

Commit
•
06566f4
1
Parent(s):
e69bd77
Upload folder using huggingface_hub
Browse files- README.md +11 -11
- all_results.json +6 -6
- config.json +4 -4
- generation_config.json +1 -1
- input_embeddings.pt +3 -0
- model-00001-of-00003.safetensors +2 -2
- model-00003-of-00003.safetensors +2 -2
- model.safetensors.index.json +1 -1
- output_embeddings.pt +3 -0
- tokenizer.json +0 -0
- tokenizer.model +2 -2
- train_results.json +6 -6
- trainer_log.jsonl +0 -0
- trainer_state.json +0 -0
- training_args.bin +2 -2
- training_loss.png +0 -0
README.md
CHANGED
|
@@ -3,19 +3,19 @@ license: other
|
|
| 3 |
base_model: 01-ai/Yi-1.5-6B
|
| 4 |
tags:
|
| 5 |
- llama-factory
|
| 6 |
-
-
|
| 7 |
- generated_from_trainer
|
| 8 |
model-index:
|
| 9 |
-
- name:
|
| 10 |
results: []
|
| 11 |
---
|
| 12 |
|
| 13 |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 14 |
should probably proofread and complete it, then remove this comment. -->
|
| 15 |
|
| 16 |
-
#
|
| 17 |
|
| 18 |
-
This model is a fine-tuned version of [01-ai/Yi-1.5-6B](https://huggingface.co/01-ai/Yi-1.5-6B) on the
|
| 19 |
|
| 20 |
## Model description
|
| 21 |
|
|
@@ -34,12 +34,12 @@ More information needed
|
|
| 34 |
### Training hyperparameters
|
| 35 |
|
| 36 |
The following hyperparameters were used during training:
|
| 37 |
-
- learning_rate:
|
| 38 |
-
- train_batch_size:
|
| 39 |
- eval_batch_size: 8
|
| 40 |
- seed: 42
|
| 41 |
-
- gradient_accumulation_steps:
|
| 42 |
-
- total_train_batch_size:
|
| 43 |
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 44 |
- lr_scheduler_type: cosine
|
| 45 |
- lr_scheduler_warmup_ratio: 0.1
|
|
@@ -51,7 +51,7 @@ The following hyperparameters were used during training:
|
|
| 51 |
|
| 52 |
### Framework versions
|
| 53 |
|
| 54 |
-
- Transformers 4.41.
|
| 55 |
-
- Pytorch 2.
|
| 56 |
-
- Datasets 2.
|
| 57 |
- Tokenizers 0.19.1
|
|
|
|
| 3 |
base_model: 01-ai/Yi-1.5-6B
|
| 4 |
tags:
|
| 5 |
- llama-factory
|
| 6 |
+
- freeze
|
| 7 |
- generated_from_trainer
|
| 8 |
model-index:
|
| 9 |
+
- name: yi-1.5-6b-yub-vocab-expanded
|
| 10 |
results: []
|
| 11 |
---
|
| 12 |
|
| 13 |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 14 |
should probably proofread and complete it, then remove this comment. -->
|
| 15 |
|
| 16 |
+
# yi-1.5-6b-yub-vocab-expanded
|
| 17 |
|
| 18 |
+
This model is a fine-tuned version of [01-ai/Yi-1.5-6B](https://huggingface.co/01-ai/Yi-1.5-6B) undergone layers freezeing learning on the 300m tokens Cantonese dataset, in order to train a new words embedding in the expanded vocab. This model has not been continued pre-trainined, therefore it is not recommended to be used for further pre-training.
|
| 19 |
|
| 20 |
## Model description
|
| 21 |
|
|
|
|
| 34 |
### Training hyperparameters
|
| 35 |
|
| 36 |
The following hyperparameters were used during training:
|
| 37 |
+
- learning_rate: 0.0002
|
| 38 |
+
- train_batch_size: 8
|
| 39 |
- eval_batch_size: 8
|
| 40 |
- seed: 42
|
| 41 |
+
- gradient_accumulation_steps: 16
|
| 42 |
+
- total_train_batch_size: 128
|
| 43 |
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 44 |
- lr_scheduler_type: cosine
|
| 45 |
- lr_scheduler_warmup_ratio: 0.1
|
|
|
|
| 51 |
|
| 52 |
### Framework versions
|
| 53 |
|
| 54 |
+
- Transformers 4.41.2
|
| 55 |
+
- Pytorch 2.1.1+cu121
|
| 56 |
+
- Datasets 2.15.0
|
| 57 |
- Tokenizers 0.19.1
|
all_results.json
CHANGED
|
@@ -1,8 +1,8 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch": 0.
|
| 3 |
-
"total_flos": 1.
|
| 4 |
-
"train_loss": 2.
|
| 5 |
-
"train_runtime":
|
| 6 |
-
"train_samples_per_second":
|
| 7 |
-
"train_steps_per_second": 0.
|
| 8 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 0.9996843204390374,
|
| 3 |
+
"total_flos": 1.1741952995733012e+19,
|
| 4 |
+
"train_loss": 2.4089672912015,
|
| 5 |
+
"train_runtime": 234538.8638,
|
| 6 |
+
"train_samples_per_second": 1.405,
|
| 7 |
+
"train_steps_per_second": 0.011
|
| 8 |
}
|
config.json
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
{
|
| 2 |
-
"_name_or_path": "
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
|
@@ -24,7 +24,7 @@
|
|
| 24 |
"rope_theta": 5000000.0,
|
| 25 |
"tie_word_embeddings": false,
|
| 26 |
"torch_dtype": "bfloat16",
|
| 27 |
-
"transformers_version": "4.41.
|
| 28 |
"use_cache": false,
|
| 29 |
-
"vocab_size":
|
| 30 |
-
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"_name_or_path": "/notebooks/cantonese/llm/models/cantonesellm-cpt-freeze-stag4",
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
|
|
|
| 24 |
"rope_theta": 5000000.0,
|
| 25 |
"tie_word_embeddings": false,
|
| 26 |
"torch_dtype": "bfloat16",
|
| 27 |
+
"transformers_version": "4.41.2",
|
| 28 |
"use_cache": false,
|
| 29 |
+
"vocab_size": 64960
|
| 30 |
+
}
|
generation_config.json
CHANGED
|
@@ -3,5 +3,5 @@
|
|
| 3 |
"bos_token_id": 1,
|
| 4 |
"eos_token_id": 2,
|
| 5 |
"pad_token_id": 0,
|
| 6 |
-
"transformers_version": "4.41.
|
| 7 |
}
|
|
|
|
| 3 |
"bos_token_id": 1,
|
| 4 |
"eos_token_id": 2,
|
| 5 |
"pad_token_id": 0,
|
| 6 |
+
"transformers_version": "4.41.2"
|
| 7 |
}
|
input_embeddings.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dae04d5b3dc1f774ad3ef3dca400667e0fde0759e99ec177b99ff3bea95b33db
|
| 3 |
+
size 532153609
|
model-00001-of-00003.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8f0af518c6f76698587e49a83d16120edd6182bb7a5c8342a0e7963d4cb803bc
|
| 3 |
+
size 4940575744
|
model-00003-of-00003.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:88e33b7ea19ad5973387ea98297dec865216dc05db45c13a21f8157171ace697
|
| 3 |
+
size 2220454888
|
model.safetensors.index.json
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
{
|
| 2 |
"metadata": {
|
| 3 |
-
"total_size":
|
| 4 |
},
|
| 5 |
"weight_map": {
|
| 6 |
"lm_head.weight": "model-00003-of-00003.safetensors",
|
|
|
|
| 1 |
{
|
| 2 |
"metadata": {
|
| 3 |
+
"total_size": 12137799680
|
| 4 |
},
|
| 5 |
"weight_map": {
|
| 6 |
"lm_head.weight": "model-00003-of-00003.safetensors",
|
output_embeddings.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:403d104a28113d0f501a4e21457233d4a617bf87f8777be9db2c3f3e8e0e2133
|
| 3 |
+
size 532153614
|
tokenizer.json
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:67909bb0045622af428982dee9b3f1033cf5c4bca5c9423a028d3748364ee14f
|
| 3 |
+
size 1044277
|
train_results.json
CHANGED
|
@@ -1,8 +1,8 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch": 0.
|
| 3 |
-
"total_flos": 1.
|
| 4 |
-
"train_loss": 2.
|
| 5 |
-
"train_runtime":
|
| 6 |
-
"train_samples_per_second":
|
| 7 |
-
"train_steps_per_second": 0.
|
| 8 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 0.9996843204390374,
|
| 3 |
+
"total_flos": 1.1741952995733012e+19,
|
| 4 |
+
"train_loss": 2.4089672912015,
|
| 5 |
+
"train_runtime": 234538.8638,
|
| 6 |
+
"train_samples_per_second": 1.405,
|
| 7 |
+
"train_steps_per_second": 0.011
|
| 8 |
}
|
trainer_log.jsonl
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
trainer_state.json
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
training_args.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fb43ea03774dbe8fe1db1935888be2a5b022c32feeeccc53f0cae49079f4809f
|
| 3 |
+
size 5368
|
training_loss.png
CHANGED

|
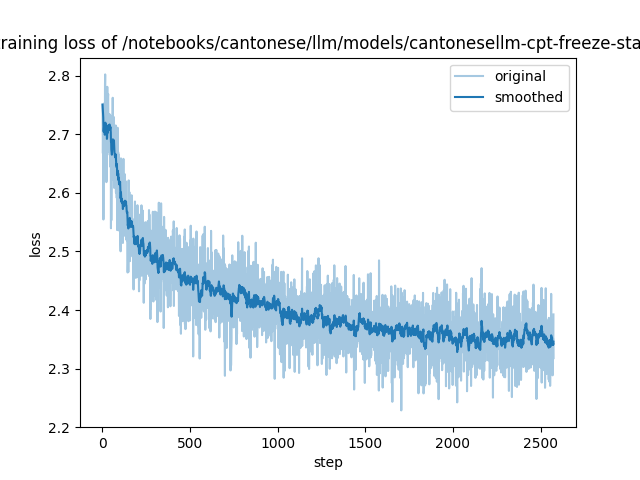
|