Spaces:
Running

Running
Commit
•
1bb6654
1
Parent(s):
ca53920
Upload 24 files
Browse files- app.py +162 -0
- requirements.txt +15 -0
- runs/detect/train/F1_curve.png +0 -0
- runs/detect/train/PR_curve.png +0 -0
- runs/detect/train/P_curve.png +0 -0
- runs/detect/train/R_curve.png +0 -0
- runs/detect/train/args.yaml +107 -0
- runs/detect/train/confusion_matrix.png +0 -0
- runs/detect/train/confusion_matrix_normalized.png +0 -0
- runs/detect/train/labels.jpg +0 -0
- runs/detect/train/labels_correlogram.jpg +0 -0
- runs/detect/train/results.csv +3 -0
- runs/detect/train/results.png +0 -0
- runs/detect/train/train_batch0.jpg +0 -0
- runs/detect/train/train_batch1.jpg +0 -0
- runs/detect/train/train_batch2.jpg +0 -0
- runs/detect/train/val_batch0_labels.jpg +0 -0
- runs/detect/train/val_batch0_pred.jpg +0 -0
- runs/detect/train/val_batch1_labels.jpg +0 -0
- runs/detect/train/val_batch1_pred.jpg +0 -0
- runs/detect/train/val_batch2_labels.jpg +0 -0
- runs/detect/train/val_batch2_pred.jpg +0 -0
- runs/detect/train/weights/best.pt +3 -0
- runs/detect/train/weights/last.pt +3 -0
app.py
ADDED
|
@@ -0,0 +1,162 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import cv2
|
| 3 |
+
import tempfile
|
| 4 |
+
from ultralytics import YOLOv10
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def yolov10_inference(image, video, model_id, image_size, conf_threshold):
|
| 8 |
+
#model = YOLOv10.from_pretrained(f'jameslahm/{model_id}')
|
| 9 |
+
model = YOLOv10("/ddn/imu_tch1/project/yolov10/yolov10-1.0/runs/detect/train9/weights/best.pt")
|
| 10 |
+
if image:
|
| 11 |
+
results = model.predict(source=image, imgsz=image_size, conf=conf_threshold)
|
| 12 |
+
annotated_image = results[0].plot()
|
| 13 |
+
return annotated_image[:, :, ::-1], None
|
| 14 |
+
else:
|
| 15 |
+
video_path = tempfile.mktemp(suffix=".webm")
|
| 16 |
+
with open(video_path, "wb") as f:
|
| 17 |
+
with open(video, "rb") as g:
|
| 18 |
+
f.write(g.read())
|
| 19 |
+
|
| 20 |
+
cap = cv2.VideoCapture(video_path)
|
| 21 |
+
fps = cap.get(cv2.CAP_PROP_FPS)
|
| 22 |
+
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
|
| 23 |
+
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
|
| 24 |
+
|
| 25 |
+
output_video_path = tempfile.mktemp(suffix=".webm")
|
| 26 |
+
out = cv2.VideoWriter(output_video_path, cv2.VideoWriter_fourcc(*'vp80'), fps, (frame_width, frame_height))
|
| 27 |
+
|
| 28 |
+
while cap.isOpened():
|
| 29 |
+
ret, frame = cap.read()
|
| 30 |
+
if not ret:
|
| 31 |
+
break
|
| 32 |
+
|
| 33 |
+
results = model.predict(source=frame, imgsz=image_size, conf=conf_threshold)
|
| 34 |
+
annotated_frame = results[0].plot()
|
| 35 |
+
out.write(annotated_frame)
|
| 36 |
+
|
| 37 |
+
cap.release()
|
| 38 |
+
out.release()
|
| 39 |
+
|
| 40 |
+
return None, output_video_path
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def yolov10_inference_for_examples(image, model_path, image_size, conf_threshold):
|
| 44 |
+
annotated_image, _ = yolov10_inference(image, None, model_path, image_size, conf_threshold)
|
| 45 |
+
return annotated_image
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def app():
|
| 49 |
+
with gr.Blocks():
|
| 50 |
+
with gr.Row():
|
| 51 |
+
with gr.Column():
|
| 52 |
+
image = gr.Image(type="pil", label="Image", visible=True)
|
| 53 |
+
video = gr.Video(label="Video", visible=False)
|
| 54 |
+
input_type = gr.Radio(
|
| 55 |
+
choices=["Image", "Video"],
|
| 56 |
+
value="Image",
|
| 57 |
+
label="Input Type",
|
| 58 |
+
)
|
| 59 |
+
model_id = gr.Dropdown(
|
| 60 |
+
label="Model",
|
| 61 |
+
choices=[
|
| 62 |
+
"yolov10n",
|
| 63 |
+
"yolov10s",
|
| 64 |
+
"yolov10m",
|
| 65 |
+
"yolov10b",
|
| 66 |
+
"yolov10l",
|
| 67 |
+
"yolov10x",
|
| 68 |
+
],
|
| 69 |
+
value="yolov10m",
|
| 70 |
+
)
|
| 71 |
+
image_size = gr.Slider(
|
| 72 |
+
label="Image Size",
|
| 73 |
+
minimum=320,
|
| 74 |
+
maximum=1280,
|
| 75 |
+
step=32,
|
| 76 |
+
value=640,
|
| 77 |
+
)
|
| 78 |
+
conf_threshold = gr.Slider(
|
| 79 |
+
label="Confidence Threshold",
|
| 80 |
+
minimum=0.0,
|
| 81 |
+
maximum=1.0,
|
| 82 |
+
step=0.05,
|
| 83 |
+
value=0.25,
|
| 84 |
+
)
|
| 85 |
+
yolov10_infer = gr.Button(value="Detect Objects")
|
| 86 |
+
|
| 87 |
+
with gr.Column():
|
| 88 |
+
output_image = gr.Image(type="numpy", label="Annotated Image", visible=True)
|
| 89 |
+
output_video = gr.Video(label="Annotated Video", visible=False)
|
| 90 |
+
|
| 91 |
+
def update_visibility(input_type):
|
| 92 |
+
image = gr.update(visible=True) if input_type == "Image" else gr.update(visible=False)
|
| 93 |
+
video = gr.update(visible=False) if input_type == "Image" else gr.update(visible=True)
|
| 94 |
+
output_image = gr.update(visible=True) if input_type == "Image" else gr.update(visible=False)
|
| 95 |
+
output_video = gr.update(visible=False) if input_type == "Image" else gr.update(visible=True)
|
| 96 |
+
|
| 97 |
+
return image, video, output_image, output_video
|
| 98 |
+
|
| 99 |
+
input_type.change(
|
| 100 |
+
fn=update_visibility,
|
| 101 |
+
inputs=[input_type],
|
| 102 |
+
outputs=[image, video, output_image, output_video],
|
| 103 |
+
)
|
| 104 |
+
|
| 105 |
+
def run_inference(image, video, model_id, image_size, conf_threshold, input_type):
|
| 106 |
+
if input_type == "Image":
|
| 107 |
+
return yolov10_inference(image, None, model_id, image_size, conf_threshold)
|
| 108 |
+
else:
|
| 109 |
+
return yolov10_inference(None, video, model_id, image_size, conf_threshold)
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
yolov10_infer.click(
|
| 113 |
+
fn=run_inference,
|
| 114 |
+
inputs=[image, video, model_id, image_size, conf_threshold, input_type],
|
| 115 |
+
outputs=[output_image, output_video],
|
| 116 |
+
)
|
| 117 |
+
|
| 118 |
+
gr.Examples(
|
| 119 |
+
examples=[
|
| 120 |
+
[
|
| 121 |
+
"ultralytics/assets/bus.jpg",
|
| 122 |
+
"yolov10s",
|
| 123 |
+
640,
|
| 124 |
+
0.25,
|
| 125 |
+
],
|
| 126 |
+
[
|
| 127 |
+
"ultralytics/assets/zidane.jpg",
|
| 128 |
+
"yolov10s",
|
| 129 |
+
640,
|
| 130 |
+
0.25,
|
| 131 |
+
],
|
| 132 |
+
],
|
| 133 |
+
fn=yolov10_inference_for_examples,
|
| 134 |
+
inputs=[
|
| 135 |
+
image,
|
| 136 |
+
model_id,
|
| 137 |
+
image_size,
|
| 138 |
+
conf_threshold,
|
| 139 |
+
],
|
| 140 |
+
outputs=[output_image],
|
| 141 |
+
cache_examples='lazy',
|
| 142 |
+
)
|
| 143 |
+
|
| 144 |
+
gradio_app = gr.Blocks()
|
| 145 |
+
with gradio_app:
|
| 146 |
+
gr.HTML(
|
| 147 |
+
"""
|
| 148 |
+
<h1 style='text-align: center'>
|
| 149 |
+
YOLOv10: Real-Time End-to-End Object Detection
|
| 150 |
+
</h1>
|
| 151 |
+
""")
|
| 152 |
+
gr.HTML(
|
| 153 |
+
"""
|
| 154 |
+
<h3 style='text-align: center'>
|
| 155 |
+
<a href='https://arxiv.org/abs/2405.14458' target='_blank'>arXiv</a> | <a href='https://github.com/THU-MIG/yolov10' target='_blank'>github</a>
|
| 156 |
+
</h3>
|
| 157 |
+
""")
|
| 158 |
+
with gr.Row():
|
| 159 |
+
with gr.Column():
|
| 160 |
+
app()
|
| 161 |
+
if __name__ == '__main__':
|
| 162 |
+
gradio_app.launch()
|
requirements.txt
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch==2.0.1
|
| 2 |
+
torchvision==0.15.2
|
| 3 |
+
onnx==1.14.0
|
| 4 |
+
onnxruntime==1.15.1
|
| 5 |
+
pycocotools==2.0.7
|
| 6 |
+
PyYAML==6.0.1
|
| 7 |
+
scipy==1.13.0
|
| 8 |
+
onnxsim==0.4.36
|
| 9 |
+
onnxruntime-gpu==1.18.0
|
| 10 |
+
gradio==4.31.5
|
| 11 |
+
opencv-python==4.9.0.80
|
| 12 |
+
psutil==5.9.8
|
| 13 |
+
py-cpuinfo==9.0.0
|
| 14 |
+
huggingface-hub==0.23.2
|
| 15 |
+
safetensors==0.4.3
|
runs/detect/train/F1_curve.png
ADDED
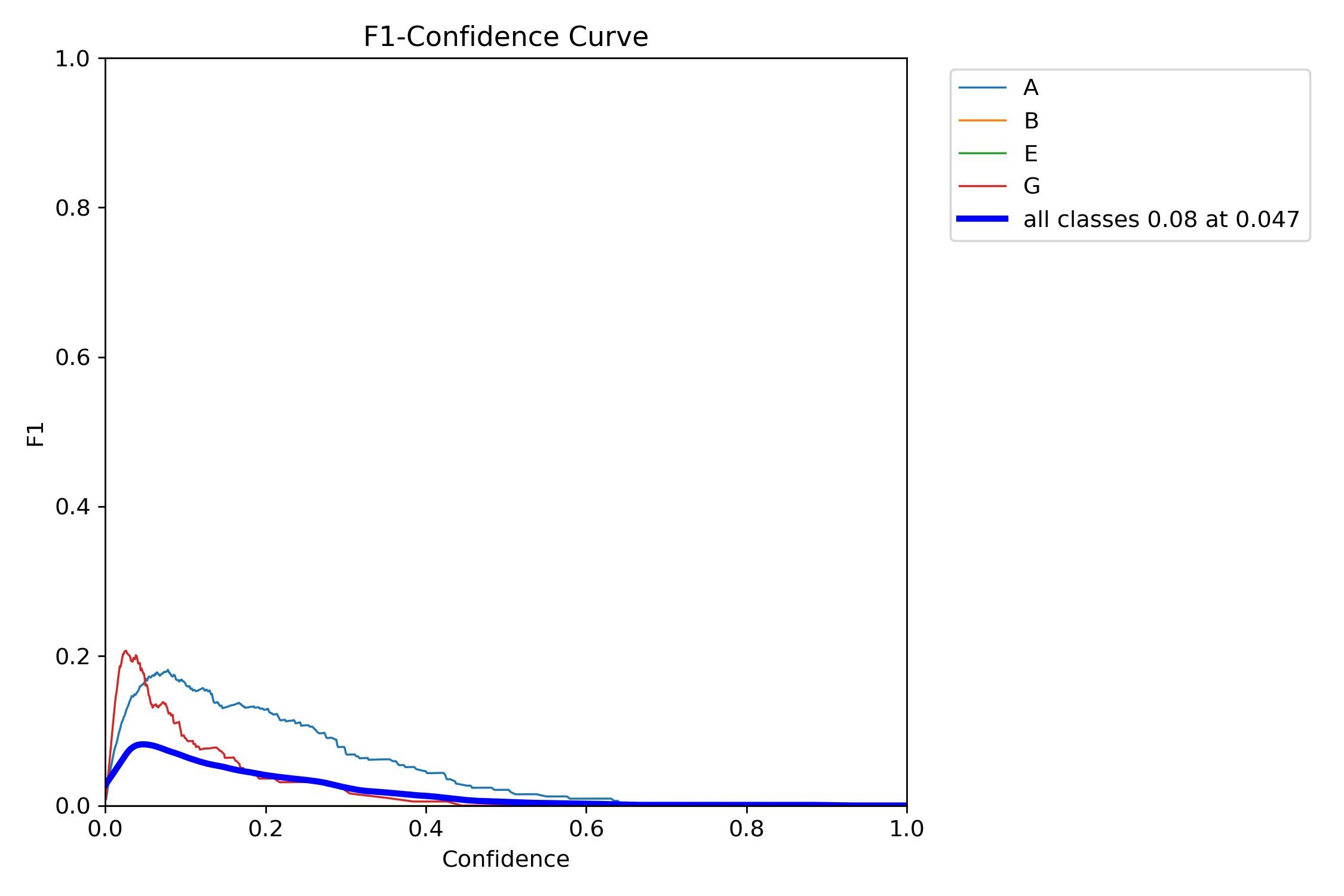
|
runs/detect/train/PR_curve.png
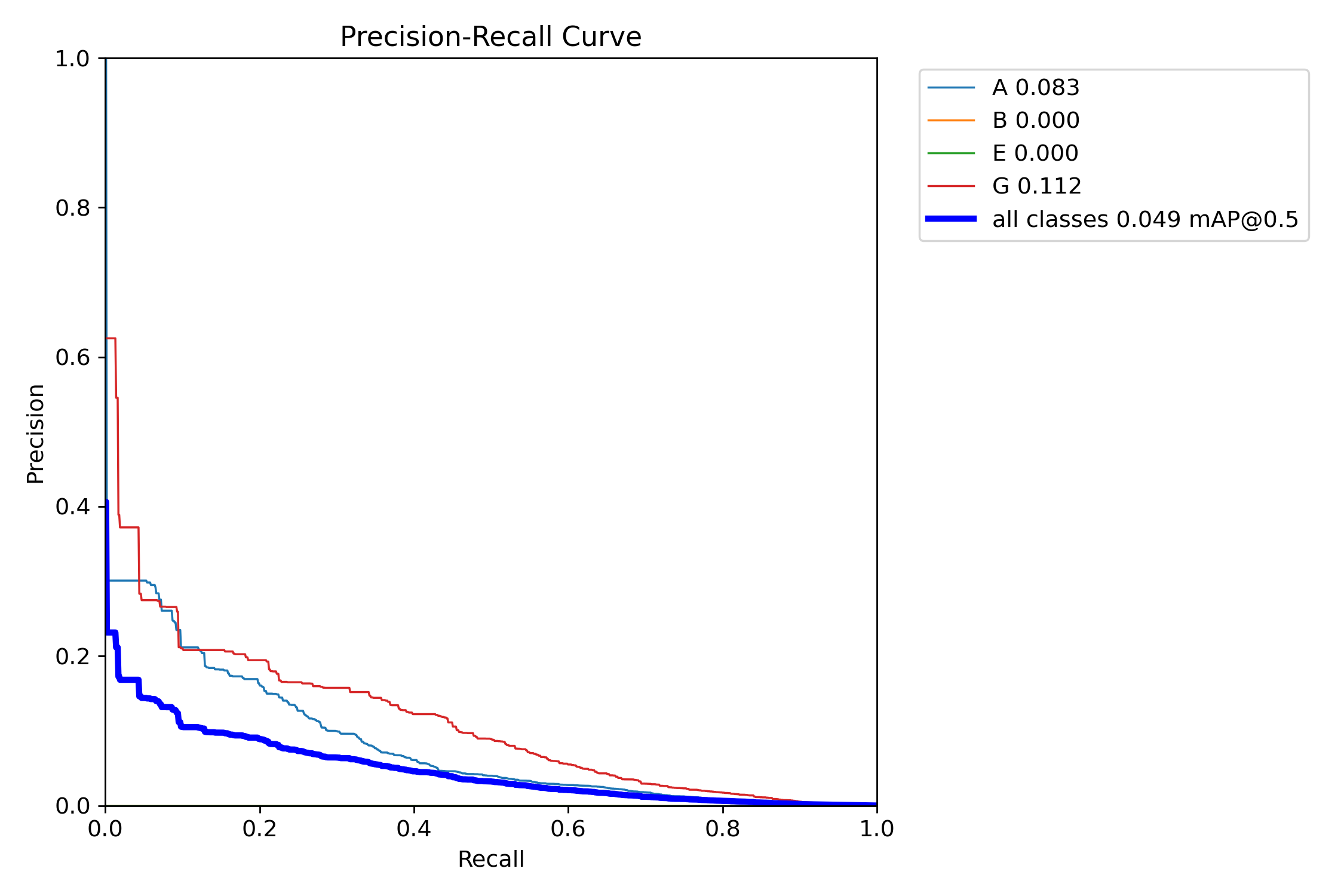
ADDED
|
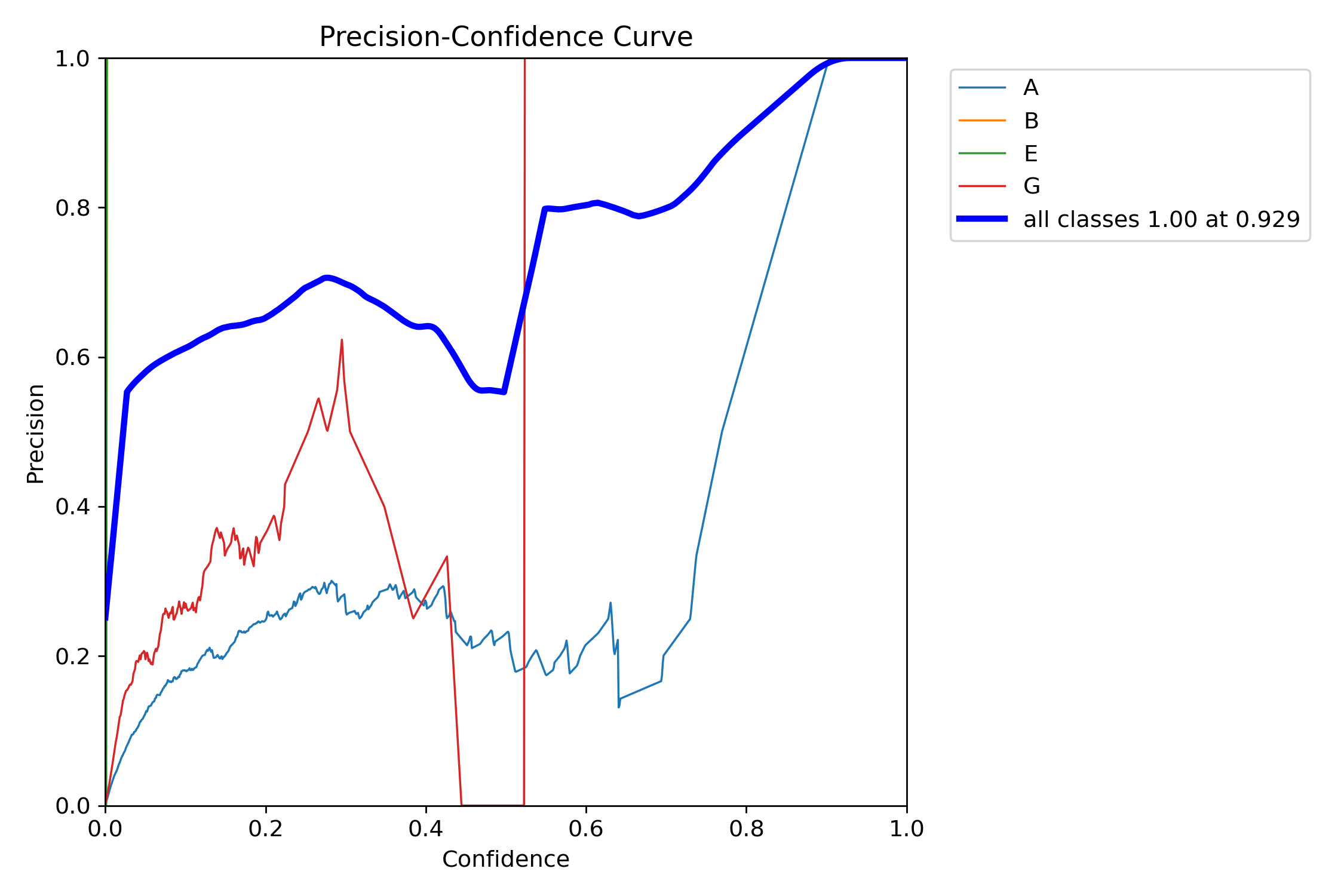
runs/detect/train/P_curve.png
ADDED
|
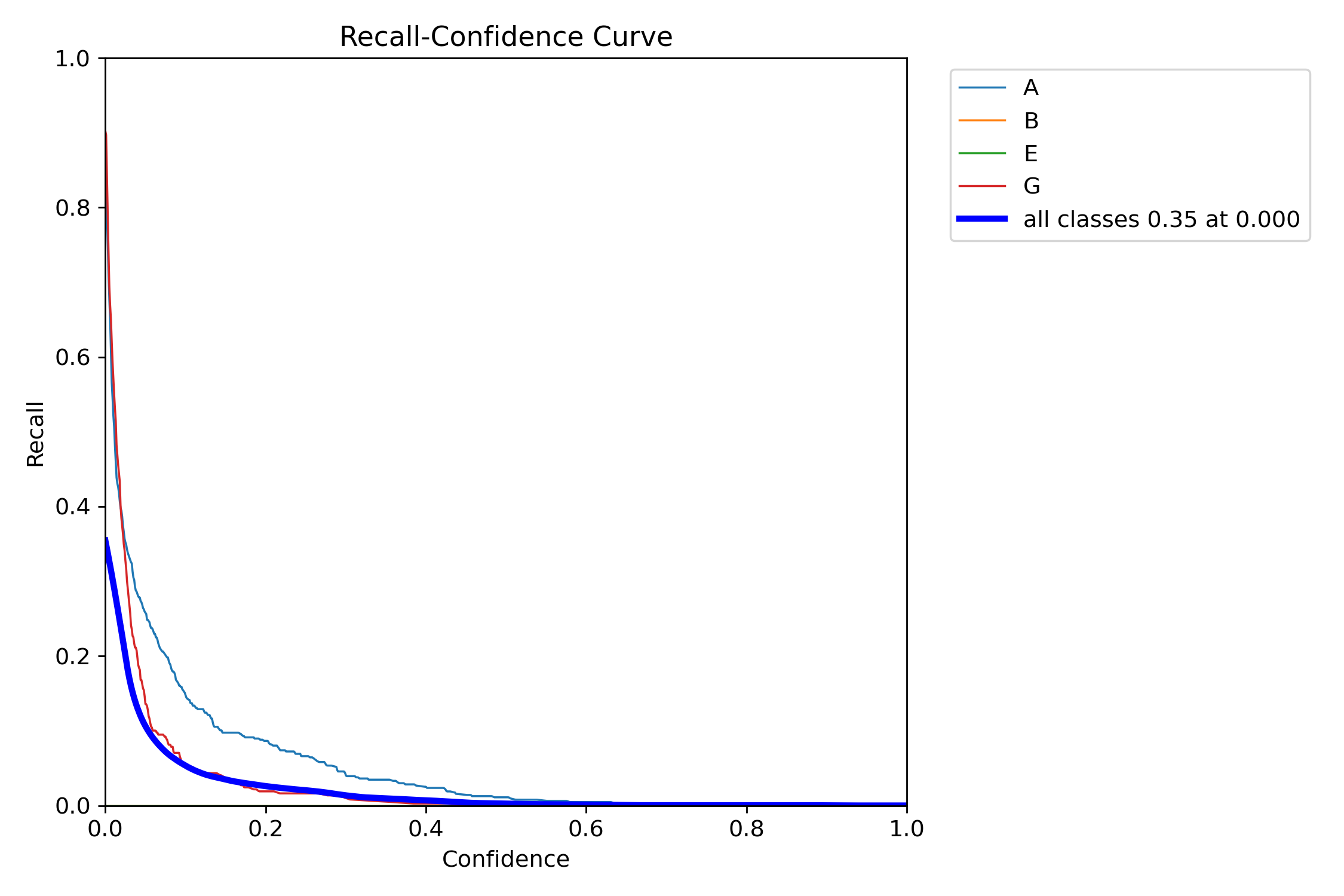
runs/detect/train/R_curve.png
ADDED
|
runs/detect/train/args.yaml
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: detect
|
| 2 |
+
mode: train
|
| 3 |
+
model: yolov10n.yaml
|
| 4 |
+
data: /ddn/imu_tsxm1/xm/GPT4V/lung/lung.yaml
|
| 5 |
+
epochs: 2
|
| 6 |
+
time: null
|
| 7 |
+
patience: 100
|
| 8 |
+
batch: 64
|
| 9 |
+
imgsz: 640
|
| 10 |
+
save: true
|
| 11 |
+
save_period: -1
|
| 12 |
+
val_period: 1
|
| 13 |
+
cache: false
|
| 14 |
+
device: null
|
| 15 |
+
workers: 8
|
| 16 |
+
project: null
|
| 17 |
+
name: train
|
| 18 |
+
exist_ok: false
|
| 19 |
+
pretrained: true
|
| 20 |
+
optimizer: auto
|
| 21 |
+
verbose: true
|
| 22 |
+
seed: 0
|
| 23 |
+
deterministic: true
|
| 24 |
+
single_cls: false
|
| 25 |
+
rect: false
|
| 26 |
+
cos_lr: false
|
| 27 |
+
close_mosaic: 10
|
| 28 |
+
resume: false
|
| 29 |
+
amp: true
|
| 30 |
+
fraction: 1.0
|
| 31 |
+
profile: false
|
| 32 |
+
freeze: null
|
| 33 |
+
multi_scale: false
|
| 34 |
+
overlap_mask: true
|
| 35 |
+
mask_ratio: 4
|
| 36 |
+
dropout: 0.0
|
| 37 |
+
val: true
|
| 38 |
+
split: val
|
| 39 |
+
save_json: false
|
| 40 |
+
save_hybrid: false
|
| 41 |
+
conf: null
|
| 42 |
+
iou: 0.7
|
| 43 |
+
max_det: 300
|
| 44 |
+
half: false
|
| 45 |
+
dnn: false
|
| 46 |
+
plots: true
|
| 47 |
+
source: null
|
| 48 |
+
vid_stride: 1
|
| 49 |
+
stream_buffer: false
|
| 50 |
+
visualize: false
|
| 51 |
+
augment: false
|
| 52 |
+
agnostic_nms: false
|
| 53 |
+
classes: null
|
| 54 |
+
retina_masks: false
|
| 55 |
+
embed: null
|
| 56 |
+
show: false
|
| 57 |
+
save_frames: false
|
| 58 |
+
save_txt: false
|
| 59 |
+
save_conf: false
|
| 60 |
+
save_crop: false
|
| 61 |
+
show_labels: true
|
| 62 |
+
show_conf: true
|
| 63 |
+
show_boxes: true
|
| 64 |
+
line_width: null
|
| 65 |
+
format: torchscript
|
| 66 |
+
keras: false
|
| 67 |
+
optimize: false
|
| 68 |
+
int8: false
|
| 69 |
+
dynamic: false
|
| 70 |
+
simplify: false
|
| 71 |
+
opset: null
|
| 72 |
+
workspace: 4
|
| 73 |
+
nms: false
|
| 74 |
+
lr0: 0.01
|
| 75 |
+
lrf: 0.01
|
| 76 |
+
momentum: 0.937
|
| 77 |
+
weight_decay: 0.0005
|
| 78 |
+
warmup_epochs: 3.0
|
| 79 |
+
warmup_momentum: 0.8
|
| 80 |
+
warmup_bias_lr: 0.1
|
| 81 |
+
box: 7.5
|
| 82 |
+
cls: 0.5
|
| 83 |
+
dfl: 1.5
|
| 84 |
+
pose: 12.0
|
| 85 |
+
kobj: 1.0
|
| 86 |
+
label_smoothing: 0.0
|
| 87 |
+
nbs: 64
|
| 88 |
+
hsv_h: 0.015
|
| 89 |
+
hsv_s: 0.7
|
| 90 |
+
hsv_v: 0.4
|
| 91 |
+
degrees: 0.0
|
| 92 |
+
translate: 0.1
|
| 93 |
+
scale: 0.5
|
| 94 |
+
shear: 0.0
|
| 95 |
+
perspective: 0.0
|
| 96 |
+
flipud: 0.0
|
| 97 |
+
fliplr: 0.5
|
| 98 |
+
bgr: 0.0
|
| 99 |
+
mosaic: 1.0
|
| 100 |
+
mixup: 0.0
|
| 101 |
+
copy_paste: 0.0
|
| 102 |
+
auto_augment: randaugment
|
| 103 |
+
erasing: 0.4
|
| 104 |
+
crop_fraction: 1.0
|
| 105 |
+
cfg: null
|
| 106 |
+
tracker: botsort.yaml
|
| 107 |
+
save_dir: /ddn/imu_tsxm1/xm/yolov10/runs/detect/train
|
runs/detect/train/confusion_matrix.png
ADDED
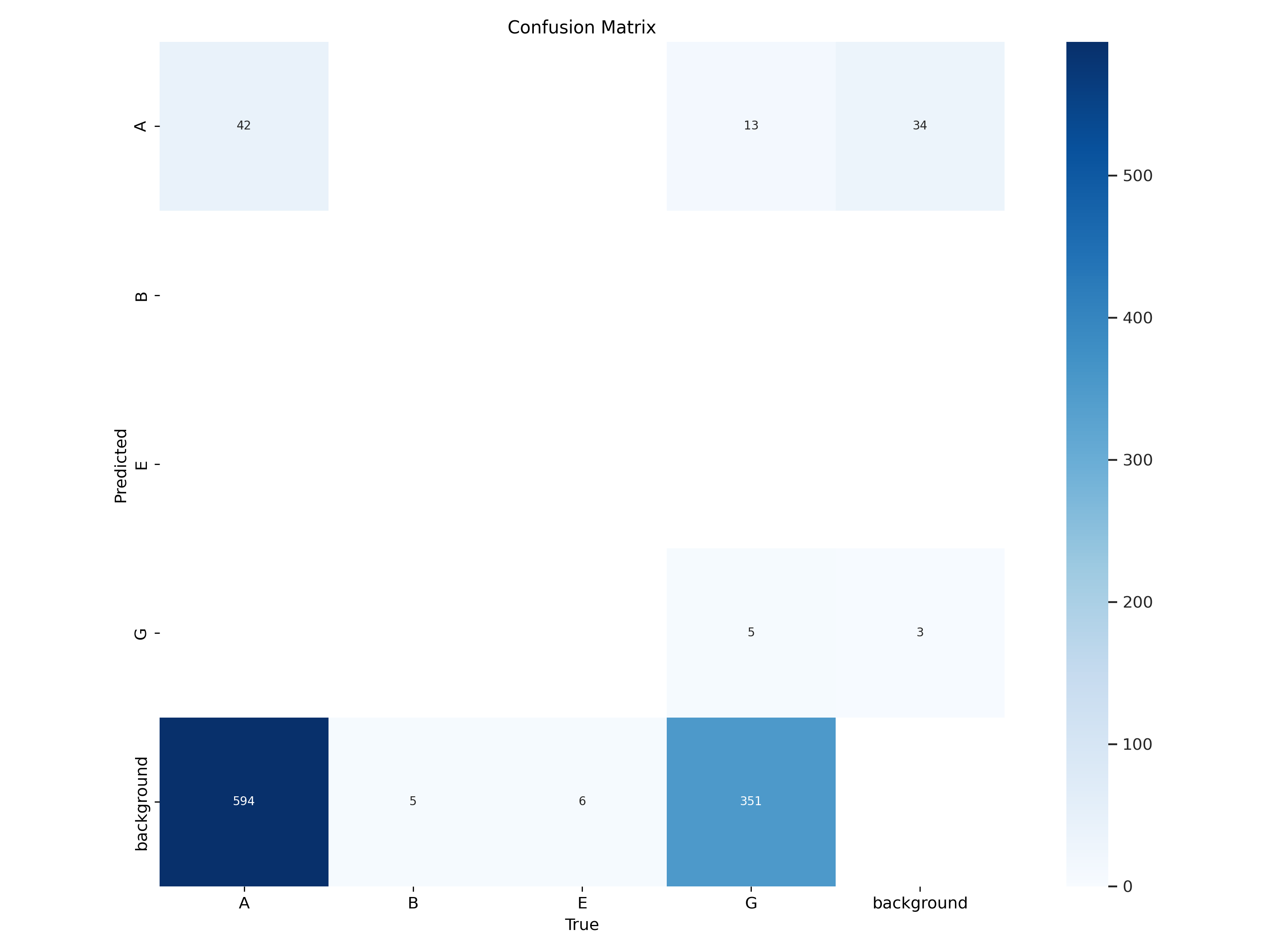
|
runs/detect/train/confusion_matrix_normalized.png
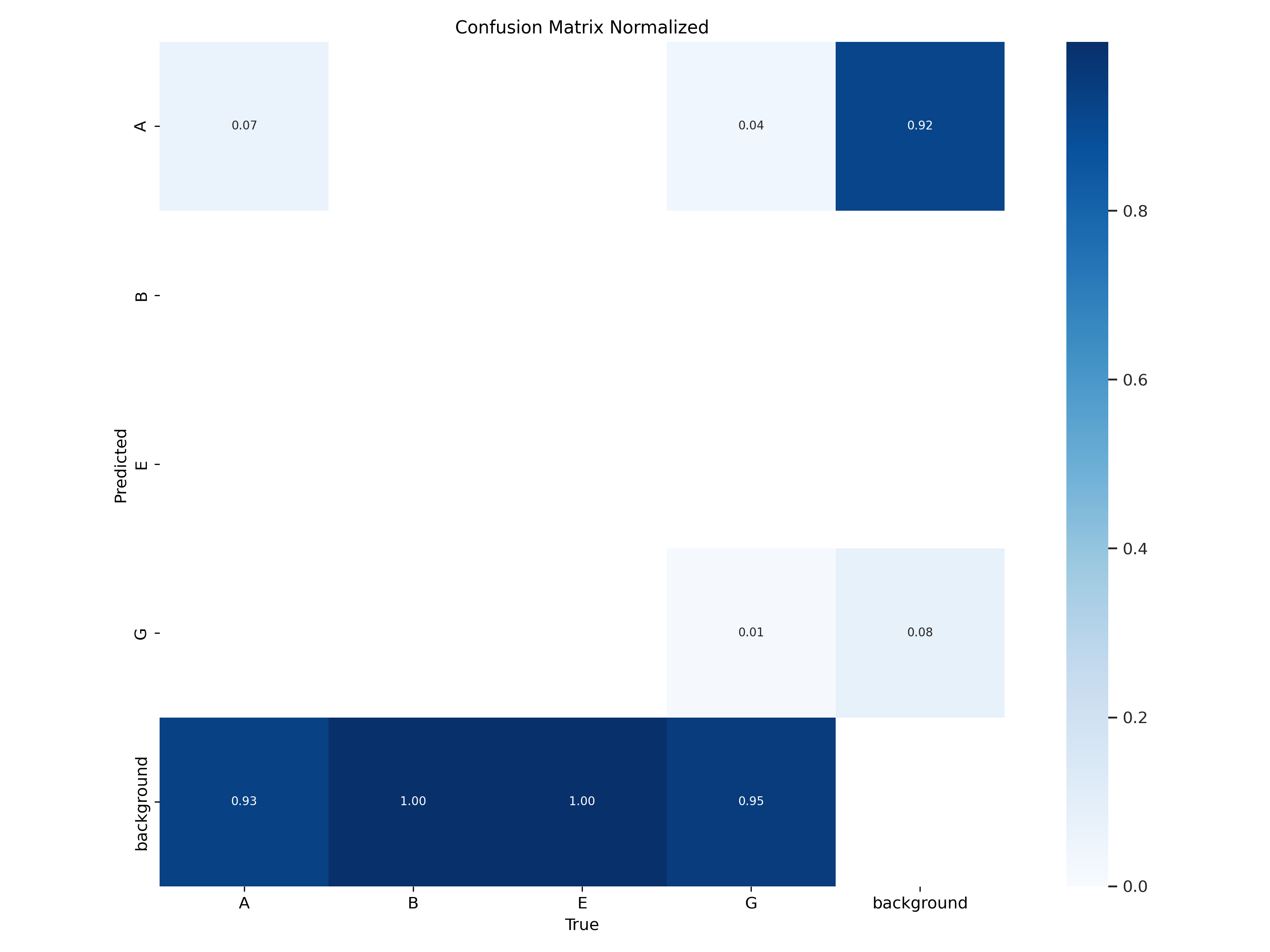
ADDED
|
runs/detect/train/labels.jpg
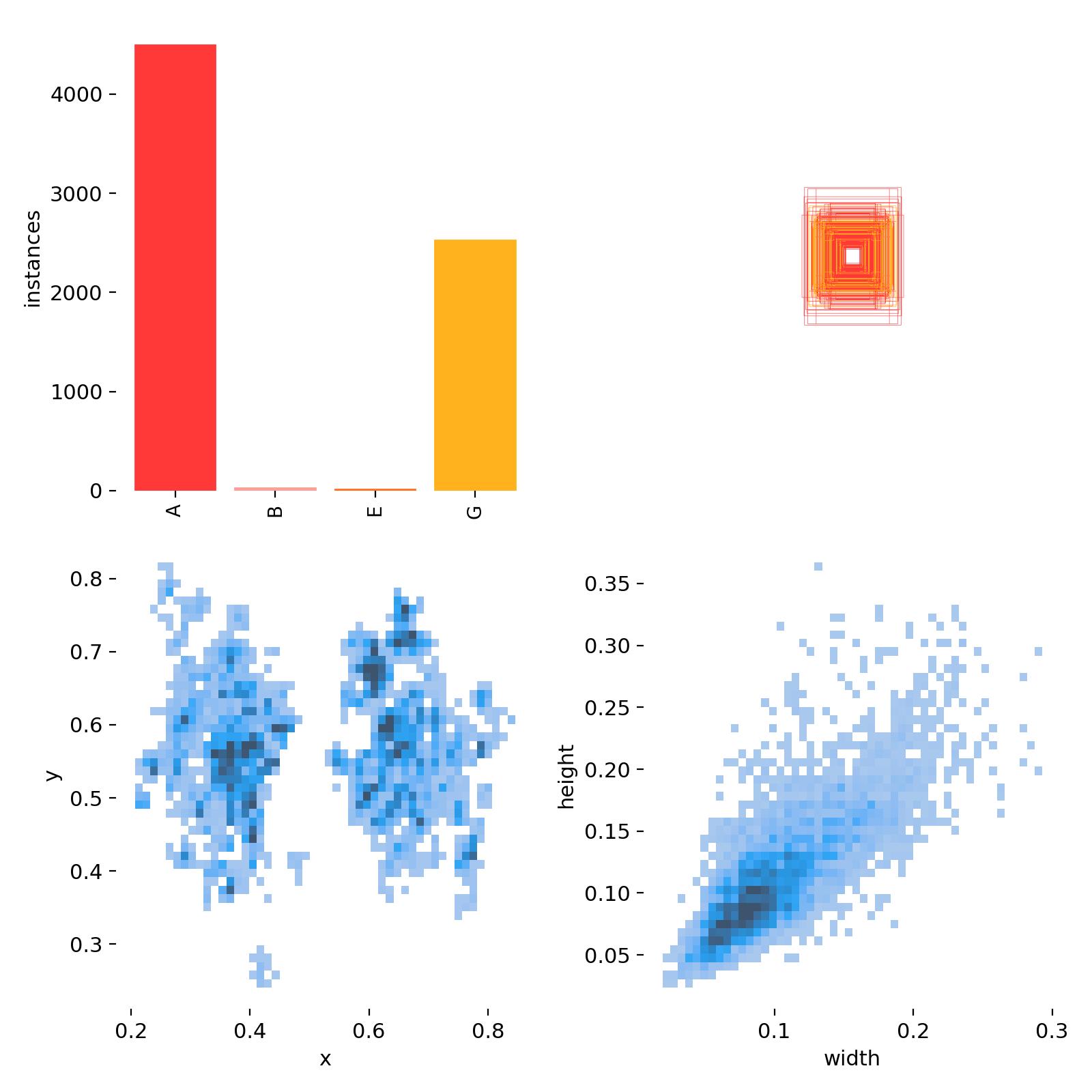
ADDED
|
runs/detect/train/labels_correlogram.jpg
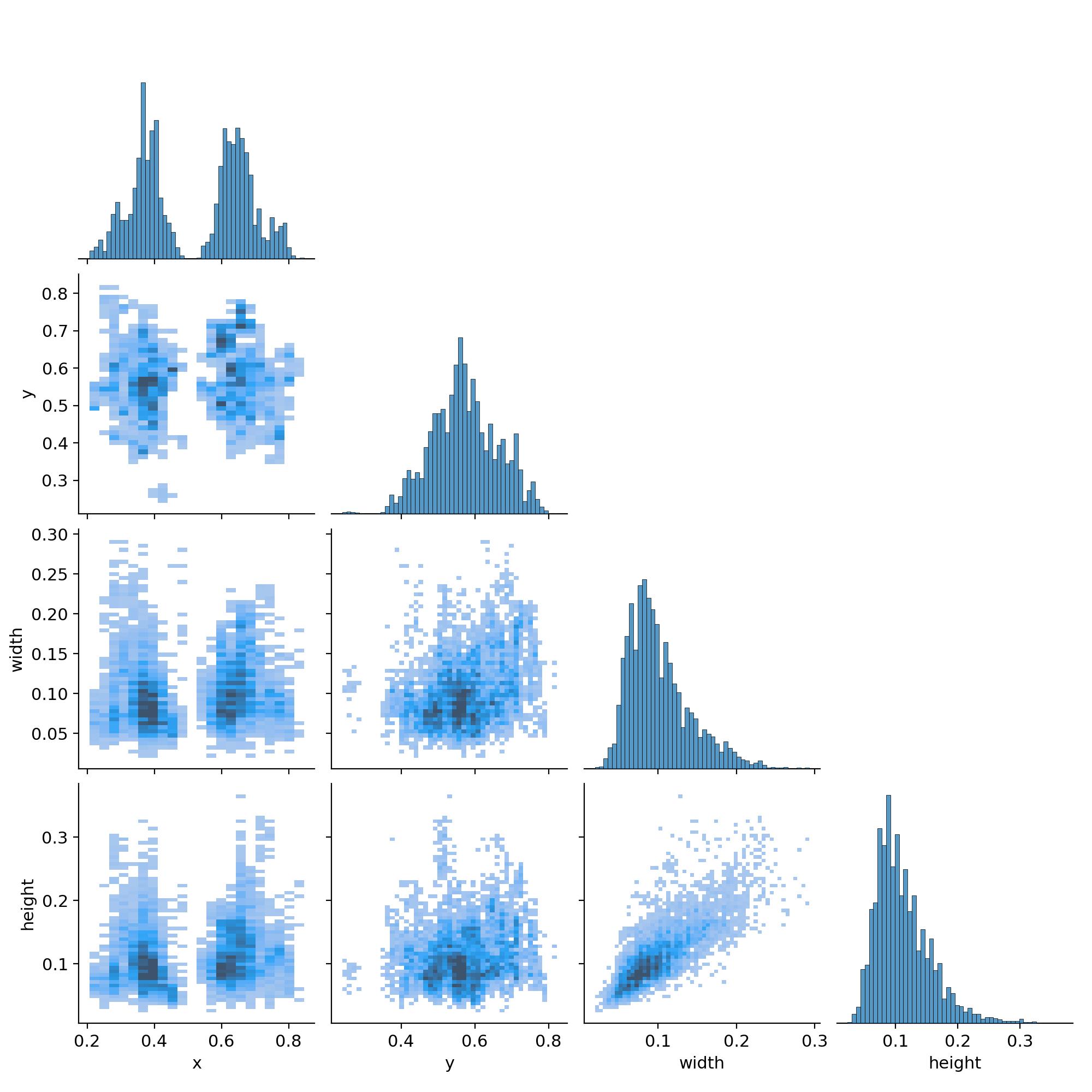
ADDED
|
runs/detect/train/results.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
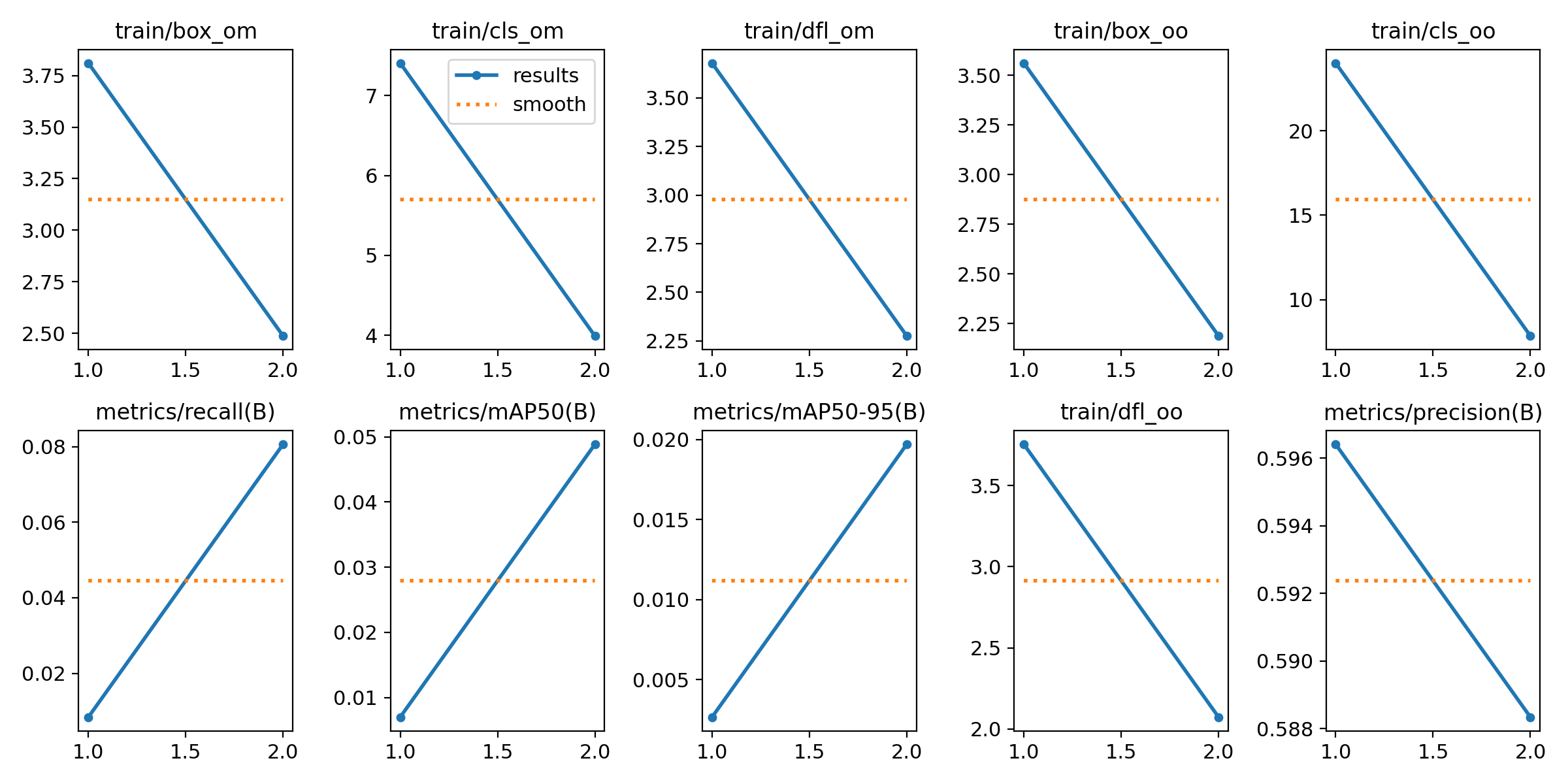
| 1 |
+
epoch, train/box_om, train/cls_om, train/dfl_om, train/box_oo, train/cls_oo, train/dfl_oo, metrics/precision(B), metrics/recall(B), metrics/mAP50(B), metrics/mAP50-95(B), val/box_om, val/cls_om, val/dfl_om, val/box_oo, val/cls_oo, val/dfl_oo, lr/pg0, lr/pg1, lr/pg2
|
| 2 |
+
1, 3.8105, 7.4064, 3.678, 3.5618, 24.024, 3.7539, 0.59641, 0.00843, 0.007, 0.00266, 2.7984, 6.3662, 3.1238, 2.4414, 15.635, 3.0117, 0.00041369, 0.00041369, 0.00041369
|
| 3 |
+
2, 2.4872, 3.9917, 2.2762, 2.1875, 7.8443, 2.0726, 0.58834, 0.0806, 0.04886, 0.0197, 2.1791, 3.5221, 2.1289, 1.8437, 6.7368, 1.8786, 0.00041933, 0.00041933, 0.00041933
|
runs/detect/train/results.png
ADDED
|
runs/detect/train/train_batch0.jpg
ADDED
|
runs/detect/train/train_batch1.jpg
ADDED
|
runs/detect/train/train_batch2.jpg
ADDED
|
runs/detect/train/val_batch0_labels.jpg
ADDED
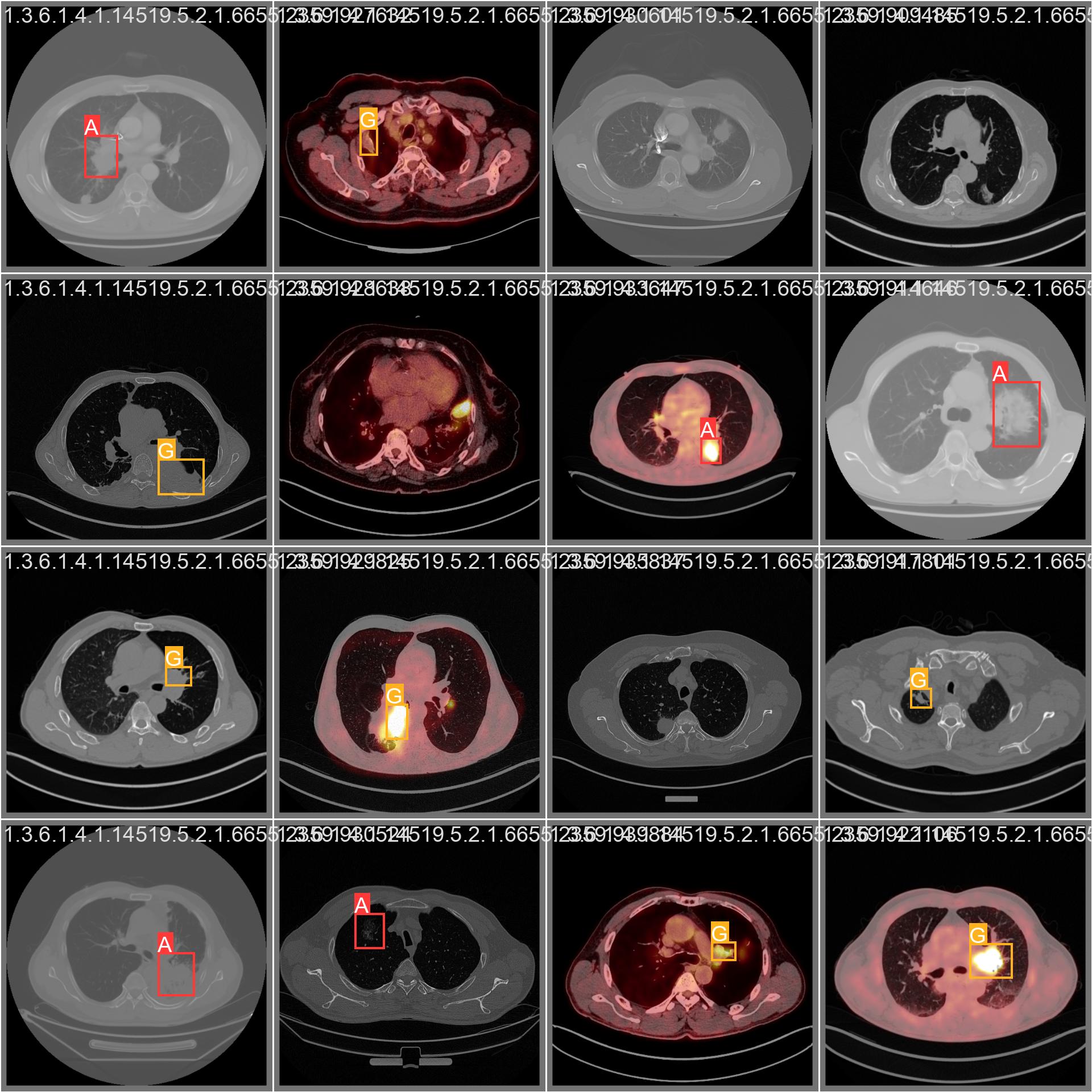
|
runs/detect/train/val_batch0_pred.jpg
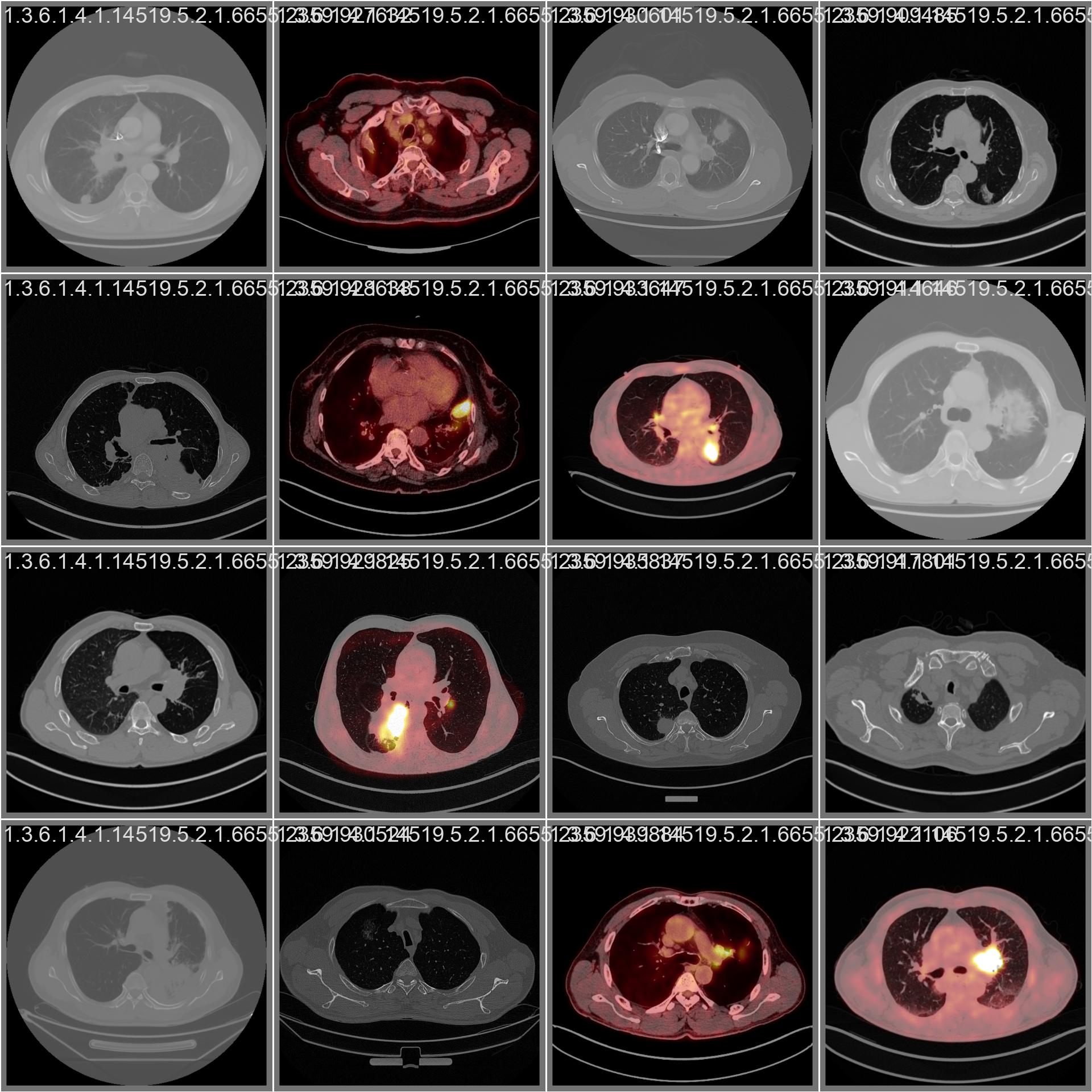
ADDED
|
runs/detect/train/val_batch1_labels.jpg
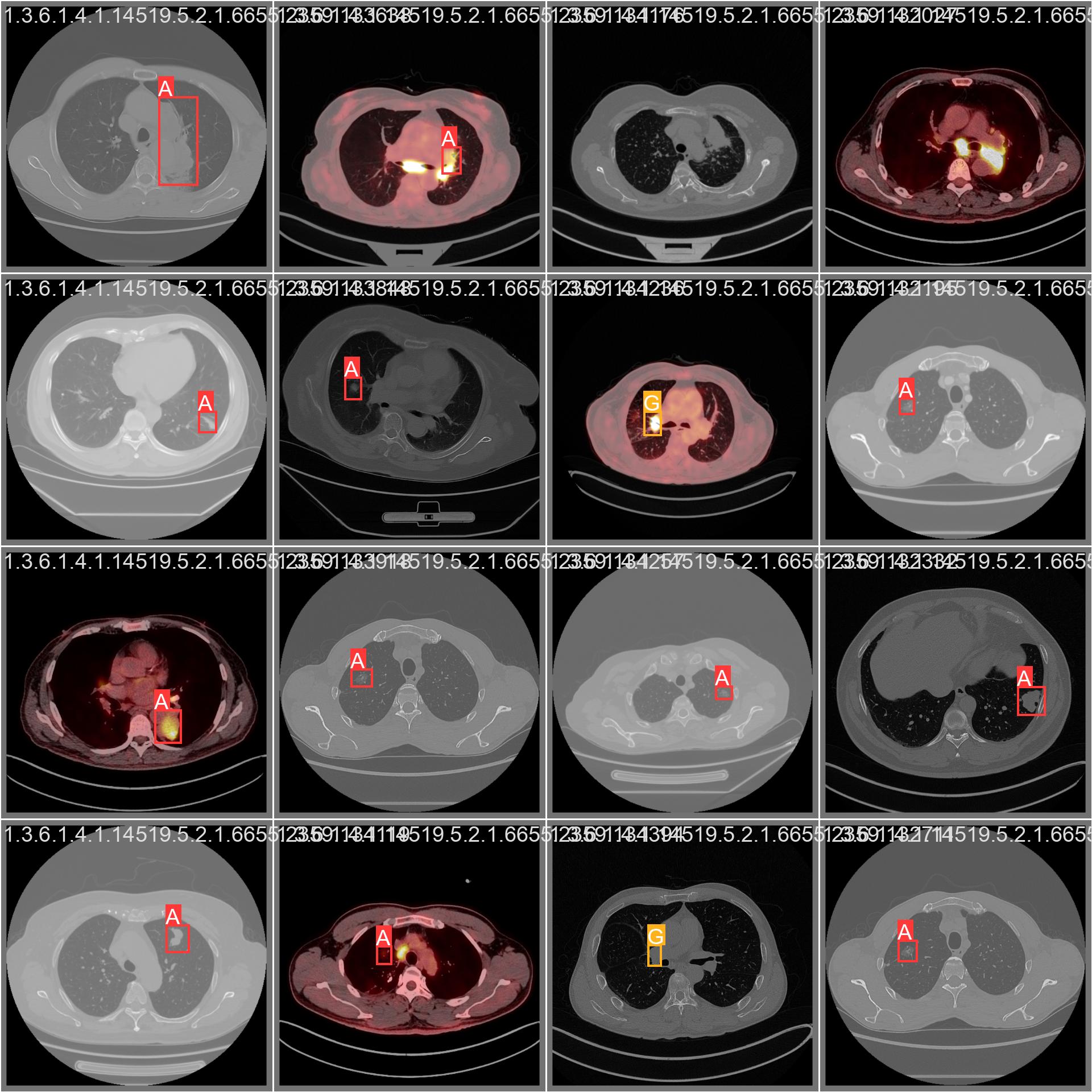
ADDED
|
runs/detect/train/val_batch1_pred.jpg
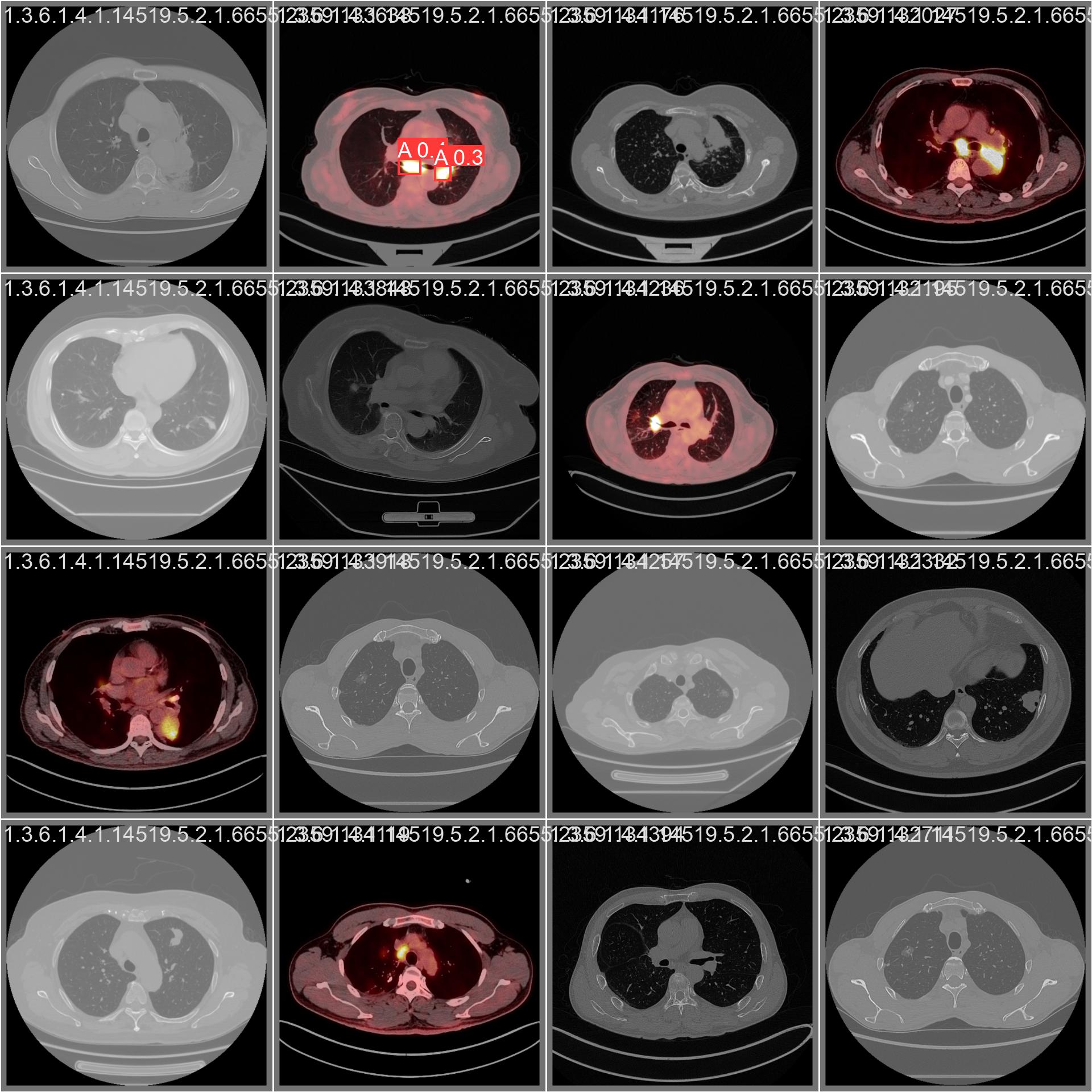
ADDED
|
runs/detect/train/val_batch2_labels.jpg
ADDED
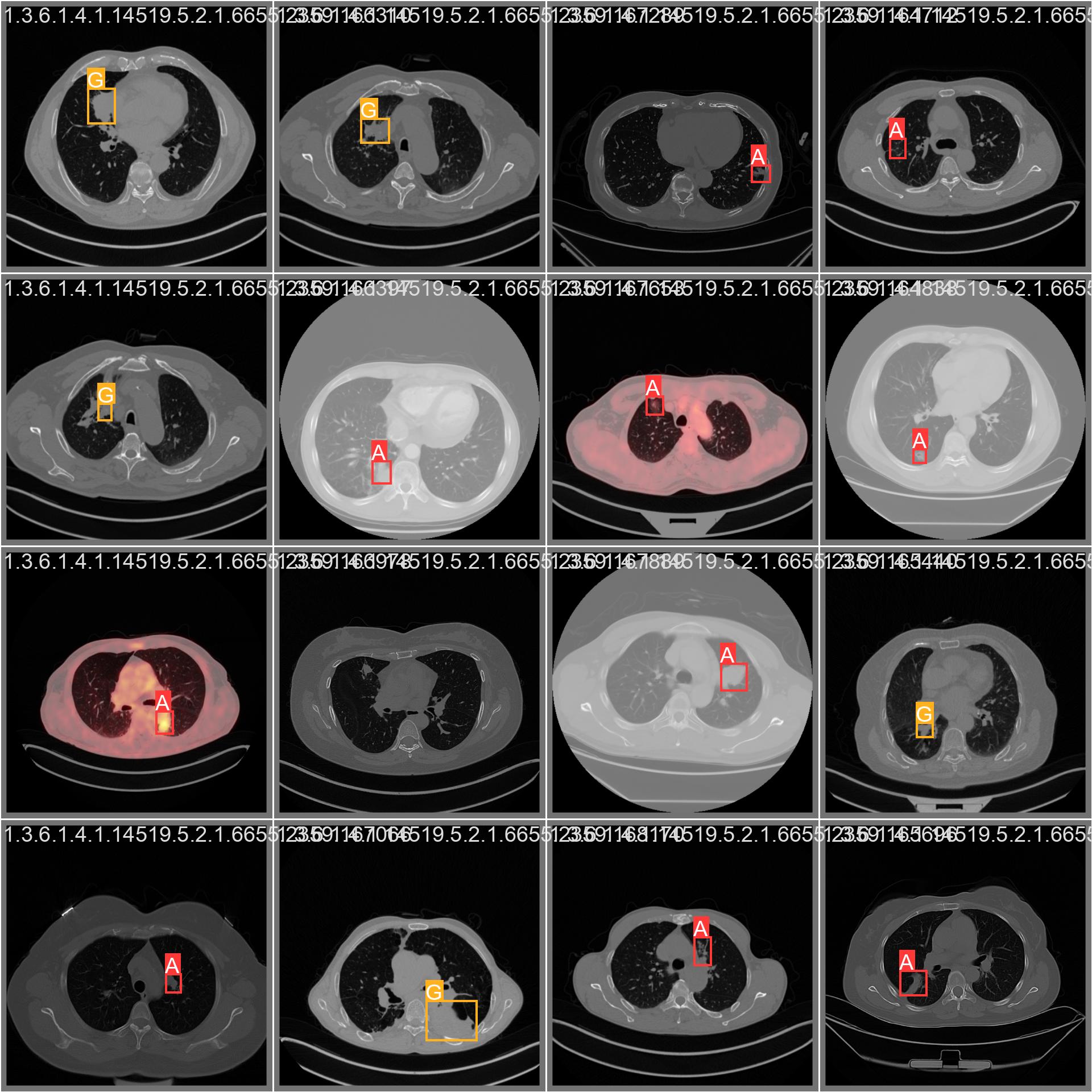
|
runs/detect/train/val_batch2_pred.jpg
ADDED
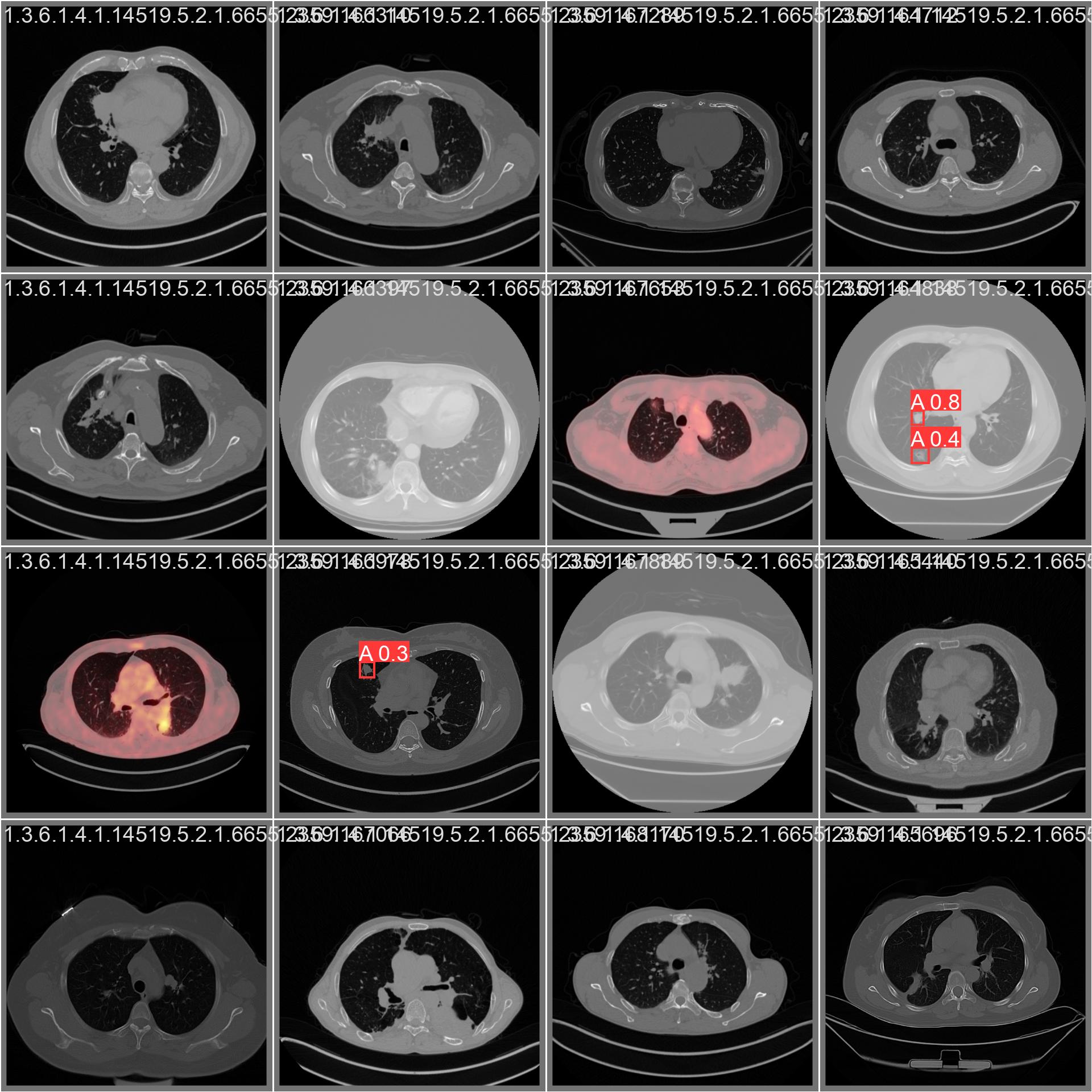
|
runs/detect/train/weights/best.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:df3622e5cb1340eee66c1411b4661bbf9ab83cbd8cf1b5847b12f28382238dc6
|
| 3 |
+
size 5748665
|
runs/detect/train/weights/last.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:67cc71bb27e03b564382e83179dd00b31a073c3cbc3c6cfcb0cfb652f824019f
|
| 3 |
+
size 5748665
|