Spaces:
Sleeping

Sleeping
Commit
•
b9c49f5
1
Parent(s):
e2a62e9
Upload 724 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- yolov10/.gitignore +166 -0
- yolov10/.pre-commit-config.yaml +86 -0
- yolov10/CONTRIBUTING.md +96 -0
- yolov10/LICENSE +661 -0
- yolov10/README.md +181 -0
- yolov10/app.py +162 -0
- yolov10/docker/Dockerfile +85 -0
- yolov10/docker/Dockerfile-arm64 +51 -0
- yolov10/docker/Dockerfile-conda +40 -0
- yolov10/docker/Dockerfile-cpu +57 -0
- yolov10/docker/Dockerfile-jetson +50 -0
- yolov10/docker/Dockerfile-python +54 -0
- yolov10/docker/Dockerfile-runner +38 -0
- yolov10/docs/README.md +140 -0
- yolov10/docs/build_docs.py +141 -0
- yolov10/docs/build_reference.py +130 -0
- yolov10/docs/coming_soon_template.md +34 -0
- yolov10/docs/en/CNAME +1 -0
- yolov10/docs/en/datasets/classify/caltech101.md +81 -0
- yolov10/docs/en/datasets/classify/caltech256.md +78 -0
- yolov10/docs/en/datasets/classify/cifar10.md +80 -0
- yolov10/docs/en/datasets/classify/cifar100.md +80 -0
- yolov10/docs/en/datasets/classify/fashion-mnist.md +79 -0
- yolov10/docs/en/datasets/classify/imagenet.md +83 -0
- yolov10/docs/en/datasets/classify/imagenet10.md +77 -0
- yolov10/docs/en/datasets/classify/imagenette.md +113 -0
- yolov10/docs/en/datasets/classify/imagewoof.md +89 -0
- yolov10/docs/en/datasets/classify/index.md +120 -0
- yolov10/docs/en/datasets/classify/mnist.md +86 -0
- yolov10/docs/en/datasets/detect/african-wildlife.md +92 -0
- yolov10/docs/en/datasets/detect/argoverse.md +97 -0
- yolov10/docs/en/datasets/detect/brain-tumor.md +91 -0
- yolov10/docs/en/datasets/detect/coco.md +105 -0
- yolov10/docs/en/datasets/detect/coco8.md +90 -0
- yolov10/docs/en/datasets/detect/globalwheat2020.md +91 -0
- yolov10/docs/en/datasets/detect/index.md +110 -0
- yolov10/docs/en/datasets/detect/objects365.md +92 -0
- yolov10/docs/en/datasets/detect/open-images-v7.md +120 -0
- yolov10/docs/en/datasets/detect/roboflow-100.md +80 -0
- yolov10/docs/en/datasets/detect/sku-110k.md +93 -0
- yolov10/docs/en/datasets/detect/visdrone.md +92 -0
- yolov10/docs/en/datasets/detect/voc.md +94 -0
- yolov10/docs/en/datasets/detect/xview.md +97 -0
- yolov10/docs/en/datasets/explorer/api.md +337 -0
- yolov10/docs/en/datasets/explorer/dashboard.md +73 -0
- yolov10/docs/en/datasets/explorer/explorer.ipynb +601 -0
- yolov10/docs/en/datasets/explorer/index.md +60 -0
- yolov10/docs/en/datasets/index.md +151 -0
- yolov10/docs/en/datasets/obb/dota-v2.md +156 -0
- yolov10/docs/en/datasets/obb/dota8.md +81 -0
yolov10/.gitignore
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
pip-wheel-metadata/
|
| 24 |
+
share/python-wheels/
|
| 25 |
+
*.egg-info/
|
| 26 |
+
.installed.cfg
|
| 27 |
+
*.egg
|
| 28 |
+
MANIFEST
|
| 29 |
+
|
| 30 |
+
# PyInstaller
|
| 31 |
+
# Usually these files are written by a python script from a template
|
| 32 |
+
# before PyInstaller builds the exe, so as to inject date/other info into it.
|
| 33 |
+
*.manifest
|
| 34 |
+
*.spec
|
| 35 |
+
|
| 36 |
+
# Installer logs
|
| 37 |
+
pip-log.txt
|
| 38 |
+
pip-delete-this-directory.txt
|
| 39 |
+
|
| 40 |
+
# Unit test / coverage reports
|
| 41 |
+
htmlcov/
|
| 42 |
+
.tox/
|
| 43 |
+
.nox/
|
| 44 |
+
.coverage
|
| 45 |
+
.coverage.*
|
| 46 |
+
.cache
|
| 47 |
+
nosetests.xml
|
| 48 |
+
coverage.xml
|
| 49 |
+
*.cover
|
| 50 |
+
*.py,cover
|
| 51 |
+
.hypothesis/
|
| 52 |
+
.pytest_cache/
|
| 53 |
+
mlruns/
|
| 54 |
+
|
| 55 |
+
# Translations
|
| 56 |
+
*.mo
|
| 57 |
+
*.pot
|
| 58 |
+
|
| 59 |
+
# Django stuff:
|
| 60 |
+
*.log
|
| 61 |
+
local_settings.py
|
| 62 |
+
db.sqlite3
|
| 63 |
+
db.sqlite3-journal
|
| 64 |
+
|
| 65 |
+
# Flask stuff:
|
| 66 |
+
instance/
|
| 67 |
+
.webassets-cache
|
| 68 |
+
|
| 69 |
+
# Scrapy stuff:
|
| 70 |
+
.scrapy
|
| 71 |
+
|
| 72 |
+
# Sphinx documentation
|
| 73 |
+
docs/_build/
|
| 74 |
+
|
| 75 |
+
# PyBuilder
|
| 76 |
+
target/
|
| 77 |
+
|
| 78 |
+
# Jupyter Notebook
|
| 79 |
+
.ipynb_checkpoints
|
| 80 |
+
|
| 81 |
+
# IPython
|
| 82 |
+
profile_default/
|
| 83 |
+
ipython_config.py
|
| 84 |
+
|
| 85 |
+
# Profiling
|
| 86 |
+
*.pclprof
|
| 87 |
+
|
| 88 |
+
# pyenv
|
| 89 |
+
.python-version
|
| 90 |
+
|
| 91 |
+
# pipenv
|
| 92 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 93 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 94 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 95 |
+
# install all needed dependencies.
|
| 96 |
+
#Pipfile.lock
|
| 97 |
+
|
| 98 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
| 99 |
+
__pypackages__/
|
| 100 |
+
|
| 101 |
+
# Celery stuff
|
| 102 |
+
celerybeat-schedule
|
| 103 |
+
celerybeat.pid
|
| 104 |
+
|
| 105 |
+
# SageMath parsed files
|
| 106 |
+
*.sage.py
|
| 107 |
+
|
| 108 |
+
# Environments
|
| 109 |
+
.env
|
| 110 |
+
.venv
|
| 111 |
+
.idea
|
| 112 |
+
env/
|
| 113 |
+
venv/
|
| 114 |
+
ENV/
|
| 115 |
+
env.bak/
|
| 116 |
+
venv.bak/
|
| 117 |
+
|
| 118 |
+
# Spyder project settings
|
| 119 |
+
.spyderproject
|
| 120 |
+
.spyproject
|
| 121 |
+
|
| 122 |
+
# VSCode project settings
|
| 123 |
+
.vscode/
|
| 124 |
+
|
| 125 |
+
# Rope project settings
|
| 126 |
+
.ropeproject
|
| 127 |
+
|
| 128 |
+
# mkdocs documentation
|
| 129 |
+
/site
|
| 130 |
+
mkdocs_github_authors.yaml
|
| 131 |
+
|
| 132 |
+
# mypy
|
| 133 |
+
.mypy_cache/
|
| 134 |
+
.dmypy.json
|
| 135 |
+
dmypy.json
|
| 136 |
+
|
| 137 |
+
# Pyre type checker
|
| 138 |
+
.pyre/
|
| 139 |
+
|
| 140 |
+
# datasets and projects
|
| 141 |
+
datasets/
|
| 142 |
+
runs/
|
| 143 |
+
wandb/
|
| 144 |
+
tests/
|
| 145 |
+
.DS_Store
|
| 146 |
+
|
| 147 |
+
# Neural Network weights -----------------------------------------------------------------------------------------------
|
| 148 |
+
weights/
|
| 149 |
+
*.weights
|
| 150 |
+
*.pt
|
| 151 |
+
*.pb
|
| 152 |
+
*.onnx
|
| 153 |
+
*.engine
|
| 154 |
+
*.mlmodel
|
| 155 |
+
*.mlpackage
|
| 156 |
+
*.torchscript
|
| 157 |
+
*.tflite
|
| 158 |
+
*.h5
|
| 159 |
+
*_saved_model/
|
| 160 |
+
*_web_model/
|
| 161 |
+
*_openvino_model/
|
| 162 |
+
*_paddle_model/
|
| 163 |
+
pnnx*
|
| 164 |
+
|
| 165 |
+
# Autogenerated files for tests
|
| 166 |
+
/ultralytics/assets/
|
yolov10/.pre-commit-config.yaml
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
| 2 |
+
# Pre-commit hooks. For more information see https://github.com/pre-commit/pre-commit-hooks/blob/main/README.md
|
| 3 |
+
# Optionally remove from local hooks with 'rm .git/hooks/pre-commit'
|
| 4 |
+
|
| 5 |
+
# Define bot property if installed via https://github.com/marketplace/pre-commit-ci
|
| 6 |
+
ci:
|
| 7 |
+
autofix_prs: true
|
| 8 |
+
autoupdate_commit_msg: "[pre-commit.ci] pre-commit suggestions"
|
| 9 |
+
autoupdate_schedule: monthly
|
| 10 |
+
submodules: true
|
| 11 |
+
|
| 12 |
+
# Exclude directories (optional)
|
| 13 |
+
# exclude: 'docs/'
|
| 14 |
+
|
| 15 |
+
# Define repos to run
|
| 16 |
+
repos:
|
| 17 |
+
- repo: https://github.com/pre-commit/pre-commit-hooks
|
| 18 |
+
rev: v4.5.0
|
| 19 |
+
hooks:
|
| 20 |
+
- id: end-of-file-fixer
|
| 21 |
+
- id: trailing-whitespace
|
| 22 |
+
- id: check-case-conflict
|
| 23 |
+
# - id: check-yaml
|
| 24 |
+
- id: check-docstring-first
|
| 25 |
+
- id: detect-private-key
|
| 26 |
+
|
| 27 |
+
- repo: https://github.com/asottile/pyupgrade
|
| 28 |
+
rev: v3.15.0
|
| 29 |
+
hooks:
|
| 30 |
+
- id: pyupgrade
|
| 31 |
+
name: Upgrade code
|
| 32 |
+
|
| 33 |
+
- repo: https://github.com/astral-sh/ruff-pre-commit
|
| 34 |
+
rev: v0.1.11
|
| 35 |
+
hooks:
|
| 36 |
+
- id: ruff
|
| 37 |
+
args: [--fix]
|
| 38 |
+
|
| 39 |
+
- repo: https://github.com/executablebooks/mdformat
|
| 40 |
+
rev: 0.7.17
|
| 41 |
+
hooks:
|
| 42 |
+
- id: mdformat
|
| 43 |
+
name: MD formatting
|
| 44 |
+
additional_dependencies:
|
| 45 |
+
- mdformat-gfm
|
| 46 |
+
- mdformat-frontmatter
|
| 47 |
+
- mdformat-mkdocs
|
| 48 |
+
args:
|
| 49 |
+
- --wrap=no
|
| 50 |
+
- --number
|
| 51 |
+
exclude: 'docs/.*\.md'
|
| 52 |
+
# exclude: "README.md|README.zh-CN.md|CONTRIBUTING.md"
|
| 53 |
+
|
| 54 |
+
- repo: https://github.com/codespell-project/codespell
|
| 55 |
+
rev: v2.2.6
|
| 56 |
+
hooks:
|
| 57 |
+
- id: codespell
|
| 58 |
+
exclude: "docs/de|docs/fr|docs/pt|docs/es|docs/mkdocs_de.yml"
|
| 59 |
+
args:
|
| 60 |
+
- --ignore-words-list=crate,nd,ned,strack,dota,ane,segway,fo,gool,winn,commend,bloc,nam,afterall
|
| 61 |
+
|
| 62 |
+
- repo: https://github.com/hadialqattan/pycln
|
| 63 |
+
rev: v2.4.0
|
| 64 |
+
hooks:
|
| 65 |
+
- id: pycln
|
| 66 |
+
args: [--all]
|
| 67 |
+
#
|
| 68 |
+
# - repo: https://github.com/PyCQA/docformatter
|
| 69 |
+
# rev: v1.7.5
|
| 70 |
+
# hooks:
|
| 71 |
+
# - id: docformatter
|
| 72 |
+
|
| 73 |
+
# - repo: https://github.com/asottile/yesqa
|
| 74 |
+
# rev: v1.4.0
|
| 75 |
+
# hooks:
|
| 76 |
+
# - id: yesqa
|
| 77 |
+
|
| 78 |
+
# - repo: https://github.com/asottile/dead
|
| 79 |
+
# rev: v1.5.0
|
| 80 |
+
# hooks:
|
| 81 |
+
# - id: dead
|
| 82 |
+
|
| 83 |
+
# - repo: https://github.com/ultralytics/pre-commit
|
| 84 |
+
# rev: bd60a414f80a53fb8f593d3bfed4701fc47e4b23
|
| 85 |
+
# hooks:
|
| 86 |
+
# - id: capitalize-comments
|
yolov10/CONTRIBUTING.md
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Contributing to YOLOv8 🚀
|
| 2 |
+
|
| 3 |
+
We love your input! We want to make contributing to YOLOv8 as easy and transparent as possible, whether it's:
|
| 4 |
+
|
| 5 |
+
- Reporting a bug
|
| 6 |
+
- Discussing the current state of the code
|
| 7 |
+
- Submitting a fix
|
| 8 |
+
- Proposing a new feature
|
| 9 |
+
- Becoming a maintainer
|
| 10 |
+
|
| 11 |
+
YOLOv8 works so well due to our combined community effort, and for every small improvement you contribute you will be helping push the frontiers of what's possible in AI 😃!
|
| 12 |
+
|
| 13 |
+
## Submitting a Pull Request (PR) 🛠️
|
| 14 |
+
|
| 15 |
+
Submitting a PR is easy! This example shows how to submit a PR for updating `requirements.txt` in 4 steps:
|
| 16 |
+
|
| 17 |
+
### 1. Select File to Update
|
| 18 |
+
|
| 19 |
+
Select `requirements.txt` to update by clicking on it in GitHub.
|
| 20 |
+
|
| 21 |
+
<p align="center"><img width="800" alt="PR_step1" src="https://user-images.githubusercontent.com/26833433/122260847-08be2600-ced4-11eb-828b-8287ace4136c.png"></p>
|
| 22 |
+
|
| 23 |
+
### 2. Click 'Edit this file'
|
| 24 |
+
|
| 25 |
+
Button is in top-right corner.
|
| 26 |
+
|
| 27 |
+
<p align="center"><img width="800" alt="PR_step2" src="https://user-images.githubusercontent.com/26833433/122260844-06f46280-ced4-11eb-9eec-b8a24be519ca.png"></p>
|
| 28 |
+
|
| 29 |
+
### 3. Make Changes
|
| 30 |
+
|
| 31 |
+
Change `matplotlib` version from `3.2.2` to `3.3`.
|
| 32 |
+
|
| 33 |
+
<p align="center"><img width="800" alt="PR_step3" src="https://user-images.githubusercontent.com/26833433/122260853-0a87e980-ced4-11eb-9fd2-3650fb6e0842.png"></p>
|
| 34 |
+
|
| 35 |
+
### 4. Preview Changes and Submit PR
|
| 36 |
+
|
| 37 |
+
Click on the **Preview changes** tab to verify your updates. At the bottom of the screen select 'Create a **new branch** for this commit', assign your branch a descriptive name such as `fix/matplotlib_version` and click the green **Propose changes** button. All done, your PR is now submitted to YOLOv8 for review and approval 😃!
|
| 38 |
+
|
| 39 |
+
<p align="center"><img width="800" alt="PR_step4" src="https://user-images.githubusercontent.com/26833433/122260856-0b208000-ced4-11eb-8e8e-77b6151cbcc3.png"></p>
|
| 40 |
+
|
| 41 |
+
### PR recommendations
|
| 42 |
+
|
| 43 |
+
To allow your work to be integrated as seamlessly as possible, we advise you to:
|
| 44 |
+
|
| 45 |
+
- ✅ Verify your PR is **up-to-date** with `ultralytics/ultralytics` `main` branch. If your PR is behind you can update your code by clicking the 'Update branch' button or by running `git pull` and `git merge main` locally.
|
| 46 |
+
|
| 47 |
+
<p align="center"><img width="751" alt="PR recommendation 1" src="https://user-images.githubusercontent.com/26833433/187295893-50ed9f44-b2c9-4138-a614-de69bd1753d7.png"></p>
|
| 48 |
+
|
| 49 |
+
- ✅ Verify all YOLOv8 Continuous Integration (CI) **checks are passing**.
|
| 50 |
+
|
| 51 |
+
<p align="center"><img width="751" alt="PR recommendation 2" src="https://user-images.githubusercontent.com/26833433/187296922-545c5498-f64a-4d8c-8300-5fa764360da6.png"></p>
|
| 52 |
+
|
| 53 |
+
- ✅ Reduce changes to the absolute **minimum** required for your bug fix or feature addition. _"It is not daily increase but daily decrease, hack away the unessential. The closer to the source, the less wastage there is."_ — Bruce Lee
|
| 54 |
+
|
| 55 |
+
### Docstrings
|
| 56 |
+
|
| 57 |
+
Not all functions or classes require docstrings but when they do, we follow [google-style docstrings format](https://google.github.io/styleguide/pyguide.html#38-comments-and-docstrings). Here is an example:
|
| 58 |
+
|
| 59 |
+
```python
|
| 60 |
+
"""
|
| 61 |
+
What the function does. Performs NMS on given detection predictions.
|
| 62 |
+
|
| 63 |
+
Args:
|
| 64 |
+
arg1: The description of the 1st argument
|
| 65 |
+
arg2: The description of the 2nd argument
|
| 66 |
+
|
| 67 |
+
Returns:
|
| 68 |
+
What the function returns. Empty if nothing is returned.
|
| 69 |
+
|
| 70 |
+
Raises:
|
| 71 |
+
Exception Class: When and why this exception can be raised by the function.
|
| 72 |
+
"""
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
## Submitting a Bug Report 🐛
|
| 76 |
+
|
| 77 |
+
If you spot a problem with YOLOv8 please submit a Bug Report!
|
| 78 |
+
|
| 79 |
+
For us to start investigating a possible problem we need to be able to reproduce it ourselves first. We've created a few short guidelines below to help users provide what we need in order to get started.
|
| 80 |
+
|
| 81 |
+
When asking a question, people will be better able to provide help if you provide **code** that they can easily understand and use to **reproduce** the problem. This is referred to by community members as creating a [minimum reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/). Your code that reproduces the problem should be:
|
| 82 |
+
|
| 83 |
+
- ✅ **Minimal** – Use as little code as possible that still produces the same problem
|
| 84 |
+
- ✅ **Complete** – Provide **all** parts someone else needs to reproduce your problem in the question itself
|
| 85 |
+
- ✅ **Reproducible** – Test the code you're about to provide to make sure it reproduces the problem
|
| 86 |
+
|
| 87 |
+
In addition to the above requirements, for [Ultralytics](https://ultralytics.com/) to provide assistance your code should be:
|
| 88 |
+
|
| 89 |
+
- ✅ **Current** – Verify that your code is up-to-date with current GitHub [main](https://github.com/ultralytics/ultralytics/tree/main) branch, and if necessary `git pull` or `git clone` a new copy to ensure your problem has not already been resolved by previous commits.
|
| 90 |
+
- ✅ **Unmodified** – Your problem must be reproducible without any modifications to the codebase in this repository. [Ultralytics](https://ultralytics.com/) does not provide support for custom code ⚠️.
|
| 91 |
+
|
| 92 |
+
If you believe your problem meets all of the above criteria, please close this issue and raise a new one using the 🐛 **Bug Report** [template](https://github.com/ultralytics/ultralytics/issues/new/choose) and providing a [minimum reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/) to help us better understand and diagnose your problem.
|
| 93 |
+
|
| 94 |
+
## License
|
| 95 |
+
|
| 96 |
+
By contributing, you agree that your contributions will be licensed under the [AGPL-3.0 license](https://choosealicense.com/licenses/agpl-3.0/)
|
yolov10/LICENSE
ADDED
|
@@ -0,0 +1,661 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
GNU AFFERO GENERAL PUBLIC LICENSE
|
| 2 |
+
Version 3, 19 November 2007
|
| 3 |
+
|
| 4 |
+
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
|
| 5 |
+
Everyone is permitted to copy and distribute verbatim copies
|
| 6 |
+
of this license document, but changing it is not allowed.
|
| 7 |
+
|
| 8 |
+
Preamble
|
| 9 |
+
|
| 10 |
+
The GNU Affero General Public License is a free, copyleft license for
|
| 11 |
+
software and other kinds of works, specifically designed to ensure
|
| 12 |
+
cooperation with the community in the case of network server software.
|
| 13 |
+
|
| 14 |
+
The licenses for most software and other practical works are designed
|
| 15 |
+
to take away your freedom to share and change the works. By contrast,
|
| 16 |
+
our General Public Licenses are intended to guarantee your freedom to
|
| 17 |
+
share and change all versions of a program--to make sure it remains free
|
| 18 |
+
software for all its users.
|
| 19 |
+
|
| 20 |
+
When we speak of free software, we are referring to freedom, not
|
| 21 |
+
price. Our General Public Licenses are designed to make sure that you
|
| 22 |
+
have the freedom to distribute copies of free software (and charge for
|
| 23 |
+
them if you wish), that you receive source code or can get it if you
|
| 24 |
+
want it, that you can change the software or use pieces of it in new
|
| 25 |
+
free programs, and that you know you can do these things.
|
| 26 |
+
|
| 27 |
+
Developers that use our General Public Licenses protect your rights
|
| 28 |
+
with two steps: (1) assert copyright on the software, and (2) offer
|
| 29 |
+
you this License which gives you legal permission to copy, distribute
|
| 30 |
+
and/or modify the software.
|
| 31 |
+
|
| 32 |
+
A secondary benefit of defending all users' freedom is that
|
| 33 |
+
improvements made in alternate versions of the program, if they
|
| 34 |
+
receive widespread use, become available for other developers to
|
| 35 |
+
incorporate. Many developers of free software are heartened and
|
| 36 |
+
encouraged by the resulting cooperation. However, in the case of
|
| 37 |
+
software used on network servers, this result may fail to come about.
|
| 38 |
+
The GNU General Public License permits making a modified version and
|
| 39 |
+
letting the public access it on a server without ever releasing its
|
| 40 |
+
source code to the public.
|
| 41 |
+
|
| 42 |
+
The GNU Affero General Public License is designed specifically to
|
| 43 |
+
ensure that, in such cases, the modified source code becomes available
|
| 44 |
+
to the community. It requires the operator of a network server to
|
| 45 |
+
provide the source code of the modified version running there to the
|
| 46 |
+
users of that server. Therefore, public use of a modified version, on
|
| 47 |
+
a publicly accessible server, gives the public access to the source
|
| 48 |
+
code of the modified version.
|
| 49 |
+
|
| 50 |
+
An older license, called the Affero General Public License and
|
| 51 |
+
published by Affero, was designed to accomplish similar goals. This is
|
| 52 |
+
a different license, not a version of the Affero GPL, but Affero has
|
| 53 |
+
released a new version of the Affero GPL which permits relicensing under
|
| 54 |
+
this license.
|
| 55 |
+
|
| 56 |
+
The precise terms and conditions for copying, distribution and
|
| 57 |
+
modification follow.
|
| 58 |
+
|
| 59 |
+
TERMS AND CONDITIONS
|
| 60 |
+
|
| 61 |
+
0. Definitions.
|
| 62 |
+
|
| 63 |
+
"This License" refers to version 3 of the GNU Affero General Public License.
|
| 64 |
+
|
| 65 |
+
"Copyright" also means copyright-like laws that apply to other kinds of
|
| 66 |
+
works, such as semiconductor masks.
|
| 67 |
+
|
| 68 |
+
"The Program" refers to any copyrightable work licensed under this
|
| 69 |
+
License. Each licensee is addressed as "you". "Licensees" and
|
| 70 |
+
"recipients" may be individuals or organizations.
|
| 71 |
+
|
| 72 |
+
To "modify" a work means to copy from or adapt all or part of the work
|
| 73 |
+
in a fashion requiring copyright permission, other than the making of an
|
| 74 |
+
exact copy. The resulting work is called a "modified version" of the
|
| 75 |
+
earlier work or a work "based on" the earlier work.
|
| 76 |
+
|
| 77 |
+
A "covered work" means either the unmodified Program or a work based
|
| 78 |
+
on the Program.
|
| 79 |
+
|
| 80 |
+
To "propagate" a work means to do anything with it that, without
|
| 81 |
+
permission, would make you directly or secondarily liable for
|
| 82 |
+
infringement under applicable copyright law, except executing it on a
|
| 83 |
+
computer or modifying a private copy. Propagation includes copying,
|
| 84 |
+
distribution (with or without modification), making available to the
|
| 85 |
+
public, and in some countries other activities as well.
|
| 86 |
+
|
| 87 |
+
To "convey" a work means any kind of propagation that enables other
|
| 88 |
+
parties to make or receive copies. Mere interaction with a user through
|
| 89 |
+
a computer network, with no transfer of a copy, is not conveying.
|
| 90 |
+
|
| 91 |
+
An interactive user interface displays "Appropriate Legal Notices"
|
| 92 |
+
to the extent that it includes a convenient and prominently visible
|
| 93 |
+
feature that (1) displays an appropriate copyright notice, and (2)
|
| 94 |
+
tells the user that there is no warranty for the work (except to the
|
| 95 |
+
extent that warranties are provided), that licensees may convey the
|
| 96 |
+
work under this License, and how to view a copy of this License. If
|
| 97 |
+
the interface presents a list of user commands or options, such as a
|
| 98 |
+
menu, a prominent item in the list meets this criterion.
|
| 99 |
+
|
| 100 |
+
1. Source Code.
|
| 101 |
+
|
| 102 |
+
The "source code" for a work means the preferred form of the work
|
| 103 |
+
for making modifications to it. "Object code" means any non-source
|
| 104 |
+
form of a work.
|
| 105 |
+
|
| 106 |
+
A "Standard Interface" means an interface that either is an official
|
| 107 |
+
standard defined by a recognized standards body, or, in the case of
|
| 108 |
+
interfaces specified for a particular programming language, one that
|
| 109 |
+
is widely used among developers working in that language.
|
| 110 |
+
|
| 111 |
+
The "System Libraries" of an executable work include anything, other
|
| 112 |
+
than the work as a whole, that (a) is included in the normal form of
|
| 113 |
+
packaging a Major Component, but which is not part of that Major
|
| 114 |
+
Component, and (b) serves only to enable use of the work with that
|
| 115 |
+
Major Component, or to implement a Standard Interface for which an
|
| 116 |
+
implementation is available to the public in source code form. A
|
| 117 |
+
"Major Component", in this context, means a major essential component
|
| 118 |
+
(kernel, window system, and so on) of the specific operating system
|
| 119 |
+
(if any) on which the executable work runs, or a compiler used to
|
| 120 |
+
produce the work, or an object code interpreter used to run it.
|
| 121 |
+
|
| 122 |
+
The "Corresponding Source" for a work in object code form means all
|
| 123 |
+
the source code needed to generate, install, and (for an executable
|
| 124 |
+
work) run the object code and to modify the work, including scripts to
|
| 125 |
+
control those activities. However, it does not include the work's
|
| 126 |
+
System Libraries, or general-purpose tools or generally available free
|
| 127 |
+
programs which are used unmodified in performing those activities but
|
| 128 |
+
which are not part of the work. For example, Corresponding Source
|
| 129 |
+
includes interface definition files associated with source files for
|
| 130 |
+
the work, and the source code for shared libraries and dynamically
|
| 131 |
+
linked subprograms that the work is specifically designed to require,
|
| 132 |
+
such as by intimate data communication or control flow between those
|
| 133 |
+
subprograms and other parts of the work.
|
| 134 |
+
|
| 135 |
+
The Corresponding Source need not include anything that users
|
| 136 |
+
can regenerate automatically from other parts of the Corresponding
|
| 137 |
+
Source.
|
| 138 |
+
|
| 139 |
+
The Corresponding Source for a work in source code form is that
|
| 140 |
+
same work.
|
| 141 |
+
|
| 142 |
+
2. Basic Permissions.
|
| 143 |
+
|
| 144 |
+
All rights granted under this License are granted for the term of
|
| 145 |
+
copyright on the Program, and are irrevocable provided the stated
|
| 146 |
+
conditions are met. This License explicitly affirms your unlimited
|
| 147 |
+
permission to run the unmodified Program. The output from running a
|
| 148 |
+
covered work is covered by this License only if the output, given its
|
| 149 |
+
content, constitutes a covered work. This License acknowledges your
|
| 150 |
+
rights of fair use or other equivalent, as provided by copyright law.
|
| 151 |
+
|
| 152 |
+
You may make, run and propagate covered works that you do not
|
| 153 |
+
convey, without conditions so long as your license otherwise remains
|
| 154 |
+
in force. You may convey covered works to others for the sole purpose
|
| 155 |
+
of having them make modifications exclusively for you, or provide you
|
| 156 |
+
with facilities for running those works, provided that you comply with
|
| 157 |
+
the terms of this License in conveying all material for which you do
|
| 158 |
+
not control copyright. Those thus making or running the covered works
|
| 159 |
+
for you must do so exclusively on your behalf, under your direction
|
| 160 |
+
and control, on terms that prohibit them from making any copies of
|
| 161 |
+
your copyrighted material outside their relationship with you.
|
| 162 |
+
|
| 163 |
+
Conveying under any other circumstances is permitted solely under
|
| 164 |
+
the conditions stated below. Sublicensing is not allowed; section 10
|
| 165 |
+
makes it unnecessary.
|
| 166 |
+
|
| 167 |
+
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
| 168 |
+
|
| 169 |
+
No covered work shall be deemed part of an effective technological
|
| 170 |
+
measure under any applicable law fulfilling obligations under article
|
| 171 |
+
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
| 172 |
+
similar laws prohibiting or restricting circumvention of such
|
| 173 |
+
measures.
|
| 174 |
+
|
| 175 |
+
When you convey a covered work, you waive any legal power to forbid
|
| 176 |
+
circumvention of technological measures to the extent such circumvention
|
| 177 |
+
is effected by exercising rights under this License with respect to
|
| 178 |
+
the covered work, and you disclaim any intention to limit operation or
|
| 179 |
+
modification of the work as a means of enforcing, against the work's
|
| 180 |
+
users, your or third parties' legal rights to forbid circumvention of
|
| 181 |
+
technological measures.
|
| 182 |
+
|
| 183 |
+
4. Conveying Verbatim Copies.
|
| 184 |
+
|
| 185 |
+
You may convey verbatim copies of the Program's source code as you
|
| 186 |
+
receive it, in any medium, provided that you conspicuously and
|
| 187 |
+
appropriately publish on each copy an appropriate copyright notice;
|
| 188 |
+
keep intact all notices stating that this License and any
|
| 189 |
+
non-permissive terms added in accord with section 7 apply to the code;
|
| 190 |
+
keep intact all notices of the absence of any warranty; and give all
|
| 191 |
+
recipients a copy of this License along with the Program.
|
| 192 |
+
|
| 193 |
+
You may charge any price or no price for each copy that you convey,
|
| 194 |
+
and you may offer support or warranty protection for a fee.
|
| 195 |
+
|
| 196 |
+
5. Conveying Modified Source Versions.
|
| 197 |
+
|
| 198 |
+
You may convey a work based on the Program, or the modifications to
|
| 199 |
+
produce it from the Program, in the form of source code under the
|
| 200 |
+
terms of section 4, provided that you also meet all of these conditions:
|
| 201 |
+
|
| 202 |
+
a) The work must carry prominent notices stating that you modified
|
| 203 |
+
it, and giving a relevant date.
|
| 204 |
+
|
| 205 |
+
b) The work must carry prominent notices stating that it is
|
| 206 |
+
released under this License and any conditions added under section
|
| 207 |
+
7. This requirement modifies the requirement in section 4 to
|
| 208 |
+
"keep intact all notices".
|
| 209 |
+
|
| 210 |
+
c) You must license the entire work, as a whole, under this
|
| 211 |
+
License to anyone who comes into possession of a copy. This
|
| 212 |
+
License will therefore apply, along with any applicable section 7
|
| 213 |
+
additional terms, to the whole of the work, and all its parts,
|
| 214 |
+
regardless of how they are packaged. This License gives no
|
| 215 |
+
permission to license the work in any other way, but it does not
|
| 216 |
+
invalidate such permission if you have separately received it.
|
| 217 |
+
|
| 218 |
+
d) If the work has interactive user interfaces, each must display
|
| 219 |
+
Appropriate Legal Notices; however, if the Program has interactive
|
| 220 |
+
interfaces that do not display Appropriate Legal Notices, your
|
| 221 |
+
work need not make them do so.
|
| 222 |
+
|
| 223 |
+
A compilation of a covered work with other separate and independent
|
| 224 |
+
works, which are not by their nature extensions of the covered work,
|
| 225 |
+
and which are not combined with it such as to form a larger program,
|
| 226 |
+
in or on a volume of a storage or distribution medium, is called an
|
| 227 |
+
"aggregate" if the compilation and its resulting copyright are not
|
| 228 |
+
used to limit the access or legal rights of the compilation's users
|
| 229 |
+
beyond what the individual works permit. Inclusion of a covered work
|
| 230 |
+
in an aggregate does not cause this License to apply to the other
|
| 231 |
+
parts of the aggregate.
|
| 232 |
+
|
| 233 |
+
6. Conveying Non-Source Forms.
|
| 234 |
+
|
| 235 |
+
You may convey a covered work in object code form under the terms
|
| 236 |
+
of sections 4 and 5, provided that you also convey the
|
| 237 |
+
machine-readable Corresponding Source under the terms of this License,
|
| 238 |
+
in one of these ways:
|
| 239 |
+
|
| 240 |
+
a) Convey the object code in, or embodied in, a physical product
|
| 241 |
+
(including a physical distribution medium), accompanied by the
|
| 242 |
+
Corresponding Source fixed on a durable physical medium
|
| 243 |
+
customarily used for software interchange.
|
| 244 |
+
|
| 245 |
+
b) Convey the object code in, or embodied in, a physical product
|
| 246 |
+
(including a physical distribution medium), accompanied by a
|
| 247 |
+
written offer, valid for at least three years and valid for as
|
| 248 |
+
long as you offer spare parts or customer support for that product
|
| 249 |
+
model, to give anyone who possesses the object code either (1) a
|
| 250 |
+
copy of the Corresponding Source for all the software in the
|
| 251 |
+
product that is covered by this License, on a durable physical
|
| 252 |
+
medium customarily used for software interchange, for a price no
|
| 253 |
+
more than your reasonable cost of physically performing this
|
| 254 |
+
conveying of source, or (2) access to copy the
|
| 255 |
+
Corresponding Source from a network server at no charge.
|
| 256 |
+
|
| 257 |
+
c) Convey individual copies of the object code with a copy of the
|
| 258 |
+
written offer to provide the Corresponding Source. This
|
| 259 |
+
alternative is allowed only occasionally and noncommercially, and
|
| 260 |
+
only if you received the object code with such an offer, in accord
|
| 261 |
+
with subsection 6b.
|
| 262 |
+
|
| 263 |
+
d) Convey the object code by offering access from a designated
|
| 264 |
+
place (gratis or for a charge), and offer equivalent access to the
|
| 265 |
+
Corresponding Source in the same way through the same place at no
|
| 266 |
+
further charge. You need not require recipients to copy the
|
| 267 |
+
Corresponding Source along with the object code. If the place to
|
| 268 |
+
copy the object code is a network server, the Corresponding Source
|
| 269 |
+
may be on a different server (operated by you or a third party)
|
| 270 |
+
that supports equivalent copying facilities, provided you maintain
|
| 271 |
+
clear directions next to the object code saying where to find the
|
| 272 |
+
Corresponding Source. Regardless of what server hosts the
|
| 273 |
+
Corresponding Source, you remain obligated to ensure that it is
|
| 274 |
+
available for as long as needed to satisfy these requirements.
|
| 275 |
+
|
| 276 |
+
e) Convey the object code using peer-to-peer transmission, provided
|
| 277 |
+
you inform other peers where the object code and Corresponding
|
| 278 |
+
Source of the work are being offered to the general public at no
|
| 279 |
+
charge under subsection 6d.
|
| 280 |
+
|
| 281 |
+
A separable portion of the object code, whose source code is excluded
|
| 282 |
+
from the Corresponding Source as a System Library, need not be
|
| 283 |
+
included in conveying the object code work.
|
| 284 |
+
|
| 285 |
+
A "User Product" is either (1) a "consumer product", which means any
|
| 286 |
+
tangible personal property which is normally used for personal, family,
|
| 287 |
+
or household purposes, or (2) anything designed or sold for incorporation
|
| 288 |
+
into a dwelling. In determining whether a product is a consumer product,
|
| 289 |
+
doubtful cases shall be resolved in favor of coverage. For a particular
|
| 290 |
+
product received by a particular user, "normally used" refers to a
|
| 291 |
+
typical or common use of that class of product, regardless of the status
|
| 292 |
+
of the particular user or of the way in which the particular user
|
| 293 |
+
actually uses, or expects or is expected to use, the product. A product
|
| 294 |
+
is a consumer product regardless of whether the product has substantial
|
| 295 |
+
commercial, industrial or non-consumer uses, unless such uses represent
|
| 296 |
+
the only significant mode of use of the product.
|
| 297 |
+
|
| 298 |
+
"Installation Information" for a User Product means any methods,
|
| 299 |
+
procedures, authorization keys, or other information required to install
|
| 300 |
+
and execute modified versions of a covered work in that User Product from
|
| 301 |
+
a modified version of its Corresponding Source. The information must
|
| 302 |
+
suffice to ensure that the continued functioning of the modified object
|
| 303 |
+
code is in no case prevented or interfered with solely because
|
| 304 |
+
modification has been made.
|
| 305 |
+
|
| 306 |
+
If you convey an object code work under this section in, or with, or
|
| 307 |
+
specifically for use in, a User Product, and the conveying occurs as
|
| 308 |
+
part of a transaction in which the right of possession and use of the
|
| 309 |
+
User Product is transferred to the recipient in perpetuity or for a
|
| 310 |
+
fixed term (regardless of how the transaction is characterized), the
|
| 311 |
+
Corresponding Source conveyed under this section must be accompanied
|
| 312 |
+
by the Installation Information. But this requirement does not apply
|
| 313 |
+
if neither you nor any third party retains the ability to install
|
| 314 |
+
modified object code on the User Product (for example, the work has
|
| 315 |
+
been installed in ROM).
|
| 316 |
+
|
| 317 |
+
The requirement to provide Installation Information does not include a
|
| 318 |
+
requirement to continue to provide support service, warranty, or updates
|
| 319 |
+
for a work that has been modified or installed by the recipient, or for
|
| 320 |
+
the User Product in which it has been modified or installed. Access to a
|
| 321 |
+
network may be denied when the modification itself materially and
|
| 322 |
+
adversely affects the operation of the network or violates the rules and
|
| 323 |
+
protocols for communication across the network.
|
| 324 |
+
|
| 325 |
+
Corresponding Source conveyed, and Installation Information provided,
|
| 326 |
+
in accord with this section must be in a format that is publicly
|
| 327 |
+
documented (and with an implementation available to the public in
|
| 328 |
+
source code form), and must require no special password or key for
|
| 329 |
+
unpacking, reading or copying.
|
| 330 |
+
|
| 331 |
+
7. Additional Terms.
|
| 332 |
+
|
| 333 |
+
"Additional permissions" are terms that supplement the terms of this
|
| 334 |
+
License by making exceptions from one or more of its conditions.
|
| 335 |
+
Additional permissions that are applicable to the entire Program shall
|
| 336 |
+
be treated as though they were included in this License, to the extent
|
| 337 |
+
that they are valid under applicable law. If additional permissions
|
| 338 |
+
apply only to part of the Program, that part may be used separately
|
| 339 |
+
under those permissions, but the entire Program remains governed by
|
| 340 |
+
this License without regard to the additional permissions.
|
| 341 |
+
|
| 342 |
+
When you convey a copy of a covered work, you may at your option
|
| 343 |
+
remove any additional permissions from that copy, or from any part of
|
| 344 |
+
it. (Additional permissions may be written to require their own
|
| 345 |
+
removal in certain cases when you modify the work.) You may place
|
| 346 |
+
additional permissions on material, added by you to a covered work,
|
| 347 |
+
for which you have or can give appropriate copyright permission.
|
| 348 |
+
|
| 349 |
+
Notwithstanding any other provision of this License, for material you
|
| 350 |
+
add to a covered work, you may (if authorized by the copyright holders of
|
| 351 |
+
that material) supplement the terms of this License with terms:
|
| 352 |
+
|
| 353 |
+
a) Disclaiming warranty or limiting liability differently from the
|
| 354 |
+
terms of sections 15 and 16 of this License; or
|
| 355 |
+
|
| 356 |
+
b) Requiring preservation of specified reasonable legal notices or
|
| 357 |
+
author attributions in that material or in the Appropriate Legal
|
| 358 |
+
Notices displayed by works containing it; or
|
| 359 |
+
|
| 360 |
+
c) Prohibiting misrepresentation of the origin of that material, or
|
| 361 |
+
requiring that modified versions of such material be marked in
|
| 362 |
+
reasonable ways as different from the original version; or
|
| 363 |
+
|
| 364 |
+
d) Limiting the use for publicity purposes of names of licensors or
|
| 365 |
+
authors of the material; or
|
| 366 |
+
|
| 367 |
+
e) Declining to grant rights under trademark law for use of some
|
| 368 |
+
trade names, trademarks, or service marks; or
|
| 369 |
+
|
| 370 |
+
f) Requiring indemnification of licensors and authors of that
|
| 371 |
+
material by anyone who conveys the material (or modified versions of
|
| 372 |
+
it) with contractual assumptions of liability to the recipient, for
|
| 373 |
+
any liability that these contractual assumptions directly impose on
|
| 374 |
+
those licensors and authors.
|
| 375 |
+
|
| 376 |
+
All other non-permissive additional terms are considered "further
|
| 377 |
+
restrictions" within the meaning of section 10. If the Program as you
|
| 378 |
+
received it, or any part of it, contains a notice stating that it is
|
| 379 |
+
governed by this License along with a term that is a further
|
| 380 |
+
restriction, you may remove that term. If a license document contains
|
| 381 |
+
a further restriction but permits relicensing or conveying under this
|
| 382 |
+
License, you may add to a covered work material governed by the terms
|
| 383 |
+
of that license document, provided that the further restriction does
|
| 384 |
+
not survive such relicensing or conveying.
|
| 385 |
+
|
| 386 |
+
If you add terms to a covered work in accord with this section, you
|
| 387 |
+
must place, in the relevant source files, a statement of the
|
| 388 |
+
additional terms that apply to those files, or a notice indicating
|
| 389 |
+
where to find the applicable terms.
|
| 390 |
+
|
| 391 |
+
Additional terms, permissive or non-permissive, may be stated in the
|
| 392 |
+
form of a separately written license, or stated as exceptions;
|
| 393 |
+
the above requirements apply either way.
|
| 394 |
+
|
| 395 |
+
8. Termination.
|
| 396 |
+
|
| 397 |
+
You may not propagate or modify a covered work except as expressly
|
| 398 |
+
provided under this License. Any attempt otherwise to propagate or
|
| 399 |
+
modify it is void, and will automatically terminate your rights under
|
| 400 |
+
this License (including any patent licenses granted under the third
|
| 401 |
+
paragraph of section 11).
|
| 402 |
+
|
| 403 |
+
However, if you cease all violation of this License, then your
|
| 404 |
+
license from a particular copyright holder is reinstated (a)
|
| 405 |
+
provisionally, unless and until the copyright holder explicitly and
|
| 406 |
+
finally terminates your license, and (b) permanently, if the copyright
|
| 407 |
+
holder fails to notify you of the violation by some reasonable means
|
| 408 |
+
prior to 60 days after the cessation.
|
| 409 |
+
|
| 410 |
+
Moreover, your license from a particular copyright holder is
|
| 411 |
+
reinstated permanently if the copyright holder notifies you of the
|
| 412 |
+
violation by some reasonable means, this is the first time you have
|
| 413 |
+
received notice of violation of this License (for any work) from that
|
| 414 |
+
copyright holder, and you cure the violation prior to 30 days after
|
| 415 |
+
your receipt of the notice.
|
| 416 |
+
|
| 417 |
+
Termination of your rights under this section does not terminate the
|
| 418 |
+
licenses of parties who have received copies or rights from you under
|
| 419 |
+
this License. If your rights have been terminated and not permanently
|
| 420 |
+
reinstated, you do not qualify to receive new licenses for the same
|
| 421 |
+
material under section 10.
|
| 422 |
+
|
| 423 |
+
9. Acceptance Not Required for Having Copies.
|
| 424 |
+
|
| 425 |
+
You are not required to accept this License in order to receive or
|
| 426 |
+
run a copy of the Program. Ancillary propagation of a covered work
|
| 427 |
+
occurring solely as a consequence of using peer-to-peer transmission
|
| 428 |
+
to receive a copy likewise does not require acceptance. However,
|
| 429 |
+
nothing other than this License grants you permission to propagate or
|
| 430 |
+
modify any covered work. These actions infringe copyright if you do
|
| 431 |
+
not accept this License. Therefore, by modifying or propagating a
|
| 432 |
+
covered work, you indicate your acceptance of this License to do so.
|
| 433 |
+
|
| 434 |
+
10. Automatic Licensing of Downstream Recipients.
|
| 435 |
+
|
| 436 |
+
Each time you convey a covered work, the recipient automatically
|
| 437 |
+
receives a license from the original licensors, to run, modify and
|
| 438 |
+
propagate that work, subject to this License. You are not responsible
|
| 439 |
+
for enforcing compliance by third parties with this License.
|
| 440 |
+
|
| 441 |
+
An "entity transaction" is a transaction transferring control of an
|
| 442 |
+
organization, or substantially all assets of one, or subdividing an
|
| 443 |
+
organization, or merging organizations. If propagation of a covered
|
| 444 |
+
work results from an entity transaction, each party to that
|
| 445 |
+
transaction who receives a copy of the work also receives whatever
|
| 446 |
+
licenses to the work the party's predecessor in interest had or could
|
| 447 |
+
give under the previous paragraph, plus a right to possession of the
|
| 448 |
+
Corresponding Source of the work from the predecessor in interest, if
|
| 449 |
+
the predecessor has it or can get it with reasonable efforts.
|
| 450 |
+
|
| 451 |
+
You may not impose any further restrictions on the exercise of the
|
| 452 |
+
rights granted or affirmed under this License. For example, you may
|
| 453 |
+
not impose a license fee, royalty, or other charge for exercise of
|
| 454 |
+
rights granted under this License, and you may not initiate litigation
|
| 455 |
+
(including a cross-claim or counterclaim in a lawsuit) alleging that
|
| 456 |
+
any patent claim is infringed by making, using, selling, offering for
|
| 457 |
+
sale, or importing the Program or any portion of it.
|
| 458 |
+
|
| 459 |
+
11. Patents.
|
| 460 |
+
|
| 461 |
+
A "contributor" is a copyright holder who authorizes use under this
|
| 462 |
+
License of the Program or a work on which the Program is based. The
|
| 463 |
+
work thus licensed is called the contributor's "contributor version".
|
| 464 |
+
|
| 465 |
+
A contributor's "essential patent claims" are all patent claims
|
| 466 |
+
owned or controlled by the contributor, whether already acquired or
|
| 467 |
+
hereafter acquired, that would be infringed by some manner, permitted
|
| 468 |
+
by this License, of making, using, or selling its contributor version,
|
| 469 |
+
but do not include claims that would be infringed only as a
|
| 470 |
+
consequence of further modification of the contributor version. For
|
| 471 |
+
purposes of this definition, "control" includes the right to grant
|
| 472 |
+
patent sublicenses in a manner consistent with the requirements of
|
| 473 |
+
this License.
|
| 474 |
+
|
| 475 |
+
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
| 476 |
+
patent license under the contributor's essential patent claims, to
|
| 477 |
+
make, use, sell, offer for sale, import and otherwise run, modify and
|
| 478 |
+
propagate the contents of its contributor version.
|
| 479 |
+
|
| 480 |
+
In the following three paragraphs, a "patent license" is any express
|
| 481 |
+
agreement or commitment, however denominated, not to enforce a patent
|
| 482 |
+
(such as an express permission to practice a patent or covenant not to
|
| 483 |
+
sue for patent infringement). To "grant" such a patent license to a
|
| 484 |
+
party means to make such an agreement or commitment not to enforce a
|
| 485 |
+
patent against the party.
|
| 486 |
+
|
| 487 |
+
If you convey a covered work, knowingly relying on a patent license,
|
| 488 |
+
and the Corresponding Source of the work is not available for anyone
|
| 489 |
+
to copy, free of charge and under the terms of this License, through a
|
| 490 |
+
publicly available network server or other readily accessible means,
|
| 491 |
+
then you must either (1) cause the Corresponding Source to be so
|
| 492 |
+
available, or (2) arrange to deprive yourself of the benefit of the
|
| 493 |
+
patent license for this particular work, or (3) arrange, in a manner
|
| 494 |
+
consistent with the requirements of this License, to extend the patent
|
| 495 |
+
license to downstream recipients. "Knowingly relying" means you have
|
| 496 |
+
actual knowledge that, but for the patent license, your conveying the
|
| 497 |
+
covered work in a country, or your recipient's use of the covered work
|
| 498 |
+
in a country, would infringe one or more identifiable patents in that
|
| 499 |
+
country that you have reason to believe are valid.
|
| 500 |
+
|
| 501 |
+
If, pursuant to or in connection with a single transaction or
|
| 502 |
+
arrangement, you convey, or propagate by procuring conveyance of, a
|
| 503 |
+
covered work, and grant a patent license to some of the parties
|
| 504 |
+
receiving the covered work authorizing them to use, propagate, modify
|
| 505 |
+
or convey a specific copy of the covered work, then the patent license
|
| 506 |
+
you grant is automatically extended to all recipients of the covered
|
| 507 |
+
work and works based on it.
|
| 508 |
+
|
| 509 |
+
A patent license is "discriminatory" if it does not include within
|
| 510 |
+
the scope of its coverage, prohibits the exercise of, or is
|
| 511 |
+
conditioned on the non-exercise of one or more of the rights that are
|
| 512 |
+
specifically granted under this License. You may not convey a covered
|
| 513 |
+
work if you are a party to an arrangement with a third party that is
|
| 514 |
+
in the business of distributing software, under which you make payment
|
| 515 |
+
to the third party based on the extent of your activity of conveying
|
| 516 |
+
the work, and under which the third party grants, to any of the
|
| 517 |
+
parties who would receive the covered work from you, a discriminatory
|
| 518 |
+
patent license (a) in connection with copies of the covered work
|
| 519 |
+
conveyed by you (or copies made from those copies), or (b) primarily
|
| 520 |
+
for and in connection with specific products or compilations that
|
| 521 |
+
contain the covered work, unless you entered into that arrangement,
|
| 522 |
+
or that patent license was granted, prior to 28 March 2007.
|
| 523 |
+
|
| 524 |
+
Nothing in this License shall be construed as excluding or limiting
|
| 525 |
+
any implied license or other defenses to infringement that may
|
| 526 |
+
otherwise be available to you under applicable patent law.
|
| 527 |
+
|
| 528 |
+
12. No Surrender of Others' Freedom.
|
| 529 |
+
|
| 530 |
+
If conditions are imposed on you (whether by court order, agreement or
|
| 531 |
+
otherwise) that contradict the conditions of this License, they do not
|
| 532 |
+
excuse you from the conditions of this License. If you cannot convey a
|
| 533 |
+
covered work so as to satisfy simultaneously your obligations under this
|
| 534 |
+
License and any other pertinent obligations, then as a consequence you may
|
| 535 |
+
not convey it at all. For example, if you agree to terms that obligate you
|
| 536 |
+
to collect a royalty for further conveying from those to whom you convey
|
| 537 |
+
the Program, the only way you could satisfy both those terms and this
|
| 538 |
+
License would be to refrain entirely from conveying the Program.
|
| 539 |
+
|
| 540 |
+
13. Remote Network Interaction; Use with the GNU General Public License.
|
| 541 |
+
|
| 542 |
+
Notwithstanding any other provision of this License, if you modify the
|
| 543 |
+
Program, your modified version must prominently offer all users
|
| 544 |
+
interacting with it remotely through a computer network (if your version
|
| 545 |
+
supports such interaction) an opportunity to receive the Corresponding
|
| 546 |
+
Source of your version by providing access to the Corresponding Source
|
| 547 |
+
from a network server at no charge, through some standard or customary
|
| 548 |
+
means of facilitating copying of software. This Corresponding Source
|
| 549 |
+
shall include the Corresponding Source for any work covered by version 3
|
| 550 |
+
of the GNU General Public License that is incorporated pursuant to the
|
| 551 |
+
following paragraph.
|
| 552 |
+
|
| 553 |
+
Notwithstanding any other provision of this License, you have
|
| 554 |
+
permission to link or combine any covered work with a work licensed
|
| 555 |
+
under version 3 of the GNU General Public License into a single
|
| 556 |
+
combined work, and to convey the resulting work. The terms of this
|
| 557 |
+
License will continue to apply to the part which is the covered work,
|
| 558 |
+
but the work with which it is combined will remain governed by version
|
| 559 |
+
3 of the GNU General Public License.
|
| 560 |
+
|
| 561 |
+
14. Revised Versions of this License.
|
| 562 |
+
|
| 563 |
+
The Free Software Foundation may publish revised and/or new versions of
|
| 564 |
+
the GNU Affero General Public License from time to time. Such new versions
|
| 565 |
+
will be similar in spirit to the present version, but may differ in detail to
|
| 566 |
+
address new problems or concerns.
|
| 567 |
+
|
| 568 |
+
Each version is given a distinguishing version number. If the
|
| 569 |
+
Program specifies that a certain numbered version of the GNU Affero General
|
| 570 |
+
Public License "or any later version" applies to it, you have the
|
| 571 |
+
option of following the terms and conditions either of that numbered
|
| 572 |
+
version or of any later version published by the Free Software
|
| 573 |
+
Foundation. If the Program does not specify a version number of the
|
| 574 |
+
GNU Affero General Public License, you may choose any version ever published
|
| 575 |
+
by the Free Software Foundation.
|
| 576 |
+
|
| 577 |
+
If the Program specifies that a proxy can decide which future
|
| 578 |
+
versions of the GNU Affero General Public License can be used, that proxy's
|
| 579 |
+
public statement of acceptance of a version permanently authorizes you
|
| 580 |
+
to choose that version for the Program.
|
| 581 |
+
|
| 582 |
+
Later license versions may give you additional or different
|
| 583 |
+
permissions. However, no additional obligations are imposed on any
|
| 584 |
+
author or copyright holder as a result of your choosing to follow a
|
| 585 |
+
later version.
|
| 586 |
+
|
| 587 |
+
15. Disclaimer of Warranty.
|
| 588 |
+
|
| 589 |
+
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
| 590 |
+
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
| 591 |
+
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
| 592 |
+
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
| 593 |
+
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
| 594 |
+
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
| 595 |
+
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
| 596 |
+
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
| 597 |
+
|
| 598 |
+
16. Limitation of Liability.
|
| 599 |
+
|
| 600 |
+
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
| 601 |
+
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
| 602 |
+
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
| 603 |
+
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
| 604 |
+
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
|
| 605 |
+
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
|
| 606 |
+
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
| 607 |
+
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
| 608 |
+
SUCH DAMAGES.
|
| 609 |
+
|
| 610 |
+
17. Interpretation of Sections 15 and 16.
|
| 611 |
+
|
| 612 |
+
If the disclaimer of warranty and limitation of liability provided
|
| 613 |
+
above cannot be given local legal effect according to their terms,
|
| 614 |
+
reviewing courts shall apply local law that most closely approximates
|
| 615 |
+
an absolute waiver of all civil liability in connection with the
|
| 616 |
+
Program, unless a warranty or assumption of liability accompanies a
|
| 617 |
+
copy of the Program in return for a fee.
|
| 618 |
+
|
| 619 |
+
END OF TERMS AND CONDITIONS
|
| 620 |
+
|
| 621 |
+
How to Apply These Terms to Your New Programs
|
| 622 |
+
|
| 623 |
+
If you develop a new program, and you want it to be of the greatest
|
| 624 |
+
possible use to the public, the best way to achieve this is to make it
|
| 625 |
+
free software which everyone can redistribute and change under these terms.
|
| 626 |
+
|
| 627 |
+
To do so, attach the following notices to the program. It is safest
|
| 628 |
+
to attach them to the start of each source file to most effectively
|
| 629 |
+
state the exclusion of warranty; and each file should have at least
|
| 630 |
+
the "copyright" line and a pointer to where the full notice is found.
|
| 631 |
+
|
| 632 |
+
<one line to give the program's name and a brief idea of what it does.>
|
| 633 |
+
Copyright (C) <year> <name of author>
|
| 634 |
+
|
| 635 |
+
This program is free software: you can redistribute it and/or modify
|
| 636 |
+
it under the terms of the GNU Affero General Public License as published by
|
| 637 |
+
the Free Software Foundation, either version 3 of the License, or
|
| 638 |
+
(at your option) any later version.
|
| 639 |
+
|
| 640 |
+
This program is distributed in the hope that it will be useful,
|
| 641 |
+
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
| 642 |
+
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
| 643 |
+
GNU Affero General Public License for more details.
|
| 644 |
+
|
| 645 |
+
You should have received a copy of the GNU Affero General Public License
|
| 646 |
+
along with this program. If not, see <https://www.gnu.org/licenses/>.
|
| 647 |
+
|
| 648 |
+
Also add information on how to contact you by electronic and paper mail.
|
| 649 |
+
|
| 650 |
+
If your software can interact with users remotely through a computer
|
| 651 |
+
network, you should also make sure that it provides a way for users to
|
| 652 |
+
get its source. For example, if your program is a web application, its
|
| 653 |
+
interface could display a "Source" link that leads users to an archive
|
| 654 |
+
of the code. There are many ways you could offer source, and different
|
| 655 |
+
solutions will be better for different programs; see section 13 for the
|
| 656 |
+
specific requirements.
|
| 657 |
+
|
| 658 |
+
You should also get your employer (if you work as a programmer) or school,
|
| 659 |
+
if any, to sign a "copyright disclaimer" for the program, if necessary.
|
| 660 |
+
For more information on this, and how to apply and follow the GNU AGPL, see
|
| 661 |
+
<https://www.gnu.org/licenses/>.
|
yolov10/README.md
ADDED
|
@@ -0,0 +1,181 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# [YOLOv10: Real-Time End-to-End Object Detection](https://arxiv.org/abs/2405.14458)
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
Official PyTorch implementation of **YOLOv10**.
|
| 5 |
+
|
| 6 |
+
<p align="center">
|
| 7 |
+
<img src="figures/latency.svg" width=48%>
|
| 8 |
+
<img src="figures/params.svg" width=48%> <br>
|
| 9 |
+
Comparisons with others in terms of latency-accuracy (left) and size-accuracy (right) trade-offs.
|
| 10 |
+
</p>
|
| 11 |
+
|
| 12 |
+
[YOLOv10: Real-Time End-to-End Object Detection](https://arxiv.org/abs/2405.14458).\
|
| 13 |
+
Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, and Guiguang Ding\
|
| 14 |
+
[](https://arxiv.org/abs/2405.14458) <a href="https://colab.research.google.com/github/roboflow-ai/notebooks/blob/main/notebooks/train-yolov10-object-detection-on-custom-dataset.ipynb#scrollTo=SaKTSzSWnG7s"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> [](https://huggingface.co/collections/jameslahm/yolov10-665b0d90b0b5bb85129460c2) [](https://huggingface.co/spaces/jameslahm/YOLOv10) [](https://huggingface.co/spaces/kadirnar/Yolov10) [](https://huggingface.co/spaces/Xenova/yolov10-web) [](https://learnopencv.com/yolov10/) [](https://openbayes.com/console/public/tutorials/im29uYrnIoz)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
<details>
|
| 18 |
+
<summary>
|
| 19 |
+
<font size="+1">Abstract</font>
|
| 20 |
+
</summary>
|
| 21 |
+
Over the past years, YOLOs have emerged as the predominant paradigm in the field of real-time object detection owing to their effective balance between computational cost and detection performance. Researchers have explored the architectural designs, optimization objectives, data augmentation strategies, and others for YOLOs, achieving notable progress. However, the reliance on the non-maximum suppression (NMS) for post-processing hampers the end-to-end deployment of YOLOs and adversely impacts the inference latency. Besides, the design of various components in YOLOs lacks the comprehensive and thorough inspection, resulting in noticeable computational redundancy and limiting the model's capability. It renders the suboptimal efficiency, along with considerable potential for performance improvements. In this work, we aim to further advance the performance-efficiency boundary of YOLOs from both the post-processing and the model architecture. To this end, we first present the consistent dual assignments for NMS-free training of YOLOs, which brings the competitive performance and low inference latency simultaneously. Moreover, we introduce the holistic efficiency-accuracy driven model design strategy for YOLOs. We comprehensively optimize various components of YOLOs from both the efficiency and accuracy perspectives, which greatly reduces the computational overhead and enhances the capability. The outcome of our effort is a new generation of YOLO series for real-time end-to-end object detection, dubbed YOLOv10. Extensive experiments show that YOLOv10 achieves the state-of-the-art performance and efficiency across various model scales. For example, our YOLOv10-S is 1.8$\times$ faster than RT-DETR-R18 under the similar AP on COCO, meanwhile enjoying 2.8$\times$ smaller number of parameters and FLOPs. Compared with YOLOv9-C, YOLOv10-B has 46\% less latency and 25\% fewer parameters for the same performance.
|
| 22 |
+
</details>
|
| 23 |
+
|
| 24 |
+
## Notes
|
| 25 |
+
- 2024/05/31: Please use the [exported format](https://github.com/THU-MIG/yolov10?tab=readme-ov-file#export) for benchmark. In the non-exported format, e.g., pytorch, the speed of YOLOv10 is biased because the unnecessary `cv2` and `cv3` operations in the `v10Detect` are executed during inference.
|
| 26 |
+
- 2024/05/30: We provide [some clarifications and suggestions](https://github.com/THU-MIG/yolov10/issues/136) for detecting smaller objects or objects in the distance with YOLOv10. Thanks to [SkalskiP](https://github.com/SkalskiP)!
|
| 27 |
+
- 2024/05/27: We have updated the [checkpoints](https://huggingface.co/collections/jameslahm/yolov10-665b0d90b0b5bb85129460c2) with class names, for ease of use.
|
| 28 |
+
|
| 29 |
+
## UPDATES 🔥
|
| 30 |
+
- 2024/06/01: Thanks to [ErlanggaYudiPradana](https://github.com/rlggyp) for the integration with [C++ | OpenVINO | OpenCV](https://github.com/rlggyp/YOLOv10-OpenVINO-CPP-Inference)
|
| 31 |
+
- 2024/06/01: Thanks to [NielsRogge](https://github.com/NielsRogge) and [AK](https://x.com/_akhaliq) for hosting the models on the HuggingFace Hub!
|
| 32 |
+
- 2024/05/31: Build [yolov10-jetson](https://github.com/Seeed-Projects/jetson-examples/blob/main/reComputer/scripts/yolov10/README.md) docker image by [youjiang](https://github.com/yuyoujiang)!
|
| 33 |
+
- 2024/05/31: Thanks to [mohamedsamirx](https://github.com/mohamedsamirx) for the integration with [BoTSORT, DeepOCSORT, OCSORT, HybridSORT, ByteTrack, StrongSORT using BoxMOT library](https://colab.research.google.com/drive/1-QV2TNfqaMsh14w5VxieEyanugVBG14V?usp=sharing)!
|
| 34 |
+
- 2024/05/31: Thanks to [kaylorchen](https://github.com/kaylorchen) for the integration with [rk3588](https://github.com/kaylorchen/rk3588-yolo-demo)!
|
| 35 |
+
- 2024/05/30: Thanks to [eaidova](https://github.com/eaidova) for the integration with [OpenVINO™](https://github.com/openvinotoolkit/openvino_notebooks/blob/0ba3c0211bcd49aa860369feddffdf7273a73c64/notebooks/yolov10-optimization/yolov10-optimization.ipynb)!
|
| 36 |
+
- 2024/05/29: Add the gradio demo for running the models locally. Thanks to [AK](https://x.com/_akhaliq)!
|
| 37 |
+
- 2024/05/27: Thanks to [sujanshresstha](sujanshresstha) for the integration with [DeepSORT](https://github.com/sujanshresstha/YOLOv10_DeepSORT.git)!
|
| 38 |
+
- 2024/05/26: Thanks to [CVHub520](https://github.com/CVHub520) for the integration into [X-AnyLabeling](https://github.com/CVHub520/X-AnyLabeling)!
|
| 39 |
+
- 2024/05/26: Thanks to [DanielSarmiento04](https://github.com/DanielSarmiento04) for integrate in [c++ | ONNX | OPENCV](https://github.com/DanielSarmiento04/yolov10cpp)!
|
| 40 |
+
- 2024/05/25: Add [Transformers.js demo](https://huggingface.co/spaces/Xenova/yolov10-web) and onnx weights(yolov10[n](https://huggingface.co/onnx-community/yolov10n)/[s](https://huggingface.co/onnx-community/yolov10s)/[m](https://huggingface.co/onnx-community/yolov10m)/[b](https://huggingface.co/onnx-community/yolov10b)/[l](https://huggingface.co/onnx-community/yolov10l)/[x](https://huggingface.co/onnx-community/yolov10x)). Thanks to [xenova](https://github.com/xenova)!
|
| 41 |
+
- 2024/05/25: Add [colab demo](https://colab.research.google.com/github/roboflow-ai/notebooks/blob/main/notebooks/train-yolov10-object-detection-on-custom-dataset.ipynb#scrollTo=SaKTSzSWnG7s), [HuggingFace Demo](https://huggingface.co/spaces/kadirnar/Yolov10), and [HuggingFace Model Page](https://huggingface.co/kadirnar/Yolov10). Thanks to [SkalskiP](https://github.com/SkalskiP) and [kadirnar](https://github.com/kadirnar)!
|
| 42 |
+
|
| 43 |
+
## Performance
|
| 44 |
+
COCO
|
| 45 |
+
|
| 46 |
+
| Model | Test Size | #Params | FLOPs | AP<sup>val</sup> | Latency |
|
| 47 |
+
|:---------------|:----:|:---:|:--:|:--:|:--:|
|
| 48 |
+
| [YOLOv10-N](https://huggingface.co/jameslahm/yolov10n) | 640 | 2.3M | 6.7G | 38.5% | 1.84ms |
|
| 49 |
+
| [YOLOv10-S](https://huggingface.co/jameslahm/yolov10s) | 640 | 7.2M | 21.6G | 46.3% | 2.49ms |
|
| 50 |
+
| [YOLOv10-M](https://huggingface.co/jameslahm/yolov10m) | 640 | 15.4M | 59.1G | 51.1% | 4.74ms |
|
| 51 |
+
| [YOLOv10-B](https://huggingface.co/jameslahm/yolov10b) | 640 | 19.1M | 92.0G | 52.5% | 5.74ms |
|
| 52 |
+
| [YOLOv10-L](https://huggingface.co/jameslahm/yolov10l) | 640 | 24.4M | 120.3G | 53.2% | 7.28ms |
|
| 53 |
+
| [YOLOv10-X](https://huggingface.co/jameslahm/yolov10x) | 640 | 29.5M | 160.4G | 54.4% | 10.70ms |
|
| 54 |
+
|
| 55 |
+
## Installation
|
| 56 |
+
`conda` virtual environment is recommended.
|
| 57 |
+
```
|
| 58 |
+
conda create -n yolov10 python=3.9
|
| 59 |
+
conda activate yolov10
|
| 60 |
+
pip install -r requirements.txt
|
| 61 |
+
pip install -e .
|
| 62 |
+
```
|
| 63 |
+
## Demo
|
| 64 |
+
```
|
| 65 |
+
python app.py
|
| 66 |
+
# Please visit http://127.0.0.1:7860
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
## Validation
|
| 70 |
+
[`yolov10n`](https://huggingface.co/jameslahm/yolov10n) [`yolov10s`](https://huggingface.co/jameslahm/yolov10s) [`yolov10m`](https://huggingface.co/jameslahm/yolov10m) [`yolov10b`](https://huggingface.co/jameslahm/yolov10b) [`yolov10l`](https://huggingface.co/jameslahm/yolov10l) [`yolov10x`](https://huggingface.co/jameslahm/yolov10x)
|
| 71 |
+
```
|
| 72 |
+
yolo val model=jameslahm/yolov10{n/s/m/b/l/x} data=coco.yaml batch=256
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
Or
|
| 76 |
+
```python
|
| 77 |
+
from ultralytics import YOLOv10
|
| 78 |
+
|
| 79 |
+
model = YOLOv10.from_pretrained('jameslahm/yolov10{n/s/m/b/l/x}')
|
| 80 |
+
# or
|
| 81 |
+
# wget https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10{n/s/m/b/l/x}.pt
|
| 82 |
+
model = YOLOv10('yolov10{n/s/m/b/l/x}.pt')
|
| 83 |
+
|
| 84 |
+
model.val(data='coco.yaml', batch=256)
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
## Training
|
| 89 |
+
```
|
| 90 |
+
yolo detect train data=coco.yaml model=yolov10n/s/m/b/l/x.yaml epochs=500 batch=256 imgsz=640 device=0,1,2,3,4,5,6,7
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
Or
|
| 94 |
+
```python
|
| 95 |
+
from ultralytics import YOLOv10
|
| 96 |
+
|
| 97 |
+
model = YOLOv10()
|
| 98 |
+
# If you want to finetune the model with pretrained weights, you could load the
|
| 99 |
+
# pretrained weights like below
|
| 100 |
+
# model = YOLOv10.from_pretrained('jameslahm/yolov10{n/s/m/b/l/x}')
|
| 101 |
+
# or
|
| 102 |
+
# wget https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10{n/s/m/b/l/x}.pt
|
| 103 |
+
# model = YOLOv10('yolov10{n/s/m/b/l/x}.pt')
|
| 104 |
+
|
| 105 |
+
model.train(data='coco.yaml', epochs=500, batch=256, imgsz=640)
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
## Push to hub to 🤗
|
| 109 |
+
|
| 110 |
+
Optionally, you can push your fine-tuned model to the [Hugging Face hub](https://huggingface.co/) as a public or private model:
|
| 111 |
+
|
| 112 |
+
```python
|
| 113 |
+
# let's say you have fine-tuned a model for crop detection
|
| 114 |
+
model.push_to_hub("<your-hf-username-or-organization/yolov10-finetuned-crop-detection")
|
| 115 |
+
|
| 116 |
+
# you can also pass `private=True` if you don't want everyone to see your model
|
| 117 |
+
model.push_to_hub("<your-hf-username-or-organization/yolov10-finetuned-crop-detection", private=True)
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
## Prediction
|
| 121 |
+
Note that a smaller confidence threshold can be set to detect smaller objects or objects in the distance. Please refer to [here](https://github.com/THU-MIG/yolov10/issues/136) for details.
|
| 122 |
+
```
|
| 123 |
+
yolo predict model=jameslahm/yolov10{n/s/m/b/l/x}
|
| 124 |
+
```
|
| 125 |
+
|
| 126 |
+
Or
|
| 127 |
+
```python
|
| 128 |
+
from ultralytics import YOLOv10
|
| 129 |
+
|
| 130 |
+
model = YOLOv10.from_pretrained('jameslahm/yolov10{n/s/m/b/l/x}')
|
| 131 |
+
# or
|
| 132 |
+
# wget https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10{n/s/m/b/l/x}.pt
|
| 133 |
+
model = YOLOv10('yolov10{n/s/m/b/l/x}.pt')
|
| 134 |
+
|
| 135 |
+
model.predict()
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
## Export
|
| 139 |
+
```
|
| 140 |
+
# End-to-End ONNX
|
| 141 |
+
yolo export model=jameslahm/yolov10{n/s/m/b/l/x} format=onnx opset=13 simplify
|
| 142 |
+
# Predict with ONNX
|
| 143 |
+
yolo predict model=yolov10n/s/m/b/l/x.onnx
|
| 144 |
+
|
| 145 |
+
# End-to-End TensorRT
|
| 146 |
+
yolo export model=jameslahm/yolov10{n/s/m/b/l/x} format=engine half=True simplify opset=13 workspace=16
|
| 147 |
+
# or
|
| 148 |
+
trtexec --onnx=yolov10n/s/m/b/l/x.onnx --saveEngine=yolov10n/s/m/b/l/x.engine --fp16
|
| 149 |
+
# Predict with TensorRT
|
| 150 |
+
yolo predict model=yolov10n/s/m/b/l/x.engine
|
| 151 |
+
```
|
| 152 |
+
|
| 153 |
+
Or
|
| 154 |
+
```python
|
| 155 |
+
from ultralytics import YOLOv10
|
| 156 |
+
|
| 157 |
+
model = YOLOv10.from_pretrained('jameslahm/yolov10{n/s/m/b/l/x}')
|
| 158 |
+
# or
|
| 159 |
+
# wget https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10{n/s/m/b/l/x}.pt
|
| 160 |
+
model = YOLOv10('yolov10{n/s/m/b/l/x}.pt')
|
| 161 |
+
|
| 162 |
+
model.export(...)
|
| 163 |
+
```
|
| 164 |
+
|
| 165 |
+
## Acknowledgement
|
| 166 |
+
|
| 167 |
+
The code base is built with [ultralytics](https://github.com/ultralytics/ultralytics) and [RT-DETR](https://github.com/lyuwenyu/RT-DETR).
|
| 168 |
+
|
| 169 |
+
Thanks for the great implementations!
|
| 170 |
+
|
| 171 |
+
## Citation
|
| 172 |
+
|
| 173 |
+
If our code or models help your work, please cite our paper:
|
| 174 |
+
```BibTeX
|
| 175 |
+
@article{wang2024yolov10,
|
| 176 |
+
title={YOLOv10: Real-Time End-to-End Object Detection},
|
| 177 |
+
author={Wang, Ao and Chen, Hui and Liu, Lihao and Chen, Kai and Lin, Zijia and Han, Jungong and Ding, Guiguang},
|
| 178 |
+
journal={arXiv preprint arXiv:2405.14458},
|
| 179 |
+
year={2024}
|
| 180 |
+
}
|
| 181 |
+
```
|
yolov10/app.py
ADDED
|
@@ -0,0 +1,162 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import cv2
|
| 3 |
+
import tempfile
|
| 4 |
+
from ultralytics import YOLOv10
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def yolov10_inference(image, video, model_id, image_size, conf_threshold):
|
| 8 |
+
#model = YOLOv10.from_pretrained(f'jameslahm/{model_id}')
|
| 9 |
+
model = YOLOv10("/ddn/imu_tch1/project/yolov10/yolov10-1.0/runs/detect/train9/weights/best.pt")
|
| 10 |
+
if image:
|
| 11 |
+
results = model.predict(source=image, imgsz=image_size, conf=conf_threshold)
|
| 12 |
+
annotated_image = results[0].plot()
|
| 13 |
+
return annotated_image[:, :, ::-1], None
|
| 14 |
+
else:
|
| 15 |
+
video_path = tempfile.mktemp(suffix=".webm")
|
| 16 |
+
with open(video_path, "wb") as f:
|
| 17 |
+
with open(video, "rb") as g:
|
| 18 |
+
f.write(g.read())
|
| 19 |
+
|
| 20 |
+
cap = cv2.VideoCapture(video_path)
|
| 21 |
+
fps = cap.get(cv2.CAP_PROP_FPS)
|
| 22 |
+
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
|
| 23 |
+
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
|
| 24 |
+
|
| 25 |
+
output_video_path = tempfile.mktemp(suffix=".webm")
|
| 26 |
+
out = cv2.VideoWriter(output_video_path, cv2.VideoWriter_fourcc(*'vp80'), fps, (frame_width, frame_height))
|
| 27 |
+
|
| 28 |
+
while cap.isOpened():
|
| 29 |
+
ret, frame = cap.read()
|
| 30 |
+
if not ret:
|
| 31 |
+
break
|
| 32 |
+
|
| 33 |
+
results = model.predict(source=frame, imgsz=image_size, conf=conf_threshold)
|
| 34 |
+
annotated_frame = results[0].plot()
|
| 35 |
+
out.write(annotated_frame)
|
| 36 |
+
|
| 37 |
+
cap.release()
|
| 38 |
+
out.release()
|
| 39 |
+
|
| 40 |
+
return None, output_video_path
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def yolov10_inference_for_examples(image, model_path, image_size, conf_threshold):
|
| 44 |
+
annotated_image, _ = yolov10_inference(image, None, model_path, image_size, conf_threshold)
|
| 45 |
+
return annotated_image
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def app():
|
| 49 |
+
with gr.Blocks():
|
| 50 |
+
with gr.Row():
|
| 51 |
+
with gr.Column():
|
| 52 |
+
image = gr.Image(type="pil", label="Image", visible=True)
|
| 53 |
+
video = gr.Video(label="Video", visible=False)
|
| 54 |
+
input_type = gr.Radio(
|
| 55 |
+
choices=["Image", "Video"],
|
| 56 |
+
value="Image",
|
| 57 |
+
label="Input Type",
|
| 58 |
+
)
|
| 59 |
+
model_id = gr.Dropdown(
|
| 60 |
+
label="Model",
|
| 61 |
+
choices=[
|
| 62 |
+
"yolov10n",
|
| 63 |
+
"yolov10s",
|
| 64 |
+
"yolov10m",
|
| 65 |
+
"yolov10b",
|
| 66 |
+
"yolov10l",
|
| 67 |
+
"yolov10x",
|
| 68 |
+
],
|
| 69 |
+
value="yolov10m",
|
| 70 |
+
)
|
| 71 |
+
image_size = gr.Slider(
|
| 72 |
+
label="Image Size",
|
| 73 |
+
minimum=320,
|
| 74 |
+
maximum=1280,
|
| 75 |
+
step=32,
|
| 76 |
+
value=640,
|
| 77 |
+
)
|
| 78 |
+
conf_threshold = gr.Slider(
|
| 79 |
+
label="Confidence Threshold",
|
| 80 |
+
minimum=0.0,
|
| 81 |
+
maximum=1.0,
|
| 82 |
+
step=0.05,
|
| 83 |
+
value=0.25,
|
| 84 |
+
)
|
| 85 |
+
yolov10_infer = gr.Button(value="Detect Objects")
|
| 86 |
+
|
| 87 |
+
with gr.Column():
|
| 88 |
+
output_image = gr.Image(type="numpy", label="Annotated Image", visible=True)
|
| 89 |
+
output_video = gr.Video(label="Annotated Video", visible=False)
|
| 90 |
+
|
| 91 |
+
def update_visibility(input_type):
|
| 92 |
+
image = gr.update(visible=True) if input_type == "Image" else gr.update(visible=False)
|
| 93 |
+
video = gr.update(visible=False) if input_type == "Image" else gr.update(visible=True)
|
| 94 |
+
output_image = gr.update(visible=True) if input_type == "Image" else gr.update(visible=False)
|
| 95 |
+
output_video = gr.update(visible=False) if input_type == "Image" else gr.update(visible=True)
|
| 96 |
+
|
| 97 |
+
return image, video, output_image, output_video
|
| 98 |
+
|
| 99 |
+
input_type.change(
|
| 100 |
+
fn=update_visibility,
|
| 101 |
+
inputs=[input_type],
|
| 102 |
+
outputs=[image, video, output_image, output_video],
|
| 103 |
+
)
|
| 104 |
+
|
| 105 |
+
def run_inference(image, video, model_id, image_size, conf_threshold, input_type):
|
| 106 |
+
if input_type == "Image":
|
| 107 |
+
return yolov10_inference(image, None, model_id, image_size, conf_threshold)
|
| 108 |
+
else:
|
| 109 |
+
return yolov10_inference(None, video, model_id, image_size, conf_threshold)
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
yolov10_infer.click(
|
| 113 |
+
fn=run_inference,
|
| 114 |
+
inputs=[image, video, model_id, image_size, conf_threshold, input_type],
|
| 115 |
+
outputs=[output_image, output_video],
|
| 116 |
+
)
|
| 117 |
+
|
| 118 |
+
gr.Examples(
|
| 119 |
+
examples=[
|
| 120 |
+
[
|
| 121 |
+
"ultralytics/assets/bus.jpg",
|
| 122 |
+
"yolov10s",
|
| 123 |
+
640,
|
| 124 |
+
0.25,
|
| 125 |
+
],
|
| 126 |
+
[
|
| 127 |
+
"ultralytics/assets/zidane.jpg",
|
| 128 |
+
"yolov10s",
|
| 129 |
+
640,
|
| 130 |
+
0.25,
|
| 131 |
+
],
|
| 132 |
+
],
|
| 133 |
+
fn=yolov10_inference_for_examples,
|
| 134 |
+
inputs=[
|
| 135 |
+
image,
|
| 136 |
+
model_id,
|
| 137 |
+
image_size,
|
| 138 |
+
conf_threshold,
|
| 139 |
+
],
|
| 140 |
+
outputs=[output_image],
|
| 141 |
+
cache_examples='lazy',
|
| 142 |
+
)
|
| 143 |
+
|
| 144 |
+
gradio_app = gr.Blocks()
|
| 145 |
+
with gradio_app:
|
| 146 |
+
gr.HTML(
|
| 147 |
+
"""
|
| 148 |
+
<h1 style='text-align: center'>
|
| 149 |
+
YOLOv10: Real-Time End-to-End Object Detection
|
| 150 |
+
</h1>
|
| 151 |
+
""")
|
| 152 |
+
gr.HTML(
|
| 153 |
+
"""
|
| 154 |
+
<h3 style='text-align: center'>
|
| 155 |
+
<a href='https://arxiv.org/abs/2405.14458' target='_blank'>arXiv</a> | <a href='https://github.com/THU-MIG/yolov10' target='_blank'>github</a>
|
| 156 |
+
</h3>
|
| 157 |
+
""")
|
| 158 |
+
with gr.Row():
|
| 159 |
+
with gr.Column():
|
| 160 |
+
app()
|
| 161 |
+
if __name__ == '__main__':
|
| 162 |
+
gradio_app.launch()
|
yolov10/docker/Dockerfile
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
| 2 |
+
# Builds ultralytics/ultralytics:latest image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
|
| 3 |
+
# Image is CUDA-optimized for YOLOv8 single/multi-GPU training and inference
|
| 4 |
+
|
| 5 |
+
# Start FROM PyTorch image https://hub.docker.com/r/pytorch/pytorch or nvcr.io/nvidia/pytorch:23.03-py3
|
| 6 |
+
FROM pytorch/pytorch:2.2.0-cuda12.1-cudnn8-runtime
|
| 7 |
+
RUN pip install --no-cache nvidia-tensorrt --index-url https://pypi.ngc.nvidia.com
|
| 8 |
+
|
| 9 |
+
# Downloads to user config dir
|
| 10 |
+
ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
|
| 11 |
+
https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
|
| 12 |
+
/root/.config/Ultralytics/
|
| 13 |
+
|
| 14 |
+
# Install linux packages
|
| 15 |
+
# g++ required to build 'tflite_support' and 'lap' packages, libusb-1.0-0 required for 'tflite_support' package
|
| 16 |
+
RUN apt update \
|
| 17 |
+
&& apt install --no-install-recommends -y gcc git zip curl htop libgl1 libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
|
| 18 |
+
|
| 19 |
+
# Security updates
|
| 20 |
+
# https://security.snyk.io/vuln/SNYK-UBUNTU1804-OPENSSL-3314796
|
| 21 |
+
RUN apt upgrade --no-install-recommends -y openssl tar
|
| 22 |
+
|
| 23 |
+
# Create working directory
|
| 24 |
+
WORKDIR /usr/src/ultralytics
|
| 25 |
+
|
| 26 |
+
# Copy contents
|
| 27 |
+
# COPY . /usr/src/ultralytics # git permission issues inside container
|
| 28 |
+
RUN git clone https://github.com/ultralytics/ultralytics -b main /usr/src/ultralytics
|
| 29 |
+
ADD https://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8n.pt /usr/src/ultralytics/
|
| 30 |
+
|
| 31 |
+
# Install pip packages
|
| 32 |
+
RUN python3 -m pip install --upgrade pip wheel
|
| 33 |
+
RUN pip install --no-cache -e ".[export]" albumentations comet pycocotools
|
| 34 |
+
|
| 35 |
+
# Run exports to AutoInstall packages
|
| 36 |
+
# Edge TPU export fails the first time so is run twice here
|
| 37 |
+
RUN yolo export model=tmp/yolov8n.pt format=edgetpu imgsz=32 || yolo export model=tmp/yolov8n.pt format=edgetpu imgsz=32
|
| 38 |
+
RUN yolo export model=tmp/yolov8n.pt format=ncnn imgsz=32
|
| 39 |
+
# Requires <= Python 3.10, bug with paddlepaddle==2.5.0 https://github.com/PaddlePaddle/X2Paddle/issues/991
|
| 40 |
+
RUN pip install --no-cache paddlepaddle>=2.6.0 x2paddle
|
| 41 |
+
# Fix error: `np.bool` was a deprecated alias for the builtin `bool` segmentation error in Tests
|
| 42 |
+
RUN pip install --no-cache numpy==1.23.5
|
| 43 |
+
# Remove exported models
|
| 44 |
+
RUN rm -rf tmp
|
| 45 |
+
|
| 46 |
+
# Set environment variables
|
| 47 |
+
ENV OMP_NUM_THREADS=1
|
| 48 |
+
# Avoid DDP error "MKL_THREADING_LAYER=INTEL is incompatible with libgomp.so.1 library" https://github.com/pytorch/pytorch/issues/37377
|
| 49 |
+
ENV MKL_THREADING_LAYER=GNU
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
# Usage Examples -------------------------------------------------------------------------------------------------------
|
| 53 |
+
|
| 54 |
+
# Build and Push
|
| 55 |
+
# t=ultralytics/ultralytics:latest && sudo docker build -f docker/Dockerfile -t $t . && sudo docker push $t
|
| 56 |
+
|
| 57 |
+
# Pull and Run with access to all GPUs
|
| 58 |
+
# t=ultralytics/ultralytics:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all $t
|
| 59 |
+
|
| 60 |
+
# Pull and Run with access to GPUs 2 and 3 (inside container CUDA devices will appear as 0 and 1)
|
| 61 |
+
# t=ultralytics/ultralytics:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus '"device=2,3"' $t
|
| 62 |
+
|
| 63 |
+
# Pull and Run with local directory access
|
| 64 |
+
# t=ultralytics/ultralytics:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all -v "$(pwd)"/datasets:/usr/src/datasets $t
|
| 65 |
+
|
| 66 |
+
# Kill all
|
| 67 |
+
# sudo docker kill $(sudo docker ps -q)
|
| 68 |
+
|
| 69 |
+
# Kill all image-based
|
| 70 |
+
# sudo docker kill $(sudo docker ps -qa --filter ancestor=ultralytics/ultralytics:latest)
|
| 71 |
+
|
| 72 |
+
# DockerHub tag update
|
| 73 |
+
# t=ultralytics/ultralytics:latest tnew=ultralytics/ultralytics:v6.2 && sudo docker pull $t && sudo docker tag $t $tnew && sudo docker push $tnew
|
| 74 |
+
|
| 75 |
+
# Clean up
|
| 76 |
+
# sudo docker system prune -a --volumes
|
| 77 |
+
|
| 78 |
+
# Update Ubuntu drivers
|
| 79 |
+
# https://www.maketecheasier.com/install-nvidia-drivers-ubuntu/
|
| 80 |
+
|
| 81 |
+
# DDP test
|
| 82 |
+
# python -m torch.distributed.run --nproc_per_node 2 --master_port 1 train.py --epochs 3
|
| 83 |
+
|
| 84 |
+
# GCP VM from Image
|
| 85 |
+
# docker.io/ultralytics/ultralytics:latest
|
yolov10/docker/Dockerfile-arm64
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
| 2 |
+
# Builds ultralytics/ultralytics:latest-arm64 image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
|
| 3 |
+
# Image is aarch64-compatible for Apple M1, M2, M3, Raspberry Pi and other ARM architectures
|
| 4 |
+
|
| 5 |
+
# Start FROM Ubuntu image https://hub.docker.com/_/ubuntu with "FROM arm64v8/ubuntu:22.04" (deprecated)
|
| 6 |
+
# Start FROM Debian image for arm64v8 https://hub.docker.com/r/arm64v8/debian (new)
|
| 7 |
+
FROM arm64v8/debian:bookworm-slim
|
| 8 |
+
|
| 9 |
+
# Downloads to user config dir
|
| 10 |
+
ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
|
| 11 |
+
https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
|
| 12 |
+
/root/.config/Ultralytics/
|
| 13 |
+
|
| 14 |
+
# Install linux packages
|
| 15 |
+
# g++ required to build 'tflite_support' and 'lap' packages, libusb-1.0-0 required for 'tflite_support' package
|
| 16 |
+
# cmake and build-essential is needed to build onnxsim when exporting to tflite
|
| 17 |
+
RUN apt update \
|
| 18 |
+
&& apt install --no-install-recommends -y python3-pip git zip curl htop gcc libgl1 libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0 build-essential
|
| 19 |
+
|
| 20 |
+
# Create working directory
|
| 21 |
+
WORKDIR /usr/src/ultralytics
|
| 22 |
+
|
| 23 |
+
# Copy contents
|
| 24 |
+
# COPY . /usr/src/ultralytics # git permission issues inside container
|
| 25 |
+
RUN git clone https://github.com/ultralytics/ultralytics -b main /usr/src/ultralytics
|
| 26 |
+
ADD https://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8n.pt /usr/src/ultralytics/
|
| 27 |
+
|
| 28 |
+
# Remove python3.11/EXTERNALLY-MANAGED to avoid 'externally-managed-environment' issue, Debian 12 Bookworm error
|
| 29 |
+
RUN rm -rf /usr/lib/python3.11/EXTERNALLY-MANAGED
|
| 30 |
+
|
| 31 |
+
# Install pip packages
|
| 32 |
+
RUN python3 -m pip install --upgrade pip wheel
|
| 33 |
+
RUN pip install --no-cache -e ".[export]"
|
| 34 |
+
|
| 35 |
+
# Creates a symbolic link to make 'python' point to 'python3'
|
| 36 |
+
RUN ln -sf /usr/bin/python3 /usr/bin/python
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
# Usage Examples -------------------------------------------------------------------------------------------------------
|
| 40 |
+
|
| 41 |
+
# Build and Push
|
| 42 |
+
# t=ultralytics/ultralytics:latest-arm64 && sudo docker build --platform linux/arm64 -f docker/Dockerfile-arm64 -t $t . && sudo docker push $t
|
| 43 |
+
|
| 44 |
+
# Run
|
| 45 |
+
# t=ultralytics/ultralytics:latest-arm64 && sudo docker run -it --ipc=host $t
|
| 46 |
+
|
| 47 |
+
# Pull and Run
|
| 48 |
+
# t=ultralytics/ultralytics:latest-arm64 && sudo docker pull $t && sudo docker run -it --ipc=host $t
|
| 49 |
+
|
| 50 |
+
# Pull and Run with local volume mounted
|
| 51 |
+
# t=ultralytics/ultralytics:latest-arm64 && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/datasets:/usr/src/datasets $t
|
yolov10/docker/Dockerfile-conda
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
| 2 |
+
# Builds ultralytics/ultralytics:latest-conda image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
|
| 3 |
+
# Image is optimized for Ultralytics Anaconda (https://anaconda.org/conda-forge/ultralytics) installation and usage
|
| 4 |
+
|
| 5 |
+
# Start FROM miniconda3 image https://hub.docker.com/r/continuumio/miniconda3
|
| 6 |
+
FROM continuumio/miniconda3:latest
|
| 7 |
+
|
| 8 |
+
# Downloads to user config dir
|
| 9 |
+
ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
|
| 10 |
+
https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
|
| 11 |
+
/root/.config/Ultralytics/
|
| 12 |
+
|
| 13 |
+
# Install linux packages
|
| 14 |
+
RUN apt update \
|
| 15 |
+
&& apt install --no-install-recommends -y libgl1
|
| 16 |
+
|
| 17 |
+
# Copy contents
|
| 18 |
+
ADD https://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8n.pt .
|
| 19 |
+
|
| 20 |
+
# Install conda packages
|
| 21 |
+
# mkl required to fix 'OSError: libmkl_intel_lp64.so.2: cannot open shared object file: No such file or directory'
|
| 22 |
+
RUN conda config --set solver libmamba && \
|
| 23 |
+
conda install pytorch torchvision pytorch-cuda=11.8 -c pytorch -c nvidia && \
|
| 24 |
+
conda install -c conda-forge ultralytics mkl
|
| 25 |
+
# conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=11.8 ultralytics mkl
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
# Usage Examples -------------------------------------------------------------------------------------------------------
|
| 29 |
+
|
| 30 |
+
# Build and Push
|
| 31 |
+
# t=ultralytics/ultralytics:latest-conda && sudo docker build -f docker/Dockerfile-cpu -t $t . && sudo docker push $t
|
| 32 |
+
|
| 33 |
+
# Run
|
| 34 |
+
# t=ultralytics/ultralytics:latest-conda && sudo docker run -it --ipc=host $t
|
| 35 |
+
|
| 36 |
+
# Pull and Run
|
| 37 |
+
# t=ultralytics/ultralytics:latest-conda && sudo docker pull $t && sudo docker run -it --ipc=host $t
|
| 38 |
+
|
| 39 |
+
# Pull and Run with local volume mounted
|
| 40 |
+
# t=ultralytics/ultralytics:latest-conda && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/datasets:/usr/src/datasets $t
|
yolov10/docker/Dockerfile-cpu
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
| 2 |
+
# Builds ultralytics/ultralytics:latest-cpu image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
|
| 3 |
+
# Image is CPU-optimized for ONNX, OpenVINO and PyTorch YOLOv8 deployments
|
| 4 |
+
|
| 5 |
+
# Start FROM Ubuntu image https://hub.docker.com/_/ubuntu
|
| 6 |
+
FROM ubuntu:23.10
|
| 7 |
+
|
| 8 |
+
# Downloads to user config dir
|
| 9 |
+
ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
|
| 10 |
+
https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
|
| 11 |
+
/root/.config/Ultralytics/
|
| 12 |
+
|
| 13 |
+
# Install linux packages
|
| 14 |
+
# g++ required to build 'tflite_support' and 'lap' packages, libusb-1.0-0 required for 'tflite_support' package
|
| 15 |
+
RUN apt update \
|
| 16 |
+
&& apt install --no-install-recommends -y python3-pip git zip curl htop libgl1 libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
|
| 17 |
+
|
| 18 |
+
# Create working directory
|
| 19 |
+
WORKDIR /usr/src/ultralytics
|
| 20 |
+
|
| 21 |
+
# Copy contents
|
| 22 |
+
# COPY . /usr/src/ultralytics # git permission issues inside container
|
| 23 |
+
RUN git clone https://github.com/ultralytics/ultralytics -b main /usr/src/ultralytics
|
| 24 |
+
ADD https://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8n.pt /usr/src/ultralytics/
|
| 25 |
+
|
| 26 |
+
# Remove python3.11/EXTERNALLY-MANAGED or use 'pip install --break-system-packages' avoid 'externally-managed-environment' Ubuntu nightly error
|
| 27 |
+
RUN rm -rf /usr/lib/python3.11/EXTERNALLY-MANAGED
|
| 28 |
+
|
| 29 |
+
# Install pip packages
|
| 30 |
+
RUN python3 -m pip install --upgrade pip wheel
|
| 31 |
+
RUN pip install --no-cache -e ".[export]" --extra-index-url https://download.pytorch.org/whl/cpu
|
| 32 |
+
|
| 33 |
+
# Run exports to AutoInstall packages
|
| 34 |
+
RUN yolo export model=tmp/yolov8n.pt format=edgetpu imgsz=32
|
| 35 |
+
RUN yolo export model=tmp/yolov8n.pt format=ncnn imgsz=32
|
| 36 |
+
# Requires <= Python 3.10, bug with paddlepaddle==2.5.0 https://github.com/PaddlePaddle/X2Paddle/issues/991
|
| 37 |
+
# RUN pip install --no-cache paddlepaddle>=2.6.0 x2paddle
|
| 38 |
+
# Remove exported models
|
| 39 |
+
RUN rm -rf tmp
|
| 40 |
+
|
| 41 |
+
# Creates a symbolic link to make 'python' point to 'python3'
|
| 42 |
+
RUN ln -sf /usr/bin/python3 /usr/bin/python
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
# Usage Examples -------------------------------------------------------------------------------------------------------
|
| 46 |
+
|
| 47 |
+
# Build and Push
|
| 48 |
+
# t=ultralytics/ultralytics:latest-cpu && sudo docker build -f docker/Dockerfile-cpu -t $t . && sudo docker push $t
|
| 49 |
+
|
| 50 |
+
# Run
|
| 51 |
+
# t=ultralytics/ultralytics:latest-cpu && sudo docker run -it --ipc=host --name NAME $t
|
| 52 |
+
|
| 53 |
+
# Pull and Run
|
| 54 |
+
# t=ultralytics/ultralytics:latest-cpu && sudo docker pull $t && sudo docker run -it --ipc=host --name NAME $t
|
| 55 |
+
|
| 56 |
+
# Pull and Run with local volume mounted
|
| 57 |
+
# t=ultralytics/ultralytics:latest-cpu && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/datasets:/usr/src/datasets $t
|
yolov10/docker/Dockerfile-jetson
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
| 2 |
+
# Builds ultralytics/ultralytics:jetson image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
|
| 3 |
+
# Supports JetPack for YOLOv8 on Jetson Nano, TX1/TX2, Xavier NX, AGX Xavier, AGX Orin, and Orin NX
|
| 4 |
+
|
| 5 |
+
# Start FROM https://catalog.ngc.nvidia.com/orgs/nvidia/containers/l4t-pytorch
|
| 6 |
+
FROM nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3
|
| 7 |
+
|
| 8 |
+
# Downloads to user config dir
|
| 9 |
+
ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
|
| 10 |
+
https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
|
| 11 |
+
/root/.config/Ultralytics/
|
| 12 |
+
|
| 13 |
+
# Install linux packages
|
| 14 |
+
# g++ required to build 'tflite_support' and 'lap' packages, libusb-1.0-0 required for 'tflite_support' package
|
| 15 |
+
RUN apt update \
|
| 16 |
+
&& apt install --no-install-recommends -y gcc git zip curl htop libgl1 libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
|
| 17 |
+
|
| 18 |
+
# Create working directory
|
| 19 |
+
WORKDIR /usr/src/ultralytics
|
| 20 |
+
|
| 21 |
+
# Copy contents
|
| 22 |
+
# COPY . /usr/src/ultralytics # git permission issues inside container
|
| 23 |
+
RUN git clone https://github.com/ultralytics/ultralytics -b main /usr/src/ultralytics
|
| 24 |
+
ADD https://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8n.pt /usr/src/ultralytics/
|
| 25 |
+
|
| 26 |
+
# Remove opencv-python from Ultralytics dependencies as it conflicts with opencv-python installed in base image
|
| 27 |
+
RUN grep -v "opencv-python" pyproject.toml > temp.toml && mv temp.toml pyproject.toml
|
| 28 |
+
|
| 29 |
+
# Install pip packages manually for TensorRT compatibility https://github.com/NVIDIA/TensorRT/issues/2567
|
| 30 |
+
RUN python3 -m pip install --upgrade pip wheel
|
| 31 |
+
RUN pip install --no-cache tqdm matplotlib pyyaml psutil pandas onnx "numpy==1.23"
|
| 32 |
+
RUN pip install --no-cache -e .
|
| 33 |
+
|
| 34 |
+
# Set environment variables
|
| 35 |
+
ENV OMP_NUM_THREADS=1
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
# Usage Examples -------------------------------------------------------------------------------------------------------
|
| 39 |
+
|
| 40 |
+
# Build and Push
|
| 41 |
+
# t=ultralytics/ultralytics:latest-jetson && sudo docker build --platform linux/arm64 -f docker/Dockerfile-jetson -t $t . && sudo docker push $t
|
| 42 |
+
|
| 43 |
+
# Run
|
| 44 |
+
# t=ultralytics/ultralytics:latest-jetson && sudo docker run -it --ipc=host $t
|
| 45 |
+
|
| 46 |
+
# Pull and Run
|
| 47 |
+
# t=ultralytics/ultralytics:latest-jetson && sudo docker pull $t && sudo docker run -it --ipc=host $t
|
| 48 |
+
|
| 49 |
+
# Pull and Run with NVIDIA runtime
|
| 50 |
+
# t=ultralytics/ultralytics:latest-jetson && sudo docker pull $t && sudo docker run -it --ipc=host --runtime=nvidia $t
|
yolov10/docker/Dockerfile-python
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
| 2 |
+
# Builds ultralytics/ultralytics:latest-cpu image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
|
| 3 |
+
# Image is CPU-optimized for ONNX, OpenVINO and PyTorch YOLOv8 deployments
|
| 4 |
+
|
| 5 |
+
# Use the official Python 3.10 slim-bookworm as base image
|
| 6 |
+
FROM python:3.10-slim-bookworm
|
| 7 |
+
|
| 8 |
+
# Downloads to user config dir
|
| 9 |
+
ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
|
| 10 |
+
https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
|
| 11 |
+
/root/.config/Ultralytics/
|
| 12 |
+
|
| 13 |
+
# Install linux packages
|
| 14 |
+
# g++ required to build 'tflite_support' and 'lap' packages, libusb-1.0-0 required for 'tflite_support' package
|
| 15 |
+
RUN apt update \
|
| 16 |
+
&& apt install --no-install-recommends -y python3-pip git zip curl htop libgl1 libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
|
| 17 |
+
|
| 18 |
+
# Create working directory
|
| 19 |
+
WORKDIR /usr/src/ultralytics
|
| 20 |
+
|
| 21 |
+
# Copy contents
|
| 22 |
+
# COPY . /usr/src/ultralytics # git permission issues inside container
|
| 23 |
+
RUN git clone https://github.com/ultralytics/ultralytics -b main /usr/src/ultralytics
|
| 24 |
+
ADD https://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8n.pt /usr/src/ultralytics/
|
| 25 |
+
|
| 26 |
+
# Remove python3.11/EXTERNALLY-MANAGED or use 'pip install --break-system-packages' avoid 'externally-managed-environment' Ubuntu nightly error
|
| 27 |
+
# RUN rm -rf /usr/lib/python3.11/EXTERNALLY-MANAGED
|
| 28 |
+
|
| 29 |
+
# Install pip packages
|
| 30 |
+
RUN python3 -m pip install --upgrade pip wheel
|
| 31 |
+
RUN pip install --no-cache -e ".[export]" --extra-index-url https://download.pytorch.org/whl/cpu
|
| 32 |
+
|
| 33 |
+
# Run exports to AutoInstall packages
|
| 34 |
+
RUN yolo export model=tmp/yolov8n.pt format=edgetpu imgsz=32
|
| 35 |
+
RUN yolo export model=tmp/yolov8n.pt format=ncnn imgsz=32
|
| 36 |
+
# Requires <= Python 3.10, bug with paddlepaddle==2.5.0 https://github.com/PaddlePaddle/X2Paddle/issues/991
|
| 37 |
+
RUN pip install --no-cache paddlepaddle>=2.6.0 x2paddle
|
| 38 |
+
# Remove exported models
|
| 39 |
+
RUN rm -rf tmp
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
# Usage Examples -------------------------------------------------------------------------------------------------------
|
| 43 |
+
|
| 44 |
+
# Build and Push
|
| 45 |
+
# t=ultralytics/ultralytics:latest-python && sudo docker build -f docker/Dockerfile-python -t $t . && sudo docker push $t
|
| 46 |
+
|
| 47 |
+
# Run
|
| 48 |
+
# t=ultralytics/ultralytics:latest-python && sudo docker run -it --ipc=host $t
|
| 49 |
+
|
| 50 |
+
# Pull and Run
|
| 51 |
+
# t=ultralytics/ultralytics:latest-python && sudo docker pull $t && sudo docker run -it --ipc=host $t
|
| 52 |
+
|
| 53 |
+
# Pull and Run with local volume mounted
|
| 54 |
+
# t=ultralytics/ultralytics:latest-python && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/datasets:/usr/src/datasets $t
|
yolov10/docker/Dockerfile-runner
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
| 2 |
+
# Builds GitHub actions CI runner image for deployment to DockerHub https://hub.docker.com/r/ultralytics/ultralytics
|
| 3 |
+
# Image is CUDA-optimized for YOLOv8 single/multi-GPU training and inference tests
|
| 4 |
+
|
| 5 |
+
# Start FROM Ultralytics GPU image
|
| 6 |
+
FROM ultralytics/ultralytics:latest
|
| 7 |
+
|
| 8 |
+
# Set the working directory
|
| 9 |
+
WORKDIR /actions-runner
|
| 10 |
+
|
| 11 |
+
# Download and unpack the latest runner from https://github.com/actions/runner
|
| 12 |
+
RUN FILENAME=actions-runner-linux-x64-2.309.0.tar.gz && \
|
| 13 |
+
curl -o $FILENAME -L https://github.com/actions/runner/releases/download/v2.309.0/$FILENAME && \
|
| 14 |
+
tar xzf $FILENAME && \
|
| 15 |
+
rm $FILENAME
|
| 16 |
+
|
| 17 |
+
# Install runner dependencies
|
| 18 |
+
ENV RUNNER_ALLOW_RUNASROOT=1
|
| 19 |
+
ENV DEBIAN_FRONTEND=noninteractive
|
| 20 |
+
RUN ./bin/installdependencies.sh && \
|
| 21 |
+
apt-get -y install libicu-dev
|
| 22 |
+
|
| 23 |
+
# Inline ENTRYPOINT command to configure and start runner with default TOKEN and NAME
|
| 24 |
+
ENTRYPOINT sh -c './config.sh --url https://github.com/ultralytics/ultralytics \
|
| 25 |
+
--token ${GITHUB_RUNNER_TOKEN:-TOKEN} \
|
| 26 |
+
--name ${GITHUB_RUNNER_NAME:-NAME} \
|
| 27 |
+
--labels gpu-latest \
|
| 28 |
+
--replace && \
|
| 29 |
+
./run.sh'
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
# Usage Examples -------------------------------------------------------------------------------------------------------
|
| 33 |
+
|
| 34 |
+
# Build and Push
|
| 35 |
+
# t=ultralytics/ultralytics:latest-runner && sudo docker build -f docker/Dockerfile-runner -t $t . && sudo docker push $t
|
| 36 |
+
|
| 37 |
+
# Pull and Run in detached mode with access to GPUs 0 and 1
|
| 38 |
+
# t=ultralytics/ultralytics:latest-runner && sudo docker run -d -e GITHUB_RUNNER_TOKEN=TOKEN -e GITHUB_RUNNER_NAME=NAME --ipc=host --gpus '"device=0,1"' $t
|
yolov10/docs/README.md
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<br>
|
| 2 |
+
<img src="https://raw.githubusercontent.com/ultralytics/assets/main/logo/Ultralytics_Logotype_Original.svg" width="320">
|
| 3 |
+
|
| 4 |
+
# 📚 Ultralytics Docs
|
| 5 |
+
|
| 6 |
+
Ultralytics Docs are the gateway to understanding and utilizing our cutting-edge machine learning tools. These documents are deployed to [https://docs.ultralytics.com](https://docs.ultralytics.com) for your convenience.
|
| 7 |
+
|
| 8 |
+
[](https://github.com/ultralytics/docs/actions/workflows/pages/pages-build-deployment) [](https://github.com/ultralytics/docs/actions/workflows/links.yml) [](https://github.com/ultralytics/docs/actions/workflows/check_domains.yml) [](https://github.com/ultralytics/docs/actions/workflows/format.yml) <a href="https://ultralytics.com/discord"><img alt="Discord" src="https://img.shields.io/discord/1089800235347353640?logo=discord&logoColor=white&label=Discord&color=blue"></a>
|
| 9 |
+
|
| 10 |
+
## 🛠️ Installation
|
| 11 |
+
|
| 12 |
+
[](https://badge.fury.io/py/ultralytics) [](https://pepy.tech/project/ultralytics)
|
| 13 |
+
|
| 14 |
+
To install the ultralytics package in developer mode, ensure you have Git and Python 3 installed on your system. Then, follow these steps:
|
| 15 |
+
|
| 16 |
+
1. Clone the ultralytics repository to your local machine using Git:
|
| 17 |
+
|
| 18 |
+
```bash
|
| 19 |
+
git clone https://github.com/ultralytics/ultralytics.git
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
2. Navigate to the cloned repository's root directory:
|
| 23 |
+
|
| 24 |
+
```bash
|
| 25 |
+
cd ultralytics
|
| 26 |
+
```
|
| 27 |
+
|
| 28 |
+
3. Install the package in developer mode using pip (or pip3 for Python 3):
|
| 29 |
+
|
| 30 |
+
```bash
|
| 31 |
+
pip install -e '.[dev]'
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
- This command installs the ultralytics package along with all development dependencies, allowing you to modify the package code and have the changes immediately reflected in your Python environment.
|
| 35 |
+
|
| 36 |
+
## 🚀 Building and Serving Locally
|
| 37 |
+
|
| 38 |
+
The `mkdocs serve` command builds and serves a local version of your MkDocs documentation, ideal for development and testing:
|
| 39 |
+
|
| 40 |
+
```bash
|
| 41 |
+
mkdocs serve
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
- #### Command Breakdown:
|
| 45 |
+
|
| 46 |
+
- `mkdocs` is the main MkDocs command-line interface.
|
| 47 |
+
- `serve` is the subcommand to build and locally serve your documentation.
|
| 48 |
+
|
| 49 |
+
- 🧐 Note:
|
| 50 |
+
|
| 51 |
+
- Grasp changes to the docs in real-time as `mkdocs serve` supports live reloading.
|
| 52 |
+
- To stop the local server, press `CTRL+C`.
|
| 53 |
+
|
| 54 |
+
## 🌍 Building and Serving Multi-Language
|
| 55 |
+
|
| 56 |
+
Supporting multi-language documentation? Follow these steps:
|
| 57 |
+
|
| 58 |
+
1. Stage all new language \*.md files with Git:
|
| 59 |
+
|
| 60 |
+
```bash
|
| 61 |
+
git add docs/**/*.md -f
|
| 62 |
+
```
|
| 63 |
+
|
| 64 |
+
2. Build all languages to the `/site` folder, ensuring relevant root-level files are present:
|
| 65 |
+
|
| 66 |
+
```bash
|
| 67 |
+
# Clear existing /site directory
|
| 68 |
+
rm -rf site
|
| 69 |
+
|
| 70 |
+
# Loop through each language config file and build
|
| 71 |
+
mkdocs build -f docs/mkdocs.yml
|
| 72 |
+
for file in docs/mkdocs_*.yml; do
|
| 73 |
+
echo "Building MkDocs site with $file"
|
| 74 |
+
mkdocs build -f "$file"
|
| 75 |
+
done
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
3. To preview your site, initiate a simple HTTP server:
|
| 79 |
+
|
| 80 |
+
```bash
|
| 81 |
+
cd site
|
| 82 |
+
python -m http.server
|
| 83 |
+
# Open in your preferred browser
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
- 🖥️ Access the live site at `http://localhost:8000`.
|
| 87 |
+
|
| 88 |
+
## 📤 Deploying Your Documentation Site
|
| 89 |
+
|
| 90 |
+
Choose a hosting provider and deployment method for your MkDocs documentation:
|
| 91 |
+
|
| 92 |
+
- Configure `mkdocs.yml` with deployment settings.
|
| 93 |
+
- Use `mkdocs deploy` to build and deploy your site.
|
| 94 |
+
|
| 95 |
+
* ### GitHub Pages Deployment Example:
|
| 96 |
+
```bash
|
| 97 |
+
mkdocs gh-deploy
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
- Update the "Custom domain" in your repository's settings for a personalized URL.
|
| 101 |
+
|
| 102 |
+
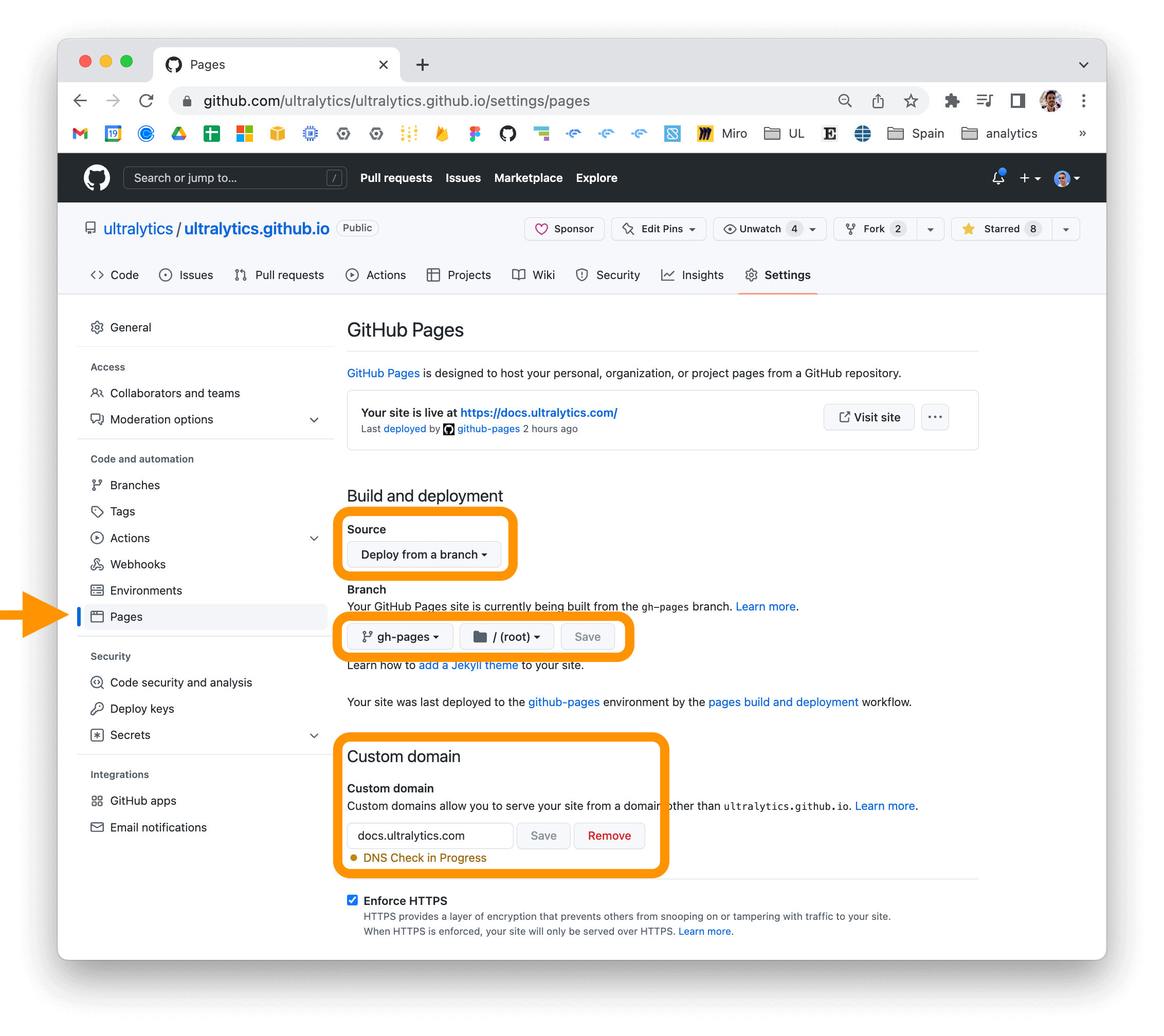
|
| 103 |
+
|
| 104 |
+
- For detailed deployment guidance, consult the [MkDocs documentation](https://www.mkdocs.org/user-guide/deploying-your-docs/).
|
| 105 |
+
|
| 106 |
+
## 💡 Contribute
|
| 107 |
+
|
| 108 |
+
We cherish the community's input as it drives Ultralytics open-source initiatives. Dive into the [Contributing Guide](https://docs.ultralytics.com/help/contributing) and share your thoughts via our [Survey](https://ultralytics.com/survey?utm_source=github&utm_medium=social&utm_campaign=Survey). A heartfelt thank you 🙏 to each contributor!
|
| 109 |
+
|
| 110 |
+
<!-- Pictorial representation of our dedicated contributor community -->
|
| 111 |
+
|
| 112 |
+

|
| 113 |
+
|
| 114 |
+
## 📜 License
|
| 115 |
+
|
| 116 |
+
Ultralytics presents two licensing options:
|
| 117 |
+
|
| 118 |
+
- **AGPL-3.0 License**: Perfect for academia and open collaboration. Details are in the [LICENSE](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) file.
|
| 119 |
+
- **Enterprise License**: Tailored for commercial usage, offering a seamless blend of Ultralytics technology in your products. Learn more at [Ultralytics Licensing](https://ultralytics.com/license).
|
| 120 |
+
|
| 121 |
+
## ✉️ Contact
|
| 122 |
+
|
| 123 |
+
For bug reports and feature requests, navigate to [GitHub Issues](https://github.com/ultralytics/docs/issues). Engage with peers and the Ultralytics team on [Discord](https://ultralytics.com/discord) for enriching conversations!
|
| 124 |
+
|
| 125 |
+
<br>
|
| 126 |
+
<div align="center">
|
| 127 |
+
<a href="https://github.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-github.png" width="3%" alt="Ultralytics GitHub"></a>
|
| 128 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
| 129 |
+
<a href="https://www.linkedin.com/company/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-linkedin.png" width="3%" alt="Ultralytics LinkedIn"></a>
|
| 130 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
| 131 |
+
<a href="https://twitter.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-twitter.png" width="3%" alt="Ultralytics Twitter"></a>
|
| 132 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
| 133 |
+
<a href="https://youtube.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-youtube.png" width="3%" alt="Ultralytics YouTube"></a>
|
| 134 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
| 135 |
+
<a href="https://www.tiktok.com/@ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-tiktok.png" width="3%" alt="Ultralytics TikTok"></a>
|
| 136 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
| 137 |
+
<a href="https://www.instagram.com/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-instagram.png" width="3%" alt="Ultralytics Instagram"></a>
|
| 138 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="space">
|
| 139 |
+
<a href="https://ultralytics.com/discord"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-discord.png" width="3%" alt="Ultralytics Discord"></a>
|
| 140 |
+
</div>
|
yolov10/docs/build_docs.py
ADDED
|
@@ -0,0 +1,141 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
| 2 |
+
"""
|
| 3 |
+
This Python script is designed to automate the building and post-processing of MkDocs documentation, particularly for
|
| 4 |
+
projects with multilingual content. It streamlines the workflow for generating localized versions of the documentation
|
| 5 |
+
and updating HTML links to ensure they are correctly formatted.
|
| 6 |
+
|
| 7 |
+
Key Features:
|
| 8 |
+
- Automated building of MkDocs documentation: The script compiles both the main documentation and
|
| 9 |
+
any localized versions specified in separate MkDocs configuration files.
|
| 10 |
+
- Post-processing of generated HTML files: After the documentation is built, the script updates all
|
| 11 |
+
HTML files to remove the '.md' extension from internal links. This ensures that links in the built
|
| 12 |
+
HTML documentation correctly point to other HTML pages rather than Markdown files, which is crucial
|
| 13 |
+
for proper navigation within the web-based documentation.
|
| 14 |
+
|
| 15 |
+
Usage:
|
| 16 |
+
- Run the script from the root directory of your MkDocs project.
|
| 17 |
+
- Ensure that MkDocs is installed and that all MkDocs configuration files (main and localized versions)
|
| 18 |
+
are present in the project directory.
|
| 19 |
+
- The script first builds the documentation using MkDocs, then scans the generated HTML files in the 'site'
|
| 20 |
+
directory to update the internal links.
|
| 21 |
+
- It's ideal for projects where the documentation is written in Markdown and needs to be served as a static website.
|
| 22 |
+
|
| 23 |
+
Note:
|
| 24 |
+
- This script is built to be run in an environment where Python and MkDocs are installed and properly configured.
|
| 25 |
+
"""
|
| 26 |
+
|
| 27 |
+
import os
|
| 28 |
+
import re
|
| 29 |
+
import shutil
|
| 30 |
+
import subprocess
|
| 31 |
+
from pathlib import Path
|
| 32 |
+
|
| 33 |
+
from tqdm import tqdm
|
| 34 |
+
|
| 35 |
+
DOCS = Path(__file__).parent.resolve()
|
| 36 |
+
SITE = DOCS.parent / "site"
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def build_docs(clone_repos=True):
|
| 40 |
+
"""Build docs using mkdocs."""
|
| 41 |
+
if SITE.exists():
|
| 42 |
+
print(f"Removing existing {SITE}")
|
| 43 |
+
shutil.rmtree(SITE)
|
| 44 |
+
|
| 45 |
+
# Get hub-sdk repo
|
| 46 |
+
if clone_repos:
|
| 47 |
+
repo = "https://github.com/ultralytics/hub-sdk"
|
| 48 |
+
local_dir = DOCS.parent / Path(repo).name
|
| 49 |
+
if not local_dir.exists():
|
| 50 |
+
os.system(f"git clone {repo} {local_dir}")
|
| 51 |
+
os.system(f"git -C {local_dir} pull") # update repo
|
| 52 |
+
shutil.rmtree(DOCS / "en/hub/sdk", ignore_errors=True) # delete if exists
|
| 53 |
+
shutil.copytree(local_dir / "docs", DOCS / "en/hub/sdk") # for docs
|
| 54 |
+
shutil.rmtree(DOCS.parent / "hub_sdk", ignore_errors=True) # delete if exists
|
| 55 |
+
shutil.copytree(local_dir / "hub_sdk", DOCS.parent / "hub_sdk") # for mkdocstrings
|
| 56 |
+
print(f"Cloned/Updated {repo} in {local_dir}")
|
| 57 |
+
|
| 58 |
+
# Build the main documentation
|
| 59 |
+
print(f"Building docs from {DOCS}")
|
| 60 |
+
subprocess.run(f"mkdocs build -f {DOCS.parent}/mkdocs.yml", check=True, shell=True)
|
| 61 |
+
print(f"Site built at {SITE}")
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def update_page_title(file_path: Path, new_title: str):
|
| 65 |
+
"""Update the title of an HTML file."""
|
| 66 |
+
|
| 67 |
+
# Read the content of the file
|
| 68 |
+
with open(file_path, encoding="utf-8") as file:
|
| 69 |
+
content = file.read()
|
| 70 |
+
|
| 71 |
+
# Replace the existing title with the new title
|
| 72 |
+
updated_content = re.sub(r"<title>.*?</title>", f"<title>{new_title}</title>", content)
|
| 73 |
+
|
| 74 |
+
# Write the updated content back to the file
|
| 75 |
+
with open(file_path, "w", encoding="utf-8") as file:
|
| 76 |
+
file.write(updated_content)
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def update_html_head(script=""):
|
| 80 |
+
"""Update the HTML head section of each file."""
|
| 81 |
+
html_files = Path(SITE).rglob("*.html")
|
| 82 |
+
for html_file in tqdm(html_files, desc="Processing HTML files"):
|
| 83 |
+
with html_file.open("r", encoding="utf-8") as file:
|
| 84 |
+
html_content = file.read()
|
| 85 |
+
|
| 86 |
+
if script in html_content: # script already in HTML file
|
| 87 |
+
return
|
| 88 |
+
|
| 89 |
+
head_end_index = html_content.lower().rfind("</head>")
|
| 90 |
+
if head_end_index != -1:
|
| 91 |
+
# Add the specified JavaScript to the HTML file just before the end of the head tag.
|
| 92 |
+
new_html_content = html_content[:head_end_index] + script + html_content[head_end_index:]
|
| 93 |
+
with html_file.open("w", encoding="utf-8") as file:
|
| 94 |
+
file.write(new_html_content)
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def update_subdir_edit_links(subdir="", docs_url=""):
|
| 98 |
+
"""Update the HTML head section of each file."""
|
| 99 |
+
from bs4 import BeautifulSoup
|
| 100 |
+
|
| 101 |
+
if str(subdir[0]) == "/":
|
| 102 |
+
subdir = str(subdir[0])[1:]
|
| 103 |
+
html_files = (SITE / subdir).rglob("*.html")
|
| 104 |
+
for html_file in tqdm(html_files, desc="Processing subdir files"):
|
| 105 |
+
with html_file.open("r", encoding="utf-8") as file:
|
| 106 |
+
soup = BeautifulSoup(file, "html.parser")
|
| 107 |
+
|
| 108 |
+
# Find the anchor tag and update its href attribute
|
| 109 |
+
a_tag = soup.find("a", {"class": "md-content__button md-icon"})
|
| 110 |
+
if a_tag and a_tag["title"] == "Edit this page":
|
| 111 |
+
a_tag["href"] = f"{docs_url}{a_tag['href'].split(subdir)[-1]}"
|
| 112 |
+
|
| 113 |
+
# Write the updated HTML back to the file
|
| 114 |
+
with open(html_file, "w", encoding="utf-8") as file:
|
| 115 |
+
file.write(str(soup))
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def main():
|
| 119 |
+
"""Builds docs, updates titles and edit links, and prints local server command."""
|
| 120 |
+
build_docs()
|
| 121 |
+
|
| 122 |
+
# Update titles
|
| 123 |
+
update_page_title(SITE / "404.html", new_title="Ultralytics Docs - Not Found")
|
| 124 |
+
|
| 125 |
+
# Update edit links
|
| 126 |
+
update_subdir_edit_links(
|
| 127 |
+
subdir="hub/sdk/", # do not use leading slash
|
| 128 |
+
docs_url="https://github.com/ultralytics/hub-sdk/tree/develop/docs/",
|
| 129 |
+
)
|
| 130 |
+
|
| 131 |
+
# Update HTML file head section
|
| 132 |
+
script = ""
|
| 133 |
+
if any(script):
|
| 134 |
+
update_html_head(script)
|
| 135 |
+
|
| 136 |
+
# Show command to serve built website
|
| 137 |
+
print('Serve site at http://localhost:8000 with "python -m http.server --directory site"')
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
if __name__ == "__main__":
|
| 141 |
+
main()
|
yolov10/docs/build_reference.py
ADDED
|
@@ -0,0 +1,130 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
| 2 |
+
"""
|
| 3 |
+
Helper file to build Ultralytics Docs reference section. Recursively walks through ultralytics dir and builds an MkDocs
|
| 4 |
+
reference section of *.md files composed of classes and functions, and also creates a nav menu for use in mkdocs.yaml.
|
| 5 |
+
|
| 6 |
+
Note: Must be run from repository root directory. Do not run from docs directory.
|
| 7 |
+
"""
|
| 8 |
+
|
| 9 |
+
import re
|
| 10 |
+
from collections import defaultdict
|
| 11 |
+
from pathlib import Path
|
| 12 |
+
|
| 13 |
+
# Get package root i.e. /Users/glennjocher/PycharmProjects/ultralytics/ultralytics
|
| 14 |
+
from ultralytics.utils import ROOT as PACKAGE_DIR
|
| 15 |
+
|
| 16 |
+
# Constants
|
| 17 |
+
REFERENCE_DIR = PACKAGE_DIR.parent / "docs/en/reference"
|
| 18 |
+
GITHUB_REPO = "ultralytics/ultralytics"
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def extract_classes_and_functions(filepath: Path) -> tuple:
|
| 22 |
+
"""Extracts class and function names from a given Python file."""
|
| 23 |
+
content = filepath.read_text()
|
| 24 |
+
class_pattern = r"(?:^|\n)class\s(\w+)(?:\(|:)"
|
| 25 |
+
func_pattern = r"(?:^|\n)def\s(\w+)\("
|
| 26 |
+
|
| 27 |
+
classes = re.findall(class_pattern, content)
|
| 28 |
+
functions = re.findall(func_pattern, content)
|
| 29 |
+
|
| 30 |
+
return classes, functions
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def create_markdown(py_filepath: Path, module_path: str, classes: list, functions: list):
|
| 34 |
+
"""Creates a Markdown file containing the API reference for the given Python module."""
|
| 35 |
+
md_filepath = py_filepath.with_suffix(".md")
|
| 36 |
+
|
| 37 |
+
# Read existing content and keep header content between first two ---
|
| 38 |
+
header_content = ""
|
| 39 |
+
if md_filepath.exists():
|
| 40 |
+
existing_content = md_filepath.read_text()
|
| 41 |
+
header_parts = existing_content.split("---")
|
| 42 |
+
for part in header_parts:
|
| 43 |
+
if "description:" in part or "comments:" in part:
|
| 44 |
+
header_content += f"---{part}---\n\n"
|
| 45 |
+
|
| 46 |
+
module_name = module_path.replace(".__init__", "")
|
| 47 |
+
module_path = module_path.replace(".", "/")
|
| 48 |
+
url = f"https://github.com/{GITHUB_REPO}/blob/main/{module_path}.py"
|
| 49 |
+
edit = f"https://github.com/{GITHUB_REPO}/edit/main/{module_path}.py"
|
| 50 |
+
title_content = (
|
| 51 |
+
f"# Reference for `{module_path}.py`\n\n"
|
| 52 |
+
f"!!! Note\n\n"
|
| 53 |
+
f" This file is available at [{url}]({url}). If you spot a problem please help fix it by [contributing](https://docs.ultralytics.com/help/contributing/) a [Pull Request]({edit}) 🛠️. Thank you 🙏!\n\n"
|
| 54 |
+
)
|
| 55 |
+
md_content = ["<br><br>\n"] + [f"## ::: {module_name}.{class_name}\n\n<br><br>\n" for class_name in classes]
|
| 56 |
+
md_content.extend(f"## ::: {module_name}.{func_name}\n\n<br><br>\n" for func_name in functions)
|
| 57 |
+
md_content = header_content + title_content + "\n".join(md_content)
|
| 58 |
+
if not md_content.endswith("\n"):
|
| 59 |
+
md_content += "\n"
|
| 60 |
+
|
| 61 |
+
md_filepath.parent.mkdir(parents=True, exist_ok=True)
|
| 62 |
+
md_filepath.write_text(md_content)
|
| 63 |
+
|
| 64 |
+
return md_filepath.relative_to(PACKAGE_DIR.parent)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def nested_dict() -> defaultdict:
|
| 68 |
+
"""Creates and returns a nested defaultdict."""
|
| 69 |
+
return defaultdict(nested_dict)
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def sort_nested_dict(d: dict) -> dict:
|
| 73 |
+
"""Sorts a nested dictionary recursively."""
|
| 74 |
+
return {key: sort_nested_dict(value) if isinstance(value, dict) else value for key, value in sorted(d.items())}
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def create_nav_menu_yaml(nav_items: list, save: bool = False):
|
| 78 |
+
"""Creates a YAML file for the navigation menu based on the provided list of items."""
|
| 79 |
+
nav_tree = nested_dict()
|
| 80 |
+
|
| 81 |
+
for item_str in nav_items:
|
| 82 |
+
item = Path(item_str)
|
| 83 |
+
parts = item.parts
|
| 84 |
+
current_level = nav_tree["reference"]
|
| 85 |
+
for part in parts[2:-1]: # skip the first two parts (docs and reference) and the last part (filename)
|
| 86 |
+
current_level = current_level[part]
|
| 87 |
+
|
| 88 |
+
md_file_name = parts[-1].replace(".md", "")
|
| 89 |
+
current_level[md_file_name] = item
|
| 90 |
+
|
| 91 |
+
nav_tree_sorted = sort_nested_dict(nav_tree)
|
| 92 |
+
|
| 93 |
+
def _dict_to_yaml(d, level=0):
|
| 94 |
+
"""Converts a nested dictionary to a YAML-formatted string with indentation."""
|
| 95 |
+
yaml_str = ""
|
| 96 |
+
indent = " " * level
|
| 97 |
+
for k, v in d.items():
|
| 98 |
+
if isinstance(v, dict):
|
| 99 |
+
yaml_str += f"{indent}- {k}:\n{_dict_to_yaml(v, level + 1)}"
|
| 100 |
+
else:
|
| 101 |
+
yaml_str += f"{indent}- {k}: {str(v).replace('docs/en/', '')}\n"
|
| 102 |
+
return yaml_str
|
| 103 |
+
|
| 104 |
+
# Print updated YAML reference section
|
| 105 |
+
print("Scan complete, new mkdocs.yaml reference section is:\n\n", _dict_to_yaml(nav_tree_sorted))
|
| 106 |
+
|
| 107 |
+
# Save new YAML reference section
|
| 108 |
+
if save:
|
| 109 |
+
(PACKAGE_DIR.parent / "nav_menu_updated.yml").write_text(_dict_to_yaml(nav_tree_sorted))
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
def main():
|
| 113 |
+
"""Main function to extract class and function names, create Markdown files, and generate a YAML navigation menu."""
|
| 114 |
+
nav_items = []
|
| 115 |
+
|
| 116 |
+
for py_filepath in PACKAGE_DIR.rglob("*.py"):
|
| 117 |
+
classes, functions = extract_classes_and_functions(py_filepath)
|
| 118 |
+
|
| 119 |
+
if classes or functions:
|
| 120 |
+
py_filepath_rel = py_filepath.relative_to(PACKAGE_DIR)
|
| 121 |
+
md_filepath = REFERENCE_DIR / py_filepath_rel
|
| 122 |
+
module_path = f"{PACKAGE_DIR.name}.{py_filepath_rel.with_suffix('').as_posix().replace('/', '.')}"
|
| 123 |
+
md_rel_filepath = create_markdown(md_filepath, module_path, classes, functions)
|
| 124 |
+
nav_items.append(str(md_rel_filepath))
|
| 125 |
+
|
| 126 |
+
create_nav_menu_yaml(nav_items)
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
if __name__ == "__main__":
|
| 130 |
+
main()
|
yolov10/docs/coming_soon_template.md
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
description: Discover what's next for Ultralytics with our under-construction page, previewing new, groundbreaking AI and ML features coming soon.
|
| 3 |
+
keywords: Ultralytics, coming soon, under construction, new features, AI updates, ML advancements, YOLO, technology preview
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
# Under Construction 🏗️🌟
|
| 7 |
+
|
| 8 |
+
Welcome to the Ultralytics "Under Construction" page! Here, we're hard at work developing the next generation of AI and ML innovations. This page serves as a teaser for the exciting updates and new features we're eager to share with you!
|
| 9 |
+
|
| 10 |
+
## Exciting New Features on the Way 🎉
|
| 11 |
+
|
| 12 |
+
- **Innovative Breakthroughs:** Get ready for advanced features and services that will transform your AI and ML experience.
|
| 13 |
+
- **New Horizons:** Anticipate novel products that redefine AI and ML capabilities.
|
| 14 |
+
- **Enhanced Services:** We're upgrading our services for greater efficiency and user-friendliness.
|
| 15 |
+
|
| 16 |
+
## Stay Updated 🚧
|
| 17 |
+
|
| 18 |
+
This placeholder page is your first stop for upcoming developments. Keep an eye out for:
|
| 19 |
+
|
| 20 |
+
- **Newsletter:** Subscribe [here](https://ultralytics.com/#newsletter) for the latest news.
|
| 21 |
+
- **Social Media:** Follow us [here](https://www.linkedin.com/company/ultralytics) for updates and teasers.
|
| 22 |
+
- **Blog:** Visit our [blog](https://ultralytics.com/blog) for detailed insights.
|
| 23 |
+
|
| 24 |
+
## We Value Your Input 🗣️
|
| 25 |
+
|
| 26 |
+
Your feedback shapes our future releases. Share your thoughts and suggestions [here](https://ultralytics.com/contact).
|
| 27 |
+
|
| 28 |
+
## Thank You, Community! 🌍
|
| 29 |
+
|
| 30 |
+
Your [contributions](https://docs.ultralytics.com/help/contributing) inspire our continuous [innovation](https://github.com/ultralytics/ultralytics). Stay tuned for the big reveal of what's next in AI and ML at Ultralytics!
|
| 31 |
+
|
| 32 |
+
---
|
| 33 |
+
|
| 34 |
+
Excited for what's coming? Bookmark this page and get ready for a transformative AI and ML journey with Ultralytics! 🛠️🤖
|
yolov10/docs/en/CNAME
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
docs.ultralytics.com
|
yolov10/docs/en/datasets/classify/caltech101.md
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Learn about the Caltech-101 dataset, its structure and uses in machine learning. Includes instructions to train a YOLO model using this dataset.
|
| 4 |
+
keywords: Caltech-101, dataset, YOLO training, machine learning, object recognition, ultralytics
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# Caltech-101 Dataset
|
| 8 |
+
|
| 9 |
+
The [Caltech-101](https://data.caltech.edu/records/mzrjq-6wc02) dataset is a widely used dataset for object recognition tasks, containing around 9,000 images from 101 object categories. The categories were chosen to reflect a variety of real-world objects, and the images themselves were carefully selected and annotated to provide a challenging benchmark for object recognition algorithms.
|
| 10 |
+
|
| 11 |
+
## Key Features
|
| 12 |
+
|
| 13 |
+
- The Caltech-101 dataset comprises around 9,000 color images divided into 101 categories.
|
| 14 |
+
- The categories encompass a wide variety of objects, including animals, vehicles, household items, and people.
|
| 15 |
+
- The number of images per category varies, with about 40 to 800 images in each category.
|
| 16 |
+
- Images are of variable sizes, with most images being medium resolution.
|
| 17 |
+
- Caltech-101 is widely used for training and testing in the field of machine learning, particularly for object recognition tasks.
|
| 18 |
+
|
| 19 |
+
## Dataset Structure
|
| 20 |
+
|
| 21 |
+
Unlike many other datasets, the Caltech-101 dataset is not formally split into training and testing sets. Users typically create their own splits based on their specific needs. However, a common practice is to use a random subset of images for training (e.g., 30 images per category) and the remaining images for testing.
|
| 22 |
+
|
| 23 |
+
## Applications
|
| 24 |
+
|
| 25 |
+
The Caltech-101 dataset is extensively used for training and evaluating deep learning models in object recognition tasks, such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. Its wide variety of categories and high-quality images make it an excellent dataset for research and development in the field of machine learning and computer vision.
|
| 26 |
+
|
| 27 |
+
## Usage
|
| 28 |
+
|
| 29 |
+
To train a YOLO model on the Caltech-101 dataset for 100 epochs, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 30 |
+
|
| 31 |
+
!!! Example "Train Example"
|
| 32 |
+
|
| 33 |
+
=== "Python"
|
| 34 |
+
|
| 35 |
+
```python
|
| 36 |
+
from ultralytics import YOLO
|
| 37 |
+
|
| 38 |
+
# Load a model
|
| 39 |
+
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
| 40 |
+
|
| 41 |
+
# Train the model
|
| 42 |
+
results = model.train(data='caltech101', epochs=100, imgsz=416)
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
=== "CLI"
|
| 46 |
+
|
| 47 |
+
```bash
|
| 48 |
+
# Start training from a pretrained *.pt model
|
| 49 |
+
yolo detect train data=caltech101 model=yolov8n-cls.pt epochs=100 imgsz=416
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
## Sample Images and Annotations
|
| 53 |
+
|
| 54 |
+
The Caltech-101 dataset contains high-quality color images of various objects, providing a well-structured dataset for object recognition tasks. Here are some examples of images from the dataset:
|
| 55 |
+
|
| 56 |
+

|
| 57 |
+
|
| 58 |
+
The example showcases the variety and complexity of the objects in the Caltech-101 dataset, emphasizing the significance of a diverse dataset for training robust object recognition models.
|
| 59 |
+
|
| 60 |
+
## Citations and Acknowledgments
|
| 61 |
+
|
| 62 |
+
If you use the Caltech-101 dataset in your research or development work, please cite the following paper:
|
| 63 |
+
|
| 64 |
+
!!! Quote ""
|
| 65 |
+
|
| 66 |
+
=== "BibTeX"
|
| 67 |
+
|
| 68 |
+
```bibtex
|
| 69 |
+
@article{fei2007learning,
|
| 70 |
+
title={Learning generative visual models from few training examples: An incremental Bayesian approach tested on 101 object categories},
|
| 71 |
+
author={Fei-Fei, Li and Fergus, Rob and Perona, Pietro},
|
| 72 |
+
journal={Computer vision and Image understanding},
|
| 73 |
+
volume={106},
|
| 74 |
+
number={1},
|
| 75 |
+
pages={59--70},
|
| 76 |
+
year={2007},
|
| 77 |
+
publisher={Elsevier}
|
| 78 |
+
}
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
We would like to acknowledge Li Fei-Fei, Rob Fergus, and Pietro Perona for creating and maintaining the Caltech-101 dataset as a valuable resource for the machine learning and computer vision research community. For more information about the Caltech-101 dataset and its creators, visit the [Caltech-101 dataset website](https://data.caltech.edu/records/mzrjq-6wc02).
|
yolov10/docs/en/datasets/classify/caltech256.md
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Explore the Caltech-256 dataset, a diverse collection of images used for object recognition tasks in machine learning. Learn to train a YOLO model on the dataset.
|
| 4 |
+
keywords: Ultralytics, YOLO, Caltech-256, dataset, object recognition, machine learning, computer vision, deep learning
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# Caltech-256 Dataset
|
| 8 |
+
|
| 9 |
+
The [Caltech-256](https://data.caltech.edu/records/nyy15-4j048) dataset is an extensive collection of images used for object classification tasks. It contains around 30,000 images divided into 257 categories (256 object categories and 1 background category). The images are carefully curated and annotated to provide a challenging and diverse benchmark for object recognition algorithms.
|
| 10 |
+
|
| 11 |
+
## Key Features
|
| 12 |
+
|
| 13 |
+
- The Caltech-256 dataset comprises around 30,000 color images divided into 257 categories.
|
| 14 |
+
- Each category contains a minimum of 80 images.
|
| 15 |
+
- The categories encompass a wide variety of real-world objects, including animals, vehicles, household items, and people.
|
| 16 |
+
- Images are of variable sizes and resolutions.
|
| 17 |
+
- Caltech-256 is widely used for training and testing in the field of machine learning, particularly for object recognition tasks.
|
| 18 |
+
|
| 19 |
+
## Dataset Structure
|
| 20 |
+
|
| 21 |
+
Like Caltech-101, the Caltech-256 dataset does not have a formal split between training and testing sets. Users typically create their own splits according to their specific needs. A common practice is to use a random subset of images for training and the remaining images for testing.
|
| 22 |
+
|
| 23 |
+
## Applications
|
| 24 |
+
|
| 25 |
+
The Caltech-256 dataset is extensively used for training and evaluating deep learning models in object recognition tasks, such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. Its diverse set of categories and high-quality images make it an invaluable dataset for research and development in the field of machine learning and computer vision.
|
| 26 |
+
|
| 27 |
+
## Usage
|
| 28 |
+
|
| 29 |
+
To train a YOLO model on the Caltech-256 dataset for 100 epochs, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 30 |
+
|
| 31 |
+
!!! Example "Train Example"
|
| 32 |
+
|
| 33 |
+
=== "Python"
|
| 34 |
+
|
| 35 |
+
```python
|
| 36 |
+
from ultralytics import YOLO
|
| 37 |
+
|
| 38 |
+
# Load a model
|
| 39 |
+
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
| 40 |
+
|
| 41 |
+
# Train the model
|
| 42 |
+
results = model.train(data='caltech256', epochs=100, imgsz=416)
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
=== "CLI"
|
| 46 |
+
|
| 47 |
+
```bash
|
| 48 |
+
# Start training from a pretrained *.pt model
|
| 49 |
+
yolo detect train data=caltech256 model=yolov8n-cls.pt epochs=100 imgsz=416
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
## Sample Images and Annotations
|
| 53 |
+
|
| 54 |
+
The Caltech-256 dataset contains high-quality color images of various objects, providing a comprehensive dataset for object recognition tasks. Here are some examples of images from the dataset ([credit](https://ml4a.github.io/demos/tsne_viewer.html)):
|
| 55 |
+
|
| 56 |
+

|
| 57 |
+
|
| 58 |
+
The example showcases the diversity and complexity of the objects in the Caltech-256 dataset, emphasizing the importance of a varied dataset for training robust object recognition models.
|
| 59 |
+
|
| 60 |
+
## Citations and Acknowledgments
|
| 61 |
+
|
| 62 |
+
If you use the Caltech-256 dataset in your research or development work, please cite the following paper:
|
| 63 |
+
|
| 64 |
+
!!! Quote ""
|
| 65 |
+
|
| 66 |
+
=== "BibTeX"
|
| 67 |
+
|
| 68 |
+
```bibtex
|
| 69 |
+
@article{griffin2007caltech,
|
| 70 |
+
title={Caltech-256 object category dataset},
|
| 71 |
+
author={Griffin, Gregory and Holub, Alex and Perona, Pietro},
|
| 72 |
+
year={2007}
|
| 73 |
+
}
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
We would like to acknowledge Gregory Griffin, Alex Holub, and Pietro Perona for creating and maintaining the Caltech-256 dataset as a valuable resource for the machine learning and computer vision research community. For more information about the
|
| 77 |
+
|
| 78 |
+
Caltech-256 dataset and its creators, visit the [Caltech-256 dataset website](https://data.caltech.edu/records/nyy15-4j048).
|
yolov10/docs/en/datasets/classify/cifar10.md
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Explore the CIFAR-10 dataset, widely used for training in machine learning and computer vision, and learn how to use it with Ultralytics YOLO.
|
| 4 |
+
keywords: CIFAR-10, dataset, machine learning, image classification, computer vision, YOLO, Ultralytics, training, testing, deep learning, Convolutional Neural Networks, Support Vector Machines
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# CIFAR-10 Dataset
|
| 8 |
+
|
| 9 |
+
The [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html) (Canadian Institute For Advanced Research) dataset is a collection of images used widely for machine learning and computer vision algorithms. It was developed by researchers at the CIFAR institute and consists of 60,000 32x32 color images in 10 different classes.
|
| 10 |
+
|
| 11 |
+
## Key Features
|
| 12 |
+
|
| 13 |
+
- The CIFAR-10 dataset consists of 60,000 images, divided into 10 classes.
|
| 14 |
+
- Each class contains 6,000 images, split into 5,000 for training and 1,000 for testing.
|
| 15 |
+
- The images are colored and of size 32x32 pixels.
|
| 16 |
+
- The 10 different classes represent airplanes, cars, birds, cats, deer, dogs, frogs, horses, ships, and trucks.
|
| 17 |
+
- CIFAR-10 is commonly used for training and testing in the field of machine learning and computer vision.
|
| 18 |
+
|
| 19 |
+
## Dataset Structure
|
| 20 |
+
|
| 21 |
+
The CIFAR-10 dataset is split into two subsets:
|
| 22 |
+
|
| 23 |
+
1. **Training Set**: This subset contains 50,000 images used for training machine learning models.
|
| 24 |
+
2. **Testing Set**: This subset consists of 10,000 images used for testing and benchmarking the trained models.
|
| 25 |
+
|
| 26 |
+
## Applications
|
| 27 |
+
|
| 28 |
+
The CIFAR-10 dataset is widely used for training and evaluating deep learning models in image classification tasks, such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. The diversity of the dataset in terms of classes and the presence of color images make it a well-rounded dataset for research and development in the field of machine learning and computer vision.
|
| 29 |
+
|
| 30 |
+
## Usage
|
| 31 |
+
|
| 32 |
+
To train a YOLO model on the CIFAR-10 dataset for 100 epochs with an image size of 32x32, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 33 |
+
|
| 34 |
+
!!! Example "Train Example"
|
| 35 |
+
|
| 36 |
+
=== "Python"
|
| 37 |
+
|
| 38 |
+
```python
|
| 39 |
+
from ultralytics import YOLO
|
| 40 |
+
|
| 41 |
+
# Load a model
|
| 42 |
+
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
| 43 |
+
|
| 44 |
+
# Train the model
|
| 45 |
+
results = model.train(data='cifar10', epochs=100, imgsz=32)
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
=== "CLI"
|
| 49 |
+
|
| 50 |
+
```bash
|
| 51 |
+
# Start training from a pretrained *.pt model
|
| 52 |
+
yolo detect train data=cifar10 model=yolov8n-cls.pt epochs=100 imgsz=32
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
## Sample Images and Annotations
|
| 56 |
+
|
| 57 |
+
The CIFAR-10 dataset contains color images of various objects, providing a well-structured dataset for image classification tasks. Here are some examples of images from the dataset:
|
| 58 |
+
|
| 59 |
+

|
| 60 |
+
|
| 61 |
+
The example showcases the variety and complexity of the objects in the CIFAR-10 dataset, highlighting the importance of a diverse dataset for training robust image classification models.
|
| 62 |
+
|
| 63 |
+
## Citations and Acknowledgments
|
| 64 |
+
|
| 65 |
+
If you use the CIFAR-10 dataset in your research or development work, please cite the following paper:
|
| 66 |
+
|
| 67 |
+
!!! Quote ""
|
| 68 |
+
|
| 69 |
+
=== "BibTeX"
|
| 70 |
+
|
| 71 |
+
```bibtex
|
| 72 |
+
@TECHREPORT{Krizhevsky09learningmultiple,
|
| 73 |
+
author={Alex Krizhevsky},
|
| 74 |
+
title={Learning multiple layers of features from tiny images},
|
| 75 |
+
institution={},
|
| 76 |
+
year={2009}
|
| 77 |
+
}
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
We would like to acknowledge Alex Krizhevsky for creating and maintaining the CIFAR-10 dataset as a valuable resource for the machine learning and computer vision research community. For more information about the CIFAR-10 dataset and its creator, visit the [CIFAR-10 dataset website](https://www.cs.toronto.edu/~kriz/cifar.html).
|
yolov10/docs/en/datasets/classify/cifar100.md
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Discover how to leverage the CIFAR-100 dataset for machine learning and computer vision tasks with YOLO. Gain insights on its structure, use, and utilization for model training.
|
| 4 |
+
keywords: Ultralytics, YOLO, CIFAR-100 dataset, image classification, machine learning, computer vision, YOLO model training
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# CIFAR-100 Dataset
|
| 8 |
+
|
| 9 |
+
The [CIFAR-100](https://www.cs.toronto.edu/~kriz/cifar.html) (Canadian Institute For Advanced Research) dataset is a significant extension of the CIFAR-10 dataset, composed of 60,000 32x32 color images in 100 different classes. It was developed by researchers at the CIFAR institute, offering a more challenging dataset for more complex machine learning and computer vision tasks.
|
| 10 |
+
|
| 11 |
+
## Key Features
|
| 12 |
+
|
| 13 |
+
- The CIFAR-100 dataset consists of 60,000 images, divided into 100 classes.
|
| 14 |
+
- Each class contains 600 images, split into 500 for training and 100 for testing.
|
| 15 |
+
- The images are colored and of size 32x32 pixels.
|
| 16 |
+
- The 100 different classes are grouped into 20 coarse categories for higher level classification.
|
| 17 |
+
- CIFAR-100 is commonly used for training and testing in the field of machine learning and computer vision.
|
| 18 |
+
|
| 19 |
+
## Dataset Structure
|
| 20 |
+
|
| 21 |
+
The CIFAR-100 dataset is split into two subsets:
|
| 22 |
+
|
| 23 |
+
1. **Training Set**: This subset contains 50,000 images used for training machine learning models.
|
| 24 |
+
2. **Testing Set**: This subset consists of 10,000 images used for testing and benchmarking the trained models.
|
| 25 |
+
|
| 26 |
+
## Applications
|
| 27 |
+
|
| 28 |
+
The CIFAR-100 dataset is extensively used for training and evaluating deep learning models in image classification tasks, such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. The diversity of the dataset in terms of classes and the presence of color images make it a more challenging and comprehensive dataset for research and development in the field of machine learning and computer vision.
|
| 29 |
+
|
| 30 |
+
## Usage
|
| 31 |
+
|
| 32 |
+
To train a YOLO model on the CIFAR-100 dataset for 100 epochs with an image size of 32x32, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 33 |
+
|
| 34 |
+
!!! Example "Train Example"
|
| 35 |
+
|
| 36 |
+
=== "Python"
|
| 37 |
+
|
| 38 |
+
```python
|
| 39 |
+
from ultralytics import YOLO
|
| 40 |
+
|
| 41 |
+
# Load a model
|
| 42 |
+
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
| 43 |
+
|
| 44 |
+
# Train the model
|
| 45 |
+
results = model.train(data='cifar100', epochs=100, imgsz=32)
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
=== "CLI"
|
| 49 |
+
|
| 50 |
+
```bash
|
| 51 |
+
# Start training from a pretrained *.pt model
|
| 52 |
+
yolo detect train data=cifar100 model=yolov8n-cls.pt epochs=100 imgsz=32
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
## Sample Images and Annotations
|
| 56 |
+
|
| 57 |
+
The CIFAR-100 dataset contains color images of various objects, providing a well-structured dataset for image classification tasks. Here are some examples of images from the dataset:
|
| 58 |
+
|
| 59 |
+

|
| 60 |
+
|
| 61 |
+
The example showcases the variety and complexity of the objects in the CIFAR-100 dataset, highlighting the importance of a diverse dataset for training robust image classification models.
|
| 62 |
+
|
| 63 |
+
## Citations and Acknowledgments
|
| 64 |
+
|
| 65 |
+
If you use the CIFAR-100 dataset in your research or development work, please cite the following paper:
|
| 66 |
+
|
| 67 |
+
!!! Quote ""
|
| 68 |
+
|
| 69 |
+
=== "BibTeX"
|
| 70 |
+
|
| 71 |
+
```bibtex
|
| 72 |
+
@TECHREPORT{Krizhevsky09learningmultiple,
|
| 73 |
+
author={Alex Krizhevsky},
|
| 74 |
+
title={Learning multiple layers of features from tiny images},
|
| 75 |
+
institution={},
|
| 76 |
+
year={2009}
|
| 77 |
+
}
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
We would like to acknowledge Alex Krizhevsky for creating and maintaining the CIFAR-100 dataset as a valuable resource for the machine learning and computer vision research community. For more information about the CIFAR-100 dataset and its creator, visit the [CIFAR-100 dataset website](https://www.cs.toronto.edu/~kriz/cifar.html).
|
yolov10/docs/en/datasets/classify/fashion-mnist.md
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Learn how to use the Fashion-MNIST dataset for image classification with the Ultralytics YOLO model. Covers dataset structure, labels, applications, and usage.
|
| 4 |
+
keywords: Ultralytics, YOLO, Fashion-MNIST, dataset, image classification, machine learning, deep learning, neural networks, training, testing
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# Fashion-MNIST Dataset
|
| 8 |
+
|
| 9 |
+
The [Fashion-MNIST](https://github.com/zalandoresearch/fashion-mnist) dataset is a database of Zalando's article images—consisting of a training set of 60,000 examples and a test set of 10,000 examples. Each example is a 28x28 grayscale image, associated with a label from 10 classes. Fashion-MNIST is intended to serve as a direct drop-in replacement for the original MNIST dataset for benchmarking machine learning algorithms.
|
| 10 |
+
|
| 11 |
+
## Key Features
|
| 12 |
+
|
| 13 |
+
- Fashion-MNIST contains 60,000 training images and 10,000 testing images of Zalando's article images.
|
| 14 |
+
- The dataset comprises grayscale images of size 28x28 pixels.
|
| 15 |
+
- Each pixel has a single pixel-value associated with it, indicating the lightness or darkness of that pixel, with higher numbers meaning darker. This pixel-value is an integer between 0 and 255.
|
| 16 |
+
- Fashion-MNIST is widely used for training and testing in the field of machine learning, especially for image classification tasks.
|
| 17 |
+
|
| 18 |
+
## Dataset Structure
|
| 19 |
+
|
| 20 |
+
The Fashion-MNIST dataset is split into two subsets:
|
| 21 |
+
|
| 22 |
+
1. **Training Set**: This subset contains 60,000 images used for training machine learning models.
|
| 23 |
+
2. **Testing Set**: This subset consists of 10,000 images used for testing and benchmarking the trained models.
|
| 24 |
+
|
| 25 |
+
## Labels
|
| 26 |
+
|
| 27 |
+
Each training and test example is assigned to one of the following labels:
|
| 28 |
+
|
| 29 |
+
0. T-shirt/top
|
| 30 |
+
1. Trouser
|
| 31 |
+
2. Pullover
|
| 32 |
+
3. Dress
|
| 33 |
+
4. Coat
|
| 34 |
+
5. Sandal
|
| 35 |
+
6. Shirt
|
| 36 |
+
7. Sneaker
|
| 37 |
+
8. Bag
|
| 38 |
+
9. Ankle boot
|
| 39 |
+
|
| 40 |
+
## Applications
|
| 41 |
+
|
| 42 |
+
The Fashion-MNIST dataset is widely used for training and evaluating deep learning models in image classification tasks, such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. The dataset's simple and well-structured format makes it an essential resource for researchers and practitioners in the field of machine learning and computer vision.
|
| 43 |
+
|
| 44 |
+
## Usage
|
| 45 |
+
|
| 46 |
+
To train a CNN model on the Fashion-MNIST dataset for 100 epochs with an image size of 28x28, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 47 |
+
|
| 48 |
+
!!! Example "Train Example"
|
| 49 |
+
|
| 50 |
+
=== "Python"
|
| 51 |
+
|
| 52 |
+
```python
|
| 53 |
+
from ultralytics import YOLO
|
| 54 |
+
|
| 55 |
+
# Load a model
|
| 56 |
+
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
| 57 |
+
|
| 58 |
+
# Train the model
|
| 59 |
+
results = model.train(data='fashion-mnist', epochs=100, imgsz=28)
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
=== "CLI"
|
| 63 |
+
|
| 64 |
+
```bash
|
| 65 |
+
# Start training from a pretrained *.pt model
|
| 66 |
+
yolo detect train data=fashion-mnist model=yolov8n-cls.pt epochs=100 imgsz=28
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
## Sample Images and Annotations
|
| 70 |
+
|
| 71 |
+
The Fashion-MNIST dataset contains grayscale images of Zalando's article images, providing a well-structured dataset for image classification tasks. Here are some examples of images from the dataset:
|
| 72 |
+
|
| 73 |
+

|
| 74 |
+
|
| 75 |
+
The example showcases the variety and complexity of the images in the Fashion-MNIST dataset, highlighting the importance of a diverse dataset for training robust image classification models.
|
| 76 |
+
|
| 77 |
+
## Acknowledgments
|
| 78 |
+
|
| 79 |
+
If you use the Fashion-MNIST dataset in your research or development work, please acknowledge the dataset by linking to the [GitHub repository](https://github.com/zalandoresearch/fashion-mnist). This dataset was made available by Zalando Research.
|
yolov10/docs/en/datasets/classify/imagenet.md
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Understand how to use ImageNet, an extensive annotated image dataset for object recognition research, with Ultralytics YOLO models. Learn about its structure, usage, and significance in computer vision.
|
| 4 |
+
keywords: Ultralytics, YOLO, ImageNet, dataset, object recognition, deep learning, computer vision, machine learning, dataset training, model training, image classification, object detection
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# ImageNet Dataset
|
| 8 |
+
|
| 9 |
+
[ImageNet](https://www.image-net.org/) is a large-scale database of annotated images designed for use in visual object recognition research. It contains over 14 million images, with each image annotated using WordNet synsets, making it one of the most extensive resources available for training deep learning models in computer vision tasks.
|
| 10 |
+
|
| 11 |
+
## Key Features
|
| 12 |
+
|
| 13 |
+
- ImageNet contains over 14 million high-resolution images spanning thousands of object categories.
|
| 14 |
+
- The dataset is organized according to the WordNet hierarchy, with each synset representing a category.
|
| 15 |
+
- ImageNet is widely used for training and benchmarking in the field of computer vision, particularly for image classification and object detection tasks.
|
| 16 |
+
- The annual ImageNet Large Scale Visual Recognition Challenge (ILSVRC) has been instrumental in advancing computer vision research.
|
| 17 |
+
|
| 18 |
+
## Dataset Structure
|
| 19 |
+
|
| 20 |
+
The ImageNet dataset is organized using the WordNet hierarchy. Each node in the hierarchy represents a category, and each category is described by a synset (a collection of synonymous terms). The images in ImageNet are annotated with one or more synsets, providing a rich resource for training models to recognize various objects and their relationships.
|
| 21 |
+
|
| 22 |
+
## ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
|
| 23 |
+
|
| 24 |
+
The annual [ImageNet Large Scale Visual Recognition Challenge (ILSVRC)](https://image-net.org/challenges/LSVRC/) has been an important event in the field of computer vision. It has provided a platform for researchers and developers to evaluate their algorithms and models on a large-scale dataset with standardized evaluation metrics. The ILSVRC has led to significant advancements in the development of deep learning models for image classification, object detection, and other computer vision tasks.
|
| 25 |
+
|
| 26 |
+
## Applications
|
| 27 |
+
|
| 28 |
+
The ImageNet dataset is widely used for training and evaluating deep learning models in various computer vision tasks, such as image classification, object detection, and object localization. Some popular deep learning architectures, such as AlexNet, VGG, and ResNet, were developed and benchmarked using the ImageNet dataset.
|
| 29 |
+
|
| 30 |
+
## Usage
|
| 31 |
+
|
| 32 |
+
To train a deep learning model on the ImageNet dataset for 100 epochs with an image size of 224x224, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 33 |
+
|
| 34 |
+
!!! Example "Train Example"
|
| 35 |
+
|
| 36 |
+
=== "Python"
|
| 37 |
+
|
| 38 |
+
```python
|
| 39 |
+
from ultralytics import YOLO
|
| 40 |
+
|
| 41 |
+
# Load a model
|
| 42 |
+
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
| 43 |
+
|
| 44 |
+
# Train the model
|
| 45 |
+
results = model.train(data='imagenet', epochs=100, imgsz=224)
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
=== "CLI"
|
| 49 |
+
|
| 50 |
+
```bash
|
| 51 |
+
# Start training from a pretrained *.pt model
|
| 52 |
+
yolo train data=imagenet model=yolov8n-cls.pt epochs=100 imgsz=224
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
## Sample Images and Annotations
|
| 56 |
+
|
| 57 |
+
The ImageNet dataset contains high-resolution images spanning thousands of object categories, providing a diverse and extensive dataset for training and evaluating computer vision models. Here are some examples of images from the dataset:
|
| 58 |
+
|
| 59 |
+

|
| 60 |
+
|
| 61 |
+
The example showcases the variety and complexity of the images in the ImageNet dataset, highlighting the importance of a diverse dataset for training robust computer vision models.
|
| 62 |
+
|
| 63 |
+
## Citations and Acknowledgments
|
| 64 |
+
|
| 65 |
+
If you use the ImageNet dataset in your research or development work, please cite the following paper:
|
| 66 |
+
|
| 67 |
+
!!! Quote ""
|
| 68 |
+
|
| 69 |
+
=== "BibTeX"
|
| 70 |
+
|
| 71 |
+
```bibtex
|
| 72 |
+
@article{ILSVRC15,
|
| 73 |
+
author = {Olga Russakovsky and Jia Deng and Hao Su and Jonathan Krause and Sanjeev Satheesh and Sean Ma and Zhiheng Huang and Andrej Karpathy and Aditya Khosla and Michael Bernstein and Alexander C. Berg and Li Fei-Fei},
|
| 74 |
+
title={ImageNet Large Scale Visual Recognition Challenge},
|
| 75 |
+
year={2015},
|
| 76 |
+
journal={International Journal of Computer Vision (IJCV)},
|
| 77 |
+
volume={115},
|
| 78 |
+
number={3},
|
| 79 |
+
pages={211-252}
|
| 80 |
+
}
|
| 81 |
+
```
|
| 82 |
+
|
| 83 |
+
We would like to acknowledge the ImageNet team, led by Olga Russakovsky, Jia Deng, and Li Fei-Fei, for creating and maintaining the ImageNet dataset as a valuable resource for the machine learning and computer vision research community. For more information about the ImageNet dataset and its creators, visit the [ImageNet website](https://www.image-net.org/).
|
yolov10/docs/en/datasets/classify/imagenet10.md
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Explore the compact ImageNet10 Dataset developed by Ultralytics. Ideal for fast testing of computer vision training pipelines and CV model sanity checks.
|
| 4 |
+
keywords: Ultralytics, YOLO, ImageNet10 Dataset, Image detection, Deep Learning, ImageNet, AI model testing, Computer vision, Machine learning
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# ImageNet10 Dataset
|
| 8 |
+
|
| 9 |
+
The [ImageNet10](https://github.com/ultralytics/yolov5/releases/download/v1.0/imagenet10.zip) dataset is a small-scale subset of the [ImageNet](https://www.image-net.org/) database, developed by [Ultralytics](https://ultralytics.com) and designed for CI tests, sanity checks, and fast testing of training pipelines. This dataset is composed of the first image in the training set and the first image from the validation set of the first 10 classes in ImageNet. Although significantly smaller, it retains the structure and diversity of the original ImageNet dataset.
|
| 10 |
+
|
| 11 |
+
## Key Features
|
| 12 |
+
|
| 13 |
+
- ImageNet10 is a compact version of ImageNet, with 20 images representing the first 10 classes of the original dataset.
|
| 14 |
+
- The dataset is organized according to the WordNet hierarchy, mirroring the structure of the full ImageNet dataset.
|
| 15 |
+
- It is ideally suited for CI tests, sanity checks, and rapid testing of training pipelines in computer vision tasks.
|
| 16 |
+
- Although not designed for model benchmarking, it can provide a quick indication of a model's basic functionality and correctness.
|
| 17 |
+
|
| 18 |
+
## Dataset Structure
|
| 19 |
+
|
| 20 |
+
The ImageNet10 dataset, like the original ImageNet, is organized using the WordNet hierarchy. Each of the 10 classes in ImageNet10 is described by a synset (a collection of synonymous terms). The images in ImageNet10 are annotated with one or more synsets, providing a compact resource for testing models to recognize various objects and their relationships.
|
| 21 |
+
|
| 22 |
+
## Applications
|
| 23 |
+
|
| 24 |
+
The ImageNet10 dataset is useful for quickly testing and debugging computer vision models and pipelines. Its small size allows for rapid iteration, making it ideal for continuous integration tests and sanity checks. It can also be used for fast preliminary testing of new models or changes to existing models before moving on to full-scale testing with the complete ImageNet dataset.
|
| 25 |
+
|
| 26 |
+
## Usage
|
| 27 |
+
|
| 28 |
+
To test a deep learning model on the ImageNet10 dataset with an image size of 224x224, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 29 |
+
|
| 30 |
+
!!! Example "Test Example"
|
| 31 |
+
|
| 32 |
+
=== "Python"
|
| 33 |
+
|
| 34 |
+
```python
|
| 35 |
+
from ultralytics import YOLO
|
| 36 |
+
|
| 37 |
+
# Load a model
|
| 38 |
+
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
| 39 |
+
|
| 40 |
+
# Train the model
|
| 41 |
+
results = model.train(data='imagenet10', epochs=5, imgsz=224)
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
=== "CLI"
|
| 45 |
+
|
| 46 |
+
```bash
|
| 47 |
+
# Start training from a pretrained *.pt model
|
| 48 |
+
yolo train data=imagenet10 model=yolov8n-cls.pt epochs=5 imgsz=224
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
## Sample Images and Annotations
|
| 52 |
+
|
| 53 |
+
The ImageNet10 dataset contains a subset of images from the original ImageNet dataset. These images are chosen to represent the first 10 classes in the dataset, providing a diverse yet compact dataset for quick testing and evaluation.
|
| 54 |
+
|
| 55 |
+
 The example showcases the variety and complexity of the images in the ImageNet10 dataset, highlighting its usefulness for sanity checks and quick testing of computer vision models.
|
| 56 |
+
|
| 57 |
+
## Citations and Acknowledgments
|
| 58 |
+
|
| 59 |
+
If you use the ImageNet10 dataset in your research or development work, please cite the original ImageNet paper:
|
| 60 |
+
|
| 61 |
+
!!! Quote ""
|
| 62 |
+
|
| 63 |
+
=== "BibTeX"
|
| 64 |
+
|
| 65 |
+
```bibtex
|
| 66 |
+
@article{ILSVRC15,
|
| 67 |
+
author = {Olga Russakovsky and Jia Deng and Hao Su and Jonathan Krause and Sanjeev Satheesh and Sean Ma and Zhiheng Huang and Andrej Karpathy and Aditya Khosla and Michael Bernstein and Alexander C. Berg and Li Fei-Fei},
|
| 68 |
+
title={ImageNet Large Scale Visual Recognition Challenge},
|
| 69 |
+
year={2015},
|
| 70 |
+
journal={International Journal of Computer Vision (IJCV)},
|
| 71 |
+
volume={115},
|
| 72 |
+
number={3},
|
| 73 |
+
pages={211-252}
|
| 74 |
+
}
|
| 75 |
+
```
|
| 76 |
+
|
| 77 |
+
We would like to acknowledge the ImageNet team, led by Olga Russakovsky, Jia Deng, and Li Fei-Fei, for creating and maintaining the ImageNet dataset. The ImageNet10 dataset, while a compact subset, is a valuable resource for quick testing and debugging in the machine learning and computer vision research community. For more information about the ImageNet dataset and its creators, visit the [ImageNet website](https://www.image-net.org/).
|
yolov10/docs/en/datasets/classify/imagenette.md
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Learn about the ImageNette dataset and its usage in deep learning model training. Find code snippets for model training and explore ImageNette datatypes.
|
| 4 |
+
keywords: ImageNette dataset, Ultralytics, YOLO, Image classification, Machine Learning, Deep learning, Training code snippets, CNN, ImageNette160, ImageNette320
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# ImageNette Dataset
|
| 8 |
+
|
| 9 |
+
The [ImageNette](https://github.com/fastai/imagenette) dataset is a subset of the larger [Imagenet](https://www.image-net.org/) dataset, but it only includes 10 easily distinguishable classes. It was created to provide a quicker, easier-to-use version of Imagenet for software development and education.
|
| 10 |
+
|
| 11 |
+
## Key Features
|
| 12 |
+
|
| 13 |
+
- ImageNette contains images from 10 different classes such as tench, English springer, cassette player, chain saw, church, French horn, garbage truck, gas pump, golf ball, parachute.
|
| 14 |
+
- The dataset comprises colored images of varying dimensions.
|
| 15 |
+
- ImageNette is widely used for training and testing in the field of machine learning, especially for image classification tasks.
|
| 16 |
+
|
| 17 |
+
## Dataset Structure
|
| 18 |
+
|
| 19 |
+
The ImageNette dataset is split into two subsets:
|
| 20 |
+
|
| 21 |
+
1. **Training Set**: This subset contains several thousands of images used for training machine learning models. The exact number varies per class.
|
| 22 |
+
2. **Validation Set**: This subset consists of several hundreds of images used for validating and benchmarking the trained models. Again, the exact number varies per class.
|
| 23 |
+
|
| 24 |
+
## Applications
|
| 25 |
+
|
| 26 |
+
The ImageNette dataset is widely used for training and evaluating deep learning models in image classification tasks, such as Convolutional Neural Networks (CNNs), and various other machine learning algorithms. The dataset's straightforward format and well-chosen classes make it a handy resource for both beginner and experienced practitioners in the field of machine learning and computer vision.
|
| 27 |
+
|
| 28 |
+
## Usage
|
| 29 |
+
|
| 30 |
+
To train a model on the ImageNette dataset for 100 epochs with a standard image size of 224x224, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 31 |
+
|
| 32 |
+
!!! Example "Train Example"
|
| 33 |
+
|
| 34 |
+
=== "Python"
|
| 35 |
+
|
| 36 |
+
```python
|
| 37 |
+
from ultralytics import YOLO
|
| 38 |
+
|
| 39 |
+
# Load a model
|
| 40 |
+
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
| 41 |
+
|
| 42 |
+
# Train the model
|
| 43 |
+
results = model.train(data='imagenette', epochs=100, imgsz=224)
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
=== "CLI"
|
| 47 |
+
|
| 48 |
+
```bash
|
| 49 |
+
# Start training from a pretrained *.pt model
|
| 50 |
+
yolo detect train data=imagenette model=yolov8n-cls.pt epochs=100 imgsz=224
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
## Sample Images and Annotations
|
| 54 |
+
|
| 55 |
+
The ImageNette dataset contains colored images of various objects and scenes, providing a diverse dataset for image classification tasks. Here are some examples of images from the dataset:
|
| 56 |
+
|
| 57 |
+

|
| 58 |
+
|
| 59 |
+
The example showcases the variety and complexity of the images in the ImageNette dataset, highlighting the importance of a diverse dataset for training robust image classification models.
|
| 60 |
+
|
| 61 |
+
## ImageNette160 and ImageNette320
|
| 62 |
+
|
| 63 |
+
For faster prototyping and training, the ImageNette dataset is also available in two reduced sizes: ImageNette160 and ImageNette320. These datasets maintain the same classes and structure as the full ImageNette dataset, but the images are resized to a smaller dimension. As such, these versions of the dataset are particularly useful for preliminary model testing, or when computational resources are limited.
|
| 64 |
+
|
| 65 |
+
To use these datasets, simply replace 'imagenette' with 'imagenette160' or 'imagenette320' in the training command. The following code snippets illustrate this:
|
| 66 |
+
|
| 67 |
+
!!! Example "Train Example with ImageNette160"
|
| 68 |
+
|
| 69 |
+
=== "Python"
|
| 70 |
+
|
| 71 |
+
```python
|
| 72 |
+
from ultralytics import YOLO
|
| 73 |
+
|
| 74 |
+
# Load a model
|
| 75 |
+
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
| 76 |
+
|
| 77 |
+
# Train the model with ImageNette160
|
| 78 |
+
results = model.train(data='imagenette160', epochs=100, imgsz=160)
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
=== "CLI"
|
| 82 |
+
|
| 83 |
+
```bash
|
| 84 |
+
# Start training from a pretrained *.pt model with ImageNette160
|
| 85 |
+
yolo detect train data=imagenette160 model=yolov8n-cls.pt epochs=100 imgsz=160
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
!!! Example "Train Example with ImageNette320"
|
| 89 |
+
|
| 90 |
+
=== "Python"
|
| 91 |
+
|
| 92 |
+
```python
|
| 93 |
+
from ultralytics import YOLO
|
| 94 |
+
|
| 95 |
+
# Load a model
|
| 96 |
+
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
| 97 |
+
|
| 98 |
+
# Train the model with ImageNette320
|
| 99 |
+
results = model.train(data='imagenette320', epochs=100, imgsz=320)
|
| 100 |
+
```
|
| 101 |
+
|
| 102 |
+
=== "CLI"
|
| 103 |
+
|
| 104 |
+
```bash
|
| 105 |
+
# Start training from a pretrained *.pt model with ImageNette320
|
| 106 |
+
yolo detect train data=imagenette320 model=yolov8n-cls.pt epochs=100 imgsz=320
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
These smaller versions of the dataset allow for rapid iterations during the development process while still providing valuable and realistic image classification tasks.
|
| 110 |
+
|
| 111 |
+
## Citations and Acknowledgments
|
| 112 |
+
|
| 113 |
+
If you use the ImageNette dataset in your research or development work, please acknowledge it appropriately. For more information about the ImageNette dataset, visit the [ImageNette dataset GitHub page](https://github.com/fastai/imagenette).
|
yolov10/docs/en/datasets/classify/imagewoof.md
ADDED
|
@@ -0,0 +1,89 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Explore the ImageWoof dataset, designed for challenging dog breed classification. Train AI models with Ultralytics YOLO using this dataset.
|
| 4 |
+
keywords: ImageWoof, image classification, dog breeds, machine learning, deep learning, Ultralytics, YOLO, dataset
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# ImageWoof Dataset
|
| 8 |
+
|
| 9 |
+
The [ImageWoof](https://github.com/fastai/imagenette) dataset is a subset of the ImageNet consisting of 10 classes that are challenging to classify, since they're all dog breeds. It was created as a more difficult task for image classification algorithms to solve, aiming at encouraging development of more advanced models.
|
| 10 |
+
|
| 11 |
+
## Key Features
|
| 12 |
+
|
| 13 |
+
- ImageWoof contains images of 10 different dog breeds: Australian terrier, Border terrier, Samoyed, Beagle, Shih-Tzu, English foxhound, Rhodesian ridgeback, Dingo, Golden retriever, and Old English sheepdog.
|
| 14 |
+
- The dataset provides images at various resolutions (full size, 320px, 160px), accommodating for different computational capabilities and research needs.
|
| 15 |
+
- It also includes a version with noisy labels, providing a more realistic scenario where labels might not always be reliable.
|
| 16 |
+
|
| 17 |
+
## Dataset Structure
|
| 18 |
+
|
| 19 |
+
The ImageWoof dataset structure is based on the dog breed classes, with each breed having its own directory of images.
|
| 20 |
+
|
| 21 |
+
## Applications
|
| 22 |
+
|
| 23 |
+
The ImageWoof dataset is widely used for training and evaluating deep learning models in image classification tasks, especially when it comes to more complex and similar classes. The dataset's challenge lies in the subtle differences between the dog breeds, pushing the limits of model's performance and generalization.
|
| 24 |
+
|
| 25 |
+
## Usage
|
| 26 |
+
|
| 27 |
+
To train a CNN model on the ImageWoof dataset for 100 epochs with an image size of 224x224, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 28 |
+
|
| 29 |
+
!!! Example "Train Example"
|
| 30 |
+
|
| 31 |
+
=== "Python"
|
| 32 |
+
|
| 33 |
+
```python
|
| 34 |
+
from ultralytics import YOLO
|
| 35 |
+
|
| 36 |
+
# Load a model
|
| 37 |
+
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
| 38 |
+
|
| 39 |
+
# Train the model
|
| 40 |
+
results = model.train(data='imagewoof', epochs=100, imgsz=224)
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
=== "CLI"
|
| 44 |
+
|
| 45 |
+
```bash
|
| 46 |
+
# Start training from a pretrained *.pt model
|
| 47 |
+
yolo detect train data=imagewoof model=yolov8n-cls.pt epochs=100 imgsz=224
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
## Dataset Variants
|
| 51 |
+
|
| 52 |
+
ImageWoof dataset comes in three different sizes to accommodate various research needs and computational capabilities:
|
| 53 |
+
|
| 54 |
+
1. **Full Size (imagewoof)**: This is the original version of the ImageWoof dataset. It contains full-sized images and is ideal for final training and performance benchmarking.
|
| 55 |
+
|
| 56 |
+
2. **Medium Size (imagewoof320)**: This version contains images resized to have a maximum edge length of 320 pixels. It's suitable for faster training without significantly sacrificing model performance.
|
| 57 |
+
|
| 58 |
+
3. **Small Size (imagewoof160)**: This version contains images resized to have a maximum edge length of 160 pixels. It's designed for rapid prototyping and experimentation where training speed is a priority.
|
| 59 |
+
|
| 60 |
+
To use these variants in your training, simply replace 'imagewoof' in the dataset argument with 'imagewoof320' or 'imagewoof160'. For example:
|
| 61 |
+
|
| 62 |
+
```python
|
| 63 |
+
from ultralytics import YOLO
|
| 64 |
+
|
| 65 |
+
# Load a model
|
| 66 |
+
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
| 67 |
+
|
| 68 |
+
# For medium-sized dataset
|
| 69 |
+
model.train(data='imagewoof320', epochs=100, imgsz=224)
|
| 70 |
+
|
| 71 |
+
# For small-sized dataset
|
| 72 |
+
model.train(data='imagewoof160', epochs=100, imgsz=224)
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
It's important to note that using smaller images will likely yield lower performance in terms of classification accuracy. However, it's an excellent way to iterate quickly in the early stages of model development and prototyping.
|
| 76 |
+
|
| 77 |
+
## Sample Images and Annotations
|
| 78 |
+
|
| 79 |
+
The ImageWoof dataset contains colorful images of various dog breeds, providing a challenging dataset for image classification tasks. Here are some examples of images from the dataset:
|
| 80 |
+
|
| 81 |
+

|
| 82 |
+
|
| 83 |
+
The example showcases the subtle differences and similarities among the different dog breeds in the ImageWoof dataset, highlighting the complexity and difficulty of the classification task.
|
| 84 |
+
|
| 85 |
+
## Citations and Acknowledgments
|
| 86 |
+
|
| 87 |
+
If you use the ImageWoof dataset in your research or development work, please make sure to acknowledge the creators of the dataset by linking to the [official dataset repository](https://github.com/fastai/imagenette).
|
| 88 |
+
|
| 89 |
+
We would like to acknowledge the FastAI team for creating and maintaining the ImageWoof dataset as a valuable resource for the machine learning and computer vision research community. For more information about the ImageWoof dataset, visit the [ImageWoof dataset repository](https://github.com/fastai/imagenette).
|
yolov10/docs/en/datasets/classify/index.md
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Explore image classification datasets supported by Ultralytics, learn the standard dataset format, and set up your own dataset for training models.
|
| 4 |
+
keywords: Ultralytics, image classification, dataset, machine learning, CIFAR-10, ImageNet, MNIST, torchvision
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# Image Classification Datasets Overview
|
| 8 |
+
|
| 9 |
+
## Dataset format
|
| 10 |
+
|
| 11 |
+
The folder structure for classification datasets in torchvision typically follows a standard format:
|
| 12 |
+
|
| 13 |
+
```
|
| 14 |
+
root/
|
| 15 |
+
|-- class1/
|
| 16 |
+
| |-- img1.jpg
|
| 17 |
+
| |-- img2.jpg
|
| 18 |
+
| |-- ...
|
| 19 |
+
|
|
| 20 |
+
|-- class2/
|
| 21 |
+
| |-- img1.jpg
|
| 22 |
+
| |-- img2.jpg
|
| 23 |
+
| |-- ...
|
| 24 |
+
|
|
| 25 |
+
|-- class3/
|
| 26 |
+
| |-- img1.jpg
|
| 27 |
+
| |-- img2.jpg
|
| 28 |
+
| |-- ...
|
| 29 |
+
|
|
| 30 |
+
|-- ...
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
In this folder structure, the `root` directory contains one subdirectory for each class in the dataset. Each subdirectory is named after the corresponding class and contains all the images for that class. Each image file is named uniquely and is typically in a common image file format such as JPEG or PNG.
|
| 34 |
+
|
| 35 |
+
** Example **
|
| 36 |
+
|
| 37 |
+
For example, in the CIFAR10 dataset, the folder structure would look like this:
|
| 38 |
+
|
| 39 |
+
```
|
| 40 |
+
cifar-10-/
|
| 41 |
+
|
|
| 42 |
+
|-- train/
|
| 43 |
+
| |-- airplane/
|
| 44 |
+
| | |-- 10008_airplane.png
|
| 45 |
+
| | |-- 10009_airplane.png
|
| 46 |
+
| | |-- ...
|
| 47 |
+
| |
|
| 48 |
+
| |-- automobile/
|
| 49 |
+
| | |-- 1000_automobile.png
|
| 50 |
+
| | |-- 1001_automobile.png
|
| 51 |
+
| | |-- ...
|
| 52 |
+
| |
|
| 53 |
+
| |-- bird/
|
| 54 |
+
| | |-- 10014_bird.png
|
| 55 |
+
| | |-- 10015_bird.png
|
| 56 |
+
| | |-- ...
|
| 57 |
+
| |
|
| 58 |
+
| |-- ...
|
| 59 |
+
|
|
| 60 |
+
|-- test/
|
| 61 |
+
| |-- airplane/
|
| 62 |
+
| | |-- 10_airplane.png
|
| 63 |
+
| | |-- 11_airplane.png
|
| 64 |
+
| | |-- ...
|
| 65 |
+
| |
|
| 66 |
+
| |-- automobile/
|
| 67 |
+
| | |-- 100_automobile.png
|
| 68 |
+
| | |-- 101_automobile.png
|
| 69 |
+
| | |-- ...
|
| 70 |
+
| |
|
| 71 |
+
| |-- bird/
|
| 72 |
+
| | |-- 1000_bird.png
|
| 73 |
+
| | |-- 1001_bird.png
|
| 74 |
+
| | |-- ...
|
| 75 |
+
| |
|
| 76 |
+
| |-- ...
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
In this example, the `train` directory contains subdirectories for each class in the dataset, and each class subdirectory contains all the images for that class. The `test` directory has a similar structure. The `root` directory also contains other files that are part of the CIFAR10 dataset.
|
| 80 |
+
|
| 81 |
+
## Usage
|
| 82 |
+
|
| 83 |
+
!!! Example
|
| 84 |
+
|
| 85 |
+
=== "Python"
|
| 86 |
+
|
| 87 |
+
```python
|
| 88 |
+
from ultralytics import YOLO
|
| 89 |
+
|
| 90 |
+
# Load a model
|
| 91 |
+
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
| 92 |
+
|
| 93 |
+
# Train the model
|
| 94 |
+
results = model.train(data='path/to/dataset', epochs=100, imgsz=640)
|
| 95 |
+
```
|
| 96 |
+
=== "CLI"
|
| 97 |
+
|
| 98 |
+
```bash
|
| 99 |
+
# Start training from a pretrained *.pt model
|
| 100 |
+
yolo detect train data=path/to/data model=yolov8n-cls.pt epochs=100 imgsz=640
|
| 101 |
+
```
|
| 102 |
+
|
| 103 |
+
## Supported Datasets
|
| 104 |
+
|
| 105 |
+
Ultralytics supports the following datasets with automatic download:
|
| 106 |
+
|
| 107 |
+
- [Caltech 101](caltech101.md): A dataset containing images of 101 object categories for image classification tasks.
|
| 108 |
+
- [Caltech 256](caltech256.md): An extended version of Caltech 101 with 256 object categories and more challenging images.
|
| 109 |
+
- [CIFAR-10](cifar10.md): A dataset of 60K 32x32 color images in 10 classes, with 6K images per class.
|
| 110 |
+
- [CIFAR-100](cifar100.md): An extended version of CIFAR-10 with 100 object categories and 600 images per class.
|
| 111 |
+
- [Fashion-MNIST](fashion-mnist.md): A dataset consisting of 70,000 grayscale images of 10 fashion categories for image classification tasks.
|
| 112 |
+
- [ImageNet](imagenet.md): A large-scale dataset for object detection and image classification with over 14 million images and 20,000 categories.
|
| 113 |
+
- [ImageNet-10](imagenet10.md): A smaller subset of ImageNet with 10 categories for faster experimentation and testing.
|
| 114 |
+
- [Imagenette](imagenette.md): A smaller subset of ImageNet that contains 10 easily distinguishable classes for quicker training and testing.
|
| 115 |
+
- [Imagewoof](imagewoof.md): A more challenging subset of ImageNet containing 10 dog breed categories for image classification tasks.
|
| 116 |
+
- [MNIST](mnist.md): A dataset of 70,000 grayscale images of handwritten digits for image classification tasks.
|
| 117 |
+
|
| 118 |
+
### Adding your own dataset
|
| 119 |
+
|
| 120 |
+
If you have your own dataset and would like to use it for training classification models with Ultralytics, ensure that it follows the format specified above under "Dataset format" and then point your `data` argument to the dataset directory.
|
yolov10/docs/en/datasets/classify/mnist.md
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Detailed guide on the MNIST Dataset, a benchmark in the machine learning community for image classification tasks. Learn about its structure, usage and application.
|
| 4 |
+
keywords: MNIST dataset, Ultralytics, image classification, machine learning, computer vision, deep learning, AI, dataset guide
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# MNIST Dataset
|
| 8 |
+
|
| 9 |
+
The [MNIST](http://yann.lecun.com/exdb/mnist/) (Modified National Institute of Standards and Technology) dataset is a large database of handwritten digits that is commonly used for training various image processing systems and machine learning models. It was created by "re-mixing" the samples from NIST's original datasets and has become a benchmark for evaluating the performance of image classification algorithms.
|
| 10 |
+
|
| 11 |
+
## Key Features
|
| 12 |
+
|
| 13 |
+
- MNIST contains 60,000 training images and 10,000 testing images of handwritten digits.
|
| 14 |
+
- The dataset comprises grayscale images of size 28x28 pixels.
|
| 15 |
+
- The images are normalized to fit into a 28x28 pixel bounding box and anti-aliased, introducing grayscale levels.
|
| 16 |
+
- MNIST is widely used for training and testing in the field of machine learning, especially for image classification tasks.
|
| 17 |
+
|
| 18 |
+
## Dataset Structure
|
| 19 |
+
|
| 20 |
+
The MNIST dataset is split into two subsets:
|
| 21 |
+
|
| 22 |
+
1. **Training Set**: This subset contains 60,000 images of handwritten digits used for training machine learning models.
|
| 23 |
+
2. **Testing Set**: This subset consists of 10,000 images used for testing and benchmarking the trained models.
|
| 24 |
+
|
| 25 |
+
## Extended MNIST (EMNIST)
|
| 26 |
+
|
| 27 |
+
Extended MNIST (EMNIST) is a newer dataset developed and released by NIST to be the successor to MNIST. While MNIST included images only of handwritten digits, EMNIST includes all the images from NIST Special Database 19, which is a large database of handwritten uppercase and lowercase letters as well as digits. The images in EMNIST were converted into the same 28x28 pixel format, by the same process, as were the MNIST images. Accordingly, tools that work with the older, smaller MNIST dataset will likely work unmodified with EMNIST.
|
| 28 |
+
|
| 29 |
+
## Applications
|
| 30 |
+
|
| 31 |
+
The MNIST dataset is widely used for training and evaluating deep learning models in image classification tasks, such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. The dataset's simple and well-structured format makes it an essential resource for researchers and practitioners in the field of machine learning and computer vision.
|
| 32 |
+
|
| 33 |
+
## Usage
|
| 34 |
+
|
| 35 |
+
To train a CNN model on the MNIST dataset for 100 epochs with an image size of 32x32, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 36 |
+
|
| 37 |
+
!!! Example "Train Example"
|
| 38 |
+
|
| 39 |
+
=== "Python"
|
| 40 |
+
|
| 41 |
+
```python
|
| 42 |
+
from ultralytics import YOLO
|
| 43 |
+
|
| 44 |
+
# Load a model
|
| 45 |
+
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
| 46 |
+
|
| 47 |
+
# Train the model
|
| 48 |
+
results = model.train(data='mnist', epochs=100, imgsz=32)
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
=== "CLI"
|
| 52 |
+
|
| 53 |
+
```bash
|
| 54 |
+
# Start training from a pretrained *.pt model
|
| 55 |
+
cnn detect train data=mnist model=yolov8n-cls.pt epochs=100 imgsz=28
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
## Sample Images and Annotations
|
| 59 |
+
|
| 60 |
+
The MNIST dataset contains grayscale images of handwritten digits, providing a well-structured dataset for image classification tasks. Here are some examples of images from the dataset:
|
| 61 |
+
|
| 62 |
+

|
| 63 |
+
|
| 64 |
+
The example showcases the variety and complexity of the handwritten digits in the MNIST dataset, highlighting the importance of a diverse dataset for training robust image classification models.
|
| 65 |
+
|
| 66 |
+
## Citations and Acknowledgments
|
| 67 |
+
|
| 68 |
+
If you use the MNIST dataset in your
|
| 69 |
+
|
| 70 |
+
research or development work, please cite the following paper:
|
| 71 |
+
|
| 72 |
+
!!! Quote ""
|
| 73 |
+
|
| 74 |
+
=== "BibTeX"
|
| 75 |
+
|
| 76 |
+
```bibtex
|
| 77 |
+
@article{lecun2010mnist,
|
| 78 |
+
title={MNIST handwritten digit database},
|
| 79 |
+
author={LeCun, Yann and Cortes, Corinna and Burges, CJ},
|
| 80 |
+
journal={ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist},
|
| 81 |
+
volume={2},
|
| 82 |
+
year={2010}
|
| 83 |
+
}
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
We would like to acknowledge Yann LeCun, Corinna Cortes, and Christopher J.C. Burges for creating and maintaining the MNIST dataset as a valuable resource for the machine learning and computer vision research community. For more information about the MNIST dataset and its creators, visit the [MNIST dataset website](http://yann.lecun.com/exdb/mnist/).
|
yolov10/docs/en/datasets/detect/african-wildlife.md
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: African Wildlife objects detection, a leading dataset for object detection in forests, integrates with Ultralytics. Discover ways to use it for training YOLO models.
|
| 4 |
+
keywords: Ultralytics, African Wildlife dataset, object detection, YOLO, YOLO model training, object tracking, computer vision, deep learning models, forest research, animals tracking
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# African Wildlife Dataset
|
| 8 |
+
|
| 9 |
+
This dataset showcases four common animal classes typically found in South African nature reserves. It includes images of African wildlife such as buffalo, elephant, rhino, and zebra, providing valuable insights into their characteristics. Essential for training computer vision algorithms, this dataset aids in identifying animals in various habitats, from zoos to forests, and supports wildlife research.
|
| 10 |
+
|
| 11 |
+
## Dataset Structure
|
| 12 |
+
|
| 13 |
+
The African wildlife objects detection dataset is split into three subsets:
|
| 14 |
+
|
| 15 |
+
- **Training set**: Contains 1052 images, each with corresponding annotations.
|
| 16 |
+
- **Validation set**: Includes 225 images, each with paired annotations.
|
| 17 |
+
- **Testing set**: Comprises 227 images, each with paired annotations.
|
| 18 |
+
|
| 19 |
+
## Applications
|
| 20 |
+
|
| 21 |
+
This dataset can be applied in various computer vision tasks such as object detection, object tracking, and research. Specifically, it can be used to train and evaluate models for identifying African wildlife objects in images, which can have applications in wildlife conservation, ecological research, and monitoring efforts in natural reserves and protected areas. Additionally, it can serve as a valuable resource for educational purposes, enabling students and researchers to study and understand the characteristics and behaviors of different animal species.
|
| 22 |
+
|
| 23 |
+
## Dataset YAML
|
| 24 |
+
|
| 25 |
+
A YAML (Yet Another Markup Language) file defines the dataset configuration, including paths, classes, and other pertinent details. For the African wildlife dataset, the `african-wildlife.yaml` file is located at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/african-wildlife.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/african-wildlife.yaml).
|
| 26 |
+
|
| 27 |
+
!!! Example "ultralytics/cfg/datasets/african-wildlife.yaml"
|
| 28 |
+
|
| 29 |
+
```yaml
|
| 30 |
+
--8<-- "ultralytics/cfg/datasets/african-wildlife.yaml"
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
## Usage
|
| 34 |
+
|
| 35 |
+
To train a YOLOv8n model on the African wildlife dataset for 100 epochs with an image size of 640, use the provided code samples. For a comprehensive list of available parameters, refer to the model's [Training](../../modes/train.md) page.
|
| 36 |
+
|
| 37 |
+
!!! Example "Train Example"
|
| 38 |
+
|
| 39 |
+
=== "Python"
|
| 40 |
+
|
| 41 |
+
```python
|
| 42 |
+
from ultralytics import YOLO
|
| 43 |
+
|
| 44 |
+
# Load a model
|
| 45 |
+
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
| 46 |
+
|
| 47 |
+
# Train the model
|
| 48 |
+
results = model.train(data='african-wildlife.yaml', epochs=100, imgsz=640)
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
=== "CLI"
|
| 52 |
+
|
| 53 |
+
```bash
|
| 54 |
+
# Start training from a pretrained *.pt model
|
| 55 |
+
yolo detect train data=african-wildlife.yaml model=yolov8n.pt epochs=100 imgsz=640
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
!!! Example "Inference Example"
|
| 59 |
+
|
| 60 |
+
=== "Python"
|
| 61 |
+
|
| 62 |
+
```python
|
| 63 |
+
from ultralytics import YOLO
|
| 64 |
+
|
| 65 |
+
# Load a model
|
| 66 |
+
model = YOLO('path/to/best.pt') # load a brain-tumor fine-tuned model
|
| 67 |
+
|
| 68 |
+
# Inference using the model
|
| 69 |
+
results = model.predict("https://ultralytics.com/assets/african-wildlife-sample.jpg")
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
=== "CLI"
|
| 73 |
+
|
| 74 |
+
```bash
|
| 75 |
+
# Start prediction with a finetuned *.pt model
|
| 76 |
+
yolo detect predict model='path/to/best.pt' imgsz=640 source="https://ultralytics.com/assets/african-wildlife-sample.jpg"
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
## Sample Images and Annotations
|
| 81 |
+
|
| 82 |
+
The African wildlife dataset comprises a wide variety of images showcasing diverse animal species and their natural habitats. Below are examples of images from the dataset, each accompanied by its corresponding annotations.
|
| 83 |
+
|
| 84 |
+

|
| 85 |
+
|
| 86 |
+
- **Mosaiced Image**: Here, we present a training batch consisting of mosaiced dataset images. Mosaicing, a training technique, combines multiple images into one, enriching batch diversity. This method helps enhance the model's ability to generalize across different object sizes, aspect ratios, and contexts.
|
| 87 |
+
|
| 88 |
+
This example illustrates the variety and complexity of images in the African wildlife dataset, emphasizing the benefits of including mosaicing during the training process.
|
| 89 |
+
|
| 90 |
+
## Citations and Acknowledgments
|
| 91 |
+
|
| 92 |
+
The dataset has been released available under the [AGPL-3.0 License](https://github.com/ultralytics/ultralytics/blob/main/LICENSE).
|
yolov10/docs/en/datasets/detect/argoverse.md
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Explore Argoverse, a comprehensive dataset for autonomous driving tasks including 3D tracking, motion forecasting and depth estimation used in YOLO.
|
| 4 |
+
keywords: Argoverse dataset, autonomous driving, YOLO, 3D tracking, motion forecasting, LiDAR data, HD maps, ultralytics documentation
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# Argoverse Dataset
|
| 8 |
+
|
| 9 |
+
The [Argoverse](https://www.argoverse.org/) dataset is a collection of data designed to support research in autonomous driving tasks, such as 3D tracking, motion forecasting, and stereo depth estimation. Developed by Argo AI, the dataset provides a wide range of high-quality sensor data, including high-resolution images, LiDAR point clouds, and map data.
|
| 10 |
+
|
| 11 |
+
!!! Note
|
| 12 |
+
|
| 13 |
+
The Argoverse dataset `*.zip` file required for training was removed from Amazon S3 after the shutdown of Argo AI by Ford, but we have made it available for manual download on [Google Drive](https://drive.google.com/file/d/1st9qW3BeIwQsnR0t8mRpvbsSWIo16ACi/view?usp=drive_link).
|
| 14 |
+
|
| 15 |
+
## Key Features
|
| 16 |
+
|
| 17 |
+
- Argoverse contains over 290K labeled 3D object tracks and 5 million object instances across 1,263 distinct scenes.
|
| 18 |
+
- The dataset includes high-resolution camera images, LiDAR point clouds, and richly annotated HD maps.
|
| 19 |
+
- Annotations include 3D bounding boxes for objects, object tracks, and trajectory information.
|
| 20 |
+
- Argoverse provides multiple subsets for different tasks, such as 3D tracking, motion forecasting, and stereo depth estimation.
|
| 21 |
+
|
| 22 |
+
## Dataset Structure
|
| 23 |
+
|
| 24 |
+
The Argoverse dataset is organized into three main subsets:
|
| 25 |
+
|
| 26 |
+
1. **Argoverse 3D Tracking**: This subset contains 113 scenes with over 290K labeled 3D object tracks, focusing on 3D object tracking tasks. It includes LiDAR point clouds, camera images, and sensor calibration information.
|
| 27 |
+
2. **Argoverse Motion Forecasting**: This subset consists of 324K vehicle trajectories collected from 60 hours of driving data, suitable for motion forecasting tasks.
|
| 28 |
+
3. **Argoverse Stereo Depth Estimation**: This subset is designed for stereo depth estimation tasks and includes over 10K stereo image pairs with corresponding LiDAR point clouds for ground truth depth estimation.
|
| 29 |
+
|
| 30 |
+
## Applications
|
| 31 |
+
|
| 32 |
+
The Argoverse dataset is widely used for training and evaluating deep learning models in autonomous driving tasks such as 3D object tracking, motion forecasting, and stereo depth estimation. The dataset's diverse set of sensor data, object annotations, and map information make it a valuable resource for researchers and practitioners in the field of autonomous driving.
|
| 33 |
+
|
| 34 |
+
## Dataset YAML
|
| 35 |
+
|
| 36 |
+
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the Argoverse dataset, the `Argoverse.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/Argoverse.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/Argoverse.yaml).
|
| 37 |
+
|
| 38 |
+
!!! Example "ultralytics/cfg/datasets/Argoverse.yaml"
|
| 39 |
+
|
| 40 |
+
```yaml
|
| 41 |
+
--8<-- "ultralytics/cfg/datasets/Argoverse.yaml"
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
## Usage
|
| 45 |
+
|
| 46 |
+
To train a YOLOv8n model on the Argoverse dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 47 |
+
|
| 48 |
+
!!! Example "Train Example"
|
| 49 |
+
|
| 50 |
+
=== "Python"
|
| 51 |
+
|
| 52 |
+
```python
|
| 53 |
+
from ultralytics import YOLO
|
| 54 |
+
|
| 55 |
+
# Load a model
|
| 56 |
+
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
| 57 |
+
|
| 58 |
+
# Train the model
|
| 59 |
+
results = model.train(data='Argoverse.yaml', epochs=100, imgsz=640)
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
=== "CLI"
|
| 63 |
+
|
| 64 |
+
```bash
|
| 65 |
+
# Start training from a pretrained *.pt model
|
| 66 |
+
yolo detect train data=Argoverse.yaml model=yolov8n.pt epochs=100 imgsz=640
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
## Sample Data and Annotations
|
| 70 |
+
|
| 71 |
+
The Argoverse dataset contains a diverse set of sensor data, including camera images, LiDAR point clouds, and HD map information, providing rich context for autonomous driving tasks. Here are some examples of data from the dataset, along with their corresponding annotations:
|
| 72 |
+
|
| 73 |
+

|
| 74 |
+
|
| 75 |
+
- **Argoverse 3D Tracking**: This image demonstrates an example of 3D object tracking, where objects are annotated with 3D bounding boxes. The dataset provides LiDAR point clouds and camera images to facilitate the development of models for this task.
|
| 76 |
+
|
| 77 |
+
The example showcases the variety and complexity of the data in the Argoverse dataset and highlights the importance of high-quality sensor data for autonomous driving tasks.
|
| 78 |
+
|
| 79 |
+
## Citations and Acknowledgments
|
| 80 |
+
|
| 81 |
+
If you use the Argoverse dataset in your research or development work, please cite the following paper:
|
| 82 |
+
|
| 83 |
+
!!! Quote ""
|
| 84 |
+
|
| 85 |
+
=== "BibTeX"
|
| 86 |
+
|
| 87 |
+
```bibtex
|
| 88 |
+
@inproceedings{chang2019argoverse,
|
| 89 |
+
title={Argoverse: 3D Tracking and Forecasting with Rich Maps},
|
| 90 |
+
author={Chang, Ming-Fang and Lambert, John and Sangkloy, Patsorn and Singh, Jagjeet and Bak, Slawomir and Hartnett, Andrew and Wang, Dequan and Carr, Peter and Lucey, Simon and Ramanan, Deva and others},
|
| 91 |
+
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
|
| 92 |
+
pages={8748--8757},
|
| 93 |
+
year={2019}
|
| 94 |
+
}
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
We would like to acknowledge Argo AI for creating and maintaining the Argoverse dataset as a valuable resource for the autonomous driving research community. For more information about the Argoverse dataset and its creators, visit the [Argoverse dataset website](https://www.argoverse.org/).
|
yolov10/docs/en/datasets/detect/brain-tumor.md
ADDED
|
@@ -0,0 +1,91 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Brain tumor detection, a leading dataset for medical imaging, integrates with Ultralytics. Discover ways to use it for training YOLO models.
|
| 4 |
+
keywords: Ultralytics, Brain Tumor dataset, object detection, YOLO, YOLO model training, object tracking, computer vision, deep learning models
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# Brain Tumor Dataset
|
| 8 |
+
|
| 9 |
+
A brain tumor detection dataset consists of medical images from MRI or CT scans, containing information about brain tumor presence, location, and characteristics. This dataset is essential for training computer vision algorithms to automate brain tumor identification, aiding in early diagnosis and treatment planning.
|
| 10 |
+
|
| 11 |
+
## Dataset Structure
|
| 12 |
+
|
| 13 |
+
The brain tumor dataset is divided into two subsets:
|
| 14 |
+
|
| 15 |
+
- **Training set**: Consisting of 893 images, each accompanied by corresponding annotations.
|
| 16 |
+
- **Testing set**: Comprising 223 images, with annotations paired for each one.
|
| 17 |
+
|
| 18 |
+
## Applications
|
| 19 |
+
|
| 20 |
+
The application of brain tumor detection using computer vision enables early diagnosis, treatment planning, and monitoring of tumor progression. By analyzing medical imaging data like MRI or CT scans, computer vision systems assist in accurately identifying brain tumors, aiding in timely medical intervention and personalized treatment strategies.
|
| 21 |
+
|
| 22 |
+
## Dataset YAML
|
| 23 |
+
|
| 24 |
+
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the brain tumor dataset, the `brain-tumor.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/brain-tumor.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/brain-tumor.yaml).
|
| 25 |
+
|
| 26 |
+
!!! Example "ultralytics/cfg/datasets/brain-tumor.yaml"
|
| 27 |
+
|
| 28 |
+
```yaml
|
| 29 |
+
--8<-- "ultralytics/cfg/datasets/brain-tumor.yaml"
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
## Usage
|
| 33 |
+
|
| 34 |
+
To train a YOLOv8n model on the brain tumor dataset for 100 epochs with an image size of 640, utilize the provided code snippets. For a detailed list of available arguments, consult the model's [Training](../../modes/train.md) page.
|
| 35 |
+
|
| 36 |
+
!!! Example "Train Example"
|
| 37 |
+
|
| 38 |
+
=== "Python"
|
| 39 |
+
|
| 40 |
+
```python
|
| 41 |
+
from ultralytics import YOLO
|
| 42 |
+
|
| 43 |
+
# Load a model
|
| 44 |
+
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
| 45 |
+
|
| 46 |
+
# Train the model
|
| 47 |
+
results = model.train(data='brain-tumor.yaml', epochs=100, imgsz=640)
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
=== "CLI"
|
| 51 |
+
|
| 52 |
+
```bash
|
| 53 |
+
# Start training from a pretrained *.pt model
|
| 54 |
+
yolo detect train data=brain-tumor.yaml model=yolov8n.pt epochs=100 imgsz=640
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
!!! Example "Inference Example"
|
| 58 |
+
|
| 59 |
+
=== "Python"
|
| 60 |
+
|
| 61 |
+
```python
|
| 62 |
+
from ultralytics import YOLO
|
| 63 |
+
|
| 64 |
+
# Load a model
|
| 65 |
+
model = YOLO('path/to/best.pt') # load a brain-tumor fine-tuned model
|
| 66 |
+
|
| 67 |
+
# Inference using the model
|
| 68 |
+
results = model.predict("https://ultralytics.com/assets/brain-tumor-sample.jpg")
|
| 69 |
+
```
|
| 70 |
+
|
| 71 |
+
=== "CLI"
|
| 72 |
+
|
| 73 |
+
```bash
|
| 74 |
+
# Start prediction with a finetuned *.pt model
|
| 75 |
+
yolo detect predict model='path/to/best.pt' imgsz=640 source="https://ultralytics.com/assets/brain-tumor-sample.jpg"
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
## Sample Images and Annotations
|
| 80 |
+
|
| 81 |
+
The brain tumor dataset encompasses a wide array of images featuring diverse object categories and intricate scenes. Presented below are examples of images from the dataset, accompanied by their respective annotations
|
| 82 |
+
|
| 83 |
+
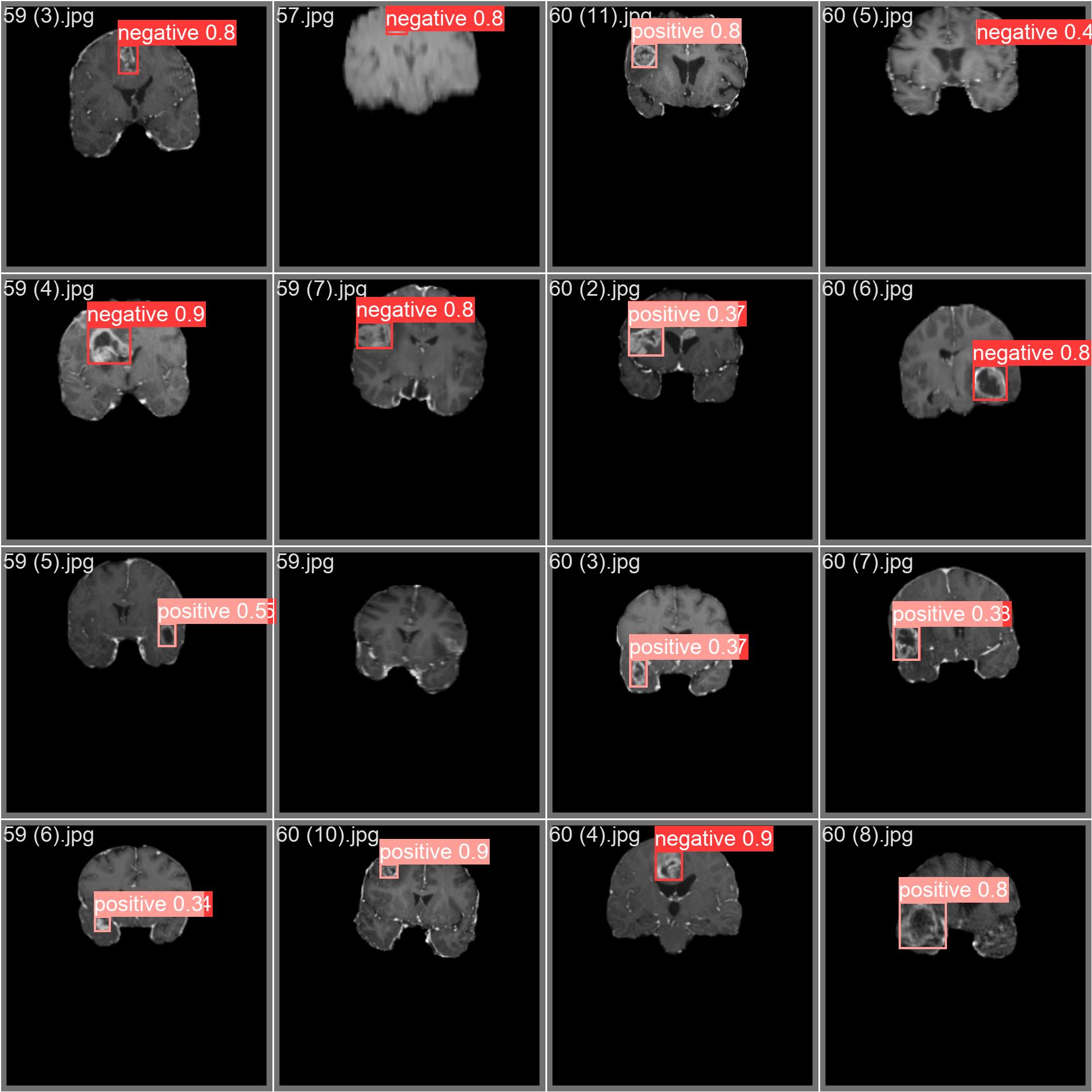
|
| 84 |
+
|
| 85 |
+
- **Mosaiced Image**: Displayed here is a training batch comprising mosaiced dataset images. Mosaicing, a training technique, consolidates multiple images into one, enhancing batch diversity. This approach aids in improving the model's capacity to generalize across various object sizes, aspect ratios, and contexts.
|
| 86 |
+
|
| 87 |
+
This example highlights the diversity and intricacy of images within the brain tumor dataset, underscoring the advantages of incorporating mosaicing during the training phase.
|
| 88 |
+
|
| 89 |
+
## Citations and Acknowledgments
|
| 90 |
+
|
| 91 |
+
The dataset has been released available under the [AGPL-3.0 License](https://github.com/ultralytics/ultralytics/blob/main/LICENSE).
|
yolov10/docs/en/datasets/detect/coco.md
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Learn how COCO, a leading dataset for object detection and segmentation, integrates with Ultralytics. Discover ways to use it for training YOLO models.
|
| 4 |
+
keywords: Ultralytics, COCO dataset, object detection, YOLO, YOLO model training, image segmentation, computer vision, deep learning models
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# COCO Dataset
|
| 8 |
+
|
| 9 |
+
The [COCO](https://cocodataset.org/#home) (Common Objects in Context) dataset is a large-scale object detection, segmentation, and captioning dataset. It is designed to encourage research on a wide variety of object categories and is commonly used for benchmarking computer vision models. It is an essential dataset for researchers and developers working on object detection, segmentation, and pose estimation tasks.
|
| 10 |
+
|
| 11 |
+
<p align="center">
|
| 12 |
+
<br>
|
| 13 |
+
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/uDrn9QZJ2lk"
|
| 14 |
+
title="YouTube video player" frameborder="0"
|
| 15 |
+
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
| 16 |
+
allowfullscreen>
|
| 17 |
+
</iframe>
|
| 18 |
+
<br>
|
| 19 |
+
<strong>Watch:</strong> Ultralytics COCO Dataset Overview
|
| 20 |
+
</p>
|
| 21 |
+
|
| 22 |
+
## Key Features
|
| 23 |
+
|
| 24 |
+
- COCO contains 330K images, with 200K images having annotations for object detection, segmentation, and captioning tasks.
|
| 25 |
+
- The dataset comprises 80 object categories, including common objects like cars, bicycles, and animals, as well as more specific categories such as umbrellas, handbags, and sports equipment.
|
| 26 |
+
- Annotations include object bounding boxes, segmentation masks, and captions for each image.
|
| 27 |
+
- COCO provides standardized evaluation metrics like mean Average Precision (mAP) for object detection, and mean Average Recall (mAR) for segmentation tasks, making it suitable for comparing model performance.
|
| 28 |
+
|
| 29 |
+
## Dataset Structure
|
| 30 |
+
|
| 31 |
+
The COCO dataset is split into three subsets:
|
| 32 |
+
|
| 33 |
+
1. **Train2017**: This subset contains 118K images for training object detection, segmentation, and captioning models.
|
| 34 |
+
2. **Val2017**: This subset has 5K images used for validation purposes during model training.
|
| 35 |
+
3. **Test2017**: This subset consists of 20K images used for testing and benchmarking the trained models. Ground truth annotations for this subset are not publicly available, and the results are submitted to the [COCO evaluation server](https://codalab.lisn.upsaclay.fr/competitions/7384) for performance evaluation.
|
| 36 |
+
|
| 37 |
+
## Applications
|
| 38 |
+
|
| 39 |
+
The COCO dataset is widely used for training and evaluating deep learning models in object detection (such as YOLO, Faster R-CNN, and SSD), instance segmentation (such as Mask R-CNN), and keypoint detection (such as OpenPose). The dataset's diverse set of object categories, large number of annotated images, and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners.
|
| 40 |
+
|
| 41 |
+
## Dataset YAML
|
| 42 |
+
|
| 43 |
+
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO dataset, the `coco.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml).
|
| 44 |
+
|
| 45 |
+
!!! Example "ultralytics/cfg/datasets/coco.yaml"
|
| 46 |
+
|
| 47 |
+
```yaml
|
| 48 |
+
--8<-- "ultralytics/cfg/datasets/coco.yaml"
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
## Usage
|
| 52 |
+
|
| 53 |
+
To train a YOLOv8n model on the COCO dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 54 |
+
|
| 55 |
+
!!! Example "Train Example"
|
| 56 |
+
|
| 57 |
+
=== "Python"
|
| 58 |
+
|
| 59 |
+
```python
|
| 60 |
+
from ultralytics import YOLO
|
| 61 |
+
|
| 62 |
+
# Load a model
|
| 63 |
+
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
| 64 |
+
|
| 65 |
+
# Train the model
|
| 66 |
+
results = model.train(data='coco.yaml', epochs=100, imgsz=640)
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
=== "CLI"
|
| 70 |
+
|
| 71 |
+
```bash
|
| 72 |
+
# Start training from a pretrained *.pt model
|
| 73 |
+
yolo detect train data=coco.yaml model=yolov8n.pt epochs=100 imgsz=640
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
## Sample Images and Annotations
|
| 77 |
+
|
| 78 |
+
The COCO dataset contains a diverse set of images with various object categories and complex scenes. Here are some examples of images from the dataset, along with their corresponding annotations:
|
| 79 |
+
|
| 80 |
+
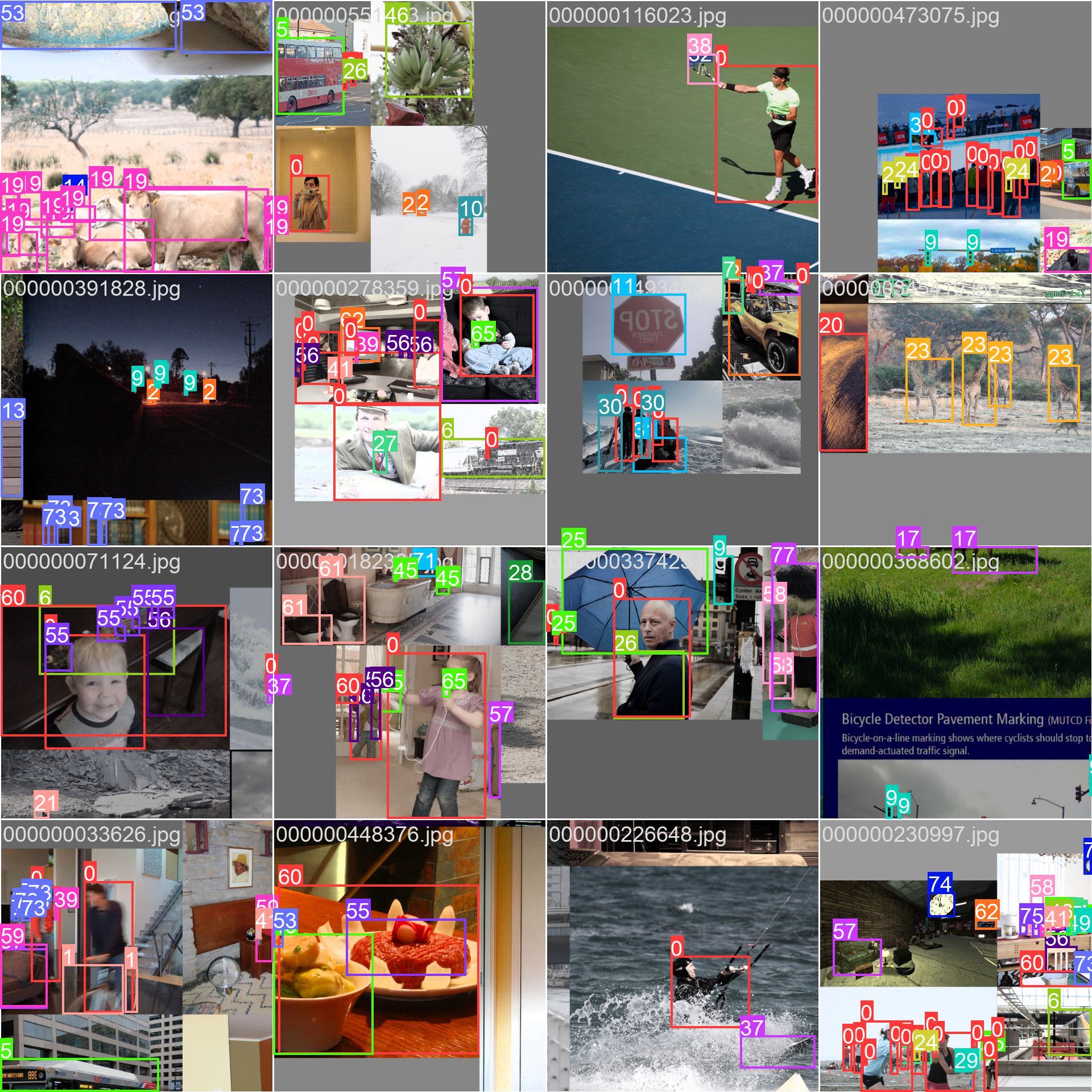
|
| 81 |
+
|
| 82 |
+
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
|
| 83 |
+
|
| 84 |
+
The example showcases the variety and complexity of the images in the COCO dataset and the benefits of using mosaicing during the training process.
|
| 85 |
+
|
| 86 |
+
## Citations and Acknowledgments
|
| 87 |
+
|
| 88 |
+
If you use the COCO dataset in your research or development work, please cite the following paper:
|
| 89 |
+
|
| 90 |
+
!!! Quote ""
|
| 91 |
+
|
| 92 |
+
=== "BibTeX"
|
| 93 |
+
|
| 94 |
+
```bibtex
|
| 95 |
+
@misc{lin2015microsoft,
|
| 96 |
+
title={Microsoft COCO: Common Objects in Context},
|
| 97 |
+
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
| 98 |
+
year={2015},
|
| 99 |
+
eprint={1405.0312},
|
| 100 |
+
archivePrefix={arXiv},
|
| 101 |
+
primaryClass={cs.CV}
|
| 102 |
+
}
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
yolov10/docs/en/datasets/detect/coco8.md
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Discover the benefits of using the practical and diverse COCO8 dataset for object detection model testing. Learn to configure and use it via Ultralytics HUB and YOLOv8.
|
| 4 |
+
keywords: Ultralytics, COCO8 dataset, object detection, model testing, dataset configuration, detection approaches, sanity check, training pipelines, YOLOv8
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# COCO8 Dataset
|
| 8 |
+
|
| 9 |
+
## Introduction
|
| 10 |
+
|
| 11 |
+
[Ultralytics](https://ultralytics.com) COCO8 is a small, but versatile object detection dataset composed of the first 8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
|
| 12 |
+
|
| 13 |
+
<p align="center">
|
| 14 |
+
<br>
|
| 15 |
+
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/uDrn9QZJ2lk"
|
| 16 |
+
title="YouTube video player" frameborder="0"
|
| 17 |
+
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
| 18 |
+
allowfullscreen>
|
| 19 |
+
</iframe>
|
| 20 |
+
<br>
|
| 21 |
+
<strong>Watch:</strong> Ultralytics COCO Dataset Overview
|
| 22 |
+
</p>
|
| 23 |
+
|
| 24 |
+
This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com) and [YOLOv8](https://github.com/ultralytics/ultralytics).
|
| 25 |
+
|
| 26 |
+
## Dataset YAML
|
| 27 |
+
|
| 28 |
+
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO8 dataset, the `coco8.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8.yaml).
|
| 29 |
+
|
| 30 |
+
!!! Example "ultralytics/cfg/datasets/coco8.yaml"
|
| 31 |
+
|
| 32 |
+
```yaml
|
| 33 |
+
--8<-- "ultralytics/cfg/datasets/coco8.yaml"
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
## Usage
|
| 37 |
+
|
| 38 |
+
To train a YOLOv8n model on the COCO8 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 39 |
+
|
| 40 |
+
!!! Example "Train Example"
|
| 41 |
+
|
| 42 |
+
=== "Python"
|
| 43 |
+
|
| 44 |
+
```python
|
| 45 |
+
from ultralytics import YOLO
|
| 46 |
+
|
| 47 |
+
# Load a model
|
| 48 |
+
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
| 49 |
+
|
| 50 |
+
# Train the model
|
| 51 |
+
results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
=== "CLI"
|
| 55 |
+
|
| 56 |
+
```bash
|
| 57 |
+
# Start training from a pretrained *.pt model
|
| 58 |
+
yolo detect train data=coco8.yaml model=yolov8n.pt epochs=100 imgsz=640
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
## Sample Images and Annotations
|
| 62 |
+
|
| 63 |
+
Here are some examples of images from the COCO8 dataset, along with their corresponding annotations:
|
| 64 |
+
|
| 65 |
+
<img src="https://user-images.githubusercontent.com/26833433/236818348-e6260a3d-0454-436b-83a9-de366ba07235.jpg" alt="Dataset sample image" width="800">
|
| 66 |
+
|
| 67 |
+
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
|
| 68 |
+
|
| 69 |
+
The example showcases the variety and complexity of the images in the COCO8 dataset and the benefits of using mosaicing during the training process.
|
| 70 |
+
|
| 71 |
+
## Citations and Acknowledgments
|
| 72 |
+
|
| 73 |
+
If you use the COCO dataset in your research or development work, please cite the following paper:
|
| 74 |
+
|
| 75 |
+
!!! Quote ""
|
| 76 |
+
|
| 77 |
+
=== "BibTeX"
|
| 78 |
+
|
| 79 |
+
```bibtex
|
| 80 |
+
@misc{lin2015microsoft,
|
| 81 |
+
title={Microsoft COCO: Common Objects in Context},
|
| 82 |
+
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
| 83 |
+
year={2015},
|
| 84 |
+
eprint={1405.0312},
|
| 85 |
+
archivePrefix={arXiv},
|
| 86 |
+
primaryClass={cs.CV}
|
| 87 |
+
}
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
yolov10/docs/en/datasets/detect/globalwheat2020.md
ADDED
|
@@ -0,0 +1,91 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Understand how to utilize the vast Global Wheat Head Dataset for building wheat head detection models. Features, structure, applications, usage, sample data, and citation.
|
| 4 |
+
keywords: Ultralytics, YOLO, Global Wheat Head Dataset, wheat head detection, plant phenotyping, crop management, deep learning, outdoor images, annotations, YAML configuration
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# Global Wheat Head Dataset
|
| 8 |
+
|
| 9 |
+
The [Global Wheat Head Dataset](https://www.global-wheat.com/) is a collection of images designed to support the development of accurate wheat head detection models for applications in wheat phenotyping and crop management. Wheat heads, also known as spikes, are the grain-bearing parts of the wheat plant. Accurate estimation of wheat head density and size is essential for assessing crop health, maturity, and yield potential. The dataset, created by a collaboration of nine research institutes from seven countries, covers multiple growing regions to ensure models generalize well across different environments.
|
| 10 |
+
|
| 11 |
+
## Key Features
|
| 12 |
+
|
| 13 |
+
- The dataset contains over 3,000 training images from Europe (France, UK, Switzerland) and North America (Canada).
|
| 14 |
+
- It includes approximately 1,000 test images from Australia, Japan, and China.
|
| 15 |
+
- Images are outdoor field images, capturing the natural variability in wheat head appearances.
|
| 16 |
+
- Annotations include wheat head bounding boxes to support object detection tasks.
|
| 17 |
+
|
| 18 |
+
## Dataset Structure
|
| 19 |
+
|
| 20 |
+
The Global Wheat Head Dataset is organized into two main subsets:
|
| 21 |
+
|
| 22 |
+
1. **Training Set**: This subset contains over 3,000 images from Europe and North America. The images are labeled with wheat head bounding boxes, providing ground truth for training object detection models.
|
| 23 |
+
2. **Test Set**: This subset consists of approximately 1,000 images from Australia, Japan, and China. These images are used for evaluating the performance of trained models on unseen genotypes, environments, and observational conditions.
|
| 24 |
+
|
| 25 |
+
## Applications
|
| 26 |
+
|
| 27 |
+
The Global Wheat Head Dataset is widely used for training and evaluating deep learning models in wheat head detection tasks. The dataset's diverse set of images, capturing a wide range of appearances, environments, and conditions, make it a valuable resource for researchers and practitioners in the field of plant phenotyping and crop management.
|
| 28 |
+
|
| 29 |
+
## Dataset YAML
|
| 30 |
+
|
| 31 |
+
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the Global Wheat Head Dataset, the `GlobalWheat2020.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/GlobalWheat2020.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/GlobalWheat2020.yaml).
|
| 32 |
+
|
| 33 |
+
!!! Example "ultralytics/cfg/datasets/GlobalWheat2020.yaml"
|
| 34 |
+
|
| 35 |
+
```yaml
|
| 36 |
+
--8<-- "ultralytics/cfg/datasets/GlobalWheat2020.yaml"
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
## Usage
|
| 40 |
+
|
| 41 |
+
To train a YOLOv8n model on the Global Wheat Head Dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 42 |
+
|
| 43 |
+
!!! Example "Train Example"
|
| 44 |
+
|
| 45 |
+
=== "Python"
|
| 46 |
+
|
| 47 |
+
```python
|
| 48 |
+
from ultralytics import YOLO
|
| 49 |
+
|
| 50 |
+
# Load a model
|
| 51 |
+
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
| 52 |
+
|
| 53 |
+
# Train the model
|
| 54 |
+
results = model.train(data='GlobalWheat2020.yaml', epochs=100, imgsz=640)
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
=== "CLI"
|
| 58 |
+
|
| 59 |
+
```bash
|
| 60 |
+
# Start training from a pretrained *.pt model
|
| 61 |
+
yolo detect train data=GlobalWheat2020.yaml model=yolov8n.pt epochs=100 imgsz=640
|
| 62 |
+
```
|
| 63 |
+
|
| 64 |
+
## Sample Data and Annotations
|
| 65 |
+
|
| 66 |
+
The Global Wheat Head Dataset contains a diverse set of outdoor field images, capturing the natural variability in wheat head appearances, environments, and conditions. Here are some examples of data from the dataset, along with their corresponding annotations:
|
| 67 |
+
|
| 68 |
+

|
| 69 |
+
|
| 70 |
+
- **Wheat Head Detection**: This image demonstrates an example of wheat head detection, where wheat heads are annotated with bounding boxes. The dataset provides a variety of images to facilitate the development of models for this task.
|
| 71 |
+
|
| 72 |
+
The example showcases the variety and complexity of the data in the Global Wheat Head Dataset and highlights the importance of accurate wheat head detection for applications in wheat phenotyping and crop management.
|
| 73 |
+
|
| 74 |
+
## Citations and Acknowledgments
|
| 75 |
+
|
| 76 |
+
If you use the Global Wheat Head Dataset in your research or development work, please cite the following paper:
|
| 77 |
+
|
| 78 |
+
!!! Quote ""
|
| 79 |
+
|
| 80 |
+
=== "BibTeX"
|
| 81 |
+
|
| 82 |
+
```bibtex
|
| 83 |
+
@article{david2020global,
|
| 84 |
+
title={Global Wheat Head Detection (GWHD) Dataset: A Large and Diverse Dataset of High-Resolution RGB-Labelled Images to Develop and Benchmark Wheat Head Detection Methods},
|
| 85 |
+
author={David, Etienne and Madec, Simon and Sadeghi-Tehran, Pouria and Aasen, Helge and Zheng, Bangyou and Liu, Shouyang and Kirchgessner, Norbert and Ishikawa, Goro and Nagasawa, Koichi and Badhon, Minhajul and others},
|
| 86 |
+
journal={arXiv preprint arXiv:2005.02162},
|
| 87 |
+
year={2020}
|
| 88 |
+
}
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
We would like to acknowledge the researchers and institutions that contributed to the creation and maintenance of the Global Wheat Head Dataset as a valuable resource for the plant phenotyping and crop management research community. For more information about the dataset and its creators, visit the [Global Wheat Head Dataset website](https://www.global-wheat.com/).
|
yolov10/docs/en/datasets/detect/index.md
ADDED
|
@@ -0,0 +1,110 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Navigate through supported dataset formats, methods to utilize them and how to add your own datasets. Get insights on porting or converting label formats.
|
| 4 |
+
keywords: Ultralytics, YOLO, datasets, object detection, dataset formats, label formats, data conversion
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# Object Detection Datasets Overview
|
| 8 |
+
|
| 9 |
+
Training a robust and accurate object detection model requires a comprehensive dataset. This guide introduces various formats of datasets that are compatible with the Ultralytics YOLO model and provides insights into their structure, usage, and how to convert between different formats.
|
| 10 |
+
|
| 11 |
+
## Supported Dataset Formats
|
| 12 |
+
|
| 13 |
+
### Ultralytics YOLO format
|
| 14 |
+
|
| 15 |
+
The Ultralytics YOLO format is a dataset configuration format that allows you to define the dataset root directory, the relative paths to training/validation/testing image directories or `*.txt` files containing image paths, and a dictionary of class names. Here is an example:
|
| 16 |
+
|
| 17 |
+
```yaml
|
| 18 |
+
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
| 19 |
+
path: ../datasets/coco8 # dataset root dir
|
| 20 |
+
train: images/train # train images (relative to 'path') 4 images
|
| 21 |
+
val: images/val # val images (relative to 'path') 4 images
|
| 22 |
+
test: # test images (optional)
|
| 23 |
+
|
| 24 |
+
# Classes (80 COCO classes)
|
| 25 |
+
names:
|
| 26 |
+
0: person
|
| 27 |
+
1: bicycle
|
| 28 |
+
2: car
|
| 29 |
+
# ...
|
| 30 |
+
77: teddy bear
|
| 31 |
+
78: hair drier
|
| 32 |
+
79: toothbrush
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
Labels for this format should be exported to YOLO format with one `*.txt` file per image. If there are no objects in an image, no `*.txt` file is required. The `*.txt` file should be formatted with one row per object in `class x_center y_center width height` format. Box coordinates must be in **normalized xywh** format (from 0 to 1). If your boxes are in pixels, you should divide `x_center` and `width` by image width, and `y_center` and `height` by image height. Class numbers should be zero-indexed (start with 0).
|
| 36 |
+
|
| 37 |
+
<p align="center"><img width="750" src="https://user-images.githubusercontent.com/26833433/91506361-c7965000-e886-11ea-8291-c72b98c25eec.jpg" alt="Example labelled image"></p>
|
| 38 |
+
|
| 39 |
+
The label file corresponding to the above image contains 2 persons (class `0`) and a tie (class `27`):
|
| 40 |
+
|
| 41 |
+
<p align="center"><img width="428" src="https://user-images.githubusercontent.com/26833433/112467037-d2568c00-8d66-11eb-8796-55402ac0d62f.png" alt="Example label file"></p>
|
| 42 |
+
|
| 43 |
+
When using the Ultralytics YOLO format, organize your training and validation images and labels as shown in the example below.
|
| 44 |
+
|
| 45 |
+
<p align="center"><img width="700" src="https://user-images.githubusercontent.com/26833433/134436012-65111ad1-9541-4853-81a6-f19a3468b75f.png" alt="Example dataset directory structure"></p>
|
| 46 |
+
|
| 47 |
+
## Usage
|
| 48 |
+
|
| 49 |
+
Here's how you can use these formats to train your model:
|
| 50 |
+
|
| 51 |
+
!!! Example
|
| 52 |
+
|
| 53 |
+
=== "Python"
|
| 54 |
+
|
| 55 |
+
```python
|
| 56 |
+
from ultralytics import YOLO
|
| 57 |
+
|
| 58 |
+
# Load a model
|
| 59 |
+
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
| 60 |
+
|
| 61 |
+
# Train the model
|
| 62 |
+
results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
|
| 63 |
+
```
|
| 64 |
+
=== "CLI"
|
| 65 |
+
|
| 66 |
+
```bash
|
| 67 |
+
# Start training from a pretrained *.pt model
|
| 68 |
+
yolo detect train data=coco8.yaml model=yolov8n.pt epochs=100 imgsz=640
|
| 69 |
+
```
|
| 70 |
+
|
| 71 |
+
## Supported Datasets
|
| 72 |
+
|
| 73 |
+
Here is a list of the supported datasets and a brief description for each:
|
| 74 |
+
|
| 75 |
+
- [**Argoverse**](argoverse.md): A collection of sensor data collected from autonomous vehicles. It contains 3D tracking annotations for car objects.
|
| 76 |
+
- [**COCO**](coco.md): Common Objects in Context (COCO) is a large-scale object detection, segmentation, and captioning dataset with 80 object categories.
|
| 77 |
+
- [**COCO8**](coco8.md): A smaller subset of the COCO dataset, COCO8 is more lightweight and faster to train.
|
| 78 |
+
- [**GlobalWheat2020**](globalwheat2020.md): A dataset containing images of wheat heads for the Global Wheat Challenge 2020.
|
| 79 |
+
- [**Objects365**](objects365.md): A large-scale object detection dataset with 365 object categories and 600k images, aimed at advancing object detection research.
|
| 80 |
+
- [**OpenImagesV7**](open-images-v7.md): A comprehensive dataset by Google with 1.7M train images and 42k validation images.
|
| 81 |
+
- [**SKU-110K**](sku-110k.md): A dataset containing images of densely packed retail products, intended for retail environment object detection.
|
| 82 |
+
- [**VisDrone**](visdrone.md): A dataset focusing on drone-based images, containing various object categories like cars, pedestrians, and cyclists.
|
| 83 |
+
- [**VOC**](voc.md): PASCAL VOC is a popular object detection dataset with 20 object categories including vehicles, animals, and furniture.
|
| 84 |
+
- [**xView**](xview.md): A dataset containing high-resolution satellite imagery, designed for the detection of various object classes in overhead views.
|
| 85 |
+
- [**Brain-tumor**](brain-tumor.md): This dataset comprises MRI or CT scan images containing information about brain tumor presence, location, and characteristics. It plays a crucial role in training computer vision models to automate tumor identification, facilitating early diagnosis and treatment planning.
|
| 86 |
+
- [**African-wildlife**](african-wildlife.md): Featuring images of African wildlife such as buffalo, elephant, rhino, and zebra, this dataset is instrumental in training computer vision models. It is indispensable for identifying animals across different habitats and contributes significantly to wildlife research endeavors.
|
| 87 |
+
|
| 88 |
+
### Adding your own dataset
|
| 89 |
+
|
| 90 |
+
If you have your own dataset and would like to use it for training detection models with Ultralytics YOLO format, ensure that it follows the format specified above under "Ultralytics YOLO format". Convert your annotations to the required format and specify the paths, number of classes, and class names in the YAML configuration file.
|
| 91 |
+
|
| 92 |
+
## Port or Convert Label Formats
|
| 93 |
+
|
| 94 |
+
### COCO Dataset Format to YOLO Format
|
| 95 |
+
|
| 96 |
+
You can easily convert labels from the popular COCO dataset format to the YOLO format using the following code snippet:
|
| 97 |
+
|
| 98 |
+
!!! Example
|
| 99 |
+
|
| 100 |
+
=== "Python"
|
| 101 |
+
|
| 102 |
+
```python
|
| 103 |
+
from ultralytics.data.converter import convert_coco
|
| 104 |
+
|
| 105 |
+
convert_coco(labels_dir='path/to/coco/annotations/')
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
This conversion tool can be used to convert the COCO dataset or any dataset in the COCO format to the Ultralytics YOLO format.
|
| 109 |
+
|
| 110 |
+
Remember to double-check if the dataset you want to use is compatible with your model and follows the necessary format conventions. Properly formatted datasets are crucial for training successful object detection models.
|
yolov10/docs/en/datasets/detect/objects365.md
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Discover the Objects365 dataset, a wide-scale, high-quality resource for object detection research. Learn to use it with the Ultralytics YOLO model.
|
| 4 |
+
keywords: Objects365, object detection, Ultralytics, dataset, YOLO, bounding boxes, annotations, computer vision, deep learning, training models
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# Objects365 Dataset
|
| 8 |
+
|
| 9 |
+
The [Objects365](https://www.objects365.org/) dataset is a large-scale, high-quality dataset designed to foster object detection research with a focus on diverse objects in the wild. Created by a team of [Megvii](https://en.megvii.com/) researchers, the dataset offers a wide range of high-resolution images with a comprehensive set of annotated bounding boxes covering 365 object categories.
|
| 10 |
+
|
| 11 |
+
## Key Features
|
| 12 |
+
|
| 13 |
+
- Objects365 contains 365 object categories, with 2 million images and over 30 million bounding boxes.
|
| 14 |
+
- The dataset includes diverse objects in various scenarios, providing a rich and challenging benchmark for object detection tasks.
|
| 15 |
+
- Annotations include bounding boxes for objects, making it suitable for training and evaluating object detection models.
|
| 16 |
+
- Objects365 pre-trained models significantly outperform ImageNet pre-trained models, leading to better generalization on various tasks.
|
| 17 |
+
|
| 18 |
+
## Dataset Structure
|
| 19 |
+
|
| 20 |
+
The Objects365 dataset is organized into a single set of images with corresponding annotations:
|
| 21 |
+
|
| 22 |
+
- **Images**: The dataset includes 2 million high-resolution images, each containing a variety of objects across 365 categories.
|
| 23 |
+
- **Annotations**: The images are annotated with over 30 million bounding boxes, providing comprehensive ground truth information for object detection tasks.
|
| 24 |
+
|
| 25 |
+
## Applications
|
| 26 |
+
|
| 27 |
+
The Objects365 dataset is widely used for training and evaluating deep learning models in object detection tasks. The dataset's diverse set of object categories and high-quality annotations make it a valuable resource for researchers and practitioners in the field of computer vision.
|
| 28 |
+
|
| 29 |
+
## Dataset YAML
|
| 30 |
+
|
| 31 |
+
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the Objects365 Dataset, the `Objects365.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/Objects365.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/Objects365.yaml).
|
| 32 |
+
|
| 33 |
+
!!! Example "ultralytics/cfg/datasets/Objects365.yaml"
|
| 34 |
+
|
| 35 |
+
```yaml
|
| 36 |
+
--8<-- "ultralytics/cfg/datasets/Objects365.yaml"
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
## Usage
|
| 40 |
+
|
| 41 |
+
To train a YOLOv8n model on the Objects365 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 42 |
+
|
| 43 |
+
!!! Example "Train Example"
|
| 44 |
+
|
| 45 |
+
=== "Python"
|
| 46 |
+
|
| 47 |
+
```python
|
| 48 |
+
from ultralytics import YOLO
|
| 49 |
+
|
| 50 |
+
# Load a model
|
| 51 |
+
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
| 52 |
+
|
| 53 |
+
# Train the model
|
| 54 |
+
results = model.train(data='Objects365.yaml', epochs=100, imgsz=640)
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
=== "CLI"
|
| 58 |
+
|
| 59 |
+
```bash
|
| 60 |
+
# Start training from a pretrained *.pt model
|
| 61 |
+
yolo detect train data=Objects365.yaml model=yolov8n.pt epochs=100 imgsz=640
|
| 62 |
+
```
|
| 63 |
+
|
| 64 |
+
## Sample Data and Annotations
|
| 65 |
+
|
| 66 |
+
The Objects365 dataset contains a diverse set of high-resolution images with objects from 365 categories, providing rich context for object detection tasks. Here are some examples of the images in the dataset:
|
| 67 |
+
|
| 68 |
+

|
| 69 |
+
|
| 70 |
+
- **Objects365**: This image demonstrates an example of object detection, where objects are annotated with bounding boxes. The dataset provides a wide range of images to facilitate the development of models for this task.
|
| 71 |
+
|
| 72 |
+
The example showcases the variety and complexity of the data in the Objects365 dataset and highlights the importance of accurate object detection for computer vision applications.
|
| 73 |
+
|
| 74 |
+
## Citations and Acknowledgments
|
| 75 |
+
|
| 76 |
+
If you use the Objects365 dataset in your research or development work, please cite the following paper:
|
| 77 |
+
|
| 78 |
+
!!! Quote ""
|
| 79 |
+
|
| 80 |
+
=== "BibTeX"
|
| 81 |
+
|
| 82 |
+
```bibtex
|
| 83 |
+
@inproceedings{shao2019objects365,
|
| 84 |
+
title={Objects365: A Large-scale, High-quality Dataset for Object Detection},
|
| 85 |
+
author={Shao, Shuai and Li, Zeming and Zhang, Tianyuan and Peng, Chao and Yu, Gang and Li, Jing and Zhang, Xiangyu and Sun, Jian},
|
| 86 |
+
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
|
| 87 |
+
pages={8425--8434},
|
| 88 |
+
year={2019}
|
| 89 |
+
}
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
We would like to acknowledge the team of researchers who created and maintain the Objects365 dataset as a valuable resource for the computer vision research community. For more information about the Objects365 dataset and its creators, visit the [Objects365 dataset website](https://www.objects365.org/).
|
yolov10/docs/en/datasets/detect/open-images-v7.md
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Dive into Google's Open Images V7, a comprehensive dataset offering a broad scope for computer vision research. Understand its usage with deep learning models.
|
| 4 |
+
keywords: Open Images V7, object detection, segmentation masks, visual relationships, localized narratives, computer vision, deep learning, annotations, bounding boxes
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# Open Images V7 Dataset
|
| 8 |
+
|
| 9 |
+
[Open Images V7](https://storage.googleapis.com/openimages/web/index.html) is a versatile and expansive dataset championed by Google. Aimed at propelling research in the realm of computer vision, it boasts a vast collection of images annotated with a plethora of data, including image-level labels, object bounding boxes, object segmentation masks, visual relationships, and localized narratives.
|
| 10 |
+
|
| 11 |
+
## Open Images V7 Pretrained Models
|
| 12 |
+
|
| 13 |
+
| Model | size<br><sup>(pixels) | mAP<sup>val<br>50-95 | Speed<br><sup>CPU ONNX<br>(ms) | Speed<br><sup>A100 TensorRT<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>(B) |
|
| 14 |
+
|-------------------------------------------------------------------------------------------|-----------------------|----------------------|--------------------------------|-------------------------------------|--------------------|-------------------|
|
| 15 |
+
| [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8n-oiv7.pt) | 640 | 18.4 | 142.4 | 1.21 | 3.5 | 10.5 |
|
| 16 |
+
| [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8s-oiv7.pt) | 640 | 27.7 | 183.1 | 1.40 | 11.4 | 29.7 |
|
| 17 |
+
| [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8m-oiv7.pt) | 640 | 33.6 | 408.5 | 2.26 | 26.2 | 80.6 |
|
| 18 |
+
| [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8l-oiv7.pt) | 640 | 34.9 | 596.9 | 2.43 | 44.1 | 167.4 |
|
| 19 |
+
| [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8x-oiv7.pt) | 640 | 36.3 | 860.6 | 3.56 | 68.7 | 260.6 |
|
| 20 |
+
|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
## Key Features
|
| 24 |
+
|
| 25 |
+
- Encompasses ~9M images annotated in various ways to suit multiple computer vision tasks.
|
| 26 |
+
- Houses a staggering 16M bounding boxes across 600 object classes in 1.9M images. These boxes are primarily hand-drawn by experts ensuring high precision.
|
| 27 |
+
- Visual relationship annotations totaling 3.3M are available, detailing 1,466 unique relationship triplets, object properties, and human activities.
|
| 28 |
+
- V5 introduced segmentation masks for 2.8M objects across 350 classes.
|
| 29 |
+
- V6 introduced 675k localized narratives that amalgamate voice, text, and mouse traces highlighting described objects.
|
| 30 |
+
- V7 introduced 66.4M point-level labels on 1.4M images, spanning 5,827 classes.
|
| 31 |
+
- Encompasses 61.4M image-level labels across a diverse set of 20,638 classes.
|
| 32 |
+
- Provides a unified platform for image classification, object detection, relationship detection, instance segmentation, and multimodal image descriptions.
|
| 33 |
+
|
| 34 |
+
## Dataset Structure
|
| 35 |
+
|
| 36 |
+
Open Images V7 is structured in multiple components catering to varied computer vision challenges:
|
| 37 |
+
|
| 38 |
+
- **Images**: About 9 million images, often showcasing intricate scenes with an average of 8.3 objects per image.
|
| 39 |
+
- **Bounding Boxes**: Over 16 million boxes that demarcate objects across 600 categories.
|
| 40 |
+
- **Segmentation Masks**: These detail the exact boundary of 2.8M objects across 350 classes.
|
| 41 |
+
- **Visual Relationships**: 3.3M annotations indicating object relationships, properties, and actions.
|
| 42 |
+
- **Localized Narratives**: 675k descriptions combining voice, text, and mouse traces.
|
| 43 |
+
- **Point-Level Labels**: 66.4M labels across 1.4M images, suitable for zero/few-shot semantic segmentation.
|
| 44 |
+
|
| 45 |
+
## Applications
|
| 46 |
+
|
| 47 |
+
Open Images V7 is a cornerstone for training and evaluating state-of-the-art models in various computer vision tasks. The dataset's broad scope and high-quality annotations make it indispensable for researchers and developers specializing in computer vision.
|
| 48 |
+
|
| 49 |
+
## Dataset YAML
|
| 50 |
+
|
| 51 |
+
Typically, datasets come with a YAML (Yet Another Markup Language) file that delineates the dataset's configuration. For the case of Open Images V7, a hypothetical `OpenImagesV7.yaml` might exist. For accurate paths and configurations, one should refer to the dataset's official repository or documentation.
|
| 52 |
+
|
| 53 |
+
!!! Example "OpenImagesV7.yaml"
|
| 54 |
+
|
| 55 |
+
```yaml
|
| 56 |
+
--8<-- "ultralytics/cfg/datasets/open-images-v7.yaml"
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
## Usage
|
| 60 |
+
|
| 61 |
+
To train a YOLOv8n model on the Open Images V7 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 62 |
+
|
| 63 |
+
!!! Warning
|
| 64 |
+
|
| 65 |
+
The complete Open Images V7 dataset comprises 1,743,042 training images and 41,620 validation images, requiring approximately **561 GB of storage space** upon download.
|
| 66 |
+
|
| 67 |
+
Executing the commands provided below will trigger an automatic download of the full dataset if it's not already present locally. Before running the below example it's crucial to:
|
| 68 |
+
|
| 69 |
+
- Verify that your device has enough storage capacity.
|
| 70 |
+
- Ensure a robust and speedy internet connection.
|
| 71 |
+
|
| 72 |
+
!!! Example "Train Example"
|
| 73 |
+
|
| 74 |
+
=== "Python"
|
| 75 |
+
|
| 76 |
+
```python
|
| 77 |
+
from ultralytics import YOLO
|
| 78 |
+
|
| 79 |
+
# Load a COCO-pretrained YOLOv8n model
|
| 80 |
+
model = YOLO('yolov8n.pt')
|
| 81 |
+
|
| 82 |
+
# Train the model on the Open Images V7 dataset
|
| 83 |
+
results = model.train(data='open-images-v7.yaml', epochs=100, imgsz=640)
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
=== "CLI"
|
| 87 |
+
|
| 88 |
+
```bash
|
| 89 |
+
# Train a COCO-pretrained YOLOv8n model on the Open Images V7 dataset
|
| 90 |
+
yolo detect train data=open-images-v7.yaml model=yolov8n.pt epochs=100 imgsz=640
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
## Sample Data and Annotations
|
| 94 |
+
|
| 95 |
+
Illustrations of the dataset help provide insights into its richness:
|
| 96 |
+
|
| 97 |
+

|
| 98 |
+
|
| 99 |
+
- **Open Images V7**: This image exemplifies the depth and detail of annotations available, including bounding boxes, relationships, and segmentation masks.
|
| 100 |
+
|
| 101 |
+
Researchers can gain invaluable insights into the array of computer vision challenges that the dataset addresses, from basic object detection to intricate relationship identification.
|
| 102 |
+
|
| 103 |
+
## Citations and Acknowledgments
|
| 104 |
+
|
| 105 |
+
For those employing Open Images V7 in their work, it's prudent to cite the relevant papers and acknowledge the creators:
|
| 106 |
+
|
| 107 |
+
!!! Quote ""
|
| 108 |
+
|
| 109 |
+
=== "BibTeX"
|
| 110 |
+
|
| 111 |
+
```bibtex
|
| 112 |
+
@article{OpenImages,
|
| 113 |
+
author = {Alina Kuznetsova and Hassan Rom and Neil Alldrin and Jasper Uijlings and Ivan Krasin and Jordi Pont-Tuset and Shahab Kamali and Stefan Popov and Matteo Malloci and Alexander Kolesnikov and Tom Duerig and Vittorio Ferrari},
|
| 114 |
+
title = {The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale},
|
| 115 |
+
year = {2020},
|
| 116 |
+
journal = {IJCV}
|
| 117 |
+
}
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
A heartfelt acknowledgment goes out to the Google AI team for creating and maintaining the Open Images V7 dataset. For a deep dive into the dataset and its offerings, navigate to the [official Open Images V7 website](https://storage.googleapis.com/openimages/web/index.html).
|
yolov10/docs/en/datasets/detect/roboflow-100.md
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Get to know Roboflow 100, a comprehensive object detection benchmark that brings together 100 datasets from different domains.
|
| 4 |
+
keywords: Ultralytics, YOLOv8, YOLO models, Roboflow 100, object detection, benchmark, computer vision, datasets, deep learning models
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# Roboflow 100 Dataset
|
| 8 |
+
|
| 9 |
+
Roboflow 100, developed by [Roboflow](https://roboflow.com/?ref=ultralytics) and sponsored by Intel, is a groundbreaking [object detection](../../tasks/detect.md) benchmark. It includes 100 diverse datasets sampled from over 90,000 public datasets. This benchmark is designed to test the adaptability of models to various domains, including healthcare, aerial imagery, and video games.
|
| 10 |
+
|
| 11 |
+
<p align="center">
|
| 12 |
+
<img width="640" src="https://user-images.githubusercontent.com/15908060/202452898-9ca6b8f7-4805-4e8e-949a-6e080d7b94d2.jpg" alt="Roboflow 100 Overview">
|
| 13 |
+
</p>
|
| 14 |
+
|
| 15 |
+
## Key Features
|
| 16 |
+
|
| 17 |
+
- Includes 100 datasets across seven domains: Aerial, Video games, Microscopic, Underwater, Documents, Electromagnetic, and Real World.
|
| 18 |
+
- The benchmark comprises 224,714 images across 805 classes, thanks to over 11,170 hours of labeling efforts.
|
| 19 |
+
- All images are resized to 640x640 pixels, with a focus on eliminating class ambiguity and filtering out underrepresented classes.
|
| 20 |
+
- Annotations include bounding boxes for objects, making it suitable for [training](../../modes/train.md) and evaluating object detection models.
|
| 21 |
+
|
| 22 |
+
## Dataset Structure
|
| 23 |
+
|
| 24 |
+
The Roboflow 100 dataset is organized into seven categories, each with a distinct set of datasets, images, and classes:
|
| 25 |
+
|
| 26 |
+
- **Aerial**: Consists of 7 datasets with a total of 9,683 images, covering 24 distinct classes.
|
| 27 |
+
- **Video Games**: Includes 7 datasets, featuring 11,579 images across 88 classes.
|
| 28 |
+
- **Microscopic**: Comprises 11 datasets with 13,378 images, spanning 28 classes.
|
| 29 |
+
- **Underwater**: Contains 5 datasets, encompassing 18,003 images in 39 classes.
|
| 30 |
+
- **Documents**: Consists of 8 datasets with 24,813 images, divided into 90 classes.
|
| 31 |
+
- **Electromagnetic**: Made up of 12 datasets, totaling 36,381 images in 41 classes.
|
| 32 |
+
- **Real World**: The largest category with 50 datasets, offering 110,615 images across 495 classes.
|
| 33 |
+
|
| 34 |
+
This structure enables a diverse and extensive testing ground for object detection models, reflecting real-world application scenarios.
|
| 35 |
+
|
| 36 |
+
## Applications
|
| 37 |
+
|
| 38 |
+
Roboflow 100 is invaluable for various applications related to computer vision and deep learning. Researchers and engineers can use this benchmark to:
|
| 39 |
+
|
| 40 |
+
- Evaluate the performance of object detection models in a multi-domain context.
|
| 41 |
+
- Test the adaptability of models to real-world scenarios beyond common object recognition.
|
| 42 |
+
- Benchmark the capabilities of object detection models across diverse datasets, including those in healthcare, aerial imagery, and video games.
|
| 43 |
+
|
| 44 |
+
For more ideas and inspiration on real-world applications, be sure to check out [our guides on real-world projects](../../guides/index.md).
|
| 45 |
+
|
| 46 |
+
## Usage
|
| 47 |
+
|
| 48 |
+
The Roboflow 100 dataset is available on both [GitHub](https://github.com/roboflow/roboflow-100-benchmark) and [Roboflow Universe](https://universe.roboflow.com/roboflow-100).
|
| 49 |
+
|
| 50 |
+
You can access it directly from the Roboflow 100 GitHub repository. In addition, on Roboflow Universe, you have the flexibility to download individual datasets by simply clicking the export button within each dataset.
|
| 51 |
+
|
| 52 |
+
## Sample Data and Annotations
|
| 53 |
+
|
| 54 |
+
Roboflow 100 consists of datasets with diverse images and videos captured from various angles and domains. Here’s a look at examples of annotated images in the RF100 benchmark.
|
| 55 |
+
|
| 56 |
+
<p align="center">
|
| 57 |
+
<img width="640" src="https://blog.roboflow.com/content/images/2022/11/image-2.png" alt="Sample Data and Annotations">
|
| 58 |
+
</p>
|
| 59 |
+
|
| 60 |
+
The diversity in the Roboflow 100 benchmark that can be seen above is a significant advancement from traditional benchmarks which often focus on optimizing a single metric within a limited domain.
|
| 61 |
+
|
| 62 |
+
## Citations and Acknowledgments
|
| 63 |
+
|
| 64 |
+
If you use the Roboflow 100 dataset in your research or development work, please cite the following paper:
|
| 65 |
+
|
| 66 |
+
!!! Quote ""
|
| 67 |
+
|
| 68 |
+
=== "BibTeX"
|
| 69 |
+
|
| 70 |
+
```bibtex
|
| 71 |
+
@misc{2211.13523,
|
| 72 |
+
Author = {Floriana Ciaglia and Francesco Saverio Zuppichini and Paul Guerrie and Mark McQuade and Jacob Solawetz},
|
| 73 |
+
Title = {Roboflow 100: A Rich, Multi-Domain Object Detection Benchmark},
|
| 74 |
+
Eprint = {arXiv:2211.13523},
|
| 75 |
+
}
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
Our thanks go to the Roboflow team and all the contributors for their hard work in creating and sustaining the Roboflow 100 dataset.
|
| 79 |
+
|
| 80 |
+
If you are interested in exploring more datasets to enhance your object detection and machine learning projects, feel free to visit [our comprehensive dataset collection](../index.md).
|
yolov10/docs/en/datasets/detect/sku-110k.md
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Explore the SKU-110k dataset of densely packed retail shelf images for object detection research. Learn how to use it with Ultralytics.
|
| 4 |
+
keywords: SKU-110k dataset, object detection, retail shelf images, Ultralytics, YOLO, computer vision, deep learning models
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# SKU-110k Dataset
|
| 8 |
+
|
| 9 |
+
The [SKU-110k](https://github.com/eg4000/SKU110K_CVPR19) dataset is a collection of densely packed retail shelf images, designed to support research in object detection tasks. Developed by Eran Goldman et al., the dataset contains over 110,000 unique store keeping unit (SKU) categories with densely packed objects, often looking similar or even identical, positioned in close proximity.
|
| 10 |
+
|
| 11 |
+

|
| 12 |
+
|
| 13 |
+
## Key Features
|
| 14 |
+
|
| 15 |
+
- SKU-110k contains images of store shelves from around the world, featuring densely packed objects that pose challenges for state-of-the-art object detectors.
|
| 16 |
+
- The dataset includes over 110,000 unique SKU categories, providing a diverse range of object appearances.
|
| 17 |
+
- Annotations include bounding boxes for objects and SKU category labels.
|
| 18 |
+
|
| 19 |
+
## Dataset Structure
|
| 20 |
+
|
| 21 |
+
The SKU-110k dataset is organized into three main subsets:
|
| 22 |
+
|
| 23 |
+
1. **Training set**: This subset contains images and annotations used for training object detection models.
|
| 24 |
+
2. **Validation set**: This subset consists of images and annotations used for model validation during training.
|
| 25 |
+
3. **Test set**: This subset is designed for the final evaluation of trained object detection models.
|
| 26 |
+
|
| 27 |
+
## Applications
|
| 28 |
+
|
| 29 |
+
The SKU-110k dataset is widely used for training and evaluating deep learning models in object detection tasks, especially in densely packed scenes such as retail shelf displays. The dataset's diverse set of SKU categories and densely packed object arrangements make it a valuable resource for researchers and practitioners in the field of computer vision.
|
| 30 |
+
|
| 31 |
+
## Dataset YAML
|
| 32 |
+
|
| 33 |
+
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the SKU-110K dataset, the `SKU-110K.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/SKU-110K.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/SKU-110K.yaml).
|
| 34 |
+
|
| 35 |
+
!!! Example "ultralytics/cfg/datasets/SKU-110K.yaml"
|
| 36 |
+
|
| 37 |
+
```yaml
|
| 38 |
+
--8<-- "ultralytics/cfg/datasets/SKU-110K.yaml"
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
## Usage
|
| 42 |
+
|
| 43 |
+
To train a YOLOv8n model on the SKU-110K dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 44 |
+
|
| 45 |
+
!!! Example "Train Example"
|
| 46 |
+
|
| 47 |
+
=== "Python"
|
| 48 |
+
|
| 49 |
+
```python
|
| 50 |
+
from ultralytics import YOLO
|
| 51 |
+
|
| 52 |
+
# Load a model
|
| 53 |
+
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
| 54 |
+
|
| 55 |
+
# Train the model
|
| 56 |
+
results = model.train(data='SKU-110K.yaml', epochs=100, imgsz=640)
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
=== "CLI"
|
| 60 |
+
|
| 61 |
+
```bash
|
| 62 |
+
# Start training from a pretrained *.pt model
|
| 63 |
+
yolo detect train data=SKU-110K.yaml model=yolov8n.pt epochs=100 imgsz=640
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
## Sample Data and Annotations
|
| 67 |
+
|
| 68 |
+
The SKU-110k dataset contains a diverse set of retail shelf images with densely packed objects, providing rich context for object detection tasks. Here are some examples of data from the dataset, along with their corresponding annotations:
|
| 69 |
+
|
| 70 |
+

|
| 71 |
+
|
| 72 |
+
- **Densely packed retail shelf image**: This image demonstrates an example of densely packed objects in a retail shelf setting. Objects are annotated with bounding boxes and SKU category labels.
|
| 73 |
+
|
| 74 |
+
The example showcases the variety and complexity of the data in the SKU-110k dataset and highlights the importance of high-quality data for object detection tasks.
|
| 75 |
+
|
| 76 |
+
## Citations and Acknowledgments
|
| 77 |
+
|
| 78 |
+
If you use the SKU-110k dataset in your research or development work, please cite the following paper:
|
| 79 |
+
|
| 80 |
+
!!! Quote ""
|
| 81 |
+
|
| 82 |
+
=== "BibTeX"
|
| 83 |
+
|
| 84 |
+
```bibtex
|
| 85 |
+
@inproceedings{goldman2019dense,
|
| 86 |
+
author = {Eran Goldman and Roei Herzig and Aviv Eisenschtat and Jacob Goldberger and Tal Hassner},
|
| 87 |
+
title = {Precise Detection in Densely Packed Scenes},
|
| 88 |
+
booktitle = {Proc. Conf. Comput. Vision Pattern Recognition (CVPR)},
|
| 89 |
+
year = {2019}
|
| 90 |
+
}
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
We would like to acknowledge Eran Goldman et al. for creating and maintaining the SKU-110k dataset as a valuable resource for the computer vision research community. For more information about the SKU-110k dataset and its creators, visit the [SKU-110k dataset GitHub repository](https://github.com/eg4000/SKU110K_CVPR19).
|
yolov10/docs/en/datasets/detect/visdrone.md
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Explore the VisDrone Dataset, a large-scale benchmark for drone-based image analysis, and learn how to train a YOLO model using it.
|
| 4 |
+
keywords: VisDrone Dataset, Ultralytics, drone-based image analysis, YOLO model, object detection, object tracking, crowd counting
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# VisDrone Dataset
|
| 8 |
+
|
| 9 |
+
The [VisDrone Dataset](https://github.com/VisDrone/VisDrone-Dataset) is a large-scale benchmark created by the AISKYEYE team at the Lab of Machine Learning and Data Mining, Tianjin University, China. It contains carefully annotated ground truth data for various computer vision tasks related to drone-based image and video analysis.
|
| 10 |
+
|
| 11 |
+
VisDrone is composed of 288 video clips with 261,908 frames and 10,209 static images, captured by various drone-mounted cameras. The dataset covers a wide range of aspects, including location (14 different cities across China), environment (urban and rural), objects (pedestrians, vehicles, bicycles, etc.), and density (sparse and crowded scenes). The dataset was collected using various drone platforms under different scenarios and weather and lighting conditions. These frames are manually annotated with over 2.6 million bounding boxes of targets such as pedestrians, cars, bicycles, and tricycles. Attributes like scene visibility, object class, and occlusion are also provided for better data utilization.
|
| 12 |
+
|
| 13 |
+
## Dataset Structure
|
| 14 |
+
|
| 15 |
+
The VisDrone dataset is organized into five main subsets, each focusing on a specific task:
|
| 16 |
+
|
| 17 |
+
1. **Task 1**: Object detection in images
|
| 18 |
+
2. **Task 2**: Object detection in videos
|
| 19 |
+
3. **Task 3**: Single-object tracking
|
| 20 |
+
4. **Task 4**: Multi-object tracking
|
| 21 |
+
5. **Task 5**: Crowd counting
|
| 22 |
+
|
| 23 |
+
## Applications
|
| 24 |
+
|
| 25 |
+
The VisDrone dataset is widely used for training and evaluating deep learning models in drone-based computer vision tasks such as object detection, object tracking, and crowd counting. The dataset's diverse set of sensor data, object annotations, and attributes make it a valuable resource for researchers and practitioners in the field of drone-based computer vision.
|
| 26 |
+
|
| 27 |
+
## Dataset YAML
|
| 28 |
+
|
| 29 |
+
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the Visdrone dataset, the `VisDrone.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/VisDrone.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/VisDrone.yaml).
|
| 30 |
+
|
| 31 |
+
!!! Example "ultralytics/cfg/datasets/VisDrone.yaml"
|
| 32 |
+
|
| 33 |
+
```yaml
|
| 34 |
+
--8<-- "ultralytics/cfg/datasets/VisDrone.yaml"
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
## Usage
|
| 38 |
+
|
| 39 |
+
To train a YOLOv8n model on the VisDrone dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 40 |
+
|
| 41 |
+
!!! Example "Train Example"
|
| 42 |
+
|
| 43 |
+
=== "Python"
|
| 44 |
+
|
| 45 |
+
```python
|
| 46 |
+
from ultralytics import YOLO
|
| 47 |
+
|
| 48 |
+
# Load a model
|
| 49 |
+
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
| 50 |
+
|
| 51 |
+
# Train the model
|
| 52 |
+
results = model.train(data='VisDrone.yaml', epochs=100, imgsz=640)
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
=== "CLI"
|
| 56 |
+
|
| 57 |
+
```bash
|
| 58 |
+
# Start training from a pretrained *.pt model
|
| 59 |
+
yolo detect train data=VisDrone.yaml model=yolov8n.pt epochs=100 imgsz=640
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
## Sample Data and Annotations
|
| 63 |
+
|
| 64 |
+
The VisDrone dataset contains a diverse set of images and videos captured by drone-mounted cameras. Here are some examples of data from the dataset, along with their corresponding annotations:
|
| 65 |
+
|
| 66 |
+

|
| 67 |
+
|
| 68 |
+
- **Task 1**: Object detection in images - This image demonstrates an example of object detection in images, where objects are annotated with bounding boxes. The dataset provides a wide variety of images taken from different locations, environments, and densities to facilitate the development of models for this task.
|
| 69 |
+
|
| 70 |
+
The example showcases the variety and complexity of the data in the VisDrone dataset and highlights the importance of high-quality sensor data for drone-based computer vision tasks.
|
| 71 |
+
|
| 72 |
+
## Citations and Acknowledgments
|
| 73 |
+
|
| 74 |
+
If you use the VisDrone dataset in your research or development work, please cite the following paper:
|
| 75 |
+
|
| 76 |
+
!!! Quote ""
|
| 77 |
+
|
| 78 |
+
=== "BibTeX"
|
| 79 |
+
|
| 80 |
+
```bibtex
|
| 81 |
+
@ARTICLE{9573394,
|
| 82 |
+
author={Zhu, Pengfei and Wen, Longyin and Du, Dawei and Bian, Xiao and Fan, Heng and Hu, Qinghua and Ling, Haibin},
|
| 83 |
+
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
|
| 84 |
+
title={Detection and Tracking Meet Drones Challenge},
|
| 85 |
+
year={2021},
|
| 86 |
+
volume={},
|
| 87 |
+
number={},
|
| 88 |
+
pages={1-1},
|
| 89 |
+
doi={10.1109/TPAMI.2021.3119563}}
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
We would like to acknowledge the AISKYEYE team at the Lab of Machine Learning and Data Mining, Tianjin University, China, for creating and maintaining the VisDrone dataset as a valuable resource for the drone-based computer vision research community. For more information about the VisDrone dataset and its creators, visit the [VisDrone Dataset GitHub repository](https://github.com/VisDrone/VisDrone-Dataset).
|
yolov10/docs/en/datasets/detect/voc.md
ADDED
|
@@ -0,0 +1,94 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: A complete guide to the PASCAL VOC dataset used for object detection, segmentation and classification tasks with relevance to YOLO model training.
|
| 4 |
+
keywords: Ultralytics, PASCAL VOC dataset, object detection, segmentation, image classification, YOLO, model training, VOC.yaml, deep learning
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# VOC Dataset
|
| 8 |
+
|
| 9 |
+
The [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/) (Visual Object Classes) dataset is a well-known object detection, segmentation, and classification dataset. It is designed to encourage research on a wide variety of object categories and is commonly used for benchmarking computer vision models. It is an essential dataset for researchers and developers working on object detection, segmentation, and classification tasks.
|
| 10 |
+
|
| 11 |
+
## Key Features
|
| 12 |
+
|
| 13 |
+
- VOC dataset includes two main challenges: VOC2007 and VOC2012.
|
| 14 |
+
- The dataset comprises 20 object categories, including common objects like cars, bicycles, and animals, as well as more specific categories such as boats, sofas, and dining tables.
|
| 15 |
+
- Annotations include object bounding boxes and class labels for object detection and classification tasks, and segmentation masks for the segmentation tasks.
|
| 16 |
+
- VOC provides standardized evaluation metrics like mean Average Precision (mAP) for object detection and classification, making it suitable for comparing model performance.
|
| 17 |
+
|
| 18 |
+
## Dataset Structure
|
| 19 |
+
|
| 20 |
+
The VOC dataset is split into three subsets:
|
| 21 |
+
|
| 22 |
+
1. **Train**: This subset contains images for training object detection, segmentation, and classification models.
|
| 23 |
+
2. **Validation**: This subset has images used for validation purposes during model training.
|
| 24 |
+
3. **Test**: This subset consists of images used for testing and benchmarking the trained models. Ground truth annotations for this subset are not publicly available, and the results are submitted to the [PASCAL VOC evaluation server](http://host.robots.ox.ac.uk:8080/leaderboard/displaylb.php) for performance evaluation.
|
| 25 |
+
|
| 26 |
+
## Applications
|
| 27 |
+
|
| 28 |
+
The VOC dataset is widely used for training and evaluating deep learning models in object detection (such as YOLO, Faster R-CNN, and SSD), instance segmentation (such as Mask R-CNN), and image classification. The dataset's diverse set of object categories, large number of annotated images, and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners.
|
| 29 |
+
|
| 30 |
+
## Dataset YAML
|
| 31 |
+
|
| 32 |
+
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the VOC dataset, the `VOC.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/VOC.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/VOC.yaml).
|
| 33 |
+
|
| 34 |
+
!!! Example "ultralytics/cfg/datasets/VOC.yaml"
|
| 35 |
+
|
| 36 |
+
```yaml
|
| 37 |
+
--8<-- "ultralytics/cfg/datasets/VOC.yaml"
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
## Usage
|
| 41 |
+
|
| 42 |
+
To train a YOLOv8n model on the VOC dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 43 |
+
|
| 44 |
+
!!! Example "Train Example"
|
| 45 |
+
|
| 46 |
+
=== "Python"
|
| 47 |
+
|
| 48 |
+
```python
|
| 49 |
+
from ultralytics import YOLO
|
| 50 |
+
|
| 51 |
+
# Load a model
|
| 52 |
+
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
| 53 |
+
|
| 54 |
+
# Train the model
|
| 55 |
+
results = model.train(data='VOC.yaml', epochs=100, imgsz=640)
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
=== "CLI"
|
| 59 |
+
|
| 60 |
+
```bash
|
| 61 |
+
# Start training from a pretrained *.pt model
|
| 62 |
+
yolo detect train data=VOC.yaml model=yolov8n.pt epochs=100 imgsz=640
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
## Sample Images and Annotations
|
| 66 |
+
|
| 67 |
+
The VOC dataset contains a diverse set of images with various object categories and complex scenes. Here are some examples of images from the dataset, along with their corresponding annotations:
|
| 68 |
+
|
| 69 |
+

|
| 70 |
+
|
| 71 |
+
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
|
| 72 |
+
|
| 73 |
+
The example showcases the variety and complexity of the images in the VOC dataset and the benefits of using mosaicing during the training process.
|
| 74 |
+
|
| 75 |
+
## Citations and Acknowledgments
|
| 76 |
+
|
| 77 |
+
If you use the VOC dataset in your research or development work, please cite the following paper:
|
| 78 |
+
|
| 79 |
+
!!! Quote ""
|
| 80 |
+
|
| 81 |
+
=== "BibTeX"
|
| 82 |
+
|
| 83 |
+
```bibtex
|
| 84 |
+
@misc{everingham2010pascal,
|
| 85 |
+
title={The PASCAL Visual Object Classes (VOC) Challenge},
|
| 86 |
+
author={Mark Everingham and Luc Van Gool and Christopher K. I. Williams and John Winn and Andrew Zisserman},
|
| 87 |
+
year={2010},
|
| 88 |
+
eprint={0909.5206},
|
| 89 |
+
archivePrefix={arXiv},
|
| 90 |
+
primaryClass={cs.CV}
|
| 91 |
+
}
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
We would like to acknowledge the PASCAL VOC Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the VOC dataset and its creators, visit the [PASCAL VOC dataset website](http://host.robots.ox.ac.uk/pascal/VOC/).
|
yolov10/docs/en/datasets/detect/xview.md
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Explore xView, a large-scale, high resolution satellite imagery dataset for object detection. Dive into dataset structure, usage examples & its potential applications.
|
| 4 |
+
keywords: Ultralytics, YOLO, computer vision, xView dataset, satellite imagery, object detection, overhead imagery, training, deep learning, dataset YAML
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# xView Dataset
|
| 8 |
+
|
| 9 |
+
The [xView](http://xviewdataset.org/) dataset is one of the largest publicly available datasets of overhead imagery, containing images from complex scenes around the world annotated using bounding boxes. The goal of the xView dataset is to accelerate progress in four computer vision frontiers:
|
| 10 |
+
|
| 11 |
+
1. Reduce minimum resolution for detection.
|
| 12 |
+
2. Improve learning efficiency.
|
| 13 |
+
3. Enable discovery of more object classes.
|
| 14 |
+
4. Improve detection of fine-grained classes.
|
| 15 |
+
|
| 16 |
+
xView builds on the success of challenges like Common Objects in Context (COCO) and aims to leverage computer vision to analyze the growing amount of available imagery from space in order to understand the visual world in new ways and address a range of important applications.
|
| 17 |
+
|
| 18 |
+
## Key Features
|
| 19 |
+
|
| 20 |
+
- xView contains over 1 million object instances across 60 classes.
|
| 21 |
+
- The dataset has a resolution of 0.3 meters, providing higher resolution imagery than most public satellite imagery datasets.
|
| 22 |
+
- xView features a diverse collection of small, rare, fine-grained, and multi-type objects with bounding box annotation.
|
| 23 |
+
- Comes with a pre-trained baseline model using the TensorFlow object detection API and an example for PyTorch.
|
| 24 |
+
|
| 25 |
+
## Dataset Structure
|
| 26 |
+
|
| 27 |
+
The xView dataset is composed of satellite images collected from WorldView-3 satellites at a 0.3m ground sample distance. It contains over 1 million objects across 60 classes in over 1,400 km² of imagery.
|
| 28 |
+
|
| 29 |
+
## Applications
|
| 30 |
+
|
| 31 |
+
The xView dataset is widely used for training and evaluating deep learning models for object detection in overhead imagery. The dataset's diverse set of object classes and high-resolution imagery make it a valuable resource for researchers and practitioners in the field of computer vision, especially for satellite imagery analysis.
|
| 32 |
+
|
| 33 |
+
## Dataset YAML
|
| 34 |
+
|
| 35 |
+
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the xView dataset, the `xView.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/xView.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/xView.yaml).
|
| 36 |
+
|
| 37 |
+
!!! Example "ultralytics/cfg/datasets/xView.yaml"
|
| 38 |
+
|
| 39 |
+
```yaml
|
| 40 |
+
--8<-- "ultralytics/cfg/datasets/xView.yaml"
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
## Usage
|
| 44 |
+
|
| 45 |
+
To train a model on the xView dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 46 |
+
|
| 47 |
+
!!! Example "Train Example"
|
| 48 |
+
|
| 49 |
+
=== "Python"
|
| 50 |
+
|
| 51 |
+
```python
|
| 52 |
+
from ultralytics import YOLO
|
| 53 |
+
|
| 54 |
+
# Load a model
|
| 55 |
+
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
| 56 |
+
|
| 57 |
+
# Train the model
|
| 58 |
+
results = model.train(data='xView.yaml', epochs=100, imgsz=640)
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
=== "CLI"
|
| 62 |
+
|
| 63 |
+
```bash
|
| 64 |
+
# Start training from a pretrained *.pt model
|
| 65 |
+
yolo detect train data=xView.yaml model=yolov8n.pt epochs=100 imgsz=640
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
## Sample Data and Annotations
|
| 69 |
+
|
| 70 |
+
The xView dataset contains high-resolution satellite images with a diverse set of objects annotated using bounding boxes. Here are some examples of data from the dataset, along with their corresponding annotations:
|
| 71 |
+
|
| 72 |
+

|
| 73 |
+
|
| 74 |
+
- **Overhead Imagery**: This image demonstrates an example of object detection in overhead imagery, where objects are annotated with bounding boxes. The dataset provides high-resolution satellite images to facilitate the development of models for this task.
|
| 75 |
+
|
| 76 |
+
The example showcases the variety and complexity of the data in the xView dataset and highlights the importance of high-quality satellite imagery for object detection tasks.
|
| 77 |
+
|
| 78 |
+
## Citations and Acknowledgments
|
| 79 |
+
|
| 80 |
+
If you use the xView dataset in your research or development work, please cite the following paper:
|
| 81 |
+
|
| 82 |
+
!!! Quote ""
|
| 83 |
+
|
| 84 |
+
=== "BibTeX"
|
| 85 |
+
|
| 86 |
+
```bibtex
|
| 87 |
+
@misc{lam2018xview,
|
| 88 |
+
title={xView: Objects in Context in Overhead Imagery},
|
| 89 |
+
author={Darius Lam and Richard Kuzma and Kevin McGee and Samuel Dooley and Michael Laielli and Matthew Klaric and Yaroslav Bulatov and Brendan McCord},
|
| 90 |
+
year={2018},
|
| 91 |
+
eprint={1802.07856},
|
| 92 |
+
archivePrefix={arXiv},
|
| 93 |
+
primaryClass={cs.CV}
|
| 94 |
+
}
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
We would like to acknowledge the [Defense Innovation Unit](https://www.diu.mil/) (DIU) and the creators of the xView dataset for their valuable contribution to the computer vision research community. For more information about the xView dataset and its creators, visit the [xView dataset website](http://xviewdataset.org/).
|
yolov10/docs/en/datasets/explorer/api.md
ADDED
|
@@ -0,0 +1,337 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Explore and analyze CV datasets with Ultralytics Explorer API, offering SQL, vector similarity, and semantic searches for efficient dataset insights.
|
| 4 |
+
keywords: Ultralytics Explorer API, Dataset Exploration, SQL Queries, Vector Similarity Search, Semantic Search, Embeddings Table, Image Similarity, Python API for Datasets, CV Dataset Analysis, LanceDB Integration
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# Ultralytics Explorer API
|
| 8 |
+
|
| 9 |
+
## Introduction
|
| 10 |
+
|
| 11 |
+
<a href="https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/docs/en/datasets/explorer/explorer.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>
|
| 12 |
+
The Explorer API is a Python API for exploring your datasets. It supports filtering and searching your dataset using SQL queries, vector similarity search and semantic search.
|
| 13 |
+
|
| 14 |
+
<p align="center">
|
| 15 |
+
<br>
|
| 16 |
+
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/3VryynorQeo?start=279"
|
| 17 |
+
title="YouTube video player" frameborder="0"
|
| 18 |
+
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
| 19 |
+
allowfullscreen>
|
| 20 |
+
</iframe>
|
| 21 |
+
<br>
|
| 22 |
+
<strong>Watch:</strong> Ultralytics Explorer API Overview
|
| 23 |
+
</p>
|
| 24 |
+
|
| 25 |
+
## Installation
|
| 26 |
+
|
| 27 |
+
Explorer depends on external libraries for some of its functionality. These are automatically installed on usage. To manually install these dependencies, use the following command:
|
| 28 |
+
|
| 29 |
+
```bash
|
| 30 |
+
pip install ultralytics[explorer]
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
## Usage
|
| 34 |
+
|
| 35 |
+
```python
|
| 36 |
+
from ultralytics import Explorer
|
| 37 |
+
|
| 38 |
+
# Create an Explorer object
|
| 39 |
+
explorer = Explorer(data='coco128.yaml', model='yolov8n.pt')
|
| 40 |
+
|
| 41 |
+
# Create embeddings for your dataset
|
| 42 |
+
explorer.create_embeddings_table()
|
| 43 |
+
|
| 44 |
+
# Search for similar images to a given image/images
|
| 45 |
+
dataframe = explorer.get_similar(img='path/to/image.jpg')
|
| 46 |
+
|
| 47 |
+
# Or search for similar images to a given index/indices
|
| 48 |
+
dataframe = explorer.get_similar(idx=0)
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
!!! Tip "Note"
|
| 52 |
+
|
| 53 |
+
Embeddings table for a given dataset and model pair is only created once and reused. These use [LanceDB](https://lancedb.github.io/lancedb/) under the hood, which scales on-disk, so you can create and reuse embeddings for large datasets like COCO without running out of memory.
|
| 54 |
+
|
| 55 |
+
In case you want to force update the embeddings table, you can pass `force=True` to `create_embeddings_table` method.
|
| 56 |
+
You can directly access the LanceDB table object to perform advanced analysis. Learn more about it in [Working with table section](#4-advanced---working-with-embeddings-table)
|
| 57 |
+
|
| 58 |
+
## 1. Similarity Search
|
| 59 |
+
|
| 60 |
+
Similarity search is a technique for finding similar images to a given image. It is based on the idea that similar images will have similar embeddings. Once the embeddings table is built, you can get run semantic search in any of the following ways:
|
| 61 |
+
|
| 62 |
+
- On a given index or list of indices in the dataset: `exp.get_similar(idx=[1,10], limit=10)`
|
| 63 |
+
- On any image or list of images not in the dataset: `exp.get_similar(img=["path/to/img1", "path/to/img2"], limit=10)`
|
| 64 |
+
|
| 65 |
+
In case of multiple inputs, the aggregate of their embeddings is used.
|
| 66 |
+
|
| 67 |
+
You get a pandas dataframe with the `limit` number of most similar data points to the input, along with their distance in the embedding space. You can use this dataset to perform further filtering
|
| 68 |
+
|
| 69 |
+
!!! Example "Semantic Search"
|
| 70 |
+
|
| 71 |
+
=== "Using Images"
|
| 72 |
+
|
| 73 |
+
```python
|
| 74 |
+
from ultralytics import Explorer
|
| 75 |
+
|
| 76 |
+
# create an Explorer object
|
| 77 |
+
exp = Explorer(data='coco128.yaml', model='yolov8n.pt')
|
| 78 |
+
exp.create_embeddings_table()
|
| 79 |
+
|
| 80 |
+
similar = exp.get_similar(img='https://ultralytics.com/images/bus.jpg', limit=10)
|
| 81 |
+
print(similar.head())
|
| 82 |
+
|
| 83 |
+
# Search using multiple indices
|
| 84 |
+
similar = exp.get_similar(
|
| 85 |
+
img=['https://ultralytics.com/images/bus.jpg',
|
| 86 |
+
'https://ultralytics.com/images/bus.jpg'],
|
| 87 |
+
limit=10
|
| 88 |
+
)
|
| 89 |
+
print(similar.head())
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
=== "Using Dataset Indices"
|
| 93 |
+
|
| 94 |
+
```python
|
| 95 |
+
from ultralytics import Explorer
|
| 96 |
+
|
| 97 |
+
# create an Explorer object
|
| 98 |
+
exp = Explorer(data='coco128.yaml', model='yolov8n.pt')
|
| 99 |
+
exp.create_embeddings_table()
|
| 100 |
+
|
| 101 |
+
similar = exp.get_similar(idx=1, limit=10)
|
| 102 |
+
print(similar.head())
|
| 103 |
+
|
| 104 |
+
# Search using multiple indices
|
| 105 |
+
similar = exp.get_similar(idx=[1,10], limit=10)
|
| 106 |
+
print(similar.head())
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
### Plotting Similar Images
|
| 110 |
+
|
| 111 |
+
You can also plot the similar images using the `plot_similar` method. This method takes the same arguments as `get_similar` and plots the similar images in a grid.
|
| 112 |
+
|
| 113 |
+
!!! Example "Plotting Similar Images"
|
| 114 |
+
|
| 115 |
+
=== "Using Images"
|
| 116 |
+
|
| 117 |
+
```python
|
| 118 |
+
from ultralytics import Explorer
|
| 119 |
+
|
| 120 |
+
# create an Explorer object
|
| 121 |
+
exp = Explorer(data='coco128.yaml', model='yolov8n.pt')
|
| 122 |
+
exp.create_embeddings_table()
|
| 123 |
+
|
| 124 |
+
plt = exp.plot_similar(img='https://ultralytics.com/images/bus.jpg', limit=10)
|
| 125 |
+
plt.show()
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
=== "Using Dataset Indices"
|
| 129 |
+
|
| 130 |
+
```python
|
| 131 |
+
from ultralytics import Explorer
|
| 132 |
+
|
| 133 |
+
# create an Explorer object
|
| 134 |
+
exp = Explorer(data='coco128.yaml', model='yolov8n.pt')
|
| 135 |
+
exp.create_embeddings_table()
|
| 136 |
+
|
| 137 |
+
plt = exp.plot_similar(idx=1, limit=10)
|
| 138 |
+
plt.show()
|
| 139 |
+
```
|
| 140 |
+
|
| 141 |
+
## 2. Ask AI (Natural Language Querying)
|
| 142 |
+
|
| 143 |
+
This allows you to write how you want to filter your dataset using natural language. You don't have to be proficient in writing SQL queries. Our AI powered query generator will automatically do that under the hood. For example - you can say - "show me 100 images with exactly one person and 2 dogs. There can be other objects too" and it'll internally generate the query and show you those results.
|
| 144 |
+
Note: This works using LLMs under the hood so the results are probabilistic and might get things wrong sometimes
|
| 145 |
+
|
| 146 |
+
!!! Example "Ask AI"
|
| 147 |
+
|
| 148 |
+
```python
|
| 149 |
+
from ultralytics import Explorer
|
| 150 |
+
from ultralytics.data.explorer import plot_query_result
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
# create an Explorer object
|
| 154 |
+
exp = Explorer(data='coco128.yaml', model='yolov8n.pt')
|
| 155 |
+
exp.create_embeddings_table()
|
| 156 |
+
|
| 157 |
+
df = exp.ask_ai("show me 100 images with exactly one person and 2 dogs. There can be other objects too")
|
| 158 |
+
print(df.head())
|
| 159 |
+
|
| 160 |
+
# plot the results
|
| 161 |
+
plt = plot_query_result(df)
|
| 162 |
+
plt.show()
|
| 163 |
+
```
|
| 164 |
+
|
| 165 |
+
## 3. SQL Querying
|
| 166 |
+
|
| 167 |
+
You can run SQL queries on your dataset using the `sql_query` method. This method takes a SQL query as input and returns a pandas dataframe with the results.
|
| 168 |
+
|
| 169 |
+
!!! Example "SQL Query"
|
| 170 |
+
|
| 171 |
+
```python
|
| 172 |
+
from ultralytics import Explorer
|
| 173 |
+
|
| 174 |
+
# create an Explorer object
|
| 175 |
+
exp = Explorer(data='coco128.yaml', model='yolov8n.pt')
|
| 176 |
+
exp.create_embeddings_table()
|
| 177 |
+
|
| 178 |
+
df = exp.sql_query("WHERE labels LIKE '%person%' AND labels LIKE '%dog%'")
|
| 179 |
+
print(df.head())
|
| 180 |
+
```
|
| 181 |
+
|
| 182 |
+
### Plotting SQL Query Results
|
| 183 |
+
|
| 184 |
+
You can also plot the results of a SQL query using the `plot_sql_query` method. This method takes the same arguments as `sql_query` and plots the results in a grid.
|
| 185 |
+
|
| 186 |
+
!!! Example "Plotting SQL Query Results"
|
| 187 |
+
|
| 188 |
+
```python
|
| 189 |
+
from ultralytics import Explorer
|
| 190 |
+
|
| 191 |
+
# create an Explorer object
|
| 192 |
+
exp = Explorer(data='coco128.yaml', model='yolov8n.pt')
|
| 193 |
+
exp.create_embeddings_table()
|
| 194 |
+
|
| 195 |
+
# plot the SQL Query
|
| 196 |
+
exp.plot_sql_query("WHERE labels LIKE '%person%' AND labels LIKE '%dog%' LIMIT 10")
|
| 197 |
+
```
|
| 198 |
+
|
| 199 |
+
## 4. Advanced - Working with Embeddings Table
|
| 200 |
+
|
| 201 |
+
You can also work with the embeddings table directly. Once the embeddings table is created, you can access it using the `Explorer.table`
|
| 202 |
+
|
| 203 |
+
!!! Tip "Explorer works on [LanceDB](https://lancedb.github.io/lancedb/) tables internally. You can access this table directly, using `Explorer.table` object and run raw queries, push down pre- and post-filters, etc."
|
| 204 |
+
|
| 205 |
+
```python
|
| 206 |
+
from ultralytics import Explorer
|
| 207 |
+
|
| 208 |
+
exp = Explorer()
|
| 209 |
+
exp.create_embeddings_table()
|
| 210 |
+
table = exp.table
|
| 211 |
+
```
|
| 212 |
+
|
| 213 |
+
Here are some examples of what you can do with the table:
|
| 214 |
+
|
| 215 |
+
### Get raw Embeddings
|
| 216 |
+
|
| 217 |
+
!!! Example
|
| 218 |
+
|
| 219 |
+
```python
|
| 220 |
+
from ultralytics import Explorer
|
| 221 |
+
|
| 222 |
+
exp = Explorer()
|
| 223 |
+
exp.create_embeddings_table()
|
| 224 |
+
table = exp.table
|
| 225 |
+
|
| 226 |
+
embeddings = table.to_pandas()["vector"]
|
| 227 |
+
print(embeddings)
|
| 228 |
+
```
|
| 229 |
+
|
| 230 |
+
### Advanced Querying with pre- and post-filters
|
| 231 |
+
|
| 232 |
+
!!! Example
|
| 233 |
+
|
| 234 |
+
```python
|
| 235 |
+
from ultralytics import Explorer
|
| 236 |
+
|
| 237 |
+
exp = Explorer(model="yolov8n.pt")
|
| 238 |
+
exp.create_embeddings_table()
|
| 239 |
+
table = exp.table
|
| 240 |
+
|
| 241 |
+
# Dummy embedding
|
| 242 |
+
embedding = [i for i in range(256)]
|
| 243 |
+
rs = table.search(embedding).metric("cosine").where("").limit(10)
|
| 244 |
+
```
|
| 245 |
+
|
| 246 |
+
### Create Vector Index
|
| 247 |
+
|
| 248 |
+
When using large datasets, you can also create a dedicated vector index for faster querying. This is done using the `create_index` method on LanceDB table.
|
| 249 |
+
|
| 250 |
+
```python
|
| 251 |
+
table.create_index(num_partitions=..., num_sub_vectors=...)
|
| 252 |
+
```
|
| 253 |
+
|
| 254 |
+
Find more details on the type vector indices available and parameters [here](https://lancedb.github.io/lancedb/ann_indexes/#types-of-index) In the future, we will add support for creating vector indices directly from Explorer API.
|
| 255 |
+
|
| 256 |
+
## 5. Embeddings Applications
|
| 257 |
+
|
| 258 |
+
You can use the embeddings table to perform a variety of exploratory analysis. Here are some examples:
|
| 259 |
+
|
| 260 |
+
### Similarity Index
|
| 261 |
+
|
| 262 |
+
Explorer comes with a `similarity_index` operation:
|
| 263 |
+
|
| 264 |
+
- It tries to estimate how similar each data point is with the rest of the dataset.
|
| 265 |
+
- It does that by counting how many image embeddings lie closer than `max_dist` to the current image in the generated embedding space, considering `top_k` similar images at a time.
|
| 266 |
+
|
| 267 |
+
It returns a pandas dataframe with the following columns:
|
| 268 |
+
|
| 269 |
+
- `idx`: Index of the image in the dataset
|
| 270 |
+
- `im_file`: Path to the image file
|
| 271 |
+
- `count`: Number of images in the dataset that are closer than `max_dist` to the current image
|
| 272 |
+
- `sim_im_files`: List of paths to the `count` similar images
|
| 273 |
+
|
| 274 |
+
!!! Tip
|
| 275 |
+
|
| 276 |
+
For a given dataset, model, `max_dist` & `top_k` the similarity index once generated will be reused. In case, your dataset has changed, or you simply need to regenerate the similarity index, you can pass `force=True`.
|
| 277 |
+
|
| 278 |
+
!!! Example "Similarity Index"
|
| 279 |
+
|
| 280 |
+
```python
|
| 281 |
+
from ultralytics import Explorer
|
| 282 |
+
|
| 283 |
+
exp = Explorer()
|
| 284 |
+
exp.create_embeddings_table()
|
| 285 |
+
|
| 286 |
+
sim_idx = exp.similarity_index()
|
| 287 |
+
```
|
| 288 |
+
|
| 289 |
+
You can use similarity index to build custom conditions to filter out the dataset. For example, you can filter out images that are not similar to any other image in the dataset using the following code:
|
| 290 |
+
|
| 291 |
+
```python
|
| 292 |
+
import numpy as np
|
| 293 |
+
|
| 294 |
+
sim_count = np.array(sim_idx["count"])
|
| 295 |
+
sim_idx['im_file'][sim_count > 30]
|
| 296 |
+
```
|
| 297 |
+
|
| 298 |
+
### Visualize Embedding Space
|
| 299 |
+
|
| 300 |
+
You can also visualize the embedding space using the plotting tool of your choice. For example here is a simple example using matplotlib:
|
| 301 |
+
|
| 302 |
+
```python
|
| 303 |
+
import numpy as np
|
| 304 |
+
from sklearn.decomposition import PCA
|
| 305 |
+
import matplotlib.pyplot as plt
|
| 306 |
+
from mpl_toolkits.mplot3d import Axes3D
|
| 307 |
+
|
| 308 |
+
# Reduce dimensions using PCA to 3 components for visualization in 3D
|
| 309 |
+
pca = PCA(n_components=3)
|
| 310 |
+
reduced_data = pca.fit_transform(embeddings)
|
| 311 |
+
|
| 312 |
+
# Create a 3D scatter plot using Matplotlib Axes3D
|
| 313 |
+
fig = plt.figure(figsize=(8, 6))
|
| 314 |
+
ax = fig.add_subplot(111, projection='3d')
|
| 315 |
+
|
| 316 |
+
# Scatter plot
|
| 317 |
+
ax.scatter(reduced_data[:, 0], reduced_data[:, 1], reduced_data[:, 2], alpha=0.5)
|
| 318 |
+
ax.set_title('3D Scatter Plot of Reduced 256-Dimensional Data (PCA)')
|
| 319 |
+
ax.set_xlabel('Component 1')
|
| 320 |
+
ax.set_ylabel('Component 2')
|
| 321 |
+
ax.set_zlabel('Component 3')
|
| 322 |
+
|
| 323 |
+
plt.show()
|
| 324 |
+
```
|
| 325 |
+
|
| 326 |
+
Start creating your own CV dataset exploration reports using the Explorer API. For inspiration, check out the
|
| 327 |
+
|
| 328 |
+
## Apps Built Using Ultralytics Explorer
|
| 329 |
+
|
| 330 |
+
Try our GUI Demo based on Explorer API
|
| 331 |
+
|
| 332 |
+
## Coming Soon
|
| 333 |
+
|
| 334 |
+
- [ ] Merge specific labels from datasets. Example - Import all `person` labels from COCO and `car` labels from Cityscapes
|
| 335 |
+
- [ ] Remove images that have a higher similarity index than the given threshold
|
| 336 |
+
- [ ] Automatically persist new datasets after merging/removing entries
|
| 337 |
+
- [ ] Advanced Dataset Visualizations
|
yolov10/docs/en/datasets/explorer/dashboard.md
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Learn about Ultralytics Explorer GUI for semantic search, SQL queries, and AI-powered natural language search in CV datasets.
|
| 4 |
+
keywords: Ultralytics, Explorer GUI, semantic search, vector similarity search, AI queries, SQL queries, computer vision, dataset exploration, image search, OpenAI integration
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# Explorer GUI
|
| 8 |
+
|
| 9 |
+
Explorer GUI is like a playground build using [Ultralytics Explorer API](api.md). It allows you to run semantic/vector similarity search, SQL queries and even search using natural language using our ask AI feature powered by LLMs.
|
| 10 |
+
|
| 11 |
+
<p>
|
| 12 |
+
<img width="1709" alt="Explorer Dashboard Screenshot 1" src="https://github.com/ultralytics/ultralytics/assets/15766192/feb1fe05-58c5-4173-a9ff-e611e3bba3d0">
|
| 13 |
+
</p>
|
| 14 |
+
|
| 15 |
+
<p align="center">
|
| 16 |
+
<br>
|
| 17 |
+
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/3VryynorQeo?start=306"
|
| 18 |
+
title="YouTube video player" frameborder="0"
|
| 19 |
+
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
| 20 |
+
allowfullscreen>
|
| 21 |
+
</iframe>
|
| 22 |
+
<br>
|
| 23 |
+
<strong>Watch:</strong> Ultralytics Explorer Dashboard Overview
|
| 24 |
+
</p>
|
| 25 |
+
|
| 26 |
+
### Installation
|
| 27 |
+
|
| 28 |
+
```bash
|
| 29 |
+
pip install ultralytics[explorer]
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
!!! note "Note"
|
| 33 |
+
|
| 34 |
+
Ask AI feature works using OpenAI, so you'll be prompted to set the api key for OpenAI when you first run the GUI.
|
| 35 |
+
You can set it like this - `yolo settings openai_api_key="..."`
|
| 36 |
+
|
| 37 |
+
## Semantic Search / Vector Similarity Search
|
| 38 |
+
|
| 39 |
+
Semantic search is a technique for finding similar images to a given image. It is based on the idea that similar images will have similar embeddings. In the UI, you can select one of more images and search for the images similar to them. This can be useful when you want to find images similar to a given image or a set of images that don't perform as expected.
|
| 40 |
+
|
| 41 |
+
For example:
|
| 42 |
+
In this VOC Exploration dashboard, user selects a couple airplane images like this:
|
| 43 |
+
<p>
|
| 44 |
+
<img width="1710" alt="Explorer Dashboard Screenshot 2" src="https://github.com/RizwanMunawar/RizwanMunawar/assets/62513924/3becdc1d-45dc-43b7-88ff-84ff0b443894">
|
| 45 |
+
</p>
|
| 46 |
+
|
| 47 |
+
On performing similarity search, you should see a similar result:
|
| 48 |
+
<p>
|
| 49 |
+
<img width="1710" alt="Explorer Dashboard Screenshot 3" src="https://github.com/RizwanMunawar/RizwanMunawar/assets/62513924/aeea2e16-bc2b-41bb-9aef-4a33bfa1a800">
|
| 50 |
+
</p>
|
| 51 |
+
|
| 52 |
+
## Ask AI
|
| 53 |
+
|
| 54 |
+
This allows you to write how you want to filter your dataset using natural language. You don't have to be proficient in writing SQL queries. Our AI powered query generator will automatically do that under the hood. For example - you can say - "show me 100 images with exactly one person and 2 dogs. There can be other objects too" and it'll internally generate the query and show you those results. Here's an example output when asked to "Show 10 images with exactly 5 persons" and you'll see a result like this:
|
| 55 |
+
<p>
|
| 56 |
+
<img width="1709" alt="Explorer Dashboard Screenshot 4" src="https://github.com/RizwanMunawar/RizwanMunawar/assets/62513924/55a67181-3b25-4d2f-b786-2a6a08a0cb6b">
|
| 57 |
+
</p>
|
| 58 |
+
|
| 59 |
+
Note: This works using LLMs under the hood so the results are probabilistic and might get things wrong sometimes
|
| 60 |
+
|
| 61 |
+
## Run SQL queries on your CV datasets
|
| 62 |
+
|
| 63 |
+
You can run SQL queries on your dataset to filter it. It also works if you only provide the WHERE clause. Example SQL query would show only the images that have at least one 1 person and 1 dog in them:
|
| 64 |
+
|
| 65 |
+
```sql
|
| 66 |
+
WHERE labels LIKE '%person%' AND labels LIKE '%dog%'
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
<p>
|
| 70 |
+
<img width="1707" alt="Explorer Dashboard Screenshot 5" src="https://github.com/RizwanMunawar/RizwanMunawar/assets/62513924/14fbb237-0b2d-4b7c-8f62-2fca4e6cc26f">
|
| 71 |
+
</p>
|
| 72 |
+
|
| 73 |
+
This is a Demo build using the Explorer API. You can use the API to build your own exploratory notebooks or scripts to get insights into your datasets. Learn more about the Explorer API [here](api.md).
|
yolov10/docs/en/datasets/explorer/explorer.ipynb
ADDED
|
@@ -0,0 +1,601 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "aa923c26-81c8-4565-9277-1cb686e3702e",
|
| 6 |
+
"metadata": {
|
| 7 |
+
"id": "aa923c26-81c8-4565-9277-1cb686e3702e"
|
| 8 |
+
},
|
| 9 |
+
"source": [
|
| 10 |
+
"# VOC Exploration Example\n",
|
| 11 |
+
"<div align=\"center\">\n",
|
| 12 |
+
"\n",
|
| 13 |
+
" <a href=\"https://ultralytics.com/yolov8\" target=\"_blank\">\n",
|
| 14 |
+
" <img width=\"1024\", src=\"https://raw.githubusercontent.com/ultralytics/assets/main/yolov8/banner-yolov8.png\"></a>\n",
|
| 15 |
+
"\n",
|
| 16 |
+
" [中文](https://docs.ultralytics.com/zh/) | [한국어](https://docs.ultralytics.com/ko/) | [日本語](https://docs.ultralytics.com/ja/) | [Русский](https://docs.ultralytics.com/ru/) | [Deutsch](https://docs.ultralytics.com/de/) | [Français](https://docs.ultralytics.com/fr/) | [Español](https://docs.ultralytics.com/es/) | [Português](https://docs.ultralytics.com/pt/) | [हिन्दी](https://docs.ultralytics.com/hi/) | [العربية](https://docs.ultralytics.com/ar/)\n",
|
| 17 |
+
"\n",
|
| 18 |
+
" <a href=\"https://console.paperspace.com/github/ultralytics/ultralytics\"><img src=\"https://assets.paperspace.io/img/gradient-badge.svg\" alt=\"Run on Gradient\"/></a>\n",
|
| 19 |
+
" <a href=\"https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"></a>\n",
|
| 20 |
+
" <a href=\"https://www.kaggle.com/ultralytics/yolov8\"><img src=\"https://kaggle.com/static/images/open-in-kaggle.svg\" alt=\"Open In Kaggle\"></a>\n",
|
| 21 |
+
"\n",
|
| 22 |
+
"Welcome to the Ultralytics Explorer API notebook! This notebook serves as the starting point for exploring the various resources available to help you get started with using Ultralytics to explore your datasets using with the power of semantic search. You can utilities out of the box that allow you to examine specific types of labels using vector search or even SQL queries.\n",
|
| 23 |
+
"\n",
|
| 24 |
+
"We hope that the resources in this notebook will help you get the most out of Ultralytics. Please browse the Explorer <a href=\"https://docs.ultralytics.com/\">Docs</a> for details, raise an issue on <a href=\"https://github.com/ultralytics/ultralytics\">GitHub</a> for support, and join our <a href=\"https://ultralytics.com/discord\">Discord</a> community for questions and discussions!\n",
|
| 25 |
+
"\n",
|
| 26 |
+
"Try `yolo explorer` powered by Exlorer API\n",
|
| 27 |
+
"\n",
|
| 28 |
+
"Simply `pip install ultralytics` and run `yolo explorer` in your terminal to run custom queries and semantic search on your datasets right inside your browser!\n",
|
| 29 |
+
"\n",
|
| 30 |
+
"</div>"
|
| 31 |
+
]
|
| 32 |
+
},
|
| 33 |
+
{
|
| 34 |
+
"cell_type": "markdown",
|
| 35 |
+
"id": "2454d9ba-9db4-4b37-98e8-201ba285c92f",
|
| 36 |
+
"metadata": {
|
| 37 |
+
"id": "2454d9ba-9db4-4b37-98e8-201ba285c92f"
|
| 38 |
+
},
|
| 39 |
+
"source": [
|
| 40 |
+
"## Setup\n",
|
| 41 |
+
"Pip install `ultralytics` and [dependencies](https://github.com/ultralytics/ultralytics/blob/main/pyproject.toml) and check software and hardware."
|
| 42 |
+
]
|
| 43 |
+
},
|
| 44 |
+
{
|
| 45 |
+
"cell_type": "code",
|
| 46 |
+
"execution_count": null,
|
| 47 |
+
"id": "433f3a4d-a914-42cb-b0b6-be84a84e5e41",
|
| 48 |
+
"metadata": {
|
| 49 |
+
"id": "433f3a4d-a914-42cb-b0b6-be84a84e5e41"
|
| 50 |
+
},
|
| 51 |
+
"outputs": [],
|
| 52 |
+
"source": [
|
| 53 |
+
"%pip install ultralytics[explorer] openai\n",
|
| 54 |
+
"import ultralytics\n",
|
| 55 |
+
"ultralytics.checks()"
|
| 56 |
+
]
|
| 57 |
+
},
|
| 58 |
+
{
|
| 59 |
+
"cell_type": "code",
|
| 60 |
+
"execution_count": null,
|
| 61 |
+
"id": "ae602549-3419-4909-9f82-35cba515483f",
|
| 62 |
+
"metadata": {
|
| 63 |
+
"id": "ae602549-3419-4909-9f82-35cba515483f"
|
| 64 |
+
},
|
| 65 |
+
"outputs": [],
|
| 66 |
+
"source": [
|
| 67 |
+
"from ultralytics import Explorer"
|
| 68 |
+
]
|
| 69 |
+
},
|
| 70 |
+
{
|
| 71 |
+
"cell_type": "markdown",
|
| 72 |
+
"id": "d8c06350-be8e-45cf-b3a6-b5017bbd943c",
|
| 73 |
+
"metadata": {
|
| 74 |
+
"id": "d8c06350-be8e-45cf-b3a6-b5017bbd943c"
|
| 75 |
+
},
|
| 76 |
+
"source": [
|
| 77 |
+
"## Similarity search\n",
|
| 78 |
+
"Utilize the power of vector similarity search to find the similar data points in your dataset along with their distance in the embedding space. Simply create an embeddings table for the given dataset-model pair. It is only needed once and it is reused automatically.\n"
|
| 79 |
+
]
|
| 80 |
+
},
|
| 81 |
+
{
|
| 82 |
+
"cell_type": "code",
|
| 83 |
+
"execution_count": null,
|
| 84 |
+
"id": "334619da-6deb-4b32-9fe0-74e0a79cee20",
|
| 85 |
+
"metadata": {
|
| 86 |
+
"id": "334619da-6deb-4b32-9fe0-74e0a79cee20"
|
| 87 |
+
},
|
| 88 |
+
"outputs": [],
|
| 89 |
+
"source": [
|
| 90 |
+
"exp = Explorer(\"VOC.yaml\", model=\"yolov8n.pt\")\n",
|
| 91 |
+
"exp.create_embeddings_table()"
|
| 92 |
+
]
|
| 93 |
+
},
|
| 94 |
+
{
|
| 95 |
+
"cell_type": "markdown",
|
| 96 |
+
"id": "b6c5e42d-bc7e-4b4c-bde0-643072a2165d",
|
| 97 |
+
"metadata": {
|
| 98 |
+
"id": "b6c5e42d-bc7e-4b4c-bde0-643072a2165d"
|
| 99 |
+
},
|
| 100 |
+
"source": [
|
| 101 |
+
"One the embeddings table is built, you can get run semantic search in any of the following ways:\n",
|
| 102 |
+
"- On a given index / list of indices in the dataset like - `exp.get_similar(idx=[1,10], limit=10)`\n",
|
| 103 |
+
"- On any image/ list of images not in the dataset - `exp.get_similar(img=[\"path/to/img1\", \"path/to/img2\"], limit=10)`\n",
|
| 104 |
+
"In case of multiple inputs, the aggregade of their embeddings is used.\n",
|
| 105 |
+
"\n",
|
| 106 |
+
"You get a pandas dataframe with the `limit` number of most similar data points to the input, along with their distance in the embedding space. You can use this dataset to perform further filtering\n",
|
| 107 |
+
"<img width=\"1120\" alt=\"Screenshot 2024-01-06 at 9 45 42 PM\" src=\"https://github.com/AyushExel/assets/assets/15766192/7742ac57-e22a-4cea-a0f9-2b2a257483c5\">\n"
|
| 108 |
+
]
|
| 109 |
+
},
|
| 110 |
+
{
|
| 111 |
+
"cell_type": "code",
|
| 112 |
+
"execution_count": null,
|
| 113 |
+
"id": "b485f05b-d92d-42bc-8da7-5e361667b341",
|
| 114 |
+
"metadata": {
|
| 115 |
+
"id": "b485f05b-d92d-42bc-8da7-5e361667b341"
|
| 116 |
+
},
|
| 117 |
+
"outputs": [],
|
| 118 |
+
"source": [
|
| 119 |
+
"similar = exp.get_similar(idx=1, limit=10)\n",
|
| 120 |
+
"similar.head()"
|
| 121 |
+
]
|
| 122 |
+
},
|
| 123 |
+
{
|
| 124 |
+
"cell_type": "markdown",
|
| 125 |
+
"id": "acf4b489-2161-4176-a1fe-d1d067d8083d",
|
| 126 |
+
"metadata": {
|
| 127 |
+
"id": "acf4b489-2161-4176-a1fe-d1d067d8083d"
|
| 128 |
+
},
|
| 129 |
+
"source": [
|
| 130 |
+
"You can use the also plot the similar samples directly using the `plot_similar` util\n",
|
| 131 |
+
"<p>\n",
|
| 132 |
+
"\n",
|
| 133 |
+
" <img src=\"https://github.com/AyushExel/assets/assets/15766192/a3c9247b-9271-47df-aaa5-36d96c5034b1\" />\n",
|
| 134 |
+
"</p>\n"
|
| 135 |
+
]
|
| 136 |
+
},
|
| 137 |
+
{
|
| 138 |
+
"cell_type": "code",
|
| 139 |
+
"execution_count": null,
|
| 140 |
+
"id": "9dbfe7d0-8613-4529-adb6-6e0632d7cce7",
|
| 141 |
+
"metadata": {
|
| 142 |
+
"id": "9dbfe7d0-8613-4529-adb6-6e0632d7cce7"
|
| 143 |
+
},
|
| 144 |
+
"outputs": [],
|
| 145 |
+
"source": [
|
| 146 |
+
"exp.plot_similar(idx=6500, limit=20)\n",
|
| 147 |
+
"#exp.plot_similar(idx=[100,101], limit=10) # Can also pass list of idxs or imgs\n"
|
| 148 |
+
]
|
| 149 |
+
},
|
| 150 |
+
{
|
| 151 |
+
"cell_type": "code",
|
| 152 |
+
"execution_count": null,
|
| 153 |
+
"id": "260e09bf-4960-4089-a676-cb0e76ff3c0d",
|
| 154 |
+
"metadata": {
|
| 155 |
+
"id": "260e09bf-4960-4089-a676-cb0e76ff3c0d"
|
| 156 |
+
},
|
| 157 |
+
"outputs": [],
|
| 158 |
+
"source": [
|
| 159 |
+
"exp.plot_similar(img=\"https://ultralytics.com/images/bus.jpg\", limit=10, labels=False) # Can also pass any external images\n"
|
| 160 |
+
]
|
| 161 |
+
},
|
| 162 |
+
{
|
| 163 |
+
"cell_type": "markdown",
|
| 164 |
+
"id": "faa0b7a7-6318-40e4-b0f4-45a8113bdc3a",
|
| 165 |
+
"metadata": {
|
| 166 |
+
"id": "faa0b7a7-6318-40e4-b0f4-45a8113bdc3a"
|
| 167 |
+
},
|
| 168 |
+
"source": [
|
| 169 |
+
"<p>\n",
|
| 170 |
+
"<img src=\"https://github.com/AyushExel/assets/assets/15766192/8e011195-b0da-43ef-b3cd-5fb6f383037e\">\n",
|
| 171 |
+
"\n",
|
| 172 |
+
"</p>"
|
| 173 |
+
]
|
| 174 |
+
},
|
| 175 |
+
{
|
| 176 |
+
"cell_type": "markdown",
|
| 177 |
+
"id": "0cea63f1-71f1-46da-af2b-b1b7d8f73553",
|
| 178 |
+
"metadata": {
|
| 179 |
+
"id": "0cea63f1-71f1-46da-af2b-b1b7d8f73553"
|
| 180 |
+
},
|
| 181 |
+
"source": [
|
| 182 |
+
"## 2. Ask AI: Search or filter with Natural Language\n",
|
| 183 |
+
"You can prompt the Explorer object with the kind of data points you want to see and it'll try to return a dataframe with those. Because it is powered by LLMs, it doesn't always get it right. In that case, it'll return None.\n",
|
| 184 |
+
"<p>\n",
|
| 185 |
+
"<img width=\"1131\" alt=\"Screenshot 2024-01-07 at 2 34 53 PM\" src=\"https://github.com/AyushExel/assets/assets/15766192/c4a69fd9-e54f-4d6a-aba5-dc9cfae1bc04\">\n",
|
| 186 |
+
"\n",
|
| 187 |
+
"</p>\n",
|
| 188 |
+
"\n"
|
| 189 |
+
]
|
| 190 |
+
},
|
| 191 |
+
{
|
| 192 |
+
"cell_type": "code",
|
| 193 |
+
"execution_count": null,
|
| 194 |
+
"id": "92fb92ac-7f76-465a-a9ba-ea7492498d9c",
|
| 195 |
+
"metadata": {
|
| 196 |
+
"id": "92fb92ac-7f76-465a-a9ba-ea7492498d9c"
|
| 197 |
+
},
|
| 198 |
+
"outputs": [],
|
| 199 |
+
"source": [
|
| 200 |
+
"df = exp.ask_ai(\"show me images containing more than 10 objects with at least 2 persons\")\n",
|
| 201 |
+
"df.head(5)"
|
| 202 |
+
]
|
| 203 |
+
},
|
| 204 |
+
{
|
| 205 |
+
"cell_type": "markdown",
|
| 206 |
+
"id": "f2a7d26e-0ce5-4578-ad1a-b1253805280f",
|
| 207 |
+
"metadata": {
|
| 208 |
+
"id": "f2a7d26e-0ce5-4578-ad1a-b1253805280f"
|
| 209 |
+
},
|
| 210 |
+
"source": [
|
| 211 |
+
"for plotting these results you can use `plot_query_result` util\n",
|
| 212 |
+
"Example:\n",
|
| 213 |
+
"```\n",
|
| 214 |
+
"plt = plot_query_result(exp.ask_ai(\"show me 10 images containing exactly 2 persons\"))\n",
|
| 215 |
+
"Image.fromarray(plt)\n",
|
| 216 |
+
"```\n",
|
| 217 |
+
"<p>\n",
|
| 218 |
+
" <img src=\"https://github.com/AyushExel/assets/assets/15766192/2cb780de-d05b-4412-a526-7f7f0f10e669\">\n",
|
| 219 |
+
"\n",
|
| 220 |
+
"</p>"
|
| 221 |
+
]
|
| 222 |
+
},
|
| 223 |
+
{
|
| 224 |
+
"cell_type": "code",
|
| 225 |
+
"execution_count": null,
|
| 226 |
+
"id": "b1cfab84-9835-4da0-8e9a-42b30cf84511",
|
| 227 |
+
"metadata": {
|
| 228 |
+
"id": "b1cfab84-9835-4da0-8e9a-42b30cf84511"
|
| 229 |
+
},
|
| 230 |
+
"outputs": [],
|
| 231 |
+
"source": [
|
| 232 |
+
"# plot\n",
|
| 233 |
+
"from ultralytics.data.explorer import plot_query_result\n",
|
| 234 |
+
"from PIL import Image\n",
|
| 235 |
+
"\n",
|
| 236 |
+
"plt = plot_query_result(exp.ask_ai(\"show me 10 images containing exactly 2 persons\"))\n",
|
| 237 |
+
"Image.fromarray(plt)"
|
| 238 |
+
]
|
| 239 |
+
},
|
| 240 |
+
{
|
| 241 |
+
"cell_type": "markdown",
|
| 242 |
+
"id": "35315ae6-d827-40e4-8813-279f97a83b34",
|
| 243 |
+
"metadata": {
|
| 244 |
+
"id": "35315ae6-d827-40e4-8813-279f97a83b34"
|
| 245 |
+
},
|
| 246 |
+
"source": [
|
| 247 |
+
"## 3. Run SQL queries on your Dataset!\n",
|
| 248 |
+
"Sometimes you might want to investigate a certain type of entries in your dataset. For this Explorer allows you to execute SQL queries.\n",
|
| 249 |
+
"It accepts either of the formats:\n",
|
| 250 |
+
"- Queries beginning with \"WHERE\" will automatically select all columns. This can be thought of as a short-hand query\n",
|
| 251 |
+
"- You can also write full queries where you can specify which columns to select\n",
|
| 252 |
+
"\n",
|
| 253 |
+
"This can be used to investigate model performance and specific data points. For example:\n",
|
| 254 |
+
"- let's say your model struggles on images that have humans and dogs. You can write a query like this to select the points that have at least 2 humans AND at least one dog.\n",
|
| 255 |
+
"\n",
|
| 256 |
+
"You can combine SQL query and semantic search to filter down to specific type of results\n",
|
| 257 |
+
"<img width=\"994\" alt=\"Screenshot 2024-01-06 at 9 47 30 PM\" src=\"https://github.com/AyushExel/assets/assets/15766192/92bc3178-c151-4cd5-8007-c76178deb113\">\n"
|
| 258 |
+
]
|
| 259 |
+
},
|
| 260 |
+
{
|
| 261 |
+
"cell_type": "code",
|
| 262 |
+
"execution_count": null,
|
| 263 |
+
"id": "8cd1072f-3100-4331-a0e3-4e2f6b1005bf",
|
| 264 |
+
"metadata": {
|
| 265 |
+
"id": "8cd1072f-3100-4331-a0e3-4e2f6b1005bf"
|
| 266 |
+
},
|
| 267 |
+
"outputs": [],
|
| 268 |
+
"source": [
|
| 269 |
+
"table = exp.sql_query(\"WHERE labels LIKE '%person, person%' AND labels LIKE '%dog%' LIMIT 10\")\n",
|
| 270 |
+
"table"
|
| 271 |
+
]
|
| 272 |
+
},
|
| 273 |
+
{
|
| 274 |
+
"cell_type": "markdown",
|
| 275 |
+
"id": "debf8a00-c9f6-448b-bd3b-454cf62f39ab",
|
| 276 |
+
"metadata": {
|
| 277 |
+
"id": "debf8a00-c9f6-448b-bd3b-454cf62f39ab"
|
| 278 |
+
},
|
| 279 |
+
"source": [
|
| 280 |
+
"Just like similarity search, you also get a util to directly plot the sql queries using `exp.plot_sql_query`\n",
|
| 281 |
+
"<img src=\"https://github.com/AyushExel/assets/assets/15766192/f8b66629-8dd0-419e-8f44-9837969ba678\">\n"
|
| 282 |
+
]
|
| 283 |
+
},
|
| 284 |
+
{
|
| 285 |
+
"cell_type": "code",
|
| 286 |
+
"execution_count": null,
|
| 287 |
+
"id": "18b977e7-d048-4b22-b8c4-084a03b04f23",
|
| 288 |
+
"metadata": {
|
| 289 |
+
"id": "18b977e7-d048-4b22-b8c4-084a03b04f23"
|
| 290 |
+
},
|
| 291 |
+
"outputs": [],
|
| 292 |
+
"source": [
|
| 293 |
+
"exp.plot_sql_query(\"WHERE labels LIKE '%person, person%' AND labels LIKE '%dog%' LIMIT 10\", labels=True)"
|
| 294 |
+
]
|
| 295 |
+
},
|
| 296 |
+
{
|
| 297 |
+
"cell_type": "markdown",
|
| 298 |
+
"id": "f26804c5-840b-4fd1-987f-e362f29e3e06",
|
| 299 |
+
"metadata": {
|
| 300 |
+
"id": "f26804c5-840b-4fd1-987f-e362f29e3e06"
|
| 301 |
+
},
|
| 302 |
+
"source": [
|
| 303 |
+
"## 3. Working with embeddings Table (Advanced)\n",
|
| 304 |
+
"Explorer works on [LanceDB](https://lancedb.github.io/lancedb/) tables internally. You can access this table directly, using `Explorer.table` object and run raw queries, push down pre and post filters, etc."
|
| 305 |
+
]
|
| 306 |
+
},
|
| 307 |
+
{
|
| 308 |
+
"cell_type": "code",
|
| 309 |
+
"execution_count": null,
|
| 310 |
+
"id": "ea69260a-3407-40c9-9f42-8b34a6e6af7a",
|
| 311 |
+
"metadata": {
|
| 312 |
+
"id": "ea69260a-3407-40c9-9f42-8b34a6e6af7a"
|
| 313 |
+
},
|
| 314 |
+
"outputs": [],
|
| 315 |
+
"source": [
|
| 316 |
+
"table = exp.table\n",
|
| 317 |
+
"table.schema"
|
| 318 |
+
]
|
| 319 |
+
},
|
| 320 |
+
{
|
| 321 |
+
"cell_type": "markdown",
|
| 322 |
+
"id": "238db292-8610-40b3-9af7-dfd6be174892",
|
| 323 |
+
"metadata": {
|
| 324 |
+
"id": "238db292-8610-40b3-9af7-dfd6be174892"
|
| 325 |
+
},
|
| 326 |
+
"source": [
|
| 327 |
+
"### Run raw queries\n",
|
| 328 |
+
"Vector Search finds the nearest vectors from the database. In a recommendation system or search engine, you can find similar products from the one you searched. In LLM and other AI applications, each data point can be presented by the embeddings generated from some models, it returns the most relevant features.\n",
|
| 329 |
+
"\n",
|
| 330 |
+
"A search in high-dimensional vector space, is to find K-Nearest-Neighbors (KNN) of the query vector.\n",
|
| 331 |
+
"\n",
|
| 332 |
+
"Metric\n",
|
| 333 |
+
"In LanceDB, a Metric is the way to describe the distance between a pair of vectors. Currently, it supports the following metrics:\n",
|
| 334 |
+
"- L2\n",
|
| 335 |
+
"- Cosine\n",
|
| 336 |
+
"- Dot\n",
|
| 337 |
+
"Explorer's similarity search uses L2 by default. You can run queries on tables directly, or use the lance format to build custom utilities to manage datasets. More details on available LanceDB table ops in the [docs](https://lancedb.github.io/lancedb/)\n",
|
| 338 |
+
"\n",
|
| 339 |
+
"<img width=\"1015\" alt=\"Screenshot 2024-01-06 at 9 48 35 PM\" src=\"https://github.com/AyushExel/assets/assets/15766192/a2ccdaf3-8877-4f70-bf47-8a9bd2bb20c0\">\n"
|
| 340 |
+
]
|
| 341 |
+
},
|
| 342 |
+
{
|
| 343 |
+
"cell_type": "code",
|
| 344 |
+
"execution_count": null,
|
| 345 |
+
"id": "d74430fe-5aee-45a1-8863-3f2c31338792",
|
| 346 |
+
"metadata": {
|
| 347 |
+
"id": "d74430fe-5aee-45a1-8863-3f2c31338792"
|
| 348 |
+
},
|
| 349 |
+
"outputs": [],
|
| 350 |
+
"source": [
|
| 351 |
+
"dummy_img_embedding = [i for i in range(256)]\n",
|
| 352 |
+
"table.search(dummy_img_embedding).limit(5).to_pandas()"
|
| 353 |
+
]
|
| 354 |
+
},
|
| 355 |
+
{
|
| 356 |
+
"cell_type": "markdown",
|
| 357 |
+
"id": "587486b4-0d19-4214-b994-f032fb2e8eb5",
|
| 358 |
+
"metadata": {
|
| 359 |
+
"id": "587486b4-0d19-4214-b994-f032fb2e8eb5"
|
| 360 |
+
},
|
| 361 |
+
"source": [
|
| 362 |
+
"### Inter-conversion to popular data formats"
|
| 363 |
+
]
|
| 364 |
+
},
|
| 365 |
+
{
|
| 366 |
+
"cell_type": "code",
|
| 367 |
+
"execution_count": null,
|
| 368 |
+
"id": "bb2876ea-999b-4eba-96bc-c196ba02c41c",
|
| 369 |
+
"metadata": {
|
| 370 |
+
"id": "bb2876ea-999b-4eba-96bc-c196ba02c41c"
|
| 371 |
+
},
|
| 372 |
+
"outputs": [],
|
| 373 |
+
"source": [
|
| 374 |
+
"df = table.to_pandas()\n",
|
| 375 |
+
"pa_table = table.to_arrow()\n"
|
| 376 |
+
]
|
| 377 |
+
},
|
| 378 |
+
{
|
| 379 |
+
"cell_type": "markdown",
|
| 380 |
+
"id": "42659d63-ad76-49d6-8dfc-78d77278db72",
|
| 381 |
+
"metadata": {
|
| 382 |
+
"id": "42659d63-ad76-49d6-8dfc-78d77278db72"
|
| 383 |
+
},
|
| 384 |
+
"source": [
|
| 385 |
+
"### Work with Embeddings\n",
|
| 386 |
+
"You can access the raw embedding from lancedb Table and analyse it. The image embeddings are stored in column `vector`"
|
| 387 |
+
]
|
| 388 |
+
},
|
| 389 |
+
{
|
| 390 |
+
"cell_type": "code",
|
| 391 |
+
"execution_count": null,
|
| 392 |
+
"id": "66d69e9b-046e-41c8-80d7-c0ee40be3bca",
|
| 393 |
+
"metadata": {
|
| 394 |
+
"id": "66d69e9b-046e-41c8-80d7-c0ee40be3bca"
|
| 395 |
+
},
|
| 396 |
+
"outputs": [],
|
| 397 |
+
"source": [
|
| 398 |
+
"import numpy as np\n",
|
| 399 |
+
"\n",
|
| 400 |
+
"embeddings = table.to_pandas()[\"vector\"].tolist()\n",
|
| 401 |
+
"embeddings = np.array(embeddings)"
|
| 402 |
+
]
|
| 403 |
+
},
|
| 404 |
+
{
|
| 405 |
+
"cell_type": "markdown",
|
| 406 |
+
"id": "e8df0a49-9596-4399-954b-b8ae1fd7a602",
|
| 407 |
+
"metadata": {
|
| 408 |
+
"id": "e8df0a49-9596-4399-954b-b8ae1fd7a602"
|
| 409 |
+
},
|
| 410 |
+
"source": [
|
| 411 |
+
"### Scatterplot\n",
|
| 412 |
+
"One of the preliminary steps in analysing embeddings is by plotting them in 2D space via dimensionality reduction. Let's try an example\n",
|
| 413 |
+
"\n",
|
| 414 |
+
"<img width=\"646\" alt=\"Screenshot 2024-01-06 at 9 48 58 PM\" src=\"https://github.com/AyushExel/assets/assets/15766192/9e1da25c-face-4426-abc0-2f64a4e4952c\">\n"
|
| 415 |
+
]
|
| 416 |
+
},
|
| 417 |
+
{
|
| 418 |
+
"cell_type": "code",
|
| 419 |
+
"execution_count": null,
|
| 420 |
+
"id": "d9a150e8-8092-41b3-82f8-2247f8187fc8",
|
| 421 |
+
"metadata": {
|
| 422 |
+
"id": "d9a150e8-8092-41b3-82f8-2247f8187fc8"
|
| 423 |
+
},
|
| 424 |
+
"outputs": [],
|
| 425 |
+
"source": [
|
| 426 |
+
"!pip install scikit-learn --q"
|
| 427 |
+
]
|
| 428 |
+
},
|
| 429 |
+
{
|
| 430 |
+
"cell_type": "code",
|
| 431 |
+
"execution_count": null,
|
| 432 |
+
"id": "196079c3-45a9-4325-81ab-af79a881e37a",
|
| 433 |
+
"metadata": {
|
| 434 |
+
"id": "196079c3-45a9-4325-81ab-af79a881e37a"
|
| 435 |
+
},
|
| 436 |
+
"outputs": [],
|
| 437 |
+
"source": [
|
| 438 |
+
"%matplotlib inline\n",
|
| 439 |
+
"import numpy as np\n",
|
| 440 |
+
"from sklearn.decomposition import PCA\n",
|
| 441 |
+
"import matplotlib.pyplot as plt\n",
|
| 442 |
+
"from mpl_toolkits.mplot3d import Axes3D\n",
|
| 443 |
+
"\n",
|
| 444 |
+
"# Reduce dimensions using PCA to 3 components for visualization in 3D\n",
|
| 445 |
+
"pca = PCA(n_components=3)\n",
|
| 446 |
+
"reduced_data = pca.fit_transform(embeddings)\n",
|
| 447 |
+
"\n",
|
| 448 |
+
"# Create a 3D scatter plot using Matplotlib's Axes3D\n",
|
| 449 |
+
"fig = plt.figure(figsize=(8, 6))\n",
|
| 450 |
+
"ax = fig.add_subplot(111, projection='3d')\n",
|
| 451 |
+
"\n",
|
| 452 |
+
"# Scatter plot\n",
|
| 453 |
+
"ax.scatter(reduced_data[:, 0], reduced_data[:, 1], reduced_data[:, 2], alpha=0.5)\n",
|
| 454 |
+
"ax.set_title('3D Scatter Plot of Reduced 256-Dimensional Data (PCA)')\n",
|
| 455 |
+
"ax.set_xlabel('Component 1')\n",
|
| 456 |
+
"ax.set_ylabel('Component 2')\n",
|
| 457 |
+
"ax.set_zlabel('Component 3')\n",
|
| 458 |
+
"\n",
|
| 459 |
+
"plt.show()"
|
| 460 |
+
]
|
| 461 |
+
},
|
| 462 |
+
{
|
| 463 |
+
"cell_type": "markdown",
|
| 464 |
+
"id": "1c843c23-e3f2-490e-8d6c-212fa038a149",
|
| 465 |
+
"metadata": {
|
| 466 |
+
"id": "1c843c23-e3f2-490e-8d6c-212fa038a149"
|
| 467 |
+
},
|
| 468 |
+
"source": [
|
| 469 |
+
"## 4. Similarity Index\n",
|
| 470 |
+
"Here's a simple example of an operation powered by the embeddings table. Explorer comes with a `similarity_index` operation-\n",
|
| 471 |
+
"* It tries to estimate how similar each data point is with the rest of the dataset.\n",
|
| 472 |
+
"* It does that by counting how many image embeddings lie closer than `max_dist` to the current image in the generated embedding space, considering `top_k` similar images at a time.\n",
|
| 473 |
+
"\n",
|
| 474 |
+
"For a given dataset, model, `max_dist` & `top_k` the similarity index once generated will be reused. In case, your dataset has changed, or you simply need to regenerate the similarity index, you can pass `force=True`.\n",
|
| 475 |
+
"Similar to vector and SQL search, this also comes with a util to directly plot it. Let's look at the plot first\n",
|
| 476 |
+
"<img width=\"633\" alt=\"Screenshot 2024-01-06 at 9 49 36 PM\" src=\"https://github.com/AyushExel/assets/assets/15766192/96a9d984-4a72-4784-ace1-428676ee2bdd\">\n",
|
| 477 |
+
"\n"
|
| 478 |
+
]
|
| 479 |
+
},
|
| 480 |
+
{
|
| 481 |
+
"cell_type": "code",
|
| 482 |
+
"execution_count": null,
|
| 483 |
+
"id": "953c2a5f-1b61-4acf-a8e4-ed08547dbafc",
|
| 484 |
+
"metadata": {
|
| 485 |
+
"id": "953c2a5f-1b61-4acf-a8e4-ed08547dbafc"
|
| 486 |
+
},
|
| 487 |
+
"outputs": [],
|
| 488 |
+
"source": [
|
| 489 |
+
"exp.plot_similarity_index(max_dist=0.2, top_k=0.01)"
|
| 490 |
+
]
|
| 491 |
+
},
|
| 492 |
+
{
|
| 493 |
+
"cell_type": "markdown",
|
| 494 |
+
"id": "28228a9a-b727-45b5-8ca7-8db662c0b937",
|
| 495 |
+
"metadata": {
|
| 496 |
+
"id": "28228a9a-b727-45b5-8ca7-8db662c0b937"
|
| 497 |
+
},
|
| 498 |
+
"source": [
|
| 499 |
+
"Now let's look at the output of the operation"
|
| 500 |
+
]
|
| 501 |
+
},
|
| 502 |
+
{
|
| 503 |
+
"cell_type": "code",
|
| 504 |
+
"execution_count": null,
|
| 505 |
+
"id": "f4161aaa-20e6-4df0-8e87-d2293ee0530a",
|
| 506 |
+
"metadata": {
|
| 507 |
+
"id": "f4161aaa-20e6-4df0-8e87-d2293ee0530a"
|
| 508 |
+
},
|
| 509 |
+
"outputs": [],
|
| 510 |
+
"source": [
|
| 511 |
+
"import numpy as np\n",
|
| 512 |
+
"\n",
|
| 513 |
+
"sim_idx = exp.similarity_index(max_dist=0.2, top_k=0.01, force=False)"
|
| 514 |
+
]
|
| 515 |
+
},
|
| 516 |
+
{
|
| 517 |
+
"cell_type": "code",
|
| 518 |
+
"execution_count": null,
|
| 519 |
+
"id": "b01d5b1a-9adb-4c3c-a873-217c71527c8d",
|
| 520 |
+
"metadata": {
|
| 521 |
+
"id": "b01d5b1a-9adb-4c3c-a873-217c71527c8d"
|
| 522 |
+
},
|
| 523 |
+
"outputs": [],
|
| 524 |
+
"source": [
|
| 525 |
+
"sim_idx"
|
| 526 |
+
]
|
| 527 |
+
},
|
| 528 |
+
{
|
| 529 |
+
"cell_type": "markdown",
|
| 530 |
+
"id": "22b28e54-4fbb-400e-ad8c-7068cbba11c4",
|
| 531 |
+
"metadata": {
|
| 532 |
+
"id": "22b28e54-4fbb-400e-ad8c-7068cbba11c4"
|
| 533 |
+
},
|
| 534 |
+
"source": [
|
| 535 |
+
"Let's create a query to see what data points have similarity count of more than 30 and plot images similar to them."
|
| 536 |
+
]
|
| 537 |
+
},
|
| 538 |
+
{
|
| 539 |
+
"cell_type": "code",
|
| 540 |
+
"execution_count": null,
|
| 541 |
+
"id": "58d2557b-d401-43cf-937d-4f554c7bc808",
|
| 542 |
+
"metadata": {
|
| 543 |
+
"id": "58d2557b-d401-43cf-937d-4f554c7bc808"
|
| 544 |
+
},
|
| 545 |
+
"outputs": [],
|
| 546 |
+
"source": [
|
| 547 |
+
"import numpy as np\n",
|
| 548 |
+
"\n",
|
| 549 |
+
"sim_count = np.array(sim_idx[\"count\"])\n",
|
| 550 |
+
"sim_idx['im_file'][sim_count > 30]"
|
| 551 |
+
]
|
| 552 |
+
},
|
| 553 |
+
{
|
| 554 |
+
"cell_type": "markdown",
|
| 555 |
+
"id": "a5ec8d76-271a-41ab-ac74-cf8c0084ba5e",
|
| 556 |
+
"metadata": {
|
| 557 |
+
"id": "a5ec8d76-271a-41ab-ac74-cf8c0084ba5e"
|
| 558 |
+
},
|
| 559 |
+
"source": [
|
| 560 |
+
"You should see something like this\n",
|
| 561 |
+
"<img src=\"https://github.com/AyushExel/assets/assets/15766192/649bc366-ca2d-46ea-bfd9-3097cf575584\">\n"
|
| 562 |
+
]
|
| 563 |
+
},
|
| 564 |
+
{
|
| 565 |
+
"cell_type": "code",
|
| 566 |
+
"execution_count": null,
|
| 567 |
+
"id": "3a7b2ee3-9f35-48a2-9c38-38379516f4d2",
|
| 568 |
+
"metadata": {
|
| 569 |
+
"id": "3a7b2ee3-9f35-48a2-9c38-38379516f4d2"
|
| 570 |
+
},
|
| 571 |
+
"outputs": [],
|
| 572 |
+
"source": [
|
| 573 |
+
"exp.plot_similar(idx=[7146, 14035]) # Using avg embeddings of 2 images"
|
| 574 |
+
]
|
| 575 |
+
}
|
| 576 |
+
],
|
| 577 |
+
"metadata": {
|
| 578 |
+
"kernelspec": {
|
| 579 |
+
"display_name": "Python 3 (ipykernel)",
|
| 580 |
+
"language": "python",
|
| 581 |
+
"name": "python3"
|
| 582 |
+
},
|
| 583 |
+
"language_info": {
|
| 584 |
+
"codemirror_mode": {
|
| 585 |
+
"name": "ipython",
|
| 586 |
+
"version": 3
|
| 587 |
+
},
|
| 588 |
+
"file_extension": ".py",
|
| 589 |
+
"mimetype": "text/x-python",
|
| 590 |
+
"name": "python",
|
| 591 |
+
"nbconvert_exporter": "python",
|
| 592 |
+
"pygments_lexer": "ipython3",
|
| 593 |
+
"version": "3.9.6"
|
| 594 |
+
},
|
| 595 |
+
"colab": {
|
| 596 |
+
"provenance": []
|
| 597 |
+
}
|
| 598 |
+
},
|
| 599 |
+
"nbformat": 4,
|
| 600 |
+
"nbformat_minor": 5
|
| 601 |
+
}
|
yolov10/docs/en/datasets/explorer/index.md
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Discover the Ultralytics Explorer, a versatile tool and Python API for CV dataset exploration, enabling semantic search, SQL queries, and vector similarity searches.
|
| 4 |
+
keywords: Ultralytics Explorer, CV Dataset Tools, Semantic Search, SQL Dataset Queries, Vector Similarity, Python API, GUI Explorer, Dataset Analysis, YOLO Explorer, Data Insights
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# Ultralytics Explorer
|
| 8 |
+
|
| 9 |
+
<p>
|
| 10 |
+
<img width="1709" alt="Ultralytics Explorer Screenshot 1" src="https://github.com/ultralytics/ultralytics/assets/15766192/feb1fe05-58c5-4173-a9ff-e611e3bba3d0">
|
| 11 |
+
</p>
|
| 12 |
+
|
| 13 |
+
<a href="https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/docs/en/datasets/explorer/explorer.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>
|
| 14 |
+
Ultralytics Explorer is a tool for exploring CV datasets using semantic search, SQL queries, vector similarity search and even using natural language. It is also a Python API for accessing the same functionality.
|
| 15 |
+
|
| 16 |
+
<p align="center">
|
| 17 |
+
<br>
|
| 18 |
+
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/3VryynorQeo"
|
| 19 |
+
title="YouTube video player" frameborder="0"
|
| 20 |
+
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
| 21 |
+
allowfullscreen>
|
| 22 |
+
</iframe>
|
| 23 |
+
<br>
|
| 24 |
+
<strong>Watch:</strong> Ultralytics Explorer API | Semantic Search, SQL Queries & Ask AI Features
|
| 25 |
+
</p>
|
| 26 |
+
|
| 27 |
+
### Installation of optional dependencies
|
| 28 |
+
|
| 29 |
+
Explorer depends on external libraries for some of its functionality. These are automatically installed on usage. To manually install these dependencies, use the following command:
|
| 30 |
+
|
| 31 |
+
```bash
|
| 32 |
+
pip install ultralytics[explorer]
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
!!! tip
|
| 36 |
+
|
| 37 |
+
Explorer works on embedding/semantic search & SQL querying and is powered by [LanceDB](https://lancedb.com/) serverless vector database. Unlike traditional in-memory DBs, it is persisted on disk without sacrificing performance, so you can scale locally to large datasets like COCO without running out of memory.
|
| 38 |
+
|
| 39 |
+
### Explorer API
|
| 40 |
+
|
| 41 |
+
This is a Python API for Exploring your datasets. It also powers the GUI Explorer. You can use this to create your own exploratory notebooks or scripts to get insights into your datasets.
|
| 42 |
+
|
| 43 |
+
Learn more about the Explorer API [here](api.md).
|
| 44 |
+
|
| 45 |
+
## GUI Explorer Usage
|
| 46 |
+
|
| 47 |
+
The GUI demo runs in your browser allowing you to create embeddings for your dataset and search for similar images, run SQL queries and perform semantic search. It can be run using the following command:
|
| 48 |
+
|
| 49 |
+
```bash
|
| 50 |
+
yolo explorer
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
!!! note "Note"
|
| 54 |
+
|
| 55 |
+
Ask AI feature works using OpenAI, so you'll be prompted to set the api key for OpenAI when you first run the GUI.
|
| 56 |
+
You can set it like this - `yolo settings openai_api_key="..."`
|
| 57 |
+
|
| 58 |
+
<p>
|
| 59 |
+
<img width="1709" alt="Ultralytics Explorer OpenAI Integration" src="https://github.com/AyushExel/assets/assets/15766192/1b5f3708-be3e-44c5-9ea3-adcd522dfc75">
|
| 60 |
+
</p>
|
yolov10/docs/en/datasets/index.md
ADDED
|
@@ -0,0 +1,151 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Explore various computer vision datasets supported by Ultralytics for object detection, segmentation, pose estimation, image classification, and multi-object tracking.
|
| 4 |
+
keywords: computer vision, datasets, Ultralytics, YOLO, object detection, instance segmentation, pose estimation, image classification, multi-object tracking
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# Datasets Overview
|
| 8 |
+
|
| 9 |
+
Ultralytics provides support for various datasets to facilitate computer vision tasks such as detection, instance segmentation, pose estimation, classification, and multi-object tracking. Below is a list of the main Ultralytics datasets, followed by a summary of each computer vision task and the respective datasets.
|
| 10 |
+
|
| 11 |
+
<p align="center">
|
| 12 |
+
<br>
|
| 13 |
+
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/YDXKa1EljmU"
|
| 14 |
+
title="YouTube video player" frameborder="0"
|
| 15 |
+
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
| 16 |
+
allowfullscreen>
|
| 17 |
+
</iframe>
|
| 18 |
+
<br>
|
| 19 |
+
<strong>Watch:</strong> Ultralytics Datasets Overview
|
| 20 |
+
</p>
|
| 21 |
+
|
| 22 |
+
## NEW 🚀 Ultralytics Explorer
|
| 23 |
+
|
| 24 |
+
Create embeddings for your dataset, search for similar images, run SQL queries, perform semantic search and even search using natural language! You can get started with our GUI app or build your own using the API. Learn more [here](explorer/index.md).
|
| 25 |
+
|
| 26 |
+
<p>
|
| 27 |
+
<img alt="Ultralytics Explorer Screenshot" src="https://github.com/RizwanMunawar/RizwanMunawar/assets/62513924/d2ebaffd-e065-4d88-983a-33cb6f593785">
|
| 28 |
+
</p>
|
| 29 |
+
|
| 30 |
+
- Try the [GUI Demo](explorer/index.md)
|
| 31 |
+
- Learn more about the [Explorer API](explorer/index.md)
|
| 32 |
+
|
| 33 |
+
## [Detection Datasets](detect/index.md)
|
| 34 |
+
|
| 35 |
+
Bounding box object detection is a computer vision technique that involves detecting and localizing objects in an image by drawing a bounding box around each object.
|
| 36 |
+
|
| 37 |
+
- [Argoverse](detect/argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations.
|
| 38 |
+
- [COCO](detect/coco.md): A large-scale dataset designed for object detection, segmentation, and captioning with over 200K labeled images.
|
| 39 |
+
- [COCO8](detect/coco8.md): Contains the first 4 images from COCO train and COCO val, suitable for quick tests.
|
| 40 |
+
- [Global Wheat 2020](detect/globalwheat2020.md): A dataset of wheat head images collected from around the world for object detection and localization tasks.
|
| 41 |
+
- [Objects365](detect/objects365.md): A high-quality, large-scale dataset for object detection with 365 object categories and over 600K annotated images.
|
| 42 |
+
- [OpenImagesV7](detect/open-images-v7.md): A comprehensive dataset by Google with 1.7M train images and 42k validation images.
|
| 43 |
+
- [SKU-110K](detect/sku-110k.md): A dataset featuring dense object detection in retail environments with over 11K images and 1.7 million bounding boxes.
|
| 44 |
+
- [VisDrone](detect/visdrone.md): A dataset containing object detection and multi-object tracking data from drone-captured imagery with over 10K images and video sequences.
|
| 45 |
+
- [VOC](detect/voc.md): The Pascal Visual Object Classes (VOC) dataset for object detection and segmentation with 20 object classes and over 11K images.
|
| 46 |
+
- [xView](detect/xview.md): A dataset for object detection in overhead imagery with 60 object categories and over 1 million annotated objects.
|
| 47 |
+
- [Roboflow 100](detect/roboflow-100.md): A diverse object detection benchmark with 100 datasets spanning seven imagery domains for comprehensive model evaluation.
|
| 48 |
+
- [Brain-tumor](detect/brain-tumor.md): A dataset for detecting brain tumors includes MRI or CT scan images with details on tumor presence, location, and characteristics. It's vital for training computer vision models to automate tumor identification, aiding in early diagnosis and treatment planning.
|
| 49 |
+
- [African-wildlife](detect/african-wildlife.md): A dataset featuring images of African wildlife, including buffalo, elephant, rhino, and zebra, aids in training computer vision models. Essential for identifying animals in various habitats, it supports wildlife research.
|
| 50 |
+
|
| 51 |
+
## [Instance Segmentation Datasets](segment/index.md)
|
| 52 |
+
|
| 53 |
+
Instance segmentation is a computer vision technique that involves identifying and localizing objects in an image at the pixel level.
|
| 54 |
+
|
| 55 |
+
- [COCO](segment/coco.md): A large-scale dataset designed for object detection, segmentation, and captioning tasks with over 200K labeled images.
|
| 56 |
+
- [COCO8-seg](segment/coco8-seg.md): A smaller dataset for instance segmentation tasks, containing a subset of 8 COCO images with segmentation annotations.
|
| 57 |
+
- [Crack-seg](segment/crack-seg.md): Specifically crafted dataset for detecting cracks on roads and walls, applicable for both object detection and segmentation tasks.
|
| 58 |
+
- [Package-seg](segment/package-seg.md): Tailored dataset for identifying packages in warehouses or industrial settings, suitable for both object detection and segmentation applications.
|
| 59 |
+
- [Carparts-seg](segment/carparts-seg.md): Purpose-built dataset for identifying vehicle parts, catering to design, manufacturing, and research needs. It serves for both object detection and segmentation tasks.
|
| 60 |
+
|
| 61 |
+
## [Pose Estimation](pose/index.md)
|
| 62 |
+
|
| 63 |
+
Pose estimation is a technique used to determine the pose of the object relative to the camera or the world coordinate system.
|
| 64 |
+
|
| 65 |
+
- [COCO](pose/coco.md): A large-scale dataset with human pose annotations designed for pose estimation tasks.
|
| 66 |
+
- [COCO8-pose](pose/coco8-pose.md): A smaller dataset for pose estimation tasks, containing a subset of 8 COCO images with human pose annotations.
|
| 67 |
+
- [Tiger-pose](pose/tiger-pose.md): A compact dataset consisting of 263 images focused on tigers, annotated with 12 keypoints per tiger for pose estimation tasks.
|
| 68 |
+
|
| 69 |
+
## [Classification](classify/index.md)
|
| 70 |
+
|
| 71 |
+
Image classification is a computer vision task that involves categorizing an image into one or more predefined classes or categories based on its visual content.
|
| 72 |
+
|
| 73 |
+
- [Caltech 101](classify/caltech101.md): A dataset containing images of 101 object categories for image classification tasks.
|
| 74 |
+
- [Caltech 256](classify/caltech256.md): An extended version of Caltech 101 with 256 object categories and more challenging images.
|
| 75 |
+
- [CIFAR-10](classify/cifar10.md): A dataset of 60K 32x32 color images in 10 classes, with 6K images per class.
|
| 76 |
+
- [CIFAR-100](classify/cifar100.md): An extended version of CIFAR-10 with 100 object categories and 600 images per class.
|
| 77 |
+
- [Fashion-MNIST](classify/fashion-mnist.md): A dataset consisting of 70,000 grayscale images of 10 fashion categories for image classification tasks.
|
| 78 |
+
- [ImageNet](classify/imagenet.md): A large-scale dataset for object detection and image classification with over 14 million images and 20,000 categories.
|
| 79 |
+
- [ImageNet-10](classify/imagenet10.md): A smaller subset of ImageNet with 10 categories for faster experimentation and testing.
|
| 80 |
+
- [Imagenette](classify/imagenette.md): A smaller subset of ImageNet that contains 10 easily distinguishable classes for quicker training and testing.
|
| 81 |
+
- [Imagewoof](classify/imagewoof.md): A more challenging subset of ImageNet containing 10 dog breed categories for image classification tasks.
|
| 82 |
+
- [MNIST](classify/mnist.md): A dataset of 70,000 grayscale images of handwritten digits for image classification tasks.
|
| 83 |
+
|
| 84 |
+
## [Oriented Bounding Boxes (OBB)](obb/index.md)
|
| 85 |
+
|
| 86 |
+
Oriented Bounding Boxes (OBB) is a method in computer vision for detecting angled objects in images using rotated bounding boxes, often applied to aerial and satellite imagery.
|
| 87 |
+
|
| 88 |
+
- [DOTAv2](obb/dota-v2.md): A popular OBB aerial imagery dataset with 1.7 million instances and 11,268 images.
|
| 89 |
+
|
| 90 |
+
## [Multi-Object Tracking](track/index.md)
|
| 91 |
+
|
| 92 |
+
Multi-object tracking is a computer vision technique that involves detecting and tracking multiple objects over time in a video sequence.
|
| 93 |
+
|
| 94 |
+
- [Argoverse](detect/argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations for multi-object tracking tasks.
|
| 95 |
+
- [VisDrone](detect/visdrone.md): A dataset containing object detection and multi-object tracking data from drone-captured imagery with over 10K images and video sequences.
|
| 96 |
+
|
| 97 |
+
## Contribute New Datasets
|
| 98 |
+
|
| 99 |
+
Contributing a new dataset involves several steps to ensure that it aligns well with the existing infrastructure. Below are the necessary steps:
|
| 100 |
+
|
| 101 |
+
### Steps to Contribute a New Dataset
|
| 102 |
+
|
| 103 |
+
1. **Collect Images**: Gather the images that belong to the dataset. These could be collected from various sources, such as public databases or your own collection.
|
| 104 |
+
|
| 105 |
+
2. **Annotate Images**: Annotate these images with bounding boxes, segments, or keypoints, depending on the task.
|
| 106 |
+
|
| 107 |
+
3. **Export Annotations**: Convert these annotations into the YOLO `*.txt` file format which Ultralytics supports.
|
| 108 |
+
|
| 109 |
+
4. **Organize Dataset**: Arrange your dataset into the correct folder structure. You should have `train/` and `val/` top-level directories, and within each, an `images/` and `labels/` subdirectory.
|
| 110 |
+
|
| 111 |
+
```
|
| 112 |
+
dataset/
|
| 113 |
+
├── train/
|
| 114 |
+
│ ├── images/
|
| 115 |
+
│ └── labels/
|
| 116 |
+
└── val/
|
| 117 |
+
├── images/
|
| 118 |
+
└── labels/
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
+
5. **Create a `data.yaml` File**: In your dataset's root directory, create a `data.yaml` file that describes the dataset, classes, and other necessary information.
|
| 122 |
+
|
| 123 |
+
6. **Optimize Images (Optional)**: If you want to reduce the size of the dataset for more efficient processing, you can optimize the images using the code below. This is not required, but recommended for smaller dataset sizes and faster download speeds.
|
| 124 |
+
|
| 125 |
+
7. **Zip Dataset**: Compress the entire dataset folder into a zip file.
|
| 126 |
+
|
| 127 |
+
8. **Document and PR**: Create a documentation page describing your dataset and how it fits into the existing framework. After that, submit a Pull Request (PR). Refer to [Ultralytics Contribution Guidelines](https://docs.ultralytics.com/help/contributing) for more details on how to submit a PR.
|
| 128 |
+
|
| 129 |
+
### Example Code to Optimize and Zip a Dataset
|
| 130 |
+
|
| 131 |
+
!!! Example "Optimize and Zip a Dataset"
|
| 132 |
+
|
| 133 |
+
=== "Python"
|
| 134 |
+
|
| 135 |
+
```python
|
| 136 |
+
from pathlib import Path
|
| 137 |
+
from ultralytics.data.utils import compress_one_image
|
| 138 |
+
from ultralytics.utils.downloads import zip_directory
|
| 139 |
+
|
| 140 |
+
# Define dataset directory
|
| 141 |
+
path = Path('path/to/dataset')
|
| 142 |
+
|
| 143 |
+
# Optimize images in dataset (optional)
|
| 144 |
+
for f in path.rglob('*.jpg'):
|
| 145 |
+
compress_one_image(f)
|
| 146 |
+
|
| 147 |
+
# Zip dataset into 'path/to/dataset.zip'
|
| 148 |
+
zip_directory(path)
|
| 149 |
+
```
|
| 150 |
+
|
| 151 |
+
By following these steps, you can contribute a new dataset that integrates well with Ultralytics' existing structure.
|
yolov10/docs/en/datasets/obb/dota-v2.md
ADDED
|
@@ -0,0 +1,156 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Delve into DOTA, an Oriented Bounding Box (OBB) aerial imagery dataset with 1.7 million instances and 11,268 images.
|
| 4 |
+
keywords: DOTA v1, DOTA v1.5, DOTA v2, object detection, aerial images, computer vision, deep learning, annotations, oriented bounding boxes, OBB
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# DOTA Dataset with OBB
|
| 8 |
+
|
| 9 |
+
[DOTA](https://captain-whu.github.io/DOTA/index.html) stands as a specialized dataset, emphasizing object detection in aerial images. Originating from the DOTA series of datasets, it offers annotated images capturing a diverse array of aerial scenes with Oriented Bounding Boxes (OBB).
|
| 10 |
+
|
| 11 |
+

|
| 12 |
+
|
| 13 |
+
## Key Features
|
| 14 |
+
|
| 15 |
+
- Collection from various sensors and platforms, with image sizes ranging from 800 × 800 to 20,000 × 20,000 pixels.
|
| 16 |
+
- Features more than 1.7M Oriented Bounding Boxes across 18 categories.
|
| 17 |
+
- Encompasses multiscale object detection.
|
| 18 |
+
- Instances are annotated by experts using arbitrary (8 d.o.f.) quadrilateral, capturing objects of different scales, orientations, and shapes.
|
| 19 |
+
|
| 20 |
+
## Dataset Versions
|
| 21 |
+
|
| 22 |
+
### DOTA-v1.0
|
| 23 |
+
|
| 24 |
+
- Contains 15 common categories.
|
| 25 |
+
- Comprises 2,806 images with 188,282 instances.
|
| 26 |
+
- Split ratios: 1/2 for training, 1/6 for validation, and 1/3 for testing.
|
| 27 |
+
|
| 28 |
+
### DOTA-v1.5
|
| 29 |
+
|
| 30 |
+
- Incorporates the same images as DOTA-v1.0.
|
| 31 |
+
- Very small instances (less than 10 pixels) are also annotated.
|
| 32 |
+
- Addition of a new category: "container crane".
|
| 33 |
+
- A total of 403,318 instances.
|
| 34 |
+
- Released for the DOAI Challenge 2019 on Object Detection in Aerial Images.
|
| 35 |
+
|
| 36 |
+
### DOTA-v2.0
|
| 37 |
+
|
| 38 |
+
- Collections from Google Earth, GF-2 Satellite, and other aerial images.
|
| 39 |
+
- Contains 18 common categories.
|
| 40 |
+
- Comprises 11,268 images with a whopping 1,793,658 instances.
|
| 41 |
+
- New categories introduced: "airport" and "helipad".
|
| 42 |
+
- Image splits:
|
| 43 |
+
- Training: 1,830 images with 268,627 instances.
|
| 44 |
+
- Validation: 593 images with 81,048 instances.
|
| 45 |
+
- Test-dev: 2,792 images with 353,346 instances.
|
| 46 |
+
- Test-challenge: 6,053 images with 1,090,637 instances.
|
| 47 |
+
|
| 48 |
+
## Dataset Structure
|
| 49 |
+
|
| 50 |
+
DOTA exhibits a structured layout tailored for OBB object detection challenges:
|
| 51 |
+
|
| 52 |
+
- **Images**: A vast collection of high-resolution aerial images capturing diverse terrains and structures.
|
| 53 |
+
- **Oriented Bounding Boxes**: Annotations in the form of rotated rectangles encapsulating objects irrespective of their orientation, ideal for capturing objects like airplanes, ships, and buildings.
|
| 54 |
+
|
| 55 |
+
## Applications
|
| 56 |
+
|
| 57 |
+
DOTA serves as a benchmark for training and evaluating models specifically tailored for aerial image analysis. With the inclusion of OBB annotations, it provides a unique challenge, enabling the development of specialized object detection models that cater to aerial imagery's nuances.
|
| 58 |
+
|
| 59 |
+
## Dataset YAML
|
| 60 |
+
|
| 61 |
+
Typically, datasets incorporate a YAML (Yet Another Markup Language) file detailing the dataset's configuration. For DOTA v1 and DOTA v1.5, Ultralytics provides `DOTAv1.yaml` and `DOTAv1.5.yaml` files. For additional details on these as well as DOTA v2 please consult DOTA's official repository and documentation.
|
| 62 |
+
|
| 63 |
+
!!! Example "DOTAv1.yaml"
|
| 64 |
+
|
| 65 |
+
```yaml
|
| 66 |
+
--8<-- "ultralytics/cfg/datasets/DOTAv1.yaml"
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
## Split DOTA images
|
| 70 |
+
|
| 71 |
+
To train DOTA dataset, we split original DOTA images with high-resolution into images with 1024x1024 resolution in multiscale way.
|
| 72 |
+
|
| 73 |
+
!!! Example "Split images"
|
| 74 |
+
|
| 75 |
+
=== "Python"
|
| 76 |
+
|
| 77 |
+
```python
|
| 78 |
+
from ultralytics.data.split_dota import split_trainval, split_test
|
| 79 |
+
|
| 80 |
+
# split train and val set, with labels.
|
| 81 |
+
split_trainval(
|
| 82 |
+
data_root='path/to/DOTAv1.0/',
|
| 83 |
+
save_dir='path/to/DOTAv1.0-split/',
|
| 84 |
+
rates=[0.5, 1.0, 1.5], # multiscale
|
| 85 |
+
gap=500
|
| 86 |
+
)
|
| 87 |
+
# split test set, without labels.
|
| 88 |
+
split_test(
|
| 89 |
+
data_root='path/to/DOTAv1.0/',
|
| 90 |
+
save_dir='path/to/DOTAv1.0-split/',
|
| 91 |
+
rates=[0.5, 1.0, 1.5], # multiscale
|
| 92 |
+
gap=500
|
| 93 |
+
)
|
| 94 |
+
```
|
| 95 |
+
|
| 96 |
+
## Usage
|
| 97 |
+
|
| 98 |
+
To train a model on the DOTA v1 dataset, you can utilize the following code snippets. Always refer to your model's documentation for a thorough list of available arguments.
|
| 99 |
+
|
| 100 |
+
!!! Warning
|
| 101 |
+
|
| 102 |
+
Please note that all images and associated annotations in the DOTAv1 dataset can be used for academic purposes, but commercial use is prohibited. Your understanding and respect for the dataset creators' wishes are greatly appreciated!
|
| 103 |
+
|
| 104 |
+
!!! Example "Train Example"
|
| 105 |
+
|
| 106 |
+
=== "Python"
|
| 107 |
+
|
| 108 |
+
```python
|
| 109 |
+
from ultralytics import YOLO
|
| 110 |
+
|
| 111 |
+
# Create a new YOLOv8n-OBB model from scratch
|
| 112 |
+
model = YOLO('yolov8n-obb.yaml')
|
| 113 |
+
|
| 114 |
+
# Train the model on the DOTAv2 dataset
|
| 115 |
+
results = model.train(data='DOTAv1.yaml', epochs=100, imgsz=640)
|
| 116 |
+
```
|
| 117 |
+
|
| 118 |
+
=== "CLI"
|
| 119 |
+
|
| 120 |
+
```bash
|
| 121 |
+
# Train a new YOLOv8n-OBB model on the DOTAv2 dataset
|
| 122 |
+
yolo obb train data=DOTAv1.yaml model=yolov8n-obb.pt epochs=100 imgsz=640
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
## Sample Data and Annotations
|
| 126 |
+
|
| 127 |
+
Having a glance at the dataset illustrates its depth:
|
| 128 |
+
|
| 129 |
+

|
| 130 |
+
|
| 131 |
+
- **DOTA examples**: This snapshot underlines the complexity of aerial scenes and the significance of Oriented Bounding Box annotations, capturing objects in their natural orientation.
|
| 132 |
+
|
| 133 |
+
The dataset's richness offers invaluable insights into object detection challenges exclusive to aerial imagery.
|
| 134 |
+
|
| 135 |
+
## Citations and Acknowledgments
|
| 136 |
+
|
| 137 |
+
For those leveraging DOTA in their endeavors, it's pertinent to cite the relevant research papers:
|
| 138 |
+
|
| 139 |
+
!!! Quote ""
|
| 140 |
+
|
| 141 |
+
=== "BibTeX"
|
| 142 |
+
|
| 143 |
+
```bibtex
|
| 144 |
+
@article{9560031,
|
| 145 |
+
author={Ding, Jian and Xue, Nan and Xia, Gui-Song and Bai, Xiang and Yang, Wen and Yang, Michael and Belongie, Serge and Luo, Jiebo and Datcu, Mihai and Pelillo, Marcello and Zhang, Liangpei},
|
| 146 |
+
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
|
| 147 |
+
title={Object Detection in Aerial Images: A Large-Scale Benchmark and Challenges},
|
| 148 |
+
year={2021},
|
| 149 |
+
volume={},
|
| 150 |
+
number={},
|
| 151 |
+
pages={1-1},
|
| 152 |
+
doi={10.1109/TPAMI.2021.3117983}
|
| 153 |
+
}
|
| 154 |
+
```
|
| 155 |
+
|
| 156 |
+
A special note of gratitude to the team behind the DOTA datasets for their commendable effort in curating this dataset. For an exhaustive understanding of the dataset and its nuances, please visit the [official DOTA website](https://captain-whu.github.io/DOTA/index.html).
|
yolov10/docs/en/datasets/obb/dota8.md
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
comments: true
|
| 3 |
+
description: Discover the versatile DOTA8 dataset, perfect for testing and debugging oriented detection models. Learn how to get started with YOLOv8-obb model training.
|
| 4 |
+
keywords: Ultralytics, YOLOv8, oriented detection, DOTA8 dataset, dataset, model training, YAML
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# DOTA8 Dataset
|
| 8 |
+
|
| 9 |
+
## Introduction
|
| 10 |
+
|
| 11 |
+
[Ultralytics](https://ultralytics.com) DOTA8 is a small, but versatile oriented object detection dataset composed of the first 8 images of 8 images of the split DOTAv1 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
|
| 12 |
+
|
| 13 |
+
This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com) and [YOLOv8](https://github.com/ultralytics/ultralytics).
|
| 14 |
+
|
| 15 |
+
## Dataset YAML
|
| 16 |
+
|
| 17 |
+
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the DOTA8 dataset, the `dota8.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/dota8.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/dota8.yaml).
|
| 18 |
+
|
| 19 |
+
!!! Example "ultralytics/cfg/datasets/dota8.yaml"
|
| 20 |
+
|
| 21 |
+
```yaml
|
| 22 |
+
--8<-- "ultralytics/cfg/datasets/dota8.yaml"
|
| 23 |
+
```
|
| 24 |
+
|
| 25 |
+
## Usage
|
| 26 |
+
|
| 27 |
+
To train a YOLOv8n-obb model on the DOTA8 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
| 28 |
+
|
| 29 |
+
!!! Example "Train Example"
|
| 30 |
+
|
| 31 |
+
=== "Python"
|
| 32 |
+
|
| 33 |
+
```python
|
| 34 |
+
from ultralytics import YOLO
|
| 35 |
+
|
| 36 |
+
# Load a model
|
| 37 |
+
model = YOLO('yolov8n-obb.pt') # load a pretrained model (recommended for training)
|
| 38 |
+
|
| 39 |
+
# Train the model
|
| 40 |
+
results = model.train(data='dota8.yaml', epochs=100, imgsz=640)
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
=== "CLI"
|
| 44 |
+
|
| 45 |
+
```bash
|
| 46 |
+
# Start training from a pretrained *.pt model
|
| 47 |
+
yolo obb train data=dota8.yaml model=yolov8n-obb.pt epochs=100 imgsz=640
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
## Sample Images and Annotations
|
| 51 |
+
|
| 52 |
+
Here are some examples of images from the DOTA8 dataset, along with their corresponding annotations:
|
| 53 |
+
|
| 54 |
+
<img src="https://github.com/Laughing-q/assets/assets/61612323/965d3ff7-5b9b-4add-b62e-9795921b60de" alt="Dataset sample image" width="800">
|
| 55 |
+
|
| 56 |
+
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
|
| 57 |
+
|
| 58 |
+
The example showcases the variety and complexity of the images in the DOTA8 dataset and the benefits of using mosaicing during the training process.
|
| 59 |
+
|
| 60 |
+
## Citations and Acknowledgments
|
| 61 |
+
|
| 62 |
+
If you use the DOTA dataset in your research or development work, please cite the following paper:
|
| 63 |
+
|
| 64 |
+
!!! Quote ""
|
| 65 |
+
|
| 66 |
+
=== "BibTeX"
|
| 67 |
+
|
| 68 |
+
```bibtex
|
| 69 |
+
@article{9560031,
|
| 70 |
+
author={Ding, Jian and Xue, Nan and Xia, Gui-Song and Bai, Xiang and Yang, Wen and Yang, Michael and Belongie, Serge and Luo, Jiebo and Datcu, Mihai and Pelillo, Marcello and Zhang, Liangpei},
|
| 71 |
+
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
|
| 72 |
+
title={Object Detection in Aerial Images: A Large-Scale Benchmark and Challenges},
|
| 73 |
+
year={2021},
|
| 74 |
+
volume={},
|
| 75 |
+
number={},
|
| 76 |
+
pages={1-1},
|
| 77 |
+
doi={10.1109/TPAMI.2021.3117983}
|
| 78 |
+
}
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
A special note of gratitude to the team behind the DOTA datasets for their commendable effort in curating this dataset. For an exhaustive understanding of the dataset and its nuances, please visit the [official DOTA website](https://captain-whu.github.io/DOTA/index.html).
|