Spaces:
Runtime error

Runtime error
RockeyCoss
commited on
Commit
•
0702ffc
1
Parent(s):
3ed28cb
reconstruct implementation
Browse files- .gitattributes +0 -34
- README.md +237 -13
- app.py +157 -19
- assets/example1.jpg +0 -0
- assets/example2.jpg +0 -0
- assets/example3.jpg +0 -0
- assets/example4.jpg +0 -0
- assets/example5.jpg +0 -0
- assets/img1.jpg +0 -0
- assets/img2.jpg +0 -0
- assets/img3.jpg +0 -0
- assets/img4.jpg +0 -0
- flagged/Input/tmpaytsmk0e.jpg +0 -0
- flagged/Output/tmpgs59m7u_.png +0 -0
- flagged/log.csv +0 -2
- mmdet/apis/inference.py +3 -4
- projects/configs/hdetr/r50-hdetr_sam-vit-b_best-in-multi.py +82 -0
- projects/configs/hdetr/r50-hdetr_sam-vit-b_best-in-multi_cascade.py +83 -0
- projects/configs/hdetr/r50-hdetr_sam-vit-b_cascade.py +83 -0
- projects/instance_segment_anything/__init__.py +2 -1
- projects/instance_segment_anything/models/det_wrapper_instance_sam.py +25 -7
- projects/instance_segment_anything/models/det_wrapper_instance_sam_cascade.py +127 -0
- projects/instance_segment_anything/ops/functions/ms_deform_attn_func.py +0 -1
- projects/instance_segment_anything/ops/modules/ms_deform_attn.py +1 -0
- requirements.txt +1 -2
- setup.cfg +21 -0
- setup.py +220 -0
- tools/dist_test.sh +20 -0
- tools/test.py +308 -0
.gitattributes
DELETED
|
@@ -1,34 +0,0 @@
|
|
| 1 |
-
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
-
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
-
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
-
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
-
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
-
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
-
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
-
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
-
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
-
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
-
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
-
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
-
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
-
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
-
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
-
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
-
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
-
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
-
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
-
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
-
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
-
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
-
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
-
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
-
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
-
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
-
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
-
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 29 |
-
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 30 |
-
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 31 |
-
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 32 |
-
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
-
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
-
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
README.md
CHANGED
|
@@ -1,13 +1,237 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Prompt-Segment-Anything
|
| 2 |
+
This is an implementation of zero-shot instance segmentation using [Segment Anything](https://github.com/facebookresearch/segment-anything). Thanks to the authors of Segment Anything for their wonderful work!
|
| 3 |
+
|
| 4 |
+
This repository is based on [MMDetection](https://github.com/open-mmlab/mmdetection) and includes some code from [H-Deformable-DETR](https://github.com/HDETR/H-Deformable-DETR) and [FocalNet-DINO](https://github.com/FocalNet/FocalNet-DINO).
|
| 5 |
+
|
| 6 |
+

|
| 7 |
+
|
| 8 |
+
## News
|
| 9 |
+
|
| 10 |
+
**2023.04.12** Multimask output mode and cascade prompt mode is available now.
|
| 11 |
+
|
| 12 |
+
**2023.04.11** Our [demo](https://huggingface.co/spaces/rockeycoss/Prompt-Segment-Anything-Demo) is available now. Please feel free to check it out.
|
| 13 |
+
|
| 14 |
+
**2023.04.11** [Swin-L+H-Deformable-DETR + SAM](https://github.com/RockeyCoss/Instance-Segment-Anything/blob/master/projects/configs/hdetr/swin-l-hdetr_sam-vit-h.py)/[FocalNet-L+DINO + SAM](https://github.com/RockeyCoss/Instance-Segment-Anything/blob/master/projects/configs/hdetr/swin-l-hdetr_sam-vit-h.py) achieves strong COCO instance segmentation results: mask AP=46.8/49.1 by simply prompting SAM with boxes predicted by Swin-L+H-Deformable-DETR/FocalNet-L+DINO. (mask AP=46.5 based on ViTDet)🍺
|
| 15 |
+
|
| 16 |
+
## Catalog
|
| 17 |
+
|
| 18 |
+
- [x] Support Swin-L+H-Deformable-DETR+SAM
|
| 19 |
+
- [x] Support FocalNet-L+DINO+SAM
|
| 20 |
+
- [x] Support R50+H-Deformable-DETR+SAM/Swin-T+H-Deformable-DETR
|
| 21 |
+
- [x] Support HuggingFace gradio demo
|
| 22 |
+
- [x] Support cascade prompts (box prompt + mask prompt)
|
| 23 |
+
|
| 24 |
+
## Box-as-Prompt Results
|
| 25 |
+
|
| 26 |
+
| Detector | SAM | multimask ouput | Detector's Box AP | Mask AP | Config |
|
| 27 |
+
| :---------------------: | :-------: | :---------------: | :-----: | :----------------------------------------------------------: | ----------------------- |
|
| 28 |
+
| R50+H-Deformable-DETR | sam-vit-b | :x: | 50.0 | 38.2 | [config](https://github.com/RockeyCoss/Instance-Segment-Anything/blob/master/projects/configs/hdetr/r50-hdetr_sam-vit-b.py) |
|
| 29 |
+
| R50+H-Deformable-DETR | sam-vit-b | :heavy_check_mark: | 50.0 | 39.9 | [config](https://github.com/RockeyCoss/Instance-Segment-Anything/blob/master/projects/configs/hdetr/r50-hdetr_sam-vit-b_best-in-multi.py) |
|
| 30 |
+
| R50+H-Deformable-DETR | sam-vit-l | :x: | 50.0 | 41.5 | [config](https://github.com/RockeyCoss/Instance-Segment-Anything/blob/master/projects/configs/hdetr/r50-hdetr_sam-vit-l.py) |
|
| 31 |
+
| Swin-T+H-Deformable-DETR | sam-vit-b | :x: | 53.2 | 40.0 | [config](https://github.com/RockeyCoss/Instance-Segment-Anything/blob/master/projects/configs/hdetr/swin-t-hdetr_sam-vit-b.py) |
|
| 32 |
+
| Swin-T+H-Deformable-DETR | sam-vit-l | :x: | 53.2 | 43.5 | [config](https://github.com/RockeyCoss/Instance-Segment-Anything/blob/master/projects/configs/hdetr/swin-t-hdetr_sam-vit-l.py) |
|
| 33 |
+
| Swin-L+H-Deformable-DETR | sam-vit-b | :x: | 58.0 | 42.5 | [config](https://github.com/RockeyCoss/Instance-Segment-Anything/blob/master/projects/configs/hdetr/swin-l-hdetr_sam-vit-b.py) |
|
| 34 |
+
| Swin-L+H-Deformable-DETR | sam-vit-l | :x: | 58.0 | 46.3 | [config](https://github.com/RockeyCoss/Instance-Segment-Anything/blob/master/projects/configs/hdetr/swin-l-hdetr_sam-vit-l.py) |
|
| 35 |
+
| Swin-L+H-Deformable-DETR | sam-vit-h | :x: | 58.0 | 46.8 | [config](https://github.com/RockeyCoss/Instance-Segment-Anything/blob/master/projects/configs/hdetr/swin-l-hdetr_sam-vit-h.py) |
|
| 36 |
+
| FocalNet-L+DINO | sam-vit-b | :x: | 63.2 | 44.5 | [config](https://github.com/RockeyCoss/Instance-Segment-Anything/blob/master/projects/configs/hdetr/swin-l-hdetr_sam-vit-b.py) |
|
| 37 |
+
| FocalNet-L+DINO | sam-vit-l | :x: | 63.2 | 48.6 | [config](https://github.com/RockeyCoss/Instance-Segment-Anything/blob/master/projects/configs/hdetr/swin-l-hdetr_sam-vit-l.py) |
|
| 38 |
+
| FocalNet-L+DINO | sam-vit-h | :x: | 63.2 | 49.1 | [config](https://github.com/RockeyCoss/Instance-Segment-Anything/blob/master/projects/configs/hdetr/swin-l-hdetr_sam-vit-h.py) |
|
| 39 |
+
|
| 40 |
+
## Cascade-Prompt Results
|
| 41 |
+
|
| 42 |
+
| Detector | SAM | multimask ouput | Detector's Box AP | Mask AP | Config |
|
| 43 |
+
| :-------------------: | :-------: | :----------------: | :---------------: | :-----: | ------------------------------------------------------------ |
|
| 44 |
+
| R50+H-Deformable-DETR | sam-vit-b | :x: | 50.0 | 38.8 | [config](https://github.com/RockeyCoss/Instance-Segment-Anything/blob/master/projects/configs/hdetr/r50-hdetr_sam-vit-b_cascade.py) |
|
| 45 |
+
| R50+H-Deformable-DETR | sam-vit-b | :heavy_check_mark: | 50.0 | 40.5 | [config](https://github.com/RockeyCoss/Instance-Segment-Anything/blob/master/projects/configs/hdetr/r50-hdetr_sam-vit-b_best-in-multi_cascade.py) |
|
| 46 |
+
|
| 47 |
+
***Note***
|
| 48 |
+
|
| 49 |
+
**multimask ouput**: If multimask output is :heavy_check_mark:, SAM will predict three masks for each prompt, and the segmentation result will be the one with the highest predicted IoU. Otherwise, if multimask output is :x:, SAM will return only one mask for each prompt, which will be used as the segmentation result.
|
| 50 |
+
|
| 51 |
+
**cascade-prompt**: In the cascade-prompt setting, the segmentation process involves two stages. In the first stage, a coarse mask is predicted with a bounding box prompt. The second stage then utilizes both the bounding box and the coarse mask as prompts to predict the final segmentation result. Note that if multimask output is :heavy_check_mark:, the first stage will predict three coarse masks, and the second stage will use the mask with the highest predicted IoU as the prompt.
|
| 52 |
+
|
| 53 |
+
## Installation
|
| 54 |
+
|
| 55 |
+
🍺🍺🍺 Add dockerhub enviroment
|
| 56 |
+
|
| 57 |
+
```
|
| 58 |
+
docker pull kxqt/prompt-sam-torch1.12-cuda11.6:20230410
|
| 59 |
+
nvidia-docker run -it --shm-size=4096m -v {your_path}:{path_in_docker} kxqt/prompt-sam-torch1.12-cuda11.6:20230410
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
We test the models under `python=3.7.10,pytorch=1.10.2,cuda=10.2`. Other versions might be available as well.
|
| 63 |
+
|
| 64 |
+
1. Clone this repository
|
| 65 |
+
|
| 66 |
+
```
|
| 67 |
+
git clone https://github.com/RockeyCoss/Instance-Segment-Anything
|
| 68 |
+
cd Instance-Segment-Anything
|
| 69 |
+
```
|
| 70 |
+
|
| 71 |
+
2. Install PyTorch
|
| 72 |
+
|
| 73 |
+
```bash
|
| 74 |
+
# an example
|
| 75 |
+
pip install torch torchvision
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
3. Install MMCV
|
| 79 |
+
|
| 80 |
+
```
|
| 81 |
+
pip install -U openmim
|
| 82 |
+
mim install "mmcv>=2.0.0"
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
4. Install MMDetection's requirements
|
| 86 |
+
|
| 87 |
+
```
|
| 88 |
+
pip install -r requirements.txt
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
5. Compile CUDA operators
|
| 92 |
+
|
| 93 |
+
```bash
|
| 94 |
+
cd projects/instance_segment_anything/ops
|
| 95 |
+
python setup.py build install
|
| 96 |
+
cd ../../..
|
| 97 |
+
```
|
| 98 |
+
|
| 99 |
+
## Prepare COCO Dataset
|
| 100 |
+
|
| 101 |
+
Please refer to [data preparation](https://mmdetection.readthedocs.io/en/latest/user_guides/dataset_prepare.html).
|
| 102 |
+
|
| 103 |
+
## Prepare Checkpoints
|
| 104 |
+
|
| 105 |
+
1. Install wget
|
| 106 |
+
|
| 107 |
+
```
|
| 108 |
+
pip install wget
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
2. SAM checkpoints
|
| 112 |
+
|
| 113 |
+
```bash
|
| 114 |
+
mkdir ckpt
|
| 115 |
+
cd ckpt
|
| 116 |
+
python -m wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_b_01ec64.pth
|
| 117 |
+
python -m wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_l_0b3195.pth
|
| 118 |
+
python -m wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
|
| 119 |
+
cd ..
|
| 120 |
+
```
|
| 121 |
+
|
| 122 |
+
3. Here are the checkpoints for the detection models. You can download only the checkpoints you need.
|
| 123 |
+
|
| 124 |
+
```bash
|
| 125 |
+
# R50+H-Deformable-DETR
|
| 126 |
+
cd ckpt
|
| 127 |
+
python -m wget https://github.com/HDETR/H-Deformable-DETR/releases/download/v0.1/r50_hybrid_branch_lambda1_group6_t1500_dp0_mqs_lft_deformable_detr_plus_iterative_bbox_refinement_plus_plus_two_stage_36eps.pth -o r50_hdetr.pth
|
| 128 |
+
cd ..
|
| 129 |
+
python tools/convert_ckpt.py ckpt/r50_hdetr.pth ckpt/r50_hdetr.pth
|
| 130 |
+
|
| 131 |
+
# Swin-T+H-Deformable-DETR
|
| 132 |
+
cd ckpt
|
| 133 |
+
python -m wget https://github.com/HDETR/H-Deformable-DETR/releases/download/v0.1/swin_tiny_hybrid_branch_lambda1_group6_t1500_dp0_mqs_lft_deformable_detr_plus_iterative_bbox_refinement_plus_plus_two_stage_36eps.pth -o swin_t_hdetr.pth
|
| 134 |
+
cd ..
|
| 135 |
+
python tools/convert_ckpt.py ckpt/swin_t_hdetr.pth ckpt/swin_t_hdetr.pth
|
| 136 |
+
|
| 137 |
+
# Swin-L+H-Deformable-DETR
|
| 138 |
+
cd ckpt
|
| 139 |
+
python -m wget https://github.com/HDETR/H-Deformable-DETR/releases/download/v0.1/decay0.05_drop_path0.5_swin_large_hybrid_branch_lambda1_group6_t1500_n900_dp0_mqs_lft_deformable_detr_plus_iterative_bbox_refinement_plus_plus_two_stage_36eps.pth -o swin_l_hdetr.pth
|
| 140 |
+
cd ..
|
| 141 |
+
python tools/convert_ckpt.py ckpt/swin_l_hdetr.pth ckpt/swin_l_hdetr.pth
|
| 142 |
+
|
| 143 |
+
# FocalNet-L+DINO
|
| 144 |
+
cd ckpt
|
| 145 |
+
python -m wget https://projects4jw.blob.core.windows.net/focalnet/release/detection/focalnet_large_fl4_o365_finetuned_on_coco.pth -o focalnet_l_dino.pth
|
| 146 |
+
cd ..
|
| 147 |
+
python tools/convert_ckpt.py ckpt/focalnet_l_dino.pth ckpt/focalnet_l_dino.pth
|
| 148 |
+
```
|
| 149 |
+
|
| 150 |
+
## Run Evaluation
|
| 151 |
+
|
| 152 |
+
1. Evaluate Metrics
|
| 153 |
+
|
| 154 |
+
```bash
|
| 155 |
+
# single GPU
|
| 156 |
+
python tools/test.py path/to/the/config/file --eval segm
|
| 157 |
+
# multiple GPUs
|
| 158 |
+
bash tools/dist_test.sh path/to/the/config/file num_gpus --eval segm
|
| 159 |
+
```
|
| 160 |
+
|
| 161 |
+
2. Visualize Segmentation Results
|
| 162 |
+
|
| 163 |
+
```bash
|
| 164 |
+
python tools/test.py path/to/the/config/file --show-dir path/to/the/visualization/results
|
| 165 |
+
```
|
| 166 |
+
## Gradio Demo
|
| 167 |
+
|
| 168 |
+
We also provide a UI for displaying the segmentation results that is built with gradio. To launch the demo, simply run the following command in a terminal:
|
| 169 |
+
|
| 170 |
+
```bash
|
| 171 |
+
pip install gradio
|
| 172 |
+
python app.py
|
| 173 |
+
```
|
| 174 |
+
|
| 175 |
+
This demo is also hosted on HuggingFace [here](https://huggingface.co/spaces/rockeycoss/Prompt-Segment-Anything-Demo).
|
| 176 |
+
|
| 177 |
+
## More Segmentation Examples
|
| 178 |
+
|
| 179 |
+

|
| 180 |
+

|
| 181 |
+

|
| 182 |
+

|
| 183 |
+
|
| 184 |
+
## Citation
|
| 185 |
+
|
| 186 |
+
**Segment Anything**
|
| 187 |
+
|
| 188 |
+
```latex
|
| 189 |
+
@article{kirillov2023segany,
|
| 190 |
+
title={Segment Anything},
|
| 191 |
+
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{\'a}r, Piotr and Girshick, Ross},
|
| 192 |
+
journal={arXiv:2304.02643},
|
| 193 |
+
year={2023}
|
| 194 |
+
}
|
| 195 |
+
```
|
| 196 |
+
**H-Deformable-DETR**
|
| 197 |
+
|
| 198 |
+
```latex
|
| 199 |
+
@article{jia2022detrs,
|
| 200 |
+
title={DETRs with Hybrid Matching},
|
| 201 |
+
author={Jia, Ding and Yuan, Yuhui and He, Haodi and Wu, Xiaopei and Yu, Haojun and Lin, Weihong and Sun, Lei and Zhang, Chao and Hu, Han},
|
| 202 |
+
journal={arXiv preprint arXiv:2207.13080},
|
| 203 |
+
year={2022}
|
| 204 |
+
}
|
| 205 |
+
```
|
| 206 |
+
**Swin Transformer**
|
| 207 |
+
|
| 208 |
+
```latex
|
| 209 |
+
@inproceedings{liu2021Swin,
|
| 210 |
+
title={Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
|
| 211 |
+
author={Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining},
|
| 212 |
+
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
|
| 213 |
+
year={2021}
|
| 214 |
+
}
|
| 215 |
+
```
|
| 216 |
+
**DINO**
|
| 217 |
+
|
| 218 |
+
```latex
|
| 219 |
+
@misc{zhang2022dino,
|
| 220 |
+
title={DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection},
|
| 221 |
+
author={Hao Zhang and Feng Li and Shilong Liu and Lei Zhang and Hang Su and Jun Zhu and Lionel M. Ni and Heung-Yeung Shum},
|
| 222 |
+
year={2022},
|
| 223 |
+
eprint={2203.03605},
|
| 224 |
+
archivePrefix={arXiv},
|
| 225 |
+
primaryClass={cs.CV}
|
| 226 |
+
}
|
| 227 |
+
```
|
| 228 |
+
**FocalNet**
|
| 229 |
+
|
| 230 |
+
```latex
|
| 231 |
+
@misc{yang2022focalnet,
|
| 232 |
+
author = {Yang, Jianwei and Li, Chunyuan and Dai, Xiyang and Yuan, Lu and Gao, Jianfeng},
|
| 233 |
+
title = {Focal Modulation Networks},
|
| 234 |
+
publisher = {arXiv},
|
| 235 |
+
year = {2022},
|
| 236 |
+
}
|
| 237 |
+
```
|
app.py
CHANGED
|
@@ -1,28 +1,54 @@
|
|
| 1 |
-
# Copyright (c) OpenMMLab. All rights reserved.
|
| 2 |
import os
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
from collections import OrderedDict
|
|
|
|
| 4 |
|
|
|
|
|
|
|
| 5 |
import torch
|
| 6 |
|
| 7 |
-
|
| 8 |
-
# torch_ver, cuda_ver = torch.__version__.split('+')
|
| 9 |
-
# os.system('pip list')
|
| 10 |
-
# os.system(f'pip install pycocotools==2.0.0 mmdet mmcv-full==1.5.0 -f https://download.openmmlab.com/mmcv/dist/{cuda_ver}/torch1.10.0/index.html --no-cache-dir')
|
| 11 |
-
os.system(r'python -m wget https://github.com/HDETR/H-Deformable-DETR/releases/download/v0.1/r50_hybrid_branch_lambda1_group6_t1500_dp0_mqs_lft_deformable_detr_plus_iterative_bbox_refinement_plus_plus_two_stage_36eps.pth -o ckpt/r50_hdetr.pth')
|
| 12 |
-
os.system(r'python -m wget https://github.com/HDETR/H-Deformable-DETR/releases/download/v0.1/swin_tiny_hybrid_branch_lambda1_group6_t1500_dp0_mqs_lft_deformable_detr_plus_iterative_bbox_refinement_plus_plus_two_stage_36eps.pth -o ckpt/swin_t_hdetr.pth')
|
| 13 |
-
os.system(r'python tools/convert_ckpt.py ckpt/r50_hdetr.pth ckpt/r50_hdetr.pth')
|
| 14 |
-
os.system(r'python tools/convert_ckpt.py ckpt/swin_t_hdetr.pth ckpt/swin_t_hdetr.pth')
|
| 15 |
-
|
| 16 |
from mmcv import Config
|
|
|
|
|
|
|
|
|
|
| 17 |
from mmcv.utils import IS_CUDA_AVAILABLE, IS_MLU_AVAILABLE
|
| 18 |
|
| 19 |
-
from mmdet.
|
| 20 |
-
from mmdet.datasets import (CocoDataset)
|
|
|
|
|
|
|
| 21 |
from mmdet.utils import (compat_cfg, replace_cfg_vals, setup_multi_processes,
|
| 22 |
update_data_root)
|
| 23 |
|
| 24 |
-
import gradio as gr
|
| 25 |
-
|
| 26 |
config_dict = OrderedDict([('r50-hdetr_sam-vit-b', 'projects/configs/hdetr/r50-hdetr_sam-vit-b.py'),
|
| 27 |
('r50-hdetr_sam-vit-l', 'projects/configs/hdetr/r50-hdetr_sam-vit-l.py'),
|
| 28 |
('swin-t-hdetr_sam-vit-b', 'projects/configs/hdetr/swin-t-hdetr_sam-vit-b.py'),
|
|
@@ -33,7 +59,118 @@ config_dict = OrderedDict([('r50-hdetr_sam-vit-b', 'projects/configs/hdetr/r50-h
|
|
| 33 |
('focalnet-l-dino_sam-vit-b', 'projects/configs/focalnet_dino/focalnet-l-dino_sam-vit-b.py'),
|
| 34 |
# ('focalnet-l-dino_sam-vit-l', 'projects/configs/focalnet_dino/focalnet-l-dino_sam-vit-l.py'),
|
| 35 |
# ('focalnet-l-dino_sam-vit-h', 'projects/configs/focalnet_dino/focalnet-l-dino_sam-vit-h.py')
|
| 36 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 37 |
|
| 38 |
|
| 39 |
def inference(img, config):
|
|
@@ -85,10 +222,10 @@ def inference(img, config):
|
|
| 85 |
device = "cuda"
|
| 86 |
else:
|
| 87 |
device = "cpu"
|
| 88 |
-
model =
|
| 89 |
model.CLASSES = CocoDataset.CLASSES
|
| 90 |
|
| 91 |
-
results =
|
| 92 |
visualize = model.show_result(
|
| 93 |
img,
|
| 94 |
results,
|
|
@@ -108,9 +245,10 @@ description = """
|
|
| 108 |
Github link: [Link](https://github.com/RockeyCoss/Prompt-Segment-Anything)
|
| 109 |
You can select the model you want to use from the "Model" dropdown menu and click "Submit" to segment the image you uploaded to the "Input Image" box.
|
| 110 |
"""
|
| 111 |
-
if
|
| 112 |
description += f'\n<p>For faster inference without waiting in queue, you may duplicate the space and upgrade to GPU in settings. <a href="https://huggingface.co/spaces/{SPACE_ID}?duplicate=true"><img style="display: inline; margin-top: 0em; margin-bottom: 0em" src="https://bit.ly/3gLdBN6" alt="Duplicate Space" /></a></p>'
|
| 113 |
-
|
|
|
|
| 114 |
def main():
|
| 115 |
with gr.Blocks() as demo:
|
| 116 |
gr.Markdown(description)
|
|
|
|
|
|
|
| 1 |
import os
|
| 2 |
+
|
| 3 |
+
SPACE_ID = os.getenv('SPACE_ID')
|
| 4 |
+
if SPACE_ID is not None:
|
| 5 |
+
# running on huggingface space
|
| 6 |
+
os.system(r'mkdir ckpt')
|
| 7 |
+
os.system(
|
| 8 |
+
r'python -m wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_b_01ec64.pth -o ckpt/sam_vit_b_01ec64.pth')
|
| 9 |
+
os.system(
|
| 10 |
+
r'python -m wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_l_0b3195.pth -o ckpt/sam_vit_l_0b3195.pth')
|
| 11 |
+
os.system(
|
| 12 |
+
r'python -m wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth -o ckpt/sam_vit_h_4b8939.pth')
|
| 13 |
+
|
| 14 |
+
os.system(
|
| 15 |
+
r'python -m wget https://github.com/HDETR/H-Deformable-DETR/releases/download/v0.1'
|
| 16 |
+
r'/r50_hybrid_branch_lambda1_group6_t1500_dp0_mqs_lft_deformable_detr_plus_iterative_bbox_refinement_plus_plus_two_stage_36eps.pth -o ckpt/r50_hdetr.pth')
|
| 17 |
+
os.system(
|
| 18 |
+
r'python -m wget https://github.com/HDETR/H-Deformable-DETR/releases/download/v0.1'
|
| 19 |
+
r'/swin_tiny_hybrid_branch_lambda1_group6_t1500_dp0_mqs_lft_deformable_detr_plus_iterative_bbox_refinement_plus_plus_two_stage_36eps.pth -o ckpt/swin_t_hdetr.pth')
|
| 20 |
+
os.system(
|
| 21 |
+
r'python -m wget https://github.com/HDETR/H-Deformable-DETR/releases/download/v0.1/decay0.05_drop_path0'
|
| 22 |
+
r'.5_swin_large_hybrid_branch_lambda1_group6_t1500_n900_dp0_mqs_lft_deformable_detr_plus_iterative_bbox_refinement_plus_plus_two_stage_36eps.pth -o ckpt/swin_l_hdetr.pth')
|
| 23 |
+
os.system(r'python -m wget https://projects4jw.blob.core.windows.net/focalnet/release/detection'
|
| 24 |
+
r'/focalnet_large_fl4_o365_finetuned_on_coco.pth -o ckpt/focalnet_l_dino.pth')
|
| 25 |
+
|
| 26 |
+
os.system(r'python tools/convert_ckpt.py ckpt/r50_hdetr.pth ckpt/r50_hdetr.pth')
|
| 27 |
+
os.system(r'python tools/convert_ckpt.py ckpt/swin_t_hdetr.pth ckpt/swin_t_hdetr.pth')
|
| 28 |
+
os.system(r'python tools/convert_ckpt.py ckpt/swin_l_hdetr.pth ckpt/swin_l_hdetr.pth')
|
| 29 |
+
os.system(r'python tools/convert_ckpt.py ckpt/focalnet_l_dino.pth ckpt/focalnet_l_dino.pth')
|
| 30 |
+
import warnings
|
| 31 |
from collections import OrderedDict
|
| 32 |
+
from pathlib import Path
|
| 33 |
|
| 34 |
+
import gradio as gr
|
| 35 |
+
import numpy as np
|
| 36 |
import torch
|
| 37 |
|
| 38 |
+
import mmcv
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 39 |
from mmcv import Config
|
| 40 |
+
from mmcv.ops import RoIPool
|
| 41 |
+
from mmcv.parallel import collate, scatter
|
| 42 |
+
from mmcv.runner import load_checkpoint
|
| 43 |
from mmcv.utils import IS_CUDA_AVAILABLE, IS_MLU_AVAILABLE
|
| 44 |
|
| 45 |
+
from mmdet.core import get_classes
|
| 46 |
+
from mmdet.datasets import (CocoDataset, replace_ImageToTensor)
|
| 47 |
+
from mmdet.datasets.pipelines import Compose
|
| 48 |
+
from mmdet.models import build_detector
|
| 49 |
from mmdet.utils import (compat_cfg, replace_cfg_vals, setup_multi_processes,
|
| 50 |
update_data_root)
|
| 51 |
|
|
|
|
|
|
|
| 52 |
config_dict = OrderedDict([('r50-hdetr_sam-vit-b', 'projects/configs/hdetr/r50-hdetr_sam-vit-b.py'),
|
| 53 |
('r50-hdetr_sam-vit-l', 'projects/configs/hdetr/r50-hdetr_sam-vit-l.py'),
|
| 54 |
('swin-t-hdetr_sam-vit-b', 'projects/configs/hdetr/swin-t-hdetr_sam-vit-b.py'),
|
|
|
|
| 59 |
('focalnet-l-dino_sam-vit-b', 'projects/configs/focalnet_dino/focalnet-l-dino_sam-vit-b.py'),
|
| 60 |
# ('focalnet-l-dino_sam-vit-l', 'projects/configs/focalnet_dino/focalnet-l-dino_sam-vit-l.py'),
|
| 61 |
# ('focalnet-l-dino_sam-vit-h', 'projects/configs/focalnet_dino/focalnet-l-dino_sam-vit-h.py')
|
| 62 |
+
])
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def init_demo_detector(config, checkpoint=None, device='cuda:0', cfg_options=None):
|
| 66 |
+
"""Initialize a detector from config file.
|
| 67 |
+
Args:
|
| 68 |
+
config (str, :obj:`Path`, or :obj:`mmcv.Config`): Config file path,
|
| 69 |
+
:obj:`Path`, or the config object.
|
| 70 |
+
checkpoint (str, optional): Checkpoint path. If left as None, the model
|
| 71 |
+
will not load any weights.
|
| 72 |
+
cfg_options (dict): Options to override some settings in the used
|
| 73 |
+
config.
|
| 74 |
+
Returns:
|
| 75 |
+
nn.Module: The constructed detector.
|
| 76 |
+
"""
|
| 77 |
+
if isinstance(config, (str, Path)):
|
| 78 |
+
config = mmcv.Config.fromfile(config)
|
| 79 |
+
elif not isinstance(config, mmcv.Config):
|
| 80 |
+
raise TypeError('config must be a filename or Config object, '
|
| 81 |
+
f'but got {type(config)}')
|
| 82 |
+
if cfg_options is not None:
|
| 83 |
+
config.merge_from_dict(cfg_options)
|
| 84 |
+
if 'pretrained' in config.model:
|
| 85 |
+
config.model.pretrained = None
|
| 86 |
+
elif (config.model.get('backbone', None) is not None
|
| 87 |
+
and 'init_cfg' in config.model.backbone):
|
| 88 |
+
config.model.backbone.init_cfg = None
|
| 89 |
+
config.model.train_cfg = None
|
| 90 |
+
model = build_detector(config.model, test_cfg=config.get('test_cfg'))
|
| 91 |
+
if checkpoint is not None:
|
| 92 |
+
checkpoint = load_checkpoint(model, checkpoint, map_location='cpu')
|
| 93 |
+
if 'CLASSES' in checkpoint.get('meta', {}):
|
| 94 |
+
model.CLASSES = checkpoint['meta']['CLASSES']
|
| 95 |
+
else:
|
| 96 |
+
warnings.simplefilter('once')
|
| 97 |
+
warnings.warn('Class names are not saved in the checkpoint\'s '
|
| 98 |
+
'meta data, use COCO classes by default.')
|
| 99 |
+
model.CLASSES = get_classes('coco')
|
| 100 |
+
model.cfg = config # save the config in the model for convenience
|
| 101 |
+
model.to(device)
|
| 102 |
+
model.eval()
|
| 103 |
+
|
| 104 |
+
if device == 'npu':
|
| 105 |
+
from mmcv.device.npu import NPUDataParallel
|
| 106 |
+
model = NPUDataParallel(model)
|
| 107 |
+
model.cfg = config
|
| 108 |
+
|
| 109 |
+
return model
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
def inference_demo_detector(model, imgs):
|
| 113 |
+
"""Inference image(s) with the detector.
|
| 114 |
+
Args:
|
| 115 |
+
model (nn.Module): The loaded detector.
|
| 116 |
+
imgs (str/ndarray or list[str/ndarray] or tuple[str/ndarray]):
|
| 117 |
+
Either image files or loaded images.
|
| 118 |
+
Returns:
|
| 119 |
+
If imgs is a list or tuple, the same length list type results
|
| 120 |
+
will be returned, otherwise return the detection results directly.
|
| 121 |
+
"""
|
| 122 |
+
ori_img = imgs
|
| 123 |
+
if isinstance(imgs, (list, tuple)):
|
| 124 |
+
is_batch = True
|
| 125 |
+
else:
|
| 126 |
+
imgs = [imgs]
|
| 127 |
+
is_batch = False
|
| 128 |
+
|
| 129 |
+
cfg = model.cfg
|
| 130 |
+
device = next(model.parameters()).device # model device
|
| 131 |
+
|
| 132 |
+
if isinstance(imgs[0], np.ndarray):
|
| 133 |
+
cfg = cfg.copy()
|
| 134 |
+
# set loading pipeline type
|
| 135 |
+
cfg.data.test.pipeline[0].type = 'LoadImageFromWebcam'
|
| 136 |
+
|
| 137 |
+
cfg.data.test.pipeline = replace_ImageToTensor(cfg.data.test.pipeline)
|
| 138 |
+
test_pipeline = Compose(cfg.data.test.pipeline)
|
| 139 |
+
|
| 140 |
+
datas = []
|
| 141 |
+
for img in imgs:
|
| 142 |
+
# prepare data
|
| 143 |
+
if isinstance(img, np.ndarray):
|
| 144 |
+
# directly add img
|
| 145 |
+
data = dict(img=img)
|
| 146 |
+
else:
|
| 147 |
+
# add information into dict
|
| 148 |
+
data = dict(img_info=dict(filename=img), img_prefix=None)
|
| 149 |
+
# build the data pipeline
|
| 150 |
+
data = test_pipeline(data)
|
| 151 |
+
datas.append(data)
|
| 152 |
+
|
| 153 |
+
data = collate(datas, samples_per_gpu=len(imgs))
|
| 154 |
+
# just get the actual data from DataContainer
|
| 155 |
+
data['img_metas'] = [img_metas.data[0] for img_metas in data['img_metas']]
|
| 156 |
+
data['img'] = [img.data[0] for img in data['img']]
|
| 157 |
+
if next(model.parameters()).is_cuda:
|
| 158 |
+
# scatter to specified GPU
|
| 159 |
+
data = scatter(data, [device])[0]
|
| 160 |
+
else:
|
| 161 |
+
for m in model.modules():
|
| 162 |
+
assert not isinstance(
|
| 163 |
+
m, RoIPool
|
| 164 |
+
), 'CPU inference with RoIPool is not supported currently.'
|
| 165 |
+
|
| 166 |
+
# forward the model
|
| 167 |
+
with torch.no_grad():
|
| 168 |
+
results = model(return_loss=False, rescale=True, **data, ori_img=ori_img)
|
| 169 |
+
|
| 170 |
+
if not is_batch:
|
| 171 |
+
return results[0]
|
| 172 |
+
else:
|
| 173 |
+
return results
|
| 174 |
|
| 175 |
|
| 176 |
def inference(img, config):
|
|
|
|
| 222 |
device = "cuda"
|
| 223 |
else:
|
| 224 |
device = "cpu"
|
| 225 |
+
model = init_demo_detector(cfg, None, device=device)
|
| 226 |
model.CLASSES = CocoDataset.CLASSES
|
| 227 |
|
| 228 |
+
results = inference_demo_detector(model, img)
|
| 229 |
visualize = model.show_result(
|
| 230 |
img,
|
| 231 |
results,
|
|
|
|
| 245 |
Github link: [Link](https://github.com/RockeyCoss/Prompt-Segment-Anything)
|
| 246 |
You can select the model you want to use from the "Model" dropdown menu and click "Submit" to segment the image you uploaded to the "Input Image" box.
|
| 247 |
"""
|
| 248 |
+
if SPACE_ID is not None:
|
| 249 |
description += f'\n<p>For faster inference without waiting in queue, you may duplicate the space and upgrade to GPU in settings. <a href="https://huggingface.co/spaces/{SPACE_ID}?duplicate=true"><img style="display: inline; margin-top: 0em; margin-bottom: 0em" src="https://bit.ly/3gLdBN6" alt="Duplicate Space" /></a></p>'
|
| 250 |
+
|
| 251 |
+
|
| 252 |
def main():
|
| 253 |
with gr.Blocks() as demo:
|
| 254 |
gr.Markdown(description)
|
assets/example1.jpg
ADDED

|
assets/example2.jpg
ADDED
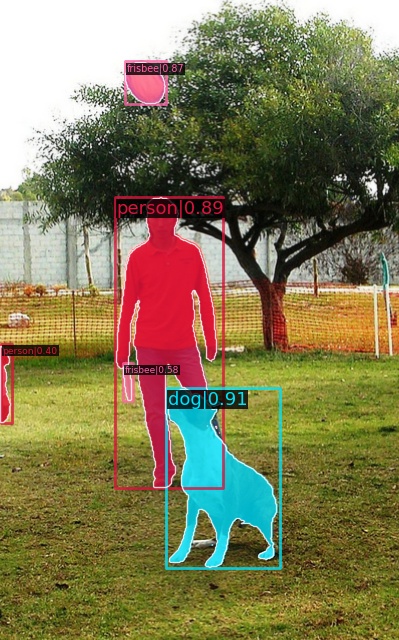
|
assets/example3.jpg
ADDED

|
assets/example4.jpg
ADDED

|
assets/example5.jpg
ADDED

|
assets/img1.jpg
ADDED

|
assets/img2.jpg
ADDED

|
assets/img3.jpg
ADDED

|
assets/img4.jpg
ADDED

|
flagged/Input/tmpaytsmk0e.jpg
DELETED
|
Binary file (111 kB)
|
|
|
flagged/Output/tmpgs59m7u_.png
DELETED
|
Binary file (498 kB)
|
|
|
flagged/log.csv
DELETED
|
@@ -1,2 +0,0 @@
|
|
| 1 |
-
Input,Output,flag,username,timestamp
|
| 2 |
-
C:\Users\13502\Documents\msra\prompt_segment_anything_demo\flagged\Input\tmpaytsmk0e.jpg,C:\Users\13502\Documents\msra\prompt_segment_anything_demo\flagged\Output\tmpgs59m7u_.png,,,2023-04-10 20:52:40.908980
|
|
|
|
|
|
|
|
|
mmdet/apis/inference.py
CHANGED
|
@@ -38,8 +38,7 @@ def init_detector(config, checkpoint=None, device='cuda:0', cfg_options=None):
|
|
| 38 |
config.merge_from_dict(cfg_options)
|
| 39 |
if 'pretrained' in config.model:
|
| 40 |
config.model.pretrained = None
|
| 41 |
-
elif
|
| 42 |
-
and 'init_cfg' in config.model.backbone):
|
| 43 |
config.model.backbone.init_cfg = None
|
| 44 |
config.model.train_cfg = None
|
| 45 |
model = build_detector(config.model, test_cfg=config.get('test_cfg'))
|
|
@@ -109,7 +108,7 @@ def inference_detector(model, imgs):
|
|
| 109 |
If imgs is a list or tuple, the same length list type results
|
| 110 |
will be returned, otherwise return the detection results directly.
|
| 111 |
"""
|
| 112 |
-
|
| 113 |
if isinstance(imgs, (list, tuple)):
|
| 114 |
is_batch = True
|
| 115 |
else:
|
|
@@ -155,7 +154,7 @@ def inference_detector(model, imgs):
|
|
| 155 |
|
| 156 |
# forward the model
|
| 157 |
with torch.no_grad():
|
| 158 |
-
results = model(return_loss=False, rescale=True, **data
|
| 159 |
|
| 160 |
if not is_batch:
|
| 161 |
return results[0]
|
|
|
|
| 38 |
config.merge_from_dict(cfg_options)
|
| 39 |
if 'pretrained' in config.model:
|
| 40 |
config.model.pretrained = None
|
| 41 |
+
elif 'init_cfg' in config.model.backbone:
|
|
|
|
| 42 |
config.model.backbone.init_cfg = None
|
| 43 |
config.model.train_cfg = None
|
| 44 |
model = build_detector(config.model, test_cfg=config.get('test_cfg'))
|
|
|
|
| 108 |
If imgs is a list or tuple, the same length list type results
|
| 109 |
will be returned, otherwise return the detection results directly.
|
| 110 |
"""
|
| 111 |
+
|
| 112 |
if isinstance(imgs, (list, tuple)):
|
| 113 |
is_batch = True
|
| 114 |
else:
|
|
|
|
| 154 |
|
| 155 |
# forward the model
|
| 156 |
with torch.no_grad():
|
| 157 |
+
results = model(return_loss=False, rescale=True, **data)
|
| 158 |
|
| 159 |
if not is_batch:
|
| 160 |
return results[0]
|
projects/configs/hdetr/r50-hdetr_sam-vit-b_best-in-multi.py
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = [
|
| 2 |
+
'../_base_/datasets/coco_panoptic.py', '../_base_/default_runtime.py'
|
| 3 |
+
]
|
| 4 |
+
|
| 5 |
+
plugin = True
|
| 6 |
+
plugin_dir = 'projects/instance_segment_anything/'
|
| 7 |
+
|
| 8 |
+
model = dict(
|
| 9 |
+
type='DetWrapperInstanceSAM',
|
| 10 |
+
det_wrapper_type='hdetr',
|
| 11 |
+
det_wrapper_cfg=dict(aux_loss=True,
|
| 12 |
+
backbone='resnet50',
|
| 13 |
+
num_classes=91,
|
| 14 |
+
cache_mode=False,
|
| 15 |
+
dec_layers=6,
|
| 16 |
+
dec_n_points=4,
|
| 17 |
+
dilation=False,
|
| 18 |
+
dim_feedforward=2048,
|
| 19 |
+
drop_path_rate=0.2,
|
| 20 |
+
dropout=0.0,
|
| 21 |
+
enc_layers=6,
|
| 22 |
+
enc_n_points=4,
|
| 23 |
+
focal_alpha=0.25,
|
| 24 |
+
frozen_weights=None,
|
| 25 |
+
hidden_dim=256,
|
| 26 |
+
k_one2many=6,
|
| 27 |
+
lambda_one2many=1.0,
|
| 28 |
+
look_forward_twice=True,
|
| 29 |
+
masks=False,
|
| 30 |
+
mixed_selection=True,
|
| 31 |
+
nheads=8,
|
| 32 |
+
num_feature_levels=4,
|
| 33 |
+
num_queries_one2many=1500,
|
| 34 |
+
num_queries_one2one=300,
|
| 35 |
+
position_embedding='sine',
|
| 36 |
+
position_embedding_scale=6.283185307179586,
|
| 37 |
+
remove_difficult=False,
|
| 38 |
+
topk=100,
|
| 39 |
+
two_stage=True,
|
| 40 |
+
use_checkpoint=False,
|
| 41 |
+
use_fp16=False,
|
| 42 |
+
with_box_refine=True),
|
| 43 |
+
det_model_ckpt='ckpt/r50_hdetr.pth',
|
| 44 |
+
num_classes=80,
|
| 45 |
+
model_type='vit_b',
|
| 46 |
+
sam_checkpoint='ckpt/sam_vit_b_01ec64.pth',
|
| 47 |
+
use_sam_iou=True,
|
| 48 |
+
best_in_multi_mask=True,
|
| 49 |
+
)
|
| 50 |
+
img_norm_cfg = dict(
|
| 51 |
+
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
|
| 52 |
+
# test_pipeline, NOTE the Pad's size_divisor is different from the default
|
| 53 |
+
# setting (size_divisor=32). While there is little effect on the performance
|
| 54 |
+
# whether we use the default setting or use size_divisor=1.
|
| 55 |
+
|
| 56 |
+
test_pipeline = [
|
| 57 |
+
dict(type='LoadImageFromFile'),
|
| 58 |
+
dict(
|
| 59 |
+
type='MultiScaleFlipAug',
|
| 60 |
+
img_scale=(1333, 800),
|
| 61 |
+
flip=False,
|
| 62 |
+
transforms=[
|
| 63 |
+
dict(type='Resize', keep_ratio=True),
|
| 64 |
+
dict(type='RandomFlip'),
|
| 65 |
+
dict(type='Normalize', **img_norm_cfg),
|
| 66 |
+
dict(type='Pad', size_divisor=1),
|
| 67 |
+
dict(type='ImageToTensor', keys=['img']),
|
| 68 |
+
dict(type='Collect', keys=['img'])
|
| 69 |
+
])
|
| 70 |
+
]
|
| 71 |
+
|
| 72 |
+
dataset_type = 'CocoDataset'
|
| 73 |
+
data_root = 'data/coco/'
|
| 74 |
+
|
| 75 |
+
data = dict(
|
| 76 |
+
samples_per_gpu=1,
|
| 77 |
+
workers_per_gpu=1,
|
| 78 |
+
test=dict(
|
| 79 |
+
type=dataset_type,
|
| 80 |
+
ann_file=data_root + 'annotations/instances_val2017.json',
|
| 81 |
+
img_prefix=data_root + 'val2017/',
|
| 82 |
+
pipeline=test_pipeline))
|
projects/configs/hdetr/r50-hdetr_sam-vit-b_best-in-multi_cascade.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = [
|
| 2 |
+
'../_base_/datasets/coco_panoptic.py', '../_base_/default_runtime.py'
|
| 3 |
+
]
|
| 4 |
+
|
| 5 |
+
plugin = True
|
| 6 |
+
plugin_dir = 'projects/instance_segment_anything/'
|
| 7 |
+
|
| 8 |
+
model = dict(
|
| 9 |
+
type='DetWrapperInstanceSAMCascade',
|
| 10 |
+
det_wrapper_type='hdetr',
|
| 11 |
+
det_wrapper_cfg=dict(aux_loss=True,
|
| 12 |
+
backbone='resnet50',
|
| 13 |
+
num_classes=91,
|
| 14 |
+
cache_mode=False,
|
| 15 |
+
dec_layers=6,
|
| 16 |
+
dec_n_points=4,
|
| 17 |
+
dilation=False,
|
| 18 |
+
dim_feedforward=2048,
|
| 19 |
+
drop_path_rate=0.2,
|
| 20 |
+
dropout=0.0,
|
| 21 |
+
enc_layers=6,
|
| 22 |
+
enc_n_points=4,
|
| 23 |
+
focal_alpha=0.25,
|
| 24 |
+
frozen_weights=None,
|
| 25 |
+
hidden_dim=256,
|
| 26 |
+
k_one2many=6,
|
| 27 |
+
lambda_one2many=1.0,
|
| 28 |
+
look_forward_twice=True,
|
| 29 |
+
masks=False,
|
| 30 |
+
mixed_selection=True,
|
| 31 |
+
nheads=8,
|
| 32 |
+
num_feature_levels=4,
|
| 33 |
+
num_queries_one2many=1500,
|
| 34 |
+
num_queries_one2one=300,
|
| 35 |
+
position_embedding='sine',
|
| 36 |
+
position_embedding_scale=6.283185307179586,
|
| 37 |
+
remove_difficult=False,
|
| 38 |
+
topk=100,
|
| 39 |
+
two_stage=True,
|
| 40 |
+
use_checkpoint=False,
|
| 41 |
+
use_fp16=False,
|
| 42 |
+
with_box_refine=True),
|
| 43 |
+
det_model_ckpt='ckpt/r50_hdetr.pth',
|
| 44 |
+
num_classes=80,
|
| 45 |
+
model_type='vit_b',
|
| 46 |
+
sam_checkpoint='ckpt/sam_vit_b_01ec64.pth',
|
| 47 |
+
use_sam_iou=True,
|
| 48 |
+
best_in_multi_mask=True,
|
| 49 |
+
stage_1_multi_mask=True,
|
| 50 |
+
)
|
| 51 |
+
img_norm_cfg = dict(
|
| 52 |
+
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
|
| 53 |
+
# test_pipeline, NOTE the Pad's size_divisor is different from the default
|
| 54 |
+
# setting (size_divisor=32). While there is little effect on the performance
|
| 55 |
+
# whether we use the default setting or use size_divisor=1.
|
| 56 |
+
|
| 57 |
+
test_pipeline = [
|
| 58 |
+
dict(type='LoadImageFromFile'),
|
| 59 |
+
dict(
|
| 60 |
+
type='MultiScaleFlipAug',
|
| 61 |
+
img_scale=(1333, 800),
|
| 62 |
+
flip=False,
|
| 63 |
+
transforms=[
|
| 64 |
+
dict(type='Resize', keep_ratio=True),
|
| 65 |
+
dict(type='RandomFlip'),
|
| 66 |
+
dict(type='Normalize', **img_norm_cfg),
|
| 67 |
+
dict(type='Pad', size_divisor=1),
|
| 68 |
+
dict(type='ImageToTensor', keys=['img']),
|
| 69 |
+
dict(type='Collect', keys=['img'])
|
| 70 |
+
])
|
| 71 |
+
]
|
| 72 |
+
|
| 73 |
+
dataset_type = 'CocoDataset'
|
| 74 |
+
data_root = 'data/coco/'
|
| 75 |
+
|
| 76 |
+
data = dict(
|
| 77 |
+
samples_per_gpu=1,
|
| 78 |
+
workers_per_gpu=1,
|
| 79 |
+
test=dict(
|
| 80 |
+
type=dataset_type,
|
| 81 |
+
ann_file=data_root + 'annotations/instances_val2017.json',
|
| 82 |
+
img_prefix=data_root + 'val2017/',
|
| 83 |
+
pipeline=test_pipeline))
|
projects/configs/hdetr/r50-hdetr_sam-vit-b_cascade.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = [
|
| 2 |
+
'../_base_/datasets/coco_panoptic.py', '../_base_/default_runtime.py'
|
| 3 |
+
]
|
| 4 |
+
|
| 5 |
+
plugin = True
|
| 6 |
+
plugin_dir = 'projects/instance_segment_anything/'
|
| 7 |
+
|
| 8 |
+
model = dict(
|
| 9 |
+
type='DetWrapperInstanceSAMCascade',
|
| 10 |
+
det_wrapper_type='hdetr',
|
| 11 |
+
det_wrapper_cfg=dict(aux_loss=True,
|
| 12 |
+
backbone='resnet50',
|
| 13 |
+
num_classes=91,
|
| 14 |
+
cache_mode=False,
|
| 15 |
+
dec_layers=6,
|
| 16 |
+
dec_n_points=4,
|
| 17 |
+
dilation=False,
|
| 18 |
+
dim_feedforward=2048,
|
| 19 |
+
drop_path_rate=0.2,
|
| 20 |
+
dropout=0.0,
|
| 21 |
+
enc_layers=6,
|
| 22 |
+
enc_n_points=4,
|
| 23 |
+
focal_alpha=0.25,
|
| 24 |
+
frozen_weights=None,
|
| 25 |
+
hidden_dim=256,
|
| 26 |
+
k_one2many=6,
|
| 27 |
+
lambda_one2many=1.0,
|
| 28 |
+
look_forward_twice=True,
|
| 29 |
+
masks=False,
|
| 30 |
+
mixed_selection=True,
|
| 31 |
+
nheads=8,
|
| 32 |
+
num_feature_levels=4,
|
| 33 |
+
num_queries_one2many=1500,
|
| 34 |
+
num_queries_one2one=300,
|
| 35 |
+
position_embedding='sine',
|
| 36 |
+
position_embedding_scale=6.283185307179586,
|
| 37 |
+
remove_difficult=False,
|
| 38 |
+
topk=100,
|
| 39 |
+
two_stage=True,
|
| 40 |
+
use_checkpoint=False,
|
| 41 |
+
use_fp16=False,
|
| 42 |
+
with_box_refine=True),
|
| 43 |
+
det_model_ckpt='ckpt/r50_hdetr.pth',
|
| 44 |
+
num_classes=80,
|
| 45 |
+
model_type='vit_b',
|
| 46 |
+
sam_checkpoint='ckpt/sam_vit_b_01ec64.pth',
|
| 47 |
+
use_sam_iou=True,
|
| 48 |
+
best_in_multi_mask=False,
|
| 49 |
+
stage_1_multi_mask=False,
|
| 50 |
+
)
|
| 51 |
+
img_norm_cfg = dict(
|
| 52 |
+
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
|
| 53 |
+
# test_pipeline, NOTE the Pad's size_divisor is different from the default
|
| 54 |
+
# setting (size_divisor=32). While there is little effect on the performance
|
| 55 |
+
# whether we use the default setting or use size_divisor=1.
|
| 56 |
+
|
| 57 |
+
test_pipeline = [
|
| 58 |
+
dict(type='LoadImageFromFile'),
|
| 59 |
+
dict(
|
| 60 |
+
type='MultiScaleFlipAug',
|
| 61 |
+
img_scale=(1333, 800),
|
| 62 |
+
flip=False,
|
| 63 |
+
transforms=[
|
| 64 |
+
dict(type='Resize', keep_ratio=True),
|
| 65 |
+
dict(type='RandomFlip'),
|
| 66 |
+
dict(type='Normalize', **img_norm_cfg),
|
| 67 |
+
dict(type='Pad', size_divisor=1),
|
| 68 |
+
dict(type='ImageToTensor', keys=['img']),
|
| 69 |
+
dict(type='Collect', keys=['img'])
|
| 70 |
+
])
|
| 71 |
+
]
|
| 72 |
+
|
| 73 |
+
dataset_type = 'CocoDataset'
|
| 74 |
+
data_root = 'data/coco/'
|
| 75 |
+
|
| 76 |
+
data = dict(
|
| 77 |
+
samples_per_gpu=1,
|
| 78 |
+
workers_per_gpu=1,
|
| 79 |
+
test=dict(
|
| 80 |
+
type=dataset_type,
|
| 81 |
+
ann_file=data_root + 'annotations/instances_val2017.json',
|
| 82 |
+
img_prefix=data_root + 'val2017/',
|
| 83 |
+
pipeline=test_pipeline))
|
projects/instance_segment_anything/__init__.py
CHANGED
|
@@ -1 +1,2 @@
|
|
| 1 |
-
from .models.det_wrapper_instance_sam import DetWrapperInstanceSAM
|
|
|
|
|
|
| 1 |
+
from .models.det_wrapper_instance_sam import DetWrapperInstanceSAM
|
| 2 |
+
from .models.det_wrapper_instance_sam_cascade import DetWrapperInstanceSAMCascade
|
projects/instance_segment_anything/models/det_wrapper_instance_sam.py
CHANGED
|
@@ -25,6 +25,7 @@ class DetWrapperInstanceSAM(BaseDetector):
|
|
| 25 |
model_type='vit_b',
|
| 26 |
sam_checkpoint=None,
|
| 27 |
use_sam_iou=True,
|
|
|
|
| 28 |
|
| 29 |
init_cfg=None,
|
| 30 |
train_cfg=None,
|
|
@@ -45,12 +46,16 @@ class DetWrapperInstanceSAM(BaseDetector):
|
|
| 45 |
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
|
| 46 |
_ = sam.to(device=self.learnable_placeholder.weight.device)
|
| 47 |
self.predictor = SamPredictor(sam)
|
|
|
|
| 48 |
self.use_sam_iou = use_sam_iou
|
|
|
|
|
|
|
|
|
|
| 49 |
|
| 50 |
def init_weights(self):
|
| 51 |
pass
|
| 52 |
|
| 53 |
-
def simple_test(self, img, img_metas,
|
| 54 |
"""Test without augmentation.
|
| 55 |
Args:
|
| 56 |
imgs (Tensor): A batch of images.
|
|
@@ -66,22 +71,35 @@ class DetWrapperInstanceSAM(BaseDetector):
|
|
| 66 |
# Tensor(n,4), xyxy, ori image scale
|
| 67 |
output_boxes = results[0]['boxes']
|
| 68 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 69 |
self.predictor.set_image(ori_img)
|
| 70 |
|
| 71 |
transformed_boxes = self.predictor.transform.apply_boxes_torch(output_boxes, ori_img.shape[:2])
|
| 72 |
|
| 73 |
-
# mask_pred: n,1,h,w
|
| 74 |
-
# sam_score: n, 1
|
| 75 |
mask_pred, sam_score, _ = self.predictor.predict_torch(
|
| 76 |
point_coords=None,
|
| 77 |
point_labels=None,
|
| 78 |
boxes=transformed_boxes,
|
| 79 |
-
multimask_output=
|
| 80 |
return_logits=True,
|
| 81 |
)
|
| 82 |
-
|
| 83 |
-
|
| 84 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 85 |
|
| 86 |
# Tensor(n,)
|
| 87 |
label_pred = results[0]['labels']
|
|
|
|
| 25 |
model_type='vit_b',
|
| 26 |
sam_checkpoint=None,
|
| 27 |
use_sam_iou=True,
|
| 28 |
+
best_in_multi_mask=False,
|
| 29 |
|
| 30 |
init_cfg=None,
|
| 31 |
train_cfg=None,
|
|
|
|
| 46 |
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
|
| 47 |
_ = sam.to(device=self.learnable_placeholder.weight.device)
|
| 48 |
self.predictor = SamPredictor(sam)
|
| 49 |
+
# Whether use SAM's predicted IoU to calibrate the confidence score.
|
| 50 |
self.use_sam_iou = use_sam_iou
|
| 51 |
+
# If True, set multimask_output=True and return the mask with highest predicted IoU.
|
| 52 |
+
# if False, set multimask_output=False and return the unique output mask.
|
| 53 |
+
self.best_in_multi_mask = best_in_multi_mask
|
| 54 |
|
| 55 |
def init_weights(self):
|
| 56 |
pass
|
| 57 |
|
| 58 |
+
def simple_test(self, img, img_metas, rescale=True, ori_img=None):
|
| 59 |
"""Test without augmentation.
|
| 60 |
Args:
|
| 61 |
imgs (Tensor): A batch of images.
|
|
|
|
| 71 |
# Tensor(n,4), xyxy, ori image scale
|
| 72 |
output_boxes = results[0]['boxes']
|
| 73 |
|
| 74 |
+
if ori_img is None:
|
| 75 |
+
image_path = img_metas[0]['filename']
|
| 76 |
+
ori_img = cv2.imread(image_path)
|
| 77 |
+
ori_img = cv2.cvtColor(ori_img, cv2.COLOR_BGR2RGB)
|
| 78 |
self.predictor.set_image(ori_img)
|
| 79 |
|
| 80 |
transformed_boxes = self.predictor.transform.apply_boxes_torch(output_boxes, ori_img.shape[:2])
|
| 81 |
|
| 82 |
+
# mask_pred: n,1/3,h,w
|
| 83 |
+
# sam_score: n, 1/3
|
| 84 |
mask_pred, sam_score, _ = self.predictor.predict_torch(
|
| 85 |
point_coords=None,
|
| 86 |
point_labels=None,
|
| 87 |
boxes=transformed_boxes,
|
| 88 |
+
multimask_output=self.best_in_multi_mask,
|
| 89 |
return_logits=True,
|
| 90 |
)
|
| 91 |
+
if self.best_in_multi_mask:
|
| 92 |
+
# sam_score: n
|
| 93 |
+
sam_score, max_iou_idx = torch.max(sam_score, dim=1)
|
| 94 |
+
# mask_pred: n,h,w
|
| 95 |
+
mask_pred = mask_pred[torch.arange(mask_pred.size(0)),
|
| 96 |
+
max_iou_idx]
|
| 97 |
+
else:
|
| 98 |
+
# Tensor(n,h,w), raw mask pred
|
| 99 |
+
# n,1,h,w->n,h,w
|
| 100 |
+
mask_pred = mask_pred.squeeze(1)
|
| 101 |
+
# n,1->n
|
| 102 |
+
sam_score = sam_score.squeeze(-1)
|
| 103 |
|
| 104 |
# Tensor(n,)
|
| 105 |
label_pred = results[0]['labels']
|
projects/instance_segment_anything/models/det_wrapper_instance_sam_cascade.py
ADDED
|
@@ -0,0 +1,127 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
from mmdet.core import bbox2result
|
| 5 |
+
from mmdet.models import DETECTORS
|
| 6 |
+
from .det_wrapper_instance_sam import DetWrapperInstanceSAM
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
@DETECTORS.register_module()
|
| 10 |
+
class DetWrapperInstanceSAMCascade(DetWrapperInstanceSAM):
|
| 11 |
+
def __init__(self,
|
| 12 |
+
stage_1_multi_mask=False,
|
| 13 |
+
|
| 14 |
+
det_wrapper_type='hdetr',
|
| 15 |
+
det_wrapper_cfg=None,
|
| 16 |
+
det_model_ckpt=None,
|
| 17 |
+
num_classes=80,
|
| 18 |
+
model_type='vit_b',
|
| 19 |
+
sam_checkpoint=None,
|
| 20 |
+
use_sam_iou=True,
|
| 21 |
+
best_in_multi_mask=False,
|
| 22 |
+
init_cfg=None,
|
| 23 |
+
train_cfg=None,
|
| 24 |
+
test_cfg=None):
|
| 25 |
+
super(DetWrapperInstanceSAMCascade, self).__init__(det_wrapper_type=det_wrapper_type,
|
| 26 |
+
det_wrapper_cfg=det_wrapper_cfg,
|
| 27 |
+
det_model_ckpt=det_model_ckpt,
|
| 28 |
+
num_classes=num_classes,
|
| 29 |
+
model_type=model_type,
|
| 30 |
+
sam_checkpoint=sam_checkpoint,
|
| 31 |
+
use_sam_iou=use_sam_iou,
|
| 32 |
+
best_in_multi_mask=best_in_multi_mask,
|
| 33 |
+
init_cfg=init_cfg,
|
| 34 |
+
train_cfg=train_cfg,
|
| 35 |
+
test_cfg=test_cfg)
|
| 36 |
+
# If True, then the coarse mask output by stage 1 will be the
|
| 37 |
+
# one with the highest predicted IoU among the three masks.
|
| 38 |
+
# If False, then stage 1 will only output one coarse mask.
|
| 39 |
+
self.stage_1_multi_mask = stage_1_multi_mask
|
| 40 |
+
|
| 41 |
+
def simple_test(self, img, img_metas, rescale=True, ori_img=None):
|
| 42 |
+
"""Test without augmentation.
|
| 43 |
+
Args:
|
| 44 |
+
imgs (Tensor): A batch of images.
|
| 45 |
+
img_metas (list[dict]): List of image information.
|
| 46 |
+
"""
|
| 47 |
+
assert rescale
|
| 48 |
+
assert len(img_metas) == 1
|
| 49 |
+
# results: List[dict(scores, labels, boxes)]
|
| 50 |
+
results = self.det_model.simple_test(img,
|
| 51 |
+
img_metas,
|
| 52 |
+
rescale)
|
| 53 |
+
|
| 54 |
+
# Tensor(n,4), xyxy, ori image scale
|
| 55 |
+
output_boxes = results[0]['boxes']
|
| 56 |
+
|
| 57 |
+
if ori_img is None:
|
| 58 |
+
image_path = img_metas[0]['filename']
|
| 59 |
+
ori_img = cv2.imread(image_path)
|
| 60 |
+
ori_img = cv2.cvtColor(ori_img, cv2.COLOR_BGR2RGB)
|
| 61 |
+
self.predictor.set_image(ori_img)
|
| 62 |
+
|
| 63 |
+
transformed_boxes = self.predictor.transform.apply_boxes_torch(output_boxes, ori_img.shape[:2])
|
| 64 |
+
|
| 65 |
+
# mask_pred: n,1/3,h,w
|
| 66 |
+
# sam_score: n, 1/3
|
| 67 |
+
# coarse_mask: n,1/3,256,256
|
| 68 |
+
_1, coarse_mask_score, coarse_mask = self.predictor.predict_torch(
|
| 69 |
+
point_coords=None,
|
| 70 |
+
point_labels=None,
|
| 71 |
+
boxes=transformed_boxes,
|
| 72 |
+
multimask_output=self.stage_1_multi_mask,
|
| 73 |
+
return_logits=True,
|
| 74 |
+
)
|
| 75 |
+
if self.stage_1_multi_mask:
|
| 76 |
+
max_iou_idx = torch.max(coarse_mask_score, dim=1)[1]
|
| 77 |
+
coarse_mask = (coarse_mask[torch.arange(coarse_mask.size(0)),
|
| 78 |
+
max_iou_idx]).unsqueeze(1)
|
| 79 |
+
mask_pred, sam_score, _ = self.predictor.predict_torch(
|
| 80 |
+
point_coords=None,
|
| 81 |
+
point_labels=None,
|
| 82 |
+
boxes=transformed_boxes,
|
| 83 |
+
mask_input=coarse_mask,
|
| 84 |
+
multimask_output=self.best_in_multi_mask,
|
| 85 |
+
return_logits=True,
|
| 86 |
+
)
|
| 87 |
+
if self.best_in_multi_mask:
|
| 88 |
+
# sam_score: n
|
| 89 |
+
sam_score, max_iou_idx = torch.max(sam_score, dim=1)
|
| 90 |
+
# mask_pred: n,h,w
|
| 91 |
+
mask_pred = mask_pred[torch.arange(mask_pred.size(0)),
|
| 92 |
+
max_iou_idx]
|
| 93 |
+
else:
|
| 94 |
+
# Tensor(n,h,w), raw mask pred
|
| 95 |
+
# n,1,h,w->n,h,w
|
| 96 |
+
mask_pred = mask_pred.squeeze(1)
|
| 97 |
+
# n,1->n
|
| 98 |
+
sam_score = sam_score.squeeze(-1)
|
| 99 |
+
|
| 100 |
+
# Tensor(n,)
|
| 101 |
+
label_pred = results[0]['labels']
|
| 102 |
+
|
| 103 |
+
score_pred = results[0]['scores']
|
| 104 |
+
|
| 105 |
+
# mask_pred: Tensor(n,h,w)
|
| 106 |
+
# label_pred: Tensor(n,)
|
| 107 |
+
# score_pred: Tensor(n,)
|
| 108 |
+
# sam_score: Tensor(n,)
|
| 109 |
+
mask_pred_binary = (mask_pred > self.predictor.model.mask_threshold).float()
|
| 110 |
+
if self.use_sam_iou:
|
| 111 |
+
det_scores = score_pred * sam_score
|
| 112 |
+
else:
|
| 113 |
+
# n
|
| 114 |
+
mask_scores_per_image = (mask_pred * mask_pred_binary).flatten(1).sum(1) / (
|
| 115 |
+
mask_pred_binary.flatten(1).sum(1) + 1e-6)
|
| 116 |
+
det_scores = score_pred * mask_scores_per_image
|
| 117 |
+
# det_scores = score_pred
|
| 118 |
+
mask_pred_binary = mask_pred_binary.bool()
|
| 119 |
+
bboxes = torch.cat([output_boxes, det_scores[:, None]], dim=-1)
|
| 120 |
+
bbox_results = bbox2result(bboxes, label_pred, self.num_classes)
|
| 121 |
+
mask_results = [[] for _ in range(self.num_classes)]
|
| 122 |
+
for j, label in enumerate(label_pred):
|
| 123 |
+
mask = mask_pred_binary[j].detach().cpu().numpy()
|
| 124 |
+
mask_results[label].append(mask)
|
| 125 |
+
output_results = [(bbox_results, mask_results)]
|
| 126 |
+
|
| 127 |
+
return output_results
|
projects/instance_segment_anything/ops/functions/ms_deform_attn_func.py
CHANGED
|
@@ -24,7 +24,6 @@ try:
|
|
| 24 |
except:
|
| 25 |
pass
|
| 26 |
|
| 27 |
-
|
| 28 |
class MSDeformAttnFunction(Function):
|
| 29 |
@staticmethod
|
| 30 |
@torch.cuda.amp.custom_fwd(cast_inputs=torch.float32)
|
|
|
|
| 24 |
except:
|
| 25 |
pass
|
| 26 |
|
|
|
|
| 27 |
class MSDeformAttnFunction(Function):
|
| 28 |
@staticmethod
|
| 29 |
@torch.cuda.amp.custom_fwd(cast_inputs=torch.float32)
|
projects/instance_segment_anything/ops/modules/ms_deform_attn.py
CHANGED
|
@@ -21,6 +21,7 @@ import torch
|
|
| 21 |
from torch import nn
|
| 22 |
import torch.nn.functional as F
|
| 23 |
from torch.nn.init import xavier_uniform_, constant_
|
|
|
|
| 24 |
from mmcv.utils import IS_CUDA_AVAILABLE, IS_MLU_AVAILABLE
|
| 25 |
|
| 26 |
from ..functions import MSDeformAttnFunction, ms_deform_attn_core_pytorch
|
|
|
|
| 21 |
from torch import nn
|
| 22 |
import torch.nn.functional as F
|
| 23 |
from torch.nn.init import xavier_uniform_, constant_
|
| 24 |
+
|
| 25 |
from mmcv.utils import IS_CUDA_AVAILABLE, IS_MLU_AVAILABLE
|
| 26 |
|
| 27 |
from ..functions import MSDeformAttnFunction, ms_deform_attn_core_pytorch
|
requirements.txt
CHANGED
|
@@ -12,5 +12,4 @@ timm
|
|
| 12 |
wget
|
| 13 |
gradio
|
| 14 |
--find-links https://download.openmmlab.com/mmcv/dist/cpu/torch1.12.0/index.html
|
| 15 |
-
mmcv-full==1.6.0
|
| 16 |
-
|
|
|
|
| 12 |
wget
|
| 13 |
gradio
|
| 14 |
--find-links https://download.openmmlab.com/mmcv/dist/cpu/torch1.12.0/index.html
|
| 15 |
+
mmcv-full==1.6.0
|
|
|
setup.cfg
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[isort]
|
| 2 |
+
line_length = 79
|
| 3 |
+
multi_line_output = 0
|
| 4 |
+
extra_standard_library = setuptools
|
| 5 |
+
known_first_party = mmdet
|
| 6 |
+
known_third_party = PIL,asynctest,cityscapesscripts,cv2,gather_models,matplotlib,mmcv,numpy,onnx,onnxruntime,pycocotools,pytest,pytorch_sphinx_theme,requests,scipy,seaborn,six,terminaltables,torch,ts,yaml
|
| 7 |
+
no_lines_before = STDLIB,LOCALFOLDER
|
| 8 |
+
default_section = THIRDPARTY
|
| 9 |
+
|
| 10 |
+
[yapf]
|
| 11 |
+
BASED_ON_STYLE = pep8
|
| 12 |
+
BLANK_LINE_BEFORE_NESTED_CLASS_OR_DEF = true
|
| 13 |
+
SPLIT_BEFORE_EXPRESSION_AFTER_OPENING_PAREN = true
|
| 14 |
+
|
| 15 |
+
# ignore-words-list needs to be lowercase format. For example, if we want to
|
| 16 |
+
# ignore word "BA", then we need to append "ba" to ignore-words-list rather
|
| 17 |
+
# than "BA"
|
| 18 |
+
[codespell]
|
| 19 |
+
skip = *.ipynb
|
| 20 |
+
quiet-level = 3
|
| 21 |
+
ignore-words-list = patten,nd,ty,mot,hist,formating,winn,gool,datas,wan,confids,TOOD,tood,ba,warmup,nam,dota,DOTA
|
setup.py
ADDED
|
@@ -0,0 +1,220 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# Copyright (c) OpenMMLab. All rights reserved.
|
| 3 |
+
import os
|
| 4 |
+
import os.path as osp
|
| 5 |
+
import platform
|
| 6 |
+
import shutil
|
| 7 |
+
import sys
|
| 8 |
+
import warnings
|
| 9 |
+
from setuptools import find_packages, setup
|
| 10 |
+
|
| 11 |
+
import torch
|
| 12 |
+
from torch.utils.cpp_extension import (BuildExtension, CppExtension,
|
| 13 |
+
CUDAExtension)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def readme():
|
| 17 |
+
with open('README.md', encoding='utf-8') as f:
|
| 18 |
+
content = f.read()
|
| 19 |
+
return content
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
version_file = 'mmdet/version.py'
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def get_version():
|
| 26 |
+
with open(version_file, 'r') as f:
|
| 27 |
+
exec(compile(f.read(), version_file, 'exec'))
|
| 28 |
+
return locals()['__version__']
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def make_cuda_ext(name, module, sources, sources_cuda=[]):
|
| 32 |
+
|
| 33 |
+
define_macros = []
|
| 34 |
+
extra_compile_args = {'cxx': []}
|
| 35 |
+
|
| 36 |
+
if torch.cuda.is_available() or os.getenv('FORCE_CUDA', '0') == '1':
|
| 37 |
+
define_macros += [('WITH_CUDA', None)]
|
| 38 |
+
extension = CUDAExtension
|
| 39 |
+
extra_compile_args['nvcc'] = [
|
| 40 |
+
'-D__CUDA_NO_HALF_OPERATORS__',
|
| 41 |
+
'-D__CUDA_NO_HALF_CONVERSIONS__',
|
| 42 |
+
'-D__CUDA_NO_HALF2_OPERATORS__',
|
| 43 |
+
]
|
| 44 |
+
sources += sources_cuda
|
| 45 |
+
else:
|
| 46 |
+
print(f'Compiling {name} without CUDA')
|
| 47 |
+
extension = CppExtension
|
| 48 |
+
|
| 49 |
+
return extension(
|
| 50 |
+
name=f'{module}.{name}',
|
| 51 |
+
sources=[os.path.join(*module.split('.'), p) for p in sources],
|
| 52 |
+
define_macros=define_macros,
|
| 53 |
+
extra_compile_args=extra_compile_args)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def parse_requirements(fname='requirements.txt', with_version=True):
|
| 57 |
+
"""Parse the package dependencies listed in a requirements file but strips
|
| 58 |
+
specific versioning information.
|
| 59 |
+
|
| 60 |
+
Args:
|
| 61 |
+
fname (str): path to requirements file
|
| 62 |
+
with_version (bool, default=False): if True include version specs
|
| 63 |
+
|
| 64 |
+
Returns:
|
| 65 |
+
List[str]: list of requirements items
|
| 66 |
+
|
| 67 |
+
CommandLine:
|
| 68 |
+
python -c "import setup; print(setup.parse_requirements())"
|
| 69 |
+
"""
|
| 70 |
+
import re
|
| 71 |
+
import sys
|
| 72 |
+
from os.path import exists
|
| 73 |
+
require_fpath = fname
|
| 74 |
+
|
| 75 |
+
def parse_line(line):
|
| 76 |
+
"""Parse information from a line in a requirements text file."""
|
| 77 |
+
if line.startswith('-r '):
|
| 78 |
+
# Allow specifying requirements in other files
|
| 79 |
+
target = line.split(' ')[1]
|
| 80 |
+
for info in parse_require_file(target):
|
| 81 |
+
yield info
|
| 82 |
+
else:
|
| 83 |
+
info = {'line': line}
|
| 84 |
+
if line.startswith('-e '):
|
| 85 |
+
info['package'] = line.split('#egg=')[1]
|
| 86 |
+
elif '@git+' in line:
|
| 87 |
+
info['package'] = line
|
| 88 |
+
else:
|
| 89 |
+
# Remove versioning from the package
|
| 90 |
+
pat = '(' + '|'.join(['>=', '==', '>']) + ')'
|
| 91 |
+
parts = re.split(pat, line, maxsplit=1)
|
| 92 |
+
parts = [p.strip() for p in parts]
|
| 93 |
+
|
| 94 |
+
info['package'] = parts[0]
|
| 95 |
+
if len(parts) > 1:
|
| 96 |
+
op, rest = parts[1:]
|
| 97 |
+
if ';' in rest:
|
| 98 |
+
# Handle platform specific dependencies
|
| 99 |
+
# http://setuptools.readthedocs.io/en/latest/setuptools.html#declaring-platform-specific-dependencies
|
| 100 |
+
version, platform_deps = map(str.strip,
|
| 101 |
+
rest.split(';'))
|
| 102 |
+
info['platform_deps'] = platform_deps
|
| 103 |
+
else:
|
| 104 |
+
version = rest # NOQA
|
| 105 |
+
info['version'] = (op, version)
|
| 106 |
+
yield info
|
| 107 |
+
|
| 108 |
+
def parse_require_file(fpath):
|
| 109 |
+
with open(fpath, 'r') as f:
|
| 110 |
+
for line in f.readlines():
|
| 111 |
+
line = line.strip()
|
| 112 |
+
if line and not line.startswith('#'):
|
| 113 |
+
for info in parse_line(line):
|
| 114 |
+
yield info
|
| 115 |
+
|
| 116 |
+
def gen_packages_items():
|
| 117 |
+
if exists(require_fpath):
|
| 118 |
+
for info in parse_require_file(require_fpath):
|
| 119 |
+
parts = [info['package']]
|
| 120 |
+
if with_version and 'version' in info:
|
| 121 |
+
parts.extend(info['version'])
|
| 122 |
+
if not sys.version.startswith('3.4'):
|
| 123 |
+
# apparently package_deps are broken in 3.4
|
| 124 |
+
platform_deps = info.get('platform_deps')
|
| 125 |
+
if platform_deps is not None:
|
| 126 |
+
parts.append(';' + platform_deps)
|
| 127 |
+
item = ''.join(parts)
|
| 128 |
+
yield item
|
| 129 |
+
|
| 130 |
+
packages = list(gen_packages_items())
|
| 131 |
+
return packages
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
def add_mim_extension():
|
| 135 |
+
"""Add extra files that are required to support MIM into the package.
|
| 136 |
+
|
| 137 |
+
These files will be added by creating a symlink to the originals if the
|
| 138 |
+
package is installed in `editable` mode (e.g. pip install -e .), or by
|
| 139 |
+
copying from the originals otherwise.
|
| 140 |
+
"""
|
| 141 |
+
|
| 142 |
+
# parse installment mode
|
| 143 |
+
if 'develop' in sys.argv:
|
| 144 |
+
# installed by `pip install -e .`
|
| 145 |
+
if platform.system() == 'Windows':
|
| 146 |
+
# set `copy` mode here since symlink fails on Windows.
|
| 147 |
+
mode = 'copy'
|
| 148 |
+
else:
|
| 149 |
+
mode = 'symlink'
|
| 150 |
+
elif 'sdist' in sys.argv or 'bdist_wheel' in sys.argv:
|
| 151 |
+
# installed by `pip install .`
|
| 152 |
+
# or create source distribution by `python setup.py sdist`
|
| 153 |
+
mode = 'copy'
|
| 154 |
+
else:
|
| 155 |
+
return
|
| 156 |
+
|
| 157 |
+
filenames = ['tools', 'configs', 'demo', 'model-index.yml']
|
| 158 |
+
repo_path = osp.dirname(__file__)
|
| 159 |
+
mim_path = osp.join(repo_path, 'mmdet', '.mim')
|
| 160 |
+
os.makedirs(mim_path, exist_ok=True)
|
| 161 |
+
|
| 162 |
+
for filename in filenames:
|
| 163 |
+
if osp.exists(filename):
|
| 164 |
+
src_path = osp.join(repo_path, filename)
|
| 165 |
+
tar_path = osp.join(mim_path, filename)
|
| 166 |
+
|
| 167 |
+
if osp.isfile(tar_path) or osp.islink(tar_path):
|
| 168 |
+
os.remove(tar_path)
|
| 169 |
+
elif osp.isdir(tar_path):
|
| 170 |
+
shutil.rmtree(tar_path)
|
| 171 |
+
|
| 172 |
+
if mode == 'symlink':
|
| 173 |
+
src_relpath = osp.relpath(src_path, osp.dirname(tar_path))
|
| 174 |
+
os.symlink(src_relpath, tar_path)
|
| 175 |
+
elif mode == 'copy':
|
| 176 |
+
if osp.isfile(src_path):
|
| 177 |
+
shutil.copyfile(src_path, tar_path)
|
| 178 |
+
elif osp.isdir(src_path):
|
| 179 |
+
shutil.copytree(src_path, tar_path)
|
| 180 |
+
else:
|
| 181 |
+
warnings.warn(f'Cannot copy file {src_path}.')
|
| 182 |
+
else:
|
| 183 |
+
raise ValueError(f'Invalid mode {mode}')
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
if __name__ == '__main__':
|
| 187 |
+
add_mim_extension()
|
| 188 |
+
setup(
|
| 189 |
+
name='mmdet',
|
| 190 |
+
version=get_version(),
|
| 191 |
+
description='OpenMMLab Detection Toolbox and Benchmark',
|
| 192 |
+
long_description=readme(),
|
| 193 |
+
long_description_content_type='text/markdown',
|
| 194 |
+
author='MMDetection Contributors',
|
| 195 |
+
author_email='[email protected]',
|
| 196 |
+
keywords='computer vision, object detection',
|
| 197 |
+
url='https://github.com/open-mmlab/mmdetection',
|
| 198 |
+
packages=find_packages(exclude=('configs', 'tools', 'demo')),
|
| 199 |
+
include_package_data=True,
|
| 200 |
+
classifiers=[
|
| 201 |
+
'Development Status :: 5 - Production/Stable',
|
| 202 |
+
'License :: OSI Approved :: Apache Software License',
|
| 203 |
+
'Operating System :: OS Independent',
|
| 204 |
+
'Programming Language :: Python :: 3',
|
| 205 |
+
'Programming Language :: Python :: 3.7',
|
| 206 |
+
'Programming Language :: Python :: 3.8',
|
| 207 |
+
'Programming Language :: Python :: 3.9',
|
| 208 |
+
],
|
| 209 |
+
license='Apache License 2.0',
|
| 210 |
+
install_requires=parse_requirements('requirements/runtime.txt'),
|
| 211 |
+
extras_require={
|
| 212 |
+
'all': parse_requirements('requirements.txt'),
|
| 213 |
+
'tests': parse_requirements('requirements/tests.txt'),
|
| 214 |
+
'build': parse_requirements('requirements/build.txt'),
|
| 215 |
+
'optional': parse_requirements('requirements/optional.txt'),
|
| 216 |
+
'mim': parse_requirements('requirements/mminstall.txt'),
|
| 217 |
+
},
|
| 218 |
+
ext_modules=[],
|
| 219 |
+
cmdclass={'build_ext': BuildExtension},
|
| 220 |
+
zip_safe=False)
|
tools/dist_test.sh
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env bash
|
| 2 |
+
|
| 3 |
+
CONFIG=$1
|
| 4 |
+
GPUS=$2
|
| 5 |
+
NNODES=${NNODES:-1}
|
| 6 |
+
NODE_RANK=${NODE_RANK:-0}
|
| 7 |
+
PORT=${PORT:-29500}
|
| 8 |
+
MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
|
| 9 |
+
|
| 10 |
+
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
|
| 11 |
+
python -m torch.distributed.launch \
|
| 12 |
+
--nnodes=$NNODES \
|
| 13 |
+
--node_rank=$NODE_RANK \
|
| 14 |
+
--master_addr=$MASTER_ADDR \
|
| 15 |
+
--nproc_per_node=$GPUS \
|
| 16 |
+
--master_port=$PORT \
|
| 17 |
+
$(dirname "$0")/test.py \
|
| 18 |
+
$CONFIG \
|
| 19 |
+
--launcher pytorch \
|
| 20 |
+
${@:3}
|
tools/test.py
ADDED
|
@@ -0,0 +1,308 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) OpenMMLab. All rights reserved.
|
| 2 |
+
import argparse
|
| 3 |
+
import os
|
| 4 |
+
import os.path as osp
|
| 5 |
+
import time
|
| 6 |
+
import warnings
|
| 7 |
+
|
| 8 |
+
import mmcv
|
| 9 |
+
import torch
|
| 10 |
+
from mmcv import Config, DictAction
|
| 11 |
+
from mmcv.cnn import fuse_conv_bn
|
| 12 |
+
from mmcv.runner import (get_dist_info, init_dist, load_checkpoint,
|
| 13 |
+
wrap_fp16_model)
|
| 14 |
+
|
| 15 |
+
from mmdet.apis import multi_gpu_test, single_gpu_test
|
| 16 |
+
from mmdet.datasets import (build_dataloader, build_dataset,
|
| 17 |
+
replace_ImageToTensor)
|
| 18 |
+
from mmdet.models import build_detector
|
| 19 |
+
from mmdet.utils import (build_ddp, build_dp, compat_cfg, get_device,
|
| 20 |
+
replace_cfg_vals, setup_multi_processes,
|
| 21 |
+
update_data_root)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def parse_args():
|
| 25 |
+
parser = argparse.ArgumentParser(
|
| 26 |
+
description='MMDet test (and eval) a model')
|
| 27 |
+
parser.add_argument('config', help='test config file path')
|
| 28 |
+
parser.add_argument(
|
| 29 |
+
'--work-dir',
|
| 30 |
+
help='the directory to save the file containing evaluation metrics')
|
| 31 |
+
parser.add_argument('--out', help='output result file in pickle format')
|
| 32 |
+
parser.add_argument(
|
| 33 |
+
'--fuse-conv-bn',
|
| 34 |
+
action='store_true',
|
| 35 |
+
help='Whether to fuse conv and bn, this will slightly increase'
|
| 36 |
+
'the inference speed')
|
| 37 |
+
parser.add_argument(
|
| 38 |
+
'--gpu-ids',
|
| 39 |
+
type=int,
|
| 40 |
+
nargs='+',
|
| 41 |
+
help='(Deprecated, please use --gpu-id) ids of gpus to use '
|
| 42 |
+
'(only applicable to non-distributed training)')
|
| 43 |
+
parser.add_argument(
|
| 44 |
+
'--gpu-id',
|
| 45 |
+
type=int,
|
| 46 |
+
default=0,
|
| 47 |
+
help='id of gpu to use '
|
| 48 |
+
'(only applicable to non-distributed testing)')
|
| 49 |
+
parser.add_argument(
|
| 50 |
+
'--format-only',
|
| 51 |
+
action='store_true',
|
| 52 |
+
help='Format the output results without perform evaluation. It is'
|
| 53 |
+
'useful when you want to format the result to a specific format and '
|
| 54 |
+
'submit it to the test server')
|
| 55 |
+
parser.add_argument(
|
| 56 |
+
'--eval',
|
| 57 |
+
type=str,
|
| 58 |
+
nargs='+',
|
| 59 |
+
help='evaluation metrics, which depends on the dataset, e.g., "bbox",'
|
| 60 |
+
' "segm", "proposal" for COCO, and "mAP", "recall" for PASCAL VOC')
|
| 61 |
+
parser.add_argument('--show', action='store_true', help='show results')
|
| 62 |
+
parser.add_argument(
|
| 63 |
+
'--show-dir', help='directory where painted images will be saved')
|
| 64 |
+
parser.add_argument(
|
| 65 |
+
'--show-score-thr',
|
| 66 |
+
type=float,
|
| 67 |
+
default=0.3,
|
| 68 |
+
help='score threshold (default: 0.3)')
|
| 69 |
+
parser.add_argument(
|
| 70 |
+
'--gpu-collect',
|
| 71 |
+
action='store_true',
|
| 72 |
+
help='whether to use gpu to collect results.')
|
| 73 |
+
parser.add_argument(
|
| 74 |
+
'--tmpdir',
|
| 75 |
+
help='tmp directory used for collecting results from multiple '
|
| 76 |
+
'workers, available when gpu-collect is not specified')
|
| 77 |
+
parser.add_argument(
|
| 78 |
+
'--cfg-options',
|
| 79 |
+
nargs='+',
|
| 80 |
+
action=DictAction,
|
| 81 |
+
help='override some settings in the used config, the key-value pair '
|
| 82 |
+
'in xxx=yyy format will be merged into config file. If the value to '
|
| 83 |
+
'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
|
| 84 |
+
'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
|
| 85 |
+
'Note that the quotation marks are necessary and that no white space '
|
| 86 |
+
'is allowed.')
|
| 87 |
+
parser.add_argument(
|
| 88 |
+
'--options',
|
| 89 |
+
nargs='+',
|
| 90 |
+
action=DictAction,
|
| 91 |
+
help='custom options for evaluation, the key-value pair in xxx=yyy '
|
| 92 |
+
'format will be kwargs for dataset.evaluate() function (deprecate), '
|
| 93 |
+
'change to --eval-options instead.')
|
| 94 |
+
parser.add_argument(
|
| 95 |
+
'--eval-options',
|
| 96 |
+
nargs='+',
|
| 97 |
+
action=DictAction,
|
| 98 |
+
help='custom options for evaluation, the key-value pair in xxx=yyy '
|
| 99 |
+
'format will be kwargs for dataset.evaluate() function')
|
| 100 |
+
parser.add_argument(
|
| 101 |
+
'--launcher',
|
| 102 |
+
choices=['none', 'pytorch', 'slurm', 'mpi'],
|
| 103 |
+
default='none',
|
| 104 |
+
help='job launcher')
|
| 105 |
+
parser.add_argument('--local_rank', type=int, default=0)
|
| 106 |
+
args = parser.parse_args()
|
| 107 |
+
if 'LOCAL_RANK' not in os.environ:
|
| 108 |
+
os.environ['LOCAL_RANK'] = str(args.local_rank)
|
| 109 |
+
|
| 110 |
+
if args.options and args.eval_options:
|
| 111 |
+
raise ValueError(
|
| 112 |
+
'--options and --eval-options cannot be both '
|
| 113 |
+
'specified, --options is deprecated in favor of --eval-options')
|
| 114 |
+
if args.options:
|
| 115 |
+
warnings.warn('--options is deprecated in favor of --eval-options')
|
| 116 |
+
args.eval_options = args.options
|
| 117 |
+
return args
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def main():
|
| 121 |
+
args = parse_args()
|
| 122 |
+
|
| 123 |
+
assert args.out or args.eval or args.format_only or args.show \
|
| 124 |
+
or args.show_dir, \
|
| 125 |
+
('Please specify at least one operation (save/eval/format/show the '
|
| 126 |
+
'results / save the results) with the argument "--out", "--eval"'
|
| 127 |
+
', "--format-only", "--show" or "--show-dir"')
|
| 128 |
+
|
| 129 |
+
if args.eval and args.format_only:
|
| 130 |
+
raise ValueError('--eval and --format_only cannot be both specified')
|
| 131 |
+
|
| 132 |
+
if args.out is not None and not args.out.endswith(('.pkl', '.pickle')):
|
| 133 |
+
raise ValueError('The output file must be a pkl file.')
|
| 134 |
+
|
| 135 |
+
cfg = Config.fromfile(args.config)
|
| 136 |
+
|
| 137 |
+
# replace the ${key} with the value of cfg.key
|
| 138 |
+
cfg = replace_cfg_vals(cfg)
|
| 139 |
+
|
| 140 |
+
# update data root according to MMDET_DATASETS
|
| 141 |
+
update_data_root(cfg)
|
| 142 |
+
|
| 143 |
+
if args.cfg_options is not None:
|
| 144 |
+
cfg.merge_from_dict(args.cfg_options)
|
| 145 |
+
|
| 146 |
+
cfg = compat_cfg(cfg)
|
| 147 |
+
|
| 148 |
+
# set multi-process settings
|
| 149 |
+
setup_multi_processes(cfg)
|
| 150 |
+
|
| 151 |
+
# import modules from plguin/xx, registry will be updated
|
| 152 |
+
if hasattr(cfg, 'plugin'):
|
| 153 |
+
if cfg.plugin:
|
| 154 |
+
import importlib
|
| 155 |
+
if hasattr(cfg, 'plugin_dir'):
|
| 156 |
+
plugin_dir = cfg.plugin_dir
|
| 157 |
+
_module_dir = os.path.dirname(plugin_dir)
|
| 158 |
+
_module_dir = _module_dir.split('/')
|
| 159 |
+
_module_path = _module_dir[0]
|
| 160 |
+
|
| 161 |
+
for m in _module_dir[1:]:
|
| 162 |
+
_module_path = _module_path + '.' + m
|
| 163 |
+
print(_module_path)
|
| 164 |
+
plg_lib = importlib.import_module(_module_path)
|
| 165 |
+
else:
|
| 166 |
+
# import dir is the dirpath for the config file
|
| 167 |
+
_module_dir = os.path.dirname(args.config)
|
| 168 |
+
_module_dir = _module_dir.split('/')
|
| 169 |
+
_module_path = _module_dir[0]
|
| 170 |
+
for m in _module_dir[1:]:
|
| 171 |
+
_module_path = _module_path + '.' + m
|
| 172 |
+
# print(_module_path)
|
| 173 |
+
plg_lib = importlib.import_module(_module_path)
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
# set cudnn_benchmark
|
| 177 |
+
if cfg.get('cudnn_benchmark', False):
|
| 178 |
+
torch.backends.cudnn.benchmark = True
|
| 179 |
+
|
| 180 |
+
if 'pretrained' in cfg.model:
|
| 181 |
+
cfg.model.pretrained = None
|
| 182 |
+
elif (cfg.model.get('backbone', None) is not None
|
| 183 |
+
and 'init_cfg' in cfg.model.backbone):
|
| 184 |
+
cfg.model.backbone.init_cfg = None
|
| 185 |
+
|
| 186 |
+
if cfg.model.get('neck'):
|
| 187 |
+
if isinstance(cfg.model.neck, list):
|
| 188 |
+
for neck_cfg in cfg.model.neck:
|
| 189 |
+
if neck_cfg.get('rfp_backbone'):
|
| 190 |
+
if neck_cfg.rfp_backbone.get('pretrained'):
|
| 191 |
+
neck_cfg.rfp_backbone.pretrained = None
|
| 192 |
+
elif cfg.model.neck.get('rfp_backbone'):
|
| 193 |
+
if cfg.model.neck.rfp_backbone.get('pretrained'):
|
| 194 |
+
cfg.model.neck.rfp_backbone.pretrained = None
|
| 195 |
+
|
| 196 |
+
if args.gpu_ids is not None:
|
| 197 |
+
cfg.gpu_ids = args.gpu_ids[0:1]
|
| 198 |
+
warnings.warn('`--gpu-ids` is deprecated, please use `--gpu-id`. '
|
| 199 |
+
'Because we only support single GPU mode in '
|
| 200 |
+
'non-distributed testing. Use the first GPU '
|
| 201 |
+
'in `gpu_ids` now.')
|
| 202 |
+
else:
|
| 203 |
+
cfg.gpu_ids = [args.gpu_id]
|
| 204 |
+
cfg.device = get_device()
|
| 205 |
+
# init distributed env first, since logger depends on the dist info.
|
| 206 |
+
if args.launcher == 'none':
|
| 207 |
+
distributed = False
|
| 208 |
+
else:
|
| 209 |
+
distributed = True
|
| 210 |
+
init_dist(args.launcher, **cfg.dist_params)
|
| 211 |
+
|
| 212 |
+
test_dataloader_default_args = dict(
|
| 213 |
+
samples_per_gpu=1, workers_per_gpu=2, dist=distributed, shuffle=False)
|
| 214 |
+
|
| 215 |
+
# in case the test dataset is concatenated
|
| 216 |
+
if isinstance(cfg.data.test, dict):
|
| 217 |
+
cfg.data.test.test_mode = True
|
| 218 |
+
if cfg.data.test_dataloader.get('samples_per_gpu', 1) > 1:
|
| 219 |
+
# Replace 'ImageToTensor' to 'DefaultFormatBundle'
|
| 220 |
+
cfg.data.test.pipeline = replace_ImageToTensor(
|
| 221 |
+
cfg.data.test.pipeline)
|
| 222 |
+
elif isinstance(cfg.data.test, list):
|
| 223 |
+
for ds_cfg in cfg.data.test:
|
| 224 |
+
ds_cfg.test_mode = True
|
| 225 |
+
if cfg.data.test_dataloader.get('samples_per_gpu', 1) > 1:
|
| 226 |
+
for ds_cfg in cfg.data.test:
|
| 227 |
+
ds_cfg.pipeline = replace_ImageToTensor(ds_cfg.pipeline)
|
| 228 |
+
|
| 229 |
+
test_loader_cfg = {
|
| 230 |
+
**test_dataloader_default_args,
|
| 231 |
+
**cfg.data.get('test_dataloader', {})
|
| 232 |
+
}
|
| 233 |
+
|
| 234 |
+
rank, _ = get_dist_info()
|
| 235 |
+
# allows not to create
|
| 236 |
+
if args.work_dir is not None and rank == 0:
|
| 237 |
+
mmcv.mkdir_or_exist(osp.abspath(args.work_dir))
|
| 238 |
+
timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime())
|
| 239 |
+
json_file = osp.join(args.work_dir, f'eval_{timestamp}.json')
|
| 240 |
+
|
| 241 |
+
# build the dataloader
|
| 242 |
+
dataset = build_dataset(cfg.data.test)
|
| 243 |
+
data_loader = build_dataloader(dataset, **test_loader_cfg)
|
| 244 |
+
|
| 245 |
+
# build the model and load checkpoint
|
| 246 |
+
cfg.model.train_cfg = None
|
| 247 |
+
model = build_detector(cfg.model, test_cfg=cfg.get('test_cfg'))
|
| 248 |
+
fp16_cfg = cfg.get('fp16', None)
|
| 249 |
+
if fp16_cfg is not None:
|
| 250 |
+
wrap_fp16_model(model)
|
| 251 |
+
# checkpoint = load_checkpoint(model, args.checkpoint, map_location='cpu')
|
| 252 |
+
checkpoint = {}
|
| 253 |
+
if args.fuse_conv_bn:
|
| 254 |
+
model = fuse_conv_bn(model)
|
| 255 |
+
# old versions did not save class info in checkpoints, this walkaround is
|
| 256 |
+
# for backward compatibility
|
| 257 |
+
if 'CLASSES' in checkpoint.get('meta', {}):
|
| 258 |
+
model.CLASSES = checkpoint['meta']['CLASSES']
|
| 259 |
+
else:
|
| 260 |
+
model.CLASSES = dataset.CLASSES
|
| 261 |
+
|
| 262 |
+
if not distributed:
|
| 263 |
+
model = build_dp(model, cfg.device, device_ids=cfg.gpu_ids)
|
| 264 |
+
outputs = single_gpu_test(model, data_loader, args.show, args.show_dir,
|
| 265 |
+
args.show_score_thr)
|
| 266 |
+
else:
|
| 267 |
+
model = build_ddp(
|
| 268 |
+
model,
|
| 269 |
+
cfg.device,
|
| 270 |
+
device_ids=[int(os.environ['LOCAL_RANK'])],
|
| 271 |
+
broadcast_buffers=False)
|
| 272 |
+
|
| 273 |
+
# In multi_gpu_test, if tmpdir is None, some tesnors
|
| 274 |
+
# will init on cuda by default, and no device choice supported.
|
| 275 |
+
# Init a tmpdir to avoid error on npu here.
|
| 276 |
+
if cfg.device == 'npu' and args.tmpdir is None:
|
| 277 |
+
args.tmpdir = './npu_tmpdir'
|
| 278 |
+
|
| 279 |
+
outputs = multi_gpu_test(
|
| 280 |
+
model, data_loader, args.tmpdir, args.gpu_collect
|
| 281 |
+
or cfg.evaluation.get('gpu_collect', False))
|
| 282 |
+
|
| 283 |
+
rank, _ = get_dist_info()
|
| 284 |
+
if rank == 0:
|
| 285 |
+
if args.out:
|
| 286 |
+
print(f'\nwriting results to {args.out}')
|
| 287 |
+
mmcv.dump(outputs, args.out)
|
| 288 |
+
kwargs = {} if args.eval_options is None else args.eval_options
|
| 289 |
+
if args.format_only:
|
| 290 |
+
dataset.format_results(outputs, **kwargs)
|
| 291 |
+
if args.eval:
|
| 292 |
+
eval_kwargs = cfg.get('evaluation', {}).copy()
|
| 293 |
+
# hard-code way to remove EvalHook args
|
| 294 |
+
for key in [
|
| 295 |
+
'interval', 'tmpdir', 'start', 'gpu_collect', 'save_best',
|
| 296 |
+
'rule', 'dynamic_intervals'
|
| 297 |
+
]:
|
| 298 |
+
eval_kwargs.pop(key, None)
|
| 299 |
+
eval_kwargs.update(dict(metric=args.eval, **kwargs))
|
| 300 |
+
metric = dataset.evaluate(outputs, **eval_kwargs)
|
| 301 |
+
print(metric)
|
| 302 |
+
metric_dict = dict(config=args.config, metric=metric)
|
| 303 |
+
if args.work_dir is not None and rank == 0:
|
| 304 |
+
mmcv.dump(metric_dict, json_file)
|
| 305 |
+
|
| 306 |
+
|
| 307 |
+
if __name__ == '__main__':
|
| 308 |
+
main()
|