Spaces:
Runtime error

Runtime error
Kirili4ik
commited on
Commit
•
ae84b44
1
Parent(s):
c5dc12a
init
Browse files- Fine_tune_RuDialoGPT3_on_telegram_chat.ipynb +689 -0
- LICENSE +21 -0
- README.md +26 -28
- app.py +242 -0
- how-to-export-chat.jpg +0 -0
- how-to-upload-json.jpg +0 -0
- requirements.txt +2 -0
- sample1.jpg +0 -0
- sample2.jpg +0 -0
Fine_tune_RuDialoGPT3_on_telegram_chat.ipynb
ADDED
|
@@ -0,0 +1,689 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"nbformat": 4,
|
| 3 |
+
"nbformat_minor": 0,
|
| 4 |
+
"metadata": {
|
| 5 |
+
"colab": {
|
| 6 |
+
"name": "Fine tune RuDialoGPT3 on telegram chat",
|
| 7 |
+
"provenance": [],
|
| 8 |
+
"collapsed_sections": [
|
| 9 |
+
"uPZXtklAd0Cd",
|
| 10 |
+
"ESogNuUOEmj_",
|
| 11 |
+
"psXZnJk0Eo3J"
|
| 12 |
+
],
|
| 13 |
+
"toc_visible": true,
|
| 14 |
+
"include_colab_link": true
|
| 15 |
+
},
|
| 16 |
+
"kernelspec": {
|
| 17 |
+
"display_name": "Python 3",
|
| 18 |
+
"name": "python3"
|
| 19 |
+
},
|
| 20 |
+
"language_info": {
|
| 21 |
+
"name": "python"
|
| 22 |
+
}
|
| 23 |
+
},
|
| 24 |
+
"cells": [
|
| 25 |
+
{
|
| 26 |
+
"cell_type": "markdown",
|
| 27 |
+
"metadata": {
|
| 28 |
+
"id": "view-in-github",
|
| 29 |
+
"colab_type": "text"
|
| 30 |
+
},
|
| 31 |
+
"source": [
|
| 32 |
+
"<a href=\"https://colab.research.google.com/github/Kirili4ik/ruDialoGpt3-finetune-colab/blob/main/Fine_tune_RuDialoGPT3_on_telegram_chat.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>"
|
| 33 |
+
]
|
| 34 |
+
},
|
| 35 |
+
{
|
| 36 |
+
"cell_type": "markdown",
|
| 37 |
+
"metadata": {
|
| 38 |
+
"id": "ocoQoLlek3cb"
|
| 39 |
+
},
|
| 40 |
+
"source": [
|
| 41 |
+
"# Fine-Tuning DialoGPT3 on your telegram chat"
|
| 42 |
+
]
|
| 43 |
+
},
|
| 44 |
+
{
|
| 45 |
+
"cell_type": "markdown",
|
| 46 |
+
"metadata": {
|
| 47 |
+
"id": "_ptkarFllCDr"
|
| 48 |
+
},
|
| 49 |
+
"source": [
|
| 50 |
+
"Here is a ready-to-run code for fine-tuning a RuDialoGPT3 model using HuggingFace and PyTorch on **your telegram chat**.\n",
|
| 51 |
+
"\n",
|
| 52 |
+
"I used RuDialoGPT-3 trained on forums to fine tune. It was trained by [@Grossmend](https://github.com/Grossmend) on Russian forums. The training process took 12 days using 4x RTX 2080 Ti (2 epochs on 32GB text corpus). The training procedure of GPT-3 for dialogue is described in Grossmend's [blogpost](https://habr.com/ru/company/icl_services/blog/548244/) (in Russian).\n",
|
| 53 |
+
"\n",
|
| 54 |
+
"I have created a simple pipeline and fine tuned that model on my own exported telegram chat (~30mb json). It is in fact very easy to get the data from telegram and fine tune a model. Therefore, I made this notebook!"
|
| 55 |
+
]
|
| 56 |
+
},
|
| 57 |
+
{
|
| 58 |
+
"cell_type": "markdown",
|
| 59 |
+
"metadata": {
|
| 60 |
+
"id": "GAB9ev-Gd8lH"
|
| 61 |
+
},
|
| 62 |
+
"source": [
|
| 63 |
+
"If you want just to try / to talk to my fine-tuned model than go **straight to the Inference section**."
|
| 64 |
+
]
|
| 65 |
+
},
|
| 66 |
+
{
|
| 67 |
+
"cell_type": "markdown",
|
| 68 |
+
"metadata": {
|
| 69 |
+
"id": "uPZXtklAd0Cd"
|
| 70 |
+
},
|
| 71 |
+
"source": [
|
| 72 |
+
"## Uploading your data for fine-tuning"
|
| 73 |
+
]
|
| 74 |
+
},
|
| 75 |
+
{
|
| 76 |
+
"cell_type": "code",
|
| 77 |
+
"metadata": {
|
| 78 |
+
"id": "VL5BXKmva2-Q"
|
| 79 |
+
},
|
| 80 |
+
"source": [
|
| 81 |
+
"# installing huggingface datasets and accelerate \n",
|
| 82 |
+
"! pip install datasets transformers[sentencepiece]\n",
|
| 83 |
+
"! pip install accelerate\n",
|
| 84 |
+
"\n",
|
| 85 |
+
"# [optional] Login to google drive to save models\n",
|
| 86 |
+
"from google.colab import drive\n",
|
| 87 |
+
"drive.mount('/content/drive')\n",
|
| 88 |
+
"\n",
|
| 89 |
+
"# [optional] Login to wandb to track model's behaviour\n",
|
| 90 |
+
"'''! pip install wandb\n",
|
| 91 |
+
"! wandb login\n",
|
| 92 |
+
"wandb.init(project=\"fine tune RuDialoGPT2 on KirArChat\")'''"
|
| 93 |
+
],
|
| 94 |
+
"execution_count": null,
|
| 95 |
+
"outputs": []
|
| 96 |
+
},
|
| 97 |
+
{
|
| 98 |
+
"cell_type": "code",
|
| 99 |
+
"metadata": {
|
| 100 |
+
"cellView": "form",
|
| 101 |
+
"id": "Iq78W4qhrYmN"
|
| 102 |
+
},
|
| 103 |
+
"source": [
|
| 104 |
+
"#@title Imports\n",
|
| 105 |
+
"import sys\n",
|
| 106 |
+
"import re\n",
|
| 107 |
+
"import json\n",
|
| 108 |
+
"\n",
|
| 109 |
+
"from sklearn.model_selection import train_test_split\n",
|
| 110 |
+
"from tqdm import tqdm\n",
|
| 111 |
+
"\n",
|
| 112 |
+
"import torch\n",
|
| 113 |
+
"from transformers import TextDataset, DataCollatorForLanguageModeling\n",
|
| 114 |
+
"from torch.utils.data import DataLoader\n",
|
| 115 |
+
"\n",
|
| 116 |
+
"from accelerate import Accelerator\n",
|
| 117 |
+
"from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler"
|
| 118 |
+
],
|
| 119 |
+
"execution_count": null,
|
| 120 |
+
"outputs": []
|
| 121 |
+
},
|
| 122 |
+
{
|
| 123 |
+
"cell_type": "markdown",
|
| 124 |
+
"metadata": {
|
| 125 |
+
"id": "7fRNBMkYnAUV"
|
| 126 |
+
},
|
| 127 |
+
"source": [
|
| 128 |
+
"Next cell downloads model and tokenizer using HuggingFace.\n",
|
| 129 |
+
"\n",
|
| 130 |
+
"You can start with my version or @Grossmend's: \"Grossmend/rudialogpt3_medium_based_on_gpt2\". Moreover, you can even start with any different DialoGPT trained on your language (with the notation of |x|y|text)."
|
| 131 |
+
]
|
| 132 |
+
},
|
| 133 |
+
{
|
| 134 |
+
"cell_type": "code",
|
| 135 |
+
"metadata": {
|
| 136 |
+
"id": "fn9KxEnfaxwo"
|
| 137 |
+
},
|
| 138 |
+
"source": [
|
| 139 |
+
"from transformers import AutoModelForCausalLM, AutoTokenizer\n",
|
| 140 |
+
"\n",
|
| 141 |
+
"checkpoint = \"Kirili4ik/ruDialoGpt3-medium-finetuned-telegram\" \n",
|
| 142 |
+
"tokenizer = AutoTokenizer.from_pretrained(checkpoint)\n",
|
| 143 |
+
"model = AutoModelForCausalLM.from_pretrained(checkpoint)"
|
| 144 |
+
],
|
| 145 |
+
"execution_count": null,
|
| 146 |
+
"outputs": []
|
| 147 |
+
},
|
| 148 |
+
{
|
| 149 |
+
"cell_type": "code",
|
| 150 |
+
"metadata": {
|
| 151 |
+
"id": "SulpoPQxpJrK",
|
| 152 |
+
"cellView": "form"
|
| 153 |
+
},
|
| 154 |
+
"source": [
|
| 155 |
+
"#@title Utility functions\n",
|
| 156 |
+
"def get_length_param(text: str, tokenizer) -> str:\n",
|
| 157 |
+
" \"\"\"Maps text to 1 of 4 buckets based on length after encoding.\n",
|
| 158 |
+
"\n",
|
| 159 |
+
" Parameters\n",
|
| 160 |
+
" ----------\n",
|
| 161 |
+
" text: str\n",
|
| 162 |
+
" The text to be given 1 of 4 length parameters.\n",
|
| 163 |
+
"\n",
|
| 164 |
+
" tokenizer: HuggingFace tokenizer \n",
|
| 165 |
+
" Tokenizer that used to compute the length of the text after encoding.\n",
|
| 166 |
+
" For more info ee https://huggingface.co/transformers/main_classes/tokenizer.html\n",
|
| 167 |
+
"\n",
|
| 168 |
+
" Returns\n",
|
| 169 |
+
" -------\n",
|
| 170 |
+
" len_param: str\n",
|
| 171 |
+
" One of four buckets: \n",
|
| 172 |
+
" '1' for short, '2' for medium, '3' for long texts and '-' for all others. \n",
|
| 173 |
+
" \"\"\"\n",
|
| 174 |
+
" tokens_count = len(tokenizer.encode(text))\n",
|
| 175 |
+
" if tokens_count <= 15:\n",
|
| 176 |
+
" len_param = '1'\n",
|
| 177 |
+
" elif tokens_count <= 50:\n",
|
| 178 |
+
" len_param = '2'\n",
|
| 179 |
+
" elif tokens_count <= 256:\n",
|
| 180 |
+
" len_param = '3'\n",
|
| 181 |
+
" else:\n",
|
| 182 |
+
" len_param = '-'\n",
|
| 183 |
+
" return len_param\n",
|
| 184 |
+
"\n",
|
| 185 |
+
"\n",
|
| 186 |
+
"def get_user_param(text: dict, machine_name_in_chat: str) -> str:\n",
|
| 187 |
+
" \"\"\"Maps text by 1/0 for it to be the person or the machine in the dialog\n",
|
| 188 |
+
"\n",
|
| 189 |
+
" Parameters\n",
|
| 190 |
+
" ----------\n",
|
| 191 |
+
" text: Dict[..., 'from', ...]\n",
|
| 192 |
+
" Dict containing field 'from' with the name of the user who sent the message\n",
|
| 193 |
+
"\n",
|
| 194 |
+
" machine_name_in_chat: str\n",
|
| 195 |
+
" Str with the name of the machine - it will be predicted\n",
|
| 196 |
+
" \"\"\"\n",
|
| 197 |
+
" if text['from'] == machine_name_in_chat:\n",
|
| 198 |
+
" return '1' # machine\n",
|
| 199 |
+
" else:\n",
|
| 200 |
+
" return '0' # human\n",
|
| 201 |
+
"\n",
|
| 202 |
+
"\n",
|
| 203 |
+
"def build_text_file(data_json: dict, dest_path: str, \n",
|
| 204 |
+
" tokenizer, machine_name_in_chat='Кирилл Гельван'):\n",
|
| 205 |
+
" \"\"\"Create a text file for training in special format for ruDialoGPT-3.\n",
|
| 206 |
+
"\n",
|
| 207 |
+
" Parameters\n",
|
| 208 |
+
" ----------\n",
|
| 209 |
+
" data_json: dict\n",
|
| 210 |
+
" Dict containing 'text' (message) and 'from' (user who sent the message)\n",
|
| 211 |
+
" \n",
|
| 212 |
+
" dest_path: str\n",
|
| 213 |
+
" String containing path to write data there\n",
|
| 214 |
+
"\n",
|
| 215 |
+
" tokenizer: HuggingFace tokenizer \n",
|
| 216 |
+
" Tokenizer that used to compute the length of the text after encoding.\n",
|
| 217 |
+
" For more info ee https://huggingface.co/transformers/main_classes/tokenizer.html\n",
|
| 218 |
+
" \"\"\"\n",
|
| 219 |
+
" f = open(dest_path, 'w')\n",
|
| 220 |
+
" new_data = ''\n",
|
| 221 |
+
" for i in range(len(data_json) - 1):\n",
|
| 222 |
+
" message, next_message = data_json[i], data_json[i+1]\n",
|
| 223 |
+
" if message['text'] == '' or type(message['text']) != str:\n",
|
| 224 |
+
" continue\n",
|
| 225 |
+
" if next_message['text'] == '' or type(next_message['text']) != str:\n",
|
| 226 |
+
" continue\n",
|
| 227 |
+
"\n",
|
| 228 |
+
" user = get_user_param(message, machine_name_in_chat=machine_name_in_chat)\n",
|
| 229 |
+
" length = get_length_param(data_json[i+1]['text'], tokenizer)\n",
|
| 230 |
+
" message_text = re.sub(r\"\\n\", \". \", message['text'])\n",
|
| 231 |
+
" new_data += f\"|{user}|{length}|{message_text}{tokenizer.eos_token}\" + \"\\n\"\n",
|
| 232 |
+
"\n",
|
| 233 |
+
" f.write(new_data)\n",
|
| 234 |
+
"\n",
|
| 235 |
+
"\n",
|
| 236 |
+
"def load_dataset(train_path, test_path, tokenizer):\n",
|
| 237 |
+
" \"\"\"Creates train and test PyTorch datasets and collate_fn using HuggingFace.\n",
|
| 238 |
+
"\n",
|
| 239 |
+
" Parameters\n",
|
| 240 |
+
" ----------\n",
|
| 241 |
+
" train_path: str\n",
|
| 242 |
+
" String containing path to train data\n",
|
| 243 |
+
" \n",
|
| 244 |
+
" test_path: str\n",
|
| 245 |
+
" String containing path to test data\n",
|
| 246 |
+
"\n",
|
| 247 |
+
" tokenizer: HuggingFace tokenizer \n",
|
| 248 |
+
" Tokenizer that used to compute the length of the text after encoding.\n",
|
| 249 |
+
" For more info ee https://huggingface.co/transformers/main_classes/tokenizer.html\n",
|
| 250 |
+
" \"\"\"\n",
|
| 251 |
+
" train_dataset = TextDataset(\n",
|
| 252 |
+
" tokenizer = tokenizer,\n",
|
| 253 |
+
" file_path = train_path,\n",
|
| 254 |
+
" block_size = 256)\n",
|
| 255 |
+
" \n",
|
| 256 |
+
" test_dataset = TextDataset(\n",
|
| 257 |
+
" tokenizer = tokenizer,\n",
|
| 258 |
+
" file_path = test_path,\n",
|
| 259 |
+
" block_size = 256) \n",
|
| 260 |
+
" \n",
|
| 261 |
+
" data_collator = DataCollatorForLanguageModeling(\n",
|
| 262 |
+
" tokenizer=tokenizer, mlm=False\n",
|
| 263 |
+
" )\n",
|
| 264 |
+
" return train_dataset, test_dataset, data_collator"
|
| 265 |
+
],
|
| 266 |
+
"execution_count": null,
|
| 267 |
+
"outputs": []
|
| 268 |
+
},
|
| 269 |
+
{
|
| 270 |
+
"cell_type": "markdown",
|
| 271 |
+
"metadata": {
|
| 272 |
+
"id": "wS5aTe48GF_N"
|
| 273 |
+
},
|
| 274 |
+
"source": [
|
| 275 |
+
"1) Export your telegram chat\n",
|
| 276 |
+
"\n",
|
| 277 |
+
"\n",
|
| 278 |
+
"\n",
|
| 279 |
+
"2) Upload it to colab\n",
|
| 280 |
+
"\n",
|
| 281 |
+
"\n",
|
| 282 |
+
"\n",
|
| 283 |
+
"3) Next cell creates train and test set from it\n",
|
| 284 |
+
"\n",
|
| 285 |
+
"4) :tada:"
|
| 286 |
+
]
|
| 287 |
+
},
|
| 288 |
+
{
|
| 289 |
+
"cell_type": "code",
|
| 290 |
+
"metadata": {
|
| 291 |
+
"id": "19JKNqTS2Nu7",
|
| 292 |
+
"cellView": "form"
|
| 293 |
+
},
|
| 294 |
+
"source": [
|
| 295 |
+
"#@markdown Your telegram chat json path 'ChatExport.../YourChatName.json':\n",
|
| 296 |
+
"path_to_telegram_chat_json = 'example: /content/drive/MyDrive/char27.json' #@param {type : \"string\"}\n",
|
| 297 |
+
"#@markdown Name of the user to predict by GPT-3:\n",
|
| 298 |
+
"machine_name_in_chat = 'example: Kirill Gelvan' #@param {type : \"string\"}\n",
|
| 299 |
+
"\n",
|
| 300 |
+
"\n",
|
| 301 |
+
"with open(path_to_telegram_chat_json) as f: data = json.load(f)['messages']\n",
|
| 302 |
+
"\n",
|
| 303 |
+
"# test data is first 10% of chat, train - last 90%\n",
|
| 304 |
+
"train, test = data[int(len(data)*0.1):], data[:int(len(data)*0.1)]\n",
|
| 305 |
+
"\n",
|
| 306 |
+
"build_text_file(train, 'train_dataset.txt', tokenizer)\n",
|
| 307 |
+
"build_text_file(test, 'test_dataset.txt', tokenizer)\n",
|
| 308 |
+
"\n",
|
| 309 |
+
"print(\"Train dataset length: \" + str(len(train)) + \"samples\")\n",
|
| 310 |
+
"print(\"Test dataset length: \" + str(len(test)) + \"samples\")"
|
| 311 |
+
],
|
| 312 |
+
"execution_count": null,
|
| 313 |
+
"outputs": []
|
| 314 |
+
},
|
| 315 |
+
{
|
| 316 |
+
"cell_type": "code",
|
| 317 |
+
"metadata": {
|
| 318 |
+
"id": "qO1-aAHF6TxB"
|
| 319 |
+
},
|
| 320 |
+
"source": [
|
| 321 |
+
"# let's look at our data\n",
|
| 322 |
+
"! head -n 10 train_dataset.txt"
|
| 323 |
+
],
|
| 324 |
+
"execution_count": null,
|
| 325 |
+
"outputs": []
|
| 326 |
+
},
|
| 327 |
+
{
|
| 328 |
+
"cell_type": "markdown",
|
| 329 |
+
"metadata": {
|
| 330 |
+
"id": "J6dMhVaeIO8x"
|
| 331 |
+
},
|
| 332 |
+
"source": [
|
| 333 |
+
"Here the first number is the spearker number - '1' for GPT and '0' for the person. \n",
|
| 334 |
+
"\n",
|
| 335 |
+
"The second number is the lengths of the expected answer: '1' for short, '2' for medium, '3' for long texts and '-' for all others. \n"
|
| 336 |
+
]
|
| 337 |
+
},
|
| 338 |
+
{
|
| 339 |
+
"cell_type": "code",
|
| 340 |
+
"metadata": {
|
| 341 |
+
"id": "-ty6A-qTzhya"
|
| 342 |
+
},
|
| 343 |
+
"source": [
|
| 344 |
+
"# Create PyTorch Datasets\n",
|
| 345 |
+
"train_dataset, test_dataset, data_collator = load_dataset('train_dataset.txt', 'test_dataset.txt', tokenizer)\n",
|
| 346 |
+
"\n",
|
| 347 |
+
"# Create PyTorch Dataloaders\n",
|
| 348 |
+
"train_loader = DataLoader(train_dataset, shuffle=True, batch_size=2, collate_fn=data_collator)\n",
|
| 349 |
+
"test_loader = DataLoader(test_dataset, batch_size=2, collate_fn=data_collator)"
|
| 350 |
+
],
|
| 351 |
+
"execution_count": null,
|
| 352 |
+
"outputs": []
|
| 353 |
+
},
|
| 354 |
+
{
|
| 355 |
+
"cell_type": "code",
|
| 356 |
+
"metadata": {
|
| 357 |
+
"id": "NWhfc7ElAbkY"
|
| 358 |
+
},
|
| 359 |
+
"source": [
|
| 360 |
+
"# this cell checks 1 forward pass\n",
|
| 361 |
+
"try:\n",
|
| 362 |
+
" for batch in train_loader:\n",
|
| 363 |
+
" break\n",
|
| 364 |
+
" {k: v.shape for k, v in batch.items()}\n",
|
| 365 |
+
"\n",
|
| 366 |
+
" outputs = model(**batch)\n",
|
| 367 |
+
"except:\n",
|
| 368 |
+
" print(\"Unexpected error:\", sys.exc_info()[0])\n",
|
| 369 |
+
" raise"
|
| 370 |
+
],
|
| 371 |
+
"execution_count": null,
|
| 372 |
+
"outputs": []
|
| 373 |
+
},
|
| 374 |
+
{
|
| 375 |
+
"cell_type": "markdown",
|
| 376 |
+
"metadata": {
|
| 377 |
+
"id": "ESogNuUOEmj_"
|
| 378 |
+
},
|
| 379 |
+
"source": [
|
| 380 |
+
"## Fine-tuning"
|
| 381 |
+
]
|
| 382 |
+
},
|
| 383 |
+
{
|
| 384 |
+
"cell_type": "code",
|
| 385 |
+
"metadata": {
|
| 386 |
+
"id": "mZBWIviea2-Y",
|
| 387 |
+
"cellView": "form"
|
| 388 |
+
},
|
| 389 |
+
"source": [
|
| 390 |
+
"#@title Fine-tuning params\n",
|
| 391 |
+
"num_epochs = 3 #@param {type:\"integer\"}\n",
|
| 392 |
+
"optimizer = AdamW(model.parameters(), lr=3e-5) #@param\n",
|
| 393 |
+
"save_checkpoint_path = 'exmaple: drive/MyDrive/GPT2_checkpoint-more-data-2ep.pt' #@param {type:\"string\"}\n",
|
| 394 |
+
"\n",
|
| 395 |
+
"\n",
|
| 396 |
+
"num_training_steps = num_epochs * len(train_dataset)\n",
|
| 397 |
+
"lr_scheduler = get_scheduler(\n",
|
| 398 |
+
" \"linear\",\n",
|
| 399 |
+
" optimizer=optimizer,\n",
|
| 400 |
+
" num_warmup_steps=100,\n",
|
| 401 |
+
" num_training_steps=num_training_steps\n",
|
| 402 |
+
")\n",
|
| 403 |
+
"\n",
|
| 404 |
+
"accelerator = Accelerator()\n",
|
| 405 |
+
"train_dl, test_dl, model, optimizer = accelerator.prepare(\n",
|
| 406 |
+
" train_loader, test_loader, model, optimizer\n",
|
| 407 |
+
")\n",
|
| 408 |
+
"# wandb.watch(model, log=\"all\")"
|
| 409 |
+
],
|
| 410 |
+
"execution_count": null,
|
| 411 |
+
"outputs": []
|
| 412 |
+
},
|
| 413 |
+
{
|
| 414 |
+
"cell_type": "code",
|
| 415 |
+
"metadata": {
|
| 416 |
+
"id": "rEV3EcZOCOhw"
|
| 417 |
+
},
|
| 418 |
+
"source": [
|
| 419 |
+
"progress_bar = tqdm(range(num_training_steps))\n",
|
| 420 |
+
"\n",
|
| 421 |
+
"for epoch in range(num_epochs):\n",
|
| 422 |
+
" \n",
|
| 423 |
+
" ### TRAIN EPOCH\n",
|
| 424 |
+
" model.train()\n",
|
| 425 |
+
" for batch in train_dl:\n",
|
| 426 |
+
" optimizer.zero_grad()\n",
|
| 427 |
+
" outputs = model(**batch)\n",
|
| 428 |
+
" loss = outputs.loss\n",
|
| 429 |
+
" accelerator.backward(loss)\n",
|
| 430 |
+
" \n",
|
| 431 |
+
" # wandb.log({'train_loss':loss.item()})\n",
|
| 432 |
+
" optimizer.step()\n",
|
| 433 |
+
" lr_scheduler.step()\n",
|
| 434 |
+
" progress_bar.update(1)\n",
|
| 435 |
+
"\n",
|
| 436 |
+
" ### SAVE\n",
|
| 437 |
+
" torch.save({\n",
|
| 438 |
+
" 'model_state_dict': model.state_dict(),\n",
|
| 439 |
+
" }, save_checkpoint_path)\n",
|
| 440 |
+
" \n",
|
| 441 |
+
" ### VALIDATE ONCE\n",
|
| 442 |
+
" cum_loss = 0\n",
|
| 443 |
+
" model.eval()\n",
|
| 444 |
+
" with torch.inference_mode():\n",
|
| 445 |
+
" for batch in test_dl:\n",
|
| 446 |
+
" outputs = model(**batch)\n",
|
| 447 |
+
" cum_loss += float(outputs.loss.item())\n",
|
| 448 |
+
" \n",
|
| 449 |
+
" print(cum_loss/len(test_loader))\n",
|
| 450 |
+
" # wandb.log({'val_mean_loss':cum_loss/len(test_loader)})"
|
| 451 |
+
],
|
| 452 |
+
"execution_count": null,
|
| 453 |
+
"outputs": []
|
| 454 |
+
},
|
| 455 |
+
{
|
| 456 |
+
"cell_type": "markdown",
|
| 457 |
+
"metadata": {
|
| 458 |
+
"id": "psXZnJk0Eo3J"
|
| 459 |
+
},
|
| 460 |
+
"source": [
|
| 461 |
+
"## Inference"
|
| 462 |
+
]
|
| 463 |
+
},
|
| 464 |
+
{
|
| 465 |
+
"cell_type": "code",
|
| 466 |
+
"metadata": {
|
| 467 |
+
"cellView": "form",
|
| 468 |
+
"id": "3N13Nwd1axA4"
|
| 469 |
+
},
|
| 470 |
+
"source": [
|
| 471 |
+
"#@title Installs and Utility functions\n",
|
| 472 |
+
"\n",
|
| 473 |
+
"%%capture\n",
|
| 474 |
+
"# installing huggingface datasets and accelerate \n",
|
| 475 |
+
"! pip install datasets transformers[sentencepiece]\n",
|
| 476 |
+
"! pip install accelerate\n",
|
| 477 |
+
"\n",
|
| 478 |
+
"def get_length_param(text: str, tokenizer) -> str:\n",
|
| 479 |
+
" \"\"\"Maps text to 1 of 4 buckets based on length after encoding.\n",
|
| 480 |
+
"\n",
|
| 481 |
+
" Parameters\n",
|
| 482 |
+
" ----------\n",
|
| 483 |
+
" text: str\n",
|
| 484 |
+
" The text to be given 1 of 4 length parameters.\n",
|
| 485 |
+
"\n",
|
| 486 |
+
" tokenizer: HuggingFace tokenizer \n",
|
| 487 |
+
" Tokenizer that used to compute the length of the text after encoding.\n",
|
| 488 |
+
" For more info ee https://huggingface.co/transformers/main_classes/tokenizer.html\n",
|
| 489 |
+
"\n",
|
| 490 |
+
" Returns\n",
|
| 491 |
+
" -------\n",
|
| 492 |
+
" len_param: str\n",
|
| 493 |
+
" One of four buckets: \n",
|
| 494 |
+
" '1' for short, '2' for medium, '3' for long texts and '-' for all others. \n",
|
| 495 |
+
" \"\"\"\n",
|
| 496 |
+
" tokens_count = len(tokenizer.encode(text))\n",
|
| 497 |
+
" if tokens_count <= 15:\n",
|
| 498 |
+
" len_param = '1'\n",
|
| 499 |
+
" elif tokens_count <= 50:\n",
|
| 500 |
+
" len_param = '2'\n",
|
| 501 |
+
" elif tokens_count <= 256:\n",
|
| 502 |
+
" len_param = '3'\n",
|
| 503 |
+
" else:\n",
|
| 504 |
+
" len_param = '-'\n",
|
| 505 |
+
" return len_param\n",
|
| 506 |
+
"\n",
|
| 507 |
+
"\n",
|
| 508 |
+
"def get_user_param(text: dict, machine_name_in_chat: str) -> str:\n",
|
| 509 |
+
" \"\"\"Maps text by 1/0 for it to be the person or the machine in the dialogue\n",
|
| 510 |
+
"\n",
|
| 511 |
+
" Parameters\n",
|
| 512 |
+
" ----------\n",
|
| 513 |
+
" text: Dict[..., 'from', ...]\n",
|
| 514 |
+
" Dict containing field 'from' with the name of the user who sent the message\n",
|
| 515 |
+
"\n",
|
| 516 |
+
" machine_name_in_chat: str\n",
|
| 517 |
+
" Str with the name of the machine - it will be predicted\n",
|
| 518 |
+
" \"\"\"\n",
|
| 519 |
+
" if text['from'] == machine_name_in_chat:\n",
|
| 520 |
+
" return '1' # machine\n",
|
| 521 |
+
" else:\n",
|
| 522 |
+
" return '0' # human\n",
|
| 523 |
+
"\n",
|
| 524 |
+
"\n",
|
| 525 |
+
"def build_text_file(data_json: dict, dest_path: str, \n",
|
| 526 |
+
" tokenizer, machine_name_in_chat='Кирилл Гельван'):\n",
|
| 527 |
+
" \"\"\"Create a text file for training in special format for ruDialoGPT-3.\n",
|
| 528 |
+
"\n",
|
| 529 |
+
" Parameters\n",
|
| 530 |
+
" ----------\n",
|
| 531 |
+
" data_json: dict\n",
|
| 532 |
+
" Dict containing 'text' (message) and 'from' (user who sent the message)\n",
|
| 533 |
+
" \n",
|
| 534 |
+
" dest_path: str\n",
|
| 535 |
+
" String containing path to write data there\n",
|
| 536 |
+
"\n",
|
| 537 |
+
" tokenizer: HuggingFace tokenizer \n",
|
| 538 |
+
" Tokenizer that used to compute the length of the text after encoding.\n",
|
| 539 |
+
" For more info ee https://huggingface.co/transformers/main_classes/tokenizer.html\n",
|
| 540 |
+
" \"\"\"\n",
|
| 541 |
+
" f = open(dest_path, 'w')\n",
|
| 542 |
+
" new_data = ''\n",
|
| 543 |
+
" for i in range(len(data_json) - 1):\n",
|
| 544 |
+
" message, next_message = data_json[i], data_json[i+1]\n",
|
| 545 |
+
" if message['text'] == '' or type(message['text']) != str:\n",
|
| 546 |
+
" continue\n",
|
| 547 |
+
" if next_message['text'] == '' or type(next_message['text']) != str:\n",
|
| 548 |
+
" continue\n",
|
| 549 |
+
"\n",
|
| 550 |
+
" user = get_user_param(message, machine_name_in_chat=machine_name_in_chat)\n",
|
| 551 |
+
" length = get_length_param(data_json[i+1]['text'], tokenizer)\n",
|
| 552 |
+
" message_text = re.sub(r\"\\n\", \". \", message['text'])\n",
|
| 553 |
+
" new_data += f\"|{user}|{length}|{message_text}{tokenizer.eos_token}\" + \"\\n\"\n",
|
| 554 |
+
"\n",
|
| 555 |
+
" f.write(new_data)\n",
|
| 556 |
+
"\n",
|
| 557 |
+
"\n",
|
| 558 |
+
"def load_dataset(train_path, test_path, tokenizer):\n",
|
| 559 |
+
" \"\"\"Creates train and test PyTorch datasets and collate_fn using HuggingFace.\n",
|
| 560 |
+
"\n",
|
| 561 |
+
" Parameters\n",
|
| 562 |
+
" ----------\n",
|
| 563 |
+
" train_path: str\n",
|
| 564 |
+
" String containing path to train data\n",
|
| 565 |
+
" \n",
|
| 566 |
+
" test_path: str\n",
|
| 567 |
+
" String containing path to test data\n",
|
| 568 |
+
"\n",
|
| 569 |
+
" tokenizer: HuggingFace tokenizer \n",
|
| 570 |
+
" Tokenizer that used to compute the length of the text after encoding.\n",
|
| 571 |
+
" For more info ee https://huggingface.co/transformers/main_classes/tokenizer.html\n",
|
| 572 |
+
" \"\"\"\n",
|
| 573 |
+
" train_dataset = TextDataset(\n",
|
| 574 |
+
" tokenizer = tokenizer,\n",
|
| 575 |
+
" file_path = train_path,\n",
|
| 576 |
+
" block_size = 256)\n",
|
| 577 |
+
" \n",
|
| 578 |
+
" test_dataset = TextDataset(\n",
|
| 579 |
+
" tokenizer = tokenizer,\n",
|
| 580 |
+
" file_path = test_path,\n",
|
| 581 |
+
" block_size = 256) \n",
|
| 582 |
+
" \n",
|
| 583 |
+
" data_collator = DataCollatorForLanguageModeling(\n",
|
| 584 |
+
" tokenizer=tokenizer, mlm=False\n",
|
| 585 |
+
" )\n",
|
| 586 |
+
" return train_dataset, test_dataset, data_collator"
|
| 587 |
+
],
|
| 588 |
+
"execution_count": null,
|
| 589 |
+
"outputs": []
|
| 590 |
+
},
|
| 591 |
+
{
|
| 592 |
+
"cell_type": "code",
|
| 593 |
+
"metadata": {
|
| 594 |
+
"id": "vvsSRglEA0kt"
|
| 595 |
+
},
|
| 596 |
+
"source": [
|
| 597 |
+
"import torch\n",
|
| 598 |
+
"from transformers import AutoModelForCausalLM, AutoTokenizer\n",
|
| 599 |
+
"\n",
|
| 600 |
+
"# Download checkpoint:\n",
|
| 601 |
+
"checkpoint = \"Kirili4ik/ruDialoGpt3-medium-finetuned-telegram\" \n",
|
| 602 |
+
"tokenizer = AutoTokenizer.from_pretrained(checkpoint)\n",
|
| 603 |
+
"model = AutoModelForCausalLM.from_pretrained(checkpoint)\n",
|
| 604 |
+
"\n",
|
| 605 |
+
"# [optional] Insert your checkpoint if needed:\n",
|
| 606 |
+
"'''from google.colab import drive\n",
|
| 607 |
+
"drive.mount('/content/drive')\n",
|
| 608 |
+
"checkpoint = torch.load('drive/MyDrive/GPT2_checkpoint.pt', map_location='cpu')\n",
|
| 609 |
+
"model.load_state_dict(checkpoint['model_state_dict'])'''\n",
|
| 610 |
+
"\n",
|
| 611 |
+
"model = model.to('cpu')\n",
|
| 612 |
+
"model.eval()\n",
|
| 613 |
+
"print()"
|
| 614 |
+
],
|
| 615 |
+
"execution_count": null,
|
| 616 |
+
"outputs": []
|
| 617 |
+
},
|
| 618 |
+
{
|
| 619 |
+
"cell_type": "code",
|
| 620 |
+
"metadata": {
|
| 621 |
+
"id": "MGdCxVnOhK_K"
|
| 622 |
+
},
|
| 623 |
+
"source": [
|
| 624 |
+
"### INFERENCE\n",
|
| 625 |
+
"\n",
|
| 626 |
+
"chat_history_ids = torch.zeros((1, 0), dtype=torch.int)\n",
|
| 627 |
+
"\n",
|
| 628 |
+
"while True:\n",
|
| 629 |
+
" \n",
|
| 630 |
+
" next_who = input(\"Who's phrase?\\t\") #input(\"H / G?\") # Human or GPT\n",
|
| 631 |
+
"\n",
|
| 632 |
+
" # In case Human\n",
|
| 633 |
+
" if next_who == \"H\":\n",
|
| 634 |
+
" input_user = input(\"===> Human: \")\n",
|
| 635 |
+
" \n",
|
| 636 |
+
" # encode the new user input, add parameters and return a tensor in Pytorch\n",
|
| 637 |
+
" new_user_input_ids = tokenizer.encode(f\"|0|{get_length_param(input_user, tokenizer)}|\" \\\n",
|
| 638 |
+
" + input_user + tokenizer.eos_token, return_tensors=\"pt\")\n",
|
| 639 |
+
" # append the new user input tokens to the chat history\n",
|
| 640 |
+
" chat_history_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1)\n",
|
| 641 |
+
"\n",
|
| 642 |
+
" if next_who == \"G\":\n",
|
| 643 |
+
"\n",
|
| 644 |
+
" next_len = input(\"Phrase len? 1/2/3/-\\t\") #input(\"Exp. len?(-/1/2/3): \")\n",
|
| 645 |
+
" # encode the new user input, add parameters and return a tensor in Pytorch\n",
|
| 646 |
+
" new_user_input_ids = tokenizer.encode(f\"|1|{next_len}|\", return_tensors=\"pt\")\n",
|
| 647 |
+
" # append the new user input tokens to the chat history\n",
|
| 648 |
+
" chat_history_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1)\n",
|
| 649 |
+
" \n",
|
| 650 |
+
" # print(tokenizer.decode(chat_history_ids[-1])) # uncomment to see full gpt input\n",
|
| 651 |
+
" \n",
|
| 652 |
+
" # save previous len\n",
|
| 653 |
+
" input_len = chat_history_ids.shape[-1]\n",
|
| 654 |
+
" # generated a response; PS you can read about the parameters at hf.co/blog/how-to-generate\n",
|
| 655 |
+
" chat_history_ids = model.generate(\n",
|
| 656 |
+
" chat_history_ids,\n",
|
| 657 |
+
" num_return_sequences=1, # use for more variants, but have to print [i]\n",
|
| 658 |
+
" max_length=512,\n",
|
| 659 |
+
" no_repeat_ngram_size=3,\n",
|
| 660 |
+
" do_sample=True,\n",
|
| 661 |
+
" top_k=50,\n",
|
| 662 |
+
" top_p=0.9,\n",
|
| 663 |
+
" temperature = 0.6, # 0 for greedy\n",
|
| 664 |
+
" mask_token_id=tokenizer.mask_token_id,\n",
|
| 665 |
+
" eos_token_id=tokenizer.eos_token_id,\n",
|
| 666 |
+
" unk_token_id=tokenizer.unk_token_id,\n",
|
| 667 |
+
" pad_token_id=tokenizer.pad_token_id,\n",
|
| 668 |
+
" device='cpu'\n",
|
| 669 |
+
" )\n",
|
| 670 |
+
" \n",
|
| 671 |
+
" # pretty print last ouput tokens from bot\n",
|
| 672 |
+
" print(f\"===> GPT-3: {tokenizer.decode(chat_history_ids[:, input_len:][0], skip_special_tokens=True)}\")"
|
| 673 |
+
],
|
| 674 |
+
"execution_count": null,
|
| 675 |
+
"outputs": []
|
| 676 |
+
},
|
| 677 |
+
{
|
| 678 |
+
"cell_type": "code",
|
| 679 |
+
"metadata": {
|
| 680 |
+
"id": "mjEQiv5TMjZW"
|
| 681 |
+
},
|
| 682 |
+
"source": [
|
| 683 |
+
""
|
| 684 |
+
],
|
| 685 |
+
"execution_count": null,
|
| 686 |
+
"outputs": []
|
| 687 |
+
}
|
| 688 |
+
]
|
| 689 |
+
}
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2021 Kirill Gelvan
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,37 +1,35 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
emoji: 🐨
|
| 4 |
-
colorFrom: pink
|
| 5 |
-
colorTo: indigo
|
| 6 |
-
sdk: gradio
|
| 7 |
-
app_file: app.py
|
| 8 |
-
pinned: false
|
| 9 |
-
---
|
| 10 |
|
| 11 |
-
|
| 12 |
|
| 13 |
-
|
| 14 |
-
Display title for the Space
|
| 15 |
|
| 16 |
-
`emoji`: _string_
|
| 17 |
-
Space emoji (emoji-only character allowed)
|
| 18 |
|
| 19 |
-
|
| 20 |
-
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
|
| 21 |
|
| 22 |
-
|
| 23 |
-
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
|
| 24 |
|
| 25 |
-
|
| 26 |
-
Can be either `gradio` or `streamlit`
|
| 27 |
|
| 28 |
-
|
| 29 |
-
Only applicable for `streamlit` SDK.
|
| 30 |
-
See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
|
| 31 |
|
| 32 |
-
|
| 33 |
-
Path to your main application file (which contains either `gradio` or `streamlit` Python code).
|
| 34 |
-
Path is relative to the root of the repository.
|
| 35 |
|
| 36 |
-
|
| 37 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ruDialoGpt3 colab for finetuning on telegram chat
|
| 2 |
+
This is a ready-for-use-colab tutorial for finetuning ruDialoGpt3 model on your telegram chat using HuggingFace and PyTorch.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
|
| 4 |
+
- 🤗 [Model page](https://huggingface.co/Kirili4ik/ruDialoGpt3-medium-finetuned-telegram)
|
| 5 |
|
| 6 |
+
- [](https://colab.research.google.com/drive/1fnAVURjyZRK9VQg1Co_-SKUQnRES8l9R?usp=sharing) Colab tutorial
|
|
|
|
| 7 |
|
|
|
|
|
|
|
| 8 |
|
| 9 |
+
I used RuDialoGPT-3 trained on forums to fine tune. It was trained by [@Grossmend](https://github.com/Grossmend) on Russian forums. The training procedure of the model for dialogue is described in Grossmend's [blogpost](https://habr.com/ru/company/icl_services/blog/548244/) (in Russian). **I have created a simple pipeline and fine tuned that model on my own exported telegram chat (~30mb json, 3 hours of fine tuning**). It is in fact very easy to get the data from telegram and fine tune a model:
|
|
|
|
| 10 |
|
| 11 |
+
1) Export your telegram chat as JSON
|
|
|
|
| 12 |
|
| 13 |
+

|
|
|
|
| 14 |
|
| 15 |
+
2) Upload it to colab
|
|
|
|
|
|
|
| 16 |
|
| 17 |
+

|
|
|
|
|
|
|
| 18 |
|
| 19 |
+
3) The code will create a dataset for you
|
| 20 |
+
|
| 21 |
+
4) Wait a bit!
|
| 22 |
+
|
| 23 |
+
5) :tada: (Inference and smile)
|
| 24 |
+
|
| 25 |
+
Or you can just go to google colab and play with my finetuned model!:
|
| 26 |
+
|
| 27 |
+
<details>
|
| 28 |
+
<summary><b>A couple of dialogue samples:</b>
|
| 29 |
+
</summary>
|
| 30 |
+
<img src="https://raw.githubusercontent.com/Kirili4ik/ruDialoGpt3-finetune-colab/main/sample1.jpg">
|
| 31 |
+
<img src="https://raw.githubusercontent.com/Kirili4ik/ruDialoGpt3-finetune-colab/main/sample2.jpg">
|
| 32 |
+
</details>
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
[](https://colab.research.google.com/drive/1fnAVURjyZRK9VQg1Co_-SKUQnRES8l9R?usp=sharing#scrollTo=psXZnJk0Eo3J) Inference part
|
app.py
ADDED
|
@@ -0,0 +1,242 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import gradio as gr
|
| 3 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def get_length_param(text: str, tokenizer) -> str:
|
| 7 |
+
"""Maps text to 1 of 4 buckets based on length after encoding.
|
| 8 |
+
|
| 9 |
+
Parameters
|
| 10 |
+
----------
|
| 11 |
+
text: str
|
| 12 |
+
The text to be given 1 of 4 length parameters.
|
| 13 |
+
|
| 14 |
+
tokenizer: HuggingFace tokenizer
|
| 15 |
+
Tokenizer that used to compute the length of the text after encoding.
|
| 16 |
+
For more info ee https://huggingface.co/transformers/main_classes/tokenizer.html
|
| 17 |
+
|
| 18 |
+
Returns
|
| 19 |
+
-------
|
| 20 |
+
len_param: str
|
| 21 |
+
One of four buckets:
|
| 22 |
+
'1' for short, '2' for medium, '3' for long texts and '-' for all others.
|
| 23 |
+
"""
|
| 24 |
+
tokens_count = len(tokenizer.encode(text))
|
| 25 |
+
if tokens_count <= 15:
|
| 26 |
+
len_param = '1'
|
| 27 |
+
elif tokens_count <= 50:
|
| 28 |
+
len_param = '2'
|
| 29 |
+
elif tokens_count <= 256:
|
| 30 |
+
len_param = '3'
|
| 31 |
+
else:
|
| 32 |
+
len_param = '-'
|
| 33 |
+
return len_param
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def get_user_param(text: dict, machine_name_in_chat: str) -> str:
|
| 37 |
+
"""Maps text by 1/0 for it to be the person or the machine in the dialogue
|
| 38 |
+
|
| 39 |
+
Parameters
|
| 40 |
+
----------
|
| 41 |
+
text: Dict[..., 'from', ...]
|
| 42 |
+
Dict containing field 'from' with the name of the user who sent the message
|
| 43 |
+
|
| 44 |
+
machine_name_in_chat: str
|
| 45 |
+
Str with the name of the machine - it will be predicted
|
| 46 |
+
"""
|
| 47 |
+
if text['from'] == machine_name_in_chat:
|
| 48 |
+
return '1' # machine
|
| 49 |
+
else:
|
| 50 |
+
return '0' # human
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def build_text_file(data_json: dict, dest_path: str,
|
| 54 |
+
tokenizer, machine_name_in_chat='Кирилл Гельван'):
|
| 55 |
+
"""Create a text file for training in special format for ruDialoGPT-3.
|
| 56 |
+
|
| 57 |
+
Parameters
|
| 58 |
+
----------
|
| 59 |
+
data_json: dict
|
| 60 |
+
Dict containing 'text' (message) and 'from' (user who sent the message)
|
| 61 |
+
|
| 62 |
+
dest_path: str
|
| 63 |
+
String containing path to write data there
|
| 64 |
+
|
| 65 |
+
tokenizer: HuggingFace tokenizer
|
| 66 |
+
Tokenizer that used to compute the length of the text after encoding.
|
| 67 |
+
For more info ee https://huggingface.co/transformers/main_classes/tokenizer.html
|
| 68 |
+
"""
|
| 69 |
+
f = open(dest_path, 'w')
|
| 70 |
+
new_data = ''
|
| 71 |
+
for i in range(len(data_json) - 1):
|
| 72 |
+
message, next_message = data_json[i], data_json[i+1]
|
| 73 |
+
if message['text'] == '' or type(message['text']) != str:
|
| 74 |
+
continue
|
| 75 |
+
if next_message['text'] == '' or type(next_message['text']) != str:
|
| 76 |
+
continue
|
| 77 |
+
|
| 78 |
+
user = get_user_param(message, machine_name_in_chat=machine_name_in_chat)
|
| 79 |
+
length = get_length_param(data_json[i+1]['text'], tokenizer)
|
| 80 |
+
message_text = re.sub(r"\n", ". ", message['text'])
|
| 81 |
+
new_data += f"|{user}|{length}|{message_text}{tokenizer.eos_token}" + "\n"
|
| 82 |
+
|
| 83 |
+
f.write(new_data)
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
def load_dataset(train_path, test_path, tokenizer):
|
| 87 |
+
"""Creates train and test PyTorch datasets and collate_fn using HuggingFace.
|
| 88 |
+
|
| 89 |
+
Parameters
|
| 90 |
+
----------
|
| 91 |
+
train_path: str
|
| 92 |
+
String containing path to train data
|
| 93 |
+
|
| 94 |
+
test_path: str
|
| 95 |
+
String containing path to test data
|
| 96 |
+
|
| 97 |
+
tokenizer: HuggingFace tokenizer
|
| 98 |
+
Tokenizer that used to compute the length of the text after encoding.
|
| 99 |
+
For more info ee https://huggingface.co/transformers/main_classes/tokenizer.html
|
| 100 |
+
"""
|
| 101 |
+
train_dataset = TextDataset(
|
| 102 |
+
tokenizer = tokenizer,
|
| 103 |
+
file_path = train_path,
|
| 104 |
+
block_size = 256)
|
| 105 |
+
|
| 106 |
+
test_dataset = TextDataset(
|
| 107 |
+
tokenizer = tokenizer,
|
| 108 |
+
file_path = test_path,
|
| 109 |
+
block_size = 256)
|
| 110 |
+
|
| 111 |
+
data_collator = DataCollatorForLanguageModeling(
|
| 112 |
+
tokenizer=tokenizer, mlm=False
|
| 113 |
+
)
|
| 114 |
+
return train_dataset, test_dataset, data_collator
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def chat_function(message, length_of_the_answer, who_is_next, creativity): # model, tokenizer
|
| 118 |
+
|
| 119 |
+
input_user = message
|
| 120 |
+
|
| 121 |
+
if length_of_the_answer == 'short':
|
| 122 |
+
next_len = '1'
|
| 123 |
+
elif length_of_the_answer == 'medium':
|
| 124 |
+
next_len = '2'
|
| 125 |
+
elif length_of_the_answer == 'long':
|
| 126 |
+
next_len = '3'
|
| 127 |
+
else:
|
| 128 |
+
next_len = '-'
|
| 129 |
+
|
| 130 |
+
print(who_is_next)
|
| 131 |
+
if who_is_next == 'Kirill':
|
| 132 |
+
next_who = 'G'
|
| 133 |
+
elif who_is_next == 'Me':
|
| 134 |
+
next_who = 'H'
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
history = gr.get_state() or []
|
| 139 |
+
chat_history_ids = torch.zeros((1, 0), dtype=torch.int) if history == [] else torch.tensor(history[-1][2], dtype=torch.long)
|
| 140 |
+
|
| 141 |
+
######### next_who = input("Who's phrase?\t") #input("H / G?") # Human or GPT
|
| 142 |
+
|
| 143 |
+
# In case Human
|
| 144 |
+
##### if next_who == "H":
|
| 145 |
+
|
| 146 |
+
######## input_user = input("===> Human: ")
|
| 147 |
+
# encode the new user input, add parameters and return a tensor in Pytorch
|
| 148 |
+
if len(input_user) != 0:
|
| 149 |
+
|
| 150 |
+
new_user_input_ids = tokenizer.encode(f"|0|{get_length_param(input_user, tokenizer)}|" \
|
| 151 |
+
+ input_user + tokenizer.eos_token, return_tensors="pt")
|
| 152 |
+
# append the new user input tokens to the chat history
|
| 153 |
+
chat_history_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1)
|
| 154 |
+
else:
|
| 155 |
+
input_user = '-'
|
| 156 |
+
|
| 157 |
+
if next_who == "G":
|
| 158 |
+
|
| 159 |
+
######## next_len = input("Phrase len? 1/2/3/-\t") #input("Exp. len?(-/1/2/3): ")
|
| 160 |
+
# encode the new user input, add parameters and return a tensor in Pytorch
|
| 161 |
+
new_user_input_ids = tokenizer.encode(f"|1|{next_len}|", return_tensors="pt")
|
| 162 |
+
# append the new user input tokens to the chat history
|
| 163 |
+
chat_history_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1)
|
| 164 |
+
|
| 165 |
+
print(tokenizer.decode(chat_history_ids[-1])) # uncomment to see full gpt input
|
| 166 |
+
|
| 167 |
+
# save previous len
|
| 168 |
+
input_len = chat_history_ids.shape[-1]
|
| 169 |
+
# generated a response; PS you can read about the parameters at hf.co/blog/how-to-generate
|
| 170 |
+
chat_history_ids = model.generate(
|
| 171 |
+
chat_history_ids,
|
| 172 |
+
num_return_sequences=1, # use for more variants, but have to print [i]
|
| 173 |
+
max_length=512,
|
| 174 |
+
no_repeat_ngram_size=3,
|
| 175 |
+
do_sample=True,
|
| 176 |
+
top_k=50,
|
| 177 |
+
top_p=0.9,
|
| 178 |
+
temperature = float(creativity), # 0 for greedy
|
| 179 |
+
mask_token_id=tokenizer.mask_token_id,
|
| 180 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 181 |
+
unk_token_id=tokenizer.unk_token_id,
|
| 182 |
+
pad_token_id=tokenizer.pad_token_id,
|
| 183 |
+
device='cpu'
|
| 184 |
+
)
|
| 185 |
+
|
| 186 |
+
response = tokenizer.decode(chat_history_ids[:, input_len:][0], skip_special_tokens=True)
|
| 187 |
+
else:
|
| 188 |
+
response = '-'
|
| 189 |
+
|
| 190 |
+
history.append((input_user, response, chat_history_ids.tolist()))
|
| 191 |
+
gr.set_state(history)
|
| 192 |
+
|
| 193 |
+
html = "<div class='chatbot'>"
|
| 194 |
+
for user_msg, resp_msg, _ in history:
|
| 195 |
+
if user_msg != '-':
|
| 196 |
+
html += f"<div class='user_msg'>{user_msg}</div>"
|
| 197 |
+
if resp_msg != '-':
|
| 198 |
+
html += f"<div class='resp_msg'>{resp_msg}</div>"
|
| 199 |
+
html += "</div>"
|
| 200 |
+
return html
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
# Download checkpoint:
|
| 205 |
+
checkpoint = "Kirili4ik/ruDialoGpt3-medium-finetuned-telegram"
|
| 206 |
+
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
|
| 207 |
+
model = AutoModelForCausalLM.from_pretrained(checkpoint)
|
| 208 |
+
model = model.eval()
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
checkbox_group = gr.inputs.CheckboxGroup(['Kirill', 'Me'], default=['Kirill'], type="value", label=None)
|
| 212 |
+
|
| 213 |
+
inputs = gr.inputs.Textbox(lines=1, label="???")
|
| 214 |
+
outputs = gr.outputs.Textbox(label="Kirill (GPT-2):")
|
| 215 |
+
title = "Chat with Kirill (in Russian)"
|
| 216 |
+
description = "Тут можно поболтать со мной. Но вместо меня бот. Оставь message пустым, чтобы Кирилл продолжил говорить. Подбробнее о технике по ссылке внизу."
|
| 217 |
+
article = "<p style='text-align: center'><a href='https://github.com/Kirili4ik/ruDialoGpt3-finetune-colab'>Github with fine-tuning GPT-2 on your chat</a></p>"
|
| 218 |
+
examples = [
|
| 219 |
+
["Привет, как дела?", 'medium', 'Kirill', 0.6],
|
| 220 |
+
["Сколько тебе лет?", 'medium', 'Kirill', 0.3],
|
| 221 |
+
]
|
| 222 |
+
|
| 223 |
+
iface = gr.Interface(chat_function,
|
| 224 |
+
[
|
| 225 |
+
"text",
|
| 226 |
+
gr.inputs.Radio(["short", "medium", "long"], default='medium'),
|
| 227 |
+
gr.inputs.Radio(["Kirill", "Me"], default='Kirill'),
|
| 228 |
+
gr.inputs.Slider(0, 1, default=0.6)
|
| 229 |
+
],
|
| 230 |
+
"html",
|
| 231 |
+
title=title, description=description, article=article, examples=examples,
|
| 232 |
+
css= """
|
| 233 |
+
.chatbox {display:flex;flex-direction:column}
|
| 234 |
+
.user_msg, .resp_msg {padding:4px;margin-bottom:4px;border-radius:4px;width:80%}
|
| 235 |
+
.user_msg {background-color:cornflowerblue;color:white;align-self:start}
|
| 236 |
+
.resp_msg {background-color:lightgray;align-self:self-end}
|
| 237 |
+
""",
|
| 238 |
+
allow_screenshot=True,
|
| 239 |
+
allow_flagging=False
|
| 240 |
+
)
|
| 241 |
+
|
| 242 |
+
iface.launch()
|
how-to-export-chat.jpg
ADDED
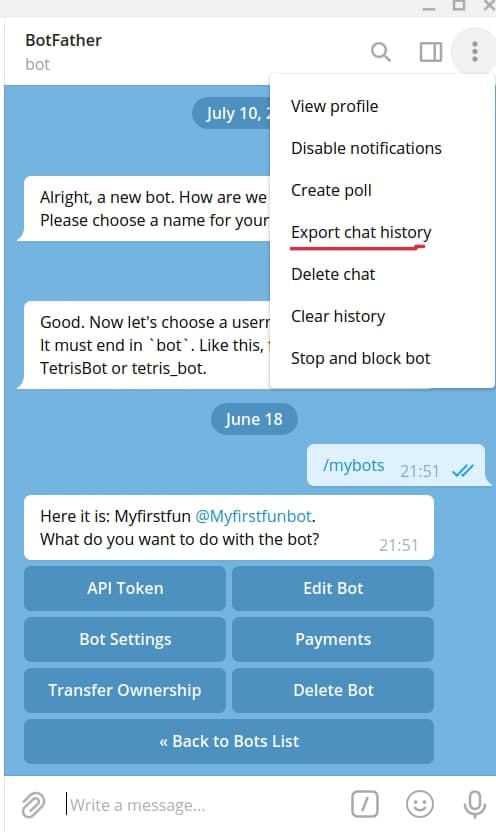
|
how-to-upload-json.jpg
ADDED
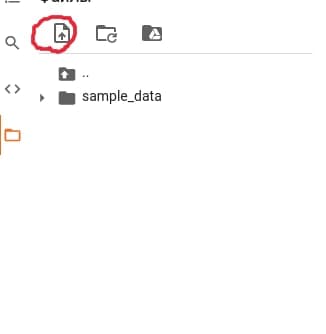
|
requirements.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
transformers
|
| 2 |
+
torch
|
sample1.jpg
ADDED

|
sample2.jpg
ADDED

|