---
license: mit
pipeline_tag: text-generation
---
We extend the context length of Llama-3-8B-Instruct to 80K using QLoRA and 3.5K long-context training data synthesized from GPT-4. The entire training cycle is super efficient, which takes 8 hours on a 8xA800 (80G) machine. Yet, the resulted model achieves remarkable performance on a series of downstream long-context evaluation benchmarks.
**NOTE**: This model is the result of merging [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) and [namespace-Pt/Llama-3-8B-Instruct-80K-QLoRA](https://huggingface.co/namespace-Pt/Llama-3-8B-Instruct-80K-QLoRA).
# Evaluation
All the following evaluation results can be reproduced following instructions [here](https://github.com/FlagOpen/FlagEmbedding/tree/master/Long_LLM/longllm_qlora).
## Needle in a Haystack
We evaluate the model on the Needle-In-A-HayStack task using the official setting. The blue vertical line indicates the training context length, i.e. 80K.
 ## LongBench
We evaluate the model on [LongBench](https://arxiv.org/abs/2308.14508) using 32K context length and the official prompt template. For [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct), we use 8K context length.
|Model|Single-Doc QA|Multi-Doc QA|Summarization|Few-Shot Learning|Synthetic|Code|Avg|
|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|
|[meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)|37.33|36.04|26.83|**69.56**|37.75|53.24|43.20|
|[gradientai/Llama-3-8B-Instruct-262k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k)|37.29|31.20|26.18|67.25|44.25|**62.71**|43.73|
|Llama-3-8B-Instruct-80K-QLoRA-Merged|**43.57**|**43.07**|**28.93**|69.15|**48.50**|51.95|**47.19**|
## InfiniteBench
We evaluate the model on [InfiniteBench](https://arxiv.org/pdf/2402.13718.pdf) using 80K context length and the official prompt template. The results of GPT-4 is copied from the [paper](https://arxiv.org/pdf/2402.13718.pdf). For [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct), we use 8K context length.
|Model|LongBookQA Eng|LongBookSum Eng|
|:-:|:-:|:-:|
|GPT-4|22.22|14.73|
|[meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)|7.00|**16.40**|
|[gradientai/Llama-3-8B-Instruct-262k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k)|20.30|10.34|
|Llama-3-8B-Instruct-80K-QLoRA-Merged|**30.92**|14.73|
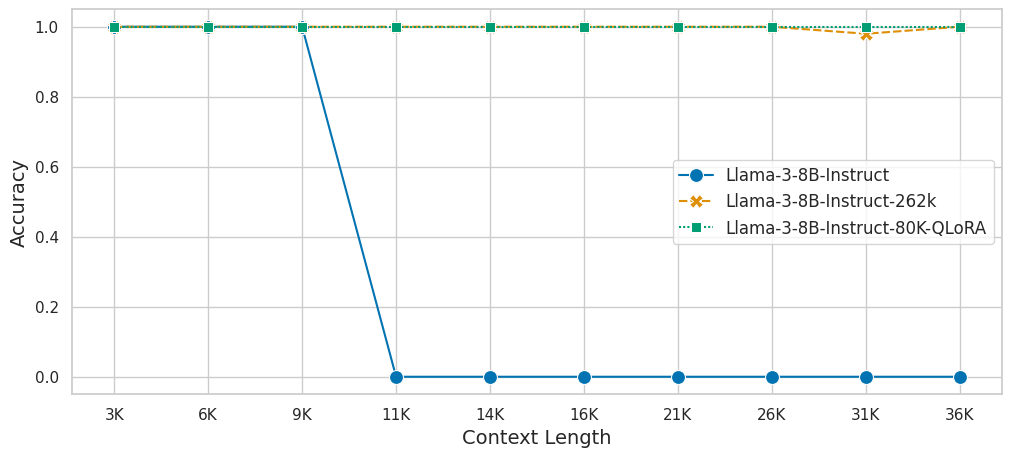
## Topic Retrieval
We evaluate the model on [Topic Retrieval](https://lmsys.org/blog/2023-06-29-longchat/) task with `[5,10,15,20,25,30,40,50,60,70]` topics.
## LongBench
We evaluate the model on [LongBench](https://arxiv.org/abs/2308.14508) using 32K context length and the official prompt template. For [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct), we use 8K context length.
|Model|Single-Doc QA|Multi-Doc QA|Summarization|Few-Shot Learning|Synthetic|Code|Avg|
|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|
|[meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)|37.33|36.04|26.83|**69.56**|37.75|53.24|43.20|
|[gradientai/Llama-3-8B-Instruct-262k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k)|37.29|31.20|26.18|67.25|44.25|**62.71**|43.73|
|Llama-3-8B-Instruct-80K-QLoRA-Merged|**43.57**|**43.07**|**28.93**|69.15|**48.50**|51.95|**47.19**|
## InfiniteBench
We evaluate the model on [InfiniteBench](https://arxiv.org/pdf/2402.13718.pdf) using 80K context length and the official prompt template. The results of GPT-4 is copied from the [paper](https://arxiv.org/pdf/2402.13718.pdf). For [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct), we use 8K context length.
|Model|LongBookQA Eng|LongBookSum Eng|
|:-:|:-:|:-:|
|GPT-4|22.22|14.73|
|[meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)|7.00|**16.40**|
|[gradientai/Llama-3-8B-Instruct-262k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k)|20.30|10.34|
|Llama-3-8B-Instruct-80K-QLoRA-Merged|**30.92**|14.73|
## Topic Retrieval
We evaluate the model on [Topic Retrieval](https://lmsys.org/blog/2023-06-29-longchat/) task with `[5,10,15,20,25,30,40,50,60,70]` topics.
 ## MMLU
We evaluate the model's zero-shot performance on MMLU benchmark as a reflection of its short-context capability.
|Model|STEM|Social Sciences|Humanities|Others|Avg|
|:-:|:-:|:-:|:-:|:-:|:-:|
|[Llama-2-7B-Chat](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf)|35.92|54.37|51.74|51.42|47.22|
|[Mistral-7B-v0.2-Instruct](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)|48.79|69.95|64.99|61.64|60.10|
|[meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)|**53.87**|**75.66**|**69.44**|69.75|**65.91**|
|[gradientai/Llama-3-8B-Instruct-262k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k)|52.10|73.26|67.15|**69.80**|64.34|
|Llama-3-8B-Instruct-80K-QLoRA-Merged|53.10|73.24|67.32|68.79|64.44|
# Environment
```bash
torch==2.2.2
flash_attn==2.5.6
transformers==4.39.3
```
# Usage
```python
import json
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "namespace-Pt/Llama-3-8B-Instruct-80K-QLoRA-Merged"
torch_dtype = torch.bfloat16
# place the model on GPU
device_map = {"": "cuda"}
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map=device_map,
attn_implementation="flash_attention_2",
).eval()
with torch.no_grad():
# short context
messages = [{"role": "user", "content": "Tell me about yourself."}]
inputs = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt", return_dict=True).to("cuda")
outputs = model.generate(**inputs, max_new_tokens=50)[:, inputs["input_ids"].shape[1]:]
print(f"Input Length: {inputs['input_ids'].shape[1]}")
print(f"Output: {tokenizer.decode(outputs[0])}")
# long context
with open("data/narrativeqa.json", encoding="utf-8") as f:
example = json.load(f)
messages = [{"role": "user", "content": example["context"]}]
inputs = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt", return_dict=True).to("cuda")
outputs = model.generate(**inputs, do_sample=False, top_p=1, temperature=1, max_new_tokens=20)[:, inputs["input_ids"].shape[1]:]
print("*"*20)
print(f"Input Length: {inputs['input_ids'].shape[1]}")
print(f"Answers: {example['answer']}")
print(f"Prediction: {tokenizer.decode(outputs[0])}")
```
You may observe messages like:
`This is a friendly reminder - the current text generation call will exceed the model's predefined maximum length (8192). Depending on the model, you may observe exceptions, performance degradation, or nothing at all.` or `Setting pad_token_id to eos_token_id:128001 for open-end generation`. They do not matter. Just ignore them.
## MMLU
We evaluate the model's zero-shot performance on MMLU benchmark as a reflection of its short-context capability.
|Model|STEM|Social Sciences|Humanities|Others|Avg|
|:-:|:-:|:-:|:-:|:-:|:-:|
|[Llama-2-7B-Chat](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf)|35.92|54.37|51.74|51.42|47.22|
|[Mistral-7B-v0.2-Instruct](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)|48.79|69.95|64.99|61.64|60.10|
|[meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)|**53.87**|**75.66**|**69.44**|69.75|**65.91**|
|[gradientai/Llama-3-8B-Instruct-262k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k)|52.10|73.26|67.15|**69.80**|64.34|
|Llama-3-8B-Instruct-80K-QLoRA-Merged|53.10|73.24|67.32|68.79|64.44|
# Environment
```bash
torch==2.2.2
flash_attn==2.5.6
transformers==4.39.3
```
# Usage
```python
import json
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "namespace-Pt/Llama-3-8B-Instruct-80K-QLoRA-Merged"
torch_dtype = torch.bfloat16
# place the model on GPU
device_map = {"": "cuda"}
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map=device_map,
attn_implementation="flash_attention_2",
).eval()
with torch.no_grad():
# short context
messages = [{"role": "user", "content": "Tell me about yourself."}]
inputs = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt", return_dict=True).to("cuda")
outputs = model.generate(**inputs, max_new_tokens=50)[:, inputs["input_ids"].shape[1]:]
print(f"Input Length: {inputs['input_ids'].shape[1]}")
print(f"Output: {tokenizer.decode(outputs[0])}")
# long context
with open("data/narrativeqa.json", encoding="utf-8") as f:
example = json.load(f)
messages = [{"role": "user", "content": example["context"]}]
inputs = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt", return_dict=True).to("cuda")
outputs = model.generate(**inputs, do_sample=False, top_p=1, temperature=1, max_new_tokens=20)[:, inputs["input_ids"].shape[1]:]
print("*"*20)
print(f"Input Length: {inputs['input_ids'].shape[1]}")
print(f"Answers: {example['answer']}")
print(f"Prediction: {tokenizer.decode(outputs[0])}")
```
You may observe messages like:
`This is a friendly reminder - the current text generation call will exceed the model's predefined maximum length (8192). Depending on the model, you may observe exceptions, performance degradation, or nothing at all.` or `Setting pad_token_id to eos_token_id:128001 for open-end generation`. They do not matter. Just ignore them.