

Unit 4: 深入研究扩散模型
欢迎来到 Hugging Face 扩散模型课程的第四单元!在这个单元中,我们将探讨最新研究中出现的扩散模型的许多改进和扩展。它将比以往的单元代码更少,旨在为您提供进一步研究的起点。
开始本单元 :rocket:
以下是本单元的学习步骤:
- 请确保你已经 注册了该课程 以便在课程中添加其他单元时通知您
- 阅读下面的材料,以了解本单元中涉及的不同主题的概要
- 通过链接的视频和资源深入了解任何您感兴趣的主题
- 浏览演示笔记本,然后阅读“下一步”部分以获取一些项目建议
:loudspeaker: 别忘了加入我们的 Discord频道, 在这里,您可以讨论课程内容,并在#diffusion-models-class 频道中分享您的作品!
Table of Contents
通过蒸馏进行快速采样
渐进蒸馏是一种采用现有扩散模型、并使用它来训练需要更少推理步骤的模型的新版本的技术。“学生”模型初始化自“教师”模型的权重。在训练过程中,教师模型执行两个采样步骤,学生模型尝试在一个步骤中匹配结果预测。这个过程可以重复多次,上一次迭代的学生模型成为下一阶段的教师模型。结果是,这个模型可以用比原来的教师模型少得多的步骤(通常是4或8步)生成较好的样本。核心机制如下图所示,图片来源于这篇论文:
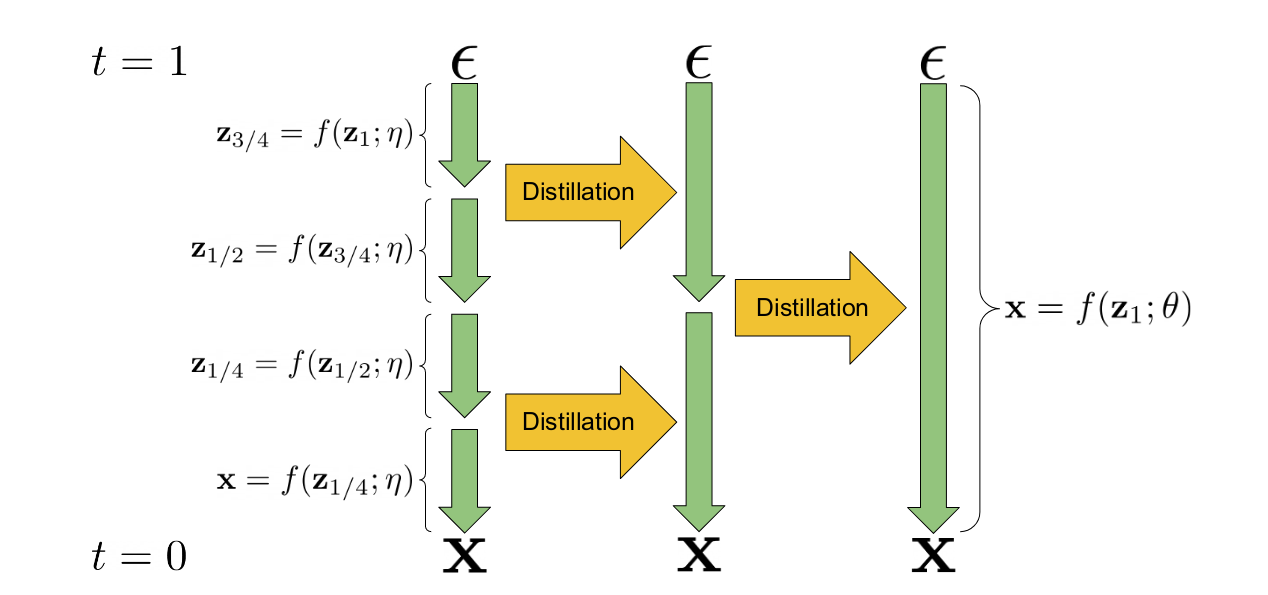
渐进蒸馏图示 (来源于该篇论文)
使用现有模型“教授”新模型的想法可以扩展到创建指导模型,其中教师模型使用无分类器指导技术,学生模型必须学会在指定目标指导尺度的额外输入的基础上,在单个步骤中产生等价的输出。这个视频 对该方法做了一个概述。
NB: Stable Diffusion的蒸馏版将很快发布。
主要文献:
- Progressive Distillation For Fast Sampling Of Diffusion Models
- On Distillation Of Guided Diffusion Models
训练改进
研究者们现在已经开发了一些额外的技巧来改进扩散模型的训练过程。在本节中,我们试图从最近的论文中寻找一些相关的核心理念。更多关于改进方法的研究论文也是不断涌现,因此,如果你看到一篇你觉得应该添加在这里的论文,请联系我们!
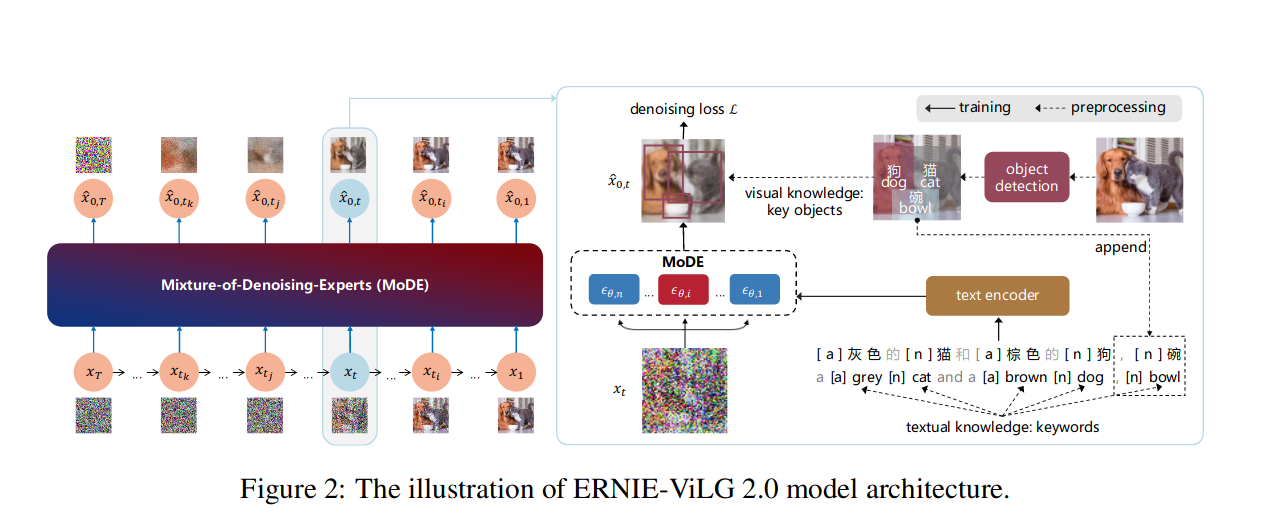 图像2来自于 ERNIE-ViLG 2.0 paper
图像2来自于 ERNIE-ViLG 2.0 paper
关键的训练改进:
- 调整噪声计划、损失加权和采样轨迹,以获得更有效的训练。这里是一篇探讨这些设计选择的优秀论文 Elucidating the Design Space of Diffusion-Based Generative Models by Karras et al.
- 在不同的长宽比上进行训练。这一方法被描述在课程启动活动提到的这个视频中
- 级联扩散模型,首先训练一个低分辨率模型,然后训练一个或多个超分辨率模型。这一方法被广泛运用于DALLE-2,Imagen等高分辨率图像生成模型中。
- Better conditioning, incorporating rich text embeddings (Imagen uses a large language model called T5) or multiple types of conditioning (eDiffi)
- 更好的调节、结合富文本嵌入 (Imagen 使用了一个名为T-5的大语言模型) 或进行多种类型的调节 (eDiffi)
- “知识增强” - 将预先训练的图像描述和物体检测模型纳入训练过程,以创建更有信息的描述,并产生更好的表现 (ERNIE-ViLG 2.0)
- “复合降噪专家” (MoDE) - 训练模型的不同变体(“专家”)以适应不同的噪声水平,如上图所示 ERNIE-ViLG 2.0 paper.
主要文献:
- Elucidating the Design Space of Diffusion-Based Generative Models
- eDiffi: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
- ERNIE-ViLG 2.0: Improving Text-to-Image Diffusion Model with Knowledge-Enhanced Mixture-of-Denoising-Experts
- Imagen - Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (demo site)
对生成与编辑的更多控制
除了训练方面的改进,在采样和推断阶段也有一些创新方法。这其中有许多甚至可以为现有扩散模型添加新的功能。
 由'paint-with-words'生成的样本 (eDiffi)
由'paint-with-words'生成的样本 (eDiffi)
这个视频 '使用扩散模型编辑图片' 概述了如何使用的不同的方法来通过应用扩散模型对已有的图片进行编辑。可用的技术主要分为四个主要类别:
- 添加噪声,然后用一个新的提示(prompt)来进行去噪. 这就是 'img2img ' 管道背后的思想,已经在各种论文中得到了扩展:
- SDEdit and MagicMix 这两篇论文都是建立在这一理念的基础上的
- DDIM 反演 (TODO link tutorial)使用模型来“反转”采样轨迹来取代添加随机噪声, 从而提供了更多的控制
- Null-text Inversion 通过在每一步中优化用于无分类器引导的无条件文本嵌入,允许极高质量的基于文本的图像编辑,极大地增强了这种方法的性能。
- 扩展了(1)中的思想,但使用蒙版来控制效果的应用位置
- Blended Diffusion 介绍了基础的理念
- 这个 demo 使用现有的分割模型(CLIPSeg)来创建基于文本描述的掩码
- DiffEdit 是一篇展示了如何使用扩散模型本身来生成适当的掩码,以根据文本编辑图像的优秀论文。
- SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model 微调扩散模型以获得更准确的掩模引导图像修补。
- 交叉注意力控制:利用扩散模型中的交叉注意力机制控制编辑的空间位置,实现更细粒度的控制。
- Prompt-to-Prompt Image Editing with Cross Attention Control 是介绍这一想法的关键论文,并且该技术已经应用于Stable Diffusion
- 这个想法也被用于 'paint-with-words'中 (eDiffi)
- 对单个图像进行微调(“过拟合”),然后使用微调模型进行图像生成。以下论文几乎在同一时间发表了非常类似的想法:
- Imagic: Text-Based Real Image Editing with Diffusion Models
- UniTune: Text-Driven Image Editing by Fine Tuning an Image Generation Model on a Single Image
值得注意的是,这篇论文 InstructPix2Pix: Learning to Follow Image Editing Instructions 使用了上面描述的一些图像编辑技术来构建一个图像对的合成数据集以及图像编辑指令(由GPT3.5生成),训练生成了一个能够基于自然语言指令编辑图像的新模型。
视频
 Still frames from 样本视频通过Imagen Video生成
Still frames from 样本视频通过Imagen Video生成
视频可以表示为一组图像的序列,而扩散模型的核心思想可以被应用于这些序列。最近的工作主要集中在寻找合适的架构(例如“3D unet”,它可以对整个序列进行操作)并有效地处理视频数据。由于高帧率视频比静止图像涉及更多的数据,目前的方法倾向于首先生成低分辨率和低帧率视频,然后应用空间和时间超分辨率方法来生成最终的高质量视频输出。
主要文献:
音频
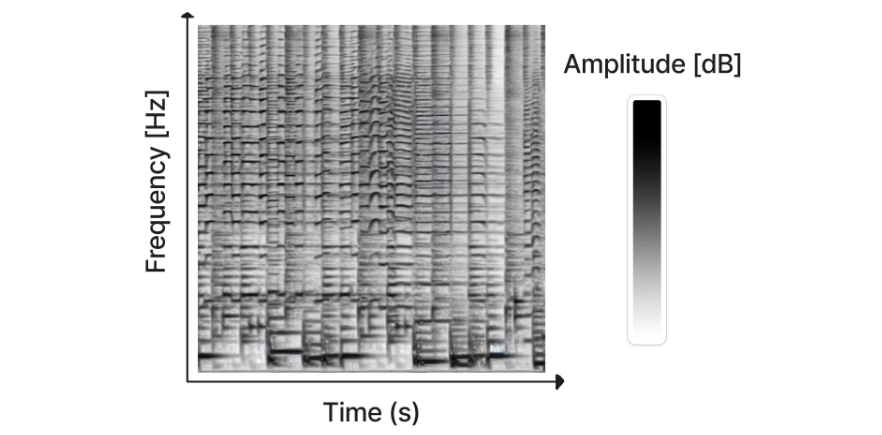
用Riffusion生成的一幅光谱图 (图片来源)
虽然已经有一些直接使用扩散模型生成音频的工作(e.g. DiffWave),但迄今为止最成功的方法还是将音频信号转换为一种称为频谱图的东西,这种方法有效地将音频“编码”为2D“图像”,然后可以用于训练我们用来做图像生成的扩散模型。之后就可以使用现有方法将生成的频谱图转换为音频。最近发布的Riffusion模型就是基于这样的设计思路。该模型通过微调Stable Diffusion模型来基于文字生成频谱图 - 点击这里进行尝试。
音频生成领域发展非常迅速。至少有5个新的进展在过去的一周(在撰写本文时)被发布了。在下面的列表中,我们用星号将他们标了出来:
主要文献:
- DiffWave: A Versatile Diffusion Model for Audio Synthesis
- 'Riffusion' (and code)
- *MusicLM 通过谷歌从文本生成一致的音频,并可以调节哼唱或吹口哨的旋律
- *RAVE2 - 一个新版本的变分自动编码器,可以被用在latent diffusion音频任务上。 这个新结构将被用在下面这篇即将发布的模型中 *AudioLDM
- *Noise2Music - 该扩散模型可以基于文本描述来生成一段高质量的30秒音频片段
- *Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models - 该扩散模型可以基于文本描述来生成不同的声音
- *Moûsai: Text-to-Music Generation with Long-Context Latent Diffusion
新的体系结构和方法 - 走向“迭代优化”

图片1来自 Cold Diffusion paper
我们正在慢慢地超越最初的“扩散”模型的狭义定义,并向更一般的、执行迭代优化的一类模型前进。这其中某种形式的破坏(例如在正向扩散过程中添加高斯噪声)被逐渐逆转以生成样本。这篇有关“冷扩散”的论文证明了许多其他类型的退化过程可以迭代地被“撤销”以生成图像(如上所示的示例)。同时最近基于transformer的方法也证明了符记替换(token replacement)或遮蔽(masking)作为噪声策略的有效性。
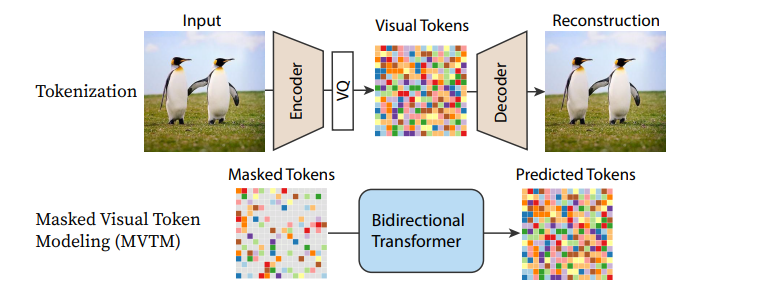
Pipeline from MaskGIT
目前许多扩散模型的核心UNet架构也正在被不同的替代方案所取代,最显著的是各种基于transformer的架构。在 Scalable Diffusion Models with Transformers (DiT)中,transformer结构被用来替换了一个标准扩散模型方法中的UNet结构, 并获得了相当不错的成果。 Recurrent Interface Networks 应用一种新的基于transformer的架构和训练策略,以追求额外的效率。MaskGIT 和 MUSE 使用 transformer 模型来处理图像的标记化表示。 而Paella这篇文章也表示,UNet结构同样可以在这些token-based的设计中成功发挥作用。
随着每一篇新论文的发表,更有效的方法正在陆续被开发出来。我们可能还需要一段时间才能看到这种迭代细化任务的巅峰性能。我们十分期待还有更多的东西被探索和发掘!
主要文献
- Cold Diffusion: Inverting Arbitrary Image Transforms Without Noise
- Scalable Diffusion Models with Transformers (DiT)
- MaskGIT: Masked Generative Image Transformer
- Muse: Text-To-Image Generation via Masked Generative Transformers
- Fast Text-Conditional Discrete Denoising on Vector-Quantized Latent Spaces (Paella)
- Recurrent Interface Networks - 一种很有前途的新架构,可以在不依赖latent diffusion或超分辨率模型的情况下生成高分辨率图像。另请参阅 simple diffusion: End-to-end diffusion for high-resolution images 该论文强调了噪声表(noise schedule)在高分辨率训练中的重要性。
动手笔记本
| 章节 | Colab | Kaggle | Gradient | Studio Lab |
|---|---|---|---|---|
| DDIM Inversion |  |
 |
||
| Diffusion for Audio | |
|
在本单元中,我们已经讨论了很多不同的想法,其中许多值得在未来的后续课程中进行更详细的学习。现在,你可以通过我们准备的动手笔记本来学习其中的两个主题。
- DDIM Inversion 展示了如何使用一种被称为“反转”的技术来使用已有的扩散模型编辑图像
- Diffusion for Audio 介绍了频谱图的思想,并展示了如何对特定音乐风格的音频扩散模型进行微调。
下一步?
这是本课程的最后一个单元,这意味着接下来要做什么取决于你! 请记得你永远都可以来Hugging Face discord频道上来询问问题或者聊聊你自己的project。 我们期待看到你的创作! 🤗