Fish Speech V1 - New Multilingual Open Source TTS Model







Introduction
Fish Audio's latest TTS model, Fish Speech V1, has been released and is available on Hugging Face. The code can be found on Github. With this release, we have kept our commitment made five months ago to train a model on a massive multilingual dataset, and even gone beyond it.
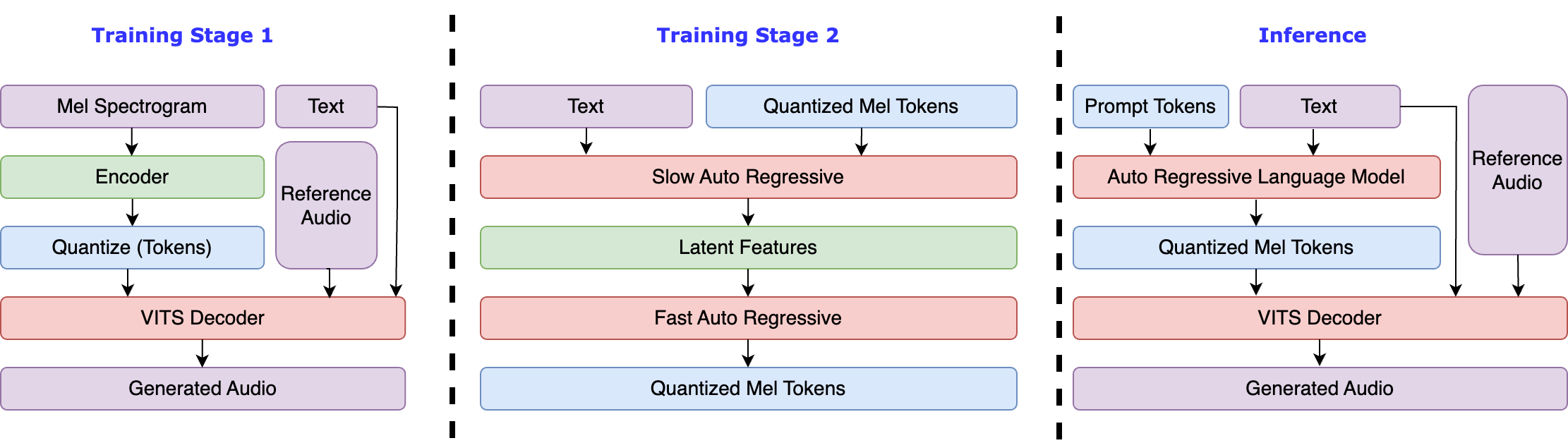
Fish Speech 1 is a series of TTS model that has been trained for 50k hours each on English, Chinese, and Japanese speech, totalling 150k hours. This extensive training, which requires a week on 16xA800 GPUs, was followed by SFT on a 1000-hour high-quality mixed language dataset. We have released both the pretrained and SFT model, resulting in the most powerful open-source text-to-speech model we have ever seen.
Significantly, Fish Speech is the only open-source TTS model operating at roughly 20 tokens per second. This speed enables us to generate content much faster (around 20 seconds per second on a 4090 GPU), reducing the likelihood of losing or repeating words and sentences.
We plan to release both Medium (400M) and Large (1B)’s Pretrain and SFT model in the following week.
Demo
We have provided demos in the following places:
- Fish Audio Website (medium sft): https://fish.audio/text-to-speech/
- Hugging Face Space (medium sft): https://huggingface.co/spaces/fishaudio/fish-speech-1
Finetuning On Your Data
Open sourcing Fish Speech allows everyone to customize and experiment with it. To fine-tune the software, follow these steps:
- Divide your data into 10-second chunks, store their corresponding texts, and quanitze them.
- Start fine-tuning your language model.
- (optional) Fine-tune the VQ decoder to enhance timbre similarity.
A step-by-step tutorial is available courtesy of the community on our documentation page: https://speech.fish.audio/en/.
Technical Details
Scaling
With the scaling law in mind, we expanded the model from 400M to 1B and increased the data size from 10k hours to 150k hours. This provided significant improvements.
Stable Decoding
However, we found that the generation of Fish Speech 1 was unstable, potentially introducing artifacts and losing words when using a naive codebook decoding strategy. As such, we explored various codebook decoding strategies, including:
- Naive (Fish Speech V0.4): decoding all codebooks simultaneously.
- AR+NAR (bark): using a GPT-like model to decode the most important codebooks (dependent on RVQ), followed by a BERT-like model to decode the remaining.
- Delay Pattern (Parler TTS, Stable TTS): shifting the encoding mask by one.
- Dual AR, also known as slow-fast (UniAudio): using one AR to decode hidden features (~20 tokens per second), then another AR to decode codebooks.
We found that Dual AR was the most reliable method for speech generation, as other methods could not guarantee dependencies between codebooks. When the number of codebooks increased significantly (and not RVQ), all other methods failed.
Better Compression Rate
Another crucial aspect is vector quantization. Various papers have shown that as the codebook size increases, the VQ's codebook utilization drops drastically. Thus, we explored FSQ and LFQ, as offered by Vector Quantize PyTorch. FSQ performed the best.
Choosing between Residual or Group quantization posed an additional issue. Group quantization had a better compression ratio but lacked strong dependency (like coarse to fine in RVQ), making it more challenging to learn. We found that Dual AR could predict them correctly.
Next Steps
We plan to integrate our model into the TTS arena in the next few weeks. Over the upcoming months, we'll continue to collect pre-training data to expand our model to more languages. Additionally, we aim to improve our data quality by introducing RLHF.





