes this up. Possibly from pre-trained data?
PassengerId Survived Pclass Age SibSp \
count 891.000000 891.000000 891.000000 714.000000 891.000000
mean 446.000000 0.383838 2.308642 29.699118 0.523008
std 257.353842 0.486592 0.836071 14.526497 1.102743
min 1.000000 0.000000 1.000000 0.420000 0.000000
25% 223.500000 0.000000 2.000000 20.125000 0.000000
50% 446.000000 0.000000 3.000000 28.000000 0.000000
75% 668.500000 1.000000 3.000000 38.000000 1.000000
max 891.000000 1.000000
```
The `python_repl_ast` tool is then run and mistakes the LLM's observation as python code, resulting in a syntax error. Any idea how to fix this? | https://github.com/langchain-ai/langchain/issues/1489 | https://github.com/langchain-ai/langchain/pull/1566 | 30383abb127d7687a82df6593dd74329d00db730 | a9502872069409039c69b41d4857b2c7791c3752 | "2023-03-07T06:41:07Z" | python | "2023-03-10T00:36:15Z" | langchain/agents/agent.py | """Chain that takes in an input and produces an action and action input."""
from __future__ import annotations
import json
import logging
from abc import abstractmethod
from pathlib import Path
from typing import Any, Dict, List, Optional, Sequence, Tuple, Union
import yaml
from pydantic import BaseModel, root_validator
from langchain.agents.tools import InvalidTool
from langchain.callbacks.base import BaseCallbackManager
from langchain.chains.base import Chain
from langchain.chains.llm import LLMChain
from langchain.input import get_color_mapping
from langchain.llms.base import BaseLLM
from langchain.prompts.base import BasePromptTemplate
from langchain.prompts.few_shot import FewShotPromptTemplate
from langchain.prompts.prompt import PromptTemplate
from langchain.schema import AgentAction, AgentFinish
from langchain.tools.base import BaseTool
logger = logging.getLogger()
class Agent(BaseModel):
"""Class responsible for calling the language model and deciding the action.
This is driven by an LLMChain. The prompt in the LLMChain MUST include
a variable called "agent_scratchpad" where the agent can put its
intermediary work.
"""
llm_chain: LLMChain
allowed_tools: Optional[List[str]] = None
return_values: List[str] = ["output"]
@abstractmethod
def _extract_tool_and_input(self, text: str) -> Optional[Tuple[str, str]]:
"""Extract tool and tool input from llm output."""
def _fix_text(self, text: str) -> str:
"""Fix the text."""
raise ValueError("fix_text not implemented for this agent.")
@property
def _stop(self) -> List[str]:
return [f"\n{self.observation_prefix}", f"\n\t{self.observation_prefix}"]
def _construct_scratchpad(
self, intermediate_steps: List[Tuple[AgentAction, str]]
) -> str:
"""Construct the scratchpad that lets the agent continue its thought process."""
thoughts = ""
for action, observation in intermediate_steps:
thoughts += action.log
thoughts += f"\n{self.observation_prefix}{observation}\n{self.llm_prefix}"
return thoughts
def _get_next_action(self, full_inputs: Dict[str, str]) -> AgentAction:
full_output = self.llm_chain.predict(**full_inputs)
parsed_output = self._extract_tool_and_input(full_output)
while parsed_output is None:
full_output = self._fix_text(full_output)
full_inputs["agent_scratchpad"] += full_output
output = self.llm_chain.predict(**full_inputs)
full_output += output
parsed_output = self._extract_tool_and_input(full_output)
return AgentAction(
tool=parsed_output[0], tool_input=parsed_output[1], log=full_output
)
async def _aget_next_action(self, full_inputs: Dict[str, str]) -> AgentAction:
full_output = await self.llm_chain.apredict(**full_inputs)
parsed_output = self._extract_tool_and_input(full_output)
while parsed_output is None:
full_output = self._fix_text(full_output)
full_inputs["agent_scratchpad"] += full_output
output = await self.llm_chain.apredict(**full_inputs)
full_output += output
parsed_output = self._extract_tool_and_input(full_output)
return AgentAction(
tool=parsed_output[0], tool_input=parsed_output[1], log=full_output
)
def plan(
self, intermediate_steps: List[Tuple[AgentAction, str]], **kwargs: Any
) -> Union[AgentAction, AgentFinish]:
"""Given input, decided what to do.
Args:
intermediate_steps: Steps the LLM has taken to date,
along with observations
**kwargs: User inputs.
Returns:
Action specifying what tool to use.
"""
full_inputs = self.get_full_inputs(intermediate_steps, **kwargs)
action = self._get_next_action(full_inputs)
if action.tool == self.finish_tool_name:
return AgentFinish({"output": action.tool_input}, action.log)
return action
async def aplan(
self, intermediate_steps: List[Tuple[AgentAction, str]], **kwargs: Any
) -> Union[AgentAction, AgentFinish]:
"""Given input, decided what to do.
Args:
intermediate_steps: Steps the LLM has taken to date,
along with observations
**kwargs: User inputs.
Returns:
Action specifying what tool to use.
"""
full_inputs = self.get_full_inputs(intermediate_steps, **kwargs)
action = await self._aget_next_action(full_inputs)
if action.tool == self.finish_tool_name:
return AgentFinish({"output": action.tool_input}, action.log)
return action
def get_full_inputs(
self, intermediate_steps: List[Tuple[AgentAction, str]], **kwargs: Any
) -> Dict[str, Any]:
"""Create the full inputs for the LLMChain from intermediate steps."""
thoughts = self._construct_scratchpad(intermediate_steps)
new_inputs = {"agent_scratchpad": thoughts, "stop": self._stop}
full_inputs = {**kwargs, **new_inputs}
return full_inputs
def prepare_for_new_call(self) -> None:
"""Prepare the agent for new call, if needed."""
pass
@property
def finish_tool_name(self) -> str:
"""Name of the tool to use to finish the chain."""
return "Final Answer"
@property
def input_keys(self) -> List[str]:
"""Return the input keys.
:meta private:
"""
return list(set(self.llm_chain.input_keys) - {"agent_scratchpad"})
@root_validator()
def validate_prompt(cls, values: Dict) -> Dict:
"""Validate that prompt matches format."""
prompt = values["llm_chain"].prompt
if "agent_scratchpad" not in prompt.input_variables:
logger.warning(
"`agent_scratchpad` should be a variable in prompt.input_variables."
" Did not find it, so adding it at the end."
)
prompt.input_variables.append("agent_scratchpad")
if isinstance(prompt, PromptTemplate):
prompt.template += "\n{agent_scratchpad}"
elif isinstance(prompt, FewShotPromptTemplate):
prompt.suffix += "\n{agent_scratchpad}"
else:
raise ValueError(f"Got unexpected prompt type {type(prompt)}")
return values
@property
@abstractmethod
def observation_prefix(self) -> str:
"""Prefix to append the observation with."""
@property
@abstractmethod
def llm_prefix(self) -> str:
"""Prefix to append the LLM call with."""
@classmethod
@abstractmethod
def create_prompt(cls, tools: Sequence[BaseTool]) -> BasePromptTemplate:
"""Create a prompt for this class."""
@classmethod
def _validate_tools(cls, tools: Sequence[BaseTool]) -> None:
"""Validate that appropriate tools are passed in."""
pass
@classmethod
def from_llm_and_tools(
cls,
llm: BaseLLM,
tools: Sequence[BaseTool],
callback_manager: Optional[BaseCallbackManager] = None,
**kwargs: Any,
) -> Agent:
"""Construct an agent from an LLM and tools."""
cls._validate_tools(tools)
llm_chain = LLMChain(
llm=llm,
prompt=cls.create_prompt(tools),
callback_manager=callback_manager,
)
tool_names = [tool.name for tool in tools]
return cls(llm_chain=llm_chain, allowed_tools=tool_names, **kwargs)
def return_stopped_response(
self,
early_stopping_method: str,
intermediate_steps: List[Tuple[AgentAction, str]],
**kwargs: Any,
) -> AgentFinish:
"""Return response when agent has been stopped due to max iterations."""
if early_stopping_method == "force":
# `force` just returns a constant string
return AgentFinish({"output": "Agent stopped due to max iterations."}, "")
elif early_stopping_method == "generate":
# Generate does one final forward pass
thoughts = ""
for action, observation in intermediate_steps:
thoughts += action.log
thoughts += (
f"\n{self.observation_prefix}{observation}\n{self.llm_prefix}"
)
# Adding to the previous steps, we now tell the LLM to make a final pred
thoughts += (
"\n\nI now need to return a final answer based on the previous steps:"
)
new_inputs = {"agent_scratchpad": thoughts, "stop": self._stop}
full_inputs = {**kwargs, **new_inputs}
full_output = self.llm_chain.predict(**full_inputs)
# We try to extract a final answer
parsed_output = self._extract_tool_and_input(full_output)
if parsed_output is None:
# If we cannot extract, we just return the full output
return AgentFinish({"output": full_output}, full_output)
tool, tool_input = parsed_output
if tool == self.finish_tool_name:
# If we can extract, we send the correct stuff
return AgentFinish({"output": tool_input}, full_output)
else:
# If we can extract, but the tool is not the final tool,
# we just return the full output
return AgentFinish({"output": full_output}, full_output)
else:
raise ValueError(
"early_stopping_method should be one of `force` or `generate`, "
f"got {early_stopping_method}"
)
@property
@abstractmethod
def _agent_type(self) -> str:
"""Return Identifier of agent type."""
def dict(self, **kwargs: Any) -> Dict:
"""Return dictionary representation of agent."""
_dict = super().dict()
_dict["_type"] = self._agent_type
return _dict
def save(self, file_path: Union[Path, str]) -> None:
"""Save the agent.
Args:
file_path: Path to file to save the agent to.
Example:
.. code-block:: python
# If working with agent executor
agent.agent.save(file_path="path/agent.yaml")
"""
# Convert file to Path object.
if isinstance(file_path, str):
save_path = Path(file_path)
else:
save_path = file_path
directory_path = save_path.parent
directory_path.mkdir(parents=True, exist_ok=True)
# Fetch dictionary to save
agent_dict = self.dict()
if save_path.suffix == ".json":
with open(file_path, "w") as f:
json.dump(agent_dict, f, indent=4)
elif save_path.suffix == ".yaml":
with open(file_path, "w") as f:
yaml.dump(agent_dict, f, default_flow_style=False)
else:
raise ValueError(f"{save_path} must be json or yaml")
class AgentExecutor(Chain, BaseModel):
"""Consists of an agent using tools."""
agent: Agent
tools: Sequence[BaseTool]
return_intermediate_steps: bool = False
max_iterations: Optional[int] = 15
early_stopping_method: str = "force"
@classmethod
def from_agent_and_tools(
cls,
agent: Agent,
tools: Sequence[BaseTool],
callback_manager: Optional[BaseCallbackManager] = None,
**kwargs: Any,
) -> AgentExecutor:
"""Create from agent and tools."""
return cls(
agent=agent, tools=tools, callback_manager=callback_manager, **kwargs
)
@root_validator()
def validate_tools(cls, values: Dict) -> Dict:
"""Validate that tools are compatible with agent."""
agent = values["agent"]
tools = values["tools"]
if agent.allowed_tools is not None:
if set(agent.allowed_tools) != set([tool.name for tool in tools]):
raise ValueError(
f"Allowed tools ({agent.allowed_tools}) different than "
f"provided tools ({[tool.name for tool in tools]})"
)
return values
def save(self, file_path: Union[Path, str]) -> None:
"""Raise error - saving not supported for Agent Executors."""
raise ValueError(
"Saving not supported for agent executors. "
"If you are trying to save the agent, please use the "
"`.save_agent(...)`"
)
def save_agent(self, file_path: Union[Path, str]) -> None:
"""Save the underlying agent."""
return self.agent.save(file_path)
@property
def input_keys(self) -> List[str]:
"""Return the input keys.
:meta private:
"""
return self.agent.input_keys
@property
def output_keys(self) -> List[str]:
"""Return the singular output key.
:meta private:
"""
if self.return_intermediate_steps:
return self.agent.return_values + ["intermediate_steps"]
else:
return self.agent.return_values
def _should_continue(self, iterations: int) -> bool:
if self.max_iterations is None:
return True
else:
return iterations < self.max_iterations
def _return(self, output: AgentFinish, intermediate_steps: list) -> Dict[str, Any]:
self.callback_manager.on_agent_finish(
output, color="green", verbose=self.verbose
)
final_output = output.return_values
if self.return_intermediate_steps:
final_output["intermediate_steps"] = intermediate_steps
return final_output
async def _areturn(
self, output: AgentFinish, intermediate_steps: list
) -> Dict[str, Any]:
if self.callback_manager.is_async:
await self.callback_manager.on_agent_finish(
output, color="green", verbose=self.verbose
)
else:
self.callback_manager.on_agent_finish(
output, color="green", verbose=self.verbose
)
final_output = output.return_values
if self.return_intermediate_steps:
final_output["intermediate_steps"] = intermediate_steps
return final_output
def _take_next_step(
self,
name_to_tool_map: Dict[str, BaseTool],
color_mapping: Dict[str, str],
inputs: Dict[str, str],
intermediate_steps: List[Tuple[AgentAction, str]],
) -> Union[AgentFinish, Tuple[AgentAction, str]]:
"""Take a single step in the thought-action-observation loop.
Override this to take control of how the agent makes and acts on choices.
"""
# Call the LLM to see what to do.
output = self.agent.plan(intermediate_steps, **inputs)
# If the tool chosen is the finishing tool, then we end and return.
if isinstance(output, AgentFinish):
return output
self.callback_manager.on_agent_action(
output, verbose=self.verbose, color="green"
)
# Otherwise we lookup the tool
if output.tool in name_to_tool_map:
tool = name_to_tool_map[output.tool]
return_direct = tool.return_direct
color = color_mapping[output.tool]
llm_prefix = "" if return_direct else self.agent.llm_prefix
# We then call the tool on the tool input to get an observation
observation = tool.run(
output.tool_input,
verbose=self.verbose,
color=color,
llm_prefix=llm_prefix,
observation_prefix=self.agent.observation_prefix,
)
else:
observation = InvalidTool().run(
output.tool,
verbose=self.verbose,
color=None,
llm_prefix="",
observation_prefix=self.agent.observation_prefix,
)
return_direct = False
if return_direct:
# Set the log to "" because we do not want to log it.
return AgentFinish({self.agent.return_values[0]: observation}, "")
return output, observation
async def _atake_next_step(
self,
name_to_tool_map: Dict[str, BaseTool],
color_mapping: Dict[str, str],
inputs: Dict[str, str],
intermediate_steps: List[Tuple[AgentAction, str]],
) -> Union[AgentFinish, Tuple[AgentAction, str]]:
"""Take a single step in the thought-action-observation loop.
Override this to take control of how the agent makes and acts on choices.
"""
# Call the LLM to see what to do.
output = await self.agent.aplan(intermediate_steps, **inputs)
# If the tool chosen is the finishing tool, then we end and return.
if isinstance(output, AgentFinish):
return output
self.callback_manager.on_agent_action(
output, verbose=self.verbose, color="green"
)
# Otherwise we lookup the tool
if output.tool in name_to_tool_map:
tool = name_to_tool_map[output.tool]
return_direct = tool.return_direct
color = color_mapping[output.tool]
llm_prefix = "" if return_direct else self.agent.llm_prefix
# We then call the tool on the tool input to get an observation
observation = await tool.arun(
output.tool_input,
verbose=self.verbose,
color=color,
llm_prefix=llm_prefix,
observation_prefix=self.agent.observation_prefix,
)
else:
observation = await InvalidTool().arun(
output.tool,
verbose=self.verbose,
color=None,
llm_prefix="",
observation_prefix=self.agent.observation_prefix,
)
return_direct = False
if return_direct:
# Set the log to "" because we do not want to log it.
return AgentFinish({self.agent.return_values[0]: observation}, "")
return output, observation
def _call(self, inputs: Dict[str, str]) -> Dict[str, Any]:
"""Run text through and get agent response."""
# Do any preparation necessary when receiving a new input.
self.agent.prepare_for_new_call()
# Construct a mapping of tool name to tool for easy lookup
name_to_tool_map = {tool.name: tool for tool in self.tools}
# We construct a mapping from each tool to a color, used for logging.
color_mapping = get_color_mapping(
[tool.name for tool in self.tools], excluded_colors=["green"]
)
intermediate_steps: List[Tuple[AgentAction, str]] = []
# Let's start tracking the iterations the agent has gone through
iterations = 0
# We now enter the agent loop (until it returns something).
while self._should_continue(iterations):
next_step_output = self._take_next_step(
name_to_tool_map, color_mapping, inputs, intermediate_steps
)
if isinstance(next_step_output, AgentFinish):
return self._return(next_step_output, intermediate_steps)
intermediate_steps.append(next_step_output)
iterations += 1
output = self.agent.return_stopped_response(
self.early_stopping_method, intermediate_steps, **inputs
)
return self._return(output, intermediate_steps)
async def _acall(self, inputs: Dict[str, str]) -> Dict[str, str]:
"""Run text through and get agent response."""
# Do any preparation necessary when receiving a new input.
self.agent.prepare_for_new_call()
# Construct a mapping of tool name to tool for easy lookup
name_to_tool_map = {tool.name: tool for tool in self.tools}
# We construct a mapping from each tool to a color, used for logging.
color_mapping = get_color_mapping(
[tool.name for tool in self.tools], excluded_colors=["green"]
)
intermediate_steps: List[Tuple[AgentAction, str]] = []
# Let's start tracking the iterations the agent has gone through
iterations = 0
# We now enter the agent loop (until it returns something).
while self._should_continue(iterations):
next_step_output = await self._atake_next_step(
name_to_tool_map, color_mapping, inputs, intermediate_steps
)
if isinstance(next_step_output, AgentFinish):
return await self._areturn(next_step_output, intermediate_steps)
intermediate_steps.append(next_step_output)
iterations += 1
output = self.agent.return_stopped_response(
self.early_stopping_method, intermediate_steps, **inputs
)
return await self._areturn(output, intermediate_steps)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,756 | namespace argument not taken into account when creating Pinecone index | # Quick summary
Using the `namespace` argument in the function `Pinecone.from_existing_index` has no effect. Indeed, it is passed to `pinecone.Index`, which has no `namespace` argument.
# Steps to reproduce a relevant bug
```
import pinecone
from langchain.docstore.document import Document
from langchain.vectorstores.pinecone import Pinecone
from tests.integration_tests.vectorstores.fake_embeddings import FakeEmbeddings
index = pinecone.Index("langchain-demo") # this should be a new index
texts = ["foo", "bar", "baz"]
metadatas = [{"page": i} for i in range(len(texts))]
Pinecone.from_texts(
texts,
FakeEmbeddings(),
index_name="langchain-demo",
metadatas=metadatas,
namespace="test-namespace",
)
texts = ["foo2", "bar2", "baz2"]
metadatas = [{"page": i} for i in range(len(texts))]
Pinecone.from_texts(
texts,
FakeEmbeddings(),
index_name="langchain-demo",
metadatas=metadatas,
namespace="test-namespace2",
)
# Search with namespace
docsearch = Pinecone.from_existing_index("langchain-demo",
embedding=FakeEmbeddings(),
namespace="test-namespace")
output = docsearch.similarity_search("foo", k=6)
# check that we don't get results from the other namespace
page_contents = [o.page_content for o in output]
assert set(page_contents) == set(["foo", "bar", "baz"])
```
# Fix
The `namespace` argument used in `Pinecone.from_existing_index` and `Pinecone.from_texts` should be stored as an attribute and used by default by every method. | https://github.com/langchain-ai/langchain/issues/1756 | https://github.com/langchain-ai/langchain/pull/1757 | 280cb4160d9bd6cdb80edb5f766a06216610002c | 3701b2901e76f2f97239c2152a6a7d01754fb666 | "2023-03-18T12:26:39Z" | python | "2023-03-19T02:55:38Z" | langchain/vectorstores/pinecone.py | """Wrapper around Pinecone vector database."""
from __future__ import annotations
import uuid
from typing import Any, Callable, Iterable, List, Optional, Tuple
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from langchain.vectorstores.base import VectorStore
class Pinecone(VectorStore):
"""Wrapper around Pinecone vector database.
To use, you should have the ``pinecone-client`` python package installed.
Example:
.. code-block:: python
from langchain.vectorstores import Pinecone
from langchain.embeddings.openai import OpenAIEmbeddings
import pinecone
pinecone.init(api_key="***", environment="us-west1-gcp")
index = pinecone.Index("langchain-demo")
embeddings = OpenAIEmbeddings()
vectorstore = Pinecone(index, embeddings.embed_query, "text")
"""
def __init__(
self,
index: Any,
embedding_function: Callable,
text_key: str,
):
"""Initialize with Pinecone client."""
try:
import pinecone
except ImportError:
raise ValueError(
"Could not import pinecone python package. "
"Please install it with `pip install pinecone-client`."
)
if not isinstance(index, pinecone.index.Index):
raise ValueError(
f"client should be an instance of pinecone.index.Index, "
f"got {type(index)}"
)
self._index = index
self._embedding_function = embedding_function
self._text_key = text_key
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
ids: Optional[List[str]] = None,
namespace: Optional[str] = None,
batch_size: int = 32,
**kwargs: Any,
) -> List[str]:
"""Run more texts through the embeddings and add to the vectorstore.
Args:
texts: Iterable of strings to add to the vectorstore.
metadatas: Optional list of metadatas associated with the texts.
ids: Optional list of ids to associate with the texts.
namespace: Optional pinecone namespace to add the texts to.
Returns:
List of ids from adding the texts into the vectorstore.
"""
# Embed and create the documents
docs = []
ids = ids or [str(uuid.uuid4()) for _ in texts]
for i, text in enumerate(texts):
embedding = self._embedding_function(text)
metadata = metadatas[i] if metadatas else {}
metadata[self._text_key] = text
docs.append((ids[i], embedding, metadata))
# upsert to Pinecone
self._index.upsert(vectors=docs, namespace=namespace, batch_size=batch_size)
return ids
def similarity_search_with_score(
self,
query: str,
k: int = 5,
filter: Optional[dict] = None,
namespace: Optional[str] = None,
) -> List[Tuple[Document, float]]:
"""Return pinecone documents most similar to query, along with scores.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
filter: Dictionary of argument(s) to filter on metadata
namespace: Namespace to search in. Default will search in '' namespace.
Returns:
List of Documents most similar to the query and score for each
"""
query_obj = self._embedding_function(query)
docs = []
results = self._index.query(
[query_obj],
top_k=k,
include_metadata=True,
namespace=namespace,
filter=filter,
)
for res in results["matches"]:
metadata = res["metadata"]
text = metadata.pop(self._text_key)
docs.append((Document(page_content=text, metadata=metadata), res["score"]))
return docs
def similarity_search(
self,
query: str,
k: int = 5,
filter: Optional[dict] = None,
namespace: Optional[str] = None,
**kwargs: Any,
) -> List[Document]:
"""Return pinecone documents most similar to query.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
filter: Dictionary of argument(s) to filter on metadata
namespace: Namespace to search in. Default will search in '' namespace.
Returns:
List of Documents most similar to the query and score for each
"""
query_obj = self._embedding_function(query)
docs = []
results = self._index.query(
[query_obj],
top_k=k,
include_metadata=True,
namespace=namespace,
filter=filter,
)
for res in results["matches"]:
metadata = res["metadata"]
text = metadata.pop(self._text_key)
docs.append(Document(page_content=text, metadata=metadata))
return docs
@classmethod
def from_texts(
cls,
texts: List[str],
embedding: Embeddings,
metadatas: Optional[List[dict]] = None,
ids: Optional[List[str]] = None,
batch_size: int = 32,
text_key: str = "text",
index_name: Optional[str] = None,
namespace: Optional[str] = None,
**kwargs: Any,
) -> Pinecone:
"""Construct Pinecone wrapper from raw documents.
This is a user friendly interface that:
1. Embeds documents.
2. Adds the documents to a provided Pinecone index
This is intended to be a quick way to get started.
Example:
.. code-block:: python
from langchain import Pinecone
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
pinecone = Pinecone.from_texts(
texts,
embeddings,
index_name="langchain-demo"
)
"""
try:
import pinecone
except ImportError:
raise ValueError(
"Could not import pinecone python package. "
"Please install it with `pip install pinecone-client`."
)
_index_name = index_name or str(uuid.uuid4())
indexes = pinecone.list_indexes() # checks if provided index exists
if _index_name in indexes:
index = pinecone.Index(_index_name)
else:
index = None
for i in range(0, len(texts), batch_size):
# set end position of batch
i_end = min(i + batch_size, len(texts))
# get batch of texts and ids
lines_batch = texts[i:i_end]
# create ids if not provided
if ids:
ids_batch = ids[i:i_end]
else:
ids_batch = [str(uuid.uuid4()) for n in range(i, i_end)]
# create embeddings
embeds = embedding.embed_documents(lines_batch)
# prep metadata and upsert batch
if metadatas:
metadata = metadatas[i:i_end]
else:
metadata = [{} for _ in range(i, i_end)]
for j, line in enumerate(lines_batch):
metadata[j][text_key] = line
to_upsert = zip(ids_batch, embeds, metadata)
# Create index if it does not exist
if index is None:
pinecone.create_index(_index_name, dimension=len(embeds[0]))
index = pinecone.Index(_index_name)
# upsert to Pinecone
index.upsert(vectors=list(to_upsert), namespace=namespace)
return cls(index, embedding.embed_query, text_key)
@classmethod
def from_existing_index(
cls,
index_name: str,
embedding: Embeddings,
text_key: str = "text",
namespace: Optional[str] = None,
) -> Pinecone:
"""Load pinecone vectorstore from index name."""
try:
import pinecone
except ImportError:
raise ValueError(
"Could not import pinecone python package. "
"Please install it with `pip install pinecone-client`."
)
return cls(
pinecone.Index(index_name, namespace), embedding.embed_query, text_key
)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,756 | namespace argument not taken into account when creating Pinecone index | # Quick summary
Using the `namespace` argument in the function `Pinecone.from_existing_index` has no effect. Indeed, it is passed to `pinecone.Index`, which has no `namespace` argument.
# Steps to reproduce a relevant bug
```
import pinecone
from langchain.docstore.document import Document
from langchain.vectorstores.pinecone import Pinecone
from tests.integration_tests.vectorstores.fake_embeddings import FakeEmbeddings
index = pinecone.Index("langchain-demo") # this should be a new index
texts = ["foo", "bar", "baz"]
metadatas = [{"page": i} for i in range(len(texts))]
Pinecone.from_texts(
texts,
FakeEmbeddings(),
index_name="langchain-demo",
metadatas=metadatas,
namespace="test-namespace",
)
texts = ["foo2", "bar2", "baz2"]
metadatas = [{"page": i} for i in range(len(texts))]
Pinecone.from_texts(
texts,
FakeEmbeddings(),
index_name="langchain-demo",
metadatas=metadatas,
namespace="test-namespace2",
)
# Search with namespace
docsearch = Pinecone.from_existing_index("langchain-demo",
embedding=FakeEmbeddings(),
namespace="test-namespace")
output = docsearch.similarity_search("foo", k=6)
# check that we don't get results from the other namespace
page_contents = [o.page_content for o in output]
assert set(page_contents) == set(["foo", "bar", "baz"])
```
# Fix
The `namespace` argument used in `Pinecone.from_existing_index` and `Pinecone.from_texts` should be stored as an attribute and used by default by every method. | https://github.com/langchain-ai/langchain/issues/1756 | https://github.com/langchain-ai/langchain/pull/1757 | 280cb4160d9bd6cdb80edb5f766a06216610002c | 3701b2901e76f2f97239c2152a6a7d01754fb666 | "2023-03-18T12:26:39Z" | python | "2023-03-19T02:55:38Z" | tests/integration_tests/vectorstores/test_pinecone.py | """Test Pinecone functionality."""
import pinecone
from langchain.docstore.document import Document
from langchain.vectorstores.pinecone import Pinecone
from tests.integration_tests.vectorstores.fake_embeddings import FakeEmbeddings
pinecone.init(api_key="YOUR_API_KEY", environment="YOUR_ENV")
index = pinecone.Index("langchain-demo")
def test_pinecone() -> None:
"""Test end to end construction and search."""
texts = ["foo", "bar", "baz"]
docsearch = Pinecone.from_texts(
texts, FakeEmbeddings(), index_name="langchain-demo", namespace="test"
)
output = docsearch.similarity_search("foo", k=1, namespace="test")
assert output == [Document(page_content="foo")]
def test_pinecone_with_metadatas() -> None:
"""Test end to end construction and search."""
texts = ["foo", "bar", "baz"]
metadatas = [{"page": i} for i in range(len(texts))]
docsearch = Pinecone.from_texts(
texts,
FakeEmbeddings(),
index_name="langchain-demo",
metadatas=metadatas,
namespace="test-metadata",
)
output = docsearch.similarity_search("foo", k=1, namespace="test-metadata")
assert output == [Document(page_content="foo", metadata={"page": 0})]
def test_pinecone_with_scores() -> None:
"""Test end to end construction and search with scores and IDs."""
texts = ["foo", "bar", "baz"]
metadatas = [{"page": i} for i in range(len(texts))]
docsearch = Pinecone.from_texts(
texts,
FakeEmbeddings(),
index_name="langchain-demo",
metadatas=metadatas,
namespace="test-metadata-score",
)
output = docsearch.similarity_search_with_score(
"foo", k=3, namespace="test-metadata-score"
)
docs = [o[0] for o in output]
scores = [o[1] for o in output]
assert docs == [
Document(page_content="foo", metadata={"page": 0}),
Document(page_content="bar", metadata={"page": 1}),
Document(page_content="baz", metadata={"page": 2}),
]
assert scores[0] > scores[1] > scores[2]
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,339 | UT test_bash.py broken on MacOS dev environment | I forked & cloned the project to my dev env on MacOS, then ran 'make test', the test case 'test_incorrect_command_return_err_output' from test_bash.py failed with the following output:
<img width="1139" alt="image" src="https://user-images.githubusercontent.com/64731944/221828313-4c3f6284-9fd4-4bb5-b489-8d7e911ada03.png">
I then tried the test in my Linux dev env, the test case passed successfully.
this line of code in the test case:
`output = session.run(["invalid_command"])`
its output on MacOS is:
`/bin/sh: invalid_command: command not found\n`
and on Linux it is
`/bin/sh: 1: invalid_command: not found\n`
The difference is from the underlying "subprocess" library, and as lots of developers use MacOS as their dev env, I think it makes sense to make the test case support both MacOS and Linux, so I would suggest using a regex to do the assertion:
`assert re.match(r'^/bin/sh:.*invalid_command.*not found.*$', output)`
| https://github.com/langchain-ai/langchain/issues/1339 | https://github.com/langchain-ai/langchain/pull/1837 | b706966ebc7e17cef3ced81c8e59c8f2d648a8c8 | a92344f476fc3f18599442790a1423505eec9eb4 | "2023-02-28T10:51:39Z" | python | "2023-03-21T16:06:52Z" | tests/unit_tests/test_bash.py | """Test the bash utility."""
import subprocess
from pathlib import Path
from langchain.utilities.bash import BashProcess
def test_pwd_command() -> None:
"""Test correct functionality."""
session = BashProcess()
commands = ["pwd"]
output = session.run(commands)
assert output == subprocess.check_output("pwd", shell=True).decode()
def test_incorrect_command() -> None:
"""Test handling of incorrect command."""
session = BashProcess()
output = session.run(["invalid_command"])
assert output == "Command 'invalid_command' returned non-zero exit status 127."
def test_incorrect_command_return_err_output() -> None:
"""Test optional returning of shell output on incorrect command."""
session = BashProcess(return_err_output=True)
output = session.run(["invalid_command"])
assert output == "/bin/sh: 1: invalid_command: not found\n"
def test_create_directory_and_files(tmp_path: Path) -> None:
"""Test creation of a directory and files in a temporary directory."""
session = BashProcess(strip_newlines=True)
# create a subdirectory in the temporary directory
temp_dir = tmp_path / "test_dir"
temp_dir.mkdir()
# run the commands in the temporary directory
commands = [
f"touch {temp_dir}/file1.txt",
f"touch {temp_dir}/file2.txt",
f"echo 'hello world' > {temp_dir}/file2.txt",
f"cat {temp_dir}/file2.txt",
]
output = session.run(commands)
assert output == "hello world"
# check that the files were created in the temporary directory
output = session.run([f"ls {temp_dir}"])
assert output == "file1.txt\nfile2.txt"
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,805 | Document loader for Azure Blob storage | Lots of customers is asking if langchain have a document loader like AWS S3 or GCS for Azure Blob Storage as well. As you know Microsoft is a big partner for OpenAI , so there is a real need to have native document loader for Azure Blob storage as well. We will be very happy to see this feature ASAP. | https://github.com/langchain-ai/langchain/issues/1805 | https://github.com/langchain-ai/langchain/pull/1890 | 42d725223ea3765a7699e19d46a6e0c70b4baa79 | c1a9d83b34441592d063c4d0753029c187b1c16a | "2023-03-20T02:39:16Z" | python | "2023-03-27T15:17:14Z" | docs/modules/document_loaders/examples/azure_blob_storage_container.ipynb | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,805 | Document loader for Azure Blob storage | Lots of customers is asking if langchain have a document loader like AWS S3 or GCS for Azure Blob Storage as well. As you know Microsoft is a big partner for OpenAI , so there is a real need to have native document loader for Azure Blob storage as well. We will be very happy to see this feature ASAP. | https://github.com/langchain-ai/langchain/issues/1805 | https://github.com/langchain-ai/langchain/pull/1890 | 42d725223ea3765a7699e19d46a6e0c70b4baa79 | c1a9d83b34441592d063c4d0753029c187b1c16a | "2023-03-20T02:39:16Z" | python | "2023-03-27T15:17:14Z" | docs/modules/document_loaders/examples/azure_blob_storage_file.ipynb | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,805 | Document loader for Azure Blob storage | Lots of customers is asking if langchain have a document loader like AWS S3 or GCS for Azure Blob Storage as well. As you know Microsoft is a big partner for OpenAI , so there is a real need to have native document loader for Azure Blob storage as well. We will be very happy to see this feature ASAP. | https://github.com/langchain-ai/langchain/issues/1805 | https://github.com/langchain-ai/langchain/pull/1890 | 42d725223ea3765a7699e19d46a6e0c70b4baa79 | c1a9d83b34441592d063c4d0753029c187b1c16a | "2023-03-20T02:39:16Z" | python | "2023-03-27T15:17:14Z" | langchain/document_loaders/__init__.py | """All different types of document loaders."""
from langchain.document_loaders.airbyte_json import AirbyteJSONLoader
from langchain.document_loaders.azlyrics import AZLyricsLoader
from langchain.document_loaders.blackboard import BlackboardLoader
from langchain.document_loaders.college_confidential import CollegeConfidentialLoader
from langchain.document_loaders.conllu import CoNLLULoader
from langchain.document_loaders.csv_loader import CSVLoader
from langchain.document_loaders.directory import DirectoryLoader
from langchain.document_loaders.email import UnstructuredEmailLoader
from langchain.document_loaders.evernote import EverNoteLoader
from langchain.document_loaders.facebook_chat import FacebookChatLoader
from langchain.document_loaders.gcs_directory import GCSDirectoryLoader
from langchain.document_loaders.gcs_file import GCSFileLoader
from langchain.document_loaders.gitbook import GitbookLoader
from langchain.document_loaders.googledrive import GoogleDriveLoader
from langchain.document_loaders.gutenberg import GutenbergLoader
from langchain.document_loaders.hn import HNLoader
from langchain.document_loaders.html import UnstructuredHTMLLoader
from langchain.document_loaders.html_bs import BSHTMLLoader
from langchain.document_loaders.ifixit import IFixitLoader
from langchain.document_loaders.image import UnstructuredImageLoader
from langchain.document_loaders.imsdb import IMSDbLoader
from langchain.document_loaders.markdown import UnstructuredMarkdownLoader
from langchain.document_loaders.notebook import NotebookLoader
from langchain.document_loaders.notion import NotionDirectoryLoader
from langchain.document_loaders.obsidian import ObsidianLoader
from langchain.document_loaders.pdf import (
OnlinePDFLoader,
PDFMinerLoader,
PyMuPDFLoader,
PyPDFLoader,
UnstructuredPDFLoader,
)
from langchain.document_loaders.powerpoint import UnstructuredPowerPointLoader
from langchain.document_loaders.readthedocs import ReadTheDocsLoader
from langchain.document_loaders.roam import RoamLoader
from langchain.document_loaders.s3_directory import S3DirectoryLoader
from langchain.document_loaders.s3_file import S3FileLoader
from langchain.document_loaders.srt import SRTLoader
from langchain.document_loaders.telegram import TelegramChatLoader
from langchain.document_loaders.text import TextLoader
from langchain.document_loaders.unstructured import (
UnstructuredFileIOLoader,
UnstructuredFileLoader,
)
from langchain.document_loaders.url import UnstructuredURLLoader
from langchain.document_loaders.web_base import WebBaseLoader
from langchain.document_loaders.word_document import UnstructuredWordDocumentLoader
from langchain.document_loaders.youtube import (
GoogleApiClient,
GoogleApiYoutubeLoader,
YoutubeLoader,
)
"""Legacy: only for backwards compat. use PyPDFLoader instead"""
PagedPDFSplitter = PyPDFLoader
__all__ = [
"UnstructuredFileLoader",
"UnstructuredFileIOLoader",
"UnstructuredURLLoader",
"DirectoryLoader",
"NotionDirectoryLoader",
"ReadTheDocsLoader",
"GoogleDriveLoader",
"UnstructuredHTMLLoader",
"BSHTMLLoader",
"UnstructuredPowerPointLoader",
"UnstructuredWordDocumentLoader",
"UnstructuredPDFLoader",
"UnstructuredImageLoader",
"ObsidianLoader",
"UnstructuredEmailLoader",
"UnstructuredMarkdownLoader",
"RoamLoader",
"YoutubeLoader",
"S3FileLoader",
"TextLoader",
"HNLoader",
"GitbookLoader",
"S3DirectoryLoader",
"GCSFileLoader",
"GCSDirectoryLoader",
"WebBaseLoader",
"IMSDbLoader",
"AZLyricsLoader",
"CollegeConfidentialLoader",
"IFixitLoader",
"GutenbergLoader",
"PagedPDFSplitter",
"PyPDFLoader",
"EverNoteLoader",
"AirbyteJSONLoader",
"OnlinePDFLoader",
"PDFMinerLoader",
"PyMuPDFLoader",
"TelegramChatLoader",
"SRTLoader",
"FacebookChatLoader",
"NotebookLoader",
"CoNLLULoader",
"GoogleApiYoutubeLoader",
"GoogleApiClient",
"CSVLoader",
"BlackboardLoader",
]
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,805 | Document loader for Azure Blob storage | Lots of customers is asking if langchain have a document loader like AWS S3 or GCS for Azure Blob Storage as well. As you know Microsoft is a big partner for OpenAI , so there is a real need to have native document loader for Azure Blob storage as well. We will be very happy to see this feature ASAP. | https://github.com/langchain-ai/langchain/issues/1805 | https://github.com/langchain-ai/langchain/pull/1890 | 42d725223ea3765a7699e19d46a6e0c70b4baa79 | c1a9d83b34441592d063c4d0753029c187b1c16a | "2023-03-20T02:39:16Z" | python | "2023-03-27T15:17:14Z" | langchain/document_loaders/azure_blob_storage_container.py | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,805 | Document loader for Azure Blob storage | Lots of customers is asking if langchain have a document loader like AWS S3 or GCS for Azure Blob Storage as well. As you know Microsoft is a big partner for OpenAI , so there is a real need to have native document loader for Azure Blob storage as well. We will be very happy to see this feature ASAP. | https://github.com/langchain-ai/langchain/issues/1805 | https://github.com/langchain-ai/langchain/pull/1890 | 42d725223ea3765a7699e19d46a6e0c70b4baa79 | c1a9d83b34441592d063c4d0753029c187b1c16a | "2023-03-20T02:39:16Z" | python | "2023-03-27T15:17:14Z" | langchain/document_loaders/azure_blob_storage_file.py | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,801 | Poetry 1.4.0 installation fails | `poetry install -E all` fails with Poetry >=1.4.0 due to upstream incompatibility between `poetry>=1.4.0` and `pydata_sphinx_theme`.
This is a tracking issue. I've already created an issue upstream here: https://github.com/pydata/pydata-sphinx-theme/issues/1253 | https://github.com/langchain-ai/langchain/issues/1801 | https://github.com/langchain-ai/langchain/pull/1935 | 3d3e52352005aef549f9e19ad6ab18428887865c | c50fafb35d22f0f2b4e39ebb24a5ee6177c8f44e | "2023-03-19T23:42:55Z" | python | "2023-03-27T15:27:54Z" | poetry.toml | [virtualenvs]
in-project = true
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,838 | How metadata is being used during similarity search and query? | I have 3 pdf files in my directory and I "documentized", added metadata, split, embed and store them in pinecone, like this:
```
loader = DirectoryLoader('data/dir', glob="**/*.pdf", loader_cls=UnstructuredPDFLoader)
data = loader.load()
#I added company names explicitly for now
data[0].metadata["company"]="Apple"
data[1].metadata["company"]="Miscrosoft"
data[2].metadata["company"]="Tesla"
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=200)
texts = text_splitter.split_documents(data)
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
)
metadatas = []
for text in texts:
metadatas.append({
"company": text.metadata["company"]
})
Pinecone.from_texts([t.page_content for t in texts], embeddings, index_name=index_name, metadatas=metadatas)
```
I want to build a Q&A system, so that I will mention a company name in my query and pinecon should look for the documents having company `A` in the metadata. Here what I have:
```
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
)
index_name = "index"
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
docsearch = Pinecone.from_existing_index(index_name=index_name, embedding=embeddings)
llm = ChatOpenAI(temperature=0, openai_api_key=OPENAI_API_KEY)
chain = load_qa_chain(llm, chain_type="stuff")
query = "What is the total revenue of Apple?"
docs = docsearch.similarity_search(query, include_metadata=True)
res = chain.run(input_documents=docs, question=query)
print(res)
```
However, there are still document chunks from non-Apple documents in the output of `docs`. What am I doing wrong here and how do I utilize the information in metadata both on doc_search and chat-gpt query (If possible)? Thanks | https://github.com/langchain-ai/langchain/issues/1838 | https://github.com/langchain-ai/langchain/pull/1964 | f257b08406563af9ffb044da45b829d0707d755b | 953e58d0040773c76f68e633c3db3cd371c9c350 | "2023-03-21T01:32:20Z" | python | "2023-03-27T22:04:53Z" | langchain/vectorstores/chroma.py | """Wrapper around ChromaDB embeddings platform."""
from __future__ import annotations
import logging
import uuid
from typing import TYPE_CHECKING, Any, Dict, Iterable, List, Optional, Tuple
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from langchain.vectorstores.base import VectorStore
if TYPE_CHECKING:
import chromadb
import chromadb.config
logger = logging.getLogger()
def _results_to_docs(results: Any) -> List[Document]:
return [doc for doc, _ in _results_to_docs_and_scores(results)]
def _results_to_docs_and_scores(results: Any) -> List[Tuple[Document, float]]:
return [
# TODO: Chroma can do batch querying,
# we shouldn't hard code to the 1st result
(Document(page_content=result[0], metadata=result[1] or {}), result[2])
for result in zip(
results["documents"][0],
results["metadatas"][0],
results["distances"][0],
)
]
class Chroma(VectorStore):
"""Wrapper around ChromaDB embeddings platform.
To use, you should have the ``chromadb`` python package installed.
Example:
.. code-block:: python
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
vectorstore = Chroma("langchain_store", embeddings.embed_query)
"""
_LANGCHAIN_DEFAULT_COLLECTION_NAME = "langchain"
def __init__(
self,
collection_name: str = _LANGCHAIN_DEFAULT_COLLECTION_NAME,
embedding_function: Optional[Embeddings] = None,
persist_directory: Optional[str] = None,
client_settings: Optional[chromadb.config.Settings] = None,
) -> None:
"""Initialize with Chroma client."""
try:
import chromadb
import chromadb.config
except ImportError:
raise ValueError(
"Could not import chromadb python package. "
"Please install it with `pip install chromadb`."
)
if client_settings:
self._client_settings = client_settings
else:
self._client_settings = chromadb.config.Settings()
if persist_directory is not None:
self._client_settings = chromadb.config.Settings(
chroma_db_impl="duckdb+parquet", persist_directory=persist_directory
)
self._client = chromadb.Client(self._client_settings)
self._embedding_function = embedding_function
self._persist_directory = persist_directory
self._collection = self._client.get_or_create_collection(
name=collection_name,
embedding_function=self._embedding_function.embed_documents
if self._embedding_function is not None
else None,
)
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
ids: Optional[List[str]] = None,
**kwargs: Any,
) -> List[str]:
"""Run more texts through the embeddings and add to the vectorstore.
Args:
texts (Iterable[str]): Texts to add to the vectorstore.
metadatas (Optional[List[dict]], optional): Optional list of metadatas.
ids (Optional[List[str]], optional): Optional list of IDs.
Returns:
List[str]: List of IDs of the added texts.
"""
# TODO: Handle the case where the user doesn't provide ids on the Collection
if ids is None:
ids = [str(uuid.uuid1()) for _ in texts]
embeddings = None
if self._embedding_function is not None:
embeddings = self._embedding_function.embed_documents(list(texts))
self._collection.add(
metadatas=metadatas, embeddings=embeddings, documents=texts, ids=ids
)
return ids
def similarity_search(
self,
query: str,
k: int = 4,
filter: Optional[Dict[str, str]] = None,
**kwargs: Any,
) -> List[Document]:
"""Run similarity search with Chroma.
Args:
query (str): Query text to search for.
k (int): Number of results to return. Defaults to 4.
filter (Optional[Dict[str, str]]): Filter by metadata. Defaults to None.
Returns:
List[Document]: List of documents most simmilar to the query text.
"""
docs_and_scores = self.similarity_search_with_score(query, k, where=filter)
return [doc for doc, _ in docs_and_scores]
def similarity_search_by_vector(
self,
embedding: List[float],
k: int = 4,
filter: Optional[Dict[str, str]] = None,
**kwargs: Any,
) -> List[Document]:
"""Return docs most similar to embedding vector.
Args:
embedding: Embedding to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the query vector.
"""
results = self._collection.query(
query_embeddings=embedding, n_results=k, where=filter
)
return _results_to_docs(results)
def similarity_search_with_score(
self,
query: str,
k: int = 4,
filter: Optional[Dict[str, str]] = None,
**kwargs: Any,
) -> List[Tuple[Document, float]]:
"""Run similarity search with Chroma with distance.
Args:
query (str): Query text to search for.
k (int): Number of results to return. Defaults to 4.
filter (Optional[Dict[str, str]]): Filter by metadata. Defaults to None.
Returns:
List[Tuple[Document, float]]: List of documents most similar to the query
text with distance in float.
"""
if self._embedding_function is None:
results = self._collection.query(
query_texts=[query], n_results=k, where=filter
)
else:
query_embedding = self._embedding_function.embed_query(query)
results = self._collection.query(
query_embeddings=[query_embedding], n_results=k, where=filter
)
return _results_to_docs_and_scores(results)
def delete_collection(self) -> None:
"""Delete the collection."""
self._client.delete_collection(self._collection.name)
def persist(self) -> None:
"""Persist the collection.
This can be used to explicitly persist the data to disk.
It will also be called automatically when the object is destroyed.
"""
if self._persist_directory is None:
raise ValueError(
"You must specify a persist_directory on"
"creation to persist the collection."
)
self._client.persist()
@classmethod
def from_texts(
cls,
texts: List[str],
embedding: Optional[Embeddings] = None,
metadatas: Optional[List[dict]] = None,
ids: Optional[List[str]] = None,
collection_name: str = _LANGCHAIN_DEFAULT_COLLECTION_NAME,
persist_directory: Optional[str] = None,
client_settings: Optional[chromadb.config.Settings] = None,
**kwargs: Any,
) -> Chroma:
"""Create a Chroma vectorstore from a raw documents.
If a persist_directory is specified, the collection will be persisted there.
Otherwise, the data will be ephemeral in-memory.
Args:
texts (List[str]): List of texts to add to the collection.
collection_name (str): Name of the collection to create.
persist_directory (Optional[str]): Directory to persist the collection.
embedding (Optional[Embeddings]): Embedding function. Defaults to None.
metadatas (Optional[List[dict]]): List of metadatas. Defaults to None.
ids (Optional[List[str]]): List of document IDs. Defaults to None.
client_settings (Optional[chromadb.config.Settings]): Chroma client settings
Returns:
Chroma: Chroma vectorstore.
"""
chroma_collection = cls(
collection_name=collection_name,
embedding_function=embedding,
persist_directory=persist_directory,
client_settings=client_settings,
)
chroma_collection.add_texts(texts=texts, metadatas=metadatas, ids=ids)
return chroma_collection
@classmethod
def from_documents(
cls,
documents: List[Document],
embedding: Optional[Embeddings] = None,
ids: Optional[List[str]] = None,
collection_name: str = _LANGCHAIN_DEFAULT_COLLECTION_NAME,
persist_directory: Optional[str] = None,
client_settings: Optional[chromadb.config.Settings] = None,
**kwargs: Any,
) -> Chroma:
"""Create a Chroma vectorstore from a list of documents.
If a persist_directory is specified, the collection will be persisted there.
Otherwise, the data will be ephemeral in-memory.
Args:
collection_name (str): Name of the collection to create.
persist_directory (Optional[str]): Directory to persist the collection.
ids (Optional[List[str]]): List of document IDs. Defaults to None.
documents (List[Document]): List of documents to add to the vectorstore.
embedding (Optional[Embeddings]): Embedding function. Defaults to None.
client_settings (Optional[chromadb.config.Settings]): Chroma client settings
Returns:
Chroma: Chroma vectorstore.
"""
texts = [doc.page_content for doc in documents]
metadatas = [doc.metadata for doc in documents]
return cls.from_texts(
texts=texts,
embedding=embedding,
metadatas=metadatas,
ids=ids,
collection_name=collection_name,
persist_directory=persist_directory,
client_settings=client_settings,
)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,712 | bug(QA with Sources): source parsing is not reliable | I was going through [Vectorstore Agent](https://langchain.readthedocs.io/en/latest/modules/agents/agent_toolkits/vectorstore.html?highlight=vectorstore%20agent#vectorstore-agent) tutorial and I am facing issues with the `VectorStoreQAWithSourcesTool`.
Looking closely at the code https://github.com/hwchase17/langchain/blob/3c2468452284ee37b8a88a20b864255fa4385b65/langchain/chains/qa_with_sources/base.py#L119-L120
it appears, the parsing rule might be too strict for extract the list of sources. Often, when the agent is fetching information from the vectorstore, the `VectorStoreQAWithSourcesTool` output is something like `....SOURCES:\n<source1>\n<source2>...` instead of `...SOURCES: <source1>,<source2>...`.
Due to this, the `VectorStoreQAWithSourcesTool` output is broken and the agent response is impacted.
P.S. I used `Chroma` as the vectorstore db and `OpenAI(temperature=0)` as the LLM. | https://github.com/langchain-ai/langchain/issues/1712 | https://github.com/langchain-ai/langchain/pull/2118 | c33e055f17d59e225cc009c49b28d4400d56e709 | 859502b16c132e6d2f02d5233233f20f78847bdb | "2023-03-16T15:47:53Z" | python | "2023-03-28T22:28:20Z" | langchain/chains/qa_with_sources/base.py | """Question answering with sources over documents."""
from __future__ import annotations
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional
from pydantic import BaseModel, Extra, root_validator
from langchain.chains.base import Chain
from langchain.chains.combine_documents.base import BaseCombineDocumentsChain
from langchain.chains.combine_documents.map_reduce import MapReduceDocumentsChain
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.chains.llm import LLMChain
from langchain.chains.qa_with_sources.loading import load_qa_with_sources_chain
from langchain.chains.qa_with_sources.map_reduce_prompt import (
COMBINE_PROMPT,
EXAMPLE_PROMPT,
QUESTION_PROMPT,
)
from langchain.docstore.document import Document
from langchain.prompts.base import BasePromptTemplate
from langchain.schema import BaseLanguageModel
class BaseQAWithSourcesChain(Chain, BaseModel, ABC):
"""Question answering with sources over documents."""
combine_documents_chain: BaseCombineDocumentsChain
"""Chain to use to combine documents."""
question_key: str = "question" #: :meta private:
input_docs_key: str = "docs" #: :meta private:
answer_key: str = "answer" #: :meta private:
sources_answer_key: str = "sources" #: :meta private:
return_source_documents: bool = False
"""Return the source documents."""
@classmethod
def from_llm(
cls,
llm: BaseLanguageModel,
document_prompt: BasePromptTemplate = EXAMPLE_PROMPT,
question_prompt: BasePromptTemplate = QUESTION_PROMPT,
combine_prompt: BasePromptTemplate = COMBINE_PROMPT,
**kwargs: Any,
) -> BaseQAWithSourcesChain:
"""Construct the chain from an LLM."""
llm_question_chain = LLMChain(llm=llm, prompt=question_prompt)
llm_combine_chain = LLMChain(llm=llm, prompt=combine_prompt)
combine_results_chain = StuffDocumentsChain(
llm_chain=llm_combine_chain,
document_prompt=document_prompt,
document_variable_name="summaries",
)
combine_document_chain = MapReduceDocumentsChain(
llm_chain=llm_question_chain,
combine_document_chain=combine_results_chain,
document_variable_name="context",
)
return cls(
combine_documents_chain=combine_document_chain,
**kwargs,
)
@classmethod
def from_chain_type(
cls,
llm: BaseLanguageModel,
chain_type: str = "stuff",
chain_type_kwargs: Optional[dict] = None,
**kwargs: Any,
) -> BaseQAWithSourcesChain:
"""Load chain from chain type."""
_chain_kwargs = chain_type_kwargs or {}
combine_document_chain = load_qa_with_sources_chain(
llm, chain_type=chain_type, **_chain_kwargs
)
return cls(combine_documents_chain=combine_document_chain, **kwargs)
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
@property
def input_keys(self) -> List[str]:
"""Expect input key.
:meta private:
"""
return [self.question_key]
@property
def output_keys(self) -> List[str]:
"""Return output key.
:meta private:
"""
_output_keys = [self.answer_key, self.sources_answer_key]
if self.return_source_documents:
_output_keys = _output_keys + ["source_documents"]
return _output_keys
@root_validator(pre=True)
def validate_naming(cls, values: Dict) -> Dict:
"""Fix backwards compatability in naming."""
if "combine_document_chain" in values:
values["combine_documents_chain"] = values.pop("combine_document_chain")
return values
@abstractmethod
def _get_docs(self, inputs: Dict[str, Any]) -> List[Document]:
"""Get docs to run questioning over."""
def _call(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
docs = self._get_docs(inputs)
answer, _ = self.combine_documents_chain.combine_docs(docs, **inputs)
if "SOURCES: " in answer:
answer, sources = answer.split("SOURCES: ")
else:
sources = ""
result: Dict[str, Any] = {
self.answer_key: answer,
self.sources_answer_key: sources,
}
if self.return_source_documents:
result["source_documents"] = docs
return result
class QAWithSourcesChain(BaseQAWithSourcesChain, BaseModel):
"""Question answering with sources over documents."""
input_docs_key: str = "docs" #: :meta private:
@property
def input_keys(self) -> List[str]:
"""Expect input key.
:meta private:
"""
return [self.input_docs_key, self.question_key]
def _get_docs(self, inputs: Dict[str, Any]) -> List[Document]:
return inputs.pop(self.input_docs_key)
@property
def _chain_type(self) -> str:
return "qa_with_sources_chain"
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,834 | LLMMathChain to allow ChatOpenAI as an llm | 1. Cannot initialize match chain with ChatOpenAI LLM
llm_math = LLMMathChain(llm=ChatOpenAI(temperature=0))
---------------------------------------------------------------------------
ValidationError Traceback (most recent call last)
Cell In[33], line 1
----> 1 llm_math = LLMMathChain(llm=ChatOpenAI(temperature=0))
File ~/anaconda3/envs/gpt_index/lib/python3.8/site-packages/pydantic/main.py:341, in pydantic.main.BaseModel.__init__()
ValidationError: 1 validation error for LLMMathChain
llm
Can't instantiate abstract class BaseLLM with abstract methods _agenerate, _generate, _llm_type (type=type_error)
2. Works ok with OpenAI LLM
llm_math = LLMMathChain(llm=OpenAI(temperature=0))
| https://github.com/langchain-ai/langchain/issues/1834 | https://github.com/langchain-ai/langchain/pull/2183 | 3207a7482915a658cf8f473ae0a81ba9998c8531 | fd1fcb5a7d48cbe18b480b1493b66540e4709745 | "2023-03-20T23:12:24Z" | python | "2023-03-30T14:52:58Z" | langchain/chains/llm_math/base.py | """Chain that interprets a prompt and executes python code to do math."""
from typing import Dict, List
from pydantic import BaseModel, Extra
from langchain.chains.base import Chain
from langchain.chains.llm import LLMChain
from langchain.chains.llm_math.prompt import PROMPT
from langchain.llms.base import BaseLLM
from langchain.prompts.base import BasePromptTemplate
from langchain.python import PythonREPL
class LLMMathChain(Chain, BaseModel):
"""Chain that interprets a prompt and executes python code to do math.
Example:
.. code-block:: python
from langchain import LLMMathChain, OpenAI
llm_math = LLMMathChain(llm=OpenAI())
"""
llm: BaseLLM
"""LLM wrapper to use."""
prompt: BasePromptTemplate = PROMPT
"""Prompt to use to translate to python if neccessary."""
input_key: str = "question" #: :meta private:
output_key: str = "answer" #: :meta private:
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
@property
def input_keys(self) -> List[str]:
"""Expect input key.
:meta private:
"""
return [self.input_key]
@property
def output_keys(self) -> List[str]:
"""Expect output key.
:meta private:
"""
return [self.output_key]
def _process_llm_result(self, t: str) -> Dict[str, str]:
python_executor = PythonREPL()
self.callback_manager.on_text(t, color="green", verbose=self.verbose)
t = t.strip()
if t.startswith("```python"):
code = t[9:-4]
output = python_executor.run(code)
self.callback_manager.on_text("\nAnswer: ", verbose=self.verbose)
self.callback_manager.on_text(output, color="yellow", verbose=self.verbose)
answer = "Answer: " + output
elif t.startswith("Answer:"):
answer = t
elif "Answer:" in t:
answer = "Answer: " + t.split("Answer:")[-1]
else:
raise ValueError(f"unknown format from LLM: {t}")
return {self.output_key: answer}
def _call(self, inputs: Dict[str, str]) -> Dict[str, str]:
llm_executor = LLMChain(
prompt=self.prompt, llm=self.llm, callback_manager=self.callback_manager
)
self.callback_manager.on_text(inputs[self.input_key], verbose=self.verbose)
t = llm_executor.predict(question=inputs[self.input_key], stop=["```output"])
return self._process_llm_result(t)
async def _acall(self, inputs: Dict[str, str]) -> Dict[str, str]:
llm_executor = LLMChain(
prompt=self.prompt, llm=self.llm, callback_manager=self.callback_manager
)
self.callback_manager.on_text(inputs[self.input_key], verbose=self.verbose)
t = await llm_executor.apredict(
question=inputs[self.input_key], stop=["```output"]
)
return self._process_llm_result(t)
@property
def _chain_type(self) -> str:
return "llm_math_chain"
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,245 | Wrong PromptLayer Dashboard hyperlink | In the docs, in https://python.langchain.com/en/latest/modules/models/llms/integrations/promptlayer_openai.html there is a hyperlink to the PromptLayer dashboard that links to "https://ww.promptlayer.com", which is incorrect. | https://github.com/langchain-ai/langchain/issues/2245 | https://github.com/langchain-ai/langchain/pull/2246 | e57b045402b52c2a602f4895c5b06fa2c22b745a | 632c2b49dabbccab92e37d01e4d1d86b6fa68457 | "2023-03-31T20:33:41Z" | python | "2023-03-31T23:16:23Z" | docs/modules/models/llms/integrations/promptlayer_openai.ipynb | {
"cells": [
{
"attachments": {},
"cell_type": "markdown",
"id": "959300d4",
"metadata": {},
"source": [
"# PromptLayer OpenAI\n",
"\n",
"This example showcases how to connect to [PromptLayer](https://www.promptlayer.com) to start recording your OpenAI requests."
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "6a45943e",
"metadata": {},
"source": [
"## Install PromptLayer\n",
"The `promptlayer` package is required to use PromptLayer with OpenAI. Install `promptlayer` using pip."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "dbe09bd8",
"metadata": {
"vscode": {
"languageId": "powershell"
}
},
"outputs": [],
"source": [
"pip install promptlayer"
]
},
{
"cell_type": "markdown",
"id": "536c1dfa",
"metadata": {},
"source": [
"## Imports"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "c16da3b5",
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"from langchain.llms import PromptLayerOpenAI\n",
"import promptlayer"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "8564ce7d",
"metadata": {},
"source": [
"## Set the Environment API Key\n",
"You can create a PromptLayer API Key at [www.promptlayer.com](https://www.promptlayer.com) by clicking the settings cog in the navbar.\n",
"\n",
"Set it as an environment variable called `PROMPTLAYER_API_KEY`."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "46ba25dc",
"metadata": {},
"outputs": [],
"source": [
"os.environ[\"PROMPTLAYER_API_KEY\"] = \"********\""
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "bf0294de",
"metadata": {},
"source": [
"## Use the PromptLayerOpenAI LLM like normal\n",
"*You can optionally pass in `pl_tags` to track your requests with PromptLayer's tagging feature.*"
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "3acf0069",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"' to go outside\\n\\nUnfortunately, cats cannot go outside without being supervised by a human. Going outside can be dangerous for cats, as they may come into contact with cars, other animals, or other dangers. If you want to go outside, ask your human to take you on a supervised walk or to a safe, enclosed outdoor space.'"
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"llm = PromptLayerOpenAI(pl_tags=[\"langchain\"])\n",
"llm(\"I am a cat and I want\")"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "a2d76826",
"metadata": {},
"source": [
"**The above request should now appear on your [PromptLayer dashboard](https://ww.promptlayer.com).**"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "05e9e2fe",
"metadata": {},
"source": [
"## Using PromptLayer Track\n",
"If you would like to use any of the [PromptLayer tracking features](https://magniv.notion.site/Track-4deee1b1f7a34c1680d085f82567dab9), you need to pass the argument `return_pl_id` when instantializing the PromptLayer LLM to get the request id. "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "1a7315b9",
"metadata": {},
"outputs": [],
"source": [
"llm = PromptLayerOpenAI(return_pl_id=True)\n",
"llm_results = llm.generate([\"Tell me a joke\"])\n",
"\n",
"for res in llm_results.generations:\n",
" pl_request_id = res[0].generation_info[\"pl_request_id\"]\n",
" promptlayer.track.score(request_id=pl_request_id, score=100)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "7eb19139",
"metadata": {},
"source": [
"Using this allows you to track the performance of your model in the PromptLayer dashboard. If you are using a prompt template, you can attach a template to a request as well.\n",
"Overall, this gives you the opportunity to track the performance of different templates and models in the PromptLayer dashboard."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "base",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.8 (default, Apr 13 2021, 12:59:45) \n[Clang 10.0.0 ]"
},
"vscode": {
"interpreter": {
"hash": "8a5edab282632443219e051e4ade2d1d5bbc671c781051bf1437897cbdfea0f1"
}
}
},
"nbformat": 4,
"nbformat_minor": 5
}
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,174 | failed tests on Windows platform | NOTE: fixed in #2238 PR.
I'm running `tests/unit_tests` on the Windows platform and several tests related to `bash` failed.
>test_llm_bash/
test_simple_question
and
>test_bash/
test_pwd_command
test_incorrect_command
test_incorrect_command_return_err_output
test_create_directory_and_files
If it is because these tests should run only on Linux, we can add
>if not sys.platform.startswith("win"):
pytest.skip("skipping windows-only tests", allow_module_level=True)
to the `test_bash.py`
and
>@pytest.mark.skipif(sys.platform.startswith("win", reason="skipping windows-only tests")
to `test_llm_bash/test_simple_question`
regarding [this](https://docs.pytest.org/en/7.1.x/how-to/skipping.html).
If you want you can assign this issue to me :)
UPDATE:
Probably` tests/unit_test/utilities/test_loading/[test_success, test_failed_request]` (tests with correspondent `_teardown`) are also failing because of the Windows environment. | https://github.com/langchain-ai/langchain/issues/2174 | https://github.com/langchain-ai/langchain/pull/2238 | 609b14a57004b4679341a05729577ec5dbcaff7d | 579ad85785a4011bdcb9fc316d2c1bcddfb9d427 | "2023-03-30T03:43:17Z" | python | "2023-04-01T19:52:21Z" | tests/unit_tests/chains/test_llm_bash.py | """Test LLM Bash functionality."""
import pytest
from langchain.chains.llm_bash.base import LLMBashChain
from langchain.chains.llm_bash.prompt import _PROMPT_TEMPLATE
from tests.unit_tests.llms.fake_llm import FakeLLM
@pytest.fixture
def fake_llm_bash_chain() -> LLMBashChain:
"""Fake LLM Bash chain for testing."""
question = "Please write a bash script that prints 'Hello World' to the console."
prompt = _PROMPT_TEMPLATE.format(question=question)
queries = {prompt: "```bash\nexpr 1 + 1\n```"}
fake_llm = FakeLLM(queries=queries)
return LLMBashChain(llm=fake_llm, input_key="q", output_key="a")
def test_simple_question(fake_llm_bash_chain: LLMBashChain) -> None:
"""Test simple question that should not need python."""
question = "Please write a bash script that prints 'Hello World' to the console."
output = fake_llm_bash_chain.run(question)
assert output == "2\n"
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,174 | failed tests on Windows platform | NOTE: fixed in #2238 PR.
I'm running `tests/unit_tests` on the Windows platform and several tests related to `bash` failed.
>test_llm_bash/
test_simple_question
and
>test_bash/
test_pwd_command
test_incorrect_command
test_incorrect_command_return_err_output
test_create_directory_and_files
If it is because these tests should run only on Linux, we can add
>if not sys.platform.startswith("win"):
pytest.skip("skipping windows-only tests", allow_module_level=True)
to the `test_bash.py`
and
>@pytest.mark.skipif(sys.platform.startswith("win", reason="skipping windows-only tests")
to `test_llm_bash/test_simple_question`
regarding [this](https://docs.pytest.org/en/7.1.x/how-to/skipping.html).
If you want you can assign this issue to me :)
UPDATE:
Probably` tests/unit_test/utilities/test_loading/[test_success, test_failed_request]` (tests with correspondent `_teardown`) are also failing because of the Windows environment. | https://github.com/langchain-ai/langchain/issues/2174 | https://github.com/langchain-ai/langchain/pull/2238 | 609b14a57004b4679341a05729577ec5dbcaff7d | 579ad85785a4011bdcb9fc316d2c1bcddfb9d427 | "2023-03-30T03:43:17Z" | python | "2023-04-01T19:52:21Z" | tests/unit_tests/test_bash.py | """Test the bash utility."""
import re
import subprocess
from pathlib import Path
from langchain.utilities.bash import BashProcess
def test_pwd_command() -> None:
"""Test correct functionality."""
session = BashProcess()
commands = ["pwd"]
output = session.run(commands)
assert output == subprocess.check_output("pwd", shell=True).decode()
def test_incorrect_command() -> None:
"""Test handling of incorrect command."""
session = BashProcess()
output = session.run(["invalid_command"])
assert output == "Command 'invalid_command' returned non-zero exit status 127."
def test_incorrect_command_return_err_output() -> None:
"""Test optional returning of shell output on incorrect command."""
session = BashProcess(return_err_output=True)
output = session.run(["invalid_command"])
assert re.match(r"^/bin/sh:.*invalid_command.*not found.*$", output)
def test_create_directory_and_files(tmp_path: Path) -> None:
"""Test creation of a directory and files in a temporary directory."""
session = BashProcess(strip_newlines=True)
# create a subdirectory in the temporary directory
temp_dir = tmp_path / "test_dir"
temp_dir.mkdir()
# run the commands in the temporary directory
commands = [
f"touch {temp_dir}/file1.txt",
f"touch {temp_dir}/file2.txt",
f"echo 'hello world' > {temp_dir}/file2.txt",
f"cat {temp_dir}/file2.txt",
]
output = session.run(commands)
assert output == "hello world"
# check that the files were created in the temporary directory
output = session.run([f"ls {temp_dir}"])
assert output == "file1.txt\nfile2.txt"
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,500 | OpenSearchVectorSearch doesn't permit the user to specify a field name | Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're populating your OpenSearch instance with data via LangChain, but doesn't work well if you're attempting to query a vector field with a different name that's been populated by some other process. For maximum utility, users should be able to customize which field is being queried. | https://github.com/langchain-ai/langchain/issues/2500 | https://github.com/langchain-ai/langchain/pull/2509 | ad87584c35f78551b3b02b2322c720b173584860 | 2ffb90b1613b01f238a084b5848bed80882f4720 | "2023-04-06T15:46:29Z" | python | "2023-04-06T19:45:56Z" | docs/modules/indexes/vectorstores/examples/opensearch.ipynb | {
"cells": [
{
"cell_type": "markdown",
"id": "683953b3",
"metadata": {},
"source": [
"# OpenSearch\n",
"\n",
"This notebook shows how to use functionality related to the OpenSearch database.\n",
"\n",
"To run, you should have the opensearch instance up and running: [here](https://opensearch.org/docs/latest/install-and-configure/install-opensearch/index/)\n",
"`similarity_search` by default performs the Approximate k-NN Search which uses one of the several algorithms like lucene, nmslib, faiss recommended for\n",
"large datasets. To perform brute force search we have other search methods known as Script Scoring and Painless Scripting.\n",
"Check [this](https://opensearch.org/docs/latest/search-plugins/knn/index/) for more details."
]
},
{
"cell_type": "code",
"execution_count": 1,
"id": "aac9563e",
"metadata": {},
"outputs": [],
"source": [
"from langchain.embeddings.openai import OpenAIEmbeddings\n",
"from langchain.text_splitter import CharacterTextSplitter\n",
"from langchain.vectorstores import OpenSearchVectorSearch\n",
"from langchain.document_loaders import TextLoader"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "a3c3999a",
"metadata": {},
"outputs": [],
"source": [
"from langchain.document_loaders import TextLoader\n",
"loader = TextLoader('../../../state_of_the_union.txt')\n",
"documents = loader.load()\n",
"text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)\n",
"docs = text_splitter.split_documents(documents)\n",
"\n",
"embeddings = OpenAIEmbeddings()"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "db3fa309",
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"docsearch = OpenSearchVectorSearch.from_texts(texts, embeddings, opensearch_url=\"http://localhost:9200\")\n",
"\n",
"query = \"What did the president say about Ketanji Brown Jackson\"\n",
"docs = docsearch.similarity_search(query)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "c160d5bb",
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"print(docs[0].page_content)"
]
},
{
"cell_type": "markdown",
"id": "01a9a035",
"metadata": {},
"source": [
"#### similarity_search using Approximate k-NN Search with Custom Parameters"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "96215c90",
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"docsearch = OpenSearchVectorSearch.from_texts(texts, embeddings, opensearch_url=\"http://localhost:9200\", engine=\"faiss\", space_type=\"innerproduct\", ef_construction=256, m=48)\n",
"\n",
"query = \"What did the president say about Ketanji Brown Jackson\"\n",
"docs = docsearch.similarity_search(query)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "62a7cea0",
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"print(docs[0].page_content)"
]
},
{
"cell_type": "markdown",
"id": "0d0cd877",
"metadata": {},
"source": [
"#### similarity_search using Script Scoring with Custom Parameters"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "0a8e3c0e",
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"docsearch = OpenSearchVectorSearch.from_texts(texts, embeddings, opensearch_url=\"http://localhost:9200\", is_appx_search=False)\n",
"\n",
"query = \"What did the president say about Ketanji Brown Jackson\"\n",
"docs = docsearch.similarity_search(\"What did the president say about Ketanji Brown Jackson\", k=1, search_type=\"script_scoring\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "92bc40db",
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"print(docs[0].page_content)"
]
},
{
"cell_type": "markdown",
"id": "a4af96cc",
"metadata": {},
"source": [
"#### similarity_search using Painless Scripting with Custom Parameters"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "6d9f436e",
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"docsearch = OpenSearchVectorSearch.from_texts(texts, embeddings, opensearch_url=\"http://localhost:9200\", is_appx_search=False)\n",
"filter = {\"bool\": {\"filter\": {\"term\": {\"text\": \"smuggling\"}}}}\n",
"query = \"What did the president say about Ketanji Brown Jackson\"\n",
"docs = docsearch.similarity_search(\"What did the president say about Ketanji Brown Jackson\", search_type=\"painless_scripting\", space_type=\"cosineSimilarity\", pre_filter=filter)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "8ca50bce",
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"print(docs[0].page_content)"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.1"
}
},
"nbformat": 4,
"nbformat_minor": 5
}
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,500 | OpenSearchVectorSearch doesn't permit the user to specify a field name | Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're populating your OpenSearch instance with data via LangChain, but doesn't work well if you're attempting to query a vector field with a different name that's been populated by some other process. For maximum utility, users should be able to customize which field is being queried. | https://github.com/langchain-ai/langchain/issues/2500 | https://github.com/langchain-ai/langchain/pull/2509 | ad87584c35f78551b3b02b2322c720b173584860 | 2ffb90b1613b01f238a084b5848bed80882f4720 | "2023-04-06T15:46:29Z" | python | "2023-04-06T19:45:56Z" | langchain/vectorstores/opensearch_vector_search.py | """Wrapper around OpenSearch vector database."""
from __future__ import annotations
import uuid
from typing import Any, Dict, Iterable, List, Optional
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from langchain.utils import get_from_dict_or_env
from langchain.vectorstores.base import VectorStore
IMPORT_OPENSEARCH_PY_ERROR = (
"Could not import OpenSearch. Please install it with `pip install opensearch-py`."
)
SCRIPT_SCORING_SEARCH = "script_scoring"
PAINLESS_SCRIPTING_SEARCH = "painless_scripting"
MATCH_ALL_QUERY = {"match_all": {}} # type: Dict
def _import_opensearch() -> Any:
"""Import OpenSearch if available, otherwise raise error."""
try:
from opensearchpy import OpenSearch
except ImportError:
raise ValueError(IMPORT_OPENSEARCH_PY_ERROR)
return OpenSearch
def _import_bulk() -> Any:
"""Import bulk if available, otherwise raise error."""
try:
from opensearchpy.helpers import bulk
except ImportError:
raise ValueError(IMPORT_OPENSEARCH_PY_ERROR)
return bulk
def _get_opensearch_client(opensearch_url: str, **kwargs: Any) -> Any:
"""Get OpenSearch client from the opensearch_url, otherwise raise error."""
try:
opensearch = _import_opensearch()
client = opensearch(opensearch_url, **kwargs)
except ValueError as e:
raise ValueError(
f"OpenSearch client string provided is not in proper format. "
f"Got error: {e} "
)
return client
def _validate_embeddings_and_bulk_size(embeddings_length: int, bulk_size: int) -> None:
"""Validate Embeddings Length and Bulk Size."""
if embeddings_length == 0:
raise RuntimeError("Embeddings size is zero")
if bulk_size < embeddings_length:
raise RuntimeError(
f"The embeddings count, {embeddings_length} is more than the "
f"[bulk_size], {bulk_size}. Increase the value of [bulk_size]."
)
def _bulk_ingest_embeddings(
client: Any,
index_name: str,
embeddings: List[List[float]],
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
) -> List[str]:
"""Bulk Ingest Embeddings into given index."""
bulk = _import_bulk()
requests = []
ids = []
for i, text in enumerate(texts):
metadata = metadatas[i] if metadatas else {}
_id = str(uuid.uuid4())
request = {
"_op_type": "index",
"_index": index_name,
"vector_field": embeddings[i],
"text": text,
"metadata": metadata,
"_id": _id,
}
requests.append(request)
ids.append(_id)
bulk(client, requests)
client.indices.refresh(index=index_name)
return ids
def _default_scripting_text_mapping(dim: int) -> Dict:
"""For Painless Scripting or Script Scoring,the default mapping to create index."""
return {
"mappings": {
"properties": {
"vector_field": {"type": "knn_vector", "dimension": dim},
}
}
}
def _default_text_mapping(
dim: int,
engine: str = "nmslib",
space_type: str = "l2",
ef_search: int = 512,
ef_construction: int = 512,
m: int = 16,
) -> Dict:
"""For Approximate k-NN Search, this is the default mapping to create index."""
return {
"settings": {"index": {"knn": True, "knn.algo_param.ef_search": ef_search}},
"mappings": {
"properties": {
"vector_field": {
"type": "knn_vector",
"dimension": dim,
"method": {
"name": "hnsw",
"space_type": space_type,
"engine": engine,
"parameters": {"ef_construction": ef_construction, "m": m},
},
}
}
},
}
def _default_approximate_search_query(
query_vector: List[float], size: int = 4, k: int = 4
) -> Dict:
"""For Approximate k-NN Search, this is the default query."""
return {
"size": size,
"query": {"knn": {"vector_field": {"vector": query_vector, "k": k}}},
}
def _default_script_query(
query_vector: List[float],
space_type: str = "l2",
pre_filter: Dict = MATCH_ALL_QUERY,
) -> Dict:
"""For Script Scoring Search, this is the default query."""
return {
"query": {
"script_score": {
"query": pre_filter,
"script": {
"source": "knn_score",
"lang": "knn",
"params": {
"field": "vector_field",
"query_value": query_vector,
"space_type": space_type,
},
},
}
}
}
def __get_painless_scripting_source(space_type: str, query_vector: List[float]) -> str:
"""For Painless Scripting, it returns the script source based on space type."""
source_value = (
"(1.0 + " + space_type + "(" + str(query_vector) + ", doc['vector_field']))"
)
if space_type == "cosineSimilarity":
return source_value
else:
return "1/" + source_value
def _default_painless_scripting_query(
query_vector: List[float],
space_type: str = "l2Squared",
pre_filter: Dict = MATCH_ALL_QUERY,
) -> Dict:
"""For Painless Scripting Search, this is the default query."""
source = __get_painless_scripting_source(space_type, query_vector)
return {
"query": {
"script_score": {
"query": pre_filter,
"script": {
"source": source,
"params": {
"field": "vector_field",
"query_value": query_vector,
},
},
}
}
}
def _get_kwargs_value(kwargs: Any, key: str, default_value: Any) -> Any:
"""Get the value of the key if present. Else get the default_value."""
if key in kwargs:
return kwargs.get(key)
return default_value
class OpenSearchVectorSearch(VectorStore):
"""Wrapper around OpenSearch as a vector database.
Example:
.. code-block:: python
from langchain import OpenSearchVectorSearch
opensearch_vector_search = OpenSearchVectorSearch(
"http://localhost:9200",
"embeddings",
embedding_function
)
"""
def __init__(
self,
opensearch_url: str,
index_name: str,
embedding_function: Embeddings,
**kwargs: Any,
):
"""Initialize with necessary components."""
self.embedding_function = embedding_function
self.index_name = index_name
self.client = _get_opensearch_client(opensearch_url, **kwargs)
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
bulk_size: int = 500,
**kwargs: Any,
) -> List[str]:
"""Run more texts through the embeddings and add to the vectorstore.
Args:
texts: Iterable of strings to add to the vectorstore.
metadatas: Optional list of metadatas associated with the texts.
bulk_size: Bulk API request count; Default: 500
Returns:
List of ids from adding the texts into the vectorstore.
"""
embeddings = [
self.embedding_function.embed_documents([text])[0] for text in texts
]
_validate_embeddings_and_bulk_size(len(embeddings), bulk_size)
return _bulk_ingest_embeddings(
self.client, self.index_name, embeddings, texts, metadatas
)
def similarity_search(
self, query: str, k: int = 4, **kwargs: Any
) -> List[Document]:
"""Return docs most similar to query.
By default supports Approximate Search.
Also supports Script Scoring and Painless Scripting.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the query.
Optional Args for Approximate Search:
search_type: "approximate_search"; default: "approximate_search"
size: number of results the query actually returns; default: 4
Optional Args for Script Scoring Search:
search_type: "script_scoring"; default: "approximate_search"
space_type: "l2", "l1", "linf", "cosinesimil", "innerproduct",
"hammingbit"; default: "l2"
pre_filter: script_score query to pre-filter documents before identifying
nearest neighbors; default: {"match_all": {}}
Optional Args for Painless Scripting Search:
search_type: "painless_scripting"; default: "approximate_search"
space_type: "l2Squared", "l1Norm", "cosineSimilarity"; default: "l2Squared"
pre_filter: script_score query to pre-filter documents before identifying
nearest neighbors; default: {"match_all": {}}
"""
embedding = self.embedding_function.embed_query(query)
search_type = _get_kwargs_value(kwargs, "search_type", "approximate_search")
if search_type == "approximate_search":
size = _get_kwargs_value(kwargs, "size", 4)
search_query = _default_approximate_search_query(embedding, size, k)
elif search_type == SCRIPT_SCORING_SEARCH:
space_type = _get_kwargs_value(kwargs, "space_type", "l2")
pre_filter = _get_kwargs_value(kwargs, "pre_filter", MATCH_ALL_QUERY)
search_query = _default_script_query(embedding, space_type, pre_filter)
elif search_type == PAINLESS_SCRIPTING_SEARCH:
space_type = _get_kwargs_value(kwargs, "space_type", "l2Squared")
pre_filter = _get_kwargs_value(kwargs, "pre_filter", MATCH_ALL_QUERY)
search_query = _default_painless_scripting_query(
embedding, space_type, pre_filter
)
else:
raise ValueError("Invalid `search_type` provided as an argument")
response = self.client.search(index=self.index_name, body=search_query)
hits = [hit["_source"] for hit in response["hits"]["hits"][:k]]
documents = [
Document(page_content=hit["text"], metadata=hit["metadata"]) for hit in hits
]
return documents
@classmethod
def from_texts(
cls,
texts: List[str],
embedding: Embeddings,
metadatas: Optional[List[dict]] = None,
bulk_size: int = 500,
**kwargs: Any,
) -> OpenSearchVectorSearch:
"""Construct OpenSearchVectorSearch wrapper from raw documents.
Example:
.. code-block:: python
from langchain import OpenSearchVectorSearch
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
opensearch_vector_search = OpenSearchVectorSearch.from_texts(
texts,
embeddings,
opensearch_url="http://localhost:9200"
)
OpenSearch by default supports Approximate Search powered by nmslib, faiss
and lucene engines recommended for large datasets. Also supports brute force
search through Script Scoring and Painless Scripting.
Optional Keyword Args for Approximate Search:
engine: "nmslib", "faiss", "hnsw"; default: "nmslib"
space_type: "l2", "l1", "cosinesimil", "linf", "innerproduct"; default: "l2"
ef_search: Size of the dynamic list used during k-NN searches. Higher values
lead to more accurate but slower searches; default: 512
ef_construction: Size of the dynamic list used during k-NN graph creation.
Higher values lead to more accurate graph but slower indexing speed;
default: 512
m: Number of bidirectional links created for each new element. Large impact
on memory consumption. Between 2 and 100; default: 16
Keyword Args for Script Scoring or Painless Scripting:
is_appx_search: False
"""
opensearch_url = get_from_dict_or_env(
kwargs, "opensearch_url", "OPENSEARCH_URL"
)
client = _get_opensearch_client(opensearch_url)
embeddings = embedding.embed_documents(texts)
_validate_embeddings_and_bulk_size(len(embeddings), bulk_size)
dim = len(embeddings[0])
# Get the index name from either from kwargs or ENV Variable
# before falling back to random generation
index_name = get_from_dict_or_env(
kwargs, "index_name", "OPENSEARCH_INDEX_NAME", default=uuid.uuid4().hex
)
is_appx_search = _get_kwargs_value(kwargs, "is_appx_search", True)
if is_appx_search:
engine = _get_kwargs_value(kwargs, "engine", "nmslib")
space_type = _get_kwargs_value(kwargs, "space_type", "l2")
ef_search = _get_kwargs_value(kwargs, "ef_search", 512)
ef_construction = _get_kwargs_value(kwargs, "ef_construction", 512)
m = _get_kwargs_value(kwargs, "m", 16)
mapping = _default_text_mapping(
dim, engine, space_type, ef_search, ef_construction, m
)
else:
mapping = _default_scripting_text_mapping(dim)
client.indices.create(index=index_name, body=mapping)
_bulk_ingest_embeddings(client, index_name, embeddings, texts, metadatas)
return cls(opensearch_url, index_name, embedding)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,634 | GoogleDriveLoader not loading docs from Share Drives | https://github.com/hwchase17/langchain/blob/cb646082baa173fdee7f2b1e361be368acef4e7e/langchain/document_loaders/googledrive.py#L120
Suggestion: Include optional param `includeItemsFromAllDrives` when calling `service.files().list()`
Reference: https://stackoverflow.com/questions/65388539/using-python-i-cant-access-shared-drive-folders-from-google-drive-api-v3 | https://github.com/langchain-ai/langchain/issues/1634 | https://github.com/langchain-ai/langchain/pull/2562 | 7bf5b0ccd36a72395ac16ebafdfb3453d57c6e9d | 125afb51d791577ef078554f0ceec817a7ca4e22 | "2023-03-13T15:03:55Z" | python | "2023-04-08T15:46:55Z" | langchain/document_loaders/googledrive.py | """Loader that loads data from Google Drive."""
# Prerequisites:
# 1. Create a Google Cloud project
# 2. Enable the Google Drive API:
# https://console.cloud.google.com/flows/enableapi?apiid=drive.googleapis.com
# 3. Authorize credentials for desktop app:
# https://developers.google.com/drive/api/quickstart/python#authorize_credentials_for_a_desktop_application # noqa: E501
# 4. For service accounts visit
# https://cloud.google.com/iam/docs/service-accounts-create
from pathlib import Path
from typing import Any, Dict, List, Optional
from pydantic import BaseModel, root_validator, validator
from langchain.docstore.document import Document
from langchain.document_loaders.base import BaseLoader
SCOPES = ["https://www.googleapis.com/auth/drive.readonly"]
class GoogleDriveLoader(BaseLoader, BaseModel):
"""Loader that loads Google Docs from Google Drive."""
service_account_key: Path = Path.home() / ".credentials" / "keys.json"
credentials_path: Path = Path.home() / ".credentials" / "credentials.json"
token_path: Path = Path.home() / ".credentials" / "token.json"
folder_id: Optional[str] = None
document_ids: Optional[List[str]] = None
file_ids: Optional[List[str]] = None
@root_validator
def validate_folder_id_or_document_ids(
cls, values: Dict[str, Any]
) -> Dict[str, Any]:
"""Validate that either folder_id or document_ids is set, but not both."""
if values.get("folder_id") and (
values.get("document_ids") or values.get("file_ids")
):
raise ValueError(
"Cannot specify both folder_id and document_ids nor "
"folder_id and file_ids"
)
if (
not values.get("folder_id")
and not values.get("document_ids")
and not values.get("file_ids")
):
raise ValueError("Must specify either folder_id, document_ids, or file_ids")
return values
@validator("credentials_path")
def validate_credentials_path(cls, v: Any, **kwargs: Any) -> Any:
"""Validate that credentials_path exists."""
if not v.exists():
raise ValueError(f"credentials_path {v} does not exist")
return v
def _load_credentials(self) -> Any:
"""Load credentials."""
# Adapted from https://developers.google.com/drive/api/v3/quickstart/python
try:
from google.auth.transport.requests import Request
from google.oauth2 import service_account
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
except ImportError:
raise ImportError(
"You must run"
"`pip install --upgrade "
"google-api-python-client google-auth-httplib2 "
"google-auth-oauthlib`"
"to use the Google Drive loader."
)
creds = None
if self.service_account_key.exists():
return service_account.Credentials.from_service_account_file(
str(self.service_account_key), scopes=SCOPES
)
if self.token_path.exists():
creds = Credentials.from_authorized_user_file(str(self.token_path), SCOPES)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(
str(self.credentials_path), SCOPES
)
creds = flow.run_local_server(port=0)
with open(self.token_path, "w") as token:
token.write(creds.to_json())
return creds
def _load_sheet_from_id(self, id: str) -> List[Document]:
"""Load a sheet and all tabs from an ID."""
from googleapiclient.discovery import build
creds = self._load_credentials()
sheets_service = build("sheets", "v4", credentials=creds)
spreadsheet = sheets_service.spreadsheets().get(spreadsheetId=id).execute()
sheets = spreadsheet.get("sheets", [])
documents = []
for sheet in sheets:
sheet_name = sheet["properties"]["title"]
result = (
sheets_service.spreadsheets()
.values()
.get(spreadsheetId=id, range=sheet_name)
.execute()
)
values = result.get("values", [])
header = values[0]
for i, row in enumerate(values[1:], start=1):
metadata = {
"source": (
f"https://docs.google.com/spreadsheets/d/{id}/"
f"edit?gid={sheet['properties']['sheetId']}"
),
"title": f"{spreadsheet['properties']['title']} - {sheet_name}",
"row": i,
}
content = []
for j, v in enumerate(row):
title = header[j].strip() if len(header) > j else ""
content.append(f"{title}: {v.strip()}")
page_content = "\n".join(content)
documents.append(Document(page_content=page_content, metadata=metadata))
return documents
def _load_document_from_id(self, id: str) -> Document:
"""Load a document from an ID."""
from io import BytesIO
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from googleapiclient.http import MediaIoBaseDownload
creds = self._load_credentials()
service = build("drive", "v3", credentials=creds)
file = service.files().get(fileId=id).execute()
request = service.files().export_media(fileId=id, mimeType="text/plain")
fh = BytesIO()
downloader = MediaIoBaseDownload(fh, request)
done = False
try:
while done is False:
status, done = downloader.next_chunk()
except HttpError as e:
if e.resp.status == 404:
print("File not found: {}".format(id))
else:
print("An error occurred: {}".format(e))
text = fh.getvalue().decode("utf-8")
metadata = {
"source": f"https://docs.google.com/document/d/{id}/edit",
"title": f"{file.get('name')}",
}
return Document(page_content=text, metadata=metadata)
def _load_documents_from_folder(self) -> List[Document]:
"""Load documents from a folder."""
from googleapiclient.discovery import build
creds = self._load_credentials()
service = build("drive", "v3", credentials=creds)
results = (
service.files()
.list(
q=f"'{self.folder_id}' in parents",
pageSize=1000,
fields="nextPageToken, files(id, name, mimeType)",
)
.execute()
)
items = results.get("files", [])
returns = []
for item in items:
if item["mimeType"] == "application/vnd.google-apps.document":
returns.append(self._load_document_from_id(item["id"]))
elif item["mimeType"] == "application/vnd.google-apps.spreadsheet":
returns.extend(self._load_sheet_from_id(item["id"]))
elif item["mimeType"] == "application/pdf":
returns.extend(self._load_file_from_id(item["id"]))
else:
pass
return returns
def _load_documents_from_ids(self) -> List[Document]:
"""Load documents from a list of IDs."""
if not self.document_ids:
raise ValueError("document_ids must be set")
return [self._load_document_from_id(doc_id) for doc_id in self.document_ids]
def _load_file_from_id(self, id: str) -> List[Document]:
"""Load a file from an ID."""
from io import BytesIO
from googleapiclient.discovery import build
from googleapiclient.http import MediaIoBaseDownload
creds = self._load_credentials()
service = build("drive", "v3", credentials=creds)
file = service.files().get(fileId=id).execute()
request = service.files().get_media(fileId=id)
fh = BytesIO()
downloader = MediaIoBaseDownload(fh, request)
done = False
while done is False:
status, done = downloader.next_chunk()
content = fh.getvalue()
from PyPDF2 import PdfReader
pdf_reader = PdfReader(BytesIO(content))
return [
Document(
page_content=page.extract_text(),
metadata={
"source": f"https://drive.google.com/file/d/{id}/view",
"title": f"{file.get('name')}",
"page": i,
},
)
for i, page in enumerate(pdf_reader.pages)
]
def _load_file_from_ids(self) -> List[Document]:
"""Load files from a list of IDs."""
if not self.file_ids:
raise ValueError("file_ids must be set")
docs = []
for file_id in self.file_ids:
docs.extend(self._load_file_from_id(file_id))
return docs
def load(self) -> List[Document]:
"""Load documents."""
if self.folder_id:
return self._load_documents_from_folder()
elif self.document_ids:
return self._load_documents_from_ids()
else:
return self._load_file_from_ids()
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,624 | Missing import in AzureOpenAI embedding example | ## What's the issue?
Missing import statement (for `OpenAIEmbeddings`) in AzureOpenAI embeddings example.
<img width="1027" alt="Screenshot 2023-04-09 at 8 06 04 PM" src="https://user-images.githubusercontent.com/19938474/230779010-e7935543-6ae7-477c-872d-8a5220fc60c9.png">
https://github.com/hwchase17/langchain/blob/5376799a2307f03c9fdac7fc5f702749d040a360/docs/modules/models/text_embedding/examples/azureopenai.ipynb
## Expected behaviour
Import `from langchain.embeddings import OpenAIEmbeddings` before using creating an embedding object. | https://github.com/langchain-ai/langchain/issues/2624 | https://github.com/langchain-ai/langchain/pull/2625 | 0f5d3b339009f0bc0d5a59356e82870d9f0f15d6 | 9aed565f130b44a6e6287ac572be6be26f064f71 | "2023-04-09T14:38:44Z" | python | "2023-04-09T19:25:31Z" | docs/modules/models/text_embedding/examples/azureopenai.ipynb | {
"cells": [
{
"cell_type": "markdown",
"id": "c3852491",
"metadata": {},
"source": [
"# AzureOpenAI\n",
"\n",
"Let's load the OpenAI Embedding class with environment variables set to indicate to use Azure endpoints."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "1b40f827",
"metadata": {},
"outputs": [],
"source": [
"# set the environment variables needed for openai package to know to reach out to azure\n",
"import os\n",
"\n",
"os.environ[\"OPENAI_API_TYPE\"] = \"azure\"\n",
"os.environ[\"OPENAI_API_BASE\"] = \"https://<your-endpoint.openai.azure.com/\"\n",
"os.environ[\"OPENAI_API_KEY\"] = \"your AzureOpenAI key\""
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "bb36d16c",
"metadata": {},
"outputs": [],
"source": [
"embeddings = OpenAIEmbeddings(model=\"your-embeddings-deployment-name\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "228abcbb",
"metadata": {},
"outputs": [],
"source": [
"text = \"This is a test document.\""
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "60dd7fad",
"metadata": {},
"outputs": [],
"source": [
"query_result = embeddings.embed_query(text)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "83bc1a72",
"metadata": {},
"outputs": [],
"source": [
"doc_result = embeddings.embed_documents([text])"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "aaad49f8",
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.1"
},
"vscode": {
"interpreter": {
"hash": "7377c2ccc78bc62c2683122d48c8cd1fb85a53850a1b1fc29736ed39852c9885"
}
}
},
"nbformat": 4,
"nbformat_minor": 5
}
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,677 | Langchain should use tiktoken tokenizer for python 3.8 | I noticed that `langchain` will not try to use the `tiktoken` tokenizer if python version is 3.8 and will switch to Hugging Face tokenizer instead ([see line 331 here](https://github.com/hwchase17/langchain/blob/master/langchain/chat_models/openai.py)). It assumes that `tiktoken` does not support python 3.8. However this does not seem to be the case (see [line 10 here](https://github.com/openai/tiktoken/blob/main/pyproject.toml)). | https://github.com/langchain-ai/langchain/issues/2677 | https://github.com/langchain-ai/langchain/pull/2709 | 186ca9d3e485f3209aa6b465377a46c23fb98c87 | f435f2267c015ffd97ff5eea9ad8c8051ea0dc0f | "2023-04-10T18:40:46Z" | python | "2023-04-11T18:02:28Z" | langchain/chat_models/openai.py | """OpenAI chat wrapper."""
from __future__ import annotations
import logging
import sys
from typing import Any, Callable, Dict, List, Mapping, Optional, Tuple
from pydantic import Extra, Field, root_validator
from tenacity import (
before_sleep_log,
retry,
retry_if_exception_type,
stop_after_attempt,
wait_exponential,
)
from langchain.chat_models.base import BaseChatModel
from langchain.schema import (
AIMessage,
BaseMessage,
ChatGeneration,
ChatMessage,
ChatResult,
HumanMessage,
SystemMessage,
)
from langchain.utils import get_from_dict_or_env
logger = logging.getLogger(__file__)
def _create_retry_decorator(llm: ChatOpenAI) -> Callable[[Any], Any]:
import openai
min_seconds = 4
max_seconds = 10
# Wait 2^x * 1 second between each retry starting with
# 4 seconds, then up to 10 seconds, then 10 seconds afterwards
return retry(
reraise=True,
stop=stop_after_attempt(llm.max_retries),
wait=wait_exponential(multiplier=1, min=min_seconds, max=max_seconds),
retry=(
retry_if_exception_type(openai.error.Timeout)
| retry_if_exception_type(openai.error.APIError)
| retry_if_exception_type(openai.error.APIConnectionError)
| retry_if_exception_type(openai.error.RateLimitError)
| retry_if_exception_type(openai.error.ServiceUnavailableError)
),
before_sleep=before_sleep_log(logger, logging.WARNING),
)
async def acompletion_with_retry(llm: ChatOpenAI, **kwargs: Any) -> Any:
"""Use tenacity to retry the async completion call."""
retry_decorator = _create_retry_decorator(llm)
@retry_decorator
async def _completion_with_retry(**kwargs: Any) -> Any:
# Use OpenAI's async api https://github.com/openai/openai-python#async-api
return await llm.client.acreate(**kwargs)
return await _completion_with_retry(**kwargs)
def _convert_dict_to_message(_dict: dict) -> BaseMessage:
role = _dict["role"]
if role == "user":
return HumanMessage(content=_dict["content"])
elif role == "assistant":
return AIMessage(content=_dict["content"])
elif role == "system":
return SystemMessage(content=_dict["content"])
else:
return ChatMessage(content=_dict["content"], role=role)
def _convert_message_to_dict(message: BaseMessage) -> dict:
if isinstance(message, ChatMessage):
message_dict = {"role": message.role, "content": message.content}
elif isinstance(message, HumanMessage):
message_dict = {"role": "user", "content": message.content}
elif isinstance(message, AIMessage):
message_dict = {"role": "assistant", "content": message.content}
elif isinstance(message, SystemMessage):
message_dict = {"role": "system", "content": message.content}
else:
raise ValueError(f"Got unknown type {message}")
if "name" in message.additional_kwargs:
message_dict["name"] = message.additional_kwargs["name"]
return message_dict
class ChatOpenAI(BaseChatModel):
"""Wrapper around OpenAI Chat large language models.
To use, you should have the ``openai`` python package installed, and the
environment variable ``OPENAI_API_KEY`` set with your API key.
Any parameters that are valid to be passed to the openai.create call can be passed
in, even if not explicitly saved on this class.
Example:
.. code-block:: python
from langchain.chat_models import ChatOpenAI
openai = ChatOpenAI(model_name="gpt-3.5-turbo")
"""
client: Any #: :meta private:
model_name: str = "gpt-3.5-turbo"
"""Model name to use."""
temperature: float = 0.7
"""What sampling temperature to use."""
model_kwargs: Dict[str, Any] = Field(default_factory=dict)
"""Holds any model parameters valid for `create` call not explicitly specified."""
openai_api_key: Optional[str] = None
openai_organization: Optional[str] = None
request_timeout: int = 60
"""Timeout in seconds for the OpenAPI request."""
max_retries: int = 6
"""Maximum number of retries to make when generating."""
streaming: bool = False
"""Whether to stream the results or not."""
n: int = 1
"""Number of chat completions to generate for each prompt."""
max_tokens: Optional[int] = None
"""Maximum number of tokens to generate."""
class Config:
"""Configuration for this pydantic object."""
extra = Extra.ignore
@root_validator(pre=True)
def build_extra(cls, values: Dict[str, Any]) -> Dict[str, Any]:
"""Build extra kwargs from additional params that were passed in."""
all_required_field_names = {field.alias for field in cls.__fields__.values()}
extra = values.get("model_kwargs", {})
for field_name in list(values):
if field_name not in all_required_field_names:
if field_name in extra:
raise ValueError(f"Found {field_name} supplied twice.")
extra[field_name] = values.pop(field_name)
values["model_kwargs"] = extra
return values
@root_validator()
def validate_environment(cls, values: Dict) -> Dict:
"""Validate that api key and python package exists in environment."""
openai_api_key = get_from_dict_or_env(
values, "openai_api_key", "OPENAI_API_KEY"
)
openai_organization = get_from_dict_or_env(
values,
"openai_organization",
"OPENAI_ORGANIZATION",
default="",
)
try:
import openai
openai.api_key = openai_api_key
if openai_organization:
openai.organization = openai_organization
except ImportError:
raise ValueError(
"Could not import openai python package. "
"Please it install it with `pip install openai`."
)
try:
values["client"] = openai.ChatCompletion
except AttributeError:
raise ValueError(
"`openai` has no `ChatCompletion` attribute, this is likely "
"due to an old version of the openai package. Try upgrading it "
"with `pip install --upgrade openai`."
)
if values["n"] < 1:
raise ValueError("n must be at least 1.")
if values["n"] > 1 and values["streaming"]:
raise ValueError("n must be 1 when streaming.")
return values
@property
def _default_params(self) -> Dict[str, Any]:
"""Get the default parameters for calling OpenAI API."""
return {
"model": self.model_name,
"request_timeout": self.request_timeout,
"max_tokens": self.max_tokens,
"stream": self.streaming,
"n": self.n,
"temperature": self.temperature,
**self.model_kwargs,
}
def _create_retry_decorator(self) -> Callable[[Any], Any]:
import openai
min_seconds = 4
max_seconds = 10
# Wait 2^x * 1 second between each retry starting with
# 4 seconds, then up to 10 seconds, then 10 seconds afterwards
return retry(
reraise=True,
stop=stop_after_attempt(self.max_retries),
wait=wait_exponential(multiplier=1, min=min_seconds, max=max_seconds),
retry=(
retry_if_exception_type(openai.error.Timeout)
| retry_if_exception_type(openai.error.APIError)
| retry_if_exception_type(openai.error.APIConnectionError)
| retry_if_exception_type(openai.error.RateLimitError)
| retry_if_exception_type(openai.error.ServiceUnavailableError)
),
before_sleep=before_sleep_log(logger, logging.WARNING),
)
def completion_with_retry(self, **kwargs: Any) -> Any:
"""Use tenacity to retry the completion call."""
retry_decorator = self._create_retry_decorator()
@retry_decorator
def _completion_with_retry(**kwargs: Any) -> Any:
return self.client.create(**kwargs)
return _completion_with_retry(**kwargs)
def _combine_llm_outputs(self, llm_outputs: List[Optional[dict]]) -> dict:
overall_token_usage: dict = {}
for output in llm_outputs:
if output is None:
# Happens in streaming
continue
token_usage = output["token_usage"]
for k, v in token_usage.items():
if k in overall_token_usage:
overall_token_usage[k] += v
else:
overall_token_usage[k] = v
return {"token_usage": overall_token_usage, "model_name": self.model_name}
def _generate(
self, messages: List[BaseMessage], stop: Optional[List[str]] = None
) -> ChatResult:
message_dicts, params = self._create_message_dicts(messages, stop)
if self.streaming:
inner_completion = ""
role = "assistant"
params["stream"] = True
for stream_resp in self.completion_with_retry(
messages=message_dicts, **params
):
role = stream_resp["choices"][0]["delta"].get("role", role)
token = stream_resp["choices"][0]["delta"].get("content", "")
inner_completion += token
self.callback_manager.on_llm_new_token(
token,
verbose=self.verbose,
)
message = _convert_dict_to_message(
{"content": inner_completion, "role": role}
)
return ChatResult(generations=[ChatGeneration(message=message)])
response = self.completion_with_retry(messages=message_dicts, **params)
return self._create_chat_result(response)
def _create_message_dicts(
self, messages: List[BaseMessage], stop: Optional[List[str]]
) -> Tuple[List[Dict[str, Any]], Dict[str, Any]]:
params: Dict[str, Any] = {**{"model": self.model_name}, **self._default_params}
if stop is not None:
if "stop" in params:
raise ValueError("`stop` found in both the input and default params.")
params["stop"] = stop
message_dicts = [_convert_message_to_dict(m) for m in messages]
return message_dicts, params
def _create_chat_result(self, response: Mapping[str, Any]) -> ChatResult:
generations = []
for res in response["choices"]:
message = _convert_dict_to_message(res["message"])
gen = ChatGeneration(message=message)
generations.append(gen)
llm_output = {"token_usage": response["usage"], "model_name": self.model_name}
return ChatResult(generations=generations, llm_output=llm_output)
async def _agenerate(
self, messages: List[BaseMessage], stop: Optional[List[str]] = None
) -> ChatResult:
message_dicts, params = self._create_message_dicts(messages, stop)
if self.streaming:
inner_completion = ""
role = "assistant"
params["stream"] = True
async for stream_resp in await acompletion_with_retry(
self, messages=message_dicts, **params
):
role = stream_resp["choices"][0]["delta"].get("role", role)
token = stream_resp["choices"][0]["delta"].get("content", "")
inner_completion += token
if self.callback_manager.is_async:
await self.callback_manager.on_llm_new_token(
token,
verbose=self.verbose,
)
else:
self.callback_manager.on_llm_new_token(
token,
verbose=self.verbose,
)
message = _convert_dict_to_message(
{"content": inner_completion, "role": role}
)
return ChatResult(generations=[ChatGeneration(message=message)])
else:
response = await acompletion_with_retry(
self, messages=message_dicts, **params
)
return self._create_chat_result(response)
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters."""
return {**{"model_name": self.model_name}, **self._default_params}
def get_num_tokens(self, text: str) -> int:
"""Calculate num tokens with tiktoken package."""
# tiktoken NOT supported for Python 3.8 or below
if sys.version_info[1] <= 8:
return super().get_num_tokens(text)
try:
import tiktoken
except ImportError:
raise ValueError(
"Could not import tiktoken python package. "
"This is needed in order to calculate get_num_tokens. "
"Please it install it with `pip install tiktoken`."
)
# create a GPT-3.5-Turbo encoder instance
enc = tiktoken.encoding_for_model(self.model_name)
# encode the text using the GPT-3.5-Turbo encoder
tokenized_text = enc.encode(text)
# calculate the number of tokens in the encoded text
return len(tokenized_text)
def get_num_tokens_from_messages(self, messages: List[BaseMessage]) -> int:
"""Calculate num tokens for gpt-3.5-turbo and gpt-4 with tiktoken package.
Official documentation: https://github.com/openai/openai-cookbook/blob/
main/examples/How_to_format_inputs_to_ChatGPT_models.ipynb"""
try:
import tiktoken
except ImportError:
raise ValueError(
"Could not import tiktoken python package. "
"This is needed in order to calculate get_num_tokens. "
"Please it install it with `pip install tiktoken`."
)
model = self.model_name
if model == "gpt-3.5-turbo":
# gpt-3.5-turbo may change over time.
# Returning num tokens assuming gpt-3.5-turbo-0301.
model = "gpt-3.5-turbo-0301"
elif model == "gpt-4":
# gpt-4 may change over time.
# Returning num tokens assuming gpt-4-0314.
model = "gpt-4-0314"
# Returns the number of tokens used by a list of messages.
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
logger.warning("Warning: model not found. Using cl100k_base encoding.")
encoding = tiktoken.get_encoding("cl100k_base")
if model == "gpt-3.5-turbo-0301":
# every message follows <im_start>{role/name}\n{content}<im_end>\n
tokens_per_message = 4
# if there's a name, the role is omitted
tokens_per_name = -1
elif model == "gpt-4-0314":
tokens_per_message = 3
tokens_per_name = 1
else:
raise NotImplementedError(
f"get_num_tokens_from_messages() is not presently implemented "
f"for model {model}."
"See https://github.com/openai/openai-python/blob/main/chatml.md for "
"information on how messages are converted to tokens."
)
num_tokens = 0
messages_dict = [_convert_message_to_dict(m) for m in messages]
for message in messages_dict:
num_tokens += tokens_per_message
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name":
num_tokens += tokens_per_name
# every reply is primed with <im_start>assistant
num_tokens += 3
return num_tokens
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,962 | AttributeError: type object 'YoutubeLoader' has no attribute 'from_youtube_url' | I am trying to load load video and came across below issue.
I am using langchain version 0.0.121
| https://github.com/langchain-ai/langchain/issues/1962 | https://github.com/langchain-ai/langchain/pull/2734 | 0ab364404ecfcda96a67c0fe81b24fc870617976 | 744c25cd0ac74c5608a564312c6e5b48c6276359 | "2023-03-24T10:08:17Z" | python | "2023-04-12T04:12:58Z" | langchain/document_loaders/youtube.py | """Loader that loads YouTube transcript."""
from __future__ import annotations
from pathlib import Path
from typing import Any, Dict, List, Optional
from pydantic import root_validator
from pydantic.dataclasses import dataclass
from langchain.docstore.document import Document
from langchain.document_loaders.base import BaseLoader
SCOPES = ["https://www.googleapis.com/auth/drive.readonly"]
@dataclass
class GoogleApiClient:
"""A Generic Google Api Client.
To use, you should have the ``google_auth_oauthlib,youtube_transcript_api,google``
python package installed.
As the google api expects credentials you need to set up a google account and
register your Service. "https://developers.google.com/docs/api/quickstart/python"
Example:
.. code-block:: python
from langchain.document_loaders import GoogleApiClient
google_api_client = GoogleApiClient(
service_account_path=Path("path_to_your_sec_file.json")
)
"""
credentials_path: Path = Path.home() / ".credentials" / "credentials.json"
service_account_path: Path = Path.home() / ".credentials" / "credentials.json"
token_path: Path = Path.home() / ".credentials" / "token.json"
def __post_init__(self) -> None:
self.creds = self._load_credentials()
@root_validator
def validate_channel_or_videoIds_is_set(
cls, values: Dict[str, Any]
) -> Dict[str, Any]:
"""Validate that either folder_id or document_ids is set, but not both."""
if not values.get("credentials_path") and not values.get(
"service_account_path"
):
raise ValueError("Must specify either channel_name or video_ids")
return values
def _load_credentials(self) -> Any:
"""Load credentials."""
# Adapted from https://developers.google.com/drive/api/v3/quickstart/python
try:
from google.auth.transport.requests import Request
from google.oauth2 import service_account
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
from youtube_transcript_api import YouTubeTranscriptApi # noqa: F401
except ImportError:
raise ImportError(
"You must run"
"`pip install --upgrade "
"google-api-python-client google-auth-httplib2 "
"google-auth-oauthlib"
"youtube-transcript-api`"
"to use the Google Drive loader"
)
creds = None
if self.service_account_path.exists():
return service_account.Credentials.from_service_account_file(
str(self.service_account_path)
)
if self.token_path.exists():
creds = Credentials.from_authorized_user_file(str(self.token_path), SCOPES)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(
str(self.credentials_path), SCOPES
)
creds = flow.run_local_server(port=0)
with open(self.token_path, "w") as token:
token.write(creds.to_json())
return creds
class YoutubeLoader(BaseLoader):
"""Loader that loads Youtube transcripts."""
def __init__(
self, video_id: str, add_video_info: bool = False, language: str = "en"
):
"""Initialize with YouTube video ID."""
self.video_id = video_id
self.add_video_info = add_video_info
self.language = language
@classmethod
def from_youtube_channel(cls, youtube_url: str, **kwargs: Any) -> YoutubeLoader:
"""Given a channel name, load all videos."""
video_id = youtube_url.split("youtube.com/watch?v=")[-1]
return cls(video_id, **kwargs)
def load(self) -> List[Document]:
"""Load documents."""
try:
from youtube_transcript_api import NoTranscriptFound, YouTubeTranscriptApi
except ImportError:
raise ImportError(
"Could not import youtube_transcript_api python package. "
"Please install it with `pip install youtube-transcript-api`."
)
metadata = {"source": self.video_id}
if self.add_video_info:
# Get more video meta info
# Such as title, description, thumbnail url, publish_date
video_info = self._get_video_info()
metadata.update(video_info)
transcript_list = YouTubeTranscriptApi.list_transcripts(self.video_id)
try:
transcript = transcript_list.find_transcript([self.language])
except NoTranscriptFound:
en_transcript = transcript_list.find_transcript(["en"])
transcript = en_transcript.translate(self.language)
transcript_pieces = transcript.fetch()
transcript = " ".join([t["text"].strip(" ") for t in transcript_pieces])
return [Document(page_content=transcript, metadata=metadata)]
def _get_video_info(self) -> dict:
"""Get important video information.
Components are:
- title
- description
- thumbnail url,
- publish_date
- channel_author
- and more.
"""
try:
from pytube import YouTube
except ImportError:
raise ImportError(
"Could not import pytube python package. "
"Please install it with `pip install pytube`."
)
yt = YouTube(f"https://www.youtube.com/watch?v={self.video_id}")
video_info = {
"title": yt.title,
"description": yt.description,
"view_count": yt.views,
"thumbnail_url": yt.thumbnail_url,
"publish_date": yt.publish_date,
"length": yt.length,
"author": yt.author,
}
return video_info
@dataclass
class GoogleApiYoutubeLoader(BaseLoader):
"""Loader that loads all Videos from a Channel
To use, you should have the ``googleapiclient,youtube_transcript_api``
python package installed.
As the service needs a google_api_client, you first have to initialize
the GoogleApiClient.
Additionally you have to either provide a channel name or a list of videoids
"https://developers.google.com/docs/api/quickstart/python"
Example:
.. code-block:: python
from langchain.document_loaders import GoogleApiClient
from langchain.document_loaders import GoogleApiYoutubeLoader
google_api_client = GoogleApiClient(
service_account_path=Path("path_to_your_sec_file.json")
)
loader = GoogleApiYoutubeLoader(
google_api_client=google_api_client,
channel_name = "CodeAesthetic"
)
load.load()
"""
google_api_client: GoogleApiClient
channel_name: Optional[str] = None
video_ids: Optional[List[str]] = None
add_video_info: bool = True
captions_language: str = "en"
def __post_init__(self) -> None:
self.youtube_client = self._build_youtube_client(self.google_api_client.creds)
def _build_youtube_client(self, creds: Any) -> Any:
try:
from googleapiclient.discovery import build
from youtube_transcript_api import YouTubeTranscriptApi # noqa: F401
except ImportError:
raise ImportError(
"You must run"
"`pip install --upgrade "
"google-api-python-client google-auth-httplib2 "
"google-auth-oauthlib"
"youtube-transcript-api`"
"to use the Google Drive loader"
)
return build("youtube", "v3", credentials=creds)
@root_validator
def validate_channel_or_videoIds_is_set(
cls, values: Dict[str, Any]
) -> Dict[str, Any]:
"""Validate that either folder_id or document_ids is set, but not both."""
if not values.get("channel_name") and not values.get("video_ids"):
raise ValueError("Must specify either channel_name or video_ids")
return values
def _get_transcripe_for_video_id(self, video_id: str) -> str:
from youtube_transcript_api import NoTranscriptFound, YouTubeTranscriptApi
transcript_list = YouTubeTranscriptApi.list_transcripts(self.video_ids)
try:
transcript = transcript_list.find_transcript([self.captions_language])
except NoTranscriptFound:
en_transcript = transcript_list.find_transcript(["en"])
transcript = en_transcript.translate(self.captions_language)
transcript_pieces = transcript.fetch()
return " ".join([t["text"].strip(" ") for t in transcript_pieces])
def _get_document_for_video_id(self, video_id: str, **kwargs: Any) -> Document:
captions = self._get_transcripe_for_video_id(video_id)
video_response = (
self.youtube_client.videos()
.list(
part="id,snippet",
id=video_id,
)
.execute()
)
return Document(
page_content=captions,
metadata=video_response.get("items")[0],
)
def _get_channel_id(self, channel_name: str) -> str:
request = self.youtube_client.search().list(
part="id",
q=channel_name,
type="channel",
maxResults=1, # we only need one result since channel names are unique
)
response = request.execute()
channel_id = response["items"][0]["id"]["channelId"]
return channel_id
def _get_document_for_channel(self, channel: str, **kwargs: Any) -> List[Document]:
channel_id = self._get_channel_id(channel)
request = self.youtube_client.search().list(
part="id,snippet",
channelId=channel_id,
maxResults=50, # adjust this value to retrieve more or fewer videos
)
video_ids = []
while request is not None:
response = request.execute()
# Add each video ID to the list
for item in response["items"]:
if not item["id"].get("videoId"):
continue
meta_data = {"videoId": item["id"]["videoId"]}
if self.add_video_info:
item["snippet"].pop("thumbnails")
meta_data.update(item["snippet"])
video_ids.append(
Document(
page_content=self._get_transcripe_for_video_id(
item["id"]["videoId"]
),
metadata=meta_data,
)
)
request = self.youtube_client.search().list_next(request, response)
return video_ids
def load(self) -> List[Document]:
"""Load documents."""
document_list = []
if self.channel_name:
document_list.extend(self._get_document_for_channel(self.channel_name))
elif self.video_ids:
document_list.extend(
[
self._get_document_for_video_id(video_id)
for video_id in self.video_ids
]
)
else:
raise ValueError("Must specify either channel_name or video_ids")
return document_list
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/output_parsers/fix.py | from __future__ import annotations
from typing import Any
from langchain.chains.llm import LLMChain
from langchain.output_parsers.prompts import NAIVE_FIX_PROMPT
from langchain.prompts.base import BasePromptTemplate
from langchain.schema import BaseLanguageModel, BaseOutputParser, OutputParserException
class OutputFixingParser(BaseOutputParser):
"""Wraps a parser and tries to fix parsing errors."""
parser: BaseOutputParser
retry_chain: LLMChain
@classmethod
def from_llm(
cls,
llm: BaseLanguageModel,
parser: BaseOutputParser,
prompt: BasePromptTemplate = NAIVE_FIX_PROMPT,
) -> OutputFixingParser:
chain = LLMChain(llm=llm, prompt=prompt)
return cls(parser=parser, retry_chain=chain)
def parse(self, completion: str) -> Any:
try:
parsed_completion = self.parser.parse(completion)
except OutputParserException as e:
new_completion = self.retry_chain.run(
instructions=self.parser.get_format_instructions(),
completion=completion,
error=repr(e),
)
parsed_completion = self.parser.parse(new_completion)
return parsed_completion
def get_format_instructions(self) -> str:
return self.parser.get_format_instructions()
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/output_parsers/pydantic.py | import json
import re
from typing import Any
from pydantic import BaseModel, ValidationError
from langchain.output_parsers.format_instructions import PYDANTIC_FORMAT_INSTRUCTIONS
from langchain.schema import BaseOutputParser, OutputParserException
class PydanticOutputParser(BaseOutputParser):
pydantic_object: Any
def parse(self, text: str) -> BaseModel:
try:
# Greedy search for 1st json candidate.
match = re.search(
"\{.*\}", text.strip(), re.MULTILINE | re.IGNORECASE | re.DOTALL
)
json_str = ""
if match:
json_str = match.group()
json_object = json.loads(json_str)
return self.pydantic_object.parse_obj(json_object)
except (json.JSONDecodeError, ValidationError) as e:
name = self.pydantic_object.__name__
msg = f"Failed to parse {name} from completion {text}. Got: {e}"
raise OutputParserException(msg)
def get_format_instructions(self) -> str:
schema = self.pydantic_object.schema()
# Remove extraneous fields.
reduced_schema = schema
if "title" in reduced_schema:
del reduced_schema["title"]
if "type" in reduced_schema:
del reduced_schema["type"]
# Ensure json in context is well-formed with double quotes.
schema = json.dumps(reduced_schema)
return PYDANTIC_FORMAT_INSTRUCTIONS.format(schema=schema)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/output_parsers/retry.py | from __future__ import annotations
from typing import Any
from langchain.chains.llm import LLMChain
from langchain.prompts.base import BasePromptTemplate
from langchain.prompts.prompt import PromptTemplate
from langchain.schema import (
BaseLanguageModel,
BaseOutputParser,
OutputParserException,
PromptValue,
)
NAIVE_COMPLETION_RETRY = """Prompt:
{prompt}
Completion:
{completion}
Above, the Completion did not satisfy the constraints given in the Prompt.
Please try again:"""
NAIVE_COMPLETION_RETRY_WITH_ERROR = """Prompt:
{prompt}
Completion:
{completion}
Above, the Completion did not satisfy the constraints given in the Prompt.
Details: {error}
Please try again:"""
NAIVE_RETRY_PROMPT = PromptTemplate.from_template(NAIVE_COMPLETION_RETRY)
NAIVE_RETRY_WITH_ERROR_PROMPT = PromptTemplate.from_template(
NAIVE_COMPLETION_RETRY_WITH_ERROR
)
class RetryOutputParser(BaseOutputParser):
"""Wraps a parser and tries to fix parsing errors.
Does this by passing the original prompt and the completion to another
LLM, and telling it the completion did not satisfy criteria in the prompt.
"""
parser: BaseOutputParser
retry_chain: LLMChain
@classmethod
def from_llm(
cls,
llm: BaseLanguageModel,
parser: BaseOutputParser,
prompt: BasePromptTemplate = NAIVE_RETRY_PROMPT,
) -> RetryOutputParser:
chain = LLMChain(llm=llm, prompt=prompt)
return cls(parser=parser, retry_chain=chain)
def parse_with_prompt(self, completion: str, prompt_value: PromptValue) -> Any:
try:
parsed_completion = self.parser.parse(completion)
except OutputParserException:
new_completion = self.retry_chain.run(
prompt=prompt_value.to_string(), completion=completion
)
parsed_completion = self.parser.parse(new_completion)
return parsed_completion
def parse(self, completion: str) -> Any:
raise NotImplementedError(
"This OutputParser can only be called by the `parse_with_prompt` method."
)
def get_format_instructions(self) -> str:
return self.parser.get_format_instructions()
class RetryWithErrorOutputParser(BaseOutputParser):
"""Wraps a parser and tries to fix parsing errors.
Does this by passing the original prompt, the completion, AND the error
that was raised to another language and telling it that the completion
did not work, and raised the given error. Differs from RetryOutputParser
in that this implementation provides the error that was raised back to the
LLM, which in theory should give it more information on how to fix it.
"""
parser: BaseOutputParser
retry_chain: LLMChain
@classmethod
def from_llm(
cls,
llm: BaseLanguageModel,
parser: BaseOutputParser,
prompt: BasePromptTemplate = NAIVE_RETRY_WITH_ERROR_PROMPT,
) -> RetryWithErrorOutputParser:
chain = LLMChain(llm=llm, prompt=prompt)
return cls(parser=parser, retry_chain=chain)
def parse_with_prompt(self, completion: str, prompt_value: PromptValue) -> Any:
try:
parsed_completion = self.parser.parse(completion)
except OutputParserException as e:
new_completion = self.retry_chain.run(
prompt=prompt_value.to_string(), completion=completion, error=repr(e)
)
parsed_completion = self.parser.parse(new_completion)
return parsed_completion
def parse(self, completion: str) -> Any:
raise NotImplementedError(
"This OutputParser can only be called by the `parse_with_prompt` method."
)
def get_format_instructions(self) -> str:
return self.parser.get_format_instructions()
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/output_parsers/structured.py | from __future__ import annotations
import json
from typing import List
from pydantic import BaseModel
from langchain.output_parsers.format_instructions import STRUCTURED_FORMAT_INSTRUCTIONS
from langchain.schema import BaseOutputParser, OutputParserException
line_template = '\t"{name}": {type} // {description}'
class ResponseSchema(BaseModel):
name: str
description: str
def _get_sub_string(schema: ResponseSchema) -> str:
return line_template.format(
name=schema.name, description=schema.description, type="string"
)
class StructuredOutputParser(BaseOutputParser):
response_schemas: List[ResponseSchema]
@classmethod
def from_response_schemas(
cls, response_schemas: List[ResponseSchema]
) -> StructuredOutputParser:
return cls(response_schemas=response_schemas)
def get_format_instructions(self) -> str:
schema_str = "\n".join(
[_get_sub_string(schema) for schema in self.response_schemas]
)
return STRUCTURED_FORMAT_INSTRUCTIONS.format(format=schema_str)
def parse(self, text: str) -> BaseModel:
json_string = text.split("```json")[1].strip().strip("```").strip()
try:
json_obj = json.loads(json_string)
except json.JSONDecodeError as e:
raise OutputParserException(f"Got invalid JSON object. Error: {e}")
for schema in self.response_schemas:
if schema.name not in json_obj:
raise OutputParserException(
f"Got invalid return object. Expected key `{schema.name}` "
f"to be present, but got {json_obj}"
)
return json_obj
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | langchain/schema.py | """Common schema objects."""
from __future__ import annotations
from abc import ABC, abstractmethod
from typing import Any, Dict, List, NamedTuple, Optional
from pydantic import BaseModel, Extra, Field, root_validator
def get_buffer_string(
messages: List[BaseMessage], human_prefix: str = "Human", ai_prefix: str = "AI"
) -> str:
"""Get buffer string of messages."""
string_messages = []
for m in messages:
if isinstance(m, HumanMessage):
role = human_prefix
elif isinstance(m, AIMessage):
role = ai_prefix
elif isinstance(m, SystemMessage):
role = "System"
elif isinstance(m, ChatMessage):
role = m.role
else:
raise ValueError(f"Got unsupported message type: {m}")
string_messages.append(f"{role}: {m.content}")
return "\n".join(string_messages)
class AgentAction(NamedTuple):
"""Agent's action to take."""
tool: str
tool_input: str
log: str
class AgentFinish(NamedTuple):
"""Agent's return value."""
return_values: dict
log: str
class Generation(BaseModel):
"""Output of a single generation."""
text: str
"""Generated text output."""
generation_info: Optional[Dict[str, Any]] = None
"""Raw generation info response from the provider"""
"""May include things like reason for finishing (e.g. in OpenAI)"""
# TODO: add log probs
class BaseMessage(BaseModel):
"""Message object."""
content: str
additional_kwargs: dict = Field(default_factory=dict)
@property
@abstractmethod
def type(self) -> str:
"""Type of the message, used for serialization."""
class HumanMessage(BaseMessage):
"""Type of message that is spoken by the human."""
@property
def type(self) -> str:
"""Type of the message, used for serialization."""
return "human"
class AIMessage(BaseMessage):
"""Type of message that is spoken by the AI."""
@property
def type(self) -> str:
"""Type of the message, used for serialization."""
return "ai"
class SystemMessage(BaseMessage):
"""Type of message that is a system message."""
@property
def type(self) -> str:
"""Type of the message, used for serialization."""
return "system"
class ChatMessage(BaseMessage):
"""Type of message with arbitrary speaker."""
role: str
@property
def type(self) -> str:
"""Type of the message, used for serialization."""
return "chat"
def _message_to_dict(message: BaseMessage) -> dict:
return {"type": message.type, "data": message.dict()}
def messages_to_dict(messages: List[BaseMessage]) -> List[dict]:
return [_message_to_dict(m) for m in messages]
def _message_from_dict(message: dict) -> BaseMessage:
_type = message["type"]
if _type == "human":
return HumanMessage(**message["data"])
elif _type == "ai":
return AIMessage(**message["data"])
elif _type == "system":
return SystemMessage(**message["data"])
elif _type == "chat":
return ChatMessage(**message["data"])
else:
raise ValueError(f"Got unexpected type: {_type}")
def messages_from_dict(messages: List[dict]) -> List[BaseMessage]:
return [_message_from_dict(m) for m in messages]
class ChatGeneration(Generation):
"""Output of a single generation."""
text = ""
message: BaseMessage
@root_validator
def set_text(cls, values: Dict[str, Any]) -> Dict[str, Any]:
values["text"] = values["message"].content
return values
class ChatResult(BaseModel):
"""Class that contains all relevant information for a Chat Result."""
generations: List[ChatGeneration]
"""List of the things generated."""
llm_output: Optional[dict] = None
"""For arbitrary LLM provider specific output."""
class LLMResult(BaseModel):
"""Class that contains all relevant information for an LLM Result."""
generations: List[List[Generation]]
"""List of the things generated. This is List[List[]] because
each input could have multiple generations."""
llm_output: Optional[dict] = None
"""For arbitrary LLM provider specific output."""
class PromptValue(BaseModel, ABC):
@abstractmethod
def to_string(self) -> str:
"""Return prompt as string."""
@abstractmethod
def to_messages(self) -> List[BaseMessage]:
"""Return prompt as messages."""
class BaseLanguageModel(BaseModel, ABC):
@abstractmethod
def generate_prompt(
self, prompts: List[PromptValue], stop: Optional[List[str]] = None
) -> LLMResult:
"""Take in a list of prompt values and return an LLMResult."""
@abstractmethod
async def agenerate_prompt(
self, prompts: List[PromptValue], stop: Optional[List[str]] = None
) -> LLMResult:
"""Take in a list of prompt values and return an LLMResult."""
def get_num_tokens(self, text: str) -> int:
"""Get the number of tokens present in the text."""
# TODO: this method may not be exact.
# TODO: this method may differ based on model (eg codex).
try:
from transformers import GPT2TokenizerFast
except ImportError:
raise ValueError(
"Could not import transformers python package. "
"This is needed in order to calculate get_num_tokens. "
"Please install it with `pip install transformers`."
)
# create a GPT-3 tokenizer instance
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
# tokenize the text using the GPT-3 tokenizer
tokenized_text = tokenizer.tokenize(text)
# calculate the number of tokens in the tokenized text
return len(tokenized_text)
def get_num_tokens_from_messages(self, messages: List[BaseMessage]) -> int:
"""Get the number of tokens in the message."""
return sum([self.get_num_tokens(get_buffer_string([m])) for m in messages])
class BaseMemory(BaseModel, ABC):
"""Base interface for memory in chains."""
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
@property
@abstractmethod
def memory_variables(self) -> List[str]:
"""Input keys this memory class will load dynamically."""
@abstractmethod
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
"""Return key-value pairs given the text input to the chain.
If None, return all memories
"""
@abstractmethod
def save_context(self, inputs: Dict[str, Any], outputs: Dict[str, str]) -> None:
"""Save the context of this model run to memory."""
@abstractmethod
def clear(self) -> None:
"""Clear memory contents."""
class BaseChatMessageHistory(ABC):
"""Base interface for chat message history
See `ChatMessageHistory` for default implementation.
"""
"""
Example:
.. code-block:: python
class FileChatMessageHistory(BaseChatMessageHistory):
storage_path: str
session_id: str
@property
def messages(self):
with open(os.path.join(storage_path, session_id), 'r:utf-8') as f:
messages = json.loads(f.read())
return messages_from_dict(messages)
def add_user_message(self, message: str):
message_ = HumanMessage(content=message)
messages = self.messages.append(_message_to_dict(_message))
with open(os.path.join(storage_path, session_id), 'w') as f:
json.dump(f, messages)
def add_ai_message(self, message: str):
message_ = AIMessage(content=message)
messages = self.messages.append(_message_to_dict(_message))
with open(os.path.join(storage_path, session_id), 'w') as f:
json.dump(f, messages)
def clear(self):
with open(os.path.join(storage_path, session_id), 'w') as f:
f.write("[]")
"""
messages: List[BaseMessage]
@abstractmethod
def add_user_message(self, message: str) -> None:
"""Add a user message to the store"""
@abstractmethod
def add_ai_message(self, message: str) -> None:
"""Add an AI message to the store"""
@abstractmethod
def clear(self) -> None:
"""Remove all messages from the store"""
class Document(BaseModel):
"""Interface for interacting with a document."""
page_content: str
metadata: dict = Field(default_factory=dict)
class BaseRetriever(ABC):
@abstractmethod
def get_relevant_documents(self, query: str) -> List[Document]:
"""Get documents relevant for a query.
Args:
query: string to find relevant documents for
Returns:
List of relevant documents
"""
@abstractmethod
async def aget_relevant_documents(self, query: str) -> List[Document]:
"""Get documents relevant for a query.
Args:
query: string to find relevant documents for
Returns:
List of relevant documents
"""
# For backwards compatibility
Memory = BaseMemory
class BaseOutputParser(BaseModel, ABC):
"""Class to parse the output of an LLM call.
Output parsers help structure language model responses.
"""
@abstractmethod
def parse(self, text: str) -> Any:
"""Parse the output of an LLM call.
A method which takes in a string (assumed output of language model )
and parses it into some structure.
Args:
text: output of language model
Returns:
structured output
"""
def parse_with_prompt(self, completion: str, prompt: PromptValue) -> Any:
"""Optional method to parse the output of an LLM call with a prompt.
The prompt is largely provided in the event the OutputParser wants
to retry or fix the output in some way, and needs information from
the prompt to do so.
Args:
completion: output of language model
prompt: prompt value
Returns:
structured output
"""
return self.parse(completion)
def get_format_instructions(self) -> str:
"""Instructions on how the LLM output should be formatted."""
raise NotImplementedError
@property
def _type(self) -> str:
"""Return the type key."""
raise NotImplementedError
def dict(self, **kwargs: Any) -> Dict:
"""Return dictionary representation of output parser."""
output_parser_dict = super().dict()
output_parser_dict["_type"] = self._type
return output_parser_dict
class OutputParserException(Exception):
"""Exception that output parsers should raise to signify a parsing error.
This exists to differentiate parsing errors from other code or execution errors
that also may arise inside the output parser. OutputParserExceptions will be
available to catch and handle in ways to fix the parsing error, while other
errors will be raised.
"""
pass
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | "2023-04-11T14:20:29Z" | python | "2023-04-12T16:12:20Z" | tests/unit_tests/output_parsers/test_pydantic_parser.py | """Test PydanticOutputParser"""
from enum import Enum
from typing import Optional
from pydantic import BaseModel, Field
from langchain.output_parsers.pydantic import PydanticOutputParser
from langchain.schema import OutputParserException
class Actions(Enum):
SEARCH = "Search"
CREATE = "Create"
UPDATE = "Update"
DELETE = "Delete"
class TestModel(BaseModel):
action: Actions = Field(description="Action to be performed")
action_input: str = Field(description="Input to be used in the action")
additional_fields: Optional[str] = Field(
description="Additional fields", default=None
)
DEF_RESULT = """{
"action": "Update",
"action_input": "The PydanticOutputParser class is powerful",
"additional_fields": null
}"""
# action 'update' with a lowercase 'u' to test schema validation failure.
DEF_RESULT_FAIL = """{
"action": "update",
"action_input": "The PydanticOutputParser class is powerful",
"additional_fields": null
}"""
DEF_EXPECTED_RESULT = TestModel(
action=Actions.UPDATE,
action_input="The PydanticOutputParser class is powerful",
additional_fields=None,
)
def test_pydantic_output_parser() -> None:
"""Test PydanticOutputParser."""
pydantic_parser = PydanticOutputParser(pydantic_object=TestModel)
result = pydantic_parser.parse(DEF_RESULT)
print("parse_result:", result)
assert DEF_EXPECTED_RESULT == result
def test_pydantic_output_parser_fail() -> None:
"""Test PydanticOutputParser where completion result fails schema validation."""
pydantic_parser = PydanticOutputParser(pydantic_object=TestModel)
try:
pydantic_parser.parse(DEF_RESULT_FAIL)
except OutputParserException as e:
print("parse_result:", e)
assert "Failed to parse TestModel from completion" in str(e)
else:
assert False, "Expected OutputParserException"
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,905 | Ignore files from `.gitignore` in Git loader | those files may be `node_modules` or `.pycache` files or sensitive env files, all of which should be ignored by default | https://github.com/langchain-ai/langchain/issues/2905 | https://github.com/langchain-ai/langchain/pull/2909 | 7ee87eb0c8df10315b45ebbddcad36a72b7fe7b9 | 66bef1d7ed17f00e7b554ca5413e336970489253 | "2023-04-14T17:08:38Z" | python | "2023-04-14T22:02:21Z" | langchain/document_loaders/git.py | import os
from typing import Callable, List, Optional
from langchain.docstore.document import Document
from langchain.document_loaders.base import BaseLoader
class GitLoader(BaseLoader):
"""Loads files from a Git repository into a list of documents.
Repository can be local on disk available at `repo_path`,
or remote at `clone_url` that will be cloned to `repo_path`.
Currently supports only text files.
Each document represents one file in the repository. The `path` points to
the local Git repository, and the `branch` specifies the branch to load
files from. By default, it loads from the `main` branch.
"""
def __init__(
self,
repo_path: str,
clone_url: Optional[str] = None,
branch: Optional[str] = "main",
file_filter: Optional[Callable[[str], bool]] = None,
):
self.repo_path = repo_path
self.clone_url = clone_url
self.branch = branch
self.file_filter = file_filter
def load(self) -> List[Document]:
try:
from git import Blob, Repo # type: ignore
except ImportError as ex:
raise ImportError(
"Could not import git python package. "
"Please install it with `pip install GitPython`."
) from ex
if not os.path.exists(self.repo_path) and self.clone_url is None:
raise ValueError(f"Path {self.repo_path} does not exist")
elif self.clone_url:
repo = Repo.clone_from(self.clone_url, self.repo_path)
repo.git.checkout(self.branch)
else:
repo = Repo(self.repo_path)
repo.git.checkout(self.branch)
docs: List[Document] = []
for item in repo.tree().traverse():
if not isinstance(item, Blob):
continue
file_path = os.path.join(self.repo_path, item.path)
# uses filter to skip files
if self.file_filter and not self.file_filter(file_path):
continue
rel_file_path = os.path.relpath(file_path, self.repo_path)
try:
with open(file_path, "rb") as f:
content = f.read()
file_type = os.path.splitext(item.name)[1]
# loads only text files
try:
text_content = content.decode("utf-8")
except UnicodeDecodeError:
continue
metadata = {
"file_path": rel_file_path,
"file_name": item.name,
"file_type": file_type,
}
doc = Document(page_content=text_content, metadata=metadata)
docs.append(doc)
except Exception as e:
print(f"Error reading file {file_path}: {e}")
return docs
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,842 | Add Annoy as VectorStore | Adds Annoy index as VectorStore: https://github.com/spotify/annoy
Annoy might be useful in situations where a "read only" vector store is required/sufficient.
context: https://discord.com/channels/1038097195422978059/1051632794427723827/1096089994168377354 | https://github.com/langchain-ai/langchain/issues/2842 | https://github.com/langchain-ai/langchain/pull/2939 | e12e00df12c6830cd267df18e96fda1ef8df6c7a | a9310a3e8b6781bdc8f64a379eb844f8c8154584 | "2023-04-13T17:10:45Z" | python | "2023-04-16T20:44:04Z" | docs/modules/indexes/vectorstores/examples/annoy.ipynb | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,842 | Add Annoy as VectorStore | Adds Annoy index as VectorStore: https://github.com/spotify/annoy
Annoy might be useful in situations where a "read only" vector store is required/sufficient.
context: https://discord.com/channels/1038097195422978059/1051632794427723827/1096089994168377354 | https://github.com/langchain-ai/langchain/issues/2842 | https://github.com/langchain-ai/langchain/pull/2939 | e12e00df12c6830cd267df18e96fda1ef8df6c7a | a9310a3e8b6781bdc8f64a379eb844f8c8154584 | "2023-04-13T17:10:45Z" | python | "2023-04-16T20:44:04Z" | langchain/vectorstores/__init__.py | """Wrappers on top of vector stores."""
from langchain.vectorstores.atlas import AtlasDB
from langchain.vectorstores.base import VectorStore
from langchain.vectorstores.chroma import Chroma
from langchain.vectorstores.deeplake import DeepLake
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores.faiss import FAISS
from langchain.vectorstores.milvus import Milvus
from langchain.vectorstores.opensearch_vector_search import OpenSearchVectorSearch
from langchain.vectorstores.pinecone import Pinecone
from langchain.vectorstores.qdrant import Qdrant
from langchain.vectorstores.weaviate import Weaviate
__all__ = [
"ElasticVectorSearch",
"FAISS",
"VectorStore",
"Pinecone",
"Weaviate",
"Qdrant",
"Milvus",
"Chroma",
"OpenSearchVectorSearch",
"AtlasDB",
"DeepLake",
]
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,842 | Add Annoy as VectorStore | Adds Annoy index as VectorStore: https://github.com/spotify/annoy
Annoy might be useful in situations where a "read only" vector store is required/sufficient.
context: https://discord.com/channels/1038097195422978059/1051632794427723827/1096089994168377354 | https://github.com/langchain-ai/langchain/issues/2842 | https://github.com/langchain-ai/langchain/pull/2939 | e12e00df12c6830cd267df18e96fda1ef8df6c7a | a9310a3e8b6781bdc8f64a379eb844f8c8154584 | "2023-04-13T17:10:45Z" | python | "2023-04-16T20:44:04Z" | langchain/vectorstores/annoy.py | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,842 | Add Annoy as VectorStore | Adds Annoy index as VectorStore: https://github.com/spotify/annoy
Annoy might be useful in situations where a "read only" vector store is required/sufficient.
context: https://discord.com/channels/1038097195422978059/1051632794427723827/1096089994168377354 | https://github.com/langchain-ai/langchain/issues/2842 | https://github.com/langchain-ai/langchain/pull/2939 | e12e00df12c6830cd267df18e96fda1ef8df6c7a | a9310a3e8b6781bdc8f64a379eb844f8c8154584 | "2023-04-13T17:10:45Z" | python | "2023-04-16T20:44:04Z" | tests/integration_tests/vectorstores/test_annoy.py | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,944 | Question Answering over Docs giving cryptic error upon query | After ingesting some markdown files using a slightly modified version of the question-answering over docs example, I ran the qa.py script as it was in the example
```
# qa.py
import faiss
from langchain import OpenAI, HuggingFaceHub, LLMChain
from langchain.chains import VectorDBQAWithSourcesChain
import pickle
import argparse
parser = argparse.ArgumentParser(description='Ask a question to the notion DB.')
parser.add_argument('question', type=str, help='The question to ask the notion DB')
args = parser.parse_args()
# Load the LangChain.
index = faiss.read_index("docs.index")
with open("faiss_store.pkl", "rb") as f:
store = pickle.load(f)
store.index = index
chain = VectorDBQAWithSourcesChain.from_llm(llm=OpenAI(temperature=0), vectorstore=store)
result = chain({"question": args.question})
print(f"Answer: {result['answer']}")
```
Only to get this cryptic error
```
Traceback (most recent call last):
File "C:\Users\ahmad\OneDrive\Desktop\Coding\LANGCHAINSSSSSS\notion-qa\qa.py", line 22, in <module>
result = chain({"question": args.question})
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 146, in __call__
raise e
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 142, in __call__
outputs = self._call(inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\qa_with_sources\base.py", line 97, in _call
answer, _ = self.combine_document_chain.combine_docs(docs, **inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\map_reduce.py", line 150, in combine_docs
num_tokens = length_func(result_docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 77, in prompt_length
inputs = self._get_inputs(docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 64, in _get_inputs
document_info = {
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 65, in <dictcomp>
k: base_info[k] for k in self.document_prompt.input_variables
KeyError: 'source'
```
Here is the code I used for ingesting
|
```
"""This is the logic for ingesting Notion data into LangChain."""
from pathlib import Path
from langchain.text_splitter import CharacterTextSplitter
import faiss
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
import pickle
import time
from tqdm import tqdm
# Here we load in the data in the format that Notion exports it in.
folder = list(Path("Notion_DB/").glob("**/*.md"))
files = []
sources = []
for myFile in folder:
with open(myFile, 'r', encoding='utf-8') as f:
print(myFile.name)
files.append(f.read())
sources.append(myFile)
# Here we split the documents, as needed, into smaller chunks.
# We do this due to the context limits of the LLMs.
text_splitter = CharacterTextSplitter(chunk_size=800, separator="\n")
docs = []
metadatas = []
for i, f in enumerate(files):
splits = text_splitter.split_text(f)
docs.extend(splits)
metadatas.extend([{"source": sources[i]}] * len(splits))
# Add each element in docs into FAISS store, keeping a delay between inserting elements so we don't exceed rate limit
store = None
for (index, chunk) in tqdm(enumerate(docs)):
if index == 0:
store = FAISS.from_texts([chunk], OpenAIEmbeddings())
else:
time.sleep(1) # wait for a second to not exceed any rate limits
store.add_texts([chunk])
# print('finished with index '+index.__str__())
print('Done yayy!')
# # Here we create a vector store from the documents and save it to disk.
faiss.write_index(store.index, "docs.index")
store.index = None
with open("faiss_store.pkl", "wb") as f:
pickle.dump(store, f)
```
| https://github.com/langchain-ai/langchain/issues/2944 | https://github.com/langchain-ai/langchain/pull/3026 | 3453b7457ca60227430d85e6f6f58a2aafae559d | 19c85aa9907765c0a2dbe7c46e9d5dd2d6df0f30 | "2023-04-15T15:38:36Z" | python | "2023-04-18T03:28:01Z" | langchain/chains/combine_documents/base.py | """Base interface for chains combining documents."""
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional, Tuple
from pydantic import Field
from langchain.chains.base import Chain
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter, TextSplitter
class BaseCombineDocumentsChain(Chain, ABC):
"""Base interface for chains combining documents."""
input_key: str = "input_documents" #: :meta private:
output_key: str = "output_text" #: :meta private:
@property
def input_keys(self) -> List[str]:
"""Expect input key.
:meta private:
"""
return [self.input_key]
@property
def output_keys(self) -> List[str]:
"""Return output key.
:meta private:
"""
return [self.output_key]
def prompt_length(self, docs: List[Document], **kwargs: Any) -> Optional[int]:
"""Return the prompt length given the documents passed in.
Returns None if the method does not depend on the prompt length.
"""
return None
@abstractmethod
def combine_docs(self, docs: List[Document], **kwargs: Any) -> Tuple[str, dict]:
"""Combine documents into a single string."""
@abstractmethod
async def acombine_docs(
self, docs: List[Document], **kwargs: Any
) -> Tuple[str, dict]:
"""Combine documents into a single string asynchronously."""
def _call(self, inputs: Dict[str, Any]) -> Dict[str, str]:
docs = inputs[self.input_key]
# Other keys are assumed to be needed for LLM prediction
other_keys = {k: v for k, v in inputs.items() if k != self.input_key}
output, extra_return_dict = self.combine_docs(docs, **other_keys)
extra_return_dict[self.output_key] = output
return extra_return_dict
async def _acall(self, inputs: Dict[str, Any]) -> Dict[str, str]:
docs = inputs[self.input_key]
# Other keys are assumed to be needed for LLM prediction
other_keys = {k: v for k, v in inputs.items() if k != self.input_key}
output, extra_return_dict = await self.acombine_docs(docs, **other_keys)
extra_return_dict[self.output_key] = output
return extra_return_dict
class AnalyzeDocumentChain(Chain):
"""Chain that splits documents, then analyzes it in pieces."""
input_key: str = "input_document" #: :meta private:
output_key: str = "output_text" #: :meta private:
text_splitter: TextSplitter = Field(default_factory=RecursiveCharacterTextSplitter)
combine_docs_chain: BaseCombineDocumentsChain
@property
def input_keys(self) -> List[str]:
"""Expect input key.
:meta private:
"""
return [self.input_key]
@property
def output_keys(self) -> List[str]:
"""Return output key.
:meta private:
"""
return [self.output_key]
def _call(self, inputs: Dict[str, Any]) -> Dict[str, str]:
document = inputs[self.input_key]
docs = self.text_splitter.create_documents([document])
# Other keys are assumed to be needed for LLM prediction
other_keys = {k: v for k, v in inputs.items() if k != self.input_key}
other_keys[self.combine_docs_chain.input_key] = docs
return self.combine_docs_chain(other_keys, return_only_outputs=True)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,944 | Question Answering over Docs giving cryptic error upon query | After ingesting some markdown files using a slightly modified version of the question-answering over docs example, I ran the qa.py script as it was in the example
```
# qa.py
import faiss
from langchain import OpenAI, HuggingFaceHub, LLMChain
from langchain.chains import VectorDBQAWithSourcesChain
import pickle
import argparse
parser = argparse.ArgumentParser(description='Ask a question to the notion DB.')
parser.add_argument('question', type=str, help='The question to ask the notion DB')
args = parser.parse_args()
# Load the LangChain.
index = faiss.read_index("docs.index")
with open("faiss_store.pkl", "rb") as f:
store = pickle.load(f)
store.index = index
chain = VectorDBQAWithSourcesChain.from_llm(llm=OpenAI(temperature=0), vectorstore=store)
result = chain({"question": args.question})
print(f"Answer: {result['answer']}")
```
Only to get this cryptic error
```
Traceback (most recent call last):
File "C:\Users\ahmad\OneDrive\Desktop\Coding\LANGCHAINSSSSSS\notion-qa\qa.py", line 22, in <module>
result = chain({"question": args.question})
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 146, in __call__
raise e
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 142, in __call__
outputs = self._call(inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\qa_with_sources\base.py", line 97, in _call
answer, _ = self.combine_document_chain.combine_docs(docs, **inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\map_reduce.py", line 150, in combine_docs
num_tokens = length_func(result_docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 77, in prompt_length
inputs = self._get_inputs(docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 64, in _get_inputs
document_info = {
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 65, in <dictcomp>
k: base_info[k] for k in self.document_prompt.input_variables
KeyError: 'source'
```
Here is the code I used for ingesting
|
```
"""This is the logic for ingesting Notion data into LangChain."""
from pathlib import Path
from langchain.text_splitter import CharacterTextSplitter
import faiss
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
import pickle
import time
from tqdm import tqdm
# Here we load in the data in the format that Notion exports it in.
folder = list(Path("Notion_DB/").glob("**/*.md"))
files = []
sources = []
for myFile in folder:
with open(myFile, 'r', encoding='utf-8') as f:
print(myFile.name)
files.append(f.read())
sources.append(myFile)
# Here we split the documents, as needed, into smaller chunks.
# We do this due to the context limits of the LLMs.
text_splitter = CharacterTextSplitter(chunk_size=800, separator="\n")
docs = []
metadatas = []
for i, f in enumerate(files):
splits = text_splitter.split_text(f)
docs.extend(splits)
metadatas.extend([{"source": sources[i]}] * len(splits))
# Add each element in docs into FAISS store, keeping a delay between inserting elements so we don't exceed rate limit
store = None
for (index, chunk) in tqdm(enumerate(docs)):
if index == 0:
store = FAISS.from_texts([chunk], OpenAIEmbeddings())
else:
time.sleep(1) # wait for a second to not exceed any rate limits
store.add_texts([chunk])
# print('finished with index '+index.__str__())
print('Done yayy!')
# # Here we create a vector store from the documents and save it to disk.
faiss.write_index(store.index, "docs.index")
store.index = None
with open("faiss_store.pkl", "wb") as f:
pickle.dump(store, f)
```
| https://github.com/langchain-ai/langchain/issues/2944 | https://github.com/langchain-ai/langchain/pull/3026 | 3453b7457ca60227430d85e6f6f58a2aafae559d | 19c85aa9907765c0a2dbe7c46e9d5dd2d6df0f30 | "2023-04-15T15:38:36Z" | python | "2023-04-18T03:28:01Z" | langchain/chains/combine_documents/refine.py | """Combining documents by doing a first pass and then refining on more documents."""
from __future__ import annotations
from typing import Any, Dict, List, Tuple
from pydantic import Extra, Field, root_validator
from langchain.chains.combine_documents.base import BaseCombineDocumentsChain
from langchain.chains.llm import LLMChain
from langchain.docstore.document import Document
from langchain.prompts.base import BasePromptTemplate
from langchain.prompts.prompt import PromptTemplate
def _get_default_document_prompt() -> PromptTemplate:
return PromptTemplate(input_variables=["page_content"], template="{page_content}")
class RefineDocumentsChain(BaseCombineDocumentsChain):
"""Combine documents by doing a first pass and then refining on more documents."""
initial_llm_chain: LLMChain
"""LLM chain to use on initial document."""
refine_llm_chain: LLMChain
"""LLM chain to use when refining."""
document_variable_name: str
"""The variable name in the initial_llm_chain to put the documents in.
If only one variable in the initial_llm_chain, this need not be provided."""
initial_response_name: str
"""The variable name to format the initial response in when refining."""
document_prompt: BasePromptTemplate = Field(
default_factory=_get_default_document_prompt
)
"""Prompt to use to format each document."""
return_intermediate_steps: bool = False
"""Return the results of the refine steps in the output."""
@property
def output_keys(self) -> List[str]:
"""Expect input key.
:meta private:
"""
_output_keys = super().output_keys
if self.return_intermediate_steps:
_output_keys = _output_keys + ["intermediate_steps"]
return _output_keys
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
@root_validator(pre=True)
def get_return_intermediate_steps(cls, values: Dict) -> Dict:
"""For backwards compatibility."""
if "return_refine_steps" in values:
values["return_intermediate_steps"] = values["return_refine_steps"]
del values["return_refine_steps"]
return values
@root_validator(pre=True)
def get_default_document_variable_name(cls, values: Dict) -> Dict:
"""Get default document variable name, if not provided."""
if "document_variable_name" not in values:
llm_chain_variables = values["initial_llm_chain"].prompt.input_variables
if len(llm_chain_variables) == 1:
values["document_variable_name"] = llm_chain_variables[0]
else:
raise ValueError(
"document_variable_name must be provided if there are "
"multiple llm_chain input_variables"
)
else:
llm_chain_variables = values["initial_llm_chain"].prompt.input_variables
if values["document_variable_name"] not in llm_chain_variables:
raise ValueError(
f"document_variable_name {values['document_variable_name']} was "
f"not found in llm_chain input_variables: {llm_chain_variables}"
)
return values
def combine_docs(self, docs: List[Document], **kwargs: Any) -> Tuple[str, dict]:
"""Combine by mapping first chain over all, then stuffing into final chain."""
inputs = self._construct_initial_inputs(docs, **kwargs)
res = self.initial_llm_chain.predict(**inputs)
refine_steps = [res]
for doc in docs[1:]:
base_inputs = self._construct_refine_inputs(doc, res)
inputs = {**base_inputs, **kwargs}
res = self.refine_llm_chain.predict(**inputs)
refine_steps.append(res)
return self._construct_result(refine_steps, res)
async def acombine_docs(
self, docs: List[Document], **kwargs: Any
) -> Tuple[str, dict]:
"""Combine by mapping first chain over all, then stuffing into final chain."""
inputs = self._construct_initial_inputs(docs, **kwargs)
res = await self.initial_llm_chain.apredict(**inputs)
refine_steps = [res]
for doc in docs[1:]:
base_inputs = self._construct_refine_inputs(doc, res)
inputs = {**base_inputs, **kwargs}
res = await self.refine_llm_chain.apredict(**inputs)
refine_steps.append(res)
return self._construct_result(refine_steps, res)
def _construct_result(self, refine_steps: List[str], res: str) -> Tuple[str, dict]:
if self.return_intermediate_steps:
extra_return_dict = {"intermediate_steps": refine_steps}
else:
extra_return_dict = {}
return res, extra_return_dict
def _construct_refine_inputs(self, doc: Document, res: str) -> Dict[str, Any]:
base_info = {"page_content": doc.page_content}
base_info.update(doc.metadata)
document_info = {k: base_info[k] for k in self.document_prompt.input_variables}
base_inputs = {
self.document_variable_name: self.document_prompt.format(**document_info),
self.initial_response_name: res,
}
return base_inputs
def _construct_initial_inputs(
self, docs: List[Document], **kwargs: Any
) -> Dict[str, Any]:
base_info = {"page_content": docs[0].page_content}
base_info.update(docs[0].metadata)
document_info = {k: base_info[k] for k in self.document_prompt.input_variables}
base_inputs: dict = {
self.document_variable_name: self.document_prompt.format(**document_info)
}
inputs = {**base_inputs, **kwargs}
return inputs
@property
def _chain_type(self) -> str:
return "refine_documents_chain"
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,944 | Question Answering over Docs giving cryptic error upon query | After ingesting some markdown files using a slightly modified version of the question-answering over docs example, I ran the qa.py script as it was in the example
```
# qa.py
import faiss
from langchain import OpenAI, HuggingFaceHub, LLMChain
from langchain.chains import VectorDBQAWithSourcesChain
import pickle
import argparse
parser = argparse.ArgumentParser(description='Ask a question to the notion DB.')
parser.add_argument('question', type=str, help='The question to ask the notion DB')
args = parser.parse_args()
# Load the LangChain.
index = faiss.read_index("docs.index")
with open("faiss_store.pkl", "rb") as f:
store = pickle.load(f)
store.index = index
chain = VectorDBQAWithSourcesChain.from_llm(llm=OpenAI(temperature=0), vectorstore=store)
result = chain({"question": args.question})
print(f"Answer: {result['answer']}")
```
Only to get this cryptic error
```
Traceback (most recent call last):
File "C:\Users\ahmad\OneDrive\Desktop\Coding\LANGCHAINSSSSSS\notion-qa\qa.py", line 22, in <module>
result = chain({"question": args.question})
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 146, in __call__
raise e
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 142, in __call__
outputs = self._call(inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\qa_with_sources\base.py", line 97, in _call
answer, _ = self.combine_document_chain.combine_docs(docs, **inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\map_reduce.py", line 150, in combine_docs
num_tokens = length_func(result_docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 77, in prompt_length
inputs = self._get_inputs(docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 64, in _get_inputs
document_info = {
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 65, in <dictcomp>
k: base_info[k] for k in self.document_prompt.input_variables
KeyError: 'source'
```
Here is the code I used for ingesting
|
```
"""This is the logic for ingesting Notion data into LangChain."""
from pathlib import Path
from langchain.text_splitter import CharacterTextSplitter
import faiss
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
import pickle
import time
from tqdm import tqdm
# Here we load in the data in the format that Notion exports it in.
folder = list(Path("Notion_DB/").glob("**/*.md"))
files = []
sources = []
for myFile in folder:
with open(myFile, 'r', encoding='utf-8') as f:
print(myFile.name)
files.append(f.read())
sources.append(myFile)
# Here we split the documents, as needed, into smaller chunks.
# We do this due to the context limits of the LLMs.
text_splitter = CharacterTextSplitter(chunk_size=800, separator="\n")
docs = []
metadatas = []
for i, f in enumerate(files):
splits = text_splitter.split_text(f)
docs.extend(splits)
metadatas.extend([{"source": sources[i]}] * len(splits))
# Add each element in docs into FAISS store, keeping a delay between inserting elements so we don't exceed rate limit
store = None
for (index, chunk) in tqdm(enumerate(docs)):
if index == 0:
store = FAISS.from_texts([chunk], OpenAIEmbeddings())
else:
time.sleep(1) # wait for a second to not exceed any rate limits
store.add_texts([chunk])
# print('finished with index '+index.__str__())
print('Done yayy!')
# # Here we create a vector store from the documents and save it to disk.
faiss.write_index(store.index, "docs.index")
store.index = None
with open("faiss_store.pkl", "wb") as f:
pickle.dump(store, f)
```
| https://github.com/langchain-ai/langchain/issues/2944 | https://github.com/langchain-ai/langchain/pull/3026 | 3453b7457ca60227430d85e6f6f58a2aafae559d | 19c85aa9907765c0a2dbe7c46e9d5dd2d6df0f30 | "2023-04-15T15:38:36Z" | python | "2023-04-18T03:28:01Z" | langchain/chains/combine_documents/stuff.py | """Chain that combines documents by stuffing into context."""
from typing import Any, Dict, List, Optional, Tuple
from pydantic import Extra, Field, root_validator
from langchain.chains.combine_documents.base import BaseCombineDocumentsChain
from langchain.chains.llm import LLMChain
from langchain.docstore.document import Document
from langchain.prompts.base import BasePromptTemplate
from langchain.prompts.prompt import PromptTemplate
def _get_default_document_prompt() -> PromptTemplate:
return PromptTemplate(input_variables=["page_content"], template="{page_content}")
class StuffDocumentsChain(BaseCombineDocumentsChain):
"""Chain that combines documents by stuffing into context."""
llm_chain: LLMChain
"""LLM wrapper to use after formatting documents."""
document_prompt: BasePromptTemplate = Field(
default_factory=_get_default_document_prompt
)
"""Prompt to use to format each document."""
document_variable_name: str
"""The variable name in the llm_chain to put the documents in.
If only one variable in the llm_chain, this need not be provided."""
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
@root_validator(pre=True)
def get_default_document_variable_name(cls, values: Dict) -> Dict:
"""Get default document variable name, if not provided."""
if "document_variable_name" not in values:
llm_chain_variables = values["llm_chain"].prompt.input_variables
if len(llm_chain_variables) == 1:
values["document_variable_name"] = llm_chain_variables[0]
else:
raise ValueError(
"document_variable_name must be provided if there are "
"multiple llm_chain_variables"
)
else:
llm_chain_variables = values["llm_chain"].prompt.input_variables
if values["document_variable_name"] not in llm_chain_variables:
raise ValueError(
f"document_variable_name {values['document_variable_name']} was "
f"not found in llm_chain input_variables: {llm_chain_variables}"
)
return values
def _get_inputs(self, docs: List[Document], **kwargs: Any) -> dict:
# Get relevant information from each document.
doc_dicts = []
for doc in docs:
base_info = {"page_content": doc.page_content}
base_info.update(doc.metadata)
document_info = {
k: base_info[k] for k in self.document_prompt.input_variables
}
doc_dicts.append(document_info)
# Format each document according to the prompt
doc_strings = [self.document_prompt.format(**doc) for doc in doc_dicts]
# Join the documents together to put them in the prompt.
inputs = {
k: v
for k, v in kwargs.items()
if k in self.llm_chain.prompt.input_variables
}
inputs[self.document_variable_name] = "\n\n".join(doc_strings)
return inputs
def prompt_length(self, docs: List[Document], **kwargs: Any) -> Optional[int]:
"""Get the prompt length by formatting the prompt."""
inputs = self._get_inputs(docs, **kwargs)
prompt = self.llm_chain.prompt.format(**inputs)
return self.llm_chain.llm.get_num_tokens(prompt)
def combine_docs(self, docs: List[Document], **kwargs: Any) -> Tuple[str, dict]:
"""Stuff all documents into one prompt and pass to LLM."""
inputs = self._get_inputs(docs, **kwargs)
# Call predict on the LLM.
return self.llm_chain.predict(**inputs), {}
async def acombine_docs(
self, docs: List[Document], **kwargs: Any
) -> Tuple[str, dict]:
"""Stuff all documents into one prompt and pass to LLM."""
inputs = self._get_inputs(docs, **kwargs)
# Call predict on the LLM.
return await self.llm_chain.apredict(**inputs), {}
@property
def _chain_type(self) -> str:
return "stuff_documents_chain"
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,944 | Question Answering over Docs giving cryptic error upon query | After ingesting some markdown files using a slightly modified version of the question-answering over docs example, I ran the qa.py script as it was in the example
```
# qa.py
import faiss
from langchain import OpenAI, HuggingFaceHub, LLMChain
from langchain.chains import VectorDBQAWithSourcesChain
import pickle
import argparse
parser = argparse.ArgumentParser(description='Ask a question to the notion DB.')
parser.add_argument('question', type=str, help='The question to ask the notion DB')
args = parser.parse_args()
# Load the LangChain.
index = faiss.read_index("docs.index")
with open("faiss_store.pkl", "rb") as f:
store = pickle.load(f)
store.index = index
chain = VectorDBQAWithSourcesChain.from_llm(llm=OpenAI(temperature=0), vectorstore=store)
result = chain({"question": args.question})
print(f"Answer: {result['answer']}")
```
Only to get this cryptic error
```
Traceback (most recent call last):
File "C:\Users\ahmad\OneDrive\Desktop\Coding\LANGCHAINSSSSSS\notion-qa\qa.py", line 22, in <module>
result = chain({"question": args.question})
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 146, in __call__
raise e
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 142, in __call__
outputs = self._call(inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\qa_with_sources\base.py", line 97, in _call
answer, _ = self.combine_document_chain.combine_docs(docs, **inputs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\map_reduce.py", line 150, in combine_docs
num_tokens = length_func(result_docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 77, in prompt_length
inputs = self._get_inputs(docs, **kwargs)
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 64, in _get_inputs
document_info = {
File "C:\Users\ahmad\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\combine_documents\stuff.py", line 65, in <dictcomp>
k: base_info[k] for k in self.document_prompt.input_variables
KeyError: 'source'
```
Here is the code I used for ingesting
|
```
"""This is the logic for ingesting Notion data into LangChain."""
from pathlib import Path
from langchain.text_splitter import CharacterTextSplitter
import faiss
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
import pickle
import time
from tqdm import tqdm
# Here we load in the data in the format that Notion exports it in.
folder = list(Path("Notion_DB/").glob("**/*.md"))
files = []
sources = []
for myFile in folder:
with open(myFile, 'r', encoding='utf-8') as f:
print(myFile.name)
files.append(f.read())
sources.append(myFile)
# Here we split the documents, as needed, into smaller chunks.
# We do this due to the context limits of the LLMs.
text_splitter = CharacterTextSplitter(chunk_size=800, separator="\n")
docs = []
metadatas = []
for i, f in enumerate(files):
splits = text_splitter.split_text(f)
docs.extend(splits)
metadatas.extend([{"source": sources[i]}] * len(splits))
# Add each element in docs into FAISS store, keeping a delay between inserting elements so we don't exceed rate limit
store = None
for (index, chunk) in tqdm(enumerate(docs)):
if index == 0:
store = FAISS.from_texts([chunk], OpenAIEmbeddings())
else:
time.sleep(1) # wait for a second to not exceed any rate limits
store.add_texts([chunk])
# print('finished with index '+index.__str__())
print('Done yayy!')
# # Here we create a vector store from the documents and save it to disk.
faiss.write_index(store.index, "docs.index")
store.index = None
with open("faiss_store.pkl", "wb") as f:
pickle.dump(store, f)
```
| https://github.com/langchain-ai/langchain/issues/2944 | https://github.com/langchain-ai/langchain/pull/3026 | 3453b7457ca60227430d85e6f6f58a2aafae559d | 19c85aa9907765c0a2dbe7c46e9d5dd2d6df0f30 | "2023-04-15T15:38:36Z" | python | "2023-04-18T03:28:01Z" | tests/unit_tests/chains/test_combine_documents.py | """Test functionality related to combining documents."""
from typing import Any, List
import pytest
from langchain.chains.combine_documents.map_reduce import (
_collapse_docs,
_split_list_of_docs,
)
from langchain.docstore.document import Document
def _fake_docs_len_func(docs: List[Document]) -> int:
return len(_fake_combine_docs_func(docs))
def _fake_combine_docs_func(docs: List[Document], **kwargs: Any) -> str:
return "".join([d.page_content for d in docs])
def test__split_list_long_single_doc() -> None:
"""Test splitting of a long single doc."""
docs = [Document(page_content="foo" * 100)]
with pytest.raises(ValueError):
_split_list_of_docs(docs, _fake_docs_len_func, 100)
def test__split_list_long_pair_doc() -> None:
"""Test splitting of a list with two medium docs."""
docs = [Document(page_content="foo" * 30)] * 2
with pytest.raises(ValueError):
_split_list_of_docs(docs, _fake_docs_len_func, 100)
def test__split_list_single_doc() -> None:
"""Test splitting works with just a single doc."""
docs = [Document(page_content="foo")]
doc_list = _split_list_of_docs(docs, _fake_docs_len_func, 100)
assert doc_list == [docs]
def test__split_list_double_doc() -> None:
"""Test splitting works with just two docs."""
docs = [Document(page_content="foo"), Document(page_content="bar")]
doc_list = _split_list_of_docs(docs, _fake_docs_len_func, 100)
assert doc_list == [docs]
def test__split_list_works_correctly() -> None:
"""Test splitting works correctly."""
docs = [
Document(page_content="foo"),
Document(page_content="bar"),
Document(page_content="baz"),
Document(page_content="foo" * 2),
Document(page_content="bar"),
Document(page_content="baz"),
]
doc_list = _split_list_of_docs(docs, _fake_docs_len_func, 10)
expected_result = [
# Test a group of three.
[
Document(page_content="foo"),
Document(page_content="bar"),
Document(page_content="baz"),
],
# Test a group of two, where one is bigger.
[Document(page_content="foo" * 2), Document(page_content="bar")],
# Test no errors on last
[Document(page_content="baz")],
]
assert doc_list == expected_result
def test__collapse_docs_no_metadata() -> None:
"""Test collapse documents functionality when no metadata."""
docs = [
Document(page_content="foo"),
Document(page_content="bar"),
Document(page_content="baz"),
]
output = _collapse_docs(docs, _fake_combine_docs_func)
expected_output = Document(page_content="foobarbaz")
assert output == expected_output
def test__collapse_docs_one_doc() -> None:
"""Test collapse documents functionality when only one document present."""
# Test with no metadata.
docs = [Document(page_content="foo")]
output = _collapse_docs(docs, _fake_combine_docs_func)
assert output == docs[0]
# Test with metadata.
docs = [Document(page_content="foo", metadata={"source": "a"})]
output = _collapse_docs(docs, _fake_combine_docs_func)
assert output == docs[0]
def test__collapse_docs_metadata() -> None:
"""Test collapse documents functionality when metadata exists."""
metadata1 = {"source": "a", "foo": 2, "bar": "1", "extra1": "foo"}
metadata2 = {"source": "b", "foo": "3", "bar": 2, "extra2": "bar"}
docs = [
Document(page_content="foo", metadata=metadata1),
Document(page_content="bar", metadata=metadata2),
]
output = _collapse_docs(docs, _fake_combine_docs_func)
expected_metadata = {
"source": "a, b",
"foo": "2, 3",
"bar": "1, 2",
"extra1": "foo",
"extra2": "bar",
}
expected_output = Document(page_content="foobar", metadata=expected_metadata)
assert output == expected_output
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,874 | Redundunt piece of code | In Agents -> loading.py on line 40 there is a redundant piece of code.
```
if config_type not in AGENT_TO_CLASS:
raise ValueError(f"Loading {config_type} agent not supported")
``` | https://github.com/langchain-ai/langchain/issues/2874 | https://github.com/langchain-ai/langchain/pull/2934 | b40f90ea042b20440cb7c1a9e70a6e4cd4a0089c | ae7ed31386c10cee1683419a4ab45562830bf8eb | "2023-04-14T05:28:42Z" | python | "2023-04-18T04:05:48Z" | langchain/agents/loading.py | """Functionality for loading agents."""
import json
from pathlib import Path
from typing import Any, Dict, List, Optional, Type, Union
import yaml
from langchain.agents.agent import BaseSingleActionAgent
from langchain.agents.agent_types import AgentType
from langchain.agents.chat.base import ChatAgent
from langchain.agents.conversational.base import ConversationalAgent
from langchain.agents.conversational_chat.base import ConversationalChatAgent
from langchain.agents.mrkl.base import ZeroShotAgent
from langchain.agents.react.base import ReActDocstoreAgent
from langchain.agents.self_ask_with_search.base import SelfAskWithSearchAgent
from langchain.agents.tools import Tool
from langchain.chains.loading import load_chain, load_chain_from_config
from langchain.llms.base import BaseLLM
from langchain.utilities.loading import try_load_from_hub
AGENT_TO_CLASS: Dict[AgentType, Type[BaseSingleActionAgent]] = {
AgentType.ZERO_SHOT_REACT_DESCRIPTION: ZeroShotAgent,
AgentType.REACT_DOCSTORE: ReActDocstoreAgent,
AgentType.SELF_ASK_WITH_SEARCH: SelfAskWithSearchAgent,
AgentType.CONVERSATIONAL_REACT_DESCRIPTION: ConversationalAgent,
AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION: ChatAgent,
AgentType.CHAT_CONVERSATIONAL_REACT_DESCRIPTION: ConversationalChatAgent,
}
URL_BASE = "https://raw.githubusercontent.com/hwchase17/langchain-hub/master/agents/"
def _load_agent_from_tools(
config: dict, llm: BaseLLM, tools: List[Tool], **kwargs: Any
) -> BaseSingleActionAgent:
config_type = config.pop("_type")
if config_type not in AGENT_TO_CLASS:
raise ValueError(f"Loading {config_type} agent not supported")
if config_type not in AGENT_TO_CLASS:
raise ValueError(f"Loading {config_type} agent not supported")
agent_cls = AGENT_TO_CLASS[config_type]
combined_config = {**config, **kwargs}
return agent_cls.from_llm_and_tools(llm, tools, **combined_config)
def load_agent_from_config(
config: dict,
llm: Optional[BaseLLM] = None,
tools: Optional[List[Tool]] = None,
**kwargs: Any,
) -> BaseSingleActionAgent:
"""Load agent from Config Dict."""
if "_type" not in config:
raise ValueError("Must specify an agent Type in config")
load_from_tools = config.pop("load_from_llm_and_tools", False)
if load_from_tools:
if llm is None:
raise ValueError(
"If `load_from_llm_and_tools` is set to True, "
"then LLM must be provided"
)
if tools is None:
raise ValueError(
"If `load_from_llm_and_tools` is set to True, "
"then tools must be provided"
)
return _load_agent_from_tools(config, llm, tools, **kwargs)
config_type = config.pop("_type")
if config_type not in AGENT_TO_CLASS:
raise ValueError(f"Loading {config_type} agent not supported")
agent_cls = AGENT_TO_CLASS[config_type]
if "llm_chain" in config:
config["llm_chain"] = load_chain_from_config(config.pop("llm_chain"))
elif "llm_chain_path" in config:
config["llm_chain"] = load_chain(config.pop("llm_chain_path"))
else:
raise ValueError("One of `llm_chain` and `llm_chain_path` should be specified.")
combined_config = {**config, **kwargs}
return agent_cls(**combined_config) # type: ignore
def load_agent(path: Union[str, Path], **kwargs: Any) -> BaseSingleActionAgent:
"""Unified method for loading a agent from LangChainHub or local fs."""
if hub_result := try_load_from_hub(
path, _load_agent_from_file, "agents", {"json", "yaml"}
):
return hub_result
else:
return _load_agent_from_file(path, **kwargs)
def _load_agent_from_file(
file: Union[str, Path], **kwargs: Any
) -> BaseSingleActionAgent:
"""Load agent from file."""
# Convert file to Path object.
if isinstance(file, str):
file_path = Path(file)
else:
file_path = file
# Load from either json or yaml.
if file_path.suffix == ".json":
with open(file_path) as f:
config = json.load(f)
elif file_path.suffix == ".yaml":
with open(file_path, "r") as f:
config = yaml.safe_load(f)
else:
raise ValueError("File type must be json or yaml")
# Load the agent from the config now.
return load_agent_from_config(config, **kwargs)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,057 | Error when parsing code from LLM response ValueError: Could not parse LLM output: | Sometimes the LLM response (generated code) tends to miss the ending ticks "```". Therefore causing the text parsing to fail due to `not enough values to unpack`.
Suggest to simply the `_, action, _' to just `action` then with index
Error message below
```
> Entering new AgentExecutor chain...
Traceback (most recent call last):
File "E:\open_source_contrib\langchain-venv\lib\site-packages\langchain\agents\chat\output_parser.py", line 17, in parse
_, action, _ = text.split("```")
ValueError: not enough values to unpack (expected 3, got 2)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "E:\open_source_contrib\test.py", line 67, in <module>
agent_msg = agent.run(prompt_template)
File "E:\open_source_contrib\langchain-venv\lib\site-packages\langchain\chains\base.py", line 213, in run
return self(args[0])[self.output_keys[0]]
File "E:\open_source_contrib\langchain-venv\lib\site-packages\langchain\chains\base.py", line 116, in __call__
raise e
File "E:\open_source_contrib\langchain-venv\lib\site-packages\langchain\chains\base.py", line 113, in __call__
outputs = self._call(inputs)
File "E:\open_source_contrib\langchain-venv\lib\site-packages\langchain\agents\agent.py", line 792, in _call
next_step_output = self._take_next_step(
File "E:\open_source_contrib\langchain-venv\lib\site-packages\langchain\agents\agent.py", line 672, in _take_next_step
output = self.agent.plan(intermediate_steps, **inputs)
File "E:\open_source_contrib\langchain-venv\lib\site-packages\langchain\agents\agent.py", line 385, in plan
return self.output_parser.parse(full_output)
File "E:\open_source_contrib\langchain-venv\lib\site-packages\langchain\agents\chat\output_parser.py", line 23, in parse
raise ValueError(f"Could not parse LLM output: {text}")
ValueError: Could not parse LLM output: Question: How do I put the given data into a pandas dataframe and save it into a csv file at the specified path?
Thought: I need to use the Python REPL tool to import pandas, create a dataframe with the given data, and then use the to_csv method to save it to the specified file path.
Action:
```
{
"action": "Python REPL",
"action_input": "import pandas as pd\n\n# create dataframe\ndata = {\n 'Quarter': ['Q4-2021', 'Q1-2022', 'Q2-2022', 'Q3-2022', 'Q4-2022'],\n 'EPS attributable to common stockholders, diluted (GAAP)': [1.07, 0.95, 0.76, 0.95, 1.07],\n 'EPS attributable to common stockholders, diluted (non-GAAP)': [1.19, 1.05, 0.85, 1.05, 1.19]\n}\ndf = pd.DataFrame(data)\n\n# save to csv\ndf.to_csv('E:\\\\open_source_contrib\\\\output\\\\agent_output.xlsx', index=False)"
}
(langchain-venv) PS E:\open_source_contrib>
``` | https://github.com/langchain-ai/langchain/issues/3057 | https://github.com/langchain-ai/langchain/pull/3058 | db968284f8f3964630f119c95cca923f112ad47b | 2984ad39645c80411cee5e7f77a3c116b88d008e | "2023-04-18T04:13:20Z" | python | "2023-04-18T04:42:13Z" | langchain/agents/chat/output_parser.py | import json
from typing import Union
from langchain.agents.agent import AgentOutputParser
from langchain.schema import AgentAction, AgentFinish
FINAL_ANSWER_ACTION = "Final Answer:"
class ChatOutputParser(AgentOutputParser):
def parse(self, text: str) -> Union[AgentAction, AgentFinish]:
if FINAL_ANSWER_ACTION in text:
return AgentFinish(
{"output": text.split(FINAL_ANSWER_ACTION)[-1].strip()}, text
)
try:
_, action, _ = text.split("```")
response = json.loads(action.strip())
return AgentAction(response["action"], response["action_input"], text)
except Exception:
raise ValueError(f"Could not parse LLM output: {text}")
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,157 | Missing Observation and Thought prefix in output | The console output when running a tool is missing the "Observation" and "Thought" prefixes.
I noticed this when using the SQL Toolkit, but other tools are likely affected.
Here is the current INCORRECT output format:
```
> Entering new AgentExecutor chain...
Action: list_tables_sql_db
Action Input: ""invoice_items, invoices, tracks, sqlite_sequence, employees, media_types, sqlite_stat1, customers, playlists, playlist_track, albums, genres, artistsThere is a table called "employees" that I can query.
Action: schema_sql_db
Action Input: "employees"
```
Here is the expected output format:
```
> Entering new AgentExecutor chain...
Action: list_tables_sql_db
Action Input: ""
Observation: invoice_items, invoices, tracks, sqlite_sequence, employees, media_types, sqlite_stat1, customers, playlists, playlist_track, albums, genres, artists
Thought:There is a table called "employees" that I can query.
Action: schema_sql_db
Action Input: "employees"
```
Note: this appears to only affect the console output. The `agent_scratchpad` is updated correctly with the "Observation" and "Thought" prefixes. | https://github.com/langchain-ai/langchain/issues/3157 | https://github.com/langchain-ai/langchain/pull/3158 | 126d7f11dd17a8ea71a4427951f10cefc862ba3a | 0b542661b46d42ee501c6681a4519f2c4e76de23 | "2023-04-19T15:15:26Z" | python | "2023-04-19T16:00:10Z" | langchain/tools/base.py | """Base implementation for tools or skills."""
from abc import ABC, abstractmethod
from inspect import signature
from typing import Any, Dict, Optional, Sequence, Tuple, Type, Union
from pydantic import BaseModel, Extra, Field, validate_arguments, validator
from langchain.callbacks import get_callback_manager
from langchain.callbacks.base import BaseCallbackManager
def _to_args_and_kwargs(run_input: Union[str, Dict]) -> Tuple[Sequence, dict]:
# For backwards compatability, if run_input is a string,
# pass as a positional argument.
if isinstance(run_input, str):
return (run_input,), {}
else:
return [], run_input
class BaseTool(ABC, BaseModel):
"""Interface LangChain tools must implement."""
name: str
description: str
args_schema: Optional[Type[BaseModel]] = None
"""Pydantic model class to validate and parse the tool's input arguments."""
return_direct: bool = False
verbose: bool = False
callback_manager: BaseCallbackManager = Field(default_factory=get_callback_manager)
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
@property
def args(self) -> dict:
if self.args_schema is not None:
return self.args_schema.schema()["properties"]
else:
inferred_model = validate_arguments(self._run).model # type: ignore
schema = inferred_model.schema()["properties"]
valid_keys = signature(self._run).parameters
return {k: schema[k] for k in valid_keys}
def _parse_input(
self,
tool_input: Union[str, Dict],
) -> None:
"""Convert tool input to pydantic model."""
input_args = self.args_schema
if isinstance(tool_input, str):
if input_args is not None:
key_ = next(iter(input_args.__fields__.keys()))
input_args.validate({key_: tool_input})
else:
if input_args is not None:
input_args.validate(tool_input)
@validator("callback_manager", pre=True, always=True)
def set_callback_manager(
cls, callback_manager: Optional[BaseCallbackManager]
) -> BaseCallbackManager:
"""If callback manager is None, set it.
This allows users to pass in None as callback manager, which is a nice UX.
"""
return callback_manager or get_callback_manager()
@abstractmethod
def _run(self, *args: Any, **kwargs: Any) -> str:
"""Use the tool."""
@abstractmethod
async def _arun(self, *args: Any, **kwargs: Any) -> str:
"""Use the tool asynchronously."""
def run(
self,
tool_input: Union[str, Dict],
verbose: Optional[bool] = None,
start_color: Optional[str] = "green",
color: Optional[str] = "green",
**kwargs: Any,
) -> str:
"""Run the tool."""
self._parse_input(tool_input)
if not self.verbose and verbose is not None:
verbose_ = verbose
else:
verbose_ = self.verbose
self.callback_manager.on_tool_start(
{"name": self.name, "description": self.description},
tool_input if isinstance(tool_input, str) else str(tool_input),
verbose=verbose_,
color=start_color,
**kwargs,
)
try:
args, kwargs = _to_args_and_kwargs(tool_input)
observation = self._run(*args, **kwargs)
except (Exception, KeyboardInterrupt) as e:
self.callback_manager.on_tool_error(e, verbose=verbose_)
raise e
self.callback_manager.on_tool_end(
observation, verbose=verbose_, color=color, name=self.name, **kwargs
)
return observation
async def arun(
self,
tool_input: Union[str, Dict],
verbose: Optional[bool] = None,
start_color: Optional[str] = "green",
color: Optional[str] = "green",
**kwargs: Any,
) -> str:
"""Run the tool asynchronously."""
self._parse_input(tool_input)
if not self.verbose and verbose is not None:
verbose_ = verbose
else:
verbose_ = self.verbose
if self.callback_manager.is_async:
await self.callback_manager.on_tool_start(
{"name": self.name, "description": self.description},
tool_input if isinstance(tool_input, str) else str(tool_input),
verbose=verbose_,
color=start_color,
**kwargs,
)
else:
self.callback_manager.on_tool_start(
{"name": self.name, "description": self.description},
tool_input if isinstance(tool_input, str) else str(tool_input),
verbose=verbose_,
color=start_color,
**kwargs,
)
try:
# We then call the tool on the tool input to get an observation
args, kwargs = _to_args_and_kwargs(tool_input)
observation = await self._arun(*args, **kwargs)
except (Exception, KeyboardInterrupt) as e:
if self.callback_manager.is_async:
await self.callback_manager.on_tool_error(e, verbose=verbose_)
else:
self.callback_manager.on_tool_error(e, verbose=verbose_)
raise e
if self.callback_manager.is_async:
await self.callback_manager.on_tool_end(
observation, verbose=verbose_, color=color, name=self.name, **kwargs
)
else:
self.callback_manager.on_tool_end(
observation, verbose=verbose_, color=color, name=self.name, **kwargs
)
return observation
def __call__(self, tool_input: str) -> str:
"""Make tool callable."""
return self.run(tool_input)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,077 | Error `can only concatenate str (not "tuple") to str` when using `ConversationBufferWindowMemory` | I'm facing a weird issue with the `ConversationBufferWindowMemory`
Running `memory.load_memory_variables({})` prints:
```
{'chat_history': [HumanMessage(content='Hi my name is Ismail', additional_kwargs={}), AIMessage(content='Hello Ismail! How can I assist you today?', additional_kwargs={})]}
```
The error I get after sending a second message to the chain is:
```
> Entering new ConversationalRetrievalChain chain...
[2023-04-18 10:34:52,512] ERROR in app: Exception on /api/v1/chat [POST]
Traceback (most recent call last):
File "/Users/homanp/Projects/ADGPT_ENV/lib/python3.9/site-packages/flask/app.py", line 2528, in wsgi_app
response = self.full_dispatch_request()
File "/Users/homanp/Projects/ADGPT_ENV/lib/python3.9/site-packages/flask/app.py", line 1825, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/Users/homanp/Projects/ADGPT_ENV/lib/python3.9/site-packages/flask/app.py", line 1823, in full_dispatch_request
rv = self.dispatch_request()
File "/Users/homanp/Projects/ADGPT_ENV/lib/python3.9/site-packages/flask/app.py", line 1799, in dispatch_request
return self.ensure_sync(self.view_functions[rule.endpoint])(**view_args)
File "/Users/homanp/Projects/ad-gpt/app.py", line 46, in chat
result = chain({"question": message, "chat_history": []})
File "/Users/homanp/Projects/ADGPT_ENV/lib/python3.9/site-packages/langchain/chains/base.py", line 116, in __call__
raise e
File "/Users/homanp/Projects/ADGPT_ENV/lib/python3.9/site-packages/langchain/chains/base.py", line 113, in __call__
outputs = self._call(inputs)
File "/Users/homanp/Projects/ADGPT_ENV/lib/python3.9/site-packages/langchain/chains/conversational_retrieval/base.py", line 71, in _call
chat_history_str = get_chat_history(inputs["chat_history"])
File "/Users/homanp/Projects/ADGPT_ENV/lib/python3.9/site-packages/langchain/chains/conversational_retrieval/base.py", line 25, in _get_chat_history
human = "Human: " + human_s
TypeError: can only concatenate str (not "tuple") to str
```
Current implementaion:
```
memory = ConversationBufferWindowMemory(memory_key='chat_history', k=2, return_messages=True)
chain = ConversationalRetrievalChain.from_llm(model,
memory=memory,
verbose=True,
retriever=retriever,
qa_prompt=QA_PROMPT,
condense_question_prompt=CONDENSE_QUESTION_PROMPT,)
``` | https://github.com/langchain-ai/langchain/issues/3077 | https://github.com/langchain-ai/langchain/pull/3187 | 6adf2d1c39ca4e157377f20d3029d062342093e6 | c757c3cde45a24e0cd6a3ebe6bb0f8176cae4726 | "2023-04-18T08:38:57Z" | python | "2023-04-20T00:08:10Z" | docs/modules/models/llms/integrations/huggingface_hub.ipynb | {
"cells": [
{
"cell_type": "markdown",
"id": "959300d4",
"metadata": {},
"source": [
"# Hugging Face Hub\n",
"\n",
"The [Hugging Face Hub](https://huggingface.co/docs/hub/index) is a platform with over 120k models, 20k datasets, and 50k demo apps (Spaces), all open source and publicly available, in an online platform where people can easily collaborate and build ML together.\n",
"\n",
"This example showcases how to connect to the Hugging Face Hub."
]
},
{
"cell_type": "markdown",
"id": "4c1b8450-5eaf-4d34-8341-2d785448a1ff",
"metadata": {
"tags": []
},
"source": [
"To use, you should have the ``huggingface_hub`` python [package installed](https://huggingface.co/docs/huggingface_hub/installation)."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "d772b637-de00-4663-bd77-9bc96d798db2",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"!pip install huggingface_hub"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "d597a792-354c-4ca5-b483-5965eec5d63d",
"metadata": {},
"outputs": [],
"source": [
"# get a token: https://huggingface.co/docs/api-inference/quicktour#get-your-api-token\n",
"\n",
"from getpass import getpass\n",
"\n",
"HUGGINGFACEHUB_API_TOKEN = getpass()"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "b8c5b88c-e4b8-4d0d-9a35-6e8f106452c2",
"metadata": {},
"outputs": [],
"source": [
"os.environ[\"HUGGINGFACEHUB_API_TOKEN\"] = HUGGINGFACEHUB_API_TOKEN"
]
},
{
"cell_type": "code",
"execution_count": 41,
"id": "3acf0069",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"The FIFA World Cup is a football tournament that is played every 4 years. The year 1994 was the 44th FIFA World Cup. The final answer: Brazil.\n"
]
}
],
"source": [
"from langchain import PromptTemplate, HuggingFaceHub, LLMChain\n",
"\n",
"template = \"\"\"Question: {question}\n",
"\n",
"Answer: Let's think step by step.\"\"\"\n",
"prompt = PromptTemplate(template=template, input_variables=[\"question\"])\n",
"llm_chain = LLMChain(prompt=prompt, llm=HuggingFaceHub(repo_id=\"google/flan-t5-xl\", model_kwargs={\"temperature\":0, \"max_length\":64}))\n",
"\n",
"question = \"Who won the FIFA World Cup in the year 1994? \"\n",
"\n",
"print(llm_chain.run(question))"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "843a3837",
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.6"
}
},
"nbformat": 4,
"nbformat_minor": 5
}
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,077 | Error `can only concatenate str (not "tuple") to str` when using `ConversationBufferWindowMemory` | I'm facing a weird issue with the `ConversationBufferWindowMemory`
Running `memory.load_memory_variables({})` prints:
```
{'chat_history': [HumanMessage(content='Hi my name is Ismail', additional_kwargs={}), AIMessage(content='Hello Ismail! How can I assist you today?', additional_kwargs={})]}
```
The error I get after sending a second message to the chain is:
```
> Entering new ConversationalRetrievalChain chain...
[2023-04-18 10:34:52,512] ERROR in app: Exception on /api/v1/chat [POST]
Traceback (most recent call last):
File "/Users/homanp/Projects/ADGPT_ENV/lib/python3.9/site-packages/flask/app.py", line 2528, in wsgi_app
response = self.full_dispatch_request()
File "/Users/homanp/Projects/ADGPT_ENV/lib/python3.9/site-packages/flask/app.py", line 1825, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/Users/homanp/Projects/ADGPT_ENV/lib/python3.9/site-packages/flask/app.py", line 1823, in full_dispatch_request
rv = self.dispatch_request()
File "/Users/homanp/Projects/ADGPT_ENV/lib/python3.9/site-packages/flask/app.py", line 1799, in dispatch_request
return self.ensure_sync(self.view_functions[rule.endpoint])(**view_args)
File "/Users/homanp/Projects/ad-gpt/app.py", line 46, in chat
result = chain({"question": message, "chat_history": []})
File "/Users/homanp/Projects/ADGPT_ENV/lib/python3.9/site-packages/langchain/chains/base.py", line 116, in __call__
raise e
File "/Users/homanp/Projects/ADGPT_ENV/lib/python3.9/site-packages/langchain/chains/base.py", line 113, in __call__
outputs = self._call(inputs)
File "/Users/homanp/Projects/ADGPT_ENV/lib/python3.9/site-packages/langchain/chains/conversational_retrieval/base.py", line 71, in _call
chat_history_str = get_chat_history(inputs["chat_history"])
File "/Users/homanp/Projects/ADGPT_ENV/lib/python3.9/site-packages/langchain/chains/conversational_retrieval/base.py", line 25, in _get_chat_history
human = "Human: " + human_s
TypeError: can only concatenate str (not "tuple") to str
```
Current implementaion:
```
memory = ConversationBufferWindowMemory(memory_key='chat_history', k=2, return_messages=True)
chain = ConversationalRetrievalChain.from_llm(model,
memory=memory,
verbose=True,
retriever=retriever,
qa_prompt=QA_PROMPT,
condense_question_prompt=CONDENSE_QUESTION_PROMPT,)
``` | https://github.com/langchain-ai/langchain/issues/3077 | https://github.com/langchain-ai/langchain/pull/3187 | 6adf2d1c39ca4e157377f20d3029d062342093e6 | c757c3cde45a24e0cd6a3ebe6bb0f8176cae4726 | "2023-04-18T08:38:57Z" | python | "2023-04-20T00:08:10Z" | docs/modules/models/llms/integrations/huggingface_pipelines.ipynb | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,301 | Output using llamacpp is garbage | Hi there,
Trying to setup a langchain with llamacpp as a first step to use langchain offline:
`from langchain.llms import LlamaCpp
llm = LlamaCpp(model_path="../llama/models/ggml-vicuna-13b-4bit-rev1.bin")
text = "Question: What NFL team won the Super Bowl in the year Justin Bieber was born? Answer: Let's think step by step."
print(llm(text))`
The result is:
`Plenement that whciation - if a praged and as Work 1 -- but a nice bagingrading per 1, In Homewooded ETenscent is the 0sm toth, ECORO Efph at as an outs! ce, found unprint this a PC, Thom. The RxR-1 dot emD In Not OslKNOT
The Home On-a-a-a-aEOEfa-a-aP E. NOT, hotness of-aEF and Life in better-A (resondri Euler, rsa! Home WI Retection and O no-aL25 1 fate to Hosp doubate, p. T, this guiltEisenR-getus WEFI, duro as these disksada Tl.Eis-aRDA* plantly-aRing the Prospecttypen`
Running the same question using llama_cpp_python with the same model bin file, the result is (allthough wrong, correctly formatted):
`{
"id": "cmpl-d64b69f6-cd50-41e9-8d1c-25b1a5859fac",
"object": "text_completion",
"created": 1682085552,
"model": "./models/ggml-alpaca-7b-native-q4.bin",
"choices": [
{
"text": "Question: What NFL team won the Super Bowl in the year Justin Bieber was born? Answer: Let's think step by step. Justin was born in 1985, so he was born in the same year as the Super Bowl victory of the Chicago Bears in 1986. So, the answer is the Chicago Bears!",
"index": 0,
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 32,
"completion_tokens": 45,
"total_tokens": 77
}
}`
What could be the issue, encoding/decoding? | https://github.com/langchain-ai/langchain/issues/3301 | https://github.com/langchain-ai/langchain/pull/3320 | 3a1bdce3f51e302d468807e980455d676c0f5fd6 | 77bb6c99f7ee189ce3734c47b27e70dc237bbce7 | "2023-04-21T14:01:59Z" | python | "2023-04-23T01:46:55Z" | langchain/llms/llamacpp.py | """Wrapper around llama.cpp."""
import logging
from typing import Any, Dict, List, Optional
from pydantic import Field, root_validator
from langchain.llms.base import LLM
logger = logging.getLogger(__name__)
class LlamaCpp(LLM):
"""Wrapper around the llama.cpp model.
To use, you should have the llama-cpp-python library installed, and provide the
path to the Llama model as a named parameter to the constructor.
Check out: https://github.com/abetlen/llama-cpp-python
Example:
.. code-block:: python
from langchain.llms import LlamaCppEmbeddings
llm = LlamaCppEmbeddings(model_path="/path/to/llama/model")
"""
client: Any #: :meta private:
model_path: str
"""The path to the Llama model file."""
n_ctx: int = Field(512, alias="n_ctx")
"""Token context window."""
n_parts: int = Field(-1, alias="n_parts")
"""Number of parts to split the model into.
If -1, the number of parts is automatically determined."""
seed: int = Field(-1, alias="seed")
"""Seed. If -1, a random seed is used."""
f16_kv: bool = Field(False, alias="f16_kv")
"""Use half-precision for key/value cache."""
logits_all: bool = Field(False, alias="logits_all")
"""Return logits for all tokens, not just the last token."""
vocab_only: bool = Field(False, alias="vocab_only")
"""Only load the vocabulary, no weights."""
use_mlock: bool = Field(False, alias="use_mlock")
"""Force system to keep model in RAM."""
n_threads: Optional[int] = Field(None, alias="n_threads")
"""Number of threads to use.
If None, the number of threads is automatically determined."""
n_batch: Optional[int] = Field(8, alias="n_batch")
"""Number of tokens to process in parallel.
Should be a number between 1 and n_ctx."""
suffix: Optional[str] = Field(None)
"""A suffix to append to the generated text. If None, no suffix is appended."""
max_tokens: Optional[int] = 256
"""The maximum number of tokens to generate."""
temperature: Optional[float] = 0.8
"""The temperature to use for sampling."""
top_p: Optional[float] = 0.95
"""The top-p value to use for sampling."""
logprobs: Optional[int] = Field(None)
"""The number of logprobs to return. If None, no logprobs are returned."""
echo: Optional[bool] = False
"""Whether to echo the prompt."""
stop: Optional[List[str]] = []
"""A list of strings to stop generation when encountered."""
repeat_penalty: Optional[float] = 1.1
"""The penalty to apply to repeated tokens."""
top_k: Optional[int] = 40
"""The top-k value to use for sampling."""
last_n_tokens_size: Optional[int] = 64
"""The number of tokens to look back when applying the repeat_penalty."""
@root_validator()
def validate_environment(cls, values: Dict) -> Dict:
"""Validate that llama-cpp-python library is installed."""
model_path = values["model_path"]
n_ctx = values["n_ctx"]
n_parts = values["n_parts"]
seed = values["seed"]
f16_kv = values["f16_kv"]
logits_all = values["logits_all"]
vocab_only = values["vocab_only"]
use_mlock = values["use_mlock"]
n_threads = values["n_threads"]
n_batch = values["n_batch"]
last_n_tokens_size = values["last_n_tokens_size"]
try:
from llama_cpp import Llama
values["client"] = Llama(
model_path=model_path,
n_ctx=n_ctx,
n_parts=n_parts,
seed=seed,
f16_kv=f16_kv,
logits_all=logits_all,
vocab_only=vocab_only,
use_mlock=use_mlock,
n_threads=n_threads,
n_batch=n_batch,
last_n_tokens_size=last_n_tokens_size,
)
except ImportError:
raise ModuleNotFoundError(
"Could not import llama-cpp-python library. "
"Please install the llama-cpp-python library to "
"use this embedding model: pip install llama-cpp-python"
)
except Exception:
raise NameError(f"Could not load Llama model from path: {model_path}")
return values
@property
def _default_params(self) -> Dict[str, Any]:
"""Get the default parameters for calling llama_cpp."""
return {
"suffix": self.suffix,
"max_tokens": self.max_tokens,
"temperature": self.temperature,
"top_p": self.top_p,
"logprobs": self.logprobs,
"echo": self.echo,
"stop_sequences": self.stop,
"repeat_penalty": self.repeat_penalty,
"top_k": self.top_k,
}
@property
def _identifying_params(self) -> Dict[str, Any]:
"""Get the identifying parameters."""
return {**{"model_path": self.model_path}, **self._default_params}
@property
def _llm_type(self) -> str:
"""Return type of llm."""
return "llama.cpp"
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
"""Call the Llama model and return the output.
Args:
prompt: The prompt to use for generation.
stop: A list of strings to stop generation when encountered.
Returns:
The generated text.
Example:
.. code-block:: python
from langchain.llms import LlamaCppEmbeddings
llm = LlamaCppEmbeddings(model_path="/path/to/local/llama/model.bin")
llm("This is a prompt.")
"""
params = self._default_params
if self.stop and stop is not None:
raise ValueError("`stop` found in both the input and default params.")
elif self.stop:
params["stop_sequences"] = self.stop
elif stop:
params["stop_sequences"] = stop
else:
params["stop_sequences"] = []
"""Call the Llama model and return the output."""
text = self.client(
prompt=prompt,
max_tokens=params["max_tokens"],
temperature=params["temperature"],
top_p=params["top_p"],
logprobs=params["logprobs"],
echo=params["echo"],
stop=params["stop_sequences"],
repeat_penalty=params["repeat_penalty"],
top_k=params["top_k"],
)
return text["choices"][0]["text"]
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,241 | llama.cpp => model runs fine but bad output | Hi,
Windows 11 environement
Python: 3.10.11
I installed
- llama-cpp-python and it works fine and provides output
- transformers
- pytorch
Code run:
```
from langchain.llms import LlamaCpp
from langchain import PromptTemplate, LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm = LlamaCpp(model_path=r"D:\Win10User\Downloads\AI\Model\vicuna-13B-1.1-GPTQ-4bit-128g.GGML.bin")
llm_chain = LLMChain(prompt=prompt, llm=llm)
question = "What is the capital of Belgium?"
llm_chain.run(question)
```
Output:
```
llama.cpp: loading model from D:\Win10User\Downloads\AI\Model\vicuna-13B-1.1-GPTQ-4bit-128g.GGML.bin
llama_model_load_internal: format = ggjt v1 (latest)
llama_model_load_internal: n_vocab = 32000
llama_model_load_internal: n_ctx = 512
llama_model_load_internal: n_embd = 5120
llama_model_load_internal: n_mult = 256
llama_model_load_internal: n_head = 40
llama_model_load_internal: n_layer = 40
llama_model_load_internal: n_rot = 128
llama_model_load_internal: ftype = 4 (mostly Q4_1, some F16)
llama_model_load_internal: n_ff = 13824
llama_model_load_internal: n_parts = 1
llama_model_load_internal: model size = 13B
llama_model_load_internal: ggml ctx size = 73.73 KB
llama_model_load_internal: mem required = 11749.65 MB (+ 3216.00 MB per state)
llama_init_from_file: kv self size = 800.00 MB
AVX = 1 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 |
llama_print_timings: load time = 2154.68 ms
llama_print_timings: sample time = 75.88 ms / 256 runs ( 0.30 ms per run)
llama_print_timings: prompt eval time = 5060.58 ms / 23 tokens ( 220.03 ms per token)
llama_print_timings: eval time = 72461.40 ms / 255 runs ( 284.16 ms per run)
llama_print_timings: total time = 77664.50 ms
```
But there is no answer to the question.... Am I supposed to Print() something?
| https://github.com/langchain-ai/langchain/issues/3241 | https://github.com/langchain-ai/langchain/pull/3320 | 3a1bdce3f51e302d468807e980455d676c0f5fd6 | 77bb6c99f7ee189ce3734c47b27e70dc237bbce7 | "2023-04-20T20:36:45Z" | python | "2023-04-23T01:46:55Z" | langchain/llms/llamacpp.py | """Wrapper around llama.cpp."""
import logging
from typing import Any, Dict, List, Optional
from pydantic import Field, root_validator
from langchain.llms.base import LLM
logger = logging.getLogger(__name__)
class LlamaCpp(LLM):
"""Wrapper around the llama.cpp model.
To use, you should have the llama-cpp-python library installed, and provide the
path to the Llama model as a named parameter to the constructor.
Check out: https://github.com/abetlen/llama-cpp-python
Example:
.. code-block:: python
from langchain.llms import LlamaCppEmbeddings
llm = LlamaCppEmbeddings(model_path="/path/to/llama/model")
"""
client: Any #: :meta private:
model_path: str
"""The path to the Llama model file."""
n_ctx: int = Field(512, alias="n_ctx")
"""Token context window."""
n_parts: int = Field(-1, alias="n_parts")
"""Number of parts to split the model into.
If -1, the number of parts is automatically determined."""
seed: int = Field(-1, alias="seed")
"""Seed. If -1, a random seed is used."""
f16_kv: bool = Field(False, alias="f16_kv")
"""Use half-precision for key/value cache."""
logits_all: bool = Field(False, alias="logits_all")
"""Return logits for all tokens, not just the last token."""
vocab_only: bool = Field(False, alias="vocab_only")
"""Only load the vocabulary, no weights."""
use_mlock: bool = Field(False, alias="use_mlock")
"""Force system to keep model in RAM."""
n_threads: Optional[int] = Field(None, alias="n_threads")
"""Number of threads to use.
If None, the number of threads is automatically determined."""
n_batch: Optional[int] = Field(8, alias="n_batch")
"""Number of tokens to process in parallel.
Should be a number between 1 and n_ctx."""
suffix: Optional[str] = Field(None)
"""A suffix to append to the generated text. If None, no suffix is appended."""
max_tokens: Optional[int] = 256
"""The maximum number of tokens to generate."""
temperature: Optional[float] = 0.8
"""The temperature to use for sampling."""
top_p: Optional[float] = 0.95
"""The top-p value to use for sampling."""
logprobs: Optional[int] = Field(None)
"""The number of logprobs to return. If None, no logprobs are returned."""
echo: Optional[bool] = False
"""Whether to echo the prompt."""
stop: Optional[List[str]] = []
"""A list of strings to stop generation when encountered."""
repeat_penalty: Optional[float] = 1.1
"""The penalty to apply to repeated tokens."""
top_k: Optional[int] = 40
"""The top-k value to use for sampling."""
last_n_tokens_size: Optional[int] = 64
"""The number of tokens to look back when applying the repeat_penalty."""
@root_validator()
def validate_environment(cls, values: Dict) -> Dict:
"""Validate that llama-cpp-python library is installed."""
model_path = values["model_path"]
n_ctx = values["n_ctx"]
n_parts = values["n_parts"]
seed = values["seed"]
f16_kv = values["f16_kv"]
logits_all = values["logits_all"]
vocab_only = values["vocab_only"]
use_mlock = values["use_mlock"]
n_threads = values["n_threads"]
n_batch = values["n_batch"]
last_n_tokens_size = values["last_n_tokens_size"]
try:
from llama_cpp import Llama
values["client"] = Llama(
model_path=model_path,
n_ctx=n_ctx,
n_parts=n_parts,
seed=seed,
f16_kv=f16_kv,
logits_all=logits_all,
vocab_only=vocab_only,
use_mlock=use_mlock,
n_threads=n_threads,
n_batch=n_batch,
last_n_tokens_size=last_n_tokens_size,
)
except ImportError:
raise ModuleNotFoundError(
"Could not import llama-cpp-python library. "
"Please install the llama-cpp-python library to "
"use this embedding model: pip install llama-cpp-python"
)
except Exception:
raise NameError(f"Could not load Llama model from path: {model_path}")
return values
@property
def _default_params(self) -> Dict[str, Any]:
"""Get the default parameters for calling llama_cpp."""
return {
"suffix": self.suffix,
"max_tokens": self.max_tokens,
"temperature": self.temperature,
"top_p": self.top_p,
"logprobs": self.logprobs,
"echo": self.echo,
"stop_sequences": self.stop,
"repeat_penalty": self.repeat_penalty,
"top_k": self.top_k,
}
@property
def _identifying_params(self) -> Dict[str, Any]:
"""Get the identifying parameters."""
return {**{"model_path": self.model_path}, **self._default_params}
@property
def _llm_type(self) -> str:
"""Return type of llm."""
return "llama.cpp"
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
"""Call the Llama model and return the output.
Args:
prompt: The prompt to use for generation.
stop: A list of strings to stop generation when encountered.
Returns:
The generated text.
Example:
.. code-block:: python
from langchain.llms import LlamaCppEmbeddings
llm = LlamaCppEmbeddings(model_path="/path/to/local/llama/model.bin")
llm("This is a prompt.")
"""
params = self._default_params
if self.stop and stop is not None:
raise ValueError("`stop` found in both the input and default params.")
elif self.stop:
params["stop_sequences"] = self.stop
elif stop:
params["stop_sequences"] = stop
else:
params["stop_sequences"] = []
"""Call the Llama model and return the output."""
text = self.client(
prompt=prompt,
max_tokens=params["max_tokens"],
temperature=params["temperature"],
top_p=params["top_p"],
logprobs=params["logprobs"],
echo=params["echo"],
stop=params["stop_sequences"],
repeat_penalty=params["repeat_penalty"],
top_k=params["top_k"],
)
return text["choices"][0]["text"]
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,404 | marathon_times.ipynb: mismatched text and code | Text mentions inflation and tuition:
Here is the prompt comparing inflation and college tuition.
Code is about marathon times:
agent.run(["What were the winning boston marathon times for the past 5 years? Generate a table of the names, countries of origin, and times."]) | https://github.com/langchain-ai/langchain/issues/3404 | https://github.com/langchain-ai/langchain/pull/3408 | b4de839ed8a1bea7425a6923b2cd635068b6015a | 73bc70b4fa7bb69647d9dbe81943b88ce6ccc180 | "2023-04-23T21:06:49Z" | python | "2023-04-24T01:14:11Z" | docs/use_cases/autonomous_agents/marathon_times.ipynb | {
"cells": [
{
"cell_type": "markdown",
"id": "14f8b67b",
"metadata": {},
"source": [
"## AutoGPT example finding Winning Marathon Times\n",
"\n",
"* Implementation of https://github.com/Significant-Gravitas/Auto-GPT \n",
"* With LangChain primitives (LLMs, PromptTemplates, VectorStores, Embeddings, Tools)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "ef972313-c05a-4c49-8fd1-03e599e21033",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# !pip install bs4\n",
"# !pip install nest_asyncio"
]
},
{
"cell_type": "code",
"execution_count": 1,
"id": "1cff42fd",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# General \n",
"import pandas as pd\n",
"from langchain.experimental.autonomous_agents.autogpt.agent import AutoGPT\n",
"from langchain.chat_models import ChatOpenAI\n",
"\n",
"from langchain.agents.agent_toolkits.pandas.base import create_pandas_dataframe_agent\n",
"from langchain.docstore.document import Document\n",
"from langchain.chains import RetrievalQA\n",
"import asyncio\n",
"import nest_asyncio\n",
"\n",
"\n",
"# Needed synce jupyter runs an async eventloop\n",
"nest_asyncio.apply()"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "01283ac7-1da0-41ba-8011-bd455d21dd82",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"llm = ChatOpenAI(model_name=\"gpt-3.5-turbo\", temperature=1.0)"
]
},
{
"cell_type": "markdown",
"id": "192496a7",
"metadata": {},
"source": [
"### Set up tools\n",
"\n",
"* We'll set up an AutoGPT with a `search` tool, and `write-file` tool, and a `read-file` tool, and a web browsing tool"
]
},
{
"cell_type": "markdown",
"id": "708a426f",
"metadata": {},
"source": [
"Define any other `tools` you want to use here"
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "cef4c150-0ef1-4a33-836b-01062fec134e",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# Tools\n",
"from typing import Optional\n",
"from langchain.agents import tool\n",
"from langchain.tools.file_management.read import ReadFileTool\n",
"from langchain.tools.file_management.write import WriteFileTool\n",
"\n",
"@tool\n",
"def process_csv(csv_file_path: str, instructions: str, output_path: Optional[str] = None) -> str:\n",
" \"\"\"Process a CSV by with pandas in a limited REPL. Only use this after writing data to disk as a csv file. Any figures must be saved to disk to be viewed by the human. Instructions should be written in natural language, not code. Assume the dataframe is already loaded.\"\"\"\n",
" try:\n",
" df = pd.read_csv(csv_file_path)\n",
" except Exception as e:\n",
" return f\"Error: {e}\"\n",
" agent = create_pandas_dataframe_agent(llm, df, max_iterations=30, verbose=True)\n",
" if output_path is not None:\n",
" instructions += f\" Save output to disk at {output_path}\"\n",
" try:\n",
" return agent.run(instructions)\n",
" except Exception as e:\n",
" return f\"Error: {e}\"\n"
]
},
{
"cell_type": "markdown",
"id": "51c07298-00e0-42d6-8aff-bd2e6bbd35a3",
"metadata": {},
"source": [
"**Web Search Tool**\n",
"\n",
"No need for API Tokens to use this tool, but it will require an optional dependency"
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "4afdedb2-f295-4ab8-9397-3640f5eeeed3",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# !pip install duckduckgo_search"
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "45f143de-e49e-4e27-88eb-ee44a4fdf933",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"import json\n",
"from duckduckgo_search import ddg"
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "e2e799f4-86fb-4190-a298-4ae5c7b7a540",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"@tool\n",
"def web_search(query: str, num_results: int = 8) -> str:\n",
" \"\"\"Useful for general internet search queries.\"\"\"\n",
" search_results = []\n",
" if not query:\n",
" return json.dumps(search_results)\n",
"\n",
" results = ddg(query, max_results=num_results)\n",
" if not results:\n",
" return json.dumps(search_results)\n",
"\n",
" for j in results:\n",
" search_results.append(j)\n",
"\n",
" return json.dumps(search_results, ensure_ascii=False, indent=4)"
]
},
{
"cell_type": "markdown",
"id": "69975008-654a-4cbb-bdf6-63c8bae07eaa",
"metadata": {
"tags": []
},
"source": [
"**Browse a web page with PlayWright**"
]
},
{
"cell_type": "code",
"execution_count": 7,
"id": "6bb5e47b-0f54-4faa-ae42-49a28fa5497b",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# !pip install playwright\n",
"# !playwright install"
]
},
{
"cell_type": "code",
"execution_count": 8,
"id": "26b497d7-8e52-4c7f-8e7e-da0a48820a3c",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"async def async_load_playwright(url: str) -> str:\n",
" \"\"\"Load the specified URLs using Playwright and parse using BeautifulSoup.\"\"\"\n",
" from bs4 import BeautifulSoup\n",
" from playwright.async_api import async_playwright\n",
"\n",
" results = \"\"\n",
" async with async_playwright() as p:\n",
" browser = await p.chromium.launch(headless=True)\n",
" try:\n",
" page = await browser.new_page()\n",
" await page.goto(url)\n",
"\n",
" page_source = await page.content()\n",
" soup = BeautifulSoup(page_source, \"html.parser\")\n",
"\n",
" for script in soup([\"script\", \"style\"]):\n",
" script.extract()\n",
"\n",
" text = soup.get_text()\n",
" lines = (line.strip() for line in text.splitlines())\n",
" chunks = (phrase.strip() for line in lines for phrase in line.split(\" \"))\n",
" results = \"\\n\".join(chunk for chunk in chunks if chunk)\n",
" except Exception as e:\n",
" results = f\"Error: {e}\"\n",
" await browser.close()\n",
" return results\n",
"\n",
"def run_async(coro):\n",
" event_loop = asyncio.get_event_loop()\n",
" return event_loop.run_until_complete(coro)\n",
"\n",
"@tool\n",
"def browse_web_page(url: str) -> str:\n",
" \"\"\"Verbose way to scrape a whole webpage. Likely to cause issues parsing.\"\"\"\n",
" return run_async(async_load_playwright(url))"
]
},
{
"cell_type": "markdown",
"id": "5ea71762-67ca-4e75-8c4d-00563064be71",
"metadata": {},
"source": [
"**Q&A Over a webpage**\n",
"\n",
"Help the model ask more directed questions of web pages to avoid cluttering its memory"
]
},
{
"cell_type": "code",
"execution_count": 9,
"id": "1842929d-f18d-4edc-9fdd-82c929181141",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"from langchain.tools.base import BaseTool\n",
"from langchain.text_splitter import RecursiveCharacterTextSplitter\n",
"\n",
"from langchain.document_loaders import WebBaseLoader\n",
"from pydantic import Field\n",
"from langchain.chains.qa_with_sources.loading import load_qa_with_sources_chain, BaseCombineDocumentsChain\n",
"\n",
"def _get_text_splitter():\n",
" return RecursiveCharacterTextSplitter(\n",
" # Set a really small chunk size, just to show.\n",
" chunk_size = 500,\n",
" chunk_overlap = 20,\n",
" length_function = len,\n",
" )\n",
"\n",
"\n",
"class WebpageQATool(BaseTool):\n",
" name = \"query_webpage\"\n",
" description = \"Browse a webpage and retrieve the information relevant to the question.\"\n",
" text_splitter: RecursiveCharacterTextSplitter = Field(default_factory=_get_text_splitter)\n",
" qa_chain: BaseCombineDocumentsChain\n",
" \n",
" def _run(self, url: str, question: str) -> str:\n",
" \"\"\"Useful for browsing websites and scraping the text information.\"\"\"\n",
" result = browse_web_page.run(url)\n",
" docs = [Document(page_content=result, metadata={\"source\": url})]\n",
" web_docs = self.text_splitter.split_documents(docs)\n",
" results = []\n",
" # TODO: Handle this with a MapReduceChain\n",
" for i in range(0, len(web_docs), 4):\n",
" input_docs = web_docs[i:i+4]\n",
" window_result = self.qa_chain({\"input_documents\": input_docs, \"question\": question}, return_only_outputs=True)\n",
" results.append(f\"Response from window {i} - {window_result}\")\n",
" results_docs = [Document(page_content=\"\\n\".join(results), metadata={\"source\": url})]\n",
" return self.qa_chain({\"input_documents\": results_docs, \"question\": question}, return_only_outputs=True)\n",
" \n",
" async def _arun(self, url: str, question: str) -> str:\n",
" raise NotImplementedError\n",
" "
]
},
{
"cell_type": "code",
"execution_count": 10,
"id": "e6f72bd0",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"query_website_tool = WebpageQATool(qa_chain=load_qa_with_sources_chain(llm))"
]
},
{
"cell_type": "markdown",
"id": "8e39ee28",
"metadata": {},
"source": [
"### Set up memory\n",
"\n",
"* The memory here is used for the agents intermediate steps"
]
},
{
"cell_type": "code",
"execution_count": 11,
"id": "1df7b724",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# Memory\n",
"import faiss\n",
"from langchain.vectorstores import FAISS\n",
"from langchain.docstore import InMemoryDocstore\n",
"from langchain.embeddings import OpenAIEmbeddings\n",
"from langchain.tools.human.tool import HumanInputRun\n",
"\n",
"embeddings_model = OpenAIEmbeddings()\n",
"embedding_size = 1536\n",
"index = faiss.IndexFlatL2(embedding_size)\n",
"vectorstore = FAISS(embeddings_model.embed_query, index, InMemoryDocstore({}), {})"
]
},
{
"cell_type": "markdown",
"id": "e40fd657",
"metadata": {},
"source": [
"### Setup model and AutoGPT\n",
"\n",
"`Model set-up`"
]
},
{
"cell_type": "code",
"execution_count": 12,
"id": "88c8b184-67d7-4c35-84ae-9b14bef8c4e3",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"tools = [\n",
" web_search,\n",
" WriteFileTool(),\n",
" ReadFileTool(),\n",
" process_csv,\n",
" query_website_tool,\n",
" # HumanInputRun(), # Activate if you want the permit asking for help from the human\n",
"]"
]
},
{
"cell_type": "code",
"execution_count": 13,
"id": "709c08c2",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"agent = AutoGPT.from_llm_and_tools(\n",
" ai_name=\"Tom\",\n",
" ai_role=\"Assistant\",\n",
" tools=tools,\n",
" llm=llm,\n",
" memory=vectorstore.as_retriever(search_kwargs={\"k\": 8}),\n",
" # human_in_the_loop=True, # Set to True if you want to add feedback at each step.\n",
")\n",
"# agent.chain.verbose = True"
]
},
{
"cell_type": "markdown",
"id": "fc9b51ba",
"metadata": {},
"source": [
"### AutoGPT as a research / data munger \n",
"\n",
"#### `inflation` and `college tuition`\n",
" \n",
"Let's use AutoGPT as researcher and data munger / cleaner.\n",
" \n",
"I spent a lot of time over the years crawling data sources and cleaning data. \n",
"\n",
"Let's see if AutoGPT can do all of this for us!\n",
"\n",
"Here is the prompt comparing `inflation` and `college tuition`."
]
},
{
"cell_type": "code",
"execution_count": 14,
"id": "64455d70-a134-4d11-826a-33e34c2ce287",
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"WARNING:root:Failed to persist run: Object of type 'FAISS' is not JSON serializable\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"{\n",
" \"thoughts\": {\n",
" \"text\": \"I need to find the winning Boston Marathon times for the past 5 years.\",\n",
" \"reasoning\": \"I'll start by conducting a web search for the requested information.\",\n",
" \"plan\": \"- Conduct a web search\\n- Query relevant webpage\\n- Generate table\\n- Save data to file\",\n",
" \"criticism\": \"None\",\n",
" \"speak\": \"I will begin by conducting a web search to find the past 5 years' Boston Marathon winning times.\"\n",
" },\n",
" \"command\": {\n",
" \"name\": \"web_search\",\n",
" \"args\": {\n",
" \"query\": \"winning Boston Marathon times for the past 5 years\"\n",
" }\n",
" }\n",
"}\n"
]
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"WARNING:root:Failed to persist run: Object of type 'FAISS' is not JSON serializable\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"{\n",
" \"thoughts\": {\n",
" \"text\": \"I found several relevant search results, and I will use the query_webpage command on a specific URL to gather the information.\",\n",
" \"reasoning\": \"The Boston Athletic Association's official website (www.baa.org) is likely the most accurate source.\",\n",
" \"plan\": \"- Query the Boston Athletic Association webpage\\n- Filter and parse the data\\n- Generate table and save to file\",\n",
" \"criticism\": \"None\",\n",
" \"speak\": \"I will now query the Boston Athletic Association webpage to retrieve the information on the past 5 years' winning times.\"\n",
" },\n",
" \"command\": {\n",
" \"name\": \"query_webpage\",\n",
" \"args\": {\n",
" \"url\": \"https://www.baa.org/races/boston-marathon/results/champions\",\n",
" \"question\": \"winning times of the Boston Marathon for the past 5 years\"\n",
" }\n",
" }\n",
"}\n"
]
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"WARNING:root:Failed to persist run: Object of type 'FAISS' is not JSON serializable\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"{\n",
" \"thoughts\": {\n",
" \"text\": \"I have the winning times of the Boston Marathon for the past 5 years. I need to create a table with the names, countries of origin, and times.\",\n",
" \"reasoning\": \"I can use the information I've retrieved to generate a CSV file, then process the CSV file to create the table.\",\n",
" \"plan\": \"- Save data to a CSV file\\n- Process CSV file to generate table\",\n",
" \"criticism\": \"None\",\n",
" \"speak\": \"I will save the Boston Marathon data to a CSV file and then process it to generate a table.\"\n",
" },\n",
" \"command\": {\n",
" \"name\": \"write_file\",\n",
" \"args\": {\n",
" \"file_path\": \"boston_marathon_data.csv\",\n",
" \"text\": \"Year,Name,Country,Time\\n2022,Evans Chebet,Kenya,2:06:51\\n2021,Benson Kipruto,Kenya,2:09:51\\n2019,Lawrence Cherono,Kenya,2:07:57\\n2018,Yuki Kawauchi,Japan,2:15:58\\n2017,Geoffrey Kirui,Kenya,2:09:37\"\n",
" }\n",
" }\n",
"}\n"
]
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"WARNING:root:Failed to persist run: Object of type 'FAISS' is not JSON serializable\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"{\n",
" \"thoughts\": {\n",
" \"text\": \"I have the winning times for the Boston Marathon for the past 5 years. Now, I need to turn it into a table, save it as a CSV, and process it.\",\n",
" \"reasoning\": \"Saving data as a CSV will allow for a clean table format and output.\",\n",
" \"plan\": \"- Format the data as a CSV\\n- Write the CSV to disk\\n- Process the CSV and generate a table\",\n",
" \"criticism\": \"None\",\n",
" \"speak\": \"I will now format the winning times data as a CSV, save it, and process it to generate a table.\"\n",
" },\n",
" \"command\": {\n",
" \"name\": \"write_file\",\n",
" \"args\": {\n",
" \"file_path\": \"boston_marathon_winners.csv\",\n",
" \"text\": \"Year,Name,Country,Time\\n2022,Evans Chebet,Kenya,2:06:51\\n2021,Benson Kipruto,Kenya,2:09:51\\n2019,Lawrence Cherono,Kenya,2:07:57\\n2018,Yuki Kawauchi,Japan,2:15:58\\n2017,Geoffrey Kirui,Kenya,2:09:37\"\n",
" }\n",
" }\n",
"}\n"
]
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"WARNING:root:Failed to persist run: Object of type 'FAISS' is not JSON serializable\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"{\n",
" \"thoughts\": {\n",
" \"text\": \"I have the winning times for the past 5 years, now I need to organize the information into a table and save it as a file.\",\n",
" \"reasoning\": \"Storing the information in a table file format will make it easier to access and present the data.\",\n",
" \"plan\": \"- Save data in a CSV file\\n- Generate a table\",\n",
" \"criticism\": \"None\",\n",
" \"speak\": \"I will save the winning marathon times in a table format as a CSV file and generate a table.\"\n",
" },\n",
" \"command\": {\n",
" \"name\": \"write_file\",\n",
" \"args\": {\n",
" \"file_path\": \"boston_marathon_winners.csv\",\n",
" \"text\": \"Year,Name,Country,Time\\n2022,Evans Chebet,Kenya,2:06:51\\n2021,Benson Kipruto,Kenya,2:09:51\\n2019,Lawrence Cherono,Kenya,2:07:57\\n2018,Yuki Kawauchi,Japan,2:15:58\\n2017,Geoffrey Kirui,Kenya,2:09:37\"\n",
" }\n",
" }\n",
"}\n"
]
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"WARNING:root:Failed to persist run: Object of type 'FAISS' is not JSON serializable\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"{\n",
" \"thoughts\": {\n",
" \"text\": \"I previously found the winning times of the Boston Marathon for the past 5 years and saved it as a CSV file. Now, I need to process the CSV to create a table with the names, countries of origin, and times.\",\n",
" \"reasoning\": \"Processing the CSV will help generate a clean table to provide the answer.\",\n",
" \"plan\": \"- Process the CSV file\\n- Generate a table with the required columns\",\n",
" \"criticism\": \"None\",\n",
" \"speak\": \"I will process the Boston Marathon winners' CSV file to create a table with the names, countries of origin, and times.\"\n",
" },\n",
" \"command\": {\n",
" \"name\": \"process_csv\",\n",
" \"args\": {\n",
" \"csv_file_path\": \"boston_marathon_winners.csv\",\n",
" \"instructions\": \"Generate a table with columns Year, Name, Country, and Time.\"\n",
" }\n",
" }\n",
"}\n",
"\n",
"\n",
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
"\u001b[32;1m\u001b[1;3mThought: I need to convert the provided dataframe to a string in Markdown table format.\n",
"Action: python_repl_ast\n",
"Action Input: df.to_markdown(index=False)\u001b[0m\n",
"Observation: \u001b[36;1m\u001b[1;3m| Year | Name | Country | Time |\n",
"|-------:|:-----------------|:----------|:--------|\n",
"| 2022 | Evans Chebet | Kenya | 2:06:51 |\n",
"| 2021 | Benson Kipruto | Kenya | 2:09:51 |\n",
"| 2019 | Lawrence Cherono | Kenya | 2:07:57 |\n",
"| 2018 | Yuki Kawauchi | Japan | 2:15:58 |\n",
"| 2017 | Geoffrey Kirui | Kenya | 2:09:37 |\u001b[0m\n",
"Thought:\u001b[32;1m\u001b[1;3mI now know the final answer.\n",
"Final Answer: \n",
"\n",
"| Year | Name | Country | Time |\n",
"|-------:|:-----------------|:----------|:--------|\n",
"| 2022 | Evans Chebet | Kenya | 2:06:51 |\n",
"| 2021 | Benson Kipruto | Kenya | 2:09:51 |\n",
"| 2019 | Lawrence Cherono | Kenya | 2:07:57 |\n",
"| 2018 | Yuki Kawauchi | Japan | 2:15:58 |\n",
"| 2017 | Geoffrey Kirui | Kenya | 2:09:37 |\u001b[0m\n",
"\n",
"\u001b[1m> Finished chain.\u001b[0m\n"
]
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"WARNING:root:Failed to persist run: Object of type 'FAISS' is not JSON serializable\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"{\n",
" \"thoughts\": {\n",
" \"text\": \"I have already retrieved the winning times for the past 5 years of the Boston Marathon and created a table. My objective is complete.\",\n",
" \"reasoning\": \"I have completed my task on this topic, so I don't need to use any other commands.\",\n",
" \"plan\": \"- Inform the user that the task is complete\",\n",
" \"criticism\": \"None\",\n",
" \"speak\": \"I have found the winning times for the past 5 years of the Boston Marathon and created a table. My task is complete.\"\n",
" },\n",
" \"command\": {\n",
" \"name\": \"finish\",\n",
" \"args\": {\n",
" \"response\": \"I have found the winning times for the past 5 years of the Boston Marathon and created a table. My task is complete.\"\n",
" }\n",
" }\n",
"}\n"
]
},
{
"data": {
"text/plain": [
"'I have found the winning times for the past 5 years of the Boston Marathon and created a table. My task is complete.'"
]
},
"execution_count": 14,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"agent.run([\"What were the winning boston marathon times for the past 5 years? Generate a table of the names, countries of origin, and times.\"])"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "a6b4f96e",
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.11.2"
}
},
"nbformat": 4,
"nbformat_minor": 5
}
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,404 | marathon_times.ipynb: mismatched text and code | Text mentions inflation and tuition:
Here is the prompt comparing inflation and college tuition.
Code is about marathon times:
agent.run(["What were the winning boston marathon times for the past 5 years? Generate a table of the names, countries of origin, and times."]) | https://github.com/langchain-ai/langchain/issues/3404 | https://github.com/langchain-ai/langchain/pull/3408 | b4de839ed8a1bea7425a6923b2cd635068b6015a | 73bc70b4fa7bb69647d9dbe81943b88ce6ccc180 | "2023-04-23T21:06:49Z" | python | "2023-04-24T01:14:11Z" | langchain/tools/ddg_search/__init__.py | """DuckDuckGo Search API toolkit."""
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,384 | ValueError in cosine_similarity when using FAISS index as vector store | Getting the below error
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "...\langchain\vectorstores\faiss.py", line 285, in max_marginal_relevance_search
docs = self.max_marginal_relevance_search_by_vector(embedding, k, fetch_k)
File "...\langchain\vectorstores\faiss.py", line 248, in max_marginal_relevance_search_by_vector
mmr_selected = maximal_marginal_relevance(
File "...\langchain\langchain\vectorstores\utils.py", line 19, in maximal_marginal_relevance
similarity_to_query = cosine_similarity([query_embedding], embedding_list)[0]
File "...\langchain\langchain\math_utils.py", line 16, in cosine_similarity
raise ValueError("Number of columns in X and Y must be the same.")
ValueError: Number of columns in X and Y must be the same.
```
Code to reproduce this error
```
>>> model_name = "sentence-transformers/all-mpnet-base-v2"
>>> model_kwargs = {'device': 'cpu'}
>>> from langchain.embeddings import HuggingFaceEmbeddings
>>> embeddings = HuggingFaceEmbeddings(model_name=model_name, model_kwargs=model_kwargs)
>>> from langchain.vectorstores import FAISS
>>> FAISS_INDEX_PATH = 'faiss_index'
>>> db = FAISS.load_local(FAISS_INDEX_PATH, embeddings)
>>> query = 'query'
>>> results = db.max_marginal_relevance_search(query)
```
While going through the error it seems that in this case `query_embedding` is 1 x model_dimension while embedding_list is no_docs x model dimension vectors. Hence we should probably change the code to `similarity_to_query = cosine_similarity(query_embedding, embedding_list)[0]` i.e. remove the list from the query_embedding.
Since this is a common function not sure if this change would affect other embedding classes as well. | https://github.com/langchain-ai/langchain/issues/3384 | https://github.com/langchain-ai/langchain/pull/3475 | 53b14de636080e09e128d829aafa9ea34ac34a94 | b2564a63911f8a77272ac9e93e5558384f00155c | "2023-04-23T07:51:56Z" | python | "2023-04-25T02:54:15Z" | langchain/math_utils.py | """Math utils."""
from typing import List, Union
import numpy as np
Matrix = Union[List[List[float]], List[np.ndarray], np.ndarray]
def cosine_similarity(X: Matrix, Y: Matrix) -> np.ndarray:
"""Row-wise cosine similarity between two equal-width matrices."""
if len(X) == 0 or len(Y) == 0:
return np.array([])
X = np.array(X)
Y = np.array(Y)
if X.shape[1] != Y.shape[1]:
raise ValueError("Number of columns in X and Y must be the same.")
X_norm = np.linalg.norm(X, axis=1)
Y_norm = np.linalg.norm(Y, axis=1)
similarity = np.dot(X, Y.T) / np.outer(X_norm, Y_norm)
similarity[np.isnan(similarity) | np.isinf(similarity)] = 0.0
return similarity
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,384 | ValueError in cosine_similarity when using FAISS index as vector store | Getting the below error
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "...\langchain\vectorstores\faiss.py", line 285, in max_marginal_relevance_search
docs = self.max_marginal_relevance_search_by_vector(embedding, k, fetch_k)
File "...\langchain\vectorstores\faiss.py", line 248, in max_marginal_relevance_search_by_vector
mmr_selected = maximal_marginal_relevance(
File "...\langchain\langchain\vectorstores\utils.py", line 19, in maximal_marginal_relevance
similarity_to_query = cosine_similarity([query_embedding], embedding_list)[0]
File "...\langchain\langchain\math_utils.py", line 16, in cosine_similarity
raise ValueError("Number of columns in X and Y must be the same.")
ValueError: Number of columns in X and Y must be the same.
```
Code to reproduce this error
```
>>> model_name = "sentence-transformers/all-mpnet-base-v2"
>>> model_kwargs = {'device': 'cpu'}
>>> from langchain.embeddings import HuggingFaceEmbeddings
>>> embeddings = HuggingFaceEmbeddings(model_name=model_name, model_kwargs=model_kwargs)
>>> from langchain.vectorstores import FAISS
>>> FAISS_INDEX_PATH = 'faiss_index'
>>> db = FAISS.load_local(FAISS_INDEX_PATH, embeddings)
>>> query = 'query'
>>> results = db.max_marginal_relevance_search(query)
```
While going through the error it seems that in this case `query_embedding` is 1 x model_dimension while embedding_list is no_docs x model dimension vectors. Hence we should probably change the code to `similarity_to_query = cosine_similarity(query_embedding, embedding_list)[0]` i.e. remove the list from the query_embedding.
Since this is a common function not sure if this change would affect other embedding classes as well. | https://github.com/langchain-ai/langchain/issues/3384 | https://github.com/langchain-ai/langchain/pull/3475 | 53b14de636080e09e128d829aafa9ea34ac34a94 | b2564a63911f8a77272ac9e93e5558384f00155c | "2023-04-23T07:51:56Z" | python | "2023-04-25T02:54:15Z" | langchain/vectorstores/utils.py | """Utility functions for working with vectors and vectorstores."""
from typing import List
import numpy as np
from langchain.math_utils import cosine_similarity
def maximal_marginal_relevance(
query_embedding: np.ndarray,
embedding_list: list,
lambda_mult: float = 0.5,
k: int = 4,
) -> List[int]:
"""Calculate maximal marginal relevance."""
if min(k, len(embedding_list)) <= 0:
return []
similarity_to_query = cosine_similarity([query_embedding], embedding_list)[0]
most_similar = int(np.argmax(similarity_to_query))
idxs = [most_similar]
selected = np.array([embedding_list[most_similar]])
while len(idxs) < min(k, len(embedding_list)):
best_score = -np.inf
idx_to_add = -1
similarity_to_selected = cosine_similarity(embedding_list, selected)
for i, query_score in enumerate(similarity_to_query):
if i in idxs:
continue
redundant_score = max(similarity_to_selected[i])
equation_score = (
lambda_mult * query_score - (1 - lambda_mult) * redundant_score
)
if equation_score > best_score:
best_score = equation_score
idx_to_add = i
idxs.append(idx_to_add)
selected = np.append(selected, [embedding_list[idx_to_add]], axis=0)
return idxs
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,384 | ValueError in cosine_similarity when using FAISS index as vector store | Getting the below error
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "...\langchain\vectorstores\faiss.py", line 285, in max_marginal_relevance_search
docs = self.max_marginal_relevance_search_by_vector(embedding, k, fetch_k)
File "...\langchain\vectorstores\faiss.py", line 248, in max_marginal_relevance_search_by_vector
mmr_selected = maximal_marginal_relevance(
File "...\langchain\langchain\vectorstores\utils.py", line 19, in maximal_marginal_relevance
similarity_to_query = cosine_similarity([query_embedding], embedding_list)[0]
File "...\langchain\langchain\math_utils.py", line 16, in cosine_similarity
raise ValueError("Number of columns in X and Y must be the same.")
ValueError: Number of columns in X and Y must be the same.
```
Code to reproduce this error
```
>>> model_name = "sentence-transformers/all-mpnet-base-v2"
>>> model_kwargs = {'device': 'cpu'}
>>> from langchain.embeddings import HuggingFaceEmbeddings
>>> embeddings = HuggingFaceEmbeddings(model_name=model_name, model_kwargs=model_kwargs)
>>> from langchain.vectorstores import FAISS
>>> FAISS_INDEX_PATH = 'faiss_index'
>>> db = FAISS.load_local(FAISS_INDEX_PATH, embeddings)
>>> query = 'query'
>>> results = db.max_marginal_relevance_search(query)
```
While going through the error it seems that in this case `query_embedding` is 1 x model_dimension while embedding_list is no_docs x model dimension vectors. Hence we should probably change the code to `similarity_to_query = cosine_similarity(query_embedding, embedding_list)[0]` i.e. remove the list from the query_embedding.
Since this is a common function not sure if this change would affect other embedding classes as well. | https://github.com/langchain-ai/langchain/issues/3384 | https://github.com/langchain-ai/langchain/pull/3475 | 53b14de636080e09e128d829aafa9ea34ac34a94 | b2564a63911f8a77272ac9e93e5558384f00155c | "2023-04-23T07:51:56Z" | python | "2023-04-25T02:54:15Z" | tests/unit_tests/vectorstores/__init__.py | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,384 | ValueError in cosine_similarity when using FAISS index as vector store | Getting the below error
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "...\langchain\vectorstores\faiss.py", line 285, in max_marginal_relevance_search
docs = self.max_marginal_relevance_search_by_vector(embedding, k, fetch_k)
File "...\langchain\vectorstores\faiss.py", line 248, in max_marginal_relevance_search_by_vector
mmr_selected = maximal_marginal_relevance(
File "...\langchain\langchain\vectorstores\utils.py", line 19, in maximal_marginal_relevance
similarity_to_query = cosine_similarity([query_embedding], embedding_list)[0]
File "...\langchain\langchain\math_utils.py", line 16, in cosine_similarity
raise ValueError("Number of columns in X and Y must be the same.")
ValueError: Number of columns in X and Y must be the same.
```
Code to reproduce this error
```
>>> model_name = "sentence-transformers/all-mpnet-base-v2"
>>> model_kwargs = {'device': 'cpu'}
>>> from langchain.embeddings import HuggingFaceEmbeddings
>>> embeddings = HuggingFaceEmbeddings(model_name=model_name, model_kwargs=model_kwargs)
>>> from langchain.vectorstores import FAISS
>>> FAISS_INDEX_PATH = 'faiss_index'
>>> db = FAISS.load_local(FAISS_INDEX_PATH, embeddings)
>>> query = 'query'
>>> results = db.max_marginal_relevance_search(query)
```
While going through the error it seems that in this case `query_embedding` is 1 x model_dimension while embedding_list is no_docs x model dimension vectors. Hence we should probably change the code to `similarity_to_query = cosine_similarity(query_embedding, embedding_list)[0]` i.e. remove the list from the query_embedding.
Since this is a common function not sure if this change would affect other embedding classes as well. | https://github.com/langchain-ai/langchain/issues/3384 | https://github.com/langchain-ai/langchain/pull/3475 | 53b14de636080e09e128d829aafa9ea34ac34a94 | b2564a63911f8a77272ac9e93e5558384f00155c | "2023-04-23T07:51:56Z" | python | "2023-04-25T02:54:15Z" | tests/unit_tests/vectorstores/test_utils.py | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,766 | Update poetry lock to allow SQLAlchemy v2 | It seems that #1578 adds support for SQLAlchemy v2 but the [poetry lock file](https://github.com/hwchase17/langchain/blob/8685d53adcdd0310e76349ecb4e2b87f980c4673/poetry.lock#L6211) is still at 1.4.46. | https://github.com/langchain-ai/langchain/issues/1766 | https://github.com/langchain-ai/langchain/pull/3310 | 7c2c73af5f15799c9326e99ed15c4a30fd19ad11 | b7658059643cd2f8fa58a2132b7d723638445ebc | "2023-03-19T01:48:23Z" | python | "2023-04-25T04:10:56Z" | langchain/sql_database.py | """SQLAlchemy wrapper around a database."""
from __future__ import annotations
import warnings
from typing import Any, Iterable, List, Optional
from sqlalchemy import MetaData, Table, create_engine, inspect, select, text
from sqlalchemy.engine import Engine
from sqlalchemy.exc import ProgrammingError, SQLAlchemyError
from sqlalchemy.schema import CreateTable
def _format_index(index: dict) -> str:
return (
f'Name: {index["name"]}, Unique: {index["unique"]},'
f' Columns: {str(index["column_names"])}'
)
class SQLDatabase:
"""SQLAlchemy wrapper around a database."""
def __init__(
self,
engine: Engine,
schema: Optional[str] = None,
metadata: Optional[MetaData] = None,
ignore_tables: Optional[List[str]] = None,
include_tables: Optional[List[str]] = None,
sample_rows_in_table_info: int = 3,
indexes_in_table_info: bool = False,
custom_table_info: Optional[dict] = None,
view_support: Optional[bool] = False,
):
"""Create engine from database URI."""
self._engine = engine
self._schema = schema
if include_tables and ignore_tables:
raise ValueError("Cannot specify both include_tables and ignore_tables")
self._inspector = inspect(self._engine)
# including view support by adding the views as well as tables to the all
# tables list if view_support is True
self._all_tables = set(
self._inspector.get_table_names(schema=schema)
+ (self._inspector.get_view_names(schema=schema) if view_support else [])
)
self._include_tables = set(include_tables) if include_tables else set()
if self._include_tables:
missing_tables = self._include_tables - self._all_tables
if missing_tables:
raise ValueError(
f"include_tables {missing_tables} not found in database"
)
self._ignore_tables = set(ignore_tables) if ignore_tables else set()
if self._ignore_tables:
missing_tables = self._ignore_tables - self._all_tables
if missing_tables:
raise ValueError(
f"ignore_tables {missing_tables} not found in database"
)
usable_tables = self.get_usable_table_names()
self._usable_tables = set(usable_tables) if usable_tables else self._all_tables
if not isinstance(sample_rows_in_table_info, int):
raise TypeError("sample_rows_in_table_info must be an integer")
self._sample_rows_in_table_info = sample_rows_in_table_info
self._indexes_in_table_info = indexes_in_table_info
self._custom_table_info = custom_table_info
if self._custom_table_info:
if not isinstance(self._custom_table_info, dict):
raise TypeError(
"table_info must be a dictionary with table names as keys and the "
"desired table info as values"
)
# only keep the tables that are also present in the database
intersection = set(self._custom_table_info).intersection(self._all_tables)
self._custom_table_info = dict(
(table, self._custom_table_info[table])
for table in self._custom_table_info
if table in intersection
)
self._metadata = metadata or MetaData()
# including view support if view_support = true
self._metadata.reflect(
views=view_support,
bind=self._engine,
only=self._usable_tables,
schema=self._schema,
)
@classmethod
def from_uri(
cls, database_uri: str, engine_args: Optional[dict] = None, **kwargs: Any
) -> SQLDatabase:
"""Construct a SQLAlchemy engine from URI."""
_engine_args = engine_args or {}
return cls(create_engine(database_uri, **_engine_args), **kwargs)
@property
def dialect(self) -> str:
"""Return string representation of dialect to use."""
return self._engine.dialect.name
def get_usable_table_names(self) -> Iterable[str]:
"""Get names of tables available."""
if self._include_tables:
return self._include_tables
return self._all_tables - self._ignore_tables
def get_table_names(self) -> Iterable[str]:
"""Get names of tables available."""
warnings.warn(
"This method is deprecated - please use `get_usable_table_names`."
)
return self.get_usable_table_names()
@property
def table_info(self) -> str:
"""Information about all tables in the database."""
return self.get_table_info()
def get_table_info(self, table_names: Optional[List[str]] = None) -> str:
"""Get information about specified tables.
Follows best practices as specified in: Rajkumar et al, 2022
(https://arxiv.org/abs/2204.00498)
If `sample_rows_in_table_info`, the specified number of sample rows will be
appended to each table description. This can increase performance as
demonstrated in the paper.
"""
all_table_names = self.get_usable_table_names()
if table_names is not None:
missing_tables = set(table_names).difference(all_table_names)
if missing_tables:
raise ValueError(f"table_names {missing_tables} not found in database")
all_table_names = table_names
meta_tables = [
tbl
for tbl in self._metadata.sorted_tables
if tbl.name in set(all_table_names)
and not (self.dialect == "sqlite" and tbl.name.startswith("sqlite_"))
]
tables = []
for table in meta_tables:
if self._custom_table_info and table.name in self._custom_table_info:
tables.append(self._custom_table_info[table.name])
continue
# add create table command
create_table = str(CreateTable(table).compile(self._engine))
table_info = f"{create_table.rstrip()}"
has_extra_info = (
self._indexes_in_table_info or self._sample_rows_in_table_info
)
if has_extra_info:
table_info += "\n\n/*"
if self._indexes_in_table_info:
table_info += f"\n{self._get_table_indexes(table)}\n"
if self._sample_rows_in_table_info:
table_info += f"\n{self._get_sample_rows(table)}\n"
if has_extra_info:
table_info += "*/"
tables.append(table_info)
final_str = "\n\n".join(tables)
return final_str
def _get_table_indexes(self, table: Table) -> str:
indexes = self._inspector.get_indexes(table.name)
indexes_formatted = "\n".join(map(_format_index, indexes))
return f"Table Indexes:\n{indexes_formatted}"
def _get_sample_rows(self, table: Table) -> str:
# build the select command
command = select([table]).limit(self._sample_rows_in_table_info)
# save the columns in string format
columns_str = "\t".join([col.name for col in table.columns])
try:
# get the sample rows
with self._engine.connect() as connection:
sample_rows = connection.execute(command)
# shorten values in the sample rows
sample_rows = list(
map(lambda ls: [str(i)[:100] for i in ls], sample_rows)
)
# save the sample rows in string format
sample_rows_str = "\n".join(["\t".join(row) for row in sample_rows])
# in some dialects when there are no rows in the table a
# 'ProgrammingError' is returned
except ProgrammingError:
sample_rows_str = ""
return (
f"{self._sample_rows_in_table_info} rows from {table.name} table:\n"
f"{columns_str}\n"
f"{sample_rows_str}"
)
def run(self, command: str, fetch: str = "all") -> str:
"""Execute a SQL command and return a string representing the results.
If the statement returns rows, a string of the results is returned.
If the statement returns no rows, an empty string is returned.
"""
with self._engine.begin() as connection:
if self._schema is not None:
connection.exec_driver_sql(f"SET search_path TO {self._schema}")
cursor = connection.execute(text(command))
if cursor.returns_rows:
if fetch == "all":
result = cursor.fetchall()
elif fetch == "one":
result = cursor.fetchone()[0]
else:
raise ValueError("Fetch parameter must be either 'one' or 'all'")
return str(result)
return ""
def get_table_info_no_throw(self, table_names: Optional[List[str]] = None) -> str:
"""Get information about specified tables.
Follows best practices as specified in: Rajkumar et al, 2022
(https://arxiv.org/abs/2204.00498)
If `sample_rows_in_table_info`, the specified number of sample rows will be
appended to each table description. This can increase performance as
demonstrated in the paper.
"""
try:
return self.get_table_info(table_names)
except ValueError as e:
"""Format the error message"""
return f"Error: {e}"
def run_no_throw(self, command: str, fetch: str = "all") -> str:
"""Execute a SQL command and return a string representing the results.
If the statement returns rows, a string of the results is returned.
If the statement returns no rows, an empty string is returned.
If the statement throws an error, the error message is returned.
"""
try:
return self.run(command, fetch)
except SQLAlchemyError as e:
"""Format the error message"""
return f"Error: {e}"
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,766 | Update poetry lock to allow SQLAlchemy v2 | It seems that #1578 adds support for SQLAlchemy v2 but the [poetry lock file](https://github.com/hwchase17/langchain/blob/8685d53adcdd0310e76349ecb4e2b87f980c4673/poetry.lock#L6211) is still at 1.4.46. | https://github.com/langchain-ai/langchain/issues/1766 | https://github.com/langchain-ai/langchain/pull/3310 | 7c2c73af5f15799c9326e99ed15c4a30fd19ad11 | b7658059643cd2f8fa58a2132b7d723638445ebc | "2023-03-19T01:48:23Z" | python | "2023-04-25T04:10:56Z" | pyproject.toml | [tool.poetry]
name = "langchain"
version = "0.0.148"
description = "Building applications with LLMs through composability"
authors = []
license = "MIT"
readme = "README.md"
repository = "https://www.github.com/hwchase17/langchain"
[tool.poetry.scripts]
langchain-server = "langchain.server:main"
[tool.poetry.dependencies]
python = ">=3.8.1,<4.0"
pydantic = "^1"
SQLAlchemy = "^1"
requests = "^2"
PyYAML = ">=5.4.1"
numpy = "^1"
tqdm = {version = ">=4.48.0", optional = true}
openapi-schema-pydantic = "^1.2"
faiss-cpu = {version = "^1", optional = true}
wikipedia = {version = "^1", optional = true}
elasticsearch = {version = "^8", optional = true}
opensearch-py = {version = "^2.0.0", optional = true}
redis = {version = "^4", optional = true}
manifest-ml = {version = "^0.0.1", optional = true}
spacy = {version = "^3", optional = true}
nltk = {version = "^3", optional = true}
transformers = {version = "^4", optional = true}
beautifulsoup4 = {version = "^4", optional = true}
torch = {version = ">=1,<3", optional = true}
jinja2 = {version = "^3", optional = true}
tiktoken = {version = "^0.3.2", optional = true, python="^3.9"}
pinecone-client = {version = "^2", optional = true}
pinecone-text = {version = "^0.4.2", optional = true}
clickhouse-connect = {version="^0.5.14", optional=true}
weaviate-client = {version = "^3", optional = true}
google-api-python-client = {version = "2.70.0", optional = true}
wolframalpha = {version = "5.0.0", optional = true}
anthropic = {version = "^0.2.6", optional = true}
qdrant-client = {version = "^1.1.2", optional = true, python = ">=3.8.1,<3.12"}
dataclasses-json = "^0.5.7"
tensorflow-text = {version = "^2.11.0", optional = true, python = "^3.10, <3.12"}
tenacity = "^8.1.0"
cohere = {version = "^3", optional = true}
openai = {version = "^0", optional = true}
nlpcloud = {version = "^1", optional = true}
nomic = {version = "^1.0.43", optional = true}
huggingface_hub = {version = "^0", optional = true}
jina = {version = "^3.14", optional = true}
google-search-results = {version = "^2", optional = true}
sentence-transformers = {version = "^2", optional = true}
aiohttp = "^3.8.3"
arxiv = {version = "^1.4", optional = true}
pypdf = {version = "^3.4.0", optional = true}
networkx = {version="^2.6.3", optional = true}
aleph-alpha-client = {version="^2.15.0", optional = true}
deeplake = {version = "^3.3.0", optional = true}
pgvector = {version = "^0.1.6", optional = true}
psycopg2-binary = {version = "^2.9.5", optional = true}
#boto3 = {version = "^1.26.96", optional = true} # TODO: fix it, commented because the version failed with deeplake
pyowm = {version = "^3.3.0", optional = true}
async-timeout = {version = "^4.0.0", python = "<3.11"}
azure-identity = {version = "^1.12.0", optional=true}
gptcache = {version = ">=0.1.7", optional = true}
atlassian-python-api = {version = "^3.36.0", optional=true}
pytesseract = {version = "^0.3.10", optional=true}
html2text = {version="^2020.1.16", optional=true}
numexpr = "^2.8.4"
duckduckgo-search = {version="^2.8.6", optional=true}
[tool.poetry.group.docs.dependencies]
autodoc_pydantic = "^1.8.0"
myst_parser = "^0.18.1"
nbsphinx = "^0.8.9"
sphinx = "^4.5.0"
sphinx-autobuild = "^2021.3.14"
sphinx_book_theme = "^0.3.3"
sphinx_rtd_theme = "^1.0.0"
sphinx-typlog-theme = "^0.8.0"
sphinx-panels = "^0.6.0"
toml = "^0.10.2"
myst-nb = "^0.17.1"
linkchecker = "^10.2.1"
sphinx-copybutton = "^0.5.1"
[tool.poetry.group.test.dependencies]
pytest = "^7.3.0"
pytest-cov = "^4.0.0"
pytest-dotenv = "^0.5.2"
duckdb-engine = "^0.7.0"
pytest-watcher = "^0.2.6"
freezegun = "^1.2.2"
responses = "^0.22.0"
pytest-asyncio = "^0.20.3"
[tool.poetry.group.test_integration]
optional = true
[tool.poetry.group.test_integration.dependencies]
pytest-vcr = "^1.0.2"
wrapt = "^1.15.0"
openai = "^0.27.4"
elasticsearch = {extras = ["async"], version = "^8.6.2"}
redis = "^4.5.4"
pinecone-client = "^2.2.1"
pinecone-text = "^0.4.2"
clickhouse-connect = "^0.5.14"
pgvector = "^0.1.6"
transformers = "^4.27.4"
pandas = "^2.0.0"
deeplake = "^3.2.21"
weaviate-client = "^3.15.5"
torch = "^1.0.0"
chromadb = "^0.3.21"
tiktoken = "^0.3.3"
python-dotenv = "^1.0.0"
sentence-transformers = "^2"
gptcache = "^0.1.9"
promptlayer = "^0.1.80"
[tool.poetry.group.lint.dependencies]
ruff = "^0.0.249"
types-toml = "^0.10.8.1"
types-redis = "^4.3.21.6"
black = "^23.1.0"
[tool.poetry.group.typing.dependencies]
mypy = "^0.991"
types-pyyaml = "^6.0.12.2"
types-requests = "^2.28.11.5"
[tool.poetry.group.dev]
optional = true
[tool.poetry.group.dev.dependencies]
jupyter = "^1.0.0"
playwright = "^1.28.0"
setuptools = "^67.6.1"
[tool.poetry.extras]
llms = ["anthropic", "cohere", "openai", "nlpcloud", "huggingface_hub", "manifest-ml", "torch", "transformers"]
qdrant = ["qdrant-client"]
openai = ["openai"]
cohere = ["cohere"]
embeddings = ["sentence-transformers"]
all = ["anthropic", "cohere", "openai", "nlpcloud", "huggingface_hub", "jina", "manifest-ml", "elasticsearch", "opensearch-py", "google-search-results", "faiss-cpu", "sentence-transformers", "transformers", "spacy", "nltk", "wikipedia", "beautifulsoup4", "tiktoken", "torch", "jinja2", "pinecone-client", "pinecone-text", "weaviate-client", "redis", "google-api-python-client", "wolframalpha", "qdrant-client", "tensorflow-text", "pypdf", "networkx", "nomic", "aleph-alpha-client", "deeplake", "pgvector", "psycopg2-binary", "boto3", "pyowm", "pytesseract", "html2text", "atlassian-python-api", "gptcache", "duckduckgo-search", "arxiv", "azure-identity", "clickhouse-connect"]
[tool.ruff]
select = [
"E", # pycodestyle
"F", # pyflakes
"I", # isort
]
exclude = [
"tests/integration_tests/examples/non-utf8-encoding.py",
]
[tool.mypy]
ignore_missing_imports = "True"
disallow_untyped_defs = "True"
exclude = ["notebooks"]
[tool.coverage.run]
omit = [
"tests/*",
]
[build-system]
requires = ["poetry-core>=1.0.0"]
build-backend = "poetry.core.masonry.api"
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,695 | Allow Weaviate initialization with alternative embedding implementation | I would like to provide an 'embeddings' parameter for the initialization of the Weaviate vector store, as I do not want to start the Weaviate server with the OpenAI key in order to make use of embeddings through the Azure OpenAI Service.
The addition of the embeddings parameter affects the __init__ method, as shown in the code snippet above. To accommodate this change, you'll also need to modify the add_texts method.
```python
def __init__(
self,
client: Any,
index_name: str,
text_key: str,
embedding_function: Optional[Embeddings] = None,
attributes: Optional[List[str]] = None,
):
"""Initialize with Weaviate client."""
try:
import weaviate
except ImportError:
raise ValueError(
"Could not import weaviate python package. "
"Please install it with `pip install weaviate-client`."
)
if not isinstance(client, weaviate.Client):
raise ValueError(
f"client should be an instance of weaviate.Client, got {type(client)}"
)
self._client = client
self._index_name = index_name
self._text_key = text_key
self._embedding_function = embedding_function
self._query_attrs = [self._text_key]
if attributes is not None:
self._query_attrs.extend(attributes)
```
To check if the embeddings parameter was provided during initialization and perform the necessary actions, you can modify the add_texts method in the following way:
```python
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> List[str]:
"""Upload texts with metadata (properties) to Weaviate."""
from weaviate.util import get_valid_uuid
with self._client.batch as batch:
ids = []
for i, doc in enumerate(texts):
data_properties = {
self._text_key: doc,
}
if metadatas is not None:
for key in metadatas[i].keys():
data_properties[key] = metadatas[i][key]
_id = get_valid_uuid(uuid4())
if self._embedding_function is not None:
embeddings = self._embedding_function.embed_documents(list(doc))
batch.add_data_object(data_properties, self._index_name, _id, vector=embeddings[0])
else:
batch.add_data_object(data_properties, self._index_name, _id)
ids.append(_id)
return ids
``` | https://github.com/langchain-ai/langchain/issues/2695 | https://github.com/langchain-ai/langchain/pull/3608 | 615812581ea3175b3ae9ec59036008d013052396 | 440c98e24bf3f18c132694309872592ef550e1bc | "2023-04-11T05:19:00Z" | python | "2023-04-27T04:45:03Z" | langchain/vectorstores/weaviate.py | """Wrapper around weaviate vector database."""
from __future__ import annotations
from typing import Any, Dict, Iterable, List, Optional, Type
from uuid import uuid4
import numpy as np
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from langchain.utils import get_from_dict_or_env
from langchain.vectorstores.base import VectorStore
from langchain.vectorstores.utils import maximal_marginal_relevance
def _default_schema(index_name: str) -> Dict:
return {
"class": index_name,
"properties": [
{
"name": "text",
"dataType": ["text"],
}
],
}
def _create_weaviate_client(**kwargs: Any) -> Any:
client = kwargs.get("client")
if client is not None:
return client
weaviate_url = get_from_dict_or_env(kwargs, "weaviate_url", "WEAVIATE_URL")
weaviate_api_key = get_from_dict_or_env(
kwargs, "weaviate_api_key", "WEAVIATE_API_KEY", None
)
try:
import weaviate
except ImportError:
raise ValueError(
"Could not import weaviate python package. "
"Please install it with `pip instal weaviate-client`"
)
auth = (
weaviate.auth.AuthApiKey(api_key=weaviate_api_key)
if weaviate_api_key is not None
else None
)
client = weaviate.Client(weaviate_url, auth_client_secret=auth)
return client
class Weaviate(VectorStore):
"""Wrapper around Weaviate vector database.
To use, you should have the ``weaviate-client`` python package installed.
Example:
.. code-block:: python
import weaviate
from langchain.vectorstores import Weaviate
client = weaviate.Client(url=os.environ["WEAVIATE_URL"], ...)
weaviate = Weaviate(client, index_name, text_key)
"""
def __init__(
self,
client: Any,
index_name: str,
text_key: str,
embedding: Optional[Embeddings] = None,
attributes: Optional[List[str]] = None,
):
"""Initialize with Weaviate client."""
try:
import weaviate
except ImportError:
raise ValueError(
"Could not import weaviate python package. "
"Please install it with `pip install weaviate-client`."
)
if not isinstance(client, weaviate.Client):
raise ValueError(
f"client should be an instance of weaviate.Client, got {type(client)}"
)
self._client = client
self._index_name = index_name
self._embedding = embedding
self._text_key = text_key
self._query_attrs = [self._text_key]
if attributes is not None:
self._query_attrs.extend(attributes)
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> List[str]:
"""Upload texts with metadata (properties) to Weaviate."""
from weaviate.util import get_valid_uuid
with self._client.batch as batch:
ids = []
for i, doc in enumerate(texts):
data_properties = {
self._text_key: doc,
}
if metadatas is not None:
for key in metadatas[i].keys():
data_properties[key] = metadatas[i][key]
_id = get_valid_uuid(uuid4())
batch.add_data_object(
data_object=data_properties, class_name=self._index_name, uuid=_id
)
ids.append(_id)
return ids
def similarity_search(
self, query: str, k: int = 4, **kwargs: Any
) -> List[Document]:
"""Return docs most similar to query.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the query.
"""
content: Dict[str, Any] = {"concepts": [query]}
if kwargs.get("search_distance"):
content["certainty"] = kwargs.get("search_distance")
query_obj = self._client.query.get(self._index_name, self._query_attrs)
if kwargs.get("where_filter"):
query_obj = query_obj.with_where(kwargs.get("where_filter"))
result = query_obj.with_near_text(content).with_limit(k).do()
if "errors" in result:
raise ValueError(f"Error during query: {result['errors']}")
docs = []
for res in result["data"]["Get"][self._index_name]:
text = res.pop(self._text_key)
docs.append(Document(page_content=text, metadata=res))
return docs
def similarity_search_by_vector(
self, embedding: List[float], k: int = 4, **kwargs: Any
) -> List[Document]:
"""Look up similar documents by embedding vector in Weaviate."""
vector = {"vector": embedding}
query_obj = self._client.query.get(self._index_name, self._query_attrs)
if kwargs.get("where_filter"):
query_obj = query_obj.with_where(kwargs.get("where_filter"))
result = query_obj.with_near_vector(vector).with_limit(k).do()
if "errors" in result:
raise ValueError(f"Error during query: {result['errors']}")
docs = []
for res in result["data"]["Get"][self._index_name]:
text = res.pop(self._text_key)
docs.append(Document(page_content=text, metadata=res))
return docs
def max_marginal_relevance_search(
self,
query: str,
k: int = 4,
fetch_k: int = 20,
lambda_mult: float = 0.5,
**kwargs: Any,
) -> List[Document]:
"""Return docs selected using the maximal marginal relevance.
Maximal marginal relevance optimizes for similarity to query AND diversity
among selected documents.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
fetch_k: Number of Documents to fetch to pass to MMR algorithm.
lambda_mult: Number between 0 and 1 that determines the degree
of diversity among the results with 0 corresponding
to maximum diversity and 1 to minimum diversity.
Defaults to 0.5.
Returns:
List of Documents selected by maximal marginal relevance.
"""
if self._embedding is not None:
embedding = self._embedding.embed_query(query)
else:
raise ValueError(
"max_marginal_relevance_search requires a suitable Embeddings object"
)
return self.max_marginal_relevance_search_by_vector(
embedding, k=k, fetch_k=fetch_k, lambda_mult=lambda_mult, **kwargs
)
def max_marginal_relevance_search_by_vector(
self,
embedding: List[float],
k: int = 4,
fetch_k: int = 20,
lambda_mult: float = 0.5,
**kwargs: Any,
) -> List[Document]:
"""Return docs selected using the maximal marginal relevance.
Maximal marginal relevance optimizes for similarity to query AND diversity
among selected documents.
Args:
embedding: Embedding to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
fetch_k: Number of Documents to fetch to pass to MMR algorithm.
lambda_mult: Number between 0 and 1 that determines the degree
of diversity among the results with 0 corresponding
to maximum diversity and 1 to minimum diversity.
Defaults to 0.5.
Returns:
List of Documents selected by maximal marginal relevance.
"""
vector = {"vector": embedding}
query_obj = self._client.query.get(self._index_name, self._query_attrs)
if kwargs.get("where_filter"):
query_obj = query_obj.with_where(kwargs.get("where_filter"))
results = (
query_obj.with_additional("vector")
.with_near_vector(vector)
.with_limit(fetch_k)
.do()
)
payload = results["data"]["Get"][self._index_name]
embeddings = [result["_additional"]["vector"] for result in payload]
mmr_selected = maximal_marginal_relevance(
np.array(embedding), embeddings, k=k, lambda_mult=lambda_mult
)
docs = []
for idx in mmr_selected:
text = payload[idx].pop(self._text_key)
payload[idx].pop("_additional")
meta = payload[idx]
docs.append(Document(page_content=text, metadata=meta))
return docs
@classmethod
def from_texts(
cls: Type[Weaviate],
texts: List[str],
embedding: Embeddings,
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> Weaviate:
"""Construct Weaviate wrapper from raw documents.
This is a user-friendly interface that:
1. Embeds documents.
2. Creates a new index for the embeddings in the Weaviate instance.
3. Adds the documents to the newly created Weaviate index.
This is intended to be a quick way to get started.
Example:
.. code-block:: python
from langchain.vectorstores.weaviate import Weaviate
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
weaviate = Weaviate.from_texts(
texts,
embeddings,
weaviate_url="http://localhost:8080"
)
"""
client = _create_weaviate_client(**kwargs)
from weaviate.util import get_valid_uuid
index_name = kwargs.get("index_name", f"LangChain_{uuid4().hex}")
embeddings = embedding.embed_documents(texts) if embedding else None
text_key = "text"
schema = _default_schema(index_name)
attributes = list(metadatas[0].keys()) if metadatas else None
# check whether the index already exists
if not client.schema.contains(schema):
client.schema.create_class(schema)
with client.batch as batch:
for i, text in enumerate(texts):
data_properties = {
text_key: text,
}
if metadatas is not None:
for key in metadatas[i].keys():
data_properties[key] = metadatas[i][key]
_id = get_valid_uuid(uuid4())
# if an embedding strategy is not provided, we let
# weaviate create the embedding. Note that this will only
# work if weaviate has been installed with a vectorizer module
# like text2vec-contextionary for example
params = {
"uuid": _id,
"data_object": data_properties,
"class_name": index_name,
}
if embeddings is not None:
params["vector"] = embeddings[i]
batch.add_data_object(**params)
batch.flush()
return cls(client, index_name, text_key, embedding, attributes)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,695 | Allow Weaviate initialization with alternative embedding implementation | I would like to provide an 'embeddings' parameter for the initialization of the Weaviate vector store, as I do not want to start the Weaviate server with the OpenAI key in order to make use of embeddings through the Azure OpenAI Service.
The addition of the embeddings parameter affects the __init__ method, as shown in the code snippet above. To accommodate this change, you'll also need to modify the add_texts method.
```python
def __init__(
self,
client: Any,
index_name: str,
text_key: str,
embedding_function: Optional[Embeddings] = None,
attributes: Optional[List[str]] = None,
):
"""Initialize with Weaviate client."""
try:
import weaviate
except ImportError:
raise ValueError(
"Could not import weaviate python package. "
"Please install it with `pip install weaviate-client`."
)
if not isinstance(client, weaviate.Client):
raise ValueError(
f"client should be an instance of weaviate.Client, got {type(client)}"
)
self._client = client
self._index_name = index_name
self._text_key = text_key
self._embedding_function = embedding_function
self._query_attrs = [self._text_key]
if attributes is not None:
self._query_attrs.extend(attributes)
```
To check if the embeddings parameter was provided during initialization and perform the necessary actions, you can modify the add_texts method in the following way:
```python
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> List[str]:
"""Upload texts with metadata (properties) to Weaviate."""
from weaviate.util import get_valid_uuid
with self._client.batch as batch:
ids = []
for i, doc in enumerate(texts):
data_properties = {
self._text_key: doc,
}
if metadatas is not None:
for key in metadatas[i].keys():
data_properties[key] = metadatas[i][key]
_id = get_valid_uuid(uuid4())
if self._embedding_function is not None:
embeddings = self._embedding_function.embed_documents(list(doc))
batch.add_data_object(data_properties, self._index_name, _id, vector=embeddings[0])
else:
batch.add_data_object(data_properties, self._index_name, _id)
ids.append(_id)
return ids
``` | https://github.com/langchain-ai/langchain/issues/2695 | https://github.com/langchain-ai/langchain/pull/3608 | 615812581ea3175b3ae9ec59036008d013052396 | 440c98e24bf3f18c132694309872592ef550e1bc | "2023-04-11T05:19:00Z" | python | "2023-04-27T04:45:03Z" | tests/integration_tests/vectorstores/cassettes/test_weaviate/TestWeaviate.test_max_marginal_relevance_search.yaml | interactions:
- request:
body: '{"input": [[8134], [2308], [43673]], "encoding_format": "base64"}'
headers:
Accept:
- '*/*'
Accept-Encoding:
- gzip, deflate
Connection:
- keep-alive
Content-Length:
- '65'
Content-Type:
- application/json
User-Agent:
- User-Agent-DUMMY
X-OpenAI-Client-User-Agent:
- X-OpenAI-Client-User-Agent-DUMMY
authorization:
- authorization-DUMMY
method: POST
uri: https://api.openai.com/v1/engines/text-embedding-ada-002/embeddings
response:
body:
string: !!binary |
H4sIAAAAAAAAA1R5W9OCPLPl/f4Vb723TpWIQNrvDgGRkwmCx7kCVARETiaB7D8/pc+umZobq8AU
Denu1Wut/Pd//fPPv01a3rPPv//5599XMXz+/V/fe7fkk/z7n3/+93/9888///z37/f/W3mv0/vt
Vrzz3/Lfn8X7dh///c8/0v+98/8W/eeffzflpGFN69f9MvIWnnbx7i9m87FBQt6VGfjhmzMj2ix8
XtuLCtWQbNg6XazMUY4gQIF5Vilv+xsarRVgKGGW4qXo7HIpja9K+7jJQIKF3vvT4zo/IT2zJIKD
3kR8UDZ3OB2mgq1fxttsH+f7DBF/JTOXo9Sn7e6Qac8bLYiXZFL6jYfh+dFiKpdZno4qa20Qnwsn
Jm72aMLP0wHN5KJga3mlmgPfnStw4qAi5rJcp+OOdxH4ejqnKprKsto+ywAlO75mj0VvIeZLgYKK
eG0R1xhRz9Bna8BhHhFcmzvh9/12naGVlhyI1Z1qMfiRZSPWNC/mWffanK7HrkBzulaJ+dpuEU9c
PNOKc+aSLXt7Md+CCuixXhvMQ/s+ntLTtQLTmdk079U8Hc5EG6BtxZ5OhMVodOnRhmMjbbB4nHnM
jgaXULzIW2Z0+9ofXX2dgeHNfWIGx51JsfAaKLuLSU79O/WFZWwAUK1uSXCa6zEz6B5Qci0+xJpv
NqkcNKoDu/pWMeOdrGKxPYYXWJ4uIUvczxGJXX/NUX1MGmYLa9fz8/XmoWdFdarZ/tqU9Rm5qHBQ
DLJ/NSESefWsYePomJzh5JrTc4joSjBxZvZ1aM3mbIch7G9Whpvd5l3SFBMKkpVgQqI8KKeo7HPI
5lXE1tYuNCd9RhLtoeCQBVNw7we5cBw0efsNM2vJEJK31SrI2OVJkmqxFxMRKoVXlFFimRR8MdOv
OcrW7wszon6GxGvUQ6imaEV2RaX3PGSNAfMim+PCEq3J4+k+/OKT4Ib6uA52XQKgxwGtbl3VT3sp
5yAqfKNMqkQ5dK43oditA7KTp2UpdqExgV3EjCpzYotJm9YZzE9DTLz5YdtPm8gBWGTxlvjlpi1H
1+0VUMhsQ9HtOKWDWskSJLzwiVFLcT9d/KsO53h/JgZ/b+PRaK8BlII7eMbQ3Z9eindQ7Qc7MWdV
9GKwTl0D32usMvuZ8h1dK2AtpRvxvv3NeKRaSDTznspueYj5/ugcAFddSAiVMp+eWOzNWW8GzLqH
OOZ1X08wfDqd+E4thIiWPICePQ60ASh88VRuBYqKitGhzSEeGfiAZmjPKUjJOp2eCU1gJ/dHHO4T
rx9399UM2p0sEaN6UtRsiazApqtrPL/XL7/polcAi+MjpfJ1aP2ueYMH6vF+weKdBGVVX57a6sjd
gfjbcymmFBkTbIbVjqSn+d4UaHHRYL9e9sQ6VoE51nORraxRH5m1NFxfvAVRoBymjnYcdSkz3IYj
TfJmxD1pYTw1apPBnjxMZhlFUzLp3lDkzosCq6eDXXJV7h20kY8RW3f7k5gehYuhOF57sl0GaTxl
m8MJvU024EWZjf63ngvo5puJHnf6uRSXqahXFy974d/+fDZXX0e1IYd41lzb8uOmIV7JxAypVMdd
KZ7eWlnR8XEmDs2dlJdTVMAPT5z0XonBnvIM7mGbM2e32Zb0YWsZfPGIxtxmPj8TjSJqOjEhSdmg
aSNPDjBFOpEj3jpoYgtXg7I5vphT8b3JVX3TQak8T8QdlLtoM3V/X/VyNrGN/AzReLuPHBYGMunU
VL45Ld+OAt98YOV10sT4GbUMTkbgsetqHfeca1GHJOuCqbAUraex60u/a3Y+FJ1geHAqUKzPAbNv
/qfjy20gapOU/fCVHQ1FRvv6/qRFt7dN8bzhCSX0NjCSxXnKs5c1wSHIbYYfn7f/24/VIxs/zNt7
TSw6AjLKkeOR3afciqruaw76cpGzred+UsG9d4DOo/3Ek9SVvRCqc0HfecLctJTT0S4PhSavU4Wq
0b6LJ+00UXA0vMarRV2ZbcAERtvrfUWcObGR1C1PCRDhb5g1q1bo7V9kBw1tgMiWrfVSvhzQHcqy
PhNval5x2ywdG1ZlssQafbXmrz4AHQ6MPcx7a07Z2enArLSSvp/4Y/7lT3PwEy8BJjTemixAUXtJ
yZq4iWjcIglBSYeR1lJ86wWPRlujWtsR/3acYnZpdQ9Qvk2J85RsfxFLcwupMznDEm7W/jRbvAPU
+vcd2S1VR/B2pgZIuvGI+c8LLvlZKhW4XxeCBItaEuK2f3jIiXFFdvZRpNTOogx2TW6wPemKePD2
NwNgmSUk4u93zIOSJyjtLJ3FC7lOKcbXO6RzY078h7GLxRJqBxL/U2J13+f9uPNHG9hTUslmdUvR
pBPBUTrX58Se7qYQBr0CKh1XogqejHKRxGMAF0lPqSzrSt8eB3MAqVdfxHbOueBmcPVQod8HOuyJ
a47y8pWg50mRSWy/jv3QJo6Bhlo6kKxbm0K+Q65BEn3WWK24nrZDkATgn9OM3k+l2jdrHofIOa8m
uuDjte/YbDhBt61TLK3Tcyz62bKAZq9d6N6sWjGKLWog3Tw8ssGfqRRSYzrQpHaPF33h9lOUrC1I
lV2MV0vVQWOidAnk++r4nc+39KXQyVgdVrsRi6jHJo93nxzdPuqJeMyfUJ9cPEXz/Y5T6fXRBW+d
lKLrpw6Zvc4Vfzq6mgLj0TtiKV5y9JGpASigPGXXbVT67IuPaFk4QGxzJ8zm7mcOrIPsRHzaaT3b
ausKakMKSeDUpsk55xjpEL0YvuuBP7oxPkEgWMqM7B71/JDrGlAlNontuTOzlmL5jprqzllALd3n
ct9VSDmoG+K8zYX4zisN1Cy08Gptlz0dVjZG9fZ9p8rhnaXcd9oGdqoJOKpxi0Sz6U/o7Tgj247n
tRCkevHVvjAz4t9QZn5O83kDcq1T4rERejoritNv3rKg7Iue2muTwvJRlcS6vpt0GpMiQEVsWszx
kSp4Jo823PqCYW22k1OxStQAvvznh7c9X70tA6TreUfII8BiWvimrX2/j4p3MvS//V1NQkZ4drae
/gjN4oRm/WaOlfxzEJPLFxmM90PDDN0rzUl5UBs1he3iZYEac9JO2qBNWvcmNk3f5TR3vEYly9pj
ru2P4otXCVQ3L2Br3ROCX8OWAxHuhv3mH+/mTQi3C5wZNiI7Zevl5qR1IlcICcW+/OPfF0W0+M3D
sB9n+NhBU1guewT8GHPJ9v7mGWX7K0q/88/7PY/Ogr5E4qAuJVQs3hnuNa9Np0nOdbAZ2tL5bmmX
fD4ec7A29gEv8Cfqp81rJ8GX/xILN0+THubtCWbT5oZnGzymfHV71oBPC5sEzgb1zTPQIrjUZE8X
J05RmbuJBCRz38SMNlY8XU0Zg52Aw9zD2++/+bJAj5QnnuWw9JlC3Br5buRiEe+XSAhVv4CYzx1K
z9ba5IfcUWBeKxbZLTZZyXMOCQqxypmnzOxy4b1ain54ve5no+h3EgKUf446Cc4vz+TeLLRWv/ka
WMY8Fd3z6cF7FT8ZuYSWKbt8lcEiHHbMGXZmOfkBOoASFXfmMHvyGUnNA7B16/zxjfE4mFQVt2DO
tuhjICmRDQOi6DJjulkl5USlRIZne8NMX/hDP+60YECv19rGC/deoNFeOPKPj7BM40XcJ/apRvFS
Db/8pS6nTdonYDxnLdkeCg9NGioV9OuHTa2WPQ8P+wjWmkioom2uMd83uwApFjsQommH8hNtpATt
7Fjgj+ooolXf5wCSs2ezrXDnfocmXqwOyv3XT04s1++dBZm5mtP3Nx69HMQdFNe5kptSEH+M7f6O
tI+bM3OlGr2ojsZ3PlZn5hiD50+nQ3CBbzyqktsNfVr2CbU3hhvx/SQ3+dU5a6jYEI2QT+P0o7na
OCiXPxsKLBT9cBIgI6InwH540If7RkHLy7TEalCx+I8PT6s1ZlZjFuZn2gYVyqXTnViO0iKmzYII
zqP1pCvqjj0PjWEGxWanMVzyMh1fIZ9WX35B4fzyfGEp5R2S+x5hjY3ZT694UIrJIetQjeJfvwBs
bYUqX3wRCc6z1U//rZg89NPdNi8/fY1XloF7yhxbAgrUITheV+JjO5vptx8Y7fk65k+00+B4aQ7s
obyZ4FKHclh1QUk2J+/lc6zEF8CH+4O5M0pLrqZZgi6rgLL1++ijyTVaGXVnHrAdgo0pT+4wA+bc
JRK0eRbz98zzIBben15N+2MQR4D6Q0AIxVM6abswXD1Pmown3TPNKX2AjkJBL3SxTu1eqp63CAW4
6oj3duSS//bDrJSS6VWG/U/vlw6Y0cnH2lHgdLo/Ew+V86PBgtvx2U/vg45huV/5mOt9YHLpebVh
vJ8a2odt6AuLrQ14hdaWWa9PLuihSipgKFj99GT/ua6PkqZH2pOYt+4Yj2UfZvDDdyLvccn3947D
9qYYLLLzyuTv4SbDrASPjk2FEH9fwxm0VvNkpj/U6If/mnWMNt96LfpGttUEFlctp/IZxpLXhXUA
x5Ue33l7MQVKPAc5x5fPfvxdrvm7gO9+k7VIrZTr60uNum2VUh5vN/0k6WqFiPsiX76clNPpxQc4
PjKdXdJ7hSZ0fk4ocU9AnKuv+4tio2D4nMs5c7dRaTL/qRvIkNUGI+VG0+7H75sLtehyXPXlp82a
BO58sSfOZNz8YfvsMagJqTHNT5+UX8PnBD9+pmtJFvf7VyahOJrtsTw4BloqhX1HWjnfEWOXMX/M
gnsCX/+IasrtYU7ttGlgqtfjL9/9x43xAYZTU7Kv/hDjDF0oXLru9NdvvKuu+Y+/k2C/mBB7xsMJ
9OPeYU6RMCEW552C5KBrqRffduZYXisP7HabMnd+UNLpGjgWvDeTRwL5Y5vDEGchLOCuMG9QsDkA
m1/QkfsDXbV534t3+7pD9D6u2Pa1jP9Hb9QZPuDlE+98QeZSDvhKPkzPrqMQfNlF6LxYMuZ88VDQ
yNNhjDdLFkRg+eIZDweNbtGTbc+QI36e2Qc4MPvOPHcb+NMm0mcA1rAnxPqo/qTmRw/9/ITO/SzQ
Tx/B9AxLcmhaH02L+3YGb6+8fJ+nC36Weg1to3bP1oEs+2MuMq5JtymiM+rm6FPLex0S4xky/2F8
0sm98fqnn7/8c5l2yoNaMFzXHilEfvwffyzUcovcs3hvchs8DV00aUsSP+Gij9YJRbFbBVSuep72
B368wI8v59v1zhySRIQwQzGnizFa+4vyOnhgyKhhehe80in6bAA6fNnS8aFc0ym1XhGogRWTC7kM
MbtdWwMyEnD244PTOI8vUJqXmm3168mf7tBocD62M7o8LUg/vspFgx5datMfX2X3Ust/9UPHQJbN
tq4qClE/GlRdvW+pOL47A+0qe0V++eFVt6RwPeCATnFQx+N3/eo3762vvuaZrFrQ6iTDf/3RpOoB
0s7Wab59n9BnkbJaVbPIIkYc2LEMTxShU/t5ks2s+vhjX48afPTgyswAyYjOZ7mDvn4lwwzNfCqx
HYZpWNzI1twVMecPUwO6KTRGGPrE4jO0w49Pke03/vQIMw2drGpk7pgVPd8f9RN0iSOY7ye6/40f
AjtZO/Llr6VYVXH3x//I2Y36Xz5/eoJ5dRGgaW1fD3AICpvOonwVT28j1dA8ty9El5VtL5NV5sFW
t1Wih1IupmY81T88w5onbf3BHL0DHPtgYLuSH/zqYE0e+vpFXz5Zx+we2RisbYbITz+Ir/5AyaRN
ON3zZywqPzfQY0wqEmhEQ8Pwcioog0pl/un6Tif3WFOQ8lP/6xdzgPhiI37Vtz/9mLKnt9aQmuxq
sn3ib//3lz9+gKftsCxZpaJOY9J1z0i424rRwN4ddt6gkEA132nxq0f5+Wrx8l1Rf7itvQYupdwx
LE81God3M4P9RHZ0nsV6/Ocv4+vu8/1e6cfvbGjPgcrsdzVDo24qoP3wuX2dPF9a+52N7tq6Ip5y
m/vVhFwKlq/pf/NN+fql6sa7LIgZXtx0nHdpBjw/UvriPhNCvA8WOlGnZvhUXsvx8WgkYN4yxXLV
h6mcPiQDFdvwgmUcaGm7TVoPUmguxPa6V8l+9XP5GCtiLY3WH9WbxFUd7zsW5PugHNytmcNKVA3Z
5k0Z8/dwlP78tuLrv32/ZwZVsQkI+fqZP78N+aBHNJ1reckrfElQy6sZ2/BRLUUqOYMmN9cjSTKX
9IOV7yzEPqnAkk5MwVeKcoBjYVzJdp1vY7HV1jUQS15TrmIHjaA9O/SiuyuV60sff+d1jfJ9fWTf
fjK5fd5ThA4nhqXpapoc1v0Eic9Kym+5aXIn/MxQupCHr94cfP646fefn80852nEbFXFDexjzWXm
9a2afFmRCdZiRb98JYobtZrJ8MVPghf9oqfVR5FhtXl/6LSZZ6WUujMDYoPnf/jfkWJ3AbbuHZxo
/bOkX38ZHdlcY/6eqILdSv+OLitMf/rNH8twTbWHED4h3fgQ0yBKDl9/EXdszMpvfAk0DTpiRd4C
iQTAgijUz+RUz44+Q4tQgefbfpNNQ1exuJdTAV9+y8xl+YyHZD5k0C3UB0a98xJ0be8PsB5fW/Kb
Z+J9aiqgc5vh5XXUyrEoHgVaPY3wp7dNNsaNB996xTN2lFJ5eZ8bcAfL+Os/KXHtGTw29+0Pr1L6
6PsGSubvmX+wi58/X6CPexnYtdQdxJfJ66R965U2eCrKkZyMCuLjSWE7G9187qc0h68fTHS68GPa
jPcazZJ6w3aqo6Cpfm8sTdRvi/lfPivdDiSHarVcYh6EN5MqGsiwTZfVn1+1fFmbAFbB9YrRDWU+
//XfqWVP4rnbwR+V225ALa9n9J0oPWptZzdB3s2uX/63SMdMvd7BuNQV2bh3Q0wnr51Bc7tFLNNI
gsao+9TwAW/x9Q+dWGL3TEYPMfpUgxx9z0cuCbqlpxnBIc3/3g8pBDYs6N6f8usva0jeSCvmhy33
RbrdNeiLv8RoPQm1Z51O6NufZCc9IsS110uBxzMQFB2jk8kPOKshxe2N/c5zpikmCbB+HVDRepXP
50F1AqLORmbv9FrwctceID02iKwX46vkbhGF8MVbts7mnfh8z+cgvj99Ylb6qR89L5r9+UvdTe76
uzGT77DQ7D0tNtdJDNaoJsjn45O5+afy5UV9lcDt1OF7XiDFbdG1F+Tr1zn5nRcxR+MdcuUDYVtT
BKaQzP0MvvwfS7V6SOn74GD01ePMzO5PNElsF8CGHSVCcqhj4YmjBI/GeOBxo/nmGE76ZfXFVyxM
M0fjN39o9dRD5r2dU9//+PS4PfsM2yiIR+/1pKvepC2Vd3VY8vBwDcH+FDlzv/VJ54OQUDjfR3Q4
KswcG29nwPV2ebAw9Z7ix79hu4y2hLinh8kf65EiuNtHtqW5aopLPgt/+vDHJ8w/vt7OghPz6/cs
pXrvFZDLbEMs36clLZywBksjFsN41pQjAxNgdRzvLPjqcfb1Y+GBu4SCHa4Rjx9XCa2ViyA/P2Dq
sVmsxnS2Jp7tP83JfkkKIsZYEvs1Pctvvk+wLZYGfr8r7I+owSEsQvp/AAAA//+knUuvo8CWpef1
K0p3Sl+BMRBBzXiblwlexrbUagG2MWCMDUQAIdV/L+Fzu9WDGnUPM5XHacdjr7W+vc05bvnQoLVf
kRgGE98gtSO1TodwEH79loDlIzwQQzMZ6MYWQObLt4cd+hxKuPGqgNNqu1k+ZX/5+deNJ8ZgZeTF
ggoz+MgGa5qs4Nv1UhEdeeLIatLMt/RQAVnhHsRP6omOm178rb87A7eg9F0a8MK+Tr9+VrPxuC+g
9iIht+lU8Oe//MjTcV/nCNChvgRQWtYz8iT3k9DDMaggI2cBOroXNMzNmldQXnwVuRuPw84s32EE
iip4qnsMSEy6TNzuz18/e7deBAlufPovfwxRIV1++oC0a/0eZrUTOHnTX/zjJ3P6aVLIFo/nrx+l
r+GYCbDqmhRzcK0GutzcDgrXzEWaz7+K5YpD4c+f60WaevO9+0rQdvgHOTCfI6XaHuZAdpU1kJru
SalWTr10IrKE9Hv40CcaZRbMwtONmE9nTGYvNgwoH74exiGuvOVUf0LAdNkS3HZd6/3dr19/Wbt7
07CdHx6GUBiwuPWrh9uBG+EusbgfH2qWa9m24OevVI1R9DkU3fKXN4hXrQZdZkg1+I/fVMB//o//
h4mC3X8/UZCb8xuDg1Z7i/FNcnDJ05DEl88DtEl5DAFP3BdBUDkUPNMLGtCjyCBIwsUw1YpayqLs
35D/xYU3Fw6PocMyLmYXbZcsVdz38CCOLDpIqgSW82QzMOXbOHDNE6NPy1r2EE2WTrRAFovv9XVp
AXjVJgmWMB4WqoBMir+DgrxFQWB2udCS+cCKie6rb7DocO2gpxlLsPIvfaCHXOphjl8lFotzmEzD
m+kArx414tyKAx2PKMLAvT8s5Nz5T7FkvmcDPAshSYfkBbDLVqEsntWSBPv0A+ZJcVJQCGwVMMn4
aMY13jrwkbuioANZQiON8GDu+oqYQthvHa+ZAxJcxq0DK1Is7twMPm1vR47zaHhTx2QpvEWJjacB
sMnk1XEon58vIaBpPDbDIKc+PBFJI2p1VLy+S6ccik8+whx2Pjqhu8KAzxh+SRFVafKZizGEX20N
kB6Vn6Q/3W0In/13Rgcy3pvefPYxlApyRWp4q5N5+lwEAKUlRz4r5gUFhpaLMtdaxBlEkS4XsRGg
qXIOuZxvDMCvl8jBj1TNRHs1eTGTJu2hDeIjscE+pYvyFBWorEcdqeYjLGj4eUrQn40HigZf1FeW
rXL5GRZJIGvk1swhz/uw8XYfou+d1RuFz+pC81wh5PBmpU9fowkhuxsbPOforM8jc2yBmUKBmNWl
aLC9qF+wLG8Y7EWhpd9F1kuYchpAPjjghgxyGYD29D0hRN50mIXTI5SKJskxdy7EYh4fegmhnC3I
kY1rMWecmMHP9X7DcwnbZLlbjwpEw+Cgg69PxSI7XQbtc98Qx7BFsJ79sYL3j8kRtcp4b4zB4QKp
vQ//zjtFJ6TBu60+MRzXeJiNR9uBkx9e0CVJezDj68GHka0/kHmrLwn5nZ/00mOihZfCm93TewUf
qZ6Rn/vRML8/dggvjWMFPCNMdEbOrYTfthAxjFttIPZLMaA10pZs+1sQJ64EmcPvCpl42jfkbvqr
tD9JbMBcurxY2+gOAR8YMbF0gae0wS2EjBv7yBnEKxjdr/Zl2/D5RhqnvIr5ol8UWBqnCTk1yybE
aowcHIpAD4ThNBTz13AEUFOFI9bhTOhU3FcI22O+D+Zxd/EW5Tx0gKWOjxRt7xZLf3bvQIZpj4L5
boGZ8n4JtSpY0MFhT5SeEs0G47s+4Tb+HIdBueAMTl3tE8VvZoBhx2Uwk0ILIatY6Fzcrx343u0c
JXCsB3IsvBj2p7OAkAgRXSfuach8HZ0wL3D8MNKBVSDzYGJiAF0fZku49OBVaVfkOcKrIBYhGeDr
5ET8a1NQWtz6AB7v7xyHwOX0+RuOPOiydSUuI9GEfvSwlo9t9CQBP6T6EA7sRRQMiUfGbhG8/jNd
75BQhSdqDbhiHN63ACZP6UQMTSS0dxyfl+g19YJhWYtmjo74C7nwI+Oeu5Q6zfhb+fv8SOvD9zAX
FbHAUUdBwOAcFaP5rGLojEAgSq/7xXB7ihcI59uTuI9IBfz7sWvhVwn2yBDuZjKHXmTDKqtclEi9
p+NDqHPwzfMwqGH01ee7ydjSwAQtss+3O13mYoyhLzcHvKuQ2czKJLXA8kgUsFfKDP3z/vVhdHSP
xDVPd52O99iQ2ws1iNFoqrd2t8qCuDsUAWaoBgaRXWyoECMhl/IsNuR8LlKw8OMXbevnUb5ke+Bb
MyYmSyq6LGv6hV3wTJF+NS4JbpFzB/ldMZC2P5NibsPUly7Vm2BsGyFYgZhUsDiLR2KkfKHPte8p
QIJBitRJtAp8+lxteJWfTgBzRi7mcucwcN/wDXJ72S4W88wFcACf47Z+TzqpKOKk7f2TIIju+oSf
fSWJpe2iQ/XK6FIMJwEIO9lB6HKRvWUu2hiCQ/ckh+e+Lqh1YRhw6+QAGeP+1sw1W2mymx0/SO3y
YzKLrqCBs9K8Avo83bw1BXMG3W5syXl5V/pSK879r9578rUpeofZZ8A1+wgpzfpOcNT4MShAvQ8q
Ix51XLtCCNshK5DW+bO3rAzbgXtzxUh7ZCNdFlgbUrVTLaS8jo636AfbgE1qHvAs79WEDjRYAXO7
AGSC9+qN54uBIZOYGrJ33/fQCalfg1fa+6gYg1anF+FqQ21dbeRd2KkY9/CawmoMQoKi+kqXWlHv
8hkx/qY/WrL7CHYIDzDOyMEfdW8dkyaGl0o7ByxUDsme6B8XViFvIGQ8PgmdKtIBGDGv4P2NZH10
udCAKE4QQld1BfMBqZY0sSeVBItoJ9xdTGzgBDkkSvy2vYlIXS5SokRE51pK1zEZYlBH8EkO2+th
3WEgnFPTQaoEeTr9/ERo38NAkMGYLEdz+oLnbQ+QKQ+fYUkPIoSlcZ4IUpW5WLT1ZcM+Lzuy/Tzo
Nj0CyDgNyJiPSjO34jCLW31Exxde9aWZvj7c/Aa68qai02NQpTDqqxw5Zv4qcGonKYjCUMaiAJpi
+/cBDEL7g+XdHdEuj8VcOuydHh1Lbt+s+Azv4Mh+JqRZIzfMb3b+gm/HhpiZ7xYlo7MPpMMxfuDq
dfx48/y6pHBq4C6YPxmrTxN/8wUAfI+cqfYc8CnuZ3Gv+GIweZXmrf1zCaH57RnkcY8efNpCV+T4
XEVI+fZus/jte4WV3XXE5T/BMN7G2ZeesxQQRQ6GYYWLukIB+QTpdh2Atbv1FrAShhDHzM1iP6bG
F+78xkABQzU6Zt5nhb0g10QtklfxaUO5A0u/WMRT56whH/1SQS/PAmTi9jnQ93fM4fiuTsRdto6A
uGtG+acHZsJHYH2eHhVk59eOHFQc6b10PNYwL8qJbPU+WV9Fe5HCjvWDERzw8OdvqkU4E2eYG7p+
i50CWh73wXuZM2/tkriXx9K2ydVsimI5uagEMsx6/CoYpeEn1TDgcxYConyyh9czXOjLonU3UGBP
1rCH+TpDtxAJ0phjPMyjXRgw9qcSedt9mltdjEEc8R4Wdt9Ds9PWyYYdeb/xaQIeXdP36Q5l9nYm
3jNcdYozO4Uqd/qgo6I6ydL7OwW6yrNBSC56unDHewjZL8D4uXueEvz+ehoEpu4iG1Yu2PTNB1a2
TWR1a5WsN8HO4ftp88TVpTKZO1u7Q7fIzrhxO8vjPo2vwddX/JLNP2/1x4jhazc+iCtMnUfdHQyg
Yp0BUpv2qy87nFrg3YxH9NgLQjE6DJuC8/MtBPMNh/p4D70O7i/3LIBfDLx1Z04SYL9ZhhR5/0zm
8eHd4R5aCrEHRtXnY+daYk01jrjedZdMa5LX8GHdlUAKkDBgJz0p8MYGA147P/Socuky+Ii4Y9AW
Te+tl6APpEI7HogOIoXuAjnh4ZEdpoAx902yfnAZQOPoegR98i5ZTfUVgDvj18iZVZtSZXJ84HUR
xZ/XOA6Td/E5SINnRrToaw17Gwh3CK/TgTj3I20ovtw4eFKZBwmIbuqTeYYBsImkBLvL7A+jjwse
qLyokD9/vvlFOEqDQVTw8geumWwelvp6wlh87pP101orHOezh/fn2vK4g4RtwD6aJ2auggmWyRVc
GH8/CinLK+sRlWSjlO6dL2Y659ssVKF//gapPFUAlkahhcvygsQKJaXgitR34aieUnKc9SChlK0q
ORWJin73cdr8nAS6ww1/L21K5zHlNci+UE+Q2yjDqqd+/ltvFD9YreFxrW55gneCEcxtsnjeRxAq
S0fIvfJVMXfumYFb/SKmfxb1b24PEMhmh4gNgoe36aMCjSNpAmksn8Vkz1Uob36BKHqleOvz0TJw
CBMVBVfBpD3rKb2ct1GDjIbzwbLpNdSm4Uq816UCn+kjxWBsGQYpEbMmtAUHAQra+YEZ8bkvVpme
YxgUuoRMmXsMuH8uMZhXbQpgQ55gvs7CCtWeLYl5XKWB5msqQRo0WbBH+bmY5teCoasbElL14kLX
2bzFYN3hJ/KkpvLmToYQLpyTED3PdMo1JEvhc/APeN/zxbDcRa6Cd7cVAj44Jt6aQxvCOGUkpORo
r+MUCBl0DFMP2mPg68vrFd5l5JRXUjiCmeyVGsww7g+fYHeKkmFV6vgCw/V8JQ6TGXRX+skK7lT6
EHcs1eTzWL4rTIL4S1x8ccB87DRLHqWPgfzGGvVxJ9guDIy5JCfcqgNl/XH9+7zz6TYkJId1Kgvq
esDyRghng08hFNVTho7HiQy05DsLFmdwxHNypfSX1+XqbdbESOKm+E4800ntkBbofB5KfWgEKf/5
FaLqcQ1oqdAWqu69whDWc7LGU4Rl/xV9yTF+gGJMIpYHc8jkmPt+Q2/Toxnui5eJHDu0B+5a3gRB
xYZL9K/1bJb9QfEh68Q6lnE/NlNweKZy+bCfJLZGrlmzHbTAVk+Q96VawbknMoOC+XREu8anYQrk
ggNOrbwxl06mRzNXyOF8LzS8VBmvz19DFSBP7Bex0Y6A6XT/ZvCrnzq8FnsKlscNbRMgRxn9ziP9
+WG0zi46jCdumLd6KMQopoF4cnX9l0/g7VO//vzkuOV54Fh9jkx+1xULQN8O8ul5Iao3yg3Z2y4D
P/p8RofWQGDjJyn85cnj7k7oegzLEoq6NCH3YzHF8n6UARTLqQ6Y9qjpy6eZcrj5U+K89Aysby4s
f34YS0oTF/Maiy4krGBt9yculooxR8hz/EjM8PGmI74iH54HsGDZoCd9Eb3rBXBYs/Hc62NCRT91
5e8ymyTVDq0+Uc+ewVi6drA+WG3gtW7oYO2HOUn2zqqvQ3+G0P/mF3SA2Na5C95Z8Ml3Kf6KjwjQ
dDVCoHQ8/5eXl2AWBAgP3kxM4XrXx0lRUzkKYzngLzUqRjrsFbDxImIOe64guB5CyWOaEEvo2XpL
xlau9KvvUieGlHay3oFy9nfEtQdV53f65SJu9YOovDvovXJ9YGmfnHpi2kHj0SLJt6mPl0BczggL
/OMfm78jrslQMO3XVwi2vB5s61HQi9T10uV2Z1HwrDi6zl1iwW29gt1J+iR0vdcY6Nf6GfCRzhe0
vxx9sEvXGm/nw1vPU53CxgsjvN/82xLuNAMe9WOAVKzBZIxqpwI//97v1AWQa3Q2JJrNHEqy/Zd2
1uXWgWaPF+Te2CzZ/JkBW86LcD/OR4/GRlPBLZ+S48uEyVj7ugLlVSPEpNmx2P/y+XL6nv/81FfM
bB9ejeMVs5s/X+3F+QJHCg102/wvtsQih2Wu02DH3HbJ4hwu44+HBdyI38OMnNNdsBtlJsFp3nsz
MeL6x7fw4SIf6Er3Bx926bFAfgR8MIfVkZMMJQZ47RgAlmfKuEBq4B6ZidF5RGRFG1rrbUD6Yuag
e6y+C0upwsH6fi8NFdJJ+N0vdAj6oaGdg1u4dEeC3LND9dFVgAF++qjdgJfs+bdpwWbn5UiXes/b
qejKSdBQ1WDYeBwVtWCUfv6ZNR6f4ovi0JWztlPIwQNMQjrZ6+AhO5zI0Qc63bPaIwUvYR9g+Vvd
6CrcIwYOF73B/Za3vtT72rAHlYici2IV+0aQLtA5oxWZU5x5i+zgDF6DZ0z0Bc/DpsfKj/8Rq3KZ
ZHos3xls+0l82ev05VePri1Og9flwINVzOwAft4XFWWv1wNQLrsw8LNnr3g90bKZts8H3fvNCiiI
Krq+ivEi2Spz217P0kkSzAx44pRHzq140/bH8+YQ5sSKxlFfh3XKAX+9P1AQ2LY3O47BQe0tJ8H7
ua+T6fWeGLhPzj1m22Ue8OmhY/hwui0fNEVCM/50h+8GHzHdHT/DGshyAL3XWCD9sbwK6kvHHCof
+UXQExwT/ObCO5i7b4WMdDL1fgCzAUJTEJFzghjQvEcllCw9wXDz+3i8CRhufID48XRp/vLKxm83
3urosziir2RQ6UWCjbfwBLccZB4wxoBl1GEfaW9ekDShRRezr4fxteQaBIA2m16FBfiMvQGbMWs3
/Vc8TnRnRU5IKhN/0zPKh+UIkp1uEP384RuSKTUDURwhYt07a9i3qOZhfK4jos7EaZad8Kwl9fhC
RFtcTZ9d7mLBSX9I6HBw1gG3UcaIeia7+KI5TkOfN4GDws1NMHfcq3Tn450P2TvjbLxoLOiT+wQ/
/UJWtx+K9XbWOuh/L5dNT2d9Xe9qCidIv8Ey7DCdtVfF/fINKtS3MtBqnSoQDNUOGUMJKD3ZcIRJ
Vtubv6wAac1TDnfx0dv4sVSMVyRByBreCdOQJsMCr4ICA/PEBeB1qegcC6IEK7j0yH8LezCLSt1B
Uu44otRVAaZcli1YsRlLtCJgvAUIqw11R+8wU3BBMh+KVoFvMU+IqkxGQw8it8KPbB2Q/eNpZBTw
rz5iSZdgMneU1ACW8X3LF0995xy2iTeQN8SAb5D06CakMK0kP4C0Pw0Lk4AZQInmBKmfTqeRL8fQ
uS4OOagmKNYd3pVQi6NjQDY+NsEuZqTp0wNk4UdeUKnxaxAwho8CGBgDvzMnAXZEQeiC/FyfDK7n
4XdZTYSe8bmZ7TW9QG0yVHJuJ7P5DnDl5GY/Ln9+4SMfQg4SPy7xfnlX3tIaeQ+FKtJxc52wvvYK
uANpf+gCkOcY4Dc/QbBz2In4L1cfxPklYnjatQ7a/LS+W9by+6tPwS7TH8VPzwFkBZvcderR3Xb+
ZLJrj6T4PDMwHqKsg0GfW8hDJaTjnul4OHtxQrQHWw/Lr78h7FgnoFt9Gq7R2YLoW42YIbuZkuis
YbjznwYxZ1tMVuxdK7itD/7V53HTA+nSeBY6pOnq0dqLvlBmH+dgtQ98gdcq4yH5+gpKj/vnr/5v
34YA2i+vgR//goeBFkHNHNeh5YuiAlmQM8hJiJrsclk2pGg5h0TDt5RSIX1JsLi9E+KxJ4/ylQ07
ENxeEXEJHZI5mXsX2jmNf/wZUC2vNXi9ggfmpHyi6yGPQmDnSxxk523i+G64mqQynxpLbPPxJu9i
cJA4k4nJVY3B+lrTWf71U/T13CV/vPV9bLzgV39WFF9ceAIhQm7yzT0qM5YFh7zbJloqLqGvlbch
O2u3QJDKJJmSUB9/55X47fNI5yO6jqDTex15rXUqqJl9SmD7Oxyctv7DmuRSDXkVaeR4YtJklrCX
AZsIyh9/2Zeeo8D3XbOI0jjRsCLbHSXLmyLiBlbdjJzPCQCfap0c4kM7kJzZ89A+fxukXT4smD8E
MzCeKNl4X+N9Hrl0gRo9VcE+ugd0fXOXEkhdHeAiParDuPUT4OdhN+QYZK9ina+CC7/tVSROXyNK
l467w2UQdwQ50pdSLgsZKNzshBy2fhBm3AMGLX64eL7h2Rs/07WEP3060lxIcPD2ebic+jO5eVWt
j+X+XAJLmmxiP1egf/CzqqVffrXYZ9OsE/ex4PyhKJBnHSczfIktDJrkQg7O8estv/y08XOkuFmT
TKH6siB8HVJi1FcvoXQ49jBaTiFm3aYaplRuN/1RE7znbk1BWMXhAR4CB5m7RgIrq+6YHw/69WP1
1R2OFxA6ar/V93hYJ9W3QIT9iriS/R5Wc38e4c6Rp2DekXggP79WRdcSHc61pXPuY+fDV7B9YyAf
Tx49WI8VsI/nM/jiy4eOiqAocOuPIlO4MjopHrsRKp/Lkfi9YoH25HQWDNyyRreJzehKBCkEF+Pr
4n3Qew0ufdkFHrg80dGram+9kD0PB0PiiL/T9wkeOu0O4oOaoQOKnsVfP/mnz0rjLA2W6TmE63uW
if3zm+hR3qFnHiu09dvoUtw3vXivLIZnttXno8SvkHwDZfNvUTNvegs4rNjEP7OtN71elxJcNIuS
wDZmSky/1OB2vojG4+svX7WwPn/fwdKyA1i4czPKo7xQpAlr5I3ieOjBxscxFqwd/fW3YLXTLUyv
xqWYtvv86xejM9XUYdn8EeiF3CVeenw2mM+VFdZ+nOOm53h9TspjDKt7OCLDfd5/+bcFQt7BYIen
80CPrxBDD+TPzV+XCbGmiPv5dSyNpVrwnu+FYMtzWNr4KgcMsMIfH1MnsSvW6xsbQHXLiiDp9Wow
P4s23PgnOey9fTPXqtzBIh41klmvVt/yTAu3fiDm2ac+4OdnzeX/j4kC/r+fKOgDF5PDrjc9vnyw
LpBpeyB3ItqAvnBhwE7zDOLD0gP74uy4UGbRnrgRu29oGpxmKL9bO3h53gzG4ugw8NRJKp7f55bS
nClHwJO3FyxZdB1W/WvnULmWHTJv3kQnB3wt0NrZndhe/wTTp55HqCeRRuy6zgvyZmIeAtBdkIHw
qOOjPfEQYUHCfVuLYH5xCQPFR7uiQ9u/C/K4JxDka6MQqzEfzWJ53wqMd9vCTxJl+hCcPQ0EJytE
x7w8FPTOlBbY3g/JIq8riEOEFM63JUT21xyKtRSGGqQcUYPrZKoexfdohsfFSpFT1BEYUXqO4Utz
AmKU3r4hi9muoFLOBjIr79gsj6+J4UM4WSgIxGkYJw/HEvVeE17Us9LwV5Zt4TEDEX5PvVXQ+17p
ZVe2ZuIZLAGr/UxsQBBsA0mpfQ8H/dRDWcxZony5uJiD03yXqrh2kGl4UbIwkmNAtDNUVAD2Dej+
1EhwWRYdGQH2ALnhNIX2OY6Q67AXsERDNUPtWsYBlEWRrtd+tCSlSQrivNl7QW4HZYX2V2Sx2Jq1
t66XKgTezRiweKrXZpy8LgRVe1bQYegtQF9M4oJzOvborPU+XfPnJZOF42ripeU+3gQl5wJU9f4g
RuKJw3cQPhmcXtsEBinPlOyDSwkz64nJkSsbfb4YJwYE/cQQY+el3sCU/AVe4wYFUl+blP/0z1a+
fesWGVfsFuR2L2P4dD2KvJL1vfWyXDDoapclfl4uxTIujxDYT9NCuhv1Hq2DooPdgYUBcFhMp6Ge
LzD3T0zAl33cTOca1NK0Z5ZgvLF1schLOsN1eK/BNJZtgcW9FUv8Z03wcuO+DaWnsQbgWFyDpYvO
+igWbQmv38ZH7oM9DTOS9RE+7Qyiw7H3Eiqemg6eBCwQfxVBMdfDG8LTvdkhxGejtzpLLsDP3W6J
M9WYrt6St1DeXRgsh+LeI/KpZuAFjgU5e6aYjJ2shPI+mn0U7aMU0Ns9DWGaPWVkml40LC/XgFC/
3R2iJZyW8B3Z9XCP3lawPiI8rCJaMYtyiSFGj9/DOj5gD+s5G4KyFmU6GzezBF/GPqHDoR/Aqi8J
Dy7CmBOtjY507Ymcga1jHbBDNg0zKbAG2AK9kf9inx41D0YFAg146PDtu2b43vMLALsixvzOLIcp
XyUI/C84B8zWIaQWfqywk1wYjN8Sg8kbPhgeznER8LrX65Oq8Rz81PYThbvoXuBMaO/QUEsVFZB9
6zM66pw87eFCAi27DbN/mmeYzMQlx05MwAqJ5MMaZh+ErttAcHJpGYAkSSQq5Q5FS9MrA40h3GHe
8t6UamdDAokkRcjemx99OQzfDA5v2SQHbHL6CNtLCeC7i4Pdtt5vj8yanHPnPR4G9pusD5b5wnKt
Ryx866u+vtGulgDbXtFhMRM6lbkVQ+QYB6JOnK2v58uYgi5zFOQpde3Nk9fFYPdZbxgu5TFZEq/v
QbF9Z9Z9s2mx3h8MBy4pvhOXY9dinVh4F7+5e0V6HFlgZYgoQPV6L5F96hVvESRXg4NlJ4F4NDv9
dz6AdY5fyA3qr07rF7Hgh3EfxBS8Dx1EJlRk+Y2kQJTr8e+8QduLY6KNkd9MJqhH2flYzF/9Xq2o
uEiFW8nB7uIFYKnzYwoffIXIXRFRQ8/4FkvHyLii5Bi9Aa3edgyGico4feM+WQVWkn76ghytPiXr
9/KpoZZEfrC/mvuBktNkg7PVtH/1aTFW/gJRLjDEbLxJn92TaIhFibWgxdgCVH0sFaxWhyfHi7gD
9HRwNcl+mQcs/uqdsBswWBuok6AS3WG/TUgAAbWQbHqQLNlKW1jxlYmsTz8X43EntPAW1F+k3rjv
MH8HjMFBNU9EO0cILFfJGuE4LRRZh35H59ek1DJN3gMW6loqhvKtSLK1jytk8t63mA8v8Q6Gux2S
uy4SfYFfNZOvFU6Iy9R1Q98mTgHQ2wppAAsN/tUD0SnGAI4i9PCjb2y433dsQI94N6xmbmtQed5b
pFEsUkqDqyEtyZtFflquHj0cfB9q4v2In/sopXPInQ2gsyEI5FmMvbVQLz6Ajy5FWorv+rhwsSW1
rndCqBWVZh+eXSywLGqQl7LHor3IbgmfZSqQq2G+9bXpv/Xf/hmpJ9CFk7QeEsS02/oQsAz1nEN9
iNngd79WQ1Jc+OIdE+mvyNDJVk/hy05TFCgiGqjNChe4W9YC+VZJwSwbYQqtq1mioyvum9WN4hlq
YnkkKhslzfKRfB8ah1BEASt2yXpU4xxcyzEjwV58/85fCPb7lkXp4O0Ajpaoh8+8VpGzne9l77qu
dM/qO9KNqKdDzNwg3O3mMpBUNveI+/ZGqcpqFwu0Fjy8e4Ac6o9IQc7Cls3s7QQJMqeLiLxHKSX0
ebBt6JtWi5TLuWvo+X7yoYNiJ7AWTy3G5001oPkyX0F1Pr8Tst0HKH2KG6YuPoElLfocRj2pgqFm
vWLByx2CZJyOCLH0Aqaw+Ggw7qTH33pPnHq3QTpOOtEzzA1LlB846JkGJorEEYqls+XC/II9criY
52JthLoDb+xS5J5ZHmC771pYwUzG/Wq63oh2c/g7b3gP+jbBWz0DK4AKSbb3R+6vN4ZvVv4S6+EZ
BX3iAsOv5pbBuuLr8Ht92L/Zhmhi9C3oFZdQclfwwQJrHgDGds/D9C4dg2XbP2qwiwLTTvKIrfU1
mPXXakBvMXriN+xzoJfgZksBFg2ikHMz4KP94mTpc70hRGhRYNJXvXxA8S2gEw6HRS2aQO4erIj3
U98lo8BFLjwr40hMxvt4lJYslD652wRzeH7TRXadAHa5owa77X6uO0RT+bFWASl/52/bL6DSKEIW
8Z6UZm+Vg5E/dWjzLx4tg7KCmDIdOnimWCyJV/XwUZ0dhEDm6fh0GXs4SNszVNayaWa5aDh46gQV
2aDm6bogCsFVGMNNbz26vF3jK21+jajKuUqWNj9qUB2SJOColzbrB8nBT39JYGSyvuyeJwj1d8yQ
Q2hehvnc3i0xZSQ7EESzHz46GBRArvSK+ajnvPHJpR3km/eRBJk4/ukvOFlPASecdwNLF4sxHDo7
IEbt8eDbsIwGts+Lg0780Cka+hW2mZMSJTu/dUrLPSPKx8JE+vbzs3GSFJB3jYrMM67AR1JvASQv
egmgwZqAg214h68wiwOYl1GxiMsph97L+BCvYb1m3b+tCmrPMiT2WF+a1e5xB3S19FBgiRiMDGh6
eKxBGOz4/uItpsb7wH4erEC61v0w//Y7TkkerBlX68v81X2YMxWDrI9XNwuU1Bz+9I3m0auhMuRr
uHrvPRYJK+uEliwDvBU88J72ZkPve7uHVVD75BiX9rCIuSoAz7EIUVfuoPN2j9ufv8JMJbrN2KdJ
BTXznhEX16ZHb2ebg4p4f+JnH/HNGqnXFWpqeSJ5xJ6HPSx5DP2d9cAwYQ19l2vUAs4qUiy9a2vg
/JvvQ+zBidhDLRZUfRuMHOYCRy6WGRazYS4QFuOJ/Onh2tp1Lpfj+YXchY0HfFiKAKQ2OWCeeCrg
ZvDiIRetXwxXsUjWcxQK8uaPkcFjc6DuWf+C7fWRW7KZN3FR5sPUkrZnoPRZM7JFU8NvwiY/v0H3
0d6toHkz3xhWbK3PUZrBv3yQrN69oM5BF8C3ts/E35djMxk1kwHOezVEn/FcrGc15CCcri5RLO5c
jJALK7mJnRtClmjQtbt8XZileEV+Kj4A1R+LL/86Jr/8icP+lcGSrybigpItsOHaIRhYWUPGBx/A
wrq2AEePVYOBY/tilZFkgJ8fSxV8BLOchjk8VeM2Yec5BR2DXINBZCFic+ZnoNWL5PCVOW4AX6yq
z7f25MLUn+xf/R/GykhHaL0ORbB/mBmYrzc3hUcsBkSrOCXZO2ROZRPFSwBbUS5G3Ob9330TH+yj
GQacu9L7zU4InbKZ9n1a1PBa4gw5B7MbpkY6urBu05GUGavT3bpkKWxg9gh4pc+K5VqDAPz259CZ
p2S9PPYrPB6NMrgQ81vMVZqu0KDxZg5MpVjSobrLWz1HGe8pxbR3NReW/ulL3L5+0a8vdApcAONu
9/UFyJb/5S7wNMzx+NXQ8TVVoG6zESnBuS9mUzZjGFtCi+y8Bs1aPi8arFxH/tNfku/VEGz+EWlr
5AEyMHEAH+3Z/dOrCaqpAF9plgR7qW+3PHhjICjaG1H5iBvI9ezc4bqsIhZ39bH55Wd4YZoY87xX
FVhgJUF8lpkQ7M5YoePduCkAnSyLmOdeLsjTfIcwtYSQbB2hZqsXAdSSxMf7tTeLv/vHHo4DMntv
LGbGG2YgHYtmu09HfX5PSgAlp6iJlmM5GY8voYKXe3Mmh95M6RoKUw7kR+cGQZMJgG55Taa3dUXu
p7b0Xi4GDm5+HqnKWSn2wj0MgHMzWHJ4mnyygOVkwDiXKhLEWeFRFz9cqcL1AdlbB2uVWKmDC4Ih
UVou2fxSW8OkJ37Aytl3IPNrFICfiQXSPK5pqI2ECg6dG/z847CwucLId+N8Dfa3vgfTtAouTFNi
Eedl1sUccOfLz98SbR+5YD1dxi/wVvER8KHXeX/1RXsnNq5yLqXLvNx7oL3KKKCrxyTj8+YYf/XV
H0WoL8M63+UkJSHxc/GhU+NsdNLPvwRmqQD+oCaZ7N6sHTGe2NH5+4PhgS7fDaRcOa6hyVnLAZGX
E3H5WgdjM9kc+OUHFItNMzZcGUI+WjOiSpxJl6d0LIHzMRjkJSz22jmNY+lwDgvik3KigxmcIfx2
9gVTGCne0n39FeyiucLsg97oyp+DGZhePAf7j7nTl7OEFKDK9wtRPmcjoeZDEMB4ojyWN560OMNX
E6JO+JCfX93qHfO7j3jxosKj5mOWQPv1woBdaA5mR/a/oMO2jMIPt+pL7lo1vAXVF+8P/UBpvndi
cLo/d8SXSj/p67S8AybpNLxTcestKIYY6LsDRyzkWWD3kYxAuq/1JVjjKASrL2BNCjTRQ00adcWM
07yD13ZMUamUaUN3kJ2le1BV6DR5XrLxjRXclHMdzA8uATNTsyFwXwYl3sZHyCE49xAtloLlRuQ8
WuDyC109VIkxYyuh9ttXoPy8arhWonjzC0sMjzvjhC5nE+sr1/eKlNXPHtkf09M5YzpWQH3dC3S8
lW9vjdRohbvT+sQ0id7eWj8YH/zyW2mylk5YyPhw4wnBxs+GgTPHOyjH0ytgInEq1nN0kaQtfwRC
ZGJAD2TuIaoFiJzVrPQ/P07OTI1fnhdSqqKllHfLXCD0Fit9fLQlBze/EpwOuEkG/+3l0sGLy6CO
ormhTMnkcMhdFLzM/lHQh/luhc1fkuAjOsMSFM8UwujqIz8q1+SlagwP958rIHqHYw+f1QsPxaj4
bvyl3vIkaOGKGAv5BmtSLKPVgqPlOshgsTHQhbnG8Jcv/vx7UUsCfOAqQgejH4u1vdR3GNVSTw5N
33urESWjtPEdzC/eM1lOXp/CGnsvvNO9WOfUl5RDwVkN5Hg1V0wnUAUwY5oOBUZZNdMx3h5AOMQs
lhORb8buaF8gwx4nLNXsrsBIjS0oRAVH0CWbm3XoPzGIGKFDYcTtAB4Jh6EE2ppoJBr1FbJSDJ9f
Dwd482fz2OYQni5YDrjay8D8aFMevh8sIVrI1duTiFYMwaO9k2DK9l4zB9EFPO0UIvShpdfujKiD
JglH3JbefiDjPbfA58Deg89oKpR4RNDAxjOQLZp9Qw9734CXvMlwa2N/mHdG1MrBPEHiJ2zrbXwl
g6BpC1Ju/mG6rCCG3P51I4oc3fSfvwbdmFlEBZzl8QCtF0jldQpEvT4NexcJPvzkdoOimBu9v/x/
6p6UOHMdDOB8duYfP0PKnpu92TaX9NdBDOYvtybLJzqvcHlRI9gbvZ9QABke5HA8kEAv1WJXfINM
cBYL4k3Pk5UKlQGbr5MTdePHq/uMOeg4Bx0dYK//iy/yyxoFPOrTZmaNi/L7MxbKGnjjPo1S0VkM
SPyOVQtun16zvzw3HcVzsXJ9pcDltRhYyM0JjN7RvwPbPPjBykVDMo9pLMD9Mh9QNEe7BOP9gf/5
8x8PpL96AeVDd0RHTRQo5vpeg8ieRBRo5dObzePxIm5PZAsEo2boLx8Bi8Q1/t7rd7NIkoPhftk6
iHsWgOESnFyYjSMJ+J0JB+wKOIMnS7AwE4jHYVGHJgSBBHTit6Kc4FRoZ3itxoQYZ+xSzjsadwiP
V4SFvenoxAweDOhYlgsEv74187ctYslpQosUXllSfnxwX6h5SbCtb9Wsk/BRYMelBjlIfeuN8/Ca
IfoYGolk7tXgbf2BuBSvze+/vdWQbBdKh25AaJcNFAfCC4vP1RnRdp68uZzUGQQYGEG/9TtWRy0U
yJ/mM7rINV98HE1upY0HIC8qYTJDrzWgcrq/SNCLTjE/uFKANHkNSOeiZ4EJC23w21/RN19g0mqm
/+Vt4vls0PDkjDAohVNLnMI0vB9/ggyLJoLcbC14/hyskDu/6mC9cwrdVfnxC4baPiIVcq+CDuY0
wivEEZas2kt2fHSTQGJJ+e8bHAXV9z6Gu9P8xBGOdnRsuDSGi7k4W30IhzngHhc4ibTH0r5uvW3/
0j9e0m39mbmaVBcuALpES6MwoUK5T6Eq3s9Ep5HmTeJyy+H5/nwiM8LqwMfCZEg/HqfTqPZwEV1i
aK9A3vKzPuzxbgrB6MkqMl5eNlAbn+9w/awAs5bYgpU5HO+iQLo9Uu+RkKxfImuwtrOVBJ3ogPV2
GXKI98yb2KJpN3z4vEpQPx5AsEjci87u5HeQmS48UjUu2PjOLAAnBgJm3SzenrHJ3oH+DplgcGrV
2+dMiuHNrT9YvJnNMB/Tcwt7xv4gX2O7YlrVewm380CMDLtN+fLeNSQUlhvP5RJ6O9grdF0w413m
kWJuPMKBxsjexNp42XIEzxLqcmmgw6l3N57Q9nA+wwtJT97Vm8IVVrDDrozXze9RFGzPUM0FBgul
ORVjJHv5X15YvAh4vSofhV+eJifZ6wH3uiklzDg84c3v6UO9V7b7TETM1NmlmZ9c2YGzgkeiFdzT
6/vhrcEf3/dk9l0sL9dn4MY3yY8/76yaUaB5DknAnulDX/f7oBPjTngE64ilok1uXgjFpiVEO3FP
sPEUHhbpaSVG4511vF6qGGLEYGLs8YtSL3hoPz4f7G1TpM/D8E3ha0xDYkk91tcaMS54xt6y8bMd
ne6adIfRXRqI9y5FvX/eHAsyh1ZHTlInOmYfCweYR6cgbcViM69trv36i8HnVi/JcgKVD9doZcih
7PuBnvEphokl5CgauH4gNVPcYcRNj4BNRV3feIMtT2eGx6sUfYfhslc74Oihh8xHD73RPYkWYLzW
CDiEfW9XrZIGlwIizGy8cobcpYLOPtaQukSnYQzN2YKNnfUEgWzwfn4Kvvz0hHQ/OgzEO+gdfHyr
EOljpDWr+bX/VT+8T3lpyC4IZ3jjq4Zo14gU635vtTCrxgV/HfZCaXcvFKBPJo/0IdILWr3e+S/f
Izdlz8nPLwIUTnv8udVRMdonMQdbnkSqz420O6hFBsmTnol65CYdF+w+BC2XXdARZkwyMtzFh/BU
bM/0FNXi8+PjGw/CXOtlxbLLtVq+89UV5XNtNPsfL932H1m2dygovxsV6cPYDyzTsqEkfrt38Fjr
gKhMRAsyMLkPHdmSiCbjizcL3oh/+kqsRx97Y3gSbJhmjYy8Le8vu9yt5IN5yBAS6bVp40lPYVum
Oa6l6Nss0yrYsI29JNibZu5tvJWBN+GcB4wtBgmtgkKAi0xVzPTipyD+Wc8gv387uD3jLx3bo4Lh
La7eRN34+poJbQmVJiqQpnFts7p9F//xpZ3Q7xt8UIsU/PrB+1tvA842xfSXDzEwS3lYmK+qyaLe
cgh5WTzQ+K3dYWGMJtG16FPgUmhqsP8UAIMd2zdL6QYB/PUTio2f8Wpu93DjG3i+ni2wkvMB/+9n
FPzbv//7//z9FoSuv91f22DAdF+mf/6fUYF/5rf8nxzH/5Pwf78tAY95df/Hf/xrCOEfn6HvPtP/
mvr2/h7/8R//vv+bNvjH1E/56//663/b/q///Lf/AgAA//8DAOaLvFiFYQAA
headers:
CF-Cache-Status:
- DYNAMIC
CF-RAY:
- 7bd02a723868dd70-LHR
Connection:
- keep-alive
Content-Encoding:
- gzip
Content-Type:
- application/json
Date:
- Mon, 24 Apr 2023 17:46:27 GMT
Server:
- cloudflare
Transfer-Encoding:
- chunked
access-control-allow-origin:
- '*'
alt-svc:
- h3=":443"; ma=86400, h3-29=":443"; ma=86400
openai-organization:
- user-iy0qn7phyookv8vra62ulvxe
openai-processing-ms:
- '286'
openai-version:
- '2020-10-01'
strict-transport-security:
- max-age=15724800; includeSubDomains
x-ratelimit-limit-requests:
- '60'
x-ratelimit-remaining-requests:
- '58'
x-ratelimit-reset-requests:
- 1.587s
x-request-id:
- 7789d01d26c1a0508cea5217b26757a5
status:
code: 200
message: OK
- request:
body: '{"input": [[8134]], "encoding_format": "base64"}'
headers:
Accept:
- '*/*'
Accept-Encoding:
- gzip, deflate
Connection:
- keep-alive
Content-Length:
- '48'
Content-Type:
- application/json
User-Agent:
- User-Agent-DUMMY
X-OpenAI-Client-User-Agent:
- X-OpenAI-Client-User-Agent-DUMMY
authorization:
- authorization-DUMMY
method: POST
uri: https://api.openai.com/v1/engines/text-embedding-ada-002/embeddings
response:
body:
string: !!binary |
H4sIAAAAAAAAA1R6XQ+ySrPl/fsrdvat80ZEpMt9h4CIgN0Ifk4mE0BEQOTL7oY+Of99gs/JmZkb
E5DY0lW1aq1V/R//+uuvv+u4SJPv3//89fc7779//4/p3iP6Rn//89f//Ndff/3113/8Pv+/J9Mq
Th+P/JP9Hv99mX8e6fD3P39J/33n/z70z19/b4tRxarabbpl4Cwc9eakb2bxoUZCPhQJuP6HMz3Y
LlxeWYsSVRBt2SZerI1BDsBDnnFdUd50DzSYa8BQwCzGS9FaxVIa3qX63Uc98RZa547P+/yCtMSU
CPY6A/Fe2aZwOY0527z1j9E8r+kMEXctsz1HsUubwylRXw+aEydKpHhaD8Prq4ZULpIsHlassUB8
b5wYuD6iEb8uJzST85xt5PXK6PnhWoIdeiUxlsUmHg68DcDV4jldobEoyt2r8FB04Bv2XHQmYq7k
KSgPNybZ6wPqGPrudDjNA4Ir4yDcrtttErRWoxMx20slejcwLcTq+s0cM62M8X5uczSnmxUx3rsd
4tEez9T8muzJjn2ckO9gBei52ejMQccuHOPLvQTDnlk061ZZ3F+J2kPTiCMdCQvRsKdnC861tMXi
eeUhO+tcQuEia5jeHit32GubBHRn7hLDOx8MioVTQ9HeDHLpPrErTH0LgKrVjniXuRYynR4BRff8
S8z5dhvLXr2y4VA9SqZ/onUodmf/BsvLzWfR/ntG4tDdM1Sdo5pZwjx0/Hp/OOhVUo2qlrsxZG1G
bis4KTo5vmsfiax8VbC1NUyucNkb46sP6FowcWXWvW+M+mr5PhwfZoLrw/ZT0BgTCpIZYUKCzCvG
oOgySOZlwDbmwTdGbUYi9algn3mjl3a9nNs2Gp3jlhmVpAvJ2aklJOz2IlG5OIqRiBWFd5BQYhoU
XDHT7hlKNp8b04NuhsR70Hwox2BNDnmpddxntQ7zPJnj3BSNwcMx7X/rE++BurDyDm0EoIUeLR9t
2Y1HKeMgSvygTCpF0bd7Z0ThvvLIQR6XhTj4+ghWHjKqzIklRnXcJDC/9CFx5qddN24DG2CRhDvi
FtumGPb7TgGFzLYUPc5j3K9KWYKI5y7RKynsxpt71+AaHq9E559dOOjN3YNCcBvPGErd8a04p5X1
ZBdmr/NO9OalrWG6xitmvWJ+oBsFzKX0IM5U34wHKxOJet5ReV+cQn482yfAZesTQqXEpRcWOnPW
GR4zUx+HvOqqEfpvqxHXroQQwZJ70LHnidYAuSteyiNHQV4y2jcZhAMDF9AMHTkFKdrE4yuiERzk
7oz9Y+R0wyFdz6A5yBLRyxdF9Y7ICmzbqsLztHq7dRu8PVicnzGV733jtvUHHFid0xsWn8gryur2
Utdnvu+Ju7sWYoyRPsK2Xx9IfJkfDYEWNxWOm2VHzHPpGUM1F8naHLSBmUt974qPIAoU/djSlqM2
Zvq+5kiVnBnZX1Q/HOtVncCRPA1m6nldMCmtKdrP8xyvLier4Cu5s9FWPgds0x4vYnzmewz5+d6R
3dKLwzHZni7oY7AeL4pkcKd8zqGdb0d6PmjXQtzGvFrfnOSNf/vz3d5dDVW67ONZfW+K7z728Vom
hk+lKmwL8XI2ypoOzyuxaWbHvBiDHH54YsdpKXprzBJI/SZj9mG7K+jTUhOY8IiG3GIuvxKVImrY
ISFRUaNxK482MEW6kDPe2Whki70KRX1+M7vkR4OvtG0LhfK6kH2vpKJJVsd03cnJyLbyy0fDIx04
LHRk0LEuXWNcfmwFpnhg5X1RxfAd1AQuuuew+3oTdpyrQYsk84apMBW1o+HelX7X7HrKW8Fwb5eg
mN8TZlP8x/N7X0PQRDH74Ss764qMjlX6onl7tAzxeuARRfTRM5KEWcyTtznCycsshp/fj/vbj/Uz
Gb7MOTp1KFoCMsqQ7ZDDt9iJsuoqDtpykbGds//GgjsfD10H64VHqS06IVb2DU39hO3jQo4Hqzjl
qryJFboKjm04qpeRgq3iDV4vqtJoPCYw2t3TNbHnxEJSu7xEQIS7ZeasXKOPe5Nt1DceIju20Qr5
dkIpFEV1Jc5Yv8OmXtoWrItoiVX6boxffgA6nRh7GmljjMnVbsEo1YJ+Xvhr/ImfauMXXgKMaHjU
iYeC5haTDdlHot7nkQ9K3A+0ksJHJ3gwWCpVm5a4j/MYslujOYCyXUzsl2S5i1Cam2g1kxMs4Xrj
jrPFx0ONmx7IYbmyBW9mKw9JDx4w93XDBb9KhQLpfSGIt6gkIR7Hp4PsEJfkYJ1FTK0kSOBQZzo7
kjYPe+f40AGWSUQC/vmE3Ct4hOLW1Fi4kKuYYnxPIZ7rc+I+9UMollDZELnfAq+OXdYNB3ewgL2k
FdmuHzEaNSI4iufanFhjagih0zugwt5LVMGjXiyicPDgJmkxlWVN6Zpzb/Qgdas3sexrJrjh3R2U
a2lP+yPZG4O8fEfodVFkElrvc9c3ka2jvpJOJGk3hpBTyFSIgu8Gr0quxU3vRR641zih6aVYdfWG
hz6yr+uRLvhw71o26y/Q7qoYS5v4GoputsyhPqo3ejTKRgxih2qIt0+HbPF3LIRUGzbUsdXhRZfv
uzGINibEyiHE6+XKRkOktBFkx/I89edH/FboqK9P68OARdBhg4eHb4Ye39WFOMwdURfdHEV13ZZT
6f3VBG/smKL7t/KZtckUdzzvVQWGs3PGUrjk6CtTHZBHeczuu6Bw2YSPaJnbQCzjIIw6dRMbNl5y
IS5t1Y7t1E0JlS75xLMrw+Ccc4w0CN4Mp5rnDvsQX8ATLGZ6kgYdP2WaClQJDWI5+5lRSaGcorpM
OfOoqblc7toSKafVltgfYyGmfqXCKvFNvN5YRUf7tYVRtfukVDl9kpi7dlPDYWUADircIFFvuwv6
2PbAdsN1IwQp33x9zI2EuA+UGN/LfF6DXGmUOGyAjs7y/PLrt8wruryj1sagsHyWBTHvnzoehyj3
UB4aJrNdtBI8kQcLHl3OsDo7yLFYRysPJv7zw9uOrz+mDtL9eiDk6WExLlzDUqf3o+IT9d1vf9ej
kBGeXc2XO0C9uKBZt51jJfuexLjniwSG9FQzXXMKY1Se1EJ1bu3xMke1MaoXtVdHtf0Qi8afYpzb
Tr0iy8phe8sdxIRXEZQPx2MbzRGC3/2GAxH7Lfv1P97Oax8eN7gyrAdWzDbL7UVtRaYQ4otj8Yd/
3xTR4A/3/W6Y4XMLdW7u2dPj55BLlvOnn1F2vKN46n/O7/fozOsKJE6rpYTyxSfBneo08TjKmQYW
Qzs6Pyytgs+Hcwbm1jrhBf4G3bh9HySY+C8xcf0y6GneXGA2bh94tsVDzNePVwX4srCIZ29RV788
NYBbRY50ceEUFdk+koAk+w8xgq0ZjndDxmBFYLP96eN2U7xM0ALlhWcZLF2mkH2F3H2wxyI8LpEQ
K+0GYj63Kb2aG4OfMluBeaWY5LDYJgXPOETIxyvOHGVmFQvn3VD0w+tNNxtEd5AQoOx71oh3fTsG
d2a+uf71V8/U57FoXy8HPuvwxcjNNw15z9cJLPz+wOz+YBSj66ETKEGeMptZo8tIbJyAbRr7D98Y
zr1BV+LhzdkOfXUkRbKuQxDcZkwzyqgYqRTJ8GoemGkLt++Gg+r16P3eWHixT3M0WAtb/vERlqg8
D7vIulQoXK78ib9UxbiNuwj016whu1PuoFFFhYJ+9bCtVkXH/dMxgI0qIqqo23vIj/XBQ4rJToSo
6qn4BlspQgcrFPi7shXRrD5XD6KrY7Gd2M/dFo08X5+U9FdPdihXn4MJibGe08+0Hr2dRArK3r6T
h5ITdwitLkXqd58xY73SO1Ge9ak/lldm673jjpeTd4NpPboijwf6Nuzrqx8MD+K6UWbwu31VUb4l
KiHf2u4GY721USZ/txSYL7r+IkBGRIuA/fCg84+1gpa3cYlXXsnCP3x4XG8wM2sjN77jzitRJl1S
YtpKg5g68wK4DuaLrul+6Liv9zPItweV4YIX8fD2+bie+AWF69txhakUKUTpEWGVDclPrzhQiNEm
G38VhL96AdhZClUmfBERzpL1T/+tmdx3Y2oZt5++xmtTxx1ltiUBBWoTHG5K8bXs7fjbD4yOfBPy
FzqocL7VJ/ZUPkxwqUUZrFuvINuL83Y5VsIb4FP6ZPsZpQVfxUmEbmuPss3n7KJxrzcyaq/cYwcE
W0Me9/0MmJ1KxGuyJOSfmeNAKJw/ejXuzl4YAOpOHiEUj/GoHnx//bqoMh41xzDG+Aka8gW90cUm
tjqpfD0C5OGyJc7Hlgv+2w+jVAqmlQl2v51b2GAEFxerZ4HjMX1FDirmZ515j/OrGz8nDcPyuHYx
1zrP4NLrbsGQXmra+Y3vCpNtdHj75o6Z728m6KmMSmDIW//0ZPe9b86SqgXqixiP9hwORecn8MN3
Ih9xwY9py2H3UHQWWFlp8E//kGFWgEOHukSIf+7+DBqzfjHD7Sv0w3/VPAfbKV/zrpatVQSLu5pR
+QpDwavcPIG9l55Tv70ZAkWOjezz22U//i5X/JPDtN9kI2Iz5trmVqF2V8aUh7ttN0raqkRk/yYT
X46K8fLmPZyficZucVqiEV1fI4r2FyD23dXcRb5VMHyvxZztd0FhMPel6UiXVzVGyoPG7Y/f1zdq
0uWw7opvk9QRpHxxJPaoP9x+9+owrCJSYZpdvjG/+68RfvxMU6Mk7I7vREJhMDtiubd1tFRyK0Vq
MT8Q/ZAwd0i8NILJP6Kq8ngaYzNuaxirzfCLd/fdh/gE/aUu2KQ/xDBDNwq3tr38qTfelvfsx9+J
d1yMiL3C/gLa+WgzO4+YEIvrQUGy1zbUCR8HYyjupQNWs4vZfn5S4vHu2SZ8tqNDPPlrGX0fJj4s
IFWY0yvY6IHNb+jM3Z6um6zrxKd5pxB8zmu2ey/D/9IbVYJPePnCB1eQuZQBvpMv05L7IARftgG6
LpaM2RMeCho4Ggzhdsm8AExXvML+pNIderHdFTLErzPrBCdmpczZ7zx33AbaDMDsj4SY35U7rrKz
g35+Qrv/LtBPH8H48gtyqhsXjYt0N4OPU9ym39MEv0qdinZBc2QbT5bdIRMJV6XHGNAZ3WfoW8lH
DSL95TP3qX/jcf/g1U8/T/xzGbfKk5rQ3zcOyUV2/i9/zFczk6RJeDS4BY6Kbqq0I5EbcdEFm4ii
cF96VC47Hncnfr7Bjy9nu83B6KNI+DBDIaeLIdi4i+LeO6DLqGZa673jMfhuAVp829HhqdzjMTbf
Aaw8MyQ3cutD9rg3OiTE4+zHB8dhHt6gMG4V22n3izumUKtwPTczurwsSDe8i0WNnm1s0R9fZWmh
Zr/8oYMny0ZTlSWFoBt0ulp/HrE4f1odHUprTX7x4WW7pHA/YY+OoVeFw/T8+tfvzUlf80RemdBo
JMF/6qOOVyeIW0uj2e5zQd9FzKrVKglMooeeFcrwQgG6NN8X2c7Krzt01aDCV/PuzPCQjOh8ltlo
8isZZmjmUokdMIz94kF2xiEPOX8aKtBtrjLC0DcU377pf3yK7Kb1x6efqOhilgPbD0ne8eNZu0Ab
2YK5bqS50/o+sIt5IBN/LcS6DNs//I9c90H3i+dPTzCnyj00bqz7CU5ebtFZkK3D8aPHKppn1o1o
srLrZLJOHNhp1opovpSJsR4u1Q/PsOpIO7c3BucE587r2aHgJ7c8maODJr9o4pNVyNLAwmDuEkR+
+kFM+gNFozri+MhfoSjdTEfPISqJpxIV9f3bLqHwyhVzL/dPPO7PFQUpu3S/ejF6CG8W4ndt99OP
MXs5GxWtokNFdi881X93+8MP8LjrlwUrV6hVmXQ/MuIfdmLQsZPCwekV4q2MT5z/8lF+vRu8/JTU
7R8bp4ZbIbcMy2OFhv5Tz+A4kgOdJ6EW/vGX8f3wnd5X+vE7C5qrt2LWp5yhQTMUUH/43Lwvjitt
3NZCqbopiaM85m45oj0F01W1P/1NmfzS1da5LYjh3/bxMG/jBHh2pvTNXSaE+JxMdKF2xfCluBfD
81lLwJxljOWy82M5fko6ynf+DcvYU+NmFzUOxFDfiOW074L98uf21dfEXOqNO6weEl9p+NgyLzt6
Rb/fGRmsRVmTXVYXIf/0Z+mP35ZP/tv0PjMo861HyORn/vw25IIW0HiuZgUv8S1CDS9nbMuHVSFi
ye5Vub6fSZTsSdeb2cFE7BsLLGnEEHytKCc45/qd7DbZLhQ7dVMBMeUN5StsowHUV4ve9HCncnXr
wqlfVyg7Vmc21ZPBreuRInS6MCyNd8PgsOlGiFxWUP7IDIPb/neG4oXcT3qzd/nzoaU/P5s59ksP
2boMaziG6p4Z98/K4MuSjLARazrxlSCsV+VMhgk/CV50i46WX0WG9fbzpeN2nhRSvJ/pEOo8+4P/
LckPN2CbzsaR2r0KOvnL6MzmKnOPZCXYo3BTdFtj+tNv7lD4G6o+hXAJaYenGHtRcJj8RdyyISmm
9SVQVWiJGTgLJCIAEwJfu5JLNTu7DC18BV4f60O2NV2HIi3GHCZ+y4xl8Qr7aN4n0C5WT4w6+y3o
xjqeYDO8d+TXz8TnUpdA5xbDy/ugFkOeP3O0fun+T28bbAhrB6Z8xTN2lmJ5mc51SMHU/9SfFO2t
GTy36e6HVzF9dl0NBXOPzD1Z+c+fz9F3f+vZvdBsxJfR+6JO+UprPObFQC56CeH5orCDhR4ud2Oa
weQHE40u3JDWQ1qhWVRt2WFlK2isPltTFdXHZO7EZ6XHiWRQrpdLzD3/YVBFBRl28bL841ct3+bW
g7V3v2P0QInLf/V3adiLOPtd7w7K49Cjhlcz+omUDjWWfRgha2f3if8t4iFZ3VPQb1VJtvtUF+PF
aWZQPx4BS1QSoSFovxV8wVlM/qEdSixNZPQUg0tVyNA0H7lF6BFfZgT7NPvz/5BCYMu89vMtJn9Z
RfJWWjPXb7gr4t2hRhP+Er1xJNRcNTqiqT7JQXoGiKvvtwLPlycoOgcXg59wUkGMmwf7zXPGMSQR
sG7jUdE4pcvnXnkBspoNzDpoleDFoTlBfK4R2SyGd8H3eeDDhLdsk8xb8Z3mcxCmL5cYpXbpBscJ
Zn/8pfYht12qz+QUFqp1pPn2PoreHFYRcvnwYvvsW7ryorpLsG9X/TQvkMImb5sbcrX7nPzmRcxW
eYv28omwnSE8Q0jGcQYT/8dStTrF9HOyMZr0ODOS9IVGiR082LKzREgGVSgccZbgWetPPGxV1xj8
UbutJ3zFwjAyNEzxQ+uX5jPnY1+67senh93VZdhCXjg47xdddwZtqHyo/IL7p7sP1jfP2H7KTzrv
hYT8+TGg/VlhxlA7Bx3uj9uT+bHzEj/+DbtlsCNkf3ka/LkZKILUOrMdzVaGuGUz/6cPf3zC+MPX
m5l3YW71mcVU65wcMpltiem6tKC57VdgqsRkGM/qYmBgAKzPQ8q8SY+zyY+FJ24jCpa/QTx83iW0
UW6C/PyAscNGvh7i2YY4lvsyRustKYjoQ0Gs9/gqpnhfYJcvdfz5lNgdUI19WPj0MOlDU+RexgLA
X7kgm4rlhuj8TvnNW/BcPtKOmfp2Bk5gIbJ9e3a3IM0ugcmvwpKe28XQJPXtx18nPzFA42w9WKDN
Oo/YaDyFI2qrWo2PB5nt15uw4I/TLkNrTXoyL8y/op/6xZ/9dzhyYiE+iQm3+fv8m2cVkx/XImEP
KnGKaoP+8C/v6Bq0ziOCRJffMKjDeCWu6jSh2B1wBrP1BZODcyMdL8Yog/XgbYgz+XF0z9cpHFGc
4ddmSRELWHVZTfXzZ569GG+KCpM//Ud/dMdYvf36A9Hv+afjm0qR1lP/pT//hJ+a4gTz+Pn6zaOM
0e8vCmRVcaISjFknhodTgXK/OET35Hc83Kmv/OHnRnw6uTytWhXsvfxku1lzEEJfQoTWjjZitahe
QujJt1bPbK0SI/WfxlccLxZc/PODbV/7PuRuYJqw3rUupT7N3OGcNz6aVZcBPxZV6f6pr998WU/d
bzfljww+KB1dTfPq7rGTeliElvTzh4rhnpQl+vGrjT7TDO6vnOSnN5ibjaYYOAgd/v6dCvjPf/31
1//6nTCo6kf6ng4GfNPh++//Pirw7+gR/VuS5H8z+c9JBNpHWfr3P/91COHvpqur5vu/v3WZfvq/
//lr8ee0wd/f+hu9/5/b/5rW+s9//R8AAAD//wMACEOkc+EgAAA=
headers:
CF-Cache-Status:
- DYNAMIC
CF-RAY:
- 7bd02a7a2ea3dd70-LHR
Connection:
- keep-alive
Content-Encoding:
- gzip
Content-Type:
- application/json
Date:
- Mon, 24 Apr 2023 17:46:29 GMT
Server:
- cloudflare
Transfer-Encoding:
- chunked
access-control-allow-origin:
- '*'
alt-svc:
- h3=":443"; ma=86400, h3-29=":443"; ma=86400
openai-organization:
- user-iy0qn7phyookv8vra62ulvxe
openai-processing-ms:
- '160'
openai-version:
- '2020-10-01'
strict-transport-security:
- max-age=15724800; includeSubDomains
x-ratelimit-limit-requests:
- '60'
x-ratelimit-remaining-requests:
- '57'
x-ratelimit-reset-requests:
- 2.325s
x-request-id:
- 92be107f229b82b86d22c38edb3f9c8a
status:
code: 200
message: OK
- request:
body: '{"input": [[8134]], "encoding_format": "base64"}'
headers:
Accept:
- '*/*'
Accept-Encoding:
- gzip, deflate
Connection:
- keep-alive
Content-Length:
- '48'
Content-Type:
- application/json
User-Agent:
- User-Agent-DUMMY
X-OpenAI-Client-User-Agent:
- X-OpenAI-Client-User-Agent-DUMMY
authorization:
- authorization-DUMMY
method: POST
uri: https://api.openai.com/v1/engines/text-embedding-ada-002/embeddings
response:
body:
string: !!binary |
H4sIAAAAAAAAA1R6XQ+ySrPl/fsrdvat80ZEpMt9h4CIgN0Ifk4mE0BEQOTL7oY+Of99gs/JmZkb
E5DY0lW1aq1V/R//+uuvv+u4SJPv3//89fc7779//4/p3iP6Rn//89f//Ndff/3113/8Pv+/J9Mq
Th+P/JP9Hv99mX8e6fD3P39J/33n/z70z19/b4tRxarabbpl4Cwc9eakb2bxoUZCPhQJuP6HMz3Y
LlxeWYsSVRBt2SZerI1BDsBDnnFdUd50DzSYa8BQwCzGS9FaxVIa3qX63Uc98RZa547P+/yCtMSU
CPY6A/Fe2aZwOY0527z1j9E8r+kMEXctsz1HsUubwylRXw+aEydKpHhaD8Prq4ZULpIsHlassUB8
b5wYuD6iEb8uJzST85xt5PXK6PnhWoIdeiUxlsUmHg68DcDV4jldobEoyt2r8FB04Bv2XHQmYq7k
KSgPNybZ6wPqGPrudDjNA4Ir4yDcrtttErRWoxMx20slejcwLcTq+s0cM62M8X5uczSnmxUx3rsd
4tEez9T8muzJjn2ckO9gBei52ejMQccuHOPLvQTDnlk061ZZ3F+J2kPTiCMdCQvRsKdnC861tMXi
eeUhO+tcQuEia5jeHit32GubBHRn7hLDOx8MioVTQ9HeDHLpPrErTH0LgKrVjniXuRYynR4BRff8
S8z5dhvLXr2y4VA9SqZ/onUodmf/BsvLzWfR/ntG4tDdM1Sdo5pZwjx0/Hp/OOhVUo2qlrsxZG1G
bis4KTo5vmsfiax8VbC1NUyucNkb46sP6FowcWXWvW+M+mr5PhwfZoLrw/ZT0BgTCpIZYUKCzCvG
oOgySOZlwDbmwTdGbUYi9algn3mjl3a9nNs2Gp3jlhmVpAvJ2aklJOz2IlG5OIqRiBWFd5BQYhoU
XDHT7hlKNp8b04NuhsR70Hwox2BNDnmpddxntQ7zPJnj3BSNwcMx7X/rE++BurDyDm0EoIUeLR9t
2Y1HKeMgSvygTCpF0bd7Z0ThvvLIQR6XhTj4+ghWHjKqzIklRnXcJDC/9CFx5qddN24DG2CRhDvi
FtumGPb7TgGFzLYUPc5j3K9KWYKI5y7RKynsxpt71+AaHq9E559dOOjN3YNCcBvPGErd8a04p5X1
ZBdmr/NO9OalrWG6xitmvWJ+oBsFzKX0IM5U34wHKxOJet5ReV+cQn482yfAZesTQqXEpRcWOnPW
GR4zUx+HvOqqEfpvqxHXroQQwZJ70LHnidYAuSteyiNHQV4y2jcZhAMDF9AMHTkFKdrE4yuiERzk
7oz9Y+R0wyFdz6A5yBLRyxdF9Y7ICmzbqsLztHq7dRu8PVicnzGV733jtvUHHFid0xsWn8gryur2
Utdnvu+Ju7sWYoyRPsK2Xx9IfJkfDYEWNxWOm2VHzHPpGUM1F8naHLSBmUt974qPIAoU/djSlqM2
Zvq+5kiVnBnZX1Q/HOtVncCRPA1m6nldMCmtKdrP8xyvLier4Cu5s9FWPgds0x4vYnzmewz5+d6R
3dKLwzHZni7oY7AeL4pkcKd8zqGdb0d6PmjXQtzGvFrfnOSNf/vz3d5dDVW67ONZfW+K7z728Vom
hk+lKmwL8XI2ypoOzyuxaWbHvBiDHH54YsdpKXprzBJI/SZj9mG7K+jTUhOY8IiG3GIuvxKVImrY
ISFRUaNxK482MEW6kDPe2Whki70KRX1+M7vkR4OvtG0LhfK6kH2vpKJJVsd03cnJyLbyy0fDIx04
LHRk0LEuXWNcfmwFpnhg5X1RxfAd1AQuuuew+3oTdpyrQYsk84apMBW1o+HelX7X7HrKW8Fwb5eg
mN8TZlP8x/N7X0PQRDH74Ss764qMjlX6onl7tAzxeuARRfTRM5KEWcyTtznCycsshp/fj/vbj/Uz
Gb7MOTp1KFoCMsqQ7ZDDt9iJsuoqDtpykbGds//GgjsfD10H64VHqS06IVb2DU39hO3jQo4Hqzjl
qryJFboKjm04qpeRgq3iDV4vqtJoPCYw2t3TNbHnxEJSu7xEQIS7ZeasXKOPe5Nt1DceIju20Qr5
dkIpFEV1Jc5Yv8OmXtoWrItoiVX6boxffgA6nRh7GmljjMnVbsEo1YJ+Xvhr/ImfauMXXgKMaHjU
iYeC5haTDdlHot7nkQ9K3A+0ksJHJ3gwWCpVm5a4j/MYslujOYCyXUzsl2S5i1Cam2g1kxMs4Xrj
jrPFx0ONmx7IYbmyBW9mKw9JDx4w93XDBb9KhQLpfSGIt6gkIR7Hp4PsEJfkYJ1FTK0kSOBQZzo7
kjYPe+f40AGWSUQC/vmE3Ct4hOLW1Fi4kKuYYnxPIZ7rc+I+9UMollDZELnfAq+OXdYNB3ewgL2k
FdmuHzEaNSI4iufanFhjagih0zugwt5LVMGjXiyicPDgJmkxlWVN6Zpzb/Qgdas3sexrJrjh3R2U
a2lP+yPZG4O8fEfodVFkElrvc9c3ka2jvpJOJGk3hpBTyFSIgu8Gr0quxU3vRR641zih6aVYdfWG
hz6yr+uRLvhw71o26y/Q7qoYS5v4GoputsyhPqo3ejTKRgxih2qIt0+HbPF3LIRUGzbUsdXhRZfv
uzGINibEyiHE6+XKRkOktBFkx/I89edH/FboqK9P68OARdBhg4eHb4Ye39WFOMwdURfdHEV13ZZT
6f3VBG/smKL7t/KZtckUdzzvVQWGs3PGUrjk6CtTHZBHeczuu6Bw2YSPaJnbQCzjIIw6dRMbNl5y
IS5t1Y7t1E0JlS75xLMrw+Ccc4w0CN4Mp5rnDvsQX8ATLGZ6kgYdP2WaClQJDWI5+5lRSaGcorpM
OfOoqblc7toSKafVltgfYyGmfqXCKvFNvN5YRUf7tYVRtfukVDl9kpi7dlPDYWUADircIFFvuwv6
2PbAdsN1IwQp33x9zI2EuA+UGN/LfF6DXGmUOGyAjs7y/PLrt8wruryj1sagsHyWBTHvnzoehyj3
UB4aJrNdtBI8kQcLHl3OsDo7yLFYRysPJv7zw9uOrz+mDtL9eiDk6WExLlzDUqf3o+IT9d1vf9ej
kBGeXc2XO0C9uKBZt51jJfuexLjniwSG9FQzXXMKY1Se1EJ1bu3xMke1MaoXtVdHtf0Qi8afYpzb
Tr0iy8phe8sdxIRXEZQPx2MbzRGC3/2GAxH7Lfv1P97Oax8eN7gyrAdWzDbL7UVtRaYQ4otj8Yd/
3xTR4A/3/W6Y4XMLdW7u2dPj55BLlvOnn1F2vKN46n/O7/fozOsKJE6rpYTyxSfBneo08TjKmQYW
Qzs6Pyytgs+Hcwbm1jrhBf4G3bh9HySY+C8xcf0y6GneXGA2bh94tsVDzNePVwX4srCIZ29RV788
NYBbRY50ceEUFdk+koAk+w8xgq0ZjndDxmBFYLP96eN2U7xM0ALlhWcZLF2mkH2F3H2wxyI8LpEQ
K+0GYj63Kb2aG4OfMluBeaWY5LDYJgXPOETIxyvOHGVmFQvn3VD0w+tNNxtEd5AQoOx71oh3fTsG
d2a+uf71V8/U57FoXy8HPuvwxcjNNw15z9cJLPz+wOz+YBSj66ETKEGeMptZo8tIbJyAbRr7D98Y
zr1BV+LhzdkOfXUkRbKuQxDcZkwzyqgYqRTJ8GoemGkLt++Gg+r16P3eWHixT3M0WAtb/vERlqg8
D7vIulQoXK78ib9UxbiNuwj016whu1PuoFFFhYJ+9bCtVkXH/dMxgI0qIqqo23vIj/XBQ4rJToSo
6qn4BlspQgcrFPi7shXRrD5XD6KrY7Gd2M/dFo08X5+U9FdPdihXn4MJibGe08+0Hr2dRArK3r6T
h5ITdwitLkXqd58xY73SO1Ge9ak/lldm673jjpeTd4NpPboijwf6Nuzrqx8MD+K6UWbwu31VUb4l
KiHf2u4GY721USZ/txSYL7r+IkBGRIuA/fCg84+1gpa3cYlXXsnCP3x4XG8wM2sjN77jzitRJl1S
YtpKg5g68wK4DuaLrul+6Liv9zPItweV4YIX8fD2+bie+AWF69txhakUKUTpEWGVDclPrzhQiNEm
G38VhL96AdhZClUmfBERzpL1T/+tmdx3Y2oZt5++xmtTxx1ltiUBBWoTHG5K8bXs7fjbD4yOfBPy
FzqocL7VJ/ZUPkxwqUUZrFuvINuL83Y5VsIb4FP6ZPsZpQVfxUmEbmuPss3n7KJxrzcyaq/cYwcE
W0Me9/0MmJ1KxGuyJOSfmeNAKJw/ejXuzl4YAOpOHiEUj/GoHnx//bqoMh41xzDG+Aka8gW90cUm
tjqpfD0C5OGyJc7Hlgv+2w+jVAqmlQl2v51b2GAEFxerZ4HjMX1FDirmZ515j/OrGz8nDcPyuHYx
1zrP4NLrbsGQXmra+Y3vCpNtdHj75o6Z728m6KmMSmDIW//0ZPe9b86SqgXqixiP9hwORecn8MN3
Ih9xwY9py2H3UHQWWFlp8E//kGFWgEOHukSIf+7+DBqzfjHD7Sv0w3/VPAfbKV/zrpatVQSLu5pR
+QpDwavcPIG9l55Tv70ZAkWOjezz22U//i5X/JPDtN9kI2Iz5trmVqF2V8aUh7ttN0raqkRk/yYT
X46K8fLmPZyficZucVqiEV1fI4r2FyD23dXcRb5VMHyvxZztd0FhMPel6UiXVzVGyoPG7Y/f1zdq
0uWw7opvk9QRpHxxJPaoP9x+9+owrCJSYZpdvjG/+68RfvxMU6Mk7I7vREJhMDtiubd1tFRyK0Vq
MT8Q/ZAwd0i8NILJP6Kq8ngaYzNuaxirzfCLd/fdh/gE/aUu2KQ/xDBDNwq3tr38qTfelvfsx9+J
d1yMiL3C/gLa+WgzO4+YEIvrQUGy1zbUCR8HYyjupQNWs4vZfn5S4vHu2SZ8tqNDPPlrGX0fJj4s
IFWY0yvY6IHNb+jM3Z6um6zrxKd5pxB8zmu2ey/D/9IbVYJPePnCB1eQuZQBvpMv05L7IARftgG6
LpaM2RMeCho4Ggzhdsm8AExXvML+pNIderHdFTLErzPrBCdmpczZ7zx33AbaDMDsj4SY35U7rrKz
g35+Qrv/LtBPH8H48gtyqhsXjYt0N4OPU9ym39MEv0qdinZBc2QbT5bdIRMJV6XHGNAZ3WfoW8lH
DSL95TP3qX/jcf/g1U8/T/xzGbfKk5rQ3zcOyUV2/i9/zFczk6RJeDS4BY6Kbqq0I5EbcdEFm4ii
cF96VC47Hncnfr7Bjy9nu83B6KNI+DBDIaeLIdi4i+LeO6DLqGZa673jMfhuAVp829HhqdzjMTbf
Aaw8MyQ3cutD9rg3OiTE4+zHB8dhHt6gMG4V22n3izumUKtwPTczurwsSDe8i0WNnm1s0R9fZWmh
Zr/8oYMny0ZTlSWFoBt0ulp/HrE4f1odHUprTX7x4WW7pHA/YY+OoVeFw/T8+tfvzUlf80RemdBo
JMF/6qOOVyeIW0uj2e5zQd9FzKrVKglMooeeFcrwQgG6NN8X2c7Krzt01aDCV/PuzPCQjOh8ltlo
8isZZmjmUokdMIz94kF2xiEPOX8aKtBtrjLC0DcU377pf3yK7Kb1x6efqOhilgPbD0ne8eNZu0Ab
2YK5bqS50/o+sIt5IBN/LcS6DNs//I9c90H3i+dPTzCnyj00bqz7CU5ebtFZkK3D8aPHKppn1o1o
srLrZLJOHNhp1opovpSJsR4u1Q/PsOpIO7c3BucE587r2aHgJ7c8maODJr9o4pNVyNLAwmDuEkR+
+kFM+gNFozri+MhfoSjdTEfPISqJpxIV9f3bLqHwyhVzL/dPPO7PFQUpu3S/ejF6CG8W4ndt99OP
MXs5GxWtokNFdi881X93+8MP8LjrlwUrV6hVmXQ/MuIfdmLQsZPCwekV4q2MT5z/8lF+vRu8/JTU
7R8bp4ZbIbcMy2OFhv5Tz+A4kgOdJ6EW/vGX8f3wnd5X+vE7C5qrt2LWp5yhQTMUUH/43Lwvjitt
3NZCqbopiaM85m45oj0F01W1P/1NmfzS1da5LYjh3/bxMG/jBHh2pvTNXSaE+JxMdKF2xfCluBfD
81lLwJxljOWy82M5fko6ynf+DcvYU+NmFzUOxFDfiOW074L98uf21dfEXOqNO6weEl9p+NgyLzt6
Rb/fGRmsRVmTXVYXIf/0Z+mP35ZP/tv0PjMo861HyORn/vw25IIW0HiuZgUv8S1CDS9nbMuHVSFi
ye5Vub6fSZTsSdeb2cFE7BsLLGnEEHytKCc45/qd7DbZLhQ7dVMBMeUN5StsowHUV4ve9HCncnXr
wqlfVyg7Vmc21ZPBreuRInS6MCyNd8PgsOlGiFxWUP7IDIPb/neG4oXcT3qzd/nzoaU/P5s59ksP
2boMaziG6p4Z98/K4MuSjLARazrxlSCsV+VMhgk/CV50i46WX0WG9fbzpeN2nhRSvJ/pEOo8+4P/
LckPN2CbzsaR2r0KOvnL6MzmKnOPZCXYo3BTdFtj+tNv7lD4G6o+hXAJaYenGHtRcJj8RdyyISmm
9SVQVWiJGTgLJCIAEwJfu5JLNTu7DC18BV4f60O2NV2HIi3GHCZ+y4xl8Qr7aN4n0C5WT4w6+y3o
xjqeYDO8d+TXz8TnUpdA5xbDy/ugFkOeP3O0fun+T28bbAhrB6Z8xTN2lmJ5mc51SMHU/9SfFO2t
GTy36e6HVzF9dl0NBXOPzD1Z+c+fz9F3f+vZvdBsxJfR+6JO+UprPObFQC56CeH5orCDhR4ud2Oa
weQHE40u3JDWQ1qhWVRt2WFlK2isPltTFdXHZO7EZ6XHiWRQrpdLzD3/YVBFBRl28bL841ct3+bW
g7V3v2P0QInLf/V3adiLOPtd7w7K49Cjhlcz+omUDjWWfRgha2f3if8t4iFZ3VPQb1VJtvtUF+PF
aWZQPx4BS1QSoSFovxV8wVlM/qEdSixNZPQUg0tVyNA0H7lF6BFfZgT7NPvz/5BCYMu89vMtJn9Z
RfJWWjPXb7gr4t2hRhP+Er1xJNRcNTqiqT7JQXoGiKvvtwLPlycoOgcXg59wUkGMmwf7zXPGMSQR
sG7jUdE4pcvnXnkBspoNzDpoleDFoTlBfK4R2SyGd8H3eeDDhLdsk8xb8Z3mcxCmL5cYpXbpBscJ
Zn/8pfYht12qz+QUFqp1pPn2PoreHFYRcvnwYvvsW7ryorpLsG9X/TQvkMImb5sbcrX7nPzmRcxW
eYv28omwnSE8Q0jGcQYT/8dStTrF9HOyMZr0ODOS9IVGiR082LKzREgGVSgccZbgWetPPGxV1xj8
UbutJ3zFwjAyNEzxQ+uX5jPnY1+67senh93VZdhCXjg47xdddwZtqHyo/IL7p7sP1jfP2H7KTzrv
hYT8+TGg/VlhxlA7Bx3uj9uT+bHzEj/+DbtlsCNkf3ka/LkZKILUOrMdzVaGuGUz/6cPf3zC+MPX
m5l3YW71mcVU65wcMpltiem6tKC57VdgqsRkGM/qYmBgAKzPQ8q8SY+zyY+FJ24jCpa/QTx83iW0
UW6C/PyAscNGvh7i2YY4lvsyRustKYjoQ0Gs9/gqpnhfYJcvdfz5lNgdUI19WPj0MOlDU+RexgLA
X7kgm4rlhuj8TvnNW/BcPtKOmfp2Bk5gIbJ9e3a3IM0ugcmvwpKe28XQJPXtx18nPzFA42w9WKDN
Oo/YaDyFI2qrWo2PB5nt15uw4I/TLkNrTXoyL8y/op/6xZ/9dzhyYiE+iQm3+fv8m2cVkx/XImEP
KnGKaoP+8C/v6Bq0ziOCRJffMKjDeCWu6jSh2B1wBrP1BZODcyMdL8Yog/XgbYgz+XF0z9cpHFGc
4ddmSRELWHVZTfXzZ569GG+KCpM//Ud/dMdYvf36A9Hv+afjm0qR1lP/pT//hJ+a4gTz+Pn6zaOM
0e8vCmRVcaISjFknhodTgXK/OET35Hc83Kmv/OHnRnw6uTytWhXsvfxku1lzEEJfQoTWjjZitahe
QujJt1bPbK0SI/WfxlccLxZc/PODbV/7PuRuYJqw3rUupT7N3OGcNz6aVZcBPxZV6f6pr998WU/d
bzfljww+KB1dTfPq7rGTeliElvTzh4rhnpQl+vGrjT7TDO6vnOSnN5ibjaYYOAgd/v6dCvjPf/31
1//6nTCo6kf6ng4GfNPh++//Pirw7+gR/VuS5H8z+c9JBNpHWfr3P/91COHvpqur5vu/v3WZfvq/
//lr8ee0wd/f+hu9/5/b/5rW+s9//R8AAAD//wMACEOkc+EgAAA=
headers:
CF-Cache-Status:
- DYNAMIC
CF-RAY:
- 7bd02a7cab52dd70-LHR
Connection:
- keep-alive
Content-Encoding:
- gzip
Content-Type:
- application/json
Date:
- Mon, 24 Apr 2023 17:46:29 GMT
Server:
- cloudflare
Transfer-Encoding:
- chunked
access-control-allow-origin:
- '*'
alt-svc:
- h3=":443"; ma=86400, h3-29=":443"; ma=86400
openai-organization:
- user-iy0qn7phyookv8vra62ulvxe
openai-processing-ms:
- '221'
openai-version:
- '2020-10-01'
strict-transport-security:
- max-age=15724800; includeSubDomains
x-ratelimit-limit-requests:
- '60'
x-ratelimit-remaining-requests:
- '57'
x-ratelimit-reset-requests:
- 2.92s
x-request-id:
- eee2fed77cd860a77c31a0b325ca3987
status:
code: 200
message: OK
version: 1
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,695 | Allow Weaviate initialization with alternative embedding implementation | I would like to provide an 'embeddings' parameter for the initialization of the Weaviate vector store, as I do not want to start the Weaviate server with the OpenAI key in order to make use of embeddings through the Azure OpenAI Service.
The addition of the embeddings parameter affects the __init__ method, as shown in the code snippet above. To accommodate this change, you'll also need to modify the add_texts method.
```python
def __init__(
self,
client: Any,
index_name: str,
text_key: str,
embedding_function: Optional[Embeddings] = None,
attributes: Optional[List[str]] = None,
):
"""Initialize with Weaviate client."""
try:
import weaviate
except ImportError:
raise ValueError(
"Could not import weaviate python package. "
"Please install it with `pip install weaviate-client`."
)
if not isinstance(client, weaviate.Client):
raise ValueError(
f"client should be an instance of weaviate.Client, got {type(client)}"
)
self._client = client
self._index_name = index_name
self._text_key = text_key
self._embedding_function = embedding_function
self._query_attrs = [self._text_key]
if attributes is not None:
self._query_attrs.extend(attributes)
```
To check if the embeddings parameter was provided during initialization and perform the necessary actions, you can modify the add_texts method in the following way:
```python
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> List[str]:
"""Upload texts with metadata (properties) to Weaviate."""
from weaviate.util import get_valid_uuid
with self._client.batch as batch:
ids = []
for i, doc in enumerate(texts):
data_properties = {
self._text_key: doc,
}
if metadatas is not None:
for key in metadatas[i].keys():
data_properties[key] = metadatas[i][key]
_id = get_valid_uuid(uuid4())
if self._embedding_function is not None:
embeddings = self._embedding_function.embed_documents(list(doc))
batch.add_data_object(data_properties, self._index_name, _id, vector=embeddings[0])
else:
batch.add_data_object(data_properties, self._index_name, _id)
ids.append(_id)
return ids
``` | https://github.com/langchain-ai/langchain/issues/2695 | https://github.com/langchain-ai/langchain/pull/3608 | 615812581ea3175b3ae9ec59036008d013052396 | 440c98e24bf3f18c132694309872592ef550e1bc | "2023-04-11T05:19:00Z" | python | "2023-04-27T04:45:03Z" | tests/integration_tests/vectorstores/cassettes/test_weaviate/TestWeaviate.test_max_marginal_relevance_search_by_vector.yaml | interactions:
- request:
body: '{"input": [[8134], [2308], [43673]], "encoding_format": "base64"}'
headers:
Accept:
- '*/*'
Accept-Encoding:
- gzip, deflate
Connection:
- keep-alive
Content-Length:
- '65'
Content-Type:
- application/json
User-Agent:
- User-Agent-DUMMY
X-OpenAI-Client-User-Agent:
- X-OpenAI-Client-User-Agent-DUMMY
authorization:
- authorization-DUMMY
method: POST
uri: https://api.openai.com/v1/engines/text-embedding-ada-002/embeddings
response:
body:
string: !!binary |
H4sIAAAAAAAAA1SZS9OCvLfl5+dTvPVO7SoRgWz/MwREbiYIXnsEqAiI3EwCOV++S59T3dUTq1CK
SJK99m+t/Pd//fPPv01a3rPPv//5599XMXz+/V/f727JJ/n3P//87//6559//vnv3+f/d+e9Tu+3
W/HOf7f/fizet/v473/+kf7vN//vpv/88++mnDSsaf26X0bewtMu3v3FbD42SMi7MgM/fHNmRJuF
z2t7UaEakg1bp4uVOcoRBCgwzyrlbX9Do7UCDCXMUrwUnV0upfFVaR83GUiw0Ht/elznJ6RnlkRw
0JuID8rmDqfDVLD1y3ib7eN8nyHir2TmcpT6tN0dMu15owXxkkxKv+NheH60mMpllqejylobxOfC
iYmbPZrw83RAM7ko2FpeqebAd+cKnDioiLks1+m4410Evp7OqYqmsqy2zzJAyY6v2WPRW4j5UqCg
Il5bxDVG1DP02RpwmEcE1+ZO+H2/XWdopSUHYnWnWgx+ZNmINc2Leda9NqfrsSvQnK5VYr62W8QT
F8+04py5ZMveXsy3oAJ6rNcG89C+j6f0dK3AdGY2zXs1T4cz0QZoW7GnE2ExGl16tOHYSBssHmce
s6PBJRQv8pYZ3b72R1dfZ2B4c5+YwXFnUiy8BsruYpJT/059YRkbAFSrWxKc5nrMDLoHlFyLD7Hm
m00qB43qwK6+Vcx4J6tYbI/hBZanS8gS93NEYtdfc1Qfk4bZwtr1/Hy9eehZUZ1qtr82ZX1GLioc
FIPsX02IRF49a9g4OiZnOLnm9BwiuhJMnJl9HVqzOdthCPubleFmt3mXNMWEgmQlmJAoD8opKvsc
snkVsbW1C81Jn5FEeyg4ZMEU3PtBLhwHTd5+w8xaMoTkbbUKMnZ5kqRa7MVEhErhFWWUWCYFX8z0
a46y9fvCjKifIfEa9RCqKVqRXVHpPQ9ZY8C8yOa4sERr8ni6D7/xSXBDfVwHuy4B0OOAVreu6qe9
lHMQFb5RJlWiHDrXm1Ds1gHZydOyFLvQmMAuYkaVObHFpE3rDOanISbe/LDtp03kACyyeEv8ctOW
o+v2CihktqHodpzSQa1kCRJe+MSopbifLv5Vh3O8PxODv7fxaLTXAErBHTxj6O5PL8U7qPaDnZiz
KnoxWKeuge81Vpn9TPmOrhWwltKNeN/6ZjxSLSSaeU9ltzzEfH90DoCrLiSESplPTyz25qw3A2bd
Qxzzuq8nGD6dTnynFkJESx5Azx4H2gAUvngqtwJFRcXo0OYQjwx8QDO05xSkZJ1Oz4QmsJP7Iw73
idePu/tqBu1OlohRPSlqtkRWYNPVNZ7f65ffdNErgMXxkVL5OrR+17zBA/V4v2DxToKyqi9PbXXk
7kD87bkUU4qMCTbDakfS03xvCrS4aLBfL3tiHavAHOu5yFbWqI/MWhquL96CKFAOU0c7jrqUGW7D
kSZ5M+KetDCeGrXJYE8eJrOMoimZdG8ocudFgdXTwS65KvcO2sjHiK27/UlMj8LFUByvPdkugzSe
ss3hhN4mG/CizEb/u58L6OabiR53+rkUl6moVxcve+Hf/Hw2V19HtSGHeNZc2/LjpiFeycQMqVTH
XSme3lpZ0fFxJg7NnZSXU1TAT0+c9F6JwZ7yDO5hmzNnt9mW9GFrGXz1iMbcZj4/E40iajoxIUnZ
oGkjTw4wRTqRI946aGILV4OyOb6YU/G9yVV900GpPE/EHZS7aDN1f1/1cjaxjfwM0Xi7jxwWBjLp
1FS+OS3fjgLf9cDK66SJ8TNqGZyMwGPX1TruOdeiDknWBVNhKVpPY9eXftfsfCg6wfDgVKBYnwNm
3/Wfji+3gahNUvbTV3Y0FBnt6/uTFt3eNsXzhieU0NvASBbnKc9e1gSHILcZfnze/m8+Vo9s/DBv
7zWx6AjIKEeOR3afciuquq856MtFzrae+0kF994BOo/2E09SV/ZCqM4FffsJc9NSTke7PBSavE4V
qkb7Lp6000TB0fAarxZ1ZbYBExhtr/cVcebERlK3PCVAhL9h1qxaobd/kR00tAEiW7bWS/lyQHco
y/pMvKl5xW2zdGxYlckSa/TVmr/9AehwYOxh3ltzys5OB2allfT9xB/zb/00Bz/xEmBC463JAhS1
l5SsiZuIxi2SEJR0GGktxbde8Gi0Naq1HfFvxylml1b3AOXblDhPyfYXsTS3kDqTMyzhZu1Ps8U7
QK1/35HdUnUEb2dqgKQbj5j/vOCSn6VSgft1IUiwqCUhbvuHh5wYV2RnH0VK7SzKYNfkBtuTrogH
b38zAJZZQiL+fsc8KHmC0s7SWbyQ65RifL1DOjfmxH8Yu1gsoXYg8T8lVvd93o87f7SBPSWVbFa3
FE06ERylc31O7OluCmHQK6DScSWq4MkoF0k8BnCR9JTKsq707XEwB5B69UVs55wLbgZXDxX6faDD
nrjmKC9fCXqeFJnE9uvYD23iGGiopQPJurUp5DvkGiTRZ43ViutpOwRJAP45zej9VKp9s+ZxiJzz
aqILPl77js2GE3TbOsXSOj3Hop8tC2j22oXuzaoVo9iiBtLNwyMb/JlKITWmA01q93jRF24/Rcna
glTZxXi1VB00JkqXQL6vjt/+fEtfCp2M1WG1G7GIemzyePfJ0e2jnojH/An1ycVTNN/vOJVeH13w
1kkpun7qkNnrXPGno6spMB69I5biJUcfmRqAAspTdt1Gpc+++oiWhQPENnfCbO5+5sA6yE7Ep53W
s622rqA2pJAETm2anHOOkQ7Ri+G7HvijG+MTBIKlzMjuUc8Pua4BVWKT2J47M2splu+oqe6cBdTS
fS73XYWUg7ohzttciG+/0kDNQguv1nbZ02FlY1Rv33eqHN5Zyn2nbWCnmoCjGrdINJv+hN6OM7Lt
eF4LQaoXX+0LMyP+DWXm5zSfNyDXOiUeG6Gns6I4/fotC8q+6Km9NiksH1VJrOu7SacxKQJUxKbF
HB+pgmfyaMOtLxjWZjs5FatEDeDLPz+97fnqbRkgXc87Qh4BFtPCN23t+35UvJOh/83vahIywrOz
9fRHaBYnNOs3c6zkn4OYXL7IYLwfGmboXmlOyoPaqClsFy8L1JiTdtIGbdK6N7Fp+i6nueM1KlnW
HnNtfxRfvUqgunkBW+ueEPwathyIcDfs1/94N29CuF3gzLAR2SlbLzcnrRO5Qkgo9uUff18U0eI3
D8N+nOFjB01huewR8GPMJdv762eU7a8o/fY/7/c8Ogv6EomDupRQsXhnuNe8Np0mOdfBZmhL57ul
XfL5eMzB2tgHvMCfqJ82r50EX/4lFm6eJj3M2xPMps0NzzZ4TPnq9qwBnxY2CZwN6ptnoEVwqcme
Lk6cojJ3EwlI5r6JGW2seLqaMgY7AYe5h7fff9fLAj1SnniWw9JnCnFr5LuRi0W8XyIhVP0CYj53
KD1ba5MfckeBea1YZLfYZCXPOSQoxCpnnjKzy4X3ain66fW6n42i30kIUP456iQ4vzyTe7PQWv36
a2AZ81R0z6cH71X8ZOQSWqbs8lUGi3DYMWfYmeXkB+gASlTcmcPsyWckNQ/A1q3zxxvjcTCpKm7B
nG3Rx0BSIhsGRNFlxnSzSsqJSokMz/aGmb7wh37cacGAXq+1jRfuvUCjvXDkH4+wTONF3Cf2qUbx
Ug2//FKX0ybtEzCes5ZsD4WHJg2VCvrVw6ZWy56Hh30Ea00kVNE215jvm12AFIsdCNG0Q/mJNlKC
dnYs8Ed1FNGq73MAydmz2Va4c79DEy9WB+X+qycnluv3zoLMXM3p+zsevRzEHRTXuZKbUhB/jO3+
jrSPmzNzpRq9qI7Gtz9WZ+YYg+dPp0Nwge94VCW3G/q07BNqbww34vtJbvKrc9ZQsSEaIZ/G6Udz
tXFQLn82FFgo+uEkQEZET4D99KAP942ClpdpidWgYvEfD0+rNWZWYxbmZ9oGFcql051YjtIips2C
CM6j9aQr6o49D41hBsVmpzFc8jIdXyGfVl++oHB+eb6wlPIOyX2PsMbG7OdXPCjF5JB1qEbxr14A
trZCla++iATn2ern/1ZMHvrpbpuXn7/GK8vAPWWOLQEF6hAcryvxsZ3N9JsPjPZ8HfMn2mlwvDQH
9lDeTHCpQzmsuqAkm5P38jlW4gvgw/3B3BmlJVfTLEGXVUDZ+n300eQarYy6Mw/YDsHGlCd3mAFz
7hIJ2jyL+XvmeRAL78+vpv0xiCNA/SEghOIpnbRdGK6eJ03Gk+6Z5pQ+QEehoBe6WKd2L1XPW4QC
XHXEeztyyX/zYVZKyfQqw/6n90sHzOjkY+0ocDrdn4mHyvnRYMHt+Oyn90HHsNyvfMz1PjC59Lza
MN5PDe3DNvSFxdYGvEJry6zXJxf0UCUVMBSsfn6y/1zXR0nTI+1JzFt3jMeyDzP46TuR97jk+3vH
YXtTDBbZeWXy93CTYVaCR8emQoi/r+EMWqt5MtMfavTTf806Rpvvfi36RrbVBBZXLafyGcaS14V1
AMeVHt9+ezEFSjwHOceXz378Ltf8XcB3vslapFbK9fWlRt22SimPt5t+knS1QsR9kS8vJ+V0evEB
jo9MZ5f0XqEJnZ8TStwTEOfq6/6i2CgYPudyztxtVJrMf+oGMmS1wUi50bT78X1zoRZdjqu+/LRZ
k8CdL/bEmYybP2yfPQY1ITWm+emT8mv4nODHZ7qWZHG/f2USiqPZHsuDY6ClUth3pJXzHTF2GfPH
LLgn8M2PqKbcHubUTpsGpno9/ta7/7gxPsBwakr29R9inKELhUvXnf7qjXfVNf/xOwn2iwmxZzyc
QD/uHeYUCRNicd4pSA66lnrxbWeO5bXywG63KXPnByWdroFjwXszeSSQP7Y5DHEWwgLuCvMGBZsD
sPkFHbk/0FWb9714t687RO/jim1fy/h//Ead4QNePvHOF2Qu5YCv5MP07DoKwZddhM6LJWPOVw8F
jTwdxnizZEEEli+e8XDQ6BY92fYMOeLnmX2AA7PvzHO3gT9tIn0GYA17QqyP6k9qfvTQL0/o3M8C
/fwRTM+wJIem9dG0uG9n8PbKy/d5uuBnqdfQNmr3bB3Isj/mIuOadJsiOqNujj61vNchMZ4h8x/G
J53cG69//vnLn8u0Ux7UguG69kgh8uP/5GOhllvknsV7k9vgaeiiSVuS+AkXfbROKIrdKqBy1fO0
P/DjBX68nG/XO3NIEhHCDMWcLsZo7S/K6+CBIaOG6V3wSqfoswHo8GVLx4dyTafUekWgBlZMLuQy
xOx2bQ3ISMDZjwencR5foDQvNdvq15M/3aHR4HxsZ3R5WpB+fJWLBj261KY/XmX3Ust/+4eOgSyb
bV1VFKJ+NKi6et9ScXx3BtpV9or81odX3ZLC9YADOsVBHY/f+1e/fm99/TXPZNWCVicZ/quPJlUP
kHa2TvPt+4Q+i5TVqppFFjHiwI5leKIIndrPk2xm1ccf+3rU4KMHV2YGSEZ0Pssd9M0rGWZo5lOJ
7TBMw+JGtuauiDl/mBrQTaExwtAnFp+hHX48Rbbf8adHmGnoZFUjc8es6Pn+qJ+gSxzBfD/R/e/4
IbCTtSNffi3Fqoq7P/4jZzfqf+v58xPMq4sATWv7eoBDUNh0FuWreHobqYbmuX0huqxse5msMg+2
uq0SPZRyMTXjqf7pGdY8aesP5ugd4NgHA9uV/OBXB2vy0Dcv+vJkHbN7ZGOwthkiP/8gvv4DJZM2
4XTPn7Go/NxAjzGpSKARDQ3Dy6mgDCqV+afrO53cY01Byk/9r17MAeKLjfhV3/78Y8qe3lpDarKr
yfaJv/XfX/74AE/bYVmySkWdxqTrnpFwtxWjgb077LxBIYFqvtPitx/l56vFy3dF/eG29hq4lHLH
sDzVaBzezQz2E9nReRbr8V++jK+7z/d9pR/f2dCeA5XZ72qGRt1UQPvpc/s6eb609jsb3bV1RTzl
NverCbkULF/T//qb8s1L1Y13WRAzvLjpOO/SDHh+pPTFfSaEeB8sdKJOzfCpvJbj49FIwLxliuWq
D1M5fUgGKrbhBcs40NJ2m7QepNBciO11r5L99s/lY6yItTRaf1RvEld1vO9YkO+DcnC3Zg4rUTVk
mzdlzN/DUfrL24pv/vZ9nxlUxSYg5Jtn/vI25IMe0XSu5SWv8CVBLa9mbMNHtRSp5Aya3FyPJMlc
0g9WvrMQ+6QCSzoxBV8pygGOhXEl23W+jcVWW9dALHlNuYodNIL27NCL7q5Uri99/O3XNcr39ZF9
68nk9nlPETqcGJamq2lyWPcTJD4rKb/lpsmd8DND6UIevn5z8Pnjpt9/eTbznKcRs1UVN7CPNZeZ
17dq8mVFJliLFf3yShQ3ajWT4aufBC/6RU+rjyLDavP+0Gkzz0opdWcGxAbP//S/I8XuAmzdOzjR
+mdJv/kyOrK5xvw9UQW7lf4dXVaY/vybP5bhmmoPIXxCuvEhpkGUHL75Iu7YmJXf8SXQNOiIFXkL
JBIAC6JQP5NTPTv6DC1CBZ5v+002DV3F4l5OBXz5lpnL8hkPyXzIoFuoD4x65yXo2t4fYD2+tuTX
z8T71FRA5zbDy+uolWNRPAq0ehrhz2+bbIwbD777Fc/YUUrl5X1uwB0s46/+pMS1Z/DY3Lc/vUrp
o+8bKJm/Z/7BLn75fIE+7mVg11J3EF8mr5P23a+0wVNRjuRkVBAfTwrb2ejmcz+lOXzzYKLThR/T
ZrzXaJbUG7ZTHQVN9XtjaaJ+W8z/8qx0O5AcqtVyiXkQ3kyqaCDDNl1Wf3nV8mVtAlgF1ytGN5T5
/Fd/p5Y9ieduB39UbrsBtbye0Xei9Ki1nd0EeTe7fvlvkY6Zer2DcakrsnHvhphOXjuD5naLWKaR
BI1R96nhA97imx86scTumYweYvSpBjn6no9cEnRLTzOCQ5r//T+kENiwoHt/ym++rCF5I62YH7bc
F+l216Cv/hKj9STUnnU6oW99kp30iBDXXi8FHs9AUHSMTiY/4KyGFLc39jvPmaaYJMD6dUBF61U+
nwfVCYg6G5m902vBy117gPTYILJejK+Su0UUwldv2Tqbd+LzPZ+D+P70iVnpp370vGj2ly91N7nr
78ZMvsNCs/e02FwnMVijmiCfj0/m5p/Klxf1VQK3U4fveYEUt0XXXpCvX+fkd17EHI13yJUPhG1N
EZhCMvcz+PI/lmr1kNL3wcHo68eZmd2faJLYLoANO0qE5FDHwhNHCR6N8cDjRvPNMZz0y+qrr1iY
Zo7G7/qh1VMPmfd2Tn3/4+lxe/YZtlEQj97rSVe9SVsq7+qw5OHhGoL9KXLmfvcnnQ9CQuF8H9Hh
qDBzbLydAdfb5cHC1HuKH3/DdhltCXFPD5M/1iNFcLePbEtz1RSXfBb+/OGPJ8w/Xm9nwYn59XuW
Ur33CshltiGW79OSFk5Yg6URi2E8a8qRgQmwOo53Fnz9OPvmsfDAXULBDteIx4+rhNbKRZBfHjD1
2CxWYzpbE8/2n+ZkvyQFEWMsif2anuV3vU+wLZYGfr8r7I+owSEsQrr7+kNLFEHOIsAfuSTrmhWm
6MNe+Z234Lm8pz2zjM0MvMhGZPMKnH5B2m0G37wKS0bhlGObNZcfv37zxAhNs9Vogz7rA+Kg6RBP
qKsbLd3vZOau1nHJb4dtjlb6/wEAAP//nFrL0rKwsn2XPWVXiQgkDLkq93ATcSaKIIpck0Cqzruf
8vunZ3TmQCVNd6/VazX/JH76Wtj8w4t/8XcpcEvGvncTFrvP+c/Pan963AiYvcrIbTsN/ONffuwZ
uH/dEGDTqwihvG4X5MnukLJTENaQU/IQBW6BJtputxoqq68h96fHYYcqFYxBWYeNdsCAJKTLpV/9
/POz91shyvCnT/+bP6a4lIs/fED69fWdqNaJvPLDX/ynn9BsaDO4K5/Nnx9lbNGci7Du2gzzcKsn
tj7cDorX3EW6L3zK9Yoj8R8/N8os82jVjTK0HeFJTtwQMKYf4A0orrqFcts1jOn3pZfPRJGRUUVP
Y2FxfoR5dH4Qq3HmlHqJaULlNHoYR7j21vNriADX5Wv42Hdv7199/fnLeuUt0y9/BBhBccLSz6+e
Hid+hvv0yP/pQ+16vb/f4I9faTqnGjSS3PvfvEG8ejPZSiHT4X/+tgL+57//j42C/f+9UXCz6BeD
k/7yVnNMb6C4ZRFJiuEJ3uk9iIBA3A9BUD2VAteLOjDi2CRIxuW0vFTtrkiK/0D+iEuPlo6AobPj
XLxb9X261knfw5M079BJ1mSwXhabg5nwTkLXOnPGsm73HqLlaBA9VKRyvH6KNwCfl0XCNUqmlakg
l5NxUpG3qghQl4+OihAeE2L42hesBtw66OnmGm7Cx5jY6Sb38IY/dyyVlyhdpi/XAUELdOI8yhOb
AxRj4FbPI3IqYSjX3PdsgKkYkWxKPwC7uzpSpIt2J+EhGwBdVCcDpbirQy6dn+28JT8HPnY3FHYg
T1msEwHQrq+JJUb9z/GiPJDhOv8cWIlhae/msLG9PQnobHpLx+UZfMSpjZcJ7NLFeyWRcmk+Ysiy
ZG6nScl8eCayTrQ6UL2+y5YblBohxjx2BoOwfWnCJoEjKeM6SwdazhEc9S1ERnwf0v5c2RA2/UjR
icxV21tNn0C5JFekRY9XSpehEAGU1xvyd9KtZMDUb5LCv4/EmSSJrYXUitDSeIcUlwcH8Ocj8XCQ
a0r0T3srKWmzHtogCYgNDhlb1UZSoboFBtKsZ1SyaGhk6FPzieLJl4xtt6tvShOVaajo5NHSSBB8
2Hr7gRgHZ/NmcdhcaF1qhBzBqo1lNNsI7vZzi+kNXQw6c8EbWBkUiVUXZYvtVRvBun5heJDENxtX
xbjDjNcB8sEJt2RS7iF4n8czQuTLJiqen5FctukN85dSKun8NO4QKvmKHMW8ljTnpRwO1+qB6R2+
07U6PmsQT5ODTr6xlKvidDm0L31LHNOWwHbx5xpWg8UTrc4Fb07AqYDMPkT/8p2hM9JhZWsNhvOW
TNR8vjtw9qMCFWnWA4qvJx/GtvFE1uNVpOQvf7Kix0SPitKj7vm7gUF+UeTf/Hii38GOYNE6x1Dg
xIVR5DzucHyXEobJW5+I/VFNeJzZm/z+b0mcpBYVHn9rZOHl0JLK8jf5cJZ3IVd0t3J7xxUEQmgm
5GiIAmMtfkPIuYmPnEm6gtkd9XH3jpov0nn1U9LCKFR4N88Lcl67XUqOrXkDpzI0QnE6TyUdTUcE
L6by5Hi6ELaU1QbhO7gdQjrvC29VL1MHdszxkaof3HLtL24FFJj1KKTVEVAm+Heo1+GKTs7uzNg5
1W0wf19n/E6GYJrUAudw6V4+Uf2WAgw7Poe5HB0ROpYro2V17cBY2TeUwvk1kaD0EtifLyJCEkRs
W/jGVIRXfMaCyAvTzKadCrknlxATGMZEj2LRg0+tX5HniJ+SHAnJgfBKz8S/tiVj5aMPYVB9bzgC
Lm/QMZoF0OXbRlxOZikbjOilBO+4IaEwZcYUTbtCEk1ZQOZ+Fb1+WK4VJEwViPYCfDlP30cI00Y+
E1OXCOsdxxdkds28cFq3sqVxgEfIR4OCe764GywXHve/+yO9j74TLWtyBIGBwpDDN1TOVlMn0JmB
SNTe8Mvp0UgFhPTREPcZa0D4PvdvOKrhAZliZaU08mIb1nntolTuPQOfIoOHX0GA4QvGo0Eri7Pl
iQvfyL48KrbSck6gr7QnvK+R1VJ1kd/g6JE43F0ZN/VNNfowDtyAuNa5MthcJabyLphJzFbXvK17
1EeIu1MZYo7pYJJ2qw1VYqakuF+kllwuZQZWYR7RL34eE+67HvhHiom1IzVb1y0bYRc2GTKuZpHi
N3IqcKtUE+mHCynpO8p8uai/BGPbjMAGpLSG5UUKiJkJpUFfvqcCGYYZ0hbpWOLzcLXhVWmcEN44
paT3vcPBQyu0yO0Vu1ytCx/CCQzBL34NWzQU8/Lv/CQM48pYcNPXsnS3XXSqPzlby+ksAnGvOAgV
heKttHwnEJy6hpyaw6tkx4LjwKNTQmTOh0dLX7taV9w8GJDW3YKUSq6og4vafkLWnB/elgGaQ7eb
3+SyfmtjfalO9a/fe8q1LXuHO+TAtfoYqe32TXHc+gkowesQ1mYyG/jlihF8T3mJ9M6n3rpxuw5U
7RUj/ZnPbF3hy5TrvXZE6idwvNU42SZsM+uEqXLQUjaxcAPcowDIAt/Nmy+FiSGXWjqy9+N36sTM
f4FP1vuonMO3wQrxakN922zkFbulnA/wmsF6DiOC4teVrS9Vq5QL4vwf/ujpfhDtCJ5gkpOTPxve
NqdtAotav4Q7qJ7SAzEGF9aRYCJkPoeULTXpAIy5T/gdY8WYXT4yIUpShNBV2wA9Ie0oL7uzRsJV
slO+klIbOOENEjX52t5C5O4mMaLGxODfjG1zOiXgFcOGnH7fw4bDQUgzy0GaDAW2/PGJyK6iUFTA
nK6BtYygeRwAspRpmNbsJEF4Ny8LQZpKy1XfPjbsb/eO/N4H3Q+PADLPEzJpoLb0LU1U+vVHFHzw
ZqztMvrwxzfQVbBUgwVhncG4r2/IsW6fEmd2moE4ihQsiaAtf8+HMIzsASv7CrHulkg3+XRwehTc
+UO74QusQLAbFqQfZ36i3x0dwdjtIszR6sjI7BxC+RQkT1x/gsGj9FNkcGnhPqRDvjOWRXj4IgC+
Ry5MbyZ8TnoqHVRfChev1r2tb9YIWmPPIY9/9mB4l4aqJJc6RurYu+3qv78brO2uI64whNP8mKkv
N1QOiaqE07TBVdugiHyCDPsVgq179EdwTDlCHOtmlYc5M0e491sThRzT2Zx7wwZ7UXkRrUw/5fCO
lA6s/XoknkbzlgxGUUPvlofIwu9mYt9xvsH5W5+Ju/4cAWnfzsofHlipEIOtOT9ruKOfPTlpODZ6
OQhe8FbeF/Lr9+n2Kd+FHHU7P5zBCU//+E29ihfiTLRl21juVfAWcB9+V5p7W5cmvTLfbZtcrbYs
17OL7kCBeY8/Jae2wqKZJmyoGBJ1yJ9ez/GRr0jHykShvRynA7xtFLqlRJDOBclEZ7s0YeIvd+T9
6om+DSkBSSx4WNyPp3avb4sNO/L94vMCPLZl33MFld3jQrwm2gyGczuDGn8eUKBqTrr2/l6Frtq0
CCllz1Y+qCK4GwHGzb45p/g7ejoEluEiG9Yu+OGbD475byOr2+p0e4j2DX4bWyCuId9T2tl6Bd0y
v+DW7Y4eP7S+Dj+jNJIff/71HzOBn/38JK64dB5z9zCE6vECkNa+R2Pd4+wIvu0coOdBFMvZ4XYZ
uDRfMaQPHBlzFXkdPBRVHsIRA2/bW4sMdmOeI1U5NCmdn14FD/CoEnviNIMGnXuUXkznietd9+my
pbcXfB4rNZRDJE7Yyc4qfOzCCW+dH3lMLbocPmM+CN9l23tbEfahXOrBiRggVtk+VFIBBrtpCTnr
0KbbgO8hNAPXI2i4delmaZ8QVJz/Qg7VbMbUxfGB18UMD595nhav8HnIwiYnejwep4MNxArC63Ii
ThWwluHiwcOzxj1JSAzLWKwLDIFNZDXcF9SfZh+XAtAESSX/+PmPL8JZnkyigY8/8e1iC/BubGeM
peaQbsP7uMGZXjx8uLyOHn+SsQ12z7bB3FW0wLq4oguTcVDJ/X7deUQj+SxnB2fEXOeM7cpUloP/
BQAA//+knUuPgzDWpvf9K1q9RS0IN5tvF64hmOBwCSTSaATkBoSQADZg6fvvI1I9o1nMbpZVUqUS
2+ec933OwVn1DdZFtgVEHeQGzvMLUueobguhSHwPDvopoYfJDGLG+MdDSxSq4188jqueU0G7u5Lv
uUnYNCSiAfkX7ij26m2/mImf/9YbR3feqEVS6aufEPfBAKYmnhH6yPLDMTH2LuKjmFov4+Cav6jt
Z4r5zd0eAs1uMXVBcEdrfdxC60DrQB3KZzG60+OorXqBbs3HFi3Pe8PB/hjrOLjINut4tO20vAlr
bNWCD+a1XkNj7C8Uvc4P8Bk/agSGhuPwNuSWmDVgJ0PZyO6EU55SsWgsi2BQmCq2NeHek+45R2Ba
jDGANX2C6TLJC9Q7vqT2YVF7li+JCllQp4GE86wYp9dMoGdaKtbN4syWyb5GYNmQJ0Zq/UBTq0EI
Z2EfUzNPTSbUNE3gs/d3ROrEop9vivCAN6+RAzE4xGjJoQthlHAq3uZYMkkC5BTuLdsMmkPgm/Pr
dbxpeF9eaLGX7VjaVmCCUbf7BJtTGPfLtorO8LhkF7rnUottSj9ewI2pH+oNpR5/7vN3gXEQfalH
znswHVrD0Qb1Y2G/dgZz2MiuBwNrKumJNHrPeH9Y/j7vdLr2Mc1hlWiyvuyIthLCyRITCBX9lOLD
YaQ9K8XWgUUGDmSKL4z9/Lr2eNsVteKoLr6jyLVq0ycFzrK+NPtaVvOfXqG6GVWAlVvWQN27PQiE
1RQv0RgSzX+FX3qI7qAY4pAXwXTkciJ8v0e01qMJSsXLxnv36PbCpbzKsk4sj5pf51nP0m7rQ34f
mUQj3VCPwe6ZaOXdfdLIGYR6STfQAWs+wejLjELwTnQCBfdpqXGJTv0YaIUA9tX2TYRktBFLPTmH
060wyPxIRXP6WroMReq+qIs3FIyn2zeFX/PUkqWQGJjvV7xOgBw0/DuP7KeH8TJ5eDechH5a86Ec
4YgFyskzzZ8/gddP9frTk8Pq58He6XJsi5u2mAH+tlBMspnqaNBqKrkeBz/mlOFdY2Gw8pME/vzk
YXOjbDkcyxIqpjpi7+Nwxfy+lwFUyrEKuOZgmPOnHnO46lO6f5kpWN7CsfzpYaJu66iYlkjxIOVl
Z42fqJgfnD1AURAHah/vbzaQC/Zh1oOZaBY7mbOCLmcgEMMlU2cOMVP8xNO+82TTxNg15siQO4Gh
9NxgufNGLxpt38LKP+Y0lvaLufRdBqH/zc94B4lrCmeyceBTbBPyVe4hYMliHcG2FcU/vzwHkyxD
uEMTteXLzRzGrZ5o4THSAvFc4WJgvbQFKy+idi8JBSVVf1QRVx+Jip8NmlP+4am//K62ypGxVjNb
UE7+hnpur5vixjyflTV/UF30erPbXu5EleJTR203qBEr4nyd+njJ1BOsY0F+/GPVd9SzOQZGaXkd
werXg3U9CnZW2049X288Dp4PgS1TGztwXa9gc1I/MVtuFQHmpXoGYmiKBevOBx9skqUi6/lASzZW
CazRMSTSqt/m48aw4ME8BFgnBoyHsNo/wE+/dxt9BvQSZpbK0knAcSp9Weucry2oJTJj78qn8arP
LNgIKCTdMB0Qi6z6AVd/Sg8vG8ZD5ZtbqC0GpTZLD4X08+fz6Zv96amvkro+vFiHC+FXfb648/4L
9urRwtdV/xJHKXJY5iYLNtx1E8/73Xn48bBAGMi7n/D+dJPdejvR4DRJaKJWVP34FtmdtR1bmLTz
YZscCuyHwAfT8XEQVGsbAbK0HADzM+E8oNZQwnZstYgqvOJCZ7n22JztHLT3xfdgqT5IsLzfc83k
ZJR/8YV3QdfXrN2TBs7tgWIv2zNz8LbAAr/6aFwBiiXxbTuw3qAcm2qH0EbHF0GFlq4H/crjmGIE
g/rTz7x1/xRfHB09LW3aLd0hwMW01VALd+nuRA8+MJnEG/cEvGQpINr3cWWLfAs52J/NmnSr3/oy
9HVhBx4K3p+3TiHVsnqG+wwv2B6jFM3anqTwEjwjas5k6td6vP3xP+o8PC4e7/N3Aut+Ul9DrTn/
8tGlIUnwOu9EsCipG8DP+6zj9PW6AyakZw5+JP5ClhMr63H9fNC7XZ2AgfDBllcxnFVX567r6zkm
jYOJA0+SiHh/Ld6s+fG86Qhz6oTDYC79MuZAvNzuOAhcF037vSVA463FwfspVfH4eo8clOKsI3wz
Tz053U0C7/t29Qd1EbNUPN3guyYHwjaHT78EmhZA9BoKbN7nV8F89ZDD7Ud7UfwEh5i8heMNTO33
ga1ktM2uB5MFjras4P0JEsDyDpdQdcyYwFXvk+EqE7jyAepH47n+8ysrv115696clAF/VYupLxqs
vEWkpBEgd4cRATyn91JovEVZNeQGn+2u6ofXnBsQAFav9epYgM/QWbAe0mat/1skKN601WKaaNRf
6xkTj+UA4o1pUTP7iDVNtxUHcRRi6txap5caXIkwyqqQ6hPd1/NGflaqfnhhasyeYU6ecHbgaN5V
vNvtl540YcopZqp55Gzs9zV7XmUBylcvJsJB0tnGJxsf8jduv/KioWBP4RP86hd2WqkvlmtmtND/
ns9rPZ3MZbnpCRwh+wZzvyFsMl4P4edvcKG/tz17LOMDBP1jg62+BIydXDjAOK3cVV8+AG3sUw43
0QGt/FgthgtWIeQtdCLsyOJ+hhd5CwP7JATgdX6wKZIVFT7g3GH/LUtgUrZVC2m5Eei2ehRgzDXN
gQ8+5alRBByagby40NybLeEKIYinXdFs4VvJY6pvR6tmO0VY4Edzdtj98TQ6yOSXH4lqqjCeWkYr
AMvotvqLp7nZ79aJN5DX1IJvEHf4Kicweah+AFl36mcuBhOAKssp1j+tyUJfi+D+Mu/pTrdBsWzI
poRGFB4CuvKxEbYRp46fDmCH3POCqbVfgYCzfBzAwOrFjT3KsKVbjM/Yz83REjoRfufFxvgZZfXk
LskZGqOl06wZ7frbw0XQammY//TCR9sdBUj9qCTS/H6gubHyDsqP0CT1ZSTm0m3BDajSrg1AnhNA
3uIIwWbPj9R/eWavTC+FwNOm2eNVT5ubeSm/v/wUbFLzXvzqOYC87NKbyRDbrOdPo5vmQIvPMwXD
LkxbGHS5gxEuIRskrhXhhKKYGne+6udff0Pe8PuArfmpv4SZA/H3MRCObiZGw8wgcOM/LWpPrhIv
BF0ecF0f8svPw1oP1HONHLxLkgWxCoVfqPH3LFjcnViQ5ZGKkH79LU4O0vOX/9enIYDx82vgx7/g
rmdFUHGHpW/EoniANMg5vI+pHm9yTbPUcM6O1CDXhDE5eamwuL5jivgTYuLDhS0Irq+QepT18RRP
nQfdnEU//gyYkVcGvFzAnQhqPrJll4dH4OZzFKTZOnF8szxD1blPRVS+/qARnS0B0v1oE3rRI7C8
lmTSfv0Uc8na+I+3vg81Cn75Z8HR2YMncMTYi785YhrnOLDP23Wi5SHE7LWILuQn4xrIahnHY3w0
h995pX7zPLDpgC8DaM3OxKhxTgWz008JXH9DgtPaf1jiXK2gqGODHk5cEk8qQSlwqbz94y9SifZb
+L4ZDt3W+7BfsOsNqoPGkHqBU9WD4AsyIKfKpLto1/Q05yQRutm3xsb5w4PpQwkHo5HRlffV6HPP
1TM02OkRSOEtYMtbOJdAbauAFMlB74e1nwA/d7emhyB9Fct0kT34bS4K3XcVZmxuhRuce2VD8V79
MiakRw7KVzemu7UfRDhvR0BD7h6ZrmRCw2e8lPBXnw4sl2MSvH0Rzqcuo1f0qMyhlLISOOroUve5
APNDno9K/flXh3/W9TIKHwdOH4YDbTJJPMGX0sCgjs90tz980fzzTys/x1svrePxqL8cCF+7hFrV
BcWM9YcOhvPpSHivfvRjojVr/dFjIgnXuqD8di8C0gd7bG9qFSy8vuF+POjXjzUXrz+cwXGvd2t+
j/pl1H0HhMR/UE913/1iS9kAN3ttDKYNjXr602uP8FLiXVY5puDdNz58BesTA/lwQmzn3BfA35/P
4EvOHzZs5e0Wrv1RbMsXzqTFfTPA7ed8oH63dUBz2rcODLyywteRT9lCZfUIztbXI1LQoZqUvuYB
BM5PfECPCi1nKomwt1SB+htTiknfGjcQ7fQU73D4LP76yb/6vK33c000lh3h8p406v70Jr6XN4js
wwOv/TY2F7e1XrwXnsCMb8zpoIoLpN9gu+q3sJ7WegsEsnWpn/ENGl+vcwnOhsNo4FoTo7ZfGnA9
X9QQyeXnrxpYZd93MDd8D2Yhqwdt0GaGDXkJ0aAMuw6sfJwQ2dmwX38LPjamQ9jFOhfjGs+/fjHO
mKH386qPQCfnHkXJ4VkTMd8usPKjnNSdIJpTXB4i+LgdB2x5z9vP/zZAzlsYbMiY9ezwOhKIQP5c
9XUZU2cMhZ9eJ+pQ6oWIfHQEq58j6spXBWCBBf74mD4qbbFc3sQCulc+KFZfr5qIk+LClX/SnYSk
eqp0rYVFNBg0dV6NufqZBq79QCLyT7Mnz8+Sa/8fEwXi/3uioAs8QnebzkZieec9oLFmR29UcQF7
kcKCrYEs6sMSAanI9h7UeCxRL+SlmiXBaYLau3GDF0ITGIrDnoOnVtXJ9M4axnKuHIBI3yiY0/DS
L+bXzeH2UrbYvqKRjXvwdUDjpjfqou4Jxk81DdCMQ4O6VZUX9M1FIgSgPWMLk8EkB3cUISaySrqm
UsD0EmIOKvdmwbumexf0foshyJd6S53avtezg74PMNxchzxpmJp9kCEDBCfniA95uSvYjSsdsL4f
moaoLeieygmcrvMRu1+7L5ZS7iuQCFQPLqOtI0Zu4QQPs5PgfVGFYMBJFsGXsQ+oVSKpprPdLOCx
zSxsP9Chnu9fm8C7fHJwEChjP4yIRCpDr5HMeratxQvPN/CQgpC8x84p2E3adpqnORNFFk/B4j5j
F1AMm0DdVj4iQTd2UFNynm6/QlRMwWm6qY+o2mPbQmE8c+regnhj6bgA/Bsw6VSrcJ5nE1sBQYBe
SZJAN4tC7O35M5jD/jFB41JGAdQUhS2XbnDUbR0XdP/mbwW97rYLdL8KT5TGrtCynB9HgK5WT5RT
tdTDiNojeDTZFu/6zgHsxcUeyJKhw5nR+WzJn+dUkw+LTeZG+KARqvsz0PXbnVoxUvpvL39SOL7W
CQxaZoxKwbmEqfMk9CCUtTmdrRMHgm7kqLVBCeq5UjzDS1TjQO0qm4mf7tlo12/VYOtCvIJeb2UE
nx5iGJW8j5bzfCagrTye+nk5F/Mw34/AfdoONr2wQ6wKiha2Ox4GYM8TNvbVdIa5f+ICseyieswq
UKmjxM3BcOWrYtbmZIJL/16CcSibgiiSE6niZ4nJfBW+NWOnoQLgUFyCuQ0zc1CKpoSXb+1j786f
+glr5gCfbgrx7tChmCmnuoUnmcjUXxRQTFX/hvB0qzcYi+mAlv2cy/Bzcxu6HyvCFjTnDdQ2Z45o
R0VCVDtVHDzDoaAZspV4aLXtUZPCycehFCaAXW/JESbpU8O2jcJ+fnkWhOb1tqdGLBix2NJNByX8
doLlHpJ+UfBCeJyrHLU68u6X4Q47WE1pH5SVorHJutol+HLuCe92XQ8Wc45FcJaHnBpNeGBLR7UU
rB3rgO/TsZ9oQQzAF/iN/Rf/RMzeWQ8QGADh3bdr6/57y88AbIqIiBu77Md8USHwvyALuLVDyBxy
X2CrejAYviUBI+o/BO6yqAhEE3XmqBuiAD+V+8THTXgrSCo3N2jppY4LyL/NCR9MQRslONPASK/9
5J+mCcYT9eihVWKwQKr6sILpB+PLOhAcnxsOYFVVqM6EXdGw5MJBqz9uiOigN2NGZqkgVtUQu5L9
Medd/01h/9ZsuiO2YA6wOZcAvtso2Kzr/UZ0MrRcyCTS9/w3Xu4894XlUg1E/lYXc3njTaUCvrng
3WzHbCxzJ4J4b+2oPgquuWTnIQFtut9itK0qNI2ojcDms1wJnMtDPMeo60CxPjPrvfmkWG53TgDn
hNyoJ/BLsYw8vCnf3LtgMwodsHBUkaF+uZXYPXVbNMuqZ8DeceNAOdit+TsfwMmiF/aC6muy6kUd
+OG8O7Vl9GG9wh23mvbGaqBo1fB33qCLoogaQ+jXow2qQdt/HO4vfy9OWJzVwntoweaMAjBX+SGB
d/GB6W2r4Jpl5Bqph9C64PgQvgF7vN0I9CPTSPImXbzIvKr+6gveG9UpXr7nTwWNOPQD6WJLPaOn
0QWZUzd/+Wm2FvEMcS5z1K7RaE7eSbGUoiRG0BDiAKbf5wd8LHuRHs7KBrDTzjNU92XviPLLd/Km
J2CpoUmDh+L10johAWTcQLrWg3hOF9bAh/iwsfPppmI4bOQGXoPqi/Wr8O2nb08I2On2iRpZiMF8
UZ0BDuPMsLPrNmx6jdtKY/G7J3JVqUVfvreq5kjRA9si+hbT7qXcQH9zj/RmKtSc4VdPtcuDxNTj
qqpmb5skAJjNAxuAyDX55QNlXwwBHBSIyL2rXShJLR+wA9n0i527Btw+bw02GFEYY8HFUuf4zWM/
KRfEdjvfh4ZyO5CnFCZsOgqZBUz+CAJtUiK0FPrZB/DeJthIyM0cZiFy1MZDJ4wbZVtLx8wjMs/j
GqOEPxTNWfNK+CwTmV4s+20udfet/vbPSpDMZkE1Okgx16zrQ8HcV1MOzT7ig198LZa69eBL3NvY
fIWWSdd8Cl9ukuBgq+Ceubx8hpt5KbDvlAxMmnVMoHOxS3zwFKlevDCaoKGUB6rzYVzPH9X3obU7
KjjglTZeDnqUg0s5pDSQlPfv/B2BJDU8Tnq0ASScww4+80rH+/V8z5LneeotrW7YtMKO9RF3hXCz
mcpA1fkcUe+NBvWRVh6RWSUjsrmDHJr3cIv3M1/WE9rIKuROZwWje6nG7LlzXejbToO356ytWXY7
+XCPo33gzEgvhudVt6D9sl/BI8veMV3jAaqf4kqYR05gToouh2FHH0Ff8aiYyXyDIB7GA8Y8O4Px
WHwMGLXq/W+9R0G/uSAZRpOaKRH6Ocx3AkS2RehWFSgjauZ4MD8TRHdnOyuWWq5a8CYew17Gi4C4
XdvAB0w10i22hwa8mY6/80Yk0DUxWfMZWADc0nh9f/T2ehP45rUvde7IKtiTFAR+Da8MloVc+t/r
w+7N19RQwm/BLqSEqreAD5F5ewcIcTsRJjf1EMzr/jGLn7cwaVVEXaOrwGS+Fgui2eqoX/PPnp2D
q6sGRLHolmZ1Tw7uS9DUz+WKMWVFQWj36LQdjq4BG8mxn/WiDrT2zitEGrs2HmQh9GC2HQZqc+iD
GCt5qH5yrw6mY/Zms+btA9jmez3YrPG5bDBLtPvyCGj5O3/rfgGdhSF2KHoylr51AYb+2OJVvyBW
BuUDEsa1eIdspZhj9Ojg/ZHtMQYpMsnpPHSwV9c7VJayrietqAV4amUdu6AS2TJjBsFFHo5rvUVs
fnvWV131GtW32SOem/xgQL2P40BgKKmXD9aCX/2lgZVq5rx5niA03xFHd0f73E9Zc3OUhFPdQFbs
rv+YoN8CemEXIoadgIankLRQrN8HGqTK8Fd/wcl5yiQW0BXMbaREsG/dgFoVEsG35jkDrJ+XBK3y
YWPYdwts0n1Ct2n2NhkrJU7RDoWNzfXvJ+ukbkHe1jq2M/IAH1W/BpC+2DmAFm8DATbHG3wd0yiA
eRkWszKfcohe1oeimkf1Ir2dBzSe5ZG6Q3WuF7cjLTD1EuHAUQgYOFB38FCBY7ARuzOabUP0gfvc
OYF6qbp++u13lNA8WFKhMufpa/ow5x4cdj6oqmeo6jn81TeWh6+aaVCs4ILeElEor5mUlTwH0ALu
RGKdXbOb5HbwEVQ+PUSl289KrssA7R1K9UXYmaLbkeanrwj3ULx66JL4AQ37llKPVDZi18wV4Fa5
PcmzC8V6CfXLAg29PNE85LNegqVIoL9x7gTGvGVucoM5YL8ojKjvyukF/+r7kCA4UrevlILpb4vT
jrks0LNjH4vJsmcIi+FE/+rh0rhVrpVD9sLezEc92c1FABKX7ohIkQ6ECbxEKITLl8BFKeIlC4+y
tupjbInE7pmXmV+wvj72Sj5FoxCmPkwcdb0DpUvrgS/qCn5jPv7pDSaFkveA9tV+E/jgK3MKkxT+
+YN4QbeC7XemDL6Vm1FfKod6tCouBQJ61dScyFQsmX4UIBwvHt06QlYMUDg+tDraXzF2FIst7fnr
wTQhC/YT5Q6YeZ997dcx+flPcuxeKSzFx0g9UPIFsTz3CHpeM7D1ITsw854rwwHxetALfFcsGlYt
8NNjyZYcwKQlxxyeHsM6YYf2BRuC3IBB6GDqCvanZ48XzeEr3XsBfPG6OV2bkwcTf3R/+b8fHlYy
QOe1KwLpbqdguly9BB6IElDjIWxjaU+nRLNxNAewUbRiIE3e/cWbcufvdd+T3FPfb37E+JROrOuS
ooKXkqR4v7PbfqzVgwerJhlomfIm2yxzmsAapvdA3HZpMV8qEIDf/uxa+xQv57u0wMPBKoMztb/F
9EiSBVosWsWBvS3mpH/ctDWf41RE22KUPMODpX/6Uq+rXuzry+0WzoDz1nh9Abr6f60NkEEEkbxq
NrzGB6iadMDbIOuKydbsCEaO3GA3r0C9lM+zAR/eXvurvzSX9CNY9SM2lhAB2nNRAO9N5v3VqxHq
iQxfSRoHkto1qx+8chAUzZXqYij09JLtb3CZF4Uom+pQ//wzPHN1REQRPQoi86qsPMtUDjYZ2bLh
Zl23AJ8ch9pZpxX0ab+PMHHkI107QvWaLwJoxLFPpKWzi7/443eHHtsdGoqJQ/0E1ENRr/F0MKf3
uA2gui8qauREi4fDS37A863O6K6zE7Yc5TEH2r31gqBOZcBWv6ax67Jg71M5ZqcVvQBXPY/1bbYt
JPl2DMD+avF097TFeAbzyYJRrj5oEKUFYh65e+qDVDvsrh2sReXVFs4YHum2EeJVLzUVjDvqB7yW
fns6vQYZ+KlSYAMJdc1cLD9g33rBTz/2M59vOe1mZZdAunYdGMdF9mCSUIfuX3ZVTIGQnX/6lhpS
6IHldB6+AC3KPRCPqEV/+cV4xy555ELC5mm+dcB4lWHAFsTFw/O6t/7yqz8o0Jz7ZbppcUKP1M+V
u8mszGrVn34J7HILxJ0ep5p3dTbUepK9Kd7unAhM7Wbh7UUQahZnRg6oNp+oJ1YmGOrRFcDPP+BI
qeuhFsojFMMlpboq2Gx+qocS7D8Wh1HME9RMSRSpu+xYUJ+WI+vtIIPw27pnwmC4RXP79RewCacH
4e/syhYxCyZgo2gKpI+9MedMxVuga7cz3X4yK2b2XZbBcGIi0VaeNO/7ryGHrfyhP7265jvuF49k
RmGBmH2fVNB80THgZ5aDaa/5X9ASV8PHj7CYc+45FbwGjy+Rdl3PWC7tI3C6PTfUV0s/7qqkvAEu
bg2y0UmDZhxBAszNTqAORg7YfFQrUG9LdQ6WKDyCxZeJoQaGgnCdhG0xkSRv4aUZElxuy6RmG8hP
6i14PPBpRChe+cYCrtusCqa7EIOJq/gj8F4Wo2jlI3QXZB3Es7MlWq0IiBWk/ELPPOrUmogTM/ft
b6H2vBik2obRqhfmCB421gmfM5uYi9B1WzWtnh12PzYyBWs8PID+uhX4cC3faAn1cIGb0/IkLA7f
aKnunA9+/q20ecekPOR8uPKEYOVnfS/Yww2Uw+kVcKEyFksWnlV19R+BHNoEsB2dOogrGeL9Yj/M
Pz1OM64iL4SOjOl4LrXNPBUYv5WHOdybUoCrXglOO1LHvf9GubpDURlUYTjVjCu5HPa5h4OX3d0L
drffjbzqSxp8lH0/B8UzgTC8+NgPyyV+6QYnQulzAdRsSYRIpp9FqITFd+Uv1eonQQMXzDnYt3ib
EQ0vDhwcb48tnlg9m7lLBH/+4k+/F5Uqwzt5hHhndUOxNOfqBsNK7eiu7jq0WGE8qCvfIeKMnvF8
Ql0CK4JeZGOiyBT0l5pDeb9YeI8qoRhP4BHAlKtbHFjlox4P0XoBYR/xRIsVsR7ag3uGHH8YiVrx
m4JgPXKgHBYCxed0qpe++0Qg5OQWH0NhA8hABQJV0FTUoOFgLpBXI/j8IhKQVZ9NQ5NDeDoTLRAq
lILp3iQifN95So2jUK03ES0Egntzo8GYSqiegvAMnm4CMf6wEjUbK2yhTY8DaUok9XS45Q747Phb
8BnsLaOIygZYeQZ2Fbur2U7yLXjO65Q0LvH7aWOFjRZMI6R+zDdo5SspBHVT0HLVD+N5AREUpNeV
brXwav70NWiH1KE6EBwkArycIdOWMVDM6tRLHpZ9+MndGoeRMKA//39qn4zupyroQZbtpx8/w1tJ
mNDk2nPy6yAG01dY4vkTZgucX8wKJKvzYwYgJ4IcDjsamKVebIpvkMr72YFkrefxwuSHBevvPqf6
yo8X7xkJcL/fmXgHO/M/fFGclzAQcZfUE2+dt7+fiVxWAA1SEibKfrYg9VteLwQpuaR/fm48KFmx
CN1jC+fXbBE5t0cwoIN/A66984NFCPt4GpJIhtI87XA4hZuYEGkn/vT5jweyX76A2q494IOhyIwI
XWdA7I4KDozyiSb7cDgr641sgWxVHPv5I+DQqCLfW/WuZ1XdEyjNawdR4gHoz8HJg+kw0EDc2LAn
nkxSeHJkh3CBcuhnva+PIFCBSf1G0WKSyM0EL48hplZGPCagg3WD8HDBRJbsvUnt4M6BlueFQPar
az19myJS9/XRoQUqSyYOd+ELDRQH6/o+6mWUP1vYColFd2rXoGHqXxPEH8ugoSa8arKuP1Dm4rXq
/TdaLNX1oLpre4w3ac9IIL+I8lz2A17PE5rKUZ9AQIAVdGu/Y9nrxRaKpynDZ60Si8/e0Bp15QEY
hSWMJ4gaC25PtxcNOmVfTHehlCGLXz02hfBZEMpDF/z2V/HtFxiNiut+fpsinw9qkWaYgFI+NXRf
2Bb68SfI8Xik2EuXQhSzYIFC9qqC5SZs2eaRH76gr9wD1qHwKlhvjwO8QBIS1alQvBHDqwpiR81/
T3AUzJR8Ajen6UlCEm7YUAtJBGd73q/54dhPgXA/w1FhHVGlqkHr/iV/vKRd+zPTY9Q9OAPoUSMJ
jzGTSymBunLLqMlCA43KfM1hdns+sR0SvRcjebTUH48zWVghUoTnCLoL0Fb/bPYS2YxHMCBNx9YL
pT1zSXaDy2cBhHeUBizc7nBTZNpKWL+Fcrx8qWbAyk0XGrTKHizXc59DInFv6iq2W4vH50WF5mEH
glkVXmzyRr+F3HgWsW4Iwcp3JhnsIyAT3kuj9Y5N/gbM95EL+n2lIynnEgKvXvUhytWu++mQZA3s
OPeDfYNvi3HRbyVczwO1UuLV5Qu9K0gZLFeeK8TsunMX6HlgIpsU0WKqERVAbaVv6qy8bD6AZwlN
rbTw7tR5K09oOjhl8EyTE7qg8bjAB2yJp5Fl1XsMB+sdqrnMEbm0x2IINZT/+YUZhQB1unaQf36a
njTUAeF13ZYwFchIVr1n9pW0XeOZKoSr0nM9PYWyBdmWDNQohCfquv5twB/fRxr/LuaX53Nw5Zv0
x583TsVtoZ0dacBn7G4ukhS0StTK92AZiFo08RUdoVI3lBon4QlWniLCIjkt1KpRZpLl/IggwRyh
lkRejKHgbvz4fCC5tsKeu/6bwNeQHKmjdsRcKsx54BmheeVnGzbeDPUGw5vaU/QuFbN7XvcO5HaN
ifdxFZuEv88C4O7tFhsLUeppaXLj118MPtdqjucTePhwCReO7squ61lGThGMHTnHYS90Pa244gZD
YbwHfKKY5sobXG3MOJEsavjt+7Okt2BvHhG27x1Eg3dSHMChxgoETHy0eSyqAecCYsKtvHKCwvkB
91JkYH0OT/1wtCcH1m7aUQzSHv30FHz5yQmbfrjrKdqZLbx/H0dsDqFRL/bX/U/+QJ/yXNNNcJzg
VXzU1LiEtFgkyWlg+hhm8t3zZ8baW7EF5miL2OxDs2CP1zv/+XvsJXwW//QiwMdRIp9rFRaDe1Jy
sPpJrPvCwNqdXqSQPllG9YMwmqTgpSNohPSMDzDl4oETzj6Ep2K901PRi8+Pj688iAgNSot5kxuV
dhMfF5xPlVVLP1667j92XLQrmLgZtuqHc+9EY2XNaPT2buC+VAHVuZAVtOdyH+41R6WGRs5oktFA
fvWVOvcuQsPxJLswSWsNo9Xvz5vce2g7e5dirLBL3USjmcCmTHJSqeG3nsdFdmEToTiQbDtHK2/l
4FXO8oBzlSBmj6CQ4awxnXCd8imon5kpFKX3njQZ+bKhOWwJvEaPN9VXvr6kclPCbR0W2DCEpl68
ro3++NJG7qSa7PQiAb9+sHTtXCC4tpL8/CEBdqn1M/fVDU0xGwFjlEY9i97GDRbWYFPTCD8FKeW6
AtKnAARs+K6eSy8I4K+fUKz8TNRzt4Mr3yDTJXPAQrMd+d93FPzjn//8H79vQWi76+21DgaMt3n8
9/8ZFfh3fs3/LQjiv6n4920JZMgft3/913+GEP716bv2M/7PsWtu7+Ff//VP6W/a4F9jN+av/+vX
/1j/13//438BAAD//wMA5ou8WIVhAAA=
headers:
CF-Cache-Status:
- DYNAMIC
CF-RAY:
- 7bd02a80b81b75db-LHR
Connection:
- keep-alive
Content-Encoding:
- gzip
Content-Type:
- application/json
Date:
- Mon, 24 Apr 2023 17:46:30 GMT
Server:
- cloudflare
Transfer-Encoding:
- chunked
access-control-allow-origin:
- '*'
alt-svc:
- h3=":443"; ma=86400, h3-29=":443"; ma=86400
openai-organization:
- user-iy0qn7phyookv8vra62ulvxe
openai-processing-ms:
- '68'
openai-version:
- '2020-10-01'
strict-transport-security:
- max-age=15724800; includeSubDomains
x-ratelimit-limit-requests:
- '60'
x-ratelimit-remaining-requests:
- '56'
x-ratelimit-reset-requests:
- 3.264s
x-request-id:
- 327380602cad71a931c429f23bbfd21b
status:
code: 200
message: OK
- request:
body: '{"input": [[8134]], "encoding_format": "base64"}'
headers:
Accept:
- '*/*'
Accept-Encoding:
- gzip, deflate
Connection:
- keep-alive
Content-Length:
- '48'
Content-Type:
- application/json
User-Agent:
- User-Agent-DUMMY
X-OpenAI-Client-User-Agent:
- X-OpenAI-Client-User-Agent-DUMMY
authorization:
- authorization-DUMMY
method: POST
uri: https://api.openai.com/v1/engines/text-embedding-ada-002/embeddings
response:
body:
string: !!binary |
H4sIAAAAAAAAA1R6XQ+ySrPl/fsrdvat80ZEpMt9h4CIgN0Ifk4mE0BEQOTL7oY+Of99gs/JmZkb
E5DY0lW1aq1V/R//+uuvv+u4SJPv3//89fc7779//4/p3iP6Rn//89f//Ndff/3113/8Pv+/J9Mq
Th+P/JP9Hv99mX8e6fD3P39J/33n/z70z19/b4tRxarabbpl4Cwc9eakb2bxoUZCPhQJuP6HMz3Y
LlxeWYsSVRBt2SZerI1BDsBDnnFdUd50DzSYa8BQwCzGS9FaxVIa3qX63Uc98RZa547P+/yCtMSU
CPY6A/Fe2aZwOY0527z1j9E8r+kMEXctsz1HsUubwylRXw+aEydKpHhaD8Prq4ZULpIsHlassUB8
b5wYuD6iEb8uJzST85xt5PXK6PnhWoIdeiUxlsUmHg68DcDV4jldobEoyt2r8FB04Bv2XHQmYq7k
KSgPNybZ6wPqGPrudDjNA4Ir4yDcrtttErRWoxMx20slejcwLcTq+s0cM62M8X5uczSnmxUx3rsd
4tEez9T8muzJjn2ckO9gBei52ejMQccuHOPLvQTDnlk061ZZ3F+J2kPTiCMdCQvRsKdnC861tMXi
eeUhO+tcQuEia5jeHit32GubBHRn7hLDOx8MioVTQ9HeDHLpPrErTH0LgKrVjniXuRYynR4BRff8
S8z5dhvLXr2y4VA9SqZ/onUodmf/BsvLzWfR/ntG4tDdM1Sdo5pZwjx0/Hp/OOhVUo2qlrsxZG1G
bis4KTo5vmsfiax8VbC1NUyucNkb46sP6FowcWXWvW+M+mr5PhwfZoLrw/ZT0BgTCpIZYUKCzCvG
oOgySOZlwDbmwTdGbUYi9algn3mjl3a9nNs2Gp3jlhmVpAvJ2aklJOz2IlG5OIqRiBWFd5BQYhoU
XDHT7hlKNp8b04NuhsR70Hwox2BNDnmpddxntQ7zPJnj3BSNwcMx7X/rE++BurDyDm0EoIUeLR9t
2Y1HKeMgSvygTCpF0bd7Z0ThvvLIQR6XhTj4+ghWHjKqzIklRnXcJDC/9CFx5qddN24DG2CRhDvi
FtumGPb7TgGFzLYUPc5j3K9KWYKI5y7RKynsxpt71+AaHq9E559dOOjN3YNCcBvPGErd8a04p5X1
ZBdmr/NO9OalrWG6xitmvWJ+oBsFzKX0IM5U34wHKxOJet5ReV+cQn482yfAZesTQqXEpRcWOnPW
GR4zUx+HvOqqEfpvqxHXroQQwZJ70LHnidYAuSteyiNHQV4y2jcZhAMDF9AMHTkFKdrE4yuiERzk
7oz9Y+R0wyFdz6A5yBLRyxdF9Y7ICmzbqsLztHq7dRu8PVicnzGV733jtvUHHFid0xsWn8gryur2
Utdnvu+Ju7sWYoyRPsK2Xx9IfJkfDYEWNxWOm2VHzHPpGUM1F8naHLSBmUt974qPIAoU/djSlqM2
Zvq+5kiVnBnZX1Q/HOtVncCRPA1m6nldMCmtKdrP8xyvLier4Cu5s9FWPgds0x4vYnzmewz5+d6R
3dKLwzHZni7oY7AeL4pkcKd8zqGdb0d6PmjXQtzGvFrfnOSNf/vz3d5dDVW67ONZfW+K7z728Vom
hk+lKmwL8XI2ypoOzyuxaWbHvBiDHH54YsdpKXprzBJI/SZj9mG7K+jTUhOY8IiG3GIuvxKVImrY
ISFRUaNxK482MEW6kDPe2Whki70KRX1+M7vkR4OvtG0LhfK6kH2vpKJJVsd03cnJyLbyy0fDIx04
LHRk0LEuXWNcfmwFpnhg5X1RxfAd1AQuuuew+3oTdpyrQYsk84apMBW1o+HelX7X7HrKW8Fwb5eg
mN8TZlP8x/N7X0PQRDH74Ss764qMjlX6onl7tAzxeuARRfTRM5KEWcyTtznCycsshp/fj/vbj/Uz
Gb7MOTp1KFoCMsqQ7ZDDt9iJsuoqDtpykbGds//GgjsfD10H64VHqS06IVb2DU39hO3jQo4Hqzjl
qryJFboKjm04qpeRgq3iDV4vqtJoPCYw2t3TNbHnxEJSu7xEQIS7ZeasXKOPe5Nt1DceIju20Qr5
dkIpFEV1Jc5Yv8OmXtoWrItoiVX6boxffgA6nRh7GmljjMnVbsEo1YJ+Xvhr/ImfauMXXgKMaHjU
iYeC5haTDdlHot7nkQ9K3A+0ksJHJ3gwWCpVm5a4j/MYslujOYCyXUzsl2S5i1Cam2g1kxMs4Xrj
jrPFx0ONmx7IYbmyBW9mKw9JDx4w93XDBb9KhQLpfSGIt6gkIR7Hp4PsEJfkYJ1FTK0kSOBQZzo7
kjYPe+f40AGWSUQC/vmE3Ct4hOLW1Fi4kKuYYnxPIZ7rc+I+9UMollDZELnfAq+OXdYNB3ewgL2k
FdmuHzEaNSI4iufanFhjagih0zugwt5LVMGjXiyicPDgJmkxlWVN6Zpzb/Qgdas3sexrJrjh3R2U
a2lP+yPZG4O8fEfodVFkElrvc9c3ka2jvpJOJGk3hpBTyFSIgu8Gr0quxU3vRR641zih6aVYdfWG
hz6yr+uRLvhw71o26y/Q7qoYS5v4GoputsyhPqo3ejTKRgxih2qIt0+HbPF3LIRUGzbUsdXhRZfv
uzGINibEyiHE6+XKRkOktBFkx/I89edH/FboqK9P68OARdBhg4eHb4Ye39WFOMwdURfdHEV13ZZT
6f3VBG/smKL7t/KZtckUdzzvVQWGs3PGUrjk6CtTHZBHeczuu6Bw2YSPaJnbQCzjIIw6dRMbNl5y
IS5t1Y7t1E0JlS75xLMrw+Ccc4w0CN4Mp5rnDvsQX8ATLGZ6kgYdP2WaClQJDWI5+5lRSaGcorpM
OfOoqblc7toSKafVltgfYyGmfqXCKvFNvN5YRUf7tYVRtfukVDl9kpi7dlPDYWUADircIFFvuwv6
2PbAdsN1IwQp33x9zI2EuA+UGN/LfF6DXGmUOGyAjs7y/PLrt8wruryj1sagsHyWBTHvnzoehyj3
UB4aJrNdtBI8kQcLHl3OsDo7yLFYRysPJv7zw9uOrz+mDtL9eiDk6WExLlzDUqf3o+IT9d1vf9ej
kBGeXc2XO0C9uKBZt51jJfuexLjniwSG9FQzXXMKY1Se1EJ1bu3xMke1MaoXtVdHtf0Qi8afYpzb
Tr0iy8phe8sdxIRXEZQPx2MbzRGC3/2GAxH7Lfv1P97Oax8eN7gyrAdWzDbL7UVtRaYQ4otj8Yd/
3xTR4A/3/W6Y4XMLdW7u2dPj55BLlvOnn1F2vKN46n/O7/fozOsKJE6rpYTyxSfBneo08TjKmQYW
Qzs6Pyytgs+Hcwbm1jrhBf4G3bh9HySY+C8xcf0y6GneXGA2bh94tsVDzNePVwX4srCIZ29RV788
NYBbRY50ceEUFdk+koAk+w8xgq0ZjndDxmBFYLP96eN2U7xM0ALlhWcZLF2mkH2F3H2wxyI8LpEQ
K+0GYj63Kb2aG4OfMluBeaWY5LDYJgXPOETIxyvOHGVmFQvn3VD0w+tNNxtEd5AQoOx71oh3fTsG
d2a+uf71V8/U57FoXy8HPuvwxcjNNw15z9cJLPz+wOz+YBSj66ETKEGeMptZo8tIbJyAbRr7D98Y
zr1BV+LhzdkOfXUkRbKuQxDcZkwzyqgYqRTJ8GoemGkLt++Gg+r16P3eWHixT3M0WAtb/vERlqg8
D7vIulQoXK78ib9UxbiNuwj016whu1PuoFFFhYJ+9bCtVkXH/dMxgI0qIqqo23vIj/XBQ4rJToSo
6qn4BlspQgcrFPi7shXRrD5XD6KrY7Gd2M/dFo08X5+U9FdPdihXn4MJibGe08+0Hr2dRArK3r6T
h5ITdwitLkXqd58xY73SO1Ge9ak/lldm673jjpeTd4NpPboijwf6Nuzrqx8MD+K6UWbwu31VUb4l
KiHf2u4GY721USZ/txSYL7r+IkBGRIuA/fCg84+1gpa3cYlXXsnCP3x4XG8wM2sjN77jzitRJl1S
YtpKg5g68wK4DuaLrul+6Liv9zPItweV4YIX8fD2+bie+AWF69txhakUKUTpEWGVDclPrzhQiNEm
G38VhL96AdhZClUmfBERzpL1T/+tmdx3Y2oZt5++xmtTxx1ltiUBBWoTHG5K8bXs7fjbD4yOfBPy
FzqocL7VJ/ZUPkxwqUUZrFuvINuL83Y5VsIb4FP6ZPsZpQVfxUmEbmuPss3n7KJxrzcyaq/cYwcE
W0Me9/0MmJ1KxGuyJOSfmeNAKJw/ejXuzl4YAOpOHiEUj/GoHnx//bqoMh41xzDG+Aka8gW90cUm
tjqpfD0C5OGyJc7Hlgv+2w+jVAqmlQl2v51b2GAEFxerZ4HjMX1FDirmZ515j/OrGz8nDcPyuHYx
1zrP4NLrbsGQXmra+Y3vCpNtdHj75o6Z728m6KmMSmDIW//0ZPe9b86SqgXqixiP9hwORecn8MN3
Ih9xwY9py2H3UHQWWFlp8E//kGFWgEOHukSIf+7+DBqzfjHD7Sv0w3/VPAfbKV/zrpatVQSLu5pR
+QpDwavcPIG9l55Tv70ZAkWOjezz22U//i5X/JPDtN9kI2Iz5trmVqF2V8aUh7ttN0raqkRk/yYT
X46K8fLmPZyficZucVqiEV1fI4r2FyD23dXcRb5VMHyvxZztd0FhMPel6UiXVzVGyoPG7Y/f1zdq
0uWw7opvk9QRpHxxJPaoP9x+9+owrCJSYZpdvjG/+68RfvxMU6Mk7I7vREJhMDtiubd1tFRyK0Vq
MT8Q/ZAwd0i8NILJP6Kq8ngaYzNuaxirzfCLd/fdh/gE/aUu2KQ/xDBDNwq3tr38qTfelvfsx9+J
d1yMiL3C/gLa+WgzO4+YEIvrQUGy1zbUCR8HYyjupQNWs4vZfn5S4vHu2SZ8tqNDPPlrGX0fJj4s
IFWY0yvY6IHNb+jM3Z6um6zrxKd5pxB8zmu2ey/D/9IbVYJPePnCB1eQuZQBvpMv05L7IARftgG6
LpaM2RMeCho4Ggzhdsm8AExXvML+pNIderHdFTLErzPrBCdmpczZ7zx33AbaDMDsj4SY35U7rrKz
g35+Qrv/LtBPH8H48gtyqhsXjYt0N4OPU9ym39MEv0qdinZBc2QbT5bdIRMJV6XHGNAZ3WfoW8lH
DSL95TP3qX/jcf/g1U8/T/xzGbfKk5rQ3zcOyUV2/i9/zFczk6RJeDS4BY6Kbqq0I5EbcdEFm4ii
cF96VC47Hncnfr7Bjy9nu83B6KNI+DBDIaeLIdi4i+LeO6DLqGZa673jMfhuAVp829HhqdzjMTbf
Aaw8MyQ3cutD9rg3OiTE4+zHB8dhHt6gMG4V22n3izumUKtwPTczurwsSDe8i0WNnm1s0R9fZWmh
Zr/8oYMny0ZTlSWFoBt0ulp/HrE4f1odHUprTX7x4WW7pHA/YY+OoVeFw/T8+tfvzUlf80RemdBo
JMF/6qOOVyeIW0uj2e5zQd9FzKrVKglMooeeFcrwQgG6NN8X2c7Krzt01aDCV/PuzPCQjOh8ltlo
8isZZmjmUokdMIz94kF2xiEPOX8aKtBtrjLC0DcU377pf3yK7Kb1x6efqOhilgPbD0ne8eNZu0Ab
2YK5bqS50/o+sIt5IBN/LcS6DNs//I9c90H3i+dPTzCnyj00bqz7CU5ebtFZkK3D8aPHKppn1o1o
srLrZLJOHNhp1opovpSJsR4u1Q/PsOpIO7c3BucE587r2aHgJ7c8maODJr9o4pNVyNLAwmDuEkR+
+kFM+gNFozri+MhfoSjdTEfPISqJpxIV9f3bLqHwyhVzL/dPPO7PFQUpu3S/ejF6CG8W4ndt99OP
MXs5GxWtokNFdi881X93+8MP8LjrlwUrV6hVmXQ/MuIfdmLQsZPCwekV4q2MT5z/8lF+vRu8/JTU
7R8bp4ZbIbcMy2OFhv5Tz+A4kgOdJ6EW/vGX8f3wnd5X+vE7C5qrt2LWp5yhQTMUUH/43Lwvjitt
3NZCqbopiaM85m45oj0F01W1P/1NmfzS1da5LYjh3/bxMG/jBHh2pvTNXSaE+JxMdKF2xfCluBfD
81lLwJxljOWy82M5fko6ynf+DcvYU+NmFzUOxFDfiOW074L98uf21dfEXOqNO6weEl9p+NgyLzt6
Rb/fGRmsRVmTXVYXIf/0Z+mP35ZP/tv0PjMo861HyORn/vw25IIW0HiuZgUv8S1CDS9nbMuHVSFi
ye5Vub6fSZTsSdeb2cFE7BsLLGnEEHytKCc45/qd7DbZLhQ7dVMBMeUN5StsowHUV4ve9HCncnXr
wqlfVyg7Vmc21ZPBreuRInS6MCyNd8PgsOlGiFxWUP7IDIPb/neG4oXcT3qzd/nzoaU/P5s59ksP
2boMaziG6p4Z98/K4MuSjLARazrxlSCsV+VMhgk/CV50i46WX0WG9fbzpeN2nhRSvJ/pEOo8+4P/
LckPN2CbzsaR2r0KOvnL6MzmKnOPZCXYo3BTdFtj+tNv7lD4G6o+hXAJaYenGHtRcJj8RdyyISmm
9SVQVWiJGTgLJCIAEwJfu5JLNTu7DC18BV4f60O2NV2HIi3GHCZ+y4xl8Qr7aN4n0C5WT4w6+y3o
xjqeYDO8d+TXz8TnUpdA5xbDy/ugFkOeP3O0fun+T28bbAhrB6Z8xTN2lmJ5mc51SMHU/9SfFO2t
GTy36e6HVzF9dl0NBXOPzD1Z+c+fz9F3f+vZvdBsxJfR+6JO+UprPObFQC56CeH5orCDhR4ud2Oa
weQHE40u3JDWQ1qhWVRt2WFlK2isPltTFdXHZO7EZ6XHiWRQrpdLzD3/YVBFBRl28bL841ct3+bW
g7V3v2P0QInLf/V3adiLOPtd7w7K49Cjhlcz+omUDjWWfRgha2f3if8t4iFZ3VPQb1VJtvtUF+PF
aWZQPx4BS1QSoSFovxV8wVlM/qEdSixNZPQUg0tVyNA0H7lF6BFfZgT7NPvz/5BCYMu89vMtJn9Z
RfJWWjPXb7gr4t2hRhP+Er1xJNRcNTqiqT7JQXoGiKvvtwLPlycoOgcXg59wUkGMmwf7zXPGMSQR
sG7jUdE4pcvnXnkBspoNzDpoleDFoTlBfK4R2SyGd8H3eeDDhLdsk8xb8Z3mcxCmL5cYpXbpBscJ
Zn/8pfYht12qz+QUFqp1pPn2PoreHFYRcvnwYvvsW7ryorpLsG9X/TQvkMImb5sbcrX7nPzmRcxW
eYv28omwnSE8Q0jGcQYT/8dStTrF9HOyMZr0ODOS9IVGiR082LKzREgGVSgccZbgWetPPGxV1xj8
UbutJ3zFwjAyNEzxQ+uX5jPnY1+67senh93VZdhCXjg47xdddwZtqHyo/IL7p7sP1jfP2H7KTzrv
hYT8+TGg/VlhxlA7Bx3uj9uT+bHzEj/+DbtlsCNkf3ka/LkZKILUOrMdzVaGuGUz/6cPf3zC+MPX
m5l3YW71mcVU65wcMpltiem6tKC57VdgqsRkGM/qYmBgAKzPQ8q8SY+zyY+FJ24jCpa/QTx83iW0
UW6C/PyAscNGvh7i2YY4lvsyRustKYjoQ0Gs9/gqpnhfYJcvdfz5lNgdUI19WPj0MOlDU+RexgLA
X7kgm4rlhuj8TvnNW/BcPtKOmfp2Bk5gIbJ9e3a3IM0ugcmvwpKe28XQJPXtx18nPzFA42w9WKDN
Oo/YaDyFI2qrWo2PB5nt15uw4I/TLkNrTXoyL8y/op/6xZ/9dzhyYiE+iQm3+fv8m2cVkx/XImEP
KnGKaoP+8C/v6Bq0ziOCRJffMKjDeCWu6jSh2B1wBrP1BZODcyMdL8Yog/XgbYgz+XF0z9cpHFGc
4ddmSRELWHVZTfXzZ569GG+KCpM//Ud/dMdYvf36A9Hv+afjm0qR1lP/pT//hJ+a4gTz+Pn6zaOM
0e8vCmRVcaISjFknhodTgXK/OET35Hc83Kmv/OHnRnw6uTytWhXsvfxku1lzEEJfQoTWjjZitahe
QujJt1bPbK0SI/WfxlccLxZc/PODbV/7PuRuYJqw3rUupT7N3OGcNz6aVZcBPxZV6f6pr998WU/d
bzfljww+KB1dTfPq7rGTeliElvTzh4rhnpQl+vGrjT7TDO6vnOSnN5ibjaYYOAgd/v6dCvjPf/31
1//6nTCo6kf6ng4GfNPh++//Pirw7+gR/VuS5H8z+c9JBNpHWfr3P/91COHvpqur5vu/v3WZfvq/
//lr8ee0wd/f+hu9/5/b/5rW+s9//R8AAAD//wMACEOkc+EgAAA=
headers:
CF-Cache-Status:
- DYNAMIC
CF-RAY:
- 7bd02a842c6375db-LHR
Connection:
- keep-alive
Content-Encoding:
- gzip
Content-Type:
- application/json
Date:
- Mon, 24 Apr 2023 17:46:30 GMT
Server:
- cloudflare
Transfer-Encoding:
- chunked
access-control-allow-origin:
- '*'
alt-svc:
- h3=":443"; ma=86400, h3-29=":443"; ma=86400
openai-organization:
- user-iy0qn7phyookv8vra62ulvxe
openai-processing-ms:
- '263'
openai-version:
- '2020-10-01'
strict-transport-security:
- max-age=15724800; includeSubDomains
x-ratelimit-limit-requests:
- '60'
x-ratelimit-remaining-requests:
- '56'
x-ratelimit-reset-requests:
- 3.725s
x-request-id:
- 11dea59c8b54d5678da987091c2feaa0
status:
code: 200
message: OK
version: 1
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,695 | Allow Weaviate initialization with alternative embedding implementation | I would like to provide an 'embeddings' parameter for the initialization of the Weaviate vector store, as I do not want to start the Weaviate server with the OpenAI key in order to make use of embeddings through the Azure OpenAI Service.
The addition of the embeddings parameter affects the __init__ method, as shown in the code snippet above. To accommodate this change, you'll also need to modify the add_texts method.
```python
def __init__(
self,
client: Any,
index_name: str,
text_key: str,
embedding_function: Optional[Embeddings] = None,
attributes: Optional[List[str]] = None,
):
"""Initialize with Weaviate client."""
try:
import weaviate
except ImportError:
raise ValueError(
"Could not import weaviate python package. "
"Please install it with `pip install weaviate-client`."
)
if not isinstance(client, weaviate.Client):
raise ValueError(
f"client should be an instance of weaviate.Client, got {type(client)}"
)
self._client = client
self._index_name = index_name
self._text_key = text_key
self._embedding_function = embedding_function
self._query_attrs = [self._text_key]
if attributes is not None:
self._query_attrs.extend(attributes)
```
To check if the embeddings parameter was provided during initialization and perform the necessary actions, you can modify the add_texts method in the following way:
```python
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> List[str]:
"""Upload texts with metadata (properties) to Weaviate."""
from weaviate.util import get_valid_uuid
with self._client.batch as batch:
ids = []
for i, doc in enumerate(texts):
data_properties = {
self._text_key: doc,
}
if metadatas is not None:
for key in metadatas[i].keys():
data_properties[key] = metadatas[i][key]
_id = get_valid_uuid(uuid4())
if self._embedding_function is not None:
embeddings = self._embedding_function.embed_documents(list(doc))
batch.add_data_object(data_properties, self._index_name, _id, vector=embeddings[0])
else:
batch.add_data_object(data_properties, self._index_name, _id)
ids.append(_id)
return ids
``` | https://github.com/langchain-ai/langchain/issues/2695 | https://github.com/langchain-ai/langchain/pull/3608 | 615812581ea3175b3ae9ec59036008d013052396 | 440c98e24bf3f18c132694309872592ef550e1bc | "2023-04-11T05:19:00Z" | python | "2023-04-27T04:45:03Z" | tests/integration_tests/vectorstores/cassettes/test_weaviate/TestWeaviate.test_max_marginal_relevance_search_with_filter.yaml | interactions:
- request:
body: '{"input": [[8134], [2308], [43673]], "encoding_format": "base64"}'
headers:
Accept:
- '*/*'
Accept-Encoding:
- gzip, deflate
Connection:
- keep-alive
Content-Length:
- '65'
Content-Type:
- application/json
User-Agent:
- User-Agent-DUMMY
X-OpenAI-Client-User-Agent:
- X-OpenAI-Client-User-Agent-DUMMY
authorization:
- authorization-DUMMY
method: POST
uri: https://api.openai.com/v1/engines/text-embedding-ada-002/embeddings
response:
body:
string: !!binary |
H4sIAAAAAAAAA1R5W9OCPLPl/f4Vb723TpWIQNrvDgGRkwmCx7kCVARETiaB7D8/pc+umZobq8AU
Denu1Wut/Pd//fPPv01a3rPPv//5599XMXz+/V/fe7fkk/z7n3/+93/9888///z37/f/W3mv0/vt
Vrzz3/Lfn8X7dh///c8/0v+98/8W/eeffzflpGFN69f9MvIWnnbx7i9m87FBQt6VGfjhmzMj2ix8
XtuLCtWQbNg6XazMUY4gQIF5Vilv+xsarRVgKGGW4qXo7HIpja9K+7jJQIKF3vvT4zo/IT2zJIKD
3kR8UDZ3OB2mgq1fxttsH+f7DBF/JTOXo9Sn7e6Qac8bLYiXZFL6jYfh+dFiKpdZno4qa20Qnwsn
Jm72aMLP0wHN5KJga3mlmgPfnStw4qAi5rJcp+OOdxH4ejqnKprKsto+ywAlO75mj0VvIeZLgYKK
eG0R1xhRz9Bna8BhHhFcmzvh9/12naGVlhyI1Z1qMfiRZSPWNC/mWffanK7HrkBzulaJ+dpuEU9c
PNOKc+aSLXt7Md+CCuixXhvMQ/s+ntLTtQLTmdk079U8Hc5EG6BtxZ5OhMVodOnRhmMjbbB4nHnM
jgaXULzIW2Z0+9ofXX2dgeHNfWIGx51JsfAaKLuLSU79O/WFZWwAUK1uSXCa6zEz6B5Qci0+xJpv
NqkcNKoDu/pWMeOdrGKxPYYXWJ4uIUvczxGJXX/NUX1MGmYLa9fz8/XmoWdFdarZ/tqU9Rm5qHBQ
DLJ/NSESefWsYePomJzh5JrTc4joSjBxZvZ1aM3mbIch7G9Whpvd5l3SFBMKkpVgQqI8KKeo7HPI
5lXE1tYuNCd9RhLtoeCQBVNw7we5cBw0efsNM2vJEJK31SrI2OVJkmqxFxMRKoVXlFFimRR8MdOv
OcrW7wszon6GxGvUQ6imaEV2RaX3PGSNAfMim+PCEq3J4+k+/OKT4Ib6uA52XQKgxwGtbl3VT3sp
5yAqfKNMqkQ5dK43oditA7KTp2UpdqExgV3EjCpzYotJm9YZzE9DTLz5YdtPm8gBWGTxlvjlpi1H
1+0VUMhsQ9HtOKWDWskSJLzwiVFLcT9d/KsO53h/JgZ/b+PRaK8BlII7eMbQ3Z9eindQ7Qc7MWdV
9GKwTl0D32usMvuZ8h1dK2AtpRvxvv3NeKRaSDTznspueYj5/ugcAFddSAiVMp+eWOzNWW8GzLqH
OOZ1X08wfDqd+E4thIiWPICePQ60ASh88VRuBYqKitGhzSEeGfiAZmjPKUjJOp2eCU1gJ/dHHO4T
rx9399UM2p0sEaN6UtRsiazApqtrPL/XL7/polcAi+MjpfJ1aP2ueYMH6vF+weKdBGVVX57a6sjd
gfjbcymmFBkTbIbVjqSn+d4UaHHRYL9e9sQ6VoE51nORraxRH5m1NFxfvAVRoBymjnYcdSkz3IYj
TfJmxD1pYTw1apPBnjxMZhlFUzLp3lDkzosCq6eDXXJV7h20kY8RW3f7k5gehYuhOF57sl0GaTxl
m8MJvU024EWZjf63ngvo5puJHnf6uRSXqahXFy974d/+fDZXX0e1IYd41lzb8uOmIV7JxAypVMdd
KZ7eWlnR8XEmDs2dlJdTVMAPT5z0XonBnvIM7mGbM2e32Zb0YWsZfPGIxtxmPj8TjSJqOjEhSdmg
aSNPDjBFOpEj3jpoYgtXg7I5vphT8b3JVX3TQak8T8QdlLtoM3V/X/VyNrGN/AzReLuPHBYGMunU
VL45Ld+OAt98YOV10sT4GbUMTkbgsetqHfeca1GHJOuCqbAUraex60u/a3Y+FJ1geHAqUKzPAbNv
/qfjy20gapOU/fCVHQ1FRvv6/qRFt7dN8bzhCSX0NjCSxXnKs5c1wSHIbYYfn7f/24/VIxs/zNt7
TSw6AjLKkeOR3afciqruaw76cpGzred+UsG9d4DOo/3Ek9SVvRCqc0HfecLctJTT0S4PhSavU4Wq
0b6LJ+00UXA0vMarRV2ZbcAERtvrfUWcObGR1C1PCRDhb5g1q1bo7V9kBw1tgMiWrfVSvhzQHcqy
PhNval5x2ywdG1ZlssQafbXmrz4AHQ6MPcx7a07Z2enArLSSvp/4Y/7lT3PwEy8BJjTemixAUXtJ
yZq4iWjcIglBSYeR1lJ86wWPRlujWtsR/3acYnZpdQ9Qvk2J85RsfxFLcwupMznDEm7W/jRbvAPU
+vcd2S1VR/B2pgZIuvGI+c8LLvlZKhW4XxeCBItaEuK2f3jIiXFFdvZRpNTOogx2TW6wPemKePD2
NwNgmSUk4u93zIOSJyjtLJ3FC7lOKcbXO6RzY078h7GLxRJqBxL/U2J13+f9uPNHG9hTUslmdUvR
pBPBUTrX58Se7qYQBr0CKh1XogqejHKRxGMAF0lPqSzrSt8eB3MAqVdfxHbOueBmcPVQod8HOuyJ
a47y8pWg50mRSWy/jv3QJo6Bhlo6kKxbm0K+Q65BEn3WWK24nrZDkATgn9OM3k+l2jdrHofIOa8m
uuDjte/YbDhBt61TLK3Tcyz62bKAZq9d6N6sWjGKLWog3Tw8ssGfqRRSYzrQpHaPF33h9lOUrC1I
lV2MV0vVQWOidAnk++r4nc+39KXQyVgdVrsRi6jHJo93nxzdPuqJeMyfUJ9cPEXz/Y5T6fXRBW+d
lKLrpw6Zvc4Vfzq6mgLj0TtiKV5y9JGpASigPGXXbVT67IuPaFk4QGxzJ8zm7mcOrIPsRHzaaT3b
ausKakMKSeDUpsk55xjpEL0YvuuBP7oxPkEgWMqM7B71/JDrGlAlNontuTOzlmL5jprqzllALd3n
ct9VSDmoG+K8zYX4zisN1Cy08Gptlz0dVjZG9fZ9p8rhnaXcd9oGdqoJOKpxi0Sz6U/o7Tgj247n
tRCkevHVvjAz4t9QZn5O83kDcq1T4rERejoritNv3rKg7Iue2muTwvJRlcS6vpt0GpMiQEVsWszx
kSp4Jo823PqCYW22k1OxStQAvvznh7c9X70tA6TreUfII8BiWvimrX2/j4p3MvS//V1NQkZ4drae
/gjN4oRm/WaOlfxzEJPLFxmM90PDDN0rzUl5UBs1he3iZYEac9JO2qBNWvcmNk3f5TR3vEYly9pj
ru2P4otXCVQ3L2Br3ROCX8OWAxHuhv3mH+/mTQi3C5wZNiI7Zevl5qR1IlcICcW+/OPfF0W0+M3D
sB9n+NhBU1guewT8GHPJ9v7mGWX7K0q/88/7PY/Ogr5E4qAuJVQs3hnuNa9Np0nOdbAZ2tL5bmmX
fD4ec7A29gEv8Cfqp81rJ8GX/xILN0+THubtCWbT5oZnGzymfHV71oBPC5sEzgb1zTPQIrjUZE8X
J05RmbuJBCRz38SMNlY8XU0Zg52Aw9zD2++/+bJAj5QnnuWw9JlC3Br5buRiEe+XSAhVv4CYzx1K
z9ba5IfcUWBeKxbZLTZZyXMOCQqxypmnzOxy4b1ain54ve5no+h3EgKUf446Cc4vz+TeLLRWv/ka
WMY8Fd3z6cF7FT8ZuYSWKbt8lcEiHHbMGXZmOfkBOoASFXfmMHvyGUnNA7B16/zxjfE4mFQVt2DO
tuhjICmRDQOi6DJjulkl5USlRIZne8NMX/hDP+60YECv19rGC/deoNFeOPKPj7BM40XcJ/apRvFS
Db/8pS6nTdonYDxnLdkeCg9NGioV9OuHTa2WPQ8P+wjWmkioom2uMd83uwApFjsQommH8hNtpATt
7Fjgj+ooolXf5wCSs2ezrXDnfocmXqwOyv3XT04s1++dBZm5mtP3Nx69HMQdFNe5kptSEH+M7f6O
tI+bM3OlGr2ojsZ3PlZn5hiD50+nQ3CBbzyqktsNfVr2CbU3hhvx/SQ3+dU5a6jYEI2QT+P0o7na
OCiXPxsKLBT9cBIgI6InwH540If7RkHLy7TEalCx+I8PT6s1ZlZjFuZn2gYVyqXTnViO0iKmzYII
zqP1pCvqjj0PjWEGxWanMVzyMh1fIZ9WX35B4fzyfGEp5R2S+x5hjY3ZT694UIrJIetQjeJfvwBs
bYUqX3wRCc6z1U//rZg89NPdNi8/fY1XloF7yhxbAgrUITheV+JjO5vptx8Y7fk65k+00+B4aQ7s
obyZ4FKHclh1QUk2J+/lc6zEF8CH+4O5M0pLrqZZgi6rgLL1++ijyTVaGXVnHrAdgo0pT+4wA+bc
JRK0eRbz98zzIBben15N+2MQR4D6Q0AIxVM6abswXD1Pmown3TPNKX2AjkJBL3SxTu1eqp63CAW4
6oj3duSS//bDrJSS6VWG/U/vlw6Y0cnH2lHgdLo/Ew+V86PBgtvx2U/vg45huV/5mOt9YHLpebVh
vJ8a2odt6AuLrQ14hdaWWa9PLuihSipgKFj99GT/ua6PkqZH2pOYt+4Yj2UfZvDDdyLvccn3947D
9qYYLLLzyuTv4SbDrASPjk2FEH9fwxm0VvNkpj/U6If/mnWMNt96LfpGttUEFlctp/IZxpLXhXUA
x5Ue33l7MQVKPAc5x5fPfvxdrvm7gO9+k7VIrZTr60uNum2VUh5vN/0k6WqFiPsiX76clNPpxQc4
PjKdXdJ7hSZ0fk4ocU9AnKuv+4tio2D4nMs5c7dRaTL/qRvIkNUGI+VG0+7H75sLtehyXPXlp82a
BO58sSfOZNz8YfvsMagJqTHNT5+UX8PnBD9+pmtJFvf7VyahOJrtsTw4BloqhX1HWjnfEWOXMX/M
gnsCX/+IasrtYU7ttGlgqtfjL9/9x43xAYZTU7Kv/hDjDF0oXLru9NdvvKuu+Y+/k2C/mBB7xsMJ
9OPeYU6RMCEW552C5KBrqRffduZYXisP7HabMnd+UNLpGjgWvDeTRwL5Y5vDEGchLOCuMG9QsDkA
m1/QkfsDXbV534t3+7pD9D6u2Pa1jP9Hb9QZPuDlE+98QeZSDvhKPkzPrqMQfNlF6LxYMuZ88VDQ
yNNhjDdLFkRg+eIZDweNbtGTbc+QI36e2Qc4MPvOPHcb+NMm0mcA1rAnxPqo/qTmRw/9/ITO/SzQ
Tx/B9AxLcmhaH02L+3YGb6+8fJ+nC36Weg1to3bP1oEs+2MuMq5JtymiM+rm6FPLex0S4xky/2F8
0sm98fqnn7/8c5l2yoNaMFzXHilEfvwffyzUcovcs3hvchs8DV00aUsSP+Gij9YJRbFbBVSuep72
B368wI8v59v1zhySRIQwQzGnizFa+4vyOnhgyKhhehe80in6bAA6fNnS8aFc0ym1XhGogRWTC7kM
MbtdWwMyEnD244PTOI8vUJqXmm3168mf7tBocD62M7o8LUg/vspFgx5datMfX2X3Ust/9UPHQJbN
tq4qClE/GlRdvW+pOL47A+0qe0V++eFVt6RwPeCATnFQx+N3/eo3762vvuaZrFrQ6iTDf/3RpOoB
0s7Wab59n9BnkbJaVbPIIkYc2LEMTxShU/t5ks2s+vhjX48afPTgyswAyYjOZ7mDvn4lwwzNfCqx
HYZpWNzI1twVMecPUwO6KTRGGPrE4jO0w49Pke03/vQIMw2drGpk7pgVPd8f9RN0iSOY7ye6/40f
AjtZO/Llr6VYVXH3x//I2Y36Xz5/eoJ5dRGgaW1fD3AICpvOonwVT28j1dA8ty9El5VtL5NV5sFW
t1Wih1IupmY81T88w5onbf3BHL0DHPtgYLuSH/zqYE0e+vpFXz5Zx+we2RisbYbITz+Ir/5AyaRN
ON3zZywqPzfQY0wqEmhEQ8Pwcioog0pl/un6Tif3WFOQ8lP/6xdzgPhiI37Vtz/9mLKnt9aQmuxq
sn3ib//3lz9+gKftsCxZpaJOY9J1z0i424rRwN4ddt6gkEA132nxq0f5+Wrx8l1Rf7itvQYupdwx
LE81God3M4P9RHZ0nsV6/Ocv4+vu8/1e6cfvbGjPgcrsdzVDo24qoP3wuX2dPF9a+52N7tq6Ip5y
m/vVhFwKlq/pf/NN+fql6sa7LIgZXtx0nHdpBjw/UvriPhNCvA8WOlGnZvhUXsvx8WgkYN4yxXLV
h6mcPiQDFdvwgmUcaGm7TVoPUmguxPa6V8l+9XP5GCtiLY3WH9WbxFUd7zsW5PugHNytmcNKVA3Z
5k0Z8/dwlP78tuLrv32/ZwZVsQkI+fqZP78N+aBHNJ1reckrfElQy6sZ2/BRLUUqOYMmN9cjSTKX
9IOV7yzEPqnAkk5MwVeKcoBjYVzJdp1vY7HV1jUQS15TrmIHjaA9O/SiuyuV60sff+d1jfJ9fWTf
fjK5fd5ThA4nhqXpapoc1v0Eic9Kym+5aXIn/MxQupCHr94cfP646fefn80852nEbFXFDexjzWXm
9a2afFmRCdZiRb98JYobtZrJ8MVPghf9oqfVR5FhtXl/6LSZZ6WUujMDYoPnf/jfkWJ3AbbuHZxo
/bOkX38ZHdlcY/6eqILdSv+OLitMf/rNH8twTbWHED4h3fgQ0yBKDl9/EXdszMpvfAk0DTpiRd4C
iQTAgijUz+RUz44+Q4tQgefbfpNNQ1exuJdTAV9+y8xl+YyHZD5k0C3UB0a98xJ0be8PsB5fW/Kb
Z+J9aiqgc5vh5XXUyrEoHgVaPY3wp7dNNsaNB996xTN2lFJ5eZ8bcAfL+Os/KXHtGTw29+0Pr1L6
6PsGSubvmX+wi58/X6CPexnYtdQdxJfJ66R965U2eCrKkZyMCuLjSWE7G9187qc0h68fTHS68GPa
jPcazZJ6w3aqo6Cpfm8sTdRvi/lfPivdDiSHarVcYh6EN5MqGsiwTZfVn1+1fFmbAFbB9YrRDWU+
//XfqWVP4rnbwR+V225ALa9n9J0oPWptZzdB3s2uX/63SMdMvd7BuNQV2bh3Q0wnr51Bc7tFLNNI
gsao+9TwAW/x9Q+dWGL3TEYPMfpUgxx9z0cuCbqlpxnBIc3/3g8pBDYs6N6f8usva0jeSCvmhy33
RbrdNeiLv8RoPQm1Z51O6NufZCc9IsS110uBxzMQFB2jk8kPOKshxe2N/c5zpikmCbB+HVDRepXP
50F1AqLORmbv9FrwctceID02iKwX46vkbhGF8MVbts7mnfh8z+cgvj99Ylb6qR89L5r9+UvdTe76
uzGT77DQ7D0tNtdJDNaoJsjn45O5+afy5UV9lcDt1OF7XiDFbdG1F+Tr1zn5nRcxR+MdcuUDYVtT
BKaQzP0MvvwfS7V6SOn74GD01ePMzO5PNElsF8CGHSVCcqhj4YmjBI/GeOBxo/nmGE76ZfXFVyxM
M0fjN39o9dRD5r2dU9//+PS4PfsM2yiIR+/1pKvepC2Vd3VY8vBwDcH+FDlzv/VJ54OQUDjfR3Q4
KswcG29nwPV2ebAw9Z7ix79hu4y2hLinh8kf65EiuNtHtqW5aopLPgt/+vDHJ8w/vt7OghPz6/cs
pXrvFZDLbEMs36clLZywBksjFsN41pQjAxNgdRzvLPjqcfb1Y+GBu4SCHa4Rjx9XCa2ViyA/P2Dq
sVmsxnS2Jp7tP83JfkkKIsZYEvs1Pctvvk+wLZYGfr8r7I+owSEs/g8AAAD//6RbydKCOhZ+l97S
VSIiOSyZROYgoOIOHBAUkSEBUtXv3oX/9q6692pJPPnGY0j8xR8arPQKGkEwCBVWa1rqrAs78de3
BCvhQDpqaDsOnMhEePf2rG6Nv/srLHlVwGulVU3fa5P+9OuSJ0Zo5uTJBIXrPGyhOYln1NaNlB98
gdqyGlfjLdkXSFb4B/XicmD9whd/5++MyMkZ+1wNSFfv46/PqpY8rkXMmiTsVLWK/vSXd3B10pQZ
Rqwr0wCkaT5jV3K+Mdv7QQGcfAqw76S4G6s5K0CePBU7Sx5H7FG+wwHlRfBUNwTRiNan7XJ//vrs
9ZyKEiz59J//6A65lP74AWuX8tONai3y8sK/5JefjMm3SmCVP56/Pkqfw/4kQlFXCeFhLjo23Zwa
xMvJwZonvPPpQkLxT5/reZK4471uJbBs4UH33NdnTNtAhmRHmQOpqp+MadehkY5UlrB+Dx/6wA4n
E07h8UZ3T7uPRzcyDJD3rUtISAp3OpbfEHH1aQpu6/rl/t2vX7+s3d2hW+ZHgBDEjmyXvrq77fke
1rHJ//KharpcXy/001eqxin6GG6d689vULeYDTaNwDT4128r4D///h82Ctb/vFGQ7cYPQXutdCej
jTOUZklIo/T7QK/46odIoM6bYlD2ucA1oob0w8GgWCJ5N5SKepW3snfDXktyd8xtgYC94hyymrR1
PBVR08B+26/wXlIlNJ0Hi4NEeEWBszty+jDN1wbwYOpUC+Rt3l7e6Quhd7mjwRRG3cQUdJKitlOw
OykYjQ4fmrIQmBHVPfWDJh3mGlzNmIJZeOsd22dSAxl5X8k2P4fx0H24Ggmqr1H7lu9Z7+MDQc79
YWL7Lnzz6eS5FiKjGNKki9+IOKsilLdn9UqDTfJF46DYCcrFVRFwcf+o+jlaGviDM+OgRqeYHTQq
oLFuCroTw2ZpvEYeSTD1SwO7ZWS7dk7wtNw19cfecIeaOyVwO8QWGTq0ige3jEL5/HyLAUuivuo6
OfHgSCWNqoWvuE2dDBlsn8KB8MT+6pStcwOeEbQ0PxRJ/B3zPoRWmwOsH67fuDneLYBn0454T/t7
1eyeTQRSTi9YDW9lPA7fVEQgTRn2VtssZ8jQsq3Mv0xqd9stm9JtJcJO5W2anm8cIu/3loevVIxU
e1dZPtIqacBCkU8ttEnYpDy3Ciizr2N19whzFn6fEnij8cCHztvq82pVZPIzzONA1uitGkNB8KBy
11+qb+zZ7cXv7MDuXGBsC7tCH1qjCmG17isyZvisjz3nv9AuAZHuijSviDWpLZqmDwSbrfhi7STr
V0h4DWEP7UlFO/kaoNexPWJMP6wbxeMjlPIqzgh/zrf52D/0K4B8mrAtG5d8PPHbE3wv9xsZr/CK
p7v5KNCh62y89/Qhn2S7PoF1bipqG9YWzWevL+D+3fFULU6C20donwKzNuHfvDN8xBrcLfVJoJ+j
bjQerxodvTDFaZw0aCSXvQcHS3/g3a1MY/qbnyRtCNXCNHdH5/iZ0VcqR+xl3qEbP18rhLSyzUDg
xIGN2L5doX3lWwLRS+uo9VYMMHv2osvvm1M7KkSZJ58C78iwqeh9583S5iitAi6ts3x+He6AhMCI
qKmLAmMVeQFwTuRhu9teUO+0Wrt6hc8P1njlnY+pnipwNY4DtsvVKqZmZWRonwd6IHbHLh9bwxZR
yRSemvszZUN+nwFefrYJxn6dupNy7mq0YraHFW3j5FNzdu5IhqTBwXg30cgE7wpaEUx4b6+OjB1j
zUL9pzySV/T1u05JyQmGuvSo4lUjIlDzJzhJoYmxmU9szO+XGrV3K8Mx9GVH/dyNoDmeRYy3gNk8
8E9DFsrDkQgiL3Q961YKcA8uogbS9W40xbRB70K7YNcW3zk1KT0hoYyP1LtUOWP5rQnAv38yEiKH
18c27AVUn+aZOpzEYvbVw1L2X4cnDYQu0buwW6Vb0ZAEbKwn0W2+w+UOlCkCVUvE5333uQUQP6Uj
NbQtZY1te4LELokbdNOcV+PBJy3w4VcmDZ9edXYSbtff82OtCT/dmBfURL6Og4AjGc773bOIwO6R
SJVG9/Lu9tymAOPtSZ3HQUXC57F+QasEG2yI9108hu7BguJUODiWGlcn+1Dn4SMIEJRwaPXxvuMs
qeOCF7bOtzubxryPwJOrPVkXeFeNyiC9kOnSQ7C6MK5rnvfWg4Pv+NTZHe866++RIb9SZlCj0lR3
rm+FCaTe5wHhmIa67WqyQKFGTNPreVvR8zlP0CT0LV7Oz2XCddUgzxwJ3a1owaZpTlqog2eC9YuR
xuSF7TvK7oqBtc2Z5uMrTDwpLT6UEMsI0Yy2cQH5eetTIxFyfSw9V0ESBAlWh62Zk+P3YsFFftoB
ZJycj9e1zcGmEirsNLKVT7szH0CHvv5yfk82qPjAS8v3p0FwuOsDeTaFtL1aDt4X7xOb8u4oInEt
2xinqexOY/6KAO3rJ90/N2XOzJTj0K2WA2z0m1s1lqtCk52T/8VqnfnxuHVEDZ2V6h2w5/Hmzgka
T+DU/Yuep0+hT6Vi3//w3pUvVd7Y3OaEnF1zwEo1f2JyqLwI5ajcBIUR9TopHTGEV3fKsVZ7ozvN
3KpG9+pCsPY49WyaoDSkYq2aWHn7tjvpe8uAKtntyShv1Jh1LJgRd0sR3qHP7Pbn1CDAxTsNW+v2
09Vi4pXonTQezvvgpbNUvFigzbOF3XQ15P0GLgkUfRBSfCgvbCoV9S6fMect/KPF669ohbCH6ET3
Xq+7cx9XEaSFdg5WoOzjDdW/DhShYGBsPL4xGwpaIzhw7+DTHmS9d/jQABzFGOOLOqNxj1VTGlZH
lQbT1or5+za2kB1kQJXoY7kDlepsy6hyoDr/Ymzu4y5C5QGedL98HtFtDmBMdjZWJRDY8NMToXUP
A1FGfTz5u6FFz9sG4Z3cfbsp2W8BrsZ5oFhVxnzS5rcFTXat6fJ+VC98hLBx7LAx+ko1vrbduF3w
EftvMutTNbQeLHoDX4SdojM/KBI4NEWG7V32zklixQk6hKFMtiKq8uX1AQSh9SXy+o5ZnUXbTNpv
7Ab7V35TzeQMd+SvvgPWzJ7vxs9qbFFbr0LCjXeT0d7eBNLejx6kePtfdxzfaQJDBetg/J5W+jAI
N09EyHPpmWnPjhyjZtxuFG8bDG6huXPznELYtQ2HXf7RoO8r1xU5OhcHrLSNU03e6zNDYdU1dYRv
0PW3fvSk5ygFVJGDrpthUmcQsUexbpUBmutbYyIz5ii1d9ku3/SJ0cLaqwwccExj/cn9ztCIcknV
PH7n31co12hqJpO66niq6FdPC3CzU4B35PXs2KftM+g/xZE609IIbNdVL//4YBcLBzQ/j48CVuN7
TfcqOeiN5PslZPl1oAvex/M7f6VSWK+8oEd70v3pm2ISz9TuxorNbb5W0EsgTfCZxpM713HUyP3V
suhlV+X5dHTwFclwasg755RKGFTDgOcoBlT5nh5uw/GhJ2/Nu4EDazC7DWTzCE6+pVjj/Kgbeys3
IPKGK3aX+zS+9G2EooPgEnHd7qu1Ng8W1PTzIccBuWxOPsc7yKvbmbrPcNYZOVkJqPzxi31FteOp
8dYKOMqzwljOGzbx/j2EVYsIea6fx5h8WlcDtNMdbEHhoIXfPGSelo2sei7i+SZaGXyelkAdXbrG
Y21pd3Dy05lUTm26/LfyNHi325Yu+nnBHyOC97p/UEccapc5awhAMc8Iq9Wr1ac1SUz0qXofPzai
mPc2t0rQ+fkRg/FGQr2/h24Nm/R+CqAlyJ3Xu0FCq/Z0woq8ecZj/3DvsAFToVbHqfro1465LZnG
U8e9rONhjrMSHuZdCaQAix2xk6MCt1XQkbn2QpcpaX2Cx4H3g1deNe6cBk0g5Zq/pzo6KGwdyLEA
/qobAm63qeL5S64BGL7jUvzN6njeqe8A3TmvxPaoWowpg+0htz4w8n33fTe4qccDC54nqh1as9tY
SLwDXIY9te8+qxhJbzwcVe5BA6rv9GF3hgBZVFKCdTp6Xe+RXECqsFXonz5f9CL0UmdQFb29jq8G
S4CrPh8J2T438fx9mTP049klm3NpuvxeIhZaPaon4S7iDk2DIzoQtV+FXq+XlUtVeuqlZGO3hKvt
tpqYwv70DVYFpiAi9eILpukN1AwlJefzxHOgV48J9Uc9iBlbFYWcbKmKf/dxWPSchOr9jbTpK2Fj
nwgarN64odiplG7WEy/7nTeOHiutEkipLn5CsIMeja94ct2vKBamjrFzEYp8rJ0zBwt+0Z133upt
ZnWA5F2NqYWCh7vwowKGT6tA6q/PfLDGIpQXvUAVvVDc+fl4cdCFsYqDi7hjzcpVGjl7HSpsVLyH
poWvQRu6C3XfaYG+w1eKUP/iOKwcuDlmL7QXQdTOD8Jtn5t8ltk5giDXJbyT+UdHmucUoXHWhgAq
+kTjZRRnUJvVle78WepYNicSsKA6BRucnfNhfE8EHN2QsKrnKZvH3S1C85o8sStVhTvWMgBMvB1T
PTvpjK/oKYFn5+3JphHybrpv+QLuzksMhMCP3TkDCyBKOAkrGd7oJEHiCWxjpwcvP/D06f0O7zK2
rxea2+Iu3iglGiFq9t9gfTzE3ayUUQrhfL5QmzsZbH314hndmfSlTn9V4+9jameIg6ilDkltNPq1
Zsq99DWwV5m93q9Fy4HAGK/0SF5qx1ZeP/8973i8dTHNoExkUZ33RF4SwtEQEoCtejxh3x9ox65C
bUJ+Rj4Z4wtjP78uF59dSY04qvJ2ELhaenVJjs/n7qp3lShlP71CVT0qEbsq7AWqcy8IQDnGczQc
iOy9Dy31owfK+/iwEtAYchnh2zZ0Fz4aYZO/d9i2QqvjL9ebKKrEcKjems9q2uwVD1Z2pBOZNH01
BPtnIl8f1pNGZs9X82kNJlrwBLst03LeOdIR5dy3ptolOnZDIOc8skvlQ/hk2Lns5IgZjPdcI1Nx
EvSxNVQRBGq9qYXXFA3He3uCVj/WZM43DE2PG142QHwZ/+aR/fQwnkcH7/sj340LHooRjliwPTq6
/vMncPuW7z892S9+Htlmk+GdsK7zCeG2BiE5T1R1e7miG8vh4KuPZ7x/GRgt+UkCPz/pr++UzX54
vcJWlwbsfE0unz6PawDb61AG3MvX9OlbDRks+pTab/2E5g8fXn96mEhKFeXjHG0doCvRXO5PlE8F
t+tB4IWe7sLHh/Xkgj04d2gissGO+rR1LyniiWaRsdH7mG29xJHbadzRRNu/9IG51oj6q2MF82Ol
dYJWdzWUXpjReGPP+tw1ZwCvzVK8B2LpfErWJjyFOiHt9nFALJmNECm1IPz55SkYRRFg7450J17u
ej8oaiIfwkgOhLTEec+6jYKWvIjuug2fU1J2oeRyVUgk/Hy502lVONIP36V6GzJWy3qNrqO3po7V
qbqw1tN0u+AHVQWn0xvl8iDSJj42dGcFlcvyOFu2Pt4idXgjzMkv/1j0HXV2HEPDZn6HaPHrwXIe
OUulupHS232Fg2fBs3msYxOW8wrWR+kbs/leEqRfymcgHHQhZ03qe2idzCVZ5sOdz0OZQOWGB7JZ
9NsUrjUDfN0PsEo0iPtDaRfop9+btTohejmcDYmdRh7Hp03LajO91ajakAk7t9UpXvSZAS/ePZCm
H32XRUZVwOJPqf/eQdyXnq6APGuU7tjJzzc/fz4d2/Ofnmq3J8uDi+FfyGrR57M12S2ypdDAt0X/
EnObZ3DNdBasuds6nux92v/ysIDvyacbsX28i1aljDQ4jht3pEZU/vItsk/lPZvZZu9Bnfg59g7I
Q2NY+LxkKBEic80hND0TzkFSBRu8i43apdvV1gJzvnVYn3YZqh+z58BVKkgwfz5TxcRkEH/3C++D
pqtYbZMXTLVPsXO2md47CjLQjx+1G3LjjfDZmVCt3QzrUuO6axVfeAkMVQ26JY9jWy3opZ9+XhmP
b97iKHTk06tW6N5FXExr2a1hf9ofqe8hnW1W2iNBb3ETELktbmwW7wcOulSvSLP4rZa5rQUNKrbY
ThUz31SilIJ9xjPeDdHJnWSbnOASPCOqT2TsFj5WfvkfNQuHi4fH1I5o+T2pJ7u1Pv3w6PIiSfBO
9wKatycrgO8nVfHp/X4gxp9SDr6b1YXMR3athuX5wLnfzIChQ8Hmd96nkqVyt+XzTJ3GwcihJ0kE
bN/yD3v98rwxhIyah77X524eMiRc7g8cBJbljrZt8KB95Dj4PDdlPLw/Aweb+NyQ1WsaO3J86AQe
dr34gyqP2Uk43uFTEZ+wtf/t5kCWA3DffY71x/TOmSf5GShf+U3xE/kx+fDhHY11W2AjGXZ606HR
QOFO3GL7CASxrMFXkEw9JrDofdLfRAJLPkC9aEirP7+y5LdL3mrr47bHrWQw6U2DJW8RKHnxwD0g
ImjFqd3moH0EUdLEF053Tdn17ynTACFWLXwV5ujbNwZU/em18L/i8ltnVOSYJjL1Fj5jQnjtUbzW
Daqfv0JFT0rJAY4OmJr32uw2L1wKEJ3LA1VHalfTWnyWkuq/MdUmR9NHh09NGPSHhPd7e+7I63Di
tvpJdkiq2XbFnjeRB/HmxIT3Nypbe2TtwerO2Ute1OfsyX+DH39hs950+Xw7azV4bZoufDrq83xX
ExiAtcHUrQkbtXfB//wNztWP0rFiHgoUdMUaG90VMXa0oIf4VFqLviwQfe2OGawj313yYynvL1gC
WBnukbCQxd0EF1GBYHfkA/ROCzZG4laCAqYGex9xg8atUtZAr2ueKmWRoyGTZROK1WlFtTzg3AmJ
swW6rdeEy/kgHvf5S4HPNoupqgxGxfZbfoavbO6x9cvTaC+SHz4SSZcgHmtGSwTX6L74i6e+tvfL
xhvKKmrAB8UNvokJJIXkBcCaYzdxMRoRSCyjWP3WOjt4cgT2ZbLpXt2hfF6T9RW06OAHdMnHBqgj
Thq+DcImeWQ5kyqvRAFneDiAwOiE9W4QoaYKxin2Mn0w+EaAdpp3GD+jczVac5KCNhgqPb+GXdV2
MPNytemnP73wlfchD9SLrmQzfQp3ehlZA2Jx0El1GYg+Nwq6I2mzrwOUZQSRjzAAWturgXpvR++2
43tL4Lh+2XjR0/p6mq/tD5+C9Ul/5D8+R7ASLXrXmcvWy/zJdP3yaf59nlC/P5xqCJrMxC6+Aus3
XC3A6EYx1R6rspt+/Ya4XtkBW/CpuxzOJuC26AlH1yOjh7NGYO09DbobrW08E/dSwHI+5IfP/cIH
Ulq5Jt4nyeyy0j20IK8e52C29kJO5uIkAG09BSf+5vnD/+XfEEj7+TX0y79g37E8KDl/7l5Cnhfo
FGQctmOqxutMlg3pMJ1DqpFbwpiYvCXIb5+Yuqujy4TCghoFt/eBOpR18RiPjQNWxqJf/oyYlpUa
XC7oQXgpG9i8zw4hsrIpCk7nZeP4bjiapHLfkkir6usObmrwQO1hR+hFjdD8npNR/vUp+nyu47+8
9eNXbvDDnxlHqQNHFGLsxG3mMpkzTeiyetloKfiYvWfBgtWo3QJRusbxEId6/5tX6r2ePht9fOlR
rTc6dl/mMWe70/eKLG9NguPSP8xxJpUgqFij/pFL4lEi7glZVFT+8pfN1bUV+Nw1kyqVfehmbDm9
ZLrDgTqBWVY97/EiIsdSp/to/+poxm0EsM5thbX0u0LjlxIOooHRJe+r3O8jk1LQ2LEINod7wOYP
n16RVJcByRNf7fqlT4Dvw6qoH5ze+TxeRAfa12VL7abEjE01f4ep264ptqWWMf4UciDerJjulz6I
cM6eoBd5OGS8kdHtv8PlCj9+8lkmxiT4eAJMx+ZMb25R6v11c74iUxosaj1npH/Jsyiln381V8+q
mgf+a8L4ZTiQR53EI7y3LwiqOKV722/d6eeflvwcK86piodQfZsA731CjfLixox1fgOH6RiSlVMV
3ZDIr4V/1Jhs+FuV05ViC4h0gY1360pC80pdc7886NfH6rPT+SkKbbVZ8D3q5kH1THQgXkEdyfp0
825z7mFty0MwrmnU0Z9eKw6XK96fS1Pnncfag3ew/GMg648u25uPGa0ez2fQkvTLekVUFFj6UbwT
L5xO88e6B+Wb+tRrFBO9jnZtQuBcS3wbVic2U1EKUWq0DtkEjVuRqyc7yEXpE/tuUbpzSjcCdIbE
U2+tb2LS1dodRXv1hPf48Mz/+uQfPyuVPVVEZucQ5s8oU+unN/Hjegd35xd46dvYlN8XvvjMKwLn
1UsffUmYgbaBsui3QzUufIt4oljUO69e7vB+p1eUaiajgWWMjO68qwbLfFFNIJefv3pBeW4/wfRa
dWjiz1Uv9/LEsCbOB7ff9vsGLfk4IaK5Zr9+C4q1bhJ2MdJ8WO7zry/GZ6ap3bToI9SImUPdxH9W
RMiUGUovykjV8II+xlc/guIe9thwnvef/30hMashWJPh3DH/HRJwUfZc9PU1puZw4H96nUj9Vc0F
13NDtPg5Ii35Ko8MNMMvH1OHbZ3Plw8xkOpcC4ql97siwri1YMk/6X7jbqqxVOUa8qjX6Ml8v/TF
z7xg6QOJsHrqHXl+50z+PzYKhH/eKGgCh9D9utm5wvWxcpDMXnt6p/8FAAD//0ydW8+CsLau7+ev
mJm3ZAaUQ8u6k6NItZWDoMnKCiAqoKJACzRZ/30Hv7l39uVn8nloO8Z432fUoeoB/qS5DV8mstke
FgjIebrzoS4SmfmBKNc8xqcR6u/Gw0+ERtDnh50ATy/NoOM7bTjPhKIHa/ZGeEqCSzdbXy+Dm0vx
Is4VDXzYga8LGi8pmYfaBxg+1dhDKwpM5lVVlrO3EK4hAK8zsQntLXrwhjUkVNFo21QqGJ9SJED1
1sxk27TvnN3KCIJsrjfMrZ1bPbnoewd96bn0wYLE6nCKTIBP7pEcsmKb81IoXLC8H5YE6JWzHVNi
OF6nI/G+TpfPhdJVIJaYgS+DYyBOy2CEh8mNyS6vAtCTOA3h09xhZhdIrtnkNDO4b1KbOHd0qKfb
16HwppxcgrE6dP2AaKhx9BzoZKSben0RxQYeEhDQ99C6OS/lTav7ujsyZIsMzN4j8gAjsMHaptoj
ituhhbqaiWzzlcJ8xKex1O5htSOOjYJoErSdDcnKNkgOxDfg8qnW4DRNFrExRYBdaRxDLw0D4u/E
M5iC7j5C81KEGOqqyudL27vapo5ytnuLZc6u280Mva8qUrVxKjTP5/sRoKvdUfVUzXU/oNcR3Jt0
Q7Zd6wL+FCIfpHHfktRs93zOHudEVw6zQ6dG+qABarszMIzyxuwIqd23Uz4JHJ7LDQxWpJzJ+FzA
xH1QdpCK2hrP9kkAuB0EZq9QjDqhWJ/hJawJ1trK4etP+2j067dqiH2hfs6uZRHCh484QYW4R/N5
OlPwqnyR7bNiyqd+uh2B93BcYvlBi3iF8xd8bUWIwU6kfOiq8Qyz/UnA66IN6yGtQKUNsjDh/ipW
+aRP8Qjn7j3joS+anKqyG2rrzxzR6Sp9a85PfQXAIb/g6RWkVq/mTQEv33pP/Jt46kaiWz18eAkk
20OLIq6e6hc8KVRh+1kF+Vh1bwhPZb0iZJ30aN5NmQI/pdew3VBRPqMpa6C+OgtUP6oyYvqpEuAZ
9jlLkaNG/UvfHHU5GPckkIMY8GsZH2GcPHTiOCjopqdvQ2hdyx0zI8mM1i+2aqFM3i6ebwHtZpXM
VCSZJjC7pe9u7m+whdWYdLioVJ2P9tUpwFfwTmS7bTswW1O0Bmelz5jZBAc+t0xPwNKxxmKXDN3I
cmoCMSdvsn+KD8SdrX0H2ASIbL/tq+6+ZXYGYJWHdL1yim7IZg2C/RekWFg6hNyltxm+NB/i/ltQ
MKDuQ+E2DXO8tlBrDYa5luCn8h7kuArKnCZKU0LbKAySQ/FtjeRgSfogw4lhM7l24/40jjAamc8O
LzUCM2TaHlYw+RByWS4ER+dGAETTVGZwaZs3PL4I0O6OK7p20ZtzM7U1EGlaQDzZ+VjTtvsmsHvr
DttSR7J62JwLAN+vEK+W9X4jNpp6JqUy7TrxG803UfjCYq56qnyrizW/yarSgNhcyHZyIj4UmRtC
srO3zBgkz5rTcx+DV7LbELSpKjQO6BWC1We+UjgVh2iKUNuCfPnOrP8W43wub4IEzjEtmS+Jcz4P
IizVb+ZfiBUGLpgFpirQuJQF8U7tBk2K5puwc70IqwfnZf3OB3DT8El8XH0tXj2ZCz+Cf2OOgj68
U4XjRtffRMOqXvV/5w16KAyZ2Qf7enBA1eu7jyv85e/ZDfKzlvt3Ha/OCIOpyg4xvK3vhJUbldQ8
pddQOwT2hUSH4A34/e2FoBu4TuM3baNZETXtV1/IzqxO0fw9fypoRsEeyxdH7jg7DR5I3br5y0+T
Pa/PkGSKwJwaDdbon1RbzQtq4oZSF3DjNt3hfd6t2eGsrgA/bX1T857Olqq/fKesOgrmGloM31W/
k5cbEkAhDWRLPYimZOYNvK/vDnE/7Zj3h5XSwCuuvsS4St9u/HaUgq3hnJiZBgRMF83tYT9MnLjb
dsXH57CpdB69O6pUlZZ3xXuj6a4c3omzRt983D7VEnSld2SlpTJrgl8j0S93GjFfqKqavx0aA2A1
d2ICqtT0lw/UXd5j2KsQ0Vtbe1CWXyLmB7rqZifzTLh5lA0xOVU55/hia1P0Fsk+LmbEt9v9Hppq
eaAPOYj5eJRSG1jiEWB9VEM058Z5D+DtFRMzpqXVT1Loao2PToQ06qaWj6lPFVEkNUGxeMibs+4X
8FHECrvYztua6/Zb/e2fHSOFT5JmtpARoVnWh4Gpq8YMWl0o4l98zba28eFzvXOI9Qxsiy35FD69
OCZ4o5KOe6JyhqtpzsneLTgYdfsYQ/fiFOTgq3I9+0E4QlMtDswQg6iePtp+D+3tUSVYVF/RfDDC
DFyKPmFYVt+/83cEstyIJO7QCtBgClr4yCqD7JbzPcm+72tlUpXEsoOWd6FwhXC1GgusGWKGmP9G
vXZPKp8qvFIQXd1ABq1bsCG7SSzqEa0UDQqns0rQrdAi/th6Htw7bkM25/RV87Q87eGOhDvsTsjI
+8fVsKHzdJ74nqbviC3xALVPfqXcpycwxXmbwaBld9xVIsonOpUQRP1wIETkZzAc848Jw5d2+1vv
QTJKD8T9YDEroVI3BdlWgsixKdtoEuNUS10fZmeK2PbspPlcK9ULvKnPiZ+Ka0C99tXAO0x02s6O
j3qyGo+/80Zl0DYRXfIZmAHcsGh5f6x8vil8i/qXuTdk5/xBcwq/pl/geaaX7vf8sH2LNTPV4Jvz
Cy2g5s/gQxXR2QJKvXYN41I74GnZP26L0wbGLw0xz2wrMFrP2YZoslu2r8VHx8/46mmYqjbbsLTu
6MF7Srr2uVwJYTzPKWvvrb4l4RXzgR67ychrrL9uokrloX1FvSIFPkw3fc8cAX0Q54UItU/m13g8
pm8+6f4Ow1e2M/Bqic95RXis3+Y7ZsXv/C37BQweBMRl6MF58jYkGOyHF1n0C+IFLu6QcuFFtshR
8ylC9xbe7umOEJAgi57OfQs7bZmhMhd1Pep5LcHTSzGIB6o1nyfCIbgo/XGpt4hPb9/+aoteY8Ym
vUdTkx1MaHRRhCWO4nr+EB3/6i/DdqJb0+pxgtB6hwLbHp1zN6ZN6aqxoHlYUZ22+1ig2wB24Re6
DloJ9Q8pfsF1/T4wnKj9X/0FJ/eh0EhCVzC9QjWE3cvDzK7QGnxrUTDB8nkpfqkfPgRdO8Mm2cVs
k6Rvi/NCFlT9kDvEWv5/tE/aBmSv2iBOSu/goxlXDNmTnzG0RQdIsDmW8HlMQgyzIsgndTplED3t
D0O1iOpZfrt3aD6KI/P66lzPXktfwDIKRLCrUtALoG7hoQJHvFq3ZzQ55noPvMfWxdqlarvxt99h
zDI8J1JlTePX2sNMuAvE/aCqnqBmZPBX33gWPGuuw3UFZ/SWqcpE3WK8EAWAZnCjMm+dmpey18I7
rvbsEBZeN6mZoQC0cxkzZmlrrb2WNj99RYW76td9G0d3aDplwnxaOYhfU0+CG7V80EcbrOs5MC4z
NI3ixLJATDsZFmsK9yv3RmEk2tYqM7kLdrPKqfau3E7aX/d7SBEcmNdVas6Nty3ox0yR2Nl1jvlo
OxOEeX9if/Vwbrwq04s+fRJ/EsOObqccg9hjW7pmyADSCJ5rKAXzl8JZzaM5DY6KvuhjYq+p03E/
tb5geX7iF2KCBilI9jB2tWUGSpvUvZjXFfxGYvTTG1wOZP8OnavzpvAuVtYYxAn88wfRjMqc77aW
Ar6Vl7K9XPT1YFdCAiT0rJk10jGfU+MoQThcfLZxpTTvoXS863W4uxLiqjafX+evD5OYzmQfqzfA
rdu0138dk5//pMf2mcBifR+YDwoxp7bvHUEn6iaxP3QLJtH3FNgj0cCdJLb5rBPNBj89Fm/oAYx6
fMzg6d4vN+zQLuc9zkyIA5cwT3I+Hb8/WQafyc7H8Cka1nhtTj6M94P3y/9df7fjHrrPbY7lm5OA
8XL1Y3igKmbmXdpE8o6Nse6QcMKwUfW8p03W/sWbehNvddfRzNfeb3Eg5JSMvG3jvIKXgiZkt3Ve
3VBrBx9WTdyzIhEtvpqnJIY1TG54vWmTfLpUAIPf/mxfzimazzd5hoeDXeAzc775eI/jGdo8XMSB
s8mnuLuX+pLPSbJGm3yQfdOHxf70ZX5bPfl3r7w2cAKCv8TrE7DF/+svjEwqremz5v1zuIOqSXqy
wWmbj47uhDB0lYZ4WQXquXicTXj3d/pf/WWZbBzBoh+JOQcIsE4IMbw1qf9XrwZoxAp8xkmEZa1t
Fj94FSDImysz1oHUsUu6K+E8zSpVV9Wh/vlneBbqkK7X6J5TRdQU9VEkCl6ldMP70r5uADm5LnPS
Vs/Zw3kfYewqR7Z0hOolX2BoRtGeynPr5H/xJ24PHXFa1OejgLoRaIe8XuLpYI3vYYOhtssrZmZU
j/rDU7nDc1mnbNs6MZ+PypAB/fbyMa4TBfDFr+n8Os/E/1Su1ep5J8FFzxNjk25yWSmPGOyutsi2
D2cdTWA62TDMtDvDYZIj7tObr91ptSXe0sGaNVF7wYnAI9s0UrTopaaCUcv2WNSTb8fGZ6+AfaLm
xERSXXOPKHfYvXz804/dJGYbQS/t9ILla9uCYZgVH8Yxc9nu6VT5iKX0/NO3zJQDH8ync/8FaFZv
eH1EL/SXX8x35NF7JsV8GqeyBeazCDCfkRD1j+vO/suv+16F1tTNY6lHMTuyfabeLG6n9kv76Rfs
FBuw3hpRovtXd8XsB91Z6/ImrIGllzbZXCSp5lFqZoDp04n568oCfT14Evj5BxKqdd3XUnGE62BO
mKFJDp8e2qEAu48tEBSJFDVjHIbaNj3mbM+KgXcOTiH8vrwz5TDYoOn13c9gFYx3Kt74lc/rFI/A
QeGI5Y+zsqZUIxtg6OWZbT6pHXHnpiigP/E11ReeNO26r6kEL+XDfnp1yXfCLx7phIIccec2aqD5
oiMWJ56Bcafvv+BFPZ0cP9JsTZnvVvCK718qb9uO80zeheBUPlZsrxX7qK3iogRC9DLpyqANmkgI
KbBWW4m5BLlg9dFsrJVzdcZzGBzBvFeoqWFTRaSOg1c+0jh7wUvTx6TYFHHNV1ActRLf7+Q0IBQt
fGMG101a4fEmRWAUKvEI/KfNGVr4CNvitIVkcjdUr1UJ8ZwWX+hbR4PZI3Uj7r33G6g/LiatNkG4
6IUphIeVfSLn1KHWLLXtRkuqR0u8j4MsyR4Od2A8y5wcrsUbzYERzHB1mh+UR8EbzdVN2IOffysc
0bWYCIU9XHgCXvhZ10lOX4KiPz2xEKhDPqfBWdMW/4GVwKGAb9nYQlIpkOxm52796XGWChV9InTk
3CBToa+mMSfkrd6t/tYUElz0Cj5taR11+zfKtC0KC1wFwVhzoRAy2GU+wU+nveX85rwbZdGXDH/U
XTfh/BFDGFz2ZB8Uc/Q0TGEN5c8FMOtFQ0RT47yGapB/F/5SLX4SNHAmgkv2tuhwqpPZhb3r74gt
Urvjk3AJ4c9f/On3vNIUeKP3gGztts/n5lyVMKi0lm3rtkWzHUS9tvAdup7QI5pOqI1hRdGTriwU
WpLx1DKo7Gab7FAl5cMJ3DFMhPpFsF3c6+EQLgMIu1CkeqSu6/518M5QEA8D1SpxlVNihC5Uglxi
5JyM9dy1nxAEgvIix0BaAdoziUINNBUzWdBbMxS1ED6+iGK66LOxbzIIT2eqY6lCCRhvTbyG75vI
mHmUqmUS0UwhuDUlw0Mio3rEwRk8vBgS8uEFalZ28IIOO/a0KZDcsb7MXPDZiiX+9M6GM8QUEyw8
g3iq09Z8K+9teM7qhDYe3Xfjyg4aHY8DZPtIbNDCVxII6iZnxaIfhvMMQijJzyvb6MHV+ulr8OoT
lxlActEakPkMuT4PWLWqUyf7RNnDT+bVJAilHv35/9PrwdlurHAH0nQ3/vgZ2cjSiEbPmeJfBxGP
X2mOpk+QznB6chvLdruPOIDCGmSw3zJsFUa+yr84UXaTC+lSz6OZK3cb1t9dxoyFH8/+I5Tgbre1
yBa21n/44nqaA7wmbVyPon3e/P6mSlEB1MtxEKu7yYZs/xKNXJLjS/Ln54aDmuaz1N43cHpONlUy
ZwA9OuxL4DnbPZ6loIvGPg4VKE/jlgRjsIoolbfrnz7/8UD+yxdQ374O5GCqCqdS25qQeINKsFk8
0OgcDmd1mciGFbsS+M8fAZeFFf2W1bueNG1HoTwtHURZBKA745MPk75neL1yYEd9hSbw5CouFbB6
6Cajq48Aa8Bi+0bVIxorzQgv9z5idkp9LqGDXUJ4uBCqyM7OYg6+CeAlihJW9tW1Hr9NHmq7+uiy
HBUFX/c36QtNFOFlfe/1PCifDXxJsc22WtugfuyeIyQf22SBLj1ruqw/UKf8uej9N5ptzfOhtn11
hKySjlOsPKn6mHc9Wc4TGovBGAGmwMbt0u+Yd0a+gevTmJKzXq3zz87UG23hAQQFBYxGiBobbk7l
k+FW3eXjTSoUyKNnRywpeOSUidADv/1V984TDGYltD+/zdBexPWapYSCQjk1bJc7NvrxJyiIZGDE
T+Z8vU7xDKX0WeG5lDZ8dc8OX9BV3oEYUHrmvHOGHl4gDajmViharYOrBiJXy37f4Mi5Je8pXJ3G
Bw1osOJ9LcUhnJxpt+SHYzdi6XaGg8pbqslVg5b9i/94yWvpz4z3wfDhBKDPzDg4Rlwp5Bgaapky
iwcmGtTpmsG0fDyIE1CjW4fKYGs/HmfxoEI0D84h9GagL/7Z6mS6Go6gR7pB7CdKOu7RtITzZwZU
dNUGzML2UKoKe8nEKAMlmr9MN2HlJTPDL3UH5uu5yyCVhTfzVMer18fHRYPWYQvwpElPPvrD/gWF
4bwmhinhhe+MCtiFQKGin4TLjE2xBNb7KOBuVxlIzoSYwqtffah6depuPMRpA1vB+5C9Kb7yYTbK
Ai7ngdkJ9eviid4VZBwWC8+VIn7dejP0fTDSVYJYPtaISaC2kzdzF142HcCjgJZe2GR7av2FJzQt
HFN4ZvEJXdBwnOEdvqiv03nRe5zgZYZqpghUKZwh7wMdZX9+YUIBQK2hH5Sfn2YnHbVAel43BUwk
OtBF71ldJW+WeGYqFarkXI8PqXiBdEN7ZubSA7Vt9zbhj+8jXXzn09PfC3Dhm+zHn1duJWygkx4Z
FlN+s2ZZxi81fCk3PPdUy5voio5QrRvGzJP0AAtPWcM8Ps3MrlFq0fl8DyElAmW2TJ+cI3wzf3we
y56j8se2+8bw2cdH5motteaKCD54hGha+NmKD6WplTAotY6hd6Fa7eO6c6GwbSyyi6rIouJtkoBw
e22IOVO1HucmM3/9Rfy5VlM0ncB9D+dgFti2aNuOp/QUwshVMhJ0UtuxSshLGEjDDYuxalkLb/D0
IRXWdNaCb9edZeMFdtYREefWQtT7J9UFAmpsLBG6R6v7rJlwyiGhwsIrRyid73AnhyYxpuDU9Udn
dGHtJS0jIOnQT0/B5z4+EWsfbDuGttYL3r73I7H6wKxn5+v9J3+gT3Gu2QofR3hd32tmXgKWz7Ls
NjC59xP97sQz568y3wBrcNbE6gIr5/fnO/v5e+LHYhr99CIgx0Gmn2sV5L13UjOw+Eli7KWev7ZG
nkD24CkzDtJg0VyUj6CRkjM5wESIekE67yE85ctMT9XIPz8+vvAgKjUoyadVZlZ6ub5fSDZWdi3/
eOmy/8T10Dbn61W/0T6Cd6M6L2rOwrdfgttcYWYIAc9ZJ2R7uNNdjZk6PaNRQT391Vfm3toQ9ceT
4sE4qXWCFr8/rTL/rm+dbUKIyi91Ew5WDJsizmilBd96GmbFg02IIiw7ToYW3irAq5JmWPBUHPE7
zhU46dygQqt+crZPrQSu5feONin98r45bCi8hvc3Mxa+PidKU8BNHeTENKWmnv32Ff7xpZXSyjXd
GnkMfv1g+dp6QPIcNf75QwqcQu8m4WuYumo1EiEoCTsevs0S5nbvMMsMPjktlLoC8icHFKzEtp4K
H2P46yfkCz9bG5nXwoVv0PGSumBm6Zb+3xkF//jnP//79ysIr/ZaPpeLAUM5Df/+f1cF/p1ds39L
0vrfbP33awm0z+7lv/7rP5cQ/vXp2tdn+J+hbcp3/6//+qf8d9vgX0M7ZM//7+F/LK/1v//4PwAA
AP//AwDmi7xYhWEAAA==
headers:
CF-Cache-Status:
- DYNAMIC
CF-RAY:
- 7bcba8c6fee5accd-ATL
Connection:
- keep-alive
Content-Encoding:
- gzip
Content-Type:
- application/json
Date:
- Mon, 24 Apr 2023 04:38:53 GMT
Server:
- cloudflare
Transfer-Encoding:
- chunked
access-control-allow-origin:
- '*'
alt-svc:
- h3=":443"; ma=86400, h3-29=":443"; ma=86400
openai-organization:
- user-dvhgf0lntotpa5mrg7zv7aur
openai-processing-ms:
- '281'
openai-version:
- '2020-10-01'
strict-transport-security:
- max-age=15724800; includeSubDomains
x-ratelimit-limit-requests:
- '3000'
x-ratelimit-remaining-requests:
- '2999'
x-ratelimit-reset-requests:
- 20ms
x-request-id:
- f7de1b8475e1f63a3a9ddf12abbac967
status:
code: 200
message: OK
- request:
body: '{"input": [[8134]], "encoding_format": "base64"}'
headers:
Accept:
- '*/*'
Accept-Encoding:
- gzip, deflate
Connection:
- keep-alive
Content-Length:
- '48'
Content-Type:
- application/json
User-Agent:
- User-Agent-DUMMY
X-OpenAI-Client-User-Agent:
- X-OpenAI-Client-User-Agent-DUMMY
authorization:
- authorization-DUMMY
method: POST
uri: https://api.openai.com/v1/engines/text-embedding-ada-002/embeddings
response:
body:
string: !!binary |
H4sIAAAAAAAAA1R6XQ+ySrPl/fsrdvat80ZEpMt9h4CIgN0Ifk4mE0BEQOTL7oY+Of99gs/JmZkb
E5DY0lW1aq1V/R//+uuvv+u4SJPv3//89fc7779//4/p3iP6Rn//89f//Ndff/3113/8Pv+/J9Mq
Th+P/JP9Hv99mX8e6fD3P39J/33n/z70z19/b4tRxarabbpl4Cwc9eakb2bxoUZCPhQJuP6HMz3Y
LlxeWYsSVRBt2SZerI1BDsBDnnFdUd50DzSYa8BQwCzGS9FaxVIa3qX63Uc98RZa547P+/yCtMSU
CPY6A/Fe2aZwOY0527z1j9E8r+kMEXctsz1HsUubwylRXw+aEydKpHhaD8Prq4ZULpIsHlassUB8
b5wYuD6iEb8uJzST85xt5PXK6PnhWoIdeiUxlsUmHg68DcDV4jldobEoyt2r8FB04Bv2XHQmYq7k
KSgPNybZ6wPqGPrudDjNA4Ir4yDcrtttErRWoxMx20slejcwLcTq+s0cM62M8X5uczSnmxUx3rsd
4tEez9T8muzJjn2ckO9gBei52ejMQccuHOPLvQTDnlk061ZZ3F+J2kPTiCMdCQvRsKdnC861tMXi
eeUhO+tcQuEia5jeHit32GubBHRn7hLDOx8MioVTQ9HeDHLpPrErTH0LgKrVjniXuRYynR4BRff8
S8z5dhvLXr2y4VA9SqZ/onUodmf/BsvLzWfR/ntG4tDdM1Sdo5pZwjx0/Hp/OOhVUo2qlrsxZG1G
bis4KTo5vmsfiax8VbC1NUyucNkb46sP6FowcWXWvW+M+mr5PhwfZoLrw/ZT0BgTCpIZYUKCzCvG
oOgySOZlwDbmwTdGbUYi9algn3mjl3a9nNs2Gp3jlhmVpAvJ2aklJOz2IlG5OIqRiBWFd5BQYhoU
XDHT7hlKNp8b04NuhsR70Hwox2BNDnmpddxntQ7zPJnj3BSNwcMx7X/rE++BurDyDm0EoIUeLR9t
2Y1HKeMgSvygTCpF0bd7Z0ThvvLIQR6XhTj4+ghWHjKqzIklRnXcJDC/9CFx5qddN24DG2CRhDvi
FtumGPb7TgGFzLYUPc5j3K9KWYKI5y7RKynsxpt71+AaHq9E559dOOjN3YNCcBvPGErd8a04p5X1
ZBdmr/NO9OalrWG6xitmvWJ+oBsFzKX0IM5U34wHKxOJet5ReV+cQn482yfAZesTQqXEpRcWOnPW
GR4zUx+HvOqqEfpvqxHXroQQwZJ70LHnidYAuSteyiNHQV4y2jcZhAMDF9AMHTkFKdrE4yuiERzk
7oz9Y+R0wyFdz6A5yBLRyxdF9Y7ICmzbqsLztHq7dRu8PVicnzGV733jtvUHHFid0xsWn8gryur2
Utdnvu+Ju7sWYoyRPsK2Xx9IfJkfDYEWNxWOm2VHzHPpGUM1F8naHLSBmUt974qPIAoU/djSlqM2
Zvq+5kiVnBnZX1Q/HOtVncCRPA1m6nldMCmtKdrP8xyvLier4Cu5s9FWPgds0x4vYnzmewz5+d6R
3dKLwzHZni7oY7AeL4pkcKd8zqGdb0d6PmjXQtzGvFrfnOSNf/vz3d5dDVW67ONZfW+K7z728Vom
hk+lKmwL8XI2ypoOzyuxaWbHvBiDHH54YsdpKXprzBJI/SZj9mG7K+jTUhOY8IiG3GIuvxKVImrY
ISFRUaNxK482MEW6kDPe2Whki70KRX1+M7vkR4OvtG0LhfK6kH2vpKJJVsd03cnJyLbyy0fDIx04
LHRk0LEuXWNcfmwFpnhg5X1RxfAd1AQuuuew+3oTdpyrQYsk84apMBW1o+HelX7X7HrKW8Fwb5eg
mN8TZlP8x/N7X0PQRDH74Ss764qMjlX6onl7tAzxeuARRfTRM5KEWcyTtznCycsshp/fj/vbj/Uz
Gb7MOTp1KFoCMsqQ7ZDDt9iJsuoqDtpykbGds//GgjsfD10H64VHqS06IVb2DU39hO3jQo4Hqzjl
qryJFboKjm04qpeRgq3iDV4vqtJoPCYw2t3TNbHnxEJSu7xEQIS7ZeasXKOPe5Nt1DceIju20Qr5
dkIpFEV1Jc5Yv8OmXtoWrItoiVX6boxffgA6nRh7GmljjMnVbsEo1YJ+Xvhr/ImfauMXXgKMaHjU
iYeC5haTDdlHot7nkQ9K3A+0ksJHJ3gwWCpVm5a4j/MYslujOYCyXUzsl2S5i1Cam2g1kxMs4Xrj
jrPFx0ONmx7IYbmyBW9mKw9JDx4w93XDBb9KhQLpfSGIt6gkIR7Hp4PsEJfkYJ1FTK0kSOBQZzo7
kjYPe+f40AGWSUQC/vmE3Ct4hOLW1Fi4kKuYYnxPIZ7rc+I+9UMollDZELnfAq+OXdYNB3ewgL2k
FdmuHzEaNSI4iufanFhjagih0zugwt5LVMGjXiyicPDgJmkxlWVN6Zpzb/Qgdas3sexrJrjh3R2U
a2lP+yPZG4O8fEfodVFkElrvc9c3ka2jvpJOJGk3hpBTyFSIgu8Gr0quxU3vRR641zih6aVYdfWG
hz6yr+uRLvhw71o26y/Q7qoYS5v4GoputsyhPqo3ejTKRgxih2qIt0+HbPF3LIRUGzbUsdXhRZfv
uzGINibEyiHE6+XKRkOktBFkx/I89edH/FboqK9P68OARdBhg4eHb4Ye39WFOMwdURfdHEV13ZZT
6f3VBG/smKL7t/KZtckUdzzvVQWGs3PGUrjk6CtTHZBHeczuu6Bw2YSPaJnbQCzjIIw6dRMbNl5y
IS5t1Y7t1E0JlS75xLMrw+Ccc4w0CN4Mp5rnDvsQX8ATLGZ6kgYdP2WaClQJDWI5+5lRSaGcorpM
OfOoqblc7toSKafVltgfYyGmfqXCKvFNvN5YRUf7tYVRtfukVDl9kpi7dlPDYWUADircIFFvuwv6
2PbAdsN1IwQp33x9zI2EuA+UGN/LfF6DXGmUOGyAjs7y/PLrt8wruryj1sagsHyWBTHvnzoehyj3
UB4aJrNdtBI8kQcLHl3OsDo7yLFYRysPJv7zw9uOrz+mDtL9eiDk6WExLlzDUqf3o+IT9d1vf9ej
kBGeXc2XO0C9uKBZt51jJfuexLjniwSG9FQzXXMKY1Se1EJ1bu3xMke1MaoXtVdHtf0Qi8afYpzb
Tr0iy8phe8sdxIRXEZQPx2MbzRGC3/2GAxH7Lfv1P97Oax8eN7gyrAdWzDbL7UVtRaYQ4otj8Yd/
3xTR4A/3/W6Y4XMLdW7u2dPj55BLlvOnn1F2vKN46n/O7/fozOsKJE6rpYTyxSfBneo08TjKmQYW
Qzs6Pyytgs+Hcwbm1jrhBf4G3bh9HySY+C8xcf0y6GneXGA2bh94tsVDzNePVwX4srCIZ29RV788
NYBbRY50ceEUFdk+koAk+w8xgq0ZjndDxmBFYLP96eN2U7xM0ALlhWcZLF2mkH2F3H2wxyI8LpEQ
K+0GYj63Kb2aG4OfMluBeaWY5LDYJgXPOETIxyvOHGVmFQvn3VD0w+tNNxtEd5AQoOx71oh3fTsG
d2a+uf71V8/U57FoXy8HPuvwxcjNNw15z9cJLPz+wOz+YBSj66ETKEGeMptZo8tIbJyAbRr7D98Y
zr1BV+LhzdkOfXUkRbKuQxDcZkwzyqgYqRTJ8GoemGkLt++Gg+r16P3eWHixT3M0WAtb/vERlqg8
D7vIulQoXK78ib9UxbiNuwj016whu1PuoFFFhYJ+9bCtVkXH/dMxgI0qIqqo23vIj/XBQ4rJToSo
6qn4BlspQgcrFPi7shXRrD5XD6KrY7Gd2M/dFo08X5+U9FdPdihXn4MJibGe08+0Hr2dRArK3r6T
h5ITdwitLkXqd58xY73SO1Ge9ak/lldm673jjpeTd4NpPboijwf6Nuzrqx8MD+K6UWbwu31VUb4l
KiHf2u4GY721USZ/txSYL7r+IkBGRIuA/fCg84+1gpa3cYlXXsnCP3x4XG8wM2sjN77jzitRJl1S
YtpKg5g68wK4DuaLrul+6Liv9zPItweV4YIX8fD2+bie+AWF69txhakUKUTpEWGVDclPrzhQiNEm
G38VhL96AdhZClUmfBERzpL1T/+tmdx3Y2oZt5++xmtTxx1ltiUBBWoTHG5K8bXs7fjbD4yOfBPy
FzqocL7VJ/ZUPkxwqUUZrFuvINuL83Y5VsIb4FP6ZPsZpQVfxUmEbmuPss3n7KJxrzcyaq/cYwcE
W0Me9/0MmJ1KxGuyJOSfmeNAKJw/ejXuzl4YAOpOHiEUj/GoHnx//bqoMh41xzDG+Aka8gW90cUm
tjqpfD0C5OGyJc7Hlgv+2w+jVAqmlQl2v51b2GAEFxerZ4HjMX1FDirmZ515j/OrGz8nDcPyuHYx
1zrP4NLrbsGQXmra+Y3vCpNtdHj75o6Z728m6KmMSmDIW//0ZPe9b86SqgXqixiP9hwORecn8MN3
Ih9xwY9py2H3UHQWWFlp8E//kGFWgEOHukSIf+7+DBqzfjHD7Sv0w3/VPAfbKV/zrpatVQSLu5pR
+QpDwavcPIG9l55Tv70ZAkWOjezz22U//i5X/JPDtN9kI2Iz5trmVqF2V8aUh7ttN0raqkRk/yYT
X46K8fLmPZyficZucVqiEV1fI4r2FyD23dXcRb5VMHyvxZztd0FhMPel6UiXVzVGyoPG7Y/f1zdq
0uWw7opvk9QRpHxxJPaoP9x+9+owrCJSYZpdvjG/+68RfvxMU6Mk7I7vREJhMDtiubd1tFRyK0Vq
MT8Q/ZAwd0i8NILJP6Kq8ngaYzNuaxirzfCLd/fdh/gE/aUu2KQ/xDBDNwq3tr38qTfelvfsx9+J
d1yMiL3C/gLa+WgzO4+YEIvrQUGy1zbUCR8HYyjupQNWs4vZfn5S4vHu2SZ8tqNDPPlrGX0fJj4s
IFWY0yvY6IHNb+jM3Z6um6zrxKd5pxB8zmu2ey/D/9IbVYJPePnCB1eQuZQBvpMv05L7IARftgG6
LpaM2RMeCho4Ggzhdsm8AExXvML+pNIderHdFTLErzPrBCdmpczZ7zx33AbaDMDsj4SY35U7rrKz
g35+Qrv/LtBPH8H48gtyqhsXjYt0N4OPU9ym39MEv0qdinZBc2QbT5bdIRMJV6XHGNAZ3WfoW8lH
DSL95TP3qX/jcf/g1U8/T/xzGbfKk5rQ3zcOyUV2/i9/zFczk6RJeDS4BY6Kbqq0I5EbcdEFm4ii
cF96VC47Hncnfr7Bjy9nu83B6KNI+DBDIaeLIdi4i+LeO6DLqGZa673jMfhuAVp829HhqdzjMTbf
Aaw8MyQ3cutD9rg3OiTE4+zHB8dhHt6gMG4V22n3izumUKtwPTczurwsSDe8i0WNnm1s0R9fZWmh
Zr/8oYMny0ZTlSWFoBt0ulp/HrE4f1odHUprTX7x4WW7pHA/YY+OoVeFw/T8+tfvzUlf80RemdBo
JMF/6qOOVyeIW0uj2e5zQd9FzKrVKglMooeeFcrwQgG6NN8X2c7Krzt01aDCV/PuzPCQjOh8ltlo
8isZZmjmUokdMIz94kF2xiEPOX8aKtBtrjLC0DcU377pf3yK7Kb1x6efqOhilgPbD0ne8eNZu0Ab
2YK5bqS50/o+sIt5IBN/LcS6DNs//I9c90H3i+dPTzCnyj00bqz7CU5ebtFZkK3D8aPHKppn1o1o
srLrZLJOHNhp1opovpSJsR4u1Q/PsOpIO7c3BucE587r2aHgJ7c8maODJr9o4pNVyNLAwmDuEkR+
+kFM+gNFozri+MhfoSjdTEfPISqJpxIV9f3bLqHwyhVzL/dPPO7PFQUpu3S/ejF6CG8W4ndt99OP
MXs5GxWtokNFdi881X93+8MP8LjrlwUrV6hVmXQ/MuIfdmLQsZPCwekV4q2MT5z/8lF+vRu8/JTU
7R8bp4ZbIbcMy2OFhv5Tz+A4kgOdJ6EW/vGX8f3wnd5X+vE7C5qrt2LWp5yhQTMUUH/43Lwvjitt
3NZCqbopiaM85m45oj0F01W1P/1NmfzS1da5LYjh3/bxMG/jBHh2pvTNXSaE+JxMdKF2xfCluBfD
81lLwJxljOWy82M5fko6ynf+DcvYU+NmFzUOxFDfiOW074L98uf21dfEXOqNO6weEl9p+NgyLzt6
Rb/fGRmsRVmTXVYXIf/0Z+mP35ZP/tv0PjMo861HyORn/vw25IIW0HiuZgUv8S1CDS9nbMuHVSFi
ye5Vub6fSZTsSdeb2cFE7BsLLGnEEHytKCc45/qd7DbZLhQ7dVMBMeUN5StsowHUV4ve9HCncnXr
wqlfVyg7Vmc21ZPBreuRInS6MCyNd8PgsOlGiFxWUP7IDIPb/neG4oXcT3qzd/nzoaU/P5s59ksP
2boMaziG6p4Z98/K4MuSjLARazrxlSCsV+VMhgk/CV50i46WX0WG9fbzpeN2nhRSvJ/pEOo8+4P/
LckPN2CbzsaR2r0KOvnL6MzmKnOPZCXYo3BTdFtj+tNv7lD4G6o+hXAJaYenGHtRcJj8RdyyISmm
9SVQVWiJGTgLJCIAEwJfu5JLNTu7DC18BV4f60O2NV2HIi3GHCZ+y4xl8Qr7aN4n0C5WT4w6+y3o
xjqeYDO8d+TXz8TnUpdA5xbDy/ugFkOeP3O0fun+T28bbAhrB6Z8xTN2lmJ5mc51SMHU/9SfFO2t
GTy36e6HVzF9dl0NBXOPzD1Z+c+fz9F3f+vZvdBsxJfR+6JO+UprPObFQC56CeH5orCDhR4ud2Oa
weQHE40u3JDWQ1qhWVRt2WFlK2isPltTFdXHZO7EZ6XHiWRQrpdLzD3/YVBFBRl28bL841ct3+bW
g7V3v2P0QInLf/V3adiLOPtd7w7K49Cjhlcz+omUDjWWfRgha2f3if8t4iFZ3VPQb1VJtvtUF+PF
aWZQPx4BS1QSoSFovxV8wVlM/qEdSixNZPQUg0tVyNA0H7lF6BFfZgT7NPvz/5BCYMu89vMtJn9Z
RfJWWjPXb7gr4t2hRhP+Er1xJNRcNTqiqT7JQXoGiKvvtwLPlycoOgcXg59wUkGMmwf7zXPGMSQR
sG7jUdE4pcvnXnkBspoNzDpoleDFoTlBfK4R2SyGd8H3eeDDhLdsk8xb8Z3mcxCmL5cYpXbpBscJ
Zn/8pfYht12qz+QUFqp1pPn2PoreHFYRcvnwYvvsW7ryorpLsG9X/TQvkMImb5sbcrX7nPzmRcxW
eYv28omwnSE8Q0jGcQYT/8dStTrF9HOyMZr0ODOS9IVGiR082LKzREgGVSgccZbgWetPPGxV1xj8
UbutJ3zFwjAyNEzxQ+uX5jPnY1+67senh93VZdhCXjg47xdddwZtqHyo/IL7p7sP1jfP2H7KTzrv
hYT8+TGg/VlhxlA7Bx3uj9uT+bHzEj/+DbtlsCNkf3ka/LkZKILUOrMdzVaGuGUz/6cPf3zC+MPX
m5l3YW71mcVU65wcMpltiem6tKC57VdgqsRkGM/qYmBgAKzPQ8q8SY+zyY+FJ24jCpa/QTx83iW0
UW6C/PyAscNGvh7i2YY4lvsyRustKYjoQ0Gs9/gqpnhfYJcvdfz5lNgdUI19WPj0MOlDU+RexgLA
X7kgm4rlhuj8TvnNW/BcPtKOmfp2Bk5gIbJ9e3a3IM0ugcmvwpKe28XQJPXtx18nPzFA42w9WKDN
Oo/YaDyFI2qrWo2PB5nt15uw4I/TLkNrTXoyL8y/op/6xZ/9dzhyYiE+iQm3+fv8m2cVkx/XImEP
KnGKaoP+8C/v6Bq0ziOCRJffMKjDeCWu6jSh2B1wBrP1BZODcyMdL8Yog/XgbYgz+XF0z9cpHFGc
4ddmSRELWHVZTfXzZ569GG+KCpM//Ud/dMdYvf36A9Hv+afjm0qR1lP/pT//hJ+a4gTz+Pn6zaOM
0e8vCmRVcaISjFknhodTgXK/OET35Hc83Kmv/OHnRnw6uTytWhXsvfxku1lzEEJfQoTWjjZitahe
QujJt1bPbK0SI/WfxlccLxZc/PODbV/7PuRuYJqw3rUupT7N3OGcNz6aVZcBPxZV6f6pr998WU/d
bzfljww+KB1dTfPq7rGTeliElvTzh4rhnpQl+vGrjT7TDO6vnOSnN5ibjaYYOAgd/v6dCvjPf/31
1//6nTCo6kf6ng4GfNPh++//Pirw7+gR/VuS5H8z+c9JBNpHWfr3P/91COHvpqur5vu/v3WZfvq/
//lr8ee0wd/f+hu9/5/b/5rW+s9//R8AAAD//wMACEOkc+EgAAA=
headers:
CF-Cache-Status:
- DYNAMIC
CF-RAY:
- 7bcba8cb2aa7accd-ATL
Connection:
- keep-alive
Content-Encoding:
- gzip
Content-Type:
- application/json
Date:
- Mon, 24 Apr 2023 04:38:54 GMT
Server:
- cloudflare
Transfer-Encoding:
- chunked
access-control-allow-origin:
- '*'
alt-svc:
- h3=":443"; ma=86400, h3-29=":443"; ma=86400
openai-organization:
- user-dvhgf0lntotpa5mrg7zv7aur
openai-processing-ms:
- '375'
openai-version:
- '2020-10-01'
strict-transport-security:
- max-age=15724800; includeSubDomains
x-ratelimit-limit-requests:
- '3000'
x-ratelimit-remaining-requests:
- '2999'
x-ratelimit-reset-requests:
- 20ms
x-request-id:
- eecb4503410fcc7505b7554b7109e6b1
status:
code: 200
message: OK
- request:
body: '{"input": [[8134]], "encoding_format": "base64"}'
headers:
Accept:
- '*/*'
Accept-Encoding:
- gzip, deflate
Connection:
- keep-alive
Content-Length:
- '48'
Content-Type:
- application/json
User-Agent:
- User-Agent-DUMMY
X-OpenAI-Client-User-Agent:
- X-OpenAI-Client-User-Agent-DUMMY
authorization:
- authorization-DUMMY
method: POST
uri: https://api.openai.com/v1/engines/text-embedding-ada-002/embeddings
response:
body:
string: !!binary |
H4sIAAAAAAAAA1R6XQ+ySrPl/fsrdvat80ZEpMt9h4CIgN0Ifk4mE0BEQOTL7oY+Of99gs/JmZkb
E5DY0lW1aq1V/R//+uuvv+u4SJPv3//89fc7779//4/p3iP6Rn//89f//Ndff/3113/8Pv+/J9Mq
Th+P/JP9Hv99mX8e6fD3P39J/33n/z70z19/b4tRxarabbpl4Cwc9eakb2bxoUZCPhQJuP6HMz3Y
LlxeWYsSVRBt2SZerI1BDsBDnnFdUd50DzSYa8BQwCzGS9FaxVIa3qX63Uc98RZa547P+/yCtMSU
CPY6A/Fe2aZwOY0527z1j9E8r+kMEXctsz1HsUubwylRXw+aEydKpHhaD8Prq4ZULpIsHlassUB8
b5wYuD6iEb8uJzST85xt5PXK6PnhWoIdeiUxlsUmHg68DcDV4jldobEoyt2r8FB04Bv2XHQmYq7k
KSgPNybZ6wPqGPrudDjNA4Ir4yDcrtttErRWoxMx20slejcwLcTq+s0cM62M8X5uczSnmxUx3rsd
4tEez9T8muzJjn2ckO9gBei52ejMQccuHOPLvQTDnlk061ZZ3F+J2kPTiCMdCQvRsKdnC861tMXi
eeUhO+tcQuEia5jeHit32GubBHRn7hLDOx8MioVTQ9HeDHLpPrErTH0LgKrVjniXuRYynR4BRff8
S8z5dhvLXr2y4VA9SqZ/onUodmf/BsvLzWfR/ntG4tDdM1Sdo5pZwjx0/Hp/OOhVUo2qlrsxZG1G
bis4KTo5vmsfiax8VbC1NUyucNkb46sP6FowcWXWvW+M+mr5PhwfZoLrw/ZT0BgTCpIZYUKCzCvG
oOgySOZlwDbmwTdGbUYi9algn3mjl3a9nNs2Gp3jlhmVpAvJ2aklJOz2IlG5OIqRiBWFd5BQYhoU
XDHT7hlKNp8b04NuhsR70Hwox2BNDnmpddxntQ7zPJnj3BSNwcMx7X/rE++BurDyDm0EoIUeLR9t
2Y1HKeMgSvygTCpF0bd7Z0ThvvLIQR6XhTj4+ghWHjKqzIklRnXcJDC/9CFx5qddN24DG2CRhDvi
FtumGPb7TgGFzLYUPc5j3K9KWYKI5y7RKynsxpt71+AaHq9E559dOOjN3YNCcBvPGErd8a04p5X1
ZBdmr/NO9OalrWG6xitmvWJ+oBsFzKX0IM5U34wHKxOJet5ReV+cQn482yfAZesTQqXEpRcWOnPW
GR4zUx+HvOqqEfpvqxHXroQQwZJ70LHnidYAuSteyiNHQV4y2jcZhAMDF9AMHTkFKdrE4yuiERzk
7oz9Y+R0wyFdz6A5yBLRyxdF9Y7ICmzbqsLztHq7dRu8PVicnzGV733jtvUHHFid0xsWn8gryur2
Utdnvu+Ju7sWYoyRPsK2Xx9IfJkfDYEWNxWOm2VHzHPpGUM1F8naHLSBmUt974qPIAoU/djSlqM2
Zvq+5kiVnBnZX1Q/HOtVncCRPA1m6nldMCmtKdrP8xyvLier4Cu5s9FWPgds0x4vYnzmewz5+d6R
3dKLwzHZni7oY7AeL4pkcKd8zqGdb0d6PmjXQtzGvFrfnOSNf/vz3d5dDVW67ONZfW+K7z728Vom
hk+lKmwL8XI2ypoOzyuxaWbHvBiDHH54YsdpKXprzBJI/SZj9mG7K+jTUhOY8IiG3GIuvxKVImrY
ISFRUaNxK482MEW6kDPe2Whki70KRX1+M7vkR4OvtG0LhfK6kH2vpKJJVsd03cnJyLbyy0fDIx04
LHRk0LEuXWNcfmwFpnhg5X1RxfAd1AQuuuew+3oTdpyrQYsk84apMBW1o+HelX7X7HrKW8Fwb5eg
mN8TZlP8x/N7X0PQRDH74Ss764qMjlX6onl7tAzxeuARRfTRM5KEWcyTtznCycsshp/fj/vbj/Uz
Gb7MOTp1KFoCMsqQ7ZDDt9iJsuoqDtpykbGds//GgjsfD10H64VHqS06IVb2DU39hO3jQo4Hqzjl
qryJFboKjm04qpeRgq3iDV4vqtJoPCYw2t3TNbHnxEJSu7xEQIS7ZeasXKOPe5Nt1DceIju20Qr5
dkIpFEV1Jc5Yv8OmXtoWrItoiVX6boxffgA6nRh7GmljjMnVbsEo1YJ+Xvhr/ImfauMXXgKMaHjU
iYeC5haTDdlHot7nkQ9K3A+0ksJHJ3gwWCpVm5a4j/MYslujOYCyXUzsl2S5i1Cam2g1kxMs4Xrj
jrPFx0ONmx7IYbmyBW9mKw9JDx4w93XDBb9KhQLpfSGIt6gkIR7Hp4PsEJfkYJ1FTK0kSOBQZzo7
kjYPe+f40AGWSUQC/vmE3Ct4hOLW1Fi4kKuYYnxPIZ7rc+I+9UMollDZELnfAq+OXdYNB3ewgL2k
FdmuHzEaNSI4iufanFhjagih0zugwt5LVMGjXiyicPDgJmkxlWVN6Zpzb/Qgdas3sexrJrjh3R2U
a2lP+yPZG4O8fEfodVFkElrvc9c3ka2jvpJOJGk3hpBTyFSIgu8Gr0quxU3vRR641zih6aVYdfWG
hz6yr+uRLvhw71o26y/Q7qoYS5v4GoputsyhPqo3ejTKRgxih2qIt0+HbPF3LIRUGzbUsdXhRZfv
uzGINibEyiHE6+XKRkOktBFkx/I89edH/FboqK9P68OARdBhg4eHb4Ye39WFOMwdURfdHEV13ZZT
6f3VBG/smKL7t/KZtckUdzzvVQWGs3PGUrjk6CtTHZBHeczuu6Bw2YSPaJnbQCzjIIw6dRMbNl5y
IS5t1Y7t1E0JlS75xLMrw+Ccc4w0CN4Mp5rnDvsQX8ATLGZ6kgYdP2WaClQJDWI5+5lRSaGcorpM
OfOoqblc7toSKafVltgfYyGmfqXCKvFNvN5YRUf7tYVRtfukVDl9kpi7dlPDYWUADircIFFvuwv6
2PbAdsN1IwQp33x9zI2EuA+UGN/LfF6DXGmUOGyAjs7y/PLrt8wruryj1sagsHyWBTHvnzoehyj3
UB4aJrNdtBI8kQcLHl3OsDo7yLFYRysPJv7zw9uOrz+mDtL9eiDk6WExLlzDUqf3o+IT9d1vf9ej
kBGeXc2XO0C9uKBZt51jJfuexLjniwSG9FQzXXMKY1Se1EJ1bu3xMke1MaoXtVdHtf0Qi8afYpzb
Tr0iy8phe8sdxIRXEZQPx2MbzRGC3/2GAxH7Lfv1P97Oax8eN7gyrAdWzDbL7UVtRaYQ4otj8Yd/
3xTR4A/3/W6Y4XMLdW7u2dPj55BLlvOnn1F2vKN46n/O7/fozOsKJE6rpYTyxSfBneo08TjKmQYW
Qzs6Pyytgs+Hcwbm1jrhBf4G3bh9HySY+C8xcf0y6GneXGA2bh94tsVDzNePVwX4srCIZ29RV788
NYBbRY50ceEUFdk+koAk+w8xgq0ZjndDxmBFYLP96eN2U7xM0ALlhWcZLF2mkH2F3H2wxyI8LpEQ
K+0GYj63Kb2aG4OfMluBeaWY5LDYJgXPOETIxyvOHGVmFQvn3VD0w+tNNxtEd5AQoOx71oh3fTsG
d2a+uf71V8/U57FoXy8HPuvwxcjNNw15z9cJLPz+wOz+YBSj66ETKEGeMptZo8tIbJyAbRr7D98Y
zr1BV+LhzdkOfXUkRbKuQxDcZkwzyqgYqRTJ8GoemGkLt++Gg+r16P3eWHixT3M0WAtb/vERlqg8
D7vIulQoXK78ib9UxbiNuwj016whu1PuoFFFhYJ+9bCtVkXH/dMxgI0qIqqo23vIj/XBQ4rJToSo
6qn4BlspQgcrFPi7shXRrD5XD6KrY7Gd2M/dFo08X5+U9FdPdihXn4MJibGe08+0Hr2dRArK3r6T
h5ITdwitLkXqd58xY73SO1Ge9ak/lldm673jjpeTd4NpPboijwf6Nuzrqx8MD+K6UWbwu31VUb4l
KiHf2u4GY721USZ/txSYL7r+IkBGRIuA/fCg84+1gpa3cYlXXsnCP3x4XG8wM2sjN77jzitRJl1S
YtpKg5g68wK4DuaLrul+6Liv9zPItweV4YIX8fD2+bie+AWF69txhakUKUTpEWGVDclPrzhQiNEm
G38VhL96AdhZClUmfBERzpL1T/+tmdx3Y2oZt5++xmtTxx1ltiUBBWoTHG5K8bXs7fjbD4yOfBPy
FzqocL7VJ/ZUPkxwqUUZrFuvINuL83Y5VsIb4FP6ZPsZpQVfxUmEbmuPss3n7KJxrzcyaq/cYwcE
W0Me9/0MmJ1KxGuyJOSfmeNAKJw/ejXuzl4YAOpOHiEUj/GoHnx//bqoMh41xzDG+Aka8gW90cUm
tjqpfD0C5OGyJc7Hlgv+2w+jVAqmlQl2v51b2GAEFxerZ4HjMX1FDirmZ515j/OrGz8nDcPyuHYx
1zrP4NLrbsGQXmra+Y3vCpNtdHj75o6Z728m6KmMSmDIW//0ZPe9b86SqgXqixiP9hwORecn8MN3
Ih9xwY9py2H3UHQWWFlp8E//kGFWgEOHukSIf+7+DBqzfjHD7Sv0w3/VPAfbKV/zrpatVQSLu5pR
+QpDwavcPIG9l55Tv70ZAkWOjezz22U//i5X/JPDtN9kI2Iz5trmVqF2V8aUh7ttN0raqkRk/yYT
X46K8fLmPZyficZucVqiEV1fI4r2FyD23dXcRb5VMHyvxZztd0FhMPel6UiXVzVGyoPG7Y/f1zdq
0uWw7opvk9QRpHxxJPaoP9x+9+owrCJSYZpdvjG/+68RfvxMU6Mk7I7vREJhMDtiubd1tFRyK0Vq
MT8Q/ZAwd0i8NILJP6Kq8ngaYzNuaxirzfCLd/fdh/gE/aUu2KQ/xDBDNwq3tr38qTfelvfsx9+J
d1yMiL3C/gLa+WgzO4+YEIvrQUGy1zbUCR8HYyjupQNWs4vZfn5S4vHu2SZ8tqNDPPlrGX0fJj4s
IFWY0yvY6IHNb+jM3Z6um6zrxKd5pxB8zmu2ey/D/9IbVYJPePnCB1eQuZQBvpMv05L7IARftgG6
LpaM2RMeCho4Ggzhdsm8AExXvML+pNIderHdFTLErzPrBCdmpczZ7zx33AbaDMDsj4SY35U7rrKz
g35+Qrv/LtBPH8H48gtyqhsXjYt0N4OPU9ym39MEv0qdinZBc2QbT5bdIRMJV6XHGNAZ3WfoW8lH
DSL95TP3qX/jcf/g1U8/T/xzGbfKk5rQ3zcOyUV2/i9/zFczk6RJeDS4BY6Kbqq0I5EbcdEFm4ii
cF96VC47Hncnfr7Bjy9nu83B6KNI+DBDIaeLIdi4i+LeO6DLqGZa673jMfhuAVp829HhqdzjMTbf
Aaw8MyQ3cutD9rg3OiTE4+zHB8dhHt6gMG4V22n3izumUKtwPTczurwsSDe8i0WNnm1s0R9fZWmh
Zr/8oYMny0ZTlSWFoBt0ulp/HrE4f1odHUprTX7x4WW7pHA/YY+OoVeFw/T8+tfvzUlf80RemdBo
JMF/6qOOVyeIW0uj2e5zQd9FzKrVKglMooeeFcrwQgG6NN8X2c7Krzt01aDCV/PuzPCQjOh8ltlo
8isZZmjmUokdMIz94kF2xiEPOX8aKtBtrjLC0DcU377pf3yK7Kb1x6efqOhilgPbD0ne8eNZu0Ab
2YK5bqS50/o+sIt5IBN/LcS6DNs//I9c90H3i+dPTzCnyj00bqz7CU5ebtFZkK3D8aPHKppn1o1o
srLrZLJOHNhp1opovpSJsR4u1Q/PsOpIO7c3BucE587r2aHgJ7c8maODJr9o4pNVyNLAwmDuEkR+
+kFM+gNFozri+MhfoSjdTEfPISqJpxIV9f3bLqHwyhVzL/dPPO7PFQUpu3S/ejF6CG8W4ndt99OP
MXs5GxWtokNFdi881X93+8MP8LjrlwUrV6hVmXQ/MuIfdmLQsZPCwekV4q2MT5z/8lF+vRu8/JTU
7R8bp4ZbIbcMy2OFhv5Tz+A4kgOdJ6EW/vGX8f3wnd5X+vE7C5qrt2LWp5yhQTMUUH/43Lwvjitt
3NZCqbopiaM85m45oj0F01W1P/1NmfzS1da5LYjh3/bxMG/jBHh2pvTNXSaE+JxMdKF2xfCluBfD
81lLwJxljOWy82M5fko6ynf+DcvYU+NmFzUOxFDfiOW074L98uf21dfEXOqNO6weEl9p+NgyLzt6
Rb/fGRmsRVmTXVYXIf/0Z+mP35ZP/tv0PjMo861HyORn/vw25IIW0HiuZgUv8S1CDS9nbMuHVSFi
ye5Vub6fSZTsSdeb2cFE7BsLLGnEEHytKCc45/qd7DbZLhQ7dVMBMeUN5StsowHUV4ve9HCncnXr
wqlfVyg7Vmc21ZPBreuRInS6MCyNd8PgsOlGiFxWUP7IDIPb/neG4oXcT3qzd/nzoaU/P5s59ksP
2boMaziG6p4Z98/K4MuSjLARazrxlSCsV+VMhgk/CV50i46WX0WG9fbzpeN2nhRSvJ/pEOo8+4P/
LckPN2CbzsaR2r0KOvnL6MzmKnOPZCXYo3BTdFtj+tNv7lD4G6o+hXAJaYenGHtRcJj8RdyyISmm
9SVQVWiJGTgLJCIAEwJfu5JLNTu7DC18BV4f60O2NV2HIi3GHCZ+y4xl8Qr7aN4n0C5WT4w6+y3o
xjqeYDO8d+TXz8TnUpdA5xbDy/ugFkOeP3O0fun+T28bbAhrB6Z8xTN2lmJ5mc51SMHU/9SfFO2t
GTy36e6HVzF9dl0NBXOPzD1Z+c+fz9F3f+vZvdBsxJfR+6JO+UprPObFQC56CeH5orCDhR4ud2Oa
weQHE40u3JDWQ1qhWVRt2WFlK2isPltTFdXHZO7EZ6XHiWRQrpdLzD3/YVBFBRl28bL841ct3+bW
g7V3v2P0QInLf/V3adiLOPtd7w7K49Cjhlcz+omUDjWWfRgha2f3if8t4iFZ3VPQb1VJtvtUF+PF
aWZQPx4BS1QSoSFovxV8wVlM/qEdSixNZPQUg0tVyNA0H7lF6BFfZgT7NPvz/5BCYMu89vMtJn9Z
RfJWWjPXb7gr4t2hRhP+Er1xJNRcNTqiqT7JQXoGiKvvtwLPlycoOgcXg59wUkGMmwf7zXPGMSQR
sG7jUdE4pcvnXnkBspoNzDpoleDFoTlBfK4R2SyGd8H3eeDDhLdsk8xb8Z3mcxCmL5cYpXbpBscJ
Zn/8pfYht12qz+QUFqp1pPn2PoreHFYRcvnwYvvsW7ryorpLsG9X/TQvkMImb5sbcrX7nPzmRcxW
eYv28omwnSE8Q0jGcQYT/8dStTrF9HOyMZr0ODOS9IVGiR082LKzREgGVSgccZbgWetPPGxV1xj8
UbutJ3zFwjAyNEzxQ+uX5jPnY1+67senh93VZdhCXjg47xdddwZtqHyo/IL7p7sP1jfP2H7KTzrv
hYT8+TGg/VlhxlA7Bx3uj9uT+bHzEj/+DbtlsCNkf3ka/LkZKILUOrMdzVaGuGUz/6cPf3zC+MPX
m5l3YW71mcVU65wcMpltiem6tKC57VdgqsRkGM/qYmBgAKzPQ8q8SY+zyY+FJ24jCpa/QTx83iW0
UW6C/PyAscNGvh7i2YY4lvsyRustKYjoQ0Gs9/gqpnhfYJcvdfz5lNgdUI19WPj0MOlDU+RexgLA
X7kgm4rlhuj8TvnNW/BcPtKOmfp2Bk5gIbJ9e3a3IM0ugcmvwpKe28XQJPXtx18nPzFA42w9WKDN
Oo/YaDyFI2qrWo2PB5nt15uw4I/TLkNrTXoyL8y/op/6xZ/9dzhyYiE+iQm3+fv8m2cVkx/XImEP
KnGKaoP+8C/v6Bq0ziOCRJffMKjDeCWu6jSh2B1wBrP1BZODcyMdL8Yog/XgbYgz+XF0z9cpHFGc
4ddmSRELWHVZTfXzZ569GG+KCpM//Ud/dMdYvf36A9Hv+afjm0qR1lP/pT//hJ+a4gTz+Pn6zaOM
0e8vCmRVcaISjFknhodTgXK/OET35Hc83Kmv/OHnRnw6uTytWhXsvfxku1lzEEJfQoTWjjZitahe
QujJt1bPbK0SI/WfxlccLxZc/PODbV/7PuRuYJqw3rUupT7N3OGcNz6aVZcBPxZV6f6pr998WU/d
bzfljww+KB1dTfPq7rGTeliElvTzh4rhnpQl+vGrjT7TDO6vnOSnN5ibjaYYOAgd/v6dCvjPf/31
1//6nTCo6kf6ng4GfNPh++//Pirw7+gR/VuS5H8z+c9JBNpHWfr3P/91COHvpqur5vu/v3WZfvq/
//lr8ee0wd/f+hu9/5/b/5rW+s9//R8AAAD//wMACEOkc+EgAAA=
headers:
CF-Cache-Status:
- DYNAMIC
CF-RAY:
- 7bcba8ce4dc5accd-ATL
Connection:
- keep-alive
Content-Encoding:
- gzip
Content-Type:
- application/json
Date:
- Mon, 24 Apr 2023 04:38:54 GMT
Server:
- cloudflare
Transfer-Encoding:
- chunked
access-control-allow-origin:
- '*'
alt-svc:
- h3=":443"; ma=86400, h3-29=":443"; ma=86400
openai-organization:
- user-dvhgf0lntotpa5mrg7zv7aur
openai-processing-ms:
- '407'
openai-version:
- '2020-10-01'
strict-transport-security:
- max-age=15724800; includeSubDomains
x-ratelimit-limit-requests:
- '3000'
x-ratelimit-remaining-requests:
- '2999'
x-ratelimit-reset-requests:
- 20ms
x-request-id:
- 6a3f8b11cfa466968b57d3335d4394e9
status:
code: 200
message: OK
version: 1
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,695 | Allow Weaviate initialization with alternative embedding implementation | I would like to provide an 'embeddings' parameter for the initialization of the Weaviate vector store, as I do not want to start the Weaviate server with the OpenAI key in order to make use of embeddings through the Azure OpenAI Service.
The addition of the embeddings parameter affects the __init__ method, as shown in the code snippet above. To accommodate this change, you'll also need to modify the add_texts method.
```python
def __init__(
self,
client: Any,
index_name: str,
text_key: str,
embedding_function: Optional[Embeddings] = None,
attributes: Optional[List[str]] = None,
):
"""Initialize with Weaviate client."""
try:
import weaviate
except ImportError:
raise ValueError(
"Could not import weaviate python package. "
"Please install it with `pip install weaviate-client`."
)
if not isinstance(client, weaviate.Client):
raise ValueError(
f"client should be an instance of weaviate.Client, got {type(client)}"
)
self._client = client
self._index_name = index_name
self._text_key = text_key
self._embedding_function = embedding_function
self._query_attrs = [self._text_key]
if attributes is not None:
self._query_attrs.extend(attributes)
```
To check if the embeddings parameter was provided during initialization and perform the necessary actions, you can modify the add_texts method in the following way:
```python
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> List[str]:
"""Upload texts with metadata (properties) to Weaviate."""
from weaviate.util import get_valid_uuid
with self._client.batch as batch:
ids = []
for i, doc in enumerate(texts):
data_properties = {
self._text_key: doc,
}
if metadatas is not None:
for key in metadatas[i].keys():
data_properties[key] = metadatas[i][key]
_id = get_valid_uuid(uuid4())
if self._embedding_function is not None:
embeddings = self._embedding_function.embed_documents(list(doc))
batch.add_data_object(data_properties, self._index_name, _id, vector=embeddings[0])
else:
batch.add_data_object(data_properties, self._index_name, _id)
ids.append(_id)
return ids
``` | https://github.com/langchain-ai/langchain/issues/2695 | https://github.com/langchain-ai/langchain/pull/3608 | 615812581ea3175b3ae9ec59036008d013052396 | 440c98e24bf3f18c132694309872592ef550e1bc | "2023-04-11T05:19:00Z" | python | "2023-04-27T04:45:03Z" | tests/integration_tests/vectorstores/cassettes/test_weaviate/TestWeaviate.test_similarity_search_with_metadata.yaml | interactions:
- request:
body: '{"input": [[8134], [2308], [43673]], "encoding_format": "base64"}'
headers:
Accept:
- '*/*'
Accept-Encoding:
- gzip, deflate
Connection:
- keep-alive
Content-Length:
- '65'
Content-Type:
- application/json
User-Agent:
- User-Agent-DUMMY
X-OpenAI-Client-User-Agent:
- X-OpenAI-Client-User-Agent-DUMMY
authorization:
- authorization-DUMMY
method: POST
uri: https://api.openai.com/v1/engines/text-embedding-ada-002/embeddings
response:
body:
string: !!binary |
H4sIAAAAAAAAA5x6S8+CTLfl/PyKN9+Uk4gIVPHNEBC5WYWAtx4BIgIiN6sK6qT/e0efk+500qOe
mKglJbX3Xnuttfmv//jnn391WV3kn3/9+59/varp86///H52Tz/pv/79z//4j3/++eef//q9/l8r
izYr7vfqXf6W/76s3vdi/te//xH/9yf/Z9G///nXrl5UpKrjdtxE3tpTr17xojabO8ClQ51DP3wz
akS7tc9ae92AFqY7us3WmjlLEQxAYF4UwvrxDmZLgwjWUMjQhg92vRHnV6N+3HTCwVof/eVxW52B
nlsiRsFoAjbJuwKek6Wi25fxNvvHpRAA9jWJugxkPukPSa4+76TCXpqL2Xc/BJ8fNSZSnZfZrNDe
hvxzZdhE3REs6HlOgCBVFd1KmmJO7HBpoBMHDTY39TabD2yIoK9nK6KApa6b/bMOQHpgW/pYjxag
vhjIoIq3FnaNGYwUfPYGTFYRRq154P447rc50NQ0wdZwbvnkR5YNaNe9qGcVrbncTkMFVmSrYPO1
3wOWukhQq0vu4j19ezHbQwWCx3ZrUA8cx3jJzrcGmo5gk3JUymy6YHWCfc+PZME0BrNLTjY8deIO
8ceFxfRkMBHE67KnxnBs/dnVtzk0vJWPzeB0MAniXgfr4Wri8/jOfG4ZOwhBq+xxcF7pMTXIEYL0
Vn2wtdrtMinoFAce2ntDjXeqxXx/Cq9wc76GNHU/J8AP460E7SntqM2tw8gut7sHng3RiWr7W1PS
BXxVYCIb+PjqQsDL5tnCnaMjfIFn11yeU0Q0TvmF2repN7uLHYbweLdy1B1275pkCBMoWinCOCqD
eonqsYT5qono1jqE5qILOFUfMgppsATFOEmV44DFO+6o2YoGF7292sCcXp84bdZHvmCuEPiKcoIt
k0CfC/qtBPn2faVGNAqAv2Y9hM0SafhQNfrIQtoZcFXlK1RZvDdZvBTTb38c3MEYt8FhSCHU44A0
96EZl6NYMsgbdCdUbHg9Da63gNhtA3yQlk3ND6GxQLuKKZFX2OaLumxzuDpPMfZWyX5cdpED4TqP
99ivd309u+4oQxkLOwLupyWblEYSYcoqHxutGI/L1b/p8BIfL9hg7308G/0tgDVnDhIoKPzlJXuJ
Yj/omTpaNfLJOg8d/L5HCrWfGTuQrQytjXjH3re+KYsUC/BuNRLJrZOYHU9OAlEzhBgTMffJmcbe
io5mQK0iRDFrx3aB02fQse+0nPNowwI40kdCOggrnz/lewWiqqFk6ksYzxT6EAjgyAgU0222PFOS
woM0nlB4TL1xPhSaAPuDJGKjeRLQ7bEkw93QtmhVtC+/G6JXANenR0ak29T7Q/eGHlROxRXxdxrU
TXt9qtqJuRP295eaLxkwFribtAPOzqujycH6qsLjdjNi69QE5tyueK5Zsz5Ta2O4Pn9zLMN6WgYy
MDBk1HA7BlTRE7B7VsN46ZQuh0f8MKllVF1NxaIjwF1VFVLOiV0zRRodsJNOEd0OxzNfHpWLYHW6
jXi/CbJ4yXfJGbxNOqF1nc/+N58rOKx2Czkd9EvNr0vValcvf6Hf+Xx2N18HrSGFSOhuff1xsxBp
EjZDIrbxUPOnt5U1Mj8u2CGlk7F6iSr4wxMnKxo+2UuZwyLsS+ocdvuaPGw1h188IjGzqc8uWCWA
mE6McVp3YNlJiwOpLJ7xCe0dsNC1q8K6O72o07CjyRR9N8Bafp6xO8kF73PlWGijlC90Jz1DMN+L
mcG1AUyydI1vLpu3I8NvPJD8Oqt8/sxqDs9G4NGbto1HxtRoAKJ1RYRbsjqS2PXF33t6SaqBUzQ5
DZStT4LoN/7L6eV2MOrTjP7wlZ4MWQLHtniSajjaJn/e0QJScp8ozuMyY/nLWmASlDZFj8/b/52H
9sjnD/WOXhfzAUMJlMDx8OFT73nTji2D+mZd0r3nfjLOvHcALrP9RIs41CPninMF335C3ayWstmu
k0qVtplMlOg4xIt6Xgh0VLRF2rptzD6gHIH9rdCws8I2EIfNOYWY+ztqCY0G3v5VcsDUBwDv6Vav
pWsCCljX7QV7S/eK+27j2FCr0w1Syas3f/kBQZJQ+jCL3lzyizNAs1Fr8n6ij/kXP9VBT7SBcAHz
vcsDEPXXDG+xm/LOrdIQytk0k1aM7yNn0WyrRO0H7N9PS0yvve5BUO4z7DxF21/H4soCiiDlSETd
1l+E9TsAvV8c8GGjOJz1ghIA8c4i6j+vqGYXsZZhcVtzHKxbkfP78eEBJ0YNPtgnnhE7j3J46EqD
HvFQxZN3vBsQbvIUR+z9jllQsxRkg6XTeC21GUHoVsBsZayw/zAOMd/A1oGp/6mRchzLcT74sw3p
U1TwTrtnYNExZyBb6StsL4XJuUFuENSOKxIZLUa9TuM5gFdRz4gk6fLYnyZzguKovLDtXErOzODm
gUovJjIdsWvO0uaVgudZlnBsv07j1KeOAaZWTHA+bE0uFbBUYRp9tkhpmJ71U5AG0L9kOSnOtTJ2
WxaHwLloC1mz+TYOVJjOcNi3GRK32SXmo7CpYHdUr+RoNj2f+R50MNs9PLxDn6XmYmc6sMvsEa3H
yh2XKN1aMJMPMdI2igPmVB5SWB6b07c/37OXTBZDS7TDjHg0IpPFh08J7h/ljD3qL2BMr56s+v7A
iPj66Jz1TkbA7dOG1N6Wsr+cXFWG88k7ITHeMPCRiAFBQFhGb/uo9ukXH8GmciC2zQM3u8LPHbgN
8jP2yaCOdK9uG9gaYogDpzVNxhhDQIfRi6JCD/zZjdEZBpxm1MiLaGRJqauQyLGJbc8VzFaMpQJ0
TcFoQCzdZ9I4NEBOlB123uaaf/uVCpU8tJC2teuRTJqNQLt/F0RO3nnGfKfv4EExIYpa1APe7cYz
eDvOTPfzZcs5bl5MO1Zmjv07yM3PebXqoNTqBHt0hiMRqur867c0qMdqJPbWJHDzaGps3d5dtsxp
FYAqNi3q+EDhLJdmG97HiiJVOEgZ11IlgF/+88PbkWlvy4Di7XLA+BEgvqx901a/90f4O53G3/lq
C5cAEi7W059htz4DYdytkFx+Er64bJ3DuUg6auhebS7yg9igq2wXbSrQmYt6Vid1UYc3tkn2rpeV
43UK3rQedW1/5l+8SmFz9wK61T3O2S3sGcTc3dFf/2PDqgvh/QovFBmRndHtZndWB17KGIf8WP/x
76vMe/RmYTjOAjoNsKsslz4CdoqZaHt//YzQ4w1k3/7n/a5HhGCsAU+UjQiq9TtHo+r12bJIpQ5t
CvZkddjYNVvNpxJaOztBa/SJxmX3Oojwy3+xhbqnSZJVf4bCsrsjYYfmjGn3ZwvReW3jwNmBsXsG
agSvLT6S9ZkRUJduKkKcu29sRjsrXm6mhKCdQoe6ydsfv/GyoB7JTySUcONTGbst8N3IRTw+bgDn
in6FfLVyCLlYW5MlpSPDVStb+LDe5TUrGUxBiBRGPVmw67X36gn44fV2FGY+HkQAQfk56Ti4vDyT
eUJoab/+GljGKuPD8+nBtxY/Kb6Glim5TMvhOpwO1JkOZr34AUigHFUFdai9+BRnZgLptnf++MZ8
mkyi8HuwonvwMYCYSoYBo+gqUN1s0nohYirBZ39HVF/70zgf1GACr9fWRmu3qMBsrx3px0dorrIq
HlP73IJ4o4Rf/tLWyy4bU2g8hR7vk8oDiwpqGfzqYdcq9cjC5BjBrcpTIqu7W8yO3SEAskUTjFU1
qT/RTkzBwY45+iiOzHvlfQlgevFsuufuyh/AwiotkYtfPTmx1L4PFsxNbUXe3/3INeEFlF3nhu9y
hf05tscCqB+3pKamGCNvTsa3PzYX6hiT5y/nJLjC735Ewfc7+PT0E6pvBO/Y99PSZDfnooJqh1WM
P50zzqa2c0ApfXYE0pCP05lDCWA9hfSHB2N47GSwuS4bpAQNjf/48KJtEbU6szI/yz5oQCmeC2w5
cg+oKgQRvMzWk2jEnUcWGpMAq91BpahmdTa/QrZoX35B4OXl+dyS6wKmxREglc75T694sOaLg7eh
EsW/eoFwb8tE/uILT1GZaz/9p1FpGpfCNq8/fY00y0AjoY4tQgKJg1G8bfjHdnbL7zwQOLJtzJ7g
oMLTtUvoQ35TzsQBlFAbghrvzt7LZ0iOrxAlxYO6AiE1U7I8BVctIHT7PvlgcY1eAsOFBfQA4M6U
FncSIHUKEQd9mcfsLXgejLn3p1ez8RTEEQRjEmBM0JIt6iEMtedZldCie6a5ZA+og5CTK1lvM3sU
m+c9AgFqBuy9Halmv/MwG7mmepMj/zP6tQPN6Owj9cRRthTP1AP16mTQ4H56jss70RHcHDUfMX0M
TCY+bzaci3NHxrAPfW7RrQFfobWn1utTcpI0aQMpCLSfnhw/t+1JVPVIfWLzPpziuR7DHP7wHUtH
VLNjMTC4v8sGjeyyMdl7uktQqKFH5q4BgL1voQB7q3tS059a8MN/1TpFu2++VmMn2UoK1ze1JNIF
zjVrKyuBjis+vv32anKQeg5wTi+f/vi71LJ3Bb/njbc8szKmb68tGPZNRli8342LqCsNwO4Lf/ly
Wi/nF5vg6ZHr9JoVDVjA5bmA1D1D7Nx83V9XOxnBz6VeUXcf1Sb1n7oBDEnpEJDvJBt+/L67Eots
Zm2sP33epbBg6yN2FuPuT/vniKCS4haR8vzJ2C18LvDHz3Q1zePx+MpFEEfCEUmTY4CNXNkFUOvV
ARuHnPpzHhQp/PpHRJXvD3Ppl10Hl3Y7/+I9ftwYJXA6dzX96g8+C+BK4HUYzn/1xobmVv74Ow6O
6wXQZzydoX46OtSpUsr5+nKQgRQMPfHi+8Gc61vjQbvfZ9RdJXK23ALHgu/d4uFA+tjmNMV5CNew
kKk3ycicIF1dwYn5E9H6chz5u38VMHqfNLp/beL/1httjhK0eaKDz/FKLCG64Q/V89vMOdsMEbis
N5Q6XzzkJPJ0OMe7DQ0iaPn8GU+JSvbgSfcXWAJ2EewEJtQuqOfuA3/ZRboAoTUdMbY+ir8o5ckD
Pz9hcD9r8NNHcHmGNU663gfLutgL8O3V1+/1dM4u4qiCfdQf6TaQJH8uec5U8b5ERCBuCT6tdNRh
ajxD6j+MT7a4d9b+9POXf26yQX4QC063rYcrXp7+2x8L1dLCRR4fTWZDTwVXVdzj1E8ZH6NtSkDs
NgGRmpFlY8JOV/jjy+V+ezCnNOUhFEDMyHqOtv66vk0eNCTQUX0IXtkSfXYQDui6J/NDvmVLZr0i
qARWjK/4OsX0fusNmOOA0R8fXOZVfIW1eW3pXr+d/aWAnQovp14gm/Maj/OrXnfgMWQ2+fFVWtRq
+csfMgeSZPZt0xAYjbNBFO19z/jpPRjg0Nga/sWHNcOGwFuCArLEQRvP3/Xar99bX33NckmxYK/j
HP3VR5cpCcwGWyfl/n0Gn3VGW0XJIwsbcWDHEnyCCJz7zxPvhObjz2M7q/CjBzdqBkACZCWUDvj6
lRRRIPhEpAcEl2l9x3vzUMWMPUwVkl2lUkzBJ+afqZ9+fArvv/svjzBXwdlqZurOeTWy40k/wyF1
OPX9VPe/+4eQnq0D/vLXmmtNPPzxP3xxo/EXz5+eoF5bBWDZ2rcEJkFlEyEqtXh5G5kKVqV9xbok
70cJa7kH97qtYD0US75087n94RlSPXHvT+bsJfA0BhM91Czxm8RaPPD1i758so1pEdkIWvsc4J9+
4F/9AdJFXVB2ZM+YN35pgMecNjhQsQqm6eU0sA4ahfrn2ztb3FNLoFiex1+9mBOMrzZgN33/048Z
fXpbFSjpocX7J/rW/3j94wdo2U+bmjYKGFQq3o4Uh4c9nw3kFfDgTTIOFPOdVb98lJ6vHm3eDfGn
+9br4LWWBoqkpQXz9O4EeFzwgazyWI///GV0O3y+9yv++J0N+0ugUPvdCGDWTRmqP3zuX2fPF7f+
YINC3TbYk+8rv1mAS6Dlq/pff5O/fqmy865rbIZXN5tXQ5ZDVp4IeTGfcs7fiQXOxGkpOte3en48
OhFSb5MhqRnDTMoeogGqfXhFEgrUrN+nvQcz2F2x7Q2vmv7y5/oxNGxtjN6flbvIFB0dBxqUx6Ce
3L1ZQo03Hd6XXR2z93QS//y26uu/fe9HgE21CzD++pk/vw34UI9ItlLLmjXomoKeNQLdsVmpeSY6
kyp1txNOcxePk1UeLEA/GUeijk3ONFlO4Kkybni/Lfcx36vbFmJL2hKmIAfMUH0O4EUONyK11zH+
9usWlMf2RL/1ZDL7ciQAJGeKxOVmmgxuxwWmPq0Ju5emyZzwI4BsLU1fvTn57HHXi5+fTT3nacRU
a+IOHmPVpebtrZhs0+AFbrlGvnwlijulEST4xU+M1uN6JM1HlqC2e3/IslvltZi5ggFjg5V/+D/g
6nCFdDs6KFXHZ02+/jI40ZVK/SNWOL3XfgGuGiI//ebPdbgl6oNzH+NhfvBl4jWDX38RDXTO6+/+
IlRVOGAr8taApxBaMAr1Cz63wsmnYB3K8Pm233jXES3mRb1U8Mtvqbmpn/GUrqYcDmvlgcDovDjZ
2scEbufXHv/6GX+fuwaSlU3R5jar9VxVjwpoTyP86W2TznHnwW++IoGexEzaFCsDFtAy/upPTF1b
gI9dsf/hVUYe49jBmvpH6id29fPnK/BxrxO91boD2CZ9ndVvvpIOLVU947PRwPh0lunBBnef+Rkp
4dcPxjpZ+zHp5qIFQtru6EFxZLC0752l8vZtUf/LZ8V7gkvYaJsNYkF4N4msQgnus03z51dtXtYu
gFpwuyFwB7nPfvV37ukTe+5+8mf5fphAz1qBvFN5BL3tHBZYDsLty//W2ZwrtwIa17bBO7cw+HL2
egF293tEcxWnYI6GTws/0Ft//UMnFmmRS+DBZ5+osATf+cg1BffsLGAUkvLv/wEZwx0Nhven/vrL
KpB2okb9sGc+z/aHDnzxFxu9J4L+opMFfOsTH8RHBJj6esnw8Qw4AafobLIE5S3MUH+nv3nOssQ4
hXTcBoT3XuOzVdCcIVaEmdoHveWsPvQJzE4dwNv1/KqZW0Uh/OIt3eargX++8zkYF08fm41+HmfP
i4Q/f2m4S8NYGIJUwLVqH0m1uy18smYlBT6bn9QtP40vrdubCN1Bmb7zAjHuq6G/Al+/rfBvXkQd
lQ3AlRJM9yYPTC6aRwF++T8SWyXJyDtxEPjqcWrmxRMsIj0EcEdPIsYlbGPu8ZMIH53xQPNO9c05
XPSr9sVXxE2zBPM3fkB76iH13s55HH98et5ffIpsEMSz93oSbTRJT6RDG9YsTG4htD9VSd1vfpLV
xEUQro4RmU4yNefOOxjwdr8+aJh5T/7j33C/ifYYu+eHyR7bmQBY2Ce6J6Vi8msphD99+OMT5h9f
74XgTP32LWREH70KlhLdYcv3SU0qJ2yhpWKLIiR09UyhCaF2mgsafPU4/fqx8IGGlEA73AIWP24i
2MpXjn9+wDIis9LmTNhiz/af5mK/RBlgY66x/Vqe9TfeZ7ivNgZ6vxvkz6BDIVyH5PDVhxavgpJG
EH2kGm9bWpl8DEf5N29BK+lIRmoZOwF6kQ3w7hU44xr3+xx+/SokGpVTz33eXX/89esnRmARtNmG
ujAG2AFLEi9gaDs1Ox4k6mrbuGb3ZF8CTRcfNIirD5++/eLv/D0GvIzzd27B6+p1+s2z6q8fNwDu
zCr26nYL/vhXcPRN0lUpBnysrgiq83LBvur1Md8fUAkF7YzwwbvikdVLWkJtDrbY+/pxxGVaAY8g
K9FzuyGARrQ9K9/6+Ztnr5errMKvP/2nP8Zjpl5//QEbt+o9sm0ri9q3/5Kff8KSvk7gKns8f/Mo
cwmnswzLtk6ICJdy5PPda6F8O3vYCKRXNt9IKP/xczNLEp8V7aBCx5UedC/0B86NDUyB5ukLUuv2
ybmRfzr1RDUVm0X4MD/8eLbhOTzd6e7pTjHzI8uC2n7wCQlJ6c+nqg+B0J5ndF+3jf9XX7/5slH4
n/GbPxIMoTwS5TuvHu97cYLr2BZ//lA93/KmAT9+tTUE3WSh4uU/vUH9crH4zCA34L9+TwX8z//8
/3iiYP3/fqIg3bE3AXuj8mdriFNwTZOQRtf+AZo4P4RAot6LYqjvM0noZAOYx6NFsUqy8VPp21xT
tOCOg4FkPstciUB3JXhkNRvreC6jroN7ZVrhvbpVwXz5OAJMpCZC3u4kmJ95yTuIP7ZJDaQp2XB7
XRsAXtWOojmMxpnr4KxGw6hjf9YxYJ4Y2pqE7IiawfYNZhMuLfQNa0aL9DJHvk/VDqbklRMlu4Tx
Z3wLLZC2B4O692zPpwM+EuAVDxu7hdRn8znwHUCYHNJkjF+AeKsy1JTLNqdok/SAfXQ3AZm8KpEQ
T496WqLvBP7oLRi14Bzzo0ElwNqupDs57L4TLyYCFc7TdwKrcKKsvTN8Ov6aHthk+Z9WOCfwfowd
8hnBKv74VRRql+dLRjyJpnoctSSAJ6oadFsedL9rk08Klad0JCJxe5PydWbBZwQHmh3LJO5ZNoVw
MBaEzWPex92pcCB8dgPDezoVdbd7dhFUM3rD2/BexezTX2UA1TnFwUpJMw4sI1U0sbGpOyoKn69K
LcPdVnTp9XIXAHm9FBH2asmo8arTjNE66aADogN1wCbhs/5UdKgvBxNvd48w42H/VGHArAc+joFi
LqtVmWrPMIuRZtB7zUJJCmDtr3tqbtzFn+R+8eDuUmLsSrvS/AxWHcLVeqoJS/HFZJNwaMAugTLd
ldesJs68HcA8vyHaKHLDh1kzc5iIBsAB2JOajlqOQHMaThjTNx+ZfHqEalbHKREvmZKx6WHmEGrn
GbuadcvYWVTOsL8Vd8Jy2MRzYT9KcBxHF+8D85PNmtueoXPpaupajgKWSzCVsOh3It2WZ8mfIrC/
Qu5swr985/iEDVg42yeB0xKNzHo0LTgF4RVf46QDjNz2ATw65gPv7tU1pr/8Sa4doUZ4zXzmnd4L
6NWK4SANjiN7904Ir7VrI0mQP5xh957DockUAqPGGKnz0i1oT7yh3/hm1I1KWRPJu8Q78tnUtNgF
i7o5qSskXNs0W5pjAYGErIjapixxXpMGQsGLAuyOyg1M3mAMqyZ8vrEh6q+MXc2rDnPr9MFutVrF
1K6tFOwzZCJ5PI0ZGyxXBhXXRWrvL5R/smKBsDmkG8Sm9dWf9cvYghV3A6wbGy+bu4tXAA0mHUas
sAHjUpBDo0Qz3rurE+en2HDA9K5OpIn6wzjqV3KGn7YKqB7UDBDYimd4VkMbYzubOcuKWwuGwklx
DKdqpIfMj2B3usgYKxDz5SM+LU2qjiciyaI0Tnxc6VB4CBG1gGmOzJavHXiVxg37rvzKqE3pGUhV
fKLBrc44z+4dgofinZIQeKLJhnCSQHteFuoJKo95b4aVdmiOT4qkMTHHcFxdFdlSJWytZ9nv+s+t
gJTrEt1WQMym8X1HMH6qJ2oZCuWd6waSym+Jj8Z5yWp2PJABimGvkU685iY/S/f8d//Y6ML3yLKS
2uBgYoQEkuJs2j3LCLoTkKnemUE23p/KFUJ2f1LvcdwC6f1YN3DQ0QZbcrGLWegfHVieSw/Haueb
ZB+aInxLEkQVPA4mK3aCo44CarBzuRd8ZtkUwUCr92Rd4l3N9I/aANunR7S6cWHsnsUQwOPBO1Bv
dypMPhWRpTVXblGrNrb+0t5LG5J2nyEicAOMymp2oE6tmF7zi1LTyyVLwCxNA/6en8+lfNWBwGaE
7la05PO8JANs0TPB5s26xqTBbgHSQrewsbnQjDVhEqjX8k0JcawQLECJS5hdlAO1EikzWRX4OlAh
SvD2o9gZOfU3B960p4tgKmgZy9euADe1VGOv05xs3l1EBEfQH77n9+SfLT6K6vf/U4SOhfkhz65U
ldzx8L58nfmcjScZyGvNxfh61fyZZU0Ewb590v1zU2XcvgoCuLcawta0udesWpWG5p0PPd626SFm
iicb4KLXL8Sfp7u/JICdoddODb3M79KcK90t/vDe12511rnC5gy8XXfEer28Y3KsgwhkoNqg0oom
k1SeHMJmPGfYaAPmz4uwakFR3wg2HueJzzOsLLVcb22svw6uP5t7x4J1stsTpm22MR85WoBwvwK8
A+/Fny5Xi0Ah3hnYWQ/vsZWToAKvpAtwNqHG5Ff55kBjWRzsX1efbNrAWwLLCYUUH6sbnyt9W2gX
LATf/mPE6152QriH0Znug8n0lymuI3gtjQtaQX0fb6jZe7AMJQtj69HH/FPSFsCj8ELv4aiZkyeG
FsRRjDG+bRfA9nhrq5/VaUvRrDixWCixA1yUQqpHb8f/ULVNFU71IzXFhvNliscIVEf4pPvv9Yjp
ChCyZOfirQol/vnxidApQiRrYIrnw+4zgOd9A/BOG/txTvYKhLl1+VC81Vk2G8vLgV2at/T7e9B+
+xHA1mnEFjvoNWuUkSlffMSHF1nMuf4MAfzyDXyTdrrJD6hM4LErU+zu0ldGEidOwDEMNaLIoM6+
6xFEodMTbV1g3qaRkqr7jdvhQy5u6oVcYAEOq/6DDXsSR/ZesQEM7SokAitsTid3g9T9IXqQ8nXo
fcZe1wR+arhGrD+vzM9HugcyAIFPL9x4juQUdUzZ6IGCPn5p+Ev3nEO4GzoB++KjA32TmboWXcoj
1ofOq+egeS+wdNqWelKPxuk+sUB9MhVRXUPjuMB5u0AZBxSbToXA0t47G9ixQKm7S3fZZkqsAa6D
2sJI4Aafzn6/wO5/AQAA//+knUuPgzDWpvf9K1q9RS0IN5tvxz0EExwuIYk0GgG5ASEkgA1Y+v77
iFTPaBazm2WVVKnE9jnnfZ9zcGStokaRvIpPc9BaMHezS5ExZTX9WOcHRHkWYoc0z569v0MOh/fj
SP157Qgom3rQfvXAScQILM/j/QH56bWhW4NEVqfu9xXMi3Kka75PllfRnNVDywfhALak/9M3j1k+
0V0/1Wz5FhsdNCLpwvc8ZWhpk7jThtLz6MWpi2I++rgEGsw68io4vRZHw7bhc5JDqn+yO+o44RBo
inuzceiNbi/BfJmgXygUm9w+7qfBK2wYB2OJ0RpPU2MpMYgjERF5893WG3MZPdjS95scR4DYkr6P
N6jx1xNFz8NiMZJ5KTSE4wfvdWOXzF2w0aGvP2uMtaJjs7C/HSD/BYQ8N89jQt5fZELgWD724MMH
a30LgJutE1nt8kiWq+zl8P30ROpbaplMrWfeoF9kJ1L7rYuETx2Y8PVVvnTVz2v+sWP42gx36stj
i5i/gSHU3RPARt18rXlDUhe862GP75IsF8OO41Nwer7lcLqSgzXcDqiF0vmWhfBLAFo2zqgC/ptl
WNekZzINd3SDEnR16vWcYU371neVipkC9dFlk4xLklfw7t70UA2x3JNdetThlQ97srTBATH93Gbw
Hgn7sCnqDi3nsAvVwtxvqQUinW1CLRHhnu/HkHOkOlk+pAyhvfcRxZ+8TRbHeIXgxgUV3k2Gx5g+
7gKA2oiRz2sY+hGdAwGy8JlRM/q6veQB+QbhZdzS3W3PakbOVwEeDe5OQ2o51uicYAg8qurh5jwF
/RCQQgSGqOj0T5+vehEOam9TA7yCXqhHT4SltRwJUZ5Ssnwad4HDdEJEOlUuErYq8QB/r5+Eu8gO
mEdf9mH8/ei0LC88ogbNBjWVdl/CtbtvPTOd/ekbbIhMB0Qd5AbO8wtS96DqhVCkgQ8H45jS/WSF
CWP846GlCjXwLx7HVc+poN1eyffcpGwaUtGE/At3FPu13i9WGuS/9cbxnTdrkVTG6ifEXTiAqUlm
hD6y/HAtjP2L+Cim1j9xcM1f1AlOivXNvR4CzWkx9UB4R2t91KG9p3WoDuWzGL3pcdBWvUB166Gj
5XlvONgfEgOHF9lhHY/0TsubqMZ2LQRgXus1NMf+QtHr/ACf8aPGYGg4DusRtySsAVsZyubpTjjl
KRWLxk4xDAtLxY4m3HvSPecYTIs5hrCmTzBdJnmBRseX1Nkvas/yJVUhC+sslHB+KsbpNRPoW7aK
Das4s2VyrjFYNuSJkVo/0NRqEMJZ2CXUyjOLCTXNUvjsgy2ROrHo55siPODNb+RQDPcJWnLoQRin
nIr1HEsWSYGcwZ3tWGGzDwNrfr0ONw3vygstdrKTSHoFJhh320+4OUZJv+hVfIaH5XShOy6z2aYM
kgXcmPqh/lAayec+fxeYhPGX+uS8A9O+NV1tUD82Dmp3sIaN7PkwtKeSHklj9IwPhuXv807Ha5/Q
HFapJhvLlmgrIZxsMYVQMY4Z3u9H2rNSbF1YnMCeTMmFsZ9f1x5vp6J2EtfFdxS5Vm36tMCnU19a
fS2r+U+vUMOKK8BKnTXQ8G8PAmE1JUs8RkQLXtGX7uM7KIYk4kUwHbicCN/vAa31aIJS8XLwzjt4
vXApr7JsENun1td91rO01QPI72KLaKQb6jHcPlOtvHtPGruDUC/ZBrpgzScYfZlZCP6RTqDgPi01
L/GxH0OtEMCu0t9ESEcHscyXczjdCpPMj0y0pq9tyFCk3ot6eEPBeLx9M/i1ji1ZComB+X7F6wTI
XsO/88h+ehgvk4+3w1HopzUfyjGOWagcfcv6+RN4/VSvPz05rH4e7Nwux464aYsZ4G8LxfQ0UwMN
Wk0lz+fgx5pOeNvYGKz8JIU/P7nf3Chb9oeyhIqljtj/uFwxv+9lCJVyrEKu2ZvW/KnHHK76lO5e
VgaWt3Aof3qYqHodF9MSKz6kvOyu8RMX84NzBigK4kCdw/3NBnLBATz1YCaazY7WrKDLGQjE9MjU
WUPClCD1te88OTQ1t401MuRNYCh9L1zuvNmLZtu3sAoOOU2k3WItfXeCMPjmZ7yFxLOEM9m48Cm2
Kfkq9wiwdLEPQG9F8c8vz+EkyxBu0UQd+XKzhlE3Ui06xFoonitcDKyXdLDyIur0klBQUvUHFXH1
gaj42aA54x+++svvaqscGGs1qwXlFGyo7/WGJW6s81lZ8wc1RL+3Ov1yJ6qUHDvqeGGNWJHk69TH
S6a+YB8K8uMfq76jvsMxMErL6wBWvx6u61Gws9p26vl643H4fAhsmdrEhet6hZuj+knYcqsIsC7V
MxQjSyxYd94HYJMuFVnPB1pOY5XCGh0iIq36bT5sTBvurX2IDWLCZIiq3QP89Hu3MWZAL9HJVlk2
CTjJpC9r3fO1BbVEZuxf+SxZ9ZkNGwFFpBumPWKxXT/g6k/p/uXAZKgCS4faYlLqsGxfSD9/Ph+/
pz899VUyL4AXe38h/KrPF2/efcFOPdj4uupf4ipFDsvcYuGGu26Sebc9Dz8eFgoDefcT3h1vslfr
Ew2Pk4QmasfVj2+R7VnbsoVJ2wC26b7AQQQCMB0ee0G19RiQpeUAmJ8p5wO1hhJ2ErtFVOEVD7rL
tcfW7OSgvS+BD0v1QcLl/Z5rJqej/IsvvA27vmbtjjRwbvcU+6cdswZfBzb41UfzClAiiW/HhfUG
5dhSO4Q2Br4IKrQNI+xXHscUMxzUn37m7fun+OL44GtZ0+p0iwCX0FZDLdxm2yPdB8BiEm/eU/CS
pZBo38eVLfIt4mB/tmrSrX7ry9DXgx14KHh31t1CqmX1DHcnvGBnjDM0azuSwUv4jKk1k6lf67H+
43/UffhcMt7n7wTW/aSBhlpr/uWjS0PS8HXeimBRMi+En/fZwNnrdQdMyM4c/Ej8hSxHVtbj+vmg
f7u6IQPRgy2vYjirnsFd19dzLZqEEweeJBXx7lq8WfPjedMB5tSNhsFa+mXMgXi53XEYeh6adjtb
gOZbS8L3U6qS8fUeOSglp47wzTz15Hi3CLzv2tUf1EXCMvF4g++a7Anb7D/9EmpaCNFrKLB1n18F
C9R9DvWP9qL4CfYJeQuHG5ja7wPb6ehYXQ8mGxwcWcG7IySA5R0uoepaCYGr3ifDVSZw5QM0iMdz
/edXVn678tadNSkD/qo2U180XHmLSEkjQO4OYwJ4zuilyHyLsmrKDT47XdUPrzk3IQCsXuvVoQCf
obNhPWTNWv91JCj+pGsJTTUarPWMiYdyAMnGsql1+og1zfSKgziOMHVvrdtLDa5EGJ+qiBoT3dXz
Rn5WqrF/YWrOvmlNvnB24WjdVbzd7paeNFHGKVam+eRs7nY1e15lAcpXPyHCXjLYJiCbAPI3brfy
oqFgT+ET/uoXdlupL5bryWxh8D2f13o6WctyM1I4QvYN535D2GS+HsLP3+DCeOs9eyzjA4T9Y4Pt
vgSMHT04wCSrvFVfPgBtnGMON/EerfxYLYYLViHkbXQk7MCSfoYXWYehcxRC8Do/2BTLigofcO5w
8JYlMCl61UJabgSqV48CjLmmufDBZzw1i5BDM5AXD1o7qyVcIYTJtC0aHb6VPKGGPto12yrCAj+a
u8Xej6fRQSa//EhUS4XJ1DJaAVjGt9VfPK3NbrtOvIG8pjZ8g6TDVzmF6UMNQsi6Yz9zCZgAVFlO
sfFpLRYFWgx3l3lHt4YDimVDNiU042gf0pWPjbCNOXX8dAC75J4XTK2DCoScHeAQhnYvbpxRhi3V
MT7jILdGW+hE+J0XB+NnfKonb0nP0Bxtg56a0am/PVwErZaG+U8vfLTtQYA0iEsize8Hmhs776D8
iCxSX0ZiLZ0ObkCVtm0I8pwA8hZHCDY7fqTBy7d6ZXopBB43zQ6vetrazEv5/eWncJNZ9+JXzwHk
ZY/eLIbYZj1/Gt00e1p8nhkYtlHWwrDLXYxwCdkgca0IJxQn1LzzVT//+hvyht+FbM1P/SU6uRB/
HwPh6GZiNDqZBG6Cp02dyVOShaDLA67rQ375eVjrgXqukYu3abogVqHoCzX+fgoXbysWZHlkIqTf
QMfpXnr+8v/6NAQwf34N/PgX3PasCCtuv/SNWBQPkIU5h3cJNZJNrmm2Gs2nAzXJNWVMTl8qLK7v
hCL+iJj48GALwusroj5lfTIlU+dDL2fxjz8DZuaVCS8XcCeCmo9s2ebRAXj5HIfZaZ04vtm+qRrc
pyIqX3/QiM62AOludAi9GDFYXks6ab9+irWc2uSPt773NQp/+WfB8dmHR3DA2E++OWIa57qwz9t1
ouUhJOy1iB7kJ/MaymqZJGNysIbfeaVB89yzaY8vA2itzsKocY8Fc7JPCbxgQ8Lj2n9YklytoGhg
k+6PXJpMKkEZ8Kis//EXqUQ7Hb5vpkv1ehf1C/b8QXXRGFE/dKt6EAJBBuRYWXQbb5ue5pwkQu/0
rbF5/vBg+lDCwXhkdOV9Nfrcc/UMTXZ8hFJ0C9nyFs4lUNsqJEW6N/ph7SfAz92r6T7MXsUyXWQf
fpuLQnddhRmbW+EG517ZULxTv4wJ2YGD8tVL6HbtBxHO3xLQkLtPpiuZ0PAZLyX81ac9y+WEhO9A
hPOxO9ErelTWUEqnErjq6FHvuQDrQ56PSv35V5d/1vUyCh8XTh+GQ22ySDLBl9LAsE7OdLvbf9H8
808rP8e6n9XJeDBeLoSvbUrt6oISxvp9B6P5eCC8Xz/6MdWatf4YCZGEa11QXt+JgPThDjubWgUL
b2y4Hw/69WOtxe/3Z3DYGd2a3+N+GY3ABREJHtRXvXe/ONJpgJudNobThsY9/em1R3Qp8fZUuZbg
3zcBfIXrEwP5cERs694XwN+fz/BLzh826LKuw7U/ih35wlm0uG8GqH/Oexp0ugua4651YeiXFb6O
fMYWKqsHcLa/PpHCDtWkDDQfIHB+4j16VGg5U0mEva0KNNhYUkL61ryBeGtkeIujZ/HXT/7VZ73e
zTXR2OkAl/ekUe+nN/G9vEHk7B947bexubit9eK98ASe+Maa9qq4QPoN9VW/RfW01lsgEN2jwYlv
0Ph6nUtwNl1GQ8+eGHWC0oTr+aKmSC4/f9XA6vR9h3PD92AWTvWgDdrMsCkvERqUYduBlY8TIrsb
9utvwcfGcgm72OdiXOP51y/GJ2Ya/bzqI9DJuU9Run/WRMz1BVZBnJO6E0RrSsp9DB+3w4Bt/3n7
+d8GyHkLww0ZTz3bvw4EIpA/V31dJtQdI+Gn14k6lEYhogAdwOrniLryVQHYYIE/PmaMSlsslzex
geGXD4rV16sm4qR4cOWfdCshqZ4qQ2thEQ8mzdxXY61+poFrP5CI/NPqyfOz5Nr/x0SB+P+eKOhC
n9DtpnOQWN55H2is2dIbVTzAXqSwYWsimwawREAqTjsfajyWqB/xUs3S8DhB7d144QuhCQzFfsfB
Y6saZHqfGsZyrhyASN8onLPo0i/W18uhfilb7FzRyMYd+Lqg8bIb9VD3BOOnmgZoJZFJvarKC/rm
YhEC0J6xjclgkb03ihATWSVdUylgegkJB5V7s+Bt070Ler8lEORLrVO3du717KLvAww3zyVPGmVW
H56QCcKje8D7vNwW7MaVLljfD80i1BZ0R+UUTtf5gL2v0xdLKfcVSAVqhJfRMRAjt2iC+9lN8a6o
IjDg9BTDl7kLqV0iqaaz0yzgoZ9s7DzQvp7vX4fAu3x0cRgqYz+MiMQqQ6+RzMZJr8ULzzdwn4GI
vMfOLdhN0jvN19yJIpunYPGeiQcohk2o6lWASNiNHdSUnKf6V4iLKTxON/URVzvs2ChKZk7d2RBv
bAMXgH8DJh1rFc7zbGE7JAjQK0lT6J3iCPs7/gzmqH9M0LyUcQg1RWHLpRtcVa+Tgu7e/K2g162+
QO+r8ERpnAoty/lxAOhq90Q5Vks9jKg9gEdz0vG271zAXlzig1M6dPhkdgFb8uc50+T94pC5ET5o
hOruDAzjdqd2gpT+28ufDI6vdQKDlidGpfBcwsx9EroXytqazvaRA2E3ctTeoBT1XCme4SWucah2
lcPET/dstOu3arB9IX5Br7cyhk8fMYxKPkDLeT4T0FY+T4O8nIt5mO8H4D0dF1t+1CFWhUUL2y0P
Q7DjCRv7ajrDPDhyoVh2cT2eKlCpo8TN4XDlq2LW5nSCS/9ewnEom4Iokhur4mdJyHwVvjVjx6EC
YF9cwrmNTtagFE0JL986wP6dP/YT1qwBPr0M4u2+QwlTjnULjzKRabAooJiq/g3h8VZvMBazAS27
OZfh5+Y1dDdWhC1ozhuobc4c0Q6KhKh2rDh4hkNBT8hRkqHV9IMmRVOAIylKAbve0gNMs6eGHQdF
/fzybQit621HzUQwE7Glmw5K+O2Gyz0i/aLghfA4Vzlqd+TdL8MddrCasj4sK0Vjk311SvDlvCPe
brseLNaciOAsDzk1m2jPlo5qGVg71iHfZ2M/0YKYgC/wGwcv/omYs7UfIDQBwttv19b995afAdgU
MRE3TtmP+aJCEHzBKeTWDiFzyX2BrerDcPiWBIyo/xC4PcVFKFqos0bDFAX4qbwnPmyiW0EyublB
2ygNXED+bU14bwnaKMGZhmZ27afgOE0wmahP962SgAVSNYAVzD4YX9aB4OTccACrqkINJmyLhqUX
Dtr9YUNEF70ZM0+2ChJVjbAnOR9r3vbfDPZvzaFb4gjWAJtzCeC7jcPNut5vRCdTy4WTRPqe/ybL
nee+sFyqgcjf6mItb7ypVMA3F7ydnYSNZe7GEO/sLTVGwbOW03lIQZvtdIz0qkLTiNoYbD7LlcC5
3CdzgroOFOszs/6bT4vlducEcE7JjfoCvxTLyMOb8s39C7biyAULRxUZGpdbib1jp6NZVn0T9q6X
hMreaa3f+QDuKX5hP6y+Fqte1IUfzr9TR0Yf1ivcQde0N1ZDRauGv/MGPRTH1ByioB4dUA3a7uNy
f/l7caPirBb+Qws3ZxSCucr3KbyLD0xvuoJrdiLXWN1H9gUn++gN2OPtxaAfmUbSN+mSReZV9Vdf
8M6sjsnyPX8qaCZREEoXR+oZPY4eOLl185efZnsRzxDnMkedGo3W5B8VWylKYoYNIS5gxn1+wMey
E+n+rGwAO259U/VezpYov3wnb3oClhpaNHwofi+tExJAxg2kaz1I5mxhDXyIDwe7n24qhv1GbuA1
rL7YuArffvr2hICt4RypeYowmC+qO8BhnBl2t92GTa9RrzSWvHsiV5Va9OVbVzVXih/YEdG3mLYv
5Qb6m3egN0uh1gy/RqZdHiShPldVNXs7JAXAah7YBESuyS8fKLtiCOGgQETuXe1BSWr5kO3Jpl+c
3DOh/rw12GREYYyFF1udkzePg7RcENtugwCaym1PnlKUsukgnGxg8QcQapMSo6UwzgGA9zbFZkpu
1jALsas2Pjpi3Ch6LR1OPpF5HtcYpfy+aM6aX8Jnmcr0Yjtva6m7b/W3f3aKZDYLqtlBirlmXR8K
5r6acmj1MR/+4muxVd2HL3HnYOsV2RZd8yl8eWmKQ13BPfN4+Qw381LgwC0ZmDT7kEL34pR47ytS
vfhRPEFTKffU4KOknj9qEEB7e1BwyCttsuyNOAeXcshoKCnv3/k7AElqeJz2aANINEcdfOaVgXfr
+Z4l3/fVW1bdsGVHHetj7grhZjOVoWrwOaL+Gw3qI6t8IrNKRmRzBzm07pGOdzNf1hPayCrkjmcF
o3upJuy59TwYOG6D9fOprdnpdgzgDse70J2RUQzPq2FD5+W8wsfp9E7oGg9Q/RRXwnxyBHNadDmM
OvoI+4pHxUzmGwTJMO4x5tkZjIfiY8K4Ve9/6z0Kxs0D6TBa1MqI0M9RvhUgcmxCdVWgjKgn14f5
mSC6PTunYqnlqgVv4jPsn3gREK9rG/iAmUa6xfHRgDfT4XfeiAS6JiFrPgMLgDpN1vdHb683gW9e
+1L3juyCPUlB4Nf0y3BZyKX/vT7s3nxNTSX6FuxCSqj6C/gQmXe2gBCvE2F6U/fhvO4fs/lZh2mr
IuqZXQUm67XYEM12R4Oaf/bsHF49NSSKTXV6qnuy916Cpn4uV4wpKwpCu0enbXF8DdlIDv1sFHWo
tXdeIdLYtckgC5EPT/owUIdDH8RYyUP1k/t1OB1ObzZr/i6Ebb4zws0an8sGs1S7L4+Qlr/zt+4X
MFgUYZeiJ2PZ2xBgFIwtXvULYmVYPiBhXIu3yFGKOUGPDt4fpx3GIEMWOZ6HDvbqeofKUtb1pBW1
AI+tbGAPVCJbZswguMjDYa23iM1v3/6qq16jhn56JHOT701o9EkSCgyl9fLBWvirvzS0M82aN88j
hNY75uj24Jz76dTcXCXlVC+UFafrPxbodUAv7ELEqBPQ8BTSFor1e0/DTBn+6i84uk+ZJAK6grmN
lRj2rRdSu0Ii+NY8Z4L185KwVT5sjPpugU22S6mend4WY6XEKdq+cLC1/v1kH1Ud5G1tYOdEHuCj
GtcQ0hc7h9DmHSDA5nCDr0MWhzAvo2JW5mMO0cv+UFTzqF6kt/uA5rM8UG+ozvXidaQFllEiHLoK
AQMH6g7uK3AIN2J3RrNjigHwnls3VC9V10+//Y5TmodLJlTWPH2tAObcg8PuB1X1DFUjh7/6xvLo
VTMNihVc0FsiCuU1i7KS5wBawJ1IrHNqdpO8Dj7CKqD7uPT6WckNGaCdS6mxCFtL9DrS/PQV4R6K
Xw9dmjyg6dwy6pPKQex68gSoK7cneXaRWC+RcVmgaZRHmkf8qZdgKRIYbNw7gQlvW5vcZC7YLQoj
6rtyeyG4BgEkCI7U6yulYMbb5rRDLgv07DqHYrKdGcJiONK/erg0XpVr5XB6YX/m455s5yIEqUe3
RKTIAMIEXiIUouVL4KIUyXKKDrK26mNsi8TpmX+yvmB9feyXfIZGIcoCmLrqegdKl9UDX9QV/CZ8
8tMbTIok/wGdq/Mm8MFX1hSlGfzzB8mCbgXbbS0ZfCvvRAOpHOrRrrgMCOhVU2siU7GcjIMA4Xjx
qe4Kp2KAwuGh1fHuirGr2Gxpz18fZilZcJAqd8Cs+xxov47Jz3+SQ/fKYCk+RuqDki+I7XsH0POa
ie0P2YKZ9z0ZDog3wl7gu2LRsGqDnx5LdbIHk5Yecnh8DOuEHdoVbAhzE4aRi6knOJ+ePV40h69s
54fwxRvWdG2OPkyD0fvl/3542OkA3de2CKW7k4HpcvVTuCdKSM2HoCfSjk6p5uB4DmGjaMVAmrz7
izflzt/rvie5r77f/IjxMZtY16VFBS8lyfBu67T9WKt7H1ZNOtAy4y22WeYshTXM7qGod1kxXyoQ
gt/+bFvnmCznu7TA/d4uwzN1vsX0SNMF2ixexYGjF3PaP27ams9xJiK9GCXf9GEZHL/U76oX+wZy
q8MZcP4ary9AV/+vtSEyiSCSV82G1/gAVZMNWA9PXTE5mhPD2JUb7OUVqJfyeTbhw99pf/WX5pJx
AKt+xOYSIUB7Lg7hvTn5f/VqhEYqw1eaJaGkds3qB68cBEVzpYYYCT29nHY3uMyLQpRNta9//hme
uTomoogeBZF5VVaeZSaHmxPR2XCzrzrAR9elzqnTCvp03geYuvKBrh2hes0XITSTJCDS0jnFX/zx
232PnQ4NxcShfgLqvqjXeNpb03vUQ6juioqaOdGSYf+SH/B8q0902zkpWw7ymAPt3vphWGcyYKtf
09h1WbD/qVyr04pegKuex4Z+0gtJvh1CsLvaPN0+HTGZwXy0YZyrDxrGWYGYT+6++iDVFntrB2tR
ebWFM4YHqjdCsuqlpoJJR4OQ17JvT6fXIIMgUwpsIqGumYflB+xbP/zpx37mc53TbvbpEkrXrgPj
uMg+TFPq0t3LqYopFE7nn76lphT5YDmehy9Ai3IPxQNq0V9+Md+JRx65kLJ5mm8dMF9lFLIFccnw
vO7sv/waDAq05n6ZblqS0gMNcuVuMftkt+pPv4ROqQNxaySZ5l/dDbWfZGeJtzsnAku72Vi/CELN
kpOZA6rNR+qLlQWGevQE8PMPOFbqeqiF8gDFaMmooQoOm5/qvgS7j81hlPAENVMax+r2dChoQMuR
9U54gvDbemfCYKSjuf0GC9hE04Pwd3Zli3gKJ+CgeAqlj7Ox5pOKdWBotzPVPyc7Yc5dlsFwZCLR
Vp407/qvKUet/KE/vbrmO+4Xj2RGUYGYc59U0HzRIeRnloNppwVf0BJPw4ePsFhz7rsVvIaPL5G2
Xc9YLu1icLw9NzRQyyDpqrS8AS5pTbIxSINmHEMCrM1WoC5GLth8VDtUb0t1Dpc4OoAlkImphqaC
cJ1GbTGRNG/hpRlSXOplWrMN5Cf1Fj4e+DgilKx8YwFX/VSF011IwMRV/AH4L5tRtPIRug1PHcSz
qxOtVgTEClJ+oW8dDGpPxE2Y9w50qD0vJqn0KF71whzD/cY+4vPJIdYidJ2uZtWzw97HQZZgj/sH
MF63Au+v5RstkREtcHNcnoQl0Rst1Z0LwM+/lQ7vWpSHXABXnhCu/KzvBWe4gXI4vkIuUsZiOUVn
VV39RyhHDgFsS6cO4kqGeLc4D+tPj9MTV5EXQgfGDDyX2maeCozfysMa7k0pwFWvhMctqZM+eKNc
3aK4DKsommrGlVwO+9zH4cvp7gW7O+9GXvUlDT/Krp/D4plCGF0CHETlkrwMkxOh9LkAarUkRuRk
nEWoRMV35S/V6idBAxfMuTiweYcRDS8uHFx/h22e2D2buUsMf/7iT78XlSrDO3lEeGt3Q7E05+oG
o0rt6LbuOrTYUTKoK98h4oyeyXxEXQorgl5kY6HYEoyXmkN5t9h4hyqhGI/gEcKMq1sc2uWjHvfx
egFhH/NESxSxHtq9d4Ycvx+JWvGbgmAjdqEcFQLF52yql777xCDi5BYfImEDyEAFAlXQVNSk0WAt
kFdj+PwiEpJVn01Dk0N4PBMtFCqUgenepCJ833lKzYNQrTcRLQSCe3Oj4ZhJqJ7C6AyeXgox/rAS
NRs7aqFDDwNpSiT1dLjlLvhs+Vv4GRydUURlE6w8A3uK09VsKwU2POd1RhqPBP20saNGC6cR0iDh
G7TylQyCuiloueqH8byAGArS60p1LbpaP30N2iFzqQEEF4kAL2fItGUMFas69pKP5QB+cq/GUSwM
6M//H9sno7upCntwOu2mHz/DuiRMaPKcOf11EMPpKyzJ/IlOC5xfzA4luwsSBiAnghwOWxpapVFs
im+YybvZhWSt58nC5IcN6+8up8bKjxf/GQtwt9taeAs76z98UZyXKBRxl9YTb5/1389ELiuABimN
UmU325AGLW8UgpResj8/N+6VU7EI3UOH82u2iZw7IxjQPrgBz9kG4SJEfTINaSxDaZ62OJqiTUKI
tBV/+vzHA9kvX0Bt2+7x3lRkRoSuMyH2RgWHZvlEk7Pfn5X1RrZQtiuO/fwRcGlcke+tetezqu4I
lOa1gyjxAPTn8OjDbBhoKG4c2BNfJhk8urJLuFDZ97PR1wcQqsCiQaNoCUnlZoKXx5BQ+0R8JqC9
fYNwf8FElpydRZ3wzoGW54VQDqprPX2bIlZ39cGlBSpLJg534QtNlITr+j7qZZQ/OmyF1KZbtWvQ
MPWvCeKPbdJIE141WdcfKHPxWvX+Gy226vlQ3bY9xpusZySUX0R5LrsBr+cJTeVoTCAkwA67td+x
7IxCh+JxOuGzVonFZ2dqjbryAIyiEiYTRI0N9ePtRcNO2RXTXShlyJJXjy0hehaE8tADv/1VAucF
RrPiup/fpijgw1qkJ0xAKR8buiscG/34E+R4PFLsZ0shiqdwgcLpVYXLTdDZ5pHvv6CvvD02oPAq
WO+MA7xAEhHVrVCyEaOrChJXzX9PcBTMkgICN8fpSSISbdhQC2kMZ2ferfnh0E+hcD/DUWEdUaWq
Qev+pX+8pF37M9NjNHw4A+hTM40OCZNLKYWGcjtRi0UmGpX5msPT7fnETkSMXozl0VZ/PM5iUYVI
EZ1j6C1AW/2z1UtkMx7AgDQD2y+U9cwjpxtcPgsgvKs0YOG2+5si01bCxi2Sk+VLNRNWXrbQsFV2
YLme+xwSiXtTT3G8Wjw8Lyq09lsQzqrwYpM/Bi3kxrOIDVMIV74zyWAXA5nwfhavd2zyN2C9D1zY
7yoDSTmXEnj1qw9Rrk7dT/v01MCO8z44MPm2GBfjVsL1PFA7I35dvtC7gpTBcuW5QsKuW2+Bvg8m
sskQLaYaUQHUdvam7srL5j14ltDSShtvj52/8oSmg9MJnml6RBc0Hhb4gC3xNbKseo/hcL1DNZc5
IpfOWAyRhvI/vzCjCKDO0Pbyz0/To4Y6ILyuegkzgYxk1XtWX0n6Gs9UIVyVnevpKZQtOOlkoGYh
PFHX9W8T/vg+0vh3Mb/8gIMr36Q//rxxK06HzulAQ/7E7tYiSWGrxK18D5eBqEWTXNEBKnVDqXkU
nmDlKSIs0uNC7RqdLLKcHzEkmCPUlsiLMRTezR+fDyXPUdhz239T+BrSA3XVjlhLhTkfPGM0r/xs
w8abqd5gdFN7it6lYnXP686F3Lax8C6pEovw91kA3L3VsbkQpZ6WJjd//cXwc63mZD6CRwCXaOHo
tuy6np3IMYaJK+c46oWupxVX3GAkjPeQTxXLWnmDp40nTiSLGn37/iwZLdhZB4SdewfR4B8VF3Co
sUMBkwBtHotqwrmAmHArr5ygcH7AnRSb2JijYz8cnMmFtZd1FIOsRz89BV9BesRWEG17irZWC+/f
xwFbQ2TWi/P1/pM/0Kc813QTHiZ4FR81NS8RLRZJchuYPYaZfHf8mbH2VujAGh0RW31kFezxeuc/
f4/9lD8lP70I8GGUyOdaRcXgHZUcrH4SG4EwsHZrFBmkT3aixl4YLVLw0gE0QnbGe5hxycAJ5wDC
Y7He6akYxefHx1ceRIQGZcW8yc1Ku4mPC86nyq6lHy9d9x+7HtoWTNwMuvrhvDvRWFkzGr/9G7gv
VUgNLmIF7bk8gDvNVampkTOaZDSQX32l7r2L0XA4yh5Ms1rDaPX78yb3H9rW2WYYK+xSN/FopbAp
05xUavSt53GRPdjEKAklx8nRyls5eJVPech5SpiwR1jIcNaYQbhO+RQ0OFkZFKX3jjQn8mVDs9cJ
vMaPNzVWvr5kclNCvY4KbJpCUy9+18Z/fGkjd1JNtkaRgl8/WLp2HhA8R0l//pAAp9T6mfsapqZY
jYAxyuKexW/zBgt7cKhlRp+ClHJdAelTAAI2fFfPpR+G8NdPKFZ+Jhq518GVb5DpcnLBQk9b8r/v
KPjHP//5P37fgtB219trHQwYb/P47/8zKvDv/Jr/WxDEf1Px79sSyJA/bv/6r/8MIfzr03ftZ/yf
Y9fc3sO//uuf0t+0wb/Gbsxf/9ev/7H+r//+x/8CAAD//wMA5ou8WIVhAAA=
headers:
CF-Cache-Status:
- DYNAMIC
CF-RAY:
- 7bd02a678ad8dd86-LHR
Connection:
- keep-alive
Content-Encoding:
- gzip
Content-Type:
- application/json
Date:
- Mon, 24 Apr 2023 17:46:26 GMT
Server:
- cloudflare
Transfer-Encoding:
- chunked
access-control-allow-origin:
- '*'
alt-svc:
- h3=":443"; ma=86400, h3-29=":443"; ma=86400
openai-organization:
- user-iy0qn7phyookv8vra62ulvxe
openai-processing-ms:
- '362'
openai-version:
- '2020-10-01'
strict-transport-security:
- max-age=15724800; includeSubDomains
x-ratelimit-limit-requests:
- '60'
x-ratelimit-remaining-requests:
- '58'
x-ratelimit-reset-requests:
- 1.302s
x-request-id:
- 0d03d8038beee517067eba903c658f2e
status:
code: 200
message: OK
version: 1
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,695 | Allow Weaviate initialization with alternative embedding implementation | I would like to provide an 'embeddings' parameter for the initialization of the Weaviate vector store, as I do not want to start the Weaviate server with the OpenAI key in order to make use of embeddings through the Azure OpenAI Service.
The addition of the embeddings parameter affects the __init__ method, as shown in the code snippet above. To accommodate this change, you'll also need to modify the add_texts method.
```python
def __init__(
self,
client: Any,
index_name: str,
text_key: str,
embedding_function: Optional[Embeddings] = None,
attributes: Optional[List[str]] = None,
):
"""Initialize with Weaviate client."""
try:
import weaviate
except ImportError:
raise ValueError(
"Could not import weaviate python package. "
"Please install it with `pip install weaviate-client`."
)
if not isinstance(client, weaviate.Client):
raise ValueError(
f"client should be an instance of weaviate.Client, got {type(client)}"
)
self._client = client
self._index_name = index_name
self._text_key = text_key
self._embedding_function = embedding_function
self._query_attrs = [self._text_key]
if attributes is not None:
self._query_attrs.extend(attributes)
```
To check if the embeddings parameter was provided during initialization and perform the necessary actions, you can modify the add_texts method in the following way:
```python
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> List[str]:
"""Upload texts with metadata (properties) to Weaviate."""
from weaviate.util import get_valid_uuid
with self._client.batch as batch:
ids = []
for i, doc in enumerate(texts):
data_properties = {
self._text_key: doc,
}
if metadatas is not None:
for key in metadatas[i].keys():
data_properties[key] = metadatas[i][key]
_id = get_valid_uuid(uuid4())
if self._embedding_function is not None:
embeddings = self._embedding_function.embed_documents(list(doc))
batch.add_data_object(data_properties, self._index_name, _id, vector=embeddings[0])
else:
batch.add_data_object(data_properties, self._index_name, _id)
ids.append(_id)
return ids
``` | https://github.com/langchain-ai/langchain/issues/2695 | https://github.com/langchain-ai/langchain/pull/3608 | 615812581ea3175b3ae9ec59036008d013052396 | 440c98e24bf3f18c132694309872592ef550e1bc | "2023-04-11T05:19:00Z" | python | "2023-04-27T04:45:03Z" | tests/integration_tests/vectorstores/cassettes/test_weaviate/TestWeaviate.test_similarity_search_with_metadata_and_filter.yaml | interactions:
- request:
body: '{"input": [[8134], [2308], [43673]], "encoding_format": "base64"}'
headers:
Accept:
- '*/*'
Accept-Encoding:
- gzip, deflate
Connection:
- keep-alive
Content-Length:
- '65'
Content-Type:
- application/json
User-Agent:
- User-Agent-DUMMY
X-OpenAI-Client-User-Agent:
- X-OpenAI-Client-User-Agent-DUMMY
authorization:
- authorization-DUMMY
method: POST
uri: https://api.openai.com/v1/engines/text-embedding-ada-002/embeddings
response:
body:
string: !!binary |
H4sIAAAAAAAAA1R5W9OCPLPl/f4Vb723TpWIQNrvDgGRkwmCx7kCVARETiaB7D8/pc+umZobq8AU
Denu1Wut/Pd//fPPv01a3rPPv//5599XMXz+/V/fe7fkk/z7n3/+93/9888///z37/f/W3mv0/vt
Vrzz3/Lfn8X7dh///c8/0v+98/8W/eeffzflpGFN69f9MvIWnnbx7i9m87FBQt6VGfjhmzMj2ix8
XtuLCtWQbNg6XazMUY4gQIF5Vilv+xsarRVgKGGW4qXo7HIpja9K+7jJQIKF3vvT4zo/IT2zJIKD
3kR8UDZ3OB2mgq1fxttsH+f7DBF/JTOXo9Sn7e6Qac8bLYiXZFL6jYfh+dFiKpdZno4qa20Qnwsn
Jm72aMLP0wHN5KJga3mlmgPfnStw4qAi5rJcp+OOdxH4ejqnKprKsto+ywAlO75mj0VvIeZLgYKK
eG0R1xhRz9Bna8BhHhFcmzvh9/12naGVlhyI1Z1qMfiRZSPWNC/mWffanK7HrkBzulaJ+dpuEU9c
PNOKc+aSLXt7Md+CCuixXhvMQ/s+ntLTtQLTmdk079U8Hc5EG6BtxZ5OhMVodOnRhmMjbbB4nHnM
jgaXULzIW2Z0+9ofXX2dgeHNfWIGx51JsfAaKLuLSU79O/WFZWwAUK1uSXCa6zEz6B5Qci0+xJpv
NqkcNKoDu/pWMeOdrGKxPYYXWJ4uIUvczxGJXX/NUX1MGmYLa9fz8/XmoWdFdarZ/tqU9Rm5qHBQ
DLJ/NSESefWsYePomJzh5JrTc4joSjBxZvZ1aM3mbIch7G9Whpvd5l3SFBMKkpVgQqI8KKeo7HPI
5lXE1tYuNCd9RhLtoeCQBVNw7we5cBw0efsNM2vJEJK31SrI2OVJkmqxFxMRKoVXlFFimRR8MdOv
OcrW7wszon6GxGvUQ6imaEV2RaX3PGSNAfMim+PCEq3J4+k+/OKT4Ib6uA52XQKgxwGtbl3VT3sp
5yAqfKNMqkQ5dK43oditA7KTp2UpdqExgV3EjCpzYotJm9YZzE9DTLz5YdtPm8gBWGTxlvjlpi1H
1+0VUMhsQ9HtOKWDWskSJLzwiVFLcT9d/KsO53h/JgZ/b+PRaK8BlII7eMbQ3Z9eindQ7Qc7MWdV
9GKwTl0D32usMvuZ8h1dK2AtpRvxvv3NeKRaSDTznspueYj5/ugcAFddSAiVMp+eWOzNWW8GzLqH
OOZ1X08wfDqd+E4thIiWPICePQ60ASh88VRuBYqKitGhzSEeGfiAZmjPKUjJOp2eCU1gJ/dHHO4T
rx9399UM2p0sEaN6UtRsiazApqtrPL/XL7/polcAi+MjpfJ1aP2ueYMH6vF+weKdBGVVX57a6sjd
gfjbcymmFBkTbIbVjqSn+d4UaHHRYL9e9sQ6VoE51nORraxRH5m1NFxfvAVRoBymjnYcdSkz3IYj
TfJmxD1pYTw1apPBnjxMZhlFUzLp3lDkzosCq6eDXXJV7h20kY8RW3f7k5gehYuhOF57sl0GaTxl
m8MJvU024EWZjf63ngvo5puJHnf6uRSXqahXFy974d/+fDZXX0e1IYd41lzb8uOmIV7JxAypVMdd
KZ7eWlnR8XEmDs2dlJdTVMAPT5z0XonBnvIM7mGbM2e32Zb0YWsZfPGIxtxmPj8TjSJqOjEhSdmg
aSNPDjBFOpEj3jpoYgtXg7I5vphT8b3JVX3TQak8T8QdlLtoM3V/X/VyNrGN/AzReLuPHBYGMunU
VL45Ld+OAt98YOV10sT4GbUMTkbgsetqHfeca1GHJOuCqbAUraex60u/a3Y+FJ1geHAqUKzPAbNv
/qfjy20gapOU/fCVHQ1FRvv6/qRFt7dN8bzhCSX0NjCSxXnKs5c1wSHIbYYfn7f/24/VIxs/zNt7
TSw6AjLKkeOR3afciqruaw76cpGzred+UsG9d4DOo/3Ek9SVvRCqc0HfecLctJTT0S4PhSavU4Wq
0b6LJ+00UXA0vMarRV2ZbcAERtvrfUWcObGR1C1PCRDhb5g1q1bo7V9kBw1tgMiWrfVSvhzQHcqy
PhNval5x2ywdG1ZlssQafbXmrz4AHQ6MPcx7a07Z2enArLSSvp/4Y/7lT3PwEy8BJjTemixAUXtJ
yZq4iWjcIglBSYeR1lJ86wWPRlujWtsR/3acYnZpdQ9Qvk2J85RsfxFLcwupMznDEm7W/jRbvAPU
+vcd2S1VR/B2pgZIuvGI+c8LLvlZKhW4XxeCBItaEuK2f3jIiXFFdvZRpNTOogx2TW6wPemKePD2
NwNgmSUk4u93zIOSJyjtLJ3FC7lOKcbXO6RzY078h7GLxRJqBxL/U2J13+f9uPNHG9hTUslmdUvR
pBPBUTrX58Se7qYQBr0CKh1XogqejHKRxGMAF0lPqSzrSt8eB3MAqVdfxHbOueBmcPVQod8HOuyJ
a47y8pWg50mRSWy/jv3QJo6Bhlo6kKxbm0K+Q65BEn3WWK24nrZDkATgn9OM3k+l2jdrHofIOa8m
uuDjte/YbDhBt61TLK3Tcyz62bKAZq9d6N6sWjGKLWog3Tw8ssGfqRRSYzrQpHaPF33h9lOUrC1I
lV2MV0vVQWOidAnk++r4nc+39KXQyVgdVrsRi6jHJo93nxzdPuqJeMyfUJ9cPEXz/Y5T6fXRBW+d
lKLrpw6Zvc4Vfzq6mgLj0TtiKV5y9JGpASigPGXXbVT67IuPaFk4QGxzJ8zm7mcOrIPsRHzaaT3b
ausKakMKSeDUpsk55xjpEL0YvuuBP7oxPkEgWMqM7B71/JDrGlAlNontuTOzlmL5jprqzllALd3n
ct9VSDmoG+K8zYX4zisN1Cy08Gptlz0dVjZG9fZ9p8rhnaXcd9oGdqoJOKpxi0Sz6U/o7Tgj247n
tRCkevHVvjAz4t9QZn5O83kDcq1T4rERejoritNv3rKg7Iue2muTwvJRlcS6vpt0GpMiQEVsWszx
kSp4Jo823PqCYW22k1OxStQAvvznh7c9X70tA6TreUfII8BiWvimrX2/j4p3MvS//V1NQkZ4drae
/gjN4oRm/WaOlfxzEJPLFxmM90PDDN0rzUl5UBs1he3iZYEac9JO2qBNWvcmNk3f5TR3vEYly9pj
ru2P4otXCVQ3L2Br3ROCX8OWAxHuhv3mH+/mTQi3C5wZNiI7Zevl5qR1IlcICcW+/OPfF0W0+M3D
sB9n+NhBU1guewT8GHPJ9v7mGWX7K0q/88/7PY/Ogr5E4qAuJVQs3hnuNa9Np0nOdbAZ2tL5bmmX
fD4ec7A29gEv8Cfqp81rJ8GX/xILN0+THubtCWbT5oZnGzymfHV71oBPC5sEzgb1zTPQIrjUZE8X
J05RmbuJBCRz38SMNlY8XU0Zg52Aw9zD2++/+bJAj5QnnuWw9JlC3Br5buRiEe+XSAhVv4CYzx1K
z9ba5IfcUWBeKxbZLTZZyXMOCQqxypmnzOxy4b1ain54ve5no+h3EgKUf446Cc4vz+TeLLRWv/ka
WMY8Fd3z6cF7FT8ZuYSWKbt8lcEiHHbMGXZmOfkBOoASFXfmMHvyGUnNA7B16/zxjfE4mFQVt2DO
tuhjICmRDQOi6DJjulkl5USlRIZne8NMX/hDP+60YECv19rGC/deoNFeOPKPj7BM40XcJ/apRvFS
Db/8pS6nTdonYDxnLdkeCg9NGioV9OuHTa2WPQ8P+wjWmkioom2uMd83uwApFjsQommH8hNtpATt
7Fjgj+ooolXf5wCSs2ezrXDnfocmXqwOyv3XT04s1++dBZm5mtP3Nx69HMQdFNe5kptSEH+M7f6O
tI+bM3OlGr2ojsZ3PlZn5hiD50+nQ3CBbzyqktsNfVr2CbU3hhvx/SQ3+dU5a6jYEI2QT+P0o7na
OCiXPxsKLBT9cBIgI6InwH540If7RkHLy7TEalCx+I8PT6s1ZlZjFuZn2gYVyqXTnViO0iKmzYII
zqP1pCvqjj0PjWEGxWanMVzyMh1fIZ9WX35B4fzyfGEp5R2S+x5hjY3ZT694UIrJIetQjeJfvwBs
bYUqX3wRCc6z1U//rZg89NPdNi8/fY1XloF7yhxbAgrUITheV+JjO5vptx8Y7fk65k+00+B4aQ7s
obyZ4FKHclh1QUk2J+/lc6zEF8CH+4O5M0pLrqZZgi6rgLL1++ijyTVaGXVnHrAdgo0pT+4wA+bc
JRK0eRbz98zzIBben15N+2MQR4D6Q0AIxVM6abswXD1Pmown3TPNKX2AjkJBL3SxTu1eqp63CAW4
6oj3duSS//bDrJSS6VWG/U/vlw6Y0cnH2lHgdLo/Ew+V86PBgtvx2U/vg45huV/5mOt9YHLpebVh
vJ8a2odt6AuLrQ14hdaWWa9PLuihSipgKFj99GT/ua6PkqZH2pOYt+4Yj2UfZvDDdyLvccn3947D
9qYYLLLzyuTv4SbDrASPjk2FEH9fwxm0VvNkpj/U6If/mnWMNt96LfpGttUEFlctp/IZxpLXhXUA
x5Ue33l7MQVKPAc5x5fPfvxdrvm7gO9+k7VIrZTr60uNum2VUh5vN/0k6WqFiPsiX76clNPpxQc4
PjKdXdJ7hSZ0fk4ocU9AnKuv+4tio2D4nMs5c7dRaTL/qRvIkNUGI+VG0+7H75sLtehyXPXlp82a
BO58sSfOZNz8YfvsMagJqTHNT5+UX8PnBD9+pmtJFvf7VyahOJrtsTw4BloqhX1HWjnfEWOXMX/M
gnsCX/+IasrtYU7ttGlgqtfjL9/9x43xAYZTU7Kv/hDjDF0oXLru9NdvvKuu+Y+/k2C/mBB7xsMJ
9OPeYU6RMCEW552C5KBrqRffduZYXisP7HabMnd+UNLpGjgWvDeTRwL5Y5vDEGchLOCuMG9QsDkA
m1/QkfsDXbV534t3+7pD9D6u2Pa1jP9Hb9QZPuDlE+98QeZSDvhKPkzPrqMQfNlF6LxYMuZ88VDQ
yNNhjDdLFkRg+eIZDweNbtGTbc+QI36e2Qc4MPvOPHcb+NMm0mcA1rAnxPqo/qTmRw/9/ITO/SzQ
Tx/B9AxLcmhaH02L+3YGb6+8fJ+nC36Weg1to3bP1oEs+2MuMq5JtymiM+rm6FPLex0S4xky/2F8
0sm98fqnn7/8c5l2yoNaMFzXHilEfvwffyzUcovcs3hvchs8DV00aUsSP+Gij9YJRbFbBVSuep72
B368wI8v59v1zhySRIQwQzGnizFa+4vyOnhgyKhhehe80in6bAA6fNnS8aFc0ym1XhGogRWTC7kM
MbtdWwMyEnD244PTOI8vUJqXmm3168mf7tBocD62M7o8LUg/vspFgx5datMfX2X3Ust/9UPHQJbN
tq4qClE/GlRdvW+pOL47A+0qe0V++eFVt6RwPeCATnFQx+N3/eo3762vvuaZrFrQ6iTDf/3RpOoB
0s7Wab59n9BnkbJaVbPIIkYc2LEMTxShU/t5ks2s+vhjX48afPTgyswAyYjOZ7mDvn4lwwzNfCqx
HYZpWNzI1twVMecPUwO6KTRGGPrE4jO0w49Pke03/vQIMw2drGpk7pgVPd8f9RN0iSOY7ye6/40f
AjtZO/Llr6VYVXH3x//I2Y36Xz5/eoJ5dRGgaW1fD3AICpvOonwVT28j1dA8ty9El5VtL5NV5sFW
t1Wih1IupmY81T88w5onbf3BHL0DHPtgYLuSH/zqYE0e+vpFXz5Zx+we2RisbYbITz+Ir/5AyaRN
ON3zZywqPzfQY0wqEmhEQ8Pwcioog0pl/un6Tif3WFOQ8lP/6xdzgPhiI37Vtz/9mLKnt9aQmuxq
sn3ib//3lz9+gKftsCxZpaJOY9J1z0i424rRwN4ddt6gkEA132nxq0f5+Wrx8l1Rf7itvQYupdwx
LE81God3M4P9RHZ0nsV6/Ocv4+vu8/1e6cfvbGjPgcrsdzVDo24qoP3wuX2dPF9a+52N7tq6Ip5y
m/vVhFwKlq/pf/NN+fql6sa7LIgZXtx0nHdpBjw/UvriPhNCvA8WOlGnZvhUXsvx8WgkYN4yxXLV
h6mcPiQDFdvwgmUcaGm7TVoPUmguxPa6V8l+9XP5GCtiLY3WH9WbxFUd7zsW5PugHNytmcNKVA3Z
5k0Z8/dwlP78tuLrv32/ZwZVsQkI+fqZP78N+aBHNJ1reckrfElQy6sZ2/BRLUUqOYMmN9cjSTKX
9IOV7yzEPqnAkk5MwVeKcoBjYVzJdp1vY7HV1jUQS15TrmIHjaA9O/SiuyuV60sff+d1jfJ9fWTf
fjK5fd5ThA4nhqXpapoc1v0Eic9Kym+5aXIn/MxQupCHr94cfP646fefn80852nEbFXFDexjzWXm
9a2afFmRCdZiRb98JYobtZrJ8MVPghf9oqfVR5FhtXl/6LSZZ6WUujMDYoPnf/jfkWJ3AbbuHZxo
/bOkX38ZHdlcY/6eqILdSv+OLitMf/rNH8twTbWHED4h3fgQ0yBKDl9/EXdszMpvfAk0DTpiRd4C
iQTAgijUz+RUz44+Q4tQgefbfpNNQ1exuJdTAV9+y8xl+YyHZD5k0C3UB0a98xJ0be8PsB5fW/Kb
Z+J9aiqgc5vh5XXUyrEoHgVaPY3wp7dNNsaNB996xTN2lFJ5eZ8bcAfL+Os/KXHtGTw29+0Pr1L6
6PsGSubvmX+wi58/X6CPexnYtdQdxJfJ66R965U2eCrKkZyMCuLjSWE7G9187qc0h68fTHS68GPa
jPcazZJ6w3aqo6Cpfm8sTdRvi/lfPivdDiSHarVcYh6EN5MqGsiwTZfVn1+1fFmbAFbB9YrRDWU+
//XfqWVP4rnbwR+V225ALa9n9J0oPWptZzdB3s2uX/63SMdMvd7BuNQV2bh3Q0wnr51Bc7tFLNNI
gsao+9TwAW/x9Q+dWGL3TEYPMfpUgxx9z0cuCbqlpxnBIc3/3g8pBDYs6N6f8usva0jeSCvmhy33
RbrdNeiLv8RoPQm1Z51O6NufZCc9IsS110uBxzMQFB2jk8kPOKshxe2N/c5zpikmCbB+HVDRepXP
50F1AqLORmbv9FrwctceID02iKwX46vkbhGF8MVbts7mnfh8z+cgvj99Ylb6qR89L5r9+UvdTe76
uzGT77DQ7D0tNtdJDNaoJsjn45O5+afy5UV9lcDt1OF7XiDFbdG1F+Tr1zn5nRcxR+MdcuUDYVtT
BKaQzP0MvvwfS7V6SOn74GD01ePMzO5PNElsF8CGHSVCcqhj4YmjBI/GeOBxo/nmGE76ZfXFVyxM
M0fjN39o9dRD5r2dU9//+PS4PfsM2yiIR+/1pKvepC2Vd3VY8vBwDcH+FDlzv/VJ54OQUDjfR3Q4
KswcG29nwPV2ebAw9Z7ix79hu4y2hLinh8kf65EiuNtHtqW5aopLPgt/+vDHJ8w/vt7OghPz6/cs
pXrvFZDLbEMs36clLZywBksjFsN41pQjAxNgdRzvLPjqcfb1Y+GBu4SCHa4Rjx9XCa2ViyA/P2Dq
sVmsxnS2Jp7tP83JfkkKIsZYEvs1Pctvvk+wLZYGfr8r7I+owSEs/g8AAAD//6SdS6+jwJal5/Ur
SndKX4ExEEHNeJuXCV7GttRqAbYxYIwNRAAh1X8v4XO71YMadQ8zlcdpx2Ovtb69zQnxccuHBq39
isQwmPgGqR2pdTqEg/DrtwQsH+GBGJrJQDe2ADJfvj3s0OdQwo1XBZxW283yKfvLz79uPDEGKyMv
FlSYwUc2WNNkBd+ul4royBNHVpNmvqWHCsgK9yB+Uk903PTib/3dGbgFpe/SgBf2dfr1s5qNx30B
tRcJuU2ngj//5Ueejvs6R4AO9SWA0rKekSe5n4QejkEFGTkL0NG9oGFu1ryC8uKryN14HHZm+Q4j
UFTBU91jQGLSZeJ2f/762bv1Ikhw49N/+WOICuny0wekXev3MKudwMmb/uIfP5nTT5NCtng8f/0o
fQ3HTIBV16SYg2s10OXmdlC4Zi7SfP5VLFccCn/+XC/S1Jvv3VeCtsM/yIH5HCnV9jAHsqusgdR0
T0q1cuqlE5ElpN/Dhz7RKLNgFp5uxHw6YzJ7sWFA+fD1MA5x5S2n+hMCpsuW4LbrWu/vfv36y9rd
m4bt/PAwhMKAxa1fPdwO3Ah3icX9+FCzXMu2BT9/pWqMos+h6Ja/vEG8ajXoMkOqwX/8pgL+83/8
P0wU7P77iYLcnN8YHLTaW4xvkoNLnoYkvnweoE3KYwh44r4Igsqh4Jle0IAeRQZBEi6GqVbUUhZl
/4b8Ly68uXB4DB2WcTG7aLtkqeK+hwdxZNFBUiWwnCebgSnfxoFrnhh9Wtayh2iydKIFslh8r69L
C8CrNkmwhPGwUAVkUvwdFOQtCgKzy4WWzAdWTHRffYNFh2sHPc1YgpV/6QM95FIPc/wqsVicw2Qa
3kwHePWoEedWHOh4RBEG7v1hIefOf4ol8z0b4FkISTokL4Bdtgpl8ayWJNinHzBPipOCQmCrgEnG
RzOu8daBj9wVBR3IEhpphAdz11fEFMJ+63jNHJDgMm4dWJFicedm8Gl7O3KcR8ObOiZL4S1KbDwN
gE0mr45D+fx8CQFN47EZBjn14YlIGlGro+L1XTrlUHzyEeaw89EJ3RUGfMbwS4qoSpPPXIwh/Gpr
gPSo/CT96W5D+Oy/MzqQ8d705rOPoVSQK1LDW53M0+ciACgtOfJZMS8oMLRclLnWIs4ginS5iI0A
TZVzyOV8YwB+vUQOfqRqJtqryYuZNGkPbRAfiQ32KV2Up6hAZT3qSDUfYUHDz1OC/mw8UDT4or6y
bJXLz7BIAlkjt2YOed6Hjbf7EH3vrN4ofFYXmucKIYc3K336Gk0I2d3Y4DlHZ30emWMLzBQKxKwu
RYPtRf2CZXnDYC8KLf0usl7ClNMA8sEBN2SQywC0p+8JIfKmwyycHqFUNEmOuXMhFvP40EsI5WxB
jmxciznjxAx+rvcbnkvYJsvdelQgGgYHHXx9KhbZ6TJon/uGOIYtgvXsjxW8f0yOqFXGe2MMDhdI
7X34d94pOiEN3m31ieG4xsNsPNoOnPzwgi5J2oMZXw8+jGz9gcxbfUnI7/yklx4TLbwU3uye3iv4
SPWM/NyPhvn9sUN4aRwr4BlhojNybiX8toWIYdxqA7FfigGtkbZk29+COHElyBx+V8jE074hd9Nf
pf1JYgPm0uXF2kZ3CPjAiImlCzylDW4hZNzYR84gXsHofrUv24bPN9I45VXMF/2iwNI4TcipWTYh
VmPk4FAEeiAMp6GYv4YjgJoqHLEOZ0Kn4r5C2B7zfTCPu4u3KOehAyx1fKRoe7dY+rN7BzJMexTM
dwvMlPdLqFXBgg4Oe6L0lGg2GN/1Cbfx5zgMygVncOpqnyh+MwMMOy6DmRRaCFnFQufifu3A927n
KIFjPZBj4cWwP50FhESI6DpxT0Pm6+iEeYHjh5EOrAKZBxMTA+j6MFvCpQevSrsizxFeBbEIyQBf
JyfiX5uC0uLWB/B4f+c4BC6nz99w5EGXrStxGYkm9KOHtXxsoycJ+CHVh3BgL6JgSDwydovg9Z/p
eoeEKjxRa8AV4/C+BTB5SidiaCKhveP4vESvqRcMy1o0c3TEX8iFHxn33KXUacbfyt/nR1ofvoe5
qIgFjjoKAgbnqBjNZxVDZwQCUXrdL4bbU7xAON+exH1EKuDfj10Lv0qwR4ZwN5M59CIbVlnlokTq
PR0fQp2Db56HQQ2jrz7fTcaWBiZokX2+3ekyF2MMfbk54F2FzGZWJqkFlkeigL1SZuif968Po6N7
JK55uut0vMeG3F6oQYxGU721u1UWxN2hCDBDNTCI7GJDhRgJuZRnsSHnc5GChR+/aFs/j/Il2wPf
mjExWVLRZVnTL+yCZ4r0q3FJcIucO8jvioG0/ZkUcxumvnSp3gRj2wjBCsSkgsVZPBIj5Qt9rn1P
ARIMUqROolXg0+dqw6v8dAKYM3IxlzuHgfuGb5Dby3axmGcugAP4HLf1e9JJRREnbe+fBEF01yf8
7CtJLG0XHapXRpdiOAlA2MkOQpeL7C1z0cYQHLonOTz3dUGtC8OAWycHyBj3t2au2UqT3ez4QWqX
H5NZdAUNnJXmFdDn6eatKZgz6HZjS87Lu9KXWnHuf/Xek69N0TvMPgOu2UdIadZ3gqPGj0EB6n1Q
GfGo49oVQtgOWYG0zp+9ZWXYDtybK0baIxvpssDakKqdaiHldXS8RT/YBmxS84Bnea8mdKDBCpjb
BSATvFdvPF8MDJnE1JC9+76HTkj9GrzS3kfFGLQ6vQhXG2rraiPvwk7FuIfXFFZjEBIU1Ve61Ip6
l8+I8Tf90ZLdR7BDeIBxRg7+qHvrmDQxvFTaOWChckj2RP+4sAp5AyHj8UnoVJEOwIh5Be9vJOuj
y4UGRHGCELqqK5gPSLWkiT2pJFhEO+HuYmIDJ8ghUeK37U1E6nKREiUiOtdSuo7JEIM6gk9y2F4P
6w4D4ZyaDlIlyNPp5ydC+x4GggzGZDma0xc8b3uATHn4DEt6ECEsjfNEkKrMxaKtLxv2edmR7edB
t+kRQMZpQMZ8VJq5FYdZ3OojOr7wqi/N9PXh5jfQlTcVnR6DKoVRX+XIMfNXgVM7SUEUhjIWBdAU
278PYBDaHyzv7oh2eSzm0mHv9OhYcvtmxWd4B0f2MyHNGrlhfrPzF3w7NsTMfLcoGZ19IB2O8QNX
r+PHm+fXJYVTA3fB/MlYfZr4my8A4HvkTLXngE9xP4t7xReDyas0b+2fSwjNb88gj3v04NMWuiLH
5ypCyrd3m8Vv3yus7K4jLv8JhvE2zr70nKWAKHIwDCtc1BUKyCdIt+sArN2tt4CVMIQ4Zm4W+zE1
vnDnNwYKGKrRMfM+K+wFuSZqkbyKTxvKHVj6xSKeOmcN+eiXCnp5FiATt8+Bvr9jDsd3dSLusnUE
xF0zyj89MBM+Auvz9KggO7925KDiSO+l47GGeVFOZKv3yfoq2osUdqwfjOCAhz9/Uy3CmTjD3ND1
W+wU0PK4D97LnHlrl8S9PJa2Ta5mUxTLyUUlkGHW41fBKA0/qYYBn7MQEOWTPbye4UJfFq27gQJ7
soY9zNcZuoVIkMYc42Ee7cKAsT+VyNvu09zqYgziiPewsPsemp22TjbsyPuNTxPw6Jq+T3cos7cz
8Z7hqlOc2SlUudMHHRXVSZbe3ynQVZ4NQnLR04U73kPIfgHGz93zlOD319MgMHUX2bBywaZvPrCy
bSKrW6tkvQl2Dt9PmyeuLpXJ3NnaHbpFdsaN21ke92l8Db6+4pds/nmrP0YMX7vxQVxh6jzq7mAA
FesMkNq0X33Z4dQC72Y8osdeEIrRYdgUnJ9vIZhvONTHe+h1cH+5ZwH8YuCtO3OSAPvNMqTI+2cy
jw/vDvfQUog9MKo+HzvXEmuqccT1rrtkWpO8hg/rrgRSgIQBO+lJgTc2GPDa+aFHlUuXwUfEHYO2
aHpvvQR9IBXa8UB0ECl0F8gJD4/sMAWMuW+S9YPLABpH1yPok3fJaqqvANwZv0bOrNqUKpPjA6+L
KP68xnGYvIvPQRo8M6JFX2vY20C4Q3idDsS5H2lD8eXGwZPKPEhAdFOfzDMMgE0kJdhdZn8YfVzw
QOVFhfz5880vwlEaDKKClz9wzWTzsNTXE8bic5+sn9Za4TifPbw/15bHHSRsA/bRPDFzFUywTK7g
wvj7UUhZXlmPqCQbpXTvfDHTOd9moQr98zdI5akCsDQKLVyWFyRWKCkFV6S+C0f1lJLjrAcJpWxV
yalIVPS7j9Pm5yTQHW74e2lTOo8pr0H2hXqC3EYZVj318996o/jBag2Pa3XLE7wTjGBuk8XzPoJQ
WTpC7pWvirlzzwzc6hcx/bOof3N7gEA2O0RsEDy8TR8VaBxJE0hj+Swme65CefMLRNErxVufj5aB
Q5ioKLgKJu1ZT+nlvI0aZDScD5ZNr6E2DVfivS4V+EwfKQZjyzBIiZg1oS04CFDQzg/MiM99scr0
HMOg0CVkytxjwP1zicG8alMAG/IE83UWVqj2bEnM4yoNNF9TCdKgyYI9ys/FNL8WDF3dkJCqFxe6
zuYtBusOP5EnNZU3dzKEcOGchOh5plOuIVkKn4N/wPueL4blLnIVvLutEPDBMfHWHNoQxikjISVH
ex2nQMigY5h60B4DX19er/AuI6e8ksIRzGSv1GCGcX/4BLtTlAyrUscXGK7nK3GYzKC70k9WcKfS
h7hjqSafx/JdYRLEX+LiiwPmY6dZ8ih9DOQ31qiPO8F2YWDMJTnhVh0o64/r3+edT7chITmsU1lQ
1wOWN0I4G3wKoaieMnQ8TmSgJd9ZsDiDI56TK6W/vC5Xb7MmRhI3xXfimU5qh7RA5/NQ6kMjSPnP
rxBVj2tAS4W2UHXvFYawnpM1niIs+6/oS47xAxRjErE8mEMmx9z3G3qbHs1wX7xM5NihPXDX8iYI
KjZcon+tZ7PsD4oPWSfWsYz7sZmCwzOVy4f9JLE1cs2a7aAFtnqCvC/VCs49kRkUzKcj2jU+DVMg
FxxwauWNuXQyPZq5Qg7ne6Hhpcp4ff4aqgB5Yr+IjXYETKf7N4Nf/dThtdhTsDxuaJsAOcrodx7p
zw+jdXbRYTxxw7zVQyFGMQ3Ek6vrv3wCb5/69ecnxy3PA8fqc2Tyu65YAPp2kE/PC1G9UW7I3nYZ
+NHnMzq0BgIbP0nhL08ed3dC12NYllDUpQm5H4splvejDKBYTnXAtEdNXz7NlMPNnxLnpWdgfXNh
+fPDWFKauJjXWHQhYQVruz9xsVSMOUKe40diho83HfEV+fA8gAXLBj3pi+hdL4DDmo3nXh8TKvqp
K3+X2SSpdmj1iXr2DMbStYP1wWoDr3VDB2s/zEmyd1Z9HfozhP43v6ADxLbOXfDOgk++S/FXfESA
pqsRAqXj+b+8vASzIEB48GZiCte7Pk6KmspRGMsBf6lRMdJhr4CNFxFz2HMFwfUQSh7ThFhCz9Zb
MrZypV99lzoxpLST9Q6Us78jrj2oOr/TLxdxqx9E5d1B75XrA0v75NQT0w4ajxZJvk19vATickZY
4B//2PwdcU2Ggmm/vkKw5fVgW4+CXqSuly63O4uCZ8XRde4SC27rFexO0ieh673GQL/Wz4CPdL6g
/eXog1261ng7H956nuoUNl4Y4f3m35ZwpxnwqB8DpGINJmNUOxX4+fd+py6AXKOzIdFs5lCS7b+0
sy63DjR7vCD3xmbJ5s8M2HJehPtxPno0NpoKbvmUHF8mTMba1xUorxohJs2Oxf6Xz5fT9/znp75i
ZvvwahyvmN38+Wovzhc4Umig2+Z/sSUWOSxznQY75rZLFudwGX88LOBG/B5m5Jzugt0oMwlO896b
iRHXP76FDxf5QFe6P/iwS48F8iPggzmsjpxkKDHAa8cAsDxTxgVSA/fITIzOIyIr2tBabwPSFzMH
3WP1XVhKFQ7W93tpqJBOwu9+oUPQDw3tHNzCpTsS5J4dqo+uAgzw00ftBrxkz79NCzY7L0e61Hve
TkVXToKGqgbDxuOoqAWj9PPPrPH4FF8Uh66ctZ1CDh5gEtLJXgcP2eFEjj7Q6Z7VHil4CfsAy9/q
RlfhHjFwuOgN7re89aXe14Y9qETkXBSr2DeCdIHOGa3InOLMW2QHZ/AaPGOiL3geNj1WfvyPWJXL
JNNj+c5g20/iy16nL796dG1xGrwuBx6sYmYH8PO+qCh7vR6ActmFgZ89e8XriZbNtH0+6N5vVkBB
VNH1VYwXyVaZ2/Z6lk6SYGbAE6c8cm7Fm7Y/njeHMCdWNI76OqxTDvjr/YGCwLa92XEMDmpvOQne
z32dTK/3xMB9cu4x2y7zgE8PHcOH0235oCkSmvGnO3w3+Ijp7vgZ1kCWA+i9xgLpj+VVUF865lD5
yC+CnuCY4DcX3sHcfStkpJOp9wOYDRCagoicE8SA5j0qoWTpCYab38fjTcBw4wPEj6dL85dXNn67
8VZHn8URfSWDSi8SbLyFJ7jlIPOAMQYsow77SHvzgqQJLbqYfT2MryXXIAC02fQqLMBn7A3YjFm7
6b/icaI7K3JCUpn4m55RPixHkOx0g+jnD9+QTKkZiOIIEeveWcO+RTUP43MdEXUmTrPshGctqccX
ItriavrschcLTvpDQoeDsw64jTJG1DPZxRfNcRr6vAkcFG5ugrnjXqU7H+98yN4ZZ+NFY0Gf3Cf4
6Reyuv1QrLez1kH/e7lsejrr63pXUzhB+g2WYYfprL0q7pdvUKG+lYFW61SBYKh2yBhKQOnJhiNM
stre/GUFSGuecriLj97Gj6VivCIJQtbwTpiGNBkWeBUUGJgnLgCvS0XnWBAlWMGlR/5b2INZVOoO
knLHEaWuCjDlsmzBis1YohUB4y1AWG2oO3qHmYILkvlQtAp8i3lCVGUyGnoQuRV+ZOuA7B9PI6OA
f/URS7oEk7mjpAawjO9bvnjqO+ewTbyBvCEGfIOkRzchhWkl+QGk/WlYmATMAEo0J0j9dDqNfDmG
znVxyEE1QbHu8K6EWhwdA7LxsQl2MSNNnx4gCz/ygkqNX4OAMXwUwMAY+J05CbAjCkIX5Of6ZHA9
D7/LaiL0jM/NbK/pBWqToZJzO5nNd4ArJzf7cfnzCx/5EHKQ+HGJ98u78pbWyHsoVJGOm+uE9bVX
wB1I+0MXgDzHAL/5CYKdw07Ef7n6IM4vEcPTrnXQ5qf13bKW3199CnaZ/ih+eg4gK9jkrlOP7rbz
J5NdeyTF55mB8RBlHQz63EIeKiEd90zHw9mLE6I92HpYfv0NYcc6Ad3q03CNzhZE32rEDNnNlERn
DcOd/zSIOdtismLvWsFtffCvPo+bHkiXxrPQIU1Xj9Ze9IUy+zgHq33gC7xWGQ/J11dQetw/f/V/
+zYE0H55Dfz4FzwMtAhq5rgOLV8UFciCnEFOQtRkl8uyIUXLOSQavqWUCulLgsXtnRCPPXmUr2zY
geD2iohL6JDMydy70M5p/OPPgGp5rcHrFTwwJ+UTXQ95FAI7X+IgO28Tx3fD1SSV+dRYYpuPN3kX
g4PEmUxMrmoM1teazvKvn6Kv5y75463vY+MFv/qzovjiwhMIEXKTb+5RmbEsOOTdNtFScQl9rbwN
2Vm7BYJUJsmUhPr4O6/Eb59HOh/RdQSd3uvIa61TQc3sUwLb3+HgtPUf1iSXasirSCPHE5Mms4S9
DNhEUP74y770HAW+75pFlMaJhhXZ7ihZ3hQRN7DqZuR8TgD4VOvkEB/ageTMnof2+dsg7fJhwfwh
mIHxRMnG+xrv88ilC9ToqQr20T2g65u7lEDq6gAX6VEdxq2fAD8PuyHHIHsV63wVXPhtryJx+hpR
unTcHS6DuCPIkb6UclnIQOFmJ+Sw9YMw4x4waPHDxfMNz974ma4l/OnTkeZCgoO3z8Pl1J/Jzatq
fSz35xJY0mQT+7kC/YOfVS398qvFPptmnbiPBecPRYE86ziZ4UtsYdAkF3Jwjl9v+eWnjZ8jxc2a
ZArVlwXh65ASo756CaXDsYfRcgox6zbVMKVyu+mPmuA9d2sKwioOD/AQOMjcNRJYWXXH/HjQrx+r
r+5wvIDQUfutvsfDOqm+BSLsV8SV7PewmvvzCHeOPAXzjsQD+fm1KrqW6HCuLZ1zHzsfvoLtGwP5
ePLowXqsgH08n8EXXz50VARFgVt/FJnCldFJ8diNUPlcjsTvFQu0J6ezYOCWNbpNbEZXIkghuBhf
F++D3mtw6csu8MDliY5eVXvrhex5OBgSR/ydvk/w0Gl3EB/UDB1Q9Cz++sk/fVYaZ2mwTM8hXN+z
TOyf30SP8g4981ihrd9Gl+K+6cV7ZTE8s60+HyV+heQbKJt/i5p501vAYcUm/pltven1upTgolmU
BLYxU2L6pQa380U0Hl9/+aqF9fn7DpaWHcDCnZtRHuWFIk1YI28Ux0MPNj6OsWDt6K+/BaudbmF6
NS7FtN3nX78YnammDsvmj0Av5C7x0uOzwXyurLD24xw3Pcfrc1IeY1jdwxEZ7vP+y78tEPIOBjs8
nQd6fIUYeiB/bv66TIg1RdzPr2NpLNWC93wvBFuew9LGVzlggBX++Jg6iV2xXt/YAKpbVgRJr1eD
+Vm04cY/yWHv7Zu5VuUOFvGokcx6tfqWZ1q49QMxzz71AT8/ay7/f0wU8P/9REEfuJgcdr3p8eWD
dYFM2wO5E9EG9IULA3aaZxAflh7YF2fHhTKL9sSN2H1D0+A0Q/nd2sHL82YwFkeHgadOUvH8PreU
5kw5Ap68vWDJouuw6l87h8q17JB58yY6OeBrgdbO7sT2+ieYPvU8Qj2JNGLXdV6QNxPzEIDuggyE
Rx0f7YmHCAsS7ttaBPOLSxgoPtoVHdr+XZDHPYEgXxuFWI35aBbL+1ZgvNsWfpIo04fg7GkgOFkh
OubloaB3prTA9n5IFnldQRwipHC+LSGyv+ZQrKUw1CDliBpcJ1P1KL5HMzwuVoqcoo7AiNJzDF+a
ExCj9PYNWcx2BZVyNpBZecdmeXxNDB/CyUJBIE7DOHk4lqj3mvCinpWGv7JsC48ZiPB76q2C3vdK
L7uyNRPPYAlY7WdiA4JgG0hK7Xs46KceymLOEuXLxcUcnOa7VMW1g0zDi5KFkRwDop2hogKwb0D3
p0aCy7LoyAiwB8gNpym0z3GEXIe9gCUaqhlq1zIOoCyKdL32oyUpTVIQ583eC3I7KCu0vyKLxdas
vXW9VCHwbsaAxVO9NuPkdSGo2rOCDkNvAfpiEhec07FHZ6336Zo/L5ksHFcTLy338SYoORegqvcH
MRJPHL6D8Mng9NomMEh5pmQfXEqYWU9MjlzZ6PPFODEg6CeGGDsv9Qam5C/wGjcokPrapPynf7by
7Vu3yLhityC3exnDp+tR5JWs762X5YJBV7ss8fNyKZZxeYTAfpoW0t2o92gdFB3sDiwMgMNiOg31
fIG5f2ICvuzjZjrXoJamPbME442ti0Ve0hmuw3sNprFsCyzurVjiP2uClxv3bSg9jTUAx+IaLF10
1kexaEt4/TY+ch/saZiRrI/waWcQHY69l1Dx1HTwJGCB+KsIirke3hCe7s0OIT4bvdVZcgF+7nZL
nKnGdPWWvIXy7sJgORT3HpFPNQMvcCzI2TPFZOxkJZT30eyjaB+lgN7uaQjT7Ckj0/SiYXm5BoT6
7e4QLeG0hO/Irod79LaC9RHhYRXRilmUSwwxevwe1vEBe1jP2RCUtSjT2biZJfgy9gkdDv0AVn1J
eHARxpxobXSka0/kDGwd64AdsmmYSYE1wBbojfwX+/SoeTAqEGjAQ4dv3zXD955fANgVMeZ3ZjlM
+SpB4H/BOWC2DiG18GOFneTCYPyWGEze8MHwcI6LgNe9Xp9Ujefgp7afKNxF9wJnQnuHhlqqqIDs
W5/RUefkaQ8XEmjZbZj90zzDZCYuOXZiAlZIJB/WMPsgdN0GgpNLywAkSSJRKXcoWppeGWgM4Q7z
lvemVDsbEkgkKUL23vzoy2H4ZnB4yyY5YJPTR9heSgDfXRzstvV+e2TW5Jw77/EwsN9kfbDMF5Zr
PWLhW1/19Y12tQTY9ooOi5nQqcytGCLHOBB14mx9PV/GFHSZoyBPqWtvnrwuBrvPesNwKY/Jknh9
D4rtO7Pum02L9f5gOHBJ8Z24HLsW68TCu/jN3SvS48gCK0NEAarXe4nsU694iyC5GhwsOwnEo9np
v/MBrHP8Qm5Qf3Vav4gFP4z7IKbgfeggMqEiy28kBaJcj3/nDdpeHBNtjPxmMkE9ys7HYv7q92pF
xUUq3EoOdhcvAEudH1P44CtE7oqIGnrGt1g6RsYVJcfoDWj1tmMwTFTG6Rv3ySqwkvTTF+Ro9SlZ
v5dPDbUk8oP91dwPlJwmG5ytpv2rT4ux8heIcoEhZuNN+uyeREMsSqwFLcYWoOpjqWC1Ojw5XsQd
oKeDq0n2yzxg8VfvhN2AwdpAnQSV6A77bUICCKiFZNODZMlW2sKKr0xkffq5GI87oYW3oP4i9cZ9
h/k7YAwOqnki2jlCYLlK1gjHaaHIOvQ7Or8mpZZp8h6wUNdSMZRvRZKtfVwhk/e+xXx4iXcw3O2Q
3HWR6Av8qpl8rXBCXKauG/o2cQqA3lZIA1ho8K8eiE4xBnAUoYcffWPD/b5jA3rEu2E1c1uDyvPe
Io1ikVIaXA1pSd4s8tNy9ejh4PtQE+9H/NxHKZ1D7mwAnQ1BIM9i7K2FevEBfHQp0lJ818eFiy2p
db0TQq2oNPvw7GKBZVGDvJQ9Fu1Fdkv4LFOBXA3zra9N/63/9s9IPYEunKT1kCCm3daHgGWo5xzq
Q8wGv/u1GpLiwhfvmEh/RYZOtnoKX3aaokAR0UBtVrjA3bIWyLdKCmbZCFNoXc0SHV1x36xuFM9Q
E8sjUdkoaZaP5PvQOIQiClixS9ajGufgWo4ZCfbi+3f+QrDftyxKB28HcLREPXzmtYqc7Xwve9d1
pXtW35FuRD0dYuYG4W43l4GksrlH3Lc3SlVWu1igteDh3QPkUH9ECnIWtmxmbydIkDldROQ9Simh
z4NtQ9+0WqRczl1Dz/eTDx0UO4G1eGoxPm+qAc2X+Qqq8/mdkO0+QOlT3DB18QksadHnMOpJFQw1
6xULXu4QJON0RIilFzCFxUeDcSc9/tZ74tS7DdJx0omeYW5YovzAQc80MFEkjlAsnS0X5hfskcPF
PBdrI9QdeGOXIvfM8gDbfdfCCmYy7lfT9Ua0m8PfecN70LcJ3uoZWAFUSLK9P3J/vTF8s/KXWA/P
KOgTFxh+NbcM1hVfh9/rw/7NNkQTo29Br7iEkruCDxZY8wAwtnsepnfpGCzb/lGDXRSYdpJHbK2v
way/VgN6i9ETv2GfA70EN1sKsGgQhZybAR/tFydLn+sNIUKLApO+6uUDim8BnXA4LGrRBHL3YEW8
n/ouGQUucuFZGUdiMt7Ho7RkofTJ3SaYw/ObLrLrBLDLHTXYbfdz3SGayo+1Ckj5O3/bfgGVRhGy
iPekNHurHIz8qUObf/FoGZQVxJTp0MEzxWJJvKqHj+rsIAQyT8eny9jDQdqeobKWTTPLRcPBUyeo
yAY1T9cFUQiuwhhueuvR5e0aX2nza0RVzlWytPlRg+qQJAFHvbRZP0gOfvpLAiOT9WX3PEGov2OG
HELzMszn9m6JKSPZgSCa/fDRwaAAcqVXzEc9541PLu0g37yPJMjE8U9/wcl6CjjhvBtYuliM4dDZ
ATFqjwffhmU0sH1eHHTih07R0K+wzZyUKNn5rVNa7hlRPhYm0refn42TpIC8a1RknnEFPpJ6CyB5
0UsADdYEHGzDO3yFWRzAvIyKRVxOOfRexod4Des16/5tVVB7liGxx/rSrHaPO6CrpYcCS8RgZEDT
w2MNwmDH9xdvMTXeB/bzYAXSte6H+bffcUryYM24Wl/mr+7DnKkYZH28ulmgpObwp280j14NlSFf
w9V777FIWFkntGQZ4K3ggfe0Nxt639s9rILaJ8e4tIdFzFUBeI5FiLpyB523e9z+/BVmKtFtxj5N
KqiZ94y4uDY9ejvbHFTE+xM/+4hv1ki9rlBTyxPJI/Y87GHJY+jvrAeGCWvou1yjFnBWkWLpXVsD
5998H2IPTsQearGg6ttg5DAXOHKxzLCYDXOBsBhP5E8P19auc7kczy/kLmw84MNSBCC1yQHzxFMB
N4MXD7lo/WK4ikWynqNQkDd/jAwemwN1z/oXbK+P3JLNvImLMh+mlrQ9A6XPmpEtmhp+Ezb5+Q26
j/ZuBc2b+cawYmt9jtIM/uWDZPXuBXUOugC+tX0m/r4cm8momQxw3qsh+oznYj2rIQfhdHWJYnHn
YoRcWMlN7NwQskSDrt3l68IsxSvyU/EBqP5YfPnXMfnlTxz2rwyWfDURF5RsgQ3XDsHAyhoyPvgA
Fta1BTh6rBoMHNsXq4wkA/z8WKrgI5jlNMzhqRq3CTvPKegY5BoMIgsRmzM/A61eJIevzHED+GJV
fb61Jxem/mT/6v8wVkY6Qut1KIL9w8zAfL25KTxiMSBaxSnJ3iFzKpsoXgLYinIx4jbv/+6b+GAf
zTDg3JXeb3ZC6JTNtO/ToobXEmfIOZjdMDXS0YV1m46kzFid7tYlS2EDs0fAK31WLNcaBOC3P4fO
PCXr5bFf4fFolMGFmN9irtJ0hQaNN3NgKsWSDtVd3uo5ynhPKaa9q7mw9E9f4vb1i359oVPgAhh3
u68vQLb8L3eBp2GOx6+Gjq+pAnWbjUgJzn0xm7IZw9gSWmTnNWjW8nnRYOU68p/+knyvhmDzj0hb
Iw+QgYkD+GjP7p9eTVBNBfhKsyTYS3275cEbA0HR3ojKR9xArmfnDtdlFbG4q4/NLz/DC9PEmOe9
qsACKwnis8yEYHfGCh3vxk0B6GRZxDz3ckGe5juEqSWEZOsINVu9CKCWJD7er71Z/N0/9nAckNl7
YzEz3jAD6Vg023066vN7UgIoOUVNtBzLyXh8CRW83JszOfRmStdQmHIgPzo3CJpMAHTLazK9rSty
P7Wl93IxcHDz80hVzkqxF+5hAJybwZLD0+STBSwnA8a5VJEgzgqPuvjhShWuD8jeOlirxEodXBAM
idJyyeaX2homPfEDVs6+A5lfowD8TCyQ5nFNQ20kVHDo3ODnH4eFzRVGvhvna7C/9T2YplVwYZoS
izgvsy7mgDtffv6WaPvIBevpMn6Bt4qPgA+9zvurL9o7sXGVcyld5uXeA+1VRgFdPSYZnzfH+Kuv
/ihCfRnW+S4nKQmJn4sPnRpno5N+/iUwSwXwBzXJZPdm7YjxxI7O3x8MD3T5biDlynENTc5aDoi8
nIjL1zoYm8nmwC8/oFhsmrHhyhDy0ZoRVeJMujylYwmcj8EgL2Gx185pHEuHc1gQn5QTHczgDOG3
sy+Ywkjxlu7rr2AXzRVmH/RGV/4czMD04jnYf8ydvpwlpABVvl+I8jkbCTUfggDGE+WxvPGkxRm+
mhB1wof8/OpW75jffcSLFxUeNR+zBNqvFwbsQnMwO7L/BR22ZRR+uFVfcteq4S2ovnh/6AdK870T
g9P9uSO+VPpJX6flHTBJp+GdiltvQTHEQN8dOGIhzwK7j2QE0n2tL8EaRyFYfQFrUqCJHmrSqCtm
nOYdvLZjikqlTBu6g+ws3YOqQqfJ85KNb6zgppzrYH5wCZiZmg2B+zIo8TY+Qg7BuYdosRQsNyLn
0QKXX+jqoUqMGVsJtd++AuXnVcO1EsWbX1hieNwZJ3Q5m1hfub5XpKx+9sj+mJ7OGdOxAurrXqDj
rXx7a6RGK9yd1iemSfT21vrB+OCX30qTtXTCQsaHG08INn42DJw53kE5nl4BE4lTsZ6jiyRt+SMQ
IhMDeiBzD1EtQOSsZqX/+XFyZmr88ryQUhUtpbxb5gKht1jp46MtObj5leB0wE0y+G8vlw5eXAZ1
FM0NZUomh0PuouBl9o+CPsx3K2z+kgQf0RmWoHimEEZXH/lRuSYvVWN4uP9cAdE7HHv4rF54KEbF
d+Mv9ZYnQQtXxFjIN1iTYhmtFhwt10EGi42BLsw1hr988effi1oS4ANXEToY/Vis7aW+w6iWenJo
+t5bjSgZpY3vYH7xnsly8voU1th74Z3uxTqnvqQcCs5qIMeruWI6gSqAGdN0KDDKqpmO8fYAwiFm
sZyIfDN2R/sCGfY4YalmdwVGamxBISo4gi7Z3KxD/4lBxAgdCiNuB/BIOAwl0NZEI9Gor5CVYvj8
ejjAmz+bxzaH8HTBcsDVXgbmR5vy8P1gCdFCrt6eRLRiCB7tnQRTtveaOYgu4GmnEKEPLb12Z0Qd
NEk44rb09gMZ77kFPgf2HnxGU6HEI4IGNp6BbNHsG3rY+wa85E2GWxv7w7wzolYO5gkSP2Fbb+Mr
GQRNW5By8w/TZQUx5PavG1Hk6Kb//DXoxswiKuAsjwdovUAqr1Mg6vVp2LtI8OEntxsUxdzo/eX/
U/ekxJnrYADnszP/+BlS9tzszba5pL8OYjB/uTVZPtF5hcuLGsHe6P2EAsjwIIfjgQR6qRa74htk
grNYEG96nqxUqAzYfJ2cqBs/Xt1nzEHHOejoAHv9X3yRX9Yo4FGfNjNrXJTfn7FQ1sAb92mUis5i
QOJ3rFpw+/Sa/eW56Siei5XrKwUur8XAQm5OYPSO/h3Y5sEPVi4aknlMYwHul/mAojnaJRjvD/zP
n/94IP3VCygfuiM6aqJAMdf3GkT2JKJAK5/ebB6PF3F7IlsgGDVDf/kIWCSu8fdev5tFkhwM98vW
QdyzAAyX4OTCbBxJwO9MOGBXwBk8WYKFmUA8Dos6NCEIJKATvxXlBKdCO8NrNSbEOGOXct7RuEN4
vCIs7E1HJ2bwYEDHslwg+PWtmb9tEUtOE1qk8MqS8uOD+0LNS4JtfatmnYSPAjsuNchB6ltvnIfX
DNHH0Egkc68Gb+sPxKV4bX7/7a2GZLtQOnQDQrtsoDgQXlh8rs6ItvPkzeWkziDAwAj6rd+xOmqh
QP40n9FFrvni42hyK208AHlRCZMZeq0BldP9RYJedIr5wZUCpMlrQDoXPQtMWGiD3/6KvvkCk1Yz
/S9vE89ng4YnZ4RBKZxa4hSm4f34E2RYNBHkZmvB8+dghdz5VQfrnVPorsqPXzDU9hGpkHsVdDCn
EV4hjrBk1V6y46ObBBJLyn/f4Ciovvcx3J3mJ45wtKNjw6UxXMzF2epDOMwB97jASaQ9lvZ16237
l/7xkm7rz8zVpLpwAdAlWhqFCRXKfQpV8X4mOo00bxKXWw7P9+cTmRFWBz4WJkP68TidRrWHi+gS
Q3sF8paf9WGPd1MIRk9WkfHysoHa+HyH62cFmLXEFqzM4XgXBdLtkXqPhGT9ElmDtZ2tJOhEB6y3
y5BDvGfexBZNu+HD51WC+vEAgkXiXnR2J7+DzHThkapxwcZ3ZgE4MRAw62bx9oxN9g70d8gEg1Or
3j5nUgxvbv3B4s1shvmYnlvYM/YH+RrbFdOq3ku4nQdiZNhtypf3riGhsNx4LpfQ28FeoeuCGe8y
jxRz4xEONEb2JtbGy5YjeJZQl0sDHU69u/GEtofzGV5IevKu3hSusIIddmW8bn6PomB7hmouMFgo
zakYI9nL//LC4kXA61X5KPzyNDnJXg+4100pYcbhCW9+Tx/qvbLdZyJips4uzfzkyg6cFTwSreCe
Xt8Pbw3++L4ns+9iebk+Aze+SX78eWfVjALNc0gC9kwf+rrfB50Yd8IjWEcsFW1y80IoNi0h2ol7
go2n8LBITysxGu+s4/VSxRAjBhNjj1+UesFD+/H5YG+bIn0ehm8KX2MaEkvqsb7WiHHBM/aWjZ/t
6HTXpDuM7tJAvHcp6v3z5liQObQ6cpI60TH7WDjAPDoFaSsWm3ltc+3XXww+t3pJlhOofLhGK0MO
Zd8P9IxPMUwsIUfRwPUDqZniDiNuegRsKur6xhtseTozPF6l6DsMl73aAUcPPWQ+euiN7km0AOO1
RsAh7Hu7apU0uBQQYWbjlTPkLhV09rGG1CU6DWNozhZs7KwnCGSD9/NT8OWnJ6T70WEg3kHv4ONb
hUgfI61Zza/9r/rhfcpLQ3ZBOMMbXzVEu0akWPd7q4VZNS7467AXSrt7oQB9MnmkD5Fe0Or1zn/5
Hrkpe05+fhGgcNrjz62OitE+iTnY8iRSfW6k3UEtMkie9EzUIzfpuGD3IWi57IKOMGOSkeEuPoSn
Ynump6gWnx8f33gQ5lovK5ZdrtXyna+uKJ9ro9n/eOm2/8iyvUNB+d2oSB/GfmCZlg0l8du9g8da
B0RlIlqQgcl96MiWRDQZX7xZ8Eb801diPfrYG8OTYMM0a2TkbXl/2eVuJR/MQ4aQSK9NG096Ctsy
zXEtRd9mmVbBhm3sJcHeNHNv460MvAnnPGBsMUhoFRQCXGSqYqYXPwXxz3oG+f3bwe0Zf+nYHhUM
b3H1JurG19dMaEuoNFGBNI1rm9Xtu/iPL+2Eft/gg1qk4NcP3t96G3C2Kaa/fIiBWcrDwnxVTRb1
lkPIy+KBxm/tDgtjNImuRZ8Cl0JTg/2nABjs2L5ZSjcI4K+fUGz8jFdzu4cb38Dz9WyBlZwP+H8/
o+Df/v3f/+fvtyB0/e3+2gYDpvsy/fP/jAr8M7/l/+Q4/p+E//ttCXjMq/s//uNfQwj/+Ax995n+
19S39/f4j//49/3ftME/pn7KX//XX//b9n/957/9FwAAAP//AwDmi7xYhWEAAA==
headers:
CF-Cache-Status:
- DYNAMIC
CF-RAY:
- 7bcba8bfb902137d-ATL
Connection:
- keep-alive
Content-Encoding:
- gzip
Content-Type:
- application/json
Date:
- Mon, 24 Apr 2023 04:38:52 GMT
Server:
- cloudflare
Transfer-Encoding:
- chunked
access-control-allow-origin:
- '*'
alt-svc:
- h3=":443"; ma=86400, h3-29=":443"; ma=86400
openai-organization:
- user-dvhgf0lntotpa5mrg7zv7aur
openai-processing-ms:
- '153'
openai-version:
- '2020-10-01'
strict-transport-security:
- max-age=15724800; includeSubDomains
x-ratelimit-limit-requests:
- '3000'
x-ratelimit-remaining-requests:
- '2999'
x-ratelimit-reset-requests:
- 20ms
x-request-id:
- b45bb5c2f0a8d630fb99fe0cc9fd89ac
status:
code: 200
message: OK
version: 1
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,695 | Allow Weaviate initialization with alternative embedding implementation | I would like to provide an 'embeddings' parameter for the initialization of the Weaviate vector store, as I do not want to start the Weaviate server with the OpenAI key in order to make use of embeddings through the Azure OpenAI Service.
The addition of the embeddings parameter affects the __init__ method, as shown in the code snippet above. To accommodate this change, you'll also need to modify the add_texts method.
```python
def __init__(
self,
client: Any,
index_name: str,
text_key: str,
embedding_function: Optional[Embeddings] = None,
attributes: Optional[List[str]] = None,
):
"""Initialize with Weaviate client."""
try:
import weaviate
except ImportError:
raise ValueError(
"Could not import weaviate python package. "
"Please install it with `pip install weaviate-client`."
)
if not isinstance(client, weaviate.Client):
raise ValueError(
f"client should be an instance of weaviate.Client, got {type(client)}"
)
self._client = client
self._index_name = index_name
self._text_key = text_key
self._embedding_function = embedding_function
self._query_attrs = [self._text_key]
if attributes is not None:
self._query_attrs.extend(attributes)
```
To check if the embeddings parameter was provided during initialization and perform the necessary actions, you can modify the add_texts method in the following way:
```python
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> List[str]:
"""Upload texts with metadata (properties) to Weaviate."""
from weaviate.util import get_valid_uuid
with self._client.batch as batch:
ids = []
for i, doc in enumerate(texts):
data_properties = {
self._text_key: doc,
}
if metadatas is not None:
for key in metadatas[i].keys():
data_properties[key] = metadatas[i][key]
_id = get_valid_uuid(uuid4())
if self._embedding_function is not None:
embeddings = self._embedding_function.embed_documents(list(doc))
batch.add_data_object(data_properties, self._index_name, _id, vector=embeddings[0])
else:
batch.add_data_object(data_properties, self._index_name, _id)
ids.append(_id)
return ids
``` | https://github.com/langchain-ai/langchain/issues/2695 | https://github.com/langchain-ai/langchain/pull/3608 | 615812581ea3175b3ae9ec59036008d013052396 | 440c98e24bf3f18c132694309872592ef550e1bc | "2023-04-11T05:19:00Z" | python | "2023-04-27T04:45:03Z" | tests/integration_tests/vectorstores/cassettes/test_weaviate/TestWeaviate.test_similarity_search_without_metadata.yaml | interactions:
- request:
body: '{"input": [[8134], [2308], [43673]], "encoding_format": "base64"}'
headers:
Accept:
- '*/*'
Accept-Encoding:
- gzip, deflate
Connection:
- keep-alive
Content-Length:
- '65'
Content-Type:
- application/json
User-Agent:
- User-Agent-DUMMY
X-OpenAI-Client-User-Agent:
- X-OpenAI-Client-User-Agent-DUMMY
authorization:
- authorization-DUMMY
method: POST
uri: https://api.openai.com/v1/engines/text-embedding-ada-002/embeddings
response:
body:
string: !!binary |
H4sIAAAAAAAAA1R5W9OCPLPl/f4Vb723TpWIQNrvDgGRkwmCx7kCVARETiaB7D8/pc+umZobq8AU
Denu1Wut/Pd//fPPv01a3rPPv//5599XMXz+/V/fe7fkk/z7n3/+93/9888///z37/f/W3mv0/vt
Vrzz3/Lfn8X7dh///c8/0v+98/8W/eeffzflpGFN69f9MvIWnnbx7i9m87FBQt6VGfjhmzMj2ix8
XtuLCtWQbNg6XazMUY4gQIF5Vilv+xsarRVgKGGW4qXo7HIpja9K+7jJQIKF3vvT4zo/IT2zJIKD
3kR8UDZ3OB2mgq1fxttsH+f7DBF/JTOXo9Sn7e6Qac8bLYiXZFL6jYfh+dFiKpdZno4qa20Qnwsn
Jm72aMLP0wHN5KJga3mlmgPfnStw4qAi5rJcp+OOdxH4ejqnKprKsto+ywAlO75mj0VvIeZLgYKK
eG0R1xhRz9Bna8BhHhFcmzvh9/12naGVlhyI1Z1qMfiRZSPWNC/mWffanK7HrkBzulaJ+dpuEU9c
PNOKc+aSLXt7Md+CCuixXhvMQ/s+ntLTtQLTmdk079U8Hc5EG6BtxZ5OhMVodOnRhmMjbbB4nHnM
jgaXULzIW2Z0+9ofXX2dgeHNfWIGx51JsfAaKLuLSU79O/WFZWwAUK1uSXCa6zEz6B5Qci0+xJpv
NqkcNKoDu/pWMeOdrGKxPYYXWJ4uIUvczxGJXX/NUX1MGmYLa9fz8/XmoWdFdarZ/tqU9Rm5qHBQ
DLJ/NSESefWsYePomJzh5JrTc4joSjBxZvZ1aM3mbIch7G9Whpvd5l3SFBMKkpVgQqI8KKeo7HPI
5lXE1tYuNCd9RhLtoeCQBVNw7we5cBw0efsNM2vJEJK31SrI2OVJkmqxFxMRKoVXlFFimRR8MdOv
OcrW7wszon6GxGvUQ6imaEV2RaX3PGSNAfMim+PCEq3J4+k+/OKT4Ib6uA52XQKgxwGtbl3VT3sp
5yAqfKNMqkQ5dK43oditA7KTp2UpdqExgV3EjCpzYotJm9YZzE9DTLz5YdtPm8gBWGTxlvjlpi1H
1+0VUMhsQ9HtOKWDWskSJLzwiVFLcT9d/KsO53h/JgZ/b+PRaK8BlII7eMbQ3Z9eindQ7Qc7MWdV
9GKwTl0D32usMvuZ8h1dK2AtpRvxvv3NeKRaSDTznspueYj5/ugcAFddSAiVMp+eWOzNWW8GzLqH
OOZ1X08wfDqd+E4thIiWPICePQ60ASh88VRuBYqKitGhzSEeGfiAZmjPKUjJOp2eCU1gJ/dHHO4T
rx9399UM2p0sEaN6UtRsiazApqtrPL/XL7/polcAi+MjpfJ1aP2ueYMH6vF+weKdBGVVX57a6sjd
gfjbcymmFBkTbIbVjqSn+d4UaHHRYL9e9sQ6VoE51nORraxRH5m1NFxfvAVRoBymjnYcdSkz3IYj
TfJmxD1pYTw1apPBnjxMZhlFUzLp3lDkzosCq6eDXXJV7h20kY8RW3f7k5gehYuhOF57sl0GaTxl
m8MJvU024EWZjf63ngvo5puJHnf6uRSXqahXFy974d/+fDZXX0e1IYd41lzb8uOmIV7JxAypVMdd
KZ7eWlnR8XEmDs2dlJdTVMAPT5z0XonBnvIM7mGbM2e32Zb0YWsZfPGIxtxmPj8TjSJqOjEhSdmg
aSNPDjBFOpEj3jpoYgtXg7I5vphT8b3JVX3TQak8T8QdlLtoM3V/X/VyNrGN/AzReLuPHBYGMunU
VL45Ld+OAt98YOV10sT4GbUMTkbgsetqHfeca1GHJOuCqbAUraex60u/a3Y+FJ1geHAqUKzPAbNv
/qfjy20gapOU/fCVHQ1FRvv6/qRFt7dN8bzhCSX0NjCSxXnKs5c1wSHIbYYfn7f/24/VIxs/zNt7
TSw6AjLKkeOR3afciqruaw76cpGzred+UsG9d4DOo/3Ek9SVvRCqc0HfecLctJTT0S4PhSavU4Wq
0b6LJ+00UXA0vMarRV2ZbcAERtvrfUWcObGR1C1PCRDhb5g1q1bo7V9kBw1tgMiWrfVSvhzQHcqy
PhNval5x2ywdG1ZlssQafbXmrz4AHQ6MPcx7a07Z2enArLSSvp/4Y/7lT3PwEy8BJjTemixAUXtJ
yZq4iWjcIglBSYeR1lJ86wWPRlujWtsR/3acYnZpdQ9Qvk2J85RsfxFLcwupMznDEm7W/jRbvAPU
+vcd2S1VR/B2pgZIuvGI+c8LLvlZKhW4XxeCBItaEuK2f3jIiXFFdvZRpNTOogx2TW6wPemKePD2
NwNgmSUk4u93zIOSJyjtLJ3FC7lOKcbXO6RzY078h7GLxRJqBxL/U2J13+f9uPNHG9hTUslmdUvR
pBPBUTrX58Se7qYQBr0CKh1XogqejHKRxGMAF0lPqSzrSt8eB3MAqVdfxHbOueBmcPVQod8HOuyJ
a47y8pWg50mRSWy/jv3QJo6Bhlo6kKxbm0K+Q65BEn3WWK24nrZDkATgn9OM3k+l2jdrHofIOa8m
uuDjte/YbDhBt61TLK3Tcyz62bKAZq9d6N6sWjGKLWog3Tw8ssGfqRRSYzrQpHaPF33h9lOUrC1I
lV2MV0vVQWOidAnk++r4nc+39KXQyVgdVrsRi6jHJo93nxzdPuqJeMyfUJ9cPEXz/Y5T6fXRBW+d
lKLrpw6Zvc4Vfzq6mgLj0TtiKV5y9JGpASigPGXXbVT67IuPaFk4QGxzJ8zm7mcOrIPsRHzaaT3b
ausKakMKSeDUpsk55xjpEL0YvuuBP7oxPkEgWMqM7B71/JDrGlAlNontuTOzlmL5jprqzllALd3n
ct9VSDmoG+K8zYX4zisN1Cy08Gptlz0dVjZG9fZ9p8rhnaXcd9oGdqoJOKpxi0Sz6U/o7Tgj247n
tRCkevHVvjAz4t9QZn5O83kDcq1T4rERejoritNv3rKg7Iue2muTwvJRlcS6vpt0GpMiQEVsWszx
kSp4Jo823PqCYW22k1OxStQAvvznh7c9X70tA6TreUfII8BiWvimrX2/j4p3MvS//V1NQkZ4drae
/gjN4oRm/WaOlfxzEJPLFxmM90PDDN0rzUl5UBs1he3iZYEac9JO2qBNWvcmNk3f5TR3vEYly9pj
ru2P4otXCVQ3L2Br3ROCX8OWAxHuhv3mH+/mTQi3C5wZNiI7Zevl5qR1IlcICcW+/OPfF0W0+M3D
sB9n+NhBU1guewT8GHPJ9v7mGWX7K0q/88/7PY/Ogr5E4qAuJVQs3hnuNa9Np0nOdbAZ2tL5bmmX
fD4ec7A29gEv8Cfqp81rJ8GX/xILN0+THubtCWbT5oZnGzymfHV71oBPC5sEzgb1zTPQIrjUZE8X
J05RmbuJBCRz38SMNlY8XU0Zg52Aw9zD2++/+bJAj5QnnuWw9JlC3Br5buRiEe+XSAhVv4CYzx1K
z9ba5IfcUWBeKxbZLTZZyXMOCQqxypmnzOxy4b1ain54ve5no+h3EgKUf446Cc4vz+TeLLRWv/ka
WMY8Fd3z6cF7FT8ZuYSWKbt8lcEiHHbMGXZmOfkBOoASFXfmMHvyGUnNA7B16/zxjfE4mFQVt2DO
tuhjICmRDQOi6DJjulkl5USlRIZne8NMX/hDP+60YECv19rGC/deoNFeOPKPj7BM40XcJ/apRvFS
Db/8pS6nTdonYDxnLdkeCg9NGioV9OuHTa2WPQ8P+wjWmkioom2uMd83uwApFjsQommH8hNtpATt
7Fjgj+ooolXf5wCSs2ezrXDnfocmXqwOyv3XT04s1++dBZm5mtP3Nx69HMQdFNe5kptSEH+M7f6O
tI+bM3OlGr2ojsZ3PlZn5hiD50+nQ3CBbzyqktsNfVr2CbU3hhvx/SQ3+dU5a6jYEI2QT+P0o7na
OCiXPxsKLBT9cBIgI6InwH540If7RkHLy7TEalCx+I8PT6s1ZlZjFuZn2gYVyqXTnViO0iKmzYII
zqP1pCvqjj0PjWEGxWanMVzyMh1fIZ9WX35B4fzyfGEp5R2S+x5hjY3ZT694UIrJIetQjeJfvwBs
bYUqX3wRCc6z1U//rZg89NPdNi8/fY1XloF7yhxbAgrUITheV+JjO5vptx8Y7fk65k+00+B4aQ7s
obyZ4FKHclh1QUk2J+/lc6zEF8CH+4O5M0pLrqZZgi6rgLL1++ijyTVaGXVnHrAdgo0pT+4wA+bc
JRK0eRbz98zzIBben15N+2MQR4D6Q0AIxVM6abswXD1Pmown3TPNKX2AjkJBL3SxTu1eqp63CAW4
6oj3duSS//bDrJSS6VWG/U/vlw6Y0cnH2lHgdLo/Ew+V86PBgtvx2U/vg45huV/5mOt9YHLpebVh
vJ8a2odt6AuLrQ14hdaWWa9PLuihSipgKFj99GT/ua6PkqZH2pOYt+4Yj2UfZvDDdyLvccn3947D
9qYYLLLzyuTv4SbDrASPjk2FEH9fwxm0VvNkpj/U6If/mnWMNt96LfpGttUEFlctp/IZxpLXhXUA
x5Ue33l7MQVKPAc5x5fPfvxdrvm7gO9+k7VIrZTr60uNum2VUh5vN/0k6WqFiPsiX76clNPpxQc4
PjKdXdJ7hSZ0fk4ocU9AnKuv+4tio2D4nMs5c7dRaTL/qRvIkNUGI+VG0+7H75sLtehyXPXlp82a
BO58sSfOZNz8YfvsMagJqTHNT5+UX8PnBD9+pmtJFvf7VyahOJrtsTw4BloqhX1HWjnfEWOXMX/M
gnsCX/+IasrtYU7ttGlgqtfjL9/9x43xAYZTU7Kv/hDjDF0oXLru9NdvvKuu+Y+/k2C/mBB7xsMJ
9OPeYU6RMCEW552C5KBrqRffduZYXisP7HabMnd+UNLpGjgWvDeTRwL5Y5vDEGchLOCuMG9QsDkA
m1/QkfsDXbV534t3+7pD9D6u2Pa1jP9Hb9QZPuDlE+98QeZSDvhKPkzPrqMQfNlF6LxYMuZ88VDQ
yNNhjDdLFkRg+eIZDweNbtGTbc+QI36e2Qc4MPvOPHcb+NMm0mcA1rAnxPqo/qTmRw/9/ITO/SzQ
Tx/B9AxLcmhaH02L+3YGb6+8fJ+nC36Weg1to3bP1oEs+2MuMq5JtymiM+rm6FPLex0S4xky/2F8
0sm98fqnn7/8c5l2yoNaMFzXHilEfvwffyzUcovcs3hvchs8DV00aUsSP+Gij9YJRbFbBVSuep72
B368wI8v59v1zhySRIQwQzGnizFa+4vyOnhgyKhhehe80in6bAA6fNnS8aFc0ym1XhGogRWTC7kM
MbtdWwMyEnD244PTOI8vUJqXmm3168mf7tBocD62M7o8LUg/vspFgx5datMfX2X3Ust/9UPHQJbN
tq4qClE/GlRdvW+pOL47A+0qe0V++eFVt6RwPeCATnFQx+N3/eo3762vvuaZrFrQ6iTDf/3RpOoB
0s7Wab59n9BnkbJaVbPIIkYc2LEMTxShU/t5ks2s+vhjX48afPTgyswAyYjOZ7mDvn4lwwzNfCqx
HYZpWNzI1twVMecPUwO6KTRGGPrE4jO0w49Pke03/vQIMw2drGpk7pgVPd8f9RN0iSOY7ye6/40f
AjtZO/Llr6VYVXH3x//I2Y36Xz5/eoJ5dRGgaW1fD3AICpvOonwVT28j1dA8ty9El5VtL5NV5sFW
t1Wih1IupmY81T88w5onbf3BHL0DHPtgYLuSH/zqYE0e+vpFXz5Zx+we2RisbYbITz+Ir/5AyaRN
ON3zZywqPzfQY0wqEmhEQ8Pwcioog0pl/un6Tif3WFOQ8lP/6xdzgPhiI37Vtz/9mLKnt9aQmuxq
sn3ib//3lz9+gKftsCxZpaJOY9J1z0i424rRwN4ddt6gkEA132nxq0f5+Wrx8l1Rf7itvQYupdwx
LE81God3M4P9RHZ0nsV6/Ocv4+vu8/1e6cfvbGjPgcrsdzVDo24qoP3wuX2dPF9a+52N7tq6Ip5y
m/vVhFwKlq/pf/NN+fql6sa7LIgZXtx0nHdpBjw/UvriPhNCvA8WOlGnZvhUXsvx8WgkYN4yxXLV
h6mcPiQDFdvwgmUcaGm7TVoPUmguxPa6V8l+9XP5GCtiLY3WH9WbxFUd7zsW5PugHNytmcNKVA3Z
5k0Z8/dwlP78tuLrv32/ZwZVsQkI+fqZP78N+aBHNJ1reckrfElQy6sZ2/BRLUUqOYMmN9cjSTKX
9IOV7yzEPqnAkk5MwVeKcoBjYVzJdp1vY7HV1jUQS15TrmIHjaA9O/SiuyuV60sff+d1jfJ9fWTf
fjK5fd5ThA4nhqXpapoc1v0Eic9Kym+5aXIn/MxQupCHr94cfP646fefn80852nEbFXFDexjzWXm
9a2afFmRCdZiRb98JYobtZrJ8MVPghf9oqfVR5FhtXl/6LSZZ6WUujMDYoPnf/jfkWJ3AbbuHZxo
/bOkX38ZHdlcY/6eqILdSv+OLitMf/rNH8twTbWHED4h3fgQ0yBKDl9/EXdszMpvfAk0DTpiRd4C
iQTAgijUz+RUz44+Q4tQgefbfpNNQ1exuJdTAV9+y8xl+YyHZD5k0C3UB0a98xJ0be8PsB5fW/Kb
Z+J9aiqgc5vh5XXUyrEoHgVaPY3wp7dNNsaNB996xTN2lFJ5eZ8bcAfL+Os/KXHtGTw29+0Pr1L6
6PsGSubvmX+wi58/X6CPexnYtdQdxJfJ66R965U2eCrKkZyMCuLjSWE7G9187qc0h68fTHS68GPa
jPcazZJ6w3aqo6Cpfm8sTdRvi/lfPivdDiSHarVcYh6EN5MqGsiwTZfVn1+1fFmbAFbB9YrRDWU+
//XfqWVP4rnbwR+V225ALa9n9J0oPWptZzdB3s2uX/63SMdMvd7BuNQV2bh3Q0wnr51Bc7tFLNNI
gsao+9TwAW/x9Q+dWGL3TEYPMfpUgxx9z0cuCbqlpxnBIc3/3g8pBDYs6N6f8usva0jeSCvmhy33
RbrdNeiLv8RoPQm1Z51O6NufZCc9IsS110uBxzMQFB2jk8kPOKshxe2N/c5zpikmCbB+HVDRepXP
50F1AqLORmbv9FrwctceID02iKwX46vkbhGF8MVbts7mnfh8z+cgvj99Ylb6qR89L5r9+UvdTe76
uzGT77DQ7D0tNtdJDNaoJsjn45O5+afy5UV9lcDt1OF7XiDFbdG1F+Tr1zn5nRcxR+MdcuUDYVtT
BKaQzP0MvvwfS7V6SOn74GD01ePMzO5PNElsF8CGHSVCcqhj4YmjBI/GeOBxo/nmGE76ZfXFVyxM
M0fjN39o9dRD5r2dU9//+PS4PfsM2yiIR+/1pKvepC2Vd3VY8vBwDcH+FDlzv/VJ54OQUDjfR3Q4
KswcG29nwPV2ebAw9Z7ix79hu4y2hLinh8kf65EiuNtHtqW5aopLPgt/+vDHJ8w/vt7OghPz6/cs
pXrvFZDLbEMs36clLZywBksjFsN41pQjAxNgdRzvLPjqcfb1Y+GBu4SCHa4Rjx9XCa2ViyA/P2Dq
sVmsxnS2Jp7tP83JfkkKIsZYEvs1Pctvvk+wLZYGfr8r7I+owSEsQrojOP4/AAAA//+knUuvo8CW
pef1K0p3Sl+BMRBBzXiblwlexrbUagG2MWCMDUQAIdV/L+Fzu9WDGnUPM5XHacdjr7W+vc1RDVr7
FYlhMPENUjtS63QIB+HXbwlYPsIDMTSTgW5sAWS+fHvYoc+hhBuvCjittpvlU/aXn3/deGIMVkZe
LKgwg49ssKbJCr5dLxXRkSeOrCbNfEsPFZAV7kH8pJ7ouOnF3/q7M3ALSt+lAS/s6/TrZzUbj/sC
ai8ScptOBX/+y488Hfd1jgAd6ksApWU9I09yPwk9HIMKMnIWoKN7QcPcrHkF5cVXkbvxOOzM8h1G
oKiCp7rHgMSky8Tt/vz1s3frRZDgxqf/8scQFdLlpw9Iu9bvYVY7gZM3/cU/fjKnnyaFbPF4/vpR
+hqOmQCrrkkxB9dqoMvN7aBwzVyk+fyrWK44FP78uV6kqTffu68EbYd/kAPzOVKq7WEOZFdZA6np
npRq5dRLJyJLSL+HD32iUWbBLDzdiPl0xmT2YsOA8uHrYRziyltO9ScETJctwW3Xtd7f/fr1l7W7
Nw3b+eFhCIUBi1u/ergduBHuEov78aFmuZZtC37+StUYRZ9D0S1/eYN41WrQZYZUg//4TQX85//4
f5go2P33EwW5Ob8xOGi1txjfJAeXPA1JfPk8QJuUxxDwxH0RBJVDwTO9oAE9igyCJFwMU62opSzK
/g35X1x4c+HwGDos42J20XbJUsV9Dw/iyKKDpEpgOU82A1O+jQPXPDH6tKxlD9Fk6UQLZLH4Xl+X
FoBXbZJgCeNhoQrIpPg7KMhbFARmlwstmQ+smOi++gaLDtcOepqxBCv/0gd6yKUe5vhVYrE4h8k0
vJkO8OpRI86tONDxiCIM3PvDQs6d/xRL5ns2wLMQknRIXgC7bBXK4lktSbBPP2CeFCcFhcBWAZOM
j2Zc460DH7krCjqQJTTSCA/mrq+IKYT91vGaOSDBZdw6sCLF4s7N4NP2duQ4j4Y3dUyWwluU2Hga
AJtMXh2H8vn5EgKaxmMzDHLqwxORNKJWR8Xru3TKofjkI8xh56MTuisM+IzhlxRRlSafuRhD+NXW
AOlR+Un6092G8Nl/Z3Qg473pzWcfQ6kgV6SGtzqZp89FAFBacuSzYl5QYGi5KHOtRZxBFOlyERsB
mirnkMv5xgD8eokc/EjVTLRXkxczadIe2iA+EhvsU7ooT1GBynrUkWo+woKGn6cE/dl4oGjwRX1l
2SqXn2GRBLJGbs0c8rwPG2/3IfreWb1R+KwuNM8VQg5vVvr0NZoQsruxwXOOzvo8MscWmCkUiFld
igbbi/oFy/KGwV4UWvpdZL2EKacB5IMDbsgglwFoT98TQuRNh1k4PUKpaJIcc+dCLObxoZcQytmC
HNm4FnPGiRn8XO83PJewTZa79ahANAwOOvj6VCyy02XQPvcNcQxbBOvZHyt4/5gcUauM98YYHC6Q
2vvw77xTdEIavNvqE8NxjYfZeLQdOPnhBV2StAczvh58GNn6A5m3+pKQ3/lJLz0mWngpvNk9vVfw
keoZ+bkfDfP7Y4fw0jhWwDPCRGfk3Er4bQsRw7jVBmK/FANaI23Jtr8FceJKkDn8rpCJp31D7qa/
SvuTxAbMpcuLtY3uEPCBERNLF3hKG9xCyLixj5xBvILR/Wpftg2fb6RxyquYL/pFgaVxmpBTs2xC
rMbIwaEI9EAYTkMxfw1HADVVOGIdzoROxX2FsD3m+2AedxdvUc5DB1jq+EjR9m6x9Gf3DmSY9iiY
7xaYKe+XUKuCBR0c9kTpKdFsML7rE27jz3EYlAvO4NTVPlH8ZgYYdlwGMym0ELKKhc7F/dqB793O
UQLHeiDHwothfzoLCIkQ0XXinobM19EJ8wLHDyMdWAUyDyYmBtD1YbaESw9elXZFniO8CmIRkgG+
Tk7EvzYFpcWtD+Dx/s5xCFxOn7/hyIMuW1fiMhJN6EcPa/nYRk8S8EOqD+HAXkTBkHhk7BbB6z/T
9Q4JVXii1oArxuF9C2DylE7E0ERCe8fxeYleUy8YlrVo5uiIv5ALPzLuuUup04y/lb/Pj7Q+fA9z
URELHHUUBAzOUTGazyqGzggEovS6Xwy3p3iBcL49ifuIVMC/H7sWfpVgjwzhbiZz6EU2rLLKRYnU
ezo+hDoH3zwPgxpGX32+m4wtDUzQIvt8u9NlLsYY+nJzwLsKmc2sTFILLI9EAXulzNA/718fRkf3
SFzzdNfpeI8Nub1QgxiNpnprd6ssiLtDEWCGamAQ2cWGCjEScinPYkPO5yIFCz9+0bZ+HuVLtge+
NWNisqSiy7KmX9gFzxTpV+OS4BY5d5DfFQNp+zMp5jZMfelSvQnGthGCFYhJBYuzeCRGyhf6XPue
AiQYpEidRKvAp8/Vhlf56QQwZ+RiLncOA/cN3yC3l+1iMc9cAAfwOW7r96STiiJO2t4/CYLork/4
2VeSWNouOlSvjC7FcBKAsJMdhC4X2Vvmoo0hOHRPcnju64JaF4YBt04OkDHub81cs5Umu9nxg9Qu
Pyaz6AoaOCvNK6DP081bUzBn0O3GlpyXd6UvteLc/+q9J1+boneYfQZcs4+Q0qzvBEeNH4MC1Pug
MuJRx7UrhLAdsgJpnT97y8qwHbg3V4y0RzbSZYG1IVU71ULK6+h4i36wDdik5gHP8l5N6ECDFTC3
C0AmeK/eeL4YGDKJqSF7930PnZD6NXilvY+KMWh1ehGuNtTW1UbehZ2KcQ+vKazGICQoqq90qRX1
Lp8R42/6oyW7j2CH8ADjjBz8UffWMWlieKm0c8BC5ZDsif5xYRXyBkLG45PQqSIdgBHzCt7fSNZH
lwsNiOIEIXRVVzAfkGpJE3tSSbCIdsLdxcQGTpBDosRv25uI1OUiJUpEdK6ldB2TIQZ1BJ/ksL0e
1h0Gwjk1HaRKkKfTz0+E9j0MBBmMyXI0py943vYAmfLwGZb0IEJYGueJIFWZi0VbXzbs87Ij28+D
btMjgIzTgIz5qDRzKw6zuNVHdHzhVV+a6evDzW+gK28qOj0GVQqjvsqRY+avAqd2koIoDGUsCqAp
tn8fwCC0P1je3RHt8ljMpcPe6dGx5PbNis/wDo7sZ0KaNXLD/GbnL/h2bIiZ+W5RMjr7QDoc4weu
XsePN8+vSwqnBu6C+ZOx+jTxN18AwPfImWrPAZ/ifhb3ii8Gk1dp3to/lxCa355BHvfowactdEWO
z1WElG/vNovfvldY2V1HXP4TDONtnH3pOUsBUeRgGFa4qCsUkE+QbtcBWLtbbwErYQhxzNws9mNq
fOHObwwUMFSjY+Z9VtgLck3UInkVnzaUO7D0i0U8dc4a8tEvFfTyLEAmbp8DfX/HHI7v6kTcZesI
iLtmlH96YCZ8BNbn6VFBdn7tyEHFkd5Lx2MN86KcyFbvk/VVtBcp7Fg/GMEBD3/+plqEM3GGuaHr
t9gpoOVxH7yXOfPWLol7eSxtm1zNpiiWk4tKIMOsx6+CURp+Ug0DPmchIMone3g9w4W+LFp3AwX2
ZA17mK8zdAuRII05xsM82oUBY38qkbfdp7nVxRjEEe9hYfc9NDttnWzYkfcbnybg0TV9n+5QZm9n
4j3DVac4s1OocqcPOiqqkyy9v1OgqzwbhOSipwt3vIeQ/QKMn7vnKcHvr6dBYOousmHlgk3ffGBl
20RWt1bJehPsHL6fNk9cXSqTubO1O3SL7Iwbt7M87tP4Gnx9xS/Z/PNWf4wYvnbjg7jC1HnU3cEA
KtYZILVpv/qyw6kF3s14RI+9IBSjw7ApOD/fQjDfcKiP99Dr4P5yzwL4xcBbd+YkAfabZUiR989k
Hh/eHe6hpRB7YFR9PnauJdZU44jrXXfJtCZ5DR/WXQmkAAkDdtKTAm9sMOC180OPKpcug4+IOwZt
0fTeegn6QCq044HoIFLoLpATHh7ZYQoYc98k6weXATSOrkfQJ++S1VRfAbgzfo2cWbUpVSbHB14X
Ufx5jeMweRefgzR4ZkSLvtawt4Fwh/A6HYhzP9KG4suNgyeVeZCA6KY+mWcYAJtISrC7zP4w+rjg
gcqLCvnz55tfhKM0GEQFL3/gmsnmYamvJ4zF5z5ZP621wnE+e3h/ri2PO0jYBuyjeWLmKphgmVzB
hfH3o5CyvLIeUUk2Sune+WKmc77NQhX652+QylMFYGkUWrgsL0isUFIKrkh9F47qKSXHWQ8SStmq
klORqOh3H6fNz0mgO9zw99KmdB5TXoPsC/UEuY0yrHrq57/1RvGD1Roe1+qWJ3gnGMHcJovnfQSh
snSE3CtfFXPnnhm41S9i+mdR/+b2AIFsdojYIHh4mz4q0DiSJpDG8llM9lyF8uYXiKJXirc+Hy0D
hzBRUXAVTNqzntLLeRs1yGg4HyybXkNtGq7Ee10q8Jk+UgzGlmGQEjFrQltwEKCgnR+YEZ/7YpXp
OYZBoUvIlLnHgPvnEoN51aYANuQJ5ussrFDt2ZKYx1UaaL6mEqRBkwV7lJ+LaX4tGLq6ISFVLy50
nc1bDNYdfiJPaipv7mQI4cI5CdHzTKdcQ7IUPgf/gPc9XwzLXeQqeHdbIeCDY+KtObQhjFNGQkqO
9jpOgZBBxzD1oD0Gvr68XuFdRk55JYUjmMleqcEM4/7wCXanKBlWpY4vMFzPV+IwmUF3pZ+s4E6l
D3HHUk0+j+W7wiSIv8TFFwfMx06z5FH6GMhvrFEfd4LtwsCYS3LCrTpQ1h/Xv887n25DQnJYp7Kg
rgcsb4RwNvgUQlE9Zeh4nMhAS76zYHEGRzwnV0p/eV2u3mZNjCRuiu/EM53UDmmBzueh1IdGkPKf
XyGqHteAlgptoereKwxhPSdrPEVY9l/RlxzjByjGJGJ5MIdMjrnvN/Q2PZrhvniZyLFDe+Cu5U0Q
VGy4RP9az2bZHxQfsk6sYxn3YzMFh2cqlw/7SWJr5Jo120ELbPUEeV+qFZx7IjMomE9HtGt8GqZA
Ljjg1Mobc+lkejRzhRzO90LDS5Xx+vw1VAHyxH4RG+0ImE73bwa/+qnDa7GnYHnc0DYBcpTR7zzS
nx9G6+yiw3jihnmrh0KMYhqIJ1fXf/kE3j71689PjlueB47V58jkd12xAPTtIJ+eF6J6o9yQve0y
8KPPZ3RoDQQ2fpLCX5487u6ErsewLKGoSxNyPxZTLO9HGUCxnOqAaY+avnyaKYebPyXOS8/A+ubC
8ueHsaQ0cTGvsehCwgrWdn/iYqkYc4Q8x4/EDB9vOuIr8uF5AAuWDXrSF9G7XgCHNRvPvT4mVPRT
V/4us0lS7dDqE/XsGYylawfrg9UGXuuGDtZ+mJNk76z6OvRnCP1vfkEHiG2du+CdBZ98l+Kv+IgA
TVcjBErH8395eQlmQYDw4M3EFK53fZwUNZWjMJYD/lKjYqTDXgEbLyLmsOcKgushlDymCbGEnq23
ZGzlSr/6LnViSGkn6x0oZ39HXHtQdX6nXy7iVj+IyruD3ivXB5b2yaknph00Hi2SfJv6eAnE5Yyw
wD/+sfk74poMBdN+fYVgy+vBth4FvUhdL11udxYFz4qj69wlFtzWK9idpE9C13uNgX6tnwEf6XxB
+8vRB7t0rfF2Prz1PNUpbLwwwvvNvy3hTjPgUT8GSMUaTMaodirw8+/9Tl0AuUZnQ6LZzKEk239p
Z11uHWj2eEHujc2SzZ8ZsOW8CPfjfPRobDQV3PIpOb5MmIy1rytQXjVCTJodi/0vny+n7/nPT33F
zPbh1TheMbv589VenC9wpNBAt83/YksscljmOg12zG2XLM7hMv54WMCN+D3MyDndBbtRZhKc5r03
EyOuf3wLHy7yga50f/Bhlx4L5EfAB3NYHTnJUGKA144BYHmmjAukBu6RmRidR0RWtKG13gakL2YO
usfqu7CUKhys7/fSUCGdhN/9QoegHxraObiFS3ckyD07VB9dBRjgp4/aDXjJnn+bFmx2Xo50qfe8
nYqunAQNVQ2GjcdRUQtG6eefWePxKb4oDl05azuFHDzAJKSTvQ4essOJHH2g0z2rPVLwEvYBlr/V
ja7CPWLgcNEb3G9560u9rw17UInIuShWsW8E6QKdM1qROcWZt8gOzuA1eMZEX/A8bHqs/PgfsSqX
SabH8p3Btp/El71OX3716NriNHhdDjxYxcwO4Od9UVH2ej0A5bILAz979orXEy2baft80L3frICC
qKLrqxgvkq0yt+31LJ0kwcyAJ0555NyKN21/PG8OYU6saBz1dVinHPDX+wMFgW17s+MYHNTechK8
n/s6mV7viYH75Nxjtl3mAZ8eOoYPp9vyQVMkNONPd/hu8BHT3fEzrIEsB9B7jQXSH8uroL50zKHy
kV8EPcExwW8uvIO5+1bISCdT7wcwGyA0BRE5J4gBzXtUQsnSEww3v4/Hm4DhxgeIH0+X5i+vbPx2
462OPosj+koGlV4k2HgLT3DLQeYBYwxYRh32kfbmBUkTWnQx+3oYX0uuQQBos+lVWIDP2BuwGbN2
03/F40R3VuSEpDLxNz2jfFiOINnpBtHPH74hmVIzEMURIta9s4Z9i2oexuc6IupMnGbZCc9aUo8v
RLTF1fTZ5S4WnPSHhA4HZx1wG2WMqGeyiy+a4zT0eRM4KNzcBHPHvUp3Pt75kL0zzsaLxoI+uU/w
0y9kdfuhWG9nrYP+93LZ9HTW1/WupnCC9Bssww7TWXtV3C/foEJ9KwOt1qkCwVDtkDGUgNKTDUeY
ZLW9+csKkNY85XAXH72NH0vFeEUShKzhnTANaTIs8CooMDBPXABel4rOsSBKsIJLj/y3sAezqNQd
JOWOI0pdFWDKZdmCFZuxRCsCxluAsNpQd/QOMwUXJPOhaBX4FvOEqMpkNPQgciv8yNYB2T+eRkYB
/+ojlnQJJnNHSQ1gGd+3fPHUd85hm3gDeUMM+AZJj25CCtNK8gNI+9OwMAmYAZRoTpD66XQa+XIM
nevikINqgmLd4V0JtTg6BmTjYxPsYkaaPj1AFn7kBZUavwYBY/gogIEx8DtzEmBHFIQuyM/1yeB6
Hn6X1UToGZ+b2V7TC9QmQyXndjKb7wBXTm724/LnFz7yIeQg8eMS75d35S2tkfdQqCIdN9cJ62uv
gDuQ9ocuAHmOAX7zEwQ7h52I/3L1QZxfIoanXeugzU/ru2Utv7/6FOwy/VH89BxAVrDJXace3W3n
Tya79kiKzzMD4yHKOhj0uYU8VEI67pmOh7MXJ0R7sPWw/Pobwo51ArrVp+EanS2IvtWIGbKbKYnO
GoY7/2kQc7bFZMXetYLb+uBffR43PZAujWehQ5quHq296Atl9nEOVvvAF3itMh6Sr6+g9Lh//ur/
9m0IoP3yGvjxL3gYaBHUzHEdWr4oKpAFOYOchKjJLpdlQ4qWc0g0fEspFdKXBIvbOyEee/IoX9mw
A8HtFRGX0CGZk7l3oZ3T+MefAdXyWoPXK3hgTsonuh7yKAR2vsRBdt4mju+Gq0kq86mxxDYfb/Iu
BgeJM5mYXNUYrK81neVfP0Vfz13yx1vfx8YLfvVnRfHFhScQIuQm39yjMmNZcMi7baKl4hL6Wnkb
srN2CwSpTJIpCfXxd16J3z6PdD6i6wg6vdeR11qngprZpwS2v8PBaes/rEku1ZBXkUaOJyZNZgl7
GbCJoPzxl33pOQp83zWLKI0TDSuy3VGyvCkibmDVzcj5nADwqdbJIT60A8mZPQ/t87dB2uXDgvlD
MAPjiZKN9zXe55FLF6jRUxXso3tA1zd3KYHU1QEu0qM6jFs/AX4edkOOQfYq1vkquPDbXkXi9DWi
dOm4O1wGcUeQI30p5bKQgcLNTshh6wdhxj1g0OKHi+cbnr3xM11L+NOnI82FBAdvn4fLqT+Tm1fV
+ljuzyWwpMkm9nMF+gc/q1r65VeLfTbNOnEfC84figJ51nEyw5fYwqBJLuTgHL/e8stPGz9Hips1
yRSqLwvC1yElRn31EkqHYw+j5RRi1m2qYUrldtMfNcF77tYUhFUcHuAhcJC5aySwsuqO+fGgXz9W
X93heAGho/ZbfY+HdVJ9C0TYr4gr2e9hNffnEe4ceQrmHYkH8vNrVXQt0eFcWzrnPnY+fAXbNwby
8eTRg/VYAft4PoMvvnzoqAiKArf+KDKFK6OT4rEbofK5HInfKxZoT05nwcAta3Sb2IyuRJBCcDG+
Lt4Hvdfg0pdd4IHLEx29qvbWC9nzcDAkjvg7fZ/godPuID6oGTqg6Fn89ZN/+qw0ztJgmZ5DuL5n
mdg/v4ke5R165rFCW7+NLsV904v3ymJ4Zlt9Pkr8Csk3UDb/FjXzpreAw4pN/DPbetPrdSnBRbMo
CWxjpsT0Sw1u54toPL7+8lUL6/P3HSwtO4CFOzejPMoLRZqwRt4ojocebHwcY8Ha0V9/C1Y73cL0
alyKabvPv34xOlNNHZbNH4FeyF3ipcdng/lcWWHtxzlueo7X56Q8xrC6hyMy3Of9l39bIOQdDHZ4
Og/0+Aox9ED+3Px1mRBririfX8fSWKoF7/leCLY8h6WNr3LAACv88TF1Ertivb6xAVS3rAiSXq8G
87Now41/ksPe2zdzrcodLOJRI5n1avUtz7Rw6wdinn3qA35+1lz+/5go4P/7iYI+cDE57HrT48sH
6wKZtgdyJ6IN6AsXBuw0zyA+LD2wL86OC2UW7YkbsfuGpsFphvK7tYOX581gLI4OA0+dpOL5fW4p
zZlyBDx5e8GSRddh1b92DpVr2SHz5k10csDXAq2d3Ynt9U8wfep5hHoSacSu67wgbybmIQDdBRkI
jzo+2hMPERYk3Le1COYXlzBQfLQrOrT9uyCPewJBvjYKsRrz0SyW963AeLct/CRRpg/B2dNAcLJC
dMzLQ0HvTGmB7f2QLPK6gjhESOF8W0Jkf82hWEthqEHKETW4TqbqUXyPZnhcrBQ5RR2BEaXnGL40
JyBG6e0bspjtCirlbCCz8o7N8viaGD6Ek4WCQJyGcfJwLFHvNeFFPSsNf2XZFh4zEOH31FsFve+V
XnZlayaewRKw2s/EBgTBNpCU2vdw0E89lMWcJcqXi4s5OM13qYprB5mGFyULIzkGRDtDRQVg34Du
T40El2XRkRFgD5AbTlNon+MIuQ57AUs0VDPUrmUcQFkU6XrtR0tSmqQgzpu9F+R2UFZof0UWi61Z
e+t6qULg3YwBi6d6bcbJ60JQtWcFHYbeAvTFJC44p2OPzlrv0zV/XjJZOK4mXlru401Qci5AVe8P
YiSeOHwH4ZPB6bVNYJDyTMk+uJQws56YHLmy0eeLcWJA0E8MMXZe6g1MyV/gNW5QIPW1SflP/2zl
27dukXHFbkFu9zKGT9ejyCtZ31svywWDrnZZ4uflUizj8giB/TQtpLtR79E6KDrYHVgYAIfFdBrq
+QJz/8QEfNnHzXSuQS1Ne2YJxhtbF4u8pDNch/caTGPZFljcW7HEf9YELzfu21B6GmsAjsU1WLro
rI9i0Zbw+m185D7Y0zAjWR/h084gOhx7L6HiqengScAC8VcRFHM9vCE83ZsdQnw2equz5AL83O2W
OFON6eoteQvl3YXBcijuPSKfagZe4FiQs2eKydjJSijvo9lH0T5KAb3d0xCm2VNGpulFw/JyDQj1
290hWsJpCd+RXQ/36G0F6yPCwyqiFbMolxhi9Pg9rOMD9rCesyEoa1Gms3EzS/Bl7BM6HPoBrPqS
8OAijDnR2uhI157IGdg61gE7ZNMwkwJrgC3QG/kv9ulR82BUINCAhw7fvmuG7z2/ALArYszvzHKY
8lWCwP+Cc8BsHUJq4ccKO8mFwfgtMZi84YPh4RwXAa97vT6pGs/BT20/UbiL7gXOhPYODbVUUQHZ
tz6jo87J0x4uJNCy2zD7p3mGyUxccuzEBKyQSD6sYfZB6LoNBCeXlgFIkkSiUu5QtDS9MtAYwh3m
Le9NqXY2JJBIUoTsvfnRl8PwzeDwlk1ywCanj7C9lAC+uzjYbev99sisyTl33uNhYL/J+mCZLyzX
esTCt77q6xvtagmw7RUdFjOhU5lbMUSOcSDqxNn6er6MKegyR0GeUtfePHldDHaf9YbhUh6TJfH6
HhTbd2bdN5sW6/3BcOCS4jtxOXYt1omFd/Gbu1ekx5EFVoaIAlSv9xLZp17xFkFyNThYdhKIR7PT
f+cDWOf4hdyg/uq0fhELfhj3QUzB+9BBZEJFlt9ICkS5Hv/OG7S9OCbaGPnNZIJ6lJ2PxfzV79WK
iotUuJUc7C5eAJY6P6bwwVeI3BURNfSMb7F0jIwrSo7RG9DqbcdgmKiM0zfuk1VgJemnL8jR6lOy
fi+fGmpJ5Af7q7kfKDlNNjhbTftXnxZj5S8Q5QJDzMab9Nk9iYZYlFgLWowtQNXHUsFqdXhyvIg7
QE8HV5Psl3nA4q/eCbsBg7WBOgkq0R3224QEEFALyaYHyZKttIUVX5nI+vRzMR53QgtvQf1F6o37
DvN3wBgcVPNEtHOEwHKVrBGO00KRdeh3dH5NSi3T5D1goa6lYijfiiRb+7hCJu99i/nwEu9guNsh
uesi0Rf4VTP5WuGEuExdN/Rt4hQAva2QBrDQ4F89EJ1iDOAoQg8/+saG+33HBvSId8Nq5rYGlee9
RRrFIqU0uBrSkrxZ5Kfl6tHDwfehJt6P+LmPUjqH3NkAOhuCQJ7F2FsL9eID+OhSpKX4ro8LF1tS
63onhFpRafbh2cUCy6IGeSl7LNqL7JbwWaYCuRrmW1+b/lv/7Z+RegJdOEnrIUFMu60PActQzznU
h5gNfvdrNSTFhS/eMZH+igydbPUUvuw0RYEiooHarHCBu2UtkG+VFMyyEabQupolOrrivlndKJ6h
JpZHorJR0iwfyfehcQhFFLBil6xHNc7BtRwzEuzF9+/8hWC/b1mUDt4O4GiJevjMaxU52/le9q7r
SvesviPdiHo6xMwNwt1uLgNJZXOPuG9vlKqsdrFAa8HDuwfIof6IFOQsbNnM3k6QIHO6iMh7lFJC
nwfbhr5ptUi5nLuGnu8nHzoodgJr8dRifN5UA5ov8xVU5/M7Idt9gNKnuGHq4hNY0qLPYdSTKhhq
1isWvNwhSMbpiBBLL2AKi48G4056/K33xKl3G6TjpBM9w9ywRPmBg55pYKJIHKFYOlsuzC/YI4eL
eS7WRqg78MYuRe6Z5QG2+66FFcxk3K+m641oN4e/84b3oG8TvNUzsAKokGR7f+T+emP4ZuUvsR6e
UdAnLjD8am4ZrCu+Dr/Xh/2bbYgmRt+CXnEJJXcFHyyw5gFgbPc8TO/SMVi2/aMGuygw7SSP2Fpf
g1l/rQb0FqMnfsM+B3oJbrYUYNEgCjk3Az7aL06WPtcbQoQWBSZ91csHFN8COuFwWNSiCeTuwYp4
P/VdMgpc5MKzMo7EZLyPR2nJQumTu00wh+c3XWTXCWCXO2qw2+7nukM0lR9rFZDyd/62/QIqjSJk
Ee9JafZWORj5U4c2/+LRMigriCnToYNnisWSeFUPH9XZQQhkno5Pl7GHg7Q9Q2Utm2aWi4aDp05Q
kQ1qnq4LohBchTHc9Najy9s1vtLm14iqnKtkafOjBtUhSQKOemmzfpAc/PSXBEYm68vueYJQf8cM
OYTmZZjP7d0SU0ayA0E0++Gjg0EB5EqvmI96zhufXNpBvnkfSZCJ45/+gpP1FHDCeTewdLEYw6Gz
A2LUHg++DctoYPu8OOjED52ioV9hmzkpUbLzW6e03DOifCxMpG8/PxsnSQF516jIPOMKfCT1FkDy
opcAGqwJONiGd/gKsziAeRkVi7iccui9jA/xGtZr1v3bqqD2LENij/WlWe0ed0BXSw8FlojByICm
h8cahMGO7y/eYmq8D+znwQqka90P82+/45TkwZpxtb7MX92HOVMxyPp4dbNASc3hT99oHr0aKkO+
hqv33mORsLJOaMkywFvBA+9pbzb0vrd7WAW1T45xaQ+LmKsC8ByLEHXlDjpv97j9+SvMVKLbjH2a
VFAz7xlxcW169Ha2OaiI9yd+9hHfrJF6XaGmlieSR+x52MOSx9DfWQ8ME9bQd7lGLeCsIsXSu7YG
zr/5PsQenIg91GJB1bfByGEucORimWExG+YCYTGeyJ8erq1d53I5nl/IXdh4wIelCEBqkwPmiacC
bgYvHnLR+sVwFYtkPUehIG/+GBk8NgfqnvUv2F4fuSWbeRMXZT5MLWl7BkqfNSNbNDX8Jmzy8xt0
H+3dCpo3841hxdb6HKUZ/MsHyerdC+ocdAF8a/tM/H05NpNRMxngvFdD9BnPxXpWQw7C6eoSxeLO
xQi5sJKb2LkhZIkGXbvL14VZilfkp+IDUP2x+PKvY/LLnzjsXxks+WoiLijZAhuuHYKBlTVkfPAB
LKxrC3D0WDUYOLYvVhlJBvj5sVTBRzDLaZjDUzVuE3aeU9AxyDUYRBYiNmd+Blq9SA5fmeMG8MWq
+nxrTy5M/cn+1f9hrIx0hNbrUAT7h5mB+XpzU3jEYkC0ilOSvUPmVDZRvASwFeVixG3e/9038cE+
mmHAuSu93+yE0Cmbad+nRQ2vJc6QczC7YWqkowvrNh1JmbE63a1LlsIGZo+AV/qsWK41CMBvfw6d
eUrWy2O/wuPRKIMLMb/FXKXpCg0ab+bAVIolHaq7vNVzlPGeUkx7V3Nh6Z++xO3rF/36QqfABTDu
dl9fgGz5X+4CT8Mcj18NHV9TBeo2G5ESnPtiNmUzhrEltMjOa9Cs5fOiwcp15D/9JfleDcHmH5G2
Rh4gAxMH8NGe3T+9mqCaCvCVZkmwl/p2y4M3BoKivRGVj7iBXM/OHa7LKmJxVx+bX36GF6aJMc97
VYEFVhLEZ5kJwe6MFTrejZsC0MmyiHnu5YI8zXcIU0sIydYRarZ6EUAtSXy8X3uz+Lt/7OE4ILP3
xmJmvGEG0rFotvt01Of3pARQcoqaaDmWk/H4Eip4uTdncujNlK6hMOVAfnRuEDSZAOiW12R6W1fk
fmpL7+Vi4ODm55GqnJViL9zDADg3gyWHp8knC1hOBoxzqSJBnBUedfHDlSpcH5C9dbBWiZU6uCAY
EqXlks0vtTVMeuIHrJx9BzK/RgH4mVggzeOahtpIqODQucHPPw4LmyuMfDfO12B/63swTavgwjQl
FnFeZl3MAXe+/Pwt0faRC9bTZfwCbxUfAR96nfdXX7R3YuMq51K6zMu9B9qrjAK6ekwyPm+O8Vdf
/VGE+jKs811OUhISPxcfOjXORif9/EtglgrgD2qSye7N2hHjiR2dvz8YHujy3UDKleMampy1HBB5
ORGXr3UwNpPNgV9+QLHYNGPDlSHkozUjqsSZdHlKxxI4H4NBXsJir53TOJYO57AgPiknOpjBGcJv
Z18whZHiLd3XX8EumivMPuiNrvw5mIHpxXOw/5g7fTlLSAGqfL8Q5XM2Emo+BAGMJ8pjeeNJizN8
NSHqhA/5+dWt3jG/+4gXLyo8aj5mCbRfLwzYheZgdmT/Czpsyyj8cKu+5K5Vw1tQffH+0A+U5nsn
Bqf7c0d8qfSTvk7LO2CSTsM7FbfegmKIgb47cMRCngV2H8kIpPtaX4I1jkKw+gLWpEATPdSkUVfM
OM07eG3HFJVKmTZ0B9lZugdVhU6T5yUb31jBTTnXwfzgEjAzNRsC92VQ4m18hByCcw/RYilYbkTO
owUuv9DVQ5UYM7YSar99BcrPq4ZrJYo3v7DE8LgzTuhyNrG+cn2vSFn97JH9MT2dM6ZjBdTXvUDH
W/n21kiNVrg7rU9Mk+jtrfWD8cEvv5Uma+mEhYwPN54QbPxsGDhzvINyPL0CJhKnYj1HF0na8kcg
RCYG9EDmHqJagMhZzUr/8+PkzNT45XkhpSpaSnm3zAVCb7HSx0dbcnDzK8HpgJtk8N9eLh28uAzq
KJobypRMDofcRcHL7B8FfZjvVtj8JQk+ojMsQfFMIYyuPvKjck1eqsbwcP+5AqJ3OPbwWb3wUIyK
78Zf6i1PghauiLGQb7AmxTJaLTharoMMFhsDXZhrDH/54s+/F7UkwAeuInQw+rFY20t9h1Et9eTQ
9L23GlEyShvfwfziPZPl5PUprLH3wjvdi3VOfUk5FJzVQI5Xc8V0AlUAM6bpUGCUVTMd4+0BhEPM
YjkR+WbsjvYFMuxxwlLN7gqM1NiCQlRwBF2yuVmH/hODiBE6FEbcDuCRcBhKoK2JRqJRXyErxfD5
9XCAN382j20O4emC5YCrvQzMjzbl4fvBEqKFXL09iWjFEDzaOwmmbO81cxBdwNNOIUIfWnrtzog6
aJJwxG3p7Qcy3nMLfA7sPfiMpkKJRwQNbDwD2aLZN/Sw9w14yZsMtzb2h3lnRK0czBMkfsK23sZX
MgiatiDl5h+mywpiyO1fN6LI0U3/+WvQjZlFVMBZHg/QeoFUXqdA1OvTsHeR4MNPbjcoirnR+8v/
p+5JiTPXwQDOZ2f+8TOk7LnZm21zSX8dxGD+cmuyfKLzCpcXNYK90fsJBZDhQQ7HAwn0Ui12xTfI
BGexIN70PFmpUBmw+To5UTd+vLrPmIOOc9DRAfb6v/giv6xRwKM+bWbWuCi/P2OhrIE37tMoFZ3F
gMTvWLXg9uk1+8tz01E8FyvXVwpcXouBhdycwOgd/TuwzYMfrFw0JPOYxgLcL/MBRXO0SzDeH/if
P//xQPqrF1A+dEd01ESBYq7vNYjsSUSBVj692TweL+L2RLZAMGqG/vIRsEhc4++9fjeLJDkY7pet
g7hnARguwcmF2TiSgN+ZcMCugDN4sgQLM4F4HBZ1aEIQSEAnfivKCU6FdobXakyIccYu5byjcYfw
eEVY2JuOTszgwYCOZblA8OtbM3/bIpacJrRI4ZUl5ccH94WalwTb+lbNOgkfBXZcapCD1LfeOA+v
GaKPoZFI5l4N3tYfiEvx2vz+21sNyXahdOgGhHbZQHEgvLD4XJ0RbefJm8tJnUGAgRH0W79jddRC
gfxpPqOLXPPFx9HkVtp4APKiEiYz9FoDKqf7iwS96BTzgysFSJPXgHQuehaYsNAGv/0VffMFJq1m
+l/eJp7PBg1PzgiDUji1xClMw/vxJ8iwaCLIzdaC58/BCrnzqw7WO6fQXZUfv2Co7SNSIfcq6GBO
I7xCHGHJqr1kx0c3CSSWlP++wVFQfe9juDvNTxzhaEfHhktjuJiLs9WHcJgD7nGBk0h7LO3r1tv2
L/3jJd3Wn5mrSXXhAqBLtDQKEyqU+xSq4v1MdBpp3iQutxye788nMiOsDnwsTIb043E6jWoPF9El
hvYK5C0/68Me76YQjJ6sIuPlZQO18fkO188KMGuJLViZw/EuCqTbI/UeCcn6JbIGaztbSdCJDlhv
lyGHeM+8iS2adsOHz6sE9eMBBIvEvejsTn4HmenCI1Xjgo3vzAJwYiBg1s3i7Rmb7B3o75AJBqdW
vX3OpBje3PqDxZvZDPMxPbewZ+wP8jW2K6ZVvZdwOw/EyLDblC/vXUNCYbnxXC6ht4O9QtcFM95l
HinmxiMcaIzsTayNly1H8CyhLpcGOpx6d+MJbQ/nM7yQ9ORdvSlcYQU77Mp43fweRcH2DNVcYLBQ
mlMxRrKX/+WFxYuA16vyUfjlaXKSvR5wr5tSwozDE978nj7Ue2W7z0TETJ1dmvnJlR04K3gkWsE9
vb4f3hr88X1PZt/F8nJ9Bm58k/z4886qGQWa55AE7Jk+9HW/Dzox7oRHsI5YKtrk5oVQbFpCtBP3
BBtP4WGRnlZiNN5Zx+uliiFGDCbGHr8o9YKH9uPzwd42Rfo8DN8UvsY0JJbUY32tEeOCZ+wtGz/b
0emuSXcY3aWBeO9S1PvnzbEgc2h15CR1omP2sXCAeXQK0lYsNvPa5tqvvxh8bvWSLCdQ+XCNVoYc
yr4f6BmfYphYQo6igesHUjPFHUbc9AjYVNT1jTfY8nRmeLxK0XcYLnu1A44eesh89NAb3ZNoAcZr
jYBD2Pd21SppcCkgwszGK2fIXSro7GMNqUt0GsbQnC3Y2FlPEMgG7+en4MtPT0j3o8NAvIPewce3
CpE+Rlqzml/7X/XD+5SXhuyCcIY3vmqIdo1Ise73Vguzalzw12EvlHb3QgH6ZPJIHyK9oNXrnf/y
PXJT9pz8/CJA4bTHn1sdFaN9EnOw5Umk+txIu4NaZJA86ZmoR27SccHuQ9By2QUdYcYkI8NdfAhP
xfZMT1EtPj8+vvEgzLVeViy7XKvlO19dUT7XRrP/8dJt/5Fle4eC8rtRkT6M/cAyLRtK4rd7B4+1
DojKRLQgA5P70JEtiWgyvniz4I34p6/EevSxN4YnwYZp1sjI2/L+ssvdSj6YhwwhkV6bNp70FLZl
muNair7NMq2CDdvYS4K9aebexlsZeBPOecDYYpDQKigEuMhUxUwvfgrin/UM8vu3g9sz/tKxPSoY
3uLqTdSNr6+Z0JZQaaICaRrXNqvbd/EfX9oJ/b7BB7VIwa8fvL/1NuBsU0x/+RADs5SHhfmqmizq
LYeQl8UDjd/aHRbGaBJdiz4FLoWmBvtPATDYsX2zlG4QwF8/odj4Ga/mdg83voHn69kCKzkf8P9+
RsG//fu//8/fb0Ho+tv9tQ0GTPdl+uf/GRX4Z37L/8lx/D8J//fbEvCYV/d//Me/hhD+8Rn67jP9
r6lv7+/xH//x7/u/aYN/TP2Uv/6vv/637f/6z3/7LwAAAP//AwDmi7xYhWEAAA==
headers:
CF-Cache-Status:
- DYNAMIC
CF-RAY:
- 7bd02f926f51dc93-LHR
Connection:
- keep-alive
Content-Encoding:
- gzip
Content-Type:
- application/json
Date:
- Mon, 24 Apr 2023 17:49:57 GMT
Server:
- cloudflare
Transfer-Encoding:
- chunked
access-control-allow-origin:
- '*'
alt-svc:
- h3=":443"; ma=86400, h3-29=":443"; ma=86400
openai-organization:
- user-iy0qn7phyookv8vra62ulvxe
openai-processing-ms:
- '175'
openai-version:
- '2020-10-01'
strict-transport-security:
- max-age=15724800; includeSubDomains
x-ratelimit-limit-requests:
- '60'
x-ratelimit-remaining-requests:
- '59'
x-ratelimit-reset-requests:
- 1s
x-request-id:
- 65b18c2ab828f8b407f94720e7dc95db
status:
code: 200
message: OK
version: 1
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,695 | Allow Weaviate initialization with alternative embedding implementation | I would like to provide an 'embeddings' parameter for the initialization of the Weaviate vector store, as I do not want to start the Weaviate server with the OpenAI key in order to make use of embeddings through the Azure OpenAI Service.
The addition of the embeddings parameter affects the __init__ method, as shown in the code snippet above. To accommodate this change, you'll also need to modify the add_texts method.
```python
def __init__(
self,
client: Any,
index_name: str,
text_key: str,
embedding_function: Optional[Embeddings] = None,
attributes: Optional[List[str]] = None,
):
"""Initialize with Weaviate client."""
try:
import weaviate
except ImportError:
raise ValueError(
"Could not import weaviate python package. "
"Please install it with `pip install weaviate-client`."
)
if not isinstance(client, weaviate.Client):
raise ValueError(
f"client should be an instance of weaviate.Client, got {type(client)}"
)
self._client = client
self._index_name = index_name
self._text_key = text_key
self._embedding_function = embedding_function
self._query_attrs = [self._text_key]
if attributes is not None:
self._query_attrs.extend(attributes)
```
To check if the embeddings parameter was provided during initialization and perform the necessary actions, you can modify the add_texts method in the following way:
```python
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> List[str]:
"""Upload texts with metadata (properties) to Weaviate."""
from weaviate.util import get_valid_uuid
with self._client.batch as batch:
ids = []
for i, doc in enumerate(texts):
data_properties = {
self._text_key: doc,
}
if metadatas is not None:
for key in metadatas[i].keys():
data_properties[key] = metadatas[i][key]
_id = get_valid_uuid(uuid4())
if self._embedding_function is not None:
embeddings = self._embedding_function.embed_documents(list(doc))
batch.add_data_object(data_properties, self._index_name, _id, vector=embeddings[0])
else:
batch.add_data_object(data_properties, self._index_name, _id)
ids.append(_id)
return ids
``` | https://github.com/langchain-ai/langchain/issues/2695 | https://github.com/langchain-ai/langchain/pull/3608 | 615812581ea3175b3ae9ec59036008d013052396 | 440c98e24bf3f18c132694309872592ef550e1bc | "2023-04-11T05:19:00Z" | python | "2023-04-27T04:45:03Z" | tests/integration_tests/vectorstores/test_weaviate.py | """Test Weaviate functionality."""
import logging
import os
from typing import Generator, Union
import pytest
from weaviate import Client
from langchain.docstore.document import Document
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores.weaviate import Weaviate
logging.basicConfig(level=logging.DEBUG)
"""
cd tests/integration_tests/vectorstores/docker-compose
docker compose -f weaviate.yml up
"""
class TestWeaviate:
@classmethod
def setup_class(cls) -> None:
if not os.getenv("OPENAI_API_KEY"):
raise ValueError("OPENAI_API_KEY environment variable is not set")
@pytest.fixture(scope="class", autouse=True)
def weaviate_url(self) -> Union[str, Generator[str, None, None]]:
"""Return the weaviate url."""
url = "http://localhost:8080"
yield url
# Clear the test index
client = Client(url)
client.schema.delete_all()
@pytest.mark.vcr(ignore_localhost=True)
def test_similarity_search_without_metadata(
self, weaviate_url: str, embedding_openai: OpenAIEmbeddings
) -> None:
"""Test end to end construction and search without metadata."""
texts = ["foo", "bar", "baz"]
docsearch = Weaviate.from_texts(
texts,
embedding_openai,
weaviate_url=weaviate_url,
)
output = docsearch.similarity_search("foo", k=1)
assert output == [Document(page_content="foo")]
@pytest.mark.vcr(ignore_localhost=True)
def test_similarity_search_with_metadata(
self, weaviate_url: str, embedding_openai: OpenAIEmbeddings
) -> None:
"""Test end to end construction and search with metadata."""
texts = ["foo", "bar", "baz"]
metadatas = [{"page": i} for i in range(len(texts))]
docsearch = Weaviate.from_texts(
texts, embedding_openai, metadatas=metadatas, weaviate_url=weaviate_url
)
output = docsearch.similarity_search("foo", k=1)
assert output == [Document(page_content="foo", metadata={"page": 0})]
@pytest.mark.vcr(ignore_localhost=True)
def test_similarity_search_with_metadata_and_filter(
self, weaviate_url: str, embedding_openai: OpenAIEmbeddings
) -> None:
"""Test end to end construction and search with metadata."""
texts = ["foo", "bar", "baz"]
metadatas = [{"page": i} for i in range(len(texts))]
docsearch = Weaviate.from_texts(
texts, embedding_openai, metadatas=metadatas, weaviate_url=weaviate_url
)
output = docsearch.similarity_search(
"foo",
k=2,
where_filter={"path": ["page"], "operator": "Equal", "valueNumber": 0},
)
assert output == [Document(page_content="foo", metadata={"page": 0})]
@pytest.mark.vcr(ignore_localhost=True)
def test_max_marginal_relevance_search(
self, weaviate_url: str, embedding_openai: OpenAIEmbeddings
) -> None:
"""Test end to end construction and MRR search."""
texts = ["foo", "bar", "baz"]
metadatas = [{"page": i} for i in range(len(texts))]
docsearch = Weaviate.from_texts(
texts, embedding_openai, metadatas=metadatas, weaviate_url=weaviate_url
)
# if lambda=1 the algorithm should be equivalent to standard ranking
standard_ranking = docsearch.similarity_search("foo", k=2)
output = docsearch.max_marginal_relevance_search(
"foo", k=2, fetch_k=3, lambda_mult=1.0
)
assert output == standard_ranking
# if lambda=0 the algorithm should favour maximal diversity
output = docsearch.max_marginal_relevance_search(
"foo", k=2, fetch_k=3, lambda_mult=0.0
)
assert output == [
Document(page_content="foo", metadata={"page": 0}),
Document(page_content="bar", metadata={"page": 1}),
]
@pytest.mark.vcr(ignore_localhost=True)
def test_max_marginal_relevance_search_by_vector(
self, weaviate_url: str, embedding_openai: OpenAIEmbeddings
) -> None:
"""Test end to end construction and MRR search by vector."""
texts = ["foo", "bar", "baz"]
metadatas = [{"page": i} for i in range(len(texts))]
docsearch = Weaviate.from_texts(
texts, embedding_openai, metadatas=metadatas, weaviate_url=weaviate_url
)
foo_embedding = embedding_openai.embed_query("foo")
# if lambda=1 the algorithm should be equivalent to standard ranking
standard_ranking = docsearch.similarity_search("foo", k=2)
output = docsearch.max_marginal_relevance_search_by_vector(
foo_embedding, k=2, fetch_k=3, lambda_mult=1.0
)
assert output == standard_ranking
# if lambda=0 the algorithm should favour maximal diversity
output = docsearch.max_marginal_relevance_search_by_vector(
foo_embedding, k=2, fetch_k=3, lambda_mult=0.0
)
assert output == [
Document(page_content="foo", metadata={"page": 0}),
Document(page_content="bar", metadata={"page": 1}),
]
@pytest.mark.vcr(ignore_localhost=True)
def test_max_marginal_relevance_search_with_filter(
self, weaviate_url: str, embedding_openai: OpenAIEmbeddings
) -> None:
"""Test end to end construction and MRR search."""
texts = ["foo", "bar", "baz"]
metadatas = [{"page": i} for i in range(len(texts))]
docsearch = Weaviate.from_texts(
texts, embedding_openai, metadatas=metadatas, weaviate_url=weaviate_url
)
where_filter = {"path": ["page"], "operator": "Equal", "valueNumber": 0}
# if lambda=1 the algorithm should be equivalent to standard ranking
standard_ranking = docsearch.similarity_search(
"foo", k=2, where_filter=where_filter
)
output = docsearch.max_marginal_relevance_search(
"foo", k=2, fetch_k=3, lambda_mult=1.0, where_filter=where_filter
)
assert output == standard_ranking
# if lambda=0 the algorithm should favour maximal diversity
output = docsearch.max_marginal_relevance_search(
"foo", k=2, fetch_k=3, lambda_mult=0.0, where_filter=where_filter
)
assert output == [
Document(page_content="foo", metadata={"page": 0}),
]
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,664 | import error when importing `from langchain import OpenAI` on 0.0.151 | got the following error when running today:
``` File "venv/lib/python3.11/site-packages/langchain/__init__.py", line 6, in <module>
from langchain.agents import MRKLChain, ReActChain, SelfAskWithSearchChain
File "venv/lib/python3.11/site-packages/langchain/agents/__init__.py", line 2, in <module>
from langchain.agents.agent import (
File "venv/lib/python3.11/site-packages/langchain/agents/agent.py", line 17, in <module>
from langchain.chains.base import Chain
File "venv/lib/python3.11/site-packages/langchain/chains/__init__.py", line 2, in <module>
from langchain.chains.api.base import APIChain
File "venv/lib/python3.11/site-packages/langchain/chains/api/base.py", line 8, in <module>
from langchain.chains.api.prompt import API_RESPONSE_PROMPT, API_URL_PROMPT
File "venv/lib/python3.11/site-packages/langchain/chains/api/prompt.py", line 2, in <module>
from langchain.prompts.prompt import PromptTemplate
File "venv/lib/python3.11/site-packages/langchain/prompts/__init__.py", line 14, in <module>
from langchain.prompts.loading import load_prompt
File "venv/lib/python3.11/site-packages/langchain/prompts/loading.py", line 14, in <module>
from langchain.utilities.loading import try_load_from_hub
File "venv/lib/python3.11/site-packages/langchain/utilities/__init__.py", line 5, in <module>
from langchain.utilities.bash import BashProcess
File "venv/lib/python3.11/site-packages/langchain/utilities/bash.py", line 7, in <module>
import pexpect
ModuleNotFoundError: No module named 'pexpect'
```
does this need to be added to project dependencies? | https://github.com/langchain-ai/langchain/issues/3664 | https://github.com/langchain-ai/langchain/pull/3667 | 708787dddb2fa3cdb2d1dabefa00c01ffec572f6 | 1b5721c999c9fc310cefec383666f43c80ec9620 | "2023-04-27T16:24:30Z" | python | "2023-04-27T18:39:01Z" | langchain/utilities/bash.py | """Wrapper around subprocess to run commands."""
import re
import subprocess
from typing import List, Union
from uuid import uuid4
import pexpect
class BashProcess:
"""Executes bash commands and returns the output."""
def __init__(
self,
strip_newlines: bool = False,
return_err_output: bool = False,
persistent: bool = False,
):
"""Initialize with stripping newlines."""
self.strip_newlines = strip_newlines
self.return_err_output = return_err_output
self.prompt = ""
self.process = None
if persistent:
self.prompt = str(uuid4())
self.process = self._initialize_persistent_process(self.prompt)
@staticmethod
def _initialize_persistent_process(prompt: str) -> pexpect.spawn:
# Start bash in a clean environment
process = pexpect.spawn(
"env", ["-i", "bash", "--norc", "--noprofile"], encoding="utf-8"
)
# Set the custom prompt
process.sendline("PS1=" + prompt)
process.expect_exact(prompt, timeout=10)
return process
def run(self, commands: Union[str, List[str]]) -> str:
"""Run commands and return final output."""
if isinstance(commands, str):
commands = [commands]
commands = ";".join(commands)
if self.process is not None:
return self._run_persistent(
commands,
)
else:
return self._run(commands)
def _run(self, command: str) -> str:
"""Run commands and return final output."""
try:
output = subprocess.run(
command,
shell=True,
check=True,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
).stdout.decode()
except subprocess.CalledProcessError as error:
if self.return_err_output:
return error.stdout.decode()
return str(error)
if self.strip_newlines:
output = output.strip()
return output
def process_output(self, output: str, command: str) -> str:
# Remove the command from the output using a regular expression
pattern = re.escape(command) + r"\s*\n"
output = re.sub(pattern, "", output, count=1)
return output.strip()
def _run_persistent(self, command: str) -> str:
"""Run commands and return final output."""
if self.process is None:
raise ValueError("Process not initialized")
self.process.sendline(command)
# Clear the output with an empty string
self.process.expect(self.prompt, timeout=10)
self.process.sendline("")
try:
self.process.expect([self.prompt, pexpect.EOF], timeout=10)
except pexpect.TIMEOUT:
return f"Timeout error while executing command {command}"
if self.process.after == pexpect.EOF:
return f"Exited with error status: {self.process.exitstatus}"
output = self.process.before
output = self.process_output(output, command)
if self.strip_newlines:
return output.strip()
return output
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,664 | import error when importing `from langchain import OpenAI` on 0.0.151 | got the following error when running today:
``` File "venv/lib/python3.11/site-packages/langchain/__init__.py", line 6, in <module>
from langchain.agents import MRKLChain, ReActChain, SelfAskWithSearchChain
File "venv/lib/python3.11/site-packages/langchain/agents/__init__.py", line 2, in <module>
from langchain.agents.agent import (
File "venv/lib/python3.11/site-packages/langchain/agents/agent.py", line 17, in <module>
from langchain.chains.base import Chain
File "venv/lib/python3.11/site-packages/langchain/chains/__init__.py", line 2, in <module>
from langchain.chains.api.base import APIChain
File "venv/lib/python3.11/site-packages/langchain/chains/api/base.py", line 8, in <module>
from langchain.chains.api.prompt import API_RESPONSE_PROMPT, API_URL_PROMPT
File "venv/lib/python3.11/site-packages/langchain/chains/api/prompt.py", line 2, in <module>
from langchain.prompts.prompt import PromptTemplate
File "venv/lib/python3.11/site-packages/langchain/prompts/__init__.py", line 14, in <module>
from langchain.prompts.loading import load_prompt
File "venv/lib/python3.11/site-packages/langchain/prompts/loading.py", line 14, in <module>
from langchain.utilities.loading import try_load_from_hub
File "venv/lib/python3.11/site-packages/langchain/utilities/__init__.py", line 5, in <module>
from langchain.utilities.bash import BashProcess
File "venv/lib/python3.11/site-packages/langchain/utilities/bash.py", line 7, in <module>
import pexpect
ModuleNotFoundError: No module named 'pexpect'
```
does this need to be added to project dependencies? | https://github.com/langchain-ai/langchain/issues/3664 | https://github.com/langchain-ai/langchain/pull/3667 | 708787dddb2fa3cdb2d1dabefa00c01ffec572f6 | 1b5721c999c9fc310cefec383666f43c80ec9620 | "2023-04-27T16:24:30Z" | python | "2023-04-27T18:39:01Z" | pyproject.toml | [tool.poetry]
name = "langchain"
version = "0.0.151"
description = "Building applications with LLMs through composability"
authors = []
license = "MIT"
readme = "README.md"
repository = "https://www.github.com/hwchase17/langchain"
[tool.poetry.scripts]
langchain-server = "langchain.server:main"
[tool.poetry.dependencies]
python = ">=3.8.1,<4.0"
pydantic = "^1"
SQLAlchemy = ">1.3,<3"
requests = "^2"
PyYAML = ">=5.4.1"
numpy = "^1"
azure-core = {version = "^1.26.4", optional=true}
tqdm = {version = ">=4.48.0", optional = true}
openapi-schema-pydantic = "^1.2"
faiss-cpu = {version = "^1", optional = true}
wikipedia = {version = "^1", optional = true}
elasticsearch = {version = "^8", optional = true}
opensearch-py = {version = "^2.0.0", optional = true}
redis = {version = "^4", optional = true}
manifest-ml = {version = "^0.0.1", optional = true}
spacy = {version = "^3", optional = true}
nltk = {version = "^3", optional = true}
transformers = {version = "^4", optional = true}
beautifulsoup4 = {version = "^4", optional = true}
torch = {version = ">=1,<3", optional = true}
jinja2 = {version = "^3", optional = true}
tiktoken = {version = "^0.3.2", optional = true, python="^3.9"}
pinecone-client = {version = "^2", optional = true}
pinecone-text = {version = "^0.4.2", optional = true}
clickhouse-connect = {version="^0.5.14", optional=true}
weaviate-client = {version = "^3", optional = true}
google-api-python-client = {version = "2.70.0", optional = true}
wolframalpha = {version = "5.0.0", optional = true}
anthropic = {version = "^0.2.6", optional = true}
qdrant-client = {version = "^1.1.2", optional = true, python = ">=3.8.1,<3.12"}
dataclasses-json = "^0.5.7"
tensorflow-text = {version = "^2.11.0", optional = true, python = "^3.10, <3.12"}
tenacity = "^8.1.0"
cohere = {version = "^3", optional = true}
openai = {version = "^0", optional = true}
nlpcloud = {version = "^1", optional = true}
nomic = {version = "^1.0.43", optional = true}
huggingface_hub = {version = "^0", optional = true}
jina = {version = "^3.14", optional = true}
google-search-results = {version = "^2", optional = true}
sentence-transformers = {version = "^2", optional = true}
aiohttp = "^3.8.3"
arxiv = {version = "^1.4", optional = true}
pypdf = {version = "^3.4.0", optional = true}
networkx = {version="^2.6.3", optional = true}
aleph-alpha-client = {version="^2.15.0", optional = true}
deeplake = {version = "^3.3.0", optional = true}
pgvector = {version = "^0.1.6", optional = true}
psycopg2-binary = {version = "^2.9.5", optional = true}
#boto3 = {version = "^1.26.96", optional = true} # TODO: fix it, commented because the version failed with deeplake
pyowm = {version = "^3.3.0", optional = true}
async-timeout = {version = "^4.0.0", python = "<3.11"}
azure-identity = {version = "^1.12.0", optional=true}
gptcache = {version = ">=0.1.7", optional = true}
atlassian-python-api = {version = "^3.36.0", optional=true}
pytesseract = {version = "^0.3.10", optional=true}
html2text = {version="^2020.1.16", optional=true}
numexpr = "^2.8.4"
duckduckgo-search = {version="^2.8.6", optional=true}
azure-cosmos = {version="^4.4.0b1", optional=true}
lark = {version="^1.1.5", optional=true}
lancedb = {version = "^0.1", optional = true}
[tool.poetry.group.docs.dependencies]
autodoc_pydantic = "^1.8.0"
myst_parser = "^0.18.1"
nbsphinx = "^0.8.9"
sphinx = "^4.5.0"
sphinx-autobuild = "^2021.3.14"
sphinx_book_theme = "^0.3.3"
sphinx_rtd_theme = "^1.0.0"
sphinx-typlog-theme = "^0.8.0"
sphinx-panels = "^0.6.0"
toml = "^0.10.2"
myst-nb = "^0.17.1"
linkchecker = "^10.2.1"
sphinx-copybutton = "^0.5.1"
[tool.poetry.group.test.dependencies]
pytest = "^7.3.0"
pytest-cov = "^4.0.0"
pytest-dotenv = "^0.5.2"
duckdb-engine = "^0.7.0"
pytest-watcher = "^0.2.6"
freezegun = "^1.2.2"
responses = "^0.22.0"
pytest-asyncio = "^0.20.3"
[tool.poetry.group.test_integration]
optional = true
[tool.poetry.group.test_integration.dependencies]
pytest-vcr = "^1.0.2"
wrapt = "^1.15.0"
openai = "^0.27.4"
elasticsearch = {extras = ["async"], version = "^8.6.2"}
redis = "^4.5.4"
pinecone-client = "^2.2.1"
pinecone-text = "^0.4.2"
clickhouse-connect = "^0.5.14"
pgvector = "^0.1.6"
transformers = "^4.27.4"
pandas = "^2.0.0"
deeplake = "^3.2.21"
weaviate-client = "^3.15.5"
torch = "^1.0.0"
chromadb = "^0.3.21"
tiktoken = "^0.3.3"
python-dotenv = "^1.0.0"
sentence-transformers = "^2"
gptcache = "^0.1.9"
promptlayer = "^0.1.80"
[tool.poetry.group.lint.dependencies]
ruff = "^0.0.249"
types-toml = "^0.10.8.1"
types-redis = "^4.3.21.6"
black = "^23.1.0"
[tool.poetry.group.typing.dependencies]
mypy = "^0.991"
types-pyyaml = "^6.0.12.2"
types-requests = "^2.28.11.5"
[tool.poetry.group.dev]
optional = true
[tool.poetry.group.dev.dependencies]
jupyter = "^1.0.0"
playwright = "^1.28.0"
setuptools = "^67.6.1"
[tool.poetry.extras]
llms = ["anthropic", "cohere", "openai", "nlpcloud", "huggingface_hub", "manifest-ml", "torch", "transformers"]
qdrant = ["qdrant-client"]
openai = ["openai"]
cohere = ["cohere"]
embeddings = ["sentence-transformers"]
azure = ["azure-identity", "azure-cosmos", "openai", "azure-core"]
all = ["anthropic", "cohere", "openai", "nlpcloud", "huggingface_hub", "jina", "manifest-ml", "elasticsearch", "opensearch-py", "google-search-results", "faiss-cpu", "sentence-transformers", "transformers", "spacy", "nltk", "wikipedia", "beautifulsoup4", "tiktoken", "torch", "jinja2", "pinecone-client", "pinecone-text", "weaviate-client", "redis", "google-api-python-client", "wolframalpha", "qdrant-client", "tensorflow-text", "pypdf", "networkx", "nomic", "aleph-alpha-client", "deeplake", "pgvector", "psycopg2-binary", "boto3", "pyowm", "pytesseract", "html2text", "atlassian-python-api", "gptcache", "duckduckgo-search", "arxiv", "azure-identity", "clickhouse-connect", "azure-cosmos", "lancedb", "lark"]
[tool.ruff]
select = [
"E", # pycodestyle
"F", # pyflakes
"I", # isort
]
exclude = [
"tests/integration_tests/examples/non-utf8-encoding.py",
]
[tool.mypy]
ignore_missing_imports = "True"
disallow_untyped_defs = "True"
exclude = ["notebooks"]
[tool.coverage.run]
omit = [
"tests/*",
]
[build-system]
requires = ["poetry-core>=1.0.0"]
build-backend = "poetry.core.masonry.api"
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,628 | Chroma.py max_marginal_relevance_search_by_vector method currently broken | Using MMR with Chroma currently does not work because the max_marginal_relevance_search_by_vector method calls self.__query_collection with the parameter "include:", but "include" is not an accepted parameter for __query_collection. This appears to be a regression introduced with #3372
Excerpt from max_marginal_relevance_search_by_vector method:
```
results = self.__query_collection(
query_embeddings=embedding,
n_results=fetch_k,
where=filter,
include=["metadatas", "documents", "distances", "embeddings"],
)
```
__query_collection does not accept include:
```
def __query_collection(
self,
query_texts: Optional[List[str]] = None,
query_embeddings: Optional[List[List[float]]] = None,
n_results: int = 4,
where: Optional[Dict[str, str]] = None,
) -> List[Document]:
```
This results in an unexpected keyword error.
The short term fix is to use self._collection.query instead of self.__query_collection in max_marginal_relevance_search_by_vector, although that loses the protection when the user requests more records than exist in the store.
```
results = self._collection.query(
query_embeddings=embedding,
n_results=fetch_k,
where=filter,
include=["metadatas", "documents", "distances", "embeddings"],
)
``` | https://github.com/langchain-ai/langchain/issues/3628 | https://github.com/langchain-ai/langchain/pull/3897 | 3e1cb31f63b5c7147939feca7f8095377f64e145 | 245131097557b73774197b01e326206fa2a1b83a | "2023-04-27T00:21:42Z" | python | "2023-05-01T17:47:15Z" | langchain/vectorstores/chroma.py | """Wrapper around ChromaDB embeddings platform."""
from __future__ import annotations
import logging
import uuid
from typing import TYPE_CHECKING, Any, Dict, Iterable, List, Optional, Tuple, Type
import numpy as np
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from langchain.utils import xor_args
from langchain.vectorstores.base import VectorStore
from langchain.vectorstores.utils import maximal_marginal_relevance
if TYPE_CHECKING:
import chromadb
import chromadb.config
logger = logging.getLogger(__name__)
def _results_to_docs(results: Any) -> List[Document]:
return [doc for doc, _ in _results_to_docs_and_scores(results)]
def _results_to_docs_and_scores(results: Any) -> List[Tuple[Document, float]]:
return [
# TODO: Chroma can do batch querying,
# we shouldn't hard code to the 1st result
(Document(page_content=result[0], metadata=result[1] or {}), result[2])
for result in zip(
results["documents"][0],
results["metadatas"][0],
results["distances"][0],
)
]
class Chroma(VectorStore):
"""Wrapper around ChromaDB embeddings platform.
To use, you should have the ``chromadb`` python package installed.
Example:
.. code-block:: python
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
vectorstore = Chroma("langchain_store", embeddings.embed_query)
"""
_LANGCHAIN_DEFAULT_COLLECTION_NAME = "langchain"
def __init__(
self,
collection_name: str = _LANGCHAIN_DEFAULT_COLLECTION_NAME,
embedding_function: Optional[Embeddings] = None,
persist_directory: Optional[str] = None,
client_settings: Optional[chromadb.config.Settings] = None,
collection_metadata: Optional[Dict] = None,
client: Optional[chromadb.Client] = None,
) -> None:
"""Initialize with Chroma client."""
try:
import chromadb
import chromadb.config
except ImportError:
raise ValueError(
"Could not import chromadb python package. "
"Please install it with `pip install chromadb`."
)
if client is not None:
self._client = client
else:
if client_settings:
self._client_settings = client_settings
else:
self._client_settings = chromadb.config.Settings()
if persist_directory is not None:
self._client_settings = chromadb.config.Settings(
chroma_db_impl="duckdb+parquet",
persist_directory=persist_directory,
)
self._client = chromadb.Client(self._client_settings)
self._embedding_function = embedding_function
self._persist_directory = persist_directory
self._collection = self._client.get_or_create_collection(
name=collection_name,
embedding_function=self._embedding_function.embed_documents
if self._embedding_function is not None
else None,
metadata=collection_metadata,
)
@xor_args(("query_texts", "query_embeddings"))
def __query_collection(
self,
query_texts: Optional[List[str]] = None,
query_embeddings: Optional[List[List[float]]] = None,
n_results: int = 4,
where: Optional[Dict[str, str]] = None,
) -> List[Document]:
"""Query the chroma collection."""
for i in range(n_results, 0, -1):
try:
return self._collection.query(
query_texts=query_texts,
query_embeddings=query_embeddings,
n_results=i,
where=where,
)
except chromadb.errors.NotEnoughElementsException:
logger.error(
f"Chroma collection {self._collection.name} "
f"contains fewer than {i} elements."
)
raise chromadb.errors.NotEnoughElementsException(
f"No documents found for Chroma collection {self._collection.name}"
)
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
ids: Optional[List[str]] = None,
**kwargs: Any,
) -> List[str]:
"""Run more texts through the embeddings and add to the vectorstore.
Args:
texts (Iterable[str]): Texts to add to the vectorstore.
metadatas (Optional[List[dict]], optional): Optional list of metadatas.
ids (Optional[List[str]], optional): Optional list of IDs.
Returns:
List[str]: List of IDs of the added texts.
"""
# TODO: Handle the case where the user doesn't provide ids on the Collection
if ids is None:
ids = [str(uuid.uuid1()) for _ in texts]
embeddings = None
if self._embedding_function is not None:
embeddings = self._embedding_function.embed_documents(list(texts))
self._collection.add(
metadatas=metadatas, embeddings=embeddings, documents=texts, ids=ids
)
return ids
def similarity_search(
self,
query: str,
k: int = 4,
filter: Optional[Dict[str, str]] = None,
**kwargs: Any,
) -> List[Document]:
"""Run similarity search with Chroma.
Args:
query (str): Query text to search for.
k (int): Number of results to return. Defaults to 4.
filter (Optional[Dict[str, str]]): Filter by metadata. Defaults to None.
Returns:
List[Document]: List of documents most similar to the query text.
"""
docs_and_scores = self.similarity_search_with_score(query, k, filter=filter)
return [doc for doc, _ in docs_and_scores]
def similarity_search_by_vector(
self,
embedding: List[float],
k: int = 4,
filter: Optional[Dict[str, str]] = None,
**kwargs: Any,
) -> List[Document]:
"""Return docs most similar to embedding vector.
Args:
embedding: Embedding to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the query vector.
"""
results = self.__query_collection(
query_embeddings=embedding, n_results=k, where=filter
)
return _results_to_docs(results)
def similarity_search_with_score(
self,
query: str,
k: int = 4,
filter: Optional[Dict[str, str]] = None,
**kwargs: Any,
) -> List[Tuple[Document, float]]:
"""Run similarity search with Chroma with distance.
Args:
query (str): Query text to search for.
k (int): Number of results to return. Defaults to 4.
filter (Optional[Dict[str, str]]): Filter by metadata. Defaults to None.
Returns:
List[Tuple[Document, float]]: List of documents most similar to the query
text with distance in float.
"""
if self._embedding_function is None:
results = self.__query_collection(
query_texts=[query], n_results=k, where=filter
)
else:
query_embedding = self._embedding_function.embed_query(query)
results = self.__query_collection(
query_embeddings=[query_embedding], n_results=k, where=filter
)
return _results_to_docs_and_scores(results)
def max_marginal_relevance_search_by_vector(
self,
embedding: List[float],
k: int = 4,
fetch_k: int = 20,
lambda_mult: float = 0.5,
filter: Optional[Dict[str, str]] = None,
**kwargs: Any,
) -> List[Document]:
"""Return docs selected using the maximal marginal relevance.
Maximal marginal relevance optimizes for similarity to query AND diversity
among selected documents.
Args:
embedding: Embedding to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
fetch_k: Number of Documents to fetch to pass to MMR algorithm.
lambda_mult: Number between 0 and 1 that determines the degree
of diversity among the results with 0 corresponding
to maximum diversity and 1 to minimum diversity.
Defaults to 0.5.
filter (Optional[Dict[str, str]]): Filter by metadata. Defaults to None.
Returns:
List of Documents selected by maximal marginal relevance.
"""
results = self.__query_collection(
query_embeddings=embedding,
n_results=fetch_k,
where=filter,
include=["metadatas", "documents", "distances", "embeddings"],
)
mmr_selected = maximal_marginal_relevance(
np.array(embedding, dtype=np.float32),
results["embeddings"][0],
k=k,
lambda_mult=lambda_mult,
)
candidates = _results_to_docs(results)
selected_results = [r for i, r in enumerate(candidates) if i in mmr_selected]
return selected_results
def max_marginal_relevance_search(
self,
query: str,
k: int = 4,
fetch_k: int = 20,
lambda_mult: float = 0.5,
filter: Optional[Dict[str, str]] = None,
**kwargs: Any,
) -> List[Document]:
"""Return docs selected using the maximal marginal relevance.
Maximal marginal relevance optimizes for similarity to query AND diversity
among selected documents.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
fetch_k: Number of Documents to fetch to pass to MMR algorithm.
lambda_mult: Number between 0 and 1 that determines the degree
of diversity among the results with 0 corresponding
to maximum diversity and 1 to minimum diversity.
Defaults to 0.5.
filter (Optional[Dict[str, str]]): Filter by metadata. Defaults to None.
Returns:
List of Documents selected by maximal marginal relevance.
"""
if self._embedding_function is None:
raise ValueError(
"For MMR search, you must specify an embedding function on" "creation."
)
embedding = self._embedding_function.embed_query(query)
docs = self.max_marginal_relevance_search_by_vector(
embedding, k, fetch_k, lambda_mul=lambda_mult, filter=filter
)
return docs
def delete_collection(self) -> None:
"""Delete the collection."""
self._client.delete_collection(self._collection.name)
def persist(self) -> None:
"""Persist the collection.
This can be used to explicitly persist the data to disk.
It will also be called automatically when the object is destroyed.
"""
if self._persist_directory is None:
raise ValueError(
"You must specify a persist_directory on"
"creation to persist the collection."
)
self._client.persist()
def update_document(self, document_id: str, document: Document) -> None:
"""Update a document in the collection.
Args:
document_id (str): ID of the document to update.
document (Document): Document to update.
"""
text = document.page_content
metadata = document.metadata
self._collection.update_document(document_id, text, metadata)
@classmethod
def from_texts(
cls: Type[Chroma],
texts: List[str],
embedding: Optional[Embeddings] = None,
metadatas: Optional[List[dict]] = None,
ids: Optional[List[str]] = None,
collection_name: str = _LANGCHAIN_DEFAULT_COLLECTION_NAME,
persist_directory: Optional[str] = None,
client_settings: Optional[chromadb.config.Settings] = None,
client: Optional[chromadb.Client] = None,
**kwargs: Any,
) -> Chroma:
"""Create a Chroma vectorstore from a raw documents.
If a persist_directory is specified, the collection will be persisted there.
Otherwise, the data will be ephemeral in-memory.
Args:
texts (List[str]): List of texts to add to the collection.
collection_name (str): Name of the collection to create.
persist_directory (Optional[str]): Directory to persist the collection.
embedding (Optional[Embeddings]): Embedding function. Defaults to None.
metadatas (Optional[List[dict]]): List of metadatas. Defaults to None.
ids (Optional[List[str]]): List of document IDs. Defaults to None.
client_settings (Optional[chromadb.config.Settings]): Chroma client settings
Returns:
Chroma: Chroma vectorstore.
"""
chroma_collection = cls(
collection_name=collection_name,
embedding_function=embedding,
persist_directory=persist_directory,
client_settings=client_settings,
client=client,
)
chroma_collection.add_texts(texts=texts, metadatas=metadatas, ids=ids)
return chroma_collection
@classmethod
def from_documents(
cls: Type[Chroma],
documents: List[Document],
embedding: Optional[Embeddings] = None,
ids: Optional[List[str]] = None,
collection_name: str = _LANGCHAIN_DEFAULT_COLLECTION_NAME,
persist_directory: Optional[str] = None,
client_settings: Optional[chromadb.config.Settings] = None,
client: Optional[chromadb.Client] = None, # Add this line
**kwargs: Any,
) -> Chroma:
"""Create a Chroma vectorstore from a list of documents.
If a persist_directory is specified, the collection will be persisted there.
Otherwise, the data will be ephemeral in-memory.
Args:
collection_name (str): Name of the collection to create.
persist_directory (Optional[str]): Directory to persist the collection.
ids (Optional[List[str]]): List of document IDs. Defaults to None.
documents (List[Document]): List of documents to add to the vectorstore.
embedding (Optional[Embeddings]): Embedding function. Defaults to None.
client_settings (Optional[chromadb.config.Settings]): Chroma client settings
Returns:
Chroma: Chroma vectorstore.
"""
texts = [doc.page_content for doc in documents]
metadatas = [doc.metadata for doc in documents]
return cls.from_texts(
texts=texts,
embedding=embedding,
metadatas=metadatas,
ids=ids,
collection_name=collection_name,
persist_directory=persist_directory,
client_settings=client_settings,
client=client,
)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,628 | Chroma.py max_marginal_relevance_search_by_vector method currently broken | Using MMR with Chroma currently does not work because the max_marginal_relevance_search_by_vector method calls self.__query_collection with the parameter "include:", but "include" is not an accepted parameter for __query_collection. This appears to be a regression introduced with #3372
Excerpt from max_marginal_relevance_search_by_vector method:
```
results = self.__query_collection(
query_embeddings=embedding,
n_results=fetch_k,
where=filter,
include=["metadatas", "documents", "distances", "embeddings"],
)
```
__query_collection does not accept include:
```
def __query_collection(
self,
query_texts: Optional[List[str]] = None,
query_embeddings: Optional[List[List[float]]] = None,
n_results: int = 4,
where: Optional[Dict[str, str]] = None,
) -> List[Document]:
```
This results in an unexpected keyword error.
The short term fix is to use self._collection.query instead of self.__query_collection in max_marginal_relevance_search_by_vector, although that loses the protection when the user requests more records than exist in the store.
```
results = self._collection.query(
query_embeddings=embedding,
n_results=fetch_k,
where=filter,
include=["metadatas", "documents", "distances", "embeddings"],
)
``` | https://github.com/langchain-ai/langchain/issues/3628 | https://github.com/langchain-ai/langchain/pull/3897 | 3e1cb31f63b5c7147939feca7f8095377f64e145 | 245131097557b73774197b01e326206fa2a1b83a | "2023-04-27T00:21:42Z" | python | "2023-05-01T17:47:15Z" | tests/integration_tests/vectorstores/test_chroma.py | """Test Chroma functionality."""
import pytest
from langchain.docstore.document import Document
from langchain.vectorstores import Chroma
from tests.integration_tests.vectorstores.fake_embeddings import FakeEmbeddings
def test_chroma() -> None:
"""Test end to end construction and search."""
texts = ["foo", "bar", "baz"]
docsearch = Chroma.from_texts(
collection_name="test_collection", texts=texts, embedding=FakeEmbeddings()
)
output = docsearch.similarity_search("foo", k=1)
assert output == [Document(page_content="foo")]
@pytest.mark.asyncio
async def test_chroma_async() -> None:
"""Test end to end construction and search."""
texts = ["foo", "bar", "baz"]
docsearch = Chroma.from_texts(
collection_name="test_collection", texts=texts, embedding=FakeEmbeddings()
)
output = await docsearch.asimilarity_search("foo", k=1)
assert output == [Document(page_content="foo")]
def test_chroma_with_metadatas() -> None:
"""Test end to end construction and search."""
texts = ["foo", "bar", "baz"]
metadatas = [{"page": str(i)} for i in range(len(texts))]
docsearch = Chroma.from_texts(
collection_name="test_collection",
texts=texts,
embedding=FakeEmbeddings(),
metadatas=metadatas,
)
output = docsearch.similarity_search("foo", k=1)
assert output == [Document(page_content="foo", metadata={"page": "0"})]
def test_chroma_with_metadatas_with_scores() -> None:
"""Test end to end construction and scored search."""
texts = ["foo", "bar", "baz"]
metadatas = [{"page": str(i)} for i in range(len(texts))]
docsearch = Chroma.from_texts(
collection_name="test_collection",
texts=texts,
embedding=FakeEmbeddings(),
metadatas=metadatas,
)
output = docsearch.similarity_search_with_score("foo", k=1)
assert output == [(Document(page_content="foo", metadata={"page": "0"}), 0.0)]
def test_chroma_search_filter() -> None:
"""Test end to end construction and search with metadata filtering."""
texts = ["far", "bar", "baz"]
metadatas = [{"first_letter": "{}".format(text[0])} for text in texts]
docsearch = Chroma.from_texts(
collection_name="test_collection",
texts=texts,
embedding=FakeEmbeddings(),
metadatas=metadatas,
)
output = docsearch.similarity_search("far", k=1, filter={"first_letter": "f"})
assert output == [Document(page_content="far", metadata={"first_letter": "f"})]
output = docsearch.similarity_search("far", k=1, filter={"first_letter": "b"})
assert output == [Document(page_content="bar", metadata={"first_letter": "b"})]
def test_chroma_search_filter_with_scores() -> None:
"""Test end to end construction and scored search with metadata filtering."""
texts = ["far", "bar", "baz"]
metadatas = [{"first_letter": "{}".format(text[0])} for text in texts]
docsearch = Chroma.from_texts(
collection_name="test_collection",
texts=texts,
embedding=FakeEmbeddings(),
metadatas=metadatas,
)
output = docsearch.similarity_search_with_score(
"far", k=1, filter={"first_letter": "f"}
)
assert output == [
(Document(page_content="far", metadata={"first_letter": "f"}), 0.0)
]
output = docsearch.similarity_search_with_score(
"far", k=1, filter={"first_letter": "b"}
)
assert output == [
(Document(page_content="bar", metadata={"first_letter": "b"}), 1.0)
]
def test_chroma_with_persistence() -> None:
"""Test end to end construction and search, with persistence."""
chroma_persist_dir = "./tests/persist_dir"
collection_name = "test_collection"
texts = ["foo", "bar", "baz"]
docsearch = Chroma.from_texts(
collection_name=collection_name,
texts=texts,
embedding=FakeEmbeddings(),
persist_directory=chroma_persist_dir,
)
output = docsearch.similarity_search("foo", k=1)
assert output == [Document(page_content="foo")]
docsearch.persist()
# Get a new VectorStore from the persisted directory
docsearch = Chroma(
collection_name=collection_name,
embedding_function=FakeEmbeddings(),
persist_directory=chroma_persist_dir,
)
output = docsearch.similarity_search("foo", k=1)
# Clean up
docsearch.delete_collection()
# Persist doesn't need to be called again
# Data will be automatically persisted on object deletion
# Or on program exit
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,988 | LangChain openAI callback doesn't allow finetuned models | Hi all!
I have an [application](https://github.com/ur-whitelab/BO-LIFT) based on langchain.
A few months ago, I used it with fine-tuned (FT) models.
We added a token usage counter later, and I haven't tried fine-tuned models again since then.
Recently we have been interested in using (FT) models again, but the callback to expose the token usage isn't accepting the model.
Minimal code to reproduce the error:
```
from langchain.llms import OpenAI
from langchain.callbacks import get_openai_callback
llm = OpenAI(
model_name=FT_MODEL,
temperature=0.7,
n=5,
max_tokens=64,
)
with get_openai_callback() as cb:
completion_response = llm.generate(["QUERY"])
token_usage = cb.total_tokens
```
It works fine if the model name is a basic openAI model. For instance, ```model_name="text-davinci-003"```
But when I try to use one of my FT models, I get this error:
```
Error in on_llm_end callback: Unknown model: FT_MODEL. Please provide a valid OpenAI model name.Known models are: gpt-4, gpt-4-0314, gpt-4-completion, gpt-4-0314-completion, gpt-4-32k, gpt-4-32k-0314, gpt-4-32k-completion, gpt-4-32k-0314-completion, gpt-3.5-turbo, gpt-3.5-turbo-0301, text-ada-001, ada, text-babbage-001, babbage, text-curie-001, curie, text-davinci-003, text-davinci-002, code-davinci-002
```
It works if I remove the callback and avoid token counting, but it'd be nice to have any suggestions on how to make it work.
Is there a workaround for that?
Any help is welcome!
Thanks! | https://github.com/langchain-ai/langchain/issues/3988 | https://github.com/langchain-ai/langchain/pull/4009 | aa383559999b3d6a781c62ed7f8589fef8892879 | f08a76250fe8995fb3f05bf785677070922d4b0d | "2023-05-02T18:00:22Z" | python | "2023-05-02T23:19:57Z" | langchain/callbacks/openai_info.py | """Callback Handler that prints to std out."""
from typing import Any, Dict, List, Optional, Union
from langchain.callbacks.base import BaseCallbackHandler
from langchain.schema import AgentAction, AgentFinish, LLMResult
def get_openai_model_cost_per_1k_tokens(
model_name: str, is_completion: bool = False
) -> float:
model_cost_mapping = {
"gpt-4": 0.03,
"gpt-4-0314": 0.03,
"gpt-4-completion": 0.06,
"gpt-4-0314-completion": 0.06,
"gpt-4-32k": 0.06,
"gpt-4-32k-0314": 0.06,
"gpt-4-32k-completion": 0.12,
"gpt-4-32k-0314-completion": 0.12,
"gpt-3.5-turbo": 0.002,
"gpt-3.5-turbo-0301": 0.002,
"text-ada-001": 0.0004,
"ada": 0.0004,
"text-babbage-001": 0.0005,
"babbage": 0.0005,
"text-curie-001": 0.002,
"curie": 0.002,
"text-davinci-003": 0.02,
"text-davinci-002": 0.02,
"code-davinci-002": 0.02,
}
cost = model_cost_mapping.get(
model_name.lower()
+ ("-completion" if is_completion and model_name.startswith("gpt-4") else ""),
None,
)
if cost is None:
raise ValueError(
f"Unknown model: {model_name}. Please provide a valid OpenAI model name."
"Known models are: " + ", ".join(model_cost_mapping.keys())
)
return cost
class OpenAICallbackHandler(BaseCallbackHandler):
"""Callback Handler that tracks OpenAI info."""
total_tokens: int = 0
prompt_tokens: int = 0
completion_tokens: int = 0
successful_requests: int = 0
total_cost: float = 0.0
def __repr__(self) -> str:
return (
f"Tokens Used: {self.total_tokens}\n"
f"\tPrompt Tokens: {self.prompt_tokens}\n"
f"\tCompletion Tokens: {self.completion_tokens}\n"
f"Successful Requests: {self.successful_requests}\n"
f"Total Cost (USD): ${self.total_cost}"
)
@property
def always_verbose(self) -> bool:
"""Whether to call verbose callbacks even if verbose is False."""
return True
def on_llm_start(
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
) -> None:
"""Print out the prompts."""
pass
def on_llm_new_token(self, token: str, **kwargs: Any) -> None:
"""Print out the token."""
pass
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
"""Collect token usage."""
if response.llm_output is not None:
self.successful_requests += 1
if "token_usage" in response.llm_output:
token_usage = response.llm_output["token_usage"]
if "model_name" in response.llm_output:
completion_cost = get_openai_model_cost_per_1k_tokens(
response.llm_output["model_name"], is_completion=True
) * (token_usage.get("completion_tokens", 0) / 1000)
prompt_cost = get_openai_model_cost_per_1k_tokens(
response.llm_output["model_name"]
) * (token_usage.get("prompt_tokens", 0) / 1000)
self.total_cost += prompt_cost + completion_cost
if "total_tokens" in token_usage:
self.total_tokens += token_usage["total_tokens"]
if "prompt_tokens" in token_usage:
self.prompt_tokens += token_usage["prompt_tokens"]
if "completion_tokens" in token_usage:
self.completion_tokens += token_usage["completion_tokens"]
def on_llm_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> None:
"""Do nothing."""
pass
def on_chain_start(
self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs: Any
) -> None:
"""Print out that we are entering a chain."""
pass
def on_chain_end(self, outputs: Dict[str, Any], **kwargs: Any) -> None:
"""Print out that we finished a chain."""
pass
def on_chain_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> None:
"""Do nothing."""
pass
def on_tool_start(
self,
serialized: Dict[str, Any],
input_str: str,
**kwargs: Any,
) -> None:
"""Print out the log in specified color."""
pass
def on_tool_end(
self,
output: str,
color: Optional[str] = None,
observation_prefix: Optional[str] = None,
llm_prefix: Optional[str] = None,
**kwargs: Any,
) -> None:
"""If not the final action, print out observation."""
pass
def on_tool_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> None:
"""Do nothing."""
pass
def on_agent_action(self, action: AgentAction, **kwargs: Any) -> Any:
"""Run on agent action."""
pass
def on_agent_finish(
self, finish: AgentFinish, color: Optional[str] = None, **kwargs: Any
) -> None:
"""Run on agent end."""
pass
def __copy__(self) -> "OpenAICallbackHandler":
"""Return a copy of the callback handler."""
return self
def __deepcopy__(self, memo: Any) -> "OpenAICallbackHandler":
"""Return a deep copy of the callback handler."""
return self
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,988 | LangChain openAI callback doesn't allow finetuned models | Hi all!
I have an [application](https://github.com/ur-whitelab/BO-LIFT) based on langchain.
A few months ago, I used it with fine-tuned (FT) models.
We added a token usage counter later, and I haven't tried fine-tuned models again since then.
Recently we have been interested in using (FT) models again, but the callback to expose the token usage isn't accepting the model.
Minimal code to reproduce the error:
```
from langchain.llms import OpenAI
from langchain.callbacks import get_openai_callback
llm = OpenAI(
model_name=FT_MODEL,
temperature=0.7,
n=5,
max_tokens=64,
)
with get_openai_callback() as cb:
completion_response = llm.generate(["QUERY"])
token_usage = cb.total_tokens
```
It works fine if the model name is a basic openAI model. For instance, ```model_name="text-davinci-003"```
But when I try to use one of my FT models, I get this error:
```
Error in on_llm_end callback: Unknown model: FT_MODEL. Please provide a valid OpenAI model name.Known models are: gpt-4, gpt-4-0314, gpt-4-completion, gpt-4-0314-completion, gpt-4-32k, gpt-4-32k-0314, gpt-4-32k-completion, gpt-4-32k-0314-completion, gpt-3.5-turbo, gpt-3.5-turbo-0301, text-ada-001, ada, text-babbage-001, babbage, text-curie-001, curie, text-davinci-003, text-davinci-002, code-davinci-002
```
It works if I remove the callback and avoid token counting, but it'd be nice to have any suggestions on how to make it work.
Is there a workaround for that?
Any help is welcome!
Thanks! | https://github.com/langchain-ai/langchain/issues/3988 | https://github.com/langchain-ai/langchain/pull/4009 | aa383559999b3d6a781c62ed7f8589fef8892879 | f08a76250fe8995fb3f05bf785677070922d4b0d | "2023-05-02T18:00:22Z" | python | "2023-05-02T23:19:57Z" | tests/unit_tests/callbacks/test_openai_info.py | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,997 | Llama-cpp docs loading has CallbackManager error | As in title, I think it might be because of deprecation and renaming at some point? Updated to use BaseCallbackManager in PR #3996 , please merge, thanks! | https://github.com/langchain-ai/langchain/issues/3997 | https://github.com/langchain-ai/langchain/pull/4010 | f08a76250fe8995fb3f05bf785677070922d4b0d | df3bc707fc916811183d2487e2fac5dc69327177 | "2023-05-02T20:13:28Z" | python | "2023-05-02T23:20:16Z" | docs/modules/models/chat/integrations/anthropic.ipynb | {
"cells": [
{
"cell_type": "markdown",
"id": "bf733a38-db84-4363-89e2-de6735c37230",
"metadata": {},
"source": [
"# Anthropic\n",
"\n",
"This notebook covers how to get started with Anthropic chat models."
]
},
{
"cell_type": "code",
"execution_count": 1,
"id": "d4a7c55d-b235-4ca4-a579-c90cc9570da9",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"from langchain.chat_models import ChatAnthropic\n",
"from langchain.prompts.chat import (\n",
" ChatPromptTemplate,\n",
" SystemMessagePromptTemplate,\n",
" AIMessagePromptTemplate,\n",
" HumanMessagePromptTemplate,\n",
")\n",
"from langchain.schema import (\n",
" AIMessage,\n",
" HumanMessage,\n",
" SystemMessage\n",
")"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "70cf04e8-423a-4ff6-8b09-f11fb711c817",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"chat = ChatAnthropic()"
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "8199ef8f-eb8b-4253-9ea0-6c24a013ca4c",
"metadata": {
"tags": []
},
"outputs": [
{
"data": {
"text/plain": [
"AIMessage(content=\" J'aime programmer. \", additional_kwargs={})"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"messages = [\n",
" HumanMessage(content=\"Translate this sentence from English to French. I love programming.\")\n",
"]\n",
"chat(messages)"
]
},
{
"cell_type": "markdown",
"id": "c361ab1e-8c0c-4206-9e3c-9d1424a12b9c",
"metadata": {},
"source": [
"## `ChatAnthropic` also supports async and streaming functionality:"
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "93a21c5c-6ef9-4688-be60-b2e1f94842fb",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"from langchain.callbacks.base import CallbackManager\n",
"from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler"
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "c5fac0e9-05a4-4fc1-a3b3-e5bbb24b971b",
"metadata": {
"tags": []
},
"outputs": [
{
"data": {
"text/plain": [
"LLMResult(generations=[[ChatGeneration(text=\" J'aime la programmation.\", generation_info=None, message=AIMessage(content=\" J'aime la programmation.\", additional_kwargs={}))]], llm_output={})"
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"await chat.agenerate([messages])"
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "025be980-e50d-4a68-93dc-c9c7b500ce34",
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
" J'adore programmer."
]
},
{
"data": {
"text/plain": [
"AIMessage(content=\" J'adore programmer.\", additional_kwargs={})"
]
},
"execution_count": 6,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"chat = ChatAnthropic(streaming=True, verbose=True, callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]))\n",
"chat(messages)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "df45f59f",
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.1"
}
},
"nbformat": 4,
"nbformat_minor": 5
}
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,997 | Llama-cpp docs loading has CallbackManager error | As in title, I think it might be because of deprecation and renaming at some point? Updated to use BaseCallbackManager in PR #3996 , please merge, thanks! | https://github.com/langchain-ai/langchain/issues/3997 | https://github.com/langchain-ai/langchain/pull/4010 | f08a76250fe8995fb3f05bf785677070922d4b0d | df3bc707fc916811183d2487e2fac5dc69327177 | "2023-05-02T20:13:28Z" | python | "2023-05-02T23:20:16Z" | docs/modules/models/llms/integrations/llamacpp.ipynb | {
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Llama-cpp\n",
"\n",
"[llama-cpp](https://github.com/abetlen/llama-cpp-python) is a Python binding for [llama.cpp](https://github.com/ggerganov/llama.cpp). \n",
"It supports [several LLMs](https://github.com/ggerganov/llama.cpp).\n",
"\n",
"This notebook goes over how to run `llama-cpp` within LangChain."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"!pip install llama-cpp-python"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Make sure you are following all instructions to [install all necessary model files](https://github.com/ggerganov/llama.cpp).\n",
"\n",
"You don't need an `API_TOKEN`!"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"from langchain.llms import LlamaCpp\n",
"from langchain import PromptTemplate, LLMChain\n",
"from langchain.callbacks.base import CallbackManager\n",
"from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"template = \"\"\"Question: {question}\n",
"\n",
"Answer: Let's think step by step.\"\"\"\n",
"\n",
"prompt = PromptTemplate(template=template, input_variables=[\"question\"])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# Callbacks support token-wise streaming\n",
"callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])\n",
"# Verbose is required to pass to the callback manager\n",
"\n",
"# Make sure the model path is correct for your system!\n",
"llm = LlamaCpp(\n",
" model_path=\"./ggml-model-q4_0.bin\", callback_manager=callback_manager, verbose=True\n",
")"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [],
"source": [
"llm_chain = LLMChain(prompt=prompt, llm=llm)"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
" First we need to identify what year Justin Beiber was born in. A quick google search reveals that he was born on March 1st, 1994. Now we know when the Super Bowl was played in, so we can look up which NFL team won it. The NFL Superbowl of the year 1994 was won by the San Francisco 49ers against the San Diego Chargers."
]
},
{
"data": {
"text/plain": [
"' First we need to identify what year Justin Beiber was born in. A quick google search reveals that he was born on March 1st, 1994. Now we know when the Super Bowl was played in, so we can look up which NFL team won it. The NFL Superbowl of the year 1994 was won by the San Francisco 49ers against the San Diego Chargers.'"
]
},
"execution_count": 6,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"question = \"What NFL team won the Super Bowl in the year Justin Bieber was born?\"\n",
"\n",
"llm_chain.run(question)"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.6"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,053 | Tools with partials (Partial functions not yet supported in tools) | We commonly used this pattern to create tools:
```py
from langchain.tools import Tool
from functools import partial
def foo(x, y):
return y
Tool.from_function(
func=partial(foo, "bar"),
name = "foo",
description="foobar"
)
```
which as of 0.0.148 (I think) gives a pydantic error "Partial functions not yet supported in tools." We must use instead this format:
```py
from langchain.tools import Tool
from functools import partial
def foo(x, y):
return y
Tool.from_function(
func=lambda y: foo(x="bar",y=y),
name = "foo",
description="foobar"
)
```
It would be nice to again support partials. | https://github.com/langchain-ai/langchain/issues/4053 | https://github.com/langchain-ai/langchain/pull/4058 | 7e967aa4d581bec8b29e9ea44267505b0bad18b9 | afa9d1292b0a152e36d338dde7b02f0b93bd37d9 | "2023-05-03T17:28:46Z" | python | "2023-05-03T20:16:41Z" | langchain/tools/base.py | """Base implementation for tools or skills."""
from __future__ import annotations
import warnings
from abc import ABC, abstractmethod
from functools import partial
from inspect import signature
from typing import Any, Awaitable, Callable, Dict, Optional, Tuple, Type, Union
from pydantic import (
BaseModel,
Extra,
Field,
create_model,
root_validator,
validate_arguments,
validator,
)
from pydantic.main import ModelMetaclass
from langchain.callbacks.base import BaseCallbackManager
from langchain.callbacks.manager import (
AsyncCallbackManager,
AsyncCallbackManagerForToolRun,
CallbackManager,
CallbackManagerForToolRun,
Callbacks,
)
class SchemaAnnotationError(TypeError):
"""Raised when 'args_schema' is missing or has an incorrect type annotation."""
class ToolMetaclass(ModelMetaclass):
"""Metaclass for BaseTool to ensure the provided args_schema
doesn't silently ignored."""
def __new__(
cls: Type[ToolMetaclass], name: str, bases: Tuple[Type, ...], dct: dict
) -> ToolMetaclass:
"""Create the definition of the new tool class."""
schema_type: Optional[Type[BaseModel]] = dct.get("args_schema")
if schema_type is not None:
schema_annotations = dct.get("__annotations__", {})
args_schema_type = schema_annotations.get("args_schema", None)
if args_schema_type is None or args_schema_type == BaseModel:
# Throw errors for common mis-annotations.
# TODO: Use get_args / get_origin and fully
# specify valid annotations.
typehint_mandate = """
class ChildTool(BaseTool):
...
args_schema: Type[BaseModel] = SchemaClass
..."""
raise SchemaAnnotationError(
f"Tool definition for {name} must include valid type annotations"
f" for argument 'args_schema' to behave as expected.\n"
f"Expected annotation of 'Type[BaseModel]'"
f" but got '{args_schema_type}'.\n"
f"Expected class looks like:\n"
f"{typehint_mandate}"
)
# Pass through to Pydantic's metaclass
return super().__new__(cls, name, bases, dct)
def _create_subset_model(
name: str, model: BaseModel, field_names: list
) -> Type[BaseModel]:
"""Create a pydantic model with only a subset of model's fields."""
fields = {
field_name: (
model.__fields__[field_name].type_,
model.__fields__[field_name].default,
)
for field_name in field_names
if field_name in model.__fields__
}
return create_model(name, **fields) # type: ignore
def get_filtered_args(
inferred_model: Type[BaseModel],
func: Callable,
) -> dict:
"""Get the arguments from a function's signature."""
schema = inferred_model.schema()["properties"]
valid_keys = signature(func).parameters
return {k: schema[k] for k in valid_keys if k != "run_manager"}
class _SchemaConfig:
"""Configuration for the pydantic model."""
extra = Extra.forbid
arbitrary_types_allowed = True
def create_schema_from_function(
model_name: str,
func: Callable,
) -> Type[BaseModel]:
"""Create a pydantic schema from a function's signature."""
validated = validate_arguments(func, config=_SchemaConfig) # type: ignore
inferred_model = validated.model # type: ignore
if "run_manager" in inferred_model.__fields__:
del inferred_model.__fields__["run_manager"]
# Pydantic adds placeholder virtual fields we need to strip
filtered_args = get_filtered_args(inferred_model, func)
return _create_subset_model(
f"{model_name}Schema", inferred_model, list(filtered_args)
)
class BaseTool(ABC, BaseModel, metaclass=ToolMetaclass):
"""Interface LangChain tools must implement."""
name: str
"""The unique name of the tool that clearly communicates its purpose."""
description: str
"""Used to tell the model how/when/why to use the tool.
You can provide few-shot examples as a part of the description.
"""
args_schema: Optional[Type[BaseModel]] = None
"""Pydantic model class to validate and parse the tool's input arguments."""
return_direct: bool = False
"""Whether to return the tool's output directly. Setting this to True means
that after the tool is called, the AgentExecutor will stop looping.
"""
verbose: bool = False
"""Whether to log the tool's progress."""
callbacks: Callbacks = None
"""Callbacks to be called during tool execution."""
callback_manager: Optional[BaseCallbackManager] = None
"""Deprecated. Please use callbacks instead."""
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
@property
def is_single_input(self) -> bool:
"""Whether the tool only accepts a single input."""
return len(self.args) == 1
@property
def args(self) -> dict:
if self.args_schema is not None:
return self.args_schema.schema()["properties"]
else:
schema = create_schema_from_function(self.name, self._run)
return schema.schema()["properties"]
def _parse_input(
self,
tool_input: Union[str, Dict],
) -> None:
"""Convert tool input to pydantic model."""
input_args = self.args_schema
if isinstance(tool_input, str):
if input_args is not None:
key_ = next(iter(input_args.__fields__.keys()))
input_args.validate({key_: tool_input})
else:
if input_args is not None:
input_args.validate(tool_input)
@root_validator()
def raise_deprecation(cls, values: Dict) -> Dict:
"""Raise deprecation warning if callback_manager is used."""
if values.get("callback_manager") is not None:
warnings.warn(
"callback_manager is deprecated. Please use callbacks instead.",
DeprecationWarning,
)
values["callbacks"] = values.pop("callback_manager", None)
return values
@abstractmethod
def _run(
self,
*args: Any,
**kwargs: Any,
) -> Any:
"""Use the tool.
Add run_manager: Optional[CallbackManagerForToolRun] = None
to child implementations to enable tracing,
"""
@abstractmethod
async def _arun(
self,
*args: Any,
**kwargs: Any,
) -> Any:
"""Use the tool asynchronously.
Add run_manager: Optional[AsyncCallbackManagerForToolRun] = None
to child implementations to enable tracing,
"""
def _to_args_and_kwargs(self, tool_input: Union[str, Dict]) -> Tuple[Tuple, Dict]:
# For backwards compatibility, if run_input is a string,
# pass as a positional argument.
if isinstance(tool_input, str):
return (tool_input,), {}
else:
return (), tool_input
def run(
self,
tool_input: Union[str, Dict],
verbose: Optional[bool] = None,
start_color: Optional[str] = "green",
color: Optional[str] = "green",
callbacks: Callbacks = None,
**kwargs: Any,
) -> Any:
"""Run the tool."""
self._parse_input(tool_input)
if not self.verbose and verbose is not None:
verbose_ = verbose
else:
verbose_ = self.verbose
callback_manager = CallbackManager.configure(
callbacks, self.callbacks, verbose=verbose_
)
# TODO: maybe also pass through run_manager is _run supports kwargs
new_arg_supported = signature(self._run).parameters.get("run_manager")
run_manager = callback_manager.on_tool_start(
{"name": self.name, "description": self.description},
tool_input if isinstance(tool_input, str) else str(tool_input),
color=start_color,
**kwargs,
)
try:
tool_args, tool_kwargs = self._to_args_and_kwargs(tool_input)
observation = (
self._run(*tool_args, run_manager=run_manager, **tool_kwargs)
if new_arg_supported
else self._run(*tool_args, **tool_kwargs)
)
except (Exception, KeyboardInterrupt) as e:
run_manager.on_tool_error(e)
raise e
run_manager.on_tool_end(str(observation), color=color, name=self.name, **kwargs)
return observation
async def arun(
self,
tool_input: Union[str, Dict],
verbose: Optional[bool] = None,
start_color: Optional[str] = "green",
color: Optional[str] = "green",
callbacks: Callbacks = None,
**kwargs: Any,
) -> Any:
"""Run the tool asynchronously."""
self._parse_input(tool_input)
if not self.verbose and verbose is not None:
verbose_ = verbose
else:
verbose_ = self.verbose
callback_manager = AsyncCallbackManager.configure(
callbacks, self.callbacks, verbose=verbose_
)
new_arg_supported = signature(self._arun).parameters.get("run_manager")
run_manager = await callback_manager.on_tool_start(
{"name": self.name, "description": self.description},
tool_input if isinstance(tool_input, str) else str(tool_input),
color=start_color,
**kwargs,
)
try:
# We then call the tool on the tool input to get an observation
tool_args, tool_kwargs = self._to_args_and_kwargs(tool_input)
observation = (
await self._arun(*tool_args, run_manager=run_manager, **tool_kwargs)
if new_arg_supported
else await self._arun(*tool_args, **tool_kwargs)
)
except (Exception, KeyboardInterrupt) as e:
await run_manager.on_tool_error(e)
raise e
await run_manager.on_tool_end(
str(observation), color=color, name=self.name, **kwargs
)
return observation
def __call__(self, tool_input: str, callbacks: Callbacks = None) -> str:
"""Make tool callable."""
return self.run(tool_input, callbacks=callbacks)
class Tool(BaseTool):
"""Tool that takes in function or coroutine directly."""
description: str = ""
func: Callable[..., str]
"""The function to run when the tool is called."""
coroutine: Optional[Callable[..., Awaitable[str]]] = None
"""The asynchronous version of the function."""
@validator("func", pre=True, always=True)
def validate_func_not_partial(cls, func: Callable) -> Callable:
"""Check that the function is not a partial."""
if isinstance(func, partial):
raise ValueError("Partial functions not yet supported in tools.")
return func
@property
def args(self) -> dict:
"""The tool's input arguments."""
if self.args_schema is not None:
return self.args_schema.schema()["properties"]
# For backwards compatibility, if the function signature is ambiguous,
# assume it takes a single string input.
return {"tool_input": {"type": "string"}}
def _to_args_and_kwargs(self, tool_input: Union[str, Dict]) -> Tuple[Tuple, Dict]:
"""Convert tool input to pydantic model."""
args, kwargs = super()._to_args_and_kwargs(tool_input)
# For backwards compatibility. The tool must be run with a single input
all_args = list(args) + list(kwargs.values())
if len(all_args) != 1:
raise ValueError(
f"Too many arguments to single-input tool {self.name}."
f" Args: {all_args}"
)
return tuple(all_args), {}
def _run(
self,
*args: Any,
run_manager: Optional[CallbackManagerForToolRun] = None,
**kwargs: Any,
) -> Any:
"""Use the tool."""
new_argument_supported = signature(self.func).parameters.get("callbacks")
return (
self.func(
*args,
callbacks=run_manager.get_child() if run_manager else None,
**kwargs,
)
if new_argument_supported
else self.func(*args, **kwargs)
)
async def _arun(
self,
*args: Any,
run_manager: Optional[AsyncCallbackManagerForToolRun] = None,
**kwargs: Any,
) -> Any:
"""Use the tool asynchronously."""
if self.coroutine:
new_argument_supported = signature(self.coroutine).parameters.get(
"callbacks"
)
return (
await self.coroutine(
*args,
callbacks=run_manager.get_child() if run_manager else None,
**kwargs,
)
if new_argument_supported
else await self.coroutine(*args, **kwargs)
)
raise NotImplementedError("Tool does not support async")
# TODO: this is for backwards compatibility, remove in future
def __init__(
self, name: str, func: Callable, description: str, **kwargs: Any
) -> None:
"""Initialize tool."""
super(Tool, self).__init__(
name=name, func=func, description=description, **kwargs
)
@classmethod
def from_function(
cls,
func: Callable,
name: str, # We keep these required to support backwards compatibility
description: str,
return_direct: bool = False,
args_schema: Optional[Type[BaseModel]] = None,
**kwargs: Any,
) -> Tool:
"""Initialize tool from a function."""
return cls(
name=name,
func=func,
description=description,
return_direct=return_direct,
args_schema=args_schema,
**kwargs,
)
class StructuredTool(BaseTool):
"""Tool that can operate on any number of inputs."""
description: str = ""
args_schema: Type[BaseModel] = Field(..., description="The tool schema.")
"""The input arguments' schema."""
func: Callable[..., Any]
"""The function to run when the tool is called."""
coroutine: Optional[Callable[..., Awaitable[Any]]] = None
"""The asynchronous version of the function."""
@property
def args(self) -> dict:
"""The tool's input arguments."""
return self.args_schema.schema()["properties"]
def _run(
self,
*args: Any,
run_manager: Optional[CallbackManagerForToolRun] = None,
**kwargs: Any,
) -> Any:
"""Use the tool."""
new_argument_supported = signature(self.func).parameters.get("callbacks")
return (
self.func(
*args,
callbacks=run_manager.get_child() if run_manager else None,
**kwargs,
)
if new_argument_supported
else self.func(*args, **kwargs)
)
async def _arun(
self,
*args: Any,
run_manager: Optional[AsyncCallbackManagerForToolRun] = None,
**kwargs: Any,
) -> str:
"""Use the tool asynchronously."""
if self.coroutine:
new_argument_supported = signature(self.coroutine).parameters.get(
"callbacks"
)
return (
await self.coroutine(
*args,
callbacks=run_manager.get_child() if run_manager else None,
**kwargs,
)
if new_argument_supported
else await self.coroutine(*args, **kwargs)
)
raise NotImplementedError("Tool does not support async")
@classmethod
def from_function(
cls,
func: Callable,
name: Optional[str] = None,
description: Optional[str] = None,
return_direct: bool = False,
args_schema: Optional[Type[BaseModel]] = None,
infer_schema: bool = True,
**kwargs: Any,
) -> StructuredTool:
name = name or func.__name__
description = description or func.__doc__
assert (
description is not None
), "Function must have a docstring if description not provided."
# Description example:
# search_api(query: str) - Searches the API for the query.
description = f"{name}{signature(func)} - {description.strip()}"
_args_schema = args_schema
if _args_schema is None and infer_schema:
_args_schema = create_schema_from_function(f"{name}Schema", func)
return cls(
name=name,
func=func,
args_schema=_args_schema,
description=description,
return_direct=return_direct,
**kwargs,
)
def tool(
*args: Union[str, Callable],
return_direct: bool = False,
args_schema: Optional[Type[BaseModel]] = None,
infer_schema: bool = True,
) -> Callable:
"""Make tools out of functions, can be used with or without arguments.
Args:
*args: The arguments to the tool.
return_direct: Whether to return directly from the tool rather
than continuing the agent loop.
args_schema: optional argument schema for user to specify
infer_schema: Whether to infer the schema of the arguments from
the function's signature. This also makes the resultant tool
accept a dictionary input to its `run()` function.
Requires:
- Function must be of type (str) -> str
- Function must have a docstring
Examples:
.. code-block:: python
@tool
def search_api(query: str) -> str:
# Searches the API for the query.
return
@tool("search", return_direct=True)
def search_api(query: str) -> str:
# Searches the API for the query.
return
"""
def _make_with_name(tool_name: str) -> Callable:
def _make_tool(func: Callable) -> BaseTool:
if infer_schema or args_schema is not None:
return StructuredTool.from_function(
func,
name=tool_name,
return_direct=return_direct,
args_schema=args_schema,
infer_schema=infer_schema,
)
# If someone doesn't want a schema applied, we must treat it as
# a simple string->string function
assert func.__doc__ is not None, "Function must have a docstring"
return Tool(
name=tool_name,
func=func,
description=f"{tool_name} tool",
return_direct=return_direct,
)
return _make_tool
if len(args) == 1 and isinstance(args[0], str):
# if the argument is a string, then we use the string as the tool name
# Example usage: @tool("search", return_direct=True)
return _make_with_name(args[0])
elif len(args) == 1 and callable(args[0]):
# if the argument is a function, then we use the function name as the tool name
# Example usage: @tool
return _make_with_name(args[0].__name__)(args[0])
elif len(args) == 0:
# if there are no arguments, then we use the function name as the tool name
# Example usage: @tool(return_direct=True)
def _partial(func: Callable[[str], str]) -> BaseTool:
return _make_with_name(func.__name__)(func)
return _partial
else:
raise ValueError("Too many arguments for tool decorator")
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,053 | Tools with partials (Partial functions not yet supported in tools) | We commonly used this pattern to create tools:
```py
from langchain.tools import Tool
from functools import partial
def foo(x, y):
return y
Tool.from_function(
func=partial(foo, "bar"),
name = "foo",
description="foobar"
)
```
which as of 0.0.148 (I think) gives a pydantic error "Partial functions not yet supported in tools." We must use instead this format:
```py
from langchain.tools import Tool
from functools import partial
def foo(x, y):
return y
Tool.from_function(
func=lambda y: foo(x="bar",y=y),
name = "foo",
description="foobar"
)
```
It would be nice to again support partials. | https://github.com/langchain-ai/langchain/issues/4053 | https://github.com/langchain-ai/langchain/pull/4058 | 7e967aa4d581bec8b29e9ea44267505b0bad18b9 | afa9d1292b0a152e36d338dde7b02f0b93bd37d9 | "2023-05-03T17:28:46Z" | python | "2023-05-03T20:16:41Z" | tests/unit_tests/agents/test_tools.py | """Test tool utils."""
from datetime import datetime
from functools import partial
from typing import Any, Optional, Type, Union
from unittest.mock import MagicMock
import pydantic
import pytest
from pydantic import BaseModel
from langchain.agents.agent import Agent
from langchain.agents.chat.base import ChatAgent
from langchain.agents.conversational.base import ConversationalAgent
from langchain.agents.conversational_chat.base import ConversationalChatAgent
from langchain.agents.mrkl.base import ZeroShotAgent
from langchain.agents.react.base import ReActDocstoreAgent, ReActTextWorldAgent
from langchain.agents.self_ask_with_search.base import SelfAskWithSearchAgent
from langchain.agents.tools import Tool, tool
from langchain.tools.base import BaseTool, SchemaAnnotationError, StructuredTool
def test_unnamed_decorator() -> None:
"""Test functionality with unnamed decorator."""
@tool
def search_api(query: str) -> str:
"""Search the API for the query."""
return "API result"
assert isinstance(search_api, BaseTool)
assert search_api.name == "search_api"
assert not search_api.return_direct
assert search_api("test") == "API result"
class _MockSchema(BaseModel):
arg1: int
arg2: bool
arg3: Optional[dict] = None
class _MockStructuredTool(BaseTool):
name = "structured_api"
args_schema: Type[BaseModel] = _MockSchema
description = "A Structured Tool"
def _run(self, arg1: int, arg2: bool, arg3: Optional[dict] = None) -> str:
return f"{arg1} {arg2} {arg3}"
async def _arun(self, arg1: int, arg2: bool, arg3: Optional[dict] = None) -> str:
raise NotImplementedError
def test_structured_args() -> None:
"""Test functionality with structured arguments."""
structured_api = _MockStructuredTool()
assert isinstance(structured_api, BaseTool)
assert structured_api.name == "structured_api"
expected_result = "1 True {'foo': 'bar'}"
args = {"arg1": 1, "arg2": True, "arg3": {"foo": "bar"}}
assert structured_api.run(args) == expected_result
def test_unannotated_base_tool_raises_error() -> None:
"""Test that a BaseTool without type hints raises an exception.""" ""
with pytest.raises(SchemaAnnotationError):
class _UnAnnotatedTool(BaseTool):
name = "structured_api"
# This would silently be ignored without the custom metaclass
args_schema = _MockSchema
description = "A Structured Tool"
def _run(self, arg1: int, arg2: bool, arg3: Optional[dict] = None) -> str:
return f"{arg1} {arg2} {arg3}"
async def _arun(
self, arg1: int, arg2: bool, arg3: Optional[dict] = None
) -> str:
raise NotImplementedError
def test_misannotated_base_tool_raises_error() -> None:
"""Test that a BaseTool with the incorrrect typehint raises an exception.""" ""
with pytest.raises(SchemaAnnotationError):
class _MisAnnotatedTool(BaseTool):
name = "structured_api"
# This would silently be ignored without the custom metaclass
args_schema: BaseModel = _MockSchema # type: ignore
description = "A Structured Tool"
def _run(self, arg1: int, arg2: bool, arg3: Optional[dict] = None) -> str:
return f"{arg1} {arg2} {arg3}"
async def _arun(
self, arg1: int, arg2: bool, arg3: Optional[dict] = None
) -> str:
raise NotImplementedError
def test_forward_ref_annotated_base_tool_accepted() -> None:
"""Test that a using forward ref annotation syntax is accepted.""" ""
class _ForwardRefAnnotatedTool(BaseTool):
name = "structured_api"
args_schema: "Type[BaseModel]" = _MockSchema
description = "A Structured Tool"
def _run(self, arg1: int, arg2: bool, arg3: Optional[dict] = None) -> str:
return f"{arg1} {arg2} {arg3}"
async def _arun(
self, arg1: int, arg2: bool, arg3: Optional[dict] = None
) -> str:
raise NotImplementedError
def test_subclass_annotated_base_tool_accepted() -> None:
"""Test BaseTool child w/ custom schema isn't overwritten."""
class _ForwardRefAnnotatedTool(BaseTool):
name = "structured_api"
args_schema: Type[_MockSchema] = _MockSchema
description = "A Structured Tool"
def _run(self, arg1: int, arg2: bool, arg3: Optional[dict] = None) -> str:
return f"{arg1} {arg2} {arg3}"
async def _arun(
self, arg1: int, arg2: bool, arg3: Optional[dict] = None
) -> str:
raise NotImplementedError
assert issubclass(_ForwardRefAnnotatedTool, BaseTool)
tool = _ForwardRefAnnotatedTool()
assert tool.args_schema == _MockSchema
def test_decorator_with_specified_schema() -> None:
"""Test that manually specified schemata are passed through to the tool."""
@tool(args_schema=_MockSchema)
def tool_func(arg1: int, arg2: bool, arg3: Optional[dict] = None) -> str:
"""Return the arguments directly."""
return f"{arg1} {arg2} {arg3}"
assert isinstance(tool_func, BaseTool)
assert tool_func.args_schema == _MockSchema
def test_decorated_function_schema_equivalent() -> None:
"""Test that a BaseTool without a schema meets expectations."""
@tool
def structured_tool_input(
arg1: int, arg2: bool, arg3: Optional[dict] = None
) -> str:
"""Return the arguments directly."""
return f"{arg1} {arg2} {arg3}"
assert isinstance(structured_tool_input, BaseTool)
assert structured_tool_input.args_schema is not None
assert (
structured_tool_input.args_schema.schema()["properties"]
== _MockSchema.schema()["properties"]
== structured_tool_input.args
)
def test_structured_args_decorator_no_infer_schema() -> None:
"""Test functionality with structured arguments parsed as a decorator."""
@tool(infer_schema=False)
def structured_tool_input(
arg1: int, arg2: Union[float, datetime], opt_arg: Optional[dict] = None
) -> str:
"""Return the arguments directly."""
return f"{arg1}, {arg2}, {opt_arg}"
assert isinstance(structured_tool_input, BaseTool)
assert structured_tool_input.name == "structured_tool_input"
args = {"arg1": 1, "arg2": 0.001, "opt_arg": {"foo": "bar"}}
expected_result = "1, 0.001, {'foo': 'bar'}"
with pytest.raises(ValueError):
assert structured_tool_input.run(args) == expected_result
def test_structured_single_str_decorator_no_infer_schema() -> None:
"""Test functionality with structured arguments parsed as a decorator."""
@tool(infer_schema=False)
def unstructured_tool_input(tool_input: str) -> str:
"""Return the arguments directly."""
return f"{tool_input}"
assert isinstance(unstructured_tool_input, BaseTool)
assert unstructured_tool_input.args_schema is None
assert unstructured_tool_input.run("foo") == "foo"
def test_base_tool_inheritance_base_schema() -> None:
"""Test schema is correctly inferred when inheriting from BaseTool."""
class _MockSimpleTool(BaseTool):
name = "simple_tool"
description = "A Simple Tool"
def _run(self, tool_input: str) -> str:
return f"{tool_input}"
async def _arun(self, tool_input: str) -> str:
raise NotImplementedError
simple_tool = _MockSimpleTool()
assert simple_tool.args_schema is None
expected_args = {"tool_input": {"title": "Tool Input", "type": "string"}}
assert simple_tool.args == expected_args
def test_tool_lambda_args_schema() -> None:
"""Test args schema inference when the tool argument is a lambda function."""
tool = Tool(
name="tool",
description="A tool",
func=lambda tool_input: tool_input,
)
assert tool.args_schema is None
expected_args = {"tool_input": {"type": "string"}}
assert tool.args == expected_args
def test_structured_tool_lambda_multi_args_schema() -> None:
"""Test args schema inference when the tool argument is a lambda function."""
tool = StructuredTool.from_function(
name="tool",
description="A tool",
func=lambda tool_input, other_arg: f"{tool_input}{other_arg}", # type: ignore
)
assert tool.args_schema is not None
expected_args = {
"tool_input": {"title": "Tool Input"},
"other_arg": {"title": "Other Arg"},
}
assert tool.args == expected_args
def test_tool_partial_function_args_schema() -> None:
"""Test args schema inference when the tool argument is a partial function."""
def func(tool_input: str, other_arg: str) -> str:
return tool_input + other_arg
with pytest.raises(pydantic.error_wrappers.ValidationError):
# We don't yet support args_schema inference for partial functions
# so want to make sure we proactively raise an error
Tool(
name="tool",
description="A tool",
func=partial(func, other_arg="foo"),
)
def test_empty_args_decorator() -> None:
"""Test inferred schema of decorated fn with no args."""
@tool
def empty_tool_input() -> str:
"""Return a constant."""
return "the empty result"
assert isinstance(empty_tool_input, BaseTool)
assert empty_tool_input.name == "empty_tool_input"
assert empty_tool_input.args == {}
assert empty_tool_input.run({}) == "the empty result"
def test_named_tool_decorator() -> None:
"""Test functionality when arguments are provided as input to decorator."""
@tool("search")
def search_api(query: str) -> str:
"""Search the API for the query."""
return "API result"
assert isinstance(search_api, BaseTool)
assert search_api.name == "search"
assert not search_api.return_direct
def test_named_tool_decorator_return_direct() -> None:
"""Test functionality when arguments and return direct are provided as input."""
@tool("search", return_direct=True)
def search_api(query: str) -> str:
"""Search the API for the query."""
return "API result"
assert isinstance(search_api, BaseTool)
assert search_api.name == "search"
assert search_api.return_direct
def test_unnamed_tool_decorator_return_direct() -> None:
"""Test functionality when only return direct is provided."""
@tool(return_direct=True)
def search_api(query: str) -> str:
"""Search the API for the query."""
return "API result"
assert isinstance(search_api, BaseTool)
assert search_api.name == "search_api"
assert search_api.return_direct
def test_tool_with_kwargs() -> None:
"""Test functionality when only return direct is provided."""
@tool(return_direct=True)
def search_api(
arg_0: str,
arg_1: float = 4.3,
ping: str = "hi",
) -> str:
"""Search the API for the query."""
return f"arg_0={arg_0}, arg_1={arg_1}, ping={ping}"
assert isinstance(search_api, BaseTool)
result = search_api.run(
tool_input={
"arg_0": "foo",
"arg_1": 3.2,
"ping": "pong",
}
)
assert result == "arg_0=foo, arg_1=3.2, ping=pong"
result = search_api.run(
tool_input={
"arg_0": "foo",
}
)
assert result == "arg_0=foo, arg_1=4.3, ping=hi"
# For backwards compatibility, we still accept a single str arg
result = search_api.run("foobar")
assert result == "arg_0=foobar, arg_1=4.3, ping=hi"
def test_missing_docstring() -> None:
"""Test error is raised when docstring is missing."""
# expect to throw a value error if theres no docstring
with pytest.raises(AssertionError, match="Function must have a docstring"):
@tool
def search_api(query: str) -> str:
return "API result"
def test_create_tool_positional_args() -> None:
"""Test that positional arguments are allowed."""
test_tool = Tool("test_name", lambda x: x, "test_description")
assert test_tool("foo") == "foo"
assert test_tool.name == "test_name"
assert test_tool.description == "test_description"
assert test_tool.is_single_input
def test_create_tool_keyword_args() -> None:
"""Test that keyword arguments are allowed."""
test_tool = Tool(name="test_name", func=lambda x: x, description="test_description")
assert test_tool.is_single_input
assert test_tool("foo") == "foo"
assert test_tool.name == "test_name"
assert test_tool.description == "test_description"
@pytest.mark.asyncio
async def test_create_async_tool() -> None:
"""Test that async tools are allowed."""
async def _test_func(x: str) -> str:
return x
test_tool = Tool(
name="test_name",
func=lambda x: x,
description="test_description",
coroutine=_test_func,
)
assert test_tool.is_single_input
assert test_tool("foo") == "foo"
assert test_tool.name == "test_name"
assert test_tool.description == "test_description"
assert test_tool.coroutine is not None
assert await test_tool.arun("foo") == "foo"
@pytest.mark.parametrize(
"agent_cls",
[
ZeroShotAgent,
ChatAgent,
ConversationalChatAgent,
ConversationalAgent,
ReActDocstoreAgent,
ReActTextWorldAgent,
SelfAskWithSearchAgent,
],
)
def test_single_input_agent_raises_error_on_structured_tool(
agent_cls: Type[Agent],
) -> None:
"""Test that older agents raise errors on older tools."""
@tool
def the_tool(foo: str, bar: str) -> str:
"""Return the concat of foo and bar."""
return foo + bar
with pytest.raises(
ValueError,
match=f"{agent_cls.__name__} does not support" # type: ignore
f" multi-input tool {the_tool.name}.",
):
agent_cls.from_llm_and_tools(MagicMock(), [the_tool]) # type: ignore
def test_tool_no_args_specified_assumes_str() -> None:
"""Older tools could assume *args and **kwargs were passed in."""
def ambiguous_function(*args: Any, **kwargs: Any) -> str:
"""An ambiguously defined function."""
return args[0]
some_tool = Tool(
name="chain_run",
description="Run the chain",
func=ambiguous_function,
)
expected_args = {"tool_input": {"type": "string"}}
assert some_tool.args == expected_args
assert some_tool.run("foobar") == "foobar"
assert some_tool.run({"tool_input": "foobar"}) == "foobar"
with pytest.raises(ValueError, match="Too many arguments to single-input tool"):
some_tool.run({"tool_input": "foobar", "other_input": "bar"})
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,052 | Arxiv loader does not work | Hey,
I tried to use the Arxiv loader but it seems that this type of document does not exist anymore. The documentation is still there https://python.langchain.com/en/latest/modules/indexes/document_loaders/examples/arxiv.html
Do you have any details on that? | https://github.com/langchain-ai/langchain/issues/4052 | https://github.com/langchain-ai/langchain/pull/4068 | 374725a715d287fe2ddb9dfda36e0dc14efa254d | 9b830f437cdfd82d9b53bd38e58b27bb9ecf970c | "2023-05-03T16:23:51Z" | python | "2023-05-04T00:54:30Z" | docs/modules/indexes/document_loaders/examples/arxiv.ipynb | {
"cells": [
{
"cell_type": "markdown",
"id": "bda1f3f5",
"metadata": {},
"source": [
"# Arxiv\n",
"\n",
">[arXiv](https://arxiv.org/) is an open-access archive for 2 million scholarly articles in the fields of physics, mathematics, computer science, quantitative biology, quantitative finance, statistics, electrical engineering and systems science, and economics.\n",
"\n",
"This notebook shows how to load scientific articles from `Arxiv.org` into a document format that we can use downstream."
]
},
{
"cell_type": "markdown",
"id": "1b7a1eef-7bf7-4e7d-8bfc-c4e27c9488cb",
"metadata": {},
"source": [
"## Installation"
]
},
{
"cell_type": "markdown",
"id": "2abd5578-aa3d-46b9-99af-8b262f0b3df8",
"metadata": {},
"source": [
"First, you need to install `arxiv` python package."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "b674aaea-ed3a-4541-8414-260a8f67f623",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"#!pip install arxiv"
]
},
{
"cell_type": "markdown",
"id": "094b5f13-7e54-4354-9d83-26d6926ecaa0",
"metadata": {
"tags": []
},
"source": [
"Second, you need to install `PyMuPDF` python package which transform PDF files from the `arxiv.org` site into the text format."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "7cd91121-2e96-43ba-af50-319853695f86",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"#!pip install pymupdf"
]
},
{
"cell_type": "markdown",
"id": "95f05e1c-195e-4e2b-ae8e-8d6637f15be6",
"metadata": {},
"source": [
"## Examples"
]
},
{
"cell_type": "markdown",
"id": "e29b954c-1407-4797-ae21-6ba8937156be",
"metadata": {},
"source": [
"`ArxivLoader` has these arguments:\n",
"- `query`: free text which used to find documents in the Arxiv\n",
"- optional `load_max_docs`: default=100. Use it to limit number of downloaded documents. It takes time to download all 100 documents, so use a small number for experiments.\n",
"- optional `load_all_available_meta`: default=False. By default only the most important fields downloaded: `Published` (date when document was published/last updated), `Title`, `Authors`, `Summary`. If True, other fields also downloaded."
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "9bfd5e46",
"metadata": {},
"outputs": [],
"source": [
"from langchain.document_loaders.base import Document\n",
"from langchain.document_loaders import ArxivLoader"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "700e4ef2",
"metadata": {},
"outputs": [],
"source": [
"docs = ArxivLoader(query=\"1605.08386\", load_max_docs=2).load()\n",
"len(docs)"
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "8977bac0-0042-4f23-9754-247dbd32439b",
"metadata": {
"tags": []
},
"outputs": [
{
"data": {
"text/plain": [
"{'Published': '2016-05-26',\n",
" 'Title': 'Heat-bath random walks with Markov bases',\n",
" 'Authors': 'Caprice Stanley, Tobias Windisch',\n",
" 'Summary': 'Graphs on lattice points are studied whose edges come from a finite set of\\nallowed moves of arbitrary length. We show that the diameter of these graphs on\\nfibers of a fixed integer matrix can be bounded from above by a constant. We\\nthen study the mixing behaviour of heat-bath random walks on these graphs. We\\nalso state explicit conditions on the set of moves so that the heat-bath random\\nwalk, a generalization of the Glauber dynamics, is an expander in fixed\\ndimension.'}"
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"docs[0].metadata # meta-information of the Document"
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "46969806-45a9-4c4d-a61b-cfb9658fc9de",
"metadata": {
"tags": []
},
"outputs": [
{
"data": {
"text/plain": [
"'arXiv:1605.08386v1 [math.CO] 26 May 2016\\nHEAT-BATH RANDOM WALKS WITH MARKOV BASES\\nCAPRICE STANLEY AND TOBIAS WINDISCH\\nAbstract. Graphs on lattice points are studied whose edges come from a finite set of\\nallowed moves of arbitrary length. We show that the diameter of these graphs on fibers of a\\nfixed integer matrix can be bounded from above by a constant. We then study the mixing\\nbehaviour of heat-b'"
]
},
"execution_count": 6,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"docs[0].page_content[:400] # all pages of the Document content\n"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.6"
}
},
"nbformat": 4,
"nbformat_minor": 5
}
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,142 | ImportError: cannot import name 'CursorResult' from 'sqlalchemy' | ### System Info
# Name Version Build Channel
_libgcc_mutex 0.1 main
_openmp_mutex 5.1 1_gnu
aiohttp 3.8.3 py310h5eee18b_0
aiosignal 1.3.1 pyhd8ed1ab_0 conda-forge
async-timeout 4.0.2 pyhd8ed1ab_0 conda-forge
attrs 23.1.0 pyh71513ae_0 conda-forge
blas 1.0 mkl
brotlipy 0.7.0 py310h5764c6d_1004 conda-forge
bzip2 1.0.8 h7b6447c_0
ca-certificates 2023.01.10 h06a4308_0
certifi 2022.12.7 py310h06a4308_0
cffi 1.15.0 py310h0fdd8cc_0 conda-forge
charset-normalizer 2.0.4 pyhd3eb1b0_0
colorama 0.4.6 pyhd8ed1ab_0 conda-forge
cryptography 3.4.8 py310h685ca39_1 conda-forge
dataclasses-json 0.5.7 pyhd8ed1ab_0 conda-forge
frozenlist 1.3.3 py310h5eee18b_0
greenlet 2.0.1 py310h6a678d5_0
idna 3.4 pyhd8ed1ab_0 conda-forge
intel-openmp 2021.4.0 h06a4308_3561
langchain 0.0.158 pyhd8ed1ab_0 conda-forge
ld_impl_linux-64 2.38 h1181459_1
libffi 3.4.2 h6a678d5_6
libgcc-ng 11.2.0 h1234567_1
libgomp 11.2.0 h1234567_1
libstdcxx-ng 11.2.0 h1234567_1
libuuid 1.41.5 h5eee18b_0
marshmallow 3.19.0 pyhd8ed1ab_0 conda-forge
marshmallow-enum 1.5.1 pyh9f0ad1d_3 conda-forge
mkl 2021.4.0 h06a4308_640
mkl-service 2.4.0 py310ha2c4b55_0 conda-forge
mkl_fft 1.3.1 py310hd6ae3a3_0
mkl_random 1.2.2 py310h00e6091_0
multidict 6.0.2 py310h5eee18b_0
mypy_extensions 1.0.0 pyha770c72_0 conda-forge
ncurses 6.4 h6a678d5_0
numexpr 2.8.4 py310h8879344_0
numpy 1.24.3 py310hd5efca6_0
numpy-base 1.24.3 py310h8e6c178_0
openapi-schema-pydantic 1.2.4 pyhd8ed1ab_0 conda-forge
openssl 1.1.1t h7f8727e_0
packaging 23.1 pyhd8ed1ab_0 conda-forge
pip 22.2.2 pypi_0 pypi
pycparser 2.21 pyhd8ed1ab_0 conda-forge
pydantic 1.10.2 py310h5eee18b_0
pyopenssl 20.0.1 pyhd8ed1ab_0 conda-forge
pysocks 1.7.1 pyha2e5f31_6 conda-forge
python 3.10.9 h7a1cb2a_2
python_abi 3.10 2_cp310 conda-forge
pyyaml 6.0 py310h5764c6d_4 conda-forge
readline 8.2 h5eee18b_0
requests 2.29.0 pyhd8ed1ab_0 conda-forge
setuptools 66.0.0 py310h06a4308_0
six 1.16.0 pyh6c4a22f_0 conda-forge
sqlalchemy 1.4.39 py310h5eee18b_0
sqlite 3.41.2 h5eee18b_0
stringcase 1.2.0 py_0 conda-forge
tenacity 8.2.2 pyhd8ed1ab_0 conda-forge
tk 8.6.12 h1ccaba5_0
tqdm 4.65.0 pyhd8ed1ab_1 conda-forge
typing-extensions 4.5.0 hd8ed1ab_0 conda-forge
typing_extensions 4.5.0 pyha770c72_0 conda-forge
typing_inspect 0.8.0 pyhd8ed1ab_0 conda-forge
tzdata 2023c h04d1e81_0
urllib3 1.26.15 pyhd8ed1ab_0 conda-forge
wheel 0.38.4 py310h06a4308_0
xz 5.4.2 h5eee18b_0
yaml 0.2.5 h7f98852_2 conda-forge
yarl 1.7.2 py310h5764c6d_2 conda-forge
zlib 1.2.13 h5eee18b_0
Traceback (most recent call last):
File "/home/bachar/projects/op-stack/./app.py", line 1, in <module>
from langchain.document_loaders import DirectoryLoader
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/__init__.py", line 6, in <module>
from langchain.agents import MRKLChain, ReActChain, SelfAskWithSearchChain
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/agents/__init__.py", line 2, in <module>
from langchain.agents.agent import (
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/agents/agent.py", line 15, in <module>
from langchain.agents.tools import InvalidTool
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/agents/tools.py", line 8, in <module>
from langchain.tools.base import BaseTool, Tool, tool
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/tools/__init__.py", line 32, in <module>
from langchain.tools.vectorstore.tool import (
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/tools/vectorstore/tool.py", line 13, in <module>
from langchain.chains import RetrievalQA, RetrievalQAWithSourcesChain
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/chains/__init__.py", line 19, in <module>
from langchain.chains.loading import load_chain
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/chains/loading.py", line 24, in <module>
from langchain.chains.sql_database.base import SQLDatabaseChain
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/chains/sql_database/base.py", line 15, in <module>
from langchain.sql_database import SQLDatabase
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/sql_database.py", line 8, in <module>
from sqlalchemy import (
ImportError: cannot import name 'CursorResult' from 'sqlalchemy' (/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/sqlalchemy/__init__.py)
(/home/bachar/projects/op-stack/venv)
### Who can help?
_No response_
### Information
- [ ] The official example notebooks/scripts
- [ ] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [X] Document Loaders
- [ ] Vector Stores / Retrievers
- [ ] Memory
- [ ] Agents / Agent Executors
- [ ] Tools / Toolkits
- [ ] Chains
- [ ] Callbacks/Tracing
- [ ] Async
### Reproduction
from langchain.document_loaders import DirectoryLoader
docs = DirectoryLoader("./pdfs", "**/*.pdf").load()
### Expected behavior
no errors should be thrown | https://github.com/langchain-ai/langchain/issues/4142 | https://github.com/langchain-ai/langchain/pull/4145 | 2f087d63af45a172fc363b3370e49141bd663ed2 | fea639c1fc1ac324f1300016a02b6d30a2f8d249 | "2023-05-05T00:47:24Z" | python | "2023-05-05T03:46:38Z" | langchain/sql_database.py | """SQLAlchemy wrapper around a database."""
from __future__ import annotations
import warnings
from typing import Any, Iterable, List, Optional
import sqlalchemy
from sqlalchemy import (
CursorResult,
MetaData,
Table,
create_engine,
inspect,
select,
text,
)
from sqlalchemy.engine import Engine
from sqlalchemy.exc import ProgrammingError, SQLAlchemyError
from sqlalchemy.schema import CreateTable
def _format_index(index: sqlalchemy.engine.interfaces.ReflectedIndex) -> str:
return (
f'Name: {index["name"]}, Unique: {index["unique"]},'
f' Columns: {str(index["column_names"])}'
)
class SQLDatabase:
"""SQLAlchemy wrapper around a database."""
def __init__(
self,
engine: Engine,
schema: Optional[str] = None,
metadata: Optional[MetaData] = None,
ignore_tables: Optional[List[str]] = None,
include_tables: Optional[List[str]] = None,
sample_rows_in_table_info: int = 3,
indexes_in_table_info: bool = False,
custom_table_info: Optional[dict] = None,
view_support: bool = False,
):
"""Create engine from database URI."""
self._engine = engine
self._schema = schema
if include_tables and ignore_tables:
raise ValueError("Cannot specify both include_tables and ignore_tables")
self._inspector = inspect(self._engine)
# including view support by adding the views as well as tables to the all
# tables list if view_support is True
self._all_tables = set(
self._inspector.get_table_names(schema=schema)
+ (self._inspector.get_view_names(schema=schema) if view_support else [])
)
self._include_tables = set(include_tables) if include_tables else set()
if self._include_tables:
missing_tables = self._include_tables - self._all_tables
if missing_tables:
raise ValueError(
f"include_tables {missing_tables} not found in database"
)
self._ignore_tables = set(ignore_tables) if ignore_tables else set()
if self._ignore_tables:
missing_tables = self._ignore_tables - self._all_tables
if missing_tables:
raise ValueError(
f"ignore_tables {missing_tables} not found in database"
)
usable_tables = self.get_usable_table_names()
self._usable_tables = set(usable_tables) if usable_tables else self._all_tables
if not isinstance(sample_rows_in_table_info, int):
raise TypeError("sample_rows_in_table_info must be an integer")
self._sample_rows_in_table_info = sample_rows_in_table_info
self._indexes_in_table_info = indexes_in_table_info
self._custom_table_info = custom_table_info
if self._custom_table_info:
if not isinstance(self._custom_table_info, dict):
raise TypeError(
"table_info must be a dictionary with table names as keys and the "
"desired table info as values"
)
# only keep the tables that are also present in the database
intersection = set(self._custom_table_info).intersection(self._all_tables)
self._custom_table_info = dict(
(table, self._custom_table_info[table])
for table in self._custom_table_info
if table in intersection
)
self._metadata = metadata or MetaData()
# including view support if view_support = true
self._metadata.reflect(
views=view_support,
bind=self._engine,
only=list(self._usable_tables),
schema=self._schema,
)
@classmethod
def from_uri(
cls, database_uri: str, engine_args: Optional[dict] = None, **kwargs: Any
) -> SQLDatabase:
"""Construct a SQLAlchemy engine from URI."""
_engine_args = engine_args or {}
return cls(create_engine(database_uri, **_engine_args), **kwargs)
@property
def dialect(self) -> str:
"""Return string representation of dialect to use."""
return self._engine.dialect.name
def get_usable_table_names(self) -> Iterable[str]:
"""Get names of tables available."""
if self._include_tables:
return self._include_tables
return self._all_tables - self._ignore_tables
def get_table_names(self) -> Iterable[str]:
"""Get names of tables available."""
warnings.warn(
"This method is deprecated - please use `get_usable_table_names`."
)
return self.get_usable_table_names()
@property
def table_info(self) -> str:
"""Information about all tables in the database."""
return self.get_table_info()
def get_table_info(self, table_names: Optional[List[str]] = None) -> str:
"""Get information about specified tables.
Follows best practices as specified in: Rajkumar et al, 2022
(https://arxiv.org/abs/2204.00498)
If `sample_rows_in_table_info`, the specified number of sample rows will be
appended to each table description. This can increase performance as
demonstrated in the paper.
"""
all_table_names = self.get_usable_table_names()
if table_names is not None:
missing_tables = set(table_names).difference(all_table_names)
if missing_tables:
raise ValueError(f"table_names {missing_tables} not found in database")
all_table_names = table_names
meta_tables = [
tbl
for tbl in self._metadata.sorted_tables
if tbl.name in set(all_table_names)
and not (self.dialect == "sqlite" and tbl.name.startswith("sqlite_"))
]
tables = []
for table in meta_tables:
if self._custom_table_info and table.name in self._custom_table_info:
tables.append(self._custom_table_info[table.name])
continue
# add create table command
create_table = str(CreateTable(table).compile(self._engine))
table_info = f"{create_table.rstrip()}"
has_extra_info = (
self._indexes_in_table_info or self._sample_rows_in_table_info
)
if has_extra_info:
table_info += "\n\n/*"
if self._indexes_in_table_info:
table_info += f"\n{self._get_table_indexes(table)}\n"
if self._sample_rows_in_table_info:
table_info += f"\n{self._get_sample_rows(table)}\n"
if has_extra_info:
table_info += "*/"
tables.append(table_info)
final_str = "\n\n".join(tables)
return final_str
def _get_table_indexes(self, table: Table) -> str:
indexes = self._inspector.get_indexes(table.name)
indexes_formatted = "\n".join(map(_format_index, indexes))
return f"Table Indexes:\n{indexes_formatted}"
def _get_sample_rows(self, table: Table) -> str:
# build the select command
command = select(table).limit(self._sample_rows_in_table_info)
# save the columns in string format
columns_str = "\t".join([col.name for col in table.columns])
try:
# get the sample rows
with self._engine.connect() as connection:
sample_rows_result: CursorResult = connection.execute(command)
# shorten values in the sample rows
sample_rows = list(
map(lambda ls: [str(i)[:100] for i in ls], sample_rows_result)
)
# save the sample rows in string format
sample_rows_str = "\n".join(["\t".join(row) for row in sample_rows])
# in some dialects when there are no rows in the table a
# 'ProgrammingError' is returned
except ProgrammingError:
sample_rows_str = ""
return (
f"{self._sample_rows_in_table_info} rows from {table.name} table:\n"
f"{columns_str}\n"
f"{sample_rows_str}"
)
def run(self, command: str, fetch: str = "all") -> str:
"""Execute a SQL command and return a string representing the results.
If the statement returns rows, a string of the results is returned.
If the statement returns no rows, an empty string is returned.
"""
with self._engine.begin() as connection:
if self._schema is not None:
connection.exec_driver_sql(f"SET search_path TO {self._schema}")
cursor = connection.execute(text(command))
if cursor.returns_rows:
if fetch == "all":
result = cursor.fetchall()
elif fetch == "one":
result = cursor.fetchone()[0] # type: ignore
else:
raise ValueError("Fetch parameter must be either 'one' or 'all'")
return str(result)
return ""
def get_table_info_no_throw(self, table_names: Optional[List[str]] = None) -> str:
"""Get information about specified tables.
Follows best practices as specified in: Rajkumar et al, 2022
(https://arxiv.org/abs/2204.00498)
If `sample_rows_in_table_info`, the specified number of sample rows will be
appended to each table description. This can increase performance as
demonstrated in the paper.
"""
try:
return self.get_table_info(table_names)
except ValueError as e:
"""Format the error message"""
return f"Error: {e}"
def run_no_throw(self, command: str, fetch: str = "all") -> str:
"""Execute a SQL command and return a string representing the results.
If the statement returns rows, a string of the results is returned.
If the statement returns no rows, an empty string is returned.
If the statement throws an error, the error message is returned.
"""
try:
return self.run(command, fetch)
except SQLAlchemyError as e:
"""Format the error message"""
return f"Error: {e}"
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,142 | ImportError: cannot import name 'CursorResult' from 'sqlalchemy' | ### System Info
# Name Version Build Channel
_libgcc_mutex 0.1 main
_openmp_mutex 5.1 1_gnu
aiohttp 3.8.3 py310h5eee18b_0
aiosignal 1.3.1 pyhd8ed1ab_0 conda-forge
async-timeout 4.0.2 pyhd8ed1ab_0 conda-forge
attrs 23.1.0 pyh71513ae_0 conda-forge
blas 1.0 mkl
brotlipy 0.7.0 py310h5764c6d_1004 conda-forge
bzip2 1.0.8 h7b6447c_0
ca-certificates 2023.01.10 h06a4308_0
certifi 2022.12.7 py310h06a4308_0
cffi 1.15.0 py310h0fdd8cc_0 conda-forge
charset-normalizer 2.0.4 pyhd3eb1b0_0
colorama 0.4.6 pyhd8ed1ab_0 conda-forge
cryptography 3.4.8 py310h685ca39_1 conda-forge
dataclasses-json 0.5.7 pyhd8ed1ab_0 conda-forge
frozenlist 1.3.3 py310h5eee18b_0
greenlet 2.0.1 py310h6a678d5_0
idna 3.4 pyhd8ed1ab_0 conda-forge
intel-openmp 2021.4.0 h06a4308_3561
langchain 0.0.158 pyhd8ed1ab_0 conda-forge
ld_impl_linux-64 2.38 h1181459_1
libffi 3.4.2 h6a678d5_6
libgcc-ng 11.2.0 h1234567_1
libgomp 11.2.0 h1234567_1
libstdcxx-ng 11.2.0 h1234567_1
libuuid 1.41.5 h5eee18b_0
marshmallow 3.19.0 pyhd8ed1ab_0 conda-forge
marshmallow-enum 1.5.1 pyh9f0ad1d_3 conda-forge
mkl 2021.4.0 h06a4308_640
mkl-service 2.4.0 py310ha2c4b55_0 conda-forge
mkl_fft 1.3.1 py310hd6ae3a3_0
mkl_random 1.2.2 py310h00e6091_0
multidict 6.0.2 py310h5eee18b_0
mypy_extensions 1.0.0 pyha770c72_0 conda-forge
ncurses 6.4 h6a678d5_0
numexpr 2.8.4 py310h8879344_0
numpy 1.24.3 py310hd5efca6_0
numpy-base 1.24.3 py310h8e6c178_0
openapi-schema-pydantic 1.2.4 pyhd8ed1ab_0 conda-forge
openssl 1.1.1t h7f8727e_0
packaging 23.1 pyhd8ed1ab_0 conda-forge
pip 22.2.2 pypi_0 pypi
pycparser 2.21 pyhd8ed1ab_0 conda-forge
pydantic 1.10.2 py310h5eee18b_0
pyopenssl 20.0.1 pyhd8ed1ab_0 conda-forge
pysocks 1.7.1 pyha2e5f31_6 conda-forge
python 3.10.9 h7a1cb2a_2
python_abi 3.10 2_cp310 conda-forge
pyyaml 6.0 py310h5764c6d_4 conda-forge
readline 8.2 h5eee18b_0
requests 2.29.0 pyhd8ed1ab_0 conda-forge
setuptools 66.0.0 py310h06a4308_0
six 1.16.0 pyh6c4a22f_0 conda-forge
sqlalchemy 1.4.39 py310h5eee18b_0
sqlite 3.41.2 h5eee18b_0
stringcase 1.2.0 py_0 conda-forge
tenacity 8.2.2 pyhd8ed1ab_0 conda-forge
tk 8.6.12 h1ccaba5_0
tqdm 4.65.0 pyhd8ed1ab_1 conda-forge
typing-extensions 4.5.0 hd8ed1ab_0 conda-forge
typing_extensions 4.5.0 pyha770c72_0 conda-forge
typing_inspect 0.8.0 pyhd8ed1ab_0 conda-forge
tzdata 2023c h04d1e81_0
urllib3 1.26.15 pyhd8ed1ab_0 conda-forge
wheel 0.38.4 py310h06a4308_0
xz 5.4.2 h5eee18b_0
yaml 0.2.5 h7f98852_2 conda-forge
yarl 1.7.2 py310h5764c6d_2 conda-forge
zlib 1.2.13 h5eee18b_0
Traceback (most recent call last):
File "/home/bachar/projects/op-stack/./app.py", line 1, in <module>
from langchain.document_loaders import DirectoryLoader
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/__init__.py", line 6, in <module>
from langchain.agents import MRKLChain, ReActChain, SelfAskWithSearchChain
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/agents/__init__.py", line 2, in <module>
from langchain.agents.agent import (
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/agents/agent.py", line 15, in <module>
from langchain.agents.tools import InvalidTool
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/agents/tools.py", line 8, in <module>
from langchain.tools.base import BaseTool, Tool, tool
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/tools/__init__.py", line 32, in <module>
from langchain.tools.vectorstore.tool import (
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/tools/vectorstore/tool.py", line 13, in <module>
from langchain.chains import RetrievalQA, RetrievalQAWithSourcesChain
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/chains/__init__.py", line 19, in <module>
from langchain.chains.loading import load_chain
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/chains/loading.py", line 24, in <module>
from langchain.chains.sql_database.base import SQLDatabaseChain
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/chains/sql_database/base.py", line 15, in <module>
from langchain.sql_database import SQLDatabase
File "/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/langchain/sql_database.py", line 8, in <module>
from sqlalchemy import (
ImportError: cannot import name 'CursorResult' from 'sqlalchemy' (/home/bachar/projects/op-stack/venv/lib/python3.10/site-packages/sqlalchemy/__init__.py)
(/home/bachar/projects/op-stack/venv)
### Who can help?
_No response_
### Information
- [ ] The official example notebooks/scripts
- [ ] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [X] Document Loaders
- [ ] Vector Stores / Retrievers
- [ ] Memory
- [ ] Agents / Agent Executors
- [ ] Tools / Toolkits
- [ ] Chains
- [ ] Callbacks/Tracing
- [ ] Async
### Reproduction
from langchain.document_loaders import DirectoryLoader
docs = DirectoryLoader("./pdfs", "**/*.pdf").load()
### Expected behavior
no errors should be thrown | https://github.com/langchain-ai/langchain/issues/4142 | https://github.com/langchain-ai/langchain/pull/4145 | 2f087d63af45a172fc363b3370e49141bd663ed2 | fea639c1fc1ac324f1300016a02b6d30a2f8d249 | "2023-05-05T00:47:24Z" | python | "2023-05-05T03:46:38Z" | pyproject.toml | [tool.poetry]
name = "langchain"
version = "0.0.158"
description = "Building applications with LLMs through composability"
authors = []
license = "MIT"
readme = "README.md"
repository = "https://www.github.com/hwchase17/langchain"
[tool.poetry.scripts]
langchain-server = "langchain.server:main"
[tool.poetry.dependencies]
python = ">=3.8.1,<4.0"
pydantic = "^1"
SQLAlchemy = ">=1.3,<3"
requests = "^2"
PyYAML = ">=5.4.1"
numpy = "^1"
azure-core = {version = "^1.26.4", optional=true}
tqdm = {version = ">=4.48.0", optional = true}
openapi-schema-pydantic = "^1.2"
faiss-cpu = {version = "^1", optional = true}
wikipedia = {version = "^1", optional = true}
elasticsearch = {version = "^8", optional = true}
opensearch-py = {version = "^2.0.0", optional = true}
redis = {version = "^4", optional = true}
manifest-ml = {version = "^0.0.1", optional = true}
spacy = {version = "^3", optional = true}
nltk = {version = "^3", optional = true}
transformers = {version = "^4", optional = true}
beautifulsoup4 = {version = "^4", optional = true}
torch = {version = ">=1,<3", optional = true}
jinja2 = {version = "^3", optional = true}
tiktoken = {version = "^0.3.2", optional = true, python="^3.9"}
pinecone-client = {version = "^2", optional = true}
pinecone-text = {version = "^0.4.2", optional = true}
clickhouse-connect = {version="^0.5.14", optional=true}
weaviate-client = {version = "^3", optional = true}
google-api-python-client = {version = "2.70.0", optional = true}
wolframalpha = {version = "5.0.0", optional = true}
anthropic = {version = "^0.2.6", optional = true}
qdrant-client = {version = "^1.1.2", optional = true, python = ">=3.8.1,<3.12"}
dataclasses-json = "^0.5.7"
tensorflow-text = {version = "^2.11.0", optional = true, python = "^3.10, <3.12"}
tenacity = "^8.1.0"
cohere = {version = "^3", optional = true}
openai = {version = "^0", optional = true}
nlpcloud = {version = "^1", optional = true}
nomic = {version = "^1.0.43", optional = true}
huggingface_hub = {version = "^0", optional = true}
jina = {version = "^3.14", optional = true}
google-search-results = {version = "^2", optional = true}
sentence-transformers = {version = "^2", optional = true}
aiohttp = "^3.8.3"
arxiv = {version = "^1.4", optional = true}
pypdf = {version = "^3.4.0", optional = true}
networkx = {version="^2.6.3", optional = true}
aleph-alpha-client = {version="^2.15.0", optional = true}
deeplake = {version = "^3.3.0", optional = true}
pgvector = {version = "^0.1.6", optional = true}
psycopg2-binary = {version = "^2.9.5", optional = true}
#boto3 = {version = "^1.26.96", optional = true} # TODO: fix it, commented because the version failed with deeplake
pyowm = {version = "^3.3.0", optional = true}
async-timeout = {version = "^4.0.0", python = "<3.11"}
azure-identity = {version = "^1.12.0", optional=true}
gptcache = {version = ">=0.1.7", optional = true}
atlassian-python-api = {version = "^3.36.0", optional=true}
pytesseract = {version = "^0.3.10", optional=true}
html2text = {version="^2020.1.16", optional=true}
numexpr = "^2.8.4"
duckduckgo-search = {version="^2.8.6", optional=true}
azure-cosmos = {version="^4.4.0b1", optional=true}
lark = {version="^1.1.5", optional=true}
lancedb = {version = "^0.1", optional = true}
pexpect = {version = "^4.8.0", optional = true}
pyvespa = {version = "^0.33.0", optional = true}
O365 = {version = "^2.0.26", optional = true}
[tool.poetry.group.docs.dependencies]
autodoc_pydantic = "^1.8.0"
myst_parser = "^0.18.1"
nbsphinx = "^0.8.9"
sphinx = "^4.5.0"
sphinx-autobuild = "^2021.3.14"
sphinx_book_theme = "^0.3.3"
sphinx_rtd_theme = "^1.0.0"
sphinx-typlog-theme = "^0.8.0"
sphinx-panels = "^0.6.0"
toml = "^0.10.2"
myst-nb = "^0.17.1"
linkchecker = "^10.2.1"
sphinx-copybutton = "^0.5.1"
[tool.poetry.group.test.dependencies]
pytest = "^7.3.0"
pytest-cov = "^4.0.0"
pytest-dotenv = "^0.5.2"
duckdb-engine = "^0.7.0"
pytest-watcher = "^0.2.6"
freezegun = "^1.2.2"
responses = "^0.22.0"
pytest-asyncio = "^0.20.3"
lark = "^1.1.5"
pytest-mock = "^3.10.0"
[tool.poetry.group.test_integration]
optional = true
[tool.poetry.group.test_integration.dependencies]
pytest-vcr = "^1.0.2"
wrapt = "^1.15.0"
openai = "^0.27.4"
elasticsearch = {extras = ["async"], version = "^8.6.2"}
redis = "^4.5.4"
pinecone-client = "^2.2.1"
pinecone-text = "^0.4.2"
clickhouse-connect = "^0.5.14"
pgvector = "^0.1.6"
transformers = "^4.27.4"
pandas = "^2.0.0"
deeplake = "^3.2.21"
weaviate-client = "^3.15.5"
torch = "^1.0.0"
chromadb = "^0.3.21"
tiktoken = "^0.3.3"
python-dotenv = "^1.0.0"
sentence-transformers = "^2"
gptcache = "^0.1.9"
promptlayer = "^0.1.80"
tair = "^1.3.3"
[tool.poetry.group.lint.dependencies]
ruff = "^0.0.249"
types-toml = "^0.10.8.1"
types-redis = "^4.3.21.6"
black = "^23.1.0"
[tool.poetry.group.typing.dependencies]
mypy = "^0.991"
types-pyyaml = "^6.0.12.2"
types-requests = "^2.28.11.5"
[tool.poetry.group.dev]
optional = true
[tool.poetry.group.dev.dependencies]
jupyter = "^1.0.0"
playwright = "^1.28.0"
setuptools = "^67.6.1"
[tool.poetry.extras]
llms = ["anthropic", "cohere", "openai", "nlpcloud", "huggingface_hub", "manifest-ml", "torch", "transformers"]
qdrant = ["qdrant-client"]
openai = ["openai"]
cohere = ["cohere"]
embeddings = ["sentence-transformers"]
azure = ["azure-identity", "azure-cosmos", "openai", "azure-core"]
all = ["anthropic", "cohere", "openai", "nlpcloud", "huggingface_hub", "jina", "manifest-ml", "elasticsearch", "opensearch-py", "google-search-results", "faiss-cpu", "sentence-transformers", "transformers", "spacy", "nltk", "wikipedia", "beautifulsoup4", "tiktoken", "torch", "jinja2", "pinecone-client", "pinecone-text", "weaviate-client", "redis", "google-api-python-client", "wolframalpha", "qdrant-client", "tensorflow-text", "pypdf", "networkx", "nomic", "aleph-alpha-client", "deeplake", "pgvector", "psycopg2-binary", "boto3", "pyowm", "pytesseract", "html2text", "atlassian-python-api", "gptcache", "duckduckgo-search", "arxiv", "azure-identity", "clickhouse-connect", "azure-cosmos", "lancedb", "lark", "pexpect", "pyvespa", "O365"]
[tool.ruff]
select = [
"E", # pycodestyle
"F", # pyflakes
"I", # isort
]
exclude = [
"tests/integration_tests/examples/non-utf8-encoding.py",
]
[tool.mypy]
ignore_missing_imports = "True"
disallow_untyped_defs = "True"
exclude = ["notebooks"]
[tool.coverage.run]
omit = [
"tests/*",
]
[build-system]
requires = ["poetry-core>=1.0.0"]
build-backend = "poetry.core.masonry.api"
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,129 | Bug introduced in 0.0.158 | Updates in version 0.0.158 have introduced a bug that prevents this import from being successful, while it works in 0.0.157
```
Traceback (most recent call last):
File "path", line 5, in <module>
from langchain.chains import OpenAIModerationChain, SequentialChain, ConversationChain
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/__init__.py", line 6, in <module>
from langchain.agents import MRKLChain, ReActChain, SelfAskWithSearchChain
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/agents/__init__.py", line 2, in <module>
from langchain.agents.agent import (
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/agents/agent.py", line 15, in <module>
from langchain.agents.tools import InvalidTool
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/agents/tools.py", line 8, in <module>
from langchain.tools.base import BaseTool, Tool, tool
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/tools/__init__.py", line 32, in <module>
from langchain.tools.vectorstore.tool import (
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/tools/vectorstore/tool.py", line 13, in <module>
from langchain.chains import RetrievalQA, RetrievalQAWithSourcesChain
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/chains/__init__.py", line 19, in <module>
from langchain.chains.loading import load_chain
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/chains/loading.py", line 24, in <module>
from langchain.chains.sql_database.base import SQLDatabaseChain
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/chains/sql_database/base.py", line 15, in <module>
from langchain.sql_database import SQLDatabase
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/sql_database.py", line 8, in <module>
from sqlalchemy import (
ImportError: cannot import name 'CursorResult' from 'sqlalchemy' (/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/sqlalchemy/__init__.py)
``` | https://github.com/langchain-ai/langchain/issues/4129 | https://github.com/langchain-ai/langchain/pull/4145 | 2f087d63af45a172fc363b3370e49141bd663ed2 | fea639c1fc1ac324f1300016a02b6d30a2f8d249 | "2023-05-04T19:24:15Z" | python | "2023-05-05T03:46:38Z" | langchain/sql_database.py | """SQLAlchemy wrapper around a database."""
from __future__ import annotations
import warnings
from typing import Any, Iterable, List, Optional
import sqlalchemy
from sqlalchemy import (
CursorResult,
MetaData,
Table,
create_engine,
inspect,
select,
text,
)
from sqlalchemy.engine import Engine
from sqlalchemy.exc import ProgrammingError, SQLAlchemyError
from sqlalchemy.schema import CreateTable
def _format_index(index: sqlalchemy.engine.interfaces.ReflectedIndex) -> str:
return (
f'Name: {index["name"]}, Unique: {index["unique"]},'
f' Columns: {str(index["column_names"])}'
)
class SQLDatabase:
"""SQLAlchemy wrapper around a database."""
def __init__(
self,
engine: Engine,
schema: Optional[str] = None,
metadata: Optional[MetaData] = None,
ignore_tables: Optional[List[str]] = None,
include_tables: Optional[List[str]] = None,
sample_rows_in_table_info: int = 3,
indexes_in_table_info: bool = False,
custom_table_info: Optional[dict] = None,
view_support: bool = False,
):
"""Create engine from database URI."""
self._engine = engine
self._schema = schema
if include_tables and ignore_tables:
raise ValueError("Cannot specify both include_tables and ignore_tables")
self._inspector = inspect(self._engine)
# including view support by adding the views as well as tables to the all
# tables list if view_support is True
self._all_tables = set(
self._inspector.get_table_names(schema=schema)
+ (self._inspector.get_view_names(schema=schema) if view_support else [])
)
self._include_tables = set(include_tables) if include_tables else set()
if self._include_tables:
missing_tables = self._include_tables - self._all_tables
if missing_tables:
raise ValueError(
f"include_tables {missing_tables} not found in database"
)
self._ignore_tables = set(ignore_tables) if ignore_tables else set()
if self._ignore_tables:
missing_tables = self._ignore_tables - self._all_tables
if missing_tables:
raise ValueError(
f"ignore_tables {missing_tables} not found in database"
)
usable_tables = self.get_usable_table_names()
self._usable_tables = set(usable_tables) if usable_tables else self._all_tables
if not isinstance(sample_rows_in_table_info, int):
raise TypeError("sample_rows_in_table_info must be an integer")
self._sample_rows_in_table_info = sample_rows_in_table_info
self._indexes_in_table_info = indexes_in_table_info
self._custom_table_info = custom_table_info
if self._custom_table_info:
if not isinstance(self._custom_table_info, dict):
raise TypeError(
"table_info must be a dictionary with table names as keys and the "
"desired table info as values"
)
# only keep the tables that are also present in the database
intersection = set(self._custom_table_info).intersection(self._all_tables)
self._custom_table_info = dict(
(table, self._custom_table_info[table])
for table in self._custom_table_info
if table in intersection
)
self._metadata = metadata or MetaData()
# including view support if view_support = true
self._metadata.reflect(
views=view_support,
bind=self._engine,
only=list(self._usable_tables),
schema=self._schema,
)
@classmethod
def from_uri(
cls, database_uri: str, engine_args: Optional[dict] = None, **kwargs: Any
) -> SQLDatabase:
"""Construct a SQLAlchemy engine from URI."""
_engine_args = engine_args or {}
return cls(create_engine(database_uri, **_engine_args), **kwargs)
@property
def dialect(self) -> str:
"""Return string representation of dialect to use."""
return self._engine.dialect.name
def get_usable_table_names(self) -> Iterable[str]:
"""Get names of tables available."""
if self._include_tables:
return self._include_tables
return self._all_tables - self._ignore_tables
def get_table_names(self) -> Iterable[str]:
"""Get names of tables available."""
warnings.warn(
"This method is deprecated - please use `get_usable_table_names`."
)
return self.get_usable_table_names()
@property
def table_info(self) -> str:
"""Information about all tables in the database."""
return self.get_table_info()
def get_table_info(self, table_names: Optional[List[str]] = None) -> str:
"""Get information about specified tables.
Follows best practices as specified in: Rajkumar et al, 2022
(https://arxiv.org/abs/2204.00498)
If `sample_rows_in_table_info`, the specified number of sample rows will be
appended to each table description. This can increase performance as
demonstrated in the paper.
"""
all_table_names = self.get_usable_table_names()
if table_names is not None:
missing_tables = set(table_names).difference(all_table_names)
if missing_tables:
raise ValueError(f"table_names {missing_tables} not found in database")
all_table_names = table_names
meta_tables = [
tbl
for tbl in self._metadata.sorted_tables
if tbl.name in set(all_table_names)
and not (self.dialect == "sqlite" and tbl.name.startswith("sqlite_"))
]
tables = []
for table in meta_tables:
if self._custom_table_info and table.name in self._custom_table_info:
tables.append(self._custom_table_info[table.name])
continue
# add create table command
create_table = str(CreateTable(table).compile(self._engine))
table_info = f"{create_table.rstrip()}"
has_extra_info = (
self._indexes_in_table_info or self._sample_rows_in_table_info
)
if has_extra_info:
table_info += "\n\n/*"
if self._indexes_in_table_info:
table_info += f"\n{self._get_table_indexes(table)}\n"
if self._sample_rows_in_table_info:
table_info += f"\n{self._get_sample_rows(table)}\n"
if has_extra_info:
table_info += "*/"
tables.append(table_info)
final_str = "\n\n".join(tables)
return final_str
def _get_table_indexes(self, table: Table) -> str:
indexes = self._inspector.get_indexes(table.name)
indexes_formatted = "\n".join(map(_format_index, indexes))
return f"Table Indexes:\n{indexes_formatted}"
def _get_sample_rows(self, table: Table) -> str:
# build the select command
command = select(table).limit(self._sample_rows_in_table_info)
# save the columns in string format
columns_str = "\t".join([col.name for col in table.columns])
try:
# get the sample rows
with self._engine.connect() as connection:
sample_rows_result: CursorResult = connection.execute(command)
# shorten values in the sample rows
sample_rows = list(
map(lambda ls: [str(i)[:100] for i in ls], sample_rows_result)
)
# save the sample rows in string format
sample_rows_str = "\n".join(["\t".join(row) for row in sample_rows])
# in some dialects when there are no rows in the table a
# 'ProgrammingError' is returned
except ProgrammingError:
sample_rows_str = ""
return (
f"{self._sample_rows_in_table_info} rows from {table.name} table:\n"
f"{columns_str}\n"
f"{sample_rows_str}"
)
def run(self, command: str, fetch: str = "all") -> str:
"""Execute a SQL command and return a string representing the results.
If the statement returns rows, a string of the results is returned.
If the statement returns no rows, an empty string is returned.
"""
with self._engine.begin() as connection:
if self._schema is not None:
connection.exec_driver_sql(f"SET search_path TO {self._schema}")
cursor = connection.execute(text(command))
if cursor.returns_rows:
if fetch == "all":
result = cursor.fetchall()
elif fetch == "one":
result = cursor.fetchone()[0] # type: ignore
else:
raise ValueError("Fetch parameter must be either 'one' or 'all'")
return str(result)
return ""
def get_table_info_no_throw(self, table_names: Optional[List[str]] = None) -> str:
"""Get information about specified tables.
Follows best practices as specified in: Rajkumar et al, 2022
(https://arxiv.org/abs/2204.00498)
If `sample_rows_in_table_info`, the specified number of sample rows will be
appended to each table description. This can increase performance as
demonstrated in the paper.
"""
try:
return self.get_table_info(table_names)
except ValueError as e:
"""Format the error message"""
return f"Error: {e}"
def run_no_throw(self, command: str, fetch: str = "all") -> str:
"""Execute a SQL command and return a string representing the results.
If the statement returns rows, a string of the results is returned.
If the statement returns no rows, an empty string is returned.
If the statement throws an error, the error message is returned.
"""
try:
return self.run(command, fetch)
except SQLAlchemyError as e:
"""Format the error message"""
return f"Error: {e}"
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,129 | Bug introduced in 0.0.158 | Updates in version 0.0.158 have introduced a bug that prevents this import from being successful, while it works in 0.0.157
```
Traceback (most recent call last):
File "path", line 5, in <module>
from langchain.chains import OpenAIModerationChain, SequentialChain, ConversationChain
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/__init__.py", line 6, in <module>
from langchain.agents import MRKLChain, ReActChain, SelfAskWithSearchChain
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/agents/__init__.py", line 2, in <module>
from langchain.agents.agent import (
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/agents/agent.py", line 15, in <module>
from langchain.agents.tools import InvalidTool
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/agents/tools.py", line 8, in <module>
from langchain.tools.base import BaseTool, Tool, tool
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/tools/__init__.py", line 32, in <module>
from langchain.tools.vectorstore.tool import (
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/tools/vectorstore/tool.py", line 13, in <module>
from langchain.chains import RetrievalQA, RetrievalQAWithSourcesChain
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/chains/__init__.py", line 19, in <module>
from langchain.chains.loading import load_chain
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/chains/loading.py", line 24, in <module>
from langchain.chains.sql_database.base import SQLDatabaseChain
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/chains/sql_database/base.py", line 15, in <module>
from langchain.sql_database import SQLDatabase
File "/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/langchain/sql_database.py", line 8, in <module>
from sqlalchemy import (
ImportError: cannot import name 'CursorResult' from 'sqlalchemy' (/Users/chasemcdo/.pyenv/versions/3.11.1/lib/python3.11/site-packages/sqlalchemy/__init__.py)
``` | https://github.com/langchain-ai/langchain/issues/4129 | https://github.com/langchain-ai/langchain/pull/4145 | 2f087d63af45a172fc363b3370e49141bd663ed2 | fea639c1fc1ac324f1300016a02b6d30a2f8d249 | "2023-05-04T19:24:15Z" | python | "2023-05-05T03:46:38Z" | pyproject.toml | [tool.poetry]
name = "langchain"
version = "0.0.158"
description = "Building applications with LLMs through composability"
authors = []
license = "MIT"
readme = "README.md"
repository = "https://www.github.com/hwchase17/langchain"
[tool.poetry.scripts]
langchain-server = "langchain.server:main"
[tool.poetry.dependencies]
python = ">=3.8.1,<4.0"
pydantic = "^1"
SQLAlchemy = ">=1.3,<3"
requests = "^2"
PyYAML = ">=5.4.1"
numpy = "^1"
azure-core = {version = "^1.26.4", optional=true}
tqdm = {version = ">=4.48.0", optional = true}
openapi-schema-pydantic = "^1.2"
faiss-cpu = {version = "^1", optional = true}
wikipedia = {version = "^1", optional = true}
elasticsearch = {version = "^8", optional = true}
opensearch-py = {version = "^2.0.0", optional = true}
redis = {version = "^4", optional = true}
manifest-ml = {version = "^0.0.1", optional = true}
spacy = {version = "^3", optional = true}
nltk = {version = "^3", optional = true}
transformers = {version = "^4", optional = true}
beautifulsoup4 = {version = "^4", optional = true}
torch = {version = ">=1,<3", optional = true}
jinja2 = {version = "^3", optional = true}
tiktoken = {version = "^0.3.2", optional = true, python="^3.9"}
pinecone-client = {version = "^2", optional = true}
pinecone-text = {version = "^0.4.2", optional = true}
clickhouse-connect = {version="^0.5.14", optional=true}
weaviate-client = {version = "^3", optional = true}
google-api-python-client = {version = "2.70.0", optional = true}
wolframalpha = {version = "5.0.0", optional = true}
anthropic = {version = "^0.2.6", optional = true}
qdrant-client = {version = "^1.1.2", optional = true, python = ">=3.8.1,<3.12"}
dataclasses-json = "^0.5.7"
tensorflow-text = {version = "^2.11.0", optional = true, python = "^3.10, <3.12"}
tenacity = "^8.1.0"
cohere = {version = "^3", optional = true}
openai = {version = "^0", optional = true}
nlpcloud = {version = "^1", optional = true}
nomic = {version = "^1.0.43", optional = true}
huggingface_hub = {version = "^0", optional = true}
jina = {version = "^3.14", optional = true}
google-search-results = {version = "^2", optional = true}
sentence-transformers = {version = "^2", optional = true}
aiohttp = "^3.8.3"
arxiv = {version = "^1.4", optional = true}
pypdf = {version = "^3.4.0", optional = true}
networkx = {version="^2.6.3", optional = true}
aleph-alpha-client = {version="^2.15.0", optional = true}
deeplake = {version = "^3.3.0", optional = true}
pgvector = {version = "^0.1.6", optional = true}
psycopg2-binary = {version = "^2.9.5", optional = true}
#boto3 = {version = "^1.26.96", optional = true} # TODO: fix it, commented because the version failed with deeplake
pyowm = {version = "^3.3.0", optional = true}
async-timeout = {version = "^4.0.0", python = "<3.11"}
azure-identity = {version = "^1.12.0", optional=true}
gptcache = {version = ">=0.1.7", optional = true}
atlassian-python-api = {version = "^3.36.0", optional=true}
pytesseract = {version = "^0.3.10", optional=true}
html2text = {version="^2020.1.16", optional=true}
numexpr = "^2.8.4"
duckduckgo-search = {version="^2.8.6", optional=true}
azure-cosmos = {version="^4.4.0b1", optional=true}
lark = {version="^1.1.5", optional=true}
lancedb = {version = "^0.1", optional = true}
pexpect = {version = "^4.8.0", optional = true}
pyvespa = {version = "^0.33.0", optional = true}
O365 = {version = "^2.0.26", optional = true}
[tool.poetry.group.docs.dependencies]
autodoc_pydantic = "^1.8.0"
myst_parser = "^0.18.1"
nbsphinx = "^0.8.9"
sphinx = "^4.5.0"
sphinx-autobuild = "^2021.3.14"
sphinx_book_theme = "^0.3.3"
sphinx_rtd_theme = "^1.0.0"
sphinx-typlog-theme = "^0.8.0"
sphinx-panels = "^0.6.0"
toml = "^0.10.2"
myst-nb = "^0.17.1"
linkchecker = "^10.2.1"
sphinx-copybutton = "^0.5.1"
[tool.poetry.group.test.dependencies]
pytest = "^7.3.0"
pytest-cov = "^4.0.0"
pytest-dotenv = "^0.5.2"
duckdb-engine = "^0.7.0"
pytest-watcher = "^0.2.6"
freezegun = "^1.2.2"
responses = "^0.22.0"
pytest-asyncio = "^0.20.3"
lark = "^1.1.5"
pytest-mock = "^3.10.0"
[tool.poetry.group.test_integration]
optional = true
[tool.poetry.group.test_integration.dependencies]
pytest-vcr = "^1.0.2"
wrapt = "^1.15.0"
openai = "^0.27.4"
elasticsearch = {extras = ["async"], version = "^8.6.2"}
redis = "^4.5.4"
pinecone-client = "^2.2.1"
pinecone-text = "^0.4.2"
clickhouse-connect = "^0.5.14"
pgvector = "^0.1.6"
transformers = "^4.27.4"
pandas = "^2.0.0"
deeplake = "^3.2.21"
weaviate-client = "^3.15.5"
torch = "^1.0.0"
chromadb = "^0.3.21"
tiktoken = "^0.3.3"
python-dotenv = "^1.0.0"
sentence-transformers = "^2"
gptcache = "^0.1.9"
promptlayer = "^0.1.80"
tair = "^1.3.3"
[tool.poetry.group.lint.dependencies]
ruff = "^0.0.249"
types-toml = "^0.10.8.1"
types-redis = "^4.3.21.6"
black = "^23.1.0"
[tool.poetry.group.typing.dependencies]
mypy = "^0.991"
types-pyyaml = "^6.0.12.2"
types-requests = "^2.28.11.5"
[tool.poetry.group.dev]
optional = true
[tool.poetry.group.dev.dependencies]
jupyter = "^1.0.0"
playwright = "^1.28.0"
setuptools = "^67.6.1"
[tool.poetry.extras]
llms = ["anthropic", "cohere", "openai", "nlpcloud", "huggingface_hub", "manifest-ml", "torch", "transformers"]
qdrant = ["qdrant-client"]
openai = ["openai"]
cohere = ["cohere"]
embeddings = ["sentence-transformers"]
azure = ["azure-identity", "azure-cosmos", "openai", "azure-core"]
all = ["anthropic", "cohere", "openai", "nlpcloud", "huggingface_hub", "jina", "manifest-ml", "elasticsearch", "opensearch-py", "google-search-results", "faiss-cpu", "sentence-transformers", "transformers", "spacy", "nltk", "wikipedia", "beautifulsoup4", "tiktoken", "torch", "jinja2", "pinecone-client", "pinecone-text", "weaviate-client", "redis", "google-api-python-client", "wolframalpha", "qdrant-client", "tensorflow-text", "pypdf", "networkx", "nomic", "aleph-alpha-client", "deeplake", "pgvector", "psycopg2-binary", "boto3", "pyowm", "pytesseract", "html2text", "atlassian-python-api", "gptcache", "duckduckgo-search", "arxiv", "azure-identity", "clickhouse-connect", "azure-cosmos", "lancedb", "lark", "pexpect", "pyvespa", "O365"]
[tool.ruff]
select = [
"E", # pycodestyle
"F", # pyflakes
"I", # isort
]
exclude = [
"tests/integration_tests/examples/non-utf8-encoding.py",
]
[tool.mypy]
ignore_missing_imports = "True"
disallow_untyped_defs = "True"
exclude = ["notebooks"]
[tool.coverage.run]
omit = [
"tests/*",
]
[build-system]
requires = ["poetry-core>=1.0.0"]
build-backend = "poetry.core.masonry.api"
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,120 | [Feature Request] Allow users to pass additional arguments to the WebDriver | Description:
Currently, when creating a Chrome or Firefox web driver using the `selenium.webdriver` module, users can only pass a limited set of arguments such as `headless` mode and hardcoded `no-sandbox`. However, there are many additional options available for these browsers that cannot be passed in using the existing API. I personally was limited by this when I had to add the `--disable-dev-shm-usage` and `--disable-gpu` arguments to the Chrome WebDeriver.
To address this limitation, I propose adding a new `arguments` parameter to the `SeleniumURLLoader` that allows users to pass additional arguments as a list of strings.
| https://github.com/langchain-ai/langchain/issues/4120 | https://github.com/langchain-ai/langchain/pull/4121 | 2a3c5f83537817d06ea8fad2836bbcd1cb33a551 | 19e28d8784adef90553da071ed891fc3252b2c63 | "2023-05-04T18:15:03Z" | python | "2023-05-05T20:24:42Z" | langchain/document_loaders/url_selenium.py | """Loader that uses Selenium to load a page, then uses unstructured to load the html.
"""
import logging
from typing import TYPE_CHECKING, List, Literal, Optional, Union
if TYPE_CHECKING:
from selenium.webdriver import Chrome, Firefox
from langchain.docstore.document import Document
from langchain.document_loaders.base import BaseLoader
logger = logging.getLogger(__name__)
class SeleniumURLLoader(BaseLoader):
"""Loader that uses Selenium and to load a page and unstructured to load the html.
This is useful for loading pages that require javascript to render.
Attributes:
urls (List[str]): List of URLs to load.
continue_on_failure (bool): If True, continue loading other URLs on failure.
browser (str): The browser to use, either 'chrome' or 'firefox'.
executable_path (Optional[str]): The path to the browser executable.
headless (bool): If True, the browser will run in headless mode.
"""
def __init__(
self,
urls: List[str],
continue_on_failure: bool = True,
browser: Literal["chrome", "firefox"] = "chrome",
executable_path: Optional[str] = None,
headless: bool = True,
):
"""Load a list of URLs using Selenium and unstructured."""
try:
import selenium # noqa:F401
except ImportError:
raise ValueError(
"selenium package not found, please install it with "
"`pip install selenium`"
)
try:
import unstructured # noqa:F401
except ImportError:
raise ValueError(
"unstructured package not found, please install it with "
"`pip install unstructured`"
)
self.urls = urls
self.continue_on_failure = continue_on_failure
self.browser = browser
self.executable_path = executable_path
self.headless = headless
def _get_driver(self) -> Union["Chrome", "Firefox"]:
"""Create and return a WebDriver instance based on the specified browser.
Raises:
ValueError: If an invalid browser is specified.
Returns:
Union[Chrome, Firefox]: A WebDriver instance for the specified browser.
"""
if self.browser.lower() == "chrome":
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options as ChromeOptions
chrome_options = ChromeOptions()
if self.headless:
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
if self.executable_path is None:
return Chrome(options=chrome_options)
return Chrome(executable_path=self.executable_path, options=chrome_options)
elif self.browser.lower() == "firefox":
from selenium.webdriver import Firefox
from selenium.webdriver.firefox.options import Options as FirefoxOptions
firefox_options = FirefoxOptions()
if self.headless:
firefox_options.add_argument("--headless")
if self.executable_path is None:
return Firefox(options=firefox_options)
return Firefox(
executable_path=self.executable_path, options=firefox_options
)
else:
raise ValueError("Invalid browser specified. Use 'chrome' or 'firefox'.")
def load(self) -> List[Document]:
"""Load the specified URLs using Selenium and create Document instances.
Returns:
List[Document]: A list of Document instances with loaded content.
"""
from unstructured.partition.html import partition_html
docs: List[Document] = list()
driver = self._get_driver()
for url in self.urls:
try:
driver.get(url)
page_content = driver.page_source
elements = partition_html(text=page_content)
text = "\n\n".join([str(el) for el in elements])
metadata = {"source": url}
docs.append(Document(page_content=text, metadata=metadata))
except Exception as e:
if self.continue_on_failure:
logger.error(f"Error fetching or processing {url}, exception: {e}")
else:
raise e
driver.quit()
return docs
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,304 | [Feature Request] Allow users to pass binary location to Selenium WebDriver | ### Feature request
Problem:
Unable to set binary_location for the Webdriver via SeleniumURLLoader
Proposal:
The proposal is to adding a new arguments parameter to the SeleniumURLLoader that allows users to pass binary_location
### Motivation
To deploy Selenium on Heroku ([tutorial](https://romik-kelesh.medium.com/how-to-deploy-a-python-web-scraper-with-selenium-on-heroku-1459cb3ac76c)), the browser binary must be installed as a buildpack and its location must be set as the binary_location for the driver browser options. Currently when creating a Chrome or Firefox web driver via SeleniumURLLoader, users cannot set the binary_location of the WebDriver.
### Your contribution
I can submit the PR to add this capability to SeleniumURLLoader | https://github.com/langchain-ai/langchain/issues/4304 | https://github.com/langchain-ai/langchain/pull/4305 | 65c95f9fb2b86cf3281f2f3939b37e71f048f741 | 637c61cffbd279dc2431f9e224cfccec9c81f6cd | "2023-05-07T23:25:37Z" | python | "2023-05-08T15:05:55Z" | langchain/document_loaders/url_selenium.py | """Loader that uses Selenium to load a page, then uses unstructured to load the html.
"""
import logging
from typing import TYPE_CHECKING, List, Literal, Optional, Union
if TYPE_CHECKING:
from selenium.webdriver import Chrome, Firefox
from langchain.docstore.document import Document
from langchain.document_loaders.base import BaseLoader
logger = logging.getLogger(__name__)
class SeleniumURLLoader(BaseLoader):
"""Loader that uses Selenium and to load a page and unstructured to load the html.
This is useful for loading pages that require javascript to render.
Attributes:
urls (List[str]): List of URLs to load.
continue_on_failure (bool): If True, continue loading other URLs on failure.
browser (str): The browser to use, either 'chrome' or 'firefox'.
executable_path (Optional[str]): The path to the browser executable.
headless (bool): If True, the browser will run in headless mode.
arguments [List[str]]: List of arguments to pass to the browser.
"""
def __init__(
self,
urls: List[str],
continue_on_failure: bool = True,
browser: Literal["chrome", "firefox"] = "chrome",
executable_path: Optional[str] = None,
headless: bool = True,
arguments: List[str] = [],
):
"""Load a list of URLs using Selenium and unstructured."""
try:
import selenium # noqa:F401
except ImportError:
raise ValueError(
"selenium package not found, please install it with "
"`pip install selenium`"
)
try:
import unstructured # noqa:F401
except ImportError:
raise ValueError(
"unstructured package not found, please install it with "
"`pip install unstructured`"
)
self.urls = urls
self.continue_on_failure = continue_on_failure
self.browser = browser
self.executable_path = executable_path
self.headless = headless
self.arguments = arguments
def _get_driver(self) -> Union["Chrome", "Firefox"]:
"""Create and return a WebDriver instance based on the specified browser.
Raises:
ValueError: If an invalid browser is specified.
Returns:
Union[Chrome, Firefox]: A WebDriver instance for the specified browser.
"""
if self.browser.lower() == "chrome":
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options as ChromeOptions
chrome_options = ChromeOptions()
for arg in self.arguments:
chrome_options.add_argument(arg)
if self.headless:
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
if self.executable_path is None:
return Chrome(options=chrome_options)
return Chrome(executable_path=self.executable_path, options=chrome_options)
elif self.browser.lower() == "firefox":
from selenium.webdriver import Firefox
from selenium.webdriver.firefox.options import Options as FirefoxOptions
firefox_options = FirefoxOptions()
for arg in self.arguments:
firefox_options.add_argument(arg)
if self.headless:
firefox_options.add_argument("--headless")
if self.executable_path is None:
return Firefox(options=firefox_options)
return Firefox(
executable_path=self.executable_path, options=firefox_options
)
else:
raise ValueError("Invalid browser specified. Use 'chrome' or 'firefox'.")
def load(self) -> List[Document]:
"""Load the specified URLs using Selenium and create Document instances.
Returns:
List[Document]: A list of Document instances with loaded content.
"""
from unstructured.partition.html import partition_html
docs: List[Document] = list()
driver = self._get_driver()
for url in self.urls:
try:
driver.get(url)
page_content = driver.page_source
elements = partition_html(text=page_content)
text = "\n\n".join([str(el) for el in elements])
metadata = {"source": url}
docs.append(Document(page_content=text, metadata=metadata))
except Exception as e:
if self.continue_on_failure:
logger.error(f"Error fetching or processing {url}, exception: {e}")
else:
raise e
driver.quit()
return docs
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,096 | Callbacks are ignored when passed to load_tools | Hello,
I cannot figure out how to pass callback when using `load_tools`, I used to pass a callback_manager but I understand that it's now deprecated. I was able to reproduce with the following snippet:
```python
from langchain.agents import load_tools
from langchain.callbacks.base import BaseCallbackHandler
from langchain.tools import ShellTool
class MyCustomHandler(BaseCallbackHandler):
def on_tool_start(self, serialized, input_str: str, **kwargs):
"""Run when tool starts running."""
print("ON TOOL START!")
def on_tool_end(self, output: str, **kwargs):
"""Run when tool ends running."""
print("ON TOOL END!")
# load_tools doesn't works
print("LOAD TOOLS!")
tools = load_tools(["terminal"], callbacks=[MyCustomHandler()])
print(tools[0].run({"commands": ["echo 'Hello World!'", "time"]}))
# direct tool instantiation works
print("Direct tool")
shell_tool = ShellTool(callbacks=[MyCustomHandler()])
print(shell_tool.run({"commands": ["echo 'Hello World!'", "time"]}))
```
Here is the output I'm seeing:
```
LOAD TOOLS!
/home/lothiraldan/project/cometml/langchain/langchain/tools/shell/tool.py:33: UserWarning: The shell tool has no safeguards by default. Use at your own risk.
warnings.warn(
Hello World!
user 0m0,00s
sys 0m0,00s
Direct tool
ON TOOL START!
ON TOOL END!
Hello World!
user 0m0,00s
sys 0m0,00s
```
In this example, when I pass the callbacks to `load_tools`, the `on_tool_*` methods are not called. But maybe it's not the correct way to pass callbacks to the `load_tools` helper.
I reproduced with Langchain master, specifically the following commit https://github.com/hwchase17/langchain/commit/a9c24503309e2e3eb800f335e0fbc7c22531bda0.
Pip list output:
```
Package Version Editable project location
----------------------- --------- -------------------------------------------
aiohttp 3.8.4
aiosignal 1.3.1
async-timeout 4.0.2
attrs 23.1.0
certifi 2022.12.7
charset-normalizer 3.1.0
dataclasses-json 0.5.7
frozenlist 1.3.3
greenlet 2.0.2
idna 3.4
langchain 0.0.157 /home/lothiraldan/project/cometml/langchain
marshmallow 3.19.0
marshmallow-enum 1.5.1
multidict 6.0.4
mypy-extensions 1.0.0
numexpr 2.8.4
numpy 1.24.3
openai 0.27.6
openapi-schema-pydantic 1.2.4
packaging 23.1
pip 23.0.1
pydantic 1.10.7
PyYAML 6.0
requests 2.29.0
setuptools 67.6.1
SQLAlchemy 2.0.12
tenacity 8.2.2
tqdm 4.65.0
typing_extensions 4.5.0
typing-inspect 0.8.0
urllib3 1.26.15
wheel 0.40.0
yarl 1.9.2
``` | https://github.com/langchain-ai/langchain/issues/4096 | https://github.com/langchain-ai/langchain/pull/4298 | 0870a45a697a75ac839b724311ce7a8b59a09058 | 35c9e6ab407003e0c1f16fcf6d4c73f6637db731 | "2023-05-04T09:05:12Z" | python | "2023-05-08T15:44:26Z" | langchain/agents/load_tools.py | # flake8: noqa
"""Load tools."""
import warnings
from typing import Any, Dict, List, Optional, Callable, Tuple
from mypy_extensions import Arg, KwArg
from langchain.agents.tools import Tool
from langchain.base_language import BaseLanguageModel
from langchain.callbacks.base import BaseCallbackManager
from langchain.chains.api import news_docs, open_meteo_docs, podcast_docs, tmdb_docs
from langchain.chains.api.base import APIChain
from langchain.chains.llm_math.base import LLMMathChain
from langchain.chains.pal.base import PALChain
from langchain.requests import TextRequestsWrapper
from langchain.tools.arxiv.tool import ArxivQueryRun
from langchain.tools.base import BaseTool
from langchain.tools.bing_search.tool import BingSearchRun
from langchain.tools.ddg_search.tool import DuckDuckGoSearchRun
from langchain.tools.google_search.tool import GoogleSearchResults, GoogleSearchRun
from langchain.tools.google_serper.tool import GoogleSerperResults, GoogleSerperRun
from langchain.tools.human.tool import HumanInputRun
from langchain.tools.python.tool import PythonREPLTool
from langchain.tools.requests.tool import (
RequestsDeleteTool,
RequestsGetTool,
RequestsPatchTool,
RequestsPostTool,
RequestsPutTool,
)
from langchain.tools.scenexplain.tool import SceneXplainTool
from langchain.tools.searx_search.tool import SearxSearchResults, SearxSearchRun
from langchain.tools.shell.tool import ShellTool
from langchain.tools.wikipedia.tool import WikipediaQueryRun
from langchain.tools.wolfram_alpha.tool import WolframAlphaQueryRun
from langchain.utilities import ArxivAPIWrapper
from langchain.utilities.bing_search import BingSearchAPIWrapper
from langchain.utilities.duckduckgo_search import DuckDuckGoSearchAPIWrapper
from langchain.utilities.google_search import GoogleSearchAPIWrapper
from langchain.utilities.google_serper import GoogleSerperAPIWrapper
from langchain.utilities.awslambda import LambdaWrapper
from langchain.utilities.searx_search import SearxSearchWrapper
from langchain.utilities.serpapi import SerpAPIWrapper
from langchain.utilities.wikipedia import WikipediaAPIWrapper
from langchain.utilities.wolfram_alpha import WolframAlphaAPIWrapper
def _get_python_repl() -> BaseTool:
return PythonREPLTool()
def _get_tools_requests_get() -> BaseTool:
return RequestsGetTool(requests_wrapper=TextRequestsWrapper())
def _get_tools_requests_post() -> BaseTool:
return RequestsPostTool(requests_wrapper=TextRequestsWrapper())
def _get_tools_requests_patch() -> BaseTool:
return RequestsPatchTool(requests_wrapper=TextRequestsWrapper())
def _get_tools_requests_put() -> BaseTool:
return RequestsPutTool(requests_wrapper=TextRequestsWrapper())
def _get_tools_requests_delete() -> BaseTool:
return RequestsDeleteTool(requests_wrapper=TextRequestsWrapper())
def _get_terminal() -> BaseTool:
return ShellTool()
_BASE_TOOLS: Dict[str, Callable[[], BaseTool]] = {
"python_repl": _get_python_repl,
"requests": _get_tools_requests_get, # preserved for backwards compatability
"requests_get": _get_tools_requests_get,
"requests_post": _get_tools_requests_post,
"requests_patch": _get_tools_requests_patch,
"requests_put": _get_tools_requests_put,
"requests_delete": _get_tools_requests_delete,
"terminal": _get_terminal,
}
def _get_pal_math(llm: BaseLanguageModel) -> BaseTool:
return Tool(
name="PAL-MATH",
description="A language model that is really good at solving complex word math problems. Input should be a fully worded hard word math problem.",
func=PALChain.from_math_prompt(llm).run,
)
def _get_pal_colored_objects(llm: BaseLanguageModel) -> BaseTool:
return Tool(
name="PAL-COLOR-OBJ",
description="A language model that is really good at reasoning about position and the color attributes of objects. Input should be a fully worded hard reasoning problem. Make sure to include all information about the objects AND the final question you want to answer.",
func=PALChain.from_colored_object_prompt(llm).run,
)
def _get_llm_math(llm: BaseLanguageModel) -> BaseTool:
return Tool(
name="Calculator",
description="Useful for when you need to answer questions about math.",
func=LLMMathChain.from_llm(llm=llm).run,
coroutine=LLMMathChain.from_llm(llm=llm).arun,
)
def _get_open_meteo_api(llm: BaseLanguageModel) -> BaseTool:
chain = APIChain.from_llm_and_api_docs(llm, open_meteo_docs.OPEN_METEO_DOCS)
return Tool(
name="Open Meteo API",
description="Useful for when you want to get weather information from the OpenMeteo API. The input should be a question in natural language that this API can answer.",
func=chain.run,
)
_LLM_TOOLS: Dict[str, Callable[[BaseLanguageModel], BaseTool]] = {
"pal-math": _get_pal_math,
"pal-colored-objects": _get_pal_colored_objects,
"llm-math": _get_llm_math,
"open-meteo-api": _get_open_meteo_api,
}
def _get_news_api(llm: BaseLanguageModel, **kwargs: Any) -> BaseTool:
news_api_key = kwargs["news_api_key"]
chain = APIChain.from_llm_and_api_docs(
llm, news_docs.NEWS_DOCS, headers={"X-Api-Key": news_api_key}
)
return Tool(
name="News API",
description="Use this when you want to get information about the top headlines of current news stories. The input should be a question in natural language that this API can answer.",
func=chain.run,
)
def _get_tmdb_api(llm: BaseLanguageModel, **kwargs: Any) -> BaseTool:
tmdb_bearer_token = kwargs["tmdb_bearer_token"]
chain = APIChain.from_llm_and_api_docs(
llm,
tmdb_docs.TMDB_DOCS,
headers={"Authorization": f"Bearer {tmdb_bearer_token}"},
)
return Tool(
name="TMDB API",
description="Useful for when you want to get information from The Movie Database. The input should be a question in natural language that this API can answer.",
func=chain.run,
)
def _get_podcast_api(llm: BaseLanguageModel, **kwargs: Any) -> BaseTool:
listen_api_key = kwargs["listen_api_key"]
chain = APIChain.from_llm_and_api_docs(
llm,
podcast_docs.PODCAST_DOCS,
headers={"X-ListenAPI-Key": listen_api_key},
)
return Tool(
name="Podcast API",
description="Use the Listen Notes Podcast API to search all podcasts or episodes. The input should be a question in natural language that this API can answer.",
func=chain.run,
)
def _get_lambda_api(**kwargs: Any) -> BaseTool:
return Tool(
name=kwargs["awslambda_tool_name"],
description=kwargs["awslambda_tool_description"],
func=LambdaWrapper(**kwargs).run,
)
def _get_wolfram_alpha(**kwargs: Any) -> BaseTool:
return WolframAlphaQueryRun(api_wrapper=WolframAlphaAPIWrapper(**kwargs))
def _get_google_search(**kwargs: Any) -> BaseTool:
return GoogleSearchRun(api_wrapper=GoogleSearchAPIWrapper(**kwargs))
def _get_wikipedia(**kwargs: Any) -> BaseTool:
return WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper(**kwargs))
def _get_arxiv(**kwargs: Any) -> BaseTool:
return ArxivQueryRun(api_wrapper=ArxivAPIWrapper(**kwargs))
def _get_google_serper(**kwargs: Any) -> BaseTool:
return GoogleSerperRun(api_wrapper=GoogleSerperAPIWrapper(**kwargs))
def _get_google_serper_results_json(**kwargs: Any) -> BaseTool:
return GoogleSerperResults(api_wrapper=GoogleSerperAPIWrapper(**kwargs))
def _get_google_search_results_json(**kwargs: Any) -> BaseTool:
return GoogleSearchResults(api_wrapper=GoogleSearchAPIWrapper(**kwargs))
def _get_serpapi(**kwargs: Any) -> BaseTool:
return Tool(
name="Search",
description="A search engine. Useful for when you need to answer questions about current events. Input should be a search query.",
func=SerpAPIWrapper(**kwargs).run,
coroutine=SerpAPIWrapper(**kwargs).arun,
)
def _get_searx_search(**kwargs: Any) -> BaseTool:
return SearxSearchRun(wrapper=SearxSearchWrapper(**kwargs))
def _get_searx_search_results_json(**kwargs: Any) -> BaseTool:
wrapper_kwargs = {k: v for k, v in kwargs.items() if k != "num_results"}
return SearxSearchResults(wrapper=SearxSearchWrapper(**wrapper_kwargs), **kwargs)
def _get_bing_search(**kwargs: Any) -> BaseTool:
return BingSearchRun(api_wrapper=BingSearchAPIWrapper(**kwargs))
def _get_ddg_search(**kwargs: Any) -> BaseTool:
return DuckDuckGoSearchRun(api_wrapper=DuckDuckGoSearchAPIWrapper(**kwargs))
def _get_human_tool(**kwargs: Any) -> BaseTool:
return HumanInputRun(**kwargs)
def _get_scenexplain(**kwargs: Any) -> BaseTool:
return SceneXplainTool(**kwargs)
_EXTRA_LLM_TOOLS: Dict[
str,
Tuple[Callable[[Arg(BaseLanguageModel, "llm"), KwArg(Any)], BaseTool], List[str]],
] = {
"news-api": (_get_news_api, ["news_api_key"]),
"tmdb-api": (_get_tmdb_api, ["tmdb_bearer_token"]),
"podcast-api": (_get_podcast_api, ["listen_api_key"]),
}
_EXTRA_OPTIONAL_TOOLS: Dict[str, Tuple[Callable[[KwArg(Any)], BaseTool], List[str]]] = {
"wolfram-alpha": (_get_wolfram_alpha, ["wolfram_alpha_appid"]),
"google-search": (_get_google_search, ["google_api_key", "google_cse_id"]),
"google-search-results-json": (
_get_google_search_results_json,
["google_api_key", "google_cse_id", "num_results"],
),
"searx-search-results-json": (
_get_searx_search_results_json,
["searx_host", "engines", "num_results", "aiosession"],
),
"bing-search": (_get_bing_search, ["bing_subscription_key", "bing_search_url"]),
"ddg-search": (_get_ddg_search, []),
"google-serper": (_get_google_serper, ["serper_api_key", "aiosession"]),
"google-serper-results-json": (
_get_google_serper_results_json,
["serper_api_key", "aiosession"],
),
"serpapi": (_get_serpapi, ["serpapi_api_key", "aiosession"]),
"searx-search": (_get_searx_search, ["searx_host", "engines", "aiosession"]),
"wikipedia": (_get_wikipedia, ["top_k_results", "lang"]),
"arxiv": (
_get_arxiv,
["top_k_results", "load_max_docs", "load_all_available_meta"],
),
"human": (_get_human_tool, ["prompt_func", "input_func"]),
"awslambda": (
_get_lambda_api,
["awslambda_tool_name", "awslambda_tool_description", "function_name"],
),
"sceneXplain": (_get_scenexplain, []),
}
def load_tools(
tool_names: List[str],
llm: Optional[BaseLanguageModel] = None,
callback_manager: Optional[BaseCallbackManager] = None,
**kwargs: Any,
) -> List[BaseTool]:
"""Load tools based on their name.
Args:
tool_names: name of tools to load.
llm: Optional language model, may be needed to initialize certain tools.
callback_manager: Optional callback manager. If not provided, default global callback manager will be used.
Returns:
List of tools.
"""
tools = []
for name in tool_names:
if name == "requests":
warnings.warn(
"tool name `requests` is deprecated - "
"please use `requests_all` or specify the requests method"
)
if name == "requests_all":
# expand requests into various methods
requests_method_tools = [
_tool for _tool in _BASE_TOOLS if _tool.startswith("requests_")
]
tool_names.extend(requests_method_tools)
elif name in _BASE_TOOLS:
tools.append(_BASE_TOOLS[name]())
elif name in _LLM_TOOLS:
if llm is None:
raise ValueError(f"Tool {name} requires an LLM to be provided")
tool = _LLM_TOOLS[name](llm)
if callback_manager is not None:
tool.callback_manager = callback_manager
tools.append(tool)
elif name in _EXTRA_LLM_TOOLS:
if llm is None:
raise ValueError(f"Tool {name} requires an LLM to be provided")
_get_llm_tool_func, extra_keys = _EXTRA_LLM_TOOLS[name]
missing_keys = set(extra_keys).difference(kwargs)
if missing_keys:
raise ValueError(
f"Tool {name} requires some parameters that were not "
f"provided: {missing_keys}"
)
sub_kwargs = {k: kwargs[k] for k in extra_keys}
tool = _get_llm_tool_func(llm=llm, **sub_kwargs)
if callback_manager is not None:
tool.callback_manager = callback_manager
tools.append(tool)
elif name in _EXTRA_OPTIONAL_TOOLS:
_get_tool_func, extra_keys = _EXTRA_OPTIONAL_TOOLS[name]
sub_kwargs = {k: kwargs[k] for k in extra_keys if k in kwargs}
tool = _get_tool_func(**sub_kwargs)
if callback_manager is not None:
tool.callback_manager = callback_manager
tools.append(tool)
else:
raise ValueError(f"Got unknown tool {name}")
return tools
def get_all_tool_names() -> List[str]:
"""Get a list of all possible tool names."""
return (
list(_BASE_TOOLS)
+ list(_EXTRA_OPTIONAL_TOOLS)
+ list(_EXTRA_LLM_TOOLS)
+ list(_LLM_TOOLS)
)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,096 | Callbacks are ignored when passed to load_tools | Hello,
I cannot figure out how to pass callback when using `load_tools`, I used to pass a callback_manager but I understand that it's now deprecated. I was able to reproduce with the following snippet:
```python
from langchain.agents import load_tools
from langchain.callbacks.base import BaseCallbackHandler
from langchain.tools import ShellTool
class MyCustomHandler(BaseCallbackHandler):
def on_tool_start(self, serialized, input_str: str, **kwargs):
"""Run when tool starts running."""
print("ON TOOL START!")
def on_tool_end(self, output: str, **kwargs):
"""Run when tool ends running."""
print("ON TOOL END!")
# load_tools doesn't works
print("LOAD TOOLS!")
tools = load_tools(["terminal"], callbacks=[MyCustomHandler()])
print(tools[0].run({"commands": ["echo 'Hello World!'", "time"]}))
# direct tool instantiation works
print("Direct tool")
shell_tool = ShellTool(callbacks=[MyCustomHandler()])
print(shell_tool.run({"commands": ["echo 'Hello World!'", "time"]}))
```
Here is the output I'm seeing:
```
LOAD TOOLS!
/home/lothiraldan/project/cometml/langchain/langchain/tools/shell/tool.py:33: UserWarning: The shell tool has no safeguards by default. Use at your own risk.
warnings.warn(
Hello World!
user 0m0,00s
sys 0m0,00s
Direct tool
ON TOOL START!
ON TOOL END!
Hello World!
user 0m0,00s
sys 0m0,00s
```
In this example, when I pass the callbacks to `load_tools`, the `on_tool_*` methods are not called. But maybe it's not the correct way to pass callbacks to the `load_tools` helper.
I reproduced with Langchain master, specifically the following commit https://github.com/hwchase17/langchain/commit/a9c24503309e2e3eb800f335e0fbc7c22531bda0.
Pip list output:
```
Package Version Editable project location
----------------------- --------- -------------------------------------------
aiohttp 3.8.4
aiosignal 1.3.1
async-timeout 4.0.2
attrs 23.1.0
certifi 2022.12.7
charset-normalizer 3.1.0
dataclasses-json 0.5.7
frozenlist 1.3.3
greenlet 2.0.2
idna 3.4
langchain 0.0.157 /home/lothiraldan/project/cometml/langchain
marshmallow 3.19.0
marshmallow-enum 1.5.1
multidict 6.0.4
mypy-extensions 1.0.0
numexpr 2.8.4
numpy 1.24.3
openai 0.27.6
openapi-schema-pydantic 1.2.4
packaging 23.1
pip 23.0.1
pydantic 1.10.7
PyYAML 6.0
requests 2.29.0
setuptools 67.6.1
SQLAlchemy 2.0.12
tenacity 8.2.2
tqdm 4.65.0
typing_extensions 4.5.0
typing-inspect 0.8.0
urllib3 1.26.15
wheel 0.40.0
yarl 1.9.2
``` | https://github.com/langchain-ai/langchain/issues/4096 | https://github.com/langchain-ai/langchain/pull/4298 | 0870a45a697a75ac839b724311ce7a8b59a09058 | 35c9e6ab407003e0c1f16fcf6d4c73f6637db731 | "2023-05-04T09:05:12Z" | python | "2023-05-08T15:44:26Z" | tests/unit_tests/agents/test_tools.py | """Test tool utils."""
from typing import Any, Type
from unittest.mock import MagicMock
import pytest
from langchain.agents.agent import Agent
from langchain.agents.chat.base import ChatAgent
from langchain.agents.conversational.base import ConversationalAgent
from langchain.agents.conversational_chat.base import ConversationalChatAgent
from langchain.agents.mrkl.base import ZeroShotAgent
from langchain.agents.react.base import ReActDocstoreAgent, ReActTextWorldAgent
from langchain.agents.self_ask_with_search.base import SelfAskWithSearchAgent
from langchain.agents.tools import Tool, tool
@pytest.mark.parametrize(
"agent_cls",
[
ZeroShotAgent,
ChatAgent,
ConversationalChatAgent,
ConversationalAgent,
ReActDocstoreAgent,
ReActTextWorldAgent,
SelfAskWithSearchAgent,
],
)
def test_single_input_agent_raises_error_on_structured_tool(
agent_cls: Type[Agent],
) -> None:
"""Test that older agents raise errors on older tools."""
@tool
def the_tool(foo: str, bar: str) -> str:
"""Return the concat of foo and bar."""
return foo + bar
with pytest.raises(
ValueError,
match=f"{agent_cls.__name__} does not support" # type: ignore
f" multi-input tool {the_tool.name}.",
):
agent_cls.from_llm_and_tools(MagicMock(), [the_tool]) # type: ignore
def test_tool_no_args_specified_assumes_str() -> None:
"""Older tools could assume *args and **kwargs were passed in."""
def ambiguous_function(*args: Any, **kwargs: Any) -> str:
"""An ambiguously defined function."""
return args[0]
some_tool = Tool(
name="chain_run",
description="Run the chain",
func=ambiguous_function,
)
expected_args = {"tool_input": {"type": "string"}}
assert some_tool.args == expected_args
assert some_tool.run("foobar") == "foobar"
assert some_tool.run({"tool_input": "foobar"}) == "foobar"
with pytest.raises(ValueError, match="Too many arguments to single-input tool"):
some_tool.run({"tool_input": "foobar", "other_input": "bar"})
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,331 | Issue: Model and model_name inconsistency in OpenAI LLMs such as ChatOpenAI | ### Issue you'd like to raise.
Argument `model_name` is the standard way of defining a model in LangChain's [ChatOpenAI](https://github.com/hwchase17/langchain/blob/65c95f9fb2b86cf3281f2f3939b37e71f048f741/langchain/chat_models/openai.py#L115). However, OpenAI uses `model` in their own [API](https://platform.openai.com/docs/api-reference/completions/create). To handle this discrepancy, LangChain transforms `model_name` into `model` [here](https://github.com/hwchase17/langchain/blob/65c95f9fb2b86cf3281f2f3939b37e71f048f741/langchain/chat_models/openai.py#L202).
The problem is that, if you ignore model_name and use model in the LLM instantiation e.g. `ChatOpenAI(model=...)`, it still works! It works because model becomes part of `model_kwargs`, which takes precedence over the default `model_name` (which would be "gpt-3.5-turbo"). This leads to an inconsistency: the `model` can be anything (e.g. "gpt-4-0314"), but `model_name` will be the default value.
This inconsistency won't cause any direct issue but can be problematic when you're trying to understand what models are actually being called and used. I'm raising this issue because I lost a couple of hours myself trying to understand what was happening.
### Suggestion:
There are three ways to solve it:
1. Raise an error or warning if model is used as an argument and suggest using model_name instead
2. Raise a warning if model is defined differently from model_name
3. Change from model_name to model to make it consistent with OpenAI's API
I think (3) is unfeasible due to the breaking change, but raising a warning seems low effort and safe enough. | https://github.com/langchain-ai/langchain/issues/4331 | https://github.com/langchain-ai/langchain/pull/4366 | 02ebb15c4a92a23818c2c17486bdaf9f590dc6a5 | ba0057c07712e5e725c7c5e14c02d223783b183c | "2023-05-08T10:49:23Z" | python | "2023-05-08T23:37:34Z" | langchain/chat_models/openai.py | """OpenAI chat wrapper."""
from __future__ import annotations
import logging
import sys
from typing import Any, Callable, Dict, List, Mapping, Optional, Tuple, Union
from pydantic import Extra, Field, root_validator
from tenacity import (
before_sleep_log,
retry,
retry_if_exception_type,
stop_after_attempt,
wait_exponential,
)
from langchain.callbacks.manager import (
AsyncCallbackManagerForLLMRun,
CallbackManagerForLLMRun,
)
from langchain.chat_models.base import BaseChatModel
from langchain.schema import (
AIMessage,
BaseMessage,
ChatGeneration,
ChatMessage,
ChatResult,
HumanMessage,
SystemMessage,
)
from langchain.utils import get_from_dict_or_env
logger = logging.getLogger(__name__)
def _create_retry_decorator(llm: ChatOpenAI) -> Callable[[Any], Any]:
import openai
min_seconds = 1
max_seconds = 60
# Wait 2^x * 1 second between each retry starting with
# 4 seconds, then up to 10 seconds, then 10 seconds afterwards
return retry(
reraise=True,
stop=stop_after_attempt(llm.max_retries),
wait=wait_exponential(multiplier=1, min=min_seconds, max=max_seconds),
retry=(
retry_if_exception_type(openai.error.Timeout)
| retry_if_exception_type(openai.error.APIError)
| retry_if_exception_type(openai.error.APIConnectionError)
| retry_if_exception_type(openai.error.RateLimitError)
| retry_if_exception_type(openai.error.ServiceUnavailableError)
),
before_sleep=before_sleep_log(logger, logging.WARNING),
)
async def acompletion_with_retry(llm: ChatOpenAI, **kwargs: Any) -> Any:
"""Use tenacity to retry the async completion call."""
retry_decorator = _create_retry_decorator(llm)
@retry_decorator
async def _completion_with_retry(**kwargs: Any) -> Any:
# Use OpenAI's async api https://github.com/openai/openai-python#async-api
return await llm.client.acreate(**kwargs)
return await _completion_with_retry(**kwargs)
def _convert_dict_to_message(_dict: dict) -> BaseMessage:
role = _dict["role"]
if role == "user":
return HumanMessage(content=_dict["content"])
elif role == "assistant":
return AIMessage(content=_dict["content"])
elif role == "system":
return SystemMessage(content=_dict["content"])
else:
return ChatMessage(content=_dict["content"], role=role)
def _convert_message_to_dict(message: BaseMessage) -> dict:
if isinstance(message, ChatMessage):
message_dict = {"role": message.role, "content": message.content}
elif isinstance(message, HumanMessage):
message_dict = {"role": "user", "content": message.content}
elif isinstance(message, AIMessage):
message_dict = {"role": "assistant", "content": message.content}
elif isinstance(message, SystemMessage):
message_dict = {"role": "system", "content": message.content}
else:
raise ValueError(f"Got unknown type {message}")
if "name" in message.additional_kwargs:
message_dict["name"] = message.additional_kwargs["name"]
return message_dict
class ChatOpenAI(BaseChatModel):
"""Wrapper around OpenAI Chat large language models.
To use, you should have the ``openai`` python package installed, and the
environment variable ``OPENAI_API_KEY`` set with your API key.
Any parameters that are valid to be passed to the openai.create call can be passed
in, even if not explicitly saved on this class.
Example:
.. code-block:: python
from langchain.chat_models import ChatOpenAI
openai = ChatOpenAI(model_name="gpt-3.5-turbo")
"""
client: Any #: :meta private:
model_name: str = "gpt-3.5-turbo"
"""Model name to use."""
temperature: float = 0.7
"""What sampling temperature to use."""
model_kwargs: Dict[str, Any] = Field(default_factory=dict)
"""Holds any model parameters valid for `create` call not explicitly specified."""
openai_api_key: Optional[str] = None
openai_organization: Optional[str] = None
request_timeout: Optional[Union[float, Tuple[float, float]]] = None
"""Timeout for requests to OpenAI completion API. Default is 600 seconds."""
max_retries: int = 6
"""Maximum number of retries to make when generating."""
streaming: bool = False
"""Whether to stream the results or not."""
n: int = 1
"""Number of chat completions to generate for each prompt."""
max_tokens: Optional[int] = None
"""Maximum number of tokens to generate."""
class Config:
"""Configuration for this pydantic object."""
extra = Extra.ignore
@root_validator(pre=True)
def build_extra(cls, values: Dict[str, Any]) -> Dict[str, Any]:
"""Build extra kwargs from additional params that were passed in."""
all_required_field_names = {field.alias for field in cls.__fields__.values()}
extra = values.get("model_kwargs", {})
for field_name in list(values):
if field_name not in all_required_field_names:
if field_name in extra:
raise ValueError(f"Found {field_name} supplied twice.")
extra[field_name] = values.pop(field_name)
values["model_kwargs"] = extra
return values
@root_validator()
def validate_environment(cls, values: Dict) -> Dict:
"""Validate that api key and python package exists in environment."""
openai_api_key = get_from_dict_or_env(
values, "openai_api_key", "OPENAI_API_KEY"
)
openai_organization = get_from_dict_or_env(
values,
"openai_organization",
"OPENAI_ORGANIZATION",
default="",
)
openai_api_base = get_from_dict_or_env(
values,
"openai_api_base",
"OPENAI_API_BASE",
default="",
)
try:
import openai
except ImportError:
raise ValueError(
"Could not import openai python package. "
"Please install it with `pip install openai`."
)
openai.api_key = openai_api_key
if openai_organization:
openai.organization = openai_organization
if openai_api_base:
openai.api_base = openai_api_base
try:
values["client"] = openai.ChatCompletion
except AttributeError:
raise ValueError(
"`openai` has no `ChatCompletion` attribute, this is likely "
"due to an old version of the openai package. Try upgrading it "
"with `pip install --upgrade openai`."
)
if values["n"] < 1:
raise ValueError("n must be at least 1.")
if values["n"] > 1 and values["streaming"]:
raise ValueError("n must be 1 when streaming.")
return values
@property
def _default_params(self) -> Dict[str, Any]:
"""Get the default parameters for calling OpenAI API."""
return {
"model": self.model_name,
"request_timeout": self.request_timeout,
"max_tokens": self.max_tokens,
"stream": self.streaming,
"n": self.n,
"temperature": self.temperature,
**self.model_kwargs,
}
def _create_retry_decorator(self) -> Callable[[Any], Any]:
import openai
min_seconds = 1
max_seconds = 60
# Wait 2^x * 1 second between each retry starting with
# 4 seconds, then up to 10 seconds, then 10 seconds afterwards
return retry(
reraise=True,
stop=stop_after_attempt(self.max_retries),
wait=wait_exponential(multiplier=1, min=min_seconds, max=max_seconds),
retry=(
retry_if_exception_type(openai.error.Timeout)
| retry_if_exception_type(openai.error.APIError)
| retry_if_exception_type(openai.error.APIConnectionError)
| retry_if_exception_type(openai.error.RateLimitError)
| retry_if_exception_type(openai.error.ServiceUnavailableError)
),
before_sleep=before_sleep_log(logger, logging.WARNING),
)
def completion_with_retry(self, **kwargs: Any) -> Any:
"""Use tenacity to retry the completion call."""
retry_decorator = self._create_retry_decorator()
@retry_decorator
def _completion_with_retry(**kwargs: Any) -> Any:
return self.client.create(**kwargs)
return _completion_with_retry(**kwargs)
def _combine_llm_outputs(self, llm_outputs: List[Optional[dict]]) -> dict:
overall_token_usage: dict = {}
for output in llm_outputs:
if output is None:
# Happens in streaming
continue
token_usage = output["token_usage"]
for k, v in token_usage.items():
if k in overall_token_usage:
overall_token_usage[k] += v
else:
overall_token_usage[k] = v
return {"token_usage": overall_token_usage, "model_name": self.model_name}
def _generate(
self,
messages: List[BaseMessage],
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
) -> ChatResult:
message_dicts, params = self._create_message_dicts(messages, stop)
if self.streaming:
inner_completion = ""
role = "assistant"
params["stream"] = True
for stream_resp in self.completion_with_retry(
messages=message_dicts, **params
):
role = stream_resp["choices"][0]["delta"].get("role", role)
token = stream_resp["choices"][0]["delta"].get("content", "")
inner_completion += token
if run_manager:
run_manager.on_llm_new_token(token)
message = _convert_dict_to_message(
{"content": inner_completion, "role": role}
)
return ChatResult(generations=[ChatGeneration(message=message)])
response = self.completion_with_retry(messages=message_dicts, **params)
return self._create_chat_result(response)
def _create_message_dicts(
self, messages: List[BaseMessage], stop: Optional[List[str]]
) -> Tuple[List[Dict[str, Any]], Dict[str, Any]]:
params: Dict[str, Any] = {**{"model": self.model_name}, **self._default_params}
if stop is not None:
if "stop" in params:
raise ValueError("`stop` found in both the input and default params.")
params["stop"] = stop
message_dicts = [_convert_message_to_dict(m) for m in messages]
return message_dicts, params
def _create_chat_result(self, response: Mapping[str, Any]) -> ChatResult:
generations = []
for res in response["choices"]:
message = _convert_dict_to_message(res["message"])
gen = ChatGeneration(message=message)
generations.append(gen)
llm_output = {"token_usage": response["usage"], "model_name": self.model_name}
return ChatResult(generations=generations, llm_output=llm_output)
async def _agenerate(
self,
messages: List[BaseMessage],
stop: Optional[List[str]] = None,
run_manager: Optional[AsyncCallbackManagerForLLMRun] = None,
) -> ChatResult:
message_dicts, params = self._create_message_dicts(messages, stop)
if self.streaming:
inner_completion = ""
role = "assistant"
params["stream"] = True
async for stream_resp in await acompletion_with_retry(
self, messages=message_dicts, **params
):
role = stream_resp["choices"][0]["delta"].get("role", role)
token = stream_resp["choices"][0]["delta"].get("content", "")
inner_completion += token
if run_manager:
await run_manager.on_llm_new_token(token)
message = _convert_dict_to_message(
{"content": inner_completion, "role": role}
)
return ChatResult(generations=[ChatGeneration(message=message)])
else:
response = await acompletion_with_retry(
self, messages=message_dicts, **params
)
return self._create_chat_result(response)
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters."""
return {**{"model_name": self.model_name}, **self._default_params}
def get_num_tokens(self, text: str) -> int:
"""Calculate num tokens with tiktoken package."""
# tiktoken NOT supported for Python 3.7 or below
if sys.version_info[1] <= 7:
return super().get_num_tokens(text)
try:
import tiktoken
except ImportError:
raise ValueError(
"Could not import tiktoken python package. "
"This is needed in order to calculate get_num_tokens. "
"Please install it with `pip install tiktoken`."
)
# create a GPT-3.5-Turbo encoder instance
enc = tiktoken.encoding_for_model(self.model_name)
# encode the text using the GPT-3.5-Turbo encoder
tokenized_text = enc.encode(text)
# calculate the number of tokens in the encoded text
return len(tokenized_text)
def get_num_tokens_from_messages(self, messages: List[BaseMessage]) -> int:
"""Calculate num tokens for gpt-3.5-turbo and gpt-4 with tiktoken package.
Official documentation: https://github.com/openai/openai-cookbook/blob/
main/examples/How_to_format_inputs_to_ChatGPT_models.ipynb"""
try:
import tiktoken
except ImportError:
raise ValueError(
"Could not import tiktoken python package. "
"This is needed in order to calculate get_num_tokens. "
"Please install it with `pip install tiktoken`."
)
model = self.model_name
if model == "gpt-3.5-turbo":
# gpt-3.5-turbo may change over time.
# Returning num tokens assuming gpt-3.5-turbo-0301.
model = "gpt-3.5-turbo-0301"
elif model == "gpt-4":
# gpt-4 may change over time.
# Returning num tokens assuming gpt-4-0314.
model = "gpt-4-0314"
# Returns the number of tokens used by a list of messages.
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
logger.warning("Warning: model not found. Using cl100k_base encoding.")
encoding = tiktoken.get_encoding("cl100k_base")
if model == "gpt-3.5-turbo-0301":
# every message follows <im_start>{role/name}\n{content}<im_end>\n
tokens_per_message = 4
# if there's a name, the role is omitted
tokens_per_name = -1
elif model == "gpt-4-0314":
tokens_per_message = 3
tokens_per_name = 1
else:
raise NotImplementedError(
f"get_num_tokens_from_messages() is not presently implemented "
f"for model {model}."
"See https://github.com/openai/openai-python/blob/main/chatml.md for "
"information on how messages are converted to tokens."
)
num_tokens = 0
messages_dict = [_convert_message_to_dict(m) for m in messages]
for message in messages_dict:
num_tokens += tokens_per_message
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name":
num_tokens += tokens_per_name
# every reply is primed with <im_start>assistant
num_tokens += 3
return num_tokens
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,331 | Issue: Model and model_name inconsistency in OpenAI LLMs such as ChatOpenAI | ### Issue you'd like to raise.
Argument `model_name` is the standard way of defining a model in LangChain's [ChatOpenAI](https://github.com/hwchase17/langchain/blob/65c95f9fb2b86cf3281f2f3939b37e71f048f741/langchain/chat_models/openai.py#L115). However, OpenAI uses `model` in their own [API](https://platform.openai.com/docs/api-reference/completions/create). To handle this discrepancy, LangChain transforms `model_name` into `model` [here](https://github.com/hwchase17/langchain/blob/65c95f9fb2b86cf3281f2f3939b37e71f048f741/langchain/chat_models/openai.py#L202).
The problem is that, if you ignore model_name and use model in the LLM instantiation e.g. `ChatOpenAI(model=...)`, it still works! It works because model becomes part of `model_kwargs`, which takes precedence over the default `model_name` (which would be "gpt-3.5-turbo"). This leads to an inconsistency: the `model` can be anything (e.g. "gpt-4-0314"), but `model_name` will be the default value.
This inconsistency won't cause any direct issue but can be problematic when you're trying to understand what models are actually being called and used. I'm raising this issue because I lost a couple of hours myself trying to understand what was happening.
### Suggestion:
There are three ways to solve it:
1. Raise an error or warning if model is used as an argument and suggest using model_name instead
2. Raise a warning if model is defined differently from model_name
3. Change from model_name to model to make it consistent with OpenAI's API
I think (3) is unfeasible due to the breaking change, but raising a warning seems low effort and safe enough. | https://github.com/langchain-ai/langchain/issues/4331 | https://github.com/langchain-ai/langchain/pull/4366 | 02ebb15c4a92a23818c2c17486bdaf9f590dc6a5 | ba0057c07712e5e725c7c5e14c02d223783b183c | "2023-05-08T10:49:23Z" | python | "2023-05-08T23:37:34Z" | langchain/llms/openai.py | """Wrapper around OpenAI APIs."""
from __future__ import annotations
import logging
import sys
import warnings
from typing import (
AbstractSet,
Any,
Callable,
Collection,
Dict,
Generator,
List,
Literal,
Mapping,
Optional,
Set,
Tuple,
Union,
)
from pydantic import Extra, Field, root_validator
from tenacity import (
before_sleep_log,
retry,
retry_if_exception_type,
stop_after_attempt,
wait_exponential,
)
from langchain.callbacks.manager import (
AsyncCallbackManagerForLLMRun,
CallbackManagerForLLMRun,
)
from langchain.llms.base import BaseLLM
from langchain.schema import Generation, LLMResult
from langchain.utils import get_from_dict_or_env
logger = logging.getLogger(__name__)
def update_token_usage(
keys: Set[str], response: Dict[str, Any], token_usage: Dict[str, Any]
) -> None:
"""Update token usage."""
_keys_to_use = keys.intersection(response["usage"])
for _key in _keys_to_use:
if _key not in token_usage:
token_usage[_key] = response["usage"][_key]
else:
token_usage[_key] += response["usage"][_key]
def _update_response(response: Dict[str, Any], stream_response: Dict[str, Any]) -> None:
"""Update response from the stream response."""
response["choices"][0]["text"] += stream_response["choices"][0]["text"]
response["choices"][0]["finish_reason"] = stream_response["choices"][0][
"finish_reason"
]
response["choices"][0]["logprobs"] = stream_response["choices"][0]["logprobs"]
def _streaming_response_template() -> Dict[str, Any]:
return {
"choices": [
{
"text": "",
"finish_reason": None,
"logprobs": None,
}
]
}
def _create_retry_decorator(llm: Union[BaseOpenAI, OpenAIChat]) -> Callable[[Any], Any]:
import openai
min_seconds = 4
max_seconds = 10
# Wait 2^x * 1 second between each retry starting with
# 4 seconds, then up to 10 seconds, then 10 seconds afterwards
return retry(
reraise=True,
stop=stop_after_attempt(llm.max_retries),
wait=wait_exponential(multiplier=1, min=min_seconds, max=max_seconds),
retry=(
retry_if_exception_type(openai.error.Timeout)
| retry_if_exception_type(openai.error.APIError)
| retry_if_exception_type(openai.error.APIConnectionError)
| retry_if_exception_type(openai.error.RateLimitError)
| retry_if_exception_type(openai.error.ServiceUnavailableError)
),
before_sleep=before_sleep_log(logger, logging.WARNING),
)
def completion_with_retry(llm: Union[BaseOpenAI, OpenAIChat], **kwargs: Any) -> Any:
"""Use tenacity to retry the completion call."""
retry_decorator = _create_retry_decorator(llm)
@retry_decorator
def _completion_with_retry(**kwargs: Any) -> Any:
return llm.client.create(**kwargs)
return _completion_with_retry(**kwargs)
async def acompletion_with_retry(
llm: Union[BaseOpenAI, OpenAIChat], **kwargs: Any
) -> Any:
"""Use tenacity to retry the async completion call."""
retry_decorator = _create_retry_decorator(llm)
@retry_decorator
async def _completion_with_retry(**kwargs: Any) -> Any:
# Use OpenAI's async api https://github.com/openai/openai-python#async-api
return await llm.client.acreate(**kwargs)
return await _completion_with_retry(**kwargs)
class BaseOpenAI(BaseLLM):
"""Wrapper around OpenAI large language models."""
client: Any #: :meta private:
model_name: str = "text-davinci-003"
"""Model name to use."""
temperature: float = 0.7
"""What sampling temperature to use."""
max_tokens: int = 256
"""The maximum number of tokens to generate in the completion.
-1 returns as many tokens as possible given the prompt and
the models maximal context size."""
top_p: float = 1
"""Total probability mass of tokens to consider at each step."""
frequency_penalty: float = 0
"""Penalizes repeated tokens according to frequency."""
presence_penalty: float = 0
"""Penalizes repeated tokens."""
n: int = 1
"""How many completions to generate for each prompt."""
best_of: int = 1
"""Generates best_of completions server-side and returns the "best"."""
model_kwargs: Dict[str, Any] = Field(default_factory=dict)
"""Holds any model parameters valid for `create` call not explicitly specified."""
openai_api_key: Optional[str] = None
openai_api_base: Optional[str] = None
openai_organization: Optional[str] = None
batch_size: int = 20
"""Batch size to use when passing multiple documents to generate."""
request_timeout: Optional[Union[float, Tuple[float, float]]] = None
"""Timeout for requests to OpenAI completion API. Default is 600 seconds."""
logit_bias: Optional[Dict[str, float]] = Field(default_factory=dict)
"""Adjust the probability of specific tokens being generated."""
max_retries: int = 6
"""Maximum number of retries to make when generating."""
streaming: bool = False
"""Whether to stream the results or not."""
allowed_special: Union[Literal["all"], AbstractSet[str]] = set()
"""Set of special tokens that are allowed。"""
disallowed_special: Union[Literal["all"], Collection[str]] = "all"
"""Set of special tokens that are not allowed。"""
def __new__(cls, **data: Any) -> Union[OpenAIChat, BaseOpenAI]: # type: ignore
"""Initialize the OpenAI object."""
model_name = data.get("model_name", "")
if model_name.startswith("gpt-3.5-turbo") or model_name.startswith("gpt-4"):
warnings.warn(
"You are trying to use a chat model. This way of initializing it is "
"no longer supported. Instead, please use: "
"`from langchain.chat_models import ChatOpenAI`"
)
return OpenAIChat(**data)
return super().__new__(cls)
class Config:
"""Configuration for this pydantic object."""
extra = Extra.ignore
@root_validator(pre=True)
def build_extra(cls, values: Dict[str, Any]) -> Dict[str, Any]:
"""Build extra kwargs from additional params that were passed in."""
all_required_field_names = {field.alias for field in cls.__fields__.values()}
extra = values.get("model_kwargs", {})
for field_name in list(values):
if field_name not in all_required_field_names:
if field_name in extra:
raise ValueError(f"Found {field_name} supplied twice.")
logger.warning(
f"""WARNING! {field_name} is not default parameter.
{field_name} was transfered to model_kwargs.
Please confirm that {field_name} is what you intended."""
)
extra[field_name] = values.pop(field_name)
values["model_kwargs"] = extra
return values
@root_validator()
def validate_environment(cls, values: Dict) -> Dict:
"""Validate that api key and python package exists in environment."""
openai_api_key = get_from_dict_or_env(
values, "openai_api_key", "OPENAI_API_KEY"
)
openai_api_base = get_from_dict_or_env(
values,
"openai_api_base",
"OPENAI_API_BASE",
default="",
)
openai_organization = get_from_dict_or_env(
values,
"openai_organization",
"OPENAI_ORGANIZATION",
default="",
)
try:
import openai
openai.api_key = openai_api_key
if openai_api_base:
openai.api_base = openai_api_base
if openai_organization:
openai.organization = openai_organization
values["client"] = openai.Completion
except ImportError:
raise ValueError(
"Could not import openai python package. "
"Please install it with `pip install openai`."
)
if values["streaming"] and values["n"] > 1:
raise ValueError("Cannot stream results when n > 1.")
if values["streaming"] and values["best_of"] > 1:
raise ValueError("Cannot stream results when best_of > 1.")
return values
@property
def _default_params(self) -> Dict[str, Any]:
"""Get the default parameters for calling OpenAI API."""
normal_params = {
"temperature": self.temperature,
"max_tokens": self.max_tokens,
"top_p": self.top_p,
"frequency_penalty": self.frequency_penalty,
"presence_penalty": self.presence_penalty,
"n": self.n,
"request_timeout": self.request_timeout,
"logit_bias": self.logit_bias,
}
# Azure gpt-35-turbo doesn't support best_of
# don't specify best_of if it is 1
if self.best_of > 1:
normal_params["best_of"] = self.best_of
return {**normal_params, **self.model_kwargs}
def _generate(
self,
prompts: List[str],
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
) -> LLMResult:
"""Call out to OpenAI's endpoint with k unique prompts.
Args:
prompts: The prompts to pass into the model.
stop: Optional list of stop words to use when generating.
Returns:
The full LLM output.
Example:
.. code-block:: python
response = openai.generate(["Tell me a joke."])
"""
# TODO: write a unit test for this
params = self._invocation_params
sub_prompts = self.get_sub_prompts(params, prompts, stop)
choices = []
token_usage: Dict[str, int] = {}
# Get the token usage from the response.
# Includes prompt, completion, and total tokens used.
_keys = {"completion_tokens", "prompt_tokens", "total_tokens"}
for _prompts in sub_prompts:
if self.streaming:
if len(_prompts) > 1:
raise ValueError("Cannot stream results with multiple prompts.")
params["stream"] = True
response = _streaming_response_template()
for stream_resp in completion_with_retry(
self, prompt=_prompts, **params
):
if run_manager:
run_manager.on_llm_new_token(
stream_resp["choices"][0]["text"],
verbose=self.verbose,
logprobs=stream_resp["choices"][0]["logprobs"],
)
_update_response(response, stream_resp)
choices.extend(response["choices"])
else:
response = completion_with_retry(self, prompt=_prompts, **params)
choices.extend(response["choices"])
if not self.streaming:
# Can't update token usage if streaming
update_token_usage(_keys, response, token_usage)
return self.create_llm_result(choices, prompts, token_usage)
async def _agenerate(
self,
prompts: List[str],
stop: Optional[List[str]] = None,
run_manager: Optional[AsyncCallbackManagerForLLMRun] = None,
) -> LLMResult:
"""Call out to OpenAI's endpoint async with k unique prompts."""
params = self._invocation_params
sub_prompts = self.get_sub_prompts(params, prompts, stop)
choices = []
token_usage: Dict[str, int] = {}
# Get the token usage from the response.
# Includes prompt, completion, and total tokens used.
_keys = {"completion_tokens", "prompt_tokens", "total_tokens"}
for _prompts in sub_prompts:
if self.streaming:
if len(_prompts) > 1:
raise ValueError("Cannot stream results with multiple prompts.")
params["stream"] = True
response = _streaming_response_template()
async for stream_resp in await acompletion_with_retry(
self, prompt=_prompts, **params
):
if run_manager:
await run_manager.on_llm_new_token(
stream_resp["choices"][0]["text"],
verbose=self.verbose,
logprobs=stream_resp["choices"][0]["logprobs"],
)
_update_response(response, stream_resp)
choices.extend(response["choices"])
else:
response = await acompletion_with_retry(self, prompt=_prompts, **params)
choices.extend(response["choices"])
if not self.streaming:
# Can't update token usage if streaming
update_token_usage(_keys, response, token_usage)
return self.create_llm_result(choices, prompts, token_usage)
def get_sub_prompts(
self,
params: Dict[str, Any],
prompts: List[str],
stop: Optional[List[str]] = None,
) -> List[List[str]]:
"""Get the sub prompts for llm call."""
if stop is not None:
if "stop" in params:
raise ValueError("`stop` found in both the input and default params.")
params["stop"] = stop
if params["max_tokens"] == -1:
if len(prompts) != 1:
raise ValueError(
"max_tokens set to -1 not supported for multiple inputs."
)
params["max_tokens"] = self.max_tokens_for_prompt(prompts[0])
sub_prompts = [
prompts[i : i + self.batch_size]
for i in range(0, len(prompts), self.batch_size)
]
return sub_prompts
def create_llm_result(
self, choices: Any, prompts: List[str], token_usage: Dict[str, int]
) -> LLMResult:
"""Create the LLMResult from the choices and prompts."""
generations = []
for i, _ in enumerate(prompts):
sub_choices = choices[i * self.n : (i + 1) * self.n]
generations.append(
[
Generation(
text=choice["text"],
generation_info=dict(
finish_reason=choice.get("finish_reason"),
logprobs=choice.get("logprobs"),
),
)
for choice in sub_choices
]
)
llm_output = {"token_usage": token_usage, "model_name": self.model_name}
return LLMResult(generations=generations, llm_output=llm_output)
def stream(self, prompt: str, stop: Optional[List[str]] = None) -> Generator:
"""Call OpenAI with streaming flag and return the resulting generator.
BETA: this is a beta feature while we figure out the right abstraction.
Once that happens, this interface could change.
Args:
prompt: The prompts to pass into the model.
stop: Optional list of stop words to use when generating.
Returns:
A generator representing the stream of tokens from OpenAI.
Example:
.. code-block:: python
generator = openai.stream("Tell me a joke.")
for token in generator:
yield token
"""
params = self.prep_streaming_params(stop)
generator = self.client.create(prompt=prompt, **params)
return generator
def prep_streaming_params(self, stop: Optional[List[str]] = None) -> Dict[str, Any]:
"""Prepare the params for streaming."""
params = self._invocation_params
if params["best_of"] != 1:
raise ValueError("OpenAI only supports best_of == 1 for streaming")
if stop is not None:
if "stop" in params:
raise ValueError("`stop` found in both the input and default params.")
params["stop"] = stop
params["stream"] = True
return params
@property
def _invocation_params(self) -> Dict[str, Any]:
"""Get the parameters used to invoke the model."""
return self._default_params
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters."""
return {**{"model_name": self.model_name}, **self._default_params}
@property
def _llm_type(self) -> str:
"""Return type of llm."""
return "openai"
def get_num_tokens(self, text: str) -> int:
"""Calculate num tokens with tiktoken package."""
# tiktoken NOT supported for Python < 3.8
if sys.version_info[1] < 8:
return super().get_num_tokens(text)
try:
import tiktoken
except ImportError:
raise ValueError(
"Could not import tiktoken python package. "
"This is needed in order to calculate get_num_tokens. "
"Please install it with `pip install tiktoken`."
)
enc = tiktoken.encoding_for_model(self.model_name)
tokenized_text = enc.encode(
text,
allowed_special=self.allowed_special,
disallowed_special=self.disallowed_special,
)
# calculate the number of tokens in the encoded text
return len(tokenized_text)
def modelname_to_contextsize(self, modelname: str) -> int:
"""Calculate the maximum number of tokens possible to generate for a model.
Args:
modelname: The modelname we want to know the context size for.
Returns:
The maximum context size
Example:
.. code-block:: python
max_tokens = openai.modelname_to_contextsize("text-davinci-003")
"""
model_token_mapping = {
"gpt-4": 8192,
"gpt-4-0314": 8192,
"gpt-4-32k": 32768,
"gpt-4-32k-0314": 32768,
"gpt-3.5-turbo": 4096,
"gpt-3.5-turbo-0301": 4096,
"text-ada-001": 2049,
"ada": 2049,
"text-babbage-001": 2040,
"babbage": 2049,
"text-curie-001": 2049,
"curie": 2049,
"davinci": 2049,
"text-davinci-003": 4097,
"text-davinci-002": 4097,
"code-davinci-002": 8001,
"code-davinci-001": 8001,
"code-cushman-002": 2048,
"code-cushman-001": 2048,
}
context_size = model_token_mapping.get(modelname, None)
if context_size is None:
raise ValueError(
f"Unknown model: {modelname}. Please provide a valid OpenAI model name."
"Known models are: " + ", ".join(model_token_mapping.keys())
)
return context_size
def max_tokens_for_prompt(self, prompt: str) -> int:
"""Calculate the maximum number of tokens possible to generate for a prompt.
Args:
prompt: The prompt to pass into the model.
Returns:
The maximum number of tokens to generate for a prompt.
Example:
.. code-block:: python
max_tokens = openai.max_token_for_prompt("Tell me a joke.")
"""
num_tokens = self.get_num_tokens(prompt)
# get max context size for model by name
max_size = self.modelname_to_contextsize(self.model_name)
return max_size - num_tokens
class OpenAI(BaseOpenAI):
"""Wrapper around OpenAI large language models.
To use, you should have the ``openai`` python package installed, and the
environment variable ``OPENAI_API_KEY`` set with your API key.
Any parameters that are valid to be passed to the openai.create call can be passed
in, even if not explicitly saved on this class.
Example:
.. code-block:: python
from langchain.llms import OpenAI
openai = OpenAI(model_name="text-davinci-003")
"""
@property
def _invocation_params(self) -> Dict[str, Any]:
return {**{"model": self.model_name}, **super()._invocation_params}
class AzureOpenAI(BaseOpenAI):
"""Wrapper around Azure-specific OpenAI large language models.
To use, you should have the ``openai`` python package installed, and the
environment variable ``OPENAI_API_KEY`` set with your API key.
Any parameters that are valid to be passed to the openai.create call can be passed
in, even if not explicitly saved on this class.
Example:
.. code-block:: python
from langchain.llms import AzureOpenAI
openai = AzureOpenAI(model_name="text-davinci-003")
"""
deployment_name: str = ""
"""Deployment name to use."""
@property
def _identifying_params(self) -> Mapping[str, Any]:
return {
**{"deployment_name": self.deployment_name},
**super()._identifying_params,
}
@property
def _invocation_params(self) -> Dict[str, Any]:
return {**{"engine": self.deployment_name}, **super()._invocation_params}
@property
def _llm_type(self) -> str:
"""Return type of llm."""
return "azure"
class OpenAIChat(BaseLLM):
"""Wrapper around OpenAI Chat large language models.
To use, you should have the ``openai`` python package installed, and the
environment variable ``OPENAI_API_KEY`` set with your API key.
Any parameters that are valid to be passed to the openai.create call can be passed
in, even if not explicitly saved on this class.
Example:
.. code-block:: python
from langchain.llms import OpenAIChat
openaichat = OpenAIChat(model_name="gpt-3.5-turbo")
"""
client: Any #: :meta private:
model_name: str = "gpt-3.5-turbo"
"""Model name to use."""
model_kwargs: Dict[str, Any] = Field(default_factory=dict)
"""Holds any model parameters valid for `create` call not explicitly specified."""
openai_api_key: Optional[str] = None
openai_api_base: Optional[str] = None
max_retries: int = 6
"""Maximum number of retries to make when generating."""
prefix_messages: List = Field(default_factory=list)
"""Series of messages for Chat input."""
streaming: bool = False
"""Whether to stream the results or not."""
allowed_special: Union[Literal["all"], AbstractSet[str]] = set()
"""Set of special tokens that are allowed。"""
disallowed_special: Union[Literal["all"], Collection[str]] = "all"
"""Set of special tokens that are not allowed。"""
class Config:
"""Configuration for this pydantic object."""
extra = Extra.ignore
@root_validator(pre=True)
def build_extra(cls, values: Dict[str, Any]) -> Dict[str, Any]:
"""Build extra kwargs from additional params that were passed in."""
all_required_field_names = {field.alias for field in cls.__fields__.values()}
extra = values.get("model_kwargs", {})
for field_name in list(values):
if field_name not in all_required_field_names:
if field_name in extra:
raise ValueError(f"Found {field_name} supplied twice.")
extra[field_name] = values.pop(field_name)
values["model_kwargs"] = extra
return values
@root_validator()
def validate_environment(cls, values: Dict) -> Dict:
"""Validate that api key and python package exists in environment."""
openai_api_key = get_from_dict_or_env(
values, "openai_api_key", "OPENAI_API_KEY"
)
openai_api_base = get_from_dict_or_env(
values,
"openai_api_base",
"OPENAI_API_BASE",
default="",
)
openai_organization = get_from_dict_or_env(
values, "openai_organization", "OPENAI_ORGANIZATION", default=""
)
try:
import openai
openai.api_key = openai_api_key
if openai_api_base:
openai.api_base = openai_api_base
if openai_organization:
openai.organization = openai_organization
except ImportError:
raise ValueError(
"Could not import openai python package. "
"Please install it with `pip install openai`."
)
try:
values["client"] = openai.ChatCompletion
except AttributeError:
raise ValueError(
"`openai` has no `ChatCompletion` attribute, this is likely "
"due to an old version of the openai package. Try upgrading it "
"with `pip install --upgrade openai`."
)
warnings.warn(
"You are trying to use a chat model. This way of initializing it is "
"no longer supported. Instead, please use: "
"`from langchain.chat_models import ChatOpenAI`"
)
return values
@property
def _default_params(self) -> Dict[str, Any]:
"""Get the default parameters for calling OpenAI API."""
return self.model_kwargs
def _get_chat_params(
self, prompts: List[str], stop: Optional[List[str]] = None
) -> Tuple:
if len(prompts) > 1:
raise ValueError(
f"OpenAIChat currently only supports single prompt, got {prompts}"
)
messages = self.prefix_messages + [{"role": "user", "content": prompts[0]}]
params: Dict[str, Any] = {**{"model": self.model_name}, **self._default_params}
if stop is not None:
if "stop" in params:
raise ValueError("`stop` found in both the input and default params.")
params["stop"] = stop
if params.get("max_tokens") == -1:
# for ChatGPT api, omitting max_tokens is equivalent to having no limit
del params["max_tokens"]
return messages, params
def _generate(
self,
prompts: List[str],
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
) -> LLMResult:
messages, params = self._get_chat_params(prompts, stop)
if self.streaming:
response = ""
params["stream"] = True
for stream_resp in completion_with_retry(self, messages=messages, **params):
token = stream_resp["choices"][0]["delta"].get("content", "")
response += token
if run_manager:
run_manager.on_llm_new_token(
token,
)
return LLMResult(
generations=[[Generation(text=response)]],
)
else:
full_response = completion_with_retry(self, messages=messages, **params)
llm_output = {
"token_usage": full_response["usage"],
"model_name": self.model_name,
}
return LLMResult(
generations=[
[Generation(text=full_response["choices"][0]["message"]["content"])]
],
llm_output=llm_output,
)
async def _agenerate(
self,
prompts: List[str],
stop: Optional[List[str]] = None,
run_manager: Optional[AsyncCallbackManagerForLLMRun] = None,
) -> LLMResult:
messages, params = self._get_chat_params(prompts, stop)
if self.streaming:
response = ""
params["stream"] = True
async for stream_resp in await acompletion_with_retry(
self, messages=messages, **params
):
token = stream_resp["choices"][0]["delta"].get("content", "")
response += token
if run_manager:
await run_manager.on_llm_new_token(
token,
)
return LLMResult(
generations=[[Generation(text=response)]],
)
else:
full_response = await acompletion_with_retry(
self, messages=messages, **params
)
llm_output = {
"token_usage": full_response["usage"],
"model_name": self.model_name,
}
return LLMResult(
generations=[
[Generation(text=full_response["choices"][0]["message"]["content"])]
],
llm_output=llm_output,
)
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters."""
return {**{"model_name": self.model_name}, **self._default_params}
@property
def _llm_type(self) -> str:
"""Return type of llm."""
return "openai-chat"
def get_num_tokens(self, text: str) -> int:
"""Calculate num tokens with tiktoken package."""
# tiktoken NOT supported for Python < 3.8
if sys.version_info[1] < 8:
return super().get_num_tokens(text)
try:
import tiktoken
except ImportError:
raise ValueError(
"Could not import tiktoken python package. "
"This is needed in order to calculate get_num_tokens. "
"Please install it with `pip install tiktoken`."
)
# create a GPT-3.5-Turbo encoder instance
enc = tiktoken.encoding_for_model("gpt-3.5-turbo")
# encode the text using the GPT-3.5-Turbo encoder
tokenized_text = enc.encode(
text,
allowed_special=self.allowed_special,
disallowed_special=self.disallowed_special,
)
# calculate the number of tokens in the encoded text
return len(tokenized_text)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,331 | Issue: Model and model_name inconsistency in OpenAI LLMs such as ChatOpenAI | ### Issue you'd like to raise.
Argument `model_name` is the standard way of defining a model in LangChain's [ChatOpenAI](https://github.com/hwchase17/langchain/blob/65c95f9fb2b86cf3281f2f3939b37e71f048f741/langchain/chat_models/openai.py#L115). However, OpenAI uses `model` in their own [API](https://platform.openai.com/docs/api-reference/completions/create). To handle this discrepancy, LangChain transforms `model_name` into `model` [here](https://github.com/hwchase17/langchain/blob/65c95f9fb2b86cf3281f2f3939b37e71f048f741/langchain/chat_models/openai.py#L202).
The problem is that, if you ignore model_name and use model in the LLM instantiation e.g. `ChatOpenAI(model=...)`, it still works! It works because model becomes part of `model_kwargs`, which takes precedence over the default `model_name` (which would be "gpt-3.5-turbo"). This leads to an inconsistency: the `model` can be anything (e.g. "gpt-4-0314"), but `model_name` will be the default value.
This inconsistency won't cause any direct issue but can be problematic when you're trying to understand what models are actually being called and used. I'm raising this issue because I lost a couple of hours myself trying to understand what was happening.
### Suggestion:
There are three ways to solve it:
1. Raise an error or warning if model is used as an argument and suggest using model_name instead
2. Raise a warning if model is defined differently from model_name
3. Change from model_name to model to make it consistent with OpenAI's API
I think (3) is unfeasible due to the breaking change, but raising a warning seems low effort and safe enough. | https://github.com/langchain-ai/langchain/issues/4331 | https://github.com/langchain-ai/langchain/pull/4366 | 02ebb15c4a92a23818c2c17486bdaf9f590dc6a5 | ba0057c07712e5e725c7c5e14c02d223783b183c | "2023-05-08T10:49:23Z" | python | "2023-05-08T23:37:34Z" | tests/integration_tests/chat_models/test_openai.py | """Test ChatOpenAI wrapper."""
import pytest
from langchain.callbacks.manager import CallbackManager
from langchain.chat_models.openai import ChatOpenAI
from langchain.schema import (
BaseMessage,
ChatGeneration,
ChatResult,
HumanMessage,
LLMResult,
SystemMessage,
)
from tests.unit_tests.callbacks.fake_callback_handler import FakeCallbackHandler
def test_chat_openai() -> None:
"""Test ChatOpenAI wrapper."""
chat = ChatOpenAI(max_tokens=10)
message = HumanMessage(content="Hello")
response = chat([message])
assert isinstance(response, BaseMessage)
assert isinstance(response.content, str)
def test_chat_openai_system_message() -> None:
"""Test ChatOpenAI wrapper with system message."""
chat = ChatOpenAI(max_tokens=10)
system_message = SystemMessage(content="You are to chat with the user.")
human_message = HumanMessage(content="Hello")
response = chat([system_message, human_message])
assert isinstance(response, BaseMessage)
assert isinstance(response.content, str)
def test_chat_openai_generate() -> None:
"""Test ChatOpenAI wrapper with generate."""
chat = ChatOpenAI(max_tokens=10, n=2)
message = HumanMessage(content="Hello")
response = chat.generate([[message], [message]])
assert isinstance(response, LLMResult)
assert len(response.generations) == 2
for generations in response.generations:
assert len(generations) == 2
for generation in generations:
assert isinstance(generation, ChatGeneration)
assert isinstance(generation.text, str)
assert generation.text == generation.message.content
def test_chat_openai_multiple_completions() -> None:
"""Test ChatOpenAI wrapper with multiple completions."""
chat = ChatOpenAI(max_tokens=10, n=5)
message = HumanMessage(content="Hello")
response = chat._generate([message])
assert isinstance(response, ChatResult)
assert len(response.generations) == 5
for generation in response.generations:
assert isinstance(generation.message, BaseMessage)
assert isinstance(generation.message.content, str)
def test_chat_openai_streaming() -> None:
"""Test that streaming correctly invokes on_llm_new_token callback."""
callback_handler = FakeCallbackHandler()
callback_manager = CallbackManager([callback_handler])
chat = ChatOpenAI(
max_tokens=10,
streaming=True,
temperature=0,
callback_manager=callback_manager,
verbose=True,
)
message = HumanMessage(content="Hello")
response = chat([message])
assert callback_handler.llm_streams > 0
assert isinstance(response, BaseMessage)
def test_chat_openai_llm_output_contains_model_name() -> None:
"""Test llm_output contains model_name."""
chat = ChatOpenAI(max_tokens=10)
message = HumanMessage(content="Hello")
llm_result = chat.generate([[message]])
assert llm_result.llm_output is not None
assert llm_result.llm_output["model_name"] == chat.model_name
def test_chat_openai_streaming_llm_output_contains_model_name() -> None:
"""Test llm_output contains model_name."""
chat = ChatOpenAI(max_tokens=10, streaming=True)
message = HumanMessage(content="Hello")
llm_result = chat.generate([[message]])
assert llm_result.llm_output is not None
assert llm_result.llm_output["model_name"] == chat.model_name
def test_chat_openai_invalid_streaming_params() -> None:
"""Test that streaming correctly invokes on_llm_new_token callback."""
with pytest.raises(ValueError):
ChatOpenAI(
max_tokens=10,
streaming=True,
temperature=0,
n=5,
)
@pytest.mark.asyncio
async def test_async_chat_openai() -> None:
"""Test async generation."""
chat = ChatOpenAI(max_tokens=10, n=2)
message = HumanMessage(content="Hello")
response = await chat.agenerate([[message], [message]])
assert isinstance(response, LLMResult)
assert len(response.generations) == 2
for generations in response.generations:
assert len(generations) == 2
for generation in generations:
assert isinstance(generation, ChatGeneration)
assert isinstance(generation.text, str)
assert generation.text == generation.message.content
@pytest.mark.asyncio
async def test_async_chat_openai_streaming() -> None:
"""Test that streaming correctly invokes on_llm_new_token callback."""
callback_handler = FakeCallbackHandler()
callback_manager = CallbackManager([callback_handler])
chat = ChatOpenAI(
max_tokens=10,
streaming=True,
temperature=0,
callback_manager=callback_manager,
verbose=True,
)
message = HumanMessage(content="Hello")
response = await chat.agenerate([[message], [message]])
assert callback_handler.llm_streams > 0
assert isinstance(response, LLMResult)
assert len(response.generations) == 2
for generations in response.generations:
assert len(generations) == 1
for generation in generations:
assert isinstance(generation, ChatGeneration)
assert isinstance(generation.text, str)
assert generation.text == generation.message.content
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,331 | Issue: Model and model_name inconsistency in OpenAI LLMs such as ChatOpenAI | ### Issue you'd like to raise.
Argument `model_name` is the standard way of defining a model in LangChain's [ChatOpenAI](https://github.com/hwchase17/langchain/blob/65c95f9fb2b86cf3281f2f3939b37e71f048f741/langchain/chat_models/openai.py#L115). However, OpenAI uses `model` in their own [API](https://platform.openai.com/docs/api-reference/completions/create). To handle this discrepancy, LangChain transforms `model_name` into `model` [here](https://github.com/hwchase17/langchain/blob/65c95f9fb2b86cf3281f2f3939b37e71f048f741/langchain/chat_models/openai.py#L202).
The problem is that, if you ignore model_name and use model in the LLM instantiation e.g. `ChatOpenAI(model=...)`, it still works! It works because model becomes part of `model_kwargs`, which takes precedence over the default `model_name` (which would be "gpt-3.5-turbo"). This leads to an inconsistency: the `model` can be anything (e.g. "gpt-4-0314"), but `model_name` will be the default value.
This inconsistency won't cause any direct issue but can be problematic when you're trying to understand what models are actually being called and used. I'm raising this issue because I lost a couple of hours myself trying to understand what was happening.
### Suggestion:
There are three ways to solve it:
1. Raise an error or warning if model is used as an argument and suggest using model_name instead
2. Raise a warning if model is defined differently from model_name
3. Change from model_name to model to make it consistent with OpenAI's API
I think (3) is unfeasible due to the breaking change, but raising a warning seems low effort and safe enough. | https://github.com/langchain-ai/langchain/issues/4331 | https://github.com/langchain-ai/langchain/pull/4366 | 02ebb15c4a92a23818c2c17486bdaf9f590dc6a5 | ba0057c07712e5e725c7c5e14c02d223783b183c | "2023-05-08T10:49:23Z" | python | "2023-05-08T23:37:34Z" | tests/integration_tests/llms/test_openai.py | """Test OpenAI API wrapper."""
from pathlib import Path
from typing import Generator
import pytest
from langchain.callbacks.manager import CallbackManager
from langchain.llms.loading import load_llm
from langchain.llms.openai import OpenAI, OpenAIChat
from langchain.schema import LLMResult
from tests.unit_tests.callbacks.fake_callback_handler import FakeCallbackHandler
def test_openai_call() -> None:
"""Test valid call to openai."""
llm = OpenAI(max_tokens=10)
output = llm("Say foo:")
assert isinstance(output, str)
def test_openai_extra_kwargs() -> None:
"""Test extra kwargs to openai."""
# Check that foo is saved in extra_kwargs.
llm = OpenAI(foo=3, max_tokens=10)
assert llm.max_tokens == 10
assert llm.model_kwargs == {"foo": 3}
# Test that if extra_kwargs are provided, they are added to it.
llm = OpenAI(foo=3, model_kwargs={"bar": 2})
assert llm.model_kwargs == {"foo": 3, "bar": 2}
# Test that if provided twice it errors
with pytest.raises(ValueError):
OpenAI(foo=3, model_kwargs={"foo": 2})
def test_openai_llm_output_contains_model_name() -> None:
"""Test llm_output contains model_name."""
llm = OpenAI(max_tokens=10)
llm_result = llm.generate(["Hello, how are you?"])
assert llm_result.llm_output is not None
assert llm_result.llm_output["model_name"] == llm.model_name
def test_openai_stop_valid() -> None:
"""Test openai stop logic on valid configuration."""
query = "write an ordered list of five items"
first_llm = OpenAI(stop="3", temperature=0)
first_output = first_llm(query)
second_llm = OpenAI(temperature=0)
second_output = second_llm(query, stop=["3"])
# Because it stops on new lines, shouldn't return anything
assert first_output == second_output
def test_openai_stop_error() -> None:
"""Test openai stop logic on bad configuration."""
llm = OpenAI(stop="3", temperature=0)
with pytest.raises(ValueError):
llm("write an ordered list of five items", stop=["\n"])
def test_saving_loading_llm(tmp_path: Path) -> None:
"""Test saving/loading an OpenAI LLM."""
llm = OpenAI(max_tokens=10)
llm.save(file_path=tmp_path / "openai.yaml")
loaded_llm = load_llm(tmp_path / "openai.yaml")
assert loaded_llm == llm
def test_openai_streaming() -> None:
"""Test streaming tokens from OpenAI."""
llm = OpenAI(max_tokens=10)
generator = llm.stream("I'm Pickle Rick")
assert isinstance(generator, Generator)
for token in generator:
assert isinstance(token["choices"][0]["text"], str)
def test_openai_streaming_error() -> None:
"""Test error handling in stream."""
llm = OpenAI(best_of=2)
with pytest.raises(ValueError):
llm.stream("I'm Pickle Rick")
def test_openai_streaming_best_of_error() -> None:
"""Test validation for streaming fails if best_of is not 1."""
with pytest.raises(ValueError):
OpenAI(best_of=2, streaming=True)
def test_openai_streaming_n_error() -> None:
"""Test validation for streaming fails if n is not 1."""
with pytest.raises(ValueError):
OpenAI(n=2, streaming=True)
def test_openai_streaming_multiple_prompts_error() -> None:
"""Test validation for streaming fails if multiple prompts are given."""
with pytest.raises(ValueError):
OpenAI(streaming=True).generate(["I'm Pickle Rick", "I'm Pickle Rick"])
def test_openai_streaming_call() -> None:
"""Test valid call to openai."""
llm = OpenAI(max_tokens=10, streaming=True)
output = llm("Say foo:")
assert isinstance(output, str)
def test_openai_streaming_callback() -> None:
"""Test that streaming correctly invokes on_llm_new_token callback."""
callback_handler = FakeCallbackHandler()
callback_manager = CallbackManager([callback_handler])
llm = OpenAI(
max_tokens=10,
streaming=True,
temperature=0,
callback_manager=callback_manager,
verbose=True,
)
llm("Write me a sentence with 100 words.")
assert callback_handler.llm_streams == 10
@pytest.mark.asyncio
async def test_openai_async_generate() -> None:
"""Test async generation."""
llm = OpenAI(max_tokens=10)
output = await llm.agenerate(["Hello, how are you?"])
assert isinstance(output, LLMResult)
@pytest.mark.asyncio
async def test_openai_async_streaming_callback() -> None:
"""Test that streaming correctly invokes on_llm_new_token callback."""
callback_handler = FakeCallbackHandler()
callback_manager = CallbackManager([callback_handler])
llm = OpenAI(
max_tokens=10,
streaming=True,
temperature=0,
callback_manager=callback_manager,
verbose=True,
)
result = await llm.agenerate(["Write me a sentence with 100 words."])
assert callback_handler.llm_streams == 10
assert isinstance(result, LLMResult)
def test_openai_chat_wrong_class() -> None:
"""Test OpenAIChat with wrong class still works."""
llm = OpenAI(model_name="gpt-3.5-turbo")
output = llm("Say foo:")
assert isinstance(output, str)
def test_openai_chat() -> None:
"""Test OpenAIChat."""
llm = OpenAIChat(max_tokens=10)
output = llm("Say foo:")
assert isinstance(output, str)
def test_openai_chat_streaming() -> None:
"""Test OpenAIChat with streaming option."""
llm = OpenAIChat(max_tokens=10, streaming=True)
output = llm("Say foo:")
assert isinstance(output, str)
def test_openai_chat_streaming_callback() -> None:
"""Test that streaming correctly invokes on_llm_new_token callback."""
callback_handler = FakeCallbackHandler()
callback_manager = CallbackManager([callback_handler])
llm = OpenAIChat(
max_tokens=10,
streaming=True,
temperature=0,
callback_manager=callback_manager,
verbose=True,
)
llm("Write me a sentence with 100 words.")
assert callback_handler.llm_streams != 0
@pytest.mark.asyncio
async def test_openai_chat_async_generate() -> None:
"""Test async chat."""
llm = OpenAIChat(max_tokens=10)
output = await llm.agenerate(["Hello, how are you?"])
assert isinstance(output, LLMResult)
@pytest.mark.asyncio
async def test_openai_chat_async_streaming_callback() -> None:
"""Test that streaming correctly invokes on_llm_new_token callback."""
callback_handler = FakeCallbackHandler()
callback_manager = CallbackManager([callback_handler])
llm = OpenAIChat(
max_tokens=10,
streaming=True,
temperature=0,
callback_manager=callback_manager,
verbose=True,
)
result = await llm.agenerate(["Write me a sentence with 100 words."])
assert callback_handler.llm_streams != 0
assert isinstance(result, LLMResult)
def test_openai_modelname_to_contextsize_valid() -> None:
"""Test model name to context size on a valid model."""
assert OpenAI().modelname_to_contextsize("davinci") == 2049
def test_openai_modelname_to_contextsize_invalid() -> None:
"""Test model name to context size on an invalid model."""
with pytest.raises(ValueError):
OpenAI().modelname_to_contextsize("foobar")
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,153 | WhatsAppChatLoader doesn't work on chats exported from WhatsApp | ### System Info
langchain 0.0.158
Mac OS M1
Python 3.11
### Who can help?
@ey
### Information
- [X] The official example notebooks/scripts
- [ ] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [X] Document Loaders
- [ ] Vector Stores / Retrievers
- [ ] Memory
- [ ] Agents / Agent Executors
- [ ] Tools / Toolkits
- [ ] Chains
- [ ] Callbacks/Tracing
- [ ] Async
### Reproduction
1. Use 'Export Chat' feature on WhatsApp.
2. Observe this format for the txt file
```
[11/8/21, 9:41:32 AM] User name: Message text
```
The regular expression used by WhatsAppChatLoader doesn't parse this format successfully
### Expected behavior
Parsing fails | https://github.com/langchain-ai/langchain/issues/4153 | https://github.com/langchain-ai/langchain/pull/4420 | f2150285a495fc530a7707218ea4980c17a170e5 | 2b1403612614127da4e3bd3d22595ce7b3eb1540 | "2023-05-05T05:25:38Z" | python | "2023-05-09T22:00:04Z" | langchain/document_loaders/whatsapp_chat.py | import re
from pathlib import Path
from typing import List
from langchain.docstore.document import Document
from langchain.document_loaders.base import BaseLoader
def concatenate_rows(date: str, sender: str, text: str) -> str:
"""Combine message information in a readable format ready to be used."""
return f"{sender} on {date}: {text}\n\n"
class WhatsAppChatLoader(BaseLoader):
"""Loader that loads WhatsApp messages text file."""
def __init__(self, path: str):
"""Initialize with path."""
self.file_path = path
def load(self) -> List[Document]:
"""Load documents."""
p = Path(self.file_path)
text_content = ""
with open(p, encoding="utf8") as f:
lines = f.readlines()
message_line_regex = r"""
\[?
(
\d{1,2}
[\/.]
\d{1,2}
[\/.]
\d{2,4}
,\s
\d{1,2}
:\d{2}
(?:
:\d{2}
)?
(?:[ _](?:AM|PM))?
)
\]?
[\s-]*
([\w\s]+)
[:]+
\s
(.+)
"""
for line in lines:
result = re.match(message_line_regex, line.strip(), flags=re.VERBOSE)
if result:
date, sender, text = result.groups()
text_content += concatenate_rows(date, sender, text)
metadata = {"source": str(p)}
return [Document(page_content=text_content, metadata=metadata)]
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,153 | WhatsAppChatLoader doesn't work on chats exported from WhatsApp | ### System Info
langchain 0.0.158
Mac OS M1
Python 3.11
### Who can help?
@ey
### Information
- [X] The official example notebooks/scripts
- [ ] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [X] Document Loaders
- [ ] Vector Stores / Retrievers
- [ ] Memory
- [ ] Agents / Agent Executors
- [ ] Tools / Toolkits
- [ ] Chains
- [ ] Callbacks/Tracing
- [ ] Async
### Reproduction
1. Use 'Export Chat' feature on WhatsApp.
2. Observe this format for the txt file
```
[11/8/21, 9:41:32 AM] User name: Message text
```
The regular expression used by WhatsAppChatLoader doesn't parse this format successfully
### Expected behavior
Parsing fails | https://github.com/langchain-ai/langchain/issues/4153 | https://github.com/langchain-ai/langchain/pull/4420 | f2150285a495fc530a7707218ea4980c17a170e5 | 2b1403612614127da4e3bd3d22595ce7b3eb1540 | "2023-05-05T05:25:38Z" | python | "2023-05-09T22:00:04Z" | tests/integration_tests/document_loaders/test_whatsapp_chat.py | from pathlib import Path
from langchain.document_loaders import WhatsAppChatLoader
def test_whatsapp_chat_loader() -> None:
"""Test WhatsAppChatLoader."""
file_path = Path(__file__).parent.parent / "examples" / "whatsapp_chat.txt"
loader = WhatsAppChatLoader(str(file_path))
docs = loader.load()
assert len(docs) == 1
assert docs[0].metadata["source"] == str(file_path)
assert docs[0].page_content == (
"James on 05.05.23, 15:48:11: Hi here\n\n"
"User name on 11/8/21, 9:41:32 AM: Message 123\n\n"
"User 2 on 1/23/23, 3:19 AM: Bye!\n\n"
"User 1 on 1/23/23, 3:22_AM: And let me know if anything changes\n\n"
)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,153 | WhatsAppChatLoader doesn't work on chats exported from WhatsApp | ### System Info
langchain 0.0.158
Mac OS M1
Python 3.11
### Who can help?
@ey
### Information
- [X] The official example notebooks/scripts
- [ ] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [X] Document Loaders
- [ ] Vector Stores / Retrievers
- [ ] Memory
- [ ] Agents / Agent Executors
- [ ] Tools / Toolkits
- [ ] Chains
- [ ] Callbacks/Tracing
- [ ] Async
### Reproduction
1. Use 'Export Chat' feature on WhatsApp.
2. Observe this format for the txt file
```
[11/8/21, 9:41:32 AM] User name: Message text
```
The regular expression used by WhatsAppChatLoader doesn't parse this format successfully
### Expected behavior
Parsing fails | https://github.com/langchain-ai/langchain/issues/4153 | https://github.com/langchain-ai/langchain/pull/4420 | f2150285a495fc530a7707218ea4980c17a170e5 | 2b1403612614127da4e3bd3d22595ce7b3eb1540 | "2023-05-05T05:25:38Z" | python | "2023-05-09T22:00:04Z" | tests/integration_tests/examples/whatsapp_chat.txt | [05.05.23, 15:48:11] James: Hi here
[11/8/21, 9:41:32 AM] User name: Message 123
1/23/23, 3:19 AM - User 2: Bye!
1/23/23, 3:22_AM - User 1: And let me know if anything changes |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,619 | ChromaDB does not support filtering when using ```similarity_search``` or ```similarity_search_by_vector``` | Whereas it should be possible to filter by metadata :
- ```langchain.vectorstores.chroma.similarity_search``` takes a ```filter``` input parameter but do not forward it to ```langchain.vectorstores.chroma.similarity_search_with_score```
- ```langchain.vectorstores.chroma.similarity_search_by_vector``` don't take this parameter in input, although it could be very useful, without any additional complexity - and it would thus be coherent with the syntax of the two other functions | https://github.com/langchain-ai/langchain/issues/1619 | https://github.com/langchain-ai/langchain/pull/1621 | 28091c21018677355a124dd9c46213db3a229183 | d383c0cb435273de83595160c14a2cb45dcecf2a | "2023-03-12T23:58:13Z" | python | "2023-05-09T23:43:00Z" | langchain/vectorstores/chroma.py | """Wrapper around ChromaDB embeddings platform."""
from __future__ import annotations
import logging
import uuid
from typing import TYPE_CHECKING, Any, Dict, Iterable, List, Optional, Tuple, Type
import numpy as np
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from langchain.utils import xor_args
from langchain.vectorstores.base import VectorStore
from langchain.vectorstores.utils import maximal_marginal_relevance
if TYPE_CHECKING:
import chromadb
import chromadb.config
logger = logging.getLogger(__name__)
def _results_to_docs(results: Any) -> List[Document]:
return [doc for doc, _ in _results_to_docs_and_scores(results)]
def _results_to_docs_and_scores(results: Any) -> List[Tuple[Document, float]]:
return [
# TODO: Chroma can do batch querying,
# we shouldn't hard code to the 1st result
(Document(page_content=result[0], metadata=result[1] or {}), result[2])
for result in zip(
results["documents"][0],
results["metadatas"][0],
results["distances"][0],
)
]
class Chroma(VectorStore):
"""Wrapper around ChromaDB embeddings platform.
To use, you should have the ``chromadb`` python package installed.
Example:
.. code-block:: python
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
vectorstore = Chroma("langchain_store", embeddings.embed_query)
"""
_LANGCHAIN_DEFAULT_COLLECTION_NAME = "langchain"
def __init__(
self,
collection_name: str = _LANGCHAIN_DEFAULT_COLLECTION_NAME,
embedding_function: Optional[Embeddings] = None,
persist_directory: Optional[str] = None,
client_settings: Optional[chromadb.config.Settings] = None,
collection_metadata: Optional[Dict] = None,
client: Optional[chromadb.Client] = None,
) -> None:
"""Initialize with Chroma client."""
try:
import chromadb
import chromadb.config
except ImportError:
raise ValueError(
"Could not import chromadb python package. "
"Please install it with `pip install chromadb`."
)
if client is not None:
self._client = client
else:
if client_settings:
self._client_settings = client_settings
else:
self._client_settings = chromadb.config.Settings()
if persist_directory is not None:
self._client_settings = chromadb.config.Settings(
chroma_db_impl="duckdb+parquet",
persist_directory=persist_directory,
)
self._client = chromadb.Client(self._client_settings)
self._embedding_function = embedding_function
self._persist_directory = persist_directory
self._collection = self._client.get_or_create_collection(
name=collection_name,
embedding_function=self._embedding_function.embed_documents
if self._embedding_function is not None
else None,
metadata=collection_metadata,
)
@xor_args(("query_texts", "query_embeddings"))
def __query_collection(
self,
query_texts: Optional[List[str]] = None,
query_embeddings: Optional[List[List[float]]] = None,
n_results: int = 4,
where: Optional[Dict[str, str]] = None,
**kwargs: Any,
) -> List[Document]:
"""Query the chroma collection."""
try:
import chromadb
except ImportError:
raise ValueError(
"Could not import chromadb python package. "
"Please install it with `pip install chromadb`."
)
for i in range(n_results, 0, -1):
try:
return self._collection.query(
query_texts=query_texts,
query_embeddings=query_embeddings,
n_results=i,
where=where,
**kwargs,
)
except chromadb.errors.NotEnoughElementsException:
logger.error(
f"Chroma collection {self._collection.name} "
f"contains fewer than {i} elements."
)
raise chromadb.errors.NotEnoughElementsException(
f"No documents found for Chroma collection {self._collection.name}"
)
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
ids: Optional[List[str]] = None,
**kwargs: Any,
) -> List[str]:
"""Run more texts through the embeddings and add to the vectorstore.
Args:
texts (Iterable[str]): Texts to add to the vectorstore.
metadatas (Optional[List[dict]], optional): Optional list of metadatas.
ids (Optional[List[str]], optional): Optional list of IDs.
Returns:
List[str]: List of IDs of the added texts.
"""
# TODO: Handle the case where the user doesn't provide ids on the Collection
if ids is None:
ids = [str(uuid.uuid1()) for _ in texts]
embeddings = None
if self._embedding_function is not None:
embeddings = self._embedding_function.embed_documents(list(texts))
self._collection.add(
metadatas=metadatas, embeddings=embeddings, documents=texts, ids=ids
)
return ids
def similarity_search(
self,
query: str,
k: int = 4,
filter: Optional[Dict[str, str]] = None,
**kwargs: Any,
) -> List[Document]:
"""Run similarity search with Chroma.
Args:
query (str): Query text to search for.
k (int): Number of results to return. Defaults to 4.
filter (Optional[Dict[str, str]]): Filter by metadata. Defaults to None.
Returns:
List[Document]: List of documents most similar to the query text.
"""
docs_and_scores = self.similarity_search_with_score(query, k, filter=filter)
return [doc for doc, _ in docs_and_scores]
def similarity_search_by_vector(
self,
embedding: List[float],
k: int = 4,
filter: Optional[Dict[str, str]] = None,
**kwargs: Any,
) -> List[Document]:
"""Return docs most similar to embedding vector.
Args:
embedding: Embedding to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the query vector.
"""
results = self.__query_collection(
query_embeddings=embedding, n_results=k, where=filter
)
return _results_to_docs(results)
def similarity_search_with_score(
self,
query: str,
k: int = 4,
filter: Optional[Dict[str, str]] = None,
**kwargs: Any,
) -> List[Tuple[Document, float]]:
"""Run similarity search with Chroma with distance.
Args:
query (str): Query text to search for.
k (int): Number of results to return. Defaults to 4.
filter (Optional[Dict[str, str]]): Filter by metadata. Defaults to None.
Returns:
List[Tuple[Document, float]]: List of documents most similar to the query
text with distance in float.
"""
if self._embedding_function is None:
results = self.__query_collection(
query_texts=[query], n_results=k, where=filter
)
else:
query_embedding = self._embedding_function.embed_query(query)
results = self.__query_collection(
query_embeddings=[query_embedding], n_results=k, where=filter
)
return _results_to_docs_and_scores(results)
def max_marginal_relevance_search_by_vector(
self,
embedding: List[float],
k: int = 4,
fetch_k: int = 20,
lambda_mult: float = 0.5,
filter: Optional[Dict[str, str]] = None,
**kwargs: Any,
) -> List[Document]:
"""Return docs selected using the maximal marginal relevance.
Maximal marginal relevance optimizes for similarity to query AND diversity
among selected documents.
Args:
embedding: Embedding to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
fetch_k: Number of Documents to fetch to pass to MMR algorithm.
lambda_mult: Number between 0 and 1 that determines the degree
of diversity among the results with 0 corresponding
to maximum diversity and 1 to minimum diversity.
Defaults to 0.5.
filter (Optional[Dict[str, str]]): Filter by metadata. Defaults to None.
Returns:
List of Documents selected by maximal marginal relevance.
"""
results = self.__query_collection(
query_embeddings=embedding,
n_results=fetch_k,
where=filter,
include=["metadatas", "documents", "distances", "embeddings"],
)
mmr_selected = maximal_marginal_relevance(
np.array(embedding, dtype=np.float32),
results["embeddings"][0],
k=k,
lambda_mult=lambda_mult,
)
candidates = _results_to_docs(results)
selected_results = [r for i, r in enumerate(candidates) if i in mmr_selected]
return selected_results
def max_marginal_relevance_search(
self,
query: str,
k: int = 4,
fetch_k: int = 20,
lambda_mult: float = 0.5,
filter: Optional[Dict[str, str]] = None,
**kwargs: Any,
) -> List[Document]:
"""Return docs selected using the maximal marginal relevance.
Maximal marginal relevance optimizes for similarity to query AND diversity
among selected documents.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
fetch_k: Number of Documents to fetch to pass to MMR algorithm.
lambda_mult: Number between 0 and 1 that determines the degree
of diversity among the results with 0 corresponding
to maximum diversity and 1 to minimum diversity.
Defaults to 0.5.
filter (Optional[Dict[str, str]]): Filter by metadata. Defaults to None.
Returns:
List of Documents selected by maximal marginal relevance.
"""
if self._embedding_function is None:
raise ValueError(
"For MMR search, you must specify an embedding function on" "creation."
)
embedding = self._embedding_function.embed_query(query)
docs = self.max_marginal_relevance_search_by_vector(
embedding, k, fetch_k, lambda_mul=lambda_mult, filter=filter
)
return docs
def delete_collection(self) -> None:
"""Delete the collection."""
self._client.delete_collection(self._collection.name)
def get(self) -> Chroma:
"""Gets the collection"""
return self._collection.get()
def persist(self) -> None:
"""Persist the collection.
This can be used to explicitly persist the data to disk.
It will also be called automatically when the object is destroyed.
"""
if self._persist_directory is None:
raise ValueError(
"You must specify a persist_directory on"
"creation to persist the collection."
)
self._client.persist()
def update_document(self, document_id: str, document: Document) -> None:
"""Update a document in the collection.
Args:
document_id (str): ID of the document to update.
document (Document): Document to update.
"""
text = document.page_content
metadata = document.metadata
self._collection.update_document(document_id, text, metadata)
@classmethod
def from_texts(
cls: Type[Chroma],
texts: List[str],
embedding: Optional[Embeddings] = None,
metadatas: Optional[List[dict]] = None,
ids: Optional[List[str]] = None,
collection_name: str = _LANGCHAIN_DEFAULT_COLLECTION_NAME,
persist_directory: Optional[str] = None,
client_settings: Optional[chromadb.config.Settings] = None,
client: Optional[chromadb.Client] = None,
**kwargs: Any,
) -> Chroma:
"""Create a Chroma vectorstore from a raw documents.
If a persist_directory is specified, the collection will be persisted there.
Otherwise, the data will be ephemeral in-memory.
Args:
texts (List[str]): List of texts to add to the collection.
collection_name (str): Name of the collection to create.
persist_directory (Optional[str]): Directory to persist the collection.
embedding (Optional[Embeddings]): Embedding function. Defaults to None.
metadatas (Optional[List[dict]]): List of metadatas. Defaults to None.
ids (Optional[List[str]]): List of document IDs. Defaults to None.
client_settings (Optional[chromadb.config.Settings]): Chroma client settings
Returns:
Chroma: Chroma vectorstore.
"""
chroma_collection = cls(
collection_name=collection_name,
embedding_function=embedding,
persist_directory=persist_directory,
client_settings=client_settings,
client=client,
)
chroma_collection.add_texts(texts=texts, metadatas=metadatas, ids=ids)
return chroma_collection
@classmethod
def from_documents(
cls: Type[Chroma],
documents: List[Document],
embedding: Optional[Embeddings] = None,
ids: Optional[List[str]] = None,
collection_name: str = _LANGCHAIN_DEFAULT_COLLECTION_NAME,
persist_directory: Optional[str] = None,
client_settings: Optional[chromadb.config.Settings] = None,
client: Optional[chromadb.Client] = None, # Add this line
**kwargs: Any,
) -> Chroma:
"""Create a Chroma vectorstore from a list of documents.
If a persist_directory is specified, the collection will be persisted there.
Otherwise, the data will be ephemeral in-memory.
Args:
collection_name (str): Name of the collection to create.
persist_directory (Optional[str]): Directory to persist the collection.
ids (Optional[List[str]]): List of document IDs. Defaults to None.
documents (List[Document]): List of documents to add to the vectorstore.
embedding (Optional[Embeddings]): Embedding function. Defaults to None.
client_settings (Optional[chromadb.config.Settings]): Chroma client settings
Returns:
Chroma: Chroma vectorstore.
"""
texts = [doc.page_content for doc in documents]
metadatas = [doc.metadata for doc in documents]
return cls.from_texts(
texts=texts,
embedding=embedding,
metadatas=metadatas,
ids=ids,
collection_name=collection_name,
persist_directory=persist_directory,
client_settings=client_settings,
client=client,
)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,368 | Add distance metric param to to redis vectorstore index | ### Feature request
Redis vectorstore allows for three different distance metrics: `L2` (flat L2), `COSINE`, and `IP` (inner product). Currently, the `Redis._create_index` method hard codes the distance metric to COSINE.
```py
def _create_index(self, dim: int = 1536) -> None:
try:
from redis.commands.search.field import TextField, VectorField
from redis.commands.search.indexDefinition import IndexDefinition, IndexType
except ImportError:
raise ValueError(
"Could not import redis python package. "
"Please install it with `pip install redis`."
)
# Check if index exists
if not _check_index_exists(self.client, self.index_name):
# Constants
distance_metric = (
"COSINE" # distance metric for the vectors (ex. COSINE, IP, L2)
)
schema = (
TextField(name=self.content_key),
TextField(name=self.metadata_key),
VectorField(
self.vector_key,
"FLAT",
{
"TYPE": "FLOAT32",
"DIM": dim,
"DISTANCE_METRIC": distance_metric,
},
),
)
prefix = _redis_prefix(self.index_name)
# Create Redis Index
self.client.ft(self.index_name).create_index(
fields=schema,
definition=IndexDefinition(prefix=[prefix], index_type=IndexType.HASH),
)
```
This should be parameterized.
### Motivation
I'd like to be able to use L2 distance metrics.
### Your contribution
I've already forked and made a branch that parameterizes the distance metric in `langchain.vectorstores.redis`:
```py
def _create_index(self, dim: int = 1536, distance_metric: REDIS_DISTANCE_METRICS = "COSINE") -> None:
try:
from redis.commands.search.field import TextField, VectorField
from redis.commands.search.indexDefinition import IndexDefinition, IndexType
except ImportError:
raise ValueError(
"Could not import redis python package. "
"Please install it with `pip install redis`."
)
# Check if index exists
if not _check_index_exists(self.client, self.index_name):
# Define schema
schema = (
TextField(name=self.content_key),
TextField(name=self.metadata_key),
VectorField(
self.vector_key,
"FLAT",
{
"TYPE": "FLOAT32",
"DIM": dim,
"DISTANCE_METRIC": distance_metric,
},
),
)
prefix = _redis_prefix(self.index_name)
# Create Redis Index
self.client.ft(self.index_name).create_index(
fields=schema,
definition=IndexDefinition(prefix=[prefix], index_type=IndexType.HASH),
) def _create_index(self, dim: int = 1536, distance_metric: REDIS_DISTANCE_METRICS = "COSINE") -> None:
try:
from redis.commands.search.field import TextField, VectorField
from redis.commands.search.indexDefinition import IndexDefinition, IndexType
except ImportError:
raise ValueError(
"Could not import redis python package. "
"Please install it with `pip install redis`."
)
# Check if index exists
if not _check_index_exists(self.client, self.index_name):
# Define schema
schema = (
TextField(name=self.content_key),
TextField(name=self.metadata_key),
VectorField(
self.vector_key,
"FLAT",
{
"TYPE": "FLOAT32",
"DIM": dim,
"DISTANCE_METRIC": distance_metric,
},
),
)
prefix = _redis_prefix(self.index_name)
# Create Redis Index
self.client.ft(self.index_name).create_index(
fields=schema,
definition=IndexDefinition(prefix=[prefix], index_type=IndexType.HASH),
)
...
@classmethod
def from_texts(
cls: Type[Redis],
texts: List[str],
embedding: Embeddings,
metadatas: Optional[List[dict]] = None,
index_name: Optional[str] = None,
content_key: str = "content",
metadata_key: str = "metadata",
vector_key: str = "content_vector",
distance_metric: REDIS_DISTANCE_METRICS = "COSINE",
**kwargs: Any,
) -> Redis:
"""Create a Redis vectorstore from raw documents.
This is a user-friendly interface that:
1. Embeds documents.
2. Creates a new index for the embeddings in Redis.
3. Adds the documents to the newly created Redis index.
This is intended to be a quick way to get started.
Example:
.. code-block:: python
from langchain.vectorstores import Redis
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
redisearch = RediSearch.from_texts(
texts,
embeddings,
redis_url="redis://username:password@localhost:6379"
)
"""
redis_url = get_from_dict_or_env(kwargs, "redis_url", "REDIS_URL")
if "redis_url" in kwargs:
kwargs.pop("redis_url")
# Name of the search index if not given
if not index_name:
index_name = uuid.uuid4().hex
# Create instance
instance = cls(
redis_url=redis_url,
index_name=index_name,
embedding_function=embedding.embed_query,
content_key=content_key,
metadata_key=metadata_key,
vector_key=vector_key,
**kwargs,
)
# Create embeddings over documents
embeddings = embedding.embed_documents(texts)
# Create the search index
instance._create_index(dim=len(embeddings[0]), distance_metric=distance_metric)
# Add data to Redis
instance.add_texts(texts, metadatas, embeddings)
return instance
```
I'll make the PR and link this issue | https://github.com/langchain-ai/langchain/issues/4368 | https://github.com/langchain-ai/langchain/pull/4375 | f46710d4087c3f27e95cfc4b2c96956d7c4560e8 | f668251948c715ef3102b2bf84ff31aed45867b5 | "2023-05-09T00:40:32Z" | python | "2023-05-11T07:20:01Z" | langchain/vectorstores/redis.py | """Wrapper around Redis vector database."""
from __future__ import annotations
import json
import logging
import uuid
from typing import (
TYPE_CHECKING,
Any,
Callable,
Dict,
Iterable,
List,
Mapping,
Optional,
Tuple,
Type,
)
import numpy as np
from pydantic import BaseModel, root_validator
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from langchain.schema import BaseRetriever
from langchain.utils import get_from_dict_or_env
from langchain.vectorstores.base import VectorStore
logger = logging.getLogger(__name__)
if TYPE_CHECKING:
from redis.client import Redis as RedisType
from redis.commands.search.query import Query
# required modules
REDIS_REQUIRED_MODULES = [
{"name": "search", "ver": 20400},
{"name": "searchlight", "ver": 20400},
]
def _check_redis_module_exist(client: RedisType, required_modules: List[dict]) -> None:
"""Check if the correct Redis modules are installed."""
installed_modules = client.module_list()
installed_modules = {
module[b"name"].decode("utf-8"): module for module in installed_modules
}
for module in required_modules:
if module["name"] in installed_modules and int(
installed_modules[module["name"]][b"ver"]
) >= int(module["ver"]):
return
# otherwise raise error
error_message = (
"You must add the RediSearch (>= 2.4) module from Redis Stack. "
"Please refer to Redis Stack docs: https://redis.io/docs/stack/"
)
logging.error(error_message)
raise ValueError(error_message)
def _check_index_exists(client: RedisType, index_name: str) -> bool:
"""Check if Redis index exists."""
try:
client.ft(index_name).info()
except: # noqa: E722
logger.info("Index does not exist")
return False
logger.info("Index already exists")
return True
def _redis_key(prefix: str) -> str:
"""Redis key schema for a given prefix."""
return f"{prefix}:{uuid.uuid4().hex}"
def _redis_prefix(index_name: str) -> str:
"""Redis key prefix for a given index."""
return f"doc:{index_name}"
def _default_relevance_score(val: float) -> float:
return 1 - val
class Redis(VectorStore):
"""Wrapper around Redis vector database.
To use, you should have the ``redis`` python package installed.
Example:
.. code-block:: python
from langchain.vectorstores import Redis
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
vectorstore = Redis(
redis_url="redis://username:password@localhost:6379"
index_name="my-index",
embedding_function=embeddings.embed_query,
)
"""
def __init__(
self,
redis_url: str,
index_name: str,
embedding_function: Callable,
content_key: str = "content",
metadata_key: str = "metadata",
vector_key: str = "content_vector",
relevance_score_fn: Optional[
Callable[[float], float]
] = _default_relevance_score,
**kwargs: Any,
):
"""Initialize with necessary components."""
try:
import redis
except ImportError:
raise ValueError(
"Could not import redis python package. "
"Please install it with `pip install redis`."
)
self.embedding_function = embedding_function
self.index_name = index_name
try:
# connect to redis from url
redis_client = redis.from_url(redis_url, **kwargs)
# check if redis has redisearch module installed
_check_redis_module_exist(redis_client, REDIS_REQUIRED_MODULES)
except ValueError as e:
raise ValueError(f"Redis failed to connect: {e}")
self.client = redis_client
self.content_key = content_key
self.metadata_key = metadata_key
self.vector_key = vector_key
self.relevance_score_fn = relevance_score_fn
def _create_index(self, dim: int = 1536) -> None:
try:
from redis.commands.search.field import TextField, VectorField
from redis.commands.search.indexDefinition import IndexDefinition, IndexType
except ImportError:
raise ValueError(
"Could not import redis python package. "
"Please install it with `pip install redis`."
)
# Check if index exists
if not _check_index_exists(self.client, self.index_name):
# Constants
distance_metric = (
"COSINE" # distance metric for the vectors (ex. COSINE, IP, L2)
)
schema = (
TextField(name=self.content_key),
TextField(name=self.metadata_key),
VectorField(
self.vector_key,
"FLAT",
{
"TYPE": "FLOAT32",
"DIM": dim,
"DISTANCE_METRIC": distance_metric,
},
),
)
prefix = _redis_prefix(self.index_name)
# Create Redis Index
self.client.ft(self.index_name).create_index(
fields=schema,
definition=IndexDefinition(prefix=[prefix], index_type=IndexType.HASH),
)
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
embeddings: Optional[List[List[float]]] = None,
keys: Optional[List[str]] = None,
batch_size: int = 1000,
**kwargs: Any,
) -> List[str]:
"""Add more texts to the vectorstore.
Args:
texts (Iterable[str]): Iterable of strings/text to add to the vectorstore.
metadatas (Optional[List[dict]], optional): Optional list of metadatas.
Defaults to None.
embeddings (Optional[List[List[float]]], optional): Optional pre-generated
embeddings. Defaults to None.
keys (Optional[List[str]], optional): Optional key values to use as ids.
Defaults to None.
batch_size (int, optional): Batch size to use for writes. Defaults to 1000.
Returns:
List[str]: List of ids added to the vectorstore
"""
ids = []
prefix = _redis_prefix(self.index_name)
# Write data to redis
pipeline = self.client.pipeline(transaction=False)
for i, text in enumerate(texts):
# Use provided values by default or fallback
key = keys[i] if keys else _redis_key(prefix)
metadata = metadatas[i] if metadatas else {}
embedding = embeddings[i] if embeddings else self.embedding_function(text)
pipeline.hset(
key,
mapping={
self.content_key: text,
self.vector_key: np.array(embedding, dtype=np.float32).tobytes(),
self.metadata_key: json.dumps(metadata),
},
)
ids.append(key)
# Write batch
if i % batch_size == 0:
pipeline.execute()
# Cleanup final batch
pipeline.execute()
return ids
def similarity_search(
self, query: str, k: int = 4, **kwargs: Any
) -> List[Document]:
"""
Returns the most similar indexed documents to the query text.
Args:
query (str): The query text for which to find similar documents.
k (int): The number of documents to return. Default is 4.
Returns:
List[Document]: A list of documents that are most similar to the query text.
"""
docs_and_scores = self.similarity_search_with_score(query, k=k)
return [doc for doc, _ in docs_and_scores]
def similarity_search_limit_score(
self, query: str, k: int = 4, score_threshold: float = 0.2, **kwargs: Any
) -> List[Document]:
"""
Returns the most similar indexed documents to the query text within the
score_threshold range.
Args:
query (str): The query text for which to find similar documents.
k (int): The number of documents to return. Default is 4.
score_threshold (float): The minimum matching score required for a document
to be considered a match. Defaults to 0.2.
Because the similarity calculation algorithm is based on cosine similarity,
the smaller the angle, the higher the similarity.
Returns:
List[Document]: A list of documents that are most similar to the query text,
including the match score for each document.
Note:
If there are no documents that satisfy the score_threshold value,
an empty list is returned.
"""
docs_and_scores = self.similarity_search_with_score(query, k=k)
return [doc for doc, score in docs_and_scores if score < score_threshold]
def _prepare_query(self, k: int) -> Query:
try:
from redis.commands.search.query import Query
except ImportError:
raise ValueError(
"Could not import redis python package. "
"Please install it with `pip install redis`."
)
# Prepare the Query
hybrid_fields = "*"
base_query = (
f"{hybrid_fields}=>[KNN {k} @{self.vector_key} $vector AS vector_score]"
)
return_fields = [self.metadata_key, self.content_key, "vector_score"]
return (
Query(base_query)
.return_fields(*return_fields)
.sort_by("vector_score")
.paging(0, k)
.dialect(2)
)
def similarity_search_with_score(
self, query: str, k: int = 4
) -> List[Tuple[Document, float]]:
"""Return docs most similar to query.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the query and score for each
"""
# Creates embedding vector from user query
embedding = self.embedding_function(query)
# Creates Redis query
redis_query = self._prepare_query(k)
params_dict: Mapping[str, str] = {
"vector": np.array(embedding) # type: ignore
.astype(dtype=np.float32)
.tobytes()
}
# Perform vector search
results = self.client.ft(self.index_name).search(redis_query, params_dict)
# Prepare document results
docs = [
(
Document(
page_content=result.content, metadata=json.loads(result.metadata)
),
float(result.vector_score),
)
for result in results.docs
]
return docs
def _similarity_search_with_relevance_scores(
self,
query: str,
k: int = 4,
**kwargs: Any,
) -> List[Tuple[Document, float]]:
"""Return docs and relevance scores, normalized on a scale from 0 to 1.
0 is dissimilar, 1 is most similar.
"""
if self.relevance_score_fn is None:
raise ValueError(
"relevance_score_fn must be provided to"
" Weaviate constructor to normalize scores"
)
docs_and_scores = self.similarity_search_with_score(query, k=k)
return [(doc, self.relevance_score_fn(score)) for doc, score in docs_and_scores]
@classmethod
def from_texts(
cls: Type[Redis],
texts: List[str],
embedding: Embeddings,
metadatas: Optional[List[dict]] = None,
index_name: Optional[str] = None,
content_key: str = "content",
metadata_key: str = "metadata",
vector_key: str = "content_vector",
**kwargs: Any,
) -> Redis:
"""Create a Redis vectorstore from raw documents.
This is a user-friendly interface that:
1. Embeds documents.
2. Creates a new index for the embeddings in Redis.
3. Adds the documents to the newly created Redis index.
This is intended to be a quick way to get started.
Example:
.. code-block:: python
from langchain.vectorstores import Redis
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
redisearch = RediSearch.from_texts(
texts,
embeddings,
redis_url="redis://username:password@localhost:6379"
)
"""
redis_url = get_from_dict_or_env(kwargs, "redis_url", "REDIS_URL")
if "redis_url" in kwargs:
kwargs.pop("redis_url")
# Name of the search index if not given
if not index_name:
index_name = uuid.uuid4().hex
# Create instance
instance = cls(
redis_url=redis_url,
index_name=index_name,
embedding_function=embedding.embed_query,
content_key=content_key,
metadata_key=metadata_key,
vector_key=vector_key,
**kwargs,
)
# Create embeddings over documents
embeddings = embedding.embed_documents(texts)
# Create the search index
instance._create_index(dim=len(embeddings[0]))
# Add data to Redis
instance.add_texts(texts, metadatas, embeddings)
return instance
@staticmethod
def drop_index(
index_name: str,
delete_documents: bool,
**kwargs: Any,
) -> bool:
"""
Drop a Redis search index.
Args:
index_name (str): Name of the index to drop.
delete_documents (bool): Whether to drop the associated documents.
Returns:
bool: Whether or not the drop was successful.
"""
redis_url = get_from_dict_or_env(kwargs, "redis_url", "REDIS_URL")
try:
import redis
except ImportError:
raise ValueError(
"Could not import redis python package. "
"Please install it with `pip install redis`."
)
try:
# We need to first remove redis_url from kwargs,
# otherwise passing it to Redis will result in an error.
if "redis_url" in kwargs:
kwargs.pop("redis_url")
client = redis.from_url(url=redis_url, **kwargs)
except ValueError as e:
raise ValueError(f"Your redis connected error: {e}")
# Check if index exists
try:
client.ft(index_name).dropindex(delete_documents)
logger.info("Drop index")
return True
except: # noqa: E722
# Index not exist
return False
@classmethod
def from_existing_index(
cls,
embedding: Embeddings,
index_name: str,
content_key: str = "content",
metadata_key: str = "metadata",
vector_key: str = "content_vector",
**kwargs: Any,
) -> Redis:
"""Connect to an existing Redis index."""
redis_url = get_from_dict_or_env(kwargs, "redis_url", "REDIS_URL")
try:
import redis
except ImportError:
raise ValueError(
"Could not import redis python package. "
"Please install it with `pip install redis`."
)
try:
# We need to first remove redis_url from kwargs,
# otherwise passing it to Redis will result in an error.
if "redis_url" in kwargs:
kwargs.pop("redis_url")
client = redis.from_url(url=redis_url, **kwargs)
# check if redis has redisearch module installed
_check_redis_module_exist(client, REDIS_REQUIRED_MODULES)
# ensure that the index already exists
assert _check_index_exists(
client, index_name
), f"Index {index_name} does not exist"
except Exception as e:
raise ValueError(f"Redis failed to connect: {e}")
return cls(
redis_url,
index_name,
embedding.embed_query,
content_key=content_key,
metadata_key=metadata_key,
vector_key=vector_key,
**kwargs,
)
def as_retriever(self, **kwargs: Any) -> BaseRetriever:
return RedisVectorStoreRetriever(vectorstore=self, **kwargs)
class RedisVectorStoreRetriever(BaseRetriever, BaseModel):
vectorstore: Redis
search_type: str = "similarity"
k: int = 4
score_threshold: float = 0.4
class Config:
"""Configuration for this pydantic object."""
arbitrary_types_allowed = True
@root_validator()
def validate_search_type(cls, values: Dict) -> Dict:
"""Validate search type."""
if "search_type" in values:
search_type = values["search_type"]
if search_type not in ("similarity", "similarity_limit"):
raise ValueError(f"search_type of {search_type} not allowed.")
return values
def get_relevant_documents(self, query: str) -> List[Document]:
if self.search_type == "similarity":
docs = self.vectorstore.similarity_search(query, k=self.k)
elif self.search_type == "similarity_limit":
docs = self.vectorstore.similarity_search_limit_score(
query, k=self.k, score_threshold=self.score_threshold
)
else:
raise ValueError(f"search_type of {self.search_type} not allowed.")
return docs
async def aget_relevant_documents(self, query: str) -> List[Document]:
raise NotImplementedError("RedisVectorStoreRetriever does not support async")
def add_documents(self, documents: List[Document], **kwargs: Any) -> List[str]:
"""Add documents to vectorstore."""
return self.vectorstore.add_documents(documents, **kwargs)
async def aadd_documents(
self, documents: List[Document], **kwargs: Any
) -> List[str]:
"""Add documents to vectorstore."""
return await self.vectorstore.aadd_documents(documents, **kwargs)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,368 | Add distance metric param to to redis vectorstore index | ### Feature request
Redis vectorstore allows for three different distance metrics: `L2` (flat L2), `COSINE`, and `IP` (inner product). Currently, the `Redis._create_index` method hard codes the distance metric to COSINE.
```py
def _create_index(self, dim: int = 1536) -> None:
try:
from redis.commands.search.field import TextField, VectorField
from redis.commands.search.indexDefinition import IndexDefinition, IndexType
except ImportError:
raise ValueError(
"Could not import redis python package. "
"Please install it with `pip install redis`."
)
# Check if index exists
if not _check_index_exists(self.client, self.index_name):
# Constants
distance_metric = (
"COSINE" # distance metric for the vectors (ex. COSINE, IP, L2)
)
schema = (
TextField(name=self.content_key),
TextField(name=self.metadata_key),
VectorField(
self.vector_key,
"FLAT",
{
"TYPE": "FLOAT32",
"DIM": dim,
"DISTANCE_METRIC": distance_metric,
},
),
)
prefix = _redis_prefix(self.index_name)
# Create Redis Index
self.client.ft(self.index_name).create_index(
fields=schema,
definition=IndexDefinition(prefix=[prefix], index_type=IndexType.HASH),
)
```
This should be parameterized.
### Motivation
I'd like to be able to use L2 distance metrics.
### Your contribution
I've already forked and made a branch that parameterizes the distance metric in `langchain.vectorstores.redis`:
```py
def _create_index(self, dim: int = 1536, distance_metric: REDIS_DISTANCE_METRICS = "COSINE") -> None:
try:
from redis.commands.search.field import TextField, VectorField
from redis.commands.search.indexDefinition import IndexDefinition, IndexType
except ImportError:
raise ValueError(
"Could not import redis python package. "
"Please install it with `pip install redis`."
)
# Check if index exists
if not _check_index_exists(self.client, self.index_name):
# Define schema
schema = (
TextField(name=self.content_key),
TextField(name=self.metadata_key),
VectorField(
self.vector_key,
"FLAT",
{
"TYPE": "FLOAT32",
"DIM": dim,
"DISTANCE_METRIC": distance_metric,
},
),
)
prefix = _redis_prefix(self.index_name)
# Create Redis Index
self.client.ft(self.index_name).create_index(
fields=schema,
definition=IndexDefinition(prefix=[prefix], index_type=IndexType.HASH),
) def _create_index(self, dim: int = 1536, distance_metric: REDIS_DISTANCE_METRICS = "COSINE") -> None:
try:
from redis.commands.search.field import TextField, VectorField
from redis.commands.search.indexDefinition import IndexDefinition, IndexType
except ImportError:
raise ValueError(
"Could not import redis python package. "
"Please install it with `pip install redis`."
)
# Check if index exists
if not _check_index_exists(self.client, self.index_name):
# Define schema
schema = (
TextField(name=self.content_key),
TextField(name=self.metadata_key),
VectorField(
self.vector_key,
"FLAT",
{
"TYPE": "FLOAT32",
"DIM": dim,
"DISTANCE_METRIC": distance_metric,
},
),
)
prefix = _redis_prefix(self.index_name)
# Create Redis Index
self.client.ft(self.index_name).create_index(
fields=schema,
definition=IndexDefinition(prefix=[prefix], index_type=IndexType.HASH),
)
...
@classmethod
def from_texts(
cls: Type[Redis],
texts: List[str],
embedding: Embeddings,
metadatas: Optional[List[dict]] = None,
index_name: Optional[str] = None,
content_key: str = "content",
metadata_key: str = "metadata",
vector_key: str = "content_vector",
distance_metric: REDIS_DISTANCE_METRICS = "COSINE",
**kwargs: Any,
) -> Redis:
"""Create a Redis vectorstore from raw documents.
This is a user-friendly interface that:
1. Embeds documents.
2. Creates a new index for the embeddings in Redis.
3. Adds the documents to the newly created Redis index.
This is intended to be a quick way to get started.
Example:
.. code-block:: python
from langchain.vectorstores import Redis
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
redisearch = RediSearch.from_texts(
texts,
embeddings,
redis_url="redis://username:password@localhost:6379"
)
"""
redis_url = get_from_dict_or_env(kwargs, "redis_url", "REDIS_URL")
if "redis_url" in kwargs:
kwargs.pop("redis_url")
# Name of the search index if not given
if not index_name:
index_name = uuid.uuid4().hex
# Create instance
instance = cls(
redis_url=redis_url,
index_name=index_name,
embedding_function=embedding.embed_query,
content_key=content_key,
metadata_key=metadata_key,
vector_key=vector_key,
**kwargs,
)
# Create embeddings over documents
embeddings = embedding.embed_documents(texts)
# Create the search index
instance._create_index(dim=len(embeddings[0]), distance_metric=distance_metric)
# Add data to Redis
instance.add_texts(texts, metadatas, embeddings)
return instance
```
I'll make the PR and link this issue | https://github.com/langchain-ai/langchain/issues/4368 | https://github.com/langchain-ai/langchain/pull/4375 | f46710d4087c3f27e95cfc4b2c96956d7c4560e8 | f668251948c715ef3102b2bf84ff31aed45867b5 | "2023-05-09T00:40:32Z" | python | "2023-05-11T07:20:01Z" | tests/integration_tests/vectorstores/test_redis.py | """Test Redis functionality."""
from langchain.docstore.document import Document
from langchain.vectorstores.redis import Redis
from tests.integration_tests.vectorstores.fake_embeddings import FakeEmbeddings
TEST_INDEX_NAME = "test"
TEST_REDIS_URL = "redis://localhost:6379"
TEST_SINGLE_RESULT = [Document(page_content="foo")]
TEST_RESULT = [Document(page_content="foo"), Document(page_content="foo")]
def drop(index_name: str) -> bool:
return Redis.drop_index(
index_name=index_name, delete_documents=True, redis_url=TEST_REDIS_URL
)
def test_redis() -> None:
"""Test end to end construction and search."""
texts = ["foo", "bar", "baz"]
docsearch = Redis.from_texts(texts, FakeEmbeddings(), redis_url=TEST_REDIS_URL)
output = docsearch.similarity_search("foo", k=1)
assert output == TEST_SINGLE_RESULT
assert drop(docsearch.index_name)
def test_redis_new_vector() -> None:
"""Test adding a new document"""
texts = ["foo", "bar", "baz"]
docsearch = Redis.from_texts(texts, FakeEmbeddings(), redis_url=TEST_REDIS_URL)
docsearch.add_texts(["foo"])
output = docsearch.similarity_search("foo", k=2)
assert output == TEST_RESULT
assert drop(docsearch.index_name)
def test_redis_from_existing() -> None:
"""Test adding a new document"""
texts = ["foo", "bar", "baz"]
Redis.from_texts(
texts, FakeEmbeddings(), index_name=TEST_INDEX_NAME, redis_url=TEST_REDIS_URL
)
# Test creating from an existing
docsearch2 = Redis.from_existing_index(
FakeEmbeddings(), index_name=TEST_INDEX_NAME, redis_url=TEST_REDIS_URL
)
output = docsearch2.similarity_search("foo", k=1)
assert output == TEST_SINGLE_RESULT
def test_redis_add_texts_to_existing() -> None:
"""Test adding a new document"""
# Test creating from an existing
docsearch = Redis.from_existing_index(
FakeEmbeddings(), index_name=TEST_INDEX_NAME, redis_url=TEST_REDIS_URL
)
docsearch.add_texts(["foo"])
output = docsearch.similarity_search("foo", k=2)
assert output == TEST_RESULT
assert drop(TEST_INDEX_NAME)
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,513 | [pyproject.toml] add `tiktoken` to `tool.poetry.extras.openai` | ### System Info
langchain[openai]==0.0.165
Ubuntu 22.04.2 LTS (Jammy Jellyfish)
python 3.10.6
### Who can help?
@vowelparrot
### Information
- [ ] The official example notebooks/scripts
- [X] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [ ] Document Loaders
- [ ] Vector Stores / Retrievers
- [ ] Memory
- [ ] Agents / Agent Executors
- [X] Tools / Toolkits
- [ ] Chains
- [ ] Callbacks/Tracing
- [ ] Async
### Reproduction
The OpenAI component requires `tiktoken` package, but if we install like below, the `tiktoken` package is not found.
```
langchain[openai]==0.0.165
```
It's natural to add `tiktoken`, since there is a dependency in the `pyproject.toml` file.
https://github.com/hwchase17/langchain/blob/46b100ea630b5d1d7fedd6a32d5eb9ecbadeb401/pyproject.toml#L35-L36
Besides, the missing of `tiktoken` would cause an issue under some dependency pinning tool, like bazel or [jazzband/pip-tools](https://github.com/jazzband/pip-tools)
```
Traceback (most recent call last):
File "/home/ofey/.cache/bazel/_bazel_ofey/90bb890b04415910673f256b166d6c9b/sandbox/linux-sandbox/15/execroot/walking_shadows/bazel-out/k8-fastbuild/bin/src/backend/services/world/internal/memory/test/test_test.runfiles/pip_langchain/site-packages/langchain/embeddings/openai.py", line 186, in _get_len_safe_embeddings
import tiktoken
ModuleNotFoundError: No module named 'tiktoken'
...
File "/home/ofey/.cache/bazel/_bazel_ofey/90bb890b04415910673f256b166d6c9b/sandbox/linux-sandbox/15/execroot/walking_shadows/bazel-out/k8-fastbuild/bin/src/backend/services/world/internal/memory/test/test_test.runfiles/pip_langchain/site-packages/langchain/embeddings/openai.py", line 240, in _get_len_safe_embeddings
raise ValueError(
ValueError: Could not import tiktoken python package. This is needed in order to for OpenAIEmbeddings. Please install it with `pip install tiktoken`.
```
### Expected behavior
Add a dependency in `pyproject.toml`
```
[tool.poetry.extras]
...
openai = ["openai", "tiktoken"]
```
Actually I'm using langchain with bazel, this is my project: [ofey404/WalkingShadows](https://github.com/ofey404/WalkingShadows) | https://github.com/langchain-ai/langchain/issues/4513 | https://github.com/langchain-ai/langchain/pull/4514 | 4ee47926cafba0eb00851972783c1d66236f6f00 | 1c0ec26e40f07cdf9eabae2f018dff05f97d8595 | "2023-05-11T07:54:40Z" | python | "2023-05-11T19:21:06Z" | pyproject.toml | [tool.poetry]
name = "langchain"
version = "0.0.166"
description = "Building applications with LLMs through composability"
authors = []
license = "MIT"
readme = "README.md"
repository = "https://www.github.com/hwchase17/langchain"
[tool.poetry.scripts]
langchain-server = "langchain.server:main"
[tool.poetry.dependencies]
python = ">=3.8.1,<4.0"
pydantic = "^1"
SQLAlchemy = ">=1.4,<3"
requests = "^2"
PyYAML = ">=5.4.1"
numpy = "^1"
azure-core = {version = "^1.26.4", optional=true}
tqdm = {version = ">=4.48.0", optional = true}
openapi-schema-pydantic = "^1.2"
faiss-cpu = {version = "^1", optional = true}
wikipedia = {version = "^1", optional = true}
elasticsearch = {version = "^8", optional = true}
opensearch-py = {version = "^2.0.0", optional = true}
redis = {version = "^4", optional = true}
manifest-ml = {version = "^0.0.1", optional = true}
spacy = {version = "^3", optional = true}
nltk = {version = "^3", optional = true}
transformers = {version = "^4", optional = true}
beautifulsoup4 = {version = "^4", optional = true}
torch = {version = ">=1,<3", optional = true}
jinja2 = {version = "^3", optional = true}
tiktoken = {version = "^0.3.2", optional = true, python="^3.9"}
pinecone-client = {version = "^2", optional = true}
pinecone-text = {version = "^0.4.2", optional = true}
clickhouse-connect = {version="^0.5.14", optional=true}
weaviate-client = {version = "^3", optional = true}
google-api-python-client = {version = "2.70.0", optional = true}
wolframalpha = {version = "5.0.0", optional = true}
anthropic = {version = "^0.2.6", optional = true}
qdrant-client = {version = "^1.1.2", optional = true, python = ">=3.8.1,<3.12"}
dataclasses-json = "^0.5.7"
tensorflow-text = {version = "^2.11.0", optional = true, python = "^3.10, <3.12"}
tenacity = "^8.1.0"
cohere = {version = "^3", optional = true}
openai = {version = "^0", optional = true}
nlpcloud = {version = "^1", optional = true}
nomic = {version = "^1.0.43", optional = true}
huggingface_hub = {version = "^0", optional = true}
jina = {version = "^3.14", optional = true}
google-search-results = {version = "^2", optional = true}
sentence-transformers = {version = "^2", optional = true}
aiohttp = "^3.8.3"
arxiv = {version = "^1.4", optional = true}
pypdf = {version = "^3.4.0", optional = true}
networkx = {version="^2.6.3", optional = true}
aleph-alpha-client = {version="^2.15.0", optional = true}
deeplake = {version = "^3.3.0", optional = true}
pgvector = {version = "^0.1.6", optional = true}
psycopg2-binary = {version = "^2.9.5", optional = true}
#boto3 = {version = "^1.26.96", optional = true} # TODO: fix it, commented because the version failed with deeplake
pyowm = {version = "^3.3.0", optional = true}
async-timeout = {version = "^4.0.0", python = "<3.11"}
azure-identity = {version = "^1.12.0", optional=true}
gptcache = {version = ">=0.1.7", optional = true}
atlassian-python-api = {version = "^3.36.0", optional=true}
pytesseract = {version = "^0.3.10", optional=true}
html2text = {version="^2020.1.16", optional=true}
numexpr = "^2.8.4"
duckduckgo-search = {version="^2.8.6", optional=true}
azure-cosmos = {version="^4.4.0b1", optional=true}
lark = {version="^1.1.5", optional=true}
lancedb = {version = "^0.1", optional = true}
pexpect = {version = "^4.8.0", optional = true}
pyvespa = {version = "^0.33.0", optional = true}
O365 = {version = "^2.0.26", optional = true}
jq = {version = "^1.4.1", optional = true}
pdfminer-six = {version = "^20221105", optional = true}
docarray = {version="^0.31.0", optional=true}
protobuf = {version="3.19", optional=true}
hnswlib = {version="^0.7.0", optional=true}
[tool.poetry.group.docs.dependencies]
autodoc_pydantic = "^1.8.0"
myst_parser = "^0.18.1"
nbsphinx = "^0.8.9"
sphinx = "^4.5.0"
sphinx-autobuild = "^2021.3.14"
sphinx_book_theme = "^0.3.3"
sphinx_rtd_theme = "^1.0.0"
sphinx-typlog-theme = "^0.8.0"
sphinx-panels = "^0.6.0"
toml = "^0.10.2"
myst-nb = "^0.17.1"
linkchecker = "^10.2.1"
sphinx-copybutton = "^0.5.1"
[tool.poetry.group.test.dependencies]
pytest = "^7.3.0"
pytest-cov = "^4.0.0"
pytest-dotenv = "^0.5.2"
duckdb-engine = "^0.7.0"
pytest-watcher = "^0.2.6"
freezegun = "^1.2.2"
responses = "^0.22.0"
pytest-asyncio = "^0.20.3"
lark = "^1.1.5"
pytest-mock = "^3.10.0"
[tool.poetry.group.test_integration]
optional = true
[tool.poetry.group.test_integration.dependencies]
pytest-vcr = "^1.0.2"
wrapt = "^1.15.0"
openai = "^0.27.4"
elasticsearch = {extras = ["async"], version = "^8.6.2"}
redis = "^4.5.4"
pinecone-client = "^2.2.1"
pinecone-text = "^0.4.2"
clickhouse-connect = "^0.5.14"
pgvector = "^0.1.6"
transformers = "^4.27.4"
pandas = "^2.0.0"
deeplake = "^3.2.21"
weaviate-client = "^3.15.5"
torch = "^1.0.0"
chromadb = "^0.3.21"
tiktoken = "^0.3.3"
python-dotenv = "^1.0.0"
sentence-transformers = "^2"
gptcache = "^0.1.9"
promptlayer = "^0.1.80"
tair = "^1.3.3"
wikipedia = "^1"
pymongo = "^4.3.3"
[tool.poetry.group.lint.dependencies]
ruff = "^0.0.249"
types-toml = "^0.10.8.1"
types-redis = "^4.3.21.6"
black = "^23.1.0"
[tool.poetry.group.typing.dependencies]
mypy = "^0.991"
types-pyyaml = "^6.0.12.2"
types-requests = "^2.28.11.5"
[tool.poetry.group.dev]
optional = true
[tool.poetry.group.dev.dependencies]
jupyter = "^1.0.0"
playwright = "^1.28.0"
setuptools = "^67.6.1"
[tool.poetry.extras]
llms = ["anthropic", "cohere", "openai", "nlpcloud", "huggingface_hub", "manifest-ml", "torch", "transformers"]
qdrant = ["qdrant-client"]
openai = ["openai"]
cohere = ["cohere"]
in_memory_store = ["docarray"]
hnswlib = ["docarray", "protobuf", "hnswlib"]
embeddings = ["sentence-transformers"]
azure = ["azure-identity", "azure-cosmos", "openai", "azure-core"]
all = ["anthropic", "cohere", "openai", "nlpcloud", "huggingface_hub", "jina", "manifest-ml", "elasticsearch", "opensearch-py", "google-search-results", "faiss-cpu", "sentence-transformers", "transformers", "spacy", "nltk", "wikipedia", "beautifulsoup4", "tiktoken", "torch", "jinja2", "pinecone-client", "pinecone-text", "weaviate-client", "redis", "google-api-python-client", "wolframalpha", "qdrant-client", "tensorflow-text", "pypdf", "networkx", "nomic", "aleph-alpha-client", "deeplake", "pgvector", "psycopg2-binary", "boto3", "pyowm", "pytesseract", "html2text", "atlassian-python-api", "gptcache", "duckduckgo-search", "arxiv", "azure-identity", "clickhouse-connect", "azure-cosmos", "lancedb", "lark", "pexpect", "pyvespa", "O365", "jq", "docarray", "protobuf", "hnswlib"]
# An extra used to be able to add extended testing.
extended_testing = ["pypdf", "pdfminer.six"]
[tool.ruff]
select = [
"E", # pycodestyle
"F", # pyflakes
"I", # isort
]
exclude = [
"tests/integration_tests/examples/non-utf8-encoding.py",
]
[tool.mypy]
ignore_missing_imports = "True"
disallow_untyped_defs = "True"
exclude = ["notebooks"]
[tool.coverage.run]
omit = [
"tests/*",
]
[build-system]
requires = ["poetry-core>=1.0.0"]
build-backend = "poetry.core.masonry.api"
[tool.pytest.ini_options]
# --strict-markers will raise errors on unknown marks.
# https://docs.pytest.org/en/7.1.x/how-to/mark.html#raising-errors-on-unknown-marks
#
# https://docs.pytest.org/en/7.1.x/reference/reference.html
# --strict-config any warnings encountered while parsing the `pytest`
# section of the configuration file raise errors.
addopts = "--strict-markers --strict-config --durations=5"
# Registering custom markers.
# https://docs.pytest.org/en/7.1.x/example/markers.html#registering-markers
markers = [
"requires: mark tests as requiring a specific library"
]
|