Efficient Table Pre-training without Real Data: An Introduction to TAPEX

In recent years, language model pre-training has achieved great success via leveraging large-scale textual data. By employing pre-training tasks such as masked language modeling, these models have demonstrated surprising performance on several downstream tasks. However, the dramatic gap between the pre-training task (e.g., language modeling) and the downstream task (e.g., table question answering) makes existing pre-training not efficient enough. In practice, we often need an extremely large amount of pre-training data to obtain promising improvement, even for domain-adaptive pretraining. How might we design a pre-training task to close the gap, and thus accelerate pre-training?
Overview
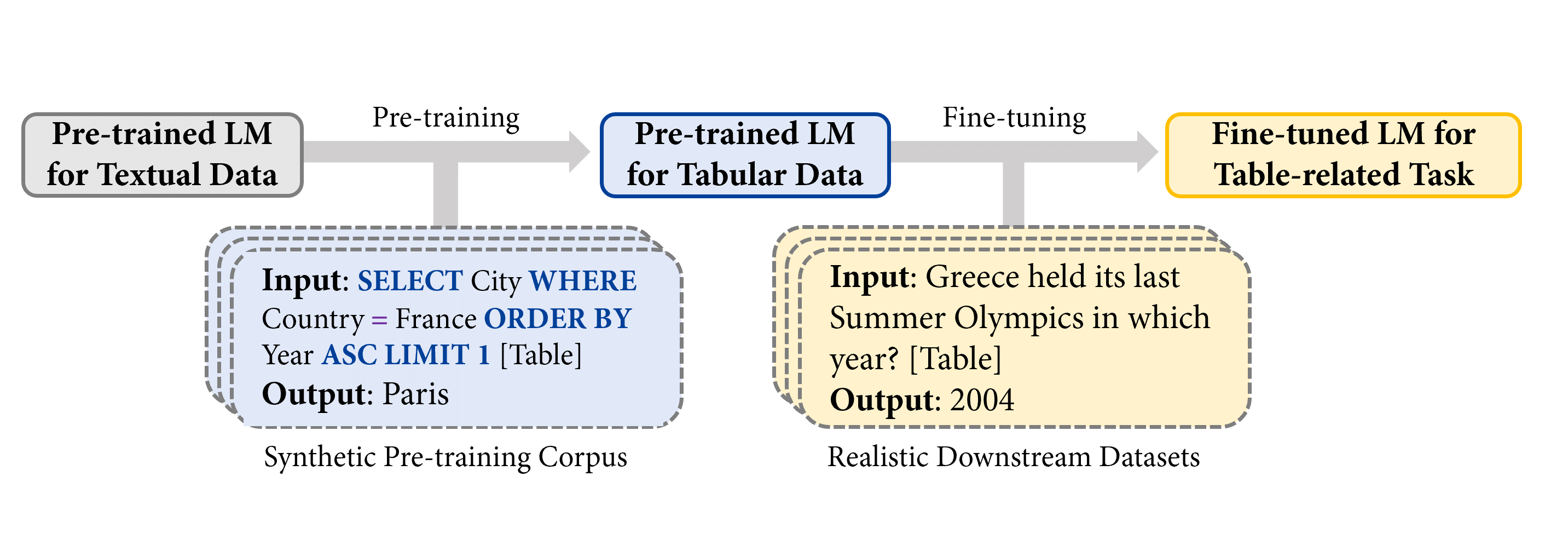
In "TAPEX: Table Pre-training via Learning a Neural SQL Executor", we explore using synthetic data as a proxy for real data during pre-training, and demonstrate its powerfulness with TAPEX (Table Pre-training via Execution) as an example. In TAPEX, we show that table pre-training can be achieved by learning a neural SQL executor over a synthetic corpus.
Note: [Table] is a placeholder for the user provided table in the input.
As shown in the figure above, by systematically sampling executable SQL queries and their execution outputs over tables, TAPEX first synthesizes a synthetic and non-natural pre-training corpus. Then, it continues to pre-train a language model (e.g., BART) to output the execution results of SQL queries, which mimics the process of a neural SQL executor.
Pre-training
The following figure illustrates the pre-training process. At each step, we first take a table from the web. The example table is about Olympics Games. Then we can sample an executable SQL query SELECT City WHERE Country = France ORDER BY Year ASC LIMIT 1. Through an off-the-shelf SQL executor (e.g., MySQL), we can obtain the query’s execution result Paris. Similarly, by feeding the concatenation of the SQL query and the flattened table to the model (e.g., BART encoder) as input, the execution result serves as the supervision for the model (e.g., BART decoder) as output.

Why use programs such as SQL queries rather than natural language sentences as a source for pre-training? The greatest advantage is that the diversity and scale of programs can be systematically guaranteed, compared to uncontrollable natural language sentences. Therefore, we can easily synthesize a diverse, large-scale, and high-quality pre-training corpus by sampling SQL queries.
You can try the trained neural SQL executor in 🤗 Transformers as below:
from transformers import TapexTokenizer, BartForConditionalGeneration
import pandas as pd
tokenizer = TapexTokenizer.from_pretrained("microsoft/tapex-large-sql-execution")
model = BartForConditionalGeneration.from_pretrained("microsoft/tapex-large-sql-execution")
data = {
"year": [1896, 1900, 1904, 2004, 2008, 2012],
"city": ["athens", "paris", "st. louis", "athens", "beijing", "london"]
}
table = pd.DataFrame.from_dict(data)
# tapex accepts uncased input since it is pre-trained on the uncased corpus
query = "select year where city = beijing"
encoding = tokenizer(table=table, query=query, return_tensors="pt")
outputs = model.generate(**encoding)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
# ['2008']
Fine-tuning
During fine-tuning, we feed the concatenation of the natural language question and the flattened table to the model as input, the answer labeled by annotators serves as the supervision for the model as output. Want to fine-tune TAPEX by yourself? You can look at the fine-tuning script here, which has been officially integrated into 🤗 Transformers 4.19.0!
And by now, all available TAPEX models have interactive widgets officially supported by Huggingface! You can try to answer some questions as below.
| Repository | Stars | Contributors | Programming language |
|---|---|---|---|
| Transformers | 36542 | 651 | Python |
| Datasets | 4512 | 77 | Python |
| Tokenizers | 3934 | 34 | Rust, Python and NodeJS |
Experiments
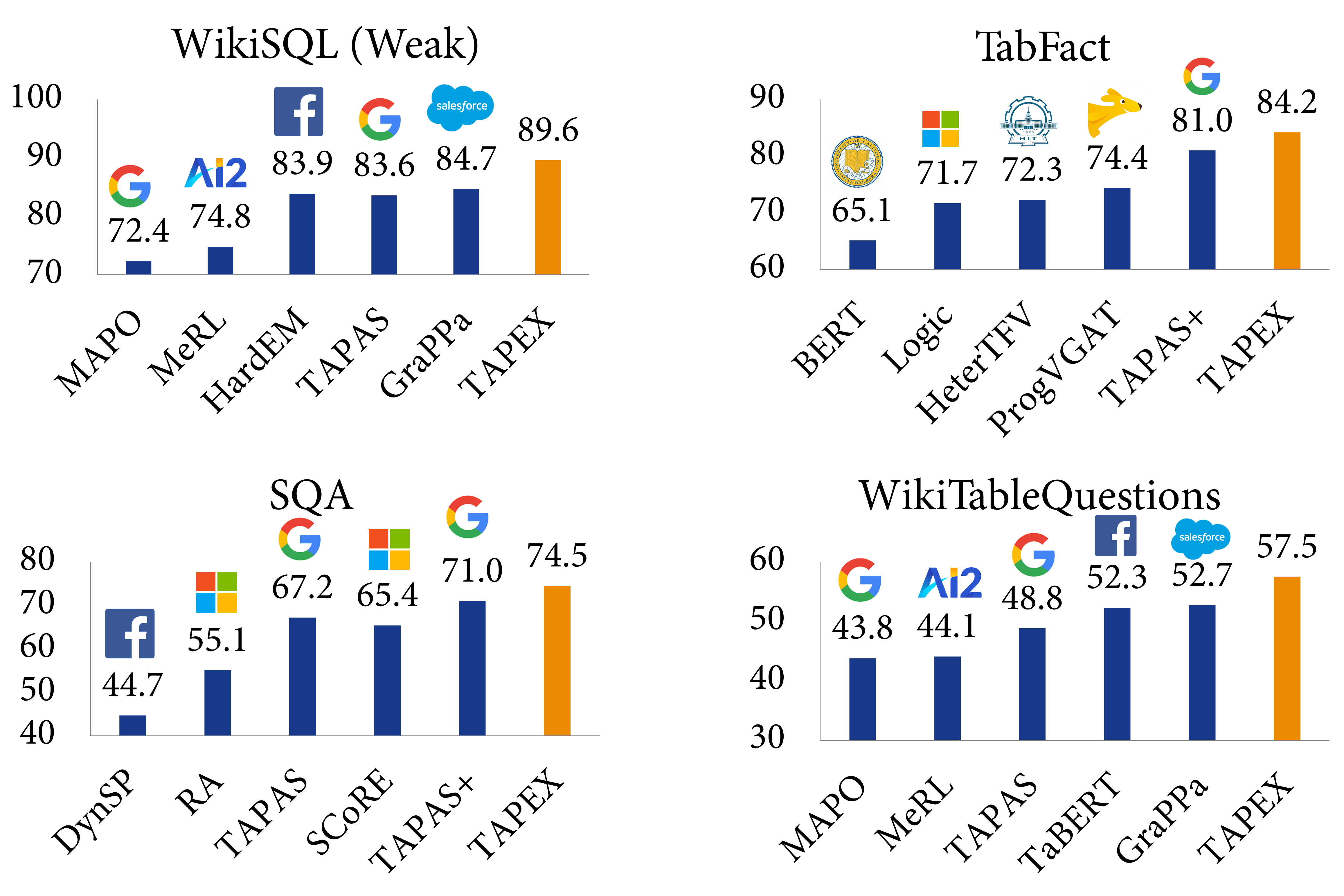
We evaluate TAPEX on four benchmark datasets, including WikiSQL (Weak), WikiTableQuestions, SQA and TabFact. The first three datasets are about table question answering, while the last one is about table fact verification, both requiring joint reasoning about tables and natural language. Below are some examples from the most challenging dataset, WikiTableQuestions:
| Question | Answer |
|---|---|
| according to the table, what is the last title that spicy horse produced? | Akaneiro: Demon Hunters |
| what is the difference in runners-up from coleraine academical institution and royal school dungannon? | 20 |
| what were the first and last movies greenstreet acted in? | The Maltese Falcon, Malaya |
| in which olympic games did arasay thondike not finish in the top 20? | 2012 |
| which broadcaster hosted 3 titles but they had only 1 episode? | Channel 4 |
Experimental results demonstrate that TAPEX outperforms previous table pre-training approaches by a large margin and ⭐achieves new state-of-the-art results on all of them⭐. This includes the improvements on the weakly-supervised WikiSQL denotation accuracy to 89.6% (+2.3% over SOTA, +3.8% over BART), the TabFact accuracy to 84.2% (+3.2% over SOTA, +3.0% over BART), the SQA denotation accuracy to 74.5% (+3.5% over SOTA, +15.9% over BART), and the WikiTableQuestion denotation accuracy to 57.5% (+4.8% over SOTA, +19.5% over BART). To our knowledge, this is the first work to exploit pre-training via synthetic executable programs and to achieve new state-of-the-art results on various downstream tasks.
Comparison to Previous Table Pre-training
The earliest work on table pre-training, TAPAS from Google Research - also available in 🤗 Transformers - and TaBERT from Meta AI, have revealed that collecting more domain-adaptive data can improve the downstream performance. However, these previous works mainly employ general-purpose pre-training tasks, e.g., language modeling or its variants. TAPEX explores a different path by sacrificing the naturalness of the pre-trained source in order to obtain a domain-adaptive pre-trained task, i.e. SQL execution. A graphical comparison of BERT, TAPAS/TaBERT and our TAPEX can be seen below.

We believe the SQL execution task is closer to the downstream table question answering task, especially from the perspective of structural reasoning capabilities. Imagine you are faced with a SQL query SELECT City ORDER BY Year and a natural question Sort all cities by year. The reasoning paths required by the SQL query and the question are similar, except that SQL is a bit more rigid than natural language. If a language model can be pre-trained to faithfully “execute” SQL queries and produce correct results, it should have a deep understanding on natural language with similar intents.
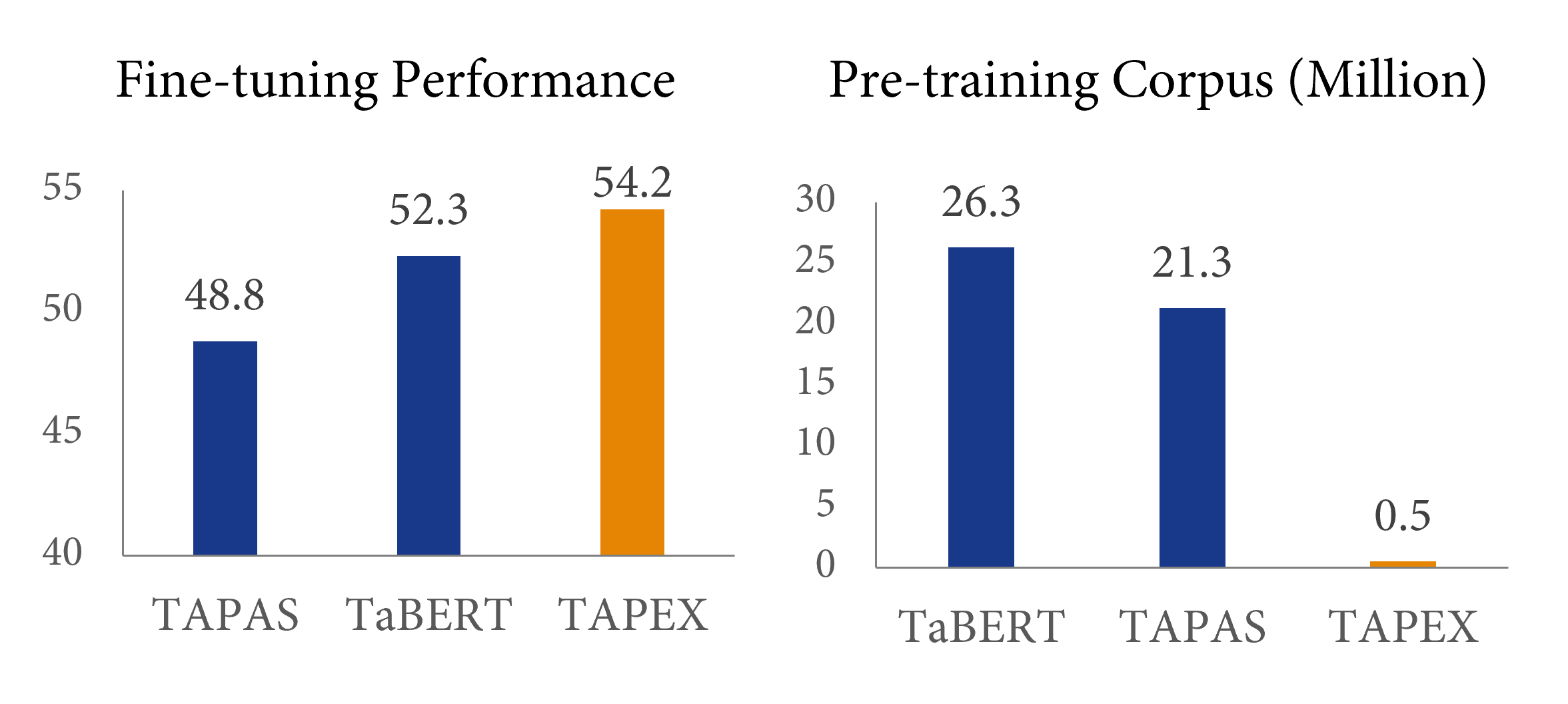
What about the efficiency? How efficient is such a pre-training method compared to the previous pre-training? The answer is given in the above figure: compared with previous table pre-training method TaBERT, TAPEX could yield 2% improvement only using 2% of the pre-training corpus, achieving a speedup of nearly 50 times! With a larger pre-training corpus (e.g., 5 million <SQL, Table, Execution Result> pairs), the performance on downstream datasets would be better.
Conclusion
In this blog, we introduce TAPEX, a table pre-training approach whose corpus is automatically synthesized via sampling SQL queries and their execution results. TAPEX addresses the data scarcity challenge in table pre-training by learning a neural SQL executor on a diverse, large-scale, and high-quality synthetic corpus. Experimental results on four downstream datasets demonstrate that TAPEX outperforms previous table pre-training approaches by a large margin, with a higher pre-training efficiency.
Take Away
What can we learn from the success of TAPEX? I suggest that, especially if you want to perform efficient continual pre-training, you may try these options:
- Synthesize an accurate and small corpus, instead of mining a large but noisy corpus from the Internet.
- Simulate domain-adaptive skills via programs, instead of general-purpose language modeling via natural language sentences.
