

metadata
license: mit
Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models
If our project helps you, please give us a star ⭐ on GitHub and cite our paper!
📰 News
- [2024.05.25] 🔥 Our checkpoints are available now!
- [2024.05.23] 🔥 Our paper is released!
😎 What's Interesting?
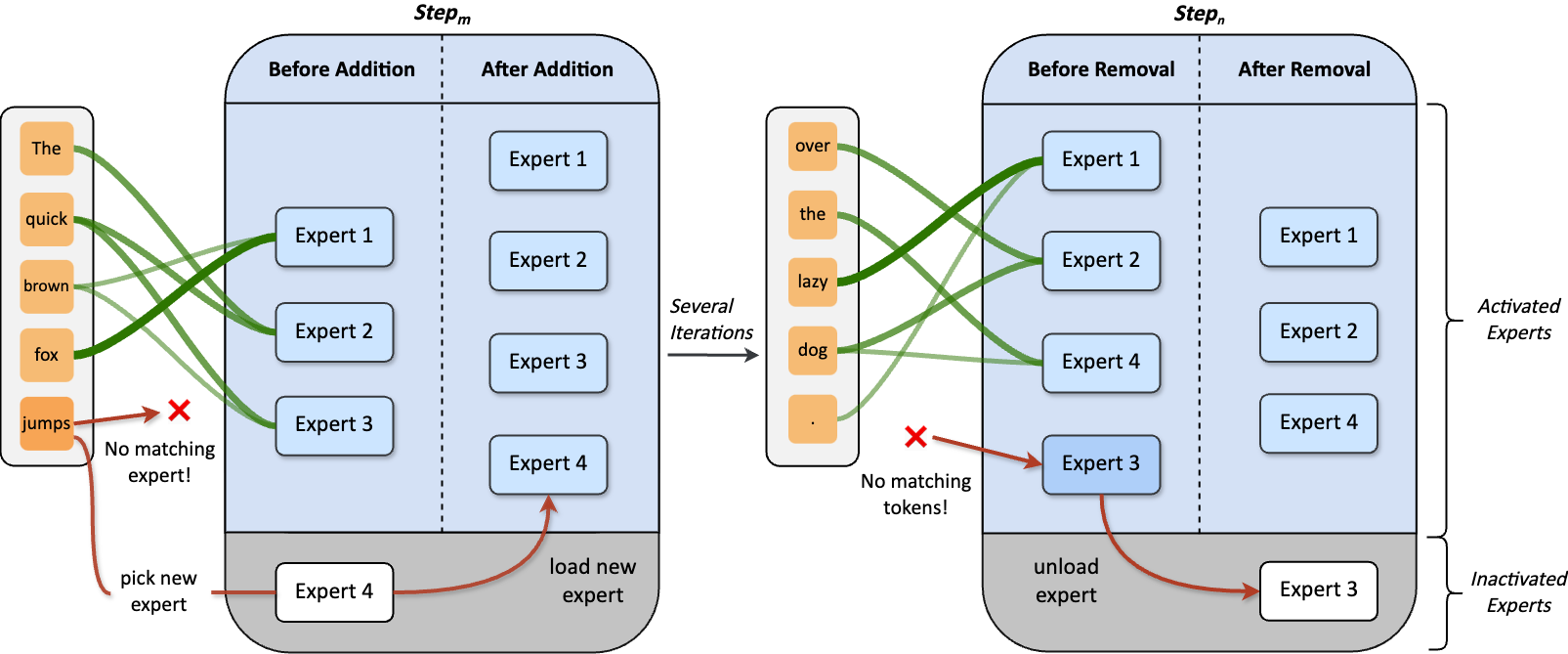
Dynamic Mixture of Experts (DynMoE) incorporates (1) a novel gating method that enables each token to automatically determine the number of experts to activate. (2) An adaptive process automatically adjusts the number of experts during training.
Top-Any Gating
Adaptive Training Process
💡 Model Details
- 🤔 DynMoE-StableLM is a MoE model with dynamic top-k gating, finetuned on LanguageBind/MoE-LLaVA-StableLM-Stage2.
- 🚀 Our DynMoE-StableLM-1.6B has totally 2.9B parameters, but only 1.8B are activated! (average top-k = 1.25)
- ⌛ With the DynMoE tuning stage, we can complete training on 8 A100 GPUs within 40 hours.
👍 Acknowledgement
We are grateful for the following awesome projects:
🔒 License
This project is released under the MIT license as found in the LICENSE file.
✏️ Citation
@misc{guo2024dynamic,
title={Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models},
author={Yongxin Guo and Zhenglin Cheng and Xiaoying Tang and Tao Lin},
year={2024},
eprint={2405.14297},
archivePrefix={arXiv},
primaryClass={cs.LG}
}