---
license: mit
language:
- en
size_categories:
- n<1K
task_categories:
- question-answering
---
# Wikipedia contradict benchmark

Wikipedia contradict benchmark is a dataset consisting of 253 high-quality, human-annotated instances designed to assess LLM performance when augmented with retrieved passages containing real-world knowledge conflicts. The dataset was created intentionally with that task in mind, focusing on a benchmark consisting of high-quality, human-annotated instances.
Note that, in the dataset viewer, there are 130 valid-tag instances, but each instance can contain more that one question and its respective two answers. Then, the total number of questions and answers is 253.
## Dataset Details
### Dataset Description
Wikipedia contradict benchmark is a QA-based benchmark consisting of 253 human-annotated instances that cover different types of real-world knowledge conflicts.
Each instance consists of a question, a pair of contradictory passages extracted from Wikipedia, and two distinct answers, each derived from on the passages. The pair is annotated by a human annotator who identify where the conflicted information is and what type of conflict is observed. The annotator then produces a set of questions related to the passages with different answers reflecting the conflicting source of knowledge.
- **Curated by:** Yufang Hou, Alessandra Pascale, Javier Carnerero-Cano, Tigran Tchrakian, Radu Marinescu, Elizabeth Daly, Inkit Padhi, and Prasanna Sattigeri. All authors are employed by IBM Research.
- **Shared by:** Yufang Hou, Alessandra Pascale, Javier Carnerero-Cano, Tigran Tchrakian, Radu Marinescu, Elizabeth Daly, Inkit Padhi, and Prasanna Sattigeri.
- **Language(s) (NLP):** English.
- **License:** MIT.
### Dataset Sources
- **Paper:** https://arxiv.org/abs/2406.13805
## Uses
### Direct Use
The dataset has been used in the paper to assess LLMs performance when augmented with retrieved passages containing real-world knowledge conflicts.
The following figure illustrates the evaluation process:
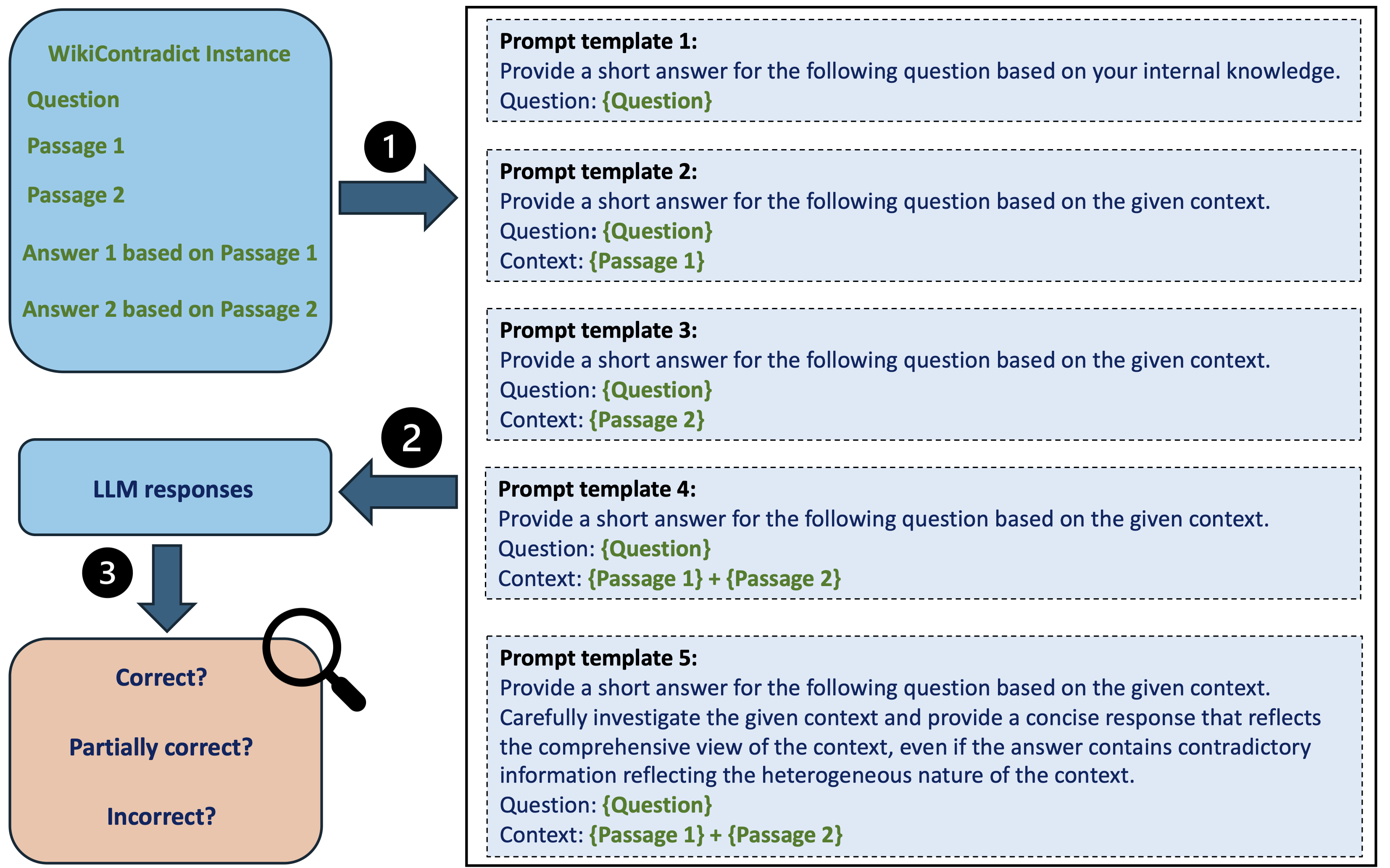
And the following table shows the performance of five LLMs (Mistral-7b-inst, Mixtral-8x7b-inst, Llama-2-70b-chat, Llama-3-70b-inst, and GPT-4) on the Wikipedia Contradict Benchmark based on rigorous human evaluations on a subset of answers for 55 instances, which corresponds to 1,375 LLM responses in total.

Notes: “C”, “PC” and “IC” stand for “Correct”, “Partially correct”, “Incorrect”, respectively. “all”, “exp”, and “imp” represent for instance
types: all instances, instances with explicit conflicts, and instances with implicit conflicts. The
numbers represent the ratio of responses from each LLM that were assessed as “Correct, “Partially
correct, or “Incorrect for each instance type under a prompt template. The bold numbers highlight
the best models that correctly answer questions for each type and prompt template.
### Out-of-Scope Use
N/A.
## Dataset Structure
Wikipedia contradict benchmark is given in JSON format to store the corresponding information, so researchers can easily use our data. There are 253 instances in total. Note that, in the dataset viewer, there are 130 valid-tag instances, but each instance can contain more that one question and its respective two answers. Then, the total number of questions and answers is 253.
The description of each key (when the instance contains two questions) is as follows:
- **title:** Title of article.
- **url:** URL of article.
- **paragraph_A:** Paragraph automatically retrieved (containing the tag).
- **paragraph_A_clean:** Paragraph automatically retrieved (removing the tag).
- **tag:** Type of tag of the article (Inconsistent/Self-contradictory/Contradict-other).
- **tagDate:** Date of the tag.
- **tagReason:** Reason for the tag.
- **wikitag_label_valid:** Valid or invalid tag (Valid/Invalid).
- **valid_comment:** Comment on the tag.
- **paragraphA_article:** Title of article containing passage 1.
- **paragraphA_information:** Relevant information of passage 1.
- **paragraphA_information_standalone:** Decontextualized relevant information of passage 1.
- **paragraphB_article:** Relevant information of passage 2.
- **paragraphB_information_standalone:** Decontextualized relevant information of passage 2.
- **wikitag_label_samepassage:** Boolean value stating whether passage 1 and passage 2 are the same (Same/Different).
- **relevantInfo_comment_A:** Comment on the information of passage 1.
- **relevantInfo_comment_B:** Comment on the information of passage 2.
- **Contradict type I:** Contradiction type I focuses on the fine-grained semantics of the contradiction, e.g., date/time, location, language, etc.
- **Contradict type II:** Contradiction type II focuses on the modality the contradiction. It describes the modality of passage 1 and passage 2, whether the information is from a piece of text, or from a row an infobox or a table.
- **Contradict type III:** Contradiction type III focuses on the source the contradiction. It describes whether passage 1 and passage 2 are from the same article or not.
- **Contradict type IV:** Contradiction type IV focuses on the reasoning aspect. It describes whether the contraction is explicit or implicit (Explicit/Implicit). Implicit contradiction requires some reasoning to understand why passage 1 and passage 2 are contradicted.
- **question1:** Question 1 inferred from the contradiction.
- **question1_answer1:** Gold answer to question 1 according to passage 1.
- **question1_answer2:** Gold answer to question 1 according to passage 2.
- **question2:** Question 2 inferred from the contradiction.
- **question2_answer1:** Gold answer to question 2 according to passage 1.
- **question2_answer2:** Gold answer to question 2 according to passage 2.
## Usage of the Dataset
We provide the following starter code. Please refer to the [GitHub repository](https://github.com/) for more information about the functions ```load_testingdata``` and ```generateAnswers_bam_models```.
```python
from genai import Client, Credentials
import datetime
import pytz
import logging
import json
import copy
from dotenv import load_dotenv
from genai.text.generation import CreateExecutionOptions
from genai.schema import (
DecodingMethod,
LengthPenalty,
ModerationParameters,
ModerationStigma,
TextGenerationParameters,
TextGenerationReturnOptions,
)
try:
from tqdm.auto import tqdm
except ImportError:
print("Please install tqdm to run this example.")
raise
load_dotenv()
client = Client(credentials=Credentials.from_env())
logging.getLogger("bampy").setLevel(logging.DEBUG)
fh = logging.FileHandler('bampy.log')
fh.setLevel(logging.DEBUG)
logging.getLogger("bampy").addHandler(fh)
parameters = TextGenerationParameters(
max_new_tokens=250,
min_new_tokens=1,
decoding_method=DecodingMethod.GREEDY,
return_options=TextGenerationReturnOptions(
# if ordered is False, you can use return_options to retrieve the corresponding prompt
input_text=True,
),
)
# load dataset
testingUnits = load_testingdata()
# test LLMs models
generateAnswers_bam_models(testingUnits)
```
## Dataset Creation
### Curation Rationale
Retrieval-augmented generation (RAG) has emerged as a promising solution to mitigate the limitations of large language models (LLMs), such as hallucinations and outdated information. However, it remains unclear how LLMs handle knowledge conflicts arising from different augmented retrieved passages, especially when these passages originate from the same source and have equal trustworthiness. In this regard, the motivation of Wikipedia Contradict Benchmark is to comprehensively evaluate LLM-generated answers to questions that have varying answers based on contradictory passages from Wikipedia, a dataset widely regarded as a high-quality pre-training resource for most LLMs.
### Source Data
#### Data Collection and Processing
The data was mostly observable as raw text. The raw data was retrieved from Wikipedia articles containing inconsistent, self-contradictory, and contradict-other tags. The first two tags denote contradictory statements within the same article, whereas the third tag highlights instances where the content of one article contradicts that of another article. In total, we collected around 1,200 articles that contain these tags through the Wikipedia maintenance category “Wikipedia articles with content issues”. Given a content inconsistency tag provided by Wikipedia editors, the annotators verified whether the tag is valid by checking the relevant article content, the editor’s comment, as well as the information in the edit history and the article’s talk page if necessary.
#### Who are the source data producers?
Wikipedia contributors.
### Annotations
#### Annotation process
The annotation interface was developed using [Label Studio](https://labelstud.io/).
The annotators were required to slightly modify the original passages to make them stand-alone (decontextualization). Normally, this requires resolving the coreference anaphors or the bridging anaphors in the first sentence (see annotation guidelines). In Wikipedia, oftentimes the antecedents for these anaphors are the article titles themselves.
For further information, see the annotation guidelines of the paper.
#### Who are the annotators?
Yufang Hou, Alessandra Pascale, Javier Carnerero-Cano, Tigran Tchrakian, Radu Marinescu, Elizabeth Daly, Inkit Padhi
#### Personal and Sensitive Information
N/A.
## Bias, Risks, and Limitations
Each annotation instance contains at least one question and two possible answers, but some instances may contain more than one question (and the corresponding two possible answers for each question). Some instances may not contain a value for **paragraphA_clean**, **tagDate**, and **tagReason**.
### Recommendations
Our data is downloaded from Wikipedia. As such, the data is biased towards the original content and sources. Given that human data annotation involves some degree of subjectivity we created a comprehensive 17-page annotation guidelines document to clarify important cases during the annotation process. The annotators were explicitly instructed not to take their personal feeling about the particular topic. Nevertheless, some degree of intrinsic subjectivity might have impacted the techniques picked up by the annotators during the annotation.
Since our dataset requires manual annotation, annotation noise is inevitably introduced.
## Citation
If this dataset is utilized in your research, kindly cite the following paper:
**BibTeX:**
```
@article{hou2024wikicontradict,
title={{WikiContradict: A Benchmark for Evaluating LLMs on Real-World Knowledge Conflicts from Wikipedia}},
author={Hou, Yufang and Pascale, Alessandra and Carnerero-Cano, Javier and Tchrakian, Tigran and Marinescu, Radu and Daly, Elizabeth and Padhi, Inkit and Sattigeri, Prasanna},
journal={arXiv preprint arXiv:2406.13805},
year={2024}
}
```
**APA:**
Hou, Y., Pascale, A., Carnerero-Cano, J., Tchrakian, T., Marinescu, R., Daly, E., Padhi, I., & Sattigeri, P. (2024). WikiContradict: A Benchmark for Evaluating LLMs on Real-World Knowledge Conflicts from Wikipedia. *arXiv preprint arXiv:2406.13805*.
## Dataset Card Authors
Yufang Hou, Alessandra Pascale, Javier Carnerero-Cano, Tigran Tchrakian, Radu Marinescu, Elizabeth Daly, Inkit Padhi, and Prasanna Sattigeri.
## Dataset Card Contact
Yufang Hou (yhou@ie.ibm.com), Alessandra Pascale (apascale@ie.ibm.com), Javier Carnerero-Cano (javier.cano@ibm.com), Tigran Tchrakian (tigran@ie.ibm.com), Radu Marinescu (radu.marinescu@ie.ibm.com), Elizabeth Daly (elizabeth.daly@ie.ibm.com), Inkit Padhi (inkpad@ibm.com), and Prasanna Sattigeri (psattig@us.ibm.com).