Announcing BigCodeBench-Hard, and More






We are excited to release BigCodeBench-Hard! BigCodeBench-Hard compiles a subset of 148 tasks from the BigCodeBench dataset. You can now install the latest
bigcodebench==v0.1.8 and try evaluating your model on BigCodeBench-Hard with the following command 👇:
# update bigcodebench
pip install -U bigcodebench
# bigcodebench.generate with greedy
bigcodebench.generate \
--model [model_name] \
--split [complete|instruct] \
--subset [full|hard] \
--greedy
# bigcodebench.sanitize
bigcodebench.sanitize --samples samples.jsonl --calibrate
# bigcodebench.evaluate
# note that you need to have a separate environment for evaluation
bigcodebench.evaluate --split [complete|instruct] --subset [full|hard] --samples samples-sanitized-calibrated.jsonl
Introducing BigCodeBench-Hard
The workflow to construct BigCodeBench-Hard is mainly inspired by MixEval, which utilizes a small number of benchmark samples to align user-facing evaluation. While MixEval focuses on general-domain evaluation and considers only code generation tasks with minimal samples from MBPP and HumanEval, we extend the idea to make code generation evaluation more user-centric. Specifically, we follow these steps to create BigCodeBench-Hard:

First, we choose an anonymized archive of Stack Overflow that has been preprocessed by the BigCode community. Details of the preprocessing can be found in the StarCoder2 report. The archive contains 10.4 million questions and answers, covering diverse programming languages and topics, making it a good source of user queries.
To bridge the query source and BigCodeBench, we leverage all-mpnet-base-v2, a pre-trained sentence embedding model recommended by the Sentence Transformers documentation. This model, trained on a mixture of text and code data, is suitable for identifying similarities between programming queries and BigCodeBench tasks.
We use the model to retrieve the most similar tasks for each query in the Stack Overflow archive, ranking them by the dot product between normalized embeddings. Based on manual inspection of the retrieved tasks, we conclude that a similarity score above 0.7 is a good threshold for task selection. By applying this threshold, we obtain 6,895 queries and 626 BigCodeBench tasks after deduplication.
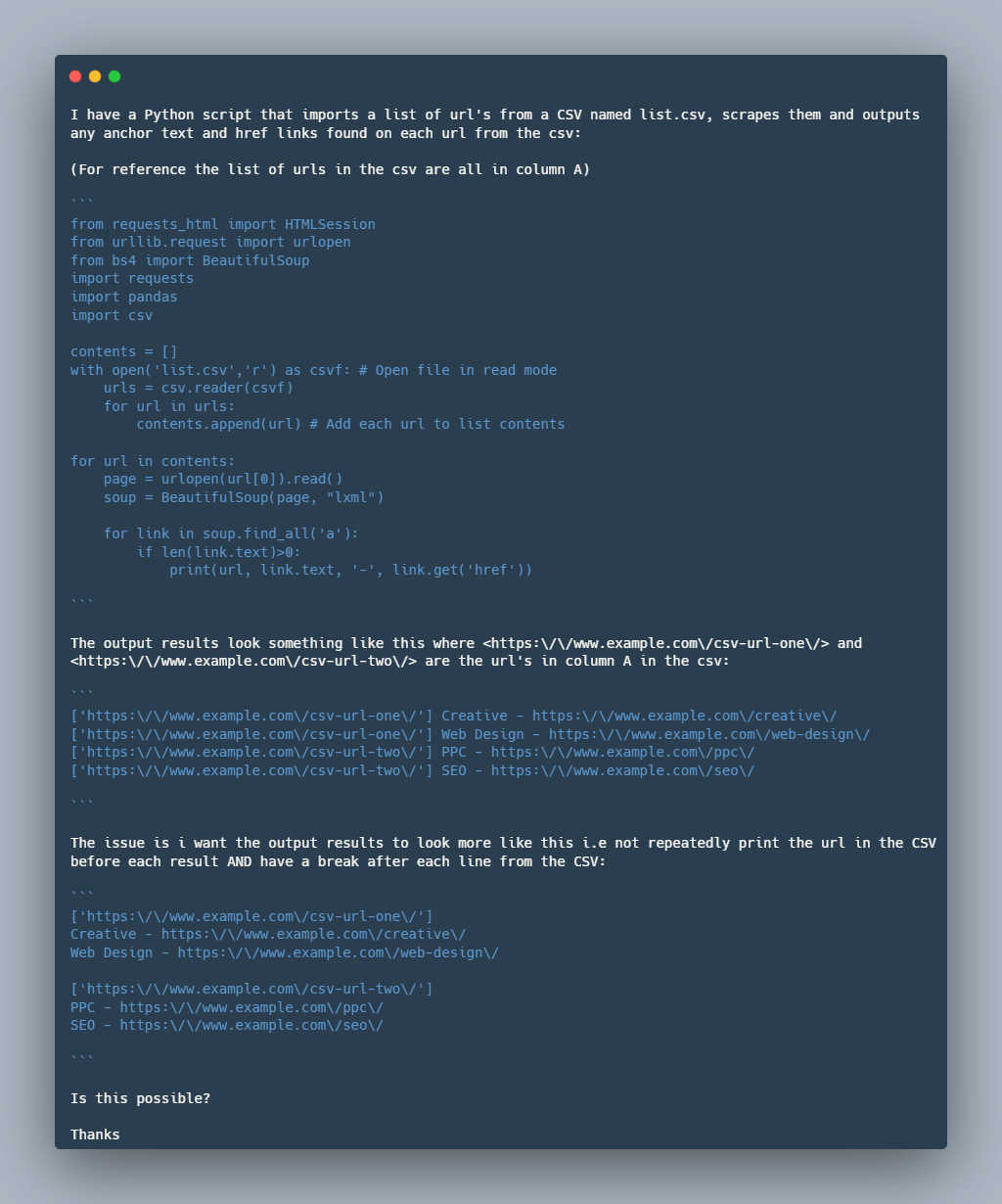
We illustrate the alignment between the Stack Overflow queries and the BigCodeBench tasks in the following example. As shown in the given example, both the query and the task prompt revolve around web scraping to extract hyperlinks from web pages, using Python libraries to handle HTTP requests and parse HTML. Both involve interaction with CSV files to either read input URLs or write output data. While the specific implementation details differ, the core objective of extracting and handling hyperlink data from web pages is a shared aspect, aligning their overall scope closely.
Stack Overflow Query
Retrieved BigCodeBench Task Prompt
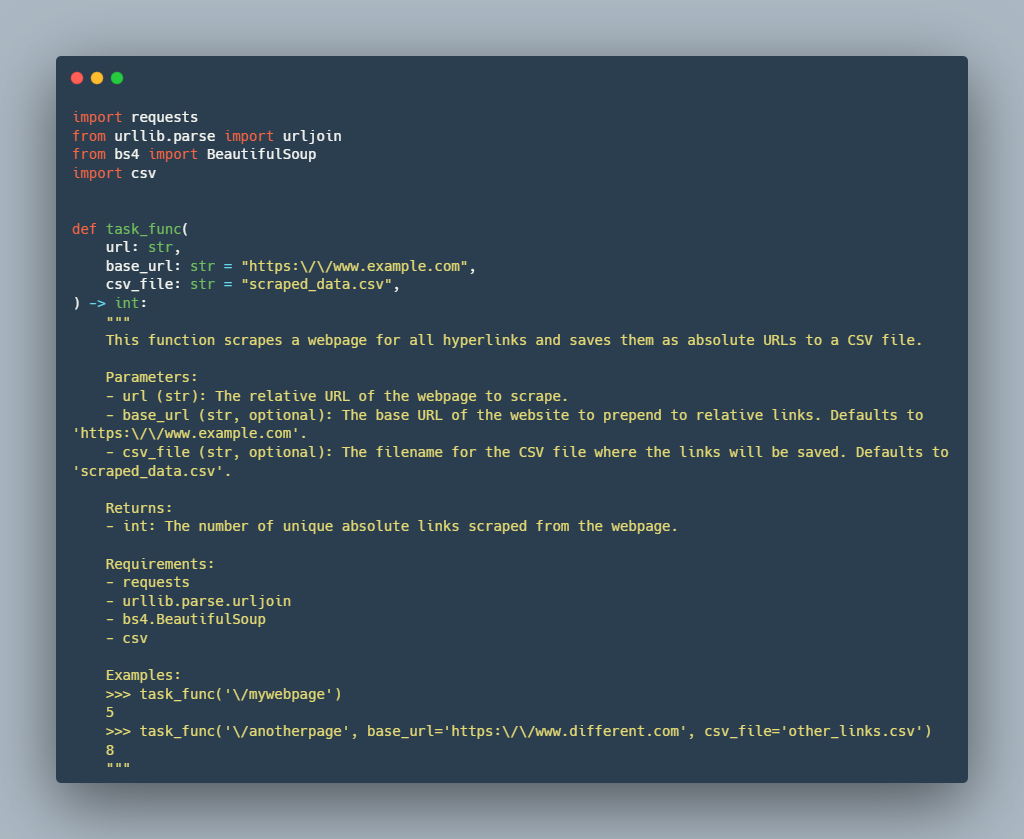
However, the retrieved 626 tasks are still infeasible for evaluation. To improve evaluation efficiency, we further filter the tasks by difficulty. Unlike the construction of MixEval-Hard, we define the following more explainable criteria:
Library Usage: Each task in BigCodeBench emphasizes the compositional reasoning ability for coding and requires the use of at least two libraries. For BigCodeBench-Hard, we keep only the tasks that require more than two libraries, challenging the models to choose more diverse function calls as tools to solve the tasks.
Solution Length: We set the threshold at 426 tokens, which is the average solution length of the tasks in BigCodeBench. The ground-truth solution provides a reference for the task complexity, and tasks with longer solutions are more challenging to solve.
Solve Rate: We compute the solve rate per task based on all the evaluated models on the leaderboard. The solve rate is defined as the number of models that can solve the task divided by the total number of models. Specifically, we deem tasks with a solve rate below 50% as hard tasks.

Through the comparison, we notice that the model performance on BigCodeBench-Hard differ significantly from the one on the full set of BigCodeBench. We suggest that these differences arise from the imbalanced distribution of target domains and a large number of easy tasks in BigCodeBench, resulting in a slight misalignment between the evaluation and the user-facing tasks. For example, GPT-4o-2024-05-13 and GPT-4-0613 may be over-fitting to the easy tasks in BigCodeBench, leading to low performance on BigCodeBench-Hard.
To validate the effectiveness of BigCodeBench-Hard, we use a private leaderboard, SEAL-Coding curated by Scale AI, as a reference. The SEAL-Coding leaderboard is designed to evaluate models on a set of user-facing tasks across various application domains and programming languages. Specifically, SEAL-Coding compares four of the best closed LLMs on Python, with the following rankings: (1) GPT-4-Turbo Preview, (2) Claude 3.5 Sonnet, (3) GPT-4o, and (4) Gemini 1.5 Pro (May 2024). These rankings align with our results based on the average score of the Complete and Instruct splits of BigCodeBench-Hard, indicating that BigCodeBench-Hard is more user-centric and challenging for model evaluation.
We encourage the community to use BigCodeBench-Hard when the budget is limited and the evaluation needs to be more user-centric. Additionally, we note that BigCodeBench-Hard can be dynamic by design, depending on user queries and the evaluated models. We can periodically update BigCodeBench-Hard to keep the evaluation challenging and user-centric.
96 Models On the Leaderboard!
We update the BigCodeBench Leaderboard with a total of 96 models. To delve deeper into the leaderboard, we explore the following questions using BigCodeBench-Hard:
Did you notice the recent DeepSeek-V2-Chat Upgrade?

The recent upgrade to DeepSeek-V2-Chat on June 28, 2024, has brought significant improvements to its performance. The results demonstrate a remarkable 109% increase in Complete performance, with the score rising from 15.5 to 32.4. While BigCodeBench-Instruct also shows an enhancement, its improvement was more modest, with a 15.7% increase from 21.6 to 25.0. These upgrades demonstrate DeepSeek's commitment to enhancing their chat model.
Is Gemma-2-27B-Instruct better than Llama-3-70B-Instruct at coding?

On both the Complete and Instruct splits, Llama-3-70B-Instruct still outperformed Gemma-2-27B-Instruct, albeit by small margins. The difference was more pronounced on the Complete tasks (3.7% difference) compared to Instruct (1.8% difference). It's worth noting that despite having fewer parameters (27B vs 70B), Gemma-2-Instruct comes close to Llama-3-70B-Instruct's performance. This is impressive given the significant difference in model size.
How good is the secret update of Phi-3-Mini?

We use Phi-3-Mini-128k-Instruct for the comparison. The significant improvements shown in the plot indicate that the secret update was highly effective. The larger relative gain on the Instruct split (24.3% vs. 13.8% on Complete) suggests that the update may have focused on optimizing the model's ability to understand and execute less verbose instructions.
One More Thing 🤗
We are happy to announce our collaboration with the EvalPlus team to create a new variant of BigCodeBench: BigCodeBench+, a benchmark that enhances the test rigorousness!
Additionally, we will also work with the CRUXEval team to create another variant, CRUX-BigCodeBench, a benchmark focusing on more practical code reasoning and understanding.
Stay tuned for more updates on BigCodeBench!
Resource
We open-source all the artifacts of BigCodeBench-Hard, including the data, code, and leaderboard. You can find them as follows:
- GitHub Repository
- BigCodeBench-Hard Dataset
- BigCodeBench Leaderboard
- Stack Overflow Embeddings
- BigCodeBench Embeddings
- Retrieved BigCodeBench Tasks
Citation
If you find our evaluations useful, please consider citing our work:
@article{zhuo2024bigcodebench,
title={BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions},
author={Zhuo, Terry Yue and Vu, Minh Chien and Chim, Jenny and Hu, Han and Yu, Wenhao and Widyasari, Ratnadira and Yusuf, Imam Nur Bani and Zhan, Haolan and He, Junda and Paul, Indraneil and others},
journal={arXiv preprint arXiv:2406.15877},
year={2024}
}



