

Commit
•
e14e53f
1
Parent(s):
347b252
Review: translation fixes and typesetting
Browse files- lora_cn.md +33 -23
lora_cn.md
CHANGED
|
@@ -33,32 +33,35 @@
|
|
| 33 |
|
| 34 |
[LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) 是微软研究员引入的一项新技术,主要用于处理大模型微调的问题。目前超过数十亿以上参数的具有强能力的大模型(例如 GPT-3)通常在为了适应其下游任务的微调中会呈现出巨大开销。 LoRA 建议冻结预训练模型的权重并在每个 Transformer 块中注入可训练层(_秩-分解矩阵_)。因为不需要为大多数模型权重计算梯度,所以大大减少了需要训练参数的数量并且降低了 GPU 的内存要求。研究人员发现,通过聚焦大模型的 Transformer 注意力块,使用 LoRA 进行的微调质量与全模型微调相当,同时速度更快且需要更少的计算。
|
| 35 |
|
|
|
|
|
|
|
| 36 |
## 用于 Diffusers 的 LoRA 🧨
|
| 37 |
|
| 38 |
-
尽管 LoRA 最初是为大模型提出的,并在 transformer 块上进行了演示,但该技术也可以应用于其他地方。在微调 Stable Diffusion 的情况下,LoRA
|
|
|
|
|
|
|
| 39 |
|
| 40 |
-
|
| 41 |
|
| 42 |
-
|
| 43 |
-
为了将 LoRA 的可训练矩阵注入到与交叉注意力层一样深的模型中,过去人们需要以富有想象力(但脆弱)的方式破解 [diffusers](https://github.com/huggingface/diffusers) 的源代码。如果 Stable Diffusion 向我们展示了一件事,那就是社区总是会想出办法来改变和调整模型以达到创造性目的,我们喜欢这样!由于许多其他原因,提供操纵交叉注意力层的灵活性可能是有益的,例如更容易采用 [xFormers](https://github.com/facebookresearch/xformers) 等优化技术。 [Prompt-to-Prompt](https://arxiv.org/abs/2208.01626) 等其他创意项目可以使用一些简单的方法来访问这些层,因此我们决定 [为用户提供一种通用的方法来做到这一点](https://github.com/huggingface/diffusers/pull/1639)。自 12 月下旬以来,我们一直在测试,并在我们的 [diffusers](https://github.com/huggingface/diffusers/releases/tag/v0.12.0) 中正式发布。
|
| 44 |
|
| 45 |
-
我们一直在与
|
| 46 |
|
| 47 |
-
-
|
| 48 |
- 计算要求较低。我们可以在具有 11 GB VRAM 的 2080 Ti 中创建一个全微调模型!
|
| 49 |
-
-
|
| 50 |
|
| 51 |
-
我们对最后一点特别兴奋。为了让用户分享他们出色的微调或
|
| 52 |
|
| 53 |
使用 LoRA,现在可以发布 [单个 3.29 MB 文件](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4/blob/main/pytorch_lora_weights.bin) 以允许其他人使用你的微调模型。
|
| 54 |
|
| 55 |
-
|
| 56 |
|
| 57 |
-
## LoRA微调
|
| 58 |
|
| 59 |
Stable Diffusion 的全模型微调过去既缓慢又困难,这也是 Dreambooth 或 Textual Inversion 等轻量级方法变得如此流行的部分原因。使用 LoRA,在自定义数据集上微调模型要容易得多。
|
| 60 |
|
| 61 |
-
Diffusers 现在提供了一个 [LoRA 微调脚本](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora.py),可以在低至 11 GB 的 GPU RAM 中运行而无需借助到诸如 8-bit
|
| 62 |
|
| 63 |
```bash
|
| 64 |
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
|
|
@@ -86,17 +89,17 @@ accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
|
|
| 86 |
--seed=1337
|
| 87 |
```
|
| 88 |
|
| 89 |
-
这里需要注意的一件事是学习率为“1e-4”,远大于常规微调的通常学习率(通常为“~1e-6
|
| 90 |
|
| 91 |
-
开始,我们可以使用这段代码:
|
| 100 |
|
| 101 |
```Python
|
| 102 |
from huggingface_hub import model_info
|
|
@@ -111,7 +114,7 @@ print(model_base) # CompVis/stable-diffusion-v1-4
|
|
| 111 |
|
| 112 |
此代码段将打印他用于微调的模型,即“CompVis/stable-diffusion-v1-4”。就我而言,我从 Stable Diffusion 1.5 版开始训练我的模型,因此如果您使用 [我的 LoRA 模型](https://huggingface.co/pcuenq/pokemon-lora) 运行相同的代码,您会看到输出是 `runwayml/stable-diffusion-v1-5`。
|
| 113 |
|
| 114 |
-
如果您使用
|
| 115 |
|
| 116 |
在我们确定了用于使用 LoRA 进行微调的基础模型之后,我们加载了一个正常的稳定扩散管道。我们将使用 `DPMSolverMultistepScheduler` 对其进行自定义,以实现非常快速的推理:
|
| 117 |
|
|
@@ -123,7 +126,7 @@ pipe = StableDiffusionPipeline.from_pretrained(model_base, torch_dtype=torch.flo
|
|
| 123 |
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
|
| 124 |
```
|
| 125 |
|
| 126 |
-
**神奇的地方来了**。我们从 hub 加载 LoRA 权重
|
| 127 |
|
| 128 |
```Python
|
| 129 |
pipe.unet.load_attn_procs(model_path)
|
|
@@ -138,18 +141,25 @@ image.save("green_pokemon.png")
|
|
| 138 |
Dreambooth 允许您向 Stable Diffusion 模型“教授”新概念。 LoRA 与 Dreambooth 兼容,过程类似于微调,有几个优点:
|
| 139 |
|
| 140 |
- 训练更快。
|
| 141 |
-
-
|
| 142 |
-
-
|
| 143 |
|
| 144 |
-
要使用 LoRA 训练 Dreambooth,您需要使用 [此 diffusers 脚本](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth_lora.py)。请看一下 [README](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth#training-with-low-rank-adaptation-of-large-language-models-lora
|
| 145 |
|
| 146 |
## 其他方法
|
| 147 |
|
| 148 |
-
对轻松微调的追求并不新鲜。除了 Dreambooth 之外,[
|
| 149 |
|
| 150 |
[Pivotal Tuning](https://arxiv.org/abs/2106.05744) 是一种尝试将 Textual Inversion 与 LoRA 相结合的方法。首先,您使用 textual inversion 技术向模型教授一个新概念,获得一个新的标记嵌入来表示它。然后,您使用 LoRA 训练该 token 嵌入以获得两全其美。
|
| 151 |
|
| 152 |
我们还没有使用 LoRA 探索过 Pivotal Tuning。欢迎挑战? 🤗
|
| 153 |
|
| 154 |
-
|
| 155 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
|
| 34 |
[LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) 是微软研究员引入的一项新技术,主要用于处理大模型微调的问题。目前超过数十亿以上参数的具有强能力的大模型(例如 GPT-3)通常在为了适应其下游任务的微调中会呈现出巨大开销。 LoRA 建议冻结预训练模型的权重并在每个 Transformer 块中注入可训练层(_秩-分解矩阵_)。因为不需要为大多数模型权重计算梯度,所以大大减少了需要训练参数的数量并且降低了 GPU 的内存要求。研究人员发现,通过聚焦大模型的 Transformer 注意力块,使用 LoRA 进行的微调质量与全模型微调相当,同时速度更快且需要更少的计算。
|
| 35 |
|
| 36 |
+
[LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) 是微软研究员引入的一项新技术,主要用于处理大模型微调的问题。目前超过数十亿以上参数的具有强能力的大模型 (例如 GPT-3) 通常在为了适应其下游任务的微调中会呈现出巨大开销。 LoRA 建议冻结预训练模型的权重并在每个 Transformer 块中注入可训练层 (秩-分解矩阵)。因为不需要为大多数模型权重计算梯度,所以大大减少了需要训练参数的数量并且降低了 GPU 的内存要求。研究人员发现,通过聚焦大模型的 Transformer 注意力块,使用 LoRA 进行的微调质量与全模型微调相当,同时速度更快且需要更少的计算。
|
| 37 |
+
|
| 38 |
## 用于 Diffusers 的 LoRA 🧨
|
| 39 |
|
| 40 |
+
尽管 LoRA 最初是为大模型提出的,并在 transformer 块上进行了演示,但该技术也可以应用于其他地方。在微调 Stable Diffusion 的情况下,LoRA 可以应用于将图像表示与描述它们的提示相关联的交叉注意层。下图的细节 (摘自 [Stable Diffusion 论文](https://arxiv.org/abs/2112.10752)) 并不重要,只需要注意黄色块是负责建立图文之间的关系表示就行。
|
| 41 |
+
|
| 42 |
+
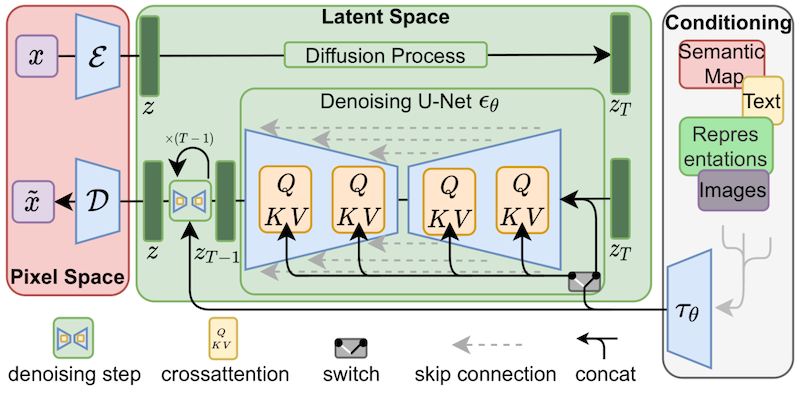
|
| 43 |
|
| 44 |
+
据我们所知,Simo Ryu (GitHub 用户名 `@cloneofsimo`) 是第一个提出适用于 Stable Diffusion 的 LoRA 实现的人。如果想查看相关示例和许多其他有趣的讨论和见解。请一定要看看 [他们的 GitHub 项目](https://github.com/cloneofsimo/lora)。
|
| 45 |
|
| 46 |
+
为了将 LoRA 的可训练矩阵注入到与交叉注意力层一样深的模型中,过去人们需要以富有想象力 (但脆弱) 的方式破解 [diffusers](https://github.com/huggingface/diffusers) 的源代码。如果 Stable Diffusion 向我们展示了一件事,那就是社区总是会想出办法来改变和调整模型以达到创造性目的,我们喜欢这样!由于许多其他原因,提供操纵交叉注意力层的灵活性可能是有益的,例如更容易采用 [xFormers](https://github.com/facebookresearch/xformers) 等优化技术。 [Prompt-to-Prompt](https://arxiv.org/abs/2208.01626) 等其他创意项目可以使用一些简单的方法来访问这些层,因此我们决定 [为用户提供一种通用的方法来做到这一点](https://github.com/huggingface/diffusers/pull/1639)。自 12 月下旬以来,我们一直在测试,并在我们的 [diffusers](https://github.com/huggingface/diffusers/releases/tag/v0.12.0) 中正式发布。
|
|
|
|
| 47 |
|
| 48 |
+
我们一直在与 `@cloneofsimo` 合作,为 Dreambooth 和全微调方法提供 Diffusions 中的 LoRA 训练支持!这些技术提供了以下好处:
|
| 49 |
|
| 50 |
+
- 更快的训练速度
|
| 51 |
- 计算要求较低。我们可以在具有 11 GB VRAM 的 2080 Ti 中创建一个全微调模型!
|
| 52 |
+
- **小了很多的训练模型**。由于原始模型已冻结,我们注入了新层进行训练,因此我们可以将新层的权重保存为大小约为 3 MB 的单个文件。这比 UNet 模型的原始大小小一千倍
|
| 53 |
|
| 54 |
+
我们对最后一点特别兴奋。为了让用户分享他们出色的微调或 **dreamboothed** 模型,他们必须分享最终模型的完整副本。其他想要试用它们的用户必须在他们最喜欢的 UI 中下载经过微调的权重,这会增加大量存储和下载成本。截至今天,大约有 [1,000 个 Dreambooth 模型在 Dreambooth 概念库中注册](https://huggingface.co/sd-dreambooth-library),可能还有更多未在库中注册。
|
| 55 |
|
| 56 |
使用 LoRA,现在可以发布 [单个 3.29 MB 文件](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4/blob/main/pytorch_lora_weights.bin) 以允许其他人使用你的微调模型。
|
| 57 |
|
| 58 |
+
(感谢 GitHub 用户 `@mishig25`,他是我了解到的首个在平常对话中将 **dreamboothing** 作为动词的人)。
|
| 59 |
|
| 60 |
+
## LoRA 微调
|
| 61 |
|
| 62 |
Stable Diffusion 的全模型微调过去既缓慢又困难,这也是 Dreambooth 或 Textual Inversion 等轻量级方法变得如此流行的部分原因。使用 LoRA,在自定义数据集上微调模型要容易得多。
|
| 63 |
|
| 64 |
+
Diffusers 现在提供了一个 [LoRA 微调脚本](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora.py),可以在低至 11 GB 的 GPU RAM 中运行而无需借助到诸如 8-bit 优化器之类的技巧。这里展示了您如何借助它来使用 [Lambda Labs Pokémon 数据集](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions) 微调模型:
|
| 65 |
|
| 66 |
```bash
|
| 67 |
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
|
|
|
|
| 89 |
--seed=1337
|
| 90 |
```
|
| 91 |
|
| 92 |
+
这里需要注意的一件事是学习率为“1e-4”,远大于常规微调的通常学习率(通常为“~1e-6”的数量级)。这是上次运行的 [W&B dashboard](https://wandb.ai/pcuenq/text2image-fine-tune/runs/b4k1w0tn?workspace=user-pcuenq),在 2080 Ti GPU (11 GB 内存)。我没有尝试优化超参数,所以请自行尝试 在 T4 (16 GB 内存) 上又跑了一次,这是 [他的最终模型](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4),这里是 [使用它的演示空间](https://huggingface.co/spaces/pcuenq/lora-pokemon)。
|
| 93 |
|
| 94 |
+

|
| 95 |
|
| 96 |
+
有关 diffusers 中 LoRA 支持的更多详细信息,请参阅 [我们的文档](https://huggingface.co/docs/diffusers/main/en/training/lora)——它将始终与实现保持同步。
|
| 97 |
|
| 98 |
## 推理
|
| 99 |
|
| 100 |
正如我们所讨论的,LoRA 的主要优势之一是您可以通过训练比原始模型大小少几个数量级的权重来获得出色的结果。我们设计了一个推理过程,允许在未修改的 Stable Diffusion 模型权重之上加载额外的权重。让我们看看它是如何工作的。
|
| 101 |
|
| 102 |
+
首先,我们将使用 Hub API 自动确定用于微调 LoRA 模型的基本模型是什么。从 [Sayak的模型](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4) 开始,我们可以使用这段代码:
|
| 103 |
|
| 104 |
```Python
|
| 105 |
from huggingface_hub import model_info
|
|
|
|
| 114 |
|
| 115 |
此代码段将打印他用于微调的模型,即“CompVis/stable-diffusion-v1-4”。就我而言,我从 Stable Diffusion 1.5 版开始训练我的模型,因此如果您使用 [我的 LoRA 模型](https://huggingface.co/pcuenq/pokemon-lora) 运行相同的代码,您会看到输出是 `runwayml/stable-diffusion-v1-5`。
|
| 116 |
|
| 117 |
+
如果您使用 `--push_to_hub` 选项,我们在上一节中看到的微调脚本会自动填充有关基本模型的信息。正如您在 [pokemon-lora 的介绍文档](https://huggingface.co/pcuenq/pokemon-lora/blob/main/README.md) 中所见,这被记录为模型存储库的“自述文件”文件中的元数据标签。
|
| 118 |
|
| 119 |
在我们确定了用于使用 LoRA 进行微调的基础模型之后,我们加载了一个正常的稳定扩散管道。我们将使用 `DPMSolverMultistepScheduler` 对其进行自定义,以实现非常快速的推理:
|
| 120 |
|
|
|
|
| 126 |
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
|
| 127 |
```
|
| 128 |
|
| 129 |
+
**神奇的地方来了**。我们从 hub 加载 LoRA 权重 **在常规模型权重之上**,将 pipline 移动到 cuda 设备并运行推理:
|
| 130 |
|
| 131 |
```Python
|
| 132 |
pipe.unet.load_attn_procs(model_path)
|
|
|
|
| 141 |
Dreambooth 允许您向 Stable Diffusion 模型“教授”新概念。 LoRA 与 Dreambooth 兼容,过程类似于微调,有几个优点:
|
| 142 |
|
| 143 |
- 训练更快。
|
| 144 |
+
- 我们只需要几张我们想要训练的主题的图像 (通常 5 或 10 张就足够了)。
|
| 145 |
+
- 如果需要,我们可以调整文本编码器,以提高对训练主体的保真度。
|
| 146 |
|
| 147 |
+
要使用 LoRA 训练 Dreambooth,您需要使用 [此 diffusers 脚本](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth_lora.py)。请看一下 [README](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth#training-with-low-rank-adaptation-of-large-language-models-lora)、[文档](https://huggingface.co/docs/diffusers/main/en/training/lora) 和 [我们的超参数探索博文](https://huggingface.co/blog/dreambooth) 了解详细信息.
|
| 148 |
|
| 149 |
## 其他方法
|
| 150 |
|
| 151 |
+
对轻松微调的追求并不新鲜。除了 Dreambooth 之外,[textual inversion](https://huggingface.co/docs/diffusers/main/en/training/text_inversion) 是另一种流行的方法,它试图向训练有素的稳定扩散模型教授新概念。使用 Textual Inversion 的主要原因之一是经过训练的权重也很小且易于共享。然而,它们只适用于单个主题 (或一小部分主题),而 LoRA 可用于通用微调,这意味着它可以适应新的领域或数据集。
|
| 152 |
|
| 153 |
[Pivotal Tuning](https://arxiv.org/abs/2106.05744) 是一种尝试将 Textual Inversion 与 LoRA 相结合的方法。首先,您使用 textual inversion 技术向模型教授一个新概念,获得一个新的标记嵌入来表示它。然后,您使用 LoRA 训练该 token 嵌入以获得两全其美。
|
| 154 |
|
| 155 |
我们还没有使用 LoRA 探索过 Pivotal Tuning。欢迎挑战? 🤗
|
| 156 |
|
| 157 |
+
<hr>
|
| 158 |
+
|
| 159 |
+
>>>> 英文原文: https://huggingface.co/blog/lora
|
| 160 |
+
>>>>
|
| 161 |
+
>>>> 原文作者: Pedro Cuenca, Sayak Paul
|
| 162 |
+
>>>>
|
| 163 |
+
>>>> 中文译者: innovation64 (李洋)
|
| 164 |
+
>>>>
|
| 165 |
+
>>>> 审校: zhongdongy (忠东)
|