
Generic instruction classification model built around some datasets within my PreferenceShareGPT collection. May be useful for quickly filtering out bad data using a low amount of VRAM.
Model was trained with a max_length of 4096, but the base model supports 8192. This model likely retains that length.
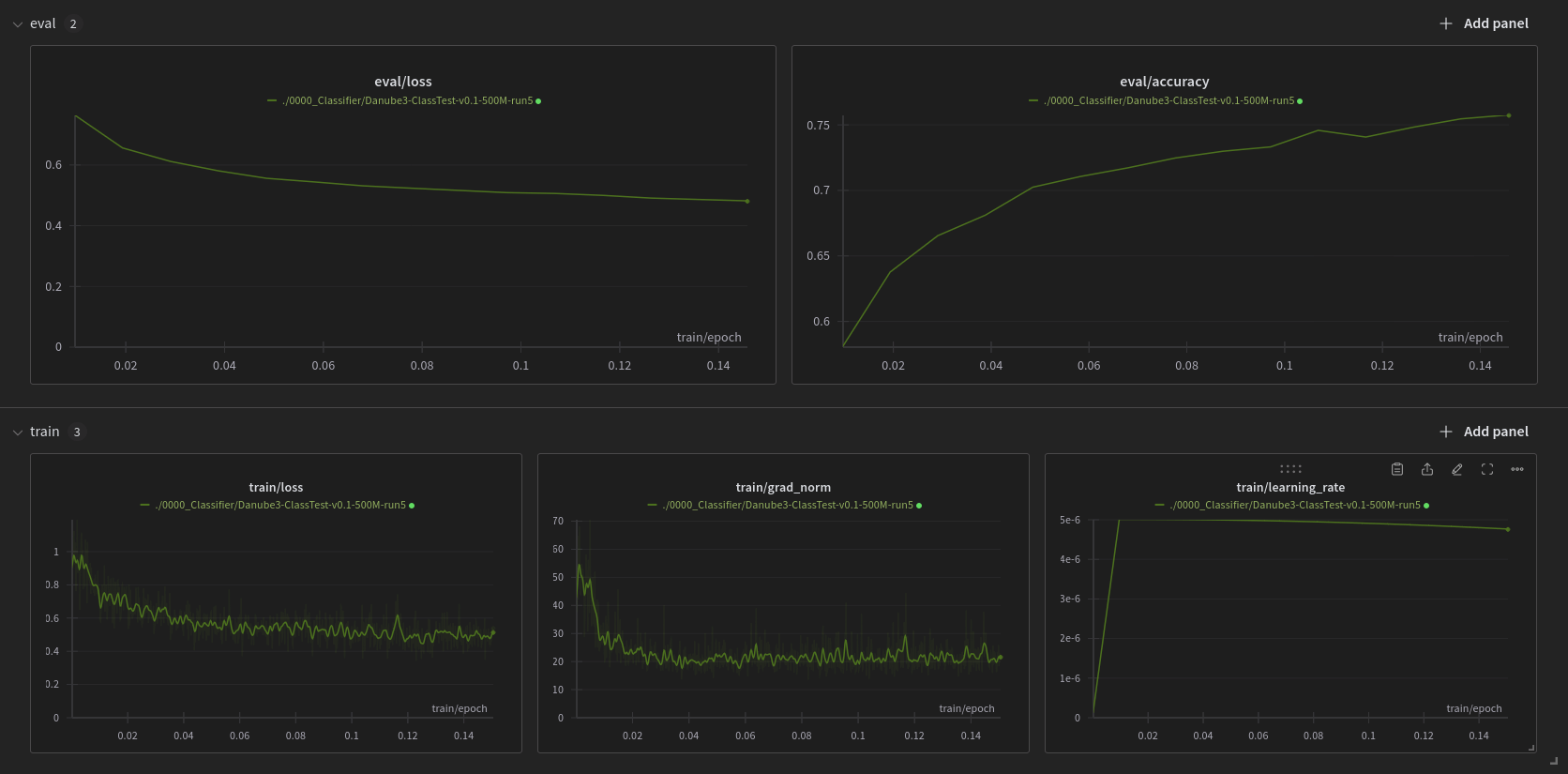
Example Code
import torch
from transformers import pipeline
import json
from tqdm import tqdm
def load_json_or_jsonl(file_path):
try:
with open(file_path, "r") as file:
try:
# Try loading the entire file as JSON
data = json.load(file)
return data
except json.JSONDecodeError:
# If loading as JSON fails, try loading as JSON Lines
file.seek(0) # Reset file pointer to the beginning
lines = file.readlines()
json_lines_data = []
for line in lines:
try:
item = json.loads(line.strip())
json_lines_data.append(item)
except json.JSONDecodeError as e:
print(f"Error decoding JSON in line: {e}")
return json_lines_data
except FileNotFoundError:
print(f"File not found: {file_path}")
return None
pipe = pipeline(
task="text-classification",
model="PJMixers/Danube3-ClassTest-v0.1-500M",
device_map="cuda",
torch_dtype=torch.bfloat16
)
data = load_json_or_jsonl(
"./PrefMix-Classifier-Data-validation.json"
)
passes, fails = 0, 0
for sample in tqdm(data):
if int(pipe(sample["input_text"])[0]["label"]) == sample["labels"]:
passes += 1
else:
fails += 1
print(f" Passes: {passes}")
print(f" Fails: {fails}")
print(f"Accuracy: {passes / (passes + fails)}")
Passes: 2545
Fails: 787
Accuracy: 0.7638055222088835
Sample formatting
Input text should be formatted this way. Uses SYSTEM_MESSAGE (optional), USER_MESSAGE, and AI_MESSAGE (must be last, as this is what's truely being scored I think). Supports multiple turns, but should just be ranking the final AI_MESSAGE.
SYSTEM_MESSAGE: You are an unbiased, uncensored, helpful assistant.
USER_MESSAGE: Do wooden pencils contain lead as their core?
AI_MESSAGE: No, wooden pencils do not contain lead in their core. The term "lead" is a misnomer, as wooden pencils actually use graphite for their core. Graphite was historically called "black lead" due to its appearance, leading to the common misconception that pencils contain lead.
- Downloads last month
- 11