diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..fae4af312de275aa4ac2803f200be251d0c8132e
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,29 @@
+.DS_Store
+__pycache__
+/TEMP
+*.pyd
+.venv
+/opt
+tools/aria2c/
+tools/flag.txt
+
+# Imported from huggingface.co/lj1995/VoiceConversionWebUI
+/pretrained
+/pretrained_v2
+/uvr5_weights
+hubert_base.pt
+rmvpe.onnx
+rmvpe.pt
+
+# Generated by RVC
+/logs
+/weights
+
+# To set a Python version for the project
+.tool-versions
+
+/runtime
+/assets/
+/assets/weights/*
+ffmpeg.*
+ffprobe.*
\ No newline at end of file
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
new file mode 100644
index 0000000000000000000000000000000000000000..4588018131bfd03b936a1d67eaf26a5637c90f9e
--- /dev/null
+++ b/CONTRIBUTING.md
@@ -0,0 +1,11 @@
+# 贡献规则
+1. 一般来说,作者`@RVC-Boss`将拒绝所有的算法更改,除非它是为了修复某个代码层面的错误或警告
+2. 您可以贡献本仓库的其他位置,如翻译和WebUI,但请尽量作最小更改
+3. 所有更改都需要由`@RVC-Boss`批准,因此您的PR可能会被搁置
+4. 由此带来的不便请您谅解
+
+# Contributing Rules
+1. Generally, the author `@RVC-Boss` will reject all algorithm changes unless what is to fix a code-level error or warning.
+2. You can contribute to other parts of this repo like translations and WebUI, but please minimize your changes as much as possible.
+3. All changes need to be approved by `@RVC-Boss`, so your PR may be put on hold.
+4. Please accept our apologies for any inconvenience caused.
diff --git a/Dockerfile b/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..71eb4ff776cc4ddad3e4f2289becd6d629eee408
--- /dev/null
+++ b/Dockerfile
@@ -0,0 +1,46 @@
+# syntax=docker/dockerfile:1
+
+FROM nvidia/cuda:11.6.2-cudnn8-runtime-ubuntu20.04
+
+EXPOSE 7865
+
+WORKDIR /app
+
+# Install dependenceis to add PPAs
+RUN apt-get update && \
+ apt-get install -y -qq ffmpeg aria2 && apt clean && \
+ apt-get install -y software-properties-common && \
+ apt-get clean && \
+ rm -rf /var/lib/apt/lists/*
+# Add the deadsnakes PPA to get Python 3.9
+RUN add-apt-repository ppa:deadsnakes/ppa
+
+# Install Python 3.9 and pip
+RUN apt-get update && \
+ apt-get install -y build-essential python-dev python3-dev python3.9-distutils python3.9-dev python3.9 curl && \
+ apt-get clean && \
+ update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.9 1 && \
+ curl https://bootstrap.pypa.io/get-pip.py | python3.9
+
+# Set Python 3.9 as the default
+RUN update-alternatives --install /usr/bin/python python /usr/bin/python3.9 1
+
+COPY . .
+
+RUN python3 -m pip install --no-cache-dir -r requirements.txt
+
+RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/D40k.pth -d assets/pretrained_v2/ -o D40k.pth
+RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/G40k.pth -d assets/pretrained_v2/ -o G40k.pth
+RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/f0D40k.pth -d assets/pretrained_v2/ -o f0D40k.pth
+RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/f0G40k.pth -d assets/pretrained_v2/ -o f0G40k.pth
+
+RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/HP2-人声vocals+非人声instrumentals.pth -d assets/uvr5_weights/ -o HP2-人声vocals+非人声instrumentals.pth
+RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/HP5-主旋律人声vocals+其他instrumentals.pth -d assets/uvr5_weights/ -o HP5-主旋律人声vocals+其他instrumentals.pth
+
+RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -d assets/hubert -o hubert_base.pt
+
+RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/rmvpe.pt -d assets/rmvpe -o rmvpe.pt
+
+VOLUME [ "/app/weights", "/app/opt" ]
+
+CMD ["python3", "infer-web.py"]
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..f703dbe29b18893275d97329f4e4d36d793aad1e
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,23 @@
+MIT License
+
+Copyright (c) 2023-2024 liujing04
+Copyright (c) 2023-2024 fumiama
+Copyright (c) 2023-2024 Ftps
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git "a/MIT\345\215\217\350\256\256\346\232\250\347\233\270\345\205\263\345\274\225\347\224\250\345\272\223\345\215\217\350\256\256" "b/MIT\345\215\217\350\256\256\346\232\250\347\233\270\345\205\263\345\274\225\347\224\250\345\272\223\345\215\217\350\256\256"
new file mode 100644
index 0000000000000000000000000000000000000000..d6ec5c0897b7fdea4e394645e972448ca7f63daa
--- /dev/null
+++ "b/MIT\345\215\217\350\256\256\346\232\250\347\233\270\345\205\263\345\274\225\347\224\250\345\272\223\345\215\217\350\256\256"
@@ -0,0 +1,45 @@
+本软件及其相关代码以MIT协议开源,作者不对软件具备任何控制力,使用软件者、传播软件导出的声音者自负全责。
+如不认可该条款,则不能使用或引用软件包内任何代码和文件。
+
+特此授予任何获得本软件和相关文档文件(以下简称“软件”)副本的人免费使用、复制、修改、合并、出版、分发、再授权和/或销售本软件的权利,以及授予本软件所提供的人使用本软件的权利,但须符合以下条件:
+上述版权声明和本许可声明应包含在软件的所有副本或实质部分中。
+软件是“按原样”提供的,没有任何明示或暗示的保证,包括但不限于适销性、适用于特定目的和不侵权的保证。在任何情况下,作者或版权持有人均不承担因软件或软件的使用或其他交易而产生、产生或与之相关的任何索赔、损害赔偿或其他责任,无论是在合同诉讼、侵权诉讼还是其他诉讼中。
+
+
+The LICENCEs for related libraries are as follows.
+相关引用库协议如下:
+
+ContentVec
+https://github.com/auspicious3000/contentvec/blob/main/LICENSE
+MIT License
+
+VITS
+https://github.com/jaywalnut310/vits/blob/main/LICENSE
+MIT License
+
+HIFIGAN
+https://github.com/jik876/hifi-gan/blob/master/LICENSE
+MIT License
+
+gradio
+https://github.com/gradio-app/gradio/blob/main/LICENSE
+Apache License 2.0
+
+ffmpeg
+https://github.com/FFmpeg/FFmpeg/blob/master/COPYING.LGPLv3
+https://github.com/BtbN/FFmpeg-Builds/releases/download/autobuild-2021-02-28-12-32/ffmpeg-n4.3.2-160-gfbb9368226-win64-lgpl-4.3.zip
+LPGLv3 License
+MIT License
+
+ultimatevocalremovergui
+https://github.com/Anjok07/ultimatevocalremovergui/blob/master/LICENSE
+https://github.com/yang123qwe/vocal_separation_by_uvr5
+MIT License
+
+audio-slicer
+https://github.com/openvpi/audio-slicer/blob/main/LICENSE
+MIT License
+
+FreeSimpleGUI
+https://github.com/spyoungtech/FreeSimpleGUI/blob/master/license.txt
+LPGLv3 License
diff --git a/app.py b/app.py
new file mode 100644
index 0000000000000000000000000000000000000000..306c448281905549678f0a93800754e7977d5057
--- /dev/null
+++ b/app.py
@@ -0,0 +1,1623 @@
+import os
+import sys
+from dotenv import load_dotenv
+
+now_dir = os.getcwd()
+sys.path.append(now_dir)
+load_dotenv()
+load_dotenv("sha256.env")
+from infer.modules.vc.modules import VC
+from infer.modules.uvr5.modules import uvr
+from infer.lib.train.process_ckpt import (
+ change_info,
+ extract_small_model,
+ merge,
+ show_info,
+)
+from i18n.i18n import I18nAuto
+from configs.config import Config
+from sklearn.cluster import MiniBatchKMeans
+import torch, platform
+import numpy as np
+import gradio as gr
+import faiss
+import fairseq
+import pathlib
+import json
+from time import sleep
+from subprocess import Popen
+from random import shuffle
+import warnings
+import traceback
+import threading
+import shutil
+import logging
+
+
+logging.getLogger("numba").setLevel(logging.WARNING)
+logging.getLogger("httpx").setLevel(logging.WARNING)
+
+logger = logging.getLogger(__name__)
+
+tmp = os.path.join(now_dir, "TEMP")
+shutil.rmtree(tmp, ignore_errors=True)
+shutil.rmtree("%s/runtime/Lib/site-packages/infer_pack" % (now_dir), ignore_errors=True)
+shutil.rmtree("%s/runtime/Lib/site-packages/uvr5_pack" % (now_dir), ignore_errors=True)
+os.makedirs(tmp, exist_ok=True)
+os.makedirs(os.path.join(now_dir, "logs"), exist_ok=True)
+os.makedirs(os.path.join(now_dir, "assets/weights"), exist_ok=True)
+os.environ["TEMP"] = tmp
+warnings.filterwarnings("ignore")
+torch.manual_seed(114514)
+
+
+config = Config()
+vc = VC(config)
+
+if not config.nocheck:
+ from infer.lib.rvcmd import check_all_assets, download_all_assets
+
+ if not check_all_assets(update=config.update):
+ if config.update:
+ download_all_assets(tmpdir=tmp)
+ if not check_all_assets(update=config.update):
+ logging.error("counld not satisfy all assets needed.")
+ exit(1)
+
+if config.dml == True:
+
+ def forward_dml(ctx, x, scale):
+ ctx.scale = scale
+ res = x.clone().detach()
+ return res
+
+ fairseq.modules.grad_multiply.GradMultiply.forward = forward_dml
+i18n = I18nAuto()
+logger.info(i18n)
+# 判断是否有能用来训练和加速推理的N卡
+ngpu = torch.cuda.device_count()
+gpu_infos = []
+mem = []
+if_gpu_ok = False
+
+if torch.cuda.is_available() or ngpu != 0:
+ for i in range(ngpu):
+ gpu_name = torch.cuda.get_device_name(i)
+ if any(
+ value in gpu_name.upper()
+ for value in [
+ "10",
+ "16",
+ "20",
+ "30",
+ "40",
+ "A2",
+ "A3",
+ "A4",
+ "P4",
+ "A50",
+ "500",
+ "A60",
+ "70",
+ "80",
+ "90",
+ "M4",
+ "T4",
+ "TITAN",
+ "4060",
+ "L",
+ "6000",
+ ]
+ ):
+ # A10#A100#V100#A40#P40#M40#K80#A4500
+ if_gpu_ok = True # 至少有一张能用的N卡
+ gpu_infos.append("%s\t%s" % (i, gpu_name))
+ mem.append(
+ int(
+ torch.cuda.get_device_properties(i).total_memory
+ / 1024
+ / 1024
+ / 1024
+ + 0.4
+ )
+ )
+if if_gpu_ok and len(gpu_infos) > 0:
+ gpu_info = "\n".join(gpu_infos)
+ default_batch_size = min(mem) // 2
+else:
+ gpu_info = i18n("很遗憾您这没有能用的显卡来支持您训练")
+ default_batch_size = 1
+gpus = "-".join([i[0] for i in gpu_infos])
+
+
+weight_root = os.getenv("weight_root")
+weight_uvr5_root = os.getenv("weight_uvr5_root")
+index_root = os.getenv("index_root")
+outside_index_root = os.getenv("outside_index_root")
+
+names = []
+for name in os.listdir(weight_root):
+ if name.endswith(".pth"):
+ names.append(name)
+index_paths = []
+
+
+def lookup_indices(index_root):
+ global index_paths
+ for root, dirs, files in os.walk(index_root, topdown=False):
+ for name in files:
+ if name.endswith(".index") and "trained" not in name:
+ index_paths.append("%s/%s" % (root, name))
+
+
+lookup_indices(index_root)
+lookup_indices(outside_index_root)
+uvr5_names = []
+for name in os.listdir(weight_uvr5_root):
+ if name.endswith(".pth") or "onnx" in name:
+ uvr5_names.append(name.replace(".pth", ""))
+
+
+def change_choices():
+ names = []
+ for name in os.listdir(weight_root):
+ if name.endswith(".pth"):
+ names.append(name)
+ index_paths = []
+ for root, dirs, files in os.walk(index_root, topdown=False):
+ for name in files:
+ if name.endswith(".index") and "trained" not in name:
+ index_paths.append("%s/%s" % (root, name))
+ return {"choices": sorted(names), "__type__": "update"}, {
+ "choices": sorted(index_paths),
+ "__type__": "update",
+ }
+
+
+def clean():
+ return {"value": "", "__type__": "update"}
+
+
+def export_onnx(ModelPath, ExportedPath):
+ from infer.modules.onnx.export import export_onnx as eo
+
+ eo(ModelPath, ExportedPath)
+
+
+sr_dict = {
+ "32k": 32000,
+ "40k": 40000,
+ "48k": 48000,
+}
+
+
+def if_done(done, p):
+ while 1:
+ if p.poll() is None:
+ sleep(0.5)
+ else:
+ break
+ done[0] = True
+
+
+def if_done_multi(done, ps):
+ while 1:
+ # poll==None代表进程未结束
+ # 只要有一个进程未结束都不停
+ flag = 1
+ for p in ps:
+ if p.poll() is None:
+ flag = 0
+ sleep(0.5)
+ break
+ if flag == 1:
+ break
+ done[0] = True
+
+
+def preprocess_dataset(trainset_dir, exp_dir, sr, n_p):
+ sr = sr_dict[sr]
+ os.makedirs("%s/logs/%s" % (now_dir, exp_dir), exist_ok=True)
+ f = open("%s/logs/%s/preprocess.log" % (now_dir, exp_dir), "w")
+ f.close()
+ cmd = '"%s" infer/modules/train/preprocess.py "%s" %s %s "%s/logs/%s" %s %.1f' % (
+ config.python_cmd,
+ trainset_dir,
+ sr,
+ n_p,
+ now_dir,
+ exp_dir,
+ config.noparallel,
+ config.preprocess_per,
+ )
+ logger.info("Execute: " + cmd)
+ # , stdin=PIPE, stdout=PIPE,stderr=PIPE,cwd=now_dir
+ p = Popen(cmd, shell=True)
+ # 煞笔gr, popen read都非得全跑完了再一次性读取, 不用gr就正常读一句输出一句;只能额外弄出一个文本流定时读
+ done = [False]
+ threading.Thread(
+ target=if_done,
+ args=(
+ done,
+ p,
+ ),
+ ).start()
+ while 1:
+ with open("%s/logs/%s/preprocess.log" % (now_dir, exp_dir), "r") as f:
+ yield (f.read())
+ sleep(1)
+ if done[0]:
+ break
+ with open("%s/logs/%s/preprocess.log" % (now_dir, exp_dir), "r") as f:
+ log = f.read()
+ logger.info(log)
+ yield log
+
+
+# but2.click(extract_f0,[gpus6,np7,f0method8,if_f0_3,trainset_dir4],[info2])
+def extract_f0_feature(gpus, n_p, f0method, if_f0, exp_dir, version19, gpus_rmvpe):
+ gpus = gpus.split("-")
+ os.makedirs("%s/logs/%s" % (now_dir, exp_dir), exist_ok=True)
+ f = open("%s/logs/%s/extract_f0_feature.log" % (now_dir, exp_dir), "w")
+ f.close()
+ if if_f0:
+ if f0method != "rmvpe_gpu":
+ cmd = (
+ '"%s" infer/modules/train/extract/extract_f0_print.py "%s/logs/%s" %s %s'
+ % (
+ config.python_cmd,
+ now_dir,
+ exp_dir,
+ n_p,
+ f0method,
+ )
+ )
+ logger.info("Execute: " + cmd)
+ p = Popen(
+ cmd, shell=True, cwd=now_dir
+ ) # , stdin=PIPE, stdout=PIPE,stderr=PIPE
+ # 煞笔gr, popen read都非得全跑完了再一次性读取, 不用gr就正常读一句输出一句;只能额外弄出一个文本流定时读
+ done = [False]
+ threading.Thread(
+ target=if_done,
+ args=(
+ done,
+ p,
+ ),
+ ).start()
+ else:
+ if gpus_rmvpe != "-":
+ gpus_rmvpe = gpus_rmvpe.split("-")
+ leng = len(gpus_rmvpe)
+ ps = []
+ for idx, n_g in enumerate(gpus_rmvpe):
+ cmd = (
+ '"%s" infer/modules/train/extract/extract_f0_rmvpe.py %s %s %s "%s/logs/%s" %s '
+ % (
+ config.python_cmd,
+ leng,
+ idx,
+ n_g,
+ now_dir,
+ exp_dir,
+ config.is_half,
+ )
+ )
+ logger.info("Execute: " + cmd)
+ p = Popen(
+ cmd, shell=True, cwd=now_dir
+ ) # , shell=True, stdin=PIPE, stdout=PIPE, stderr=PIPE, cwd=now_dir
+ ps.append(p)
+ # 煞笔gr, popen read都非得全跑完了再一次性读取, 不用gr就正常读一句输出一句;只能额外弄出一个文本流定时读
+ done = [False]
+ threading.Thread(
+ target=if_done_multi, #
+ args=(
+ done,
+ ps,
+ ),
+ ).start()
+ else:
+ cmd = (
+ config.python_cmd
+ + ' infer/modules/train/extract/extract_f0_rmvpe_dml.py "%s/logs/%s" '
+ % (
+ now_dir,
+ exp_dir,
+ )
+ )
+ logger.info("Execute: " + cmd)
+ p = Popen(
+ cmd, shell=True, cwd=now_dir
+ ) # , shell=True, stdin=PIPE, stdout=PIPE, stderr=PIPE, cwd=now_dir
+ p.wait()
+ done = [True]
+ while 1:
+ with open(
+ "%s/logs/%s/extract_f0_feature.log" % (now_dir, exp_dir), "r"
+ ) as f:
+ yield (f.read())
+ sleep(1)
+ if done[0]:
+ break
+ with open("%s/logs/%s/extract_f0_feature.log" % (now_dir, exp_dir), "r") as f:
+ log = f.read()
+ logger.info(log)
+ yield log
+ # 对不同part分别开多进程
+ """
+ n_part=int(sys.argv[1])
+ i_part=int(sys.argv[2])
+ i_gpu=sys.argv[3]
+ exp_dir=sys.argv[4]
+ os.environ["CUDA_VISIBLE_DEVICES"]=str(i_gpu)
+ """
+ leng = len(gpus)
+ ps = []
+ for idx, n_g in enumerate(gpus):
+ cmd = (
+ '"%s" infer/modules/train/extract_feature_print.py %s %s %s %s "%s/logs/%s" %s %s'
+ % (
+ config.python_cmd,
+ config.device,
+ leng,
+ idx,
+ n_g,
+ now_dir,
+ exp_dir,
+ version19,
+ config.is_half,
+ )
+ )
+ logger.info("Execute: " + cmd)
+ p = Popen(
+ cmd, shell=True, cwd=now_dir
+ ) # , shell=True, stdin=PIPE, stdout=PIPE, stderr=PIPE, cwd=now_dir
+ ps.append(p)
+ # 煞笔gr, popen read都非得全跑完了再一次性读取, 不用gr就正常读一句输出一句;只能额外弄出一个文本流定时读
+ done = [False]
+ threading.Thread(
+ target=if_done_multi,
+ args=(
+ done,
+ ps,
+ ),
+ ).start()
+ while 1:
+ with open("%s/logs/%s/extract_f0_feature.log" % (now_dir, exp_dir), "r") as f:
+ yield (f.read())
+ sleep(1)
+ if done[0]:
+ break
+ with open("%s/logs/%s/extract_f0_feature.log" % (now_dir, exp_dir), "r") as f:
+ log = f.read()
+ logger.info(log)
+ yield log
+
+
+def get_pretrained_models(path_str, f0_str, sr2):
+ if_pretrained_generator_exist = os.access(
+ "assets/pretrained%s/%sG%s.pth" % (path_str, f0_str, sr2), os.F_OK
+ )
+ if_pretrained_discriminator_exist = os.access(
+ "assets/pretrained%s/%sD%s.pth" % (path_str, f0_str, sr2), os.F_OK
+ )
+ if not if_pretrained_generator_exist:
+ logger.warning(
+ "assets/pretrained%s/%sG%s.pth not exist, will not use pretrained model",
+ path_str,
+ f0_str,
+ sr2,
+ )
+ if not if_pretrained_discriminator_exist:
+ logger.warning(
+ "assets/pretrained%s/%sD%s.pth not exist, will not use pretrained model",
+ path_str,
+ f0_str,
+ sr2,
+ )
+ return (
+ (
+ "assets/pretrained%s/%sG%s.pth" % (path_str, f0_str, sr2)
+ if if_pretrained_generator_exist
+ else ""
+ ),
+ (
+ "assets/pretrained%s/%sD%s.pth" % (path_str, f0_str, sr2)
+ if if_pretrained_discriminator_exist
+ else ""
+ ),
+ )
+
+
+def change_sr2(sr2, if_f0_3, version19):
+ path_str = "" if version19 == "v1" else "_v2"
+ f0_str = "f0" if if_f0_3 else ""
+ return get_pretrained_models(path_str, f0_str, sr2)
+
+
+def change_version19(sr2, if_f0_3, version19):
+ path_str = "" if version19 == "v1" else "_v2"
+ if sr2 == "32k" and version19 == "v1":
+ sr2 = "40k"
+ to_return_sr2 = (
+ {"choices": ["40k", "48k"], "__type__": "update", "value": sr2}
+ if version19 == "v1"
+ else {"choices": ["40k", "48k", "32k"], "__type__": "update", "value": sr2}
+ )
+ f0_str = "f0" if if_f0_3 else ""
+ return (
+ *get_pretrained_models(path_str, f0_str, sr2),
+ to_return_sr2,
+ )
+
+
+def change_f0(if_f0_3, sr2, version19): # f0method8,pretrained_G14,pretrained_D15
+ path_str = "" if version19 == "v1" else "_v2"
+ return (
+ {"visible": if_f0_3, "__type__": "update"},
+ {"visible": if_f0_3, "__type__": "update"},
+ *get_pretrained_models(path_str, "f0" if if_f0_3 == True else "", sr2),
+ )
+
+
+# but3.click(click_train,[exp_dir1,sr2,if_f0_3,save_epoch10,total_epoch11,batch_size12,if_save_latest13,pretrained_G14,pretrained_D15,gpus16])
+def click_train(
+ exp_dir1,
+ sr2,
+ if_f0_3,
+ spk_id5,
+ save_epoch10,
+ total_epoch11,
+ batch_size12,
+ if_save_latest13,
+ pretrained_G14,
+ pretrained_D15,
+ gpus16,
+ if_cache_gpu17,
+ if_save_every_weights18,
+ version19,
+):
+ # 生成filelist
+ exp_dir = "%s/logs/%s" % (now_dir, exp_dir1)
+ os.makedirs(exp_dir, exist_ok=True)
+ gt_wavs_dir = "%s/0_gt_wavs" % (exp_dir)
+ feature_dir = (
+ "%s/3_feature256" % (exp_dir)
+ if version19 == "v1"
+ else "%s/3_feature768" % (exp_dir)
+ )
+ if if_f0_3:
+ f0_dir = "%s/2a_f0" % (exp_dir)
+ f0nsf_dir = "%s/2b-f0nsf" % (exp_dir)
+ names = (
+ set([name.split(".")[0] for name in os.listdir(gt_wavs_dir)])
+ & set([name.split(".")[0] for name in os.listdir(feature_dir)])
+ & set([name.split(".")[0] for name in os.listdir(f0_dir)])
+ & set([name.split(".")[0] for name in os.listdir(f0nsf_dir)])
+ )
+ else:
+ names = set([name.split(".")[0] for name in os.listdir(gt_wavs_dir)]) & set(
+ [name.split(".")[0] for name in os.listdir(feature_dir)]
+ )
+ opt = []
+ for name in names:
+ if if_f0_3:
+ opt.append(
+ "%s/%s.wav|%s/%s.npy|%s/%s.wav.npy|%s/%s.wav.npy|%s"
+ % (
+ gt_wavs_dir.replace("\\", "\\\\"),
+ name,
+ feature_dir.replace("\\", "\\\\"),
+ name,
+ f0_dir.replace("\\", "\\\\"),
+ name,
+ f0nsf_dir.replace("\\", "\\\\"),
+ name,
+ spk_id5,
+ )
+ )
+ else:
+ opt.append(
+ "%s/%s.wav|%s/%s.npy|%s"
+ % (
+ gt_wavs_dir.replace("\\", "\\\\"),
+ name,
+ feature_dir.replace("\\", "\\\\"),
+ name,
+ spk_id5,
+ )
+ )
+ fea_dim = 256 if version19 == "v1" else 768
+ if if_f0_3:
+ for _ in range(2):
+ opt.append(
+ "%s/logs/mute/0_gt_wavs/mute%s.wav|%s/logs/mute/3_feature%s/mute.npy|%s/logs/mute/2a_f0/mute.wav.npy|%s/logs/mute/2b-f0nsf/mute.wav.npy|%s"
+ % (now_dir, sr2, now_dir, fea_dim, now_dir, now_dir, spk_id5)
+ )
+ else:
+ for _ in range(2):
+ opt.append(
+ "%s/logs/mute/0_gt_wavs/mute%s.wav|%s/logs/mute/3_feature%s/mute.npy|%s"
+ % (now_dir, sr2, now_dir, fea_dim, spk_id5)
+ )
+ shuffle(opt)
+ with open("%s/filelist.txt" % exp_dir, "w") as f:
+ f.write("\n".join(opt))
+ logger.debug("Write filelist done")
+ # 生成config#无需生成config
+ # cmd = python_cmd + " train_nsf_sim_cache_sid_load_pretrain.py -e mi-test -sr 40k -f0 1 -bs 4 -g 0 -te 10 -se 5 -pg pretrained/f0G40k.pth -pd pretrained/f0D40k.pth -l 1 -c 0"
+ logger.info("Use gpus: %s", str(gpus16))
+ if pretrained_G14 == "":
+ logger.info("No pretrained Generator")
+ if pretrained_D15 == "":
+ logger.info("No pretrained Discriminator")
+ if version19 == "v1" or sr2 == "40k":
+ config_path = "v1/%s.json" % sr2
+ else:
+ config_path = "v2/%s.json" % sr2
+ config_save_path = os.path.join(exp_dir, "config.json")
+ if not pathlib.Path(config_save_path).exists():
+ with open(config_save_path, "w", encoding="utf-8") as f:
+ json.dump(
+ config.json_config[config_path],
+ f,
+ ensure_ascii=False,
+ indent=4,
+ sort_keys=True,
+ )
+ f.write("\n")
+ if gpus16:
+ cmd = (
+ '"%s" infer/modules/train/train.py -e "%s" -sr %s -f0 %s -bs %s -g %s -te %s -se %s %s %s -l %s -c %s -sw %s -v %s'
+ % (
+ config.python_cmd,
+ exp_dir1,
+ sr2,
+ 1 if if_f0_3 else 0,
+ batch_size12,
+ gpus16,
+ total_epoch11,
+ save_epoch10,
+ "-pg %s" % pretrained_G14 if pretrained_G14 != "" else "",
+ "-pd %s" % pretrained_D15 if pretrained_D15 != "" else "",
+ 1 if if_save_latest13 == i18n("是") else 0,
+ 1 if if_cache_gpu17 == i18n("是") else 0,
+ 1 if if_save_every_weights18 == i18n("是") else 0,
+ version19,
+ )
+ )
+ else:
+ cmd = (
+ '"%s" infer/modules/train/train.py -e "%s" -sr %s -f0 %s -bs %s -te %s -se %s %s %s -l %s -c %s -sw %s -v %s'
+ % (
+ config.python_cmd,
+ exp_dir1,
+ sr2,
+ 1 if if_f0_3 else 0,
+ batch_size12,
+ total_epoch11,
+ save_epoch10,
+ "-pg %s" % pretrained_G14 if pretrained_G14 != "" else "",
+ "-pd %s" % pretrained_D15 if pretrained_D15 != "" else "",
+ 1 if if_save_latest13 == i18n("是") else 0,
+ 1 if if_cache_gpu17 == i18n("是") else 0,
+ 1 if if_save_every_weights18 == i18n("是") else 0,
+ version19,
+ )
+ )
+ logger.info("Execute: " + cmd)
+ p = Popen(cmd, shell=True, cwd=now_dir)
+ p.wait()
+ return "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log"
+
+
+# but4.click(train_index, [exp_dir1], info3)
+def train_index(exp_dir1, version19):
+ # exp_dir = "%s/logs/%s" % (now_dir, exp_dir1)
+ exp_dir = "logs/%s" % (exp_dir1)
+ os.makedirs(exp_dir, exist_ok=True)
+ feature_dir = (
+ "%s/3_feature256" % (exp_dir)
+ if version19 == "v1"
+ else "%s/3_feature768" % (exp_dir)
+ )
+ if not os.path.exists(feature_dir):
+ return "请先进行特征提取!"
+ listdir_res = list(os.listdir(feature_dir))
+ if len(listdir_res) == 0:
+ return "请先进行特征提取!"
+ infos = []
+ npys = []
+ for name in sorted(listdir_res):
+ phone = np.load("%s/%s" % (feature_dir, name))
+ npys.append(phone)
+ big_npy = np.concatenate(npys, 0)
+ big_npy_idx = np.arange(big_npy.shape[0])
+ np.random.shuffle(big_npy_idx)
+ big_npy = big_npy[big_npy_idx]
+ if big_npy.shape[0] > 2e5:
+ infos.append("Trying doing kmeans %s shape to 10k centers." % big_npy.shape[0])
+ yield "\n".join(infos)
+ try:
+ big_npy = (
+ MiniBatchKMeans(
+ n_clusters=10000,
+ verbose=True,
+ batch_size=256 * config.n_cpu,
+ compute_labels=False,
+ init="random",
+ )
+ .fit(big_npy)
+ .cluster_centers_
+ )
+ except:
+ info = traceback.format_exc()
+ logger.info(info)
+ infos.append(info)
+ yield "\n".join(infos)
+
+ np.save("%s/total_fea.npy" % exp_dir, big_npy)
+ n_ivf = min(int(16 * np.sqrt(big_npy.shape[0])), big_npy.shape[0] // 39)
+ infos.append("%s,%s" % (big_npy.shape, n_ivf))
+ yield "\n".join(infos)
+ index = faiss.index_factory(256 if version19 == "v1" else 768, "IVF%s,Flat" % n_ivf)
+ # index = faiss.index_factory(256if version19=="v1"else 768, "IVF%s,PQ128x4fs,RFlat"%n_ivf)
+ infos.append("training")
+ yield "\n".join(infos)
+ index_ivf = faiss.extract_index_ivf(index) #
+ index_ivf.nprobe = 1
+ index.train(big_npy)
+ faiss.write_index(
+ index,
+ "%s/trained_IVF%s_Flat_nprobe_%s_%s_%s.index"
+ % (exp_dir, n_ivf, index_ivf.nprobe, exp_dir1, version19),
+ )
+ infos.append("adding")
+ yield "\n".join(infos)
+ batch_size_add = 8192
+ for i in range(0, big_npy.shape[0], batch_size_add):
+ index.add(big_npy[i : i + batch_size_add])
+ faiss.write_index(
+ index,
+ "%s/added_IVF%s_Flat_nprobe_%s_%s_%s.index"
+ % (exp_dir, n_ivf, index_ivf.nprobe, exp_dir1, version19),
+ )
+ infos.append(
+ "成功构建索引 added_IVF%s_Flat_nprobe_%s_%s_%s.index"
+ % (n_ivf, index_ivf.nprobe, exp_dir1, version19)
+ )
+ try:
+ link = os.link if platform.system() == "Windows" else os.symlink
+ link(
+ "%s/added_IVF%s_Flat_nprobe_%s_%s_%s.index"
+ % (exp_dir, n_ivf, index_ivf.nprobe, exp_dir1, version19),
+ "%s/%s_IVF%s_Flat_nprobe_%s_%s_%s.index"
+ % (
+ outside_index_root,
+ exp_dir1,
+ n_ivf,
+ index_ivf.nprobe,
+ exp_dir1,
+ version19,
+ ),
+ )
+ infos.append("链接索引到外部-%s" % (outside_index_root))
+ except:
+ infos.append("链接索引到外部-%s失败" % (outside_index_root))
+
+ # faiss.write_index(index, '%s/added_IVF%s_Flat_FastScan_%s.index'%(exp_dir,n_ivf,version19))
+ # infos.append("成功构建索引,added_IVF%s_Flat_FastScan_%s.index"%(n_ivf,version19))
+ yield "\n".join(infos)
+
+
+# but5.click(train1key, [exp_dir1, sr2, if_f0_3, trainset_dir4, spk_id5, gpus6, np7, f0method8, save_epoch10, total_epoch11, batch_size12, if_save_latest13, pretrained_G14, pretrained_D15, gpus16, if_cache_gpu17], info3)
+def train1key(
+ exp_dir1,
+ sr2,
+ if_f0_3,
+ trainset_dir4,
+ spk_id5,
+ np7,
+ f0method8,
+ save_epoch10,
+ total_epoch11,
+ batch_size12,
+ if_save_latest13,
+ pretrained_G14,
+ pretrained_D15,
+ gpus16,
+ if_cache_gpu17,
+ if_save_every_weights18,
+ version19,
+ gpus_rmvpe,
+):
+ infos = []
+
+ def get_info_str(strr):
+ infos.append(strr)
+ return "\n".join(infos)
+
+ # step1:处理数据
+ yield get_info_str(i18n("step1:正在处理数据"))
+ [get_info_str(_) for _ in preprocess_dataset(trainset_dir4, exp_dir1, sr2, np7)]
+
+ # step2a:提取音高
+ yield get_info_str(i18n("step2:正在提取音高&正在提取特征"))
+ [
+ get_info_str(_)
+ for _ in extract_f0_feature(
+ gpus16, np7, f0method8, if_f0_3, exp_dir1, version19, gpus_rmvpe
+ )
+ ]
+
+ # step3a:训练模型
+ yield get_info_str(i18n("step3a:正在训练模型"))
+ click_train(
+ exp_dir1,
+ sr2,
+ if_f0_3,
+ spk_id5,
+ save_epoch10,
+ total_epoch11,
+ batch_size12,
+ if_save_latest13,
+ pretrained_G14,
+ pretrained_D15,
+ gpus16,
+ if_cache_gpu17,
+ if_save_every_weights18,
+ version19,
+ )
+ yield get_info_str(
+ i18n("训练结束, 您可查看控制台训练日志或实验文件夹下的train.log")
+ )
+
+ # step3b:训练索引
+ [get_info_str(_) for _ in train_index(exp_dir1, version19)]
+ yield get_info_str(i18n("全流程结束!"))
+
+
+# ckpt_path2.change(change_info_,[ckpt_path2],[sr__,if_f0__])
+def change_info_(ckpt_path):
+ if not os.path.exists(ckpt_path.replace(os.path.basename(ckpt_path), "train.log")):
+ return {"__type__": "update"}, {"__type__": "update"}, {"__type__": "update"}
+ try:
+ with open(
+ ckpt_path.replace(os.path.basename(ckpt_path), "train.log"), "r"
+ ) as f:
+ info = eval(f.read().strip("\n").split("\n")[0].split("\t")[-1])
+ sr, f0 = info["sample_rate"], info["if_f0"]
+ version = "v2" if ("version" in info and info["version"] == "v2") else "v1"
+ return sr, str(f0), version
+ except:
+ traceback.print_exc()
+ return {"__type__": "update"}, {"__type__": "update"}, {"__type__": "update"}
+
+
+F0GPUVisible = config.dml == False
+
+
+def change_f0_method(f0method8):
+ if f0method8 == "rmvpe_gpu":
+ visible = F0GPUVisible
+ else:
+ visible = False
+ return {"visible": visible, "__type__": "update"}
+
+
+with gr.Blocks(title="RVC WebUI") as app:
+ gr.Markdown("## RVC WebUI")
+ gr.Markdown(
+ value=i18n(
+ "本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责.
如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录LICENSE."
+ )
+ )
+ with gr.Tabs():
+ with gr.TabItem(i18n("模型推理")):
+ with gr.Row():
+ sid0 = gr.Dropdown(label=i18n("推理音色"), choices=sorted(names))
+ with gr.Column():
+ refresh_button = gr.Button(
+ i18n("刷新音色列表和索引路径"), variant="primary"
+ )
+ clean_button = gr.Button(i18n("卸载音色省显存"), variant="primary")
+ spk_item = gr.Slider(
+ minimum=0,
+ maximum=2333,
+ step=1,
+ label=i18n("请选择说话人id"),
+ value=0,
+ visible=False,
+ interactive=True,
+ )
+ clean_button.click(
+ fn=clean, inputs=[], outputs=[sid0], api_name="infer_clean"
+ )
+ with gr.TabItem(i18n("单次推理")):
+ with gr.Group():
+ with gr.Row():
+ with gr.Column():
+ vc_transform0 = gr.Number(
+ label=i18n("变调(整数, 半音数量, 升八度12降八度-12)"),
+ value=0,
+ )
+ input_audio0 = gr.Textbox(
+ label=i18n(
+ "输入待处理音频文件路径(默认是正确格式示例)"
+ ),
+ placeholder="C:\\Users\\Desktop\\audio_example.wav",
+ )
+ file_index1 = gr.Textbox(
+ label=i18n(
+ "特征检索库文件路径,为空则使用下拉的选择结果"
+ ),
+ placeholder="C:\\Users\\Desktop\\model_example.index",
+ interactive=True,
+ )
+ file_index2 = gr.Dropdown(
+ label=i18n("自动检测index路径,下拉式选择(dropdown)"),
+ choices=sorted(index_paths),
+ interactive=True,
+ )
+ f0method0 = gr.Radio(
+ label=i18n(
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU"
+ ),
+ choices=(
+ ["pm", "harvest", "crepe", "rmvpe"]
+ if config.dml == False
+ else ["pm", "harvest", "rmvpe"]
+ ),
+ value="rmvpe",
+ interactive=True,
+ )
+
+ with gr.Column():
+ resample_sr0 = gr.Slider(
+ minimum=0,
+ maximum=48000,
+ label=i18n("后处理重采样至最终采样率,0为不进行重采样"),
+ value=0,
+ step=1,
+ interactive=True,
+ )
+ rms_mix_rate0 = gr.Slider(
+ minimum=0,
+ maximum=1,
+ label=i18n(
+ "输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络"
+ ),
+ value=0.25,
+ interactive=True,
+ )
+ protect0 = gr.Slider(
+ minimum=0,
+ maximum=0.5,
+ label=i18n(
+ "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果"
+ ),
+ value=0.33,
+ step=0.01,
+ interactive=True,
+ )
+ filter_radius0 = gr.Slider(
+ minimum=0,
+ maximum=7,
+ label=i18n(
+ ">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音"
+ ),
+ value=3,
+ step=1,
+ interactive=True,
+ )
+ index_rate1 = gr.Slider(
+ minimum=0,
+ maximum=1,
+ label=i18n("检索特征占比"),
+ value=0.75,
+ interactive=True,
+ )
+ f0_file = gr.File(
+ label=i18n(
+ "F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调"
+ ),
+ visible=False,
+ )
+
+ refresh_button.click(
+ fn=change_choices,
+ inputs=[],
+ outputs=[sid0, file_index2],
+ api_name="infer_refresh",
+ )
+ # file_big_npy1 = gr.Textbox(
+ # label=i18n("特征文件路径"),
+ # value="E:\\codes\py39\\vits_vc_gpu_train\\logs\\mi-test-1key\\total_fea.npy",
+ # interactive=True,
+ # )
+ with gr.Group():
+ with gr.Column():
+ but0 = gr.Button(i18n("转换"), variant="primary")
+ with gr.Row():
+ vc_output1 = gr.Textbox(label=i18n("输出信息"))
+ vc_output2 = gr.Audio(
+ label=i18n("输出音频(右下角三个点,点了可以下载)")
+ )
+
+ but0.click(
+ vc.vc_single,
+ [
+ spk_item,
+ input_audio0,
+ vc_transform0,
+ f0_file,
+ f0method0,
+ file_index1,
+ file_index2,
+ # file_big_npy1,
+ index_rate1,
+ filter_radius0,
+ resample_sr0,
+ rms_mix_rate0,
+ protect0,
+ ],
+ [vc_output1, vc_output2],
+ api_name="infer_convert",
+ )
+ with gr.TabItem(i18n("批量推理")):
+ gr.Markdown(
+ value=i18n(
+ "批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. "
+ )
+ )
+ with gr.Row():
+ with gr.Column():
+ vc_transform1 = gr.Number(
+ label=i18n("变调(整数, 半音数量, 升八度12降八度-12)"),
+ value=0,
+ )
+ opt_input = gr.Textbox(
+ label=i18n("指定输出文件夹"), value="opt"
+ )
+ file_index3 = gr.Textbox(
+ label=i18n("特征检索库文件路径,为空则使用下拉的选择结果"),
+ value="",
+ interactive=True,
+ )
+ file_index4 = gr.Dropdown(
+ label=i18n("自动检测index路径,下拉式选择(dropdown)"),
+ choices=sorted(index_paths),
+ interactive=True,
+ )
+ f0method1 = gr.Radio(
+ label=i18n(
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU"
+ ),
+ choices=(
+ ["pm", "harvest", "crepe", "rmvpe"]
+ if config.dml == False
+ else ["pm", "harvest", "rmvpe"]
+ ),
+ value="rmvpe",
+ interactive=True,
+ )
+ format1 = gr.Radio(
+ label=i18n("导出文件格式"),
+ choices=["wav", "flac", "mp3", "m4a"],
+ value="wav",
+ interactive=True,
+ )
+
+ refresh_button.click(
+ fn=lambda: change_choices()[1],
+ inputs=[],
+ outputs=file_index4,
+ api_name="infer_refresh_batch",
+ )
+ # file_big_npy2 = gr.Textbox(
+ # label=i18n("特征文件路径"),
+ # value="E:\\codes\\py39\\vits_vc_gpu_train\\logs\\mi-test-1key\\total_fea.npy",
+ # interactive=True,
+ # )
+
+ with gr.Column():
+ resample_sr1 = gr.Slider(
+ minimum=0,
+ maximum=48000,
+ label=i18n("后处理重采样至最终采样率,0为不进行重采样"),
+ value=0,
+ step=1,
+ interactive=True,
+ )
+ rms_mix_rate1 = gr.Slider(
+ minimum=0,
+ maximum=1,
+ label=i18n(
+ "输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络"
+ ),
+ value=1,
+ interactive=True,
+ )
+ protect1 = gr.Slider(
+ minimum=0,
+ maximum=0.5,
+ label=i18n(
+ "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果"
+ ),
+ value=0.33,
+ step=0.01,
+ interactive=True,
+ )
+ filter_radius1 = gr.Slider(
+ minimum=0,
+ maximum=7,
+ label=i18n(
+ ">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音"
+ ),
+ value=3,
+ step=1,
+ interactive=True,
+ )
+ index_rate2 = gr.Slider(
+ minimum=0,
+ maximum=1,
+ label=i18n("检索特征占比"),
+ value=1,
+ interactive=True,
+ )
+ with gr.Row():
+ dir_input = gr.Textbox(
+ label=i18n(
+ "输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)"
+ ),
+ placeholder="C:\\Users\\Desktop\\input_vocal_dir",
+ )
+ inputs = gr.File(
+ file_count="multiple",
+ label=i18n("也可批量输入音频文件, 二选一, 优先读文件夹"),
+ )
+
+ with gr.Row():
+ but1 = gr.Button(i18n("转换"), variant="primary")
+ vc_output3 = gr.Textbox(label=i18n("输出信息"))
+
+ but1.click(
+ vc.vc_multi,
+ [
+ spk_item,
+ dir_input,
+ opt_input,
+ inputs,
+ vc_transform1,
+ f0method1,
+ file_index3,
+ file_index4,
+ # file_big_npy2,
+ index_rate2,
+ filter_radius1,
+ resample_sr1,
+ rms_mix_rate1,
+ protect1,
+ format1,
+ ],
+ [vc_output3],
+ api_name="infer_convert_batch",
+ )
+ sid0.change(
+ fn=vc.get_vc,
+ inputs=[sid0, protect0, protect1],
+ outputs=[spk_item, protect0, protect1, file_index2, file_index4],
+ api_name="infer_change_voice",
+ )
+ with gr.TabItem(i18n("伴奏人声分离&去混响&去回声")):
+ with gr.Group():
+ gr.Markdown(
+ value=i18n(
+ "人声伴奏分离批量处理, 使用UVR5模型。
合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。
模型分为三类:
1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点;
2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型;
3、去混响、去延迟模型(by FoxJoy):
(1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;
(234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。
去混响/去延迟,附:
1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;
2、MDX-Net-Dereverb模型挺慢的;
3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。"
+ )
+ )
+ with gr.Row():
+ with gr.Column():
+ dir_wav_input = gr.Textbox(
+ label=i18n("输入待处理音频文件夹路径"),
+ placeholder="C:\\Users\\Desktop\\todo-songs",
+ )
+ wav_inputs = gr.File(
+ file_count="multiple",
+ label=i18n("也可批量输入音频文件, 二选一, 优先读文件夹"),
+ )
+ with gr.Column():
+ model_choose = gr.Dropdown(
+ label=i18n("模型"), choices=uvr5_names
+ )
+ agg = gr.Slider(
+ minimum=0,
+ maximum=20,
+ step=1,
+ label="人声提取激进程度",
+ value=10,
+ interactive=True,
+ visible=False, # 先不开放调整
+ )
+ opt_vocal_root = gr.Textbox(
+ label=i18n("指定输出主人声文件夹"), value="opt"
+ )
+ opt_ins_root = gr.Textbox(
+ label=i18n("指定输出非主人声文件夹"), value="opt"
+ )
+ format0 = gr.Radio(
+ label=i18n("导出文件格式"),
+ choices=["wav", "flac", "mp3", "m4a"],
+ value="flac",
+ interactive=True,
+ )
+ but2 = gr.Button(i18n("转换"), variant="primary")
+ vc_output4 = gr.Textbox(label=i18n("输出信息"))
+ but2.click(
+ uvr,
+ [
+ model_choose,
+ dir_wav_input,
+ opt_vocal_root,
+ wav_inputs,
+ opt_ins_root,
+ agg,
+ format0,
+ ],
+ [vc_output4],
+ api_name="uvr_convert",
+ )
+ with gr.TabItem(i18n("训练")):
+ gr.Markdown(
+ value=i18n(
+ "step1: 填写实验配置. 实验数据放在logs下, 每个实验一个文件夹, 需手工输入实验名路径, 内含实验配置, 日志, 训练得到的模型文件. "
+ )
+ )
+ with gr.Row():
+ exp_dir1 = gr.Textbox(label=i18n("输入实验名"), value="mi-test")
+ sr2 = gr.Radio(
+ label=i18n("目标采样率"),
+ choices=["40k", "48k"],
+ value="40k",
+ interactive=True,
+ )
+ if_f0_3 = gr.Radio(
+ label=i18n("模型是否带音高指导(唱歌一定要, 语音可以不要)"),
+ choices=[i18n("是"), i18n("否")],
+ value=i18n("是"),
+ interactive=True,
+ )
+ version19 = gr.Radio(
+ label=i18n("版本"),
+ choices=["v1", "v2"],
+ value="v2",
+ interactive=True,
+ visible=True,
+ )
+ np7 = gr.Slider(
+ minimum=0,
+ maximum=config.n_cpu,
+ step=1,
+ label=i18n("提取音高和处理数据使用的CPU进程数"),
+ value=int(np.ceil(config.n_cpu / 1.5)),
+ interactive=True,
+ )
+ with gr.Group(): # 暂时单人的, 后面支持最多4人的#数据处理
+ gr.Markdown(
+ value=i18n(
+ "step2a: 自动遍历训练文件夹下所有可解码成音频的文件并进行切片归一化, 在实验目录下生成2个wav文件夹; 暂时只支持单人训练. "
+ )
+ )
+ with gr.Row():
+ trainset_dir4 = gr.Textbox(
+ label=i18n("输入训练文件夹路径"),
+ value=i18n("E:\\语音音频+标注\\米津玄师\\src"),
+ )
+ spk_id5 = gr.Slider(
+ minimum=0,
+ maximum=4,
+ step=1,
+ label=i18n("请指定说话人id"),
+ value=0,
+ interactive=True,
+ )
+ but1 = gr.Button(i18n("处理数据"), variant="primary")
+ info1 = gr.Textbox(label=i18n("输出信息"), value="")
+ but1.click(
+ preprocess_dataset,
+ [trainset_dir4, exp_dir1, sr2, np7],
+ [info1],
+ api_name="train_preprocess",
+ )
+ with gr.Group():
+ gr.Markdown(
+ value=i18n(
+ "step2b: 使用CPU提取音高(如果模型带音高), 使用GPU提取特征(选择卡号)"
+ )
+ )
+ with gr.Row():
+ with gr.Column():
+ gpus6 = gr.Textbox(
+ label=i18n(
+ "以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2"
+ ),
+ value=gpus,
+ interactive=True,
+ visible=F0GPUVisible,
+ )
+ gpu_info9 = gr.Textbox(
+ label=i18n("显卡信息"), value=gpu_info, visible=F0GPUVisible
+ )
+ with gr.Column():
+ f0method8 = gr.Radio(
+ label=i18n(
+ "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU"
+ ),
+ choices=["pm", "harvest", "dio", "rmvpe", "rmvpe_gpu"],
+ value="rmvpe_gpu",
+ interactive=True,
+ )
+ gpus_rmvpe = gr.Textbox(
+ label=i18n(
+ "rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程"
+ ),
+ value="%s-%s" % (gpus, gpus),
+ interactive=True,
+ visible=F0GPUVisible,
+ )
+ but2 = gr.Button(i18n("特征提取"), variant="primary")
+ info2 = gr.Textbox(label=i18n("输出信息"), value="", max_lines=8)
+ f0method8.change(
+ fn=change_f0_method,
+ inputs=[f0method8],
+ outputs=[gpus_rmvpe],
+ )
+ but2.click(
+ extract_f0_feature,
+ [
+ gpus6,
+ np7,
+ f0method8,
+ if_f0_3,
+ exp_dir1,
+ version19,
+ gpus_rmvpe,
+ ],
+ [info2],
+ api_name="train_extract_f0_feature",
+ )
+ with gr.Group():
+ gr.Markdown(value=i18n("step3: 填写训练设置, 开始训练模型和索引"))
+ with gr.Row():
+ save_epoch10 = gr.Slider(
+ minimum=1,
+ maximum=50,
+ step=1,
+ label=i18n("保存频率save_every_epoch"),
+ value=5,
+ interactive=True,
+ )
+ total_epoch11 = gr.Slider(
+ minimum=2,
+ maximum=1000,
+ step=1,
+ label=i18n("总训练轮数total_epoch"),
+ value=20,
+ interactive=True,
+ )
+ batch_size12 = gr.Slider(
+ minimum=1,
+ maximum=40,
+ step=1,
+ label=i18n("每张显卡的batch_size"),
+ value=default_batch_size,
+ interactive=True,
+ )
+ if_save_latest13 = gr.Radio(
+ label=i18n("是否仅保存最新的ckpt文件以节省硬盘空间"),
+ choices=[i18n("是"), i18n("否")],
+ value=i18n("否"),
+ interactive=True,
+ )
+ if_cache_gpu17 = gr.Radio(
+ label=i18n(
+ "是否缓存所有训练集至显存. 10min以下小数据可缓存以加速训练, 大数据缓存会炸显存也加不了多少速"
+ ),
+ choices=[i18n("是"), i18n("否")],
+ value=i18n("否"),
+ interactive=True,
+ )
+ if_save_every_weights18 = gr.Radio(
+ label=i18n(
+ "是否在每次保存时间点将最终小模型保存至weights文件夹"
+ ),
+ choices=[i18n("是"), i18n("否")],
+ value=i18n("否"),
+ interactive=True,
+ )
+ with gr.Row():
+ pretrained_G14 = gr.Textbox(
+ label=i18n("加载预训练底模G路径"),
+ value="assets/pretrained_v2/f0G40k.pth",
+ interactive=True,
+ )
+ pretrained_D15 = gr.Textbox(
+ label=i18n("加载预训练底模D路径"),
+ value="assets/pretrained_v2/f0D40k.pth",
+ interactive=True,
+ )
+ sr2.change(
+ change_sr2,
+ [sr2, if_f0_3, version19],
+ [pretrained_G14, pretrained_D15],
+ )
+ version19.change(
+ change_version19,
+ [sr2, if_f0_3, version19],
+ [pretrained_G14, pretrained_D15, sr2],
+ )
+ if_f0_3.change(
+ change_f0,
+ [if_f0_3, sr2, version19],
+ [f0method8, gpus_rmvpe, pretrained_G14, pretrained_D15],
+ )
+ gpus16 = gr.Textbox(
+ label=i18n(
+ "以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2"
+ ),
+ value=gpus,
+ interactive=True,
+ )
+ but3 = gr.Button(i18n("训练模型"), variant="primary")
+ but4 = gr.Button(i18n("训练特征索引"), variant="primary")
+ but5 = gr.Button(i18n("一键训练"), variant="primary")
+ info3 = gr.Textbox(label=i18n("输出信息"), value="", max_lines=10)
+ but3.click(
+ click_train,
+ [
+ exp_dir1,
+ sr2,
+ if_f0_3,
+ spk_id5,
+ save_epoch10,
+ total_epoch11,
+ batch_size12,
+ if_save_latest13,
+ pretrained_G14,
+ pretrained_D15,
+ gpus16,
+ if_cache_gpu17,
+ if_save_every_weights18,
+ version19,
+ ],
+ info3,
+ api_name="train_start",
+ )
+ but4.click(train_index, [exp_dir1, version19], info3)
+ but5.click(
+ train1key,
+ [
+ exp_dir1,
+ sr2,
+ if_f0_3,
+ trainset_dir4,
+ spk_id5,
+ np7,
+ f0method8,
+ save_epoch10,
+ total_epoch11,
+ batch_size12,
+ if_save_latest13,
+ pretrained_G14,
+ pretrained_D15,
+ gpus16,
+ if_cache_gpu17,
+ if_save_every_weights18,
+ version19,
+ gpus_rmvpe,
+ ],
+ info3,
+ api_name="train_start_all",
+ )
+
+ with gr.TabItem(i18n("ckpt处理")):
+ with gr.Group():
+ gr.Markdown(value=i18n("模型融合, 可用于测试音色融合"))
+ with gr.Row():
+ ckpt_a = gr.Textbox(
+ label=i18n("A模型路径"), value="", interactive=True
+ )
+ ckpt_b = gr.Textbox(
+ label=i18n("B模型路径"), value="", interactive=True
+ )
+ alpha_a = gr.Slider(
+ minimum=0,
+ maximum=1,
+ label=i18n("A模型权重"),
+ value=0.5,
+ interactive=True,
+ )
+ with gr.Row():
+ sr_ = gr.Radio(
+ label=i18n("目标采样率"),
+ choices=["40k", "48k"],
+ value="40k",
+ interactive=True,
+ )
+ if_f0_ = gr.Radio(
+ label=i18n("模型是否带音高指导"),
+ choices=[i18n("是"), i18n("否")],
+ value=i18n("是"),
+ interactive=True,
+ )
+ info__ = gr.Textbox(
+ label=i18n("要置入的模型信息"),
+ value="",
+ max_lines=8,
+ interactive=True,
+ )
+ name_to_save0 = gr.Textbox(
+ label=i18n("保存的模型名不带后缀"),
+ value="",
+ max_lines=1,
+ interactive=True,
+ )
+ version_2 = gr.Radio(
+ label=i18n("模型版本型号"),
+ choices=["v1", "v2"],
+ value="v1",
+ interactive=True,
+ )
+ with gr.Row():
+ but6 = gr.Button(i18n("融合"), variant="primary")
+ info4 = gr.Textbox(label=i18n("输出信息"), value="", max_lines=8)
+ but6.click(
+ merge,
+ [
+ ckpt_a,
+ ckpt_b,
+ alpha_a,
+ sr_,
+ if_f0_,
+ info__,
+ name_to_save0,
+ version_2,
+ ],
+ info4,
+ api_name="ckpt_merge",
+ ) # def merge(path1,path2,alpha1,sr,f0,info):
+ with gr.Group():
+ gr.Markdown(
+ value=i18n("修改模型信息(仅支持weights文件夹下提取的小模型文件)")
+ )
+ with gr.Row():
+ ckpt_path0 = gr.Textbox(
+ label=i18n("模型路径"), value="", interactive=True
+ )
+ info_ = gr.Textbox(
+ label=i18n("要改的模型信息"),
+ value="",
+ max_lines=8,
+ interactive=True,
+ )
+ name_to_save1 = gr.Textbox(
+ label=i18n("保存的文件名, 默认空为和源文件同名"),
+ value="",
+ max_lines=8,
+ interactive=True,
+ )
+ with gr.Row():
+ but7 = gr.Button(i18n("修改"), variant="primary")
+ info5 = gr.Textbox(label=i18n("输出信息"), value="", max_lines=8)
+ but7.click(
+ change_info,
+ [ckpt_path0, info_, name_to_save1],
+ info5,
+ api_name="ckpt_modify",
+ )
+ with gr.Group():
+ gr.Markdown(
+ value=i18n("查看模型信息(仅支持weights文件夹下提取的小模型文件)")
+ )
+ with gr.Row():
+ ckpt_path1 = gr.Textbox(
+ label=i18n("模型路径"), value="", interactive=True
+ )
+ but8 = gr.Button(i18n("查看"), variant="primary")
+ info6 = gr.Textbox(label=i18n("输出信息"), value="", max_lines=8)
+ but8.click(show_info, [ckpt_path1], info6, api_name="ckpt_show")
+ with gr.Group():
+ gr.Markdown(
+ value=i18n(
+ "模型提取(输入logs文件夹下大文件模型路径),适用于训一半不想训了模型没有自动提取保存小文件模型,或者想测试中间模型的情况"
+ )
+ )
+ with gr.Row():
+ ckpt_path2 = gr.Textbox(
+ label=i18n("模型路径"),
+ value="E:\\codes\\py39\\logs\\mi-test_f0_48k\\G_23333.pth",
+ interactive=True,
+ )
+ save_name = gr.Textbox(
+ label=i18n("保存名"), value="", interactive=True
+ )
+ sr__ = gr.Radio(
+ label=i18n("目标采样率"),
+ choices=["32k", "40k", "48k"],
+ value="40k",
+ interactive=True,
+ )
+ if_f0__ = gr.Radio(
+ label=i18n("模型是否带音高指导,1是0否"),
+ choices=["1", "0"],
+ value="1",
+ interactive=True,
+ )
+ version_1 = gr.Radio(
+ label=i18n("模型版本型号"),
+ choices=["v1", "v2"],
+ value="v2",
+ interactive=True,
+ )
+ info___ = gr.Textbox(
+ label=i18n("要置入的模型信息"),
+ value="",
+ max_lines=8,
+ interactive=True,
+ )
+ but9 = gr.Button(i18n("提取"), variant="primary")
+ info7 = gr.Textbox(label=i18n("输出信息"), value="", max_lines=8)
+ ckpt_path2.change(
+ change_info_, [ckpt_path2], [sr__, if_f0__, version_1]
+ )
+ but9.click(
+ extract_small_model,
+ [ckpt_path2, save_name, sr__, if_f0__, info___, version_1],
+ info7,
+ api_name="ckpt_extract",
+ )
+
+ with gr.TabItem(i18n("Onnx导出")):
+ with gr.Row():
+ ckpt_dir = gr.Textbox(
+ label=i18n("RVC模型路径"), value="", interactive=True
+ )
+ with gr.Row():
+ onnx_dir = gr.Textbox(
+ label=i18n("Onnx输出路径"), value="", interactive=True
+ )
+ with gr.Row():
+ infoOnnx = gr.Label(label="info")
+ with gr.Row():
+ butOnnx = gr.Button(i18n("导出Onnx模型"), variant="primary")
+ butOnnx.click(
+ export_onnx, [ckpt_dir, onnx_dir], infoOnnx, api_name="export_onnx"
+ )
+
+ tab_faq = i18n("常见问题解答")
+ with gr.TabItem(tab_faq):
+ try:
+ if tab_faq == "常见问题解答":
+ with open("docs/cn/faq.md", "r", encoding="utf8") as f:
+ info = f.read()
+ else:
+ with open("docs/en/faq_en.md", "r", encoding="utf8") as f:
+ info = f.read()
+ gr.Markdown(value=info)
+ except:
+ gr.Markdown(traceback.format_exc())
+
+ try:
+ if config.iscolab:
+ app.queue(max_size=1022).launch(share=True, max_threads=511)
+ else:
+ app.queue(max_size=1022).launch(
+ max_threads=511,
+ server_name="0.0.0.0",
+ inbrowser=not config.noautoopen,
+ server_port=config.listen_port,
+ quiet=True,
+ )
+ except Exception as e:
+ logger.error(str(e))
diff --git a/configs/config.json b/configs/config.json
new file mode 100644
index 0000000000000000000000000000000000000000..e79bd50a7c10c3993cd588e1847876e186c14fa4
--- /dev/null
+++ b/configs/config.json
@@ -0,0 +1 @@
+{"pth_path": "assets/weights/kikiV1.pth", "index_path": "logs/kikiV1.index", "sg_hostapi": "MME", "sg_wasapi_exclusive": false, "sg_input_device": "VoiceMeeter Output (VB-Audio Vo", "sg_output_device": "VoiceMeeter Input (VB-Audio Voi", "sr_type": "sr_device", "threhold": -60.0, "pitch": 12.0, "formant": 0.0, "rms_mix_rate": 0.5, "index_rate": 0.0, "block_time": 0.15, "crossfade_length": 0.08, "extra_time": 2.0, "n_cpu": 4.0, "use_jit": false, "use_pv": false, "f0method": "fcpe"}
\ No newline at end of file
diff --git a/configs/config.py b/configs/config.py
new file mode 100644
index 0000000000000000000000000000000000000000..b6fffb25f3ae9396cb33610bfea8a7d9b0385f82
--- /dev/null
+++ b/configs/config.py
@@ -0,0 +1,264 @@
+import argparse
+import os
+import sys
+import json
+import shutil
+from multiprocessing import cpu_count
+
+import torch
+
+try:
+ import intel_extension_for_pytorch as ipex # pylint: disable=import-error, unused-import
+
+ if torch.xpu.is_available():
+ from infer.modules.ipex import ipex_init
+
+ ipex_init()
+except Exception: # pylint: disable=broad-exception-caught
+ pass
+import logging
+
+logger = logging.getLogger(__name__)
+
+
+version_config_list = [
+ "v1/32k.json",
+ "v1/40k.json",
+ "v1/48k.json",
+ "v2/48k.json",
+ "v2/32k.json",
+]
+
+
+def singleton_variable(func):
+ def wrapper(*args, **kwargs):
+ if not wrapper.instance:
+ wrapper.instance = func(*args, **kwargs)
+ return wrapper.instance
+
+ wrapper.instance = None
+ return wrapper
+
+
+@singleton_variable
+class Config:
+ def __init__(self):
+ self.device = "cuda:0"
+ self.is_half = True
+ self.use_jit = False
+ self.n_cpu = 0
+ self.gpu_name = None
+ self.json_config = self.load_config_json()
+ self.gpu_mem = None
+ (
+ self.python_cmd,
+ self.listen_port,
+ self.iscolab,
+ self.noparallel,
+ self.noautoopen,
+ self.dml,
+ self.nocheck,
+ self.update,
+ ) = self.arg_parse()
+ self.instead = ""
+ self.preprocess_per = 3.7
+ self.x_pad, self.x_query, self.x_center, self.x_max = self.device_config()
+
+ @staticmethod
+ def load_config_json() -> dict:
+ d = {}
+ for config_file in version_config_list:
+ p = f"configs/inuse/{config_file}"
+ if not os.path.exists(p):
+ shutil.copy(f"configs/{config_file}", p)
+ with open(f"configs/inuse/{config_file}", "r") as f:
+ d[config_file] = json.load(f)
+ return d
+
+ @staticmethod
+ def arg_parse() -> tuple:
+ exe = sys.executable or "python"
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--port", type=int, default=7865, help="Listen port")
+ parser.add_argument("--pycmd", type=str, default='python', help="Python command")
+ parser.add_argument("--colab", action="store_true", help="Launch in colab")
+ parser.add_argument(
+ "--noparallel", action="store_true", help="Disable parallel processing"
+ )
+ parser.add_argument(
+ "--noautoopen",
+ action="store_true",
+ help="Do not open in browser automatically",
+ )
+ parser.add_argument(
+ "--dml",
+ action="store_true",
+ help="torch_dml",
+ )
+ parser.add_argument(
+ "--nocheck", action="store_true", help="Run without checking assets"
+ )
+ parser.add_argument(
+ "--update", action="store_true", help="Update to latest assets"
+ )
+ cmd_opts = parser.parse_args()
+
+ cmd_opts.port = cmd_opts.port if 0 <= cmd_opts.port <= 65535 else 7865
+
+ return (
+ cmd_opts.pycmd,
+ cmd_opts.port,
+ cmd_opts.colab,
+ cmd_opts.noparallel,
+ cmd_opts.noautoopen,
+ cmd_opts.dml,
+ cmd_opts.nocheck,
+ cmd_opts.update,
+ )
+
+ # has_mps is only available in nightly pytorch (for now) and MasOS 12.3+.
+ # check `getattr` and try it for compatibility
+ @staticmethod
+ def has_mps() -> bool:
+ if not torch.backends.mps.is_available():
+ return False
+ try:
+ torch.zeros(1).to(torch.device("mps"))
+ return True
+ except Exception:
+ return False
+
+ @staticmethod
+ def has_xpu() -> bool:
+ if hasattr(torch, "xpu") and torch.xpu.is_available():
+ return True
+ else:
+ return False
+
+ def use_fp32_config(self):
+ for config_file in version_config_list:
+ self.json_config[config_file]["train"]["fp16_run"] = False
+ with open(f"configs/inuse/{config_file}", "r") as f:
+ strr = f.read().replace("true", "false")
+ with open(f"configs/inuse/{config_file}", "w") as f:
+ f.write(strr)
+ logger.info("overwrite " + config_file)
+ self.preprocess_per = 3.0
+ logger.info("overwrite preprocess_per to %d" % (self.preprocess_per))
+
+ def device_config(self) -> tuple:
+ if torch.cuda.is_available():
+ if self.has_xpu():
+ self.device = self.instead = "xpu:0"
+ self.is_half = True
+ i_device = int(self.device.split(":")[-1])
+ self.gpu_name = torch.cuda.get_device_name(i_device)
+ if (
+ ("16" in self.gpu_name and "V100" not in self.gpu_name.upper())
+ or "P40" in self.gpu_name.upper()
+ or "P10" in self.gpu_name.upper()
+ or "1060" in self.gpu_name
+ or "1070" in self.gpu_name
+ or "1080" in self.gpu_name
+ ):
+ logger.info("Found GPU %s, force to fp32", self.gpu_name)
+ self.is_half = False
+ self.use_fp32_config()
+ else:
+ logger.info("Found GPU %s", self.gpu_name)
+ self.gpu_mem = int(
+ torch.cuda.get_device_properties(i_device).total_memory
+ / 1024
+ / 1024
+ / 1024
+ + 0.4
+ )
+ if self.gpu_mem <= 4:
+ self.preprocess_per = 3.0
+ elif self.has_mps():
+ logger.info("No supported Nvidia GPU found")
+ self.device = self.instead = "mps"
+ self.is_half = False
+ self.use_fp32_config()
+ else:
+ logger.info("No supported Nvidia GPU found")
+ self.device = self.instead = "cpu"
+ self.is_half = False
+ self.use_fp32_config()
+
+ if self.n_cpu == 0:
+ self.n_cpu = cpu_count()
+
+ if self.is_half:
+ # 6G显存配置
+ x_pad = 3
+ x_query = 10
+ x_center = 60
+ x_max = 65
+ else:
+ # 5G显存配置
+ x_pad = 1
+ x_query = 6
+ x_center = 38
+ x_max = 41
+
+ if self.gpu_mem is not None and self.gpu_mem <= 4:
+ x_pad = 1
+ x_query = 5
+ x_center = 30
+ x_max = 32
+ if self.dml:
+ logger.info("Use DirectML instead")
+ if (
+ os.path.exists(
+ "runtime\Lib\site-packages\onnxruntime\capi\DirectML.dll"
+ )
+ == False
+ ):
+ try:
+ os.rename(
+ "runtime\Lib\site-packages\onnxruntime",
+ "runtime\Lib\site-packages\onnxruntime-cuda",
+ )
+ except:
+ pass
+ try:
+ os.rename(
+ "runtime\Lib\site-packages\onnxruntime-dml",
+ "runtime\Lib\site-packages\onnxruntime",
+ )
+ except:
+ pass
+ # if self.device != "cpu":
+ import torch_directml
+
+ self.device = torch_directml.device(torch_directml.default_device())
+ self.is_half = False
+ else:
+ if self.instead:
+ logger.info(f"Use {self.instead} instead")
+ if (
+ os.path.exists(
+ "runtime\Lib\site-packages\onnxruntime\capi\onnxruntime_providers_cuda.dll"
+ )
+ == False
+ ):
+ try:
+ os.rename(
+ "runtime\Lib\site-packages\onnxruntime",
+ "runtime\Lib\site-packages\onnxruntime-dml",
+ )
+ except:
+ pass
+ try:
+ os.rename(
+ "runtime\Lib\site-packages\onnxruntime-cuda",
+ "runtime\Lib\site-packages\onnxruntime",
+ )
+ except:
+ pass
+ logger.info(
+ "Half-precision floating-point: %s, device: %s"
+ % (self.is_half, self.device)
+ )
+ return x_pad, x_query, x_center, x_max
diff --git a/configs/inuse/.gitignore b/configs/inuse/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..419423674c957a466a985a929c6b846494643f57
--- /dev/null
+++ b/configs/inuse/.gitignore
@@ -0,0 +1,4 @@
+*
+!.gitignore
+!v1
+!v2
diff --git a/configs/inuse/v1/.gitignore b/configs/inuse/v1/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..d6b7ef32c8478a48c3994dcadc86837f4371184d
--- /dev/null
+++ b/configs/inuse/v1/.gitignore
@@ -0,0 +1,2 @@
+*
+!.gitignore
diff --git a/configs/inuse/v2/.gitignore b/configs/inuse/v2/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..d6b7ef32c8478a48c3994dcadc86837f4371184d
--- /dev/null
+++ b/configs/inuse/v2/.gitignore
@@ -0,0 +1,2 @@
+*
+!.gitignore
diff --git a/configs/v1/32k.json b/configs/v1/32k.json
new file mode 100644
index 0000000000000000000000000000000000000000..d5f16d691ed798f4c974b431167c36269b2ce7d2
--- /dev/null
+++ b/configs/v1/32k.json
@@ -0,0 +1,46 @@
+{
+ "train": {
+ "log_interval": 200,
+ "seed": 1234,
+ "epochs": 20000,
+ "learning_rate": 1e-4,
+ "betas": [0.8, 0.99],
+ "eps": 1e-9,
+ "batch_size": 4,
+ "fp16_run": true,
+ "lr_decay": 0.999875,
+ "segment_size": 12800,
+ "init_lr_ratio": 1,
+ "warmup_epochs": 0,
+ "c_mel": 45,
+ "c_kl": 1.0
+ },
+ "data": {
+ "max_wav_value": 32768.0,
+ "sampling_rate": 32000,
+ "filter_length": 1024,
+ "hop_length": 320,
+ "win_length": 1024,
+ "n_mel_channels": 80,
+ "mel_fmin": 0.0,
+ "mel_fmax": null
+ },
+ "model": {
+ "inter_channels": 192,
+ "hidden_channels": 192,
+ "filter_channels": 768,
+ "n_heads": 2,
+ "n_layers": 6,
+ "kernel_size": 3,
+ "p_dropout": 0,
+ "resblock": "1",
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+ "upsample_rates": [10,4,2,2,2],
+ "upsample_initial_channel": 512,
+ "upsample_kernel_sizes": [16,16,4,4,4],
+ "use_spectral_norm": false,
+ "gin_channels": 256,
+ "spk_embed_dim": 109
+ }
+}
diff --git a/configs/v1/40k.json b/configs/v1/40k.json
new file mode 100644
index 0000000000000000000000000000000000000000..4ffc87b9e9725fcd59d81a68d41a61962213b777
--- /dev/null
+++ b/configs/v1/40k.json
@@ -0,0 +1,46 @@
+{
+ "train": {
+ "log_interval": 200,
+ "seed": 1234,
+ "epochs": 20000,
+ "learning_rate": 1e-4,
+ "betas": [0.8, 0.99],
+ "eps": 1e-9,
+ "batch_size": 4,
+ "fp16_run": true,
+ "lr_decay": 0.999875,
+ "segment_size": 12800,
+ "init_lr_ratio": 1,
+ "warmup_epochs": 0,
+ "c_mel": 45,
+ "c_kl": 1.0
+ },
+ "data": {
+ "max_wav_value": 32768.0,
+ "sampling_rate": 40000,
+ "filter_length": 2048,
+ "hop_length": 400,
+ "win_length": 2048,
+ "n_mel_channels": 125,
+ "mel_fmin": 0.0,
+ "mel_fmax": null
+ },
+ "model": {
+ "inter_channels": 192,
+ "hidden_channels": 192,
+ "filter_channels": 768,
+ "n_heads": 2,
+ "n_layers": 6,
+ "kernel_size": 3,
+ "p_dropout": 0,
+ "resblock": "1",
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+ "upsample_rates": [10,10,2,2],
+ "upsample_initial_channel": 512,
+ "upsample_kernel_sizes": [16,16,4,4],
+ "use_spectral_norm": false,
+ "gin_channels": 256,
+ "spk_embed_dim": 109
+ }
+}
diff --git a/configs/v1/48k.json b/configs/v1/48k.json
new file mode 100644
index 0000000000000000000000000000000000000000..2d0e05beb794f6f61b769b48c7ae728bf59e6335
--- /dev/null
+++ b/configs/v1/48k.json
@@ -0,0 +1,46 @@
+{
+ "train": {
+ "log_interval": 200,
+ "seed": 1234,
+ "epochs": 20000,
+ "learning_rate": 1e-4,
+ "betas": [0.8, 0.99],
+ "eps": 1e-9,
+ "batch_size": 4,
+ "fp16_run": true,
+ "lr_decay": 0.999875,
+ "segment_size": 11520,
+ "init_lr_ratio": 1,
+ "warmup_epochs": 0,
+ "c_mel": 45,
+ "c_kl": 1.0
+ },
+ "data": {
+ "max_wav_value": 32768.0,
+ "sampling_rate": 48000,
+ "filter_length": 2048,
+ "hop_length": 480,
+ "win_length": 2048,
+ "n_mel_channels": 128,
+ "mel_fmin": 0.0,
+ "mel_fmax": null
+ },
+ "model": {
+ "inter_channels": 192,
+ "hidden_channels": 192,
+ "filter_channels": 768,
+ "n_heads": 2,
+ "n_layers": 6,
+ "kernel_size": 3,
+ "p_dropout": 0,
+ "resblock": "1",
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+ "upsample_rates": [10,6,2,2,2],
+ "upsample_initial_channel": 512,
+ "upsample_kernel_sizes": [16,16,4,4,4],
+ "use_spectral_norm": false,
+ "gin_channels": 256,
+ "spk_embed_dim": 109
+ }
+}
diff --git a/configs/v2/32k.json b/configs/v2/32k.json
new file mode 100644
index 0000000000000000000000000000000000000000..70e534f4c641a5a2c8e5c1e172f61398ee97e6e0
--- /dev/null
+++ b/configs/v2/32k.json
@@ -0,0 +1,46 @@
+{
+ "train": {
+ "log_interval": 200,
+ "seed": 1234,
+ "epochs": 20000,
+ "learning_rate": 1e-4,
+ "betas": [0.8, 0.99],
+ "eps": 1e-9,
+ "batch_size": 4,
+ "fp16_run": true,
+ "lr_decay": 0.999875,
+ "segment_size": 12800,
+ "init_lr_ratio": 1,
+ "warmup_epochs": 0,
+ "c_mel": 45,
+ "c_kl": 1.0
+ },
+ "data": {
+ "max_wav_value": 32768.0,
+ "sampling_rate": 32000,
+ "filter_length": 1024,
+ "hop_length": 320,
+ "win_length": 1024,
+ "n_mel_channels": 80,
+ "mel_fmin": 0.0,
+ "mel_fmax": null
+ },
+ "model": {
+ "inter_channels": 192,
+ "hidden_channels": 192,
+ "filter_channels": 768,
+ "n_heads": 2,
+ "n_layers": 6,
+ "kernel_size": 3,
+ "p_dropout": 0,
+ "resblock": "1",
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+ "upsample_rates": [10,8,2,2],
+ "upsample_initial_channel": 512,
+ "upsample_kernel_sizes": [20,16,4,4],
+ "use_spectral_norm": false,
+ "gin_channels": 256,
+ "spk_embed_dim": 109
+ }
+}
diff --git a/configs/v2/48k.json b/configs/v2/48k.json
new file mode 100644
index 0000000000000000000000000000000000000000..75f770cdacff3467e9e925ed2393b480881d0303
--- /dev/null
+++ b/configs/v2/48k.json
@@ -0,0 +1,46 @@
+{
+ "train": {
+ "log_interval": 200,
+ "seed": 1234,
+ "epochs": 20000,
+ "learning_rate": 1e-4,
+ "betas": [0.8, 0.99],
+ "eps": 1e-9,
+ "batch_size": 4,
+ "fp16_run": true,
+ "lr_decay": 0.999875,
+ "segment_size": 17280,
+ "init_lr_ratio": 1,
+ "warmup_epochs": 0,
+ "c_mel": 45,
+ "c_kl": 1.0
+ },
+ "data": {
+ "max_wav_value": 32768.0,
+ "sampling_rate": 48000,
+ "filter_length": 2048,
+ "hop_length": 480,
+ "win_length": 2048,
+ "n_mel_channels": 128,
+ "mel_fmin": 0.0,
+ "mel_fmax": null
+ },
+ "model": {
+ "inter_channels": 192,
+ "hidden_channels": 192,
+ "filter_channels": 768,
+ "n_heads": 2,
+ "n_layers": 6,
+ "kernel_size": 3,
+ "p_dropout": 0,
+ "resblock": "1",
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+ "upsample_rates": [12,10,2,2],
+ "upsample_initial_channel": 512,
+ "upsample_kernel_sizes": [24,20,4,4],
+ "use_spectral_norm": false,
+ "gin_channels": 256,
+ "spk_embed_dim": 109
+ }
+}
diff --git a/docker-compose.yml b/docker-compose.yml
new file mode 100644
index 0000000000000000000000000000000000000000..0768b30333350f9f80afa4870b95e7e472d02256
--- /dev/null
+++ b/docker-compose.yml
@@ -0,0 +1,20 @@
+version: "3.8"
+services:
+ rvc:
+ build:
+ context: .
+ dockerfile: Dockerfile
+ container_name: rvc
+ volumes:
+ - ./weights:/app/assets/weights
+ - ./opt:/app/opt
+ # - ./dataset:/app/dataset # you can use this folder in order to provide your dataset for model training
+ ports:
+ - 7865:7865
+ deploy:
+ resources:
+ reservations:
+ devices:
+ - driver: nvidia
+ count: 1
+ capabilities: [gpu]
\ No newline at end of file
diff --git a/docs/cn/Changelog_CN.md b/docs/cn/Changelog_CN.md
new file mode 100644
index 0000000000000000000000000000000000000000..c3753ec2bbcad7813ddbe48066a7576ef34ac1f5
--- /dev/null
+++ b/docs/cn/Changelog_CN.md
@@ -0,0 +1,109 @@
+### 20231006更新
+
+我们制作了一个用于实时变声的界面go-realtime-gui.bat/gui_v1.py(事实上早就存在了),本次更新重点也优化了实时变声的性能。对比0813版:
+ - 1、优优化界面操作:参数热更新(调整参数不需要中止再启动),懒加载模型(已加载过的模型不需要重新加载),增加响度因子参数(响度向输入音频靠近)
+ - 2、优化自带降噪效果与速度
+ - 3、大幅优化推理速度
+
+注意输入输出设备应该选择同种类型,例如都选MME类型。
+
+1006版本整体的更新为:
+ - 1、继续提升rmvpe音高提取算法效果,对于男低音有更大的提升
+ - 2、优化推理界面布局
+
+### 20230813更新
+1-常规bug修复
+ - 保存频率总轮数最低改为1 总轮数最低改为2
+ - 修复无pretrain模型训练报错
+ - 增加伴奏人声分离完毕清理显存
+ - faiss保存路径绝对路径改为相对路径
+ - 支持路径包含空格(训练集路径+实验名称均支持,不再会报错)
+ - filelist取消强制utf8编码
+ - 解决实时变声中开启索引导致的CPU极大占用问题
+
+2-重点更新
+ - 训练出当前最强开源人声音高提取模型RMVPE,并用于RVC的训练、离线/实时推理,支持pytorch/onnx/DirectML
+ - 通过pytorch-dml支持A卡和I卡的
+(1)实时变声(2)推理(3)人声伴奏分离(4)训练暂未支持,会切换至CPU训练;通过onnx_dml支持rmvpe_gpu的推理
+
+### 20230618更新
+- v2增加32k和48k两个新预训练模型
+- 修复非f0模型推理报错
+- 对于超过一小时的训练集的索引建立环节,自动kmeans缩小特征处理以加速索引训练、加入和查询
+- 附送一个人声转吉他玩具仓库
+- 数据处理剔除异常值切片
+- onnx导出选项卡
+
+失败的实验:
+- ~~特征检索增加时序维度:寄,没啥效果~~
+- ~~特征检索增加PCAR降维可选项:寄,数据大用kmeans缩小数据量,数据小降维操作耗时比省下的匹配耗时还多~~
+- ~~支持onnx推理(附带仅推理的小压缩包):寄,生成nsf还是需要pytorch~~
+- ~~训练时在音高、gender、eq、噪声等方面对输入进行随机增强:寄,没啥效果~~
+- ~~接入小型声码器调研:寄,效果变差~~
+
+todolist:
+- ~~训练集音高识别支持crepe:已经被RMVPE取代,不需要~~
+- ~~多进程harvest推理:已经被RMVPE取代,不需要~~
+- ~~crepe的精度支持和RVC-config同步:已经被RMVPE取代,不需要。支持这个还要同步torchcrepe的库,麻烦~~
+- 对接F0编辑器
+
+
+### 20230528更新
+- 增加v2的jupyter notebook,韩文changelog,增加一些环境依赖
+- 增加呼吸、清辅音、齿音保护模式
+- 支持crepe-full推理
+- UVR5人声伴奏分离加上3个去延迟模型和MDX-Net去混响模型,增加HP3人声提取模型
+- 索引名称增加版本和实验名称
+- 人声伴奏分离、推理批量导出增加音频导出格式选项
+- 废弃32k模型的训练
+
+### 20230513更新
+- 清除一键包内部老版本runtime内残留的lib.infer_pack和uvr5_pack
+- 修复训练集预处理伪多进程的bug
+- 增加harvest识别音高可选通过中值滤波削弱哑音现象,可调整中值滤波半径
+- 导出音频增加后处理重采样
+- 训练n_cpu进程数从"仅调整f0提取"改为"调整数据预处理和f0提取"
+- 自动检测logs文件夹下的index路径,提供下拉列表功能
+- tab页增加"常见问题解答"(也可参考github-rvc-wiki)
+- 相同路径的输入音频推理增加了音高缓存(用途:使用harvest音高提取,整个pipeline会经历漫长且重复的音高提取过程,如果不使用缓存,实验不同音色、索引、音高中值滤波半径参数的用户在第一次测试后的等待结果会非常痛苦)
+
+### 20230514更新
+- 音量包络对齐输入混合(可以缓解“输入静音输出小幅度噪声”的问题。如果输入音频背景底噪大则不建议开启,默认不开启(值为1可视为不开启))
+- 支持按照指定频率保存提取的小模型(假如你想尝试不同epoch下的推理效果,但是不想保存所有大checkpoint并且每次都要ckpt手工处理提取小模型,这项功能会非常实用)
+- 通过设置环境变量解决服务端开了系统全局代理导致浏览器连接错误的问题
+- 支持v2预训练模型(目前只公开了40k版本进行测试,另外2个采样率还没有训练完全)
+- 推理前限制超过1的过大音量
+- 微调数据预处理参数
+
+
+### 20230409更新
+- 修正训练参数,提升显卡平均利用率,A100最高从25%提升至90%左右,V100:50%->90%左右,2060S:60%->85%左右,P40:25%->95%左右,训练速度显著提升
+- 修正参数:总batch_size改为每张卡的batch_size
+- 修正total_epoch:最大限制100解锁至1000;默认10提升至默认20
+- 修复ckpt提取识别是否带音高错误导致推理异常的问题
+- 修复分布式训练每个rank都保存一次ckpt的问题
+- 特征提取进行nan特征过滤
+- 修复静音输入输出随机辅音or噪声的问题(老版模型需要重做训练集重训)
+
+### 20230416更新
+- 新增本地实时变声迷你GUI,双击go-realtime-gui.bat启动
+- 训练推理均对<50Hz的频段进行滤波过滤
+- 训练推理音高提取pyworld最低音高从默认80下降至50,50-80hz间的男声低音不会哑
+- WebUI支持根据系统区域变更语言(现支持en_US,ja_JP,zh_CN,zh_HK,zh_SG,zh_TW,不支持的默认en_US)
+- 修正部分显卡识别(例如V100-16G识别失败,P4识别失败)
+
+### 20230428更新
+- 升级faiss索引设置,速度更快,质量更高
+- 取消total_npy依赖,后续分享模型不再需要填写total_npy
+- 解锁16系限制。4G显存GPU给到4G的推理设置。
+- 修复部分音频格式下UVR5人声伴奏分离的bug
+- 实时变声迷你gui增加对非40k与不懈怠音高模型的支持
+
+### 后续计划:
+功能:
+- 支持多人训练选项卡(至多4人)
+
+底模:
+- 收集呼吸wav加入训练集修正呼吸变声电音的问题
+- 我们正在训练增加了歌声训练集的底模,未来会公开
+
diff --git a/docs/cn/faq.md b/docs/cn/faq.md
new file mode 100644
index 0000000000000000000000000000000000000000..43587231dfb083af43ffb1c68e2e8944598f5cbe
--- /dev/null
+++ b/docs/cn/faq.md
@@ -0,0 +1,108 @@
+## Q1:ffmpeg error/utf8 error.
+
+大概率不是ffmpeg问题,而是音频路径问题;
+ffmpeg读取路径带空格、()等特殊符号,可能出现ffmpeg error;训练集音频带中文路径,在写入filelist.txt的时候可能出现utf8 error;
+
+## Q2:一键训练结束没有索引
+
+显示"Training is done. The program is closed."则模型训练成功,后续紧邻的报错是假的;
+
+一键训练结束完成没有added开头的索引文件,可能是因为训练集太大卡住了添加索引的步骤;已通过批处理add索引解决内存add索引对内存需求过大的问题。临时可尝试再次点击"训练索引"按钮。
+
+## Q3:训练结束推理没看到训练集的音色
+点刷新音色再看看,如果还没有看看训练有没有报错,控制台和webui的截图,logs/实验名下的log,都可以发给开发者看看。
+
+## Q4:如何分享模型
+ rvc_root/logs/实验名 下面存储的pth不是用来分享模型用来推理的,而是为了存储实验状态供复现,以及继续训练用的。用来分享的模型应该是weights文件夹下大小为60+MB的pth文件;
+ 后续将把weights/exp_name.pth和logs/exp_name/added_xxx.index合并打包成weights/exp_name.zip省去填写index的步骤,那么zip文件用来分享,不要分享pth文件,除非是想换机器继续训练;
+ 如果你把logs文件夹下的几百MB的pth文件复制/分享到weights文件夹下强行用于推理,可能会出现f0,tgt_sr等各种key不存在的报错。你需要用ckpt选项卡最下面,手工或自动(本地logs下如果能找到相关信息则会自动)选择是否携带音高、目标音频采样率的选项后进行ckpt小模型提取(输入路径填G开头的那个),提取完在weights文件夹下会出现60+MB的pth文件,刷新音色后可以选择使用。
+
+## Q5:Connection Error.
+也许你关闭了控制台(黑色窗口)。
+
+## Q6:WebUI弹出Expecting value: line 1 column 1 (char 0).
+请关闭系统局域网代理/全局代理。
+
+这个不仅是客户端的代理,也包括服务端的代理(例如你使用autodl设置了http_proxy和https_proxy学术加速,使用时也需要unset关掉)
+
+## Q7:不用WebUI如何通过命令训练推理
+训练脚本:
+可先跑通WebUI,消息窗内会显示数据集处理和训练用命令行;
+
+推理脚本:
+https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/myinfer.py
+
+例子:
+
+runtime\python.exe myinfer.py 0 "E:\codes\py39\RVC-beta\todo-songs\1111.wav" "E:\codes\py39\logs\mi-test\added_IVF677_Flat_nprobe_7.index" harvest "test.wav" "weights/mi-test.pth" 0.6 cuda:0 True
+
+f0up_key=sys.argv[1]
+input_path=sys.argv[2]
+index_path=sys.argv[3]
+f0method=sys.argv[4]#harvest or pm
+opt_path=sys.argv[5]
+model_path=sys.argv[6]
+index_rate=float(sys.argv[7])
+device=sys.argv[8]
+is_half=bool(sys.argv[9])
+
+## Q8:Cuda error/Cuda out of memory.
+小概率是cuda配置问题、设备不支持;大概率是显存不够(out of memory);
+
+训练的话缩小batch size(如果缩小到1还不够只能更换显卡训练),推理的话酌情缩小config.py结尾的x_pad,x_query,x_center,x_max。4G以下显存(例如1060(3G)和各种2G显卡)可以直接放弃,4G显存显卡还有救。
+
+## Q9:total_epoch调多少比较好
+
+如果训练集音质差底噪大,20~30足够了,调太高,底模音质无法带高你的低音质训练集
+如果训练集音质高底噪低时长多,可以调高,200是ok的(训练速度很快,既然你有条件准备高音质训练集,显卡想必条件也不错,肯定不在乎多一些训练时间)
+
+## Q10:需要多少训练集时长
+ 推荐10min至50min
+ 保证音质高底噪低的情况下,如果有个人特色的音色统一,则多多益善
+ 高水平的训练集(精简+音色有特色),5min至10min也是ok的,仓库作者本人就经常这么玩
+ 也有人拿1min至2min的数据来训练并且训练成功的,但是成功经验是其他人不可复现的,不太具备参考价值。这要求训练集音色特色非常明显(比如说高频气声较明显的萝莉少女音),且音质高;
+ 1min以下时长数据目前没见有人尝试(成功)过。不建议进行这种鬼畜行为。
+
+## Q11:index rate干嘛用的,怎么调(科普)
+ 如果底模和推理源的音质高于训练集的音质,他们可以带高推理结果的音质,但代价可能是音色往底模/推理源的音色靠,这种现象叫做"音色泄露";
+ index rate用来削减/解决音色泄露问题。调到1,则理论上不存在推理源的音色泄露问题,但音质更倾向于训练集。如果训练集音质比推理源低,则index rate调高可能降低音质。调到0,则不具备利用检索混合来保护训练集音色的效果;
+ 如果训练集优质时长多,可调高total_epoch,此时模型本身不太会引用推理源和底模的音色,很少存在"音色泄露"问题,此时index_rate不重要,你甚至可以不建立/分享index索引文件。
+
+## Q11:推理怎么选gpu
+config.py文件里device cuda:后面选择卡号;
+卡号和显卡的映射关系,在训练选项卡的显卡信息栏里能看到。
+
+## Q12:如何推理训练中间保存的pth
+通过ckpt选项卡最下面提取小模型。
+
+
+## Q13:如何中断和继续训练
+现阶段只能关闭WebUI控制台双击go-web.bat重启程序。网页参数也要刷新重新填写;
+继续训练:相同网页参数点训练模型,就会接着上次的checkpoint继续训练。
+
+## Q14:训练时出现文件页面/内存error
+进程开太多了,内存炸了。你可能可以通过如下方式解决
+1、"提取音高和处理数据使用的CPU进程数" 酌情拉低;
+2、训练集音频手工切一下,不要太长。
+
+
+## Q15:如何中途加数据训练
+1、所有数据新建一个实验名;
+2、拷贝上一次的最新的那个G和D文件(或者你想基于哪个中间ckpt训练,也可以拷贝中间的)到新实验名;下
+3、一键训练新实验名,他会继续上一次的最新进度训练。
+
+## Q16: error about llvmlite.dll
+
+OSError: Could not load shared object file: llvmlite.dll
+
+FileNotFoundError: Could not find module lib\site-packages\llvmlite\binding\llvmlite.dll (or one of its dependencies). Try using the full path with constructor syntax.
+
+win平台会报这个错,装上https://aka.ms/vs/17/release/vc_redist.x64.exe这个再重启WebUI就好了。
+
+## Q17: RuntimeError: The expanded size of the tensor (17280) must match the existing size (0) at non-singleton dimension 1. Target sizes: [1, 17280]. Tensor sizes: [0]
+
+wavs16k文件夹下,找到文件大小显著比其他都小的一些音频文件,删掉,点击训练模型,就不会报错了,不过由于一键流程中断了你训练完模型还要点训练索引。
+
+## Q18: RuntimeError: The size of tensor a (24) must match the size of tensor b (16) at non-singleton dimension 2
+
+不要中途变更采样率继续训练。如果一定要变更,应更换实验名从头训练。当然你也可以把上次提取的音高和特征(0/1/2/2b folders)拷贝过去加速训练流程。
diff --git a/docs/en/Changelog_EN.md b/docs/en/Changelog_EN.md
new file mode 100644
index 0000000000000000000000000000000000000000..46ded0c756d4d30f4c11aef03713f5d49203dde2
--- /dev/null
+++ b/docs/en/Changelog_EN.md
@@ -0,0 +1,105 @@
+### 2023-10-06
+- We have created a GUI for real-time voice change: go-realtime-gui.bat/gui_v1.py (Note that you should choose the same type of input and output device, e.g. MME and MME).
+- We trained a better pitch extract RMVPE model.
+- Optimize inference GUI layout.
+
+### 2023-08-13
+1-Regular bug fix
+- Change the minimum total epoch number to 1, and change the minimum total epoch number to 2
+- Fix training errors of not using pre-train models
+- After accompaniment vocals separation, clear graphics memory
+- Change faiss save path absolute path to relative path
+- Support path containing spaces (both training set path and experiment name are supported, and errors will no longer be reported)
+- Filelist cancels mandatory utf8 encoding
+- Solve the CPU consumption problem caused by faiss searching during real-time voice changes
+
+2-Key updates
+- Train the current strongest open-source vocal pitch extraction model RMVPE, and use it for RVC training, offline/real-time inference, supporting PyTorch/Onnx/DirectML
+- Support for AMD and Intel graphics cards through Pytorch_DML
+
+(1) Real time voice change (2) Inference (3) Separation of vocal accompaniment (4) Training not currently supported, will switch to CPU training; supports RMVPE inference of gpu by Onnx_Dml
+
+
+### 2023-06-18
+- New pretrained v2 models: 32k and 48k
+- Fix non-f0 model inference errors
+- For training-set exceeding 1 hour, do automatic minibatch-kmeans to reduce feature shape, so that index training, adding, and searching will be much faster.
+- Provide a toy vocal2guitar huggingface space
+- Auto delete outlier short cut training-set audios
+- Onnx export tab
+
+Failed experiments:
+- ~~Feature retrieval: add temporal feature retrieval: not effective~~
+- ~~Feature retrieval: add PCAR dimensionality reduction: searching is even slower~~
+- ~~Random data augmentation when training: not effective~~
+
+todolist:
+- ~~Vocos-RVC (tiny vocoder): not effective~~
+- ~~Crepe support for training:replaced by RMVPE~~
+- ~~Half precision crepe inference:replaced by RMVPE. And hard to achive.~~
+- F0 editor support
+
+### 2023-05-28
+- Add v2 jupyter notebook, korean changelog, fix some environment requirments
+- Add voiceless consonant and breath protection mode
+- Support crepe-full pitch detect
+- UVR5 vocal separation: support dereverb models and de-echo models
+- Add experiment name and version on the name of index
+- Support users to manually select export format of output audios when batch voice conversion processing and UVR5 vocal separation
+- v1 32k model training is no more supported
+
+### 2023-05-13
+- Clear the redundant codes in the old version of runtime in the one-click-package: lib.infer_pack and uvr5_pack
+- Fix pseudo multiprocessing bug in training set preprocessing
+- Adding median filtering radius adjustment for harvest pitch recognize algorithm
+- Support post processing resampling for exporting audio
+- Multi processing "n_cpu" setting for training is changed from "f0 extraction" to "data preprocessing and f0 extraction"
+- Automatically detect the index paths under the logs folder and provide a drop-down list function
+- Add "Frequently Asked Questions and Answers" on the tab page (you can also refer to github RVC wiki)
+- When inference, harvest pitch is cached when using same input audio path (purpose: using harvest pitch extraction, the entire pipeline will go through a long and repetitive pitch extraction process. If caching is not used, users who experiment with different timbre, index, and pitch median filtering radius settings will experience a very painful waiting process after the first inference)
+
+### 2023-05-14
+- Use volume envelope of input to mix or replace the volume envelope of output (can alleviate the problem of "input muting and output small amplitude noise". If the input audio background noise is high, it is not recommended to turn it on, and it is not turned on by default (1 can be considered as not turned on)
+- Support saving extracted small models at a specified frequency (if you want to see the performance under different epochs, but do not want to save all large checkpoints and manually extract small models by ckpt-processing every time, this feature will be very practical)
+- Resolve the issue of "connection errors" caused by the server's global proxy by setting environment variables
+- Supports pre-trained v2 models (currently only 40k versions are publicly available for testing, and the other two sampling rates have not been fully trained yet)
+- Limit excessive volume exceeding 1 before inference
+- Slightly adjusted the settings of training-set preprocessing
+
+
+#######################
+
+History changelogs:
+
+### 2023-04-09
+- Fixed training parameters to improve GPU utilization rate: A100 increased from 25% to around 90%, V100: 50% to around 90%, 2060S: 60% to around 85%, P40: 25% to around 95%; significantly improved training speed
+- Changed parameter: total batch_size is now per GPU batch_size
+- Changed total_epoch: maximum limit increased from 100 to 1000; default increased from 10 to 20
+- Fixed issue of ckpt extraction recognizing pitch incorrectly, causing abnormal inference
+- Fixed issue of distributed training saving ckpt for each rank
+- Applied nan feature filtering for feature extraction
+- Fixed issue with silent input/output producing random consonants or noise (old models need to retrain with a new dataset)
+
+### 2023-04-16 Update
+- Added local real-time voice changing mini-GUI, start by double-clicking go-realtime-gui.bat
+- Applied filtering for frequency bands below 50Hz during training and inference
+- Lowered the minimum pitch extraction of pyworld from the default 80 to 50 for training and inference, allowing male low-pitched voices between 50-80Hz not to be muted
+- WebUI supports changing languages according to system locale (currently supporting en_US, ja_JP, zh_CN, zh_HK, zh_SG, zh_TW; defaults to en_US if not supported)
+- Fixed recognition of some GPUs (e.g., V100-16G recognition failure, P4 recognition failure)
+
+### 2023-04-28 Update
+- Upgraded faiss index settings for faster speed and higher quality
+- Removed dependency on total_npy; future model sharing will not require total_npy input
+- Unlocked restrictions for the 16-series GPUs, providing 4GB inference settings for 4GB VRAM GPUs
+- Fixed bug in UVR5 vocal accompaniment separation for certain audio formats
+- Real-time voice changing mini-GUI now supports non-40k and non-lazy pitch models
+
+### Future Plans:
+Features:
+- Add option: extract small models for each epoch save
+- Add option: export additional mp3 to the specified path during inference
+- Support multi-person training tab (up to 4 people)
+
+Base model:
+- Collect breathing wav files to add to the training dataset to fix the issue of distorted breath sounds
+- We are currently training a base model with an extended singing dataset, which will be released in the future
diff --git a/docs/en/README.en.md b/docs/en/README.en.md
new file mode 100644
index 0000000000000000000000000000000000000000..325251fd89d94a2b546d754a9dd9813441c7e340
--- /dev/null
+++ b/docs/en/README.en.md
@@ -0,0 +1,232 @@
+
+
+
Retrieval-based-Voice-Conversion-WebUI
+An easy-to-use voice conversion framework based on VITS.
+
+[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
+
+

+
+[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/tools/ipynb/v1.ipynb)
+[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/tools/ipynb/v2.ipynb)
+[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
+[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
+
+[](https://discord.gg/HcsmBBGyVk)
+
+[**Changelog**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_EN.md) | [**FAQ (Frequently Asked Questions)**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/FAQ-(Frequently-Asked-Questions))
+
+[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
+
+
+
+ | Training and inference Webui |
+ Real-time voice changing GUI |
+
+
+ 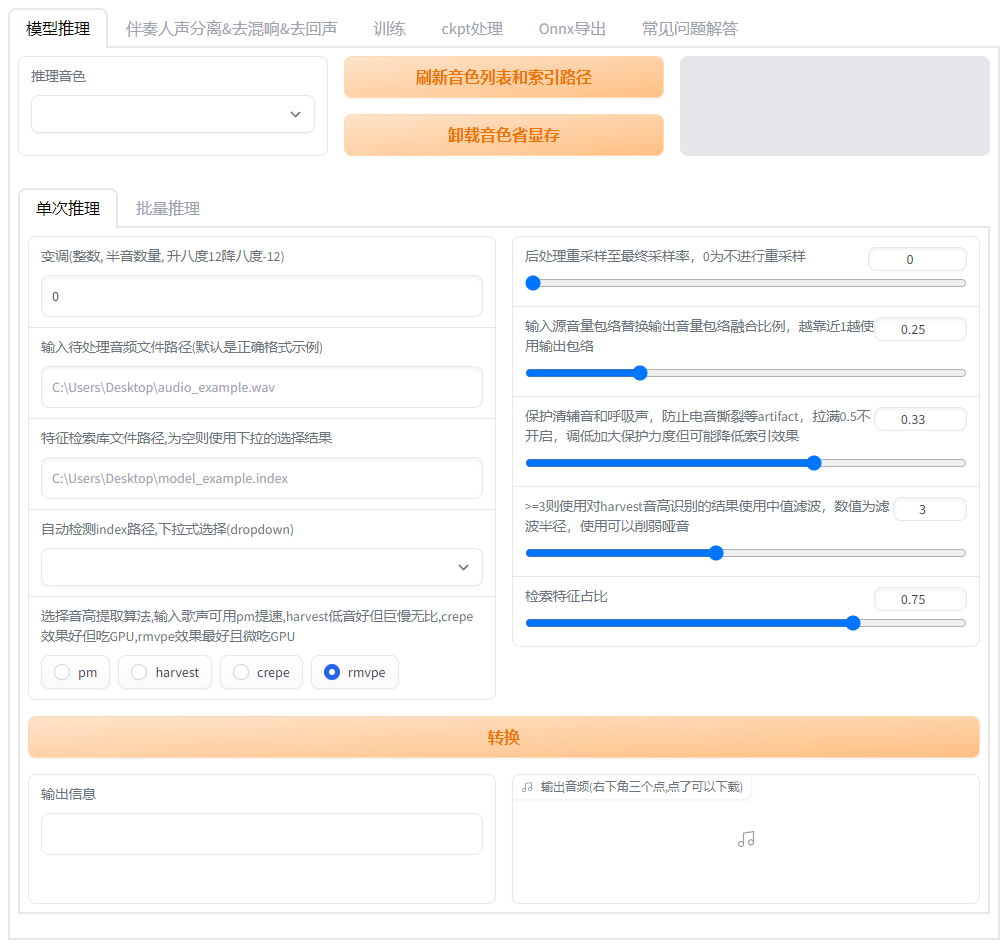 |
+  |
+
+
+ | go-web.bat |
+ go-realtime-gui.bat |
+
+
+ | You can freely choose the action you want to perform. |
+ We have achieved an end-to-end latency of 170ms. With the use of ASIO input and output devices, we have managed to achieve an end-to-end latency of 90ms, but it is highly dependent on hardware driver support. |
+
+
+
+## Features:
++ Reduce tone leakage by replacing the source feature to training-set feature using top1 retrieval;
++ Easy + fast training, even on poor graphics cards;
++ Training with a small amounts of data (>=10min low noise speech recommended);
++ Model fusion to change timbres (using ckpt processing tab->ckpt merge);
++ Easy-to-use WebUI;
++ UVR5 model to quickly separate vocals and instruments;
++ High-pitch Voice Extraction Algorithm [InterSpeech2023-RMVPE](#Credits) to prevent a muted sound problem. Provides the best results (significantly) and is faster with lower resource consumption than Crepe_full;
++ AMD/Intel graphics cards acceleration supported;
++ Intel ARC graphics cards acceleration with IPEX supported.
+
+Check out our [Demo Video](https://www.bilibili.com/video/BV1pm4y1z7Gm/) here!
+
+## Environment Configuration
+### Python Version Limitation
+> It is recommended to use conda to manage the Python environment.
+
+> For the reason of the version limitation, please refer to this [bug](https://github.com/facebookresearch/fairseq/issues/5012).
+
+```bash
+python --version # 3.8 <= Python < 3.11
+```
+
+### Linux/MacOS One-click Dependency Installation & Startup Script
+By executing `run.sh` in the project root directory, you can configure the `venv` virtual environment, automatically install the required dependencies, and start the main program with one click.
+```bash
+sh ./run.sh
+```
+
+### Manual Installation of Dependencies
+1. Install `pytorch` and its core dependencies, skip if already installed. Refer to: https://pytorch.org/get-started/locally/
+ ```bash
+ pip install torch torchvision torchaudio
+ ```
+2. If you are using Nvidia Ampere architecture (RTX30xx) in Windows, according to the experience of #21, you need to specify the cuda version corresponding to pytorch.
+ ```bash
+ pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
+ ```
+3. Install the corresponding dependencies according to your own graphics card.
+- Nvidia GPU
+ ```bash
+ pip install -r requirements.txt
+ ```
+- AMD/Intel GPU
+ ```bash
+ pip install -r requirements-dml.txt
+ ```
+- AMD ROCM (Linux)
+ ```bash
+ pip install -r requirements-amd.txt
+ ```
+- Intel IPEX (Linux)
+ ```bash
+ pip install -r requirements-ipex.txt
+ ```
+
+## Preparation of Other Files
+### 1. Assets
+> RVC requires some models located in the `assets` folder for inference and training.
+#### Check/Download Automatically (Default)
+> By default, RVC can automatically check the integrity of the required resources when the main program starts.
+
+> Even if the resources are not complete, the program will continue to start.
+
+- If you want to download all resources, please add the `--update` parameter.
+- If you want to skip the resource integrity check at startup, please add the `--nocheck` parameter.
+
+#### Download Manually
+> All resource files are located in [Hugging Face space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
+
+> You can find some scripts to download them in the `tools` folder
+
+> You can also use the [one-click downloader](https://github.com/RVC-Project/RVC-Models-Downloader) for models/integration packages/tools
+
+Below is a list that includes the names of all pre-models and other files required by RVC.
+
+- ./assets/hubert/hubert_base.pt
+ ```bash
+ rvcmd assets/hubert # RVC-Models-Downloader command
+ ```
+- ./assets/pretrained
+ ```bash
+ rvcmd assets/v1 # RVC-Models-Downloader command
+ ```
+- ./assets/uvr5_weights
+ ```bash
+ rvcmd assets/uvr5 # RVC-Models-Downloader command
+ ```
+If you want to use the v2 version of the model, you need to download additional resources in
+
+- ./assets/pretrained_v2
+ ```bash
+ rvcmd assets/v2 # RVC-Models-Downloader command
+ ```
+
+### 2. Install ffmpeg tool
+If `ffmpeg` and `ffprobe` have already been installed, you can skip this step.
+#### Ubuntu/Debian
+```bash
+sudo apt install ffmpeg
+```
+#### MacOS
+```bash
+brew install ffmpeg
+```
+#### Windows
+After downloading, place it in the root directory.
+```bash
+rvcmd tools/ffmpeg # RVC-Models-Downloader command
+```
+- [ffmpeg.exe](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe)
+
+- [ffprobe.exe](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe)
+
+### 3. Download the required files for the rmvpe vocal pitch extraction algorithm
+
+If you want to use the latest RMVPE vocal pitch extraction algorithm, you need to download the pitch extraction model parameters and place them in `assets/rmvpe`.
+
+- [rmvpe.pt](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt)
+ ```bash
+ rvcmd assets/rmvpe # RVC-Models-Downloader command
+ ```
+
+#### Download DML environment of RMVPE (optional, for AMD/Intel GPU)
+
+- [rmvpe.onnx](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx)
+ ```bash
+ rvcmd assets/rmvpe # RVC-Models-Downloader command
+ ```
+
+### 4. AMD ROCM (optional, Linux only)
+
+If you want to run RVC on a Linux system based on AMD's ROCM technology, please first install the required drivers [here](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html).
+
+If you are using Arch Linux, you can use pacman to install the required drivers.
+````
+pacman -S rocm-hip-sdk rocm-opencl-sdk
+````
+For some models of graphics cards, you may need to configure the following environment variables (such as: RX6700XT).
+````
+export ROCM_PATH=/opt/rocm
+export HSA_OVERRIDE_GFX_VERSION=10.3.0
+````
+Also, make sure your current user is in the `render` and `video` user groups.
+````
+sudo usermod -aG render $USERNAME
+sudo usermod -aG video $USERNAME
+````
+## Getting Started
+### Direct Launch
+Use the following command to start the WebUI.
+```bash
+python infer-web.py
+```
+### Linux/MacOS
+```bash
+./run.sh
+```
+### For I-card users who need to use IPEX technology (Linux only)
+```bash
+source /opt/intel/oneapi/setvars.sh
+./run.sh
+```
+### Using the Integration Package (Windows Users)
+Download and unzip `RVC-beta.7z`. After unzipping, double-click `go-web.bat` to start the program with one click.
+```bash
+rvcmd packs/general/latest # RVC-Models-Downloader command
+```
+
+## Credits
++ [ContentVec](https://github.com/auspicious3000/contentvec/)
++ [VITS](https://github.com/jaywalnut310/vits)
++ [HIFIGAN](https://github.com/jik876/hifi-gan)
++ [Gradio](https://github.com/gradio-app/gradio)
++ [FFmpeg](https://github.com/FFmpeg/FFmpeg)
++ [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
++ [audio-slicer](https://github.com/openvpi/audio-slicer)
++ [Vocal pitch extraction:RMVPE](https://github.com/Dream-High/RMVPE)
+ + The pretrained model is trained and tested by [yxlllc](https://github.com/yxlllc/RMVPE) and [RVC-Boss](https://github.com/RVC-Boss).
+
+## Thanks to all contributors for their efforts
+
+  +
diff --git a/docs/en/faiss_tips_en.md b/docs/en/faiss_tips_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..aafad6ed67f70ee1ea3a2a21ee0b5066ab1dcfa8
--- /dev/null
+++ b/docs/en/faiss_tips_en.md
@@ -0,0 +1,102 @@
+faiss tuning TIPS
+==================
+# about faiss
+faiss is a library of neighborhood searches for dense vectors, developed by facebook research, which efficiently implements many approximate neighborhood search methods.
+Approximate Neighbor Search finds similar vectors quickly while sacrificing some accuracy.
+
+## faiss in RVC
+In RVC, for the embedding of features converted by HuBERT, we search for embeddings similar to the embedding generated from the training data and mix them to achieve a conversion that is closer to the original speech. However, since this search takes time if performed naively, high-speed conversion is realized by using approximate neighborhood search.
+
+# implementation overview
+In '/logs/your-experiment/3_feature256' where the model is located, features extracted by HuBERT from each voice data are located.
+From here we read the npy files in order sorted by filename and concatenate the vectors to create big_npy. (This vector has shape [N, 256].)
+After saving big_npy as /logs/your-experiment/total_fea.npy, train it with faiss.
+
+In this article, I will explain the meaning of these parameters.
+
+# Explanation of the method
+## index factory
+An index factory is a unique faiss notation that expresses a pipeline that connects multiple approximate neighborhood search methods as a string.
+This allows you to try various approximate neighborhood search methods simply by changing the index factory string.
+In RVC it is used like this:
+
+```python
+index = faiss.index_factory(256, "IVF%s,Flat" % n_ivf)
+```
+Among the arguments of index_factory, the first is the number of dimensions of the vector, the second is the index factory string, and the third is the distance to use.
+
+For more detailed notation
+https://github.com/facebookresearch/faiss/wiki/The-index-factory
+
+## index for distance
+There are two typical indexes used as similarity of embedding as follows.
+
+- Euclidean distance (METRIC_L2)
+- inner product (METRIC_INNER_PRODUCT)
+
+Euclidean distance takes the squared difference in each dimension, sums the differences in all dimensions, and then takes the square root. This is the same as the distance in 2D and 3D that we use on a daily basis.
+The inner product is not used as an index of similarity as it is, and the cosine similarity that takes the inner product after being normalized by the L2 norm is generally used.
+
+Which is better depends on the case, but cosine similarity is often used in embedding obtained by word2vec and similar image retrieval models learned by ArcFace. If you want to do l2 normalization on vector X with numpy, you can do it with the following code with eps small enough to avoid 0 division.
+
+```python
+X_normed = X / np.maximum(eps, np.linalg.norm(X, ord=2, axis=-1, keepdims=True))
+```
+
+Also, for the index factory, you can change the distance index used for calculation by choosing the value to pass as the third argument.
+
+```python
+index = faiss.index_factory(dimention, text, faiss.METRIC_INNER_PRODUCT)
+```
+
+## IVF
+IVF (Inverted file indexes) is an algorithm similar to the inverted index in full-text search.
+During learning, the search target is clustered with kmeans, and Voronoi partitioning is performed using the cluster center. Each data point is assigned a cluster, so we create a dictionary that looks up the data points from the clusters.
+
+For example, if clusters are assigned as follows
+|index|Cluster|
+|-----|-------|
+|1|A|
+|2|B|
+|3|A|
+|4|C|
+|5|B|
+
+The resulting inverted index looks like this:
+
+|cluster|index|
+|-------|-----|
+|A|1, 3|
+|B|2, 5|
+|C|4|
+
+When searching, we first search n_probe clusters from the clusters, and then calculate the distances for the data points belonging to each cluster.
+
+# recommend parameter
+There are official guidelines on how to choose an index, so I will explain accordingly.
+https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index
+
+For datasets below 1M, 4bit-PQ is the most efficient method available in faiss as of April 2023.
+Combining this with IVF, narrowing down the candidates with 4bit-PQ, and finally recalculating the distance with an accurate index can be described by using the following index factory.
+
+```python
+index = faiss.index_factory(256, "IVF1024,PQ128x4fs,RFlat")
+```
+
+## Recommended parameters for IVF
+Consider the case of too many IVFs. For example, if coarse quantization by IVF is performed for the number of data, this is the same as a naive exhaustive search and is inefficient.
+For 1M or less, IVF values are recommended between 4*sqrt(N) ~ 16*sqrt(N) for N number of data points.
+
+Since the calculation time increases in proportion to the number of n_probes, please consult with the accuracy and choose appropriately. Personally, I don't think RVC needs that much accuracy, so n_probe = 1 is fine.
+
+## FastScan
+FastScan is a method that enables high-speed approximation of distances by Cartesian product quantization by performing them in registers.
+Cartesian product quantization performs clustering independently for each d dimension (usually d = 2) during learning, calculates the distance between clusters in advance, and creates a lookup table. At the time of prediction, the distance of each dimension can be calculated in O(1) by looking at the lookup table.
+So the number you specify after PQ usually specifies half the dimension of the vector.
+
+For a more detailed description of FastScan, please refer to the official documentation.
+https://github.com/facebookresearch/faiss/wiki/Fast-accumulation-of-PQ-and-AQ-codes-(FastScan)
+
+## RFlat
+RFlat is an instruction to recalculate the rough distance calculated by FastScan with the exact distance specified by the third argument of index factory.
+When getting k neighbors, k*k_factor points are recalculated.
diff --git a/docs/en/faq_en.md b/docs/en/faq_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..063c0e9b377cc49fced29cd3e3922b74ef934058
--- /dev/null
+++ b/docs/en/faq_en.md
@@ -0,0 +1,119 @@
+## Q1:ffmpeg error/utf8 error.
+It is most likely not a FFmpeg issue, but rather an audio path issue;
+
+FFmpeg may encounter an error when reading paths containing special characters like spaces and (), which may cause an FFmpeg error; and when the training set's audio contains Chinese paths, writing it into filelist.txt may cause a utf8 error.
+
diff --git a/docs/en/faiss_tips_en.md b/docs/en/faiss_tips_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..aafad6ed67f70ee1ea3a2a21ee0b5066ab1dcfa8
--- /dev/null
+++ b/docs/en/faiss_tips_en.md
@@ -0,0 +1,102 @@
+faiss tuning TIPS
+==================
+# about faiss
+faiss is a library of neighborhood searches for dense vectors, developed by facebook research, which efficiently implements many approximate neighborhood search methods.
+Approximate Neighbor Search finds similar vectors quickly while sacrificing some accuracy.
+
+## faiss in RVC
+In RVC, for the embedding of features converted by HuBERT, we search for embeddings similar to the embedding generated from the training data and mix them to achieve a conversion that is closer to the original speech. However, since this search takes time if performed naively, high-speed conversion is realized by using approximate neighborhood search.
+
+# implementation overview
+In '/logs/your-experiment/3_feature256' where the model is located, features extracted by HuBERT from each voice data are located.
+From here we read the npy files in order sorted by filename and concatenate the vectors to create big_npy. (This vector has shape [N, 256].)
+After saving big_npy as /logs/your-experiment/total_fea.npy, train it with faiss.
+
+In this article, I will explain the meaning of these parameters.
+
+# Explanation of the method
+## index factory
+An index factory is a unique faiss notation that expresses a pipeline that connects multiple approximate neighborhood search methods as a string.
+This allows you to try various approximate neighborhood search methods simply by changing the index factory string.
+In RVC it is used like this:
+
+```python
+index = faiss.index_factory(256, "IVF%s,Flat" % n_ivf)
+```
+Among the arguments of index_factory, the first is the number of dimensions of the vector, the second is the index factory string, and the third is the distance to use.
+
+For more detailed notation
+https://github.com/facebookresearch/faiss/wiki/The-index-factory
+
+## index for distance
+There are two typical indexes used as similarity of embedding as follows.
+
+- Euclidean distance (METRIC_L2)
+- inner product (METRIC_INNER_PRODUCT)
+
+Euclidean distance takes the squared difference in each dimension, sums the differences in all dimensions, and then takes the square root. This is the same as the distance in 2D and 3D that we use on a daily basis.
+The inner product is not used as an index of similarity as it is, and the cosine similarity that takes the inner product after being normalized by the L2 norm is generally used.
+
+Which is better depends on the case, but cosine similarity is often used in embedding obtained by word2vec and similar image retrieval models learned by ArcFace. If you want to do l2 normalization on vector X with numpy, you can do it with the following code with eps small enough to avoid 0 division.
+
+```python
+X_normed = X / np.maximum(eps, np.linalg.norm(X, ord=2, axis=-1, keepdims=True))
+```
+
+Also, for the index factory, you can change the distance index used for calculation by choosing the value to pass as the third argument.
+
+```python
+index = faiss.index_factory(dimention, text, faiss.METRIC_INNER_PRODUCT)
+```
+
+## IVF
+IVF (Inverted file indexes) is an algorithm similar to the inverted index in full-text search.
+During learning, the search target is clustered with kmeans, and Voronoi partitioning is performed using the cluster center. Each data point is assigned a cluster, so we create a dictionary that looks up the data points from the clusters.
+
+For example, if clusters are assigned as follows
+|index|Cluster|
+|-----|-------|
+|1|A|
+|2|B|
+|3|A|
+|4|C|
+|5|B|
+
+The resulting inverted index looks like this:
+
+|cluster|index|
+|-------|-----|
+|A|1, 3|
+|B|2, 5|
+|C|4|
+
+When searching, we first search n_probe clusters from the clusters, and then calculate the distances for the data points belonging to each cluster.
+
+# recommend parameter
+There are official guidelines on how to choose an index, so I will explain accordingly.
+https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index
+
+For datasets below 1M, 4bit-PQ is the most efficient method available in faiss as of April 2023.
+Combining this with IVF, narrowing down the candidates with 4bit-PQ, and finally recalculating the distance with an accurate index can be described by using the following index factory.
+
+```python
+index = faiss.index_factory(256, "IVF1024,PQ128x4fs,RFlat")
+```
+
+## Recommended parameters for IVF
+Consider the case of too many IVFs. For example, if coarse quantization by IVF is performed for the number of data, this is the same as a naive exhaustive search and is inefficient.
+For 1M or less, IVF values are recommended between 4*sqrt(N) ~ 16*sqrt(N) for N number of data points.
+
+Since the calculation time increases in proportion to the number of n_probes, please consult with the accuracy and choose appropriately. Personally, I don't think RVC needs that much accuracy, so n_probe = 1 is fine.
+
+## FastScan
+FastScan is a method that enables high-speed approximation of distances by Cartesian product quantization by performing them in registers.
+Cartesian product quantization performs clustering independently for each d dimension (usually d = 2) during learning, calculates the distance between clusters in advance, and creates a lookup table. At the time of prediction, the distance of each dimension can be calculated in O(1) by looking at the lookup table.
+So the number you specify after PQ usually specifies half the dimension of the vector.
+
+For a more detailed description of FastScan, please refer to the official documentation.
+https://github.com/facebookresearch/faiss/wiki/Fast-accumulation-of-PQ-and-AQ-codes-(FastScan)
+
+## RFlat
+RFlat is an instruction to recalculate the rough distance calculated by FastScan with the exact distance specified by the third argument of index factory.
+When getting k neighbors, k*k_factor points are recalculated.
diff --git a/docs/en/faq_en.md b/docs/en/faq_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..063c0e9b377cc49fced29cd3e3922b74ef934058
--- /dev/null
+++ b/docs/en/faq_en.md
@@ -0,0 +1,119 @@
+## Q1:ffmpeg error/utf8 error.
+It is most likely not a FFmpeg issue, but rather an audio path issue;
+
+FFmpeg may encounter an error when reading paths containing special characters like spaces and (), which may cause an FFmpeg error; and when the training set's audio contains Chinese paths, writing it into filelist.txt may cause a utf8 error.
+
+## Q2:Cannot find index file after "One-click Training".
+If it displays "Training is done. The program is closed," then the model has been trained successfully, and the subsequent errors are fake;
+
+The lack of an 'added' index file after One-click training may be due to the training set being too large, causing the addition of the index to get stuck; this has been resolved by using batch processing to add the index, which solves the problem of memory overload when adding the index. As a temporary solution, try clicking the "Train Index" button again.
+
+## Q3:Cannot find the model in “Inferencing timbre” after training
+Click “Refresh timbre list” and check again; if still not visible, check if there are any errors during training and send screenshots of the console, web UI, and logs/experiment_name/*.log to the developers for further analysis.
+
+## Q4:How to share a model/How to use others' models?
+The pth files stored in rvc_root/logs/experiment_name are not meant for sharing or inference, but for storing the experiment checkpoits for reproducibility and further training. The model to be shared should be the 60+MB pth file in the weights folder;
+
+In the future, weights/exp_name.pth and logs/exp_name/added_xxx.index will be merged into a single weights/exp_name.zip file to eliminate the need for manual index input; so share the zip file, not the pth file, unless you want to continue training on a different machine;
+
+Copying/sharing the several hundred MB pth files from the logs folder to the weights folder for forced inference may result in errors such as missing f0, tgt_sr, or other keys. You need to use the ckpt tab at the bottom to manually or automatically (if the information is found in the logs/exp_name), select whether to include pitch infomation and target audio sampling rate options and then extract the smaller model. After extraction, there will be a 60+ MB pth file in the weights folder, and you can refresh the voices to use it.
+
+## Q5:Connection Error.
+You may have closed the console (black command line window).
+
+## Q6:WebUI popup 'Expecting value: line 1 column 1 (char 0)'.
+Please disable system LAN proxy/global proxy and then refresh.
+
+## Q7:How to train and infer without the WebUI?
+Training script:
+You can run training in WebUI first, and the command-line versions of dataset preprocessing and training will be displayed in the message window.
+
+Inference script:
+https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/myinfer.py
+
+
+e.g.
+
+runtime\python.exe myinfer.py 0 "E:\codes\py39\RVC-beta\todo-songs\1111.wav" "E:\codes\py39\logs\mi-test\added_IVF677_Flat_nprobe_7.index" harvest "test.wav" "weights/mi-test.pth" 0.6 cuda:0 True
+
+
+f0up_key=sys.argv[1]
+input_path=sys.argv[2]
+index_path=sys.argv[3]
+f0method=sys.argv[4]#harvest or pm
+opt_path=sys.argv[5]
+model_path=sys.argv[6]
+index_rate=float(sys.argv[7])
+device=sys.argv[8]
+is_half=bool(sys.argv[9])
+
+## Q8:Cuda error/Cuda out of memory.
+There is a small chance that there is a problem with the CUDA configuration or the device is not supported; more likely, there is not enough memory (out of memory).
+
+For training, reduce the batch size (if reducing to 1 is still not enough, you may need to change the graphics card); for inference, adjust the x_pad, x_query, x_center, and x_max settings in the config.py file as needed. 4G or lower memory cards (e.g. 1060(3G) and various 2G cards) can be abandoned, while 4G memory cards still have a chance.
+
+## Q9:How many total_epoch are optimal?
+If the training dataset's audio quality is poor and the noise floor is high, 20-30 epochs are sufficient. Setting it too high won't improve the audio quality of your low-quality training set.
+
+If the training set audio quality is high, the noise floor is low, and there is sufficient duration, you can increase it. 200 is acceptable (since training is fast, and if you're able to prepare a high-quality training set, your GPU likely can handle a longer training duration without issue).
+
+## Q10:How much training set duration is needed?
+
+A dataset of around 10min to 50min is recommended.
+
+With guaranteed high sound quality and low bottom noise, more can be added if the dataset's timbre is uniform.
+
+For a high-level training set (lean + distinctive tone), 5min to 10min is fine.
+
+There are some people who have trained successfully with 1min to 2min data, but the success is not reproducible by others and is not very informative.
This requires that the training set has a very distinctive timbre (e.g. a high-frequency airy anime girl sound) and the quality of the audio is high;
+Data of less than 1min duration has not been successfully attempted so far. This is not recommended.
+
+
+## Q11:What is the index rate for and how to adjust it?
+If the tone quality of the pre-trained model and inference source is higher than that of the training set, they can bring up the tone quality of the inference result, but at the cost of a possible tone bias towards the tone of the underlying model/inference source rather than the tone of the training set, which is generally referred to as "tone leakage".
+
+The index rate is used to reduce/resolve the timbre leakage problem. If the index rate is set to 1, theoretically there is no timbre leakage from the inference source and the timbre quality is more biased towards the training set. If the training set has a lower sound quality than the inference source, then a higher index rate may reduce the sound quality. Turning it down to 0 does not have the effect of using retrieval blending to protect the training set tones.
+
+If the training set has good audio quality and long duration, turn up the total_epoch, when the model itself is less likely to refer to the inferred source and the pretrained underlying model, and there is little "tone leakage", the index_rate is not important and you can even not create/share the index file.
+
+## Q12:How to choose the gpu when inferring?
+In the config.py file, select the card number after "device cuda:".
+
+The mapping between card number and graphics card can be seen in the graphics card information section of the training tab.
+
+## Q13:How to use the model saved in the middle of training?
+Save via model extraction at the bottom of the ckpt processing tab.
+
+## Q14:File/memory error(when training)?
+Too many processes and your memory is not enough. You may fix it by:
+
+1、decrease the input in field "Threads of CPU".
+
+2、pre-cut trainset to shorter audio files.
+
+## Q15: How to continue training using more data
+
+step1: put all wav data to path2.
+
+step2: exp_name2+path2 -> process dataset and extract feature.
+
+step3: copy the latest G and D file of exp_name1 (your previous experiment) into exp_name2 folder.
+
+step4: click "train the model", and it will continue training from the beginning of your previous exp model epoch.
+
+## Q16: error about llvmlite.dll
+
+OSError: Could not load shared object file: llvmlite.dll
+
+FileNotFoundError: Could not find module lib\site-packages\llvmlite\binding\llvmlite.dll (or one of its dependencies). Try using the full path with constructor syntax.
+
+The issue will happen in windows, install https://aka.ms/vs/17/release/vc_redist.x64.exe and it will be fixed.
+
+## Q17: RuntimeError: The expanded size of the tensor (17280) must match the existing size (0) at non-singleton dimension 1. Target sizes: [1, 17280]. Tensor sizes: [0]
+
+Delete the wav files whose size is significantly smaller than others, and that won't happen again. Than click "train the model"and "train the index".
+
+## Q18: RuntimeError: The size of tensor a (24) must match the size of tensor b (16) at non-singleton dimension 2
+
+Do not change the sampling rate and then continue training. If it is necessary to change, the exp name should be changed and the model will be trained from scratch. You can also copy the pitch and features (0/1/2/2b folders) extracted last time to accelerate the training process.
+
diff --git a/docs/en/training_tips_en.md b/docs/en/training_tips_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..2aca8a77a864298a890b8b926505a6eef5f27319
--- /dev/null
+++ b/docs/en/training_tips_en.md
@@ -0,0 +1,65 @@
+Instructions and tips for RVC training
+======================================
+This TIPS explains how data training is done.
+
+# Training flow
+I will explain along the steps in the training tab of the GUI.
+
+## step1
+Set the experiment name here.
+
+You can also set here whether the model should take pitch into account.
+If the model doesn't consider pitch, the model will be lighter, but not suitable for singing.
+
+Data for each experiment is placed in `/logs/your-experiment-name/`.
+
+## step2a
+Loads and preprocesses audio.
+
+### load audio
+If you specify a folder with audio, the audio files in that folder will be read automatically.
+For example, if you specify `C:Users\hoge\voices`, `C:Users\hoge\voices\voice.mp3` will be loaded, but `C:Users\hoge\voices\dir\voice.mp3` will Not loaded.
+
+Since ffmpeg is used internally for reading audio, if the extension is supported by ffmpeg, it will be read automatically.
+After converting to int16 with ffmpeg, convert to float32 and normalize between -1 to 1.
+
+### denoising
+The audio is smoothed by scipy's filtfilt.
+
+### Audio Split
+First, the input audio is divided by detecting parts of silence that last longer than a certain period (max_sil_kept=5 seconds?). After splitting the audio on silence, split the audio every 4 seconds with an overlap of 0.3 seconds. For audio separated within 4 seconds, after normalizing the volume, convert the wav file to `/logs/your-experiment-name/0_gt_wavs` and then convert it to 16k sampling rate to `/logs/your-experiment-name/1_16k_wavs ` as a wav file.
+
+## step2b
+### Extract pitch
+Extract pitch information from wav files. Extract the pitch information (=f0) using the method built into parselmouth or pyworld and save it in `/logs/your-experiment-name/2a_f0`. Then logarithmically convert the pitch information to an integer between 1 and 255 and save it in `/logs/your-experiment-name/2b-f0nsf`.
+
+### Extract feature_print
+Convert the wav file to embedding in advance using HuBERT. Read the wav file saved in `/logs/your-experiment-name/1_16k_wavs`, convert the wav file to 256-dimensional features with HuBERT, and save in npy format in `/logs/your-experiment-name/3_feature256`.
+
+## step3
+train the model.
+### Glossary for Beginners
+In deep learning, the data set is divided and the learning proceeds little by little. In one model update (step), batch_size data are retrieved and predictions and error corrections are performed. Doing this once for a dataset counts as one epoch.
+
+Therefore, the learning time is the learning time per step x (the number of data in the dataset / batch size) x the number of epochs. In general, the larger the batch size, the more stable the learning becomes (learning time per step ÷ batch size) becomes smaller, but it uses more GPU memory. GPU RAM can be checked with the nvidia-smi command. Learning can be done in a short time by increasing the batch size as much as possible according to the machine of the execution environment.
+
+### Specify pretrained model
+RVC starts training the model from pretrained weights instead of from 0, so it can be trained with a small dataset.
+
+By default
+
+- If you consider pitch, it loads `rvc-location/pretrained/f0G40k.pth` and `rvc-location/pretrained/f0D40k.pth`.
+- If you don't consider pitch, it loads `rvc-location/pretrained/G40k.pth` and `rvc-location/pretrained/D40k.pth`.
+
+When learning, model parameters are saved in `logs/your-experiment-name/G_{}.pth` and `logs/your-experiment-name/D_{}.pth` for each save_every_epoch, but by specifying this path, you can start learning. You can restart or start training from model weights learned in a different experiment.
+
+### learning index
+RVC saves the HuBERT feature values used during training, and during inference, searches for feature values that are similar to the feature values used during learning to perform inference. In order to perform this search at high speed, the index is learned in advance.
+For index learning, we use the approximate neighborhood search library faiss. Read the feature value of `logs/your-experiment-name/3_feature256` and use it to learn the index, and save it as `logs/your-experiment-name/add_XXX.index`.
+
+(From the 20230428update version, it is read from the index, and saving / specifying is no longer necessary.)
+
+### Button description
+- Train model: After executing step2b, press this button to train the model.
+- Train feature index: After training the model, perform index learning.
+- One-click training: step2b, model training and feature index training all at once.
\ No newline at end of file
diff --git a/docs/fr/Changelog_FR.md b/docs/fr/Changelog_FR.md
new file mode 100644
index 0000000000000000000000000000000000000000..a0b4e07a3b83fc250cefaecf4fa95cf42e94c124
--- /dev/null
+++ b/docs/fr/Changelog_FR.md
@@ -0,0 +1,102 @@
+### 2023-08-13
+1-Corrections régulières de bugs
+- Modification du nombre total d'époques minimum à 1 et changement du nombre total d'époques minimum à 2
+- Correction des erreurs d'entraînement sans utiliser de modèles pré-entraînés
+- Après la séparation des voix d'accompagnement, libération de la mémoire graphique
+- Changement du chemin absolu d'enregistrement de faiss en chemin relatif
+- Prise en charge des chemins contenant des espaces (le chemin du jeu de données d'entraînement et le nom de l'expérience sont pris en charge, et aucune erreur ne sera signalée)
+- La liste de fichiers annule l'encodage utf8 obligatoire
+- Résolution du problème de consommation de CPU causé par la recherche faiss lors des changements de voix en temps réel
+
+2-Mises à jour clés
+- Entraînement du modèle d'extraction de hauteur vocale open-source le plus puissant actuel, RMVPE, et utilisation pour l'entraînement, l'inférence hors ligne/en temps réel de RVC, supportant PyTorch/Onnx/DirectML
+- Prise en charge des cartes graphiques AMD et Intel via Pytorch_DML
+
+(1) Changement de voix en temps réel (2) Inférence (3) Séparation de l'accompagnement vocal (4) L'entraînement n'est pas actuellement pris en charge, passera à l'entraînement CPU; prend en charge l'inférence RMVPE de la GPU par Onnx_Dml
+
+### 2023-06-18
+- Nouveaux modèles pré-entraînés v2 : 32k et 48k
+- Correction des erreurs d'inférence du modèle non-f0
+- Pour un jeu de données d'entraînement dépassant 1 heure, réalisation automatique de minibatch-kmeans pour réduire la forme des caractéristiques, afin que l'entraînement, l'ajout et la recherche d'index soient beaucoup plus rapides.
+- Fourniture d'un espace huggingface vocal2guitar jouet
+- Suppression automatique des audios de jeu de données d'entraînement court-circuitant les valeurs aberrantes
+- Onglet d'exportation Onnx
+
+Expériences échouées:
+- ~~Récupération de caractéristiques : ajout de la récupération de caractéristiques temporelles : non efficace~~
+- ~~Récupération de caractéristiques : ajout de la réduction de dimensionnalité PCAR : la recherche est encore plus lente~~
+- ~~Augmentation aléatoire des données lors de l'entraînement : non efficace~~
+
+Liste de tâches:
+- ~~Vocos-RVC (vocodeur minuscule) : non efficace~~
+- ~~Support de Crepe pour l'entraînement : remplacé par RMVPE~~
+- ~~Inférence de précision à moitié crepe : remplacée par RMVPE. Et difficile à réaliser.~~
+- Support de l'éditeur F0
+
+### 2023-05-28
+- Ajout d'un cahier v2, changelog coréen, correction de certaines exigences environnementales
+- Ajout d'un mode de protection des consonnes muettes et de la respiration
+- Support de la détection de hauteur crepe-full
+- Séparation vocale UVR5 : support des modèles de déréverbération et de désécho
+- Ajout du nom de l'expérience et de la version sur le nom de l'index
+- Support pour les utilisateurs de sélectionner manuellement le format d'exportation des audios de sortie lors du traitement de conversion vocale en lots et de la séparation vocale UVR5
+- L'entraînement du modèle v1 32k n'est plus pris en charge
+
+### 2023-05-13
+- Nettoyage des codes redondants de l'ancienne version du runtime dans le package en un clic : lib.infer_pack et uvr5_pack
+- Correction du bug de multiprocessus pseudo dans la préparation du jeu de données d'entraînement
+- Ajout de l'ajustement du rayon de filtrage médian pour l'algorithme de reconnaissance de hauteur de récolte
+- Prise en charge du rééchantillonnage post-traitement pour l'exportation audio
+- Réglage de multi-traitement "n_cpu" pour l'entraînement est passé de "extraction f0" à "prétraitement des données et extraction f0"
+- Détection automatique des chemins d'index sous le dossier de logs et fourniture d'une fonction de liste déroulante
+- Ajout de "Questions fréquemment posées et réponses" sur la page d'onglet (vous pouvez également consulter le wiki github RVC)
+- Lors de l'inférence, la hauteur de la récolte est mise en cache lors de l'utilisation du même chemin d'accès audio d'entrée (objectif : en utilisant l'extraction de
+
+ la hauteur de la récolte, l'ensemble du pipeline passera par un long processus d'extraction de la hauteur répétitif. Si la mise en cache n'est pas utilisée, les utilisateurs qui expérimentent différents timbres, index, et réglages de rayon de filtrage médian de hauteur connaîtront un processus d'attente très douloureux après la première inférence)
+
+### 2023-05-14
+- Utilisation de l'enveloppe de volume de l'entrée pour mixer ou remplacer l'enveloppe de volume de la sortie (peut atténuer le problème du "muet en entrée et bruit de faible amplitude en sortie". Si le bruit de fond de l'audio d'entrée est élevé, il n'est pas recommandé de l'activer, et il n'est pas activé par défaut (1 peut être considéré comme n'étant pas activé)
+- Prise en charge de la sauvegarde des modèles extraits à une fréquence spécifiée (si vous voulez voir les performances sous différentes époques, mais que vous ne voulez pas sauvegarder tous les grands points de contrôle et extraire manuellement les petits modèles par ckpt-processing à chaque fois, cette fonctionnalité sera très pratique)
+- Résolution du problème des "erreurs de connexion" causées par le proxy global du serveur en définissant des variables d'environnement
+- Prise en charge des modèles pré-entraînés v2 (actuellement, seule la version 40k est disponible au public pour les tests, et les deux autres taux d'échantillonnage n'ont pas encore été entièrement entraînés)
+- Limite le volume excessif dépassant 1 avant l'inférence
+- Réglages légèrement ajustés de la préparation du jeu de données d'entraînement
+
+#######################
+
+Historique des changelogs:
+
+### 2023-04-09
+- Correction des paramètres d'entraînement pour améliorer le taux d'utilisation du GPU : A100 est passé de 25% à environ 90%, V100 : de 50% à environ 90%, 2060S : de 60% à environ 85%, P40 : de 25% à environ 95% ; amélioration significative de la vitesse d'entraînement
+- Changement de paramètre : la taille de batch_size totale est maintenant la taille de batch_size par GPU
+- Changement de total_epoch : la limite maximale est passée de 100 à 1000 ; la valeur par défaut est passée de 10 à 20
+- Correction du problème d'extraction de ckpt reconnaissant la hauteur de manière incorrecte, causant une inférence anormale
+- Correction du problème d'entraînement distribué sauvegardant ckpt pour chaque rang
+- Application du filtrage des caractéristiques nan pour l'extraction des caractéristiques
+- Correction du problème d'entrée/sortie silencieuse produisant des consonnes aléatoires ou du bruit (les anciens modèles doivent être réentraînés avec un nouveau jeu de données)
+
+### 2023-04-16 Mise à jour
+- Ajout d'une mini-interface graphique pour le changement de voix en temps réel, démarrage par double-clic sur go-realtime-gui.bat
+- Application d'un filtrage pour les bandes de fréquences inférieures à 50Hz pendant l'entraînement et l'inférence
+- Abaissement de l'extraction de hauteur minimale de pyworld du défaut 80 à 50 pour l'entraînement et l'inférence, permettant aux voix masculines graves entre 50-80Hz de ne pas être mises en sourdine
+- WebUI prend en charge le changement de langue en fonction des paramètres régionaux du système (prise en charge actuelle de en_US, ja_JP, zh_CN, zh_HK, zh_SG, zh_TW ; défaut à en_US si non pris en charge)
+- Correction de la reconnaissance de certains GPU (par exemple, échec de reconnaissance V100-16G, échec de reconnaissance P4)
+
+### 2023-04-28 Mise à jour
+- Mise à niveau des paramètres d'index de faiss pour une vitesse plus rapide et une meilleure qualité
+- Suppression de la dépendance à total_npy ; le partage futur de modèles ne nécessitera pas d'entrée total
+
+_npy
+- Levée des restrictions pour les GPU de la série 16, fournissant des paramètres d'inférence de 4 Go pour les GPU VRAM de 4 Go
+- Correction d'un bug dans la séparation vocale d'accompagnement UVR5 pour certains formats audio
+- La mini-interface de changement de voix en temps réel prend maintenant en charge les modèles de hauteur non-40k et non-lazy
+
+### Plans futurs :
+Fonctionnalités :
+- Ajouter une option : extraire de petits modèles pour chaque sauvegarde d'époque
+- Ajouter une option : exporter un mp3 supplémentaire vers le chemin spécifié pendant l'inférence
+- Prise en charge de l'onglet d'entraînement multi-personnes (jusqu'à 4 personnes)
+
+Modèle de base :
+- Collecter des fichiers wav de respiration pour les ajouter au jeu de données d'entraînement pour résoudre le problème des sons de respiration déformés
+- Nous entraînons actuellement un modèle de base avec un jeu de données de chant étendu, qui sera publié à l'avenir
diff --git a/docs/fr/README.fr.md b/docs/fr/README.fr.md
new file mode 100644
index 0000000000000000000000000000000000000000..d466c933a2693573280cabe7768ac133c9f40b15
--- /dev/null
+++ b/docs/fr/README.fr.md
@@ -0,0 +1,179 @@
+
+
+
Retrieval-based-Voice-Conversion-WebUI
+Un framework simple et facile à utiliser pour la conversion vocale (modificateur de voix) basé sur VITS
+
+[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
+
+
+
+[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/tools/ipynb/v1.ipynb)
+[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/tools/ipynb/v2.ipynb)
+[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
+[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
+
+[](https://discord.gg/HcsmBBGyVk)
+
+[**Journal de mise à jour**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_CN.md) | [**FAQ**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·Formation d'un chanteur AI pour 5 centimes**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**Enregistrement des expériences comparatives**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95) | [**Démonstration en ligne**](https://huggingface.co/spaces/Ricecake123/RVC-demo)
+
+
+
+## Q2: Impossible de trouver le fichier index après "Entraînement en un clic".
+Si l'affichage indique "L'entraînement est terminé. Le programme est fermé", alors le modèle a été formé avec succès, et les erreurs subséquentes sont fausses ;
+
+L'absence d'un fichier index 'ajouté' après un entraînement en un clic peut être due au fait que le jeu d'entraînement est trop grand, ce qui bloque l'ajout de l'index ; cela a été résolu en utilisant un traitement par lots pour ajouter l'index, ce qui résout le problème de surcharge de mémoire lors de l'ajout de l'index. Comme solution temporaire, essayez de cliquer à nouveau sur le bouton "Entraîner l'index".
+
+## Q3: Impossible de trouver le modèle dans “Inférence du timbre” après l'entraînement
+Cliquez sur “Actualiser la liste des timbres” et vérifiez à nouveau ; si vous ne le voyez toujours pas, vérifiez s'il y a des erreurs pendant l'entraînement et envoyez des captures d'écran de la console, de l'interface utilisateur web, et des logs/nom_de_l'expérience/*.log aux développeurs pour une analyse plus approfondie.
+
+## Q4: Comment partager un modèle/Comment utiliser les modèles d'autres personnes ?
+Les fichiers pth stockés dans rvc_root/logs/nom_de_l'expérience ne sont pas destinés à être partagés ou inférés, mais à stocker les points de contrôle de l'expérience pour la reproductibilité et l'entraînement ultérieur. Le modèle à partager doit être le fichier pth de 60+MB dans le dossier des poids ;
+
+À l'avenir, les poids/nom_de_l'expérience.pth et les logs/nom_de_l'expérience/ajouté_xxx.index seront fusionnés en un seul fichier poids/nom_de_l'expérience.zip pour éliminer le besoin d'une entrée d'index manuelle ; partagez donc le fichier zip, et non le fichier pth, sauf si vous souhaitez continuer l'entraînement sur une machine différente ;
+
+Copier/partager les fichiers pth de plusieurs centaines de Mo du dossier des logs au dossier des poids pour une inférence forcée peut entraîner des erreurs telles que des f0, tgt_sr, ou d'autres clés manquantes. Vous devez utiliser l'onglet ckpt en bas pour sélectionner manuellement ou automatiquement (si l'information se trouve dans les logs/nom_de_l'expérience), si vous souhaitez inclure les informations sur la hauteur et les options de taux d'échantillonnage audio cible, puis extraire le modèle plus petit. Après extraction, il y aura un fichier pth de 60+ MB dans le dossier des poids, et vous pouvez actualiser les voix pour l'utiliser.
+
+## Q5: Erreur de connexion.
+Il se peut que vous ayez fermé la console (fenêtre de ligne de commande noire).
+
+## Q6: WebUI affiche 'Expecting value: line 1 column 1 (char 0)'.
+Veuillez désactiver le proxy système LAN/proxy global puis rafraîchir.
+
+## Q7: Comment s'entraîner et déduire sans le WebUI ?
+Script d'entraînement :
+Vous pouvez d'abord lancer l'entraînement dans WebUI, et les versions en ligne de commande de la préparation du jeu de données et de l'entraînement seront affichées dans la fenêtre de message.
+
+Script d'inférence :
+https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/myinfer.py
+
+Par exemple :
+
+runtime\python.exe myinfer.py 0 "E:\codes\py39\RVC-beta\todo-songs\1111.wav" "E:\codes\py39\logs\mi-test\added_IVF677_Flat_nprobe_7.index" récolte "test.wav" "weights/mi-test.pth" 0.6 cuda:0 True
+
+f0up_key=sys.argv[1]
+input_path=sys.argv[2]
+index_path=sys.argv[3]
+f0method=sys.argv[4]#récolte ou pm
+opt_path=sys.argv[5]
+model_path=sys.argv[6]
+index_rate=float(sys.argv[7])
+device=sys.argv[8]
+is_half=bool(sys.argv[9])
+
+### Explication des arguments :
+
+1. **Numéro de voix cible** : `0` (dans cet exemple)
+2. **Chemin du fichier audio d'entrée** : `"C:\ YOUR PATH FOR THE ROOT (RVC0813Nvidia)\INPUTS_VOCAL\vocal.wav"`
+3. **Chemin du fichier index** : `"C:\ YOUR PATH FOR THE ROOT (RVC0813Nvidia)\logs\Hagrid.index"`
+4. **Méthode pour l'extraction du pitch (F0)** : `harvest` (dans cet exemple)
+5. **Chemin de sortie pour le fichier audio traité** : `"C:\ YOUR PATH FOR THE ROOT (RVC0813Nvidia)\INPUTS_VOCAL\test.wav"`
+6. **Chemin du modèle** : `"C:\ YOUR PATH FOR THE ROOT (RVC0813Nvidia)\weights\HagridFR.pth"`
+7. **Taux d'index** : `0.6` (dans cet exemple)
+8. **Périphérique pour l'exécution (GPU/CPU)** : `cuda:0` pour une carte NVIDIA, par exemple.
+9. **Protection des droits d'auteur (True/False)**.
+
+
+
+## Q8: Erreur Cuda/Mémoire Cuda épuisée.
+Il y a une faible chance qu'il y ait un problème avec la configuration CUDA ou que le dispositif ne soit pas pris en charge ; plus probablement, il n'y a pas assez de mémoire (manque de mémoire).
+
+Pour l'entraînement, réduisez la taille du lot (si la réduction à 1 n'est toujours pas suffisante, vous devrez peut-être changer la carte graphique) ; pour l'inférence, ajustez les paramètres x_pad, x_query, x_center, et x_max dans le fichier config.py selon les besoins. Les cartes mémoire de 4 Go ou moins (par exemple 1060(3G) et diverses cartes de 2 Go) peuvent être abandonnées, tandis que les cartes mémoire de 4 Go ont encore une chance.
+
+## Q9: Combien de total_epoch sont optimaux ?
+Si la qualité audio du jeu d'entraînement est médiocre et que le niveau de bruit est élevé, 20-30 époques sont suffisantes. Le fixer trop haut n'améliorera pas la qualité audio de votre jeu d'entraînement de faible qualité.
+
+Si la qualité audio du jeu d'entraînement est élevée, le niveau de bruit est faible, et la durée est suffisante, vous pouvez l'augmenter. 200 est acceptable (puisque l'entraînement est rapide, et si vous êtes capable de préparer un jeu d'entraînement de haute qualité, votre GPU peut probablement gérer une durée d'entraînement plus longue sans problème).
+
+## Q10: Quelle durée de jeu d'entraînement est nécessaire ?
+Un jeu d'environ 10 min à 50 min est recommandé.
+
+Avec une garantie de haute qualité sonore et de faible bruit de fond, plus peut être ajouté si le timbre du jeu est uniforme.
+
+Pour un jeu d'entraînement de haut niveau (ton maigre + ton distinctif), 5 min à 10 min sont suffisantes.
+
+Il y a des personnes qui ont réussi à s'entraîner avec des données de 1 min à 2 min, mais le succès n'est pas reproductible par d'autres et n'est pas très informatif.
Cela nécessite que le jeu d'entraînement ait un timbre très distinctif (par exemple, un son de fille d'anime aérien à haute fréquence) et que la qualité de l'audio soit élevée ;
+Aucune tentative réussie n'a été faite jusqu'à présent avec des données de moins de 1 min. Cela n'est pas recommandé.
+
+## Q11: À quoi sert le taux d'index et comment l'ajuster ?
+Si la qualité tonale du modèle pré-entraîné et de la source d'inférence est supérieure à celle du jeu d'entraînement, ils peuvent améliorer la qualité tonale du résultat d'inférence, mais au prix d'un possible biais tonal vers le ton du modèle sous-jacent/source d'inférence plutôt que le ton du jeu d'entraînement, ce qui est généralement appelé "fuite de ton".
+
+Le taux d'index est utilisé pour réduire/résoudre le problème de la fuite de timbre. Si le taux d'index est fixé à 1, théoriquement il n'y a pas de fuite de timbre de la source d'inférence et la qualité du timbre est plus biaisée vers le jeu d'entraînement. Si le jeu d'entraînement a une qualité sonore inférieure à celle de la source d'inférence, alors un taux d'index plus élevé peut réduire la qualité sonore. Le réduire à 0 n'a pas l'effet d'utiliser le mélange de récupération pour protéger les tons du jeu d'entraînement.
+
+Si le jeu d'entraînement a une bonne qualité audio et une longue durée, augmentez le total_epoch, lorsque le modèle lui-même est moins susceptible de se référer à la source déduite et au modèle sous-jacent pré-entraîné, et qu'il y a peu de "fuite de ton", le taux d'index n'est pas important et vous pouvez même ne pas créer/partager le fichier index.
+
+## Q12: Comment choisir le gpu lors de l'inférence ?
+Dans le fichier config.py, sélectionnez le numéro de carte après "device cuda:".
+
+La correspondance entre le numéro de carte et la carte graphique peut être vue dans la section d'information de la carte graphique de l'onglet d'entraînement.
+
+## Q13: Comment utiliser le modèle sauvegardé au milieu de l'entraînement ?
+Sauvegardez via l'extraction de modèle en bas de l'onglet de traitement ckpt.
+
+## Q14: Erreur de fichier/erreur de mémoire (lors de l'entraînement) ?
+Il y a trop de processus et votre mémoire n'est pas suffisante. Vous pouvez le corriger en :
+
+1. Diminuer l'entrée dans le champ "Threads of CPU".
+
+2. Pré-découper le jeu d'entraînement en fichiers audio plus courts.
+
+## Q15: Comment poursuivre l'entraînement avec plus de données
+
+étape 1 : mettre toutes les données wav dans path2.
+
+étape 2 : exp_name2+path2 -> traiter le jeu de données et extraire la caractéristique.
+
+étape 3 : copier les derniers fichiers G et D de exp_name1 (votre expérience précédente) dans le dossier exp_name2.
+
+étape 4 : cliquez sur "entraîner le modèle", et il continuera l'entraînement depuis le début de votre époque de modèle exp précédente.
+
+## Q16: erreur à propos de llvmlite.dll
+
+OSError: Impossible de charger le fichier objet partagé : llvmlite.dll
+
+FileNotFoundError: Impossible de trouver le module lib\site-packages\llvmlite\binding\llvmlite.dll (ou l'une de ses dépendances). Essayez d'utiliser la syntaxe complète du constructeur.
+
+Le problème se produira sous Windows, installez https://aka.ms/vs/17/release/vc_redist.x64.exe et il sera corrigé.
+
+## Q17: RuntimeError: La taille étendue du tensor (17280) doit correspondre à la taille existante (0) à la dimension non-singleton 1. Tailles cibles : [1, 17280]. Tailles des tensors : [0]
+
+Supprimez les fichiers wav dont la taille est nettement inférieure à celle des autres, et cela ne se reproduira plus. Ensuite, cliquez sur "entraîner le modèle" et "entraîner l'index".
+
+## Q18: RuntimeError: La taille du tensor a (24) doit correspondre à la taille du tensor b (16) à la dimension non-singleton 2
+
+Ne changez pas le taux d'échantillonnage puis continuez l'entraînement. S'il est nécessaire de changer, le nom de l'expérience doit être modifié et le modèle sera formé à partir de zéro. Vous pouvez également copier les hauteurs et caractéristiques (dossiers 0/1/2/2b) extraites la dernière fois pour accélérer le processus d'entraînement.
+
diff --git a/docs/fr/training_tips_fr.md b/docs/fr/training_tips_fr.md
new file mode 100644
index 0000000000000000000000000000000000000000..836b45049c31741fd80efb4b1a344935c89bb878
--- /dev/null
+++ b/docs/fr/training_tips_fr.md
@@ -0,0 +1,65 @@
+Instructions et conseils pour la formation RVC
+======================================
+Ces conseils expliquent comment se déroule la formation des données.
+
+# Flux de formation
+Je vais expliquer selon les étapes de l'onglet de formation de l'interface graphique.
+
+## étape 1
+Définissez ici le nom de l'expérience.
+
+Vous pouvez également définir ici si le modèle doit prendre en compte le pitch.
+Si le modèle ne considère pas le pitch, le modèle sera plus léger, mais pas adapté au chant.
+
+Les données de chaque expérience sont placées dans `/logs/nom-de-votre-experience/`.
+
+## étape 2a
+Charge et pré-traite l'audio.
+
+### charger l'audio
+Si vous spécifiez un dossier avec de l'audio, les fichiers audio de ce dossier seront lus automatiquement.
+Par exemple, si vous spécifiez `C:Users\hoge\voices`, `C:Users\hoge\voices\voice.mp3` sera chargé, mais `C:Users\hoge\voices\dir\voice.mp3` ne sera pas chargé.
+
+Comme ffmpeg est utilisé en interne pour lire l'audio, si l'extension est prise en charge par ffmpeg, elle sera lue automatiquement.
+Après la conversion en int16 avec ffmpeg, convertir en float32 et normaliser entre -1 et 1.
+
+### débruitage
+L'audio est lissé par filtfilt de scipy.
+
+### Séparation audio
+Tout d'abord, l'audio d'entrée est divisé en détectant des parties de silence qui durent plus d'une certaine période (max_sil_kept = 5 secondes ?). Après avoir séparé l'audio sur le silence, séparez l'audio toutes les 4 secondes avec un chevauchement de 0,3 seconde. Pour l'audio séparé en 4 secondes, après normalisation du volume, convertir le fichier wav en `/logs/nom-de-votre-experience/0_gt_wavs` puis le convertir à un taux d'échantillonnage de 16k dans `/logs/nom-de-votre-experience/1_16k_wavs` sous forme de fichier wav.
+
+## étape 2b
+### Extraire le pitch
+Extrait les informations de pitch des fichiers wav. Extraire les informations de pitch (=f0) en utilisant la méthode intégrée dans parselmouth ou pyworld et les sauvegarder dans `/logs/nom-de-votre-experience/2a_f0`. Convertissez ensuite logarithmiquement les informations de pitch en un entier entre 1 et 255 et sauvegardez-le dans `/logs/nom-de-votre-experience/2b-f0nsf`.
+
+### Extraire l'empreinte de caractéristique
+Convertissez le fichier wav en incorporation à l'avance en utilisant HuBERT. Lisez le fichier wav sauvegardé dans `/logs/nom-de-votre-experience/1_16k_wavs`, convertissez le fichier wav en caractéristiques de dimension 256 avec HuBERT, et sauvegardez au format npy dans `/logs/nom-de-votre-experience/3_feature256`.
+
+## étape 3
+former le modèle.
+### Glossaire pour les débutants
+Dans l'apprentissage profond, l'ensemble de données est divisé et l'apprentissage progresse petit à petit. Dans une mise à jour de modèle (étape), les données de batch_size sont récupérées et des prédictions et corrections d'erreur sont effectuées. Faire cela une fois pour un ensemble de données compte comme une époque.
+
+Par conséquent, le temps d'apprentissage est le temps d'apprentissage par étape x (le nombre de données dans l'ensemble de données / taille du lot) x le nombre d'époques. En général, plus la taille du lot est grande, plus l'apprentissage devient stable (temps d'apprentissage par étape ÷ taille du lot) devient plus petit, mais il utilise plus de mémoire GPU. La RAM GPU peut être vérifiée avec la commande nvidia-smi. L'apprentissage peut être effectué en peu de temps en augmentant la taille du lot autant que possible selon la machine de l'environnement d'exécution.
+
+### Spécifier le modèle pré-entraîné
+RVC commence à former le modèle à partir de poids pré-entraînés plutôt que de zéro, il peut donc être formé avec un petit ensemble de données.
+
+Par défaut :
+
+- Si vous considérez le pitch, il charge `rvc-location/pretrained/f0G40k.pth` et `rvc-location/pretrained/f0D40k.pth`.
+- Si vous ne considérez pas le pitch, il charge `rvc-location/pretrained/f0G40k.pth` et `rvc-location/pretrained/f0D40k.pth`.
+
+Lors de l'apprentissage, les paramètres du modèle sont sauvegardés dans `logs/nom-de-votre-experience/G_{}.pth` et `logs/nom-de-votre-experience/D_{}.pth` pour chaque save_every_epoch, mais en spécifiant ce chemin, vous pouvez démarrer l'apprentissage. Vous pouvez redémarrer ou commencer à former à partir de poids de modèle appris lors d'une expérience différente.
+
+### Index d'apprentissage
+RVC sauvegarde les valeurs de caractéristique HuBERT utilisées lors de la formation, et pendant l'inférence, recherche les valeurs de caractéristique qui sont similaires aux valeurs de caractéristique utilisées lors de l'apprentissage pour effectuer l'inférence. Afin d'effectuer cette recherche à haute vitesse, l'index est appris à l'avance.
+Pour l'apprentissage d'index, nous utilisons la bibliothèque de recherche de voisinage approximatif faiss. Lisez la valeur de caractéristique de `logs/nom-de-votre-experience/3_feature256` et utilisez-la pour apprendre l'index, et sauvegardez-la sous `logs/nom-de-votre-experience/add_XXX.index`.
+
+(À partir de la version de mise à jour 20230428, elle est lue à partir de l'index, et la sauvegarde / spécification n'est plus nécessaire.)
+
+### Description du bouton
+- Former le modèle : après avoir exécuté l'étape 2b, appuyez sur ce bouton pour former le modèle.
+- Former l'index de caractéristique : après avoir formé le modèle, effectuez un apprentissage d'index.
+- Formation en un clic : étape 2b, formation du modèle et formation de l'index de caractéristique tout d'un coup.```
diff --git a/docs/jp/Changelog_JA.md b/docs/jp/Changelog_JA.md
new file mode 100644
index 0000000000000000000000000000000000000000..80d3a0ee38fb0dafcd2a325446397b811ca55f9e
--- /dev/null
+++ b/docs/jp/Changelog_JA.md
@@ -0,0 +1,123 @@
+### 2023 年 10 月 6 日更新
+
+リアルタイム声変換のためのインターフェース go-realtime-gui.bat/gui_v1.py を作成しました(実際には既に存在していました)。今回のアップデートでは、リアルタイム声変換のパフォーマンスを重点的に最適化しました。0813 版との比較:
+
+- 1. インターフェース操作の最適化:パラメータのホット更新(パラメータ調整時に中断して再起動する必要がない)、レイジーロードモデル(既にロードされたモデルは再ロードする必要がない)、音量因子パラメータ追加(音量を入力オーディオに近づける)
+- 2. 内蔵ノイズリダクション効果と速度の最適化
+- 3. 推論速度の大幅な最適化
+
+入出力デバイスは同じタイプを選択する必要があります。例えば、両方とも MME タイプを選択します。
+
+1006 バージョンの全体的な更新は:
+
+- 1. rmvpe 音声ピッチ抽出アルゴリズムの効果をさらに向上、特に男性の低音部分で大きな改善
+- 2. 推論インターフェースレイアウトの最適化
+
+### 2023 年 8 月 13 日更新
+
+1-通常のバグ修正
+
+- 保存頻度と総ラウンド数の最小値を 1 に変更。総ラウンド数の最小値を 2 に変更
+- pretrain モデルなしでのトレーニングエラーを修正
+- 伴奏とボーカルの分離完了後の VRAM クリア
+- faiss 保存パスを絶対パスから相対パスに変更
+- パスに空白が含まれる場合のサポート(トレーニングセットのパス+実験名がサポートされ、エラーにならない)
+- filelist の強制的な utf8 エンコーディングをキャンセル
+- リアルタイム声変換中にインデックスを有効にすることによる CPU の大幅な使用問題を解決
+
+2-重要なアップデート
+
+- 現在最も強力なオープンソースの人間の声のピッチ抽出モデル RMVPE をトレーニングし、RVC のトレーニング、オフライン/リアルタイム推論に使用。pytorch/onnx/DirectML をサポート
+- pytorch-dml を通じて A カードと I カードのサポート
+ (1)リアルタイム声変換(2)推論(3)ボーカルと伴奏の分離(4)トレーニングはまだサポートされておらず、CPU でのトレーニングに切り替わります。onnx_dml を通じて rmvpe_gpu の推論をサポート
+
+### 2023 年 6 月 18 日更新
+
+- v2 に 32k と 48k の 2 つの新しい事前トレーニングモデルを追加
+- 非 f0 モデルの推論エラーを修正
+- 1 時間を超えるトレーニングセットのインデックス構築フェーズでは、自動的に kmeans で特徴を縮小し、インデックスのトレーニングを加速し、検索に追加
+- 人間の声をギターに変換するおもちゃのリポジトリを添付
+- データ処理で異常値スライスを除外
+- onnx エクスポートオプションタブ
+
+失敗した実験:
+
+- ~~特徴検索に時間次元を追加:ダメ、効果がない~~
+- ~~特徴検索に PCAR 次元削減オプションを追加:ダメ、大きなデータは kmeans でデータ量を減らし、小さいデータは次元削減の時間が節約するマッチングの時間よりも長い~~
+- ~~onnx 推論のサポート(推論のみの小さな圧縮パッケージ付き):ダメ、nsf の生成には pytorch が必要~~
+- ~~トレーニング中に音声、ジェンダー、eq、ノイズなどで入力をランダムに増強:ダメ、効果がない~~
+- ~~小型声码器の接続調査:ダメ、効果が悪化~~
+
+todolist:
+
+- ~~トレーニングセットの音声ピッチ認識に crepe をサポート:既に RMVPE に置き換えられているため不要~~
+- ~~多プロセス harvest 推論:既に RMVPE に置き換えられているため不要~~
+- ~~crepe の精度サポートと RVC-config の同期:既に RMVPE に置き換えられているため不要。これをサポートするには torchcrepe ライブラリも同期する必要があり、面倒~~
+- F0 エディタとの連携
+
+### 2023 年 5 月 28 日更新
+
+- v2 の jupyter notebook を追加、韓国語の changelog を追加、いくつかの環境依存関係を追加
+- 呼吸、清辅音、歯音の保護モードを追加
+- crepe-full 推論をサポート
+- UVR5 人間の声と伴奏の分離に 3 つの遅延除去モデルと MDX-Net の混响除去モデルを追加、HP3 人声抽出モデルを追加
+- インデックス名にバージョンと実験名を追加
+- 人間の声と伴奏の分離、推論のバッチエクスポートにオーディオエクスポートフォーマットオプションを追加
+- 32k モデルのトレーニングを廃止
+
+### 2023 年 5 月 13 日更新
+
+- ワンクリックパッケージ内の古いバージョンの runtime 内の lib.infer_pack と uvr5_pack の残骸をクリア
+- トレーニングセットの事前処理の擬似マルチプロセスバグを修正
+- harvest による音声ピッチ認識で無声音現象を弱めるために中間値フィルターを追加、中間値フィルターの半径を調整可能
+- 音声エクスポートにポストプロセスリサンプリングを追加
+- トレーニング時の n_cpu プロセス数を「F0 抽出のみ調整」から「データ事前処理と F0 抽出の調整」に変更
+- logs フォルダ下の index パスを自動検出し、ドロップダウンリスト機能を提供
+- タブページに「よくある質問」を追加(または github-rvc-wiki を参照)
+- 同じパスの入力音声推論に音声ピッチキャッシュを追加(用途:harvest 音声ピッチ抽出を使用すると、全体のパイプラインが長く繰り返される音声ピッチ抽出プロセスを経験し、キャッシュを使用しない場合、異なる音色、インデックス、音声ピッチ中間値フィルター半径パラメーターをテストするユーザーは、最初のテスト後の待機結果が非常に苦痛になります)
+
+### 2023 年 5 月 14 日更新
+
+- 音量エンベロープのアライメント入力ミックス(「入力が無音で出力がわずかなノイズ」の問題を緩和することができます。入力音声の背景ノイズが大きい場合は、オンにしないことをお勧めします。デフォルトではオフ(1 として扱われる))
+- 指定された頻度で抽出された小型モデルを保存する機能をサポート(異なるエポックでの推論効果を試したいが、すべての大きなチェックポイントを保存して手動で小型モデルを抽出するのが面倒な場合、この機能は非常に便利です)
+- システム全体のプロキシが開かれている場合にブラウザの接続エラーが発生する問題を環境変数の設定で解決
+- v2 事前訓練モデルをサポート(現在、テストのために 40k バージョンのみが公開されており、他の 2 つのサンプリングレートはまだ完全に訓練されていません)
+- 推論前に 1 を超える過大な音量を制限
+- データ事前処理パラメーターを微調整
+
+### 2023 年 4 月 9 日更新
+
+- トレーニングパラメーターを修正し、GPU の平均利用率を向上させる。A100 は最高 25%から約 90%に、V100 は 50%から約 90%に、2060S は 60%から約 85%に、P40 は 25%から約 95%に向上し、トレーニング速度が大幅に向上
+- パラメーターを修正:全体の batch_size を各カードの batch_size に変更
+- total_epoch を修正:最大制限 100 から 1000 に解除; デフォルト 10 からデフォルト 20 に引き上げ
+- ckpt 抽出時に音声ピッチの有無を誤って認識し、推論が異常になる問題を修正
+- 分散トレーニングで各ランクが ckpt を 1 回ずつ保存する問題を修正
+- 特徴抽出で nan 特徴をフィルタリング
+- 入力が無音で出力がランダムな子音またはノイズになる問題を修正(旧バージョンのモデルはトレーニングセットを作り直して再トレーニングする必要があります)
+
+### 2023 年 4 月 16 日更新
+
+- ローカルリアルタイム音声変換ミニ GUI を新設、go-realtime-gui.bat をダブルクリックで起動
+- トレーニングと推論で 50Hz 以下の周波数帯をフィルタリング
+- トレーニングと推論の音声ピッチ抽出 pyworld の最低音声ピッチをデフォルトの 80 から 50 に下げ、50-80hz の男性低音声が無声にならないように
+- WebUI がシステムの地域に基づいて言語を変更する機能をサポート(現在サポートされているのは en_US、ja_JP、zh_CN、zh_HK、zh_SG、zh_TW、サポートされていない場合はデフォルトで en_US になります)
+- 一部のグラフィックカードの認識を修正(例えば V100-16G の認識失敗、P4 の認識失敗)
+
+### 2023 年 4 月 28 日更新
+
+- faiss インデックス設定をアップグレードし、速度が速く、品質が高くなりました
+- total_npy 依存をキャンセルし、今後のモデル共有では total_npy の記入は不要
+- 16 シリーズの制限を解除。4G メモリ GPU に 4G の推論設定を提供
+- 一部のオーディオ形式で UVR5 の人声伴奏分離のバグを修正
+- リアルタイム音声変換ミニ gui に 40k 以外のモデルと妥協のない音声ピッチモデルのサポートを追加
+
+### 今後の計画:
+
+機能:
+
+- 複数人のトレーニングタブのサポート(最大 4 人)
+
+底層モデル:
+
+- 呼吸 wav をトレーニングセットに追加し、呼吸が音声変換の電子音の問題を修正
+- 歌声トレーニングセットを追加した底層モデルをトレーニングしており、将来的には公開する予定です
diff --git a/docs/jp/README.ja.md b/docs/jp/README.ja.md
new file mode 100644
index 0000000000000000000000000000000000000000..1fa6b5d250b85357cdacde92ce4d81c748b416a4
--- /dev/null
+++ b/docs/jp/README.ja.md
@@ -0,0 +1,237 @@
+
+
+
Retrieval-based-Voice-Conversion-WebUI
+VITSに基づく使いやすい音声変換(voice changer)framework
+
+[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
+
+
+
+[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/tools/ipynb/v1.ipynb)
+[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/tools/ipynb/v2.ipynb)
+[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
+[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
+
+[](https://discord.gg/HcsmBBGyVk)
+
+[**更新日誌**](./Changelog_JA.md) | [**よくある質問**](./faq_ja.md) | [**AutoDLで推論(中国語のみ)**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**対照実験記録**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95) | [**オンラインデモ(中国語のみ)**](https://modelscope.cn/studios/FlowerCry/RVCv2demo)
+
+[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
+
+
+
+ | 学習・推論 |
+ 即時音声変換 |
+
+
+ |
+ |
+
+
+ | go-web.bat |
+ go-realtime-gui.bat |
+
+
+ | 実行したい操作を自由に選択できます。 |
+ 既に端から端までの170msの遅延を実現しました。ASIO入出力デバイスを使用すれば、端から端までの90msの遅延を達成できますが、ハードウェアドライバーの支援に非常に依存しています。 |
+
+
+
+## はじめに
+
+本リポジトリには下記の特徴があります。
+
+- Top1 検索を用いることで、生の特徴量を学習用データセット特徴量に変換し、トーンリーケージを削減します。
+- 比較的貧弱な GPU でも、高速かつ簡単に学習できます。
+- 少量のデータセットからでも、比較的良い結果を得ることができます。(10 分以上のノイズの少ない音声を推奨します。)
+- モデルを融合することで、音声を混ぜることができます。(ckpt processing タブの、ckpt merge を使用します。)
+- 使いやすい WebUI。
+- UVR5 Model も含んでいるため、人の声と BGM を素早く分離できます。
+- 最先端の[人間の声のピッチ抽出アルゴリズム InterSpeech2023-RMVPE](#参照プロジェクト)を使用して無声音問題を解決します。効果は最高(著しく)で、crepe_full よりも速く、リソース使用が少ないです。
+- AMD GPU と Intel GPU の加速サポート
+
+デモ動画は[こちら](https://www.bilibili.com/video/BV1pm4y1z7Gm/)でご覧ください。
+
+## 環境構築
+### Python バージョン制限
+> conda で Python 環境を管理することがお勧めです
+
+> バージョン制限の原因はこの [bug](https://github.com/facebookresearch/fairseq/issues/5012) を参照してください。
+
+```bash
+python --version # 3.8 <= Python < 3.11
+```
+
+### Linux/MacOS ワンクリック依存関係インストール・起動するスクリプト
+プロジェクトのルートディレクトリで`run.sh`を実行するだけで、`venv`仮想環境を一括設定し、必要な依存関係を自動的にインストールし、メインプログラムを起動できます。
+```bash
+sh ./run.sh
+```
+
+### 依存関係のマニュアルインストレーション
+1. `pytorch`とそのコア依存関係をインストールします。すでにインストールされている場合は見送りできます。参考: https://pytorch.org/get-started/locally/
+ ```bash
+ pip install torch torchvision torchaudio
+ ```
+2. もし、Windows + Nvidia Ampere (RTX30xx)の場合、#21 の経験に基づき、pytorchの対応する CUDA バージョンを指定する必要があります。
+ ```bash
+ pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
+ ```
+3. 自分の GPU に対応する依存関係をインストールします。
+- Nvidia GPU
+ ```bash
+ pip install -r requirements.txt
+ ```
+- AMD/Intel GPU
+ ```bash
+ pip install -r requirements-dml.txt
+ ```
+- AMD ROCM (Linux)
+ ```bash
+ pip install -r requirements-amd.txt
+ ```
+- Intel IPEX (Linux)
+ ```bash
+ pip install -r requirements-ipex.txt
+ ```
+
+## その他のデータを準備
+
+### 1. アセット
+> RVCは、`assets`フォルダにある幾つかのモデルリソースで推論・学習することが必要です。
+#### リソースの自動チェック/ダウンロード(デフォルト)
+> デフォルトでは、RVC は主プログラムの起動時に必要なリソースの完全性を自動的にチェックしできます。
+
+> リソースが不完全でも、プログラムは起動し続けます。
+
+- すべてのリソースをダウンロードしたい場合は、`--update`パラメータを追加してください。
+- 起動時のリソース完全性チェックを不要の場合は、`--nocheck`パラメータを追加してください。
+
+#### リソースのマニュアルダウンロード
+> すべてのリソースファイルは[Hugging Face space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)にあります。
+
+> `tools`フォルダでそれらをダウンロードするスクリプトを見つけることができます。
+
+> モデル/統合パッケージ/ツールの一括ダウンローダー、[RVC-Models-Downloader](https://github.com/RVC-Project/RVC-Models-Downloader)も使用できます。
+
+以下は、RVCが必要とするすべての事前モデルデータやその他のファイルの名前を含むリストです。
+
+- ./assets/hubert/hubert_base.pt
+ ```bash
+ rvcmd assets/hubert # RVC-Models-Downloader command
+ ```
+- ./assets/pretrained
+ ```bash
+ rvcmd assets/v1 # RVC-Models-Downloader command
+ ```
+- ./assets/uvr5_weights
+ ```bash
+ rvcmd assets/uvr5 # RVC-Models-Downloader command
+ ```
+v2バージョンのモデルを使用したい場合は、追加ダウンロードが必要です。
+
+- ./assets/pretrained_v2
+ ```bash
+ rvcmd assets/v2 # RVC-Models-Downloader command
+ ```
+
+### 2. ffmpegツールのインストール
+`ffmpeg`と`ffprobe`がすでにインストールされている場合は、このステップをスキップできます。
+
+#### Ubuntu/Debian
+```bash
+sudo apt install ffmpeg
+```
+#### MacOS
+```bash
+brew install ffmpeg
+```
+#### Windows
+ダウンロード後、ルートディレクトリに配置しましょう。
+```bash
+rvcmd tools/ffmpeg # RVC-Models-Downloader command
+```
+- [ffmpeg.exe](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe)
+
+- [ffprobe.exe](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe)
+
+### 3. RMVPE人声音高抽出アルゴリズムに必要なファイルのダウンロード
+
+最新のRMVPE人声音高抽出アルゴリズムを使用したい場合は、音高抽出モデルをダウンロードし、`assets/rmvpe`に配置する必要があります。
+
+- [rmvpe.pt](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt)
+ ```bash
+ rvcmd assets/rmvpe # RVC-Models-Downloader command
+ ```
+
+#### RMVPE(dml環境)のダウンロード(オプション、AMD/Intel GPU ユーザー)
+
+- [rmvpe.onnx](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx)
+ ```bash
+ rvcmd assets/rmvpe # RVC-Models-Downloader command
+ ```
+
+### 4. AMD ROCM(オプション、Linuxのみ)
+
+AMDのRocm技術を基にLinuxシステムでRVCを実行したい場合は、まず[ここ](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html)で必要なドライバをインストールしてください。
+
+Arch Linuxを使用している場合は、pacmanを使用して必要なドライバをインストールできます。
+````
+pacman -S rocm-hip-sdk rocm-opencl-sdk
+````
+一部のグラフィックカードモデルでは、以下のような環境変数を追加で設定する必要があるかもしれません(例:RX6700XT)。
+````
+export ROCM_PATH=/opt/rocm
+export HSA_OVERRIDE_GFX_VERSION=10.3.0
+````
+また、現在のユーザーが`render`および`video`ユーザーグループに所属していることを確認してください。
+````
+sudo usermod -aG render $USERNAME
+sudo usermod -aG video $USERNAME
+````
+
+## 利用開始
+### 直接起動
+以下のコマンドで WebUI を起動します
+```bash
+python infer-web.py
+```
+### Linux/MacOS
+```bash
+./run.sh
+```
+### IPEX 技術が必要な Intel GPU ユーザー向け(Linux のみ)
+```bash
+source /opt/intel/oneapi/setvars.sh
+./run.sh
+```
+### 統合パッケージの使用 (Windowsのみ)
+`RVC-beta.7z`をダウンロードして解凍し、`go-web.bat`をダブルクリック。
+```bash
+rvcmd packs/general/latest # RVC-Models-Downloader command
+```
+
+## 参考プロジェクト
+- [ContentVec](https://github.com/auspicious3000/contentvec/)
+- [VITS](https://github.com/jaywalnut310/vits)
+- [HIFIGAN](https://github.com/jik876/hifi-gan)
+- [Gradio](https://github.com/gradio-app/gradio)
+- [FFmpeg](https://github.com/FFmpeg/FFmpeg)
+- [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
+- [audio-slicer](https://github.com/openvpi/audio-slicer)
+- [Vocal pitch extraction:RMVPE](https://github.com/Dream-High/RMVPE)
+ - 事前学習されたモデルは[yxlllc](https://github.com/yxlllc/RMVPE)と[RVC-Boss](https://github.com/RVC-Boss)によって学習され、テストされました。
+
+## すべての貢献者の努力に感謝します
+
+
+
+
diff --git a/docs/jp/faiss_tips_ja.md b/docs/jp/faiss_tips_ja.md
new file mode 100644
index 0000000000000000000000000000000000000000..89cf5ba565d6c2ccdab5c8ec9566663bfdc3fbfc
--- /dev/null
+++ b/docs/jp/faiss_tips_ja.md
@@ -0,0 +1,101 @@
+faiss tuning TIPS
+==================
+# about faiss
+faissはfacebook researchの開発する、密なベクトルに対する近傍探索をまとめたライブラリで、多くの近似近傍探索の手法を効率的に実装しています。
+近似近傍探索はある程度精度を犠牲にしながら高速に類似するベクトルを探します。
+
+## faiss in RVC
+RVCではHuBERTで変換した特徴量のEmbeddingに対し、学習データから生成されたEmbeddingと類似するものを検索し、混ぜることでより元の音声に近い変換を実現しています。ただ、この検索は愚直に行うと時間がかかるため、近似近傍探索を用いることで高速な変換を実現しています。
+
+# 実装のoverview
+モデルが配置されている '/logs/your-experiment/3_feature256'には各音声データからHuBERTで抽出された特徴量が配置されています。
+ここからnpyファイルをファイル名でソートした順番で読み込み、ベクトルを連結してbig_npyを作成しfaissを学習させます。(このベクトルのshapeは[N, 256]です。)
+
+本Tipsではまずこれらのパラメータの意味を解説します。
+
+# 手法の解説
+## index factory
+index factoryは複数の近似近傍探索の手法を繋げるパイプラインをstringで表記するfaiss独自の記法です。
+これにより、index factoryの文字列を変更するだけで様々な近似近傍探索の手法を試せます。
+RVCでは以下のように使われています。
+
+```python
+index = faiss.index_factory(256, "IVF%s,Flat" % n_ivf)
+```
+index_factoryの引数のうち、1つ目はベクトルの次元数、2つ目はindex factoryの文字列で、3つ目には用いる距離を指定することができます。
+
+より詳細な記法については
+https://github.com/facebookresearch/faiss/wiki/The-index-factory
+
+## 距離指標
+embeddingの類似度として用いられる代表的な指標として以下の二つがあります。
+
+- ユークリッド距離(METRIC_L2)
+- 内積(METRIC_INNER_PRODUCT)
+
+ユークリッド距離では各次元において二乗の差をとり、全次元の差を足してから平方根をとります。これは日常的に用いる2次元、3次元での距離と同じです。
+内積はこのままでは類似度の指標として用いず、一般的にはL2ノルムで正規化してから内積をとるコサイン類似度を用います。
+
+どちらがよいかは場合によりますが、word2vec等で得られるembeddingやArcFace等で学習した類似画像検索のモデルではコサイン類似度が用いられることが多いです。ベクトルXに対してl2正規化をnumpyで行う場合は、0 divisionを避けるために十分に小さな値をepsとして以下のコードで可能です。
+
+```python
+X_normed = X / np.maximum(eps, np.linalg.norm(X, ord=2, axis=-1, keepdims=True))
+```
+
+また、index factoryには第3引数に渡す値を選ぶことで計算に用いる距離指標を変更できます。
+
+```python
+index = faiss.index_factory(dimention, text, faiss.METRIC_INNER_PRODUCT)
+```
+
+## IVF
+IVF(Inverted file indexes)は全文検索における転置インデックスと似たようなアルゴリズムです。
+学習時には検索対象に対してkmeansでクラスタリングを行い、クラスタ中心を用いてボロノイ分割を行います。各データ点には一つずつクラスタが割り当てられるので、クラスタからデータ点を逆引きする辞書を作成します。
+
+例えば以下のようにクラスタが割り当てられた場合
+|index|クラスタ|
+|-----|-------|
+|1|A|
+|2|B|
+|3|A|
+|4|C|
+|5|B|
+
+作成される転置インデックスは以下のようになります。
+
+|クラスタ|index|
+|-------|-----|
+|A|1, 3|
+|B|2, 5|
+|C|4|
+
+検索時にはまずクラスタからn_probe個のクラスタを検索し、次にそれぞれのクラスタに属するデータ点について距離を計算します。
+
+# 推奨されるパラメータ
+indexの選び方については公式にガイドラインがあるので、それに準じて説明します。
+https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index
+
+1M以下のデータセットにおいては4bit-PQが2023年4月時点ではfaissで利用できる最も効率的な手法です。
+これをIVFと組み合わせ、4bit-PQで候補を絞り、最後に正確な指標で距離を再計算するには以下のindex factoryを用いることで記載できます。
+
+```python
+index = faiss.index_factory(256, "IVF1024,PQ128x4fs,RFlat")
+```
+
+## IVFの推奨パラメータ
+IVFの数が多すぎる場合、たとえばデータ数の数だけIVFによる粗量子化を行うと、これは愚直な全探索と同じになり効率が悪いです。
+1M以下の場合ではIVFの値はデータ点の数Nに対して4*sqrt(N) ~ 16*sqrt(N)に推奨しています。
+
+n_probeはn_probeの数に比例して計算時間が増えるので、精度と相談して適切に選んでください。個人的にはRVCにおいてそこまで精度は必要ないと思うのでn_probe = 1で良いと思います。
+
+## FastScan
+FastScanは直積量子化で大まかに距離を近似するのを、レジスタ内で行うことにより高速に行うようにした手法です。
+直積量子化は学習時にd次元ごと(通常はd=2)に独立してクラスタリングを行い、クラスタ同士の距離を事前計算してlookup tableを作成します。予測時はlookup tableを見ることで各次元の距離をO(1)で計算できます。
+そのため、PQの次に指定する数字は通常ベクトルの半分の次元を指定します。
+
+FastScanに関するより詳細な説明は公式のドキュメントを参照してください。
+https://github.com/facebookresearch/faiss/wiki/Fast-accumulation-of-PQ-and-AQ-codes-(FastScan)
+
+## RFlat
+RFlatはFastScanで計算した大まかな距離を、index factoryの第三引数で指定した正確な距離で再計算する指示です。
+k個の近傍を取得する際は、k*k_factor個の点について再計算が行われます。
diff --git a/docs/jp/faq_ja.md b/docs/jp/faq_ja.md
new file mode 100644
index 0000000000000000000000000000000000000000..704f55fb393e27c5506d32aad3a1232e7ea15d78
--- /dev/null
+++ b/docs/jp/faq_ja.md
@@ -0,0 +1,122 @@
+## Q1: ffmpeg error/utf8 error
+
+大体の場合、ffmpeg の問題ではなく、音声パスの問題です。
+ffmpeg は空白や()などの特殊文字を含むパスを読み込む際に ffmpeg error が発生する可能性があります。トレーニングセットの音声が中国語のパスを含む場合、filelist.txt に書き込む際に utf8 error が発生する可能性があります。
+
+## Q2: ワンクリックトレーニングが終わってもインデックスがない
+
+"Training is done. The program is closed."と表示された場合、モデルトレーニングは成功しています。その直後のエラーは誤りです。
+
+ワンクリックトレーニングが終了しても added で始まるインデックスファイルがない場合、トレーニングセットが大きすぎてインデックス追加のステップが停止している可能性があります。バッチ処理 add インデックスでメモリの要求が高すぎる問題を解決しました。一時的に「トレーニングインデックス」ボタンをもう一度クリックしてみてください。
+
+## Q3: トレーニングが終了してもトレーニングセットの音色が見えない
+
+音色をリフレッシュしてもう一度確認してください。それでも見えない場合は、トレーニングにエラーがなかったか、コンソールと WebUI のスクリーンショット、logs/実験名の下のログを開発者に送って確認してみてください。
+
+## Q4: モデルをどのように共有するか
+
+rvc_root/logs/実験名の下に保存されている pth は、推論に使用するために共有するためのものではなく、実験の状態を保存して再現およびトレーニングを続けるためのものです。共有するためのモデルは、weights フォルダの下にある 60MB 以上の pth ファイルです。
+ 今後、weights/exp_name.pth と logs/exp_name/added_xxx.index を組み合わせて weights/exp_name.zip にパッケージ化し、インデックスの記入ステップを省略します。その場合、zip ファイルを共有し、pth ファイルは共有しないでください。別のマシンでトレーニングを続ける場合を除きます。
+ logs フォルダの数百 MB の pth ファイルを weights フォルダにコピー/共有して推論に強制的に使用すると、f0、tgt_sr などのさまざまなキーが存在しないというエラーが発生する可能性があります。ckpt タブの一番下で、音高、目標オーディオサンプリングレートを手動または自動(ローカルの logs に関連情報が見つかる場合は自動的に)で選択してから、ckpt の小型モデルを抽出する必要があります(入力パスに G で始まるものを記入)。抽出が完了すると、weights フォルダに 60MB 以上の pth ファイルが表示され、音色をリフレッシュした後に使用できます。
+
+## Q5: Connection Error
+
+コンソール(黒いウィンドウ)を閉じた可能性があります。
+
+## Q6: WebUI が Expecting value: line 1 column 1 (char 0)と表示する
+
+システムのローカルネットワークプロキシ/グローバルプロキシを閉じてください。
+
+これはクライアントのプロキシだけでなく、サーバー側のプロキシも含まれます(例えば autodl で http_proxy と https_proxy を設定して学術的な加速を行っている場合、使用する際には unset でオフにする必要があります)。
+
+## Q7: WebUI を使わずにコマンドでトレーニングや推論を行うには
+
+トレーニングスクリプト:
+まず WebUI を実行し、メッセージウィンドウにデータセット処理とトレーニング用のコマンドラインが表示されます。
+
+推論スクリプト:
+https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/myinfer.py
+
+例:
+
+runtime\python.exe myinfer.py 0 "E:\codes\py39\RVC-beta\todo-songs\1111.wav" "E:\codes\py39\logs\mi-test\added_IVF677_Flat_nprobe_7.index" harvest "test.wav" "weights/mi-test.pth" 0.6 cuda:0 True
+
+f0up_key=sys.argv[1]
+input_path=sys.argv[2]
+index_path=sys.argv[3]
+f0method=sys.argv[4]#harvest or pm
+opt_path=sys.argv[5]
+model_path=sys.argv[6]
+index_rate=float(sys.argv[7])
+device=sys.argv[8]
+is_half=bool(sys.argv[9])
+
+## Q8: Cuda error/Cuda out of memory
+
+まれに cuda の設定問題やデバイスがサポートされていない可能性がありますが、大半はメモリ不足(out of memory)が原因です。
+
+トレーニングの場合は batch size を小さくします(1 にしても足りない場合はグラフィックカードを変更するしかありません)。推論の場合は、config.py の末尾にある x_pad、x_query、x_center、x_max を適宜小さくします。4GB 以下のメモリ(例えば 1060(3G)や各種 2GB のグラフィックカード)は諦めることをお勧めしますが、4GB のメモリのグラフィックカードはまだ救いがあります。
+
+## Q9: total_epoch はどのくらいに設定するのが良いですか
+
+トレーニングセットの音質が悪く、ノイズが多い場合は、20〜30 で十分です。高すぎると、ベースモデルの音質が低音質のトレーニングセットを高めることができません。
+トレーニングセットの音質が高く、ノイズが少なく、長い場合は、高く設定できます。200 は問題ありません(トレーニング速度が速いので、高音質のトレーニングセットを準備できる条件がある場合、グラフィックカードも条件が良いはずなので、少しトレーニング時間が長くなることを気にすることはありません)。
+
+## Q10: トレーニングセットはどれくらいの長さが必要ですか
+
+10 分から 50 分を推奨します。
+ 音質が良く、バックグラウンドノイズが低い場合、個人的な特徴のある音色であれば、多ければ多いほど良いです。
+ 高品質のトレーニングセット(精巧に準備された + 特徴的な音色)であれば、5 分から 10 分でも大丈夫です。リポジトリの作者もよくこの方法で遊びます。
+ 1 分から 2 分のデータでトレーニングに成功した人もいますが、その成功体験は他人には再現できないため、あまり参考になりません。トレーニングセットの音色が非常に特徴的である必要があります(例:高い周波数の透明な声や少女の声など)、そして音質が良い必要があります。
+ 1 分未満のデータでトレーニングを試みた(成功した)ケースはまだ見たことがありません。このような試みはお勧めしません。
+
+## Q11: index rate は何に使うもので、どのように調整するのか(啓蒙)
+
+もしベースモデルや推論ソースの音質がトレーニングセットよりも高い場合、推論結果の音質を向上させることができますが、音色がベースモデル/推論ソースの音色に近づくことがあります。これを「音色漏れ」と言います。
+ index rate は音色漏れの問題を減少させたり解決するために使用されます。1 に設定すると、理論的には推論ソースの音色漏れの問題は存在しませんが、音質はトレーニングセットに近づきます。トレーニングセットの音質が推論ソースよりも低い場合、index rate を高くすると音質が低下する可能性があります。0 に設定すると、検索ミックスを利用してトレーニングセットの音色を保護する効果はありません。
+ トレーニングセットが高品質で長い場合、total_epoch を高く設定することができ、この場合、モデル自体は推論ソースやベースモデルの音色をあまり参照しないため、「音色漏れ」の問題はほとんど発生しません。この時、index rate は重要ではなく、インデックスファイルを作成したり共有したりする必要もありません。
+
+## Q11: 推論時に GPU をどのように選択するか
+
+config.py ファイルの device cuda:の後にカード番号を選択します。
+カード番号とグラフィックカードのマッピング関係は、トレーニングタブのグラフィックカード情報欄で確認できます。
+
+## Q12: トレーニング中に保存された pth ファイルをどのように推論するか
+
+ckpt タブの一番下で小型モデルを抽出します。
+
+## Q13: トレーニングをどのように中断し、続行するか
+
+現在の段階では、WebUI コンソールを閉じて go-web.bat をダブルクリックしてプログラムを再起動するしかありません。ウェブページのパラメータもリフレッシュして再度入力する必要があります。
+トレーニングを続けるには:同じウェブページのパラメータでトレーニングモデルをクリックすると、前回のチェックポイントからトレーニングを続けます。
+
+## Q14: トレーニング中にファイルページ/メモリエラーが発生した場合の対処法
+
+プロセスが多すぎてメモリがオーバーフローしました。以下の方法で解決できるかもしれません。
+
+1. 「音高抽出とデータ処理に使用する CPU プロセス数」を適宜下げます。
+2. トレーニングセットのオーディオを手動でカットして、あまり長くならないようにします。
+
+## Q15: 途中でデータを追加してトレーニングする方法
+
+1. 全データに新しい実験名を作成します。
+2. 前回の最新の G と D ファイル(あるいはどの中間 ckpt を基にトレーニングしたい場合は、その中間のものをコピーすることもできます)を新しい実験名にコピーします。
+3. 新しい実験名でワンクリックトレーニングを開始すると、前回の最新の進捗からトレーニングを続けます。
+
+## Q16: llvmlite.dll に関するエラー
+
+```bash
+OSError: Could not load shared object file: llvmlite.dll
+
+FileNotFoundError: Could not find module lib\site-packages\llvmlite\binding\llvmlite.dll (or one of its dependencies). Try using the full path with constructor syntax.
+```
+
+Windows プラットフォームではこのエラーが発生しますが、https://aka.ms/vs/17/release/vc_redist.x64.exeをインストールしてWebUIを再起動すれば解決します。
+
+## Q17: RuntimeError: テンソルの拡張サイズ(17280)は、非シングルトン次元 1 での既存サイズ(0)と一致する必要があります。 ターゲットサイズ:[1, 17280]。 テンソルサイズ:[0]
+
+wavs16k フォルダーの下で、他のファイルよりも明らかに小さいいくつかのオーディオファイルを見つけて削除し、トレーニングモデルをクリックすればエラーは発生しませんが、ワンクリックプロセスが中断されたため、モデルのトレーニングが完了したらインデックスのトレーニングをクリックする必要があります。
+
+## Q18: RuntimeError: テンソル a のサイズ(24)は、非シングルトン次元 2 でテンソル b(16)のサイズと一致する必要があります
+
+トレーニング中にサンプリングレートを変更してはいけません。変更する必要がある場合は、実験名を変更して最初からトレーニングする必要があります。もちろん、前回抽出した音高と特徴(0/1/2/2b フォルダ)をコピーしてトレーニングプロセスを加速することもできます。
diff --git a/docs/jp/training_tips_ja.md b/docs/jp/training_tips_ja.md
new file mode 100644
index 0000000000000000000000000000000000000000..c5b06f2fdaa603a690c51ee2b79daecc4305fbd5
--- /dev/null
+++ b/docs/jp/training_tips_ja.md
@@ -0,0 +1,64 @@
+RVCの訓練における説明、およびTIPS
+===============================
+本TIPSではどのようにデータの訓練が行われているかを説明します。
+
+# 訓練の流れ
+GUIの訓練タブのstepに沿って説明します。
+
+## step1
+実験名の設定を行います。
+
+また、モデルに音高ガイド(ピッチ)を考慮させるかもここで設定できます。考慮させない場合はモデルは軽量になりますが、歌唱には向かなくなります。
+
+各実験のデータは`/logs/実験名/`に配置されます。
+
+## step2a
+音声の読み込みと前処理を行います。
+
+### load audio
+音声のあるフォルダを指定すると、そのフォルダ内にある音声ファイルを自動で読み込みます。
+例えば`C:Users\hoge\voices`を指定した場合、`C:Users\hoge\voices\voice.mp3`は読み込まれますが、`C:Users\hoge\voices\dir\voice.mp3`は読み込まれません。
+
+音声の読み込みには内部でffmpegを利用しているので、ffmpegで対応している拡張子であれば自動的に読み込まれます。
+ffmpegでint16に変換した後、float32に変換し、-1 ~ 1の間に正規化されます。
+
+### denoising
+音声についてscipyのfiltfiltによる平滑化を行います。
+
+### 音声の分割
+入力した音声はまず、一定期間(max_sil_kept=5秒?)より長く無音が続く部分を検知して音声を分割します。無音で音声を分割した後は、0.3秒のoverlapを含む4秒ごとに音声を分割します。4秒以内に区切られた音声は、音量の正規化を行った後wavファイルを`/logs/実験名/0_gt_wavs`に、そこから16kのサンプリングレートに変換して`/logs/実験名/1_16k_wavs`にwavファイルで保存します。
+
+## step2b
+### ピッチの抽出
+wavファイルからピッチ(音の高低)の情報を抽出します。parselmouthやpyworldに内蔵されている手法でピッチ情報(=f0)を抽出し、`/logs/実験名/2a_f0`に保存します。その後、ピッチ情報を対数で変換して1~255の整数に変換し、`/logs/実験名/2b-f0nsf`に保存します。
+
+### feature_printの抽出
+HuBERTを用いてwavファイルを事前にembeddingに変換します。`/logs/実験名/1_16k_wavs`に保存したwavファイルを読み込み、HuBERTでwavファイルを256次元の特徴量に変換し、npy形式で`/logs/実験名/3_feature256`に保存します。
+
+## step3
+モデルのトレーニングを行います。
+### 初心者向け用語解説
+深層学習ではデータセットを分割し、少しずつ学習を進めていきます。一回のモデルの更新(step)では、batch_size個のデータを取り出し予測と誤差の修正を行います。これをデータセットに対して一通り行うと一epochと数えます。
+
+そのため、学習時間は 1step当たりの学習時間 x (データセット内のデータ数 ÷ バッチサイズ) x epoch数 かかります。一般にバッチサイズを大きくするほど学習は安定し、(1step当たりの学習時間÷バッチサイズ)は小さくなりますが、その分GPUのメモリを多く使用します。GPUのRAMはnvidia-smiコマンド等で確認できます。実行環境のマシンに合わせてバッチサイズをできるだけ大きくするとより短時間で学習が可能です。
+
+### pretrained modelの指定
+RVCではモデルの訓練を0からではなく、事前学習済みの重みから開始するため、少ないデータセットで学習を行えます。
+
+デフォルトでは
+
+- 音高ガイドを考慮する場合、`RVCのある場所/pretrained/f0G40k.pth`と`RVCのある場所/pretrained/f0D40k.pth`を読み込みます。
+- 音高ガイドを考慮しない場合、`RVCのある場所/pretrained/G40k.pth`と`RVCのある場所/pretrained/D40k.pth`を読み込みます。
+
+学習時はsave_every_epochごとにモデルのパラメータが`logs/実験名/G_{}.pth`と`logs/実験名/D_{}.pth`に保存されますが、このパスを指定することで学習を再開したり、もしくは違う実験で学習したモデルの重みから学習を開始できます。
+
+### indexの学習
+RVCでは学習時に使われたHuBERTの特徴量を保存し、推論時は学習時の特徴量から近い特徴量を探してきて推論を行います。この検索を高速に行うために事前にindexの学習を行います。
+indexの学習には近似近傍探索ライブラリのfaissを用います。`/logs/実験名/3_feature256`の特徴量を読み込み、それを用いて学習したindexを`/logs/実験名/add_XXX.index`として保存します。
+(20230428updateよりtotal_fea.npyはindexから読み込むので不要になりました。)
+
+### ボタンの説明
+- モデルのトレーニング: step2bまでを実行した後、このボタンを押すとモデルの学習を行います。
+- 特徴インデックスのトレーニング: モデルのトレーニング後、indexの学習を行います。
+- ワンクリックトレーニング: step2bまでとモデルのトレーニング、特徴インデックスのトレーニングを一括で行います。
+
diff --git a/docs/kr/Changelog_KO.md b/docs/kr/Changelog_KO.md
new file mode 100644
index 0000000000000000000000000000000000000000..c9ba32fbb907459c5119e7778b3748766e6b6a58
--- /dev/null
+++ b/docs/kr/Changelog_KO.md
@@ -0,0 +1,124 @@
+### 2023년 10월 6일 업데이트
+
+실시간 음성 변환을 위한 인터페이스인 go-realtime-gui.bat/gui_v1.py를 제작했습니다(사실 이는 이미 존재했었습니다). 이번 업데이트는 주로 실시간 음성 변환 성능을 최적화하는 데 중점을 두었습니다. 0813 버전과 비교하여:
+
+- 1. 인터페이스 조작 최적화: 매개변수 핫 업데이트(매개변수 조정 시 중단 후 재시작 필요 없음), 모델 지연 로딩(이미 로드된 모델은 재로드 필요 없음), 음량 인자 매개변수 추가(음량을 입력 오디오에 가깝게 조정)
+- 2. 내장된 노이즈 감소 효과 및 속도 최적화
+- 3. 추론 속도 크게 향상
+
+입력 및 출력 장치는 동일한 유형을 선택해야 합니다. 예를 들어, 모두 MME 유형을 선택해야 합니다.
+
+1006 버전의 전체 업데이트는 다음과 같습니다:
+
+- 1. rmvpe 음성 피치 추출 알고리즘의 효과를 계속해서 향상, 특히 남성 저음역에 대한 개선이 큼
+- 2. 추론 인터페이스 레이아웃 최적화
+
+### 2023년 08월 13일 업데이트
+
+1-정기적인 버그 수정
+
+- 최소 총 에포크 수를 1로 변경하고, 최소 총 에포크 수를 2로 변경합니다.
+- 사전 훈련(pre-train) 모델을 사용하지 않는 훈련 오류 수정
+- 반주 보컬 분리 후 그래픽 메모리 지우기
+- 페이즈 저장 경로 절대 경로를 상대 경로로 변경
+- 공백이 포함된 경로 지원(훈련 세트 경로와 실험 이름 모두 지원되며 더 이상 오류가 보고되지 않음)
+- 파일 목록에서 필수 utf8 인코딩 취소
+- 실시간 음성 변경 중 faiss 검색으로 인한 CPU 소모 문제 해결
+
+2-키 업데이트
+
+- 현재 가장 강력한 오픈 소스 보컬 피치 추출 모델 RMVPE를 훈련하고, 이를 RVC 훈련, 오프라인/실시간 추론에 사용하며, PyTorch/Onx/DirectML을 지원합니다.
+- 파이토치\_DML을 통한 AMD 및 인텔 그래픽 카드 지원
+ (1) 실시간 음성 변화 (2) 추론 (3) 보컬 반주 분리 (4) 현재 지원되지 않는 훈련은 CPU 훈련으로 전환, Onnx_Dml을 통한 gpu의 RMVPE 추론 지원
+
+### 2023년 6월 18일 업데이트
+
+- v2 버전에서 새로운 32k와 48k 사전 학습 모델을 추가.
+- non-f0 모델들의 추론 오류 수정.
+- 학습 세트가 1시간을 넘어가는 경우, 인덱스 생성 단계에서 minibatch-kmeans을 사용해, 학습속도 가속화.
+- [huggingface](https://huggingface.co/spaces/lj1995/vocal2guitar)에서 vocal2guitar 제공.
+- 데이터 처리 단계에서 이상 값 자동으로 제거.
+- ONNX로 내보내는(export) 옵션 탭 추가.
+
+업데이트에 적용되지 않았지만 시도한 것들 :
+
+- ~~시계열 차원을 추가하여 특징 검색을 진행했지만, 유의미한 효과는 없었습니다.~~
+- ~~PCA 차원 축소를 추가하여 특징 검색을 진행했지만, 유의미한 효과는 없었습니다.~~
+- ~~ONNX 추론을 지원하는 것에 실패했습니다. nsf 생성시, Pytorch가 필요하기 때문입니다.~~
+- ~~훈련 중에 입력에 대한 음고, 성별, 이퀄라이저, 노이즈 등 무작위로 강화하는 것에, 유의미한 효과는 없었습니다.~~
+
+추후 업데이트 목록:
+
+- ~~Vocos-RVC (소형 보코더) 통합 예정.~~
+- ~~학습 단계에 음고 인식을 위한 Crepe 지원 예정.~~
+- ~~Crepe의 정밀도를 REC-config와 동기화하여 지원 예정.~~
+- FO 에디터 지원 예정.
+
+### 2023년 5월 28일 업데이트
+
+- v2 jupyter notebook 추가, 한국어 업데이트 로그 추가, 의존성 모듈 일부 수정.
+- 무성음 및 숨소리 보호 모드 추가.
+- crepe-full pitch 감지 지원.
+- UVR5 보컬 분리: 디버브 및 디-에코 모델 지원.
+- index 이름에 experiment 이름과 버전 추가.
+- 배치 음성 변환 처리 및 UVR5 보컬 분리 시, 사용자가 수동으로 출력 오디오의 내보내기(export) 형식을 선택할 수 있도록 지원.
+- 32k 훈련 모델 지원 종료.
+
+### 2023년 5월 13일 업데이트
+
+- 원클릭 패키지의 이전 버전 런타임 내, 불필요한 코드(lib.infer_pack 및 uvr5_pack) 제거.
+- 훈련 세트 전처리의 유사 다중 처리 버그 수정.
+- Harvest 피치 인식 알고리즘에 대한 중위수 필터링 반경 조정 추가.
+- 오디오 내보낼 때, 후처리 리샘플링 지원.
+- 훈련에 대한 다중 처리 "n_cpu" 설정이 "f0 추출"에서 "데이터 전처리 및 f0 추출"로 변경.
+- logs 폴더 하의 인덱스 경로를 자동으로 감지 및 드롭다운 목록 기능 제공.
+- 탭 페이지에 "자주 묻는 질문과 답변" 추가. (github RVC wiki 참조 가능)
+- 동일한 입력 오디오 경로를 사용할 때 추론, Harvest 피치를 캐시.
+ (주의: Harvest 피치 추출을 사용하면 전체 파이프라인은 길고 반복적인 피치 추출 과정을 거치게됩니다. 캐싱을 하지 않는다면, 첫 inference 이후의 단계에서 timbre, 인덱스, 피치 중위수 필터링 반경 설정 등 대기시간이 엄청나게 길어집니다!)
+
+### 2023년 5월 14일 업데이트
+
+- 입력의 볼륨 캡슐을 사용하여 출력의 볼륨 캡슐을 혼합하거나 대체. (입력이 무음이거나 출력의 노이즈 문제를 최소화 할 수 있습니다. 입력 오디오의 배경 노이즈(소음)가 큰 경우 해당 기능을 사용하지 않는 것이 좋습니다. 기본적으로 비활성화 되어있는 옵션입니다. (1: 비활성화 상태))
+- 추출된 소형 모델을 지정된 빈도로 저장하는 기능을 지원. (다양한 에폭 하에서의 성능을 보려고 하지만 모든 대형 체크포인트를 저장하고 매번 ckpt 처리를 통해 소형 모델을 수동으로 추출하고 싶지 않은 경우 이 기능은 매우 유용합니다)
+- 환경 변수를 설정하여 서버의 전역 프록시로 인한 "연결 오류" 문제 해결.
+- 사전 훈련된 v2 모델 지원. (현재 40k 버전만 테스트를 위해 공개적으로 사용 가능하며, 다른 두 개의 샘플링 비율은 아직 완전히 훈련되지 않아 보류되었습니다.)
+- 추론 전, 1을 초과하는 과도한 볼륨 제한.
+- 데이터 전처리 매개변수 미세 조정.
+
+### 2023년 4월 9일 업데이트
+
+- GPU 이용률 향상을 위해 훈련 파라미터 수정: A100은 25%에서 약 90%로 증가, V100: 50%에서 약 90%로 증가, 2060S: 60%에서 약 85%로 증가, P40: 25%에서 약 95%로 증가.
+ 훈련 속도가 크게 향상.
+- 매개변수 기준 변경: total batch_size는 GPU당 batch_size를 의미.
+- total_epoch 변경: 최대 한도가 100에서 1000으로 증가. 기본값이 10에서 20으로 증가.
+- ckpt 추출이 피치를 잘못 인식하여 비정상적인 추론을 유발하는 문제 수정.
+- 분산 훈련 과정에서 각 랭크마다 ckpt를 저장하는 문제 수정.
+- 특성 추출 과정에 나노 특성 필터링 적용.
+- 무음 입력/출력이 랜덤하게 소음을 생성하는 문제 수정. (이전 모델은 새 데이터셋으로 다시 훈련해야 합니다)
+
+### 2023년 4월 16일 업데이트
+
+- 로컬 실시간 음성 변경 미니-GUI 추가, go-realtime-gui.bat를 더블 클릭하여 시작.
+- 훈련 및 추론 중 50Hz 이하의 주파수 대역에 대해 필터링 적용.
+- 훈련 및 추론의 pyworld 최소 피치 추출을 기본 80에서 50으로 낮춤. 이로 인해, 50-80Hz 사이의 남성 저음이 무음화되지 않습니다.
+- 시스템 지역에 따른 WebUI 언어 변경 지원. (현재 en_US, ja_JP, zh_CN, zh_HK, zh_SG, zh_TW를 지원하며, 지원되지 않는 경우 기본값은 en_US)
+- 일부 GPU의 인식 수정. (예: V100-16G 인식 실패, P4 인식 실패)
+
+### 2023년 4월 28일 업데이트
+
+- Faiss 인덱스 설정 업그레이드로 속도가 더 빨라지고 품질이 향상.
+- total_npy에 대한 의존성 제거. 추후의 모델 공유는 total_npy 입력을 필요로 하지 않습니다.
+- 16 시리즈 GPU에 대한 제한 해제, 4GB VRAM GPU에 대한 4GB 추론 설정 제공.
+- 일부 오디오 형식에 대한 UVR5 보컬 동반 분리에서의 버그 수정.
+- 실시간 음성 변경 미니-GUI는 이제 non-40k 및 non-lazy 피치 모델을 지원합니다.
+
+### 추후 계획
+
+Features:
+
+- 다중 사용자 훈련 탭 지원.(최대 4명)
+
+Base model:
+
+- 훈련 데이터셋에 숨소리 wav 파일을 추가하여, 보컬의 호흡이 노이즈로 변환되는 문제 수정.
+- 보컬 훈련 세트의 기본 모델을 추가하기 위한 작업을 진행중이며, 이는 향후에 발표될 예정.
diff --git a/docs/kr/README.ko.han.md b/docs/kr/README.ko.han.md
new file mode 100644
index 0000000000000000000000000000000000000000..0273b615ac10d6c24dcdf910588be0b34204b27f
--- /dev/null
+++ b/docs/kr/README.ko.han.md
@@ -0,0 +1,106 @@
+
+
+
Retrieval-based-Voice-Conversion-WebUI
+VITS基盤의 簡單하고使用하기 쉬운音聲變換틀
+
+[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
+
+
+
+[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/tools/ipynb/v1.ipynb)
+[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/tools/ipynb/v2.ipynb)
+[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
+[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
+
+[](https://discord.gg/HcsmBBGyVk)
+
+
+
+
Retrieval-based-Voice-Conversion-WebUI
+VITS 기반의 간단하고 사용하기 쉬운 음성 변환 프레임워크.
+
+[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
+
+
+
+[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/tools/ipynb/v1.ipynb)
+[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/tools/ipynb/v2.ipynb)
+[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
+[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
+
+[](https://discord.gg/HcsmBBGyVk)
+
+[**업데이트 로그**](./Changelog_KO.md) | [**자주 묻는 질문**](./faq_ko.md) | [**AutoDL·5원으로 AI 가수 훈련**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**대조 실험 기록**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95) | [**온라인 데모**](https://modelscope.cn/studios/FlowerCry/RVCv2demo)
+
+[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md) | [**Português**](../pt/README.pt.md)
+
+
+
+ | 훈련 및 추론 인터페이스 |
+ 실시간 음성 변환 인터페이스 |
+
+
+ |
+ |
+
+
+ | go-web.bat |
+ go-realtime-gui.bat |
+
+
+ | 원하는 작업을 자유롭게 선택할 수 있습니다. |
+ 우리는 이미 끝에서 끝까지 170ms의 지연을 실현했습니다. ASIO 입력 및 출력 장치를 사용하면 끝에서 끝까지 90ms의 지연을 달성할 수 있지만, 이는 하드웨어 드라이버 지원에 매우 의존적입니다. |
+
+
+
+## 소개
+
+본 Repo는 다음과 같은 특징을 가지고 있습니다:
+
+- top1 검색을 이용하여 입력 음색 특징을 훈련 세트 음색 특징으로 대체하여 음색의 누출을 방지
+- 상대적으로 낮은 성능의 GPU에서도 빠른 훈련 가능
+- 적은 양의 데이터로 훈련해도 좋은 결과를 얻을 수 있음 (최소 10분 이상의 저잡음 음성 데이터를 사용하는 것을 권장)
+- 모델 융합을 통한 음색의 변조 가능 (ckpt 처리 탭->ckpt 병합 선택)
+- 사용하기 쉬운 WebUI (웹 인터페이스)
+- UVR5 모델을 이용하여 목소리와 배경음악의 빠른 분리;
+- 최첨단 [음성 피치 추출 알고리즘 InterSpeech2023-RMVPE](#参考项目)을 사용하여 무성음 문제를 해결합니다. 효과는 최고(압도적)이며 crepe_full보다 더 빠르고 리소스 사용이 적음
+- A카드와 I카드 가속을 지원
+
+해당 프로젝트의 [데모 비디오](https://www.bilibili.com/video/BV1pm4y1z7Gm/)를 확인해보세요!
+
+## 환경 설정
+
+다음 명령은 Python 버전이 3.8 이상인 환경에서 실행해야 합니다.
+
+### Windows/Linux/MacOS 등 플랫폼 공통 방법
+
+아래 방법 중 하나를 선택하세요.
+
+#### 1. pip를 통한 의존성 설치
+
+1. Pytorch 및 의존성 모듈 설치, 이미 설치되어 있으면 생략. 참조: https://pytorch.org/get-started/locally/
+
+```bash
+pip install torch torchvision torchaudio
+```
+
+2. win 시스템 + Nvidia Ampere 아키텍처(RTX30xx) 사용 시, #21의 사례에 따라 pytorch에 해당하는 cuda 버전을 지정
+
+```bash
+pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
+```
+
+3. 자신의 그래픽 카드에 맞는 의존성 설치
+
+- N카드
+
+```bash
+pip install -r requirements.txt
+```
+
+- A카드/I카드
+
+```bash
+pip install -r requirements-dml.txt
+```
+
+- A카드ROCM(Linux)
+
+```bash
+pip install -r requirements-amd.txt
+```
+
+- I카드IPEX(Linux)
+
+```bash
+pip install -r requirements-ipex.txt
+```
+
+#### 2. poetry를 통한 의존성 설치
+
+Poetry 의존성 관리 도구 설치, 이미 설치된 경우 생략. 참조: https://python-poetry.org/docs/#installation
+
+```bash
+curl -sSL https://install.python-poetry.org | python3 -
+```
+
+poetry를 통한 의존성 설치
+
+```bash
+poetry install
+```
+
+### MacOS
+
+`run.sh`를 통해 의존성 설치 가능
+
+```bash
+sh ./run.sh
+```
+
+## 기타 사전 훈련된 모델 준비
+
+RVC는 추론과 훈련을 위해 다른 일부 사전 훈련된 모델이 필요합니다.
+
+이러한 모델은 저희의 [Hugging Face space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)에서 다운로드할 수 있습니다.
+
+### 1. assets 다운로드
+
+다음은 RVC에 필요한 모든 사전 훈련된 모델과 기타 파일의 목록입니다. `tools` 폴더에서 이들을 다운로드하는 스크립트를 찾을 수 있습니다.
+
+- ./assets/hubert/hubert_base.pt
+
+- ./assets/pretrained
+
+- ./assets/uvr5_weights
+
+v2 버전 모델을 사용하려면 추가로 다음을 다운로드해야 합니다.
+
+- ./assets/pretrained_v2
+
+### 2. ffmpeg 설치
+
+ffmpeg와 ffprobe가 이미 설치되어 있다면 건너뜁니다.
+
+#### Ubuntu/Debian 사용자
+
+```bash
+sudo apt install ffmpeg
+```
+
+#### MacOS 사용자
+
+```bash
+brew install ffmpeg
+```
+
+#### Windows 사용자
+
+다운로드 후 루트 디렉토리에 배치.
+
+- [ffmpeg.exe 다운로드](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe)
+
+- [ffprobe.exe 다운로드](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe)
+
+### 3. RMVPE 인간 음성 피치 추출 알고리즘에 필요한 파일 다운로드
+
+최신 RMVPE 인간 음성 피치 추출 알고리즘을 사용하려면 음피치 추출 모델 매개변수를 다운로드하고 RVC 루트 디렉토리에 배치해야 합니다.
+
+- [rmvpe.pt 다운로드](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt)
+
+#### dml 환경의 RMVPE 다운로드(선택사항, A카드/I카드 사용자)
+
+- [rmvpe.onnx 다운로드](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx)
+
+### 4. AMD 그래픽 카드 Rocm(선택사항, Linux만 해당)
+
+Linux 시스템에서 AMD의 Rocm 기술을 기반으로 RVC를 실행하려면 [여기](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html)에서 필요한 드라이버를 먼저 설치하세요.
+
+Arch Linux를 사용하는 경우 pacman을 사용하여 필요한 드라이버를 설치할 수 있습니다.
+
+```
+pacman -S rocm-hip-sdk rocm-opencl-sdk
+```
+
+일부 모델의 그래픽 카드(예: RX6700XT)의 경우, 다음과 같은 환경 변수를 추가로 설정해야 할 수 있습니다.
+
+```
+export ROCM_PATH=/opt/rocm
+export HSA_OVERRIDE_GFX_VERSION=10.3.0
+```
+
+동시에 현재 사용자가 `render` 및 `video` 사용자 그룹에 속해 있는지 확인하세요.
+
+```
+sudo usermod -aG render $USERNAME
+sudo usermod -aG video $USERNAME
+```
+
+## 시작하기
+
+### 직접 시작
+
+다음 명령어로 WebUI를 시작하세요
+
+```bash
+python infer-web.py
+```
+
+### 통합 패키지 사용
+
+`RVC-beta.7z`를 다운로드하고 압축 해제
+
+#### Windows 사용자
+
+`go-web.bat` 더블 클릭
+
+#### MacOS 사용자
+
+```bash
+sh ./run.sh
+```
+
+### IPEX 기술이 필요한 I카드 사용자를 위한 지침(Linux만 해당)
+
+```bash
+source /opt/intel/oneapi/setvars.sh
+```
+
+## 참조 프로젝트
+
+- [ContentVec](https://github.com/auspicious3000/contentvec/)
+- [VITS](https://github.com/jaywalnut310/vits)
+- [HIFIGAN](https://github.com/jik876/hifi-gan)
+- [Gradio](https://github.com/gradio-app/gradio)
+- [FFmpeg](https://github.com/FFmpeg/FFmpeg)
+- [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
+- [audio-slicer](https://github.com/openvpi/audio-slicer)
+- [Vocal pitch extraction:RMVPE](https://github.com/Dream-High/RMVPE)
+ - 사전 훈련된 모델은 [yxlllc](https://github.com/yxlllc/RMVPE)와 [RVC-Boss](https://github.com/RVC-Boss)에 의해 훈련되고 테스트되었습니다.
+
+## 모든 기여자들의 노력에 감사드립니다
+
+
+
+
diff --git a/docs/kr/faiss_tips_ko.md b/docs/kr/faiss_tips_ko.md
new file mode 100644
index 0000000000000000000000000000000000000000..ecd518ca2a89996898057983761fc469eaf969d2
--- /dev/null
+++ b/docs/kr/faiss_tips_ko.md
@@ -0,0 +1,132 @@
+Facebook AI Similarity Search (Faiss) 팁
+==================
+# Faiss에 대하여
+Faiss 는 Facebook Research가 개발하는, 고밀도 벡터 이웃 검색 라이브러리입니다. 근사 근접 탐색법 (Approximate Neigbor Search)은 약간의 정확성을 희생하여 유사 벡터를 고속으로 찾습니다.
+
+## RVC에 있어서 Faiss
+RVC에서는 HuBERT로 변환한 feature의 embedding을 위해 훈련 데이터에서 생성된 embedding과 유사한 embadding을 검색하고 혼합하여 원래의 음성에 더욱 가까운 변환을 달성합니다. 그러나, 이 탐색법은 단순히 수행하면 시간이 다소 소모되므로, 근사 근접 탐색법을 통해 고속 변환을 가능케 하고 있습니다.
+
+# 구현 개요
+모델이 위치한 `/logs/your-experiment/3_feature256`에는 각 음성 데이터에서 HuBERT가 추출한 feature들이 있습니다. 여기에서 파일 이름별로 정렬된 npy 파일을 읽고, 벡터를 연결하여 big_npy ([N, 256] 모양의 벡터) 를 만듭니다. big_npy를 `/logs/your-experiment/total_fea.npy`로 저장한 후, Faiss로 학습시킵니다.
+
+2023/04/18 기준으로, Faiss의 Index Factory 기능을 이용해, L2 거리에 근거하는 IVF를 이용하고 있습니다. IVF의 분할수(n_ivf)는 N//39로, n_probe는 int(np.power(n_ivf, 0.3))가 사용되고 있습니다. (infer-web.py의 train_index 주위를 찾으십시오.)
+
+이 팁에서는 먼저 이러한 매개 변수의 의미를 설명하고, 개발자가 추후 더 나은 index를 작성할 수 있도록 하는 조언을 작성합니다.
+
+# 방법의 설명
+## Index factory
+index factory는 여러 근사 근접 탐색법을 문자열로 연결하는 pipeline을 문자열로 표기하는 Faiss만의 독자적인 기법입니다. 이를 통해 index factory의 문자열을 변경하는 것만으로 다양한 근사 근접 탐색을 시도해 볼 수 있습니다. RVC에서는 다음과 같이 사용됩니다:
+
+```python
+index = Faiss.index_factory(256, "IVF%s,Flat" % n_ivf)
+```
+`index_factory`의 인수들 중 첫 번째는 벡터의 차원 수이고, 두번째는 index factory 문자열이며, 세번째에는 사용할 거리를 지정할 수 있습니다.
+
+기법의 보다 자세한 설명은 https://github.com/facebookresearch/Faiss/wiki/The-index-factory 를 확인해 주십시오.
+
+## 거리에 대한 index
+embedding의 유사도로서 사용되는 대표적인 지표로서 이하의 2개가 있습니다.
+
+- 유클리드 거리 (METRIC_L2)
+- 내적(内積) (METRIC_INNER_PRODUCT)
+
+유클리드 거리에서는 각 차원에서 제곱의 차를 구하고, 각 차원에서 구한 차를 모두 더한 후 제곱근을 취합니다. 이것은 일상적으로 사용되는 2차원, 3차원에서의 거리의 연산법과 같습니다. 내적은 그 값을 그대로 유사도 지표로 사용하지 않고, L2 정규화를 한 이후 내적을 취하는 코사인 유사도를 사용합니다.
+
+어느 쪽이 더 좋은지는 경우에 따라 다르지만, word2vec에서 얻은 embedding 및 ArcFace를 활용한 이미지 검색 모델은 코사인 유사성이 이용되는 경우가 많습니다. numpy를 사용하여 벡터 X에 대해 L2 정규화를 하고자 하는 경우, 0 division을 피하기 위해 충분히 작은 값을 eps로 한 뒤 이하에 코드를 활용하면 됩니다.
+
+```python
+X_normed = X / np.maximum(eps, np.linalg.norm(X, ord=2, axis=-1, keepdims=True))
+```
+
+또한, `index factory`의 3번째 인수에 건네주는 값을 선택하는 것을 통해 계산에 사용하는 거리 index를 변경할 수 있습니다.
+
+```python
+index = Faiss.index_factory(dimention, text, Faiss.METRIC_INNER_PRODUCT)
+```
+
+## IVF
+IVF (Inverted file indexes)는 역색인 탐색법과 유사한 알고리즘입니다. 학습시에는 검색 대상에 대해 k-평균 군집법을 실시하고 클러스터 중심을 이용해 보로노이 분할을 실시합니다. 각 데이터 포인트에는 클러스터가 할당되므로, 클러스터에서 데이터 포인트를 조회하는 dictionary를 만듭니다.
+
+예를 들어, 클러스터가 다음과 같이 할당된 경우
+|index|Cluster|
+|-----|-------|
+|1|A|
+|2|B|
+|3|A|
+|4|C|
+|5|B|
+
+IVF 이후의 결과는 다음과 같습니다:
+
+|cluster|index|
+|-------|-----|
+|A|1, 3|
+|B|2, 5|
+|C|4|
+
+탐색 시, 우선 클러스터에서 `n_probe`개의 클러스터를 탐색한 다음, 각 클러스터에 속한 데이터 포인트의 거리를 계산합니다.
+
+# 권장 매개변수
+index의 선택 방법에 대해서는 공식적으로 가이드 라인이 있으므로, 거기에 준해 설명합니다.
+https://github.com/facebookresearch/Faiss/wiki/Guidelines-to-choose-an-index
+
+1M 이하의 데이터 세트에 있어서는 4bit-PQ가 2023년 4월 시점에서는 Faiss로 이용할 수 있는 가장 효율적인 수법입니다. 이것을 IVF와 조합해, 4bit-PQ로 후보를 추려내고, 마지막으로 이하의 index factory를 이용하여 정확한 지표로 거리를 재계산하면 됩니다.
+
+```python
+index = Faiss.index_factory(256, "IVF1024,PQ128x4fs,RFlat")
+```
+
+## IVF 권장 매개변수
+IVF의 수가 너무 많으면, 가령 데이터 수의 수만큼 IVF로 양자화(Quantization)를 수행하면, 이것은 완전탐색과 같아져 효율이 나빠지게 됩니다. 1M 이하의 경우 IVF 값은 데이터 포인트 수 N에 대해 4sqrt(N) ~ 16sqrt(N)를 사용하는 것을 권장합니다.
+
+n_probe는 n_probe의 수에 비례하여 계산 시간이 늘어나므로 정확도와 시간을 적절히 균형을 맞추어 주십시오. 개인적으로 RVC에 있어서 그렇게까지 정확도는 필요 없다고 생각하기 때문에 n_probe = 1이면 된다고 생각합니다.
+
+## FastScan
+FastScan은 직적 양자화를 레지스터에서 수행함으로써 거리의 고속 근사를 가능하게 하는 방법입니다.직적 양자화는 학습시에 d차원마다(보통 d=2)에 독립적으로 클러스터링을 실시해, 클러스터끼리의 거리를 사전 계산해 lookup table를 작성합니다. 예측시는 lookup table을 보면 각 차원의 거리를 O(1)로 계산할 수 있습니다. 따라서 PQ 다음에 지정하는 숫자는 일반적으로 벡터의 절반 차원을 지정합니다.
+
+FastScan에 대한 자세한 설명은 공식 문서를 참조하십시오.
+https://github.com/facebookresearch/Faiss/wiki/Fast-accumulation-of-PQ-and-AQ-codes-(FastScan)
+
+## RFlat
+RFlat은 FastScan이 계산한 대략적인 거리를 index factory의 3번째 인수로 지정한 정확한 거리로 다시 계산하라는 인스트럭션입니다. k개의 근접 변수를 가져올 때 k*k_factor개의 점에 대해 재계산이 이루어집니다.
+
+# Embedding 테크닉
+## Alpha 쿼리 확장
+퀴리 확장이란 탐색에서 사용되는 기술로, 예를 들어 전문 탐색 시, 입력된 검색문에 단어를 몇 개를 추가함으로써 검색 정확도를 올리는 방법입니다. 백터 탐색을 위해서도 몇가지 방법이 제안되었는데, 그 중 α-쿼리 확장은 추가 학습이 필요 없는 매우 효과적인 방법으로 알려져 있습니다. [Attention-Based Query Expansion Learning](https://arxiv.org/abs/2007.08019)와 [2nd place solution of kaggle shopee competition](https://www.kaggle.com/code/lyakaap/2nd-place-solution/notebook) 논문에서 소개된 바 있습니다..
+
+α-쿼리 확장은 한 벡터에 인접한 벡터를 유사도의 α곱한 가중치로 더해주면 됩니다. 코드로 예시를 들어 보겠습니다. big_npy를 α query expansion로 대체합니다.
+
+```python
+alpha = 3.
+index = Faiss.index_factory(256, "IVF512,PQ128x4fs,RFlat")
+original_norm = np.maximum(np.linalg.norm(big_npy, ord=2, axis=1, keepdims=True), 1e-9)
+big_npy /= original_norm
+index.train(big_npy)
+index.add(big_npy)
+dist, neighbor = index.search(big_npy, num_expand)
+
+expand_arrays = []
+ixs = np.arange(big_npy.shape[0])
+for i in range(-(-big_npy.shape[0]//batch_size)):
+ ix = ixs[i*batch_size:(i+1)*batch_size]
+ weight = np.power(np.einsum("nd,nmd->nm", big_npy[ix], big_npy[neighbor[ix]]), alpha)
+ expand_arrays.append(np.sum(big_npy[neighbor[ix]] * np.expand_dims(weight, axis=2),axis=1))
+big_npy = np.concatenate(expand_arrays, axis=0)
+
+# index version 정규화
+big_npy = big_npy / np.maximum(np.linalg.norm(big_npy, ord=2, axis=1, keepdims=True), 1e-9)
+```
+
+위 테크닉은 탐색을 수행하는 쿼리에도, 탐색 대상 DB에도 적응 가능한 테크닉입니다.
+
+## MiniBatch KMeans에 의한 embedding 압축
+
+total_fea.npy가 너무 클 경우 K-means를 이용하여 벡터를 작게 만드는 것이 가능합니다. 이하 코드로 embedding의 압축이 가능합니다. n_clusters에 압축하고자 하는 크기를 지정하고 batch_size에 256 * CPU의 코어 수를 지정함으로써 CPU 병렬화의 혜택을 충분히 얻을 수 있습니다.
+
+```python
+import multiprocessing
+from sklearn.cluster import MiniBatchKMeans
+kmeans = MiniBatchKMeans(n_clusters=10000, batch_size=256 * multiprocessing.cpu_count(), init="random")
+kmeans.fit(big_npy)
+sample_npy = kmeans.cluster_centers_
+```
\ No newline at end of file
diff --git a/docs/kr/faq_ko.md b/docs/kr/faq_ko.md
new file mode 100644
index 0000000000000000000000000000000000000000..a51d098e3b125cb399aea768b76bb8ea8d77b91f
--- /dev/null
+++ b/docs/kr/faq_ko.md
@@ -0,0 +1,130 @@
+## Q1:ffmpeg 오류/utf8 오류
+
+대부분의 경우 ffmpeg 문제가 아니라 오디오 경로 문제입니다.
+ffmpeg가 공백, () 등의 특수 문자가 포함된 경로를 읽을 때 ffmpeg 오류가 발생할 수 있습니다. 트레이닝 세트 오디오가 중문 경로일 때 filelist.txt에 쓸 때 utf8 오류가 발생할 수 있습니다.
+
+## Q2:일괄 트레이닝이 끝나고 인덱스가 없음
+
+"Training is done. The program is closed."라고 표시되면 모델 트레이닝이 성공한 것이며, 이어지는 오류는 가짜입니다.
+
+일괄 트레이닝이 끝나고 'added'로 시작하는 인덱스 파일이 없으면 트레이닝 세트가 너무 커서 인덱스 추가 단계에서 멈췄을 수 있습니다. 메모리에 대한 인덱스 추가 요구 사항이 너무 큰 문제를 배치 처리 add 인덱스로 해결했습니다. 임시로 "트레이닝 인덱스" 버튼을 다시 클릭해 보세요.
+
+## Q3:트레이닝이 끝나고 트레이닝 세트의 음색을 추론에서 보지 못함
+
+'음색 새로고침'을 클릭해 보세요. 여전히 없다면 트레이닝에 오류가 있는지, 콘솔 및 webui의 스크린샷, logs/실험명 아래의 로그를 개발자에게 보내 확인해 보세요.
+
+## Q4:모델 공유 방법
+
+rvc_root/logs/실험명 아래에 저장된 pth는 추론에 사용하기 위한 것이 아니라 실험 상태를 저장하고 복원하며, 트레이닝을 계속하기 위한 것입니다. 공유에 사용되는 모델은 weights 폴더 아래 60MB 이상인 pth 파일입니다.
+
+향후에는 weights/exp_name.pth와 logs/exp_name/added_xxx.index를 결합하여 weights/exp_name.zip으로 만들어 index 입력 단계를 생략할 예정입니다. 그러면 zip 파일을 공유하고 pth 파일은 공유하지 마세요. 단지 다른 기계에서 트레이닝을 계속하려는 경우에만 공유하세요.
+
+logs 폴더 아래 수백 MB의 pth 파일을 weights 폴더에 복사/공유하여 강제로 추론에 사용하면 f0, tgt_sr 등의 키가 없다는 오류가 발생할 수 있습니다. ckpt 탭 아래에서 수동 또는 자동(로컬 logs에서 관련 정보를 찾을 수 있는 경우 자동)으로 음성, 대상 오디오 샘플링률 옵션을 선택한 후 ckpt 소형 모델을 추출해야 합니다(입력 경로에 G로 시작하는 경로를 입력). 추출 후 weights 폴더에 60MB 이상의 pth 파일이 생성되며, 음색 새로고침 후 사용할 수 있습니다.
+
+## Q5:연결 오류
+
+아마도 컨트롤 콘솔(검은 창)을 닫았을 것입니다.
+
+## Q6:WebUI에서 "Expecting value: line 1 column 1 (char 0)" 오류가 발생함
+
+시스템 로컬 네트워크 프록시/글로벌 프록시를 닫으세요.
+
+이는 클라이언트의 프록시뿐만 아니라 서버 측의 프록시도 포함합니다(예: autodl로 http_proxy 및 https_proxy를 설정한 경우 사용 시 unset으로 끄세요).
+
+## Q7:WebUI 없이 명령으로 트레이닝 및 추론하는 방법
+
+트레이닝 스크립트:
+먼저 WebUI를 실행하여 데이터 세트 처리 및 트레이닝에 사용되는 명령줄을 메시지 창에서 확인할 수 있습니다.
+
+추론 스크립트:
+https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/myinfer.py
+
+예제:
+
+runtime\python.exe myinfer.py 0 "E:\codes\py39\RVC-beta\todo-songs\1111.wav" "E:\codes\py39\logs\mi-test\added_IVF677_Flat_nprobe_7.index" harvest "test.wav" "weights/mi-test.pth" 0.6 cuda:0 True
+
+f0up_key=sys.argv[1]
+input_path=sys.argv[2]
+index_path=sys.argv[3]
+f0method=sys.argv[4]#harvest 또는 pm
+opt_path=sys.argv[5]
+model_path=sys.argv[6]
+index_rate=float(sys.argv[7])
+device=sys.argv[8]
+is_half=bool(sys.argv[9])
+
+## Q8:Cuda 오류/Cuda 메모리 부족
+
+아마도 cuda 설정 문제이거나 장치가 지원되지 않을 수 있습니다. 대부분의 경우 메모리가 부족합니다(out of memory).
+
+트레이닝의 경우 batch size를 줄이세요(1로 줄여도 부족하다면 다른 그래픽 카드로 트레이닝을 해야 합니다). 추론의 경우 config.py 파일 끝에 있는 x_pad, x_query, x_center, x_max를 적절히 줄이세요. 4GB 미만의 메모리(예: 1060(3GB) 및 여러 2GB 그래픽 카드)를 가진 경우는 포기하세요. 4GB 메모리 그래픽 카드는 아직 구할 수 있습니다.
+
+## Q9:total_epoch를 몇으로 설정하는 것이 좋을까요
+
+트레이닝 세트의 오디오 품질이 낮고 배경 소음이 많으면 20~30이면 충분합니다. 너무 높게 설정하면 바닥 모델의 오디오 품질이 낮은 트레이닝 세트를 높일 수 없습니다.
+트레이닝 세트의 오디오 품질이 높고 배경 소음이 적고 길이가 길 경우 높게 설정할 수 있습니다. 200도 괜찮습니다(트레이닝 속도가 빠르므로, 고품질 트레이닝 세트를 준비할 수 있는 조건이 있다면, 그래픽 카드도 좋을 것이므로, 조금 더 긴 트레이닝 시간에 대해 걱정하지 않을 것입니다).
+
+## Q10: 트레이닝 세트는 얼마나 길어야 하나요
+
+10분에서 50분을 추천합니다.
+
+음질이 좋고 백그라운드 노이즈가 낮은 상태에서, 개인적인 특색 있는 음색이라면 더 많으면 더 좋습니다.
+
+고품질의 트레이닝 세트(정교하게 준비된 + 특색 있는 음색)라면, 5분에서 10분도 괜찮습니다. 저장소의 저자도 종종 이렇게 합니다.
+
+1분에서 2분의 데이터로 트레이닝에 성공한 사람도 있지만, 그러한 성공 사례는 다른 사람이 재현하기 어려우며 참고 가치가 크지 않습니다. 이는 트레이닝 세트의 음색이 매우 뚜렷해야 하며(예: 높은 주파수의 명확한 목소리나 소녀음) 음질이 좋아야 합니다.
+
+1분 미만의 데이터로 트레이닝을 시도(성공)한 사례는 아직 보지 못했습니다. 이런 시도는 권장하지 않습니다.
+
+## Q11: index rate는 무엇이며, 어떻게 조정하나요? (과학적 설명)
+
+만약 베이스 모델과 추론 소스의 음질이 트레이닝 세트보다 높다면, 그들은 추론 결과의 음질을 높일 수 있지만, 음색이 베이스 모델/추론 소스의 음색으로 기울어질 수 있습니다. 이 현상을 "음색 유출"이라고 합니다.
+
+index rate는 음색 유출 문제를 줄이거나 해결하는 데 사용됩니다. 1로 조정하면 이론적으로 추론 소스의 음색 유출 문제가 없지만, 음질은 트레이닝 세트에 더 가깝게 됩니다. 만약 트레이닝 세트의 음질이 추론 소스보다 낮다면, index rate를 높이면 음질이 낮아질 수 있습니다. 0으로 조정하면 검색 혼합을 이용하여 트레이닝 세트의 음색을 보호하는 효과가 없습니다.
+
+트레이닝 세트가 고품질이고 길이가 길 경우, total_epoch를 높일 수 있으며, 이 경우 모델 자체가 추론 소스와 베이스 모델의 음색을 거의 참조하지 않아 "음색 유출" 문제가 거의 발생하지 않습니다. 이때 index rate는 중요하지 않으며, 심지어 index 색인 파일을 생성하거나 공유하지 않아도 됩니다.
+
+## Q11: 추론시 GPU를 어떻게 선택하나요?
+
+config.py 파일에서 device cuda: 다음에 카드 번호를 선택합니다.
+카드 번호와 그래픽 카드의 매핑 관계는 트레이닝 탭의 그래픽 카드 정보란에서 볼 수 있습니다.
+
+## Q12: 트레이닝 중간에 저장된 pth를 어떻게 추론하나요?
+
+ckpt 탭 하단에서 소형 모델을 추출합니다.
+
+## Q13: 트레이닝을 어떻게 중단하고 계속할 수 있나요?
+
+현재 단계에서는 WebUI 콘솔을 닫고 go-web.bat을 더블 클릭하여 프로그램을 다시 시작해야 합니다. 웹 페이지 매개변수도 새로 고쳐서 다시 입력해야 합니다.
+트레이닝을 계속하려면: 같은 웹 페이지 매개변수로 트레이닝 모델을 클릭하면 이전 체크포인트에서 트레이닝을 계속합니다.
+
+## Q14: 트레이닝 중 파일 페이지/메모리 오류가 발생하면 어떻게 해야 하나요?
+
+프로세스가 너무 많이 열려 메모리가 폭발했습니다. 다음과 같은 방법으로 해결할 수 있습니다.
+
+1. "음높이 추출 및 데이터 처리에 사용되는 CPU 프로세스 수"를 적당히 낮춥니다.
+2. 트레이닝 세트 오디오를 수동으로 잘라 너무 길지 않게 합니다.
+
+## Q15: 트레이닝 도중 데이터를 어떻게 추가하나요?
+
+1. 모든 데이터에 새로운 실험 이름을 만듭니다.
+2. 이전에 가장 최신의 G와 D 파일(또는 어떤 중간 ckpt를 기반으로 트레이닝하고 싶다면 중간 것을 복사할 수도 있음)을 새 실험 이름으로 복사합니다.
+3. 새 실험 이름으로 원클릭 트레이닝을 시작하면 이전의 최신 진행 상황에서 계속 트레이닝합니다.
+
+## Q16: llvmlite.dll에 관한 오류
+
+```bash
+OSError: Could not load shared object file: llvmlite.dll
+
+FileNotFoundError: Could not find module lib\site-packages\llvmlite\binding\llvmlite.dll (or one of its dependencies). Try using the full path with constructor syntax.
+```
+
+Windows 플랫폼에서 이 오류가 발생하면 https://aka.ms/vs/17/release/vc_redist.x64.exe를 설치하고 WebUI를 다시 시작하면 해결됩니다.
+
+## Q17: RuntimeError: 텐서의 확장된 크기(17280)는 비 단일 항목 차원 1에서 기존 크기(0)와 일치해야 합니다. 대상 크기: [1, 17280]. 텐서 크기: [0]
+
+wavs16k 폴더 아래에서 다른 파일들보다 크기가 현저히 작은 일부 오디오 파일을 찾아 삭제하고, 트레이닝 모델을 클릭하면 오류가 발생하지 않습니다. 하지만 원클릭 프로세스가 중단되었기 때문에 모델 트레이닝이 완료된 후에는 인덱스 트레이닝을 클릭해야 합니다.
+
+## Q18: RuntimeError: 텐서 a의 크기(24)가 비 단일 항목 차원 2에서 텐서 b(16)의 크기와 일치해야 합니다.
+
+트레이닝 도중에 샘플링 레이트를 변경해서는 안 됩니다. 변경해야 한다면 실험 이름을 변경하고 처음부터 트레이닝해야 합니다. 물론, 이전에 추출한 음높이와 특징(0/1/2/2b 폴더)을 복사하여 트레이닝 프로세스를 가속화할 수도 있습니다.
diff --git a/docs/kr/training_tips_ko.md b/docs/kr/training_tips_ko.md
new file mode 100644
index 0000000000000000000000000000000000000000..8b3b6245862aef69480f57263d268c94d5e843ca
--- /dev/null
+++ b/docs/kr/training_tips_ko.md
@@ -0,0 +1,53 @@
+RVC 훈련에 대한 설명과 팁들
+======================================
+본 팁에서는 어떻게 데이터 훈련이 이루어지고 있는지 설명합니다.
+
+# 훈련의 흐름
+GUI의 훈련 탭의 단계를 따라 설명합니다.
+
+## step1
+실험 이름을 지정합니다. 또한, 모델이 피치(소리의 높낮이)를 고려해야 하는지 여부를 여기에서 설정할 수도 있습니다..
+각 실험을 위한 데이터는 `/logs/experiment name/`에 배치됩니다..
+
+## step2a
+음성 파일을 불러오고 전처리합니다.
+
+### 음성 파일 불러오기
+음성 파일이 있는 폴더를 지정하면 해당 폴더에 있는 음성 파일이 자동으로 가져와집니다.
+예를 들어 `C:Users\hoge\voices`를 지정하면 `C:Users\hoge\voices\voice.mp3`가 읽히지만 `C:Users\hoge\voices\dir\voice.mp3`는 읽히지 않습니다.
+
+음성 로드에는 내부적으로 ffmpeg를 이용하고 있으므로, ffmpeg로 대응하고 있는 확장자라면 자동적으로 읽힙니다.
+ffmpeg에서 int16으로 변환한 후 float32로 변환하고 -1과 1 사이에 정규화됩니다.
+
+### 잡음 제거
+음성 파일에 대해 scipy의 filtfilt를 이용하여 잡음을 처리합니다.
+
+### 음성 분할
+입력한 음성 파일은 먼저 일정 기간(max_sil_kept=5초?)보다 길게 무음이 지속되는 부분을 감지하여 음성을 분할합니다.무음으로 음성을 분할한 후에는 0.3초의 overlap을 포함하여 4초마다 음성을 분할합니다.4초 이내에 구분된 음성은 음량의 정규화를 실시한 후 wav 파일을 `/logs/실험명/0_gt_wavs`로, 거기에서 16k의 샘플링 레이트로 변환해 `/logs/실험명/1_16k_wavs`에 wav 파일로 저장합니다.
+
+## step2b
+### 피치 추출
+wav 파일에서 피치(소리의 높낮이) 정보를 추출합니다. parselmouth나 pyworld에 내장되어 있는 메서드으로 피치 정보(=f0)를 추출해, `/logs/실험명/2a_f0`에 저장합니다. 그 후 피치 정보를 로그로 변환하여 1~255 정수로 변환하고 `/logs/실험명/2b-f0nsf`에 저장합니다.
+
+### feature_print 추출
+HuBERT를 이용하여 wav 파일을 미리 embedding으로 변환합니다. `/logs/실험명/1_16k_wavs`에 저장한 wav 파일을 읽고 HuBERT에서 wav 파일을 256차원 feature들로 변환한 후 npy 형식으로 `/logs/실험명/3_feature256`에 저장합니다.
+
+## step3
+모델의 훈련을 진행합니다.
+
+### 초보자용 용어 해설
+심층학습(딥러닝)에서는 데이터셋을 분할하여 조금씩 학습을 진행합니다.한 번의 모델 업데이트(step) 단계 당 batch_size개의 데이터를 탐색하여 예측과 오차를 수정합니다. 데이터셋 전부에 대해 이 작업을 한 번 수행하는 이를 하나의 epoch라고 계산합니다.
+
+따라서 학습 시간은 단계당 학습 시간 x (데이터셋 내 데이터의 수 / batch size) x epoch 수가 소요됩니다. 일반적으로 batch size가 클수록 학습이 안정적이게 됩니다. (step당 학습 시간 ÷ batch size)는 작아지지만 GPU 메모리를 더 많이 사용합니다. GPU RAM은 nvidia-smi 명령어를 통해 확인할 수 있습니다. 실행 환경에 따라 배치 크기를 최대한 늘리면 짧은 시간 내에 학습이 가능합니다.
+
+### 사전 학습된 모델 지정
+RVC는 적은 데이터셋으로도 훈련이 가능하도록 사전 훈련된 가중치에서 모델 훈련을 시작합니다. 기본적으로 `rvc-location/pretrained/f0G40k.pth` 및 `rvc-location/pretrained/f0D40k.pth`를 불러옵니다. 학습을 할 시에, 모델 파라미터는 각 save_every_epoch별로 `logs/experiment name/G_{}.pth` 와 `logs/experiment name/D_{}.pth`로 저장이 되는데, 이 경로를 지정함으로써 학습을 재개하거나, 다른 실험에서 학습한 모델의 가중치에서 학습을 시작할 수 있습니다.
+
+### index의 학습
+RVC에서는 학습시에 사용된 HuBERT의 feature값을 저장하고, 추론 시에는 학습 시 사용한 feature값과 유사한 feature 값을 탐색해 추론을 진행합니다. 이 탐색을 고속으로 수행하기 위해 사전에 index을 학습하게 됩니다.
+Index 학습에는 근사 근접 탐색법 라이브러리인 Faiss를 사용하게 됩니다. `/logs/실험명/3_feature256`의 feature값을 불러와, 이를 모두 결합시킨 feature값을 `/logs/실험명/total_fea.npy`로서 저장, 그것을 사용해 학습한 index를`/logs/실험명/add_XXX.index`로 저장합니다.
+
+### 버튼 설명
+- モデルのトレーニング (모델 학습): step2b까지 실행한 후, 이 버튼을 눌러 모델을 학습합니다.
+- 特徴インデックスのトレーニング (특징 지수 훈련): 모델의 훈련 후, index를 학습합니다.
+- ワンクリックトレーニング (원클릭 트레이닝): step2b까지의 모델 훈련, feature index 훈련을 일괄로 실시합니다.
\ No newline at end of file
diff --git a/docs/pt/Changelog_pt.md b/docs/pt/Changelog_pt.md
new file mode 100644
index 0000000000000000000000000000000000000000..4833893f79a2512d61fd691c94fa3bc5d2d36c41
--- /dev/null
+++ b/docs/pt/Changelog_pt.md
@@ -0,0 +1,105 @@
+### 2023-10-06
+- Criamos uma GUI para alteração de voz em tempo real: go-realtime-gui.bat/gui_v1.py (observe que você deve escolher o mesmo tipo de dispositivo de entrada e saída, por exemplo, MME e MME).
+- Treinamos um modelo RMVPE de extração de pitch melhor.
+- Otimizar o layout da GUI de inferência.
+
+### 2023-08-13
+1-Correção de bug regular
+- Alterar o número total mínimo de épocas para 1 e alterar o número total mínimo de epoch para 2
+- Correção de erros de treinamento por não usar modelos de pré-treinamento
+- Após a separação dos vocais de acompanhamento, limpe a memória dos gráficos
+- Alterar o caminho absoluto do faiss save para o caminho relativo
+- Suporte a caminhos com espaços (tanto o caminho do conjunto de treinamento quanto o nome do experimento são suportados, e os erros não serão mais relatados)
+- A lista de arquivos cancela a codificação utf8 obrigatória
+- Resolver o problema de consumo de CPU causado pela busca do faiss durante alterações de voz em tempo real
+
+Atualizações do 2-Key
+- Treine o modelo de extração de pitch vocal de código aberto mais forte do momento, o RMVPE, e use-o para treinamento de RVC, inferência off-line/em tempo real, com suporte a PyTorch/Onnx/DirectML
+- Suporte para placas gráficas AMD e Intel por meio do Pytorch_DML
+
+(1) Mudança de voz em tempo real (2) Inferência (3) Separação do acompanhamento vocal (4) Não há suporte para treinamento no momento, mudaremos para treinamento de CPU; há suporte para inferência RMVPE de gpu por Onnx_Dml
+
+
+### 2023-06-18
+- Novos modelos v2 pré-treinados: 32k e 48k
+- Correção de erros de inferência de modelo não-f0
+- Para conjuntos de treinamento que excedam 1 hora, faça minibatch-kmeans automáticos para reduzir a forma dos recursos, de modo que o treinamento, a adição e a pesquisa do Index sejam muito mais rápidos.
+- Fornecer um espaço de brinquedo vocal2guitar huggingface
+- Exclusão automática de áudios de conjunto de treinamento de atalhos discrepantes
+- Guia de exportação Onnx
+
+Experimentos com falha:
+- ~~Recuperação de recurso: adicionar recuperação de recurso temporal: não eficaz~~
+- ~~Recuperação de recursos: adicionar redução de dimensionalidade PCAR: a busca é ainda mais lenta~~
+- ~~Aumento de dados aleatórios durante o treinamento: não é eficaz~~
+
+Lista de tarefas:
+- ~~Vocos-RVC (vocoder minúsculo): não é eficaz~~
+- ~~Suporte de crepe para treinamento: substituído pelo RMVPE~~
+- ~~Inferência de crepe de meia precisão:substituída pelo RMVPE. E difícil de conseguir.~~
+- Suporte ao editor de F0
+
+### 2023-05-28
+- Adicionar notebook jupyter v2, changelog em coreano, corrigir alguns requisitos de ambiente
+- Adicionar consoante sem voz e modo de proteção de respiração
+- Suporte à detecção de pitch crepe-full
+- Separação vocal UVR5: suporte a modelos dereverb e modelos de-echo
+- Adicionar nome e versão do experimento no nome do Index
+- Suporte aos usuários para selecionar manualmente o formato de exportação dos áudios de saída durante o processamento de conversão de voz em lote e a separação vocal UVR5
+- Não há mais suporte para o treinamento do modelo v1 32k
+
+### 2023-05-13
+- Limpar os códigos redundantes na versão antiga do tempo de execução no pacote de um clique: lib.infer_pack e uvr5_pack
+- Correção do bug de pseudo multiprocessamento no pré-processamento do conjunto de treinamento
+- Adição do ajuste do raio de filtragem mediana para o algoritmo de reconhecimento de inclinação da extração
+- Suporte à reamostragem de pós-processamento para exportação de áudio
+- A configuração "n_cpu" de multiprocessamento para treinamento foi alterada de "extração de f0" para "pré-processamento de dados e extração de f0"
+- Detectar automaticamente os caminhos de Index na pasta de registros e fornecer uma função de lista suspensa
+- Adicionar "Perguntas e respostas frequentes" na página da guia (você também pode consultar o wiki do RVC no github)
+- Durante a inferência, o pitch da colheita é armazenado em cache quando se usa o mesmo caminho de áudio de entrada (finalidade: usando a extração do pitch da colheita, todo o pipeline passará por um processo longo e repetitivo de extração do pitch. Se o armazenamento em cache não for usado, os usuários que experimentarem diferentes configurações de raio de filtragem de timbre, Index e mediana de pitch terão um processo de espera muito doloroso após a primeira inferência)
+
+### 2023-05-14
+- Use o envelope de volume da entrada para misturar ou substituir o envelope de volume da saída (pode aliviar o problema de "muting de entrada e ruído de pequena amplitude de saída"). Se o ruído de fundo do áudio de entrada for alto, não é recomendável ativá-lo, e ele não é ativado por padrão (1 pode ser considerado como não ativado)
+- Suporte ao salvamento de modelos pequenos extraídos em uma frequência especificada (se você quiser ver o desempenho em épocas diferentes, mas não quiser salvar todos os pontos de verificação grandes e extrair manualmente modelos pequenos pelo processamento ckpt todas as vezes, esse recurso será muito prático)
+- Resolver o problema de "erros de conexão" causados pelo proxy global do servidor, definindo variáveis de ambiente
+- Oferece suporte a modelos v2 pré-treinados (atualmente, apenas as versões 40k estão disponíveis publicamente para teste e as outras duas taxas de amostragem ainda não foram totalmente treinadas)
+- Limita o volume excessivo que excede 1 antes da inferência
+- Ajustou ligeiramente as configurações do pré-processamento do conjunto de treinamento
+
+
+#######################
+
+Histórico de registros de alterações:
+
+### 2023-04-09
+- Parâmetros de treinamento corrigidos para melhorar a taxa de utilização da GPU: A100 aumentou de 25% para cerca de 90%, V100: 50% para cerca de 90%, 2060S: 60% para cerca de 85%, P40: 25% para cerca de 95%; melhorou significativamente a velocidade de treinamento
+- Parâmetro alterado: total batch_size agora é por GPU batch_size
+- Total_epoch alterado: limite máximo aumentado de 100 para 1000; padrão aumentado de 10 para 20
+- Corrigido o problema da extração de ckpt que reconhecia o pitch incorretamente, causando inferência anormal
+- Corrigido o problema do treinamento distribuído que salvava o ckpt para cada classificação
+- Aplicada a filtragem de recursos nan para extração de recursos
+- Corrigido o problema com a entrada/saída silenciosa que produzia consoantes aleatórias ou ruído (os modelos antigos precisavam ser treinados novamente com um novo conjunto de dados)
+
+### Atualização 2023-04-16
+- Adicionada uma mini-GUI de alteração de voz local em tempo real, iniciada com um clique duplo em go-realtime-gui.bat
+- Filtragem aplicada para bandas de frequência abaixo de 50 Hz durante o treinamento e a inferência
+- Diminuição da extração mínima de tom do pyworld do padrão 80 para 50 para treinamento e inferência, permitindo que vozes masculinas de tom baixo entre 50-80 Hz não sejam silenciadas
+- A WebUI suporta a alteração de idiomas de acordo com a localidade do sistema (atualmente suporta en_US, ja_JP, zh_CN, zh_HK, zh_SG, zh_TW; o padrão é en_US se não for suportado)
+- Correção do reconhecimento de algumas GPUs (por exemplo, falha no reconhecimento da V100-16G, falha no reconhecimento da P4)
+
+### Atualização de 2023-04-28
+- Atualizadas as configurações do Index faiss para maior velocidade e qualidade
+- Removida a dependência do total_npy; o futuro compartilhamento de modelos não exigirá a entrada do total_npy
+- Restrições desbloqueadas para as GPUs da série 16, fornecendo configurações de inferência de 4 GB para GPUs com VRAM de 4 GB
+- Corrigido o erro na separação do acompanhamento vocal do UVR5 para determinados formatos de áudio
+- A mini-GUI de alteração de voz em tempo real agora suporta modelos de pitch não 40k e que não são lentos
+
+### Planos futuros:
+Recursos:
+- Opção de adição: extrair modelos pequenos para cada epoch salvo
+- Adicionar opção: exportar mp3 adicional para o caminho especificado durante a inferência
+- Suporte à guia de treinamento para várias pessoas (até 4 pessoas)
+
+Modelo básico:
+- Coletar arquivos wav de respiração para adicionar ao conjunto de dados de treinamento para corrigir o problema de sons de respiração distorcidos
+- No momento, estamos treinando um modelo básico com um conjunto de dados de canto estendido, que será lançado no futuro
\ No newline at end of file
diff --git a/docs/pt/README.pt.md b/docs/pt/README.pt.md
new file mode 100644
index 0000000000000000000000000000000000000000..4b8ec50a4c9d4d8dd2982288360d096d5855bcd1
--- /dev/null
+++ b/docs/pt/README.pt.md
@@ -0,0 +1,194 @@
+
+
+
Retrieval-based-Voice-Conversion-WebUI
+Uma estrutura de conversão de voz fácil de usar baseada em VITS.
+
+[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
+
+
+
+[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/tools/ipynb/v1.ipynb)
+[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/tools/ipynb/v2.ipynb)
+[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
+[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
+
+[](https://discord.gg/HcsmBBGyVk)
+
+
+
+## O que é index?
+Basicamente o que define o sotaque. Quanto maior o numero, mas próximo o sotaque fica do original. Porém, quando o modelo é bem, não é necessário um index.
+
+## O que significa cada sigla (pm, harvest, crepe, magio-crepe, RMVPE)?
+
+- pm = extração mais rápida, mas discurso de qualidade inferior;
+- harvest = graves melhores, mas extremamente lentos;
+- dio = conversão rápida mas pitch ruim;
+- crepe = melhor qualidade, mas intensivo em GPU;
+- crepe-tiny = mesma coisa que o crepe, só que com a qualidade um pouco inferior;
+- **mangio-crepe = melhor qualidade, mais otimizado; (MELHOR OPÇÃO)**
+- mangio-crepe-tiny = mesma coisa que o mangio-crepe, só que com a qualidade um pouco inferior;
+- RMVPE: um modelo robusto para estimativa de afinação vocal em música polifônica;
+
+## Pra rodar localmente, quais os requisitos minimos?
+Já tivemos relatos de pessoas com GTX 1050 rodando inferencia, se for treinar numa 1050 vai demorar muito mesmo e inferior a isso, normalmente da tela azul
+
+O mais importante é placa de vídeo, vram na verdade
+Se você tiver 4GB ou mais, você tem uma chance.
+
+**NOS DOIS CASOS NÃO É RECOMENDADO UTILIZAR O PC ENQUANTO ESTÁ UTILIZNDO, CHANCE DE TELA AZUL É ALTA**
+### Inference
+Não é algo oficial para requisitos minimos
+- Placa de vídeo: nvidia de 4gb
+- Memoria ram: 8gb
+- CPU: ?
+- Armanezamento: 20gb (sem modelos)
+
+### Treinamento de voz
+Não é algo oficial para requisitos minimos
+- Placa de vídeo: nvidia de 6gb
+- Memoria ram: 16gb
+- CPU: ?
+- Armanezamento: 20gb (sem modelos)
+
+## Limite de GPU no Google Colab excedido, apenas CPU o que fazer?
+Recomendamos esperar outro dia pra liberar mais 15gb ou 12 horas pra você. Ou você pode contribuir com o Google pagando algum dos planos, ai aumenta seu limite.
+Utilizar apenas CPU no Google Colab demora DEMAIS.
+
+
+## Google Colab desconectando com muita frequencia, o que fazer?
+Neste caso realmente não tem muito o que fazer. Apenas aguardar o proprietário do código corrigir ou a gente do AI HUB Brasil achar alguma solução. Isso acontece por diversos motivos, um incluindo a Google barrando o treinamento de voz.
+
+## O que é Batch Size/Tamanho de lote e qual numero utilizar?
+Batch Size/Tamanho do lote é basicamente quantos epoch faz ao mesmo tempo. Se por 20, ele fazer 20 epoch ao mesmo tempo e isso faz pesar mais na máquina e etc.
+
+No Google Colab você pode utilizar até 20 de boa.
+Se rodando localmente, depende da sua placa de vídeo, começa por baixo (6) e vai testando.
+
+## Sobre backup na hora do treinamento
+Backup vai de cada um. Eu quando uso a ``easierGUI`` utilizo a cada 100 epoch (meu caso isolado).
+No colab, se instavel, coloque a cada 10 epoch
+Recomendo utilizarem entre 25 e 50 pra garantir.
+
+Lembrando que cada arquivo geral é por volta de 50mb, então tenha muito cuidado quanto você coloca. Pois assim pode acabar lotando seu Google Drive ou seu PC.
+
+Depois de finalizado, da pra apagar os epoch de backup.
+
+## Como continuar da onde parou pra fazer mais epochs?
+Primeira coisa que gostaria de lembrar, não necessariamente quanto mais epochs melhor. Se fizer epochs demais vai dar **overtraining** o que pode ser ruim.
+
+### GUI NORMAL
+- Inicie normalmente a GUI novamente.
+- Na aba de treino utilize o MESMO nome que estava treinando, assim vai continuar o treino onde parou o ultimo backup.
+- Ignore as opções ``Processar o Conjunto de dados`` e ``Extrair Tom``
+- Antes de clicar pra treinar, arrume os epoch, bakcup e afins.
+ - Obviamente tem que ser um numero maior do qu estava em epoch.
+ - Backup você pode aumentar ou diminuir
+- Agora você vai ver a opção ``Carregue o caminho G do modelo base pré-treinado:`` e ``Carregue o caminho D do modelo base pré-treinado:``
+ -Aqui você vai por o caminho dos modelos que estão em ``./logs/minha-voz``
+ - Vai ficar algo parecido com isso ``e:/RVC/logs/minha-voz/G_0000.pth`` e ``e:/RVC/logs/minha-voz/D_0000.pth``
+-Coloque pra treinar
+
+**Lembrando que a pasta logs tem que ter todos os arquivos e não somente o arquivo ``G`` e ``D``**
+
+### EasierGUI
+- Inicie normalmente a easierGUI novamente.
+- Na aba de treino utilize o MESMO nome que estava treinando, assim vai continuar o treino onde parou o ultimo backup.
+- Selecione 'Treinar modelo', pode pular os 2 primeiros passos já que vamos continuar o treino.
+
+
+# FAQ Original traduzido
+## Q1: erro ffmpeg/erro utf8.
+Provavelmente não é um problema do FFmpeg, mas sim um problema de caminho de áudio;
+
+O FFmpeg pode encontrar um erro ao ler caminhos contendo caracteres especiais como spaces e (), o que pode causar um erro FFmpeg; e quando o áudio do conjunto de treinamento contém caminhos chineses, gravá-lo em filelist.txt pode causar um erro utf8.
+
+## Q2:Não é possível encontrar o arquivo de Index após "Treinamento com um clique".
+Se exibir "O treinamento está concluído. O programa é fechado ", então o modelo foi treinado com sucesso e os erros subsequentes são falsos;
+
+A falta de um arquivo de index 'adicionado' após o treinamento com um clique pode ser devido ao conjunto de treinamento ser muito grande, fazendo com que a adição do index fique presa; isso foi resolvido usando o processamento em lote para adicionar o index, o que resolve o problema de sobrecarga de memória ao adicionar o index. Como solução temporária, tente clicar no botão "Treinar Index" novamente.
+
+## Q3:Não é possível encontrar o modelo em “Modelo de voz” após o treinamento
+Clique em "Atualizar lista de voz" ou "Atualizar na EasyGUI e verifique novamente; se ainda não estiver visível, verifique se há erros durante o treinamento e envie capturas de tela do console, da interface do usuário da Web e dos ``logs/experiment_name/*.log`` para os desenvolvedores para análise posterior.
+
+## Q4:Como compartilhar um modelo/Como usar os modelos dos outros?
+Os arquivos ``.pth`` armazenados em ``*/logs/minha-voz`` não são destinados para compartilhamento ou inference, mas para armazenar os checkpoits do experimento para reprodutibilidade e treinamento adicional. O modelo a ser compartilhado deve ser o arquivo ``.pth`` de 60+MB na pasta **weights**;
+
+No futuro, ``weights/minha-voz.pth`` e ``logs/minha-voz/added_xxx.index`` serão mesclados em um único arquivo de ``weights/minha-voz.zip`` para eliminar a necessidade de entrada manual de index; portanto, compartilhe o arquivo zip, não somente o arquivo .pth, a menos que você queira continuar treinando em uma máquina diferente;
+
+Copiar/compartilhar os vários arquivos .pth de centenas de MB da pasta de logs para a pasta de weights para inference forçada pode resultar em erros como falta de f0, tgt_sr ou outras chaves. Você precisa usar a guia ckpt na parte inferior para manualmente ou automaticamente (se as informações forem encontradas nos ``logs/minha-voz``), selecione se deseja incluir informações de tom e opções de taxa de amostragem de áudio de destino e, em seguida, extrair o modelo menor. Após a extração, haverá um arquivo pth de 60+ MB na pasta de weights, e você pode atualizar as vozes para usá-lo.
+
+## Q5 Erro de conexão:
+Para sermos otimistas, aperte F5/recarregue a página, pode ter sido apenas um bug da GUI
+
+Se não...
+Você pode ter fechado o console (janela de linha de comando preta).
+Ou o Google Colab, no caso do Colab, as vezes pode simplesmente fechar
+
+## Q6: Pop-up WebUI 'Valor esperado: linha 1 coluna 1 (caractere 0)'.
+Desative o proxy LAN do sistema/proxy global e atualize.
+
+## Q7:Como treinar e inferir sem a WebUI?
+Script de treinamento:
+
Você pode executar o treinamento em WebUI primeiro, e as versões de linha de comando do pré-processamento e treinamento do conjunto de dados serão exibidas na janela de mensagens.
+
+Script de inference:
+
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/myinfer.py
+
+
+por exemplo
+
+``runtime\python.exe myinfer.py 0 "E:\audios\1111.wav" "E:\RVC\logs\minha-voz\added_IVF677_Flat_nprobe_7.index" harvest "test.wav" "weights/mi-test.pth" 0.6 cuda:0 True``
+
+
+f0up_key=sys.argv[1]
+input_path=sys.argv[2]
+index_path=sys.argv[3]
+f0method=sys.argv[4]#harvest or pm
+opt_path=sys.argv[5]
+model_path=sys.argv[6]
+index_rate=float(sys.argv[7])
+device=sys.argv[8]
+is_half=bool(sys.argv[9])
+
+## Q8: Erro Cuda/Cuda sem memória.
+Há uma pequena chance de que haja um problema com a configuração do CUDA ou o dispositivo não seja suportado; mais provavelmente, não há memória suficiente (falta de memória).
+
+Para treinamento, reduza o (batch size) tamanho do lote (se reduzir para 1 ainda não for suficiente, talvez seja necessário alterar a placa gráfica); para inference, ajuste as configurações x_pad, x_query, x_center e x_max no arquivo config.py conforme necessário. Cartões de memória 4G ou inferiores (por exemplo, 1060(3G) e várias placas 2G) podem ser abandonados, enquanto os placas de vídeo com memória 4G ainda têm uma chance.
+
+## Q9:Quantos total_epoch são ótimos?
+Se a qualidade de áudio do conjunto de dados de treinamento for ruim e o nível de ruído for alto, **20-30 epochs** são suficientes. Defini-lo muito alto não melhorará a qualidade de áudio do seu conjunto de treinamento de baixa qualidade.
+
+Se a qualidade de áudio do conjunto de treinamento for alta, o nível de ruído for baixo e houver duração suficiente, você poderá aumentá-lo. **200 é aceitável** (uma vez que o treinamento é rápido e, se você puder preparar um conjunto de treinamento de alta qualidade, sua GPU provavelmente poderá lidar com uma duração de treinamento mais longa sem problemas).
+
+## Q10:Quanto tempo de treinamento é necessário?
+
+**Recomenda-se um conjunto de dados de cerca de 10 min a 50 min.**
+
+Com garantia de alta qualidade de som e baixo ruído de fundo, mais pode ser adicionado se o timbre do conjunto de dados for uniforme.
+
+Para um conjunto de treinamento de alto nível (limpo + distintivo), 5min a 10min é bom.
+
+Há algumas pessoas que treinaram com sucesso com dados de 1 a 2 minutos, mas o sucesso não é reproduzível por outros e não é muito informativo.
Isso requer que o conjunto de treinamento tenha um timbre muito distinto (por exemplo, um som de menina de anime arejado de alta frequência) e a qualidade do áudio seja alta;
+Dados com menos de 1 minuto, já obtivemo sucesso. Mas não é recomendado.
+
+
+## Q11:Qual é a taxa do index e como ajustá-la?
+Se a qualidade do tom do modelo pré-treinado e da fonte de inference for maior do que a do conjunto de treinamento, eles podem trazer a qualidade do tom do resultado do inference, mas ao custo de um possível viés de tom em direção ao tom do modelo subjacente/fonte de inference, em vez do tom do conjunto de treinamento, que é geralmente referido como "vazamento de tom".
+
+A taxa de index é usada para reduzir/resolver o problema de vazamento de timbre. Se a taxa do index for definida como 1, teoricamente não há vazamento de timbre da fonte de inference e a qualidade do timbre é mais tendenciosa em relação ao conjunto de treinamento. Se o conjunto de treinamento tiver uma qualidade de som mais baixa do que a fonte de inference, uma taxa de index mais alta poderá reduzir a qualidade do som. Reduzi-lo a 0 não tem o efeito de usar a mistura de recuperação para proteger os tons definidos de treinamento.
+
+Se o conjunto de treinamento tiver boa qualidade de áudio e longa duração, aumente o total_epoch, quando o modelo em si é menos propenso a se referir à fonte inferida e ao modelo subjacente pré-treinado, e há pouco "vazamento de tom", o index_rate não é importante e você pode até não criar/compartilhar o arquivo de index.
+
+## Q12:Como escolher o GPU ao inferir?
+No arquivo ``config.py``, selecione o número da placa em "device cuda:".
+
+O mapeamento entre o número da placa e a placa gráfica pode ser visto na seção de informações da placa gráfica da guia de treinamento.
+
+## Q13:Como usar o modelo salvo no meio do treinamento?
+Salvar via extração de modelo na parte inferior da guia de processamento do ckpt.
+
+## Q14: Erro de arquivo/memória (durante o treinamento)?
+Muitos processos e sua memória não é suficiente. Você pode corrigi-lo por:
+
+1. Diminuir a entrada no campo "Threads da CPU".
+2. Diminuir o tamanho do conjunto de dados.
+
+## Q15: Como continuar treinando usando mais dados
+
+passo 1: coloque todos os dados wav no path2.
+
+etapa 2: exp_name2 + path2 -> processar conjunto de dados e extrair recurso.
+
+passo 3: copie o arquivo G e D mais recente de exp_name1 (seu experimento anterior) para a pasta exp_name2.
+
+passo 4: clique em "treinar o modelo" e ele continuará treinando desde o início da época anterior do modelo exp.
+
+## Q16: erro sobre llvmlite.dll
+
+OSError: Não foi possível carregar o arquivo de objeto compartilhado: llvmlite.dll
+
+FileNotFoundError: Não foi possível encontrar o módulo lib\site-packages\llvmlite\binding\llvmlite.dll (ou uma de suas dependências). Tente usar o caminho completo com sintaxe de construtor.
+
+O problema acontecerá no Windows, instale https://aka.ms/vs/17/release/vc_redist.x64.exe e será corrigido.
+
+## Q17: RuntimeError: O tamanho expandido do tensor (17280) deve corresponder ao tamanho existente (0) na dimensão 1 não singleton. Tamanhos de destino: [1, 17280]. Tamanhos de tensor: [0]
+
+Exclua os arquivos wav cujo tamanho seja significativamente menor que outros e isso não acontecerá novamente. Em seguida, clique em "treinar o modelo" e "treinar o índice".
+
+## Q18: RuntimeError: O tamanho do tensor a (24) deve corresponder ao tamanho do tensor b (16) na dimensão não singleton 2
+
+Não altere a taxa de amostragem e continue o treinamento. Caso seja necessário alterar, o nome do exp deverá ser alterado e o modelo será treinado do zero. Você também pode copiar o pitch e os recursos (pastas 0/1/2/2b) extraídos da última vez para acelerar o processo de treinamento.
+
diff --git a/docs/pt/training_tips_pt.md b/docs/pt/training_tips_pt.md
new file mode 100644
index 0000000000000000000000000000000000000000..985ab4fc1a8af99eb0d968b11a5eba7d3299230b
--- /dev/null
+++ b/docs/pt/training_tips_pt.md
@@ -0,0 +1,65 @@
+Instruções e dicas para treinamento RVC
+======================================
+Estas DICAS explicam como o treinamento de dados é feito.
+
+# Fluxo de treinamento
+Explicarei ao longo das etapas na guia de treinamento da GUI.
+
+## Passo 1
+Defina o nome do experimento aqui.
+
+Você também pode definir aqui se o modelo deve levar em consideração o pitch.
+Se o modelo não considerar o tom, o modelo será mais leve, mas não será adequado para cantar.
+
+Os dados de cada experimento são colocados em `/logs/nome-do-seu-modelo/`.
+
+## Passo 2a
+Carrega e pré-processa áudio.
+
+### Carregar áudio
+Se você especificar uma pasta com áudio, os arquivos de áudio dessa pasta serão lidos automaticamente.
+Por exemplo, se você especificar `C:Users\hoge\voices`, `C:Users\hoge\voices\voice.mp3` será carregado, mas `C:Users\hoge\voices\dir\voice.mp3` será Não carregado.
+
+Como o ffmpeg é usado internamente para leitura de áudio, se a extensão for suportada pelo ffmpeg, ela será lida automaticamente.
+Após converter para int16 com ffmpeg, converta para float32 e normalize entre -1 e 1.
+
+### Eliminar ruído
+O áudio é suavizado pelo filtfilt do scipy.
+
+### Divisão de áudio
+Primeiro, o áudio de entrada é dividido pela detecção de partes de silêncio que duram mais que um determinado período (max_sil_kept=5 segundos?). Após dividir o áudio no silêncio, divida o áudio a cada 4 segundos com uma sobreposição de 0,3 segundos. Para áudio separado em 4 segundos, após normalizar o volume, converta o arquivo wav para `/logs/nome-do-seu-modelo/0_gt_wavs` e, em seguida, converta-o para taxa de amostragem de 16k para `/logs/nome-do-seu-modelo/1_16k_wavs ` como um arquivo wav.
+
+## Passo 2b
+### Extrair pitch
+Extraia informações de pitch de arquivos wav. Extraia as informações de pitch (=f0) usando o método incorporado em Parselmouth ou pyworld e salve-as em `/logs/nome-do-seu-modelo/2a_f0`. Em seguida, converta logaritmicamente as informações de pitch para um número inteiro entre 1 e 255 e salve-as em `/logs/nome-do-seu-modelo/2b-f0nsf`.
+
+### Extrair feature_print
+Converta o arquivo wav para incorporação antecipadamente usando HuBERT. Leia o arquivo wav salvo em `/logs/nome-do-seu-modelo/1_16k_wavs`, converta o arquivo wav em recursos de 256 dimensões com HuBERT e salve no formato npy em `/logs/nome-do-seu-modelo/3_feature256`.
+
+## Passo 3
+treinar o modelo.
+### Glossário para iniciantes
+No aprendizado profundo, o conjunto de dados é dividido e o aprendizado avança aos poucos. Em uma atualização do modelo (etapa), os dados batch_size são recuperados e previsões e correções de erros são realizadas. Fazer isso uma vez para um conjunto de dados conta como um epoch.
+
+Portanto, o tempo de aprendizagem é o tempo de aprendizagem por etapa x (o número de dados no conjunto de dados/tamanho do lote) x o número de epoch. Em geral, quanto maior o tamanho do lote, mais estável se torna o aprendizado (tempo de aprendizado por etapa ÷ tamanho do lote) fica menor, mas usa mais memória GPU. A RAM da GPU pode ser verificada com o comando nvidia-smi. O aprendizado pode ser feito em pouco tempo aumentando o tamanho do lote tanto quanto possível de acordo com a máquina do ambiente de execução.
+
+### Especifique o modelo pré-treinado
+O RVC começa a treinar o modelo a partir de pesos pré-treinados em vez de 0, para que possa ser treinado com um pequeno conjunto de dados.
+
+Por padrão
+
+- Se você considerar o pitch, ele carrega `rvc-location/pretrained/f0G40k.pth` e `rvc-location/pretrained/f0D40k.pth`.
+- Se você não considerar o pitch, ele carrega `rvc-location/pretrained/f0G40k.pth` e `rvc-location/pretrained/f0D40k.pth`.
+
+Ao aprender, os parâmetros do modelo são salvos em `logs/nome-do-seu-modelo/G_{}.pth` e `logs/nome-do-seu-modelo/D_{}.pth` para cada save_every_epoch, mas especificando nesse caminho, você pode começar a aprender. Você pode reiniciar ou iniciar o treinamento a partir de weights de modelo aprendidos em um experimento diferente.
+
+### Index de aprendizado
+O RVC salva os valores de recursos do HuBERT usados durante o treinamento e, durante a inferência, procura valores de recursos que sejam semelhantes aos valores de recursos usados durante o aprendizado para realizar a inferência. Para realizar esta busca em alta velocidade, o index é aprendido previamente.
+Para aprendizagem de index, usamos a biblioteca de pesquisa de associação de áreas aproximadas faiss. Leia o valor do recurso `logs/nome-do-seu-modelo/3_feature256` e use-o para aprender o index, e salve-o como `logs/nome-do-seu-modelo/add_XXX.index`.
+
+(A partir da versão 20230428update, ele é lido do index e não é mais necessário salvar/especificar.)
+
+### Descrição do botão
+- Treinar modelo: Após executar o passo 2b, pressione este botão para treinar o modelo.
+- Treinar índice de recursos: após treinar o modelo, execute o aprendizado do index.
+- Treinamento com um clique: etapa 2b, treinamento de modelo e treinamento de index de recursos, tudo de uma vez.
\ No newline at end of file
diff --git a/docs/tr/Changelog_TR.md b/docs/tr/Changelog_TR.md
new file mode 100644
index 0000000000000000000000000000000000000000..aaec5be95f506e5a6c1a5c7d7b72b1cbe2890af0
--- /dev/null
+++ b/docs/tr/Changelog_TR.md
@@ -0,0 +1,97 @@
+
+### 2023-08-13
+1- Düzenli hata düzeltmeleri
+- Minimum toplam epoch sayısını 1 olarak değiştirin ve minimum toplam epoch sayısını 2 olarak değiştirin
+- Ön eğitim modellerini kullanmama nedeniyle oluşan eğitim hatalarını düzeltin
+- Eşlik eden vokallerin ayrılmasından sonra grafik belleğini temizleyin
+- Faiss kaydetme yolu mutlak yoldan göreli yola değiştirilmiştir
+- Boşluk içeren yolu destekleyin (hem eğitim kümesi yolu hem de deney adı desteklenir ve artık hata rapor edilmez)
+- Filelist, zorunlu utf8 kodlamasını iptal eder
+- Gerçek zamanlı ses değişikliği sırasında faiss aramasından kaynaklanan CPU tüketim sorununu çözün
+
+2- Temel güncellemeler
+- Geçerli en güçlü açık kaynak vokal ton çıkarma modeli RMVPE'yi eğitin ve RVC eğitimi, çevrimdışı/gerçek zamanlı çıkarım için kullanın, PyTorch/Onnx/DirectML destekler
+- Pytorch_DML aracılığıyla AMD ve Intel grafik kartları için destek ekleyin
+
+(1) Gerçek zamanlı ses değişimi (2) Çıkarım (3) Vokal eşlik ayrımı (4) Şu anda desteklenmeyen eğitim, CPU eğitimine geçiş yapacaktır; Onnx_Dml ile gpu için RMVPE çıkarımını destekler
+
+
+### 2023-06-18
+- Yeni ön eğitilmiş v2 modeller: 32k ve 48k
+- F0 modeli çıkarım hatalarını düzeltme
+- Eğitim kümesi 1 saati aşarsa, özelliği şekil açısından küçültmek için otomatik minibatch-kmeans yapın, böylece indeks eğitimi, eklemesi ve araması çok daha hızlı olur.
+- Bir oyunca vokal2guitar huggingface alanı sağlama
+- Aykırı kısa kesim eğitim kümesi seslerini otomatik olarak silme
+- Onnx dışa aktarma sekmesi
+
+Başarısız deneyler:
+- ~~Özellik çıkarımı: zamansal özellik çıkarımı ekleme: etkili değil~~
+- ~~Özellik çıkarımı: PCAR boyut azaltma ekleme: arama daha yavaş~~
+- ~~Eğitim sırasında rastgele veri artırma: etkili değil~~
+
+Yapılacaklar listesi:
+- ~~Vocos-RVC (küçük vokoder): etkili değil~~
+- ~~Eğitim için Crepe desteği: RMVPE ile değiştirildi~~
+- ~~Yarı hassas Crepe çıkarımı: RMVPE ile değiştirildi. Ve zor gerçekleştirilebilir.~~
+- F0 düzenleyici desteği
+
+### 2023-05-28
+- v2 jupyter notebook, korece değişiklik günlüğü, bazı çevre gereksinimlerini düzeltme
+- Sesli olmayan ünsüz ve nefes koruma modu ekleme
+- Crepe-full ton algılama desteği ekleme
+- UVR5 vokal ayrımı: yankı kaldırma modelleri ve yankı kaldırma modelleri destekleme
+- İndeks adında deney adı ve sürüm ekleme
+- Toplu ses dönüşüm işleme ve UVR5 vokal ayrımı sırasında çıkış seslerinin ihracat formatını kullanıcıların manuel olarak seçmelerine olanak tanıma
+- v1 32k model eğitimi artık desteklenmiyor
+
+### 2023-05-13
+- Tek tıklamayla paketin eski sürümündeki çalışma zamanındaki gereksiz kodları temizleme: lib.infer_pack ve uvr5_pack
+- Eğitim seti ön işleme içindeki sahte çoklu işlem hatasını düzeltme
+- Harvest ton tanıma algoritması için ortanca filtre yarıçap ayarı ekleme
+- Çıkış sesi için örnek alma örneği için yeniden örnekleme desteği ekleme
+- Eğitim için "n_cpu" çoklu işlem ayarı, "f0 çıkarma" yerine "veri ön işleme ve f0 çıkarma" için değiştirildi
+- Günlükler klasörü altındaki indeks yollarını otomatik olarak tespit etme ve bir açılır liste işlevi sağlama
+- Sekme sayfasına "Sıkça Sorulan Sorular ve Cevaplar"ı ekleme (ayrıca github RVC wiki'ye de bakabilirsiniz)
+- Çıkarım sırasında aynı giriş sesi yolunu kullanırken harvest tonunu önbelleğe alma (amaç: harvest ton çıkarımı kullanırken, tüm işlem hattı uzun ve tekrarlayan bir ton çıkarım işlemi geçirecektir. Önbellekleme kullanılmazsa, farklı timbre, indeks ve ton ortanca filtreleme yarıçapı ayarlarıyla deney yapan kullanıcılar, ilk çıkarım sonrası çok acı verici bir bekleme süreci yaşayacaktır)
+
+### 2023-05-14
+- Girişin hacim zarfını çıktının hacim zarfıyla karıştırmak veya değiştirmek için girişin hacim zarfını kullanma (problemi "giriş sessizleştirme ve çıktı küçük
+
+ amplitüdlü gürültü" sorununu hafifletebilir. Giriş sesi arka plan gürültüsü yüksekse, açık olması önerilmez ve varsayılan olarak açık değildir (1 varsayılan olarak kapalı olarak kabul edilir)
+- Belirli bir frekansta filtreleme uygulama eğitim ve çıkarım için 50Hz'nin altındaki frekans bantları için
+- Pyworld'un varsayılan 80'den 50'ye minimum ton çıkarma sınırlamasını eğitim ve çıkarım için düşürme, 50-80Hz arasındaki erkek alçak seslerin sessizleştirilmemesine izin verme
+- WebUI, sistem yereli diline göre dil değiştirme (şu anda en_US, ja_JP, zh_CN, zh_HK, zh_SG, zh_TW'yi destekliyor; desteklenmeyen durumda varsayılan olarak en_US'ye geçer)
+- Belirli bir giriş sesi yolunu kullanırken harvest tonunu önbelleğe alma (amaç: harvest ton çıkarma kullanırken, tüm işlem hattı uzun ve tekrarlayan bir ton çıkarma süreci geçirecektir. Önbellekleme kullanılmazsa, farklı timbre, indeks ve ton ortanca filtreleme yarıçapı ayarlarıyla deney yapan kullanıcılar, ilk çıkarım sonrası çok acı verici bir bekleme süreci yaşayacaktır)
+
+### 2023-04-09 Güncellemesi
+- GPU kullanım oranını artırmak için eğitim parametrelerini düzeltme: A100, %25'ten yaklaşık %90'a, V100: %50'den yaklaşık %90'a, 2060S: %60'tan yaklaşık %85'e, P40: %25'ten yaklaşık %95'e; eğitim hızını önemli ölçüde artırma
+- Parametre değişti: toplam_batch_size artık GPU başına batch_size
+- Toplam_epoch değişti: maksimum sınırı 1000'e yükseltildi; varsayılan 10'dan 20'ye yükseltildi
+- ckpt çıkarımı ile çalma tanıma hatasını düzeltme, anormal çıkarım oluşturan
+- Dağıtılmış eğitimde her sıra için ckpt kaydetme sorununu düzeltme
+- Özellik çıkarımı için NaN özellik filtrelemesi uygulama
+- Sessiz giriş/çıkışın rastgele ünsüzler veya gürültü üretme sorununu düzeltme (eski modeller yeni bir veri kümesiyle tekrar eğitilmelidir)
+
+### 2023-04-16 Güncellemesi
+- Yerel gerçek zamanlı ses değiştirme mini-GUI'si ekleme, çift tıklayarak go-realtime-gui.bat ile başlayın
+- Eğitim ve çıkarım sırasında 50Hz'nin altındaki frekans bantlarını filtreleme uygulama
+- Pyworld'deki varsayılan 80'den 50'ye minimum ton çıkarma sınırlamasını eğitim ve çıkarım için düşürme, 50-80Hz arasındaki erkek alçak seslerin sessizleştirilmemesine izin verme
+- WebUI, sistem yereli diline göre dil değiştirme (şu anda en_US, ja_JP, zh_CN, zh_HK, zh_SG, zh_TW'yi destekliyor; desteklenmeyen durumda varsayılan olarak en_US'ye geçer)
+- Bazı GPU'ların tanınmasını düzeltme (örneğin, V100-16G tanınmama sorunu, P4 tanınmama sorunu)
+
+### 2023-04-28 Güncellemesi
+- Daha hızlı hız ve daha yüksek kalite için faiss indeks ayarlarını yükseltme
+- Toplam_npy bağımlılığını kaldırma; gelecekteki model paylaşımları için total_npy girdisi gerekmeyecek
+- 16-serisi GPU'lar için kısıtlamaları açma, 4GB VRAM GPU'lar için 4GB çıkarım ayarları sağlama
+- Belirli ses biçimlerine yönelik UVR5 vokal eşlik ayrımındaki hata düzeltme
+- Gerçek zamanlı ses değiştirme mini-GUI şimdi 40k dışı ve tembel ton modellerini destekler
+
+### Gelecekteki Planlar:
+Özellikler:
+- Her epoch kaydetmek için küçük modeller çıkar seçeneğini ekleme
+- Çıkarım sırasında çıkış seslerini belirtilen yolda ekstra mp3 olarak kaydetme seçeneğini ekleme
+- Birden fazla kişinin eğitim sekmesini destekleme (en fazla 4 kişiye kadar)
+
+Temel model:
+- Bozuk nefes seslerinin sorununu düzeltmek için nefes alma wav dosyalarını eğitim veri kümesine eklemek
+- Şu anda genişletilmiş bir şarkı veri kümesiyle temel model eğitimi yapıyoruz ve gelecekte yayınlanacak
diff --git a/docs/tr/README.tr.md b/docs/tr/README.tr.md
new file mode 100644
index 0000000000000000000000000000000000000000..8f93d155a020fb54359241a83cd7d22aaa209779
--- /dev/null
+++ b/docs/tr/README.tr.md
@@ -0,0 +1,155 @@
+
+
+
+
Çekme Temelli Ses Dönüşümü Web Arayüzü
+VITS'e dayalı kullanımı kolay bir Ses Dönüşümü çerçevesi.
+
+[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
+
+
+
+[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/tools/ipynb/v1.ipynb)
+[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/tools/ipynb/v2.ipynb)
+[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
+[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
+
+[](https://discord.gg/HcsmBBGyVk)
+
+
+
+## Q2: "Tek Tıklamayla Eğitim" Sonrası İndeks Dosyası Bulunamıyor
+Eğer "Eğitim tamamlandı. Program kapatıldı." mesajını görüyorsa, model başarıyla eğitilmiş demektir ve sonraki hatalar sahte;
+
+"Added" dizini oluşturulduğu halde "Tek Tıklamayla Eğitim" sonrası indeks dosyası bulunamıyorsa, bu genellikle eğitim setinin çok büyük olmasından kaynaklanabilir ve indeksin eklenmesi sıkışabilir. Bu sorun indeks eklerken bellek yükünü azaltmak için toplu işlem yaparak çözülmüştür. Geçici bir çözüm olarak, "Eğitim İndeksini Eğit" düğmesine tekrar tıklamayı deneyin.
+
+## Q3: Eğitim Sonrası "Tonlama İnceleniyor" Bölümünde Model Bulunamıyor
+"Lanetleme İstemi Listesini Yenile" düğmesine tıklayarak tekrar kontrol edin; hala görünmüyorsa, eğitim sırasında herhangi bir hata olup olmadığını kontrol edin ve geliştiricilere daha fazla analiz için konsol, web arayüzü ve logs/experiment_name/*.log ekran görüntülerini gönderin.
+
+## Q4: Bir Model Nasıl Paylaşılır/Başkalarının Modelleri Nasıl Kullanılır?
+rvc_root/logs/experiment_name dizininde saklanan pth dosyaları paylaşım veya çıkarım için değildir, bunlar deney checkpoint'larıdır ve çoğaltılabilirlik ve daha fazla eğitim için saklanır. Paylaşılacak olan model, weights klasöründeki 60+MB'lık pth dosyası olmalıdır;
+
+Gelecekte, weights/exp_name.pth ve logs/exp_name/added_xxx.index birleştirilerek tek bir weights/exp_name.zip dosyasına dönüştürülecek ve manuel indeks girişi gereksinimini ortadan kaldıracaktır; bu nedenle pth dosyasını değil, farklı bir makinede eğitime devam etmek istemezseniz zip dosyasını paylaşın;
+
+Çıkarılmış modelleri zorlama çıkarım için logs klasöründen weights klasörüne birkaç yüz MB'lık pth dosyalarını kopyalamak/paylaşmak, eksik f0, tgt_sr veya diğer anahtarlar gibi hatalara neden olabilir. Smaller modeli manuel veya otomatik olarak çıkarmak için alttaki ckpt sekmesini kullanmanız gerekmektedir (eğer bilgi logs/exp_name içinde bulunuyorsa), pitch bilgisini ve hedef ses örnekleme oranı seçeneklerini seçmeli ve ardından daha küçük modele çıkarmalısınız. Çıkardıktan sonra weights klasöründe 60+ MB'lık bir pth dosyası olacaktır ve sesleri yeniden güncelleyebilirsiniz.
+
+## Q5: Bağlantı Hatası
+Büyük ihtimalle konsolu (siyah komut satırı penceresi) kapatmış olabilirsiniz.
+
+## Q6: Web Arayüzünde 'Beklenen Değer: Satır 1 Sütun 1 (Karakter 0)' Hatası
+Lütfen sistem LAN proxy/global proxy'sini devre dışı bırakın ve ardından sayfayı yenileyin.
+
+## Q7: WebUI Olmadan Nasıl Eğitim Yapılır ve Tahmin Yapılır?
+Eğitim komut dosyası:
+Önce WebUI'de eğitimi çalıştırabilirsiniz, ardından veri seti önişleme ve eğitiminin komut satırı sürümleri mesaj penceresinde görüntülenecektir.
+
+Tahmin komut dosyası:
+https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/myinfer.py
+
+
+örn:
+
+runtime\python.exe myinfer.py 0 "E:\codes\py39\RVC-beta\todo-songs\1111.wav" "E:\codes\py39\logs\mi-test\added_IVF677_Flat_nprobe_7.index" harvest "test.wav" "weights/mi-test.pth" 0.6 cuda:0 True
+
+
+f0up_key=sys.argv[1]
+input_path=sys.argv[2]
+index_path=sys.argv[3]
+f0method=sys.argv[4]#harvest or pm
+opt_path=sys.argv[5]
+model_path=sys.argv[6]
+index_rate=float(sys.argv[7])
+device=sys.argv[8]
+is_half=bool(sys.argv[9])
+
+## Q8: Cuda Hatası/Cuda Bellek Yetersizliği
+Küçük bir ihtimalle CUDA konfigürasyonunda bir problem olabilir veya cihaz desteklenmiyor olabilir; daha muhtemel olarak yetersiz bellek olabilir (bellek yetersizliği).
+
+Eğitim için toplu işlem boyutunu azaltın (1'e indirgemek yeterli değilse, grafik kartını değiştirmeniz gerekebilir); çıkarım için ise config.py dosyasındaki x_pad, x_query, x_center ve x_max ayarlarını ihtiyaca göre düzenleyin. 4GB veya daha düşük bellekli kartlar (örneğin 1060(3G) ve çeşit
+
+li 2GB kartlar) terk edilebilir, 4GB bellekli kartlar hala bir şansı vardır.
+
+## Q9: Optimal Olarak Kaç total_epoch Gerekli?
+Eğitim veri setinin ses kalitesi düşük ve gürültü seviyesi yüksekse, 20-30 dönem yeterlidir. Fazla yüksek bir değer belirlemek, düşük kaliteli eğitim setinizin ses kalitesini artırmaz.
+
+Eğitim setinin ses kalitesi yüksek, gürültü seviyesi düşük ve yeterli süre varsa, bu değeri artırabilirsiniz. 200 kabul edilebilir bir değerdir (çünkü eğitim hızlıdır ve yüksek kaliteli bir eğitim seti hazırlayabiliyorsanız, GPU'nuz muhtemelen uzun bir eğitim süresini sorunsuz bir şekilde yönetebilir).
+
+## Q10: Kaç Dakika Eğitim Verisi Süresi Gerekli?
+
+10 ila 50 dakika arası bir veri seti önerilir.
+
+Garantili yüksek ses kalitesi ve düşük arka plan gürültüsü varsa, veri setinin tonlaması homojen ise daha fazlası eklenebilir.
+
+Yüksek seviyede bir eğitim seti (zarif ve belirgin tonlama), 5 ila 10 dakika arası uygundur.
+
+1 ila 2 dakika veri ile başarılı bir şekilde eğitim yapan bazı insanlar olsa da, başarı diğerleri tarafından tekrarlanabilir değil ve çok bilgilendirici değil. Bu, eğitim setinin çok belirgin bir tonlamaya sahip olmasını (örneğin yüksek frekansta havadar bir anime kız sesi gibi) ve ses kalitesinin yüksek olmasını gerektirir; 1 dakikadan daha kısa süreli veri denenmemiştir ve önerilmez.
+
+
+## Q11: İndeks Oranı Nedir ve Nasıl Ayarlanır?
+Eğer önceden eğitilmiş model ve tahmin kaynağının ton kalitesi, eğitim setinden daha yüksekse, tahmin sonucunun ton kalitesini yükseltebilirler, ancak altta yatan modelin/tahmin kaynağının tonu yerine eğitim setinin tonuna yönelik olası bir ton önyargısıyla sonuçlanır, bu genellikle "ton sızıntısı" olarak adlandırılır.
+
+İndeks oranı, ton sızıntı sorununu azaltmak/çözmek için kullanılır. İndeks oranı 1 olarak ayarlandığında, teorik olarak tahmin kaynağından ton sızıntısı olmaz ve ton kalitesi daha çok eğitim setine yönelik olur. Eğer eğitim seti, tahmin kaynağından daha düşük ses kalitesine sahipse, daha yüksek bir indeks oranı ses kalitesini azaltabilir. Oranı 0'a düşürmek, eğitim seti tonlarını korumak için getirme karıştırmasını kullanmanın etkisine sahip değildir.
+
+Eğer eğitim seti iyi ses kalitesine ve uzun süreye sahipse, total_epoch'u artırın. Model, tahmin kaynağına ve önceden eğitilmiş alt modeline daha az başvurduğunda ve "ton sızıntısı" daha az olduğunda, indeks oranı önemli değil ve hatta indeks dosyası oluşturmak/paylaşmak gerekli değildir.
+
+## Q12: Tahmin Yaparken Hangi GPU'yu Seçmeli?
+config.py dosyasında "device cuda:" ardından kart numarasını seçin.
+
+Kart numarası ile grafik kartı arasındaki eşleme, eğitim sekmesinin grafik kartı bilgileri bölümünde görülebilir.
+
+## Q13: Eğitimin Ortasında Kaydedilen Model Nasıl Kullanılır?
+Kaydetme işlemini ckpt işleme sekmesinin altında yer alan model çıkarımı ile yapabilirsiniz.
+
+## Q14: Dosya/Bellek Hatası (Eğitim Sırasında)?
+Çok fazla işlem ve yetersiz bellek olabilir. Bu sorunu düzeltebilirsiniz:
+
+1. "CPU İş Parçacıkları" alanındaki girişi azaltarak.
+
+2. Eğitim verisini daha kısa ses dosyalarına önceden keserek.
+
+## Q15: Daha Fazla Veri Kullanarak Eğitime Nasıl Devam Edilir?
+
+Adım 1: Tüm wav verilerini path2 dizinine yerleştirin.
+
+Adım 2: exp_name2+path2 -> veri setini önişleme ve özellik çıkarma.
+
+Adım 3: exp_name1 (önceki deneyinizin) en son G ve D dosyalarını exp_name2 klasörüne kopyalayın.
+
+Adım 4: "modeli eğit" düğmesine tıklayın ve önceki deneyinizin model döneminden başlayarak eğitime devam edecektir.
diff --git a/docs/tr/training_tips_tr.md b/docs/tr/training_tips_tr.md
new file mode 100644
index 0000000000000000000000000000000000000000..144cd7705865a0af19eb60097f9fa772bc2cf1e1
--- /dev/null
+++ b/docs/tr/training_tips_tr.md
@@ -0,0 +1,67 @@
+## RVC Eğitimi için Talimatlar ve İpuçları
+======================================
+Bu TALİMAT, veri eğitiminin nasıl yapıldığını açıklamaktadır.
+
+# Eğitim Akışı
+Eğitim sekmesindeki adımları takip ederek açıklayacağım.
+
+## Adım 1
+Deney adını burada belirleyin.
+
+Ayrıca burada modelin pitch'i dikkate alıp almayacağını da belirleyebilirsiniz.
+Eğer model pitch'i dikkate almazsa, model daha hafif olacak, ancak şarkı söyleme için uygun olmayacaktır.
+
+Her deney için veriler `/logs/your-experiment-name/` dizinine yerleştirilir.
+
+## Adım 2a
+Ses yüklenir ve ön işleme yapılır.
+
+### Ses Yükleme
+Ses içeren bir klasör belirtirseniz, bu klasördeki ses dosyaları otomatik olarak okunur.
+Örneğin, `C:Users\hoge\voices` belirtirseniz, `C:Users\hoge\voices\voice.mp3` yüklenecek, ancak `C:Users\hoge\voices\dir\voice.mp3` yüklenmeyecektir.
+
+Ses okumak için dahili olarak ffmpeg kullanıldığından, uzantı ffmpeg tarafından destekleniyorsa otomatik olarak okunacaktır.
+ffmpeg ile int16'ya dönüştürüldükten sonra float32'ye dönüştürülüp -1 ile 1 arasında normalize edilir.
+
+### Gürültü Temizleme
+Ses scipy'nin filtfilt işlevi ile yumuşatılır.
+
+### Ses Ayırma
+İlk olarak, giriş sesi belirli bir süreden (max_sil_kept=5 saniye?) daha uzun süren sessiz kısımları tespit ederek böler. Sessizlik üzerinde ses bölündükten sonra sesi 4 saniyede bir 0.3 saniyelik bir örtüşme ile böler. 4 saniye içinde ayrılan sesler için ses normalleştirildikten sonra wav dosyası olarak `/logs/your-experiment-name/0_gt_wavs`'a, ardından 16 kHz örnekleme hızına dönüştürülerek `/logs/your-experiment-name/1_16k_wavs` olarak kaydedilir.
+
+## Adım 2b
+### Pitch Çıkarımı
+Wav dosyalarından pitch bilgisi çıkarılır. ParSelMouth veya PyWorld'e dahili olarak yerleştirilmiş yöntemi kullanarak pitch bilgisi (=f0) çıkarılır ve `/logs/your-experiment-name/2a_f0` dizinine kaydedilir. Ardından pitch bilgisi logaritmik olarak 1 ile 255 arasında bir tamsayıya dönüştürülüp `/logs/your-experiment-name/2b-f0nsf` dizinine kaydedilir.
+
+### Özellik Çıkarımı
+HuBERT'i kullanarak önceden gömme olarak wav dosyasını çıkarır. `/logs/your-experiment-name/1_16k_wavs`'a kaydedilen wav dosyasını okuyarak, wav dosyasını 256 boyutlu HuBERT özelliklerine dönüştürür ve npy formatında `/logs/your-experiment-name/3_feature256` dizinine kaydeder.
+
+## Adım 3
+Modeli eğit.
+### Başlangıç Seviyesi Sözlüğü
+Derin öğrenmede, veri kümesi bölmeye ve öğrenmeye adım adım devam eder. Bir model güncellemesinde (adım), batch_size veri alınır ve tahminler ve hata düzeltmeleri yapılır. Bunun bir defa bir veri kümesi için yapılması bir dönem olarak sayılır.
+
+Bu nedenle, öğrenme zamanı adım başına öğrenme zamanı x (veri kümesindeki veri sayısı / batch boyutu) x dönem sayısıdır. Genel olarak, batch boyutu ne kadar büyükse, öğrenme daha istikrarlı hale gelir (adım başına öğrenme süresi ÷ batch boyutu) küçülür, ancak daha fazla GPU belleği kullanır. GPU RAM'ı nvidia-smi komutu ile kontrol edilebilir. Çalışma ortamının makinesine göre batch boyutunu mümkün olduğunca artırarak öğrenme süresini kısa sürede yapabilirsiniz.
+
+### Önceden Eğitilmiş Modeli Belirtme
+RVC, modeli 0'dan değil önceden eğitilmiş ağırlıklardan başlatarak eğitir, bu nedenle küçük bir veri kümesi ile eğitilebilir.
+
+Varsayılan olarak
+
+- Eğer pitch'i dikkate alıyorsanız, `rvc-location/pretrained/f0G40k.pth` ve `rvc-location/pretrained/f0D40k.pth` yüklenir.
+- Eğer pitch'i dikkate almıyorsanız, yine `rvc-location/pretrained/f0G40k.pth` ve `rvc-location/pretrained/f0D40k.pth` yüklenir.
+
+Öğrenirken model parametreleri her save_every_epoch için `logs/your-experiment-name/G_{}.pth` ve `logs/your-experiment-name/D_{}.pth` olarak kaydedilir, ancak bu yolu belirterek öğrenmeye başlayabilirsiniz. Farklı bir deneyde öğrenilen model ağırlıklarından öğrenmeye yeniden başlayabilir veya eğitimi başlatabilirsiniz.
+
+### Öğrenme İndeksi
+RVC, eğitim sırasında kullanılan HuBERT özellik değerlerini kaydeder ve çıkarım sırasında, öğrenme sırasında kullanılan özellik değerlerine benzer özellik değerlerini arayarak çıkarım yapar. Bu aramayı yüksek hızda gerçekleştirebilmek için indeks öğrenilir.
+İndeks öğrenimi için yaklaş
+
+ık komşuluk arama kütüphanesi faiss kullanılır. `/logs/your-experiment-name/3_feature256`'daki özellik değerini okur ve indeksi öğrenmek için kullanır, `logs/your-experiment-name/add_XXX.index` olarak kaydedilir.
+
+(20230428 güncelleme sürümünden itibaren indeks okunur ve kaydetmek/belirtmek artık gerekli değildir.)
+
+### Düğme Açıklaması
+- Modeli Eğit: Adım 2b'yi çalıştırdıktan sonra, modeli eğitmek için bu düğmeye basın.
+- Özellik İndeksini Eğit: Modeli eğittikten sonra, indeks öğrenme işlemi yapın.
+- Tek Tıklamayla Eğitim: Adım 2b, model eğitimi ve özellik indeks eğitimini bir arada yapar.
diff --git a/environment_dml.yaml b/environment_dml.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..9da21d38755edf6425bb0a0ca3b08a4a5bfc1bcc
--- /dev/null
+++ b/environment_dml.yaml
@@ -0,0 +1,186 @@
+name: pydml
+channels:
+ - pytorch
+ - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
+ - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
+ - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
+ - https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
+ - defaults
+ - https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/fastai/
+ - https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
+ - https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
+dependencies:
+ - abseil-cpp=20211102.0=hd77b12b_0
+ - absl-py=1.3.0=py310haa95532_0
+ - aiohttp=3.8.3=py310h2bbff1b_0
+ - aiosignal=1.2.0=pyhd3eb1b0_0
+ - async-timeout=4.0.2=py310haa95532_0
+ - attrs=22.1.0=py310haa95532_0
+ - blas=1.0=mkl
+ - blinker=1.4=py310haa95532_0
+ - bottleneck=1.3.5=py310h9128911_0
+ - brotli=1.0.9=h2bbff1b_7
+ - brotli-bin=1.0.9=h2bbff1b_7
+ - brotlipy=0.7.0=py310h2bbff1b_1002
+ - bzip2=1.0.8=he774522_0
+ - c-ares=1.19.0=h2bbff1b_0
+ - ca-certificates=2023.05.30=haa95532_0
+ - cachetools=4.2.2=pyhd3eb1b0_0
+ - certifi=2023.5.7=py310haa95532_0
+ - cffi=1.15.1=py310h2bbff1b_3
+ - charset-normalizer=2.0.4=pyhd3eb1b0_0
+ - click=8.0.4=py310haa95532_0
+ - colorama=0.4.6=py310haa95532_0
+ - contourpy=1.0.5=py310h59b6b97_0
+ - cryptography=39.0.1=py310h21b164f_0
+ - cycler=0.11.0=pyhd3eb1b0_0
+ - fonttools=4.25.0=pyhd3eb1b0_0
+ - freetype=2.12.1=ha860e81_0
+ - frozenlist=1.3.3=py310h2bbff1b_0
+ - giflib=5.2.1=h8cc25b3_3
+ - glib=2.69.1=h5dc1a3c_2
+ - google-auth=2.6.0=pyhd3eb1b0_0
+ - google-auth-oauthlib=0.4.4=pyhd3eb1b0_0
+ - grpc-cpp=1.48.2=hf108199_0
+ - grpcio=1.48.2=py310hf108199_0
+ - gst-plugins-base=1.18.5=h9e645db_0
+ - gstreamer=1.18.5=hd78058f_0
+ - icu=58.2=ha925a31_3
+ - idna=3.4=py310haa95532_0
+ - intel-openmp=2023.1.0=h59b6b97_46319
+ - jpeg=9e=h2bbff1b_1
+ - kiwisolver=1.4.4=py310hd77b12b_0
+ - krb5=1.19.4=h5b6d351_0
+ - lerc=3.0=hd77b12b_0
+ - libbrotlicommon=1.0.9=h2bbff1b_7
+ - libbrotlidec=1.0.9=h2bbff1b_7
+ - libbrotlienc=1.0.9=h2bbff1b_7
+ - libclang=14.0.6=default_hb5a9fac_1
+ - libclang13=14.0.6=default_h8e68704_1
+ - libdeflate=1.17=h2bbff1b_0
+ - libffi=3.4.4=hd77b12b_0
+ - libiconv=1.16=h2bbff1b_2
+ - libogg=1.3.5=h2bbff1b_1
+ - libpng=1.6.39=h8cc25b3_0
+ - libprotobuf=3.20.3=h23ce68f_0
+ - libtiff=4.5.0=h6c2663c_2
+ - libuv=1.44.2=h2bbff1b_0
+ - libvorbis=1.3.7=he774522_0
+ - libwebp=1.2.4=hbc33d0d_1
+ - libwebp-base=1.2.4=h2bbff1b_1
+ - libxml2=2.10.3=h0ad7f3c_0
+ - libxslt=1.1.37=h2bbff1b_0
+ - lz4-c=1.9.4=h2bbff1b_0
+ - markdown=3.4.1=py310haa95532_0
+ - markupsafe=2.1.1=py310h2bbff1b_0
+ - matplotlib=3.7.1=py310haa95532_1
+ - matplotlib-base=3.7.1=py310h4ed8f06_1
+ - mkl=2023.1.0=h8bd8f75_46356
+ - mkl-service=2.4.0=py310h2bbff1b_1
+ - mkl_fft=1.3.6=py310h4ed8f06_1
+ - mkl_random=1.2.2=py310h4ed8f06_1
+ - multidict=6.0.2=py310h2bbff1b_0
+ - munkres=1.1.4=py_0
+ - numexpr=2.8.4=py310h2cd9be0_1
+ - numpy=1.24.3=py310h055cbcc_1
+ - numpy-base=1.24.3=py310h65a83cf_1
+ - oauthlib=3.2.2=py310haa95532_0
+ - openssl=1.1.1t=h2bbff1b_0
+ - packaging=23.0=py310haa95532_0
+ - pandas=1.5.3=py310h4ed8f06_0
+ - pcre=8.45=hd77b12b_0
+ - pillow=9.4.0=py310hd77b12b_0
+ - pip=23.0.1=py310haa95532_0
+ - ply=3.11=py310haa95532_0
+ - protobuf=3.20.3=py310hd77b12b_0
+ - pyasn1=0.4.8=pyhd3eb1b0_0
+ - pyasn1-modules=0.2.8=py_0
+ - pycparser=2.21=pyhd3eb1b0_0
+ - pyjwt=2.4.0=py310haa95532_0
+ - pyopenssl=23.0.0=py310haa95532_0
+ - pyparsing=3.0.9=py310haa95532_0
+ - pyqt=5.15.7=py310hd77b12b_0
+ - pyqt5-sip=12.11.0=py310hd77b12b_0
+ - pysocks=1.7.1=py310haa95532_0
+ - python=3.10.11=h966fe2a_2
+ - python-dateutil=2.8.2=pyhd3eb1b0_0
+ - pytorch-mutex=1.0=cpu
+ - pytz=2022.7=py310haa95532_0
+ - pyyaml=6.0=py310h2bbff1b_1
+ - qt-main=5.15.2=he8e5bd7_8
+ - qt-webengine=5.15.9=hb9a9bb5_5
+ - qtwebkit=5.212=h2bbfb41_5
+ - re2=2022.04.01=hd77b12b_0
+ - requests=2.29.0=py310haa95532_0
+ - requests-oauthlib=1.3.0=py_0
+ - rsa=4.7.2=pyhd3eb1b0_1
+ - setuptools=67.8.0=py310haa95532_0
+ - sip=6.6.2=py310hd77b12b_0
+ - six=1.16.0=pyhd3eb1b0_1
+ - sqlite=3.41.2=h2bbff1b_0
+ - tbb=2021.8.0=h59b6b97_0
+ - tensorboard=2.10.0=py310haa95532_0
+ - tensorboard-data-server=0.6.1=py310haa95532_0
+ - tensorboard-plugin-wit=1.8.1=py310haa95532_0
+ - tk=8.6.12=h2bbff1b_0
+ - toml=0.10.2=pyhd3eb1b0_0
+ - tornado=6.2=py310h2bbff1b_0
+ - tqdm=4.65.0=py310h9909e9c_0
+ - typing_extensions=4.5.0=py310haa95532_0
+ - tzdata=2023c=h04d1e81_0
+ - urllib3=1.26.16=py310haa95532_0
+ - vc=14.2=h21ff451_1
+ - vs2015_runtime=14.27.29016=h5e58377_2
+ - werkzeug=2.2.3=py310haa95532_0
+ - wheel=0.38.4=py310haa95532_0
+ - win_inet_pton=1.1.0=py310haa95532_0
+ - xz=5.4.2=h8cc25b3_0
+ - yaml=0.2.5=he774522_0
+ - yarl=1.8.1=py310h2bbff1b_0
+ - zlib=1.2.13=h8cc25b3_0
+ - zstd=1.5.5=hd43e919_0
+ - pip:
+ - antlr4-python3-runtime==4.8
+ - appdirs==1.4.4
+ - audioread==3.0.0
+ - bitarray==2.7.4
+ - cython==0.29.35
+ - decorator==5.1.1
+ - fairseq==0.12.2
+ - faiss-cpu==1.7.4
+ - filelock==3.12.0
+ - hydra-core==1.0.7
+ - jinja2==3.1.2
+ - joblib==1.2.0
+ - lazy-loader==0.2
+ - librosa==0.10.0.post2
+ - llvmlite==0.40.0
+ - lxml==4.9.2
+ - mpmath==1.3.0
+ - msgpack==1.0.5
+ - networkx==3.1
+ - noisereduce==2.0.1
+ - numba==0.57.0
+ - omegaconf==2.0.6
+ - opencv-python==4.7.0.72
+ - pooch==1.6.0
+ - portalocker==2.7.0
+ - FreeSimpleGUI
+ - pywin32==306
+ - pyworld==0.3.3
+ - regex==2023.5.5
+ - sacrebleu==2.3.1
+ - scikit-learn==1.2.2
+ - scipy==1.10.1
+ - sounddevice==0.4.6
+ - soundfile==0.12.1
+ - soxr==0.3.5
+ - sympy==1.12
+ - tabulate==0.9.0
+ - threadpoolctl==3.1.0
+ - torch==2.0.0
+ - torch-directml==0.2.0.dev230426
+ - torchaudio==2.0.1
+ - torchvision==0.15.1
+ - wget==3.2
+prefix: D:\ProgramData\anaconda3_\envs\pydml
diff --git a/go-realtime-gui-dml.bat b/go-realtime-gui-dml.bat
new file mode 100644
index 0000000000000000000000000000000000000000..0f92142b86efe1c5ce83ea7c187b5fdde7dcbbd1
--- /dev/null
+++ b/go-realtime-gui-dml.bat
@@ -0,0 +1,2 @@
+runtime\python.exe gui_v1.py --pycmd runtime\python.exe --nocheck --dml
+pause
diff --git a/go-realtime-gui.bat b/go-realtime-gui.bat
new file mode 100644
index 0000000000000000000000000000000000000000..d1eeb9e1b957d3822c9feb2bc00298931c75aa28
--- /dev/null
+++ b/go-realtime-gui.bat
@@ -0,0 +1,2 @@
+runtime\python.exe gui_v1.py --nocheck
+pause
diff --git a/go-web-dml.bat b/go-web-dml.bat
new file mode 100644
index 0000000000000000000000000000000000000000..2bb290199cadaef38266d661fea189cc9a9d2842
--- /dev/null
+++ b/go-web-dml.bat
@@ -0,0 +1,2 @@
+runtime\python.exe infer-web.py --pycmd runtime\python.exe --nocheck --port 7897 --dml
+pause
diff --git a/go-web.bat b/go-web.bat
new file mode 100644
index 0000000000000000000000000000000000000000..3b91773463f94b65cbedb28b3280ca727609e0aa
--- /dev/null
+++ b/go-web.bat
@@ -0,0 +1,2 @@
+runtime\python.exe infer-web.py --pycmd runtime\python.exe --nocheck --port 7897
+pause
diff --git a/gui_v1.py b/gui_v1.py
new file mode 100644
index 0000000000000000000000000000000000000000..45a58917a14d3df073fa51049bd0ea19e3e9f1bf
--- /dev/null
+++ b/gui_v1.py
@@ -0,0 +1,1085 @@
+import os
+import sys
+from dotenv import load_dotenv
+import shutil
+
+load_dotenv()
+load_dotenv("sha256.env")
+
+os.environ["OMP_NUM_THREADS"] = "4"
+if sys.platform == "darwin":
+ os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1"
+
+now_dir = os.getcwd()
+sys.path.append(now_dir)
+import multiprocessing
+
+flag_vc = False
+
+
+def printt(strr, *args):
+ if len(args) == 0:
+ print(strr)
+ else:
+ print(strr % args)
+
+
+def phase_vocoder(a, b, fade_out, fade_in):
+ window = torch.sqrt(fade_out * fade_in)
+ fa = torch.fft.rfft(a * window)
+ fb = torch.fft.rfft(b * window)
+ absab = torch.abs(fa) + torch.abs(fb)
+ n = a.shape[0]
+ if n % 2 == 0:
+ absab[1:-1] *= 2
+ else:
+ absab[1:] *= 2
+ phia = torch.angle(fa)
+ phib = torch.angle(fb)
+ deltaphase = phib - phia
+ deltaphase = deltaphase - 2 * np.pi * torch.floor(deltaphase / 2 / np.pi + 0.5)
+ w = 2 * np.pi * torch.arange(n // 2 + 1).to(a) + deltaphase
+ t = torch.arange(n).unsqueeze(-1).to(a) / n
+ result = (
+ a * (fade_out**2)
+ + b * (fade_in**2)
+ + torch.sum(absab * torch.cos(w * t + phia), -1) * window / n
+ )
+ return result
+
+
+class Harvest(multiprocessing.Process):
+ def __init__(self, inp_q, opt_q):
+ multiprocessing.Process.__init__(self)
+ self.inp_q = inp_q
+ self.opt_q = opt_q
+
+ def run(self):
+ import numpy as np
+ import pyworld
+
+ while 1:
+ idx, x, res_f0, n_cpu, ts = self.inp_q.get()
+ f0, t = pyworld.harvest(
+ x.astype(np.double),
+ fs=16000,
+ f0_ceil=1100,
+ f0_floor=50,
+ frame_period=10,
+ )
+ res_f0[idx] = f0
+ if len(res_f0.keys()) >= n_cpu:
+ self.opt_q.put(ts)
+
+
+if __name__ == "__main__":
+ import json
+ import multiprocessing
+ import re
+ import time
+ from multiprocessing import Queue, cpu_count
+
+ import librosa
+ from infer.modules.gui import TorchGate
+ import numpy as np
+ import FreeSimpleGUI as sg
+ import sounddevice as sd
+ import torch
+ import torch.nn.functional as F
+ import torchaudio.transforms as tat
+
+ import infer.lib.rtrvc as rtrvc
+ from i18n.i18n import I18nAuto
+ from configs.config import Config
+
+ i18n = I18nAuto()
+
+ # device = rvc_for_realtime.config.device
+ # device = torch.device(
+ # "cuda"
+ # if torch.cuda.is_available()
+ # else ("mps" if torch.backends.mps.is_available() else "cpu")
+ # )
+ current_dir = os.getcwd()
+ inp_q = Queue()
+ opt_q = Queue()
+ n_cpu = min(cpu_count(), 8)
+ for _ in range(n_cpu):
+ p = Harvest(inp_q, opt_q)
+ p.daemon = True
+ p.start()
+
+ class GUIConfig:
+ def __init__(self) -> None:
+ self.pth_path: str = ""
+ self.index_path: str = ""
+ self.pitch: int = 0
+ self.formant: float = 0.0
+ self.sr_type: str = "sr_model"
+ self.block_time: float = 0.25 # s
+ self.threhold: int = -60
+ self.crossfade_time: float = 0.05
+ self.extra_time: float = 2.5
+ self.I_noise_reduce: bool = False
+ self.O_noise_reduce: bool = False
+ self.use_pv: bool = False
+ self.rms_mix_rate: float = 0.0
+ self.index_rate: float = 0.0
+ self.n_cpu: int = min(n_cpu, 4)
+ self.f0method: str = "fcpe"
+ self.sg_hostapi: str = ""
+ self.wasapi_exclusive: bool = False
+ self.sg_input_device: str = ""
+ self.sg_output_device: str = ""
+
+ class GUI:
+ def __init__(self) -> None:
+ self.gui_config = GUIConfig()
+ self.config = Config()
+ self.function = "vc"
+ self.delay_time = 0
+ self.hostapis = None
+ self.input_devices = None
+ self.output_devices = None
+ self.input_devices_indices = None
+ self.output_devices_indices = None
+ self.stream = None
+ if not self.config.nocheck:
+ self.check_assets()
+ self.update_devices()
+ self.launcher()
+
+ def check_assets(self):
+ global now_dir
+ from infer.lib.rvcmd import check_all_assets, download_all_assets
+
+ tmp = os.path.join(now_dir, "TEMP")
+ shutil.rmtree(tmp, ignore_errors=True)
+ os.makedirs(tmp, exist_ok=True)
+ if not check_all_assets(update=self.config.update):
+ if self.config.update:
+ download_all_assets(tmpdir=tmp)
+ if not check_all_assets(update=self.config.update):
+ printt("counld not satisfy all assets needed.")
+ exit(1)
+
+ def load(self):
+ try:
+ if not os.path.exists("configs/inuse/config.json"):
+ shutil.copy("configs/config.json", "configs/inuse/config.json")
+ with open("configs/inuse/config.json", "r") as j:
+ data = json.load(j)
+ data["sr_model"] = data["sr_type"] == "sr_model"
+ data["sr_device"] = data["sr_type"] == "sr_device"
+ data["pm"] = data["f0method"] == "pm"
+ data["harvest"] = data["f0method"] == "harvest"
+ data["crepe"] = data["f0method"] == "crepe"
+ data["rmvpe"] = data["f0method"] == "rmvpe"
+ data["fcpe"] = data["f0method"] == "fcpe"
+ if data["sg_hostapi"] in self.hostapis:
+ self.update_devices(hostapi_name=data["sg_hostapi"])
+ if (
+ data["sg_input_device"] not in self.input_devices
+ or data["sg_output_device"] not in self.output_devices
+ ):
+ self.update_devices()
+ data["sg_hostapi"] = self.hostapis[0]
+ data["sg_input_device"] = self.input_devices[
+ self.input_devices_indices.index(sd.default.device[0])
+ ]
+ data["sg_output_device"] = self.output_devices[
+ self.output_devices_indices.index(sd.default.device[1])
+ ]
+ else:
+ data["sg_hostapi"] = self.hostapis[0]
+ data["sg_input_device"] = self.input_devices[
+ self.input_devices_indices.index(sd.default.device[0])
+ ]
+ data["sg_output_device"] = self.output_devices[
+ self.output_devices_indices.index(sd.default.device[1])
+ ]
+ except:
+ with open("configs/inuse/config.json", "w") as j:
+ data = {
+ "pth_path": "",
+ "index_path": "",
+ "sg_hostapi": self.hostapis[0],
+ "sg_wasapi_exclusive": False,
+ "sg_input_device": self.input_devices[
+ self.input_devices_indices.index(sd.default.device[0])
+ ],
+ "sg_output_device": self.output_devices[
+ self.output_devices_indices.index(sd.default.device[1])
+ ],
+ "sr_type": "sr_model",
+ "threhold": -60,
+ "pitch": 0,
+ "formant": 0.0,
+ "index_rate": 0,
+ "rms_mix_rate": 0,
+ "block_time": 0.25,
+ "crossfade_length": 0.05,
+ "extra_time": 2.5,
+ "n_cpu": 4,
+ "f0method": "rmvpe",
+ "use_jit": False,
+ "use_pv": False,
+ }
+ data["sr_model"] = data["sr_type"] == "sr_model"
+ data["sr_device"] = data["sr_type"] == "sr_device"
+ data["pm"] = data["f0method"] == "pm"
+ data["harvest"] = data["f0method"] == "harvest"
+ data["crepe"] = data["f0method"] == "crepe"
+ data["rmvpe"] = data["f0method"] == "rmvpe"
+ data["fcpe"] = data["f0method"] == "fcpe"
+ return data
+
+ def launcher(self):
+ data = self.load()
+ self.config.use_jit = False # data.get("use_jit", self.config.use_jit)
+ sg.theme("LightBlue3")
+ layout = [
+ [
+ sg.Frame(
+ title=i18n("加载模型"),
+ layout=[
+ [
+ sg.Input(
+ default_text=data.get("pth_path", ""),
+ key="pth_path",
+ ),
+ sg.FileBrowse(
+ i18n("选择.pth文件"),
+ initial_folder=os.path.join(
+ os.getcwd(), "assets/weights"
+ ),
+ file_types=((". pth"),),
+ ),
+ ],
+ [
+ sg.Input(
+ default_text=data.get("index_path", ""),
+ key="index_path",
+ ),
+ sg.FileBrowse(
+ i18n("选择.index文件"),
+ initial_folder=os.path.join(os.getcwd(), "logs"),
+ file_types=((". index"),),
+ ),
+ ],
+ ],
+ )
+ ],
+ [
+ sg.Frame(
+ layout=[
+ [
+ sg.Text(i18n("设备类型")),
+ sg.Combo(
+ self.hostapis,
+ key="sg_hostapi",
+ default_value=data.get("sg_hostapi", ""),
+ enable_events=True,
+ size=(20, 1),
+ ),
+ sg.Checkbox(
+ i18n("独占 WASAPI 设备"),
+ key="sg_wasapi_exclusive",
+ default=data.get("sg_wasapi_exclusive", False),
+ enable_events=True,
+ ),
+ ],
+ [
+ sg.Text(i18n("输入设备")),
+ sg.Combo(
+ self.input_devices,
+ key="sg_input_device",
+ default_value=data.get("sg_input_device", ""),
+ enable_events=True,
+ size=(45, 1),
+ ),
+ ],
+ [
+ sg.Text(i18n("输出设备")),
+ sg.Combo(
+ self.output_devices,
+ key="sg_output_device",
+ default_value=data.get("sg_output_device", ""),
+ enable_events=True,
+ size=(45, 1),
+ ),
+ ],
+ [
+ sg.Button(i18n("重载设备列表"), key="reload_devices"),
+ sg.Radio(
+ i18n("使用模型采样率"),
+ "sr_type",
+ key="sr_model",
+ default=data.get("sr_model", True),
+ enable_events=True,
+ ),
+ sg.Radio(
+ i18n("使用设备采样率"),
+ "sr_type",
+ key="sr_device",
+ default=data.get("sr_device", False),
+ enable_events=True,
+ ),
+ sg.Text(i18n("采样率:")),
+ sg.Text("", key="sr_stream"),
+ ],
+ ],
+ title=i18n("音频设备"),
+ )
+ ],
+ [
+ sg.Frame(
+ layout=[
+ [
+ sg.Text(i18n("响应阈值")),
+ sg.Slider(
+ range=(-60, 0),
+ key="threhold",
+ resolution=1,
+ orientation="h",
+ default_value=data.get("threhold", -60),
+ enable_events=True,
+ ),
+ ],
+ [
+ sg.Text(i18n("音调设置")),
+ sg.Slider(
+ range=(-24, 24),
+ key="pitch",
+ resolution=1,
+ orientation="h",
+ default_value=data.get("pitch", 0),
+ enable_events=True,
+ ),
+ ],
+ [
+ sg.Text(i18n("共振偏移")),
+ sg.Slider(
+ range=(-5, 5),
+ key="formant",
+ resolution=0.01,
+ orientation="h",
+ default_value=data.get("formant", 0.0),
+ enable_events=True,
+ ),
+ ],
+ [
+ sg.Text(i18n("Index Rate")),
+ sg.Slider(
+ range=(0.0, 1.0),
+ key="index_rate",
+ resolution=0.01,
+ orientation="h",
+ default_value=data.get("index_rate", 0),
+ enable_events=True,
+ ),
+ ],
+ [
+ sg.Text(i18n("响度因子")),
+ sg.Slider(
+ range=(0.0, 1.0),
+ key="rms_mix_rate",
+ resolution=0.01,
+ orientation="h",
+ default_value=data.get("rms_mix_rate", 0),
+ enable_events=True,
+ ),
+ ],
+ [
+ sg.Text(i18n("音高算法")),
+ sg.Radio(
+ "pm",
+ "f0method",
+ key="pm",
+ default=data.get("pm", False),
+ enable_events=True,
+ ),
+ sg.Radio(
+ "harvest",
+ "f0method",
+ key="harvest",
+ default=data.get("harvest", False),
+ enable_events=True,
+ ),
+ sg.Radio(
+ "crepe",
+ "f0method",
+ key="crepe",
+ default=data.get("crepe", False),
+ enable_events=True,
+ ),
+ sg.Radio(
+ "rmvpe",
+ "f0method",
+ key="rmvpe",
+ default=data.get("rmvpe", False),
+ enable_events=True,
+ ),
+ sg.Radio(
+ "fcpe",
+ "f0method",
+ key="fcpe",
+ default=data.get("fcpe", True),
+ enable_events=True,
+ ),
+ ],
+ ],
+ title=i18n("常规设置"),
+ ),
+ sg.Frame(
+ layout=[
+ [
+ sg.Text(i18n("采样长度")),
+ sg.Slider(
+ range=(0.02, 1.5),
+ key="block_time",
+ resolution=0.01,
+ orientation="h",
+ default_value=data.get("block_time", 0.25),
+ enable_events=True,
+ ),
+ ],
+ # [
+ # sg.Text("设备延迟"),
+ # sg.Slider(
+ # range=(0, 1),
+ # key="device_latency",
+ # resolution=0.001,
+ # orientation="h",
+ # default_value=data.get("device_latency", 0.1),
+ # enable_events=True,
+ # ),
+ # ],
+ [
+ sg.Text(i18n("harvest进程数")),
+ sg.Slider(
+ range=(1, n_cpu),
+ key="n_cpu",
+ resolution=1,
+ orientation="h",
+ default_value=data.get(
+ "n_cpu", min(self.gui_config.n_cpu, n_cpu)
+ ),
+ enable_events=True,
+ ),
+ ],
+ [
+ sg.Text(i18n("淡入淡出长度")),
+ sg.Slider(
+ range=(0.01, 0.15),
+ key="crossfade_length",
+ resolution=0.01,
+ orientation="h",
+ default_value=data.get("crossfade_length", 0.05),
+ enable_events=True,
+ ),
+ ],
+ [
+ sg.Text(i18n("额外推理时长")),
+ sg.Slider(
+ range=(0.05, 5.00),
+ key="extra_time",
+ resolution=0.01,
+ orientation="h",
+ default_value=data.get("extra_time", 2.5),
+ enable_events=True,
+ ),
+ ],
+ [
+ sg.Checkbox(
+ i18n("输入降噪"),
+ key="I_noise_reduce",
+ enable_events=True,
+ ),
+ sg.Checkbox(
+ i18n("输出降噪"),
+ key="O_noise_reduce",
+ enable_events=True,
+ ),
+ sg.Checkbox(
+ i18n("启用相位声码器"),
+ key="use_pv",
+ default=data.get("use_pv", False),
+ enable_events=True,
+ ),
+ # sg.Checkbox(
+ # "JIT加速",
+ # default=self.config.use_jit,
+ # key="use_jit",
+ # enable_events=False,
+ # ),
+ ],
+ # [sg.Text("注:首次使用JIT加速时,会出现卡顿,\n 并伴随一些噪音,但这是正常现象!")],
+ ],
+ title=i18n("性能设置"),
+ ),
+ ],
+ [
+ sg.Button(i18n("开始音频转换"), key="start_vc"),
+ sg.Button(i18n("停止音频转换"), key="stop_vc"),
+ sg.Radio(
+ i18n("输入监听"),
+ "function",
+ key="im",
+ default=False,
+ enable_events=True,
+ ),
+ sg.Radio(
+ i18n("输出变声"),
+ "function",
+ key="vc",
+ default=True,
+ enable_events=True,
+ ),
+ sg.Text(i18n("算法延迟(ms):")),
+ sg.Text("0", key="delay_time"),
+ sg.Text(i18n("推理时间(ms):")),
+ sg.Text("0", key="infer_time"),
+ ],
+ ]
+ self.window = sg.Window("RVC - GUI", layout=layout, finalize=True)
+ self.event_handler()
+
+ def event_handler(self):
+ global flag_vc
+ while True:
+ event, values = self.window.read()
+ if event == sg.WINDOW_CLOSED:
+ self.stop_stream()
+ exit()
+ if event == "reload_devices" or event == "sg_hostapi":
+ self.gui_config.sg_hostapi = values["sg_hostapi"]
+ self.update_devices(hostapi_name=values["sg_hostapi"])
+ if self.gui_config.sg_hostapi not in self.hostapis:
+ self.gui_config.sg_hostapi = self.hostapis[0]
+ self.window["sg_hostapi"].Update(values=self.hostapis)
+ self.window["sg_hostapi"].Update(value=self.gui_config.sg_hostapi)
+ if (
+ self.gui_config.sg_input_device not in self.input_devices
+ and len(self.input_devices) > 0
+ ):
+ self.gui_config.sg_input_device = self.input_devices[0]
+ self.window["sg_input_device"].Update(values=self.input_devices)
+ self.window["sg_input_device"].Update(
+ value=self.gui_config.sg_input_device
+ )
+ if self.gui_config.sg_output_device not in self.output_devices:
+ self.gui_config.sg_output_device = self.output_devices[0]
+ self.window["sg_output_device"].Update(values=self.output_devices)
+ self.window["sg_output_device"].Update(
+ value=self.gui_config.sg_output_device
+ )
+ if event == "start_vc" and not flag_vc:
+ if self.set_values(values) == True:
+ printt("cuda_is_available: %s", torch.cuda.is_available())
+ self.start_vc()
+ settings = {
+ "pth_path": values["pth_path"],
+ "index_path": values["index_path"],
+ "sg_hostapi": values["sg_hostapi"],
+ "sg_wasapi_exclusive": values["sg_wasapi_exclusive"],
+ "sg_input_device": values["sg_input_device"],
+ "sg_output_device": values["sg_output_device"],
+ "sr_type": ["sr_model", "sr_device"][
+ [
+ values["sr_model"],
+ values["sr_device"],
+ ].index(True)
+ ],
+ "threhold": values["threhold"],
+ "pitch": values["pitch"],
+ "formant": values["formant"],
+ "rms_mix_rate": values["rms_mix_rate"],
+ "index_rate": values["index_rate"],
+ # "device_latency": values["device_latency"],
+ "block_time": values["block_time"],
+ "crossfade_length": values["crossfade_length"],
+ "extra_time": values["extra_time"],
+ "n_cpu": values["n_cpu"],
+ # "use_jit": values["use_jit"],
+ "use_jit": False,
+ "use_pv": values["use_pv"],
+ "f0method": ["pm", "harvest", "crepe", "rmvpe", "fcpe"][
+ [
+ values["pm"],
+ values["harvest"],
+ values["crepe"],
+ values["rmvpe"],
+ values["fcpe"],
+ ].index(True)
+ ],
+ }
+ with open("configs/inuse/config.json", "w") as j:
+ json.dump(settings, j)
+ if self.stream is not None:
+ self.delay_time = (
+ self.stream.latency[-1]
+ + values["block_time"]
+ + values["crossfade_length"]
+ + 0.01
+ )
+ if values["I_noise_reduce"]:
+ self.delay_time += min(values["crossfade_length"], 0.04)
+ self.window["sr_stream"].update(self.gui_config.samplerate)
+ self.window["delay_time"].update(
+ int(np.round(self.delay_time * 1000))
+ )
+ # Parameter hot update
+ if event == "threhold":
+ self.gui_config.threhold = values["threhold"]
+ elif event == "pitch":
+ self.gui_config.pitch = values["pitch"]
+ if hasattr(self, "rvc"):
+ self.rvc.change_key(values["pitch"])
+ elif event == "formant":
+ self.gui_config.formant = values["formant"]
+ if hasattr(self, "rvc"):
+ self.rvc.change_formant(values["formant"])
+ elif event == "index_rate":
+ self.gui_config.index_rate = values["index_rate"]
+ if hasattr(self, "rvc"):
+ self.rvc.change_index_rate(values["index_rate"])
+ elif event == "rms_mix_rate":
+ self.gui_config.rms_mix_rate = values["rms_mix_rate"]
+ elif event in ["pm", "harvest", "crepe", "rmvpe", "fcpe"]:
+ self.gui_config.f0method = event
+ elif event == "I_noise_reduce":
+ self.gui_config.I_noise_reduce = values["I_noise_reduce"]
+ if self.stream is not None:
+ self.delay_time += (
+ 1 if values["I_noise_reduce"] else -1
+ ) * min(values["crossfade_length"], 0.04)
+ self.window["delay_time"].update(
+ int(np.round(self.delay_time * 1000))
+ )
+ elif event == "O_noise_reduce":
+ self.gui_config.O_noise_reduce = values["O_noise_reduce"]
+ elif event == "use_pv":
+ self.gui_config.use_pv = values["use_pv"]
+ elif event in ["vc", "im"]:
+ self.function = event
+ elif event == "stop_vc" or event != "start_vc":
+ # Other parameters do not support hot update
+ self.stop_stream()
+
+ def set_values(self, values):
+ if len(values["pth_path"].strip()) == 0:
+ sg.popup(i18n("请选择pth文件"))
+ return False
+ if len(values["index_path"].strip()) == 0:
+ sg.popup(i18n("请选择index文件"))
+ return False
+ pattern = re.compile("[^\x00-\x7F]+")
+ if pattern.findall(values["pth_path"]):
+ sg.popup(i18n("pth文件路径不可包含中文"))
+ return False
+ if pattern.findall(values["index_path"]):
+ sg.popup(i18n("index文件路径不可包含中文"))
+ return False
+ self.set_devices(values["sg_input_device"], values["sg_output_device"])
+ self.config.use_jit = False # values["use_jit"]
+ # self.device_latency = values["device_latency"]
+ self.gui_config.sg_hostapi = values["sg_hostapi"]
+ self.gui_config.sg_wasapi_exclusive = values["sg_wasapi_exclusive"]
+ self.gui_config.sg_input_device = values["sg_input_device"]
+ self.gui_config.sg_output_device = values["sg_output_device"]
+ self.gui_config.pth_path = values["pth_path"]
+ self.gui_config.index_path = values["index_path"]
+ self.gui_config.sr_type = ["sr_model", "sr_device"][
+ [
+ values["sr_model"],
+ values["sr_device"],
+ ].index(True)
+ ]
+ self.gui_config.threhold = values["threhold"]
+ self.gui_config.pitch = values["pitch"]
+ self.gui_config.formant = values["formant"]
+ self.gui_config.block_time = values["block_time"]
+ self.gui_config.crossfade_time = values["crossfade_length"]
+ self.gui_config.extra_time = values["extra_time"]
+ self.gui_config.I_noise_reduce = values["I_noise_reduce"]
+ self.gui_config.O_noise_reduce = values["O_noise_reduce"]
+ self.gui_config.use_pv = values["use_pv"]
+ self.gui_config.rms_mix_rate = values["rms_mix_rate"]
+ self.gui_config.index_rate = values["index_rate"]
+ self.gui_config.n_cpu = values["n_cpu"]
+ self.gui_config.f0method = ["pm", "harvest", "crepe", "rmvpe", "fcpe"][
+ [
+ values["pm"],
+ values["harvest"],
+ values["crepe"],
+ values["rmvpe"],
+ values["fcpe"],
+ ].index(True)
+ ]
+ return True
+
+ def start_vc(self):
+ torch.cuda.empty_cache()
+ self.rvc = rtrvc.RVC(
+ self.gui_config.pitch,
+ self.gui_config.formant,
+ self.gui_config.pth_path,
+ self.gui_config.index_path,
+ self.gui_config.index_rate,
+ self.gui_config.n_cpu,
+ inp_q,
+ opt_q,
+ self.config,
+ self.rvc if hasattr(self, "rvc") else None,
+ )
+ self.gui_config.samplerate = (
+ self.rvc.tgt_sr
+ if self.gui_config.sr_type == "sr_model"
+ else self.get_device_samplerate()
+ )
+ self.gui_config.channels = self.get_device_channels()
+ self.zc = self.gui_config.samplerate // 100
+ self.block_frame = (
+ int(
+ np.round(
+ self.gui_config.block_time
+ * self.gui_config.samplerate
+ / self.zc
+ )
+ )
+ * self.zc
+ )
+ self.block_frame_16k = 160 * self.block_frame // self.zc
+ self.crossfade_frame = (
+ int(
+ np.round(
+ self.gui_config.crossfade_time
+ * self.gui_config.samplerate
+ / self.zc
+ )
+ )
+ * self.zc
+ )
+ self.sola_buffer_frame = min(self.crossfade_frame, 4 * self.zc)
+ self.sola_search_frame = self.zc
+ self.extra_frame = (
+ int(
+ np.round(
+ self.gui_config.extra_time
+ * self.gui_config.samplerate
+ / self.zc
+ )
+ )
+ * self.zc
+ )
+ self.input_wav: torch.Tensor = torch.zeros(
+ self.extra_frame
+ + self.crossfade_frame
+ + self.sola_search_frame
+ + self.block_frame,
+ device=self.config.device,
+ dtype=torch.float32,
+ )
+ self.input_wav_denoise: torch.Tensor = self.input_wav.clone()
+ self.input_wav_res: torch.Tensor = torch.zeros(
+ 160 * self.input_wav.shape[0] // self.zc,
+ device=self.config.device,
+ dtype=torch.float32,
+ )
+ self.rms_buffer: np.ndarray = np.zeros(4 * self.zc, dtype="float32")
+ self.sola_buffer: torch.Tensor = torch.zeros(
+ self.sola_buffer_frame, device=self.config.device, dtype=torch.float32
+ )
+ self.nr_buffer: torch.Tensor = self.sola_buffer.clone()
+ self.output_buffer: torch.Tensor = self.input_wav.clone()
+ self.skip_head = self.extra_frame // self.zc
+ self.return_length = (
+ self.block_frame + self.sola_buffer_frame + self.sola_search_frame
+ ) // self.zc
+ self.fade_in_window: torch.Tensor = (
+ torch.sin(
+ 0.5
+ * np.pi
+ * torch.linspace(
+ 0.0,
+ 1.0,
+ steps=self.sola_buffer_frame,
+ device=self.config.device,
+ dtype=torch.float32,
+ )
+ )
+ ** 2
+ )
+ self.fade_out_window: torch.Tensor = 1 - self.fade_in_window
+ self.resampler = tat.Resample(
+ orig_freq=self.gui_config.samplerate,
+ new_freq=16000,
+ dtype=torch.float32,
+ ).to(self.config.device)
+ if self.rvc.tgt_sr != self.gui_config.samplerate:
+ self.resampler2 = tat.Resample(
+ orig_freq=self.rvc.tgt_sr,
+ new_freq=self.gui_config.samplerate,
+ dtype=torch.float32,
+ ).to(self.config.device)
+ else:
+ self.resampler2 = None
+ self.tg = TorchGate(
+ sr=self.gui_config.samplerate, n_fft=4 * self.zc, prop_decrease=0.9
+ ).to(self.config.device)
+ self.start_stream()
+
+ def start_stream(self):
+ global flag_vc
+ if not flag_vc:
+ flag_vc = True
+ if (
+ "WASAPI" in self.gui_config.sg_hostapi
+ and self.gui_config.sg_wasapi_exclusive
+ ):
+ extra_settings = sd.WasapiSettings(exclusive=True)
+ else:
+ extra_settings = None
+ self.stream = sd.Stream(
+ callback=self.audio_callback,
+ blocksize=self.block_frame,
+ samplerate=self.gui_config.samplerate,
+ channels=self.gui_config.channels,
+ dtype="float32",
+ extra_settings=extra_settings,
+ )
+ self.stream.start()
+
+ def stop_stream(self):
+ global flag_vc
+ if flag_vc:
+ flag_vc = False
+ if self.stream is not None:
+ self.stream.abort()
+ self.stream.close()
+ self.stream = None
+
+ def audio_callback(
+ self, indata: np.ndarray, outdata: np.ndarray, frames, times, status
+ ):
+ """
+ 音频处理
+ """
+ global flag_vc
+ start_time = time.perf_counter()
+ indata = librosa.to_mono(indata.T)
+ if self.gui_config.threhold > -60:
+ indata = np.append(self.rms_buffer, indata)
+ rms = librosa.feature.rms(
+ y=indata, frame_length=4 * self.zc, hop_length=self.zc
+ )[:, 2:]
+ self.rms_buffer[:] = indata[-4 * self.zc :]
+ indata = indata[2 * self.zc - self.zc // 2 :]
+ db_threhold = (
+ librosa.amplitude_to_db(rms, ref=1.0)[0] < self.gui_config.threhold
+ )
+ for i in range(db_threhold.shape[0]):
+ if db_threhold[i]:
+ indata[i * self.zc : (i + 1) * self.zc] = 0
+ indata = indata[self.zc // 2 :]
+ self.input_wav[: -self.block_frame] = self.input_wav[
+ self.block_frame :
+ ].clone()
+ self.input_wav[-indata.shape[0] :] = torch.from_numpy(indata).to(
+ self.config.device
+ )
+ self.input_wav_res[: -self.block_frame_16k] = self.input_wav_res[
+ self.block_frame_16k :
+ ].clone()
+ # input noise reduction and resampling
+ if self.gui_config.I_noise_reduce:
+ self.input_wav_denoise[: -self.block_frame] = self.input_wav_denoise[
+ self.block_frame :
+ ].clone()
+ input_wav = self.input_wav[-self.sola_buffer_frame - self.block_frame :]
+ input_wav = self.tg(
+ input_wav.unsqueeze(0), self.input_wav.unsqueeze(0)
+ ).squeeze(0)
+ input_wav[: self.sola_buffer_frame] *= self.fade_in_window
+ input_wav[: self.sola_buffer_frame] += (
+ self.nr_buffer * self.fade_out_window
+ )
+ self.input_wav_denoise[-self.block_frame :] = input_wav[
+ : self.block_frame
+ ]
+ self.nr_buffer[:] = input_wav[self.block_frame :]
+ self.input_wav_res[-self.block_frame_16k - 160 :] = self.resampler(
+ self.input_wav_denoise[-self.block_frame - 2 * self.zc :]
+ )[160:]
+ else:
+ self.input_wav_res[-160 * (indata.shape[0] // self.zc + 1) :] = (
+ self.resampler(self.input_wav[-indata.shape[0] - 2 * self.zc :])[
+ 160:
+ ]
+ )
+ # infer
+ if self.function == "vc":
+ infer_wav = self.rvc.infer(
+ self.input_wav_res,
+ self.block_frame_16k,
+ self.skip_head,
+ self.return_length,
+ self.gui_config.f0method,
+ )
+ if self.resampler2 is not None:
+ infer_wav = self.resampler2(infer_wav)
+ elif self.gui_config.I_noise_reduce:
+ infer_wav = self.input_wav_denoise[self.extra_frame :].clone()
+ else:
+ infer_wav = self.input_wav[self.extra_frame :].clone()
+ # output noise reduction
+ if self.gui_config.O_noise_reduce and self.function == "vc":
+ self.output_buffer[: -self.block_frame] = self.output_buffer[
+ self.block_frame :
+ ].clone()
+ self.output_buffer[-self.block_frame :] = infer_wav[-self.block_frame :]
+ infer_wav = self.tg(
+ infer_wav.unsqueeze(0), self.output_buffer.unsqueeze(0)
+ ).squeeze(0)
+ # volume envelop mixing
+ if self.gui_config.rms_mix_rate < 1 and self.function == "vc":
+ if self.gui_config.I_noise_reduce:
+ input_wav = self.input_wav_denoise[self.extra_frame :]
+ else:
+ input_wav = self.input_wav[self.extra_frame :]
+ rms1 = librosa.feature.rms(
+ y=input_wav[: infer_wav.shape[0]].cpu().numpy(),
+ frame_length=4 * self.zc,
+ hop_length=self.zc,
+ )
+ rms1 = torch.from_numpy(rms1).to(self.config.device)
+ rms1 = F.interpolate(
+ rms1.unsqueeze(0),
+ size=infer_wav.shape[0] + 1,
+ mode="linear",
+ align_corners=True,
+ )[0, 0, :-1]
+ rms2 = librosa.feature.rms(
+ y=infer_wav[:].cpu().numpy(),
+ frame_length=4 * self.zc,
+ hop_length=self.zc,
+ )
+ rms2 = torch.from_numpy(rms2).to(self.config.device)
+ rms2 = F.interpolate(
+ rms2.unsqueeze(0),
+ size=infer_wav.shape[0] + 1,
+ mode="linear",
+ align_corners=True,
+ )[0, 0, :-1]
+ rms2 = torch.max(rms2, torch.zeros_like(rms2) + 1e-3)
+ infer_wav *= torch.pow(
+ rms1 / rms2, torch.tensor(1 - self.gui_config.rms_mix_rate)
+ )
+ # SOLA algorithm from https://github.com/yxlllc/DDSP-SVC
+ conv_input = infer_wav[
+ None, None, : self.sola_buffer_frame + self.sola_search_frame
+ ]
+ cor_nom = F.conv1d(conv_input, self.sola_buffer[None, None, :])
+ cor_den = torch.sqrt(
+ F.conv1d(
+ conv_input**2,
+ torch.ones(1, 1, self.sola_buffer_frame, device=self.config.device),
+ )
+ + 1e-8
+ )
+ if sys.platform == "darwin":
+ _, sola_offset = torch.max(cor_nom[0, 0] / cor_den[0, 0])
+ sola_offset = sola_offset.item()
+ else:
+ sola_offset = torch.argmax(cor_nom[0, 0] / cor_den[0, 0])
+ printt("sola_offset = %d", int(sola_offset))
+ infer_wav = infer_wav[sola_offset:]
+ if "privateuseone" in str(self.config.device) or not self.gui_config.use_pv:
+ infer_wav[: self.sola_buffer_frame] *= self.fade_in_window
+ infer_wav[: self.sola_buffer_frame] += (
+ self.sola_buffer * self.fade_out_window
+ )
+ else:
+ infer_wav[: self.sola_buffer_frame] = phase_vocoder(
+ self.sola_buffer,
+ infer_wav[: self.sola_buffer_frame],
+ self.fade_out_window,
+ self.fade_in_window,
+ )
+ self.sola_buffer[:] = infer_wav[
+ self.block_frame : self.block_frame + self.sola_buffer_frame
+ ]
+ outdata[:] = (
+ infer_wav[: self.block_frame]
+ .repeat(self.gui_config.channels, 1)
+ .t()
+ .cpu()
+ .numpy()
+ )
+ total_time = time.perf_counter() - start_time
+ if flag_vc:
+ self.window["infer_time"].update(int(total_time * 1000))
+ printt("Infer time: %.2f", total_time)
+
+ def update_devices(self, hostapi_name=None):
+ """获取设备列表"""
+ global flag_vc
+ flag_vc = False
+ sd._terminate()
+ sd._initialize()
+ devices = sd.query_devices()
+ hostapis = sd.query_hostapis()
+ for hostapi in hostapis:
+ for device_idx in hostapi["devices"]:
+ devices[device_idx]["hostapi_name"] = hostapi["name"]
+ self.hostapis = [hostapi["name"] for hostapi in hostapis]
+ if hostapi_name not in self.hostapis:
+ hostapi_name = self.hostapis[0]
+ self.input_devices = [
+ d["name"]
+ for d in devices
+ if d["max_input_channels"] > 0 and d["hostapi_name"] == hostapi_name
+ ]
+ self.output_devices = [
+ d["name"]
+ for d in devices
+ if d["max_output_channels"] > 0 and d["hostapi_name"] == hostapi_name
+ ]
+ self.input_devices_indices = [
+ d["index"] if "index" in d else d["name"]
+ for d in devices
+ if d["max_input_channels"] > 0 and d["hostapi_name"] == hostapi_name
+ ]
+ self.output_devices_indices = [
+ d["index"] if "index" in d else d["name"]
+ for d in devices
+ if d["max_output_channels"] > 0 and d["hostapi_name"] == hostapi_name
+ ]
+
+ def set_devices(self, input_device, output_device):
+ """设置输出设备"""
+ sd.default.device[0] = self.input_devices_indices[
+ self.input_devices.index(input_device)
+ ]
+ sd.default.device[1] = self.output_devices_indices[
+ self.output_devices.index(output_device)
+ ]
+ printt("Input device: %s:%s", str(sd.default.device[0]), input_device)
+ printt("Output device: %s:%s", str(sd.default.device[1]), output_device)
+
+ def get_device_samplerate(self):
+ return int(
+ sd.query_devices(device=sd.default.device[0])["default_samplerate"]
+ )
+
+ def get_device_channels(self):
+ max_input_channels = sd.query_devices(device=sd.default.device[0])[
+ "max_input_channels"
+ ]
+ max_output_channels = sd.query_devices(device=sd.default.device[1])[
+ "max_output_channels"
+ ]
+ return min(max_input_channels, max_output_channels, 2)
+
+ gui = GUI()
diff --git a/i18n/i18n.py b/i18n/i18n.py
new file mode 100644
index 0000000000000000000000000000000000000000..00e91bf3fddc0658586eab33868ca824ef425688
--- /dev/null
+++ b/i18n/i18n.py
@@ -0,0 +1,27 @@
+import json
+import locale
+import os
+
+
+def load_language_list(language):
+ with open(f"./i18n/locale/{language}.json", "r", encoding="utf-8") as f:
+ language_list = json.load(f)
+ return language_list
+
+
+class I18nAuto:
+ def __init__(self, language=None):
+ if language in ["Auto", None]:
+ language = locale.getdefaultlocale()[
+ 0
+ ] # getlocale can't identify the system's language ((None, None))
+ if not os.path.exists(f"./i18n/locale/{language}.json"):
+ language = "en_US"
+ self.language = language
+ self.language_map = load_language_list(language)
+
+ def __call__(self, key):
+ return self.language_map.get(key, key)
+
+ def __repr__(self):
+ return "Use Language: " + self.language
diff --git a/i18n/locale/en_US.json b/i18n/locale/en_US.json
new file mode 100644
index 0000000000000000000000000000000000000000..be09af72409f9fe665e8ee973e5e94f922562367
--- /dev/null
+++ b/i18n/locale/en_US.json
@@ -0,0 +1,138 @@
+{
+ ">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音": "If >=3: apply median filtering to the harvested pitch results. The value represents the filter radius and can reduce breathiness.",
+ "A模型权重": "Weight (w) for Model A:",
+ "A模型路径": "Path to Model A:",
+ "B模型路径": "Path to Model B:",
+ "E:\\语音音频+标注\\米津玄师\\src": "C:\\Users\\Desktop\\src",
+ "F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调": "F0 curve file (optional). One pitch per line. Replaces the default F0 and pitch modulation:",
+ "Index Rate": "Index Rate",
+ "Onnx导出": "Export Onnx",
+ "Onnx输出路径": "Onnx Export Path:",
+ "RVC模型路径": "RVC Model Path:",
+ "ckpt处理": "ckpt Processing",
+ "harvest进程数": "Number of CPU processes used for harvest pitch algorithm",
+ "index文件路径不可包含中文": "index文件路径不可包含中文",
+ "pth文件路径不可包含中文": "pth文件路径不可包含中文",
+ "rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程": "Enter the GPU index(es) separated by '-', e.g., 0-0-1 to use 2 processes in GPU0 and 1 process in GPU1",
+ "step1: 填写实验配置. 实验数据放在logs下, 每个实验一个文件夹, 需手工输入实验名路径, 内含实验配置, 日志, 训练得到的模型文件. ": "Step 1: Fill in the experimental configuration. Experimental data is stored in the 'logs' folder, with each experiment having a separate folder. Manually enter the experiment name path, which contains the experimental configuration, logs, and trained model files.",
+ "step1:正在处理数据": "Step 1: Processing data",
+ "step2:正在提取音高&正在提取特征": "step2:Pitch extraction & feature extraction",
+ "step2a: 自动遍历训练文件夹下所有可解码成音频的文件并进行切片归一化, 在实验目录下生成2个wav文件夹; 暂时只支持单人训练. ": "Step 2a: Automatically traverse all files in the training folder that can be decoded into audio and perform slice normalization. Generates 2 wav folders in the experiment directory. Currently, only single-singer/speaker training is supported.",
+ "step2b: 使用CPU提取音高(如果模型带音高), 使用GPU提取特征(选择卡号)": "Step 2b: Use CPU to extract pitch (if the model has pitch), use GPU to extract features (select GPU index):",
+ "step3: 填写训练设置, 开始训练模型和索引": "Step 3: Fill in the training settings and start training the model and index",
+ "step3a:正在训练模型": "Step 3a: Model training started",
+ "一键训练": "One-click training",
+ "也可批量输入音频文件, 二选一, 优先读文件夹": "Multiple audio files can also be imported. If a folder path exists, this input is ignored.",
+ "人声伴奏分离批量处理, 使用UVR5模型。
合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。
模型分为三类:
1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点;
2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型;
3、去混响、去延迟模型(by FoxJoy):
(1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;
(234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。
去混响/去延迟,附:
1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;
2、MDX-Net-Dereverb模型挺慢的;
3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "Batch processing for vocal accompaniment separation using the UVR5 model.
Example of a valid folder path format: D:\\path\\to\\input\\folder (copy it from the file manager address bar).
The model is divided into three categories:
1. Preserve vocals: Choose this option for audio without harmonies. It preserves vocals better than HP5. It includes two built-in models: HP2 and HP3. HP3 may slightly leak accompaniment but preserves vocals slightly better than HP2.
2. Preserve main vocals only: Choose this option for audio with harmonies. It may weaken the main vocals. It includes one built-in model: HP5.
3. De-reverb and de-delay models (by FoxJoy):
(1) MDX-Net: The best choice for stereo reverb removal but cannot remove mono reverb;
(234) DeEcho: Removes delay effects. Aggressive mode removes more thoroughly than Normal mode. DeReverb additionally removes reverb and can remove mono reverb, but not very effectively for heavily reverberated high-frequency content.
De-reverb/de-delay notes:
1. The processing time for the DeEcho-DeReverb model is approximately twice as long as the other two DeEcho models.
2. The MDX-Net-Dereverb model is quite slow.
3. The recommended cleanest configuration is to apply MDX-Net first and then DeEcho-Aggressive.",
+ "以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "Enter the GPU index(es) separated by '-', e.g., 0-1-2 to use GPU 0, 1, and 2:",
+ "伴奏人声分离&去混响&去回声": "Vocals/Accompaniment Separation & Reverberation Removal",
+ "使用模型采样率": "使用模型采样率",
+ "使用设备采样率": "使用设备采样率",
+ "保存名": "Save name:",
+ "保存的文件名, 默认空为和源文件同名": "Save file name (default: same as the source file):",
+ "保存的模型名不带后缀": "Saved model name (without extension):",
+ "保存频率save_every_epoch": "Save frequency (save_every_epoch):",
+ "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果": "Protect voiceless consonants and breath sounds to prevent artifacts such as tearing in electronic music. Set to 0.5 to disable. Decrease the value to increase protection, but it may reduce indexing accuracy:",
+ "修改": "Modify",
+ "修改模型信息(仅支持weights文件夹下提取的小模型文件)": "Modify model information (only supported for small model files extracted from the 'weights' folder)",
+ "停止音频转换": "Stop audio conversion",
+ "全流程结束!": "All processes have been completed!",
+ "共振偏移": "共振偏移",
+ "刷新音色列表和索引路径": "Refresh voice list and index path",
+ "加载模型": "Load model",
+ "加载预训练底模D路径": "Load pre-trained base model D path:",
+ "加载预训练底模G路径": "Load pre-trained base model G path:",
+ "单次推理": "Single Inference",
+ "卸载音色省显存": "Unload voice to save GPU memory:",
+ "变调(整数, 半音数量, 升八度12降八度-12)": "Transpose (integer, number of semitones, raise by an octave: 12, lower by an octave: -12):",
+ "后处理重采样至最终采样率,0为不进行重采样": "Resample the output audio in post-processing to the final sample rate. Set to 0 for no resampling:",
+ "否": "No",
+ "启用相位声码器": "启用相位声码器",
+ "响应阈值": "Response threshold",
+ "响度因子": "loudness factor",
+ "处理数据": "Process data",
+ "导出Onnx模型": "Export Onnx Model",
+ "导出文件格式": "Export file format",
+ "常见问题解答": "FAQ (Frequently Asked Questions)",
+ "常规设置": "General settings",
+ "开始音频转换": "Start audio conversion",
+ "很遗憾您这没有能用的显卡来支持您训练": "Unfortunately, there is no compatible GPU available to support your training.",
+ "性能设置": "Performance settings",
+ "总训练轮数total_epoch": "Total training epochs (total_epoch):",
+ "批量推理": "Batch Inference",
+ "批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. ": "Batch conversion. Enter the folder containing the audio files to be converted or upload multiple audio files. The converted audio will be output in the specified folder (default: 'opt').",
+ "指定输出主人声文件夹": "Specify the output folder for vocals:",
+ "指定输出文件夹": "Specify output folder:",
+ "指定输出非主人声文件夹": "Specify the output folder for accompaniment:",
+ "推理时间(ms):": "Inference time (ms):",
+ "推理音色": "Inferencing voice:",
+ "提取": "Extract",
+ "提取音高和处理数据使用的CPU进程数": "Number of CPU processes used for pitch extraction and data processing:",
+ "是": "Yes",
+ "是否仅保存最新的ckpt文件以节省硬盘空间": "Save only the latest '.ckpt' file to save disk space:",
+ "是否在每次保存时间点将最终小模型保存至weights文件夹": "Save a small final model to the 'weights' folder at each save point:",
+ "是否缓存所有训练集至显存. 10min以下小数据可缓存以加速训练, 大数据缓存会炸显存也加不了多少速": "Cache all training sets to GPU memory. Caching small datasets (less than 10 minutes) can speed up training, but caching large datasets will consume a lot of GPU memory and may not provide much speed improvement:",
+ "显卡信息": "GPU Information",
+ "本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责.
如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录LICENSE.": "This software is open source under the MIT license. The author does not have any control over the software. Users who use the software and distribute the sounds exported by the software are solely responsible.
If you do not agree with this clause, you cannot use or reference any codes and files within the software package. See the root directory Agreement-LICENSE.txt for details.",
+ "查看": "View",
+ "查看模型信息(仅支持weights文件夹下提取的小模型文件)": "View model information (only supported for small model files extracted from the 'weights' folder)",
+ "检索特征占比": "Search feature ratio (controls accent strength, too high has artifacting):",
+ "模型": "Model",
+ "模型推理": "Model Inference",
+ "模型提取(输入logs文件夹下大文件模型路径),适用于训一半不想训了模型没有自动提取保存小文件模型,或者想测试中间模型的情况": "Model extraction (enter the path of the large file model under the 'logs' folder). This is useful if you want to stop training halfway and manually extract and save a small model file, or if you want to test an intermediate model:",
+ "模型是否带音高指导": "Whether the model has pitch guidance:",
+ "模型是否带音高指导(唱歌一定要, 语音可以不要)": "Whether the model has pitch guidance (required for singing, optional for speech):",
+ "模型是否带音高指导,1是0否": "Whether the model has pitch guidance (1: yes, 0: no):",
+ "模型版本型号": "Model architecture version:",
+ "模型融合, 可用于测试音色融合": "Model fusion, can be used to test timbre fusion",
+ "模型路径": "Path to Model:",
+ "每张显卡的batch_size": "Batch size per GPU:",
+ "淡入淡出长度": "Fade length",
+ "版本": "Version",
+ "特征提取": "Feature extraction",
+ "特征检索库文件路径,为空则使用下拉的选择结果": "Path to the feature index file. Leave blank to use the selected result from the dropdown:",
+ "独占 WASAPI 设备": "独占 WASAPI 设备",
+ "男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Recommended +12 key for male to female conversion, and -12 key for female to male conversion. If the sound range goes too far and the voice is distorted, you can also adjust it to the appropriate range by yourself.",
+ "目标采样率": "Target sample rate:",
+ "算法延迟(ms):": "Algorithmic delays(ms):",
+ "自动检测index路径,下拉式选择(dropdown)": "Auto-detect index path and select from the dropdown:",
+ "融合": "Fusion",
+ "要改的模型信息": "Model information to be modified:",
+ "要置入的模型信息": "Model information to be placed:",
+ "训练": "Train",
+ "训练模型": "Train model",
+ "训练特征索引": "Train feature index",
+ "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Training complete. You can check the training logs in the console or the 'train.log' file under the experiment folder.",
+ "设备类型": "设备类型",
+ "请指定说话人id": "Please specify the speaker/singer ID:",
+ "请选择index文件": "Please choose the .index file",
+ "请选择pth文件": "Please choose the .pth file",
+ "请选择说话人id": "Select Speaker/Singer ID:",
+ "转换": "Convert",
+ "输入实验名": "Enter the experiment name:",
+ "输入待处理音频文件夹路径": "Enter the path of the audio folder to be processed:",
+ "输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)": "Enter the path of the audio folder to be processed (copy it from the address bar of the file manager):",
+ "输入待处理音频文件路径(默认是正确格式示例)": "Enter the path of the audio file to be processed (default is the correct format example):",
+ "输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络": "Adjust the volume envelope scaling. Closer to 0, the more it mimicks the volume of the original vocals. Can help mask noise and make volume sound more natural when set relatively low. Closer to 1 will be more of a consistently loud volume:",
+ "输入监听": "Input voice monitor",
+ "输入训练文件夹路径": "Enter the path of the training folder:",
+ "输入设备": "Input device",
+ "输入降噪": "Input noise reduction",
+ "输出信息": "Output information",
+ "输出变声": "Output converted voice",
+ "输出设备": "Output device",
+ "输出降噪": "Output noise reduction",
+ "输出音频(右下角三个点,点了可以下载)": "Export audio (click on the three dots in the lower right corner to download)",
+ "选择.index文件": "Select the .index file",
+ "选择.pth文件": "Select the .pth file",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "Select the pitch extraction algorithm ('pm': faster extraction but lower-quality speech; 'harvest': better bass but extremely slow; 'crepe': better quality but GPU intensive), 'rmvpe': best quality, and little GPU requirement",
+ "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "Select the pitch extraction algorithm: when extracting singing, you can use 'pm' to speed up. For high-quality speech with fast performance, but worse CPU usage, you can use 'dio'. 'harvest' results in better quality but is slower. 'rmvpe' has the best results and consumes less CPU/GPU",
+ "采样率:": "采样率:",
+ "采样长度": "Sample length",
+ "重载设备列表": "Reload device list",
+ "音调设置": "Pitch settings",
+ "音频设备": "Audio device",
+ "音高算法": "pitch detection algorithm",
+ "额外推理时长": "Extra inference time"
+}
diff --git a/i18n/locale/es_ES.json b/i18n/locale/es_ES.json
new file mode 100644
index 0000000000000000000000000000000000000000..99961ec443e8fe51eea41419b7db37f0e9c5a3ff
--- /dev/null
+++ b/i18n/locale/es_ES.json
@@ -0,0 +1,138 @@
+{
+ ">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音": "Si es >=3, entonces use el resultado del reconocimiento de tono de 'harvest' con filtro de mediana, el valor es el radio del filtro, su uso puede debilitar el sonido sordo",
+ "A模型权重": "Un peso modelo para el modelo A.",
+ "A模型路径": "Modelo A ruta.",
+ "B模型路径": "Modelo B ruta.",
+ "E:\\语音音频+标注\\米津玄师\\src": "E:\\语音音频+标注\\米津玄师\\src",
+ "F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调": "Archivo de curva F0, opcional, un tono por línea, en lugar de F0 predeterminado y cambio de tono",
+ "Index Rate": "Tasa de índice",
+ "Onnx导出": "Exportar Onnx",
+ "Onnx输出路径": "Ruta de salida Onnx",
+ "RVC模型路径": "Ruta del modelo RVC",
+ "ckpt处理": "Procesamiento de recibos",
+ "harvest进程数": "Número de procesos",
+ "index文件路径不可包含中文": "La ruta del archivo .index no debe contener caracteres chinos.",
+ "pth文件路径不可包含中文": "La ruta del archivo .pth no debe contener caracteres chinos.",
+ "rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程": "Separe los números de identificación de la GPU con '-' al ingresarlos. Por ejemplo, '0-1-2' significa usar GPU 0, GPU 1 y GPU 2.",
+ "step1: 填写实验配置. 实验数据放在logs下, 每个实验一个文件夹, 需手工输入实验名路径, 内含实验配置, 日志, 训练得到的模型文件. ": "Paso 1: Complete la configuración del experimento. Los datos del experimento se almacenan en el directorio 'logs', con cada experimento en una carpeta separada. La ruta del nombre del experimento debe ingresarse manualmente y debe contener la configuración del experimento, los registros y los archivos del modelo entrenado.",
+ "step1:正在处理数据": "Paso 1: Procesando datos",
+ "step2:正在提取音高&正在提取特征": "Paso 2: Extracción del tono y extracción de características",
+ "step2a: 自动遍历训练文件夹下所有可解码成音频的文件并进行切片归一化, 在实验目录下生成2个wav文件夹; 暂时只支持单人训练. ": "Paso 2a: Recorra automáticamente la carpeta de capacitación y corte y normalice todos los archivos de audio que se pueden decodificar en audio. Se generarán dos carpetas 'wav' en el directorio del experimento. Actualmente, solo se admite la capacitación de una sola persona.",
+ "step2b: 使用CPU提取音高(如果模型带音高), 使用GPU提取特征(选择卡号)": "Paso 2b: Use la CPU para extraer el tono (si el modelo tiene guía de tono) y la GPU para extraer características (seleccione el número de tarjeta).",
+ "step3: 填写训练设置, 开始训练模型和索引": "Paso 3: Complete la configuración de entrenamiento y comience a entrenar el modelo y el índice.",
+ "step3a:正在训练模型": "Paso 3a: Entrenando el modelo",
+ "一键训练": "Entrenamiento con un clic",
+ "也可批量输入音频文件, 二选一, 优先读文件夹": "También se pueden importar varios archivos de audio. Si existe una ruta de carpeta, esta entrada se ignora.",
+ "人声伴奏分离批量处理, 使用UVR5模型。
合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。
模型分为三类:
1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点;
2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型;
3、去混响、去延迟模型(by FoxJoy):
(1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;
(234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。
去混响/去延迟,附:
1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;
2、MDX-Net-Dereverb模型挺慢的;
3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "Procesamiento por lotes para la separación de acompañamiento vocal utilizando el modelo UVR5.
Ejemplo de formato de ruta de carpeta válido: D:\\ruta\\a\\la\\carpeta\\de\\entrada (copiar desde la barra de direcciones del administrador de archivos).
El modelo se divide en tres categorías:
1. Preservar voces: Elija esta opción para audio sin armonías. Preserva las voces mejor que HP5. Incluye dos modelos incorporados: HP2 y HP3. HP3 puede filtrar ligeramente el acompañamiento pero conserva las voces un poco mejor que HP2.
2. Preservar solo voces principales: Elija esta opción para audio con armonías. Puede debilitar las voces principales. Incluye un modelo incorporado: HP5.
3. Modelos de des-reverberación y des-retardo (por FoxJoy):
(1) MDX-Net: La mejor opción para la eliminación de reverberación estéreo pero no puede eliminar la reverberación mono;
(234) DeEcho: Elimina efectos de retardo. El modo Agresivo elimina más a fondo que el modo Normal. DeReverb adicionalmente elimina la reverberación y puede eliminar la reverberación mono, pero no muy efectivamente para contenido de alta frecuencia fuertemente reverberado.
Notas de des-reverberación/des-retardo:
1. El tiempo de procesamiento para el modelo DeEcho-DeReverb es aproximadamente el doble que los otros dos modelos DeEcho.
2. El modelo MDX-Net-Dereverb es bastante lento.
3. La configuración más limpia recomendada es aplicar primero MDX-Net y luego DeEcho-Agresivo.",
+ "以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "Separe los números de identificación de la GPU con '-' al ingresarlos. Por ejemplo, '0-1-2' significa usar GPU 0, GPU 1 y GPU 2.",
+ "伴奏人声分离&去混响&去回声": "Separación de voz acompañante & eliminación de reverberación & eco",
+ "使用模型采样率": "使用模型采样率",
+ "使用设备采样率": "使用设备采样率",
+ "保存名": "Guardar nombre",
+ "保存的文件名, 默认空为和源文件同名": "Nombre del archivo que se guardará, el valor predeterminado es el mismo que el nombre del archivo de origen",
+ "保存的模型名不带后缀": "Nombre del modelo guardado sin extensión.",
+ "保存频率save_every_epoch": "Frecuencia de guardado (save_every_epoch)",
+ "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果": "Proteger las consonantes claras y la respiración, prevenir artefactos como la distorsión de sonido electrónico, 0.5 no está activado, reducir aumentará la protección pero puede reducir el efecto del índice",
+ "修改": "Modificar",
+ "修改模型信息(仅支持weights文件夹下提取的小模型文件)": "Modificar la información del modelo (solo admite archivos de modelos pequeños extraídos en la carpeta weights)",
+ "停止音频转换": "Detener la conversión de audio",
+ "全流程结束!": "¡Todo el proceso ha terminado!",
+ "共振偏移": "共振偏移",
+ "刷新音色列表和索引路径": "Actualizar la lista de modelos e índice de rutas",
+ "加载模型": "Cargar modelo",
+ "加载预训练底模D路径": "Cargue la ruta del modelo D base pre-entrenada.",
+ "加载预训练底模G路径": "Cargue la ruta del modelo G base pre-entrenada.",
+ "单次推理": "单次推理",
+ "卸载音色省显存": "Descargue la voz para ahorrar memoria GPU",
+ "变调(整数, 半音数量, 升八度12降八度-12)": "Cambio de tono (entero, número de semitonos, subir una octava +12 o bajar una octava -12)",
+ "后处理重采样至最终采样率,0为不进行重采样": "Remuestreo posterior al proceso a la tasa de muestreo final, 0 significa no remuestrear",
+ "否": "No",
+ "启用相位声码器": "启用相位声码器",
+ "响应阈值": "Umbral de respuesta",
+ "响度因子": "factor de sonoridad",
+ "处理数据": "Procesar datos",
+ "导出Onnx模型": "Exportar modelo Onnx",
+ "导出文件格式": "Formato de archivo de exportación",
+ "常见问题解答": "Preguntas frecuentes",
+ "常规设置": "Configuración general",
+ "开始音频转换": "Iniciar conversión de audio",
+ "很遗憾您这没有能用的显卡来支持您训练": "Lamentablemente, no tiene una tarjeta gráfica adecuada para soportar su entrenamiento",
+ "性能设置": "Configuración de rendimiento",
+ "总训练轮数total_epoch": "Total de épocas de entrenamiento (total_epoch)",
+ "批量推理": "批量推理",
+ "批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. ": "Conversión por lotes, ingrese la carpeta que contiene los archivos de audio para convertir o cargue varios archivos de audio. El audio convertido se emitirá en la carpeta especificada (opción predeterminada).",
+ "指定输出主人声文件夹": "Especifique la carpeta de salida para la voz principal",
+ "指定输出文件夹": "Especificar carpeta de salida",
+ "指定输出非主人声文件夹": "Especifique la carpeta de salida para las voces no principales",
+ "推理时间(ms):": "Inferir tiempo (ms):",
+ "推理音色": "inferencia de voz",
+ "提取": "Extraer",
+ "提取音高和处理数据使用的CPU进程数": "Número de procesos de CPU utilizados para extraer el tono y procesar los datos",
+ "是": "Sí",
+ "是否仅保存最新的ckpt文件以节省硬盘空间": "Guardar solo el archivo ckpt más reciente para ahorrar espacio en disco",
+ "是否在每次保存时间点将最终小模型保存至weights文件夹": "Guardar pequeño modelo final en la carpeta 'weights' en cada punto de guardado",
+ "是否缓存所有训练集至显存. 10min以下小数据可缓存以加速训练, 大数据缓存会炸显存也加不了多少速": "Si almacenar en caché todos los conjuntos de entrenamiento en la memoria de la GPU. Los conjuntos de datos pequeños (menos de 10 minutos) se pueden almacenar en caché para acelerar el entrenamiento, pero el almacenamiento en caché de conjuntos de datos grandes puede causar errores de memoria en la GPU y no aumenta la velocidad de manera significativa.",
+ "显卡信息": "información de la GPU",
+ "本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责.
如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录LICENSE.": "Este software es de código abierto bajo la licencia MIT, el autor no tiene ningún control sobre el software, y aquellos que usan el software y difunden los sonidos exportados por el software son los únicos responsables.
Si no está de acuerdo con esta cláusula , no puede utilizar ni citar ningún código ni archivo del paquete de software Consulte el directorio raíz Agreement-LICENSE.txt para obtener más información.",
+ "查看": "Ver",
+ "查看模型信息(仅支持weights文件夹下提取的小模型文件)": "Ver información del modelo (solo aplicable a archivos de modelos pequeños extraídos de la carpeta 'pesos')",
+ "检索特征占比": "Proporción de función de búsqueda",
+ "模型": "Modelo",
+ "模型推理": "inferencia del modelo",
+ "模型提取(输入logs文件夹下大文件模型路径),适用于训一半不想训了模型没有自动提取保存小文件模型,或者想测试中间模型的情况": "Extracción de modelo (ingrese la ruta de un archivo de modelo grande en la carpeta 'logs'), aplicable cuando desea extraer un archivo de modelo pequeño después de entrenar a mitad de camino y no se guardó automáticamente, o cuando desea probar un modelo intermedio",
+ "模型是否带音高指导": "Si el modelo tiene guía de tono.",
+ "模型是否带音高指导(唱歌一定要, 语音可以不要)": "Si el modelo tiene guía de tono (necesaria para cantar, pero no para hablar)",
+ "模型是否带音高指导,1是0否": "Si el modelo tiene guía de tono, 1 para sí, 0 para no",
+ "模型版本型号": "Versión y modelo del modelo",
+ "模型融合, 可用于测试音色融合": "Fusión de modelos, se puede utilizar para fusionar diferentes voces",
+ "模型路径": "Ruta del modelo",
+ "每张显卡的batch_size": "Tamaño del lote (batch_size) por tarjeta gráfica",
+ "淡入淡出长度": "Duración del fundido de entrada/salida",
+ "版本": "Versión",
+ "特征提取": "Extracción de características",
+ "特征检索库文件路径,为空则使用下拉的选择结果": "Ruta del archivo de la biblioteca de características, si está vacío, se utilizará el resultado de la selección desplegable",
+ "独占 WASAPI 设备": "独占 WASAPI 设备",
+ "男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Tecla +12 recomendada para conversión de voz de hombre a mujer, tecla -12 para conversión de voz de mujer a hombre. Si el rango de tono es demasiado amplio y causa distorsión, ajústelo usted mismo a un rango adecuado.",
+ "目标采样率": "Tasa de muestreo objetivo",
+ "算法延迟(ms):": "算法延迟(ms):",
+ "自动检测index路径,下拉式选择(dropdown)": "Detección automática de la ruta del índice, selección desplegable (dropdown)",
+ "融合": "Fusión",
+ "要改的模型信息": "Información del modelo a modificar",
+ "要置入的模型信息": "Información del modelo a colocar.",
+ "训练": "Entrenamiento",
+ "训练模型": "Entrenar Modelo",
+ "训练特征索引": "Índice de características",
+ "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Entrenamiento finalizado, puede ver el registro de entrenamiento en la consola o en el archivo train.log en la carpeta del experimento",
+ "设备类型": "设备类型",
+ "请指定说话人id": "ID del modelo",
+ "请选择index文件": "Seleccione el archivo .index",
+ "请选择pth文件": "Seleccione el archivo .pth",
+ "请选择说话人id": "Seleccione una identificación de altavoz",
+ "转换": "Conversión",
+ "输入实验名": "Ingrese el nombre del modelo",
+ "输入待处理音频文件夹路径": "Ingrese la ruta a la carpeta de audio que se procesará",
+ "输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)": "Ingrese la ruta a la carpeta de audio que se procesará (simplemente cópiela desde la barra de direcciones del administrador de archivos)",
+ "输入待处理音频文件路径(默认是正确格式示例)": "Ingrese la ruta del archivo del audio que se procesará (el formato predeterminado es el ejemplo correcto)",
+ "输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络": "Proporción de fusión para reemplazar el sobre de volumen de entrada con el sobre de volumen de salida, cuanto más cerca de 1, más se utiliza el sobre de salida",
+ "输入监听": "输入监听",
+ "输入训练文件夹路径": "Introduzca la ruta de la carpeta de entrenamiento",
+ "输入设备": "Dispositivo de entrada",
+ "输入降噪": "Reducción de ruido de entrada",
+ "输出信息": "Información de salida",
+ "输出变声": "输出变声",
+ "输出设备": "Dispositivo de salida",
+ "输出降噪": "Reducción de ruido de salida",
+ "输出音频(右下角三个点,点了可以下载)": "Salida de audio (haga clic en los tres puntos en la esquina inferior derecha para descargar)",
+ "选择.index文件": "Seleccione el archivo .index",
+ "选择.pth文件": "Seleccione el archivo .pth",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "Seleccione el algoritmo de extracción de tono, las voces de entrada se pueden acelerar con pm, harvest tiene buenos graves pero es muy lento, crepe es bueno pero se come las GPUs",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "Seleccione el algoritmo de extracción de tono, use 'pm' para acelerar la entrada de canto, 'harvest' es bueno para los graves pero extremadamente lento, 'crepe' tiene buenos resultados pero consume GPU",
+ "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "Seleccione el algoritmo de extracción de tono: la canción de entrada se puede acelerar con pm, la voz de alta calidad pero CPU pobre se puede acelerar con dio, harvest es mejor pero más lento, rmvpe es el mejor y se come ligeramente la CPU/GPU",
+ "采样率:": "采样率:",
+ "采样长度": "Longitud de muestreo",
+ "重载设备列表": "Actualizar lista de dispositivos",
+ "音调设置": "Ajuste de tono",
+ "音频设备": "Dispositivo de audio",
+ "音高算法": "Algoritmo de tono",
+ "额外推理时长": "Tiempo de inferencia adicional"
+}
diff --git a/i18n/locale/fr_FR.json b/i18n/locale/fr_FR.json
new file mode 100644
index 0000000000000000000000000000000000000000..7fb7710d39542d527df80e4a8263cd828b77ef06
--- /dev/null
+++ b/i18n/locale/fr_FR.json
@@ -0,0 +1,138 @@
+{
+ ">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音": "Si >=3 : appliquer un filtrage médian aux résultats de la reconnaissance de la hauteur de récolte. La valeur représente le rayon du filtre et peut réduire la respiration.",
+ "A模型权重": "Poids (w) pour le modèle A :",
+ "A模型路径": "Chemin d'accès au modèle A :",
+ "B模型路径": "Chemin d'accès au modèle B :",
+ "E:\\语音音频+标注\\米津玄师\\src": "E:\\语音音频+标注\\米津玄师\\src",
+ "F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调": "Fichier de courbe F0 (facultatif). Une hauteur par ligne. Remplace la fréquence fondamentale par défaut et la modulation de la hauteur :",
+ "Index Rate": "Taux d'indexation",
+ "Onnx导出": "Exporter en ONNX",
+ "Onnx输出路径": "Chemin d'exportation ONNX :",
+ "RVC模型路径": "Chemin du modèle RVC :",
+ "ckpt处理": "Traitement des fichiers .ckpt",
+ "harvest进程数": "Nombre de processus CPU utilisés pour l'algorithme de reconnaissance de la hauteur (pitch) dans le cadre de la récolte (harvest).",
+ "index文件路径不可包含中文": "Le chemin du fichier d'index ne doit pas contenir de caractères chinois.",
+ "pth文件路径不可包含中文": "Le chemin du fichier .pth ne doit pas contenir de caractères chinois.",
+ "rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程": "Configuration des numéros de carte RMVPE : séparez les index GPU par des tirets \"-\", par exemple, 0-0-1 pour utiliser 2 processus sur GPU0 et 1 processus sur GPU1.",
+ "step1: 填写实验配置. 实验数据放在logs下, 每个实验一个文件夹, 需手工输入实验名路径, 内含实验配置, 日志, 训练得到的模型文件. ": "Étape 1 : Remplissez la configuration expérimentale. Les données expérimentales sont stockées dans le dossier 'logs', avec chaque expérience ayant un dossier distinct. Entrez manuellement le chemin du nom de l'expérience, qui contient la configuration expérimentale, les journaux et les fichiers de modèle entraînés.",
+ "step1:正在处理数据": "Étape 1 : Traitement des données en cours.",
+ "step2:正在提取音高&正在提取特征": "Étape 2 : Extraction de la hauteur et extraction des caractéristiques en cours.",
+ "step2a: 自动遍历训练文件夹下所有可解码成音频的文件并进行切片归一化, 在实验目录下生成2个wav文件夹; 暂时只支持单人训练. ": "Étape 2a : Parcours automatique de tous les fichiers du dossier d'entraînement qui peuvent être décodés en fichiers audio et réalisation d'une normalisation par tranches. Génère 2 dossiers wav dans le répertoire de l'expérience. Actuellement, seule la formation avec un seul chanteur/locuteur est prise en charge.",
+ "step2b: 使用CPU提取音高(如果模型带音高), 使用GPU提取特征(选择卡号)": "Étape 2b : Utilisez le CPU pour extraire la hauteur (si le modèle le permet), utilisez le GPU pour extraire les caractéristiques (sélectionnez l'index du GPU) :",
+ "step3: 填写训练设置, 开始训练模型和索引": "Étape 3 : Remplissez les paramètres d'entraînement et démarrez l'entraînement du modèle ainsi que l'indexation.",
+ "step3a:正在训练模型": "Étape 3a : L'entraînement du modèle a commencé.",
+ "一键训练": "Entraînement en un clic",
+ "也可批量输入音频文件, 二选一, 优先读文件夹": "Il est également possible d'importer plusieurs fichiers audio. Si un chemin de dossier existe, cette entrée est ignorée.",
+ "人声伴奏分离批量处理, 使用UVR5模型。
合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。
模型分为三类:
1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点;
2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型;
3、去混响、去延迟模型(by FoxJoy):
(1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;
(234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。
去混响/去延迟,附:
1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;
2、MDX-Net-Dereverb模型挺慢的;
3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "Traitement en lot pour la séparation de la voix et de l'accompagnement vocal à l'aide du modèle UVR5.
Exemple d'un format de chemin de dossier valide : D:\\chemin\\vers\\dossier\\d'entrée (copiez-le depuis la barre d'adresse du gestionnaire de fichiers).
Le modèle est divisé en trois catégories :
1. Préserver la voix : Choisissez cette option pour l'audio sans harmonies. Elle préserve la voix mieux que HP5. Il comprend deux modèles intégrés : HP2 et HP3. HP3 peut légèrement laisser passer l'accompagnement mais préserve légèrement mieux la voix que HP2.
2. Préserver uniquement la voix principale : Choisissez cette option pour l'audio avec harmonies. Cela peut affaiblir la voix principale. Il comprend un modèle intégré : HP5.
3. Modèles de suppression de la réverbération et du délai (par FoxJoy) :
(1) MDX-Net : Le meilleur choix pour la suppression de la réverbération stéréo, mais ne peut pas supprimer la réverbération mono.
(234) DeEcho : Supprime les effets de délai. Le mode Aggressive supprime plus efficacement que le mode Normal. DeReverb supprime également la réverbération et peut supprimer la réverbération mono, mais pas très efficacement pour les contenus à haute fréquence fortement réverbérés.
Notes sur la suppression de la réverbération et du délai :
1. Le temps de traitement pour le modèle DeEcho-DeReverb est environ deux fois plus long que pour les autres deux modèles DeEcho.
2. Le modèle MDX-Net-Dereverb est assez lent.
3. La configuration la plus propre recommandée est d'appliquer d'abord MDX-Net, puis DeEcho-Aggressive.",
+ "以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "Entrez le(s) index GPU séparé(s) par '-', par exemple, 0-1-2 pour utiliser les GPU 0, 1 et 2 :",
+ "伴奏人声分离&去混响&去回声": "Séparation des voix/accompagnement et suppression de la réverbération",
+ "使用模型采样率": "使用模型采样率",
+ "使用设备采样率": "使用设备采样率",
+ "保存名": "Nom de sauvegarde :",
+ "保存的文件名, 默认空为和源文件同名": "Nom du fichier de sauvegarde (par défaut : identique au nom du fichier source) :",
+ "保存的模型名不带后缀": "Nom du modèle enregistré (sans extension) :",
+ "保存频率save_every_epoch": "Fréquence de sauvegarde (save_every_epoch) :",
+ "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果": "Protéger les consonnes sourdes et les bruits de respiration pour éviter les artefacts tels que le déchirement dans la musique électronique. Réglez à 0,5 pour désactiver. Diminuez la valeur pour renforcer la protection, mais cela peut réduire la précision de l'indexation :",
+ "修改": "Modifier",
+ "修改模型信息(仅支持weights文件夹下提取的小模型文件)": "Modifier les informations du modèle (uniquement pris en charge pour les petits fichiers de modèle extraits du dossier 'weights')",
+ "停止音频转换": "Arrêter la conversion audio",
+ "全流程结束!": "Toutes les étapes ont été terminées !",
+ "共振偏移": "共振偏移",
+ "刷新音色列表和索引路径": "Actualiser la liste des voix et le vers l'index.",
+ "加载模型": "Charger le modèle.",
+ "加载预训练底模D路径": "Charger le chemin du modèle de base pré-entraîné D :",
+ "加载预训练底模G路径": "Charger le chemin du modèle de base pré-entraîné G :",
+ "单次推理": "单次推理",
+ "卸载音色省显存": "Décharger la voix pour économiser la mémoire GPU.",
+ "变调(整数, 半音数量, 升八度12降八度-12)": "Transposer (entier, nombre de demi-tons, monter d'une octave : 12, descendre d'une octave : -12) :",
+ "后处理重采样至最终采样率,0为不进行重采样": "Rééchantillonner l'audio de sortie en post-traitement à la fréquence d'échantillonnage finale. Réglez sur 0 pour ne pas effectuer de rééchantillonnage :",
+ "否": "Non",
+ "启用相位声码器": "启用相位声码器",
+ "响应阈值": "Seuil de réponse",
+ "响度因子": "Facteur de volume sonore",
+ "处理数据": "Traitement des données",
+ "导出Onnx模型": "Exporter le modèle au format ONNX.",
+ "导出文件格式": "Format de fichier d'exportation",
+ "常见问题解答": "FAQ (Foire Aux Questions)",
+ "常规设置": "Paramètres généraux",
+ "开始音频转换": "Démarrer la conversion audio.",
+ "很遗憾您这没有能用的显卡来支持您训练": "Malheureusement, il n'y a pas de GPU compatible disponible pour prendre en charge votre entrainement.",
+ "性能设置": "Paramètres de performance",
+ "总训练轮数total_epoch": "Nombre total d'époques d'entraînement (total_epoch) :",
+ "批量推理": "批量推理",
+ "批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. ": "Conversion en lot. Entrez le dossier contenant les fichiers audio à convertir ou téléchargez plusieurs fichiers audio. Les fichiers audio convertis seront enregistrés dans le dossier spécifié (par défaut : 'opt').",
+ "指定输出主人声文件夹": "Spécifiez le dossier de sortie pour les fichiers de voix :",
+ "指定输出文件夹": "Spécifiez le dossier de sortie :",
+ "指定输出非主人声文件夹": "Spécifiez le dossier de sortie pour l'accompagnement :",
+ "推理时间(ms):": "Temps d'inférence (ms) :",
+ "推理音色": "Voix pour l'inférence",
+ "提取": "Extraire",
+ "提取音高和处理数据使用的CPU进程数": "Nombre de processus CPU utilisés pour l'extraction de la hauteur et le traitement des données :",
+ "是": "Oui",
+ "是否仅保存最新的ckpt文件以节省硬盘空间": "Enregistrer uniquement le dernier fichier '.ckpt' pour économiser de l'espace disque :",
+ "是否在每次保存时间点将最终小模型保存至weights文件夹": "Enregistrer un petit modèle final dans le dossier 'weights' à chaque point de sauvegarde :",
+ "是否缓存所有训练集至显存. 10min以下小数据可缓存以加速训练, 大数据缓存会炸显存也加不了多少速": "Mettre en cache tous les ensembles d'entrainement dans la mémoire GPU. Mettre en cache de petits ensembles de données (moins de 10 minutes) peut accélérer l'entrainement, mais mettre en cache de grands ensembles de données consommera beaucoup de mémoire GPU et peut ne pas apporter beaucoup d'amélioration de vitesse :",
+ "显卡信息": "Informations sur la carte graphique (GPU)",
+ "本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责.
如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录LICENSE.": "Ce logiciel est open source sous la licence MIT. L'auteur n'a aucun contrôle sur le logiciel. Les utilisateurs qui utilisent le logiciel et distribuent les sons exportés par le logiciel en sont entièrement responsables.
Si vous n'acceptez pas cette clause, vous ne pouvez pas utiliser ou faire référence à aucun code ni fichier contenu dans le package logiciel. Consultez le fichier Agreement-LICENSE.txt dans le répertoire racine pour plus de détails.",
+ "查看": "Voir",
+ "查看模型信息(仅支持weights文件夹下提取的小模型文件)": "Afficher les informations sur le modèle (uniquement pour les petits fichiers de modèle extraits du dossier \"weights\")",
+ "检索特征占比": "Rapport de recherche de caractéristiques (contrôle l'intensité de l'accent, un rapport trop élevé provoque des artefacts) :",
+ "模型": "Modèle",
+ "模型推理": "Inférence du modèle",
+ "模型提取(输入logs文件夹下大文件模型路径),适用于训一半不想训了模型没有自动提取保存小文件模型,或者想测试中间模型的情况": "Extraction du modèle (saisissez le chemin d'accès au modèle du grand fichier dans le dossier \"logs\"). Cette fonction est utile si vous souhaitez arrêter l'entrainement à mi-chemin et extraire et enregistrer manuellement un petit fichier de modèle, ou si vous souhaitez tester un modèle intermédiaire :",
+ "模型是否带音高指导": "Indique si le modèle dispose d'un guidage en hauteur :",
+ "模型是否带音高指导(唱歌一定要, 语音可以不要)": "Indique si le modèle dispose d'un système de guidage de la hauteur (obligatoire pour le chant, facultatif pour la parole) :",
+ "模型是否带音高指导,1是0否": "Le modèle dispose-t-il d'un guide de hauteur (1 : oui, 0 : non) ?",
+ "模型版本型号": "Version de l'architecture du modèle :",
+ "模型融合, 可用于测试音色融合": "Fusion de modèles, peut être utilisée pour tester la fusion de timbres",
+ "模型路径": "Le chemin vers le modèle :",
+ "每张显卡的batch_size": "Taille du batch par GPU :",
+ "淡入淡出长度": "Longueur de la transition",
+ "版本": "Version",
+ "特征提取": "Extraction des caractéristiques",
+ "特征检索库文件路径,为空则使用下拉的选择结果": "Chemin d'accès au fichier d'index des caractéristiques. Laisser vide pour utiliser le résultat sélectionné dans la liste déroulante :",
+ "独占 WASAPI 设备": "独占 WASAPI 设备",
+ "男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Il est recommandé d'utiliser la clé +12 pour la conversion homme-femme et la clé -12 pour la conversion femme-homme. Si la plage sonore est trop large et que la voix est déformée, vous pouvez également l'ajuster vous-même à la plage appropriée.",
+ "目标采样率": "Taux d'échantillonnage cible :",
+ "算法延迟(ms):": "Délais algorithmiques (ms):",
+ "自动检测index路径,下拉式选择(dropdown)": "Détecter automatiquement le chemin d'accès à l'index et le sélectionner dans la liste déroulante :",
+ "融合": "Fusion",
+ "要改的模型信息": "Informations sur le modèle à modifier :",
+ "要置入的模型信息": "Informations sur le modèle à placer :",
+ "训练": "Entraîner",
+ "训练模型": "Entraîner le modèle",
+ "训练特征索引": "Entraîner l'index des caractéristiques",
+ "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Entraînement terminé. Vous pouvez consulter les rapports d'entraînement dans la console ou dans le fichier 'train.log' situé dans le dossier de l'expérience.",
+ "设备类型": "设备类型",
+ "请指定说话人id": "Veuillez spécifier l'ID de l'orateur ou du chanteur :",
+ "请选择index文件": "Veuillez sélectionner le fichier d'index",
+ "请选择pth文件": "Veuillez sélectionner le fichier pth",
+ "请选择说话人id": "Sélectionner l'ID de l'orateur ou du chanteur :",
+ "转换": "Convertir",
+ "输入实验名": "Saisissez le nom de l'expérience :",
+ "输入待处理音频文件夹路径": "Entrez le chemin du dossier audio à traiter :",
+ "输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)": "Entrez le chemin du dossier audio à traiter (copiez-le depuis la barre d'adresse du gestionnaire de fichiers) :",
+ "输入待处理音频文件路径(默认是正确格式示例)": "Entrez le chemin d'accès du fichier audio à traiter (par défaut, l'exemple de format correct) :",
+ "输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络": "Ajustez l'échelle de l'enveloppe de volume. Plus il est proche de 0, plus il imite le volume des voix originales. Cela peut aider à masquer les bruits et à rendre le volume plus naturel lorsqu'il est réglé relativement bas. Plus le volume est proche de 1, plus le volume sera fort et constant :",
+ "输入监听": "Moniteur vocal d'entrée",
+ "输入训练文件夹路径": "Indiquez le chemin d'accès au dossier d'entraînement :",
+ "输入设备": "Dispositif d'entrée",
+ "输入降噪": "Réduction du bruit d'entrée",
+ "输出信息": "Informations sur la sortie",
+ "输出变声": "Sortie voix convertie",
+ "输出设备": "Dispositif de sortie",
+ "输出降噪": "Réduction du bruit de sortie",
+ "输出音频(右下角三个点,点了可以下载)": "Exporter l'audio (cliquer sur les trois points dans le coin inférieur droit pour télécharger)",
+ "选择.index文件": "Sélectionner le fichier .index",
+ "选择.pth文件": "Sélectionner le fichier .pth",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "Sélection de l'algorithme d'extraction de la hauteur, les voix d'entrée peuvent être accélérées avec pm, harvest a de bonnes basses mais est très lent, crepe est bon mais consomme beaucoup de ressources GPU.",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "Sélectionnez l'algorithme d'extraction de la hauteur de ton (\"pm\" : extraction plus rapide mais parole de moindre qualité ; \"harvest\" : meilleure basse mais extrêmement lente ; \"crepe\" : meilleure qualité mais utilisation intensive du GPU), \"rmvpe\" : meilleure qualité et peu d'utilisation du GPU.",
+ "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "Sélection de l'algorithme d'extraction de la hauteur : la chanson d'entrée peut être traitée plus rapidement par pm, avec une voix de haute qualité mais un CPU médiocre, par dio, harvest est meilleur mais plus lent, rmvpe est le meilleur, mais consomme légèrement le CPU/GPU.",
+ "采样率:": "采样率:",
+ "采样长度": "Longueur de l'échantillon",
+ "重载设备列表": "Recharger la liste des dispositifs",
+ "音调设置": "Réglages de la hauteur",
+ "音频设备": "Périphérique audio",
+ "音高算法": "algorithme de détection de la hauteur",
+ "额外推理时长": "Temps d'inférence supplémentaire"
+}
diff --git a/i18n/locale/it_IT.json b/i18n/locale/it_IT.json
new file mode 100644
index 0000000000000000000000000000000000000000..deb3ff43a52737d1ba7f7670d83ecee3271a2f0f
--- /dev/null
+++ b/i18n/locale/it_IT.json
@@ -0,0 +1,138 @@
+{
+ ">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音": "Se >=3: applica il filtro mediano ai risultati del pitch raccolto. ",
+ "A模型权重": "Peso (w) per il modello A:",
+ "A模型路径": "Percorso per il modello A:",
+ "B模型路径": "Percorso per il modello B:",
+ "E:\\语音音频+标注\\米津玄师\\src": "E:\\语音音频+标注\\米津玄师\\src",
+ "F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调": "File curva F0 (opzionale). ",
+ "Index Rate": "Tasso di indice",
+ "Onnx导出": "Esporta Onnx",
+ "Onnx输出路径": "Percorso di esportazione Onnx:",
+ "RVC模型路径": "Percorso modello RVC:",
+ "ckpt处理": "Elaborazione ckpt",
+ "harvest进程数": "harvest进程数",
+ "index文件路径不可包含中文": "index文件路径不可包含中文",
+ "pth文件路径不可包含中文": "pth è un'app per il futuro",
+ "rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程": "rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程",
+ "step1: 填写实验配置. 实验数据放在logs下, 每个实验一个文件夹, 需手工输入实验名路径, 内含实验配置, 日志, 训练得到的模型文件. ": "Passaggio 1: compilare la configurazione sperimentale. ",
+ "step1:正在处理数据": "Passaggio 1: elaborazione dei dati",
+ "step2:正在提取音高&正在提取特征": "step2:正在提取音高&正在提取特征",
+ "step2a: 自动遍历训练文件夹下所有可解码成音频的文件并进行切片归一化, 在实验目录下生成2个wav文件夹; 暂时只支持单人训练. ": "Passaggio 2a: attraversa automaticamente tutti i file nella cartella di addestramento che possono essere decodificati in audio ed esegui la normalizzazione delle sezioni. ",
+ "step2b: 使用CPU提取音高(如果模型带音高), 使用GPU提取特征(选择卡号)": "Passaggio 2b: utilizzare la CPU per estrarre il tono (se il modello ha il tono), utilizzare la GPU per estrarre le caratteristiche (selezionare l'indice GPU):",
+ "step3: 填写训练设置, 开始训练模型和索引": "Passaggio 3: compilare le impostazioni di addestramento e avviare l'addestramento del modello e dell'indice",
+ "step3a:正在训练模型": "Passaggio 3a: è iniziato l'addestramento del modello",
+ "一键训练": "Addestramento con un clic",
+ "也可批量输入音频文件, 二选一, 优先读文件夹": "也可批量输入音频文件, 二选一, 优先读文件夹",
+ "人声伴奏分离批量处理, 使用UVR5模型。
合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。
模型分为三类:
1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点;
2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型;
3、去混响、去延迟模型(by FoxJoy):
(1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;
(234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。
去混响/去延迟,附:
1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;
2、MDX-Net-Dereverb模型挺慢的;
3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "Elaborazione batch per la separazione dell'accompagnamento vocale utilizzando il modello UVR5.
Esempio di un formato di percorso di cartella valido: D:\\path\\to\\input\\folder (copialo dalla barra degli indirizzi del file manager).
Il modello è suddiviso in tre categorie:
1. Conserva la voce: scegli questa opzione per l'audio senza armonie.
2. Mantieni solo la voce principale: scegli questa opzione per l'audio con armonie.
3. Modelli di de-riverbero e de-delay (di FoxJoy):
(1) MDX-Net: la scelta migliore per la rimozione del riverbero stereo ma non può rimuovere il riverbero mono;
Note di de-riverbero/de-delay:
1. Il tempo di elaborazione per il modello DeEcho-DeReverb è circa il doppio rispetto agli altri due modelli DeEcho.
2. Il modello MDX-Net-Dereverb è piuttosto lento.
3. La configurazione più pulita consigliata consiste nell'applicare prima MDX-Net e poi DeEcho-Aggressive.",
+ "以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "Inserisci gli indici GPU separati da '-', ad esempio 0-1-2 per utilizzare GPU 0, 1 e 2:",
+ "伴奏人声分离&去混响&去回声": "Separazione voce/accompagnamento",
+ "使用模型采样率": "使用模型采样率",
+ "使用设备采样率": "使用设备采样率",
+ "保存名": "Salva nome:",
+ "保存的文件名, 默认空为和源文件同名": "Salva il nome del file (predefinito: uguale al file di origine):",
+ "保存的模型名不带后缀": "Nome del modello salvato (senza estensione):",
+ "保存频率save_every_epoch": "Frequenza di salvataggio (save_every_epoch):",
+ "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果": "Proteggi le consonanti senza voce e i suoni del respiro per evitare artefatti come il tearing nella musica elettronica. ",
+ "修改": "Modificare",
+ "修改模型信息(仅支持weights文件夹下提取的小模型文件)": "Modifica le informazioni sul modello (supportato solo per i file di modello di piccole dimensioni estratti dalla cartella 'weights')",
+ "停止音频转换": "Arresta la conversione audio",
+ "全流程结束!": "Tutti i processi sono stati completati!",
+ "共振偏移": "共振偏移",
+ "刷新音色列表和索引路径": "Aggiorna l'elenco delle voci e il percorso dell'indice",
+ "加载模型": "Carica modello",
+ "加载预训练底模D路径": "Carica il percorso D del modello base pre-addestrato:",
+ "加载预训练底模G路径": "Carica il percorso G del modello base pre-addestrato:",
+ "单次推理": "单次推理",
+ "卸载音色省显存": "Scarica la voce per risparmiare memoria della GPU:",
+ "变调(整数, 半音数量, 升八度12降八度-12)": "Trasposizione (numero intero, numero di semitoni, alza di un'ottava: 12, abbassa di un'ottava: -12):",
+ "后处理重采样至最终采样率,0为不进行重采样": "Ricampiona l'audio di output in post-elaborazione alla frequenza di campionamento finale. ",
+ "否": "NO",
+ "启用相位声码器": "启用相位声码器",
+ "响应阈值": "Soglia di risposta",
+ "响度因子": "fattore di sonorità",
+ "处理数据": "Processa dati",
+ "导出Onnx模型": "Esporta modello Onnx",
+ "导出文件格式": "Formato file di esportazione",
+ "常见问题解答": "FAQ (Domande frequenti)",
+ "常规设置": "Impostazioni generali",
+ "开始音频转换": "Avvia la conversione audio",
+ "很遗憾您这没有能用的显卡来支持您训练": "Sfortunatamente, non è disponibile alcuna GPU compatibile per supportare l'addestramento.",
+ "性能设置": "Impostazioni delle prestazioni",
+ "总训练轮数total_epoch": "Epoch totali di addestramento (total_epoch):",
+ "批量推理": "批量推理",
+ "批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. ": "Conversione massiva. Inserisci il percorso della cartella che contiene i file da convertire o carica più file audio. I file convertiti finiranno nella cartella specificata. (default: opt) ",
+ "指定输出主人声文件夹": "Specifica la cartella di output per le voci:",
+ "指定输出文件夹": "Specifica la cartella di output:",
+ "指定输出非主人声文件夹": "Specificare la cartella di output per l'accompagnamento:",
+ "推理时间(ms):": "Tempo di inferenza (ms):",
+ "推理音色": "Voce di inferenza:",
+ "提取": "Estrai",
+ "提取音高和处理数据使用的CPU进程数": "Numero di processi CPU utilizzati per l'estrazione del tono e l'elaborazione dei dati:",
+ "是": "SÌ",
+ "是否仅保存最新的ckpt文件以节省硬盘空间": "Salva solo l'ultimo file '.ckpt' per risparmiare spazio su disco:",
+ "是否在每次保存时间点将最终小模型保存至weights文件夹": "Salva un piccolo modello finale nella cartella \"weights\" in ogni punto di salvataggio:",
+ "是否缓存所有训练集至显存. 10min以下小数据可缓存以加速训练, 大数据缓存会炸显存也加不了多少速": "Memorizza nella cache tutti i set di addestramento nella memoria della GPU. ",
+ "显卡信息": "Informazioni GPU",
+ "本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责.
如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录LICENSE.": "Questo software è open source con licenza MIT.
Se non si accetta questa clausola, non è possibile utilizzare o fare riferimento a codici e file all'interno del pacchetto software. Contratto-LICENZA.txt per dettagli.",
+ "查看": "Visualizzazione",
+ "查看模型信息(仅支持weights文件夹下提取的小模型文件)": "Visualizza le informazioni sul modello (supportato solo per file di modello piccoli estratti dalla cartella 'weights')",
+ "检索特征占比": "Rapporto funzionalità di ricerca (controlla la forza dell'accento, troppo alto ha artefatti):",
+ "模型": "Modello",
+ "模型推理": "Inferenza del modello",
+ "模型提取(输入logs文件夹下大文件模型路径),适用于训一半不想训了模型没有自动提取保存小文件模型,或者想测试中间模型的情况": "Estrazione del modello (inserire il percorso del modello di file di grandi dimensioni nella cartella \"logs\"). ",
+ "模型是否带音高指导": "Se il modello ha una guida del tono:",
+ "模型是否带音高指导(唱歌一定要, 语音可以不要)": "Se il modello ha una guida del tono (necessario per il canto, facoltativo per il parlato):",
+ "模型是否带音高指导,1是0否": "Se il modello ha una guida del tono (1: sì, 0: no):",
+ "模型版本型号": "Versione dell'architettura del modello:",
+ "模型融合, 可用于测试音色融合": "Model fusion, può essere utilizzato per testare la fusione timbrica",
+ "模型路径": "Percorso al modello:",
+ "每张显卡的batch_size": "Dimensione batch per GPU:",
+ "淡入淡出长度": "Lunghezza dissolvenza",
+ "版本": "Versione",
+ "特征提取": "Estrazione delle caratteristiche",
+ "特征检索库文件路径,为空则使用下拉的选择结果": "Percorso del file di indice delle caratteristiche. ",
+ "独占 WASAPI 设备": "独占 WASAPI 设备",
+ "男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Tonalità +12 consigliata per la conversione da maschio a femmina e tonalità -12 per la conversione da femmina a maschio. ",
+ "目标采样率": "Frequenza di campionamento target:",
+ "算法延迟(ms):": "算法延迟(ms):",
+ "自动检测index路径,下拉式选择(dropdown)": "Rileva automaticamente il percorso dell'indice e seleziona dal menu a tendina:",
+ "融合": "Fusione",
+ "要改的模型信息": "Informazioni sul modello da modificare:",
+ "要置入的模型信息": "Informazioni sul modello da posizionare:",
+ "训练": "Addestramento",
+ "训练模型": "Addestra modello",
+ "训练特征索引": "Addestra indice delle caratteristiche",
+ "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Addestramento completato. ",
+ "设备类型": "设备类型",
+ "请指定说话人id": "Si prega di specificare l'ID del locutore/cantante:",
+ "请选择index文件": "请选择index文件",
+ "请选择pth文件": "请选择pth 文件",
+ "请选择说话人id": "Seleziona ID locutore/cantante:",
+ "转换": "Convertire",
+ "输入实验名": "Inserisci il nome dell'esperimento:",
+ "输入待处理音频文件夹路径": "Immettere il percorso della cartella audio da elaborare:",
+ "输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)": "Immettere il percorso della cartella audio da elaborare (copiarlo dalla barra degli indirizzi del file manager):",
+ "输入待处理音频文件路径(默认是正确格式示例)": "Immettere il percorso del file audio da elaborare (l'impostazione predefinita è l'esempio di formato corretto):",
+ "输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络": "Regola il ridimensionamento dell'inviluppo del volume. ",
+ "输入监听": "输入监听",
+ "输入训练文件夹路径": "Inserisci il percorso della cartella di addestramento:",
+ "输入设备": "Dispositivo di input",
+ "输入降噪": "Riduzione del rumore in ingresso",
+ "输出信息": "Informazioni sull'uscita",
+ "输出变声": "输出变声",
+ "输出设备": "Dispositivo di uscita",
+ "输出降噪": "Riduzione del rumore in uscita",
+ "输出音频(右下角三个点,点了可以下载)": "Esporta audio (clicca sui tre puntini in basso a destra per scaricarlo)",
+ "选择.index文件": "Seleziona il file .index",
+ "选择.pth文件": "Seleziona il file .pth",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "Seleziona l'algoritmo di estrazione del tono (\"pm\": estrazione più veloce ma risultato di qualità inferiore; \"harvest\": bassi migliori ma estremamente lenti; \"crepe\": qualità migliore ma utilizzo intensivo della GPU):",
+ "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU",
+ "采样率:": "采样率:",
+ "采样长度": "Lunghezza del campione",
+ "重载设备列表": "Ricaricare l'elenco dei dispositivi",
+ "音调设置": "Impostazioni del tono",
+ "音频设备": "Dispositivo audio",
+ "音高算法": "音高算法",
+ "额外推理时长": "Tempo di inferenza extra"
+}
diff --git a/i18n/locale/ja_JP.json b/i18n/locale/ja_JP.json
new file mode 100644
index 0000000000000000000000000000000000000000..a5d03aa5e0eb2244831d9096c2eff5f630f74e02
--- /dev/null
+++ b/i18n/locale/ja_JP.json
@@ -0,0 +1,138 @@
+{
+ ">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音": ">=3 次に、harvestピッチの認識結果に対してメディアンフィルタを使用します。値はフィルター半径で、ミュートを減衰させるために使用します。",
+ "A模型权重": "Aモデルの重み",
+ "A模型路径": "Aモデルのパス",
+ "B模型路径": "Bモデルのパス",
+ "E:\\语音音频+标注\\米津玄师\\src": "E:\\语音音频+标注\\米津玄师\\src",
+ "F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调": "F0(最低共振周波数)カーブファイル(オプション、1行に1ピッチ、デフォルトのF0(最低共振周波数)とエレベーションを置き換えます。)",
+ "Index Rate": "Index Rate",
+ "Onnx导出": "Onnxエクスポート",
+ "Onnx输出路径": "Onnx出力パス",
+ "RVC模型路径": "RVCモデルパス",
+ "ckpt处理": "ckptファイルの処理",
+ "harvest进程数": "harvestプロセス数",
+ "index文件路径不可包含中文": "indexファイルのパスに漢字を含んではいけません",
+ "pth文件路径不可包含中文": "pthファイルのパスに漢字を含んではいけません",
+ "rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程": "rmvpeカード番号設定:異なるプロセスに使用するカード番号を入力する。例えば、0-0-1でカード0に2つのプロセス、カード1に1つのプロセスを実行する。",
+ "step1: 填写实验配置. 实验数据放在logs下, 每个实验一个文件夹, 需手工输入实验名路径, 内含实验配置, 日志, 训练得到的模型文件. ": "ステップ1:実験設定を入力します。実験データはlogsに保存され、各実験にはフォルダーがあります。実験名のパスを手動で入力する必要があり、実験設定、ログ、トレーニングされたモデルファイルが含まれます。",
+ "step1:正在处理数据": "step1:処理中のデータ",
+ "step2:正在提取音高&正在提取特征": "step2:ピッチ抽出と特徴抽出",
+ "step2a: 自动遍历训练文件夹下所有可解码成音频的文件并进行切片归一化, 在实验目录下生成2个wav文件夹; 暂时只支持单人训练. ": "ステップ2a: 訓練フォルダー内のすべての音声ファイルを自動的に探索し、スライスと正規化を行い、2つのwavフォルダーを実験ディレクトリに生成します。現在は一人でのトレーニングのみをサポートしています。",
+ "step2b: 使用CPU提取音高(如果模型带音高), 使用GPU提取特征(选择卡号)": "ステップ2b: CPUを使用して音高を抽出する(モデルに音高がある場合)、GPUを使用して特徴を抽出する(GPUの番号を選択する)",
+ "step3: 填写训练设置, 开始训练模型和索引": "ステップ3: トレーニング設定を入力して、モデルとインデックスのトレーニングを開始します",
+ "step3a:正在训练模型": "step3a:トレーニング中のモデル",
+ "一键训练": "ワンクリックトレーニング",
+ "也可批量输入音频文件, 二选一, 优先读文件夹": "複数のオーディオファイルをインポートすることもできます。フォルダパスが存在する場合、この入力は無視されます。",
+ "人声伴奏分离批量处理, 使用UVR5模型。
合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。
模型分为三类:
1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点;
2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型;
3、去混响、去延迟模型(by FoxJoy):
(1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;
(234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。
去混响/去延迟,附:
1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;
2、MDX-Net-Dereverb模型挺慢的;
3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "UVR5モデルを使用したボーカル伴奏の分離バッチ処理。
有効なフォルダーパスフォーマットの例: D:\\path\\to\\input\\folder (エクスプローラーのアドレスバーからコピーします)。
モデルは三つのカテゴリに分かれています:
1. ボーカルを保持: ハーモニーのないオーディオに対してこれを選択します。HP5よりもボーカルをより良く保持します。HP2とHP3の二つの内蔵モデルが含まれています。HP3は伴奏をわずかに漏らす可能性がありますが、HP2よりもわずかにボーカルをより良く保持します。
2. 主なボーカルのみを保持: ハーモニーのあるオーディオに対してこれを選択します。主なボーカルを弱める可能性があります。HP5の一つの内蔵モデルが含まれています。
3. ディリバーブとディレイモデル (by FoxJoy):
(1) MDX-Net: ステレオリバーブの除去に最適な選択肢ですが、モノリバーブは除去できません;
(234) DeEcho: ディレイ効果を除去します。AggressiveモードはNormalモードよりも徹底的に除去します。DeReverbはさらにリバーブを除去し、モノリバーブを除去することができますが、高周波のリバーブが強い内容に対しては非常に効果的ではありません。
ディリバーブ/ディレイに関する注意点:
1. DeEcho-DeReverbモデルの処理時間は、他の二つのDeEchoモデルの約二倍です。
2. MDX-Net-Dereverbモデルは非常に遅いです。
3. 推奨される最もクリーンな設定は、最初にMDX-Netを適用し、その後にDeEcho-Aggressiveを適用することです。",
+ "以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "ハイフンで区切って使用するGPUの番号を入力します。例えば0-1-2はGPU0、GPU1、GPU2を使用します",
+ "伴奏人声分离&去混响&去回声": "伴奏ボーカル分離&残響除去&エコー除去",
+ "使用模型采样率": "使用模型采样率",
+ "使用设备采样率": "使用设备采样率",
+ "保存名": "保存ファイル名",
+ "保存的文件名, 默认空为和源文件同名": "保存するファイル名、デフォルトでは空欄で元のファイル名と同じ名前になります",
+ "保存的模型名不带后缀": "拡張子のない保存するモデル名",
+ "保存频率save_every_epoch": "エポックごとの保存頻度",
+ "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果": "明確な子音と呼吸音を保護し、電子音の途切れやその他のアーティファクトを防止します。0.5でオフになります。下げると保護が強化されますが、indexの効果が低下する可能性があります。",
+ "修改": "変更",
+ "修改模型信息(仅支持weights文件夹下提取的小模型文件)": "モデル情報の修正(weightsフォルダから抽出された小さなモデルファイルのみ対応)",
+ "停止音频转换": "音声変換を停止",
+ "全流程结束!": "全工程が完了!",
+ "共振偏移": "共振偏移",
+ "刷新音色列表和索引路径": "音源リストとインデックスパスの更新",
+ "加载模型": "モデルをロード",
+ "加载预训练底模D路径": "事前学習済みのDモデルのパス",
+ "加载预训练底模G路径": "事前学習済みのGモデルのパス",
+ "单次推理": "单次推理",
+ "卸载音色省显存": "音源を削除してメモリを節約",
+ "变调(整数, 半音数量, 升八度12降八度-12)": "ピッチ変更(整数、半音数、上下オクターブ12-12)",
+ "后处理重采样至最终采样率,0为不进行重采样": "最終的なサンプリングレートへのポストプロセッシングのリサンプリング リサンプリングしない場合は0",
+ "否": "いいえ",
+ "启用相位声码器": "启用相位声码器",
+ "响应阈值": "反応閾値",
+ "响度因子": "ラウドネス係数",
+ "处理数据": "データ処理",
+ "导出Onnx模型": "Onnxに変換",
+ "导出文件格式": "エクスポート形式",
+ "常见问题解答": "よくある質問",
+ "常规设置": "一般設定",
+ "开始音频转换": "音声変換を開始",
+ "很遗憾您这没有能用的显卡来支持您训练": "トレーニングに対応したGPUが動作しないのは残念です。",
+ "性能设置": "パフォーマンス設定",
+ "总训练轮数total_epoch": "総エポック数",
+ "批量推理": "批量推理",
+ "批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. ": "一括変換、変換する音声フォルダを入力、または複数の音声ファイルをアップロードし、指定したフォルダ(デフォルトのopt)に変換した音声を出力します。",
+ "指定输出主人声文件夹": "マスターの出力音声フォルダーを指定する",
+ "指定输出文件夹": "出力フォルダを指定してください",
+ "指定输出非主人声文件夹": "マスター以外の出力音声フォルダーを指定する",
+ "推理时间(ms):": "推論時間(ms):",
+ "推理音色": "音源推論",
+ "提取": "抽出",
+ "提取音高和处理数据使用的CPU进程数": "ピッチの抽出やデータ処理に使用するCPUスレッド数",
+ "是": "はい",
+ "是否仅保存最新的ckpt文件以节省硬盘空间": "ハードディスク容量を節約するため、最新のckptファイルのみを保存しますか?",
+ "是否在每次保存时间点将最终小模型保存至weights文件夹": "各保存時点の小モデルを全部weightsフォルダに保存するかどうか",
+ "是否缓存所有训练集至显存. 10min以下小数据可缓存以加速训练, 大数据缓存会炸显存也加不了多少速": "すべてのトレーニングデータをメモリにキャッシュするかどうか。10分以下の小さなデータはキャッシュしてトレーニングを高速化できますが、大きなデータをキャッシュするとメモリが破裂し、あまり速度が上がりません。",
+ "显卡信息": "GPU情報",
+ "本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责.
如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录LICENSE.": "本ソフトウェアはMITライセンスに基づくオープンソースであり、製作者は本ソフトウェアに対していかなる責任を持ちません。本ソフトウェアの利用者および本ソフトウェアから派生した音源(成果物)を配布する者は、本ソフトウェアに対して自身で責任を負うものとします。
この条項に同意しない場合、パッケージ内のコードやファイルを使用や参照を禁じます。詳しくはLICENSEをご覧ください。",
+ "查看": "表示",
+ "查看模型信息(仅支持weights文件夹下提取的小模型文件)": "モデル情報を表示する(小さいモデルファイルはweightsフォルダーからのみサポートされています)",
+ "检索特征占比": "検索特徴率",
+ "模型": "モデル",
+ "模型推理": "モデル推論",
+ "模型提取(输入logs文件夹下大文件模型路径),适用于训一半不想训了模型没有自动提取保存小文件模型,或者想测试中间模型的情况": "モデル抽出(ログフォルダー内の大きなファイルのモデルパスを入力)、モデルを半分までトレーニングし、自動的に小さいファイルモデルを保存しなかったり、中間モデルをテストしたい場合に適用されます。",
+ "模型是否带音高指导": "モデルに音高ガイドを付けるかどうか",
+ "模型是否带音高指导(唱歌一定要, 语音可以不要)": "モデルに音高ガイドがあるかどうか(歌唱には必要ですが、音声には必要ありません)",
+ "模型是否带音高指导,1是0否": "モデルに音高ガイドを付けるかどうか、1は付ける、0は付けない",
+ "模型版本型号": "モデルのバージョン",
+ "模型融合, 可用于测试音色融合": "モデルのマージ、音源のマージテストに使用できます",
+ "模型路径": "モデルパス",
+ "每张显卡的batch_size": "GPUごとのバッチサイズ",
+ "淡入淡出长度": "フェードイン/フェードアウト長",
+ "版本": "バージョン",
+ "特征提取": "特徴抽出",
+ "特征检索库文件路径,为空则使用下拉的选择结果": "特徴検索ライブラリへのパス 空の場合はドロップダウンで選択",
+ "独占 WASAPI 设备": "独占 WASAPI 设备",
+ "男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男性から女性へは+12キーをお勧めします。女性から男性へは-12キーをお勧めします。音域が広すぎて音質が劣化した場合は、適切な音域に自分で調整してください。",
+ "目标采样率": "目標サンプリングレート",
+ "算法延迟(ms):": "算法延迟(ms):",
+ "自动检测index路径,下拉式选择(dropdown)": "インデックスパスの自動検出 ドロップダウンで選択",
+ "融合": "マージ",
+ "要改的模型信息": "変更するモデル情報",
+ "要置入的模型信息": "挿入するモデル情報",
+ "训练": "トレーニング",
+ "训练模型": "モデルのトレーニング",
+ "训练特征索引": "特徴インデックスのトレーニング",
+ "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "トレーニング終了時に、トレーニングログやフォルダ内のtrain.logを確認することができます",
+ "设备类型": "设备类型",
+ "请指定说话人id": "話者IDを指定してください",
+ "请选择index文件": "indexファイルを選択してください",
+ "请选择pth文件": "pthファイルを選択してください",
+ "请选择说话人id": "話者IDを選択してください",
+ "转换": "変換",
+ "输入实验名": "モデル名",
+ "输入待处理音频文件夹路径": "処理するオーディオファイルのフォルダパスを入力してください",
+ "输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)": "処理対象音声フォルダーのパスを入力してください(エクスプローラーのアドレスバーからコピーしてください)",
+ "输入待处理音频文件路径(默认是正确格式示例)": "処理対象音声ファイルのパスを入力してください(デフォルトは正しいフォーマットの例です)",
+ "输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络": "入力ソースの音量エンベロープと出力音量エンベロープの融合率 1に近づくほど、出力音量エンベロープの割合が高くなる",
+ "输入监听": "输入监听",
+ "输入训练文件夹路径": "トレーニング用フォルダのパスを入力してください",
+ "输入设备": "入力デバイス",
+ "输入降噪": "入力ノイズの低減",
+ "输出信息": "出力情報",
+ "输出变声": "输出变声",
+ "输出设备": "出力デバイス",
+ "输出降噪": "出力ノイズの低減",
+ "输出音频(右下角三个点,点了可以下载)": "出力音声(右下の三点をクリックしてダウンロードできます)",
+ "选择.index文件": ".indexファイルを選択",
+ "选择.pth文件": ".pthファイルを選択",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "ピッチ抽出アルゴリズムの選択、歌声はpmで高速化でき、harvestは低音が良いが信じられないほど遅く、crepeは良く動くがGPUを食います。",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "ピッチ抽出アルゴリズムの選択、歌声はpmで高速化でき、harvestは低音が良いが信じられないほど遅く、crepeは良く動くがGPUを喰います",
+ "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "ピッチ抽出アルゴリズムの選択:歌声はpmで高速化でき、入力した音声が高音質でCPUが貧弱な場合はdioで高速化でき、harvestの方が良いが遅く、rmvpeがベストだがCPU/GPUを若干食います。",
+ "采样率:": "采样率:",
+ "采样长度": "サンプル長",
+ "重载设备列表": "デバイスリストをリロードする",
+ "音调设置": "音程設定",
+ "音频设备": "オーディオデバイス",
+ "音高算法": "ピッチアルゴリズム",
+ "额外推理时长": "追加推論時間"
+}
diff --git a/i18n/locale/ko_KR.json b/i18n/locale/ko_KR.json
new file mode 100644
index 0000000000000000000000000000000000000000..dfc9140c56a7f1318f4e52bd9829bd40c851a05b
--- /dev/null
+++ b/i18n/locale/ko_KR.json
@@ -0,0 +1,138 @@
+{
+ ">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音": ">=3인 경우 harvest 피치 인식 결과에 중간값 필터 적용, 필터 반경은 값으로 지정, 사용 시 무성음 감소 가능",
+ "A模型权重": "A 모델 가중치",
+ "A模型路径": "A 모델 경로",
+ "B模型路径": "B 모델 경로",
+ "E:\\语音音频+标注\\米津玄师\\src": "E:\\음성 오디오+표시\\米津玄师\\src",
+ "F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调": "F0 곡선 파일, 선택적, 한 줄에 하나의 피치, 기본 F0 및 음높이 조절 대체",
+ "Index Rate": "인덱스 비율",
+ "Onnx导出": "Onnx 내보내기",
+ "Onnx输出路径": "Onnx 출력 경로",
+ "RVC模型路径": "RVC 모델 경로",
+ "ckpt处理": "ckpt 처리",
+ "harvest进程数": "harvest 프로세스 수",
+ "index文件路径不可包含中文": "index 파일 경로는 중국어를 포함할 수 없음",
+ "pth文件路径不可包含中文": "pth 파일 경로는 중국어를 포함할 수 없음",
+ "rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程": "rmvpe 카드 번호 설정: -로 구분된 입력 사용 카드 번호, 예: 0-0-1은 카드 0에서 2개 프로세스, 카드 1에서 1개 프로세스 실행",
+ "step1: 填写实验配置. 实验数据放在logs下, 每个实验一个文件夹, 需手工输入实验名路径, 内含实验配置, 日志, 训练得到的模型文件. ": "step1: 실험 구성 작성. 실험 데이터는 logs에 저장, 각 실험은 하나의 폴더, 수동으로 실험 이름 경로 입력 필요, 실험 구성, 로그, 훈련된 모델 파일 포함.",
+ "step1:正在处理数据": "step1: 데이터 처리 중",
+ "step2:正在提取音高&正在提取特征": "step2: 음높이 추출 & 특징 추출 중",
+ "step2a: 自动遍历训练文件夹下所有可解码成音频的文件并进行切片归一化, 在实验目录下生成2个wav文件夹; 暂时只支持单人训练. ": "step2a: 훈련 폴더 아래 모든 오디오로 디코딩 가능한 파일을 자동 순회하며 슬라이스 정규화 진행, 실험 디렉토리 아래 2개의 wav 폴더 생성; 현재 단일 사용자 훈련만 지원.",
+ "step2b: 使用CPU提取音高(如果模型带音高), 使用GPU提取特征(选择卡号)": "step2b: CPU를 사용하여 음높이 추출(모델이 음높이 포함 시), GPU를 사용하여 특징 추출(카드 번호 선택)",
+ "step3: 填写训练设置, 开始训练模型和索引": "step3: 훈련 설정 작성, 모델 및 인덱스 훈련 시작",
+ "step3a:正在训练模型": "step3a: 모델 훈련 중",
+ "一键训练": "원클릭 훈련",
+ "也可批量输入音频文件, 二选一, 优先读文件夹": "여러 오디오 파일을 일괄 입력할 수도 있음, 둘 중 하나 선택, 폴더 우선 읽기",
+ "人声伴奏分离批量处理, 使用UVR5模型。
合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。
模型分为三类:
1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点;
2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型;
3、去混响、去延迟模型(by FoxJoy):
(1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;
(234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。
去混响/去延迟,附:
1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;
2、MDX-Net-Dereverb模型挺慢的;
3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "인간 목소리와 반주 분리 배치 처리, UVR5 모델 사용.
적절한 폴더 경로 예시: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(파일 관리자 주소 표시줄에서 복사하면 됨).
모델은 세 가지 유형으로 나뉨:
1. 인간 목소리 보존: 화음이 없는 오디오에 이것을 선택, HP5보다 주된 인간 목소리 보존에 더 좋음. 내장된 HP2와 HP3 두 모델, HP3는 약간의 반주 누락 가능성이 있지만 HP2보다 주된 인간 목소리 보존이 약간 더 좋음;
2. 주된 인간 목소리만 보존: 화음이 있는 오디오에 이것을 선택, 주된 인간 목소리에 약간의 약화 가능성 있음. 내장된 HP5 모델 하나;
3. 혼효음 제거, 지연 제거 모델(by FoxJoy):
(1)MDX-Net(onnx_dereverb): 이중 채널 혼효음에는 최선의 선택, 단일 채널 혼효음은 제거할 수 없음;
(234)DeEcho: 지연 제거 효과. Aggressive는 Normal보다 더 철저하게 제거, DeReverb는 추가로 혼효음을 제거, 단일 채널 혼효음은 제거 가능하지만 고주파 중심의 판 혼효음은 완전히 제거하기 어려움.
혼효음/지연 제거, 부록:
1. DeEcho-DeReverb 모델의 처리 시간은 다른 두 개의 DeEcho 모델의 거의 2배임;
2. MDX-Net-Dereverb 모델은 상당히 느림;
3. 개인적으로 추천하는 가장 깨끗한 구성은 MDX-Net 다음에 DeEcho-Aggressive 사용.",
+ "以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "-로 구분하여 입력하는 카드 번호, 예: 0-1-2는 카드 0, 카드 1, 카드 2 사용",
+ "伴奏人声分离&去混响&去回声": "반주 인간 목소리 분리 & 혼효음 제거 & 에코 제거",
+ "使用模型采样率": "모델 샘플링 레이트 사용",
+ "使用设备采样率": "장치 샘플링 레이트 사용",
+ "保存名": "저장 이름",
+ "保存的文件名, 默认空为和源文件同名": "저장될 파일명, 기본적으로 빈 공간은 원본 파일과 동일한 이름으로",
+ "保存的模型名不带后缀": "저장된 모델명은 접미사 없음",
+ "保存频率save_every_epoch": "저장 빈도 save_every_epoch",
+ "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果": "청자음과 호흡 소리를 보호, 전자음 찢김 등의 아티팩트 방지, 0.5까지 올려서 비활성화, 낮추면 보호 강도 증가하지만 인덱스 효과 감소 가능성 있음",
+ "修改": "수정",
+ "修改模型信息(仅支持weights文件夹下提取的小模型文件)": "모델 정보 수정(오직 weights 폴더 아래에서 추출된 작은 모델 파일만 지원)",
+ "停止音频转换": "오디오 변환 중지",
+ "全流程结束!": "전체 과정 완료!",
+ "共振偏移": "共振偏移",
+ "刷新音色列表和索引路径": "음색 목록 및 인덱스 경로 새로고침",
+ "加载模型": "모델 로드",
+ "加载预训练底模D路径": "미리 훈련된 베이스 모델 D 경로 로드",
+ "加载预训练底模G路径": "미리 훈련된 베이스 모델 G 경로 로드",
+ "单次推理": "단일 추론",
+ "卸载音色省显存": "음색 언로드로 디스플레이 메모리 절약",
+ "变调(整数, 半音数量, 升八度12降八度-12)": "키 변경(정수, 반음 수, 옥타브 상승 12, 옥타브 하강 -12)",
+ "后处理重采样至最终采样率,0为不进行重采样": "후처리 재샘플링을 최종 샘플링 레이트로, 0은 재샘플링하지 않음",
+ "否": "아니오",
+ "启用相位声码器": "위상 보코더 활성화",
+ "响应阈值": "응답 임계값",
+ "响度因子": "음량 인자",
+ "处理数据": "데이터 처리",
+ "导出Onnx模型": "Onnx 모델 내보내기",
+ "导出文件格式": "내보낼 파일 형식",
+ "常见问题解答": "자주 묻는 질문",
+ "常规设置": "일반 설정",
+ "开始音频转换": "오디오 변환 시작",
+ "很遗憾您这没有能用的显卡来支持您训练": "사용 가능한 그래픽 카드가 없어 훈련을 지원할 수 없습니다",
+ "性能设置": "성능 설정",
+ "总训练轮数total_epoch": "총 훈련 라운드 수 total_epoch",
+ "批量推理": "일괄 추론",
+ "批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. ": "일괄 변환, 변환할 오디오 파일 폴더 입력 또는 여러 오디오 파일 업로드, 지정된 폴더(기본값 opt)에 변환된 오디오 출력.",
+ "指定输出主人声文件夹": "주된 목소리 출력 폴더 지정",
+ "指定输出文件夹": "출력 파일 폴더 지정",
+ "指定输出非主人声文件夹": "주된 목소리가 아닌 출력 폴더 지정",
+ "推理时间(ms):": "추론 시간(ms):",
+ "推理音色": "추론 음색",
+ "提取": "추출",
+ "提取音高和处理数据使用的CPU进程数": "음높이 추출 및 데이터 처리에 사용되는 CPU 프로세스 수",
+ "是": "예",
+ "是否仅保存最新的ckpt文件以节省硬盘空间": "디스크 공간을 절약하기 위해 최신 ckpt 파일만 저장할지 여부",
+ "是否在每次保存时间点将最终小模型保存至weights文件夹": "저장 시마다 최종 소형 모델을 weights 폴더에 저장할지 여부",
+ "是否缓存所有训练集至显存. 10min以下小数据可缓存以加速训练, 大数据缓存会炸显存也加不了多少速": "모든 훈련 세트를 VRAM에 캐시할지 여부. 10분 미만의 소량 데이터는 캐시하여 훈련 속도를 높일 수 있지만, 대량 데이터 캐시는 VRAM을 과부하시키고 속도를 크게 향상시키지 못함",
+ "显卡信息": "그래픽 카드 정보",
+ "本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责.
如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录LICENSE.": "이 소프트웨어는 MIT 라이선스로 공개되며, 저자는 소프트웨어에 대해 어떠한 통제권도 가지지 않습니다. 모든 귀책사유는 소프트웨어 사용자 및 소프트웨어에서 생성된 결과물을 사용하는 당사자에게 있습니다.
해당 조항을 인정하지 않는 경우, 소프트웨어 패키지의 어떠한 코드나 파일도 사용하거나 인용할 수 없습니다. 자세한 내용은 루트 디렉토리의 LICENSE를 참조하세요.",
+ "查看": "보기",
+ "查看模型信息(仅支持weights文件夹下提取的小模型文件)": "모델 정보 보기(오직 weights 폴더에서 추출된 소형 모델 파일만 지원)",
+ "检索特征占比": "검색 특징 비율",
+ "模型": "모델",
+ "模型推理": "모델 추론",
+ "模型提取(输入logs文件夹下大文件模型路径),适用于训一半不想训了模型没有自动提取保存小文件模型,或者想测试中间模型的情况": "모델 추출(logs 폴더 아래의 큰 파일 모델 경로 입력), 훈련 중간에 중단한 모델의 자동 추출 및 소형 파일 모델 저장이 안 되거나 중간 모델을 테스트하고 싶은 경우에 적합",
+ "模型是否带音高指导": "모델이 음높이 지도를 포함하는지 여부",
+ "模型是否带音高指导(唱歌一定要, 语音可以不要)": "모델이 음높이 지도를 포함하는지 여부(노래에는 반드시 필요, 음성에는 필요 없음)",
+ "模型是否带音高指导,1是0否": "모델이 음높이 지도를 포함하는지 여부, 1은 예, 0은 아니오",
+ "模型版本型号": "모델 버전 및 모델",
+ "模型融合, 可用于测试音色融合": "모델 융합, 음색 융합 테스트에 사용 가능",
+ "模型路径": "모델 경로",
+ "每张显卡的batch_size": "각 그래픽 카드의 batch_size",
+ "淡入淡出长度": "페이드 인/아웃 길이",
+ "版本": "버전",
+ "特征提取": "특징 추출",
+ "特征检索库文件路径,为空则使用下拉的选择结果": "특징 검색 라이브러리 파일 경로, 비어 있으면 드롭다운 선택 결과 사용",
+ "独占 WASAPI 设备": "独占 WASAPI 设备",
+ "男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "남성에서 여성으로 변경 시 +12 키 권장, 여성에서 남성으로 변경 시 -12 키 권장, 음역대 폭발로 음색이 왜곡되면 적절한 음역대로 조정 가능.",
+ "目标采样率": "목표 샘플링률",
+ "算法延迟(ms):": "알고리즘 지연(ms):",
+ "自动检测index路径,下拉式选择(dropdown)": "자동으로 index 경로 감지, 드롭다운 선택(dropdown)",
+ "融合": "융합",
+ "要改的模型信息": "변경할 모델 정보",
+ "要置入的模型信息": "삽입할 모델 정보",
+ "训练": "훈련",
+ "训练模型": "모델 훈련",
+ "训练特征索引": "특징 인덱스 훈련",
+ "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "훈련 완료, 콘솔 훈련 로그 또는 실험 폴더 내의 train.log 확인 가능",
+ "设备类型": "设备类型",
+ "请指定说话人id": "화자 ID 지정 필요",
+ "请选择index文件": "index 파일 선택",
+ "请选择pth文件": "pth 파일 선택",
+ "请选择说话人id": "화자 ID 선택",
+ "转换": "변환",
+ "输入实验名": "실험명 입력",
+ "输入待处理音频文件夹路径": "처리할 오디오 파일 폴더 경로 입력",
+ "输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)": "처리할 오디오 파일 폴더 경로 입력(파일 탐색기 주소 표시줄에서 복사)",
+ "输入待处理音频文件路径(默认是正确格式示例)": "처리할 오디오 파일 경로 입력(기본적으로 올바른 형식 예시)",
+ "输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络": "입력 소스 볼륨 엔벨로프와 출력 볼륨 엔벨로프의 결합 비율 입력, 1에 가까울수록 출력 엔벨로프 사용",
+ "输入监听": "입력 모니터링",
+ "输入训练文件夹路径": "훈련 파일 폴더 경로 입력",
+ "输入设备": "입력 장치",
+ "输入降噪": "입력 노이즈 감소",
+ "输出信息": "출력 정보",
+ "输出变声": "출력 음성 변조",
+ "输出设备": "출력 장치",
+ "输出降噪": "출력 노이즈 감소",
+ "输出音频(右下角三个点,点了可以下载)": "출력 오디오(오른쪽 하단 세 개의 점, 클릭하면 다운로드 가능)",
+ "选择.index文件": ".index 파일 선택",
+ "选择.pth文件": ".pth 파일 선택",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "음높이 추출 알고리즘 선택, 노래 입력 시 pm으로 속도 향상, harvest는 저음이 좋지만 매우 느림, crepe는 효과가 좋지만 GPU 사용",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "음높이 추출 알고리즘 선택, 노래 입력 시 pm으로 속도 향상, harvest는 저음이 좋지만 매우 느림, crepe는 효과가 좋지만 GPU 사용, rmvpe는 효과가 가장 좋으며 GPU를 적게 사용",
+ "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "음높이 추출 알고리즘 선택: 노래 입력 시 pm으로 속도 향상, 고품질 음성에는 CPU가 부족할 때 dio 사용, harvest는 품질이 더 좋지만 느림, rmvpe는 효과가 가장 좋으며 CPU/GPU를 적게 사용",
+ "采样率:": "샘플링률:",
+ "采样长度": "샘플링 길이",
+ "重载设备列表": "장치 목록 재로드",
+ "音调设置": "음조 설정",
+ "音频设备": "音频设备",
+ "音高算法": "음높이 알고리즘",
+ "额外推理时长": "추가 추론 시간"
+}
diff --git a/i18n/locale/pt_BR.json b/i18n/locale/pt_BR.json
new file mode 100644
index 0000000000000000000000000000000000000000..74b5a3baa24cd07f94303b07dc2aad6050cf98f3
--- /dev/null
+++ b/i18n/locale/pt_BR.json
@@ -0,0 +1,138 @@
+{
+ ">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音": ">=3, use o filtro mediano para o resultado do reconhecimento do tom da heverst, e o valor é o raio do filtro, que pode enfraquecer o mudo.",
+ "A模型权重": "Peso (w) para o modelo A:",
+ "A模型路径": "Caminho para o Modelo A:",
+ "B模型路径": "Caminho para o Modelo B:",
+ "E:\\语音音频+标注\\米津玄师\\src": "E:\\meu-dataset",
+ "F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调": "Arquivo de curva F0 (opcional). Um arremesso por linha. Substitui a modulação padrão F0 e tom:",
+ "Index Rate": "Taxa do Index",
+ "Onnx导出": "Exportar Onnx",
+ "Onnx输出路径": "Caminho de exportação ONNX:",
+ "RVC模型路径": "Caminho do Modelo RVC:",
+ "ckpt处理": "processamento ckpt",
+ "harvest进程数": "Número de processos harvest",
+ "index文件路径不可包含中文": "O caminho do arquivo de Index não pode conter caracteres chineses",
+ "pth文件路径不可包含中文": "o caminho do arquivo pth não pode conter caracteres chineses",
+ "rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程": "Configuração do número do cartão rmvpe: Use - para separar os números dos cartões de entrada de diferentes processos. Por exemplo, 0-0-1 é usado para executar 2 processos no cartão 0 e 1 processo no cartão 1.",
+ "step1: 填写实验配置. 实验数据放在logs下, 每个实验一个文件夹, 需手工输入实验名路径, 内含实验配置, 日志, 训练得到的模型文件. ": "Etapa 1: Preencha a configuração experimental. Os dados experimentais são armazenados na pasta 'logs', com cada experimento tendo uma pasta separada. Digite manualmente o caminho do nome do experimento, que contém a configuração experimental, os logs e os arquivos de modelo treinados.",
+ "step1:正在处理数据": "Etapa 1: Processamento de dados",
+ "step2:正在提取音高&正在提取特征": "step2:正在提取音高&正在提取特征",
+ "step2a: 自动遍历训练文件夹下所有可解码成音频的文件并进行切片归一化, 在实验目录下生成2个wav文件夹; 暂时只支持单人训练. ": "Etapa 2a: Percorra automaticamente todos os arquivos na pasta de treinamento que podem ser decodificados em áudio e execute a normalização da fatia. Gera 2 pastas wav no diretório do experimento. Atualmente, apenas o treinamento de um único cantor/palestrante é suportado.",
+ "step2b: 使用CPU提取音高(如果模型带音高), 使用GPU提取特征(选择卡号)": "Etapa 2b: Use a CPU para extrair o tom (se o modelo tiver tom), use a GPU para extrair recursos (selecione o índice da GPU):",
+ "step3: 填写训练设置, 开始训练模型和索引": "Etapa 3: Preencha as configurações de treinamento e comece a treinar o modelo e o Index",
+ "step3a:正在训练模型": "Etapa 3a: Treinamento do modelo iniciado",
+ "一键训练": "Treinamento com um clique",
+ "也可批量输入音频文件, 二选一, 优先读文件夹": "Você também pode inserir arquivos de áudio em lotes. Escolha uma das duas opções. É dada prioridade à leitura da pasta.",
+ "人声伴奏分离批量处理, 使用UVR5模型。
合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。
模型分为三类:
1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点;
2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型;
3、去混响、去延迟模型(by FoxJoy):
(1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;
(234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。
去混响/去延迟,附:
1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;
2、MDX-Net-Dereverb模型挺慢的;
3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "Processamento em lote para separação de acompanhamento vocal usando o modelo UVR5.
Exemplo de um formato de caminho de pasta válido: D:\\caminho\\para a pasta\\entrada\\ (copie-o da barra de endereços do gerenciador de arquivos).
O modelo é dividido em três categorias:
1. Preservar vocais: Escolha esta opção para áudio sem harmonias. Ele preserva os vocais melhor do que o HP5. Inclui dois modelos integrados: HP2 e HP3. O HP3 pode vazar ligeiramente o acompanhamento, mas preserva os vocais um pouco melhor do que o HP2.
2 Preservar apenas os vocais principais: Escolha esta opção para áudio com harmonias. Isso pode enfraquecer os vocais principais. Ele inclui um modelo embutido: HP5.
3. Modelos de de-reverb e de-delay (por FoxJoy):
(1) MDX-Net: A melhor escolha para remoção de reverb estéreo, mas não pode remover reverb mono;
(234) DeEcho: Remove efeitos de atraso. O modo agressivo remove mais completamente do que o modo normal. O DeReverb também remove reverb e pode remover reverb mono, mas não de forma muito eficaz para conteúdo de alta frequência fortemente reverberado.
Notas de de-reverb/de-delay:
1. O tempo de processamento para o modelo DeEcho-DeReverb é aproximadamente duas vezes maior que os outros dois modelos DeEcho.
2 O modelo MDX-Net-Dereverb é bastante lento.
3. A configuração mais limpa recomendada é aplicar MDX-Net primeiro e depois DeEcho-Aggressive.",
+ "以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "Digite o (s) índice(s) da GPU separados por '-', por exemplo, 0-1-2 para usar a GPU 0, 1 e 2:",
+ "伴奏人声分离&去混响&去回声": "UVR5",
+ "使用模型采样率": "使用模型采样率",
+ "使用设备采样率": "使用设备采样率",
+ "保存名": "Salvar nome",
+ "保存的文件名, 默认空为和源文件同名": "Salvar nome do arquivo (padrão: igual ao arquivo de origem):",
+ "保存的模型名不带后缀": "Nome do modelo salvo (sem extensão):",
+ "保存频率save_every_epoch": "Faça backup a cada # de Epoch:",
+ "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果": "Proteja consoantes sem voz e sons respiratórios, evite artefatos como quebra de som eletrônico e desligue-o quando estiver cheio de 0,5. Diminua-o para aumentar a proteção, mas pode reduzir o efeito de indexação:",
+ "修改": "Editar",
+ "修改模型信息(仅支持weights文件夹下提取的小模型文件)": "Modificar informações do modelo (suportado apenas para arquivos de modelo pequenos extraídos da pasta 'weights')",
+ "停止音频转换": "Conversão de áudio",
+ "全流程结束!": "Todos os processos foram concluídos!",
+ "共振偏移": "共振偏移",
+ "刷新音色列表和索引路径": "Atualizar lista de voz e caminho do Index",
+ "加载模型": "Modelo",
+ "加载预训练底模D路径": "Carregue o caminho D do modelo base pré-treinado:",
+ "加载预训练底模G路径": "Carregue o caminho G do modelo base pré-treinado:",
+ "单次推理": "Único",
+ "卸载音色省显存": "Descarregue a voz para liberar a memória da GPU:",
+ "变调(整数, 半音数量, 升八度12降八度-12)": "Mude o tom aqui. Se a voz for do mesmo sexo, não é necessario alterar (12 caso seja Masculino para feminino, -12 caso seja ao contrário).",
+ "后处理重采样至最终采样率,0为不进行重采样": "Reamostragem pós-processamento para a taxa de amostragem final, 0 significa sem reamostragem:",
+ "否": "Não",
+ "启用相位声码器": "启用相位声码器",
+ "响应阈值": "Limiar de resposta",
+ "响度因子": "Fator de volume",
+ "处理数据": "Processar o Conjunto de Dados",
+ "导出Onnx模型": "Exportar Modelo Onnx",
+ "导出文件格式": "Qual formato de arquivo você prefere?",
+ "常见问题解答": "FAQ (Perguntas frequentes)",
+ "常规设置": "Configurações gerais",
+ "开始音频转换": "Iniciar conversão de áudio",
+ "很遗憾您这没有能用的显卡来支持您训练": "Infelizmente, não há GPU compatível disponível para apoiar o seu treinamento.",
+ "性能设置": "Configurações de desempenho.",
+ "总训练轮数total_epoch": "Número total de ciclos(epoch) de treino (se escolher um valor alto demais, o seu modelo parecerá terrivelmente sobretreinado):",
+ "批量推理": "Conversão em Lote",
+ "批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. ": "Conversão em Massa.",
+ "指定输出主人声文件夹": "Especifique a pasta de saída para vocais:",
+ "指定输出文件夹": "Especifique a pasta de saída:",
+ "指定输出非主人声文件夹": "Informar a pasta de saída para acompanhamento:",
+ "推理时间(ms):": "Tempo de inferência (ms):",
+ "推理音色": "Escolha o seu Modelo:",
+ "提取": "Extrato",
+ "提取音高和处理数据使用的CPU进程数": "Número de processos de CPU usados para extração de tom e processamento de dados:",
+ "是": "Sim",
+ "是否仅保存最新的ckpt文件以节省硬盘空间": "Só deve salvar apenas o arquivo ckpt mais recente para economizar espaço em disco:",
+ "是否在每次保存时间点将最终小模型保存至weights文件夹": "Salve um pequeno modelo final na pasta 'weights' em cada ponto de salvamento:",
+ "是否缓存所有训练集至显存. 10min以下小数据可缓存以加速训练, 大数据缓存会炸显存也加不了多少速": "Se deve armazenar em cache todos os conjuntos de treinamento na memória de vídeo. Pequenos dados com menos de 10 minutos podem ser armazenados em cache para acelerar o treinamento, e um cache de dados grande irá explodir a memória de vídeo e não aumentar muito a velocidade:",
+ "显卡信息": "Informações da GPU",
+ "本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责.
如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录LICENSE.": "The Mangio-RVC 💻 | Tradução por Krisp e Rafael Godoy Ebert | AI HUB BRASIL
Este software é de código aberto sob a licença MIT. O autor não tem qualquer controle sobre o software. Aqueles que usam o software e divulgam os sons exportados pelo software são totalmente responsáveis.
Se você não concorda com este termo, você não pode usar ou citar nenhum código e arquivo no pacote de software. Para obter detalhes, consulte o diretório raiz O acordo a ser seguido para uso LICENSE",
+ "查看": "Visualizar",
+ "查看模型信息(仅支持weights文件夹下提取的小模型文件)": "Exibir informações do modelo (suportado apenas para arquivos de modelo pequenos extraídos da pasta 'weights')",
+ "检索特征占比": "Taxa de recurso de recuperação:",
+ "模型": "Modelo",
+ "模型推理": "Inference",
+ "模型提取(输入logs文件夹下大文件模型路径),适用于训一半不想训了模型没有自动提取保存小文件模型,或者想测试中间模型的情况": "Extração do modelo (insira o caminho do modelo de arquivo grande na pasta 'logs'). Isso é útil se você quiser interromper o treinamento no meio do caminho e extrair e salvar manualmente um arquivo de modelo pequeno, ou se quiser testar um modelo intermediário:",
+ "模型是否带音高指导": "Se o modelo tem orientação de tom:",
+ "模型是否带音高指导(唱歌一定要, 语音可以不要)": "Se o modelo tem orientação de tom (necessário para cantar, opcional para fala):",
+ "模型是否带音高指导,1是0否": "Se o modelo tem orientação de passo (1: sim, 0: não):",
+ "模型版本型号": "Versão:",
+ "模型融合, 可用于测试音色融合": "A fusão modelo, pode ser usada para testar a fusão do timbre",
+ "模型路径": "Caminho para o Modelo:",
+ "每张显卡的batch_size": "Batch Size (DEIXE COMO ESTÁ a menos que saiba o que está fazendo, no Colab pode deixar até 20!):",
+ "淡入淡出长度": "Comprimento de desvanecimento",
+ "版本": "Versão",
+ "特征提取": "Extrair Tom",
+ "特征检索库文件路径,为空则使用下拉的选择结果": "Caminho para o arquivo de Index. Deixe em branco para usar o resultado selecionado no menu debaixo:",
+ "独占 WASAPI 设备": "独占 WASAPI 设备",
+ "男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Recomendado +12 chave para conversão de homem para mulher e -12 chave para conversão de mulher para homem. Se a faixa de som for muito longe e a voz estiver distorcida, você também pode ajustá-la à faixa apropriada por conta própria.",
+ "目标采样率": "Taxa de amostragem:",
+ "算法延迟(ms):": "Atrasos algorítmicos (ms):",
+ "自动检测index路径,下拉式选择(dropdown)": "Detecte automaticamente o caminho do Index e selecione no menu suspenso:",
+ "融合": "Fusão",
+ "要改的模型信息": "Informações do modelo a ser modificado:",
+ "要置入的模型信息": "Informações do modelo a ser colocado:",
+ "训练": "Treinar",
+ "训练模型": "Treinar Modelo",
+ "训练特征索引": "Treinar Index",
+ "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Após o término do treinamento, você pode verificar o log de treinamento do console ou train.log na pasta de experimentos",
+ "设备类型": "设备类型",
+ "请指定说话人id": "Especifique o ID do locutor/cantor:",
+ "请选择index文件": "Selecione o arquivo de Index",
+ "请选择pth文件": "Selecione o arquivo pth",
+ "请选择说话人id": "Selecione Palestrantes/Cantores ID:",
+ "转换": "Converter",
+ "输入实验名": "Nome da voz:",
+ "输入待处理音频文件夹路径": "Caminho da pasta de áudio a ser processada:",
+ "输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)": "Caminho da pasta de áudio a ser processada (copie-o da barra de endereços do gerenciador de arquivos):",
+ "输入待处理音频文件路径(默认是正确格式示例)": "Caminho para o seu conjunto de dados (áudios, não zipado):",
+ "输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络": "O envelope de volume da fonte de entrada substitui a taxa de fusão do envelope de volume de saída, quanto mais próximo de 1, mais o envelope de saída é usado:",
+ "输入监听": "Monitoramento de entrada",
+ "输入训练文件夹路径": "Caminho da pasta de treinamento:",
+ "输入设备": "Dispositivo de entrada",
+ "输入降噪": "Redução de ruído de entrada",
+ "输出信息": "Informação de saída",
+ "输出变声": "Mudança de voz de saída",
+ "输出设备": "Dispositivo de saída",
+ "输出降噪": "Redução de ruído de saída",
+ "输出音频(右下角三个点,点了可以下载)": "Exportar áudio (clique nos três pontos no canto inferior direito para baixar)",
+ "选择.index文件": "Selecione o Index",
+ "选择.pth文件": "Selecione o Arquivo",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "Selecione o algoritmo de extração de tom \n'pm': extração mais rápida, mas discurso de qualidade inferior; \n'harvest': graves melhores, mas extremamente lentos; \n'harvest': melhor qualidade, mas extração mais lenta); 'crepe': melhor qualidade, mas intensivo em GPU; 'magio-crepe': melhor opção; 'RMVPE': um modelo robusto para estimativa de afinação vocal em música polifônica;",
+ "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "Selecione o algoritmo de extração de tom \n'pm': extração mais rápida, mas discurso de qualidade inferior; \n'harvest': graves melhores, mas extremamente lentos; \n'crepe': melhor qualidade (mas intensivo em GPU);\n rmvpe tem o melhor efeito e consome menos CPU/GPU.",
+ "采样率:": "采样率:",
+ "采样长度": "Comprimento da Amostra",
+ "重载设备列表": "Recarregar lista de dispositivos",
+ "音调设置": "Configurações de tom",
+ "音频设备": "音频设备",
+ "音高算法": "Algoritmo de detecção de pitch",
+ "额外推理时长": "Tempo extra de inferência"
+}
diff --git a/i18n/locale/ru_RU.json b/i18n/locale/ru_RU.json
new file mode 100644
index 0000000000000000000000000000000000000000..f75ebd1c33831da18bce6a7f920e2b9d9cd9a5e3
--- /dev/null
+++ b/i18n/locale/ru_RU.json
@@ -0,0 +1,138 @@
+{
+ ">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音": "Если значение больше 3: применить медианную фильтрацию к вытащенным тональностям. Значение контролирует радиус фильтра и может уменьшить излишнее дыхание.",
+ "A模型权重": "Весы (w) модели А:",
+ "A模型路径": "Путь к модели А:",
+ "B模型路径": "Путь к модели Б:",
+ "E:\\语音音频+标注\\米津玄师\\src": "E:\\语音音频+标注\\米津玄师\\src",
+ "F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调": "Файл дуги F0 (не обязательно). Одна тональность на каждую строчку. Заменяет обычный F0 и модуляцию тональности:",
+ "Index Rate": "Темп индекса",
+ "Onnx导出": "Экспорт ONNX",
+ "Onnx输出路径": "Путь для сохранения модели в формате ONNX:",
+ "RVC模型路径": "Путь к модели RVC:",
+ "ckpt处理": "Обработка ckpt",
+ "harvest进程数": "Количество процессор harvest",
+ "index文件路径不可包含中文": "Путь к файлу индекса",
+ "pth文件路径不可包含中文": "Путь к файлу pth",
+ "rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程": "Введите номера графических процессоров, разделенные символом «-», например, 0-0-1, чтобы запустить два процесса на GPU 0 и один процесс на GPU 1:",
+ "step1: 填写实验配置. 实验数据放在logs下, 每个实验一个文件夹, 需手工输入实验名路径, 内含实验配置, 日志, 训练得到的模型文件. ": "Шаг 1. Конфигурирование модели. Данные обучения модели сохраняются в папку 'logs', и для каждой модели создаётся отдельная папка. Введите вручную путь к настройкам для модели, в которой находятся логи и тренировочные файлы.",
+ "step1:正在处理数据": "Шаг 1. Переработка данных",
+ "step2:正在提取音高&正在提取特征": "step2:正在提取音高&正在提取特征",
+ "step2a: 自动遍历训练文件夹下所有可解码成音频的文件并进行切片归一化, 在实验目录下生成2个wav文件夹; 暂时只支持单人训练. ": "Шаг 2А. Автоматическая обработка исходных аудиозаписей для обучения и выполнение нормализации среза. Создаст 2 папки wav в папке модели. В данный момент поддерживается обучение только на одноголосных записях.",
+ "step2b: 使用CPU提取音高(如果模型带音高), 使用GPU提取特征(选择卡号)": "Шаг 2Б. Оценка и извлечение тональности в аудиофайлах с помощью процессора (если включена поддержка изменения высоты звука), извлечение черт с помощью GPU (выберите номер GPU):",
+ "step3: 填写训练设置, 开始训练模型和索引": "Шаг 3. Заполнение дополнительных настроек обучения и запуск обучения модели и индекса",
+ "step3a:正在训练模型": "Шаг 3. Запуск обучения модели",
+ "一键训练": "Обучение в одно нажатие",
+ "也可批量输入音频文件, 二选一, 优先读文件夹": "Можно также импортировать несколько аудиофайлов. Если путь к папке существует, то этот ввод игнорируется.",
+ "人声伴奏分离批量处理, 使用UVR5模型。
合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。
模型分为三类:
1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点;
2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型;
3、去混响、去延迟模型(by FoxJoy):
(1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;
(234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。
去混响/去延迟,附:
1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;
2、MDX-Net-Dereverb模型挺慢的;
3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "Пакетная обработка для разделения вокального сопровождения с использованием модели UVR5.
Пример допустимого формата пути к папке: D:\\path\\to\\input\\folder
Модель разделена на три категории:
1. Сохранить вокал: выберите этот вариант для звука без гармоний. Он сохраняет вокал лучше, чем HP5. Он включает в себя две встроенные модели: HP2 и HP3. HP3 может немного пропускать инструментал, но сохраняет вокал немного лучше, чем HP2.
2. Сохранить только основной вокал: выберите этот вариант для звука с гармониями. Это может ослабить основной вокал. Он включает одну встроенную модель: HP5.
3. Модели удаления реверберации и задержки (от FoxJoy):
(1) MDX-Net: лучший выбор для удаления стереореверберации, но он не может удалить монореверберацию;
(234) DeEcho: удаляет эффекты задержки. Агрессивный режим удаляет более тщательно, чем Нормальный режим. DeReverb дополнительно удаляет реверберацию и может удалять монореверберацию, но не очень эффективно для сильно реверберированного высокочастотного контента.
Примечания по удалению реверберации/задержки:
1. Время обработки для модели DeEcho-DeReverb примерно в два раза больше, чем для двух других моделей DeEcho.
2. Модель MDX-Net-Dereverb довольно медленная.
3. Рекомендуемая самая чистая конфигурация — сначала применить MDX-Net, а затем DeEcho-Aggressive.",
+ "以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "Введите, какие(-ую) GPU(-у) хотите использовать через '-', например 0-1-2, чтобы использовать GPU с номерами 0, 1 и 2:",
+ "伴奏人声分离&去混响&去回声": "Разделение вокала/аккомпанемента и удаление эхо",
+ "使用模型采样率": "使用模型采样率",
+ "使用设备采样率": "使用设备采样率",
+ "保存名": "Имя файла для сохранения:",
+ "保存的文件名, 默认空为和源文件同名": "Название сохранённого файла (по умолчанию: такое же, как и у входного):",
+ "保存的模型名不带后缀": "Имя файла модели для сохранения (без расширения):",
+ "保存频率save_every_epoch": "Частота сохранения (save_every_epoch):",
+ "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果": "Защитить глухие согласные и звуки дыхания для предотвращения артефактов, например, разрывания в электронной музыке. Поставьте на 0.5, чтобы выключить. Уменьшите значение для повышения защиты, но учтите, что при этом может ухудшиться точность индексирования:",
+ "修改": "Изменить",
+ "修改模型信息(仅支持weights文件夹下提取的小模型文件)": "Изменить информацию о модели (работает только с маленькими моделями, взятыми из папки 'weights')",
+ "停止音频转换": "Закончить конвертацию аудио",
+ "全流程结束!": "Все процессы завершены!",
+ "共振偏移": "共振偏移",
+ "刷新音色列表和索引路径": "Обновить список голосов и индексов",
+ "加载模型": "Загрузить модель",
+ "加载预训练底模D路径": "Путь к предварительно обученной базовой модели D:",
+ "加载预训练底模G路径": "Путь к предварительно обученной базовой модели G:",
+ "单次推理": "单次推理",
+ "卸载音色省显存": "Выгрузить модель из памяти GPU для освобождения ресурсов",
+ "变调(整数, 半音数量, 升八度12降八度-12)": "Изменить высоту голоса (укажите количество полутонов; чтобы поднять голос на октаву, выберите 12, понизить на октаву — -12):",
+ "后处理重采样至最终采样率,0为不进行重采样": "Изменить частоту дискретизации в выходном файле на финальную. Поставьте 0, чтобы ничего не изменялось:",
+ "否": "Нет",
+ "启用相位声码器": "启用相位声码器",
+ "响应阈值": "Порог ответа",
+ "响度因子": "коэффициент громкости",
+ "处理数据": "Обработать данные",
+ "导出Onnx模型": "Экспортировать модель",
+ "导出文件格式": "Формат выходных файлов",
+ "常见问题解答": "ЧаВо (часто задаваемые вопросы)",
+ "常规设置": "Основные настройки",
+ "开始音频转换": "Начать конвертацию аудио",
+ "很遗憾您这没有能用的显卡来支持您训练": "К сожалению, у вас нету графического процессора, который поддерживает обучение моделей.",
+ "性能设置": "Настройки быстроты",
+ "总训练轮数total_epoch": "Полное количество эпох (total_epoch):",
+ "批量推理": "批量推理",
+ "批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. ": "Массовое преобразование. Введите путь к папке, в которой находятся файлы для преобразования голоса или выгрузите несколько аудиофайлов. Сконвертированные файлы будут сохранены в указанной папке (по умолчанию: 'opt').",
+ "指定输出主人声文件夹": "Путь к папке для сохранения вокала:",
+ "指定输出文件夹": "Папка для результатов:",
+ "指定输出非主人声文件夹": "Путь к папке для сохранения аккомпанемента:",
+ "推理时间(ms):": "Время переработки (мс):",
+ "推理音色": "Желаемый голос:",
+ "提取": "Создать модель",
+ "提取音高和处理数据使用的CPU进程数": "Число процессов ЦП, используемое для оценки высоты голоса и обработки данных:",
+ "是": "Да",
+ "是否仅保存最新的ckpt文件以节省硬盘空间": "Сохранять только последний файл '.ckpt', чтобы сохранить место на диске:",
+ "是否在每次保存时间点将最终小模型保存至weights文件夹": "Сохранять маленькую финальную модель в папку 'weights' на каждой точке сохранения:",
+ "是否缓存所有训练集至显存. 10min以下小数据可缓存以加速训练, 大数据缓存会炸显存也加不了多少速": "Кэшировать все тренировочные сеты в видеопамять. Кэширование маленький датасетов (меньше 10 минут) может ускорить тренировку, но кэширование больших, наоборот, займёт много видеопамяти и не сильно ускорит тренировку:",
+ "显卡信息": "Информация о графических процессорах (GPUs):",
+ "本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责.
如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录LICENSE.": "Это программное обеспечение с открытым исходным кодом распространяется по лицензии MIT. Автор никак не контролирует это программное обеспечение. Пользователи, которые используют эту программу и распространяют аудиозаписи, полученные с помощью этой программы, несут полную ответственность за это. Если вы не согласны с этим, вы не можете использовать какие-либо коды и файлы в рамках этой программы или ссылаться на них. Подробнее в файле Agreement-LICENSE.txt в корневом каталоге программы.",
+ "查看": "Просмотреть информацию",
+ "查看模型信息(仅支持weights文件夹下提取的小模型文件)": "Просмотреть информацию о модели (работает только с маленькими моделями, взятыми из папки 'weights')",
+ "检索特征占比": "Соотношение поиска черт:",
+ "模型": "Модели",
+ "模型推理": "Изменение голоса",
+ "模型提取(输入logs文件夹下大文件模型路径),适用于训一半不想训了模型没有自动提取保存小文件模型,或者想测试中间模型的情况": "Создание модели из данных, полученных в процессе обучения (введите путь к большому файлу модели в папке 'logs'). Может пригодиться, если вам нужно завершить обучение и получить маленький файл готовой модели, или если вам нужно проверить недообученную модель:",
+ "模型是否带音高指导": "Поддерживает ли модель изменение высоты голоса (1: да, 0: нет):",
+ "模型是否带音高指导(唱歌一定要, 语音可以不要)": "Поддержка изменения высоты звука (обязательно для пения, необязательно для речи):",
+ "模型是否带音高指导,1是0否": "Поддерживает ли модель изменение высоты голоса (1: да, 0: нет):",
+ "模型版本型号": "Версия архитектуры модели:",
+ "模型融合, 可用于测试音色融合": "Слияние моделей, может быть использовано для проверки слияния тембра",
+ "模型路径": "Путь к папке:",
+ "每张显卡的batch_size": "Размер пачки для GPU:",
+ "淡入淡出长度": "Длина затухания",
+ "版本": "Версия архитектуры модели:",
+ "特征提取": "Извлечь черты",
+ "特征检索库文件路径,为空则使用下拉的选择结果": "Путь к файлу индекса черт. Оставьте пустым, чтобы использовать выбранный вариант из списка ниже:",
+ "独占 WASAPI 设备": "独占 WASAPI 设备",
+ "男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Рекомендуется выбрать +12 для конвертирования мужского голоса в женский и -12 для конвертирования женского в мужской. Если диапазон голоса слишком велик, и голос искажается, можно выбрать значение на свой вкус.",
+ "目标采样率": "Частота дискретизации аудио:",
+ "算法延迟(ms):": "算法延迟(ms):",
+ "自动检测index路径,下拉式选择(dropdown)": "Автоматически найденные файлы индексов черт (выберите вариант из списка):",
+ "融合": "Запустить слияние",
+ "要改的模型信息": "Информация, которая будет изменена:",
+ "要置入的模型信息": "Информация о модели:",
+ "训练": "Обучение модели",
+ "训练模型": "Обучить модель",
+ "训练特征索引": "Обучить индекс черт",
+ "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Обучение модели завершено. Журнал обучения можно просмотреть в консоли или в файле 'train.log' в папке с моделью.",
+ "设备类型": "设备类型",
+ "请指定说话人id": "Номер говорящего/поющего:",
+ "请选择index文件": "Пожалуйста, выберите файл индекса",
+ "请选择pth文件": "Пожалуйста, выберите файл pth",
+ "请选择说话人id": "Номер говорящего:",
+ "转换": "Преобразовать",
+ "输入实验名": "Название модели:",
+ "输入待处理音频文件夹路径": "Путь к папке с аудиофайлами для обработки:",
+ "输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)": "Путь к папке с аудиофайлами для переработки (можно скопировать путь из адресной строки файлового менеджера):",
+ "输入待处理音频文件路径(默认是正确格式示例)": "Путь к аудиофайлу, который хотите обработать (ниже указан пример пути к файлу):",
+ "输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络": "Использовать громкость входного файла для замены или перемешивания с громкостью выходного файла. Чем ближе соотношение к 1, тем больше используется звука из выходного файла:",
+ "输入监听": "输入监听",
+ "输入训练文件夹路径": "Путь к папке с аудиозаписями, на которых будет обучаться модель:",
+ "输入设备": "Входное устройство",
+ "输入降噪": "Уменьшение входного шума",
+ "输出信息": "Статистика",
+ "输出变声": "输出变声",
+ "输出设备": "Выходное устройство",
+ "输出降噪": "Уменьшение выходного шума",
+ "输出音频(右下角三个点,点了可以下载)": "Аудиофайл (чтобы скачать, нажмите на три точки справа в плеере)",
+ "选择.index文件": "Выбрать файл .index",
+ "选择.pth文件": "Выбрать файл .pth",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "Выберите алгоритм оценки высоты голоса ('pm': работает быстро, но даёт низкое качество речи; 'harvest': басы лучше, но работает очень медленно; 'crepe': лучшее качество, но сильно нагружает GPU; 'rmvpe': лучшее качество и минимальная нагрузка на GPU):",
+ "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU",
+ "采样率:": "采样率:",
+ "采样长度": "Длина сэмпла",
+ "重载设备列表": "Обновить список устройств",
+ "音调设置": "Настройка высоты звука",
+ "音频设备": "Аудиоустройство",
+ "音高算法": "Алгоритм оценки высоты звука",
+ "额外推理时长": "Доп. время переработки"
+}
diff --git a/i18n/locale/tr_TR.json b/i18n/locale/tr_TR.json
new file mode 100644
index 0000000000000000000000000000000000000000..e81eca4f4154457e1bb89a9365b6e0c2d42f8a41
--- /dev/null
+++ b/i18n/locale/tr_TR.json
@@ -0,0 +1,138 @@
+{
+ ">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音": "Eğer >=3 ise, elde edilen pitch sonuçlarına median filtreleme uygula. Bu değer, filtre yarıçapını temsil eder ve nefesliliği azaltabilir.",
+ "A模型权重": "A Modeli Ağırlığı:",
+ "A模型路径": "A Modeli Yolu:",
+ "B模型路径": "B Modeli Yolu:",
+ "E:\\语音音频+标注\\米津玄师\\src": "E:\\语音音频+标注\\米津玄师\\src",
+ "F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调": "F0 eğrisi dosyası (isteğe bağlı). Her satırda bir pitch değeri bulunur. Varsayılan F0 ve pitch modülasyonunu değiştirir:",
+ "Index Rate": "Index Oranı",
+ "Onnx导出": "Onnx Dışa Aktar",
+ "Onnx输出路径": "Onnx Dışa Aktarım Yolu:",
+ "RVC模型路径": "RVC Model Yolu:",
+ "ckpt处理": "ckpt İşleme",
+ "harvest进程数": "harvest进程数",
+ "index文件路径不可包含中文": ".index dosya yolu Çince karakter içeremez",
+ "pth文件路径不可包含中文": ".pth dosya yolu Çince karakter içeremez",
+ "rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程": "rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程",
+ "step1: 填写实验配置. 实验数据放在logs下, 每个实验一个文件夹, 需手工输入实验名路径, 内含实验配置, 日志, 训练得到的模型文件. ": "Adım 1: Deneysel yapılandırmayı doldurun. Deneysel veriler 'logs' klasöründe saklanır ve her bir deney için ayrı bir klasör vardır. Deneysel adı yolu manuel olarak girin; bu yol, deneysel yapılandırmayı, günlükleri ve eğitilmiş model dosyalarını içerir.",
+ "step1:正在处理数据": "Adım 1: Veri işleme",
+ "step2:正在提取音高&正在提取特征": "step2:正在提取音高&正在提取特征",
+ "step2a: 自动遍历训练文件夹下所有可解码成音频的文件并进行切片归一化, 在实验目录下生成2个wav文件夹; 暂时只支持单人训练. ": "Adım 2a: Eğitim klasöründe ses dosyalarını otomatik olarak gezinerek dilimleme normalizasyonu yapın. Deney dizini içinde 2 wav klasörü oluşturur. Şu anda sadece tek kişilik eğitim desteklenmektedir.",
+ "step2b: 使用CPU提取音高(如果模型带音高), 使用GPU提取特征(选择卡号)": "Adım 2b: Ses yüksekliği (Pitch) çıkartmak için CPU kullanın (eğer model ses yüksekliği içeriyorsa), özellikleri çıkartmak için GPU kullanın (GPU indeksini seçin):",
+ "step3: 填写训练设置, 开始训练模型和索引": "Adım 3: Eğitim ayarlarını doldurun ve modeli ve dizini eğitmeye başlayın",
+ "step3a:正在训练模型": "Adım 3a: Model eğitimi başladı",
+ "一键训练": "Tek Tuşla Eğit",
+ "也可批量输入音频文件, 二选一, 优先读文件夹": "Ses dosyaları ayrıca toplu olarak, iki seçimle, öncelikli okuma klasörüyle içe aktarılabilir",
+ "人声伴奏分离批量处理, 使用UVR5模型。
合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。
模型分为三类:
1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点;
2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型;
3、去混响、去延迟模型(by FoxJoy):
(1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;
(234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。
去混响/去延迟,附:
1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;
2、MDX-Net-Dereverb模型挺慢的;
3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "Batch işleme kullanarak vokal eşlik ayrımı için UVR5 modeli kullanılır.
Geçerli bir klasör yol formatı örneği: D:\\path\\to\\input\\folder (dosya yöneticisi adres çubuğundan kopyalanır).
Model üç kategoriye ayrılır:
1. Vokalleri koru: Bu seçeneği, harmoni içermeyen sesler için kullanın. HP5'ten daha iyi bir şekilde vokalleri korur. İki dahili model içerir: HP2 ve HP3. HP3, eşlik sesini hafifçe sızdırabilir, ancak vokalleri HP2'den biraz daha iyi korur.
2. Sadece ana vokalleri koru: Bu seçeneği, harmoni içeren sesler için kullanın. Ana vokalleri zayıflatabilir. Bir dahili model içerir: HP5.
3. Reverb ve gecikme modelleri (FoxJoy tarafından):
(1) MDX-Net: Stereo reverb'i kaldırmak için en iyi seçenek, ancak mono reverb'i kaldıramaz;
(234) DeEcho: Gecikme efektlerini kaldırır. Agresif mod, Normal moda göre daha kapsamlı bir şekilde kaldırma yapar. DeReverb ayrıca reverb'i kaldırır ve mono reverb'i kaldırabilir, ancak yoğun yankılı yüksek frekanslı içerikler için çok etkili değildir.
Reverb/gecikme notları:
1. DeEcho-DeReverb modelinin işleme süresi diğer iki DeEcho modeline göre yaklaşık olarak iki kat daha uzundur.
2. MDX-Net-Dereverb modeli oldukça yavaştır.
3. Tavsiye edilen en temiz yapılandırma önce MDX-Net'i uygulamak ve ardından DeEcho-Aggressive uygulamaktır.",
+ "以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "GPU indekslerini '-' ile ayırarak girin, örneğin 0-1-2, GPU 0, 1 ve 2'yi kullanmak için:",
+ "伴奏人声分离&去混响&去回声": "Vokal/Müzik Ayrıştırma ve Yankı Giderme",
+ "使用模型采样率": "使用模型采样率",
+ "使用设备采样率": "使用设备采样率",
+ "保存名": "Kaydetme Adı:",
+ "保存的文件名, 默认空为和源文件同名": "Kaydedilecek dosya adı (varsayılan: kaynak dosya ile aynı):",
+ "保存的模型名不带后缀": "Kaydedilecek model adı (uzantı olmadan):",
+ "保存频率save_every_epoch": "Kaydetme sıklığı (save_every_epoch):",
+ "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果": "Sessiz ünsüzleri ve nefes seslerini koruyarak elektronik müzikte yırtılma gibi sanal hataların oluşmasını engeller. 0.5 olarak ayarlandığında devre dışı kalır. Değerin azaltılması korumayı artırabilir, ancak indeksleme doğruluğunu azaltabilir:",
+ "修改": "Düzenle",
+ "修改模型信息(仅支持weights文件夹下提取的小模型文件)": "Model bilgilerini düzenle (sadece 'weights' klasöründen çıkarılan küçük model dosyaları desteklenir)",
+ "停止音频转换": "Ses dönüştürmeyi durdur",
+ "全流程结束!": "Tüm işlemler tamamlandı!",
+ "共振偏移": "共振偏移",
+ "刷新音色列表和索引路径": "Ses listesini ve indeks yolunu yenile",
+ "加载模型": "Model yükle",
+ "加载预训练底模D路径": "Önceden eğitilmiş temel D modelini yükleme yolu:",
+ "加载预训练底模G路径": "Önceden eğitilmiş temel G modelini yükleme yolu:",
+ "单次推理": "单次推理",
+ "卸载音色省显存": "GPU bellek kullanımını azaltmak için sesi kaldır",
+ "变调(整数, 半音数量, 升八度12降八度-12)": "Transpoze et (tamsayı, yarıton sayısıyla; bir oktav yükseltmek için: 12, bir oktav düşürmek için: -12):",
+ "后处理重采样至最终采样率,0为不进行重采样": "Son işleme aşamasında çıktı sesini son örnekleme hızına yeniden örnekle. 0 değeri için yeniden örnekleme yapılmaz:",
+ "否": "Hayır",
+ "启用相位声码器": "启用相位声码器",
+ "响应阈值": "Tepki eşiği",
+ "响度因子": "ses yüksekliği faktörü",
+ "处理数据": "Verileri işle",
+ "导出Onnx模型": "Onnx Modeli Dışa Aktar",
+ "导出文件格式": "Dışa aktarma dosya formatı",
+ "常见问题解答": "Sıkça Sorulan Sorular (SSS)",
+ "常规设置": "Genel ayarlar",
+ "开始音频转换": "Ses dönüştürmeyi başlat",
+ "很遗憾您这没有能用的显卡来支持您训练": "Maalesef, eğitiminizi desteklemek için uyumlu bir GPU bulunmamaktadır.",
+ "性能设置": "Performans ayarları",
+ "总训练轮数total_epoch": "Toplam eğitim turu (total_epoch):",
+ "批量推理": "批量推理",
+ "批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. ": "Toplu dönüştür. Dönüştürülecek ses dosyalarının bulunduğu klasörü girin veya birden çok ses dosyasını yükleyin. Dönüştürülen ses dosyaları belirtilen klasöre ('opt' varsayılan olarak) dönüştürülecektir",
+ "指定输出主人声文件夹": "Vokal için çıkış klasörünü belirtin:",
+ "指定输出文件夹": "Çıkış klasörünü belirt:",
+ "指定输出非主人声文件夹": "Müzik ve diğer sesler için çıkış klasörünü belirtin:",
+ "推理时间(ms):": "Çıkarsama süresi (ms):",
+ "推理音色": "Ses çıkartma (Inference):",
+ "提取": "Çıkart",
+ "提取音高和处理数据使用的CPU进程数": "Ses yüksekliği çıkartmak (Pitch) ve verileri işlemek için kullanılacak CPU işlemci sayısı:",
+ "是": "Evet",
+ "是否仅保存最新的ckpt文件以节省硬盘空间": "Sadece en son '.ckpt' dosyasını kaydet:",
+ "是否在每次保存时间点将最终小模型保存至weights文件夹": "Her kaydetme noktasında son küçük bir modeli 'weights' klasörüne kaydetmek için:",
+ "是否缓存所有训练集至显存. 10min以下小数据可缓存以加速训练, 大数据缓存会炸显存也加不了多少速": "Tüm eğitim verilerini GPU belleğine önbelleğe alıp almayacağınızı belirtin. Küçük veri setlerini (10 dakikadan az) önbelleğe almak eğitimi hızlandırabilir, ancak büyük veri setlerini önbelleğe almak çok fazla GPU belleği tüketir ve çok fazla hız artışı sağlamaz:",
+ "显卡信息": "GPU Bilgisi",
+ "本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责.
如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录LICENSE.": "Bu yazılım, MIT lisansı altında açık kaynaklıdır. Yazarın yazılım üzerinde herhangi bir kontrolü yoktur. Yazılımı kullanan ve yazılım tarafından dışa aktarılan sesleri dağıtan kullanıcılar sorumludur.
Eğer bu maddeyle aynı fikirde değilseniz, yazılım paketi içindeki herhangi bir kod veya dosyayı kullanamaz veya referans göremezsiniz. Detaylar için kök dizindeki Agreement-LICENSE.txt dosyasına bakınız.",
+ "查看": "Görüntüle",
+ "查看模型信息(仅支持weights文件夹下提取的小模型文件)": "Model bilgilerini görüntüle (sadece 'weights' klasöründen çıkarılan küçük model dosyaları desteklenir)",
+ "检索特征占比": "Arama özelliği oranı (vurgu gücünü kontrol eder, çok yüksek olması sanal etkilere neden olur)",
+ "模型": "Model",
+ "模型推理": "Model çıkartma (Inference)",
+ "模型提取(输入logs文件夹下大文件模型路径),适用于训一半不想训了模型没有自动提取保存小文件模型,或者想测试中间模型的情况": "Model çıkartma (büyük dosya modeli yolunu 'logs' klasöründe girin). Bu, eğitimi yarıda bırakmak istediğinizde ve manuel olarak küçük bir model dosyası çıkartmak ve kaydetmek istediğinizde veya bir ara modeli test etmek istediğinizde kullanışlıdır:",
+ "模型是否带音高指导": "Modelin ses yüksekliği rehberi içerip içermediği:",
+ "模型是否带音高指导(唱歌一定要, 语音可以不要)": "Modelin ses yüksekliği (Pitch) rehberliği içerip içermediği (şarkı söyleme için şarttır, konuşma için isteğe bağlıdır):",
+ "模型是否带音高指导,1是0否": "Modelin ses yüksekliği rehberi içerip içermediği (1: evet, 0: hayır):",
+ "模型版本型号": "Model mimari versiyonu:",
+ "模型融合, 可用于测试音色融合": "Model birleştirme, ses rengi birleştirmesi için kullanılabilir",
+ "模型路径": "Model Yolu:",
+ "每张显卡的batch_size": "Her GPU için yığın boyutu (batch_size):",
+ "淡入淡出长度": "Geçiş (Fade) uzunluğu",
+ "版本": "Sürüm",
+ "特征提取": "Özellik çıkartma",
+ "特征检索库文件路径,为空则使用下拉的选择结果": "Özellik indeksi dosyasının yolunu belirtin. Seçilen sonucu kullanmak için boş bırakın veya açılır menüden seçim yapın.",
+ "独占 WASAPI 设备": "独占 WASAPI 设备",
+ "男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Erkekten kadına çevirmek için +12 tuş önerilir, kadından erkeğe çevirmek için ise -12 tuş önerilir. Eğer ses aralığı çok fazla genişler ve ses bozulursa, isteğe bağlı olarak uygun aralığa kendiniz de ayarlayabilirsiniz.",
+ "目标采样率": "Hedef örnekleme oranı:",
+ "算法延迟(ms):": "算法延迟(ms):",
+ "自动检测index路径,下拉式选择(dropdown)": "İndeks yolunu otomatik olarak tespit et ve açılır menüden seçim yap.",
+ "融合": "Birleştir",
+ "要改的模型信息": "Düzenlenecek model bilgileri:",
+ "要置入的模型信息": "Eklemek için model bilgileri:",
+ "训练": "Eğitim",
+ "训练模型": "Modeli Eğit",
+ "训练特征索引": "Özellik Dizinini Eğit",
+ "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Eğitim tamamlandı. Eğitim günlüklerini konsolda veya deney klasörü altındaki train.log dosyasında kontrol edebilirsiniz.",
+ "设备类型": "设备类型",
+ "请指定说话人id": "Lütfen konuşmacı/sanatçı no belirtin:",
+ "请选择index文件": "Lütfen .index dosyası seçin",
+ "请选择pth文件": "Lütfen .pth dosyası seçin",
+ "请选择说话人id": "Konuşmacı/Şarkıcı No seçin:",
+ "转换": "Dönüştür",
+ "输入实验名": "Deneysel adı girin:",
+ "输入待处理音频文件夹路径": "İşlenecek ses klasörünün yolunu girin:",
+ "输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)": "İşlenecek ses klasörünün yolunu girin (dosya yöneticisinin adres çubuğundan kopyalayın):",
+ "输入待处理音频文件路径(默认是正确格式示例)": "İşlenecek ses dosyasının yolunu girin (varsayılan doğru format örneğidir):",
+ "输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络": "Sesin hacim zarfını ayarlayın. 0'a yakın değerler, sesin orijinal vokallerin hacmine benzer olmasını sağlar. Düşük bir değerle ses gürültüsünü maskeleyebilir ve hacmi daha doğal bir şekilde duyulabilir hale getirebilirsiniz. 1'e yaklaştıkça sürekli bir yüksek ses seviyesi elde edilir:",
+ "输入监听": "输入监听",
+ "输入训练文件夹路径": "Eğitim klasörünün yolunu girin:",
+ "输入设备": "Giriş cihazı",
+ "输入降噪": "Giriş gürültü azaltma",
+ "输出信息": "Çıkış bilgisi",
+ "输出变声": "输出变声",
+ "输出设备": "Çıkış cihazı",
+ "输出降噪": "Çıkış gürültü azaltma",
+ "输出音频(右下角三个点,点了可以下载)": "Ses dosyasını dışa aktar (indirmek için sağ alt köşedeki üç noktaya tıklayın)",
+ "选择.index文件": ".index dosyası seç",
+ "选择.pth文件": ".pth dosyası seç",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "Pitch algoritmasını seçin ('pm': daha hızlı çıkarır ancak daha düşük kaliteli konuşma; 'harvest': daha iyi konuşma sesi ancak son derece yavaş; 'crepe': daha da iyi kalite ancak GPU yoğunluğu gerektirir):",
+ "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU",
+ "采样率:": "采样率:",
+ "采样长度": "Örnekleme uzunluğu",
+ "重载设备列表": "Cihaz listesini yeniden yükle",
+ "音调设置": "Pitch ayarları",
+ "音频设备": "Ses cihazı",
+ "音高算法": "音高算法",
+ "额外推理时长": "Ekstra çıkartma süresi"
+}
diff --git a/i18n/locale/zh_CN.json b/i18n/locale/zh_CN.json
new file mode 100644
index 0000000000000000000000000000000000000000..8d847602f89e0c2c5a44d7945be270ca8ed1f7c7
--- /dev/null
+++ b/i18n/locale/zh_CN.json
@@ -0,0 +1,138 @@
+{
+ ">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音": ">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音",
+ "A模型权重": "A模型权重",
+ "A模型路径": "A模型路径",
+ "B模型路径": "B模型路径",
+ "E:\\语音音频+标注\\米津玄师\\src": "E:\\语音音频+标注\\米津玄师\\src",
+ "F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调": "F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调",
+ "Index Rate": "Index Rate",
+ "Onnx导出": "Onnx导出",
+ "Onnx输出路径": "Onnx输出路径",
+ "RVC模型路径": "RVC模型路径",
+ "ckpt处理": "ckpt处理",
+ "harvest进程数": "harvest进程数",
+ "index文件路径不可包含中文": "index文件路径不可包含中文",
+ "pth文件路径不可包含中文": "pth文件路径不可包含中文",
+ "rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程": "rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程",
+ "step1: 填写实验配置. 实验数据放在logs下, 每个实验一个文件夹, 需手工输入实验名路径, 内含实验配置, 日志, 训练得到的模型文件. ": "step1: 填写实验配置. 实验数据放在logs下, 每个实验一个文件夹, 需手工输入实验名路径, 内含实验配置, 日志, 训练得到的模型文件. ",
+ "step1:正在处理数据": "step1:正在处理数据",
+ "step2:正在提取音高&正在提取特征": "step2:正在提取音高&正在提取特征",
+ "step2a: 自动遍历训练文件夹下所有可解码成音频的文件并进行切片归一化, 在实验目录下生成2个wav文件夹; 暂时只支持单人训练. ": "step2a: 自动遍历训练文件夹下所有可解码成音频的文件并进行切片归一化, 在实验目录下生成2个wav文件夹; 暂时只支持单人训练. ",
+ "step2b: 使用CPU提取音高(如果模型带音高), 使用GPU提取特征(选择卡号)": "step2b: 使用CPU提取音高(如果模型带音高), 使用GPU提取特征(选择卡号)",
+ "step3: 填写训练设置, 开始训练模型和索引": "step3: 填写训练设置, 开始训练模型和索引",
+ "step3a:正在训练模型": "step3a:正在训练模型",
+ "一键训练": "一键训练",
+ "也可批量输入音频文件, 二选一, 优先读文件夹": "也可批量输入音频文件, 二选一, 优先读文件夹",
+ "人声伴奏分离批量处理, 使用UVR5模型。
合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。
模型分为三类:
1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点;
2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型;
3、去混响、去延迟模型(by FoxJoy):
(1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;
(234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。
去混响/去延迟,附:
1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;
2、MDX-Net-Dereverb模型挺慢的;
3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "人声伴奏分离批量处理, 使用UVR5模型。
合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。
模型分为三类:
1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点;
2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型;
3、去混响、去延迟模型(by FoxJoy):
(1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;
(234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。
去混响/去延迟,附:
1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;
2、MDX-Net-Dereverb模型挺慢的;
3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。",
+ "以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2",
+ "伴奏人声分离&去混响&去回声": "伴奏人声分离&去混响&去回声",
+ "使用模型采样率": "使用模型采样率",
+ "使用设备采样率": "使用设备采样率",
+ "保存名": "保存名",
+ "保存的文件名, 默认空为和源文件同名": "保存的文件名, 默认空为和源文件同名",
+ "保存的模型名不带后缀": "保存的模型名不带后缀",
+ "保存频率save_every_epoch": "保存频率save_every_epoch",
+ "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果": "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果",
+ "修改": "修改",
+ "修改模型信息(仅支持weights文件夹下提取的小模型文件)": "修改模型信息(仅支持weights文件夹下提取的小模型文件)",
+ "停止音频转换": "停止音频转换",
+ "全流程结束!": "全流程结束!",
+ "共振偏移": "共振偏移",
+ "刷新音色列表和索引路径": "刷新音色列表和索引路径",
+ "加载模型": "加载模型",
+ "加载预训练底模D路径": "加载预训练底模D路径",
+ "加载预训练底模G路径": "加载预训练底模G路径",
+ "单次推理": "单次推理",
+ "卸载音色省显存": "卸载音色省显存",
+ "变调(整数, 半音数量, 升八度12降八度-12)": "变调(整数, 半音数量, 升八度12降八度-12)",
+ "后处理重采样至最终采样率,0为不进行重采样": "后处理重采样至最终采样率,0为不进行重采样",
+ "否": "否",
+ "启用相位声码器": "启用相位声码器",
+ "响应阈值": "响应阈值",
+ "响度因子": "响度因子",
+ "处理数据": "处理数据",
+ "导出Onnx模型": "导出Onnx模型",
+ "导出文件格式": "导出文件格式",
+ "常见问题解答": "常见问题解答",
+ "常规设置": "常规设置",
+ "开始音频转换": "开始音频转换",
+ "很遗憾您这没有能用的显卡来支持您训练": "很遗憾您这没有能用的显卡来支持您训练",
+ "性能设置": "性能设置",
+ "总训练轮数total_epoch": "总训练轮数total_epoch",
+ "批量推理": "批量推理",
+ "批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. ": "批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. ",
+ "指定输出主人声文件夹": "指定输出主人声文件夹",
+ "指定输出文件夹": "指定输出文件夹",
+ "指定输出非主人声文件夹": "指定输出非主人声文件夹",
+ "推理时间(ms):": "推理时间(ms):",
+ "推理音色": "推理音色",
+ "提取": "提取",
+ "提取音高和处理数据使用的CPU进程数": "提取音高和处理数据使用的CPU进程数",
+ "是": "是",
+ "是否仅保存最新的ckpt文件以节省硬盘空间": "是否仅保存最新的ckpt文件以节省硬盘空间",
+ "是否在每次保存时间点将最终小模型保存至weights文件夹": "是否在每次保存时间点将最终小模型保存至weights文件夹",
+ "是否缓存所有训练集至显存. 10min以下小数据可缓存以加速训练, 大数据缓存会炸显存也加不了多少速": "是否缓存所有训练集至显存. 10min以下小数据可缓存以加速训练, 大数据缓存会炸显存也加不了多少速",
+ "显卡信息": "显卡信息",
+ "本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责.
如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录LICENSE.": "本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责.
如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录LICENSE.",
+ "查看": "查看",
+ "查看模型信息(仅支持weights文件夹下提取的小模型文件)": "查看模型信息(仅支持weights文件夹下提取的小模型文件)",
+ "检索特征占比": "检索特征占比",
+ "模型": "模型",
+ "模型推理": "模型推理",
+ "模型提取(输入logs文件夹下大文件模型路径),适用于训一半不想训了模型没有自动提取保存小文件模型,或者想测试中间模型的情况": "模型提取(输入logs文件夹下大文件模型路径),适用于训一半不想训了模型没有自动提取保存小文件模型,或者想测试中间模型的情况",
+ "模型是否带音高指导": "模型是否带音高指导",
+ "模型是否带音高指导(唱歌一定要, 语音可以不要)": "模型是否带音高指导(唱歌一定要, 语音可以不要)",
+ "模型是否带音高指导,1是0否": "模型是否带音高指导,1是0否",
+ "模型版本型号": "模型版本型号",
+ "模型融合, 可用于测试音色融合": "模型融合, 可用于测试音色融合",
+ "模型路径": "模型路径",
+ "每张显卡的batch_size": "每张显卡的batch_size",
+ "淡入淡出长度": "淡入淡出长度",
+ "版本": "版本",
+ "特征提取": "特征提取",
+ "特征检索库文件路径,为空则使用下拉的选择结果": "特征检索库文件路径,为空则使用下拉的选择结果",
+ "独占 WASAPI 设备": "独占 WASAPI 设备",
+ "男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ",
+ "目标采样率": "目标采样率",
+ "算法延迟(ms):": "算法延迟(ms):",
+ "自动检测index路径,下拉式选择(dropdown)": "自动检测index路径,下拉式选择(dropdown)",
+ "融合": "融合",
+ "要改的模型信息": "要改的模型信息",
+ "要置入的模型信息": "要置入的模型信息",
+ "训练": "训练",
+ "训练模型": "训练模型",
+ "训练特征索引": "训练特征索引",
+ "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log",
+ "设备类型": "设备类型",
+ "请指定说话人id": "请指定说话人id",
+ "请选择index文件": "请选择index文件",
+ "请选择pth文件": "请选择pth文件",
+ "请选择说话人id": "请选择说话人id",
+ "转换": "转换",
+ "输入实验名": "输入实验名",
+ "输入待处理音频文件夹路径": "输入待处理音频文件夹路径",
+ "输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)": "输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)",
+ "输入待处理音频文件路径(默认是正确格式示例)": "输入待处理音频文件路径(默认是正确格式示例)",
+ "输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络": "输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络",
+ "输入监听": "输入监听",
+ "输入训练文件夹路径": "输入训练文件夹路径",
+ "输入设备": "输入设备",
+ "输入降噪": "输入降噪",
+ "输出信息": "输出信息",
+ "输出变声": "输出变声",
+ "输出设备": "输出设备",
+ "输出降噪": "输出降噪",
+ "输出音频(右下角三个点,点了可以下载)": "输出音频(右下角三个点,点了可以下载)",
+ "选择.index文件": "选择.index文件",
+ "选择.pth文件": "选择.pth文件",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU",
+ "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU",
+ "采样率:": "采样率:",
+ "采样长度": "采样长度",
+ "重载设备列表": "重载设备列表",
+ "音调设置": "音调设置",
+ "音频设备": "音频设备",
+ "音高算法": "音高算法",
+ "额外推理时长": "额外推理时长"
+}
diff --git a/i18n/locale/zh_HK.json b/i18n/locale/zh_HK.json
new file mode 100644
index 0000000000000000000000000000000000000000..4b3774a7b87200cbb828a2126bd4f5fb834207e2
--- /dev/null
+++ b/i18n/locale/zh_HK.json
@@ -0,0 +1,138 @@
+{
+ ">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音": ">=3則使用對harvest音高識別的結果使用中值濾波,數值為濾波半徑,使用可以削弱啞音",
+ "A模型权重": "A模型權重",
+ "A模型路径": "A模型路徑",
+ "B模型路径": "B模型路徑",
+ "E:\\语音音频+标注\\米津玄师\\src": "E:\\语音音频+标注\\米津玄师\\src",
+ "F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调": "F0曲線檔案,可選,一行一個音高,代替預設的F0及升降調",
+ "Index Rate": "Index Rate",
+ "Onnx导出": "Onnx导出",
+ "Onnx输出路径": "Onnx输出路径",
+ "RVC模型路径": "RVC模型路径",
+ "ckpt处理": "ckpt處理",
+ "harvest进程数": "harvest進程數",
+ "index文件路径不可包含中文": "index文件路径不可包含中文",
+ "pth文件路径不可包含中文": "pth文件路径不可包含中文",
+ "rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程": "rmvpe卡號配置:以-分隔輸入使用的不同進程卡號,例如0-0-1使用在卡0上跑2個進程並在卡1上跑1個進程",
+ "step1: 填写实验配置. 实验数据放在logs下, 每个实验一个文件夹, 需手工输入实验名路径, 内含实验配置, 日志, 训练得到的模型文件. ": "step1:填寫實驗配置。實驗數據放在logs下,每個實驗一個資料夾,需手動輸入實驗名路徑,內含實驗配置、日誌、訓練得到的模型檔案。",
+ "step1:正在处理数据": "step1:正在处理数据",
+ "step2:正在提取音高&正在提取特征": "step2:正在提取音高&正在提取特征",
+ "step2a: 自动遍历训练文件夹下所有可解码成音频的文件并进行切片归一化, 在实验目录下生成2个wav文件夹; 暂时只支持单人训练. ": "step2a:自動遍歷訓練資料夾下所有可解碼成音頻的檔案並進行切片歸一化,在實驗目錄下生成2個wav資料夾;暫時只支援單人訓練。",
+ "step2b: 使用CPU提取音高(如果模型带音高), 使用GPU提取特征(选择卡号)": "步驟2b: 使用CPU提取音高(如果模型帶音高), 使用GPU提取特徵(選擇卡號)",
+ "step3: 填写训练设置, 开始训练模型和索引": "步驟3: 填寫訓練設定, 開始訓練模型和索引",
+ "step3a:正在训练模型": "step3a:正在训练模型",
+ "一键训练": "一鍵訓練",
+ "也可批量输入音频文件, 二选一, 优先读文件夹": "也可批量输入音频文件, 二选一, 优先读文件夹",
+ "人声伴奏分离批量处理, 使用UVR5模型。
合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。
模型分为三类:
1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点;
2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型;
3、去混响、去延迟模型(by FoxJoy):
(1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;
(234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。
去混响/去延迟,附:
1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;
2、MDX-Net-Dereverb模型挺慢的;
3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "使用UVR5模型進行人聲伴奏分離的批次處理。
有效資料夾路徑格式的例子:D:\\path\\to\\input\\folder(從檔案管理員地址欄複製)。
模型分為三類:
1. 保留人聲:選擇這個選項適用於沒有和聲的音訊。它比HP5更好地保留了人聲。它包括兩個內建模型:HP2和HP3。HP3可能輕微漏出伴奏,但比HP2更好地保留了人聲;
2. 僅保留主人聲:選擇這個選項適用於有和聲的音訊。它可能會削弱主人聲。它包括一個內建模型:HP5。
3. 消除混響和延遲模型(由FoxJoy提供):
(1) MDX-Net:對於立體聲混響的移除是最好的選擇,但不能移除單聲道混響;
(234) DeEcho:移除延遲效果。Aggressive模式比Normal模式移除得更徹底。DeReverb另外移除混響,可以移除單聲道混響,但對於高頻重的板式混響移除不乾淨。
消除混響/延遲注意事項:
1. DeEcho-DeReverb模型的處理時間是其他兩個DeEcho模型的近兩倍;
2. MDX-Net-Dereverb模型相當慢;
3. 個人推薦的最乾淨配置是先使用MDX-Net,然後使用DeEcho-Aggressive。",
+ "以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "以-分隔輸入使用的卡號, 例如 0-1-2 使用卡0和卡1和卡2",
+ "伴奏人声分离&去混响&去回声": "伴奏人聲分離&去混響&去回聲",
+ "使用模型采样率": "使用模型采样率",
+ "使用设备采样率": "使用设备采样率",
+ "保存名": "儲存名",
+ "保存的文件名, 默认空为和源文件同名": "儲存的檔案名,預設空為與來源檔案同名",
+ "保存的模型名不带后缀": "儲存的模型名不帶副檔名",
+ "保存频率save_every_epoch": "保存頻率save_every_epoch",
+ "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果": "保護清輔音和呼吸聲,防止電音撕裂等artifact,拉滿0.5不開啟,調低加大保護力度但可能降低索引效果",
+ "修改": "修改",
+ "修改模型信息(仅支持weights文件夹下提取的小模型文件)": "修改模型資訊(僅支援weights資料夾下提取的小模型檔案)",
+ "停止音频转换": "停止音訊轉換",
+ "全流程结束!": "全流程结束!",
+ "共振偏移": "共振偏移",
+ "刷新音色列表和索引路径": "刷新音色列表和索引路徑",
+ "加载模型": "載入模型",
+ "加载预训练底模D路径": "加載預訓練底模D路徑",
+ "加载预训练底模G路径": "加載預訓練底模G路徑",
+ "单次推理": "单次推理",
+ "卸载音色省显存": "卸載音色節省 VRAM",
+ "变调(整数, 半音数量, 升八度12降八度-12)": "變調(整數、半音數量、升八度12降八度-12)",
+ "后处理重采样至最终采样率,0为不进行重采样": "後處理重採樣至最終採樣率,0為不進行重採樣",
+ "否": "否",
+ "启用相位声码器": "启用相位声码器",
+ "响应阈值": "響應閾值",
+ "响度因子": "響度因子",
+ "处理数据": "處理資料",
+ "导出Onnx模型": "导出Onnx模型",
+ "导出文件格式": "導出檔格式",
+ "常见问题解答": "常見問題解答",
+ "常规设置": "一般設定",
+ "开始音频转换": "開始音訊轉換",
+ "很遗憾您这没有能用的显卡来支持您训练": "很遗憾您这没有能用的显卡来支持您训练",
+ "性能设置": "效能設定",
+ "总训练轮数total_epoch": "總訓練輪數total_epoch",
+ "批量推理": "批量推理",
+ "批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. ": "批量轉換,輸入待轉換音頻資料夾,或上傳多個音頻檔案,在指定資料夾(默認opt)下輸出轉換的音頻。",
+ "指定输出主人声文件夹": "指定输出主人声文件夹",
+ "指定输出文件夹": "指定輸出資料夾",
+ "指定输出非主人声文件夹": "指定输出非主人声文件夹",
+ "推理时间(ms):": "推理時間(ms):",
+ "推理音色": "推理音色",
+ "提取": "提取",
+ "提取音高和处理数据使用的CPU进程数": "提取音高和處理數據使用的CPU進程數",
+ "是": "是",
+ "是否仅保存最新的ckpt文件以节省硬盘空间": "是否僅保存最新的ckpt檔案以節省硬碟空間",
+ "是否在每次保存时间点将最终小模型保存至weights文件夹": "是否在每次保存時間點將最終小模型保存至weights檔夾",
+ "是否缓存所有训练集至显存. 10min以下小数据可缓存以加速训练, 大数据缓存会炸显存也加不了多少速": "是否緩存所有訓練集至 VRAM。小於10分鐘的小數據可緩存以加速訓練,大數據緩存會爆 VRAM 也加不了多少速度",
+ "显卡信息": "顯示卡資訊",
+ "本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责.
如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录LICENSE.": "本軟體以MIT協議開源,作者不對軟體具備任何控制力,使用軟體者、傳播軟體導出的聲音者自負全責。
如不認可該條款,則不能使用或引用軟體包內任何程式碼和檔案。詳見根目錄使用需遵守的協議-LICENSE.txt。",
+ "查看": "查看",
+ "查看模型信息(仅支持weights文件夹下提取的小模型文件)": "查看模型資訊(僅支援weights資料夾下提取的小模型檔案)",
+ "检索特征占比": "檢索特徵佔比",
+ "模型": "模型",
+ "模型推理": "模型推理",
+ "模型提取(输入logs文件夹下大文件模型路径),适用于训一半不想训了模型没有自动提取保存小文件模型,或者想测试中间模型的情况": "模型提取(輸入logs資料夾下大檔案模型路徑),適用於訓一半不想訓了模型沒有自動提取儲存小檔案模型,或者想測試中間模型的情況",
+ "模型是否带音高指导": "模型是否帶音高指導",
+ "模型是否带音高指导(唱歌一定要, 语音可以不要)": "模型是否帶音高指導(唱歌一定要,語音可以不要)",
+ "模型是否带音高指导,1是0否": "模型是否帶音高指導,1是0否",
+ "模型版本型号": "模型版本型號",
+ "模型融合, 可用于测试音色融合": "模型融合,可用於測試音色融合",
+ "模型路径": "模型路徑",
+ "每张显卡的batch_size": "每张显卡的batch_size",
+ "淡入淡出长度": "淡入淡出長度",
+ "版本": "版本",
+ "特征提取": "特徵提取",
+ "特征检索库文件路径,为空则使用下拉的选择结果": "特徵檢索庫檔路徑,為空則使用下拉的選擇結果",
+ "独占 WASAPI 设备": "独占 WASAPI 设备",
+ "男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男性轉女性推薦+12key,女性轉男性推薦-12key,如果音域爆炸導致音色失真也可以自己調整到合適音域。",
+ "目标采样率": "目標取樣率",
+ "算法延迟(ms):": "算法延迟(ms):",
+ "自动检测index路径,下拉式选择(dropdown)": "自動檢測index路徑,下拉式選擇(dropdown)",
+ "融合": "融合",
+ "要改的模型信息": "要改的模型資訊",
+ "要置入的模型信息": "要置入的模型資訊",
+ "训练": "訓練",
+ "训练模型": "訓練模型",
+ "训练特征索引": "訓練特徵索引",
+ "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log",
+ "设备类型": "设备类型",
+ "请指定说话人id": "請指定說話人id",
+ "请选择index文件": "请选择index文件",
+ "请选择pth文件": "请选择pth文件",
+ "请选择说话人id": "請選擇說話人ID",
+ "转换": "轉換",
+ "输入实验名": "輸入實驗名稱",
+ "输入待处理音频文件夹路径": "輸入待處理音頻資料夾路徑",
+ "输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)": "輸入待處理音頻資料夾路徑(去檔案管理器地址欄拷貝即可)",
+ "输入待处理音频文件路径(默认是正确格式示例)": "輸入待處理音頻檔案路徑(預設是正確格式示例)",
+ "输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络": "輸入源音量包絡替換輸出音量包絡融合比例,越靠近1越使用輸出包絡",
+ "输入监听": "输入监听",
+ "输入训练文件夹路径": "輸入訓練檔案夾路徑",
+ "输入设备": "輸入設備",
+ "输入降噪": "輸入降噪",
+ "输出信息": "輸出訊息",
+ "输出变声": "输出变声",
+ "输出设备": "輸出設備",
+ "输出降噪": "輸出降噪",
+ "输出音频(右下角三个点,点了可以下载)": "輸出音頻(右下角三個點,點了可以下載)",
+ "选择.index文件": "選擇 .index 檔案",
+ "选择.pth文件": "選擇 .pth 檔案",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "選擇音高提取演算法,輸入歌聲可用pm提速,harvest低音好但巨慢無比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU",
+ "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU",
+ "采样率:": "采样率:",
+ "采样长度": "取樣長度",
+ "重载设备列表": "重載設備列表",
+ "音调设置": "音調設定",
+ "音频设备": "音訊設備",
+ "音高算法": "音高演算法",
+ "额外推理时长": "額外推理時長"
+}
diff --git a/i18n/locale/zh_SG.json b/i18n/locale/zh_SG.json
new file mode 100644
index 0000000000000000000000000000000000000000..4b3774a7b87200cbb828a2126bd4f5fb834207e2
--- /dev/null
+++ b/i18n/locale/zh_SG.json
@@ -0,0 +1,138 @@
+{
+ ">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音": ">=3則使用對harvest音高識別的結果使用中值濾波,數值為濾波半徑,使用可以削弱啞音",
+ "A模型权重": "A模型權重",
+ "A模型路径": "A模型路徑",
+ "B模型路径": "B模型路徑",
+ "E:\\语音音频+标注\\米津玄师\\src": "E:\\语音音频+标注\\米津玄师\\src",
+ "F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调": "F0曲線檔案,可選,一行一個音高,代替預設的F0及升降調",
+ "Index Rate": "Index Rate",
+ "Onnx导出": "Onnx导出",
+ "Onnx输出路径": "Onnx输出路径",
+ "RVC模型路径": "RVC模型路径",
+ "ckpt处理": "ckpt處理",
+ "harvest进程数": "harvest進程數",
+ "index文件路径不可包含中文": "index文件路径不可包含中文",
+ "pth文件路径不可包含中文": "pth文件路径不可包含中文",
+ "rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程": "rmvpe卡號配置:以-分隔輸入使用的不同進程卡號,例如0-0-1使用在卡0上跑2個進程並在卡1上跑1個進程",
+ "step1: 填写实验配置. 实验数据放在logs下, 每个实验一个文件夹, 需手工输入实验名路径, 内含实验配置, 日志, 训练得到的模型文件. ": "step1:填寫實驗配置。實驗數據放在logs下,每個實驗一個資料夾,需手動輸入實驗名路徑,內含實驗配置、日誌、訓練得到的模型檔案。",
+ "step1:正在处理数据": "step1:正在处理数据",
+ "step2:正在提取音高&正在提取特征": "step2:正在提取音高&正在提取特征",
+ "step2a: 自动遍历训练文件夹下所有可解码成音频的文件并进行切片归一化, 在实验目录下生成2个wav文件夹; 暂时只支持单人训练. ": "step2a:自動遍歷訓練資料夾下所有可解碼成音頻的檔案並進行切片歸一化,在實驗目錄下生成2個wav資料夾;暫時只支援單人訓練。",
+ "step2b: 使用CPU提取音高(如果模型带音高), 使用GPU提取特征(选择卡号)": "步驟2b: 使用CPU提取音高(如果模型帶音高), 使用GPU提取特徵(選擇卡號)",
+ "step3: 填写训练设置, 开始训练模型和索引": "步驟3: 填寫訓練設定, 開始訓練模型和索引",
+ "step3a:正在训练模型": "step3a:正在训练模型",
+ "一键训练": "一鍵訓練",
+ "也可批量输入音频文件, 二选一, 优先读文件夹": "也可批量输入音频文件, 二选一, 优先读文件夹",
+ "人声伴奏分离批量处理, 使用UVR5模型。
合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。
模型分为三类:
1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点;
2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型;
3、去混响、去延迟模型(by FoxJoy):
(1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;
(234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。
去混响/去延迟,附:
1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;
2、MDX-Net-Dereverb模型挺慢的;
3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "使用UVR5模型進行人聲伴奏分離的批次處理。
有效資料夾路徑格式的例子:D:\\path\\to\\input\\folder(從檔案管理員地址欄複製)。
模型分為三類:
1. 保留人聲:選擇這個選項適用於沒有和聲的音訊。它比HP5更好地保留了人聲。它包括兩個內建模型:HP2和HP3。HP3可能輕微漏出伴奏,但比HP2更好地保留了人聲;
2. 僅保留主人聲:選擇這個選項適用於有和聲的音訊。它可能會削弱主人聲。它包括一個內建模型:HP5。
3. 消除混響和延遲模型(由FoxJoy提供):
(1) MDX-Net:對於立體聲混響的移除是最好的選擇,但不能移除單聲道混響;
(234) DeEcho:移除延遲效果。Aggressive模式比Normal模式移除得更徹底。DeReverb另外移除混響,可以移除單聲道混響,但對於高頻重的板式混響移除不乾淨。
消除混響/延遲注意事項:
1. DeEcho-DeReverb模型的處理時間是其他兩個DeEcho模型的近兩倍;
2. MDX-Net-Dereverb模型相當慢;
3. 個人推薦的最乾淨配置是先使用MDX-Net,然後使用DeEcho-Aggressive。",
+ "以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "以-分隔輸入使用的卡號, 例如 0-1-2 使用卡0和卡1和卡2",
+ "伴奏人声分离&去混响&去回声": "伴奏人聲分離&去混響&去回聲",
+ "使用模型采样率": "使用模型采样率",
+ "使用设备采样率": "使用设备采样率",
+ "保存名": "儲存名",
+ "保存的文件名, 默认空为和源文件同名": "儲存的檔案名,預設空為與來源檔案同名",
+ "保存的模型名不带后缀": "儲存的模型名不帶副檔名",
+ "保存频率save_every_epoch": "保存頻率save_every_epoch",
+ "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果": "保護清輔音和呼吸聲,防止電音撕裂等artifact,拉滿0.5不開啟,調低加大保護力度但可能降低索引效果",
+ "修改": "修改",
+ "修改模型信息(仅支持weights文件夹下提取的小模型文件)": "修改模型資訊(僅支援weights資料夾下提取的小模型檔案)",
+ "停止音频转换": "停止音訊轉換",
+ "全流程结束!": "全流程结束!",
+ "共振偏移": "共振偏移",
+ "刷新音色列表和索引路径": "刷新音色列表和索引路徑",
+ "加载模型": "載入模型",
+ "加载预训练底模D路径": "加載預訓練底模D路徑",
+ "加载预训练底模G路径": "加載預訓練底模G路徑",
+ "单次推理": "单次推理",
+ "卸载音色省显存": "卸載音色節省 VRAM",
+ "变调(整数, 半音数量, 升八度12降八度-12)": "變調(整數、半音數量、升八度12降八度-12)",
+ "后处理重采样至最终采样率,0为不进行重采样": "後處理重採樣至最終採樣率,0為不進行重採樣",
+ "否": "否",
+ "启用相位声码器": "启用相位声码器",
+ "响应阈值": "響應閾值",
+ "响度因子": "響度因子",
+ "处理数据": "處理資料",
+ "导出Onnx模型": "导出Onnx模型",
+ "导出文件格式": "導出檔格式",
+ "常见问题解答": "常見問題解答",
+ "常规设置": "一般設定",
+ "开始音频转换": "開始音訊轉換",
+ "很遗憾您这没有能用的显卡来支持您训练": "很遗憾您这没有能用的显卡来支持您训练",
+ "性能设置": "效能設定",
+ "总训练轮数total_epoch": "總訓練輪數total_epoch",
+ "批量推理": "批量推理",
+ "批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. ": "批量轉換,輸入待轉換音頻資料夾,或上傳多個音頻檔案,在指定資料夾(默認opt)下輸出轉換的音頻。",
+ "指定输出主人声文件夹": "指定输出主人声文件夹",
+ "指定输出文件夹": "指定輸出資料夾",
+ "指定输出非主人声文件夹": "指定输出非主人声文件夹",
+ "推理时间(ms):": "推理時間(ms):",
+ "推理音色": "推理音色",
+ "提取": "提取",
+ "提取音高和处理数据使用的CPU进程数": "提取音高和處理數據使用的CPU進程數",
+ "是": "是",
+ "是否仅保存最新的ckpt文件以节省硬盘空间": "是否僅保存最新的ckpt檔案以節省硬碟空間",
+ "是否在每次保存时间点将最终小模型保存至weights文件夹": "是否在每次保存時間點將最終小模型保存至weights檔夾",
+ "是否缓存所有训练集至显存. 10min以下小数据可缓存以加速训练, 大数据缓存会炸显存也加不了多少速": "是否緩存所有訓練集至 VRAM。小於10分鐘的小數據可緩存以加速訓練,大數據緩存會爆 VRAM 也加不了多少速度",
+ "显卡信息": "顯示卡資訊",
+ "本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责.
如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录LICENSE.": "本軟體以MIT協議開源,作者不對軟體具備任何控制力,使用軟體者、傳播軟體導出的聲音者自負全責。
如不認可該條款,則不能使用或引用軟體包內任何程式碼和檔案。詳見根目錄使用需遵守的協議-LICENSE.txt。",
+ "查看": "查看",
+ "查看模型信息(仅支持weights文件夹下提取的小模型文件)": "查看模型資訊(僅支援weights資料夾下提取的小模型檔案)",
+ "检索特征占比": "檢索特徵佔比",
+ "模型": "模型",
+ "模型推理": "模型推理",
+ "模型提取(输入logs文件夹下大文件模型路径),适用于训一半不想训了模型没有自动提取保存小文件模型,或者想测试中间模型的情况": "模型提取(輸入logs資料夾下大檔案模型路徑),適用於訓一半不想訓了模型沒有自動提取儲存小檔案模型,或者想測試中間模型的情況",
+ "模型是否带音高指导": "模型是否帶音高指導",
+ "模型是否带音高指导(唱歌一定要, 语音可以不要)": "模型是否帶音高指導(唱歌一定要,語音可以不要)",
+ "模型是否带音高指导,1是0否": "模型是否帶音高指導,1是0否",
+ "模型版本型号": "模型版本型號",
+ "模型融合, 可用于测试音色融合": "模型融合,可用於測試音色融合",
+ "模型路径": "模型路徑",
+ "每张显卡的batch_size": "每张显卡的batch_size",
+ "淡入淡出长度": "淡入淡出長度",
+ "版本": "版本",
+ "特征提取": "特徵提取",
+ "特征检索库文件路径,为空则使用下拉的选择结果": "特徵檢索庫檔路徑,為空則使用下拉的選擇結果",
+ "独占 WASAPI 设备": "独占 WASAPI 设备",
+ "男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男性轉女性推薦+12key,女性轉男性推薦-12key,如果音域爆炸導致音色失真也可以自己調整到合適音域。",
+ "目标采样率": "目標取樣率",
+ "算法延迟(ms):": "算法延迟(ms):",
+ "自动检测index路径,下拉式选择(dropdown)": "自動檢測index路徑,下拉式選擇(dropdown)",
+ "融合": "融合",
+ "要改的模型信息": "要改的模型資訊",
+ "要置入的模型信息": "要置入的模型資訊",
+ "训练": "訓練",
+ "训练模型": "訓練模型",
+ "训练特征索引": "訓練特徵索引",
+ "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log",
+ "设备类型": "设备类型",
+ "请指定说话人id": "請指定說話人id",
+ "请选择index文件": "请选择index文件",
+ "请选择pth文件": "请选择pth文件",
+ "请选择说话人id": "請選擇說話人ID",
+ "转换": "轉換",
+ "输入实验名": "輸入實驗名稱",
+ "输入待处理音频文件夹路径": "輸入待處理音頻資料夾路徑",
+ "输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)": "輸入待處理音頻資料夾路徑(去檔案管理器地址欄拷貝即可)",
+ "输入待处理音频文件路径(默认是正确格式示例)": "輸入待處理音頻檔案路徑(預設是正確格式示例)",
+ "输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络": "輸入源音量包絡替換輸出音量包絡融合比例,越靠近1越使用輸出包絡",
+ "输入监听": "输入监听",
+ "输入训练文件夹路径": "輸入訓練檔案夾路徑",
+ "输入设备": "輸入設備",
+ "输入降噪": "輸入降噪",
+ "输出信息": "輸出訊息",
+ "输出变声": "输出变声",
+ "输出设备": "輸出設備",
+ "输出降噪": "輸出降噪",
+ "输出音频(右下角三个点,点了可以下载)": "輸出音頻(右下角三個點,點了可以下載)",
+ "选择.index文件": "選擇 .index 檔案",
+ "选择.pth文件": "選擇 .pth 檔案",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "選擇音高提取演算法,輸入歌聲可用pm提速,harvest低音好但巨慢無比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU",
+ "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU",
+ "采样率:": "采样率:",
+ "采样长度": "取樣長度",
+ "重载设备列表": "重載設備列表",
+ "音调设置": "音調設定",
+ "音频设备": "音訊設備",
+ "音高算法": "音高演算法",
+ "额外推理时长": "額外推理時長"
+}
diff --git a/i18n/locale/zh_TW.json b/i18n/locale/zh_TW.json
new file mode 100644
index 0000000000000000000000000000000000000000..4b3774a7b87200cbb828a2126bd4f5fb834207e2
--- /dev/null
+++ b/i18n/locale/zh_TW.json
@@ -0,0 +1,138 @@
+{
+ ">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音": ">=3則使用對harvest音高識別的結果使用中值濾波,數值為濾波半徑,使用可以削弱啞音",
+ "A模型权重": "A模型權重",
+ "A模型路径": "A模型路徑",
+ "B模型路径": "B模型路徑",
+ "E:\\语音音频+标注\\米津玄师\\src": "E:\\语音音频+标注\\米津玄师\\src",
+ "F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调": "F0曲線檔案,可選,一行一個音高,代替預設的F0及升降調",
+ "Index Rate": "Index Rate",
+ "Onnx导出": "Onnx导出",
+ "Onnx输出路径": "Onnx输出路径",
+ "RVC模型路径": "RVC模型路径",
+ "ckpt处理": "ckpt處理",
+ "harvest进程数": "harvest進程數",
+ "index文件路径不可包含中文": "index文件路径不可包含中文",
+ "pth文件路径不可包含中文": "pth文件路径不可包含中文",
+ "rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程": "rmvpe卡號配置:以-分隔輸入使用的不同進程卡號,例如0-0-1使用在卡0上跑2個進程並在卡1上跑1個進程",
+ "step1: 填写实验配置. 实验数据放在logs下, 每个实验一个文件夹, 需手工输入实验名路径, 内含实验配置, 日志, 训练得到的模型文件. ": "step1:填寫實驗配置。實驗數據放在logs下,每個實驗一個資料夾,需手動輸入實驗名路徑,內含實驗配置、日誌、訓練得到的模型檔案。",
+ "step1:正在处理数据": "step1:正在处理数据",
+ "step2:正在提取音高&正在提取特征": "step2:正在提取音高&正在提取特征",
+ "step2a: 自动遍历训练文件夹下所有可解码成音频的文件并进行切片归一化, 在实验目录下生成2个wav文件夹; 暂时只支持单人训练. ": "step2a:自動遍歷訓練資料夾下所有可解碼成音頻的檔案並進行切片歸一化,在實驗目錄下生成2個wav資料夾;暫時只支援單人訓練。",
+ "step2b: 使用CPU提取音高(如果模型带音高), 使用GPU提取特征(选择卡号)": "步驟2b: 使用CPU提取音高(如果模型帶音高), 使用GPU提取特徵(選擇卡號)",
+ "step3: 填写训练设置, 开始训练模型和索引": "步驟3: 填寫訓練設定, 開始訓練模型和索引",
+ "step3a:正在训练模型": "step3a:正在训练模型",
+ "一键训练": "一鍵訓練",
+ "也可批量输入音频文件, 二选一, 优先读文件夹": "也可批量输入音频文件, 二选一, 优先读文件夹",
+ "人声伴奏分离批量处理, 使用UVR5模型。
合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。
模型分为三类:
1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点;
2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型;
3、去混响、去延迟模型(by FoxJoy):
(1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;
(234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。
去混响/去延迟,附:
1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;
2、MDX-Net-Dereverb模型挺慢的;
3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "使用UVR5模型進行人聲伴奏分離的批次處理。
有效資料夾路徑格式的例子:D:\\path\\to\\input\\folder(從檔案管理員地址欄複製)。
模型分為三類:
1. 保留人聲:選擇這個選項適用於沒有和聲的音訊。它比HP5更好地保留了人聲。它包括兩個內建模型:HP2和HP3。HP3可能輕微漏出伴奏,但比HP2更好地保留了人聲;
2. 僅保留主人聲:選擇這個選項適用於有和聲的音訊。它可能會削弱主人聲。它包括一個內建模型:HP5。
3. 消除混響和延遲模型(由FoxJoy提供):
(1) MDX-Net:對於立體聲混響的移除是最好的選擇,但不能移除單聲道混響;
(234) DeEcho:移除延遲效果。Aggressive模式比Normal模式移除得更徹底。DeReverb另外移除混響,可以移除單聲道混響,但對於高頻重的板式混響移除不乾淨。
消除混響/延遲注意事項:
1. DeEcho-DeReverb模型的處理時間是其他兩個DeEcho模型的近兩倍;
2. MDX-Net-Dereverb模型相當慢;
3. 個人推薦的最乾淨配置是先使用MDX-Net,然後使用DeEcho-Aggressive。",
+ "以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "以-分隔輸入使用的卡號, 例如 0-1-2 使用卡0和卡1和卡2",
+ "伴奏人声分离&去混响&去回声": "伴奏人聲分離&去混響&去回聲",
+ "使用模型采样率": "使用模型采样率",
+ "使用设备采样率": "使用设备采样率",
+ "保存名": "儲存名",
+ "保存的文件名, 默认空为和源文件同名": "儲存的檔案名,預設空為與來源檔案同名",
+ "保存的模型名不带后缀": "儲存的模型名不帶副檔名",
+ "保存频率save_every_epoch": "保存頻率save_every_epoch",
+ "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果": "保護清輔音和呼吸聲,防止電音撕裂等artifact,拉滿0.5不開啟,調低加大保護力度但可能降低索引效果",
+ "修改": "修改",
+ "修改模型信息(仅支持weights文件夹下提取的小模型文件)": "修改模型資訊(僅支援weights資料夾下提取的小模型檔案)",
+ "停止音频转换": "停止音訊轉換",
+ "全流程结束!": "全流程结束!",
+ "共振偏移": "共振偏移",
+ "刷新音色列表和索引路径": "刷新音色列表和索引路徑",
+ "加载模型": "載入模型",
+ "加载预训练底模D路径": "加載預訓練底模D路徑",
+ "加载预训练底模G路径": "加載預訓練底模G路徑",
+ "单次推理": "单次推理",
+ "卸载音色省显存": "卸載音色節省 VRAM",
+ "变调(整数, 半音数量, 升八度12降八度-12)": "變調(整數、半音數量、升八度12降八度-12)",
+ "后处理重采样至最终采样率,0为不进行重采样": "後處理重採樣至最終採樣率,0為不進行重採樣",
+ "否": "否",
+ "启用相位声码器": "启用相位声码器",
+ "响应阈值": "響應閾值",
+ "响度因子": "響度因子",
+ "处理数据": "處理資料",
+ "导出Onnx模型": "导出Onnx模型",
+ "导出文件格式": "導出檔格式",
+ "常见问题解答": "常見問題解答",
+ "常规设置": "一般設定",
+ "开始音频转换": "開始音訊轉換",
+ "很遗憾您这没有能用的显卡来支持您训练": "很遗憾您这没有能用的显卡来支持您训练",
+ "性能设置": "效能設定",
+ "总训练轮数total_epoch": "總訓練輪數total_epoch",
+ "批量推理": "批量推理",
+ "批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. ": "批量轉換,輸入待轉換音頻資料夾,或上傳多個音頻檔案,在指定資料夾(默認opt)下輸出轉換的音頻。",
+ "指定输出主人声文件夹": "指定输出主人声文件夹",
+ "指定输出文件夹": "指定輸出資料夾",
+ "指定输出非主人声文件夹": "指定输出非主人声文件夹",
+ "推理时间(ms):": "推理時間(ms):",
+ "推理音色": "推理音色",
+ "提取": "提取",
+ "提取音高和处理数据使用的CPU进程数": "提取音高和處理數據使用的CPU進程數",
+ "是": "是",
+ "是否仅保存最新的ckpt文件以节省硬盘空间": "是否僅保存最新的ckpt檔案以節省硬碟空間",
+ "是否在每次保存时间点将最终小模型保存至weights文件夹": "是否在每次保存時間點將最終小模型保存至weights檔夾",
+ "是否缓存所有训练集至显存. 10min以下小数据可缓存以加速训练, 大数据缓存会炸显存也加不了多少速": "是否緩存所有訓練集至 VRAM。小於10分鐘的小數據可緩存以加速訓練,大數據緩存會爆 VRAM 也加不了多少速度",
+ "显卡信息": "顯示卡資訊",
+ "本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责.
如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录LICENSE.": "本軟體以MIT協議開源,作者不對軟體具備任何控制力,使用軟體者、傳播軟體導出的聲音者自負全責。
如不認可該條款,則不能使用或引用軟體包內任何程式碼和檔案。詳見根目錄使用需遵守的協議-LICENSE.txt。",
+ "查看": "查看",
+ "查看模型信息(仅支持weights文件夹下提取的小模型文件)": "查看模型資訊(僅支援weights資料夾下提取的小模型檔案)",
+ "检索特征占比": "檢索特徵佔比",
+ "模型": "模型",
+ "模型推理": "模型推理",
+ "模型提取(输入logs文件夹下大文件模型路径),适用于训一半不想训了模型没有自动提取保存小文件模型,或者想测试中间模型的情况": "模型提取(輸入logs資料夾下大檔案模型路徑),適用於訓一半不想訓了模型沒有自動提取儲存小檔案模型,或者想測試中間模型的情況",
+ "模型是否带音高指导": "模型是否帶音高指導",
+ "模型是否带音高指导(唱歌一定要, 语音可以不要)": "模型是否帶音高指導(唱歌一定要,語音可以不要)",
+ "模型是否带音高指导,1是0否": "模型是否帶音高指導,1是0否",
+ "模型版本型号": "模型版本型號",
+ "模型融合, 可用于测试音色融合": "模型融合,可用於測試音色融合",
+ "模型路径": "模型路徑",
+ "每张显卡的batch_size": "每张显卡的batch_size",
+ "淡入淡出长度": "淡入淡出長度",
+ "版本": "版本",
+ "特征提取": "特徵提取",
+ "特征检索库文件路径,为空则使用下拉的选择结果": "特徵檢索庫檔路徑,為空則使用下拉的選擇結果",
+ "独占 WASAPI 设备": "独占 WASAPI 设备",
+ "男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男性轉女性推薦+12key,女性轉男性推薦-12key,如果音域爆炸導致音色失真也可以自己調整到合適音域。",
+ "目标采样率": "目標取樣率",
+ "算法延迟(ms):": "算法延迟(ms):",
+ "自动检测index路径,下拉式选择(dropdown)": "自動檢測index路徑,下拉式選擇(dropdown)",
+ "融合": "融合",
+ "要改的模型信息": "要改的模型資訊",
+ "要置入的模型信息": "要置入的模型資訊",
+ "训练": "訓練",
+ "训练模型": "訓練模型",
+ "训练特征索引": "訓練特徵索引",
+ "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log",
+ "设备类型": "设备类型",
+ "请指定说话人id": "請指定說話人id",
+ "请选择index文件": "请选择index文件",
+ "请选择pth文件": "请选择pth文件",
+ "请选择说话人id": "請選擇說話人ID",
+ "转换": "轉換",
+ "输入实验名": "輸入實驗名稱",
+ "输入待处理音频文件夹路径": "輸入待處理音頻資料夾路徑",
+ "输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)": "輸入待處理音頻資料夾路徑(去檔案管理器地址欄拷貝即可)",
+ "输入待处理音频文件路径(默认是正确格式示例)": "輸入待處理音頻檔案路徑(預設是正確格式示例)",
+ "输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络": "輸入源音量包絡替換輸出音量包絡融合比例,越靠近1越使用輸出包絡",
+ "输入监听": "输入监听",
+ "输入训练文件夹路径": "輸入訓練檔案夾路徑",
+ "输入设备": "輸入設備",
+ "输入降噪": "輸入降噪",
+ "输出信息": "輸出訊息",
+ "输出变声": "输出变声",
+ "输出设备": "輸出設備",
+ "输出降噪": "輸出降噪",
+ "输出音频(右下角三个点,点了可以下载)": "輸出音頻(右下角三個點,點了可以下載)",
+ "选择.index文件": "選擇 .index 檔案",
+ "选择.pth文件": "選擇 .pth 檔案",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU",
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "選擇音高提取演算法,輸入歌聲可用pm提速,harvest低音好但巨慢無比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU",
+ "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU",
+ "采样率:": "采样率:",
+ "采样长度": "取樣長度",
+ "重载设备列表": "重載設備列表",
+ "音调设置": "音調設定",
+ "音频设备": "音訊設備",
+ "音高算法": "音高演算法",
+ "额外推理时长": "額外推理時長"
+}
diff --git a/i18n/locale_diff.py b/i18n/locale_diff.py
new file mode 100644
index 0000000000000000000000000000000000000000..674f7dd25a5d05b8af85d28683ba79343767e0e6
--- /dev/null
+++ b/i18n/locale_diff.py
@@ -0,0 +1,47 @@
+import json
+import os
+from collections import OrderedDict
+
+# Define the standard file name
+standard_file = "locale/zh_CN.json"
+
+# Find all JSON files in the directory
+dir_path = "locale/"
+languages = [
+ os.path.join(dir_path, f)
+ for f in os.listdir(dir_path)
+ if f.endswith(".json") and f != standard_file
+]
+
+# Load the standard file
+with open(standard_file, "r", encoding="utf-8") as f:
+ standard_data = json.load(f, object_pairs_hook=OrderedDict)
+
+# Loop through each language file
+for lang_file in languages:
+ # Load the language file
+ with open(lang_file, "r", encoding="utf-8") as f:
+ lang_data = json.load(f, object_pairs_hook=OrderedDict)
+
+ # Find the difference between the language file and the standard file
+ diff = set(standard_data.keys()) - set(lang_data.keys())
+
+ miss = set(lang_data.keys()) - set(standard_data.keys())
+
+ # Add any missing keys to the language file
+ for key in diff:
+ lang_data[key] = key
+
+ # Del any extra keys to the language file
+ for key in miss:
+ del lang_data[key]
+
+ # Sort the keys of the language file to match the order of the standard file
+ lang_data = OrderedDict(
+ sorted(lang_data.items(), key=lambda x: list(standard_data.keys()).index(x[0]))
+ )
+
+ # Save the updated language file
+ with open(lang_file, "w", encoding="utf-8") as f:
+ json.dump(lang_data, f, ensure_ascii=False, indent=4, sort_keys=True)
+ f.write("\n")
diff --git a/i18n/scan_i18n.py b/i18n/scan_i18n.py
new file mode 100644
index 0000000000000000000000000000000000000000..f3e52cf4f9f06d78877d77d2353f666aa759e36f
--- /dev/null
+++ b/i18n/scan_i18n.py
@@ -0,0 +1,75 @@
+import ast
+import glob
+import json
+from collections import OrderedDict
+
+
+def extract_i18n_strings(node):
+ i18n_strings = []
+
+ if (
+ isinstance(node, ast.Call)
+ and isinstance(node.func, ast.Name)
+ and node.func.id == "i18n"
+ ):
+ for arg in node.args:
+ if isinstance(arg, ast.Str):
+ i18n_strings.append(arg.s)
+
+ for child_node in ast.iter_child_nodes(node):
+ i18n_strings.extend(extract_i18n_strings(child_node))
+
+ return i18n_strings
+
+
+# scan the directory for all .py files (recursively)
+# for each file, parse the code into an AST
+# for each AST, extract the i18n strings
+
+strings = []
+for filename in glob.iglob("**/*.py", recursive=True):
+ with open(filename, "r") as f:
+ code = f.read()
+ if "I18nAuto" in code:
+ tree = ast.parse(code)
+ i18n_strings = extract_i18n_strings(tree)
+ print(filename, len(i18n_strings))
+ strings.extend(i18n_strings)
+code_keys = set(strings)
+"""
+n_i18n.py
+gui_v1.py 26
+app.py 16
+infer-web.py 147
+scan_i18n.py 0
+i18n.py 0
+lib/train/process_ckpt.py 1
+"""
+print()
+print("Total unique:", len(code_keys))
+
+
+standard_file = "i18n/locale/zh_CN.json"
+with open(standard_file, "r", encoding="utf-8") as f:
+ standard_data = json.load(f, object_pairs_hook=OrderedDict)
+standard_keys = set(standard_data.keys())
+
+# Define the standard file name
+unused_keys = standard_keys - code_keys
+print("Unused keys:", len(unused_keys))
+for unused_key in unused_keys:
+ print("\t", unused_key)
+
+missing_keys = code_keys - standard_keys
+print("Missing keys:", len(missing_keys))
+for missing_key in missing_keys:
+ print("\t", missing_key)
+
+code_keys_dict = OrderedDict()
+for s in strings:
+ code_keys_dict[s] = s
+
+# write back
+with open(standard_file, "w", encoding="utf-8") as f:
+ json.dump(code_keys_dict, f, ensure_ascii=False, indent=4, sort_keys=True)
+ f.write("\n")
diff --git a/infer-web.py b/infer-web.py
new file mode 100644
index 0000000000000000000000000000000000000000..306c448281905549678f0a93800754e7977d5057
--- /dev/null
+++ b/infer-web.py
@@ -0,0 +1,1623 @@
+import os
+import sys
+from dotenv import load_dotenv
+
+now_dir = os.getcwd()
+sys.path.append(now_dir)
+load_dotenv()
+load_dotenv("sha256.env")
+from infer.modules.vc.modules import VC
+from infer.modules.uvr5.modules import uvr
+from infer.lib.train.process_ckpt import (
+ change_info,
+ extract_small_model,
+ merge,
+ show_info,
+)
+from i18n.i18n import I18nAuto
+from configs.config import Config
+from sklearn.cluster import MiniBatchKMeans
+import torch, platform
+import numpy as np
+import gradio as gr
+import faiss
+import fairseq
+import pathlib
+import json
+from time import sleep
+from subprocess import Popen
+from random import shuffle
+import warnings
+import traceback
+import threading
+import shutil
+import logging
+
+
+logging.getLogger("numba").setLevel(logging.WARNING)
+logging.getLogger("httpx").setLevel(logging.WARNING)
+
+logger = logging.getLogger(__name__)
+
+tmp = os.path.join(now_dir, "TEMP")
+shutil.rmtree(tmp, ignore_errors=True)
+shutil.rmtree("%s/runtime/Lib/site-packages/infer_pack" % (now_dir), ignore_errors=True)
+shutil.rmtree("%s/runtime/Lib/site-packages/uvr5_pack" % (now_dir), ignore_errors=True)
+os.makedirs(tmp, exist_ok=True)
+os.makedirs(os.path.join(now_dir, "logs"), exist_ok=True)
+os.makedirs(os.path.join(now_dir, "assets/weights"), exist_ok=True)
+os.environ["TEMP"] = tmp
+warnings.filterwarnings("ignore")
+torch.manual_seed(114514)
+
+
+config = Config()
+vc = VC(config)
+
+if not config.nocheck:
+ from infer.lib.rvcmd import check_all_assets, download_all_assets
+
+ if not check_all_assets(update=config.update):
+ if config.update:
+ download_all_assets(tmpdir=tmp)
+ if not check_all_assets(update=config.update):
+ logging.error("counld not satisfy all assets needed.")
+ exit(1)
+
+if config.dml == True:
+
+ def forward_dml(ctx, x, scale):
+ ctx.scale = scale
+ res = x.clone().detach()
+ return res
+
+ fairseq.modules.grad_multiply.GradMultiply.forward = forward_dml
+i18n = I18nAuto()
+logger.info(i18n)
+# 判断是否有能用来训练和加速推理的N卡
+ngpu = torch.cuda.device_count()
+gpu_infos = []
+mem = []
+if_gpu_ok = False
+
+if torch.cuda.is_available() or ngpu != 0:
+ for i in range(ngpu):
+ gpu_name = torch.cuda.get_device_name(i)
+ if any(
+ value in gpu_name.upper()
+ for value in [
+ "10",
+ "16",
+ "20",
+ "30",
+ "40",
+ "A2",
+ "A3",
+ "A4",
+ "P4",
+ "A50",
+ "500",
+ "A60",
+ "70",
+ "80",
+ "90",
+ "M4",
+ "T4",
+ "TITAN",
+ "4060",
+ "L",
+ "6000",
+ ]
+ ):
+ # A10#A100#V100#A40#P40#M40#K80#A4500
+ if_gpu_ok = True # 至少有一张能用的N卡
+ gpu_infos.append("%s\t%s" % (i, gpu_name))
+ mem.append(
+ int(
+ torch.cuda.get_device_properties(i).total_memory
+ / 1024
+ / 1024
+ / 1024
+ + 0.4
+ )
+ )
+if if_gpu_ok and len(gpu_infos) > 0:
+ gpu_info = "\n".join(gpu_infos)
+ default_batch_size = min(mem) // 2
+else:
+ gpu_info = i18n("很遗憾您这没有能用的显卡来支持您训练")
+ default_batch_size = 1
+gpus = "-".join([i[0] for i in gpu_infos])
+
+
+weight_root = os.getenv("weight_root")
+weight_uvr5_root = os.getenv("weight_uvr5_root")
+index_root = os.getenv("index_root")
+outside_index_root = os.getenv("outside_index_root")
+
+names = []
+for name in os.listdir(weight_root):
+ if name.endswith(".pth"):
+ names.append(name)
+index_paths = []
+
+
+def lookup_indices(index_root):
+ global index_paths
+ for root, dirs, files in os.walk(index_root, topdown=False):
+ for name in files:
+ if name.endswith(".index") and "trained" not in name:
+ index_paths.append("%s/%s" % (root, name))
+
+
+lookup_indices(index_root)
+lookup_indices(outside_index_root)
+uvr5_names = []
+for name in os.listdir(weight_uvr5_root):
+ if name.endswith(".pth") or "onnx" in name:
+ uvr5_names.append(name.replace(".pth", ""))
+
+
+def change_choices():
+ names = []
+ for name in os.listdir(weight_root):
+ if name.endswith(".pth"):
+ names.append(name)
+ index_paths = []
+ for root, dirs, files in os.walk(index_root, topdown=False):
+ for name in files:
+ if name.endswith(".index") and "trained" not in name:
+ index_paths.append("%s/%s" % (root, name))
+ return {"choices": sorted(names), "__type__": "update"}, {
+ "choices": sorted(index_paths),
+ "__type__": "update",
+ }
+
+
+def clean():
+ return {"value": "", "__type__": "update"}
+
+
+def export_onnx(ModelPath, ExportedPath):
+ from infer.modules.onnx.export import export_onnx as eo
+
+ eo(ModelPath, ExportedPath)
+
+
+sr_dict = {
+ "32k": 32000,
+ "40k": 40000,
+ "48k": 48000,
+}
+
+
+def if_done(done, p):
+ while 1:
+ if p.poll() is None:
+ sleep(0.5)
+ else:
+ break
+ done[0] = True
+
+
+def if_done_multi(done, ps):
+ while 1:
+ # poll==None代表进程未结束
+ # 只要有一个进程未结束都不停
+ flag = 1
+ for p in ps:
+ if p.poll() is None:
+ flag = 0
+ sleep(0.5)
+ break
+ if flag == 1:
+ break
+ done[0] = True
+
+
+def preprocess_dataset(trainset_dir, exp_dir, sr, n_p):
+ sr = sr_dict[sr]
+ os.makedirs("%s/logs/%s" % (now_dir, exp_dir), exist_ok=True)
+ f = open("%s/logs/%s/preprocess.log" % (now_dir, exp_dir), "w")
+ f.close()
+ cmd = '"%s" infer/modules/train/preprocess.py "%s" %s %s "%s/logs/%s" %s %.1f' % (
+ config.python_cmd,
+ trainset_dir,
+ sr,
+ n_p,
+ now_dir,
+ exp_dir,
+ config.noparallel,
+ config.preprocess_per,
+ )
+ logger.info("Execute: " + cmd)
+ # , stdin=PIPE, stdout=PIPE,stderr=PIPE,cwd=now_dir
+ p = Popen(cmd, shell=True)
+ # 煞笔gr, popen read都非得全跑完了再一次性读取, 不用gr就正常读一句输出一句;只能额外弄出一个文本流定时读
+ done = [False]
+ threading.Thread(
+ target=if_done,
+ args=(
+ done,
+ p,
+ ),
+ ).start()
+ while 1:
+ with open("%s/logs/%s/preprocess.log" % (now_dir, exp_dir), "r") as f:
+ yield (f.read())
+ sleep(1)
+ if done[0]:
+ break
+ with open("%s/logs/%s/preprocess.log" % (now_dir, exp_dir), "r") as f:
+ log = f.read()
+ logger.info(log)
+ yield log
+
+
+# but2.click(extract_f0,[gpus6,np7,f0method8,if_f0_3,trainset_dir4],[info2])
+def extract_f0_feature(gpus, n_p, f0method, if_f0, exp_dir, version19, gpus_rmvpe):
+ gpus = gpus.split("-")
+ os.makedirs("%s/logs/%s" % (now_dir, exp_dir), exist_ok=True)
+ f = open("%s/logs/%s/extract_f0_feature.log" % (now_dir, exp_dir), "w")
+ f.close()
+ if if_f0:
+ if f0method != "rmvpe_gpu":
+ cmd = (
+ '"%s" infer/modules/train/extract/extract_f0_print.py "%s/logs/%s" %s %s'
+ % (
+ config.python_cmd,
+ now_dir,
+ exp_dir,
+ n_p,
+ f0method,
+ )
+ )
+ logger.info("Execute: " + cmd)
+ p = Popen(
+ cmd, shell=True, cwd=now_dir
+ ) # , stdin=PIPE, stdout=PIPE,stderr=PIPE
+ # 煞笔gr, popen read都非得全跑完了再一次性读取, 不用gr就正常读一句输出一句;只能额外弄出一个文本流定时读
+ done = [False]
+ threading.Thread(
+ target=if_done,
+ args=(
+ done,
+ p,
+ ),
+ ).start()
+ else:
+ if gpus_rmvpe != "-":
+ gpus_rmvpe = gpus_rmvpe.split("-")
+ leng = len(gpus_rmvpe)
+ ps = []
+ for idx, n_g in enumerate(gpus_rmvpe):
+ cmd = (
+ '"%s" infer/modules/train/extract/extract_f0_rmvpe.py %s %s %s "%s/logs/%s" %s '
+ % (
+ config.python_cmd,
+ leng,
+ idx,
+ n_g,
+ now_dir,
+ exp_dir,
+ config.is_half,
+ )
+ )
+ logger.info("Execute: " + cmd)
+ p = Popen(
+ cmd, shell=True, cwd=now_dir
+ ) # , shell=True, stdin=PIPE, stdout=PIPE, stderr=PIPE, cwd=now_dir
+ ps.append(p)
+ # 煞笔gr, popen read都非得全跑完了再一次性读取, 不用gr就正常读一句输出一句;只能额外弄出一个文本流定时读
+ done = [False]
+ threading.Thread(
+ target=if_done_multi, #
+ args=(
+ done,
+ ps,
+ ),
+ ).start()
+ else:
+ cmd = (
+ config.python_cmd
+ + ' infer/modules/train/extract/extract_f0_rmvpe_dml.py "%s/logs/%s" '
+ % (
+ now_dir,
+ exp_dir,
+ )
+ )
+ logger.info("Execute: " + cmd)
+ p = Popen(
+ cmd, shell=True, cwd=now_dir
+ ) # , shell=True, stdin=PIPE, stdout=PIPE, stderr=PIPE, cwd=now_dir
+ p.wait()
+ done = [True]
+ while 1:
+ with open(
+ "%s/logs/%s/extract_f0_feature.log" % (now_dir, exp_dir), "r"
+ ) as f:
+ yield (f.read())
+ sleep(1)
+ if done[0]:
+ break
+ with open("%s/logs/%s/extract_f0_feature.log" % (now_dir, exp_dir), "r") as f:
+ log = f.read()
+ logger.info(log)
+ yield log
+ # 对不同part分别开多进程
+ """
+ n_part=int(sys.argv[1])
+ i_part=int(sys.argv[2])
+ i_gpu=sys.argv[3]
+ exp_dir=sys.argv[4]
+ os.environ["CUDA_VISIBLE_DEVICES"]=str(i_gpu)
+ """
+ leng = len(gpus)
+ ps = []
+ for idx, n_g in enumerate(gpus):
+ cmd = (
+ '"%s" infer/modules/train/extract_feature_print.py %s %s %s %s "%s/logs/%s" %s %s'
+ % (
+ config.python_cmd,
+ config.device,
+ leng,
+ idx,
+ n_g,
+ now_dir,
+ exp_dir,
+ version19,
+ config.is_half,
+ )
+ )
+ logger.info("Execute: " + cmd)
+ p = Popen(
+ cmd, shell=True, cwd=now_dir
+ ) # , shell=True, stdin=PIPE, stdout=PIPE, stderr=PIPE, cwd=now_dir
+ ps.append(p)
+ # 煞笔gr, popen read都非得全跑完了再一次性读取, 不用gr就正常读一句输出一句;只能额外弄出一个文本流定时读
+ done = [False]
+ threading.Thread(
+ target=if_done_multi,
+ args=(
+ done,
+ ps,
+ ),
+ ).start()
+ while 1:
+ with open("%s/logs/%s/extract_f0_feature.log" % (now_dir, exp_dir), "r") as f:
+ yield (f.read())
+ sleep(1)
+ if done[0]:
+ break
+ with open("%s/logs/%s/extract_f0_feature.log" % (now_dir, exp_dir), "r") as f:
+ log = f.read()
+ logger.info(log)
+ yield log
+
+
+def get_pretrained_models(path_str, f0_str, sr2):
+ if_pretrained_generator_exist = os.access(
+ "assets/pretrained%s/%sG%s.pth" % (path_str, f0_str, sr2), os.F_OK
+ )
+ if_pretrained_discriminator_exist = os.access(
+ "assets/pretrained%s/%sD%s.pth" % (path_str, f0_str, sr2), os.F_OK
+ )
+ if not if_pretrained_generator_exist:
+ logger.warning(
+ "assets/pretrained%s/%sG%s.pth not exist, will not use pretrained model",
+ path_str,
+ f0_str,
+ sr2,
+ )
+ if not if_pretrained_discriminator_exist:
+ logger.warning(
+ "assets/pretrained%s/%sD%s.pth not exist, will not use pretrained model",
+ path_str,
+ f0_str,
+ sr2,
+ )
+ return (
+ (
+ "assets/pretrained%s/%sG%s.pth" % (path_str, f0_str, sr2)
+ if if_pretrained_generator_exist
+ else ""
+ ),
+ (
+ "assets/pretrained%s/%sD%s.pth" % (path_str, f0_str, sr2)
+ if if_pretrained_discriminator_exist
+ else ""
+ ),
+ )
+
+
+def change_sr2(sr2, if_f0_3, version19):
+ path_str = "" if version19 == "v1" else "_v2"
+ f0_str = "f0" if if_f0_3 else ""
+ return get_pretrained_models(path_str, f0_str, sr2)
+
+
+def change_version19(sr2, if_f0_3, version19):
+ path_str = "" if version19 == "v1" else "_v2"
+ if sr2 == "32k" and version19 == "v1":
+ sr2 = "40k"
+ to_return_sr2 = (
+ {"choices": ["40k", "48k"], "__type__": "update", "value": sr2}
+ if version19 == "v1"
+ else {"choices": ["40k", "48k", "32k"], "__type__": "update", "value": sr2}
+ )
+ f0_str = "f0" if if_f0_3 else ""
+ return (
+ *get_pretrained_models(path_str, f0_str, sr2),
+ to_return_sr2,
+ )
+
+
+def change_f0(if_f0_3, sr2, version19): # f0method8,pretrained_G14,pretrained_D15
+ path_str = "" if version19 == "v1" else "_v2"
+ return (
+ {"visible": if_f0_3, "__type__": "update"},
+ {"visible": if_f0_3, "__type__": "update"},
+ *get_pretrained_models(path_str, "f0" if if_f0_3 == True else "", sr2),
+ )
+
+
+# but3.click(click_train,[exp_dir1,sr2,if_f0_3,save_epoch10,total_epoch11,batch_size12,if_save_latest13,pretrained_G14,pretrained_D15,gpus16])
+def click_train(
+ exp_dir1,
+ sr2,
+ if_f0_3,
+ spk_id5,
+ save_epoch10,
+ total_epoch11,
+ batch_size12,
+ if_save_latest13,
+ pretrained_G14,
+ pretrained_D15,
+ gpus16,
+ if_cache_gpu17,
+ if_save_every_weights18,
+ version19,
+):
+ # 生成filelist
+ exp_dir = "%s/logs/%s" % (now_dir, exp_dir1)
+ os.makedirs(exp_dir, exist_ok=True)
+ gt_wavs_dir = "%s/0_gt_wavs" % (exp_dir)
+ feature_dir = (
+ "%s/3_feature256" % (exp_dir)
+ if version19 == "v1"
+ else "%s/3_feature768" % (exp_dir)
+ )
+ if if_f0_3:
+ f0_dir = "%s/2a_f0" % (exp_dir)
+ f0nsf_dir = "%s/2b-f0nsf" % (exp_dir)
+ names = (
+ set([name.split(".")[0] for name in os.listdir(gt_wavs_dir)])
+ & set([name.split(".")[0] for name in os.listdir(feature_dir)])
+ & set([name.split(".")[0] for name in os.listdir(f0_dir)])
+ & set([name.split(".")[0] for name in os.listdir(f0nsf_dir)])
+ )
+ else:
+ names = set([name.split(".")[0] for name in os.listdir(gt_wavs_dir)]) & set(
+ [name.split(".")[0] for name in os.listdir(feature_dir)]
+ )
+ opt = []
+ for name in names:
+ if if_f0_3:
+ opt.append(
+ "%s/%s.wav|%s/%s.npy|%s/%s.wav.npy|%s/%s.wav.npy|%s"
+ % (
+ gt_wavs_dir.replace("\\", "\\\\"),
+ name,
+ feature_dir.replace("\\", "\\\\"),
+ name,
+ f0_dir.replace("\\", "\\\\"),
+ name,
+ f0nsf_dir.replace("\\", "\\\\"),
+ name,
+ spk_id5,
+ )
+ )
+ else:
+ opt.append(
+ "%s/%s.wav|%s/%s.npy|%s"
+ % (
+ gt_wavs_dir.replace("\\", "\\\\"),
+ name,
+ feature_dir.replace("\\", "\\\\"),
+ name,
+ spk_id5,
+ )
+ )
+ fea_dim = 256 if version19 == "v1" else 768
+ if if_f0_3:
+ for _ in range(2):
+ opt.append(
+ "%s/logs/mute/0_gt_wavs/mute%s.wav|%s/logs/mute/3_feature%s/mute.npy|%s/logs/mute/2a_f0/mute.wav.npy|%s/logs/mute/2b-f0nsf/mute.wav.npy|%s"
+ % (now_dir, sr2, now_dir, fea_dim, now_dir, now_dir, spk_id5)
+ )
+ else:
+ for _ in range(2):
+ opt.append(
+ "%s/logs/mute/0_gt_wavs/mute%s.wav|%s/logs/mute/3_feature%s/mute.npy|%s"
+ % (now_dir, sr2, now_dir, fea_dim, spk_id5)
+ )
+ shuffle(opt)
+ with open("%s/filelist.txt" % exp_dir, "w") as f:
+ f.write("\n".join(opt))
+ logger.debug("Write filelist done")
+ # 生成config#无需生成config
+ # cmd = python_cmd + " train_nsf_sim_cache_sid_load_pretrain.py -e mi-test -sr 40k -f0 1 -bs 4 -g 0 -te 10 -se 5 -pg pretrained/f0G40k.pth -pd pretrained/f0D40k.pth -l 1 -c 0"
+ logger.info("Use gpus: %s", str(gpus16))
+ if pretrained_G14 == "":
+ logger.info("No pretrained Generator")
+ if pretrained_D15 == "":
+ logger.info("No pretrained Discriminator")
+ if version19 == "v1" or sr2 == "40k":
+ config_path = "v1/%s.json" % sr2
+ else:
+ config_path = "v2/%s.json" % sr2
+ config_save_path = os.path.join(exp_dir, "config.json")
+ if not pathlib.Path(config_save_path).exists():
+ with open(config_save_path, "w", encoding="utf-8") as f:
+ json.dump(
+ config.json_config[config_path],
+ f,
+ ensure_ascii=False,
+ indent=4,
+ sort_keys=True,
+ )
+ f.write("\n")
+ if gpus16:
+ cmd = (
+ '"%s" infer/modules/train/train.py -e "%s" -sr %s -f0 %s -bs %s -g %s -te %s -se %s %s %s -l %s -c %s -sw %s -v %s'
+ % (
+ config.python_cmd,
+ exp_dir1,
+ sr2,
+ 1 if if_f0_3 else 0,
+ batch_size12,
+ gpus16,
+ total_epoch11,
+ save_epoch10,
+ "-pg %s" % pretrained_G14 if pretrained_G14 != "" else "",
+ "-pd %s" % pretrained_D15 if pretrained_D15 != "" else "",
+ 1 if if_save_latest13 == i18n("是") else 0,
+ 1 if if_cache_gpu17 == i18n("是") else 0,
+ 1 if if_save_every_weights18 == i18n("是") else 0,
+ version19,
+ )
+ )
+ else:
+ cmd = (
+ '"%s" infer/modules/train/train.py -e "%s" -sr %s -f0 %s -bs %s -te %s -se %s %s %s -l %s -c %s -sw %s -v %s'
+ % (
+ config.python_cmd,
+ exp_dir1,
+ sr2,
+ 1 if if_f0_3 else 0,
+ batch_size12,
+ total_epoch11,
+ save_epoch10,
+ "-pg %s" % pretrained_G14 if pretrained_G14 != "" else "",
+ "-pd %s" % pretrained_D15 if pretrained_D15 != "" else "",
+ 1 if if_save_latest13 == i18n("是") else 0,
+ 1 if if_cache_gpu17 == i18n("是") else 0,
+ 1 if if_save_every_weights18 == i18n("是") else 0,
+ version19,
+ )
+ )
+ logger.info("Execute: " + cmd)
+ p = Popen(cmd, shell=True, cwd=now_dir)
+ p.wait()
+ return "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log"
+
+
+# but4.click(train_index, [exp_dir1], info3)
+def train_index(exp_dir1, version19):
+ # exp_dir = "%s/logs/%s" % (now_dir, exp_dir1)
+ exp_dir = "logs/%s" % (exp_dir1)
+ os.makedirs(exp_dir, exist_ok=True)
+ feature_dir = (
+ "%s/3_feature256" % (exp_dir)
+ if version19 == "v1"
+ else "%s/3_feature768" % (exp_dir)
+ )
+ if not os.path.exists(feature_dir):
+ return "请先进行特征提取!"
+ listdir_res = list(os.listdir(feature_dir))
+ if len(listdir_res) == 0:
+ return "请先进行特征提取!"
+ infos = []
+ npys = []
+ for name in sorted(listdir_res):
+ phone = np.load("%s/%s" % (feature_dir, name))
+ npys.append(phone)
+ big_npy = np.concatenate(npys, 0)
+ big_npy_idx = np.arange(big_npy.shape[0])
+ np.random.shuffle(big_npy_idx)
+ big_npy = big_npy[big_npy_idx]
+ if big_npy.shape[0] > 2e5:
+ infos.append("Trying doing kmeans %s shape to 10k centers." % big_npy.shape[0])
+ yield "\n".join(infos)
+ try:
+ big_npy = (
+ MiniBatchKMeans(
+ n_clusters=10000,
+ verbose=True,
+ batch_size=256 * config.n_cpu,
+ compute_labels=False,
+ init="random",
+ )
+ .fit(big_npy)
+ .cluster_centers_
+ )
+ except:
+ info = traceback.format_exc()
+ logger.info(info)
+ infos.append(info)
+ yield "\n".join(infos)
+
+ np.save("%s/total_fea.npy" % exp_dir, big_npy)
+ n_ivf = min(int(16 * np.sqrt(big_npy.shape[0])), big_npy.shape[0] // 39)
+ infos.append("%s,%s" % (big_npy.shape, n_ivf))
+ yield "\n".join(infos)
+ index = faiss.index_factory(256 if version19 == "v1" else 768, "IVF%s,Flat" % n_ivf)
+ # index = faiss.index_factory(256if version19=="v1"else 768, "IVF%s,PQ128x4fs,RFlat"%n_ivf)
+ infos.append("training")
+ yield "\n".join(infos)
+ index_ivf = faiss.extract_index_ivf(index) #
+ index_ivf.nprobe = 1
+ index.train(big_npy)
+ faiss.write_index(
+ index,
+ "%s/trained_IVF%s_Flat_nprobe_%s_%s_%s.index"
+ % (exp_dir, n_ivf, index_ivf.nprobe, exp_dir1, version19),
+ )
+ infos.append("adding")
+ yield "\n".join(infos)
+ batch_size_add = 8192
+ for i in range(0, big_npy.shape[0], batch_size_add):
+ index.add(big_npy[i : i + batch_size_add])
+ faiss.write_index(
+ index,
+ "%s/added_IVF%s_Flat_nprobe_%s_%s_%s.index"
+ % (exp_dir, n_ivf, index_ivf.nprobe, exp_dir1, version19),
+ )
+ infos.append(
+ "成功构建索引 added_IVF%s_Flat_nprobe_%s_%s_%s.index"
+ % (n_ivf, index_ivf.nprobe, exp_dir1, version19)
+ )
+ try:
+ link = os.link if platform.system() == "Windows" else os.symlink
+ link(
+ "%s/added_IVF%s_Flat_nprobe_%s_%s_%s.index"
+ % (exp_dir, n_ivf, index_ivf.nprobe, exp_dir1, version19),
+ "%s/%s_IVF%s_Flat_nprobe_%s_%s_%s.index"
+ % (
+ outside_index_root,
+ exp_dir1,
+ n_ivf,
+ index_ivf.nprobe,
+ exp_dir1,
+ version19,
+ ),
+ )
+ infos.append("链接索引到外部-%s" % (outside_index_root))
+ except:
+ infos.append("链接索引到外部-%s失败" % (outside_index_root))
+
+ # faiss.write_index(index, '%s/added_IVF%s_Flat_FastScan_%s.index'%(exp_dir,n_ivf,version19))
+ # infos.append("成功构建索引,added_IVF%s_Flat_FastScan_%s.index"%(n_ivf,version19))
+ yield "\n".join(infos)
+
+
+# but5.click(train1key, [exp_dir1, sr2, if_f0_3, trainset_dir4, spk_id5, gpus6, np7, f0method8, save_epoch10, total_epoch11, batch_size12, if_save_latest13, pretrained_G14, pretrained_D15, gpus16, if_cache_gpu17], info3)
+def train1key(
+ exp_dir1,
+ sr2,
+ if_f0_3,
+ trainset_dir4,
+ spk_id5,
+ np7,
+ f0method8,
+ save_epoch10,
+ total_epoch11,
+ batch_size12,
+ if_save_latest13,
+ pretrained_G14,
+ pretrained_D15,
+ gpus16,
+ if_cache_gpu17,
+ if_save_every_weights18,
+ version19,
+ gpus_rmvpe,
+):
+ infos = []
+
+ def get_info_str(strr):
+ infos.append(strr)
+ return "\n".join(infos)
+
+ # step1:处理数据
+ yield get_info_str(i18n("step1:正在处理数据"))
+ [get_info_str(_) for _ in preprocess_dataset(trainset_dir4, exp_dir1, sr2, np7)]
+
+ # step2a:提取音高
+ yield get_info_str(i18n("step2:正在提取音高&正在提取特征"))
+ [
+ get_info_str(_)
+ for _ in extract_f0_feature(
+ gpus16, np7, f0method8, if_f0_3, exp_dir1, version19, gpus_rmvpe
+ )
+ ]
+
+ # step3a:训练模型
+ yield get_info_str(i18n("step3a:正在训练模型"))
+ click_train(
+ exp_dir1,
+ sr2,
+ if_f0_3,
+ spk_id5,
+ save_epoch10,
+ total_epoch11,
+ batch_size12,
+ if_save_latest13,
+ pretrained_G14,
+ pretrained_D15,
+ gpus16,
+ if_cache_gpu17,
+ if_save_every_weights18,
+ version19,
+ )
+ yield get_info_str(
+ i18n("训练结束, 您可查看控制台训练日志或实验文件夹下的train.log")
+ )
+
+ # step3b:训练索引
+ [get_info_str(_) for _ in train_index(exp_dir1, version19)]
+ yield get_info_str(i18n("全流程结束!"))
+
+
+# ckpt_path2.change(change_info_,[ckpt_path2],[sr__,if_f0__])
+def change_info_(ckpt_path):
+ if not os.path.exists(ckpt_path.replace(os.path.basename(ckpt_path), "train.log")):
+ return {"__type__": "update"}, {"__type__": "update"}, {"__type__": "update"}
+ try:
+ with open(
+ ckpt_path.replace(os.path.basename(ckpt_path), "train.log"), "r"
+ ) as f:
+ info = eval(f.read().strip("\n").split("\n")[0].split("\t")[-1])
+ sr, f0 = info["sample_rate"], info["if_f0"]
+ version = "v2" if ("version" in info and info["version"] == "v2") else "v1"
+ return sr, str(f0), version
+ except:
+ traceback.print_exc()
+ return {"__type__": "update"}, {"__type__": "update"}, {"__type__": "update"}
+
+
+F0GPUVisible = config.dml == False
+
+
+def change_f0_method(f0method8):
+ if f0method8 == "rmvpe_gpu":
+ visible = F0GPUVisible
+ else:
+ visible = False
+ return {"visible": visible, "__type__": "update"}
+
+
+with gr.Blocks(title="RVC WebUI") as app:
+ gr.Markdown("## RVC WebUI")
+ gr.Markdown(
+ value=i18n(
+ "本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责.
如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录LICENSE."
+ )
+ )
+ with gr.Tabs():
+ with gr.TabItem(i18n("模型推理")):
+ with gr.Row():
+ sid0 = gr.Dropdown(label=i18n("推理音色"), choices=sorted(names))
+ with gr.Column():
+ refresh_button = gr.Button(
+ i18n("刷新音色列表和索引路径"), variant="primary"
+ )
+ clean_button = gr.Button(i18n("卸载音色省显存"), variant="primary")
+ spk_item = gr.Slider(
+ minimum=0,
+ maximum=2333,
+ step=1,
+ label=i18n("请选择说话人id"),
+ value=0,
+ visible=False,
+ interactive=True,
+ )
+ clean_button.click(
+ fn=clean, inputs=[], outputs=[sid0], api_name="infer_clean"
+ )
+ with gr.TabItem(i18n("单次推理")):
+ with gr.Group():
+ with gr.Row():
+ with gr.Column():
+ vc_transform0 = gr.Number(
+ label=i18n("变调(整数, 半音数量, 升八度12降八度-12)"),
+ value=0,
+ )
+ input_audio0 = gr.Textbox(
+ label=i18n(
+ "输入待处理音频文件路径(默认是正确格式示例)"
+ ),
+ placeholder="C:\\Users\\Desktop\\audio_example.wav",
+ )
+ file_index1 = gr.Textbox(
+ label=i18n(
+ "特征检索库文件路径,为空则使用下拉的选择结果"
+ ),
+ placeholder="C:\\Users\\Desktop\\model_example.index",
+ interactive=True,
+ )
+ file_index2 = gr.Dropdown(
+ label=i18n("自动检测index路径,下拉式选择(dropdown)"),
+ choices=sorted(index_paths),
+ interactive=True,
+ )
+ f0method0 = gr.Radio(
+ label=i18n(
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU"
+ ),
+ choices=(
+ ["pm", "harvest", "crepe", "rmvpe"]
+ if config.dml == False
+ else ["pm", "harvest", "rmvpe"]
+ ),
+ value="rmvpe",
+ interactive=True,
+ )
+
+ with gr.Column():
+ resample_sr0 = gr.Slider(
+ minimum=0,
+ maximum=48000,
+ label=i18n("后处理重采样至最终采样率,0为不进行重采样"),
+ value=0,
+ step=1,
+ interactive=True,
+ )
+ rms_mix_rate0 = gr.Slider(
+ minimum=0,
+ maximum=1,
+ label=i18n(
+ "输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络"
+ ),
+ value=0.25,
+ interactive=True,
+ )
+ protect0 = gr.Slider(
+ minimum=0,
+ maximum=0.5,
+ label=i18n(
+ "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果"
+ ),
+ value=0.33,
+ step=0.01,
+ interactive=True,
+ )
+ filter_radius0 = gr.Slider(
+ minimum=0,
+ maximum=7,
+ label=i18n(
+ ">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音"
+ ),
+ value=3,
+ step=1,
+ interactive=True,
+ )
+ index_rate1 = gr.Slider(
+ minimum=0,
+ maximum=1,
+ label=i18n("检索特征占比"),
+ value=0.75,
+ interactive=True,
+ )
+ f0_file = gr.File(
+ label=i18n(
+ "F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调"
+ ),
+ visible=False,
+ )
+
+ refresh_button.click(
+ fn=change_choices,
+ inputs=[],
+ outputs=[sid0, file_index2],
+ api_name="infer_refresh",
+ )
+ # file_big_npy1 = gr.Textbox(
+ # label=i18n("特征文件路径"),
+ # value="E:\\codes\py39\\vits_vc_gpu_train\\logs\\mi-test-1key\\total_fea.npy",
+ # interactive=True,
+ # )
+ with gr.Group():
+ with gr.Column():
+ but0 = gr.Button(i18n("转换"), variant="primary")
+ with gr.Row():
+ vc_output1 = gr.Textbox(label=i18n("输出信息"))
+ vc_output2 = gr.Audio(
+ label=i18n("输出音频(右下角三个点,点了可以下载)")
+ )
+
+ but0.click(
+ vc.vc_single,
+ [
+ spk_item,
+ input_audio0,
+ vc_transform0,
+ f0_file,
+ f0method0,
+ file_index1,
+ file_index2,
+ # file_big_npy1,
+ index_rate1,
+ filter_radius0,
+ resample_sr0,
+ rms_mix_rate0,
+ protect0,
+ ],
+ [vc_output1, vc_output2],
+ api_name="infer_convert",
+ )
+ with gr.TabItem(i18n("批量推理")):
+ gr.Markdown(
+ value=i18n(
+ "批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. "
+ )
+ )
+ with gr.Row():
+ with gr.Column():
+ vc_transform1 = gr.Number(
+ label=i18n("变调(整数, 半音数量, 升八度12降八度-12)"),
+ value=0,
+ )
+ opt_input = gr.Textbox(
+ label=i18n("指定输出文件夹"), value="opt"
+ )
+ file_index3 = gr.Textbox(
+ label=i18n("特征检索库文件路径,为空则使用下拉的选择结果"),
+ value="",
+ interactive=True,
+ )
+ file_index4 = gr.Dropdown(
+ label=i18n("自动检测index路径,下拉式选择(dropdown)"),
+ choices=sorted(index_paths),
+ interactive=True,
+ )
+ f0method1 = gr.Radio(
+ label=i18n(
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU"
+ ),
+ choices=(
+ ["pm", "harvest", "crepe", "rmvpe"]
+ if config.dml == False
+ else ["pm", "harvest", "rmvpe"]
+ ),
+ value="rmvpe",
+ interactive=True,
+ )
+ format1 = gr.Radio(
+ label=i18n("导出文件格式"),
+ choices=["wav", "flac", "mp3", "m4a"],
+ value="wav",
+ interactive=True,
+ )
+
+ refresh_button.click(
+ fn=lambda: change_choices()[1],
+ inputs=[],
+ outputs=file_index4,
+ api_name="infer_refresh_batch",
+ )
+ # file_big_npy2 = gr.Textbox(
+ # label=i18n("特征文件路径"),
+ # value="E:\\codes\\py39\\vits_vc_gpu_train\\logs\\mi-test-1key\\total_fea.npy",
+ # interactive=True,
+ # )
+
+ with gr.Column():
+ resample_sr1 = gr.Slider(
+ minimum=0,
+ maximum=48000,
+ label=i18n("后处理重采样至最终采样率,0为不进行重采样"),
+ value=0,
+ step=1,
+ interactive=True,
+ )
+ rms_mix_rate1 = gr.Slider(
+ minimum=0,
+ maximum=1,
+ label=i18n(
+ "输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络"
+ ),
+ value=1,
+ interactive=True,
+ )
+ protect1 = gr.Slider(
+ minimum=0,
+ maximum=0.5,
+ label=i18n(
+ "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果"
+ ),
+ value=0.33,
+ step=0.01,
+ interactive=True,
+ )
+ filter_radius1 = gr.Slider(
+ minimum=0,
+ maximum=7,
+ label=i18n(
+ ">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音"
+ ),
+ value=3,
+ step=1,
+ interactive=True,
+ )
+ index_rate2 = gr.Slider(
+ minimum=0,
+ maximum=1,
+ label=i18n("检索特征占比"),
+ value=1,
+ interactive=True,
+ )
+ with gr.Row():
+ dir_input = gr.Textbox(
+ label=i18n(
+ "输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)"
+ ),
+ placeholder="C:\\Users\\Desktop\\input_vocal_dir",
+ )
+ inputs = gr.File(
+ file_count="multiple",
+ label=i18n("也可批量输入音频文件, 二选一, 优先读文件夹"),
+ )
+
+ with gr.Row():
+ but1 = gr.Button(i18n("转换"), variant="primary")
+ vc_output3 = gr.Textbox(label=i18n("输出信息"))
+
+ but1.click(
+ vc.vc_multi,
+ [
+ spk_item,
+ dir_input,
+ opt_input,
+ inputs,
+ vc_transform1,
+ f0method1,
+ file_index3,
+ file_index4,
+ # file_big_npy2,
+ index_rate2,
+ filter_radius1,
+ resample_sr1,
+ rms_mix_rate1,
+ protect1,
+ format1,
+ ],
+ [vc_output3],
+ api_name="infer_convert_batch",
+ )
+ sid0.change(
+ fn=vc.get_vc,
+ inputs=[sid0, protect0, protect1],
+ outputs=[spk_item, protect0, protect1, file_index2, file_index4],
+ api_name="infer_change_voice",
+ )
+ with gr.TabItem(i18n("伴奏人声分离&去混响&去回声")):
+ with gr.Group():
+ gr.Markdown(
+ value=i18n(
+ "人声伴奏分离批量处理, 使用UVR5模型。
合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。
模型分为三类:
1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点;
2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型;
3、去混响、去延迟模型(by FoxJoy):
(1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;
(234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。
去混响/去延迟,附:
1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;
2、MDX-Net-Dereverb模型挺慢的;
3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。"
+ )
+ )
+ with gr.Row():
+ with gr.Column():
+ dir_wav_input = gr.Textbox(
+ label=i18n("输入待处理音频文件夹路径"),
+ placeholder="C:\\Users\\Desktop\\todo-songs",
+ )
+ wav_inputs = gr.File(
+ file_count="multiple",
+ label=i18n("也可批量输入音频文件, 二选一, 优先读文件夹"),
+ )
+ with gr.Column():
+ model_choose = gr.Dropdown(
+ label=i18n("模型"), choices=uvr5_names
+ )
+ agg = gr.Slider(
+ minimum=0,
+ maximum=20,
+ step=1,
+ label="人声提取激进程度",
+ value=10,
+ interactive=True,
+ visible=False, # 先不开放调整
+ )
+ opt_vocal_root = gr.Textbox(
+ label=i18n("指定输出主人声文件夹"), value="opt"
+ )
+ opt_ins_root = gr.Textbox(
+ label=i18n("指定输出非主人声文件夹"), value="opt"
+ )
+ format0 = gr.Radio(
+ label=i18n("导出文件格式"),
+ choices=["wav", "flac", "mp3", "m4a"],
+ value="flac",
+ interactive=True,
+ )
+ but2 = gr.Button(i18n("转换"), variant="primary")
+ vc_output4 = gr.Textbox(label=i18n("输出信息"))
+ but2.click(
+ uvr,
+ [
+ model_choose,
+ dir_wav_input,
+ opt_vocal_root,
+ wav_inputs,
+ opt_ins_root,
+ agg,
+ format0,
+ ],
+ [vc_output4],
+ api_name="uvr_convert",
+ )
+ with gr.TabItem(i18n("训练")):
+ gr.Markdown(
+ value=i18n(
+ "step1: 填写实验配置. 实验数据放在logs下, 每个实验一个文件夹, 需手工输入实验名路径, 内含实验配置, 日志, 训练得到的模型文件. "
+ )
+ )
+ with gr.Row():
+ exp_dir1 = gr.Textbox(label=i18n("输入实验名"), value="mi-test")
+ sr2 = gr.Radio(
+ label=i18n("目标采样率"),
+ choices=["40k", "48k"],
+ value="40k",
+ interactive=True,
+ )
+ if_f0_3 = gr.Radio(
+ label=i18n("模型是否带音高指导(唱歌一定要, 语音可以不要)"),
+ choices=[i18n("是"), i18n("否")],
+ value=i18n("是"),
+ interactive=True,
+ )
+ version19 = gr.Radio(
+ label=i18n("版本"),
+ choices=["v1", "v2"],
+ value="v2",
+ interactive=True,
+ visible=True,
+ )
+ np7 = gr.Slider(
+ minimum=0,
+ maximum=config.n_cpu,
+ step=1,
+ label=i18n("提取音高和处理数据使用的CPU进程数"),
+ value=int(np.ceil(config.n_cpu / 1.5)),
+ interactive=True,
+ )
+ with gr.Group(): # 暂时单人的, 后面支持最多4人的#数据处理
+ gr.Markdown(
+ value=i18n(
+ "step2a: 自动遍历训练文件夹下所有可解码成音频的文件并进行切片归一化, 在实验目录下生成2个wav文件夹; 暂时只支持单人训练. "
+ )
+ )
+ with gr.Row():
+ trainset_dir4 = gr.Textbox(
+ label=i18n("输入训练文件夹路径"),
+ value=i18n("E:\\语音音频+标注\\米津玄师\\src"),
+ )
+ spk_id5 = gr.Slider(
+ minimum=0,
+ maximum=4,
+ step=1,
+ label=i18n("请指定说话人id"),
+ value=0,
+ interactive=True,
+ )
+ but1 = gr.Button(i18n("处理数据"), variant="primary")
+ info1 = gr.Textbox(label=i18n("输出信息"), value="")
+ but1.click(
+ preprocess_dataset,
+ [trainset_dir4, exp_dir1, sr2, np7],
+ [info1],
+ api_name="train_preprocess",
+ )
+ with gr.Group():
+ gr.Markdown(
+ value=i18n(
+ "step2b: 使用CPU提取音高(如果模型带音高), 使用GPU提取特征(选择卡号)"
+ )
+ )
+ with gr.Row():
+ with gr.Column():
+ gpus6 = gr.Textbox(
+ label=i18n(
+ "以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2"
+ ),
+ value=gpus,
+ interactive=True,
+ visible=F0GPUVisible,
+ )
+ gpu_info9 = gr.Textbox(
+ label=i18n("显卡信息"), value=gpu_info, visible=F0GPUVisible
+ )
+ with gr.Column():
+ f0method8 = gr.Radio(
+ label=i18n(
+ "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU"
+ ),
+ choices=["pm", "harvest", "dio", "rmvpe", "rmvpe_gpu"],
+ value="rmvpe_gpu",
+ interactive=True,
+ )
+ gpus_rmvpe = gr.Textbox(
+ label=i18n(
+ "rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程"
+ ),
+ value="%s-%s" % (gpus, gpus),
+ interactive=True,
+ visible=F0GPUVisible,
+ )
+ but2 = gr.Button(i18n("特征提取"), variant="primary")
+ info2 = gr.Textbox(label=i18n("输出信息"), value="", max_lines=8)
+ f0method8.change(
+ fn=change_f0_method,
+ inputs=[f0method8],
+ outputs=[gpus_rmvpe],
+ )
+ but2.click(
+ extract_f0_feature,
+ [
+ gpus6,
+ np7,
+ f0method8,
+ if_f0_3,
+ exp_dir1,
+ version19,
+ gpus_rmvpe,
+ ],
+ [info2],
+ api_name="train_extract_f0_feature",
+ )
+ with gr.Group():
+ gr.Markdown(value=i18n("step3: 填写训练设置, 开始训练模型和索引"))
+ with gr.Row():
+ save_epoch10 = gr.Slider(
+ minimum=1,
+ maximum=50,
+ step=1,
+ label=i18n("保存频率save_every_epoch"),
+ value=5,
+ interactive=True,
+ )
+ total_epoch11 = gr.Slider(
+ minimum=2,
+ maximum=1000,
+ step=1,
+ label=i18n("总训练轮数total_epoch"),
+ value=20,
+ interactive=True,
+ )
+ batch_size12 = gr.Slider(
+ minimum=1,
+ maximum=40,
+ step=1,
+ label=i18n("每张显卡的batch_size"),
+ value=default_batch_size,
+ interactive=True,
+ )
+ if_save_latest13 = gr.Radio(
+ label=i18n("是否仅保存最新的ckpt文件以节省硬盘空间"),
+ choices=[i18n("是"), i18n("否")],
+ value=i18n("否"),
+ interactive=True,
+ )
+ if_cache_gpu17 = gr.Radio(
+ label=i18n(
+ "是否缓存所有训练集至显存. 10min以下小数据可缓存以加速训练, 大数据缓存会炸显存也加不了多少速"
+ ),
+ choices=[i18n("是"), i18n("否")],
+ value=i18n("否"),
+ interactive=True,
+ )
+ if_save_every_weights18 = gr.Radio(
+ label=i18n(
+ "是否在每次保存时间点将最终小模型保存至weights文件夹"
+ ),
+ choices=[i18n("是"), i18n("否")],
+ value=i18n("否"),
+ interactive=True,
+ )
+ with gr.Row():
+ pretrained_G14 = gr.Textbox(
+ label=i18n("加载预训练底模G路径"),
+ value="assets/pretrained_v2/f0G40k.pth",
+ interactive=True,
+ )
+ pretrained_D15 = gr.Textbox(
+ label=i18n("加载预训练底模D路径"),
+ value="assets/pretrained_v2/f0D40k.pth",
+ interactive=True,
+ )
+ sr2.change(
+ change_sr2,
+ [sr2, if_f0_3, version19],
+ [pretrained_G14, pretrained_D15],
+ )
+ version19.change(
+ change_version19,
+ [sr2, if_f0_3, version19],
+ [pretrained_G14, pretrained_D15, sr2],
+ )
+ if_f0_3.change(
+ change_f0,
+ [if_f0_3, sr2, version19],
+ [f0method8, gpus_rmvpe, pretrained_G14, pretrained_D15],
+ )
+ gpus16 = gr.Textbox(
+ label=i18n(
+ "以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2"
+ ),
+ value=gpus,
+ interactive=True,
+ )
+ but3 = gr.Button(i18n("训练模型"), variant="primary")
+ but4 = gr.Button(i18n("训练特征索引"), variant="primary")
+ but5 = gr.Button(i18n("一键训练"), variant="primary")
+ info3 = gr.Textbox(label=i18n("输出信息"), value="", max_lines=10)
+ but3.click(
+ click_train,
+ [
+ exp_dir1,
+ sr2,
+ if_f0_3,
+ spk_id5,
+ save_epoch10,
+ total_epoch11,
+ batch_size12,
+ if_save_latest13,
+ pretrained_G14,
+ pretrained_D15,
+ gpus16,
+ if_cache_gpu17,
+ if_save_every_weights18,
+ version19,
+ ],
+ info3,
+ api_name="train_start",
+ )
+ but4.click(train_index, [exp_dir1, version19], info3)
+ but5.click(
+ train1key,
+ [
+ exp_dir1,
+ sr2,
+ if_f0_3,
+ trainset_dir4,
+ spk_id5,
+ np7,
+ f0method8,
+ save_epoch10,
+ total_epoch11,
+ batch_size12,
+ if_save_latest13,
+ pretrained_G14,
+ pretrained_D15,
+ gpus16,
+ if_cache_gpu17,
+ if_save_every_weights18,
+ version19,
+ gpus_rmvpe,
+ ],
+ info3,
+ api_name="train_start_all",
+ )
+
+ with gr.TabItem(i18n("ckpt处理")):
+ with gr.Group():
+ gr.Markdown(value=i18n("模型融合, 可用于测试音色融合"))
+ with gr.Row():
+ ckpt_a = gr.Textbox(
+ label=i18n("A模型路径"), value="", interactive=True
+ )
+ ckpt_b = gr.Textbox(
+ label=i18n("B模型路径"), value="", interactive=True
+ )
+ alpha_a = gr.Slider(
+ minimum=0,
+ maximum=1,
+ label=i18n("A模型权重"),
+ value=0.5,
+ interactive=True,
+ )
+ with gr.Row():
+ sr_ = gr.Radio(
+ label=i18n("目标采样率"),
+ choices=["40k", "48k"],
+ value="40k",
+ interactive=True,
+ )
+ if_f0_ = gr.Radio(
+ label=i18n("模型是否带音高指导"),
+ choices=[i18n("是"), i18n("否")],
+ value=i18n("是"),
+ interactive=True,
+ )
+ info__ = gr.Textbox(
+ label=i18n("要置入的模型信息"),
+ value="",
+ max_lines=8,
+ interactive=True,
+ )
+ name_to_save0 = gr.Textbox(
+ label=i18n("保存的模型名不带后缀"),
+ value="",
+ max_lines=1,
+ interactive=True,
+ )
+ version_2 = gr.Radio(
+ label=i18n("模型版本型号"),
+ choices=["v1", "v2"],
+ value="v1",
+ interactive=True,
+ )
+ with gr.Row():
+ but6 = gr.Button(i18n("融合"), variant="primary")
+ info4 = gr.Textbox(label=i18n("输出信息"), value="", max_lines=8)
+ but6.click(
+ merge,
+ [
+ ckpt_a,
+ ckpt_b,
+ alpha_a,
+ sr_,
+ if_f0_,
+ info__,
+ name_to_save0,
+ version_2,
+ ],
+ info4,
+ api_name="ckpt_merge",
+ ) # def merge(path1,path2,alpha1,sr,f0,info):
+ with gr.Group():
+ gr.Markdown(
+ value=i18n("修改模型信息(仅支持weights文件夹下提取的小模型文件)")
+ )
+ with gr.Row():
+ ckpt_path0 = gr.Textbox(
+ label=i18n("模型路径"), value="", interactive=True
+ )
+ info_ = gr.Textbox(
+ label=i18n("要改的模型信息"),
+ value="",
+ max_lines=8,
+ interactive=True,
+ )
+ name_to_save1 = gr.Textbox(
+ label=i18n("保存的文件名, 默认空为和源文件同名"),
+ value="",
+ max_lines=8,
+ interactive=True,
+ )
+ with gr.Row():
+ but7 = gr.Button(i18n("修改"), variant="primary")
+ info5 = gr.Textbox(label=i18n("输出信息"), value="", max_lines=8)
+ but7.click(
+ change_info,
+ [ckpt_path0, info_, name_to_save1],
+ info5,
+ api_name="ckpt_modify",
+ )
+ with gr.Group():
+ gr.Markdown(
+ value=i18n("查看模型信息(仅支持weights文件夹下提取的小模型文件)")
+ )
+ with gr.Row():
+ ckpt_path1 = gr.Textbox(
+ label=i18n("模型路径"), value="", interactive=True
+ )
+ but8 = gr.Button(i18n("查看"), variant="primary")
+ info6 = gr.Textbox(label=i18n("输出信息"), value="", max_lines=8)
+ but8.click(show_info, [ckpt_path1], info6, api_name="ckpt_show")
+ with gr.Group():
+ gr.Markdown(
+ value=i18n(
+ "模型提取(输入logs文件夹下大文件模型路径),适用于训一半不想训了模型没有自动提取保存小文件模型,或者想测试中间模型的情况"
+ )
+ )
+ with gr.Row():
+ ckpt_path2 = gr.Textbox(
+ label=i18n("模型路径"),
+ value="E:\\codes\\py39\\logs\\mi-test_f0_48k\\G_23333.pth",
+ interactive=True,
+ )
+ save_name = gr.Textbox(
+ label=i18n("保存名"), value="", interactive=True
+ )
+ sr__ = gr.Radio(
+ label=i18n("目标采样率"),
+ choices=["32k", "40k", "48k"],
+ value="40k",
+ interactive=True,
+ )
+ if_f0__ = gr.Radio(
+ label=i18n("模型是否带音高指导,1是0否"),
+ choices=["1", "0"],
+ value="1",
+ interactive=True,
+ )
+ version_1 = gr.Radio(
+ label=i18n("模型版本型号"),
+ choices=["v1", "v2"],
+ value="v2",
+ interactive=True,
+ )
+ info___ = gr.Textbox(
+ label=i18n("要置入的模型信息"),
+ value="",
+ max_lines=8,
+ interactive=True,
+ )
+ but9 = gr.Button(i18n("提取"), variant="primary")
+ info7 = gr.Textbox(label=i18n("输出信息"), value="", max_lines=8)
+ ckpt_path2.change(
+ change_info_, [ckpt_path2], [sr__, if_f0__, version_1]
+ )
+ but9.click(
+ extract_small_model,
+ [ckpt_path2, save_name, sr__, if_f0__, info___, version_1],
+ info7,
+ api_name="ckpt_extract",
+ )
+
+ with gr.TabItem(i18n("Onnx导出")):
+ with gr.Row():
+ ckpt_dir = gr.Textbox(
+ label=i18n("RVC模型路径"), value="", interactive=True
+ )
+ with gr.Row():
+ onnx_dir = gr.Textbox(
+ label=i18n("Onnx输出路径"), value="", interactive=True
+ )
+ with gr.Row():
+ infoOnnx = gr.Label(label="info")
+ with gr.Row():
+ butOnnx = gr.Button(i18n("导出Onnx模型"), variant="primary")
+ butOnnx.click(
+ export_onnx, [ckpt_dir, onnx_dir], infoOnnx, api_name="export_onnx"
+ )
+
+ tab_faq = i18n("常见问题解答")
+ with gr.TabItem(tab_faq):
+ try:
+ if tab_faq == "常见问题解答":
+ with open("docs/cn/faq.md", "r", encoding="utf8") as f:
+ info = f.read()
+ else:
+ with open("docs/en/faq_en.md", "r", encoding="utf8") as f:
+ info = f.read()
+ gr.Markdown(value=info)
+ except:
+ gr.Markdown(traceback.format_exc())
+
+ try:
+ if config.iscolab:
+ app.queue(max_size=1022).launch(share=True, max_threads=511)
+ else:
+ app.queue(max_size=1022).launch(
+ max_threads=511,
+ server_name="0.0.0.0",
+ inbrowser=not config.noautoopen,
+ server_port=config.listen_port,
+ quiet=True,
+ )
+ except Exception as e:
+ logger.error(str(e))
diff --git a/infer/lib/audio.py b/infer/lib/audio.py
new file mode 100644
index 0000000000000000000000000000000000000000..89799abbdd1fd3741d16a27407d53765bb3a16cf
--- /dev/null
+++ b/infer/lib/audio.py
@@ -0,0 +1,50 @@
+import platform
+import ffmpeg
+import numpy as np
+import av
+
+
+def wav2(i, o, format):
+ inp = av.open(i, "r")
+ if format == "m4a":
+ format = "mp4"
+ out = av.open(o, "w", format=format)
+ if format == "ogg":
+ format = "libvorbis"
+ if format == "mp4":
+ format = "aac"
+
+ ostream = out.add_stream(format)
+
+ for frame in inp.decode(audio=0):
+ for p in ostream.encode(frame):
+ out.mux(p)
+
+ for p in ostream.encode(None):
+ out.mux(p)
+
+ out.close()
+ inp.close()
+
+
+def load_audio(file, sr):
+ try:
+ # https://github.com/openai/whisper/blob/main/whisper/audio.py#L26
+ # This launches a subprocess to decode audio while down-mixing and resampling as necessary.
+ # Requires the ffmpeg CLI and `ffmpeg-python` package to be installed.
+ file = clean_path(file) # 防止小白拷路径头尾带了空格和"和回车
+ out, _ = (
+ ffmpeg.input(file, threads=0)
+ .output("-", format="f32le", acodec="pcm_f32le", ac=1, ar=sr)
+ .run(cmd=["ffmpeg", "-nostdin"], capture_stdout=True, capture_stderr=True)
+ )
+ except Exception as e:
+ raise RuntimeError(f"Failed to load audio: {e}")
+
+ return np.frombuffer(out, np.float32).flatten()
+
+
+def clean_path(path_str):
+ if platform.system() == "Windows":
+ path_str = path_str.replace("/", "\\")
+ return path_str.strip(" ").strip('"').strip("\n").strip('"').strip(" ")
diff --git a/infer/lib/infer_pack/attentions.py b/infer/lib/infer_pack/attentions.py
new file mode 100644
index 0000000000000000000000000000000000000000..2cc745ae7d2e61ab260c6ba5b65379fb2262a240
--- /dev/null
+++ b/infer/lib/infer_pack/attentions.py
@@ -0,0 +1,459 @@
+import copy
+import math
+from typing import Optional
+
+import numpy as np
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+from infer.lib.infer_pack import commons, modules
+from infer.lib.infer_pack.modules import LayerNorm
+
+
+class Encoder(nn.Module):
+ def __init__(
+ self,
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size=1,
+ p_dropout=0.0,
+ window_size=10,
+ **kwargs
+ ):
+ super(Encoder, self).__init__()
+ self.hidden_channels = hidden_channels
+ self.filter_channels = filter_channels
+ self.n_heads = n_heads
+ self.n_layers = int(n_layers)
+ self.kernel_size = kernel_size
+ self.p_dropout = p_dropout
+ self.window_size = window_size
+
+ self.drop = nn.Dropout(p_dropout)
+ self.attn_layers = nn.ModuleList()
+ self.norm_layers_1 = nn.ModuleList()
+ self.ffn_layers = nn.ModuleList()
+ self.norm_layers_2 = nn.ModuleList()
+ for i in range(self.n_layers):
+ self.attn_layers.append(
+ MultiHeadAttention(
+ hidden_channels,
+ hidden_channels,
+ n_heads,
+ p_dropout=p_dropout,
+ window_size=window_size,
+ )
+ )
+ self.norm_layers_1.append(LayerNorm(hidden_channels))
+ self.ffn_layers.append(
+ FFN(
+ hidden_channels,
+ hidden_channels,
+ filter_channels,
+ kernel_size,
+ p_dropout=p_dropout,
+ )
+ )
+ self.norm_layers_2.append(LayerNorm(hidden_channels))
+
+ def forward(self, x, x_mask):
+ attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
+ x = x * x_mask
+ zippep = zip(
+ self.attn_layers, self.norm_layers_1, self.ffn_layers, self.norm_layers_2
+ )
+ for attn_layers, norm_layers_1, ffn_layers, norm_layers_2 in zippep:
+ y = attn_layers(x, x, attn_mask)
+ y = self.drop(y)
+ x = norm_layers_1(x + y)
+
+ y = ffn_layers(x, x_mask)
+ y = self.drop(y)
+ x = norm_layers_2(x + y)
+ x = x * x_mask
+ return x
+
+
+class Decoder(nn.Module):
+ def __init__(
+ self,
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size=1,
+ p_dropout=0.0,
+ proximal_bias=False,
+ proximal_init=True,
+ **kwargs
+ ):
+ super(Decoder, self).__init__()
+ self.hidden_channels = hidden_channels
+ self.filter_channels = filter_channels
+ self.n_heads = n_heads
+ self.n_layers = n_layers
+ self.kernel_size = kernel_size
+ self.p_dropout = p_dropout
+ self.proximal_bias = proximal_bias
+ self.proximal_init = proximal_init
+
+ self.drop = nn.Dropout(p_dropout)
+ self.self_attn_layers = nn.ModuleList()
+ self.norm_layers_0 = nn.ModuleList()
+ self.encdec_attn_layers = nn.ModuleList()
+ self.norm_layers_1 = nn.ModuleList()
+ self.ffn_layers = nn.ModuleList()
+ self.norm_layers_2 = nn.ModuleList()
+ for i in range(self.n_layers):
+ self.self_attn_layers.append(
+ MultiHeadAttention(
+ hidden_channels,
+ hidden_channels,
+ n_heads,
+ p_dropout=p_dropout,
+ proximal_bias=proximal_bias,
+ proximal_init=proximal_init,
+ )
+ )
+ self.norm_layers_0.append(LayerNorm(hidden_channels))
+ self.encdec_attn_layers.append(
+ MultiHeadAttention(
+ hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout
+ )
+ )
+ self.norm_layers_1.append(LayerNorm(hidden_channels))
+ self.ffn_layers.append(
+ FFN(
+ hidden_channels,
+ hidden_channels,
+ filter_channels,
+ kernel_size,
+ p_dropout=p_dropout,
+ causal=True,
+ )
+ )
+ self.norm_layers_2.append(LayerNorm(hidden_channels))
+
+ def forward(self, x, x_mask, h, h_mask):
+ """
+ x: decoder input
+ h: encoder output
+ """
+ self_attn_mask = commons.subsequent_mask(x_mask.size(2)).to(
+ device=x.device, dtype=x.dtype
+ )
+ encdec_attn_mask = h_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
+ x = x * x_mask
+ for i in range(self.n_layers):
+ y = self.self_attn_layers[i](x, x, self_attn_mask)
+ y = self.drop(y)
+ x = self.norm_layers_0[i](x + y)
+
+ y = self.encdec_attn_layers[i](x, h, encdec_attn_mask)
+ y = self.drop(y)
+ x = self.norm_layers_1[i](x + y)
+
+ y = self.ffn_layers[i](x, x_mask)
+ y = self.drop(y)
+ x = self.norm_layers_2[i](x + y)
+ x = x * x_mask
+ return x
+
+
+class MultiHeadAttention(nn.Module):
+ def __init__(
+ self,
+ channels,
+ out_channels,
+ n_heads,
+ p_dropout=0.0,
+ window_size=None,
+ heads_share=True,
+ block_length=None,
+ proximal_bias=False,
+ proximal_init=False,
+ ):
+ super(MultiHeadAttention, self).__init__()
+ assert channels % n_heads == 0
+
+ self.channels = channels
+ self.out_channels = out_channels
+ self.n_heads = n_heads
+ self.p_dropout = p_dropout
+ self.window_size = window_size
+ self.heads_share = heads_share
+ self.block_length = block_length
+ self.proximal_bias = proximal_bias
+ self.proximal_init = proximal_init
+ self.attn = None
+
+ self.k_channels = channels // n_heads
+ self.conv_q = nn.Conv1d(channels, channels, 1)
+ self.conv_k = nn.Conv1d(channels, channels, 1)
+ self.conv_v = nn.Conv1d(channels, channels, 1)
+ self.conv_o = nn.Conv1d(channels, out_channels, 1)
+ self.drop = nn.Dropout(p_dropout)
+
+ if window_size is not None:
+ n_heads_rel = 1 if heads_share else n_heads
+ rel_stddev = self.k_channels**-0.5
+ self.emb_rel_k = nn.Parameter(
+ torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels)
+ * rel_stddev
+ )
+ self.emb_rel_v = nn.Parameter(
+ torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels)
+ * rel_stddev
+ )
+
+ nn.init.xavier_uniform_(self.conv_q.weight)
+ nn.init.xavier_uniform_(self.conv_k.weight)
+ nn.init.xavier_uniform_(self.conv_v.weight)
+ if proximal_init:
+ with torch.no_grad():
+ self.conv_k.weight.copy_(self.conv_q.weight)
+ self.conv_k.bias.copy_(self.conv_q.bias)
+
+ def forward(
+ self, x: torch.Tensor, c: torch.Tensor, attn_mask: Optional[torch.Tensor] = None
+ ):
+ q = self.conv_q(x)
+ k = self.conv_k(c)
+ v = self.conv_v(c)
+
+ x, _ = self.attention(q, k, v, mask=attn_mask)
+
+ x = self.conv_o(x)
+ return x
+
+ def attention(
+ self,
+ query: torch.Tensor,
+ key: torch.Tensor,
+ value: torch.Tensor,
+ mask: Optional[torch.Tensor] = None,
+ ):
+ # reshape [b, d, t] -> [b, n_h, t, d_k]
+ b, d, t_s = key.size()
+ t_t = query.size(2)
+ query = query.view(b, self.n_heads, self.k_channels, t_t).transpose(2, 3)
+ key = key.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
+ value = value.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
+
+ scores = torch.matmul(query / math.sqrt(self.k_channels), key.transpose(-2, -1))
+ if self.window_size is not None:
+ assert (
+ t_s == t_t
+ ), "Relative attention is only available for self-attention."
+ key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, t_s)
+ rel_logits = self._matmul_with_relative_keys(
+ query / math.sqrt(self.k_channels), key_relative_embeddings
+ )
+ scores_local = self._relative_position_to_absolute_position(rel_logits)
+ scores = scores + scores_local
+ if self.proximal_bias:
+ assert t_s == t_t, "Proximal bias is only available for self-attention."
+ scores = scores + self._attention_bias_proximal(t_s).to(
+ device=scores.device, dtype=scores.dtype
+ )
+ if mask is not None:
+ scores = scores.masked_fill(mask == 0, -1e4)
+ if self.block_length is not None:
+ assert (
+ t_s == t_t
+ ), "Local attention is only available for self-attention."
+ block_mask = (
+ torch.ones_like(scores)
+ .triu(-self.block_length)
+ .tril(self.block_length)
+ )
+ scores = scores.masked_fill(block_mask == 0, -1e4)
+ p_attn = F.softmax(scores, dim=-1) # [b, n_h, t_t, t_s]
+ p_attn = self.drop(p_attn)
+ output = torch.matmul(p_attn, value)
+ if self.window_size is not None:
+ relative_weights = self._absolute_position_to_relative_position(p_attn)
+ value_relative_embeddings = self._get_relative_embeddings(
+ self.emb_rel_v, t_s
+ )
+ output = output + self._matmul_with_relative_values(
+ relative_weights, value_relative_embeddings
+ )
+ output = (
+ output.transpose(2, 3).contiguous().view(b, d, t_t)
+ ) # [b, n_h, t_t, d_k] -> [b, d, t_t]
+ return output, p_attn
+
+ def _matmul_with_relative_values(self, x, y):
+ """
+ x: [b, h, l, m]
+ y: [h or 1, m, d]
+ ret: [b, h, l, d]
+ """
+ ret = torch.matmul(x, y.unsqueeze(0))
+ return ret
+
+ def _matmul_with_relative_keys(self, x, y):
+ """
+ x: [b, h, l, d]
+ y: [h or 1, m, d]
+ ret: [b, h, l, m]
+ """
+ ret = torch.matmul(x, y.unsqueeze(0).transpose(-2, -1))
+ return ret
+
+ def _get_relative_embeddings(self, relative_embeddings, length: int):
+ max_relative_position = 2 * self.window_size + 1
+ # Pad first before slice to avoid using cond ops.
+ pad_length: int = max(length - (self.window_size + 1), 0)
+ slice_start_position = max((self.window_size + 1) - length, 0)
+ slice_end_position = slice_start_position + 2 * length - 1
+ if pad_length > 0:
+ padded_relative_embeddings = F.pad(
+ relative_embeddings,
+ # commons.convert_pad_shape([[0, 0], [pad_length, pad_length], [0, 0]]),
+ [0, 0, pad_length, pad_length, 0, 0],
+ )
+ else:
+ padded_relative_embeddings = relative_embeddings
+ used_relative_embeddings = padded_relative_embeddings[
+ :, slice_start_position:slice_end_position
+ ]
+ return used_relative_embeddings
+
+ def _relative_position_to_absolute_position(self, x):
+ """
+ x: [b, h, l, 2*l-1]
+ ret: [b, h, l, l]
+ """
+ batch, heads, length, _ = x.size()
+ # Concat columns of pad to shift from relative to absolute indexing.
+ x = F.pad(
+ x,
+ # commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, 1]])
+ [0, 1, 0, 0, 0, 0, 0, 0],
+ )
+
+ # Concat extra elements so to add up to shape (len+1, 2*len-1).
+ x_flat = x.view([batch, heads, length * 2 * length])
+ x_flat = F.pad(
+ x_flat,
+ # commons.convert_pad_shape([[0, 0], [0, 0], [0, int(length) - 1]])
+ [0, int(length) - 1, 0, 0, 0, 0],
+ )
+
+ # Reshape and slice out the padded elements.
+ x_final = x_flat.view([batch, heads, length + 1, 2 * length - 1])[
+ :, :, :length, length - 1 :
+ ]
+ return x_final
+
+ def _absolute_position_to_relative_position(self, x):
+ """
+ x: [b, h, l, l]
+ ret: [b, h, l, 2*l-1]
+ """
+ batch, heads, length, _ = x.size()
+ # padd along column
+ x = F.pad(
+ x,
+ # commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, int(length) - 1]])
+ [0, int(length) - 1, 0, 0, 0, 0, 0, 0],
+ )
+ x_flat = x.view([batch, heads, int(length**2) + int(length * (length - 1))])
+ # add 0's in the beginning that will skew the elements after reshape
+ x_flat = F.pad(
+ x_flat,
+ # commons.convert_pad_shape([[0, 0], [0, 0], [int(length), 0]])
+ [length, 0, 0, 0, 0, 0],
+ )
+ x_final = x_flat.view([batch, heads, length, 2 * length])[:, :, :, 1:]
+ return x_final
+
+ def _attention_bias_proximal(self, length: int):
+ """Bias for self-attention to encourage attention to close positions.
+ Args:
+ length: an integer scalar.
+ Returns:
+ a Tensor with shape [1, 1, length, length]
+ """
+ r = torch.arange(length, dtype=torch.float32)
+ diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1)
+ return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0)
+
+
+class FFN(nn.Module):
+ def __init__(
+ self,
+ in_channels,
+ out_channels,
+ filter_channels,
+ kernel_size,
+ p_dropout=0.0,
+ activation: str = None,
+ causal=False,
+ ):
+ super(FFN, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.filter_channels = filter_channels
+ self.kernel_size = kernel_size
+ self.p_dropout = p_dropout
+ self.activation = activation
+ self.causal = causal
+ self.is_activation = True if activation == "gelu" else False
+ # if causal:
+ # self.padding = self._causal_padding
+ # else:
+ # self.padding = self._same_padding
+
+ self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size)
+ self.conv_2 = nn.Conv1d(filter_channels, out_channels, kernel_size)
+ self.drop = nn.Dropout(p_dropout)
+
+ def padding(self, x: torch.Tensor, x_mask: torch.Tensor) -> torch.Tensor:
+ if self.causal:
+ padding = self._causal_padding(x * x_mask)
+ else:
+ padding = self._same_padding(x * x_mask)
+ return padding
+
+ def forward(self, x: torch.Tensor, x_mask: torch.Tensor):
+ x = self.conv_1(self.padding(x, x_mask))
+ if self.is_activation:
+ x = x * torch.sigmoid(1.702 * x)
+ else:
+ x = torch.relu(x)
+ x = self.drop(x)
+
+ x = self.conv_2(self.padding(x, x_mask))
+ return x * x_mask
+
+ def _causal_padding(self, x):
+ if self.kernel_size == 1:
+ return x
+ pad_l: int = self.kernel_size - 1
+ pad_r: int = 0
+ # padding = [[0, 0], [0, 0], [pad_l, pad_r]]
+ x = F.pad(
+ x,
+ # commons.convert_pad_shape(padding)
+ [pad_l, pad_r, 0, 0, 0, 0],
+ )
+ return x
+
+ def _same_padding(self, x):
+ if self.kernel_size == 1:
+ return x
+ pad_l: int = (self.kernel_size - 1) // 2
+ pad_r: int = self.kernel_size // 2
+ # padding = [[0, 0], [0, 0], [pad_l, pad_r]]
+ x = F.pad(
+ x,
+ # commons.convert_pad_shape(padding)
+ [pad_l, pad_r, 0, 0, 0, 0],
+ )
+ return x
diff --git a/infer/lib/infer_pack/attentions_onnx.py b/infer/lib/infer_pack/attentions_onnx.py
new file mode 100644
index 0000000000000000000000000000000000000000..934c58bc94108bb620cbff32a56ea4b9666dbd80
--- /dev/null
+++ b/infer/lib/infer_pack/attentions_onnx.py
@@ -0,0 +1,459 @@
+import copy
+import math
+from typing import Optional
+
+import numpy as np
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+from infer.lib.infer_pack import commons, modules
+from infer.lib.infer_pack.modules import LayerNorm
+
+
+class Encoder(nn.Module):
+ def __init__(
+ self,
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size=1,
+ p_dropout=0.0,
+ window_size=10,
+ **kwargs
+ ):
+ super(Encoder, self).__init__()
+ self.hidden_channels = hidden_channels
+ self.filter_channels = filter_channels
+ self.n_heads = n_heads
+ self.n_layers = int(n_layers)
+ self.kernel_size = kernel_size
+ self.p_dropout = p_dropout
+ self.window_size = window_size
+
+ self.drop = nn.Dropout(p_dropout)
+ self.attn_layers = nn.ModuleList()
+ self.norm_layers_1 = nn.ModuleList()
+ self.ffn_layers = nn.ModuleList()
+ self.norm_layers_2 = nn.ModuleList()
+ for i in range(self.n_layers):
+ self.attn_layers.append(
+ MultiHeadAttention(
+ hidden_channels,
+ hidden_channels,
+ n_heads,
+ p_dropout=p_dropout,
+ window_size=window_size,
+ )
+ )
+ self.norm_layers_1.append(LayerNorm(hidden_channels))
+ self.ffn_layers.append(
+ FFN(
+ hidden_channels,
+ hidden_channels,
+ filter_channels,
+ kernel_size,
+ p_dropout=p_dropout,
+ )
+ )
+ self.norm_layers_2.append(LayerNorm(hidden_channels))
+
+ def forward(self, x, x_mask):
+ attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
+ x = x * x_mask
+ zippep = zip(
+ self.attn_layers, self.norm_layers_1, self.ffn_layers, self.norm_layers_2
+ )
+ for attn_layers, norm_layers_1, ffn_layers, norm_layers_2 in zippep:
+ y = attn_layers(x, x, attn_mask)
+ y = self.drop(y)
+ x = norm_layers_1(x + y)
+
+ y = ffn_layers(x, x_mask)
+ y = self.drop(y)
+ x = norm_layers_2(x + y)
+ x = x * x_mask
+ return x
+
+
+class Decoder(nn.Module):
+ def __init__(
+ self,
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size=1,
+ p_dropout=0.0,
+ proximal_bias=False,
+ proximal_init=True,
+ **kwargs
+ ):
+ super(Decoder, self).__init__()
+ self.hidden_channels = hidden_channels
+ self.filter_channels = filter_channels
+ self.n_heads = n_heads
+ self.n_layers = n_layers
+ self.kernel_size = kernel_size
+ self.p_dropout = p_dropout
+ self.proximal_bias = proximal_bias
+ self.proximal_init = proximal_init
+
+ self.drop = nn.Dropout(p_dropout)
+ self.self_attn_layers = nn.ModuleList()
+ self.norm_layers_0 = nn.ModuleList()
+ self.encdec_attn_layers = nn.ModuleList()
+ self.norm_layers_1 = nn.ModuleList()
+ self.ffn_layers = nn.ModuleList()
+ self.norm_layers_2 = nn.ModuleList()
+ for i in range(self.n_layers):
+ self.self_attn_layers.append(
+ MultiHeadAttention(
+ hidden_channels,
+ hidden_channels,
+ n_heads,
+ p_dropout=p_dropout,
+ proximal_bias=proximal_bias,
+ proximal_init=proximal_init,
+ )
+ )
+ self.norm_layers_0.append(LayerNorm(hidden_channels))
+ self.encdec_attn_layers.append(
+ MultiHeadAttention(
+ hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout
+ )
+ )
+ self.norm_layers_1.append(LayerNorm(hidden_channels))
+ self.ffn_layers.append(
+ FFN(
+ hidden_channels,
+ hidden_channels,
+ filter_channels,
+ kernel_size,
+ p_dropout=p_dropout,
+ causal=True,
+ )
+ )
+ self.norm_layers_2.append(LayerNorm(hidden_channels))
+
+ def forward(self, x, x_mask, h, h_mask):
+ """
+ x: decoder input
+ h: encoder output
+ """
+ self_attn_mask = commons.subsequent_mask(x_mask.size(2)).to(
+ device=x.device, dtype=x.dtype
+ )
+ encdec_attn_mask = h_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
+ x = x * x_mask
+ for i in range(self.n_layers):
+ y = self.self_attn_layers[i](x, x, self_attn_mask)
+ y = self.drop(y)
+ x = self.norm_layers_0[i](x + y)
+
+ y = self.encdec_attn_layers[i](x, h, encdec_attn_mask)
+ y = self.drop(y)
+ x = self.norm_layers_1[i](x + y)
+
+ y = self.ffn_layers[i](x, x_mask)
+ y = self.drop(y)
+ x = self.norm_layers_2[i](x + y)
+ x = x * x_mask
+ return x
+
+
+class MultiHeadAttention(nn.Module):
+ def __init__(
+ self,
+ channels,
+ out_channels,
+ n_heads,
+ p_dropout=0.0,
+ window_size=None,
+ heads_share=True,
+ block_length=None,
+ proximal_bias=False,
+ proximal_init=False,
+ ):
+ super(MultiHeadAttention, self).__init__()
+ assert channels % n_heads == 0
+
+ self.channels = channels
+ self.out_channels = out_channels
+ self.n_heads = n_heads
+ self.p_dropout = p_dropout
+ self.window_size = window_size
+ self.heads_share = heads_share
+ self.block_length = block_length
+ self.proximal_bias = proximal_bias
+ self.proximal_init = proximal_init
+ self.attn = None
+
+ self.k_channels = channels // n_heads
+ self.conv_q = nn.Conv1d(channels, channels, 1)
+ self.conv_k = nn.Conv1d(channels, channels, 1)
+ self.conv_v = nn.Conv1d(channels, channels, 1)
+ self.conv_o = nn.Conv1d(channels, out_channels, 1)
+ self.drop = nn.Dropout(p_dropout)
+
+ if window_size is not None:
+ n_heads_rel = 1 if heads_share else n_heads
+ rel_stddev = self.k_channels**-0.5
+ self.emb_rel_k = nn.Parameter(
+ torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels)
+ * rel_stddev
+ )
+ self.emb_rel_v = nn.Parameter(
+ torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels)
+ * rel_stddev
+ )
+
+ nn.init.xavier_uniform_(self.conv_q.weight)
+ nn.init.xavier_uniform_(self.conv_k.weight)
+ nn.init.xavier_uniform_(self.conv_v.weight)
+ if proximal_init:
+ with torch.no_grad():
+ self.conv_k.weight.copy_(self.conv_q.weight)
+ self.conv_k.bias.copy_(self.conv_q.bias)
+
+ def forward(
+ self, x: torch.Tensor, c: torch.Tensor, attn_mask: Optional[torch.Tensor] = None
+ ):
+ q = self.conv_q(x)
+ k = self.conv_k(c)
+ v = self.conv_v(c)
+
+ x, _ = self.attention(q, k, v, mask=attn_mask)
+
+ x = self.conv_o(x)
+ return x
+
+ def attention(
+ self,
+ query: torch.Tensor,
+ key: torch.Tensor,
+ value: torch.Tensor,
+ mask: Optional[torch.Tensor] = None,
+ ):
+ # reshape [b, d, t] -> [b, n_h, t, d_k]
+ b, d, t_s = key.size()
+ t_t = query.size(2)
+ query = query.view(b, self.n_heads, self.k_channels, t_t).transpose(2, 3)
+ key = key.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
+ value = value.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
+
+ scores = torch.matmul(query / math.sqrt(self.k_channels), key.transpose(-2, -1))
+ if self.window_size is not None:
+ assert (
+ t_s == t_t
+ ), "Relative attention is only available for self-attention."
+ key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, t_s)
+ rel_logits = self._matmul_with_relative_keys(
+ query / math.sqrt(self.k_channels), key_relative_embeddings
+ )
+ scores_local = self._relative_position_to_absolute_position(rel_logits)
+ scores = scores + scores_local
+ if self.proximal_bias:
+ assert t_s == t_t, "Proximal bias is only available for self-attention."
+ scores = scores + self._attention_bias_proximal(t_s).to(
+ device=scores.device, dtype=scores.dtype
+ )
+ if mask is not None:
+ scores = scores.masked_fill(mask == 0, -1e4)
+ if self.block_length is not None:
+ assert (
+ t_s == t_t
+ ), "Local attention is only available for self-attention."
+ block_mask = (
+ torch.ones_like(scores)
+ .triu(-self.block_length)
+ .tril(self.block_length)
+ )
+ scores = scores.masked_fill(block_mask == 0, -1e4)
+ p_attn = F.softmax(scores, dim=-1) # [b, n_h, t_t, t_s]
+ p_attn = self.drop(p_attn)
+ output = torch.matmul(p_attn, value)
+ if self.window_size is not None:
+ relative_weights = self._absolute_position_to_relative_position(p_attn)
+ value_relative_embeddings = self._get_relative_embeddings(
+ self.emb_rel_v, t_s
+ )
+ output = output + self._matmul_with_relative_values(
+ relative_weights, value_relative_embeddings
+ )
+ output = (
+ output.transpose(2, 3).contiguous().view(b, d, t_t)
+ ) # [b, n_h, t_t, d_k] -> [b, d, t_t]
+ return output, p_attn
+
+ def _matmul_with_relative_values(self, x, y):
+ """
+ x: [b, h, l, m]
+ y: [h or 1, m, d]
+ ret: [b, h, l, d]
+ """
+ ret = torch.matmul(x, y.unsqueeze(0))
+ return ret
+
+ def _matmul_with_relative_keys(self, x, y):
+ """
+ x: [b, h, l, d]
+ y: [h or 1, m, d]
+ ret: [b, h, l, m]
+ """
+ ret = torch.matmul(x, y.unsqueeze(0).transpose(-2, -1))
+ return ret
+
+ def _get_relative_embeddings(self, relative_embeddings, length: int):
+ max_relative_position = 2 * self.window_size + 1
+ # Pad first before slice to avoid using cond ops.
+ pad_length: int = max(length - (self.window_size + 1), 0)
+ slice_start_position = max((self.window_size + 1) - length, 0)
+ slice_end_position = slice_start_position + 2 * length - 1
+ if pad_length > 0:
+ padded_relative_embeddings = F.pad(
+ relative_embeddings,
+ # commons.convert_pad_shape([[0, 0], [pad_length, pad_length], [0, 0]]),
+ [0, 0, pad_length, pad_length, 0, 0],
+ )
+ else:
+ padded_relative_embeddings = relative_embeddings
+ used_relative_embeddings = padded_relative_embeddings[
+ :, slice_start_position:slice_end_position
+ ]
+ return used_relative_embeddings
+
+ def _relative_position_to_absolute_position(self, x):
+ """
+ x: [b, h, l, 2*l-1]
+ ret: [b, h, l, l]
+ """
+ batch, heads, length, _ = x.size()
+ # Concat columns of pad to shift from relative to absolute indexing.
+ x = F.pad(
+ x,
+ # commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, 1]])
+ [0, 1, 0, 0, 0, 0, 0, 0],
+ )
+
+ # Concat extra elements so to add up to shape (len+1, 2*len-1).
+ x_flat = x.view([batch, heads, length * 2 * length])
+ x_flat = F.pad(
+ x_flat,
+ # commons.convert_pad_shape([[0, 0], [0, 0], [0, int(length) - 1]])
+ [0, length - 1, 0, 0, 0, 0],
+ )
+
+ # Reshape and slice out the padded elements.
+ x_final = x_flat.view([batch, heads, length + 1, 2 * length - 1])[
+ :, :, :length, length - 1 :
+ ]
+ return x_final
+
+ def _absolute_position_to_relative_position(self, x):
+ """
+ x: [b, h, l, l]
+ ret: [b, h, l, 2*l-1]
+ """
+ batch, heads, length, _ = x.size()
+ # padd along column
+ x = F.pad(
+ x,
+ # commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, int(length) - 1]])
+ [0, length - 1, 0, 0, 0, 0, 0, 0],
+ )
+ x_flat = x.view([batch, heads, (length**2) + (length * (length - 1))])
+ # add 0's in the beginning that will skew the elements after reshape
+ x_flat = F.pad(
+ x_flat,
+ # commons.convert_pad_shape([[0, 0], [0, 0], [int(length), 0]])
+ [length, 0, 0, 0, 0, 0],
+ )
+ x_final = x_flat.view([batch, heads, length, 2 * length])[:, :, :, 1:]
+ return x_final
+
+ def _attention_bias_proximal(self, length: int):
+ """Bias for self-attention to encourage attention to close positions.
+ Args:
+ length: an integer scalar.
+ Returns:
+ a Tensor with shape [1, 1, length, length]
+ """
+ r = torch.arange(length, dtype=torch.float32)
+ diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1)
+ return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0)
+
+
+class FFN(nn.Module):
+ def __init__(
+ self,
+ in_channels,
+ out_channels,
+ filter_channels,
+ kernel_size,
+ p_dropout=0.0,
+ activation: str = None,
+ causal=False,
+ ):
+ super(FFN, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.filter_channels = filter_channels
+ self.kernel_size = kernel_size
+ self.p_dropout = p_dropout
+ self.activation = activation
+ self.causal = causal
+ self.is_activation = True if activation == "gelu" else False
+ # if causal:
+ # self.padding = self._causal_padding
+ # else:
+ # self.padding = self._same_padding
+
+ self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size)
+ self.conv_2 = nn.Conv1d(filter_channels, out_channels, kernel_size)
+ self.drop = nn.Dropout(p_dropout)
+
+ def padding(self, x: torch.Tensor, x_mask: torch.Tensor) -> torch.Tensor:
+ if self.causal:
+ padding = self._causal_padding(x * x_mask)
+ else:
+ padding = self._same_padding(x * x_mask)
+ return padding
+
+ def forward(self, x: torch.Tensor, x_mask: torch.Tensor):
+ x = self.conv_1(self.padding(x, x_mask))
+ if self.is_activation:
+ x = x * torch.sigmoid(1.702 * x)
+ else:
+ x = torch.relu(x)
+ x = self.drop(x)
+
+ x = self.conv_2(self.padding(x, x_mask))
+ return x * x_mask
+
+ def _causal_padding(self, x):
+ if self.kernel_size == 1:
+ return x
+ pad_l: int = self.kernel_size - 1
+ pad_r: int = 0
+ # padding = [[0, 0], [0, 0], [pad_l, pad_r]]
+ x = F.pad(
+ x,
+ # commons.convert_pad_shape(padding)
+ [pad_l, pad_r, 0, 0, 0, 0],
+ )
+ return x
+
+ def _same_padding(self, x):
+ if self.kernel_size == 1:
+ return x
+ pad_l: int = (self.kernel_size - 1) // 2
+ pad_r: int = self.kernel_size // 2
+ # padding = [[0, 0], [0, 0], [pad_l, pad_r]]
+ x = F.pad(
+ x,
+ # commons.convert_pad_shape(padding)
+ [pad_l, pad_r, 0, 0, 0, 0],
+ )
+ return x
diff --git a/infer/lib/infer_pack/commons.py b/infer/lib/infer_pack/commons.py
new file mode 100644
index 0000000000000000000000000000000000000000..4ec6c244e228647b125429f62b8c9fddbe40eba9
--- /dev/null
+++ b/infer/lib/infer_pack/commons.py
@@ -0,0 +1,172 @@
+from typing import List, Optional
+import math
+
+import numpy as np
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+
+def init_weights(m, mean=0.0, std=0.01):
+ classname = m.__class__.__name__
+ if classname.find("Conv") != -1:
+ m.weight.data.normal_(mean, std)
+
+
+def get_padding(kernel_size, dilation=1):
+ return int((kernel_size * dilation - dilation) / 2)
+
+
+# def convert_pad_shape(pad_shape):
+# l = pad_shape[::-1]
+# pad_shape = [item for sublist in l for item in sublist]
+# return pad_shape
+
+
+def kl_divergence(m_p, logs_p, m_q, logs_q):
+ """KL(P||Q)"""
+ kl = (logs_q - logs_p) - 0.5
+ kl += (
+ 0.5 * (torch.exp(2.0 * logs_p) + ((m_p - m_q) ** 2)) * torch.exp(-2.0 * logs_q)
+ )
+ return kl
+
+
+def rand_gumbel(shape):
+ """Sample from the Gumbel distribution, protect from overflows."""
+ uniform_samples = torch.rand(shape) * 0.99998 + 0.00001
+ return -torch.log(-torch.log(uniform_samples))
+
+
+def rand_gumbel_like(x):
+ g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device)
+ return g
+
+
+def slice_segments(x, ids_str, segment_size=4):
+ ret = torch.zeros_like(x[:, :, :segment_size])
+ for i in range(x.size(0)):
+ idx_str = ids_str[i]
+ idx_end = idx_str + segment_size
+ ret[i] = x[i, :, idx_str:idx_end]
+ return ret
+
+
+def slice_segments2(x, ids_str, segment_size=4):
+ ret = torch.zeros_like(x[:, :segment_size])
+ for i in range(x.size(0)):
+ idx_str = ids_str[i]
+ idx_end = idx_str + segment_size
+ ret[i] = x[i, idx_str:idx_end]
+ return ret
+
+
+def rand_slice_segments(x, x_lengths=None, segment_size=4):
+ b, d, t = x.size()
+ if x_lengths is None:
+ x_lengths = t
+ ids_str_max = x_lengths - segment_size + 1
+ ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long)
+ ret = slice_segments(x, ids_str, segment_size)
+ return ret, ids_str
+
+
+def get_timing_signal_1d(length, channels, min_timescale=1.0, max_timescale=1.0e4):
+ position = torch.arange(length, dtype=torch.float)
+ num_timescales = channels // 2
+ log_timescale_increment = math.log(float(max_timescale) / float(min_timescale)) / (
+ num_timescales - 1
+ )
+ inv_timescales = min_timescale * torch.exp(
+ torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment
+ )
+ scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1)
+ signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0)
+ signal = F.pad(signal, [0, 0, 0, channels % 2])
+ signal = signal.view(1, channels, length)
+ return signal
+
+
+def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4):
+ b, channels, length = x.size()
+ signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
+ return x + signal.to(dtype=x.dtype, device=x.device)
+
+
+def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1):
+ b, channels, length = x.size()
+ signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
+ return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis)
+
+
+def subsequent_mask(length):
+ mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0)
+ return mask
+
+
+@torch.jit.script
+def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
+ n_channels_int = n_channels[0]
+ in_act = input_a + input_b
+ t_act = torch.tanh(in_act[:, :n_channels_int, :])
+ s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
+ acts = t_act * s_act
+ return acts
+
+
+# def convert_pad_shape(pad_shape):
+# l = pad_shape[::-1]
+# pad_shape = [item for sublist in l for item in sublist]
+# return pad_shape
+
+
+def convert_pad_shape(pad_shape: List[List[int]]) -> List[int]:
+ return torch.tensor(pad_shape).flip(0).reshape(-1).int().tolist()
+
+
+def shift_1d(x):
+ x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1]
+ return x
+
+
+def sequence_mask(length: torch.Tensor, max_length: Optional[int] = None):
+ if max_length is None:
+ max_length = length.max()
+ x = torch.arange(max_length, dtype=length.dtype, device=length.device)
+ return x.unsqueeze(0) < length.unsqueeze(1)
+
+
+def generate_path(duration, mask):
+ """
+ duration: [b, 1, t_x]
+ mask: [b, 1, t_y, t_x]
+ """
+ device = duration.device
+
+ b, _, t_y, t_x = mask.shape
+ cum_duration = torch.cumsum(duration, -1)
+
+ cum_duration_flat = cum_duration.view(b * t_x)
+ path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
+ path = path.view(b, t_x, t_y)
+ path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1]
+ path = path.unsqueeze(1).transpose(2, 3) * mask
+ return path
+
+
+def clip_grad_value_(parameters, clip_value, norm_type=2):
+ if isinstance(parameters, torch.Tensor):
+ parameters = [parameters]
+ parameters = list(filter(lambda p: p.grad is not None, parameters))
+ norm_type = float(norm_type)
+ if clip_value is not None:
+ clip_value = float(clip_value)
+
+ total_norm = 0
+ for p in parameters:
+ param_norm = p.grad.data.norm(norm_type)
+ total_norm += param_norm.item() ** norm_type
+ if clip_value is not None:
+ p.grad.data.clamp_(min=-clip_value, max=clip_value)
+ total_norm = total_norm ** (1.0 / norm_type)
+ return total_norm
diff --git a/infer/lib/infer_pack/models.py b/infer/lib/infer_pack/models.py
new file mode 100644
index 0000000000000000000000000000000000000000..a1a27e2e6c4681cbf466e350e064adcca499f97f
--- /dev/null
+++ b/infer/lib/infer_pack/models.py
@@ -0,0 +1,1242 @@
+import math
+import logging
+from typing import Optional
+
+logger = logging.getLogger(__name__)
+
+import numpy as np
+import torch
+from torch import nn
+from torch.nn import AvgPool1d, Conv1d, Conv2d, ConvTranspose1d
+from torch.nn import functional as F
+from torch.nn.utils import remove_weight_norm, spectral_norm, weight_norm
+from infer.lib.infer_pack import attentions, commons, modules
+from infer.lib.infer_pack.commons import get_padding, init_weights
+
+has_xpu = bool(hasattr(torch, "xpu") and torch.xpu.is_available())
+
+
+class TextEncoder(nn.Module):
+ def __init__(
+ self,
+ in_channels,
+ out_channels,
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size,
+ p_dropout,
+ f0=True,
+ ):
+ super(TextEncoder, self).__init__()
+ self.out_channels = out_channels
+ self.hidden_channels = hidden_channels
+ self.filter_channels = filter_channels
+ self.n_heads = n_heads
+ self.n_layers = n_layers
+ self.kernel_size = kernel_size
+ self.p_dropout = float(p_dropout)
+ self.emb_phone = nn.Linear(in_channels, hidden_channels)
+ self.lrelu = nn.LeakyReLU(0.1, inplace=True)
+ if f0 == True:
+ self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
+ self.encoder = attentions.Encoder(
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size,
+ float(p_dropout),
+ )
+ self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
+
+ def forward(
+ self,
+ phone: torch.Tensor,
+ pitch: torch.Tensor,
+ lengths: torch.Tensor,
+ skip_head: Optional[torch.Tensor] = None,
+ ):
+ if pitch is None:
+ x = self.emb_phone(phone)
+ else:
+ x = self.emb_phone(phone) + self.emb_pitch(pitch)
+ x = x * math.sqrt(self.hidden_channels) # [b, t, h]
+ x = self.lrelu(x)
+ x = torch.transpose(x, 1, -1) # [b, h, t]
+ x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
+ x.dtype
+ )
+ x = self.encoder(x * x_mask, x_mask)
+ if skip_head is not None:
+ assert isinstance(skip_head, torch.Tensor)
+ head = int(skip_head.item())
+ x = x[:, :, head:]
+ x_mask = x_mask[:, :, head:]
+ stats = self.proj(x) * x_mask
+ m, logs = torch.split(stats, self.out_channels, dim=1)
+ return m, logs, x_mask
+
+
+class ResidualCouplingBlock(nn.Module):
+ def __init__(
+ self,
+ channels,
+ hidden_channels,
+ kernel_size,
+ dilation_rate,
+ n_layers,
+ n_flows=4,
+ gin_channels=0,
+ ):
+ super(ResidualCouplingBlock, self).__init__()
+ self.channels = channels
+ self.hidden_channels = hidden_channels
+ self.kernel_size = kernel_size
+ self.dilation_rate = dilation_rate
+ self.n_layers = n_layers
+ self.n_flows = n_flows
+ self.gin_channels = gin_channels
+
+ self.flows = nn.ModuleList()
+ for i in range(n_flows):
+ self.flows.append(
+ modules.ResidualCouplingLayer(
+ channels,
+ hidden_channels,
+ kernel_size,
+ dilation_rate,
+ n_layers,
+ gin_channels=gin_channels,
+ mean_only=True,
+ )
+ )
+ self.flows.append(modules.Flip())
+
+ def forward(
+ self,
+ x: torch.Tensor,
+ x_mask: torch.Tensor,
+ g: Optional[torch.Tensor] = None,
+ reverse: bool = False,
+ ):
+ if not reverse:
+ for flow in self.flows:
+ x, _ = flow(x, x_mask, g=g, reverse=reverse)
+ else:
+ for flow in self.flows[::-1]:
+ x, _ = flow.forward(x, x_mask, g=g, reverse=reverse)
+ return x
+
+ def remove_weight_norm(self):
+ for i in range(self.n_flows):
+ self.flows[i * 2].remove_weight_norm()
+
+ def __prepare_scriptable__(self):
+ for i in range(self.n_flows):
+ for hook in self.flows[i * 2]._forward_pre_hooks.values():
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(self.flows[i * 2])
+
+ return self
+
+
+class PosteriorEncoder(nn.Module):
+ def __init__(
+ self,
+ in_channels,
+ out_channels,
+ hidden_channels,
+ kernel_size,
+ dilation_rate,
+ n_layers,
+ gin_channels=0,
+ ):
+ super(PosteriorEncoder, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.hidden_channels = hidden_channels
+ self.kernel_size = kernel_size
+ self.dilation_rate = dilation_rate
+ self.n_layers = n_layers
+ self.gin_channels = gin_channels
+
+ self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
+ self.enc = modules.WN(
+ hidden_channels,
+ kernel_size,
+ dilation_rate,
+ n_layers,
+ gin_channels=gin_channels,
+ )
+ self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
+
+ def forward(
+ self, x: torch.Tensor, x_lengths: torch.Tensor, g: Optional[torch.Tensor] = None
+ ):
+ x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(
+ x.dtype
+ )
+ x = self.pre(x) * x_mask
+ x = self.enc(x, x_mask, g=g)
+ stats = self.proj(x) * x_mask
+ m, logs = torch.split(stats, self.out_channels, dim=1)
+ z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask
+ return z, m, logs, x_mask
+
+ def remove_weight_norm(self):
+ self.enc.remove_weight_norm()
+
+ def __prepare_scriptable__(self):
+ for hook in self.enc._forward_pre_hooks.values():
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(self.enc)
+ return self
+
+
+class Generator(torch.nn.Module):
+ def __init__(
+ self,
+ initial_channel,
+ resblock,
+ resblock_kernel_sizes,
+ resblock_dilation_sizes,
+ upsample_rates,
+ upsample_initial_channel,
+ upsample_kernel_sizes,
+ gin_channels=0,
+ ):
+ super(Generator, self).__init__()
+ self.num_kernels = len(resblock_kernel_sizes)
+ self.num_upsamples = len(upsample_rates)
+ self.conv_pre = Conv1d(
+ initial_channel, upsample_initial_channel, 7, 1, padding=3
+ )
+ resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
+
+ self.ups = nn.ModuleList()
+ for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
+ self.ups.append(
+ weight_norm(
+ ConvTranspose1d(
+ upsample_initial_channel // (2**i),
+ upsample_initial_channel // (2 ** (i + 1)),
+ k,
+ u,
+ padding=(k - u) // 2,
+ )
+ )
+ )
+
+ self.resblocks = nn.ModuleList()
+ for i in range(len(self.ups)):
+ ch = upsample_initial_channel // (2 ** (i + 1))
+ for j, (k, d) in enumerate(
+ zip(resblock_kernel_sizes, resblock_dilation_sizes)
+ ):
+ self.resblocks.append(resblock(ch, k, d))
+
+ self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
+ self.ups.apply(init_weights)
+
+ if gin_channels != 0:
+ self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
+
+ def forward(
+ self,
+ x: torch.Tensor,
+ g: Optional[torch.Tensor] = None,
+ n_res: Optional[torch.Tensor] = None,
+ ):
+ if n_res is not None:
+ assert isinstance(n_res, torch.Tensor)
+ n = int(n_res.item())
+ if n != x.shape[-1]:
+ x = F.interpolate(x, size=n, mode="linear")
+ x = self.conv_pre(x)
+ if g is not None:
+ x = x + self.cond(g)
+
+ for i in range(self.num_upsamples):
+ x = F.leaky_relu(x, modules.LRELU_SLOPE)
+ x = self.ups[i](x)
+ xs = None
+ for j in range(self.num_kernels):
+ if xs is None:
+ xs = self.resblocks[i * self.num_kernels + j](x)
+ else:
+ xs += self.resblocks[i * self.num_kernels + j](x)
+ x = xs / self.num_kernels
+ x = F.leaky_relu(x)
+ x = self.conv_post(x)
+ x = torch.tanh(x)
+
+ return x
+
+ def __prepare_scriptable__(self):
+ for l in self.ups:
+ for hook in l._forward_pre_hooks.values():
+ # The hook we want to remove is an instance of WeightNorm class, so
+ # normally we would do `if isinstance(...)` but this class is not accessible
+ # because of shadowing, so we check the module name directly.
+ # https://github.com/pytorch/pytorch/blob/be0ca00c5ce260eb5bcec3237357f7a30cc08983/torch/nn/utils/__init__.py#L3
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(l)
+
+ for l in self.resblocks:
+ for hook in l._forward_pre_hooks.values():
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(l)
+ return self
+
+ def remove_weight_norm(self):
+ for l in self.ups:
+ remove_weight_norm(l)
+ for l in self.resblocks:
+ l.remove_weight_norm()
+
+
+class SineGen(torch.nn.Module):
+ """Definition of sine generator
+ SineGen(samp_rate, harmonic_num = 0,
+ sine_amp = 0.1, noise_std = 0.003,
+ voiced_threshold = 0,
+ flag_for_pulse=False)
+ samp_rate: sampling rate in Hz
+ harmonic_num: number of harmonic overtones (default 0)
+ sine_amp: amplitude of sine-wavefrom (default 0.1)
+ noise_std: std of Gaussian noise (default 0.003)
+ voiced_thoreshold: F0 threshold for U/V classification (default 0)
+ flag_for_pulse: this SinGen is used inside PulseGen (default False)
+ Note: when flag_for_pulse is True, the first time step of a voiced
+ segment is always sin(torch.pi) or cos(0)
+ """
+
+ def __init__(
+ self,
+ samp_rate,
+ harmonic_num=0,
+ sine_amp=0.1,
+ noise_std=0.003,
+ voiced_threshold=0,
+ flag_for_pulse=False,
+ ):
+ super(SineGen, self).__init__()
+ self.sine_amp = sine_amp
+ self.noise_std = noise_std
+ self.harmonic_num = harmonic_num
+ self.dim = self.harmonic_num + 1
+ self.sampling_rate = samp_rate
+ self.voiced_threshold = voiced_threshold
+
+ def _f02uv(self, f0):
+ # generate uv signal
+ uv = torch.ones_like(f0)
+ uv = uv * (f0 > self.voiced_threshold)
+ if uv.device.type == "privateuseone": # for DirectML
+ uv = uv.float()
+ return uv
+
+ def forward(self, f0: torch.Tensor, upp: int):
+ """sine_tensor, uv = forward(f0)
+ input F0: tensor(batchsize=1, length, dim=1)
+ f0 for unvoiced steps should be 0
+ output sine_tensor: tensor(batchsize=1, length, dim)
+ output uv: tensor(batchsize=1, length, 1)
+ """
+ with torch.no_grad():
+ f0 = f0[:, None].transpose(1, 2)
+ f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim, device=f0.device)
+ # fundamental component
+ f0_buf[:, :, 0] = f0[:, :, 0]
+ for idx in range(self.harmonic_num):
+ f0_buf[:, :, idx + 1] = f0_buf[:, :, 0] * (
+ idx + 2
+ ) # idx + 2: the (idx+1)-th overtone, (idx+2)-th harmonic
+ rad_values = (
+ f0_buf / self.sampling_rate
+ ) % 1 ###%1意味着n_har的乘积无法后处理优化
+ rand_ini = torch.rand(
+ f0_buf.shape[0], f0_buf.shape[2], device=f0_buf.device
+ )
+ rand_ini[:, 0] = 0
+ rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini
+ tmp_over_one = torch.cumsum(
+ rad_values, 1
+ ) # % 1 #####%1意味着后面的cumsum无法再优化
+ tmp_over_one *= upp
+ tmp_over_one = F.interpolate(
+ tmp_over_one.transpose(2, 1),
+ scale_factor=float(upp),
+ mode="linear",
+ align_corners=True,
+ ).transpose(2, 1)
+ rad_values = F.interpolate(
+ rad_values.transpose(2, 1), scale_factor=float(upp), mode="nearest"
+ ).transpose(
+ 2, 1
+ ) #######
+ tmp_over_one %= 1
+ tmp_over_one_idx = (tmp_over_one[:, 1:, :] - tmp_over_one[:, :-1, :]) < 0
+ cumsum_shift = torch.zeros_like(rad_values)
+ cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
+ sine_waves = torch.sin(
+ torch.cumsum(rad_values + cumsum_shift, dim=1) * 2 * torch.pi
+ )
+ sine_waves = sine_waves * self.sine_amp
+ uv = self._f02uv(f0)
+ uv = F.interpolate(
+ uv.transpose(2, 1), scale_factor=float(upp), mode="nearest"
+ ).transpose(2, 1)
+ noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
+ noise = noise_amp * torch.randn_like(sine_waves)
+ sine_waves = sine_waves * uv + noise
+ return sine_waves, uv, noise
+
+
+class SourceModuleHnNSF(torch.nn.Module):
+ """SourceModule for hn-nsf
+ SourceModule(sampling_rate, harmonic_num=0, sine_amp=0.1,
+ add_noise_std=0.003, voiced_threshod=0)
+ sampling_rate: sampling_rate in Hz
+ harmonic_num: number of harmonic above F0 (default: 0)
+ sine_amp: amplitude of sine source signal (default: 0.1)
+ add_noise_std: std of additive Gaussian noise (default: 0.003)
+ note that amplitude of noise in unvoiced is decided
+ by sine_amp
+ voiced_threshold: threhold to set U/V given F0 (default: 0)
+ Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
+ F0_sampled (batchsize, length, 1)
+ Sine_source (batchsize, length, 1)
+ noise_source (batchsize, length 1)
+ uv (batchsize, length, 1)
+ """
+
+ def __init__(
+ self,
+ sampling_rate,
+ harmonic_num=0,
+ sine_amp=0.1,
+ add_noise_std=0.003,
+ voiced_threshod=0,
+ is_half=True,
+ ):
+ super(SourceModuleHnNSF, self).__init__()
+
+ self.sine_amp = sine_amp
+ self.noise_std = add_noise_std
+ self.is_half = is_half
+ # to produce sine waveforms
+ self.l_sin_gen = SineGen(
+ sampling_rate, harmonic_num, sine_amp, add_noise_std, voiced_threshod
+ )
+
+ # to merge source harmonics into a single excitation
+ self.l_linear = torch.nn.Linear(harmonic_num + 1, 1)
+ self.l_tanh = torch.nn.Tanh()
+ # self.ddtype:int = -1
+
+ def forward(self, x: torch.Tensor, upp: int = 1):
+ # if self.ddtype ==-1:
+ # self.ddtype = self.l_linear.weight.dtype
+ sine_wavs, uv, _ = self.l_sin_gen(x, upp)
+ # print(x.dtype,sine_wavs.dtype,self.l_linear.weight.dtype)
+ # if self.is_half:
+ # sine_wavs = sine_wavs.half()
+ # sine_merge = self.l_tanh(self.l_linear(sine_wavs.to(x)))
+ # print(sine_wavs.dtype,self.ddtype)
+ # if sine_wavs.dtype != self.l_linear.weight.dtype:
+ sine_wavs = sine_wavs.to(dtype=self.l_linear.weight.dtype)
+ sine_merge = self.l_tanh(self.l_linear(sine_wavs))
+ return sine_merge, None, None # noise, uv
+
+
+class GeneratorNSF(torch.nn.Module):
+ def __init__(
+ self,
+ initial_channel,
+ resblock,
+ resblock_kernel_sizes,
+ resblock_dilation_sizes,
+ upsample_rates,
+ upsample_initial_channel,
+ upsample_kernel_sizes,
+ gin_channels,
+ sr,
+ is_half=False,
+ ):
+ super(GeneratorNSF, self).__init__()
+ self.num_kernels = len(resblock_kernel_sizes)
+ self.num_upsamples = len(upsample_rates)
+
+ self.f0_upsamp = torch.nn.Upsample(scale_factor=math.prod(upsample_rates))
+ self.m_source = SourceModuleHnNSF(
+ sampling_rate=sr, harmonic_num=0, is_half=is_half
+ )
+ self.noise_convs = nn.ModuleList()
+ self.conv_pre = Conv1d(
+ initial_channel, upsample_initial_channel, 7, 1, padding=3
+ )
+ resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
+
+ self.ups = nn.ModuleList()
+ for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
+ c_cur = upsample_initial_channel // (2 ** (i + 1))
+ self.ups.append(
+ weight_norm(
+ ConvTranspose1d(
+ upsample_initial_channel // (2**i),
+ upsample_initial_channel // (2 ** (i + 1)),
+ k,
+ u,
+ padding=(k - u) // 2,
+ )
+ )
+ )
+ if i + 1 < len(upsample_rates):
+ stride_f0 = math.prod(upsample_rates[i + 1 :])
+ self.noise_convs.append(
+ Conv1d(
+ 1,
+ c_cur,
+ kernel_size=stride_f0 * 2,
+ stride=stride_f0,
+ padding=stride_f0 // 2,
+ )
+ )
+ else:
+ self.noise_convs.append(Conv1d(1, c_cur, kernel_size=1))
+
+ self.resblocks = nn.ModuleList()
+ for i in range(len(self.ups)):
+ ch = upsample_initial_channel // (2 ** (i + 1))
+ for j, (k, d) in enumerate(
+ zip(resblock_kernel_sizes, resblock_dilation_sizes)
+ ):
+ self.resblocks.append(resblock(ch, k, d))
+
+ self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
+ self.ups.apply(init_weights)
+
+ if gin_channels != 0:
+ self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
+
+ self.upp = math.prod(upsample_rates)
+
+ self.lrelu_slope = modules.LRELU_SLOPE
+
+ def forward(
+ self,
+ x,
+ f0,
+ g: Optional[torch.Tensor] = None,
+ n_res: Optional[torch.Tensor] = None,
+ ):
+ har_source, noi_source, uv = self.m_source(f0, self.upp)
+ har_source = har_source.transpose(1, 2)
+ if n_res is not None:
+ assert isinstance(n_res, torch.Tensor)
+ n = int(n_res.item())
+ if n * self.upp != har_source.shape[-1]:
+ har_source = F.interpolate(har_source, size=n * self.upp, mode="linear")
+ if n != x.shape[-1]:
+ x = F.interpolate(x, size=n, mode="linear")
+ x = self.conv_pre(x)
+ if g is not None:
+ x = x + self.cond(g)
+ # torch.jit.script() does not support direct indexing of torch modules
+ # That's why I wrote this
+ for i, (ups, noise_convs) in enumerate(zip(self.ups, self.noise_convs)):
+ if i < self.num_upsamples:
+ x = F.leaky_relu(x, self.lrelu_slope)
+ x = ups(x)
+ x_source = noise_convs(har_source)
+ x = x + x_source
+ xs: Optional[torch.Tensor] = None
+ l = [i * self.num_kernels + j for j in range(self.num_kernels)]
+ for j, resblock in enumerate(self.resblocks):
+ if j in l:
+ if xs is None:
+ xs = resblock(x)
+ else:
+ xs += resblock(x)
+ # This assertion cannot be ignored! \
+ # If ignored, it will cause torch.jit.script() compilation errors
+ assert isinstance(xs, torch.Tensor)
+ x = xs / self.num_kernels
+ x = F.leaky_relu(x)
+ x = self.conv_post(x)
+ x = torch.tanh(x)
+
+ return x
+
+ def remove_weight_norm(self):
+ for l in self.ups:
+ remove_weight_norm(l)
+ for l in self.resblocks:
+ l.remove_weight_norm()
+
+ def __prepare_scriptable__(self):
+ for l in self.ups:
+ for hook in l._forward_pre_hooks.values():
+ # The hook we want to remove is an instance of WeightNorm class, so
+ # normally we would do `if isinstance(...)` but this class is not accessible
+ # because of shadowing, so we check the module name directly.
+ # https://github.com/pytorch/pytorch/blob/be0ca00c5ce260eb5bcec3237357f7a30cc08983/torch/nn/utils/__init__.py#L3
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(l)
+ for l in self.resblocks:
+ for hook in self.resblocks._forward_pre_hooks.values():
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(l)
+ return self
+
+
+sr2sr = {
+ "32k": 32000,
+ "40k": 40000,
+ "48k": 48000,
+}
+
+
+class SynthesizerTrnMs256NSFsid(nn.Module):
+ def __init__(
+ self,
+ spec_channels,
+ segment_size,
+ inter_channels,
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size,
+ p_dropout,
+ resblock,
+ resblock_kernel_sizes,
+ resblock_dilation_sizes,
+ upsample_rates,
+ upsample_initial_channel,
+ upsample_kernel_sizes,
+ spk_embed_dim,
+ gin_channels,
+ sr,
+ **kwargs
+ ):
+ super(SynthesizerTrnMs256NSFsid, self).__init__()
+ if isinstance(sr, str):
+ sr = sr2sr[sr]
+ self.spec_channels = spec_channels
+ self.inter_channels = inter_channels
+ self.hidden_channels = hidden_channels
+ self.filter_channels = filter_channels
+ self.n_heads = n_heads
+ self.n_layers = n_layers
+ self.kernel_size = kernel_size
+ self.p_dropout = float(p_dropout)
+ self.resblock = resblock
+ self.resblock_kernel_sizes = resblock_kernel_sizes
+ self.resblock_dilation_sizes = resblock_dilation_sizes
+ self.upsample_rates = upsample_rates
+ self.upsample_initial_channel = upsample_initial_channel
+ self.upsample_kernel_sizes = upsample_kernel_sizes
+ self.segment_size = segment_size
+ self.gin_channels = gin_channels
+ # self.hop_length = hop_length#
+ self.spk_embed_dim = spk_embed_dim
+ self.enc_p = TextEncoder(
+ 256,
+ inter_channels,
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size,
+ float(p_dropout),
+ )
+ self.dec = GeneratorNSF(
+ inter_channels,
+ resblock,
+ resblock_kernel_sizes,
+ resblock_dilation_sizes,
+ upsample_rates,
+ upsample_initial_channel,
+ upsample_kernel_sizes,
+ gin_channels=gin_channels,
+ sr=sr,
+ is_half=kwargs["is_half"],
+ )
+ self.enc_q = PosteriorEncoder(
+ spec_channels,
+ inter_channels,
+ hidden_channels,
+ 5,
+ 1,
+ 16,
+ gin_channels=gin_channels,
+ )
+ self.flow = ResidualCouplingBlock(
+ inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
+ )
+ self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
+ logger.debug(
+ "gin_channels: "
+ + str(gin_channels)
+ + ", self.spk_embed_dim: "
+ + str(self.spk_embed_dim)
+ )
+
+ def remove_weight_norm(self):
+ self.dec.remove_weight_norm()
+ self.flow.remove_weight_norm()
+ if hasattr(self, "enc_q"):
+ self.enc_q.remove_weight_norm()
+
+ def __prepare_scriptable__(self):
+ for hook in self.dec._forward_pre_hooks.values():
+ # The hook we want to remove is an instance of WeightNorm class, so
+ # normally we would do `if isinstance(...)` but this class is not accessible
+ # because of shadowing, so we check the module name directly.
+ # https://github.com/pytorch/pytorch/blob/be0ca00c5ce260eb5bcec3237357f7a30cc08983/torch/nn/utils/__init__.py#L3
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(self.dec)
+ for hook in self.flow._forward_pre_hooks.values():
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(self.flow)
+ if hasattr(self, "enc_q"):
+ for hook in self.enc_q._forward_pre_hooks.values():
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(self.enc_q)
+ return self
+
+ @torch.jit.ignore
+ def forward(
+ self,
+ phone: torch.Tensor,
+ phone_lengths: torch.Tensor,
+ pitch: torch.Tensor,
+ pitchf: torch.Tensor,
+ y: torch.Tensor,
+ y_lengths: torch.Tensor,
+ ds: Optional[torch.Tensor] = None,
+ ): # 这里ds是id,[bs,1]
+ # print(1,pitch.shape)#[bs,t]
+ g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
+ m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
+ z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
+ z_p = self.flow(z, y_mask, g=g)
+ z_slice, ids_slice = commons.rand_slice_segments(
+ z, y_lengths, self.segment_size
+ )
+ # print(-1,pitchf.shape,ids_slice,self.segment_size,self.hop_length,self.segment_size//self.hop_length)
+ pitchf = commons.slice_segments2(pitchf, ids_slice, self.segment_size)
+ # print(-2,pitchf.shape,z_slice.shape)
+ o = self.dec(z_slice, pitchf, g=g)
+ return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
+
+ @torch.jit.export
+ def infer(
+ self,
+ phone: torch.Tensor,
+ phone_lengths: torch.Tensor,
+ pitch: torch.Tensor,
+ nsff0: torch.Tensor,
+ sid: torch.Tensor,
+ skip_head: Optional[torch.Tensor] = None,
+ return_length: Optional[torch.Tensor] = None,
+ return_length2: Optional[torch.Tensor] = None,
+ ):
+ g = self.emb_g(sid).unsqueeze(-1)
+ if skip_head is not None and return_length is not None:
+ assert isinstance(skip_head, torch.Tensor)
+ assert isinstance(return_length, torch.Tensor)
+ head = int(skip_head.item())
+ length = int(return_length.item())
+ flow_head = torch.clamp(skip_head - 24, min=0)
+ dec_head = head - int(flow_head.item())
+ m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths, flow_head)
+ z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
+ z = self.flow(z_p, x_mask, g=g, reverse=True)
+ z = z[:, :, dec_head : dec_head + length]
+ x_mask = x_mask[:, :, dec_head : dec_head + length]
+ nsff0 = nsff0[:, head : head + length]
+ else:
+ m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
+ z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
+ z = self.flow(z_p, x_mask, g=g, reverse=True)
+ o = self.dec(z * x_mask, nsff0, g=g, n_res=return_length2)
+ return o, x_mask, (z, z_p, m_p, logs_p)
+
+
+class SynthesizerTrnMs768NSFsid(SynthesizerTrnMs256NSFsid):
+ def __init__(
+ self,
+ spec_channels,
+ segment_size,
+ inter_channels,
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size,
+ p_dropout,
+ resblock,
+ resblock_kernel_sizes,
+ resblock_dilation_sizes,
+ upsample_rates,
+ upsample_initial_channel,
+ upsample_kernel_sizes,
+ spk_embed_dim,
+ gin_channels,
+ sr,
+ **kwargs
+ ):
+ super(SynthesizerTrnMs768NSFsid, self).__init__(
+ spec_channels,
+ segment_size,
+ inter_channels,
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size,
+ p_dropout,
+ resblock,
+ resblock_kernel_sizes,
+ resblock_dilation_sizes,
+ upsample_rates,
+ upsample_initial_channel,
+ upsample_kernel_sizes,
+ spk_embed_dim,
+ gin_channels,
+ sr,
+ **kwargs
+ )
+ del self.enc_p
+ self.enc_p = TextEncoder(
+ 768,
+ inter_channels,
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size,
+ float(p_dropout),
+ )
+
+
+class SynthesizerTrnMs256NSFsid_nono(nn.Module):
+ def __init__(
+ self,
+ spec_channels,
+ segment_size,
+ inter_channels,
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size,
+ p_dropout,
+ resblock,
+ resblock_kernel_sizes,
+ resblock_dilation_sizes,
+ upsample_rates,
+ upsample_initial_channel,
+ upsample_kernel_sizes,
+ spk_embed_dim,
+ gin_channels,
+ sr=None,
+ **kwargs
+ ):
+ super(SynthesizerTrnMs256NSFsid_nono, self).__init__()
+ self.spec_channels = spec_channels
+ self.inter_channels = inter_channels
+ self.hidden_channels = hidden_channels
+ self.filter_channels = filter_channels
+ self.n_heads = n_heads
+ self.n_layers = n_layers
+ self.kernel_size = kernel_size
+ self.p_dropout = float(p_dropout)
+ self.resblock = resblock
+ self.resblock_kernel_sizes = resblock_kernel_sizes
+ self.resblock_dilation_sizes = resblock_dilation_sizes
+ self.upsample_rates = upsample_rates
+ self.upsample_initial_channel = upsample_initial_channel
+ self.upsample_kernel_sizes = upsample_kernel_sizes
+ self.segment_size = segment_size
+ self.gin_channels = gin_channels
+ # self.hop_length = hop_length#
+ self.spk_embed_dim = spk_embed_dim
+ self.enc_p = TextEncoder(
+ 256,
+ inter_channels,
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size,
+ float(p_dropout),
+ f0=False,
+ )
+ self.dec = Generator(
+ inter_channels,
+ resblock,
+ resblock_kernel_sizes,
+ resblock_dilation_sizes,
+ upsample_rates,
+ upsample_initial_channel,
+ upsample_kernel_sizes,
+ gin_channels=gin_channels,
+ )
+ self.enc_q = PosteriorEncoder(
+ spec_channels,
+ inter_channels,
+ hidden_channels,
+ 5,
+ 1,
+ 16,
+ gin_channels=gin_channels,
+ )
+ self.flow = ResidualCouplingBlock(
+ inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
+ )
+ self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
+ logger.debug(
+ "gin_channels: "
+ + str(gin_channels)
+ + ", self.spk_embed_dim: "
+ + str(self.spk_embed_dim)
+ )
+
+ def remove_weight_norm(self):
+ self.dec.remove_weight_norm()
+ self.flow.remove_weight_norm()
+ if hasattr(self, "enc_q"):
+ self.enc_q.remove_weight_norm()
+
+ def __prepare_scriptable__(self):
+ for hook in self.dec._forward_pre_hooks.values():
+ # The hook we want to remove is an instance of WeightNorm class, so
+ # normally we would do `if isinstance(...)` but this class is not accessible
+ # because of shadowing, so we check the module name directly.
+ # https://github.com/pytorch/pytorch/blob/be0ca00c5ce260eb5bcec3237357f7a30cc08983/torch/nn/utils/__init__.py#L3
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(self.dec)
+ for hook in self.flow._forward_pre_hooks.values():
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(self.flow)
+ if hasattr(self, "enc_q"):
+ for hook in self.enc_q._forward_pre_hooks.values():
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(self.enc_q)
+ return self
+
+ @torch.jit.ignore
+ def forward(self, phone, phone_lengths, y, y_lengths, ds): # 这里ds是id,[bs,1]
+ g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
+ m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
+ z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
+ z_p = self.flow(z, y_mask, g=g)
+ z_slice, ids_slice = commons.rand_slice_segments(
+ z, y_lengths, self.segment_size
+ )
+ o = self.dec(z_slice, g=g)
+ return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
+
+ @torch.jit.export
+ def infer(
+ self,
+ phone: torch.Tensor,
+ phone_lengths: torch.Tensor,
+ sid: torch.Tensor,
+ skip_head: Optional[torch.Tensor] = None,
+ return_length: Optional[torch.Tensor] = None,
+ return_length2: Optional[torch.Tensor] = None,
+ ):
+ g = self.emb_g(sid).unsqueeze(-1)
+ if skip_head is not None and return_length is not None:
+ assert isinstance(skip_head, torch.Tensor)
+ assert isinstance(return_length, torch.Tensor)
+ head = int(skip_head.item())
+ length = int(return_length.item())
+ flow_head = torch.clamp(skip_head - 24, min=0)
+ dec_head = head - int(flow_head.item())
+ m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths, flow_head)
+ z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
+ z = self.flow(z_p, x_mask, g=g, reverse=True)
+ z = z[:, :, dec_head : dec_head + length]
+ x_mask = x_mask[:, :, dec_head : dec_head + length]
+ else:
+ m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
+ z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
+ z = self.flow(z_p, x_mask, g=g, reverse=True)
+ o = self.dec(z * x_mask, g=g, n_res=return_length2)
+ return o, x_mask, (z, z_p, m_p, logs_p)
+
+
+class SynthesizerTrnMs768NSFsid_nono(SynthesizerTrnMs256NSFsid_nono):
+ def __init__(
+ self,
+ spec_channels,
+ segment_size,
+ inter_channels,
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size,
+ p_dropout,
+ resblock,
+ resblock_kernel_sizes,
+ resblock_dilation_sizes,
+ upsample_rates,
+ upsample_initial_channel,
+ upsample_kernel_sizes,
+ spk_embed_dim,
+ gin_channels,
+ sr=None,
+ **kwargs
+ ):
+ super(SynthesizerTrnMs768NSFsid_nono, self).__init__(
+ spec_channels,
+ segment_size,
+ inter_channels,
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size,
+ p_dropout,
+ resblock,
+ resblock_kernel_sizes,
+ resblock_dilation_sizes,
+ upsample_rates,
+ upsample_initial_channel,
+ upsample_kernel_sizes,
+ spk_embed_dim,
+ gin_channels,
+ sr,
+ **kwargs
+ )
+ del self.enc_p
+ self.enc_p = TextEncoder(
+ 768,
+ inter_channels,
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size,
+ float(p_dropout),
+ f0=False,
+ )
+
+
+class MultiPeriodDiscriminator(torch.nn.Module):
+ def __init__(self, use_spectral_norm=False):
+ super(MultiPeriodDiscriminator, self).__init__()
+ periods = [2, 3, 5, 7, 11, 17]
+ # periods = [3, 5, 7, 11, 17, 23, 37]
+
+ discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
+ discs = discs + [
+ DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods
+ ]
+ self.discriminators = nn.ModuleList(discs)
+
+ def forward(self, y, y_hat):
+ y_d_rs = [] #
+ y_d_gs = []
+ fmap_rs = []
+ fmap_gs = []
+ for i, d in enumerate(self.discriminators):
+ y_d_r, fmap_r = d(y)
+ y_d_g, fmap_g = d(y_hat)
+ # for j in range(len(fmap_r)):
+ # print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape)
+ y_d_rs.append(y_d_r)
+ y_d_gs.append(y_d_g)
+ fmap_rs.append(fmap_r)
+ fmap_gs.append(fmap_g)
+
+ return y_d_rs, y_d_gs, fmap_rs, fmap_gs
+
+
+class MultiPeriodDiscriminatorV2(torch.nn.Module):
+ def __init__(self, use_spectral_norm=False):
+ super(MultiPeriodDiscriminatorV2, self).__init__()
+ # periods = [2, 3, 5, 7, 11, 17]
+ periods = [2, 3, 5, 7, 11, 17, 23, 37]
+
+ discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
+ discs = discs + [
+ DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods
+ ]
+ self.discriminators = nn.ModuleList(discs)
+
+ def forward(self, y, y_hat):
+ y_d_rs = [] #
+ y_d_gs = []
+ fmap_rs = []
+ fmap_gs = []
+ for i, d in enumerate(self.discriminators):
+ y_d_r, fmap_r = d(y)
+ y_d_g, fmap_g = d(y_hat)
+ # for j in range(len(fmap_r)):
+ # print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape)
+ y_d_rs.append(y_d_r)
+ y_d_gs.append(y_d_g)
+ fmap_rs.append(fmap_r)
+ fmap_gs.append(fmap_g)
+
+ return y_d_rs, y_d_gs, fmap_rs, fmap_gs
+
+
+class DiscriminatorS(torch.nn.Module):
+ def __init__(self, use_spectral_norm=False):
+ super(DiscriminatorS, self).__init__()
+ norm_f = weight_norm if use_spectral_norm == False else spectral_norm
+ self.convs = nn.ModuleList(
+ [
+ norm_f(Conv1d(1, 16, 15, 1, padding=7)),
+ norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)),
+ norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)),
+ norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)),
+ norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)),
+ norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
+ ]
+ )
+ self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
+
+ def forward(self, x):
+ fmap = []
+
+ for l in self.convs:
+ x = l(x)
+ x = F.leaky_relu(x, modules.LRELU_SLOPE)
+ fmap.append(x)
+ x = self.conv_post(x)
+ fmap.append(x)
+ x = torch.flatten(x, 1, -1)
+
+ return x, fmap
+
+
+class DiscriminatorP(torch.nn.Module):
+ def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):
+ super(DiscriminatorP, self).__init__()
+ self.period = period
+ self.use_spectral_norm = use_spectral_norm
+ norm_f = weight_norm if use_spectral_norm == False else spectral_norm
+ self.convs = nn.ModuleList(
+ [
+ norm_f(
+ Conv2d(
+ 1,
+ 32,
+ (kernel_size, 1),
+ (stride, 1),
+ padding=(get_padding(kernel_size, 1), 0),
+ )
+ ),
+ norm_f(
+ Conv2d(
+ 32,
+ 128,
+ (kernel_size, 1),
+ (stride, 1),
+ padding=(get_padding(kernel_size, 1), 0),
+ )
+ ),
+ norm_f(
+ Conv2d(
+ 128,
+ 512,
+ (kernel_size, 1),
+ (stride, 1),
+ padding=(get_padding(kernel_size, 1), 0),
+ )
+ ),
+ norm_f(
+ Conv2d(
+ 512,
+ 1024,
+ (kernel_size, 1),
+ (stride, 1),
+ padding=(get_padding(kernel_size, 1), 0),
+ )
+ ),
+ norm_f(
+ Conv2d(
+ 1024,
+ 1024,
+ (kernel_size, 1),
+ 1,
+ padding=(get_padding(kernel_size, 1), 0),
+ )
+ ),
+ ]
+ )
+ self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
+
+ def forward(self, x):
+ fmap = []
+
+ # 1d to 2d
+ b, c, t = x.shape
+ if t % self.period != 0: # pad first
+ n_pad = self.period - (t % self.period)
+ if has_xpu and x.dtype == torch.bfloat16:
+ x = F.pad(x.to(dtype=torch.float16), (0, n_pad), "reflect").to(
+ dtype=torch.bfloat16
+ )
+ else:
+ x = F.pad(x, (0, n_pad), "reflect")
+ t = t + n_pad
+ x = x.view(b, c, t // self.period, self.period)
+
+ for l in self.convs:
+ x = l(x)
+ x = F.leaky_relu(x, modules.LRELU_SLOPE)
+ fmap.append(x)
+ x = self.conv_post(x)
+ fmap.append(x)
+ x = torch.flatten(x, 1, -1)
+
+ return x, fmap
diff --git a/infer/lib/infer_pack/models_onnx.py b/infer/lib/infer_pack/models_onnx.py
new file mode 100644
index 0000000000000000000000000000000000000000..b06bb9a03dfea8553b1e76505ef7c79b73fc781f
--- /dev/null
+++ b/infer/lib/infer_pack/models_onnx.py
@@ -0,0 +1,881 @@
+import math
+import logging
+from typing import Optional
+
+logger = logging.getLogger(__name__)
+
+import numpy as np
+import torch
+from torch import nn
+from torch.nn import AvgPool1d, Conv1d, Conv2d, ConvTranspose1d
+from torch.nn import functional as F
+from torch.nn.utils import remove_weight_norm, spectral_norm, weight_norm
+
+from infer.lib.infer_pack import commons, modules
+from infer.lib.infer_pack.commons import get_padding, init_weights
+import infer.lib.infer_pack.attentions_onnx as attentions
+
+has_xpu = bool(hasattr(torch, "xpu") and torch.xpu.is_available())
+
+
+class TextEncoder(nn.Module):
+ def __init__(
+ self,
+ in_channels,
+ out_channels,
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size,
+ p_dropout,
+ f0=True,
+ ):
+ super(TextEncoder, self).__init__()
+ self.out_channels = out_channels
+ self.hidden_channels = hidden_channels
+ self.filter_channels = filter_channels
+ self.n_heads = n_heads
+ self.n_layers = n_layers
+ self.kernel_size = kernel_size
+ self.p_dropout = float(p_dropout)
+ self.emb_phone = nn.Linear(in_channels, hidden_channels)
+ self.lrelu = nn.LeakyReLU(0.1, inplace=True)
+ if f0 == True:
+ self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
+ self.encoder = attentions.Encoder(
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size,
+ float(p_dropout),
+ )
+ self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
+
+ def forward(
+ self,
+ phone: torch.Tensor,
+ pitch: torch.Tensor,
+ lengths: torch.Tensor,
+ skip_head: Optional[torch.Tensor] = None,
+ ):
+ if pitch is None:
+ x = self.emb_phone(phone)
+ else:
+ x = self.emb_phone(phone) + self.emb_pitch(pitch)
+ x = x * math.sqrt(self.hidden_channels) # [b, t, h]
+ x = self.lrelu(x)
+ x = torch.transpose(x, 1, -1) # [b, h, t]
+ x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
+ x.dtype
+ )
+ x = self.encoder(x * x_mask, x_mask)
+ stats = self.proj(x) * x_mask
+ m, logs = torch.split(stats, self.out_channels, dim=1)
+ return m, logs, x_mask
+
+
+class ResidualCouplingBlock(nn.Module):
+ def __init__(
+ self,
+ channels,
+ hidden_channels,
+ kernel_size,
+ dilation_rate,
+ n_layers,
+ n_flows=4,
+ gin_channels=0,
+ ):
+ super(ResidualCouplingBlock, self).__init__()
+ self.channels = channels
+ self.hidden_channels = hidden_channels
+ self.kernel_size = kernel_size
+ self.dilation_rate = dilation_rate
+ self.n_layers = n_layers
+ self.n_flows = n_flows
+ self.gin_channels = gin_channels
+
+ self.flows = nn.ModuleList()
+ for i in range(n_flows):
+ self.flows.append(
+ modules.ResidualCouplingLayer(
+ channels,
+ hidden_channels,
+ kernel_size,
+ dilation_rate,
+ n_layers,
+ gin_channels=gin_channels,
+ mean_only=True,
+ )
+ )
+ self.flows.append(modules.Flip())
+
+ def forward(
+ self,
+ x: torch.Tensor,
+ x_mask: torch.Tensor,
+ g: Optional[torch.Tensor] = None,
+ reverse: bool = False,
+ ):
+ if not reverse:
+ for flow in self.flows:
+ x, _ = flow(x, x_mask, g=g, reverse=reverse)
+ else:
+ for flow in reversed(self.flows):
+ x, _ = flow.forward(x, x_mask, g=g, reverse=reverse)
+ return x
+
+ def remove_weight_norm(self):
+ for i in range(self.n_flows):
+ self.flows[i * 2].remove_weight_norm()
+
+ def __prepare_scriptable__(self):
+ for i in range(self.n_flows):
+ for hook in self.flows[i * 2]._forward_pre_hooks.values():
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(self.flows[i * 2])
+
+ return self
+
+
+class PosteriorEncoder(nn.Module):
+ def __init__(
+ self,
+ in_channels,
+ out_channels,
+ hidden_channels,
+ kernel_size,
+ dilation_rate,
+ n_layers,
+ gin_channels=0,
+ ):
+ super(PosteriorEncoder, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.hidden_channels = hidden_channels
+ self.kernel_size = kernel_size
+ self.dilation_rate = dilation_rate
+ self.n_layers = n_layers
+ self.gin_channels = gin_channels
+
+ self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
+ self.enc = modules.WN(
+ hidden_channels,
+ kernel_size,
+ dilation_rate,
+ n_layers,
+ gin_channels=gin_channels,
+ )
+ self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
+
+ def forward(
+ self, x: torch.Tensor, x_lengths: torch.Tensor, g: Optional[torch.Tensor] = None
+ ):
+ x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(
+ x.dtype
+ )
+ x = self.pre(x) * x_mask
+ x = self.enc(x, x_mask, g=g)
+ stats = self.proj(x) * x_mask
+ m, logs = torch.split(stats, self.out_channels, dim=1)
+ z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask
+ return z, m, logs, x_mask
+
+ def remove_weight_norm(self):
+ self.enc.remove_weight_norm()
+
+ def __prepare_scriptable__(self):
+ for hook in self.enc._forward_pre_hooks.values():
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(self.enc)
+ return self
+
+
+class Generator(torch.nn.Module):
+ def __init__(
+ self,
+ initial_channel,
+ resblock,
+ resblock_kernel_sizes,
+ resblock_dilation_sizes,
+ upsample_rates,
+ upsample_initial_channel,
+ upsample_kernel_sizes,
+ gin_channels=0,
+ ):
+ super(Generator, self).__init__()
+ self.num_kernels = len(resblock_kernel_sizes)
+ self.num_upsamples = len(upsample_rates)
+ self.conv_pre = Conv1d(
+ initial_channel, upsample_initial_channel, 7, 1, padding=3
+ )
+ resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
+
+ self.ups = nn.ModuleList()
+ for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
+ self.ups.append(
+ weight_norm(
+ ConvTranspose1d(
+ upsample_initial_channel // (2**i),
+ upsample_initial_channel // (2 ** (i + 1)),
+ k,
+ u,
+ padding=(k - u) // 2,
+ )
+ )
+ )
+
+ self.resblocks = nn.ModuleList()
+ for i in range(len(self.ups)):
+ ch = upsample_initial_channel // (2 ** (i + 1))
+ for j, (k, d) in enumerate(
+ zip(resblock_kernel_sizes, resblock_dilation_sizes)
+ ):
+ self.resblocks.append(resblock(ch, k, d))
+
+ self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
+ self.ups.apply(init_weights)
+
+ if gin_channels != 0:
+ self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
+
+ def forward(self, x: torch.Tensor, g: Optional[torch.Tensor] = None):
+ x = self.conv_pre(x)
+ if g is not None:
+ x = x + self.cond(g)
+
+ for i in range(self.num_upsamples):
+ x = F.leaky_relu(x, modules.LRELU_SLOPE)
+ x = self.ups[i](x)
+ xs = None
+ for j in range(self.num_kernels):
+ if xs is None:
+ xs = self.resblocks[i * self.num_kernels + j](x)
+ else:
+ xs += self.resblocks[i * self.num_kernels + j](x)
+ x = xs / self.num_kernels
+ x = F.leaky_relu(x)
+ x = self.conv_post(x)
+ x = torch.tanh(x)
+
+ return x
+
+ def __prepare_scriptable__(self):
+ for l in self.ups:
+ for hook in l._forward_pre_hooks.values():
+ # The hook we want to remove is an instance of WeightNorm class, so
+ # normally we would do `if isinstance(...)` but this class is not accessible
+ # because of shadowing, so we check the module name directly.
+ # https://github.com/pytorch/pytorch/blob/be0ca00c5ce260eb5bcec3237357f7a30cc08983/torch/nn/utils/__init__.py#L3
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(l)
+
+ for l in self.resblocks:
+ for hook in l._forward_pre_hooks.values():
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(l)
+ return self
+
+ def remove_weight_norm(self):
+ for l in self.ups:
+ remove_weight_norm(l)
+ for l in self.resblocks:
+ l.remove_weight_norm()
+
+
+class SineGen(torch.nn.Module):
+ """Definition of sine generator
+ SineGen(samp_rate, harmonic_num = 0,
+ sine_amp = 0.1, noise_std = 0.003,
+ voiced_threshold = 0,
+ flag_for_pulse=False)
+ samp_rate: sampling rate in Hz
+ harmonic_num: number of harmonic overtones (default 0)
+ sine_amp: amplitude of sine-wavefrom (default 0.1)
+ noise_std: std of Gaussian noise (default 0.003)
+ voiced_thoreshold: F0 threshold for U/V classification (default 0)
+ flag_for_pulse: this SinGen is used inside PulseGen (default False)
+ Note: when flag_for_pulse is True, the first time step of a voiced
+ segment is always sin(torch.pi) or cos(0)
+ """
+
+ def __init__(
+ self,
+ samp_rate,
+ harmonic_num=0,
+ sine_amp=0.1,
+ noise_std=0.003,
+ voiced_threshold=0,
+ flag_for_pulse=False,
+ ):
+ super(SineGen, self).__init__()
+ self.sine_amp = sine_amp
+ self.noise_std = noise_std
+ self.harmonic_num = harmonic_num
+ self.dim = self.harmonic_num + 1
+ self.sampling_rate = samp_rate
+ self.voiced_threshold = voiced_threshold
+
+ def _f02uv(self, f0):
+ # generate uv signal
+ uv = torch.ones_like(f0)
+ uv = uv * (f0 > self.voiced_threshold)
+ if uv.device.type == "privateuseone": # for DirectML
+ uv = uv.float()
+ return uv
+
+ def forward(self, f0: torch.Tensor, upp: int):
+ """sine_tensor, uv = forward(f0)
+ input F0: tensor(batchsize=1, length, dim=1)
+ f0 for unvoiced steps should be 0
+ output sine_tensor: tensor(batchsize=1, length, dim)
+ output uv: tensor(batchsize=1, length, 1)
+ """
+ with torch.no_grad():
+ f0 = f0[:, None].transpose(1, 2)
+ f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim, device=f0.device)
+ # fundamental component
+ f0_buf[:, :, 0] = f0[:, :, 0]
+ for idx in range(self.harmonic_num):
+ f0_buf[:, :, idx + 1] = f0_buf[:, :, 0] * (
+ idx + 2
+ ) # idx + 2: the (idx+1)-th overtone, (idx+2)-th harmonic
+ rad_values = (
+ f0_buf / self.sampling_rate
+ ) % 1 ###%1意味着n_har的乘积无法后处理优化
+ rand_ini = torch.rand(
+ f0_buf.shape[0], f0_buf.shape[2], device=f0_buf.device
+ )
+ rand_ini[:, 0] = 0
+ rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini
+ tmp_over_one = torch.cumsum(
+ rad_values, 1
+ ) # % 1 #####%1意味着后面的cumsum无法再优化
+ tmp_over_one *= upp
+ tmp_over_one = F.interpolate(
+ tmp_over_one.transpose(2, 1),
+ scale_factor=float(upp),
+ mode="linear",
+ align_corners=True,
+ ).transpose(2, 1)
+ rad_values = F.interpolate(
+ rad_values.transpose(2, 1), scale_factor=float(upp), mode="nearest"
+ ).transpose(
+ 2, 1
+ ) #######
+ tmp_over_one %= 1
+ tmp_over_one_idx = (tmp_over_one[:, 1:, :] - tmp_over_one[:, :-1, :]) < 0
+ cumsum_shift = torch.zeros_like(rad_values)
+ cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
+ sine_waves = torch.sin(
+ torch.cumsum(rad_values + cumsum_shift, dim=1) * 2 * torch.pi
+ )
+ sine_waves = sine_waves * self.sine_amp
+ uv = self._f02uv(f0)
+ uv = F.interpolate(
+ uv.transpose(2, 1), scale_factor=float(upp), mode="nearest"
+ ).transpose(2, 1)
+ noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
+ noise = noise_amp * torch.randn_like(sine_waves)
+ sine_waves = sine_waves * uv + noise
+ return sine_waves, uv, noise
+
+
+class SourceModuleHnNSF(torch.nn.Module):
+ """SourceModule for hn-nsf
+ SourceModule(sampling_rate, harmonic_num=0, sine_amp=0.1,
+ add_noise_std=0.003, voiced_threshod=0)
+ sampling_rate: sampling_rate in Hz
+ harmonic_num: number of harmonic above F0 (default: 0)
+ sine_amp: amplitude of sine source signal (default: 0.1)
+ add_noise_std: std of additive Gaussian noise (default: 0.003)
+ note that amplitude of noise in unvoiced is decided
+ by sine_amp
+ voiced_threshold: threhold to set U/V given F0 (default: 0)
+ Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
+ F0_sampled (batchsize, length, 1)
+ Sine_source (batchsize, length, 1)
+ noise_source (batchsize, length 1)
+ uv (batchsize, length, 1)
+ """
+
+ def __init__(
+ self,
+ sampling_rate,
+ harmonic_num=0,
+ sine_amp=0.1,
+ add_noise_std=0.003,
+ voiced_threshod=0,
+ is_half=True,
+ ):
+ super(SourceModuleHnNSF, self).__init__()
+
+ self.sine_amp = sine_amp
+ self.noise_std = add_noise_std
+ self.is_half = is_half
+ # to produce sine waveforms
+ self.l_sin_gen = SineGen(
+ sampling_rate, harmonic_num, sine_amp, add_noise_std, voiced_threshod
+ )
+
+ # to merge source harmonics into a single excitation
+ self.l_linear = torch.nn.Linear(harmonic_num + 1, 1)
+ self.l_tanh = torch.nn.Tanh()
+ # self.ddtype:int = -1
+
+ def forward(self, x: torch.Tensor, upp: int = 1):
+ # if self.ddtype ==-1:
+ # self.ddtype = self.l_linear.weight.dtype
+ sine_wavs, uv, _ = self.l_sin_gen(x, upp)
+ # print(x.dtype,sine_wavs.dtype,self.l_linear.weight.dtype)
+ # if self.is_half:
+ # sine_wavs = sine_wavs.half()
+ # sine_merge = self.l_tanh(self.l_linear(sine_wavs.to(x)))
+ # print(sine_wavs.dtype,self.ddtype)
+ # if sine_wavs.dtype != self.l_linear.weight.dtype:
+ sine_wavs = sine_wavs.to(dtype=self.l_linear.weight.dtype)
+ sine_merge = self.l_tanh(self.l_linear(sine_wavs))
+ return sine_merge, None, None # noise, uv
+
+
+class GeneratorNSF(torch.nn.Module):
+ def __init__(
+ self,
+ initial_channel,
+ resblock,
+ resblock_kernel_sizes,
+ resblock_dilation_sizes,
+ upsample_rates,
+ upsample_initial_channel,
+ upsample_kernel_sizes,
+ gin_channels,
+ sr,
+ is_half=False,
+ ):
+ super(GeneratorNSF, self).__init__()
+ self.num_kernels = len(resblock_kernel_sizes)
+ self.num_upsamples = len(upsample_rates)
+
+ self.f0_upsamp = torch.nn.Upsample(scale_factor=math.prod(upsample_rates))
+ self.m_source = SourceModuleHnNSF(
+ sampling_rate=sr, harmonic_num=0, is_half=is_half
+ )
+ self.noise_convs = nn.ModuleList()
+ self.conv_pre = Conv1d(
+ initial_channel, upsample_initial_channel, 7, 1, padding=3
+ )
+ resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
+
+ self.ups = nn.ModuleList()
+ for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
+ c_cur = upsample_initial_channel // (2 ** (i + 1))
+ self.ups.append(
+ weight_norm(
+ ConvTranspose1d(
+ upsample_initial_channel // (2**i),
+ upsample_initial_channel // (2 ** (i + 1)),
+ k,
+ u,
+ padding=(k - u) // 2,
+ )
+ )
+ )
+ if i + 1 < len(upsample_rates):
+ stride_f0 = math.prod(upsample_rates[i + 1 :])
+ self.noise_convs.append(
+ Conv1d(
+ 1,
+ c_cur,
+ kernel_size=stride_f0 * 2,
+ stride=stride_f0,
+ padding=stride_f0 // 2,
+ )
+ )
+ else:
+ self.noise_convs.append(Conv1d(1, c_cur, kernel_size=1))
+
+ self.resblocks = nn.ModuleList()
+ for i in range(len(self.ups)):
+ ch = upsample_initial_channel // (2 ** (i + 1))
+ for j, (k, d) in enumerate(
+ zip(resblock_kernel_sizes, resblock_dilation_sizes)
+ ):
+ self.resblocks.append(resblock(ch, k, d))
+
+ self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
+ self.ups.apply(init_weights)
+
+ if gin_channels != 0:
+ self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
+
+ self.upp = math.prod(upsample_rates)
+
+ self.lrelu_slope = modules.LRELU_SLOPE
+
+ def forward(self, x, f0, g: Optional[torch.Tensor] = None):
+ har_source, noi_source, uv = self.m_source(f0, self.upp)
+ har_source = har_source.transpose(1, 2)
+ x = self.conv_pre(x)
+ if g is not None:
+ x = x + self.cond(g)
+ # torch.jit.script() does not support direct indexing of torch modules
+ # That's why I wrote this
+ for i, (ups, noise_convs) in enumerate(zip(self.ups, self.noise_convs)):
+ if i < self.num_upsamples:
+ x = F.leaky_relu(x, self.lrelu_slope)
+ x = ups(x)
+ x_source = noise_convs(har_source)
+ x = x + x_source
+ xs: Optional[torch.Tensor] = None
+ l = [i * self.num_kernels + j for j in range(self.num_kernels)]
+ for j, resblock in enumerate(self.resblocks):
+ if j in l:
+ if xs is None:
+ xs = resblock(x)
+ else:
+ xs += resblock(x)
+ # This assertion cannot be ignored! \
+ # If ignored, it will cause torch.jit.script() compilation errors
+ assert isinstance(xs, torch.Tensor)
+ x = xs / self.num_kernels
+ x = F.leaky_relu(x)
+ x = self.conv_post(x)
+ x = torch.tanh(x)
+ return x
+
+ def remove_weight_norm(self):
+ for l in self.ups:
+ remove_weight_norm(l)
+ for l in self.resblocks:
+ l.remove_weight_norm()
+
+ def __prepare_scriptable__(self):
+ for l in self.ups:
+ for hook in l._forward_pre_hooks.values():
+ # The hook we want to remove is an instance of WeightNorm class, so
+ # normally we would do `if isinstance(...)` but this class is not accessible
+ # because of shadowing, so we check the module name directly.
+ # https://github.com/pytorch/pytorch/blob/be0ca00c5ce260eb5bcec3237357f7a30cc08983/torch/nn/utils/__init__.py#L3
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(l)
+ for l in self.resblocks:
+ for hook in self.resblocks._forward_pre_hooks.values():
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(l)
+ return self
+
+
+sr2sr = {
+ "32k": 32000,
+ "40k": 40000,
+ "48k": 48000,
+}
+
+
+class SynthesizerTrnMsNSFsidM(nn.Module):
+ def __init__(
+ self,
+ spec_channels,
+ segment_size,
+ inter_channels,
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size,
+ p_dropout,
+ resblock,
+ resblock_kernel_sizes,
+ resblock_dilation_sizes,
+ upsample_rates,
+ upsample_initial_channel,
+ upsample_kernel_sizes,
+ spk_embed_dim,
+ gin_channels,
+ sr,
+ encoder_dim,
+ **kwargs
+ ):
+ super(SynthesizerTrnMsNSFsidM, self).__init__()
+ if isinstance(sr, str):
+ sr = sr2sr[sr]
+ self.spec_channels = spec_channels
+ self.inter_channels = inter_channels
+ self.hidden_channels = hidden_channels
+ self.filter_channels = filter_channels
+ self.n_heads = n_heads
+ self.n_layers = n_layers
+ self.kernel_size = kernel_size
+ self.p_dropout = float(p_dropout)
+ self.resblock = resblock
+ self.resblock_kernel_sizes = resblock_kernel_sizes
+ self.resblock_dilation_sizes = resblock_dilation_sizes
+ self.upsample_rates = upsample_rates
+ self.upsample_initial_channel = upsample_initial_channel
+ self.upsample_kernel_sizes = upsample_kernel_sizes
+ self.segment_size = segment_size
+ self.gin_channels = gin_channels
+ # self.hop_length = hop_length#
+ self.spk_embed_dim = spk_embed_dim
+ self.enc_p = TextEncoder(
+ encoder_dim,
+ inter_channels,
+ hidden_channels,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size,
+ float(p_dropout),
+ )
+ self.dec = GeneratorNSF(
+ inter_channels,
+ resblock,
+ resblock_kernel_sizes,
+ resblock_dilation_sizes,
+ upsample_rates,
+ upsample_initial_channel,
+ upsample_kernel_sizes,
+ gin_channels=gin_channels,
+ sr=sr,
+ is_half=kwargs["is_half"],
+ )
+ self.enc_q = PosteriorEncoder(
+ spec_channels,
+ inter_channels,
+ hidden_channels,
+ 5,
+ 1,
+ 16,
+ gin_channels=gin_channels,
+ )
+ self.flow = ResidualCouplingBlock(
+ inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
+ )
+ self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
+ logger.debug(
+ "gin_channels: "
+ + str(gin_channels)
+ + ", self.spk_embed_dim: "
+ + str(self.spk_embed_dim)
+ )
+ self.speaker_map = None
+
+ def remove_weight_norm(self):
+ self.dec.remove_weight_norm()
+ self.flow.remove_weight_norm()
+ self.enc_q.remove_weight_norm()
+
+ def construct_spkmixmap(self):
+ self.speaker_map = torch.zeros((self.n_speaker, 1, 1, self.gin_channels))
+ for i in range(self.n_speaker):
+ self.speaker_map[i] = self.emb_g(torch.LongTensor([[i]]))
+ self.speaker_map = self.speaker_map.unsqueeze(0)
+
+ def forward(self, phone, phone_lengths, pitch, nsff0, g, rnd, max_len=None):
+ if self.speaker_map is not None: # [N, S] * [S, B, 1, H]
+ g = g.reshape((g.shape[0], g.shape[1], 1, 1, 1)) # [N, S, B, 1, 1]
+ g = g * self.speaker_map # [N, S, B, 1, H]
+ g = torch.sum(g, dim=1) # [N, 1, B, 1, H]
+ g = g.transpose(0, -1).transpose(0, -2).squeeze(0) # [B, H, N]
+ else:
+ g = g.unsqueeze(0)
+ g = self.emb_g(g).transpose(1, 2)
+
+ m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
+ z_p = (m_p + torch.exp(logs_p) * rnd) * x_mask
+ z = self.flow(z_p, x_mask, g=g, reverse=True)
+ o = self.dec((z * x_mask)[:, :, :max_len], nsff0, g=g)
+ return o
+
+
+class MultiPeriodDiscriminator(torch.nn.Module):
+ def __init__(self, use_spectral_norm=False):
+ super(MultiPeriodDiscriminator, self).__init__()
+ periods = [2, 3, 5, 7, 11, 17]
+ # periods = [3, 5, 7, 11, 17, 23, 37]
+
+ discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
+ discs = discs + [
+ DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods
+ ]
+ self.discriminators = nn.ModuleList(discs)
+
+ def forward(self, y, y_hat):
+ y_d_rs = [] #
+ y_d_gs = []
+ fmap_rs = []
+ fmap_gs = []
+ for i, d in enumerate(self.discriminators):
+ y_d_r, fmap_r = d(y)
+ y_d_g, fmap_g = d(y_hat)
+ # for j in range(len(fmap_r)):
+ # print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape)
+ y_d_rs.append(y_d_r)
+ y_d_gs.append(y_d_g)
+ fmap_rs.append(fmap_r)
+ fmap_gs.append(fmap_g)
+
+ return y_d_rs, y_d_gs, fmap_rs, fmap_gs
+
+
+class MultiPeriodDiscriminatorV2(torch.nn.Module):
+ def __init__(self, use_spectral_norm=False):
+ super(MultiPeriodDiscriminatorV2, self).__init__()
+ # periods = [2, 3, 5, 7, 11, 17]
+ periods = [2, 3, 5, 7, 11, 17, 23, 37]
+
+ discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
+ discs = discs + [
+ DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods
+ ]
+ self.discriminators = nn.ModuleList(discs)
+
+ def forward(self, y, y_hat):
+ y_d_rs = [] #
+ y_d_gs = []
+ fmap_rs = []
+ fmap_gs = []
+ for i, d in enumerate(self.discriminators):
+ y_d_r, fmap_r = d(y)
+ y_d_g, fmap_g = d(y_hat)
+ # for j in range(len(fmap_r)):
+ # print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape)
+ y_d_rs.append(y_d_r)
+ y_d_gs.append(y_d_g)
+ fmap_rs.append(fmap_r)
+ fmap_gs.append(fmap_g)
+
+ return y_d_rs, y_d_gs, fmap_rs, fmap_gs
+
+
+class DiscriminatorS(torch.nn.Module):
+ def __init__(self, use_spectral_norm=False):
+ super(DiscriminatorS, self).__init__()
+ norm_f = weight_norm if use_spectral_norm == False else spectral_norm
+ self.convs = nn.ModuleList(
+ [
+ norm_f(Conv1d(1, 16, 15, 1, padding=7)),
+ norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)),
+ norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)),
+ norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)),
+ norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)),
+ norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
+ ]
+ )
+ self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
+
+ def forward(self, x):
+ fmap = []
+
+ for l in self.convs:
+ x = l(x)
+ x = F.leaky_relu(x, modules.LRELU_SLOPE)
+ fmap.append(x)
+ x = self.conv_post(x)
+ fmap.append(x)
+ x = torch.flatten(x, 1, -1)
+
+ return x, fmap
+
+
+class DiscriminatorP(torch.nn.Module):
+ def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):
+ super(DiscriminatorP, self).__init__()
+ self.period = period
+ self.use_spectral_norm = use_spectral_norm
+ norm_f = weight_norm if use_spectral_norm == False else spectral_norm
+ self.convs = nn.ModuleList(
+ [
+ norm_f(
+ Conv2d(
+ 1,
+ 32,
+ (kernel_size, 1),
+ (stride, 1),
+ padding=(get_padding(kernel_size, 1), 0),
+ )
+ ),
+ norm_f(
+ Conv2d(
+ 32,
+ 128,
+ (kernel_size, 1),
+ (stride, 1),
+ padding=(get_padding(kernel_size, 1), 0),
+ )
+ ),
+ norm_f(
+ Conv2d(
+ 128,
+ 512,
+ (kernel_size, 1),
+ (stride, 1),
+ padding=(get_padding(kernel_size, 1), 0),
+ )
+ ),
+ norm_f(
+ Conv2d(
+ 512,
+ 1024,
+ (kernel_size, 1),
+ (stride, 1),
+ padding=(get_padding(kernel_size, 1), 0),
+ )
+ ),
+ norm_f(
+ Conv2d(
+ 1024,
+ 1024,
+ (kernel_size, 1),
+ 1,
+ padding=(get_padding(kernel_size, 1), 0),
+ )
+ ),
+ ]
+ )
+ self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
+
+ def forward(self, x):
+ fmap = []
+
+ # 1d to 2d
+ b, c, t = x.shape
+ if t % self.period != 0: # pad first
+ n_pad = self.period - (t % self.period)
+ if has_xpu and x.dtype == torch.bfloat16:
+ x = F.pad(x.to(dtype=torch.float16), (0, n_pad), "reflect").to(
+ dtype=torch.bfloat16
+ )
+ else:
+ x = F.pad(x, (0, n_pad), "reflect")
+ t = t + n_pad
+ x = x.view(b, c, t // self.period, self.period)
+
+ for l in self.convs:
+ x = l(x)
+ x = F.leaky_relu(x, modules.LRELU_SLOPE)
+ fmap.append(x)
+ x = self.conv_post(x)
+ fmap.append(x)
+ x = torch.flatten(x, 1, -1)
+
+ return x, fmap
diff --git a/infer/lib/infer_pack/modules.py b/infer/lib/infer_pack/modules.py
new file mode 100644
index 0000000000000000000000000000000000000000..51aeaf0799819c59714aeed0c8b6a3f8b2872f36
--- /dev/null
+++ b/infer/lib/infer_pack/modules.py
@@ -0,0 +1,615 @@
+import copy
+import math
+from typing import Optional, Tuple
+
+import numpy as np
+import scipy
+import torch
+from torch import nn
+from torch.nn import AvgPool1d, Conv1d, Conv2d, ConvTranspose1d
+from torch.nn import functional as F
+from torch.nn.utils import remove_weight_norm, weight_norm
+
+from infer.lib.infer_pack import commons
+from infer.lib.infer_pack.commons import get_padding, init_weights
+from infer.lib.infer_pack.transforms import piecewise_rational_quadratic_transform
+
+LRELU_SLOPE = 0.1
+
+
+class LayerNorm(nn.Module):
+ def __init__(self, channels, eps=1e-5):
+ super(LayerNorm, self).__init__()
+ self.channels = channels
+ self.eps = eps
+
+ self.gamma = nn.Parameter(torch.ones(channels))
+ self.beta = nn.Parameter(torch.zeros(channels))
+
+ def forward(self, x):
+ x = x.transpose(1, -1)
+ x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
+ return x.transpose(1, -1)
+
+
+class ConvReluNorm(nn.Module):
+ def __init__(
+ self,
+ in_channels,
+ hidden_channels,
+ out_channels,
+ kernel_size,
+ n_layers,
+ p_dropout,
+ ):
+ super(ConvReluNorm, self).__init__()
+ self.in_channels = in_channels
+ self.hidden_channels = hidden_channels
+ self.out_channels = out_channels
+ self.kernel_size = kernel_size
+ self.n_layers = n_layers
+ self.p_dropout = float(p_dropout)
+ assert n_layers > 1, "Number of layers should be larger than 0."
+
+ self.conv_layers = nn.ModuleList()
+ self.norm_layers = nn.ModuleList()
+ self.conv_layers.append(
+ nn.Conv1d(
+ in_channels, hidden_channels, kernel_size, padding=kernel_size // 2
+ )
+ )
+ self.norm_layers.append(LayerNorm(hidden_channels))
+ self.relu_drop = nn.Sequential(nn.ReLU(), nn.Dropout(float(p_dropout)))
+ for _ in range(n_layers - 1):
+ self.conv_layers.append(
+ nn.Conv1d(
+ hidden_channels,
+ hidden_channels,
+ kernel_size,
+ padding=kernel_size // 2,
+ )
+ )
+ self.norm_layers.append(LayerNorm(hidden_channels))
+ self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
+ self.proj.weight.data.zero_()
+ self.proj.bias.data.zero_()
+
+ def forward(self, x, x_mask):
+ x_org = x
+ for i in range(self.n_layers):
+ x = self.conv_layers[i](x * x_mask)
+ x = self.norm_layers[i](x)
+ x = self.relu_drop(x)
+ x = x_org + self.proj(x)
+ return x * x_mask
+
+
+class DDSConv(nn.Module):
+ """
+ Dialted and Depth-Separable Convolution
+ """
+
+ def __init__(self, channels, kernel_size, n_layers, p_dropout=0.0):
+ super(DDSConv, self).__init__()
+ self.channels = channels
+ self.kernel_size = kernel_size
+ self.n_layers = n_layers
+ self.p_dropout = float(p_dropout)
+
+ self.drop = nn.Dropout(float(p_dropout))
+ self.convs_sep = nn.ModuleList()
+ self.convs_1x1 = nn.ModuleList()
+ self.norms_1 = nn.ModuleList()
+ self.norms_2 = nn.ModuleList()
+ for i in range(n_layers):
+ dilation = kernel_size**i
+ padding = (kernel_size * dilation - dilation) // 2
+ self.convs_sep.append(
+ nn.Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ groups=channels,
+ dilation=dilation,
+ padding=padding,
+ )
+ )
+ self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
+ self.norms_1.append(LayerNorm(channels))
+ self.norms_2.append(LayerNorm(channels))
+
+ def forward(self, x, x_mask, g: Optional[torch.Tensor] = None):
+ if g is not None:
+ x = x + g
+ for i in range(self.n_layers):
+ y = self.convs_sep[i](x * x_mask)
+ y = self.norms_1[i](y)
+ y = F.gelu(y)
+ y = self.convs_1x1[i](y)
+ y = self.norms_2[i](y)
+ y = F.gelu(y)
+ y = self.drop(y)
+ x = x + y
+ return x * x_mask
+
+
+class WN(torch.nn.Module):
+ def __init__(
+ self,
+ hidden_channels,
+ kernel_size,
+ dilation_rate,
+ n_layers,
+ gin_channels=0,
+ p_dropout=0,
+ ):
+ super(WN, self).__init__()
+ assert kernel_size % 2 == 1
+ self.hidden_channels = hidden_channels
+ self.kernel_size = (kernel_size,)
+ self.dilation_rate = dilation_rate
+ self.n_layers = n_layers
+ self.gin_channels = gin_channels
+ self.p_dropout = float(p_dropout)
+
+ self.in_layers = torch.nn.ModuleList()
+ self.res_skip_layers = torch.nn.ModuleList()
+ self.drop = nn.Dropout(float(p_dropout))
+
+ if gin_channels != 0:
+ cond_layer = torch.nn.Conv1d(
+ gin_channels, 2 * hidden_channels * n_layers, 1
+ )
+ self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name="weight")
+
+ for i in range(n_layers):
+ dilation = dilation_rate**i
+ padding = int((kernel_size * dilation - dilation) / 2)
+ in_layer = torch.nn.Conv1d(
+ hidden_channels,
+ 2 * hidden_channels,
+ kernel_size,
+ dilation=dilation,
+ padding=padding,
+ )
+ in_layer = torch.nn.utils.weight_norm(in_layer, name="weight")
+ self.in_layers.append(in_layer)
+
+ # last one is not necessary
+ if i < n_layers - 1:
+ res_skip_channels = 2 * hidden_channels
+ else:
+ res_skip_channels = hidden_channels
+
+ res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
+ res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name="weight")
+ self.res_skip_layers.append(res_skip_layer)
+
+ def forward(
+ self, x: torch.Tensor, x_mask: torch.Tensor, g: Optional[torch.Tensor] = None
+ ):
+ output = torch.zeros_like(x)
+ n_channels_tensor = torch.IntTensor([self.hidden_channels])
+
+ if g is not None:
+ g = self.cond_layer(g)
+
+ for i, (in_layer, res_skip_layer) in enumerate(
+ zip(self.in_layers, self.res_skip_layers)
+ ):
+ x_in = in_layer(x)
+ if g is not None:
+ cond_offset = i * 2 * self.hidden_channels
+ g_l = g[:, cond_offset : cond_offset + 2 * self.hidden_channels, :]
+ else:
+ g_l = torch.zeros_like(x_in)
+
+ acts = commons.fused_add_tanh_sigmoid_multiply(x_in, g_l, n_channels_tensor)
+ acts = self.drop(acts)
+
+ res_skip_acts = res_skip_layer(acts)
+ if i < self.n_layers - 1:
+ res_acts = res_skip_acts[:, : self.hidden_channels, :]
+ x = (x + res_acts) * x_mask
+ output = output + res_skip_acts[:, self.hidden_channels :, :]
+ else:
+ output = output + res_skip_acts
+ return output * x_mask
+
+ def remove_weight_norm(self):
+ if self.gin_channels != 0:
+ torch.nn.utils.remove_weight_norm(self.cond_layer)
+ for l in self.in_layers:
+ torch.nn.utils.remove_weight_norm(l)
+ for l in self.res_skip_layers:
+ torch.nn.utils.remove_weight_norm(l)
+
+ def __prepare_scriptable__(self):
+ if self.gin_channels != 0:
+ for hook in self.cond_layer._forward_pre_hooks.values():
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(self.cond_layer)
+ for l in self.in_layers:
+ for hook in l._forward_pre_hooks.values():
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(l)
+ for l in self.res_skip_layers:
+ for hook in l._forward_pre_hooks.values():
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(l)
+ return self
+
+
+class ResBlock1(torch.nn.Module):
+ def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
+ super(ResBlock1, self).__init__()
+ self.convs1 = nn.ModuleList(
+ [
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=dilation[0],
+ padding=get_padding(kernel_size, dilation[0]),
+ )
+ ),
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=dilation[1],
+ padding=get_padding(kernel_size, dilation[1]),
+ )
+ ),
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=dilation[2],
+ padding=get_padding(kernel_size, dilation[2]),
+ )
+ ),
+ ]
+ )
+ self.convs1.apply(init_weights)
+
+ self.convs2 = nn.ModuleList(
+ [
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=1,
+ padding=get_padding(kernel_size, 1),
+ )
+ ),
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=1,
+ padding=get_padding(kernel_size, 1),
+ )
+ ),
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=1,
+ padding=get_padding(kernel_size, 1),
+ )
+ ),
+ ]
+ )
+ self.convs2.apply(init_weights)
+ self.lrelu_slope = LRELU_SLOPE
+
+ def forward(self, x: torch.Tensor, x_mask: Optional[torch.Tensor] = None):
+ for c1, c2 in zip(self.convs1, self.convs2):
+ xt = F.leaky_relu(x, self.lrelu_slope)
+ if x_mask is not None:
+ xt = xt * x_mask
+ xt = c1(xt)
+ xt = F.leaky_relu(xt, self.lrelu_slope)
+ if x_mask is not None:
+ xt = xt * x_mask
+ xt = c2(xt)
+ x = xt + x
+ if x_mask is not None:
+ x = x * x_mask
+ return x
+
+ def remove_weight_norm(self):
+ for l in self.convs1:
+ remove_weight_norm(l)
+ for l in self.convs2:
+ remove_weight_norm(l)
+
+ def __prepare_scriptable__(self):
+ for l in self.convs1:
+ for hook in l._forward_pre_hooks.values():
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(l)
+ for l in self.convs2:
+ for hook in l._forward_pre_hooks.values():
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(l)
+ return self
+
+
+class ResBlock2(torch.nn.Module):
+ def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
+ super(ResBlock2, self).__init__()
+ self.convs = nn.ModuleList(
+ [
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=dilation[0],
+ padding=get_padding(kernel_size, dilation[0]),
+ )
+ ),
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=dilation[1],
+ padding=get_padding(kernel_size, dilation[1]),
+ )
+ ),
+ ]
+ )
+ self.convs.apply(init_weights)
+ self.lrelu_slope = LRELU_SLOPE
+
+ def forward(self, x, x_mask: Optional[torch.Tensor] = None):
+ for c in self.convs:
+ xt = F.leaky_relu(x, self.lrelu_slope)
+ if x_mask is not None:
+ xt = xt * x_mask
+ xt = c(xt)
+ x = xt + x
+ if x_mask is not None:
+ x = x * x_mask
+ return x
+
+ def remove_weight_norm(self):
+ for l in self.convs:
+ remove_weight_norm(l)
+
+ def __prepare_scriptable__(self):
+ for l in self.convs:
+ for hook in l._forward_pre_hooks.values():
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(l)
+ return self
+
+
+class Log(nn.Module):
+ def forward(
+ self,
+ x: torch.Tensor,
+ x_mask: torch.Tensor,
+ g: Optional[torch.Tensor] = None,
+ reverse: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor]]:
+ if not reverse:
+ y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
+ logdet = torch.sum(-y, [1, 2])
+ return y, logdet
+ else:
+ x = torch.exp(x) * x_mask
+ return x
+
+
+class Flip(nn.Module):
+ # torch.jit.script() Compiled functions \
+ # can't take variable number of arguments or \
+ # use keyword-only arguments with defaults
+ def forward(
+ self,
+ x: torch.Tensor,
+ x_mask: torch.Tensor,
+ g: Optional[torch.Tensor] = None,
+ reverse: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor]]:
+ x = torch.flip(x, [1])
+ if not reverse:
+ logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
+ return x, logdet
+ else:
+ return x, torch.zeros([1], device=x.device)
+
+
+class ElementwiseAffine(nn.Module):
+ def __init__(self, channels):
+ super(ElementwiseAffine, self).__init__()
+ self.channels = channels
+ self.m = nn.Parameter(torch.zeros(channels, 1))
+ self.logs = nn.Parameter(torch.zeros(channels, 1))
+
+ def forward(self, x, x_mask, reverse=False, **kwargs):
+ if not reverse:
+ y = self.m + torch.exp(self.logs) * x
+ y = y * x_mask
+ logdet = torch.sum(self.logs * x_mask, [1, 2])
+ return y, logdet
+ else:
+ x = (x - self.m) * torch.exp(-self.logs) * x_mask
+ return x
+
+
+class ResidualCouplingLayer(nn.Module):
+ def __init__(
+ self,
+ channels,
+ hidden_channels,
+ kernel_size,
+ dilation_rate,
+ n_layers,
+ p_dropout=0,
+ gin_channels=0,
+ mean_only=False,
+ ):
+ assert channels % 2 == 0, "channels should be divisible by 2"
+ super(ResidualCouplingLayer, self).__init__()
+ self.channels = channels
+ self.hidden_channels = hidden_channels
+ self.kernel_size = kernel_size
+ self.dilation_rate = dilation_rate
+ self.n_layers = n_layers
+ self.half_channels = channels // 2
+ self.mean_only = mean_only
+
+ self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
+ self.enc = WN(
+ hidden_channels,
+ kernel_size,
+ dilation_rate,
+ n_layers,
+ p_dropout=float(p_dropout),
+ gin_channels=gin_channels,
+ )
+ self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
+ self.post.weight.data.zero_()
+ self.post.bias.data.zero_()
+
+ def forward(
+ self,
+ x: torch.Tensor,
+ x_mask: torch.Tensor,
+ g: Optional[torch.Tensor] = None,
+ reverse: bool = False,
+ ):
+ x0, x1 = torch.split(x, [self.half_channels] * 2, 1)
+ h = self.pre(x0) * x_mask
+ h = self.enc(h, x_mask, g=g)
+ stats = self.post(h) * x_mask
+ if not self.mean_only:
+ m, logs = torch.split(stats, [self.half_channels] * 2, 1)
+ else:
+ m = stats
+ logs = torch.zeros_like(m)
+
+ if not reverse:
+ x1 = m + x1 * torch.exp(logs) * x_mask
+ x = torch.cat([x0, x1], 1)
+ logdet = torch.sum(logs, [1, 2])
+ return x, logdet
+ else:
+ x1 = (x1 - m) * torch.exp(-logs) * x_mask
+ x = torch.cat([x0, x1], 1)
+ return x, torch.zeros([1])
+
+ def remove_weight_norm(self):
+ self.enc.remove_weight_norm()
+
+ def __prepare_scriptable__(self):
+ for hook in self.enc._forward_pre_hooks.values():
+ if (
+ hook.__module__ == "torch.nn.utils.weight_norm"
+ and hook.__class__.__name__ == "WeightNorm"
+ ):
+ torch.nn.utils.remove_weight_norm(self.enc)
+ return self
+
+
+class ConvFlow(nn.Module):
+ def __init__(
+ self,
+ in_channels,
+ filter_channels,
+ kernel_size,
+ n_layers,
+ num_bins=10,
+ tail_bound=5.0,
+ ):
+ super(ConvFlow, self).__init__()
+ self.in_channels = in_channels
+ self.filter_channels = filter_channels
+ self.kernel_size = kernel_size
+ self.n_layers = n_layers
+ self.num_bins = num_bins
+ self.tail_bound = tail_bound
+ self.half_channels = in_channels // 2
+
+ self.pre = nn.Conv1d(self.half_channels, filter_channels, 1)
+ self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.0)
+ self.proj = nn.Conv1d(
+ filter_channels, self.half_channels * (num_bins * 3 - 1), 1
+ )
+ self.proj.weight.data.zero_()
+ self.proj.bias.data.zero_()
+
+ def forward(
+ self,
+ x: torch.Tensor,
+ x_mask: torch.Tensor,
+ g: Optional[torch.Tensor] = None,
+ reverse=False,
+ ):
+ x0, x1 = torch.split(x, [self.half_channels] * 2, 1)
+ h = self.pre(x0)
+ h = self.convs(h, x_mask, g=g)
+ h = self.proj(h) * x_mask
+
+ b, c, t = x0.shape
+ h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?]
+
+ unnormalized_widths = h[..., : self.num_bins] / math.sqrt(self.filter_channels)
+ unnormalized_heights = h[..., self.num_bins : 2 * self.num_bins] / math.sqrt(
+ self.filter_channels
+ )
+ unnormalized_derivatives = h[..., 2 * self.num_bins :]
+
+ x1, logabsdet = piecewise_rational_quadratic_transform(
+ x1,
+ unnormalized_widths,
+ unnormalized_heights,
+ unnormalized_derivatives,
+ inverse=reverse,
+ tails="linear",
+ tail_bound=self.tail_bound,
+ )
+
+ x = torch.cat([x0, x1], 1) * x_mask
+ logdet = torch.sum(logabsdet * x_mask, [1, 2])
+ if not reverse:
+ return x, logdet
+ else:
+ return x
diff --git a/infer/lib/infer_pack/modules/F0Predictor/DioF0Predictor.py b/infer/lib/infer_pack/modules/F0Predictor/DioF0Predictor.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69a603440709fc7dc60e92079addbfa490778fd
--- /dev/null
+++ b/infer/lib/infer_pack/modules/F0Predictor/DioF0Predictor.py
@@ -0,0 +1,91 @@
+import numpy as np
+import pyworld
+
+from infer.lib.infer_pack.modules.F0Predictor.F0Predictor import F0Predictor
+
+
+class DioF0Predictor(F0Predictor):
+ def __init__(self, hop_length=512, f0_min=50, f0_max=1100, sampling_rate=44100):
+ self.hop_length = hop_length
+ self.f0_min = f0_min
+ self.f0_max = f0_max
+ self.sampling_rate = sampling_rate
+
+ def interpolate_f0(self, f0):
+ """
+ 对F0进行插值处理
+ """
+
+ data = np.reshape(f0, (f0.size, 1))
+
+ vuv_vector = np.zeros((data.size, 1), dtype=np.float32)
+ vuv_vector[data > 0.0] = 1.0
+ vuv_vector[data <= 0.0] = 0.0
+
+ ip_data = data
+
+ frame_number = data.size
+ last_value = 0.0
+ for i in range(frame_number):
+ if data[i] <= 0.0:
+ j = i + 1
+ for j in range(i + 1, frame_number):
+ if data[j] > 0.0:
+ break
+ if j < frame_number - 1:
+ if last_value > 0.0:
+ step = (data[j] - data[i - 1]) / float(j - i)
+ for k in range(i, j):
+ ip_data[k] = data[i - 1] + step * (k - i + 1)
+ else:
+ for k in range(i, j):
+ ip_data[k] = data[j]
+ else:
+ for k in range(i, frame_number):
+ ip_data[k] = last_value
+ else:
+ ip_data[i] = data[i] # 这里可能存在一个没有必要的拷贝
+ last_value = data[i]
+
+ return ip_data[:, 0], vuv_vector[:, 0]
+
+ def resize_f0(self, x, target_len):
+ source = np.array(x)
+ source[source < 0.001] = np.nan
+ target = np.interp(
+ np.arange(0, len(source) * target_len, len(source)) / target_len,
+ np.arange(0, len(source)),
+ source,
+ )
+ res = np.nan_to_num(target)
+ return res
+
+ def compute_f0(self, wav, p_len=None):
+ if p_len is None:
+ p_len = wav.shape[0] // self.hop_length
+ f0, t = pyworld.dio(
+ wav.astype(np.double),
+ fs=self.sampling_rate,
+ f0_floor=self.f0_min,
+ f0_ceil=self.f0_max,
+ frame_period=1000 * self.hop_length / self.sampling_rate,
+ )
+ f0 = pyworld.stonemask(wav.astype(np.double), f0, t, self.sampling_rate)
+ for index, pitch in enumerate(f0):
+ f0[index] = round(pitch, 1)
+ return self.interpolate_f0(self.resize_f0(f0, p_len))[0]
+
+ def compute_f0_uv(self, wav, p_len=None):
+ if p_len is None:
+ p_len = wav.shape[0] // self.hop_length
+ f0, t = pyworld.dio(
+ wav.astype(np.double),
+ fs=self.sampling_rate,
+ f0_floor=self.f0_min,
+ f0_ceil=self.f0_max,
+ frame_period=1000 * self.hop_length / self.sampling_rate,
+ )
+ f0 = pyworld.stonemask(wav.astype(np.double), f0, t, self.sampling_rate)
+ for index, pitch in enumerate(f0):
+ f0[index] = round(pitch, 1)
+ return self.interpolate_f0(self.resize_f0(f0, p_len))
diff --git a/infer/lib/infer_pack/modules/F0Predictor/F0Predictor.py b/infer/lib/infer_pack/modules/F0Predictor/F0Predictor.py
new file mode 100644
index 0000000000000000000000000000000000000000..0d81b05eef25f0ebeead80bb9baaaef695823b19
--- /dev/null
+++ b/infer/lib/infer_pack/modules/F0Predictor/F0Predictor.py
@@ -0,0 +1,16 @@
+class F0Predictor(object):
+ def compute_f0(self, wav, p_len):
+ """
+ input: wav:[signal_length]
+ p_len:int
+ output: f0:[signal_length//hop_length]
+ """
+ pass
+
+ def compute_f0_uv(self, wav, p_len):
+ """
+ input: wav:[signal_length]
+ p_len:int
+ output: f0:[signal_length//hop_length],uv:[signal_length//hop_length]
+ """
+ pass
diff --git a/infer/lib/infer_pack/modules/F0Predictor/HarvestF0Predictor.py b/infer/lib/infer_pack/modules/F0Predictor/HarvestF0Predictor.py
new file mode 100644
index 0000000000000000000000000000000000000000..2b13917ce07455e87b076ac4f3cfabab2e443f8e
--- /dev/null
+++ b/infer/lib/infer_pack/modules/F0Predictor/HarvestF0Predictor.py
@@ -0,0 +1,87 @@
+import numpy as np
+import pyworld
+
+from infer.lib.infer_pack.modules.F0Predictor.F0Predictor import F0Predictor
+
+
+class HarvestF0Predictor(F0Predictor):
+ def __init__(self, hop_length=512, f0_min=50, f0_max=1100, sampling_rate=44100):
+ self.hop_length = hop_length
+ self.f0_min = f0_min
+ self.f0_max = f0_max
+ self.sampling_rate = sampling_rate
+
+ def interpolate_f0(self, f0):
+ """
+ 对F0进行插值处理
+ """
+
+ data = np.reshape(f0, (f0.size, 1))
+
+ vuv_vector = np.zeros((data.size, 1), dtype=np.float32)
+ vuv_vector[data > 0.0] = 1.0
+ vuv_vector[data <= 0.0] = 0.0
+
+ ip_data = data
+
+ frame_number = data.size
+ last_value = 0.0
+ for i in range(frame_number):
+ if data[i] <= 0.0:
+ j = i + 1
+ for j in range(i + 1, frame_number):
+ if data[j] > 0.0:
+ break
+ if j < frame_number - 1:
+ if last_value > 0.0:
+ step = (data[j] - data[i - 1]) / float(j - i)
+ for k in range(i, j):
+ ip_data[k] = data[i - 1] + step * (k - i + 1)
+ else:
+ for k in range(i, j):
+ ip_data[k] = data[j]
+ else:
+ for k in range(i, frame_number):
+ ip_data[k] = last_value
+ else:
+ ip_data[i] = data[i] # 这里可能存在一个没有必要的拷贝
+ last_value = data[i]
+
+ return ip_data[:, 0], vuv_vector[:, 0]
+
+ def resize_f0(self, x, target_len):
+ source = np.array(x)
+ source[source < 0.001] = np.nan
+ target = np.interp(
+ np.arange(0, len(source) * target_len, len(source)) / target_len,
+ np.arange(0, len(source)),
+ source,
+ )
+ res = np.nan_to_num(target)
+ return res
+
+ def compute_f0(self, wav, p_len=None):
+ if p_len is None:
+ p_len = wav.shape[0] // self.hop_length
+ f0, t = pyworld.harvest(
+ wav.astype(np.double),
+ fs=self.sampling_rate,
+ f0_ceil=self.f0_max,
+ f0_floor=self.f0_min,
+ frame_period=1000 * self.hop_length / self.sampling_rate,
+ )
+ f0 = pyworld.stonemask(wav.astype(np.double), f0, t, self.fs)
+ return self.interpolate_f0(self.resize_f0(f0, p_len))[0]
+
+ def compute_f0_uv(self, wav, p_len=None):
+ if p_len is None:
+ p_len = wav.shape[0] // self.hop_length
+ f0, t = pyworld.harvest(
+ wav.astype(np.double),
+ fs=self.sampling_rate,
+ f0_floor=self.f0_min,
+ f0_ceil=self.f0_max,
+ frame_period=1000 * self.hop_length / self.sampling_rate,
+ )
+ f0 = pyworld.stonemask(wav.astype(np.double), f0, t, self.sampling_rate)
+ return self.interpolate_f0(self.resize_f0(f0, p_len))
diff --git a/infer/lib/infer_pack/modules/F0Predictor/PMF0Predictor.py b/infer/lib/infer_pack/modules/F0Predictor/PMF0Predictor.py
new file mode 100644
index 0000000000000000000000000000000000000000..957ec467ec808dc9fe78a2f4a863771b45c7ad4e
--- /dev/null
+++ b/infer/lib/infer_pack/modules/F0Predictor/PMF0Predictor.py
@@ -0,0 +1,98 @@
+import numpy as np
+import parselmouth
+
+from infer.lib.infer_pack.modules.F0Predictor.F0Predictor import F0Predictor
+
+
+class PMF0Predictor(F0Predictor):
+ def __init__(self, hop_length=512, f0_min=50, f0_max=1100, sampling_rate=44100):
+ self.hop_length = hop_length
+ self.f0_min = f0_min
+ self.f0_max = f0_max
+ self.sampling_rate = sampling_rate
+
+ def interpolate_f0(self, f0):
+ """
+ 对F0进行插值处理
+ """
+
+ data = np.reshape(f0, (f0.size, 1))
+
+ vuv_vector = np.zeros((data.size, 1), dtype=np.float32)
+ vuv_vector[data > 0.0] = 1.0
+ vuv_vector[data <= 0.0] = 0.0
+
+ ip_data = data
+
+ frame_number = data.size
+ last_value = 0.0
+ for i in range(frame_number):
+ if data[i] <= 0.0:
+ j = i + 1
+ for j in range(i + 1, frame_number):
+ if data[j] > 0.0:
+ break
+ if j < frame_number - 1:
+ if last_value > 0.0:
+ step = (data[j] - data[i - 1]) / float(j - i)
+ for k in range(i, j):
+ ip_data[k] = data[i - 1] + step * (k - i + 1)
+ else:
+ for k in range(i, j):
+ ip_data[k] = data[j]
+ else:
+ for k in range(i, frame_number):
+ ip_data[k] = last_value
+ else:
+ ip_data[i] = data[i] # 这里可能存在一个没有必要的拷贝
+ last_value = data[i]
+
+ return ip_data[:, 0], vuv_vector[:, 0]
+
+ def compute_f0(self, wav, p_len=None):
+ x = wav
+ if p_len is None:
+ p_len = x.shape[0] // self.hop_length
+ else:
+ assert abs(p_len - x.shape[0] // self.hop_length) < 4, "pad length error"
+ time_step = self.hop_length / self.sampling_rate * 1000
+ f0 = (
+ parselmouth.Sound(x, self.sampling_rate)
+ .to_pitch_ac(
+ time_step=time_step / 1000,
+ voicing_threshold=0.6,
+ pitch_floor=self.f0_min,
+ pitch_ceiling=self.f0_max,
+ )
+ .selected_array["frequency"]
+ )
+
+ pad_size = (p_len - len(f0) + 1) // 2
+ if pad_size > 0 or p_len - len(f0) - pad_size > 0:
+ f0 = np.pad(f0, [[pad_size, p_len - len(f0) - pad_size]], mode="constant")
+ f0, uv = self.interpolate_f0(f0)
+ return f0
+
+ def compute_f0_uv(self, wav, p_len=None):
+ x = wav
+ if p_len is None:
+ p_len = x.shape[0] // self.hop_length
+ else:
+ assert abs(p_len - x.shape[0] // self.hop_length) < 4, "pad length error"
+ time_step = self.hop_length / self.sampling_rate * 1000
+ f0 = (
+ parselmouth.Sound(x, self.sampling_rate)
+ .to_pitch_ac(
+ time_step=time_step / 1000,
+ voicing_threshold=0.6,
+ pitch_floor=self.f0_min,
+ pitch_ceiling=self.f0_max,
+ )
+ .selected_array["frequency"]
+ )
+
+ pad_size = (p_len - len(f0) + 1) // 2
+ if pad_size > 0 or p_len - len(f0) - pad_size > 0:
+ f0 = np.pad(f0, [[pad_size, p_len - len(f0) - pad_size]], mode="constant")
+ f0, uv = self.interpolate_f0(f0)
+ return f0, uv
diff --git a/infer/lib/infer_pack/modules/F0Predictor/__init__.py b/infer/lib/infer_pack/modules/F0Predictor/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/infer/lib/infer_pack/onnx_inference.py b/infer/lib/infer_pack/onnx_inference.py
new file mode 100644
index 0000000000000000000000000000000000000000..3d8328b2ac337a365e2ebc3e6ae767761e3e17c5
--- /dev/null
+++ b/infer/lib/infer_pack/onnx_inference.py
@@ -0,0 +1,149 @@
+import librosa
+import numpy as np
+import onnxruntime
+import soundfile
+
+import logging
+
+logger = logging.getLogger(__name__)
+
+
+class ContentVec:
+ def __init__(self, vec_path="pretrained/vec-768-layer-12.onnx", device=None):
+ logger.info("Load model(s) from {}".format(vec_path))
+ if device == "cpu" or device is None:
+ providers = ["CPUExecutionProvider"]
+ elif device == "cuda":
+ providers = ["CUDAExecutionProvider", "CPUExecutionProvider"]
+ elif device == "dml":
+ providers = ["DmlExecutionProvider"]
+ else:
+ raise RuntimeError("Unsportted Device")
+ self.model = onnxruntime.InferenceSession(vec_path, providers=providers)
+
+ def __call__(self, wav):
+ return self.forward(wav)
+
+ def forward(self, wav):
+ feats = wav
+ if feats.ndim == 2: # double channels
+ feats = feats.mean(-1)
+ assert feats.ndim == 1, feats.ndim
+ feats = np.expand_dims(np.expand_dims(feats, 0), 0)
+ onnx_input = {self.model.get_inputs()[0].name: feats}
+ logits = self.model.run(None, onnx_input)[0]
+ return logits.transpose(0, 2, 1)
+
+
+def get_f0_predictor(f0_predictor, hop_length, sampling_rate, **kargs):
+ if f0_predictor == "pm":
+ from lib.infer_pack.modules.F0Predictor.PMF0Predictor import PMF0Predictor
+
+ f0_predictor_object = PMF0Predictor(
+ hop_length=hop_length, sampling_rate=sampling_rate
+ )
+ elif f0_predictor == "harvest":
+ from lib.infer_pack.modules.F0Predictor.HarvestF0Predictor import (
+ HarvestF0Predictor,
+ )
+
+ f0_predictor_object = HarvestF0Predictor(
+ hop_length=hop_length, sampling_rate=sampling_rate
+ )
+ elif f0_predictor == "dio":
+ from lib.infer_pack.modules.F0Predictor.DioF0Predictor import DioF0Predictor
+
+ f0_predictor_object = DioF0Predictor(
+ hop_length=hop_length, sampling_rate=sampling_rate
+ )
+ else:
+ raise Exception("Unknown f0 predictor")
+ return f0_predictor_object
+
+
+class OnnxRVC:
+ def __init__(
+ self,
+ model_path,
+ sr=40000,
+ hop_size=512,
+ vec_path="vec-768-layer-12",
+ device="cpu",
+ ):
+ vec_path = f"pretrained/{vec_path}.onnx"
+ self.vec_model = ContentVec(vec_path, device)
+ if device == "cpu" or device is None:
+ providers = ["CPUExecutionProvider"]
+ elif device == "cuda":
+ providers = ["CUDAExecutionProvider", "CPUExecutionProvider"]
+ elif device == "dml":
+ providers = ["DmlExecutionProvider"]
+ else:
+ raise RuntimeError("Unsportted Device")
+ self.model = onnxruntime.InferenceSession(model_path, providers=providers)
+ self.sampling_rate = sr
+ self.hop_size = hop_size
+
+ def forward(self, hubert, hubert_length, pitch, pitchf, ds, rnd):
+ onnx_input = {
+ self.model.get_inputs()[0].name: hubert,
+ self.model.get_inputs()[1].name: hubert_length,
+ self.model.get_inputs()[2].name: pitch,
+ self.model.get_inputs()[3].name: pitchf,
+ self.model.get_inputs()[4].name: ds,
+ self.model.get_inputs()[5].name: rnd,
+ }
+ return (self.model.run(None, onnx_input)[0] * 32767).astype(np.int16)
+
+ def inference(
+ self,
+ raw_path,
+ sid,
+ f0_method="dio",
+ f0_up_key=0,
+ pad_time=0.5,
+ cr_threshold=0.02,
+ ):
+ f0_min = 50
+ f0_max = 1100
+ f0_mel_min = 1127 * np.log(1 + f0_min / 700)
+ f0_mel_max = 1127 * np.log(1 + f0_max / 700)
+ f0_predictor = get_f0_predictor(
+ f0_method,
+ hop_length=self.hop_size,
+ sampling_rate=self.sampling_rate,
+ threshold=cr_threshold,
+ )
+ wav, sr = librosa.load(raw_path, sr=self.sampling_rate)
+ org_length = len(wav)
+ if org_length / sr > 50.0:
+ raise RuntimeError("Reached Max Length")
+
+ wav16k = librosa.resample(wav, orig_sr=self.sampling_rate, target_sr=16000)
+ wav16k = wav16k
+
+ hubert = self.vec_model(wav16k)
+ hubert = np.repeat(hubert, 2, axis=2).transpose(0, 2, 1).astype(np.float32)
+ hubert_length = hubert.shape[1]
+
+ pitchf = f0_predictor.compute_f0(wav, hubert_length)
+ pitchf = pitchf * 2 ** (f0_up_key / 12)
+ pitch = pitchf.copy()
+ f0_mel = 1127 * np.log(1 + pitch / 700)
+ f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - f0_mel_min) * 254 / (
+ f0_mel_max - f0_mel_min
+ ) + 1
+ f0_mel[f0_mel <= 1] = 1
+ f0_mel[f0_mel > 255] = 255
+ pitch = np.rint(f0_mel).astype(np.int64)
+
+ pitchf = pitchf.reshape(1, len(pitchf)).astype(np.float32)
+ pitch = pitch.reshape(1, len(pitch))
+ ds = np.array([sid]).astype(np.int64)
+
+ rnd = np.random.randn(1, 192, hubert_length).astype(np.float32)
+ hubert_length = np.array([hubert_length]).astype(np.int64)
+
+ out_wav = self.forward(hubert, hubert_length, pitch, pitchf, ds, rnd).squeeze()
+ out_wav = np.pad(out_wav, (0, 2 * self.hop_size), "constant")
+ return out_wav[0:org_length]
diff --git a/infer/lib/infer_pack/transforms.py b/infer/lib/infer_pack/transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..6d07b3b12cee87869440feb1496dd634d334e96f
--- /dev/null
+++ b/infer/lib/infer_pack/transforms.py
@@ -0,0 +1,207 @@
+import numpy as np
+import torch
+from torch.nn import functional as F
+
+DEFAULT_MIN_BIN_WIDTH = 1e-3
+DEFAULT_MIN_BIN_HEIGHT = 1e-3
+DEFAULT_MIN_DERIVATIVE = 1e-3
+
+
+def piecewise_rational_quadratic_transform(
+ inputs,
+ unnormalized_widths,
+ unnormalized_heights,
+ unnormalized_derivatives,
+ inverse=False,
+ tails=None,
+ tail_bound=1.0,
+ min_bin_width=DEFAULT_MIN_BIN_WIDTH,
+ min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
+ min_derivative=DEFAULT_MIN_DERIVATIVE,
+):
+ if tails is None:
+ spline_fn = rational_quadratic_spline
+ spline_kwargs = {}
+ else:
+ spline_fn = unconstrained_rational_quadratic_spline
+ spline_kwargs = {"tails": tails, "tail_bound": tail_bound}
+
+ outputs, logabsdet = spline_fn(
+ inputs=inputs,
+ unnormalized_widths=unnormalized_widths,
+ unnormalized_heights=unnormalized_heights,
+ unnormalized_derivatives=unnormalized_derivatives,
+ inverse=inverse,
+ min_bin_width=min_bin_width,
+ min_bin_height=min_bin_height,
+ min_derivative=min_derivative,
+ **spline_kwargs
+ )
+ return outputs, logabsdet
+
+
+def searchsorted(bin_locations, inputs, eps=1e-6):
+ bin_locations[..., -1] += eps
+ return torch.sum(inputs[..., None] >= bin_locations, dim=-1) - 1
+
+
+def unconstrained_rational_quadratic_spline(
+ inputs,
+ unnormalized_widths,
+ unnormalized_heights,
+ unnormalized_derivatives,
+ inverse=False,
+ tails="linear",
+ tail_bound=1.0,
+ min_bin_width=DEFAULT_MIN_BIN_WIDTH,
+ min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
+ min_derivative=DEFAULT_MIN_DERIVATIVE,
+):
+ inside_interval_mask = (inputs >= -tail_bound) & (inputs <= tail_bound)
+ outside_interval_mask = ~inside_interval_mask
+
+ outputs = torch.zeros_like(inputs)
+ logabsdet = torch.zeros_like(inputs)
+
+ if tails == "linear":
+ unnormalized_derivatives = F.pad(unnormalized_derivatives, pad=(1, 1))
+ constant = np.log(np.exp(1 - min_derivative) - 1)
+ unnormalized_derivatives[..., 0] = constant
+ unnormalized_derivatives[..., -1] = constant
+
+ outputs[outside_interval_mask] = inputs[outside_interval_mask]
+ logabsdet[outside_interval_mask] = 0
+ else:
+ raise RuntimeError("{} tails are not implemented.".format(tails))
+
+ (
+ outputs[inside_interval_mask],
+ logabsdet[inside_interval_mask],
+ ) = rational_quadratic_spline(
+ inputs=inputs[inside_interval_mask],
+ unnormalized_widths=unnormalized_widths[inside_interval_mask, :],
+ unnormalized_heights=unnormalized_heights[inside_interval_mask, :],
+ unnormalized_derivatives=unnormalized_derivatives[inside_interval_mask, :],
+ inverse=inverse,
+ left=-tail_bound,
+ right=tail_bound,
+ bottom=-tail_bound,
+ top=tail_bound,
+ min_bin_width=min_bin_width,
+ min_bin_height=min_bin_height,
+ min_derivative=min_derivative,
+ )
+
+ return outputs, logabsdet
+
+
+def rational_quadratic_spline(
+ inputs,
+ unnormalized_widths,
+ unnormalized_heights,
+ unnormalized_derivatives,
+ inverse=False,
+ left=0.0,
+ right=1.0,
+ bottom=0.0,
+ top=1.0,
+ min_bin_width=DEFAULT_MIN_BIN_WIDTH,
+ min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
+ min_derivative=DEFAULT_MIN_DERIVATIVE,
+):
+ if torch.min(inputs) < left or torch.max(inputs) > right:
+ raise ValueError("Input to a transform is not within its domain")
+
+ num_bins = unnormalized_widths.shape[-1]
+
+ if min_bin_width * num_bins > 1.0:
+ raise ValueError("Minimal bin width too large for the number of bins")
+ if min_bin_height * num_bins > 1.0:
+ raise ValueError("Minimal bin height too large for the number of bins")
+
+ widths = F.softmax(unnormalized_widths, dim=-1)
+ widths = min_bin_width + (1 - min_bin_width * num_bins) * widths
+ cumwidths = torch.cumsum(widths, dim=-1)
+ cumwidths = F.pad(cumwidths, pad=(1, 0), mode="constant", value=0.0)
+ cumwidths = (right - left) * cumwidths + left
+ cumwidths[..., 0] = left
+ cumwidths[..., -1] = right
+ widths = cumwidths[..., 1:] - cumwidths[..., :-1]
+
+ derivatives = min_derivative + F.softplus(unnormalized_derivatives)
+
+ heights = F.softmax(unnormalized_heights, dim=-1)
+ heights = min_bin_height + (1 - min_bin_height * num_bins) * heights
+ cumheights = torch.cumsum(heights, dim=-1)
+ cumheights = F.pad(cumheights, pad=(1, 0), mode="constant", value=0.0)
+ cumheights = (top - bottom) * cumheights + bottom
+ cumheights[..., 0] = bottom
+ cumheights[..., -1] = top
+ heights = cumheights[..., 1:] - cumheights[..., :-1]
+
+ if inverse:
+ bin_idx = searchsorted(cumheights, inputs)[..., None]
+ else:
+ bin_idx = searchsorted(cumwidths, inputs)[..., None]
+
+ input_cumwidths = cumwidths.gather(-1, bin_idx)[..., 0]
+ input_bin_widths = widths.gather(-1, bin_idx)[..., 0]
+
+ input_cumheights = cumheights.gather(-1, bin_idx)[..., 0]
+ delta = heights / widths
+ input_delta = delta.gather(-1, bin_idx)[..., 0]
+
+ input_derivatives = derivatives.gather(-1, bin_idx)[..., 0]
+ input_derivatives_plus_one = derivatives[..., 1:].gather(-1, bin_idx)[..., 0]
+
+ input_heights = heights.gather(-1, bin_idx)[..., 0]
+
+ if inverse:
+ a = (inputs - input_cumheights) * (
+ input_derivatives + input_derivatives_plus_one - 2 * input_delta
+ ) + input_heights * (input_delta - input_derivatives)
+ b = input_heights * input_derivatives - (inputs - input_cumheights) * (
+ input_derivatives + input_derivatives_plus_one - 2 * input_delta
+ )
+ c = -input_delta * (inputs - input_cumheights)
+
+ discriminant = b.pow(2) - 4 * a * c
+ assert (discriminant >= 0).all()
+
+ root = (2 * c) / (-b - torch.sqrt(discriminant))
+ outputs = root * input_bin_widths + input_cumwidths
+
+ theta_one_minus_theta = root * (1 - root)
+ denominator = input_delta + (
+ (input_derivatives + input_derivatives_plus_one - 2 * input_delta)
+ * theta_one_minus_theta
+ )
+ derivative_numerator = input_delta.pow(2) * (
+ input_derivatives_plus_one * root.pow(2)
+ + 2 * input_delta * theta_one_minus_theta
+ + input_derivatives * (1 - root).pow(2)
+ )
+ logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
+
+ return outputs, -logabsdet
+ else:
+ theta = (inputs - input_cumwidths) / input_bin_widths
+ theta_one_minus_theta = theta * (1 - theta)
+
+ numerator = input_heights * (
+ input_delta * theta.pow(2) + input_derivatives * theta_one_minus_theta
+ )
+ denominator = input_delta + (
+ (input_derivatives + input_derivatives_plus_one - 2 * input_delta)
+ * theta_one_minus_theta
+ )
+ outputs = input_cumheights + numerator / denominator
+
+ derivative_numerator = input_delta.pow(2) * (
+ input_derivatives_plus_one * theta.pow(2)
+ + 2 * input_delta * theta_one_minus_theta
+ + input_derivatives * (1 - theta).pow(2)
+ )
+ logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
+
+ return outputs, logabsdet
diff --git a/infer/lib/jit/__init__.py b/infer/lib/jit/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d7f41dd6ab1a0eb0afec387dbb9aa875d1564b4f
--- /dev/null
+++ b/infer/lib/jit/__init__.py
@@ -0,0 +1,163 @@
+from io import BytesIO
+import pickle
+import time
+import torch
+from tqdm import tqdm
+from collections import OrderedDict
+
+
+def load_inputs(path, device, is_half=False):
+ parm = torch.load(path, map_location=torch.device("cpu"))
+ for key in parm.keys():
+ parm[key] = parm[key].to(device)
+ if is_half and parm[key].dtype == torch.float32:
+ parm[key] = parm[key].half()
+ elif not is_half and parm[key].dtype == torch.float16:
+ parm[key] = parm[key].float()
+ return parm
+
+
+def benchmark(
+ model, inputs_path, device=torch.device("cpu"), epoch=1000, is_half=False
+):
+ parm = load_inputs(inputs_path, device, is_half)
+ total_ts = 0.0
+ bar = tqdm(range(epoch))
+ for i in bar:
+ start_time = time.perf_counter()
+ o = model(**parm)
+ total_ts += time.perf_counter() - start_time
+ print(f"num_epoch: {epoch} | avg time(ms): {(total_ts*1000)/epoch}")
+
+
+def jit_warm_up(model, inputs_path, device=torch.device("cpu"), epoch=5, is_half=False):
+ benchmark(model, inputs_path, device, epoch=epoch, is_half=is_half)
+
+
+def to_jit_model(
+ model_path,
+ model_type: str,
+ mode: str = "trace",
+ inputs_path: str = None,
+ device=torch.device("cpu"),
+ is_half=False,
+):
+ model = None
+ if model_type.lower() == "synthesizer":
+ from .get_synthesizer import get_synthesizer
+
+ model, _ = get_synthesizer(model_path, device)
+ model.forward = model.infer
+ elif model_type.lower() == "rmvpe":
+ from .get_rmvpe import get_rmvpe
+
+ model = get_rmvpe(model_path, device)
+ elif model_type.lower() == "hubert":
+ from .get_hubert import get_hubert_model
+
+ model = get_hubert_model(model_path, device)
+ model.forward = model.infer
+ else:
+ raise ValueError(f"No model type named {model_type}")
+ model = model.eval()
+ model = model.half() if is_half else model.float()
+ if mode == "trace":
+ assert not inputs_path
+ inputs = load_inputs(inputs_path, device, is_half)
+ model_jit = torch.jit.trace(model, example_kwarg_inputs=inputs)
+ elif mode == "script":
+ model_jit = torch.jit.script(model)
+ model_jit.to(device)
+ model_jit = model_jit.half() if is_half else model_jit.float()
+ # model = model.half() if is_half else model.float()
+ return (model, model_jit)
+
+
+def export(
+ model: torch.nn.Module,
+ mode: str = "trace",
+ inputs: dict = None,
+ device=torch.device("cpu"),
+ is_half: bool = False,
+) -> dict:
+ model = model.half() if is_half else model.float()
+ model.eval()
+ if mode == "trace":
+ assert inputs is not None
+ model_jit = torch.jit.trace(model, example_kwarg_inputs=inputs)
+ elif mode == "script":
+ model_jit = torch.jit.script(model)
+ model_jit.to(device)
+ model_jit = model_jit.half() if is_half else model_jit.float()
+ buffer = BytesIO()
+ # model_jit=model_jit.cpu()
+ torch.jit.save(model_jit, buffer)
+ del model_jit
+ cpt = OrderedDict()
+ cpt["model"] = buffer.getvalue()
+ cpt["is_half"] = is_half
+ return cpt
+
+
+def load(path: str):
+ with open(path, "rb") as f:
+ return pickle.load(f)
+
+
+def save(ckpt: dict, save_path: str):
+ with open(save_path, "wb") as f:
+ pickle.dump(ckpt, f)
+
+
+def rmvpe_jit_export(
+ model_path: str,
+ mode: str = "script",
+ inputs_path: str = None,
+ save_path: str = None,
+ device=torch.device("cpu"),
+ is_half=False,
+):
+ if not save_path:
+ save_path = model_path.rstrip(".pth")
+ save_path += ".half.jit" if is_half else ".jit"
+ if "cuda" in str(device) and ":" not in str(device):
+ device = torch.device("cuda:0")
+ from .get_rmvpe import get_rmvpe
+
+ model = get_rmvpe(model_path, device)
+ inputs = None
+ if mode == "trace":
+ inputs = load_inputs(inputs_path, device, is_half)
+ ckpt = export(model, mode, inputs, device, is_half)
+ ckpt["device"] = str(device)
+ save(ckpt, save_path)
+ return ckpt
+
+
+def synthesizer_jit_export(
+ model_path: str,
+ mode: str = "script",
+ inputs_path: str = None,
+ save_path: str = None,
+ device=torch.device("cpu"),
+ is_half=False,
+):
+ if not save_path:
+ save_path = model_path.rstrip(".pth")
+ save_path += ".half.jit" if is_half else ".jit"
+ if "cuda" in str(device) and ":" not in str(device):
+ device = torch.device("cuda:0")
+ from .get_synthesizer import get_synthesizer
+
+ model, cpt = get_synthesizer(model_path, device)
+ assert isinstance(cpt, dict)
+ model.forward = model.infer
+ inputs = None
+ if mode == "trace":
+ inputs = load_inputs(inputs_path, device, is_half)
+ ckpt = export(model, mode, inputs, device, is_half)
+ cpt.pop("weight")
+ cpt["model"] = ckpt["model"]
+ cpt["device"] = device
+ save(cpt, save_path)
+ return cpt
diff --git a/infer/lib/jit/get_hubert.py b/infer/lib/jit/get_hubert.py
new file mode 100644
index 0000000000000000000000000000000000000000..aec7132fa453f6a2e3b649ffb11b8119dcd5b15d
--- /dev/null
+++ b/infer/lib/jit/get_hubert.py
@@ -0,0 +1,342 @@
+import math
+import random
+from typing import Optional, Tuple
+from fairseq.checkpoint_utils import load_model_ensemble_and_task
+import numpy as np
+import torch
+import torch.nn.functional as F
+
+# from fairseq.data.data_utils import compute_mask_indices
+from fairseq.utils import index_put
+
+
+# @torch.jit.script
+def pad_to_multiple(x, multiple, dim=-1, value=0):
+ # Inspired from https://github.com/lucidrains/local-attention/blob/master/local_attention/local_attention.py#L41
+ if x is None:
+ return None, 0
+ tsz = x.size(dim)
+ m = tsz / multiple
+ remainder = math.ceil(m) * multiple - tsz
+ if int(tsz % multiple) == 0:
+ return x, 0
+ pad_offset = (0,) * (-1 - dim) * 2
+
+ return F.pad(x, (*pad_offset, 0, remainder), value=value), remainder
+
+
+def extract_features(
+ self,
+ x,
+ padding_mask=None,
+ tgt_layer=None,
+ min_layer=0,
+):
+ if padding_mask is not None:
+ x = index_put(x, padding_mask, 0)
+
+ x_conv = self.pos_conv(x.transpose(1, 2))
+ x_conv = x_conv.transpose(1, 2)
+ x = x + x_conv
+
+ if not self.layer_norm_first:
+ x = self.layer_norm(x)
+
+ # pad to the sequence length dimension
+ x, pad_length = pad_to_multiple(x, self.required_seq_len_multiple, dim=-2, value=0)
+ if pad_length > 0 and padding_mask is None:
+ padding_mask = x.new_zeros((x.size(0), x.size(1)), dtype=torch.bool)
+ padding_mask[:, -pad_length:] = True
+ else:
+ padding_mask, _ = pad_to_multiple(
+ padding_mask, self.required_seq_len_multiple, dim=-1, value=True
+ )
+ x = F.dropout(x, p=self.dropout, training=self.training)
+
+ # B x T x C -> T x B x C
+ x = x.transpose(0, 1)
+
+ layer_results = []
+ r = None
+ for i, layer in enumerate(self.layers):
+ dropout_probability = np.random.random() if self.layerdrop > 0 else 1
+ if not self.training or (dropout_probability > self.layerdrop):
+ x, (z, lr) = layer(
+ x, self_attn_padding_mask=padding_mask, need_weights=False
+ )
+ if i >= min_layer:
+ layer_results.append((x, z, lr))
+ if i == tgt_layer:
+ r = x
+ break
+
+ if r is not None:
+ x = r
+
+ # T x B x C -> B x T x C
+ x = x.transpose(0, 1)
+
+ # undo paddding
+ if pad_length > 0:
+ x = x[:, :-pad_length]
+
+ def undo_pad(a, b, c):
+ return (
+ a[:-pad_length],
+ b[:-pad_length] if b is not None else b,
+ c[:-pad_length],
+ )
+
+ layer_results = [undo_pad(*u) for u in layer_results]
+
+ return x, layer_results
+
+
+def compute_mask_indices(
+ shape: Tuple[int, int],
+ padding_mask: Optional[torch.Tensor],
+ mask_prob: float,
+ mask_length: int,
+ mask_type: str = "static",
+ mask_other: float = 0.0,
+ min_masks: int = 0,
+ no_overlap: bool = False,
+ min_space: int = 0,
+ require_same_masks: bool = True,
+ mask_dropout: float = 0.0,
+) -> torch.Tensor:
+ """
+ Computes random mask spans for a given shape
+
+ Args:
+ shape: the the shape for which to compute masks.
+ should be of size 2 where first element is batch size and 2nd is timesteps
+ padding_mask: optional padding mask of the same size as shape, which will prevent masking padded elements
+ mask_prob: probability for each token to be chosen as start of the span to be masked. this will be multiplied by
+ number of timesteps divided by length of mask span to mask approximately this percentage of all elements.
+ however due to overlaps, the actual number will be smaller (unless no_overlap is True)
+ mask_type: how to compute mask lengths
+ static = fixed size
+ uniform = sample from uniform distribution [mask_other, mask_length*2]
+ normal = sample from normal distribution with mean mask_length and stdev mask_other. mask is min 1 element
+ poisson = sample from possion distribution with lambda = mask length
+ min_masks: minimum number of masked spans
+ no_overlap: if false, will switch to an alternative recursive algorithm that prevents spans from overlapping
+ min_space: only used if no_overlap is True, this is how many elements to keep unmasked between spans
+ require_same_masks: if true, will randomly drop out masks until same amount of masks remains in each sample
+ mask_dropout: randomly dropout this percentage of masks in each example
+ """
+
+ bsz, all_sz = shape
+ mask = torch.full((bsz, all_sz), False)
+
+ all_num_mask = int(
+ # add a random number for probabilistic rounding
+ mask_prob * all_sz / float(mask_length)
+ + torch.rand([1]).item()
+ )
+
+ all_num_mask = max(min_masks, all_num_mask)
+
+ mask_idcs = []
+ for i in range(bsz):
+ if padding_mask is not None:
+ sz = all_sz - padding_mask[i].long().sum().item()
+ num_mask = int(mask_prob * sz / float(mask_length) + np.random.rand())
+ num_mask = max(min_masks, num_mask)
+ else:
+ sz = all_sz
+ num_mask = all_num_mask
+
+ if mask_type == "static":
+ lengths = torch.full([num_mask], mask_length)
+ elif mask_type == "uniform":
+ lengths = torch.randint(mask_other, mask_length * 2 + 1, size=[num_mask])
+ elif mask_type == "normal":
+ lengths = torch.normal(mask_length, mask_other, size=[num_mask])
+ lengths = [max(1, int(round(x))) for x in lengths]
+ else:
+ raise Exception("unknown mask selection " + mask_type)
+
+ if sum(lengths) == 0:
+ lengths[0] = min(mask_length, sz - 1)
+
+ if no_overlap:
+ mask_idc = []
+
+ def arrange(s, e, length, keep_length):
+ span_start = torch.randint(low=s, high=e - length, size=[1]).item()
+ mask_idc.extend(span_start + i for i in range(length))
+
+ new_parts = []
+ if span_start - s - min_space >= keep_length:
+ new_parts.append((s, span_start - min_space + 1))
+ if e - span_start - length - min_space > keep_length:
+ new_parts.append((span_start + length + min_space, e))
+ return new_parts
+
+ parts = [(0, sz)]
+ min_length = min(lengths)
+ for length in sorted(lengths, reverse=True):
+ t = [e - s if e - s >= length + min_space else 0 for s, e in parts]
+ lens = torch.asarray(t, dtype=torch.int)
+ l_sum = torch.sum(lens)
+ if l_sum == 0:
+ break
+ probs = lens / torch.sum(lens)
+ c = torch.multinomial(probs.float(), len(parts)).item()
+ s, e = parts.pop(c)
+ parts.extend(arrange(s, e, length, min_length))
+ mask_idc = torch.asarray(mask_idc)
+ else:
+ min_len = min(lengths)
+ if sz - min_len <= num_mask:
+ min_len = sz - num_mask - 1
+ mask_idc = torch.asarray(
+ random.sample([i for i in range(sz - min_len)], num_mask)
+ )
+ mask_idc = torch.asarray(
+ [
+ mask_idc[j] + offset
+ for j in range(len(mask_idc))
+ for offset in range(lengths[j])
+ ]
+ )
+
+ mask_idcs.append(torch.unique(mask_idc[mask_idc < sz]))
+
+ min_len = min([len(m) for m in mask_idcs])
+ for i, mask_idc in enumerate(mask_idcs):
+ if isinstance(mask_idc, torch.Tensor):
+ mask_idc = torch.asarray(mask_idc, dtype=torch.float)
+ if len(mask_idc) > min_len and require_same_masks:
+ mask_idc = torch.asarray(
+ random.sample([i for i in range(mask_idc)], min_len)
+ )
+ if mask_dropout > 0:
+ num_holes = int(round(len(mask_idc) * mask_dropout))
+ mask_idc = torch.asarray(
+ random.sample([i for i in range(mask_idc)], len(mask_idc) - num_holes)
+ )
+
+ mask[i, mask_idc.int()] = True
+
+ return mask
+
+
+def apply_mask(self, x, padding_mask, target_list):
+ B, T, C = x.shape
+ torch.zeros_like(x)
+ if self.mask_prob > 0:
+ mask_indices = compute_mask_indices(
+ (B, T),
+ padding_mask,
+ self.mask_prob,
+ self.mask_length,
+ self.mask_selection,
+ self.mask_other,
+ min_masks=2,
+ no_overlap=self.no_mask_overlap,
+ min_space=self.mask_min_space,
+ )
+ mask_indices = mask_indices.to(x.device)
+ x[mask_indices] = self.mask_emb
+ else:
+ mask_indices = None
+
+ if self.mask_channel_prob > 0:
+ mask_channel_indices = compute_mask_indices(
+ (B, C),
+ None,
+ self.mask_channel_prob,
+ self.mask_channel_length,
+ self.mask_channel_selection,
+ self.mask_channel_other,
+ no_overlap=self.no_mask_channel_overlap,
+ min_space=self.mask_channel_min_space,
+ )
+ mask_channel_indices = (
+ mask_channel_indices.to(x.device).unsqueeze(1).expand(-1, T, -1)
+ )
+ x[mask_channel_indices] = 0
+
+ return x, mask_indices
+
+
+def get_hubert_model(
+ model_path="assets/hubert/hubert_base.pt", device=torch.device("cpu")
+):
+ models, _, _ = load_model_ensemble_and_task(
+ [model_path],
+ suffix="",
+ )
+ hubert_model = models[0]
+ hubert_model = hubert_model.to(device)
+
+ def _apply_mask(x, padding_mask, target_list):
+ return apply_mask(hubert_model, x, padding_mask, target_list)
+
+ hubert_model.apply_mask = _apply_mask
+
+ def _extract_features(
+ x,
+ padding_mask=None,
+ tgt_layer=None,
+ min_layer=0,
+ ):
+ return extract_features(
+ hubert_model.encoder,
+ x,
+ padding_mask=padding_mask,
+ tgt_layer=tgt_layer,
+ min_layer=min_layer,
+ )
+
+ hubert_model.encoder.extract_features = _extract_features
+
+ hubert_model._forward = hubert_model.forward
+
+ def hubert_extract_features(
+ self,
+ source: torch.Tensor,
+ padding_mask: Optional[torch.Tensor] = None,
+ mask: bool = False,
+ ret_conv: bool = False,
+ output_layer: Optional[int] = None,
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ res = self._forward(
+ source,
+ padding_mask=padding_mask,
+ mask=mask,
+ features_only=True,
+ output_layer=output_layer,
+ )
+ feature = res["features"] if ret_conv else res["x"]
+ return feature, res["padding_mask"]
+
+ def _hubert_extract_features(
+ source: torch.Tensor,
+ padding_mask: Optional[torch.Tensor] = None,
+ mask: bool = False,
+ ret_conv: bool = False,
+ output_layer: Optional[int] = None,
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ return hubert_extract_features(
+ hubert_model, source, padding_mask, mask, ret_conv, output_layer
+ )
+
+ hubert_model.extract_features = _hubert_extract_features
+
+ def infer(source, padding_mask, output_layer: torch.Tensor):
+ output_layer = output_layer.item()
+ logits = hubert_model.extract_features(
+ source=source, padding_mask=padding_mask, output_layer=output_layer
+ )
+ feats = hubert_model.final_proj(logits[0]) if output_layer == 9 else logits[0]
+ return feats
+
+ hubert_model.infer = infer
+ # hubert_model.forward=infer
+ # hubert_model.forward
+
+ return hubert_model
diff --git a/infer/lib/jit/get_rmvpe.py b/infer/lib/jit/get_rmvpe.py
new file mode 100644
index 0000000000000000000000000000000000000000..e71c39fb0275d3891690af72b6f7e8dd11b00f70
--- /dev/null
+++ b/infer/lib/jit/get_rmvpe.py
@@ -0,0 +1,12 @@
+import torch
+
+
+def get_rmvpe(model_path="assets/rmvpe/rmvpe.pt", device=torch.device("cpu")):
+ from infer.lib.rmvpe import E2E
+
+ model = E2E(4, 1, (2, 2))
+ ckpt = torch.load(model_path, map_location=device)
+ model.load_state_dict(ckpt)
+ model.eval()
+ model = model.to(device)
+ return model
diff --git a/infer/lib/jit/get_synthesizer.py b/infer/lib/jit/get_synthesizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..b8db4fa9666873eb1ac8c311bf9190279fc4587b
--- /dev/null
+++ b/infer/lib/jit/get_synthesizer.py
@@ -0,0 +1,38 @@
+import torch
+
+
+def get_synthesizer(pth_path, device=torch.device("cpu")):
+ from infer.lib.infer_pack.models import (
+ SynthesizerTrnMs256NSFsid,
+ SynthesizerTrnMs256NSFsid_nono,
+ SynthesizerTrnMs768NSFsid,
+ SynthesizerTrnMs768NSFsid_nono,
+ )
+
+ cpt = torch.load(pth_path, map_location=torch.device("cpu"))
+ # tgt_sr = cpt["config"][-1]
+ cpt["config"][-3] = cpt["weight"]["emb_g.weight"].shape[0]
+ if_f0 = cpt.get("f0", 1)
+ version = cpt.get("version", "v1")
+ if version == "v1":
+ if if_f0 == 1:
+ net_g = SynthesizerTrnMs256NSFsid(*cpt["config"], is_half=False)
+ else:
+ net_g = SynthesizerTrnMs256NSFsid_nono(*cpt["config"])
+ elif version == "v2":
+ if if_f0 == 1:
+ net_g = SynthesizerTrnMs768NSFsid(*cpt["config"], is_half=False)
+ else:
+ net_g = SynthesizerTrnMs768NSFsid_nono(*cpt["config"])
+ del net_g.enc_q
+ # net_g.forward = net_g.infer
+ # ckpt = {}
+ # ckpt["config"] = cpt["config"]
+ # ckpt["f0"] = if_f0
+ # ckpt["version"] = version
+ # ckpt["info"] = cpt.get("info", "0epoch")
+ net_g.load_state_dict(cpt["weight"], strict=False)
+ net_g = net_g.float()
+ net_g.eval().to(device)
+ net_g.remove_weight_norm()
+ return net_g, cpt
diff --git a/infer/lib/rmvpe.py b/infer/lib/rmvpe.py
new file mode 100644
index 0000000000000000000000000000000000000000..86c6899e3a4c55fc5cef8f195e994e026aa1345a
--- /dev/null
+++ b/infer/lib/rmvpe.py
@@ -0,0 +1,670 @@
+from io import BytesIO
+import os
+from typing import List, Optional, Tuple
+import numpy as np
+import torch
+
+from infer.lib import jit
+
+try:
+ # Fix "Torch not compiled with CUDA enabled"
+ import intel_extension_for_pytorch as ipex # pylint: disable=import-error, unused-import
+
+ if torch.xpu.is_available():
+ from infer.modules.ipex import ipex_init
+
+ ipex_init()
+except Exception: # pylint: disable=broad-exception-caught
+ pass
+import torch.nn as nn
+import torch.nn.functional as F
+from librosa.util import normalize, pad_center, tiny
+from scipy.signal import get_window
+
+import logging
+
+logger = logging.getLogger(__name__)
+
+
+class STFT(torch.nn.Module):
+ def __init__(
+ self, filter_length=1024, hop_length=512, win_length=None, window="hann"
+ ):
+ """
+ This module implements an STFT using 1D convolution and 1D transpose convolutions.
+ This is a bit tricky so there are some cases that probably won't work as working
+ out the same sizes before and after in all overlap add setups is tough. Right now,
+ this code should work with hop lengths that are half the filter length (50% overlap
+ between frames).
+
+ Keyword Arguments:
+ filter_length {int} -- Length of filters used (default: {1024})
+ hop_length {int} -- Hop length of STFT (restrict to 50% overlap between frames) (default: {512})
+ win_length {[type]} -- Length of the window function applied to each frame (if not specified, it
+ equals the filter length). (default: {None})
+ window {str} -- Type of window to use (options are bartlett, hann, hamming, blackman, blackmanharris)
+ (default: {'hann'})
+ """
+ super(STFT, self).__init__()
+ self.filter_length = filter_length
+ self.hop_length = hop_length
+ self.win_length = win_length if win_length else filter_length
+ self.window = window
+ self.forward_transform = None
+ self.pad_amount = int(self.filter_length / 2)
+ fourier_basis = np.fft.fft(np.eye(self.filter_length))
+
+ cutoff = int((self.filter_length / 2 + 1))
+ fourier_basis = np.vstack(
+ [np.real(fourier_basis[:cutoff, :]), np.imag(fourier_basis[:cutoff, :])]
+ )
+ forward_basis = torch.FloatTensor(fourier_basis)
+ inverse_basis = torch.FloatTensor(np.linalg.pinv(fourier_basis))
+
+ assert filter_length >= self.win_length
+ # get window and zero center pad it to filter_length
+ fft_window = get_window(window, self.win_length, fftbins=True)
+ fft_window = pad_center(fft_window, size=filter_length)
+ fft_window = torch.from_numpy(fft_window).float()
+
+ # window the bases
+ forward_basis *= fft_window
+ inverse_basis = (inverse_basis.T * fft_window).T
+
+ self.register_buffer("forward_basis", forward_basis.float())
+ self.register_buffer("inverse_basis", inverse_basis.float())
+ self.register_buffer("fft_window", fft_window.float())
+
+ def transform(self, input_data, return_phase=False):
+ """Take input data (audio) to STFT domain.
+
+ Arguments:
+ input_data {tensor} -- Tensor of floats, with shape (num_batch, num_samples)
+
+ Returns:
+ magnitude {tensor} -- Magnitude of STFT with shape (num_batch,
+ num_frequencies, num_frames)
+ phase {tensor} -- Phase of STFT with shape (num_batch,
+ num_frequencies, num_frames)
+ """
+ input_data = F.pad(
+ input_data,
+ (self.pad_amount, self.pad_amount),
+ mode="reflect",
+ )
+ forward_transform = input_data.unfold(
+ 1, self.filter_length, self.hop_length
+ ).permute(0, 2, 1)
+ forward_transform = torch.matmul(self.forward_basis, forward_transform)
+ cutoff = int((self.filter_length / 2) + 1)
+ real_part = forward_transform[:, :cutoff, :]
+ imag_part = forward_transform[:, cutoff:, :]
+ magnitude = torch.sqrt(real_part**2 + imag_part**2)
+ if return_phase:
+ phase = torch.atan2(imag_part.data, real_part.data)
+ return magnitude, phase
+ else:
+ return magnitude
+
+ def inverse(self, magnitude, phase):
+ """Call the inverse STFT (iSTFT), given magnitude and phase tensors produced
+ by the ```transform``` function.
+
+ Arguments:
+ magnitude {tensor} -- Magnitude of STFT with shape (num_batch,
+ num_frequencies, num_frames)
+ phase {tensor} -- Phase of STFT with shape (num_batch,
+ num_frequencies, num_frames)
+
+ Returns:
+ inverse_transform {tensor} -- Reconstructed audio given magnitude and phase. Of
+ shape (num_batch, num_samples)
+ """
+ cat = torch.cat(
+ [magnitude * torch.cos(phase), magnitude * torch.sin(phase)], dim=1
+ )
+ fold = torch.nn.Fold(
+ output_size=(1, (cat.size(-1) - 1) * self.hop_length + self.filter_length),
+ kernel_size=(1, self.filter_length),
+ stride=(1, self.hop_length),
+ )
+ inverse_transform = torch.matmul(self.inverse_basis, cat)
+ inverse_transform = fold(inverse_transform)[
+ :, 0, 0, self.pad_amount : -self.pad_amount
+ ]
+ window_square_sum = (
+ self.fft_window.pow(2).repeat(cat.size(-1), 1).T.unsqueeze(0)
+ )
+ window_square_sum = fold(window_square_sum)[
+ :, 0, 0, self.pad_amount : -self.pad_amount
+ ]
+ inverse_transform /= window_square_sum
+ return inverse_transform
+
+ def forward(self, input_data):
+ """Take input data (audio) to STFT domain and then back to audio.
+
+ Arguments:
+ input_data {tensor} -- Tensor of floats, with shape (num_batch, num_samples)
+
+ Returns:
+ reconstruction {tensor} -- Reconstructed audio given magnitude and phase. Of
+ shape (num_batch, num_samples)
+ """
+ self.magnitude, self.phase = self.transform(input_data, return_phase=True)
+ reconstruction = self.inverse(self.magnitude, self.phase)
+ return reconstruction
+
+
+from time import time as ttime
+
+
+class BiGRU(nn.Module):
+ def __init__(self, input_features, hidden_features, num_layers):
+ super(BiGRU, self).__init__()
+ self.gru = nn.GRU(
+ input_features,
+ hidden_features,
+ num_layers=num_layers,
+ batch_first=True,
+ bidirectional=True,
+ )
+
+ def forward(self, x):
+ return self.gru(x)[0]
+
+
+class ConvBlockRes(nn.Module):
+ def __init__(self, in_channels, out_channels, momentum=0.01):
+ super(ConvBlockRes, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=(3, 3),
+ stride=(1, 1),
+ padding=(1, 1),
+ bias=False,
+ ),
+ nn.BatchNorm2d(out_channels, momentum=momentum),
+ nn.ReLU(),
+ nn.Conv2d(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ kernel_size=(3, 3),
+ stride=(1, 1),
+ padding=(1, 1),
+ bias=False,
+ ),
+ nn.BatchNorm2d(out_channels, momentum=momentum),
+ nn.ReLU(),
+ )
+ # self.shortcut:Optional[nn.Module] = None
+ if in_channels != out_channels:
+ self.shortcut = nn.Conv2d(in_channels, out_channels, (1, 1))
+
+ def forward(self, x: torch.Tensor):
+ if not hasattr(self, "shortcut"):
+ return self.conv(x) + x
+ else:
+ return self.conv(x) + self.shortcut(x)
+
+
+class Encoder(nn.Module):
+ def __init__(
+ self,
+ in_channels,
+ in_size,
+ n_encoders,
+ kernel_size,
+ n_blocks,
+ out_channels=16,
+ momentum=0.01,
+ ):
+ super(Encoder, self).__init__()
+ self.n_encoders = n_encoders
+ self.bn = nn.BatchNorm2d(in_channels, momentum=momentum)
+ self.layers = nn.ModuleList()
+ self.latent_channels = []
+ for i in range(self.n_encoders):
+ self.layers.append(
+ ResEncoderBlock(
+ in_channels, out_channels, kernel_size, n_blocks, momentum=momentum
+ )
+ )
+ self.latent_channels.append([out_channels, in_size])
+ in_channels = out_channels
+ out_channels *= 2
+ in_size //= 2
+ self.out_size = in_size
+ self.out_channel = out_channels
+
+ def forward(self, x: torch.Tensor):
+ concat_tensors: List[torch.Tensor] = []
+ x = self.bn(x)
+ for i, layer in enumerate(self.layers):
+ t, x = layer(x)
+ concat_tensors.append(t)
+ return x, concat_tensors
+
+
+class ResEncoderBlock(nn.Module):
+ def __init__(
+ self, in_channels, out_channels, kernel_size, n_blocks=1, momentum=0.01
+ ):
+ super(ResEncoderBlock, self).__init__()
+ self.n_blocks = n_blocks
+ self.conv = nn.ModuleList()
+ self.conv.append(ConvBlockRes(in_channels, out_channels, momentum))
+ for i in range(n_blocks - 1):
+ self.conv.append(ConvBlockRes(out_channels, out_channels, momentum))
+ self.kernel_size = kernel_size
+ if self.kernel_size is not None:
+ self.pool = nn.AvgPool2d(kernel_size=kernel_size)
+
+ def forward(self, x):
+ for i, conv in enumerate(self.conv):
+ x = conv(x)
+ if self.kernel_size is not None:
+ return x, self.pool(x)
+ else:
+ return x
+
+
+class Intermediate(nn.Module): #
+ def __init__(self, in_channels, out_channels, n_inters, n_blocks, momentum=0.01):
+ super(Intermediate, self).__init__()
+ self.n_inters = n_inters
+ self.layers = nn.ModuleList()
+ self.layers.append(
+ ResEncoderBlock(in_channels, out_channels, None, n_blocks, momentum)
+ )
+ for i in range(self.n_inters - 1):
+ self.layers.append(
+ ResEncoderBlock(out_channels, out_channels, None, n_blocks, momentum)
+ )
+
+ def forward(self, x):
+ for i, layer in enumerate(self.layers):
+ x = layer(x)
+ return x
+
+
+class ResDecoderBlock(nn.Module):
+ def __init__(self, in_channels, out_channels, stride, n_blocks=1, momentum=0.01):
+ super(ResDecoderBlock, self).__init__()
+ out_padding = (0, 1) if stride == (1, 2) else (1, 1)
+ self.n_blocks = n_blocks
+ self.conv1 = nn.Sequential(
+ nn.ConvTranspose2d(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=(3, 3),
+ stride=stride,
+ padding=(1, 1),
+ output_padding=out_padding,
+ bias=False,
+ ),
+ nn.BatchNorm2d(out_channels, momentum=momentum),
+ nn.ReLU(),
+ )
+ self.conv2 = nn.ModuleList()
+ self.conv2.append(ConvBlockRes(out_channels * 2, out_channels, momentum))
+ for i in range(n_blocks - 1):
+ self.conv2.append(ConvBlockRes(out_channels, out_channels, momentum))
+
+ def forward(self, x, concat_tensor):
+ x = self.conv1(x)
+ x = torch.cat((x, concat_tensor), dim=1)
+ for i, conv2 in enumerate(self.conv2):
+ x = conv2(x)
+ return x
+
+
+class Decoder(nn.Module):
+ def __init__(self, in_channels, n_decoders, stride, n_blocks, momentum=0.01):
+ super(Decoder, self).__init__()
+ self.layers = nn.ModuleList()
+ self.n_decoders = n_decoders
+ for i in range(self.n_decoders):
+ out_channels = in_channels // 2
+ self.layers.append(
+ ResDecoderBlock(in_channels, out_channels, stride, n_blocks, momentum)
+ )
+ in_channels = out_channels
+
+ def forward(self, x: torch.Tensor, concat_tensors: List[torch.Tensor]):
+ for i, layer in enumerate(self.layers):
+ x = layer(x, concat_tensors[-1 - i])
+ return x
+
+
+class DeepUnet(nn.Module):
+ def __init__(
+ self,
+ kernel_size,
+ n_blocks,
+ en_de_layers=5,
+ inter_layers=4,
+ in_channels=1,
+ en_out_channels=16,
+ ):
+ super(DeepUnet, self).__init__()
+ self.encoder = Encoder(
+ in_channels, 128, en_de_layers, kernel_size, n_blocks, en_out_channels
+ )
+ self.intermediate = Intermediate(
+ self.encoder.out_channel // 2,
+ self.encoder.out_channel,
+ inter_layers,
+ n_blocks,
+ )
+ self.decoder = Decoder(
+ self.encoder.out_channel, en_de_layers, kernel_size, n_blocks
+ )
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ x, concat_tensors = self.encoder(x)
+ x = self.intermediate(x)
+ x = self.decoder(x, concat_tensors)
+ return x
+
+
+class E2E(nn.Module):
+ def __init__(
+ self,
+ n_blocks,
+ n_gru,
+ kernel_size,
+ en_de_layers=5,
+ inter_layers=4,
+ in_channels=1,
+ en_out_channels=16,
+ ):
+ super(E2E, self).__init__()
+ self.unet = DeepUnet(
+ kernel_size,
+ n_blocks,
+ en_de_layers,
+ inter_layers,
+ in_channels,
+ en_out_channels,
+ )
+ self.cnn = nn.Conv2d(en_out_channels, 3, (3, 3), padding=(1, 1))
+ if n_gru:
+ self.fc = nn.Sequential(
+ BiGRU(3 * 128, 256, n_gru),
+ nn.Linear(512, 360),
+ nn.Dropout(0.25),
+ nn.Sigmoid(),
+ )
+ else:
+ self.fc = nn.Sequential(
+ nn.Linear(3 * nn.N_MELS, nn.N_CLASS), nn.Dropout(0.25), nn.Sigmoid()
+ )
+
+ def forward(self, mel):
+ # print(mel.shape)
+ mel = mel.transpose(-1, -2).unsqueeze(1)
+ x = self.cnn(self.unet(mel)).transpose(1, 2).flatten(-2)
+ x = self.fc(x)
+ # print(x.shape)
+ return x
+
+
+from librosa.filters import mel
+
+
+class MelSpectrogram(torch.nn.Module):
+ def __init__(
+ self,
+ is_half,
+ n_mel_channels,
+ sampling_rate,
+ win_length,
+ hop_length,
+ n_fft=None,
+ mel_fmin=0,
+ mel_fmax=None,
+ clamp=1e-5,
+ ):
+ super().__init__()
+ n_fft = win_length if n_fft is None else n_fft
+ self.hann_window = {}
+ mel_basis = mel(
+ sr=sampling_rate,
+ n_fft=n_fft,
+ n_mels=n_mel_channels,
+ fmin=mel_fmin,
+ fmax=mel_fmax,
+ htk=True,
+ )
+ mel_basis = torch.from_numpy(mel_basis).float()
+ self.register_buffer("mel_basis", mel_basis)
+ self.n_fft = win_length if n_fft is None else n_fft
+ self.hop_length = hop_length
+ self.win_length = win_length
+ self.sampling_rate = sampling_rate
+ self.n_mel_channels = n_mel_channels
+ self.clamp = clamp
+ self.is_half = is_half
+
+ def forward(self, audio, keyshift=0, speed=1, center=True):
+ factor = 2 ** (keyshift / 12)
+ n_fft_new = int(np.round(self.n_fft * factor))
+ win_length_new = int(np.round(self.win_length * factor))
+ hop_length_new = int(np.round(self.hop_length * speed))
+ keyshift_key = str(keyshift) + "_" + str(audio.device)
+ if keyshift_key not in self.hann_window:
+ self.hann_window[keyshift_key] = torch.hann_window(win_length_new).to(
+ audio.device
+ )
+ if "privateuseone" in str(audio.device):
+ if not hasattr(self, "stft"):
+ self.stft = STFT(
+ filter_length=n_fft_new,
+ hop_length=hop_length_new,
+ win_length=win_length_new,
+ window="hann",
+ ).to(audio.device)
+ magnitude = self.stft.transform(audio)
+ else:
+ fft = torch.stft(
+ audio,
+ n_fft=n_fft_new,
+ hop_length=hop_length_new,
+ win_length=win_length_new,
+ window=self.hann_window[keyshift_key],
+ center=center,
+ return_complex=True,
+ )
+ magnitude = torch.sqrt(fft.real.pow(2) + fft.imag.pow(2))
+ if keyshift != 0:
+ size = self.n_fft // 2 + 1
+ resize = magnitude.size(1)
+ if resize < size:
+ magnitude = F.pad(magnitude, (0, 0, 0, size - resize))
+ magnitude = magnitude[:, :size, :] * self.win_length / win_length_new
+ mel_output = torch.matmul(self.mel_basis, magnitude)
+ if self.is_half == True:
+ mel_output = mel_output.half()
+ log_mel_spec = torch.log(torch.clamp(mel_output, min=self.clamp))
+ return log_mel_spec
+
+
+class RMVPE:
+ def __init__(self, model_path: str, is_half, device=None, use_jit=False):
+ self.resample_kernel = {}
+ self.resample_kernel = {}
+ self.is_half = is_half
+ if device is None:
+ device = "cuda:0" if torch.cuda.is_available() else "cpu"
+ self.device = device
+ self.mel_extractor = MelSpectrogram(
+ is_half, 128, 16000, 1024, 160, None, 30, 8000
+ ).to(device)
+ if "privateuseone" in str(device):
+ import onnxruntime as ort
+
+ ort_session = ort.InferenceSession(
+ "%s/rmvpe.onnx" % os.environ["rmvpe_root"],
+ providers=["DmlExecutionProvider"],
+ )
+ self.model = ort_session
+ else:
+ if str(self.device) == "cuda":
+ self.device = torch.device("cuda:0")
+
+ def get_jit_model():
+ jit_model_path = model_path.rstrip(".pth")
+ jit_model_path += ".half.jit" if is_half else ".jit"
+ reload = False
+ if os.path.exists(jit_model_path):
+ ckpt = jit.load(jit_model_path)
+ model_device = ckpt["device"]
+ if model_device != str(self.device):
+ reload = True
+ else:
+ reload = True
+
+ if reload:
+ ckpt = jit.rmvpe_jit_export(
+ model_path=model_path,
+ mode="script",
+ inputs_path=None,
+ save_path=jit_model_path,
+ device=device,
+ is_half=is_half,
+ )
+ model = torch.jit.load(BytesIO(ckpt["model"]), map_location=device)
+ return model
+
+ def get_default_model():
+ model = E2E(4, 1, (2, 2))
+ ckpt = torch.load(model_path, map_location="cpu")
+ model.load_state_dict(ckpt)
+ model.eval()
+ if is_half:
+ model = model.half()
+ else:
+ model = model.float()
+ return model
+
+ if use_jit:
+ if is_half and "cpu" in str(self.device):
+ logger.warning(
+ "Use default rmvpe model. \
+ Jit is not supported on the CPU for half floating point"
+ )
+ self.model = get_default_model()
+ else:
+ self.model = get_jit_model()
+ else:
+ self.model = get_default_model()
+
+ self.model = self.model.to(device)
+ cents_mapping = 20 * np.arange(360) + 1997.3794084376191
+ self.cents_mapping = np.pad(cents_mapping, (4, 4)) # 368
+
+ def mel2hidden(self, mel):
+ with torch.no_grad():
+ n_frames = mel.shape[-1]
+ n_pad = 32 * ((n_frames - 1) // 32 + 1) - n_frames
+ if n_pad > 0:
+ mel = F.pad(mel, (0, n_pad), mode="constant")
+ if "privateuseone" in str(self.device):
+ onnx_input_name = self.model.get_inputs()[0].name
+ onnx_outputs_names = self.model.get_outputs()[0].name
+ hidden = self.model.run(
+ [onnx_outputs_names],
+ input_feed={onnx_input_name: mel.cpu().numpy()},
+ )[0]
+ else:
+ mel = mel.half() if self.is_half else mel.float()
+ hidden = self.model(mel)
+ return hidden[:, :n_frames]
+
+ def decode(self, hidden, thred=0.03):
+ cents_pred = self.to_local_average_cents(hidden, thred=thred)
+ f0 = 10 * (2 ** (cents_pred / 1200))
+ f0[f0 == 10] = 0
+ # f0 = np.array([10 * (2 ** (cent_pred / 1200)) if cent_pred else 0 for cent_pred in cents_pred])
+ return f0
+
+ def infer_from_audio(self, audio, thred=0.03):
+ # torch.cuda.synchronize()
+ # t0 = ttime()
+ if not torch.is_tensor(audio):
+ audio = torch.from_numpy(audio)
+ mel = self.mel_extractor(
+ audio.float().to(self.device).unsqueeze(0), center=True
+ )
+ # print(123123123,mel.device.type)
+ # torch.cuda.synchronize()
+ # t1 = ttime()
+ hidden = self.mel2hidden(mel)
+ # torch.cuda.synchronize()
+ # t2 = ttime()
+ # print(234234,hidden.device.type)
+ if "privateuseone" not in str(self.device):
+ hidden = hidden.squeeze(0).cpu().numpy()
+ else:
+ hidden = hidden[0]
+ if self.is_half == True:
+ hidden = hidden.astype("float32")
+
+ f0 = self.decode(hidden, thred=thred)
+ # torch.cuda.synchronize()
+ # t3 = ttime()
+ # print("hmvpe:%s\t%s\t%s\t%s"%(t1-t0,t2-t1,t3-t2,t3-t0))
+ return f0
+
+ def to_local_average_cents(self, salience, thred=0.05):
+ # t0 = ttime()
+ center = np.argmax(salience, axis=1) # 帧长#index
+ salience = np.pad(salience, ((0, 0), (4, 4))) # 帧长,368
+ # t1 = ttime()
+ center += 4
+ todo_salience = []
+ todo_cents_mapping = []
+ starts = center - 4
+ ends = center + 5
+ for idx in range(salience.shape[0]):
+ todo_salience.append(salience[:, starts[idx] : ends[idx]][idx])
+ todo_cents_mapping.append(self.cents_mapping[starts[idx] : ends[idx]])
+ # t2 = ttime()
+ todo_salience = np.array(todo_salience) # 帧长,9
+ todo_cents_mapping = np.array(todo_cents_mapping) # 帧长,9
+ product_sum = np.sum(todo_salience * todo_cents_mapping, 1)
+ weight_sum = np.sum(todo_salience, 1) # 帧长
+ devided = product_sum / weight_sum # 帧长
+ # t3 = ttime()
+ maxx = np.max(salience, axis=1) # 帧长
+ devided[maxx <= thred] = 0
+ # t4 = ttime()
+ # print("decode:%s\t%s\t%s\t%s" % (t1 - t0, t2 - t1, t3 - t2, t4 - t3))
+ return devided
+
+
+if __name__ == "__main__":
+ import librosa
+ import soundfile as sf
+
+ audio, sampling_rate = sf.read(r"C:\Users\liujing04\Desktop\Z\冬之花clip1.wav")
+ if len(audio.shape) > 1:
+ audio = librosa.to_mono(audio.transpose(1, 0))
+ audio_bak = audio.copy()
+ if sampling_rate != 16000:
+ audio = librosa.resample(audio, orig_sr=sampling_rate, target_sr=16000)
+ model_path = r"D:\BaiduNetdiskDownload\RVC-beta-v2-0727AMD_realtime\rmvpe.pt"
+ thred = 0.03 # 0.01
+ device = "cuda" if torch.cuda.is_available() else "cpu"
+ rmvpe = RMVPE(model_path, is_half=False, device=device)
+ t0 = ttime()
+ f0 = rmvpe.infer_from_audio(audio, thred=thred)
+ # f0 = rmvpe.infer_from_audio(audio, thred=thred)
+ # f0 = rmvpe.infer_from_audio(audio, thred=thred)
+ # f0 = rmvpe.infer_from_audio(audio, thred=thred)
+ # f0 = rmvpe.infer_from_audio(audio, thred=thred)
+ t1 = ttime()
+ logger.info("%s %.2f", f0.shape, t1 - t0)
diff --git a/infer/lib/rtrvc.py b/infer/lib/rtrvc.py
new file mode 100644
index 0000000000000000000000000000000000000000..6e5a5e81ddd1719f734d9d18b5b70fc220abeca1
--- /dev/null
+++ b/infer/lib/rtrvc.py
@@ -0,0 +1,466 @@
+from io import BytesIO
+import os
+import sys
+import traceback
+from infer.lib import jit
+from infer.lib.jit.get_synthesizer import get_synthesizer
+from time import time as ttime
+import fairseq
+import faiss
+import numpy as np
+import parselmouth
+import pyworld
+import scipy.signal as signal
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torchcrepe
+from torchaudio.transforms import Resample
+
+now_dir = os.getcwd()
+sys.path.append(now_dir)
+from multiprocessing import Manager as M
+
+from configs.config import Config
+
+# config = Config()
+
+mm = M()
+
+
+def printt(strr, *args):
+ if len(args) == 0:
+ print(strr)
+ else:
+ print(strr % args)
+
+
+# config.device=torch.device("cpu")########强制cpu测试
+# config.is_half=False########强制cpu测试
+class RVC:
+ def __init__(
+ self,
+ key,
+ formant,
+ pth_path,
+ index_path,
+ index_rate,
+ n_cpu,
+ inp_q,
+ opt_q,
+ config: Config,
+ last_rvc=None,
+ ) -> None:
+ """
+ 初始化
+ """
+ try:
+ if config.dml == True:
+
+ def forward_dml(ctx, x, scale):
+ ctx.scale = scale
+ res = x.clone().detach()
+ return res
+
+ fairseq.modules.grad_multiply.GradMultiply.forward = forward_dml
+ # global config
+ self.config = config
+ self.inp_q = inp_q
+ self.opt_q = opt_q
+ # device="cpu"########强制cpu测试
+ self.device = config.device
+ self.f0_up_key = key
+ self.formant_shift = formant
+ self.f0_min = 50
+ self.f0_max = 1100
+ self.f0_mel_min = 1127 * np.log(1 + self.f0_min / 700)
+ self.f0_mel_max = 1127 * np.log(1 + self.f0_max / 700)
+ self.n_cpu = n_cpu
+ self.use_jit = self.config.use_jit
+ self.is_half = config.is_half
+
+ if index_rate != 0:
+ self.index = faiss.read_index(index_path)
+ self.big_npy = self.index.reconstruct_n(0, self.index.ntotal)
+ printt("Index search enabled")
+ self.pth_path: str = pth_path
+ self.index_path = index_path
+ self.index_rate = index_rate
+ self.cache_pitch: torch.Tensor = torch.zeros(
+ 1024, device=self.device, dtype=torch.long
+ )
+ self.cache_pitchf = torch.zeros(
+ 1024, device=self.device, dtype=torch.float32
+ )
+
+ self.resample_kernel = {}
+
+ if last_rvc is None:
+ models, _, _ = fairseq.checkpoint_utils.load_model_ensemble_and_task(
+ ["assets/hubert/hubert_base.pt"],
+ suffix="",
+ )
+ hubert_model = models[0]
+ hubert_model = hubert_model.to(self.device)
+ if self.is_half:
+ hubert_model = hubert_model.half()
+ else:
+ hubert_model = hubert_model.float()
+ hubert_model.eval()
+ self.model = hubert_model
+ else:
+ self.model = last_rvc.model
+
+ self.net_g: nn.Module = None
+
+ def set_default_model():
+ self.net_g, cpt = get_synthesizer(self.pth_path, self.device)
+ self.tgt_sr = cpt["config"][-1]
+ cpt["config"][-3] = cpt["weight"]["emb_g.weight"].shape[0]
+ self.if_f0 = cpt.get("f0", 1)
+ self.version = cpt.get("version", "v1")
+ if self.is_half:
+ self.net_g = self.net_g.half()
+ else:
+ self.net_g = self.net_g.float()
+
+ def set_jit_model():
+ jit_pth_path = self.pth_path.rstrip(".pth")
+ jit_pth_path += ".half.jit" if self.is_half else ".jit"
+ reload = False
+ if str(self.device) == "cuda":
+ self.device = torch.device("cuda:0")
+ if os.path.exists(jit_pth_path):
+ cpt = jit.load(jit_pth_path)
+ model_device = cpt["device"]
+ if model_device != str(self.device):
+ reload = True
+ else:
+ reload = True
+
+ if reload:
+ cpt = jit.synthesizer_jit_export(
+ self.pth_path,
+ "script",
+ None,
+ device=self.device,
+ is_half=self.is_half,
+ )
+
+ self.tgt_sr = cpt["config"][-1]
+ self.if_f0 = cpt.get("f0", 1)
+ self.version = cpt.get("version", "v1")
+ self.net_g = torch.jit.load(
+ BytesIO(cpt["model"]), map_location=self.device
+ )
+ self.net_g.infer = self.net_g.forward
+ self.net_g.eval().to(self.device)
+
+ def set_synthesizer():
+ if self.use_jit and not config.dml:
+ if self.is_half and "cpu" in str(self.device):
+ printt(
+ "Use default Synthesizer model. \
+ Jit is not supported on the CPU for half floating point"
+ )
+ set_default_model()
+ else:
+ set_jit_model()
+ else:
+ set_default_model()
+
+ if last_rvc is None or last_rvc.pth_path != self.pth_path:
+ set_synthesizer()
+ else:
+ self.tgt_sr = last_rvc.tgt_sr
+ self.if_f0 = last_rvc.if_f0
+ self.version = last_rvc.version
+ self.is_half = last_rvc.is_half
+ if last_rvc.use_jit != self.use_jit:
+ set_synthesizer()
+ else:
+ self.net_g = last_rvc.net_g
+
+ if last_rvc is not None and hasattr(last_rvc, "model_rmvpe"):
+ self.model_rmvpe = last_rvc.model_rmvpe
+ if last_rvc is not None and hasattr(last_rvc, "model_fcpe"):
+ self.device_fcpe = last_rvc.device_fcpe
+ self.model_fcpe = last_rvc.model_fcpe
+ except:
+ printt(traceback.format_exc())
+
+ def change_key(self, new_key):
+ self.f0_up_key = new_key
+
+ def change_formant(self, new_formant):
+ self.formant_shift = new_formant
+
+ def change_index_rate(self, new_index_rate):
+ if new_index_rate != 0 and self.index_rate == 0:
+ self.index = faiss.read_index(self.index_path)
+ self.big_npy = self.index.reconstruct_n(0, self.index.ntotal)
+ printt("Index search enabled")
+ self.index_rate = new_index_rate
+
+ def get_f0_post(self, f0):
+ if not torch.is_tensor(f0):
+ f0 = torch.from_numpy(f0)
+ f0 = f0.float().to(self.device).squeeze()
+ f0_mel = 1127 * torch.log(1 + f0 / 700)
+ f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - self.f0_mel_min) * 254 / (
+ self.f0_mel_max - self.f0_mel_min
+ ) + 1
+ f0_mel[f0_mel <= 1] = 1
+ f0_mel[f0_mel > 255] = 255
+ f0_coarse = torch.round(f0_mel).long()
+ return f0_coarse, f0
+
+ def get_f0(self, x, f0_up_key, n_cpu, method="harvest"):
+ n_cpu = int(n_cpu)
+ if method == "crepe":
+ return self.get_f0_crepe(x, f0_up_key)
+ if method == "rmvpe":
+ return self.get_f0_rmvpe(x, f0_up_key)
+ if method == "fcpe":
+ return self.get_f0_fcpe(x, f0_up_key)
+ x = x.cpu().numpy()
+ if method == "pm":
+ p_len = x.shape[0] // 160 + 1
+ f0_min = 65
+ l_pad = int(np.ceil(1.5 / f0_min * 16000))
+ r_pad = l_pad + 1
+ s = parselmouth.Sound(np.pad(x, (l_pad, r_pad)), 16000).to_pitch_ac(
+ time_step=0.01,
+ voicing_threshold=0.6,
+ pitch_floor=f0_min,
+ pitch_ceiling=1100,
+ )
+ assert np.abs(s.t1 - 1.5 / f0_min) < 0.001
+ f0 = s.selected_array["frequency"]
+ if len(f0) < p_len:
+ f0 = np.pad(f0, (0, p_len - len(f0)))
+ f0 = f0[:p_len]
+ f0 *= pow(2, f0_up_key / 12)
+ return self.get_f0_post(f0)
+ if n_cpu == 1:
+ f0, t = pyworld.harvest(
+ x.astype(np.double),
+ fs=16000,
+ f0_ceil=1100,
+ f0_floor=50,
+ frame_period=10,
+ )
+ f0 = signal.medfilt(f0, 3)
+ f0 *= pow(2, f0_up_key / 12)
+ return self.get_f0_post(f0)
+ f0bak = np.zeros(x.shape[0] // 160 + 1, dtype=np.float64)
+ length = len(x)
+ part_length = 160 * ((length // 160 - 1) // n_cpu + 1)
+ n_cpu = (length // 160 - 1) // (part_length // 160) + 1
+ ts = ttime()
+ res_f0 = mm.dict()
+ for idx in range(n_cpu):
+ tail = part_length * (idx + 1) + 320
+ if idx == 0:
+ self.inp_q.put((idx, x[:tail], res_f0, n_cpu, ts))
+ else:
+ self.inp_q.put(
+ (idx, x[part_length * idx - 320 : tail], res_f0, n_cpu, ts)
+ )
+ while 1:
+ res_ts = self.opt_q.get()
+ if res_ts == ts:
+ break
+ f0s = [i[1] for i in sorted(res_f0.items(), key=lambda x: x[0])]
+ for idx, f0 in enumerate(f0s):
+ if idx == 0:
+ f0 = f0[:-3]
+ elif idx != n_cpu - 1:
+ f0 = f0[2:-3]
+ else:
+ f0 = f0[2:]
+ f0bak[part_length * idx // 160 : part_length * idx // 160 + f0.shape[0]] = (
+ f0
+ )
+ f0bak = signal.medfilt(f0bak, 3)
+ f0bak *= pow(2, f0_up_key / 12)
+ return self.get_f0_post(f0bak)
+
+ def get_f0_crepe(self, x, f0_up_key):
+ if "privateuseone" in str(
+ self.device
+ ): ###不支持dml,cpu又太慢用不成,拿fcpe顶替
+ return self.get_f0(x, f0_up_key, 1, "fcpe")
+ # printt("using crepe,device:%s"%self.device)
+ f0, pd = torchcrepe.predict(
+ x.unsqueeze(0).float(),
+ 16000,
+ 160,
+ self.f0_min,
+ self.f0_max,
+ "full",
+ batch_size=512,
+ # device=self.device if self.device.type!="privateuseone" else "cpu",###crepe不用半精度全部是全精度所以不愁###cpu延迟高到没法用
+ device=self.device,
+ return_periodicity=True,
+ )
+ pd = torchcrepe.filter.median(pd, 3)
+ f0 = torchcrepe.filter.mean(f0, 3)
+ f0[pd < 0.1] = 0
+ f0 *= pow(2, f0_up_key / 12)
+ return self.get_f0_post(f0)
+
+ def get_f0_rmvpe(self, x, f0_up_key):
+ if hasattr(self, "model_rmvpe") == False:
+ from infer.lib.rmvpe import RMVPE
+
+ printt("Loading rmvpe model")
+ self.model_rmvpe = RMVPE(
+ "assets/rmvpe/rmvpe.pt",
+ is_half=self.is_half,
+ device=self.device,
+ use_jit=self.config.use_jit,
+ )
+ f0 = self.model_rmvpe.infer_from_audio(x, thred=0.03)
+ f0 *= pow(2, f0_up_key / 12)
+ return self.get_f0_post(f0)
+
+ def get_f0_fcpe(self, x, f0_up_key):
+ if hasattr(self, "model_fcpe") == False:
+ from torchfcpe import spawn_bundled_infer_model
+
+ printt("Loading fcpe model")
+ if "privateuseone" in str(self.device):
+ self.device_fcpe = "cpu"
+ else:
+ self.device_fcpe = self.device
+ self.model_fcpe = spawn_bundled_infer_model(self.device_fcpe)
+ f0 = self.model_fcpe.infer(
+ x.to(self.device_fcpe).unsqueeze(0).float(),
+ sr=16000,
+ decoder_mode="local_argmax",
+ threshold=0.006,
+ )
+ f0 *= pow(2, f0_up_key / 12)
+ return self.get_f0_post(f0)
+
+ def infer(
+ self,
+ input_wav: torch.Tensor,
+ block_frame_16k,
+ skip_head,
+ return_length,
+ f0method,
+ ) -> np.ndarray:
+ t1 = ttime()
+ with torch.no_grad():
+ if self.config.is_half:
+ feats = input_wav.half().view(1, -1)
+ else:
+ feats = input_wav.float().view(1, -1)
+ padding_mask = torch.BoolTensor(feats.shape).to(self.device).fill_(False)
+ inputs = {
+ "source": feats,
+ "padding_mask": padding_mask,
+ "output_layer": 9 if self.version == "v1" else 12,
+ }
+ logits = self.model.extract_features(**inputs)
+ feats = (
+ self.model.final_proj(logits[0]) if self.version == "v1" else logits[0]
+ )
+ feats = torch.cat((feats, feats[:, -1:, :]), 1)
+ t2 = ttime()
+ try:
+ if hasattr(self, "index") and self.index_rate != 0:
+ npy = feats[0][skip_head // 2 :].cpu().numpy().astype("float32")
+ score, ix = self.index.search(npy, k=8)
+ if (ix >= 0).all():
+ weight = np.square(1 / score)
+ weight /= weight.sum(axis=1, keepdims=True)
+ npy = np.sum(
+ self.big_npy[ix] * np.expand_dims(weight, axis=2), axis=1
+ )
+ if self.config.is_half:
+ npy = npy.astype("float16")
+ feats[0][skip_head // 2 :] = (
+ torch.from_numpy(npy).unsqueeze(0).to(self.device)
+ * self.index_rate
+ + (1 - self.index_rate) * feats[0][skip_head // 2 :]
+ )
+ else:
+ printt(
+ "Invalid index. You MUST use added_xxxx.index but not trained_xxxx.index!"
+ )
+ else:
+ printt("Index search FAILED or disabled")
+ except:
+ traceback.print_exc()
+ printt("Index search FAILED")
+ t3 = ttime()
+ p_len = input_wav.shape[0] // 160
+ factor = pow(2, self.formant_shift / 12)
+ return_length2 = int(np.ceil(return_length * factor))
+ if self.if_f0 == 1:
+ f0_extractor_frame = block_frame_16k + 800
+ if f0method == "rmvpe":
+ f0_extractor_frame = 5120 * ((f0_extractor_frame - 1) // 5120 + 1) - 160
+ pitch, pitchf = self.get_f0(
+ input_wav[-f0_extractor_frame:],
+ self.f0_up_key - self.formant_shift,
+ self.n_cpu,
+ f0method,
+ )
+ shift = block_frame_16k // 160
+ self.cache_pitch[:-shift] = self.cache_pitch[shift:].clone()
+ self.cache_pitchf[:-shift] = self.cache_pitchf[shift:].clone()
+ self.cache_pitch[4 - pitch.shape[0] :] = pitch[3:-1]
+ self.cache_pitchf[4 - pitch.shape[0] :] = pitchf[3:-1]
+ cache_pitch = self.cache_pitch[None, -p_len:]
+ cache_pitchf = (
+ self.cache_pitchf[None, -p_len:] * return_length2 / return_length
+ )
+ t4 = ttime()
+ feats = F.interpolate(feats.permute(0, 2, 1), scale_factor=2).permute(0, 2, 1)
+ feats = feats[:, :p_len, :]
+ p_len = torch.LongTensor([p_len]).to(self.device)
+ sid = torch.LongTensor([0]).to(self.device)
+ skip_head = torch.LongTensor([skip_head])
+ return_length2 = torch.LongTensor([return_length2])
+ return_length = torch.LongTensor([return_length])
+ with torch.no_grad():
+ if self.if_f0 == 1:
+ infered_audio, _, _ = self.net_g.infer(
+ feats,
+ p_len,
+ cache_pitch,
+ cache_pitchf,
+ sid,
+ skip_head,
+ return_length,
+ return_length2,
+ )
+ else:
+ infered_audio, _, _ = self.net_g.infer(
+ feats, p_len, sid, skip_head, return_length, return_length2
+ )
+ infered_audio = infered_audio.squeeze(1).float()
+ upp_res = int(np.floor(factor * self.tgt_sr // 100))
+ if upp_res != self.tgt_sr // 100:
+ if upp_res not in self.resample_kernel:
+ self.resample_kernel[upp_res] = Resample(
+ orig_freq=upp_res,
+ new_freq=self.tgt_sr // 100,
+ dtype=torch.float32,
+ ).to(self.device)
+ infered_audio = self.resample_kernel[upp_res](
+ infered_audio[:, : return_length * upp_res]
+ )
+ t5 = ttime()
+ printt(
+ "Spent time: fea = %.3fs, index = %.3fs, f0 = %.3fs, model = %.3fs",
+ t2 - t1,
+ t3 - t2,
+ t4 - t3,
+ t5 - t4,
+ )
+ return infered_audio.squeeze()
diff --git a/infer/lib/rvcmd.py b/infer/lib/rvcmd.py
new file mode 100644
index 0000000000000000000000000000000000000000..fe692744d85cbe6cc7be1fb0e11266a5df0fa39b
--- /dev/null
+++ b/infer/lib/rvcmd.py
@@ -0,0 +1,243 @@
+import os
+from pathlib import Path
+import hashlib
+import requests
+from io import BytesIO
+import logging
+
+logger = logging.getLogger(__name__)
+
+
+def sha256(f) -> str:
+ sha256_hash = hashlib.sha256()
+ # Read and update hash in chunks of 4M
+ for byte_block in iter(lambda: f.read(4 * 1024 * 1024), b""):
+ sha256_hash.update(byte_block)
+ return sha256_hash.hexdigest()
+
+
+def check_model(
+ dir_name: Path, model_name: str, hash: str, remove_incorrect=False
+) -> bool:
+ target = dir_name / model_name
+ relname = target.as_posix()
+ relname = relname[relname.rindex("assets/") :]
+ logger.debug(f"checking {relname}...")
+ if not os.path.exists(target):
+ logger.info(f"{target} not exist.")
+ return False
+ with open(target, "rb") as f:
+ digest = sha256(f)
+ bakfile = f"{target}.bak"
+ if digest != hash:
+ logger.warn(f"{target} sha256 hash mismatch.")
+ logger.info(f"expected: {hash}")
+ logger.info(f"real val: {digest}")
+ logger.warn("please add parameter --update to download the latest assets.")
+ if remove_incorrect:
+ if not os.path.exists(bakfile):
+ os.rename(str(target), bakfile)
+ else:
+ os.remove(str(target))
+ return False
+ if remove_incorrect and os.path.exists(bakfile):
+ os.remove(bakfile)
+ return True
+
+
+def check_all_assets(update=False) -> bool:
+ BASE_DIR = Path(__file__).resolve().parent.parent.parent
+
+ logger.info("checking hubret & rmvpe...")
+
+ if not check_model(
+ BASE_DIR / "assets" / "hubert",
+ "hubert_base.pt",
+ os.environ["sha256_hubert_base_pt"],
+ update,
+ ):
+ return False
+ if not check_model(
+ BASE_DIR / "assets" / "rmvpe",
+ "rmvpe.pt",
+ os.environ["sha256_rmvpe_pt"],
+ update,
+ ):
+ return False
+ if not check_model(
+ BASE_DIR / "assets" / "rmvpe",
+ "rmvpe.onnx",
+ os.environ["sha256_rmvpe_onnx"],
+ update,
+ ):
+ return False
+
+ rvc_models_dir = BASE_DIR / "assets" / "pretrained"
+ logger.info("checking pretrained models...")
+ model_names = [
+ "D32k.pth",
+ "D40k.pth",
+ "D48k.pth",
+ "G32k.pth",
+ "G40k.pth",
+ "G48k.pth",
+ "f0D32k.pth",
+ "f0D40k.pth",
+ "f0D48k.pth",
+ "f0G32k.pth",
+ "f0G40k.pth",
+ "f0G48k.pth",
+ ]
+ for model in model_names:
+ menv = model.replace(".", "_")
+ if not check_model(
+ rvc_models_dir, model, os.environ[f"sha256_v1_{menv}"], update
+ ):
+ return False
+
+ rvc_models_dir = BASE_DIR / "assets" / "pretrained_v2"
+ logger.info("checking pretrained models v2...")
+ for model in model_names:
+ menv = model.replace(".", "_")
+ if not check_model(
+ rvc_models_dir, model, os.environ[f"sha256_v2_{menv}"], update
+ ):
+ return False
+
+ logger.info("checking uvr5_weights...")
+ rvc_models_dir = BASE_DIR / "assets" / "uvr5_weights"
+ model_names = [
+ "HP2-人声vocals+非人声instrumentals.pth",
+ "HP2_all_vocals.pth",
+ "HP3_all_vocals.pth",
+ "HP5-主旋律人声vocals+其他instrumentals.pth",
+ "HP5_only_main_vocal.pth",
+ "VR-DeEchoAggressive.pth",
+ "VR-DeEchoDeReverb.pth",
+ "VR-DeEchoNormal.pth",
+ ]
+ for model in model_names:
+ menv = model.replace(".", "_")
+ if not check_model(
+ rvc_models_dir, model, os.environ[f"sha256_uvr5_{menv}"], update
+ ):
+ return False
+ if not check_model(
+ BASE_DIR / "assets" / "uvr5_weights" / "onnx_dereverb_By_FoxJoy",
+ "vocals.onnx",
+ os.environ[f"sha256_uvr5_vocals_onnx"],
+ update,
+ ):
+ return False
+
+ logger.info("all assets are already latest.")
+ return True
+
+
+def download_and_extract_tar_gz(url: str, folder: str):
+ import tarfile
+
+ logger.info(f"downloading {url}")
+ response = requests.get(url, stream=True, timeout=(5, 10))
+ with BytesIO() as out_file:
+ out_file.write(response.content)
+ out_file.seek(0)
+ logger.info(f"downloaded.")
+ with tarfile.open(fileobj=out_file, mode="r:gz") as tar:
+ tar.extractall(folder)
+ logger.info(f"extracted into {folder}")
+
+
+def download_and_extract_zip(url: str, folder: str):
+ import zipfile
+
+ logger.info(f"downloading {url}")
+ response = requests.get(url, stream=True, timeout=(5, 10))
+ with BytesIO() as out_file:
+ out_file.write(response.content)
+ out_file.seek(0)
+ logger.info(f"downloaded.")
+ with zipfile.ZipFile(out_file) as zip_ref:
+ zip_ref.extractall(folder)
+ logger.info(f"extracted into {folder}")
+
+
+def download_dns_yaml(url: str, folder: str):
+ logger.info(f"downloading {url}")
+ response = requests.get(url, stream=True, timeout=(5, 10))
+ with open(os.path.join(folder, "dns.yaml"), "wb") as out_file:
+ out_file.write(response.content)
+ logger.info(f"downloaded into {folder}")
+
+
+def download_all_assets(tmpdir: str, version="0.2.2"):
+ import subprocess
+ import platform
+
+ archs = {
+ "aarch64": "arm64",
+ "armv8l": "arm64",
+ "arm64": "arm64",
+ "x86": "386",
+ "i386": "386",
+ "i686": "386",
+ "386": "386",
+ "x86_64": "amd64",
+ "x64": "amd64",
+ "amd64": "amd64",
+ }
+ system_type = platform.system().lower()
+ architecture = platform.machine().lower()
+ is_win = system_type == "windows"
+
+ architecture = archs.get(architecture, None)
+ if not architecture:
+ logger.error(f"architecture {architecture} is not supported")
+ exit(1)
+ try:
+ BASE_URL = (
+ "https://github.com/RVC-Project/RVC-Models-Downloader/releases/download/"
+ )
+ suffix = "zip" if is_win else "tar.gz"
+ RVCMD_URL = BASE_URL + f"v{version}/rvcmd_{system_type}_{architecture}.{suffix}"
+ cmdfile = os.path.join(tmpdir, "rvcmd")
+ if is_win:
+ download_and_extract_zip(RVCMD_URL, tmpdir)
+ cmdfile += ".exe"
+ else:
+ download_and_extract_tar_gz(RVCMD_URL, tmpdir)
+ os.chmod(cmdfile, 0o755)
+ subprocess.run([cmdfile, "-notui", "-w", "0", "assets/all"])
+ except Exception:
+ BASE_URL = "https://raw.gitcode.com/u011570312/RVC-Models-Downloader/assets/"
+ suffix = {
+ "darwin_amd64": "421",
+ "darwin_arm64": "422",
+ "linux_386": "423",
+ "linux_amd64": "424",
+ "linux_arm64": "425",
+ "windows_386": "426",
+ "windows_amd64": "427",
+ }[f"{system_type}_{architecture}"]
+ RVCMD_URL = BASE_URL + suffix
+ download_dns_yaml(
+ "https://raw.gitcode.com/u011570312/RVC-Models-Downloader/raw/main/dns.yaml",
+ tmpdir,
+ )
+ if is_win:
+ download_and_extract_zip(RVCMD_URL, tmpdir)
+ cmdfile += ".exe"
+ else:
+ download_and_extract_tar_gz(RVCMD_URL, tmpdir)
+ os.chmod(cmdfile, 0o755)
+ subprocess.run(
+ [
+ cmdfile,
+ "-notui",
+ "-w",
+ "0",
+ "-dns",
+ os.path.join(tmpdir, "dns.yaml"),
+ "assets/all",
+ ]
+ )
diff --git a/infer/lib/slicer2.py b/infer/lib/slicer2.py
new file mode 100644
index 0000000000000000000000000000000000000000..7d9d16db55e30c5c732f7fd32a234af026097e13
--- /dev/null
+++ b/infer/lib/slicer2.py
@@ -0,0 +1,260 @@
+import numpy as np
+
+
+# This function is obtained from librosa.
+def get_rms(
+ y,
+ frame_length=2048,
+ hop_length=512,
+ pad_mode="constant",
+):
+ padding = (int(frame_length // 2), int(frame_length // 2))
+ y = np.pad(y, padding, mode=pad_mode)
+
+ axis = -1
+ # put our new within-frame axis at the end for now
+ out_strides = y.strides + tuple([y.strides[axis]])
+ # Reduce the shape on the framing axis
+ x_shape_trimmed = list(y.shape)
+ x_shape_trimmed[axis] -= frame_length - 1
+ out_shape = tuple(x_shape_trimmed) + tuple([frame_length])
+ xw = np.lib.stride_tricks.as_strided(y, shape=out_shape, strides=out_strides)
+ if axis < 0:
+ target_axis = axis - 1
+ else:
+ target_axis = axis + 1
+ xw = np.moveaxis(xw, -1, target_axis)
+ # Downsample along the target axis
+ slices = [slice(None)] * xw.ndim
+ slices[axis] = slice(0, None, hop_length)
+ x = xw[tuple(slices)]
+
+ # Calculate power
+ power = np.mean(np.abs(x) ** 2, axis=-2, keepdims=True)
+
+ return np.sqrt(power)
+
+
+class Slicer:
+ def __init__(
+ self,
+ sr: int,
+ threshold: float = -40.0,
+ min_length: int = 5000,
+ min_interval: int = 300,
+ hop_size: int = 20,
+ max_sil_kept: int = 5000,
+ ):
+ if not min_length >= min_interval >= hop_size:
+ raise ValueError(
+ "The following condition must be satisfied: min_length >= min_interval >= hop_size"
+ )
+ if not max_sil_kept >= hop_size:
+ raise ValueError(
+ "The following condition must be satisfied: max_sil_kept >= hop_size"
+ )
+ min_interval = sr * min_interval / 1000
+ self.threshold = 10 ** (threshold / 20.0)
+ self.hop_size = round(sr * hop_size / 1000)
+ self.win_size = min(round(min_interval), 4 * self.hop_size)
+ self.min_length = round(sr * min_length / 1000 / self.hop_size)
+ self.min_interval = round(min_interval / self.hop_size)
+ self.max_sil_kept = round(sr * max_sil_kept / 1000 / self.hop_size)
+
+ def _apply_slice(self, waveform, begin, end):
+ if len(waveform.shape) > 1:
+ return waveform[
+ :, begin * self.hop_size : min(waveform.shape[1], end * self.hop_size)
+ ]
+ else:
+ return waveform[
+ begin * self.hop_size : min(waveform.shape[0], end * self.hop_size)
+ ]
+
+ # @timeit
+ def slice(self, waveform):
+ if len(waveform.shape) > 1:
+ samples = waveform.mean(axis=0)
+ else:
+ samples = waveform
+ if samples.shape[0] <= self.min_length:
+ return [waveform]
+ rms_list = get_rms(
+ y=samples, frame_length=self.win_size, hop_length=self.hop_size
+ ).squeeze(0)
+ sil_tags = []
+ silence_start = None
+ clip_start = 0
+ for i, rms in enumerate(rms_list):
+ # Keep looping while frame is silent.
+ if rms < self.threshold:
+ # Record start of silent frames.
+ if silence_start is None:
+ silence_start = i
+ continue
+ # Keep looping while frame is not silent and silence start has not been recorded.
+ if silence_start is None:
+ continue
+ # Clear recorded silence start if interval is not enough or clip is too short
+ is_leading_silence = silence_start == 0 and i > self.max_sil_kept
+ need_slice_middle = (
+ i - silence_start >= self.min_interval
+ and i - clip_start >= self.min_length
+ )
+ if not is_leading_silence and not need_slice_middle:
+ silence_start = None
+ continue
+ # Need slicing. Record the range of silent frames to be removed.
+ if i - silence_start <= self.max_sil_kept:
+ pos = rms_list[silence_start : i + 1].argmin() + silence_start
+ if silence_start == 0:
+ sil_tags.append((0, pos))
+ else:
+ sil_tags.append((pos, pos))
+ clip_start = pos
+ elif i - silence_start <= self.max_sil_kept * 2:
+ pos = rms_list[
+ i - self.max_sil_kept : silence_start + self.max_sil_kept + 1
+ ].argmin()
+ pos += i - self.max_sil_kept
+ pos_l = (
+ rms_list[
+ silence_start : silence_start + self.max_sil_kept + 1
+ ].argmin()
+ + silence_start
+ )
+ pos_r = (
+ rms_list[i - self.max_sil_kept : i + 1].argmin()
+ + i
+ - self.max_sil_kept
+ )
+ if silence_start == 0:
+ sil_tags.append((0, pos_r))
+ clip_start = pos_r
+ else:
+ sil_tags.append((min(pos_l, pos), max(pos_r, pos)))
+ clip_start = max(pos_r, pos)
+ else:
+ pos_l = (
+ rms_list[
+ silence_start : silence_start + self.max_sil_kept + 1
+ ].argmin()
+ + silence_start
+ )
+ pos_r = (
+ rms_list[i - self.max_sil_kept : i + 1].argmin()
+ + i
+ - self.max_sil_kept
+ )
+ if silence_start == 0:
+ sil_tags.append((0, pos_r))
+ else:
+ sil_tags.append((pos_l, pos_r))
+ clip_start = pos_r
+ silence_start = None
+ # Deal with trailing silence.
+ total_frames = rms_list.shape[0]
+ if (
+ silence_start is not None
+ and total_frames - silence_start >= self.min_interval
+ ):
+ silence_end = min(total_frames, silence_start + self.max_sil_kept)
+ pos = rms_list[silence_start : silence_end + 1].argmin() + silence_start
+ sil_tags.append((pos, total_frames + 1))
+ # Apply and return slices.
+ if len(sil_tags) == 0:
+ return [waveform]
+ else:
+ chunks = []
+ if sil_tags[0][0] > 0:
+ chunks.append(self._apply_slice(waveform, 0, sil_tags[0][0]))
+ for i in range(len(sil_tags) - 1):
+ chunks.append(
+ self._apply_slice(waveform, sil_tags[i][1], sil_tags[i + 1][0])
+ )
+ if sil_tags[-1][1] < total_frames:
+ chunks.append(
+ self._apply_slice(waveform, sil_tags[-1][1], total_frames)
+ )
+ return chunks
+
+
+def main():
+ import os.path
+ from argparse import ArgumentParser
+
+ import librosa
+ import soundfile
+
+ parser = ArgumentParser()
+ parser.add_argument("audio", type=str, help="The audio to be sliced")
+ parser.add_argument(
+ "--out", type=str, help="Output directory of the sliced audio clips"
+ )
+ parser.add_argument(
+ "--db_thresh",
+ type=float,
+ required=False,
+ default=-40,
+ help="The dB threshold for silence detection",
+ )
+ parser.add_argument(
+ "--min_length",
+ type=int,
+ required=False,
+ default=5000,
+ help="The minimum milliseconds required for each sliced audio clip",
+ )
+ parser.add_argument(
+ "--min_interval",
+ type=int,
+ required=False,
+ default=300,
+ help="The minimum milliseconds for a silence part to be sliced",
+ )
+ parser.add_argument(
+ "--hop_size",
+ type=int,
+ required=False,
+ default=10,
+ help="Frame length in milliseconds",
+ )
+ parser.add_argument(
+ "--max_sil_kept",
+ type=int,
+ required=False,
+ default=500,
+ help="The maximum silence length kept around the sliced clip, presented in milliseconds",
+ )
+ args = parser.parse_args()
+ out = args.out
+ if out is None:
+ out = os.path.dirname(os.path.abspath(args.audio))
+ audio, sr = librosa.load(args.audio, sr=None, mono=False)
+ slicer = Slicer(
+ sr=sr,
+ threshold=args.db_thresh,
+ min_length=args.min_length,
+ min_interval=args.min_interval,
+ hop_size=args.hop_size,
+ max_sil_kept=args.max_sil_kept,
+ )
+ chunks = slicer.slice(audio)
+ if not os.path.exists(out):
+ os.makedirs(out)
+ for i, chunk in enumerate(chunks):
+ if len(chunk.shape) > 1:
+ chunk = chunk.T
+ soundfile.write(
+ os.path.join(
+ out,
+ f"%s_%d.wav"
+ % (os.path.basename(args.audio).rsplit(".", maxsplit=1)[0], i),
+ ),
+ chunk,
+ sr,
+ )
+
+
+if __name__ == "__main__":
+ main()
diff --git a/infer/lib/train/data_utils.py b/infer/lib/train/data_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..1e1d1dbfbcba8a83e019950492d047263f7b4e73
--- /dev/null
+++ b/infer/lib/train/data_utils.py
@@ -0,0 +1,517 @@
+import os
+import traceback
+import logging
+
+logger = logging.getLogger(__name__)
+
+import numpy as np
+import torch
+import torch.utils.data
+
+from infer.lib.train.mel_processing import spectrogram_torch
+from infer.lib.train.utils import load_filepaths_and_text, load_wav_to_torch
+
+
+class TextAudioLoaderMultiNSFsid(torch.utils.data.Dataset):
+ """
+ 1) loads audio, text pairs
+ 2) normalizes text and converts them to sequences of integers
+ 3) computes spectrograms from audio files.
+ """
+
+ def __init__(self, audiopaths_and_text, hparams):
+ self.audiopaths_and_text = load_filepaths_and_text(audiopaths_and_text)
+ self.max_wav_value = hparams.max_wav_value
+ self.sampling_rate = hparams.sampling_rate
+ self.filter_length = hparams.filter_length
+ self.hop_length = hparams.hop_length
+ self.win_length = hparams.win_length
+ self.sampling_rate = hparams.sampling_rate
+ self.min_text_len = getattr(hparams, "min_text_len", 1)
+ self.max_text_len = getattr(hparams, "max_text_len", 5000)
+ self._filter()
+
+ def _filter(self):
+ """
+ Filter text & store spec lengths
+ """
+ # Store spectrogram lengths for Bucketing
+ # wav_length ~= file_size / (wav_channels * Bytes per dim) = file_size / (1 * 2)
+ # spec_length = wav_length // hop_length
+ audiopaths_and_text_new = []
+ lengths = []
+ for audiopath, text, pitch, pitchf, dv in self.audiopaths_and_text:
+ if self.min_text_len <= len(text) and len(text) <= self.max_text_len:
+ audiopaths_and_text_new.append([audiopath, text, pitch, pitchf, dv])
+ lengths.append(os.path.getsize(audiopath) // (3 * self.hop_length))
+ self.audiopaths_and_text = audiopaths_and_text_new
+ self.lengths = lengths
+
+ def get_sid(self, sid):
+ sid = torch.LongTensor([int(sid)])
+ return sid
+
+ def get_audio_text_pair(self, audiopath_and_text):
+ # separate filename and text
+ file = audiopath_and_text[0]
+ phone = audiopath_and_text[1]
+ pitch = audiopath_and_text[2]
+ pitchf = audiopath_and_text[3]
+ dv = audiopath_and_text[4]
+
+ phone, pitch, pitchf = self.get_labels(phone, pitch, pitchf)
+ spec, wav = self.get_audio(file)
+ dv = self.get_sid(dv)
+
+ len_phone = phone.size()[0]
+ len_spec = spec.size()[-1]
+ # print(123,phone.shape,pitch.shape,spec.shape)
+ if len_phone != len_spec:
+ len_min = min(len_phone, len_spec)
+ # amor
+ len_wav = len_min * self.hop_length
+
+ spec = spec[:, :len_min]
+ wav = wav[:, :len_wav]
+
+ phone = phone[:len_min, :]
+ pitch = pitch[:len_min]
+ pitchf = pitchf[:len_min]
+
+ return (spec, wav, phone, pitch, pitchf, dv)
+
+ def get_labels(self, phone, pitch, pitchf):
+ phone = np.load(phone)
+ phone = np.repeat(phone, 2, axis=0)
+ pitch = np.load(pitch)
+ pitchf = np.load(pitchf)
+ n_num = min(phone.shape[0], 900) # DistributedBucketSampler
+ # print(234,phone.shape,pitch.shape)
+ phone = phone[:n_num, :]
+ pitch = pitch[:n_num]
+ pitchf = pitchf[:n_num]
+ phone = torch.FloatTensor(phone)
+ pitch = torch.LongTensor(pitch)
+ pitchf = torch.FloatTensor(pitchf)
+ return phone, pitch, pitchf
+
+ def get_audio(self, filename):
+ audio, sampling_rate = load_wav_to_torch(filename)
+ if sampling_rate != self.sampling_rate:
+ raise ValueError(
+ "{} SR doesn't match target {} SR".format(
+ sampling_rate, self.sampling_rate
+ )
+ )
+ audio_norm = audio
+ # audio_norm = audio / self.max_wav_value
+ # audio_norm = audio / np.abs(audio).max()
+
+ audio_norm = audio_norm.unsqueeze(0)
+ spec_filename = filename.replace(".wav", ".spec.pt")
+ if os.path.exists(spec_filename):
+ try:
+ spec = torch.load(spec_filename)
+ except:
+ logger.warning("%s %s", spec_filename, traceback.format_exc())
+ spec = spectrogram_torch(
+ audio_norm,
+ self.filter_length,
+ self.sampling_rate,
+ self.hop_length,
+ self.win_length,
+ center=False,
+ )
+ spec = torch.squeeze(spec, 0)
+ torch.save(spec, spec_filename, _use_new_zipfile_serialization=False)
+ else:
+ spec = spectrogram_torch(
+ audio_norm,
+ self.filter_length,
+ self.sampling_rate,
+ self.hop_length,
+ self.win_length,
+ center=False,
+ )
+ spec = torch.squeeze(spec, 0)
+ torch.save(spec, spec_filename, _use_new_zipfile_serialization=False)
+ return spec, audio_norm
+
+ def __getitem__(self, index):
+ return self.get_audio_text_pair(self.audiopaths_and_text[index])
+
+ def __len__(self):
+ return len(self.audiopaths_and_text)
+
+
+class TextAudioCollateMultiNSFsid:
+ """Zero-pads model inputs and targets"""
+
+ def __init__(self, return_ids=False):
+ self.return_ids = return_ids
+
+ def __call__(self, batch):
+ """Collate's training batch from normalized text and aduio
+ PARAMS
+ ------
+ batch: [text_normalized, spec_normalized, wav_normalized]
+ """
+ # Right zero-pad all one-hot text sequences to max input length
+ _, ids_sorted_decreasing = torch.sort(
+ torch.LongTensor([x[0].size(1) for x in batch]), dim=0, descending=True
+ )
+
+ max_spec_len = max([x[0].size(1) for x in batch])
+ max_wave_len = max([x[1].size(1) for x in batch])
+ spec_lengths = torch.LongTensor(len(batch))
+ wave_lengths = torch.LongTensor(len(batch))
+ spec_padded = torch.FloatTensor(len(batch), batch[0][0].size(0), max_spec_len)
+ wave_padded = torch.FloatTensor(len(batch), 1, max_wave_len)
+ spec_padded.zero_()
+ wave_padded.zero_()
+
+ max_phone_len = max([x[2].size(0) for x in batch])
+ phone_lengths = torch.LongTensor(len(batch))
+ phone_padded = torch.FloatTensor(
+ len(batch), max_phone_len, batch[0][2].shape[1]
+ ) # (spec, wav, phone, pitch)
+ pitch_padded = torch.LongTensor(len(batch), max_phone_len)
+ pitchf_padded = torch.FloatTensor(len(batch), max_phone_len)
+ phone_padded.zero_()
+ pitch_padded.zero_()
+ pitchf_padded.zero_()
+ # dv = torch.FloatTensor(len(batch), 256)#gin=256
+ sid = torch.LongTensor(len(batch))
+
+ for i in range(len(ids_sorted_decreasing)):
+ row = batch[ids_sorted_decreasing[i]]
+
+ spec = row[0]
+ spec_padded[i, :, : spec.size(1)] = spec
+ spec_lengths[i] = spec.size(1)
+
+ wave = row[1]
+ wave_padded[i, :, : wave.size(1)] = wave
+ wave_lengths[i] = wave.size(1)
+
+ phone = row[2]
+ phone_padded[i, : phone.size(0), :] = phone
+ phone_lengths[i] = phone.size(0)
+
+ pitch = row[3]
+ pitch_padded[i, : pitch.size(0)] = pitch
+ pitchf = row[4]
+ pitchf_padded[i, : pitchf.size(0)] = pitchf
+
+ # dv[i] = row[5]
+ sid[i] = row[5]
+
+ return (
+ phone_padded,
+ phone_lengths,
+ pitch_padded,
+ pitchf_padded,
+ spec_padded,
+ spec_lengths,
+ wave_padded,
+ wave_lengths,
+ # dv
+ sid,
+ )
+
+
+class TextAudioLoader(torch.utils.data.Dataset):
+ """
+ 1) loads audio, text pairs
+ 2) normalizes text and converts them to sequences of integers
+ 3) computes spectrograms from audio files.
+ """
+
+ def __init__(self, audiopaths_and_text, hparams):
+ self.audiopaths_and_text = load_filepaths_and_text(audiopaths_and_text)
+ self.max_wav_value = hparams.max_wav_value
+ self.sampling_rate = hparams.sampling_rate
+ self.filter_length = hparams.filter_length
+ self.hop_length = hparams.hop_length
+ self.win_length = hparams.win_length
+ self.sampling_rate = hparams.sampling_rate
+ self.min_text_len = getattr(hparams, "min_text_len", 1)
+ self.max_text_len = getattr(hparams, "max_text_len", 5000)
+ self._filter()
+
+ def _filter(self):
+ """
+ Filter text & store spec lengths
+ """
+ # Store spectrogram lengths for Bucketing
+ # wav_length ~= file_size / (wav_channels * Bytes per dim) = file_size / (1 * 2)
+ # spec_length = wav_length // hop_length
+ audiopaths_and_text_new = []
+ lengths = []
+ for audiopath, text, dv in self.audiopaths_and_text:
+ if self.min_text_len <= len(text) and len(text) <= self.max_text_len:
+ audiopaths_and_text_new.append([audiopath, text, dv])
+ lengths.append(os.path.getsize(audiopath) // (3 * self.hop_length))
+ self.audiopaths_and_text = audiopaths_and_text_new
+ self.lengths = lengths
+
+ def get_sid(self, sid):
+ sid = torch.LongTensor([int(sid)])
+ return sid
+
+ def get_audio_text_pair(self, audiopath_and_text):
+ # separate filename and text
+ file = audiopath_and_text[0]
+ phone = audiopath_and_text[1]
+ dv = audiopath_and_text[2]
+
+ phone = self.get_labels(phone)
+ spec, wav = self.get_audio(file)
+ dv = self.get_sid(dv)
+
+ len_phone = phone.size()[0]
+ len_spec = spec.size()[-1]
+ if len_phone != len_spec:
+ len_min = min(len_phone, len_spec)
+ len_wav = len_min * self.hop_length
+ spec = spec[:, :len_min]
+ wav = wav[:, :len_wav]
+ phone = phone[:len_min, :]
+ return (spec, wav, phone, dv)
+
+ def get_labels(self, phone):
+ phone = np.load(phone)
+ phone = np.repeat(phone, 2, axis=0)
+ n_num = min(phone.shape[0], 900) # DistributedBucketSampler
+ phone = phone[:n_num, :]
+ phone = torch.FloatTensor(phone)
+ return phone
+
+ def get_audio(self, filename):
+ audio, sampling_rate = load_wav_to_torch(filename)
+ if sampling_rate != self.sampling_rate:
+ raise ValueError(
+ "{} SR doesn't match target {} SR".format(
+ sampling_rate, self.sampling_rate
+ )
+ )
+ audio_norm = audio
+ # audio_norm = audio / self.max_wav_value
+ # audio_norm = audio / np.abs(audio).max()
+
+ audio_norm = audio_norm.unsqueeze(0)
+ spec_filename = filename.replace(".wav", ".spec.pt")
+ if os.path.exists(spec_filename):
+ try:
+ spec = torch.load(spec_filename)
+ except:
+ logger.warning("%s %s", spec_filename, traceback.format_exc())
+ spec = spectrogram_torch(
+ audio_norm,
+ self.filter_length,
+ self.sampling_rate,
+ self.hop_length,
+ self.win_length,
+ center=False,
+ )
+ spec = torch.squeeze(spec, 0)
+ torch.save(spec, spec_filename, _use_new_zipfile_serialization=False)
+ else:
+ spec = spectrogram_torch(
+ audio_norm,
+ self.filter_length,
+ self.sampling_rate,
+ self.hop_length,
+ self.win_length,
+ center=False,
+ )
+ spec = torch.squeeze(spec, 0)
+ torch.save(spec, spec_filename, _use_new_zipfile_serialization=False)
+ return spec, audio_norm
+
+ def __getitem__(self, index):
+ return self.get_audio_text_pair(self.audiopaths_and_text[index])
+
+ def __len__(self):
+ return len(self.audiopaths_and_text)
+
+
+class TextAudioCollate:
+ """Zero-pads model inputs and targets"""
+
+ def __init__(self, return_ids=False):
+ self.return_ids = return_ids
+
+ def __call__(self, batch):
+ """Collate's training batch from normalized text and aduio
+ PARAMS
+ ------
+ batch: [text_normalized, spec_normalized, wav_normalized]
+ """
+ # Right zero-pad all one-hot text sequences to max input length
+ _, ids_sorted_decreasing = torch.sort(
+ torch.LongTensor([x[0].size(1) for x in batch]), dim=0, descending=True
+ )
+
+ max_spec_len = max([x[0].size(1) for x in batch])
+ max_wave_len = max([x[1].size(1) for x in batch])
+ spec_lengths = torch.LongTensor(len(batch))
+ wave_lengths = torch.LongTensor(len(batch))
+ spec_padded = torch.FloatTensor(len(batch), batch[0][0].size(0), max_spec_len)
+ wave_padded = torch.FloatTensor(len(batch), 1, max_wave_len)
+ spec_padded.zero_()
+ wave_padded.zero_()
+
+ max_phone_len = max([x[2].size(0) for x in batch])
+ phone_lengths = torch.LongTensor(len(batch))
+ phone_padded = torch.FloatTensor(
+ len(batch), max_phone_len, batch[0][2].shape[1]
+ )
+ phone_padded.zero_()
+ sid = torch.LongTensor(len(batch))
+
+ for i in range(len(ids_sorted_decreasing)):
+ row = batch[ids_sorted_decreasing[i]]
+
+ spec = row[0]
+ spec_padded[i, :, : spec.size(1)] = spec
+ spec_lengths[i] = spec.size(1)
+
+ wave = row[1]
+ wave_padded[i, :, : wave.size(1)] = wave
+ wave_lengths[i] = wave.size(1)
+
+ phone = row[2]
+ phone_padded[i, : phone.size(0), :] = phone
+ phone_lengths[i] = phone.size(0)
+
+ sid[i] = row[3]
+
+ return (
+ phone_padded,
+ phone_lengths,
+ spec_padded,
+ spec_lengths,
+ wave_padded,
+ wave_lengths,
+ sid,
+ )
+
+
+class DistributedBucketSampler(torch.utils.data.distributed.DistributedSampler):
+ """
+ Maintain similar input lengths in a batch.
+ Length groups are specified by boundaries.
+ Ex) boundaries = [b1, b2, b3] -> any batch is included either {x | b1 < length(x) <=b2} or {x | b2 < length(x) <= b3}.
+
+ It removes samples which are not included in the boundaries.
+ Ex) boundaries = [b1, b2, b3] -> any x s.t. length(x) <= b1 or length(x) > b3 are discarded.
+ """
+
+ def __init__(
+ self,
+ dataset,
+ batch_size,
+ boundaries,
+ num_replicas=None,
+ rank=None,
+ shuffle=True,
+ ):
+ super().__init__(dataset, num_replicas=num_replicas, rank=rank, shuffle=shuffle)
+ self.lengths = dataset.lengths
+ self.batch_size = batch_size
+ self.boundaries = boundaries
+
+ self.buckets, self.num_samples_per_bucket = self._create_buckets()
+ self.total_size = sum(self.num_samples_per_bucket)
+ self.num_samples = self.total_size // self.num_replicas
+
+ def _create_buckets(self):
+ buckets = [[] for _ in range(len(self.boundaries) - 1)]
+ for i in range(len(self.lengths)):
+ length = self.lengths[i]
+ idx_bucket = self._bisect(length)
+ if idx_bucket != -1:
+ buckets[idx_bucket].append(i)
+
+ for i in range(len(buckets) - 1, -1, -1): #
+ if len(buckets[i]) == 0:
+ buckets.pop(i)
+ self.boundaries.pop(i + 1)
+
+ num_samples_per_bucket = []
+ for i in range(len(buckets)):
+ len_bucket = len(buckets[i])
+ total_batch_size = self.num_replicas * self.batch_size
+ rem = (
+ total_batch_size - (len_bucket % total_batch_size)
+ ) % total_batch_size
+ num_samples_per_bucket.append(len_bucket + rem)
+ return buckets, num_samples_per_bucket
+
+ def __iter__(self):
+ # deterministically shuffle based on epoch
+ g = torch.Generator()
+ g.manual_seed(self.epoch)
+
+ indices = []
+ if self.shuffle:
+ for bucket in self.buckets:
+ indices.append(torch.randperm(len(bucket), generator=g).tolist())
+ else:
+ for bucket in self.buckets:
+ indices.append(list(range(len(bucket))))
+
+ batches = []
+ for i in range(len(self.buckets)):
+ bucket = self.buckets[i]
+ len_bucket = len(bucket)
+ ids_bucket = indices[i]
+ num_samples_bucket = self.num_samples_per_bucket[i]
+
+ # add extra samples to make it evenly divisible
+ rem = num_samples_bucket - len_bucket
+ ids_bucket = (
+ ids_bucket
+ + ids_bucket * (rem // len_bucket)
+ + ids_bucket[: (rem % len_bucket)]
+ )
+
+ # subsample
+ ids_bucket = ids_bucket[self.rank :: self.num_replicas]
+
+ # batching
+ for j in range(len(ids_bucket) // self.batch_size):
+ batch = [
+ bucket[idx]
+ for idx in ids_bucket[
+ j * self.batch_size : (j + 1) * self.batch_size
+ ]
+ ]
+ batches.append(batch)
+
+ if self.shuffle:
+ batch_ids = torch.randperm(len(batches), generator=g).tolist()
+ batches = [batches[i] for i in batch_ids]
+ self.batches = batches
+
+ assert len(self.batches) * self.batch_size == self.num_samples
+ return iter(self.batches)
+
+ def _bisect(self, x, lo=0, hi=None):
+ if hi is None:
+ hi = len(self.boundaries) - 1
+
+ if hi > lo:
+ mid = (hi + lo) // 2
+ if self.boundaries[mid] < x and x <= self.boundaries[mid + 1]:
+ return mid
+ elif x <= self.boundaries[mid]:
+ return self._bisect(x, lo, mid)
+ else:
+ return self._bisect(x, mid + 1, hi)
+ else:
+ return -1
+
+ def __len__(self):
+ return self.num_samples // self.batch_size
diff --git a/infer/lib/train/losses.py b/infer/lib/train/losses.py
new file mode 100644
index 0000000000000000000000000000000000000000..aa7bd81cf596884a8b33e802ae49254d7810a860
--- /dev/null
+++ b/infer/lib/train/losses.py
@@ -0,0 +1,58 @@
+import torch
+
+
+def feature_loss(fmap_r, fmap_g):
+ loss = 0
+ for dr, dg in zip(fmap_r, fmap_g):
+ for rl, gl in zip(dr, dg):
+ rl = rl.float().detach()
+ gl = gl.float()
+ loss += torch.mean(torch.abs(rl - gl))
+
+ return loss * 2
+
+
+def discriminator_loss(disc_real_outputs, disc_generated_outputs):
+ loss = 0
+ r_losses = []
+ g_losses = []
+ for dr, dg in zip(disc_real_outputs, disc_generated_outputs):
+ dr = dr.float()
+ dg = dg.float()
+ r_loss = torch.mean((1 - dr) ** 2)
+ g_loss = torch.mean(dg**2)
+ loss += r_loss + g_loss
+ r_losses.append(r_loss.item())
+ g_losses.append(g_loss.item())
+
+ return loss, r_losses, g_losses
+
+
+def generator_loss(disc_outputs):
+ loss = 0
+ gen_losses = []
+ for dg in disc_outputs:
+ dg = dg.float()
+ l = torch.mean((1 - dg) ** 2)
+ gen_losses.append(l)
+ loss += l
+
+ return loss, gen_losses
+
+
+def kl_loss(z_p, logs_q, m_p, logs_p, z_mask):
+ """
+ z_p, logs_q: [b, h, t_t]
+ m_p, logs_p: [b, h, t_t]
+ """
+ z_p = z_p.float()
+ logs_q = logs_q.float()
+ m_p = m_p.float()
+ logs_p = logs_p.float()
+ z_mask = z_mask.float()
+
+ kl = logs_p - logs_q - 0.5
+ kl += 0.5 * ((z_p - m_p) ** 2) * torch.exp(-2.0 * logs_p)
+ kl = torch.sum(kl * z_mask)
+ l = kl / torch.sum(z_mask)
+ return l
diff --git a/infer/lib/train/mel_processing.py b/infer/lib/train/mel_processing.py
new file mode 100644
index 0000000000000000000000000000000000000000..3751f1eab1ea8137088f2f7d7c8294190403b4ce
--- /dev/null
+++ b/infer/lib/train/mel_processing.py
@@ -0,0 +1,127 @@
+import torch
+import torch.utils.data
+from librosa.filters import mel as librosa_mel_fn
+import logging
+
+logger = logging.getLogger(__name__)
+
+MAX_WAV_VALUE = 32768.0
+
+
+def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
+ """
+ PARAMS
+ ------
+ C: compression factor
+ """
+ return torch.log(torch.clamp(x, min=clip_val) * C)
+
+
+def dynamic_range_decompression_torch(x, C=1):
+ """
+ PARAMS
+ ------
+ C: compression factor used to compress
+ """
+ return torch.exp(x) / C
+
+
+def spectral_normalize_torch(magnitudes):
+ return dynamic_range_compression_torch(magnitudes)
+
+
+def spectral_de_normalize_torch(magnitudes):
+ return dynamic_range_decompression_torch(magnitudes)
+
+
+# Reusable banks
+mel_basis = {}
+hann_window = {}
+
+
+def spectrogram_torch(y, n_fft, sampling_rate, hop_size, win_size, center=False):
+ """Convert waveform into Linear-frequency Linear-amplitude spectrogram.
+
+ Args:
+ y :: (B, T) - Audio waveforms
+ n_fft
+ sampling_rate
+ hop_size
+ win_size
+ center
+ Returns:
+ :: (B, Freq, Frame) - Linear-frequency Linear-amplitude spectrogram
+ """
+
+ # Window - Cache if needed
+ global hann_window
+ dtype_device = str(y.dtype) + "_" + str(y.device)
+ wnsize_dtype_device = str(win_size) + "_" + dtype_device
+ if wnsize_dtype_device not in hann_window:
+ hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(
+ dtype=y.dtype, device=y.device
+ )
+
+ # Padding
+ y = torch.nn.functional.pad(
+ y.unsqueeze(1),
+ (int((n_fft - hop_size) / 2), int((n_fft - hop_size) / 2)),
+ mode="reflect",
+ )
+ y = y.squeeze(1)
+
+ # Complex Spectrogram :: (B, T) -> (B, Freq, Frame, RealComplex=2)
+ spec = torch.stft(
+ y,
+ n_fft,
+ hop_length=hop_size,
+ win_length=win_size,
+ window=hann_window[wnsize_dtype_device],
+ center=center,
+ pad_mode="reflect",
+ normalized=False,
+ onesided=True,
+ return_complex=True,
+ )
+
+ # Linear-frequency Linear-amplitude spectrogram :: (B, Freq, Frame, RealComplex=2) -> (B, Freq, Frame)
+ spec = torch.sqrt(spec.real.pow(2) + spec.imag.pow(2) + 1e-6)
+ return spec
+
+
+def spec_to_mel_torch(spec, n_fft, num_mels, sampling_rate, fmin, fmax):
+ # MelBasis - Cache if needed
+ global mel_basis
+ dtype_device = str(spec.dtype) + "_" + str(spec.device)
+ fmax_dtype_device = str(fmax) + "_" + dtype_device
+ if fmax_dtype_device not in mel_basis:
+ mel = librosa_mel_fn(
+ sr=sampling_rate, n_fft=n_fft, n_mels=num_mels, fmin=fmin, fmax=fmax
+ )
+ mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(
+ dtype=spec.dtype, device=spec.device
+ )
+
+ # Mel-frequency Log-amplitude spectrogram :: (B, Freq=num_mels, Frame)
+ melspec = torch.matmul(mel_basis[fmax_dtype_device], spec)
+ melspec = spectral_normalize_torch(melspec)
+ return melspec
+
+
+def mel_spectrogram_torch(
+ y, n_fft, num_mels, sampling_rate, hop_size, win_size, fmin, fmax, center=False
+):
+ """Convert waveform into Mel-frequency Log-amplitude spectrogram.
+
+ Args:
+ y :: (B, T) - Waveforms
+ Returns:
+ melspec :: (B, Freq, Frame) - Mel-frequency Log-amplitude spectrogram
+ """
+ # Linear-frequency Linear-amplitude spectrogram :: (B, T) -> (B, Freq, Frame)
+ spec = spectrogram_torch(y, n_fft, sampling_rate, hop_size, win_size, center)
+
+ # Mel-frequency Log-amplitude spectrogram :: (B, Freq, Frame) -> (B, Freq=num_mels, Frame)
+ melspec = spec_to_mel_torch(spec, n_fft, num_mels, sampling_rate, fmin, fmax)
+
+ return melspec
diff --git a/infer/lib/train/process_ckpt.py b/infer/lib/train/process_ckpt.py
new file mode 100644
index 0000000000000000000000000000000000000000..2529ccf6fb05935258af44bf9f3aa204532696ba
--- /dev/null
+++ b/infer/lib/train/process_ckpt.py
@@ -0,0 +1,261 @@
+import os
+import sys
+import traceback
+from collections import OrderedDict
+
+import torch
+
+from i18n.i18n import I18nAuto
+
+i18n = I18nAuto()
+
+
+def savee(ckpt, sr, if_f0, name, epoch, version, hps):
+ try:
+ opt = OrderedDict()
+ opt["weight"] = {}
+ for key in ckpt.keys():
+ if "enc_q" in key:
+ continue
+ opt["weight"][key] = ckpt[key].half()
+ opt["config"] = [
+ hps.data.filter_length // 2 + 1,
+ 32,
+ hps.model.inter_channels,
+ hps.model.hidden_channels,
+ hps.model.filter_channels,
+ hps.model.n_heads,
+ hps.model.n_layers,
+ hps.model.kernel_size,
+ hps.model.p_dropout,
+ hps.model.resblock,
+ hps.model.resblock_kernel_sizes,
+ hps.model.resblock_dilation_sizes,
+ hps.model.upsample_rates,
+ hps.model.upsample_initial_channel,
+ hps.model.upsample_kernel_sizes,
+ hps.model.spk_embed_dim,
+ hps.model.gin_channels,
+ hps.data.sampling_rate,
+ ]
+ opt["info"] = "%sepoch" % epoch
+ opt["sr"] = sr
+ opt["f0"] = if_f0
+ opt["version"] = version
+ torch.save(opt, "assets/weights/%s.pth" % name)
+ return "Success."
+ except:
+ return traceback.format_exc()
+
+
+def show_info(path):
+ try:
+ a = torch.load(path, map_location="cpu")
+ return "模型信息:%s\n采样率:%s\n模型是否输入音高引导:%s\n版本:%s" % (
+ a.get("info", "None"),
+ a.get("sr", "None"),
+ a.get("f0", "None"),
+ a.get("version", "None"),
+ )
+ except:
+ return traceback.format_exc()
+
+
+def extract_small_model(path, name, sr, if_f0, info, version):
+ try:
+ ckpt = torch.load(path, map_location="cpu")
+ if "model" in ckpt:
+ ckpt = ckpt["model"]
+ opt = OrderedDict()
+ opt["weight"] = {}
+ for key in ckpt.keys():
+ if "enc_q" in key:
+ continue
+ opt["weight"][key] = ckpt[key].half()
+ if sr == "40k":
+ opt["config"] = [
+ 1025,
+ 32,
+ 192,
+ 192,
+ 768,
+ 2,
+ 6,
+ 3,
+ 0,
+ "1",
+ [3, 7, 11],
+ [[1, 3, 5], [1, 3, 5], [1, 3, 5]],
+ [10, 10, 2, 2],
+ 512,
+ [16, 16, 4, 4],
+ 109,
+ 256,
+ 40000,
+ ]
+ elif sr == "48k":
+ if version == "v1":
+ opt["config"] = [
+ 1025,
+ 32,
+ 192,
+ 192,
+ 768,
+ 2,
+ 6,
+ 3,
+ 0,
+ "1",
+ [3, 7, 11],
+ [[1, 3, 5], [1, 3, 5], [1, 3, 5]],
+ [10, 6, 2, 2, 2],
+ 512,
+ [16, 16, 4, 4, 4],
+ 109,
+ 256,
+ 48000,
+ ]
+ else:
+ opt["config"] = [
+ 1025,
+ 32,
+ 192,
+ 192,
+ 768,
+ 2,
+ 6,
+ 3,
+ 0,
+ "1",
+ [3, 7, 11],
+ [[1, 3, 5], [1, 3, 5], [1, 3, 5]],
+ [12, 10, 2, 2],
+ 512,
+ [24, 20, 4, 4],
+ 109,
+ 256,
+ 48000,
+ ]
+ elif sr == "32k":
+ if version == "v1":
+ opt["config"] = [
+ 513,
+ 32,
+ 192,
+ 192,
+ 768,
+ 2,
+ 6,
+ 3,
+ 0,
+ "1",
+ [3, 7, 11],
+ [[1, 3, 5], [1, 3, 5], [1, 3, 5]],
+ [10, 4, 2, 2, 2],
+ 512,
+ [16, 16, 4, 4, 4],
+ 109,
+ 256,
+ 32000,
+ ]
+ else:
+ opt["config"] = [
+ 513,
+ 32,
+ 192,
+ 192,
+ 768,
+ 2,
+ 6,
+ 3,
+ 0,
+ "1",
+ [3, 7, 11],
+ [[1, 3, 5], [1, 3, 5], [1, 3, 5]],
+ [10, 8, 2, 2],
+ 512,
+ [20, 16, 4, 4],
+ 109,
+ 256,
+ 32000,
+ ]
+ if info == "":
+ info = "Extracted model."
+ opt["info"] = info
+ opt["version"] = version
+ opt["sr"] = sr
+ opt["f0"] = int(if_f0)
+ torch.save(opt, "assets/weights/%s.pth" % name)
+ return "Success."
+ except:
+ return traceback.format_exc()
+
+
+def change_info(path, info, name):
+ try:
+ ckpt = torch.load(path, map_location="cpu")
+ ckpt["info"] = info
+ if name == "":
+ name = os.path.basename(path)
+ torch.save(ckpt, "assets/weights/%s" % name)
+ return "Success."
+ except:
+ return traceback.format_exc()
+
+
+def merge(path1, path2, alpha1, sr, f0, info, name, version):
+ try:
+
+ def extract(ckpt):
+ a = ckpt["model"]
+ opt = OrderedDict()
+ opt["weight"] = {}
+ for key in a.keys():
+ if "enc_q" in key:
+ continue
+ opt["weight"][key] = a[key]
+ return opt
+
+ ckpt1 = torch.load(path1, map_location="cpu")
+ ckpt2 = torch.load(path2, map_location="cpu")
+ cfg = ckpt1["config"]
+ if "model" in ckpt1:
+ ckpt1 = extract(ckpt1)
+ else:
+ ckpt1 = ckpt1["weight"]
+ if "model" in ckpt2:
+ ckpt2 = extract(ckpt2)
+ else:
+ ckpt2 = ckpt2["weight"]
+ if sorted(list(ckpt1.keys())) != sorted(list(ckpt2.keys())):
+ return "Fail to merge the models. The model architectures are not the same."
+ opt = OrderedDict()
+ opt["weight"] = {}
+ for key in ckpt1.keys():
+ # try:
+ if key == "emb_g.weight" and ckpt1[key].shape != ckpt2[key].shape:
+ min_shape0 = min(ckpt1[key].shape[0], ckpt2[key].shape[0])
+ opt["weight"][key] = (
+ alpha1 * (ckpt1[key][:min_shape0].float())
+ + (1 - alpha1) * (ckpt2[key][:min_shape0].float())
+ ).half()
+ else:
+ opt["weight"][key] = (
+ alpha1 * (ckpt1[key].float()) + (1 - alpha1) * (ckpt2[key].float())
+ ).half()
+ # except:
+ # pdb.set_trace()
+ opt["config"] = cfg
+ """
+ if(sr=="40k"):opt["config"] = [1025, 32, 192, 192, 768, 2, 6, 3, 0, "1", [3, 7, 11], [[1, 3, 5], [1, 3, 5], [1, 3, 5]], [10, 10, 2, 2], 512, [16, 16, 4, 4,4], 109, 256, 40000]
+ elif(sr=="48k"):opt["config"] = [1025, 32, 192, 192, 768, 2, 6, 3, 0, "1", [3, 7, 11], [[1, 3, 5], [1, 3, 5], [1, 3, 5]], [10,6,2,2,2], 512, [16, 16, 4, 4], 109, 256, 48000]
+ elif(sr=="32k"):opt["config"] = [513, 32, 192, 192, 768, 2, 6, 3, 0, "1", [3, 7, 11], [[1, 3, 5], [1, 3, 5], [1, 3, 5]], [10, 4, 2, 2, 2], 512, [16, 16, 4, 4,4], 109, 256, 32000]
+ """
+ opt["sr"] = sr
+ opt["f0"] = 1 if f0 == i18n("是") else 0
+ opt["version"] = version
+ opt["info"] = info
+ torch.save(opt, "assets/weights/%s.pth" % name)
+ return "Success."
+ except:
+ return traceback.format_exc()
diff --git a/infer/lib/train/utils.py b/infer/lib/train/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..e7bb7837be0d464d07cea2e7cad988547001cb98
--- /dev/null
+++ b/infer/lib/train/utils.py
@@ -0,0 +1,478 @@
+import argparse
+import glob
+import json
+import logging
+import os
+import subprocess
+import sys
+import shutil
+
+import numpy as np
+import torch
+from scipy.io.wavfile import read
+
+MATPLOTLIB_FLAG = False
+
+logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
+logger = logging
+
+
+def load_checkpoint_d(checkpoint_path, combd, sbd, optimizer=None, load_opt=1):
+ assert os.path.isfile(checkpoint_path)
+ checkpoint_dict = torch.load(checkpoint_path, map_location="cpu")
+
+ ##################
+ def go(model, bkey):
+ saved_state_dict = checkpoint_dict[bkey]
+ if hasattr(model, "module"):
+ state_dict = model.module.state_dict()
+ else:
+ state_dict = model.state_dict()
+ new_state_dict = {}
+ for k, v in state_dict.items(): # 模型需要的shape
+ try:
+ new_state_dict[k] = saved_state_dict[k]
+ if saved_state_dict[k].shape != state_dict[k].shape:
+ logger.warning(
+ "shape-%s-mismatch. need: %s, get: %s",
+ k,
+ state_dict[k].shape,
+ saved_state_dict[k].shape,
+ ) #
+ raise KeyError
+ except:
+ # logger.info(traceback.format_exc())
+ logger.info("%s is not in the checkpoint", k) # pretrain缺失的
+ new_state_dict[k] = v # 模型自带的随机值
+ if hasattr(model, "module"):
+ model.module.load_state_dict(new_state_dict, strict=False)
+ else:
+ model.load_state_dict(new_state_dict, strict=False)
+ return model
+
+ go(combd, "combd")
+ model = go(sbd, "sbd")
+ #############
+ logger.info("Loaded model weights")
+
+ iteration = checkpoint_dict["iteration"]
+ learning_rate = checkpoint_dict["learning_rate"]
+ if (
+ optimizer is not None and load_opt == 1
+ ): ###加载不了,如果是空的的话,重新初始化,可能还会影响lr时间表的更新,因此在train文件最外围catch
+ # try:
+ optimizer.load_state_dict(checkpoint_dict["optimizer"])
+ # except:
+ # traceback.print_exc()
+ logger.info("Loaded checkpoint '{}' (epoch {})".format(checkpoint_path, iteration))
+ return model, optimizer, learning_rate, iteration
+
+
+# def load_checkpoint(checkpoint_path, model, optimizer=None):
+# assert os.path.isfile(checkpoint_path)
+# checkpoint_dict = torch.load(checkpoint_path, map_location='cpu')
+# iteration = checkpoint_dict['iteration']
+# learning_rate = checkpoint_dict['learning_rate']
+# if optimizer is not None:
+# optimizer.load_state_dict(checkpoint_dict['optimizer'])
+# # print(1111)
+# saved_state_dict = checkpoint_dict['model']
+# # print(1111)
+#
+# if hasattr(model, 'module'):
+# state_dict = model.module.state_dict()
+# else:
+# state_dict = model.state_dict()
+# new_state_dict= {}
+# for k, v in state_dict.items():
+# try:
+# new_state_dict[k] = saved_state_dict[k]
+# except:
+# logger.info("%s is not in the checkpoint" % k)
+# new_state_dict[k] = v
+# if hasattr(model, 'module'):
+# model.module.load_state_dict(new_state_dict)
+# else:
+# model.load_state_dict(new_state_dict)
+# logger.info("Loaded checkpoint '{}' (epoch {})" .format(
+# checkpoint_path, iteration))
+# return model, optimizer, learning_rate, iteration
+def load_checkpoint(checkpoint_path, model, optimizer=None, load_opt=1):
+ assert os.path.isfile(checkpoint_path)
+ checkpoint_dict = torch.load(checkpoint_path, map_location="cpu")
+
+ saved_state_dict = checkpoint_dict["model"]
+ if hasattr(model, "module"):
+ state_dict = model.module.state_dict()
+ else:
+ state_dict = model.state_dict()
+ new_state_dict = {}
+ for k, v in state_dict.items(): # 模型需要的shape
+ try:
+ new_state_dict[k] = saved_state_dict[k]
+ if saved_state_dict[k].shape != state_dict[k].shape:
+ logger.warning(
+ "shape-%s-mismatch|need-%s|get-%s",
+ k,
+ state_dict[k].shape,
+ saved_state_dict[k].shape,
+ ) #
+ raise KeyError
+ except:
+ # logger.info(traceback.format_exc())
+ logger.info("%s is not in the checkpoint", k) # pretrain缺失的
+ new_state_dict[k] = v # 模型自带的随机值
+ if hasattr(model, "module"):
+ model.module.load_state_dict(new_state_dict, strict=False)
+ else:
+ model.load_state_dict(new_state_dict, strict=False)
+ logger.info("Loaded model weights")
+
+ iteration = checkpoint_dict["iteration"]
+ learning_rate = checkpoint_dict["learning_rate"]
+ if (
+ optimizer is not None and load_opt == 1
+ ): ###加载不了,如果是空的的话,重新初始化,可能还会影响lr时间表的更新,因此在train文件最外围catch
+ # try:
+ optimizer.load_state_dict(checkpoint_dict["optimizer"])
+ # except:
+ # traceback.print_exc()
+ logger.info("Loaded checkpoint '{}' (epoch {})".format(checkpoint_path, iteration))
+ return model, optimizer, learning_rate, iteration
+
+
+def save_checkpoint(model, optimizer, learning_rate, iteration, checkpoint_path):
+ logger.info(
+ "Saving model and optimizer state at epoch {} to {}".format(
+ iteration, checkpoint_path
+ )
+ )
+ if hasattr(model, "module"):
+ state_dict = model.module.state_dict()
+ else:
+ state_dict = model.state_dict()
+ torch.save(
+ {
+ "model": state_dict,
+ "iteration": iteration,
+ "optimizer": optimizer.state_dict(),
+ "learning_rate": learning_rate,
+ },
+ checkpoint_path,
+ )
+
+
+def save_checkpoint_d(combd, sbd, optimizer, learning_rate, iteration, checkpoint_path):
+ logger.info(
+ "Saving model and optimizer state at epoch {} to {}".format(
+ iteration, checkpoint_path
+ )
+ )
+ if hasattr(combd, "module"):
+ state_dict_combd = combd.module.state_dict()
+ else:
+ state_dict_combd = combd.state_dict()
+ if hasattr(sbd, "module"):
+ state_dict_sbd = sbd.module.state_dict()
+ else:
+ state_dict_sbd = sbd.state_dict()
+ torch.save(
+ {
+ "combd": state_dict_combd,
+ "sbd": state_dict_sbd,
+ "iteration": iteration,
+ "optimizer": optimizer.state_dict(),
+ "learning_rate": learning_rate,
+ },
+ checkpoint_path,
+ )
+
+
+def summarize(
+ writer,
+ global_step,
+ scalars={},
+ histograms={},
+ images={},
+ audios={},
+ audio_sampling_rate=22050,
+):
+ for k, v in scalars.items():
+ writer.add_scalar(k, v, global_step)
+ for k, v in histograms.items():
+ writer.add_histogram(k, v, global_step)
+ for k, v in images.items():
+ writer.add_image(k, v, global_step, dataformats="HWC")
+ for k, v in audios.items():
+ writer.add_audio(k, v, global_step, audio_sampling_rate)
+
+
+def latest_checkpoint_path(dir_path, regex="G_*.pth"):
+ f_list = glob.glob(os.path.join(dir_path, regex))
+ f_list.sort(key=lambda f: int("".join(filter(str.isdigit, f))))
+ x = f_list[-1]
+ logger.debug(x)
+ return x
+
+
+def plot_spectrogram_to_numpy(spectrogram):
+ global MATPLOTLIB_FLAG
+ if not MATPLOTLIB_FLAG:
+ import matplotlib
+
+ matplotlib.use("Agg")
+ MATPLOTLIB_FLAG = True
+ mpl_logger = logging.getLogger("matplotlib")
+ mpl_logger.setLevel(logging.WARNING)
+ import matplotlib.pylab as plt
+ import numpy as np
+
+ fig, ax = plt.subplots(figsize=(10, 2))
+ im = ax.imshow(spectrogram, aspect="auto", origin="lower", interpolation="none")
+ plt.colorbar(im, ax=ax)
+ plt.xlabel("Frames")
+ plt.ylabel("Channels")
+ plt.tight_layout()
+
+ fig.canvas.draw()
+ data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep="")
+ data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
+ plt.close()
+ return data
+
+
+def plot_alignment_to_numpy(alignment, info=None):
+ global MATPLOTLIB_FLAG
+ if not MATPLOTLIB_FLAG:
+ import matplotlib
+
+ matplotlib.use("Agg")
+ MATPLOTLIB_FLAG = True
+ mpl_logger = logging.getLogger("matplotlib")
+ mpl_logger.setLevel(logging.WARNING)
+ import matplotlib.pylab as plt
+ import numpy as np
+
+ fig, ax = plt.subplots(figsize=(6, 4))
+ im = ax.imshow(
+ alignment.transpose(), aspect="auto", origin="lower", interpolation="none"
+ )
+ fig.colorbar(im, ax=ax)
+ xlabel = "Decoder timestep"
+ if info is not None:
+ xlabel += "\n\n" + info
+ plt.xlabel(xlabel)
+ plt.ylabel("Encoder timestep")
+ plt.tight_layout()
+
+ fig.canvas.draw()
+ data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep="")
+ data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
+ plt.close()
+ return data
+
+
+def load_wav_to_torch(full_path):
+ sampling_rate, data = read(full_path)
+ return torch.FloatTensor(data.astype(np.float32)), sampling_rate
+
+
+def load_filepaths_and_text(filename, split="|"):
+ with open(filename, encoding="utf-8") as f:
+ filepaths_and_text = [line.strip().split(split) for line in f]
+ return filepaths_and_text
+
+
+def get_hparams(init=True):
+ """
+ todo:
+ 结尾七人组:
+ 保存频率、总epoch done
+ bs done
+ pretrainG、pretrainD done
+ 卡号:os.en["CUDA_VISIBLE_DEVICES"] done
+ if_latest done
+ 模型:if_f0 done
+ 采样率:自动选择config done
+ 是否缓存数据集进GPU:if_cache_data_in_gpu done
+
+ -m:
+ 自动决定training_files路径,改掉train_nsf_load_pretrain.py里的hps.data.training_files done
+ -c不要了
+ """
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "-se",
+ "--save_every_epoch",
+ type=int,
+ required=True,
+ help="checkpoint save frequency (epoch)",
+ )
+ parser.add_argument(
+ "-te", "--total_epoch", type=int, required=True, help="total_epoch"
+ )
+ parser.add_argument(
+ "-pg", "--pretrainG", type=str, default="", help="Pretrained Generator path"
+ )
+ parser.add_argument(
+ "-pd", "--pretrainD", type=str, default="", help="Pretrained Discriminator path"
+ )
+ parser.add_argument("-g", "--gpus", type=str, default="0", help="split by -")
+ parser.add_argument(
+ "-bs", "--batch_size", type=int, required=True, help="batch size"
+ )
+ parser.add_argument(
+ "-e", "--experiment_dir", type=str, required=True, help="experiment dir"
+ ) # -m
+ parser.add_argument(
+ "-sr", "--sample_rate", type=str, required=True, help="sample rate, 32k/40k/48k"
+ )
+ parser.add_argument(
+ "-sw",
+ "--save_every_weights",
+ type=str,
+ default="0",
+ help="save the extracted model in weights directory when saving checkpoints",
+ )
+ parser.add_argument(
+ "-v", "--version", type=str, required=True, help="model version"
+ )
+ parser.add_argument(
+ "-f0",
+ "--if_f0",
+ type=int,
+ required=True,
+ help="use f0 as one of the inputs of the model, 1 or 0",
+ )
+ parser.add_argument(
+ "-l",
+ "--if_latest",
+ type=int,
+ required=True,
+ help="if only save the latest G/D pth file, 1 or 0",
+ )
+ parser.add_argument(
+ "-c",
+ "--if_cache_data_in_gpu",
+ type=int,
+ required=True,
+ help="if caching the dataset in GPU memory, 1 or 0",
+ )
+
+ args = parser.parse_args()
+ name = args.experiment_dir
+ experiment_dir = os.path.join("./logs", args.experiment_dir)
+
+ config_save_path = os.path.join(experiment_dir, "config.json")
+ with open(config_save_path, "r") as f:
+ config = json.load(f)
+
+ hparams = HParams(**config)
+ hparams.model_dir = hparams.experiment_dir = experiment_dir
+ hparams.save_every_epoch = args.save_every_epoch
+ hparams.name = name
+ hparams.total_epoch = args.total_epoch
+ hparams.pretrainG = args.pretrainG
+ hparams.pretrainD = args.pretrainD
+ hparams.version = args.version
+ hparams.gpus = args.gpus
+ hparams.train.batch_size = args.batch_size
+ hparams.sample_rate = args.sample_rate
+ hparams.if_f0 = args.if_f0
+ hparams.if_latest = args.if_latest
+ hparams.save_every_weights = args.save_every_weights
+ hparams.if_cache_data_in_gpu = args.if_cache_data_in_gpu
+ hparams.data.training_files = "%s/filelist.txt" % experiment_dir
+ return hparams
+
+
+def get_hparams_from_dir(model_dir):
+ config_save_path = os.path.join(model_dir, "config.json")
+ with open(config_save_path, "r") as f:
+ data = f.read()
+ config = json.loads(data)
+
+ hparams = HParams(**config)
+ hparams.model_dir = model_dir
+ return hparams
+
+
+def get_hparams_from_file(config_path):
+ with open(config_path, "r") as f:
+ data = f.read()
+ config = json.loads(data)
+
+ hparams = HParams(**config)
+ return hparams
+
+
+def check_git_hash(model_dir):
+ source_dir = os.path.dirname(os.path.realpath(__file__))
+ if not os.path.exists(os.path.join(source_dir, ".git")):
+ logger.warning(
+ "{} is not a git repository, therefore hash value comparison will be ignored.".format(
+ source_dir
+ )
+ )
+ return
+
+ cur_hash = subprocess.getoutput("git rev-parse HEAD")
+
+ path = os.path.join(model_dir, "githash")
+ if os.path.exists(path):
+ saved_hash = open(path).read()
+ if saved_hash != cur_hash:
+ logger.warning(
+ "git hash values are different. {}(saved) != {}(current)".format(
+ saved_hash[:8], cur_hash[:8]
+ )
+ )
+ else:
+ open(path, "w").write(cur_hash)
+
+
+def get_logger(model_dir, filename="train.log"):
+ global logger
+ logger = logging.getLogger(os.path.basename(model_dir))
+ logger.setLevel(logging.DEBUG)
+
+ formatter = logging.Formatter("%(asctime)s\t%(name)s\t%(levelname)s\t%(message)s")
+ if not os.path.exists(model_dir):
+ os.makedirs(model_dir)
+ h = logging.FileHandler(os.path.join(model_dir, filename))
+ h.setLevel(logging.DEBUG)
+ h.setFormatter(formatter)
+ logger.addHandler(h)
+ return logger
+
+
+class HParams:
+ def __init__(self, **kwargs):
+ for k, v in kwargs.items():
+ if type(v) == dict:
+ v = HParams(**v)
+ self[k] = v
+
+ def keys(self):
+ return self.__dict__.keys()
+
+ def items(self):
+ return self.__dict__.items()
+
+ def values(self):
+ return self.__dict__.values()
+
+ def __len__(self):
+ return len(self.__dict__)
+
+ def __getitem__(self, key):
+ return getattr(self, key)
+
+ def __setitem__(self, key, value):
+ return setattr(self, key, value)
+
+ def __contains__(self, key):
+ return key in self.__dict__
+
+ def __repr__(self):
+ return self.__dict__.__repr__()
diff --git a/infer/lib/uvr5_pack/lib_v5/dataset.py b/infer/lib/uvr5_pack/lib_v5/dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..cfd01a174978d97180a897e40cb59ecadec1d12e
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/dataset.py
@@ -0,0 +1,183 @@
+import os
+import random
+
+import numpy as np
+import torch
+import torch.utils.data
+from tqdm import tqdm
+
+from . import spec_utils
+
+
+class VocalRemoverValidationSet(torch.utils.data.Dataset):
+ def __init__(self, patch_list):
+ self.patch_list = patch_list
+
+ def __len__(self):
+ return len(self.patch_list)
+
+ def __getitem__(self, idx):
+ path = self.patch_list[idx]
+ data = np.load(path)
+
+ X, y = data["X"], data["y"]
+
+ X_mag = np.abs(X)
+ y_mag = np.abs(y)
+
+ return X_mag, y_mag
+
+
+def make_pair(mix_dir, inst_dir):
+ input_exts = [".wav", ".m4a", ".mp3", ".mp4", ".flac"]
+
+ X_list = sorted(
+ [
+ os.path.join(mix_dir, fname)
+ for fname in os.listdir(mix_dir)
+ if os.path.splitext(fname)[1] in input_exts
+ ]
+ )
+ y_list = sorted(
+ [
+ os.path.join(inst_dir, fname)
+ for fname in os.listdir(inst_dir)
+ if os.path.splitext(fname)[1] in input_exts
+ ]
+ )
+
+ filelist = list(zip(X_list, y_list))
+
+ return filelist
+
+
+def train_val_split(dataset_dir, split_mode, val_rate, val_filelist):
+ if split_mode == "random":
+ filelist = make_pair(
+ os.path.join(dataset_dir, "mixtures"),
+ os.path.join(dataset_dir, "instruments"),
+ )
+
+ random.shuffle(filelist)
+
+ if len(val_filelist) == 0:
+ val_size = int(len(filelist) * val_rate)
+ train_filelist = filelist[:-val_size]
+ val_filelist = filelist[-val_size:]
+ else:
+ train_filelist = [
+ pair for pair in filelist if list(pair) not in val_filelist
+ ]
+ elif split_mode == "subdirs":
+ if len(val_filelist) != 0:
+ raise ValueError(
+ "The `val_filelist` option is not available in `subdirs` mode"
+ )
+
+ train_filelist = make_pair(
+ os.path.join(dataset_dir, "training/mixtures"),
+ os.path.join(dataset_dir, "training/instruments"),
+ )
+
+ val_filelist = make_pair(
+ os.path.join(dataset_dir, "validation/mixtures"),
+ os.path.join(dataset_dir, "validation/instruments"),
+ )
+
+ return train_filelist, val_filelist
+
+
+def augment(X, y, reduction_rate, reduction_mask, mixup_rate, mixup_alpha):
+ perm = np.random.permutation(len(X))
+ for i, idx in enumerate(tqdm(perm)):
+ if np.random.uniform() < reduction_rate:
+ y[idx] = spec_utils.reduce_vocal_aggressively(
+ X[idx], y[idx], reduction_mask
+ )
+
+ if np.random.uniform() < 0.5:
+ # swap channel
+ X[idx] = X[idx, ::-1]
+ y[idx] = y[idx, ::-1]
+ if np.random.uniform() < 0.02:
+ # mono
+ X[idx] = X[idx].mean(axis=0, keepdims=True)
+ y[idx] = y[idx].mean(axis=0, keepdims=True)
+ if np.random.uniform() < 0.02:
+ # inst
+ X[idx] = y[idx]
+
+ if np.random.uniform() < mixup_rate and i < len(perm) - 1:
+ lam = np.random.beta(mixup_alpha, mixup_alpha)
+ X[idx] = lam * X[idx] + (1 - lam) * X[perm[i + 1]]
+ y[idx] = lam * y[idx] + (1 - lam) * y[perm[i + 1]]
+
+ return X, y
+
+
+def make_padding(width, cropsize, offset):
+ left = offset
+ roi_size = cropsize - left * 2
+ if roi_size == 0:
+ roi_size = cropsize
+ right = roi_size - (width % roi_size) + left
+
+ return left, right, roi_size
+
+
+def make_training_set(filelist, cropsize, patches, sr, hop_length, n_fft, offset):
+ len_dataset = patches * len(filelist)
+
+ X_dataset = np.zeros((len_dataset, 2, n_fft // 2 + 1, cropsize), dtype=np.complex64)
+ y_dataset = np.zeros((len_dataset, 2, n_fft // 2 + 1, cropsize), dtype=np.complex64)
+
+ for i, (X_path, y_path) in enumerate(tqdm(filelist)):
+ X, y = spec_utils.cache_or_load(X_path, y_path, sr, hop_length, n_fft)
+ coef = np.max([np.abs(X).max(), np.abs(y).max()])
+ X, y = X / coef, y / coef
+
+ l, r, roi_size = make_padding(X.shape[2], cropsize, offset)
+ X_pad = np.pad(X, ((0, 0), (0, 0), (l, r)), mode="constant")
+ y_pad = np.pad(y, ((0, 0), (0, 0), (l, r)), mode="constant")
+
+ starts = np.random.randint(0, X_pad.shape[2] - cropsize, patches)
+ ends = starts + cropsize
+ for j in range(patches):
+ idx = i * patches + j
+ X_dataset[idx] = X_pad[:, :, starts[j] : ends[j]]
+ y_dataset[idx] = y_pad[:, :, starts[j] : ends[j]]
+
+ return X_dataset, y_dataset
+
+
+def make_validation_set(filelist, cropsize, sr, hop_length, n_fft, offset):
+ patch_list = []
+ patch_dir = "cs{}_sr{}_hl{}_nf{}_of{}".format(
+ cropsize, sr, hop_length, n_fft, offset
+ )
+ os.makedirs(patch_dir, exist_ok=True)
+
+ for i, (X_path, y_path) in enumerate(tqdm(filelist)):
+ basename = os.path.splitext(os.path.basename(X_path))[0]
+
+ X, y = spec_utils.cache_or_load(X_path, y_path, sr, hop_length, n_fft)
+ coef = np.max([np.abs(X).max(), np.abs(y).max()])
+ X, y = X / coef, y / coef
+
+ l, r, roi_size = make_padding(X.shape[2], cropsize, offset)
+ X_pad = np.pad(X, ((0, 0), (0, 0), (l, r)), mode="constant")
+ y_pad = np.pad(y, ((0, 0), (0, 0), (l, r)), mode="constant")
+
+ len_dataset = int(np.ceil(X.shape[2] / roi_size))
+ for j in range(len_dataset):
+ outpath = os.path.join(patch_dir, "{}_p{}.npz".format(basename, j))
+ start = j * roi_size
+ if not os.path.exists(outpath):
+ np.savez(
+ outpath,
+ X=X_pad[:, :, start : start + cropsize],
+ y=y_pad[:, :, start : start + cropsize],
+ )
+ patch_list.append(outpath)
+
+ return VocalRemoverValidationSet(patch_list)
diff --git a/infer/lib/uvr5_pack/lib_v5/layers.py b/infer/lib/uvr5_pack/lib_v5/layers.py
new file mode 100644
index 0000000000000000000000000000000000000000..4fc1b5cb85a3327f60cbb9f5deffbeeaaac516ad
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/layers.py
@@ -0,0 +1,118 @@
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from . import spec_utils
+
+
+class Conv2DBNActiv(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(Conv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin,
+ nout,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ bias=False,
+ ),
+ nn.BatchNorm2d(nout),
+ activ(),
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class SeperableConv2DBNActiv(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(SeperableConv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin,
+ nin,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ groups=nin,
+ bias=False,
+ ),
+ nn.Conv2d(nin, nout, kernel_size=1, bias=False),
+ nn.BatchNorm2d(nout),
+ activ(),
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class Encoder(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.LeakyReLU):
+ super(Encoder, self).__init__()
+ self.conv1 = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.conv2 = Conv2DBNActiv(nout, nout, ksize, stride, pad, activ=activ)
+
+ def __call__(self, x):
+ skip = self.conv1(x)
+ h = self.conv2(skip)
+
+ return h, skip
+
+
+class Decoder(nn.Module):
+ def __init__(
+ self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.ReLU, dropout=False
+ ):
+ super(Decoder, self).__init__()
+ self.conv = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.dropout = nn.Dropout2d(0.1) if dropout else None
+
+ def __call__(self, x, skip=None):
+ x = F.interpolate(x, scale_factor=2, mode="bilinear", align_corners=True)
+ if skip is not None:
+ skip = spec_utils.crop_center(skip, x)
+ x = torch.cat([x, skip], dim=1)
+ h = self.conv(x)
+
+ if self.dropout is not None:
+ h = self.dropout(h)
+
+ return h
+
+
+class ASPPModule(nn.Module):
+ def __init__(self, nin, nout, dilations=(4, 8, 16), activ=nn.ReLU):
+ super(ASPPModule, self).__init__()
+ self.conv1 = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, None)),
+ Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ),
+ )
+ self.conv2 = Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
+ self.conv3 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[0], dilations[0], activ=activ
+ )
+ self.conv4 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[1], dilations[1], activ=activ
+ )
+ self.conv5 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ
+ )
+ self.bottleneck = nn.Sequential(
+ Conv2DBNActiv(nin * 5, nout, 1, 1, 0, activ=activ), nn.Dropout2d(0.1)
+ )
+
+ def forward(self, x):
+ _, _, h, w = x.size()
+ feat1 = F.interpolate(
+ self.conv1(x), size=(h, w), mode="bilinear", align_corners=True
+ )
+ feat2 = self.conv2(x)
+ feat3 = self.conv3(x)
+ feat4 = self.conv4(x)
+ feat5 = self.conv5(x)
+ out = torch.cat((feat1, feat2, feat3, feat4, feat5), dim=1)
+ bottle = self.bottleneck(out)
+ return bottle
diff --git a/infer/lib/uvr5_pack/lib_v5/layers_123812KB .py b/infer/lib/uvr5_pack/lib_v5/layers_123812KB .py
new file mode 100644
index 0000000000000000000000000000000000000000..4fc1b5cb85a3327f60cbb9f5deffbeeaaac516ad
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/layers_123812KB .py
@@ -0,0 +1,118 @@
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from . import spec_utils
+
+
+class Conv2DBNActiv(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(Conv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin,
+ nout,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ bias=False,
+ ),
+ nn.BatchNorm2d(nout),
+ activ(),
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class SeperableConv2DBNActiv(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(SeperableConv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin,
+ nin,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ groups=nin,
+ bias=False,
+ ),
+ nn.Conv2d(nin, nout, kernel_size=1, bias=False),
+ nn.BatchNorm2d(nout),
+ activ(),
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class Encoder(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.LeakyReLU):
+ super(Encoder, self).__init__()
+ self.conv1 = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.conv2 = Conv2DBNActiv(nout, nout, ksize, stride, pad, activ=activ)
+
+ def __call__(self, x):
+ skip = self.conv1(x)
+ h = self.conv2(skip)
+
+ return h, skip
+
+
+class Decoder(nn.Module):
+ def __init__(
+ self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.ReLU, dropout=False
+ ):
+ super(Decoder, self).__init__()
+ self.conv = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.dropout = nn.Dropout2d(0.1) if dropout else None
+
+ def __call__(self, x, skip=None):
+ x = F.interpolate(x, scale_factor=2, mode="bilinear", align_corners=True)
+ if skip is not None:
+ skip = spec_utils.crop_center(skip, x)
+ x = torch.cat([x, skip], dim=1)
+ h = self.conv(x)
+
+ if self.dropout is not None:
+ h = self.dropout(h)
+
+ return h
+
+
+class ASPPModule(nn.Module):
+ def __init__(self, nin, nout, dilations=(4, 8, 16), activ=nn.ReLU):
+ super(ASPPModule, self).__init__()
+ self.conv1 = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, None)),
+ Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ),
+ )
+ self.conv2 = Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
+ self.conv3 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[0], dilations[0], activ=activ
+ )
+ self.conv4 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[1], dilations[1], activ=activ
+ )
+ self.conv5 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ
+ )
+ self.bottleneck = nn.Sequential(
+ Conv2DBNActiv(nin * 5, nout, 1, 1, 0, activ=activ), nn.Dropout2d(0.1)
+ )
+
+ def forward(self, x):
+ _, _, h, w = x.size()
+ feat1 = F.interpolate(
+ self.conv1(x), size=(h, w), mode="bilinear", align_corners=True
+ )
+ feat2 = self.conv2(x)
+ feat3 = self.conv3(x)
+ feat4 = self.conv4(x)
+ feat5 = self.conv5(x)
+ out = torch.cat((feat1, feat2, feat3, feat4, feat5), dim=1)
+ bottle = self.bottleneck(out)
+ return bottle
diff --git a/infer/lib/uvr5_pack/lib_v5/layers_123821KB.py b/infer/lib/uvr5_pack/lib_v5/layers_123821KB.py
new file mode 100644
index 0000000000000000000000000000000000000000..4fc1b5cb85a3327f60cbb9f5deffbeeaaac516ad
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/layers_123821KB.py
@@ -0,0 +1,118 @@
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from . import spec_utils
+
+
+class Conv2DBNActiv(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(Conv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin,
+ nout,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ bias=False,
+ ),
+ nn.BatchNorm2d(nout),
+ activ(),
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class SeperableConv2DBNActiv(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(SeperableConv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin,
+ nin,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ groups=nin,
+ bias=False,
+ ),
+ nn.Conv2d(nin, nout, kernel_size=1, bias=False),
+ nn.BatchNorm2d(nout),
+ activ(),
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class Encoder(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.LeakyReLU):
+ super(Encoder, self).__init__()
+ self.conv1 = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.conv2 = Conv2DBNActiv(nout, nout, ksize, stride, pad, activ=activ)
+
+ def __call__(self, x):
+ skip = self.conv1(x)
+ h = self.conv2(skip)
+
+ return h, skip
+
+
+class Decoder(nn.Module):
+ def __init__(
+ self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.ReLU, dropout=False
+ ):
+ super(Decoder, self).__init__()
+ self.conv = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.dropout = nn.Dropout2d(0.1) if dropout else None
+
+ def __call__(self, x, skip=None):
+ x = F.interpolate(x, scale_factor=2, mode="bilinear", align_corners=True)
+ if skip is not None:
+ skip = spec_utils.crop_center(skip, x)
+ x = torch.cat([x, skip], dim=1)
+ h = self.conv(x)
+
+ if self.dropout is not None:
+ h = self.dropout(h)
+
+ return h
+
+
+class ASPPModule(nn.Module):
+ def __init__(self, nin, nout, dilations=(4, 8, 16), activ=nn.ReLU):
+ super(ASPPModule, self).__init__()
+ self.conv1 = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, None)),
+ Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ),
+ )
+ self.conv2 = Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
+ self.conv3 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[0], dilations[0], activ=activ
+ )
+ self.conv4 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[1], dilations[1], activ=activ
+ )
+ self.conv5 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ
+ )
+ self.bottleneck = nn.Sequential(
+ Conv2DBNActiv(nin * 5, nout, 1, 1, 0, activ=activ), nn.Dropout2d(0.1)
+ )
+
+ def forward(self, x):
+ _, _, h, w = x.size()
+ feat1 = F.interpolate(
+ self.conv1(x), size=(h, w), mode="bilinear", align_corners=True
+ )
+ feat2 = self.conv2(x)
+ feat3 = self.conv3(x)
+ feat4 = self.conv4(x)
+ feat5 = self.conv5(x)
+ out = torch.cat((feat1, feat2, feat3, feat4, feat5), dim=1)
+ bottle = self.bottleneck(out)
+ return bottle
diff --git a/infer/lib/uvr5_pack/lib_v5/layers_33966KB.py b/infer/lib/uvr5_pack/lib_v5/layers_33966KB.py
new file mode 100644
index 0000000000000000000000000000000000000000..9b127bc6427f5c60c8cf85603a3d8a093c3501c4
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/layers_33966KB.py
@@ -0,0 +1,126 @@
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from . import spec_utils
+
+
+class Conv2DBNActiv(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(Conv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin,
+ nout,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ bias=False,
+ ),
+ nn.BatchNorm2d(nout),
+ activ(),
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class SeperableConv2DBNActiv(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(SeperableConv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin,
+ nin,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ groups=nin,
+ bias=False,
+ ),
+ nn.Conv2d(nin, nout, kernel_size=1, bias=False),
+ nn.BatchNorm2d(nout),
+ activ(),
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class Encoder(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.LeakyReLU):
+ super(Encoder, self).__init__()
+ self.conv1 = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.conv2 = Conv2DBNActiv(nout, nout, ksize, stride, pad, activ=activ)
+
+ def __call__(self, x):
+ skip = self.conv1(x)
+ h = self.conv2(skip)
+
+ return h, skip
+
+
+class Decoder(nn.Module):
+ def __init__(
+ self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.ReLU, dropout=False
+ ):
+ super(Decoder, self).__init__()
+ self.conv = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.dropout = nn.Dropout2d(0.1) if dropout else None
+
+ def __call__(self, x, skip=None):
+ x = F.interpolate(x, scale_factor=2, mode="bilinear", align_corners=True)
+ if skip is not None:
+ skip = spec_utils.crop_center(skip, x)
+ x = torch.cat([x, skip], dim=1)
+ h = self.conv(x)
+
+ if self.dropout is not None:
+ h = self.dropout(h)
+
+ return h
+
+
+class ASPPModule(nn.Module):
+ def __init__(self, nin, nout, dilations=(4, 8, 16, 32, 64), activ=nn.ReLU):
+ super(ASPPModule, self).__init__()
+ self.conv1 = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, None)),
+ Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ),
+ )
+ self.conv2 = Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
+ self.conv3 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[0], dilations[0], activ=activ
+ )
+ self.conv4 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[1], dilations[1], activ=activ
+ )
+ self.conv5 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ
+ )
+ self.conv6 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ
+ )
+ self.conv7 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ
+ )
+ self.bottleneck = nn.Sequential(
+ Conv2DBNActiv(nin * 7, nout, 1, 1, 0, activ=activ), nn.Dropout2d(0.1)
+ )
+
+ def forward(self, x):
+ _, _, h, w = x.size()
+ feat1 = F.interpolate(
+ self.conv1(x), size=(h, w), mode="bilinear", align_corners=True
+ )
+ feat2 = self.conv2(x)
+ feat3 = self.conv3(x)
+ feat4 = self.conv4(x)
+ feat5 = self.conv5(x)
+ feat6 = self.conv6(x)
+ feat7 = self.conv7(x)
+ out = torch.cat((feat1, feat2, feat3, feat4, feat5, feat6, feat7), dim=1)
+ bottle = self.bottleneck(out)
+ return bottle
diff --git a/infer/lib/uvr5_pack/lib_v5/layers_537227KB.py b/infer/lib/uvr5_pack/lib_v5/layers_537227KB.py
new file mode 100644
index 0000000000000000000000000000000000000000..9b127bc6427f5c60c8cf85603a3d8a093c3501c4
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/layers_537227KB.py
@@ -0,0 +1,126 @@
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from . import spec_utils
+
+
+class Conv2DBNActiv(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(Conv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin,
+ nout,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ bias=False,
+ ),
+ nn.BatchNorm2d(nout),
+ activ(),
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class SeperableConv2DBNActiv(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(SeperableConv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin,
+ nin,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ groups=nin,
+ bias=False,
+ ),
+ nn.Conv2d(nin, nout, kernel_size=1, bias=False),
+ nn.BatchNorm2d(nout),
+ activ(),
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class Encoder(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.LeakyReLU):
+ super(Encoder, self).__init__()
+ self.conv1 = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.conv2 = Conv2DBNActiv(nout, nout, ksize, stride, pad, activ=activ)
+
+ def __call__(self, x):
+ skip = self.conv1(x)
+ h = self.conv2(skip)
+
+ return h, skip
+
+
+class Decoder(nn.Module):
+ def __init__(
+ self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.ReLU, dropout=False
+ ):
+ super(Decoder, self).__init__()
+ self.conv = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.dropout = nn.Dropout2d(0.1) if dropout else None
+
+ def __call__(self, x, skip=None):
+ x = F.interpolate(x, scale_factor=2, mode="bilinear", align_corners=True)
+ if skip is not None:
+ skip = spec_utils.crop_center(skip, x)
+ x = torch.cat([x, skip], dim=1)
+ h = self.conv(x)
+
+ if self.dropout is not None:
+ h = self.dropout(h)
+
+ return h
+
+
+class ASPPModule(nn.Module):
+ def __init__(self, nin, nout, dilations=(4, 8, 16, 32, 64), activ=nn.ReLU):
+ super(ASPPModule, self).__init__()
+ self.conv1 = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, None)),
+ Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ),
+ )
+ self.conv2 = Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
+ self.conv3 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[0], dilations[0], activ=activ
+ )
+ self.conv4 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[1], dilations[1], activ=activ
+ )
+ self.conv5 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ
+ )
+ self.conv6 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ
+ )
+ self.conv7 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ
+ )
+ self.bottleneck = nn.Sequential(
+ Conv2DBNActiv(nin * 7, nout, 1, 1, 0, activ=activ), nn.Dropout2d(0.1)
+ )
+
+ def forward(self, x):
+ _, _, h, w = x.size()
+ feat1 = F.interpolate(
+ self.conv1(x), size=(h, w), mode="bilinear", align_corners=True
+ )
+ feat2 = self.conv2(x)
+ feat3 = self.conv3(x)
+ feat4 = self.conv4(x)
+ feat5 = self.conv5(x)
+ feat6 = self.conv6(x)
+ feat7 = self.conv7(x)
+ out = torch.cat((feat1, feat2, feat3, feat4, feat5, feat6, feat7), dim=1)
+ bottle = self.bottleneck(out)
+ return bottle
diff --git a/infer/lib/uvr5_pack/lib_v5/layers_537238KB.py b/infer/lib/uvr5_pack/lib_v5/layers_537238KB.py
new file mode 100644
index 0000000000000000000000000000000000000000..9b127bc6427f5c60c8cf85603a3d8a093c3501c4
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/layers_537238KB.py
@@ -0,0 +1,126 @@
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from . import spec_utils
+
+
+class Conv2DBNActiv(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(Conv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin,
+ nout,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ bias=False,
+ ),
+ nn.BatchNorm2d(nout),
+ activ(),
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class SeperableConv2DBNActiv(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(SeperableConv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin,
+ nin,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ groups=nin,
+ bias=False,
+ ),
+ nn.Conv2d(nin, nout, kernel_size=1, bias=False),
+ nn.BatchNorm2d(nout),
+ activ(),
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class Encoder(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.LeakyReLU):
+ super(Encoder, self).__init__()
+ self.conv1 = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.conv2 = Conv2DBNActiv(nout, nout, ksize, stride, pad, activ=activ)
+
+ def __call__(self, x):
+ skip = self.conv1(x)
+ h = self.conv2(skip)
+
+ return h, skip
+
+
+class Decoder(nn.Module):
+ def __init__(
+ self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.ReLU, dropout=False
+ ):
+ super(Decoder, self).__init__()
+ self.conv = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ self.dropout = nn.Dropout2d(0.1) if dropout else None
+
+ def __call__(self, x, skip=None):
+ x = F.interpolate(x, scale_factor=2, mode="bilinear", align_corners=True)
+ if skip is not None:
+ skip = spec_utils.crop_center(skip, x)
+ x = torch.cat([x, skip], dim=1)
+ h = self.conv(x)
+
+ if self.dropout is not None:
+ h = self.dropout(h)
+
+ return h
+
+
+class ASPPModule(nn.Module):
+ def __init__(self, nin, nout, dilations=(4, 8, 16, 32, 64), activ=nn.ReLU):
+ super(ASPPModule, self).__init__()
+ self.conv1 = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, None)),
+ Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ),
+ )
+ self.conv2 = Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
+ self.conv3 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[0], dilations[0], activ=activ
+ )
+ self.conv4 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[1], dilations[1], activ=activ
+ )
+ self.conv5 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ
+ )
+ self.conv6 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ
+ )
+ self.conv7 = SeperableConv2DBNActiv(
+ nin, nin, 3, 1, dilations[2], dilations[2], activ=activ
+ )
+ self.bottleneck = nn.Sequential(
+ Conv2DBNActiv(nin * 7, nout, 1, 1, 0, activ=activ), nn.Dropout2d(0.1)
+ )
+
+ def forward(self, x):
+ _, _, h, w = x.size()
+ feat1 = F.interpolate(
+ self.conv1(x), size=(h, w), mode="bilinear", align_corners=True
+ )
+ feat2 = self.conv2(x)
+ feat3 = self.conv3(x)
+ feat4 = self.conv4(x)
+ feat5 = self.conv5(x)
+ feat6 = self.conv6(x)
+ feat7 = self.conv7(x)
+ out = torch.cat((feat1, feat2, feat3, feat4, feat5, feat6, feat7), dim=1)
+ bottle = self.bottleneck(out)
+ return bottle
diff --git a/infer/lib/uvr5_pack/lib_v5/layers_new.py b/infer/lib/uvr5_pack/lib_v5/layers_new.py
new file mode 100644
index 0000000000000000000000000000000000000000..44153b6a23399c6938affc61c71919eaa172bcee
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/layers_new.py
@@ -0,0 +1,125 @@
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from . import spec_utils
+
+
+class Conv2DBNActiv(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
+ super(Conv2DBNActiv, self).__init__()
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ nin,
+ nout,
+ kernel_size=ksize,
+ stride=stride,
+ padding=pad,
+ dilation=dilation,
+ bias=False,
+ ),
+ nn.BatchNorm2d(nout),
+ activ(),
+ )
+
+ def __call__(self, x):
+ return self.conv(x)
+
+
+class Encoder(nn.Module):
+ def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.LeakyReLU):
+ super(Encoder, self).__init__()
+ self.conv1 = Conv2DBNActiv(nin, nout, ksize, stride, pad, activ=activ)
+ self.conv2 = Conv2DBNActiv(nout, nout, ksize, 1, pad, activ=activ)
+
+ def __call__(self, x):
+ h = self.conv1(x)
+ h = self.conv2(h)
+
+ return h
+
+
+class Decoder(nn.Module):
+ def __init__(
+ self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.ReLU, dropout=False
+ ):
+ super(Decoder, self).__init__()
+ self.conv1 = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
+ # self.conv2 = Conv2DBNActiv(nout, nout, ksize, 1, pad, activ=activ)
+ self.dropout = nn.Dropout2d(0.1) if dropout else None
+
+ def __call__(self, x, skip=None):
+ x = F.interpolate(x, scale_factor=2, mode="bilinear", align_corners=True)
+
+ if skip is not None:
+ skip = spec_utils.crop_center(skip, x)
+ x = torch.cat([x, skip], dim=1)
+
+ h = self.conv1(x)
+ # h = self.conv2(h)
+
+ if self.dropout is not None:
+ h = self.dropout(h)
+
+ return h
+
+
+class ASPPModule(nn.Module):
+ def __init__(self, nin, nout, dilations=(4, 8, 12), activ=nn.ReLU, dropout=False):
+ super(ASPPModule, self).__init__()
+ self.conv1 = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, None)),
+ Conv2DBNActiv(nin, nout, 1, 1, 0, activ=activ),
+ )
+ self.conv2 = Conv2DBNActiv(nin, nout, 1, 1, 0, activ=activ)
+ self.conv3 = Conv2DBNActiv(
+ nin, nout, 3, 1, dilations[0], dilations[0], activ=activ
+ )
+ self.conv4 = Conv2DBNActiv(
+ nin, nout, 3, 1, dilations[1], dilations[1], activ=activ
+ )
+ self.conv5 = Conv2DBNActiv(
+ nin, nout, 3, 1, dilations[2], dilations[2], activ=activ
+ )
+ self.bottleneck = Conv2DBNActiv(nout * 5, nout, 1, 1, 0, activ=activ)
+ self.dropout = nn.Dropout2d(0.1) if dropout else None
+
+ def forward(self, x):
+ _, _, h, w = x.size()
+ feat1 = F.interpolate(
+ self.conv1(x), size=(h, w), mode="bilinear", align_corners=True
+ )
+ feat2 = self.conv2(x)
+ feat3 = self.conv3(x)
+ feat4 = self.conv4(x)
+ feat5 = self.conv5(x)
+ out = torch.cat((feat1, feat2, feat3, feat4, feat5), dim=1)
+ out = self.bottleneck(out)
+
+ if self.dropout is not None:
+ out = self.dropout(out)
+
+ return out
+
+
+class LSTMModule(nn.Module):
+ def __init__(self, nin_conv, nin_lstm, nout_lstm):
+ super(LSTMModule, self).__init__()
+ self.conv = Conv2DBNActiv(nin_conv, 1, 1, 1, 0)
+ self.lstm = nn.LSTM(
+ input_size=nin_lstm, hidden_size=nout_lstm // 2, bidirectional=True
+ )
+ self.dense = nn.Sequential(
+ nn.Linear(nout_lstm, nin_lstm), nn.BatchNorm1d(nin_lstm), nn.ReLU()
+ )
+
+ def forward(self, x):
+ N, _, nbins, nframes = x.size()
+ h = self.conv(x)[:, 0] # N, nbins, nframes
+ h = h.permute(2, 0, 1) # nframes, N, nbins
+ h, _ = self.lstm(h)
+ h = self.dense(h.reshape(-1, h.size()[-1])) # nframes * N, nbins
+ h = h.reshape(nframes, N, 1, nbins)
+ h = h.permute(1, 2, 3, 0)
+
+ return h
diff --git a/infer/lib/uvr5_pack/lib_v5/model_param_init.py b/infer/lib/uvr5_pack/lib_v5/model_param_init.py
new file mode 100644
index 0000000000000000000000000000000000000000..b995c0bfb1194746187692e2ab1c2a6dbaaaec6c
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/model_param_init.py
@@ -0,0 +1,69 @@
+import json
+import os
+import pathlib
+
+default_param = {}
+default_param["bins"] = 768
+default_param["unstable_bins"] = 9 # training only
+default_param["reduction_bins"] = 762 # training only
+default_param["sr"] = 44100
+default_param["pre_filter_start"] = 757
+default_param["pre_filter_stop"] = 768
+default_param["band"] = {}
+
+
+default_param["band"][1] = {
+ "sr": 11025,
+ "hl": 128,
+ "n_fft": 960,
+ "crop_start": 0,
+ "crop_stop": 245,
+ "lpf_start": 61, # inference only
+ "res_type": "polyphase",
+}
+
+default_param["band"][2] = {
+ "sr": 44100,
+ "hl": 512,
+ "n_fft": 1536,
+ "crop_start": 24,
+ "crop_stop": 547,
+ "hpf_start": 81, # inference only
+ "res_type": "sinc_best",
+}
+
+
+def int_keys(d):
+ r = {}
+ for k, v in d:
+ if k.isdigit():
+ k = int(k)
+ r[k] = v
+ return r
+
+
+class ModelParameters(object):
+ def __init__(self, config_path=""):
+ if ".pth" == pathlib.Path(config_path).suffix:
+ import zipfile
+
+ with zipfile.ZipFile(config_path, "r") as zip:
+ self.param = json.loads(
+ zip.read("param.json"), object_pairs_hook=int_keys
+ )
+ elif ".json" == pathlib.Path(config_path).suffix:
+ with open(config_path, "r") as f:
+ self.param = json.loads(f.read(), object_pairs_hook=int_keys)
+ else:
+ self.param = default_param
+
+ for k in [
+ "mid_side",
+ "mid_side_b",
+ "mid_side_b2",
+ "stereo_w",
+ "stereo_n",
+ "reverse",
+ ]:
+ if not k in self.param:
+ self.param[k] = False
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr16000_hl512.json b/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr16000_hl512.json
new file mode 100644
index 0000000000000000000000000000000000000000..72cb4499867ad2827185e85687f06fb73d33eced
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr16000_hl512.json
@@ -0,0 +1,19 @@
+{
+ "bins": 1024,
+ "unstable_bins": 0,
+ "reduction_bins": 0,
+ "band": {
+ "1": {
+ "sr": 16000,
+ "hl": 512,
+ "n_fft": 2048,
+ "crop_start": 0,
+ "crop_stop": 1024,
+ "hpf_start": -1,
+ "res_type": "sinc_best"
+ }
+ },
+ "sr": 16000,
+ "pre_filter_start": 1023,
+ "pre_filter_stop": 1024
+}
\ No newline at end of file
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr32000_hl512.json b/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr32000_hl512.json
new file mode 100644
index 0000000000000000000000000000000000000000..3c00ecf0a105e55a6a86a3c32db301a2635b5b41
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr32000_hl512.json
@@ -0,0 +1,19 @@
+{
+ "bins": 1024,
+ "unstable_bins": 0,
+ "reduction_bins": 0,
+ "band": {
+ "1": {
+ "sr": 32000,
+ "hl": 512,
+ "n_fft": 2048,
+ "crop_start": 0,
+ "crop_stop": 1024,
+ "hpf_start": -1,
+ "res_type": "kaiser_fast"
+ }
+ },
+ "sr": 32000,
+ "pre_filter_start": 1000,
+ "pre_filter_stop": 1021
+}
\ No newline at end of file
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr33075_hl384.json b/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr33075_hl384.json
new file mode 100644
index 0000000000000000000000000000000000000000..55666ac9a8d0547751fb4b4d3bffb1ee2c956913
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr33075_hl384.json
@@ -0,0 +1,19 @@
+{
+ "bins": 1024,
+ "unstable_bins": 0,
+ "reduction_bins": 0,
+ "band": {
+ "1": {
+ "sr": 33075,
+ "hl": 384,
+ "n_fft": 2048,
+ "crop_start": 0,
+ "crop_stop": 1024,
+ "hpf_start": -1,
+ "res_type": "sinc_best"
+ }
+ },
+ "sr": 33075,
+ "pre_filter_start": 1000,
+ "pre_filter_stop": 1021
+}
\ No newline at end of file
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr44100_hl1024.json b/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr44100_hl1024.json
new file mode 100644
index 0000000000000000000000000000000000000000..665abe20eb3cc39fe0f8493dad8f25f6ef634a14
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr44100_hl1024.json
@@ -0,0 +1,19 @@
+{
+ "bins": 1024,
+ "unstable_bins": 0,
+ "reduction_bins": 0,
+ "band": {
+ "1": {
+ "sr": 44100,
+ "hl": 1024,
+ "n_fft": 2048,
+ "crop_start": 0,
+ "crop_stop": 1024,
+ "hpf_start": -1,
+ "res_type": "sinc_best"
+ }
+ },
+ "sr": 44100,
+ "pre_filter_start": 1023,
+ "pre_filter_stop": 1024
+}
\ No newline at end of file
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr44100_hl256.json b/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr44100_hl256.json
new file mode 100644
index 0000000000000000000000000000000000000000..0e8b16f89b0231d06eabe8d2f7c2670c7caa2272
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr44100_hl256.json
@@ -0,0 +1,19 @@
+{
+ "bins": 256,
+ "unstable_bins": 0,
+ "reduction_bins": 0,
+ "band": {
+ "1": {
+ "sr": 44100,
+ "hl": 256,
+ "n_fft": 512,
+ "crop_start": 0,
+ "crop_stop": 256,
+ "hpf_start": -1,
+ "res_type": "sinc_best"
+ }
+ },
+ "sr": 44100,
+ "pre_filter_start": 256,
+ "pre_filter_stop": 256
+}
\ No newline at end of file
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr44100_hl512.json b/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr44100_hl512.json
new file mode 100644
index 0000000000000000000000000000000000000000..3b38fcaf60ba204e03a47f5bd3f5bcfe75e1983a
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr44100_hl512.json
@@ -0,0 +1,19 @@
+{
+ "bins": 1024,
+ "unstable_bins": 0,
+ "reduction_bins": 0,
+ "band": {
+ "1": {
+ "sr": 44100,
+ "hl": 512,
+ "n_fft": 2048,
+ "crop_start": 0,
+ "crop_stop": 1024,
+ "hpf_start": -1,
+ "res_type": "sinc_best"
+ }
+ },
+ "sr": 44100,
+ "pre_filter_start": 1023,
+ "pre_filter_stop": 1024
+}
\ No newline at end of file
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr44100_hl512_cut.json b/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr44100_hl512_cut.json
new file mode 100644
index 0000000000000000000000000000000000000000..630df3524e340f43a1ddb7b33ff02cc91fc1cb47
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr44100_hl512_cut.json
@@ -0,0 +1,19 @@
+{
+ "bins": 1024,
+ "unstable_bins": 0,
+ "reduction_bins": 0,
+ "band": {
+ "1": {
+ "sr": 44100,
+ "hl": 512,
+ "n_fft": 2048,
+ "crop_start": 0,
+ "crop_stop": 700,
+ "hpf_start": -1,
+ "res_type": "sinc_best"
+ }
+ },
+ "sr": 44100,
+ "pre_filter_start": 1023,
+ "pre_filter_stop": 700
+}
\ No newline at end of file
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/2band_32000.json b/infer/lib/uvr5_pack/lib_v5/modelparams/2band_32000.json
new file mode 100644
index 0000000000000000000000000000000000000000..ab9cf1150a818eb6252105408311be0a40d423b3
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/2band_32000.json
@@ -0,0 +1,30 @@
+{
+ "bins": 768,
+ "unstable_bins": 7,
+ "reduction_bins": 705,
+ "band": {
+ "1": {
+ "sr": 6000,
+ "hl": 66,
+ "n_fft": 512,
+ "crop_start": 0,
+ "crop_stop": 240,
+ "lpf_start": 60,
+ "lpf_stop": 118,
+ "res_type": "sinc_fastest"
+ },
+ "2": {
+ "sr": 32000,
+ "hl": 352,
+ "n_fft": 1024,
+ "crop_start": 22,
+ "crop_stop": 505,
+ "hpf_start": 44,
+ "hpf_stop": 23,
+ "res_type": "sinc_medium"
+ }
+ },
+ "sr": 32000,
+ "pre_filter_start": 710,
+ "pre_filter_stop": 731
+}
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/2band_44100_lofi.json b/infer/lib/uvr5_pack/lib_v5/modelparams/2band_44100_lofi.json
new file mode 100644
index 0000000000000000000000000000000000000000..7faa216d7b49aeece24123dbdd868847a1dbc03c
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/2band_44100_lofi.json
@@ -0,0 +1,30 @@
+{
+ "bins": 512,
+ "unstable_bins": 7,
+ "reduction_bins": 510,
+ "band": {
+ "1": {
+ "sr": 11025,
+ "hl": 160,
+ "n_fft": 768,
+ "crop_start": 0,
+ "crop_stop": 192,
+ "lpf_start": 41,
+ "lpf_stop": 139,
+ "res_type": "sinc_fastest"
+ },
+ "2": {
+ "sr": 44100,
+ "hl": 640,
+ "n_fft": 1024,
+ "crop_start": 10,
+ "crop_stop": 320,
+ "hpf_start": 47,
+ "hpf_stop": 15,
+ "res_type": "sinc_medium"
+ }
+ },
+ "sr": 44100,
+ "pre_filter_start": 510,
+ "pre_filter_stop": 512
+}
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/2band_48000.json b/infer/lib/uvr5_pack/lib_v5/modelparams/2band_48000.json
new file mode 100644
index 0000000000000000000000000000000000000000..7e78175052b09cb1a32345e54006475992712f9a
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/2band_48000.json
@@ -0,0 +1,30 @@
+{
+ "bins": 768,
+ "unstable_bins": 7,
+ "reduction_bins": 705,
+ "band": {
+ "1": {
+ "sr": 6000,
+ "hl": 66,
+ "n_fft": 512,
+ "crop_start": 0,
+ "crop_stop": 240,
+ "lpf_start": 60,
+ "lpf_stop": 240,
+ "res_type": "sinc_fastest"
+ },
+ "2": {
+ "sr": 48000,
+ "hl": 528,
+ "n_fft": 1536,
+ "crop_start": 22,
+ "crop_stop": 505,
+ "hpf_start": 82,
+ "hpf_stop": 22,
+ "res_type": "sinc_medium"
+ }
+ },
+ "sr": 48000,
+ "pre_filter_start": 710,
+ "pre_filter_stop": 731
+}
\ No newline at end of file
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/3band_44100.json b/infer/lib/uvr5_pack/lib_v5/modelparams/3band_44100.json
new file mode 100644
index 0000000000000000000000000000000000000000..d881d767ff83fbac0e18dfe2587ef16925b29b3c
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/3band_44100.json
@@ -0,0 +1,42 @@
+{
+ "bins": 768,
+ "unstable_bins": 5,
+ "reduction_bins": 733,
+ "band": {
+ "1": {
+ "sr": 11025,
+ "hl": 128,
+ "n_fft": 768,
+ "crop_start": 0,
+ "crop_stop": 278,
+ "lpf_start": 28,
+ "lpf_stop": 140,
+ "res_type": "polyphase"
+ },
+ "2": {
+ "sr": 22050,
+ "hl": 256,
+ "n_fft": 768,
+ "crop_start": 14,
+ "crop_stop": 322,
+ "hpf_start": 70,
+ "hpf_stop": 14,
+ "lpf_start": 283,
+ "lpf_stop": 314,
+ "res_type": "polyphase"
+ },
+ "3": {
+ "sr": 44100,
+ "hl": 512,
+ "n_fft": 768,
+ "crop_start": 131,
+ "crop_stop": 313,
+ "hpf_start": 154,
+ "hpf_stop": 141,
+ "res_type": "sinc_medium"
+ }
+ },
+ "sr": 44100,
+ "pre_filter_start": 757,
+ "pre_filter_stop": 768
+}
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/3band_44100_mid.json b/infer/lib/uvr5_pack/lib_v5/modelparams/3band_44100_mid.json
new file mode 100644
index 0000000000000000000000000000000000000000..77ec198573b19f36519a028a509767d30764c0e2
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/3band_44100_mid.json
@@ -0,0 +1,43 @@
+{
+ "mid_side": true,
+ "bins": 768,
+ "unstable_bins": 5,
+ "reduction_bins": 733,
+ "band": {
+ "1": {
+ "sr": 11025,
+ "hl": 128,
+ "n_fft": 768,
+ "crop_start": 0,
+ "crop_stop": 278,
+ "lpf_start": 28,
+ "lpf_stop": 140,
+ "res_type": "polyphase"
+ },
+ "2": {
+ "sr": 22050,
+ "hl": 256,
+ "n_fft": 768,
+ "crop_start": 14,
+ "crop_stop": 322,
+ "hpf_start": 70,
+ "hpf_stop": 14,
+ "lpf_start": 283,
+ "lpf_stop": 314,
+ "res_type": "polyphase"
+ },
+ "3": {
+ "sr": 44100,
+ "hl": 512,
+ "n_fft": 768,
+ "crop_start": 131,
+ "crop_stop": 313,
+ "hpf_start": 154,
+ "hpf_stop": 141,
+ "res_type": "sinc_medium"
+ }
+ },
+ "sr": 44100,
+ "pre_filter_start": 757,
+ "pre_filter_stop": 768
+}
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/3band_44100_msb2.json b/infer/lib/uvr5_pack/lib_v5/modelparams/3band_44100_msb2.json
new file mode 100644
index 0000000000000000000000000000000000000000..85ee8a7d44541c9176e85ea3dce8728d34990938
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/3band_44100_msb2.json
@@ -0,0 +1,43 @@
+{
+ "mid_side_b2": true,
+ "bins": 640,
+ "unstable_bins": 7,
+ "reduction_bins": 565,
+ "band": {
+ "1": {
+ "sr": 11025,
+ "hl": 108,
+ "n_fft": 1024,
+ "crop_start": 0,
+ "crop_stop": 187,
+ "lpf_start": 92,
+ "lpf_stop": 186,
+ "res_type": "polyphase"
+ },
+ "2": {
+ "sr": 22050,
+ "hl": 216,
+ "n_fft": 768,
+ "crop_start": 0,
+ "crop_stop": 212,
+ "hpf_start": 68,
+ "hpf_stop": 34,
+ "lpf_start": 174,
+ "lpf_stop": 209,
+ "res_type": "polyphase"
+ },
+ "3": {
+ "sr": 44100,
+ "hl": 432,
+ "n_fft": 640,
+ "crop_start": 66,
+ "crop_stop": 307,
+ "hpf_start": 86,
+ "hpf_stop": 72,
+ "res_type": "kaiser_fast"
+ }
+ },
+ "sr": 44100,
+ "pre_filter_start": 639,
+ "pre_filter_stop": 640
+}
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100.json b/infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100.json
new file mode 100644
index 0000000000000000000000000000000000000000..df123754204372aa50d464fbe9102a401f48cc73
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100.json
@@ -0,0 +1,54 @@
+{
+ "bins": 768,
+ "unstable_bins": 7,
+ "reduction_bins": 668,
+ "band": {
+ "1": {
+ "sr": 11025,
+ "hl": 128,
+ "n_fft": 1024,
+ "crop_start": 0,
+ "crop_stop": 186,
+ "lpf_start": 37,
+ "lpf_stop": 73,
+ "res_type": "polyphase"
+ },
+ "2": {
+ "sr": 11025,
+ "hl": 128,
+ "n_fft": 512,
+ "crop_start": 4,
+ "crop_stop": 185,
+ "hpf_start": 36,
+ "hpf_stop": 18,
+ "lpf_start": 93,
+ "lpf_stop": 185,
+ "res_type": "polyphase"
+ },
+ "3": {
+ "sr": 22050,
+ "hl": 256,
+ "n_fft": 512,
+ "crop_start": 46,
+ "crop_stop": 186,
+ "hpf_start": 93,
+ "hpf_stop": 46,
+ "lpf_start": 164,
+ "lpf_stop": 186,
+ "res_type": "polyphase"
+ },
+ "4": {
+ "sr": 44100,
+ "hl": 512,
+ "n_fft": 768,
+ "crop_start": 121,
+ "crop_stop": 382,
+ "hpf_start": 138,
+ "hpf_stop": 123,
+ "res_type": "sinc_medium"
+ }
+ },
+ "sr": 44100,
+ "pre_filter_start": 740,
+ "pre_filter_stop": 768
+}
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_mid.json b/infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_mid.json
new file mode 100644
index 0000000000000000000000000000000000000000..e91b699eb63d3382c3b9e9edf46d40ed91d6122b
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_mid.json
@@ -0,0 +1,55 @@
+{
+ "bins": 768,
+ "unstable_bins": 7,
+ "mid_side": true,
+ "reduction_bins": 668,
+ "band": {
+ "1": {
+ "sr": 11025,
+ "hl": 128,
+ "n_fft": 1024,
+ "crop_start": 0,
+ "crop_stop": 186,
+ "lpf_start": 37,
+ "lpf_stop": 73,
+ "res_type": "polyphase"
+ },
+ "2": {
+ "sr": 11025,
+ "hl": 128,
+ "n_fft": 512,
+ "crop_start": 4,
+ "crop_stop": 185,
+ "hpf_start": 36,
+ "hpf_stop": 18,
+ "lpf_start": 93,
+ "lpf_stop": 185,
+ "res_type": "polyphase"
+ },
+ "3": {
+ "sr": 22050,
+ "hl": 256,
+ "n_fft": 512,
+ "crop_start": 46,
+ "crop_stop": 186,
+ "hpf_start": 93,
+ "hpf_stop": 46,
+ "lpf_start": 164,
+ "lpf_stop": 186,
+ "res_type": "polyphase"
+ },
+ "4": {
+ "sr": 44100,
+ "hl": 512,
+ "n_fft": 768,
+ "crop_start": 121,
+ "crop_stop": 382,
+ "hpf_start": 138,
+ "hpf_stop": 123,
+ "res_type": "sinc_medium"
+ }
+ },
+ "sr": 44100,
+ "pre_filter_start": 740,
+ "pre_filter_stop": 768
+}
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_msb.json b/infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_msb.json
new file mode 100644
index 0000000000000000000000000000000000000000..f852f280ec9d98fc1b65cec688290eaafec61b84
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_msb.json
@@ -0,0 +1,55 @@
+{
+ "mid_side_b": true,
+ "bins": 768,
+ "unstable_bins": 7,
+ "reduction_bins": 668,
+ "band": {
+ "1": {
+ "sr": 11025,
+ "hl": 128,
+ "n_fft": 1024,
+ "crop_start": 0,
+ "crop_stop": 186,
+ "lpf_start": 37,
+ "lpf_stop": 73,
+ "res_type": "polyphase"
+ },
+ "2": {
+ "sr": 11025,
+ "hl": 128,
+ "n_fft": 512,
+ "crop_start": 4,
+ "crop_stop": 185,
+ "hpf_start": 36,
+ "hpf_stop": 18,
+ "lpf_start": 93,
+ "lpf_stop": 185,
+ "res_type": "polyphase"
+ },
+ "3": {
+ "sr": 22050,
+ "hl": 256,
+ "n_fft": 512,
+ "crop_start": 46,
+ "crop_stop": 186,
+ "hpf_start": 93,
+ "hpf_stop": 46,
+ "lpf_start": 164,
+ "lpf_stop": 186,
+ "res_type": "polyphase"
+ },
+ "4": {
+ "sr": 44100,
+ "hl": 512,
+ "n_fft": 768,
+ "crop_start": 121,
+ "crop_stop": 382,
+ "hpf_start": 138,
+ "hpf_stop": 123,
+ "res_type": "sinc_medium"
+ }
+ },
+ "sr": 44100,
+ "pre_filter_start": 740,
+ "pre_filter_stop": 768
+}
\ No newline at end of file
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_msb2.json b/infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_msb2.json
new file mode 100644
index 0000000000000000000000000000000000000000..f852f280ec9d98fc1b65cec688290eaafec61b84
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_msb2.json
@@ -0,0 +1,55 @@
+{
+ "mid_side_b": true,
+ "bins": 768,
+ "unstable_bins": 7,
+ "reduction_bins": 668,
+ "band": {
+ "1": {
+ "sr": 11025,
+ "hl": 128,
+ "n_fft": 1024,
+ "crop_start": 0,
+ "crop_stop": 186,
+ "lpf_start": 37,
+ "lpf_stop": 73,
+ "res_type": "polyphase"
+ },
+ "2": {
+ "sr": 11025,
+ "hl": 128,
+ "n_fft": 512,
+ "crop_start": 4,
+ "crop_stop": 185,
+ "hpf_start": 36,
+ "hpf_stop": 18,
+ "lpf_start": 93,
+ "lpf_stop": 185,
+ "res_type": "polyphase"
+ },
+ "3": {
+ "sr": 22050,
+ "hl": 256,
+ "n_fft": 512,
+ "crop_start": 46,
+ "crop_stop": 186,
+ "hpf_start": 93,
+ "hpf_stop": 46,
+ "lpf_start": 164,
+ "lpf_stop": 186,
+ "res_type": "polyphase"
+ },
+ "4": {
+ "sr": 44100,
+ "hl": 512,
+ "n_fft": 768,
+ "crop_start": 121,
+ "crop_stop": 382,
+ "hpf_start": 138,
+ "hpf_stop": 123,
+ "res_type": "sinc_medium"
+ }
+ },
+ "sr": 44100,
+ "pre_filter_start": 740,
+ "pre_filter_stop": 768
+}
\ No newline at end of file
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_reverse.json b/infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_reverse.json
new file mode 100644
index 0000000000000000000000000000000000000000..7a07d5541bd83dc1caa20b531c3b43a2ffccac88
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_reverse.json
@@ -0,0 +1,55 @@
+{
+ "reverse": true,
+ "bins": 768,
+ "unstable_bins": 7,
+ "reduction_bins": 668,
+ "band": {
+ "1": {
+ "sr": 11025,
+ "hl": 128,
+ "n_fft": 1024,
+ "crop_start": 0,
+ "crop_stop": 186,
+ "lpf_start": 37,
+ "lpf_stop": 73,
+ "res_type": "polyphase"
+ },
+ "2": {
+ "sr": 11025,
+ "hl": 128,
+ "n_fft": 512,
+ "crop_start": 4,
+ "crop_stop": 185,
+ "hpf_start": 36,
+ "hpf_stop": 18,
+ "lpf_start": 93,
+ "lpf_stop": 185,
+ "res_type": "polyphase"
+ },
+ "3": {
+ "sr": 22050,
+ "hl": 256,
+ "n_fft": 512,
+ "crop_start": 46,
+ "crop_stop": 186,
+ "hpf_start": 93,
+ "hpf_stop": 46,
+ "lpf_start": 164,
+ "lpf_stop": 186,
+ "res_type": "polyphase"
+ },
+ "4": {
+ "sr": 44100,
+ "hl": 512,
+ "n_fft": 768,
+ "crop_start": 121,
+ "crop_stop": 382,
+ "hpf_start": 138,
+ "hpf_stop": 123,
+ "res_type": "sinc_medium"
+ }
+ },
+ "sr": 44100,
+ "pre_filter_start": 740,
+ "pre_filter_stop": 768
+}
\ No newline at end of file
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_sw.json b/infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_sw.json
new file mode 100644
index 0000000000000000000000000000000000000000..ba0cf342106de793e6ec3e876854c7fd451fbf76
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_sw.json
@@ -0,0 +1,55 @@
+{
+ "stereo_w": true,
+ "bins": 768,
+ "unstable_bins": 7,
+ "reduction_bins": 668,
+ "band": {
+ "1": {
+ "sr": 11025,
+ "hl": 128,
+ "n_fft": 1024,
+ "crop_start": 0,
+ "crop_stop": 186,
+ "lpf_start": 37,
+ "lpf_stop": 73,
+ "res_type": "polyphase"
+ },
+ "2": {
+ "sr": 11025,
+ "hl": 128,
+ "n_fft": 512,
+ "crop_start": 4,
+ "crop_stop": 185,
+ "hpf_start": 36,
+ "hpf_stop": 18,
+ "lpf_start": 93,
+ "lpf_stop": 185,
+ "res_type": "polyphase"
+ },
+ "3": {
+ "sr": 22050,
+ "hl": 256,
+ "n_fft": 512,
+ "crop_start": 46,
+ "crop_stop": 186,
+ "hpf_start": 93,
+ "hpf_stop": 46,
+ "lpf_start": 164,
+ "lpf_stop": 186,
+ "res_type": "polyphase"
+ },
+ "4": {
+ "sr": 44100,
+ "hl": 512,
+ "n_fft": 768,
+ "crop_start": 121,
+ "crop_stop": 382,
+ "hpf_start": 138,
+ "hpf_stop": 123,
+ "res_type": "sinc_medium"
+ }
+ },
+ "sr": 44100,
+ "pre_filter_start": 740,
+ "pre_filter_stop": 768
+}
\ No newline at end of file
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/4band_v2.json b/infer/lib/uvr5_pack/lib_v5/modelparams/4band_v2.json
new file mode 100644
index 0000000000000000000000000000000000000000..33281a0cf9916fc33558ddfda7a0287a2547faf4
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/4band_v2.json
@@ -0,0 +1,54 @@
+{
+ "bins": 672,
+ "unstable_bins": 8,
+ "reduction_bins": 637,
+ "band": {
+ "1": {
+ "sr": 7350,
+ "hl": 80,
+ "n_fft": 640,
+ "crop_start": 0,
+ "crop_stop": 85,
+ "lpf_start": 25,
+ "lpf_stop": 53,
+ "res_type": "polyphase"
+ },
+ "2": {
+ "sr": 7350,
+ "hl": 80,
+ "n_fft": 320,
+ "crop_start": 4,
+ "crop_stop": 87,
+ "hpf_start": 25,
+ "hpf_stop": 12,
+ "lpf_start": 31,
+ "lpf_stop": 62,
+ "res_type": "polyphase"
+ },
+ "3": {
+ "sr": 14700,
+ "hl": 160,
+ "n_fft": 512,
+ "crop_start": 17,
+ "crop_stop": 216,
+ "hpf_start": 48,
+ "hpf_stop": 24,
+ "lpf_start": 139,
+ "lpf_stop": 210,
+ "res_type": "polyphase"
+ },
+ "4": {
+ "sr": 44100,
+ "hl": 480,
+ "n_fft": 960,
+ "crop_start": 78,
+ "crop_stop": 383,
+ "hpf_start": 130,
+ "hpf_stop": 86,
+ "res_type": "kaiser_fast"
+ }
+ },
+ "sr": 44100,
+ "pre_filter_start": 668,
+ "pre_filter_stop": 672
+}
\ No newline at end of file
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/4band_v2_sn.json b/infer/lib/uvr5_pack/lib_v5/modelparams/4band_v2_sn.json
new file mode 100644
index 0000000000000000000000000000000000000000..2e5c770fe188779bf6b0873190b7a324d6a867b2
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/4band_v2_sn.json
@@ -0,0 +1,55 @@
+{
+ "bins": 672,
+ "unstable_bins": 8,
+ "reduction_bins": 637,
+ "band": {
+ "1": {
+ "sr": 7350,
+ "hl": 80,
+ "n_fft": 640,
+ "crop_start": 0,
+ "crop_stop": 85,
+ "lpf_start": 25,
+ "lpf_stop": 53,
+ "res_type": "polyphase"
+ },
+ "2": {
+ "sr": 7350,
+ "hl": 80,
+ "n_fft": 320,
+ "crop_start": 4,
+ "crop_stop": 87,
+ "hpf_start": 25,
+ "hpf_stop": 12,
+ "lpf_start": 31,
+ "lpf_stop": 62,
+ "res_type": "polyphase"
+ },
+ "3": {
+ "sr": 14700,
+ "hl": 160,
+ "n_fft": 512,
+ "crop_start": 17,
+ "crop_stop": 216,
+ "hpf_start": 48,
+ "hpf_stop": 24,
+ "lpf_start": 139,
+ "lpf_stop": 210,
+ "res_type": "polyphase"
+ },
+ "4": {
+ "sr": 44100,
+ "hl": 480,
+ "n_fft": 960,
+ "crop_start": 78,
+ "crop_stop": 383,
+ "hpf_start": 130,
+ "hpf_stop": 86,
+ "convert_channels": "stereo_n",
+ "res_type": "kaiser_fast"
+ }
+ },
+ "sr": 44100,
+ "pre_filter_start": 668,
+ "pre_filter_stop": 672
+}
\ No newline at end of file
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/4band_v3.json b/infer/lib/uvr5_pack/lib_v5/modelparams/4band_v3.json
new file mode 100644
index 0000000000000000000000000000000000000000..2a73bc97ac545145a75bdca7addc5d59f5b8574b
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/4band_v3.json
@@ -0,0 +1,54 @@
+{
+ "bins": 672,
+ "unstable_bins": 8,
+ "reduction_bins": 530,
+ "band": {
+ "1": {
+ "sr": 7350,
+ "hl": 80,
+ "n_fft": 640,
+ "crop_start": 0,
+ "crop_stop": 85,
+ "lpf_start": 25,
+ "lpf_stop": 53,
+ "res_type": "polyphase"
+ },
+ "2": {
+ "sr": 7350,
+ "hl": 80,
+ "n_fft": 320,
+ "crop_start": 4,
+ "crop_stop": 87,
+ "hpf_start": 25,
+ "hpf_stop": 12,
+ "lpf_start": 31,
+ "lpf_stop": 62,
+ "res_type": "polyphase"
+ },
+ "3": {
+ "sr": 14700,
+ "hl": 160,
+ "n_fft": 512,
+ "crop_start": 17,
+ "crop_stop": 216,
+ "hpf_start": 48,
+ "hpf_stop": 24,
+ "lpf_start": 139,
+ "lpf_stop": 210,
+ "res_type": "polyphase"
+ },
+ "4": {
+ "sr": 44100,
+ "hl": 480,
+ "n_fft": 960,
+ "crop_start": 78,
+ "crop_stop": 383,
+ "hpf_start": 130,
+ "hpf_stop": 86,
+ "res_type": "kaiser_fast"
+ }
+ },
+ "sr": 44100,
+ "pre_filter_start": 668,
+ "pre_filter_stop": 672
+}
\ No newline at end of file
diff --git a/infer/lib/uvr5_pack/lib_v5/modelparams/ensemble.json b/infer/lib/uvr5_pack/lib_v5/modelparams/ensemble.json
new file mode 100644
index 0000000000000000000000000000000000000000..ee69beb46fc82f34619c5e48761e329fcabbbd00
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/modelparams/ensemble.json
@@ -0,0 +1,43 @@
+{
+ "mid_side_b2": true,
+ "bins": 1280,
+ "unstable_bins": 7,
+ "reduction_bins": 565,
+ "band": {
+ "1": {
+ "sr": 11025,
+ "hl": 108,
+ "n_fft": 2048,
+ "crop_start": 0,
+ "crop_stop": 374,
+ "lpf_start": 92,
+ "lpf_stop": 186,
+ "res_type": "polyphase"
+ },
+ "2": {
+ "sr": 22050,
+ "hl": 216,
+ "n_fft": 1536,
+ "crop_start": 0,
+ "crop_stop": 424,
+ "hpf_start": 68,
+ "hpf_stop": 34,
+ "lpf_start": 348,
+ "lpf_stop": 418,
+ "res_type": "polyphase"
+ },
+ "3": {
+ "sr": 44100,
+ "hl": 432,
+ "n_fft": 1280,
+ "crop_start": 132,
+ "crop_stop": 614,
+ "hpf_start": 172,
+ "hpf_stop": 144,
+ "res_type": "polyphase"
+ }
+ },
+ "sr": 44100,
+ "pre_filter_start": 1280,
+ "pre_filter_stop": 1280
+}
\ No newline at end of file
diff --git a/infer/lib/uvr5_pack/lib_v5/nets.py b/infer/lib/uvr5_pack/lib_v5/nets.py
new file mode 100644
index 0000000000000000000000000000000000000000..5da3948c2f2e9edcc3cdac49bdf9f738e403de40
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/nets.py
@@ -0,0 +1,123 @@
+import layers
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from . import spec_utils
+
+
+class BaseASPPNet(nn.Module):
+ def __init__(self, nin, ch, dilations=(4, 8, 16)):
+ super(BaseASPPNet, self).__init__()
+ self.enc1 = layers.Encoder(nin, ch, 3, 2, 1)
+ self.enc2 = layers.Encoder(ch, ch * 2, 3, 2, 1)
+ self.enc3 = layers.Encoder(ch * 2, ch * 4, 3, 2, 1)
+ self.enc4 = layers.Encoder(ch * 4, ch * 8, 3, 2, 1)
+
+ self.aspp = layers.ASPPModule(ch * 8, ch * 16, dilations)
+
+ self.dec4 = layers.Decoder(ch * (8 + 16), ch * 8, 3, 1, 1)
+ self.dec3 = layers.Decoder(ch * (4 + 8), ch * 4, 3, 1, 1)
+ self.dec2 = layers.Decoder(ch * (2 + 4), ch * 2, 3, 1, 1)
+ self.dec1 = layers.Decoder(ch * (1 + 2), ch, 3, 1, 1)
+
+ def __call__(self, x):
+ h, e1 = self.enc1(x)
+ h, e2 = self.enc2(h)
+ h, e3 = self.enc3(h)
+ h, e4 = self.enc4(h)
+
+ h = self.aspp(h)
+
+ h = self.dec4(h, e4)
+ h = self.dec3(h, e3)
+ h = self.dec2(h, e2)
+ h = self.dec1(h, e1)
+
+ return h
+
+
+class CascadedASPPNet(nn.Module):
+ def __init__(self, n_fft):
+ super(CascadedASPPNet, self).__init__()
+ self.stg1_low_band_net = BaseASPPNet(2, 16)
+ self.stg1_high_band_net = BaseASPPNet(2, 16)
+
+ self.stg2_bridge = layers.Conv2DBNActiv(18, 8, 1, 1, 0)
+ self.stg2_full_band_net = BaseASPPNet(8, 16)
+
+ self.stg3_bridge = layers.Conv2DBNActiv(34, 16, 1, 1, 0)
+ self.stg3_full_band_net = BaseASPPNet(16, 32)
+
+ self.out = nn.Conv2d(32, 2, 1, bias=False)
+ self.aux1_out = nn.Conv2d(16, 2, 1, bias=False)
+ self.aux2_out = nn.Conv2d(16, 2, 1, bias=False)
+
+ self.max_bin = n_fft // 2
+ self.output_bin = n_fft // 2 + 1
+
+ self.offset = 128
+
+ def forward(self, x, aggressiveness=None):
+ mix = x.detach()
+ x = x.clone()
+
+ x = x[:, :, : self.max_bin]
+
+ bandw = x.size()[2] // 2
+ aux1 = torch.cat(
+ [
+ self.stg1_low_band_net(x[:, :, :bandw]),
+ self.stg1_high_band_net(x[:, :, bandw:]),
+ ],
+ dim=2,
+ )
+
+ h = torch.cat([x, aux1], dim=1)
+ aux2 = self.stg2_full_band_net(self.stg2_bridge(h))
+
+ h = torch.cat([x, aux1, aux2], dim=1)
+ h = self.stg3_full_band_net(self.stg3_bridge(h))
+
+ mask = torch.sigmoid(self.out(h))
+ mask = F.pad(
+ input=mask,
+ pad=(0, 0, 0, self.output_bin - mask.size()[2]),
+ mode="replicate",
+ )
+
+ if self.training:
+ aux1 = torch.sigmoid(self.aux1_out(aux1))
+ aux1 = F.pad(
+ input=aux1,
+ pad=(0, 0, 0, self.output_bin - aux1.size()[2]),
+ mode="replicate",
+ )
+ aux2 = torch.sigmoid(self.aux2_out(aux2))
+ aux2 = F.pad(
+ input=aux2,
+ pad=(0, 0, 0, self.output_bin - aux2.size()[2]),
+ mode="replicate",
+ )
+ return mask * mix, aux1 * mix, aux2 * mix
+ else:
+ if aggressiveness:
+ mask[:, :, : aggressiveness["split_bin"]] = torch.pow(
+ mask[:, :, : aggressiveness["split_bin"]],
+ 1 + aggressiveness["value"] / 3,
+ )
+ mask[:, :, aggressiveness["split_bin"] :] = torch.pow(
+ mask[:, :, aggressiveness["split_bin"] :],
+ 1 + aggressiveness["value"],
+ )
+
+ return mask * mix
+
+ def predict(self, x_mag, aggressiveness=None):
+ h = self.forward(x_mag, aggressiveness)
+
+ if self.offset > 0:
+ h = h[:, :, :, self.offset : -self.offset]
+ assert h.size()[3] > 0
+
+ return h
diff --git a/infer/lib/uvr5_pack/lib_v5/nets_123812KB.py b/infer/lib/uvr5_pack/lib_v5/nets_123812KB.py
new file mode 100644
index 0000000000000000000000000000000000000000..167d4cb2198863cf43e93440f7e63c5342fc7605
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/nets_123812KB.py
@@ -0,0 +1,122 @@
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from . import layers_123821KB as layers
+
+
+class BaseASPPNet(nn.Module):
+ def __init__(self, nin, ch, dilations=(4, 8, 16)):
+ super(BaseASPPNet, self).__init__()
+ self.enc1 = layers.Encoder(nin, ch, 3, 2, 1)
+ self.enc2 = layers.Encoder(ch, ch * 2, 3, 2, 1)
+ self.enc3 = layers.Encoder(ch * 2, ch * 4, 3, 2, 1)
+ self.enc4 = layers.Encoder(ch * 4, ch * 8, 3, 2, 1)
+
+ self.aspp = layers.ASPPModule(ch * 8, ch * 16, dilations)
+
+ self.dec4 = layers.Decoder(ch * (8 + 16), ch * 8, 3, 1, 1)
+ self.dec3 = layers.Decoder(ch * (4 + 8), ch * 4, 3, 1, 1)
+ self.dec2 = layers.Decoder(ch * (2 + 4), ch * 2, 3, 1, 1)
+ self.dec1 = layers.Decoder(ch * (1 + 2), ch, 3, 1, 1)
+
+ def __call__(self, x):
+ h, e1 = self.enc1(x)
+ h, e2 = self.enc2(h)
+ h, e3 = self.enc3(h)
+ h, e4 = self.enc4(h)
+
+ h = self.aspp(h)
+
+ h = self.dec4(h, e4)
+ h = self.dec3(h, e3)
+ h = self.dec2(h, e2)
+ h = self.dec1(h, e1)
+
+ return h
+
+
+class CascadedASPPNet(nn.Module):
+ def __init__(self, n_fft):
+ super(CascadedASPPNet, self).__init__()
+ self.stg1_low_band_net = BaseASPPNet(2, 32)
+ self.stg1_high_band_net = BaseASPPNet(2, 32)
+
+ self.stg2_bridge = layers.Conv2DBNActiv(34, 16, 1, 1, 0)
+ self.stg2_full_band_net = BaseASPPNet(16, 32)
+
+ self.stg3_bridge = layers.Conv2DBNActiv(66, 32, 1, 1, 0)
+ self.stg3_full_band_net = BaseASPPNet(32, 64)
+
+ self.out = nn.Conv2d(64, 2, 1, bias=False)
+ self.aux1_out = nn.Conv2d(32, 2, 1, bias=False)
+ self.aux2_out = nn.Conv2d(32, 2, 1, bias=False)
+
+ self.max_bin = n_fft // 2
+ self.output_bin = n_fft // 2 + 1
+
+ self.offset = 128
+
+ def forward(self, x, aggressiveness=None):
+ mix = x.detach()
+ x = x.clone()
+
+ x = x[:, :, : self.max_bin]
+
+ bandw = x.size()[2] // 2
+ aux1 = torch.cat(
+ [
+ self.stg1_low_band_net(x[:, :, :bandw]),
+ self.stg1_high_band_net(x[:, :, bandw:]),
+ ],
+ dim=2,
+ )
+
+ h = torch.cat([x, aux1], dim=1)
+ aux2 = self.stg2_full_band_net(self.stg2_bridge(h))
+
+ h = torch.cat([x, aux1, aux2], dim=1)
+ h = self.stg3_full_band_net(self.stg3_bridge(h))
+
+ mask = torch.sigmoid(self.out(h))
+ mask = F.pad(
+ input=mask,
+ pad=(0, 0, 0, self.output_bin - mask.size()[2]),
+ mode="replicate",
+ )
+
+ if self.training:
+ aux1 = torch.sigmoid(self.aux1_out(aux1))
+ aux1 = F.pad(
+ input=aux1,
+ pad=(0, 0, 0, self.output_bin - aux1.size()[2]),
+ mode="replicate",
+ )
+ aux2 = torch.sigmoid(self.aux2_out(aux2))
+ aux2 = F.pad(
+ input=aux2,
+ pad=(0, 0, 0, self.output_bin - aux2.size()[2]),
+ mode="replicate",
+ )
+ return mask * mix, aux1 * mix, aux2 * mix
+ else:
+ if aggressiveness:
+ mask[:, :, : aggressiveness["split_bin"]] = torch.pow(
+ mask[:, :, : aggressiveness["split_bin"]],
+ 1 + aggressiveness["value"] / 3,
+ )
+ mask[:, :, aggressiveness["split_bin"] :] = torch.pow(
+ mask[:, :, aggressiveness["split_bin"] :],
+ 1 + aggressiveness["value"],
+ )
+
+ return mask * mix
+
+ def predict(self, x_mag, aggressiveness=None):
+ h = self.forward(x_mag, aggressiveness)
+
+ if self.offset > 0:
+ h = h[:, :, :, self.offset : -self.offset]
+ assert h.size()[3] > 0
+
+ return h
diff --git a/infer/lib/uvr5_pack/lib_v5/nets_123821KB.py b/infer/lib/uvr5_pack/lib_v5/nets_123821KB.py
new file mode 100644
index 0000000000000000000000000000000000000000..167d4cb2198863cf43e93440f7e63c5342fc7605
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/nets_123821KB.py
@@ -0,0 +1,122 @@
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from . import layers_123821KB as layers
+
+
+class BaseASPPNet(nn.Module):
+ def __init__(self, nin, ch, dilations=(4, 8, 16)):
+ super(BaseASPPNet, self).__init__()
+ self.enc1 = layers.Encoder(nin, ch, 3, 2, 1)
+ self.enc2 = layers.Encoder(ch, ch * 2, 3, 2, 1)
+ self.enc3 = layers.Encoder(ch * 2, ch * 4, 3, 2, 1)
+ self.enc4 = layers.Encoder(ch * 4, ch * 8, 3, 2, 1)
+
+ self.aspp = layers.ASPPModule(ch * 8, ch * 16, dilations)
+
+ self.dec4 = layers.Decoder(ch * (8 + 16), ch * 8, 3, 1, 1)
+ self.dec3 = layers.Decoder(ch * (4 + 8), ch * 4, 3, 1, 1)
+ self.dec2 = layers.Decoder(ch * (2 + 4), ch * 2, 3, 1, 1)
+ self.dec1 = layers.Decoder(ch * (1 + 2), ch, 3, 1, 1)
+
+ def __call__(self, x):
+ h, e1 = self.enc1(x)
+ h, e2 = self.enc2(h)
+ h, e3 = self.enc3(h)
+ h, e4 = self.enc4(h)
+
+ h = self.aspp(h)
+
+ h = self.dec4(h, e4)
+ h = self.dec3(h, e3)
+ h = self.dec2(h, e2)
+ h = self.dec1(h, e1)
+
+ return h
+
+
+class CascadedASPPNet(nn.Module):
+ def __init__(self, n_fft):
+ super(CascadedASPPNet, self).__init__()
+ self.stg1_low_band_net = BaseASPPNet(2, 32)
+ self.stg1_high_band_net = BaseASPPNet(2, 32)
+
+ self.stg2_bridge = layers.Conv2DBNActiv(34, 16, 1, 1, 0)
+ self.stg2_full_band_net = BaseASPPNet(16, 32)
+
+ self.stg3_bridge = layers.Conv2DBNActiv(66, 32, 1, 1, 0)
+ self.stg3_full_band_net = BaseASPPNet(32, 64)
+
+ self.out = nn.Conv2d(64, 2, 1, bias=False)
+ self.aux1_out = nn.Conv2d(32, 2, 1, bias=False)
+ self.aux2_out = nn.Conv2d(32, 2, 1, bias=False)
+
+ self.max_bin = n_fft // 2
+ self.output_bin = n_fft // 2 + 1
+
+ self.offset = 128
+
+ def forward(self, x, aggressiveness=None):
+ mix = x.detach()
+ x = x.clone()
+
+ x = x[:, :, : self.max_bin]
+
+ bandw = x.size()[2] // 2
+ aux1 = torch.cat(
+ [
+ self.stg1_low_band_net(x[:, :, :bandw]),
+ self.stg1_high_band_net(x[:, :, bandw:]),
+ ],
+ dim=2,
+ )
+
+ h = torch.cat([x, aux1], dim=1)
+ aux2 = self.stg2_full_band_net(self.stg2_bridge(h))
+
+ h = torch.cat([x, aux1, aux2], dim=1)
+ h = self.stg3_full_band_net(self.stg3_bridge(h))
+
+ mask = torch.sigmoid(self.out(h))
+ mask = F.pad(
+ input=mask,
+ pad=(0, 0, 0, self.output_bin - mask.size()[2]),
+ mode="replicate",
+ )
+
+ if self.training:
+ aux1 = torch.sigmoid(self.aux1_out(aux1))
+ aux1 = F.pad(
+ input=aux1,
+ pad=(0, 0, 0, self.output_bin - aux1.size()[2]),
+ mode="replicate",
+ )
+ aux2 = torch.sigmoid(self.aux2_out(aux2))
+ aux2 = F.pad(
+ input=aux2,
+ pad=(0, 0, 0, self.output_bin - aux2.size()[2]),
+ mode="replicate",
+ )
+ return mask * mix, aux1 * mix, aux2 * mix
+ else:
+ if aggressiveness:
+ mask[:, :, : aggressiveness["split_bin"]] = torch.pow(
+ mask[:, :, : aggressiveness["split_bin"]],
+ 1 + aggressiveness["value"] / 3,
+ )
+ mask[:, :, aggressiveness["split_bin"] :] = torch.pow(
+ mask[:, :, aggressiveness["split_bin"] :],
+ 1 + aggressiveness["value"],
+ )
+
+ return mask * mix
+
+ def predict(self, x_mag, aggressiveness=None):
+ h = self.forward(x_mag, aggressiveness)
+
+ if self.offset > 0:
+ h = h[:, :, :, self.offset : -self.offset]
+ assert h.size()[3] > 0
+
+ return h
diff --git a/infer/lib/uvr5_pack/lib_v5/nets_33966KB.py b/infer/lib/uvr5_pack/lib_v5/nets_33966KB.py
new file mode 100644
index 0000000000000000000000000000000000000000..73a5b836177b706c306e27875f8391c1aed4b948
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/nets_33966KB.py
@@ -0,0 +1,122 @@
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from . import layers_33966KB as layers
+
+
+class BaseASPPNet(nn.Module):
+ def __init__(self, nin, ch, dilations=(4, 8, 16, 32)):
+ super(BaseASPPNet, self).__init__()
+ self.enc1 = layers.Encoder(nin, ch, 3, 2, 1)
+ self.enc2 = layers.Encoder(ch, ch * 2, 3, 2, 1)
+ self.enc3 = layers.Encoder(ch * 2, ch * 4, 3, 2, 1)
+ self.enc4 = layers.Encoder(ch * 4, ch * 8, 3, 2, 1)
+
+ self.aspp = layers.ASPPModule(ch * 8, ch * 16, dilations)
+
+ self.dec4 = layers.Decoder(ch * (8 + 16), ch * 8, 3, 1, 1)
+ self.dec3 = layers.Decoder(ch * (4 + 8), ch * 4, 3, 1, 1)
+ self.dec2 = layers.Decoder(ch * (2 + 4), ch * 2, 3, 1, 1)
+ self.dec1 = layers.Decoder(ch * (1 + 2), ch, 3, 1, 1)
+
+ def __call__(self, x):
+ h, e1 = self.enc1(x)
+ h, e2 = self.enc2(h)
+ h, e3 = self.enc3(h)
+ h, e4 = self.enc4(h)
+
+ h = self.aspp(h)
+
+ h = self.dec4(h, e4)
+ h = self.dec3(h, e3)
+ h = self.dec2(h, e2)
+ h = self.dec1(h, e1)
+
+ return h
+
+
+class CascadedASPPNet(nn.Module):
+ def __init__(self, n_fft):
+ super(CascadedASPPNet, self).__init__()
+ self.stg1_low_band_net = BaseASPPNet(2, 16)
+ self.stg1_high_band_net = BaseASPPNet(2, 16)
+
+ self.stg2_bridge = layers.Conv2DBNActiv(18, 8, 1, 1, 0)
+ self.stg2_full_band_net = BaseASPPNet(8, 16)
+
+ self.stg3_bridge = layers.Conv2DBNActiv(34, 16, 1, 1, 0)
+ self.stg3_full_band_net = BaseASPPNet(16, 32)
+
+ self.out = nn.Conv2d(32, 2, 1, bias=False)
+ self.aux1_out = nn.Conv2d(16, 2, 1, bias=False)
+ self.aux2_out = nn.Conv2d(16, 2, 1, bias=False)
+
+ self.max_bin = n_fft // 2
+ self.output_bin = n_fft // 2 + 1
+
+ self.offset = 128
+
+ def forward(self, x, aggressiveness=None):
+ mix = x.detach()
+ x = x.clone()
+
+ x = x[:, :, : self.max_bin]
+
+ bandw = x.size()[2] // 2
+ aux1 = torch.cat(
+ [
+ self.stg1_low_band_net(x[:, :, :bandw]),
+ self.stg1_high_band_net(x[:, :, bandw:]),
+ ],
+ dim=2,
+ )
+
+ h = torch.cat([x, aux1], dim=1)
+ aux2 = self.stg2_full_band_net(self.stg2_bridge(h))
+
+ h = torch.cat([x, aux1, aux2], dim=1)
+ h = self.stg3_full_band_net(self.stg3_bridge(h))
+
+ mask = torch.sigmoid(self.out(h))
+ mask = F.pad(
+ input=mask,
+ pad=(0, 0, 0, self.output_bin - mask.size()[2]),
+ mode="replicate",
+ )
+
+ if self.training:
+ aux1 = torch.sigmoid(self.aux1_out(aux1))
+ aux1 = F.pad(
+ input=aux1,
+ pad=(0, 0, 0, self.output_bin - aux1.size()[2]),
+ mode="replicate",
+ )
+ aux2 = torch.sigmoid(self.aux2_out(aux2))
+ aux2 = F.pad(
+ input=aux2,
+ pad=(0, 0, 0, self.output_bin - aux2.size()[2]),
+ mode="replicate",
+ )
+ return mask * mix, aux1 * mix, aux2 * mix
+ else:
+ if aggressiveness:
+ mask[:, :, : aggressiveness["split_bin"]] = torch.pow(
+ mask[:, :, : aggressiveness["split_bin"]],
+ 1 + aggressiveness["value"] / 3,
+ )
+ mask[:, :, aggressiveness["split_bin"] :] = torch.pow(
+ mask[:, :, aggressiveness["split_bin"] :],
+ 1 + aggressiveness["value"],
+ )
+
+ return mask * mix
+
+ def predict(self, x_mag, aggressiveness=None):
+ h = self.forward(x_mag, aggressiveness)
+
+ if self.offset > 0:
+ h = h[:, :, :, self.offset : -self.offset]
+ assert h.size()[3] > 0
+
+ return h
diff --git a/infer/lib/uvr5_pack/lib_v5/nets_537227KB.py b/infer/lib/uvr5_pack/lib_v5/nets_537227KB.py
new file mode 100644
index 0000000000000000000000000000000000000000..823b44fb64898e8dcbb12180ba45d1718f9b03f7
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/nets_537227KB.py
@@ -0,0 +1,123 @@
+import numpy as np
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from . import layers_537238KB as layers
+
+
+class BaseASPPNet(nn.Module):
+ def __init__(self, nin, ch, dilations=(4, 8, 16)):
+ super(BaseASPPNet, self).__init__()
+ self.enc1 = layers.Encoder(nin, ch, 3, 2, 1)
+ self.enc2 = layers.Encoder(ch, ch * 2, 3, 2, 1)
+ self.enc3 = layers.Encoder(ch * 2, ch * 4, 3, 2, 1)
+ self.enc4 = layers.Encoder(ch * 4, ch * 8, 3, 2, 1)
+
+ self.aspp = layers.ASPPModule(ch * 8, ch * 16, dilations)
+
+ self.dec4 = layers.Decoder(ch * (8 + 16), ch * 8, 3, 1, 1)
+ self.dec3 = layers.Decoder(ch * (4 + 8), ch * 4, 3, 1, 1)
+ self.dec2 = layers.Decoder(ch * (2 + 4), ch * 2, 3, 1, 1)
+ self.dec1 = layers.Decoder(ch * (1 + 2), ch, 3, 1, 1)
+
+ def __call__(self, x):
+ h, e1 = self.enc1(x)
+ h, e2 = self.enc2(h)
+ h, e3 = self.enc3(h)
+ h, e4 = self.enc4(h)
+
+ h = self.aspp(h)
+
+ h = self.dec4(h, e4)
+ h = self.dec3(h, e3)
+ h = self.dec2(h, e2)
+ h = self.dec1(h, e1)
+
+ return h
+
+
+class CascadedASPPNet(nn.Module):
+ def __init__(self, n_fft):
+ super(CascadedASPPNet, self).__init__()
+ self.stg1_low_band_net = BaseASPPNet(2, 64)
+ self.stg1_high_band_net = BaseASPPNet(2, 64)
+
+ self.stg2_bridge = layers.Conv2DBNActiv(66, 32, 1, 1, 0)
+ self.stg2_full_band_net = BaseASPPNet(32, 64)
+
+ self.stg3_bridge = layers.Conv2DBNActiv(130, 64, 1, 1, 0)
+ self.stg3_full_band_net = BaseASPPNet(64, 128)
+
+ self.out = nn.Conv2d(128, 2, 1, bias=False)
+ self.aux1_out = nn.Conv2d(64, 2, 1, bias=False)
+ self.aux2_out = nn.Conv2d(64, 2, 1, bias=False)
+
+ self.max_bin = n_fft // 2
+ self.output_bin = n_fft // 2 + 1
+
+ self.offset = 128
+
+ def forward(self, x, aggressiveness=None):
+ mix = x.detach()
+ x = x.clone()
+
+ x = x[:, :, : self.max_bin]
+
+ bandw = x.size()[2] // 2
+ aux1 = torch.cat(
+ [
+ self.stg1_low_band_net(x[:, :, :bandw]),
+ self.stg1_high_band_net(x[:, :, bandw:]),
+ ],
+ dim=2,
+ )
+
+ h = torch.cat([x, aux1], dim=1)
+ aux2 = self.stg2_full_band_net(self.stg2_bridge(h))
+
+ h = torch.cat([x, aux1, aux2], dim=1)
+ h = self.stg3_full_band_net(self.stg3_bridge(h))
+
+ mask = torch.sigmoid(self.out(h))
+ mask = F.pad(
+ input=mask,
+ pad=(0, 0, 0, self.output_bin - mask.size()[2]),
+ mode="replicate",
+ )
+
+ if self.training:
+ aux1 = torch.sigmoid(self.aux1_out(aux1))
+ aux1 = F.pad(
+ input=aux1,
+ pad=(0, 0, 0, self.output_bin - aux1.size()[2]),
+ mode="replicate",
+ )
+ aux2 = torch.sigmoid(self.aux2_out(aux2))
+ aux2 = F.pad(
+ input=aux2,
+ pad=(0, 0, 0, self.output_bin - aux2.size()[2]),
+ mode="replicate",
+ )
+ return mask * mix, aux1 * mix, aux2 * mix
+ else:
+ if aggressiveness:
+ mask[:, :, : aggressiveness["split_bin"]] = torch.pow(
+ mask[:, :, : aggressiveness["split_bin"]],
+ 1 + aggressiveness["value"] / 3,
+ )
+ mask[:, :, aggressiveness["split_bin"] :] = torch.pow(
+ mask[:, :, aggressiveness["split_bin"] :],
+ 1 + aggressiveness["value"],
+ )
+
+ return mask * mix
+
+ def predict(self, x_mag, aggressiveness=None):
+ h = self.forward(x_mag, aggressiveness)
+
+ if self.offset > 0:
+ h = h[:, :, :, self.offset : -self.offset]
+ assert h.size()[3] > 0
+
+ return h
diff --git a/infer/lib/uvr5_pack/lib_v5/nets_537238KB.py b/infer/lib/uvr5_pack/lib_v5/nets_537238KB.py
new file mode 100644
index 0000000000000000000000000000000000000000..823b44fb64898e8dcbb12180ba45d1718f9b03f7
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/nets_537238KB.py
@@ -0,0 +1,123 @@
+import numpy as np
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from . import layers_537238KB as layers
+
+
+class BaseASPPNet(nn.Module):
+ def __init__(self, nin, ch, dilations=(4, 8, 16)):
+ super(BaseASPPNet, self).__init__()
+ self.enc1 = layers.Encoder(nin, ch, 3, 2, 1)
+ self.enc2 = layers.Encoder(ch, ch * 2, 3, 2, 1)
+ self.enc3 = layers.Encoder(ch * 2, ch * 4, 3, 2, 1)
+ self.enc4 = layers.Encoder(ch * 4, ch * 8, 3, 2, 1)
+
+ self.aspp = layers.ASPPModule(ch * 8, ch * 16, dilations)
+
+ self.dec4 = layers.Decoder(ch * (8 + 16), ch * 8, 3, 1, 1)
+ self.dec3 = layers.Decoder(ch * (4 + 8), ch * 4, 3, 1, 1)
+ self.dec2 = layers.Decoder(ch * (2 + 4), ch * 2, 3, 1, 1)
+ self.dec1 = layers.Decoder(ch * (1 + 2), ch, 3, 1, 1)
+
+ def __call__(self, x):
+ h, e1 = self.enc1(x)
+ h, e2 = self.enc2(h)
+ h, e3 = self.enc3(h)
+ h, e4 = self.enc4(h)
+
+ h = self.aspp(h)
+
+ h = self.dec4(h, e4)
+ h = self.dec3(h, e3)
+ h = self.dec2(h, e2)
+ h = self.dec1(h, e1)
+
+ return h
+
+
+class CascadedASPPNet(nn.Module):
+ def __init__(self, n_fft):
+ super(CascadedASPPNet, self).__init__()
+ self.stg1_low_band_net = BaseASPPNet(2, 64)
+ self.stg1_high_band_net = BaseASPPNet(2, 64)
+
+ self.stg2_bridge = layers.Conv2DBNActiv(66, 32, 1, 1, 0)
+ self.stg2_full_band_net = BaseASPPNet(32, 64)
+
+ self.stg3_bridge = layers.Conv2DBNActiv(130, 64, 1, 1, 0)
+ self.stg3_full_band_net = BaseASPPNet(64, 128)
+
+ self.out = nn.Conv2d(128, 2, 1, bias=False)
+ self.aux1_out = nn.Conv2d(64, 2, 1, bias=False)
+ self.aux2_out = nn.Conv2d(64, 2, 1, bias=False)
+
+ self.max_bin = n_fft // 2
+ self.output_bin = n_fft // 2 + 1
+
+ self.offset = 128
+
+ def forward(self, x, aggressiveness=None):
+ mix = x.detach()
+ x = x.clone()
+
+ x = x[:, :, : self.max_bin]
+
+ bandw = x.size()[2] // 2
+ aux1 = torch.cat(
+ [
+ self.stg1_low_band_net(x[:, :, :bandw]),
+ self.stg1_high_band_net(x[:, :, bandw:]),
+ ],
+ dim=2,
+ )
+
+ h = torch.cat([x, aux1], dim=1)
+ aux2 = self.stg2_full_band_net(self.stg2_bridge(h))
+
+ h = torch.cat([x, aux1, aux2], dim=1)
+ h = self.stg3_full_band_net(self.stg3_bridge(h))
+
+ mask = torch.sigmoid(self.out(h))
+ mask = F.pad(
+ input=mask,
+ pad=(0, 0, 0, self.output_bin - mask.size()[2]),
+ mode="replicate",
+ )
+
+ if self.training:
+ aux1 = torch.sigmoid(self.aux1_out(aux1))
+ aux1 = F.pad(
+ input=aux1,
+ pad=(0, 0, 0, self.output_bin - aux1.size()[2]),
+ mode="replicate",
+ )
+ aux2 = torch.sigmoid(self.aux2_out(aux2))
+ aux2 = F.pad(
+ input=aux2,
+ pad=(0, 0, 0, self.output_bin - aux2.size()[2]),
+ mode="replicate",
+ )
+ return mask * mix, aux1 * mix, aux2 * mix
+ else:
+ if aggressiveness:
+ mask[:, :, : aggressiveness["split_bin"]] = torch.pow(
+ mask[:, :, : aggressiveness["split_bin"]],
+ 1 + aggressiveness["value"] / 3,
+ )
+ mask[:, :, aggressiveness["split_bin"] :] = torch.pow(
+ mask[:, :, aggressiveness["split_bin"] :],
+ 1 + aggressiveness["value"],
+ )
+
+ return mask * mix
+
+ def predict(self, x_mag, aggressiveness=None):
+ h = self.forward(x_mag, aggressiveness)
+
+ if self.offset > 0:
+ h = h[:, :, :, self.offset : -self.offset]
+ assert h.size()[3] > 0
+
+ return h
diff --git a/infer/lib/uvr5_pack/lib_v5/nets_61968KB.py b/infer/lib/uvr5_pack/lib_v5/nets_61968KB.py
new file mode 100644
index 0000000000000000000000000000000000000000..167d4cb2198863cf43e93440f7e63c5342fc7605
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/nets_61968KB.py
@@ -0,0 +1,122 @@
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from . import layers_123821KB as layers
+
+
+class BaseASPPNet(nn.Module):
+ def __init__(self, nin, ch, dilations=(4, 8, 16)):
+ super(BaseASPPNet, self).__init__()
+ self.enc1 = layers.Encoder(nin, ch, 3, 2, 1)
+ self.enc2 = layers.Encoder(ch, ch * 2, 3, 2, 1)
+ self.enc3 = layers.Encoder(ch * 2, ch * 4, 3, 2, 1)
+ self.enc4 = layers.Encoder(ch * 4, ch * 8, 3, 2, 1)
+
+ self.aspp = layers.ASPPModule(ch * 8, ch * 16, dilations)
+
+ self.dec4 = layers.Decoder(ch * (8 + 16), ch * 8, 3, 1, 1)
+ self.dec3 = layers.Decoder(ch * (4 + 8), ch * 4, 3, 1, 1)
+ self.dec2 = layers.Decoder(ch * (2 + 4), ch * 2, 3, 1, 1)
+ self.dec1 = layers.Decoder(ch * (1 + 2), ch, 3, 1, 1)
+
+ def __call__(self, x):
+ h, e1 = self.enc1(x)
+ h, e2 = self.enc2(h)
+ h, e3 = self.enc3(h)
+ h, e4 = self.enc4(h)
+
+ h = self.aspp(h)
+
+ h = self.dec4(h, e4)
+ h = self.dec3(h, e3)
+ h = self.dec2(h, e2)
+ h = self.dec1(h, e1)
+
+ return h
+
+
+class CascadedASPPNet(nn.Module):
+ def __init__(self, n_fft):
+ super(CascadedASPPNet, self).__init__()
+ self.stg1_low_band_net = BaseASPPNet(2, 32)
+ self.stg1_high_band_net = BaseASPPNet(2, 32)
+
+ self.stg2_bridge = layers.Conv2DBNActiv(34, 16, 1, 1, 0)
+ self.stg2_full_band_net = BaseASPPNet(16, 32)
+
+ self.stg3_bridge = layers.Conv2DBNActiv(66, 32, 1, 1, 0)
+ self.stg3_full_band_net = BaseASPPNet(32, 64)
+
+ self.out = nn.Conv2d(64, 2, 1, bias=False)
+ self.aux1_out = nn.Conv2d(32, 2, 1, bias=False)
+ self.aux2_out = nn.Conv2d(32, 2, 1, bias=False)
+
+ self.max_bin = n_fft // 2
+ self.output_bin = n_fft // 2 + 1
+
+ self.offset = 128
+
+ def forward(self, x, aggressiveness=None):
+ mix = x.detach()
+ x = x.clone()
+
+ x = x[:, :, : self.max_bin]
+
+ bandw = x.size()[2] // 2
+ aux1 = torch.cat(
+ [
+ self.stg1_low_band_net(x[:, :, :bandw]),
+ self.stg1_high_band_net(x[:, :, bandw:]),
+ ],
+ dim=2,
+ )
+
+ h = torch.cat([x, aux1], dim=1)
+ aux2 = self.stg2_full_band_net(self.stg2_bridge(h))
+
+ h = torch.cat([x, aux1, aux2], dim=1)
+ h = self.stg3_full_band_net(self.stg3_bridge(h))
+
+ mask = torch.sigmoid(self.out(h))
+ mask = F.pad(
+ input=mask,
+ pad=(0, 0, 0, self.output_bin - mask.size()[2]),
+ mode="replicate",
+ )
+
+ if self.training:
+ aux1 = torch.sigmoid(self.aux1_out(aux1))
+ aux1 = F.pad(
+ input=aux1,
+ pad=(0, 0, 0, self.output_bin - aux1.size()[2]),
+ mode="replicate",
+ )
+ aux2 = torch.sigmoid(self.aux2_out(aux2))
+ aux2 = F.pad(
+ input=aux2,
+ pad=(0, 0, 0, self.output_bin - aux2.size()[2]),
+ mode="replicate",
+ )
+ return mask * mix, aux1 * mix, aux2 * mix
+ else:
+ if aggressiveness:
+ mask[:, :, : aggressiveness["split_bin"]] = torch.pow(
+ mask[:, :, : aggressiveness["split_bin"]],
+ 1 + aggressiveness["value"] / 3,
+ )
+ mask[:, :, aggressiveness["split_bin"] :] = torch.pow(
+ mask[:, :, aggressiveness["split_bin"] :],
+ 1 + aggressiveness["value"],
+ )
+
+ return mask * mix
+
+ def predict(self, x_mag, aggressiveness=None):
+ h = self.forward(x_mag, aggressiveness)
+
+ if self.offset > 0:
+ h = h[:, :, :, self.offset : -self.offset]
+ assert h.size()[3] > 0
+
+ return h
diff --git a/infer/lib/uvr5_pack/lib_v5/nets_new.py b/infer/lib/uvr5_pack/lib_v5/nets_new.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c0f4fa96d921e979fe31bd4151701b7783fbcea
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/nets_new.py
@@ -0,0 +1,133 @@
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from . import layers_new
+
+
+class BaseNet(nn.Module):
+ def __init__(
+ self, nin, nout, nin_lstm, nout_lstm, dilations=((4, 2), (8, 4), (12, 6))
+ ):
+ super(BaseNet, self).__init__()
+ self.enc1 = layers_new.Conv2DBNActiv(nin, nout, 3, 1, 1)
+ self.enc2 = layers_new.Encoder(nout, nout * 2, 3, 2, 1)
+ self.enc3 = layers_new.Encoder(nout * 2, nout * 4, 3, 2, 1)
+ self.enc4 = layers_new.Encoder(nout * 4, nout * 6, 3, 2, 1)
+ self.enc5 = layers_new.Encoder(nout * 6, nout * 8, 3, 2, 1)
+
+ self.aspp = layers_new.ASPPModule(nout * 8, nout * 8, dilations, dropout=True)
+
+ self.dec4 = layers_new.Decoder(nout * (6 + 8), nout * 6, 3, 1, 1)
+ self.dec3 = layers_new.Decoder(nout * (4 + 6), nout * 4, 3, 1, 1)
+ self.dec2 = layers_new.Decoder(nout * (2 + 4), nout * 2, 3, 1, 1)
+ self.lstm_dec2 = layers_new.LSTMModule(nout * 2, nin_lstm, nout_lstm)
+ self.dec1 = layers_new.Decoder(nout * (1 + 2) + 1, nout * 1, 3, 1, 1)
+
+ def __call__(self, x):
+ e1 = self.enc1(x)
+ e2 = self.enc2(e1)
+ e3 = self.enc3(e2)
+ e4 = self.enc4(e3)
+ e5 = self.enc5(e4)
+
+ h = self.aspp(e5)
+
+ h = self.dec4(h, e4)
+ h = self.dec3(h, e3)
+ h = self.dec2(h, e2)
+ h = torch.cat([h, self.lstm_dec2(h)], dim=1)
+ h = self.dec1(h, e1)
+
+ return h
+
+
+class CascadedNet(nn.Module):
+ def __init__(self, n_fft, nout=32, nout_lstm=128):
+ super(CascadedNet, self).__init__()
+
+ self.max_bin = n_fft // 2
+ self.output_bin = n_fft // 2 + 1
+ self.nin_lstm = self.max_bin // 2
+ self.offset = 64
+
+ self.stg1_low_band_net = nn.Sequential(
+ BaseNet(2, nout // 2, self.nin_lstm // 2, nout_lstm),
+ layers_new.Conv2DBNActiv(nout // 2, nout // 4, 1, 1, 0),
+ )
+
+ self.stg1_high_band_net = BaseNet(
+ 2, nout // 4, self.nin_lstm // 2, nout_lstm // 2
+ )
+
+ self.stg2_low_band_net = nn.Sequential(
+ BaseNet(nout // 4 + 2, nout, self.nin_lstm // 2, nout_lstm),
+ layers_new.Conv2DBNActiv(nout, nout // 2, 1, 1, 0),
+ )
+ self.stg2_high_band_net = BaseNet(
+ nout // 4 + 2, nout // 2, self.nin_lstm // 2, nout_lstm // 2
+ )
+
+ self.stg3_full_band_net = BaseNet(
+ 3 * nout // 4 + 2, nout, self.nin_lstm, nout_lstm
+ )
+
+ self.out = nn.Conv2d(nout, 2, 1, bias=False)
+ self.aux_out = nn.Conv2d(3 * nout // 4, 2, 1, bias=False)
+
+ def forward(self, x):
+ x = x[:, :, : self.max_bin]
+
+ bandw = x.size()[2] // 2
+ l1_in = x[:, :, :bandw]
+ h1_in = x[:, :, bandw:]
+ l1 = self.stg1_low_band_net(l1_in)
+ h1 = self.stg1_high_band_net(h1_in)
+ aux1 = torch.cat([l1, h1], dim=2)
+
+ l2_in = torch.cat([l1_in, l1], dim=1)
+ h2_in = torch.cat([h1_in, h1], dim=1)
+ l2 = self.stg2_low_band_net(l2_in)
+ h2 = self.stg2_high_band_net(h2_in)
+ aux2 = torch.cat([l2, h2], dim=2)
+
+ f3_in = torch.cat([x, aux1, aux2], dim=1)
+ f3 = self.stg3_full_band_net(f3_in)
+
+ mask = torch.sigmoid(self.out(f3))
+ mask = F.pad(
+ input=mask,
+ pad=(0, 0, 0, self.output_bin - mask.size()[2]),
+ mode="replicate",
+ )
+
+ if self.training:
+ aux = torch.cat([aux1, aux2], dim=1)
+ aux = torch.sigmoid(self.aux_out(aux))
+ aux = F.pad(
+ input=aux,
+ pad=(0, 0, 0, self.output_bin - aux.size()[2]),
+ mode="replicate",
+ )
+ return mask, aux
+ else:
+ return mask
+
+ def predict_mask(self, x):
+ mask = self.forward(x)
+
+ if self.offset > 0:
+ mask = mask[:, :, :, self.offset : -self.offset]
+ assert mask.size()[3] > 0
+
+ return mask
+
+ def predict(self, x, aggressiveness=None):
+ mask = self.forward(x)
+ pred_mag = x * mask
+
+ if self.offset > 0:
+ pred_mag = pred_mag[:, :, :, self.offset : -self.offset]
+ assert pred_mag.size()[3] > 0
+
+ return pred_mag
diff --git a/infer/lib/uvr5_pack/lib_v5/spec_utils.py b/infer/lib/uvr5_pack/lib_v5/spec_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..a9634fd51ff47bf90211839231774719154c37cf
--- /dev/null
+++ b/infer/lib/uvr5_pack/lib_v5/spec_utils.py
@@ -0,0 +1,672 @@
+import hashlib
+import json
+import math
+import os
+
+import librosa
+import numpy as np
+import soundfile as sf
+from tqdm import tqdm
+
+
+def crop_center(h1, h2):
+ h1_shape = h1.size()
+ h2_shape = h2.size()
+
+ if h1_shape[3] == h2_shape[3]:
+ return h1
+ elif h1_shape[3] < h2_shape[3]:
+ raise ValueError("h1_shape[3] must be greater than h2_shape[3]")
+
+ # s_freq = (h2_shape[2] - h1_shape[2]) // 2
+ # e_freq = s_freq + h1_shape[2]
+ s_time = (h1_shape[3] - h2_shape[3]) // 2
+ e_time = s_time + h2_shape[3]
+ h1 = h1[:, :, :, s_time:e_time]
+
+ return h1
+
+
+def wave_to_spectrogram(
+ wave, hop_length, n_fft, mid_side=False, mid_side_b2=False, reverse=False
+):
+ if reverse:
+ wave_left = np.flip(np.asfortranarray(wave[0]))
+ wave_right = np.flip(np.asfortranarray(wave[1]))
+ elif mid_side:
+ wave_left = np.asfortranarray(np.add(wave[0], wave[1]) / 2)
+ wave_right = np.asfortranarray(np.subtract(wave[0], wave[1]))
+ elif mid_side_b2:
+ wave_left = np.asfortranarray(np.add(wave[1], wave[0] * 0.5))
+ wave_right = np.asfortranarray(np.subtract(wave[0], wave[1] * 0.5))
+ else:
+ wave_left = np.asfortranarray(wave[0])
+ wave_right = np.asfortranarray(wave[1])
+
+ spec_left = librosa.stft(wave_left, n_fft, hop_length=hop_length)
+ spec_right = librosa.stft(wave_right, n_fft, hop_length=hop_length)
+
+ spec = np.asfortranarray([spec_left, spec_right])
+
+ return spec
+
+
+def wave_to_spectrogram_mt(
+ wave, hop_length, n_fft, mid_side=False, mid_side_b2=False, reverse=False
+):
+ import threading
+
+ if reverse:
+ wave_left = np.flip(np.asfortranarray(wave[0]))
+ wave_right = np.flip(np.asfortranarray(wave[1]))
+ elif mid_side:
+ wave_left = np.asfortranarray(np.add(wave[0], wave[1]) / 2)
+ wave_right = np.asfortranarray(np.subtract(wave[0], wave[1]))
+ elif mid_side_b2:
+ wave_left = np.asfortranarray(np.add(wave[1], wave[0] * 0.5))
+ wave_right = np.asfortranarray(np.subtract(wave[0], wave[1] * 0.5))
+ else:
+ wave_left = np.asfortranarray(wave[0])
+ wave_right = np.asfortranarray(wave[1])
+
+ def run_thread(**kwargs):
+ global spec_left
+ spec_left = librosa.stft(**kwargs)
+
+ thread = threading.Thread(
+ target=run_thread,
+ kwargs={"y": wave_left, "n_fft": n_fft, "hop_length": hop_length},
+ )
+ thread.start()
+ spec_right = librosa.stft(wave_right, n_fft, hop_length=hop_length)
+ thread.join()
+
+ spec = np.asfortranarray([spec_left, spec_right])
+
+ return spec
+
+
+def combine_spectrograms(specs, mp):
+ l = min([specs[i].shape[2] for i in specs])
+ spec_c = np.zeros(shape=(2, mp.param["bins"] + 1, l), dtype=np.complex64)
+ offset = 0
+ bands_n = len(mp.param["band"])
+
+ for d in range(1, bands_n + 1):
+ h = mp.param["band"][d]["crop_stop"] - mp.param["band"][d]["crop_start"]
+ spec_c[:, offset : offset + h, :l] = specs[d][
+ :, mp.param["band"][d]["crop_start"] : mp.param["band"][d]["crop_stop"], :l
+ ]
+ offset += h
+
+ if offset > mp.param["bins"]:
+ raise ValueError("Too much bins")
+
+ # lowpass fiter
+ if (
+ mp.param["pre_filter_start"] > 0
+ ): # and mp.param['band'][bands_n]['res_type'] in ['scipy', 'polyphase']:
+ if bands_n == 1:
+ spec_c = fft_lp_filter(
+ spec_c, mp.param["pre_filter_start"], mp.param["pre_filter_stop"]
+ )
+ else:
+ gp = 1
+ for b in range(
+ mp.param["pre_filter_start"] + 1, mp.param["pre_filter_stop"]
+ ):
+ g = math.pow(
+ 10, -(b - mp.param["pre_filter_start"]) * (3.5 - gp) / 20.0
+ )
+ gp = g
+ spec_c[:, b, :] *= g
+
+ return np.asfortranarray(spec_c)
+
+
+def spectrogram_to_image(spec, mode="magnitude"):
+ if mode == "magnitude":
+ if np.iscomplexobj(spec):
+ y = np.abs(spec)
+ else:
+ y = spec
+ y = np.log10(y**2 + 1e-8)
+ elif mode == "phase":
+ if np.iscomplexobj(spec):
+ y = np.angle(spec)
+ else:
+ y = spec
+
+ y -= y.min()
+ y *= 255 / y.max()
+ img = np.uint8(y)
+
+ if y.ndim == 3:
+ img = img.transpose(1, 2, 0)
+ img = np.concatenate([np.max(img, axis=2, keepdims=True), img], axis=2)
+
+ return img
+
+
+def reduce_vocal_aggressively(X, y, softmask):
+ v = X - y
+ y_mag_tmp = np.abs(y)
+ v_mag_tmp = np.abs(v)
+
+ v_mask = v_mag_tmp > y_mag_tmp
+ y_mag = np.clip(y_mag_tmp - v_mag_tmp * v_mask * softmask, 0, np.inf)
+
+ return y_mag * np.exp(1.0j * np.angle(y))
+
+
+def mask_silence(mag, ref, thres=0.2, min_range=64, fade_size=32):
+ if min_range < fade_size * 2:
+ raise ValueError("min_range must be >= fade_area * 2")
+
+ mag = mag.copy()
+
+ idx = np.where(ref.mean(axis=(0, 1)) < thres)[0]
+ starts = np.insert(idx[np.where(np.diff(idx) != 1)[0] + 1], 0, idx[0])
+ ends = np.append(idx[np.where(np.diff(idx) != 1)[0]], idx[-1])
+ uninformative = np.where(ends - starts > min_range)[0]
+ if len(uninformative) > 0:
+ starts = starts[uninformative]
+ ends = ends[uninformative]
+ old_e = None
+ for s, e in zip(starts, ends):
+ if old_e is not None and s - old_e < fade_size:
+ s = old_e - fade_size * 2
+
+ if s != 0:
+ weight = np.linspace(0, 1, fade_size)
+ mag[:, :, s : s + fade_size] += weight * ref[:, :, s : s + fade_size]
+ else:
+ s -= fade_size
+
+ if e != mag.shape[2]:
+ weight = np.linspace(1, 0, fade_size)
+ mag[:, :, e - fade_size : e] += weight * ref[:, :, e - fade_size : e]
+ else:
+ e += fade_size
+
+ mag[:, :, s + fade_size : e - fade_size] += ref[
+ :, :, s + fade_size : e - fade_size
+ ]
+ old_e = e
+
+ return mag
+
+
+def align_wave_head_and_tail(a, b):
+ l = min([a[0].size, b[0].size])
+
+ return a[:l, :l], b[:l, :l]
+
+
+def cache_or_load(mix_path, inst_path, mp):
+ mix_basename = os.path.splitext(os.path.basename(mix_path))[0]
+ inst_basename = os.path.splitext(os.path.basename(inst_path))[0]
+
+ cache_dir = "mph{}".format(
+ hashlib.sha1(json.dumps(mp.param, sort_keys=True).encode("utf-8")).hexdigest()
+ )
+ mix_cache_dir = os.path.join("cache", cache_dir)
+ inst_cache_dir = os.path.join("cache", cache_dir)
+
+ os.makedirs(mix_cache_dir, exist_ok=True)
+ os.makedirs(inst_cache_dir, exist_ok=True)
+
+ mix_cache_path = os.path.join(mix_cache_dir, mix_basename + ".npy")
+ inst_cache_path = os.path.join(inst_cache_dir, inst_basename + ".npy")
+
+ if os.path.exists(mix_cache_path) and os.path.exists(inst_cache_path):
+ X_spec_m = np.load(mix_cache_path)
+ y_spec_m = np.load(inst_cache_path)
+ else:
+ X_wave, y_wave, X_spec_s, y_spec_s = {}, {}, {}, {}
+
+ for d in range(len(mp.param["band"]), 0, -1):
+ bp = mp.param["band"][d]
+
+ if d == len(mp.param["band"]): # high-end band
+ X_wave[d], _ = librosa.load(
+ mix_path, bp["sr"], False, dtype=np.float32, res_type=bp["res_type"]
+ )
+ y_wave[d], _ = librosa.load(
+ inst_path,
+ bp["sr"],
+ False,
+ dtype=np.float32,
+ res_type=bp["res_type"],
+ )
+ else: # lower bands
+ X_wave[d] = librosa.resample(
+ X_wave[d + 1],
+ mp.param["band"][d + 1]["sr"],
+ bp["sr"],
+ res_type=bp["res_type"],
+ )
+ y_wave[d] = librosa.resample(
+ y_wave[d + 1],
+ mp.param["band"][d + 1]["sr"],
+ bp["sr"],
+ res_type=bp["res_type"],
+ )
+
+ X_wave[d], y_wave[d] = align_wave_head_and_tail(X_wave[d], y_wave[d])
+
+ X_spec_s[d] = wave_to_spectrogram(
+ X_wave[d],
+ bp["hl"],
+ bp["n_fft"],
+ mp.param["mid_side"],
+ mp.param["mid_side_b2"],
+ mp.param["reverse"],
+ )
+ y_spec_s[d] = wave_to_spectrogram(
+ y_wave[d],
+ bp["hl"],
+ bp["n_fft"],
+ mp.param["mid_side"],
+ mp.param["mid_side_b2"],
+ mp.param["reverse"],
+ )
+
+ del X_wave, y_wave
+
+ X_spec_m = combine_spectrograms(X_spec_s, mp)
+ y_spec_m = combine_spectrograms(y_spec_s, mp)
+
+ if X_spec_m.shape != y_spec_m.shape:
+ raise ValueError("The combined spectrograms are different: " + mix_path)
+
+ _, ext = os.path.splitext(mix_path)
+
+ np.save(mix_cache_path, X_spec_m)
+ np.save(inst_cache_path, y_spec_m)
+
+ return X_spec_m, y_spec_m
+
+
+def spectrogram_to_wave(spec, hop_length, mid_side, mid_side_b2, reverse):
+ spec_left = np.asfortranarray(spec[0])
+ spec_right = np.asfortranarray(spec[1])
+
+ wave_left = librosa.istft(spec_left, hop_length=hop_length)
+ wave_right = librosa.istft(spec_right, hop_length=hop_length)
+
+ if reverse:
+ return np.asfortranarray([np.flip(wave_left), np.flip(wave_right)])
+ elif mid_side:
+ return np.asfortranarray(
+ [np.add(wave_left, wave_right / 2), np.subtract(wave_left, wave_right / 2)]
+ )
+ elif mid_side_b2:
+ return np.asfortranarray(
+ [
+ np.add(wave_right / 1.25, 0.4 * wave_left),
+ np.subtract(wave_left / 1.25, 0.4 * wave_right),
+ ]
+ )
+ else:
+ return np.asfortranarray([wave_left, wave_right])
+
+
+def spectrogram_to_wave_mt(spec, hop_length, mid_side, reverse, mid_side_b2):
+ import threading
+
+ spec_left = np.asfortranarray(spec[0])
+ spec_right = np.asfortranarray(spec[1])
+
+ def run_thread(**kwargs):
+ global wave_left
+ wave_left = librosa.istft(**kwargs)
+
+ thread = threading.Thread(
+ target=run_thread, kwargs={"stft_matrix": spec_left, "hop_length": hop_length}
+ )
+ thread.start()
+ wave_right = librosa.istft(spec_right, hop_length=hop_length)
+ thread.join()
+
+ if reverse:
+ return np.asfortranarray([np.flip(wave_left), np.flip(wave_right)])
+ elif mid_side:
+ return np.asfortranarray(
+ [np.add(wave_left, wave_right / 2), np.subtract(wave_left, wave_right / 2)]
+ )
+ elif mid_side_b2:
+ return np.asfortranarray(
+ [
+ np.add(wave_right / 1.25, 0.4 * wave_left),
+ np.subtract(wave_left / 1.25, 0.4 * wave_right),
+ ]
+ )
+ else:
+ return np.asfortranarray([wave_left, wave_right])
+
+
+def cmb_spectrogram_to_wave(spec_m, mp, extra_bins_h=None, extra_bins=None):
+ wave_band = {}
+ bands_n = len(mp.param["band"])
+ offset = 0
+
+ for d in range(1, bands_n + 1):
+ bp = mp.param["band"][d]
+ spec_s = np.ndarray(
+ shape=(2, bp["n_fft"] // 2 + 1, spec_m.shape[2]), dtype=complex
+ )
+ h = bp["crop_stop"] - bp["crop_start"]
+ spec_s[:, bp["crop_start"] : bp["crop_stop"], :] = spec_m[
+ :, offset : offset + h, :
+ ]
+
+ offset += h
+ if d == bands_n: # higher
+ if extra_bins_h: # if --high_end_process bypass
+ max_bin = bp["n_fft"] // 2
+ spec_s[:, max_bin - extra_bins_h : max_bin, :] = extra_bins[
+ :, :extra_bins_h, :
+ ]
+ if bp["hpf_start"] > 0:
+ spec_s = fft_hp_filter(spec_s, bp["hpf_start"], bp["hpf_stop"] - 1)
+ if bands_n == 1:
+ wave = spectrogram_to_wave(
+ spec_s,
+ bp["hl"],
+ mp.param["mid_side"],
+ mp.param["mid_side_b2"],
+ mp.param["reverse"],
+ )
+ else:
+ wave = np.add(
+ wave,
+ spectrogram_to_wave(
+ spec_s,
+ bp["hl"],
+ mp.param["mid_side"],
+ mp.param["mid_side_b2"],
+ mp.param["reverse"],
+ ),
+ )
+ else:
+ sr = mp.param["band"][d + 1]["sr"]
+ if d == 1: # lower
+ spec_s = fft_lp_filter(spec_s, bp["lpf_start"], bp["lpf_stop"])
+ wave = librosa.resample(
+ spectrogram_to_wave(
+ spec_s,
+ bp["hl"],
+ mp.param["mid_side"],
+ mp.param["mid_side_b2"],
+ mp.param["reverse"],
+ ),
+ bp["sr"],
+ sr,
+ res_type="sinc_fastest",
+ )
+ else: # mid
+ spec_s = fft_hp_filter(spec_s, bp["hpf_start"], bp["hpf_stop"] - 1)
+ spec_s = fft_lp_filter(spec_s, bp["lpf_start"], bp["lpf_stop"])
+ wave2 = np.add(
+ wave,
+ spectrogram_to_wave(
+ spec_s,
+ bp["hl"],
+ mp.param["mid_side"],
+ mp.param["mid_side_b2"],
+ mp.param["reverse"],
+ ),
+ )
+ # wave = librosa.core.resample(wave2, bp['sr'], sr, res_type="sinc_fastest")
+ wave = librosa.core.resample(wave2, bp["sr"], sr, res_type="scipy")
+
+ return wave.T
+
+
+def fft_lp_filter(spec, bin_start, bin_stop):
+ g = 1.0
+ for b in range(bin_start, bin_stop):
+ g -= 1 / (bin_stop - bin_start)
+ spec[:, b, :] = g * spec[:, b, :]
+
+ spec[:, bin_stop:, :] *= 0
+
+ return spec
+
+
+def fft_hp_filter(spec, bin_start, bin_stop):
+ g = 1.0
+ for b in range(bin_start, bin_stop, -1):
+ g -= 1 / (bin_start - bin_stop)
+ spec[:, b, :] = g * spec[:, b, :]
+
+ spec[:, 0 : bin_stop + 1, :] *= 0
+
+ return spec
+
+
+def mirroring(a, spec_m, input_high_end, mp):
+ if "mirroring" == a:
+ mirror = np.flip(
+ np.abs(
+ spec_m[
+ :,
+ mp.param["pre_filter_start"]
+ - 10
+ - input_high_end.shape[1] : mp.param["pre_filter_start"]
+ - 10,
+ :,
+ ]
+ ),
+ 1,
+ )
+ mirror = mirror * np.exp(1.0j * np.angle(input_high_end))
+
+ return np.where(
+ np.abs(input_high_end) <= np.abs(mirror), input_high_end, mirror
+ )
+
+ if "mirroring2" == a:
+ mirror = np.flip(
+ np.abs(
+ spec_m[
+ :,
+ mp.param["pre_filter_start"]
+ - 10
+ - input_high_end.shape[1] : mp.param["pre_filter_start"]
+ - 10,
+ :,
+ ]
+ ),
+ 1,
+ )
+ mi = np.multiply(mirror, input_high_end * 1.7)
+
+ return np.where(np.abs(input_high_end) <= np.abs(mi), input_high_end, mi)
+
+
+def ensembling(a, specs):
+ for i in range(1, len(specs)):
+ if i == 1:
+ spec = specs[0]
+
+ ln = min([spec.shape[2], specs[i].shape[2]])
+ spec = spec[:, :, :ln]
+ specs[i] = specs[i][:, :, :ln]
+
+ if "min_mag" == a:
+ spec = np.where(np.abs(specs[i]) <= np.abs(spec), specs[i], spec)
+ if "max_mag" == a:
+ spec = np.where(np.abs(specs[i]) >= np.abs(spec), specs[i], spec)
+
+ return spec
+
+
+def stft(wave, nfft, hl):
+ wave_left = np.asfortranarray(wave[0])
+ wave_right = np.asfortranarray(wave[1])
+ spec_left = librosa.stft(wave_left, nfft, hop_length=hl)
+ spec_right = librosa.stft(wave_right, nfft, hop_length=hl)
+ spec = np.asfortranarray([spec_left, spec_right])
+
+ return spec
+
+
+def istft(spec, hl):
+ spec_left = np.asfortranarray(spec[0])
+ spec_right = np.asfortranarray(spec[1])
+
+ wave_left = librosa.istft(spec_left, hop_length=hl)
+ wave_right = librosa.istft(spec_right, hop_length=hl)
+ wave = np.asfortranarray([wave_left, wave_right])
+
+
+if __name__ == "__main__":
+ import argparse
+ import sys
+ import time
+
+ import cv2
+ from model_param_init import ModelParameters
+
+ p = argparse.ArgumentParser()
+ p.add_argument(
+ "--algorithm",
+ "-a",
+ type=str,
+ choices=["invert", "invert_p", "min_mag", "max_mag", "deep", "align"],
+ default="min_mag",
+ )
+ p.add_argument(
+ "--model_params",
+ "-m",
+ type=str,
+ default=os.path.join("modelparams", "1band_sr44100_hl512.json"),
+ )
+ p.add_argument("--output_name", "-o", type=str, default="output")
+ p.add_argument("--vocals_only", "-v", action="store_true")
+ p.add_argument("input", nargs="+")
+ args = p.parse_args()
+
+ start_time = time.time()
+
+ if args.algorithm.startswith("invert") and len(args.input) != 2:
+ raise ValueError("There should be two input files.")
+
+ if not args.algorithm.startswith("invert") and len(args.input) < 2:
+ raise ValueError("There must be at least two input files.")
+
+ wave, specs = {}, {}
+ mp = ModelParameters(args.model_params)
+
+ for i in range(len(args.input)):
+ spec = {}
+
+ for d in range(len(mp.param["band"]), 0, -1):
+ bp = mp.param["band"][d]
+
+ if d == len(mp.param["band"]): # high-end band
+ wave[d], _ = librosa.load(
+ args.input[i],
+ bp["sr"],
+ False,
+ dtype=np.float32,
+ res_type=bp["res_type"],
+ )
+
+ if len(wave[d].shape) == 1: # mono to stereo
+ wave[d] = np.array([wave[d], wave[d]])
+ else: # lower bands
+ wave[d] = librosa.resample(
+ wave[d + 1],
+ mp.param["band"][d + 1]["sr"],
+ bp["sr"],
+ res_type=bp["res_type"],
+ )
+
+ spec[d] = wave_to_spectrogram(
+ wave[d],
+ bp["hl"],
+ bp["n_fft"],
+ mp.param["mid_side"],
+ mp.param["mid_side_b2"],
+ mp.param["reverse"],
+ )
+
+ specs[i] = combine_spectrograms(spec, mp)
+
+ del wave
+
+ if args.algorithm == "deep":
+ d_spec = np.where(np.abs(specs[0]) <= np.abs(spec[1]), specs[0], spec[1])
+ v_spec = d_spec - specs[1]
+ sf.write(
+ os.path.join("{}.wav".format(args.output_name)),
+ cmb_spectrogram_to_wave(v_spec, mp),
+ mp.param["sr"],
+ )
+
+ if args.algorithm.startswith("invert"):
+ ln = min([specs[0].shape[2], specs[1].shape[2]])
+ specs[0] = specs[0][:, :, :ln]
+ specs[1] = specs[1][:, :, :ln]
+
+ if "invert_p" == args.algorithm:
+ X_mag = np.abs(specs[0])
+ y_mag = np.abs(specs[1])
+ max_mag = np.where(X_mag >= y_mag, X_mag, y_mag)
+ v_spec = specs[1] - max_mag * np.exp(1.0j * np.angle(specs[0]))
+ else:
+ specs[1] = reduce_vocal_aggressively(specs[0], specs[1], 0.2)
+ v_spec = specs[0] - specs[1]
+
+ if not args.vocals_only:
+ X_mag = np.abs(specs[0])
+ y_mag = np.abs(specs[1])
+ v_mag = np.abs(v_spec)
+
+ X_image = spectrogram_to_image(X_mag)
+ y_image = spectrogram_to_image(y_mag)
+ v_image = spectrogram_to_image(v_mag)
+
+ cv2.imwrite("{}_X.png".format(args.output_name), X_image)
+ cv2.imwrite("{}_y.png".format(args.output_name), y_image)
+ cv2.imwrite("{}_v.png".format(args.output_name), v_image)
+
+ sf.write(
+ "{}_X.wav".format(args.output_name),
+ cmb_spectrogram_to_wave(specs[0], mp),
+ mp.param["sr"],
+ )
+ sf.write(
+ "{}_y.wav".format(args.output_name),
+ cmb_spectrogram_to_wave(specs[1], mp),
+ mp.param["sr"],
+ )
+
+ sf.write(
+ "{}_v.wav".format(args.output_name),
+ cmb_spectrogram_to_wave(v_spec, mp),
+ mp.param["sr"],
+ )
+ else:
+ if not args.algorithm == "deep":
+ sf.write(
+ os.path.join("ensembled", "{}.wav".format(args.output_name)),
+ cmb_spectrogram_to_wave(ensembling(args.algorithm, specs), mp),
+ mp.param["sr"],
+ )
+
+ if args.algorithm == "align":
+ trackalignment = [
+ {
+ "file1": '"{}"'.format(args.input[0]),
+ "file2": '"{}"'.format(args.input[1]),
+ }
+ ]
+
+ for i, e in tqdm(enumerate(trackalignment), desc="Performing Alignment..."):
+ os.system(f"python lib/align_tracks.py {e['file1']} {e['file2']}")
+
+ # print('Total time: {0:.{1}f}s'.format(time.time() - start_time, 1))
diff --git a/infer/lib/uvr5_pack/name_params.json b/infer/lib/uvr5_pack/name_params.json
new file mode 100644
index 0000000000000000000000000000000000000000..8ed51a68370607a7a8693b99cfb35fc5d92b04af
--- /dev/null
+++ b/infer/lib/uvr5_pack/name_params.json
@@ -0,0 +1,263 @@
+{
+ "equivalent" : [
+ {
+ "model_hash_name" : [
+ {
+ "hash_name": "47939caf0cfe52a0e81442b85b971dfd",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100.json",
+ "param_name": "4band_44100"
+ },
+ {
+ "hash_name": "4e4ecb9764c50a8c414fee6e10395bbe",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/4band_v2.json",
+ "param_name": "4band_v2"
+ },
+ {
+ "hash_name": "ca106edd563e034bde0bdec4bb7a4b36",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/4band_v2.json",
+ "param_name": "4band_v2"
+ },
+ {
+ "hash_name": "e60a1e84803ce4efc0a6551206cc4b71",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100.json",
+ "param_name": "4band_44100"
+ },
+ {
+ "hash_name": "a82f14e75892e55e994376edbf0c8435",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100.json",
+ "param_name": "4band_44100"
+ },
+ {
+ "hash_name": "6dd9eaa6f0420af9f1d403aaafa4cc06",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/4band_v2_sn.json",
+ "param_name": "4band_v2_sn"
+ },
+ {
+ "hash_name": "08611fb99bd59eaa79ad27c58d137727",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/4band_v2_sn.json",
+ "param_name": "4band_v2_sn"
+ },
+ {
+ "hash_name": "5c7bbca45a187e81abbbd351606164e5",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/3band_44100_msb2.json",
+ "param_name": "3band_44100_msb2"
+ },
+ {
+ "hash_name": "d6b2cb685a058a091e5e7098192d3233",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/3band_44100_msb2.json",
+ "param_name": "3band_44100_msb2"
+ },
+ {
+ "hash_name": "c1b9f38170a7c90e96f027992eb7c62b",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100.json",
+ "param_name": "4band_44100"
+ },
+ {
+ "hash_name": "c3448ec923fa0edf3d03a19e633faa53",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100.json",
+ "param_name": "4band_44100"
+ },
+ {
+ "hash_name": "68aa2c8093d0080704b200d140f59e54",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/3band_44100.json",
+ "param_name": "3band_44100"
+ },
+ {
+ "hash_name": "fdc83be5b798e4bd29fe00fe6600e147",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/3band_44100_mid.json",
+ "param_name": "3band_44100_mid.json"
+ },
+ {
+ "hash_name": "2ce34bc92fd57f55db16b7a4def3d745",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/3band_44100_mid.json",
+ "param_name": "3band_44100_mid.json"
+ },
+ {
+ "hash_name": "52fdca89576f06cf4340b74a4730ee5f",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100.json",
+ "param_name": "4band_44100.json"
+ },
+ {
+ "hash_name": "41191165b05d38fc77f072fa9e8e8a30",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100.json",
+ "param_name": "4band_44100.json"
+ },
+ {
+ "hash_name": "89e83b511ad474592689e562d5b1f80e",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/2band_32000.json",
+ "param_name": "2band_32000.json"
+ },
+ {
+ "hash_name": "0b954da81d453b716b114d6d7c95177f",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/2band_32000.json",
+ "param_name": "2band_32000.json"
+ }
+
+ ],
+ "v4 Models": [
+ {
+ "hash_name": "6a00461c51c2920fd68937d4609ed6c8",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr16000_hl512.json",
+ "param_name": "1band_sr16000_hl512"
+ },
+ {
+ "hash_name": "0ab504864d20f1bd378fe9c81ef37140",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr32000_hl512.json",
+ "param_name": "1band_sr32000_hl512"
+ },
+ {
+ "hash_name": "7dd21065bf91c10f7fccb57d7d83b07f",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr32000_hl512.json",
+ "param_name": "1band_sr32000_hl512"
+ },
+ {
+ "hash_name": "80ab74d65e515caa3622728d2de07d23",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr32000_hl512.json",
+ "param_name": "1band_sr32000_hl512"
+ },
+ {
+ "hash_name": "edc115e7fc523245062200c00caa847f",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr33075_hl384.json",
+ "param_name": "1band_sr33075_hl384"
+ },
+ {
+ "hash_name": "28063e9f6ab5b341c5f6d3c67f2045b7",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr33075_hl384.json",
+ "param_name": "1band_sr33075_hl384"
+ },
+ {
+ "hash_name": "b58090534c52cbc3e9b5104bad666ef2",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr44100_hl512.json",
+ "param_name": "1band_sr44100_hl512"
+ },
+ {
+ "hash_name": "0cdab9947f1b0928705f518f3c78ea8f",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr44100_hl512.json",
+ "param_name": "1band_sr44100_hl512"
+ },
+ {
+ "hash_name": "ae702fed0238afb5346db8356fe25f13",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr44100_hl1024.json",
+ "param_name": "1band_sr44100_hl1024"
+ }
+ ]
+ }
+ ],
+ "User Models" : [
+ {
+ "1 Band": [
+ {
+ "hash_name": "1band_sr16000_hl512",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr16000_hl512.json",
+ "param_name": "1band_sr16000_hl512"
+ },
+ {
+ "hash_name": "1band_sr32000_hl512",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr32000_hl512.json",
+ "param_name": "1band_sr16000_hl512"
+ },
+ {
+ "hash_name": "1band_sr33075_hl384",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr33075_hl384.json",
+ "param_name": "1band_sr33075_hl384"
+ },
+ {
+ "hash_name": "1band_sr44100_hl256",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr44100_hl256.json",
+ "param_name": "1band_sr44100_hl256"
+ },
+ {
+ "hash_name": "1band_sr44100_hl512",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr44100_hl512.json",
+ "param_name": "1band_sr44100_hl512"
+ },
+ {
+ "hash_name": "1band_sr44100_hl1024",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/1band_sr44100_hl1024.json",
+ "param_name": "1band_sr44100_hl1024"
+ }
+ ],
+ "2 Band": [
+ {
+ "hash_name": "2band_44100_lofi",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/2band_44100_lofi.json",
+ "param_name": "2band_44100_lofi"
+ },
+ {
+ "hash_name": "2band_32000",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/2band_32000.json",
+ "param_name": "2band_32000"
+ },
+ {
+ "hash_name": "2band_48000",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/2band_48000.json",
+ "param_name": "2band_48000"
+ }
+ ],
+ "3 Band": [
+ {
+ "hash_name": "3band_44100",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/3band_44100.json",
+ "param_name": "3band_44100"
+ },
+ {
+ "hash_name": "3band_44100_mid",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/3band_44100_mid.json",
+ "param_name": "3band_44100_mid"
+ },
+ {
+ "hash_name": "3band_44100_msb2",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/3band_44100_msb2.json",
+ "param_name": "3band_44100_msb2"
+ }
+ ],
+ "4 Band": [
+ {
+ "hash_name": "4band_44100",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100.json",
+ "param_name": "4band_44100"
+ },
+ {
+ "hash_name": "4band_44100_mid",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_mid.json",
+ "param_name": "4band_44100_mid"
+ },
+ {
+ "hash_name": "4band_44100_msb",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_msb.json",
+ "param_name": "4band_44100_msb"
+ },
+ {
+ "hash_name": "4band_44100_msb2",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_msb2.json",
+ "param_name": "4band_44100_msb2"
+ },
+ {
+ "hash_name": "4band_44100_reverse",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_reverse.json",
+ "param_name": "4band_44100_reverse"
+ },
+ {
+ "hash_name": "4band_44100_sw",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/4band_44100_sw.json",
+ "param_name": "4band_44100_sw"
+ },
+ {
+ "hash_name": "4band_v2",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/4band_v2.json",
+ "param_name": "4band_v2"
+ },
+ {
+ "hash_name": "4band_v2_sn",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/4band_v2_sn.json",
+ "param_name": "4band_v2_sn"
+ },
+ {
+ "hash_name": "tmodelparam",
+ "model_params": "infer/lib/uvr5_pack/lib_v5/modelparams/tmodelparam.json",
+ "param_name": "User Model Param Set"
+ }
+ ]
+ }
+ ]
+}
\ No newline at end of file
diff --git a/infer/lib/uvr5_pack/utils.py b/infer/lib/uvr5_pack/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..f4805cdb25e7c50611412a19340ad525d1251d7b
--- /dev/null
+++ b/infer/lib/uvr5_pack/utils.py
@@ -0,0 +1,121 @@
+import json
+
+import numpy as np
+import torch
+from tqdm import tqdm
+
+
+def load_data(file_name: str = "./infer/lib/uvr5_pack/name_params.json") -> dict:
+ with open(file_name, "r") as f:
+ data = json.load(f)
+
+ return data
+
+
+def make_padding(width, cropsize, offset):
+ left = offset
+ roi_size = cropsize - left * 2
+ if roi_size == 0:
+ roi_size = cropsize
+ right = roi_size - (width % roi_size) + left
+
+ return left, right, roi_size
+
+
+def inference(X_spec, device, model, aggressiveness, data):
+ """
+ data : dic configs
+ """
+
+ def _execute(
+ X_mag_pad, roi_size, n_window, device, model, aggressiveness, is_half=True
+ ):
+ model.eval()
+ with torch.no_grad():
+ preds = []
+
+ iterations = [n_window]
+
+ total_iterations = sum(iterations)
+ for i in tqdm(range(n_window)):
+ start = i * roi_size
+ X_mag_window = X_mag_pad[
+ None, :, :, start : start + data["window_size"]
+ ]
+ X_mag_window = torch.from_numpy(X_mag_window)
+ if is_half:
+ X_mag_window = X_mag_window.half()
+ X_mag_window = X_mag_window.to(device)
+
+ pred = model.predict(X_mag_window, aggressiveness)
+
+ pred = pred.detach().cpu().numpy()
+ preds.append(pred[0])
+
+ pred = np.concatenate(preds, axis=2)
+ return pred
+
+ def preprocess(X_spec):
+ X_mag = np.abs(X_spec)
+ X_phase = np.angle(X_spec)
+
+ return X_mag, X_phase
+
+ X_mag, X_phase = preprocess(X_spec)
+
+ coef = X_mag.max()
+ X_mag_pre = X_mag / coef
+
+ n_frame = X_mag_pre.shape[2]
+ pad_l, pad_r, roi_size = make_padding(n_frame, data["window_size"], model.offset)
+ n_window = int(np.ceil(n_frame / roi_size))
+
+ X_mag_pad = np.pad(X_mag_pre, ((0, 0), (0, 0), (pad_l, pad_r)), mode="constant")
+
+ if list(model.state_dict().values())[0].dtype == torch.float16:
+ is_half = True
+ else:
+ is_half = False
+ pred = _execute(
+ X_mag_pad, roi_size, n_window, device, model, aggressiveness, is_half
+ )
+ pred = pred[:, :, :n_frame]
+
+ if data["tta"]:
+ pad_l += roi_size // 2
+ pad_r += roi_size // 2
+ n_window += 1
+
+ X_mag_pad = np.pad(X_mag_pre, ((0, 0), (0, 0), (pad_l, pad_r)), mode="constant")
+
+ pred_tta = _execute(
+ X_mag_pad, roi_size, n_window, device, model, aggressiveness, is_half
+ )
+ pred_tta = pred_tta[:, :, roi_size // 2 :]
+ pred_tta = pred_tta[:, :, :n_frame]
+
+ return (pred + pred_tta) * 0.5 * coef, X_mag, np.exp(1.0j * X_phase)
+ else:
+ return pred * coef, X_mag, np.exp(1.0j * X_phase)
+
+
+def _get_name_params(model_path, model_hash):
+ data = load_data()
+ flag = False
+ ModelName = model_path
+ for type in list(data):
+ for model in list(data[type][0]):
+ for i in range(len(data[type][0][model])):
+ if str(data[type][0][model][i]["hash_name"]) == model_hash:
+ flag = True
+ elif str(data[type][0][model][i]["hash_name"]) in ModelName:
+ flag = True
+
+ if flag:
+ model_params_auto = data[type][0][model][i]["model_params"]
+ param_name_auto = data[type][0][model][i]["param_name"]
+ if type == "equivalent":
+ return param_name_auto, model_params_auto
+ else:
+ flag = False
+ return param_name_auto, model_params_auto
diff --git a/infer/modules/gui/__init__.py b/infer/modules/gui/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8c1b5494ab8d2d3e932b7ac666121a0c5cf9c81b
--- /dev/null
+++ b/infer/modules/gui/__init__.py
@@ -0,0 +1,13 @@
+"""
+TorchGating is a PyTorch-based implementation of Spectral Gating
+================================================
+Author: Asaf Zorea
+
+Contents
+--------
+torchgate imports all the functions from PyTorch, and in addition provides:
+ TorchGating --- A PyTorch module that applies a spectral gate to an input signal
+
+"""
+
+from .torchgate import TorchGate
diff --git a/infer/modules/gui/torchgate.py b/infer/modules/gui/torchgate.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4b80c4ab6fa693c71381aedadd66c989d4ef186
--- /dev/null
+++ b/infer/modules/gui/torchgate.py
@@ -0,0 +1,280 @@
+import torch
+from infer.lib.rmvpe import STFT
+from torch.nn.functional import conv1d, conv2d
+from typing import Union, Optional
+from .utils import linspace, temperature_sigmoid, amp_to_db
+
+
+class TorchGate(torch.nn.Module):
+ """
+ A PyTorch module that applies a spectral gate to an input signal.
+
+ Arguments:
+ sr {int} -- Sample rate of the input signal.
+ nonstationary {bool} -- Whether to use non-stationary or stationary masking (default: {False}).
+ n_std_thresh_stationary {float} -- Number of standard deviations above mean to threshold noise for
+ stationary masking (default: {1.5}).
+ n_thresh_nonstationary {float} -- Number of multiplies above smoothed magnitude spectrogram. for
+ non-stationary masking (default: {1.3}).
+ temp_coeff_nonstationary {float} -- Temperature coefficient for non-stationary masking (default: {0.1}).
+ n_movemean_nonstationary {int} -- Number of samples for moving average smoothing in non-stationary masking
+ (default: {20}).
+ prop_decrease {float} -- Proportion to decrease signal by where the mask is zero (default: {1.0}).
+ n_fft {int} -- Size of FFT for STFT (default: {1024}).
+ win_length {[int]} -- Window length for STFT. If None, defaults to `n_fft` (default: {None}).
+ hop_length {[int]} -- Hop length for STFT. If None, defaults to `win_length` // 4 (default: {None}).
+ freq_mask_smooth_hz {float} -- Frequency smoothing width for mask (in Hz). If None, no smoothing is applied
+ (default: {500}).
+ time_mask_smooth_ms {float} -- Time smoothing width for mask (in ms). If None, no smoothing is applied
+ (default: {50}).
+ """
+
+ @torch.no_grad()
+ def __init__(
+ self,
+ sr: int,
+ nonstationary: bool = False,
+ n_std_thresh_stationary: float = 1.5,
+ n_thresh_nonstationary: float = 1.3,
+ temp_coeff_nonstationary: float = 0.1,
+ n_movemean_nonstationary: int = 20,
+ prop_decrease: float = 1.0,
+ n_fft: int = 1024,
+ win_length: bool = None,
+ hop_length: int = None,
+ freq_mask_smooth_hz: float = 500,
+ time_mask_smooth_ms: float = 50,
+ ):
+ super().__init__()
+
+ # General Params
+ self.sr = sr
+ self.nonstationary = nonstationary
+ assert 0.0 <= prop_decrease <= 1.0
+ self.prop_decrease = prop_decrease
+
+ # STFT Params
+ self.n_fft = n_fft
+ self.win_length = self.n_fft if win_length is None else win_length
+ self.hop_length = self.win_length // 4 if hop_length is None else hop_length
+
+ # Stationary Params
+ self.n_std_thresh_stationary = n_std_thresh_stationary
+
+ # Non-Stationary Params
+ self.temp_coeff_nonstationary = temp_coeff_nonstationary
+ self.n_movemean_nonstationary = n_movemean_nonstationary
+ self.n_thresh_nonstationary = n_thresh_nonstationary
+
+ # Smooth Mask Params
+ self.freq_mask_smooth_hz = freq_mask_smooth_hz
+ self.time_mask_smooth_ms = time_mask_smooth_ms
+ self.register_buffer("smoothing_filter", self._generate_mask_smoothing_filter())
+
+ @torch.no_grad()
+ def _generate_mask_smoothing_filter(self) -> Union[torch.Tensor, None]:
+ """
+ A PyTorch module that applies a spectral gate to an input signal using the STFT.
+
+ Returns:
+ smoothing_filter (torch.Tensor): a 2D tensor representing the smoothing filter,
+ with shape (n_grad_freq, n_grad_time), where n_grad_freq is the number of frequency
+ bins to smooth and n_grad_time is the number of time frames to smooth.
+ If both self.freq_mask_smooth_hz and self.time_mask_smooth_ms are None, returns None.
+ """
+ if self.freq_mask_smooth_hz is None and self.time_mask_smooth_ms is None:
+ return None
+
+ n_grad_freq = (
+ 1
+ if self.freq_mask_smooth_hz is None
+ else int(self.freq_mask_smooth_hz / (self.sr / (self.n_fft / 2)))
+ )
+ if n_grad_freq < 1:
+ raise ValueError(
+ f"freq_mask_smooth_hz needs to be at least {int((self.sr / (self._n_fft / 2)))} Hz"
+ )
+
+ n_grad_time = (
+ 1
+ if self.time_mask_smooth_ms is None
+ else int(self.time_mask_smooth_ms / ((self.hop_length / self.sr) * 1000))
+ )
+ if n_grad_time < 1:
+ raise ValueError(
+ f"time_mask_smooth_ms needs to be at least {int((self.hop_length / self.sr) * 1000)} ms"
+ )
+
+ if n_grad_time == 1 and n_grad_freq == 1:
+ return None
+
+ v_f = torch.cat(
+ [
+ linspace(0, 1, n_grad_freq + 1, endpoint=False),
+ linspace(1, 0, n_grad_freq + 2),
+ ]
+ )[1:-1]
+ v_t = torch.cat(
+ [
+ linspace(0, 1, n_grad_time + 1, endpoint=False),
+ linspace(1, 0, n_grad_time + 2),
+ ]
+ )[1:-1]
+ smoothing_filter = torch.outer(v_f, v_t).unsqueeze(0).unsqueeze(0)
+
+ return smoothing_filter / smoothing_filter.sum()
+
+ @torch.no_grad()
+ def _stationary_mask(
+ self, X_db: torch.Tensor, xn: Optional[torch.Tensor] = None
+ ) -> torch.Tensor:
+ """
+ Computes a stationary binary mask to filter out noise in a log-magnitude spectrogram.
+
+ Arguments:
+ X_db (torch.Tensor): 2D tensor of shape (frames, freq_bins) containing the log-magnitude spectrogram.
+ xn (torch.Tensor): 1D tensor containing the audio signal corresponding to X_db.
+
+ Returns:
+ sig_mask (torch.Tensor): Binary mask of the same shape as X_db, where values greater than the threshold
+ are set to 1, and the rest are set to 0.
+ """
+ if xn is not None:
+ if "privateuseone" in str(xn.device):
+ if not hasattr(self, "stft"):
+ self.stft = STFT(
+ filter_length=self.n_fft,
+ hop_length=self.hop_length,
+ win_length=self.win_length,
+ window="hann",
+ ).to(xn.device)
+ XN = self.stft.transform(xn)
+ else:
+ XN = torch.stft(
+ xn,
+ n_fft=self.n_fft,
+ hop_length=self.hop_length,
+ win_length=self.win_length,
+ return_complex=True,
+ pad_mode="constant",
+ center=True,
+ window=torch.hann_window(self.win_length).to(xn.device),
+ )
+ XN_db = amp_to_db(XN).to(dtype=X_db.dtype)
+ else:
+ XN_db = X_db
+
+ # calculate mean and standard deviation along the frequency axis
+ std_freq_noise, mean_freq_noise = torch.std_mean(XN_db, dim=-1)
+
+ # compute noise threshold
+ noise_thresh = mean_freq_noise + std_freq_noise * self.n_std_thresh_stationary
+
+ # create binary mask by thresholding the spectrogram
+ sig_mask = X_db > noise_thresh.unsqueeze(2)
+ return sig_mask
+
+ @torch.no_grad()
+ def _nonstationary_mask(self, X_abs: torch.Tensor) -> torch.Tensor:
+ """
+ Computes a non-stationary binary mask to filter out noise in a log-magnitude spectrogram.
+
+ Arguments:
+ X_abs (torch.Tensor): 2D tensor of shape (frames, freq_bins) containing the magnitude spectrogram.
+
+ Returns:
+ sig_mask (torch.Tensor): Binary mask of the same shape as X_abs, where values greater than the threshold
+ are set to 1, and the rest are set to 0.
+ """
+ X_smoothed = (
+ conv1d(
+ X_abs.reshape(-1, 1, X_abs.shape[-1]),
+ torch.ones(
+ self.n_movemean_nonstationary,
+ dtype=X_abs.dtype,
+ device=X_abs.device,
+ ).view(1, 1, -1),
+ padding="same",
+ ).view(X_abs.shape)
+ / self.n_movemean_nonstationary
+ )
+
+ # Compute slowness ratio and apply temperature sigmoid
+ slowness_ratio = (X_abs - X_smoothed) / (X_smoothed + 1e-6)
+ sig_mask = temperature_sigmoid(
+ slowness_ratio, self.n_thresh_nonstationary, self.temp_coeff_nonstationary
+ )
+
+ return sig_mask
+
+ def forward(
+ self, x: torch.Tensor, xn: Optional[torch.Tensor] = None
+ ) -> torch.Tensor:
+ """
+ Apply the proposed algorithm to the input signal.
+
+ Arguments:
+ x (torch.Tensor): The input audio signal, with shape (batch_size, signal_length).
+ xn (Optional[torch.Tensor]): The noise signal used for stationary noise reduction. If `None`, the input
+ signal is used as the noise signal. Default: `None`.
+
+ Returns:
+ torch.Tensor: The denoised audio signal, with the same shape as the input signal.
+ """
+
+ # Compute short-time Fourier transform (STFT)
+ if "privateuseone" in str(x.device):
+ if not hasattr(self, "stft"):
+ self.stft = STFT(
+ filter_length=self.n_fft,
+ hop_length=self.hop_length,
+ win_length=self.win_length,
+ window="hann",
+ ).to(x.device)
+ X, phase = self.stft.transform(x, return_phase=True)
+ else:
+ X = torch.stft(
+ x,
+ n_fft=self.n_fft,
+ hop_length=self.hop_length,
+ win_length=self.win_length,
+ return_complex=True,
+ pad_mode="constant",
+ center=True,
+ window=torch.hann_window(self.win_length).to(x.device),
+ )
+
+ # Compute signal mask based on stationary or nonstationary assumptions
+ if self.nonstationary:
+ sig_mask = self._nonstationary_mask(X.abs())
+ else:
+ sig_mask = self._stationary_mask(amp_to_db(X), xn)
+
+ # Propagate decrease in signal power
+ sig_mask = self.prop_decrease * (sig_mask.float() - 1.0) + 1.0
+
+ # Smooth signal mask with 2D convolution
+ if self.smoothing_filter is not None:
+ sig_mask = conv2d(
+ sig_mask.unsqueeze(1),
+ self.smoothing_filter.to(sig_mask.dtype),
+ padding="same",
+ )
+
+ # Apply signal mask to STFT magnitude and phase components
+ Y = X * sig_mask.squeeze(1)
+
+ # Inverse STFT to obtain time-domain signal
+ if "privateuseone" in str(Y.device):
+ y = self.stft.inverse(Y, phase)
+ else:
+ y = torch.istft(
+ Y,
+ n_fft=self.n_fft,
+ hop_length=self.hop_length,
+ win_length=self.win_length,
+ center=True,
+ window=torch.hann_window(self.win_length).to(Y.device),
+ )
+
+ return y.to(dtype=x.dtype)
diff --git a/infer/modules/gui/utils.py b/infer/modules/gui/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..46820981c9f60fd2200b2418b2b9e9f2e4d1fb10
--- /dev/null
+++ b/infer/modules/gui/utils.py
@@ -0,0 +1,70 @@
+import torch
+from torch.types import Number
+
+
+@torch.no_grad()
+def amp_to_db(
+ x: torch.Tensor, eps=torch.finfo(torch.float64).eps, top_db=40
+) -> torch.Tensor:
+ """
+ Convert the input tensor from amplitude to decibel scale.
+
+ Arguments:
+ x {[torch.Tensor]} -- [Input tensor.]
+
+ Keyword Arguments:
+ eps {[float]} -- [Small value to avoid numerical instability.]
+ (default: {torch.finfo(torch.float64).eps})
+ top_db {[float]} -- [threshold the output at ``top_db`` below the peak]
+ ` (default: {40})
+
+ Returns:
+ [torch.Tensor] -- [Output tensor in decibel scale.]
+ """
+ x_db = 20 * torch.log10(x.abs() + eps)
+ return torch.max(x_db, (x_db.max(-1).values - top_db).unsqueeze(-1))
+
+
+@torch.no_grad()
+def temperature_sigmoid(x: torch.Tensor, x0: float, temp_coeff: float) -> torch.Tensor:
+ """
+ Apply a sigmoid function with temperature scaling.
+
+ Arguments:
+ x {[torch.Tensor]} -- [Input tensor.]
+ x0 {[float]} -- [Parameter that controls the threshold of the sigmoid.]
+ temp_coeff {[float]} -- [Parameter that controls the slope of the sigmoid.]
+
+ Returns:
+ [torch.Tensor] -- [Output tensor after applying the sigmoid with temperature scaling.]
+ """
+ return torch.sigmoid((x - x0) / temp_coeff)
+
+
+@torch.no_grad()
+def linspace(
+ start: Number, stop: Number, num: int = 50, endpoint: bool = True, **kwargs
+) -> torch.Tensor:
+ """
+ Generate a linearly spaced 1-D tensor.
+
+ Arguments:
+ start {[Number]} -- [The starting value of the sequence.]
+ stop {[Number]} -- [The end value of the sequence, unless `endpoint` is set to False.
+ In that case, the sequence consists of all but the last of ``num + 1``
+ evenly spaced samples, so that `stop` is excluded. Note that the step
+ size changes when `endpoint` is False.]
+
+ Keyword Arguments:
+ num {[int]} -- [Number of samples to generate. Default is 50. Must be non-negative.]
+ endpoint {[bool]} -- [If True, `stop` is the last sample. Otherwise, it is not included.
+ Default is True.]
+ **kwargs -- [Additional arguments to be passed to the underlying PyTorch `linspace` function.]
+
+ Returns:
+ [torch.Tensor] -- [1-D tensor of `num` equally spaced samples from `start` to `stop`.]
+ """
+ if endpoint:
+ return torch.linspace(start, stop, num, **kwargs)
+ else:
+ return torch.linspace(start, stop, num + 1, **kwargs)[:-1]
diff --git a/infer/modules/ipex/__init__.py b/infer/modules/ipex/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..cd27bc172f28a20a0378f8e91e4fa463d4118a72
--- /dev/null
+++ b/infer/modules/ipex/__init__.py
@@ -0,0 +1,190 @@
+import os
+import sys
+import contextlib
+import torch
+import intel_extension_for_pytorch as ipex # pylint: disable=import-error, unused-import
+from .hijacks import ipex_hijacks
+from .attention import attention_init
+
+# pylint: disable=protected-access, missing-function-docstring, line-too-long
+
+
+def ipex_init(): # pylint: disable=too-many-statements
+ try:
+ # Replace cuda with xpu:
+ torch.cuda.current_device = torch.xpu.current_device
+ torch.cuda.current_stream = torch.xpu.current_stream
+ torch.cuda.device = torch.xpu.device
+ torch.cuda.device_count = torch.xpu.device_count
+ torch.cuda.device_of = torch.xpu.device_of
+ torch.cuda.get_device_name = torch.xpu.get_device_name
+ torch.cuda.get_device_properties = torch.xpu.get_device_properties
+ torch.cuda.init = torch.xpu.init
+ torch.cuda.is_available = torch.xpu.is_available
+ torch.cuda.is_initialized = torch.xpu.is_initialized
+ torch.cuda.is_current_stream_capturing = lambda: False
+ torch.cuda.set_device = torch.xpu.set_device
+ torch.cuda.stream = torch.xpu.stream
+ torch.cuda.synchronize = torch.xpu.synchronize
+ torch.cuda.Event = torch.xpu.Event
+ torch.cuda.Stream = torch.xpu.Stream
+ torch.cuda.FloatTensor = torch.xpu.FloatTensor
+ torch.Tensor.cuda = torch.Tensor.xpu
+ torch.Tensor.is_cuda = torch.Tensor.is_xpu
+ torch.cuda._initialization_lock = torch.xpu.lazy_init._initialization_lock
+ torch.cuda._initialized = torch.xpu.lazy_init._initialized
+ torch.cuda._lazy_seed_tracker = torch.xpu.lazy_init._lazy_seed_tracker
+ torch.cuda._queued_calls = torch.xpu.lazy_init._queued_calls
+ torch.cuda._tls = torch.xpu.lazy_init._tls
+ torch.cuda.threading = torch.xpu.lazy_init.threading
+ torch.cuda.traceback = torch.xpu.lazy_init.traceback
+ torch.cuda.Optional = torch.xpu.Optional
+ torch.cuda.__cached__ = torch.xpu.__cached__
+ torch.cuda.__loader__ = torch.xpu.__loader__
+ torch.cuda.ComplexFloatStorage = torch.xpu.ComplexFloatStorage
+ torch.cuda.Tuple = torch.xpu.Tuple
+ torch.cuda.streams = torch.xpu.streams
+ torch.cuda._lazy_new = torch.xpu._lazy_new
+ torch.cuda.FloatStorage = torch.xpu.FloatStorage
+ torch.cuda.Any = torch.xpu.Any
+ torch.cuda.__doc__ = torch.xpu.__doc__
+ torch.cuda.default_generators = torch.xpu.default_generators
+ torch.cuda.HalfTensor = torch.xpu.HalfTensor
+ torch.cuda._get_device_index = torch.xpu._get_device_index
+ torch.cuda.__path__ = torch.xpu.__path__
+ torch.cuda.Device = torch.xpu.Device
+ torch.cuda.IntTensor = torch.xpu.IntTensor
+ torch.cuda.ByteStorage = torch.xpu.ByteStorage
+ torch.cuda.set_stream = torch.xpu.set_stream
+ torch.cuda.BoolStorage = torch.xpu.BoolStorage
+ torch.cuda.os = torch.xpu.os
+ torch.cuda.torch = torch.xpu.torch
+ torch.cuda.BFloat16Storage = torch.xpu.BFloat16Storage
+ torch.cuda.Union = torch.xpu.Union
+ torch.cuda.DoubleTensor = torch.xpu.DoubleTensor
+ torch.cuda.ShortTensor = torch.xpu.ShortTensor
+ torch.cuda.LongTensor = torch.xpu.LongTensor
+ torch.cuda.IntStorage = torch.xpu.IntStorage
+ torch.cuda.LongStorage = torch.xpu.LongStorage
+ torch.cuda.__annotations__ = torch.xpu.__annotations__
+ torch.cuda.__package__ = torch.xpu.__package__
+ torch.cuda.__builtins__ = torch.xpu.__builtins__
+ torch.cuda.CharTensor = torch.xpu.CharTensor
+ torch.cuda.List = torch.xpu.List
+ torch.cuda._lazy_init = torch.xpu._lazy_init
+ torch.cuda.BFloat16Tensor = torch.xpu.BFloat16Tensor
+ torch.cuda.DoubleStorage = torch.xpu.DoubleStorage
+ torch.cuda.ByteTensor = torch.xpu.ByteTensor
+ torch.cuda.StreamContext = torch.xpu.StreamContext
+ torch.cuda.ComplexDoubleStorage = torch.xpu.ComplexDoubleStorage
+ torch.cuda.ShortStorage = torch.xpu.ShortStorage
+ torch.cuda._lazy_call = torch.xpu._lazy_call
+ torch.cuda.HalfStorage = torch.xpu.HalfStorage
+ torch.cuda.random = torch.xpu.random
+ torch.cuda._device = torch.xpu._device
+ torch.cuda.classproperty = torch.xpu.classproperty
+ torch.cuda.__name__ = torch.xpu.__name__
+ torch.cuda._device_t = torch.xpu._device_t
+ torch.cuda.warnings = torch.xpu.warnings
+ torch.cuda.__spec__ = torch.xpu.__spec__
+ torch.cuda.BoolTensor = torch.xpu.BoolTensor
+ torch.cuda.CharStorage = torch.xpu.CharStorage
+ torch.cuda.__file__ = torch.xpu.__file__
+ torch.cuda._is_in_bad_fork = torch.xpu.lazy_init._is_in_bad_fork
+ # torch.cuda.is_current_stream_capturing = torch.xpu.is_current_stream_capturing
+
+ # Memory:
+ torch.cuda.memory = torch.xpu.memory
+ if "linux" in sys.platform and "WSL2" in os.popen("uname -a").read():
+ torch.xpu.empty_cache = lambda: None
+ torch.cuda.empty_cache = torch.xpu.empty_cache
+ torch.cuda.memory_stats = torch.xpu.memory_stats
+ torch.cuda.memory_summary = torch.xpu.memory_summary
+ torch.cuda.memory_snapshot = torch.xpu.memory_snapshot
+ torch.cuda.memory_allocated = torch.xpu.memory_allocated
+ torch.cuda.max_memory_allocated = torch.xpu.max_memory_allocated
+ torch.cuda.memory_reserved = torch.xpu.memory_reserved
+ torch.cuda.memory_cached = torch.xpu.memory_reserved
+ torch.cuda.max_memory_reserved = torch.xpu.max_memory_reserved
+ torch.cuda.max_memory_cached = torch.xpu.max_memory_reserved
+ torch.cuda.reset_peak_memory_stats = torch.xpu.reset_peak_memory_stats
+ torch.cuda.reset_max_memory_cached = torch.xpu.reset_peak_memory_stats
+ torch.cuda.reset_max_memory_allocated = torch.xpu.reset_peak_memory_stats
+ torch.cuda.memory_stats_as_nested_dict = torch.xpu.memory_stats_as_nested_dict
+ torch.cuda.reset_accumulated_memory_stats = (
+ torch.xpu.reset_accumulated_memory_stats
+ )
+
+ # RNG:
+ torch.cuda.get_rng_state = torch.xpu.get_rng_state
+ torch.cuda.get_rng_state_all = torch.xpu.get_rng_state_all
+ torch.cuda.set_rng_state = torch.xpu.set_rng_state
+ torch.cuda.set_rng_state_all = torch.xpu.set_rng_state_all
+ torch.cuda.manual_seed = torch.xpu.manual_seed
+ torch.cuda.manual_seed_all = torch.xpu.manual_seed_all
+ torch.cuda.seed = torch.xpu.seed
+ torch.cuda.seed_all = torch.xpu.seed_all
+ torch.cuda.initial_seed = torch.xpu.initial_seed
+
+ # AMP:
+ torch.cuda.amp = torch.xpu.amp
+ if not hasattr(torch.cuda.amp, "common"):
+ torch.cuda.amp.common = contextlib.nullcontext()
+ torch.cuda.amp.common.amp_definitely_not_available = lambda: False
+ try:
+ torch.cuda.amp.GradScaler = torch.xpu.amp.GradScaler
+ except Exception: # pylint: disable=broad-exception-caught
+ try:
+ from .gradscaler import (
+ gradscaler_init,
+ ) # pylint: disable=import-outside-toplevel, import-error
+
+ gradscaler_init()
+ torch.cuda.amp.GradScaler = torch.xpu.amp.GradScaler
+ except Exception: # pylint: disable=broad-exception-caught
+ torch.cuda.amp.GradScaler = ipex.cpu.autocast._grad_scaler.GradScaler
+
+ # C
+ torch._C._cuda_getCurrentRawStream = ipex._C._getCurrentStream
+ ipex._C._DeviceProperties.major = 2023
+ ipex._C._DeviceProperties.minor = 2
+
+ # Fix functions with ipex:
+ torch.cuda.mem_get_info = lambda device=None: [
+ (
+ torch.xpu.get_device_properties(device).total_memory
+ - torch.xpu.memory_allocated(device)
+ ),
+ torch.xpu.get_device_properties(device).total_memory,
+ ]
+ torch._utils._get_available_device_type = lambda: "xpu"
+ torch.has_cuda = True
+ torch.cuda.has_half = True
+ torch.cuda.is_bf16_supported = lambda *args, **kwargs: True
+ torch.cuda.is_fp16_supported = lambda *args, **kwargs: True
+ torch.version.cuda = "11.7"
+ torch.cuda.get_device_capability = lambda *args, **kwargs: [11, 7]
+ torch.cuda.get_device_properties.major = 11
+ torch.cuda.get_device_properties.minor = 7
+ torch.cuda.ipc_collect = lambda *args, **kwargs: None
+ torch.cuda.utilization = lambda *args, **kwargs: 0
+ if hasattr(torch.xpu, "getDeviceIdListForCard"):
+ torch.cuda.getDeviceIdListForCard = torch.xpu.getDeviceIdListForCard
+ torch.cuda.get_device_id_list_per_card = torch.xpu.getDeviceIdListForCard
+ else:
+ torch.cuda.getDeviceIdListForCard = torch.xpu.get_device_id_list_per_card
+ torch.cuda.get_device_id_list_per_card = (
+ torch.xpu.get_device_id_list_per_card
+ )
+
+ ipex_hijacks()
+ attention_init()
+ try:
+ from .diffusers import ipex_diffusers
+
+ ipex_diffusers()
+ except Exception: # pylint: disable=broad-exception-caught
+ pass
+ except Exception as e:
+ return False, e
+ return True, None
diff --git a/infer/modules/ipex/attention.py b/infer/modules/ipex/attention.py
new file mode 100644
index 0000000000000000000000000000000000000000..78a4775ccf95ded03a953e07e5ffccc7bb4f29b5
--- /dev/null
+++ b/infer/modules/ipex/attention.py
@@ -0,0 +1,218 @@
+import torch
+import intel_extension_for_pytorch as ipex # pylint: disable=import-error, unused-import
+
+# pylint: disable=protected-access, missing-function-docstring, line-too-long
+
+original_torch_bmm = torch.bmm
+
+
+def torch_bmm(input, mat2, *, out=None):
+ if input.dtype != mat2.dtype:
+ mat2 = mat2.to(input.dtype)
+
+ # ARC GPUs can't allocate more than 4GB to a single block, Slice it:
+ batch_size_attention, input_tokens, mat2_shape = (
+ input.shape[0],
+ input.shape[1],
+ mat2.shape[2],
+ )
+ block_multiply = input.element_size()
+ slice_block_size = input_tokens * mat2_shape / 1024 / 1024 * block_multiply
+ block_size = batch_size_attention * slice_block_size
+
+ split_slice_size = batch_size_attention
+ if block_size > 4:
+ do_split = True
+ # Find something divisible with the input_tokens
+ while (split_slice_size * slice_block_size) > 4:
+ split_slice_size = split_slice_size // 2
+ if split_slice_size <= 1:
+ split_slice_size = 1
+ break
+ else:
+ do_split = False
+
+ split_2_slice_size = input_tokens
+ if split_slice_size * slice_block_size > 4:
+ slice_block_size2 = split_slice_size * mat2_shape / 1024 / 1024 * block_multiply
+ do_split_2 = True
+ # Find something divisible with the input_tokens
+ while (split_2_slice_size * slice_block_size2) > 4:
+ split_2_slice_size = split_2_slice_size // 2
+ if split_2_slice_size <= 1:
+ split_2_slice_size = 1
+ break
+ else:
+ do_split_2 = False
+
+ if do_split:
+ hidden_states = torch.zeros(
+ input.shape[0],
+ input.shape[1],
+ mat2.shape[2],
+ device=input.device,
+ dtype=input.dtype,
+ )
+ for i in range(batch_size_attention // split_slice_size):
+ start_idx = i * split_slice_size
+ end_idx = (i + 1) * split_slice_size
+ if do_split_2:
+ for i2 in range(
+ input_tokens // split_2_slice_size
+ ): # pylint: disable=invalid-name
+ start_idx_2 = i2 * split_2_slice_size
+ end_idx_2 = (i2 + 1) * split_2_slice_size
+ hidden_states[start_idx:end_idx, start_idx_2:end_idx_2] = (
+ original_torch_bmm(
+ input[start_idx:end_idx, start_idx_2:end_idx_2],
+ mat2[start_idx:end_idx, start_idx_2:end_idx_2],
+ out=out,
+ )
+ )
+ else:
+ hidden_states[start_idx:end_idx] = original_torch_bmm(
+ input[start_idx:end_idx], mat2[start_idx:end_idx], out=out
+ )
+ else:
+ return original_torch_bmm(input, mat2, out=out)
+ return hidden_states
+
+
+original_scaled_dot_product_attention = torch.nn.functional.scaled_dot_product_attention
+
+
+def scaled_dot_product_attention(
+ query, key, value, attn_mask=None, dropout_p=0.0, is_causal=False
+):
+ # ARC GPUs can't allocate more than 4GB to a single block, Slice it:
+ if len(query.shape) == 3:
+ batch_size_attention, query_tokens, shape_four = query.shape
+ shape_one = 1
+ no_shape_one = True
+ else:
+ shape_one, batch_size_attention, query_tokens, shape_four = query.shape
+ no_shape_one = False
+
+ block_multiply = query.element_size()
+ slice_block_size = (
+ shape_one * query_tokens * shape_four / 1024 / 1024 * block_multiply
+ )
+ block_size = batch_size_attention * slice_block_size
+
+ split_slice_size = batch_size_attention
+ if block_size > 4:
+ do_split = True
+ # Find something divisible with the shape_one
+ while (split_slice_size * slice_block_size) > 4:
+ split_slice_size = split_slice_size // 2
+ if split_slice_size <= 1:
+ split_slice_size = 1
+ break
+ else:
+ do_split = False
+
+ split_2_slice_size = query_tokens
+ if split_slice_size * slice_block_size > 4:
+ slice_block_size2 = (
+ shape_one * split_slice_size * shape_four / 1024 / 1024 * block_multiply
+ )
+ do_split_2 = True
+ # Find something divisible with the batch_size_attention
+ while (split_2_slice_size * slice_block_size2) > 4:
+ split_2_slice_size = split_2_slice_size // 2
+ if split_2_slice_size <= 1:
+ split_2_slice_size = 1
+ break
+ else:
+ do_split_2 = False
+
+ if do_split:
+ hidden_states = torch.zeros(query.shape, device=query.device, dtype=query.dtype)
+ for i in range(batch_size_attention // split_slice_size):
+ start_idx = i * split_slice_size
+ end_idx = (i + 1) * split_slice_size
+ if do_split_2:
+ for i2 in range(
+ query_tokens // split_2_slice_size
+ ): # pylint: disable=invalid-name
+ start_idx_2 = i2 * split_2_slice_size
+ end_idx_2 = (i2 + 1) * split_2_slice_size
+ if no_shape_one:
+ hidden_states[start_idx:end_idx, start_idx_2:end_idx_2] = (
+ original_scaled_dot_product_attention(
+ query[start_idx:end_idx, start_idx_2:end_idx_2],
+ key[start_idx:end_idx, start_idx_2:end_idx_2],
+ value[start_idx:end_idx, start_idx_2:end_idx_2],
+ attn_mask=(
+ attn_mask[start_idx:end_idx, start_idx_2:end_idx_2]
+ if attn_mask is not None
+ else attn_mask
+ ),
+ dropout_p=dropout_p,
+ is_causal=is_causal,
+ )
+ )
+ else:
+ hidden_states[:, start_idx:end_idx, start_idx_2:end_idx_2] = (
+ original_scaled_dot_product_attention(
+ query[:, start_idx:end_idx, start_idx_2:end_idx_2],
+ key[:, start_idx:end_idx, start_idx_2:end_idx_2],
+ value[:, start_idx:end_idx, start_idx_2:end_idx_2],
+ attn_mask=(
+ attn_mask[
+ :, start_idx:end_idx, start_idx_2:end_idx_2
+ ]
+ if attn_mask is not None
+ else attn_mask
+ ),
+ dropout_p=dropout_p,
+ is_causal=is_causal,
+ )
+ )
+ else:
+ if no_shape_one:
+ hidden_states[start_idx:end_idx] = (
+ original_scaled_dot_product_attention(
+ query[start_idx:end_idx],
+ key[start_idx:end_idx],
+ value[start_idx:end_idx],
+ attn_mask=(
+ attn_mask[start_idx:end_idx]
+ if attn_mask is not None
+ else attn_mask
+ ),
+ dropout_p=dropout_p,
+ is_causal=is_causal,
+ )
+ )
+ else:
+ hidden_states[:, start_idx:end_idx] = (
+ original_scaled_dot_product_attention(
+ query[:, start_idx:end_idx],
+ key[:, start_idx:end_idx],
+ value[:, start_idx:end_idx],
+ attn_mask=(
+ attn_mask[:, start_idx:end_idx]
+ if attn_mask is not None
+ else attn_mask
+ ),
+ dropout_p=dropout_p,
+ is_causal=is_causal,
+ )
+ )
+ else:
+ return original_scaled_dot_product_attention(
+ query,
+ key,
+ value,
+ attn_mask=attn_mask,
+ dropout_p=dropout_p,
+ is_causal=is_causal,
+ )
+ return hidden_states
+
+
+def attention_init():
+ # ARC GPUs can't allocate more than 4GB to a single block:
+ torch.bmm = torch_bmm
+ torch.nn.functional.scaled_dot_product_attention = scaled_dot_product_attention
diff --git a/infer/modules/ipex/gradscaler.py b/infer/modules/ipex/gradscaler.py
new file mode 100644
index 0000000000000000000000000000000000000000..7875151d17c390aca2f8116293c63b0879b7d4c4
--- /dev/null
+++ b/infer/modules/ipex/gradscaler.py
@@ -0,0 +1,187 @@
+from collections import defaultdict
+import torch
+import intel_extension_for_pytorch as ipex # pylint: disable=import-error, unused-import
+import intel_extension_for_pytorch._C as core # pylint: disable=import-error, unused-import
+
+# pylint: disable=protected-access, missing-function-docstring, line-too-long
+
+OptState = ipex.cpu.autocast._grad_scaler.OptState
+_MultiDeviceReplicator = ipex.cpu.autocast._grad_scaler._MultiDeviceReplicator
+_refresh_per_optimizer_state = (
+ ipex.cpu.autocast._grad_scaler._refresh_per_optimizer_state
+)
+
+
+def _unscale_grads_(
+ self, optimizer, inv_scale, found_inf, allow_fp16
+): # pylint: disable=unused-argument
+ per_device_inv_scale = _MultiDeviceReplicator(inv_scale)
+ per_device_found_inf = _MultiDeviceReplicator(found_inf)
+
+ # To set up _amp_foreach_non_finite_check_and_unscale_, split grads by device and dtype.
+ # There could be hundreds of grads, so we'd like to iterate through them just once.
+ # However, we don't know their devices or dtypes in advance.
+
+ # https://stackoverflow.com/questions/5029934/defaultdict-of-defaultdict
+ # Google says mypy struggles with defaultdicts type annotations.
+ per_device_and_dtype_grads = defaultdict(lambda: defaultdict(list)) # type: ignore[var-annotated]
+ # sync grad to master weight
+ if hasattr(optimizer, "sync_grad"):
+ optimizer.sync_grad()
+ with torch.no_grad():
+ for group in optimizer.param_groups:
+ for param in group["params"]:
+ if param.grad is None:
+ continue
+ if (not allow_fp16) and param.grad.dtype == torch.float16:
+ raise ValueError("Attempting to unscale FP16 gradients.")
+ if param.grad.is_sparse:
+ # is_coalesced() == False means the sparse grad has values with duplicate indices.
+ # coalesce() deduplicates indices and adds all values that have the same index.
+ # For scaled fp16 values, there's a good chance coalescing will cause overflow,
+ # so we should check the coalesced _values().
+ if param.grad.dtype is torch.float16:
+ param.grad = param.grad.coalesce()
+ to_unscale = param.grad._values()
+ else:
+ to_unscale = param.grad
+
+ # -: is there a way to split by device and dtype without appending in the inner loop?
+ to_unscale = to_unscale.to("cpu")
+ per_device_and_dtype_grads[to_unscale.device][to_unscale.dtype].append(
+ to_unscale
+ )
+
+ for _, per_dtype_grads in per_device_and_dtype_grads.items():
+ for grads in per_dtype_grads.values():
+ core._amp_foreach_non_finite_check_and_unscale_(
+ grads,
+ per_device_found_inf.get("cpu"),
+ per_device_inv_scale.get("cpu"),
+ )
+
+ return per_device_found_inf._per_device_tensors
+
+
+def unscale_(self, optimizer):
+ """
+ Divides ("unscales") the optimizer's gradient tensors by the scale factor.
+ :meth:`unscale_` is optional, serving cases where you need to
+ :ref:`modify or inspect gradients`
+ between the backward pass(es) and :meth:`step`.
+ If :meth:`unscale_` is not called explicitly, gradients will be unscaled automatically during :meth:`step`.
+ Simple example, using :meth:`unscale_` to enable clipping of unscaled gradients::
+ ...
+ scaler.scale(loss).backward()
+ scaler.unscale_(optimizer)
+ torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
+ scaler.step(optimizer)
+ scaler.update()
+ Args:
+ optimizer (torch.optim.Optimizer): Optimizer that owns the gradients to be unscaled.
+ .. warning::
+ :meth:`unscale_` should only be called once per optimizer per :meth:`step` call,
+ and only after all gradients for that optimizer's assigned parameters have been accumulated.
+ Calling :meth:`unscale_` twice for a given optimizer between each :meth:`step` triggers a RuntimeError.
+ .. warning::
+ :meth:`unscale_` may unscale sparse gradients out of place, replacing the ``.grad`` attribute.
+ """
+ if not self._enabled:
+ return
+
+ self._check_scale_growth_tracker("unscale_")
+
+ optimizer_state = self._per_optimizer_states[id(optimizer)]
+
+ if optimizer_state["stage"] is OptState.UNSCALED: # pylint: disable=no-else-raise
+ raise RuntimeError(
+ "unscale_() has already been called on this optimizer since the last update()."
+ )
+ elif optimizer_state["stage"] is OptState.STEPPED:
+ raise RuntimeError("unscale_() is being called after step().")
+
+ # FP32 division can be imprecise for certain compile options, so we carry out the reciprocal in FP64.
+ assert self._scale is not None
+ inv_scale = (
+ self._scale.to("cpu").double().reciprocal().float().to(self._scale.device)
+ )
+ found_inf = torch.full((1,), 0.0, dtype=torch.float32, device=self._scale.device)
+
+ optimizer_state["found_inf_per_device"] = self._unscale_grads_(
+ optimizer, inv_scale, found_inf, False
+ )
+ optimizer_state["stage"] = OptState.UNSCALED
+
+
+def update(self, new_scale=None):
+ """
+ Updates the scale factor.
+ If any optimizer steps were skipped the scale is multiplied by ``backoff_factor``
+ to reduce it. If ``growth_interval`` unskipped iterations occurred consecutively,
+ the scale is multiplied by ``growth_factor`` to increase it.
+ Passing ``new_scale`` sets the new scale value manually. (``new_scale`` is not
+ used directly, it's used to fill GradScaler's internal scale tensor. So if
+ ``new_scale`` was a tensor, later in-place changes to that tensor will not further
+ affect the scale GradScaler uses internally.)
+ Args:
+ new_scale (float or :class:`torch.FloatTensor`, optional, default=None): New scale factor.
+ .. warning::
+ :meth:`update` should only be called at the end of the iteration, after ``scaler.step(optimizer)`` has
+ been invoked for all optimizers used this iteration.
+ """
+ if not self._enabled:
+ return
+
+ _scale, _growth_tracker = self._check_scale_growth_tracker("update")
+
+ if new_scale is not None:
+ # Accept a new user-defined scale.
+ if isinstance(new_scale, float):
+ self._scale.fill_(new_scale) # type: ignore[union-attr]
+ else:
+ reason = "new_scale should be a float or a 1-element torch.FloatTensor with requires_grad=False."
+ assert isinstance(new_scale, torch.FloatTensor), reason # type: ignore[attr-defined]
+ assert new_scale.numel() == 1, reason
+ assert new_scale.requires_grad is False, reason
+ self._scale.copy_(new_scale) # type: ignore[union-attr]
+ else:
+ # Consume shared inf/nan data collected from optimizers to update the scale.
+ # If all found_inf tensors are on the same device as self._scale, this operation is asynchronous.
+ found_infs = [
+ found_inf.to(device="cpu", non_blocking=True)
+ for state in self._per_optimizer_states.values()
+ for found_inf in state["found_inf_per_device"].values()
+ ]
+
+ assert len(found_infs) > 0, "No inf checks were recorded prior to update."
+
+ found_inf_combined = found_infs[0]
+ if len(found_infs) > 1:
+ for i in range(1, len(found_infs)):
+ found_inf_combined += found_infs[i]
+
+ to_device = _scale.device
+ _scale = _scale.to("cpu")
+ _growth_tracker = _growth_tracker.to("cpu")
+
+ core._amp_update_scale_(
+ _scale,
+ _growth_tracker,
+ found_inf_combined,
+ self._growth_factor,
+ self._backoff_factor,
+ self._growth_interval,
+ )
+
+ _scale = _scale.to(to_device)
+ _growth_tracker = _growth_tracker.to(to_device)
+ # To prepare for next iteration, clear the data collected from optimizers this iteration.
+ self._per_optimizer_states = defaultdict(_refresh_per_optimizer_state)
+
+
+def gradscaler_init():
+ torch.xpu.amp.GradScaler = ipex.cpu.autocast._grad_scaler.GradScaler
+ torch.xpu.amp.GradScaler._unscale_grads_ = _unscale_grads_
+ torch.xpu.amp.GradScaler.unscale_ = unscale_
+ torch.xpu.amp.GradScaler.update = update
+ return torch.xpu.amp.GradScaler
diff --git a/infer/modules/ipex/hijacks.py b/infer/modules/ipex/hijacks.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc75f0c7cbfa41f145db95a05296f0668400e981
--- /dev/null
+++ b/infer/modules/ipex/hijacks.py
@@ -0,0 +1,365 @@
+import contextlib
+import importlib
+import torch
+import intel_extension_for_pytorch as ipex # pylint: disable=import-error, unused-import
+
+# pylint: disable=protected-access, missing-function-docstring, line-too-long, unnecessary-lambda, no-else-return
+
+
+class CondFunc: # pylint: disable=missing-class-docstring
+ def __new__(cls, orig_func, sub_func, cond_func):
+ self = super(CondFunc, cls).__new__(cls)
+ if isinstance(orig_func, str):
+ func_path = orig_func.split(".")
+ for i in range(len(func_path) - 1, -1, -1):
+ try:
+ resolved_obj = importlib.import_module(".".join(func_path[:i]))
+ break
+ except ImportError:
+ pass
+ for attr_name in func_path[i:-1]:
+ resolved_obj = getattr(resolved_obj, attr_name)
+ orig_func = getattr(resolved_obj, func_path[-1])
+ setattr(
+ resolved_obj,
+ func_path[-1],
+ lambda *args, **kwargs: self(*args, **kwargs),
+ )
+ self.__init__(orig_func, sub_func, cond_func)
+ return lambda *args, **kwargs: self(*args, **kwargs)
+
+ def __init__(self, orig_func, sub_func, cond_func):
+ self.__orig_func = orig_func
+ self.__sub_func = sub_func
+ self.__cond_func = cond_func
+
+ def __call__(self, *args, **kwargs):
+ if not self.__cond_func or self.__cond_func(self.__orig_func, *args, **kwargs):
+ return self.__sub_func(self.__orig_func, *args, **kwargs)
+ else:
+ return self.__orig_func(*args, **kwargs)
+
+
+_utils = torch.utils.data._utils
+
+
+def _shutdown_workers(self):
+ if (
+ torch.utils.data._utils is None
+ or torch.utils.data._utils.python_exit_status is True
+ or torch.utils.data._utils.python_exit_status is None
+ ):
+ return
+ if hasattr(self, "_shutdown") and not self._shutdown:
+ self._shutdown = True
+ try:
+ if hasattr(self, "_pin_memory_thread"):
+ self._pin_memory_thread_done_event.set()
+ self._worker_result_queue.put((None, None))
+ self._pin_memory_thread.join()
+ self._worker_result_queue.cancel_join_thread()
+ self._worker_result_queue.close()
+ self._workers_done_event.set()
+ for worker_id in range(len(self._workers)):
+ if self._persistent_workers or self._workers_status[worker_id]:
+ self._mark_worker_as_unavailable(worker_id, shutdown=True)
+ for w in self._workers: # pylint: disable=invalid-name
+ w.join(timeout=torch.utils.data._utils.MP_STATUS_CHECK_INTERVAL)
+ for q in self._index_queues: # pylint: disable=invalid-name
+ q.cancel_join_thread()
+ q.close()
+ finally:
+ if self._worker_pids_set:
+ torch.utils.data._utils.signal_handling._remove_worker_pids(id(self))
+ self._worker_pids_set = False
+ for w in self._workers: # pylint: disable=invalid-name
+ if w.is_alive():
+ w.terminate()
+
+
+class DummyDataParallel(
+ torch.nn.Module
+): # pylint: disable=missing-class-docstring, unused-argument, too-few-public-methods
+ def __new__(
+ cls, module, device_ids=None, output_device=None, dim=0
+ ): # pylint: disable=unused-argument
+ if isinstance(device_ids, list) and len(device_ids) > 1:
+ print("IPEX backend doesn't support DataParallel on multiple XPU devices")
+ return module.to("xpu")
+
+
+def return_null_context(*args, **kwargs): # pylint: disable=unused-argument
+ return contextlib.nullcontext()
+
+
+def check_device(device):
+ return bool(
+ (isinstance(device, torch.device) and device.type == "cuda")
+ or (isinstance(device, str) and "cuda" in device)
+ or isinstance(device, int)
+ )
+
+
+def return_xpu(device):
+ return (
+ f"xpu:{device[-1]}"
+ if isinstance(device, str) and ":" in device
+ else (
+ f"xpu:{device}"
+ if isinstance(device, int)
+ else torch.device("xpu") if isinstance(device, torch.device) else "xpu"
+ )
+ )
+
+
+def ipex_no_cuda(orig_func, *args, **kwargs):
+ torch.cuda.is_available = lambda: False
+ orig_func(*args, **kwargs)
+ torch.cuda.is_available = torch.xpu.is_available
+
+
+original_autocast = torch.autocast
+
+
+def ipex_autocast(*args, **kwargs):
+ if len(args) > 0 and args[0] == "cuda":
+ return original_autocast("xpu", *args[1:], **kwargs)
+ else:
+ return original_autocast(*args, **kwargs)
+
+
+original_torch_cat = torch.cat
+
+
+def torch_cat(tensor, *args, **kwargs):
+ if len(tensor) == 3 and (
+ tensor[0].dtype != tensor[1].dtype or tensor[2].dtype != tensor[1].dtype
+ ):
+ return original_torch_cat(
+ [tensor[0].to(tensor[1].dtype), tensor[1], tensor[2].to(tensor[1].dtype)],
+ *args,
+ **kwargs,
+ )
+ else:
+ return original_torch_cat(tensor, *args, **kwargs)
+
+
+original_interpolate = torch.nn.functional.interpolate
+
+
+def interpolate(
+ tensor,
+ size=None,
+ scale_factor=None,
+ mode="nearest",
+ align_corners=None,
+ recompute_scale_factor=None,
+ antialias=False,
+): # pylint: disable=too-many-arguments
+ if antialias or align_corners is not None:
+ return_device = tensor.device
+ return_dtype = tensor.dtype
+ return original_interpolate(
+ tensor.to("cpu", dtype=torch.float32),
+ size=size,
+ scale_factor=scale_factor,
+ mode=mode,
+ align_corners=align_corners,
+ recompute_scale_factor=recompute_scale_factor,
+ antialias=antialias,
+ ).to(return_device, dtype=return_dtype)
+ else:
+ return original_interpolate(
+ tensor,
+ size=size,
+ scale_factor=scale_factor,
+ mode=mode,
+ align_corners=align_corners,
+ recompute_scale_factor=recompute_scale_factor,
+ antialias=antialias,
+ )
+
+
+original_linalg_solve = torch.linalg.solve
+
+
+def linalg_solve(A, B, *args, **kwargs): # pylint: disable=invalid-name
+ if A.device != torch.device("cpu") or B.device != torch.device("cpu"):
+ return_device = A.device
+ return original_linalg_solve(A.to("cpu"), B.to("cpu"), *args, **kwargs).to(
+ return_device
+ )
+ else:
+ return original_linalg_solve(A, B, *args, **kwargs)
+
+
+def ipex_hijacks():
+ CondFunc(
+ "torch.Tensor.to",
+ lambda orig_func, self, device=None, *args, **kwargs: orig_func(
+ self, return_xpu(device), *args, **kwargs
+ ),
+ lambda orig_func, self, device=None, *args, **kwargs: check_device(device),
+ )
+ CondFunc(
+ "torch.Tensor.cuda",
+ lambda orig_func, self, device=None, *args, **kwargs: orig_func(
+ self, return_xpu(device), *args, **kwargs
+ ),
+ lambda orig_func, self, device=None, *args, **kwargs: check_device(device),
+ )
+ CondFunc(
+ "torch.empty",
+ lambda orig_func, *args, device=None, **kwargs: orig_func(
+ *args, device=return_xpu(device), **kwargs
+ ),
+ lambda orig_func, *args, device=None, **kwargs: check_device(device),
+ )
+ CondFunc(
+ "torch.load",
+ lambda orig_func, *args, map_location=None, **kwargs: orig_func(
+ *args, return_xpu(map_location), **kwargs
+ ),
+ lambda orig_func, *args, map_location=None, **kwargs: map_location is None
+ or check_device(map_location),
+ )
+ CondFunc(
+ "torch.randn",
+ lambda orig_func, *args, device=None, **kwargs: orig_func(
+ *args, device=return_xpu(device), **kwargs
+ ),
+ lambda orig_func, *args, device=None, **kwargs: check_device(device),
+ )
+ CondFunc(
+ "torch.ones",
+ lambda orig_func, *args, device=None, **kwargs: orig_func(
+ *args, device=return_xpu(device), **kwargs
+ ),
+ lambda orig_func, *args, device=None, **kwargs: check_device(device),
+ )
+ CondFunc(
+ "torch.zeros",
+ lambda orig_func, *args, device=None, **kwargs: orig_func(
+ *args, device=return_xpu(device), **kwargs
+ ),
+ lambda orig_func, *args, device=None, **kwargs: check_device(device),
+ )
+ CondFunc(
+ "torch.tensor",
+ lambda orig_func, *args, device=None, **kwargs: orig_func(
+ *args, device=return_xpu(device), **kwargs
+ ),
+ lambda orig_func, *args, device=None, **kwargs: check_device(device),
+ )
+ CondFunc(
+ "torch.linspace",
+ lambda orig_func, *args, device=None, **kwargs: orig_func(
+ *args, device=return_xpu(device), **kwargs
+ ),
+ lambda orig_func, *args, device=None, **kwargs: check_device(device),
+ )
+
+ CondFunc(
+ "torch.Generator",
+ lambda orig_func, device=None: torch.xpu.Generator(device),
+ lambda orig_func, device=None: device is not None
+ and device != torch.device("cpu")
+ and device != "cpu",
+ )
+
+ CondFunc(
+ "torch.batch_norm",
+ lambda orig_func, input, weight, bias, *args, **kwargs: orig_func(
+ input,
+ (
+ weight
+ if weight is not None
+ else torch.ones(input.size()[1], device=input.device)
+ ),
+ (
+ bias
+ if bias is not None
+ else torch.zeros(input.size()[1], device=input.device)
+ ),
+ *args,
+ **kwargs,
+ ),
+ lambda orig_func, input, *args, **kwargs: input.device != torch.device("cpu"),
+ )
+ CondFunc(
+ "torch.instance_norm",
+ lambda orig_func, input, weight, bias, *args, **kwargs: orig_func(
+ input,
+ (
+ weight
+ if weight is not None
+ else torch.ones(input.size()[1], device=input.device)
+ ),
+ (
+ bias
+ if bias is not None
+ else torch.zeros(input.size()[1], device=input.device)
+ ),
+ *args,
+ **kwargs,
+ ),
+ lambda orig_func, input, *args, **kwargs: input.device != torch.device("cpu"),
+ )
+
+ # Functions with dtype errors:
+ CondFunc(
+ "torch.nn.modules.GroupNorm.forward",
+ lambda orig_func, self, input: orig_func(
+ self, input.to(self.weight.data.dtype)
+ ),
+ lambda orig_func, self, input: input.dtype != self.weight.data.dtype,
+ )
+ CondFunc(
+ "torch.nn.modules.linear.Linear.forward",
+ lambda orig_func, self, input: orig_func(
+ self, input.to(self.weight.data.dtype)
+ ),
+ lambda orig_func, self, input: input.dtype != self.weight.data.dtype,
+ )
+ CondFunc(
+ "torch.nn.modules.conv.Conv2d.forward",
+ lambda orig_func, self, input: orig_func(
+ self, input.to(self.weight.data.dtype)
+ ),
+ lambda orig_func, self, input: input.dtype != self.weight.data.dtype,
+ )
+ CondFunc(
+ "torch.nn.functional.layer_norm",
+ lambda orig_func, input, normalized_shape=None, weight=None, *args, **kwargs: orig_func(
+ input.to(weight.data.dtype), normalized_shape, weight, *args, **kwargs
+ ),
+ lambda orig_func, input, normalized_shape=None, weight=None, *args, **kwargs: weight
+ is not None
+ and input.dtype != weight.data.dtype,
+ )
+
+ # Diffusers Float64 (ARC GPUs doesn't support double or Float64):
+ if not torch.xpu.has_fp64_dtype():
+ CondFunc(
+ "torch.from_numpy",
+ lambda orig_func, ndarray: orig_func(ndarray.astype("float32")),
+ lambda orig_func, ndarray: ndarray.dtype == float,
+ )
+
+ # Broken functions when torch.cuda.is_available is True:
+ CondFunc(
+ "torch.utils.data.dataloader._BaseDataLoaderIter.__init__",
+ lambda orig_func, *args, **kwargs: ipex_no_cuda(orig_func, *args, **kwargs),
+ lambda orig_func, *args, **kwargs: True,
+ )
+
+ # Functions that make compile mad with CondFunc:
+ torch.utils.data.dataloader._MultiProcessingDataLoaderIter._shutdown_workers = (
+ _shutdown_workers
+ )
+ torch.nn.DataParallel = DummyDataParallel
+ torch.autocast = ipex_autocast
+ torch.cat = torch_cat
+ torch.linalg.solve = linalg_solve
+ torch.nn.functional.interpolate = interpolate
+ torch.backends.cuda.sdp_kernel = return_null_context
diff --git a/infer/modules/onnx/export.py b/infer/modules/onnx/export.py
new file mode 100644
index 0000000000000000000000000000000000000000..b5ef2f5ecde0fae6f246355906322fa0be3c5376
--- /dev/null
+++ b/infer/modules/onnx/export.py
@@ -0,0 +1,52 @@
+import torch
+
+from infer.lib.infer_pack.models_onnx import SynthesizerTrnMsNSFsidM
+
+
+def export_onnx(ModelPath, ExportedPath):
+ cpt = torch.load(ModelPath, map_location="cpu")
+ cpt["config"][-3] = cpt["weight"]["emb_g.weight"].shape[0]
+ vec_channels = 256 if cpt.get("version", "v1") == "v1" else 768
+
+ test_phone = torch.rand(1, 200, vec_channels) # hidden unit
+ test_phone_lengths = torch.tensor([200]).long() # hidden unit 长度(貌似没啥用)
+ test_pitch = torch.randint(size=(1, 200), low=5, high=255) # 基频(单位赫兹)
+ test_pitchf = torch.rand(1, 200) # nsf基频
+ test_ds = torch.LongTensor([0]) # 说话人ID
+ test_rnd = torch.rand(1, 192, 200) # 噪声(加入随机因子)
+
+ device = "cpu" # 导出时设备(不影响使用模型)
+
+ net_g = SynthesizerTrnMsNSFsidM(
+ *cpt["config"], is_half=False, encoder_dim=vec_channels
+ ) # fp32导出(C++要支持fp16必须手动将内存重新排列所以暂时不用fp16)
+ net_g.load_state_dict(cpt["weight"], strict=False)
+ input_names = ["phone", "phone_lengths", "pitch", "pitchf", "ds", "rnd"]
+ output_names = [
+ "audio",
+ ]
+ # net_g.construct_spkmixmap() #多角色混合轨道导出
+ torch.onnx.export(
+ net_g,
+ (
+ test_phone.to(device),
+ test_phone_lengths.to(device),
+ test_pitch.to(device),
+ test_pitchf.to(device),
+ test_ds.to(device),
+ test_rnd.to(device),
+ ),
+ ExportedPath,
+ dynamic_axes={
+ "phone": [1],
+ "pitch": [1],
+ "pitchf": [1],
+ "rnd": [2],
+ },
+ do_constant_folding=False,
+ opset_version=17,
+ verbose=False,
+ input_names=input_names,
+ output_names=output_names,
+ )
+ return "Finished"
diff --git a/infer/modules/train/extract/extract_f0_print.py b/infer/modules/train/extract/extract_f0_print.py
new file mode 100644
index 0000000000000000000000000000000000000000..9d231e4e86db204704ce894a2b12ebad38665064
--- /dev/null
+++ b/infer/modules/train/extract/extract_f0_print.py
@@ -0,0 +1,175 @@
+import os
+import sys
+import traceback
+
+import parselmouth
+
+now_dir = os.getcwd()
+sys.path.append(now_dir)
+import logging
+
+import numpy as np
+import pyworld
+
+from infer.lib.audio import load_audio
+
+logging.getLogger("numba").setLevel(logging.WARNING)
+from multiprocessing import Process
+
+exp_dir = sys.argv[1]
+f = open("%s/extract_f0_feature.log" % exp_dir, "a+")
+
+
+def printt(strr):
+ print(strr)
+ f.write("%s\n" % strr)
+ f.flush()
+
+
+n_p = int(sys.argv[2])
+f0method = sys.argv[3]
+
+
+class FeatureInput(object):
+ def __init__(self, samplerate=16000, hop_size=160):
+ self.fs = samplerate
+ self.hop = hop_size
+
+ self.f0_bin = 256
+ self.f0_max = 1100.0
+ self.f0_min = 50.0
+ self.f0_mel_min = 1127 * np.log(1 + self.f0_min / 700)
+ self.f0_mel_max = 1127 * np.log(1 + self.f0_max / 700)
+
+ def compute_f0(self, path, f0_method):
+ x = load_audio(path, self.fs)
+ p_len = x.shape[0] // self.hop
+ if f0_method == "pm":
+ time_step = 160 / 16000 * 1000
+ f0_min = 50
+ f0_max = 1100
+ f0 = (
+ parselmouth.Sound(x, self.fs)
+ .to_pitch_ac(
+ time_step=time_step / 1000,
+ voicing_threshold=0.6,
+ pitch_floor=f0_min,
+ pitch_ceiling=f0_max,
+ )
+ .selected_array["frequency"]
+ )
+ pad_size = (p_len - len(f0) + 1) // 2
+ if pad_size > 0 or p_len - len(f0) - pad_size > 0:
+ f0 = np.pad(
+ f0, [[pad_size, p_len - len(f0) - pad_size]], mode="constant"
+ )
+ elif f0_method == "harvest":
+ f0, t = pyworld.harvest(
+ x.astype(np.double),
+ fs=self.fs,
+ f0_ceil=self.f0_max,
+ f0_floor=self.f0_min,
+ frame_period=1000 * self.hop / self.fs,
+ )
+ f0 = pyworld.stonemask(x.astype(np.double), f0, t, self.fs)
+ elif f0_method == "dio":
+ f0, t = pyworld.dio(
+ x.astype(np.double),
+ fs=self.fs,
+ f0_ceil=self.f0_max,
+ f0_floor=self.f0_min,
+ frame_period=1000 * self.hop / self.fs,
+ )
+ f0 = pyworld.stonemask(x.astype(np.double), f0, t, self.fs)
+ elif f0_method == "rmvpe":
+ if hasattr(self, "model_rmvpe") == False:
+ from infer.lib.rmvpe import RMVPE
+
+ print("Loading rmvpe model")
+ self.model_rmvpe = RMVPE(
+ "assets/rmvpe/rmvpe.pt", is_half=False, device="cpu"
+ )
+ f0 = self.model_rmvpe.infer_from_audio(x, thred=0.03)
+ return f0
+
+ def coarse_f0(self, f0):
+ f0_mel = 1127 * np.log(1 + f0 / 700)
+ f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - self.f0_mel_min) * (
+ self.f0_bin - 2
+ ) / (self.f0_mel_max - self.f0_mel_min) + 1
+
+ # use 0 or 1
+ f0_mel[f0_mel <= 1] = 1
+ f0_mel[f0_mel > self.f0_bin - 1] = self.f0_bin - 1
+ f0_coarse = np.rint(f0_mel).astype(int)
+ assert f0_coarse.max() <= 255 and f0_coarse.min() >= 1, (
+ f0_coarse.max(),
+ f0_coarse.min(),
+ )
+ return f0_coarse
+
+ def go(self, paths, f0_method):
+ if len(paths) == 0:
+ printt("no-f0-todo")
+ else:
+ printt("todo-f0-%s" % len(paths))
+ n = max(len(paths) // 5, 1) # 每个进程最多打印5条
+ for idx, (inp_path, opt_path1, opt_path2) in enumerate(paths):
+ try:
+ if idx % n == 0:
+ printt("f0ing,now-%s,all-%s,-%s" % (idx, len(paths), inp_path))
+ if (
+ os.path.exists(opt_path1 + ".npy") == True
+ and os.path.exists(opt_path2 + ".npy") == True
+ ):
+ continue
+ featur_pit = self.compute_f0(inp_path, f0_method)
+ np.save(
+ opt_path2,
+ featur_pit,
+ allow_pickle=False,
+ ) # nsf
+ coarse_pit = self.coarse_f0(featur_pit)
+ np.save(
+ opt_path1,
+ coarse_pit,
+ allow_pickle=False,
+ ) # ori
+ except:
+ printt("f0fail-%s-%s-%s" % (idx, inp_path, traceback.format_exc()))
+
+
+if __name__ == "__main__":
+ # exp_dir=r"E:\codes\py39\dataset\mi-test"
+ # n_p=16
+ # f = open("%s/log_extract_f0.log"%exp_dir, "w")
+ printt(" ".join(sys.argv))
+ featureInput = FeatureInput()
+ paths = []
+ inp_root = "%s/1_16k_wavs" % (exp_dir)
+ opt_root1 = "%s/2a_f0" % (exp_dir)
+ opt_root2 = "%s/2b-f0nsf" % (exp_dir)
+
+ os.makedirs(opt_root1, exist_ok=True)
+ os.makedirs(opt_root2, exist_ok=True)
+ for name in sorted(list(os.listdir(inp_root))):
+ inp_path = "%s/%s" % (inp_root, name)
+ if "spec" in inp_path:
+ continue
+ opt_path1 = "%s/%s" % (opt_root1, name)
+ opt_path2 = "%s/%s" % (opt_root2, name)
+ paths.append([inp_path, opt_path1, opt_path2])
+
+ ps = []
+ for i in range(n_p):
+ p = Process(
+ target=featureInput.go,
+ args=(
+ paths[i::n_p],
+ f0method,
+ ),
+ )
+ ps.append(p)
+ p.start()
+ for i in range(n_p):
+ ps[i].join()
diff --git a/infer/modules/train/extract/extract_f0_rmvpe.py b/infer/modules/train/extract/extract_f0_rmvpe.py
new file mode 100644
index 0000000000000000000000000000000000000000..90b20738c2efe719c3c053be25755b55da65e666
--- /dev/null
+++ b/infer/modules/train/extract/extract_f0_rmvpe.py
@@ -0,0 +1,141 @@
+import os
+import sys
+import traceback
+
+import parselmouth
+
+now_dir = os.getcwd()
+sys.path.append(now_dir)
+import logging
+
+import numpy as np
+import pyworld
+
+from infer.lib.audio import load_audio
+
+logging.getLogger("numba").setLevel(logging.WARNING)
+
+n_part = int(sys.argv[1])
+i_part = int(sys.argv[2])
+i_gpu = sys.argv[3]
+os.environ["CUDA_VISIBLE_DEVICES"] = str(i_gpu)
+exp_dir = sys.argv[4]
+is_half = sys.argv[5]
+f = open("%s/extract_f0_feature.log" % exp_dir, "a+")
+
+
+def printt(strr):
+ print(strr)
+ f.write("%s\n" % strr)
+ f.flush()
+
+
+class FeatureInput(object):
+ def __init__(self, samplerate=16000, hop_size=160):
+ self.fs = samplerate
+ self.hop = hop_size
+
+ self.f0_bin = 256
+ self.f0_max = 1100.0
+ self.f0_min = 50.0
+ self.f0_mel_min = 1127 * np.log(1 + self.f0_min / 700)
+ self.f0_mel_max = 1127 * np.log(1 + self.f0_max / 700)
+
+ def compute_f0(self, path, f0_method):
+ x = load_audio(path, self.fs)
+ # p_len = x.shape[0] // self.hop
+ if f0_method == "rmvpe":
+ if hasattr(self, "model_rmvpe") == False:
+ from infer.lib.rmvpe import RMVPE
+
+ print("Loading rmvpe model")
+ self.model_rmvpe = RMVPE(
+ "assets/rmvpe/rmvpe.pt", is_half=is_half, device="cuda"
+ )
+ f0 = self.model_rmvpe.infer_from_audio(x, thred=0.03)
+ return f0
+
+ def coarse_f0(self, f0):
+ f0_mel = 1127 * np.log(1 + f0 / 700)
+ f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - self.f0_mel_min) * (
+ self.f0_bin - 2
+ ) / (self.f0_mel_max - self.f0_mel_min) + 1
+
+ # use 0 or 1
+ f0_mel[f0_mel <= 1] = 1
+ f0_mel[f0_mel > self.f0_bin - 1] = self.f0_bin - 1
+ f0_coarse = np.rint(f0_mel).astype(int)
+ assert f0_coarse.max() <= 255 and f0_coarse.min() >= 1, (
+ f0_coarse.max(),
+ f0_coarse.min(),
+ )
+ return f0_coarse
+
+ def go(self, paths, f0_method):
+ if len(paths) == 0:
+ printt("no-f0-todo")
+ else:
+ printt("todo-f0-%s" % len(paths))
+ n = max(len(paths) // 5, 1) # 每个进程最多打印5条
+ for idx, (inp_path, opt_path1, opt_path2) in enumerate(paths):
+ try:
+ if idx % n == 0:
+ printt("f0ing,now-%s,all-%s,-%s" % (idx, len(paths), inp_path))
+ if (
+ os.path.exists(opt_path1 + ".npy") == True
+ and os.path.exists(opt_path2 + ".npy") == True
+ ):
+ continue
+ featur_pit = self.compute_f0(inp_path, f0_method)
+ np.save(
+ opt_path2,
+ featur_pit,
+ allow_pickle=False,
+ ) # nsf
+ coarse_pit = self.coarse_f0(featur_pit)
+ np.save(
+ opt_path1,
+ coarse_pit,
+ allow_pickle=False,
+ ) # ori
+ except:
+ printt("f0fail-%s-%s-%s" % (idx, inp_path, traceback.format_exc()))
+
+
+if __name__ == "__main__":
+ # exp_dir=r"E:\codes\py39\dataset\mi-test"
+ # n_p=16
+ # f = open("%s/log_extract_f0.log"%exp_dir, "w")
+ printt(" ".join(sys.argv))
+ featureInput = FeatureInput()
+ paths = []
+ inp_root = "%s/1_16k_wavs" % (exp_dir)
+ opt_root1 = "%s/2a_f0" % (exp_dir)
+ opt_root2 = "%s/2b-f0nsf" % (exp_dir)
+
+ os.makedirs(opt_root1, exist_ok=True)
+ os.makedirs(opt_root2, exist_ok=True)
+ for name in sorted(list(os.listdir(inp_root))):
+ inp_path = "%s/%s" % (inp_root, name)
+ if "spec" in inp_path:
+ continue
+ opt_path1 = "%s/%s" % (opt_root1, name)
+ opt_path2 = "%s/%s" % (opt_root2, name)
+ paths.append([inp_path, opt_path1, opt_path2])
+ try:
+ featureInput.go(paths[i_part::n_part], "rmvpe")
+ except:
+ printt("f0_all_fail-%s" % (traceback.format_exc()))
+ # ps = []
+ # for i in range(n_p):
+ # p = Process(
+ # target=featureInput.go,
+ # args=(
+ # paths[i::n_p],
+ # f0method,
+ # ),
+ # )
+ # ps.append(p)
+ # p.start()
+ # for i in range(n_p):
+ # ps[i].join()
diff --git a/infer/modules/train/extract/extract_f0_rmvpe_dml.py b/infer/modules/train/extract/extract_f0_rmvpe_dml.py
new file mode 100644
index 0000000000000000000000000000000000000000..243e825005bd46dfd464f6d49ecf78f0abf03dc2
--- /dev/null
+++ b/infer/modules/train/extract/extract_f0_rmvpe_dml.py
@@ -0,0 +1,139 @@
+import os
+import sys
+import traceback
+
+import parselmouth
+
+now_dir = os.getcwd()
+sys.path.append(now_dir)
+import logging
+
+import numpy as np
+import pyworld
+
+from infer.lib.audio import load_audio
+
+logging.getLogger("numba").setLevel(logging.WARNING)
+
+exp_dir = sys.argv[1]
+import torch_directml
+
+device = torch_directml.device(torch_directml.default_device())
+f = open("%s/extract_f0_feature.log" % exp_dir, "a+")
+
+
+def printt(strr):
+ print(strr)
+ f.write("%s\n" % strr)
+ f.flush()
+
+
+class FeatureInput(object):
+ def __init__(self, samplerate=16000, hop_size=160):
+ self.fs = samplerate
+ self.hop = hop_size
+
+ self.f0_bin = 256
+ self.f0_max = 1100.0
+ self.f0_min = 50.0
+ self.f0_mel_min = 1127 * np.log(1 + self.f0_min / 700)
+ self.f0_mel_max = 1127 * np.log(1 + self.f0_max / 700)
+
+ def compute_f0(self, path, f0_method):
+ x = load_audio(path, self.fs)
+ # p_len = x.shape[0] // self.hop
+ if f0_method == "rmvpe":
+ if hasattr(self, "model_rmvpe") == False:
+ from infer.lib.rmvpe import RMVPE
+
+ print("Loading rmvpe model")
+ self.model_rmvpe = RMVPE(
+ "assets/rmvpe/rmvpe.pt", is_half=False, device=device
+ )
+ f0 = self.model_rmvpe.infer_from_audio(x, thred=0.03)
+ return f0
+
+ def coarse_f0(self, f0):
+ f0_mel = 1127 * np.log(1 + f0 / 700)
+ f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - self.f0_mel_min) * (
+ self.f0_bin - 2
+ ) / (self.f0_mel_max - self.f0_mel_min) + 1
+
+ # use 0 or 1
+ f0_mel[f0_mel <= 1] = 1
+ f0_mel[f0_mel > self.f0_bin - 1] = self.f0_bin - 1
+ f0_coarse = np.rint(f0_mel).astype(int)
+ assert f0_coarse.max() <= 255 and f0_coarse.min() >= 1, (
+ f0_coarse.max(),
+ f0_coarse.min(),
+ )
+ return f0_coarse
+
+ def go(self, paths, f0_method):
+ if len(paths) == 0:
+ printt("no-f0-todo")
+ else:
+ printt("todo-f0-%s" % len(paths))
+ n = max(len(paths) // 5, 1) # 每个进程最多打印5条
+ for idx, (inp_path, opt_path1, opt_path2) in enumerate(paths):
+ try:
+ if idx % n == 0:
+ printt("f0ing,now-%s,all-%s,-%s" % (idx, len(paths), inp_path))
+ if (
+ os.path.exists(opt_path1 + ".npy") == True
+ and os.path.exists(opt_path2 + ".npy") == True
+ ):
+ continue
+ featur_pit = self.compute_f0(inp_path, f0_method)
+ np.save(
+ opt_path2,
+ featur_pit,
+ allow_pickle=False,
+ ) # nsf
+ coarse_pit = self.coarse_f0(featur_pit)
+ np.save(
+ opt_path1,
+ coarse_pit,
+ allow_pickle=False,
+ ) # ori
+ except:
+ printt("f0fail-%s-%s-%s" % (idx, inp_path, traceback.format_exc()))
+
+
+if __name__ == "__main__":
+ # exp_dir=r"E:\codes\py39\dataset\mi-test"
+ # n_p=16
+ # f = open("%s/log_extract_f0.log"%exp_dir, "w")
+ printt(" ".join(sys.argv))
+ featureInput = FeatureInput()
+ paths = []
+ inp_root = "%s/1_16k_wavs" % (exp_dir)
+ opt_root1 = "%s/2a_f0" % (exp_dir)
+ opt_root2 = "%s/2b-f0nsf" % (exp_dir)
+
+ os.makedirs(opt_root1, exist_ok=True)
+ os.makedirs(opt_root2, exist_ok=True)
+ for name in sorted(list(os.listdir(inp_root))):
+ inp_path = "%s/%s" % (inp_root, name)
+ if "spec" in inp_path:
+ continue
+ opt_path1 = "%s/%s" % (opt_root1, name)
+ opt_path2 = "%s/%s" % (opt_root2, name)
+ paths.append([inp_path, opt_path1, opt_path2])
+ try:
+ featureInput.go(paths, "rmvpe")
+ except:
+ printt("f0_all_fail-%s" % (traceback.format_exc()))
+ # ps = []
+ # for i in range(n_p):
+ # p = Process(
+ # target=featureInput.go,
+ # args=(
+ # paths[i::n_p],
+ # f0method,
+ # ),
+ # )
+ # ps.append(p)
+ # p.start()
+ # for i in range(n_p):
+ # ps[i].join()
diff --git a/infer/modules/train/extract_feature_print.py b/infer/modules/train/extract_feature_print.py
new file mode 100644
index 0000000000000000000000000000000000000000..96a69dee4614dc9c7cbafd24247f244b4e28f9d4
--- /dev/null
+++ b/infer/modules/train/extract_feature_print.py
@@ -0,0 +1,142 @@
+import os
+import sys
+import traceback
+
+os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1"
+os.environ["PYTORCH_MPS_HIGH_WATERMARK_RATIO"] = "0.0"
+
+device = sys.argv[1]
+n_part = int(sys.argv[2])
+i_part = int(sys.argv[3])
+if len(sys.argv) == 7:
+ exp_dir = sys.argv[4]
+ version = sys.argv[5]
+ is_half = sys.argv[6].lower() == "true"
+else:
+ i_gpu = sys.argv[4]
+ exp_dir = sys.argv[5]
+ os.environ["CUDA_VISIBLE_DEVICES"] = str(i_gpu)
+ version = sys.argv[6]
+ is_half = sys.argv[7].lower() == "true"
+import fairseq
+import numpy as np
+import soundfile as sf
+import torch
+import torch.nn.functional as F
+
+if "privateuseone" not in device:
+ device = "cpu"
+ if torch.cuda.is_available():
+ device = "cuda"
+ elif torch.backends.mps.is_available():
+ device = "mps"
+else:
+ import torch_directml
+
+ device = torch_directml.device(torch_directml.default_device())
+
+ def forward_dml(ctx, x, scale):
+ ctx.scale = scale
+ res = x.clone().detach()
+ return res
+
+ fairseq.modules.grad_multiply.GradMultiply.forward = forward_dml
+
+f = open("%s/extract_f0_feature.log" % exp_dir, "a+")
+
+
+def printt(strr):
+ print(strr)
+ f.write("%s\n" % strr)
+ f.flush()
+
+
+printt(" ".join(sys.argv))
+model_path = "assets/hubert/hubert_base.pt"
+
+printt("exp_dir: " + exp_dir)
+wavPath = "%s/1_16k_wavs" % exp_dir
+outPath = (
+ "%s/3_feature256" % exp_dir if version == "v1" else "%s/3_feature768" % exp_dir
+)
+os.makedirs(outPath, exist_ok=True)
+
+
+# wave must be 16k, hop_size=320
+def readwave(wav_path, normalize=False):
+ wav, sr = sf.read(wav_path)
+ assert sr == 16000
+ feats = torch.from_numpy(wav).float()
+ if feats.dim() == 2: # double channels
+ feats = feats.mean(-1)
+ assert feats.dim() == 1, feats.dim()
+ if normalize:
+ with torch.no_grad():
+ feats = F.layer_norm(feats, feats.shape)
+ feats = feats.view(1, -1)
+ return feats
+
+
+# HuBERT model
+printt("load model(s) from {}".format(model_path))
+# if hubert model is exist
+if os.access(model_path, os.F_OK) == False:
+ printt(
+ "Error: Extracting is shut down because %s does not exist, you may download it from https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main"
+ % model_path
+ )
+ exit(0)
+models, saved_cfg, task = fairseq.checkpoint_utils.load_model_ensemble_and_task(
+ [model_path],
+ suffix="",
+)
+model = models[0]
+model = model.to(device)
+printt("move model to %s" % device)
+if is_half:
+ if device not in ["mps", "cpu"]:
+ model = model.half()
+model.eval()
+
+todo = sorted(list(os.listdir(wavPath)))[i_part::n_part]
+n = max(1, len(todo) // 10) # 最多打印十条
+if len(todo) == 0:
+ printt("no-feature-todo")
+else:
+ printt("all-feature-%s" % len(todo))
+ for idx, file in enumerate(todo):
+ try:
+ if file.endswith(".wav"):
+ wav_path = "%s/%s" % (wavPath, file)
+ out_path = "%s/%s" % (outPath, file.replace("wav", "npy"))
+
+ if os.path.exists(out_path):
+ continue
+
+ feats = readwave(wav_path, normalize=saved_cfg.task.normalize)
+ padding_mask = torch.BoolTensor(feats.shape).fill_(False)
+ inputs = {
+ "source": (
+ feats.half().to(device)
+ if is_half and device not in ["mps", "cpu"]
+ else feats.to(device)
+ ),
+ "padding_mask": padding_mask.to(device),
+ "output_layer": 9 if version == "v1" else 12, # layer 9
+ }
+ with torch.no_grad():
+ logits = model.extract_features(**inputs)
+ feats = (
+ model.final_proj(logits[0]) if version == "v1" else logits[0]
+ )
+
+ feats = feats.squeeze(0).float().cpu().numpy()
+ if np.isnan(feats).sum() == 0:
+ np.save(out_path, feats, allow_pickle=False)
+ else:
+ printt("%s-contains nan" % file)
+ if idx % n == 0:
+ printt("now-%s,all-%s,%s,%s" % (len(todo), idx, file, feats.shape))
+ except:
+ printt(traceback.format_exc())
+ printt("all-feature-done")
diff --git a/infer/modules/train/preprocess.py b/infer/modules/train/preprocess.py
new file mode 100644
index 0000000000000000000000000000000000000000..138bb4c642ce0373b4718ea623768b4460245a6e
--- /dev/null
+++ b/infer/modules/train/preprocess.py
@@ -0,0 +1,142 @@
+import multiprocessing
+import os
+import sys
+
+from scipy import signal
+
+now_dir = os.getcwd()
+sys.path.append(now_dir)
+print(*sys.argv[1:])
+inp_root = sys.argv[1]
+sr = int(sys.argv[2])
+n_p = int(sys.argv[3])
+exp_dir = sys.argv[4]
+noparallel = sys.argv[5] == "True"
+per = float(sys.argv[6])
+import os
+import traceback
+
+import librosa
+import numpy as np
+from scipy.io import wavfile
+
+from infer.lib.audio import load_audio
+from infer.lib.slicer2 import Slicer
+
+f = open("%s/preprocess.log" % exp_dir, "a+")
+
+
+def println(strr):
+ print(strr)
+ f.write("%s\n" % strr)
+ f.flush()
+
+
+class PreProcess:
+ def __init__(self, sr, exp_dir, per=3.7):
+ self.slicer = Slicer(
+ sr=sr,
+ threshold=-42,
+ min_length=1500,
+ min_interval=400,
+ hop_size=15,
+ max_sil_kept=500,
+ )
+ self.sr = sr
+ self.bh, self.ah = signal.butter(N=5, Wn=48, btype="high", fs=self.sr)
+ self.per = per
+ self.overlap = 0.3
+ self.tail = self.per + self.overlap
+ self.max = 0.9
+ self.alpha = 0.75
+ self.exp_dir = exp_dir
+ self.gt_wavs_dir = "%s/0_gt_wavs" % exp_dir
+ self.wavs16k_dir = "%s/1_16k_wavs" % exp_dir
+ os.makedirs(self.exp_dir, exist_ok=True)
+ os.makedirs(self.gt_wavs_dir, exist_ok=True)
+ os.makedirs(self.wavs16k_dir, exist_ok=True)
+
+ def norm_write(self, tmp_audio, idx0, idx1):
+ tmp_max = np.abs(tmp_audio).max()
+ if tmp_max > 2.5:
+ print("%s-%s-%s-filtered" % (idx0, idx1, tmp_max))
+ return
+ tmp_audio = (tmp_audio / tmp_max * (self.max * self.alpha)) + (
+ 1 - self.alpha
+ ) * tmp_audio
+ wavfile.write(
+ "%s/%s_%s.wav" % (self.gt_wavs_dir, idx0, idx1),
+ self.sr,
+ tmp_audio.astype(np.float32),
+ )
+ tmp_audio = librosa.resample(
+ tmp_audio, orig_sr=self.sr, target_sr=16000
+ ) # , res_type="soxr_vhq"
+ wavfile.write(
+ "%s/%s_%s.wav" % (self.wavs16k_dir, idx0, idx1),
+ 16000,
+ tmp_audio.astype(np.float32),
+ )
+
+ def pipeline(self, path, idx0):
+ try:
+ audio = load_audio(path, self.sr)
+ # zero phased digital filter cause pre-ringing noise...
+ # audio = signal.filtfilt(self.bh, self.ah, audio)
+ audio = signal.lfilter(self.bh, self.ah, audio)
+
+ idx1 = 0
+ for audio in self.slicer.slice(audio):
+ i = 0
+ while 1:
+ start = int(self.sr * (self.per - self.overlap) * i)
+ i += 1
+ if len(audio[start:]) > self.tail * self.sr:
+ tmp_audio = audio[start : start + int(self.per * self.sr)]
+ self.norm_write(tmp_audio, idx0, idx1)
+ idx1 += 1
+ else:
+ tmp_audio = audio[start:]
+ idx1 += 1
+ break
+ self.norm_write(tmp_audio, idx0, idx1)
+ println("%s\t-> Success" % path)
+ except:
+ println("%s\t-> %s" % (path, traceback.format_exc()))
+
+ def pipeline_mp(self, infos):
+ for path, idx0 in infos:
+ self.pipeline(path, idx0)
+
+ def pipeline_mp_inp_dir(self, inp_root, n_p):
+ try:
+ infos = [
+ ("%s/%s" % (inp_root, name), idx)
+ for idx, name in enumerate(sorted(list(os.listdir(inp_root))))
+ ]
+ if noparallel:
+ for i in range(n_p):
+ self.pipeline_mp(infos[i::n_p])
+ else:
+ ps = []
+ for i in range(n_p):
+ p = multiprocessing.Process(
+ target=self.pipeline_mp, args=(infos[i::n_p],)
+ )
+ ps.append(p)
+ p.start()
+ for i in range(n_p):
+ ps[i].join()
+ except:
+ println("Fail. %s" % traceback.format_exc())
+
+
+def preprocess_trainset(inp_root, sr, n_p, exp_dir, per):
+ pp = PreProcess(sr, exp_dir, per)
+ println("start preprocess")
+ pp.pipeline_mp_inp_dir(inp_root, n_p)
+ println("end preprocess")
+
+
+if __name__ == "__main__":
+ preprocess_trainset(inp_root, sr, n_p, exp_dir, per)
diff --git a/infer/modules/train/train.py b/infer/modules/train/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..38a56782823590cee69ed4b79f4fc746d3644c1b
--- /dev/null
+++ b/infer/modules/train/train.py
@@ -0,0 +1,640 @@
+import os
+import sys
+import logging
+
+logger = logging.getLogger(__name__)
+
+now_dir = os.getcwd()
+sys.path.append(os.path.join(now_dir))
+
+import datetime
+
+from infer.lib.train import utils
+
+hps = utils.get_hparams()
+os.environ["CUDA_VISIBLE_DEVICES"] = hps.gpus.replace("-", ",")
+n_gpus = len(hps.gpus.split("-"))
+from random import randint, shuffle
+
+import torch
+
+try:
+ import intel_extension_for_pytorch as ipex # pylint: disable=import-error, unused-import
+
+ if torch.xpu.is_available():
+ from infer.modules.ipex import ipex_init
+ from infer.modules.ipex.gradscaler import gradscaler_init
+ from torch.xpu.amp import autocast
+
+ GradScaler = gradscaler_init()
+ ipex_init()
+ else:
+ from torch.cuda.amp import GradScaler, autocast
+except Exception:
+ from torch.cuda.amp import GradScaler, autocast
+
+torch.backends.cudnn.deterministic = False
+torch.backends.cudnn.benchmark = False
+from time import sleep
+from time import time as ttime
+
+import torch.distributed as dist
+import torch.multiprocessing as mp
+from torch.nn import functional as F
+from torch.nn.parallel import DistributedDataParallel as DDP
+from torch.utils.data import DataLoader
+from torch.utils.tensorboard import SummaryWriter
+
+from infer.lib.infer_pack import commons
+from infer.lib.train.data_utils import (
+ DistributedBucketSampler,
+ TextAudioCollate,
+ TextAudioCollateMultiNSFsid,
+ TextAudioLoader,
+ TextAudioLoaderMultiNSFsid,
+)
+
+if hps.version == "v1":
+ from infer.lib.infer_pack.models import MultiPeriodDiscriminator
+ from infer.lib.infer_pack.models import SynthesizerTrnMs256NSFsid as RVC_Model_f0
+ from infer.lib.infer_pack.models import (
+ SynthesizerTrnMs256NSFsid_nono as RVC_Model_nof0,
+ )
+else:
+ from infer.lib.infer_pack.models import (
+ SynthesizerTrnMs768NSFsid as RVC_Model_f0,
+ SynthesizerTrnMs768NSFsid_nono as RVC_Model_nof0,
+ MultiPeriodDiscriminatorV2 as MultiPeriodDiscriminator,
+ )
+
+from infer.lib.train.losses import (
+ discriminator_loss,
+ feature_loss,
+ generator_loss,
+ kl_loss,
+)
+from infer.lib.train.mel_processing import mel_spectrogram_torch, spec_to_mel_torch
+from infer.lib.train.process_ckpt import savee
+
+global_step = 0
+
+
+class EpochRecorder:
+ def __init__(self):
+ self.last_time = ttime()
+
+ def record(self):
+ now_time = ttime()
+ elapsed_time = now_time - self.last_time
+ self.last_time = now_time
+ elapsed_time_str = str(datetime.timedelta(seconds=elapsed_time))
+ current_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
+ return f"[{current_time}] | ({elapsed_time_str})"
+
+
+def main():
+ n_gpus = torch.cuda.device_count()
+
+ if torch.cuda.is_available() == False and torch.backends.mps.is_available() == True:
+ n_gpus = 1
+ if n_gpus < 1:
+ # patch to unblock people without gpus. there is probably a better way.
+ print("NO GPU DETECTED: falling back to CPU - this may take a while")
+ n_gpus = 1
+ os.environ["MASTER_ADDR"] = "localhost"
+ os.environ["MASTER_PORT"] = str(randint(20000, 55555))
+ children = []
+ logger = utils.get_logger(hps.model_dir)
+ for i in range(n_gpus):
+ subproc = mp.Process(
+ target=run,
+ args=(i, n_gpus, hps, logger),
+ )
+ children.append(subproc)
+ subproc.start()
+
+ for i in range(n_gpus):
+ children[i].join()
+
+
+def run(rank, n_gpus, hps, logger: logging.Logger):
+ global global_step
+ if rank == 0:
+ # logger = utils.get_logger(hps.model_dir)
+ logger.info(hps)
+ # utils.check_git_hash(hps.model_dir)
+ writer = SummaryWriter(log_dir=hps.model_dir)
+ writer_eval = SummaryWriter(log_dir=os.path.join(hps.model_dir, "eval"))
+
+ dist.init_process_group(
+ backend="gloo", init_method="env://", world_size=n_gpus, rank=rank
+ )
+ torch.manual_seed(hps.train.seed)
+ if torch.cuda.is_available():
+ torch.cuda.set_device(rank)
+
+ if hps.if_f0 == 1:
+ train_dataset = TextAudioLoaderMultiNSFsid(hps.data.training_files, hps.data)
+ else:
+ train_dataset = TextAudioLoader(hps.data.training_files, hps.data)
+ train_sampler = DistributedBucketSampler(
+ train_dataset,
+ hps.train.batch_size * n_gpus,
+ # [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1200,1400], # 16s
+ [100, 200, 300, 400, 500, 600, 700, 800, 900], # 16s
+ num_replicas=n_gpus,
+ rank=rank,
+ shuffle=True,
+ )
+ # It is possible that dataloader's workers are out of shared memory. Please try to raise your shared memory limit.
+ # num_workers=8 -> num_workers=4
+ if hps.if_f0 == 1:
+ collate_fn = TextAudioCollateMultiNSFsid()
+ else:
+ collate_fn = TextAudioCollate()
+ train_loader = DataLoader(
+ train_dataset,
+ num_workers=4,
+ shuffle=False,
+ pin_memory=True,
+ collate_fn=collate_fn,
+ batch_sampler=train_sampler,
+ persistent_workers=True,
+ prefetch_factor=8,
+ )
+ if hps.if_f0 == 1:
+ net_g = RVC_Model_f0(
+ hps.data.filter_length // 2 + 1,
+ hps.train.segment_size // hps.data.hop_length,
+ **hps.model,
+ is_half=hps.train.fp16_run,
+ sr=hps.sample_rate,
+ )
+ else:
+ net_g = RVC_Model_nof0(
+ hps.data.filter_length // 2 + 1,
+ hps.train.segment_size // hps.data.hop_length,
+ **hps.model,
+ is_half=hps.train.fp16_run,
+ )
+ if torch.cuda.is_available():
+ net_g = net_g.cuda(rank)
+ net_d = MultiPeriodDiscriminator(hps.model.use_spectral_norm)
+ if torch.cuda.is_available():
+ net_d = net_d.cuda(rank)
+ optim_g = torch.optim.AdamW(
+ net_g.parameters(),
+ hps.train.learning_rate,
+ betas=hps.train.betas,
+ eps=hps.train.eps,
+ )
+ optim_d = torch.optim.AdamW(
+ net_d.parameters(),
+ hps.train.learning_rate,
+ betas=hps.train.betas,
+ eps=hps.train.eps,
+ )
+ # net_g = DDP(net_g, device_ids=[rank], find_unused_parameters=True)
+ # net_d = DDP(net_d, device_ids=[rank], find_unused_parameters=True)
+ if hasattr(torch, "xpu") and torch.xpu.is_available():
+ pass
+ elif torch.cuda.is_available():
+ net_g = DDP(net_g, device_ids=[rank])
+ net_d = DDP(net_d, device_ids=[rank])
+ else:
+ net_g = DDP(net_g)
+ net_d = DDP(net_d)
+
+ try: # 如果能加载自动resume
+ _, _, _, epoch_str = utils.load_checkpoint(
+ utils.latest_checkpoint_path(hps.model_dir, "D_*.pth"), net_d, optim_d
+ ) # D多半加载没事
+ if rank == 0:
+ logger.info("loaded D")
+ # _, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "G_*.pth"), net_g, optim_g,load_opt=0)
+ _, _, _, epoch_str = utils.load_checkpoint(
+ utils.latest_checkpoint_path(hps.model_dir, "G_*.pth"), net_g, optim_g
+ )
+ global_step = (epoch_str - 1) * len(train_loader)
+ # epoch_str = 1
+ # global_step = 0
+ except: # 如果首次不能加载,加载pretrain
+ # traceback.print_exc()
+ epoch_str = 1
+ global_step = 0
+ if hps.pretrainG != "":
+ if rank == 0:
+ logger.info("loaded pretrained %s" % (hps.pretrainG))
+ if hasattr(net_g, "module"):
+ logger.info(
+ net_g.module.load_state_dict(
+ torch.load(hps.pretrainG, map_location="cpu")["model"]
+ )
+ ) ##测试不加载优化器
+ else:
+ logger.info(
+ net_g.load_state_dict(
+ torch.load(hps.pretrainG, map_location="cpu")["model"]
+ )
+ ) ##测试不加载优化器
+ if hps.pretrainD != "":
+ if rank == 0:
+ logger.info("loaded pretrained %s" % (hps.pretrainD))
+ if hasattr(net_d, "module"):
+ logger.info(
+ net_d.module.load_state_dict(
+ torch.load(hps.pretrainD, map_location="cpu")["model"]
+ )
+ )
+ else:
+ logger.info(
+ net_d.load_state_dict(
+ torch.load(hps.pretrainD, map_location="cpu")["model"]
+ )
+ )
+
+ scheduler_g = torch.optim.lr_scheduler.ExponentialLR(
+ optim_g, gamma=hps.train.lr_decay, last_epoch=epoch_str - 2
+ )
+ scheduler_d = torch.optim.lr_scheduler.ExponentialLR(
+ optim_d, gamma=hps.train.lr_decay, last_epoch=epoch_str - 2
+ )
+
+ scaler = GradScaler(enabled=hps.train.fp16_run)
+
+ cache = []
+ for epoch in range(epoch_str, hps.train.epochs + 1):
+ if rank == 0:
+ train_and_evaluate(
+ rank,
+ epoch,
+ hps,
+ [net_g, net_d],
+ [optim_g, optim_d],
+ [scheduler_g, scheduler_d],
+ scaler,
+ [train_loader, None],
+ logger,
+ [writer, writer_eval],
+ cache,
+ )
+ else:
+ train_and_evaluate(
+ rank,
+ epoch,
+ hps,
+ [net_g, net_d],
+ [optim_g, optim_d],
+ [scheduler_g, scheduler_d],
+ scaler,
+ [train_loader, None],
+ None,
+ None,
+ cache,
+ )
+ scheduler_g.step()
+ scheduler_d.step()
+
+
+def train_and_evaluate(
+ rank, epoch, hps, nets, optims, schedulers, scaler, loaders, logger, writers, cache
+):
+ net_g, net_d = nets
+ optim_g, optim_d = optims
+ train_loader, eval_loader = loaders
+ if writers is not None:
+ writer, writer_eval = writers
+
+ train_loader.batch_sampler.set_epoch(epoch)
+ global global_step
+
+ net_g.train()
+ net_d.train()
+
+ # Prepare data iterator
+ if hps.if_cache_data_in_gpu == True:
+ # Use Cache
+ data_iterator = cache
+ if cache == []:
+ # Make new cache
+ for batch_idx, info in enumerate(train_loader):
+ # Unpack
+ if hps.if_f0 == 1:
+ (
+ phone,
+ phone_lengths,
+ pitch,
+ pitchf,
+ spec,
+ spec_lengths,
+ wave,
+ wave_lengths,
+ sid,
+ ) = info
+ else:
+ (
+ phone,
+ phone_lengths,
+ spec,
+ spec_lengths,
+ wave,
+ wave_lengths,
+ sid,
+ ) = info
+ # Load on CUDA
+ if torch.cuda.is_available():
+ phone = phone.cuda(rank, non_blocking=True)
+ phone_lengths = phone_lengths.cuda(rank, non_blocking=True)
+ if hps.if_f0 == 1:
+ pitch = pitch.cuda(rank, non_blocking=True)
+ pitchf = pitchf.cuda(rank, non_blocking=True)
+ sid = sid.cuda(rank, non_blocking=True)
+ spec = spec.cuda(rank, non_blocking=True)
+ spec_lengths = spec_lengths.cuda(rank, non_blocking=True)
+ wave = wave.cuda(rank, non_blocking=True)
+ wave_lengths = wave_lengths.cuda(rank, non_blocking=True)
+ # Cache on list
+ if hps.if_f0 == 1:
+ cache.append(
+ (
+ batch_idx,
+ (
+ phone,
+ phone_lengths,
+ pitch,
+ pitchf,
+ spec,
+ spec_lengths,
+ wave,
+ wave_lengths,
+ sid,
+ ),
+ )
+ )
+ else:
+ cache.append(
+ (
+ batch_idx,
+ (
+ phone,
+ phone_lengths,
+ spec,
+ spec_lengths,
+ wave,
+ wave_lengths,
+ sid,
+ ),
+ )
+ )
+ else:
+ # Load shuffled cache
+ shuffle(cache)
+ else:
+ # Loader
+ data_iterator = enumerate(train_loader)
+
+ # Run steps
+ epoch_recorder = EpochRecorder()
+ for batch_idx, info in data_iterator:
+ # Data
+ ## Unpack
+ if hps.if_f0 == 1:
+ (
+ phone,
+ phone_lengths,
+ pitch,
+ pitchf,
+ spec,
+ spec_lengths,
+ wave,
+ wave_lengths,
+ sid,
+ ) = info
+ else:
+ phone, phone_lengths, spec, spec_lengths, wave, wave_lengths, sid = info
+ ## Load on CUDA
+ if (hps.if_cache_data_in_gpu == False) and torch.cuda.is_available():
+ phone = phone.cuda(rank, non_blocking=True)
+ phone_lengths = phone_lengths.cuda(rank, non_blocking=True)
+ if hps.if_f0 == 1:
+ pitch = pitch.cuda(rank, non_blocking=True)
+ pitchf = pitchf.cuda(rank, non_blocking=True)
+ sid = sid.cuda(rank, non_blocking=True)
+ spec = spec.cuda(rank, non_blocking=True)
+ spec_lengths = spec_lengths.cuda(rank, non_blocking=True)
+ wave = wave.cuda(rank, non_blocking=True)
+ # wave_lengths = wave_lengths.cuda(rank, non_blocking=True)
+
+ # Calculate
+ with autocast(enabled=hps.train.fp16_run):
+ if hps.if_f0 == 1:
+ (
+ y_hat,
+ ids_slice,
+ x_mask,
+ z_mask,
+ (z, z_p, m_p, logs_p, m_q, logs_q),
+ ) = net_g(phone, phone_lengths, pitch, pitchf, spec, spec_lengths, sid)
+ else:
+ (
+ y_hat,
+ ids_slice,
+ x_mask,
+ z_mask,
+ (z, z_p, m_p, logs_p, m_q, logs_q),
+ ) = net_g(phone, phone_lengths, spec, spec_lengths, sid)
+ mel = spec_to_mel_torch(
+ spec,
+ hps.data.filter_length,
+ hps.data.n_mel_channels,
+ hps.data.sampling_rate,
+ hps.data.mel_fmin,
+ hps.data.mel_fmax,
+ )
+ y_mel = commons.slice_segments(
+ mel, ids_slice, hps.train.segment_size // hps.data.hop_length
+ )
+ with autocast(enabled=False):
+ y_hat_mel = mel_spectrogram_torch(
+ y_hat.float().squeeze(1),
+ hps.data.filter_length,
+ hps.data.n_mel_channels,
+ hps.data.sampling_rate,
+ hps.data.hop_length,
+ hps.data.win_length,
+ hps.data.mel_fmin,
+ hps.data.mel_fmax,
+ )
+ if hps.train.fp16_run == True:
+ y_hat_mel = y_hat_mel.half()
+ wave = commons.slice_segments(
+ wave, ids_slice * hps.data.hop_length, hps.train.segment_size
+ ) # slice
+
+ # Discriminator
+ y_d_hat_r, y_d_hat_g, _, _ = net_d(wave, y_hat.detach())
+ with autocast(enabled=False):
+ loss_disc, losses_disc_r, losses_disc_g = discriminator_loss(
+ y_d_hat_r, y_d_hat_g
+ )
+ optim_d.zero_grad()
+ scaler.scale(loss_disc).backward()
+ scaler.unscale_(optim_d)
+ grad_norm_d = commons.clip_grad_value_(net_d.parameters(), None)
+ scaler.step(optim_d)
+
+ with autocast(enabled=hps.train.fp16_run):
+ # Generator
+ y_d_hat_r, y_d_hat_g, fmap_r, fmap_g = net_d(wave, y_hat)
+ with autocast(enabled=False):
+ loss_mel = F.l1_loss(y_mel, y_hat_mel) * hps.train.c_mel
+ loss_kl = kl_loss(z_p, logs_q, m_p, logs_p, z_mask) * hps.train.c_kl
+ loss_fm = feature_loss(fmap_r, fmap_g)
+ loss_gen, losses_gen = generator_loss(y_d_hat_g)
+ loss_gen_all = loss_gen + loss_fm + loss_mel + loss_kl
+ optim_g.zero_grad()
+ scaler.scale(loss_gen_all).backward()
+ scaler.unscale_(optim_g)
+ grad_norm_g = commons.clip_grad_value_(net_g.parameters(), None)
+ scaler.step(optim_g)
+ scaler.update()
+
+ if rank == 0:
+ if global_step % hps.train.log_interval == 0:
+ lr = optim_g.param_groups[0]["lr"]
+ logger.info(
+ "Train Epoch: {} [{:.0f}%]".format(
+ epoch, 100.0 * batch_idx / len(train_loader)
+ )
+ )
+ # Amor For Tensorboard display
+ if loss_mel > 75:
+ loss_mel = 75
+ if loss_kl > 9:
+ loss_kl = 9
+
+ logger.info([global_step, lr])
+ logger.info(
+ f"loss_disc={loss_disc:.3f}, loss_gen={loss_gen:.3f}, loss_fm={loss_fm:.3f},loss_mel={loss_mel:.3f}, loss_kl={loss_kl:.3f}"
+ )
+ scalar_dict = {
+ "loss/g/total": loss_gen_all,
+ "loss/d/total": loss_disc,
+ "learning_rate": lr,
+ "grad_norm_d": grad_norm_d,
+ "grad_norm_g": grad_norm_g,
+ }
+ scalar_dict.update(
+ {
+ "loss/g/fm": loss_fm,
+ "loss/g/mel": loss_mel,
+ "loss/g/kl": loss_kl,
+ }
+ )
+
+ scalar_dict.update(
+ {"loss/g/{}".format(i): v for i, v in enumerate(losses_gen)}
+ )
+ scalar_dict.update(
+ {"loss/d_r/{}".format(i): v for i, v in enumerate(losses_disc_r)}
+ )
+ scalar_dict.update(
+ {"loss/d_g/{}".format(i): v for i, v in enumerate(losses_disc_g)}
+ )
+ image_dict = {
+ "slice/mel_org": utils.plot_spectrogram_to_numpy(
+ y_mel[0].data.cpu().numpy()
+ ),
+ "slice/mel_gen": utils.plot_spectrogram_to_numpy(
+ y_hat_mel[0].data.cpu().numpy()
+ ),
+ "all/mel": utils.plot_spectrogram_to_numpy(
+ mel[0].data.cpu().numpy()
+ ),
+ }
+ utils.summarize(
+ writer=writer,
+ global_step=global_step,
+ images=image_dict,
+ scalars=scalar_dict,
+ )
+ global_step += 1
+ # /Run steps
+
+ if epoch % hps.save_every_epoch == 0 and rank == 0:
+ if hps.if_latest == 0:
+ utils.save_checkpoint(
+ net_g,
+ optim_g,
+ hps.train.learning_rate,
+ epoch,
+ os.path.join(hps.model_dir, "G_{}.pth".format(global_step)),
+ )
+ utils.save_checkpoint(
+ net_d,
+ optim_d,
+ hps.train.learning_rate,
+ epoch,
+ os.path.join(hps.model_dir, "D_{}.pth".format(global_step)),
+ )
+ else:
+ utils.save_checkpoint(
+ net_g,
+ optim_g,
+ hps.train.learning_rate,
+ epoch,
+ os.path.join(hps.model_dir, "G_{}.pth".format(2333333)),
+ )
+ utils.save_checkpoint(
+ net_d,
+ optim_d,
+ hps.train.learning_rate,
+ epoch,
+ os.path.join(hps.model_dir, "D_{}.pth".format(2333333)),
+ )
+ if rank == 0 and hps.save_every_weights == "1":
+ if hasattr(net_g, "module"):
+ ckpt = net_g.module.state_dict()
+ else:
+ ckpt = net_g.state_dict()
+ logger.info(
+ "saving ckpt %s_e%s:%s"
+ % (
+ hps.name,
+ epoch,
+ savee(
+ ckpt,
+ hps.sample_rate,
+ hps.if_f0,
+ hps.name + "_e%s_s%s" % (epoch, global_step),
+ epoch,
+ hps.version,
+ hps,
+ ),
+ )
+ )
+
+ if rank == 0:
+ logger.info("====> Epoch: {} {}".format(epoch, epoch_recorder.record()))
+ if epoch >= hps.total_epoch and rank == 0:
+ logger.info("Training is done. The program is closed.")
+
+ if hasattr(net_g, "module"):
+ ckpt = net_g.module.state_dict()
+ else:
+ ckpt = net_g.state_dict()
+ logger.info(
+ "saving final ckpt:%s"
+ % (
+ savee(
+ ckpt, hps.sample_rate, hps.if_f0, hps.name, epoch, hps.version, hps
+ )
+ )
+ )
+ sleep(1)
+ os._exit(2333333)
+
+
+if __name__ == "__main__":
+ torch.multiprocessing.set_start_method("spawn")
+ main()
diff --git a/infer/modules/uvr5/mdxnet.py b/infer/modules/uvr5/mdxnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..2f246db7a7c3186afd60f0b99b8089814331f4ba
--- /dev/null
+++ b/infer/modules/uvr5/mdxnet.py
@@ -0,0 +1,256 @@
+import os
+import logging
+
+logger = logging.getLogger(__name__)
+
+import librosa
+import numpy as np
+import soundfile as sf
+import torch
+from tqdm import tqdm
+
+cpu = torch.device("cpu")
+
+
+class ConvTDFNetTrim:
+ def __init__(
+ self, device, model_name, target_name, L, dim_f, dim_t, n_fft, hop=1024
+ ):
+ super(ConvTDFNetTrim, self).__init__()
+
+ self.dim_f = dim_f
+ self.dim_t = 2**dim_t
+ self.n_fft = n_fft
+ self.hop = hop
+ self.n_bins = self.n_fft // 2 + 1
+ self.chunk_size = hop * (self.dim_t - 1)
+ self.window = torch.hann_window(window_length=self.n_fft, periodic=True).to(
+ device
+ )
+ self.target_name = target_name
+ self.blender = "blender" in model_name
+
+ self.dim_c = 4
+ out_c = self.dim_c * 4 if target_name == "*" else self.dim_c
+ self.freq_pad = torch.zeros(
+ [1, out_c, self.n_bins - self.dim_f, self.dim_t]
+ ).to(device)
+
+ self.n = L // 2
+
+ def stft(self, x):
+ x = x.reshape([-1, self.chunk_size])
+ x = torch.stft(
+ x,
+ n_fft=self.n_fft,
+ hop_length=self.hop,
+ window=self.window,
+ center=True,
+ return_complex=True,
+ )
+ x = torch.view_as_real(x)
+ x = x.permute([0, 3, 1, 2])
+ x = x.reshape([-1, 2, 2, self.n_bins, self.dim_t]).reshape(
+ [-1, self.dim_c, self.n_bins, self.dim_t]
+ )
+ return x[:, :, : self.dim_f]
+
+ def istft(self, x, freq_pad=None):
+ freq_pad = (
+ self.freq_pad.repeat([x.shape[0], 1, 1, 1])
+ if freq_pad is None
+ else freq_pad
+ )
+ x = torch.cat([x, freq_pad], -2)
+ c = 4 * 2 if self.target_name == "*" else 2
+ x = x.reshape([-1, c, 2, self.n_bins, self.dim_t]).reshape(
+ [-1, 2, self.n_bins, self.dim_t]
+ )
+ x = x.permute([0, 2, 3, 1])
+ x = x.contiguous()
+ x = torch.view_as_complex(x)
+ x = torch.istft(
+ x, n_fft=self.n_fft, hop_length=self.hop, window=self.window, center=True
+ )
+ return x.reshape([-1, c, self.chunk_size])
+
+
+def get_models(device, dim_f, dim_t, n_fft):
+ return ConvTDFNetTrim(
+ device=device,
+ model_name="Conv-TDF",
+ target_name="vocals",
+ L=11,
+ dim_f=dim_f,
+ dim_t=dim_t,
+ n_fft=n_fft,
+ )
+
+
+class Predictor:
+ def __init__(self, args):
+ import onnxruntime as ort
+
+ logger.info(ort.get_available_providers())
+ self.args = args
+ self.model_ = get_models(
+ device=cpu, dim_f=args.dim_f, dim_t=args.dim_t, n_fft=args.n_fft
+ )
+ self.model = ort.InferenceSession(
+ os.path.join(args.onnx, self.model_.target_name + ".onnx"),
+ providers=[
+ "CUDAExecutionProvider",
+ "DmlExecutionProvider",
+ "CPUExecutionProvider",
+ ],
+ )
+ logger.info("ONNX load done")
+
+ def demix(self, mix):
+ samples = mix.shape[-1]
+ margin = self.args.margin
+ chunk_size = self.args.chunks * 44100
+ assert not margin == 0, "margin cannot be zero!"
+ if margin > chunk_size:
+ margin = chunk_size
+
+ segmented_mix = {}
+
+ if self.args.chunks == 0 or samples < chunk_size:
+ chunk_size = samples
+
+ counter = -1
+ for skip in range(0, samples, chunk_size):
+ counter += 1
+
+ s_margin = 0 if counter == 0 else margin
+ end = min(skip + chunk_size + margin, samples)
+
+ start = skip - s_margin
+
+ segmented_mix[skip] = mix[:, start:end].copy()
+ if end == samples:
+ break
+
+ sources = self.demix_base(segmented_mix, margin_size=margin)
+ """
+ mix:(2,big_sample)
+ segmented_mix:offset->(2,small_sample)
+ sources:(1,2,big_sample)
+ """
+ return sources
+
+ def demix_base(self, mixes, margin_size):
+ chunked_sources = []
+ progress_bar = tqdm(total=len(mixes))
+ progress_bar.set_description("Processing")
+ for mix in mixes:
+ cmix = mixes[mix]
+ sources = []
+ n_sample = cmix.shape[1]
+ model = self.model_
+ trim = model.n_fft // 2
+ gen_size = model.chunk_size - 2 * trim
+ pad = gen_size - n_sample % gen_size
+ mix_p = np.concatenate(
+ (np.zeros((2, trim)), cmix, np.zeros((2, pad)), np.zeros((2, trim))), 1
+ )
+ mix_waves = []
+ i = 0
+ while i < n_sample + pad:
+ waves = np.array(mix_p[:, i : i + model.chunk_size])
+ mix_waves.append(waves)
+ i += gen_size
+ mix_waves = torch.tensor(mix_waves, dtype=torch.float32).to(cpu)
+ with torch.no_grad():
+ _ort = self.model
+ spek = model.stft(mix_waves)
+ if self.args.denoise:
+ spec_pred = (
+ -_ort.run(None, {"input": -spek.cpu().numpy()})[0] * 0.5
+ + _ort.run(None, {"input": spek.cpu().numpy()})[0] * 0.5
+ )
+ tar_waves = model.istft(torch.tensor(spec_pred))
+ else:
+ tar_waves = model.istft(
+ torch.tensor(_ort.run(None, {"input": spek.cpu().numpy()})[0])
+ )
+ tar_signal = (
+ tar_waves[:, :, trim:-trim]
+ .transpose(0, 1)
+ .reshape(2, -1)
+ .numpy()[:, :-pad]
+ )
+
+ start = 0 if mix == 0 else margin_size
+ end = None if mix == list(mixes.keys())[::-1][0] else -margin_size
+ if margin_size == 0:
+ end = None
+ sources.append(tar_signal[:, start:end])
+
+ progress_bar.update(1)
+
+ chunked_sources.append(sources)
+ _sources = np.concatenate(chunked_sources, axis=-1)
+ # del self.model
+ progress_bar.close()
+ return _sources
+
+ def prediction(self, m, vocal_root, others_root, format):
+ os.makedirs(vocal_root, exist_ok=True)
+ os.makedirs(others_root, exist_ok=True)
+ basename = os.path.basename(m)
+ mix, rate = librosa.load(m, mono=False, sr=44100)
+ if mix.ndim == 1:
+ mix = np.asfortranarray([mix, mix])
+ mix = mix.T
+ sources = self.demix(mix.T)
+ opt = sources[0].T
+ if format in ["wav", "flac"]:
+ sf.write(
+ "%s/%s_main_vocal.%s" % (vocal_root, basename, format), mix - opt, rate
+ )
+ sf.write("%s/%s_others.%s" % (others_root, basename, format), opt, rate)
+ else:
+ path_vocal = "%s/%s_main_vocal.wav" % (vocal_root, basename)
+ path_other = "%s/%s_others.wav" % (others_root, basename)
+ sf.write(path_vocal, mix - opt, rate)
+ sf.write(path_other, opt, rate)
+ opt_path_vocal = path_vocal[:-4] + ".%s" % format
+ opt_path_other = path_other[:-4] + ".%s" % format
+ if os.path.exists(path_vocal):
+ os.system(
+ "ffmpeg -i %s -vn %s -q:a 2 -y" % (path_vocal, opt_path_vocal)
+ )
+ if os.path.exists(opt_path_vocal):
+ try:
+ os.remove(path_vocal)
+ except:
+ pass
+ if os.path.exists(path_other):
+ os.system(
+ "ffmpeg -i %s -vn %s -q:a 2 -y" % (path_other, opt_path_other)
+ )
+ if os.path.exists(opt_path_other):
+ try:
+ os.remove(path_other)
+ except:
+ pass
+
+
+class MDXNetDereverb:
+ def __init__(self, chunks, device):
+ self.onnx = "assets/uvr5_weights/onnx_dereverb_By_FoxJoy"
+ self.shifts = 10 # 'Predict with randomised equivariant stabilisation'
+ self.mixing = "min_mag" # ['default','min_mag','max_mag']
+ self.chunks = chunks
+ self.margin = 44100
+ self.dim_t = 9
+ self.dim_f = 3072
+ self.n_fft = 6144
+ self.denoise = True
+ self.pred = Predictor(self)
+ self.device = device
+
+ def _path_audio_(self, input, vocal_root, others_root, format, is_hp3=False):
+ self.pred.prediction(input, vocal_root, others_root, format)
diff --git a/infer/modules/uvr5/modules.py b/infer/modules/uvr5/modules.py
new file mode 100644
index 0000000000000000000000000000000000000000..bce3cef4eb83797e9ea196a7c6252abebd106a20
--- /dev/null
+++ b/infer/modules/uvr5/modules.py
@@ -0,0 +1,108 @@
+import os
+import traceback
+import logging
+
+logger = logging.getLogger(__name__)
+
+import ffmpeg
+import torch
+
+from configs.config import Config
+from infer.modules.uvr5.mdxnet import MDXNetDereverb
+from infer.modules.uvr5.vr import AudioPre, AudioPreDeEcho
+
+config = Config()
+
+
+def uvr(model_name, inp_root, save_root_vocal, paths, save_root_ins, agg, format0):
+ infos = []
+ try:
+ inp_root = inp_root.strip(" ").strip('"').strip("\n").strip('"').strip(" ")
+ save_root_vocal = (
+ save_root_vocal.strip(" ").strip('"').strip("\n").strip('"').strip(" ")
+ )
+ save_root_ins = (
+ save_root_ins.strip(" ").strip('"').strip("\n").strip('"').strip(" ")
+ )
+ if model_name == "onnx_dereverb_By_FoxJoy":
+ pre_fun = MDXNetDereverb(15, config.device)
+ else:
+ func = AudioPre if "DeEcho" not in model_name else AudioPreDeEcho
+ pre_fun = func(
+ agg=int(agg),
+ model_path=os.path.join(
+ os.getenv("weight_uvr5_root"), model_name + ".pth"
+ ),
+ device=config.device,
+ is_half=config.is_half,
+ )
+ is_hp3 = "HP3" in model_name
+ if inp_root != "":
+ paths = [os.path.join(inp_root, name) for name in os.listdir(inp_root)]
+ else:
+ paths = [path.name for path in paths]
+ for path in paths:
+ inp_path = os.path.join(inp_root, path)
+ need_reformat = 1
+ done = 0
+ try:
+ info = ffmpeg.probe(inp_path, cmd="ffprobe")
+ if (
+ info["streams"][0]["channels"] == 2
+ and info["streams"][0]["sample_rate"] == "44100"
+ ):
+ need_reformat = 0
+ pre_fun._path_audio_(
+ inp_path, save_root_ins, save_root_vocal, format0, is_hp3=is_hp3
+ )
+ done = 1
+ except:
+ need_reformat = 1
+ traceback.print_exc()
+ if need_reformat == 1:
+ tmp_path = "%s/%s.reformatted.wav" % (
+ os.path.join(os.environ["TEMP"]),
+ os.path.basename(inp_path),
+ )
+ os.system(
+ "ffmpeg -i %s -vn -acodec pcm_s16le -ac 2 -ar 44100 %s -y"
+ % (inp_path, tmp_path)
+ )
+ inp_path = tmp_path
+ try:
+ if done == 0:
+ pre_fun._path_audio_(
+ inp_path, save_root_ins, save_root_vocal, format0
+ )
+ infos.append("%s->Success" % (os.path.basename(inp_path)))
+ yield "\n".join(infos)
+ except:
+ try:
+ if done == 0:
+ pre_fun._path_audio_(
+ inp_path, save_root_ins, save_root_vocal, format0
+ )
+ infos.append("%s->Success" % (os.path.basename(inp_path)))
+ yield "\n".join(infos)
+ except:
+ infos.append(
+ "%s->%s" % (os.path.basename(inp_path), traceback.format_exc())
+ )
+ yield "\n".join(infos)
+ except:
+ infos.append(traceback.format_exc())
+ yield "\n".join(infos)
+ finally:
+ try:
+ if model_name == "onnx_dereverb_By_FoxJoy":
+ del pre_fun.pred.model
+ del pre_fun.pred.model_
+ else:
+ del pre_fun.model
+ del pre_fun
+ except:
+ traceback.print_exc()
+ if torch.cuda.is_available():
+ torch.cuda.empty_cache()
+ logger.info("Executed torch.cuda.empty_cache()")
+ yield "\n".join(infos)
diff --git a/infer/modules/uvr5/vr.py b/infer/modules/uvr5/vr.py
new file mode 100644
index 0000000000000000000000000000000000000000..ed5778438a799c98b138dfa35d0a7f81911c3855
--- /dev/null
+++ b/infer/modules/uvr5/vr.py
@@ -0,0 +1,368 @@
+import os
+import logging
+
+logger = logging.getLogger(__name__)
+
+import librosa
+import numpy as np
+import soundfile as sf
+import torch
+
+from infer.lib.uvr5_pack.lib_v5 import nets_61968KB as Nets
+from infer.lib.uvr5_pack.lib_v5 import spec_utils
+from infer.lib.uvr5_pack.lib_v5.model_param_init import ModelParameters
+from infer.lib.uvr5_pack.lib_v5.nets_new import CascadedNet
+from infer.lib.uvr5_pack.utils import inference
+
+
+class AudioPre:
+ def __init__(self, agg, model_path, device, is_half, tta=False):
+ self.model_path = model_path
+ self.device = device
+ self.data = {
+ # Processing Options
+ "postprocess": False,
+ "tta": tta,
+ # Constants
+ "window_size": 512,
+ "agg": agg,
+ "high_end_process": "mirroring",
+ }
+ mp = ModelParameters("infer/lib/uvr5_pack/lib_v5/modelparams/4band_v2.json")
+ model = Nets.CascadedASPPNet(mp.param["bins"] * 2)
+ cpk = torch.load(model_path, map_location="cpu")
+ model.load_state_dict(cpk)
+ model.eval()
+ if is_half:
+ model = model.half().to(device)
+ else:
+ model = model.to(device)
+
+ self.mp = mp
+ self.model = model
+
+ def _path_audio_(
+ self, music_file, ins_root=None, vocal_root=None, format="flac", is_hp3=False
+ ):
+ if ins_root is None and vocal_root is None:
+ return "No save root."
+ name = os.path.basename(music_file)
+ if ins_root is not None:
+ os.makedirs(ins_root, exist_ok=True)
+ if vocal_root is not None:
+ os.makedirs(vocal_root, exist_ok=True)
+ X_wave, y_wave, X_spec_s, y_spec_s = {}, {}, {}, {}
+ bands_n = len(self.mp.param["band"])
+ # print(bands_n)
+ for d in range(bands_n, 0, -1):
+ bp = self.mp.param["band"][d]
+ if d == bands_n: # high-end band
+ (
+ X_wave[d],
+ _,
+ ) = librosa.core.load( # 理论上librosa读取可能对某些音频有bug,应该上ffmpeg读取,但是太麻烦了弃坑
+ music_file,
+ bp["sr"],
+ False,
+ dtype=np.float32,
+ res_type=bp["res_type"],
+ )
+ if X_wave[d].ndim == 1:
+ X_wave[d] = np.asfortranarray([X_wave[d], X_wave[d]])
+ else: # lower bands
+ X_wave[d] = librosa.core.resample(
+ X_wave[d + 1],
+ self.mp.param["band"][d + 1]["sr"],
+ bp["sr"],
+ res_type=bp["res_type"],
+ )
+ # Stft of wave source
+ X_spec_s[d] = spec_utils.wave_to_spectrogram_mt(
+ X_wave[d],
+ bp["hl"],
+ bp["n_fft"],
+ self.mp.param["mid_side"],
+ self.mp.param["mid_side_b2"],
+ self.mp.param["reverse"],
+ )
+ # pdb.set_trace()
+ if d == bands_n and self.data["high_end_process"] != "none":
+ input_high_end_h = (bp["n_fft"] // 2 - bp["crop_stop"]) + (
+ self.mp.param["pre_filter_stop"] - self.mp.param["pre_filter_start"]
+ )
+ input_high_end = X_spec_s[d][
+ :, bp["n_fft"] // 2 - input_high_end_h : bp["n_fft"] // 2, :
+ ]
+
+ X_spec_m = spec_utils.combine_spectrograms(X_spec_s, self.mp)
+ aggresive_set = float(self.data["agg"] / 100)
+ aggressiveness = {
+ "value": aggresive_set,
+ "split_bin": self.mp.param["band"][1]["crop_stop"],
+ }
+ with torch.no_grad():
+ pred, X_mag, X_phase = inference(
+ X_spec_m, self.device, self.model, aggressiveness, self.data
+ )
+ # Postprocess
+ if self.data["postprocess"]:
+ pred_inv = np.clip(X_mag - pred, 0, np.inf)
+ pred = spec_utils.mask_silence(pred, pred_inv)
+ y_spec_m = pred * X_phase
+ v_spec_m = X_spec_m - y_spec_m
+
+ if ins_root is not None:
+ if self.data["high_end_process"].startswith("mirroring"):
+ input_high_end_ = spec_utils.mirroring(
+ self.data["high_end_process"], y_spec_m, input_high_end, self.mp
+ )
+ wav_instrument = spec_utils.cmb_spectrogram_to_wave(
+ y_spec_m, self.mp, input_high_end_h, input_high_end_
+ )
+ else:
+ wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, self.mp)
+ logger.info("%s instruments done" % name)
+ if is_hp3 == True:
+ head = "vocal_"
+ else:
+ head = "instrument_"
+ if format in ["wav", "flac"]:
+ sf.write(
+ os.path.join(
+ ins_root,
+ head + "{}_{}.{}".format(name, self.data["agg"], format),
+ ),
+ (np.array(wav_instrument) * 32768).astype("int16"),
+ self.mp.param["sr"],
+ ) #
+ else:
+ path = os.path.join(
+ ins_root, head + "{}_{}.wav".format(name, self.data["agg"])
+ )
+ sf.write(
+ path,
+ (np.array(wav_instrument) * 32768).astype("int16"),
+ self.mp.param["sr"],
+ )
+ if os.path.exists(path):
+ opt_format_path = path[:-4] + ".%s" % format
+ os.system("ffmpeg -i %s -vn %s -q:a 2 -y" % (path, opt_format_path))
+ if os.path.exists(opt_format_path):
+ try:
+ os.remove(path)
+ except:
+ pass
+ if vocal_root is not None:
+ if is_hp3 == True:
+ head = "instrument_"
+ else:
+ head = "vocal_"
+ if self.data["high_end_process"].startswith("mirroring"):
+ input_high_end_ = spec_utils.mirroring(
+ self.data["high_end_process"], v_spec_m, input_high_end, self.mp
+ )
+ wav_vocals = spec_utils.cmb_spectrogram_to_wave(
+ v_spec_m, self.mp, input_high_end_h, input_high_end_
+ )
+ else:
+ wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, self.mp)
+ logger.info("%s vocals done" % name)
+ if format in ["wav", "flac"]:
+ sf.write(
+ os.path.join(
+ vocal_root,
+ head + "{}_{}.{}".format(name, self.data["agg"], format),
+ ),
+ (np.array(wav_vocals) * 32768).astype("int16"),
+ self.mp.param["sr"],
+ )
+ else:
+ path = os.path.join(
+ vocal_root, head + "{}_{}.wav".format(name, self.data["agg"])
+ )
+ sf.write(
+ path,
+ (np.array(wav_vocals) * 32768).astype("int16"),
+ self.mp.param["sr"],
+ )
+ if os.path.exists(path):
+ opt_format_path = path[:-4] + ".%s" % format
+ os.system("ffmpeg -i %s -vn %s -q:a 2 -y" % (path, opt_format_path))
+ if os.path.exists(opt_format_path):
+ try:
+ os.remove(path)
+ except:
+ pass
+
+
+class AudioPreDeEcho:
+ def __init__(self, agg, model_path, device, is_half, tta=False):
+ self.model_path = model_path
+ self.device = device
+ self.data = {
+ # Processing Options
+ "postprocess": False,
+ "tta": tta,
+ # Constants
+ "window_size": 512,
+ "agg": agg,
+ "high_end_process": "mirroring",
+ }
+ mp = ModelParameters("infer/lib/uvr5_pack/lib_v5/modelparams/4band_v3.json")
+ nout = 64 if "DeReverb" in model_path else 48
+ model = CascadedNet(mp.param["bins"] * 2, nout)
+ cpk = torch.load(model_path, map_location="cpu")
+ model.load_state_dict(cpk)
+ model.eval()
+ if is_half:
+ model = model.half().to(device)
+ else:
+ model = model.to(device)
+
+ self.mp = mp
+ self.model = model
+
+ def _path_audio_(
+ self, music_file, vocal_root=None, ins_root=None, format="flac", is_hp3=False
+ ): # 3个VR模型vocal和ins是反的
+ if ins_root is None and vocal_root is None:
+ return "No save root."
+ name = os.path.basename(music_file)
+ if ins_root is not None:
+ os.makedirs(ins_root, exist_ok=True)
+ if vocal_root is not None:
+ os.makedirs(vocal_root, exist_ok=True)
+ X_wave, y_wave, X_spec_s, y_spec_s = {}, {}, {}, {}
+ bands_n = len(self.mp.param["band"])
+ # print(bands_n)
+ for d in range(bands_n, 0, -1):
+ bp = self.mp.param["band"][d]
+ if d == bands_n: # high-end band
+ (
+ X_wave[d],
+ _,
+ ) = librosa.core.load( # 理论上librosa读取可能对某些音频有bug,应该上ffmpeg读取,但是太麻烦了弃坑
+ music_file,
+ bp["sr"],
+ False,
+ dtype=np.float32,
+ res_type=bp["res_type"],
+ )
+ if X_wave[d].ndim == 1:
+ X_wave[d] = np.asfortranarray([X_wave[d], X_wave[d]])
+ else: # lower bands
+ X_wave[d] = librosa.core.resample(
+ X_wave[d + 1],
+ self.mp.param["band"][d + 1]["sr"],
+ bp["sr"],
+ res_type=bp["res_type"],
+ )
+ # Stft of wave source
+ X_spec_s[d] = spec_utils.wave_to_spectrogram_mt(
+ X_wave[d],
+ bp["hl"],
+ bp["n_fft"],
+ self.mp.param["mid_side"],
+ self.mp.param["mid_side_b2"],
+ self.mp.param["reverse"],
+ )
+ # pdb.set_trace()
+ if d == bands_n and self.data["high_end_process"] != "none":
+ input_high_end_h = (bp["n_fft"] // 2 - bp["crop_stop"]) + (
+ self.mp.param["pre_filter_stop"] - self.mp.param["pre_filter_start"]
+ )
+ input_high_end = X_spec_s[d][
+ :, bp["n_fft"] // 2 - input_high_end_h : bp["n_fft"] // 2, :
+ ]
+
+ X_spec_m = spec_utils.combine_spectrograms(X_spec_s, self.mp)
+ aggresive_set = float(self.data["agg"] / 100)
+ aggressiveness = {
+ "value": aggresive_set,
+ "split_bin": self.mp.param["band"][1]["crop_stop"],
+ }
+ with torch.no_grad():
+ pred, X_mag, X_phase = inference(
+ X_spec_m, self.device, self.model, aggressiveness, self.data
+ )
+ # Postprocess
+ if self.data["postprocess"]:
+ pred_inv = np.clip(X_mag - pred, 0, np.inf)
+ pred = spec_utils.mask_silence(pred, pred_inv)
+ y_spec_m = pred * X_phase
+ v_spec_m = X_spec_m - y_spec_m
+
+ if ins_root is not None:
+ if self.data["high_end_process"].startswith("mirroring"):
+ input_high_end_ = spec_utils.mirroring(
+ self.data["high_end_process"], y_spec_m, input_high_end, self.mp
+ )
+ wav_instrument = spec_utils.cmb_spectrogram_to_wave(
+ y_spec_m, self.mp, input_high_end_h, input_high_end_
+ )
+ else:
+ wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, self.mp)
+ logger.info("%s instruments done" % name)
+ if format in ["wav", "flac"]:
+ sf.write(
+ os.path.join(
+ ins_root,
+ "vocal_{}_{}.{}".format(name, self.data["agg"], format),
+ ),
+ (np.array(wav_instrument) * 32768).astype("int16"),
+ self.mp.param["sr"],
+ ) #
+ else:
+ path = os.path.join(
+ ins_root, "vocal_{}_{}.wav".format(name, self.data["agg"])
+ )
+ sf.write(
+ path,
+ (np.array(wav_instrument) * 32768).astype("int16"),
+ self.mp.param["sr"],
+ )
+ if os.path.exists(path):
+ opt_format_path = path[:-4] + ".%s" % format
+ os.system("ffmpeg -i %s -vn %s -q:a 2 -y" % (path, opt_format_path))
+ if os.path.exists(opt_format_path):
+ try:
+ os.remove(path)
+ except:
+ pass
+ if vocal_root is not None:
+ if self.data["high_end_process"].startswith("mirroring"):
+ input_high_end_ = spec_utils.mirroring(
+ self.data["high_end_process"], v_spec_m, input_high_end, self.mp
+ )
+ wav_vocals = spec_utils.cmb_spectrogram_to_wave(
+ v_spec_m, self.mp, input_high_end_h, input_high_end_
+ )
+ else:
+ wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, self.mp)
+ logger.info("%s vocals done" % name)
+ if format in ["wav", "flac"]:
+ sf.write(
+ os.path.join(
+ vocal_root,
+ "instrument_{}_{}.{}".format(name, self.data["agg"], format),
+ ),
+ (np.array(wav_vocals) * 32768).astype("int16"),
+ self.mp.param["sr"],
+ )
+ else:
+ path = os.path.join(
+ vocal_root, "instrument_{}_{}.wav".format(name, self.data["agg"])
+ )
+ sf.write(
+ path,
+ (np.array(wav_vocals) * 32768).astype("int16"),
+ self.mp.param["sr"],
+ )
+ if os.path.exists(path):
+ opt_format_path = path[:-4] + ".%s" % format
+ os.system("ffmpeg -i %s -vn %s -q:a 2 -y" % (path, opt_format_path))
+ if os.path.exists(opt_format_path):
+ try:
+ os.remove(path)
+ except:
+ pass
diff --git a/infer/modules/vc/__init__.py b/infer/modules/vc/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/infer/modules/vc/modules.py b/infer/modules/vc/modules.py
new file mode 100644
index 0000000000000000000000000000000000000000..6f695cc394bace3d0440b5fbac40e38090ad7858
--- /dev/null
+++ b/infer/modules/vc/modules.py
@@ -0,0 +1,304 @@
+import traceback
+import logging
+
+logger = logging.getLogger(__name__)
+
+import numpy as np
+import soundfile as sf
+import torch
+from io import BytesIO
+
+from infer.lib.audio import load_audio, wav2
+from infer.lib.infer_pack.models import (
+ SynthesizerTrnMs256NSFsid,
+ SynthesizerTrnMs256NSFsid_nono,
+ SynthesizerTrnMs768NSFsid,
+ SynthesizerTrnMs768NSFsid_nono,
+)
+from infer.modules.vc.pipeline import Pipeline
+from infer.modules.vc.utils import *
+
+
+class VC:
+ def __init__(self, config):
+ self.n_spk = None
+ self.tgt_sr = None
+ self.net_g = None
+ self.pipeline = None
+ self.cpt = None
+ self.version = None
+ self.if_f0 = None
+ self.version = None
+ self.hubert_model = None
+
+ self.config = config
+
+ def get_vc(self, sid, *to_return_protect):
+ logger.info("Get sid: " + sid)
+
+ to_return_protect0 = {
+ "visible": self.if_f0 != 0,
+ "value": (
+ to_return_protect[0] if self.if_f0 != 0 and to_return_protect else 0.5
+ ),
+ "__type__": "update",
+ }
+ to_return_protect1 = {
+ "visible": self.if_f0 != 0,
+ "value": (
+ to_return_protect[1] if self.if_f0 != 0 and to_return_protect else 0.33
+ ),
+ "__type__": "update",
+ }
+
+ if sid == "" or sid == []:
+ if (
+ self.hubert_model is not None
+ ): # 考虑到轮询, 需要加个判断看是否 sid 是由有模型切换到无模型的
+ logger.info("Clean model cache")
+ del (self.net_g, self.n_spk, self.hubert_model, self.tgt_sr) # ,cpt
+ self.hubert_model = self.net_g = self.n_spk = self.hubert_model = (
+ self.tgt_sr
+ ) = None
+ if torch.cuda.is_available():
+ torch.cuda.empty_cache()
+ ###楼下不这么折腾清理不干净
+ self.if_f0 = self.cpt.get("f0", 1)
+ self.version = self.cpt.get("version", "v1")
+ if self.version == "v1":
+ if self.if_f0 == 1:
+ self.net_g = SynthesizerTrnMs256NSFsid(
+ *self.cpt["config"], is_half=self.config.is_half
+ )
+ else:
+ self.net_g = SynthesizerTrnMs256NSFsid_nono(*self.cpt["config"])
+ elif self.version == "v2":
+ if self.if_f0 == 1:
+ self.net_g = SynthesizerTrnMs768NSFsid(
+ *self.cpt["config"], is_half=self.config.is_half
+ )
+ else:
+ self.net_g = SynthesizerTrnMs768NSFsid_nono(*self.cpt["config"])
+ del self.net_g, self.cpt
+ if torch.cuda.is_available():
+ torch.cuda.empty_cache()
+ return (
+ {"visible": False, "__type__": "update"},
+ {
+ "visible": True,
+ "value": to_return_protect0,
+ "__type__": "update",
+ },
+ {
+ "visible": True,
+ "value": to_return_protect1,
+ "__type__": "update",
+ },
+ "",
+ "",
+ )
+ person = f'{os.getenv("weight_root")}/{sid}'
+ logger.info(f"Loading: {person}")
+
+ self.cpt = torch.load(person, map_location="cpu")
+ self.tgt_sr = self.cpt["config"][-1]
+ self.cpt["config"][-3] = self.cpt["weight"]["emb_g.weight"].shape[0] # n_spk
+ self.if_f0 = self.cpt.get("f0", 1)
+ self.version = self.cpt.get("version", "v1")
+
+ synthesizer_class = {
+ ("v1", 1): SynthesizerTrnMs256NSFsid,
+ ("v1", 0): SynthesizerTrnMs256NSFsid_nono,
+ ("v2", 1): SynthesizerTrnMs768NSFsid,
+ ("v2", 0): SynthesizerTrnMs768NSFsid_nono,
+ }
+
+ self.net_g = synthesizer_class.get(
+ (self.version, self.if_f0), SynthesizerTrnMs256NSFsid
+ )(*self.cpt["config"], is_half=self.config.is_half)
+
+ del self.net_g.enc_q
+
+ self.net_g.load_state_dict(self.cpt["weight"], strict=False)
+ self.net_g.eval().to(self.config.device)
+ if self.config.is_half:
+ self.net_g = self.net_g.half()
+ else:
+ self.net_g = self.net_g.float()
+
+ self.pipeline = Pipeline(self.tgt_sr, self.config)
+ n_spk = self.cpt["config"][-3]
+ index = {"value": get_index_path_from_model(sid), "__type__": "update"}
+ logger.info("Select index: " + index["value"])
+
+ return (
+ (
+ {"visible": True, "maximum": n_spk, "__type__": "update"},
+ to_return_protect0,
+ to_return_protect1,
+ index,
+ index,
+ )
+ if to_return_protect
+ else {"visible": True, "maximum": n_spk, "__type__": "update"}
+ )
+
+ def vc_single(
+ self,
+ sid,
+ input_audio_path,
+ f0_up_key,
+ f0_file,
+ f0_method,
+ file_index,
+ file_index2,
+ index_rate,
+ filter_radius,
+ resample_sr,
+ rms_mix_rate,
+ protect,
+ ):
+ if input_audio_path is None:
+ return "You need to upload an audio", None
+ f0_up_key = int(f0_up_key)
+ try:
+ audio = load_audio(input_audio_path, 16000)
+ audio_max = np.abs(audio).max() / 0.95
+ if audio_max > 1:
+ audio /= audio_max
+ times = [0, 0, 0]
+
+ if self.hubert_model is None:
+ self.hubert_model = load_hubert(self.config)
+
+ if file_index:
+ file_index = (
+ file_index.strip(" ")
+ .strip('"')
+ .strip("\n")
+ .strip('"')
+ .strip(" ")
+ .replace("trained", "added")
+ )
+ elif file_index2:
+ file_index = file_index2
+ else:
+ file_index = "" # 防止小白写错,自动帮他替换掉
+
+ audio_opt = self.pipeline.pipeline(
+ self.hubert_model,
+ self.net_g,
+ sid,
+ audio,
+ input_audio_path,
+ times,
+ f0_up_key,
+ f0_method,
+ file_index,
+ index_rate,
+ self.if_f0,
+ filter_radius,
+ self.tgt_sr,
+ resample_sr,
+ rms_mix_rate,
+ self.version,
+ protect,
+ f0_file,
+ )
+ if self.tgt_sr != resample_sr >= 16000:
+ tgt_sr = resample_sr
+ else:
+ tgt_sr = self.tgt_sr
+ index_info = (
+ "Index:\n%s." % file_index
+ if os.path.exists(file_index)
+ else "Index not used."
+ )
+ return (
+ "Success.\n%s\nTime:\nnpy: %.2fs, f0: %.2fs, infer: %.2fs."
+ % (index_info, *times),
+ (tgt_sr, audio_opt),
+ )
+ except:
+ info = traceback.format_exc()
+ logger.warning(info)
+ return info, (None, None)
+
+ def vc_multi(
+ self,
+ sid,
+ dir_path,
+ opt_root,
+ paths,
+ f0_up_key,
+ f0_method,
+ file_index,
+ file_index2,
+ index_rate,
+ filter_radius,
+ resample_sr,
+ rms_mix_rate,
+ protect,
+ format1,
+ ):
+ try:
+ dir_path = (
+ dir_path.strip(" ").strip('"').strip("\n").strip('"').strip(" ")
+ ) # 防止小白拷路径头尾带了空格和"和回车
+ opt_root = opt_root.strip(" ").strip('"').strip("\n").strip('"').strip(" ")
+ os.makedirs(opt_root, exist_ok=True)
+ try:
+ if dir_path != "":
+ paths = [
+ os.path.join(dir_path, name) for name in os.listdir(dir_path)
+ ]
+ else:
+ paths = [path.name for path in paths]
+ except:
+ traceback.print_exc()
+ paths = [path.name for path in paths]
+ infos = []
+ for path in paths:
+ info, opt = self.vc_single(
+ sid,
+ path,
+ f0_up_key,
+ None,
+ f0_method,
+ file_index,
+ file_index2,
+ # file_big_npy,
+ index_rate,
+ filter_radius,
+ resample_sr,
+ rms_mix_rate,
+ protect,
+ )
+ if "Success" in info:
+ try:
+ tgt_sr, audio_opt = opt
+ if format1 in ["wav", "flac"]:
+ sf.write(
+ "%s/%s.%s"
+ % (opt_root, os.path.basename(path), format1),
+ audio_opt,
+ tgt_sr,
+ )
+ else:
+ path = "%s/%s.%s" % (
+ opt_root,
+ os.path.basename(path),
+ format1,
+ )
+ with BytesIO() as wavf:
+ sf.write(wavf, audio_opt, tgt_sr, format="wav")
+ wavf.seek(0, 0)
+ with open(path, "wb") as outf:
+ wav2(wavf, outf, format1)
+ except:
+ info += traceback.format_exc()
+ infos.append("%s->%s" % (os.path.basename(path), info))
+ yield "\n".join(infos)
+ yield "\n".join(infos)
+ except:
+ yield traceback.format_exc()
diff --git a/infer/modules/vc/pipeline.py b/infer/modules/vc/pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..371836b533cda52c23cf2a09759a30ac9e8dd16f
--- /dev/null
+++ b/infer/modules/vc/pipeline.py
@@ -0,0 +1,475 @@
+import os
+import sys
+import traceback
+import logging
+
+logger = logging.getLogger(__name__)
+
+from functools import lru_cache
+from time import time as ttime
+
+import faiss
+import librosa
+import numpy as np
+import parselmouth
+import pyworld
+import torch
+import torch.nn.functional as F
+import torchcrepe
+from scipy import signal
+
+now_dir = os.getcwd()
+sys.path.append(now_dir)
+
+bh, ah = signal.butter(N=5, Wn=48, btype="high", fs=16000)
+
+input_audio_path2wav = {}
+
+
+@lru_cache
+def cache_harvest_f0(input_audio_path, fs, f0max, f0min, frame_period):
+ audio = input_audio_path2wav[input_audio_path]
+ f0, t = pyworld.harvest(
+ audio,
+ fs=fs,
+ f0_ceil=f0max,
+ f0_floor=f0min,
+ frame_period=frame_period,
+ )
+ f0 = pyworld.stonemask(audio, f0, t, fs)
+ return f0
+
+
+def change_rms(data1, sr1, data2, sr2, rate): # 1是输入音频,2是输出音频,rate是2的占比
+ # print(data1.max(),data2.max())
+ rms1 = librosa.feature.rms(
+ y=data1, frame_length=sr1 // 2 * 2, hop_length=sr1 // 2
+ ) # 每半秒一个点
+ rms2 = librosa.feature.rms(y=data2, frame_length=sr2 // 2 * 2, hop_length=sr2 // 2)
+ rms1 = torch.from_numpy(rms1)
+ rms1 = F.interpolate(
+ rms1.unsqueeze(0), size=data2.shape[0], mode="linear"
+ ).squeeze()
+ rms2 = torch.from_numpy(rms2)
+ rms2 = F.interpolate(
+ rms2.unsqueeze(0), size=data2.shape[0], mode="linear"
+ ).squeeze()
+ rms2 = torch.max(rms2, torch.zeros_like(rms2) + 1e-6)
+ data2 *= (
+ torch.pow(rms1, torch.tensor(1 - rate))
+ * torch.pow(rms2, torch.tensor(rate - 1))
+ ).numpy()
+ return data2
+
+
+class Pipeline(object):
+ def __init__(self, tgt_sr, config):
+ self.x_pad, self.x_query, self.x_center, self.x_max, self.is_half = (
+ config.x_pad,
+ config.x_query,
+ config.x_center,
+ config.x_max,
+ config.is_half,
+ )
+ self.sr = 16000 # hubert输入采样率
+ self.window = 160 # 每帧点数
+ self.t_pad = self.sr * self.x_pad # 每条前后pad时间
+ self.t_pad_tgt = tgt_sr * self.x_pad
+ self.t_pad2 = self.t_pad * 2
+ self.t_query = self.sr * self.x_query # 查询切点前后查询时间
+ self.t_center = self.sr * self.x_center # 查询切点位置
+ self.t_max = self.sr * self.x_max # 免查询时长阈值
+ self.device = config.device
+
+ def get_f0(
+ self,
+ input_audio_path,
+ x,
+ p_len,
+ f0_up_key,
+ f0_method,
+ filter_radius,
+ inp_f0=None,
+ ):
+ global input_audio_path2wav
+ time_step = self.window / self.sr * 1000
+ f0_min = 50
+ f0_max = 1100
+ f0_mel_min = 1127 * np.log(1 + f0_min / 700)
+ f0_mel_max = 1127 * np.log(1 + f0_max / 700)
+ if f0_method == "pm":
+ f0 = (
+ parselmouth.Sound(x, self.sr)
+ .to_pitch_ac(
+ time_step=time_step / 1000,
+ voicing_threshold=0.6,
+ pitch_floor=f0_min,
+ pitch_ceiling=f0_max,
+ )
+ .selected_array["frequency"]
+ )
+ pad_size = (p_len - len(f0) + 1) // 2
+ if pad_size > 0 or p_len - len(f0) - pad_size > 0:
+ f0 = np.pad(
+ f0, [[pad_size, p_len - len(f0) - pad_size]], mode="constant"
+ )
+ elif f0_method == "harvest":
+ input_audio_path2wav[input_audio_path] = x.astype(np.double)
+ f0 = cache_harvest_f0(input_audio_path, self.sr, f0_max, f0_min, 10)
+ if filter_radius > 2:
+ f0 = signal.medfilt(f0, 3)
+ elif f0_method == "crepe":
+ model = "full"
+ # Pick a batch size that doesn't cause memory errors on your gpu
+ batch_size = 512
+ # Compute pitch using first gpu
+ audio = torch.tensor(np.copy(x))[None].float()
+ f0, pd = torchcrepe.predict(
+ audio,
+ self.sr,
+ self.window,
+ f0_min,
+ f0_max,
+ model,
+ batch_size=batch_size,
+ device=self.device,
+ return_periodicity=True,
+ )
+ pd = torchcrepe.filter.median(pd, 3)
+ f0 = torchcrepe.filter.mean(f0, 3)
+ f0[pd < 0.1] = 0
+ f0 = f0[0].cpu().numpy()
+ elif f0_method == "rmvpe":
+ if not hasattr(self, "model_rmvpe"):
+ from infer.lib.rmvpe import RMVPE
+
+ logger.info(
+ "Loading rmvpe model,%s" % "%s/rmvpe.pt" % os.environ["rmvpe_root"]
+ )
+ self.model_rmvpe = RMVPE(
+ "%s/rmvpe.pt" % os.environ["rmvpe_root"],
+ is_half=self.is_half,
+ device=self.device,
+ # use_jit=self.config.use_jit,
+ )
+ f0 = self.model_rmvpe.infer_from_audio(x, thred=0.03)
+
+ if "privateuseone" in str(self.device): # clean ortruntime memory
+ del self.model_rmvpe.model
+ del self.model_rmvpe
+ logger.info("Cleaning ortruntime memory")
+ elif f0_method == "fcpe":
+ if not hasattr(self, "model_fcpe"):
+ from torchfcpe import spawn_bundled_infer_model
+
+ logger.info("Loading fcpe model")
+ self.model_fcpe = spawn_bundled_infer_model(self.device)
+ f0 = (
+ self.model_fcpe.infer(
+ torch.from_numpy(x).to(self.device).unsqueeze(0).float(),
+ sr=16000,
+ decoder_mode="local_argmax",
+ threshold=0.006,
+ )
+ .squeeze()
+ .cpu()
+ .numpy()
+ )
+
+ f0 *= pow(2, f0_up_key / 12)
+ # with open("test.txt","w")as f:f.write("\n".join([str(i)for i in f0.tolist()]))
+ tf0 = self.sr // self.window # 每秒f0点数
+ if inp_f0 is not None:
+ delta_t = np.round(
+ (inp_f0[:, 0].max() - inp_f0[:, 0].min()) * tf0 + 1
+ ).astype("int16")
+ replace_f0 = np.interp(
+ list(range(delta_t)), inp_f0[:, 0] * 100, inp_f0[:, 1]
+ )
+ shape = f0[self.x_pad * tf0 : self.x_pad * tf0 + len(replace_f0)].shape[0]
+ f0[self.x_pad * tf0 : self.x_pad * tf0 + len(replace_f0)] = replace_f0[
+ :shape
+ ]
+ # with open("test_opt.txt","w")as f:f.write("\n".join([str(i)for i in f0.tolist()]))
+ f0bak = f0.copy()
+ f0_mel = 1127 * np.log(1 + f0 / 700)
+ f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - f0_mel_min) * 254 / (
+ f0_mel_max - f0_mel_min
+ ) + 1
+ f0_mel[f0_mel <= 1] = 1
+ f0_mel[f0_mel > 255] = 255
+ f0_coarse = np.rint(f0_mel).astype(np.int32)
+ return f0_coarse, f0bak # 1-0
+
+ def vc(
+ self,
+ model,
+ net_g,
+ sid,
+ audio0,
+ pitch,
+ pitchf,
+ times,
+ index,
+ big_npy,
+ index_rate,
+ version,
+ protect,
+ ): # ,file_index,file_big_npy
+ feats = torch.from_numpy(audio0)
+ if self.is_half:
+ feats = feats.half()
+ else:
+ feats = feats.float()
+ if feats.dim() == 2: # double channels
+ feats = feats.mean(-1)
+ assert feats.dim() == 1, feats.dim()
+ feats = feats.view(1, -1)
+ padding_mask = torch.BoolTensor(feats.shape).to(self.device).fill_(False)
+
+ inputs = {
+ "source": feats.to(self.device),
+ "padding_mask": padding_mask,
+ "output_layer": 9 if version == "v1" else 12,
+ }
+ t0 = ttime()
+ with torch.no_grad():
+ logits = model.extract_features(**inputs)
+ feats = model.final_proj(logits[0]) if version == "v1" else logits[0]
+ if protect < 0.5 and pitch is not None and pitchf is not None:
+ feats0 = feats.clone()
+ if (
+ not isinstance(index, type(None))
+ and not isinstance(big_npy, type(None))
+ and index_rate != 0
+ ):
+ npy = feats[0].cpu().numpy()
+ if self.is_half:
+ npy = npy.astype("float32")
+
+ # _, I = index.search(npy, 1)
+ # npy = big_npy[I.squeeze()]
+
+ score, ix = index.search(npy, k=8)
+ weight = np.square(1 / score)
+ weight /= weight.sum(axis=1, keepdims=True)
+ npy = np.sum(big_npy[ix] * np.expand_dims(weight, axis=2), axis=1)
+
+ if self.is_half:
+ npy = npy.astype("float16")
+ feats = (
+ torch.from_numpy(npy).unsqueeze(0).to(self.device) * index_rate
+ + (1 - index_rate) * feats
+ )
+
+ feats = F.interpolate(feats.permute(0, 2, 1), scale_factor=2).permute(0, 2, 1)
+ if protect < 0.5 and pitch is not None and pitchf is not None:
+ feats0 = F.interpolate(feats0.permute(0, 2, 1), scale_factor=2).permute(
+ 0, 2, 1
+ )
+ t1 = ttime()
+ p_len = audio0.shape[0] // self.window
+ if feats.shape[1] < p_len:
+ p_len = feats.shape[1]
+ if pitch is not None and pitchf is not None:
+ pitch = pitch[:, :p_len]
+ pitchf = pitchf[:, :p_len]
+
+ if protect < 0.5 and pitch is not None and pitchf is not None:
+ pitchff = pitchf.clone()
+ pitchff[pitchf > 0] = 1
+ pitchff[pitchf < 1] = protect
+ pitchff = pitchff.unsqueeze(-1)
+ feats = feats * pitchff + feats0 * (1 - pitchff)
+ feats = feats.to(feats0.dtype)
+ p_len = torch.tensor([p_len], device=self.device).long()
+ with torch.no_grad():
+ hasp = pitch is not None and pitchf is not None
+ arg = (feats, p_len, pitch, pitchf, sid) if hasp else (feats, p_len, sid)
+ audio1 = (net_g.infer(*arg)[0][0, 0]).data.cpu().float().numpy()
+ del hasp, arg
+ del feats, p_len, padding_mask
+ if torch.cuda.is_available():
+ torch.cuda.empty_cache()
+ t2 = ttime()
+ times[0] += t1 - t0
+ times[2] += t2 - t1
+ return audio1
+
+ def pipeline(
+ self,
+ model,
+ net_g,
+ sid,
+ audio,
+ input_audio_path,
+ times,
+ f0_up_key,
+ f0_method,
+ file_index,
+ index_rate,
+ if_f0,
+ filter_radius,
+ tgt_sr,
+ resample_sr,
+ rms_mix_rate,
+ version,
+ protect,
+ f0_file=None,
+ ):
+ if (
+ file_index != ""
+ # and file_big_npy != ""
+ # and os.path.exists(file_big_npy) == True
+ and os.path.exists(file_index)
+ and index_rate != 0
+ ):
+ try:
+ index = faiss.read_index(file_index)
+ # big_npy = np.load(file_big_npy)
+ big_npy = index.reconstruct_n(0, index.ntotal)
+ except:
+ traceback.print_exc()
+ index = big_npy = None
+ else:
+ index = big_npy = None
+ audio = signal.filtfilt(bh, ah, audio)
+ audio_pad = np.pad(audio, (self.window // 2, self.window // 2), mode="reflect")
+ opt_ts = []
+ if audio_pad.shape[0] > self.t_max:
+ audio_sum = np.zeros_like(audio)
+ for i in range(self.window):
+ audio_sum += np.abs(audio_pad[i : i - self.window])
+ for t in range(self.t_center, audio.shape[0], self.t_center):
+ opt_ts.append(
+ t
+ - self.t_query
+ + np.where(
+ audio_sum[t - self.t_query : t + self.t_query]
+ == audio_sum[t - self.t_query : t + self.t_query].min()
+ )[0][0]
+ )
+ s = 0
+ audio_opt = []
+ t = None
+ t1 = ttime()
+ audio_pad = np.pad(audio, (self.t_pad, self.t_pad), mode="reflect")
+ p_len = audio_pad.shape[0] // self.window
+ inp_f0 = None
+ if hasattr(f0_file, "name"):
+ try:
+ with open(f0_file.name, "r") as f:
+ lines = f.read().strip("\n").split("\n")
+ inp_f0 = []
+ for line in lines:
+ inp_f0.append([float(i) for i in line.split(",")])
+ inp_f0 = np.array(inp_f0, dtype="float32")
+ except:
+ traceback.print_exc()
+ sid = torch.tensor(sid, device=self.device).unsqueeze(0).long()
+ pitch, pitchf = None, None
+ if if_f0 == 1:
+ pitch, pitchf = self.get_f0(
+ input_audio_path,
+ audio_pad,
+ p_len,
+ f0_up_key,
+ f0_method,
+ filter_radius,
+ inp_f0,
+ )
+ pitch = pitch[:p_len]
+ pitchf = pitchf[:p_len]
+ if "mps" not in str(self.device) or "xpu" not in str(self.device):
+ pitchf = pitchf.astype(np.float32)
+ pitch = torch.tensor(pitch, device=self.device).unsqueeze(0).long()
+ pitchf = torch.tensor(pitchf, device=self.device).unsqueeze(0).float()
+ t2 = ttime()
+ times[1] += t2 - t1
+ for t in opt_ts:
+ t = t // self.window * self.window
+ if if_f0 == 1:
+ audio_opt.append(
+ self.vc(
+ model,
+ net_g,
+ sid,
+ audio_pad[s : t + self.t_pad2 + self.window],
+ pitch[:, s // self.window : (t + self.t_pad2) // self.window],
+ pitchf[:, s // self.window : (t + self.t_pad2) // self.window],
+ times,
+ index,
+ big_npy,
+ index_rate,
+ version,
+ protect,
+ )[self.t_pad_tgt : -self.t_pad_tgt]
+ )
+ else:
+ audio_opt.append(
+ self.vc(
+ model,
+ net_g,
+ sid,
+ audio_pad[s : t + self.t_pad2 + self.window],
+ None,
+ None,
+ times,
+ index,
+ big_npy,
+ index_rate,
+ version,
+ protect,
+ )[self.t_pad_tgt : -self.t_pad_tgt]
+ )
+ s = t
+ if if_f0 == 1:
+ audio_opt.append(
+ self.vc(
+ model,
+ net_g,
+ sid,
+ audio_pad[t:],
+ pitch[:, t // self.window :] if t is not None else pitch,
+ pitchf[:, t // self.window :] if t is not None else pitchf,
+ times,
+ index,
+ big_npy,
+ index_rate,
+ version,
+ protect,
+ )[self.t_pad_tgt : -self.t_pad_tgt]
+ )
+ else:
+ audio_opt.append(
+ self.vc(
+ model,
+ net_g,
+ sid,
+ audio_pad[t:],
+ None,
+ None,
+ times,
+ index,
+ big_npy,
+ index_rate,
+ version,
+ protect,
+ )[self.t_pad_tgt : -self.t_pad_tgt]
+ )
+ audio_opt = np.concatenate(audio_opt)
+ if rms_mix_rate != 1:
+ audio_opt = change_rms(audio, 16000, audio_opt, tgt_sr, rms_mix_rate)
+ if tgt_sr != resample_sr >= 16000:
+ audio_opt = librosa.resample(
+ audio_opt, orig_sr=tgt_sr, target_sr=resample_sr
+ )
+ audio_max = np.abs(audio_opt).max() / 0.99
+ max_int16 = 32768
+ if audio_max > 1:
+ max_int16 /= audio_max
+ audio_opt = (audio_opt * max_int16).astype(np.int16)
+ del pitch, pitchf, sid
+ if torch.cuda.is_available():
+ torch.cuda.empty_cache()
+ return audio_opt
diff --git a/infer/modules/vc/utils.py b/infer/modules/vc/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..c128707cfda839396cffcf665e44fcd2eeb0e88d
--- /dev/null
+++ b/infer/modules/vc/utils.py
@@ -0,0 +1,33 @@
+import os
+
+from fairseq import checkpoint_utils
+
+
+def get_index_path_from_model(sid):
+ return next(
+ (
+ f
+ for f in [
+ os.path.join(root, name)
+ for root, _, files in os.walk(os.getenv("index_root"), topdown=False)
+ for name in files
+ if name.endswith(".index") and "trained" not in name
+ ]
+ if sid.split(".")[0] in f
+ ),
+ "",
+ )
+
+
+def load_hubert(config):
+ models, _, _ = checkpoint_utils.load_model_ensemble_and_task(
+ ["assets/hubert/hubert_base.pt"],
+ suffix="",
+ )
+ hubert_model = models[0]
+ hubert_model = hubert_model.to(config.device)
+ if config.is_half:
+ hubert_model = hubert_model.half()
+ else:
+ hubert_model = hubert_model.float()
+ return hubert_model.eval()
diff --git a/requirements-amd.txt b/requirements-amd.txt
new file mode 100644
index 0000000000000000000000000000000000000000..cbda2dafc1523ce262f0c094460b5e034e7b3805
--- /dev/null
+++ b/requirements-amd.txt
@@ -0,0 +1,49 @@
+tensorflow-rocm
+joblib>=1.1.0
+numba==0.56.4
+numpy==1.23.5
+scipy
+librosa==0.9.1
+llvmlite==0.39.0
+fairseq==0.12.2
+faiss-cpu==1.7.3
+gradio==4.23.0
+Cython
+pydub>=0.25.1
+soundfile>=0.12.1
+ffmpeg-python>=0.2.0
+tensorboardX
+Jinja2>=3.1.2
+json5
+Markdown
+matplotlib>=3.7.0
+matplotlib-inline>=0.1.3
+praat-parselmouth>=0.4.2
+Pillow>=9.1.1
+resampy>=0.4.2
+scikit-learn
+tensorboard
+tqdm>=4.63.1
+tornado>=6.1
+Werkzeug>=2.2.3
+uc-micro-py>=1.0.1
+sympy>=1.11.1
+tabulate>=0.8.10
+PyYAML>=6.0
+pyasn1>=0.4.8
+pyasn1-modules>=0.2.8
+fsspec>=2022.11.0
+absl-py>=1.2.0
+audioread
+uvicorn>=0.21.1
+colorama>=0.4.5
+pyworld==0.3.2
+httpx
+onnxruntime
+onnxruntime-gpu
+torchcrepe==0.0.20
+fastapi
+ffmpy==0.3.1
+python-dotenv>=1.0.0
+av
+torchfcpe
diff --git a/requirements-dml.txt b/requirements-dml.txt
new file mode 100644
index 0000000000000000000000000000000000000000..2dc1b67f8dfc1cbda0d79c07e9f388966921ec97
--- /dev/null
+++ b/requirements-dml.txt
@@ -0,0 +1,47 @@
+joblib>=1.1.0
+numba==0.56.4
+numpy==1.23.5
+scipy
+librosa==0.9.1
+llvmlite==0.39.0
+fairseq==0.12.2
+faiss-cpu==1.7.3
+gradio==4.23.0
+Cython
+pydub>=0.25.1
+soundfile>=0.12.1
+ffmpeg-python>=0.2.0
+tensorboardX
+Jinja2>=3.1.2
+json5
+Markdown
+matplotlib>=3.7.0
+matplotlib-inline>=0.1.3
+praat-parselmouth>=0.4.2
+Pillow>=9.1.1
+resampy>=0.4.2
+scikit-learn
+tensorboard
+tqdm>=4.63.1
+tornado>=6.1
+Werkzeug>=2.2.3
+uc-micro-py>=1.0.1
+sympy>=1.11.1
+tabulate>=0.8.10
+PyYAML>=6.0
+pyasn1>=0.4.8
+pyasn1-modules>=0.2.8
+fsspec>=2022.11.0
+absl-py>=1.2.0
+audioread
+uvicorn>=0.21.1
+colorama>=0.4.5
+pyworld==0.3.2
+httpx
+onnxruntime-directml
+torchcrepe==0.0.20
+fastapi
+ffmpy==0.3.1
+python-dotenv>=1.0.0
+av
+torchfcpe
diff --git a/requirements-ipex.txt b/requirements-ipex.txt
new file mode 100644
index 0000000000000000000000000000000000000000..48b07122226502747416d6ff22895d0d03c3068d
--- /dev/null
+++ b/requirements-ipex.txt
@@ -0,0 +1,55 @@
+torch==2.0.1a0
+intel_extension_for_pytorch==2.0.110+xpu
+torchvision==0.15.2a0
+https://github.com/Disty0/Retrieval-based-Voice-Conversion-WebUI/releases/download/torchaudio_wheels_for_ipex/torchaudio-2.0.2+31de77d-cp310-cp310-linux_x86_64.whl
+--extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+joblib>=1.1.0
+numba==0.56.4
+numpy==1.23.5
+scipy
+librosa==0.9.1
+llvmlite==0.39.0
+fairseq==0.12.2
+faiss-cpu==1.7.3
+gradio==4.23.0
+Cython
+pydub>=0.25.1
+soundfile>=0.12.1
+ffmpeg-python>=0.2.0
+tensorboardX
+Jinja2>=3.1.2
+json5
+Markdown
+matplotlib>=3.7.0
+matplotlib-inline>=0.1.3
+praat-parselmouth>=0.4.2
+Pillow>=9.1.1
+resampy>=0.4.2
+scikit-learn
+tensorboard
+tqdm>=4.63.1
+tornado>=6.1
+Werkzeug>=2.2.3
+uc-micro-py>=1.0.1
+sympy>=1.11.1
+tabulate>=0.8.10
+PyYAML>=6.0
+pyasn1>=0.4.8
+pyasn1-modules>=0.2.8
+fsspec>=2022.11.0
+absl-py>=1.2.0
+audioread
+uvicorn>=0.21.1
+colorama>=0.4.5
+pyworld==0.3.2
+httpx
+onnxruntime; sys_platform == 'darwin'
+onnxruntime-gpu; sys_platform != 'darwin'
+torchcrepe==0.0.20
+fastapi
+ffmpy==0.3.1
+python-dotenv>=1.0.0
+av
+FreeSimpleGUI
+sounddevice
+torchfcpe
diff --git a/requirements-py311.txt b/requirements-py311.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e002fbd8b5da2f7b584c58fd4c56b5c74d6a7727
--- /dev/null
+++ b/requirements-py311.txt
@@ -0,0 +1,48 @@
+joblib>=1.1.0
+numba
+numpy
+scipy
+librosa==0.9.1
+llvmlite
+fairseq @ git+https://github.com/One-sixth/fairseq.git
+faiss-cpu
+gradio==4.23.0
+Cython
+pydub>=0.25.1
+soundfile>=0.12.1
+ffmpeg-python>=0.2.0
+tensorboardX
+Jinja2>=3.1.2
+json5
+Markdown
+matplotlib>=3.7.0
+matplotlib-inline>=0.1.3
+praat-parselmouth>=0.4.2
+Pillow>=9.1.1
+resampy>=0.4.2
+scikit-learn
+tensorboard
+tqdm>=4.63.1
+tornado>=6.1
+Werkzeug>=2.2.3
+uc-micro-py>=1.0.1
+sympy>=1.11.1
+tabulate>=0.8.10
+PyYAML>=6.0
+pyasn1>=0.4.8
+pyasn1-modules>=0.2.8
+fsspec>=2022.11.0
+absl-py>=1.2.0
+audioread
+uvicorn>=0.21.1
+colorama>=0.4.5
+pyworld==0.3.2
+httpx
+onnxruntime; sys_platform == 'darwin'
+onnxruntime-gpu; sys_platform != 'darwin'
+torchcrepe==0.0.20
+fastapi
+torchfcpe
+ffmpy==0.3.1
+python-dotenv>=1.0.0
+av
diff --git a/requirements-win-for-realtime_vc_gui-dml.txt b/requirements-win-for-realtime_vc_gui-dml.txt
new file mode 100644
index 0000000000000000000000000000000000000000..6f7e11eae099a75601c5ee9482ea306c8066b6a0
--- /dev/null
+++ b/requirements-win-for-realtime_vc_gui-dml.txt
@@ -0,0 +1,30 @@
+#1.Install torch from pytorch.org:
+#torch 2.0 with cuda 11.8
+#pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
+#torch 1.11.0 with cuda 11.3
+#pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113
+einops
+fairseq
+flask
+flask_cors
+gin
+gin_config
+librosa
+local_attention
+matplotlib
+praat-parselmouth
+pyworld
+PyYAML
+resampy
+scikit_learn
+scipy
+SoundFile
+tensorboard
+tqdm
+wave
+FreeSimpleGUI
+sounddevice
+gradio
+noisereduce
+onnxruntime-directml
+torchfcpe
\ No newline at end of file
diff --git a/requirements-win-for-realtime_vc_gui.txt b/requirements-win-for-realtime_vc_gui.txt
new file mode 100644
index 0000000000000000000000000000000000000000..55e7bd96e527cdad5666c7bb654387f219967bdb
--- /dev/null
+++ b/requirements-win-for-realtime_vc_gui.txt
@@ -0,0 +1,29 @@
+#1.Install torch from pytorch.org:
+#torch 2.0 with cuda 11.8
+#pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
+#torch 1.11.0 with cuda 11.3
+#pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113
+einops
+fairseq
+flask
+flask_cors
+gin
+gin_config
+librosa
+local_attention
+matplotlib
+praat-parselmouth
+pyworld
+PyYAML
+resampy
+scikit_learn
+scipy
+SoundFile
+tensorboard
+tqdm
+wave
+FreeSimpleGUI
+sounddevice
+gradio
+noisereduce
+torchfcpe
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..7f2268de1aa61d9ce45d3d3dc8995f8e356d39e6
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,48 @@
+joblib>=1.1.0
+numba
+numpy==1.23.5
+scipy
+librosa==0.9.1
+llvmlite
+fairseq
+faiss-cpu
+gradio==4.23.0
+Cython
+pydub>=0.25.1
+soundfile>=0.12.1
+ffmpeg-python>=0.2.0
+tensorboardX
+Jinja2>=3.1.2
+json5
+Markdown
+matplotlib>=3.7.0
+matplotlib-inline>=0.1.3
+praat-parselmouth>=0.4.2
+Pillow>=9.1.1
+resampy>=0.4.2
+scikit-learn
+tensorboard
+tqdm>=4.63.1
+tornado>=6.1
+Werkzeug>=2.2.3
+uc-micro-py>=1.0.1
+sympy>=1.11.1
+tabulate>=0.8.10
+PyYAML>=6.0
+pyasn1>=0.4.8
+pyasn1-modules>=0.2.8
+fsspec>=2022.11.0
+absl-py>=1.2.0
+audioread
+uvicorn>=0.21.1
+colorama>=0.4.5
+pyworld==0.3.2
+httpx
+onnxruntime; sys_platform == 'darwin'
+onnxruntime-gpu; sys_platform != 'darwin'
+torchcrepe==0.0.20
+fastapi
+torchfcpe
+ffmpy==0.3.1
+python-dotenv>=1.0.0
+av
diff --git a/run.sh b/run.sh
new file mode 100755
index 0000000000000000000000000000000000000000..8710ba31f1e5e921fe54a372bb33f621f3596f87
--- /dev/null
+++ b/run.sh
@@ -0,0 +1,51 @@
+#!/bin/sh
+
+if [ "$(uname)" = "Darwin" ]; then
+ # macOS specific env:
+ export PYTORCH_ENABLE_MPS_FALLBACK=1
+ export PYTORCH_MPS_HIGH_WATERMARK_RATIO=0.0
+fi
+
+if [ -d ".venv" ]; then
+ echo "Activate venv..."
+ . .venv/bin/activate
+else
+ echo "Create venv..."
+ requirements_file="requirements.txt"
+
+ # Check if Python 3.8 is installed
+ if ! command -v python3.8 >/dev/null 2>&1 || pyenv versions --bare | grep -q "3.8"; then
+ echo "Python 3 not found. Attempting to install 3.8..."
+ if [ "$(uname)" = "Darwin" ] && command -v brew >/dev/null 2>&1; then
+ brew install python@3.8
+ elif [ "$(uname)" = "Linux" ] && command -v apt-get >/dev/null 2>&1; then
+ sudo apt update
+ sudo apt install -y python3.8
+ else
+ echo "Please install Python 3.8 manually."
+ exit 1
+ fi
+ fi
+
+ python3.8 -m venv .venv
+ . .venv/bin/activate
+
+ # Check if required packages are installed and install them if not
+ if [ -f "${requirements_file}" ]; then
+ installed_packages=$(python3.8 -m pip freeze)
+ while IFS= read -r package; do
+ expr "${package}" : "^#.*" > /dev/null && continue
+ package_name=$(echo "${package}" | sed 's/[<>=!].*//')
+ if ! echo "${installed_packages}" | grep -q "${package_name}"; then
+ echo "${package_name} not found. Attempting to install..."
+ python3.8 -m pip install --upgrade "${package}"
+ fi
+ done < "${requirements_file}"
+ else
+ echo "${requirements_file} not found. Please ensure the requirements file with required packages exists."
+ exit 1
+ fi
+fi
+
+# Run the main script
+python3 infer-web.py --pycmd python3
diff --git a/sha256.env b/sha256.env
new file mode 100644
index 0000000000000000000000000000000000000000..53911bc5a898b9fb26af6b68817bc99f8a9cb12b
--- /dev/null
+++ b/sha256.env
@@ -0,0 +1,39 @@
+sha256_hubert_base_pt = f54b40fd2802423a5643779c4861af1e9ee9c1564dc9d32f54f20b5ffba7db96
+sha256_rmvpe_pt = 6d62215f4306e3ca278246188607209f09af3dc77ed4232efdd069798c4ec193
+sha256_rmvpe_onnx = 5370e71ac80af8b4b7c793d27efd51fd8bf962de3a7ede0766dac0befa3660fd
+
+sha256_v1_D32k_pth = 2ab20645829460fdad0d3c44254f1ab53c32cae50c22a66c926ae5aa30abda6f
+sha256_v1_D40k_pth = 547f66dbbcd9023b9051ed244d12ab043ba8a4e854b154cc28761ac7c002909b
+sha256_v1_D48k_pth = 8cc013fa60ed9c3f902f5bd99f48c7e3b9352d763d4d3cd6bc241c37b0bfd9ad
+sha256_v1_G32k_pth = 81817645cde7ed2e2d83f23ef883f33dda564924b497e84d792743912eca4c23
+sha256_v1_G40k_pth = e428573bda1124b0ae0ae843fd8dcded6027d3993444790b3e9b0100938b2113
+sha256_v1_G48k_pth = 3862a67ea6313e8ffefc05cee6bee656ef3e089442e9ecf4a6618d60721f3e95
+sha256_v1_f0D32k_pth = 294db3087236e2c75260d6179056791c9231245daf5d0485545d9e54c4057c77
+sha256_v1_f0D40k_pth = 7d4f5a441594b470d67579958b2fd4c6b992852ded28ff9e72eda67abcebe423
+sha256_v1_f0D48k_pth = 1b84c8bf347ad1e539c842e8f2a4c36ecd9e7fb23c16041189e4877e9b07925c
+sha256_v1_f0G32k_pth = 285f524bf48bb692c76ad7bd0bc654c12bd9e5edeb784dddf7f61a789a608574
+sha256_v1_f0G40k_pth = 9115654aeef1995f7dd3c6fc4140bebbef0ca9760bed798105a2380a34299831
+sha256_v1_f0G48k_pth = 78bc9cab27e34bcfc194f93029374d871d8b3e663ddedea32a9709e894cc8fe8
+
+sha256_v2_D32k_pth = d8043378cc6619083d385f5a045de09b83fb3bf8de45c433ca863b71723ac3ca
+sha256_v2_D40k_pth = 471378e894e7191f89a94eda8288c5947b16bbe0b10c3f1f17efdb7a1d998242
+sha256_v2_D48k_pth = db01094a93c09868a278e03dafe8bb781bfcc1a5ba8df168c948bf9168c84d82
+sha256_v2_G32k_pth = 869b26a47f75168d6126f64ac39e6de5247017a8658cfd68aca600f7323efb9f
+sha256_v2_G40k_pth = a3843da7fde33db1dab176146c70d6c2df06eafe9457f4e3aa10024e9c6a4b69
+sha256_v2_G48k_pth = 2e2b1581a436d07a76b10b9d38765f64aa02836dc65c7dee1ce4140c11ea158b
+sha256_v2_f0D32k_pth = bd7134e7793674c85474d5145d2d982e3c5d8124fc7bb6c20f710ed65808fa8a
+sha256_v2_f0D40k_pth = 6b6ab091e70801b28e3f41f335f2fc5f3f35c75b39ae2628d419644ec2b0fa09
+sha256_v2_f0D48k_pth = 2269b73c7a4cf34da09aea99274dabf99b2ddb8a42cbfb065fb3c0aa9a2fc748
+sha256_v2_f0G32k_pth = 2332611297b8d88c7436de8f17ef5f07a2119353e962cd93cda5806d59a1133d
+sha256_v2_f0G40k_pth = 3b2c44035e782c4b14ddc0bede9e2f4a724d025cd073f736d4f43708453adfcb
+sha256_v2_f0G48k_pth = b5d51f589cc3632d4eae36a315b4179397695042edc01d15312e1bddc2b764a4
+
+sha256_uvr5_HP2-人声vocals+非人声instrumentals_pth = 39796caa5db18d7f9382d8ac997ac967bfd85f7761014bb807d2543cc844ef05
+sha256_uvr5_HP2_all_vocals_pth = 39796caa5db18d7f9382d8ac997ac967bfd85f7761014bb807d2543cc844ef05
+sha256_uvr5_HP3_all_vocals_pth = 45e6b65199e781b4a6542002699be9f19cd3d1cb7d1558bc2bfbcd84674dfe28
+sha256_uvr5_HP5-主旋律人声vocals+其他instrumentals_pth = 5908891829634926119720241e8573d97cbeb8277110a7512bdb0bd7563258ee
+sha256_uvr5_HP5_only_main_vocal_pth = 5908891829634926119720241e8573d97cbeb8277110a7512bdb0bd7563258ee
+sha256_uvr5_VR-DeEchoAggressive_pth = 8c8fd1582f9aabc363e47af62ddb88df6cae7e064cae75bbf041a067a5e0aee2
+sha256_uvr5_VR-DeEchoDeReverb_pth = 01376dd2a571bf3cb9cced680732726d2d732609d09216a610b0d110f133febe
+sha256_uvr5_VR-DeEchoNormal_pth = 56aba59db3bcdd14a14464e62f3129698ecdea62eee0f003b9360923eb3ac79e
+sha256_uvr5_vocals_onnx = 233bb5c6aaa365e568659a0a81211746fa881f8f47f82d9e864fce1f7692db80
diff --git a/tools/checksum/main.go b/tools/checksum/main.go
new file mode 100644
index 0000000000000000000000000000000000000000..83594f2c2fa3335c3b937a3e9c4067a60708ec31
--- /dev/null
+++ b/tools/checksum/main.go
@@ -0,0 +1,38 @@
+package main
+
+import (
+ "crypto/sha256"
+ "encoding/hex"
+ "fmt"
+ "io"
+ "os"
+)
+
+func main() {
+ var buf [32]byte
+ h := sha256.New()
+ lst := make([]any, 0, 64)
+ for _, fname := range files {
+ f, err := os.Open("assets/" + fname)
+ if err != nil {
+ panic(err)
+ }
+ _, err = io.Copy(h, f)
+ if err != nil {
+ panic(err)
+ }
+ s := hex.EncodeToString(h.Sum(buf[:0]))
+ fmt.Println("sha256 of", fname, "=", s)
+ lst = append(lst, s)
+ h.Reset()
+ f.Close()
+ }
+ f, err := os.Create("sha256.env")
+ if err != nil {
+ panic(err)
+ }
+ _, err = fmt.Fprintf(f, envtmpl, lst...)
+ if err != nil {
+ panic(err)
+ }
+}
diff --git a/tools/checksum/tmpl.go b/tools/checksum/tmpl.go
new file mode 100644
index 0000000000000000000000000000000000000000..ab5b7a86ae3bffeb90470b642ec70059bb369cff
--- /dev/null
+++ b/tools/checksum/tmpl.go
@@ -0,0 +1,84 @@
+package main
+
+var files = [...]string{
+ "hubert/hubert_base.pt",
+ "rmvpe/rmvpe.pt",
+ "rmvpe/rmvpe.onnx",
+
+ "pretrained/D32k.pth",
+ "pretrained/D40k.pth",
+ "pretrained/D48k.pth",
+ "pretrained/G32k.pth",
+ "pretrained/G40k.pth",
+ "pretrained/G48k.pth",
+ "pretrained/f0D32k.pth",
+ "pretrained/f0D40k.pth",
+ "pretrained/f0D48k.pth",
+ "pretrained/f0G32k.pth",
+ "pretrained/f0G40k.pth",
+ "pretrained/f0G48k.pth",
+
+ "pretrained_v2/D32k.pth",
+ "pretrained_v2/D40k.pth",
+ "pretrained_v2/D48k.pth",
+ "pretrained_v2/G32k.pth",
+ "pretrained_v2/G40k.pth",
+ "pretrained_v2/G48k.pth",
+ "pretrained_v2/f0D32k.pth",
+ "pretrained_v2/f0D40k.pth",
+ "pretrained_v2/f0D48k.pth",
+ "pretrained_v2/f0G32k.pth",
+ "pretrained_v2/f0G40k.pth",
+ "pretrained_v2/f0G48k.pth",
+
+ "uvr5_weights/HP2-人声vocals+非人声instrumentals.pth",
+ "uvr5_weights/HP2_all_vocals.pth",
+ "uvr5_weights/HP3_all_vocals.pth",
+ "uvr5_weights/HP5-主旋律人声vocals+其他instrumentals.pth",
+ "uvr5_weights/HP5_only_main_vocal.pth",
+ "uvr5_weights/VR-DeEchoAggressive.pth",
+ "uvr5_weights/VR-DeEchoDeReverb.pth",
+ "uvr5_weights/VR-DeEchoNormal.pth",
+ "uvr5_weights/onnx_dereverb_By_FoxJoy/vocals.onnx",
+}
+
+const envtmpl = `sha256_hubert_base_pt = %s
+sha256_rmvpe_pt = %s
+sha256_rmvpe_onnx = %s
+
+sha256_v1_D32k_pth = %s
+sha256_v1_D40k_pth = %s
+sha256_v1_D48k_pth = %s
+sha256_v1_G32k_pth = %s
+sha256_v1_G40k_pth = %s
+sha256_v1_G48k_pth = %s
+sha256_v1_f0D32k_pth = %s
+sha256_v1_f0D40k_pth = %s
+sha256_v1_f0D48k_pth = %s
+sha256_v1_f0G32k_pth = %s
+sha256_v1_f0G40k_pth = %s
+sha256_v1_f0G48k_pth = %s
+
+sha256_v2_D32k_pth = %s
+sha256_v2_D40k_pth = %s
+sha256_v2_D48k_pth = %s
+sha256_v2_G32k_pth = %s
+sha256_v2_G40k_pth = %s
+sha256_v2_G48k_pth = %s
+sha256_v2_f0D32k_pth = %s
+sha256_v2_f0D40k_pth = %s
+sha256_v2_f0D48k_pth = %s
+sha256_v2_f0G32k_pth = %s
+sha256_v2_f0G40k_pth = %s
+sha256_v2_f0G48k_pth = %s
+
+sha256_uvr5_HP2-人声vocals+非人声instrumentals_pth = %s
+sha256_uvr5_HP2_all_vocals_pth = %s
+sha256_uvr5_HP3_all_vocals_pth = %s
+sha256_uvr5_HP5-主旋律人声vocals+其他instrumentals_pth = %s
+sha256_uvr5_HP5_only_main_vocal_pth = %s
+sha256_uvr5_VR-DeEchoAggressive_pth = %s
+sha256_uvr5_VR-DeEchoDeReverb_pth = %s
+sha256_uvr5_VR-DeEchoNormal_pth = %s
+sha256_uvr5_vocals_onnx = %s
+`
diff --git a/tools/cmd/calc_rvc_model_similarity.py b/tools/cmd/calc_rvc_model_similarity.py
new file mode 100644
index 0000000000000000000000000000000000000000..42496e088e51dc5162d0714470c2226f696e260c
--- /dev/null
+++ b/tools/cmd/calc_rvc_model_similarity.py
@@ -0,0 +1,96 @@
+# This code references https://huggingface.co/JosephusCheung/ASimilarityCalculatior/blob/main/qwerty.py
+# Fill in the path of the model to be queried and the root directory of the reference models, and this script will return the similarity between the model to be queried and all reference models.
+import os
+import logging
+
+logger = logging.getLogger(__name__)
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+def cal_cross_attn(to_q, to_k, to_v, rand_input):
+ hidden_dim, embed_dim = to_q.shape
+ attn_to_q = nn.Linear(hidden_dim, embed_dim, bias=False)
+ attn_to_k = nn.Linear(hidden_dim, embed_dim, bias=False)
+ attn_to_v = nn.Linear(hidden_dim, embed_dim, bias=False)
+ attn_to_q.load_state_dict({"weight": to_q})
+ attn_to_k.load_state_dict({"weight": to_k})
+ attn_to_v.load_state_dict({"weight": to_v})
+
+ return torch.einsum(
+ "ik, jk -> ik",
+ F.softmax(
+ torch.einsum("ij, kj -> ik", attn_to_q(rand_input), attn_to_k(rand_input)),
+ dim=-1,
+ ),
+ attn_to_v(rand_input),
+ )
+
+
+def model_hash(filename):
+ try:
+ with open(filename, "rb") as file:
+ import hashlib
+
+ m = hashlib.sha256()
+
+ file.seek(0x100000)
+ m.update(file.read(0x10000))
+ return m.hexdigest()[0:8]
+ except FileNotFoundError:
+ return "NOFILE"
+
+
+def eval(model, n, input):
+ qk = f"enc_p.encoder.attn_layers.{n}.conv_q.weight"
+ uk = f"enc_p.encoder.attn_layers.{n}.conv_k.weight"
+ vk = f"enc_p.encoder.attn_layers.{n}.conv_v.weight"
+ atoq, atok, atov = model[qk][:, :, 0], model[uk][:, :, 0], model[vk][:, :, 0]
+
+ attn = cal_cross_attn(atoq, atok, atov, input)
+ return attn
+
+
+def main(path, root):
+ torch.manual_seed(114514)
+ model_a = torch.load(path, map_location="cpu")["weight"]
+
+ logger.info("Query:\t\t%s\t%s" % (path, model_hash(path)))
+
+ map_attn_a = {}
+ map_rand_input = {}
+ for n in range(6):
+ hidden_dim, embed_dim, _ = model_a[
+ f"enc_p.encoder.attn_layers.{n}.conv_v.weight"
+ ].shape
+ rand_input = torch.randn([embed_dim, hidden_dim])
+
+ map_attn_a[n] = eval(model_a, n, rand_input)
+ map_rand_input[n] = rand_input
+
+ del model_a
+
+ for name in sorted(list(os.listdir(root))):
+ path = "%s/%s" % (root, name)
+ model_b = torch.load(path, map_location="cpu")["weight"]
+
+ sims = []
+ for n in range(6):
+ attn_a = map_attn_a[n]
+ attn_b = eval(model_b, n, map_rand_input[n])
+
+ sim = torch.mean(torch.cosine_similarity(attn_a, attn_b))
+ sims.append(sim)
+
+ logger.info(
+ "Reference:\t%s\t%s\t%s"
+ % (path, model_hash(path), f"{torch.mean(torch.stack(sims)) * 1e2:.2f}%")
+ )
+
+
+if __name__ == "__main__":
+ query_path = r"assets\weights\mi v3.pth"
+ reference_root = r"assets\weights"
+ main(query_path, reference_root)
diff --git a/tools/cmd/infer-pm-index256.py b/tools/cmd/infer-pm-index256.py
new file mode 100644
index 0000000000000000000000000000000000000000..d6b3b744e5e6d2661f4292c11c718491eeb362f1
--- /dev/null
+++ b/tools/cmd/infer-pm-index256.py
@@ -0,0 +1,203 @@
+"""
+
+对源特征进行检索
+"""
+
+import os
+import logging
+
+logger = logging.getLogger(__name__)
+
+import parselmouth
+import torch
+
+os.environ["CUDA_VISIBLE_DEVICES"] = "0"
+# import torchcrepe
+from time import time as ttime
+
+# import pyworld
+import librosa
+import numpy as np
+import soundfile as sf
+import torch.nn.functional as F
+from fairseq import checkpoint_utils
+
+# from models import SynthesizerTrn256#hifigan_nonsf
+# from lib.infer_pack.models import SynthesizerTrn256NSF as SynthesizerTrn256#hifigan_nsf
+from infer.lib.infer_pack.models import (
+ SynthesizerTrnMs256NSFsid as SynthesizerTrn256,
+) # hifigan_nsf
+from scipy.io import wavfile
+
+# from lib.infer_pack.models import SynthesizerTrnMs256NSFsid_sim as SynthesizerTrn256#hifigan_nsf
+# from models import SynthesizerTrn256NSFsim as SynthesizerTrn256#hifigan_nsf
+# from models import SynthesizerTrn256NSFsimFlow as SynthesizerTrn256#hifigan_nsf
+
+
+device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+model_path = r"E:\codes\py39\vits_vc_gpu_train\assets\hubert\hubert_base.pt" #
+logger.info("Load model(s) from {}".format(model_path))
+models, saved_cfg, task = checkpoint_utils.load_model_ensemble_and_task(
+ [model_path],
+ suffix="",
+)
+model = models[0]
+model = model.to(device)
+model = model.half()
+model.eval()
+
+# net_g = SynthesizerTrn256(1025,32,192,192,768,2,6,3,0.1,"1", [3,7,11],[[1,3,5], [1,3,5], [1,3,5]],[10,10,2,2],512,[16,16,4,4],183,256,is_half=True)#hifigan#512#256
+# net_g = SynthesizerTrn256(1025,32,192,192,768,2,6,3,0.1,"1", [3,7,11],[[1,3,5], [1,3,5], [1,3,5]],[10,10,2,2],512,[16,16,4,4],109,256,is_half=True)#hifigan#512#256
+net_g = SynthesizerTrn256(
+ 1025,
+ 32,
+ 192,
+ 192,
+ 768,
+ 2,
+ 6,
+ 3,
+ 0,
+ "1",
+ [3, 7, 11],
+ [[1, 3, 5], [1, 3, 5], [1, 3, 5]],
+ [10, 10, 2, 2],
+ 512,
+ [16, 16, 4, 4],
+ 183,
+ 256,
+ is_half=True,
+) # hifigan#512#256#no_dropout
+# net_g = SynthesizerTrn256(1025,32,192,192,768,2,3,3,0.1,"1", [3,7,11],[[1,3,5], [1,3,5], [1,3,5]],[10,10,2,2],512,[16,16,4,4],0)#ts3
+# net_g = SynthesizerTrn256(1025,32,192,192,768,2,6,3,0.1,"1", [3,7,11],[[1,3,5], [1,3,5], [1,3,5]],[10,10,2],512,[16,16,4],0)#hifigan-ps-sr
+#
+# net_g = SynthesizerTrn(1025, 32, 192, 192, 768, 2, 6, 3, 0.1, "1", [3, 7, 11], [[1, 3, 5], [1, 3, 5], [1, 3, 5]], [5,5], 512, [15,15], 0)#ms
+# net_g = SynthesizerTrn(1025, 32, 192, 192, 768, 2, 6, 3, 0.1, "1", [3, 7, 11], [[1, 3, 5], [1, 3, 5], [1, 3, 5]], [10,10], 512, [16,16], 0)#idwt2
+
+# weights=torch.load("infer/ft-mi_1k-noD.pt")
+# weights=torch.load("infer/ft-mi-freeze-vocoder-flow-enc_q_1k.pt")
+# weights=torch.load("infer/ft-mi-freeze-vocoder_true_1k.pt")
+# weights=torch.load("infer/ft-mi-sim1k.pt")
+weights = torch.load("infer/ft-mi-no_opt-no_dropout.pt")
+logger.debug(net_g.load_state_dict(weights, strict=True))
+
+net_g.eval().to(device)
+net_g.half()
+
+
+def get_f0(x, p_len, f0_up_key=0):
+ time_step = 160 / 16000 * 1000
+ f0_min = 50
+ f0_max = 1100
+ f0_mel_min = 1127 * np.log(1 + f0_min / 700)
+ f0_mel_max = 1127 * np.log(1 + f0_max / 700)
+
+ f0 = (
+ parselmouth.Sound(x, 16000)
+ .to_pitch_ac(
+ time_step=time_step / 1000,
+ voicing_threshold=0.6,
+ pitch_floor=f0_min,
+ pitch_ceiling=f0_max,
+ )
+ .selected_array["frequency"]
+ )
+
+ pad_size = (p_len - len(f0) + 1) // 2
+ if pad_size > 0 or p_len - len(f0) - pad_size > 0:
+ f0 = np.pad(f0, [[pad_size, p_len - len(f0) - pad_size]], mode="constant")
+ f0 *= pow(2, f0_up_key / 12)
+ f0bak = f0.copy()
+
+ f0_mel = 1127 * np.log(1 + f0 / 700)
+ f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - f0_mel_min) * 254 / (
+ f0_mel_max - f0_mel_min
+ ) + 1
+ f0_mel[f0_mel <= 1] = 1
+ f0_mel[f0_mel > 255] = 255
+ # f0_mel[f0_mel > 188] = 188
+ f0_coarse = np.rint(f0_mel).astype(np.int32)
+ return f0_coarse, f0bak
+
+
+import faiss
+
+index = faiss.read_index("infer/added_IVF512_Flat_mi_baseline_src_feat.index")
+big_npy = np.load("infer/big_src_feature_mi.npy")
+ta0 = ta1 = ta2 = 0
+for idx, name in enumerate(
+ [
+ "冬之花clip1.wav",
+ ]
+): ##
+ wav_path = "todo-songs/%s" % name #
+ f0_up_key = -2 #
+ audio, sampling_rate = sf.read(wav_path)
+ if len(audio.shape) > 1:
+ audio = librosa.to_mono(audio.transpose(1, 0))
+ if sampling_rate != 16000:
+ audio = librosa.resample(audio, orig_sr=sampling_rate, target_sr=16000)
+
+ feats = torch.from_numpy(audio).float()
+ if feats.dim() == 2: # double channels
+ feats = feats.mean(-1)
+ assert feats.dim() == 1, feats.dim()
+ feats = feats.view(1, -1)
+ padding_mask = torch.BoolTensor(feats.shape).fill_(False)
+ inputs = {
+ "source": feats.half().to(device),
+ "padding_mask": padding_mask.to(device),
+ "output_layer": 9, # layer 9
+ }
+ if torch.cuda.is_available():
+ torch.cuda.synchronize()
+ t0 = ttime()
+ with torch.no_grad():
+ logits = model.extract_features(**inputs)
+ feats = model.final_proj(logits[0])
+
+ ####索引优化
+ npy = feats[0].cpu().numpy().astype("float32")
+ D, I = index.search(npy, 1)
+ feats = (
+ torch.from_numpy(big_npy[I.squeeze()].astype("float16")).unsqueeze(0).to(device)
+ )
+
+ feats = F.interpolate(feats.permute(0, 2, 1), scale_factor=2).permute(0, 2, 1)
+ if torch.cuda.is_available():
+ torch.cuda.synchronize()
+ t1 = ttime()
+ # p_len = min(feats.shape[1],10000,pitch.shape[0])#太大了爆显存
+ p_len = min(feats.shape[1], 10000) #
+ pitch, pitchf = get_f0(audio, p_len, f0_up_key)
+ p_len = min(feats.shape[1], 10000, pitch.shape[0]) # 太大了爆显存
+ if torch.cuda.is_available():
+ torch.cuda.synchronize()
+ t2 = ttime()
+ feats = feats[:, :p_len, :]
+ pitch = pitch[:p_len]
+ pitchf = pitchf[:p_len]
+ p_len = torch.LongTensor([p_len]).to(device)
+ pitch = torch.LongTensor(pitch).unsqueeze(0).to(device)
+ sid = torch.LongTensor([0]).to(device)
+ pitchf = torch.FloatTensor(pitchf).unsqueeze(0).to(device)
+ with torch.no_grad():
+ audio = (
+ net_g.infer(feats, p_len, pitch, pitchf, sid)[0][0, 0]
+ .data.cpu()
+ .float()
+ .numpy()
+ ) # nsf
+ if torch.cuda.is_available():
+ torch.cuda.synchronize()
+ t3 = ttime()
+ ta0 += t1 - t0
+ ta1 += t2 - t1
+ ta2 += t3 - t2
+ # wavfile.write("ft-mi_1k-index256-noD-%s.wav"%name, 40000, audio)##
+ # wavfile.write("ft-mi-freeze-vocoder-flow-enc_q_1k-%s.wav"%name, 40000, audio)##
+ # wavfile.write("ft-mi-sim1k-%s.wav"%name, 40000, audio)##
+ wavfile.write("ft-mi-no_opt-no_dropout-%s.wav" % name, 40000, audio) ##
+
+
+logger.debug("%.2fs %.2fs %.2fs", ta0, ta1, ta2) #
diff --git a/tools/cmd/infer_batch_rvc.py b/tools/cmd/infer_batch_rvc.py
new file mode 100644
index 0000000000000000000000000000000000000000..763d17f14877a2ce35f750202e91356c1f24270f
--- /dev/null
+++ b/tools/cmd/infer_batch_rvc.py
@@ -0,0 +1,72 @@
+import argparse
+import os
+import sys
+
+print("Command-line arguments:", sys.argv)
+
+now_dir = os.getcwd()
+sys.path.append(now_dir)
+import sys
+
+import tqdm as tq
+from dotenv import load_dotenv
+from scipy.io import wavfile
+
+from configs.config import Config
+from infer.modules.vc.modules import VC
+
+
+def arg_parse() -> tuple:
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--f0up_key", type=int, default=0)
+ parser.add_argument("--input_path", type=str, help="input path")
+ parser.add_argument("--index_path", type=str, help="index path")
+ parser.add_argument("--f0method", type=str, default="harvest", help="harvest or pm")
+ parser.add_argument("--opt_path", type=str, help="opt path")
+ parser.add_argument("--model_name", type=str, help="store in assets/weight_root")
+ parser.add_argument("--index_rate", type=float, default=0.66, help="index rate")
+ parser.add_argument("--device", type=str, help="device")
+ parser.add_argument("--is_half", type=bool, help="use half -> True")
+ parser.add_argument("--filter_radius", type=int, default=3, help="filter radius")
+ parser.add_argument("--resample_sr", type=int, default=0, help="resample sr")
+ parser.add_argument("--rms_mix_rate", type=float, default=1, help="rms mix rate")
+ parser.add_argument("--protect", type=float, default=0.33, help="protect")
+
+ args = parser.parse_args()
+ sys.argv = sys.argv[:1]
+
+ return args
+
+
+def main():
+ load_dotenv()
+ args = arg_parse()
+ config = Config()
+ config.device = args.device if args.device else config.device
+ config.is_half = args.is_half if args.is_half else config.is_half
+ vc = VC(config)
+ vc.get_vc(args.model_name)
+ audios = os.listdir(args.input_path)
+ for file in tq.tqdm(audios):
+ if file.endswith(".wav"):
+ file_path = os.path.join(args.input_path, file)
+ _, wav_opt = vc.vc_single(
+ 0,
+ file_path,
+ args.f0up_key,
+ None,
+ args.f0method,
+ args.index_path,
+ None,
+ args.index_rate,
+ args.filter_radius,
+ args.resample_sr,
+ args.rms_mix_rate,
+ args.protect,
+ )
+ out_path = os.path.join(args.opt_path, file)
+ wavfile.write(out_path, wav_opt[0], wav_opt[1])
+
+
+if __name__ == "__main__":
+ main()
diff --git a/tools/cmd/infer_cli.py b/tools/cmd/infer_cli.py
new file mode 100644
index 0000000000000000000000000000000000000000..bbe0a53c1aac6a8f2d42613d554b2bdd07abea2d
--- /dev/null
+++ b/tools/cmd/infer_cli.py
@@ -0,0 +1,67 @@
+import argparse
+import os
+import sys
+
+now_dir = os.getcwd()
+sys.path.append(now_dir)
+from dotenv import load_dotenv
+from scipy.io import wavfile
+
+from configs.config import Config
+from infer.modules.vc.modules import VC
+
+####
+# USAGE
+#
+# In your Terminal or CMD or whatever
+
+
+def arg_parse() -> tuple:
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--f0up_key", type=int, default=0)
+ parser.add_argument("--input_path", type=str, help="input path")
+ parser.add_argument("--index_path", type=str, help="index path")
+ parser.add_argument("--f0method", type=str, default="harvest", help="harvest or pm")
+ parser.add_argument("--opt_path", type=str, help="opt path")
+ parser.add_argument("--model_name", type=str, help="store in assets/weight_root")
+ parser.add_argument("--index_rate", type=float, default=0.66, help="index rate")
+ parser.add_argument("--device", type=str, help="device")
+ parser.add_argument("--is_half", type=bool, help="use half -> True")
+ parser.add_argument("--filter_radius", type=int, default=3, help="filter radius")
+ parser.add_argument("--resample_sr", type=int, default=0, help="resample sr")
+ parser.add_argument("--rms_mix_rate", type=float, default=1, help="rms mix rate")
+ parser.add_argument("--protect", type=float, default=0.33, help="protect")
+
+ args = parser.parse_args()
+ sys.argv = sys.argv[:1]
+
+ return args
+
+
+def main():
+ load_dotenv()
+ args = arg_parse()
+ config = Config()
+ config.device = args.device if args.device else config.device
+ config.is_half = args.is_half if args.is_half else config.is_half
+ vc = VC(config)
+ vc.get_vc(args.model_name)
+ _, wav_opt = vc.vc_single(
+ 0,
+ args.input_path,
+ args.f0up_key,
+ None,
+ args.f0method,
+ args.index_path,
+ None,
+ args.index_rate,
+ args.filter_radius,
+ args.resample_sr,
+ args.rms_mix_rate,
+ args.protect,
+ )
+ wavfile.write(args.opt_path, wav_opt[0], wav_opt[1])
+
+
+if __name__ == "__main__":
+ main()
diff --git a/tools/cmd/train-index-v2.py b/tools/cmd/train-index-v2.py
new file mode 100644
index 0000000000000000000000000000000000000000..47c706c704440c363df3ea0689d91c8536385009
--- /dev/null
+++ b/tools/cmd/train-index-v2.py
@@ -0,0 +1,80 @@
+"""
+格式:直接cid为自带的index位;aid放不下了,通过字典来查,反正就5w个
+"""
+
+import os
+import traceback
+import logging
+
+logger = logging.getLogger(__name__)
+
+from multiprocessing import cpu_count
+
+import faiss
+import numpy as np
+from sklearn.cluster import MiniBatchKMeans
+
+# ###########如果是原始特征要先写save
+n_cpu = 0
+if n_cpu == 0:
+ n_cpu = cpu_count()
+inp_root = r"./logs/anz/3_feature768"
+npys = []
+listdir_res = list(os.listdir(inp_root))
+for name in sorted(listdir_res):
+ phone = np.load("%s/%s" % (inp_root, name))
+ npys.append(phone)
+big_npy = np.concatenate(npys, 0)
+big_npy_idx = np.arange(big_npy.shape[0])
+np.random.shuffle(big_npy_idx)
+big_npy = big_npy[big_npy_idx]
+logger.debug(big_npy.shape) # (6196072, 192)#fp32#4.43G
+if big_npy.shape[0] > 2e5:
+ # if(1):
+ info = "Trying doing kmeans %s shape to 10k centers." % big_npy.shape[0]
+ logger.info(info)
+ try:
+ big_npy = (
+ MiniBatchKMeans(
+ n_clusters=10000,
+ verbose=True,
+ batch_size=256 * n_cpu,
+ compute_labels=False,
+ init="random",
+ )
+ .fit(big_npy)
+ .cluster_centers_
+ )
+ except:
+ info = traceback.format_exc()
+ logger.warning(info)
+
+np.save("tools/infer/big_src_feature_mi.npy", big_npy)
+
+##################train+add
+# big_npy=np.load("/bili-coeus/jupyter/jupyterhub-liujing04/vits_ch/inference_f0/big_src_feature_mi.npy")
+n_ivf = min(int(16 * np.sqrt(big_npy.shape[0])), big_npy.shape[0] // 39)
+index = faiss.index_factory(768, "IVF%s,Flat" % n_ivf) # mi
+logger.info("Training...")
+index_ivf = faiss.extract_index_ivf(index) #
+index_ivf.nprobe = 1
+index.train(big_npy)
+faiss.write_index(
+ index, "tools/infer/trained_IVF%s_Flat_baseline_src_feat_v2.index" % (n_ivf)
+)
+logger.info("Adding...")
+batch_size_add = 8192
+for i in range(0, big_npy.shape[0], batch_size_add):
+ index.add(big_npy[i : i + batch_size_add])
+faiss.write_index(
+ index, "tools/infer/added_IVF%s_Flat_mi_baseline_src_feat.index" % (n_ivf)
+)
+"""
+大小(都是FP32)
+big_src_feature 2.95G
+ (3098036, 256)
+big_emb 4.43G
+ (6196072, 192)
+big_emb双倍是因为求特征要repeat后再加pitch
+
+"""
diff --git a/tools/cmd/train-index.py b/tools/cmd/train-index.py
new file mode 100644
index 0000000000000000000000000000000000000000..400adc0c949f09a1ac775073f9845ddac2bddf84
--- /dev/null
+++ b/tools/cmd/train-index.py
@@ -0,0 +1,43 @@
+"""
+格式:直接cid为自带的index位;aid放不下了,通过字典来查,反正就5w个
+"""
+
+import os
+import logging
+
+logger = logging.getLogger(__name__)
+
+import faiss
+import numpy as np
+
+# ###########如果是原始特征要先写save
+inp_root = r"E:\codes\py39\dataset\mi\2-co256"
+npys = []
+for name in sorted(list(os.listdir(inp_root))):
+ phone = np.load("%s/%s" % (inp_root, name))
+ npys.append(phone)
+big_npy = np.concatenate(npys, 0)
+logger.debug(big_npy.shape) # (6196072, 192)#fp32#4.43G
+np.save("infer/big_src_feature_mi.npy", big_npy)
+
+##################train+add
+# big_npy=np.load("/bili-coeus/jupyter/jupyterhub-liujing04/vits_ch/inference_f0/big_src_feature_mi.npy")
+logger.debug(big_npy.shape)
+index = faiss.index_factory(256, "IVF512,Flat") # mi
+logger.info("Training...")
+index_ivf = faiss.extract_index_ivf(index) #
+index_ivf.nprobe = 9
+index.train(big_npy)
+faiss.write_index(index, "infer/trained_IVF512_Flat_mi_baseline_src_feat.index")
+logger.info("Adding...")
+index.add(big_npy)
+faiss.write_index(index, "infer/added_IVF512_Flat_mi_baseline_src_feat.index")
+"""
+大小(都是FP32)
+big_src_feature 2.95G
+ (3098036, 256)
+big_emb 4.43G
+ (6196072, 192)
+big_emb双倍是因为求特征要repeat后再加pitch
+
+"""
diff --git a/tools/cmd/trans_weights.py b/tools/cmd/trans_weights.py
new file mode 100644
index 0000000000000000000000000000000000000000..a8ff3b0249b6f9c2f2748652e7563b6f28546ae0
--- /dev/null
+++ b/tools/cmd/trans_weights.py
@@ -0,0 +1,18 @@
+import pdb
+
+import torch
+
+# a=torch.load(r"E:\codes\py39\vits_vc_gpu_train\logs\ft-mi-suc\G_1000.pth")["model"]#sim_nsf#
+# a=torch.load(r"E:\codes\py39\vits_vc_gpu_train\logs\ft-mi-freeze-vocoder-flow-enc_q\G_1000.pth")["model"]#sim_nsf#
+# a=torch.load(r"E:\codes\py39\vits_vc_gpu_train\logs\ft-mi-freeze-vocoder\G_1000.pth")["model"]#sim_nsf#
+# a=torch.load(r"E:\codes\py39\vits_vc_gpu_train\logs\ft-mi-test\G_1000.pth")["model"]#sim_nsf#
+a = torch.load(
+ r"E:\codes\py39\vits_vc_gpu_train\logs\ft-mi-no_opt-no_dropout\G_1000.pth"
+)[
+ "model"
+] # sim_nsf#
+for key in a.keys():
+ a[key] = a[key].half()
+# torch.save(a,"ft-mi-freeze-vocoder_true_1k.pt")#
+# torch.save(a,"ft-mi-sim1k.pt")#
+torch.save(a, "ft-mi-no_opt-no_dropout.pt") #
diff --git a/tools/dlmodels.bat b/tools/dlmodels.bat
new file mode 100644
index 0000000000000000000000000000000000000000..b83825a28bb0e94cd26ce115db434254a2913817
--- /dev/null
+++ b/tools/dlmodels.bat
@@ -0,0 +1,362 @@
+@echo off && chcp 65001
+
+echo working dir is %cd%
+echo downloading requirement aria2 check.
+echo=
+dir /a:d/b | findstr "aria2" > flag.txt
+findstr "aria2" flag.txt >nul
+if %errorlevel% ==0 (
+ echo aria2 checked.
+ echo=
+) else (
+ echo failed. please downloading aria2 from webpage!
+ echo unzip it and put in this directory!
+ timeout /T 5
+ start https://github.com/aria2/aria2/releases/tag/release-1.36.0
+ echo=
+ goto end
+)
+
+echo envfiles checking start.
+echo=
+
+for /f %%x in ('findstr /i /c:"aria2" "flag.txt"') do (set aria2=%%x)&goto endSch
+:endSch
+
+set d32=f0D32k.pth
+set d40=f0D40k.pth
+set d48=f0D48k.pth
+set g32=f0G32k.pth
+set g40=f0G40k.pth
+set g48=f0G48k.pth
+
+set d40v2=f0D40k.pth
+set g40v2=f0G40k.pth
+
+set dld32=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0D32k.pth
+set dld40=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0D40k.pth
+set dld48=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0D48k.pth
+set dlg32=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0G32k.pth
+set dlg40=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0G40k.pth
+set dlg48=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0G48k.pth
+
+set dld40v2=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/f0D40k.pth
+set dlg40v2=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/f0G40k.pth
+
+set hp2_all=HP2_all_vocals.pth
+set hp3_all=HP3_all_vocals.pth
+set hp5_only=HP5_only_main_vocal.pth
+set VR_DeEchoAggressive=VR-DeEchoAggressive.pth
+set VR_DeEchoDeReverb=VR-DeEchoDeReverb.pth
+set VR_DeEchoNormal=VR-DeEchoNormal.pth
+set onnx_dereverb=vocals.onnx
+
+set dlhp2_all=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/HP2_all_vocals.pth
+set dlhp3_all=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/HP3_all_vocals.pth
+set dlhp5_only=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/HP5_only_main_vocal.pth
+set dlVR_DeEchoAggressive=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/VR-DeEchoAggressive.pth
+set dlVR_DeEchoDeReverb=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/VR-DeEchoDeReverb.pth
+set dlVR_DeEchoNormal=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/VR-DeEchoNormal.pth
+set dlonnx_dereverb=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/onnx_dereverb_By_FoxJoy/vocals.onnx
+
+set hb=hubert_base.pt
+
+set dlhb=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt
+
+set rmvpe=rmvpe.pt
+set dlrmvpe=https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/rmvpe.pt
+
+echo dir check start.
+echo=
+
+if exist "%~dp0assets\pretrained" (
+ echo dir .\assets\pretrained checked.
+ ) else (
+ echo failed. generating dir .\assets\pretrained.
+ mkdir pretrained
+ )
+if exist "%~dp0assets\pretrained_v2" (
+ echo dir .\assets\pretrained_v2 checked.
+ ) else (
+ echo failed. generating dir .\assets\pretrained_v2.
+ mkdir pretrained_v2
+ )
+if exist "%~dp0assets\uvr5_weights" (
+ echo dir .\assets\uvr5_weights checked.
+ ) else (
+ echo failed. generating dir .\assets\uvr5_weights.
+ mkdir uvr5_weights
+ )
+if exist "%~dp0assets\uvr5_weights\onnx_dereverb_By_FoxJoy" (
+ echo dir .\assets\uvr5_weights\onnx_dereverb_By_FoxJoy checked.
+ ) else (
+ echo failed. generating dir .\assets\uvr5_weights\onnx_dereverb_By_FoxJoy.
+ mkdir uvr5_weights\onnx_dereverb_By_FoxJoy
+ )
+
+echo=
+echo dir check finished.
+
+echo=
+echo required files check start.
+
+echo checking D32k.pth
+if exist "%~dp0assets\pretrained\D32k.pth" (
+ echo D32k.pth in .\assets\pretrained checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/D32k.pth -d %~dp0assets\pretrained -o D32k.pth
+ if exist "%~dp0assets\pretrained\D32k.pth" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking D40k.pth
+if exist "%~dp0assets\pretrained\D40k.pth" (
+ echo D40k.pth in .\assets\pretrained checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/D40k.pth -d %~dp0assets\pretrained -o D40k.pth
+ if exist "%~dp0assets\pretrained\D40k.pth" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking D40k.pth
+if exist "%~dp0assets\pretrained_v2\D40k.pth" (
+ echo D40k.pth in .\assets\pretrained_v2 checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/D40k.pth -d %~dp0assets\pretrained_v2 -o D40k.pth
+ if exist "%~dp0assets\pretrained_v2\D40k.pth" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking D48k.pth
+if exist "%~dp0assets\pretrained\D48k.pth" (
+ echo D48k.pth in .\assets\pretrained checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/D48k.pth -d %~dp0assets\pretrained -o D48k.pth
+ if exist "%~dp0assets\pretrained\D48k.pth" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking G32k.pth
+if exist "%~dp0assets\pretrained\G32k.pth" (
+ echo G32k.pth in .\assets\pretrained checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/G32k.pth -d %~dp0assets\pretrained -o G32k.pth
+ if exist "%~dp0assets\pretrained\G32k.pth" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking G40k.pth
+if exist "%~dp0assets\pretrained\G40k.pth" (
+ echo G40k.pth in .\assets\pretrained checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/G40k.pth -d %~dp0assets\pretrained -o G40k.pth
+ if exist "%~dp0assets\pretrained\G40k.pth" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking G40k.pth
+if exist "%~dp0assets\pretrained_v2\G40k.pth" (
+ echo G40k.pth in .\assets\pretrained_v2 checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/G40k.pth -d %~dp0assets\pretrained_v2 -o G40k.pth
+ if exist "%~dp0assets\pretrained_v2\G40k.pth" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking G48k.pth
+if exist "%~dp0assets\pretrained\G48k.pth" (
+ echo G48k.pth in .\assets\pretrained checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/G48k.pth -d %~dp0assets\pretrained -o G48k.pth
+ if exist "%~dp0assets\pretrained\G48k.pth" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+
+echo checking %d32%
+if exist "%~dp0assets\pretrained\%d32%" (
+ echo %d32% in .\assets\pretrained checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M %dld32% -d %~dp0assets\pretrained -o %d32%
+ if exist "%~dp0assets\pretrained\%d32%" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking %d40%
+if exist "%~dp0assets\pretrained\%d40%" (
+ echo %d40% in .\assets\pretrained checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M %dld40% -d %~dp0assets\pretrained -o %d40%
+ if exist "%~dp0assets\pretrained\%d40%" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking %d40v2%
+if exist "%~dp0assets\pretrained_v2\%d40v2%" (
+ echo %d40v2% in .\assets\pretrained_v2 checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M %dld40v2% -d %~dp0assets\pretrained_v2 -o %d40v2%
+ if exist "%~dp0assets\pretrained_v2\%d40v2%" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking %d48%
+if exist "%~dp0assets\pretrained\%d48%" (
+ echo %d48% in .\assets\pretrained checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M %dld48% -d %~dp0assets\pretrained -o %d48%
+ if exist "%~dp0assets\pretrained\%d48%" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking %g32%
+if exist "%~dp0assets\pretrained\%g32%" (
+ echo %g32% in .\assets\pretrained checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M %dlg32% -d %~dp0assets\pretrained -o %g32%
+ if exist "%~dp0assets\pretrained\%g32%" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking %g40%
+if exist "%~dp0assets\pretrained\%g40%" (
+ echo %g40% in .\assets\pretrained checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M %dlg40% -d %~dp0assets\pretrained -o %g40%
+ if exist "%~dp0assets\pretrained\%g40%" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking %g40v2%
+if exist "%~dp0assets\pretrained_v2\%g40v2%" (
+ echo %g40v2% in .\assets\pretrained_v2 checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M %dlg40v2% -d %~dp0assets\pretrained_v2 -o %g40v2%
+ if exist "%~dp0assets\pretrained_v2\%g40v2%" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking %g48%
+if exist "%~dp0assets\pretrained\%g48%" (
+ echo %g48% in .\assets\pretrained checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M %dlg48% -d %~dp0assets\pretrained -o %g48%
+ if exist "%~dp0assets\pretrained\%g48%" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+
+echo checking %hp2_all%
+if exist "%~dp0assets\uvr5_weights\%hp2_all%" (
+ echo %hp2_all% in .\assets\uvr5_weights checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M %dlhp2_all% -d %~dp0assets\uvr5_weights -o %hp2_all%
+ if exist "%~dp0assets\uvr5_weights\%hp2_all%" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking %hp3_all%
+if exist "%~dp0assets\uvr5_weights\%hp3_all%" (
+ echo %hp3_all% in .\assets\uvr5_weights checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M %dlhp3_all% -d %~dp0assets\uvr5_weights -o %hp3_all%
+ if exist "%~dp0assets\uvr5_weights\%hp3_all%" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking %hp5_only%
+if exist "%~dp0assets\uvr5_weights\%hp5_only%" (
+ echo %hp5_only% in .\assets\uvr5_weights checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M %dlhp5_only% -d %~dp0assets\uvr5_weights -o %hp5_only%
+ if exist "%~dp0assets\uvr5_weights\%hp5_only%" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking %VR_DeEchoAggressive%
+if exist "%~dp0assets\uvr5_weights\%VR_DeEchoAggressive%" (
+ echo %VR_DeEchoAggressive% in .\assets\uvr5_weights checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M %dlVR_DeEchoAggressive% -d %~dp0assets\uvr5_weights -o %VR_DeEchoAggressive%
+ if exist "%~dp0assets\uvr5_weights\%VR_DeEchoAggressive%" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking %VR_DeEchoDeReverb%
+if exist "%~dp0assets\uvr5_weights\%VR_DeEchoDeReverb%" (
+ echo %VR_DeEchoDeReverb% in .\assets\uvr5_weights checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M %dlVR_DeEchoDeReverb% -d %~dp0assets\uvr5_weights -o %VR_DeEchoDeReverb%
+ if exist "%~dp0assets\uvr5_weights\%VR_DeEchoDeReverb%" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking %VR_DeEchoNormal%
+if exist "%~dp0assets\uvr5_weights\%VR_DeEchoNormal%" (
+ echo %VR_DeEchoNormal% in .\assets\uvr5_weights checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M %dlVR_DeEchoNormal% -d %~dp0assets\uvr5_weights -o %VR_DeEchoNormal%
+ if exist "%~dp0assets\uvr5_weights\%VR_DeEchoNormal%" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+echo checking %onnx_dereverb%
+if exist "%~dp0assets\uvr5_weights\onnx_dereverb_By_FoxJoy\%onnx_dereverb%" (
+ echo %onnx_dereverb% in .\assets\uvr5_weights\onnx_dereverb_By_FoxJoy checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M %dlonnx_dereverb% -d %~dp0assets\uvr5_weights\onnx_dereverb_By_FoxJoy -o %onnx_dereverb%
+ if exist "%~dp0assets\uvr5_weights\onnx_dereverb_By_FoxJoy\%onnx_dereverb%" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+
+echo checking %hb%
+if exist "%~dp0assets\hubert\%hb%" (
+ echo %hb% in .\assets\hubert checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M %dlhb% -d %~dp0assets\hubert\ -o %hb%
+ if exist "%~dp0assets\hubert\%hb%" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+
+echo checking %rmvpe%
+if exist "%~dp0assets\rmvpe\%rmvpe%" (
+ echo %rmvpe% in .\assets\rmvpe checked.
+ echo=
+ ) else (
+ echo failed. starting download from huggingface.
+ %~dp0%aria2%\aria2c --console-log-level=error -c -x 16 -s 16 -k 1M %dlrmvpe% -d %~dp0assets\rmvpe\ -o %rmvpe%
+ if exist "%~dp0assets\rmvpe\%rmvpe%" (echo download successful.) else (echo please try again!
+ echo=)
+ )
+
+echo required files check finished.
+echo envfiles check complete.
+pause
+:end
+del flag.txt
diff --git a/tools/dlmodels.sh b/tools/dlmodels.sh
new file mode 100755
index 0000000000000000000000000000000000000000..2848e516b508e37ac41aa0dbd9043596dbc01bb7
--- /dev/null
+++ b/tools/dlmodels.sh
@@ -0,0 +1,81 @@
+#!/bin/sh
+
+printf "working dir is %s\n" "$PWD"
+echo "downloading requirement aria2 check."
+
+if command -v aria2c > /dev/null 2>&1
+then
+ echo "aria2 command found"
+else
+ echo "failed. please install aria2"
+ exit 1
+fi
+
+echo "dir check start."
+
+check_dir() {
+ [ -d "$1" ] && printf "dir %s checked\n" "$1" || \
+ printf "failed. generating dir %s\n" "$1" && mkdir -p "$1"
+}
+
+check_dir "./assets/pretrained"
+check_dir "./assets/pretrained_v2"
+check_dir "./assets/uvr5_weights"
+check_dir "./assets/uvr5_weights/onnx_dereverb_By_FoxJoy"
+
+echo "dir check finished."
+
+echo "required files check start."
+check_file_pretrained() {
+ printf "checking %s\n" "$2"
+ if [ -f "./assets/""$1""/""$2""" ]; then
+ printf "%s in ./assets/%s checked.\n" "$2" "$1"
+ else
+ echo failed. starting download from huggingface.
+ if command -v aria2c > /dev/null 2>&1; then
+ aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/"$1"/"$2" -d ./assets/"$1" -o "$2"
+ [ -f "./assets/""$1""/""$2""" ] && echo "download successful." || echo "please try again!" && exit 1
+ else
+ echo "aria2c command not found. Please install aria2c and try again."
+ exit 1
+ fi
+ fi
+}
+
+check_file_special() {
+ printf "checking %s\n" "$2"
+ if [ -f "./assets/""$1""/""$2""" ]; then
+ printf "%s in ./assets/%s checked.\n" "$2" "$1"
+ else
+ echo failed. starting download from huggingface.
+ if command -v aria2c > /dev/null 2>&1; then
+ aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/"$2" -d ./assets/"$1" -o "$2"
+ [ -f "./assets/""$1""/""$2""" ] && echo "download successful." || echo "please try again!" && exit 1
+ else
+ echo "aria2c command not found. Please install aria2c and try again."
+ exit 1
+ fi
+ fi
+}
+
+check_file_pretrained pretrained D32k.pth
+check_file_pretrained pretrained D40k.pth
+check_file_pretrained pretrained D48k.pth
+check_file_pretrained pretrained G32k.pth
+check_file_pretrained pretrained G40k.pth
+check_file_pretrained pretrained G48k.pth
+check_file_pretrained pretrained_v2 f0D40k.pth
+check_file_pretrained pretrained_v2 f0G40k.pth
+check_file_pretrained pretrained_v2 D40k.pth
+check_file_pretrained pretrained_v2 G40k.pth
+check_file_pretrained uvr5_weights HP2_all_vocals.pth
+check_file_pretrained uvr5_weights HP3_all_vocals.pth
+check_file_pretrained uvr5_weights HP5_only_main_vocal.pth
+check_file_pretrained uvr5_weights VR-DeEchoAggressive.pth
+check_file_pretrained uvr5_weights VR-DeEchoDeReverb.pth
+check_file_pretrained uvr5_weights VR-DeEchoNormal.pth
+check_file_pretrained uvr5_weights "onnx_dereverb_By_FoxJoy/vocals.onnx"
+check_file_special rmvpe rmvpe.pt
+check_file_special hubert hubert_base.pt
+
+echo "required files check finished."
diff --git a/tools/download_models.py b/tools/download_models.py
new file mode 100644
index 0000000000000000000000000000000000000000..94e03892558d8393ae5adad4be6ca228c4ab8f8e
--- /dev/null
+++ b/tools/download_models.py
@@ -0,0 +1,79 @@
+import os
+from pathlib import Path
+import requests
+
+RVC_DOWNLOAD_LINK = "https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/"
+
+BASE_DIR = Path(__file__).resolve().parent.parent
+
+
+def dl_model(link, model_name, dir_name):
+ with requests.get(f"{link}{model_name}") as r:
+ r.raise_for_status()
+ os.makedirs(os.path.dirname(dir_name / model_name), exist_ok=True)
+ with open(dir_name / model_name, "wb") as f:
+ for chunk in r.iter_content(chunk_size=8192):
+ f.write(chunk)
+
+
+if __name__ == "__main__":
+ print("Downloading hubert_base.pt...")
+ dl_model(RVC_DOWNLOAD_LINK, "hubert_base.pt", BASE_DIR / "assets/hubert")
+ print("Downloading rmvpe.pt...")
+ dl_model(RVC_DOWNLOAD_LINK, "rmvpe.pt", BASE_DIR / "assets/rmvpe")
+ print("Downloading vocals.onnx...")
+ dl_model(
+ RVC_DOWNLOAD_LINK + "uvr5_weights/onnx_dereverb_By_FoxJoy/",
+ "vocals.onnx",
+ BASE_DIR / "assets/uvr5_weights/onnx_dereverb_By_FoxJoy",
+ )
+
+ rvc_models_dir = BASE_DIR / "assets/pretrained"
+
+ print("Downloading pretrained models:")
+
+ model_names = [
+ "D32k.pth",
+ "D40k.pth",
+ "D48k.pth",
+ "G32k.pth",
+ "G40k.pth",
+ "G48k.pth",
+ "f0D32k.pth",
+ "f0D40k.pth",
+ "f0D48k.pth",
+ "f0G32k.pth",
+ "f0G40k.pth",
+ "f0G48k.pth",
+ ]
+ for model in model_names:
+ print(f"Downloading {model}...")
+ dl_model(RVC_DOWNLOAD_LINK + "pretrained/", model, rvc_models_dir)
+
+ rvc_models_dir = BASE_DIR / "assets/pretrained_v2"
+
+ print("Downloading pretrained models v2:")
+
+ for model in model_names:
+ print(f"Downloading {model}...")
+ dl_model(RVC_DOWNLOAD_LINK + "pretrained_v2/", model, rvc_models_dir)
+
+ print("Downloading uvr5_weights:")
+
+ rvc_models_dir = BASE_DIR / "assets/uvr5_weights"
+
+ model_names = [
+ "HP2-%E4%BA%BA%E5%A3%B0vocals%2B%E9%9D%9E%E4%BA%BA%E5%A3%B0instrumentals.pth",
+ "HP2_all_vocals.pth",
+ "HP3_all_vocals.pth",
+ "HP5-%E4%B8%BB%E6%97%8B%E5%BE%8B%E4%BA%BA%E5%A3%B0vocals%2B%E5%85%B6%E4%BB%96instrumentals.pth",
+ "HP5_only_main_vocal.pth",
+ "VR-DeEchoAggressive.pth",
+ "VR-DeEchoDeReverb.pth",
+ "VR-DeEchoNormal.pth",
+ ]
+ for model in model_names:
+ print(f"Downloading {model}...")
+ dl_model(RVC_DOWNLOAD_LINK + "uvr5_weights/", model, rvc_models_dir)
+
+ print("All models downloaded!")
diff --git a/tools/ipynb/v1.ipynb b/tools/ipynb/v1.ipynb
new file mode 100644
index 0000000000000000000000000000000000000000..b9e64dddb18855c6e6eb5d2543061a620a551633
--- /dev/null
+++ b/tools/ipynb/v1.ipynb
@@ -0,0 +1,353 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "WHBMn6dOWm-S"
+ },
+ "source": [
+ "# [Retrieval-based-Voice-Conversion-WebUI](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI) Training notebook"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZFFCx5J80SGa"
+ },
+ "source": [
+ "[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/tools/colab/v1.ipynb)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GmFP6bN9dvOq"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 查看显卡\n",
+ "!nvidia-smi"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "jwu07JgqoFON"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 挂载谷歌云盘\n",
+ "\n",
+ "from google.colab import drive\n",
+ "\n",
+ "drive.mount(\"/content/drive\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "wjddIFr1oS3W"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 安装依赖\n",
+ "!apt -y install build-essential python3-dev ffmpeg\n",
+ "!pip3 install --upgrade setuptools wheel\n",
+ "!pip3 install --upgrade pip"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "ge_97mfpgqTm"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 克隆仓库\n",
+ "\n",
+ "!git clone --depth=1 -b v1 https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI\n",
+ "%cd /content/Retrieval-based-Voice-Conversion-WebUI"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "BLDEZADkvlw1"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 安装依赖\n",
+ "!pip install -r requirements.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "pqE0PrnuRqI2"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 下载安装 RVC-Models-Downloader\n",
+ "!wget https://github.com/RVC-Project/RVC-Models-Downloader/releases/download/v0.2.2/rvcmd_linux_amd64.deb\n",
+ "!apt install ./rvcmd_linux_amd64.deb"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "UG3XpUwEomUz"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 下载所需资源\n",
+ "!rvcmd -notrs -w 1 -notui assets/v1\n",
+ "!rvcmd -notrs -w 1 -notui assets/rmvpe"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Mwk7Q0Loqzjx"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 从谷歌云盘加载打包好的数据集到/content/dataset\n",
+ "\n",
+ "# @markdown 数据集位置\n",
+ "DATASET = \"/content/drive/MyDrive/mydataset.zip\" # @param {type:\"string\"}\n",
+ "\n",
+ "!mkdir -p /content/dataset\n",
+ "!unzip -d /content/dataset -B {DATASET}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "PDlFxWHWEynD"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 重命名数据集中的重名文件\n",
+ "!ls -a /content/dataset/\n",
+ "!rename 's/(\\w+)\\.(\\w+)~(\\d*)/$1_$3.$2/' /content/dataset/*.*~*"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "7vh6vphDwO0b"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 启动web\n",
+ "%cd /content/Retrieval-based-Voice-Conversion-WebUI\n",
+ "# %load_ext tensorboard\n",
+ "# %tensorboard --logdir /content/Retrieval-based-Voice-Conversion-WebUI/logs\n",
+ "!python3 infer-web.py --colab --pycmd python3"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "FgJuNeAwx5Y_"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 手动将训练后的模型文件备份到谷歌云盘\n",
+ "# @markdown 需要自己查看logs文件夹下模型的文件名,手动修改下方命令末尾的文件名\n",
+ "\n",
+ "# @markdown 模型名\n",
+ "MODELNAME = \"mymodel\" # @param {type:\"string\"}\n",
+ "# @markdown 模型epoch\n",
+ "MODELEPOCH = 3200 # @param {type:\"integer\"}\n",
+ "\n",
+ "!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth /content/drive/MyDrive/{MODELNAME}_D_{MODELEPOCH}.pth\n",
+ "!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth /content/drive/MyDrive/{MODELNAME}_G_{MODELEPOCH}.pth\n",
+ "!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/added_*.index /content/drive/MyDrive/\n",
+ "!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/total_*.npy /content/drive/MyDrive/\n",
+ "\n",
+ "!cp /content/Retrieval-based-Voice-Conversion-WebUI/weights/{MODELNAME}.pth /content/drive/MyDrive/{MODELNAME}{MODELEPOCH}.pth"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "OVQoLQJXS7WX"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 从谷歌云盘恢复pth\n",
+ "# @markdown 需要自己查看logs文件夹下模型的文件名,手动修改下方命令末尾的文件名\n",
+ "\n",
+ "# @markdown 模型名\n",
+ "MODELNAME = \"mymodel\" # @param {type:\"string\"}\n",
+ "# @markdown 模型epoch\n",
+ "MODELEPOCH = 3200 # @param {type:\"integer\"}\n",
+ "\n",
+ "!mkdir -p /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}\n",
+ "\n",
+ "!cp /content/drive/MyDrive/{MODELNAME}_D_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth\n",
+ "!cp /content/drive/MyDrive/{MODELNAME}_G_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth\n",
+ "!cp /content/drive/MyDrive/*.index /content/\n",
+ "!cp /content/drive/MyDrive/*.npy /content/\n",
+ "!cp /content/drive/MyDrive/{MODELNAME}{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/weights/{MODELNAME}.pth"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "ZKAyuKb9J6dz"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 手动预处理(不推荐)\n",
+ "# @markdown 模型名\n",
+ "MODELNAME = \"mymodel\" # @param {type:\"string\"}\n",
+ "# @markdown 采样率\n",
+ "BITRATE = 48000 # @param {type:\"integer\"}\n",
+ "# @markdown 使用的进程数\n",
+ "THREADCOUNT = 8 # @param {type:\"integer\"}\n",
+ "\n",
+ "!python3 trainset_preprocess_pipeline_print.py /content/dataset {BITRATE} {THREADCOUNT} logs/{MODELNAME} True"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "CrxJqzAUKmPJ"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 手动提取特征(不推荐)\n",
+ "# @markdown 模型名\n",
+ "MODELNAME = \"mymodel\" # @param {type:\"string\"}\n",
+ "# @markdown 使用的进程数\n",
+ "THREADCOUNT = 8 # @param {type:\"integer\"}\n",
+ "# @markdown 音高提取算法\n",
+ "ALGO = \"harvest\" # @param {type:\"string\"}\n",
+ "\n",
+ "!python3 extract_f0_print.py logs/{MODELNAME} {THREADCOUNT} {ALGO}\n",
+ "\n",
+ "!python3 extract_feature_print.py cpu 1 0 0 logs/{MODELNAME} True"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "IMLPLKOaKj58"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 手动训练(不推荐)\n",
+ "# @markdown 模型名\n",
+ "MODELNAME = \"mymodel\" # @param {type:\"string\"}\n",
+ "# @markdown 使用的GPU\n",
+ "USEGPU = \"0\" # @param {type:\"string\"}\n",
+ "# @markdown 批大小\n",
+ "BATCHSIZE = 32 # @param {type:\"integer\"}\n",
+ "# @markdown 停止的epoch\n",
+ "MODELEPOCH = 3200 # @param {type:\"integer\"}\n",
+ "# @markdown 保存epoch间隔\n",
+ "EPOCHSAVE = 100 # @param {type:\"integer\"}\n",
+ "# @markdown 采样率\n",
+ "MODELSAMPLE = \"48k\" # @param {type:\"string\"}\n",
+ "# @markdown 是否缓存训练集\n",
+ "CACHEDATA = 1 # @param {type:\"integer\"}\n",
+ "# @markdown 是否仅保存最新的ckpt文件\n",
+ "ONLYLATEST = 0 # @param {type:\"integer\"}\n",
+ "\n",
+ "!python3 train_nsf_sim_cache_sid_load_pretrain.py -e lulu -sr {MODELSAMPLE} -f0 1 -bs {BATCHSIZE} -g {USEGPU} -te {MODELEPOCH} -se {EPOCHSAVE} -pg pretrained/f0G{MODELSAMPLE}.pth -pd pretrained/f0D{MODELSAMPLE}.pth -l {ONLYLATEST} -c {CACHEDATA}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "haYA81hySuDl"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 删除其它pth,只留选中的(慎点,仔细看代码)\n",
+ "# @markdown 模型名\n",
+ "MODELNAME = \"mymodel\" # @param {type:\"string\"}\n",
+ "# @markdown 选中模型epoch\n",
+ "MODELEPOCH = 3200 # @param {type:\"integer\"}\n",
+ "\n",
+ "!echo \"备份选中的模型。。。\"\n",
+ "!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth /content/{MODELNAME}_D_{MODELEPOCH}.pth\n",
+ "!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth /content/{MODELNAME}_G_{MODELEPOCH}.pth\n",
+ "\n",
+ "!echo \"正在删除。。。\"\n",
+ "!ls /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}\n",
+ "!rm /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/*.pth\n",
+ "\n",
+ "!echo \"恢复选中的模型。。。\"\n",
+ "!mv /content/{MODELNAME}_D_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth\n",
+ "!mv /content/{MODELNAME}_G_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth\n",
+ "\n",
+ "!echo \"删除完成\"\n",
+ "!ls /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "QhSiPTVPoIRh"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 清除项目下所有文件,只留选中的模型(慎点,仔细看代码)\n",
+ "# @markdown 模型名\n",
+ "MODELNAME = \"mymodel\" # @param {type:\"string\"}\n",
+ "# @markdown 选中模型epoch\n",
+ "MODELEPOCH = 3200 # @param {type:\"integer\"}\n",
+ "\n",
+ "!echo \"备份选中的模型。。。\"\n",
+ "!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth /content/{MODELNAME}_D_{MODELEPOCH}.pth\n",
+ "!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth /content/{MODELNAME}_G_{MODELEPOCH}.pth\n",
+ "\n",
+ "!echo \"正在删除。。。\"\n",
+ "!ls /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}\n",
+ "!rm -rf /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/*\n",
+ "\n",
+ "!echo \"恢复选中的模型。。。\"\n",
+ "!mv /content/{MODELNAME}_D_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth\n",
+ "!mv /content/{MODELNAME}_G_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth\n",
+ "\n",
+ "!echo \"删除完成\"\n",
+ "!ls /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "private_outputs": true,
+ "provenance": []
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ },
+ "language_info": {
+ "name": "python"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/tools/ipynb/v2.ipynb b/tools/ipynb/v2.ipynb
new file mode 100644
index 0000000000000000000000000000000000000000..e1464a85de09e6fd0ce64e1d4df1c526945122f6
--- /dev/null
+++ b/tools/ipynb/v2.ipynb
@@ -0,0 +1,352 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "QTSdqTqGcbyr"
+ },
+ "source": [
+ "# [Retrieval-based-Voice-Conversion-WebUI](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI) Training notebook"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZFFCx5J80SGa"
+ },
+ "source": [
+ "[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/tools/colab/v2.ipynb)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GmFP6bN9dvOq"
+ },
+ "outputs": [],
+ "source": [
+ "# @title #查看显卡\n",
+ "!nvidia-smi"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "jwu07JgqoFON"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 挂载谷歌云盘\n",
+ "\n",
+ "from google.colab import drive\n",
+ "\n",
+ "drive.mount(\"/content/drive\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "wjddIFr1oS3W"
+ },
+ "outputs": [],
+ "source": [
+ "# @title #安装依赖\n",
+ "!apt -y install build-essential python3-dev ffmpeg\n",
+ "!pip3 install --upgrade setuptools wheel\n",
+ "!pip3 install --upgrade pip"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "ge_97mfpgqTm"
+ },
+ "outputs": [],
+ "source": [
+ "# @title #克隆仓库\n",
+ "\n",
+ "!git clone --depth=1 -b v2.2 https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI\n",
+ "%cd /content/Retrieval-based-Voice-Conversion-WebUI"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "BLDEZADkvlw1"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 安装依赖\n",
+ "!pip install -r requirements.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "pqE0PrnuRqI2"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 下载安装 RVC-Models-Downloader\n",
+ "!wget https://github.com/RVC-Project/RVC-Models-Downloader/releases/download/v0.2.2/rvcmd_linux_amd64.deb\n",
+ "!apt install ./rvcmd_linux_amd64.deb"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "UG3XpUwEomUz"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 下载所需资源\n",
+ "!rvcmd -notrs -w 1 -notui assets/all"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Mwk7Q0Loqzjx"
+ },
+ "outputs": [],
+ "source": [
+ "# @title #从谷歌云盘加载打包好的数据集到/content/dataset\n",
+ "\n",
+ "# @markdown 数据集位置\n",
+ "DATASET = \"/content/drive/MyDrive/mydataset.zip\" # @param {type:\"string\"}\n",
+ "\n",
+ "!mkdir -p /content/dataset\n",
+ "!unzip -d /content/dataset -B {DATASET}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "PDlFxWHWEynD"
+ },
+ "outputs": [],
+ "source": [
+ "# @title #重命名数据集中的重名文件\n",
+ "!ls -a /content/dataset/\n",
+ "!rename 's/(\\w+)\\.(\\w+)~(\\d*)/$1_$3.$2/' /content/dataset/*.*~*"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "7vh6vphDwO0b"
+ },
+ "outputs": [],
+ "source": [
+ "# @title #启动webui\n",
+ "%cd /content/Retrieval-based-Voice-Conversion-WebUI\n",
+ "# %load_ext tensorboard\n",
+ "# %tensorboard --logdir /content/Retrieval-based-Voice-Conversion-WebUI/logs\n",
+ "!python3 infer-web.py --colab --pycmd python3"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "FgJuNeAwx5Y_"
+ },
+ "outputs": [],
+ "source": [
+ "# @title #手动将训练后的模型文件备份到谷歌云盘\n",
+ "# @markdown #需要自己查看logs文件夹下模型的文件名,手动修改下方命令末尾的文件名\n",
+ "\n",
+ "# @markdown #模型名\n",
+ "MODELNAME = \"mymodel\" # @param {type:\"string\"}\n",
+ "# @markdown #模型epoch\n",
+ "MODELEPOCH = 3200 # @param {type:\"integer\"}\n",
+ "\n",
+ "!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth /content/drive/MyDrive/{MODELNAME}_D_{MODELEPOCH}.pth\n",
+ "!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth /content/drive/MyDrive/{MODELNAME}_G_{MODELEPOCH}.pth\n",
+ "!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/added_*.index /content/drive/MyDrive/\n",
+ "!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/total_*.npy /content/drive/MyDrive/\n",
+ "\n",
+ "!cp /content/Retrieval-based-Voice-Conversion-WebUI/weights/{MODELNAME}.pth /content/drive/MyDrive/{MODELNAME}{MODELEPOCH}.pth"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "OVQoLQJXS7WX"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 从谷歌云盘恢复pth\n",
+ "# @markdown 需要自己查看logs文件夹下模型的文件名,手动修改下方命令末尾的文件名\n",
+ "\n",
+ "# @markdown 模型名\n",
+ "MODELNAME = \"mymodel\" # @param {type:\"string\"}\n",
+ "# @markdown 模型epoch\n",
+ "MODELEPOCH = 3200 # @param {type:\"integer\"}\n",
+ "\n",
+ "!mkdir -p /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}\n",
+ "\n",
+ "!cp /content/drive/MyDrive/{MODELNAME}_D_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth\n",
+ "!cp /content/drive/MyDrive/{MODELNAME}_G_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth\n",
+ "!cp /content/drive/MyDrive/*.index /content/\n",
+ "!cp /content/drive/MyDrive/*.npy /content/\n",
+ "!cp /content/drive/MyDrive/{MODELNAME}{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/weights/{MODELNAME}.pth"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "ZKAyuKb9J6dz"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 手动预处理(不推荐)\n",
+ "# @markdown 模型名\n",
+ "MODELNAME = \"mymodel\" # @param {type:\"string\"}\n",
+ "# @markdown 采样率\n",
+ "BITRATE = 48000 # @param {type:\"integer\"}\n",
+ "# @markdown 使用的进程数\n",
+ "THREADCOUNT = 8 # @param {type:\"integer\"}\n",
+ "\n",
+ "!python3 trainset_preprocess_pipeline_print.py /content/dataset {BITRATE} {THREADCOUNT} logs/{MODELNAME} True"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "CrxJqzAUKmPJ"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 手动提取特征(不推荐)\n",
+ "# @markdown 模型名\n",
+ "MODELNAME = \"mymodel\" # @param {type:\"string\"}\n",
+ "# @markdown 使用的进程数\n",
+ "THREADCOUNT = 8 # @param {type:\"integer\"}\n",
+ "# @markdown 音高提取算法\n",
+ "ALGO = \"harvest\" # @param {type:\"string\"}\n",
+ "\n",
+ "!python3 extract_f0_print.py logs/{MODELNAME} {THREADCOUNT} {ALGO}\n",
+ "\n",
+ "!python3 extract_feature_print.py cpu 1 0 0 logs/{MODELNAME} True"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "IMLPLKOaKj58"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 手动训练(不推荐)\n",
+ "# @markdown 模型名\n",
+ "MODELNAME = \"mymodel\" # @param {type:\"string\"}\n",
+ "# @markdown 使用的GPU\n",
+ "USEGPU = \"0\" # @param {type:\"string\"}\n",
+ "# @markdown 批大小\n",
+ "BATCHSIZE = 32 # @param {type:\"integer\"}\n",
+ "# @markdown 停止的epoch\n",
+ "MODELEPOCH = 3200 # @param {type:\"integer\"}\n",
+ "# @markdown 保存epoch间隔\n",
+ "EPOCHSAVE = 100 # @param {type:\"integer\"}\n",
+ "# @markdown 采样率\n",
+ "MODELSAMPLE = \"48k\" # @param {type:\"string\"}\n",
+ "# @markdown 是否缓存训练集\n",
+ "CACHEDATA = 1 # @param {type:\"integer\"}\n",
+ "# @markdown 是否仅保存最新的ckpt文件\n",
+ "ONLYLATEST = 0 # @param {type:\"integer\"}\n",
+ "\n",
+ "!python3 train_nsf_sim_cache_sid_load_pretrain.py -e lulu -sr {MODELSAMPLE} -f0 1 -bs {BATCHSIZE} -g {USEGPU} -te {MODELEPOCH} -se {EPOCHSAVE} -pg pretrained/f0G{MODELSAMPLE}.pth -pd pretrained/f0D{MODELSAMPLE}.pth -l {ONLYLATEST} -c {CACHEDATA}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "haYA81hySuDl"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 删除其它pth,只留选中的(慎点,仔细看代码)\n",
+ "# @markdown 模型名\n",
+ "MODELNAME = \"mymodel\" # @param {type:\"string\"}\n",
+ "# @markdown 选中模型epoch\n",
+ "MODELEPOCH = 3200 # @param {type:\"integer\"}\n",
+ "\n",
+ "!echo \"备份选中的模型。。。\"\n",
+ "!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth /content/{MODELNAME}_D_{MODELEPOCH}.pth\n",
+ "!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth /content/{MODELNAME}_G_{MODELEPOCH}.pth\n",
+ "\n",
+ "!echo \"正在删除。。。\"\n",
+ "!ls /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}\n",
+ "!rm /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/*.pth\n",
+ "\n",
+ "!echo \"恢复选中的模型。。。\"\n",
+ "!mv /content/{MODELNAME}_D_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth\n",
+ "!mv /content/{MODELNAME}_G_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth\n",
+ "\n",
+ "!echo \"删除完成\"\n",
+ "!ls /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "QhSiPTVPoIRh"
+ },
+ "outputs": [],
+ "source": [
+ "# @title 清除项目下所有文件,只留选中的模型(慎点,仔细看代码)\n",
+ "# @markdown 模型名\n",
+ "MODELNAME = \"mymodel\" # @param {type:\"string\"}\n",
+ "# @markdown 选中模型epoch\n",
+ "MODELEPOCH = 3200 # @param {type:\"integer\"}\n",
+ "\n",
+ "!echo \"备份选中的模型。。。\"\n",
+ "!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth /content/{MODELNAME}_D_{MODELEPOCH}.pth\n",
+ "!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth /content/{MODELNAME}_G_{MODELEPOCH}.pth\n",
+ "\n",
+ "!echo \"正在删除。。。\"\n",
+ "!ls /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}\n",
+ "!rm -rf /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/*\n",
+ "\n",
+ "!echo \"恢复选中的模型。。。\"\n",
+ "!mv /content/{MODELNAME}_D_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth\n",
+ "!mv /content/{MODELNAME}_G_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth\n",
+ "\n",
+ "!echo \"删除完成\"\n",
+ "!ls /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "private_outputs": true,
+ "provenance": []
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ },
+ "language_info": {
+ "name": "python"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/tools/onnx/export_onnx.py b/tools/onnx/export_onnx.py
new file mode 100644
index 0000000000000000000000000000000000000000..7776e3cb30c9cca3baa75a4cb287f8133319981f
--- /dev/null
+++ b/tools/onnx/export_onnx.py
@@ -0,0 +1,3 @@
+from infer.modules.onnx.export import export_onnx
+
+export_onnx("pt/Justin Bieber.pth", "pt/TestRvc_Rvc.onnx")
diff --git a/tools/onnx/onnx_inference_demo.py b/tools/onnx/onnx_inference_demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..67f4371e14baabb50b9f55ff1b72605e14b4119e
--- /dev/null
+++ b/tools/onnx/onnx_inference_demo.py
@@ -0,0 +1,23 @@
+import soundfile
+
+from infer.lib.infer_pack.onnx_inference import OnnxRVC
+
+hop_size = 512
+sampling_rate = 40000 # 采样率
+f0_up_key = 0 # 升降调
+sid = 0 # 角色ID
+f0_method = "dio" # F0提取算法
+model_path = "ShirohaRVC.onnx" # 模型的完整路径
+vec_name = (
+ "vec-256-layer-9" # 内部自动补齐为 f"pretrained/{vec_name}.onnx" 需要onnx的vec模型
+)
+wav_path = "123.wav" # 输入路径或ByteIO实例
+out_path = "out.wav" # 输出路径或ByteIO实例
+
+model = OnnxRVC(
+ model_path, vec_path=vec_name, sr=sampling_rate, hop_size=hop_size, device="cuda"
+)
+
+audio = model.inference(wav_path, sid, f0_method=f0_method, f0_up_key=f0_up_key)
+
+soundfile.write(out_path, audio, sampling_rate)
diff --git a/tools/web/infer-only.py b/tools/web/infer-only.py
new file mode 100644
index 0000000000000000000000000000000000000000..26901e20ada865f3fadeb0c6b433d52384aaaa60
--- /dev/null
+++ b/tools/web/infer-only.py
@@ -0,0 +1,161 @@
+import logging
+import os
+
+# os.system("wget -P cvec/ https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt")
+import gradio as gr
+from dotenv import load_dotenv
+
+from configs.config import Config
+from i18n.i18n import I18nAuto
+from infer.modules.vc.modules import VC
+
+logging.getLogger("numba").setLevel(logging.WARNING)
+logging.getLogger("markdown_it").setLevel(logging.WARNING)
+logging.getLogger("urllib3").setLevel(logging.WARNING)
+logging.getLogger("matplotlib").setLevel(logging.WARNING)
+logger = logging.getLogger(__name__)
+
+i18n = I18nAuto()
+logger.info(i18n)
+
+load_dotenv()
+config = Config()
+vc = VC(config)
+
+weight_root = os.getenv("weight_root")
+weight_uvr5_root = os.getenv("weight_uvr5_root")
+index_root = os.getenv("index_root")
+names = []
+hubert_model = None
+for name in os.listdir(weight_root):
+ if name.endswith(".pth"):
+ names.append(name)
+index_paths = []
+for root, dirs, files in os.walk(index_root, topdown=False):
+ for name in files:
+ if name.endswith(".index") and "trained" not in name:
+ index_paths.append("%s/%s" % (root, name))
+
+
+app = gr.Blocks()
+with app:
+ with gr.Tabs():
+ with gr.TabItem("在线demo"):
+ gr.Markdown(
+ value="""
+ RVC 在线demo
+ """
+ )
+ sid = gr.Dropdown(label=i18n("推理音色"), choices=sorted(names))
+ with gr.Column():
+ spk_item = gr.Slider(
+ minimum=0,
+ maximum=2333,
+ step=1,
+ label=i18n("请选择说话人id"),
+ value=0,
+ visible=False,
+ interactive=True,
+ )
+ sid.change(fn=vc.get_vc, inputs=[sid], outputs=[spk_item])
+ gr.Markdown(
+ value=i18n(
+ "男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. "
+ )
+ )
+ vc_input3 = gr.Audio(label="上传音频(长度小于90秒)")
+ vc_transform0 = gr.Number(
+ label=i18n("变调(整数, 半音数量, 升八度12降八度-12)"), value=0
+ )
+ f0method0 = gr.Radio(
+ label=i18n(
+ "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU"
+ ),
+ choices=["pm", "harvest", "crepe", "rmvpe"],
+ value="pm",
+ interactive=True,
+ )
+ filter_radius0 = gr.Slider(
+ minimum=0,
+ maximum=7,
+ label=i18n(
+ ">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音"
+ ),
+ value=3,
+ step=1,
+ interactive=True,
+ )
+ with gr.Column():
+ file_index1 = gr.Textbox(
+ label=i18n("特征检索库文件路径,为空则使用下拉的选择结果"),
+ value="",
+ interactive=False,
+ visible=False,
+ )
+ file_index2 = gr.Dropdown(
+ label=i18n("自动检测index路径,下拉式选择(dropdown)"),
+ choices=sorted(index_paths),
+ interactive=True,
+ )
+ index_rate1 = gr.Slider(
+ minimum=0,
+ maximum=1,
+ label=i18n("检索特征占比"),
+ value=0.88,
+ interactive=True,
+ )
+ resample_sr0 = gr.Slider(
+ minimum=0,
+ maximum=48000,
+ label=i18n("后处理重采样至最终采样率,0为不进行重采样"),
+ value=0,
+ step=1,
+ interactive=True,
+ )
+ rms_mix_rate0 = gr.Slider(
+ minimum=0,
+ maximum=1,
+ label=i18n(
+ "输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络"
+ ),
+ value=1,
+ interactive=True,
+ )
+ protect0 = gr.Slider(
+ minimum=0,
+ maximum=0.5,
+ label=i18n(
+ "保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果"
+ ),
+ value=0.33,
+ step=0.01,
+ interactive=True,
+ )
+ f0_file = gr.File(
+ label=i18n("F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调")
+ )
+ but0 = gr.Button(i18n("转换"), variant="primary")
+ vc_output1 = gr.Textbox(label=i18n("输出信息"))
+ vc_output2 = gr.Audio(label=i18n("输出音频(右下角三个点,点了可以下载)"))
+ but0.click(
+ vc.vc_single,
+ [
+ spk_item,
+ vc_input3,
+ vc_transform0,
+ f0_file,
+ f0method0,
+ file_index1,
+ file_index2,
+ # file_big_npy1,
+ index_rate1,
+ filter_radius0,
+ resample_sr0,
+ rms_mix_rate0,
+ protect0,
+ ],
+ [vc_output1, vc_output2],
+ )
+
+
+app.launch()