
endpoint only, no UI
Browse files- Dockerfile +1 -1
- app/engine/chunk_embed.py +1 -1
- app/engine/loaders/file.py +49 -6
- app/engine/logger.py +14 -8
- app/engine/post_process.py +74 -0
- app/engine/processing.py +113 -17
- app/engine/summary.py +53 -0
- app/engine/vectorstore.py +138 -37
- app/main_reflex.py +246 -0
- app/notebooks/upload_index.ipynb +0 -0
- app/rag/rag.py +1 -1
- app/settings.py +3 -1
- assets/IO_logo.webp +0 -0
- assets/OI_logo.jpg +0 -0
- assets/amazon_forecast.jpg +0 -0
- assets/amazon_idiot.jpg +0 -0
- assets/favicon.ico +0 -0
- assets/homepage.jpg +0 -0
- assets/irrelevant_amazon.jpg +0 -0
Dockerfile
CHANGED
|
@@ -24,4 +24,4 @@ ENV TRANSFORMERS_CACHE=/usr/local/lib/python3.10/site-packages/llama_index/legac
|
|
| 24 |
# ^ not elegant but it works
|
| 25 |
# HF warning says that TRANSFORMERS_CACHE will be deprecated in transformers v5, and advise to use HF_HOME
|
| 26 |
|
| 27 |
-
CMD ["uvicorn", "
|
|
|
|
| 24 |
# ^ not elegant but it works
|
| 25 |
# HF warning says that TRANSFORMERS_CACHE will be deprecated in transformers v5, and advise to use HF_HOME
|
| 26 |
|
| 27 |
+
CMD ["uvicorn", "main_reflex:app", "--host", "0.0.0.0", "--port", "7860"]
|
app/engine/chunk_embed.py
CHANGED
|
@@ -4,7 +4,7 @@ import os
|
|
| 4 |
import pandas as pd
|
| 5 |
import torch
|
| 6 |
|
| 7 |
-
from settings import parquet_file
|
| 8 |
|
| 9 |
import tiktoken # tokenizer library for use with OpenAI LLMs
|
| 10 |
from llama_index.legacy.text_splitter import SentenceSplitter
|
|
|
|
| 4 |
import pandas as pd
|
| 5 |
import torch
|
| 6 |
|
| 7 |
+
from app.settings import parquet_file
|
| 8 |
|
| 9 |
import tiktoken # tokenizer library for use with OpenAI LLMs
|
| 10 |
from llama_index.legacy.text_splitter import SentenceSplitter
|
app/engine/loaders/file.py
CHANGED
|
@@ -3,13 +3,15 @@ import os
|
|
| 3 |
# from langchain.document_loaders import PyPDFLoader # deprecated
|
| 4 |
from langchain_community.document_loaders import PyPDFLoader
|
| 5 |
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
|
|
|
|
|
|
| 6 |
from llama_parse import LlamaParse
|
| 7 |
|
| 8 |
from typing import Union, List, Dict
|
| 9 |
|
| 10 |
from abc import ABC, abstractmethod
|
| 11 |
|
| 12 |
-
class
|
| 13 |
|
| 14 |
def __init__(self, file_or_list: Union[str, List[str]], num_workers: int = 1, verbose: bool = False):
|
| 15 |
""" We can provide a list of files or a single file """
|
|
@@ -40,7 +42,7 @@ class PDFExtractor(ABC):
|
|
| 40 |
"""
|
| 41 |
pass
|
| 42 |
|
| 43 |
-
class _PyPDFLoader(
|
| 44 |
|
| 45 |
def extract_text(self):
|
| 46 |
output_dict = {}
|
|
@@ -58,7 +60,7 @@ class _PyPDFLoader(PDFExtractor):
|
|
| 58 |
return
|
| 59 |
|
| 60 |
|
| 61 |
-
class _LlamaParse(
|
| 62 |
|
| 63 |
def extract_text(self):
|
| 64 |
# https://github.com/run-llama/llama_parse
|
|
@@ -88,18 +90,59 @@ class _LlamaParse(PDFExtractor):
|
|
| 88 |
raise NotImplementedError("Not implemented or LlamaParse does not support table extraction")
|
| 89 |
return
|
| 90 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 91 |
|
| 92 |
-
|
| 93 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 94 |
|
| 95 |
if extractor_type == 'PyPDFLoader':
|
| 96 |
return _PyPDFLoader(*args, **kwargs)
|
| 97 |
|
| 98 |
elif extractor_type == 'LlamaParse':
|
| 99 |
return _LlamaParse(*args, **kwargs)
|
|
|
|
|
|
|
|
|
|
|
|
|
| 100 |
else:
|
| 101 |
raise ValueError(f"Unsupported PDF extractor type: {extractor_type}")
|
| 102 |
|
| 103 |
|
| 104 |
|
| 105 |
-
|
|
|
|
|
|
| 3 |
# from langchain.document_loaders import PyPDFLoader # deprecated
|
| 4 |
from langchain_community.document_loaders import PyPDFLoader
|
| 5 |
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
| 6 |
+
from langchain_community.document_loaders.csv_loader import CSVLoader
|
| 7 |
+
# ^ if we want to add CSV support, it will transform every row into a k:v pair
|
| 8 |
from llama_parse import LlamaParse
|
| 9 |
|
| 10 |
from typing import Union, List, Dict
|
| 11 |
|
| 12 |
from abc import ABC, abstractmethod
|
| 13 |
|
| 14 |
+
class Extractor(ABC):
|
| 15 |
|
| 16 |
def __init__(self, file_or_list: Union[str, List[str]], num_workers: int = 1, verbose: bool = False):
|
| 17 |
""" We can provide a list of files or a single file """
|
|
|
|
| 42 |
"""
|
| 43 |
pass
|
| 44 |
|
| 45 |
+
class _PyPDFLoader(Extractor):
|
| 46 |
|
| 47 |
def extract_text(self):
|
| 48 |
output_dict = {}
|
|
|
|
| 60 |
return
|
| 61 |
|
| 62 |
|
| 63 |
+
class _LlamaParse(Extractor):
|
| 64 |
|
| 65 |
def extract_text(self):
|
| 66 |
# https://github.com/run-llama/llama_parse
|
|
|
|
| 90 |
raise NotImplementedError("Not implemented or LlamaParse does not support table extraction")
|
| 91 |
return
|
| 92 |
|
| 93 |
+
class _TXTLoader(Extractor):
|
| 94 |
+
|
| 95 |
+
def extract_text(self):
|
| 96 |
+
output_dict = {}
|
| 97 |
+
for fpath in self.filelist:
|
| 98 |
+
fname = fpath.split('/')[-1]
|
| 99 |
+
output_dict[fname] = [open(fpath, 'r').read()]
|
| 100 |
+
# with pdfs, we use a list of strings, one for each page
|
| 101 |
+
# so we must return a list here, even if it's just one string with everything
|
| 102 |
+
return output_dict
|
| 103 |
+
|
| 104 |
+
def extract_images(self):
|
| 105 |
+
raise NotImplementedError("Not implemented or PyPDFLoader does not support image extraction")
|
| 106 |
+
return
|
| 107 |
+
|
| 108 |
+
def extract_tables(self):
|
| 109 |
+
raise NotImplementedError("Not implemented or PyPDFLoader does not support table extraction")
|
| 110 |
+
return
|
| 111 |
+
|
| 112 |
+
class _CSVLoader(Extractor):
|
| 113 |
+
# mock code for now, as a reminder of what we could do if time allows TODO
|
| 114 |
+
def extract_text(self):
|
| 115 |
+
output_dict = {}
|
| 116 |
+
for fpath in self.filelist:
|
| 117 |
+
fname = fpath.split('/')[-1]
|
| 118 |
+
output_dict[fname] = [CSVLoader(fpath).load()] # << untested!
|
| 119 |
|
| 120 |
+
return output_dict
|
| 121 |
+
|
| 122 |
+
def extract_images(self):
|
| 123 |
+
raise NotImplementedError("Not implemented or CSVLoader does not support image extraction")
|
| 124 |
+
return
|
| 125 |
+
|
| 126 |
+
def extract_tables(self):
|
| 127 |
+
raise NotImplementedError("Not implemented or CSVLoader does not support table extraction")
|
| 128 |
+
return
|
| 129 |
+
|
| 130 |
+
def extractor(extractor_type: str, *args, **kwargs) -> Extractor:
|
| 131 |
+
""" Function factory to return the appropriate PDF extractor instance, properly initialized """
|
| 132 |
|
| 133 |
if extractor_type == 'PyPDFLoader':
|
| 134 |
return _PyPDFLoader(*args, **kwargs)
|
| 135 |
|
| 136 |
elif extractor_type == 'LlamaParse':
|
| 137 |
return _LlamaParse(*args, **kwargs)
|
| 138 |
+
|
| 139 |
+
elif extractor_type == 'txt':
|
| 140 |
+
return _TXTLoader(*args, **kwargs)
|
| 141 |
+
|
| 142 |
else:
|
| 143 |
raise ValueError(f"Unsupported PDF extractor type: {extractor_type}")
|
| 144 |
|
| 145 |
|
| 146 |
|
| 147 |
+
#/usr/bin/env /Users/jpb2/Library/Caches/pypoetry/virtualenvs/reflex-Y1r5RCNB-py3.10/bin/python /Users/jpb2/.vscode/extensions/ms-python.debugpy-2024.6.0-darwin-x64/bundled/libs/debugpy/adapter/../../debugpy/launcher 51572 -- -m reflex run --frontend-port 3000 --loglevel debug
|
| 148 |
+
#/usr/bin/env /Volumes/DATA/Dropbox/IMAC_BACKUP/WORK/PROJECTS/INNOVATION/venv/bin/python /Users/jpb2/.vscode/extensions/ms-python.debugpy-2024.6.0-darwin-x64/bundled/libs/debugpy/adapter/../../debugpy/launcher 53961 -- -m reflex run --frontend-port 3001 --loglevel debug --env dev
|
app/engine/logger.py
CHANGED
|
@@ -1,10 +1,16 @@
|
|
| 1 |
import os, logging
|
|
|
|
|
|
|
| 2 |
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import os, logging
|
| 2 |
+
import reflex as rx
|
| 3 |
+
logger = logging.getLogger("uvicorn").info
|
| 4 |
|
| 5 |
+
|
| 6 |
+
# logger = lambda x: rx.console_log(x)
|
| 7 |
+
# let's use reflex's logger, but doesn't show in the console??
|
| 8 |
+
|
| 9 |
+
# environment = os.getenv("ENVIRONMENT", "dev")
|
| 10 |
+
# if environment == "dev":
|
| 11 |
+
# logger = logging.getLogger("uvicorn").info
|
| 12 |
+
# else:
|
| 13 |
+
# logger = lambda x: print(x)
|
| 14 |
+
# # we should log also in production TODO
|
| 15 |
+
# # check how it works on HuggingFace, if possible
|
| 16 |
+
# # because we don't have access to the container's file system unless in pro mode
|
app/engine/post_process.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import reflex as rx
|
| 2 |
+
import json
|
| 3 |
+
import requests
|
| 4 |
+
from typing import Optional, List
|
| 5 |
+
from pydantic import BaseModel, Field
|
| 6 |
+
# from rerank import ReRanker
|
| 7 |
+
|
| 8 |
+
# https://hub.guardrailsai.com/validator/guardrails/toxic_language
|
| 9 |
+
from guardrails.hub import ToxicLanguage
|
| 10 |
+
from guardrails import Guard
|
| 11 |
+
|
| 12 |
+
# guardrails hub install hub://guardrails/detect_pii
|
| 13 |
+
from guardrails.hub import DetectPII
|
| 14 |
+
|
| 15 |
+
# https://hub.guardrailsai.com/validator/guardrails/qa_relevance_llm_eval
|
| 16 |
+
from guardrails.hub import QARelevanceLLMEval
|
| 17 |
+
|
| 18 |
+
import logging
|
| 19 |
+
logger = logging.getLogger("uvicorn").info
|
| 20 |
+
|
| 21 |
+
from .summary import summarize_it
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def IsPii(answer: str) -> bool:
|
| 25 |
+
guard = Guard().use(DetectPII,
|
| 26 |
+
["EMAIL_ADDRESS", "PHONE_NUMBER"],
|
| 27 |
+
"exception",
|
| 28 |
+
)
|
| 29 |
+
try:
|
| 30 |
+
guard.validate(answer)
|
| 31 |
+
return True
|
| 32 |
+
|
| 33 |
+
except Exception as e:
|
| 34 |
+
print(e)
|
| 35 |
+
return False
|
| 36 |
+
|
| 37 |
+
def IsToxic(query: str, threshold=0.5) -> bool:
|
| 38 |
+
|
| 39 |
+
# https://hub.guardrailsai.com/validator/guardrails/toxic_language
|
| 40 |
+
# Use the Guard with the validator
|
| 41 |
+
guard = Guard().use(
|
| 42 |
+
ToxicLanguage,
|
| 43 |
+
threshold=threshold, # high for highly toxic only
|
| 44 |
+
validation_method="sentence",
|
| 45 |
+
on_fail="exception"
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
try:
|
| 49 |
+
guard.validate(query)
|
| 50 |
+
return False
|
| 51 |
+
|
| 52 |
+
except Exception as e:
|
| 53 |
+
print(e) # will output the toxic question
|
| 54 |
+
return True
|
| 55 |
+
|
| 56 |
+
def IsRelevant(answer: str, query: str, model: str="gpt-3.5-turbo") -> bool:
|
| 57 |
+
|
| 58 |
+
guard = Guard().use(
|
| 59 |
+
QARelevanceLLMEval,
|
| 60 |
+
llm_callable=model,
|
| 61 |
+
on_fail="exception",
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
try:
|
| 65 |
+
guard.validate(
|
| 66 |
+
answer,
|
| 67 |
+
metadata={"original_prompt": query},
|
| 68 |
+
)
|
| 69 |
+
return True
|
| 70 |
+
except Exception as e:
|
| 71 |
+
print(e)
|
| 72 |
+
return False
|
| 73 |
+
|
| 74 |
+
|
app/engine/processing.py
CHANGED
|
@@ -1,48 +1,144 @@
|
|
| 1 |
import os, pickle
|
| 2 |
from typing import List
|
| 3 |
-
from
|
| 4 |
-
from
|
| 5 |
-
from settings import parquet_file
|
| 6 |
from .logger import logger
|
| 7 |
from .vectorstore import VectorStore
|
| 8 |
-
|
| 9 |
-
|
|
|
|
|
|
|
| 10 |
|
| 11 |
-
finrag_vectorstore = VectorStore(model_path='sentence-transformers/all-mpnet-base-v2')
|
| 12 |
-
|
| 13 |
|
| 14 |
def empty_collection():
|
| 15 |
-
""" Deletes the
|
| 16 |
-
status =
|
| 17 |
return status
|
| 18 |
|
| 19 |
|
| 20 |
def index_data():
|
| 21 |
|
| 22 |
if not os.path.exists(parquet_file):
|
| 23 |
-
logger
|
| 24 |
return 'no data to index'
|
| 25 |
|
| 26 |
# load the parquet file into the vectorstore
|
| 27 |
-
|
| 28 |
os.remove(parquet_file)
|
| 29 |
# delete the files so we can load several files and index them when we want
|
| 30 |
# without having to keep track of those that have been indexed already
|
| 31 |
# this is a simple solution for now, but we can do better
|
| 32 |
|
| 33 |
return "Index creation successful"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 34 |
|
|
|
|
|
|
|
|
|
|
| 35 |
|
| 36 |
-
|
|
|
|
| 37 |
|
| 38 |
-
new_content =
|
| 39 |
-
logger
|
| 40 |
|
| 41 |
chunk_vectorize(new_content)
|
| 42 |
-
logger
|
| 43 |
return new_content
|
| 44 |
|
| 45 |
-
|
|
|
|
|
|
|
| 46 |
|
| 47 |
-
ans =
|
|
|
|
|
|
|
| 48 |
return ans
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import os, pickle
|
| 2 |
from typing import List
|
| 3 |
+
from .loaders.file import extractor
|
| 4 |
+
from .chunk_embed import chunk_vectorize
|
| 5 |
+
from ..settings import parquet_file
|
| 6 |
from .logger import logger
|
| 7 |
from .vectorstore import VectorStore
|
| 8 |
+
from .post_process import IsPii, IsToxic, IsRelevant
|
| 9 |
+
from .summary import summarize_it
|
| 10 |
+
|
| 11 |
+
multirag_vectorstore = VectorStore(model_path='sentence-transformers/all-mpnet-base-v2')
|
| 12 |
|
|
|
|
|
|
|
| 13 |
|
| 14 |
def empty_collection():
|
| 15 |
+
""" Deletes the MultiRAG collection if it exists """
|
| 16 |
+
status = multirag_vectorstore.empty_collection()
|
| 17 |
return status
|
| 18 |
|
| 19 |
|
| 20 |
def index_data():
|
| 21 |
|
| 22 |
if not os.path.exists(parquet_file):
|
| 23 |
+
logger(f"Parquet file {parquet_file} does not exists")
|
| 24 |
return 'no data to index'
|
| 25 |
|
| 26 |
# load the parquet file into the vectorstore
|
| 27 |
+
multirag_vectorstore.index_data()
|
| 28 |
os.remove(parquet_file)
|
| 29 |
# delete the files so we can load several files and index them when we want
|
| 30 |
# without having to keep track of those that have been indexed already
|
| 31 |
# this is a simple solution for now, but we can do better
|
| 32 |
|
| 33 |
return "Index creation successful"
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def process_pdf(filepath: str) -> dict:
|
| 37 |
+
|
| 38 |
+
new_content = extractor('PyPDFLoader', filepath).extract_text()
|
| 39 |
+
logger(f"Successfully extracted text from PDF")
|
| 40 |
|
| 41 |
+
chunk_vectorize(new_content)
|
| 42 |
+
logger(f"Successfully vectorized PDF content of {filepath}")
|
| 43 |
+
return new_content
|
| 44 |
|
| 45 |
+
|
| 46 |
+
def process_txt(filepath: str) -> dict:
|
| 47 |
|
| 48 |
+
new_content = extractor('txt', filepath).extract_text()
|
| 49 |
+
logger(f"Successfully extracted text from TXT")
|
| 50 |
|
| 51 |
chunk_vectorize(new_content)
|
| 52 |
+
logger(f"Successfully vectorized TXT content")
|
| 53 |
return new_content
|
| 54 |
|
| 55 |
+
|
| 56 |
+
def vector_search_raw(question: str) -> List[str]:
|
| 57 |
+
""" Just vector search """
|
| 58 |
|
| 59 |
+
ans = multirag_vectorstore.hybrid_search(query=question,
|
| 60 |
+
limit=10,
|
| 61 |
+
alpha=0.8)
|
| 62 |
return ans
|
| 63 |
+
|
| 64 |
+
def vector_search(question: str, relevance_thr=0.3) -> List[str]:
|
| 65 |
+
""" Search + pre/post processing """
|
| 66 |
+
|
| 67 |
+
## PRE PROCESSING
|
| 68 |
+
if IsToxic(question):
|
| 69 |
+
ans = [f"\"{question}\" is toxic, try again"]
|
| 70 |
+
return ans
|
| 71 |
+
|
| 72 |
+
ans = multirag_vectorstore.hybrid_search(query=question,
|
| 73 |
+
limit=10,
|
| 74 |
+
alpha=0.8)
|
| 75 |
+
|
| 76 |
+
max_score = max([score for _, _, score in ans])
|
| 77 |
+
# if no answer has a score high enough, we consider the question irrelevant
|
| 78 |
+
# we could do better with reranking but here the question is trivial, y/n
|
| 79 |
+
# it's not like reranking 100 answers to pick the best 5 for RAGing
|
| 80 |
+
if max_score < relevance_thr:
|
| 81 |
+
return [f"{question} is IRRELEVANT with max score: {max_score:.2f}, try again"]
|
| 82 |
+
else:
|
| 83 |
+
answers = [f"{question} is deemed RELEVANT with max score: {max_score:.2f}"]
|
| 84 |
+
|
| 85 |
+
# let's first quickly print the answers, without summary
|
| 86 |
+
for i, (fname, ans, score) in enumerate(ans, 1):
|
| 87 |
+
|
| 88 |
+
if score < relevance_thr:
|
| 89 |
+
continue
|
| 90 |
+
|
| 91 |
+
if IsPii(ans):
|
| 92 |
+
ans = " Pii detected -" + ans
|
| 93 |
+
|
| 94 |
+
# removed, not accurate
|
| 95 |
+
if IsRelevant(ans, question):
|
| 96 |
+
relevant = 'RELEVANT'
|
| 97 |
+
else:
|
| 98 |
+
# irrelevant answer
|
| 99 |
+
relevant = 'IRRELEVANT'
|
| 100 |
+
|
| 101 |
+
summary = summarize_it(question, [ans])
|
| 102 |
+
ans = f"{ans}\n SUMMARY: {summary}"
|
| 103 |
+
|
| 104 |
+
answers.append(f"{i}: from {fname} - score:{score:.2f} - {relevant} answer - {ans}")
|
| 105 |
+
|
| 106 |
+
# msg = f"Answers to '{self.question}' with summaries"
|
| 107 |
+
# self.chats[self.current_chat] = [qa1]
|
| 108 |
+
|
| 109 |
+
# for i, (fname, ans, score) in enumerate(self.answer['answer'], 1):
|
| 110 |
+
|
| 111 |
+
# if score < relevance_thr:
|
| 112 |
+
# continue
|
| 113 |
+
|
| 114 |
+
# msg = ""
|
| 115 |
+
# summary = summarize_it(self.question, [ans])
|
| 116 |
+
|
| 117 |
+
# # if IsPii(ans):
|
| 118 |
+
# # qa.answer += " Pii detected -"
|
| 119 |
+
|
| 120 |
+
# # removed, not accurate
|
| 121 |
+
# # if IsRelevant(ans, self.question):
|
| 122 |
+
# # relevant = 'RELEVANT'
|
| 123 |
+
# # else:
|
| 124 |
+
# # # irrelevant answer
|
| 125 |
+
# # relevant = 'IRRELEVANT'
|
| 126 |
+
# # qa.answer += f" {relevant} ANSWER - {ans} \n SUMMARY: {summary}"
|
| 127 |
+
|
| 128 |
+
# qa = QA(question=msg,
|
| 129 |
+
# answer=f"{i}: from {fname} - score:{score:.2f} - {ans} - SUMMARY: {summary}"
|
| 130 |
+
# )
|
| 131 |
+
|
| 132 |
+
# # paths are from /assets, so data is assets/data
|
| 133 |
+
# search = ans[:30].replace(" ", "%20") # let's search only first 30 chars
|
| 134 |
+
# qa.link = f'data/{fname}#:~:text={search}'
|
| 135 |
+
# qa.msg = " - Verify in the document"
|
| 136 |
+
# logger(f"Summary: {summary}")
|
| 137 |
+
|
| 138 |
+
# # it's slower now because of the summaries
|
| 139 |
+
# self.chats[self.current_chat].append(qa)
|
| 140 |
+
# yield
|
| 141 |
+
|
| 142 |
+
# msg = ""
|
| 143 |
+
|
| 144 |
+
return answers
|
app/engine/summary.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from typing import List
|
| 3 |
+
|
| 4 |
+
from app.rag.llm import LLM
|
| 5 |
+
#the LLM Class uses the OPENAI_API_KEY env var as the default api_key
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
async def summarize_it(question: str,
|
| 9 |
+
search_results: List[str],
|
| 10 |
+
model: str = 'gpt-3.5-turbo-0125',
|
| 11 |
+
) -> str:
|
| 12 |
+
|
| 13 |
+
# TODO turn this into a class if time allows
|
| 14 |
+
llm = LLM(model)
|
| 15 |
+
|
| 16 |
+
system_message = """
|
| 17 |
+
You are able to quickly understand a few paragraphs, or quips even, generated by vector search system
|
| 18 |
+
and generate a one-line summary.
|
| 19 |
+
"""
|
| 20 |
+
|
| 21 |
+
searches = "\n".join([f"Search result {i}: {v}" for i,v in enumerate(search_results,1)])
|
| 22 |
+
|
| 23 |
+
user_prompt = f"""
|
| 24 |
+
Use the below context enclosed in triple back ticks to answer the question. \n
|
| 25 |
+
The context is given by a vector search into a vector database made from the company's documents,
|
| 26 |
+
so you can assume the context is accurate. \n
|
| 27 |
+
```
|
| 28 |
+
Context:
|
| 29 |
+
```
|
| 30 |
+
{searches}
|
| 31 |
+
```
|
| 32 |
+
Question:\n
|
| 33 |
+
{question}\n
|
| 34 |
+
------------------------
|
| 35 |
+
1. If the context is not relevant to the question, simply say 'Irrelevant content' and nothing else.
|
| 36 |
+
Pay great attention to making sure your answer is relevant to the question and the context.
|
| 37 |
+
(for instance, never answer a question about a topic that is not explicitely mentioned in the question)
|
| 38 |
+
2. Using any external knowledge or resources to answer the question is forbidden.
|
| 39 |
+
3. Generate a ONE-LINE ONE-LINE summary within the limits of the context and the question.
|
| 40 |
+
4. Avoid mentioning 'search results' in the answer.
|
| 41 |
+
Instead, incorporate the information from the search results into the answer.
|
| 42 |
+
5. Create a clean answer, without backticks, or starting with a new line for instance.
|
| 43 |
+
------------------------
|
| 44 |
+
Answer:\n
|
| 45 |
+
""".format(searches=searches, question=question)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
response = await llm.chat_completion(system_message=system_message,
|
| 49 |
+
user_message=user_prompt,
|
| 50 |
+
temperature=0.01, # let's not allow the model to be creative
|
| 51 |
+
stream=False,
|
| 52 |
+
raw_response=False)
|
| 53 |
+
return response
|
app/engine/vectorstore.py
CHANGED
|
@@ -1,19 +1,109 @@
|
|
| 1 |
import os, logging
|
|
|
|
|
|
|
| 2 |
from typing import List, Any
|
| 3 |
import pandas as pd
|
| 4 |
from weaviate.classes.config import Property, DataType
|
| 5 |
|
| 6 |
from .weaviate_interface_v4 import WeaviateWCS, WeaviateIndexer
|
| 7 |
-
from .logger import logger
|
| 8 |
|
| 9 |
-
from settings import parquet_file
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 10 |
|
| 11 |
class VectorStore:
|
| 12 |
-
def __init__(self, model_path:str = 'sentence-transformers/all-mpnet-base-v2'):
|
| 13 |
# we can create several instances to test various models, especially if we finetune one
|
| 14 |
|
| 15 |
-
self.
|
| 16 |
-
Property(name='
|
| 17 |
data_type=DataType.TEXT,
|
| 18 |
description='Name of the file',
|
| 19 |
index_filterable=True,
|
|
@@ -30,45 +120,54 @@ class VectorStore:
|
|
| 30 |
index_searchable=True),
|
| 31 |
]
|
| 32 |
|
| 33 |
-
self.class_name = "
|
| 34 |
|
| 35 |
self.class_config = {'classes': [
|
| 36 |
|
| 37 |
{"class": self.class_name,
|
| 38 |
|
| 39 |
-
"description": "
|
| 40 |
|
| 41 |
"vectorIndexType": "hnsw",
|
| 42 |
|
| 43 |
-
# Vector index specific settings for HSNW
|
| 44 |
"vectorIndexConfig": {
|
| 45 |
|
| 46 |
"ef": 64, # higher is better quality vs slower search
|
| 47 |
"efConstruction": 128, # higher = better index but slower build
|
| 48 |
"maxConnections": 32, # max conn per layer - higher = more memory
|
| 49 |
},
|
| 50 |
-
|
| 51 |
"vectorizer": "none",
|
| 52 |
-
|
| 53 |
-
"properties": self.
|
| 54 |
]
|
| 55 |
}
|
| 56 |
|
| 57 |
self.model_path = model_path
|
| 58 |
-
|
| 59 |
try:
|
| 60 |
self.api_key = os.environ.get('FINRAG_WEAVIATE_API_KEY')
|
| 61 |
-
self.
|
| 62 |
-
self.
|
| 63 |
-
|
| 64 |
-
|
| 65 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 66 |
except Exception as e:
|
| 67 |
# raise Exception(f"Could not create Weaviate client: {e}")
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
|
|
|
|
|
|
|
|
|
|
| 72 |
# careful with accessing '_client' since the weaviate helper usually closes the connection every time
|
| 73 |
|
| 74 |
self.indexer = None
|
|
@@ -80,19 +179,21 @@ class VectorStore:
|
|
| 80 |
|
| 81 |
return self.client.show_all_collections()
|
| 82 |
|
| 83 |
-
def create_collection(self,
|
|
|
|
|
|
|
| 84 |
|
| 85 |
self.collection_name = collection_name
|
| 86 |
if collection_name not in self.collections:
|
| 87 |
self.client.create_collection(collection_name=collection_name,
|
| 88 |
-
properties=self.
|
| 89 |
description=description)
|
| 90 |
-
self.collection_name = collection_name
|
| 91 |
else:
|
| 92 |
-
|
| 93 |
|
| 94 |
|
| 95 |
-
def empty_collection(self, collection_name: str=
|
| 96 |
|
| 97 |
# not in the library yet, so I simply delete and recreate it
|
| 98 |
if collection_name in self.collections:
|
|
@@ -100,11 +201,11 @@ class VectorStore:
|
|
| 100 |
self.create_collection()
|
| 101 |
return True
|
| 102 |
else:
|
| 103 |
-
|
| 104 |
return False
|
| 105 |
|
| 106 |
|
| 107 |
-
def index_data(self, data: List[dict]= None, collection_name: str=
|
| 108 |
|
| 109 |
if self.indexer is None:
|
| 110 |
self.indexer = WeaviateIndexer(self.client)
|
|
@@ -127,25 +228,25 @@ class VectorStore:
|
|
| 127 |
def keyword_search(self,
|
| 128 |
query: str,
|
| 129 |
limit: int=5,
|
| 130 |
-
return_properties: List[str]=['
|
| 131 |
alpha=None # dummy parameter to match the hybrid_search signature
|
| 132 |
) -> List[str]:
|
| 133 |
response = self.client.keyword_search(
|
| 134 |
request=query,
|
| 135 |
collection_name=self.collection_name,
|
| 136 |
-
query_properties=['content'],
|
| 137 |
limit=limit,
|
| 138 |
filter=None,
|
| 139 |
return_properties=return_properties,
|
| 140 |
return_raw=False)
|
| 141 |
|
| 142 |
-
return [res['content'] for res in response]
|
| 143 |
|
| 144 |
|
| 145 |
def vector_search(self,
|
| 146 |
query: str,
|
| 147 |
limit: int=5,
|
| 148 |
-
return_properties: List[str]=['
|
| 149 |
alpha=None # dummy parameter to match the hybrid_search signature
|
| 150 |
) -> List[str]:
|
| 151 |
|
|
@@ -157,24 +258,24 @@ class VectorStore:
|
|
| 157 |
return_properties=return_properties,
|
| 158 |
return_raw=False)
|
| 159 |
|
| 160 |
-
return [res['content'] for res in response]
|
| 161 |
|
| 162 |
|
| 163 |
def hybrid_search(self,
|
| 164 |
query: str,
|
| 165 |
-
limit: int=
|
| 166 |
alpha=0.5, # higher = more vector search
|
| 167 |
-
return_properties: List[str]=['
|
| 168 |
) -> List[str]:
|
| 169 |
|
| 170 |
response = self.client.hybrid_search(
|
| 171 |
request=query,
|
| 172 |
collection_name=self.collection_name,
|
| 173 |
-
query_properties=['content'],
|
| 174 |
alpha=alpha,
|
| 175 |
limit=limit,
|
| 176 |
filter=None,
|
| 177 |
return_properties=return_properties,
|
| 178 |
return_raw=False)
|
| 179 |
|
| 180 |
-
return [res['content'] for res in response]
|
|
|
|
| 1 |
import os, logging
|
| 2 |
+
from app.engine.logger import logger
|
| 3 |
+
|
| 4 |
from typing import List, Any
|
| 5 |
import pandas as pd
|
| 6 |
from weaviate.classes.config import Property, DataType
|
| 7 |
|
| 8 |
from .weaviate_interface_v4 import WeaviateWCS, WeaviateIndexer
|
|
|
|
| 9 |
|
| 10 |
+
from ..settings import parquet_file
|
| 11 |
+
from weaviate.classes.query import Filter
|
| 12 |
+
from torch import cuda
|
| 13 |
+
|
| 14 |
+
if os.path.exists('.we_are_local'):
|
| 15 |
+
COLLECTION = 'MultiRAG_local_mr'
|
| 16 |
+
else:
|
| 17 |
+
COLLECTION = 'MultiRAG'
|
| 18 |
+
|
| 19 |
+
class dummyWeaviate:
|
| 20 |
+
""" Created to pass on HF since I had again the client creation issue
|
| 21 |
+
Temporary solution
|
| 22 |
+
"""
|
| 23 |
+
def __init__(self,
|
| 24 |
+
endpoint: str=None,
|
| 25 |
+
api_key: str=None,
|
| 26 |
+
model_name_or_path: str='sentence-transformers/all-MiniLM-L6-v2',
|
| 27 |
+
embedded: bool=False,
|
| 28 |
+
openai_api_key: str=None,
|
| 29 |
+
skip_init_checks: bool=False,
|
| 30 |
+
**kwargs
|
| 31 |
+
):
|
| 32 |
+
return
|
| 33 |
+
|
| 34 |
+
def _connect(self) -> None:
|
| 35 |
+
return
|
| 36 |
+
|
| 37 |
+
def _client(self):
|
| 38 |
+
return
|
| 39 |
+
|
| 40 |
+
def create_collection(self,
|
| 41 |
+
collection_name: str,
|
| 42 |
+
properties: list[Property],
|
| 43 |
+
description: str=None,
|
| 44 |
+
**kwargs
|
| 45 |
+
) -> None:
|
| 46 |
+
return
|
| 47 |
+
|
| 48 |
+
def show_all_collections(self,
|
| 49 |
+
detailed: bool=False,
|
| 50 |
+
max_details: bool=False
|
| 51 |
+
) -> list[str] | dict:
|
| 52 |
+
return ['abc', 'def']
|
| 53 |
+
|
| 54 |
+
def show_collection_config(self, collection_name: str):
|
| 55 |
+
return
|
| 56 |
+
|
| 57 |
+
def show_collection_properties(self, collection_name: str):
|
| 58 |
+
return
|
| 59 |
+
|
| 60 |
+
def delete_collection(self, collection_name: str):
|
| 61 |
+
return
|
| 62 |
+
|
| 63 |
+
def get_doc_count(self, collection_name: str):
|
| 64 |
+
return
|
| 65 |
+
|
| 66 |
+
def keyword_search(self,
|
| 67 |
+
request: str,
|
| 68 |
+
collection_name: str,
|
| 69 |
+
query_properties: list[str]=['content'],
|
| 70 |
+
limit: int=10,
|
| 71 |
+
filter: Filter=None,
|
| 72 |
+
return_properties: list[str]=None,
|
| 73 |
+
return_raw: bool=False
|
| 74 |
+
):
|
| 75 |
+
return
|
| 76 |
+
|
| 77 |
+
def vector_search(self,
|
| 78 |
+
request: str,
|
| 79 |
+
collection_name: str,
|
| 80 |
+
limit: int=10,
|
| 81 |
+
return_properties: list[str]=None,
|
| 82 |
+
filter: Filter=None,
|
| 83 |
+
return_raw: bool=False,
|
| 84 |
+
device: str='cuda:0' if cuda.is_available() else 'cpu'
|
| 85 |
+
):
|
| 86 |
+
return
|
| 87 |
+
|
| 88 |
+
def hybrid_search(self,
|
| 89 |
+
request: str,
|
| 90 |
+
collection_name: str,
|
| 91 |
+
query_properties: list[str]=['content'],
|
| 92 |
+
alpha: float=0.5,
|
| 93 |
+
limit: int=10,
|
| 94 |
+
filter: Filter=None,
|
| 95 |
+
return_properties: list[str]=None,
|
| 96 |
+
return_raw: bool=False,
|
| 97 |
+
device: str='cuda:0' if cuda.is_available() else 'cpu'
|
| 98 |
+
):
|
| 99 |
+
return
|
| 100 |
|
| 101 |
class VectorStore:
|
| 102 |
+
def __init__(self, model_path: str = 'sentence-transformers/all-mpnet-base-v2'):
|
| 103 |
# we can create several instances to test various models, especially if we finetune one
|
| 104 |
|
| 105 |
+
self.MultiRAG_properties = [
|
| 106 |
+
Property(name='file',
|
| 107 |
data_type=DataType.TEXT,
|
| 108 |
description='Name of the file',
|
| 109 |
index_filterable=True,
|
|
|
|
| 120 |
index_searchable=True),
|
| 121 |
]
|
| 122 |
|
| 123 |
+
self.class_name = "MultiRAG_all-mpnet-base-v2"
|
| 124 |
|
| 125 |
self.class_config = {'classes': [
|
| 126 |
|
| 127 |
{"class": self.class_name,
|
| 128 |
|
| 129 |
+
"description": "multiple types of docs",
|
| 130 |
|
| 131 |
"vectorIndexType": "hnsw",
|
| 132 |
|
| 133 |
+
# Vector index specific app.settings for HSNW
|
| 134 |
"vectorIndexConfig": {
|
| 135 |
|
| 136 |
"ef": 64, # higher is better quality vs slower search
|
| 137 |
"efConstruction": 128, # higher = better index but slower build
|
| 138 |
"maxConnections": 32, # max conn per layer - higher = more memory
|
| 139 |
},
|
| 140 |
+
|
| 141 |
"vectorizer": "none",
|
| 142 |
+
|
| 143 |
+
"properties": self.MultiRAG_properties}
|
| 144 |
]
|
| 145 |
}
|
| 146 |
|
| 147 |
self.model_path = model_path
|
| 148 |
+
|
| 149 |
try:
|
| 150 |
self.api_key = os.environ.get('FINRAG_WEAVIATE_API_KEY')
|
| 151 |
+
logger(f"API key: {self.api_key[:5]}")
|
| 152 |
+
self.url = os.environ.get('FINRAG_WEAVIATE_ENDPOINT')
|
| 153 |
+
logger(f"URL: {self.url[8:15]}")
|
| 154 |
+
self.client = WeaviateWCS(
|
| 155 |
+
endpoint=self.url,
|
| 156 |
+
api_key=self.api_key,
|
| 157 |
+
model_name_or_path=self.model_path,
|
| 158 |
+
)
|
| 159 |
+
assert self.client._client.is_live(), "Weaviate is not live"
|
| 160 |
+
assert self.client._client.is_ready(), "Weaviate is not ready"
|
| 161 |
+
logger(f"Weaviate client created")
|
| 162 |
except Exception as e:
|
| 163 |
# raise Exception(f"Could not create Weaviate client: {e}")
|
| 164 |
+
self.client = dummyWeaviate() # used when issue with HF client creation, to continue on HF
|
| 165 |
+
logger(f"Could not create Weaviate client: {e}")
|
| 166 |
+
|
| 167 |
+
# if we fail these tests 'VectorStore' object has no attribute 'client'
|
| 168 |
+
# it's prob not the env var but the model missing
|
| 169 |
+
# assert self.client._client.is_live(), "Weaviate is not live"
|
| 170 |
+
# assert self.client._client.is_ready(), "Weaviate is not ready"
|
| 171 |
# careful with accessing '_client' since the weaviate helper usually closes the connection every time
|
| 172 |
|
| 173 |
self.indexer = None
|
|
|
|
| 179 |
|
| 180 |
return self.client.show_all_collections()
|
| 181 |
|
| 182 |
+
def create_collection(self,
|
| 183 |
+
collection_name: str=COLLECTION,
|
| 184 |
+
description: str='Documents'):
|
| 185 |
|
| 186 |
self.collection_name = collection_name
|
| 187 |
if collection_name not in self.collections:
|
| 188 |
self.client.create_collection(collection_name=collection_name,
|
| 189 |
+
properties=self.MultiRAG_properties,
|
| 190 |
description=description)
|
| 191 |
+
# self.collection_name = collection_name
|
| 192 |
else:
|
| 193 |
+
logger(f"Collection {collection_name} already exists")
|
| 194 |
|
| 195 |
|
| 196 |
+
def empty_collection(self, collection_name: str=COLLECTION) -> bool:
|
| 197 |
|
| 198 |
# not in the library yet, so I simply delete and recreate it
|
| 199 |
if collection_name in self.collections:
|
|
|
|
| 201 |
self.create_collection()
|
| 202 |
return True
|
| 203 |
else:
|
| 204 |
+
logger(f"Collection {collection_name} doesn't exist")
|
| 205 |
return False
|
| 206 |
|
| 207 |
|
| 208 |
+
def index_data(self, data: List[dict]= None, collection_name: str=COLLECTION):
|
| 209 |
|
| 210 |
if self.indexer is None:
|
| 211 |
self.indexer = WeaviateIndexer(self.client)
|
|
|
|
| 228 |
def keyword_search(self,
|
| 229 |
query: str,
|
| 230 |
limit: int=5,
|
| 231 |
+
return_properties: List[str]=['file', 'content'],
|
| 232 |
alpha=None # dummy parameter to match the hybrid_search signature
|
| 233 |
) -> List[str]:
|
| 234 |
response = self.client.keyword_search(
|
| 235 |
request=query,
|
| 236 |
collection_name=self.collection_name,
|
| 237 |
+
query_properties=['file', 'content'],
|
| 238 |
limit=limit,
|
| 239 |
filter=None,
|
| 240 |
return_properties=return_properties,
|
| 241 |
return_raw=False)
|
| 242 |
|
| 243 |
+
return [(res['file'], res['content'], res['score']) for res in response]
|
| 244 |
|
| 245 |
|
| 246 |
def vector_search(self,
|
| 247 |
query: str,
|
| 248 |
limit: int=5,
|
| 249 |
+
return_properties: List[str]=['file', 'content'],
|
| 250 |
alpha=None # dummy parameter to match the hybrid_search signature
|
| 251 |
) -> List[str]:
|
| 252 |
|
|
|
|
| 258 |
return_properties=return_properties,
|
| 259 |
return_raw=False)
|
| 260 |
|
| 261 |
+
return [(res['file'], res['content'], res['score']) for res in response]
|
| 262 |
|
| 263 |
|
| 264 |
def hybrid_search(self,
|
| 265 |
query: str,
|
| 266 |
+
limit: int=10,
|
| 267 |
alpha=0.5, # higher = more vector search
|
| 268 |
+
return_properties: List[str]=['file', 'content']
|
| 269 |
) -> List[str]:
|
| 270 |
|
| 271 |
response = self.client.hybrid_search(
|
| 272 |
request=query,
|
| 273 |
collection_name=self.collection_name,
|
| 274 |
+
query_properties=['file', 'content'],
|
| 275 |
alpha=alpha,
|
| 276 |
limit=limit,
|
| 277 |
filter=None,
|
| 278 |
return_properties=return_properties,
|
| 279 |
return_raw=False)
|
| 280 |
|
| 281 |
+
return [(res['file'], res['content'], res['score']) for res in response]
|
app/main_reflex.py
ADDED
|
@@ -0,0 +1,246 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# this is the original main.py file, but without the call to fastapi
|
| 2 |
+
# since it is done by reflex's own fast api server
|
| 3 |
+
|
| 4 |
+
import os, random, logging, pickle, shutil
|
| 5 |
+
from dotenv import load_dotenv, find_dotenv
|
| 6 |
+
from typing import Optional
|
| 7 |
+
from pydantic import BaseModel, Field
|
| 8 |
+
|
| 9 |
+
from fastapi import FastAPI, HTTPException, File, UploadFile, status
|
| 10 |
+
from fastapi.responses import HTMLResponse
|
| 11 |
+
from fastapi.middleware.cors import CORSMiddleware
|
| 12 |
+
|
| 13 |
+
try:
|
| 14 |
+
load_dotenv(find_dotenv('env'))
|
| 15 |
+
|
| 16 |
+
except Exception as e:
|
| 17 |
+
pass
|
| 18 |
+
|
| 19 |
+
from .engine.processing import ( # << creates the collection already
|
| 20 |
+
process_pdf,
|
| 21 |
+
process_txt,
|
| 22 |
+
index_data,
|
| 23 |
+
empty_collection,
|
| 24 |
+
vector_search,
|
| 25 |
+
vector_search_raw
|
| 26 |
+
)
|
| 27 |
+
from .rag.rag import rag_it
|
| 28 |
+
|
| 29 |
+
from .engine.logger import logger
|
| 30 |
+
|
| 31 |
+
from .settings import datadir, datadir2
|
| 32 |
+
|
| 33 |
+
if not os.path.exists(datadir):
|
| 34 |
+
os.makedirs(datadir, exist_ok=True)
|
| 35 |
+
|
| 36 |
+
if not os.path.exists(datadir2):
|
| 37 |
+
os.makedirs(datadir2, exist_ok=True)
|
| 38 |
+
|
| 39 |
+
os.makedirs(datadir, exist_ok=True)
|
| 40 |
+
|
| 41 |
+
EXTENSIONS = ["pdf", "txt"]
|
| 42 |
+
|
| 43 |
+
app = FastAPI()
|
| 44 |
+
|
| 45 |
+
environment = os.getenv("ENVIRONMENT", "dev") # created by dockerfile
|
| 46 |
+
|
| 47 |
+
# replaced by cors_allowed_origins=['*'] in rxconfig.py when using Reflex endpoint
|
| 48 |
+
# if environment == "dev":
|
| 49 |
+
# logger("Running in development mode - allowing CORS for all origins")
|
| 50 |
+
# app.add_middleware(
|
| 51 |
+
# CORSMiddleware,
|
| 52 |
+
# allow_origins=["*"],
|
| 53 |
+
# allow_credentials=True,
|
| 54 |
+
# allow_methods=["*"],
|
| 55 |
+
# allow_headers=["*"],
|
| 56 |
+
# )
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
# not used when using Reflex endpoint
|
| 60 |
+
@app.get("/", response_class=HTMLResponse)
|
| 61 |
+
def read_root():
|
| 62 |
+
logger("Title displayed on home page")
|
| 63 |
+
return """
|
| 64 |
+
<html>
|
| 65 |
+
<body>
|
| 66 |
+
<h1>Welcome to MultiRAG, a RAG system designed by JP Bianchi!</h1>
|
| 67 |
+
</body>
|
| 68 |
+
</html>
|
| 69 |
+
"""
|
| 70 |
+
|
| 71 |
+
# already provided by Reflex
|
| 72 |
+
@app.get("/ping/")
|
| 73 |
+
def ping():
|
| 74 |
+
""" Testing """
|
| 75 |
+
logger("Someone is pinging the server")
|
| 76 |
+
return {"answer": str(int(random.random() * 100))}
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
@app.delete("/erase_data/")
|
| 80 |
+
def erase_data():
|
| 81 |
+
""" Erase all files in the data directory at the first level only,
|
| 82 |
+
(in case we would like to use it for something else)
|
| 83 |
+
but not the vector store or the parquet file.
|
| 84 |
+
We can do it since the embeddings are in the parquet file already.
|
| 85 |
+
"""
|
| 86 |
+
if len(os.listdir(datadir)) == 0:
|
| 87 |
+
logger("No data to erase")
|
| 88 |
+
return {"message": "No data to erase"}
|
| 89 |
+
|
| 90 |
+
# if we try to rmtree datadir, it looks like /data can't be deleted on HF
|
| 91 |
+
for f in os.listdir(datadir):
|
| 92 |
+
if f == '.DS_Store' or f.split('.')[-1].lower() in EXTENSIONS:
|
| 93 |
+
print(f"Removing {f}")
|
| 94 |
+
os.remove(os.path.join(datadir, f))
|
| 95 |
+
# we don't remove the parquet file, create_index does that
|
| 96 |
+
|
| 97 |
+
logger("All data has been erased")
|
| 98 |
+
return {"message": "All data has been erased"}
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
@app.delete("/empty_collection/")
|
| 102 |
+
def delete_vectors():
|
| 103 |
+
""" Empty the collection in the vector store """
|
| 104 |
+
try:
|
| 105 |
+
status = empty_collection()
|
| 106 |
+
return {"message": f"Collection{'' if status else ' NOT'} erased!"}
|
| 107 |
+
except Exception as e:
|
| 108 |
+
raise HTTPException(status_code=status.HTTP_500_INTERNAL_SERVER_ERROR, detail=str(e))
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
@app.get("/list_files/")
|
| 112 |
+
def list_files():
|
| 113 |
+
""" List all files in the data directory """
|
| 114 |
+
print("Listing files")
|
| 115 |
+
files = os.listdir(datadir)
|
| 116 |
+
logger(f"Files in data directory: {files}")
|
| 117 |
+
return {"files": files}
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
@app.post("/upload/")
|
| 121 |
+
# @limiter.limit("5/minute") see 'slowapi' for rate limiting
|
| 122 |
+
async def upload_file(file: UploadFile = File(...)):
|
| 123 |
+
""" Uploads a file in data directory, for later indexing """
|
| 124 |
+
try:
|
| 125 |
+
filepath = os.path.join(datadir, file.filename)
|
| 126 |
+
logger(f"Fiename detected: {file.filename}")
|
| 127 |
+
if os.path.exists(filepath):
|
| 128 |
+
logger(f"File {file.filename} already exists: no processing done")
|
| 129 |
+
return {"message": f"File {file.filename} already exists: no processing done"}
|
| 130 |
+
|
| 131 |
+
else:
|
| 132 |
+
logger(f"Receiving file: {file.filename}")
|
| 133 |
+
contents = await file.read()
|
| 134 |
+
logger(f"File reception complete!")
|
| 135 |
+
|
| 136 |
+
except Exception as e:
|
| 137 |
+
logger(f"Error during file upload: {str(e)}")
|
| 138 |
+
return {"message": f"Error during file upload: {str(e)}"}
|
| 139 |
+
|
| 140 |
+
if file.filename.endswith('.pdf'):
|
| 141 |
+
|
| 142 |
+
# let's save the file in /data even if it's temp storage on HF
|
| 143 |
+
with open(filepath, 'wb') as f:
|
| 144 |
+
f.write(contents)
|
| 145 |
+
|
| 146 |
+
# save it also in assets/data because data can be cleared
|
| 147 |
+
filepath2 = os.path.join(datadir2, file.filename)
|
| 148 |
+
with open(filepath2, 'wb') as f:
|
| 149 |
+
f.write(contents)
|
| 150 |
+
|
| 151 |
+
try:
|
| 152 |
+
logger(f"Starting to process {file.filename}")
|
| 153 |
+
new_content = process_pdf(filepath)
|
| 154 |
+
success = {"message": f"Successfully uploaded {file.filename}"}
|
| 155 |
+
success.update(new_content)
|
| 156 |
+
return success
|
| 157 |
+
|
| 158 |
+
except Exception as e:
|
| 159 |
+
return {"message": f"Failed to extract text from PDF: {str(e)}"}
|
| 160 |
+
|
| 161 |
+
elif file.filename.endswith('.txt'):
|
| 162 |
+
|
| 163 |
+
with open(filepath, 'wb') as f:
|
| 164 |
+
f.write(contents)
|
| 165 |
+
|
| 166 |
+
filepath2 = os.path.join(datadir2, file.filename)
|
| 167 |
+
with open(filepath2, 'wb') as f:
|
| 168 |
+
f.write(contents)
|
| 169 |
+
|
| 170 |
+
try:
|
| 171 |
+
logger(f"Reading {file.filename}")
|
| 172 |
+
new_content = process_txt(filepath)
|
| 173 |
+
success = {"message": f"Successfully uploaded {file.filename}"}
|
| 174 |
+
success.update(new_content)
|
| 175 |
+
return success
|
| 176 |
+
|
| 177 |
+
except Exception as e:
|
| 178 |
+
return {"message": f"Failed to extract text from TXT: {str(e)}"}
|
| 179 |
+
|
| 180 |
+
else:
|
| 181 |
+
return {"message": "Only PDF & txt files are accepted"}
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
@app.post("/create_index/")
|
| 185 |
+
async def create_index():
|
| 186 |
+
""" Create an index for the uploaded files """
|
| 187 |
+
|
| 188 |
+
logger("Creating index for uploaded files")
|
| 189 |
+
try:
|
| 190 |
+
msg = index_data()
|
| 191 |
+
return {"message": msg}
|
| 192 |
+
except Exception as e:
|
| 193 |
+
raise HTTPException(status_code=status.HTTP_500_INTERNAL_SERVER_ERROR, detail=str(e))
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
class Question(BaseModel):
|
| 197 |
+
question: str
|
| 198 |
+
|
| 199 |
+
@app.post("/ask/")
|
| 200 |
+
async def hybrid_search(question: Question):
|
| 201 |
+
logger(f"Processing question: {question.question}")
|
| 202 |
+
try:
|
| 203 |
+
search_results = vector_search(question.question)
|
| 204 |
+
logger(f"Answer: {search_results}")
|
| 205 |
+
return {"answer": search_results}
|
| 206 |
+
except Exception as e:
|
| 207 |
+
raise HTTPException(status_code=status.HTTP_500_INTERNAL_SERVER_ERROR, detail=str(e))
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
@app.post("/ragit/")
|
| 211 |
+
async def ragit(question: Question):
|
| 212 |
+
logger(f"Processing question: {question.question}")
|
| 213 |
+
try:
|
| 214 |
+
search_results = vector_search_raw(question.question)
|
| 215 |
+
logger(f"Search results generated: {search_results}")
|
| 216 |
+
|
| 217 |
+
answer = rag_it(question.question, search_results)
|
| 218 |
+
|
| 219 |
+
logger(f"Answer: {answer}")
|
| 220 |
+
return {"answer": answer}
|
| 221 |
+
except Exception as e:
|
| 222 |
+
raise HTTPException(status_code=status.HTTP_500_INTERNAL_SERVER_ERROR, detail=str(e))
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
if __name__ == '__main__':
|
| 226 |
+
import uvicorn
|
| 227 |
+
from os import getenv
|
| 228 |
+
port = int(getenv("PORT", 80))
|
| 229 |
+
print(f"Starting server on port {port}")
|
| 230 |
+
reload = True if environment == "dev" else False
|
| 231 |
+
uvicorn.run("main:app", host="0.0.0.0", port=port, reload=reload)
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
# Examples:
|
| 235 |
+
# curl -X POST "http://localhost:8001/upload" -F "[email protected]"
|
| 236 |
+
# curl -X DELETE "http://localhost:8001/erase_data/"
|
| 237 |
+
# curl -X GET "http://localhost:8001/list_files/"
|
| 238 |
+
|
| 239 |
+
# hf space is at https://jpbianchi-multirag.hf.space/
|
| 240 |
+
# code given by https://jpbianchi-multirag.hf.space/docs
|
| 241 |
+
# Space must be public
|
| 242 |
+
# curl -X POST "https://jpbianchi-multirag.hf.space/upload/" -F "[email protected]"
|
| 243 |
+
|
| 244 |
+
# curl -X POST http://localhost:80/ask/ -H "Content-Type: application/json" -d '{"question": "what is Amazon loss"}'
|
| 245 |
+
# curl -X POST http://localhost:80/ragit/ -H "Content-Type: application/json" -d '{"question": "Does ATT have postpaid phone customers?"}'
|
| 246 |
+
# see more in notebook upload_index.ipynb
|
app/notebooks/upload_index.ipynb
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
app/rag/rag.py
CHANGED
|
@@ -37,7 +37,7 @@ def rag_it(question: str,
|
|
| 37 |
1. If the context does not provide enough information to answer the question, then
|
| 38 |
state that you cannot answer the question with the provided context.
|
| 39 |
Pay great attention to making sure your answer is relevant to the question
|
| 40 |
-
|
| 41 |
2. Do not use any external knowledge or resources to answer the question.
|
| 42 |
3. Answer the question directly and with as much detail as possible, within the limits of the context.
|
| 43 |
4. Avoid mentioning 'search results' in the answer.
|
|
|
|
| 37 |
1. If the context does not provide enough information to answer the question, then
|
| 38 |
state that you cannot answer the question with the provided context.
|
| 39 |
Pay great attention to making sure your answer is relevant to the question
|
| 40 |
+
For instance, never answer a question about a topic or company that are not either explicitely mentioned in the context or implied by the context.
|
| 41 |
2. Do not use any external knowledge or resources to answer the question.
|
| 42 |
3. Answer the question directly and with as much detail as possible, within the limits of the context.
|
| 43 |
4. Avoid mentioning 'search results' in the answer.
|
app/settings.py
CHANGED
|
@@ -1,4 +1,6 @@
|
|
| 1 |
import os
|
| 2 |
|
| 3 |
-
datadir = '
|
|
|
|
|
|
|
| 4 |
parquet_file = os.path.join(datadir, 'text_vectors.parquet') # used by the files in 'engine'
|
|
|
|
| 1 |
import os
|
| 2 |
|
| 3 |
+
datadir = 'data' # will be used in main.py
|
| 4 |
+
datadir2 = 'assets/data' # backup since data can be emptied
|
| 5 |
+
|
| 6 |
parquet_file = os.path.join(datadir, 'text_vectors.parquet') # used by the files in 'engine'
|
assets/IO_logo.webp
ADDED
|
|
assets/OI_logo.jpg
ADDED
|
|
assets/amazon_forecast.jpg
ADDED

|
assets/amazon_idiot.jpg
ADDED

|
assets/favicon.ico
ADDED
|
|
assets/homepage.jpg
ADDED

|
assets/irrelevant_amazon.jpg
ADDED
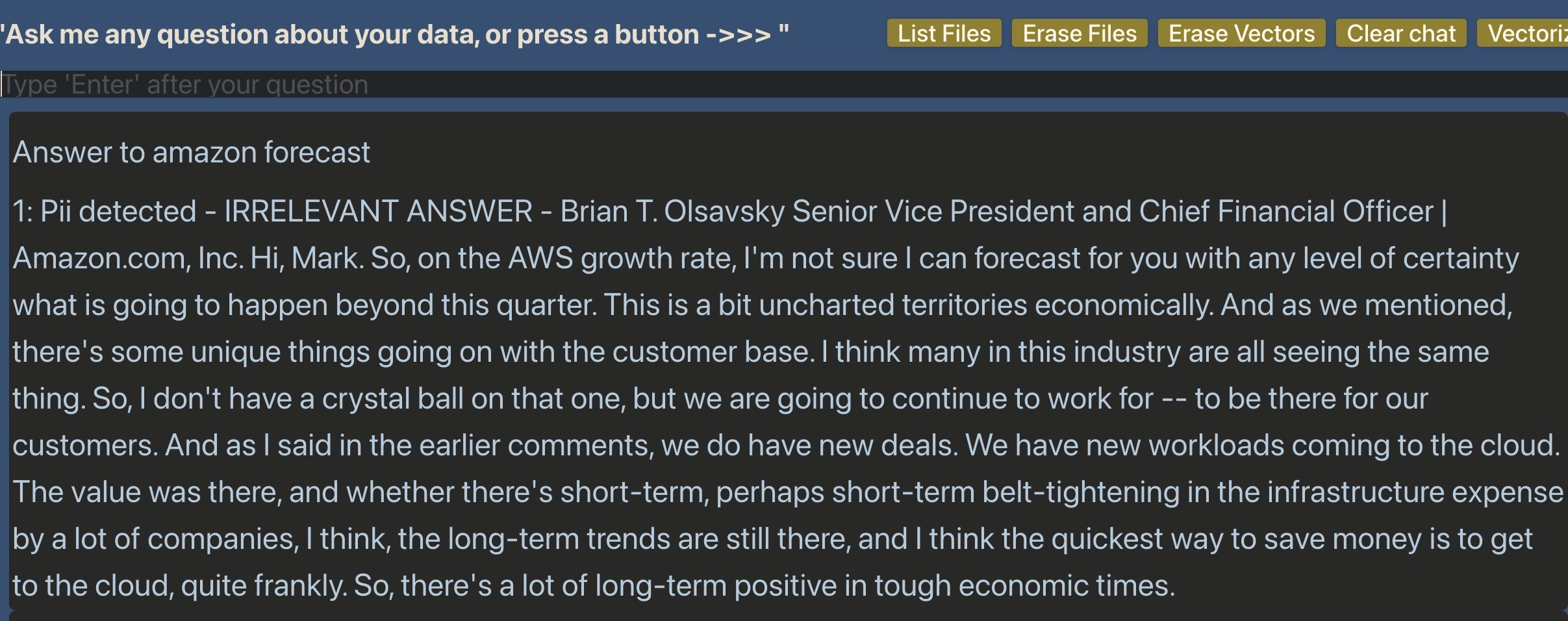
|