
Yeb Havinga
commited on
Commit
•
3f7f6f9
1
Parent(s):
a2ca396
Autoupdate README.md
Browse files- README.md +125 -86
- evaluation_t5_dutch_english.png +0 -0
README.md
CHANGED
|
@@ -17,14 +17,14 @@ A [T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.htm
|
|
| 17 |
pre-trained from scratch on [cleaned Dutch 🇳🇱🇧🇪 mC4](https://huggingface.co/datasets/yhavinga/mc4_nl_cleaned).
|
| 18 |
|
| 19 |
|
|
|
|
|
|
|
| 20 |
This **t5-v1.1** model has **247M** parameters.
|
| 21 |
-
It was pre-trained on the dataset
|
| 22 |
`mc4_nl_cleaned` config `full` for **2** epoch(s) and a duration of **6d6h**,
|
| 23 |
-
with a sequence length of **1024**, batch size **64** and **1210154** total steps.
|
| 24 |
Pre-training evaluation loss and accuracy are **0,96** and **0,78**.
|
| 25 |
-
|
| 26 |
-
(note: this evaluation model was not saved).
|
| 27 |
-
|
| 28 |
* Pre-trained T5 models need to be finetuned before they can be used for downstream tasks, therefore the inference widget on the right has been turned off.
|
| 29 |
* For a demo of the Dutch CNN summarization models, head over to the Hugging Face Spaces for
|
| 30 |
the **[Netherformer 📰](https://huggingface.co/spaces/flax-community/netherformer)** example application!
|
|
@@ -35,9 +35,6 @@ and configs, though it must be noted that this model (t5-v1.1-base-dutch-cased)
|
|
| 35 |
* **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*.
|
| 36 |
|
| 37 |
|
| 38 |
-

|
| 39 |
-
|
| 40 |
-
|
| 41 |
## Tokenizer
|
| 42 |
|
| 43 |
The model uses a cased SentencePiece tokenizer configured with the `Nmt, NFKC, Replace multi-space to single-space` normalizers
|
|
@@ -45,9 +42,9 @@ and has 32003 tokens.
|
|
| 45 |
It was trained on Dutch mc4 with scripts from the Huggingface Transformers [Flax examples](https://github.com/huggingface/transformers/tree/master/examples/flax/language-modeling).
|
| 46 |
See [./raw/main/tokenizer.json](tokenizer.json) for details.
|
| 47 |
|
| 48 |
-
## Dataset
|
| 49 |
|
| 50 |
-
All models listed below are trained on
|
| 51 |
[cleaned Dutch mC4](https://huggingface.co/datasets/yhavinga/mc4_nl_cleaned),
|
| 52 |
which is the original mC4, except
|
| 53 |
|
|
@@ -58,96 +55,138 @@ which is the original mC4, except
|
|
| 58 |
* Documents with "javascript", "lorum ipsum", "terms of use", "privacy policy", "cookie policy", "uses cookies",
|
| 59 |
"use of cookies", "use cookies", "elementen ontbreken", "deze printversie" are removed.
|
| 60 |
|
| 61 |
-
The Dutch and English models are trained on a 50/50% mix of Dutch mC4 and English C4.
|
|
|
|
|
|
|
| 62 |
|
| 63 |
-
## Models
|
| 64 |
|
| 65 |
-
Three types of models have been trained.
|
|
|
|
| 66 |
The other model types t5-v1.1 and t5-eff have `gated-relu` instead of `relu` as activation function,
|
| 67 |
and trained with a drop-out of `0.0` unless training would diverge (`t5-v1.1-large-dutch-cased`).
|
| 68 |
-
The T5-eff models are models
|
| 69 |
-
the several dimensions of these models.
|
| 70 |
-
|
| 71 |
|
| 72 |
-
| | t5-base-dutch | t5-v1.1-base-dutch-uncased | t5-v1.1-base-dutch-cased | t5-v1.1-large-dutch-cased | t5-v1_1-base-dutch-english-cased | t5-v1_1-base-dutch-english-cased-1024 | t5-small-24L-dutch-english | t5-xl-4L-dutch-english-cased | t5-base-36L-dutch-english-cased | t5-eff-xl-8l-dutch-english-cased | t5-eff-large-8l-dutch-english-cased |
|
| 73 |
|:------------------|:----------------|:-----------------------------|:---------------------------|:----------------------------|:-----------------------------------|:----------------------------------------|:-----------------------------|:-------------------------------|:----------------------------------|:-----------------------------------|:--------------------------------------|
|
| 74 |
-
| type
|
| 75 |
-
| d_model
|
| 76 |
-
| d_ff
|
| 77 |
-
| num_heads
|
| 78 |
-
| d_kv
|
| 79 |
-
| num_layers
|
| 80 |
-
| num parameters
|
| 81 |
-
| feed_forward_proj | relu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu |
|
| 82 |
-
| dropout
|
| 83 |
-
| dataset
|
| 84 |
-
| tr. seq len
|
| 85 |
-
| batch size
|
| 86 |
-
| total steps
|
| 87 |
-
| epochs
|
| 88 |
-
| duration
|
| 89 |
-
| optimizer
|
| 90 |
-
| lr
|
| 91 |
-
| warmup
|
| 92 |
-
| eval loss
|
| 93 |
-
| eval acc
|
| 94 |
-
|
| 95 |
-
## Evaluation
|
| 96 |
-
|
| 97 |
-
|
| 98 |
-
|
| 99 |
-
|
| 100 |
-
|
| 101 |
-
|
| 102 |
-
|
| 103 |
-
|
| 104 |
-
|
| 105 |
-
|
| 106 |
-
|
| 107 |
-
|
| 108 |
-
|
|
| 109 |
-
|
| 110 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 111 |
|
| 112 |
## Translation models
|
| 113 |
|
| 114 |
-
The small
|
| 115 |
-
|
| 116 |
-
|
| 117 |
-
|
| 118 |
-
|
| 119 |
-
|
| 120 |
-
|
| 121 |
-
|
| 122 |
-
|
| 123 |
-
|
|
| 124 |
-
|
| 125 |
-
|
|
| 126 |
-
|
|
| 127 |
-
|
|
| 128 |
-
|
|
| 129 |
-
| tatoeba_bp
|
| 130 |
-
|
|
| 131 |
-
|
|
| 132 |
-
|
|
| 133 |
-
|
|
| 134 |
-
|
|
| 135 |
-
|
|
| 136 |
-
|
|
| 137 |
-
|
|
| 138 |
-
|
|
| 139 |
-
|
|
| 140 |
-
|
|
|
|
|
|
|
|
|
|
|
| 141 |
|
| 142 |
## Acknowledgements
|
| 143 |
|
| 144 |
This project would not have been possible without compute generously provided by Google through the
|
| 145 |
-
[TPU Research Cloud](https://sites.research.google/trc/). The HuggingFace 🤗 ecosystem
|
| 146 |
-
|
| 147 |
-
|
| 148 |
-
have completed this project otherwise.
|
| 149 |
The following repositories where helpful in setting up the TPU-VM,
|
| 150 |
-
and getting an idea what sensible hyper-parameters are for training gpt2 from scratch
|
| 151 |
|
| 152 |
* [Gsarti's Pretrain and Fine-tune a T5 model with Flax on GCP](https://github.com/gsarti/t5-flax-gcp)
|
| 153 |
* [Flax/Jax Community week t5-base-dutch](https://huggingface.co/flax-community/t5-base-dutch)
|
|
|
|
| 17 |
pre-trained from scratch on [cleaned Dutch 🇳🇱🇧🇪 mC4](https://huggingface.co/datasets/yhavinga/mc4_nl_cleaned).
|
| 18 |
|
| 19 |
|
| 20 |
+
|
| 21 |
+
|
| 22 |
This **t5-v1.1** model has **247M** parameters.
|
| 23 |
+
It was pre-trained with masked language modeling (denoise token span corruption) objective on the dataset
|
| 24 |
`mc4_nl_cleaned` config `full` for **2** epoch(s) and a duration of **6d6h**,
|
| 25 |
+
with a sequence length of **1024**, batch size **64** and **1210154** total steps (**79B** tokens).
|
| 26 |
Pre-training evaluation loss and accuracy are **0,96** and **0,78**.
|
| 27 |
+
Refer to the evaluation section below for a comparison of the pre-trained models on summarization and translation.
|
|
|
|
|
|
|
| 28 |
* Pre-trained T5 models need to be finetuned before they can be used for downstream tasks, therefore the inference widget on the right has been turned off.
|
| 29 |
* For a demo of the Dutch CNN summarization models, head over to the Hugging Face Spaces for
|
| 30 |
the **[Netherformer 📰](https://huggingface.co/spaces/flax-community/netherformer)** example application!
|
|
|
|
| 35 |
* **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*.
|
| 36 |
|
| 37 |
|
|
|
|
|
|
|
|
|
|
| 38 |
## Tokenizer
|
| 39 |
|
| 40 |
The model uses a cased SentencePiece tokenizer configured with the `Nmt, NFKC, Replace multi-space to single-space` normalizers
|
|
|
|
| 42 |
It was trained on Dutch mc4 with scripts from the Huggingface Transformers [Flax examples](https://github.com/huggingface/transformers/tree/master/examples/flax/language-modeling).
|
| 43 |
See [./raw/main/tokenizer.json](tokenizer.json) for details.
|
| 44 |
|
| 45 |
+
## Dataset(s)
|
| 46 |
|
| 47 |
+
All models listed below are pre-trained on
|
| 48 |
[cleaned Dutch mC4](https://huggingface.co/datasets/yhavinga/mc4_nl_cleaned),
|
| 49 |
which is the original mC4, except
|
| 50 |
|
|
|
|
| 55 |
* Documents with "javascript", "lorum ipsum", "terms of use", "privacy policy", "cookie policy", "uses cookies",
|
| 56 |
"use of cookies", "use cookies", "elementen ontbreken", "deze printversie" are removed.
|
| 57 |
|
| 58 |
+
The Dutch and English models are pre-trained on a 50/50% mix of Dutch mC4 and English C4.
|
| 59 |
+
|
| 60 |
+
The translation models are fine-tuned on [CCMatrix](https://huggingface.co/datasets/yhavinga/ccmatrix).
|
| 61 |
|
| 62 |
+
## Dutch T5 Models
|
| 63 |
|
| 64 |
+
Three types of [Dutch T5 models have been trained (blog)](https://huggingface.co/spaces/yhavinga/pre-training-dutch-t5-models).
|
| 65 |
+
`t5-base-dutch` is the only model with an original T5 config.
|
| 66 |
The other model types t5-v1.1 and t5-eff have `gated-relu` instead of `relu` as activation function,
|
| 67 |
and trained with a drop-out of `0.0` unless training would diverge (`t5-v1.1-large-dutch-cased`).
|
| 68 |
+
The T5-eff models are models that differ in their number of layers. The table will list
|
| 69 |
+
the several dimensions of these models. Not all t5-eff models are efficient, the best example being the inefficient
|
| 70 |
+
`t5-xl-4L-dutch-english-cased`.
|
| 71 |
|
| 72 |
+
| | [t5-base-dutch](https://huggingface.co/yhavinga/t5-base-dutch) | [t5-v1.1-base-dutch-uncased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-uncased) | [t5-v1.1-base-dutch-cased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-cased) | [t5-v1.1-large-dutch-cased](https://huggingface.co/yhavinga/t5-v1.1-large-dutch-cased) | [t5-v1_1-base-dutch-english-cased](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased) | [t5-v1_1-base-dutch-english-cased-1024](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased-1024) | [t5-small-24L-dutch-english](https://huggingface.co/yhavinga/t5-small-24L-dutch-english) | [t5-xl-4L-dutch-english-cased](https://huggingface.co/yhavinga/t5-xl-4L-dutch-english-cased) | [t5-base-36L-dutch-english-cased](https://huggingface.co/yhavinga/t5-base-36L-dutch-english-cased) | [t5-eff-xl-8l-dutch-english-cased](https://huggingface.co/yhavinga/t5-eff-xl-8l-dutch-english-cased) | [t5-eff-large-8l-dutch-english-cased](https://huggingface.co/yhavinga/t5-eff-large-8l-dutch-english-cased) |
|
| 73 |
|:------------------|:----------------|:-----------------------------|:---------------------------|:----------------------------|:-----------------------------------|:----------------------------------------|:-----------------------------|:-------------------------------|:----------------------------------|:-----------------------------------|:--------------------------------------|
|
| 74 |
+
| *type* | t5 | t5-v1.1 | t5-v1.1 | t5-v1.1 | t5-v1.1 | t5-v1.1 | t5 eff | t5 eff | t5 eff | t5 eff | t5 eff |
|
| 75 |
+
| *d_model* | 768 | 768 | 768 | 1024 | 768 | 768 | 512 | 2048 | 768 | 1024 | 1024 |
|
| 76 |
+
| *d_ff* | 3072 | 2048 | 2048 | 2816 | 2048 | 2048 | 1920 | 5120 | 2560 | 16384 | 4096 |
|
| 77 |
+
| *num_heads* | 12 | 12 | 12 | 16 | 12 | 12 | 8 | 32 | 12 | 32 | 16 |
|
| 78 |
+
| *d_kv* | 64 | 64 | 64 | 64 | 64 | 64 | 64 | 64 | 64 | 128 | 64 |
|
| 79 |
+
| *num_layers* | 12 | 12 | 12 | 24 | 12 | 12 | 24 | 4 | 36 | 8 | 8 |
|
| 80 |
+
| *num parameters* | 223M | 248M | 248M | 783M | 248M | 248M | 250M | 585M | 729M | 1241M | 335M |
|
| 81 |
+
| *feed_forward_proj* | relu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu |
|
| 82 |
+
| *dropout* | 0.1 | 0.0 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 |
|
| 83 |
+
| *dataset* | mc4_nl_cleaned | mc4_nl_cleaned full | mc4_nl_cleaned full | mc4_nl_cleaned | mc4_nl_cleaned small_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl |
|
| 84 |
+
| *tr. seq len* | 512 | 1024 | 1024 | 512 | 512 | 1024 | 512 | 512 | 512 | 512 | 512 |
|
| 85 |
+
| *batch size* | 128 | 64 | 64 | 64 | 128 | 64 | 128 | 512 | 512 | 64 | 128 |
|
| 86 |
+
| *total steps* | 527500 | 1014525 | 1210154 | 1120k/2427498 | 2839630 | 1520k/3397024 | 851852 | 212963 | 212963 | 538k/1703705 | 851850 |
|
| 87 |
+
| *epochs* | 1 | 2 | 2 | 2 | 10 | 4 | 1 | 1 | 1 | 1 | 1 |
|
| 88 |
+
| *duration* | 2d9h | 5d5h | 6d6h | 8d13h | 11d18h | 9d1h | 4d10h | 6d1h | 17d15h | 4d 19h | 3d 23h |
|
| 89 |
+
| *optimizer* | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor |
|
| 90 |
+
| *lr* | 0.005 | 0.005 | 0.005 | 0.005 | 0.005 | 0.005 | 0.005 | 0.005 | 0.009 | 0.005 | 0.005 |
|
| 91 |
+
| *warmup* | 10000.0 | 10000.0 | 10000.0 | 10000.0 | 10000.0 | 5000.0 | 20000.0 | 2500.0 | 1000.0 | 1500.0 | 1500.0 |
|
| 92 |
+
| *eval loss* | 1,38 | 1,20 | 0,96 | 1,07 | 1,11 | 1,13 | 1,18 | 1,27 | 1,05 | 1,3019 | 1,15 |
|
| 93 |
+
| *eval acc* | 0,70 | 0,73 | 0,78 | 0,76 | 0,75 | 0,74 | 0,74 | 0,72 | 0,76 | 0,71 | 0,74 |
|
| 94 |
+
|
| 95 |
+
## Evaluation
|
| 96 |
+
|
| 97 |
+
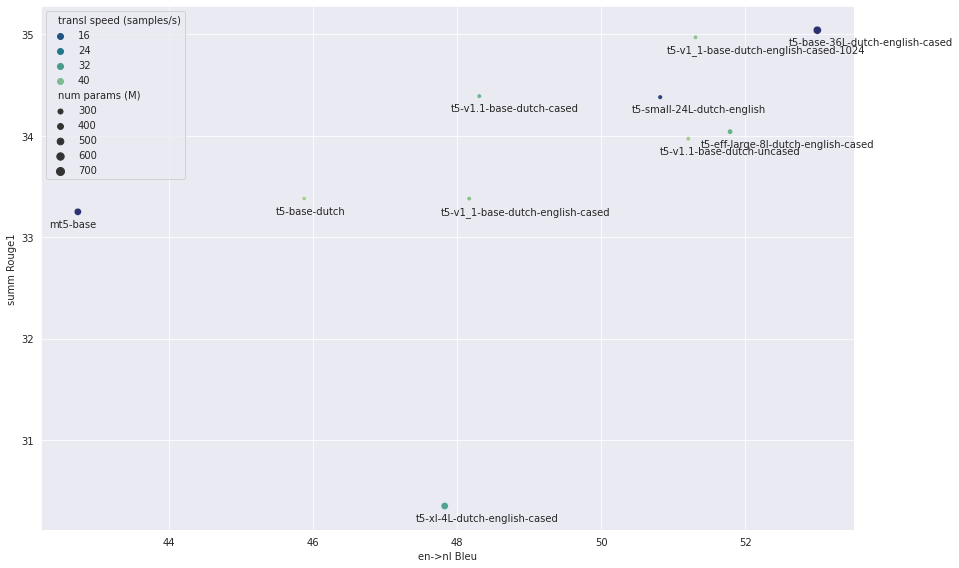
Most models from the list above have been fine-tuned for summarization and translation.
|
| 98 |
+
The figure below shows the evaluation scores, where the x-axis shows the translation Bleu score (higher is better)
|
| 99 |
+
and y-axis the summarization Rouge1 translation score (higher is better).
|
| 100 |
+
Point size is proportional to the model size. Models with faster inference speed are green, slower inference speed is
|
| 101 |
+
plotted as bleu.
|
| 102 |
+
|
| 103 |
+

|
| 104 |
+
|
| 105 |
+
Evaluation was run on fine-tuned models trained with the following settings:
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
| | Summarization | Translation |
|
| 109 |
+
|---------------:|------------------|-------------------|
|
| 110 |
+
| Dataset | CNN Dailymail NL | CCMatrix en -> nl |
|
| 111 |
+
| #train samples | 50K | 50K |
|
| 112 |
+
| Optimizer | Adam | Adam |
|
| 113 |
+
| learning rate | 0.001 | 0.0005 |
|
| 114 |
+
| source length | 1024 | 128 |
|
| 115 |
+
| target length | 142 | 128 |
|
| 116 |
+
|label smoothing | 0.05 | 0.1 |
|
| 117 |
+
| #eval samples | 1000 | 1000 |
|
| 118 |
+
|
| 119 |
+
Note that the amount of training data is limited to a fraction of the total dataset sizes, therefore the scores
|
| 120 |
+
below can only be used to compare the 'transfer-learning' strength. The fine-tuned checkpoints for this evaluation
|
| 121 |
+
are not saved, since they were trained for comparison of pre-trained models only.
|
| 122 |
+
|
| 123 |
+
The numbers for summarization are the Rouge scores on 1000 documents from the test split.
|
| 124 |
+
|
| 125 |
+
| | [t5-base-dutch](https://huggingface.co/yhavinga/t5-base-dutch) | [t5-v1.1-base-dutch-uncased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-uncased) | [t5-v1.1-base-dutch-cased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-cased) | [t5-v1_1-base-dutch-english-cased](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased) | [t5-v1_1-base-dutch-english-cased-1024](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased-1024) | [t5-small-24L-dutch-english](https://huggingface.co/yhavinga/t5-small-24L-dutch-english) | [t5-xl-4L-dutch-english-cased](https://huggingface.co/yhavinga/t5-xl-4L-dutch-english-cased) | [t5-base-36L-dutch-english-cased](https://huggingface.co/yhavinga/t5-base-36L-dutch-english-cased) | [t5-eff-large-8l-dutch-english-cased](https://huggingface.co/yhavinga/t5-eff-large-8l-dutch-english-cased) | mt5-base |
|
| 126 |
+
|:------------------------|----------------:|-----------------------------:|---------------------------:|-----------------------------------:|----------------------------------------:|-----------------------------:|-------------------------------:|----------------------------------:|--------------------------------------:|-----------:|
|
| 127 |
+
| *rouge1* | 33.38 | 33.97 | 34.39 | 33.38 | 34.97 | 34.38 | 30.35 | **35.04** | 34.04 | 33.25 |
|
| 128 |
+
| *rouge2* | 13.32 | 13.85 | 13.98 | 13.47 | 14.01 | 13.89 | 11.57 | **14.23** | 13.76 | 12.74 |
|
| 129 |
+
| *rougeL* | 24.22 | 24.72 | 25.1 | 24.34 | 24.99 | **25.25** | 22.69 | 25.05 | 24.75 | 23.5 |
|
| 130 |
+
| *rougeLsum* | 30.23 | 30.9 | 31.44 | 30.51 | 32.01 | 31.38 | 27.5 | **32.12** | 31.12 | 30.15 |
|
| 131 |
+
| *samples_per_second* | 3.18 | 3.02 | 2.99 | 3.22 | 2.97 | 1.57 | 2.8 | 0.61 | **3.27** | 1.22 |
|
| 132 |
+
|
| 133 |
+
The models below have been evaluated for English to Dutch translation.
|
| 134 |
+
Note that the first four models are pre-trained on Dutch only. That they still perform adequate is probably because
|
| 135 |
+
the translation direction is English to Dutch.
|
| 136 |
+
The numbers reported are the Bleu scores on 1000 documents from the test split.
|
| 137 |
+
|
| 138 |
+
| | [t5-base-dutch](https://huggingface.co/yhavinga/t5-base-dutch) | [t5-v1.1-base-dutch-uncased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-uncased) | [t5-v1.1-base-dutch-cased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-cased) | [t5-v1.1-large-dutch-cased](https://huggingface.co/yhavinga/t5-v1.1-large-dutch-cased) | [t5-v1_1-base-dutch-english-cased](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased) | [t5-v1_1-base-dutch-english-cased-1024](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased-1024) | [t5-small-24L-dutch-english](https://huggingface.co/yhavinga/t5-small-24L-dutch-english) | [t5-xl-4L-dutch-english-cased](https://huggingface.co/yhavinga/t5-xl-4L-dutch-english-cased) | [t5-base-36L-dutch-english-cased](https://huggingface.co/yhavinga/t5-base-36L-dutch-english-cased) | [t5-eff-large-8l-dutch-english-cased](https://huggingface.co/yhavinga/t5-eff-large-8l-dutch-english-cased) | mt5-base |
|
| 139 |
+
|:-------------------------------|----------------:|-----------------------------:|---------------------------:|----------------------------:|-----------------------------------:|----------------------------------------:|-----------------------------:|-------------------------------:|----------------------------------:|--------------------------------------:|-----------:|
|
| 140 |
+
| *precision_ng1* | 74.17 | 78.09 | 77.08 | 72.12 | 77.19 | 78.76 | 78.59 | 77.3 | **79.75** | 78.88 | 73.47 |
|
| 141 |
+
| *precision_ng2* | 52.42 | 57.52 | 55.31 | 48.7 | 55.39 | 58.01 | 57.83 | 55.27 | **59.89** | 58.27 | 50.12 |
|
| 142 |
+
| *precision_ng3* | 39.55 | 45.2 | 42.54 | 35.54 | 42.25 | 45.13 | 45.02 | 42.06 | **47.4** | 45.95 | 36.59 |
|
| 143 |
+
| *precision_ng4* | 30.23 | 36.04 | 33.26 | 26.27 | 32.74 | 35.72 | 35.41 | 32.61 | **38.1** | 36.91 | 27.26 |
|
| 144 |
+
| *bp* | 0.99 | 0.98 | 0.97 | 0.98 | 0.98 | 0.98 | 0.98 | 0.97 | 0.98 | 0.98 | 0.98 |
|
| 145 |
+
| *score* | 45.88 | 51.21 | 48.31 | 41.59 | 48.17 | 51.31 | 50.82 | 47.83 | **53** | 51.79 | 42.74 |
|
| 146 |
+
| *samples_per_second* | **45.19** | 45.05 | 38.67 | 10.12 | 42.19 | 42.61 | 12.85 | 33.74 | 9.07 | 37.86 | 9.03 |
|
| 147 |
+
|
| 148 |
|
| 149 |
## Translation models
|
| 150 |
|
| 151 |
+
The models `t5-small-24L-dutch-english` and `t5-base-36L-dutch-english` have been fine-tuned for both language
|
| 152 |
+
directions on the first 25M samples from CCMatrix, giving a total of 50M training samples.
|
| 153 |
+
Evaluation is performed on out-of-sample CCMatrix and also on Tatoeba and Opus Books.
|
| 154 |
+
The `_bp` columns list the *brevity penalty*. The `avg_bleu` score is the bleu score
|
| 155 |
+
averaged over all three evaluation datasets. The best scores displayed in bold for both translation directions.
|
| 156 |
+
|
| 157 |
+
| | [t5-base-36L-ccmatrix-multi](https://huggingface.co/yhavinga/t5-base-36L-ccmatrix-multi) | [t5-base-36L-ccmatrix-multi](https://huggingface.co/yhavinga/t5-base-36L-ccmatrix-multi) | [t5-small-24L-ccmatrix-multi](https://huggingface.co/yhavinga/t5-small-24L-ccmatrix-multi) | [t5-small-24L-ccmatrix-multi](https://huggingface.co/yhavinga/t5-small-24L-ccmatrix-multi) |
|
| 158 |
+
|:-----------------------|:-----------------------------|:-----------------------------|:------------------------------|:------------------------------|
|
| 159 |
+
| *source_lang* | en | nl | en | nl |
|
| 160 |
+
| *target_lang* | nl | en | nl | en |
|
| 161 |
+
| *source_prefix* | translate English to Dutch: | translate Dutch to English: | translate English to Dutch: | translate Dutch to English: |
|
| 162 |
+
| *ccmatrix_bleu* | **56.8** | 62.8 | 57.4 | **63.1** |
|
| 163 |
+
| *tatoeba_bleu* | **46.6** | **52.8** | 46.4 | 51.7 |
|
| 164 |
+
| *opus_books_bleu* | **13.5** | **24.9** | 12.9 | 23.4 |
|
| 165 |
+
| *ccmatrix_bp* | 0.95 | 0.96 | 0.95 | 0.96 |
|
| 166 |
+
| *tatoeba_bp* | 0.97 | 0.94 | 0.98 | 0.94 |
|
| 167 |
+
| *opus_books_bp* | 0.8 | 0.94 | 0.77 | 0.89 |
|
| 168 |
+
| *avg_bleu* | **38.96** | **46.86** | 38.92 | 46.06 |
|
| 169 |
+
| *max_source_length* | 128 | 128 | 128 | 128 |
|
| 170 |
+
| *max_target_length* | 128 | 128 | 128 | 128 |
|
| 171 |
+
| *adam_beta1* | 0.9 | 0.9 | 0.9 | 0.9 |
|
| 172 |
+
| *adam_beta2* | 0.997 | 0.997 | 0.997 | 0.997 |
|
| 173 |
+
| *weight_decay* | 0.05 | 0.05 | 0.002 | 0.002 |
|
| 174 |
+
| *lr* | 5e-05 | 5e-05 | 0.0005 | 0.0005 |
|
| 175 |
+
| *label_smoothing_factor* | 0.15 | 0.15 | 0.1 | 0.1 |
|
| 176 |
+
| *train_batch_size* | 128 | 128 | 128 | 128 |
|
| 177 |
+
| *warmup_steps* | 2000 | 2000 | 2000 | 2000 |
|
| 178 |
+
| *total steps* | 390625 | 390625 | 390625 | 390625 |
|
| 179 |
+
| *duration* | 4d 5h | 4d 5h | 3d 2h | 3d 2h |
|
| 180 |
+
| *num parameters* | 729M | 729M | 250M | 250M |
|
| 181 |
|
| 182 |
## Acknowledgements
|
| 183 |
|
| 184 |
This project would not have been possible without compute generously provided by Google through the
|
| 185 |
+
[TPU Research Cloud](https://sites.research.google/trc/). The HuggingFace 🤗 ecosystem was instrumental in all parts
|
| 186 |
+
of the training. Weights & Biases made it possible to keep track of many training sessions
|
| 187 |
+
and orchestrate hyper-parameter sweeps with insightful visualizations.
|
|
|
|
| 188 |
The following repositories where helpful in setting up the TPU-VM,
|
| 189 |
+
and getting an idea what sensible hyper-parameters are for training gpt2 from scratch:
|
| 190 |
|
| 191 |
* [Gsarti's Pretrain and Fine-tune a T5 model with Flax on GCP](https://github.com/gsarti/t5-flax-gcp)
|
| 192 |
* [Flax/Jax Community week t5-base-dutch](https://huggingface.co/flax-community/t5-base-dutch)
|
evaluation_t5_dutch_english.png
ADDED
|