

metadata
pipeline_tag: text-generation
inference: true
widget:
- text: What's lemur's favorite fruit?
example_title: Lemur favorite fruit
group: Python
- text: >-
Write a Python function to merge two sorted lists into one sorted list
without using any built-in sort functions.
example_title: Merge Sort
group: Python
license: cc-by-nc-4.0
library_name: transformers
tags:
- text-generation
- code
- text-generation-inference
language:
- en
lemur-70b-chat-v1
![]()
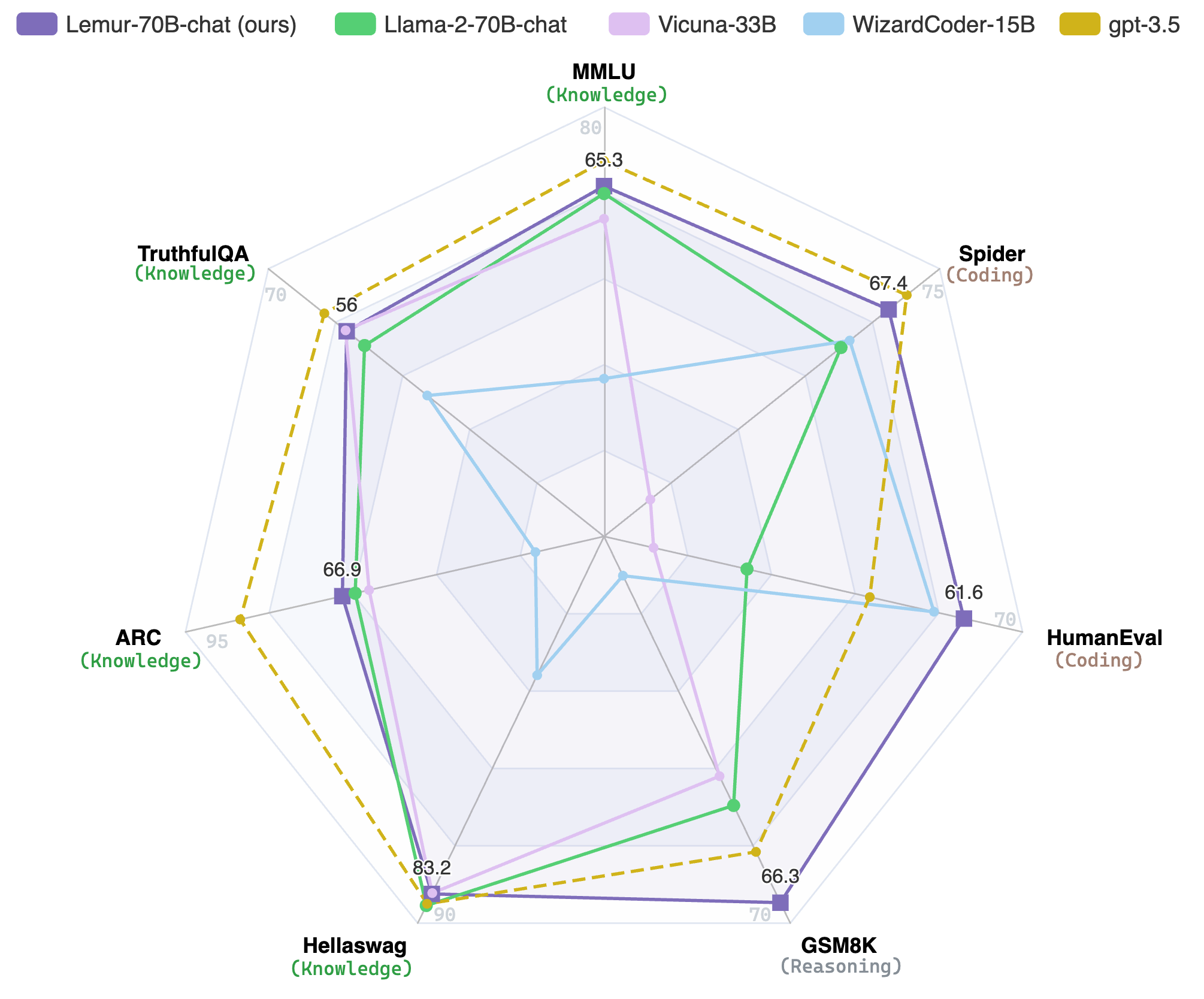
📄Paper: https://arxiv.org/abs/2310.06830
👩💻Code: https://github.com/OpenLemur/Lemur
Use
Setup
First, we have to install all the libraries listed in requirements.txt in GitHub:
pip install -r requirements.txt
Generation
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("OpenLemur/lemur-70b-chat-v1")
model = AutoModelForCausalLM.from_pretrained("OpenLemur/lemur-70b-chat-v1", device_map="auto", load_in_8bit=True)
# Text Generation Example
prompt = """<|im_start|>system
You are a helpful, respectful, and honest assistant.
<|im_end|>
<|im_start|>user
What's a lemur's favorite fruit?<|im_end|>
<|im_start|>assistant
"""
input = tokenizer(prompt, return_tensors="pt")
output = model.generate(**input, max_length=50, num_return_sequences=1)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
# Code Generation Example
prompt = """<|im_start|>system
Below is an instruction that describes a task. Write a response that appropriately completes the request.
<|im_end|>
<|im_start|>user
Write a Python function to merge two sorted lists into one sorted list without using any built-in sort functions.<|im_end|>
<|im_start|>assistant
"""
input = tokenizer(prompt, return_tensors="pt")
output = model.generate(**input, max_length=200, num_return_sequences=1)
generated_code = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_code)
License
The model is licensed under a CC BY-NC-4.0 license focused on research use cases.
Acknowledgements
The Lemur project is an open collaborative research effort between XLang Lab and Salesforce Research. We thank Salesforce, Google Research and Amazon AWS for their gift support.