

Model description | Example output | Banchmark results | How to use | Training and finetuning
Model description
Persian-mistral is the fintuned version of mistral-7b that design for persian QA and nlp tasks
Example output:
Example 1:
- Input: "درمان اصلی برای افراد مبتلا او آر اس، جایگزینی مایعات و الکترولیت ها در بدن"
- Output (After training): "درمان اصلی برای افراد مبتلا او آر اس، جایگزینی مایعات و الکترولیت ها در بدن است. که به طور معمول از طریق تزریق وریدی استفاده می شود."
- Output (Befor training): " درمان اصلی برای افراد مبتلا او آر اس، جایگزینی مایعات و الکترولیتها.The most important treatment for people with diarrhea is oral rehydration solution."
Example 2: - Input: "سال ۱۹۴۴ متفقین به فرانسه اشغال شده توسط آلمان، در عملیاتی در نرماندی حمله کرده و" - Output (After training): "سال ۱۹۴۴ متفقین به فرانسه اشغال شده توسط آلمان، در عملیاتی در نرماندی حمله کرده و 150,000 نفر از آنها را کشتند." - Output (Befor training): "سال ۱۹۴۴ متفقین به فرانسه اشغال شده توسط آلمان، در عملیاتی در نرماندی حمله کرده و خرج گرفت.The United States and France have condemned the killing of a French aid worker in Afghanistan by Tal"
Banchmark results
| model | dataset | score |
|---|---|---|
| base-model-7b | ARC-easy | 41.92% |
| base-model-7b | ARC-easy | 39.12% |
| fa-model-7b | ARC-easy | 37.89% |
| base-model-7b | ARC-challenge | 37.12% |
| fa-model-7b | ARC-challenge | 39.29% |
How to use
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("aidal/Persian-Mistral-7B")
model = AutoModelForCausalLM.from_pretrained("aidal/Persian-Mistral-7B")
input_text = "پایتخت ایران کجاست؟"
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
Training and finetuning
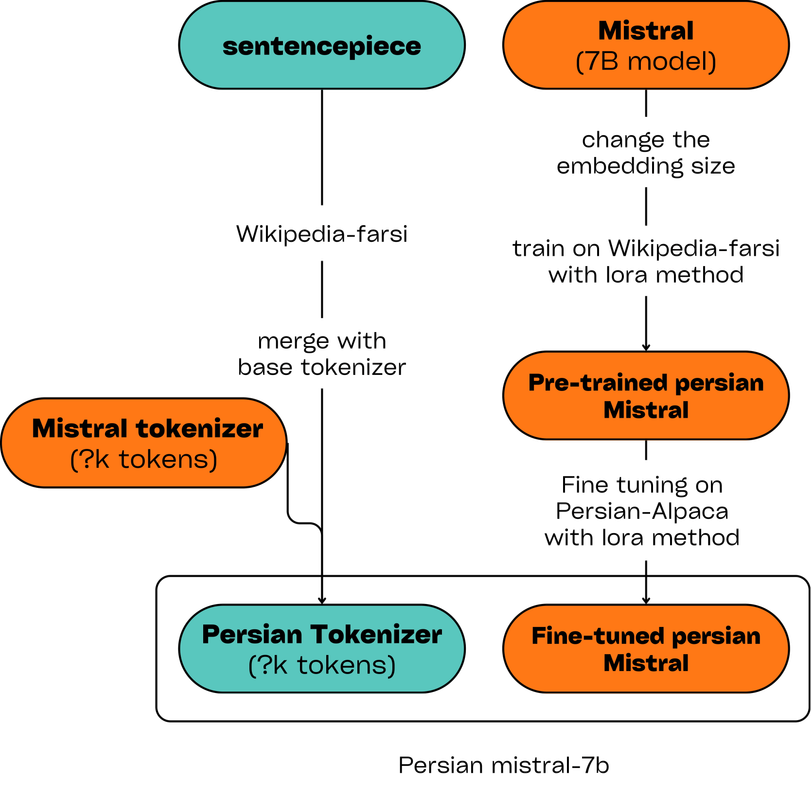
Extend tokenizer: The base Mistral tokenizer does not support Persian. As an initial step, we trained a SentencePiece tokenizer on the Farsi Wikipedia corpus and subsequently integrated it with the Mistral tokenizer.
Pre-training: In the following step, we expanded the embedding layer of the base model to match the size of the Persian tokenizer. We then employed the LoRA method to train the model on three distinct datasets: Wikipedia-Farsi, an Islamic book collection, and content from Khamenei.ir.
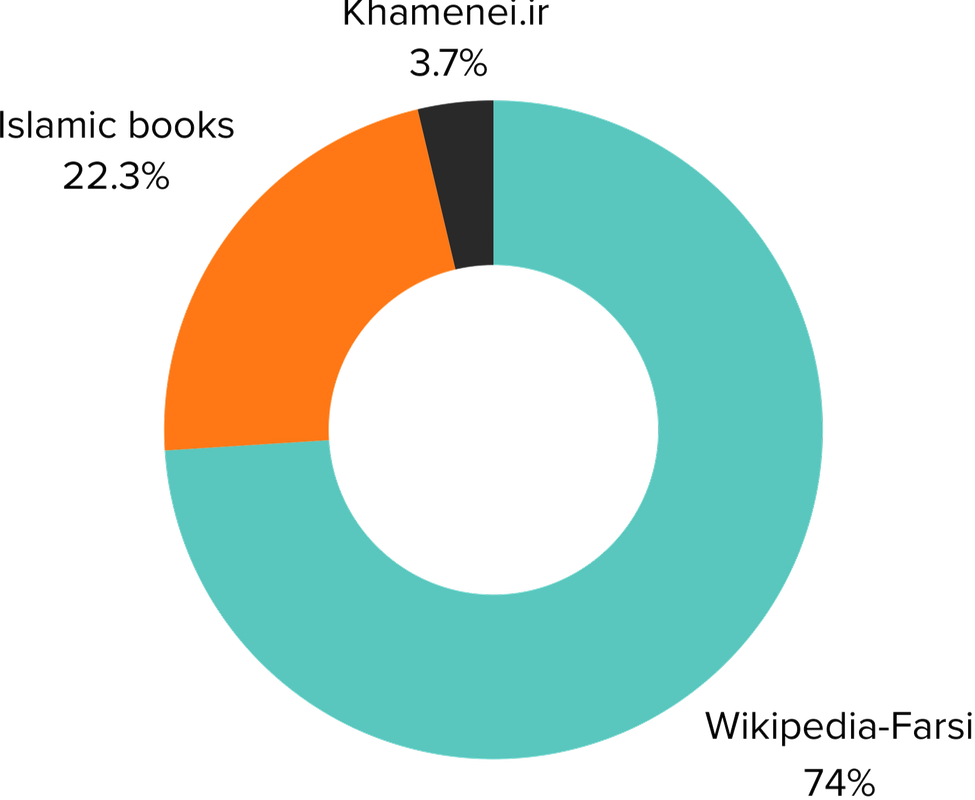
Wiki-farsi:183M tokens, Islamic books:55M tokens, Khamenei.ir:9M tokens
Instruction Fine-tuning: For the final step, we fine-tuned the model using the LoRA method on a translated version of the Stanford-alpaca to enhance the model's question-answering capabilities. This diagram illustrates the steps described above:
- Downloads last month
- 79