
This view is limited to 50 files because it contains too many changes.
See raw diff
- CITATION.cff +8 -0
- Dockerfile +26 -0
- EfficientSAM/EdgeSAM/common.py +118 -0
- EfficientSAM/EdgeSAM/rep_vit.py +370 -0
- EfficientSAM/EdgeSAM/setup_edge_sam.py +90 -0
- EfficientSAM/FastSAM/tools.py +413 -0
- EfficientSAM/LightHQSAM/example_light_hqsam.png +3 -0
- EfficientSAM/LightHQSAM/grounded_light_hqsam_annotated_image.jpg +3 -0
- EfficientSAM/LightHQSAM/setup_light_hqsam.py +45 -0
- EfficientSAM/LightHQSAM/tiny_vit_sam.py +724 -0
- EfficientSAM/MobileSAM/setup_mobile_sam.py +44 -0
- EfficientSAM/MobileSAM/tiny_vit_sam.py +716 -0
- EfficientSAM/README.md +194 -0
- EfficientSAM/RepViTSAM/repvit.py +364 -0
- EfficientSAM/RepViTSAM/setup_repvit_sam.py +53 -0
- EfficientSAM/grounded_edge_sam.py +107 -0
- EfficientSAM/grounded_efficient_sam.py +118 -0
- EfficientSAM/grounded_fast_sam.py +141 -0
- EfficientSAM/grounded_light_hqsam.py +109 -0
- EfficientSAM/grounded_mobile_sam.py +145 -0
- EfficientSAM/grounded_repvit_sam.py +107 -0
- GroundingDINO/.asset/COCO.png +3 -0
- GroundingDINO/.asset/GD_GLIGEN.png +3 -0
- GroundingDINO/.asset/GD_SD.png +3 -0
- GroundingDINO/.asset/ODinW.png +3 -0
- GroundingDINO/.asset/arch.png +3 -0
- GroundingDINO/.asset/cats.png +3 -0
- GroundingDINO/.asset/hero_figure.png +3 -0
- GroundingDINO/LICENSE +201 -0
- GroundingDINO/README.md +163 -0
- GroundingDINO/demo/gradio_app.py +125 -0
- GroundingDINO/demo/inference_on_a_image.py +172 -0
- GroundingDINO/groundingdino/__init__.py +0 -0
- GroundingDINO/groundingdino/config/GroundingDINO_SwinB.py +43 -0
- GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py +43 -0
- GroundingDINO/groundingdino/datasets/__init__.py +0 -0
- GroundingDINO/groundingdino/datasets/transforms.py +311 -0
- GroundingDINO/groundingdino/models/GroundingDINO/__init__.py +15 -0
- GroundingDINO/groundingdino/models/GroundingDINO/backbone/__init__.py +1 -0
- GroundingDINO/groundingdino/models/GroundingDINO/backbone/backbone.py +221 -0
- GroundingDINO/groundingdino/models/GroundingDINO/backbone/position_encoding.py +186 -0
- GroundingDINO/groundingdino/models/GroundingDINO/backbone/swin_transformer.py +802 -0
- GroundingDINO/groundingdino/models/GroundingDINO/bertwarper.py +273 -0
- GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn.h +64 -0
- GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cpu.cpp +43 -0
- GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cpu.h +35 -0
- GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cuda.cu +156 -0
- GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cuda.h +33 -0
- GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_im2col_cuda.cuh +1327 -0
- GroundingDINO/groundingdino/models/GroundingDINO/csrc/cuda_version.cu +7 -0
CITATION.cff
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
cff-version: 1.2.0
|
| 2 |
+
message: "If you use this software, please cite it as below."
|
| 3 |
+
authors:
|
| 4 |
+
- name: "Grounded-SAM Contributors"
|
| 5 |
+
title: "Grounded-Segment-Anything"
|
| 6 |
+
date-released: 2023-04-06
|
| 7 |
+
url: "https://github.com/IDEA-Research/Grounded-Segment-Anything"
|
| 8 |
+
license: Apache-2.0
|
Dockerfile
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM pytorch/pytorch:1.13.1-cuda11.6-cudnn8-devel
|
| 2 |
+
|
| 3 |
+
# Arguments to build Docker Image using CUDA
|
| 4 |
+
ARG USE_CUDA=0
|
| 5 |
+
ARG TORCH_ARCH=
|
| 6 |
+
|
| 7 |
+
ENV AM_I_DOCKER True
|
| 8 |
+
ENV BUILD_WITH_CUDA "${USE_CUDA}"
|
| 9 |
+
ENV TORCH_CUDA_ARCH_LIST "${TORCH_ARCH}"
|
| 10 |
+
ENV CUDA_HOME /usr/local/cuda-11.6/
|
| 11 |
+
|
| 12 |
+
RUN mkdir -p /home/appuser/Grounded-Segment-Anything
|
| 13 |
+
COPY . /home/appuser/Grounded-Segment-Anything/
|
| 14 |
+
|
| 15 |
+
RUN apt-get update && apt-get install --no-install-recommends wget ffmpeg=7:* \
|
| 16 |
+
libsm6=2:* libxext6=2:* git=1:* nano=2.* \
|
| 17 |
+
vim=2:* -y \
|
| 18 |
+
&& apt-get clean && apt-get autoremove && rm -rf /var/lib/apt/lists/*
|
| 19 |
+
|
| 20 |
+
WORKDIR /home/appuser/Grounded-Segment-Anything
|
| 21 |
+
RUN python -m pip install --no-cache-dir -e segment_anything && \
|
| 22 |
+
python -m pip install --no-cache-dir -e GroundingDINO
|
| 23 |
+
WORKDIR /home/appuser
|
| 24 |
+
RUN pip install --no-cache-dir diffusers[torch]==0.15.1 opencv-python==4.7.0.72 \
|
| 25 |
+
pycocotools==2.0.6 matplotlib==3.5.3 \
|
| 26 |
+
onnxruntime==1.14.1 onnx==1.13.1 ipykernel==6.16.2 scipy gradio openai
|
EfficientSAM/EdgeSAM/common.py
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
|
| 11 |
+
from typing import Type
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class MLPBlock(nn.Module):
|
| 15 |
+
def __init__(
|
| 16 |
+
self,
|
| 17 |
+
embedding_dim: int,
|
| 18 |
+
mlp_dim: int,
|
| 19 |
+
act: Type[nn.Module] = nn.GELU,
|
| 20 |
+
) -> None:
|
| 21 |
+
super().__init__()
|
| 22 |
+
self.lin1 = nn.Linear(embedding_dim, mlp_dim)
|
| 23 |
+
self.lin2 = nn.Linear(mlp_dim, embedding_dim)
|
| 24 |
+
self.act = act()
|
| 25 |
+
|
| 26 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 27 |
+
return self.lin2(self.act(self.lin1(x)))
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
# From https://github.com/facebookresearch/detectron2/blob/main/detectron2/layers/batch_norm.py # noqa
|
| 31 |
+
# Itself from https://github.com/facebookresearch/ConvNeXt/blob/d1fa8f6fef0a165b27399986cc2bdacc92777e40/models/convnext.py#L119 # noqa
|
| 32 |
+
class LayerNorm2d(nn.Module):
|
| 33 |
+
def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
|
| 34 |
+
super().__init__()
|
| 35 |
+
self.weight = nn.Parameter(torch.ones(num_channels))
|
| 36 |
+
self.bias = nn.Parameter(torch.zeros(num_channels))
|
| 37 |
+
self.eps = eps
|
| 38 |
+
|
| 39 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 40 |
+
u = x.mean(1, keepdim=True)
|
| 41 |
+
s = (x - u).pow(2).mean(1, keepdim=True)
|
| 42 |
+
x = (x - u) / torch.sqrt(s + self.eps)
|
| 43 |
+
x = self.weight[:, None, None] * x + self.bias[:, None, None]
|
| 44 |
+
return x
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def val2list(x: list or tuple or any, repeat_time=1) -> list:
|
| 48 |
+
if isinstance(x, (list, tuple)):
|
| 49 |
+
return list(x)
|
| 50 |
+
return [x for _ in range(repeat_time)]
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def val2tuple(x: list or tuple or any, min_len: int = 1, idx_repeat: int = -1) -> tuple:
|
| 54 |
+
x = val2list(x)
|
| 55 |
+
|
| 56 |
+
# repeat elements if necessary
|
| 57 |
+
if len(x) > 0:
|
| 58 |
+
x[idx_repeat:idx_repeat] = [x[idx_repeat] for _ in range(min_len - len(x))]
|
| 59 |
+
|
| 60 |
+
return tuple(x)
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def list_sum(x: list) -> any:
|
| 64 |
+
return x[0] if len(x) == 1 else x[0] + list_sum(x[1:])
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def resize(
|
| 68 |
+
x: torch.Tensor,
|
| 69 |
+
size: any or None = None,
|
| 70 |
+
scale_factor=None,
|
| 71 |
+
mode: str = "bicubic",
|
| 72 |
+
align_corners: bool or None = False,
|
| 73 |
+
) -> torch.Tensor:
|
| 74 |
+
if mode in ["bilinear", "bicubic"]:
|
| 75 |
+
return F.interpolate(
|
| 76 |
+
x,
|
| 77 |
+
size=size,
|
| 78 |
+
scale_factor=scale_factor,
|
| 79 |
+
mode=mode,
|
| 80 |
+
align_corners=align_corners,
|
| 81 |
+
)
|
| 82 |
+
elif mode in ["nearest", "area"]:
|
| 83 |
+
return F.interpolate(x, size=size, scale_factor=scale_factor, mode=mode)
|
| 84 |
+
else:
|
| 85 |
+
raise NotImplementedError(f"resize(mode={mode}) not implemented.")
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
class UpSampleLayer(nn.Module):
|
| 89 |
+
def __init__(
|
| 90 |
+
self,
|
| 91 |
+
mode="bicubic",
|
| 92 |
+
size=None,
|
| 93 |
+
factor=2,
|
| 94 |
+
align_corners=False,
|
| 95 |
+
):
|
| 96 |
+
super(UpSampleLayer, self).__init__()
|
| 97 |
+
self.mode = mode
|
| 98 |
+
self.size = val2list(size, 2) if size is not None else None
|
| 99 |
+
self.factor = None if self.size is not None else factor
|
| 100 |
+
self.align_corners = align_corners
|
| 101 |
+
|
| 102 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 103 |
+
return resize(x, self.size, self.factor, self.mode, self.align_corners)
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
class OpSequential(nn.Module):
|
| 107 |
+
def __init__(self, op_list):
|
| 108 |
+
super(OpSequential, self).__init__()
|
| 109 |
+
valid_op_list = []
|
| 110 |
+
for op in op_list:
|
| 111 |
+
if op is not None:
|
| 112 |
+
valid_op_list.append(op)
|
| 113 |
+
self.op_list = nn.ModuleList(valid_op_list)
|
| 114 |
+
|
| 115 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 116 |
+
for op in self.op_list:
|
| 117 |
+
x = op(x)
|
| 118 |
+
return x
|
EfficientSAM/EdgeSAM/rep_vit.py
ADDED
|
@@ -0,0 +1,370 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.nn as nn
|
| 2 |
+
from EdgeSAM.common import LayerNorm2d, UpSampleLayer, OpSequential
|
| 3 |
+
|
| 4 |
+
__all__ = ['rep_vit_m1', 'rep_vit_m2', 'rep_vit_m3', 'RepViT']
|
| 5 |
+
|
| 6 |
+
m1_cfgs = [
|
| 7 |
+
# k, t, c, SE, HS, s
|
| 8 |
+
[3, 2, 48, 1, 0, 1],
|
| 9 |
+
[3, 2, 48, 0, 0, 1],
|
| 10 |
+
[3, 2, 48, 0, 0, 1],
|
| 11 |
+
[3, 2, 96, 0, 0, 2],
|
| 12 |
+
[3, 2, 96, 1, 0, 1],
|
| 13 |
+
[3, 2, 96, 0, 0, 1],
|
| 14 |
+
[3, 2, 96, 0, 0, 1],
|
| 15 |
+
[3, 2, 192, 0, 1, 2],
|
| 16 |
+
[3, 2, 192, 1, 1, 1],
|
| 17 |
+
[3, 2, 192, 0, 1, 1],
|
| 18 |
+
[3, 2, 192, 1, 1, 1],
|
| 19 |
+
[3, 2, 192, 0, 1, 1],
|
| 20 |
+
[3, 2, 192, 1, 1, 1],
|
| 21 |
+
[3, 2, 192, 0, 1, 1],
|
| 22 |
+
[3, 2, 192, 1, 1, 1],
|
| 23 |
+
[3, 2, 192, 0, 1, 1],
|
| 24 |
+
[3, 2, 192, 1, 1, 1],
|
| 25 |
+
[3, 2, 192, 0, 1, 1],
|
| 26 |
+
[3, 2, 192, 1, 1, 1],
|
| 27 |
+
[3, 2, 192, 0, 1, 1],
|
| 28 |
+
[3, 2, 192, 1, 1, 1],
|
| 29 |
+
[3, 2, 192, 0, 1, 1],
|
| 30 |
+
[3, 2, 192, 0, 1, 1],
|
| 31 |
+
[3, 2, 384, 0, 1, 2],
|
| 32 |
+
[3, 2, 384, 1, 1, 1],
|
| 33 |
+
[3, 2, 384, 0, 1, 1]
|
| 34 |
+
]
|
| 35 |
+
|
| 36 |
+
m2_cfgs = [
|
| 37 |
+
# k, t, c, SE, HS, s
|
| 38 |
+
[3, 2, 64, 1, 0, 1],
|
| 39 |
+
[3, 2, 64, 0, 0, 1],
|
| 40 |
+
[3, 2, 64, 0, 0, 1],
|
| 41 |
+
[3, 2, 128, 0, 0, 2],
|
| 42 |
+
[3, 2, 128, 1, 0, 1],
|
| 43 |
+
[3, 2, 128, 0, 0, 1],
|
| 44 |
+
[3, 2, 128, 0, 0, 1],
|
| 45 |
+
[3, 2, 256, 0, 1, 2],
|
| 46 |
+
[3, 2, 256, 1, 1, 1],
|
| 47 |
+
[3, 2, 256, 0, 1, 1],
|
| 48 |
+
[3, 2, 256, 1, 1, 1],
|
| 49 |
+
[3, 2, 256, 0, 1, 1],
|
| 50 |
+
[3, 2, 256, 1, 1, 1],
|
| 51 |
+
[3, 2, 256, 0, 1, 1],
|
| 52 |
+
[3, 2, 256, 1, 1, 1],
|
| 53 |
+
[3, 2, 256, 0, 1, 1],
|
| 54 |
+
[3, 2, 256, 1, 1, 1],
|
| 55 |
+
[3, 2, 256, 0, 1, 1],
|
| 56 |
+
[3, 2, 256, 1, 1, 1],
|
| 57 |
+
[3, 2, 256, 0, 1, 1],
|
| 58 |
+
[3, 2, 256, 0, 1, 1],
|
| 59 |
+
[3, 2, 512, 0, 1, 2],
|
| 60 |
+
[3, 2, 512, 1, 1, 1],
|
| 61 |
+
[3, 2, 512, 0, 1, 1]
|
| 62 |
+
]
|
| 63 |
+
|
| 64 |
+
m3_cfgs = [
|
| 65 |
+
# k, t, c, SE, HS, s
|
| 66 |
+
[3, 2, 64, 1, 0, 1],
|
| 67 |
+
[3, 2, 64, 0, 0, 1],
|
| 68 |
+
[3, 2, 64, 1, 0, 1],
|
| 69 |
+
[3, 2, 64, 0, 0, 1],
|
| 70 |
+
[3, 2, 64, 0, 0, 1],
|
| 71 |
+
[3, 2, 128, 0, 0, 2],
|
| 72 |
+
[3, 2, 128, 1, 0, 1],
|
| 73 |
+
[3, 2, 128, 0, 0, 1],
|
| 74 |
+
[3, 2, 128, 1, 0, 1],
|
| 75 |
+
[3, 2, 128, 0, 0, 1],
|
| 76 |
+
[3, 2, 128, 0, 0, 1],
|
| 77 |
+
[3, 2, 256, 0, 1, 2],
|
| 78 |
+
[3, 2, 256, 1, 1, 1],
|
| 79 |
+
[3, 2, 256, 0, 1, 1],
|
| 80 |
+
[3, 2, 256, 1, 1, 1],
|
| 81 |
+
[3, 2, 256, 0, 1, 1],
|
| 82 |
+
[3, 2, 256, 1, 1, 1],
|
| 83 |
+
[3, 2, 256, 0, 1, 1],
|
| 84 |
+
[3, 2, 256, 1, 1, 1],
|
| 85 |
+
[3, 2, 256, 0, 1, 1],
|
| 86 |
+
[3, 2, 256, 1, 1, 1],
|
| 87 |
+
[3, 2, 256, 0, 1, 1],
|
| 88 |
+
[3, 2, 256, 1, 1, 1],
|
| 89 |
+
[3, 2, 256, 0, 1, 1],
|
| 90 |
+
[3, 2, 256, 1, 1, 1],
|
| 91 |
+
[3, 2, 256, 0, 1, 1],
|
| 92 |
+
[3, 2, 256, 1, 1, 1],
|
| 93 |
+
[3, 2, 256, 0, 1, 1],
|
| 94 |
+
[3, 2, 256, 1, 1, 1],
|
| 95 |
+
[3, 2, 256, 0, 1, 1],
|
| 96 |
+
[3, 2, 256, 0, 1, 1],
|
| 97 |
+
[3, 2, 512, 0, 1, 2],
|
| 98 |
+
[3, 2, 512, 1, 1, 1],
|
| 99 |
+
[3, 2, 512, 0, 1, 1]
|
| 100 |
+
]
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def _make_divisible(v, divisor, min_value=None):
|
| 104 |
+
"""
|
| 105 |
+
This function is taken from the original tf repo.
|
| 106 |
+
It ensures that all layers have a channel number that is divisible by 8
|
| 107 |
+
It can be seen here:
|
| 108 |
+
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
|
| 109 |
+
:param v:
|
| 110 |
+
:param divisor:
|
| 111 |
+
:param min_value:
|
| 112 |
+
:return:
|
| 113 |
+
"""
|
| 114 |
+
if min_value is None:
|
| 115 |
+
min_value = divisor
|
| 116 |
+
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
|
| 117 |
+
# Make sure that round down does not go down by more than 10%.
|
| 118 |
+
if new_v < 0.9 * v:
|
| 119 |
+
new_v += divisor
|
| 120 |
+
return new_v
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
from timm.models.layers import SqueezeExcite
|
| 124 |
+
|
| 125 |
+
import torch
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
class Conv2d_BN(torch.nn.Sequential):
|
| 129 |
+
def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
|
| 130 |
+
groups=1, bn_weight_init=1, resolution=-10000):
|
| 131 |
+
super().__init__()
|
| 132 |
+
self.add_module('c', torch.nn.Conv2d(
|
| 133 |
+
a, b, ks, stride, pad, dilation, groups, bias=False))
|
| 134 |
+
self.add_module('bn', torch.nn.BatchNorm2d(b))
|
| 135 |
+
torch.nn.init.constant_(self.bn.weight, bn_weight_init)
|
| 136 |
+
torch.nn.init.constant_(self.bn.bias, 0)
|
| 137 |
+
|
| 138 |
+
@torch.no_grad()
|
| 139 |
+
def fuse(self):
|
| 140 |
+
c, bn = self._modules.values()
|
| 141 |
+
w = bn.weight / (bn.running_var + bn.eps) ** 0.5
|
| 142 |
+
w = c.weight * w[:, None, None, None]
|
| 143 |
+
b = bn.bias - bn.running_mean * bn.weight / \
|
| 144 |
+
(bn.running_var + bn.eps) ** 0.5
|
| 145 |
+
m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(
|
| 146 |
+
0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation,
|
| 147 |
+
groups=self.c.groups,
|
| 148 |
+
device=c.weight.device)
|
| 149 |
+
m.weight.data.copy_(w)
|
| 150 |
+
m.bias.data.copy_(b)
|
| 151 |
+
return m
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
class Residual(torch.nn.Module):
|
| 155 |
+
def __init__(self, m, drop=0.):
|
| 156 |
+
super().__init__()
|
| 157 |
+
self.m = m
|
| 158 |
+
self.drop = drop
|
| 159 |
+
|
| 160 |
+
def forward(self, x):
|
| 161 |
+
if self.training and self.drop > 0:
|
| 162 |
+
return x + self.m(x) * torch.rand(x.size(0), 1, 1, 1,
|
| 163 |
+
device=x.device).ge_(self.drop).div(1 - self.drop).detach()
|
| 164 |
+
else:
|
| 165 |
+
return x + self.m(x)
|
| 166 |
+
|
| 167 |
+
@torch.no_grad()
|
| 168 |
+
def fuse(self):
|
| 169 |
+
if isinstance(self.m, Conv2d_BN):
|
| 170 |
+
m = self.m.fuse()
|
| 171 |
+
assert (m.groups == m.in_channels)
|
| 172 |
+
identity = torch.ones(m.weight.shape[0], m.weight.shape[1], 1, 1)
|
| 173 |
+
identity = torch.nn.functional.pad(identity, [1, 1, 1, 1])
|
| 174 |
+
m.weight += identity.to(m.weight.device)
|
| 175 |
+
return m
|
| 176 |
+
elif isinstance(self.m, torch.nn.Conv2d):
|
| 177 |
+
m = self.m
|
| 178 |
+
assert (m.groups != m.in_channels)
|
| 179 |
+
identity = torch.ones(m.weight.shape[0], m.weight.shape[1], 1, 1)
|
| 180 |
+
identity = torch.nn.functional.pad(identity, [1, 1, 1, 1])
|
| 181 |
+
m.weight += identity.to(m.weight.device)
|
| 182 |
+
return m
|
| 183 |
+
else:
|
| 184 |
+
return self
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
class RepVGGDW(torch.nn.Module):
|
| 188 |
+
def __init__(self, ed) -> None:
|
| 189 |
+
super().__init__()
|
| 190 |
+
self.conv = Conv2d_BN(ed, ed, 3, 1, 1, groups=ed)
|
| 191 |
+
self.conv1 = Conv2d_BN(ed, ed, 1, 1, 0, groups=ed)
|
| 192 |
+
self.dim = ed
|
| 193 |
+
|
| 194 |
+
def forward(self, x):
|
| 195 |
+
return self.conv(x) + self.conv1(x) + x
|
| 196 |
+
|
| 197 |
+
@torch.no_grad()
|
| 198 |
+
def fuse(self):
|
| 199 |
+
conv = self.conv.fuse()
|
| 200 |
+
conv1 = self.conv1.fuse()
|
| 201 |
+
|
| 202 |
+
conv_w = conv.weight
|
| 203 |
+
conv_b = conv.bias
|
| 204 |
+
conv1_w = conv1.weight
|
| 205 |
+
conv1_b = conv1.bias
|
| 206 |
+
|
| 207 |
+
conv1_w = torch.nn.functional.pad(conv1_w, [1, 1, 1, 1])
|
| 208 |
+
|
| 209 |
+
identity = torch.nn.functional.pad(torch.ones(conv1_w.shape[0], conv1_w.shape[1], 1, 1, device=conv1_w.device),
|
| 210 |
+
[1, 1, 1, 1])
|
| 211 |
+
|
| 212 |
+
final_conv_w = conv_w + conv1_w + identity
|
| 213 |
+
final_conv_b = conv_b + conv1_b
|
| 214 |
+
|
| 215 |
+
conv.weight.data.copy_(final_conv_w)
|
| 216 |
+
conv.bias.data.copy_(final_conv_b)
|
| 217 |
+
return conv
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
class RepViTBlock(nn.Module):
|
| 221 |
+
def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se, use_hs, skip_downsample=False):
|
| 222 |
+
super(RepViTBlock, self).__init__()
|
| 223 |
+
assert stride in [1, 2]
|
| 224 |
+
|
| 225 |
+
self.identity = stride == 1 and inp == oup
|
| 226 |
+
assert (hidden_dim == 2 * inp)
|
| 227 |
+
|
| 228 |
+
if stride == 2:
|
| 229 |
+
if skip_downsample:
|
| 230 |
+
stride = 1
|
| 231 |
+
self.token_mixer = nn.Sequential(
|
| 232 |
+
Conv2d_BN(inp, inp, kernel_size, stride, (kernel_size - 1) // 2, groups=inp),
|
| 233 |
+
SqueezeExcite(inp, 0.25) if use_se else nn.Identity(),
|
| 234 |
+
Conv2d_BN(inp, oup, ks=1, stride=1, pad=0)
|
| 235 |
+
)
|
| 236 |
+
self.channel_mixer = Residual(nn.Sequential(
|
| 237 |
+
# pw
|
| 238 |
+
Conv2d_BN(oup, 2 * oup, 1, 1, 0),
|
| 239 |
+
nn.GELU() if use_hs else nn.GELU(),
|
| 240 |
+
# pw-linear
|
| 241 |
+
Conv2d_BN(2 * oup, oup, 1, 1, 0, bn_weight_init=0),
|
| 242 |
+
))
|
| 243 |
+
else:
|
| 244 |
+
assert (self.identity)
|
| 245 |
+
self.token_mixer = nn.Sequential(
|
| 246 |
+
RepVGGDW(inp),
|
| 247 |
+
SqueezeExcite(inp, 0.25) if use_se else nn.Identity(),
|
| 248 |
+
)
|
| 249 |
+
self.channel_mixer = Residual(nn.Sequential(
|
| 250 |
+
# pw
|
| 251 |
+
Conv2d_BN(inp, hidden_dim, 1, 1, 0),
|
| 252 |
+
nn.GELU() if use_hs else nn.GELU(),
|
| 253 |
+
# pw-linear
|
| 254 |
+
Conv2d_BN(hidden_dim, oup, 1, 1, 0, bn_weight_init=0),
|
| 255 |
+
))
|
| 256 |
+
|
| 257 |
+
def forward(self, x):
|
| 258 |
+
return self.channel_mixer(self.token_mixer(x))
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
from timm.models.vision_transformer import trunc_normal_
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
class BN_Linear(torch.nn.Sequential):
|
| 265 |
+
def __init__(self, a, b, bias=True, std=0.02):
|
| 266 |
+
super().__init__()
|
| 267 |
+
self.add_module('bn', torch.nn.BatchNorm1d(a))
|
| 268 |
+
self.add_module('l', torch.nn.Linear(a, b, bias=bias))
|
| 269 |
+
trunc_normal_(self.l.weight, std=std)
|
| 270 |
+
if bias:
|
| 271 |
+
torch.nn.init.constant_(self.l.bias, 0)
|
| 272 |
+
|
| 273 |
+
@torch.no_grad()
|
| 274 |
+
def fuse(self):
|
| 275 |
+
bn, l = self._modules.values()
|
| 276 |
+
w = bn.weight / (bn.running_var + bn.eps) ** 0.5
|
| 277 |
+
b = bn.bias - self.bn.running_mean * \
|
| 278 |
+
self.bn.weight / (bn.running_var + bn.eps) ** 0.5
|
| 279 |
+
w = l.weight * w[None, :]
|
| 280 |
+
if l.bias is None:
|
| 281 |
+
b = b @ self.l.weight.T
|
| 282 |
+
else:
|
| 283 |
+
b = (l.weight @ b[:, None]).view(-1) + self.l.bias
|
| 284 |
+
m = torch.nn.Linear(w.size(1), w.size(0), device=l.weight.device)
|
| 285 |
+
m.weight.data.copy_(w)
|
| 286 |
+
m.bias.data.copy_(b)
|
| 287 |
+
return m
|
| 288 |
+
|
| 289 |
+
|
| 290 |
+
class RepViT(nn.Module):
|
| 291 |
+
arch_settings = {
|
| 292 |
+
'm1': m1_cfgs,
|
| 293 |
+
'm2': m2_cfgs,
|
| 294 |
+
'm3': m3_cfgs
|
| 295 |
+
}
|
| 296 |
+
|
| 297 |
+
def __init__(self, arch, img_size=1024, upsample_mode='bicubic'):
|
| 298 |
+
super(RepViT, self).__init__()
|
| 299 |
+
# setting of inverted residual blocks
|
| 300 |
+
self.cfgs = self.arch_settings[arch]
|
| 301 |
+
self.img_size = img_size
|
| 302 |
+
|
| 303 |
+
# building first layer
|
| 304 |
+
input_channel = self.cfgs[0][2]
|
| 305 |
+
patch_embed = torch.nn.Sequential(Conv2d_BN(3, input_channel // 2, 3, 2, 1), torch.nn.GELU(),
|
| 306 |
+
Conv2d_BN(input_channel // 2, input_channel, 3, 2, 1))
|
| 307 |
+
layers = [patch_embed]
|
| 308 |
+
# building inverted residual blocks
|
| 309 |
+
block = RepViTBlock
|
| 310 |
+
self.stage_idx = []
|
| 311 |
+
prev_c = input_channel
|
| 312 |
+
for idx, (k, t, c, use_se, use_hs, s) in enumerate(self.cfgs):
|
| 313 |
+
output_channel = _make_divisible(c, 8)
|
| 314 |
+
exp_size = _make_divisible(input_channel * t, 8)
|
| 315 |
+
skip_downsample = False
|
| 316 |
+
if c != prev_c:
|
| 317 |
+
self.stage_idx.append(idx - 1)
|
| 318 |
+
prev_c = c
|
| 319 |
+
layers.append(block(input_channel, exp_size, output_channel, k, s, use_se, use_hs, skip_downsample))
|
| 320 |
+
input_channel = output_channel
|
| 321 |
+
self.stage_idx.append(idx)
|
| 322 |
+
self.features = nn.ModuleList(layers)
|
| 323 |
+
|
| 324 |
+
stage2_channels = _make_divisible(self.cfgs[self.stage_idx[2]][2], 8)
|
| 325 |
+
stage3_channels = _make_divisible(self.cfgs[self.stage_idx[3]][2], 8)
|
| 326 |
+
self.fuse_stage2 = nn.Conv2d(stage2_channels, 256, kernel_size=1, bias=False)
|
| 327 |
+
self.fuse_stage3 = OpSequential([
|
| 328 |
+
nn.Conv2d(stage3_channels, 256, kernel_size=1, bias=False),
|
| 329 |
+
UpSampleLayer(factor=2, mode=upsample_mode),
|
| 330 |
+
])
|
| 331 |
+
|
| 332 |
+
self.neck = nn.Sequential(
|
| 333 |
+
nn.Conv2d(256, 256, kernel_size=1, bias=False),
|
| 334 |
+
LayerNorm2d(256),
|
| 335 |
+
nn.Conv2d(256, 256, kernel_size=3, padding=1, bias=False),
|
| 336 |
+
LayerNorm2d(256),
|
| 337 |
+
)
|
| 338 |
+
|
| 339 |
+
def forward(self, x):
|
| 340 |
+
counter = 0
|
| 341 |
+
output_dict = dict()
|
| 342 |
+
# patch_embed
|
| 343 |
+
x = self.features[0](x)
|
| 344 |
+
output_dict['stem'] = x
|
| 345 |
+
# stages
|
| 346 |
+
for idx, f in enumerate(self.features[1:]):
|
| 347 |
+
x = f(x)
|
| 348 |
+
if idx in self.stage_idx:
|
| 349 |
+
output_dict[f'stage{counter}'] = x
|
| 350 |
+
counter += 1
|
| 351 |
+
|
| 352 |
+
x = self.fuse_stage2(output_dict['stage2']) + self.fuse_stage3(output_dict['stage3'])
|
| 353 |
+
|
| 354 |
+
x = self.neck(x)
|
| 355 |
+
# hack this place because we modified the predictor of SAM for HQ-SAM in
|
| 356 |
+
# segment_anything/segment_anything/predictor.py line 91 to return intern features of the backbone
|
| 357 |
+
# self.features, self.interm_features = self.model.image_encoder(input_image)
|
| 358 |
+
return x, None
|
| 359 |
+
|
| 360 |
+
|
| 361 |
+
def rep_vit_m1(img_size=1024, **kwargs):
|
| 362 |
+
return RepViT('m1', img_size, **kwargs)
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
def rep_vit_m2(img_size=1024, **kwargs):
|
| 366 |
+
return RepViT('m2', img_size, **kwargs)
|
| 367 |
+
|
| 368 |
+
|
| 369 |
+
def rep_vit_m3(img_size=1024, **kwargs):
|
| 370 |
+
return RepViT('m3', img_size, **kwargs)
|
EfficientSAM/EdgeSAM/setup_edge_sam.py
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
|
| 9 |
+
from functools import partial
|
| 10 |
+
|
| 11 |
+
from segment_anything.modeling import ImageEncoderViT, MaskDecoder, PromptEncoder, Sam, TwoWayTransformer
|
| 12 |
+
from EdgeSAM.rep_vit import RepViT
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
prompt_embed_dim = 256
|
| 16 |
+
image_size = 1024
|
| 17 |
+
vit_patch_size = 16
|
| 18 |
+
image_embedding_size = image_size // vit_patch_size
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def build_edge_sam(checkpoint=None, upsample_mode="bicubic"):
|
| 22 |
+
image_encoder = RepViT(
|
| 23 |
+
arch="m1",
|
| 24 |
+
img_size=image_size,
|
| 25 |
+
upsample_mode=upsample_mode
|
| 26 |
+
)
|
| 27 |
+
return _build_sam(image_encoder, checkpoint)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
sam_model_registry = {
|
| 31 |
+
"default": build_edge_sam,
|
| 32 |
+
"edge_sam": build_edge_sam,
|
| 33 |
+
}
|
| 34 |
+
|
| 35 |
+
def _build_sam_encoder(
|
| 36 |
+
encoder_embed_dim,
|
| 37 |
+
encoder_depth,
|
| 38 |
+
encoder_num_heads,
|
| 39 |
+
encoder_global_attn_indexes,
|
| 40 |
+
):
|
| 41 |
+
image_encoder = ImageEncoderViT(
|
| 42 |
+
depth=encoder_depth,
|
| 43 |
+
embed_dim=encoder_embed_dim,
|
| 44 |
+
img_size=image_size,
|
| 45 |
+
mlp_ratio=4,
|
| 46 |
+
norm_layer=partial(torch.nn.LayerNorm, eps=1e-6),
|
| 47 |
+
num_heads=encoder_num_heads,
|
| 48 |
+
patch_size=vit_patch_size,
|
| 49 |
+
qkv_bias=True,
|
| 50 |
+
use_rel_pos=True,
|
| 51 |
+
global_attn_indexes=encoder_global_attn_indexes,
|
| 52 |
+
window_size=14,
|
| 53 |
+
out_chans=prompt_embed_dim,
|
| 54 |
+
)
|
| 55 |
+
return image_encoder
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def _build_sam(
|
| 59 |
+
image_encoder,
|
| 60 |
+
checkpoint=None,
|
| 61 |
+
):
|
| 62 |
+
sam = Sam(
|
| 63 |
+
image_encoder=image_encoder,
|
| 64 |
+
prompt_encoder=PromptEncoder(
|
| 65 |
+
embed_dim=prompt_embed_dim,
|
| 66 |
+
image_embedding_size=(image_embedding_size, image_embedding_size),
|
| 67 |
+
input_image_size=(image_size, image_size),
|
| 68 |
+
mask_in_chans=16,
|
| 69 |
+
),
|
| 70 |
+
mask_decoder=MaskDecoder(
|
| 71 |
+
num_multimask_outputs=3,
|
| 72 |
+
transformer=TwoWayTransformer(
|
| 73 |
+
depth=2,
|
| 74 |
+
embedding_dim=prompt_embed_dim,
|
| 75 |
+
mlp_dim=2048,
|
| 76 |
+
num_heads=8,
|
| 77 |
+
),
|
| 78 |
+
transformer_dim=prompt_embed_dim,
|
| 79 |
+
iou_head_depth=3,
|
| 80 |
+
iou_head_hidden_dim=256,
|
| 81 |
+
),
|
| 82 |
+
pixel_mean=[123.675, 116.28, 103.53],
|
| 83 |
+
pixel_std=[58.395, 57.12, 57.375],
|
| 84 |
+
)
|
| 85 |
+
sam.eval()
|
| 86 |
+
if checkpoint is not None:
|
| 87 |
+
with open(checkpoint, "rb") as f:
|
| 88 |
+
state_dict = torch.load(f, map_location="cpu")
|
| 89 |
+
sam.load_state_dict(state_dict)
|
| 90 |
+
return sam
|
EfficientSAM/FastSAM/tools.py
ADDED
|
@@ -0,0 +1,413 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from PIL import Image
|
| 3 |
+
import matplotlib.pyplot as plt
|
| 4 |
+
import cv2
|
| 5 |
+
import torch
|
| 6 |
+
import os
|
| 7 |
+
import clip
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def convert_box_xywh_to_xyxy(box):
|
| 11 |
+
x1 = box[0]
|
| 12 |
+
y1 = box[1]
|
| 13 |
+
x2 = box[0] + box[2]
|
| 14 |
+
y2 = box[1] + box[3]
|
| 15 |
+
return [x1, y1, x2, y2]
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def segment_image(image, bbox):
|
| 19 |
+
image_array = np.array(image)
|
| 20 |
+
segmented_image_array = np.zeros_like(image_array)
|
| 21 |
+
x1, y1, x2, y2 = bbox
|
| 22 |
+
segmented_image_array[y1:y2, x1:x2] = image_array[y1:y2, x1:x2]
|
| 23 |
+
segmented_image = Image.fromarray(segmented_image_array)
|
| 24 |
+
black_image = Image.new("RGB", image.size, (255, 255, 255))
|
| 25 |
+
# transparency_mask = np.zeros_like((), dtype=np.uint8)
|
| 26 |
+
transparency_mask = np.zeros(
|
| 27 |
+
(image_array.shape[0], image_array.shape[1]), dtype=np.uint8
|
| 28 |
+
)
|
| 29 |
+
transparency_mask[y1:y2, x1:x2] = 255
|
| 30 |
+
transparency_mask_image = Image.fromarray(transparency_mask, mode="L")
|
| 31 |
+
black_image.paste(segmented_image, mask=transparency_mask_image)
|
| 32 |
+
return black_image
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def format_results(result, filter=0):
|
| 36 |
+
annotations = []
|
| 37 |
+
n = len(result.masks.data)
|
| 38 |
+
for i in range(n):
|
| 39 |
+
annotation = {}
|
| 40 |
+
mask = result.masks.data[i] == 1.0
|
| 41 |
+
|
| 42 |
+
if torch.sum(mask) < filter:
|
| 43 |
+
continue
|
| 44 |
+
annotation["id"] = i
|
| 45 |
+
annotation["segmentation"] = mask.cpu().numpy()
|
| 46 |
+
annotation["bbox"] = result.boxes.data[i]
|
| 47 |
+
annotation["score"] = result.boxes.conf[i]
|
| 48 |
+
annotation["area"] = annotation["segmentation"].sum()
|
| 49 |
+
annotations.append(annotation)
|
| 50 |
+
return annotations
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def filter_masks(annotations): # filte the overlap mask
|
| 54 |
+
annotations.sort(key=lambda x: x["area"], reverse=True)
|
| 55 |
+
to_remove = set()
|
| 56 |
+
for i in range(0, len(annotations)):
|
| 57 |
+
a = annotations[i]
|
| 58 |
+
for j in range(i + 1, len(annotations)):
|
| 59 |
+
b = annotations[j]
|
| 60 |
+
if i != j and j not in to_remove:
|
| 61 |
+
# check if
|
| 62 |
+
if b["area"] < a["area"]:
|
| 63 |
+
if (a["segmentation"] & b["segmentation"]).sum() / b[
|
| 64 |
+
"segmentation"
|
| 65 |
+
].sum() > 0.8:
|
| 66 |
+
to_remove.add(j)
|
| 67 |
+
|
| 68 |
+
return [a for i, a in enumerate(annotations) if i not in to_remove], to_remove
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def get_bbox_from_mask(mask):
|
| 72 |
+
mask = mask.astype(np.uint8)
|
| 73 |
+
contours, hierarchy = cv2.findContours(
|
| 74 |
+
mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE
|
| 75 |
+
)
|
| 76 |
+
x1, y1, w, h = cv2.boundingRect(contours[0])
|
| 77 |
+
x2, y2 = x1 + w, y1 + h
|
| 78 |
+
if len(contours) > 1:
|
| 79 |
+
for b in contours:
|
| 80 |
+
x_t, y_t, w_t, h_t = cv2.boundingRect(b)
|
| 81 |
+
# 将多个bbox合并成一个
|
| 82 |
+
x1 = min(x1, x_t)
|
| 83 |
+
y1 = min(y1, y_t)
|
| 84 |
+
x2 = max(x2, x_t + w_t)
|
| 85 |
+
y2 = max(y2, y_t + h_t)
|
| 86 |
+
h = y2 - y1
|
| 87 |
+
w = x2 - x1
|
| 88 |
+
return [x1, y1, x2, y2]
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def fast_process(
|
| 92 |
+
annotations, args, mask_random_color, bbox=None, points=None, edges=False
|
| 93 |
+
):
|
| 94 |
+
if isinstance(annotations[0], dict):
|
| 95 |
+
annotations = [annotation["segmentation"] for annotation in annotations]
|
| 96 |
+
result_name = os.path.basename(args.img_path)
|
| 97 |
+
image = cv2.imread(args.img_path)
|
| 98 |
+
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
|
| 99 |
+
original_h = image.shape[0]
|
| 100 |
+
original_w = image.shape[1]
|
| 101 |
+
plt.figure(figsize=(original_w/100, original_h/100))
|
| 102 |
+
plt.imshow(image)
|
| 103 |
+
if args.better_quality == True:
|
| 104 |
+
if isinstance(annotations[0], torch.Tensor):
|
| 105 |
+
annotations = np.array(annotations.cpu())
|
| 106 |
+
for i, mask in enumerate(annotations):
|
| 107 |
+
mask = cv2.morphologyEx(
|
| 108 |
+
mask.astype(np.uint8), cv2.MORPH_CLOSE, np.ones((3, 3), np.uint8)
|
| 109 |
+
)
|
| 110 |
+
annotations[i] = cv2.morphologyEx(
|
| 111 |
+
mask.astype(np.uint8), cv2.MORPH_OPEN, np.ones((8, 8), np.uint8)
|
| 112 |
+
)
|
| 113 |
+
if args.device == "cpu":
|
| 114 |
+
annotations = np.array(annotations)
|
| 115 |
+
fast_show_mask(
|
| 116 |
+
annotations,
|
| 117 |
+
plt.gca(),
|
| 118 |
+
random_color=mask_random_color,
|
| 119 |
+
bbox=bbox,
|
| 120 |
+
points=points,
|
| 121 |
+
pointlabel=args.point_label,
|
| 122 |
+
retinamask=args.retina,
|
| 123 |
+
target_height=original_h,
|
| 124 |
+
target_width=original_w,
|
| 125 |
+
)
|
| 126 |
+
else:
|
| 127 |
+
if isinstance(annotations[0], np.ndarray):
|
| 128 |
+
annotations = torch.from_numpy(annotations)
|
| 129 |
+
fast_show_mask_gpu(
|
| 130 |
+
annotations,
|
| 131 |
+
plt.gca(),
|
| 132 |
+
random_color=args.randomcolor,
|
| 133 |
+
bbox=bbox,
|
| 134 |
+
points=points,
|
| 135 |
+
pointlabel=args.point_label,
|
| 136 |
+
retinamask=args.retina,
|
| 137 |
+
target_height=original_h,
|
| 138 |
+
target_width=original_w,
|
| 139 |
+
)
|
| 140 |
+
if isinstance(annotations, torch.Tensor):
|
| 141 |
+
annotations = annotations.cpu().numpy()
|
| 142 |
+
if args.withContours == True:
|
| 143 |
+
contour_all = []
|
| 144 |
+
temp = np.zeros((original_h, original_w, 1))
|
| 145 |
+
for i, mask in enumerate(annotations):
|
| 146 |
+
if type(mask) == dict:
|
| 147 |
+
mask = mask["segmentation"]
|
| 148 |
+
annotation = mask.astype(np.uint8)
|
| 149 |
+
if args.retina == False:
|
| 150 |
+
annotation = cv2.resize(
|
| 151 |
+
annotation,
|
| 152 |
+
(original_w, original_h),
|
| 153 |
+
interpolation=cv2.INTER_NEAREST,
|
| 154 |
+
)
|
| 155 |
+
contours, hierarchy = cv2.findContours(
|
| 156 |
+
annotation, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE
|
| 157 |
+
)
|
| 158 |
+
for contour in contours:
|
| 159 |
+
contour_all.append(contour)
|
| 160 |
+
cv2.drawContours(temp, contour_all, -1, (255, 255, 255), 2)
|
| 161 |
+
color = np.array([0 / 255, 0 / 255, 255 / 255, 0.8])
|
| 162 |
+
contour_mask = temp / 255 * color.reshape(1, 1, -1)
|
| 163 |
+
plt.imshow(contour_mask)
|
| 164 |
+
|
| 165 |
+
save_path = args.output
|
| 166 |
+
if not os.path.exists(save_path):
|
| 167 |
+
os.makedirs(save_path)
|
| 168 |
+
plt.axis("off")
|
| 169 |
+
fig = plt.gcf()
|
| 170 |
+
plt.draw()
|
| 171 |
+
buf = fig.canvas.tostring_rgb()
|
| 172 |
+
cols, rows = fig.canvas.get_width_height()
|
| 173 |
+
img_array = np.fromstring(buf, dtype=np.uint8).reshape(rows, cols, 3)
|
| 174 |
+
return img_array
|
| 175 |
+
# cv2.imwrite(os.path.join(save_path, result_name), cv2.cvtColor(img_array, cv2.COLOR_RGB2BGR))
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
# CPU post process
|
| 180 |
+
def fast_show_mask(
|
| 181 |
+
annotation,
|
| 182 |
+
ax,
|
| 183 |
+
random_color=False,
|
| 184 |
+
bbox=None,
|
| 185 |
+
points=None,
|
| 186 |
+
pointlabel=None,
|
| 187 |
+
retinamask=True,
|
| 188 |
+
target_height=960,
|
| 189 |
+
target_width=960,
|
| 190 |
+
):
|
| 191 |
+
msak_sum = annotation.shape[0]
|
| 192 |
+
height = annotation.shape[1]
|
| 193 |
+
weight = annotation.shape[2]
|
| 194 |
+
# 将annotation 按照面积 排序
|
| 195 |
+
areas = np.sum(annotation, axis=(1, 2))
|
| 196 |
+
sorted_indices = np.argsort(areas)
|
| 197 |
+
annotation = annotation[sorted_indices]
|
| 198 |
+
|
| 199 |
+
index = (annotation != 0).argmax(axis=0)
|
| 200 |
+
if random_color == True:
|
| 201 |
+
color = np.random.random((msak_sum, 1, 1, 3))
|
| 202 |
+
else:
|
| 203 |
+
color = np.ones((msak_sum, 1, 1, 3)) * np.array(
|
| 204 |
+
[30 / 255, 144 / 255, 255 / 255]
|
| 205 |
+
)
|
| 206 |
+
transparency = np.ones((msak_sum, 1, 1, 1)) * 0.6
|
| 207 |
+
visual = np.concatenate([color, transparency], axis=-1)
|
| 208 |
+
mask_image = np.expand_dims(annotation, -1) * visual
|
| 209 |
+
|
| 210 |
+
show = np.zeros((height, weight, 4))
|
| 211 |
+
h_indices, w_indices = np.meshgrid(
|
| 212 |
+
np.arange(height), np.arange(weight), indexing="ij"
|
| 213 |
+
)
|
| 214 |
+
indices = (index[h_indices, w_indices], h_indices, w_indices, slice(None))
|
| 215 |
+
# 使用向量化索引更新show的值
|
| 216 |
+
show[h_indices, w_indices, :] = mask_image[indices]
|
| 217 |
+
if bbox is not None:
|
| 218 |
+
x1, y1, x2, y2 = bbox
|
| 219 |
+
ax.add_patch(
|
| 220 |
+
plt.Rectangle(
|
| 221 |
+
(x1, y1), x2 - x1, y2 - y1, fill=False, edgecolor="b", linewidth=1
|
| 222 |
+
)
|
| 223 |
+
)
|
| 224 |
+
# draw point
|
| 225 |
+
if points is not None:
|
| 226 |
+
plt.scatter(
|
| 227 |
+
[point[0] for i, point in enumerate(points) if pointlabel[i] == 1],
|
| 228 |
+
[point[1] for i, point in enumerate(points) if pointlabel[i] == 1],
|
| 229 |
+
s=20,
|
| 230 |
+
c="y",
|
| 231 |
+
)
|
| 232 |
+
plt.scatter(
|
| 233 |
+
[point[0] for i, point in enumerate(points) if pointlabel[i] == 0],
|
| 234 |
+
[point[1] for i, point in enumerate(points) if pointlabel[i] == 0],
|
| 235 |
+
s=20,
|
| 236 |
+
c="m",
|
| 237 |
+
)
|
| 238 |
+
|
| 239 |
+
if retinamask == False:
|
| 240 |
+
show = cv2.resize(
|
| 241 |
+
show, (target_width, target_height), interpolation=cv2.INTER_NEAREST
|
| 242 |
+
)
|
| 243 |
+
ax.imshow(show)
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
def fast_show_mask_gpu(
|
| 247 |
+
annotation,
|
| 248 |
+
ax,
|
| 249 |
+
random_color=False,
|
| 250 |
+
bbox=None,
|
| 251 |
+
points=None,
|
| 252 |
+
pointlabel=None,
|
| 253 |
+
retinamask=True,
|
| 254 |
+
target_height=960,
|
| 255 |
+
target_width=960,
|
| 256 |
+
):
|
| 257 |
+
msak_sum = annotation.shape[0]
|
| 258 |
+
height = annotation.shape[1]
|
| 259 |
+
weight = annotation.shape[2]
|
| 260 |
+
areas = torch.sum(annotation, dim=(1, 2))
|
| 261 |
+
sorted_indices = torch.argsort(areas, descending=False)
|
| 262 |
+
annotation = annotation[sorted_indices]
|
| 263 |
+
# 找每个位置第一个非零值下标
|
| 264 |
+
index = (annotation != 0).to(torch.long).argmax(dim=0)
|
| 265 |
+
if random_color == True:
|
| 266 |
+
color = torch.rand((msak_sum, 1, 1, 3)).to(annotation.device)
|
| 267 |
+
else:
|
| 268 |
+
color = torch.ones((msak_sum, 1, 1, 3)).to(annotation.device) * torch.tensor(
|
| 269 |
+
[30 / 255, 144 / 255, 255 / 255]
|
| 270 |
+
).to(annotation.device)
|
| 271 |
+
transparency = torch.ones((msak_sum, 1, 1, 1)).to(annotation.device) * 0.6
|
| 272 |
+
visual = torch.cat([color, transparency], dim=-1)
|
| 273 |
+
mask_image = torch.unsqueeze(annotation, -1) * visual
|
| 274 |
+
# 按index取数,index指每个位置选哪个batch的数,把mask_image转成一个batch的形式
|
| 275 |
+
show = torch.zeros((height, weight, 4)).to(annotation.device)
|
| 276 |
+
h_indices, w_indices = torch.meshgrid(
|
| 277 |
+
torch.arange(height), torch.arange(weight), indexing="ij"
|
| 278 |
+
)
|
| 279 |
+
indices = (index[h_indices, w_indices], h_indices, w_indices, slice(None))
|
| 280 |
+
# 使用向量化索引更新show的值
|
| 281 |
+
show[h_indices, w_indices, :] = mask_image[indices]
|
| 282 |
+
show_cpu = show.cpu().numpy()
|
| 283 |
+
if bbox is not None:
|
| 284 |
+
x1, y1, x2, y2 = bbox
|
| 285 |
+
ax.add_patch(
|
| 286 |
+
plt.Rectangle(
|
| 287 |
+
(x1, y1), x2 - x1, y2 - y1, fill=False, edgecolor="b", linewidth=1
|
| 288 |
+
)
|
| 289 |
+
)
|
| 290 |
+
# draw point
|
| 291 |
+
if points is not None:
|
| 292 |
+
plt.scatter(
|
| 293 |
+
[point[0] for i, point in enumerate(points) if pointlabel[i] == 1],
|
| 294 |
+
[point[1] for i, point in enumerate(points) if pointlabel[i] == 1],
|
| 295 |
+
s=20,
|
| 296 |
+
c="y",
|
| 297 |
+
)
|
| 298 |
+
plt.scatter(
|
| 299 |
+
[point[0] for i, point in enumerate(points) if pointlabel[i] == 0],
|
| 300 |
+
[point[1] for i, point in enumerate(points) if pointlabel[i] == 0],
|
| 301 |
+
s=20,
|
| 302 |
+
c="m",
|
| 303 |
+
)
|
| 304 |
+
if retinamask == False:
|
| 305 |
+
show_cpu = cv2.resize(
|
| 306 |
+
show_cpu, (target_width, target_height), interpolation=cv2.INTER_NEAREST
|
| 307 |
+
)
|
| 308 |
+
ax.imshow(show_cpu)
|
| 309 |
+
|
| 310 |
+
|
| 311 |
+
# clip
|
| 312 |
+
@torch.no_grad()
|
| 313 |
+
def retriev(
|
| 314 |
+
model, preprocess, elements, search_text: str, device
|
| 315 |
+
) -> int:
|
| 316 |
+
preprocessed_images = [preprocess(image).to(device) for image in elements]
|
| 317 |
+
tokenized_text = clip.tokenize([search_text]).to(device)
|
| 318 |
+
stacked_images = torch.stack(preprocessed_images)
|
| 319 |
+
image_features = model.encode_image(stacked_images)
|
| 320 |
+
text_features = model.encode_text(tokenized_text)
|
| 321 |
+
image_features /= image_features.norm(dim=-1, keepdim=True)
|
| 322 |
+
text_features /= text_features.norm(dim=-1, keepdim=True)
|
| 323 |
+
probs = 100.0 * image_features @ text_features.T
|
| 324 |
+
return probs[:, 0].softmax(dim=0)
|
| 325 |
+
|
| 326 |
+
|
| 327 |
+
def crop_image(annotations, image_path):
|
| 328 |
+
image = Image.open(image_path)
|
| 329 |
+
ori_w, ori_h = image.size
|
| 330 |
+
mask_h, mask_w = annotations[0]["segmentation"].shape
|
| 331 |
+
if ori_w != mask_w or ori_h != mask_h:
|
| 332 |
+
image = image.resize((mask_w, mask_h))
|
| 333 |
+
cropped_boxes = []
|
| 334 |
+
cropped_images = []
|
| 335 |
+
not_crop = []
|
| 336 |
+
filter_id = []
|
| 337 |
+
# annotations, _ = filter_masks(annotations)
|
| 338 |
+
# filter_id = list(_)
|
| 339 |
+
for _, mask in enumerate(annotations):
|
| 340 |
+
if np.sum(mask["segmentation"]) <= 100:
|
| 341 |
+
filter_id.append(_)
|
| 342 |
+
continue
|
| 343 |
+
bbox = get_bbox_from_mask(mask["segmentation"]) # mask 的 bbox
|
| 344 |
+
cropped_boxes.append(segment_image(image, bbox)) # 保存裁剪的图片
|
| 345 |
+
# cropped_boxes.append(segment_image(image,mask["segmentation"]))
|
| 346 |
+
cropped_images.append(bbox) # 保存裁剪的图片的bbox
|
| 347 |
+
|
| 348 |
+
return cropped_boxes, cropped_images, not_crop, filter_id, annotations
|
| 349 |
+
|
| 350 |
+
|
| 351 |
+
def box_prompt(masks, bbox, target_height, target_width):
|
| 352 |
+
h = masks.shape[1]
|
| 353 |
+
w = masks.shape[2]
|
| 354 |
+
if h != target_height or w != target_width:
|
| 355 |
+
bbox = [
|
| 356 |
+
int(bbox[0] * w / target_width),
|
| 357 |
+
int(bbox[1] * h / target_height),
|
| 358 |
+
int(bbox[2] * w / target_width),
|
| 359 |
+
int(bbox[3] * h / target_height),
|
| 360 |
+
]
|
| 361 |
+
bbox[0] = round(bbox[0]) if round(bbox[0]) > 0 else 0
|
| 362 |
+
bbox[1] = round(bbox[1]) if round(bbox[1]) > 0 else 0
|
| 363 |
+
bbox[2] = round(bbox[2]) if round(bbox[2]) < w else w
|
| 364 |
+
bbox[3] = round(bbox[3]) if round(bbox[3]) < h else h
|
| 365 |
+
|
| 366 |
+
# IoUs = torch.zeros(len(masks), dtype=torch.float32)
|
| 367 |
+
bbox_area = (bbox[3] - bbox[1]) * (bbox[2] - bbox[0])
|
| 368 |
+
|
| 369 |
+
masks_area = torch.sum(masks[:, bbox[1] : bbox[3], bbox[0] : bbox[2]], dim=(1, 2))
|
| 370 |
+
orig_masks_area = torch.sum(masks, dim=(1, 2))
|
| 371 |
+
|
| 372 |
+
union = bbox_area + orig_masks_area - masks_area
|
| 373 |
+
IoUs = masks_area / union
|
| 374 |
+
max_iou_index = torch.argmax(IoUs)
|
| 375 |
+
|
| 376 |
+
return masks[max_iou_index].cpu().numpy(), max_iou_index
|
| 377 |
+
|
| 378 |
+
|
| 379 |
+
def point_prompt(masks, points, pointlabel, target_height, target_width): # numpy 处理
|
| 380 |
+
h = masks[0]["segmentation"].shape[0]
|
| 381 |
+
w = masks[0]["segmentation"].shape[1]
|
| 382 |
+
if h != target_height or w != target_width:
|
| 383 |
+
points = [
|
| 384 |
+
[int(point[0] * w / target_width), int(point[1] * h / target_height)]
|
| 385 |
+
for point in points
|
| 386 |
+
]
|
| 387 |
+
onemask = np.zeros((h, w))
|
| 388 |
+
for i, annotation in enumerate(masks):
|
| 389 |
+
if type(annotation) == dict:
|
| 390 |
+
mask = annotation["segmentation"]
|
| 391 |
+
else:
|
| 392 |
+
mask = annotation
|
| 393 |
+
for i, point in enumerate(points):
|
| 394 |
+
if mask[point[1], point[0]] == 1 and pointlabel[i] == 1:
|
| 395 |
+
onemask += mask
|
| 396 |
+
if mask[point[1], point[0]] == 1 and pointlabel[i] == 0:
|
| 397 |
+
onemask -= mask
|
| 398 |
+
onemask = onemask >= 1
|
| 399 |
+
return onemask, 0
|
| 400 |
+
|
| 401 |
+
|
| 402 |
+
def text_prompt(annotations, args):
|
| 403 |
+
cropped_boxes, cropped_images, not_crop, filter_id, annotaions = crop_image(
|
| 404 |
+
annotations, args.img_path
|
| 405 |
+
)
|
| 406 |
+
clip_model, preprocess = clip.load("ViT-B/32", device=args.device)
|
| 407 |
+
scores = retriev(
|
| 408 |
+
clip_model, preprocess, cropped_boxes, args.text_prompt, device=args.device
|
| 409 |
+
)
|
| 410 |
+
max_idx = scores.argsort()
|
| 411 |
+
max_idx = max_idx[-1]
|
| 412 |
+
max_idx += sum(np.array(filter_id) <= int(max_idx))
|
| 413 |
+
return annotaions[max_idx]["segmentation"], max_idx
|
EfficientSAM/LightHQSAM/example_light_hqsam.png
ADDED

|
Git LFS Details
|
EfficientSAM/LightHQSAM/grounded_light_hqsam_annotated_image.jpg
ADDED

|
Git LFS Details
|
EfficientSAM/LightHQSAM/setup_light_hqsam.py
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from LightHQSAM.tiny_vit_sam import TinyViT
|
| 2 |
+
from segment_anything.modeling import MaskDecoderHQ, PromptEncoder, Sam, TwoWayTransformer
|
| 3 |
+
|
| 4 |
+
def setup_model():
|
| 5 |
+
prompt_embed_dim = 256
|
| 6 |
+
image_size = 1024
|
| 7 |
+
vit_patch_size = 16
|
| 8 |
+
image_embedding_size = image_size // vit_patch_size
|
| 9 |
+
mobile_sam = Sam(
|
| 10 |
+
image_encoder=TinyViT(img_size=1024, in_chans=3, num_classes=1000,
|
| 11 |
+
embed_dims=[64, 128, 160, 320],
|
| 12 |
+
depths=[2, 2, 6, 2],
|
| 13 |
+
num_heads=[2, 4, 5, 10],
|
| 14 |
+
window_sizes=[7, 7, 14, 7],
|
| 15 |
+
mlp_ratio=4.,
|
| 16 |
+
drop_rate=0.,
|
| 17 |
+
drop_path_rate=0.0,
|
| 18 |
+
use_checkpoint=False,
|
| 19 |
+
mbconv_expand_ratio=4.0,
|
| 20 |
+
local_conv_size=3,
|
| 21 |
+
layer_lr_decay=0.8
|
| 22 |
+
),
|
| 23 |
+
prompt_encoder=PromptEncoder(
|
| 24 |
+
embed_dim=prompt_embed_dim,
|
| 25 |
+
image_embedding_size=(image_embedding_size, image_embedding_size),
|
| 26 |
+
input_image_size=(image_size, image_size),
|
| 27 |
+
mask_in_chans=16,
|
| 28 |
+
),
|
| 29 |
+
mask_decoder=MaskDecoderHQ(
|
| 30 |
+
num_multimask_outputs=3,
|
| 31 |
+
transformer=TwoWayTransformer(
|
| 32 |
+
depth=2,
|
| 33 |
+
embedding_dim=prompt_embed_dim,
|
| 34 |
+
mlp_dim=2048,
|
| 35 |
+
num_heads=8,
|
| 36 |
+
),
|
| 37 |
+
transformer_dim=prompt_embed_dim,
|
| 38 |
+
iou_head_depth=3,
|
| 39 |
+
iou_head_hidden_dim=256,
|
| 40 |
+
vit_dim=160,
|
| 41 |
+
),
|
| 42 |
+
pixel_mean=[123.675, 116.28, 103.53],
|
| 43 |
+
pixel_std=[58.395, 57.12, 57.375],
|
| 44 |
+
)
|
| 45 |
+
return mobile_sam
|
EfficientSAM/LightHQSAM/tiny_vit_sam.py
ADDED
|
@@ -0,0 +1,724 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# TinyViT Model Architecture
|
| 3 |
+
# Copyright (c) 2022 Microsoft
|
| 4 |
+
# Adapted from LeViT and Swin Transformer
|
| 5 |
+
# LeViT: (https://github.com/facebookresearch/levit)
|
| 6 |
+
# Swin: (https://github.com/microsoft/swin-transformer)
|
| 7 |
+
# Build the TinyViT Model
|
| 8 |
+
# --------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
import itertools
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn as nn
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
import torch.utils.checkpoint as checkpoint
|
| 15 |
+
from timm.models.layers import DropPath as TimmDropPath,\
|
| 16 |
+
to_2tuple, trunc_normal_
|
| 17 |
+
from timm.models.registry import register_model
|
| 18 |
+
from typing import Tuple
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class Conv2d_BN(torch.nn.Sequential):
|
| 22 |
+
def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
|
| 23 |
+
groups=1, bn_weight_init=1):
|
| 24 |
+
super().__init__()
|
| 25 |
+
self.add_module('c', torch.nn.Conv2d(
|
| 26 |
+
a, b, ks, stride, pad, dilation, groups, bias=False))
|
| 27 |
+
bn = torch.nn.BatchNorm2d(b)
|
| 28 |
+
torch.nn.init.constant_(bn.weight, bn_weight_init)
|
| 29 |
+
torch.nn.init.constant_(bn.bias, 0)
|
| 30 |
+
self.add_module('bn', bn)
|
| 31 |
+
|
| 32 |
+
@torch.no_grad()
|
| 33 |
+
def fuse(self):
|
| 34 |
+
c, bn = self._modules.values()
|
| 35 |
+
w = bn.weight / (bn.running_var + bn.eps)**0.5
|
| 36 |
+
w = c.weight * w[:, None, None, None]
|
| 37 |
+
b = bn.bias - bn.running_mean * bn.weight / \
|
| 38 |
+
(bn.running_var + bn.eps)**0.5
|
| 39 |
+
m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(
|
| 40 |
+
0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation, groups=self.c.groups)
|
| 41 |
+
m.weight.data.copy_(w)
|
| 42 |
+
m.bias.data.copy_(b)
|
| 43 |
+
return m
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class DropPath(TimmDropPath):
|
| 47 |
+
def __init__(self, drop_prob=None):
|
| 48 |
+
super().__init__(drop_prob=drop_prob)
|
| 49 |
+
self.drop_prob = drop_prob
|
| 50 |
+
|
| 51 |
+
def __repr__(self):
|
| 52 |
+
msg = super().__repr__()
|
| 53 |
+
msg += f'(drop_prob={self.drop_prob})'
|
| 54 |
+
return msg
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class PatchEmbed(nn.Module):
|
| 58 |
+
def __init__(self, in_chans, embed_dim, resolution, activation):
|
| 59 |
+
super().__init__()
|
| 60 |
+
img_size: Tuple[int, int] = to_2tuple(resolution)
|
| 61 |
+
self.patches_resolution = (img_size[0] // 4, img_size[1] // 4)
|
| 62 |
+
self.num_patches = self.patches_resolution[0] * \
|
| 63 |
+
self.patches_resolution[1]
|
| 64 |
+
self.in_chans = in_chans
|
| 65 |
+
self.embed_dim = embed_dim
|
| 66 |
+
n = embed_dim
|
| 67 |
+
self.seq = nn.Sequential(
|
| 68 |
+
Conv2d_BN(in_chans, n // 2, 3, 2, 1),
|
| 69 |
+
activation(),
|
| 70 |
+
Conv2d_BN(n // 2, n, 3, 2, 1),
|
| 71 |
+
)
|
| 72 |
+
|
| 73 |
+
def forward(self, x):
|
| 74 |
+
return self.seq(x)
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
class MBConv(nn.Module):
|
| 78 |
+
def __init__(self, in_chans, out_chans, expand_ratio,
|
| 79 |
+
activation, drop_path):
|
| 80 |
+
super().__init__()
|
| 81 |
+
self.in_chans = in_chans
|
| 82 |
+
self.hidden_chans = int(in_chans * expand_ratio)
|
| 83 |
+
self.out_chans = out_chans
|
| 84 |
+
|
| 85 |
+
self.conv1 = Conv2d_BN(in_chans, self.hidden_chans, ks=1)
|
| 86 |
+
self.act1 = activation()
|
| 87 |
+
|
| 88 |
+
self.conv2 = Conv2d_BN(self.hidden_chans, self.hidden_chans,
|
| 89 |
+
ks=3, stride=1, pad=1, groups=self.hidden_chans)
|
| 90 |
+
self.act2 = activation()
|
| 91 |
+
|
| 92 |
+
self.conv3 = Conv2d_BN(
|
| 93 |
+
self.hidden_chans, out_chans, ks=1, bn_weight_init=0.0)
|
| 94 |
+
self.act3 = activation()
|
| 95 |
+
|
| 96 |
+
self.drop_path = DropPath(
|
| 97 |
+
drop_path) if drop_path > 0. else nn.Identity()
|
| 98 |
+
|
| 99 |
+
def forward(self, x):
|
| 100 |
+
shortcut = x
|
| 101 |
+
|
| 102 |
+
x = self.conv1(x)
|
| 103 |
+
x = self.act1(x)
|
| 104 |
+
|
| 105 |
+
x = self.conv2(x)
|
| 106 |
+
x = self.act2(x)
|
| 107 |
+
|
| 108 |
+
x = self.conv3(x)
|
| 109 |
+
|
| 110 |
+
x = self.drop_path(x)
|
| 111 |
+
|
| 112 |
+
x += shortcut
|
| 113 |
+
x = self.act3(x)
|
| 114 |
+
|
| 115 |
+
return x
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
class PatchMerging(nn.Module):
|
| 119 |
+
def __init__(self, input_resolution, dim, out_dim, activation):
|
| 120 |
+
super().__init__()
|
| 121 |
+
|
| 122 |
+
self.input_resolution = input_resolution
|
| 123 |
+
self.dim = dim
|
| 124 |
+
self.out_dim = out_dim
|
| 125 |
+
self.act = activation()
|
| 126 |
+
self.conv1 = Conv2d_BN(dim, out_dim, 1, 1, 0)
|
| 127 |
+
stride_c=2
|
| 128 |
+
if(out_dim==320 or out_dim==448 or out_dim==576):
|
| 129 |
+
stride_c=1
|
| 130 |
+
self.conv2 = Conv2d_BN(out_dim, out_dim, 3, stride_c, 1, groups=out_dim)
|
| 131 |
+
self.conv3 = Conv2d_BN(out_dim, out_dim, 1, 1, 0)
|
| 132 |
+
|
| 133 |
+
def forward(self, x):
|
| 134 |
+
if x.ndim == 3:
|
| 135 |
+
H, W = self.input_resolution
|
| 136 |
+
B = len(x)
|
| 137 |
+
# (B, C, H, W)
|
| 138 |
+
x = x.view(B, H, W, -1).permute(0, 3, 1, 2)
|
| 139 |
+
|
| 140 |
+
x = self.conv1(x)
|
| 141 |
+
x = self.act(x)
|
| 142 |
+
|
| 143 |
+
x = self.conv2(x)
|
| 144 |
+
x = self.act(x)
|
| 145 |
+
x = self.conv3(x)
|
| 146 |
+
x = x.flatten(2).transpose(1, 2)
|
| 147 |
+
return x
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
class ConvLayer(nn.Module):
|
| 151 |
+
def __init__(self, dim, input_resolution, depth,
|
| 152 |
+
activation,
|
| 153 |
+
drop_path=0., downsample=None, use_checkpoint=False,
|
| 154 |
+
out_dim=None,
|
| 155 |
+
conv_expand_ratio=4.,
|
| 156 |
+
):
|
| 157 |
+
|
| 158 |
+
super().__init__()
|
| 159 |
+
self.dim = dim
|
| 160 |
+
self.input_resolution = input_resolution
|
| 161 |
+
self.depth = depth
|
| 162 |
+
self.use_checkpoint = use_checkpoint
|
| 163 |
+
|
| 164 |
+
# build blocks
|
| 165 |
+
self.blocks = nn.ModuleList([
|
| 166 |
+
MBConv(dim, dim, conv_expand_ratio, activation,
|
| 167 |
+
drop_path[i] if isinstance(drop_path, list) else drop_path,
|
| 168 |
+
)
|
| 169 |
+
for i in range(depth)])
|
| 170 |
+
|
| 171 |
+
# patch merging layer
|
| 172 |
+
if downsample is not None:
|
| 173 |
+
self.downsample = downsample(
|
| 174 |
+
input_resolution, dim=dim, out_dim=out_dim, activation=activation)
|
| 175 |
+
else:
|
| 176 |
+
self.downsample = None
|
| 177 |
+
|
| 178 |
+
def forward(self, x):
|
| 179 |
+
for blk in self.blocks:
|
| 180 |
+
if self.use_checkpoint:
|
| 181 |
+
x = checkpoint.checkpoint(blk, x)
|
| 182 |
+
else:
|
| 183 |
+
x = blk(x)
|
| 184 |
+
if self.downsample is not None:
|
| 185 |
+
x = self.downsample(x)
|
| 186 |
+
return x
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
class Mlp(nn.Module):
|
| 190 |
+
def __init__(self, in_features, hidden_features=None,
|
| 191 |
+
out_features=None, act_layer=nn.GELU, drop=0.):
|
| 192 |
+
super().__init__()
|
| 193 |
+
out_features = out_features or in_features
|
| 194 |
+
hidden_features = hidden_features or in_features
|
| 195 |
+
self.norm = nn.LayerNorm(in_features)
|
| 196 |
+
self.fc1 = nn.Linear(in_features, hidden_features)
|
| 197 |
+
self.fc2 = nn.Linear(hidden_features, out_features)
|
| 198 |
+
self.act = act_layer()
|
| 199 |
+
self.drop = nn.Dropout(drop)
|
| 200 |
+
|
| 201 |
+
def forward(self, x):
|
| 202 |
+
x = self.norm(x)
|
| 203 |
+
|
| 204 |
+
x = self.fc1(x)
|
| 205 |
+
x = self.act(x)
|
| 206 |
+
x = self.drop(x)
|
| 207 |
+
x = self.fc2(x)
|
| 208 |
+
x = self.drop(x)
|
| 209 |
+
return x
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
class Attention(torch.nn.Module):
|
| 213 |
+
def __init__(self, dim, key_dim, num_heads=8,
|
| 214 |
+
attn_ratio=4,
|
| 215 |
+
resolution=(14, 14),
|
| 216 |
+
):
|
| 217 |
+
super().__init__()
|
| 218 |
+
# (h, w)
|
| 219 |
+
assert isinstance(resolution, tuple) and len(resolution) == 2
|
| 220 |
+
self.num_heads = num_heads
|
| 221 |
+
self.scale = key_dim ** -0.5
|
| 222 |
+
self.key_dim = key_dim
|
| 223 |
+
self.nh_kd = nh_kd = key_dim * num_heads
|
| 224 |
+
self.d = int(attn_ratio * key_dim)
|
| 225 |
+
self.dh = int(attn_ratio * key_dim) * num_heads
|
| 226 |
+
self.attn_ratio = attn_ratio
|
| 227 |
+
h = self.dh + nh_kd * 2
|
| 228 |
+
|
| 229 |
+
self.norm = nn.LayerNorm(dim)
|
| 230 |
+
self.qkv = nn.Linear(dim, h)
|
| 231 |
+
self.proj = nn.Linear(self.dh, dim)
|
| 232 |
+
|
| 233 |
+
points = list(itertools.product(
|
| 234 |
+
range(resolution[0]), range(resolution[1])))
|
| 235 |
+
N = len(points)
|
| 236 |
+
attention_offsets = {}
|
| 237 |
+
idxs = []
|
| 238 |
+
for p1 in points:
|
| 239 |
+
for p2 in points:
|
| 240 |
+
offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))
|
| 241 |
+
if offset not in attention_offsets:
|
| 242 |
+
attention_offsets[offset] = len(attention_offsets)
|
| 243 |
+
idxs.append(attention_offsets[offset])
|
| 244 |
+
self.attention_biases = torch.nn.Parameter(
|
| 245 |
+
torch.zeros(num_heads, len(attention_offsets)))
|
| 246 |
+
self.register_buffer('attention_bias_idxs',
|
| 247 |
+
torch.LongTensor(idxs).view(N, N),
|
| 248 |
+
persistent=False)
|
| 249 |
+
|
| 250 |
+
@torch.no_grad()
|
| 251 |
+
def train(self, mode=True):
|
| 252 |
+
super().train(mode)
|
| 253 |
+
if mode and hasattr(self, 'ab'):
|
| 254 |
+
del self.ab
|
| 255 |
+
else:
|
| 256 |
+
self.register_buffer('ab',
|
| 257 |
+
self.attention_biases[:, self.attention_bias_idxs],
|
| 258 |
+
persistent=False)
|
| 259 |
+
|
| 260 |
+
def forward(self, x): # x (B,N,C)
|
| 261 |
+
B, N, _ = x.shape
|
| 262 |
+
|
| 263 |
+
# Normalization
|
| 264 |
+
x = self.norm(x)
|
| 265 |
+
|
| 266 |
+
qkv = self.qkv(x)
|
| 267 |
+
# (B, N, num_heads, d)
|
| 268 |
+
q, k, v = qkv.view(B, N, self.num_heads, -
|
| 269 |
+
1).split([self.key_dim, self.key_dim, self.d], dim=3)
|
| 270 |
+
# (B, num_heads, N, d)
|
| 271 |
+
q = q.permute(0, 2, 1, 3)
|
| 272 |
+
k = k.permute(0, 2, 1, 3)
|
| 273 |
+
v = v.permute(0, 2, 1, 3)
|
| 274 |
+
|
| 275 |
+
attn = (
|
| 276 |
+
(q @ k.transpose(-2, -1)) * self.scale
|
| 277 |
+
+
|
| 278 |
+
(self.attention_biases[:, self.attention_bias_idxs]
|
| 279 |
+
if self.training else self.ab)
|
| 280 |
+
)
|
| 281 |
+
attn = attn.softmax(dim=-1)
|
| 282 |
+
x = (attn @ v).transpose(1, 2).reshape(B, N, self.dh)
|
| 283 |
+
x = self.proj(x)
|
| 284 |
+
return x
|
| 285 |
+
|
| 286 |
+
|
| 287 |
+
class TinyViTBlock(nn.Module):
|
| 288 |
+
r""" TinyViT Block.
|
| 289 |
+
|
| 290 |
+
Args:
|
| 291 |
+
dim (int): Number of input channels.
|
| 292 |
+
input_resolution (tuple[int, int]): Input resolution.
|
| 293 |
+
num_heads (int): Number of attention heads.
|
| 294 |
+
window_size (int): Window size.
|
| 295 |
+
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
|
| 296 |
+
drop (float, optional): Dropout rate. Default: 0.0
|
| 297 |
+
drop_path (float, optional): Stochastic depth rate. Default: 0.0
|
| 298 |
+
local_conv_size (int): the kernel size of the convolution between
|
| 299 |
+
Attention and MLP. Default: 3
|
| 300 |
+
activation: the activation function. Default: nn.GELU
|
| 301 |
+
"""
|
| 302 |
+
|
| 303 |
+
def __init__(self, dim, input_resolution, num_heads, window_size=7,
|
| 304 |
+
mlp_ratio=4., drop=0., drop_path=0.,
|
| 305 |
+
local_conv_size=3,
|
| 306 |
+
activation=nn.GELU,
|
| 307 |
+
):
|
| 308 |
+
super().__init__()
|
| 309 |
+
self.dim = dim
|
| 310 |
+
self.input_resolution = input_resolution
|
| 311 |
+
self.num_heads = num_heads
|
| 312 |
+
assert window_size > 0, 'window_size must be greater than 0'
|
| 313 |
+
self.window_size = window_size
|
| 314 |
+
self.mlp_ratio = mlp_ratio
|
| 315 |
+
|
| 316 |
+
self.drop_path = DropPath(
|
| 317 |
+
drop_path) if drop_path > 0. else nn.Identity()
|
| 318 |
+
|
| 319 |
+
assert dim % num_heads == 0, 'dim must be divisible by num_heads'
|
| 320 |
+
head_dim = dim // num_heads
|
| 321 |
+
|
| 322 |
+
window_resolution = (window_size, window_size)
|
| 323 |
+
self.attn = Attention(dim, head_dim, num_heads,
|
| 324 |
+
attn_ratio=1, resolution=window_resolution)
|
| 325 |
+
|
| 326 |
+
mlp_hidden_dim = int(dim * mlp_ratio)
|
| 327 |
+
mlp_activation = activation
|
| 328 |
+
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
|
| 329 |
+
act_layer=mlp_activation, drop=drop)
|
| 330 |
+
|
| 331 |
+
pad = local_conv_size // 2
|
| 332 |
+
self.local_conv = Conv2d_BN(
|
| 333 |
+
dim, dim, ks=local_conv_size, stride=1, pad=pad, groups=dim)
|
| 334 |
+
|
| 335 |
+
def forward(self, x):
|
| 336 |
+
H, W = self.input_resolution
|
| 337 |
+
B, L, C = x.shape
|
| 338 |
+
assert L == H * W, "input feature has wrong size"
|
| 339 |
+
res_x = x
|
| 340 |
+
if H == self.window_size and W == self.window_size:
|
| 341 |
+
x = self.attn(x)
|
| 342 |
+
else:
|
| 343 |
+
x = x.view(B, H, W, C)
|
| 344 |
+
pad_b = (self.window_size - H %
|
| 345 |
+
self.window_size) % self.window_size
|
| 346 |
+
pad_r = (self.window_size - W %
|
| 347 |
+
self.window_size) % self.window_size
|
| 348 |
+
padding = pad_b > 0 or pad_r > 0
|
| 349 |
+
|
| 350 |
+
if padding:
|
| 351 |
+
x = F.pad(x, (0, 0, 0, pad_r, 0, pad_b))
|
| 352 |
+
|
| 353 |
+
pH, pW = H + pad_b, W + pad_r
|
| 354 |
+
nH = pH // self.window_size
|
| 355 |
+
nW = pW // self.window_size
|
| 356 |
+
# window partition
|
| 357 |
+
x = x.view(B, nH, self.window_size, nW, self.window_size, C).transpose(2, 3).reshape(
|
| 358 |
+
B * nH * nW, self.window_size * self.window_size, C)
|
| 359 |
+
x = self.attn(x)
|
| 360 |
+
# window reverse
|
| 361 |
+
x = x.view(B, nH, nW, self.window_size, self.window_size,
|
| 362 |
+
C).transpose(2, 3).reshape(B, pH, pW, C)
|
| 363 |
+
|
| 364 |
+
if padding:
|
| 365 |
+
x = x[:, :H, :W].contiguous()
|
| 366 |
+
|
| 367 |
+
x = x.view(B, L, C)
|
| 368 |
+
|
| 369 |
+
x = res_x + self.drop_path(x)
|
| 370 |
+
|
| 371 |
+
x = x.transpose(1, 2).reshape(B, C, H, W)
|
| 372 |
+
x = self.local_conv(x)
|
| 373 |
+
x = x.view(B, C, L).transpose(1, 2)
|
| 374 |
+
|
| 375 |
+
x = x + self.drop_path(self.mlp(x))
|
| 376 |
+
return x
|
| 377 |
+
|
| 378 |
+
def extra_repr(self) -> str:
|
| 379 |
+
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
|
| 380 |
+
f"window_size={self.window_size}, mlp_ratio={self.mlp_ratio}"
|
| 381 |
+
|
| 382 |
+
|
| 383 |
+
class BasicLayer(nn.Module):
|
| 384 |
+
""" A basic TinyViT layer for one stage.
|
| 385 |
+
|
| 386 |
+
Args:
|
| 387 |
+
dim (int): Number of input channels.
|
| 388 |
+
input_resolution (tuple[int]): Input resolution.
|
| 389 |
+
depth (int): Number of blocks.
|
| 390 |
+
num_heads (int): Number of attention heads.
|
| 391 |
+
window_size (int): Local window size.
|
| 392 |
+
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
|
| 393 |
+
drop (float, optional): Dropout rate. Default: 0.0
|
| 394 |
+
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
|
| 395 |
+
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
|
| 396 |
+
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
|
| 397 |
+
local_conv_size: the kernel size of the depthwise convolution between attention and MLP. Default: 3
|
| 398 |
+
activation: the activation function. Default: nn.GELU
|
| 399 |
+
out_dim: the output dimension of the layer. Default: dim
|
| 400 |
+
"""
|
| 401 |
+
|
| 402 |
+
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
|
| 403 |
+
mlp_ratio=4., drop=0.,
|
| 404 |
+
drop_path=0., downsample=None, use_checkpoint=False,
|
| 405 |
+
local_conv_size=3,
|
| 406 |
+
activation=nn.GELU,
|
| 407 |
+
out_dim=None,
|
| 408 |
+
):
|
| 409 |
+
|
| 410 |
+
super().__init__()
|
| 411 |
+
self.dim = dim
|
| 412 |
+
self.input_resolution = input_resolution
|
| 413 |
+
self.depth = depth
|
| 414 |
+
self.use_checkpoint = use_checkpoint
|
| 415 |
+
|
| 416 |
+
# build blocks
|
| 417 |
+
self.blocks = nn.ModuleList([
|
| 418 |
+
TinyViTBlock(dim=dim, input_resolution=input_resolution,
|
| 419 |
+
num_heads=num_heads, window_size=window_size,
|
| 420 |
+
mlp_ratio=mlp_ratio,
|
| 421 |
+
drop=drop,
|
| 422 |
+
drop_path=drop_path[i] if isinstance(
|
| 423 |
+
drop_path, list) else drop_path,
|
| 424 |
+
local_conv_size=local_conv_size,
|
| 425 |
+
activation=activation,
|
| 426 |
+
)
|
| 427 |
+
for i in range(depth)])
|
| 428 |
+
|
| 429 |
+
# patch merging layer
|
| 430 |
+
if downsample is not None:
|
| 431 |
+
self.downsample = downsample(
|
| 432 |
+
input_resolution, dim=dim, out_dim=out_dim, activation=activation)
|
| 433 |
+
else:
|
| 434 |
+
self.downsample = None
|
| 435 |
+
|
| 436 |
+
def forward(self, x):
|
| 437 |
+
for blk in self.blocks:
|
| 438 |
+
if self.use_checkpoint:
|
| 439 |
+
x = checkpoint.checkpoint(blk, x)
|
| 440 |
+
else:
|
| 441 |
+
x = blk(x)
|
| 442 |
+
if self.downsample is not None:
|
| 443 |
+
x = self.downsample(x)
|
| 444 |
+
return x
|
| 445 |
+
|
| 446 |
+
def extra_repr(self) -> str:
|
| 447 |
+
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
|
| 448 |
+
|
| 449 |
+
class LayerNorm2d(nn.Module):
|
| 450 |
+
def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
|
| 451 |
+
super().__init__()
|
| 452 |
+
self.weight = nn.Parameter(torch.ones(num_channels))
|
| 453 |
+
self.bias = nn.Parameter(torch.zeros(num_channels))
|
| 454 |
+
self.eps = eps
|
| 455 |
+
|
| 456 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 457 |
+
u = x.mean(1, keepdim=True)
|
| 458 |
+
s = (x - u).pow(2).mean(1, keepdim=True)
|
| 459 |
+
x = (x - u) / torch.sqrt(s + self.eps)
|
| 460 |
+
x = self.weight[:, None, None] * x + self.bias[:, None, None]
|
| 461 |
+
return x
|
| 462 |
+
class TinyViT(nn.Module):
|
| 463 |
+
def __init__(self, img_size=224, in_chans=3, num_classes=1000,
|
| 464 |
+
embed_dims=[96, 192, 384, 768], depths=[2, 2, 6, 2],
|
| 465 |
+
num_heads=[3, 6, 12, 24],
|
| 466 |
+
window_sizes=[7, 7, 14, 7],
|
| 467 |
+
mlp_ratio=4.,
|
| 468 |
+
drop_rate=0.,
|
| 469 |
+
drop_path_rate=0.1,
|
| 470 |
+
use_checkpoint=False,
|
| 471 |
+
mbconv_expand_ratio=4.0,
|
| 472 |
+
local_conv_size=3,
|
| 473 |
+
layer_lr_decay=1.0,
|
| 474 |
+
):
|
| 475 |
+
super().__init__()
|
| 476 |
+
self.img_size=img_size
|
| 477 |
+
self.num_classes = num_classes
|
| 478 |
+
self.depths = depths
|
| 479 |
+
self.num_layers = len(depths)
|
| 480 |
+
self.mlp_ratio = mlp_ratio
|
| 481 |
+
|
| 482 |
+
activation = nn.GELU
|
| 483 |
+
|
| 484 |
+
self.patch_embed = PatchEmbed(in_chans=in_chans,
|
| 485 |
+
embed_dim=embed_dims[0],
|
| 486 |
+
resolution=img_size,
|
| 487 |
+
activation=activation)
|
| 488 |
+
|
| 489 |
+
patches_resolution = self.patch_embed.patches_resolution
|
| 490 |
+
self.patches_resolution = patches_resolution
|
| 491 |
+
|
| 492 |
+
# stochastic depth
|
| 493 |
+
dpr = [x.item() for x in torch.linspace(0, drop_path_rate,
|
| 494 |
+
sum(depths))] # stochastic depth decay rule
|
| 495 |
+
|
| 496 |
+
# build layers
|
| 497 |
+
self.layers = nn.ModuleList()
|
| 498 |
+
for i_layer in range(self.num_layers):
|
| 499 |
+
kwargs = dict(dim=embed_dims[i_layer],
|
| 500 |
+
input_resolution=(patches_resolution[0] // (2 ** (i_layer-1 if i_layer == 3 else i_layer)),
|
| 501 |
+
patches_resolution[1] // (2 ** (i_layer-1 if i_layer == 3 else i_layer))),
|
| 502 |
+
# input_resolution=(patches_resolution[0] // (2 ** i_layer),
|
| 503 |
+
# patches_resolution[1] // (2 ** i_layer)),
|
| 504 |
+
depth=depths[i_layer],
|
| 505 |
+
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
|
| 506 |
+
downsample=PatchMerging if (
|
| 507 |
+
i_layer < self.num_layers - 1) else None,
|
| 508 |
+
use_checkpoint=use_checkpoint,
|
| 509 |
+
out_dim=embed_dims[min(
|
| 510 |
+
i_layer + 1, len(embed_dims) - 1)],
|
| 511 |
+
activation=activation,
|
| 512 |
+
)
|
| 513 |
+
if i_layer == 0:
|
| 514 |
+
layer = ConvLayer(
|
| 515 |
+
conv_expand_ratio=mbconv_expand_ratio,
|
| 516 |
+
**kwargs,
|
| 517 |
+
)
|
| 518 |
+
else:
|
| 519 |
+
layer = BasicLayer(
|
| 520 |
+
num_heads=num_heads[i_layer],
|
| 521 |
+
window_size=window_sizes[i_layer],
|
| 522 |
+
mlp_ratio=self.mlp_ratio,
|
| 523 |
+
drop=drop_rate,
|
| 524 |
+
local_conv_size=local_conv_size,
|
| 525 |
+
**kwargs)
|
| 526 |
+
self.layers.append(layer)
|
| 527 |
+
|
| 528 |
+
# Classifier head
|
| 529 |
+
self.norm_head = nn.LayerNorm(embed_dims[-1])
|
| 530 |
+
self.head = nn.Linear(
|
| 531 |
+
embed_dims[-1], num_classes) if num_classes > 0 else torch.nn.Identity()
|
| 532 |
+
|
| 533 |
+
# init weights
|
| 534 |
+
self.apply(self._init_weights)
|
| 535 |
+
self.set_layer_lr_decay(layer_lr_decay)
|
| 536 |
+
self.neck = nn.Sequential(
|
| 537 |
+
nn.Conv2d(
|
| 538 |
+
embed_dims[-1],
|
| 539 |
+
256,
|
| 540 |
+
kernel_size=1,
|
| 541 |
+
bias=False,
|
| 542 |
+
),
|
| 543 |
+
LayerNorm2d(256),
|
| 544 |
+
nn.Conv2d(
|
| 545 |
+
256,
|
| 546 |
+
256,
|
| 547 |
+
kernel_size=3,
|
| 548 |
+
padding=1,
|
| 549 |
+
bias=False,
|
| 550 |
+
),
|
| 551 |
+
LayerNorm2d(256),
|
| 552 |
+
)
|
| 553 |
+
def set_layer_lr_decay(self, layer_lr_decay):
|
| 554 |
+
decay_rate = layer_lr_decay
|
| 555 |
+
|
| 556 |
+
# layers -> blocks (depth)
|
| 557 |
+
depth = sum(self.depths)
|
| 558 |
+
lr_scales = [decay_rate ** (depth - i - 1) for i in range(depth)]
|
| 559 |
+
#print("LR SCALES:", lr_scales)
|
| 560 |
+
|
| 561 |
+
def _set_lr_scale(m, scale):
|
| 562 |
+
for p in m.parameters():
|
| 563 |
+
p.lr_scale = scale
|
| 564 |
+
|
| 565 |
+
self.patch_embed.apply(lambda x: _set_lr_scale(x, lr_scales[0]))
|
| 566 |
+
i = 0
|
| 567 |
+
for layer in self.layers:
|
| 568 |
+
for block in layer.blocks:
|
| 569 |
+
block.apply(lambda x: _set_lr_scale(x, lr_scales[i]))
|
| 570 |
+
i += 1
|
| 571 |
+
if layer.downsample is not None:
|
| 572 |
+
layer.downsample.apply(
|
| 573 |
+
lambda x: _set_lr_scale(x, lr_scales[i - 1]))
|
| 574 |
+
assert i == depth
|
| 575 |
+
for m in [self.norm_head, self.head]:
|
| 576 |
+
m.apply(lambda x: _set_lr_scale(x, lr_scales[-1]))
|
| 577 |
+
|
| 578 |
+
for k, p in self.named_parameters():
|
| 579 |
+
p.param_name = k
|
| 580 |
+
|
| 581 |
+
def _check_lr_scale(m):
|
| 582 |
+
for p in m.parameters():
|
| 583 |
+
assert hasattr(p, 'lr_scale'), p.param_name
|
| 584 |
+
|
| 585 |
+
self.apply(_check_lr_scale)
|
| 586 |
+
|
| 587 |
+
def _init_weights(self, m):
|
| 588 |
+
if isinstance(m, nn.Linear):
|
| 589 |
+
trunc_normal_(m.weight, std=.02)
|
| 590 |
+
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 591 |
+
nn.init.constant_(m.bias, 0)
|
| 592 |
+
elif isinstance(m, nn.LayerNorm):
|
| 593 |
+
nn.init.constant_(m.bias, 0)
|
| 594 |
+
nn.init.constant_(m.weight, 1.0)
|
| 595 |
+
|
| 596 |
+
@torch.jit.ignore
|
| 597 |
+
def no_weight_decay_keywords(self):
|
| 598 |
+
return {'attention_biases'}
|
| 599 |
+
|
| 600 |
+
def forward_features(self, x):
|
| 601 |
+
# x: (N, C, H, W)
|
| 602 |
+
x = self.patch_embed(x)
|
| 603 |
+
|
| 604 |
+
x = self.layers[0](x)
|
| 605 |
+
start_i = 1
|
| 606 |
+
|
| 607 |
+
interm_embeddings=[]
|
| 608 |
+
for i in range(start_i, len(self.layers)):
|
| 609 |
+
layer = self.layers[i]
|
| 610 |
+
x = layer(x)
|
| 611 |
+
# print('x shape:', x.shape, '---i:', i)
|
| 612 |
+
if i == 1:
|
| 613 |
+
interm_embeddings.append(x.view(x.shape[0], 64, 64, -1))
|
| 614 |
+
|
| 615 |
+
B,_,C=x.size()
|
| 616 |
+
x = x.view(B, 64, 64, C)
|
| 617 |
+
x=x.permute(0, 3, 1, 2)
|
| 618 |
+
x=self.neck(x)
|
| 619 |
+
return x, interm_embeddings
|
| 620 |
+
|
| 621 |
+
def forward(self, x):
|
| 622 |
+
x, interm_embeddings = self.forward_features(x)
|
| 623 |
+
#x = self.norm_head(x)
|
| 624 |
+
#x = self.head(x)
|
| 625 |
+
# print('come to here is correct'* 3)
|
| 626 |
+
return x, interm_embeddings
|
| 627 |
+
|
| 628 |
+
|
| 629 |
+
_checkpoint_url_format = \
|
| 630 |
+
'https://github.com/wkcn/TinyViT-model-zoo/releases/download/checkpoints/{}.pth'
|
| 631 |
+
_provided_checkpoints = {
|
| 632 |
+
'tiny_vit_5m_224': 'tiny_vit_5m_22kto1k_distill',
|
| 633 |
+
'tiny_vit_11m_224': 'tiny_vit_11m_22kto1k_distill',
|
| 634 |
+
'tiny_vit_21m_224': 'tiny_vit_21m_22kto1k_distill',
|
| 635 |
+
'tiny_vit_21m_384': 'tiny_vit_21m_22kto1k_384_distill',
|
| 636 |
+
'tiny_vit_21m_512': 'tiny_vit_21m_22kto1k_512_distill',
|
| 637 |
+
}
|
| 638 |
+
|
| 639 |
+
|
| 640 |
+
def register_tiny_vit_model(fn):
|
| 641 |
+
'''Register a TinyViT model
|
| 642 |
+
It is a wrapper of `register_model` with loading the pretrained checkpoint.
|
| 643 |
+
'''
|
| 644 |
+
def fn_wrapper(pretrained=False, **kwargs):
|
| 645 |
+
model = fn()
|
| 646 |
+
if pretrained:
|
| 647 |
+
model_name = fn.__name__
|
| 648 |
+
assert model_name in _provided_checkpoints, \
|
| 649 |
+
f'Sorry that the checkpoint `{model_name}` is not provided yet.'
|
| 650 |
+
url = _checkpoint_url_format.format(
|
| 651 |
+
_provided_checkpoints[model_name])
|
| 652 |
+
checkpoint = torch.hub.load_state_dict_from_url(
|
| 653 |
+
url=url,
|
| 654 |
+
map_location='cpu', check_hash=False,
|
| 655 |
+
)
|
| 656 |
+
model.load_state_dict(checkpoint['model'])
|
| 657 |
+
|
| 658 |
+
return model
|
| 659 |
+
|
| 660 |
+
# rename the name of fn_wrapper
|
| 661 |
+
fn_wrapper.__name__ = fn.__name__
|
| 662 |
+
return register_model(fn_wrapper)
|
| 663 |
+
|
| 664 |
+
|
| 665 |
+
@register_tiny_vit_model
|
| 666 |
+
def tiny_vit_5m_224(pretrained=False, num_classes=1000, drop_path_rate=0.0):
|
| 667 |
+
return TinyViT(
|
| 668 |
+
num_classes=num_classes,
|
| 669 |
+
embed_dims=[64, 128, 160, 320],
|
| 670 |
+
depths=[2, 2, 6, 2],
|
| 671 |
+
num_heads=[2, 4, 5, 10],
|
| 672 |
+
window_sizes=[7, 7, 14, 7],
|
| 673 |
+
drop_path_rate=drop_path_rate,
|
| 674 |
+
)
|
| 675 |
+
|
| 676 |
+
|
| 677 |
+
@register_tiny_vit_model
|
| 678 |
+
def tiny_vit_11m_224(pretrained=False, num_classes=1000, drop_path_rate=0.1):
|
| 679 |
+
return TinyViT(
|
| 680 |
+
num_classes=num_classes,
|
| 681 |
+
embed_dims=[64, 128, 256, 448],
|
| 682 |
+
depths=[2, 2, 6, 2],
|
| 683 |
+
num_heads=[2, 4, 8, 14],
|
| 684 |
+
window_sizes=[7, 7, 14, 7],
|
| 685 |
+
drop_path_rate=drop_path_rate,
|
| 686 |
+
)
|
| 687 |
+
|
| 688 |
+
|
| 689 |
+
@register_tiny_vit_model
|
| 690 |
+
def tiny_vit_21m_224(pretrained=False, num_classes=1000, drop_path_rate=0.2):
|
| 691 |
+
return TinyViT(
|
| 692 |
+
num_classes=num_classes,
|
| 693 |
+
embed_dims=[96, 192, 384, 576],
|
| 694 |
+
depths=[2, 2, 6, 2],
|
| 695 |
+
num_heads=[3, 6, 12, 18],
|
| 696 |
+
window_sizes=[7, 7, 14, 7],
|
| 697 |
+
drop_path_rate=drop_path_rate,
|
| 698 |
+
)
|
| 699 |
+
|
| 700 |
+
|
| 701 |
+
@register_tiny_vit_model
|
| 702 |
+
def tiny_vit_21m_384(pretrained=False, num_classes=1000, drop_path_rate=0.1):
|
| 703 |
+
return TinyViT(
|
| 704 |
+
img_size=384,
|
| 705 |
+
num_classes=num_classes,
|
| 706 |
+
embed_dims=[96, 192, 384, 576],
|
| 707 |
+
depths=[2, 2, 6, 2],
|
| 708 |
+
num_heads=[3, 6, 12, 18],
|
| 709 |
+
window_sizes=[12, 12, 24, 12],
|
| 710 |
+
drop_path_rate=drop_path_rate,
|
| 711 |
+
)
|
| 712 |
+
|
| 713 |
+
|
| 714 |
+
@register_tiny_vit_model
|
| 715 |
+
def tiny_vit_21m_512(pretrained=False, num_classes=1000, drop_path_rate=0.1):
|
| 716 |
+
return TinyViT(
|
| 717 |
+
img_size=512,
|
| 718 |
+
num_classes=num_classes,
|
| 719 |
+
embed_dims=[96, 192, 384, 576],
|
| 720 |
+
depths=[2, 2, 6, 2],
|
| 721 |
+
num_heads=[3, 6, 12, 18],
|
| 722 |
+
window_sizes=[16, 16, 32, 16],
|
| 723 |
+
drop_path_rate=drop_path_rate,
|
| 724 |
+
)
|
EfficientSAM/MobileSAM/setup_mobile_sam.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from MobileSAM.tiny_vit_sam import TinyViT
|
| 2 |
+
from segment_anything.modeling import MaskDecoder, PromptEncoder, Sam, TwoWayTransformer
|
| 3 |
+
|
| 4 |
+
def setup_model():
|
| 5 |
+
prompt_embed_dim = 256
|
| 6 |
+
image_size = 1024
|
| 7 |
+
vit_patch_size = 16
|
| 8 |
+
image_embedding_size = image_size // vit_patch_size
|
| 9 |
+
mobile_sam = Sam(
|
| 10 |
+
image_encoder=TinyViT(img_size=1024, in_chans=3, num_classes=1000,
|
| 11 |
+
embed_dims=[64, 128, 160, 320],
|
| 12 |
+
depths=[2, 2, 6, 2],
|
| 13 |
+
num_heads=[2, 4, 5, 10],
|
| 14 |
+
window_sizes=[7, 7, 14, 7],
|
| 15 |
+
mlp_ratio=4.,
|
| 16 |
+
drop_rate=0.,
|
| 17 |
+
drop_path_rate=0.0,
|
| 18 |
+
use_checkpoint=False,
|
| 19 |
+
mbconv_expand_ratio=4.0,
|
| 20 |
+
local_conv_size=3,
|
| 21 |
+
layer_lr_decay=0.8
|
| 22 |
+
),
|
| 23 |
+
prompt_encoder=PromptEncoder(
|
| 24 |
+
embed_dim=prompt_embed_dim,
|
| 25 |
+
image_embedding_size=(image_embedding_size, image_embedding_size),
|
| 26 |
+
input_image_size=(image_size, image_size),
|
| 27 |
+
mask_in_chans=16,
|
| 28 |
+
),
|
| 29 |
+
mask_decoder=MaskDecoder(
|
| 30 |
+
num_multimask_outputs=3,
|
| 31 |
+
transformer=TwoWayTransformer(
|
| 32 |
+
depth=2,
|
| 33 |
+
embedding_dim=prompt_embed_dim,
|
| 34 |
+
mlp_dim=2048,
|
| 35 |
+
num_heads=8,
|
| 36 |
+
),
|
| 37 |
+
transformer_dim=prompt_embed_dim,
|
| 38 |
+
iou_head_depth=3,
|
| 39 |
+
iou_head_hidden_dim=256,
|
| 40 |
+
),
|
| 41 |
+
pixel_mean=[123.675, 116.28, 103.53],
|
| 42 |
+
pixel_std=[58.395, 57.12, 57.375],
|
| 43 |
+
)
|
| 44 |
+
return mobile_sam
|
EfficientSAM/MobileSAM/tiny_vit_sam.py
ADDED
|
@@ -0,0 +1,716 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# TinyViT Model Architecture
|
| 3 |
+
# Copyright (c) 2022 Microsoft
|
| 4 |
+
# Adapted from LeViT and Swin Transformer
|
| 5 |
+
# LeViT: (https://github.com/facebookresearch/levit)
|
| 6 |
+
# Swin: (https://github.com/microsoft/swin-transformer)
|
| 7 |
+
# Build the TinyViT Model
|
| 8 |
+
# --------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
import itertools
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn as nn
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
import torch.utils.checkpoint as checkpoint
|
| 15 |
+
from timm.models.layers import DropPath as TimmDropPath,\
|
| 16 |
+
to_2tuple, trunc_normal_
|
| 17 |
+
from timm.models.registry import register_model
|
| 18 |
+
from typing import Tuple
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class Conv2d_BN(torch.nn.Sequential):
|
| 22 |
+
def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
|
| 23 |
+
groups=1, bn_weight_init=1):
|
| 24 |
+
super().__init__()
|
| 25 |
+
self.add_module('c', torch.nn.Conv2d(
|
| 26 |
+
a, b, ks, stride, pad, dilation, groups, bias=False))
|
| 27 |
+
bn = torch.nn.BatchNorm2d(b)
|
| 28 |
+
torch.nn.init.constant_(bn.weight, bn_weight_init)
|
| 29 |
+
torch.nn.init.constant_(bn.bias, 0)
|
| 30 |
+
self.add_module('bn', bn)
|
| 31 |
+
|
| 32 |
+
@torch.no_grad()
|
| 33 |
+
def fuse(self):
|
| 34 |
+
c, bn = self._modules.values()
|
| 35 |
+
w = bn.weight / (bn.running_var + bn.eps)**0.5
|
| 36 |
+
w = c.weight * w[:, None, None, None]
|
| 37 |
+
b = bn.bias - bn.running_mean * bn.weight / \
|
| 38 |
+
(bn.running_var + bn.eps)**0.5
|
| 39 |
+
m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(
|
| 40 |
+
0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation, groups=self.c.groups)
|
| 41 |
+
m.weight.data.copy_(w)
|
| 42 |
+
m.bias.data.copy_(b)
|
| 43 |
+
return m
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class DropPath(TimmDropPath):
|
| 47 |
+
def __init__(self, drop_prob=None):
|
| 48 |
+
super().__init__(drop_prob=drop_prob)
|
| 49 |
+
self.drop_prob = drop_prob
|
| 50 |
+
|
| 51 |
+
def __repr__(self):
|
| 52 |
+
msg = super().__repr__()
|
| 53 |
+
msg += f'(drop_prob={self.drop_prob})'
|
| 54 |
+
return msg
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class PatchEmbed(nn.Module):
|
| 58 |
+
def __init__(self, in_chans, embed_dim, resolution, activation):
|
| 59 |
+
super().__init__()
|
| 60 |
+
img_size: Tuple[int, int] = to_2tuple(resolution)
|
| 61 |
+
self.patches_resolution = (img_size[0] // 4, img_size[1] // 4)
|
| 62 |
+
self.num_patches = self.patches_resolution[0] * \
|
| 63 |
+
self.patches_resolution[1]
|
| 64 |
+
self.in_chans = in_chans
|
| 65 |
+
self.embed_dim = embed_dim
|
| 66 |
+
n = embed_dim
|
| 67 |
+
self.seq = nn.Sequential(
|
| 68 |
+
Conv2d_BN(in_chans, n // 2, 3, 2, 1),
|
| 69 |
+
activation(),
|
| 70 |
+
Conv2d_BN(n // 2, n, 3, 2, 1),
|
| 71 |
+
)
|
| 72 |
+
|
| 73 |
+
def forward(self, x):
|
| 74 |
+
return self.seq(x)
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
class MBConv(nn.Module):
|
| 78 |
+
def __init__(self, in_chans, out_chans, expand_ratio,
|
| 79 |
+
activation, drop_path):
|
| 80 |
+
super().__init__()
|
| 81 |
+
self.in_chans = in_chans
|
| 82 |
+
self.hidden_chans = int(in_chans * expand_ratio)
|
| 83 |
+
self.out_chans = out_chans
|
| 84 |
+
|
| 85 |
+
self.conv1 = Conv2d_BN(in_chans, self.hidden_chans, ks=1)
|
| 86 |
+
self.act1 = activation()
|
| 87 |
+
|
| 88 |
+
self.conv2 = Conv2d_BN(self.hidden_chans, self.hidden_chans,
|
| 89 |
+
ks=3, stride=1, pad=1, groups=self.hidden_chans)
|
| 90 |
+
self.act2 = activation()
|
| 91 |
+
|
| 92 |
+
self.conv3 = Conv2d_BN(
|
| 93 |
+
self.hidden_chans, out_chans, ks=1, bn_weight_init=0.0)
|
| 94 |
+
self.act3 = activation()
|
| 95 |
+
|
| 96 |
+
self.drop_path = DropPath(
|
| 97 |
+
drop_path) if drop_path > 0. else nn.Identity()
|
| 98 |
+
|
| 99 |
+
def forward(self, x):
|
| 100 |
+
shortcut = x
|
| 101 |
+
|
| 102 |
+
x = self.conv1(x)
|
| 103 |
+
x = self.act1(x)
|
| 104 |
+
|
| 105 |
+
x = self.conv2(x)
|
| 106 |
+
x = self.act2(x)
|
| 107 |
+
|
| 108 |
+
x = self.conv3(x)
|
| 109 |
+
|
| 110 |
+
x = self.drop_path(x)
|
| 111 |
+
|
| 112 |
+
x += shortcut
|
| 113 |
+
x = self.act3(x)
|
| 114 |
+
|
| 115 |
+
return x
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
class PatchMerging(nn.Module):
|
| 119 |
+
def __init__(self, input_resolution, dim, out_dim, activation):
|
| 120 |
+
super().__init__()
|
| 121 |
+
|
| 122 |
+
self.input_resolution = input_resolution
|
| 123 |
+
self.dim = dim
|
| 124 |
+
self.out_dim = out_dim
|
| 125 |
+
self.act = activation()
|
| 126 |
+
self.conv1 = Conv2d_BN(dim, out_dim, 1, 1, 0)
|
| 127 |
+
stride_c=2
|
| 128 |
+
if(out_dim==320 or out_dim==448 or out_dim==576):#handongshen 576
|
| 129 |
+
stride_c=1
|
| 130 |
+
self.conv2 = Conv2d_BN(out_dim, out_dim, 3, stride_c, 1, groups=out_dim)
|
| 131 |
+
self.conv3 = Conv2d_BN(out_dim, out_dim, 1, 1, 0)
|
| 132 |
+
|
| 133 |
+
def forward(self, x):
|
| 134 |
+
if x.ndim == 3:
|
| 135 |
+
H, W = self.input_resolution
|
| 136 |
+
B = len(x)
|
| 137 |
+
# (B, C, H, W)
|
| 138 |
+
x = x.view(B, H, W, -1).permute(0, 3, 1, 2)
|
| 139 |
+
|
| 140 |
+
x = self.conv1(x)
|
| 141 |
+
x = self.act(x)
|
| 142 |
+
|
| 143 |
+
x = self.conv2(x)
|
| 144 |
+
x = self.act(x)
|
| 145 |
+
x = self.conv3(x)
|
| 146 |
+
x = x.flatten(2).transpose(1, 2)
|
| 147 |
+
return x
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
class ConvLayer(nn.Module):
|
| 151 |
+
def __init__(self, dim, input_resolution, depth,
|
| 152 |
+
activation,
|
| 153 |
+
drop_path=0., downsample=None, use_checkpoint=False,
|
| 154 |
+
out_dim=None,
|
| 155 |
+
conv_expand_ratio=4.,
|
| 156 |
+
):
|
| 157 |
+
|
| 158 |
+
super().__init__()
|
| 159 |
+
self.dim = dim
|
| 160 |
+
self.input_resolution = input_resolution
|
| 161 |
+
self.depth = depth
|
| 162 |
+
self.use_checkpoint = use_checkpoint
|
| 163 |
+
|
| 164 |
+
# build blocks
|
| 165 |
+
self.blocks = nn.ModuleList([
|
| 166 |
+
MBConv(dim, dim, conv_expand_ratio, activation,
|
| 167 |
+
drop_path[i] if isinstance(drop_path, list) else drop_path,
|
| 168 |
+
)
|
| 169 |
+
for i in range(depth)])
|
| 170 |
+
|
| 171 |
+
# patch merging layer
|
| 172 |
+
if downsample is not None:
|
| 173 |
+
self.downsample = downsample(
|
| 174 |
+
input_resolution, dim=dim, out_dim=out_dim, activation=activation)
|
| 175 |
+
else:
|
| 176 |
+
self.downsample = None
|
| 177 |
+
|
| 178 |
+
def forward(self, x):
|
| 179 |
+
for blk in self.blocks:
|
| 180 |
+
if self.use_checkpoint:
|
| 181 |
+
x = checkpoint.checkpoint(blk, x)
|
| 182 |
+
else:
|
| 183 |
+
x = blk(x)
|
| 184 |
+
if self.downsample is not None:
|
| 185 |
+
x = self.downsample(x)
|
| 186 |
+
return x
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
class Mlp(nn.Module):
|
| 190 |
+
def __init__(self, in_features, hidden_features=None,
|
| 191 |
+
out_features=None, act_layer=nn.GELU, drop=0.):
|
| 192 |
+
super().__init__()
|
| 193 |
+
out_features = out_features or in_features
|
| 194 |
+
hidden_features = hidden_features or in_features
|
| 195 |
+
self.norm = nn.LayerNorm(in_features)
|
| 196 |
+
self.fc1 = nn.Linear(in_features, hidden_features)
|
| 197 |
+
self.fc2 = nn.Linear(hidden_features, out_features)
|
| 198 |
+
self.act = act_layer()
|
| 199 |
+
self.drop = nn.Dropout(drop)
|
| 200 |
+
|
| 201 |
+
def forward(self, x):
|
| 202 |
+
x = self.norm(x)
|
| 203 |
+
|
| 204 |
+
x = self.fc1(x)
|
| 205 |
+
x = self.act(x)
|
| 206 |
+
x = self.drop(x)
|
| 207 |
+
x = self.fc2(x)
|
| 208 |
+
x = self.drop(x)
|
| 209 |
+
return x
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
class Attention(torch.nn.Module):
|
| 213 |
+
def __init__(self, dim, key_dim, num_heads=8,
|
| 214 |
+
attn_ratio=4,
|
| 215 |
+
resolution=(14, 14),
|
| 216 |
+
):
|
| 217 |
+
super().__init__()
|
| 218 |
+
# (h, w)
|
| 219 |
+
assert isinstance(resolution, tuple) and len(resolution) == 2
|
| 220 |
+
self.num_heads = num_heads
|
| 221 |
+
self.scale = key_dim ** -0.5
|
| 222 |
+
self.key_dim = key_dim
|
| 223 |
+
self.nh_kd = nh_kd = key_dim * num_heads
|
| 224 |
+
self.d = int(attn_ratio * key_dim)
|
| 225 |
+
self.dh = int(attn_ratio * key_dim) * num_heads
|
| 226 |
+
self.attn_ratio = attn_ratio
|
| 227 |
+
h = self.dh + nh_kd * 2
|
| 228 |
+
|
| 229 |
+
self.norm = nn.LayerNorm(dim)
|
| 230 |
+
self.qkv = nn.Linear(dim, h)
|
| 231 |
+
self.proj = nn.Linear(self.dh, dim)
|
| 232 |
+
|
| 233 |
+
points = list(itertools.product(
|
| 234 |
+
range(resolution[0]), range(resolution[1])))
|
| 235 |
+
N = len(points)
|
| 236 |
+
attention_offsets = {}
|
| 237 |
+
idxs = []
|
| 238 |
+
for p1 in points:
|
| 239 |
+
for p2 in points:
|
| 240 |
+
offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))
|
| 241 |
+
if offset not in attention_offsets:
|
| 242 |
+
attention_offsets[offset] = len(attention_offsets)
|
| 243 |
+
idxs.append(attention_offsets[offset])
|
| 244 |
+
self.attention_biases = torch.nn.Parameter(
|
| 245 |
+
torch.zeros(num_heads, len(attention_offsets)))
|
| 246 |
+
self.register_buffer('attention_bias_idxs',
|
| 247 |
+
torch.LongTensor(idxs).view(N, N),
|
| 248 |
+
persistent=False)
|
| 249 |
+
|
| 250 |
+
@torch.no_grad()
|
| 251 |
+
def train(self, mode=True):
|
| 252 |
+
super().train(mode)
|
| 253 |
+
if mode and hasattr(self, 'ab'):
|
| 254 |
+
del self.ab
|
| 255 |
+
else:
|
| 256 |
+
self.ab = self.attention_biases[:, self.attention_bias_idxs]
|
| 257 |
+
|
| 258 |
+
def forward(self, x): # x (B,N,C)
|
| 259 |
+
B, N, _ = x.shape
|
| 260 |
+
|
| 261 |
+
# Normalization
|
| 262 |
+
x = self.norm(x)
|
| 263 |
+
|
| 264 |
+
qkv = self.qkv(x)
|
| 265 |
+
# (B, N, num_heads, d)
|
| 266 |
+
q, k, v = qkv.view(B, N, self.num_heads, -
|
| 267 |
+
1).split([self.key_dim, self.key_dim, self.d], dim=3)
|
| 268 |
+
# (B, num_heads, N, d)
|
| 269 |
+
q = q.permute(0, 2, 1, 3)
|
| 270 |
+
k = k.permute(0, 2, 1, 3)
|
| 271 |
+
v = v.permute(0, 2, 1, 3)
|
| 272 |
+
|
| 273 |
+
attn = (
|
| 274 |
+
(q @ k.transpose(-2, -1)) * self.scale
|
| 275 |
+
+
|
| 276 |
+
(self.attention_biases[:, self.attention_bias_idxs]
|
| 277 |
+
if self.training else self.ab)
|
| 278 |
+
)
|
| 279 |
+
attn = attn.softmax(dim=-1)
|
| 280 |
+
x = (attn @ v).transpose(1, 2).reshape(B, N, self.dh)
|
| 281 |
+
x = self.proj(x)
|
| 282 |
+
return x
|
| 283 |
+
|
| 284 |
+
|
| 285 |
+
class TinyViTBlock(nn.Module):
|
| 286 |
+
r""" TinyViT Block.
|
| 287 |
+
|
| 288 |
+
Args:
|
| 289 |
+
dim (int): Number of input channels.
|
| 290 |
+
input_resolution (tuple[int, int]): Input resulotion.
|
| 291 |
+
num_heads (int): Number of attention heads.
|
| 292 |
+
window_size (int): Window size.
|
| 293 |
+
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
|
| 294 |
+
drop (float, optional): Dropout rate. Default: 0.0
|
| 295 |
+
drop_path (float, optional): Stochastic depth rate. Default: 0.0
|
| 296 |
+
local_conv_size (int): the kernel size of the convolution between
|
| 297 |
+
Attention and MLP. Default: 3
|
| 298 |
+
activation: the activation function. Default: nn.GELU
|
| 299 |
+
"""
|
| 300 |
+
|
| 301 |
+
def __init__(self, dim, input_resolution, num_heads, window_size=7,
|
| 302 |
+
mlp_ratio=4., drop=0., drop_path=0.,
|
| 303 |
+
local_conv_size=3,
|
| 304 |
+
activation=nn.GELU,
|
| 305 |
+
):
|
| 306 |
+
super().__init__()
|
| 307 |
+
self.dim = dim
|
| 308 |
+
self.input_resolution = input_resolution
|
| 309 |
+
self.num_heads = num_heads
|
| 310 |
+
assert window_size > 0, 'window_size must be greater than 0'
|
| 311 |
+
self.window_size = window_size
|
| 312 |
+
self.mlp_ratio = mlp_ratio
|
| 313 |
+
|
| 314 |
+
self.drop_path = DropPath(
|
| 315 |
+
drop_path) if drop_path > 0. else nn.Identity()
|
| 316 |
+
|
| 317 |
+
assert dim % num_heads == 0, 'dim must be divisible by num_heads'
|
| 318 |
+
head_dim = dim // num_heads
|
| 319 |
+
|
| 320 |
+
window_resolution = (window_size, window_size)
|
| 321 |
+
self.attn = Attention(dim, head_dim, num_heads,
|
| 322 |
+
attn_ratio=1, resolution=window_resolution)
|
| 323 |
+
|
| 324 |
+
mlp_hidden_dim = int(dim * mlp_ratio)
|
| 325 |
+
mlp_activation = activation
|
| 326 |
+
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
|
| 327 |
+
act_layer=mlp_activation, drop=drop)
|
| 328 |
+
|
| 329 |
+
pad = local_conv_size // 2
|
| 330 |
+
self.local_conv = Conv2d_BN(
|
| 331 |
+
dim, dim, ks=local_conv_size, stride=1, pad=pad, groups=dim)
|
| 332 |
+
|
| 333 |
+
def forward(self, x):
|
| 334 |
+
H, W = self.input_resolution
|
| 335 |
+
B, L, C = x.shape
|
| 336 |
+
assert L == H * W, "input feature has wrong size"
|
| 337 |
+
res_x = x
|
| 338 |
+
if H == self.window_size and W == self.window_size:
|
| 339 |
+
x = self.attn(x)
|
| 340 |
+
else:
|
| 341 |
+
x = x.view(B, H, W, C)
|
| 342 |
+
pad_b = (self.window_size - H %
|
| 343 |
+
self.window_size) % self.window_size
|
| 344 |
+
pad_r = (self.window_size - W %
|
| 345 |
+
self.window_size) % self.window_size
|
| 346 |
+
padding = pad_b > 0 or pad_r > 0
|
| 347 |
+
|
| 348 |
+
if padding:
|
| 349 |
+
x = F.pad(x, (0, 0, 0, pad_r, 0, pad_b))
|
| 350 |
+
|
| 351 |
+
pH, pW = H + pad_b, W + pad_r
|
| 352 |
+
nH = pH // self.window_size
|
| 353 |
+
nW = pW // self.window_size
|
| 354 |
+
# window partition
|
| 355 |
+
x = x.view(B, nH, self.window_size, nW, self.window_size, C).transpose(2, 3).reshape(
|
| 356 |
+
B * nH * nW, self.window_size * self.window_size, C)
|
| 357 |
+
x = self.attn(x)
|
| 358 |
+
# window reverse
|
| 359 |
+
x = x.view(B, nH, nW, self.window_size, self.window_size,
|
| 360 |
+
C).transpose(2, 3).reshape(B, pH, pW, C)
|
| 361 |
+
|
| 362 |
+
if padding:
|
| 363 |
+
x = x[:, :H, :W].contiguous()
|
| 364 |
+
|
| 365 |
+
x = x.view(B, L, C)
|
| 366 |
+
|
| 367 |
+
x = res_x + self.drop_path(x)
|
| 368 |
+
|
| 369 |
+
x = x.transpose(1, 2).reshape(B, C, H, W)
|
| 370 |
+
x = self.local_conv(x)
|
| 371 |
+
x = x.view(B, C, L).transpose(1, 2)
|
| 372 |
+
|
| 373 |
+
x = x + self.drop_path(self.mlp(x))
|
| 374 |
+
return x
|
| 375 |
+
|
| 376 |
+
def extra_repr(self) -> str:
|
| 377 |
+
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
|
| 378 |
+
f"window_size={self.window_size}, mlp_ratio={self.mlp_ratio}"
|
| 379 |
+
|
| 380 |
+
|
| 381 |
+
class BasicLayer(nn.Module):
|
| 382 |
+
""" A basic TinyViT layer for one stage.
|
| 383 |
+
|
| 384 |
+
Args:
|
| 385 |
+
dim (int): Number of input channels.
|
| 386 |
+
input_resolution (tuple[int]): Input resolution.
|
| 387 |
+
depth (int): Number of blocks.
|
| 388 |
+
num_heads (int): Number of attention heads.
|
| 389 |
+
window_size (int): Local window size.
|
| 390 |
+
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
|
| 391 |
+
drop (float, optional): Dropout rate. Default: 0.0
|
| 392 |
+
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
|
| 393 |
+
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
|
| 394 |
+
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
|
| 395 |
+
local_conv_size: the kernel size of the depthwise convolution between attention and MLP. Default: 3
|
| 396 |
+
activation: the activation function. Default: nn.GELU
|
| 397 |
+
out_dim: the output dimension of the layer. Default: dim
|
| 398 |
+
"""
|
| 399 |
+
|
| 400 |
+
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
|
| 401 |
+
mlp_ratio=4., drop=0.,
|
| 402 |
+
drop_path=0., downsample=None, use_checkpoint=False,
|
| 403 |
+
local_conv_size=3,
|
| 404 |
+
activation=nn.GELU,
|
| 405 |
+
out_dim=None,
|
| 406 |
+
):
|
| 407 |
+
|
| 408 |
+
super().__init__()
|
| 409 |
+
self.dim = dim
|
| 410 |
+
self.input_resolution = input_resolution
|
| 411 |
+
self.depth = depth
|
| 412 |
+
self.use_checkpoint = use_checkpoint
|
| 413 |
+
|
| 414 |
+
# build blocks
|
| 415 |
+
self.blocks = nn.ModuleList([
|
| 416 |
+
TinyViTBlock(dim=dim, input_resolution=input_resolution,
|
| 417 |
+
num_heads=num_heads, window_size=window_size,
|
| 418 |
+
mlp_ratio=mlp_ratio,
|
| 419 |
+
drop=drop,
|
| 420 |
+
drop_path=drop_path[i] if isinstance(
|
| 421 |
+
drop_path, list) else drop_path,
|
| 422 |
+
local_conv_size=local_conv_size,
|
| 423 |
+
activation=activation,
|
| 424 |
+
)
|
| 425 |
+
for i in range(depth)])
|
| 426 |
+
|
| 427 |
+
# patch merging layer
|
| 428 |
+
if downsample is not None:
|
| 429 |
+
self.downsample = downsample(
|
| 430 |
+
input_resolution, dim=dim, out_dim=out_dim, activation=activation)
|
| 431 |
+
else:
|
| 432 |
+
self.downsample = None
|
| 433 |
+
|
| 434 |
+
def forward(self, x):
|
| 435 |
+
for blk in self.blocks:
|
| 436 |
+
if self.use_checkpoint:
|
| 437 |
+
x = checkpoint.checkpoint(blk, x)
|
| 438 |
+
else:
|
| 439 |
+
x = blk(x)
|
| 440 |
+
if self.downsample is not None:
|
| 441 |
+
x = self.downsample(x)
|
| 442 |
+
return x
|
| 443 |
+
|
| 444 |
+
def extra_repr(self) -> str:
|
| 445 |
+
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
|
| 446 |
+
|
| 447 |
+
class LayerNorm2d(nn.Module):
|
| 448 |
+
def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
|
| 449 |
+
super().__init__()
|
| 450 |
+
self.weight = nn.Parameter(torch.ones(num_channels))
|
| 451 |
+
self.bias = nn.Parameter(torch.zeros(num_channels))
|
| 452 |
+
self.eps = eps
|
| 453 |
+
|
| 454 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 455 |
+
u = x.mean(1, keepdim=True)
|
| 456 |
+
s = (x - u).pow(2).mean(1, keepdim=True)
|
| 457 |
+
x = (x - u) / torch.sqrt(s + self.eps)
|
| 458 |
+
x = self.weight[:, None, None] * x + self.bias[:, None, None]
|
| 459 |
+
return x
|
| 460 |
+
class TinyViT(nn.Module):
|
| 461 |
+
def __init__(self, img_size=224, in_chans=3, num_classes=1000,
|
| 462 |
+
embed_dims=[96, 192, 384, 768], depths=[2, 2, 6, 2],
|
| 463 |
+
num_heads=[3, 6, 12, 24],
|
| 464 |
+
window_sizes=[7, 7, 14, 7],
|
| 465 |
+
mlp_ratio=4.,
|
| 466 |
+
drop_rate=0.,
|
| 467 |
+
drop_path_rate=0.1,
|
| 468 |
+
use_checkpoint=False,
|
| 469 |
+
mbconv_expand_ratio=4.0,
|
| 470 |
+
local_conv_size=3,
|
| 471 |
+
layer_lr_decay=1.0,
|
| 472 |
+
):
|
| 473 |
+
super().__init__()
|
| 474 |
+
self.img_size=img_size
|
| 475 |
+
self.num_classes = num_classes
|
| 476 |
+
self.depths = depths
|
| 477 |
+
self.num_layers = len(depths)
|
| 478 |
+
self.mlp_ratio = mlp_ratio
|
| 479 |
+
|
| 480 |
+
activation = nn.GELU
|
| 481 |
+
|
| 482 |
+
self.patch_embed = PatchEmbed(in_chans=in_chans,
|
| 483 |
+
embed_dim=embed_dims[0],
|
| 484 |
+
resolution=img_size,
|
| 485 |
+
activation=activation)
|
| 486 |
+
|
| 487 |
+
patches_resolution = self.patch_embed.patches_resolution
|
| 488 |
+
self.patches_resolution = patches_resolution
|
| 489 |
+
|
| 490 |
+
# stochastic depth
|
| 491 |
+
dpr = [x.item() for x in torch.linspace(0, drop_path_rate,
|
| 492 |
+
sum(depths))] # stochastic depth decay rule
|
| 493 |
+
|
| 494 |
+
# build layers
|
| 495 |
+
self.layers = nn.ModuleList()
|
| 496 |
+
for i_layer in range(self.num_layers):
|
| 497 |
+
kwargs = dict(dim=embed_dims[i_layer],
|
| 498 |
+
input_resolution=(patches_resolution[0] // (2 ** (i_layer-1 if i_layer == 3 else i_layer)),
|
| 499 |
+
patches_resolution[1] // (2 ** (i_layer-1 if i_layer == 3 else i_layer))),
|
| 500 |
+
# input_resolution=(patches_resolution[0] // (2 ** i_layer),
|
| 501 |
+
# patches_resolution[1] // (2 ** i_layer)),
|
| 502 |
+
depth=depths[i_layer],
|
| 503 |
+
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
|
| 504 |
+
downsample=PatchMerging if (
|
| 505 |
+
i_layer < self.num_layers - 1) else None,
|
| 506 |
+
use_checkpoint=use_checkpoint,
|
| 507 |
+
out_dim=embed_dims[min(
|
| 508 |
+
i_layer + 1, len(embed_dims) - 1)],
|
| 509 |
+
activation=activation,
|
| 510 |
+
)
|
| 511 |
+
if i_layer == 0:
|
| 512 |
+
layer = ConvLayer(
|
| 513 |
+
conv_expand_ratio=mbconv_expand_ratio,
|
| 514 |
+
**kwargs,
|
| 515 |
+
)
|
| 516 |
+
else:
|
| 517 |
+
layer = BasicLayer(
|
| 518 |
+
num_heads=num_heads[i_layer],
|
| 519 |
+
window_size=window_sizes[i_layer],
|
| 520 |
+
mlp_ratio=self.mlp_ratio,
|
| 521 |
+
drop=drop_rate,
|
| 522 |
+
local_conv_size=local_conv_size,
|
| 523 |
+
**kwargs)
|
| 524 |
+
self.layers.append(layer)
|
| 525 |
+
|
| 526 |
+
# Classifier head
|
| 527 |
+
self.norm_head = nn.LayerNorm(embed_dims[-1])
|
| 528 |
+
self.head = nn.Linear(
|
| 529 |
+
embed_dims[-1], num_classes) if num_classes > 0 else torch.nn.Identity()
|
| 530 |
+
|
| 531 |
+
# init weights
|
| 532 |
+
self.apply(self._init_weights)
|
| 533 |
+
self.set_layer_lr_decay(layer_lr_decay)
|
| 534 |
+
self.neck = nn.Sequential(
|
| 535 |
+
nn.Conv2d(
|
| 536 |
+
embed_dims[-1],#handongshen
|
| 537 |
+
256,
|
| 538 |
+
kernel_size=1,
|
| 539 |
+
bias=False,
|
| 540 |
+
),
|
| 541 |
+
LayerNorm2d(256),
|
| 542 |
+
nn.Conv2d(
|
| 543 |
+
256,
|
| 544 |
+
256,
|
| 545 |
+
kernel_size=3,
|
| 546 |
+
padding=1,
|
| 547 |
+
bias=False,
|
| 548 |
+
),
|
| 549 |
+
LayerNorm2d(256),
|
| 550 |
+
)
|
| 551 |
+
def set_layer_lr_decay(self, layer_lr_decay):
|
| 552 |
+
decay_rate = layer_lr_decay
|
| 553 |
+
|
| 554 |
+
# layers -> blocks (depth)
|
| 555 |
+
depth = sum(self.depths)
|
| 556 |
+
lr_scales = [decay_rate ** (depth - i - 1) for i in range(depth)]
|
| 557 |
+
print("LR SCALES:", lr_scales)
|
| 558 |
+
|
| 559 |
+
def _set_lr_scale(m, scale):
|
| 560 |
+
for p in m.parameters():
|
| 561 |
+
p.lr_scale = scale
|
| 562 |
+
|
| 563 |
+
self.patch_embed.apply(lambda x: _set_lr_scale(x, lr_scales[0]))
|
| 564 |
+
i = 0
|
| 565 |
+
for layer in self.layers:
|
| 566 |
+
for block in layer.blocks:
|
| 567 |
+
block.apply(lambda x: _set_lr_scale(x, lr_scales[i]))
|
| 568 |
+
i += 1
|
| 569 |
+
if layer.downsample is not None:
|
| 570 |
+
layer.downsample.apply(
|
| 571 |
+
lambda x: _set_lr_scale(x, lr_scales[i - 1]))
|
| 572 |
+
assert i == depth
|
| 573 |
+
for m in [self.norm_head, self.head]:
|
| 574 |
+
m.apply(lambda x: _set_lr_scale(x, lr_scales[-1]))
|
| 575 |
+
|
| 576 |
+
for k, p in self.named_parameters():
|
| 577 |
+
p.param_name = k
|
| 578 |
+
|
| 579 |
+
def _check_lr_scale(m):
|
| 580 |
+
for p in m.parameters():
|
| 581 |
+
assert hasattr(p, 'lr_scale'), p.param_name
|
| 582 |
+
|
| 583 |
+
self.apply(_check_lr_scale)
|
| 584 |
+
|
| 585 |
+
def _init_weights(self, m):
|
| 586 |
+
if isinstance(m, nn.Linear):
|
| 587 |
+
trunc_normal_(m.weight, std=.02)
|
| 588 |
+
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 589 |
+
nn.init.constant_(m.bias, 0)
|
| 590 |
+
elif isinstance(m, nn.LayerNorm):
|
| 591 |
+
nn.init.constant_(m.bias, 0)
|
| 592 |
+
nn.init.constant_(m.weight, 1.0)
|
| 593 |
+
|
| 594 |
+
@torch.jit.ignore
|
| 595 |
+
def no_weight_decay_keywords(self):
|
| 596 |
+
return {'attention_biases'}
|
| 597 |
+
|
| 598 |
+
def forward_features(self, x):
|
| 599 |
+
# x: (N, C, H, W)
|
| 600 |
+
x = self.patch_embed(x)
|
| 601 |
+
|
| 602 |
+
x = self.layers[0](x)
|
| 603 |
+
start_i = 1
|
| 604 |
+
|
| 605 |
+
for i in range(start_i, len(self.layers)):
|
| 606 |
+
layer = self.layers[i]
|
| 607 |
+
x = layer(x)
|
| 608 |
+
B,_,C=x.size()
|
| 609 |
+
x = x.view(B, 64, 64, C)
|
| 610 |
+
x=x.permute(0, 3, 1, 2)
|
| 611 |
+
x=self.neck(x)
|
| 612 |
+
return x
|
| 613 |
+
|
| 614 |
+
def forward(self, x):
|
| 615 |
+
x = self.forward_features(x)
|
| 616 |
+
|
| 617 |
+
# We have made some hack changes here to make it compatible with SAM-HQ
|
| 618 |
+
return x, None
|
| 619 |
+
|
| 620 |
+
|
| 621 |
+
_checkpoint_url_format = \
|
| 622 |
+
'https://github.com/wkcn/TinyViT-model-zoo/releases/download/checkpoints/{}.pth'
|
| 623 |
+
_provided_checkpoints = {
|
| 624 |
+
'tiny_vit_5m_224': 'tiny_vit_5m_22kto1k_distill',
|
| 625 |
+
'tiny_vit_11m_224': 'tiny_vit_11m_22kto1k_distill',
|
| 626 |
+
'tiny_vit_21m_224': 'tiny_vit_21m_22kto1k_distill',
|
| 627 |
+
'tiny_vit_21m_384': 'tiny_vit_21m_22kto1k_384_distill',
|
| 628 |
+
'tiny_vit_21m_512': 'tiny_vit_21m_22kto1k_512_distill',
|
| 629 |
+
}
|
| 630 |
+
|
| 631 |
+
|
| 632 |
+
def register_tiny_vit_model(fn):
|
| 633 |
+
'''Register a TinyViT model
|
| 634 |
+
It is a wrapper of `register_model` with loading the pretrained checkpoint.
|
| 635 |
+
'''
|
| 636 |
+
def fn_wrapper(pretrained=False, **kwargs):
|
| 637 |
+
model = fn()
|
| 638 |
+
if pretrained:
|
| 639 |
+
model_name = fn.__name__
|
| 640 |
+
assert model_name in _provided_checkpoints, \
|
| 641 |
+
f'Sorry that the checkpoint `{model_name}` is not provided yet.'
|
| 642 |
+
url = _checkpoint_url_format.format(
|
| 643 |
+
_provided_checkpoints[model_name])
|
| 644 |
+
checkpoint = torch.hub.load_state_dict_from_url(
|
| 645 |
+
url=url,
|
| 646 |
+
map_location='cpu', check_hash=False,
|
| 647 |
+
)
|
| 648 |
+
model.load_state_dict(checkpoint['model'])
|
| 649 |
+
|
| 650 |
+
return model
|
| 651 |
+
|
| 652 |
+
# rename the name of fn_wrapper
|
| 653 |
+
fn_wrapper.__name__ = fn.__name__
|
| 654 |
+
return register_model(fn_wrapper)
|
| 655 |
+
|
| 656 |
+
|
| 657 |
+
@register_tiny_vit_model
|
| 658 |
+
def tiny_vit_5m_224(pretrained=False, num_classes=1000, drop_path_rate=0.0):
|
| 659 |
+
return TinyViT(
|
| 660 |
+
num_classes=num_classes,
|
| 661 |
+
embed_dims=[64, 128, 160, 320],
|
| 662 |
+
depths=[2, 2, 6, 2],
|
| 663 |
+
num_heads=[2, 4, 5, 10],
|
| 664 |
+
window_sizes=[7, 7, 14, 7],
|
| 665 |
+
drop_path_rate=drop_path_rate,
|
| 666 |
+
)
|
| 667 |
+
|
| 668 |
+
|
| 669 |
+
@register_tiny_vit_model
|
| 670 |
+
def tiny_vit_11m_224(pretrained=False, num_classes=1000, drop_path_rate=0.1):
|
| 671 |
+
return TinyViT(
|
| 672 |
+
num_classes=num_classes,
|
| 673 |
+
embed_dims=[64, 128, 256, 448],
|
| 674 |
+
depths=[2, 2, 6, 2],
|
| 675 |
+
num_heads=[2, 4, 8, 14],
|
| 676 |
+
window_sizes=[7, 7, 14, 7],
|
| 677 |
+
drop_path_rate=drop_path_rate,
|
| 678 |
+
)
|
| 679 |
+
|
| 680 |
+
|
| 681 |
+
@register_tiny_vit_model
|
| 682 |
+
def tiny_vit_21m_224(pretrained=False, num_classes=1000, drop_path_rate=0.2):
|
| 683 |
+
return TinyViT(
|
| 684 |
+
num_classes=num_classes,
|
| 685 |
+
embed_dims=[96, 192, 384, 576],
|
| 686 |
+
depths=[2, 2, 6, 2],
|
| 687 |
+
num_heads=[3, 6, 12, 18],
|
| 688 |
+
window_sizes=[7, 7, 14, 7],
|
| 689 |
+
drop_path_rate=drop_path_rate,
|
| 690 |
+
)
|
| 691 |
+
|
| 692 |
+
|
| 693 |
+
@register_tiny_vit_model
|
| 694 |
+
def tiny_vit_21m_384(pretrained=False, num_classes=1000, drop_path_rate=0.1):
|
| 695 |
+
return TinyViT(
|
| 696 |
+
img_size=384,
|
| 697 |
+
num_classes=num_classes,
|
| 698 |
+
embed_dims=[96, 192, 384, 576],
|
| 699 |
+
depths=[2, 2, 6, 2],
|
| 700 |
+
num_heads=[3, 6, 12, 18],
|
| 701 |
+
window_sizes=[12, 12, 24, 12],
|
| 702 |
+
drop_path_rate=drop_path_rate,
|
| 703 |
+
)
|
| 704 |
+
|
| 705 |
+
|
| 706 |
+
@register_tiny_vit_model
|
| 707 |
+
def tiny_vit_21m_512(pretrained=False, num_classes=1000, drop_path_rate=0.1):
|
| 708 |
+
return TinyViT(
|
| 709 |
+
img_size=512,
|
| 710 |
+
num_classes=num_classes,
|
| 711 |
+
embed_dims=[96, 192, 384, 576],
|
| 712 |
+
depths=[2, 2, 6, 2],
|
| 713 |
+
num_heads=[3, 6, 12, 18],
|
| 714 |
+
window_sizes=[16, 16, 32, 16],
|
| 715 |
+
drop_path_rate=drop_path_rate,
|
| 716 |
+
)
|
EfficientSAM/README.md
ADDED
|
@@ -0,0 +1,194 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Efficient Grounded-SAM
|
| 2 |
+
|
| 3 |
+
We're going to combine [Grounding-DINO](https://github.com/IDEA-Research/GroundingDINO) with efficient SAM variants for faster annotating.
|
| 4 |
+
|
| 5 |
+
<!-- Combining [Grounding-DINO](https://github.com/IDEA-Research/GroundingDINO) and [Fast-SAM](https://github.com/CASIA-IVA-Lab/FastSAM) for faster zero-shot detect and segment anything. -->
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
### Table of Contents
|
| 9 |
+
- [Installation](#installation)
|
| 10 |
+
- [Efficient SAM Series](#efficient-sams)
|
| 11 |
+
- [Run Grounded-FastSAM Demo](#run-grounded-fastsam-demo)
|
| 12 |
+
- [Run Grounded-MobileSAM Demo](#run-grounded-mobilesam-demo)
|
| 13 |
+
- [Run Grounded-LightHQSAM Demo](#run-grounded-light-hqsam-demo)
|
| 14 |
+
- [Run Grounded-Efficient-SAM Demo](#run-grounded-efficient-sam-demo)
|
| 15 |
+
- [Run Grounded-Edge-SAM Demo](#run-grounded-edge-sam-demo)
|
| 16 |
+
- [Run Grounded-RepViT-SAM Demo](#run-grounded-repvit-sam-demo)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
### Installation
|
| 20 |
+
|
| 21 |
+
- Install [Grounded-SAM](https://github.com/IDEA-Research/Grounded-Segment-Anything#installation)
|
| 22 |
+
|
| 23 |
+
- Install [Fast-SAM](https://github.com/CASIA-IVA-Lab/FastSAM#installation)
|
| 24 |
+
|
| 25 |
+
- Note that we may use the sam image as the demo image in order to compare the inference results of different efficient-sam variants.
|
| 26 |
+
|
| 27 |
+
### Efficient SAMs
|
| 28 |
+
Here's the list of Efficient SAM variants:
|
| 29 |
+
|
| 30 |
+
<div align="center">
|
| 31 |
+
|
| 32 |
+
| Title | Intro | Description | Links |
|
| 33 |
+
|:----:|:----:|:----:|:----:|
|
| 34 |
+
| [FastSAM](https://arxiv.org/pdf/2306.12156.pdf) |  | The Fast Segment Anything Model(FastSAM) is a CNN Segment Anything Model trained by only 2% of the SA-1B dataset published by SAM authors. The FastSAM achieve a comparable performance with the SAM method at 50× higher run-time speed. | [[Github](https://github.com/CASIA-IVA-Lab/FastSAM)] [[Demo](https://huggingface.co/spaces/An-619/FastSAM)] |
|
| 35 |
+
| [MobileSAM](https://arxiv.org/pdf/2306.14289.pdf) |  | MobileSAM performs on par with the original SAM (at least visually) and keeps exactly the same pipeline as the original SAM except for a change on the image encoder. Specifically, we replace the original heavyweight ViT-H encoder (632M) with a much smaller Tiny-ViT (5M). On a single GPU, MobileSAM runs around 12ms per image: 8ms on the image encoder and 4ms on the mask decoder. | [[Github](https://github.com/ChaoningZhang/MobileSAM)] |
|
| 36 |
+
| [Light-HQSAM](https://arxiv.org/pdf/2306.01567.pdf) | 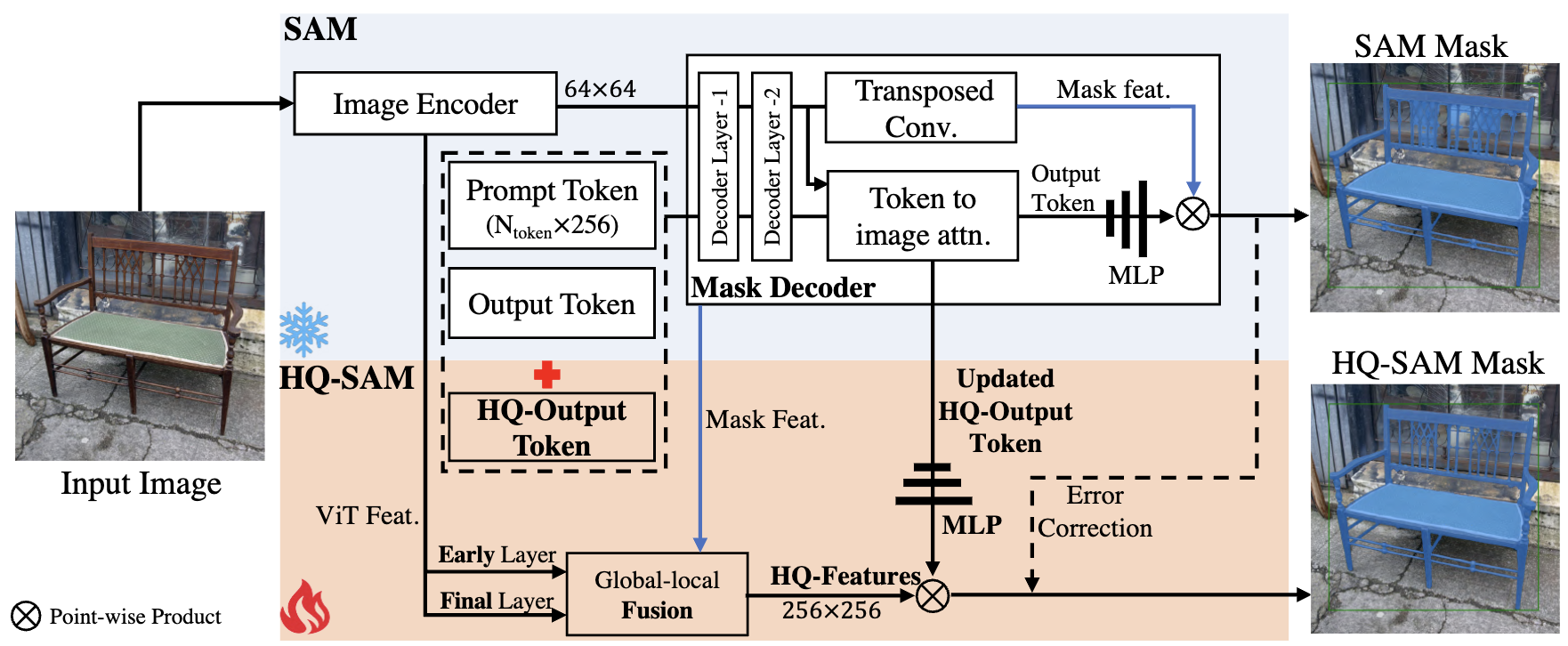 | Light HQ-SAM is based on the tiny vit image encoder provided by MobileSAM. We design a learnable High-Quality Output Token, which is injected into SAM's mask decoder and is responsible for predicting the high-quality mask. Instead of only applying it on mask-decoder features, we first fuse them with ViT features for improved mask details. Refer to [Light HQ-SAM vs. MobileSAM](https://github.com/SysCV/sam-hq#light-hq-sam-vs-mobilesam-on-coco) for more details. | [[Github](https://github.com/SysCV/sam-hq)] |
|
| 37 |
+
| [Efficient-SAM](https://github.com/yformer/EfficientSAM) | 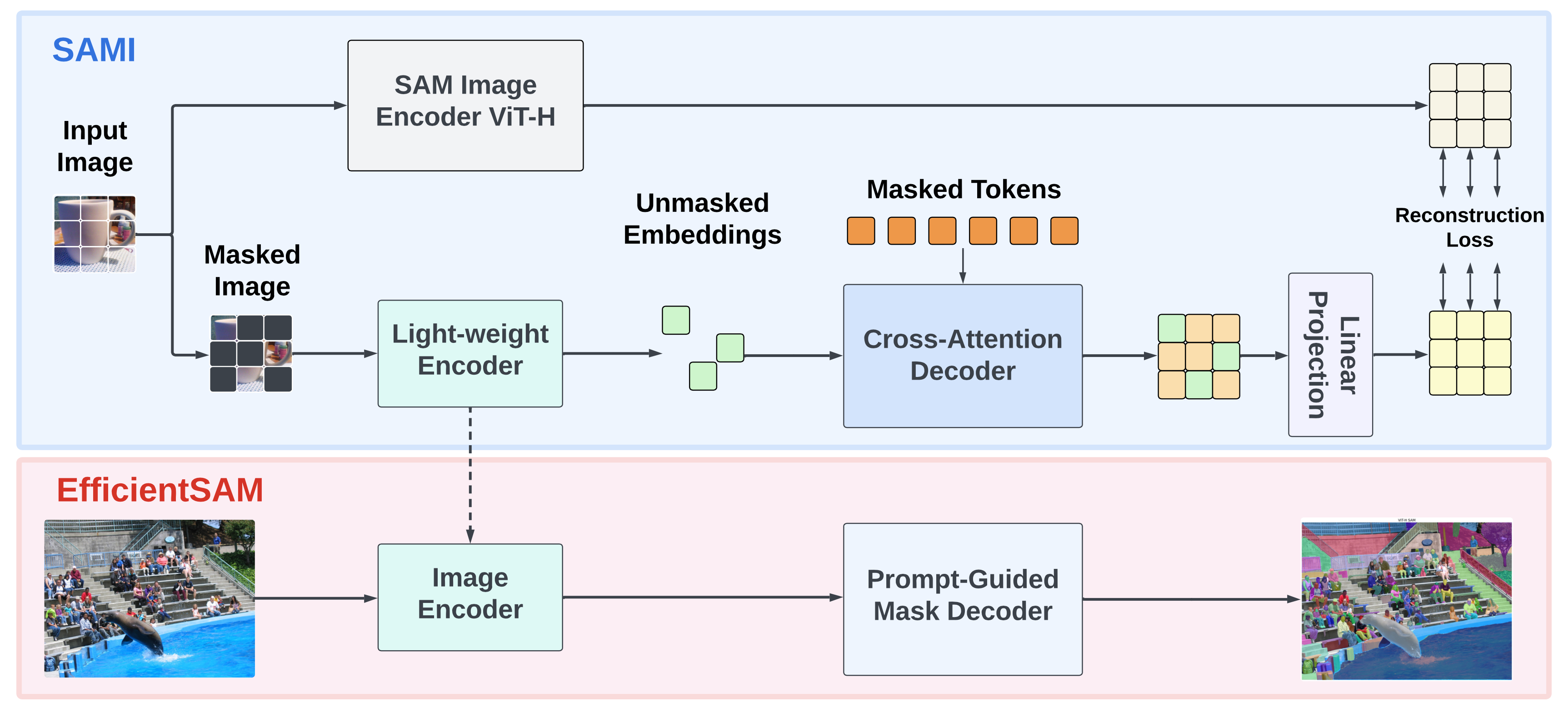 |Segment Anything Model (SAM) has emerged as a powerful tool for numerous vision applications. However, the huge computation cost of SAM model has limited its applications to wider real-world applications. To address this limitation, we propose EfficientSAMs, light-weight SAM models that exhibit decent performance with largely reduced complexity. Our idea is based on leveraging masked image pretraining, SAMI, which learns to reconstruct features from SAM image encoder for effective visual representation learning. Further, we take SAMI-pretrained light-weight image encoders and mask decoder to build EfficientSAMs, and finetune the models on SA-1B for segment anything task. Refer to [EfficientSAM arXiv](https://arxiv.org/pdf/2312.00863.pdf) for more details.| [[Github](https://github.com/yformer/EfficientSAM)] |
|
| 38 |
+
| [Edge-SAM](https://github.com/chongzhou96/EdgeSAM) | 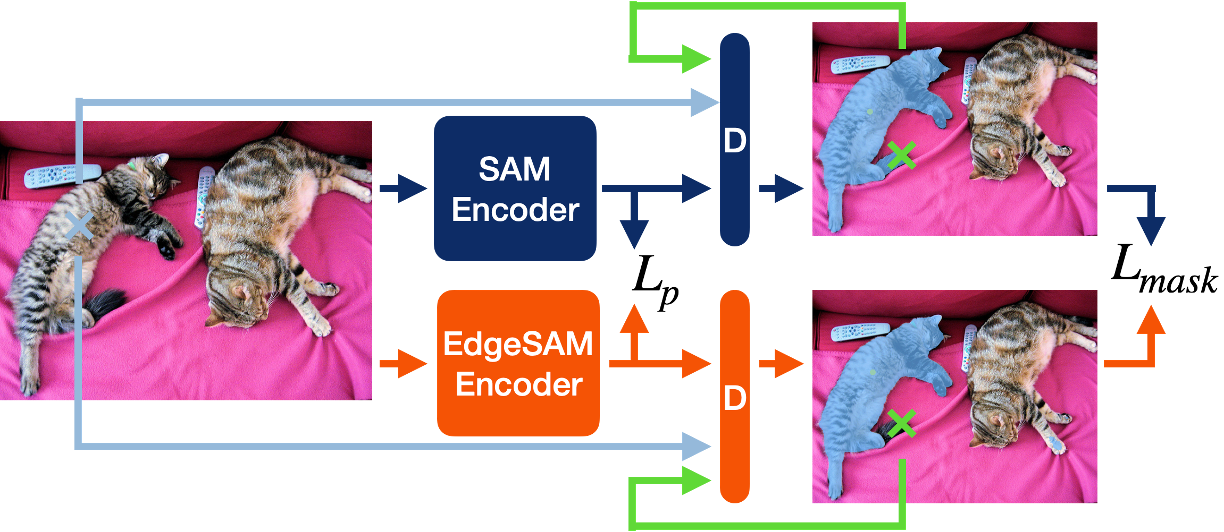 | EdgeSAM involves distilling the original ViT-based SAM image encoder into a purely CNN-based architecture, better suited for edge devices. We carefully benchmark various distillation strategies and demonstrate that task-agnostic encoder distillation fails to capture the full knowledge embodied in SAM. Refer to [Edge-SAM arXiv](https://arxiv.org/abs/2312.06660) for more details. | [[Github](https://github.com/chongzhou96/EdgeSAM)] |
|
| 39 |
+
| [RepViT-SAM](https://github.com/THU-MIG/RepViT/tree/main/sam) |  | Recently, RepViT achieves the state-of-the-art performance and latency trade-off on mobile devices by incorporating efficient architectural designs of ViTs into CNNs. Here, to achieve real-time segmenting anything on mobile devices, following MobileSAM, we replace the heavyweight image encoder in SAM with RepViT model, ending up with the RepViT-SAM model. Extensive experiments show that RepViT-SAM can enjoy significantly better zero-shot transfer capability than MobileSAM, along with nearly 10× faster inference speed. Refer to [RepViT-SAM arXiv](https://arxiv.org/pdf/2312.05760.pdf) for more details. | [[Github](https://github.com/THU-MIG/RepViT)] |
|
| 40 |
+
|
| 41 |
+
</div>
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
### Run Grounded-FastSAM Demo
|
| 45 |
+
|
| 46 |
+
- Firstly, download the pretrained Fast-SAM weight [here](https://github.com/CASIA-IVA-Lab/FastSAM#model-checkpoints)
|
| 47 |
+
|
| 48 |
+
- Run the demo with the following script:
|
| 49 |
+
|
| 50 |
+
```bash
|
| 51 |
+
cd Grounded-Segment-Anything
|
| 52 |
+
|
| 53 |
+
python EfficientSAM/grounded_fast_sam.py --model_path "./FastSAM-x.pt" --img_path "assets/demo4.jpg" --text "the black dog." --output "./output/"
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
- And the results will be saved in `./output/` as:
|
| 57 |
+
|
| 58 |
+
<div style="text-align: center">
|
| 59 |
+
|
| 60 |
+
| Input | Text | Output |
|
| 61 |
+
|:---:|:---:|:---:|
|
| 62 |
+
| | "The black dog." |  |
|
| 63 |
+
|
| 64 |
+
</div>
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
**Note**: Due to the post process of FastSAM, only one box can be annotated at a time, if there're multiple box prompts, we simply save multiple annotate images to `./output` now, which will be modified in the future release.
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
### Run Grounded-MobileSAM Demo
|
| 71 |
+
|
| 72 |
+
- Firstly, download the pretrained MobileSAM weight [here](https://github.com/ChaoningZhang/MobileSAM/tree/master/weights)
|
| 73 |
+
|
| 74 |
+
- Run the demo with the following script:
|
| 75 |
+
|
| 76 |
+
```bash
|
| 77 |
+
cd Grounded-Segment-Anything
|
| 78 |
+
|
| 79 |
+
python EfficientSAM/grounded_mobile_sam.py --MOBILE_SAM_CHECKPOINT_PATH "./EfficientSAM/mobile_sam.pt" --SOURCE_IMAGE_PATH "./assets/demo2.jpg" --CAPTION "the running dog"
|
| 80 |
+
```
|
| 81 |
+
|
| 82 |
+
- And the result will be saved as `./gronded_mobile_sam_anontated_image.jpg` as:
|
| 83 |
+
|
| 84 |
+
<div style="text-align: center">
|
| 85 |
+
|
| 86 |
+
| Input | Text | Output |
|
| 87 |
+
|:---:|:---:|:---:|
|
| 88 |
+
| | "the running dog" |  |
|
| 89 |
+
|
| 90 |
+
</div>
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
### Run Grounded-Light-HQSAM Demo
|
| 94 |
+
|
| 95 |
+
- Firstly, download the pretrained Light-HQSAM weight [here](https://github.com/SysCV/sam-hq#model-checkpoints)
|
| 96 |
+
|
| 97 |
+
- Run the demo with the following script:
|
| 98 |
+
|
| 99 |
+
```bash
|
| 100 |
+
cd Grounded-Segment-Anything
|
| 101 |
+
|
| 102 |
+
python EfficientSAM/grounded_light_hqsam.py
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
- And the result will be saved as `./gronded_light_hqsam_anontated_image.jpg` as:
|
| 106 |
+
|
| 107 |
+
<div style="text-align: center">
|
| 108 |
+
|
| 109 |
+
| Input | Text | Output |
|
| 110 |
+
|:---:|:---:|:---:|
|
| 111 |
+
| | "bench" |  |
|
| 112 |
+
|
| 113 |
+
</div>
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
### Run Grounded-Efficient-SAM Demo
|
| 117 |
+
|
| 118 |
+
- Download the pretrained EfficientSAM checkpoint from [here](https://github.com/yformer/EfficientSAM#model) and put it under `Grounded-Segment-Anything/EfficientSAM`
|
| 119 |
+
|
| 120 |
+
- Run the demo with the following script:
|
| 121 |
+
|
| 122 |
+
```bash
|
| 123 |
+
cd Grounded-Segment-Anything
|
| 124 |
+
|
| 125 |
+
python EfficientSAM/grounded_efficient_sam.py
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
- And the result will be saved as `./gronded_efficient_sam_anontated_image.jpg` as:
|
| 129 |
+
|
| 130 |
+
<div style="text-align: center">
|
| 131 |
+
|
| 132 |
+
| Input | Text | Output |
|
| 133 |
+
|:---:|:---:|:---:|
|
| 134 |
+
| | "bench" |  |
|
| 135 |
+
|
| 136 |
+
</div>
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
### Run Grounded-Edge-SAM Demo
|
| 140 |
+
|
| 141 |
+
- Download the pretrained [Edge-SAM](https://github.com/chongzhou96/EdgeSAM) checkpoint follow the [official instruction](https://github.com/chongzhou96/EdgeSAM?tab=readme-ov-file#usage-) as:
|
| 142 |
+
|
| 143 |
+
```bash
|
| 144 |
+
cd Grounded-Segment-Anything
|
| 145 |
+
wget -P EfficientSAM/ https://huggingface.co/spaces/chongzhou/EdgeSAM/resolve/main/weights/edge_sam.pth
|
| 146 |
+
wget -P EfficientSAM/ https://huggingface.co/spaces/chongzhou/EdgeSAM/resolve/main/weights/edge_sam_3x.pth
|
| 147 |
+
```
|
| 148 |
+
|
| 149 |
+
- Run the demo with the following script:
|
| 150 |
+
|
| 151 |
+
```bash
|
| 152 |
+
cd Grounded-Segment-Anything
|
| 153 |
+
|
| 154 |
+
python EfficientSAM/grounded_edge_sam.py
|
| 155 |
+
```
|
| 156 |
+
|
| 157 |
+
- And the result will be saved as `./gronded_edge_sam_anontated_image.jpg` as:
|
| 158 |
+
|
| 159 |
+
<div style="text-align: center">
|
| 160 |
+
|
| 161 |
+
| Input | Text | Output |
|
| 162 |
+
|:---:|:---:|:---:|
|
| 163 |
+
| | "bench" |  |
|
| 164 |
+
|
| 165 |
+
</div>
|
| 166 |
+
|
| 167 |
+
### Run Grounded-RepViT-SAM Demo
|
| 168 |
+
|
| 169 |
+
- Download the pretrained [RepViT-SAM](https://github.com/THU-MIG/RepViT) checkpoint follow the [official instruction](https://github.com/THU-MIG/RepViT/tree/main/sam#installation) as:
|
| 170 |
+
|
| 171 |
+
```bash
|
| 172 |
+
cd Grounded-Segment-Anything
|
| 173 |
+
wget -P EfficientSAM/ https://github.com/THU-MIG/RepViT/releases/download/v1.0/repvit_sam.pt
|
| 174 |
+
```
|
| 175 |
+
|
| 176 |
+
- Run the demo with the following script:
|
| 177 |
+
|
| 178 |
+
```bash
|
| 179 |
+
cd Grounded-Segment-Anything
|
| 180 |
+
|
| 181 |
+
python EfficientSAM/grounded_repvit_sam.py
|
| 182 |
+
```
|
| 183 |
+
|
| 184 |
+
- And the result will be saved as `./gronded_repvit_sam_anontated_image.jpg` as:
|
| 185 |
+
|
| 186 |
+
<div style="text-align: center">
|
| 187 |
+
|
| 188 |
+
| Input | Text | Output |
|
| 189 |
+
|:---:|:---:|:---:|
|
| 190 |
+
| | "bench" |  |
|
| 191 |
+
|
| 192 |
+
</div>
|
| 193 |
+
|
| 194 |
+
|
EfficientSAM/RepViTSAM/repvit.py
ADDED
|
@@ -0,0 +1,364 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.nn as nn
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
__all__ = ['repvit_m1']
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def _make_divisible(v, divisor, min_value=None):
|
| 8 |
+
"""
|
| 9 |
+
This function is taken from the original tf repo.
|
| 10 |
+
It ensures that all layers have a channel number that is divisible by 8
|
| 11 |
+
It can be seen here:
|
| 12 |
+
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
|
| 13 |
+
:param v:
|
| 14 |
+
:param divisor:
|
| 15 |
+
:param min_value:
|
| 16 |
+
:return:
|
| 17 |
+
"""
|
| 18 |
+
if min_value is None:
|
| 19 |
+
min_value = divisor
|
| 20 |
+
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
|
| 21 |
+
# Make sure that round down does not go down by more than 10%.
|
| 22 |
+
if new_v < 0.9 * v:
|
| 23 |
+
new_v += divisor
|
| 24 |
+
return new_v
|
| 25 |
+
|
| 26 |
+
from timm.models.layers import SqueezeExcite
|
| 27 |
+
|
| 28 |
+
import torch
|
| 29 |
+
|
| 30 |
+
# From https://github.com/facebookresearch/detectron2/blob/main/detectron2/layers/batch_norm.py # noqa
|
| 31 |
+
# Itself from https://github.com/facebookresearch/ConvNeXt/blob/d1fa8f6fef0a165b27399986cc2bdacc92777e40/models/convnext.py#L119 # noqa
|
| 32 |
+
class LayerNorm2d(nn.Module):
|
| 33 |
+
def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
|
| 34 |
+
super().__init__()
|
| 35 |
+
self.weight = nn.Parameter(torch.ones(num_channels))
|
| 36 |
+
self.bias = nn.Parameter(torch.zeros(num_channels))
|
| 37 |
+
self.eps = eps
|
| 38 |
+
|
| 39 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 40 |
+
u = x.mean(1, keepdim=True)
|
| 41 |
+
s = (x - u).pow(2).mean(1, keepdim=True)
|
| 42 |
+
x = (x - u) / torch.sqrt(s + self.eps)
|
| 43 |
+
x = self.weight[:, None, None] * x + self.bias[:, None, None]
|
| 44 |
+
return x
|
| 45 |
+
|
| 46 |
+
class Conv2d_BN(torch.nn.Sequential):
|
| 47 |
+
def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
|
| 48 |
+
groups=1, bn_weight_init=1, resolution=-10000):
|
| 49 |
+
super().__init__()
|
| 50 |
+
self.add_module('c', torch.nn.Conv2d(
|
| 51 |
+
a, b, ks, stride, pad, dilation, groups, bias=False))
|
| 52 |
+
self.add_module('bn', torch.nn.BatchNorm2d(b))
|
| 53 |
+
torch.nn.init.constant_(self.bn.weight, bn_weight_init)
|
| 54 |
+
torch.nn.init.constant_(self.bn.bias, 0)
|
| 55 |
+
|
| 56 |
+
@torch.no_grad()
|
| 57 |
+
def fuse(self):
|
| 58 |
+
c, bn = self._modules.values()
|
| 59 |
+
w = bn.weight / (bn.running_var + bn.eps)**0.5
|
| 60 |
+
w = c.weight * w[:, None, None, None]
|
| 61 |
+
b = bn.bias - bn.running_mean * bn.weight / \
|
| 62 |
+
(bn.running_var + bn.eps)**0.5
|
| 63 |
+
m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(
|
| 64 |
+
0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation, groups=self.c.groups,
|
| 65 |
+
device=c.weight.device)
|
| 66 |
+
m.weight.data.copy_(w)
|
| 67 |
+
m.bias.data.copy_(b)
|
| 68 |
+
return m
|
| 69 |
+
|
| 70 |
+
class Residual(torch.nn.Module):
|
| 71 |
+
def __init__(self, m, drop=0.):
|
| 72 |
+
super().__init__()
|
| 73 |
+
self.m = m
|
| 74 |
+
self.drop = drop
|
| 75 |
+
|
| 76 |
+
def forward(self, x):
|
| 77 |
+
if self.training and self.drop > 0:
|
| 78 |
+
return x + self.m(x) * torch.rand(x.size(0), 1, 1, 1,
|
| 79 |
+
device=x.device).ge_(self.drop).div(1 - self.drop).detach()
|
| 80 |
+
else:
|
| 81 |
+
return x + self.m(x)
|
| 82 |
+
|
| 83 |
+
@torch.no_grad()
|
| 84 |
+
def fuse(self):
|
| 85 |
+
if isinstance(self.m, Conv2d_BN):
|
| 86 |
+
m = self.m.fuse()
|
| 87 |
+
assert(m.groups == m.in_channels)
|
| 88 |
+
identity = torch.ones(m.weight.shape[0], m.weight.shape[1], 1, 1)
|
| 89 |
+
identity = torch.nn.functional.pad(identity, [1,1,1,1])
|
| 90 |
+
m.weight += identity.to(m.weight.device)
|
| 91 |
+
return m
|
| 92 |
+
elif isinstance(self.m, torch.nn.Conv2d):
|
| 93 |
+
m = self.m
|
| 94 |
+
assert(m.groups != m.in_channels)
|
| 95 |
+
identity = torch.ones(m.weight.shape[0], m.weight.shape[1], 1, 1)
|
| 96 |
+
identity = torch.nn.functional.pad(identity, [1,1,1,1])
|
| 97 |
+
m.weight += identity.to(m.weight.device)
|
| 98 |
+
return m
|
| 99 |
+
else:
|
| 100 |
+
return self
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
class RepVGGDW(torch.nn.Module):
|
| 104 |
+
def __init__(self, ed) -> None:
|
| 105 |
+
super().__init__()
|
| 106 |
+
self.conv = Conv2d_BN(ed, ed, 3, 1, 1, groups=ed)
|
| 107 |
+
self.conv1 = torch.nn.Conv2d(ed, ed, 1, 1, 0, groups=ed)
|
| 108 |
+
self.dim = ed
|
| 109 |
+
self.bn = torch.nn.BatchNorm2d(ed)
|
| 110 |
+
|
| 111 |
+
def forward(self, x):
|
| 112 |
+
return self.bn((self.conv(x) + self.conv1(x)) + x)
|
| 113 |
+
|
| 114 |
+
@torch.no_grad()
|
| 115 |
+
def fuse(self):
|
| 116 |
+
conv = self.conv.fuse()
|
| 117 |
+
conv1 = self.conv1
|
| 118 |
+
|
| 119 |
+
conv_w = conv.weight
|
| 120 |
+
conv_b = conv.bias
|
| 121 |
+
conv1_w = conv1.weight
|
| 122 |
+
conv1_b = conv1.bias
|
| 123 |
+
|
| 124 |
+
conv1_w = torch.nn.functional.pad(conv1_w, [1,1,1,1])
|
| 125 |
+
|
| 126 |
+
identity = torch.nn.functional.pad(torch.ones(conv1_w.shape[0], conv1_w.shape[1], 1, 1, device=conv1_w.device), [1,1,1,1])
|
| 127 |
+
|
| 128 |
+
final_conv_w = conv_w + conv1_w + identity
|
| 129 |
+
final_conv_b = conv_b + conv1_b
|
| 130 |
+
|
| 131 |
+
conv.weight.data.copy_(final_conv_w)
|
| 132 |
+
conv.bias.data.copy_(final_conv_b)
|
| 133 |
+
|
| 134 |
+
bn = self.bn
|
| 135 |
+
w = bn.weight / (bn.running_var + bn.eps)**0.5
|
| 136 |
+
w = conv.weight * w[:, None, None, None]
|
| 137 |
+
b = bn.bias + (conv.bias - bn.running_mean) * bn.weight / \
|
| 138 |
+
(bn.running_var + bn.eps)**0.5
|
| 139 |
+
conv.weight.data.copy_(w)
|
| 140 |
+
conv.bias.data.copy_(b)
|
| 141 |
+
return conv
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
class RepViTBlock(nn.Module):
|
| 145 |
+
def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se, use_hs):
|
| 146 |
+
super(RepViTBlock, self).__init__()
|
| 147 |
+
assert stride in [1, 2]
|
| 148 |
+
|
| 149 |
+
self.identity = stride == 1 and inp == oup
|
| 150 |
+
assert(hidden_dim == 2 * inp)
|
| 151 |
+
|
| 152 |
+
if stride == 2:
|
| 153 |
+
self.token_mixer = nn.Sequential(
|
| 154 |
+
Conv2d_BN(inp, inp, kernel_size, stride if inp != 320 else 1, (kernel_size - 1) // 2, groups=inp),
|
| 155 |
+
SqueezeExcite(inp, 0.25) if use_se else nn.Identity(),
|
| 156 |
+
Conv2d_BN(inp, oup, ks=1, stride=1, pad=0)
|
| 157 |
+
)
|
| 158 |
+
self.channel_mixer = Residual(nn.Sequential(
|
| 159 |
+
# pw
|
| 160 |
+
Conv2d_BN(oup, 2 * oup, 1, 1, 0),
|
| 161 |
+
nn.GELU() if use_hs else nn.GELU(),
|
| 162 |
+
# pw-linear
|
| 163 |
+
Conv2d_BN(2 * oup, oup, 1, 1, 0, bn_weight_init=0),
|
| 164 |
+
))
|
| 165 |
+
else:
|
| 166 |
+
# assert(self.identity)
|
| 167 |
+
self.token_mixer = nn.Sequential(
|
| 168 |
+
RepVGGDW(inp),
|
| 169 |
+
SqueezeExcite(inp, 0.25) if use_se else nn.Identity(),
|
| 170 |
+
)
|
| 171 |
+
if self.identity:
|
| 172 |
+
self.channel_mixer = Residual(nn.Sequential(
|
| 173 |
+
# pw
|
| 174 |
+
Conv2d_BN(inp, hidden_dim, 1, 1, 0),
|
| 175 |
+
nn.GELU() if use_hs else nn.GELU(),
|
| 176 |
+
# pw-linear
|
| 177 |
+
Conv2d_BN(hidden_dim, oup, 1, 1, 0, bn_weight_init=0),
|
| 178 |
+
))
|
| 179 |
+
else:
|
| 180 |
+
self.channel_mixer = nn.Sequential(
|
| 181 |
+
# pw
|
| 182 |
+
Conv2d_BN(inp, hidden_dim, 1, 1, 0),
|
| 183 |
+
nn.GELU() if use_hs else nn.GELU(),
|
| 184 |
+
# pw-linear
|
| 185 |
+
Conv2d_BN(hidden_dim, oup, 1, 1, 0, bn_weight_init=0),
|
| 186 |
+
)
|
| 187 |
+
|
| 188 |
+
def forward(self, x):
|
| 189 |
+
return self.channel_mixer(self.token_mixer(x))
|
| 190 |
+
|
| 191 |
+
from timm.models.vision_transformer import trunc_normal_
|
| 192 |
+
class BN_Linear(torch.nn.Sequential):
|
| 193 |
+
def __init__(self, a, b, bias=True, std=0.02):
|
| 194 |
+
super().__init__()
|
| 195 |
+
self.add_module('bn', torch.nn.BatchNorm1d(a))
|
| 196 |
+
self.add_module('l', torch.nn.Linear(a, b, bias=bias))
|
| 197 |
+
trunc_normal_(self.l.weight, std=std)
|
| 198 |
+
if bias:
|
| 199 |
+
torch.nn.init.constant_(self.l.bias, 0)
|
| 200 |
+
|
| 201 |
+
@torch.no_grad()
|
| 202 |
+
def fuse(self):
|
| 203 |
+
bn, l = self._modules.values()
|
| 204 |
+
w = bn.weight / (bn.running_var + bn.eps)**0.5
|
| 205 |
+
b = bn.bias - self.bn.running_mean * \
|
| 206 |
+
self.bn.weight / (bn.running_var + bn.eps)**0.5
|
| 207 |
+
w = l.weight * w[None, :]
|
| 208 |
+
if l.bias is None:
|
| 209 |
+
b = b @ self.l.weight.T
|
| 210 |
+
else:
|
| 211 |
+
b = (l.weight @ b[:, None]).view(-1) + self.l.bias
|
| 212 |
+
m = torch.nn.Linear(w.size(1), w.size(0), device=l.weight.device)
|
| 213 |
+
m.weight.data.copy_(w)
|
| 214 |
+
m.bias.data.copy_(b)
|
| 215 |
+
return m
|
| 216 |
+
|
| 217 |
+
class Classfier(nn.Module):
|
| 218 |
+
def __init__(self, dim, num_classes, distillation=True):
|
| 219 |
+
super().__init__()
|
| 220 |
+
self.classifier = BN_Linear(dim, num_classes) if num_classes > 0 else torch.nn.Identity()
|
| 221 |
+
self.distillation = distillation
|
| 222 |
+
if distillation:
|
| 223 |
+
self.classifier_dist = BN_Linear(dim, num_classes) if num_classes > 0 else torch.nn.Identity()
|
| 224 |
+
|
| 225 |
+
def forward(self, x):
|
| 226 |
+
if self.distillation:
|
| 227 |
+
x = self.classifier(x), self.classifier_dist(x)
|
| 228 |
+
if not self.training:
|
| 229 |
+
x = (x[0] + x[1]) / 2
|
| 230 |
+
else:
|
| 231 |
+
x = self.classifier(x)
|
| 232 |
+
return x
|
| 233 |
+
|
| 234 |
+
@torch.no_grad()
|
| 235 |
+
def fuse(self):
|
| 236 |
+
classifier = self.classifier.fuse()
|
| 237 |
+
if self.distillation:
|
| 238 |
+
classifier_dist = self.classifier_dist.fuse()
|
| 239 |
+
classifier.weight += classifier_dist.weight
|
| 240 |
+
classifier.bias += classifier_dist.bias
|
| 241 |
+
classifier.weight /= 2
|
| 242 |
+
classifier.bias /= 2
|
| 243 |
+
return classifier
|
| 244 |
+
else:
|
| 245 |
+
return classifier
|
| 246 |
+
|
| 247 |
+
class RepViT(nn.Module):
|
| 248 |
+
def __init__(self, cfgs, num_classes=1000, distillation=False, img_size=1024):
|
| 249 |
+
super(RepViT, self).__init__()
|
| 250 |
+
# setting of inverted residual blocks
|
| 251 |
+
self.cfgs = cfgs
|
| 252 |
+
|
| 253 |
+
self.img_size = img_size
|
| 254 |
+
|
| 255 |
+
# building first layer
|
| 256 |
+
input_channel = self.cfgs[0][2]
|
| 257 |
+
patch_embed = torch.nn.Sequential(Conv2d_BN(3, input_channel // 2, 3, 2, 1), torch.nn.GELU(),
|
| 258 |
+
Conv2d_BN(input_channel // 2, input_channel, 3, 2, 1))
|
| 259 |
+
layers = [patch_embed]
|
| 260 |
+
# building inverted residual blocks
|
| 261 |
+
block = RepViTBlock
|
| 262 |
+
for k, t, c, use_se, use_hs, s in self.cfgs:
|
| 263 |
+
output_channel = _make_divisible(c, 8)
|
| 264 |
+
exp_size = _make_divisible(input_channel * t, 8)
|
| 265 |
+
layers.append(block(input_channel, exp_size, output_channel, k, s, use_se, use_hs))
|
| 266 |
+
input_channel = output_channel
|
| 267 |
+
self.features = nn.ModuleList(layers)
|
| 268 |
+
# self.classifier = Classfier(output_channel, num_classes, distillation)
|
| 269 |
+
|
| 270 |
+
self.neck = nn.Sequential(
|
| 271 |
+
nn.Conv2d(
|
| 272 |
+
output_channel,
|
| 273 |
+
256,
|
| 274 |
+
kernel_size=1,
|
| 275 |
+
bias=False,
|
| 276 |
+
),
|
| 277 |
+
LayerNorm2d(256),
|
| 278 |
+
nn.Conv2d(
|
| 279 |
+
256,
|
| 280 |
+
256,
|
| 281 |
+
kernel_size=3,
|
| 282 |
+
padding=1,
|
| 283 |
+
bias=False,
|
| 284 |
+
),
|
| 285 |
+
LayerNorm2d(256),
|
| 286 |
+
)
|
| 287 |
+
|
| 288 |
+
def forward(self, x):
|
| 289 |
+
# x = self.features(x)
|
| 290 |
+
for f in self.features:
|
| 291 |
+
x = f(x)
|
| 292 |
+
# x = torch.nn.functional.adaptive_avg_pool2d(x, 1).flatten(1)
|
| 293 |
+
x = self.neck(x)
|
| 294 |
+
return x, None
|
| 295 |
+
|
| 296 |
+
from timm.models import register_model
|
| 297 |
+
|
| 298 |
+
@register_model
|
| 299 |
+
def repvit(pretrained=False, num_classes = 1000, distillation=False, **kwargs):
|
| 300 |
+
"""
|
| 301 |
+
Constructs a MobileNetV3-Large model
|
| 302 |
+
"""
|
| 303 |
+
cfgs = [
|
| 304 |
+
# k, t, c, SE, HS, s
|
| 305 |
+
[3, 2, 80, 1, 0, 1],
|
| 306 |
+
[3, 2, 80, 0, 0, 1],
|
| 307 |
+
[3, 2, 80, 1, 0, 1],
|
| 308 |
+
[3, 2, 80, 0, 0, 1],
|
| 309 |
+
[3, 2, 80, 1, 0, 1],
|
| 310 |
+
[3, 2, 80, 0, 0, 1],
|
| 311 |
+
[3, 2, 80, 0, 0, 1],
|
| 312 |
+
[3, 2, 160, 0, 0, 2],
|
| 313 |
+
[3, 2, 160, 1, 0, 1],
|
| 314 |
+
[3, 2, 160, 0, 0, 1],
|
| 315 |
+
[3, 2, 160, 1, 0, 1],
|
| 316 |
+
[3, 2, 160, 0, 0, 1],
|
| 317 |
+
[3, 2, 160, 1, 0, 1],
|
| 318 |
+
[3, 2, 160, 0, 0, 1],
|
| 319 |
+
[3, 2, 160, 0, 0, 1],
|
| 320 |
+
[3, 2, 320, 0, 1, 2],
|
| 321 |
+
[3, 2, 320, 1, 1, 1],
|
| 322 |
+
[3, 2, 320, 0, 1, 1],
|
| 323 |
+
[3, 2, 320, 1, 1, 1],
|
| 324 |
+
[3, 2, 320, 0, 1, 1],
|
| 325 |
+
[3, 2, 320, 1, 1, 1],
|
| 326 |
+
[3, 2, 320, 0, 1, 1],
|
| 327 |
+
[3, 2, 320, 1, 1, 1],
|
| 328 |
+
[3, 2, 320, 0, 1, 1],
|
| 329 |
+
[3, 2, 320, 1, 1, 1],
|
| 330 |
+
[3, 2, 320, 0, 1, 1],
|
| 331 |
+
[3, 2, 320, 1, 1, 1],
|
| 332 |
+
[3, 2, 320, 0, 1, 1],
|
| 333 |
+
[3, 2, 320, 1, 1, 1],
|
| 334 |
+
[3, 2, 320, 0, 1, 1],
|
| 335 |
+
[3, 2, 320, 1, 1, 1],
|
| 336 |
+
[3, 2, 320, 0, 1, 1],
|
| 337 |
+
[3, 2, 320, 1, 1, 1],
|
| 338 |
+
[3, 2, 320, 0, 1, 1],
|
| 339 |
+
[3, 2, 320, 1, 1, 1],
|
| 340 |
+
[3, 2, 320, 0, 1, 1],
|
| 341 |
+
[3, 2, 320, 1, 1, 1],
|
| 342 |
+
[3, 2, 320, 0, 1, 1],
|
| 343 |
+
[3, 2, 320, 1, 1, 1],
|
| 344 |
+
[3, 2, 320, 0, 1, 1],
|
| 345 |
+
[3, 2, 320, 1, 1, 1],
|
| 346 |
+
[3, 2, 320, 0, 1, 1],
|
| 347 |
+
[3, 2, 320, 1, 1, 1],
|
| 348 |
+
[3, 2, 320, 0, 1, 1],
|
| 349 |
+
[3, 2, 320, 1, 1, 1],
|
| 350 |
+
[3, 2, 320, 0, 1, 1],
|
| 351 |
+
[3, 2, 320, 1, 1, 1],
|
| 352 |
+
[3, 2, 320, 0, 1, 1],
|
| 353 |
+
[3, 2, 320, 1, 1, 1],
|
| 354 |
+
[3, 2, 320, 0, 1, 1],
|
| 355 |
+
# [3, 2, 320, 1, 1, 1],
|
| 356 |
+
# [3, 2, 320, 0, 1, 1],
|
| 357 |
+
[3, 2, 320, 0, 1, 1],
|
| 358 |
+
[3, 2, 640, 0, 1, 2],
|
| 359 |
+
[3, 2, 640, 1, 1, 1],
|
| 360 |
+
[3, 2, 640, 0, 1, 1],
|
| 361 |
+
# [3, 2, 640, 1, 1, 1],
|
| 362 |
+
# [3, 2, 640, 0, 1, 1]
|
| 363 |
+
]
|
| 364 |
+
return RepViT(cfgs, num_classes=num_classes, distillation=distillation)
|
EfficientSAM/RepViTSAM/setup_repvit_sam.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
from functools import partial
|
| 9 |
+
from segment_anything.modeling import ImageEncoderViT, MaskDecoder, PromptEncoder, Sam, TwoWayTransformer
|
| 10 |
+
from RepViTSAM import repvit
|
| 11 |
+
from timm.models import create_model
|
| 12 |
+
|
| 13 |
+
def build_sam_repvit(checkpoint=None):
|
| 14 |
+
prompt_embed_dim = 256
|
| 15 |
+
image_size = 1024
|
| 16 |
+
vit_patch_size = 16
|
| 17 |
+
image_embedding_size = image_size // vit_patch_size
|
| 18 |
+
repvit_sam = Sam(
|
| 19 |
+
image_encoder=create_model('repvit'),
|
| 20 |
+
prompt_encoder=PromptEncoder(
|
| 21 |
+
embed_dim=prompt_embed_dim,
|
| 22 |
+
image_embedding_size=(image_embedding_size, image_embedding_size),
|
| 23 |
+
input_image_size=(image_size, image_size),
|
| 24 |
+
mask_in_chans=16,
|
| 25 |
+
),
|
| 26 |
+
mask_decoder=MaskDecoder(
|
| 27 |
+
num_multimask_outputs=3,
|
| 28 |
+
transformer=TwoWayTransformer(
|
| 29 |
+
depth=2,
|
| 30 |
+
embedding_dim=prompt_embed_dim,
|
| 31 |
+
mlp_dim=2048,
|
| 32 |
+
num_heads=8,
|
| 33 |
+
),
|
| 34 |
+
transformer_dim=prompt_embed_dim,
|
| 35 |
+
iou_head_depth=3,
|
| 36 |
+
iou_head_hidden_dim=256,
|
| 37 |
+
),
|
| 38 |
+
pixel_mean=[123.675, 116.28, 103.53],
|
| 39 |
+
pixel_std=[58.395, 57.12, 57.375],
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
repvit_sam.eval()
|
| 43 |
+
if checkpoint is not None:
|
| 44 |
+
with open(checkpoint, "rb") as f:
|
| 45 |
+
state_dict = torch.load(f)
|
| 46 |
+
repvit_sam.load_state_dict(state_dict)
|
| 47 |
+
return repvit_sam
|
| 48 |
+
|
| 49 |
+
from functools import partial
|
| 50 |
+
|
| 51 |
+
sam_model_registry = {
|
| 52 |
+
"repvit": partial(build_sam_repvit),
|
| 53 |
+
}
|
EfficientSAM/grounded_edge_sam.py
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import numpy as np
|
| 3 |
+
import supervision as sv
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torchvision
|
| 7 |
+
|
| 8 |
+
from groundingdino.util.inference import Model
|
| 9 |
+
from segment_anything import SamPredictor
|
| 10 |
+
from EdgeSAM.setup_edge_sam import build_edge_sam
|
| 11 |
+
|
| 12 |
+
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 13 |
+
|
| 14 |
+
# GroundingDINO config and checkpoint
|
| 15 |
+
GROUNDING_DINO_CONFIG_PATH = "GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py"
|
| 16 |
+
GROUNDING_DINO_CHECKPOINT_PATH = "./groundingdino_swint_ogc.pth"
|
| 17 |
+
|
| 18 |
+
# Building GroundingDINO inference model
|
| 19 |
+
grounding_dino_model = Model(model_config_path=GROUNDING_DINO_CONFIG_PATH, model_checkpoint_path=GROUNDING_DINO_CHECKPOINT_PATH)
|
| 20 |
+
|
| 21 |
+
# Building MobileSAM predictor
|
| 22 |
+
EdgeSAM_CHECKPOINT_PATH = "./EfficientSAM/edge_sam_3x.pth"
|
| 23 |
+
edge_sam = build_edge_sam(checkpoint=EdgeSAM_CHECKPOINT_PATH)
|
| 24 |
+
edge_sam.to(device=DEVICE)
|
| 25 |
+
|
| 26 |
+
sam_predictor = SamPredictor(edge_sam)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
# Predict classes and hyper-param for GroundingDINO
|
| 30 |
+
SOURCE_IMAGE_PATH = "./EfficientSAM/LightHQSAM/example_light_hqsam.png"
|
| 31 |
+
CLASSES = ["bench"]
|
| 32 |
+
BOX_THRESHOLD = 0.25
|
| 33 |
+
TEXT_THRESHOLD = 0.25
|
| 34 |
+
NMS_THRESHOLD = 0.8
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
# load image
|
| 38 |
+
image = cv2.imread(SOURCE_IMAGE_PATH)
|
| 39 |
+
|
| 40 |
+
# detect objects
|
| 41 |
+
detections = grounding_dino_model.predict_with_classes(
|
| 42 |
+
image=image,
|
| 43 |
+
classes=CLASSES,
|
| 44 |
+
box_threshold=BOX_THRESHOLD,
|
| 45 |
+
text_threshold=TEXT_THRESHOLD
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
# annotate image with detections
|
| 49 |
+
box_annotator = sv.BoxAnnotator()
|
| 50 |
+
labels = [
|
| 51 |
+
f"{CLASSES[class_id]} {confidence:0.2f}"
|
| 52 |
+
for _, _, confidence, class_id, _
|
| 53 |
+
in detections]
|
| 54 |
+
annotated_frame = box_annotator.annotate(scene=image.copy(), detections=detections, labels=labels)
|
| 55 |
+
|
| 56 |
+
# save the annotated grounding dino image
|
| 57 |
+
cv2.imwrite("EfficientSAM/LightHQSAM/groundingdino_annotated_image.jpg", annotated_frame)
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
# NMS post process
|
| 61 |
+
print(f"Before NMS: {len(detections.xyxy)} boxes")
|
| 62 |
+
nms_idx = torchvision.ops.nms(
|
| 63 |
+
torch.from_numpy(detections.xyxy),
|
| 64 |
+
torch.from_numpy(detections.confidence),
|
| 65 |
+
NMS_THRESHOLD
|
| 66 |
+
).numpy().tolist()
|
| 67 |
+
|
| 68 |
+
detections.xyxy = detections.xyxy[nms_idx]
|
| 69 |
+
detections.confidence = detections.confidence[nms_idx]
|
| 70 |
+
detections.class_id = detections.class_id[nms_idx]
|
| 71 |
+
|
| 72 |
+
print(f"After NMS: {len(detections.xyxy)} boxes")
|
| 73 |
+
|
| 74 |
+
# Prompting SAM with detected boxes
|
| 75 |
+
def segment(sam_predictor: SamPredictor, image: np.ndarray, xyxy: np.ndarray) -> np.ndarray:
|
| 76 |
+
sam_predictor.set_image(image)
|
| 77 |
+
result_masks = []
|
| 78 |
+
for box in xyxy:
|
| 79 |
+
masks, scores, logits = sam_predictor.predict(
|
| 80 |
+
box=box,
|
| 81 |
+
multimask_output=False,
|
| 82 |
+
hq_token_only=True,
|
| 83 |
+
)
|
| 84 |
+
index = np.argmax(scores)
|
| 85 |
+
result_masks.append(masks[index])
|
| 86 |
+
return np.array(result_masks)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
# convert detections to masks
|
| 90 |
+
detections.mask = segment(
|
| 91 |
+
sam_predictor=sam_predictor,
|
| 92 |
+
image=cv2.cvtColor(image, cv2.COLOR_BGR2RGB),
|
| 93 |
+
xyxy=detections.xyxy
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
# annotate image with detections
|
| 97 |
+
box_annotator = sv.BoxAnnotator()
|
| 98 |
+
mask_annotator = sv.MaskAnnotator()
|
| 99 |
+
labels = [
|
| 100 |
+
f"{CLASSES[class_id]} {confidence:0.2f}"
|
| 101 |
+
for _, _, confidence, class_id, _
|
| 102 |
+
in detections]
|
| 103 |
+
annotated_image = mask_annotator.annotate(scene=image.copy(), detections=detections)
|
| 104 |
+
annotated_image = box_annotator.annotate(scene=annotated_image, detections=detections, labels=labels)
|
| 105 |
+
|
| 106 |
+
# save the annotated grounded-sam image
|
| 107 |
+
cv2.imwrite("EfficientSAM/grounded_edge_sam_annotated_image.jpg", annotated_image)
|
EfficientSAM/grounded_efficient_sam.py
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import numpy as np
|
| 3 |
+
import supervision as sv
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torchvision
|
| 7 |
+
from torchvision.transforms import ToTensor
|
| 8 |
+
|
| 9 |
+
from groundingdino.util.inference import Model
|
| 10 |
+
|
| 11 |
+
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 12 |
+
|
| 13 |
+
# GroundingDINO config and checkpoint
|
| 14 |
+
GROUNDING_DINO_CONFIG_PATH = "GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py"
|
| 15 |
+
GROUNDING_DINO_CHECKPOINT_PATH = "./groundingdino_swint_ogc.pth"
|
| 16 |
+
|
| 17 |
+
# Building GroundingDINO inference model
|
| 18 |
+
grounding_dino_model = Model(model_config_path=GROUNDING_DINO_CONFIG_PATH, model_checkpoint_path=GROUNDING_DINO_CHECKPOINT_PATH)
|
| 19 |
+
|
| 20 |
+
# Building MobileSAM predictor
|
| 21 |
+
EFFICIENT_SAM_CHECHPOINT_PATH = "./EfficientSAM/efficientsam_s_gpu.jit"
|
| 22 |
+
efficientsam = torch.jit.load(EFFICIENT_SAM_CHECHPOINT_PATH)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
# Predict classes and hyper-param for GroundingDINO
|
| 26 |
+
SOURCE_IMAGE_PATH = "./EfficientSAM/LightHQSAM/example_light_hqsam.png"
|
| 27 |
+
CLASSES = ["bench"]
|
| 28 |
+
BOX_THRESHOLD = 0.25
|
| 29 |
+
TEXT_THRESHOLD = 0.25
|
| 30 |
+
NMS_THRESHOLD = 0.8
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
# load image
|
| 34 |
+
image = cv2.imread(SOURCE_IMAGE_PATH)
|
| 35 |
+
|
| 36 |
+
# detect objects
|
| 37 |
+
detections = grounding_dino_model.predict_with_classes(
|
| 38 |
+
image=image,
|
| 39 |
+
classes=CLASSES,
|
| 40 |
+
box_threshold=BOX_THRESHOLD,
|
| 41 |
+
text_threshold=BOX_THRESHOLD
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
# annotate image with detections
|
| 45 |
+
box_annotator = sv.BoxAnnotator()
|
| 46 |
+
labels = [
|
| 47 |
+
f"{CLASSES[class_id]} {confidence:0.2f}"
|
| 48 |
+
for _, _, confidence, class_id, _
|
| 49 |
+
in detections]
|
| 50 |
+
annotated_frame = box_annotator.annotate(scene=image.copy(), detections=detections, labels=labels)
|
| 51 |
+
|
| 52 |
+
# save the annotated grounding dino image
|
| 53 |
+
cv2.imwrite("EfficientSAM/LightHQSAM/groundingdino_annotated_image.jpg", annotated_frame)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
# NMS post process
|
| 57 |
+
print(f"Before NMS: {len(detections.xyxy)} boxes")
|
| 58 |
+
nms_idx = torchvision.ops.nms(
|
| 59 |
+
torch.from_numpy(detections.xyxy),
|
| 60 |
+
torch.from_numpy(detections.confidence),
|
| 61 |
+
NMS_THRESHOLD
|
| 62 |
+
).numpy().tolist()
|
| 63 |
+
|
| 64 |
+
detections.xyxy = detections.xyxy[nms_idx]
|
| 65 |
+
detections.confidence = detections.confidence[nms_idx]
|
| 66 |
+
detections.class_id = detections.class_id[nms_idx]
|
| 67 |
+
|
| 68 |
+
print(f"After NMS: {len(detections.xyxy)} boxes")
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def efficient_sam_box_prompt_segment(image, pts_sampled, model):
|
| 72 |
+
bbox = torch.reshape(torch.tensor(pts_sampled), [1, 1, 2, 2])
|
| 73 |
+
bbox_labels = torch.reshape(torch.tensor([2, 3]), [1, 1, 2])
|
| 74 |
+
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
|
| 75 |
+
img_tensor = ToTensor()(image)
|
| 76 |
+
|
| 77 |
+
predicted_logits, predicted_iou = model(
|
| 78 |
+
img_tensor[None, ...].cuda(),
|
| 79 |
+
bbox.cuda(),
|
| 80 |
+
bbox_labels.cuda(),
|
| 81 |
+
)
|
| 82 |
+
predicted_logits = predicted_logits.cpu()
|
| 83 |
+
all_masks = torch.ge(torch.sigmoid(predicted_logits[0, 0, :, :, :]), 0.5).numpy()
|
| 84 |
+
predicted_iou = predicted_iou[0, 0, ...].cpu().detach().numpy()
|
| 85 |
+
|
| 86 |
+
max_predicted_iou = -1
|
| 87 |
+
selected_mask_using_predicted_iou = None
|
| 88 |
+
for m in range(all_masks.shape[0]):
|
| 89 |
+
curr_predicted_iou = predicted_iou[m]
|
| 90 |
+
if (
|
| 91 |
+
curr_predicted_iou > max_predicted_iou
|
| 92 |
+
or selected_mask_using_predicted_iou is None
|
| 93 |
+
):
|
| 94 |
+
max_predicted_iou = curr_predicted_iou
|
| 95 |
+
selected_mask_using_predicted_iou = all_masks[m]
|
| 96 |
+
return selected_mask_using_predicted_iou
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
# collect segment results from EfficientSAM
|
| 100 |
+
result_masks = []
|
| 101 |
+
for box in detections.xyxy:
|
| 102 |
+
mask = efficient_sam_box_prompt_segment(image, box, efficientsam)
|
| 103 |
+
result_masks.append(mask)
|
| 104 |
+
|
| 105 |
+
detections.mask = np.array(result_masks)
|
| 106 |
+
|
| 107 |
+
# annotate image with detections
|
| 108 |
+
box_annotator = sv.BoxAnnotator()
|
| 109 |
+
mask_annotator = sv.MaskAnnotator()
|
| 110 |
+
labels = [
|
| 111 |
+
f"{CLASSES[class_id]} {confidence:0.2f}"
|
| 112 |
+
for _, _, confidence, class_id, _
|
| 113 |
+
in detections]
|
| 114 |
+
annotated_image = mask_annotator.annotate(scene=image.copy(), detections=detections)
|
| 115 |
+
annotated_image = box_annotator.annotate(scene=annotated_image, detections=detections, labels=labels)
|
| 116 |
+
|
| 117 |
+
# save the annotated grounded-sam image
|
| 118 |
+
cv2.imwrite("EfficientSAM/gronded_efficient_sam_anontated_image.jpg", annotated_image)
|
EfficientSAM/grounded_fast_sam.py
ADDED
|
@@ -0,0 +1,141 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import cv2
|
| 3 |
+
from ultralytics import YOLO
|
| 4 |
+
from FastSAM.tools import *
|
| 5 |
+
from groundingdino.util.inference import load_model, load_image, predict, annotate, Model
|
| 6 |
+
from torchvision.ops import box_convert
|
| 7 |
+
import ast
|
| 8 |
+
|
| 9 |
+
def parse_args():
|
| 10 |
+
parser = argparse.ArgumentParser()
|
| 11 |
+
parser.add_argument(
|
| 12 |
+
"--model_path", type=str, default="./FastSAM/FastSAM-x.pt", help="model"
|
| 13 |
+
)
|
| 14 |
+
parser.add_argument(
|
| 15 |
+
"--img_path", type=str, default="./images/dogs.jpg", help="path to image file"
|
| 16 |
+
)
|
| 17 |
+
parser.add_argument(
|
| 18 |
+
"--text", type=str, default="the black dog.", help="text prompt for GroundingDINO"
|
| 19 |
+
)
|
| 20 |
+
parser.add_argument("--imgsz", type=int, default=1024, help="image size")
|
| 21 |
+
parser.add_argument(
|
| 22 |
+
"--iou",
|
| 23 |
+
type=float,
|
| 24 |
+
default=0.9,
|
| 25 |
+
help="iou threshold for filtering the annotations",
|
| 26 |
+
)
|
| 27 |
+
parser.add_argument(
|
| 28 |
+
"--conf", type=float, default=0.4, help="object confidence threshold"
|
| 29 |
+
)
|
| 30 |
+
parser.add_argument(
|
| 31 |
+
"--output", type=str, default="./output/", help="image save path"
|
| 32 |
+
)
|
| 33 |
+
parser.add_argument(
|
| 34 |
+
"--randomcolor", type=bool, default=True, help="mask random color"
|
| 35 |
+
)
|
| 36 |
+
parser.add_argument(
|
| 37 |
+
"--point_prompt", type=str, default="[[0,0]]", help="[[x1,y1],[x2,y2]]"
|
| 38 |
+
)
|
| 39 |
+
parser.add_argument(
|
| 40 |
+
"--point_label",
|
| 41 |
+
type=str,
|
| 42 |
+
default="[0]",
|
| 43 |
+
help="[1,0] 0:background, 1:foreground",
|
| 44 |
+
)
|
| 45 |
+
parser.add_argument("--box_prompt", type=str, default="[0,0,0,0]", help="[x,y,w,h]")
|
| 46 |
+
parser.add_argument(
|
| 47 |
+
"--better_quality",
|
| 48 |
+
type=str,
|
| 49 |
+
default=False,
|
| 50 |
+
help="better quality using morphologyEx",
|
| 51 |
+
)
|
| 52 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 53 |
+
parser.add_argument(
|
| 54 |
+
"--device", type=str, default=device, help="cuda:[0,1,2,3,4] or cpu"
|
| 55 |
+
)
|
| 56 |
+
parser.add_argument(
|
| 57 |
+
"--retina",
|
| 58 |
+
type=bool,
|
| 59 |
+
default=True,
|
| 60 |
+
help="draw high-resolution segmentation masks",
|
| 61 |
+
)
|
| 62 |
+
parser.add_argument(
|
| 63 |
+
"--withContours", type=bool, default=False, help="draw the edges of the masks"
|
| 64 |
+
)
|
| 65 |
+
return parser.parse_args()
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def main(args):
|
| 69 |
+
|
| 70 |
+
# Image Path
|
| 71 |
+
img_path = args.img_path
|
| 72 |
+
text = args.text
|
| 73 |
+
|
| 74 |
+
# path to save img
|
| 75 |
+
save_path = args.output
|
| 76 |
+
if not os.path.exists(save_path):
|
| 77 |
+
os.makedirs(save_path)
|
| 78 |
+
basename = os.path.basename(args.img_path).split(".")[0]
|
| 79 |
+
|
| 80 |
+
# Build Fast-SAM Model
|
| 81 |
+
# ckpt_path = "/comp_robot/rentianhe/code/Grounded-Segment-Anything/FastSAM/FastSAM-x.pt"
|
| 82 |
+
model = YOLO(args.model_path)
|
| 83 |
+
|
| 84 |
+
results = model(
|
| 85 |
+
args.img_path,
|
| 86 |
+
imgsz=args.imgsz,
|
| 87 |
+
device=args.device,
|
| 88 |
+
retina_masks=args.retina,
|
| 89 |
+
iou=args.iou,
|
| 90 |
+
conf=args.conf,
|
| 91 |
+
max_det=100,
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
# Build GroundingDINO Model
|
| 96 |
+
groundingdino_config = "GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py"
|
| 97 |
+
groundingdino_ckpt_path = "./groundingdino_swint_ogc.pth"
|
| 98 |
+
|
| 99 |
+
image_source, image = load_image(img_path)
|
| 100 |
+
model = load_model(groundingdino_config, groundingdino_ckpt_path)
|
| 101 |
+
|
| 102 |
+
boxes, logits, phrases = predict(
|
| 103 |
+
model=model,
|
| 104 |
+
image=image,
|
| 105 |
+
caption=text,
|
| 106 |
+
box_threshold=0.3,
|
| 107 |
+
text_threshold=0.25,
|
| 108 |
+
device=args.device,
|
| 109 |
+
)
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
# Grounded-Fast-SAM
|
| 113 |
+
|
| 114 |
+
ori_img = cv2.imread(img_path)
|
| 115 |
+
ori_h = ori_img.shape[0]
|
| 116 |
+
ori_w = ori_img.shape[1]
|
| 117 |
+
|
| 118 |
+
# Save each frame due to the post process from FastSAM
|
| 119 |
+
boxes = boxes * torch.Tensor([ori_w, ori_h, ori_w, ori_h])
|
| 120 |
+
print(f"Detected Boxes: {len(boxes)}")
|
| 121 |
+
boxes = box_convert(boxes=boxes, in_fmt="cxcywh", out_fmt="xyxy").cpu().numpy().tolist()
|
| 122 |
+
for box_idx in range(len(boxes)):
|
| 123 |
+
mask, _ = box_prompt(
|
| 124 |
+
results[0].masks.data,
|
| 125 |
+
boxes[box_idx],
|
| 126 |
+
ori_h,
|
| 127 |
+
ori_w,
|
| 128 |
+
)
|
| 129 |
+
annotations = np.array([mask])
|
| 130 |
+
img_array = fast_process(
|
| 131 |
+
annotations=annotations,
|
| 132 |
+
args=args,
|
| 133 |
+
mask_random_color=True,
|
| 134 |
+
bbox=boxes[box_idx],
|
| 135 |
+
)
|
| 136 |
+
cv2.imwrite(os.path.join(save_path, basename + f"_{str(box_idx)}_caption_{phrases[box_idx]}.jpg"), cv2.cvtColor(img_array, cv2.COLOR_RGB2BGR))
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
if __name__ == "__main__":
|
| 140 |
+
args = parse_args()
|
| 141 |
+
main(args)
|
EfficientSAM/grounded_light_hqsam.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import numpy as np
|
| 3 |
+
import supervision as sv
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torchvision
|
| 7 |
+
|
| 8 |
+
from groundingdino.util.inference import Model
|
| 9 |
+
from segment_anything import SamPredictor
|
| 10 |
+
from LightHQSAM.setup_light_hqsam import setup_model
|
| 11 |
+
|
| 12 |
+
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 13 |
+
|
| 14 |
+
# GroundingDINO config and checkpoint
|
| 15 |
+
GROUNDING_DINO_CONFIG_PATH = "GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py"
|
| 16 |
+
GROUNDING_DINO_CHECKPOINT_PATH = "./groundingdino_swint_ogc.pth"
|
| 17 |
+
|
| 18 |
+
# Building GroundingDINO inference model
|
| 19 |
+
grounding_dino_model = Model(model_config_path=GROUNDING_DINO_CONFIG_PATH, model_checkpoint_path=GROUNDING_DINO_CHECKPOINT_PATH)
|
| 20 |
+
|
| 21 |
+
# Building MobileSAM predictor
|
| 22 |
+
HQSAM_CHECKPOINT_PATH = "./EfficientSAM/sam_hq_vit_tiny.pth"
|
| 23 |
+
checkpoint = torch.load(HQSAM_CHECKPOINT_PATH)
|
| 24 |
+
light_hqsam = setup_model()
|
| 25 |
+
light_hqsam.load_state_dict(checkpoint, strict=True)
|
| 26 |
+
light_hqsam.to(device=DEVICE)
|
| 27 |
+
|
| 28 |
+
sam_predictor = SamPredictor(light_hqsam)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
# Predict classes and hyper-param for GroundingDINO
|
| 32 |
+
SOURCE_IMAGE_PATH = "./EfficientSAM/LightHQSAM/example_light_hqsam.png"
|
| 33 |
+
CLASSES = ["bench"]
|
| 34 |
+
BOX_THRESHOLD = 0.25
|
| 35 |
+
TEXT_THRESHOLD = 0.25
|
| 36 |
+
NMS_THRESHOLD = 0.8
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
# load image
|
| 40 |
+
image = cv2.imread(SOURCE_IMAGE_PATH)
|
| 41 |
+
|
| 42 |
+
# detect objects
|
| 43 |
+
detections = grounding_dino_model.predict_with_classes(
|
| 44 |
+
image=image,
|
| 45 |
+
classes=CLASSES,
|
| 46 |
+
box_threshold=BOX_THRESHOLD,
|
| 47 |
+
text_threshold=BOX_THRESHOLD
|
| 48 |
+
)
|
| 49 |
+
|
| 50 |
+
# annotate image with detections
|
| 51 |
+
box_annotator = sv.BoxAnnotator()
|
| 52 |
+
labels = [
|
| 53 |
+
f"{CLASSES[class_id]} {confidence:0.2f}"
|
| 54 |
+
for _, _, confidence, class_id, _
|
| 55 |
+
in detections]
|
| 56 |
+
annotated_frame = box_annotator.annotate(scene=image.copy(), detections=detections, labels=labels)
|
| 57 |
+
|
| 58 |
+
# save the annotated grounding dino image
|
| 59 |
+
cv2.imwrite("EfficientSAM/LightHQSAM/groundingdino_annotated_image.jpg", annotated_frame)
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
# NMS post process
|
| 63 |
+
print(f"Before NMS: {len(detections.xyxy)} boxes")
|
| 64 |
+
nms_idx = torchvision.ops.nms(
|
| 65 |
+
torch.from_numpy(detections.xyxy),
|
| 66 |
+
torch.from_numpy(detections.confidence),
|
| 67 |
+
NMS_THRESHOLD
|
| 68 |
+
).numpy().tolist()
|
| 69 |
+
|
| 70 |
+
detections.xyxy = detections.xyxy[nms_idx]
|
| 71 |
+
detections.confidence = detections.confidence[nms_idx]
|
| 72 |
+
detections.class_id = detections.class_id[nms_idx]
|
| 73 |
+
|
| 74 |
+
print(f"After NMS: {len(detections.xyxy)} boxes")
|
| 75 |
+
|
| 76 |
+
# Prompting SAM with detected boxes
|
| 77 |
+
def segment(sam_predictor: SamPredictor, image: np.ndarray, xyxy: np.ndarray) -> np.ndarray:
|
| 78 |
+
sam_predictor.set_image(image)
|
| 79 |
+
result_masks = []
|
| 80 |
+
for box in xyxy:
|
| 81 |
+
masks, scores, logits = sam_predictor.predict(
|
| 82 |
+
box=box,
|
| 83 |
+
multimask_output=False,
|
| 84 |
+
hq_token_only=True,
|
| 85 |
+
)
|
| 86 |
+
index = np.argmax(scores)
|
| 87 |
+
result_masks.append(masks[index])
|
| 88 |
+
return np.array(result_masks)
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
# convert detections to masks
|
| 92 |
+
detections.mask = segment(
|
| 93 |
+
sam_predictor=sam_predictor,
|
| 94 |
+
image=cv2.cvtColor(image, cv2.COLOR_BGR2RGB),
|
| 95 |
+
xyxy=detections.xyxy
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
# annotate image with detections
|
| 99 |
+
box_annotator = sv.BoxAnnotator()
|
| 100 |
+
mask_annotator = sv.MaskAnnotator()
|
| 101 |
+
labels = [
|
| 102 |
+
f"{CLASSES[class_id]} {confidence:0.2f}"
|
| 103 |
+
for _, _, confidence, class_id, _
|
| 104 |
+
in detections]
|
| 105 |
+
annotated_image = mask_annotator.annotate(scene=image.copy(), detections=detections)
|
| 106 |
+
annotated_image = box_annotator.annotate(scene=annotated_image, detections=detections, labels=labels)
|
| 107 |
+
|
| 108 |
+
# save the annotated grounded-sam image
|
| 109 |
+
cv2.imwrite("EfficientSAM/LightHQSAM/grounded_light_hqsam_annotated_image.jpg", annotated_image)
|
EfficientSAM/grounded_mobile_sam.py
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import numpy as np
|
| 3 |
+
import supervision as sv
|
| 4 |
+
import argparse
|
| 5 |
+
import torch
|
| 6 |
+
import torchvision
|
| 7 |
+
|
| 8 |
+
from groundingdino.util.inference import Model
|
| 9 |
+
from segment_anything import SamPredictor
|
| 10 |
+
from MobileSAM.setup_mobile_sam import setup_model
|
| 11 |
+
|
| 12 |
+
def parse_args():
|
| 13 |
+
parser = argparse.ArgumentParser()
|
| 14 |
+
parser.add_argument(
|
| 15 |
+
"--MOBILE_SAM_CHECKPOINT_PATH", type=str, default="./EfficientSAM/mobile_sam.pt", help="model"
|
| 16 |
+
)
|
| 17 |
+
parser.add_argument(
|
| 18 |
+
"--SOURCE_IMAGE_PATH", type=str, default="./assets/demo2.jpg", help="path to image file"
|
| 19 |
+
)
|
| 20 |
+
parser.add_argument(
|
| 21 |
+
"--CAPTION", type=str, default="The running dog", help="text prompt for GroundingDINO"
|
| 22 |
+
)
|
| 23 |
+
parser.add_argument(
|
| 24 |
+
"--OUT_FILE_BOX", type=str, default="groundingdino_annotated_image.jpg", help="the output filename"
|
| 25 |
+
)
|
| 26 |
+
parser.add_argument(
|
| 27 |
+
"--OUT_FILE_SEG", type=str, default="grounded_mobile_sam_annotated_image.jpg", help="the output filename"
|
| 28 |
+
)
|
| 29 |
+
parser.add_argument(
|
| 30 |
+
"--OUT_FILE_BIN_MASK", type=str, default="grounded_mobile_sam_bin_mask.jpg", help="the output filename"
|
| 31 |
+
)
|
| 32 |
+
parser.add_argument("--BOX_THRESHOLD", type=float, default=0.25, help="")
|
| 33 |
+
parser.add_argument("--TEXT_THRESHOLD", type=float, default=0.25, help="")
|
| 34 |
+
parser.add_argument("--NMS_THRESHOLD", type=float, default=0.8, help="")
|
| 35 |
+
|
| 36 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 37 |
+
parser.add_argument(
|
| 38 |
+
"--DEVICE", type=str, default=device, help="cuda:[0,1,2,3,4] or cpu"
|
| 39 |
+
)
|
| 40 |
+
return parser.parse_args()
|
| 41 |
+
|
| 42 |
+
def main(args):
|
| 43 |
+
DEVICE = args.DEVICE
|
| 44 |
+
|
| 45 |
+
# GroundingDINO config and checkpoint
|
| 46 |
+
GROUNDING_DINO_CONFIG_PATH = "GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py"
|
| 47 |
+
GROUNDING_DINO_CHECKPOINT_PATH = "./groundingdino_swint_ogc.pth"
|
| 48 |
+
|
| 49 |
+
# Building GroundingDINO inference model
|
| 50 |
+
grounding_dino_model = Model(model_config_path=GROUNDING_DINO_CONFIG_PATH, model_checkpoint_path=GROUNDING_DINO_CHECKPOINT_PATH)
|
| 51 |
+
|
| 52 |
+
# Building MobileSAM predictor
|
| 53 |
+
MOBILE_SAM_CHECKPOINT_PATH = args.MOBILE_SAM_CHECKPOINT_PATH
|
| 54 |
+
checkpoint = torch.load(MOBILE_SAM_CHECKPOINT_PATH)
|
| 55 |
+
mobile_sam = setup_model()
|
| 56 |
+
mobile_sam.load_state_dict(checkpoint, strict=True)
|
| 57 |
+
mobile_sam.to(device=DEVICE)
|
| 58 |
+
|
| 59 |
+
sam_predictor = SamPredictor(mobile_sam)
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
# Predict classes and hyper-param for GroundingDINO
|
| 63 |
+
SOURCE_IMAGE_PATH = args.SOURCE_IMAGE_PATH
|
| 64 |
+
CLASSES = [args.CAPTION]
|
| 65 |
+
BOX_THRESHOLD = args.BOX_THRESHOLD
|
| 66 |
+
TEXT_THRESHOLD = args.TEXT_THRESHOLD
|
| 67 |
+
NMS_THRESHOLD = args.NMS_THRESHOLD
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
# load image
|
| 71 |
+
image = cv2.imread(SOURCE_IMAGE_PATH)
|
| 72 |
+
|
| 73 |
+
# detect objects
|
| 74 |
+
detections = grounding_dino_model.predict_with_classes(
|
| 75 |
+
image=image,
|
| 76 |
+
classes=CLASSES,
|
| 77 |
+
box_threshold=BOX_THRESHOLD,
|
| 78 |
+
text_threshold=TEXT_THRESHOLD
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
# annotate image with detections
|
| 82 |
+
box_annotator = sv.BoxAnnotator()
|
| 83 |
+
labels = [
|
| 84 |
+
f"{CLASSES[class_id]} {confidence:0.2f}"
|
| 85 |
+
for _, _, confidence, class_id, _
|
| 86 |
+
in detections]
|
| 87 |
+
annotated_frame = box_annotator.annotate(scene=image.copy(), detections=detections, labels=labels)
|
| 88 |
+
|
| 89 |
+
# save the annotated grounding dino image
|
| 90 |
+
cv2.imwrite(args.OUT_FILE_BOX, annotated_frame)
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
# NMS post process
|
| 94 |
+
print(f"Before NMS: {len(detections.xyxy)} boxes")
|
| 95 |
+
nms_idx = torchvision.ops.nms(
|
| 96 |
+
torch.from_numpy(detections.xyxy),
|
| 97 |
+
torch.from_numpy(detections.confidence),
|
| 98 |
+
NMS_THRESHOLD
|
| 99 |
+
).numpy().tolist()
|
| 100 |
+
|
| 101 |
+
detections.xyxy = detections.xyxy[nms_idx]
|
| 102 |
+
detections.confidence = detections.confidence[nms_idx]
|
| 103 |
+
detections.class_id = detections.class_id[nms_idx]
|
| 104 |
+
|
| 105 |
+
print(f"After NMS: {len(detections.xyxy)} boxes")
|
| 106 |
+
|
| 107 |
+
# Prompting SAM with detected boxes
|
| 108 |
+
def segment(sam_predictor: SamPredictor, image: np.ndarray, xyxy: np.ndarray) -> np.ndarray:
|
| 109 |
+
sam_predictor.set_image(image)
|
| 110 |
+
result_masks = []
|
| 111 |
+
for box in xyxy:
|
| 112 |
+
masks, scores, logits = sam_predictor.predict(
|
| 113 |
+
box=box,
|
| 114 |
+
multimask_output=True
|
| 115 |
+
)
|
| 116 |
+
index = np.argmax(scores)
|
| 117 |
+
result_masks.append(masks[index])
|
| 118 |
+
return np.array(result_masks)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
# convert detections to masks
|
| 122 |
+
detections.mask = segment(
|
| 123 |
+
sam_predictor=sam_predictor,
|
| 124 |
+
image=cv2.cvtColor(image, cv2.COLOR_BGR2RGB),
|
| 125 |
+
xyxy=detections.xyxy
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
binary_mask = detections.mask[0].astype(np.uint8)*255
|
| 129 |
+
cv2.imwrite(args.OUT_FILE_BIN_MASK, binary_mask)
|
| 130 |
+
|
| 131 |
+
# annotate image with detections
|
| 132 |
+
box_annotator = sv.BoxAnnotator()
|
| 133 |
+
mask_annotator = sv.MaskAnnotator()
|
| 134 |
+
labels = [
|
| 135 |
+
f"{CLASSES[class_id]} {confidence:0.2f}"
|
| 136 |
+
for _, _, confidence, class_id, _
|
| 137 |
+
in detections]
|
| 138 |
+
annotated_image = mask_annotator.annotate(scene=image.copy(), detections=detections)
|
| 139 |
+
annotated_image = box_annotator.annotate(scene=annotated_image, detections=detections, labels=labels)
|
| 140 |
+
# save the annotated grounded-sam image
|
| 141 |
+
cv2.imwrite(args.OUT_FILE_SEG, annotated_image)
|
| 142 |
+
|
| 143 |
+
if __name__ == "__main__":
|
| 144 |
+
args = parse_args()
|
| 145 |
+
main(args)
|
EfficientSAM/grounded_repvit_sam.py
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import numpy as np
|
| 3 |
+
import supervision as sv
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torchvision
|
| 7 |
+
|
| 8 |
+
from groundingdino.util.inference import Model
|
| 9 |
+
from segment_anything import SamPredictor
|
| 10 |
+
from RepViTSAM.setup_repvit_sam import build_sam_repvit
|
| 11 |
+
|
| 12 |
+
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 13 |
+
|
| 14 |
+
# GroundingDINO config and checkpoint
|
| 15 |
+
GROUNDING_DINO_CONFIG_PATH = "GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py"
|
| 16 |
+
GROUNDING_DINO_CHECKPOINT_PATH = "./groundingdino_swint_ogc.pth"
|
| 17 |
+
|
| 18 |
+
# Building GroundingDINO inference model
|
| 19 |
+
grounding_dino_model = Model(model_config_path=GROUNDING_DINO_CONFIG_PATH, model_checkpoint_path=GROUNDING_DINO_CHECKPOINT_PATH)
|
| 20 |
+
|
| 21 |
+
# Building MobileSAM predictor
|
| 22 |
+
RepViTSAM_CHECKPOINT_PATH = "./EfficientSAM/repvit_sam.pt"
|
| 23 |
+
repvit_sam = build_sam_repvit(checkpoint=RepViTSAM_CHECKPOINT_PATH)
|
| 24 |
+
repvit_sam.to(device=DEVICE)
|
| 25 |
+
|
| 26 |
+
sam_predictor = SamPredictor(repvit_sam)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
# Predict classes and hyper-param for GroundingDINO
|
| 30 |
+
SOURCE_IMAGE_PATH = "./EfficientSAM/LightHQSAM/example_light_hqsam.png"
|
| 31 |
+
CLASSES = ["bench"]
|
| 32 |
+
BOX_THRESHOLD = 0.25
|
| 33 |
+
TEXT_THRESHOLD = 0.25
|
| 34 |
+
NMS_THRESHOLD = 0.8
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
# load image
|
| 38 |
+
image = cv2.imread(SOURCE_IMAGE_PATH)
|
| 39 |
+
|
| 40 |
+
# detect objects
|
| 41 |
+
detections = grounding_dino_model.predict_with_classes(
|
| 42 |
+
image=image,
|
| 43 |
+
classes=CLASSES,
|
| 44 |
+
box_threshold=BOX_THRESHOLD,
|
| 45 |
+
text_threshold=BOX_THRESHOLD
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
# annotate image with detections
|
| 49 |
+
box_annotator = sv.BoxAnnotator()
|
| 50 |
+
labels = [
|
| 51 |
+
f"{CLASSES[class_id]} {confidence:0.2f}"
|
| 52 |
+
for _, _, confidence, class_id, _
|
| 53 |
+
in detections]
|
| 54 |
+
annotated_frame = box_annotator.annotate(scene=image.copy(), detections=detections, labels=labels)
|
| 55 |
+
|
| 56 |
+
# save the annotated grounding dino image
|
| 57 |
+
cv2.imwrite("EfficientSAM/LightHQSAM/groundingdino_annotated_image.jpg", annotated_frame)
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
# NMS post process
|
| 61 |
+
print(f"Before NMS: {len(detections.xyxy)} boxes")
|
| 62 |
+
nms_idx = torchvision.ops.nms(
|
| 63 |
+
torch.from_numpy(detections.xyxy),
|
| 64 |
+
torch.from_numpy(detections.confidence),
|
| 65 |
+
NMS_THRESHOLD
|
| 66 |
+
).numpy().tolist()
|
| 67 |
+
|
| 68 |
+
detections.xyxy = detections.xyxy[nms_idx]
|
| 69 |
+
detections.confidence = detections.confidence[nms_idx]
|
| 70 |
+
detections.class_id = detections.class_id[nms_idx]
|
| 71 |
+
|
| 72 |
+
print(f"After NMS: {len(detections.xyxy)} boxes")
|
| 73 |
+
|
| 74 |
+
# Prompting SAM with detected boxes
|
| 75 |
+
def segment(sam_predictor: SamPredictor, image: np.ndarray, xyxy: np.ndarray) -> np.ndarray:
|
| 76 |
+
sam_predictor.set_image(image)
|
| 77 |
+
result_masks = []
|
| 78 |
+
for box in xyxy:
|
| 79 |
+
masks, scores, logits = sam_predictor.predict(
|
| 80 |
+
box=box,
|
| 81 |
+
multimask_output=False,
|
| 82 |
+
hq_token_only=True,
|
| 83 |
+
)
|
| 84 |
+
index = np.argmax(scores)
|
| 85 |
+
result_masks.append(masks[index])
|
| 86 |
+
return np.array(result_masks)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
# convert detections to masks
|
| 90 |
+
detections.mask = segment(
|
| 91 |
+
sam_predictor=sam_predictor,
|
| 92 |
+
image=cv2.cvtColor(image, cv2.COLOR_BGR2RGB),
|
| 93 |
+
xyxy=detections.xyxy
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
# annotate image with detections
|
| 97 |
+
box_annotator = sv.BoxAnnotator()
|
| 98 |
+
mask_annotator = sv.MaskAnnotator()
|
| 99 |
+
labels = [
|
| 100 |
+
f"{CLASSES[class_id]} {confidence:0.2f}"
|
| 101 |
+
for _, _, confidence, class_id, _
|
| 102 |
+
in detections]
|
| 103 |
+
annotated_image = mask_annotator.annotate(scene=image.copy(), detections=detections)
|
| 104 |
+
annotated_image = box_annotator.annotate(scene=annotated_image, detections=detections, labels=labels)
|
| 105 |
+
|
| 106 |
+
# save the annotated grounded-sam image
|
| 107 |
+
cv2.imwrite("EfficientSAM/grounded_repvit_sam_annotated_image.jpg", annotated_image)
|
GroundingDINO/.asset/COCO.png
ADDED

|
Git LFS Details
|
GroundingDINO/.asset/GD_GLIGEN.png
ADDED

|
Git LFS Details
|
GroundingDINO/.asset/GD_SD.png
ADDED

|
Git LFS Details
|
GroundingDINO/.asset/ODinW.png
ADDED

|
Git LFS Details
|
GroundingDINO/.asset/arch.png
ADDED

|
Git LFS Details
|
GroundingDINO/.asset/cats.png
ADDED

|
Git LFS Details
|
GroundingDINO/.asset/hero_figure.png
ADDED

|
Git LFS Details
|
GroundingDINO/LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright 2020 - present, Facebook, Inc
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
GroundingDINO/README.md
ADDED
|
@@ -0,0 +1,163 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Grounding DINO
|
| 2 |
+
|
| 3 |
+
---
|
| 4 |
+
|
| 5 |
+
[](https://arxiv.org/abs/2303.05499)
|
| 6 |
+
[](https://youtu.be/wxWDt5UiwY8)
|
| 7 |
+
[](https://colab.research.google.com/github/roboflow-ai/notebooks/blob/main/notebooks/zero-shot-object-detection-with-grounding-dino.ipynb)
|
| 8 |
+
[](https://youtu.be/cMa77r3YrDk)
|
| 9 |
+
[](https://huggingface.co/spaces/ShilongLiu/Grounding_DINO_demo)
|
| 10 |
+
|
| 11 |
+
[](https://paperswithcode.com/sota/zero-shot-object-detection-on-mscoco?p=grounding-dino-marrying-dino-with-grounded) \
|
| 12 |
+
[](https://paperswithcode.com/sota/zero-shot-object-detection-on-odinw?p=grounding-dino-marrying-dino-with-grounded) \
|
| 13 |
+
[](https://paperswithcode.com/sota/object-detection-on-coco-minival?p=grounding-dino-marrying-dino-with-grounded) \
|
| 14 |
+
[](https://paperswithcode.com/sota/object-detection-on-coco?p=grounding-dino-marrying-dino-with-grounded)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
Official PyTorch implementation of [Grounding DINO](https://arxiv.org/abs/2303.05499), a stronger open-set object detector. Code is available now!
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
## Highlight
|
| 22 |
+
|
| 23 |
+
- **Open-Set Detection.** Detect **everything** with language!
|
| 24 |
+
- **High Performancce.** COCO zero-shot **52.5 AP** (training without COCO data!). COCO fine-tune **63.0 AP**.
|
| 25 |
+
- **Flexible.** Collaboration with Stable Diffusion for Image Editting.
|
| 26 |
+
|
| 27 |
+
## News
|
| 28 |
+
[2023/03/28] A YouTube [video](https://youtu.be/cMa77r3YrDk) about Grounding DINO and basic object detection prompt engineering. [[SkalskiP](https://github.com/SkalskiP)] \
|
| 29 |
+
[2023/03/28] Add a [demo](https://huggingface.co/spaces/ShilongLiu/Grounding_DINO_demo) on Hugging Face Space! \
|
| 30 |
+
[2023/03/27] Support CPU-only mode. Now the model can run on machines without GPUs.\
|
| 31 |
+
[2023/03/25] A [demo](https://colab.research.google.com/github/roboflow-ai/notebooks/blob/main/notebooks/zero-shot-object-detection-with-grounding-dino.ipynb) for Grounding DINO is available at Colab. [[SkalskiP](https://github.com/SkalskiP)] \
|
| 32 |
+
[2023/03/22] Code is available Now!
|
| 33 |
+
|
| 34 |
+
<details open>
|
| 35 |
+
<summary><font size="4">
|
| 36 |
+
Description
|
| 37 |
+
</font></summary>
|
| 38 |
+
<img src=".asset/hero_figure.png" alt="ODinW" width="100%">
|
| 39 |
+
</details>
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
## TODO
|
| 44 |
+
|
| 45 |
+
- [x] Release inference code and demo.
|
| 46 |
+
- [x] Release checkpoints.
|
| 47 |
+
- [ ] Grounding DINO with Stable Diffusion and GLIGEN demos.
|
| 48 |
+
- [ ] Release training codes.
|
| 49 |
+
|
| 50 |
+
## Install
|
| 51 |
+
|
| 52 |
+
If you have a CUDA environment, please make sure the environment variable `CUDA_HOME` is set. It will be compiled under CPU-only mode if no CUDA available.
|
| 53 |
+
|
| 54 |
+
```bash
|
| 55 |
+
pip install -e .
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
## Demo
|
| 59 |
+
|
| 60 |
+
```bash
|
| 61 |
+
CUDA_VISIBLE_DEVICES=6 python demo/inference_on_a_image.py \
|
| 62 |
+
-c /path/to/config \
|
| 63 |
+
-p /path/to/checkpoint \
|
| 64 |
+
-i .asset/cats.png \
|
| 65 |
+
-o "outputs/0" \
|
| 66 |
+
-t "cat ear." \
|
| 67 |
+
[--cpu-only] # open it for cpu mode
|
| 68 |
+
```
|
| 69 |
+
See the `demo/inference_on_a_image.py` for more details.
|
| 70 |
+
|
| 71 |
+
**Web UI**
|
| 72 |
+
|
| 73 |
+
We also provide a demo code to integrate Grounding DINO with Gradio Web UI. See the file `demo/gradio_app.py` for more details.
|
| 74 |
+
|
| 75 |
+
## Checkpoints
|
| 76 |
+
|
| 77 |
+
<!-- insert a table -->
|
| 78 |
+
<table>
|
| 79 |
+
<thead>
|
| 80 |
+
<tr style="text-align: right;">
|
| 81 |
+
<th></th>
|
| 82 |
+
<th>name</th>
|
| 83 |
+
<th>backbone</th>
|
| 84 |
+
<th>Data</th>
|
| 85 |
+
<th>box AP on COCO</th>
|
| 86 |
+
<th>Checkpoint</th>
|
| 87 |
+
<th>Config</th>
|
| 88 |
+
</tr>
|
| 89 |
+
</thead>
|
| 90 |
+
<tbody>
|
| 91 |
+
<tr>
|
| 92 |
+
<th>1</th>
|
| 93 |
+
<td>GroundingDINO-T</td>
|
| 94 |
+
<td>Swin-T</td>
|
| 95 |
+
<td>O365,GoldG,Cap4M</td>
|
| 96 |
+
<td>48.4 (zero-shot) / 57.2 (fine-tune)</td>
|
| 97 |
+
<td><a href="https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth">Github link</a> | <a href="https://huggingface.co/ShilongLiu/GroundingDINO/resolve/main/groundingdino_swint_ogc.pth">HF link</a></td>
|
| 98 |
+
<td><a href="https://github.com/IDEA-Research/GroundingDINO/blob/main/groundingdino/config/GroundingDINO_SwinT_OGC.py">link</a></td>
|
| 99 |
+
</tr>
|
| 100 |
+
</tbody>
|
| 101 |
+
</table>
|
| 102 |
+
|
| 103 |
+
## Results
|
| 104 |
+
|
| 105 |
+
<details open>
|
| 106 |
+
<summary><font size="4">
|
| 107 |
+
COCO Object Detection Results
|
| 108 |
+
</font></summary>
|
| 109 |
+
<img src=".asset/COCO.png" alt="COCO" width="100%">
|
| 110 |
+
</details>
|
| 111 |
+
|
| 112 |
+
<details open>
|
| 113 |
+
<summary><font size="4">
|
| 114 |
+
ODinW Object Detection Results
|
| 115 |
+
</font></summary>
|
| 116 |
+
<img src=".asset/ODinW.png" alt="ODinW" width="100%">
|
| 117 |
+
</details>
|
| 118 |
+
|
| 119 |
+
<details open>
|
| 120 |
+
<summary><font size="4">
|
| 121 |
+
Marrying Grounding DINO with <a href="https://github.com/Stability-AI/StableDiffusion">Stable Diffusion</a> for Image Editing
|
| 122 |
+
</font></summary>
|
| 123 |
+
<img src=".asset/GD_SD.png" alt="GD_SD" width="100%">
|
| 124 |
+
</details>
|
| 125 |
+
|
| 126 |
+
<details open>
|
| 127 |
+
<summary><font size="4">
|
| 128 |
+
Marrying Grounding DINO with <a href="https://github.com/gligen/GLIGEN">GLIGEN</a> for more Detailed Image Editing
|
| 129 |
+
</font></summary>
|
| 130 |
+
<img src=".asset/GD_GLIGEN.png" alt="GD_GLIGEN" width="100%">
|
| 131 |
+
</details>
|
| 132 |
+
|
| 133 |
+
## Model
|
| 134 |
+
|
| 135 |
+
Includes: a text backbone, an image backbone, a feature enhancer, a language-guided query selection, and a cross-modality decoder.
|
| 136 |
+
|
| 137 |
+

|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
## Acknowledgement
|
| 141 |
+
|
| 142 |
+
Our model is related to [DINO](https://github.com/IDEA-Research/DINO) and [GLIP](https://github.com/microsoft/GLIP). Thanks for their great work!
|
| 143 |
+
|
| 144 |
+
We also thank great previous work including DETR, Deformable DETR, SMCA, Conditional DETR, Anchor DETR, Dynamic DETR, DAB-DETR, DN-DETR, etc. More related work are available at [Awesome Detection Transformer](https://github.com/IDEACVR/awesome-detection-transformer). A new toolbox [detrex](https://github.com/IDEA-Research/detrex) is available as well.
|
| 145 |
+
|
| 146 |
+
Thanks [Stable Diffusion](https://github.com/Stability-AI/StableDiffusion) and [GLIGEN](https://github.com/gligen/GLIGEN) for their awesome models.
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
## Citation
|
| 150 |
+
|
| 151 |
+
If you find our work helpful for your research, please consider citing the following BibTeX entry.
|
| 152 |
+
|
| 153 |
+
```bibtex
|
| 154 |
+
@inproceedings{ShilongLiu2023GroundingDM,
|
| 155 |
+
title={Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection},
|
| 156 |
+
author={Shilong Liu and Zhaoyang Zeng and Tianhe Ren and Feng Li and Hao Zhang and Jie Yang and Chunyuan Li and Jianwei Yang and Hang Su and Jun Zhu and Lei Zhang},
|
| 157 |
+
year={2023}
|
| 158 |
+
}
|
| 159 |
+
```
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
|
GroundingDINO/demo/gradio_app.py
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
from functools import partial
|
| 3 |
+
import cv2
|
| 4 |
+
import requests
|
| 5 |
+
import os
|
| 6 |
+
from io import BytesIO
|
| 7 |
+
from PIL import Image
|
| 8 |
+
import numpy as np
|
| 9 |
+
from pathlib import Path
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
import warnings
|
| 13 |
+
|
| 14 |
+
import torch
|
| 15 |
+
|
| 16 |
+
# prepare the environment
|
| 17 |
+
os.system("python setup.py build develop --user")
|
| 18 |
+
os.system("pip install packaging==21.3")
|
| 19 |
+
os.system("pip install gradio")
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
warnings.filterwarnings("ignore")
|
| 23 |
+
|
| 24 |
+
import gradio as gr
|
| 25 |
+
|
| 26 |
+
from groundingdino.models import build_model
|
| 27 |
+
from groundingdino.util.slconfig import SLConfig
|
| 28 |
+
from groundingdino.util.utils import clean_state_dict
|
| 29 |
+
from groundingdino.util.inference import annotate, load_image, predict
|
| 30 |
+
import groundingdino.datasets.transforms as T
|
| 31 |
+
|
| 32 |
+
from huggingface_hub import hf_hub_download
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
# Use this command for evaluate the GLIP-T model
|
| 37 |
+
config_file = "groundingdino/config/GroundingDINO_SwinT_OGC.py"
|
| 38 |
+
ckpt_repo_id = "ShilongLiu/GroundingDINO"
|
| 39 |
+
ckpt_filenmae = "groundingdino_swint_ogc.pth"
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def load_model_hf(model_config_path, repo_id, filename, device='cpu'):
|
| 43 |
+
args = SLConfig.fromfile(model_config_path)
|
| 44 |
+
model = build_model(args)
|
| 45 |
+
args.device = device
|
| 46 |
+
|
| 47 |
+
cache_file = hf_hub_download(repo_id=repo_id, filename=filename)
|
| 48 |
+
checkpoint = torch.load(cache_file, map_location='cpu')
|
| 49 |
+
log = model.load_state_dict(clean_state_dict(checkpoint['model']), strict=False)
|
| 50 |
+
print("Model loaded from {} \n => {}".format(cache_file, log))
|
| 51 |
+
_ = model.eval()
|
| 52 |
+
return model
|
| 53 |
+
|
| 54 |
+
def image_transform_grounding(init_image):
|
| 55 |
+
transform = T.Compose([
|
| 56 |
+
T.RandomResize([800], max_size=1333),
|
| 57 |
+
T.ToTensor(),
|
| 58 |
+
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
|
| 59 |
+
])
|
| 60 |
+
image, _ = transform(init_image, None) # 3, h, w
|
| 61 |
+
return init_image, image
|
| 62 |
+
|
| 63 |
+
def image_transform_grounding_for_vis(init_image):
|
| 64 |
+
transform = T.Compose([
|
| 65 |
+
T.RandomResize([800], max_size=1333),
|
| 66 |
+
])
|
| 67 |
+
image, _ = transform(init_image, None) # 3, h, w
|
| 68 |
+
return image
|
| 69 |
+
|
| 70 |
+
model = load_model_hf(config_file, ckpt_repo_id, ckpt_filenmae)
|
| 71 |
+
|
| 72 |
+
def run_grounding(input_image, grounding_caption, box_threshold, text_threshold):
|
| 73 |
+
init_image = input_image.convert("RGB")
|
| 74 |
+
original_size = init_image.size
|
| 75 |
+
|
| 76 |
+
_, image_tensor = image_transform_grounding(init_image)
|
| 77 |
+
image_pil: Image = image_transform_grounding_for_vis(init_image)
|
| 78 |
+
|
| 79 |
+
# run grounidng
|
| 80 |
+
boxes, logits, phrases = predict(model, image_tensor, grounding_caption, box_threshold, text_threshold, device='cpu')
|
| 81 |
+
annotated_frame = annotate(image_source=np.asarray(image_pil), boxes=boxes, logits=logits, phrases=phrases)
|
| 82 |
+
image_with_box = Image.fromarray(cv2.cvtColor(annotated_frame, cv2.COLOR_BGR2RGB))
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
return image_with_box
|
| 86 |
+
|
| 87 |
+
if __name__ == "__main__":
|
| 88 |
+
|
| 89 |
+
parser = argparse.ArgumentParser("Grounding DINO demo", add_help=True)
|
| 90 |
+
parser.add_argument("--debug", action="store_true", help="using debug mode")
|
| 91 |
+
parser.add_argument("--share", action="store_true", help="share the app")
|
| 92 |
+
args = parser.parse_args()
|
| 93 |
+
|
| 94 |
+
block = gr.Blocks().queue()
|
| 95 |
+
with block:
|
| 96 |
+
gr.Markdown("# [Grounding DINO](https://github.com/IDEA-Research/GroundingDINO)")
|
| 97 |
+
gr.Markdown("### Open-World Detection with Grounding DINO")
|
| 98 |
+
|
| 99 |
+
with gr.Row():
|
| 100 |
+
with gr.Column():
|
| 101 |
+
input_image = gr.Image(source='upload', type="pil")
|
| 102 |
+
grounding_caption = gr.Textbox(label="Detection Prompt")
|
| 103 |
+
run_button = gr.Button(label="Run")
|
| 104 |
+
with gr.Accordion("Advanced options", open=False):
|
| 105 |
+
box_threshold = gr.Slider(
|
| 106 |
+
label="Box Threshold", minimum=0.0, maximum=1.0, value=0.25, step=0.001
|
| 107 |
+
)
|
| 108 |
+
text_threshold = gr.Slider(
|
| 109 |
+
label="Text Threshold", minimum=0.0, maximum=1.0, value=0.25, step=0.001
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
with gr.Column():
|
| 113 |
+
gallery = gr.outputs.Image(
|
| 114 |
+
type="pil",
|
| 115 |
+
# label="grounding results"
|
| 116 |
+
).style(full_width=True, full_height=True)
|
| 117 |
+
# gallery = gr.Gallery(label="Generated images", show_label=False).style(
|
| 118 |
+
# grid=[1], height="auto", container=True, full_width=True, full_height=True)
|
| 119 |
+
|
| 120 |
+
run_button.click(fn=run_grounding, inputs=[
|
| 121 |
+
input_image, grounding_caption, box_threshold, text_threshold], outputs=[gallery])
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
block.launch(server_name='0.0.0.0', server_port=7579, debug=args.debug, share=args.share)
|
| 125 |
+
|
GroundingDINO/demo/inference_on_a_image.py
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
import sys
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch
|
| 7 |
+
from PIL import Image, ImageDraw, ImageFont
|
| 8 |
+
|
| 9 |
+
import groundingdino.datasets.transforms as T
|
| 10 |
+
from groundingdino.models import build_model
|
| 11 |
+
from groundingdino.util import box_ops
|
| 12 |
+
from groundingdino.util.slconfig import SLConfig
|
| 13 |
+
from groundingdino.util.utils import clean_state_dict, get_phrases_from_posmap
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def plot_boxes_to_image(image_pil, tgt):
|
| 17 |
+
H, W = tgt["size"]
|
| 18 |
+
boxes = tgt["boxes"]
|
| 19 |
+
labels = tgt["labels"]
|
| 20 |
+
assert len(boxes) == len(labels), "boxes and labels must have same length"
|
| 21 |
+
|
| 22 |
+
draw = ImageDraw.Draw(image_pil)
|
| 23 |
+
mask = Image.new("L", image_pil.size, 0)
|
| 24 |
+
mask_draw = ImageDraw.Draw(mask)
|
| 25 |
+
|
| 26 |
+
# draw boxes and masks
|
| 27 |
+
for box, label in zip(boxes, labels):
|
| 28 |
+
# from 0..1 to 0..W, 0..H
|
| 29 |
+
box = box * torch.Tensor([W, H, W, H])
|
| 30 |
+
# from xywh to xyxy
|
| 31 |
+
box[:2] -= box[2:] / 2
|
| 32 |
+
box[2:] += box[:2]
|
| 33 |
+
# random color
|
| 34 |
+
color = tuple(np.random.randint(0, 255, size=3).tolist())
|
| 35 |
+
# draw
|
| 36 |
+
x0, y0, x1, y1 = box
|
| 37 |
+
x0, y0, x1, y1 = int(x0), int(y0), int(x1), int(y1)
|
| 38 |
+
|
| 39 |
+
draw.rectangle([x0, y0, x1, y1], outline=color, width=6)
|
| 40 |
+
# draw.text((x0, y0), str(label), fill=color)
|
| 41 |
+
|
| 42 |
+
font = ImageFont.load_default()
|
| 43 |
+
if hasattr(font, "getbbox"):
|
| 44 |
+
bbox = draw.textbbox((x0, y0), str(label), font)
|
| 45 |
+
else:
|
| 46 |
+
w, h = draw.textsize(str(label), font)
|
| 47 |
+
bbox = (x0, y0, w + x0, y0 + h)
|
| 48 |
+
# bbox = draw.textbbox((x0, y0), str(label))
|
| 49 |
+
draw.rectangle(bbox, fill=color)
|
| 50 |
+
draw.text((x0, y0), str(label), fill="white")
|
| 51 |
+
|
| 52 |
+
mask_draw.rectangle([x0, y0, x1, y1], fill=255, width=6)
|
| 53 |
+
|
| 54 |
+
return image_pil, mask
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def load_image(image_path):
|
| 58 |
+
# load image
|
| 59 |
+
image_pil = Image.open(image_path).convert("RGB") # load image
|
| 60 |
+
|
| 61 |
+
transform = T.Compose(
|
| 62 |
+
[
|
| 63 |
+
T.RandomResize([800], max_size=1333),
|
| 64 |
+
T.ToTensor(),
|
| 65 |
+
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
|
| 66 |
+
]
|
| 67 |
+
)
|
| 68 |
+
image, _ = transform(image_pil, None) # 3, h, w
|
| 69 |
+
return image_pil, image
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def load_model(model_config_path, model_checkpoint_path, cpu_only=False):
|
| 73 |
+
args = SLConfig.fromfile(model_config_path)
|
| 74 |
+
args.device = "cuda" if not cpu_only else "cpu"
|
| 75 |
+
model = build_model(args)
|
| 76 |
+
checkpoint = torch.load(model_checkpoint_path, map_location="cpu")
|
| 77 |
+
load_res = model.load_state_dict(clean_state_dict(checkpoint["model"]), strict=False)
|
| 78 |
+
print(load_res)
|
| 79 |
+
_ = model.eval()
|
| 80 |
+
return model
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def get_grounding_output(model, image, caption, box_threshold, text_threshold, with_logits=True, cpu_only=False):
|
| 84 |
+
caption = caption.lower()
|
| 85 |
+
caption = caption.strip()
|
| 86 |
+
if not caption.endswith("."):
|
| 87 |
+
caption = caption + "."
|
| 88 |
+
device = "cuda" if not cpu_only else "cpu"
|
| 89 |
+
model = model.to(device)
|
| 90 |
+
image = image.to(device)
|
| 91 |
+
with torch.no_grad():
|
| 92 |
+
outputs = model(image[None], captions=[caption])
|
| 93 |
+
logits = outputs["pred_logits"].cpu().sigmoid()[0] # (nq, 256)
|
| 94 |
+
boxes = outputs["pred_boxes"].cpu()[0] # (nq, 4)
|
| 95 |
+
logits.shape[0]
|
| 96 |
+
|
| 97 |
+
# filter output
|
| 98 |
+
logits_filt = logits.clone()
|
| 99 |
+
boxes_filt = boxes.clone()
|
| 100 |
+
filt_mask = logits_filt.max(dim=1)[0] > box_threshold
|
| 101 |
+
logits_filt = logits_filt[filt_mask] # num_filt, 256
|
| 102 |
+
boxes_filt = boxes_filt[filt_mask] # num_filt, 4
|
| 103 |
+
logits_filt.shape[0]
|
| 104 |
+
|
| 105 |
+
# get phrase
|
| 106 |
+
tokenlizer = model.tokenizer
|
| 107 |
+
tokenized = tokenlizer(caption)
|
| 108 |
+
# build pred
|
| 109 |
+
pred_phrases = []
|
| 110 |
+
for logit, box in zip(logits_filt, boxes_filt):
|
| 111 |
+
pred_phrase = get_phrases_from_posmap(logit > text_threshold, tokenized, tokenlizer)
|
| 112 |
+
if with_logits:
|
| 113 |
+
pred_phrases.append(pred_phrase + f"({str(logit.max().item())[:4]})")
|
| 114 |
+
else:
|
| 115 |
+
pred_phrases.append(pred_phrase)
|
| 116 |
+
|
| 117 |
+
return boxes_filt, pred_phrases
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
if __name__ == "__main__":
|
| 121 |
+
|
| 122 |
+
parser = argparse.ArgumentParser("Grounding DINO example", add_help=True)
|
| 123 |
+
parser.add_argument("--config_file", "-c", type=str, required=True, help="path to config file")
|
| 124 |
+
parser.add_argument(
|
| 125 |
+
"--checkpoint_path", "-p", type=str, required=True, help="path to checkpoint file"
|
| 126 |
+
)
|
| 127 |
+
parser.add_argument("--image_path", "-i", type=str, required=True, help="path to image file")
|
| 128 |
+
parser.add_argument("--text_prompt", "-t", type=str, required=True, help="text prompt")
|
| 129 |
+
parser.add_argument(
|
| 130 |
+
"--output_dir", "-o", type=str, default="outputs", required=True, help="output directory"
|
| 131 |
+
)
|
| 132 |
+
|
| 133 |
+
parser.add_argument("--box_threshold", type=float, default=0.3, help="box threshold")
|
| 134 |
+
parser.add_argument("--text_threshold", type=float, default=0.25, help="text threshold")
|
| 135 |
+
|
| 136 |
+
parser.add_argument("--cpu-only", action="store_true", help="running on cpu only!, default=False")
|
| 137 |
+
args = parser.parse_args()
|
| 138 |
+
|
| 139 |
+
# cfg
|
| 140 |
+
config_file = args.config_file # change the path of the model config file
|
| 141 |
+
checkpoint_path = args.checkpoint_path # change the path of the model
|
| 142 |
+
image_path = args.image_path
|
| 143 |
+
text_prompt = args.text_prompt
|
| 144 |
+
output_dir = args.output_dir
|
| 145 |
+
box_threshold = args.box_threshold
|
| 146 |
+
text_threshold = args.text_threshold
|
| 147 |
+
|
| 148 |
+
# make dir
|
| 149 |
+
os.makedirs(output_dir, exist_ok=True)
|
| 150 |
+
# load image
|
| 151 |
+
image_pil, image = load_image(image_path)
|
| 152 |
+
# load model
|
| 153 |
+
model = load_model(config_file, checkpoint_path, cpu_only=args.cpu_only)
|
| 154 |
+
|
| 155 |
+
# visualize raw image
|
| 156 |
+
image_pil.save(os.path.join(output_dir, "raw_image.jpg"))
|
| 157 |
+
|
| 158 |
+
# run model
|
| 159 |
+
boxes_filt, pred_phrases = get_grounding_output(
|
| 160 |
+
model, image, text_prompt, box_threshold, text_threshold, cpu_only=args.cpu_only
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
# visualize pred
|
| 164 |
+
size = image_pil.size
|
| 165 |
+
pred_dict = {
|
| 166 |
+
"boxes": boxes_filt,
|
| 167 |
+
"size": [size[1], size[0]], # H,W
|
| 168 |
+
"labels": pred_phrases,
|
| 169 |
+
}
|
| 170 |
+
# import ipdb; ipdb.set_trace()
|
| 171 |
+
image_with_box = plot_boxes_to_image(image_pil, pred_dict)[0]
|
| 172 |
+
image_with_box.save(os.path.join(output_dir, "pred.jpg"))
|
GroundingDINO/groundingdino/__init__.py
ADDED
|
File without changes
|
GroundingDINO/groundingdino/config/GroundingDINO_SwinB.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
batch_size = 1
|
| 2 |
+
modelname = "groundingdino"
|
| 3 |
+
backbone = "swin_B_384_22k"
|
| 4 |
+
position_embedding = "sine"
|
| 5 |
+
pe_temperatureH = 20
|
| 6 |
+
pe_temperatureW = 20
|
| 7 |
+
return_interm_indices = [1, 2, 3]
|
| 8 |
+
backbone_freeze_keywords = None
|
| 9 |
+
enc_layers = 6
|
| 10 |
+
dec_layers = 6
|
| 11 |
+
pre_norm = False
|
| 12 |
+
dim_feedforward = 2048
|
| 13 |
+
hidden_dim = 256
|
| 14 |
+
dropout = 0.0
|
| 15 |
+
nheads = 8
|
| 16 |
+
num_queries = 900
|
| 17 |
+
query_dim = 4
|
| 18 |
+
num_patterns = 0
|
| 19 |
+
num_feature_levels = 4
|
| 20 |
+
enc_n_points = 4
|
| 21 |
+
dec_n_points = 4
|
| 22 |
+
two_stage_type = "standard"
|
| 23 |
+
two_stage_bbox_embed_share = False
|
| 24 |
+
two_stage_class_embed_share = False
|
| 25 |
+
transformer_activation = "relu"
|
| 26 |
+
dec_pred_bbox_embed_share = True
|
| 27 |
+
dn_box_noise_scale = 1.0
|
| 28 |
+
dn_label_noise_ratio = 0.5
|
| 29 |
+
dn_label_coef = 1.0
|
| 30 |
+
dn_bbox_coef = 1.0
|
| 31 |
+
embed_init_tgt = True
|
| 32 |
+
dn_labelbook_size = 2000
|
| 33 |
+
max_text_len = 256
|
| 34 |
+
text_encoder_type = "bert-base-uncased"
|
| 35 |
+
use_text_enhancer = True
|
| 36 |
+
use_fusion_layer = True
|
| 37 |
+
use_checkpoint = True
|
| 38 |
+
use_transformer_ckpt = True
|
| 39 |
+
use_text_cross_attention = True
|
| 40 |
+
text_dropout = 0.0
|
| 41 |
+
fusion_dropout = 0.0
|
| 42 |
+
fusion_droppath = 0.1
|
| 43 |
+
sub_sentence_present = True
|
GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
batch_size = 1
|
| 2 |
+
modelname = "groundingdino"
|
| 3 |
+
backbone = "swin_T_224_1k"
|
| 4 |
+
position_embedding = "sine"
|
| 5 |
+
pe_temperatureH = 20
|
| 6 |
+
pe_temperatureW = 20
|
| 7 |
+
return_interm_indices = [1, 2, 3]
|
| 8 |
+
backbone_freeze_keywords = None
|
| 9 |
+
enc_layers = 6
|
| 10 |
+
dec_layers = 6
|
| 11 |
+
pre_norm = False
|
| 12 |
+
dim_feedforward = 2048
|
| 13 |
+
hidden_dim = 256
|
| 14 |
+
dropout = 0.0
|
| 15 |
+
nheads = 8
|
| 16 |
+
num_queries = 900
|
| 17 |
+
query_dim = 4
|
| 18 |
+
num_patterns = 0
|
| 19 |
+
num_feature_levels = 4
|
| 20 |
+
enc_n_points = 4
|
| 21 |
+
dec_n_points = 4
|
| 22 |
+
two_stage_type = "standard"
|
| 23 |
+
two_stage_bbox_embed_share = False
|
| 24 |
+
two_stage_class_embed_share = False
|
| 25 |
+
transformer_activation = "relu"
|
| 26 |
+
dec_pred_bbox_embed_share = True
|
| 27 |
+
dn_box_noise_scale = 1.0
|
| 28 |
+
dn_label_noise_ratio = 0.5
|
| 29 |
+
dn_label_coef = 1.0
|
| 30 |
+
dn_bbox_coef = 1.0
|
| 31 |
+
embed_init_tgt = True
|
| 32 |
+
dn_labelbook_size = 2000
|
| 33 |
+
max_text_len = 256
|
| 34 |
+
text_encoder_type = "bert-base-uncased"
|
| 35 |
+
use_text_enhancer = True
|
| 36 |
+
use_fusion_layer = True
|
| 37 |
+
use_checkpoint = True
|
| 38 |
+
use_transformer_ckpt = True
|
| 39 |
+
use_text_cross_attention = True
|
| 40 |
+
text_dropout = 0.0
|
| 41 |
+
fusion_dropout = 0.0
|
| 42 |
+
fusion_droppath = 0.1
|
| 43 |
+
sub_sentence_present = True
|
GroundingDINO/groundingdino/datasets/__init__.py
ADDED
|
File without changes
|
GroundingDINO/groundingdino/datasets/transforms.py
ADDED
|
@@ -0,0 +1,311 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
|
| 2 |
+
"""
|
| 3 |
+
Transforms and data augmentation for both image + bbox.
|
| 4 |
+
"""
|
| 5 |
+
import os
|
| 6 |
+
import random
|
| 7 |
+
|
| 8 |
+
import PIL
|
| 9 |
+
import torch
|
| 10 |
+
import torchvision.transforms as T
|
| 11 |
+
import torchvision.transforms.functional as F
|
| 12 |
+
|
| 13 |
+
from groundingdino.util.box_ops import box_xyxy_to_cxcywh
|
| 14 |
+
from groundingdino.util.misc import interpolate
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def crop(image, target, region):
|
| 18 |
+
cropped_image = F.crop(image, *region)
|
| 19 |
+
|
| 20 |
+
target = target.copy()
|
| 21 |
+
i, j, h, w = region
|
| 22 |
+
|
| 23 |
+
# should we do something wrt the original size?
|
| 24 |
+
target["size"] = torch.tensor([h, w])
|
| 25 |
+
|
| 26 |
+
fields = ["labels", "area", "iscrowd", "positive_map"]
|
| 27 |
+
|
| 28 |
+
if "boxes" in target:
|
| 29 |
+
boxes = target["boxes"]
|
| 30 |
+
max_size = torch.as_tensor([w, h], dtype=torch.float32)
|
| 31 |
+
cropped_boxes = boxes - torch.as_tensor([j, i, j, i])
|
| 32 |
+
cropped_boxes = torch.min(cropped_boxes.reshape(-1, 2, 2), max_size)
|
| 33 |
+
cropped_boxes = cropped_boxes.clamp(min=0)
|
| 34 |
+
area = (cropped_boxes[:, 1, :] - cropped_boxes[:, 0, :]).prod(dim=1)
|
| 35 |
+
target["boxes"] = cropped_boxes.reshape(-1, 4)
|
| 36 |
+
target["area"] = area
|
| 37 |
+
fields.append("boxes")
|
| 38 |
+
|
| 39 |
+
if "masks" in target:
|
| 40 |
+
# FIXME should we update the area here if there are no boxes?
|
| 41 |
+
target["masks"] = target["masks"][:, i : i + h, j : j + w]
|
| 42 |
+
fields.append("masks")
|
| 43 |
+
|
| 44 |
+
# remove elements for which the boxes or masks that have zero area
|
| 45 |
+
if "boxes" in target or "masks" in target:
|
| 46 |
+
# favor boxes selection when defining which elements to keep
|
| 47 |
+
# this is compatible with previous implementation
|
| 48 |
+
if "boxes" in target:
|
| 49 |
+
cropped_boxes = target["boxes"].reshape(-1, 2, 2)
|
| 50 |
+
keep = torch.all(cropped_boxes[:, 1, :] > cropped_boxes[:, 0, :], dim=1)
|
| 51 |
+
else:
|
| 52 |
+
keep = target["masks"].flatten(1).any(1)
|
| 53 |
+
|
| 54 |
+
for field in fields:
|
| 55 |
+
if field in target:
|
| 56 |
+
target[field] = target[field][keep]
|
| 57 |
+
|
| 58 |
+
if os.environ.get("IPDB_SHILONG_DEBUG", None) == "INFO":
|
| 59 |
+
# for debug and visualization only.
|
| 60 |
+
if "strings_positive" in target:
|
| 61 |
+
target["strings_positive"] = [
|
| 62 |
+
_i for _i, _j in zip(target["strings_positive"], keep) if _j
|
| 63 |
+
]
|
| 64 |
+
|
| 65 |
+
return cropped_image, target
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def hflip(image, target):
|
| 69 |
+
flipped_image = F.hflip(image)
|
| 70 |
+
|
| 71 |
+
w, h = image.size
|
| 72 |
+
|
| 73 |
+
target = target.copy()
|
| 74 |
+
if "boxes" in target:
|
| 75 |
+
boxes = target["boxes"]
|
| 76 |
+
boxes = boxes[:, [2, 1, 0, 3]] * torch.as_tensor([-1, 1, -1, 1]) + torch.as_tensor(
|
| 77 |
+
[w, 0, w, 0]
|
| 78 |
+
)
|
| 79 |
+
target["boxes"] = boxes
|
| 80 |
+
|
| 81 |
+
if "masks" in target:
|
| 82 |
+
target["masks"] = target["masks"].flip(-1)
|
| 83 |
+
|
| 84 |
+
return flipped_image, target
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def resize(image, target, size, max_size=None):
|
| 88 |
+
# size can be min_size (scalar) or (w, h) tuple
|
| 89 |
+
|
| 90 |
+
def get_size_with_aspect_ratio(image_size, size, max_size=None):
|
| 91 |
+
w, h = image_size
|
| 92 |
+
if max_size is not None:
|
| 93 |
+
min_original_size = float(min((w, h)))
|
| 94 |
+
max_original_size = float(max((w, h)))
|
| 95 |
+
if max_original_size / min_original_size * size > max_size:
|
| 96 |
+
size = int(round(max_size * min_original_size / max_original_size))
|
| 97 |
+
|
| 98 |
+
if (w <= h and w == size) or (h <= w and h == size):
|
| 99 |
+
return (h, w)
|
| 100 |
+
|
| 101 |
+
if w < h:
|
| 102 |
+
ow = size
|
| 103 |
+
oh = int(size * h / w)
|
| 104 |
+
else:
|
| 105 |
+
oh = size
|
| 106 |
+
ow = int(size * w / h)
|
| 107 |
+
|
| 108 |
+
return (oh, ow)
|
| 109 |
+
|
| 110 |
+
def get_size(image_size, size, max_size=None):
|
| 111 |
+
if isinstance(size, (list, tuple)):
|
| 112 |
+
return size[::-1]
|
| 113 |
+
else:
|
| 114 |
+
return get_size_with_aspect_ratio(image_size, size, max_size)
|
| 115 |
+
|
| 116 |
+
size = get_size(image.size, size, max_size)
|
| 117 |
+
rescaled_image = F.resize(image, size)
|
| 118 |
+
|
| 119 |
+
if target is None:
|
| 120 |
+
return rescaled_image, None
|
| 121 |
+
|
| 122 |
+
ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(rescaled_image.size, image.size))
|
| 123 |
+
ratio_width, ratio_height = ratios
|
| 124 |
+
|
| 125 |
+
target = target.copy()
|
| 126 |
+
if "boxes" in target:
|
| 127 |
+
boxes = target["boxes"]
|
| 128 |
+
scaled_boxes = boxes * torch.as_tensor(
|
| 129 |
+
[ratio_width, ratio_height, ratio_width, ratio_height]
|
| 130 |
+
)
|
| 131 |
+
target["boxes"] = scaled_boxes
|
| 132 |
+
|
| 133 |
+
if "area" in target:
|
| 134 |
+
area = target["area"]
|
| 135 |
+
scaled_area = area * (ratio_width * ratio_height)
|
| 136 |
+
target["area"] = scaled_area
|
| 137 |
+
|
| 138 |
+
h, w = size
|
| 139 |
+
target["size"] = torch.tensor([h, w])
|
| 140 |
+
|
| 141 |
+
if "masks" in target:
|
| 142 |
+
target["masks"] = (
|
| 143 |
+
interpolate(target["masks"][:, None].float(), size, mode="nearest")[:, 0] > 0.5
|
| 144 |
+
)
|
| 145 |
+
|
| 146 |
+
return rescaled_image, target
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
def pad(image, target, padding):
|
| 150 |
+
# assumes that we only pad on the bottom right corners
|
| 151 |
+
padded_image = F.pad(image, (0, 0, padding[0], padding[1]))
|
| 152 |
+
if target is None:
|
| 153 |
+
return padded_image, None
|
| 154 |
+
target = target.copy()
|
| 155 |
+
# should we do something wrt the original size?
|
| 156 |
+
target["size"] = torch.tensor(padded_image.size[::-1])
|
| 157 |
+
if "masks" in target:
|
| 158 |
+
target["masks"] = torch.nn.functional.pad(target["masks"], (0, padding[0], 0, padding[1]))
|
| 159 |
+
return padded_image, target
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
class ResizeDebug(object):
|
| 163 |
+
def __init__(self, size):
|
| 164 |
+
self.size = size
|
| 165 |
+
|
| 166 |
+
def __call__(self, img, target):
|
| 167 |
+
return resize(img, target, self.size)
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
class RandomCrop(object):
|
| 171 |
+
def __init__(self, size):
|
| 172 |
+
self.size = size
|
| 173 |
+
|
| 174 |
+
def __call__(self, img, target):
|
| 175 |
+
region = T.RandomCrop.get_params(img, self.size)
|
| 176 |
+
return crop(img, target, region)
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
class RandomSizeCrop(object):
|
| 180 |
+
def __init__(self, min_size: int, max_size: int, respect_boxes: bool = False):
|
| 181 |
+
# respect_boxes: True to keep all boxes
|
| 182 |
+
# False to tolerence box filter
|
| 183 |
+
self.min_size = min_size
|
| 184 |
+
self.max_size = max_size
|
| 185 |
+
self.respect_boxes = respect_boxes
|
| 186 |
+
|
| 187 |
+
def __call__(self, img: PIL.Image.Image, target: dict):
|
| 188 |
+
init_boxes = len(target["boxes"])
|
| 189 |
+
max_patience = 10
|
| 190 |
+
for i in range(max_patience):
|
| 191 |
+
w = random.randint(self.min_size, min(img.width, self.max_size))
|
| 192 |
+
h = random.randint(self.min_size, min(img.height, self.max_size))
|
| 193 |
+
region = T.RandomCrop.get_params(img, [h, w])
|
| 194 |
+
result_img, result_target = crop(img, target, region)
|
| 195 |
+
if (
|
| 196 |
+
not self.respect_boxes
|
| 197 |
+
or len(result_target["boxes"]) == init_boxes
|
| 198 |
+
or i == max_patience - 1
|
| 199 |
+
):
|
| 200 |
+
return result_img, result_target
|
| 201 |
+
return result_img, result_target
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
class CenterCrop(object):
|
| 205 |
+
def __init__(self, size):
|
| 206 |
+
self.size = size
|
| 207 |
+
|
| 208 |
+
def __call__(self, img, target):
|
| 209 |
+
image_width, image_height = img.size
|
| 210 |
+
crop_height, crop_width = self.size
|
| 211 |
+
crop_top = int(round((image_height - crop_height) / 2.0))
|
| 212 |
+
crop_left = int(round((image_width - crop_width) / 2.0))
|
| 213 |
+
return crop(img, target, (crop_top, crop_left, crop_height, crop_width))
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
class RandomHorizontalFlip(object):
|
| 217 |
+
def __init__(self, p=0.5):
|
| 218 |
+
self.p = p
|
| 219 |
+
|
| 220 |
+
def __call__(self, img, target):
|
| 221 |
+
if random.random() < self.p:
|
| 222 |
+
return hflip(img, target)
|
| 223 |
+
return img, target
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
class RandomResize(object):
|
| 227 |
+
def __init__(self, sizes, max_size=None):
|
| 228 |
+
assert isinstance(sizes, (list, tuple))
|
| 229 |
+
self.sizes = sizes
|
| 230 |
+
self.max_size = max_size
|
| 231 |
+
|
| 232 |
+
def __call__(self, img, target=None):
|
| 233 |
+
size = random.choice(self.sizes)
|
| 234 |
+
return resize(img, target, size, self.max_size)
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
class RandomPad(object):
|
| 238 |
+
def __init__(self, max_pad):
|
| 239 |
+
self.max_pad = max_pad
|
| 240 |
+
|
| 241 |
+
def __call__(self, img, target):
|
| 242 |
+
pad_x = random.randint(0, self.max_pad)
|
| 243 |
+
pad_y = random.randint(0, self.max_pad)
|
| 244 |
+
return pad(img, target, (pad_x, pad_y))
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
class RandomSelect(object):
|
| 248 |
+
"""
|
| 249 |
+
Randomly selects between transforms1 and transforms2,
|
| 250 |
+
with probability p for transforms1 and (1 - p) for transforms2
|
| 251 |
+
"""
|
| 252 |
+
|
| 253 |
+
def __init__(self, transforms1, transforms2, p=0.5):
|
| 254 |
+
self.transforms1 = transforms1
|
| 255 |
+
self.transforms2 = transforms2
|
| 256 |
+
self.p = p
|
| 257 |
+
|
| 258 |
+
def __call__(self, img, target):
|
| 259 |
+
if random.random() < self.p:
|
| 260 |
+
return self.transforms1(img, target)
|
| 261 |
+
return self.transforms2(img, target)
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
class ToTensor(object):
|
| 265 |
+
def __call__(self, img, target):
|
| 266 |
+
return F.to_tensor(img), target
|
| 267 |
+
|
| 268 |
+
|
| 269 |
+
class RandomErasing(object):
|
| 270 |
+
def __init__(self, *args, **kwargs):
|
| 271 |
+
self.eraser = T.RandomErasing(*args, **kwargs)
|
| 272 |
+
|
| 273 |
+
def __call__(self, img, target):
|
| 274 |
+
return self.eraser(img), target
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
class Normalize(object):
|
| 278 |
+
def __init__(self, mean, std):
|
| 279 |
+
self.mean = mean
|
| 280 |
+
self.std = std
|
| 281 |
+
|
| 282 |
+
def __call__(self, image, target=None):
|
| 283 |
+
image = F.normalize(image, mean=self.mean, std=self.std)
|
| 284 |
+
if target is None:
|
| 285 |
+
return image, None
|
| 286 |
+
target = target.copy()
|
| 287 |
+
h, w = image.shape[-2:]
|
| 288 |
+
if "boxes" in target:
|
| 289 |
+
boxes = target["boxes"]
|
| 290 |
+
boxes = box_xyxy_to_cxcywh(boxes)
|
| 291 |
+
boxes = boxes / torch.tensor([w, h, w, h], dtype=torch.float32)
|
| 292 |
+
target["boxes"] = boxes
|
| 293 |
+
return image, target
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
class Compose(object):
|
| 297 |
+
def __init__(self, transforms):
|
| 298 |
+
self.transforms = transforms
|
| 299 |
+
|
| 300 |
+
def __call__(self, image, target):
|
| 301 |
+
for t in self.transforms:
|
| 302 |
+
image, target = t(image, target)
|
| 303 |
+
return image, target
|
| 304 |
+
|
| 305 |
+
def __repr__(self):
|
| 306 |
+
format_string = self.__class__.__name__ + "("
|
| 307 |
+
for t in self.transforms:
|
| 308 |
+
format_string += "\n"
|
| 309 |
+
format_string += " {0}".format(t)
|
| 310 |
+
format_string += "\n)"
|
| 311 |
+
return format_string
|
GroundingDINO/groundingdino/models/GroundingDINO/__init__.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ------------------------------------------------------------------------
|
| 2 |
+
# Grounding DINO
|
| 3 |
+
# url: https://github.com/IDEA-Research/GroundingDINO
|
| 4 |
+
# Copyright (c) 2023 IDEA. All Rights Reserved.
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 6 |
+
# ------------------------------------------------------------------------
|
| 7 |
+
# Conditional DETR
|
| 8 |
+
# Copyright (c) 2021 Microsoft. All Rights Reserved.
|
| 9 |
+
# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 10 |
+
# ------------------------------------------------------------------------
|
| 11 |
+
# Copied from DETR (https://github.com/facebookresearch/detr)
|
| 12 |
+
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
|
| 13 |
+
# ------------------------------------------------------------------------
|
| 14 |
+
|
| 15 |
+
from .groundingdino import build_groundingdino
|
GroundingDINO/groundingdino/models/GroundingDINO/backbone/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .backbone import build_backbone
|
GroundingDINO/groundingdino/models/GroundingDINO/backbone/backbone.py
ADDED
|
@@ -0,0 +1,221 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ------------------------------------------------------------------------
|
| 2 |
+
# Grounding DINO
|
| 3 |
+
# url: https://github.com/IDEA-Research/GroundingDINO
|
| 4 |
+
# Copyright (c) 2023 IDEA. All Rights Reserved.
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 6 |
+
# ------------------------------------------------------------------------
|
| 7 |
+
# Conditional DETR
|
| 8 |
+
# Copyright (c) 2021 Microsoft. All Rights Reserved.
|
| 9 |
+
# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 10 |
+
# ------------------------------------------------------------------------
|
| 11 |
+
# Copied from DETR (https://github.com/facebookresearch/detr)
|
| 12 |
+
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
|
| 13 |
+
# ------------------------------------------------------------------------
|
| 14 |
+
|
| 15 |
+
"""
|
| 16 |
+
Backbone modules.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
from typing import Dict, List
|
| 20 |
+
|
| 21 |
+
import torch
|
| 22 |
+
import torch.nn.functional as F
|
| 23 |
+
import torchvision
|
| 24 |
+
from torch import nn
|
| 25 |
+
from torchvision.models._utils import IntermediateLayerGetter
|
| 26 |
+
|
| 27 |
+
from groundingdino.util.misc import NestedTensor, clean_state_dict, is_main_process
|
| 28 |
+
|
| 29 |
+
from .position_encoding import build_position_encoding
|
| 30 |
+
from .swin_transformer import build_swin_transformer
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class FrozenBatchNorm2d(torch.nn.Module):
|
| 34 |
+
"""
|
| 35 |
+
BatchNorm2d where the batch statistics and the affine parameters are fixed.
|
| 36 |
+
|
| 37 |
+
Copy-paste from torchvision.misc.ops with added eps before rqsrt,
|
| 38 |
+
without which any other models than torchvision.models.resnet[18,34,50,101]
|
| 39 |
+
produce nans.
|
| 40 |
+
"""
|
| 41 |
+
|
| 42 |
+
def __init__(self, n):
|
| 43 |
+
super(FrozenBatchNorm2d, self).__init__()
|
| 44 |
+
self.register_buffer("weight", torch.ones(n))
|
| 45 |
+
self.register_buffer("bias", torch.zeros(n))
|
| 46 |
+
self.register_buffer("running_mean", torch.zeros(n))
|
| 47 |
+
self.register_buffer("running_var", torch.ones(n))
|
| 48 |
+
|
| 49 |
+
def _load_from_state_dict(
|
| 50 |
+
self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs
|
| 51 |
+
):
|
| 52 |
+
num_batches_tracked_key = prefix + "num_batches_tracked"
|
| 53 |
+
if num_batches_tracked_key in state_dict:
|
| 54 |
+
del state_dict[num_batches_tracked_key]
|
| 55 |
+
|
| 56 |
+
super(FrozenBatchNorm2d, self)._load_from_state_dict(
|
| 57 |
+
state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
def forward(self, x):
|
| 61 |
+
# move reshapes to the beginning
|
| 62 |
+
# to make it fuser-friendly
|
| 63 |
+
w = self.weight.reshape(1, -1, 1, 1)
|
| 64 |
+
b = self.bias.reshape(1, -1, 1, 1)
|
| 65 |
+
rv = self.running_var.reshape(1, -1, 1, 1)
|
| 66 |
+
rm = self.running_mean.reshape(1, -1, 1, 1)
|
| 67 |
+
eps = 1e-5
|
| 68 |
+
scale = w * (rv + eps).rsqrt()
|
| 69 |
+
bias = b - rm * scale
|
| 70 |
+
return x * scale + bias
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
class BackboneBase(nn.Module):
|
| 74 |
+
def __init__(
|
| 75 |
+
self,
|
| 76 |
+
backbone: nn.Module,
|
| 77 |
+
train_backbone: bool,
|
| 78 |
+
num_channels: int,
|
| 79 |
+
return_interm_indices: list,
|
| 80 |
+
):
|
| 81 |
+
super().__init__()
|
| 82 |
+
for name, parameter in backbone.named_parameters():
|
| 83 |
+
if (
|
| 84 |
+
not train_backbone
|
| 85 |
+
or "layer2" not in name
|
| 86 |
+
and "layer3" not in name
|
| 87 |
+
and "layer4" not in name
|
| 88 |
+
):
|
| 89 |
+
parameter.requires_grad_(False)
|
| 90 |
+
|
| 91 |
+
return_layers = {}
|
| 92 |
+
for idx, layer_index in enumerate(return_interm_indices):
|
| 93 |
+
return_layers.update(
|
| 94 |
+
{"layer{}".format(5 - len(return_interm_indices) + idx): "{}".format(layer_index)}
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
# if len:
|
| 98 |
+
# if use_stage1_feature:
|
| 99 |
+
# return_layers = {"layer1": "0", "layer2": "1", "layer3": "2", "layer4": "3"}
|
| 100 |
+
# else:
|
| 101 |
+
# return_layers = {"layer2": "0", "layer3": "1", "layer4": "2"}
|
| 102 |
+
# else:
|
| 103 |
+
# return_layers = {'layer4': "0"}
|
| 104 |
+
self.body = IntermediateLayerGetter(backbone, return_layers=return_layers)
|
| 105 |
+
self.num_channels = num_channels
|
| 106 |
+
|
| 107 |
+
def forward(self, tensor_list: NestedTensor):
|
| 108 |
+
xs = self.body(tensor_list.tensors)
|
| 109 |
+
out: Dict[str, NestedTensor] = {}
|
| 110 |
+
for name, x in xs.items():
|
| 111 |
+
m = tensor_list.mask
|
| 112 |
+
assert m is not None
|
| 113 |
+
mask = F.interpolate(m[None].float(), size=x.shape[-2:]).to(torch.bool)[0]
|
| 114 |
+
out[name] = NestedTensor(x, mask)
|
| 115 |
+
# import ipdb; ipdb.set_trace()
|
| 116 |
+
return out
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
class Backbone(BackboneBase):
|
| 120 |
+
"""ResNet backbone with frozen BatchNorm."""
|
| 121 |
+
|
| 122 |
+
def __init__(
|
| 123 |
+
self,
|
| 124 |
+
name: str,
|
| 125 |
+
train_backbone: bool,
|
| 126 |
+
dilation: bool,
|
| 127 |
+
return_interm_indices: list,
|
| 128 |
+
batch_norm=FrozenBatchNorm2d,
|
| 129 |
+
):
|
| 130 |
+
if name in ["resnet18", "resnet34", "resnet50", "resnet101"]:
|
| 131 |
+
backbone = getattr(torchvision.models, name)(
|
| 132 |
+
replace_stride_with_dilation=[False, False, dilation],
|
| 133 |
+
pretrained=is_main_process(),
|
| 134 |
+
norm_layer=batch_norm,
|
| 135 |
+
)
|
| 136 |
+
else:
|
| 137 |
+
raise NotImplementedError("Why you can get here with name {}".format(name))
|
| 138 |
+
# num_channels = 512 if name in ('resnet18', 'resnet34') else 2048
|
| 139 |
+
assert name not in ("resnet18", "resnet34"), "Only resnet50 and resnet101 are available."
|
| 140 |
+
assert return_interm_indices in [[0, 1, 2, 3], [1, 2, 3], [3]]
|
| 141 |
+
num_channels_all = [256, 512, 1024, 2048]
|
| 142 |
+
num_channels = num_channels_all[4 - len(return_interm_indices) :]
|
| 143 |
+
super().__init__(backbone, train_backbone, num_channels, return_interm_indices)
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
class Joiner(nn.Sequential):
|
| 147 |
+
def __init__(self, backbone, position_embedding):
|
| 148 |
+
super().__init__(backbone, position_embedding)
|
| 149 |
+
|
| 150 |
+
def forward(self, tensor_list: NestedTensor):
|
| 151 |
+
xs = self[0](tensor_list)
|
| 152 |
+
out: List[NestedTensor] = []
|
| 153 |
+
pos = []
|
| 154 |
+
for name, x in xs.items():
|
| 155 |
+
out.append(x)
|
| 156 |
+
# position encoding
|
| 157 |
+
pos.append(self[1](x).to(x.tensors.dtype))
|
| 158 |
+
|
| 159 |
+
return out, pos
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
def build_backbone(args):
|
| 163 |
+
"""
|
| 164 |
+
Useful args:
|
| 165 |
+
- backbone: backbone name
|
| 166 |
+
- lr_backbone:
|
| 167 |
+
- dilation
|
| 168 |
+
- return_interm_indices: available: [0,1,2,3], [1,2,3], [3]
|
| 169 |
+
- backbone_freeze_keywords:
|
| 170 |
+
- use_checkpoint: for swin only for now
|
| 171 |
+
|
| 172 |
+
"""
|
| 173 |
+
position_embedding = build_position_encoding(args)
|
| 174 |
+
train_backbone = True
|
| 175 |
+
if not train_backbone:
|
| 176 |
+
raise ValueError("Please set lr_backbone > 0")
|
| 177 |
+
return_interm_indices = args.return_interm_indices
|
| 178 |
+
assert return_interm_indices in [[0, 1, 2, 3], [1, 2, 3], [3]]
|
| 179 |
+
args.backbone_freeze_keywords
|
| 180 |
+
use_checkpoint = getattr(args, "use_checkpoint", False)
|
| 181 |
+
|
| 182 |
+
if args.backbone in ["resnet50", "resnet101"]:
|
| 183 |
+
backbone = Backbone(
|
| 184 |
+
args.backbone,
|
| 185 |
+
train_backbone,
|
| 186 |
+
args.dilation,
|
| 187 |
+
return_interm_indices,
|
| 188 |
+
batch_norm=FrozenBatchNorm2d,
|
| 189 |
+
)
|
| 190 |
+
bb_num_channels = backbone.num_channels
|
| 191 |
+
elif args.backbone in [
|
| 192 |
+
"swin_T_224_1k",
|
| 193 |
+
"swin_B_224_22k",
|
| 194 |
+
"swin_B_384_22k",
|
| 195 |
+
"swin_L_224_22k",
|
| 196 |
+
"swin_L_384_22k",
|
| 197 |
+
]:
|
| 198 |
+
pretrain_img_size = int(args.backbone.split("_")[-2])
|
| 199 |
+
backbone = build_swin_transformer(
|
| 200 |
+
args.backbone,
|
| 201 |
+
pretrain_img_size=pretrain_img_size,
|
| 202 |
+
out_indices=tuple(return_interm_indices),
|
| 203 |
+
dilation=False,
|
| 204 |
+
use_checkpoint=use_checkpoint,
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
bb_num_channels = backbone.num_features[4 - len(return_interm_indices) :]
|
| 208 |
+
else:
|
| 209 |
+
raise NotImplementedError("Unknown backbone {}".format(args.backbone))
|
| 210 |
+
|
| 211 |
+
assert len(bb_num_channels) == len(
|
| 212 |
+
return_interm_indices
|
| 213 |
+
), f"len(bb_num_channels) {len(bb_num_channels)} != len(return_interm_indices) {len(return_interm_indices)}"
|
| 214 |
+
|
| 215 |
+
model = Joiner(backbone, position_embedding)
|
| 216 |
+
model.num_channels = bb_num_channels
|
| 217 |
+
assert isinstance(
|
| 218 |
+
bb_num_channels, List
|
| 219 |
+
), "bb_num_channels is expected to be a List but {}".format(type(bb_num_channels))
|
| 220 |
+
# import ipdb; ipdb.set_trace()
|
| 221 |
+
return model
|
GroundingDINO/groundingdino/models/GroundingDINO/backbone/position_encoding.py
ADDED
|
@@ -0,0 +1,186 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ------------------------------------------------------------------------
|
| 2 |
+
# Grounding DINO
|
| 3 |
+
# url: https://github.com/IDEA-Research/GroundingDINO
|
| 4 |
+
# Copyright (c) 2023 IDEA. All Rights Reserved.
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 6 |
+
# ------------------------------------------------------------------------
|
| 7 |
+
# DINO
|
| 8 |
+
# Copyright (c) 2022 IDEA. All Rights Reserved.
|
| 9 |
+
# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 10 |
+
# ------------------------------------------------------------------------
|
| 11 |
+
# Conditional DETR
|
| 12 |
+
# Copyright (c) 2021 Microsoft. All Rights Reserved.
|
| 13 |
+
# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 14 |
+
# ------------------------------------------------------------------------
|
| 15 |
+
# Copied from DETR (https://github.com/facebookresearch/detr)
|
| 16 |
+
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
|
| 17 |
+
# ------------------------------------------------------------------------
|
| 18 |
+
|
| 19 |
+
"""
|
| 20 |
+
Various positional encodings for the transformer.
|
| 21 |
+
"""
|
| 22 |
+
import math
|
| 23 |
+
|
| 24 |
+
import torch
|
| 25 |
+
from torch import nn
|
| 26 |
+
|
| 27 |
+
from groundingdino.util.misc import NestedTensor
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class PositionEmbeddingSine(nn.Module):
|
| 31 |
+
"""
|
| 32 |
+
This is a more standard version of the position embedding, very similar to the one
|
| 33 |
+
used by the Attention is all you need paper, generalized to work on images.
|
| 34 |
+
"""
|
| 35 |
+
|
| 36 |
+
def __init__(self, num_pos_feats=64, temperature=10000, normalize=False, scale=None):
|
| 37 |
+
super().__init__()
|
| 38 |
+
self.num_pos_feats = num_pos_feats
|
| 39 |
+
self.temperature = temperature
|
| 40 |
+
self.normalize = normalize
|
| 41 |
+
if scale is not None and normalize is False:
|
| 42 |
+
raise ValueError("normalize should be True if scale is passed")
|
| 43 |
+
if scale is None:
|
| 44 |
+
scale = 2 * math.pi
|
| 45 |
+
self.scale = scale
|
| 46 |
+
|
| 47 |
+
def forward(self, tensor_list: NestedTensor):
|
| 48 |
+
x = tensor_list.tensors
|
| 49 |
+
mask = tensor_list.mask
|
| 50 |
+
assert mask is not None
|
| 51 |
+
not_mask = ~mask
|
| 52 |
+
y_embed = not_mask.cumsum(1, dtype=torch.float32)
|
| 53 |
+
x_embed = not_mask.cumsum(2, dtype=torch.float32)
|
| 54 |
+
if self.normalize:
|
| 55 |
+
eps = 1e-6
|
| 56 |
+
# if os.environ.get("SHILONG_AMP", None) == '1':
|
| 57 |
+
# eps = 1e-4
|
| 58 |
+
# else:
|
| 59 |
+
# eps = 1e-6
|
| 60 |
+
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
|
| 61 |
+
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
|
| 62 |
+
|
| 63 |
+
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
|
| 64 |
+
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
|
| 65 |
+
|
| 66 |
+
pos_x = x_embed[:, :, :, None] / dim_t
|
| 67 |
+
pos_y = y_embed[:, :, :, None] / dim_t
|
| 68 |
+
pos_x = torch.stack(
|
| 69 |
+
(pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4
|
| 70 |
+
).flatten(3)
|
| 71 |
+
pos_y = torch.stack(
|
| 72 |
+
(pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4
|
| 73 |
+
).flatten(3)
|
| 74 |
+
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
|
| 75 |
+
return pos
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
class PositionEmbeddingSineHW(nn.Module):
|
| 79 |
+
"""
|
| 80 |
+
This is a more standard version of the position embedding, very similar to the one
|
| 81 |
+
used by the Attention is all you need paper, generalized to work on images.
|
| 82 |
+
"""
|
| 83 |
+
|
| 84 |
+
def __init__(
|
| 85 |
+
self, num_pos_feats=64, temperatureH=10000, temperatureW=10000, normalize=False, scale=None
|
| 86 |
+
):
|
| 87 |
+
super().__init__()
|
| 88 |
+
self.num_pos_feats = num_pos_feats
|
| 89 |
+
self.temperatureH = temperatureH
|
| 90 |
+
self.temperatureW = temperatureW
|
| 91 |
+
self.normalize = normalize
|
| 92 |
+
if scale is not None and normalize is False:
|
| 93 |
+
raise ValueError("normalize should be True if scale is passed")
|
| 94 |
+
if scale is None:
|
| 95 |
+
scale = 2 * math.pi
|
| 96 |
+
self.scale = scale
|
| 97 |
+
|
| 98 |
+
def forward(self, tensor_list: NestedTensor):
|
| 99 |
+
x = tensor_list.tensors
|
| 100 |
+
mask = tensor_list.mask
|
| 101 |
+
assert mask is not None
|
| 102 |
+
not_mask = ~mask
|
| 103 |
+
y_embed = not_mask.cumsum(1, dtype=torch.float32)
|
| 104 |
+
x_embed = not_mask.cumsum(2, dtype=torch.float32)
|
| 105 |
+
|
| 106 |
+
# import ipdb; ipdb.set_trace()
|
| 107 |
+
|
| 108 |
+
if self.normalize:
|
| 109 |
+
eps = 1e-6
|
| 110 |
+
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
|
| 111 |
+
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
|
| 112 |
+
|
| 113 |
+
dim_tx = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
|
| 114 |
+
dim_tx = self.temperatureW ** (2 * (torch.div(dim_tx, 2, rounding_mode='floor')) / self.num_pos_feats)
|
| 115 |
+
pos_x = x_embed[:, :, :, None] / dim_tx
|
| 116 |
+
|
| 117 |
+
dim_ty = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
|
| 118 |
+
dim_ty = self.temperatureH ** (2 * (torch.div(dim_ty, 2, rounding_mode='floor')) / self.num_pos_feats)
|
| 119 |
+
pos_y = y_embed[:, :, :, None] / dim_ty
|
| 120 |
+
|
| 121 |
+
pos_x = torch.stack(
|
| 122 |
+
(pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4
|
| 123 |
+
).flatten(3)
|
| 124 |
+
pos_y = torch.stack(
|
| 125 |
+
(pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4
|
| 126 |
+
).flatten(3)
|
| 127 |
+
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
|
| 128 |
+
|
| 129 |
+
# import ipdb; ipdb.set_trace()
|
| 130 |
+
|
| 131 |
+
return pos
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
class PositionEmbeddingLearned(nn.Module):
|
| 135 |
+
"""
|
| 136 |
+
Absolute pos embedding, learned.
|
| 137 |
+
"""
|
| 138 |
+
|
| 139 |
+
def __init__(self, num_pos_feats=256):
|
| 140 |
+
super().__init__()
|
| 141 |
+
self.row_embed = nn.Embedding(50, num_pos_feats)
|
| 142 |
+
self.col_embed = nn.Embedding(50, num_pos_feats)
|
| 143 |
+
self.reset_parameters()
|
| 144 |
+
|
| 145 |
+
def reset_parameters(self):
|
| 146 |
+
nn.init.uniform_(self.row_embed.weight)
|
| 147 |
+
nn.init.uniform_(self.col_embed.weight)
|
| 148 |
+
|
| 149 |
+
def forward(self, tensor_list: NestedTensor):
|
| 150 |
+
x = tensor_list.tensors
|
| 151 |
+
h, w = x.shape[-2:]
|
| 152 |
+
i = torch.arange(w, device=x.device)
|
| 153 |
+
j = torch.arange(h, device=x.device)
|
| 154 |
+
x_emb = self.col_embed(i)
|
| 155 |
+
y_emb = self.row_embed(j)
|
| 156 |
+
pos = (
|
| 157 |
+
torch.cat(
|
| 158 |
+
[
|
| 159 |
+
x_emb.unsqueeze(0).repeat(h, 1, 1),
|
| 160 |
+
y_emb.unsqueeze(1).repeat(1, w, 1),
|
| 161 |
+
],
|
| 162 |
+
dim=-1,
|
| 163 |
+
)
|
| 164 |
+
.permute(2, 0, 1)
|
| 165 |
+
.unsqueeze(0)
|
| 166 |
+
.repeat(x.shape[0], 1, 1, 1)
|
| 167 |
+
)
|
| 168 |
+
return pos
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
def build_position_encoding(args):
|
| 172 |
+
N_steps = args.hidden_dim // 2
|
| 173 |
+
if args.position_embedding in ("v2", "sine"):
|
| 174 |
+
# TODO find a better way of exposing other arguments
|
| 175 |
+
position_embedding = PositionEmbeddingSineHW(
|
| 176 |
+
N_steps,
|
| 177 |
+
temperatureH=args.pe_temperatureH,
|
| 178 |
+
temperatureW=args.pe_temperatureW,
|
| 179 |
+
normalize=True,
|
| 180 |
+
)
|
| 181 |
+
elif args.position_embedding in ("v3", "learned"):
|
| 182 |
+
position_embedding = PositionEmbeddingLearned(N_steps)
|
| 183 |
+
else:
|
| 184 |
+
raise ValueError(f"not supported {args.position_embedding}")
|
| 185 |
+
|
| 186 |
+
return position_embedding
|
GroundingDINO/groundingdino/models/GroundingDINO/backbone/swin_transformer.py
ADDED
|
@@ -0,0 +1,802 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ------------------------------------------------------------------------
|
| 2 |
+
# Grounding DINO
|
| 3 |
+
# url: https://github.com/IDEA-Research/GroundingDINO
|
| 4 |
+
# Copyright (c) 2023 IDEA. All Rights Reserved.
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 6 |
+
# ------------------------------------------------------------------------
|
| 7 |
+
# DINO
|
| 8 |
+
# Copyright (c) 2022 IDEA. All Rights Reserved.
|
| 9 |
+
# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 10 |
+
# --------------------------------------------------------
|
| 11 |
+
# modified from https://github.com/SwinTransformer/Swin-Transformer-Object-Detection/blob/master/mmdet/models/backbones/swin_transformer.py
|
| 12 |
+
# --------------------------------------------------------
|
| 13 |
+
|
| 14 |
+
import numpy as np
|
| 15 |
+
import torch
|
| 16 |
+
import torch.nn as nn
|
| 17 |
+
import torch.nn.functional as F
|
| 18 |
+
import torch.utils.checkpoint as checkpoint
|
| 19 |
+
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
|
| 20 |
+
|
| 21 |
+
from groundingdino.util.misc import NestedTensor
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class Mlp(nn.Module):
|
| 25 |
+
"""Multilayer perceptron."""
|
| 26 |
+
|
| 27 |
+
def __init__(
|
| 28 |
+
self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.0
|
| 29 |
+
):
|
| 30 |
+
super().__init__()
|
| 31 |
+
out_features = out_features or in_features
|
| 32 |
+
hidden_features = hidden_features or in_features
|
| 33 |
+
self.fc1 = nn.Linear(in_features, hidden_features)
|
| 34 |
+
self.act = act_layer()
|
| 35 |
+
self.fc2 = nn.Linear(hidden_features, out_features)
|
| 36 |
+
self.drop = nn.Dropout(drop)
|
| 37 |
+
|
| 38 |
+
def forward(self, x):
|
| 39 |
+
x = self.fc1(x)
|
| 40 |
+
x = self.act(x)
|
| 41 |
+
x = self.drop(x)
|
| 42 |
+
x = self.fc2(x)
|
| 43 |
+
x = self.drop(x)
|
| 44 |
+
return x
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def window_partition(x, window_size):
|
| 48 |
+
"""
|
| 49 |
+
Args:
|
| 50 |
+
x: (B, H, W, C)
|
| 51 |
+
window_size (int): window size
|
| 52 |
+
Returns:
|
| 53 |
+
windows: (num_windows*B, window_size, window_size, C)
|
| 54 |
+
"""
|
| 55 |
+
B, H, W, C = x.shape
|
| 56 |
+
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
|
| 57 |
+
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
|
| 58 |
+
return windows
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def window_reverse(windows, window_size, H, W):
|
| 62 |
+
"""
|
| 63 |
+
Args:
|
| 64 |
+
windows: (num_windows*B, window_size, window_size, C)
|
| 65 |
+
window_size (int): Window size
|
| 66 |
+
H (int): Height of image
|
| 67 |
+
W (int): Width of image
|
| 68 |
+
Returns:
|
| 69 |
+
x: (B, H, W, C)
|
| 70 |
+
"""
|
| 71 |
+
B = int(windows.shape[0] / (H * W / window_size / window_size))
|
| 72 |
+
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
|
| 73 |
+
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
|
| 74 |
+
return x
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
class WindowAttention(nn.Module):
|
| 78 |
+
"""Window based multi-head self attention (W-MSA) module with relative position bias.
|
| 79 |
+
It supports both of shifted and non-shifted window.
|
| 80 |
+
Args:
|
| 81 |
+
dim (int): Number of input channels.
|
| 82 |
+
window_size (tuple[int]): The height and width of the window.
|
| 83 |
+
num_heads (int): Number of attention heads.
|
| 84 |
+
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
|
| 85 |
+
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
|
| 86 |
+
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
|
| 87 |
+
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
|
| 88 |
+
"""
|
| 89 |
+
|
| 90 |
+
def __init__(
|
| 91 |
+
self,
|
| 92 |
+
dim,
|
| 93 |
+
window_size,
|
| 94 |
+
num_heads,
|
| 95 |
+
qkv_bias=True,
|
| 96 |
+
qk_scale=None,
|
| 97 |
+
attn_drop=0.0,
|
| 98 |
+
proj_drop=0.0,
|
| 99 |
+
):
|
| 100 |
+
|
| 101 |
+
super().__init__()
|
| 102 |
+
self.dim = dim
|
| 103 |
+
self.window_size = window_size # Wh, Ww
|
| 104 |
+
self.num_heads = num_heads
|
| 105 |
+
head_dim = dim // num_heads
|
| 106 |
+
self.scale = qk_scale or head_dim**-0.5
|
| 107 |
+
|
| 108 |
+
# define a parameter table of relative position bias
|
| 109 |
+
self.relative_position_bias_table = nn.Parameter(
|
| 110 |
+
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)
|
| 111 |
+
) # 2*Wh-1 * 2*Ww-1, nH
|
| 112 |
+
|
| 113 |
+
# get pair-wise relative position index for each token inside the window
|
| 114 |
+
coords_h = torch.arange(self.window_size[0])
|
| 115 |
+
coords_w = torch.arange(self.window_size[1])
|
| 116 |
+
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
|
| 117 |
+
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
|
| 118 |
+
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
|
| 119 |
+
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
|
| 120 |
+
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
|
| 121 |
+
relative_coords[:, :, 1] += self.window_size[1] - 1
|
| 122 |
+
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
|
| 123 |
+
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
|
| 124 |
+
self.register_buffer("relative_position_index", relative_position_index)
|
| 125 |
+
|
| 126 |
+
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
|
| 127 |
+
self.attn_drop = nn.Dropout(attn_drop)
|
| 128 |
+
self.proj = nn.Linear(dim, dim)
|
| 129 |
+
self.proj_drop = nn.Dropout(proj_drop)
|
| 130 |
+
|
| 131 |
+
trunc_normal_(self.relative_position_bias_table, std=0.02)
|
| 132 |
+
self.softmax = nn.Softmax(dim=-1)
|
| 133 |
+
|
| 134 |
+
def forward(self, x, mask=None):
|
| 135 |
+
"""Forward function.
|
| 136 |
+
Args:
|
| 137 |
+
x: input features with shape of (num_windows*B, N, C)
|
| 138 |
+
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
|
| 139 |
+
"""
|
| 140 |
+
B_, N, C = x.shape
|
| 141 |
+
qkv = (
|
| 142 |
+
self.qkv(x)
|
| 143 |
+
.reshape(B_, N, 3, self.num_heads, C // self.num_heads)
|
| 144 |
+
.permute(2, 0, 3, 1, 4)
|
| 145 |
+
)
|
| 146 |
+
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
|
| 147 |
+
|
| 148 |
+
q = q * self.scale
|
| 149 |
+
attn = q @ k.transpose(-2, -1)
|
| 150 |
+
|
| 151 |
+
relative_position_bias = self.relative_position_bias_table[
|
| 152 |
+
self.relative_position_index.view(-1)
|
| 153 |
+
].view(
|
| 154 |
+
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1
|
| 155 |
+
) # Wh*Ww,Wh*Ww,nH
|
| 156 |
+
relative_position_bias = relative_position_bias.permute(
|
| 157 |
+
2, 0, 1
|
| 158 |
+
).contiguous() # nH, Wh*Ww, Wh*Ww
|
| 159 |
+
attn = attn + relative_position_bias.unsqueeze(0)
|
| 160 |
+
|
| 161 |
+
if mask is not None:
|
| 162 |
+
nW = mask.shape[0]
|
| 163 |
+
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
|
| 164 |
+
attn = attn.view(-1, self.num_heads, N, N)
|
| 165 |
+
attn = self.softmax(attn)
|
| 166 |
+
else:
|
| 167 |
+
attn = self.softmax(attn)
|
| 168 |
+
|
| 169 |
+
attn = self.attn_drop(attn)
|
| 170 |
+
|
| 171 |
+
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
|
| 172 |
+
x = self.proj(x)
|
| 173 |
+
x = self.proj_drop(x)
|
| 174 |
+
return x
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
class SwinTransformerBlock(nn.Module):
|
| 178 |
+
"""Swin Transformer Block.
|
| 179 |
+
Args:
|
| 180 |
+
dim (int): Number of input channels.
|
| 181 |
+
num_heads (int): Number of attention heads.
|
| 182 |
+
window_size (int): Window size.
|
| 183 |
+
shift_size (int): Shift size for SW-MSA.
|
| 184 |
+
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
|
| 185 |
+
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
|
| 186 |
+
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
|
| 187 |
+
drop (float, optional): Dropout rate. Default: 0.0
|
| 188 |
+
attn_drop (float, optional): Attention dropout rate. Default: 0.0
|
| 189 |
+
drop_path (float, optional): Stochastic depth rate. Default: 0.0
|
| 190 |
+
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
|
| 191 |
+
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
|
| 192 |
+
"""
|
| 193 |
+
|
| 194 |
+
def __init__(
|
| 195 |
+
self,
|
| 196 |
+
dim,
|
| 197 |
+
num_heads,
|
| 198 |
+
window_size=7,
|
| 199 |
+
shift_size=0,
|
| 200 |
+
mlp_ratio=4.0,
|
| 201 |
+
qkv_bias=True,
|
| 202 |
+
qk_scale=None,
|
| 203 |
+
drop=0.0,
|
| 204 |
+
attn_drop=0.0,
|
| 205 |
+
drop_path=0.0,
|
| 206 |
+
act_layer=nn.GELU,
|
| 207 |
+
norm_layer=nn.LayerNorm,
|
| 208 |
+
):
|
| 209 |
+
super().__init__()
|
| 210 |
+
self.dim = dim
|
| 211 |
+
self.num_heads = num_heads
|
| 212 |
+
self.window_size = window_size
|
| 213 |
+
self.shift_size = shift_size
|
| 214 |
+
self.mlp_ratio = mlp_ratio
|
| 215 |
+
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
|
| 216 |
+
|
| 217 |
+
self.norm1 = norm_layer(dim)
|
| 218 |
+
self.attn = WindowAttention(
|
| 219 |
+
dim,
|
| 220 |
+
window_size=to_2tuple(self.window_size),
|
| 221 |
+
num_heads=num_heads,
|
| 222 |
+
qkv_bias=qkv_bias,
|
| 223 |
+
qk_scale=qk_scale,
|
| 224 |
+
attn_drop=attn_drop,
|
| 225 |
+
proj_drop=drop,
|
| 226 |
+
)
|
| 227 |
+
|
| 228 |
+
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
|
| 229 |
+
self.norm2 = norm_layer(dim)
|
| 230 |
+
mlp_hidden_dim = int(dim * mlp_ratio)
|
| 231 |
+
self.mlp = Mlp(
|
| 232 |
+
in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop
|
| 233 |
+
)
|
| 234 |
+
|
| 235 |
+
self.H = None
|
| 236 |
+
self.W = None
|
| 237 |
+
|
| 238 |
+
def forward(self, x, mask_matrix):
|
| 239 |
+
"""Forward function.
|
| 240 |
+
Args:
|
| 241 |
+
x: Input feature, tensor size (B, H*W, C).
|
| 242 |
+
H, W: Spatial resolution of the input feature.
|
| 243 |
+
mask_matrix: Attention mask for cyclic shift.
|
| 244 |
+
"""
|
| 245 |
+
B, L, C = x.shape
|
| 246 |
+
H, W = self.H, self.W
|
| 247 |
+
assert L == H * W, "input feature has wrong size"
|
| 248 |
+
|
| 249 |
+
shortcut = x
|
| 250 |
+
x = self.norm1(x)
|
| 251 |
+
x = x.view(B, H, W, C)
|
| 252 |
+
|
| 253 |
+
# pad feature maps to multiples of window size
|
| 254 |
+
pad_l = pad_t = 0
|
| 255 |
+
pad_r = (self.window_size - W % self.window_size) % self.window_size
|
| 256 |
+
pad_b = (self.window_size - H % self.window_size) % self.window_size
|
| 257 |
+
x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
|
| 258 |
+
_, Hp, Wp, _ = x.shape
|
| 259 |
+
|
| 260 |
+
# cyclic shift
|
| 261 |
+
if self.shift_size > 0:
|
| 262 |
+
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
|
| 263 |
+
attn_mask = mask_matrix
|
| 264 |
+
else:
|
| 265 |
+
shifted_x = x
|
| 266 |
+
attn_mask = None
|
| 267 |
+
|
| 268 |
+
# partition windows
|
| 269 |
+
x_windows = window_partition(
|
| 270 |
+
shifted_x, self.window_size
|
| 271 |
+
) # nW*B, window_size, window_size, C
|
| 272 |
+
x_windows = x_windows.view(
|
| 273 |
+
-1, self.window_size * self.window_size, C
|
| 274 |
+
) # nW*B, window_size*window_size, C
|
| 275 |
+
|
| 276 |
+
# W-MSA/SW-MSA
|
| 277 |
+
attn_windows = self.attn(x_windows, mask=attn_mask) # nW*B, window_size*window_size, C
|
| 278 |
+
|
| 279 |
+
# merge windows
|
| 280 |
+
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
|
| 281 |
+
shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) # B H' W' C
|
| 282 |
+
|
| 283 |
+
# reverse cyclic shift
|
| 284 |
+
if self.shift_size > 0:
|
| 285 |
+
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
|
| 286 |
+
else:
|
| 287 |
+
x = shifted_x
|
| 288 |
+
|
| 289 |
+
if pad_r > 0 or pad_b > 0:
|
| 290 |
+
x = x[:, :H, :W, :].contiguous()
|
| 291 |
+
|
| 292 |
+
x = x.view(B, H * W, C)
|
| 293 |
+
|
| 294 |
+
# FFN
|
| 295 |
+
x = shortcut + self.drop_path(x)
|
| 296 |
+
x = x + self.drop_path(self.mlp(self.norm2(x)))
|
| 297 |
+
|
| 298 |
+
return x
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
class PatchMerging(nn.Module):
|
| 302 |
+
"""Patch Merging Layer
|
| 303 |
+
Args:
|
| 304 |
+
dim (int): Number of input channels.
|
| 305 |
+
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
|
| 306 |
+
"""
|
| 307 |
+
|
| 308 |
+
def __init__(self, dim, norm_layer=nn.LayerNorm):
|
| 309 |
+
super().__init__()
|
| 310 |
+
self.dim = dim
|
| 311 |
+
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
|
| 312 |
+
self.norm = norm_layer(4 * dim)
|
| 313 |
+
|
| 314 |
+
def forward(self, x, H, W):
|
| 315 |
+
"""Forward function.
|
| 316 |
+
Args:
|
| 317 |
+
x: Input feature, tensor size (B, H*W, C).
|
| 318 |
+
H, W: Spatial resolution of the input feature.
|
| 319 |
+
"""
|
| 320 |
+
B, L, C = x.shape
|
| 321 |
+
assert L == H * W, "input feature has wrong size"
|
| 322 |
+
|
| 323 |
+
x = x.view(B, H, W, C)
|
| 324 |
+
|
| 325 |
+
# padding
|
| 326 |
+
pad_input = (H % 2 == 1) or (W % 2 == 1)
|
| 327 |
+
if pad_input:
|
| 328 |
+
x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))
|
| 329 |
+
|
| 330 |
+
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
|
| 331 |
+
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
|
| 332 |
+
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
|
| 333 |
+
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
|
| 334 |
+
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
|
| 335 |
+
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
|
| 336 |
+
|
| 337 |
+
x = self.norm(x)
|
| 338 |
+
x = self.reduction(x)
|
| 339 |
+
|
| 340 |
+
return x
|
| 341 |
+
|
| 342 |
+
|
| 343 |
+
class BasicLayer(nn.Module):
|
| 344 |
+
"""A basic Swin Transformer layer for one stage.
|
| 345 |
+
Args:
|
| 346 |
+
dim (int): Number of feature channels
|
| 347 |
+
depth (int): Depths of this stage.
|
| 348 |
+
num_heads (int): Number of attention head.
|
| 349 |
+
window_size (int): Local window size. Default: 7.
|
| 350 |
+
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4.
|
| 351 |
+
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
|
| 352 |
+
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
|
| 353 |
+
drop (float, optional): Dropout rate. Default: 0.0
|
| 354 |
+
attn_drop (float, optional): Attention dropout rate. Default: 0.0
|
| 355 |
+
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
|
| 356 |
+
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
|
| 357 |
+
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
|
| 358 |
+
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
|
| 359 |
+
"""
|
| 360 |
+
|
| 361 |
+
def __init__(
|
| 362 |
+
self,
|
| 363 |
+
dim,
|
| 364 |
+
depth,
|
| 365 |
+
num_heads,
|
| 366 |
+
window_size=7,
|
| 367 |
+
mlp_ratio=4.0,
|
| 368 |
+
qkv_bias=True,
|
| 369 |
+
qk_scale=None,
|
| 370 |
+
drop=0.0,
|
| 371 |
+
attn_drop=0.0,
|
| 372 |
+
drop_path=0.0,
|
| 373 |
+
norm_layer=nn.LayerNorm,
|
| 374 |
+
downsample=None,
|
| 375 |
+
use_checkpoint=False,
|
| 376 |
+
):
|
| 377 |
+
super().__init__()
|
| 378 |
+
self.window_size = window_size
|
| 379 |
+
self.shift_size = window_size // 2
|
| 380 |
+
self.depth = depth
|
| 381 |
+
self.use_checkpoint = use_checkpoint
|
| 382 |
+
|
| 383 |
+
# build blocks
|
| 384 |
+
self.blocks = nn.ModuleList(
|
| 385 |
+
[
|
| 386 |
+
SwinTransformerBlock(
|
| 387 |
+
dim=dim,
|
| 388 |
+
num_heads=num_heads,
|
| 389 |
+
window_size=window_size,
|
| 390 |
+
shift_size=0 if (i % 2 == 0) else window_size // 2,
|
| 391 |
+
mlp_ratio=mlp_ratio,
|
| 392 |
+
qkv_bias=qkv_bias,
|
| 393 |
+
qk_scale=qk_scale,
|
| 394 |
+
drop=drop,
|
| 395 |
+
attn_drop=attn_drop,
|
| 396 |
+
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
|
| 397 |
+
norm_layer=norm_layer,
|
| 398 |
+
)
|
| 399 |
+
for i in range(depth)
|
| 400 |
+
]
|
| 401 |
+
)
|
| 402 |
+
|
| 403 |
+
# patch merging layer
|
| 404 |
+
if downsample is not None:
|
| 405 |
+
self.downsample = downsample(dim=dim, norm_layer=norm_layer)
|
| 406 |
+
else:
|
| 407 |
+
self.downsample = None
|
| 408 |
+
|
| 409 |
+
def forward(self, x, H, W):
|
| 410 |
+
"""Forward function.
|
| 411 |
+
Args:
|
| 412 |
+
x: Input feature, tensor size (B, H*W, C).
|
| 413 |
+
H, W: Spatial resolution of the input feature.
|
| 414 |
+
"""
|
| 415 |
+
|
| 416 |
+
# calculate attention mask for SW-MSA
|
| 417 |
+
Hp = int(np.ceil(H / self.window_size)) * self.window_size
|
| 418 |
+
Wp = int(np.ceil(W / self.window_size)) * self.window_size
|
| 419 |
+
img_mask = torch.zeros((1, Hp, Wp, 1), device=x.device) # 1 Hp Wp 1
|
| 420 |
+
h_slices = (
|
| 421 |
+
slice(0, -self.window_size),
|
| 422 |
+
slice(-self.window_size, -self.shift_size),
|
| 423 |
+
slice(-self.shift_size, None),
|
| 424 |
+
)
|
| 425 |
+
w_slices = (
|
| 426 |
+
slice(0, -self.window_size),
|
| 427 |
+
slice(-self.window_size, -self.shift_size),
|
| 428 |
+
slice(-self.shift_size, None),
|
| 429 |
+
)
|
| 430 |
+
cnt = 0
|
| 431 |
+
for h in h_slices:
|
| 432 |
+
for w in w_slices:
|
| 433 |
+
img_mask[:, h, w, :] = cnt
|
| 434 |
+
cnt += 1
|
| 435 |
+
|
| 436 |
+
mask_windows = window_partition(
|
| 437 |
+
img_mask, self.window_size
|
| 438 |
+
) # nW, window_size, window_size, 1
|
| 439 |
+
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
|
| 440 |
+
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
|
| 441 |
+
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(
|
| 442 |
+
attn_mask == 0, float(0.0)
|
| 443 |
+
)
|
| 444 |
+
|
| 445 |
+
for blk in self.blocks:
|
| 446 |
+
blk.H, blk.W = H, W
|
| 447 |
+
if self.use_checkpoint:
|
| 448 |
+
x = checkpoint.checkpoint(blk, x, attn_mask)
|
| 449 |
+
else:
|
| 450 |
+
x = blk(x, attn_mask)
|
| 451 |
+
if self.downsample is not None:
|
| 452 |
+
x_down = self.downsample(x, H, W)
|
| 453 |
+
Wh, Ww = (H + 1) // 2, (W + 1) // 2
|
| 454 |
+
return x, H, W, x_down, Wh, Ww
|
| 455 |
+
else:
|
| 456 |
+
return x, H, W, x, H, W
|
| 457 |
+
|
| 458 |
+
|
| 459 |
+
class PatchEmbed(nn.Module):
|
| 460 |
+
"""Image to Patch Embedding
|
| 461 |
+
Args:
|
| 462 |
+
patch_size (int): Patch token size. Default: 4.
|
| 463 |
+
in_chans (int): Number of input image channels. Default: 3.
|
| 464 |
+
embed_dim (int): Number of linear projection output channels. Default: 96.
|
| 465 |
+
norm_layer (nn.Module, optional): Normalization layer. Default: None
|
| 466 |
+
"""
|
| 467 |
+
|
| 468 |
+
def __init__(self, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
|
| 469 |
+
super().__init__()
|
| 470 |
+
patch_size = to_2tuple(patch_size)
|
| 471 |
+
self.patch_size = patch_size
|
| 472 |
+
|
| 473 |
+
self.in_chans = in_chans
|
| 474 |
+
self.embed_dim = embed_dim
|
| 475 |
+
|
| 476 |
+
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
|
| 477 |
+
if norm_layer is not None:
|
| 478 |
+
self.norm = norm_layer(embed_dim)
|
| 479 |
+
else:
|
| 480 |
+
self.norm = None
|
| 481 |
+
|
| 482 |
+
def forward(self, x):
|
| 483 |
+
"""Forward function."""
|
| 484 |
+
# padding
|
| 485 |
+
_, _, H, W = x.size()
|
| 486 |
+
if W % self.patch_size[1] != 0:
|
| 487 |
+
x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1]))
|
| 488 |
+
if H % self.patch_size[0] != 0:
|
| 489 |
+
x = F.pad(x, (0, 0, 0, self.patch_size[0] - H % self.patch_size[0]))
|
| 490 |
+
|
| 491 |
+
x = self.proj(x) # B C Wh Ww
|
| 492 |
+
if self.norm is not None:
|
| 493 |
+
Wh, Ww = x.size(2), x.size(3)
|
| 494 |
+
x = x.flatten(2).transpose(1, 2)
|
| 495 |
+
x = self.norm(x)
|
| 496 |
+
x = x.transpose(1, 2).view(-1, self.embed_dim, Wh, Ww)
|
| 497 |
+
|
| 498 |
+
return x
|
| 499 |
+
|
| 500 |
+
|
| 501 |
+
class SwinTransformer(nn.Module):
|
| 502 |
+
"""Swin Transformer backbone.
|
| 503 |
+
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
|
| 504 |
+
https://arxiv.org/pdf/2103.14030
|
| 505 |
+
Args:
|
| 506 |
+
pretrain_img_size (int): Input image size for training the pretrained model,
|
| 507 |
+
used in absolute postion embedding. Default 224.
|
| 508 |
+
patch_size (int | tuple(int)): Patch size. Default: 4.
|
| 509 |
+
in_chans (int): Number of input image channels. Default: 3.
|
| 510 |
+
embed_dim (int): Number of linear projection output channels. Default: 96.
|
| 511 |
+
depths (tuple[int]): Depths of each Swin Transformer stage.
|
| 512 |
+
num_heads (tuple[int]): Number of attention head of each stage.
|
| 513 |
+
window_size (int): Window size. Default: 7.
|
| 514 |
+
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4.
|
| 515 |
+
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
|
| 516 |
+
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set.
|
| 517 |
+
drop_rate (float): Dropout rate.
|
| 518 |
+
attn_drop_rate (float): Attention dropout rate. Default: 0.
|
| 519 |
+
drop_path_rate (float): Stochastic depth rate. Default: 0.2.
|
| 520 |
+
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
|
| 521 |
+
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False.
|
| 522 |
+
patch_norm (bool): If True, add normalization after patch embedding. Default: True.
|
| 523 |
+
out_indices (Sequence[int]): Output from which stages.
|
| 524 |
+
frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
|
| 525 |
+
-1 means not freezing any parameters.
|
| 526 |
+
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
|
| 527 |
+
dilation (bool): if True, the output size if 16x downsample, ow 32x downsample.
|
| 528 |
+
"""
|
| 529 |
+
|
| 530 |
+
def __init__(
|
| 531 |
+
self,
|
| 532 |
+
pretrain_img_size=224,
|
| 533 |
+
patch_size=4,
|
| 534 |
+
in_chans=3,
|
| 535 |
+
embed_dim=96,
|
| 536 |
+
depths=[2, 2, 6, 2],
|
| 537 |
+
num_heads=[3, 6, 12, 24],
|
| 538 |
+
window_size=7,
|
| 539 |
+
mlp_ratio=4.0,
|
| 540 |
+
qkv_bias=True,
|
| 541 |
+
qk_scale=None,
|
| 542 |
+
drop_rate=0.0,
|
| 543 |
+
attn_drop_rate=0.0,
|
| 544 |
+
drop_path_rate=0.2,
|
| 545 |
+
norm_layer=nn.LayerNorm,
|
| 546 |
+
ape=False,
|
| 547 |
+
patch_norm=True,
|
| 548 |
+
out_indices=(0, 1, 2, 3),
|
| 549 |
+
frozen_stages=-1,
|
| 550 |
+
dilation=False,
|
| 551 |
+
use_checkpoint=False,
|
| 552 |
+
):
|
| 553 |
+
super().__init__()
|
| 554 |
+
|
| 555 |
+
self.pretrain_img_size = pretrain_img_size
|
| 556 |
+
self.num_layers = len(depths)
|
| 557 |
+
self.embed_dim = embed_dim
|
| 558 |
+
self.ape = ape
|
| 559 |
+
self.patch_norm = patch_norm
|
| 560 |
+
self.out_indices = out_indices
|
| 561 |
+
self.frozen_stages = frozen_stages
|
| 562 |
+
self.dilation = dilation
|
| 563 |
+
|
| 564 |
+
# if use_checkpoint:
|
| 565 |
+
# print("use_checkpoint!!!!!!!!!!!!!!!!!!!!!!!!")
|
| 566 |
+
|
| 567 |
+
# split image into non-overlapping patches
|
| 568 |
+
self.patch_embed = PatchEmbed(
|
| 569 |
+
patch_size=patch_size,
|
| 570 |
+
in_chans=in_chans,
|
| 571 |
+
embed_dim=embed_dim,
|
| 572 |
+
norm_layer=norm_layer if self.patch_norm else None,
|
| 573 |
+
)
|
| 574 |
+
|
| 575 |
+
# absolute position embedding
|
| 576 |
+
if self.ape:
|
| 577 |
+
pretrain_img_size = to_2tuple(pretrain_img_size)
|
| 578 |
+
patch_size = to_2tuple(patch_size)
|
| 579 |
+
patches_resolution = [
|
| 580 |
+
pretrain_img_size[0] // patch_size[0],
|
| 581 |
+
pretrain_img_size[1] // patch_size[1],
|
| 582 |
+
]
|
| 583 |
+
|
| 584 |
+
self.absolute_pos_embed = nn.Parameter(
|
| 585 |
+
torch.zeros(1, embed_dim, patches_resolution[0], patches_resolution[1])
|
| 586 |
+
)
|
| 587 |
+
trunc_normal_(self.absolute_pos_embed, std=0.02)
|
| 588 |
+
|
| 589 |
+
self.pos_drop = nn.Dropout(p=drop_rate)
|
| 590 |
+
|
| 591 |
+
# stochastic depth
|
| 592 |
+
dpr = [
|
| 593 |
+
x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))
|
| 594 |
+
] # stochastic depth decay rule
|
| 595 |
+
|
| 596 |
+
# build layers
|
| 597 |
+
self.layers = nn.ModuleList()
|
| 598 |
+
# prepare downsample list
|
| 599 |
+
downsamplelist = [PatchMerging for i in range(self.num_layers)]
|
| 600 |
+
downsamplelist[-1] = None
|
| 601 |
+
num_features = [int(embed_dim * 2**i) for i in range(self.num_layers)]
|
| 602 |
+
if self.dilation:
|
| 603 |
+
downsamplelist[-2] = None
|
| 604 |
+
num_features[-1] = int(embed_dim * 2 ** (self.num_layers - 1)) // 2
|
| 605 |
+
for i_layer in range(self.num_layers):
|
| 606 |
+
layer = BasicLayer(
|
| 607 |
+
# dim=int(embed_dim * 2 ** i_layer),
|
| 608 |
+
dim=num_features[i_layer],
|
| 609 |
+
depth=depths[i_layer],
|
| 610 |
+
num_heads=num_heads[i_layer],
|
| 611 |
+
window_size=window_size,
|
| 612 |
+
mlp_ratio=mlp_ratio,
|
| 613 |
+
qkv_bias=qkv_bias,
|
| 614 |
+
qk_scale=qk_scale,
|
| 615 |
+
drop=drop_rate,
|
| 616 |
+
attn_drop=attn_drop_rate,
|
| 617 |
+
drop_path=dpr[sum(depths[:i_layer]) : sum(depths[: i_layer + 1])],
|
| 618 |
+
norm_layer=norm_layer,
|
| 619 |
+
# downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
|
| 620 |
+
downsample=downsamplelist[i_layer],
|
| 621 |
+
use_checkpoint=use_checkpoint,
|
| 622 |
+
)
|
| 623 |
+
self.layers.append(layer)
|
| 624 |
+
|
| 625 |
+
# num_features = [int(embed_dim * 2 ** i) for i in range(self.num_layers)]
|
| 626 |
+
self.num_features = num_features
|
| 627 |
+
|
| 628 |
+
# add a norm layer for each output
|
| 629 |
+
for i_layer in out_indices:
|
| 630 |
+
layer = norm_layer(num_features[i_layer])
|
| 631 |
+
layer_name = f"norm{i_layer}"
|
| 632 |
+
self.add_module(layer_name, layer)
|
| 633 |
+
|
| 634 |
+
self._freeze_stages()
|
| 635 |
+
|
| 636 |
+
def _freeze_stages(self):
|
| 637 |
+
if self.frozen_stages >= 0:
|
| 638 |
+
self.patch_embed.eval()
|
| 639 |
+
for param in self.patch_embed.parameters():
|
| 640 |
+
param.requires_grad = False
|
| 641 |
+
|
| 642 |
+
if self.frozen_stages >= 1 and self.ape:
|
| 643 |
+
self.absolute_pos_embed.requires_grad = False
|
| 644 |
+
|
| 645 |
+
if self.frozen_stages >= 2:
|
| 646 |
+
self.pos_drop.eval()
|
| 647 |
+
for i in range(0, self.frozen_stages - 1):
|
| 648 |
+
m = self.layers[i]
|
| 649 |
+
m.eval()
|
| 650 |
+
for param in m.parameters():
|
| 651 |
+
param.requires_grad = False
|
| 652 |
+
|
| 653 |
+
# def init_weights(self, pretrained=None):
|
| 654 |
+
# """Initialize the weights in backbone.
|
| 655 |
+
# Args:
|
| 656 |
+
# pretrained (str, optional): Path to pre-trained weights.
|
| 657 |
+
# Defaults to None.
|
| 658 |
+
# """
|
| 659 |
+
|
| 660 |
+
# def _init_weights(m):
|
| 661 |
+
# if isinstance(m, nn.Linear):
|
| 662 |
+
# trunc_normal_(m.weight, std=.02)
|
| 663 |
+
# if isinstance(m, nn.Linear) and m.bias is not None:
|
| 664 |
+
# nn.init.constant_(m.bias, 0)
|
| 665 |
+
# elif isinstance(m, nn.LayerNorm):
|
| 666 |
+
# nn.init.constant_(m.bias, 0)
|
| 667 |
+
# nn.init.constant_(m.weight, 1.0)
|
| 668 |
+
|
| 669 |
+
# if isinstance(pretrained, str):
|
| 670 |
+
# self.apply(_init_weights)
|
| 671 |
+
# logger = get_root_logger()
|
| 672 |
+
# load_checkpoint(self, pretrained, strict=False, logger=logger)
|
| 673 |
+
# elif pretrained is None:
|
| 674 |
+
# self.apply(_init_weights)
|
| 675 |
+
# else:
|
| 676 |
+
# raise TypeError('pretrained must be a str or None')
|
| 677 |
+
|
| 678 |
+
def forward_raw(self, x):
|
| 679 |
+
"""Forward function."""
|
| 680 |
+
x = self.patch_embed(x)
|
| 681 |
+
|
| 682 |
+
Wh, Ww = x.size(2), x.size(3)
|
| 683 |
+
if self.ape:
|
| 684 |
+
# interpolate the position embedding to the corresponding size
|
| 685 |
+
absolute_pos_embed = F.interpolate(
|
| 686 |
+
self.absolute_pos_embed, size=(Wh, Ww), mode="bicubic"
|
| 687 |
+
)
|
| 688 |
+
x = (x + absolute_pos_embed).flatten(2).transpose(1, 2) # B Wh*Ww C
|
| 689 |
+
else:
|
| 690 |
+
x = x.flatten(2).transpose(1, 2)
|
| 691 |
+
x = self.pos_drop(x)
|
| 692 |
+
|
| 693 |
+
outs = []
|
| 694 |
+
for i in range(self.num_layers):
|
| 695 |
+
layer = self.layers[i]
|
| 696 |
+
x_out, H, W, x, Wh, Ww = layer(x, Wh, Ww)
|
| 697 |
+
# import ipdb; ipdb.set_trace()
|
| 698 |
+
|
| 699 |
+
if i in self.out_indices:
|
| 700 |
+
norm_layer = getattr(self, f"norm{i}")
|
| 701 |
+
x_out = norm_layer(x_out)
|
| 702 |
+
|
| 703 |
+
out = x_out.view(-1, H, W, self.num_features[i]).permute(0, 3, 1, 2).contiguous()
|
| 704 |
+
outs.append(out)
|
| 705 |
+
# in:
|
| 706 |
+
# torch.Size([2, 3, 1024, 1024])
|
| 707 |
+
# outs:
|
| 708 |
+
# [torch.Size([2, 192, 256, 256]), torch.Size([2, 384, 128, 128]), \
|
| 709 |
+
# torch.Size([2, 768, 64, 64]), torch.Size([2, 1536, 32, 32])]
|
| 710 |
+
return tuple(outs)
|
| 711 |
+
|
| 712 |
+
def forward(self, tensor_list: NestedTensor):
|
| 713 |
+
x = tensor_list.tensors
|
| 714 |
+
|
| 715 |
+
"""Forward function."""
|
| 716 |
+
x = self.patch_embed(x)
|
| 717 |
+
|
| 718 |
+
Wh, Ww = x.size(2), x.size(3)
|
| 719 |
+
if self.ape:
|
| 720 |
+
# interpolate the position embedding to the corresponding size
|
| 721 |
+
absolute_pos_embed = F.interpolate(
|
| 722 |
+
self.absolute_pos_embed, size=(Wh, Ww), mode="bicubic"
|
| 723 |
+
)
|
| 724 |
+
x = (x + absolute_pos_embed).flatten(2).transpose(1, 2) # B Wh*Ww C
|
| 725 |
+
else:
|
| 726 |
+
x = x.flatten(2).transpose(1, 2)
|
| 727 |
+
x = self.pos_drop(x)
|
| 728 |
+
|
| 729 |
+
outs = []
|
| 730 |
+
for i in range(self.num_layers):
|
| 731 |
+
layer = self.layers[i]
|
| 732 |
+
x_out, H, W, x, Wh, Ww = layer(x, Wh, Ww)
|
| 733 |
+
|
| 734 |
+
if i in self.out_indices:
|
| 735 |
+
norm_layer = getattr(self, f"norm{i}")
|
| 736 |
+
x_out = norm_layer(x_out)
|
| 737 |
+
|
| 738 |
+
out = x_out.view(-1, H, W, self.num_features[i]).permute(0, 3, 1, 2).contiguous()
|
| 739 |
+
outs.append(out)
|
| 740 |
+
# in:
|
| 741 |
+
# torch.Size([2, 3, 1024, 1024])
|
| 742 |
+
# out:
|
| 743 |
+
# [torch.Size([2, 192, 256, 256]), torch.Size([2, 384, 128, 128]), \
|
| 744 |
+
# torch.Size([2, 768, 64, 64]), torch.Size([2, 1536, 32, 32])]
|
| 745 |
+
|
| 746 |
+
# collect for nesttensors
|
| 747 |
+
outs_dict = {}
|
| 748 |
+
for idx, out_i in enumerate(outs):
|
| 749 |
+
m = tensor_list.mask
|
| 750 |
+
assert m is not None
|
| 751 |
+
mask = F.interpolate(m[None].float(), size=out_i.shape[-2:]).to(torch.bool)[0]
|
| 752 |
+
outs_dict[idx] = NestedTensor(out_i, mask)
|
| 753 |
+
|
| 754 |
+
return outs_dict
|
| 755 |
+
|
| 756 |
+
def train(self, mode=True):
|
| 757 |
+
"""Convert the model into training mode while keep layers freezed."""
|
| 758 |
+
super(SwinTransformer, self).train(mode)
|
| 759 |
+
self._freeze_stages()
|
| 760 |
+
|
| 761 |
+
|
| 762 |
+
def build_swin_transformer(modelname, pretrain_img_size, **kw):
|
| 763 |
+
assert modelname in [
|
| 764 |
+
"swin_T_224_1k",
|
| 765 |
+
"swin_B_224_22k",
|
| 766 |
+
"swin_B_384_22k",
|
| 767 |
+
"swin_L_224_22k",
|
| 768 |
+
"swin_L_384_22k",
|
| 769 |
+
]
|
| 770 |
+
|
| 771 |
+
model_para_dict = {
|
| 772 |
+
"swin_T_224_1k": dict(
|
| 773 |
+
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24], window_size=7
|
| 774 |
+
),
|
| 775 |
+
"swin_B_224_22k": dict(
|
| 776 |
+
embed_dim=128, depths=[2, 2, 18, 2], num_heads=[4, 8, 16, 32], window_size=7
|
| 777 |
+
),
|
| 778 |
+
"swin_B_384_22k": dict(
|
| 779 |
+
embed_dim=128, depths=[2, 2, 18, 2], num_heads=[4, 8, 16, 32], window_size=12
|
| 780 |
+
),
|
| 781 |
+
"swin_L_224_22k": dict(
|
| 782 |
+
embed_dim=192, depths=[2, 2, 18, 2], num_heads=[6, 12, 24, 48], window_size=7
|
| 783 |
+
),
|
| 784 |
+
"swin_L_384_22k": dict(
|
| 785 |
+
embed_dim=192, depths=[2, 2, 18, 2], num_heads=[6, 12, 24, 48], window_size=12
|
| 786 |
+
),
|
| 787 |
+
}
|
| 788 |
+
kw_cgf = model_para_dict[modelname]
|
| 789 |
+
kw_cgf.update(kw)
|
| 790 |
+
model = SwinTransformer(pretrain_img_size=pretrain_img_size, **kw_cgf)
|
| 791 |
+
return model
|
| 792 |
+
|
| 793 |
+
|
| 794 |
+
if __name__ == "__main__":
|
| 795 |
+
model = build_swin_transformer("swin_L_384_22k", 384, dilation=True)
|
| 796 |
+
x = torch.rand(2, 3, 1024, 1024)
|
| 797 |
+
y = model.forward_raw(x)
|
| 798 |
+
import ipdb
|
| 799 |
+
|
| 800 |
+
ipdb.set_trace()
|
| 801 |
+
x = torch.rand(2, 3, 384, 384)
|
| 802 |
+
y = model.forward_raw(x)
|
GroundingDINO/groundingdino/models/GroundingDINO/bertwarper.py
ADDED
|
@@ -0,0 +1,273 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ------------------------------------------------------------------------
|
| 2 |
+
# Grounding DINO
|
| 3 |
+
# url: https://github.com/IDEA-Research/GroundingDINO
|
| 4 |
+
# Copyright (c) 2023 IDEA. All Rights Reserved.
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 6 |
+
# ------------------------------------------------------------------------
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
import torch.utils.checkpoint as checkpoint
|
| 11 |
+
from torch import Tensor, nn
|
| 12 |
+
from torchvision.ops.boxes import nms
|
| 13 |
+
from transformers import BertConfig, BertModel, BertPreTrainedModel
|
| 14 |
+
from transformers.modeling_outputs import BaseModelOutputWithPoolingAndCrossAttentions
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class BertModelWarper(nn.Module):
|
| 18 |
+
def __init__(self, bert_model):
|
| 19 |
+
super().__init__()
|
| 20 |
+
# self.bert = bert_modelc
|
| 21 |
+
|
| 22 |
+
self.config = bert_model.config
|
| 23 |
+
self.embeddings = bert_model.embeddings
|
| 24 |
+
self.encoder = bert_model.encoder
|
| 25 |
+
self.pooler = bert_model.pooler
|
| 26 |
+
|
| 27 |
+
self.get_extended_attention_mask = bert_model.get_extended_attention_mask
|
| 28 |
+
self.invert_attention_mask = bert_model.invert_attention_mask
|
| 29 |
+
self.get_head_mask = bert_model.get_head_mask
|
| 30 |
+
|
| 31 |
+
def forward(
|
| 32 |
+
self,
|
| 33 |
+
input_ids=None,
|
| 34 |
+
attention_mask=None,
|
| 35 |
+
token_type_ids=None,
|
| 36 |
+
position_ids=None,
|
| 37 |
+
head_mask=None,
|
| 38 |
+
inputs_embeds=None,
|
| 39 |
+
encoder_hidden_states=None,
|
| 40 |
+
encoder_attention_mask=None,
|
| 41 |
+
past_key_values=None,
|
| 42 |
+
use_cache=None,
|
| 43 |
+
output_attentions=None,
|
| 44 |
+
output_hidden_states=None,
|
| 45 |
+
return_dict=None,
|
| 46 |
+
):
|
| 47 |
+
r"""
|
| 48 |
+
encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
|
| 49 |
+
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
|
| 50 |
+
the model is configured as a decoder.
|
| 51 |
+
encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
|
| 52 |
+
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
|
| 53 |
+
the cross-attention if the model is configured as a decoder. Mask values selected in ``[0, 1]``:
|
| 54 |
+
|
| 55 |
+
- 1 for tokens that are **not masked**,
|
| 56 |
+
- 0 for tokens that are **masked**.
|
| 57 |
+
past_key_values (:obj:`tuple(tuple(torch.FloatTensor))` of length :obj:`config.n_layers` with each tuple having 4 tensors of shape :obj:`(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
|
| 58 |
+
Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
|
| 59 |
+
|
| 60 |
+
If :obj:`past_key_values` are used, the user can optionally input only the last :obj:`decoder_input_ids`
|
| 61 |
+
(those that don't have their past key value states given to this model) of shape :obj:`(batch_size, 1)`
|
| 62 |
+
instead of all :obj:`decoder_input_ids` of shape :obj:`(batch_size, sequence_length)`.
|
| 63 |
+
use_cache (:obj:`bool`, `optional`):
|
| 64 |
+
If set to :obj:`True`, :obj:`past_key_values` key value states are returned and can be used to speed up
|
| 65 |
+
decoding (see :obj:`past_key_values`).
|
| 66 |
+
"""
|
| 67 |
+
output_attentions = (
|
| 68 |
+
output_attentions if output_attentions is not None else self.config.output_attentions
|
| 69 |
+
)
|
| 70 |
+
output_hidden_states = (
|
| 71 |
+
output_hidden_states
|
| 72 |
+
if output_hidden_states is not None
|
| 73 |
+
else self.config.output_hidden_states
|
| 74 |
+
)
|
| 75 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 76 |
+
|
| 77 |
+
if self.config.is_decoder:
|
| 78 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 79 |
+
else:
|
| 80 |
+
use_cache = False
|
| 81 |
+
|
| 82 |
+
if input_ids is not None and inputs_embeds is not None:
|
| 83 |
+
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
| 84 |
+
elif input_ids is not None:
|
| 85 |
+
input_shape = input_ids.size()
|
| 86 |
+
batch_size, seq_length = input_shape
|
| 87 |
+
elif inputs_embeds is not None:
|
| 88 |
+
input_shape = inputs_embeds.size()[:-1]
|
| 89 |
+
batch_size, seq_length = input_shape
|
| 90 |
+
else:
|
| 91 |
+
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
| 92 |
+
|
| 93 |
+
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
| 94 |
+
|
| 95 |
+
# past_key_values_length
|
| 96 |
+
past_key_values_length = (
|
| 97 |
+
past_key_values[0][0].shape[2] if past_key_values is not None else 0
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
if attention_mask is None:
|
| 101 |
+
attention_mask = torch.ones(
|
| 102 |
+
((batch_size, seq_length + past_key_values_length)), device=device
|
| 103 |
+
)
|
| 104 |
+
if token_type_ids is None:
|
| 105 |
+
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
|
| 106 |
+
|
| 107 |
+
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
|
| 108 |
+
# ourselves in which case we just need to make it broadcastable to all heads.
|
| 109 |
+
extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(
|
| 110 |
+
attention_mask, input_shape, device
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
# If a 2D or 3D attention mask is provided for the cross-attention
|
| 114 |
+
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
|
| 115 |
+
if self.config.is_decoder and encoder_hidden_states is not None:
|
| 116 |
+
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
|
| 117 |
+
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
|
| 118 |
+
if encoder_attention_mask is None:
|
| 119 |
+
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
|
| 120 |
+
encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
|
| 121 |
+
else:
|
| 122 |
+
encoder_extended_attention_mask = None
|
| 123 |
+
# if os.environ.get('IPDB_SHILONG_DEBUG', None) == 'INFO':
|
| 124 |
+
# import ipdb; ipdb.set_trace()
|
| 125 |
+
|
| 126 |
+
# Prepare head mask if needed
|
| 127 |
+
# 1.0 in head_mask indicate we keep the head
|
| 128 |
+
# attention_probs has shape bsz x n_heads x N x N
|
| 129 |
+
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
|
| 130 |
+
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
|
| 131 |
+
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
|
| 132 |
+
|
| 133 |
+
embedding_output = self.embeddings(
|
| 134 |
+
input_ids=input_ids,
|
| 135 |
+
position_ids=position_ids,
|
| 136 |
+
token_type_ids=token_type_ids,
|
| 137 |
+
inputs_embeds=inputs_embeds,
|
| 138 |
+
past_key_values_length=past_key_values_length,
|
| 139 |
+
)
|
| 140 |
+
|
| 141 |
+
encoder_outputs = self.encoder(
|
| 142 |
+
embedding_output,
|
| 143 |
+
attention_mask=extended_attention_mask,
|
| 144 |
+
head_mask=head_mask,
|
| 145 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 146 |
+
encoder_attention_mask=encoder_extended_attention_mask,
|
| 147 |
+
past_key_values=past_key_values,
|
| 148 |
+
use_cache=use_cache,
|
| 149 |
+
output_attentions=output_attentions,
|
| 150 |
+
output_hidden_states=output_hidden_states,
|
| 151 |
+
return_dict=return_dict,
|
| 152 |
+
)
|
| 153 |
+
sequence_output = encoder_outputs[0]
|
| 154 |
+
pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
|
| 155 |
+
|
| 156 |
+
if not return_dict:
|
| 157 |
+
return (sequence_output, pooled_output) + encoder_outputs[1:]
|
| 158 |
+
|
| 159 |
+
return BaseModelOutputWithPoolingAndCrossAttentions(
|
| 160 |
+
last_hidden_state=sequence_output,
|
| 161 |
+
pooler_output=pooled_output,
|
| 162 |
+
past_key_values=encoder_outputs.past_key_values,
|
| 163 |
+
hidden_states=encoder_outputs.hidden_states,
|
| 164 |
+
attentions=encoder_outputs.attentions,
|
| 165 |
+
cross_attentions=encoder_outputs.cross_attentions,
|
| 166 |
+
)
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
class TextEncoderShell(nn.Module):
|
| 170 |
+
def __init__(self, text_encoder):
|
| 171 |
+
super().__init__()
|
| 172 |
+
self.text_encoder = text_encoder
|
| 173 |
+
self.config = self.text_encoder.config
|
| 174 |
+
|
| 175 |
+
def forward(self, **kw):
|
| 176 |
+
# feed into text encoder
|
| 177 |
+
return self.text_encoder(**kw)
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
def generate_masks_with_special_tokens(tokenized, special_tokens_list, tokenizer):
|
| 181 |
+
"""Generate attention mask between each pair of special tokens
|
| 182 |
+
Args:
|
| 183 |
+
input_ids (torch.Tensor): input ids. Shape: [bs, num_token]
|
| 184 |
+
special_tokens_mask (list): special tokens mask.
|
| 185 |
+
Returns:
|
| 186 |
+
torch.Tensor: attention mask between each special tokens.
|
| 187 |
+
"""
|
| 188 |
+
input_ids = tokenized["input_ids"]
|
| 189 |
+
bs, num_token = input_ids.shape
|
| 190 |
+
# special_tokens_mask: bs, num_token. 1 for special tokens. 0 for normal tokens
|
| 191 |
+
special_tokens_mask = torch.zeros((bs, num_token), device=input_ids.device).bool()
|
| 192 |
+
for special_token in special_tokens_list:
|
| 193 |
+
special_tokens_mask |= input_ids == special_token
|
| 194 |
+
|
| 195 |
+
# idxs: each row is a list of indices of special tokens
|
| 196 |
+
idxs = torch.nonzero(special_tokens_mask)
|
| 197 |
+
|
| 198 |
+
# generate attention mask and positional ids
|
| 199 |
+
attention_mask = (
|
| 200 |
+
torch.eye(num_token, device=input_ids.device).bool().unsqueeze(0).repeat(bs, 1, 1)
|
| 201 |
+
)
|
| 202 |
+
position_ids = torch.zeros((bs, num_token), device=input_ids.device)
|
| 203 |
+
previous_col = 0
|
| 204 |
+
for i in range(idxs.shape[0]):
|
| 205 |
+
row, col = idxs[i]
|
| 206 |
+
if (col == 0) or (col == num_token - 1):
|
| 207 |
+
attention_mask[row, col, col] = True
|
| 208 |
+
position_ids[row, col] = 0
|
| 209 |
+
else:
|
| 210 |
+
attention_mask[row, previous_col + 1 : col + 1, previous_col + 1 : col + 1] = True
|
| 211 |
+
position_ids[row, previous_col + 1 : col + 1] = torch.arange(
|
| 212 |
+
0, col - previous_col, device=input_ids.device
|
| 213 |
+
)
|
| 214 |
+
|
| 215 |
+
previous_col = col
|
| 216 |
+
|
| 217 |
+
# # padding mask
|
| 218 |
+
# padding_mask = tokenized['attention_mask']
|
| 219 |
+
# attention_mask = attention_mask & padding_mask.unsqueeze(1).bool() & padding_mask.unsqueeze(2).bool()
|
| 220 |
+
|
| 221 |
+
return attention_mask, position_ids.to(torch.long)
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
def generate_masks_with_special_tokens_and_transfer_map(tokenized, special_tokens_list, tokenizer):
|
| 225 |
+
"""Generate attention mask between each pair of special tokens
|
| 226 |
+
Args:
|
| 227 |
+
input_ids (torch.Tensor): input ids. Shape: [bs, num_token]
|
| 228 |
+
special_tokens_mask (list): special tokens mask.
|
| 229 |
+
Returns:
|
| 230 |
+
torch.Tensor: attention mask between each special tokens.
|
| 231 |
+
"""
|
| 232 |
+
input_ids = tokenized["input_ids"]
|
| 233 |
+
bs, num_token = input_ids.shape
|
| 234 |
+
# special_tokens_mask: bs, num_token. 1 for special tokens. 0 for normal tokens
|
| 235 |
+
special_tokens_mask = torch.zeros((bs, num_token), device=input_ids.device).bool()
|
| 236 |
+
for special_token in special_tokens_list:
|
| 237 |
+
special_tokens_mask |= input_ids == special_token
|
| 238 |
+
|
| 239 |
+
# idxs: each row is a list of indices of special tokens
|
| 240 |
+
idxs = torch.nonzero(special_tokens_mask)
|
| 241 |
+
|
| 242 |
+
# generate attention mask and positional ids
|
| 243 |
+
attention_mask = (
|
| 244 |
+
torch.eye(num_token, device=input_ids.device).bool().unsqueeze(0).repeat(bs, 1, 1)
|
| 245 |
+
)
|
| 246 |
+
position_ids = torch.zeros((bs, num_token), device=input_ids.device)
|
| 247 |
+
cate_to_token_mask_list = [[] for _ in range(bs)]
|
| 248 |
+
previous_col = 0
|
| 249 |
+
for i in range(idxs.shape[0]):
|
| 250 |
+
row, col = idxs[i]
|
| 251 |
+
if (col == 0) or (col == num_token - 1):
|
| 252 |
+
attention_mask[row, col, col] = True
|
| 253 |
+
position_ids[row, col] = 0
|
| 254 |
+
else:
|
| 255 |
+
attention_mask[row, previous_col + 1 : col + 1, previous_col + 1 : col + 1] = True
|
| 256 |
+
position_ids[row, previous_col + 1 : col + 1] = torch.arange(
|
| 257 |
+
0, col - previous_col, device=input_ids.device
|
| 258 |
+
)
|
| 259 |
+
c2t_maski = torch.zeros((num_token), device=input_ids.device).bool()
|
| 260 |
+
c2t_maski[previous_col + 1 : col] = True
|
| 261 |
+
cate_to_token_mask_list[row].append(c2t_maski)
|
| 262 |
+
previous_col = col
|
| 263 |
+
|
| 264 |
+
cate_to_token_mask_list = [
|
| 265 |
+
torch.stack(cate_to_token_mask_listi, dim=0)
|
| 266 |
+
for cate_to_token_mask_listi in cate_to_token_mask_list
|
| 267 |
+
]
|
| 268 |
+
|
| 269 |
+
# # padding mask
|
| 270 |
+
# padding_mask = tokenized['attention_mask']
|
| 271 |
+
# attention_mask = attention_mask & padding_mask.unsqueeze(1).bool() & padding_mask.unsqueeze(2).bool()
|
| 272 |
+
|
| 273 |
+
return attention_mask, position_ids.to(torch.long), cate_to_token_mask_list
|
GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn.h
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*!
|
| 2 |
+
**************************************************************************************************
|
| 3 |
+
* Deformable DETR
|
| 4 |
+
* Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 5 |
+
* Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 6 |
+
**************************************************************************************************
|
| 7 |
+
* Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
|
| 8 |
+
**************************************************************************************************
|
| 9 |
+
*/
|
| 10 |
+
|
| 11 |
+
#pragma once
|
| 12 |
+
|
| 13 |
+
#include "ms_deform_attn_cpu.h"
|
| 14 |
+
|
| 15 |
+
#ifdef WITH_CUDA
|
| 16 |
+
#include "ms_deform_attn_cuda.h"
|
| 17 |
+
#endif
|
| 18 |
+
|
| 19 |
+
namespace groundingdino {
|
| 20 |
+
|
| 21 |
+
at::Tensor
|
| 22 |
+
ms_deform_attn_forward(
|
| 23 |
+
const at::Tensor &value,
|
| 24 |
+
const at::Tensor &spatial_shapes,
|
| 25 |
+
const at::Tensor &level_start_index,
|
| 26 |
+
const at::Tensor &sampling_loc,
|
| 27 |
+
const at::Tensor &attn_weight,
|
| 28 |
+
const int im2col_step)
|
| 29 |
+
{
|
| 30 |
+
if (value.type().is_cuda())
|
| 31 |
+
{
|
| 32 |
+
#ifdef WITH_CUDA
|
| 33 |
+
return ms_deform_attn_cuda_forward(
|
| 34 |
+
value, spatial_shapes, level_start_index, sampling_loc, attn_weight, im2col_step);
|
| 35 |
+
#else
|
| 36 |
+
AT_ERROR("Not compiled with GPU support");
|
| 37 |
+
#endif
|
| 38 |
+
}
|
| 39 |
+
AT_ERROR("Not implemented on the CPU");
|
| 40 |
+
}
|
| 41 |
+
|
| 42 |
+
std::vector<at::Tensor>
|
| 43 |
+
ms_deform_attn_backward(
|
| 44 |
+
const at::Tensor &value,
|
| 45 |
+
const at::Tensor &spatial_shapes,
|
| 46 |
+
const at::Tensor &level_start_index,
|
| 47 |
+
const at::Tensor &sampling_loc,
|
| 48 |
+
const at::Tensor &attn_weight,
|
| 49 |
+
const at::Tensor &grad_output,
|
| 50 |
+
const int im2col_step)
|
| 51 |
+
{
|
| 52 |
+
if (value.type().is_cuda())
|
| 53 |
+
{
|
| 54 |
+
#ifdef WITH_CUDA
|
| 55 |
+
return ms_deform_attn_cuda_backward(
|
| 56 |
+
value, spatial_shapes, level_start_index, sampling_loc, attn_weight, grad_output, im2col_step);
|
| 57 |
+
#else
|
| 58 |
+
AT_ERROR("Not compiled with GPU support");
|
| 59 |
+
#endif
|
| 60 |
+
}
|
| 61 |
+
AT_ERROR("Not implemented on the CPU");
|
| 62 |
+
}
|
| 63 |
+
|
| 64 |
+
} // namespace groundingdino
|
GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cpu.cpp
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*!
|
| 2 |
+
**************************************************************************************************
|
| 3 |
+
* Deformable DETR
|
| 4 |
+
* Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 5 |
+
* Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 6 |
+
**************************************************************************************************
|
| 7 |
+
* Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
|
| 8 |
+
**************************************************************************************************
|
| 9 |
+
*/
|
| 10 |
+
|
| 11 |
+
#include <vector>
|
| 12 |
+
|
| 13 |
+
#include <ATen/ATen.h>
|
| 14 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 15 |
+
|
| 16 |
+
namespace groundingdino {
|
| 17 |
+
|
| 18 |
+
at::Tensor
|
| 19 |
+
ms_deform_attn_cpu_forward(
|
| 20 |
+
const at::Tensor &value,
|
| 21 |
+
const at::Tensor &spatial_shapes,
|
| 22 |
+
const at::Tensor &level_start_index,
|
| 23 |
+
const at::Tensor &sampling_loc,
|
| 24 |
+
const at::Tensor &attn_weight,
|
| 25 |
+
const int im2col_step)
|
| 26 |
+
{
|
| 27 |
+
AT_ERROR("Not implement on cpu");
|
| 28 |
+
}
|
| 29 |
+
|
| 30 |
+
std::vector<at::Tensor>
|
| 31 |
+
ms_deform_attn_cpu_backward(
|
| 32 |
+
const at::Tensor &value,
|
| 33 |
+
const at::Tensor &spatial_shapes,
|
| 34 |
+
const at::Tensor &level_start_index,
|
| 35 |
+
const at::Tensor &sampling_loc,
|
| 36 |
+
const at::Tensor &attn_weight,
|
| 37 |
+
const at::Tensor &grad_output,
|
| 38 |
+
const int im2col_step)
|
| 39 |
+
{
|
| 40 |
+
AT_ERROR("Not implement on cpu");
|
| 41 |
+
}
|
| 42 |
+
|
| 43 |
+
} // namespace groundingdino
|
GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cpu.h
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*!
|
| 2 |
+
**************************************************************************************************
|
| 3 |
+
* Deformable DETR
|
| 4 |
+
* Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 5 |
+
* Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 6 |
+
**************************************************************************************************
|
| 7 |
+
* Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
|
| 8 |
+
**************************************************************************************************
|
| 9 |
+
*/
|
| 10 |
+
|
| 11 |
+
#pragma once
|
| 12 |
+
#include <torch/extension.h>
|
| 13 |
+
|
| 14 |
+
namespace groundingdino {
|
| 15 |
+
|
| 16 |
+
at::Tensor
|
| 17 |
+
ms_deform_attn_cpu_forward(
|
| 18 |
+
const at::Tensor &value,
|
| 19 |
+
const at::Tensor &spatial_shapes,
|
| 20 |
+
const at::Tensor &level_start_index,
|
| 21 |
+
const at::Tensor &sampling_loc,
|
| 22 |
+
const at::Tensor &attn_weight,
|
| 23 |
+
const int im2col_step);
|
| 24 |
+
|
| 25 |
+
std::vector<at::Tensor>
|
| 26 |
+
ms_deform_attn_cpu_backward(
|
| 27 |
+
const at::Tensor &value,
|
| 28 |
+
const at::Tensor &spatial_shapes,
|
| 29 |
+
const at::Tensor &level_start_index,
|
| 30 |
+
const at::Tensor &sampling_loc,
|
| 31 |
+
const at::Tensor &attn_weight,
|
| 32 |
+
const at::Tensor &grad_output,
|
| 33 |
+
const int im2col_step);
|
| 34 |
+
|
| 35 |
+
} // namespace groundingdino
|
GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cuda.cu
ADDED
|
@@ -0,0 +1,156 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*!
|
| 2 |
+
**************************************************************************************************
|
| 3 |
+
* Deformable DETR
|
| 4 |
+
* Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 5 |
+
* Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 6 |
+
**************************************************************************************************
|
| 7 |
+
* Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
|
| 8 |
+
**************************************************************************************************
|
| 9 |
+
*/
|
| 10 |
+
|
| 11 |
+
#include <vector>
|
| 12 |
+
#include "ms_deform_im2col_cuda.cuh"
|
| 13 |
+
|
| 14 |
+
#include <ATen/ATen.h>
|
| 15 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 16 |
+
#include <cuda.h>
|
| 17 |
+
#include <cuda_runtime.h>
|
| 18 |
+
|
| 19 |
+
namespace groundingdino {
|
| 20 |
+
|
| 21 |
+
at::Tensor ms_deform_attn_cuda_forward(
|
| 22 |
+
const at::Tensor &value,
|
| 23 |
+
const at::Tensor &spatial_shapes,
|
| 24 |
+
const at::Tensor &level_start_index,
|
| 25 |
+
const at::Tensor &sampling_loc,
|
| 26 |
+
const at::Tensor &attn_weight,
|
| 27 |
+
const int im2col_step)
|
| 28 |
+
{
|
| 29 |
+
AT_ASSERTM(value.is_contiguous(), "value tensor has to be contiguous");
|
| 30 |
+
AT_ASSERTM(spatial_shapes.is_contiguous(), "spatial_shapes tensor has to be contiguous");
|
| 31 |
+
AT_ASSERTM(level_start_index.is_contiguous(), "level_start_index tensor has to be contiguous");
|
| 32 |
+
AT_ASSERTM(sampling_loc.is_contiguous(), "sampling_loc tensor has to be contiguous");
|
| 33 |
+
AT_ASSERTM(attn_weight.is_contiguous(), "attn_weight tensor has to be contiguous");
|
| 34 |
+
|
| 35 |
+
AT_ASSERTM(value.type().is_cuda(), "value must be a CUDA tensor");
|
| 36 |
+
AT_ASSERTM(spatial_shapes.type().is_cuda(), "spatial_shapes must be a CUDA tensor");
|
| 37 |
+
AT_ASSERTM(level_start_index.type().is_cuda(), "level_start_index must be a CUDA tensor");
|
| 38 |
+
AT_ASSERTM(sampling_loc.type().is_cuda(), "sampling_loc must be a CUDA tensor");
|
| 39 |
+
AT_ASSERTM(attn_weight.type().is_cuda(), "attn_weight must be a CUDA tensor");
|
| 40 |
+
|
| 41 |
+
const int batch = value.size(0);
|
| 42 |
+
const int spatial_size = value.size(1);
|
| 43 |
+
const int num_heads = value.size(2);
|
| 44 |
+
const int channels = value.size(3);
|
| 45 |
+
|
| 46 |
+
const int num_levels = spatial_shapes.size(0);
|
| 47 |
+
|
| 48 |
+
const int num_query = sampling_loc.size(1);
|
| 49 |
+
const int num_point = sampling_loc.size(4);
|
| 50 |
+
|
| 51 |
+
const int im2col_step_ = std::min(batch, im2col_step);
|
| 52 |
+
|
| 53 |
+
AT_ASSERTM(batch % im2col_step_ == 0, "batch(%d) must divide im2col_step(%d)", batch, im2col_step_);
|
| 54 |
+
|
| 55 |
+
auto output = at::zeros({batch, num_query, num_heads, channels}, value.options());
|
| 56 |
+
|
| 57 |
+
const int batch_n = im2col_step_;
|
| 58 |
+
auto output_n = output.view({batch/im2col_step_, batch_n, num_query, num_heads, channels});
|
| 59 |
+
auto per_value_size = spatial_size * num_heads * channels;
|
| 60 |
+
auto per_sample_loc_size = num_query * num_heads * num_levels * num_point * 2;
|
| 61 |
+
auto per_attn_weight_size = num_query * num_heads * num_levels * num_point;
|
| 62 |
+
for (int n = 0; n < batch/im2col_step_; ++n)
|
| 63 |
+
{
|
| 64 |
+
auto columns = output_n.select(0, n);
|
| 65 |
+
AT_DISPATCH_FLOATING_TYPES(value.type(), "ms_deform_attn_forward_cuda", ([&] {
|
| 66 |
+
ms_deformable_im2col_cuda(at::cuda::getCurrentCUDAStream(),
|
| 67 |
+
value.data<scalar_t>() + n * im2col_step_ * per_value_size,
|
| 68 |
+
spatial_shapes.data<int64_t>(),
|
| 69 |
+
level_start_index.data<int64_t>(),
|
| 70 |
+
sampling_loc.data<scalar_t>() + n * im2col_step_ * per_sample_loc_size,
|
| 71 |
+
attn_weight.data<scalar_t>() + n * im2col_step_ * per_attn_weight_size,
|
| 72 |
+
batch_n, spatial_size, num_heads, channels, num_levels, num_query, num_point,
|
| 73 |
+
columns.data<scalar_t>());
|
| 74 |
+
|
| 75 |
+
}));
|
| 76 |
+
}
|
| 77 |
+
|
| 78 |
+
output = output.view({batch, num_query, num_heads*channels});
|
| 79 |
+
|
| 80 |
+
return output;
|
| 81 |
+
}
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
std::vector<at::Tensor> ms_deform_attn_cuda_backward(
|
| 85 |
+
const at::Tensor &value,
|
| 86 |
+
const at::Tensor &spatial_shapes,
|
| 87 |
+
const at::Tensor &level_start_index,
|
| 88 |
+
const at::Tensor &sampling_loc,
|
| 89 |
+
const at::Tensor &attn_weight,
|
| 90 |
+
const at::Tensor &grad_output,
|
| 91 |
+
const int im2col_step)
|
| 92 |
+
{
|
| 93 |
+
|
| 94 |
+
AT_ASSERTM(value.is_contiguous(), "value tensor has to be contiguous");
|
| 95 |
+
AT_ASSERTM(spatial_shapes.is_contiguous(), "spatial_shapes tensor has to be contiguous");
|
| 96 |
+
AT_ASSERTM(level_start_index.is_contiguous(), "level_start_index tensor has to be contiguous");
|
| 97 |
+
AT_ASSERTM(sampling_loc.is_contiguous(), "sampling_loc tensor has to be contiguous");
|
| 98 |
+
AT_ASSERTM(attn_weight.is_contiguous(), "attn_weight tensor has to be contiguous");
|
| 99 |
+
AT_ASSERTM(grad_output.is_contiguous(), "grad_output tensor has to be contiguous");
|
| 100 |
+
|
| 101 |
+
AT_ASSERTM(value.type().is_cuda(), "value must be a CUDA tensor");
|
| 102 |
+
AT_ASSERTM(spatial_shapes.type().is_cuda(), "spatial_shapes must be a CUDA tensor");
|
| 103 |
+
AT_ASSERTM(level_start_index.type().is_cuda(), "level_start_index must be a CUDA tensor");
|
| 104 |
+
AT_ASSERTM(sampling_loc.type().is_cuda(), "sampling_loc must be a CUDA tensor");
|
| 105 |
+
AT_ASSERTM(attn_weight.type().is_cuda(), "attn_weight must be a CUDA tensor");
|
| 106 |
+
AT_ASSERTM(grad_output.type().is_cuda(), "grad_output must be a CUDA tensor");
|
| 107 |
+
|
| 108 |
+
const int batch = value.size(0);
|
| 109 |
+
const int spatial_size = value.size(1);
|
| 110 |
+
const int num_heads = value.size(2);
|
| 111 |
+
const int channels = value.size(3);
|
| 112 |
+
|
| 113 |
+
const int num_levels = spatial_shapes.size(0);
|
| 114 |
+
|
| 115 |
+
const int num_query = sampling_loc.size(1);
|
| 116 |
+
const int num_point = sampling_loc.size(4);
|
| 117 |
+
|
| 118 |
+
const int im2col_step_ = std::min(batch, im2col_step);
|
| 119 |
+
|
| 120 |
+
AT_ASSERTM(batch % im2col_step_ == 0, "batch(%d) must divide im2col_step(%d)", batch, im2col_step_);
|
| 121 |
+
|
| 122 |
+
auto grad_value = at::zeros_like(value);
|
| 123 |
+
auto grad_sampling_loc = at::zeros_like(sampling_loc);
|
| 124 |
+
auto grad_attn_weight = at::zeros_like(attn_weight);
|
| 125 |
+
|
| 126 |
+
const int batch_n = im2col_step_;
|
| 127 |
+
auto per_value_size = spatial_size * num_heads * channels;
|
| 128 |
+
auto per_sample_loc_size = num_query * num_heads * num_levels * num_point * 2;
|
| 129 |
+
auto per_attn_weight_size = num_query * num_heads * num_levels * num_point;
|
| 130 |
+
auto grad_output_n = grad_output.view({batch/im2col_step_, batch_n, num_query, num_heads, channels});
|
| 131 |
+
|
| 132 |
+
for (int n = 0; n < batch/im2col_step_; ++n)
|
| 133 |
+
{
|
| 134 |
+
auto grad_output_g = grad_output_n.select(0, n);
|
| 135 |
+
AT_DISPATCH_FLOATING_TYPES(value.type(), "ms_deform_attn_backward_cuda", ([&] {
|
| 136 |
+
ms_deformable_col2im_cuda(at::cuda::getCurrentCUDAStream(),
|
| 137 |
+
grad_output_g.data<scalar_t>(),
|
| 138 |
+
value.data<scalar_t>() + n * im2col_step_ * per_value_size,
|
| 139 |
+
spatial_shapes.data<int64_t>(),
|
| 140 |
+
level_start_index.data<int64_t>(),
|
| 141 |
+
sampling_loc.data<scalar_t>() + n * im2col_step_ * per_sample_loc_size,
|
| 142 |
+
attn_weight.data<scalar_t>() + n * im2col_step_ * per_attn_weight_size,
|
| 143 |
+
batch_n, spatial_size, num_heads, channels, num_levels, num_query, num_point,
|
| 144 |
+
grad_value.data<scalar_t>() + n * im2col_step_ * per_value_size,
|
| 145 |
+
grad_sampling_loc.data<scalar_t>() + n * im2col_step_ * per_sample_loc_size,
|
| 146 |
+
grad_attn_weight.data<scalar_t>() + n * im2col_step_ * per_attn_weight_size);
|
| 147 |
+
|
| 148 |
+
}));
|
| 149 |
+
}
|
| 150 |
+
|
| 151 |
+
return {
|
| 152 |
+
grad_value, grad_sampling_loc, grad_attn_weight
|
| 153 |
+
};
|
| 154 |
+
}
|
| 155 |
+
|
| 156 |
+
} // namespace groundingdino
|
GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cuda.h
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*!
|
| 2 |
+
**************************************************************************************************
|
| 3 |
+
* Deformable DETR
|
| 4 |
+
* Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 5 |
+
* Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 6 |
+
**************************************************************************************************
|
| 7 |
+
* Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
|
| 8 |
+
**************************************************************************************************
|
| 9 |
+
*/
|
| 10 |
+
|
| 11 |
+
#pragma once
|
| 12 |
+
#include <torch/extension.h>
|
| 13 |
+
|
| 14 |
+
namespace groundingdino {
|
| 15 |
+
|
| 16 |
+
at::Tensor ms_deform_attn_cuda_forward(
|
| 17 |
+
const at::Tensor &value,
|
| 18 |
+
const at::Tensor &spatial_shapes,
|
| 19 |
+
const at::Tensor &level_start_index,
|
| 20 |
+
const at::Tensor &sampling_loc,
|
| 21 |
+
const at::Tensor &attn_weight,
|
| 22 |
+
const int im2col_step);
|
| 23 |
+
|
| 24 |
+
std::vector<at::Tensor> ms_deform_attn_cuda_backward(
|
| 25 |
+
const at::Tensor &value,
|
| 26 |
+
const at::Tensor &spatial_shapes,
|
| 27 |
+
const at::Tensor &level_start_index,
|
| 28 |
+
const at::Tensor &sampling_loc,
|
| 29 |
+
const at::Tensor &attn_weight,
|
| 30 |
+
const at::Tensor &grad_output,
|
| 31 |
+
const int im2col_step);
|
| 32 |
+
|
| 33 |
+
} // namespace groundingdino
|
GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_im2col_cuda.cuh
ADDED
|
@@ -0,0 +1,1327 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*!
|
| 2 |
+
**************************************************************************
|
| 3 |
+
* Deformable DETR
|
| 4 |
+
* Copyright (c) 2020 SenseTime. All Rights Reserved.
|
| 5 |
+
* Licensed under the Apache License, Version 2.0 [see LICENSE for details]
|
| 6 |
+
**************************************************************************
|
| 7 |
+
* Modified from DCN (https://github.com/msracver/Deformable-ConvNets)
|
| 8 |
+
* Copyright (c) 2018 Microsoft
|
| 9 |
+
**************************************************************************
|
| 10 |
+
*/
|
| 11 |
+
|
| 12 |
+
#include <cstdio>
|
| 13 |
+
#include <algorithm>
|
| 14 |
+
#include <cstring>
|
| 15 |
+
|
| 16 |
+
#include <ATen/ATen.h>
|
| 17 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 18 |
+
|
| 19 |
+
#include <THC/THCAtomics.cuh>
|
| 20 |
+
|
| 21 |
+
#define CUDA_KERNEL_LOOP(i, n) \
|
| 22 |
+
for (int i = blockIdx.x * blockDim.x + threadIdx.x; \
|
| 23 |
+
i < (n); \
|
| 24 |
+
i += blockDim.x * gridDim.x)
|
| 25 |
+
|
| 26 |
+
const int CUDA_NUM_THREADS = 1024;
|
| 27 |
+
inline int GET_BLOCKS(const int N, const int num_threads)
|
| 28 |
+
{
|
| 29 |
+
return (N + num_threads - 1) / num_threads;
|
| 30 |
+
}
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
template <typename scalar_t>
|
| 34 |
+
__device__ scalar_t ms_deform_attn_im2col_bilinear(const scalar_t* &bottom_data,
|
| 35 |
+
const int &height, const int &width, const int &nheads, const int &channels,
|
| 36 |
+
const scalar_t &h, const scalar_t &w, const int &m, const int &c)
|
| 37 |
+
{
|
| 38 |
+
const int h_low = floor(h);
|
| 39 |
+
const int w_low = floor(w);
|
| 40 |
+
const int h_high = h_low + 1;
|
| 41 |
+
const int w_high = w_low + 1;
|
| 42 |
+
|
| 43 |
+
const scalar_t lh = h - h_low;
|
| 44 |
+
const scalar_t lw = w - w_low;
|
| 45 |
+
const scalar_t hh = 1 - lh, hw = 1 - lw;
|
| 46 |
+
|
| 47 |
+
const int w_stride = nheads * channels;
|
| 48 |
+
const int h_stride = width * w_stride;
|
| 49 |
+
const int h_low_ptr_offset = h_low * h_stride;
|
| 50 |
+
const int h_high_ptr_offset = h_low_ptr_offset + h_stride;
|
| 51 |
+
const int w_low_ptr_offset = w_low * w_stride;
|
| 52 |
+
const int w_high_ptr_offset = w_low_ptr_offset + w_stride;
|
| 53 |
+
const int base_ptr = m * channels + c;
|
| 54 |
+
|
| 55 |
+
scalar_t v1 = 0;
|
| 56 |
+
if (h_low >= 0 && w_low >= 0)
|
| 57 |
+
{
|
| 58 |
+
const int ptr1 = h_low_ptr_offset + w_low_ptr_offset + base_ptr;
|
| 59 |
+
v1 = bottom_data[ptr1];
|
| 60 |
+
}
|
| 61 |
+
scalar_t v2 = 0;
|
| 62 |
+
if (h_low >= 0 && w_high <= width - 1)
|
| 63 |
+
{
|
| 64 |
+
const int ptr2 = h_low_ptr_offset + w_high_ptr_offset + base_ptr;
|
| 65 |
+
v2 = bottom_data[ptr2];
|
| 66 |
+
}
|
| 67 |
+
scalar_t v3 = 0;
|
| 68 |
+
if (h_high <= height - 1 && w_low >= 0)
|
| 69 |
+
{
|
| 70 |
+
const int ptr3 = h_high_ptr_offset + w_low_ptr_offset + base_ptr;
|
| 71 |
+
v3 = bottom_data[ptr3];
|
| 72 |
+
}
|
| 73 |
+
scalar_t v4 = 0;
|
| 74 |
+
if (h_high <= height - 1 && w_high <= width - 1)
|
| 75 |
+
{
|
| 76 |
+
const int ptr4 = h_high_ptr_offset + w_high_ptr_offset + base_ptr;
|
| 77 |
+
v4 = bottom_data[ptr4];
|
| 78 |
+
}
|
| 79 |
+
|
| 80 |
+
const scalar_t w1 = hh * hw, w2 = hh * lw, w3 = lh * hw, w4 = lh * lw;
|
| 81 |
+
|
| 82 |
+
const scalar_t val = (w1 * v1 + w2 * v2 + w3 * v3 + w4 * v4);
|
| 83 |
+
return val;
|
| 84 |
+
}
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
template <typename scalar_t>
|
| 88 |
+
__device__ void ms_deform_attn_col2im_bilinear(const scalar_t* &bottom_data,
|
| 89 |
+
const int &height, const int &width, const int &nheads, const int &channels,
|
| 90 |
+
const scalar_t &h, const scalar_t &w, const int &m, const int &c,
|
| 91 |
+
const scalar_t &top_grad,
|
| 92 |
+
const scalar_t &attn_weight,
|
| 93 |
+
scalar_t* &grad_value,
|
| 94 |
+
scalar_t* grad_sampling_loc,
|
| 95 |
+
scalar_t* grad_attn_weight)
|
| 96 |
+
{
|
| 97 |
+
const int h_low = floor(h);
|
| 98 |
+
const int w_low = floor(w);
|
| 99 |
+
const int h_high = h_low + 1;
|
| 100 |
+
const int w_high = w_low + 1;
|
| 101 |
+
|
| 102 |
+
const scalar_t lh = h - h_low;
|
| 103 |
+
const scalar_t lw = w - w_low;
|
| 104 |
+
const scalar_t hh = 1 - lh, hw = 1 - lw;
|
| 105 |
+
|
| 106 |
+
const int w_stride = nheads * channels;
|
| 107 |
+
const int h_stride = width * w_stride;
|
| 108 |
+
const int h_low_ptr_offset = h_low * h_stride;
|
| 109 |
+
const int h_high_ptr_offset = h_low_ptr_offset + h_stride;
|
| 110 |
+
const int w_low_ptr_offset = w_low * w_stride;
|
| 111 |
+
const int w_high_ptr_offset = w_low_ptr_offset + w_stride;
|
| 112 |
+
const int base_ptr = m * channels + c;
|
| 113 |
+
|
| 114 |
+
const scalar_t w1 = hh * hw, w2 = hh * lw, w3 = lh * hw, w4 = lh * lw;
|
| 115 |
+
const scalar_t top_grad_value = top_grad * attn_weight;
|
| 116 |
+
scalar_t grad_h_weight = 0, grad_w_weight = 0;
|
| 117 |
+
|
| 118 |
+
scalar_t v1 = 0;
|
| 119 |
+
if (h_low >= 0 && w_low >= 0)
|
| 120 |
+
{
|
| 121 |
+
const int ptr1 = h_low_ptr_offset + w_low_ptr_offset + base_ptr;
|
| 122 |
+
v1 = bottom_data[ptr1];
|
| 123 |
+
grad_h_weight -= hw * v1;
|
| 124 |
+
grad_w_weight -= hh * v1;
|
| 125 |
+
atomicAdd(grad_value+ptr1, w1*top_grad_value);
|
| 126 |
+
}
|
| 127 |
+
scalar_t v2 = 0;
|
| 128 |
+
if (h_low >= 0 && w_high <= width - 1)
|
| 129 |
+
{
|
| 130 |
+
const int ptr2 = h_low_ptr_offset + w_high_ptr_offset + base_ptr;
|
| 131 |
+
v2 = bottom_data[ptr2];
|
| 132 |
+
grad_h_weight -= lw * v2;
|
| 133 |
+
grad_w_weight += hh * v2;
|
| 134 |
+
atomicAdd(grad_value+ptr2, w2*top_grad_value);
|
| 135 |
+
}
|
| 136 |
+
scalar_t v3 = 0;
|
| 137 |
+
if (h_high <= height - 1 && w_low >= 0)
|
| 138 |
+
{
|
| 139 |
+
const int ptr3 = h_high_ptr_offset + w_low_ptr_offset + base_ptr;
|
| 140 |
+
v3 = bottom_data[ptr3];
|
| 141 |
+
grad_h_weight += hw * v3;
|
| 142 |
+
grad_w_weight -= lh * v3;
|
| 143 |
+
atomicAdd(grad_value+ptr3, w3*top_grad_value);
|
| 144 |
+
}
|
| 145 |
+
scalar_t v4 = 0;
|
| 146 |
+
if (h_high <= height - 1 && w_high <= width - 1)
|
| 147 |
+
{
|
| 148 |
+
const int ptr4 = h_high_ptr_offset + w_high_ptr_offset + base_ptr;
|
| 149 |
+
v4 = bottom_data[ptr4];
|
| 150 |
+
grad_h_weight += lw * v4;
|
| 151 |
+
grad_w_weight += lh * v4;
|
| 152 |
+
atomicAdd(grad_value+ptr4, w4*top_grad_value);
|
| 153 |
+
}
|
| 154 |
+
|
| 155 |
+
const scalar_t val = (w1 * v1 + w2 * v2 + w3 * v3 + w4 * v4);
|
| 156 |
+
*grad_attn_weight = top_grad * val;
|
| 157 |
+
*grad_sampling_loc = width * grad_w_weight * top_grad_value;
|
| 158 |
+
*(grad_sampling_loc + 1) = height * grad_h_weight * top_grad_value;
|
| 159 |
+
}
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
template <typename scalar_t>
|
| 163 |
+
__device__ void ms_deform_attn_col2im_bilinear_gm(const scalar_t* &bottom_data,
|
| 164 |
+
const int &height, const int &width, const int &nheads, const int &channels,
|
| 165 |
+
const scalar_t &h, const scalar_t &w, const int &m, const int &c,
|
| 166 |
+
const scalar_t &top_grad,
|
| 167 |
+
const scalar_t &attn_weight,
|
| 168 |
+
scalar_t* &grad_value,
|
| 169 |
+
scalar_t* grad_sampling_loc,
|
| 170 |
+
scalar_t* grad_attn_weight)
|
| 171 |
+
{
|
| 172 |
+
const int h_low = floor(h);
|
| 173 |
+
const int w_low = floor(w);
|
| 174 |
+
const int h_high = h_low + 1;
|
| 175 |
+
const int w_high = w_low + 1;
|
| 176 |
+
|
| 177 |
+
const scalar_t lh = h - h_low;
|
| 178 |
+
const scalar_t lw = w - w_low;
|
| 179 |
+
const scalar_t hh = 1 - lh, hw = 1 - lw;
|
| 180 |
+
|
| 181 |
+
const int w_stride = nheads * channels;
|
| 182 |
+
const int h_stride = width * w_stride;
|
| 183 |
+
const int h_low_ptr_offset = h_low * h_stride;
|
| 184 |
+
const int h_high_ptr_offset = h_low_ptr_offset + h_stride;
|
| 185 |
+
const int w_low_ptr_offset = w_low * w_stride;
|
| 186 |
+
const int w_high_ptr_offset = w_low_ptr_offset + w_stride;
|
| 187 |
+
const int base_ptr = m * channels + c;
|
| 188 |
+
|
| 189 |
+
const scalar_t w1 = hh * hw, w2 = hh * lw, w3 = lh * hw, w4 = lh * lw;
|
| 190 |
+
const scalar_t top_grad_value = top_grad * attn_weight;
|
| 191 |
+
scalar_t grad_h_weight = 0, grad_w_weight = 0;
|
| 192 |
+
|
| 193 |
+
scalar_t v1 = 0;
|
| 194 |
+
if (h_low >= 0 && w_low >= 0)
|
| 195 |
+
{
|
| 196 |
+
const int ptr1 = h_low_ptr_offset + w_low_ptr_offset + base_ptr;
|
| 197 |
+
v1 = bottom_data[ptr1];
|
| 198 |
+
grad_h_weight -= hw * v1;
|
| 199 |
+
grad_w_weight -= hh * v1;
|
| 200 |
+
atomicAdd(grad_value+ptr1, w1*top_grad_value);
|
| 201 |
+
}
|
| 202 |
+
scalar_t v2 = 0;
|
| 203 |
+
if (h_low >= 0 && w_high <= width - 1)
|
| 204 |
+
{
|
| 205 |
+
const int ptr2 = h_low_ptr_offset + w_high_ptr_offset + base_ptr;
|
| 206 |
+
v2 = bottom_data[ptr2];
|
| 207 |
+
grad_h_weight -= lw * v2;
|
| 208 |
+
grad_w_weight += hh * v2;
|
| 209 |
+
atomicAdd(grad_value+ptr2, w2*top_grad_value);
|
| 210 |
+
}
|
| 211 |
+
scalar_t v3 = 0;
|
| 212 |
+
if (h_high <= height - 1 && w_low >= 0)
|
| 213 |
+
{
|
| 214 |
+
const int ptr3 = h_high_ptr_offset + w_low_ptr_offset + base_ptr;
|
| 215 |
+
v3 = bottom_data[ptr3];
|
| 216 |
+
grad_h_weight += hw * v3;
|
| 217 |
+
grad_w_weight -= lh * v3;
|
| 218 |
+
atomicAdd(grad_value+ptr3, w3*top_grad_value);
|
| 219 |
+
}
|
| 220 |
+
scalar_t v4 = 0;
|
| 221 |
+
if (h_high <= height - 1 && w_high <= width - 1)
|
| 222 |
+
{
|
| 223 |
+
const int ptr4 = h_high_ptr_offset + w_high_ptr_offset + base_ptr;
|
| 224 |
+
v4 = bottom_data[ptr4];
|
| 225 |
+
grad_h_weight += lw * v4;
|
| 226 |
+
grad_w_weight += lh * v4;
|
| 227 |
+
atomicAdd(grad_value+ptr4, w4*top_grad_value);
|
| 228 |
+
}
|
| 229 |
+
|
| 230 |
+
const scalar_t val = (w1 * v1 + w2 * v2 + w3 * v3 + w4 * v4);
|
| 231 |
+
atomicAdd(grad_attn_weight, top_grad * val);
|
| 232 |
+
atomicAdd(grad_sampling_loc, width * grad_w_weight * top_grad_value);
|
| 233 |
+
atomicAdd(grad_sampling_loc + 1, height * grad_h_weight * top_grad_value);
|
| 234 |
+
}
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
template <typename scalar_t>
|
| 238 |
+
__global__ void ms_deformable_im2col_gpu_kernel(const int n,
|
| 239 |
+
const scalar_t *data_value,
|
| 240 |
+
const int64_t *data_spatial_shapes,
|
| 241 |
+
const int64_t *data_level_start_index,
|
| 242 |
+
const scalar_t *data_sampling_loc,
|
| 243 |
+
const scalar_t *data_attn_weight,
|
| 244 |
+
const int batch_size,
|
| 245 |
+
const int spatial_size,
|
| 246 |
+
const int num_heads,
|
| 247 |
+
const int channels,
|
| 248 |
+
const int num_levels,
|
| 249 |
+
const int num_query,
|
| 250 |
+
const int num_point,
|
| 251 |
+
scalar_t *data_col)
|
| 252 |
+
{
|
| 253 |
+
CUDA_KERNEL_LOOP(index, n)
|
| 254 |
+
{
|
| 255 |
+
int _temp = index;
|
| 256 |
+
const int c_col = _temp % channels;
|
| 257 |
+
_temp /= channels;
|
| 258 |
+
const int sampling_index = _temp;
|
| 259 |
+
const int m_col = _temp % num_heads;
|
| 260 |
+
_temp /= num_heads;
|
| 261 |
+
const int q_col = _temp % num_query;
|
| 262 |
+
_temp /= num_query;
|
| 263 |
+
const int b_col = _temp;
|
| 264 |
+
|
| 265 |
+
scalar_t *data_col_ptr = data_col + index;
|
| 266 |
+
int data_weight_ptr = sampling_index * num_levels * num_point;
|
| 267 |
+
int data_loc_w_ptr = data_weight_ptr << 1;
|
| 268 |
+
const int qid_stride = num_heads * channels;
|
| 269 |
+
const int data_value_ptr_init_offset = b_col * spatial_size * qid_stride;
|
| 270 |
+
scalar_t col = 0;
|
| 271 |
+
|
| 272 |
+
for (int l_col=0; l_col < num_levels; ++l_col)
|
| 273 |
+
{
|
| 274 |
+
const int level_start_id = data_level_start_index[l_col];
|
| 275 |
+
const int spatial_h_ptr = l_col << 1;
|
| 276 |
+
const int spatial_h = data_spatial_shapes[spatial_h_ptr];
|
| 277 |
+
const int spatial_w = data_spatial_shapes[spatial_h_ptr + 1];
|
| 278 |
+
const scalar_t *data_value_ptr = data_value + (data_value_ptr_init_offset + level_start_id * qid_stride);
|
| 279 |
+
for (int p_col=0; p_col < num_point; ++p_col)
|
| 280 |
+
{
|
| 281 |
+
const scalar_t loc_w = data_sampling_loc[data_loc_w_ptr];
|
| 282 |
+
const scalar_t loc_h = data_sampling_loc[data_loc_w_ptr + 1];
|
| 283 |
+
const scalar_t weight = data_attn_weight[data_weight_ptr];
|
| 284 |
+
|
| 285 |
+
const scalar_t h_im = loc_h * spatial_h - 0.5;
|
| 286 |
+
const scalar_t w_im = loc_w * spatial_w - 0.5;
|
| 287 |
+
|
| 288 |
+
if (h_im > -1 && w_im > -1 && h_im < spatial_h && w_im < spatial_w)
|
| 289 |
+
{
|
| 290 |
+
col += ms_deform_attn_im2col_bilinear(data_value_ptr, spatial_h, spatial_w, num_heads, channels, h_im, w_im, m_col, c_col) * weight;
|
| 291 |
+
}
|
| 292 |
+
|
| 293 |
+
data_weight_ptr += 1;
|
| 294 |
+
data_loc_w_ptr += 2;
|
| 295 |
+
}
|
| 296 |
+
}
|
| 297 |
+
*data_col_ptr = col;
|
| 298 |
+
}
|
| 299 |
+
}
|
| 300 |
+
|
| 301 |
+
template <typename scalar_t, unsigned int blockSize>
|
| 302 |
+
__global__ void ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v1(const int n,
|
| 303 |
+
const scalar_t *grad_col,
|
| 304 |
+
const scalar_t *data_value,
|
| 305 |
+
const int64_t *data_spatial_shapes,
|
| 306 |
+
const int64_t *data_level_start_index,
|
| 307 |
+
const scalar_t *data_sampling_loc,
|
| 308 |
+
const scalar_t *data_attn_weight,
|
| 309 |
+
const int batch_size,
|
| 310 |
+
const int spatial_size,
|
| 311 |
+
const int num_heads,
|
| 312 |
+
const int channels,
|
| 313 |
+
const int num_levels,
|
| 314 |
+
const int num_query,
|
| 315 |
+
const int num_point,
|
| 316 |
+
scalar_t *grad_value,
|
| 317 |
+
scalar_t *grad_sampling_loc,
|
| 318 |
+
scalar_t *grad_attn_weight)
|
| 319 |
+
{
|
| 320 |
+
CUDA_KERNEL_LOOP(index, n)
|
| 321 |
+
{
|
| 322 |
+
__shared__ scalar_t cache_grad_sampling_loc[blockSize * 2];
|
| 323 |
+
__shared__ scalar_t cache_grad_attn_weight[blockSize];
|
| 324 |
+
unsigned int tid = threadIdx.x;
|
| 325 |
+
int _temp = index;
|
| 326 |
+
const int c_col = _temp % channels;
|
| 327 |
+
_temp /= channels;
|
| 328 |
+
const int sampling_index = _temp;
|
| 329 |
+
const int m_col = _temp % num_heads;
|
| 330 |
+
_temp /= num_heads;
|
| 331 |
+
const int q_col = _temp % num_query;
|
| 332 |
+
_temp /= num_query;
|
| 333 |
+
const int b_col = _temp;
|
| 334 |
+
|
| 335 |
+
const scalar_t top_grad = grad_col[index];
|
| 336 |
+
|
| 337 |
+
int data_weight_ptr = sampling_index * num_levels * num_point;
|
| 338 |
+
int data_loc_w_ptr = data_weight_ptr << 1;
|
| 339 |
+
const int grad_sampling_ptr = data_weight_ptr;
|
| 340 |
+
grad_sampling_loc += grad_sampling_ptr << 1;
|
| 341 |
+
grad_attn_weight += grad_sampling_ptr;
|
| 342 |
+
const int grad_weight_stride = 1;
|
| 343 |
+
const int grad_loc_stride = 2;
|
| 344 |
+
const int qid_stride = num_heads * channels;
|
| 345 |
+
const int data_value_ptr_init_offset = b_col * spatial_size * qid_stride;
|
| 346 |
+
|
| 347 |
+
for (int l_col=0; l_col < num_levels; ++l_col)
|
| 348 |
+
{
|
| 349 |
+
const int level_start_id = data_level_start_index[l_col];
|
| 350 |
+
const int spatial_h_ptr = l_col << 1;
|
| 351 |
+
const int spatial_h = data_spatial_shapes[spatial_h_ptr];
|
| 352 |
+
const int spatial_w = data_spatial_shapes[spatial_h_ptr + 1];
|
| 353 |
+
const int value_ptr_offset = data_value_ptr_init_offset + level_start_id * qid_stride;
|
| 354 |
+
const scalar_t *data_value_ptr = data_value + value_ptr_offset;
|
| 355 |
+
scalar_t *grad_value_ptr = grad_value + value_ptr_offset;
|
| 356 |
+
|
| 357 |
+
for (int p_col=0; p_col < num_point; ++p_col)
|
| 358 |
+
{
|
| 359 |
+
const scalar_t loc_w = data_sampling_loc[data_loc_w_ptr];
|
| 360 |
+
const scalar_t loc_h = data_sampling_loc[data_loc_w_ptr + 1];
|
| 361 |
+
const scalar_t weight = data_attn_weight[data_weight_ptr];
|
| 362 |
+
|
| 363 |
+
const scalar_t h_im = loc_h * spatial_h - 0.5;
|
| 364 |
+
const scalar_t w_im = loc_w * spatial_w - 0.5;
|
| 365 |
+
*(cache_grad_sampling_loc+(threadIdx.x << 1)) = 0;
|
| 366 |
+
*(cache_grad_sampling_loc+((threadIdx.x << 1) + 1)) = 0;
|
| 367 |
+
*(cache_grad_attn_weight+threadIdx.x)=0;
|
| 368 |
+
if (h_im > -1 && w_im > -1 && h_im < spatial_h && w_im < spatial_w)
|
| 369 |
+
{
|
| 370 |
+
ms_deform_attn_col2im_bilinear(
|
| 371 |
+
data_value_ptr, spatial_h, spatial_w, num_heads, channels, h_im, w_im, m_col, c_col,
|
| 372 |
+
top_grad, weight, grad_value_ptr,
|
| 373 |
+
cache_grad_sampling_loc+(threadIdx.x << 1), cache_grad_attn_weight+threadIdx.x);
|
| 374 |
+
}
|
| 375 |
+
|
| 376 |
+
__syncthreads();
|
| 377 |
+
if (tid == 0)
|
| 378 |
+
{
|
| 379 |
+
scalar_t _grad_w=cache_grad_sampling_loc[0], _grad_h=cache_grad_sampling_loc[1], _grad_a=cache_grad_attn_weight[0];
|
| 380 |
+
int sid=2;
|
| 381 |
+
for (unsigned int tid = 1; tid < blockSize; ++tid)
|
| 382 |
+
{
|
| 383 |
+
_grad_w += cache_grad_sampling_loc[sid];
|
| 384 |
+
_grad_h += cache_grad_sampling_loc[sid + 1];
|
| 385 |
+
_grad_a += cache_grad_attn_weight[tid];
|
| 386 |
+
sid += 2;
|
| 387 |
+
}
|
| 388 |
+
|
| 389 |
+
|
| 390 |
+
*grad_sampling_loc = _grad_w;
|
| 391 |
+
*(grad_sampling_loc + 1) = _grad_h;
|
| 392 |
+
*grad_attn_weight = _grad_a;
|
| 393 |
+
}
|
| 394 |
+
__syncthreads();
|
| 395 |
+
|
| 396 |
+
data_weight_ptr += 1;
|
| 397 |
+
data_loc_w_ptr += 2;
|
| 398 |
+
grad_attn_weight += grad_weight_stride;
|
| 399 |
+
grad_sampling_loc += grad_loc_stride;
|
| 400 |
+
}
|
| 401 |
+
}
|
| 402 |
+
}
|
| 403 |
+
}
|
| 404 |
+
|
| 405 |
+
|
| 406 |
+
template <typename scalar_t, unsigned int blockSize>
|
| 407 |
+
__global__ void ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v2(const int n,
|
| 408 |
+
const scalar_t *grad_col,
|
| 409 |
+
const scalar_t *data_value,
|
| 410 |
+
const int64_t *data_spatial_shapes,
|
| 411 |
+
const int64_t *data_level_start_index,
|
| 412 |
+
const scalar_t *data_sampling_loc,
|
| 413 |
+
const scalar_t *data_attn_weight,
|
| 414 |
+
const int batch_size,
|
| 415 |
+
const int spatial_size,
|
| 416 |
+
const int num_heads,
|
| 417 |
+
const int channels,
|
| 418 |
+
const int num_levels,
|
| 419 |
+
const int num_query,
|
| 420 |
+
const int num_point,
|
| 421 |
+
scalar_t *grad_value,
|
| 422 |
+
scalar_t *grad_sampling_loc,
|
| 423 |
+
scalar_t *grad_attn_weight)
|
| 424 |
+
{
|
| 425 |
+
CUDA_KERNEL_LOOP(index, n)
|
| 426 |
+
{
|
| 427 |
+
__shared__ scalar_t cache_grad_sampling_loc[blockSize * 2];
|
| 428 |
+
__shared__ scalar_t cache_grad_attn_weight[blockSize];
|
| 429 |
+
unsigned int tid = threadIdx.x;
|
| 430 |
+
int _temp = index;
|
| 431 |
+
const int c_col = _temp % channels;
|
| 432 |
+
_temp /= channels;
|
| 433 |
+
const int sampling_index = _temp;
|
| 434 |
+
const int m_col = _temp % num_heads;
|
| 435 |
+
_temp /= num_heads;
|
| 436 |
+
const int q_col = _temp % num_query;
|
| 437 |
+
_temp /= num_query;
|
| 438 |
+
const int b_col = _temp;
|
| 439 |
+
|
| 440 |
+
const scalar_t top_grad = grad_col[index];
|
| 441 |
+
|
| 442 |
+
int data_weight_ptr = sampling_index * num_levels * num_point;
|
| 443 |
+
int data_loc_w_ptr = data_weight_ptr << 1;
|
| 444 |
+
const int grad_sampling_ptr = data_weight_ptr;
|
| 445 |
+
grad_sampling_loc += grad_sampling_ptr << 1;
|
| 446 |
+
grad_attn_weight += grad_sampling_ptr;
|
| 447 |
+
const int grad_weight_stride = 1;
|
| 448 |
+
const int grad_loc_stride = 2;
|
| 449 |
+
const int qid_stride = num_heads * channels;
|
| 450 |
+
const int data_value_ptr_init_offset = b_col * spatial_size * qid_stride;
|
| 451 |
+
|
| 452 |
+
for (int l_col=0; l_col < num_levels; ++l_col)
|
| 453 |
+
{
|
| 454 |
+
const int level_start_id = data_level_start_index[l_col];
|
| 455 |
+
const int spatial_h_ptr = l_col << 1;
|
| 456 |
+
const int spatial_h = data_spatial_shapes[spatial_h_ptr];
|
| 457 |
+
const int spatial_w = data_spatial_shapes[spatial_h_ptr + 1];
|
| 458 |
+
const int value_ptr_offset = data_value_ptr_init_offset + level_start_id * qid_stride;
|
| 459 |
+
const scalar_t *data_value_ptr = data_value + value_ptr_offset;
|
| 460 |
+
scalar_t *grad_value_ptr = grad_value + value_ptr_offset;
|
| 461 |
+
|
| 462 |
+
for (int p_col=0; p_col < num_point; ++p_col)
|
| 463 |
+
{
|
| 464 |
+
const scalar_t loc_w = data_sampling_loc[data_loc_w_ptr];
|
| 465 |
+
const scalar_t loc_h = data_sampling_loc[data_loc_w_ptr + 1];
|
| 466 |
+
const scalar_t weight = data_attn_weight[data_weight_ptr];
|
| 467 |
+
|
| 468 |
+
const scalar_t h_im = loc_h * spatial_h - 0.5;
|
| 469 |
+
const scalar_t w_im = loc_w * spatial_w - 0.5;
|
| 470 |
+
*(cache_grad_sampling_loc+(threadIdx.x << 1)) = 0;
|
| 471 |
+
*(cache_grad_sampling_loc+((threadIdx.x << 1) + 1)) = 0;
|
| 472 |
+
*(cache_grad_attn_weight+threadIdx.x)=0;
|
| 473 |
+
if (h_im > -1 && w_im > -1 && h_im < spatial_h && w_im < spatial_w)
|
| 474 |
+
{
|
| 475 |
+
ms_deform_attn_col2im_bilinear(
|
| 476 |
+
data_value_ptr, spatial_h, spatial_w, num_heads, channels, h_im, w_im, m_col, c_col,
|
| 477 |
+
top_grad, weight, grad_value_ptr,
|
| 478 |
+
cache_grad_sampling_loc+(threadIdx.x << 1), cache_grad_attn_weight+threadIdx.x);
|
| 479 |
+
}
|
| 480 |
+
|
| 481 |
+
__syncthreads();
|
| 482 |
+
|
| 483 |
+
for (unsigned int s=blockSize/2; s>0; s>>=1)
|
| 484 |
+
{
|
| 485 |
+
if (tid < s) {
|
| 486 |
+
const unsigned int xid1 = tid << 1;
|
| 487 |
+
const unsigned int xid2 = (tid + s) << 1;
|
| 488 |
+
cache_grad_attn_weight[tid] += cache_grad_attn_weight[tid + s];
|
| 489 |
+
cache_grad_sampling_loc[xid1] += cache_grad_sampling_loc[xid2];
|
| 490 |
+
cache_grad_sampling_loc[xid1 + 1] += cache_grad_sampling_loc[xid2 + 1];
|
| 491 |
+
}
|
| 492 |
+
__syncthreads();
|
| 493 |
+
}
|
| 494 |
+
|
| 495 |
+
if (tid == 0)
|
| 496 |
+
{
|
| 497 |
+
*grad_sampling_loc = cache_grad_sampling_loc[0];
|
| 498 |
+
*(grad_sampling_loc + 1) = cache_grad_sampling_loc[1];
|
| 499 |
+
*grad_attn_weight = cache_grad_attn_weight[0];
|
| 500 |
+
}
|
| 501 |
+
__syncthreads();
|
| 502 |
+
|
| 503 |
+
data_weight_ptr += 1;
|
| 504 |
+
data_loc_w_ptr += 2;
|
| 505 |
+
grad_attn_weight += grad_weight_stride;
|
| 506 |
+
grad_sampling_loc += grad_loc_stride;
|
| 507 |
+
}
|
| 508 |
+
}
|
| 509 |
+
}
|
| 510 |
+
}
|
| 511 |
+
|
| 512 |
+
|
| 513 |
+
template <typename scalar_t>
|
| 514 |
+
__global__ void ms_deformable_col2im_gpu_kernel_shm_reduce_v1(const int n,
|
| 515 |
+
const scalar_t *grad_col,
|
| 516 |
+
const scalar_t *data_value,
|
| 517 |
+
const int64_t *data_spatial_shapes,
|
| 518 |
+
const int64_t *data_level_start_index,
|
| 519 |
+
const scalar_t *data_sampling_loc,
|
| 520 |
+
const scalar_t *data_attn_weight,
|
| 521 |
+
const int batch_size,
|
| 522 |
+
const int spatial_size,
|
| 523 |
+
const int num_heads,
|
| 524 |
+
const int channels,
|
| 525 |
+
const int num_levels,
|
| 526 |
+
const int num_query,
|
| 527 |
+
const int num_point,
|
| 528 |
+
scalar_t *grad_value,
|
| 529 |
+
scalar_t *grad_sampling_loc,
|
| 530 |
+
scalar_t *grad_attn_weight)
|
| 531 |
+
{
|
| 532 |
+
CUDA_KERNEL_LOOP(index, n)
|
| 533 |
+
{
|
| 534 |
+
extern __shared__ int _s[];
|
| 535 |
+
scalar_t* cache_grad_sampling_loc = (scalar_t*)_s;
|
| 536 |
+
scalar_t* cache_grad_attn_weight = cache_grad_sampling_loc + 2 * blockDim.x;
|
| 537 |
+
unsigned int tid = threadIdx.x;
|
| 538 |
+
int _temp = index;
|
| 539 |
+
const int c_col = _temp % channels;
|
| 540 |
+
_temp /= channels;
|
| 541 |
+
const int sampling_index = _temp;
|
| 542 |
+
const int m_col = _temp % num_heads;
|
| 543 |
+
_temp /= num_heads;
|
| 544 |
+
const int q_col = _temp % num_query;
|
| 545 |
+
_temp /= num_query;
|
| 546 |
+
const int b_col = _temp;
|
| 547 |
+
|
| 548 |
+
const scalar_t top_grad = grad_col[index];
|
| 549 |
+
|
| 550 |
+
int data_weight_ptr = sampling_index * num_levels * num_point;
|
| 551 |
+
int data_loc_w_ptr = data_weight_ptr << 1;
|
| 552 |
+
const int grad_sampling_ptr = data_weight_ptr;
|
| 553 |
+
grad_sampling_loc += grad_sampling_ptr << 1;
|
| 554 |
+
grad_attn_weight += grad_sampling_ptr;
|
| 555 |
+
const int grad_weight_stride = 1;
|
| 556 |
+
const int grad_loc_stride = 2;
|
| 557 |
+
const int qid_stride = num_heads * channels;
|
| 558 |
+
const int data_value_ptr_init_offset = b_col * spatial_size * qid_stride;
|
| 559 |
+
|
| 560 |
+
for (int l_col=0; l_col < num_levels; ++l_col)
|
| 561 |
+
{
|
| 562 |
+
const int level_start_id = data_level_start_index[l_col];
|
| 563 |
+
const int spatial_h_ptr = l_col << 1;
|
| 564 |
+
const int spatial_h = data_spatial_shapes[spatial_h_ptr];
|
| 565 |
+
const int spatial_w = data_spatial_shapes[spatial_h_ptr + 1];
|
| 566 |
+
const int value_ptr_offset = data_value_ptr_init_offset + level_start_id * qid_stride;
|
| 567 |
+
const scalar_t *data_value_ptr = data_value + value_ptr_offset;
|
| 568 |
+
scalar_t *grad_value_ptr = grad_value + value_ptr_offset;
|
| 569 |
+
|
| 570 |
+
for (int p_col=0; p_col < num_point; ++p_col)
|
| 571 |
+
{
|
| 572 |
+
const scalar_t loc_w = data_sampling_loc[data_loc_w_ptr];
|
| 573 |
+
const scalar_t loc_h = data_sampling_loc[data_loc_w_ptr + 1];
|
| 574 |
+
const scalar_t weight = data_attn_weight[data_weight_ptr];
|
| 575 |
+
|
| 576 |
+
const scalar_t h_im = loc_h * spatial_h - 0.5;
|
| 577 |
+
const scalar_t w_im = loc_w * spatial_w - 0.5;
|
| 578 |
+
*(cache_grad_sampling_loc+(threadIdx.x << 1)) = 0;
|
| 579 |
+
*(cache_grad_sampling_loc+((threadIdx.x << 1) + 1)) = 0;
|
| 580 |
+
*(cache_grad_attn_weight+threadIdx.x)=0;
|
| 581 |
+
if (h_im > -1 && w_im > -1 && h_im < spatial_h && w_im < spatial_w)
|
| 582 |
+
{
|
| 583 |
+
ms_deform_attn_col2im_bilinear(
|
| 584 |
+
data_value_ptr, spatial_h, spatial_w, num_heads, channels, h_im, w_im, m_col, c_col,
|
| 585 |
+
top_grad, weight, grad_value_ptr,
|
| 586 |
+
cache_grad_sampling_loc+(threadIdx.x << 1), cache_grad_attn_weight+threadIdx.x);
|
| 587 |
+
}
|
| 588 |
+
|
| 589 |
+
__syncthreads();
|
| 590 |
+
if (tid == 0)
|
| 591 |
+
{
|
| 592 |
+
scalar_t _grad_w=cache_grad_sampling_loc[0], _grad_h=cache_grad_sampling_loc[1], _grad_a=cache_grad_attn_weight[0];
|
| 593 |
+
int sid=2;
|
| 594 |
+
for (unsigned int tid = 1; tid < blockDim.x; ++tid)
|
| 595 |
+
{
|
| 596 |
+
_grad_w += cache_grad_sampling_loc[sid];
|
| 597 |
+
_grad_h += cache_grad_sampling_loc[sid + 1];
|
| 598 |
+
_grad_a += cache_grad_attn_weight[tid];
|
| 599 |
+
sid += 2;
|
| 600 |
+
}
|
| 601 |
+
|
| 602 |
+
|
| 603 |
+
*grad_sampling_loc = _grad_w;
|
| 604 |
+
*(grad_sampling_loc + 1) = _grad_h;
|
| 605 |
+
*grad_attn_weight = _grad_a;
|
| 606 |
+
}
|
| 607 |
+
__syncthreads();
|
| 608 |
+
|
| 609 |
+
data_weight_ptr += 1;
|
| 610 |
+
data_loc_w_ptr += 2;
|
| 611 |
+
grad_attn_weight += grad_weight_stride;
|
| 612 |
+
grad_sampling_loc += grad_loc_stride;
|
| 613 |
+
}
|
| 614 |
+
}
|
| 615 |
+
}
|
| 616 |
+
}
|
| 617 |
+
|
| 618 |
+
template <typename scalar_t>
|
| 619 |
+
__global__ void ms_deformable_col2im_gpu_kernel_shm_reduce_v2(const int n,
|
| 620 |
+
const scalar_t *grad_col,
|
| 621 |
+
const scalar_t *data_value,
|
| 622 |
+
const int64_t *data_spatial_shapes,
|
| 623 |
+
const int64_t *data_level_start_index,
|
| 624 |
+
const scalar_t *data_sampling_loc,
|
| 625 |
+
const scalar_t *data_attn_weight,
|
| 626 |
+
const int batch_size,
|
| 627 |
+
const int spatial_size,
|
| 628 |
+
const int num_heads,
|
| 629 |
+
const int channels,
|
| 630 |
+
const int num_levels,
|
| 631 |
+
const int num_query,
|
| 632 |
+
const int num_point,
|
| 633 |
+
scalar_t *grad_value,
|
| 634 |
+
scalar_t *grad_sampling_loc,
|
| 635 |
+
scalar_t *grad_attn_weight)
|
| 636 |
+
{
|
| 637 |
+
CUDA_KERNEL_LOOP(index, n)
|
| 638 |
+
{
|
| 639 |
+
extern __shared__ int _s[];
|
| 640 |
+
scalar_t* cache_grad_sampling_loc = (scalar_t*)_s;
|
| 641 |
+
scalar_t* cache_grad_attn_weight = cache_grad_sampling_loc + 2 * blockDim.x;
|
| 642 |
+
unsigned int tid = threadIdx.x;
|
| 643 |
+
int _temp = index;
|
| 644 |
+
const int c_col = _temp % channels;
|
| 645 |
+
_temp /= channels;
|
| 646 |
+
const int sampling_index = _temp;
|
| 647 |
+
const int m_col = _temp % num_heads;
|
| 648 |
+
_temp /= num_heads;
|
| 649 |
+
const int q_col = _temp % num_query;
|
| 650 |
+
_temp /= num_query;
|
| 651 |
+
const int b_col = _temp;
|
| 652 |
+
|
| 653 |
+
const scalar_t top_grad = grad_col[index];
|
| 654 |
+
|
| 655 |
+
int data_weight_ptr = sampling_index * num_levels * num_point;
|
| 656 |
+
int data_loc_w_ptr = data_weight_ptr << 1;
|
| 657 |
+
const int grad_sampling_ptr = data_weight_ptr;
|
| 658 |
+
grad_sampling_loc += grad_sampling_ptr << 1;
|
| 659 |
+
grad_attn_weight += grad_sampling_ptr;
|
| 660 |
+
const int grad_weight_stride = 1;
|
| 661 |
+
const int grad_loc_stride = 2;
|
| 662 |
+
const int qid_stride = num_heads * channels;
|
| 663 |
+
const int data_value_ptr_init_offset = b_col * spatial_size * qid_stride;
|
| 664 |
+
|
| 665 |
+
for (int l_col=0; l_col < num_levels; ++l_col)
|
| 666 |
+
{
|
| 667 |
+
const int level_start_id = data_level_start_index[l_col];
|
| 668 |
+
const int spatial_h_ptr = l_col << 1;
|
| 669 |
+
const int spatial_h = data_spatial_shapes[spatial_h_ptr];
|
| 670 |
+
const int spatial_w = data_spatial_shapes[spatial_h_ptr + 1];
|
| 671 |
+
const int value_ptr_offset = data_value_ptr_init_offset + level_start_id * qid_stride;
|
| 672 |
+
const scalar_t *data_value_ptr = data_value + value_ptr_offset;
|
| 673 |
+
scalar_t *grad_value_ptr = grad_value + value_ptr_offset;
|
| 674 |
+
|
| 675 |
+
for (int p_col=0; p_col < num_point; ++p_col)
|
| 676 |
+
{
|
| 677 |
+
const scalar_t loc_w = data_sampling_loc[data_loc_w_ptr];
|
| 678 |
+
const scalar_t loc_h = data_sampling_loc[data_loc_w_ptr + 1];
|
| 679 |
+
const scalar_t weight = data_attn_weight[data_weight_ptr];
|
| 680 |
+
|
| 681 |
+
const scalar_t h_im = loc_h * spatial_h - 0.5;
|
| 682 |
+
const scalar_t w_im = loc_w * spatial_w - 0.5;
|
| 683 |
+
*(cache_grad_sampling_loc+(threadIdx.x << 1)) = 0;
|
| 684 |
+
*(cache_grad_sampling_loc+((threadIdx.x << 1) + 1)) = 0;
|
| 685 |
+
*(cache_grad_attn_weight+threadIdx.x)=0;
|
| 686 |
+
if (h_im > -1 && w_im > -1 && h_im < spatial_h && w_im < spatial_w)
|
| 687 |
+
{
|
| 688 |
+
ms_deform_attn_col2im_bilinear(
|
| 689 |
+
data_value_ptr, spatial_h, spatial_w, num_heads, channels, h_im, w_im, m_col, c_col,
|
| 690 |
+
top_grad, weight, grad_value_ptr,
|
| 691 |
+
cache_grad_sampling_loc+(threadIdx.x << 1), cache_grad_attn_weight+threadIdx.x);
|
| 692 |
+
}
|
| 693 |
+
|
| 694 |
+
__syncthreads();
|
| 695 |
+
|
| 696 |
+
for (unsigned int s=blockDim.x/2, spre=blockDim.x; s>0; s>>=1, spre>>=1)
|
| 697 |
+
{
|
| 698 |
+
if (tid < s) {
|
| 699 |
+
const unsigned int xid1 = tid << 1;
|
| 700 |
+
const unsigned int xid2 = (tid + s) << 1;
|
| 701 |
+
cache_grad_attn_weight[tid] += cache_grad_attn_weight[tid + s];
|
| 702 |
+
cache_grad_sampling_loc[xid1] += cache_grad_sampling_loc[xid2];
|
| 703 |
+
cache_grad_sampling_loc[xid1 + 1] += cache_grad_sampling_loc[xid2 + 1];
|
| 704 |
+
if (tid + (s << 1) < spre)
|
| 705 |
+
{
|
| 706 |
+
cache_grad_attn_weight[tid] += cache_grad_attn_weight[tid + (s << 1)];
|
| 707 |
+
cache_grad_sampling_loc[xid1] += cache_grad_sampling_loc[xid2 + (s << 1)];
|
| 708 |
+
cache_grad_sampling_loc[xid1 + 1] += cache_grad_sampling_loc[xid2 + 1 + (s << 1)];
|
| 709 |
+
}
|
| 710 |
+
}
|
| 711 |
+
__syncthreads();
|
| 712 |
+
}
|
| 713 |
+
|
| 714 |
+
if (tid == 0)
|
| 715 |
+
{
|
| 716 |
+
*grad_sampling_loc = cache_grad_sampling_loc[0];
|
| 717 |
+
*(grad_sampling_loc + 1) = cache_grad_sampling_loc[1];
|
| 718 |
+
*grad_attn_weight = cache_grad_attn_weight[0];
|
| 719 |
+
}
|
| 720 |
+
__syncthreads();
|
| 721 |
+
|
| 722 |
+
data_weight_ptr += 1;
|
| 723 |
+
data_loc_w_ptr += 2;
|
| 724 |
+
grad_attn_weight += grad_weight_stride;
|
| 725 |
+
grad_sampling_loc += grad_loc_stride;
|
| 726 |
+
}
|
| 727 |
+
}
|
| 728 |
+
}
|
| 729 |
+
}
|
| 730 |
+
|
| 731 |
+
template <typename scalar_t>
|
| 732 |
+
__global__ void ms_deformable_col2im_gpu_kernel_shm_reduce_v2_multi_blocks(const int n,
|
| 733 |
+
const scalar_t *grad_col,
|
| 734 |
+
const scalar_t *data_value,
|
| 735 |
+
const int64_t *data_spatial_shapes,
|
| 736 |
+
const int64_t *data_level_start_index,
|
| 737 |
+
const scalar_t *data_sampling_loc,
|
| 738 |
+
const scalar_t *data_attn_weight,
|
| 739 |
+
const int batch_size,
|
| 740 |
+
const int spatial_size,
|
| 741 |
+
const int num_heads,
|
| 742 |
+
const int channels,
|
| 743 |
+
const int num_levels,
|
| 744 |
+
const int num_query,
|
| 745 |
+
const int num_point,
|
| 746 |
+
scalar_t *grad_value,
|
| 747 |
+
scalar_t *grad_sampling_loc,
|
| 748 |
+
scalar_t *grad_attn_weight)
|
| 749 |
+
{
|
| 750 |
+
CUDA_KERNEL_LOOP(index, n)
|
| 751 |
+
{
|
| 752 |
+
extern __shared__ int _s[];
|
| 753 |
+
scalar_t* cache_grad_sampling_loc = (scalar_t*)_s;
|
| 754 |
+
scalar_t* cache_grad_attn_weight = cache_grad_sampling_loc + 2 * blockDim.x;
|
| 755 |
+
unsigned int tid = threadIdx.x;
|
| 756 |
+
int _temp = index;
|
| 757 |
+
const int c_col = _temp % channels;
|
| 758 |
+
_temp /= channels;
|
| 759 |
+
const int sampling_index = _temp;
|
| 760 |
+
const int m_col = _temp % num_heads;
|
| 761 |
+
_temp /= num_heads;
|
| 762 |
+
const int q_col = _temp % num_query;
|
| 763 |
+
_temp /= num_query;
|
| 764 |
+
const int b_col = _temp;
|
| 765 |
+
|
| 766 |
+
const scalar_t top_grad = grad_col[index];
|
| 767 |
+
|
| 768 |
+
int data_weight_ptr = sampling_index * num_levels * num_point;
|
| 769 |
+
int data_loc_w_ptr = data_weight_ptr << 1;
|
| 770 |
+
const int grad_sampling_ptr = data_weight_ptr;
|
| 771 |
+
grad_sampling_loc += grad_sampling_ptr << 1;
|
| 772 |
+
grad_attn_weight += grad_sampling_ptr;
|
| 773 |
+
const int grad_weight_stride = 1;
|
| 774 |
+
const int grad_loc_stride = 2;
|
| 775 |
+
const int qid_stride = num_heads * channels;
|
| 776 |
+
const int data_value_ptr_init_offset = b_col * spatial_size * qid_stride;
|
| 777 |
+
|
| 778 |
+
for (int l_col=0; l_col < num_levels; ++l_col)
|
| 779 |
+
{
|
| 780 |
+
const int level_start_id = data_level_start_index[l_col];
|
| 781 |
+
const int spatial_h_ptr = l_col << 1;
|
| 782 |
+
const int spatial_h = data_spatial_shapes[spatial_h_ptr];
|
| 783 |
+
const int spatial_w = data_spatial_shapes[spatial_h_ptr + 1];
|
| 784 |
+
const int value_ptr_offset = data_value_ptr_init_offset + level_start_id * qid_stride;
|
| 785 |
+
const scalar_t *data_value_ptr = data_value + value_ptr_offset;
|
| 786 |
+
scalar_t *grad_value_ptr = grad_value + value_ptr_offset;
|
| 787 |
+
|
| 788 |
+
for (int p_col=0; p_col < num_point; ++p_col)
|
| 789 |
+
{
|
| 790 |
+
const scalar_t loc_w = data_sampling_loc[data_loc_w_ptr];
|
| 791 |
+
const scalar_t loc_h = data_sampling_loc[data_loc_w_ptr + 1];
|
| 792 |
+
const scalar_t weight = data_attn_weight[data_weight_ptr];
|
| 793 |
+
|
| 794 |
+
const scalar_t h_im = loc_h * spatial_h - 0.5;
|
| 795 |
+
const scalar_t w_im = loc_w * spatial_w - 0.5;
|
| 796 |
+
*(cache_grad_sampling_loc+(threadIdx.x << 1)) = 0;
|
| 797 |
+
*(cache_grad_sampling_loc+((threadIdx.x << 1) + 1)) = 0;
|
| 798 |
+
*(cache_grad_attn_weight+threadIdx.x)=0;
|
| 799 |
+
if (h_im > -1 && w_im > -1 && h_im < spatial_h && w_im < spatial_w)
|
| 800 |
+
{
|
| 801 |
+
ms_deform_attn_col2im_bilinear(
|
| 802 |
+
data_value_ptr, spatial_h, spatial_w, num_heads, channels, h_im, w_im, m_col, c_col,
|
| 803 |
+
top_grad, weight, grad_value_ptr,
|
| 804 |
+
cache_grad_sampling_loc+(threadIdx.x << 1), cache_grad_attn_weight+threadIdx.x);
|
| 805 |
+
}
|
| 806 |
+
|
| 807 |
+
__syncthreads();
|
| 808 |
+
|
| 809 |
+
for (unsigned int s=blockDim.x/2, spre=blockDim.x; s>0; s>>=1, spre>>=1)
|
| 810 |
+
{
|
| 811 |
+
if (tid < s) {
|
| 812 |
+
const unsigned int xid1 = tid << 1;
|
| 813 |
+
const unsigned int xid2 = (tid + s) << 1;
|
| 814 |
+
cache_grad_attn_weight[tid] += cache_grad_attn_weight[tid + s];
|
| 815 |
+
cache_grad_sampling_loc[xid1] += cache_grad_sampling_loc[xid2];
|
| 816 |
+
cache_grad_sampling_loc[xid1 + 1] += cache_grad_sampling_loc[xid2 + 1];
|
| 817 |
+
if (tid + (s << 1) < spre)
|
| 818 |
+
{
|
| 819 |
+
cache_grad_attn_weight[tid] += cache_grad_attn_weight[tid + (s << 1)];
|
| 820 |
+
cache_grad_sampling_loc[xid1] += cache_grad_sampling_loc[xid2 + (s << 1)];
|
| 821 |
+
cache_grad_sampling_loc[xid1 + 1] += cache_grad_sampling_loc[xid2 + 1 + (s << 1)];
|
| 822 |
+
}
|
| 823 |
+
}
|
| 824 |
+
__syncthreads();
|
| 825 |
+
}
|
| 826 |
+
|
| 827 |
+
if (tid == 0)
|
| 828 |
+
{
|
| 829 |
+
atomicAdd(grad_sampling_loc, cache_grad_sampling_loc[0]);
|
| 830 |
+
atomicAdd(grad_sampling_loc + 1, cache_grad_sampling_loc[1]);
|
| 831 |
+
atomicAdd(grad_attn_weight, cache_grad_attn_weight[0]);
|
| 832 |
+
}
|
| 833 |
+
__syncthreads();
|
| 834 |
+
|
| 835 |
+
data_weight_ptr += 1;
|
| 836 |
+
data_loc_w_ptr += 2;
|
| 837 |
+
grad_attn_weight += grad_weight_stride;
|
| 838 |
+
grad_sampling_loc += grad_loc_stride;
|
| 839 |
+
}
|
| 840 |
+
}
|
| 841 |
+
}
|
| 842 |
+
}
|
| 843 |
+
|
| 844 |
+
|
| 845 |
+
template <typename scalar_t>
|
| 846 |
+
__global__ void ms_deformable_col2im_gpu_kernel_gm(const int n,
|
| 847 |
+
const scalar_t *grad_col,
|
| 848 |
+
const scalar_t *data_value,
|
| 849 |
+
const int64_t *data_spatial_shapes,
|
| 850 |
+
const int64_t *data_level_start_index,
|
| 851 |
+
const scalar_t *data_sampling_loc,
|
| 852 |
+
const scalar_t *data_attn_weight,
|
| 853 |
+
const int batch_size,
|
| 854 |
+
const int spatial_size,
|
| 855 |
+
const int num_heads,
|
| 856 |
+
const int channels,
|
| 857 |
+
const int num_levels,
|
| 858 |
+
const int num_query,
|
| 859 |
+
const int num_point,
|
| 860 |
+
scalar_t *grad_value,
|
| 861 |
+
scalar_t *grad_sampling_loc,
|
| 862 |
+
scalar_t *grad_attn_weight)
|
| 863 |
+
{
|
| 864 |
+
CUDA_KERNEL_LOOP(index, n)
|
| 865 |
+
{
|
| 866 |
+
int _temp = index;
|
| 867 |
+
const int c_col = _temp % channels;
|
| 868 |
+
_temp /= channels;
|
| 869 |
+
const int sampling_index = _temp;
|
| 870 |
+
const int m_col = _temp % num_heads;
|
| 871 |
+
_temp /= num_heads;
|
| 872 |
+
const int q_col = _temp % num_query;
|
| 873 |
+
_temp /= num_query;
|
| 874 |
+
const int b_col = _temp;
|
| 875 |
+
|
| 876 |
+
const scalar_t top_grad = grad_col[index];
|
| 877 |
+
|
| 878 |
+
int data_weight_ptr = sampling_index * num_levels * num_point;
|
| 879 |
+
int data_loc_w_ptr = data_weight_ptr << 1;
|
| 880 |
+
const int grad_sampling_ptr = data_weight_ptr;
|
| 881 |
+
grad_sampling_loc += grad_sampling_ptr << 1;
|
| 882 |
+
grad_attn_weight += grad_sampling_ptr;
|
| 883 |
+
const int grad_weight_stride = 1;
|
| 884 |
+
const int grad_loc_stride = 2;
|
| 885 |
+
const int qid_stride = num_heads * channels;
|
| 886 |
+
const int data_value_ptr_init_offset = b_col * spatial_size * qid_stride;
|
| 887 |
+
|
| 888 |
+
for (int l_col=0; l_col < num_levels; ++l_col)
|
| 889 |
+
{
|
| 890 |
+
const int level_start_id = data_level_start_index[l_col];
|
| 891 |
+
const int spatial_h_ptr = l_col << 1;
|
| 892 |
+
const int spatial_h = data_spatial_shapes[spatial_h_ptr];
|
| 893 |
+
const int spatial_w = data_spatial_shapes[spatial_h_ptr + 1];
|
| 894 |
+
const int value_ptr_offset = data_value_ptr_init_offset + level_start_id * qid_stride;
|
| 895 |
+
const scalar_t *data_value_ptr = data_value + value_ptr_offset;
|
| 896 |
+
scalar_t *grad_value_ptr = grad_value + value_ptr_offset;
|
| 897 |
+
|
| 898 |
+
for (int p_col=0; p_col < num_point; ++p_col)
|
| 899 |
+
{
|
| 900 |
+
const scalar_t loc_w = data_sampling_loc[data_loc_w_ptr];
|
| 901 |
+
const scalar_t loc_h = data_sampling_loc[data_loc_w_ptr + 1];
|
| 902 |
+
const scalar_t weight = data_attn_weight[data_weight_ptr];
|
| 903 |
+
|
| 904 |
+
const scalar_t h_im = loc_h * spatial_h - 0.5;
|
| 905 |
+
const scalar_t w_im = loc_w * spatial_w - 0.5;
|
| 906 |
+
if (h_im > -1 && w_im > -1 && h_im < spatial_h && w_im < spatial_w)
|
| 907 |
+
{
|
| 908 |
+
ms_deform_attn_col2im_bilinear_gm(
|
| 909 |
+
data_value_ptr, spatial_h, spatial_w, num_heads, channels, h_im, w_im, m_col, c_col,
|
| 910 |
+
top_grad, weight, grad_value_ptr,
|
| 911 |
+
grad_sampling_loc, grad_attn_weight);
|
| 912 |
+
}
|
| 913 |
+
data_weight_ptr += 1;
|
| 914 |
+
data_loc_w_ptr += 2;
|
| 915 |
+
grad_attn_weight += grad_weight_stride;
|
| 916 |
+
grad_sampling_loc += grad_loc_stride;
|
| 917 |
+
}
|
| 918 |
+
}
|
| 919 |
+
}
|
| 920 |
+
}
|
| 921 |
+
|
| 922 |
+
|
| 923 |
+
template <typename scalar_t>
|
| 924 |
+
void ms_deformable_im2col_cuda(cudaStream_t stream,
|
| 925 |
+
const scalar_t* data_value,
|
| 926 |
+
const int64_t* data_spatial_shapes,
|
| 927 |
+
const int64_t* data_level_start_index,
|
| 928 |
+
const scalar_t* data_sampling_loc,
|
| 929 |
+
const scalar_t* data_attn_weight,
|
| 930 |
+
const int batch_size,
|
| 931 |
+
const int spatial_size,
|
| 932 |
+
const int num_heads,
|
| 933 |
+
const int channels,
|
| 934 |
+
const int num_levels,
|
| 935 |
+
const int num_query,
|
| 936 |
+
const int num_point,
|
| 937 |
+
scalar_t* data_col)
|
| 938 |
+
{
|
| 939 |
+
const int num_kernels = batch_size * num_query * num_heads * channels;
|
| 940 |
+
const int num_actual_kernels = batch_size * num_query * num_heads * channels;
|
| 941 |
+
const int num_threads = CUDA_NUM_THREADS;
|
| 942 |
+
ms_deformable_im2col_gpu_kernel<scalar_t>
|
| 943 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 944 |
+
0, stream>>>(
|
| 945 |
+
num_kernels, data_value, data_spatial_shapes, data_level_start_index, data_sampling_loc, data_attn_weight,
|
| 946 |
+
batch_size, spatial_size, num_heads, channels, num_levels, num_query, num_point, data_col);
|
| 947 |
+
|
| 948 |
+
cudaError_t err = cudaGetLastError();
|
| 949 |
+
if (err != cudaSuccess)
|
| 950 |
+
{
|
| 951 |
+
printf("error in ms_deformable_im2col_cuda: %s\n", cudaGetErrorString(err));
|
| 952 |
+
}
|
| 953 |
+
|
| 954 |
+
}
|
| 955 |
+
|
| 956 |
+
template <typename scalar_t>
|
| 957 |
+
void ms_deformable_col2im_cuda(cudaStream_t stream,
|
| 958 |
+
const scalar_t* grad_col,
|
| 959 |
+
const scalar_t* data_value,
|
| 960 |
+
const int64_t * data_spatial_shapes,
|
| 961 |
+
const int64_t * data_level_start_index,
|
| 962 |
+
const scalar_t * data_sampling_loc,
|
| 963 |
+
const scalar_t * data_attn_weight,
|
| 964 |
+
const int batch_size,
|
| 965 |
+
const int spatial_size,
|
| 966 |
+
const int num_heads,
|
| 967 |
+
const int channels,
|
| 968 |
+
const int num_levels,
|
| 969 |
+
const int num_query,
|
| 970 |
+
const int num_point,
|
| 971 |
+
scalar_t* grad_value,
|
| 972 |
+
scalar_t* grad_sampling_loc,
|
| 973 |
+
scalar_t* grad_attn_weight)
|
| 974 |
+
{
|
| 975 |
+
const int num_threads = (channels > CUDA_NUM_THREADS)?CUDA_NUM_THREADS:channels;
|
| 976 |
+
const int num_kernels = batch_size * num_query * num_heads * channels;
|
| 977 |
+
const int num_actual_kernels = batch_size * num_query * num_heads * channels;
|
| 978 |
+
if (channels > 1024)
|
| 979 |
+
{
|
| 980 |
+
if ((channels & 1023) == 0)
|
| 981 |
+
{
|
| 982 |
+
ms_deformable_col2im_gpu_kernel_shm_reduce_v2_multi_blocks<scalar_t>
|
| 983 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 984 |
+
num_threads*3*sizeof(scalar_t), stream>>>(
|
| 985 |
+
num_kernels,
|
| 986 |
+
grad_col,
|
| 987 |
+
data_value,
|
| 988 |
+
data_spatial_shapes,
|
| 989 |
+
data_level_start_index,
|
| 990 |
+
data_sampling_loc,
|
| 991 |
+
data_attn_weight,
|
| 992 |
+
batch_size,
|
| 993 |
+
spatial_size,
|
| 994 |
+
num_heads,
|
| 995 |
+
channels,
|
| 996 |
+
num_levels,
|
| 997 |
+
num_query,
|
| 998 |
+
num_point,
|
| 999 |
+
grad_value,
|
| 1000 |
+
grad_sampling_loc,
|
| 1001 |
+
grad_attn_weight);
|
| 1002 |
+
}
|
| 1003 |
+
else
|
| 1004 |
+
{
|
| 1005 |
+
ms_deformable_col2im_gpu_kernel_gm<scalar_t>
|
| 1006 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1007 |
+
0, stream>>>(
|
| 1008 |
+
num_kernels,
|
| 1009 |
+
grad_col,
|
| 1010 |
+
data_value,
|
| 1011 |
+
data_spatial_shapes,
|
| 1012 |
+
data_level_start_index,
|
| 1013 |
+
data_sampling_loc,
|
| 1014 |
+
data_attn_weight,
|
| 1015 |
+
batch_size,
|
| 1016 |
+
spatial_size,
|
| 1017 |
+
num_heads,
|
| 1018 |
+
channels,
|
| 1019 |
+
num_levels,
|
| 1020 |
+
num_query,
|
| 1021 |
+
num_point,
|
| 1022 |
+
grad_value,
|
| 1023 |
+
grad_sampling_loc,
|
| 1024 |
+
grad_attn_weight);
|
| 1025 |
+
}
|
| 1026 |
+
}
|
| 1027 |
+
else{
|
| 1028 |
+
switch(channels)
|
| 1029 |
+
{
|
| 1030 |
+
case 1:
|
| 1031 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v1<scalar_t, 1>
|
| 1032 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1033 |
+
0, stream>>>(
|
| 1034 |
+
num_kernels,
|
| 1035 |
+
grad_col,
|
| 1036 |
+
data_value,
|
| 1037 |
+
data_spatial_shapes,
|
| 1038 |
+
data_level_start_index,
|
| 1039 |
+
data_sampling_loc,
|
| 1040 |
+
data_attn_weight,
|
| 1041 |
+
batch_size,
|
| 1042 |
+
spatial_size,
|
| 1043 |
+
num_heads,
|
| 1044 |
+
channels,
|
| 1045 |
+
num_levels,
|
| 1046 |
+
num_query,
|
| 1047 |
+
num_point,
|
| 1048 |
+
grad_value,
|
| 1049 |
+
grad_sampling_loc,
|
| 1050 |
+
grad_attn_weight);
|
| 1051 |
+
break;
|
| 1052 |
+
case 2:
|
| 1053 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v1<scalar_t, 2>
|
| 1054 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1055 |
+
0, stream>>>(
|
| 1056 |
+
num_kernels,
|
| 1057 |
+
grad_col,
|
| 1058 |
+
data_value,
|
| 1059 |
+
data_spatial_shapes,
|
| 1060 |
+
data_level_start_index,
|
| 1061 |
+
data_sampling_loc,
|
| 1062 |
+
data_attn_weight,
|
| 1063 |
+
batch_size,
|
| 1064 |
+
spatial_size,
|
| 1065 |
+
num_heads,
|
| 1066 |
+
channels,
|
| 1067 |
+
num_levels,
|
| 1068 |
+
num_query,
|
| 1069 |
+
num_point,
|
| 1070 |
+
grad_value,
|
| 1071 |
+
grad_sampling_loc,
|
| 1072 |
+
grad_attn_weight);
|
| 1073 |
+
break;
|
| 1074 |
+
case 4:
|
| 1075 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v1<scalar_t, 4>
|
| 1076 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1077 |
+
0, stream>>>(
|
| 1078 |
+
num_kernels,
|
| 1079 |
+
grad_col,
|
| 1080 |
+
data_value,
|
| 1081 |
+
data_spatial_shapes,
|
| 1082 |
+
data_level_start_index,
|
| 1083 |
+
data_sampling_loc,
|
| 1084 |
+
data_attn_weight,
|
| 1085 |
+
batch_size,
|
| 1086 |
+
spatial_size,
|
| 1087 |
+
num_heads,
|
| 1088 |
+
channels,
|
| 1089 |
+
num_levels,
|
| 1090 |
+
num_query,
|
| 1091 |
+
num_point,
|
| 1092 |
+
grad_value,
|
| 1093 |
+
grad_sampling_loc,
|
| 1094 |
+
grad_attn_weight);
|
| 1095 |
+
break;
|
| 1096 |
+
case 8:
|
| 1097 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v1<scalar_t, 8>
|
| 1098 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1099 |
+
0, stream>>>(
|
| 1100 |
+
num_kernels,
|
| 1101 |
+
grad_col,
|
| 1102 |
+
data_value,
|
| 1103 |
+
data_spatial_shapes,
|
| 1104 |
+
data_level_start_index,
|
| 1105 |
+
data_sampling_loc,
|
| 1106 |
+
data_attn_weight,
|
| 1107 |
+
batch_size,
|
| 1108 |
+
spatial_size,
|
| 1109 |
+
num_heads,
|
| 1110 |
+
channels,
|
| 1111 |
+
num_levels,
|
| 1112 |
+
num_query,
|
| 1113 |
+
num_point,
|
| 1114 |
+
grad_value,
|
| 1115 |
+
grad_sampling_loc,
|
| 1116 |
+
grad_attn_weight);
|
| 1117 |
+
break;
|
| 1118 |
+
case 16:
|
| 1119 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v1<scalar_t, 16>
|
| 1120 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1121 |
+
0, stream>>>(
|
| 1122 |
+
num_kernels,
|
| 1123 |
+
grad_col,
|
| 1124 |
+
data_value,
|
| 1125 |
+
data_spatial_shapes,
|
| 1126 |
+
data_level_start_index,
|
| 1127 |
+
data_sampling_loc,
|
| 1128 |
+
data_attn_weight,
|
| 1129 |
+
batch_size,
|
| 1130 |
+
spatial_size,
|
| 1131 |
+
num_heads,
|
| 1132 |
+
channels,
|
| 1133 |
+
num_levels,
|
| 1134 |
+
num_query,
|
| 1135 |
+
num_point,
|
| 1136 |
+
grad_value,
|
| 1137 |
+
grad_sampling_loc,
|
| 1138 |
+
grad_attn_weight);
|
| 1139 |
+
break;
|
| 1140 |
+
case 32:
|
| 1141 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v1<scalar_t, 32>
|
| 1142 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1143 |
+
0, stream>>>(
|
| 1144 |
+
num_kernels,
|
| 1145 |
+
grad_col,
|
| 1146 |
+
data_value,
|
| 1147 |
+
data_spatial_shapes,
|
| 1148 |
+
data_level_start_index,
|
| 1149 |
+
data_sampling_loc,
|
| 1150 |
+
data_attn_weight,
|
| 1151 |
+
batch_size,
|
| 1152 |
+
spatial_size,
|
| 1153 |
+
num_heads,
|
| 1154 |
+
channels,
|
| 1155 |
+
num_levels,
|
| 1156 |
+
num_query,
|
| 1157 |
+
num_point,
|
| 1158 |
+
grad_value,
|
| 1159 |
+
grad_sampling_loc,
|
| 1160 |
+
grad_attn_weight);
|
| 1161 |
+
break;
|
| 1162 |
+
case 64:
|
| 1163 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v2<scalar_t, 64>
|
| 1164 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1165 |
+
0, stream>>>(
|
| 1166 |
+
num_kernels,
|
| 1167 |
+
grad_col,
|
| 1168 |
+
data_value,
|
| 1169 |
+
data_spatial_shapes,
|
| 1170 |
+
data_level_start_index,
|
| 1171 |
+
data_sampling_loc,
|
| 1172 |
+
data_attn_weight,
|
| 1173 |
+
batch_size,
|
| 1174 |
+
spatial_size,
|
| 1175 |
+
num_heads,
|
| 1176 |
+
channels,
|
| 1177 |
+
num_levels,
|
| 1178 |
+
num_query,
|
| 1179 |
+
num_point,
|
| 1180 |
+
grad_value,
|
| 1181 |
+
grad_sampling_loc,
|
| 1182 |
+
grad_attn_weight);
|
| 1183 |
+
break;
|
| 1184 |
+
case 128:
|
| 1185 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v2<scalar_t, 128>
|
| 1186 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1187 |
+
0, stream>>>(
|
| 1188 |
+
num_kernels,
|
| 1189 |
+
grad_col,
|
| 1190 |
+
data_value,
|
| 1191 |
+
data_spatial_shapes,
|
| 1192 |
+
data_level_start_index,
|
| 1193 |
+
data_sampling_loc,
|
| 1194 |
+
data_attn_weight,
|
| 1195 |
+
batch_size,
|
| 1196 |
+
spatial_size,
|
| 1197 |
+
num_heads,
|
| 1198 |
+
channels,
|
| 1199 |
+
num_levels,
|
| 1200 |
+
num_query,
|
| 1201 |
+
num_point,
|
| 1202 |
+
grad_value,
|
| 1203 |
+
grad_sampling_loc,
|
| 1204 |
+
grad_attn_weight);
|
| 1205 |
+
break;
|
| 1206 |
+
case 256:
|
| 1207 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v2<scalar_t, 256>
|
| 1208 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1209 |
+
0, stream>>>(
|
| 1210 |
+
num_kernels,
|
| 1211 |
+
grad_col,
|
| 1212 |
+
data_value,
|
| 1213 |
+
data_spatial_shapes,
|
| 1214 |
+
data_level_start_index,
|
| 1215 |
+
data_sampling_loc,
|
| 1216 |
+
data_attn_weight,
|
| 1217 |
+
batch_size,
|
| 1218 |
+
spatial_size,
|
| 1219 |
+
num_heads,
|
| 1220 |
+
channels,
|
| 1221 |
+
num_levels,
|
| 1222 |
+
num_query,
|
| 1223 |
+
num_point,
|
| 1224 |
+
grad_value,
|
| 1225 |
+
grad_sampling_loc,
|
| 1226 |
+
grad_attn_weight);
|
| 1227 |
+
break;
|
| 1228 |
+
case 512:
|
| 1229 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v2<scalar_t, 512>
|
| 1230 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1231 |
+
0, stream>>>(
|
| 1232 |
+
num_kernels,
|
| 1233 |
+
grad_col,
|
| 1234 |
+
data_value,
|
| 1235 |
+
data_spatial_shapes,
|
| 1236 |
+
data_level_start_index,
|
| 1237 |
+
data_sampling_loc,
|
| 1238 |
+
data_attn_weight,
|
| 1239 |
+
batch_size,
|
| 1240 |
+
spatial_size,
|
| 1241 |
+
num_heads,
|
| 1242 |
+
channels,
|
| 1243 |
+
num_levels,
|
| 1244 |
+
num_query,
|
| 1245 |
+
num_point,
|
| 1246 |
+
grad_value,
|
| 1247 |
+
grad_sampling_loc,
|
| 1248 |
+
grad_attn_weight);
|
| 1249 |
+
break;
|
| 1250 |
+
case 1024:
|
| 1251 |
+
ms_deformable_col2im_gpu_kernel_shm_blocksize_aware_reduce_v2<scalar_t, 1024>
|
| 1252 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1253 |
+
0, stream>>>(
|
| 1254 |
+
num_kernels,
|
| 1255 |
+
grad_col,
|
| 1256 |
+
data_value,
|
| 1257 |
+
data_spatial_shapes,
|
| 1258 |
+
data_level_start_index,
|
| 1259 |
+
data_sampling_loc,
|
| 1260 |
+
data_attn_weight,
|
| 1261 |
+
batch_size,
|
| 1262 |
+
spatial_size,
|
| 1263 |
+
num_heads,
|
| 1264 |
+
channels,
|
| 1265 |
+
num_levels,
|
| 1266 |
+
num_query,
|
| 1267 |
+
num_point,
|
| 1268 |
+
grad_value,
|
| 1269 |
+
grad_sampling_loc,
|
| 1270 |
+
grad_attn_weight);
|
| 1271 |
+
break;
|
| 1272 |
+
default:
|
| 1273 |
+
if (channels < 64)
|
| 1274 |
+
{
|
| 1275 |
+
ms_deformable_col2im_gpu_kernel_shm_reduce_v1<scalar_t>
|
| 1276 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1277 |
+
num_threads*3*sizeof(scalar_t), stream>>>(
|
| 1278 |
+
num_kernels,
|
| 1279 |
+
grad_col,
|
| 1280 |
+
data_value,
|
| 1281 |
+
data_spatial_shapes,
|
| 1282 |
+
data_level_start_index,
|
| 1283 |
+
data_sampling_loc,
|
| 1284 |
+
data_attn_weight,
|
| 1285 |
+
batch_size,
|
| 1286 |
+
spatial_size,
|
| 1287 |
+
num_heads,
|
| 1288 |
+
channels,
|
| 1289 |
+
num_levels,
|
| 1290 |
+
num_query,
|
| 1291 |
+
num_point,
|
| 1292 |
+
grad_value,
|
| 1293 |
+
grad_sampling_loc,
|
| 1294 |
+
grad_attn_weight);
|
| 1295 |
+
}
|
| 1296 |
+
else
|
| 1297 |
+
{
|
| 1298 |
+
ms_deformable_col2im_gpu_kernel_shm_reduce_v2<scalar_t>
|
| 1299 |
+
<<<GET_BLOCKS(num_actual_kernels, num_threads), num_threads,
|
| 1300 |
+
num_threads*3*sizeof(scalar_t), stream>>>(
|
| 1301 |
+
num_kernels,
|
| 1302 |
+
grad_col,
|
| 1303 |
+
data_value,
|
| 1304 |
+
data_spatial_shapes,
|
| 1305 |
+
data_level_start_index,
|
| 1306 |
+
data_sampling_loc,
|
| 1307 |
+
data_attn_weight,
|
| 1308 |
+
batch_size,
|
| 1309 |
+
spatial_size,
|
| 1310 |
+
num_heads,
|
| 1311 |
+
channels,
|
| 1312 |
+
num_levels,
|
| 1313 |
+
num_query,
|
| 1314 |
+
num_point,
|
| 1315 |
+
grad_value,
|
| 1316 |
+
grad_sampling_loc,
|
| 1317 |
+
grad_attn_weight);
|
| 1318 |
+
}
|
| 1319 |
+
}
|
| 1320 |
+
}
|
| 1321 |
+
cudaError_t err = cudaGetLastError();
|
| 1322 |
+
if (err != cudaSuccess)
|
| 1323 |
+
{
|
| 1324 |
+
printf("error in ms_deformable_col2im_cuda: %s\n", cudaGetErrorString(err));
|
| 1325 |
+
}
|
| 1326 |
+
|
| 1327 |
+
}
|
GroundingDINO/groundingdino/models/GroundingDINO/csrc/cuda_version.cu
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#include <cuda_runtime_api.h>
|
| 2 |
+
|
| 3 |
+
namespace groundingdino {
|
| 4 |
+
int get_cudart_version() {
|
| 5 |
+
return CUDART_VERSION;
|
| 6 |
+
}
|
| 7 |
+
} // namespace groundingdino
|