# 音频扩散模型
在此篇笔记,我们来看看使用扩散模型生成音频的过程。
## 你将会学习到:
- 音频在电脑中是被如何展示
- 源音频数据与频谱间的转换方法
- 如何准备一个由特定的整理函数(collate function),能够把音频片段转换到频谱的数据生成器
- 微调一个指定分类曲风的音频扩散模型
- 把自己的pipeline上传到HFhub
警告:这完全是出于教学目的 - 不能保证我们的模型一定很好听😉
我们开始吧!
## 设置与导入
```python
# !pip install -q datasets diffusers torchaudio accelerate
```
```python
import torch, random
import numpy as np
import torch.nn.functional as F
from tqdm.auto import tqdm
from IPython.display import Audio
from matplotlib import pyplot as plt
from diffusers import DiffusionPipeline
from torchaudio import transforms as AT
from torchvision import transforms as IT
```
## 从预训练的音频Pipline开始
我们通过参考[Audio Diffusion docs](https://huggingface.co/docs/diffusers/api/pipelines/audio_diffusion)来加载一个预训练的音频扩散模型pipeline:
```python
# Load a pre-trained audio diffusion pipeline
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = DiffusionPipeline.from_pretrained("teticio/audio-diffusion-instrumental-hiphop-256").to(device)
```
Fetching 5 files: 0%| | 0/5 [00:00
Your browser does not support the audio element.
这里,`rate`参数明确了音频的 _采样率_ ;过会儿我们会再深入了解它。同时你也会注意到pipeline也返回了几样其他的东西。这发生了什么?我们来仔细看看这两个输出。
第一项是一个数据数组,代表生成的音频:
```python
# The audio array:
output.audios[0].shape
```
(1, 130560)
第二项看起来像是灰度图:
```python
# The output image (spectrogram):
output.images[0].size
```
(256, 256)
这给了我们一个提示,关于这个pipeline是如何工作的。音频不是直接被扩散模型生成 - 而是,这个pipeline有着与在第一单元看到的无条件图像生成pipelines类似的2D Unet结构 [Unit 1](https://github.com/huggingface/diffusion-models-class/tree/main/unit1) 用它来生成频谱,之后再在后处理中把它变化为最终的音频。
此pipe中有额外的组件来处理这个变化,我们可以通过`pipe.mel`来进行:
```python
pipe.mel
```
Mel {
"_class_name": "Mel",
"_diffusers_version": "0.12.0.dev0",
"hop_length": 512,
"n_fft": 2048,
"n_iter": 32,
"sample_rate": 22050,
"top_db": 80,
"x_res": 256,
"y_res": 256
}
## 音频到频谱的转换
音频的'波形'从时间上表现出了源音频 - 比如,这可能是接收自麦克风的电信号。从这种'时域'的表达方式上做处理会有些棘手,所以有种更普遍的做法把它转换成其他形式,通常把这叫做频谱。频谱直接展示出在不同频率(y轴)与时间(x轴)上的剧烈程度。
```python
# Calculate and show a spectrogram for our generated audio sample using torchaudio
spec_transform = AT.Spectrogram(power=2)
spectrogram = spec_transform(torch.tensor(output.audios[0]))
print(spectrogram.min(), spectrogram.max())
log_spectrogram = spectrogram.log()
plt.imshow(log_spectrogram[0], cmap='gray');
```
tensor(0.) tensor(6.0842)

我们刚刚做好的这个频谱取值范围在0.0000000000001到1之间,其中大部分内容都接近取值下限。这对于可视化与建模并不理想 - 实际上我们需要对这些值取log来得到一个可以看到更多细节的灰度图。同样也因此,我们特别使用一种专门的梅尔频谱(Mel spectrogram),这是一种通过对不同频率成分做一些变化,专门设计的一种符合人耳感知特性而利于提取重要信息的方式。
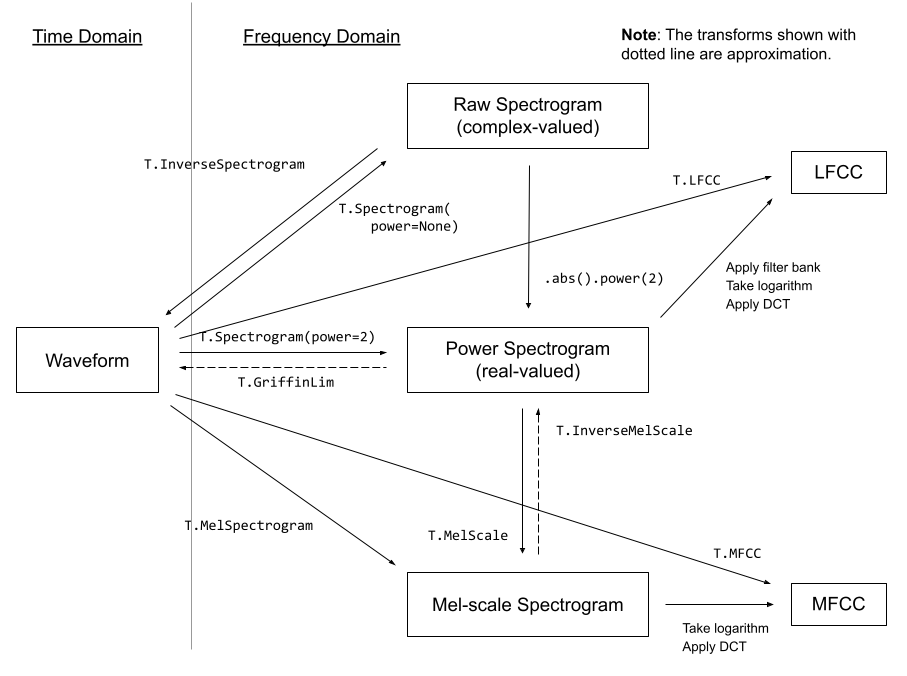
_一些来自 [torchaudio docs](https://pytorch.org/audio/stable/transforms.html)的音频转换方法_
幸运的是,我们并不需要太过于担心这些变换方法 - pipeline中的`mel`功能会为我们处理这些细节。这样操作,我们就能把频谱图像转换成音频:
```python
a = pipe.mel.image_to_audio(output.images[0])
a.shape
```
(130560,)
我们可以先读出源音频数据然后调用 `audio_slice_to_image()`函数来把音频数组数据转化为频谱图片。更长的片段会被自动切片为能够正常输出 256x256 频谱图片的长度。
```python
pipe.mel.load_audio(raw_audio=a)
im = pipe.mel.audio_slice_to_image(0)
im
```

音频被表现为一串很长的数字数组。要把它播放出来的话,我们还需要一个关键信息:采样率。我们要用到多少个采样点(单个的数值),才能够播放出单位秒的音频呢?
我们可以在pipeline中这样来看使用的采样率:
```python
sample_rate_pipeline = pipe.mel.get_sample_rate()
sample_rate_pipeline
```
22050
如果我们故意把采样率设置错误,可以得到一个可能被加速或慢放的音频:
```python
display(Audio(output.audios[0], rate=44100)) # 2x speed
```
## 微调pipeline
现在我们已经大致理解了这个pipeline是怎么工作的,现在来在一些新音频数据上对它进行微调!
这个数据集是不同类别的音频片段集合,我们可以从hub上这样加载它:
```python
from datasets import load_dataset
dataset = load_dataset('lewtun/music_genres', split='train')
dataset
```
你可以使用下面的代码来看看在数据集中各类别样本的占比:
```python
for g in list(set(dataset['genre'])):
print(g, sum(x==g for x in dataset['genre']))
```
Pop 945
Blues 58
Punk 2582
Old-Time / Historic 408
Experimental 1800
Folk 1214
Electronic 3071
Spoken 94
Classical 495
Country 142
Instrumental 1044
Chiptune / Glitch 1181
International 814
Ambient Electronic 796
Jazz 306
Soul-RnB 94
Hip-Hop 1757
Easy Listening 13
Rock 3095
这个数据集把音频存储为数组:
```python
audio_array = dataset[0]['audio']['array']
sample_rate_dataset = dataset[0]['audio']['sampling_rate']
print('Audio array shape:', audio_array.shape)
print('Sample rate:', sample_rate_dataset)
display(Audio(audio_array, rate=sample_rate_dataset))
```
Audio array shape: (1323119,)
Sample rate: 44100
注意这条音频的采样率会更高 - 如果我们想用手头的这个pipeline,需要对它'重采样'来匹配。这个片段也比pipeline所预设的长度更长。幸运的是,当我们使用`pipe.mel`在加载音频时,会自动把它切片成更短的片区。
```python
a = dataset[0]['audio']['array'] # Get the audio array
pipe.mel.load_audio(raw_audio=a) # Load it with pipe.mel
pipe.mel.audio_slice_to_image(0) # View the first 'slice' as a spectrogram
```

我们要记得去调整采样率,因为此数据集的数据在每秒中有着多两倍的数据点。
```python
sample_rate_dataset = dataset[0]['audio']['sampling_rate']
sample_rate_dataset
```
44100
这里我们用torchaudio's transforms(import as AT)来做音频的重采样,pipe中的`mel`把音频转换为图像,torchvision's transforms(导入为IT)来把图片转换为tensors。这个函数可以把音频片段转换为频谱tensor供训练使用:
```python
resampler = AT.Resample(sample_rate_dataset, sample_rate_pipeline, dtype=torch.float32)
to_t = IT.ToTensor()
def to_image(audio_array):
audio_tensor = torch.tensor(audio_array).to(torch.float32)
audio_tensor = resampler(audio_tensor)
pipe.mel.load_audio(raw_audio=np.array(audio_tensor))
num_slices = pipe.mel.get_number_of_slices()
slice_idx = random.randint(0, num_slices-1) # Pic a random slice each time (excluding the last short slice)
im = pipe.mel.audio_slice_to_image(slice_idx)
return im
```
来使用我们的`to_image()`函数来组成我们特定的整理函数(collate function)来把数据集转换到dataloader中来训练模型。整理函数定义了如何把一批来自数据集的样例变换为最终的训练用数据。在这个例子中我们把每个音频转换为频谱图像再把他们的tensors堆叠起来:
```python
def collate_fn(examples):
# to image -> to tensor -> rescale to (-1, 1) -> stack into batch
audio_ims = [to_t(to_image(x['audio']['array']))*2-1 for x in examples]
return torch.stack(audio_ims)
# Create a dataset with only the 'Chiptune / Glitch' genre of songs
batch_size=4 # 4 on colab, 12 on A100
chosen_genre = 'Electronic' # <<< Try training on different genres <<<
indexes = [i for i, g in enumerate(dataset['genre']) if g == chosen_genre]
filtered_dataset = dataset.select(indexes)
dl = torch.utils.data.DataLoader(filtered_dataset.shuffle(), batch_size=batch_size, collate_fn=collate_fn, shuffle=True)
batch = next(iter(dl))
print(batch.shape)
```
torch.Size([4, 1, 256, 256])
**留心: 你可能要用一个更小的batchsize(比如4)除非你有足够的显存可用**
## 训练循环
这是一个在dataloader中读取数据的简洁训练循环,用几个周期来微调pipeline的UNet网络。你可以跳过此块,直接使用下一块代码来加载pipeline。
```python
epochs = 3
lr = 1e-4
pipe.unet.train()
pipe.scheduler.set_timesteps(1000)
optimizer = torch.optim.AdamW(pipe.unet.parameters(), lr=lr)
for epoch in range(epochs):
for step, batch in tqdm(enumerate(dl), total=len(dl)):
# Prepare the input images
clean_images = batch.to(device)
bs = clean_images.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(
0, pipe.scheduler.num_train_timesteps, (bs,), device=clean_images.device
).long()
# Add noise to the clean images according to the noise magnitude at each timestep
noise = torch.randn(clean_images.shape).to(clean_images.device)
noisy_images = pipe.scheduler.add_noise(clean_images, noise, timesteps)
# Get the model prediction
noise_pred = pipe.unet(noisy_images, timesteps, return_dict=False)[0]
# Calculate the loss
loss = F.mse_loss(noise_pred, noise)
loss.backward(loss)
# Update the model parameters with the optimizer
optimizer.step()
optimizer.zero_grad()
```
```python
# OR: Load the version I trained earlier:
pipe = DiffusionPipeline.from_pretrained("johnowhitaker/Electronic_test").to(device)
```
Downloading: 0%| | 0.00/282 [00:00
Your browser does not support the audio element.
```python
# Make a longer sample by passing in a starting noise tensor with a different shape
noise = torch.randn(1, 1, pipe.unet.sample_size[0],pipe.unet.sample_size[1]*4).to(device)
output = pipe(noise=noise)
display(output.images[0])
display(Audio(output.audios[0], rate=22050))
```
0%| | 0/1000 [00:00
Your browser does not support the audio element.
这个输出听起来绝不是最好的,但这是一个开始 :)探索一下调整学习率和迭代周期,并在Discord上分享你的最佳结果,我们就可以来一起进步了!
一些需要考虑的事情
- 我们使用的是256像素点的方形频谱图片,这会限制住我们的batchsize。你能够从128x128的频谱中恢复出质量足够好的音频吗?
- 为了替代随机图像增强,我们每次挑选不同的音频片段,但这种做法在训练迭代的后期是否可以用其他增强方式再优化一下?
- 我们有什么其他办法可以用它来生成更长的音频?也许你可以先生成开头的5s音频然后再用类似图像修复的思路接着卡开头片段来继续生成后续内容...
- 扩散模型生成的内容与图像到图像的生成有什么相同之处?
## Push到Hub
当你对你的模型足够满意了,你就可以把它保存下来并上传到hub上给他人来共享:
```python
from huggingface_hub import get_full_repo_name, HfApi, create_repo, ModelCard
```
```python
# Pick a name for the model
model_name = "audio-diffusion-electronic"
hub_model_id = get_full_repo_name(model_name)
```
```python
# Save the pipeline locally
pipe.save_pretrained(model_name)
```
```python
# Inspect the folder contents
!ls {model_name}
```
mel model_index.json scheduler unet
```python
# Create a repository
create_repo(hub_model_id)
```
```python
# Upload the files
api = HfApi()
api.upload_folder(
folder_path=f"{model_name}/scheduler", path_in_repo="scheduler", repo_id=hub_model_id
)
api.upload_folder(
folder_path=f"{model_name}/mel", path_in_repo="mel", repo_id=hub_model_id
)
api.upload_folder(folder_path=f"{model_name}/unet", path_in_repo="unet", repo_id=hub_model_id)
api.upload_file(
path_or_fileobj=f"{model_name}/model_index.json",
path_in_repo="model_index.json",
repo_id=hub_model_id,
)
```
```python
# Push a model card
content = f"""
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-audio-generation
- diffusion-models-class
---
# Model Card for Unit 4 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional audio generation of music in the genre {chosen_genre}
## Usage
```python
from IPython.display import Audio
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("{hub_model_id}")
output = pipe()
display(output.images[0])
display(Audio(output.audios[0], rate=pipe.mel.get_sample_rate()))
```
"""
card = ModelCard(content)
card.push_to_hub(hub_model_id)
```
## 总结
希望这片笔记让你浅尝到音频生成的潜力。请再留意下此单元在介绍中的一些参考链接,去看一些更酷炫的方法和它们所创造的惊艳内容!