
Upload 15 files
Browse files- README.md +59 -0
- all_results.json +12 -0
- config.json +29 -0
- eval_results.json +7 -0
- generation_config.json +6 -0
- model.safetensors +3 -0
- special_tokens_map.json +30 -0
- tokenizer.json +0 -0
- tokenizer.model +3 -0
- tokenizer_config.json +44 -0
- train_results.json +8 -0
- trainer_log.jsonl +12 -0
- trainer_state.json +119 -0
- training_args.bin +3 -0
- training_loss.png +0 -0
README.md
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: other
|
| 3 |
+
base_model: models/tinyllama-rubra-1
|
| 4 |
+
tags:
|
| 5 |
+
- llama-factory
|
| 6 |
+
- freeze
|
| 7 |
+
- generated_from_trainer
|
| 8 |
+
model-index:
|
| 9 |
+
- name: sft
|
| 10 |
+
results: []
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 14 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 15 |
+
|
| 16 |
+
# sft
|
| 17 |
+
|
| 18 |
+
This model is a fine-tuned version of [models/tinyllama-rubra-1](https://huggingface.co/models/tinyllama-rubra-1) on the test_data1 dataset.
|
| 19 |
+
It achieves the following results on the evaluation set:
|
| 20 |
+
- Loss: 0.6092
|
| 21 |
+
|
| 22 |
+
## Model description
|
| 23 |
+
|
| 24 |
+
More information needed
|
| 25 |
+
|
| 26 |
+
## Intended uses & limitations
|
| 27 |
+
|
| 28 |
+
More information needed
|
| 29 |
+
|
| 30 |
+
## Training and evaluation data
|
| 31 |
+
|
| 32 |
+
More information needed
|
| 33 |
+
|
| 34 |
+
## Training procedure
|
| 35 |
+
|
| 36 |
+
### Training hyperparameters
|
| 37 |
+
|
| 38 |
+
The following hyperparameters were used during training:
|
| 39 |
+
- learning_rate: 0.0001
|
| 40 |
+
- train_batch_size: 1
|
| 41 |
+
- eval_batch_size: 1
|
| 42 |
+
- seed: 42
|
| 43 |
+
- gradient_accumulation_steps: 8
|
| 44 |
+
- total_train_batch_size: 8
|
| 45 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 46 |
+
- lr_scheduler_type: cosine
|
| 47 |
+
- lr_scheduler_warmup_ratio: 0.1
|
| 48 |
+
- num_epochs: 10.0
|
| 49 |
+
|
| 50 |
+
### Training results
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
### Framework versions
|
| 55 |
+
|
| 56 |
+
- Transformers 4.43.4
|
| 57 |
+
- Pytorch 2.4.0+cu121
|
| 58 |
+
- Datasets 2.20.0
|
| 59 |
+
- Tokenizers 0.19.1
|
all_results.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 9.887640449438202,
|
| 3 |
+
"eval_loss": 0.609153687953949,
|
| 4 |
+
"eval_runtime": 0.1042,
|
| 5 |
+
"eval_samples_per_second": 95.997,
|
| 6 |
+
"eval_steps_per_second": 95.997,
|
| 7 |
+
"total_flos": 582886539362304.0,
|
| 8 |
+
"train_loss": 0.49246828881177035,
|
| 9 |
+
"train_runtime": 12.5387,
|
| 10 |
+
"train_samples_per_second": 70.98,
|
| 11 |
+
"train_steps_per_second": 8.773
|
| 12 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "models/tinyllama-rubra-1",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"LlamaForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_bias": false,
|
| 7 |
+
"attention_dropout": 0.0,
|
| 8 |
+
"bos_token_id": 1,
|
| 9 |
+
"eos_token_id": 2,
|
| 10 |
+
"hidden_act": "silu",
|
| 11 |
+
"hidden_size": 2048,
|
| 12 |
+
"initializer_range": 0.02,
|
| 13 |
+
"intermediate_size": 5632,
|
| 14 |
+
"max_position_embeddings": 2048,
|
| 15 |
+
"mlp_bias": false,
|
| 16 |
+
"model_type": "llama",
|
| 17 |
+
"num_attention_heads": 32,
|
| 18 |
+
"num_hidden_layers": 23,
|
| 19 |
+
"num_key_value_heads": 4,
|
| 20 |
+
"pretraining_tp": 1,
|
| 21 |
+
"rms_norm_eps": 1e-05,
|
| 22 |
+
"rope_scaling": null,
|
| 23 |
+
"rope_theta": 10000.0,
|
| 24 |
+
"tie_word_embeddings": false,
|
| 25 |
+
"torch_dtype": "bfloat16",
|
| 26 |
+
"transformers_version": "4.43.4",
|
| 27 |
+
"use_cache": false,
|
| 28 |
+
"vocab_size": 32000
|
| 29 |
+
}
|
eval_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 9.887640449438202,
|
| 3 |
+
"eval_loss": 0.609153687953949,
|
| 4 |
+
"eval_runtime": 0.1042,
|
| 5 |
+
"eval_samples_per_second": 95.997,
|
| 6 |
+
"eval_steps_per_second": 95.997
|
| 7 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": 2,
|
| 5 |
+
"transformers_version": "4.43.4"
|
| 6 |
+
}
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0c779f8e8a597209087f318a13459fcaf0863a396916d8199c97b21f1ecbde9f
|
| 3 |
+
size 2376298056
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "</s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "</s>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"unk_token": {
|
| 24 |
+
"content": "<unk>",
|
| 25 |
+
"lstrip": false,
|
| 26 |
+
"normalized": false,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
}
|
| 30 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9e556afd44213b6bd1be2b850ebbbd98f5481437a8021afaf58ee7fb1818d347
|
| 3 |
+
size 499723
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"add_prefix_space": null,
|
| 5 |
+
"added_tokens_decoder": {
|
| 6 |
+
"0": {
|
| 7 |
+
"content": "<unk>",
|
| 8 |
+
"lstrip": false,
|
| 9 |
+
"normalized": false,
|
| 10 |
+
"rstrip": false,
|
| 11 |
+
"single_word": false,
|
| 12 |
+
"special": true
|
| 13 |
+
},
|
| 14 |
+
"1": {
|
| 15 |
+
"content": "<s>",
|
| 16 |
+
"lstrip": false,
|
| 17 |
+
"normalized": false,
|
| 18 |
+
"rstrip": false,
|
| 19 |
+
"single_word": false,
|
| 20 |
+
"special": true
|
| 21 |
+
},
|
| 22 |
+
"2": {
|
| 23 |
+
"content": "</s>",
|
| 24 |
+
"lstrip": false,
|
| 25 |
+
"normalized": false,
|
| 26 |
+
"rstrip": false,
|
| 27 |
+
"single_word": false,
|
| 28 |
+
"special": true
|
| 29 |
+
}
|
| 30 |
+
},
|
| 31 |
+
"bos_token": "<s>",
|
| 32 |
+
"chat_template": "{% set system_message = 'You are Zephyr, a helpful assistant.' %}{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ '<|system|>\n' + system_message + '</s>' }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ '<|user|>\n' + content + '</s>' + '<|assistant|>\n' }}{% elif message['role'] == 'assistant' %}{{ content + '</s>' }}{% endif %}{% endfor %}",
|
| 33 |
+
"clean_up_tokenization_spaces": false,
|
| 34 |
+
"eos_token": "</s>",
|
| 35 |
+
"legacy": false,
|
| 36 |
+
"model_max_length": 2048,
|
| 37 |
+
"pad_token": "</s>",
|
| 38 |
+
"padding_side": "right",
|
| 39 |
+
"sp_model_kwargs": {},
|
| 40 |
+
"split_special_tokens": false,
|
| 41 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 42 |
+
"unk_token": "<unk>",
|
| 43 |
+
"use_default_system_prompt": false
|
| 44 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 9.887640449438202,
|
| 3 |
+
"total_flos": 582886539362304.0,
|
| 4 |
+
"train_loss": 0.49246828881177035,
|
| 5 |
+
"train_runtime": 12.5387,
|
| 6 |
+
"train_samples_per_second": 70.98,
|
| 7 |
+
"train_steps_per_second": 8.773
|
| 8 |
+
}
|
trainer_log.jsonl
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
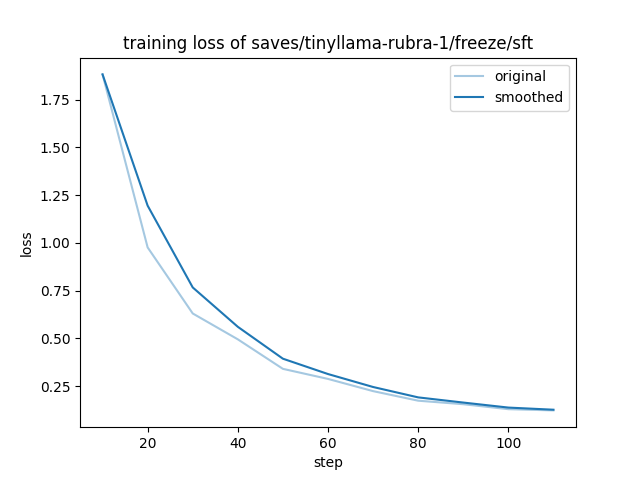
{"current_steps": 10, "total_steps": 110, "loss": 1.8819, "learning_rate": 9.090909090909092e-05, "epoch": 0.898876404494382, "percentage": 9.09, "elapsed_time": "0:00:01", "remaining_time": "0:00:13", "throughput": "0.00", "total_tokens": 0}
|
| 2 |
+
{"current_steps": 20, "total_steps": 110, "loss": 0.9762, "learning_rate": 9.797464868072488e-05, "epoch": 1.797752808988764, "percentage": 18.18, "elapsed_time": "0:00:02", "remaining_time": "0:00:10", "throughput": "0.00", "total_tokens": 0}
|
| 3 |
+
{"current_steps": 30, "total_steps": 110, "loss": 0.6304, "learning_rate": 9.118382907149165e-05, "epoch": 2.696629213483146, "percentage": 27.27, "elapsed_time": "0:00:03", "remaining_time": "0:00:08", "throughput": "0.00", "total_tokens": 0}
|
| 4 |
+
{"current_steps": 40, "total_steps": 110, "loss": 0.495, "learning_rate": 8.028048435688333e-05, "epoch": 3.595505617977528, "percentage": 36.36, "elapsed_time": "0:00:04", "remaining_time": "0:00:07", "throughput": "0.00", "total_tokens": 0}
|
| 5 |
+
{"current_steps": 50, "total_steps": 110, "loss": 0.3405, "learning_rate": 6.635339816587109e-05, "epoch": 4.49438202247191, "percentage": 45.45, "elapsed_time": "0:00:05", "remaining_time": "0:00:06", "throughput": "0.00", "total_tokens": 0}
|
| 6 |
+
{"current_steps": 60, "total_steps": 110, "loss": 0.2878, "learning_rate": 5.0793298191740404e-05, "epoch": 5.393258426966292, "percentage": 54.55, "elapsed_time": "0:00:06", "remaining_time": "0:00:05", "throughput": "0.00", "total_tokens": 0}
|
| 7 |
+
{"current_steps": 70, "total_steps": 110, "loss": 0.2239, "learning_rate": 3.515398123358627e-05, "epoch": 6.292134831460674, "percentage": 63.64, "elapsed_time": "0:00:07", "remaining_time": "0:00:04", "throughput": "0.00", "total_tokens": 0}
|
| 8 |
+
{"current_steps": 80, "total_steps": 110, "loss": 0.1738, "learning_rate": 2.09971545214401e-05, "epoch": 7.191011235955056, "percentage": 72.73, "elapsed_time": "0:00:08", "remaining_time": "0:00:03", "throughput": "0.00", "total_tokens": 0}
|
| 9 |
+
{"current_steps": 90, "total_steps": 110, "loss": 0.1554, "learning_rate": 9.73648712344707e-06, "epoch": 8.089887640449438, "percentage": 81.82, "elapsed_time": "0:00:09", "remaining_time": "0:00:02", "throughput": "0.00", "total_tokens": 0}
|
| 10 |
+
{"current_steps": 100, "total_steps": 110, "loss": 0.1294, "learning_rate": 2.496444112952734e-06, "epoch": 8.98876404494382, "percentage": 90.91, "elapsed_time": "0:00:10", "remaining_time": "0:00:01", "throughput": "0.00", "total_tokens": 0}
|
| 11 |
+
{"current_steps": 110, "total_steps": 110, "loss": 0.123, "learning_rate": 0.0, "epoch": 9.887640449438202, "percentage": 100.0, "elapsed_time": "0:00:11", "remaining_time": "0:00:00", "throughput": "0.00", "total_tokens": 0}
|
| 12 |
+
{"current_steps": 110, "total_steps": 110, "epoch": 9.887640449438202, "percentage": 100.0, "elapsed_time": "0:00:12", "remaining_time": "0:00:00", "throughput": "0.00", "total_tokens": 0}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 9.887640449438202,
|
| 5 |
+
"eval_steps": 500,
|
| 6 |
+
"global_step": 110,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 0.898876404494382,
|
| 13 |
+
"grad_norm": 4.305147647857666,
|
| 14 |
+
"learning_rate": 9.090909090909092e-05,
|
| 15 |
+
"loss": 1.8819,
|
| 16 |
+
"step": 10
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"epoch": 1.797752808988764,
|
| 20 |
+
"grad_norm": 1.784299373626709,
|
| 21 |
+
"learning_rate": 9.797464868072488e-05,
|
| 22 |
+
"loss": 0.9762,
|
| 23 |
+
"step": 20
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"epoch": 2.696629213483146,
|
| 27 |
+
"grad_norm": 2.494720458984375,
|
| 28 |
+
"learning_rate": 9.118382907149165e-05,
|
| 29 |
+
"loss": 0.6304,
|
| 30 |
+
"step": 30
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"epoch": 3.595505617977528,
|
| 34 |
+
"grad_norm": 1.597534418106079,
|
| 35 |
+
"learning_rate": 8.028048435688333e-05,
|
| 36 |
+
"loss": 0.495,
|
| 37 |
+
"step": 40
|
| 38 |
+
},
|
| 39 |
+
{
|
| 40 |
+
"epoch": 4.49438202247191,
|
| 41 |
+
"grad_norm": 1.0912885665893555,
|
| 42 |
+
"learning_rate": 6.635339816587109e-05,
|
| 43 |
+
"loss": 0.3405,
|
| 44 |
+
"step": 50
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
"epoch": 5.393258426966292,
|
| 48 |
+
"grad_norm": 1.4524614810943604,
|
| 49 |
+
"learning_rate": 5.0793298191740404e-05,
|
| 50 |
+
"loss": 0.2878,
|
| 51 |
+
"step": 60
|
| 52 |
+
},
|
| 53 |
+
{
|
| 54 |
+
"epoch": 6.292134831460674,
|
| 55 |
+
"grad_norm": 1.4030110836029053,
|
| 56 |
+
"learning_rate": 3.515398123358627e-05,
|
| 57 |
+
"loss": 0.2239,
|
| 58 |
+
"step": 70
|
| 59 |
+
},
|
| 60 |
+
{
|
| 61 |
+
"epoch": 7.191011235955056,
|
| 62 |
+
"grad_norm": 1.2836480140686035,
|
| 63 |
+
"learning_rate": 2.09971545214401e-05,
|
| 64 |
+
"loss": 0.1738,
|
| 65 |
+
"step": 80
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"epoch": 8.089887640449438,
|
| 69 |
+
"grad_norm": 0.8559394478797913,
|
| 70 |
+
"learning_rate": 9.73648712344707e-06,
|
| 71 |
+
"loss": 0.1554,
|
| 72 |
+
"step": 90
|
| 73 |
+
},
|
| 74 |
+
{
|
| 75 |
+
"epoch": 8.98876404494382,
|
| 76 |
+
"grad_norm": 1.1216458082199097,
|
| 77 |
+
"learning_rate": 2.496444112952734e-06,
|
| 78 |
+
"loss": 0.1294,
|
| 79 |
+
"step": 100
|
| 80 |
+
},
|
| 81 |
+
{
|
| 82 |
+
"epoch": 9.887640449438202,
|
| 83 |
+
"grad_norm": 0.8491550087928772,
|
| 84 |
+
"learning_rate": 0.0,
|
| 85 |
+
"loss": 0.123,
|
| 86 |
+
"step": 110
|
| 87 |
+
},
|
| 88 |
+
{
|
| 89 |
+
"epoch": 9.887640449438202,
|
| 90 |
+
"step": 110,
|
| 91 |
+
"total_flos": 582886539362304.0,
|
| 92 |
+
"train_loss": 0.49246828881177035,
|
| 93 |
+
"train_runtime": 12.5387,
|
| 94 |
+
"train_samples_per_second": 70.98,
|
| 95 |
+
"train_steps_per_second": 8.773
|
| 96 |
+
}
|
| 97 |
+
],
|
| 98 |
+
"logging_steps": 10,
|
| 99 |
+
"max_steps": 110,
|
| 100 |
+
"num_input_tokens_seen": 0,
|
| 101 |
+
"num_train_epochs": 10,
|
| 102 |
+
"save_steps": 500,
|
| 103 |
+
"stateful_callbacks": {
|
| 104 |
+
"TrainerControl": {
|
| 105 |
+
"args": {
|
| 106 |
+
"should_epoch_stop": false,
|
| 107 |
+
"should_evaluate": false,
|
| 108 |
+
"should_log": false,
|
| 109 |
+
"should_save": true,
|
| 110 |
+
"should_training_stop": true
|
| 111 |
+
},
|
| 112 |
+
"attributes": {}
|
| 113 |
+
}
|
| 114 |
+
},
|
| 115 |
+
"total_flos": 582886539362304.0,
|
| 116 |
+
"train_batch_size": 1,
|
| 117 |
+
"trial_name": null,
|
| 118 |
+
"trial_params": null
|
| 119 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b1623f16870275ae5877032e8e1b2e3536742ae1eb7bafe0d18a57e09332a980
|
| 3 |
+
size 5368
|
training_loss.png
ADDED
|