Deploying a Private Hugging Face Model for Inference with RunPod and AnythingLLM (serverless)


This guide walks you through deploying a private Hugging Face model on RunPod's Serverless infrastructure and connecting it to AnythingLLM. This setup allows you to run your own AI model for chat interactions without relying on public APIs.
Why Serverless?
The main advantage of this setup is its cost-effectiveness for running private AI models. Traditional AI offerings often require dedicated GPU resources running continuously, which can be expensive, especially for infrequent use. This approach leverages pay-per-use pricing, where you're only charged when actively using the model. For instance, you might pay around $0.00034/s for a 48 GB GPU, but crucially, when the model is idle, you pay nothing. This makes it ideal for projects with sporadic or unpredictable usage patterns. While several providers offer this type of service, such as Fireworks.ai, this guide uses RunPod as an example. By combining a serverless offering with your private Hugging Face model and AnythingLLM, you get a powerful, customized AI model with the cost-efficiency of only paying for actual usage, potentially leading to significant savings compared to always-on GPU instances.
What is AnythingLLM?
AnythingLLM is an open-source, full-stack "Chat with your documents" application that allows users to chat with their documents in a private and enterprise environment5. It is constantly evolving and provides the following key features:
- Ability to upload documents and embed them into workspaces5
- Smart reuse of data across workspaces without duplicating the original data source5
- Cost estimation for embedding documents5
- Workspace settings to customize the LLM's responses, chat history, and prompts5
- Running log of chat history to maintain context5
- Ability to add documents to existing workspaces or remove them5
AnythingLLM is developed by Mintplex Labs and can be found on GitHub: https://github.com/Mintplex-Labs/anything-llm
Part 1: Setting Up RunPod for Your Hugging Face Model
1. Choose Serverless vLLM on RunPod
Go to https://www.runpod.io/console/serverless
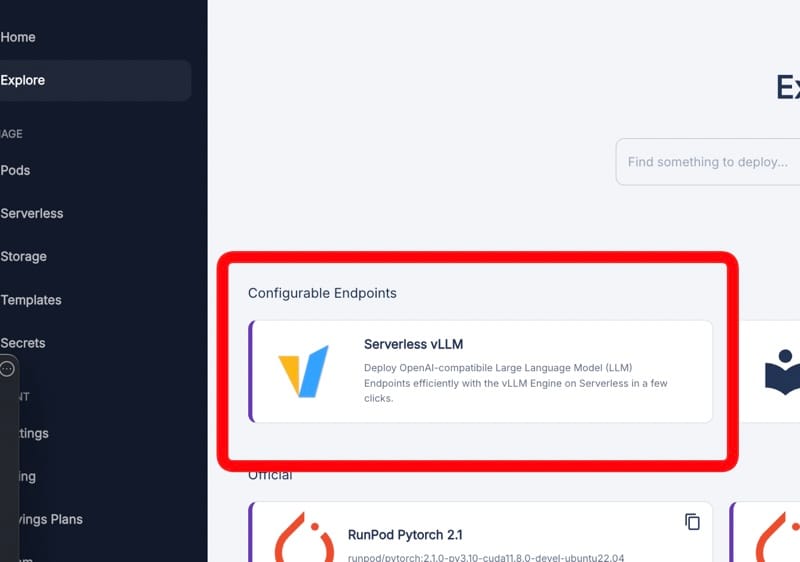
Select "Serverless vLLM". We're using this because it's optimized for running large language models and provides an OpenAI-compatible API, which we need for AnythingLLM integration.
2. Configure Your Hugging Face Model
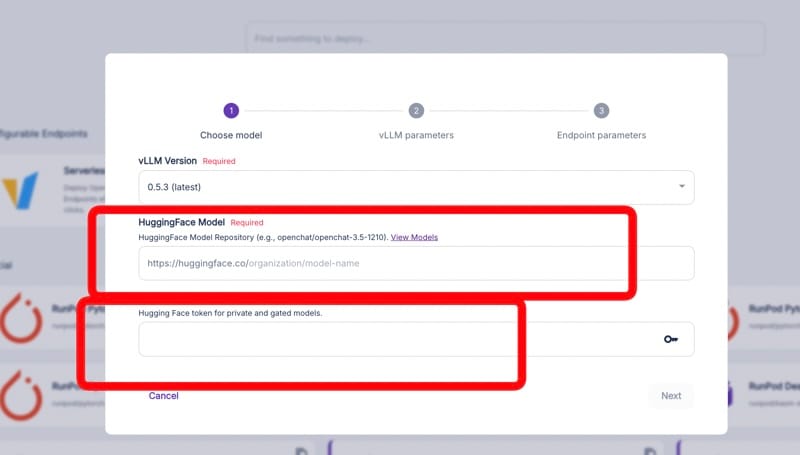
Enter your Hugging Face model details:
- Model name: The full path to your model on Hugging Face.
- Token: Your Hugging Face API token for accessing private models.
This step tells RunPod which model to deploy and how to access it.
3. Create a RunPod API Key
Go to https://www.runpod.io/console/user/settings
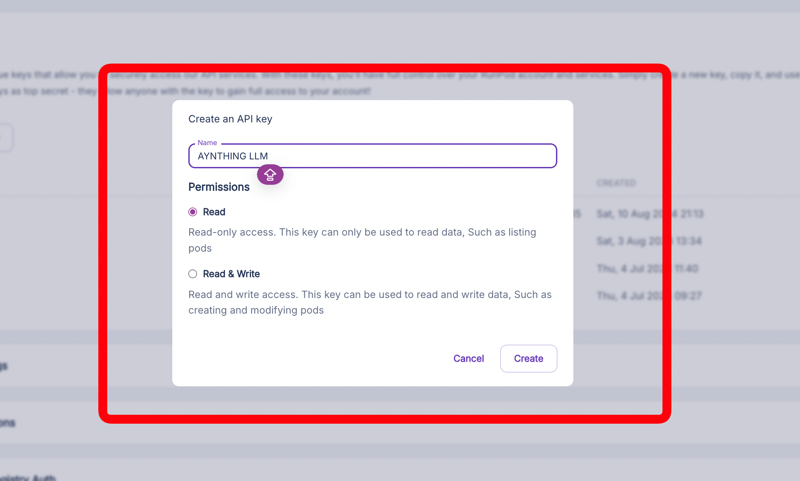
Create a new API key. This key will be used to authenticate requests to your deployed model.
4. Note Your API Keys
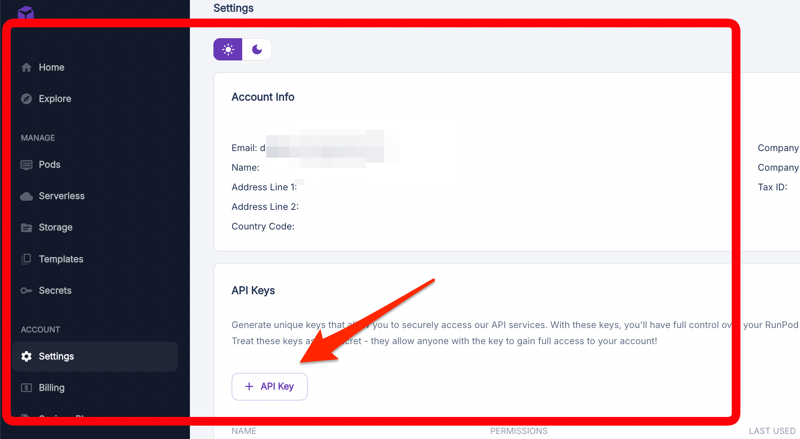
Keep track of your API keys. You'll need these to interact with your deployed model.
5. View Your Serverless Endpoint
Return to https://www.runpod.io/console/serverless
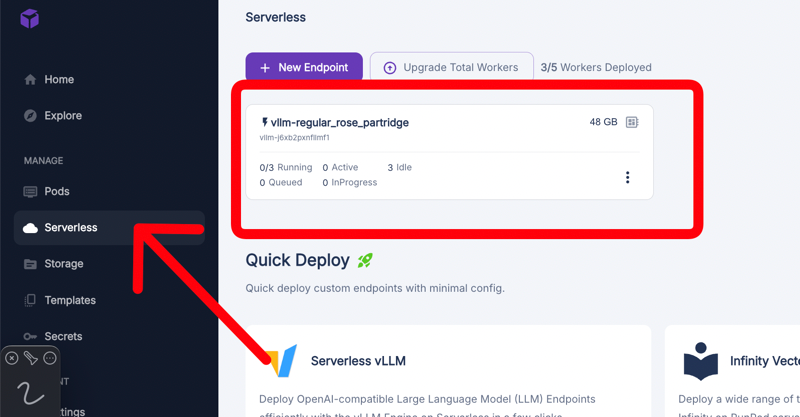
Find your newly created endpoint. This shows that your model is now deployed and ready for use.
6. Access Endpoint Details
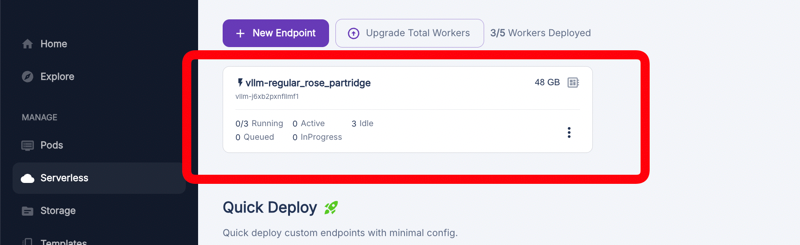
Click on your endpoint to view its details. This gives you information about your deployed model's status and usage.
7. Get the OpenAI Base URL
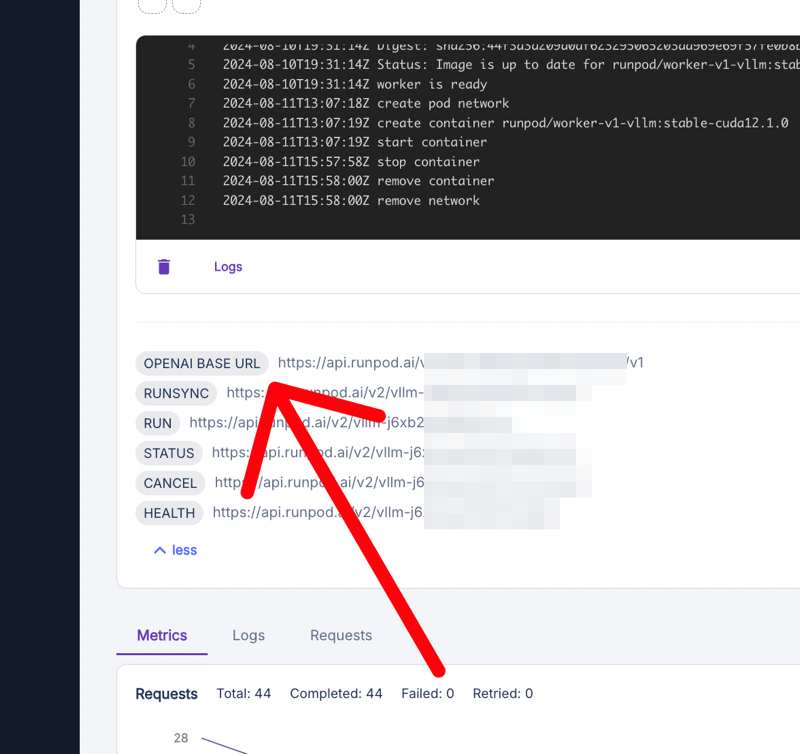
Find and copy the "OPENAI BASE URL". This URL is crucial - it's where AnythingLLM will send requests to interact with your model.
Part 2: Configuring AnythingLLM
8. Open AnythingLLM Settings
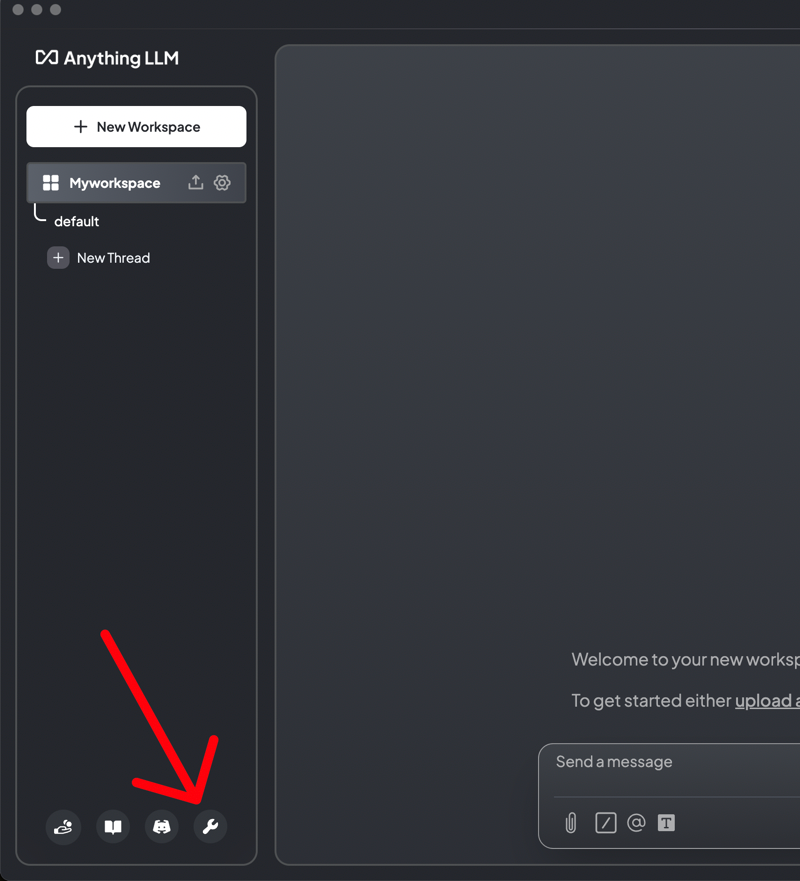
In AnythingLLM, go to settings. We need to configure it to use your RunPod-deployed model instead of the default options.
9. Navigate to AI Providers
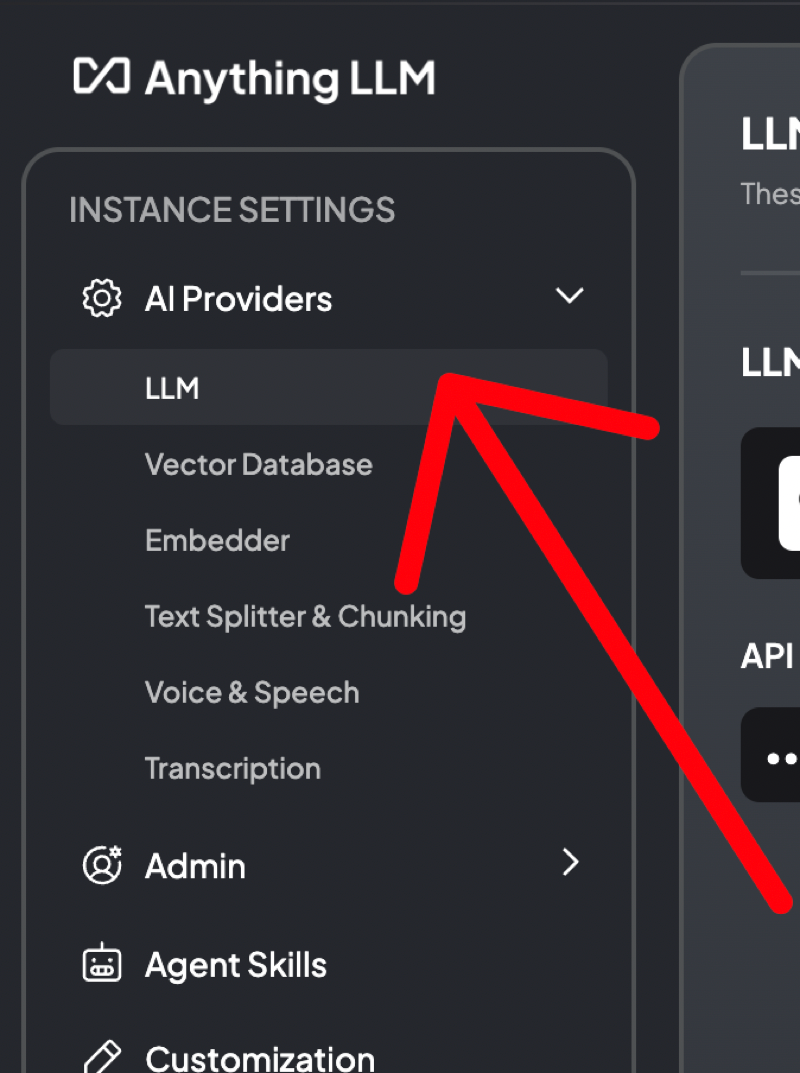
In settings, go to AI Providers and select "LLM". This is where you tell AnythingLLM about your custom model.
10. Set Up the LLM Provider
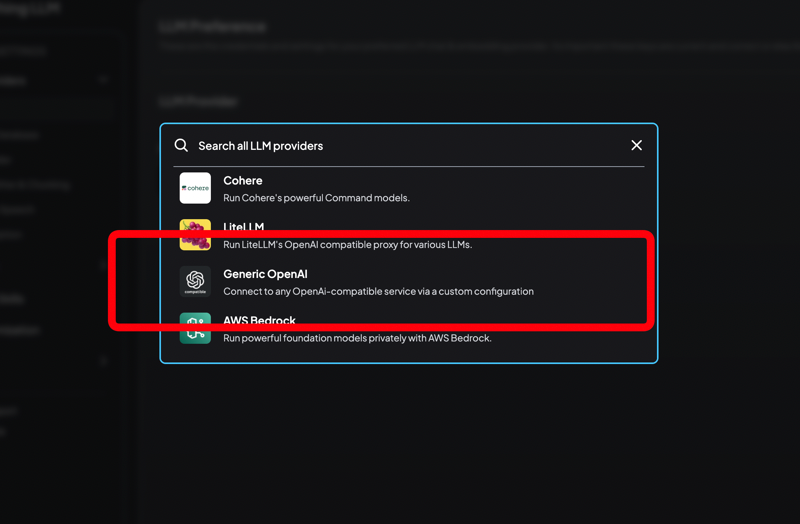
Choose "Generic OpenAI" as the provider. This option allows AnythingLLM to communicate with your RunPod-deployed model using the OpenAI-compatible API.
11. Enter Your Model Details
In the OpenAI settings (not shown in images):
- OpenAI Base URL: Paste the URL from step 7.
- API Key: Enter the RunPod API key from step 3.
- Model Name: Your Hugging Face model name.
These settings connect AnythingLLM to your specific model on RunPod.
12. Save and Test
Save your settings and test the connection. AnythingLLM should now be able to chat using your private model hosted on RunPod.
Please note that startup might take a few seconds. You can increase the idle timeout to avoid booting each time you chat with the model within a short period.
Conclusion
You've now set up a private AI chat system using your own Hugging Face model, hosted on RunPod, and integrated with AnythingLLM. This configuration gives you control over the model and keeps your data private, while still providing a ChatGPT-like experience.