QuantFactory/Llama-3.1-Herrsimian-8B-GGUF
Updated
•
210
•
1

Herrsimian is a tiny (131 samples), long-context (up to about 52k tokens) NSFW conversational dataset containing mainly data from a certain expert roleplayer who used to actively participate on a few different forums until the end of 2022. It's used in Llama-3.1-Herrsimian-8B.
The roleplays are mostly in book/novel style, with narration in past tense and third person perspective, as well as quote mark-delimited dialogue lines. Markdown-style roleplay has not been included due to lack of data.
☢️ Warning: the dataset is almost entirely composed of highly questionable content.
The dataset is mostly finished in terms of content. I plan adding more OOC messages to improve steerability, as well as fixing any issue that I might spot.
Note that the dataset is not in a standard ShareGPT format. It has a separate name field for character names, and user/assistant turns do not alternate like you would normally expect. Read further below for more details. You will have to process it with Python code for best results.
All samples are composed of an initial backtranslated instruction defining scenario, backstory (if applicable), characters, task, and then a manually curated, fully segmented conversation with user and assistant talking in turns for their own characters, narration or OOC. Usernames have been removed; only character names remain.
In addition to pure forum-style roleplay data, the dataset includes a few celebrity interviews (mainly politicians), initially included in an attempt to boost conversation capabilities beyond roleplaying and hopefully diluting the R18+ content out of it. It's unclear if they are truly helpful, especially since the dataset has grown way beyond its original size.
An intentional design quirk of this dataset is that the conversations are multicharacter. Either the user or the model may play the role of more than one character, and user/model turns may not necessarily alternate, unlike what normally happens in most other datasets and as required in many cases for proper training. This can make the dataset incompatible with certain pipelines.
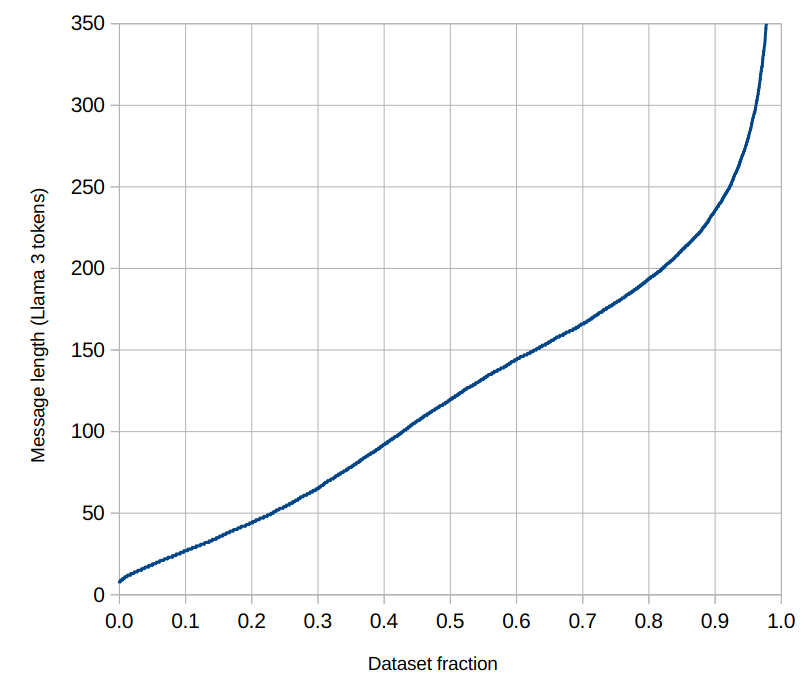
A second notable intentional design quirk is that message length is highly variable, ranging from a few to several hundred tokens length, although on average they will be around the 150 tokens range (estimated). The idea is that the model should be able to learn when to naturally use short or long messages, and not just focus on one specific length. Dataset samples never contain long sections with very short messages, in any case.
A third difference from most datasets is that oftentimes two or more characters may speak or act simultanously. This is rendered by joining more character names together with an ampersand in the form of Char1 & Char2 & CharN, similarly to what happens in the script of some Japanese visual novels.
Additionally, characters may occasionally change name; this usually happens their name gets revealed in the story. In this case, for one message the character name is transitionally rendered in the form of Oldname (Newname), with subsequent messages continuing with Newname.
The initial backtranslated instruction doesn't follow a fixed formatting, but it usually includes at least the description of the assistant character(s), title and scenario (summary of the events that will happen in the roleplay).
| Field | Description |
|---|---|
| role | For the roleplays, whenever possible the role of assistant was assigned to that roleplayer, in order to make the model more likely to write in the same style. In other cases, persons with lower-quality or shorter messages have been assigned the user role.No system role has been used yet, although the first user message most of the time can be thought as a "system" message. |
| name | The name of the character acting or speaking was also included. In its absence, it can be assumed that it's either the LLM or the user talking to each other. Some effort was put to randomize names when they were used too frequently, although more work needs to be done in this regard. OOC messages have been given either the user or assistant role depending on the context, but never a name. |
| content | The message or utterance. For roleplay, generally it's in typical book/forum style, with narration in third person and past tense and dialogue lines delimited by ASCII quote marks. |
Given the tiny number of samples, ordinary finetuning strategies intended for large amounts of data won't work well. The dataset was primarily intended to give one voice to the model via sensible overfitting. With Llama-3.1-Herrsimian-8B I used 5 training epochs via LoRA finetuning.
I would discourage masking user turns as in general their writing quality is moderately good and overall they contribute positively to the dataset. In my models I usually train the entire preformatted conversations as raw text / text completion.
To limit the horniness of the trained model it might be beneficial to clip the conversations to whatever fits the training context size and not reuse the rest, since most of the time NSFW scenes do not begin right away in the various scenes.
The first few samples in the dataset are composed of interviews with real-life celebrities and politicians, so they could be skipped. The last several samples are from the same long roleplay and they could also be skipped in order to avoid adding too much of the same content (which might promote hallucinations).