

Update README.md
Browse files
README.md
CHANGED
|
@@ -38,9 +38,9 @@ embeds_dropout_prob = 0.1
|
|
| 38 |
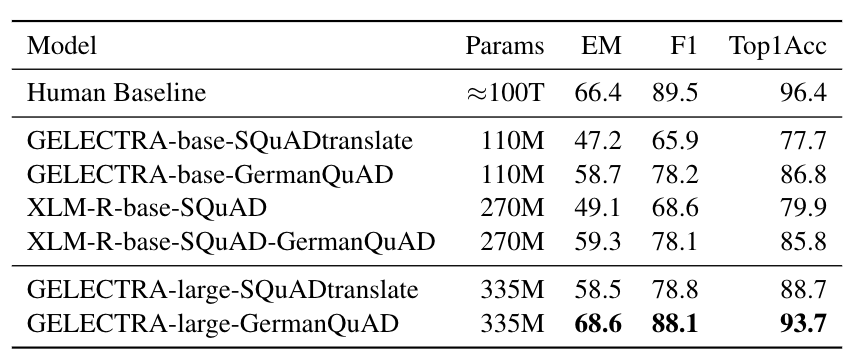
We evaluated the extractive question answering performance on our GermanQuAD test set.
|
| 39 |
Model types and training data are included in the model name.
|
| 40 |
For finetuning XLM-Roberta, we use the English SQuAD v2.0 dataset.
|
| 41 |
-
The GELECTRA models are warm started on the German translation of SQuAD v1.1 and finetuned on
|
| 42 |
The human baseline was computed for the 3-way test set by taking one answer as prediction and the other two as ground truth.
|
| 43 |
-
.
|
| 42 |
The human baseline was computed for the 3-way test set by taking one answer as prediction and the other two as ground truth.
|
| 43 |
+
|
| 44 |
|
| 45 |
## Authors
|
| 46 |
**Timo Möller:** [email protected]
|