|
--- |
|
language: zh |
|
tags: |
|
- SEGA |
|
- data augmentation |
|
- keywords-to-text generation |
|
- sketch-to-text generation |
|
license: apache-2.0 |
|
datasets: |
|
- beyond/chinese_clean_passages_80m |
|
|
|
|
|
widget: |
|
- text: "[MASK]酸菜鱼火锅[MASK]很美味,味道绝了[MASK]周末真开心[MASK]" |
|
example_title: "草稿1" |
|
- text: "自然语言处理[MASK]谷歌公司[MASK]通用人工智能[MASK]" |
|
example_title: "草稿2" |
|
|
|
inference: |
|
parameters: |
|
max_length: 100 |
|
num_beams: 3 |
|
do_sample: True |
|
--- |
|
# "SEGA-base-chinese" model |
|
|
|
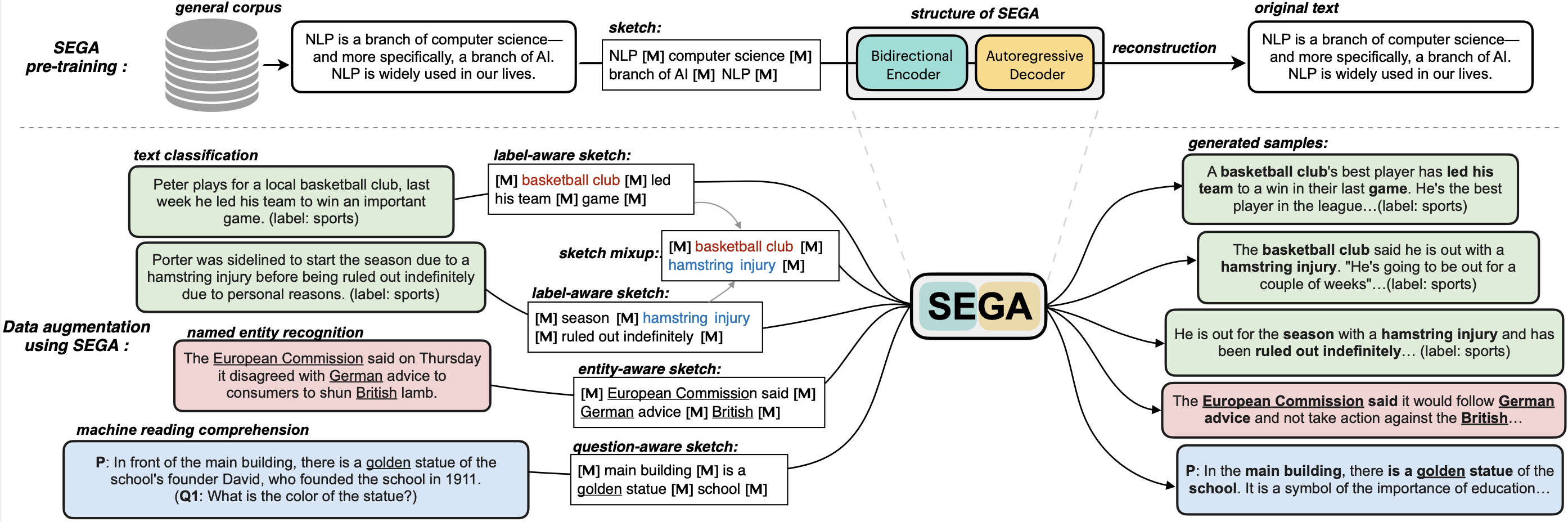
**SEGA: SkEtch-based Generative Augmentation** \ |
|
**基于草稿的生成式增强模型** |
|
|
|
**SEGA** is a **general text augmentation model** that can be used for data augmentation for **various NLP tasks** (including sentiment analysis, topic classification, NER, and QA). SEGA uses an encoder-decoder structure (based on the BART architecture) and is pre-trained on a large-scale general corpus. |
|
|
|
|
|
 |
|
|
|
- Paper: [coming soon](to_be_added) |
|
- GitHub: [SEGA](https://github.com/beyondguo/SEGA). |
|
|
|
**SEGA中文版** 可以根据你给出的一个**草稿**进行填词造句扩写,草稿可以是: |
|
- 关键词组合,例如“今天[MASK]篮球[MASK]学校[MASK]” |
|
- 短语组合,例如“自然语言处理[MASK]谷歌[MASK]通用人工智能[MASK]” |
|
- 短句子组合,例如“我昨天做了一个梦[MASK]又遇见了她[MASK]曾经那段时光让人怀恋[MASK]” |
|
- 以上的混合 |
|
|
|
### How to use / 如何使用 |
|
```python |
|
# sega-chinese |
|
from transformers import BertTokenizer, BartForConditionalGeneration, Text2TextGenerationPipeline |
|
checkpoint = 'beyond/sega-base-chinese' |
|
tokenizer = BertTokenizer.from_pretrained(checkpoint) |
|
sega_model = BartForConditionalGeneration.from_pretrained(checkpoint) |
|
sega_generator = Text2TextGenerationPipeline(sega_model, tokenizer, device=0) |
|
sega_generator |
|
|
|
sketchs = [ |
|
"今天[MASK]篮球[MASK]学校[MASK]", |
|
"自然语言处理[MASK]谷歌[MASK]通用人工智能[MASK]", |
|
"我昨天做了一个梦[MASK]又遇见了她[MASK]曾经那段时光让人怀恋[MASK]", |
|
"[MASK]疫情[MASK]公园[MASK]散步[MASK]", |
|
"[MASK]酸菜鱼火锅[MASK]很美味,味道绝了[MASK]周末真开心[MASK]" |
|
"" |
|
] |
|
for sketch in sketchs: |
|
print('input sketch:\n>>> ', sketch) |
|
print('SEGA-chinese output:\n>>> ',sega_generator(sketch, max_length=100, do_sample=True, num_beams=3)[0]['generated_text'].replace(' ',''),'\n') |
|
``` |
|
|
|
## Model variations / SEGA其他版本 |
|
|
|
| Model | #params | Language | |
|
|------------------------|--------------------------------|-------| |
|
| [`sega-large`](https://huggingface.co/beyond/sega-large) | xM | English | |
|
| [`sega-base`(coming soon)]() | xM | English | |
|
| [`sega-large-chinese`(coming soon)]() | xM | Chinese | |
|
| [`sega-base-chinese`](https://huggingface.co/beyond/sega-base-chinese) | xM | Chinese | |
|
|
|
|
|
## Comparison / 效果对比 |
|
The following comes the comparison between [BART-base-chinese](https://huggingface.co/fnlp/bart-base-chinese) and our proposed [SEGA-base-chinese](https://huggingface.co/beyond/sega-base-chinese).\ |
|
下面对比了[BART-base-chinese](https://huggingface.co/fnlp/bart-base-chinese)和我们提出的**SEGA-base-chinese**在填词造句方面的表现: |
|
|
|
``` |
|
input sketch: |
|
>>> 今天[MASK]篮球[MASK]上海财经大学[MASK] |
|
BART-chinese output: |
|
>>> 今天的篮球是上海财经大学篮球 |
|
SEGA-chinese output: |
|
>>> 今天,我们邀请到了中国篮球联盟主席、上海财经大学校长孙建国先生作为主题发言。 |
|
|
|
input sketch: |
|
>>> 自然语言处理[MASK]谷歌[MASK]通用人工智能[MASK] |
|
BART-chinese output: |
|
>>> 自然语言处理是谷歌的通用人工智能技术 |
|
SEGA-chinese output: |
|
>>> 自然语言处理是谷歌在通用人工智能领域的一个重要研究方向,其目的是为了促进人类智能的发展。 |
|
|
|
input sketch: |
|
>>> 我昨天做了一个梦[MASK]又遇见了她[MASK]曾经那段时光让人怀恋[MASK] |
|
BART-chinese output: |
|
>>> 我昨天做了一个梦今天又遇见了她我曾经那段时光让人怀恋不已 |
|
SEGA-chinese output: |
|
>>> 我昨天做了一个梦,梦见了我的妈妈,又遇见了她,我知道她曾经那段时光让人怀恋,但是现在,我不知道该怎么回事了,我只是想告诉她,不要再回去了。 |
|
|
|
input sketch: |
|
>>> [MASK]疫情[MASK]公园[MASK]漫步[MASK] |
|
BART-chinese output: |
|
>>> 在疫情防控公园内漫步徜徉 |
|
SEGA-chinese output: |
|
>>> 为了防止疫情扩散,公园内还设置了漫步区。 |
|
|
|
input sketch: |
|
>>> [MASK]酸菜鱼火锅[MASK]很美味,味道绝了[MASK]周末真开心[MASK] |
|
BART-chinese output: |
|
>>> 这酸菜鱼火锅真的很美味,味道绝了这周末真开心啊 |
|
SEGA-chinese output: |
|
>>> 这个酸菜鱼火锅真的很美味,味道绝了,吃的时间也长了,周末真开心,吃完以后就回家了,很满意的一次,很喜欢的一个品牌。 |
|
``` |
|
|
|
可以看出,BART只能填补简单的一些词,无法对这些片段进行很连贯的连接,而SEGA则可以扩写成连贯的句子甚至段落。 |
