Unbelievable! Run 70B LLM Inference on a Single 4GB GPU with This NEW Technique







Large language models require huge amounts of GPU memory. Is it possible to run inference on a single GPU? If so, what is the minimum GPU memory required?

The 70B large language model has parameter size of 130GB. Just loading the model into the GPU requires 2 A100 GPUs with 100GB memory each.
During inference, the entire input sequence also needs to be loaded into memory for complex “attention” calculations. The memory requirement of this attention mechanism scales quadratically with the input length. On top of the 130GB model size, a lot more memory is needed.
So what techniques can save so much memory and enable inference on a single 4GB GPU?
Note that here the memory optimization techniques do not require any model compression like quantization, distillation, pruning that would sacrifice model performance.
Today we will explain the key techniques for extreme memory optimization of large models.
At the end of the article we also shared the open source library to achieve this with a few lines of codes!
01
Layer-wise Inference
The most critical technique is layer-wise inference. This is essentially the basic divide and conquer approach in computer science.
Let’s first look at the architecture of large language models. Today’s large language models all adopt the Multi-head self-attention structure proposed in Google’s paper “Attention is all you need”. This is what people later call the Transformer structure.
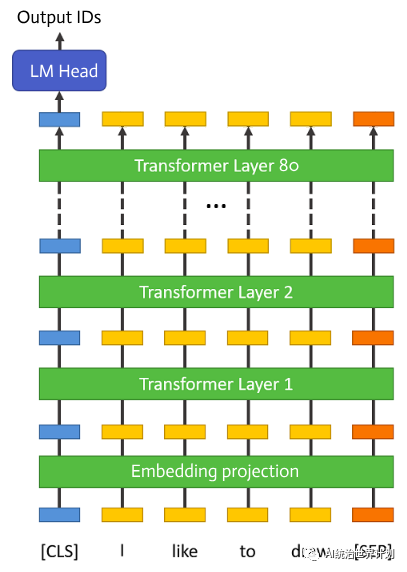
The large language model first has an embedding projection layer. After that there are 80 completely identical transformer layers. Finally there is a normalization and fully connected layer to predict the token ID probabilities.
During inference, layers are executed sequentially. The output of the previous layer is the input to the next. Only one layer executes at a time.
Therefore, it is completely unnecessary to keep all layers in GPU memory. We can load whichever layer is needed from disk when executing that layer, do all the calculations, and then completely free the memory after.
This way, the GPU memory required per layer is only about the parameter size of one transformer layer, 1/80 of the full model, around 1.6GB.
In addition, some output caches are also stored in GPU memory, the largest being the KV cache to avoid repeated computations.
A simple calculation, for the 70B model this KV cache size is about:
2 * input_length * num_layers * num_heads * vector_dim * 4
With input length 100, this cache = 2 * 100 * 80 * 8 * 128 * 4 = 30MB GPU memory.
According to our monitoring, the entire inference process uses less than 4GB GPU memory!
02
Single Layer Optimization — Flash Attention
Flash attention is perhaps one of the most important and critical optimizations in the development of large language models today.
All the various large language models use essentially the same underlying code, with flash attention being the biggest improvement.
The idea of flash attention optimization is not entirely novel though, we have to mention another paper “Self-attention Does Not Need O(n²) Memory”.
Originally self attention requires O(n²) memory (n being sequence length).
This paper proposes that we don’t actually need to keep the O(n²) intermediate results. We can compute them sequentially, continuously update one intermediate result and discard everything else. This reduces the memory complexity to O(logn).
Flash attention is similar in essence, with slightly higher memory complexity O(n), but flash attention deeply optimizes cuda memory access to achieve multi-fold speedups for inference and training.
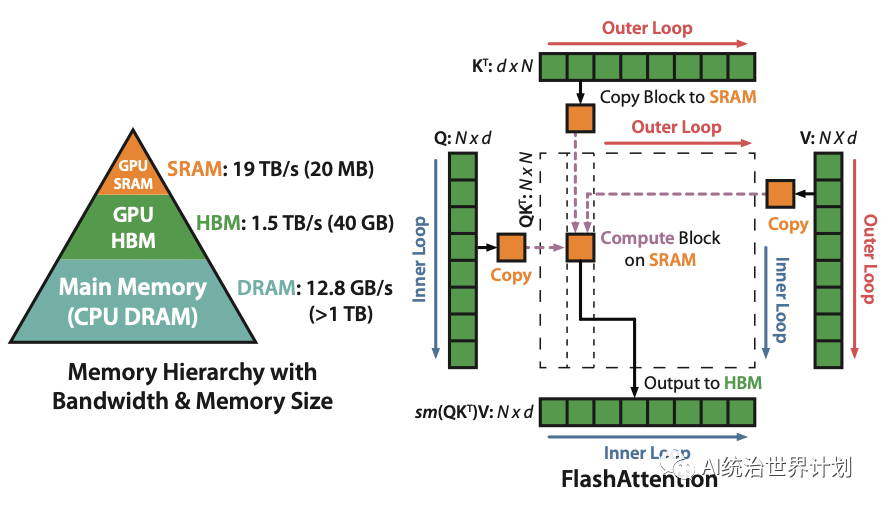
As the figure shows, originally self attention computes and stores O(n²) intermediate results. Flash attention splits the computation into many small blocks, computing block by block and reducing memory to the size of one block.
03
Model File Sharding
The original model file is usually sharded into multiple chunks, typically 10GB each.
Our execution processes layer by layer. Each layer is only 1.6GB. If we load based on the original 10GB shards, every layer execution will require reloading the entire 10GB file but only using 1.6GB.
This process wastes a lot of memory for loading and disk reading. Disk reading speed is actually the slowest bottleneck in the whole inference process, so we want to minimize it as much as possible.
Therefore, we first pre-process the original HuggingFace model file and shard it by layers.
For storage we use safetensor technology (https://github.com/huggingface/safetensors).
Safetensor ensures the storage format and in-memory format match closely, and uses memory mapping for loading to maximize speed.
04
Meta Device
In implementation we use the meta device feature provided by HuggingFace Accelerate (https://huggingface.co/docs/accelerate/usage\_guides/big\_modeling).
Meta device is a virtual device designed specifically for running ultra large models. When you load a model via meta device, the model data is not actually read in, only the code is loaded. Memory usage is 0.
You can dynamically transfer parts of the model from meta device to a real device like CPU or GPU during execution. Only then is it actually loaded into memory.
Using init_empty_weights() allows model loading via meta device.
from accelerate import init_empty_weights
with init_empty_weights():
my_model = ModelClass(...)
05
Open Source Library
We open sourced all the code — AirLLM. Allows you to achieve this with a few lines of code.
It can be found in the Anima github: **https://github.com/lyogavin/Anima/tree/main/air_llm.**
Usage is very simple. First install the package:
pip install airllm
Then layered inference can be performed like a normal Transformer model:
from airllm import AirLLMLlama2
MAX_LENGTH = 128
# could use hugging face model repo id:
model = AirLLMLlama2("garage-bAInd/Platypus2-70B-instruct")
# or use model's local path...
#model = AirLLMLlama2("/home/ubuntu/.cache/huggingface/hub/models--garage-bAInd--Platypus2-70B-instruct/snapshots/b585e74bcaae02e52665d9ac6d23f4d0dbc81a0f")
input_text = [
'What is the capital of United States?',
]
input_tokens = model.tokenizer(input_text,
return_tensors="pt",
return_attention_mask=False,
truncation=True,
max_length=MAX_LENGTH,
padding=True)
generation_output = model.generate(
input_tokens['input_ids'].cuda(),
max_new_tokens=20,
use_cache=True,
return_dict_in_generate=True)
output = model.tokenizer.decode(generation_output.sequences[0])
print(output)
We have tested this code on a 16GB Nvidia T4 GPU. The entire inference process uses less than 4GB GPU memory.
Note that lower end GPUs like T4 will be quite slow for inference. Not very suitable for interactive scenarios like chatbots. More suited for some offline data analytics like RAG, PDF analysis etc.
Currently only Llam2 based models are supported. Leave a comment if you need support for other models!
06
Can 70B Training Fit on a Single GPU?
While inference can be optimized with layering, can training work similarly on a single GPU?
Inference only needs the output of the previous layer when executing the next transformer layer, so layered execution with limited data is possible.
Training requires more data. The training process first computes the forward propagation to get the output of every layer and tensor. Then does backpropagation to compute the gradient of every tensor.
Gradient calculation needs to save the results of previous forward layers, so layered execution does not reduce memory.
There are some other techniques like gradient checkpointing that can achieve similar effects.
If you are interested in how gradient checkpointing can significantly reduce training memory requirements, leave a comment!
07
Our code references a lot from SIMJEG’s implementation on Kaggle: https://www.kaggle.com/code/simjeg/platypus2-70b-with-wikipedia-rag/notebook. Shout out to the awesome Kaggle community for their contributions!
We will continue open sourcing the latest and most effective new methods and advances in AI, contributing to the open source community. Please follow us.





