
metadata
tags:
- merge
- gguf
- not-for-all-audiences
- storywriting
- text adventure
maid-yuzu-v8-alter-iMat-GGUF
Highly requested model. Quantized from fp16 with love.
1st batch (IQ3_S, IQ3_XS) use a imatrix.dat file calculated from Q8 quant using an input file from this discussionThese have been removed in favor of later method. Please see tables below.- Later files made using .imatrix file from this repo (special thanks to ikawrakow again)
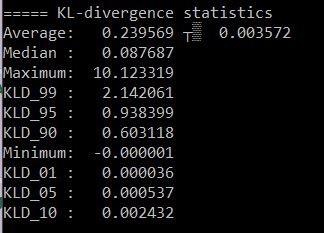
Original IQ3_XS KL Divergence (calculated vs Q8)
Updated IQ3_XS KL Divergence (calculated vs Q8)
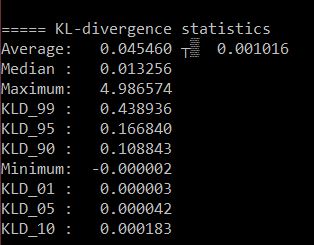
For a brief rundown of iMatrix quant performance please see this PR
All quants are verified working prior to uploading to repo for your safety and convenience.
Please note importance matrix quantizations are a work in progress, IQ3 and above is recommended for best results.
Tip: Pick a size that can fit in your GPU while still allowing some room for context for best speed. You may need to pad this further depending on if you are running image gen or TTS as well.
Original model card can be found here