---
license: apache-2.0
---
# OpenChat: Advancing Open-source Language Models with Mixed-Quality Data
GitHub Repo •
Online Demo •
Discord •
Twitter •
Huggingface •
Paper
**🔥 The first 7B model Achieves Comparable Results with ChatGPT (March)! 🔥**
**🤖 #1 Open-source model on MT-bench scoring 7.81, outperforming 70B models 🤖**
OpenChat is an innovative library of open-source language models, fine-tuned with [C-RLFT](https://arxiv.org/pdf/2309.11235.pdf) - a strategy inspired by offline reinforcement learning. Our models learn from mixed-quality data without preference labels, delivering exceptional performance on par with ChatGPT, even with a 7B model. Despite our simple approach, we are committed to developing a high-performance, commercially viable, open-source large language model, and we continue to make significant strides toward this vision.
[](https://zenodo.org/badge/latestdoi/645397533)
## Usage
To use this model, we highly recommend installing the OpenChat package by following the [installation guide](https://github.com/imoneoi/openchat#installation) in our repository and using the OpenChat OpenAI-compatible API server by running the serving command from the table below. The server is optimized for high-throughput deployment using [vLLM](https://github.com/vllm-project/vllm) and can run on a consumer GPU with 24GB RAM. To enable tensor parallelism, append `--tensor-parallel-size N` to the serving command.
Once started, the server listens at `localhost:18888` for requests and is compatible with the [OpenAI ChatCompletion API specifications](https://platform.openai.com/docs/api-reference/chat). Please refer to the example request below for reference. Additionally, you can use the [OpenChat Web UI](https://github.com/imoneoi/openchat#web-ui) for a user-friendly experience.
If you want to deploy the server as an online service, you can use `--api-keys sk-KEY1 sk-KEY2 ...` to specify allowed API keys and `--disable-log-requests --disable-log-stats --log-file openchat.log` for logging only to a file. For security purposes, we recommend using an [HTTPS gateway](https://fastapi.tiangolo.com/es/deployment/concepts/#security-https) in front of the server.
Example request (click to expand)
```bash
curl http://localhost:18888/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openchat_3.5",
"messages": [{"role": "user", "content": "You are a large language model named OpenChat. Write a poem to describe yourself"}]
}'
```
Coding Mode
```bash
curl http://localhost:18888/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openchat_3.5",
"condition": "Code",
"messages": [{"role": "user", "content": "Write an aesthetic TODO app using HTML5 and JS, in a single file. You should use round corners and gradients to make it more aesthetic."}]
}'
```
| Model | Size | Context | Weights | Serving |
|--------------|------|---------|-------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------|
| OpenChat 3.5 | 7B | 8192 | [Huggingface](https://huggingface.co/openchat/openchat_3.5) | `python -m ochat.serving.openai_api_server --model openchat/openchat_3.5 --engine-use-ray --worker-use-ray` |
For inference with Huggingface Transformers (slow and not recommended), follow the conversation template provided below.
Conversation templates (click to expand)
```python
import transformers
tokenizer = transformers.AutoTokenizer.from_pretrained("openchat/openchat_3.5")
# Single-turn
tokens = tokenizer("GPT4 Correct User: Hello<|end_of_turn|>GPT4 Correct Assistant:").input_ids
assert tokens == [1, 420, 6316, 28781, 3198, 3123, 1247, 28747, 22557, 32000, 420, 6316, 28781, 3198, 3123, 21631, 28747]
# Multi-turn
tokens = tokenizer("GPT4 Correct User: Hello<|end_of_turn|>GPT4 Correct Assistant: Hi<|end_of_turn|>GPT4 Correct User: How are you today?<|end_of_turn|>GPT4 Correct Assistant:").input_ids
assert tokens == [1, 420, 6316, 28781, 3198, 3123, 1247, 28747, 22557, 32000, 420, 6316, 28781, 3198, 3123, 21631, 28747, 15359, 32000, 420, 6316, 28781, 3198, 3123, 1247, 28747, 1602, 460, 368, 3154, 28804, 32000, 420, 6316, 28781, 3198, 3123, 21631, 28747]
# Coding Mode
tokens = tokenizer("Code User: Implement quicksort using C++<|end_of_turn|>Code Assistant:").input_ids
assert tokens == [1, 7596, 1247, 28747, 26256, 2936, 7653, 1413, 334, 1680, 32000, 7596, 21631, 28747]
```
## Benchmarks
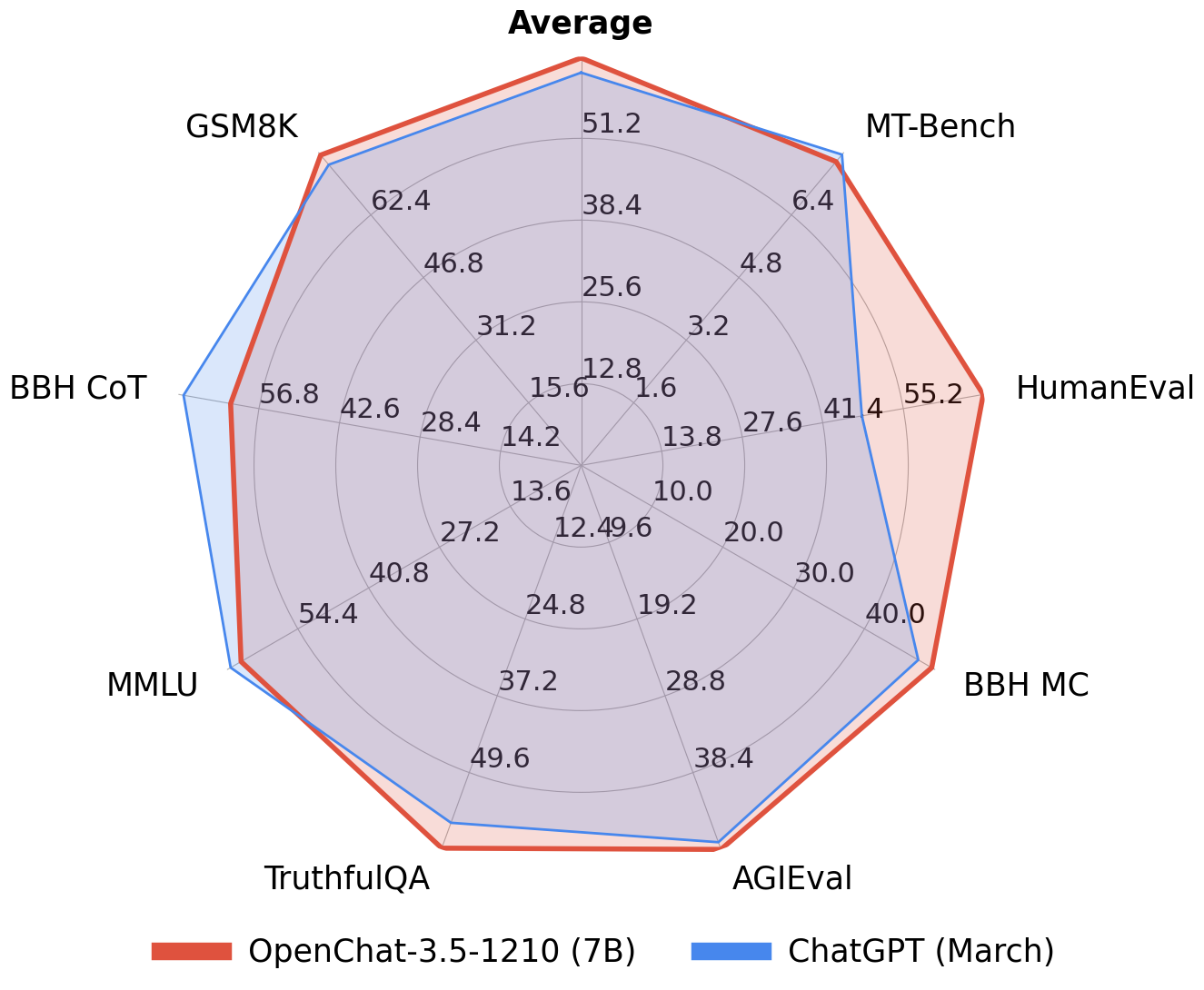
| Model | # Params | Average | MT-Bench | AGIEval | BBH MC | TruthfulQA | MMLU | HumanEval | BBH CoT | GSM8K |
|--------------------|----------|----------|--------------|----------|----------|---------------|--------------|-----------------|-------------|--------------|
| OpenChat-3.5 | **7B** | **61.6** | 7.81 | **47.4** | **47.6** | **59.1** | 64.3 | **55.5** | 63.5 | **77.3** |
| ChatGPT (March)* | ? | 61.5 | **7.94** | 47.1 | **47.6** | 57.7 | **67.3** | 48.1 | **70.1** | 74.9 |
| Mistral | 7B | - | 6.84 | 38.0 | 39.0 | - | 60.1 | 30.5 | - | 52.2 |
| Open-source SOTA** | 13B-70B | 61.4 | 7.71 | 41.7 | 49.7 | 62.3 | 63.7 | 73.2 | 41.4 | 82.3 |
| | | | WizardLM 70B | Orca 13B | Orca 13B | Platypus2 70B | WizardLM 70B | WizardCoder 34B | Flan-T5 11B | MetaMath 70B |
*: ChatGPT (March) results are from [GPT-4 Technical Report](https://arxiv.org/abs/2303.08774), [Chain-of-Thought Hub](https://github.com/FranxYao/chain-of-thought-hub), and our evaluation. Please note that ChatGPT is not a fixed baseline and evolves rapidly over time.
**: Open-source SOTA results are taken from reported results in instruction-tuned model papers and official repositories.
***: All zero-shot benchmarks follow the same setting as in the AGIEval paper and Orca paper. CoT tasks use the same configuration as Chain-of-Thought Hub, HumanEval is evaluated with EvalPlus, and MT-bench is run using FastChat. To reproduce our results, follow the instructions in [our repository](https://github.com/imoneoi/openchat/#benchmarks).
## Limitations
**Foundation Model Limitations**
Despite its advanced capabilities, OpenChat is still bound by the limitations inherent in its foundation models. These limitations may impact the model's performance in areas such as:
- Complex reasoning
- Mathematical and arithmetic tasks
- Programming and coding challenges
**Hallucination of Non-existent Information**
OpenChat may sometimes generate information that does not exist or is not accurate, also known as "hallucination". Users should be aware of this possibility and verify any critical information obtained from the model.
**Safety**
OpenChat may sometimes generate harmful, hate speech, biased responses, or answer unsafe questions. It's crucial to apply additional AI safety measures in use cases that require safe and moderated responses.
## License
Our OpenChat 3.5 code and models are distributed under the Apache License 2.0.
## Citation
```
@article{wang2023openchat,
title={OpenChat: Advancing Open-source Language Models with Mixed-Quality Data},
author={Wang, Guan and Cheng, Sijie and Zhan, Xianyuan and Li, Xiangang and Song, Sen and Liu, Yang},
journal={arXiv preprint arXiv:2309.11235},
year={2023}
}
```
## Acknowledgements
We extend our heartfelt gratitude to Alignment Lab AI, Nous Research, and Pygmalion AI for their substantial contributions to data collection and model training.
Special thanks go to Changling Liu from GPT Desk Pte. Ltd., Qiying Yu at Tsinghua University, Baochang Ma, and Hao Wan from 01.AI company for their generous provision of resources. We are also deeply grateful to Jianxiong Li and Peng Li at Tsinghua University for their insightful discussions.
Furthermore, we appreciate the developers behind the following projects for their significant contributions to our research: [Mistral](https://mistral.ai/), [Chain-of-Thought Hub](https://github.com/FranxYao/chain-of-thought-hub), [Llama 2](https://ai.meta.com/llama/), [Self-Instruct](https://arxiv.org/abs/2212.10560), [FastChat (Vicuna)](https://github.com/lm-sys/FastChat), [Alpaca](https://github.com/tatsu-lab/stanford_alpaca.git), and [StarCoder](https://github.com/bigcode-project/starcoder). Their work has been instrumental in driving our research forward.