
daliprf
commited on
Commit
•
1eced3c
1
Parent(s):
0376fae
init
Browse files- .gitattributes +2 -0
- AffectNetClass.py +130 -0
- FerPlusClass.py +143 -0
- LICENSE +21 -0
- README.md +97 -3
- RafdbClass.py +109 -0
- cnn_model.py +116 -0
- config.py +145 -0
- custom_loss.py +218 -0
- data_helper.py +80 -0
- dataset_class.py +71 -0
- img.jpg +3 -0
- main.py +12 -0
- paper_graphical_items/confm.jpg +3 -0
- paper_graphical_items/correlation_loss.jpg +3 -0
- paper_graphical_items/embedding_TSNE.jpg +3 -0
- paper_graphical_items/fd_ed.jpg +3 -0
- paper_graphical_items/md_component.jpg +3 -0
- paper_graphical_items/samples.jpg +3 -0
- requirements.txt +13 -0
- test_model.py +47 -0
- train.py +349 -0
- trained_models/AffectNet_6336.h5 +3 -0
- trained_models/Fer2013_7203.h5 +3 -0
- trained_models/RafDB_8696.h5 +3 -0
.gitattributes
CHANGED
|
@@ -29,3 +29,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 29 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 30 |
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
| 31 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 29 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 30 |
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
| 31 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.png filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.jpg filter=lfs diff=lfs merge=lfs -text
|
AffectNetClass.py
ADDED
|
@@ -0,0 +1,130 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from config import DatasetName, AffectnetConf, InputDataSize, LearningConfig, ExpressionCodesAffectnet
|
| 2 |
+
from config import LearningConfig, InputDataSize, DatasetName, AffectnetConf, DatasetType
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import os
|
| 6 |
+
import matplotlib.pyplot as plt
|
| 7 |
+
import math
|
| 8 |
+
from datetime import datetime
|
| 9 |
+
from sklearn.utils import shuffle
|
| 10 |
+
from sklearn.model_selection import train_test_split
|
| 11 |
+
from numpy import save, load, asarray, savez_compressed, savez
|
| 12 |
+
import csv
|
| 13 |
+
from skimage.io import imread
|
| 14 |
+
import pickle
|
| 15 |
+
import csv
|
| 16 |
+
from tqdm import tqdm
|
| 17 |
+
from PIL import Image
|
| 18 |
+
from skimage.transform import resize
|
| 19 |
+
import tensorflow as tf
|
| 20 |
+
import random
|
| 21 |
+
import cv2
|
| 22 |
+
from skimage.feature import hog
|
| 23 |
+
from skimage import data, exposure
|
| 24 |
+
from matplotlib.path import Path
|
| 25 |
+
from scipy import ndimage, misc
|
| 26 |
+
from data_helper import DataHelper
|
| 27 |
+
from sklearn.metrics import accuracy_score
|
| 28 |
+
from sklearn.metrics import confusion_matrix
|
| 29 |
+
from dataset_class import CustomDataset
|
| 30 |
+
from sklearn.metrics import precision_recall_fscore_support as score
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class AffectNet:
|
| 34 |
+
def __init__(self, ds_type):
|
| 35 |
+
"""we set the parameters needed during the whole class:
|
| 36 |
+
"""
|
| 37 |
+
self.ds_type = ds_type
|
| 38 |
+
if ds_type == DatasetType.train:
|
| 39 |
+
self.img_path = AffectnetConf.no_aug_train_img_path
|
| 40 |
+
self.anno_path = AffectnetConf.no_aug_train_annotation_path
|
| 41 |
+
self.img_path_aug = AffectnetConf.aug_train_img_path
|
| 42 |
+
self.masked_img_path = AffectnetConf.aug_train_masked_img_path
|
| 43 |
+
self.anno_path_aug = AffectnetConf.aug_train_annotation_path
|
| 44 |
+
|
| 45 |
+
elif ds_type == DatasetType.eval:
|
| 46 |
+
self.img_path_aug = AffectnetConf.eval_img_path
|
| 47 |
+
self.anno_path_aug = AffectnetConf.eval_annotation_path
|
| 48 |
+
self.img_path = AffectnetConf.eval_img_path
|
| 49 |
+
self.anno_path = AffectnetConf.eval_annotation_path
|
| 50 |
+
self.masked_img_path = AffectnetConf.eval_masked_img_path
|
| 51 |
+
|
| 52 |
+
elif ds_type == DatasetType.train_7:
|
| 53 |
+
self.img_path = AffectnetConf.no_aug_train_img_path_7
|
| 54 |
+
self.anno_path = AffectnetConf.no_aug_train_annotation_path_7
|
| 55 |
+
self.img_path_aug = AffectnetConf.aug_train_img_path_7
|
| 56 |
+
self.masked_img_path = AffectnetConf.aug_train_masked_img_path_7
|
| 57 |
+
self.anno_path_aug = AffectnetConf.aug_train_annotation_path_7
|
| 58 |
+
|
| 59 |
+
elif ds_type == DatasetType.eval_7:
|
| 60 |
+
self.img_path_aug = AffectnetConf.eval_img_path_7
|
| 61 |
+
self.anno_path_aug = AffectnetConf.eval_annotation_path_7
|
| 62 |
+
self.img_path = AffectnetConf.eval_img_path_7
|
| 63 |
+
self.anno_path = AffectnetConf.eval_annotation_path_7
|
| 64 |
+
self.masked_img_path = AffectnetConf.eval_masked_img_path_7
|
| 65 |
+
|
| 66 |
+
def test_accuracy(self, model, print_samples=False):
|
| 67 |
+
dhp = DataHelper()
|
| 68 |
+
|
| 69 |
+
batch_size = LearningConfig.batch_size
|
| 70 |
+
exp_pr_glob = []
|
| 71 |
+
exp_gt_glob = []
|
| 72 |
+
acc_per_label = []
|
| 73 |
+
'''create batches'''
|
| 74 |
+
img_filenames, exp_filenames = dhp.create_generator_full_path(
|
| 75 |
+
img_path=self.img_path,
|
| 76 |
+
annotation_path=self.anno_path, label=None)
|
| 77 |
+
|
| 78 |
+
print(len(img_filenames))
|
| 79 |
+
step_per_epoch = int(len(img_filenames) // batch_size)
|
| 80 |
+
exp_pr_lbl = []
|
| 81 |
+
exp_gt_lbl = []
|
| 82 |
+
|
| 83 |
+
cds = CustomDataset()
|
| 84 |
+
ds = cds.create_dataset(img_filenames=img_filenames,
|
| 85 |
+
anno_names=exp_filenames,
|
| 86 |
+
is_validation=True, ds=DatasetName.affectnet)
|
| 87 |
+
batch_index = 0
|
| 88 |
+
for img_batch, exp_gt_b in ds:
|
| 89 |
+
'''predict on batch'''
|
| 90 |
+
exp_gt_b = exp_gt_b[:, -1]
|
| 91 |
+
img_batch = img_batch[:, -1, :, :]
|
| 92 |
+
|
| 93 |
+
# probab_exp_pr_b, _ = model.predict_on_batch([img_batch]) # with embedding
|
| 94 |
+
pr_data = model.predict_on_batch([img_batch])
|
| 95 |
+
probab_exp_pr_b = pr_data[0]
|
| 96 |
+
|
| 97 |
+
scores_b = np.array([tf.nn.softmax(probab_exp_pr_b[i]) for i in range(len(probab_exp_pr_b))])
|
| 98 |
+
exp_pr_b = np.array([np.argmax(scores_b[i]) for i in range(len(probab_exp_pr_b))])
|
| 99 |
+
|
| 100 |
+
if print_samples:
|
| 101 |
+
for i in range(len(exp_pr_b)):
|
| 102 |
+
dhp.test_image_print_exp(str(i) + str(batch_index + 1), np.array(img_batch[i]),
|
| 103 |
+
np.int8(exp_gt_b[i]), np.int8(exp_pr_b[i]))
|
| 104 |
+
|
| 105 |
+
exp_pr_lbl += np.array(exp_pr_b).tolist()
|
| 106 |
+
exp_gt_lbl += np.array(exp_gt_b).tolist()
|
| 107 |
+
batch_index += 1
|
| 108 |
+
exp_pr_lbl = np.int64(np.array(exp_pr_lbl))
|
| 109 |
+
exp_gt_lbl = np.int64(np.array(exp_gt_lbl))
|
| 110 |
+
|
| 111 |
+
global_accuracy = accuracy_score(exp_gt_lbl, exp_pr_lbl)
|
| 112 |
+
|
| 113 |
+
precision, recall, fscore, support = score(exp_gt_lbl, exp_pr_lbl)
|
| 114 |
+
|
| 115 |
+
conf_mat = confusion_matrix(exp_gt_lbl, exp_pr_lbl) / 500.0
|
| 116 |
+
# conf_mat = tf.math.confusion_matrix(exp_gt_lbl, exp_pr_lbl, num_classes=7)/500.0
|
| 117 |
+
avg_acc = np.mean([conf_mat[i, i] for i in range(7)])
|
| 118 |
+
|
| 119 |
+
ds = None
|
| 120 |
+
face_img_filenames = None
|
| 121 |
+
eyes_img_filenames = None
|
| 122 |
+
nose_img_filenames = None
|
| 123 |
+
mouth_img_filenames = None
|
| 124 |
+
exp_filenames = None
|
| 125 |
+
global_bunch = None
|
| 126 |
+
upper_bunch = None
|
| 127 |
+
middle_bunch = None
|
| 128 |
+
bottom_bunch = None
|
| 129 |
+
|
| 130 |
+
return global_accuracy, conf_mat, avg_acc, precision, recall, fscore, support
|
FerPlusClass.py
ADDED
|
@@ -0,0 +1,143 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from config import DatasetName, AffectnetConf, InputDataSize, LearningConfig, ExpressionCodesAffectnet
|
| 2 |
+
from config import LearningConfig, InputDataSize, DatasetName, FerPlusConf, DatasetType
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import os
|
| 6 |
+
import matplotlib.pyplot as plt
|
| 7 |
+
import math
|
| 8 |
+
from datetime import datetime
|
| 9 |
+
from sklearn.utils import shuffle
|
| 10 |
+
from sklearn.model_selection import train_test_split
|
| 11 |
+
from numpy import save, load, asarray, savez_compressed
|
| 12 |
+
import csv
|
| 13 |
+
from skimage.io import imread
|
| 14 |
+
import pickle
|
| 15 |
+
import csv
|
| 16 |
+
from tqdm import tqdm
|
| 17 |
+
from PIL import Image
|
| 18 |
+
from skimage.transform import resize
|
| 19 |
+
import tensorflow as tf
|
| 20 |
+
import random
|
| 21 |
+
import cv2
|
| 22 |
+
from skimage.feature import hog
|
| 23 |
+
from skimage import data, exposure
|
| 24 |
+
from matplotlib.path import Path
|
| 25 |
+
from scipy import ndimage, misc
|
| 26 |
+
from data_helper import DataHelper
|
| 27 |
+
from sklearn.metrics import accuracy_score
|
| 28 |
+
from sklearn.metrics import confusion_matrix
|
| 29 |
+
from shutil import copyfile
|
| 30 |
+
from dataset_class import CustomDataset
|
| 31 |
+
from sklearn.metrics import precision_recall_fscore_support as score
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class FerPlus:
|
| 35 |
+
|
| 36 |
+
def __init__(self, ds_type):
|
| 37 |
+
"""we set the parameters needed during the whole class:
|
| 38 |
+
"""
|
| 39 |
+
self.ds_type = ds_type
|
| 40 |
+
if ds_type == DatasetType.train:
|
| 41 |
+
self.img_path = FerPlusConf.no_aug_train_img_path
|
| 42 |
+
self.anno_path = FerPlusConf.no_aug_train_annotation_path
|
| 43 |
+
self.img_path_aug = FerPlusConf.aug_train_img_path
|
| 44 |
+
self.anno_path_aug = FerPlusConf.aug_train_annotation_path
|
| 45 |
+
self.masked_img_path = FerPlusConf.aug_train_masked_img_path
|
| 46 |
+
self.orig_image_path = FerPlusConf.orig_image_path_train
|
| 47 |
+
|
| 48 |
+
elif ds_type == DatasetType.test:
|
| 49 |
+
self.img_path = FerPlusConf.test_img_path
|
| 50 |
+
self.anno_path = FerPlusConf.test_annotation_path
|
| 51 |
+
self.img_path_aug = FerPlusConf.test_img_path
|
| 52 |
+
self.anno_path_aug = FerPlusConf.test_annotation_path
|
| 53 |
+
self.masked_img_path = FerPlusConf.test_masked_img_path
|
| 54 |
+
self.orig_image_path = FerPlusConf.orig_image_path_train
|
| 55 |
+
|
| 56 |
+
def create_from_orig(self):
|
| 57 |
+
print('create_from_orig & relabel to affectNetLike--->')
|
| 58 |
+
"""
|
| 59 |
+
labels are from 1-7, but we save them from 0 to 6
|
| 60 |
+
:param ds_type:
|
| 61 |
+
:return:
|
| 62 |
+
"""
|
| 63 |
+
|
| 64 |
+
'''read the text file, and save exp, and image'''
|
| 65 |
+
dhl = DataHelper()
|
| 66 |
+
|
| 67 |
+
exp_affectnet_like_lbls = [6, 5, 4, 1, 0, 2, 3]
|
| 68 |
+
lbl_affectnet_like_lbls = ['angry/', 'disgust/', 'fear/', 'happy/', 'neutral/', 'sad/', 'surprise/']
|
| 69 |
+
|
| 70 |
+
for exp_index in range(len(lbl_affectnet_like_lbls)):
|
| 71 |
+
exp_prefix = lbl_affectnet_like_lbls[exp_index]
|
| 72 |
+
for i, file in tqdm(enumerate(os.listdir(self.orig_image_path + exp_prefix))):
|
| 73 |
+
if file.endswith(".jpg") or file.endswith(".png"):
|
| 74 |
+
img_source_address = self.orig_image_path + exp_prefix + file
|
| 75 |
+
img_dest_address = self.img_path + file
|
| 76 |
+
exp_dest_address = self.anno_path + file[:-4]
|
| 77 |
+
exp = exp_affectnet_like_lbls[exp_index]
|
| 78 |
+
|
| 79 |
+
img = np.array(Image.open(img_source_address))
|
| 80 |
+
res_img = resize(img, (InputDataSize.image_input_size, InputDataSize.image_input_size, 3),
|
| 81 |
+
anti_aliasing=True)
|
| 82 |
+
|
| 83 |
+
im = Image.fromarray(np.round(res_img * 255.0).astype(np.uint8))
|
| 84 |
+
'''save image'''
|
| 85 |
+
im.save(img_dest_address)
|
| 86 |
+
'''save annotation'''
|
| 87 |
+
np.save(exp_dest_address + '_exp', exp)
|
| 88 |
+
|
| 89 |
+
def test_accuracy(self, model, print_samples=False):
|
| 90 |
+
print('FER: test_accuracy')
|
| 91 |
+
dhp = DataHelper()
|
| 92 |
+
'''create batches'''
|
| 93 |
+
img_filenames, exp_filenames = dhp.create_generator_full_path(
|
| 94 |
+
img_path=self.img_path,
|
| 95 |
+
annotation_path=self.anno_path, label=None)
|
| 96 |
+
print(len(img_filenames))
|
| 97 |
+
exp_pr_lbl = []
|
| 98 |
+
exp_gt_lbl = []
|
| 99 |
+
|
| 100 |
+
cds = CustomDataset()
|
| 101 |
+
ds = cds.create_dataset(img_filenames=img_filenames,
|
| 102 |
+
anno_names=exp_filenames,
|
| 103 |
+
is_validation=True,
|
| 104 |
+
ds=DatasetName.fer2013)
|
| 105 |
+
|
| 106 |
+
batch_index = 0
|
| 107 |
+
print('FER: loading test ds')
|
| 108 |
+
for img_batch, exp_gt_b in tqdm(ds):
|
| 109 |
+
'''predict on batch'''
|
| 110 |
+
exp_gt_b = exp_gt_b[:, -1]
|
| 111 |
+
img_batch = img_batch[:, -1, :, :]
|
| 112 |
+
|
| 113 |
+
pr_data = model.predict_on_batch([img_batch])
|
| 114 |
+
probab_exp_pr_b = pr_data[0]
|
| 115 |
+
|
| 116 |
+
scores_b = np.array([tf.nn.softmax(probab_exp_pr_b[i]) for i in range(len(probab_exp_pr_b))])
|
| 117 |
+
exp_pr_b = np.array([np.argmax(scores_b[i]) for i in range(len(probab_exp_pr_b))])
|
| 118 |
+
|
| 119 |
+
if print_samples:
|
| 120 |
+
for i in range(len(exp_pr_b)):
|
| 121 |
+
dhp.test_image_print_exp(str(i)+str(batch_index+1), np.array(img_batch[i]),
|
| 122 |
+
np.int8(exp_gt_b[i]), np.int8(exp_pr_b[i]))
|
| 123 |
+
|
| 124 |
+
exp_pr_lbl += np.array(exp_pr_b).tolist()
|
| 125 |
+
exp_gt_lbl += np.array(exp_gt_b).tolist()
|
| 126 |
+
batch_index += 1
|
| 127 |
+
exp_pr_lbl = np.float64(np.array(exp_pr_lbl))
|
| 128 |
+
exp_gt_lbl = np.float64(np.array(exp_gt_lbl))
|
| 129 |
+
|
| 130 |
+
global_accuracy = accuracy_score(exp_gt_lbl, exp_pr_lbl)
|
| 131 |
+
precision, recall, fscore, support = score(exp_gt_lbl, exp_pr_lbl)
|
| 132 |
+
conf_mat = confusion_matrix(exp_gt_lbl, exp_pr_lbl, normalize='true')
|
| 133 |
+
# conf_mat = tf.math.confusion_matrix(exp_gt_lbl, exp_pr_lbl, num_classes=7)
|
| 134 |
+
avg_acc = np.mean([conf_mat[i,i] for i in range(7)])
|
| 135 |
+
|
| 136 |
+
ds = None
|
| 137 |
+
face_img_filenames = None
|
| 138 |
+
eyes_img_filenames = None
|
| 139 |
+
nose_img_filenames = None
|
| 140 |
+
mouth_img_filenames = None
|
| 141 |
+
exp_filenames = None
|
| 142 |
+
|
| 143 |
+
return global_accuracy, conf_mat, avg_acc, precision, recall, fscore, support
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022 Ali Pourramezan Fard
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,3 +1,97 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Ad-Corre
|
| 2 |
+
Ad-Corre: Adaptive Correlation-Based Loss for Facial Expression Recognition in the Wild
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
[](https://paperswithcode.com/sota/facial-expression-recognition-on-raf-db?p=ad-corre-adaptive-correlation-based-loss-for)
|
| 6 |
+
<!--
|
| 7 |
+
[](https://paperswithcode.com/sota/facial-expression-recognition-on-affectnet?p=ad-corre-adaptive-correlation-based-loss-for)
|
| 8 |
+
|
| 9 |
+
[](https://paperswithcode.com/sota/facial-expression-recognition-on-fer2013?p=ad-corre-adaptive-correlation-based-loss-for)
|
| 10 |
+
-->
|
| 11 |
+
|
| 12 |
+
#### Link to the paper (open access):
|
| 13 |
+
https://ieeexplore.ieee.org/document/9727163
|
| 14 |
+
|
| 15 |
+
#### Link to the paperswithcode.com:
|
| 16 |
+
https://paperswithcode.com/paper/ad-corre-adaptive-correlation-based-loss-for
|
| 17 |
+
|
| 18 |
+
```
|
| 19 |
+
Please cite this work as:
|
| 20 |
+
|
| 21 |
+
@ARTICLE{9727163,
|
| 22 |
+
author={Fard, Ali Pourramezan and Mahoor, Mohammad H.},
|
| 23 |
+
journal={IEEE Access},
|
| 24 |
+
title={Ad-Corre: Adaptive Correlation-Based Loss for Facial Expression Recognition in the Wild},
|
| 25 |
+
year={2022},
|
| 26 |
+
volume={},
|
| 27 |
+
number={},
|
| 28 |
+
pages={1-1},
|
| 29 |
+
doi={10.1109/ACCESS.2022.3156598}}
|
| 30 |
+
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
## Introduction
|
| 34 |
+
|
| 35 |
+
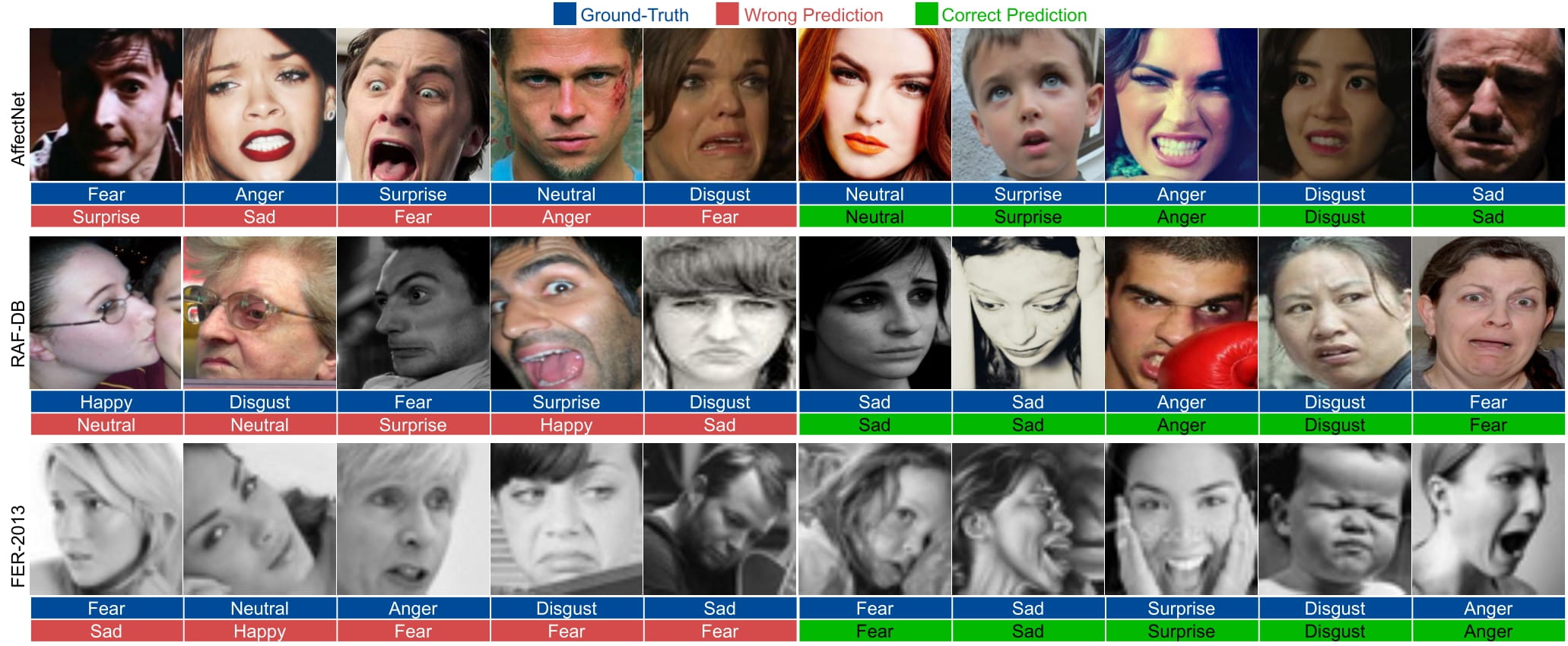
Automated Facial Expression Recognition (FER) in the wild using deep neural networks is still challenging due to intra-class variations and inter-class similarities in facial images. Deep Metric Learning (DML) is among the widely used methods to deal with these issues by improving the discriminative power of the learned embedded features. This paper proposes an Adaptive Correlation (Ad-Corre) Loss to guide the network towards generating embedded feature vectors with high correlation for within-class samples and less correlation for between-class samples. Ad-Corre consists of 3 components called Feature Discriminator, Mean Discriminator, and Embedding Discriminator. We design the Feature Discriminator component to guide the network to create the embedded feature vectors to be highly correlated if they belong to a similar class, and less correlated if they belong to different classes. In addition, the Mean Discriminator component leads the network to make the mean embedded feature vectors of different classes to be less similar to each other.We use Xception network as the backbone of our model, and contrary to previous work, we propose an embedding feature space that contains k feature vectors. Then, the Embedding Discriminator component penalizes the network to generate the embedded feature vectors, which are dissimilar.We trained our model using the combination of our proposed loss functions called Ad-Corre Loss jointly with the cross-entropy loss. We achieved a very promising recognition accuracy on AffectNet, RAF-DB, and FER-2013. Our extensive experiments and ablation study indicate the power of our method to cope well with challenging FER tasks in the wild.
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
## Evaluation and Samples
|
| 39 |
+
The following samples are taken from the paper:
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
----------------------------------------------------------------------------------------------------------------------------------
|
| 45 |
+
## Installing the requirements
|
| 46 |
+
In order to run the code you need to install python >= 3.5.
|
| 47 |
+
The requirements and the libraries needed to run the code can be installed using the following command:
|
| 48 |
+
|
| 49 |
+
```
|
| 50 |
+
pip install -r requirements.txt
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
## Using the pre-trained models
|
| 55 |
+
The pretrained models for Affectnet, RafDB, and Fer2013 are provided in the [Trained_Models](https://github.com/aliprf/Ad-Corre/tree/main/Trained_Models) folder. You can use the following code to predict the facial emotionn of a facial image:
|
| 56 |
+
|
| 57 |
+
```
|
| 58 |
+
tester = TestModels(h5_address='./trained_models/AffectNet_6336.h5')
|
| 59 |
+
tester.recognize_fer(img_path='./img.jpg')
|
| 60 |
+
|
| 61 |
+
```
|
| 62 |
+
plaese see the following [main.py](https://github.com/aliprf/Ad-Corre/tree/main/main.py) file.
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
## Training Network from scratch
|
| 66 |
+
The information and the code to train the model is provided in train.py .Plaese see the following [main.py](https://github.com/aliprf/Ad-Corre/tree/main/main.py) file:
|
| 67 |
+
|
| 68 |
+
```
|
| 69 |
+
'''training part'''
|
| 70 |
+
trainer = TrainModel(dataset_name=DatasetName.affectnet, ds_type=DatasetType.train_7)
|
| 71 |
+
trainer.train(arch="xcp", weight_path="./")
|
| 72 |
+
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
### Preparing Data
|
| 77 |
+
Data needs to be normalized and saved in npy format.
|
| 78 |
+
|
| 79 |
+
---------------------------------------------------------------
|
| 80 |
+
|
| 81 |
+
```
|
| 82 |
+
Please cite this work as:
|
| 83 |
+
|
| 84 |
+
@ARTICLE{9727163,
|
| 85 |
+
author={Fard, Ali Pourramezan and Mahoor, Mohammad H.},
|
| 86 |
+
journal={IEEE Access},
|
| 87 |
+
title={Ad-Corre: Adaptive Correlation-Based Loss for Facial Expression Recognition in the Wild},
|
| 88 |
+
year={2022},
|
| 89 |
+
volume={},
|
| 90 |
+
number={},
|
| 91 |
+
pages={1-1},
|
| 92 |
+
doi={10.1109/ACCESS.2022.3156598}}
|
| 93 |
+
|
| 94 |
+
```
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
|
RafdbClass.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from config import DatasetName, AffectnetConf, InputDataSize, LearningConfig, ExpressionCodesAffectnet
|
| 2 |
+
from config import LearningConfig, InputDataSize, DatasetName, RafDBConf, DatasetType
|
| 3 |
+
from sklearn.metrics import precision_recall_fscore_support as score
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
import os
|
| 7 |
+
import matplotlib.pyplot as plt
|
| 8 |
+
import math
|
| 9 |
+
from datetime import datetime
|
| 10 |
+
from sklearn.utils import shuffle
|
| 11 |
+
from sklearn.model_selection import train_test_split
|
| 12 |
+
from numpy import save, load, asarray, savez_compressed
|
| 13 |
+
import csv
|
| 14 |
+
from skimage.io import imread
|
| 15 |
+
import pickle
|
| 16 |
+
import csv
|
| 17 |
+
from tqdm import tqdm
|
| 18 |
+
from PIL import Image
|
| 19 |
+
from skimage.transform import resize
|
| 20 |
+
import tensorflow as tf
|
| 21 |
+
import random
|
| 22 |
+
import cv2
|
| 23 |
+
from skimage.feature import hog
|
| 24 |
+
from skimage import data, exposure
|
| 25 |
+
from matplotlib.path import Path
|
| 26 |
+
from scipy import ndimage, misc
|
| 27 |
+
from data_helper import DataHelper
|
| 28 |
+
from sklearn.metrics import accuracy_score
|
| 29 |
+
from sklearn.metrics import confusion_matrix
|
| 30 |
+
from shutil import copyfile
|
| 31 |
+
from dataset_class import CustomDataset
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class RafDB:
|
| 35 |
+
def __init__(self, ds_type):
|
| 36 |
+
"""we set the parameters needed during the whole class:
|
| 37 |
+
"""
|
| 38 |
+
self.ds_type = ds_type
|
| 39 |
+
if ds_type == DatasetType.train:
|
| 40 |
+
self.img_path = RafDBConf.no_aug_train_img_path
|
| 41 |
+
self.anno_path = RafDBConf.no_aug_train_annotation_path
|
| 42 |
+
self.img_path_aug = RafDBConf.aug_train_img_path
|
| 43 |
+
self.anno_path_aug = RafDBConf.aug_train_annotation_path
|
| 44 |
+
self.masked_img_path = RafDBConf.aug_train_masked_img_path
|
| 45 |
+
|
| 46 |
+
elif ds_type == DatasetType.test:
|
| 47 |
+
self.img_path = RafDBConf.test_img_path
|
| 48 |
+
self.anno_path = RafDBConf.test_annotation_path
|
| 49 |
+
self.img_path_aug = RafDBConf.test_img_path
|
| 50 |
+
self.anno_path_aug = RafDBConf.test_annotation_path
|
| 51 |
+
self.masked_img_path = RafDBConf.test_masked_img_path
|
| 52 |
+
|
| 53 |
+
def test_accuracy(self, model, print_samples=False):
|
| 54 |
+
dhp = DataHelper()
|
| 55 |
+
batch_size = LearningConfig.batch_size
|
| 56 |
+
# exp_pr_glob = []
|
| 57 |
+
# exp_gt_glob = []
|
| 58 |
+
# acc_per_label = []
|
| 59 |
+
'''create batches'''
|
| 60 |
+
img_filenames, exp_filenames = dhp.create_generator_full_path(
|
| 61 |
+
img_path=self.img_path,
|
| 62 |
+
annotation_path=self.anno_path, label=None)
|
| 63 |
+
print(len(img_filenames))
|
| 64 |
+
step_per_epoch = int(len(img_filenames) // batch_size)
|
| 65 |
+
exp_pr_lbl = []
|
| 66 |
+
exp_gt_lbl = []
|
| 67 |
+
|
| 68 |
+
cds = CustomDataset()
|
| 69 |
+
ds = cds.create_dataset(img_filenames=img_filenames,
|
| 70 |
+
anno_names=exp_filenames,
|
| 71 |
+
is_validation=True,
|
| 72 |
+
ds=DatasetName.rafdb)
|
| 73 |
+
|
| 74 |
+
batch_index = 0
|
| 75 |
+
for img_batch, exp_gt_b in tqdm(ds):
|
| 76 |
+
'''predict on batch'''
|
| 77 |
+
exp_gt_b = exp_gt_b[:, -1]
|
| 78 |
+
img_batch = img_batch[:, -1, :, :]
|
| 79 |
+
|
| 80 |
+
pr_data = model.predict_on_batch([img_batch])
|
| 81 |
+
|
| 82 |
+
probab_exp_pr_b = pr_data[0]
|
| 83 |
+
exp_pr_b = np.array([np.argmax(probab_exp_pr_b[i]) for i in range(len(probab_exp_pr_b))])
|
| 84 |
+
|
| 85 |
+
if print_samples:
|
| 86 |
+
for i in range(len(exp_pr_b)):
|
| 87 |
+
dhp.test_image_print_exp(str(i) + str(batch_index + 1), np.array(img_batch[i]),
|
| 88 |
+
np.int8(exp_gt_b[i]), np.int8(exp_pr_b[i]))
|
| 89 |
+
|
| 90 |
+
exp_pr_lbl += np.array(exp_pr_b).tolist()
|
| 91 |
+
exp_gt_lbl += np.array(exp_gt_b).tolist()
|
| 92 |
+
batch_index += 1
|
| 93 |
+
exp_pr_lbl = np.float64(np.array(exp_pr_lbl))
|
| 94 |
+
exp_gt_lbl = np.float64(np.array(exp_gt_lbl))
|
| 95 |
+
|
| 96 |
+
global_accuracy = accuracy_score(exp_gt_lbl, exp_pr_lbl)
|
| 97 |
+
precision, recall, fscore, support = score(exp_gt_lbl, exp_pr_lbl)
|
| 98 |
+
|
| 99 |
+
conf_mat = confusion_matrix(exp_gt_lbl, exp_pr_lbl, normalize='true')
|
| 100 |
+
avg_acc = np.mean([conf_mat[i, i] for i in range(7)])
|
| 101 |
+
|
| 102 |
+
ds = None
|
| 103 |
+
face_img_filenames = None
|
| 104 |
+
eyes_img_filenames = None
|
| 105 |
+
nose_img_filenames = None
|
| 106 |
+
mouth_img_filenames = None
|
| 107 |
+
exp_filenames = None
|
| 108 |
+
|
| 109 |
+
return global_accuracy, conf_mat, avg_acc, precision, recall, fscore, support
|
cnn_model.py
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from config import DatasetName, AffectnetConf, InputDataSize, LearningConfig
|
| 2 |
+
# from hg_Class import HourglassNet
|
| 3 |
+
|
| 4 |
+
import tensorflow as tf
|
| 5 |
+
# from tensorflow import keras
|
| 6 |
+
# from skimage.transform import resize
|
| 7 |
+
from keras.models import Model
|
| 8 |
+
|
| 9 |
+
from keras.applications import mobilenet_v2, mobilenet, resnet50, densenet, resnet
|
| 10 |
+
from keras.layers import Dense, MaxPooling2D, Conv2D, Flatten, \
|
| 11 |
+
BatchNormalization, Activation, GlobalAveragePooling2D, DepthwiseConv2D, \
|
| 12 |
+
Dropout, ReLU, Concatenate, Input, GlobalMaxPool2D, LeakyReLU, Softmax, ELU
|
| 13 |
+
|
| 14 |
+
class CNNModel:
|
| 15 |
+
def get_model(self, arch, num_of_classes, weights):
|
| 16 |
+
if arch == 'resnet':
|
| 17 |
+
model = self._create_resnetemb(num_of_classes,
|
| 18 |
+
num_of_embeddings=LearningConfig.num_embeddings,
|
| 19 |
+
input_shape=(InputDataSize.image_input_size,
|
| 20 |
+
InputDataSize.image_input_size, 3),
|
| 21 |
+
weights=weights
|
| 22 |
+
)
|
| 23 |
+
if arch == 'xcp':
|
| 24 |
+
model = self._create_Xception_l2(num_of_classes,
|
| 25 |
+
num_of_embeddings=LearningConfig.num_embeddings,
|
| 26 |
+
input_shape=(InputDataSize.image_input_size,
|
| 27 |
+
InputDataSize.image_input_size, 3),
|
| 28 |
+
weights=weights
|
| 29 |
+
)
|
| 30 |
+
|
| 31 |
+
return model
|
| 32 |
+
|
| 33 |
+
def _create_resnetemb(self, num_of_classes, input_shape, weights, num_of_embeddings):
|
| 34 |
+
resnet_model = resnet.ResNet50(
|
| 35 |
+
input_shape=input_shape,
|
| 36 |
+
include_top=True,
|
| 37 |
+
weights='imagenet',
|
| 38 |
+
# weights=None,
|
| 39 |
+
input_tensor=None,
|
| 40 |
+
pooling=None)
|
| 41 |
+
resnet_model.layers.pop()
|
| 42 |
+
|
| 43 |
+
avg_pool = resnet_model.get_layer('avg_pool').output # 2048
|
| 44 |
+
''''''
|
| 45 |
+
embeddings = []
|
| 46 |
+
for i in range(num_of_embeddings):
|
| 47 |
+
emb = tf.keras.layers.Dense(LearningConfig.embedding_size, activation=None)(avg_pool)
|
| 48 |
+
emb_l2 = tf.keras.layers.Lambda(lambda x: tf.math.l2_normalize(x, axis=1))(emb)
|
| 49 |
+
embeddings.append(emb_l2)
|
| 50 |
+
|
| 51 |
+
if num_of_embeddings > 1:
|
| 52 |
+
fused = tf.keras.layers.Concatenate(axis=1)([embeddings[i] for i in range(num_of_embeddings)])
|
| 53 |
+
else:
|
| 54 |
+
fused = embeddings[0]
|
| 55 |
+
|
| 56 |
+
fused = Dropout(rate=0.5)(fused)
|
| 57 |
+
|
| 58 |
+
'''out'''
|
| 59 |
+
out_categorical = Dense(num_of_classes,
|
| 60 |
+
activation='softmax',
|
| 61 |
+
name='out')(fused)
|
| 62 |
+
|
| 63 |
+
inp = [resnet_model.input]
|
| 64 |
+
|
| 65 |
+
revised_model = Model(inp, [out_categorical] + [embeddings[i] for i in range(num_of_embeddings)])
|
| 66 |
+
revised_model.summary()
|
| 67 |
+
'''save json'''
|
| 68 |
+
model_json = revised_model.to_json()
|
| 69 |
+
|
| 70 |
+
with open("./model_archs/resnetemb.json", "w") as json_file:
|
| 71 |
+
json_file.write(model_json)
|
| 72 |
+
|
| 73 |
+
return revised_model
|
| 74 |
+
|
| 75 |
+
def _create_Xception_l2(self, num_of_classes, num_of_embeddings, input_shape, weights):
|
| 76 |
+
xception_model = tf.keras.applications.Xception(
|
| 77 |
+
include_top=False,
|
| 78 |
+
# weights=None,
|
| 79 |
+
input_tensor=None,
|
| 80 |
+
weights='imagenet',
|
| 81 |
+
input_shape=input_shape,
|
| 82 |
+
pooling=None,
|
| 83 |
+
classes=num_of_classes
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
act_14 = xception_model.get_layer('block14_sepconv2_act').output
|
| 87 |
+
avg_pool = GlobalAveragePooling2D()(act_14)
|
| 88 |
+
|
| 89 |
+
embeddings = []
|
| 90 |
+
for i in range(num_of_embeddings):
|
| 91 |
+
emb = tf.keras.layers.Dense(LearningConfig.embedding_size, activation=None)(avg_pool)
|
| 92 |
+
emb_l2 = tf.keras.layers.Lambda(lambda x: tf.math.l2_normalize(x, axis=1))(emb)
|
| 93 |
+
|
| 94 |
+
embeddings.append(emb_l2)
|
| 95 |
+
if num_of_embeddings > 1:
|
| 96 |
+
fused = tf.keras.layers.Concatenate(axis=1)([embeddings[i] for i in range(num_of_embeddings)])
|
| 97 |
+
else:
|
| 98 |
+
fused = embeddings[0]
|
| 99 |
+
fused = Dropout(rate=0.5)(fused)
|
| 100 |
+
|
| 101 |
+
'''out'''
|
| 102 |
+
out_categorical = Dense(num_of_classes,
|
| 103 |
+
activation='softmax',
|
| 104 |
+
name='out')(fused)
|
| 105 |
+
|
| 106 |
+
inp = [xception_model.input]
|
| 107 |
+
|
| 108 |
+
revised_model = Model(inp, [out_categorical] + [embeddings[i] for i in range(num_of_embeddings)])
|
| 109 |
+
revised_model.summary()
|
| 110 |
+
'''save json'''
|
| 111 |
+
model_json = revised_model.to_json()
|
| 112 |
+
|
| 113 |
+
with open("./model_archs/xcp_embedding.json", "w") as json_file:
|
| 114 |
+
json_file.write(model_json)
|
| 115 |
+
|
| 116 |
+
return revised_model
|
config.py
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
class DatasetName:
|
| 2 |
+
affectnet = 'affectnet'
|
| 3 |
+
rafdb = 'rafdb'
|
| 4 |
+
fer2013 = 'fer2013'
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class ExpressionCodesRafdb:
|
| 8 |
+
Surprise = 1
|
| 9 |
+
Fear = 2
|
| 10 |
+
Disgust = 3
|
| 11 |
+
Happiness = 4
|
| 12 |
+
Sadness = 5
|
| 13 |
+
Anger = 6
|
| 14 |
+
Neutral = 7
|
| 15 |
+
|
| 16 |
+
class ExpressionCodesAffectnet:
|
| 17 |
+
neutral = 0
|
| 18 |
+
happy = 1
|
| 19 |
+
sad = 2
|
| 20 |
+
surprise = 3
|
| 21 |
+
fear = 4
|
| 22 |
+
disgust = 5
|
| 23 |
+
anger = 6
|
| 24 |
+
contempt = 7
|
| 25 |
+
none = 8
|
| 26 |
+
uncertain = 9
|
| 27 |
+
noface = 10
|
| 28 |
+
|
| 29 |
+
class DatasetType:
|
| 30 |
+
train = 0
|
| 31 |
+
train_7 = 1
|
| 32 |
+
eval = 2
|
| 33 |
+
eval_7 = 3
|
| 34 |
+
test = 4
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
class LearningConfig:
|
| 38 |
+
# batch_size = 100
|
| 39 |
+
batch_size = 50
|
| 40 |
+
# batch_size = 1
|
| 41 |
+
# batch_size = 5
|
| 42 |
+
virtual_batch_size = 5* batch_size
|
| 43 |
+
epochs = 300
|
| 44 |
+
embedding_size = 256 # we have 360 filters at the end
|
| 45 |
+
# embedding_size = 128 # we have 360 filters at the end
|
| 46 |
+
labels_history_frame = 1000
|
| 47 |
+
num_classes = 7
|
| 48 |
+
# num_embeddings = 7
|
| 49 |
+
num_embeddings = 10
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class InputDataSize:
|
| 53 |
+
image_input_size = 224
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
class FerPlusConf:
|
| 57 |
+
_prefix_path = './FER_plus' # --> zeue
|
| 58 |
+
|
| 59 |
+
orig_image_path_train = _prefix_path + '/orig/train/'
|
| 60 |
+
orig_image_path_test = _prefix_path + '/orig/test/'
|
| 61 |
+
|
| 62 |
+
'''only 7 labels'''
|
| 63 |
+
no_aug_train_img_path = _prefix_path + '/train_set/images/'
|
| 64 |
+
no_aug_train_annotation_path = _prefix_path + '/train_set/annotations/'
|
| 65 |
+
|
| 66 |
+
aug_train_img_path = _prefix_path + '/train_set_aug/images/'
|
| 67 |
+
aug_train_annotation_path = _prefix_path + '/train_set_aug/annotations/'
|
| 68 |
+
aug_train_masked_img_path = _prefix_path + '/train_set_aug/masked_images/'
|
| 69 |
+
|
| 70 |
+
weight_save_path = _prefix_path + '/weight_saving_path/'
|
| 71 |
+
|
| 72 |
+
'''both public&private test:'''
|
| 73 |
+
test_img_path = _prefix_path + '/test_set/images/'
|
| 74 |
+
test_annotation_path = _prefix_path + '/test_set/annotations/'
|
| 75 |
+
test_masked_img_path = _prefix_path + '/test_set/masked_images/'
|
| 76 |
+
|
| 77 |
+
'''private test:'''
|
| 78 |
+
private_test_img_path = _prefix_path + '/private_test_set/images/'
|
| 79 |
+
private_test_annotation_path = _prefix_path + '/private_test_set/annotations/'
|
| 80 |
+
'''public test-> Eval'''
|
| 81 |
+
public_test_img_path = _prefix_path + '/public_test_set/images/'
|
| 82 |
+
public_test_annotation_path = _prefix_path + '/public_test_set/annotations/'
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
class RafDBConf:
|
| 86 |
+
_prefix_path = './RAF-DB' #
|
| 87 |
+
|
| 88 |
+
orig_annotation_txt_path = _prefix_path + '/list_patition_label.txt'
|
| 89 |
+
orig_image_path = _prefix_path + '/original/'
|
| 90 |
+
orig_bounding_box = _prefix_path + '/boundingbox/'
|
| 91 |
+
|
| 92 |
+
'''only 7 labels'''
|
| 93 |
+
no_aug_train_img_path = _prefix_path + '/train_set/images/'
|
| 94 |
+
no_aug_train_annotation_path = _prefix_path + '/train_set/annotations/'
|
| 95 |
+
|
| 96 |
+
aug_train_img_path = _prefix_path + '/train_set_aug/images/'
|
| 97 |
+
aug_train_annotation_path = _prefix_path + '/train_set_aug/annotations/'
|
| 98 |
+
aug_train_masked_img_path = _prefix_path + '/train_set_aug/masked_images/'
|
| 99 |
+
|
| 100 |
+
test_img_path = _prefix_path + '/test_set/images/'
|
| 101 |
+
test_annotation_path = _prefix_path + '/test_set/annotations/'
|
| 102 |
+
test_masked_img_path = _prefix_path + '/test_set/masked_images/'
|
| 103 |
+
|
| 104 |
+
augmentation_factor = 5
|
| 105 |
+
|
| 106 |
+
weight_save_path = _prefix_path + '/weight_saving_path/'
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
class AffectnetConf:
|
| 110 |
+
""""""
|
| 111 |
+
'''atlas'''
|
| 112 |
+
_prefix_path = './affectnet' # --> Aq
|
| 113 |
+
|
| 114 |
+
orig_csv_train_path = _prefix_path + '/orig/training.csv'
|
| 115 |
+
orig_csv_evaluate_path = _prefix_path + '/orig/validation.csv'
|
| 116 |
+
|
| 117 |
+
'''8 labels'''
|
| 118 |
+
no_aug_train_img_path = _prefix_path + '/train_set/images/'
|
| 119 |
+
no_aug_train_annotation_path = _prefix_path + '/train_set/annotations/'
|
| 120 |
+
|
| 121 |
+
aug_train_img_path = _prefix_path + '/train_set_aug/images/'
|
| 122 |
+
aug_train_annotation_path = _prefix_path + '/train_set_aug/annotations/'
|
| 123 |
+
aug_train_masked_img_path = _prefix_path + '/train_set_aug/masked_images/'
|
| 124 |
+
|
| 125 |
+
eval_img_path = _prefix_path + '/eval_set/images/'
|
| 126 |
+
eval_annotation_path = _prefix_path + '/eval_set/annotations/'
|
| 127 |
+
eval_masked_img_path = _prefix_path + '/eval_set/masked_images/'
|
| 128 |
+
|
| 129 |
+
'''7 labels'''
|
| 130 |
+
no_aug_train_img_path_7 = _prefix_path + '/train_set_7/images/'
|
| 131 |
+
no_aug_train_annotation_path_7 = _prefix_path + '/train_set_7/annotations/'
|
| 132 |
+
|
| 133 |
+
aug_train_img_path_7 = _prefix_path + '/train_set_7_aug/images/'
|
| 134 |
+
aug_train_annotation_path_7 = _prefix_path + '/train_set_7_aug/annotations/'
|
| 135 |
+
aug_train_masked_img_path_7 = _prefix_path + '/train_set_7_aug/masked_images/'
|
| 136 |
+
|
| 137 |
+
eval_img_path_7 = _prefix_path + '/eval_set_7/images/'
|
| 138 |
+
eval_annotation_path_7 = _prefix_path + '/eval_set_7/annotations/'
|
| 139 |
+
eval_masked_img_path_7 = _prefix_path + '/eval_set_7/masked_images/'
|
| 140 |
+
|
| 141 |
+
weight_save_path = _prefix_path + '/weight_saving_path/'
|
| 142 |
+
|
| 143 |
+
num_of_samples_train = 2420940
|
| 144 |
+
num_of_samples_train_7 = 0
|
| 145 |
+
num_of_samples_eval = 3999
|
custom_loss.py
ADDED
|
@@ -0,0 +1,218 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import tensorflow as tf
|
| 2 |
+
import numpy as np
|
| 3 |
+
from config import DatasetName, ExpressionCodesRafdb, ExpressionCodesAffectnet
|
| 4 |
+
from keras import backend as K
|
| 5 |
+
from sklearn.metrics import confusion_matrix
|
| 6 |
+
import time
|
| 7 |
+
from config import LearningConfig
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class CustomLosses:
|
| 11 |
+
|
| 12 |
+
def embedding_loss_distance(self, embeddings):
|
| 13 |
+
|
| 14 |
+
"""
|
| 15 |
+
for each item in batch: calculate the correlation between all the embeddings
|
| 16 |
+
:param embeddings:
|
| 17 |
+
:return:
|
| 18 |
+
"""
|
| 19 |
+
'''correlation'''
|
| 20 |
+
emb_len = len(embeddings)
|
| 21 |
+
''' emb_num, bs, emb_size: '''
|
| 22 |
+
embeddings = tf.cast(embeddings, dtype=tf.dtypes.float32)
|
| 23 |
+
loss = tf.cast([np.corrcoef(embeddings[:, i, :]) for i in range(LearningConfig.batch_size)],
|
| 24 |
+
dtype=tf.dtypes.float32)
|
| 25 |
+
embedding_similarity_loss = tf.reduce_mean((1 - tf.eye(emb_len)) * # ignore the affect of the diagonal
|
| 26 |
+
(1 + np.array(loss))) # the loss -> more correlation, the better
|
| 27 |
+
return embedding_similarity_loss
|
| 28 |
+
|
| 29 |
+
def mean_embedding_loss_distance(self, embeddings, exp_gt_vec, exp_pr_vec, num_of_classes):
|
| 30 |
+
"""
|
| 31 |
+
calculate the mean distribution for each class, and force the mean_embedding to be the same
|
| 32 |
+
:param embedding: bs * embedding_size
|
| 33 |
+
:param exp_gt_vec: bs
|
| 34 |
+
:param exp_pr_vec: bs * num_of_classes
|
| 35 |
+
:param num_of_classes:
|
| 36 |
+
:return:
|
| 37 |
+
"""
|
| 38 |
+
# bs_size = tf.shape(exp_pr_vec, out_type=tf.dtypes.int64)[0]
|
| 39 |
+
# 7 * bs: for each class - which we have 7 class, not the embeddings -, is the sample belongs to it we put 1
|
| 40 |
+
# else we put 0 . THE SAME FOR ALL embeddings
|
| 41 |
+
c_map = np.array([tf.cast(tf.where(exp_gt_vec == i, 1.0, K.epsilon()), dtype=tf.dtypes.float32)
|
| 42 |
+
for i in range(num_of_classes)]) # 7 * bs
|
| 43 |
+
|
| 44 |
+
# calculate class-related mean embedding: num_of_classes * embedding_size
|
| 45 |
+
# 7 embedding, and 7 classes and each class has an embedding mean of 256 -> 7,7,256
|
| 46 |
+
mean_embeddings = np.array([[np.average(embeddings[k], axis=0, weights=c_map[i, :])
|
| 47 |
+
for i in range(num_of_classes)]
|
| 48 |
+
for k in range(len(embeddings))]) # 7:embedding,7:class, 256:size
|
| 49 |
+
|
| 50 |
+
# the correlation between each mean_embedding should be low:
|
| 51 |
+
mean_emb_correlation_loss = tf.reduce_mean([(1 - tf.eye(num_of_classes)) * # zero the diagonal
|
| 52 |
+
(1 + tf.cast(np.corrcoef(mean_embeddings[k, :, :]),
|
| 53 |
+
dtype=tf.dtypes.float32))
|
| 54 |
+
for k in range(len(embeddings))])
|
| 55 |
+
|
| 56 |
+
# the correlation between each mean_embedding should be low:
|
| 57 |
+
return mean_emb_correlation_loss
|
| 58 |
+
|
| 59 |
+
def mean_embedding_loss(self, embedding, exp_gt_vec, exp_pr_vec, num_of_classes):
|
| 60 |
+
"""
|
| 61 |
+
calculate the mean distribution for each class, and force the mean_embedding to be the same
|
| 62 |
+
:param embedding: bs * embedding_size
|
| 63 |
+
:param exp_gt_vec: bs
|
| 64 |
+
:param exp_pr_vec: bs * num_of_classes
|
| 65 |
+
:param num_of_classes:
|
| 66 |
+
:return:
|
| 67 |
+
"""
|
| 68 |
+
kl = tf.keras.losses.KLDivergence()
|
| 69 |
+
bs_size = tf.shape(exp_pr_vec, out_type=tf.dtypes.int64)[0]
|
| 70 |
+
# calculate class maps: num_of_classes * bs
|
| 71 |
+
c_map = np.array([tf.cast(tf.where(exp_gt_vec == i, 1, 0), dtype=tf.dtypes.int8)
|
| 72 |
+
for i in range(num_of_classes)]) # 7 * bs
|
| 73 |
+
# calculate class-related mean embedding: num_of_classes * embedding_size
|
| 74 |
+
mean_embeddings = np.array([np.average(embedding, axis=0, weights=c_map[i, :])
|
| 75 |
+
if np.sum(c_map[i, :]) > 0 else np.zeros(LearningConfig.embedding_size)
|
| 76 |
+
for i in range(num_of_classes)]) + \
|
| 77 |
+
K.epsilon() # added as a bias to get ride of zeros
|
| 78 |
+
|
| 79 |
+
# calculate loss:
|
| 80 |
+
# 1 -> the correlation between each mean_embedding should be low:
|
| 81 |
+
mean_emb_correlation_loss = tf.reduce_mean((1 - tf.eye(num_of_classes)) *
|
| 82 |
+
(1 + tf.cast(np.corrcoef(mean_embeddings), dtype=tf.dtypes.float32)))
|
| 83 |
+
# 2 -> the KL-divergence between the mean distribution of each class and the related
|
| 84 |
+
# embeddings should be low. Accordingly, we lead the network towards learning the mean distribution
|
| 85 |
+
mean_emb_batch = tf.cast([np.array(mean_embeddings)[i] for i in np.argmax(c_map.T, axis=1)],
|
| 86 |
+
dtype=tf.dtypes.float32)
|
| 87 |
+
emb_kl_loss = kl(y_true=mean_emb_batch, y_pred=embedding)
|
| 88 |
+
|
| 89 |
+
return mean_emb_correlation_loss, emb_kl_loss
|
| 90 |
+
|
| 91 |
+
def variance_embedding_loss(self, embedding, exp_gt_vec, exp_pr_vec, num_of_classes):
|
| 92 |
+
"""
|
| 93 |
+
calculate the variance of the distribution for each class, and force the mean_embedding to be the same
|
| 94 |
+
:param embedding:
|
| 95 |
+
:param exp_gt_vec:
|
| 96 |
+
:param exp_pr_vec:
|
| 97 |
+
:param num_of_classes:
|
| 98 |
+
:return:
|
| 99 |
+
"""
|
| 100 |
+
kl = tf.keras.losses.KLDivergence()
|
| 101 |
+
bs_size = tf.shape(exp_pr_vec, out_type=tf.dtypes.int64)[0]
|
| 102 |
+
#
|
| 103 |
+
c_map = np.array([tf.cast(tf.where(exp_gt_vec == i, 1, 0), dtype=tf.dtypes.int8)
|
| 104 |
+
for i in range(num_of_classes)]) # 7 * bs
|
| 105 |
+
# calculate class-related var embedding: num_of_classes * embedding_size
|
| 106 |
+
var_embeddings = np.array([tf.math.reduce_std(tf.math.multiply(embedding,
|
| 107 |
+
tf.repeat(tf.expand_dims(
|
| 108 |
+
tf.cast(c_map[i, :],
|
| 109 |
+
dtype=tf.dtypes.float32), -1),
|
| 110 |
+
LearningConfig.embedding_size, axis=-1, )),
|
| 111 |
+
axis=0)
|
| 112 |
+
for i in range(num_of_classes)]) \
|
| 113 |
+
+ K.epsilon() # added as a bias to get ride of zeros
|
| 114 |
+
|
| 115 |
+
# calculate loss:
|
| 116 |
+
# 1 -> the correlation between each mean_embedding should be low:
|
| 117 |
+
var_emb_correlation_loss = tf.reduce_mean((1.0 - tf.eye(num_of_classes)) *
|
| 118 |
+
(1.0 + tf.cast(np.cov(var_embeddings), dtype=tf.dtypes.float32)))
|
| 119 |
+
# embeddings should be low. Accordingly, we lead the network towards learning the mean distribution
|
| 120 |
+
var_emb_batch = tf.cast([np.array(var_embeddings)[i] for i in np.argmax(c_map.T, axis=1)],
|
| 121 |
+
dtype=tf.dtypes.float32)
|
| 122 |
+
emb_kl_loss = abs(kl(y_true=var_emb_batch, y_pred=embedding))
|
| 123 |
+
return var_emb_correlation_loss, emb_kl_loss
|
| 124 |
+
|
| 125 |
+
def correlation_loss(self, embedding, exp_gt_vec, exp_pr_vec, tr_conf_matrix):
|
| 126 |
+
bs_size = tf.shape(exp_pr_vec, out_type=tf.dtypes.int64)[0]
|
| 127 |
+
# convert from sigmoid to labels to real classes:
|
| 128 |
+
exp_pr = tf.constant([np.argmax(exp_pr_vec[i]) for i in range(bs_size)], dtype=tf.dtypes.int64)
|
| 129 |
+
# Cov matrix
|
| 130 |
+
phi_correlation_matrix = tf.cast(np.corrcoef(embedding), dtype=tf.dtypes.float32) # bs * bs
|
| 131 |
+
|
| 132 |
+
elems_col = tf.repeat(tf.expand_dims(exp_gt_vec, 0), repeats=[bs_size], axis=0)
|
| 133 |
+
elems_row = tf.repeat(tf.expand_dims(exp_gt_vec, -1), repeats=[bs_size], axis=-1)
|
| 134 |
+
delta = elems_row - elems_col
|
| 135 |
+
omega_matrix = tf.cast(tf.where(delta == 0, 1, -1), dtype=tf.dtypes.float32)
|
| 136 |
+
# creating the adaptive weights
|
| 137 |
+
adaptive_weight = self._create_adaptive_correlation_weights(bs_size=bs_size,
|
| 138 |
+
exp_gt_vec=exp_gt_vec, # real labels
|
| 139 |
+
exp_pr=exp_pr, # real labels
|
| 140 |
+
conf_mat=tr_conf_matrix)
|
| 141 |
+
# calculate correlation loss
|
| 142 |
+
cor_loss = tf.reduce_mean(adaptive_weight * tf.abs(omega_matrix - phi_correlation_matrix))
|
| 143 |
+
return cor_loss
|
| 144 |
+
|
| 145 |
+
def correlation_loss_multi(self, embeddings, exp_gt_vec, exp_pr_vec, tr_conf_matrix):
|
| 146 |
+
"""
|
| 147 |
+
here, we consider only one embedding and so want to make the embeddings of the same classes be similar
|
| 148 |
+
while the ones from different classes are different.
|
| 149 |
+
:param embeddings:
|
| 150 |
+
:param exp_gt_vec:
|
| 151 |
+
:param exp_pr_vec:
|
| 152 |
+
:param tr_conf_matrix:
|
| 153 |
+
:return:
|
| 154 |
+
"""
|
| 155 |
+
bs_size = tf.shape(exp_pr_vec, out_type=tf.dtypes.int64)[0]
|
| 156 |
+
exp_pr = tf.constant([np.argmax(exp_pr_vec[i]) for i in range(bs_size)], dtype=tf.dtypes.int64)
|
| 157 |
+
|
| 158 |
+
phi_correlation_matrices = [tf.cast(np.corrcoef(embeddings[i]), dtype=tf.dtypes.float32)
|
| 159 |
+
for i in range(len(embeddings))] # cls * bs * bs
|
| 160 |
+
#
|
| 161 |
+
elems_col = tf.repeat(tf.expand_dims(exp_gt_vec, 0), repeats=[bs_size], axis=0)
|
| 162 |
+
elems_row = tf.repeat(tf.expand_dims(exp_gt_vec, -1), repeats=[bs_size], axis=-1)
|
| 163 |
+
delta = elems_row - elems_col
|
| 164 |
+
omega_matrix = tf.repeat(tf.expand_dims(tf.cast(tf.where(delta == 0, 1, -1),
|
| 165 |
+
dtype=tf.dtypes.float32), axis=0),
|
| 166 |
+
repeats=len(embeddings), axis=0)
|
| 167 |
+
cor_loss = tf.reduce_mean(tf.abs(omega_matrix - phi_correlation_matrices))
|
| 168 |
+
|
| 169 |
+
return cor_loss
|
| 170 |
+
|
| 171 |
+
def _create_adaptive_correlation_weights(self, bs_size, exp_gt_vec, exp_pr, conf_mat):
|
| 172 |
+
"""
|
| 173 |
+
creating the weights
|
| 174 |
+
:param exp_gt_vec: real int labels
|
| 175 |
+
:param exp_pr_vec: one_hot labels
|
| 176 |
+
:param conf_mat: confusion matrix which is normalized over the rows(
|
| 177 |
+
ground-truths with respect to the number of corresponding classes)
|
| 178 |
+
:return: a bath_size * bath_size matrix containing weights. The diameter of the matrix is zero
|
| 179 |
+
"""
|
| 180 |
+
'''new'''
|
| 181 |
+
tf_identity = tf.eye(bs_size)
|
| 182 |
+
# weight based on the correct section of the conf_matrix
|
| 183 |
+
'''
|
| 184 |
+
1 : - conf_mat[exp_gt_vec[i], exp_gt_vec[i]] : sum of all the missed values=> the better the performance of
|
| 185 |
+
the model on a label, the smaller the weight
|
| 186 |
+
'''
|
| 187 |
+
correct_row_base_weight = tf.repeat(tf.expand_dims(
|
| 188 |
+
tf.map_fn(fn=lambda i: 1 - conf_mat[i, i], elems=exp_gt_vec) # map
|
| 189 |
+
, 0), # expand_dims
|
| 190 |
+
repeats=[bs_size], axis=0) # repeat
|
| 191 |
+
|
| 192 |
+
correct_col_base_weight = tf.einsum('ab->ba', correct_row_base_weight)
|
| 193 |
+
correct_weight = correct_row_base_weight + correct_col_base_weight
|
| 194 |
+
adaptive_weight = tf.cast((correct_weight), dtype=tf.dtypes.float32)
|
| 195 |
+
adaptive_weight = 1 + adaptive_weight # we don't want the weights to be zero (correct prediction)
|
| 196 |
+
adaptive_weight = (1 - tf_identity) * adaptive_weight # remove the main diagon
|
| 197 |
+
return adaptive_weight
|
| 198 |
+
|
| 199 |
+
def update_confusion_matrix(self, exp_gt_vec, exp_pr,
|
| 200 |
+
all_gt_exp, all_pr_exp):
|
| 201 |
+
# adding to the previous predicted items:
|
| 202 |
+
all_pr_exp += np.array(exp_pr).tolist()
|
| 203 |
+
all_gt_exp += np.array(exp_gt_vec).tolist()
|
| 204 |
+
# calculate confusion matrix:
|
| 205 |
+
conf_mat = confusion_matrix(y_true=all_gt_exp, y_pred=all_pr_exp, normalize='true',
|
| 206 |
+
labels=[0, 1, 2, 3, 4, 5, 6])
|
| 207 |
+
return conf_mat, all_gt_exp, all_pr_exp
|
| 208 |
+
|
| 209 |
+
def cross_entropy_loss(self, y_gt, y_pr, num_classes, ds_name):
|
| 210 |
+
y_gt_oh = tf.one_hot(y_gt, depth=num_classes)
|
| 211 |
+
''' manual weighted CE'''
|
| 212 |
+
y_pred = y_pr
|
| 213 |
+
y_pred /= tf.reduce_sum(y_pred, axis=-1, keepdims=True)
|
| 214 |
+
y_pred = K.clip(y_pred, K.epsilon(), 1)
|
| 215 |
+
loss = -tf.reduce_mean(y_gt_oh * tf.math.log(y_pred))
|
| 216 |
+
'''accuracy'''
|
| 217 |
+
accuracy = tf.reduce_mean(tf.keras.metrics.categorical_accuracy(y_pr, y_gt_oh))
|
| 218 |
+
return loss, accuracy
|
data_helper.py
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from config import DatasetName, AffectnetConf, InputDataSize, LearningConfig, ExpressionCodesAffectnet
|
| 2 |
+
from config import LearningConfig, InputDataSize, DatasetName, AffectnetConf, DatasetType
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import os
|
| 6 |
+
import matplotlib.pyplot as plt
|
| 7 |
+
import math
|
| 8 |
+
from datetime import datetime
|
| 9 |
+
from sklearn.utils import shuffle
|
| 10 |
+
from sklearn.model_selection import train_test_split
|
| 11 |
+
from numpy import save, load, asarray
|
| 12 |
+
import csv
|
| 13 |
+
from skimage.io import imread
|
| 14 |
+
import pickle
|
| 15 |
+
import csv
|
| 16 |
+
from tqdm import tqdm
|
| 17 |
+
from PIL import Image
|
| 18 |
+
from skimage.transform import resize
|
| 19 |
+
from skimage import transform
|
| 20 |
+
from skimage.transform import resize
|
| 21 |
+
import tensorflow as tf
|
| 22 |
+
import random
|
| 23 |
+
import cv2
|
| 24 |
+
from skimage.feature import hog
|
| 25 |
+
from skimage import data, exposure
|
| 26 |
+
from matplotlib.path import Path
|
| 27 |
+
from scipy import ndimage, misc
|
| 28 |
+
from skimage.transform import SimilarityTransform, AffineTransform
|
| 29 |
+
from skimage.draw import rectangle
|
| 30 |
+
from skimage.draw import line, set_color
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class DataHelper:
|
| 34 |
+
|
| 35 |
+
def create_generator_full_path(self, img_path, annotation_path, label=None):
|
| 36 |
+
img_filenames, exp_filenames = self._create_image_and_labels_name_full_path(img_path=img_path,
|
| 37 |
+
annotation_path=annotation_path,
|
| 38 |
+
label=label)
|
| 39 |
+
'''shuffle'''
|
| 40 |
+
img_filenames, exp_filenames = shuffle(img_filenames, exp_filenames)
|
| 41 |
+
return img_filenames, exp_filenames
|
| 42 |
+
|
| 43 |
+
def _create_image_and_labels_name_full_path(self, img_path, annotation_path, label):
|
| 44 |
+
img_filenames = []
|
| 45 |
+
exp_filenames = []
|
| 46 |
+
|
| 47 |
+
print('reading list -->')
|
| 48 |
+
file_names = tqdm(os.listdir(img_path))
|
| 49 |
+
print('<-')
|
| 50 |
+
|
| 51 |
+
for file in file_names:
|
| 52 |
+
if file.endswith(".jpg") or file.endswith(".png"):
|
| 53 |
+
exp_lbl_file = str(file)[:-4] + "_exp.npy" # just name
|
| 54 |
+
|
| 55 |
+
if os.path.exists(annotation_path + exp_lbl_file):
|
| 56 |
+
if label is not None:
|
| 57 |
+
exp = np.load(annotation_path + exp_lbl_file)
|
| 58 |
+
if label is not None and exp != label:
|
| 59 |
+
continue
|
| 60 |
+
|
| 61 |
+
img_filenames.append(img_path + str(file))
|
| 62 |
+
exp_filenames.append(annotation_path + exp_lbl_file)
|
| 63 |
+
|
| 64 |
+
return np.array(img_filenames), np.array(exp_filenames)
|
| 65 |
+
|
| 66 |
+
def relabel_ds(self, labels):
|
| 67 |
+
new_labels = np.copy(labels)
|
| 68 |
+
|
| 69 |
+
index_src = [0, 1, 2, 3, 4, 5, 6, 7, 17, 18, 19, 20, 21, 31, 32, 36, 37, 38, 39, 40, 41, 48, 49, 50,
|
| 70 |
+
60, 61, 67, 59, 58]
|
| 71 |
+
index_dst = [16, 15, 14, 13, 12, 11, 10, 9, 26, 25, 24, 23, 22, 35, 34, 45, 44, 43, 42, 47, 46, 54, 53, 52,
|
| 72 |
+
64, 63, 65, 55, 56]
|
| 73 |
+
|
| 74 |
+
for i in range(len(index_src)):
|
| 75 |
+
new_labels[index_src[i] * 2] = labels[index_dst[i] * 2]
|
| 76 |
+
new_labels[index_src[i] * 2 + 1] = labels[index_dst[i] * 2 + 1]
|
| 77 |
+
|
| 78 |
+
new_labels[index_dst[i] * 2] = labels[index_src[i] * 2]
|
| 79 |
+
new_labels[index_dst[i] * 2 + 1] = labels[index_src[i] * 2 + 1]
|
| 80 |
+
return new_labels
|
dataset_class.py
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from config import DatasetName, AffectnetConf, InputDataSize, LearningConfig, ExpressionCodesAffectnet
|
| 2 |
+
from config import LearningConfig, InputDataSize, DatasetName, AffectnetConf, DatasetType
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import os
|
| 6 |
+
import matplotlib.pyplot as plt
|
| 7 |
+
import math
|
| 8 |
+
from datetime import datetime
|
| 9 |
+
from sklearn.utils import shuffle
|
| 10 |
+
from sklearn.model_selection import train_test_split
|
| 11 |
+
from numpy import save, load, asarray
|
| 12 |
+
import csv
|
| 13 |
+
from skimage.io import imread
|
| 14 |
+
import pickle
|
| 15 |
+
import csv
|
| 16 |
+
from tqdm import tqdm
|
| 17 |
+
from PIL import Image
|
| 18 |
+
from skimage.transform import resize
|
| 19 |
+
from skimage import transform
|
| 20 |
+
from skimage.transform import resize
|
| 21 |
+
import tensorflow as tf
|
| 22 |
+
import random
|
| 23 |
+
import cv2
|
| 24 |
+
from skimage.feature import hog
|
| 25 |
+
from skimage import data, exposure
|
| 26 |
+
from matplotlib.path import Path
|
| 27 |
+
from scipy import ndimage, misc
|
| 28 |
+
from skimage.transform import SimilarityTransform, AffineTransform
|
| 29 |
+
from skimage.draw import rectangle
|
| 30 |
+
from skimage.draw import line, set_color
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class CustomDataset:
|
| 34 |
+
|
| 35 |
+
def create_dataset(self, img_filenames, anno_names, is_validation=False, ds=DatasetName.affectnet):
|
| 36 |
+
def get_img(file_name):
|
| 37 |
+
path = bytes.decode(file_name)
|
| 38 |
+
image_raw = tf.io.read_file(path)
|
| 39 |
+
img = tf.image.decode_image(image_raw, channels=3)
|
| 40 |
+
img = tf.cast(img, tf.float32) / 255.0
|
| 41 |
+
'''augmentation'''
|
| 42 |
+
# if not (is_validation):# or tf.random.uniform([]) <= 0.5):
|
| 43 |
+
# img = self._do_augment(img)
|
| 44 |
+
# ''''''
|
| 45 |
+
return img
|
| 46 |
+
|
| 47 |
+
def get_lbl(anno_name):
|
| 48 |
+
path = bytes.decode(anno_name)
|
| 49 |
+
lbl = load(path)
|
| 50 |
+
return lbl
|
| 51 |
+
|
| 52 |
+
def wrap_get_img(img_filename, anno_name):
|
| 53 |
+
img = tf.numpy_function(get_img, [img_filename], [tf.float32])
|
| 54 |
+
if is_validation and ds == DatasetName.affectnet:
|
| 55 |
+
lbl = tf.numpy_function(get_lbl, [anno_name], [tf.string])
|
| 56 |
+
else:
|
| 57 |
+
lbl = tf.numpy_function(get_lbl, [anno_name], [tf.int64])
|
| 58 |
+
|
| 59 |
+
return img, lbl
|
| 60 |
+
|
| 61 |
+
epoch_size = len(img_filenames)
|
| 62 |
+
|
| 63 |
+
img_filenames = tf.convert_to_tensor(img_filenames, dtype=tf.string)
|
| 64 |
+
anno_names = tf.convert_to_tensor(anno_names)
|
| 65 |
+
|
| 66 |
+
dataset = tf.data.Dataset.from_tensor_slices((img_filenames, anno_names))
|
| 67 |
+
dataset = dataset.shuffle(epoch_size)
|
| 68 |
+
dataset = dataset.map(wrap_get_img, num_parallel_calls=32) \
|
| 69 |
+
.batch(LearningConfig.batch_size, drop_remainder=True) \
|
| 70 |
+
.prefetch(10)
|
| 71 |
+
return dataset
|
img.jpg
ADDED

|
Git LFS Details
|
main.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from test_model import TestModels
|
| 2 |
+
from train import TrainModel
|
| 3 |
+
from config import DatasetName, DatasetType
|
| 4 |
+
if __name__ == "__main__":
|
| 5 |
+
|
| 6 |
+
'''testing the pre-trained models'''
|
| 7 |
+
tester = TestModels(h5_address='./trained_models/AffectNet_6336.h5')
|
| 8 |
+
tester.recognize_fer(img_path='./img.jpg')
|
| 9 |
+
|
| 10 |
+
'''training part'''
|
| 11 |
+
trainer = TrainModel(dataset_name=DatasetName.affectnet, ds_type=DatasetType.train_7)
|
| 12 |
+
trainer.train(arch="xcp", weight_path="./")
|
paper_graphical_items/confm.jpg
ADDED

|
Git LFS Details
|
paper_graphical_items/correlation_loss.jpg
ADDED

|
Git LFS Details
|
paper_graphical_items/embedding_TSNE.jpg
ADDED

|
Git LFS Details
|
paper_graphical_items/fd_ed.jpg
ADDED

|
Git LFS Details
|
paper_graphical_items/md_component.jpg
ADDED

|
Git LFS Details
|
paper_graphical_items/samples.jpg
ADDED

|
Git LFS Details
|
requirements.txt
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
bottleneck
|
| 2 |
+
tensorflow-gpu==2.4
|
| 3 |
+
keras
|
| 4 |
+
numpy
|
| 5 |
+
matplotlib
|
| 6 |
+
opencv-python
|
| 7 |
+
opencv-contrib-python
|
| 8 |
+
scipy
|
| 9 |
+
scikit-learn
|
| 10 |
+
scikit-image
|
| 11 |
+
Pillow
|
| 12 |
+
tqdm
|
| 13 |
+
tensorboard
|
test_model.py
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import tensorflow as tf
|
| 3 |
+
import tensorflow.keras as keras
|
| 4 |
+
import numpy as np
|
| 5 |
+
import matplotlib.pyplot as plt
|
| 6 |
+
import math
|
| 7 |
+
from datetime import datetime
|
| 8 |
+
from numpy import save, load, asarray
|
| 9 |
+
import csv
|
| 10 |
+
from skimage.io import imread
|
| 11 |
+
from skimage.transform import resize
|
| 12 |
+
import pickle
|
| 13 |
+
from PIL import Image
|
| 14 |
+
|
| 15 |
+
import os
|
| 16 |
+
|
| 17 |
+
# tf.test.is_gpu_available()
|
| 18 |
+
|
| 19 |
+
class TestModels:
|
| 20 |
+
def __init__(self, h5_address:str, GPU=True):
|
| 21 |
+
self.exps = ['Neutral', 'Happy', 'Sad', 'Surprise', 'Fear', 'Disgust', 'Anger']
|
| 22 |
+
|
| 23 |
+
if GPU:
|
| 24 |
+
physical_devices = tf.config.list_physical_devices('GPU')
|
| 25 |
+
tf.config.experimental.set_memory_growth(physical_devices[0], True)
|
| 26 |
+
|
| 27 |
+
self.model = self.load_model(h5_address=h5_address)
|
| 28 |
+
|
| 29 |
+
def load_model(self, h5_address: str):
|
| 30 |
+
"load weight file and create the model once"
|
| 31 |
+
model = tf.keras.models.load_model(h5_address, custom_objects={'tf': tf})
|
| 32 |
+
return model
|
| 33 |
+
|
| 34 |
+
def recognize_fer(self, img_path:str):
|
| 35 |
+
"create and image from the path and recognize expression"
|
| 36 |
+
img = imread(img_path)
|
| 37 |
+
# resize img to 1*224*224*3
|
| 38 |
+
img = resize(img, (224, 224,3))
|
| 39 |
+
img = np.expand_dims(img, axis=0)
|
| 40 |
+
#
|
| 41 |
+
prediction = self.model.predict_on_batch([img])
|
| 42 |
+
exp = np.array(prediction[0])
|
| 43 |
+
'''in case you need the embeddings'''
|
| 44 |
+
# embeddings = prediction[1:]
|
| 45 |
+
print(self.exps[np.argmax(exp)])
|
| 46 |
+
|
| 47 |
+
|
train.py
ADDED
|
@@ -0,0 +1,349 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import tensorflow as tf
|
| 3 |
+
import numpy as np
|
| 4 |
+
import matplotlib.pyplot as plt
|
| 5 |
+
import math
|
| 6 |
+
from datetime import datetime
|
| 7 |
+
from sklearn.utils import shuffle
|
| 8 |
+
from sklearn.model_selection import train_test_split
|
| 9 |
+
from numpy import save, load, asarray
|
| 10 |
+
import csv
|
| 11 |
+
from skimage.io import imread
|
| 12 |
+
import pickle
|
| 13 |
+
from sklearn.metrics import accuracy_score
|
| 14 |
+
import os
|
| 15 |
+
import time
|
| 16 |
+
|
| 17 |
+
from AffectNetClass import AffectNet
|
| 18 |
+
from RafdbClass import RafDB
|
| 19 |
+
from FerPlusClass import FerPlus
|
| 20 |
+
|
| 21 |
+
from config import DatasetName, AffectnetConf, InputDataSize, LearningConfig, DatasetType, RafDBConf, FerPlusConf
|
| 22 |
+
from cnn_model import CNNModel
|
| 23 |
+
from custom_loss import CustomLosses
|
| 24 |
+
from data_helper import DataHelper
|
| 25 |
+
from dataset_class import CustomDataset
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class TrainModel:
|
| 29 |
+
def __init__(self, dataset_name, ds_type, weights='imagenet', lr=1e-3, aug=True):
|
| 30 |
+
self.dataset_name = dataset_name
|
| 31 |
+
self.ds_type = ds_type
|
| 32 |
+
self.weights = weights
|
| 33 |
+
self.lr = lr
|
| 34 |
+
|
| 35 |
+
self.base_lr = 1e-5
|
| 36 |
+
self.max_lr = 5e-4
|
| 37 |
+
if dataset_name == DatasetName.fer2013:
|
| 38 |
+
self.drop = 0.1
|
| 39 |
+
self.epochs_drop = 5
|
| 40 |
+
if aug:
|
| 41 |
+
self.img_path = FerPlusConf.aug_train_img_path
|
| 42 |
+
self.annotation_path = FerPlusConf.aug_train_annotation_path
|
| 43 |
+
self.masked_img_path = FerPlusConf.aug_train_masked_img_path
|
| 44 |
+
else:
|
| 45 |
+
self.img_path = FerPlusConf.no_aug_train_img_path
|
| 46 |
+
self.annotation_path = FerPlusConf.no_aug_train_annotation_path
|
| 47 |
+
|
| 48 |
+
self.val_img_path = FerPlusConf.test_img_path
|
| 49 |
+
self.val_annotation_path = FerPlusConf.test_annotation_path
|
| 50 |
+
self.eval_masked_img_path = FerPlusConf.test_masked_img_path
|
| 51 |
+
self.num_of_classes = 7
|
| 52 |
+
self.num_of_samples = None
|
| 53 |
+
|
| 54 |
+
elif dataset_name == DatasetName.rafdb:
|
| 55 |
+
self.drop = 0.1
|
| 56 |
+
self.epochs_drop = 5
|
| 57 |
+
|
| 58 |
+
if aug:
|
| 59 |
+
self.img_path = RafDBConf.aug_train_img_path
|
| 60 |
+
self.annotation_path = RafDBConf.aug_train_annotation_path
|
| 61 |
+
self.masked_img_path = RafDBConf.aug_train_masked_img_path
|
| 62 |
+
else:
|
| 63 |
+
self.img_path = RafDBConf.no_aug_train_img_path
|
| 64 |
+
self.annotation_path = RafDBConf.no_aug_train_annotation_path
|
| 65 |
+
|
| 66 |
+
self.val_img_path = RafDBConf.test_img_path
|
| 67 |
+
self.val_annotation_path = RafDBConf.test_annotation_path
|
| 68 |
+
self.eval_masked_img_path = RafDBConf.test_masked_img_path
|
| 69 |
+
self.num_of_classes = 7
|
| 70 |
+
self.num_of_samples = None
|
| 71 |
+
|
| 72 |
+
elif dataset_name == DatasetName.affectnet:
|
| 73 |
+
self.drop = 0.1
|
| 74 |
+
self.epochs_drop = 5
|
| 75 |
+
|
| 76 |
+
if ds_type == DatasetType.train:
|
| 77 |
+
self.img_path = AffectnetConf.aug_train_img_path
|
| 78 |
+
self.annotation_path = AffectnetConf.aug_train_annotation_path
|
| 79 |
+
self.masked_img_path = AffectnetConf.aug_train_masked_img_path
|
| 80 |
+
self.val_img_path = AffectnetConf.eval_img_path
|
| 81 |
+
self.val_annotation_path = AffectnetConf.eval_annotation_path
|
| 82 |
+
self.eval_masked_img_path = AffectnetConf.eval_masked_img_path
|
| 83 |
+
self.num_of_classes = 8
|
| 84 |
+
self.num_of_samples = AffectnetConf.num_of_samples_train
|
| 85 |
+
elif ds_type == DatasetType.train_7:
|
| 86 |
+
if aug:
|
| 87 |
+
self.img_path = AffectnetConf.aug_train_img_path_7
|
| 88 |
+
self.annotation_path = AffectnetConf.aug_train_annotation_path_7
|
| 89 |
+
self.masked_img_path = AffectnetConf.aug_train_masked_img_path_7
|
| 90 |
+
else:
|
| 91 |
+
self.img_path = AffectnetConf.no_aug_train_img_path_7
|
| 92 |
+
self.annotation_path = AffectnetConf.no_aug_train_annotation_path_7
|
| 93 |
+
|
| 94 |
+
self.val_img_path = AffectnetConf.eval_img_path_7
|
| 95 |
+
self.val_annotation_path = AffectnetConf.eval_annotation_path_7
|
| 96 |
+
self.eval_masked_img_path = AffectnetConf.eval_masked_img_path_7
|
| 97 |
+
self.num_of_classes = 7
|
| 98 |
+
self.num_of_samples = AffectnetConf.num_of_samples_train_7
|
| 99 |
+
|
| 100 |
+
def train(self, arch, weight_path):
|
| 101 |
+
""""""
|
| 102 |
+
|
| 103 |
+
'''create loss'''
|
| 104 |
+
c_loss = CustomLosses()
|
| 105 |
+
|
| 106 |
+
'''create summary writer'''
|
| 107 |
+
summary_writer = tf.summary.create_file_writer(
|
| 108 |
+
"./train_logs/fit/" + datetime.now().strftime("%Y%m%d-%H%M%S"))
|
| 109 |
+
start_train_date = datetime.now().strftime("%Y%m%d-%H%M%S")
|
| 110 |
+
|
| 111 |
+
'''making models'''
|
| 112 |
+
model = self.make_model(arch=arch, w_path=weight_path)
|
| 113 |
+
'''create save path'''
|
| 114 |
+
if self.dataset_name == DatasetName.affectnet:
|
| 115 |
+
save_path = AffectnetConf.weight_save_path + start_train_date + '/'
|
| 116 |
+
elif self.dataset_name == DatasetName.rafdb:
|
| 117 |
+
save_path = RafDBConf.weight_save_path + start_train_date + '/'
|
| 118 |
+
elif self.dataset_name == DatasetName.fer2013:
|
| 119 |
+
save_path = FerPlusConf.weight_save_path + start_train_date + '/'
|
| 120 |
+
if not os.path.exists(save_path):
|
| 121 |
+
os.makedirs(save_path)
|
| 122 |
+
|
| 123 |
+
'''create sample generator'''
|
| 124 |
+
dhp = DataHelper()
|
| 125 |
+
|
| 126 |
+
''' Train Generator'''
|
| 127 |
+
img_filenames, exp_filenames = dhp.create_generator_full_path(img_path=self.img_path,
|
| 128 |
+
annotation_path=self.annotation_path)
|
| 129 |
+
'''create dataset'''
|
| 130 |
+
cds = CustomDataset()
|
| 131 |
+
ds = cds.create_dataset(img_filenames=img_filenames,
|
| 132 |
+
anno_names=exp_filenames,
|
| 133 |
+
is_validation=False)
|
| 134 |
+
|
| 135 |
+
'''create train configuration'''
|
| 136 |
+
step_per_epoch = len(img_filenames) // LearningConfig.batch_size
|
| 137 |
+
gradients = None
|
| 138 |
+
virtual_step_per_epoch = LearningConfig.virtual_batch_size // LearningConfig.batch_size
|
| 139 |
+
|
| 140 |
+
'''create optimizer'''
|
| 141 |
+
optimizer = tf.keras.optimizers.Adam(self.lr, decay=1e-5)
|
| 142 |
+
|
| 143 |
+
'''start train:'''
|
| 144 |
+
all_gt_exp = []
|
| 145 |
+
all_pr_exp = []
|
| 146 |
+
|
| 147 |
+
for epoch in range(LearningConfig.epochs):
|
| 148 |
+
ce_weight = 2
|
| 149 |
+
batch_index = 0
|
| 150 |
+
|
| 151 |
+
for img_batch, exp_batch in ds:
|
| 152 |
+
'''since the calculation of the confusion matrix will be time-consuming,
|
| 153 |
+
we only save 1000 labels each time. Moreover, this help us to be more qiuck on updates
|
| 154 |
+
'''
|
| 155 |
+
all_gt_exp, all_pr_exp = self._update_all_labels_arrays(all_gt_exp, all_pr_exp)
|
| 156 |
+
'''load annotation and images'''
|
| 157 |
+
'''squeeze'''
|
| 158 |
+
exp_batch = exp_batch[:, -1]
|
| 159 |
+
img_batch = img_batch[:, -1, :, :]
|
| 160 |
+
|
| 161 |
+
'''train step'''
|
| 162 |
+
step_gradients, all_gt_exp, all_pr_exp = self.train_step(epoch=epoch, step=batch_index,
|
| 163 |
+
total_steps=step_per_epoch,
|
| 164 |
+
img_batch=img_batch,
|
| 165 |
+
anno_exp=exp_batch,
|
| 166 |
+
model=model, optimizer=optimizer,
|
| 167 |
+
c_loss=c_loss,
|
| 168 |
+
ce_weight=ce_weight,
|
| 169 |
+
summary_writer=summary_writer,
|
| 170 |
+
all_gt_exp=all_gt_exp,
|
| 171 |
+
all_pr_exp=all_pr_exp)
|
| 172 |
+
batch_index += 1
|
| 173 |
+
|
| 174 |
+
'''evaluating part'''
|
| 175 |
+
global_accuracy, conf_mat, avg_acc = self._eval_model(model=model)
|
| 176 |
+
'''save weights'''
|
| 177 |
+
save_name = save_path + '_' + str(epoch) + '_' + self.dataset_name + '_AC_' + str(global_accuracy)
|
| 178 |
+
model.save(save_name + '.h5')
|
| 179 |
+
self._save_confusion_matrix(conf_mat, save_name + '.txt')
|
| 180 |
+
|
| 181 |
+
def train_step(self, epoch, step, total_steps, model, ce_weight,
|
| 182 |
+
img_batch, anno_exp, optimizer, summary_writer, c_loss, all_gt_exp, all_pr_exp):
|
| 183 |
+
with tf.GradientTape() as tape:
|
| 184 |
+
pr_data = model([img_batch], training=True)
|
| 185 |
+
exp_pr_vec = pr_data[0]
|
| 186 |
+
embeddings = pr_data[1:]
|
| 187 |
+
|
| 188 |
+
bs_size = tf.shape(exp_pr_vec, out_type=tf.dtypes.int64)[0]
|
| 189 |
+
|
| 190 |
+
loss_exp, accuracy = c_loss.cross_entropy_loss(y_pr=exp_pr_vec, y_gt=anno_exp,
|
| 191 |
+
num_classes=self.num_of_classes,
|
| 192 |
+
ds_name=self.dataset_name)
|
| 193 |
+
|
| 194 |
+
'''Feature difference loss'''
|
| 195 |
+
# embedding_similarity_loss = 0
|
| 196 |
+
embedding_similarity_loss = c_loss.embedding_loss_distance(embeddings=embeddings)
|
| 197 |
+
|
| 198 |
+
'''update confusion matrix'''
|
| 199 |
+
exp_pr = tf.constant([np.argmax(exp_pr_vec[i]) for i in range(bs_size)], dtype=tf.dtypes.int64)
|
| 200 |
+
tr_conf_matrix, all_gt_exp, all_pr_exp = c_loss.update_confusion_matrix(anno_exp, # real labels
|
| 201 |
+
exp_pr, # real labels
|
| 202 |
+
all_gt_exp,
|
| 203 |
+
all_pr_exp)
|
| 204 |
+
''' correlation between the embeddings'''
|
| 205 |
+
correlation_loss = c_loss.correlation_loss_multi(embeddings=embeddings,
|
| 206 |
+
exp_gt_vec=anno_exp,
|
| 207 |
+
exp_pr_vec=exp_pr_vec,
|
| 208 |
+
tr_conf_matrix=tr_conf_matrix)
|
| 209 |
+
'''mean loss'''
|
| 210 |
+
mean_correlation_loss = c_loss.mean_embedding_loss_distance(embeddings=embeddings,
|
| 211 |
+
exp_gt_vec=anno_exp,
|
| 212 |
+
exp_pr_vec=exp_pr_vec,
|
| 213 |
+
num_of_classes=self.num_of_classes)
|
| 214 |
+
|
| 215 |
+
lamda_param = 50
|
| 216 |
+
loss_total = lamda_param * loss_exp + \
|
| 217 |
+
embedding_similarity_loss + \
|
| 218 |
+
correlation_loss + \
|
| 219 |
+
mean_correlation_loss
|
| 220 |
+
|
| 221 |
+
# '''calculate gradient'''
|
| 222 |
+
gradients_of_model = tape.gradient(loss_total, model.trainable_variables)
|
| 223 |
+
# '''apply Gradients:'''
|
| 224 |
+
optimizer.apply_gradients(zip(gradients_of_model, model.trainable_variables))
|
| 225 |
+
# '''printing loss Values: '''
|
| 226 |
+
tf.print("->EPOCH: ", str(epoch), "->STEP: ", str(step) + '/' + str(total_steps),
|
| 227 |
+
' -> : accuracy: ', accuracy,
|
| 228 |
+
' -> : loss_total: ', loss_total,
|
| 229 |
+
' -> : loss_exp: ', loss_exp,
|
| 230 |
+
' -> : embedding_similarity_loss: ', embedding_similarity_loss,
|
| 231 |
+
' -> : correlation_loss: ', correlation_loss,
|
| 232 |
+
' -> : mean_correlation_loss: ', mean_correlation_loss)
|
| 233 |
+
with summary_writer.as_default():
|
| 234 |
+
tf.summary.scalar('loss_total', loss_total, step=epoch)
|
| 235 |
+
tf.summary.scalar('loss_exp', loss_exp, step=epoch)
|
| 236 |
+
tf.summary.scalar('correlation_loss', correlation_loss, step=epoch)
|
| 237 |
+
tf.summary.scalar('mean_correlation_loss', mean_correlation_loss, step=epoch)
|
| 238 |
+
tf.summary.scalar('embedding_similarity_loss', embedding_similarity_loss, step=epoch)
|
| 239 |
+
return gradients_of_model, all_gt_exp, all_pr_exp
|
| 240 |
+
|
| 241 |
+
def train_step_old(self, epoch, step, total_steps, model, ce_weight,
|
| 242 |
+
img_batch, anno_exp, optimizer, summary_writer, c_loss, all_gt_exp, all_pr_exp):
|
| 243 |
+
with tf.GradientTape() as tape:
|
| 244 |
+
# '''create annotation_predicted'''
|
| 245 |
+
# exp_pr, embedding = model([img_batch], training=True)
|
| 246 |
+
exp_pr_vec, embedding_class, embedding_mean, embedding_var = model([img_batch], training=True)
|
| 247 |
+
|
| 248 |
+
bs_size = tf.shape(exp_pr_vec, out_type=tf.dtypes.int64)[0]
|
| 249 |
+
# # '''CE loss'''
|
| 250 |
+
loss_exp, accuracy = c_loss.cross_entropy_loss(y_pr=exp_pr_vec, y_gt=anno_exp,
|
| 251 |
+
num_classes=self.num_of_classes,
|
| 252 |
+
ds_name=self.dataset_name)
|
| 253 |
+
#
|
| 254 |
+
loss_cls_mean, loss_cls_var, loss_mean_var = c_loss.embedding_loss_distance(
|
| 255 |
+
embedding_class=embedding_class,
|
| 256 |
+
embedding_mean=embedding_mean,
|
| 257 |
+
embedding_var=embedding_var,
|
| 258 |
+
bs_size=bs_size)
|
| 259 |
+
feature_diff_loss = loss_cls_mean + loss_cls_var + loss_mean_var
|
| 260 |
+
|
| 261 |
+
# correlation between the class_embeddings
|
| 262 |
+
cor_loss, all_gt_exp, all_pr_exp = c_loss.correlation_loss(embedding=embedding_class, # distribution
|
| 263 |
+
exp_gt_vec=anno_exp,
|
| 264 |
+
exp_pr_vec=exp_pr_vec,
|
| 265 |
+
num_of_classes=self.num_of_classes,
|
| 266 |
+
all_gt_exp=all_gt_exp,
|
| 267 |
+
all_pr_exp=all_pr_exp)
|
| 268 |
+
# correlation between the mean_emb_cor_loss
|
| 269 |
+
mean_emb_cor_loss, mean_emb_kl_loss = c_loss.mean_embedding_loss(embedding=embedding_mean,
|
| 270 |
+
exp_gt_vec=anno_exp,
|
| 271 |
+
exp_pr_vec=exp_pr_vec,
|
| 272 |
+
num_of_classes=self.num_of_classes)
|
| 273 |
+
mean_loss = mean_emb_cor_loss + 10 * mean_emb_kl_loss
|
| 274 |
+
|
| 275 |
+
var_emb_cor_loss, var_emb_kl_loss = c_loss.variance_embedding_loss(embedding=embedding_var,
|
| 276 |
+
exp_gt_vec=anno_exp,
|
| 277 |
+
exp_pr_vec=exp_pr_vec,
|
| 278 |
+
num_of_classes=self.num_of_classes)
|
| 279 |
+
var_loss = var_emb_cor_loss + 10 * var_emb_kl_loss
|
| 280 |
+
# '''total:'''
|
| 281 |
+
loss_total = 100 * loss_exp + cor_loss + 10 * feature_diff_loss + mean_loss + var_loss
|
| 282 |
+
|
| 283 |
+
# '''calculate gradient'''
|
| 284 |
+
gradients_of_model = tape.gradient(loss_total, model.trainable_variables)
|
| 285 |
+
# '''apply Gradients:'''
|
| 286 |
+
optimizer.apply_gradients(zip(gradients_of_model, model.trainable_variables))
|
| 287 |
+
# '''printing loss Values: '''
|
| 288 |
+
tf.print("->EPOCH: ", str(epoch), "->STEP: ", str(step) + '/' + str(total_steps),
|
| 289 |
+
' -> : accuracy: ', accuracy,
|
| 290 |
+
' -> : loss_total: ', loss_total,
|
| 291 |
+
' -> : loss_exp: ', loss_exp,
|
| 292 |
+
' -> : cor_loss: ', cor_loss,
|
| 293 |
+
' -> : feature_loss: ', feature_diff_loss,
|
| 294 |
+
' -> : mean_loss: ', mean_loss,
|
| 295 |
+
' -> : var_loss: ', var_loss)
|
| 296 |
+
|
| 297 |
+
with summary_writer.as_default():
|
| 298 |
+
tf.summary.scalar('loss_total', loss_total, step=epoch)
|
| 299 |
+
tf.summary.scalar('loss_exp', loss_exp, step=epoch)
|
| 300 |
+
tf.summary.scalar('loss_correlation', cor_loss, step=epoch)
|
| 301 |
+
return gradients_of_model, all_gt_exp, all_pr_exp
|
| 302 |
+
|
| 303 |
+
def _eval_model(self, model):
|
| 304 |
+
""""""
|
| 305 |
+
'''first we need to create the 4 bunch here: '''
|
| 306 |
+
|
| 307 |
+
'''for Affectnet, we need to calculate accuracy of each label and then total avg accuracy:'''
|
| 308 |
+
global_accuracy = 0
|
| 309 |
+
avg_acc = 0
|
| 310 |
+
conf_mat = []
|
| 311 |
+
if self.dataset_name == DatasetName.affectnet:
|
| 312 |
+
if self.ds_type == DatasetType.train:
|
| 313 |
+
affn = AffectNet(ds_type=DatasetType.eval)
|
| 314 |
+
else:
|
| 315 |
+
affn = AffectNet(ds_type=DatasetType.eval_7)
|
| 316 |
+
global_accuracy, conf_mat, avg_acc, precision, recall, fscore, support = \
|
| 317 |
+
affn.test_accuracy(model=model)
|
| 318 |
+
elif self.dataset_name == DatasetName.rafdb:
|
| 319 |
+
rafdb = RafDB(ds_type=DatasetType.test)
|
| 320 |
+
global_accuracy, conf_mat, avg_acc, precision, recall, fscore, support = rafdb.test_accuracy(model=model)
|
| 321 |
+
elif self.dataset_name == DatasetName.fer2013:
|
| 322 |
+
ferplus = FerPlus(ds_type=DatasetType.test)
|
| 323 |
+
global_accuracy, conf_mat, avg_acc, precision, recall, fscore, support = ferplus.test_accuracy(model=model)
|
| 324 |
+
print("================== global_accuracy =====================")
|
| 325 |
+
print(global_accuracy)
|
| 326 |
+
print("================== Average Accuracy =====================")
|
| 327 |
+
print(avg_acc)
|
| 328 |
+
print("================== Confusion Matrix =====================")
|
| 329 |
+
print(conf_mat)
|
| 330 |
+
return global_accuracy, conf_mat, avg_acc
|
| 331 |
+
|
| 332 |
+
def make_model(self, arch, w_path):
|
| 333 |
+
cnn = CNNModel()
|
| 334 |
+
model = cnn.get_model(arch=arch, num_of_classes=LearningConfig.num_classes, weights=self.weights)
|
| 335 |
+
if w_path is not None:
|
| 336 |
+
model.load_weights(w_path)
|
| 337 |
+
return model
|
| 338 |
+
|
| 339 |
+
def _save_confusion_matrix(self, conf_mat, save_name):
|
| 340 |
+
f = open(save_name, "a")
|
| 341 |
+
print(save_name)
|
| 342 |
+
f.write(np.array_str(conf_mat))
|
| 343 |
+
f.close()
|
| 344 |
+
|
| 345 |
+
def _update_all_labels_arrays(self, all_gt_exp, all_pr_exp):
|
| 346 |
+
if len(all_gt_exp) < LearningConfig.labels_history_frame:
|
| 347 |
+
return all_gt_exp, all_pr_exp
|
| 348 |
+
else: # remove the first batch:
|
| 349 |
+
return all_gt_exp[LearningConfig.batch_size:], all_pr_exp[LearningConfig.batch_size:]
|
trained_models/AffectNet_6336.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1f78e385a7c780a5f95e9f0772ec6ca18564b776875b1269d2858ad168df7956
|
| 3 |
+
size 98617720
|
trained_models/Fer2013_7203.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:60caf5d2b95d84225c8197950d973ddd35523f50a577157f0f4885df2633d28d
|
| 3 |
+
size 98617752
|
trained_models/RafDB_8696.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5dfe5e381ccce39e922479aa4a99bdcf5460dab0b421d99cc1d76a79d4c6b4d9
|
| 3 |
+
size 98617728
|