
fix: v1 model
Browse files- classifier.py +15 -0
- dataset/val/0001.png +0 -0
- dataset/val/0002.png +0 -0
- dataset/val/0003.png +0 -0
- model/checkpoint-500/trainer_state.json +0 -321
- model/{checkpoint-500 → checkpoint-80}/config.json +0 -0
- model/{checkpoint-500 → checkpoint-80}/generation_config.json +0 -0
- model/checkpoint-80/merges.txt +0 -0
- model/{checkpoint-500 → checkpoint-80}/model.safetensors +1 -1
- model/{checkpoint-500 → checkpoint-80}/optimizer.pt +1 -1
- model/checkpoint-80/preprocessor_config.json +17 -0
- model/{checkpoint-500 → checkpoint-80}/rng_state.pth +1 -1
- model/{checkpoint-500 → checkpoint-80}/scheduler.pt +1 -1
- model/checkpoint-80/special_tokens_map.json +1 -0
- model/checkpoint-80/tokenizer_config.json +1 -0
- model/checkpoint-80/trainer_state.json +213 -0
- model/{checkpoint-500 → checkpoint-80}/training_args.bin +1 -1
- model/checkpoint-80/vocab.json +0 -0
- requirements.txt +7 -6
- train.py +5 -4
classifier.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
|
| 2 |
+
from PIL import Image
|
| 3 |
+
import requests
|
| 4 |
+
|
| 5 |
+
url = './dataset/val/0003.png'
|
| 6 |
+
image = Image.open(url).convert("RGB")
|
| 7 |
+
|
| 8 |
+
processor = TrOCRProcessor.from_pretrained('./model/checkpoint-80')
|
| 9 |
+
model = VisionEncoderDecoderModel.from_pretrained('./model/checkpoint-80').to("cuda")
|
| 10 |
+
pixel_values = processor(images=image, return_tensors="pt").pixel_values.to("cuda")
|
| 11 |
+
|
| 12 |
+
generated_ids = model.generate(pixel_values)
|
| 13 |
+
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
| 14 |
+
|
| 15 |
+
print(generated_text)
|
dataset/val/0001.png
ADDED
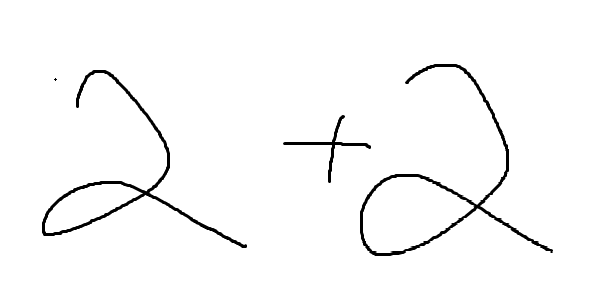
|
dataset/val/0002.png
ADDED
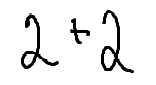
|
dataset/val/0003.png
ADDED
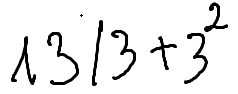
|
model/checkpoint-500/trainer_state.json
DELETED
|
@@ -1,321 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"best_metric": null,
|
| 3 |
-
"best_model_checkpoint": null,
|
| 4 |
-
"epoch": 100.0,
|
| 5 |
-
"eval_steps": 500,
|
| 6 |
-
"global_step": 500,
|
| 7 |
-
"is_hyper_param_search": false,
|
| 8 |
-
"is_local_process_zero": true,
|
| 9 |
-
"is_world_process_zero": true,
|
| 10 |
-
"log_history": [
|
| 11 |
-
{
|
| 12 |
-
"epoch": 2.0,
|
| 13 |
-
"learning_rate": 9.8e-05,
|
| 14 |
-
"loss": 8.2056,
|
| 15 |
-
"step": 10
|
| 16 |
-
},
|
| 17 |
-
{
|
| 18 |
-
"epoch": 4.0,
|
| 19 |
-
"learning_rate": 9.6e-05,
|
| 20 |
-
"loss": 4.4086,
|
| 21 |
-
"step": 20
|
| 22 |
-
},
|
| 23 |
-
{
|
| 24 |
-
"epoch": 6.0,
|
| 25 |
-
"learning_rate": 9.4e-05,
|
| 26 |
-
"loss": 3.1851,
|
| 27 |
-
"step": 30
|
| 28 |
-
},
|
| 29 |
-
{
|
| 30 |
-
"epoch": 8.0,
|
| 31 |
-
"learning_rate": 9.200000000000001e-05,
|
| 32 |
-
"loss": 3.2542,
|
| 33 |
-
"step": 40
|
| 34 |
-
},
|
| 35 |
-
{
|
| 36 |
-
"epoch": 10.0,
|
| 37 |
-
"learning_rate": 9e-05,
|
| 38 |
-
"loss": 2.6913,
|
| 39 |
-
"step": 50
|
| 40 |
-
},
|
| 41 |
-
{
|
| 42 |
-
"epoch": 12.0,
|
| 43 |
-
"learning_rate": 8.800000000000001e-05,
|
| 44 |
-
"loss": 2.3765,
|
| 45 |
-
"step": 60
|
| 46 |
-
},
|
| 47 |
-
{
|
| 48 |
-
"epoch": 14.0,
|
| 49 |
-
"learning_rate": 8.6e-05,
|
| 50 |
-
"loss": 2.2853,
|
| 51 |
-
"step": 70
|
| 52 |
-
},
|
| 53 |
-
{
|
| 54 |
-
"epoch": 16.0,
|
| 55 |
-
"learning_rate": 8.4e-05,
|
| 56 |
-
"loss": 2.3182,
|
| 57 |
-
"step": 80
|
| 58 |
-
},
|
| 59 |
-
{
|
| 60 |
-
"epoch": 18.0,
|
| 61 |
-
"learning_rate": 8.2e-05,
|
| 62 |
-
"loss": 2.156,
|
| 63 |
-
"step": 90
|
| 64 |
-
},
|
| 65 |
-
{
|
| 66 |
-
"epoch": 20.0,
|
| 67 |
-
"learning_rate": 8e-05,
|
| 68 |
-
"loss": 1.9019,
|
| 69 |
-
"step": 100
|
| 70 |
-
},
|
| 71 |
-
{
|
| 72 |
-
"epoch": 22.0,
|
| 73 |
-
"learning_rate": 7.800000000000001e-05,
|
| 74 |
-
"loss": 1.8288,
|
| 75 |
-
"step": 110
|
| 76 |
-
},
|
| 77 |
-
{
|
| 78 |
-
"epoch": 24.0,
|
| 79 |
-
"learning_rate": 7.6e-05,
|
| 80 |
-
"loss": 1.7968,
|
| 81 |
-
"step": 120
|
| 82 |
-
},
|
| 83 |
-
{
|
| 84 |
-
"epoch": 26.0,
|
| 85 |
-
"learning_rate": 7.4e-05,
|
| 86 |
-
"loss": 1.6366,
|
| 87 |
-
"step": 130
|
| 88 |
-
},
|
| 89 |
-
{
|
| 90 |
-
"epoch": 28.0,
|
| 91 |
-
"learning_rate": 7.2e-05,
|
| 92 |
-
"loss": 1.5084,
|
| 93 |
-
"step": 140
|
| 94 |
-
},
|
| 95 |
-
{
|
| 96 |
-
"epoch": 30.0,
|
| 97 |
-
"learning_rate": 7e-05,
|
| 98 |
-
"loss": 1.3425,
|
| 99 |
-
"step": 150
|
| 100 |
-
},
|
| 101 |
-
{
|
| 102 |
-
"epoch": 32.0,
|
| 103 |
-
"learning_rate": 6.800000000000001e-05,
|
| 104 |
-
"loss": 1.3157,
|
| 105 |
-
"step": 160
|
| 106 |
-
},
|
| 107 |
-
{
|
| 108 |
-
"epoch": 34.0,
|
| 109 |
-
"learning_rate": 6.6e-05,
|
| 110 |
-
"loss": 1.1184,
|
| 111 |
-
"step": 170
|
| 112 |
-
},
|
| 113 |
-
{
|
| 114 |
-
"epoch": 36.0,
|
| 115 |
-
"learning_rate": 6.400000000000001e-05,
|
| 116 |
-
"loss": 0.8982,
|
| 117 |
-
"step": 180
|
| 118 |
-
},
|
| 119 |
-
{
|
| 120 |
-
"epoch": 38.0,
|
| 121 |
-
"learning_rate": 6.2e-05,
|
| 122 |
-
"loss": 0.7471,
|
| 123 |
-
"step": 190
|
| 124 |
-
},
|
| 125 |
-
{
|
| 126 |
-
"epoch": 40.0,
|
| 127 |
-
"learning_rate": 6e-05,
|
| 128 |
-
"loss": 0.7546,
|
| 129 |
-
"step": 200
|
| 130 |
-
},
|
| 131 |
-
{
|
| 132 |
-
"epoch": 42.0,
|
| 133 |
-
"learning_rate": 5.8e-05,
|
| 134 |
-
"loss": 0.5103,
|
| 135 |
-
"step": 210
|
| 136 |
-
},
|
| 137 |
-
{
|
| 138 |
-
"epoch": 44.0,
|
| 139 |
-
"learning_rate": 5.6000000000000006e-05,
|
| 140 |
-
"loss": 0.4532,
|
| 141 |
-
"step": 220
|
| 142 |
-
},
|
| 143 |
-
{
|
| 144 |
-
"epoch": 46.0,
|
| 145 |
-
"learning_rate": 5.4000000000000005e-05,
|
| 146 |
-
"loss": 0.4687,
|
| 147 |
-
"step": 230
|
| 148 |
-
},
|
| 149 |
-
{
|
| 150 |
-
"epoch": 48.0,
|
| 151 |
-
"learning_rate": 5.2000000000000004e-05,
|
| 152 |
-
"loss": 0.4073,
|
| 153 |
-
"step": 240
|
| 154 |
-
},
|
| 155 |
-
{
|
| 156 |
-
"epoch": 50.0,
|
| 157 |
-
"learning_rate": 5e-05,
|
| 158 |
-
"loss": 0.5488,
|
| 159 |
-
"step": 250
|
| 160 |
-
},
|
| 161 |
-
{
|
| 162 |
-
"epoch": 52.0,
|
| 163 |
-
"learning_rate": 4.8e-05,
|
| 164 |
-
"loss": 0.5888,
|
| 165 |
-
"step": 260
|
| 166 |
-
},
|
| 167 |
-
{
|
| 168 |
-
"epoch": 54.0,
|
| 169 |
-
"learning_rate": 4.600000000000001e-05,
|
| 170 |
-
"loss": 0.3194,
|
| 171 |
-
"step": 270
|
| 172 |
-
},
|
| 173 |
-
{
|
| 174 |
-
"epoch": 56.0,
|
| 175 |
-
"learning_rate": 4.4000000000000006e-05,
|
| 176 |
-
"loss": 0.47,
|
| 177 |
-
"step": 280
|
| 178 |
-
},
|
| 179 |
-
{
|
| 180 |
-
"epoch": 58.0,
|
| 181 |
-
"learning_rate": 4.2e-05,
|
| 182 |
-
"loss": 0.2736,
|
| 183 |
-
"step": 290
|
| 184 |
-
},
|
| 185 |
-
{
|
| 186 |
-
"epoch": 60.0,
|
| 187 |
-
"learning_rate": 4e-05,
|
| 188 |
-
"loss": 0.2798,
|
| 189 |
-
"step": 300
|
| 190 |
-
},
|
| 191 |
-
{
|
| 192 |
-
"epoch": 62.0,
|
| 193 |
-
"learning_rate": 3.8e-05,
|
| 194 |
-
"loss": 0.322,
|
| 195 |
-
"step": 310
|
| 196 |
-
},
|
| 197 |
-
{
|
| 198 |
-
"epoch": 64.0,
|
| 199 |
-
"learning_rate": 3.6e-05,
|
| 200 |
-
"loss": 0.1707,
|
| 201 |
-
"step": 320
|
| 202 |
-
},
|
| 203 |
-
{
|
| 204 |
-
"epoch": 66.0,
|
| 205 |
-
"learning_rate": 3.4000000000000007e-05,
|
| 206 |
-
"loss": 0.1222,
|
| 207 |
-
"step": 330
|
| 208 |
-
},
|
| 209 |
-
{
|
| 210 |
-
"epoch": 68.0,
|
| 211 |
-
"learning_rate": 3.2000000000000005e-05,
|
| 212 |
-
"loss": 0.1246,
|
| 213 |
-
"step": 340
|
| 214 |
-
},
|
| 215 |
-
{
|
| 216 |
-
"epoch": 70.0,
|
| 217 |
-
"learning_rate": 3e-05,
|
| 218 |
-
"loss": 0.1404,
|
| 219 |
-
"step": 350
|
| 220 |
-
},
|
| 221 |
-
{
|
| 222 |
-
"epoch": 72.0,
|
| 223 |
-
"learning_rate": 2.8000000000000003e-05,
|
| 224 |
-
"loss": 0.1098,
|
| 225 |
-
"step": 360
|
| 226 |
-
},
|
| 227 |
-
{
|
| 228 |
-
"epoch": 74.0,
|
| 229 |
-
"learning_rate": 2.6000000000000002e-05,
|
| 230 |
-
"loss": 0.1441,
|
| 231 |
-
"step": 370
|
| 232 |
-
},
|
| 233 |
-
{
|
| 234 |
-
"epoch": 76.0,
|
| 235 |
-
"learning_rate": 2.4e-05,
|
| 236 |
-
"loss": 0.1531,
|
| 237 |
-
"step": 380
|
| 238 |
-
},
|
| 239 |
-
{
|
| 240 |
-
"epoch": 78.0,
|
| 241 |
-
"learning_rate": 2.2000000000000003e-05,
|
| 242 |
-
"loss": 0.1241,
|
| 243 |
-
"step": 390
|
| 244 |
-
},
|
| 245 |
-
{
|
| 246 |
-
"epoch": 80.0,
|
| 247 |
-
"learning_rate": 2e-05,
|
| 248 |
-
"loss": 0.103,
|
| 249 |
-
"step": 400
|
| 250 |
-
},
|
| 251 |
-
{
|
| 252 |
-
"epoch": 82.0,
|
| 253 |
-
"learning_rate": 1.8e-05,
|
| 254 |
-
"loss": 0.0907,
|
| 255 |
-
"step": 410
|
| 256 |
-
},
|
| 257 |
-
{
|
| 258 |
-
"epoch": 84.0,
|
| 259 |
-
"learning_rate": 1.6000000000000003e-05,
|
| 260 |
-
"loss": 0.0909,
|
| 261 |
-
"step": 420
|
| 262 |
-
},
|
| 263 |
-
{
|
| 264 |
-
"epoch": 86.0,
|
| 265 |
-
"learning_rate": 1.4000000000000001e-05,
|
| 266 |
-
"loss": 0.0874,
|
| 267 |
-
"step": 430
|
| 268 |
-
},
|
| 269 |
-
{
|
| 270 |
-
"epoch": 88.0,
|
| 271 |
-
"learning_rate": 1.2e-05,
|
| 272 |
-
"loss": 0.0757,
|
| 273 |
-
"step": 440
|
| 274 |
-
},
|
| 275 |
-
{
|
| 276 |
-
"epoch": 90.0,
|
| 277 |
-
"learning_rate": 1e-05,
|
| 278 |
-
"loss": 0.0753,
|
| 279 |
-
"step": 450
|
| 280 |
-
},
|
| 281 |
-
{
|
| 282 |
-
"epoch": 92.0,
|
| 283 |
-
"learning_rate": 8.000000000000001e-06,
|
| 284 |
-
"loss": 0.0763,
|
| 285 |
-
"step": 460
|
| 286 |
-
},
|
| 287 |
-
{
|
| 288 |
-
"epoch": 94.0,
|
| 289 |
-
"learning_rate": 6e-06,
|
| 290 |
-
"loss": 0.0714,
|
| 291 |
-
"step": 470
|
| 292 |
-
},
|
| 293 |
-
{
|
| 294 |
-
"epoch": 96.0,
|
| 295 |
-
"learning_rate": 4.000000000000001e-06,
|
| 296 |
-
"loss": 0.0736,
|
| 297 |
-
"step": 480
|
| 298 |
-
},
|
| 299 |
-
{
|
| 300 |
-
"epoch": 98.0,
|
| 301 |
-
"learning_rate": 2.0000000000000003e-06,
|
| 302 |
-
"loss": 0.0601,
|
| 303 |
-
"step": 490
|
| 304 |
-
},
|
| 305 |
-
{
|
| 306 |
-
"epoch": 100.0,
|
| 307 |
-
"learning_rate": 0.0,
|
| 308 |
-
"loss": 0.0731,
|
| 309 |
-
"step": 500
|
| 310 |
-
}
|
| 311 |
-
],
|
| 312 |
-
"logging_steps": 10,
|
| 313 |
-
"max_steps": 500,
|
| 314 |
-
"num_input_tokens_seen": 0,
|
| 315 |
-
"num_train_epochs": 100,
|
| 316 |
-
"save_steps": 500,
|
| 317 |
-
"total_flos": 1.4217418628923392e+18,
|
| 318 |
-
"train_batch_size": 2,
|
| 319 |
-
"trial_name": null,
|
| 320 |
-
"trial_params": null
|
| 321 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
model/{checkpoint-500 → checkpoint-80}/config.json
RENAMED
|
File without changes
|
model/{checkpoint-500 → checkpoint-80}/generation_config.json
RENAMED
|
File without changes
|
model/checkpoint-80/merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model/{checkpoint-500 → checkpoint-80}/model.safetensors
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 1335747032
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8ce666f30135fe9e723b0337705aa538819616ab1c0c45d7c0f9f549314a0dce
|
| 3 |
size 1335747032
|
model/{checkpoint-500 → checkpoint-80}/optimizer.pt
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 2667050412
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8568a62b60ef9d306370cc762c375ed8fd56ebb7d39410683030cda2df3a92bc
|
| 3 |
size 2667050412
|
model/checkpoint-80/preprocessor_config.json
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"do_normalize": true,
|
| 3 |
+
"do_resize": true,
|
| 4 |
+
"image_processor_type": "ViTImageProcessor",
|
| 5 |
+
"image_mean": [
|
| 6 |
+
0.5,
|
| 7 |
+
0.5,
|
| 8 |
+
0.5
|
| 9 |
+
],
|
| 10 |
+
"image_std": [
|
| 11 |
+
0.5,
|
| 12 |
+
0.5,
|
| 13 |
+
0.5
|
| 14 |
+
],
|
| 15 |
+
"resample": 2,
|
| 16 |
+
"size": 384
|
| 17 |
+
}
|
model/{checkpoint-500 → checkpoint-80}/rng_state.pth
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 14244
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3a8b95444924300e71db054e45eaa19e41cd683c6b7cd4716def561162febc69
|
| 3 |
size 14244
|
model/{checkpoint-500 → checkpoint-80}/scheduler.pt
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 1064
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e04a01946a1a22d7f67e161ee04b6430e62bf4eaaeb4428ef0cbe16393ea0cff
|
| 3 |
size 1064
|
model/checkpoint-80/special_tokens_map.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"bos_token": {"content": "<s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true}, "eos_token": {"content": "</s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true}, "unk_token": {"content": "<unk>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true}, "sep_token": {"content": "</s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true}, "pad_token": {"content": "<pad>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true}, "cls_token": {"content": "<s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true}, "mask_token": {"content": "<mask>", "single_word": false, "lstrip": true, "rstrip": false, "normalized": true}}
|
model/checkpoint-80/tokenizer_config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"errors": "replace", "unk_token": {"content": "<unk>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "bos_token": {"content": "<s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "eos_token": {"content": "</s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "add_prefix_space": false, "sep_token": {"content": "</s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "cls_token": {"content": "<s>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "pad_token": {"content": "<pad>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "mask_token": {"content": "<mask>", "single_word": false, "lstrip": true, "rstrip": false, "normalized": true, "__type": "AddedToken"}, "model_max_length": 512, "special_tokens_map_file": null, "name_or_path": "roberta-large", "tokenizer_class": "RobertaTokenizer"}
|
model/checkpoint-80/trainer_state.json
ADDED
|
@@ -0,0 +1,213 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 17.77777777777778,
|
| 5 |
+
"eval_steps": 500,
|
| 6 |
+
"global_step": 80,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 0.89,
|
| 13 |
+
"eval_loss": 11.255721092224121,
|
| 14 |
+
"eval_runtime": 3.4824,
|
| 15 |
+
"eval_samples_per_second": 1.436,
|
| 16 |
+
"eval_steps_per_second": 0.287,
|
| 17 |
+
"step": 4
|
| 18 |
+
},
|
| 19 |
+
{
|
| 20 |
+
"epoch": 2.0,
|
| 21 |
+
"eval_loss": 4.6637139320373535,
|
| 22 |
+
"eval_runtime": 1.651,
|
| 23 |
+
"eval_samples_per_second": 3.029,
|
| 24 |
+
"eval_steps_per_second": 0.606,
|
| 25 |
+
"step": 9
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
"epoch": 2.22,
|
| 29 |
+
"learning_rate": 8.75e-05,
|
| 30 |
+
"loss": 9.1378,
|
| 31 |
+
"step": 10
|
| 32 |
+
},
|
| 33 |
+
{
|
| 34 |
+
"epoch": 2.89,
|
| 35 |
+
"eval_loss": 3.9639782905578613,
|
| 36 |
+
"eval_runtime": 3.628,
|
| 37 |
+
"eval_samples_per_second": 1.378,
|
| 38 |
+
"eval_steps_per_second": 0.276,
|
| 39 |
+
"step": 13
|
| 40 |
+
},
|
| 41 |
+
{
|
| 42 |
+
"epoch": 4.0,
|
| 43 |
+
"eval_loss": 3.660576343536377,
|
| 44 |
+
"eval_runtime": 1.6465,
|
| 45 |
+
"eval_samples_per_second": 3.037,
|
| 46 |
+
"eval_steps_per_second": 0.607,
|
| 47 |
+
"step": 18
|
| 48 |
+
},
|
| 49 |
+
{
|
| 50 |
+
"epoch": 4.44,
|
| 51 |
+
"learning_rate": 7.500000000000001e-05,
|
| 52 |
+
"loss": 3.7563,
|
| 53 |
+
"step": 20
|
| 54 |
+
},
|
| 55 |
+
{
|
| 56 |
+
"epoch": 4.89,
|
| 57 |
+
"eval_loss": 3.774608612060547,
|
| 58 |
+
"eval_runtime": 3.6221,
|
| 59 |
+
"eval_samples_per_second": 1.38,
|
| 60 |
+
"eval_steps_per_second": 0.276,
|
| 61 |
+
"step": 22
|
| 62 |
+
},
|
| 63 |
+
{
|
| 64 |
+
"epoch": 6.0,
|
| 65 |
+
"eval_loss": 4.067192077636719,
|
| 66 |
+
"eval_runtime": 1.6587,
|
| 67 |
+
"eval_samples_per_second": 3.014,
|
| 68 |
+
"eval_steps_per_second": 0.603,
|
| 69 |
+
"step": 27
|
| 70 |
+
},
|
| 71 |
+
{
|
| 72 |
+
"epoch": 6.67,
|
| 73 |
+
"learning_rate": 6.25e-05,
|
| 74 |
+
"loss": 2.8464,
|
| 75 |
+
"step": 30
|
| 76 |
+
},
|
| 77 |
+
{
|
| 78 |
+
"epoch": 6.89,
|
| 79 |
+
"eval_loss": 4.304504871368408,
|
| 80 |
+
"eval_runtime": 3.619,
|
| 81 |
+
"eval_samples_per_second": 1.382,
|
| 82 |
+
"eval_steps_per_second": 0.276,
|
| 83 |
+
"step": 31
|
| 84 |
+
},
|
| 85 |
+
{
|
| 86 |
+
"epoch": 8.0,
|
| 87 |
+
"eval_loss": 3.801119327545166,
|
| 88 |
+
"eval_runtime": 1.8745,
|
| 89 |
+
"eval_samples_per_second": 2.667,
|
| 90 |
+
"eval_steps_per_second": 0.533,
|
| 91 |
+
"step": 36
|
| 92 |
+
},
|
| 93 |
+
{
|
| 94 |
+
"epoch": 8.89,
|
| 95 |
+
"learning_rate": 5e-05,
|
| 96 |
+
"loss": 2.462,
|
| 97 |
+
"step": 40
|
| 98 |
+
},
|
| 99 |
+
{
|
| 100 |
+
"epoch": 8.89,
|
| 101 |
+
"eval_loss": 4.001826763153076,
|
| 102 |
+
"eval_runtime": 3.9564,
|
| 103 |
+
"eval_samples_per_second": 1.264,
|
| 104 |
+
"eval_steps_per_second": 0.253,
|
| 105 |
+
"step": 40
|
| 106 |
+
},
|
| 107 |
+
{
|
| 108 |
+
"epoch": 10.0,
|
| 109 |
+
"eval_loss": 4.09613037109375,
|
| 110 |
+
"eval_runtime": 1.772,
|
| 111 |
+
"eval_samples_per_second": 2.822,
|
| 112 |
+
"eval_steps_per_second": 0.564,
|
| 113 |
+
"step": 45
|
| 114 |
+
},
|
| 115 |
+
{
|
| 116 |
+
"epoch": 10.89,
|
| 117 |
+
"eval_loss": 4.627002239227295,
|
| 118 |
+
"eval_runtime": 4.0617,
|
| 119 |
+
"eval_samples_per_second": 1.231,
|
| 120 |
+
"eval_steps_per_second": 0.246,
|
| 121 |
+
"step": 49
|
| 122 |
+
},
|
| 123 |
+
{
|
| 124 |
+
"epoch": 11.11,
|
| 125 |
+
"learning_rate": 3.7500000000000003e-05,
|
| 126 |
+
"loss": 2.1133,
|
| 127 |
+
"step": 50
|
| 128 |
+
},
|
| 129 |
+
{
|
| 130 |
+
"epoch": 12.0,
|
| 131 |
+
"eval_loss": 4.324659824371338,
|
| 132 |
+
"eval_runtime": 1.8005,
|
| 133 |
+
"eval_samples_per_second": 2.777,
|
| 134 |
+
"eval_steps_per_second": 0.555,
|
| 135 |
+
"step": 54
|
| 136 |
+
},
|
| 137 |
+
{
|
| 138 |
+
"epoch": 12.89,
|
| 139 |
+
"eval_loss": 4.851120471954346,
|
| 140 |
+
"eval_runtime": 3.967,
|
| 141 |
+
"eval_samples_per_second": 1.26,
|
| 142 |
+
"eval_steps_per_second": 0.252,
|
| 143 |
+
"step": 58
|
| 144 |
+
},
|
| 145 |
+
{
|
| 146 |
+
"epoch": 13.33,
|
| 147 |
+
"learning_rate": 2.5e-05,
|
| 148 |
+
"loss": 1.7555,
|
| 149 |
+
"step": 60
|
| 150 |
+
},
|
| 151 |
+
{
|
| 152 |
+
"epoch": 14.0,
|
| 153 |
+
"eval_loss": 4.627060413360596,
|
| 154 |
+
"eval_runtime": 1.8189,
|
| 155 |
+
"eval_samples_per_second": 2.749,
|
| 156 |
+
"eval_steps_per_second": 0.55,
|
| 157 |
+
"step": 63
|
| 158 |
+
},
|
| 159 |
+
{
|
| 160 |
+
"epoch": 14.89,
|
| 161 |
+
"eval_loss": 4.949428081512451,
|
| 162 |
+
"eval_runtime": 3.9565,
|
| 163 |
+
"eval_samples_per_second": 1.264,
|
| 164 |
+
"eval_steps_per_second": 0.253,
|
| 165 |
+
"step": 67
|
| 166 |
+
},
|
| 167 |
+
{
|
| 168 |
+
"epoch": 15.56,
|
| 169 |
+
"learning_rate": 1.25e-05,
|
| 170 |
+
"loss": 1.2005,
|
| 171 |
+
"step": 70
|
| 172 |
+
},
|
| 173 |
+
{
|
| 174 |
+
"epoch": 16.0,
|
| 175 |
+
"eval_loss": 5.440162658691406,
|
| 176 |
+
"eval_runtime": 1.803,
|
| 177 |
+
"eval_samples_per_second": 2.773,
|
| 178 |
+
"eval_steps_per_second": 0.555,
|
| 179 |
+
"step": 72
|
| 180 |
+
},
|
| 181 |
+
{
|
| 182 |
+
"epoch": 16.89,
|
| 183 |
+
"eval_loss": 5.508076190948486,
|
| 184 |
+
"eval_runtime": 4.004,
|
| 185 |
+
"eval_samples_per_second": 1.249,
|
| 186 |
+
"eval_steps_per_second": 0.25,
|
| 187 |
+
"step": 76
|
| 188 |
+
},
|
| 189 |
+
{
|
| 190 |
+
"epoch": 17.78,
|
| 191 |
+
"learning_rate": 0.0,
|
| 192 |
+
"loss": 0.8324,
|
| 193 |
+
"step": 80
|
| 194 |
+
},
|
| 195 |
+
{
|
| 196 |
+
"epoch": 17.78,
|
| 197 |
+
"eval_loss": 5.481626510620117,
|
| 198 |
+
"eval_runtime": 0.8414,
|
| 199 |
+
"eval_samples_per_second": 5.942,
|
| 200 |
+
"eval_steps_per_second": 1.188,
|
| 201 |
+
"step": 80
|
| 202 |
+
}
|
| 203 |
+
],
|
| 204 |
+
"logging_steps": 10,
|
| 205 |
+
"max_steps": 80,
|
| 206 |
+
"num_input_tokens_seen": 0,
|
| 207 |
+
"num_train_epochs": 20,
|
| 208 |
+
"save_steps": 500,
|
| 209 |
+
"total_flos": 2.267304128717783e+17,
|
| 210 |
+
"train_batch_size": 2,
|
| 211 |
+
"trial_name": null,
|
| 212 |
+
"trial_params": null
|
| 213 |
+
}
|
model/{checkpoint-500 → checkpoint-80}/training_args.bin
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4664
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9d72d8dc11b5be144d27c80846224147801c5764c4f0d0a5b47575c67d145b15
|
| 3 |
size 4664
|
model/checkpoint-80/vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
requirements.txt
CHANGED
|
@@ -1,6 +1,7 @@
|
|
| 1 |
-
transformers
|
| 2 |
-
torch
|
| 3 |
-
pandas
|
| 4 |
-
pillow
|
| 5 |
-
scikit-learn
|
| 6 |
-
accelerate
|
|
|
|
|
|
| 1 |
+
transformers~=4.37.2
|
| 2 |
+
torch~=2.2.0+cu121
|
| 3 |
+
pandas~=2.2.0
|
| 4 |
+
pillow~=10.2.0
|
| 5 |
+
scikit-learn~=1.4.1.post1
|
| 6 |
+
accelerate
|
| 7 |
+
requests~=2.31.0
|
train.py
CHANGED
|
@@ -16,7 +16,7 @@ class HandwrittenMathDataset(Dataset):
|
|
| 16 |
"""
|
| 17 |
def __init__(self, annotations_file, img_dir, processor, subset="train"):
|
| 18 |
self.img_labels = pd.read_csv(annotations_file)
|
| 19 |
-
self.train_data, self.test_data = train_test_split(self.img_labels, test_size=0.
|
| 20 |
self.data = self.train_data if subset == "train" else self.test_data
|
| 21 |
self.img_dir = img_dir
|
| 22 |
self.processor = processor
|
|
@@ -62,15 +62,16 @@ def main():
|
|
| 62 |
training_args = TrainingArguments(
|
| 63 |
output_dir='./model',
|
| 64 |
per_device_train_batch_size=2,
|
| 65 |
-
num_train_epochs=
|
| 66 |
logging_dir='./training_logs',
|
| 67 |
logging_steps=10,
|
| 68 |
save_strategy="epoch",
|
| 69 |
save_total_limit=1,
|
| 70 |
-
weight_decay=0.
|
| 71 |
learning_rate=1e-4,
|
| 72 |
gradient_checkpointing=True,
|
| 73 |
-
gradient_accumulation_steps=2
|
|
|
|
| 74 |
)
|
| 75 |
|
| 76 |
trainer = Trainer(
|
|
|
|
| 16 |
"""
|
| 17 |
def __init__(self, annotations_file, img_dir, processor, subset="train"):
|
| 18 |
self.img_labels = pd.read_csv(annotations_file)
|
| 19 |
+
self.train_data, self.test_data = train_test_split(self.img_labels, test_size=0.2, random_state=42)
|
| 20 |
self.data = self.train_data if subset == "train" else self.test_data
|
| 21 |
self.img_dir = img_dir
|
| 22 |
self.processor = processor
|
|
|
|
| 62 |
training_args = TrainingArguments(
|
| 63 |
output_dir='./model',
|
| 64 |
per_device_train_batch_size=2,
|
| 65 |
+
num_train_epochs=20,
|
| 66 |
logging_dir='./training_logs',
|
| 67 |
logging_steps=10,
|
| 68 |
save_strategy="epoch",
|
| 69 |
save_total_limit=1,
|
| 70 |
+
weight_decay=0.1,
|
| 71 |
learning_rate=1e-4,
|
| 72 |
gradient_checkpointing=True,
|
| 73 |
+
gradient_accumulation_steps=2,
|
| 74 |
+
evaluation_strategy="epoch"
|
| 75 |
)
|
| 76 |
|
| 77 |
trainer = Trainer(
|