
Commit
•
0a717d4
1
Parent(s):
0851965
Upload folder using huggingface_hub
Browse files- README.md +5 -4
- data/needle.png +2 -2
- data/topic.png +0 -0
README.md
CHANGED
|
@@ -6,7 +6,7 @@ pipeline_tag: text-generation
|
|
| 6 |
<div align="center">
|
| 7 |
<h1>Llama-3-8B-Instruct-80K-QLoRA</h1>
|
| 8 |
|
| 9 |
-
<a href="https://github.com/FlagOpen/FlagEmbedding/tree/master/Long_LLM/
|
| 10 |
</div>
|
| 11 |
|
| 12 |
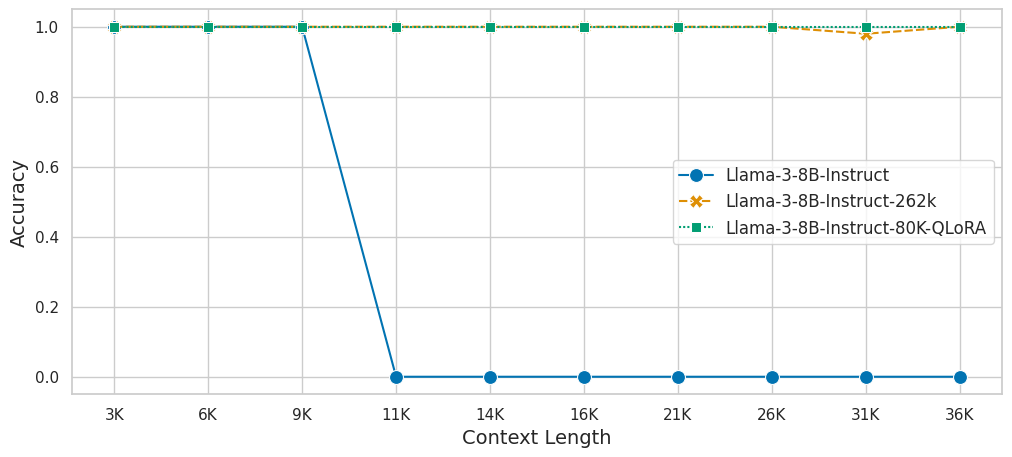
We extend the context length of Llama-3-8B-Instruct to 80K using QLoRA and 3.5K long-context training data synthesized from GPT-4. The entire training cycle is super efficient, which takes 8 hours on a 8xA800 (80G) machine. Yet, the resulted model achieves remarkable performance on a series of downstream long-context evaluation benchmarks.
|
|
@@ -27,9 +27,9 @@ We evaluate the model on [LongBench](https://arxiv.org/abs/2308.14508) using 32K
|
|
| 27 |
|
| 28 |
|Model|Single-Doc QA|Multi-Doc QA|Summarization|Few-Shot Learning|Synthetic|Code|
|
| 29 |
|:-:|:-:|:-:|:-:|:-:|:-:|:-:|
|
| 30 |
-
|[meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)|37.33|36.04|26.83
|
| 31 |
|[gradientai/Llama-3-8B-Instruct-262k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k)|37.29|31.20|26.18|67.25|44.25|**62.71**|
|
| 32 |
-
|[Llama-3-8B-Instruct-80K-QLoRA]()|**43.57**|**43.07**|**28.93
|
| 33 |
|
| 34 |
## InfiniteBench
|
| 35 |
We evaluate the model on [InfiniteBench](https://arxiv.org/pdf/2402.13718.pdf) using 80K context length and the official prompt template. The results of GPT4 is copied from the [paper](https://arxiv.org/pdf/2402.13718.pdf). For [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct), we use 8K context length.
|
|
@@ -88,7 +88,6 @@ base_model = AutoModelForCausalLM.from_pretrained(
|
|
| 88 |
|
| 89 |
# NOTE: expand rope base
|
| 90 |
rope_theta=200e6,
|
| 91 |
-
max_position_embeddings=81920,
|
| 92 |
)
|
| 93 |
|
| 94 |
model = PeftModel.from_pretrained(
|
|
@@ -119,3 +118,5 @@ with torch.no_grad():
|
|
| 119 |
print(f"Answers: {example['answer']}")
|
| 120 |
print(f"Prediction: {tokenizer.decode(outputs[0])}")
|
| 121 |
```
|
|
|
|
|
|
|
|
|
| 6 |
<div align="center">
|
| 7 |
<h1>Llama-3-8B-Instruct-80K-QLoRA</h1>
|
| 8 |
|
| 9 |
+
<a href="https://github.com/FlagOpen/FlagEmbedding/tree/master/Long_LLM/">[Data&Code]</a>
|
| 10 |
</div>
|
| 11 |
|
| 12 |
We extend the context length of Llama-3-8B-Instruct to 80K using QLoRA and 3.5K long-context training data synthesized from GPT-4. The entire training cycle is super efficient, which takes 8 hours on a 8xA800 (80G) machine. Yet, the resulted model achieves remarkable performance on a series of downstream long-context evaluation benchmarks.
|
|
|
|
| 27 |
|
| 28 |
|Model|Single-Doc QA|Multi-Doc QA|Summarization|Few-Shot Learning|Synthetic|Code|
|
| 29 |
|:-:|:-:|:-:|:-:|:-:|:-:|:-:|
|
| 30 |
+
|[meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)|37.33|36.04|26.83|**69.56**|37.75|53.24|
|
| 31 |
|[gradientai/Llama-3-8B-Instruct-262k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k)|37.29|31.20|26.18|67.25|44.25|**62.71**|
|
| 32 |
+
|[Llama-3-8B-Instruct-80K-QLoRA]()|**43.57**|**43.07**|**28.93**|69.15|**48.50**|51.95|
|
| 33 |
|
| 34 |
## InfiniteBench
|
| 35 |
We evaluate the model on [InfiniteBench](https://arxiv.org/pdf/2402.13718.pdf) using 80K context length and the official prompt template. The results of GPT4 is copied from the [paper](https://arxiv.org/pdf/2402.13718.pdf). For [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct), we use 8K context length.
|
|
|
|
| 88 |
|
| 89 |
# NOTE: expand rope base
|
| 90 |
rope_theta=200e6,
|
|
|
|
| 91 |
)
|
| 92 |
|
| 93 |
model = PeftModel.from_pretrained(
|
|
|
|
| 118 |
print(f"Answers: {example['answer']}")
|
| 119 |
print(f"Prediction: {tokenizer.decode(outputs[0])}")
|
| 120 |
```
|
| 121 |
+
You may observe messages like:
|
| 122 |
+
`This is a friendly reminder - the current text generation call will exceed the model's predefined maximum length (8192). Depending on the model, you may observe exceptions, performance degradation, or nothing at all.` or `Setting pad_token_id to eos_token_id:128001 for open-end generation`. They do not matter. Just ignore them.
|
data/needle.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
data/topic.png
ADDED
|