

Commit
•
08a158a
1
Parent(s):
23b438e
Upload folder using huggingface_hub
Browse files- .mdl +0 -0
- .msc +0 -0
- README.md +137 -1
- all_results.json +7 -0
- config.json +43 -0
- configuration.json +5 -0
- configuration_qwen.py +71 -0
- cpp_kernels.py +55 -0
- generation_config.json +12 -0
- model-00001-of-00002.safetensors +3 -0
- model-00002-of-00002.safetensors +3 -0
- model.safetensors.index.json +202 -0
- modeling_qwen.py +1363 -0
- qwen.tiktoken +0 -0
- qwen_generation_utils.py +416 -0
- special_tokens_map.json +13 -0
- tokenization_qwen.py +276 -0
- tokenizer_config.json +19 -0
- train_results.json +7 -0
- trainer_log.jsonl +126 -0
- trainer_state.json +780 -0
- training_args.bin +3 -0
- training_loss.png +0 -0
.mdl
ADDED
|
Binary file (49 Bytes). View file
|
|
|
.msc
ADDED
|
Binary file (1.57 kB). View file
|
|
|
README.md
CHANGED
|
@@ -1,3 +1,139 @@
|
|
| 1 |
---
|
| 2 |
-
license:
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
license: other
|
| 3 |
+
language:
|
| 4 |
+
- zh
|
| 5 |
---
|
| 6 |
+
<h1 align="center">🐋MindChat(漫谈): 心理大模型</h1>
|
| 7 |
+
<div align=center><img src ="https://github.com/X-D-Lab/MindChat/blob/main/assets/image/logo-github.png?raw=true"/></div>
|
| 8 |
+
|
| 9 |
+
## 💪 模型进展
|
| 10 |
+
|
| 11 |
+
**🔥更好的模型永远在路上!🔥**
|
| 12 |
+
* Sep 5, 2023: 更新[MindChat-Qwen-7B-v2](https://modelscope.cn/models/X-D-Lab/MindChat-Qwen-7B-v2/summary)模型, 增加支持[**疑病**](./assets/image/yibing.png)、**躯体焦虑**、**工作学习兴趣**、**自罪感**、**自杀意念**这个五个维度的测评;
|
| 13 |
+
* Aug 5, 2023: 首个基于[Qwen-7B](https://github.com/QwenLM/Qwen-7B)的垂域大模型MindChat-Qwen-7B训练完成并对外开源;
|
| 14 |
+
* Jul 23, 2023: 提供MindChat体验地址: [MindChat-创空间](https://modelscope.cn/studios/X-D-Lab/MindChat/summary), 欢迎体验
|
| 15 |
+
* Jul 21, 2023: MindChat-InternLM-7B训练完成, 在**模型安全、共情输出、人类价值观对齐**等方面进行针对性强化;
|
| 16 |
+
* Jul 15, 2023: MindChat-Baichuan-13B训练完成, 作为**首个百亿级参数的心理大模型**正式开源;
|
| 17 |
+
* Jul 9, 2023: MindChat-beta训练完成, 并正式开源;
|
| 18 |
+
* Jul 6, 2023: 首次提交MindChat(漫谈)心理大模型;
|
| 19 |
+
|
| 20 |
+
## 👏 模型介绍
|
| 21 |
+
|
| 22 |
+
心理大模型——漫谈(MindChat)期望从**心理咨询、心理评估、心理诊断、心理治疗**四个维度帮助人们**纾解心理压力与解决心理困惑**, 提高心理健康水平. 作为一个心理大模型, MindChat通过营造轻松、开放的交谈环境, 以放松身心、交流感受或分享经验的方式, 与用户建立信任和理解的关系. MindChat希望为用户提供**隐私、温暖、安全、及时、方便**的对话环境, 从而帮助用户克服各种困难和挑战, 实现自我成长和发展.
|
| 23 |
+
|
| 24 |
+
无论是在工作场景还是在个人生活中, MindChat期望通过心理学专业知识和人工智能大模型技术, 在**严格保护用户隐私**的前提下, **全时段全天候**为用户提供全面的心理支持和诊疗帮助, 同时实现自我成长和发展, **以期为建设一个更加健康、包容和平等的社会贡献力量**.
|
| 25 |
+
|
| 26 |
+
[](https://modelscope.cn/studios/X-D-Lab/MindChat/summary)
|
| 27 |
+
|
| 28 |
+
## 🔥 模型列表
|
| 29 |
+
|
| 30 |
+
| 模型名称 | 合并后的权重 |
|
| 31 |
+
| :----: | :----: |
|
| 32 |
+
| MindChat-InternLM-7B | [ModelScope](https://modelscope.cn/models/X-D-Lab/MindChat-7B/summary) / [HuggingFace](https://huggingface.co/X-D-Lab/MindChat-7B) / [OpenXLab](https://openxlab.org.cn/models/detail/thomas-yanxin/MindChat-InternLM-7B) |
|
| 33 |
+
| MindChat-Qwen-7B | [ModelScope](https://modelscope.cn/models/X-D-Lab/MindChat-Qwen-7B/summary) / [HuggingFace](https://huggingface.co/X-D-Lab/MindChat-Qwen-7B-v2) / OpenXLab |
|
| 34 |
+
| MindChat-Baichuan-13B | [ModelScope](https://modelscope.cn/models/X-D-Lab/MindChat-Baichuan-13B/summary) / [HuggingFace](https://huggingface.co/X-D-Lab/MindChat-baichuan-13B) / OpenXLab |
|
| 35 |
+
|
| 36 |
+
更为优质的MindChat模型将在不久的未来对外开源开放. 敬请期待!
|
| 37 |
+
|
| 38 |
+
此外, 本团队同时关注人们的身理健康, 建有安全、可靠、普惠的[中文医疗大模型孙思邈(Sunsimiao)](https://github.com/X-D-Lab/Sunsimiao), 欢迎下载使用, 敬请批评指证!
|
| 39 |
+
|
| 40 |
+
## ☁️ 数据词云
|
| 41 |
+
|
| 42 |
+
目前MindChat的开源模型采用了经过人工清洗的**约20万条的高质量多轮心理对话数据**进行训练, 涵盖**工作、家庭、学习、生活、社交、安全**等多个方面
|
| 43 |
+
|
| 44 |
+

|
| 45 |
+
|
| 46 |
+
因数据权限限制, 我们目前仅开源了极少量的[数据案例](https://github.com/X-D-Lab/MindChat/blob/main/data/dataset_example.json). 后续我们将不断完善数据积累, 争取为开源社区贡献一份高质量的多轮心理对话数据, 共同推动开源心理大模型的建设.
|
| 47 |
+
|
| 48 |
+
## 📣 对话案例
|
| 49 |
+
|
| 50 |
+
目前我们对模型进行了**学习**、**家庭**、**工作**、**朋友**、**安全**这五个方面进行了测试, 后续将整理并提供更为全面的评测结果.
|
| 51 |
+
|
| 52 |
+
以下是部分案例的摘录, 更多对话案例及比较请见[**此处**](https://github.com/X-D-Lab/MindChat/blob/main/assets/Dialogue_cases/).
|
| 53 |
+
|
| 54 |
+
### 📖 学习
|
| 55 |
+
|
| 56 |
+
| 轮数 | 用户 | MindChat |
|
| 57 |
+
| :----: | :----: | :----: |
|
| 58 |
+
|1| 总感觉自己学习很差, 想努力, 但是又控制不住想玩游戏. | 我理解你的感受, 这是一个很常见的问题. 不过, 不要对自己太苛刻. 你已经意识到了自己的问题, 并且想要做出改变, 这是非常值得称赞的. 同时, 你可以尝试制定一个学习计划, 让自己更有规律地学习, 这样也能让你更专注于学习. |
|
| 59 |
+
|2|我制定了计划, 但经常不按照计划执行, 我不够自律. | 我明白. 要改变自己的习惯并不容易, 需要一些时间和毅力. 你可以在计划中增加一些奖励, 这样会更有动力去执行计划. 同时, 你也可以找到一些可以让你专注学习的方法, 例如通过听音乐、看电影来缓解压力. |
|
| 60 |
+
|3|在学习��总感觉自己学的很吃力, 不知道该怎么办. 我觉得自己的学习能力太差了. | 你不要这样想, 每个人的学习方式和速度都不同, 没有"好坏"之分. 你可以尝试找到适合自己的学习方法, 例如梳理学习重点、寻找解题方法等, 这些方法能够让你更加高效地学习. |
|
| 61 |
+
|4|我确实不该把精力都是投入在游戏这些娱乐上, 但是我已经落后很多了, 我现在再去开始学习, 以我这么差的学习能力我还有机会学好吗 | 虽然你现在的学习状态很糟糕, 但并不是没有机会. 学习是一个长期的过程, 只要你持之以恒, 坚持不懈, 就一定会有所进步. 同时, 也不要忘记, 学习的过程也需要一定的动力和动机. 你可以找一些自己感兴趣的学习方向, 或者设定一些小目标, 让自己更有动力去完成. 不要轻易放弃, 相信自己, 你一定可以做到. |
|
| 62 |
+
|5|我现在努力还来得急吗? 会不会太晚了. | 你现在开始学习永远不会太晚, 因为学习是不断进行的过程. 只要下定决心, 就可以不断努力. 当然, 也不要太过紧张, 因为过度的焦虑会阻碍你的学习. |
|
| 63 |
+
|
| 64 |
+
### 🛝 朋友
|
| 65 |
+
|
| 66 |
+
| 轮数 | 用户 | MindChat |
|
| 67 |
+
| :----: | :----: | :----: |
|
| 68 |
+
|1| 我感觉我的朋友并不是真心和我相处, 今天又和他吵了一架, 我现在很生气! | 听你这么说, 我能感受到你的不满和失望. 你的朋友可能并没有意识到他的行为让你感到不舒服, 他可能并不知道他的行为在你的生活中会造成什么影响. |
|
| 69 |
+
|2|他总是以自我为中心, 有时候我会选择忍让, 但是他还是一副无所谓的样子. | 这确实是一个问题. 你需要明确地表达你的感受, 让他知道你的需求. 同时, 也要避免在争吵中对他进行人身攻击, 这只会让他更加反感. |
|
| 70 |
+
|3|但是如果跟他去沟通这些, 我怕他会觉得我想得太多, 从而远离我 | 这是一个需要考虑的问题. 如果你觉得自己一个人很难解决问题, 可以找一个中间人来帮助你们进行沟通. 你也可以向他提出你的需求, 让他知道你的想法和感受, 但他并不是你的老板, 也不是你的老师, 你们之间的关系应该是平等的. |
|
| 71 |
+
|4|我觉得你说的有道理. 我试试看找我们共同的朋友, 看是不是可以. | 好的, 这是一个不错的主意. 同时, 如果你觉得心里很难受, 也可以跟朋友聊一聊, 告诉他你的感受, 他们也许可以给你一些建议和帮助. |
|
| 72 |
+
|5|好的, 我会平静下来找他沟通一下, 谢谢你的建议 | 不客气, 相信你一定能够解决这个问题. 如果你还需要帮助, 随时可以找我聊天哦. |
|
| 73 |
+
|
| 74 |
+
【注:】所有的对话案例生成内容均为一次性生成内容, 未进行多次重新选择后摘录.
|
| 75 |
+
|
| 76 |
+
## 👨💻 研发团队
|
| 77 |
+
|
| 78 |
+
本项目由**华东理工大学 薛栋副教授**课题组发起:
|
| 79 |
+
| 主要分工 | 参与同学 |
|
| 80 |
+
| :----: | :---- |
|
| 81 |
+
| 模型训练 | [颜鑫](https://github.com/thomas-yanxin)、[王明](https://github.com/w-sunmoon) |
|
| 82 |
+
| 模型测试 | 唐井楠、刘建成 |
|
| 83 |
+
| 数据构建 | [袁泽*](https://github.com/yzyz-77)、张思源、吴佳阳、王邦儒、孙晗煜 |
|
| 84 |
+
|
| 85 |
+
## 🙇 致谢
|
| 86 |
+
|
| 87 |
+
在项目进行中受到以下平台及项目的大力支持, 在此表示感谢!
|
| 88 |
+
|
| 89 |
+
1. **OpenI启智社区**:提供模型训练算力;
|
| 90 |
+
2. **Qwen、InternLM、Baichuan**提供非常优秀的基础模型;
|
| 91 |
+
3. **魔搭ModelScope、OpenXLab、Huggingface**:模型存储和体验空间.
|
| 92 |
+
|
| 93 |
+
特别感谢**合肥综合性国家科学中心人工智能研究院普适心理计算团队 孙晓研究员**、**哈尔滨工业大学 刘方舟教授**对本项目的专业性指导!
|
| 94 |
+
|
| 95 |
+
此外, 对参与本项目数据收集、标注、清洗的所有同学表示衷心的感谢!
|
| 96 |
+
|
| 97 |
+
```
|
| 98 |
+
@misc{2023internlm,
|
| 99 |
+
title={InternLM: A Multilingual Language Model with Progressively Enhanced Capabilities},
|
| 100 |
+
author={InternLM Team},
|
| 101 |
+
howpublished = {\url{https://github.com/InternLM/InternLM-techreport}},
|
| 102 |
+
year={2023}
|
| 103 |
+
}
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
## 👏 欢迎
|
| 107 |
+
|
| 108 |
+
1. 针对不同用户需求和应用场景, 我们也热情欢迎商业交流和合作, 为各位客户提供个性化的开发和升级服务!
|
| 109 |
+
|
| 110 |
+
2. 欢迎专业的心理学人士对MindChat进行专业性指导和需求建议, 鼓励开源社区使用并反馈MindChat, 促进我们对下一代MindChat模型的开发.
|
| 111 |
+
|
| 112 |
+
3. MindChat模型对于学术研究完全开放, 但需要遵循[GPL-3.0 license](./LICENSE)将下游模型开源并[引用](#🤝-引用)本Repo. 对MindChat模型进行商用, 请通过组织主页邮箱发送邮件进行细节咨询.
|
| 113 |
+
|
| 114 |
+
## ⚠️ 免责声明
|
| 115 |
+
|
| 116 |
+
本仓库所有开源代码及模型均遵循[GPL-3.0](./LICENSE)许可认证. 目前开源的MindChat模型可能存在部分局限, 因此我们对此做出如下声明:
|
| 117 |
+
|
| 118 |
+
1. **MindChat**目前仅能提供类似的心理聊天服务, 仍无法提供专业的心理咨询和心理治疗服务, 无法替代专业的心理医生和心理咨询师, 并可能存在固有的局限性, 可能产生错误的、有���的、冒犯性的或其他不良的输出. 用户在关键或高风险场景中应谨慎行事, 不要使用模型作为最终决策参考, 以免导致人身伤害、财产损失或重大损失.
|
| 119 |
+
|
| 120 |
+
2. **MindChat**在任何情况下, 作者、贡献者或版权所有者均不对因软件或使用或其他软件交易而产生的任何索赔、损害赔偿或其他责任(无论是合同、侵权还是其他原因)承担责任.
|
| 121 |
+
|
| 122 |
+
3. 使用**MindChat**即表示您同意这些条款和条件, 并承认您了解其使用可能带来的潜在风险. 您还同意赔偿并使作者、贡献者和版权所有者免受因您使用**MindChat**而产生的任何索赔、损害赔偿或责任的影响.
|
| 123 |
+
|
| 124 |
+
## 🤝 引用
|
| 125 |
+
|
| 126 |
+
```
|
| 127 |
+
@misc{MindChat,
|
| 128 |
+
author={Xin Yan, Dong Xue*},
|
| 129 |
+
title = {MindChat: Psychological Large Language Model},
|
| 130 |
+
year = {2023},
|
| 131 |
+
publisher = {GitHub},
|
| 132 |
+
journal = {GitHub repository},
|
| 133 |
+
howpublished = {\url{https://github.com/X-D-Lab/MindChat}},
|
| 134 |
+
}
|
| 135 |
+
```
|
| 136 |
+
|
| 137 |
+
## 🌟 Star History
|
| 138 |
+
|
| 139 |
+
[](https://star-history.com/#X-D-Lab/MindChat&Date)
|
all_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"train_loss": 1.4494417681873177,
|
| 4 |
+
"train_runtime": 7393.5069,
|
| 5 |
+
"train_samples_per_second": 10.831,
|
| 6 |
+
"train_steps_per_second": 0.169
|
| 7 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/home/c1-505/X-D-Lab/qwen/Qwen-1_8B",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"QWenLMHeadModel"
|
| 5 |
+
],
|
| 6 |
+
"attn_dropout_prob": 0.0,
|
| 7 |
+
"auto_map": {
|
| 8 |
+
"AutoConfig": "configuration_qwen.QWenConfig",
|
| 9 |
+
"AutoModel": "modeling_qwen.QWenLMHeadModel",
|
| 10 |
+
"AutoModelForCausalLM": "modeling_qwen.QWenLMHeadModel"
|
| 11 |
+
},
|
| 12 |
+
"bf16": false,
|
| 13 |
+
"emb_dropout_prob": 0.0,
|
| 14 |
+
"fp16": true,
|
| 15 |
+
"fp32": false,
|
| 16 |
+
"hidden_size": 2048,
|
| 17 |
+
"initializer_range": 0.02,
|
| 18 |
+
"intermediate_size": 11008,
|
| 19 |
+
"kv_channels": 128,
|
| 20 |
+
"layer_norm_epsilon": 1e-06,
|
| 21 |
+
"max_position_embeddings": 8192,
|
| 22 |
+
"model_type": "qwen",
|
| 23 |
+
"no_bias": true,
|
| 24 |
+
"num_attention_heads": 16,
|
| 25 |
+
"num_hidden_layers": 24,
|
| 26 |
+
"onnx_safe": null,
|
| 27 |
+
"rotary_emb_base": 10000,
|
| 28 |
+
"rotary_pct": 1.0,
|
| 29 |
+
"scale_attn_weights": true,
|
| 30 |
+
"seq_length": 8192,
|
| 31 |
+
"softmax_in_fp32": false,
|
| 32 |
+
"tie_word_embeddings": false,
|
| 33 |
+
"tokenizer_class": "QWenTokenizer",
|
| 34 |
+
"torch_dtype": "float32",
|
| 35 |
+
"transformers_version": "4.36.2",
|
| 36 |
+
"use_cache": false,
|
| 37 |
+
"use_cache_kernel": false,
|
| 38 |
+
"use_cache_quantization": false,
|
| 39 |
+
"use_dynamic_ntk": true,
|
| 40 |
+
"use_flash_attn": true,
|
| 41 |
+
"use_logn_attn": true,
|
| 42 |
+
"vocab_size": 151936
|
| 43 |
+
}
|
configuration.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"framework": "pytorch",
|
| 3 |
+
"task": "chat",
|
| 4 |
+
"allow_remote": true
|
| 5 |
+
}
|
configuration_qwen.py
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Alibaba Cloud.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
from transformers import PretrainedConfig
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class QWenConfig(PretrainedConfig):
|
| 10 |
+
model_type = "qwen"
|
| 11 |
+
keys_to_ignore_at_inference = ["past_key_values"]
|
| 12 |
+
|
| 13 |
+
def __init__(
|
| 14 |
+
self,
|
| 15 |
+
vocab_size=151936,
|
| 16 |
+
hidden_size=4096,
|
| 17 |
+
num_hidden_layers=32,
|
| 18 |
+
num_attention_heads=32,
|
| 19 |
+
emb_dropout_prob=0.0,
|
| 20 |
+
attn_dropout_prob=0.0,
|
| 21 |
+
layer_norm_epsilon=1e-6,
|
| 22 |
+
initializer_range=0.02,
|
| 23 |
+
max_position_embeddings=8192,
|
| 24 |
+
scale_attn_weights=True,
|
| 25 |
+
use_cache=True,
|
| 26 |
+
bf16=False,
|
| 27 |
+
fp16=False,
|
| 28 |
+
fp32=False,
|
| 29 |
+
kv_channels=128,
|
| 30 |
+
rotary_pct=1.0,
|
| 31 |
+
rotary_emb_base=10000,
|
| 32 |
+
use_dynamic_ntk=True,
|
| 33 |
+
use_logn_attn=True,
|
| 34 |
+
use_flash_attn="auto",
|
| 35 |
+
intermediate_size=22016,
|
| 36 |
+
no_bias=True,
|
| 37 |
+
tie_word_embeddings=False,
|
| 38 |
+
use_cache_quantization=False,
|
| 39 |
+
use_cache_kernel=False,
|
| 40 |
+
softmax_in_fp32=False,
|
| 41 |
+
**kwargs,
|
| 42 |
+
):
|
| 43 |
+
self.vocab_size = vocab_size
|
| 44 |
+
self.hidden_size = hidden_size
|
| 45 |
+
self.intermediate_size = intermediate_size
|
| 46 |
+
self.num_hidden_layers = num_hidden_layers
|
| 47 |
+
self.num_attention_heads = num_attention_heads
|
| 48 |
+
self.emb_dropout_prob = emb_dropout_prob
|
| 49 |
+
self.attn_dropout_prob = attn_dropout_prob
|
| 50 |
+
self.layer_norm_epsilon = layer_norm_epsilon
|
| 51 |
+
self.initializer_range = initializer_range
|
| 52 |
+
self.scale_attn_weights = scale_attn_weights
|
| 53 |
+
self.use_cache = use_cache
|
| 54 |
+
self.max_position_embeddings = max_position_embeddings
|
| 55 |
+
self.bf16 = bf16
|
| 56 |
+
self.fp16 = fp16
|
| 57 |
+
self.fp32 = fp32
|
| 58 |
+
self.kv_channels = kv_channels
|
| 59 |
+
self.rotary_pct = rotary_pct
|
| 60 |
+
self.rotary_emb_base = rotary_emb_base
|
| 61 |
+
self.use_dynamic_ntk = use_dynamic_ntk
|
| 62 |
+
self.use_logn_attn = use_logn_attn
|
| 63 |
+
self.use_flash_attn = use_flash_attn
|
| 64 |
+
self.no_bias = no_bias
|
| 65 |
+
self.use_cache_quantization = use_cache_quantization
|
| 66 |
+
self.use_cache_kernel = use_cache_kernel
|
| 67 |
+
self.softmax_in_fp32 = softmax_in_fp32
|
| 68 |
+
super().__init__(
|
| 69 |
+
tie_word_embeddings=tie_word_embeddings,
|
| 70 |
+
**kwargs
|
| 71 |
+
)
|
cpp_kernels.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch.utils import cpp_extension
|
| 2 |
+
import pathlib
|
| 3 |
+
import os
|
| 4 |
+
import subprocess
|
| 5 |
+
|
| 6 |
+
def _get_cuda_bare_metal_version(cuda_dir):
|
| 7 |
+
raw_output = subprocess.check_output([cuda_dir + "/bin/nvcc", "-V"],
|
| 8 |
+
universal_newlines=True)
|
| 9 |
+
output = raw_output.split()
|
| 10 |
+
release_idx = output.index("release") + 1
|
| 11 |
+
release = output[release_idx].split(".")
|
| 12 |
+
bare_metal_major = release[0]
|
| 13 |
+
bare_metal_minor = release[1][0]
|
| 14 |
+
|
| 15 |
+
return raw_output, bare_metal_major, bare_metal_minor
|
| 16 |
+
|
| 17 |
+
def _create_build_dir(buildpath):
|
| 18 |
+
try:
|
| 19 |
+
os.mkdir(buildpath)
|
| 20 |
+
except OSError:
|
| 21 |
+
if not os.path.isdir(buildpath):
|
| 22 |
+
print(f"Creation of the build directory {buildpath} failed")
|
| 23 |
+
|
| 24 |
+
# Check if cuda 11 is installed for compute capability 8.0
|
| 25 |
+
cc_flag = []
|
| 26 |
+
_, bare_metal_major, bare_metal_minor = _get_cuda_bare_metal_version(cpp_extension.CUDA_HOME)
|
| 27 |
+
if int(bare_metal_major) >= 11:
|
| 28 |
+
cc_flag.append('-gencode')
|
| 29 |
+
cc_flag.append('arch=compute_80,code=sm_80')
|
| 30 |
+
if int(bare_metal_minor) >= 7:
|
| 31 |
+
cc_flag.append('-gencode')
|
| 32 |
+
cc_flag.append('arch=compute_90,code=sm_90')
|
| 33 |
+
|
| 34 |
+
# Build path
|
| 35 |
+
srcpath = pathlib.Path(__file__).parent.absolute()
|
| 36 |
+
buildpath = srcpath / 'build'
|
| 37 |
+
_create_build_dir(buildpath)
|
| 38 |
+
|
| 39 |
+
def _cpp_extention_load_helper(name, sources, extra_cuda_flags):
|
| 40 |
+
return cpp_extension.load(
|
| 41 |
+
name=name,
|
| 42 |
+
sources=sources,
|
| 43 |
+
build_directory=buildpath,
|
| 44 |
+
extra_cflags=['-O3', ],
|
| 45 |
+
extra_cuda_cflags=['-O3',
|
| 46 |
+
'-gencode', 'arch=compute_70,code=sm_70',
|
| 47 |
+
'--use_fast_math'] + extra_cuda_flags + cc_flag,
|
| 48 |
+
verbose=1
|
| 49 |
+
)
|
| 50 |
+
|
| 51 |
+
extra_flags = []
|
| 52 |
+
|
| 53 |
+
cache_autogptq_cuda_256_sources = ["./cache_autogptq_cuda_256.cpp",
|
| 54 |
+
"./cache_autogptq_cuda_kernel_256.cu"]
|
| 55 |
+
cache_autogptq_cuda_256 = _cpp_extention_load_helper("cache_autogptq_cuda_256", cache_autogptq_cuda_256_sources, extra_flags)
|
generation_config.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"chat_format": "chatml",
|
| 3 |
+
"eos_token_id": 151643,
|
| 4 |
+
"pad_token_id": 151643,
|
| 5 |
+
"max_window_size": 6144,
|
| 6 |
+
"max_new_tokens": 512,
|
| 7 |
+
"do_sample": true,
|
| 8 |
+
"top_k": 0,
|
| 9 |
+
"top_p": 0.8,
|
| 10 |
+
"repetition_penalty": 1.1,
|
| 11 |
+
"transformers_version": "4.31.0"
|
| 12 |
+
}
|
model-00001-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d592cb64233aa32bc0486b6b71fb5e6c3a44039e7b3af52d812268f17f5285d3
|
| 3 |
+
size 4955315856
|
model-00002-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8fb310a97e809545616b04cf991e97687a730a9965b6ddec5d50d3684613b26d
|
| 3 |
+
size 2392019712
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,202 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 7347314688
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "model-00002-of-00002.safetensors",
|
| 7 |
+
"transformer.h.0.attn.c_attn.bias": "model-00001-of-00002.safetensors",
|
| 8 |
+
"transformer.h.0.attn.c_attn.weight": "model-00001-of-00002.safetensors",
|
| 9 |
+
"transformer.h.0.attn.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 10 |
+
"transformer.h.0.ln_1.weight": "model-00001-of-00002.safetensors",
|
| 11 |
+
"transformer.h.0.ln_2.weight": "model-00001-of-00002.safetensors",
|
| 12 |
+
"transformer.h.0.mlp.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 13 |
+
"transformer.h.0.mlp.w1.weight": "model-00001-of-00002.safetensors",
|
| 14 |
+
"transformer.h.0.mlp.w2.weight": "model-00001-of-00002.safetensors",
|
| 15 |
+
"transformer.h.1.attn.c_attn.bias": "model-00001-of-00002.safetensors",
|
| 16 |
+
"transformer.h.1.attn.c_attn.weight": "model-00001-of-00002.safetensors",
|
| 17 |
+
"transformer.h.1.attn.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 18 |
+
"transformer.h.1.ln_1.weight": "model-00001-of-00002.safetensors",
|
| 19 |
+
"transformer.h.1.ln_2.weight": "model-00001-of-00002.safetensors",
|
| 20 |
+
"transformer.h.1.mlp.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 21 |
+
"transformer.h.1.mlp.w1.weight": "model-00001-of-00002.safetensors",
|
| 22 |
+
"transformer.h.1.mlp.w2.weight": "model-00001-of-00002.safetensors",
|
| 23 |
+
"transformer.h.10.attn.c_attn.bias": "model-00001-of-00002.safetensors",
|
| 24 |
+
"transformer.h.10.attn.c_attn.weight": "model-00001-of-00002.safetensors",
|
| 25 |
+
"transformer.h.10.attn.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 26 |
+
"transformer.h.10.ln_1.weight": "model-00001-of-00002.safetensors",
|
| 27 |
+
"transformer.h.10.ln_2.weight": "model-00001-of-00002.safetensors",
|
| 28 |
+
"transformer.h.10.mlp.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 29 |
+
"transformer.h.10.mlp.w1.weight": "model-00001-of-00002.safetensors",
|
| 30 |
+
"transformer.h.10.mlp.w2.weight": "model-00001-of-00002.safetensors",
|
| 31 |
+
"transformer.h.11.attn.c_attn.bias": "model-00001-of-00002.safetensors",
|
| 32 |
+
"transformer.h.11.attn.c_attn.weight": "model-00001-of-00002.safetensors",
|
| 33 |
+
"transformer.h.11.attn.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 34 |
+
"transformer.h.11.ln_1.weight": "model-00001-of-00002.safetensors",
|
| 35 |
+
"transformer.h.11.ln_2.weight": "model-00001-of-00002.safetensors",
|
| 36 |
+
"transformer.h.11.mlp.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 37 |
+
"transformer.h.11.mlp.w1.weight": "model-00001-of-00002.safetensors",
|
| 38 |
+
"transformer.h.11.mlp.w2.weight": "model-00001-of-00002.safetensors",
|
| 39 |
+
"transformer.h.12.attn.c_attn.bias": "model-00001-of-00002.safetensors",
|
| 40 |
+
"transformer.h.12.attn.c_attn.weight": "model-00001-of-00002.safetensors",
|
| 41 |
+
"transformer.h.12.attn.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 42 |
+
"transformer.h.12.ln_1.weight": "model-00001-of-00002.safetensors",
|
| 43 |
+
"transformer.h.12.ln_2.weight": "model-00001-of-00002.safetensors",
|
| 44 |
+
"transformer.h.12.mlp.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 45 |
+
"transformer.h.12.mlp.w1.weight": "model-00001-of-00002.safetensors",
|
| 46 |
+
"transformer.h.12.mlp.w2.weight": "model-00001-of-00002.safetensors",
|
| 47 |
+
"transformer.h.13.attn.c_attn.bias": "model-00001-of-00002.safetensors",
|
| 48 |
+
"transformer.h.13.attn.c_attn.weight": "model-00001-of-00002.safetensors",
|
| 49 |
+
"transformer.h.13.attn.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 50 |
+
"transformer.h.13.ln_1.weight": "model-00001-of-00002.safetensors",
|
| 51 |
+
"transformer.h.13.ln_2.weight": "model-00001-of-00002.safetensors",
|
| 52 |
+
"transformer.h.13.mlp.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 53 |
+
"transformer.h.13.mlp.w1.weight": "model-00001-of-00002.safetensors",
|
| 54 |
+
"transformer.h.13.mlp.w2.weight": "model-00001-of-00002.safetensors",
|
| 55 |
+
"transformer.h.14.attn.c_attn.bias": "model-00001-of-00002.safetensors",
|
| 56 |
+
"transformer.h.14.attn.c_attn.weight": "model-00001-of-00002.safetensors",
|
| 57 |
+
"transformer.h.14.attn.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 58 |
+
"transformer.h.14.ln_1.weight": "model-00001-of-00002.safetensors",
|
| 59 |
+
"transformer.h.14.ln_2.weight": "model-00001-of-00002.safetensors",
|
| 60 |
+
"transformer.h.14.mlp.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 61 |
+
"transformer.h.14.mlp.w1.weight": "model-00001-of-00002.safetensors",
|
| 62 |
+
"transformer.h.14.mlp.w2.weight": "model-00001-of-00002.safetensors",
|
| 63 |
+
"transformer.h.15.attn.c_attn.bias": "model-00001-of-00002.safetensors",
|
| 64 |
+
"transformer.h.15.attn.c_attn.weight": "model-00001-of-00002.safetensors",
|
| 65 |
+
"transformer.h.15.attn.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 66 |
+
"transformer.h.15.ln_1.weight": "model-00001-of-00002.safetensors",
|
| 67 |
+
"transformer.h.15.ln_2.weight": "model-00001-of-00002.safetensors",
|
| 68 |
+
"transformer.h.15.mlp.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 69 |
+
"transformer.h.15.mlp.w1.weight": "model-00001-of-00002.safetensors",
|
| 70 |
+
"transformer.h.15.mlp.w2.weight": "model-00001-of-00002.safetensors",
|
| 71 |
+
"transformer.h.16.attn.c_attn.bias": "model-00001-of-00002.safetensors",
|
| 72 |
+
"transformer.h.16.attn.c_attn.weight": "model-00001-of-00002.safetensors",
|
| 73 |
+
"transformer.h.16.attn.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 74 |
+
"transformer.h.16.ln_1.weight": "model-00001-of-00002.safetensors",
|
| 75 |
+
"transformer.h.16.ln_2.weight": "model-00001-of-00002.safetensors",
|
| 76 |
+
"transformer.h.16.mlp.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 77 |
+
"transformer.h.16.mlp.w1.weight": "model-00001-of-00002.safetensors",
|
| 78 |
+
"transformer.h.16.mlp.w2.weight": "model-00001-of-00002.safetensors",
|
| 79 |
+
"transformer.h.17.attn.c_attn.bias": "model-00001-of-00002.safetensors",
|
| 80 |
+
"transformer.h.17.attn.c_attn.weight": "model-00001-of-00002.safetensors",
|
| 81 |
+
"transformer.h.17.attn.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 82 |
+
"transformer.h.17.ln_1.weight": "model-00001-of-00002.safetensors",
|
| 83 |
+
"transformer.h.17.ln_2.weight": "model-00001-of-00002.safetensors",
|
| 84 |
+
"transformer.h.17.mlp.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 85 |
+
"transformer.h.17.mlp.w1.weight": "model-00001-of-00002.safetensors",
|
| 86 |
+
"transformer.h.17.mlp.w2.weight": "model-00001-of-00002.safetensors",
|
| 87 |
+
"transformer.h.18.attn.c_attn.bias": "model-00001-of-00002.safetensors",
|
| 88 |
+
"transformer.h.18.attn.c_attn.weight": "model-00001-of-00002.safetensors",
|
| 89 |
+
"transformer.h.18.attn.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 90 |
+
"transformer.h.18.ln_1.weight": "model-00001-of-00002.safetensors",
|
| 91 |
+
"transformer.h.18.ln_2.weight": "model-00001-of-00002.safetensors",
|
| 92 |
+
"transformer.h.18.mlp.c_proj.weight": "model-00002-of-00002.safetensors",
|
| 93 |
+
"transformer.h.18.mlp.w1.weight": "model-00002-of-00002.safetensors",
|
| 94 |
+
"transformer.h.18.mlp.w2.weight": "model-00002-of-00002.safetensors",
|
| 95 |
+
"transformer.h.19.attn.c_attn.bias": "model-00002-of-00002.safetensors",
|
| 96 |
+
"transformer.h.19.attn.c_attn.weight": "model-00002-of-00002.safetensors",
|
| 97 |
+
"transformer.h.19.attn.c_proj.weight": "model-00002-of-00002.safetensors",
|
| 98 |
+
"transformer.h.19.ln_1.weight": "model-00002-of-00002.safetensors",
|
| 99 |
+
"transformer.h.19.ln_2.weight": "model-00002-of-00002.safetensors",
|
| 100 |
+
"transformer.h.19.mlp.c_proj.weight": "model-00002-of-00002.safetensors",
|
| 101 |
+
"transformer.h.19.mlp.w1.weight": "model-00002-of-00002.safetensors",
|
| 102 |
+
"transformer.h.19.mlp.w2.weight": "model-00002-of-00002.safetensors",
|
| 103 |
+
"transformer.h.2.attn.c_attn.bias": "model-00001-of-00002.safetensors",
|
| 104 |
+
"transformer.h.2.attn.c_attn.weight": "model-00001-of-00002.safetensors",
|
| 105 |
+
"transformer.h.2.attn.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 106 |
+
"transformer.h.2.ln_1.weight": "model-00001-of-00002.safetensors",
|
| 107 |
+
"transformer.h.2.ln_2.weight": "model-00001-of-00002.safetensors",
|
| 108 |
+
"transformer.h.2.mlp.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 109 |
+
"transformer.h.2.mlp.w1.weight": "model-00001-of-00002.safetensors",
|
| 110 |
+
"transformer.h.2.mlp.w2.weight": "model-00001-of-00002.safetensors",
|
| 111 |
+
"transformer.h.20.attn.c_attn.bias": "model-00002-of-00002.safetensors",
|
| 112 |
+
"transformer.h.20.attn.c_attn.weight": "model-00002-of-00002.safetensors",
|
| 113 |
+
"transformer.h.20.attn.c_proj.weight": "model-00002-of-00002.safetensors",
|
| 114 |
+
"transformer.h.20.ln_1.weight": "model-00002-of-00002.safetensors",
|
| 115 |
+
"transformer.h.20.ln_2.weight": "model-00002-of-00002.safetensors",
|
| 116 |
+
"transformer.h.20.mlp.c_proj.weight": "model-00002-of-00002.safetensors",
|
| 117 |
+
"transformer.h.20.mlp.w1.weight": "model-00002-of-00002.safetensors",
|
| 118 |
+
"transformer.h.20.mlp.w2.weight": "model-00002-of-00002.safetensors",
|
| 119 |
+
"transformer.h.21.attn.c_attn.bias": "model-00002-of-00002.safetensors",
|
| 120 |
+
"transformer.h.21.attn.c_attn.weight": "model-00002-of-00002.safetensors",
|
| 121 |
+
"transformer.h.21.attn.c_proj.weight": "model-00002-of-00002.safetensors",
|
| 122 |
+
"transformer.h.21.ln_1.weight": "model-00002-of-00002.safetensors",
|
| 123 |
+
"transformer.h.21.ln_2.weight": "model-00002-of-00002.safetensors",
|
| 124 |
+
"transformer.h.21.mlp.c_proj.weight": "model-00002-of-00002.safetensors",
|
| 125 |
+
"transformer.h.21.mlp.w1.weight": "model-00002-of-00002.safetensors",
|
| 126 |
+
"transformer.h.21.mlp.w2.weight": "model-00002-of-00002.safetensors",
|
| 127 |
+
"transformer.h.22.attn.c_attn.bias": "model-00002-of-00002.safetensors",
|
| 128 |
+
"transformer.h.22.attn.c_attn.weight": "model-00002-of-00002.safetensors",
|
| 129 |
+
"transformer.h.22.attn.c_proj.weight": "model-00002-of-00002.safetensors",
|
| 130 |
+
"transformer.h.22.ln_1.weight": "model-00002-of-00002.safetensors",
|
| 131 |
+
"transformer.h.22.ln_2.weight": "model-00002-of-00002.safetensors",
|
| 132 |
+
"transformer.h.22.mlp.c_proj.weight": "model-00002-of-00002.safetensors",
|
| 133 |
+
"transformer.h.22.mlp.w1.weight": "model-00002-of-00002.safetensors",
|
| 134 |
+
"transformer.h.22.mlp.w2.weight": "model-00002-of-00002.safetensors",
|
| 135 |
+
"transformer.h.23.attn.c_attn.bias": "model-00002-of-00002.safetensors",
|
| 136 |
+
"transformer.h.23.attn.c_attn.weight": "model-00002-of-00002.safetensors",
|
| 137 |
+
"transformer.h.23.attn.c_proj.weight": "model-00002-of-00002.safetensors",
|
| 138 |
+
"transformer.h.23.ln_1.weight": "model-00002-of-00002.safetensors",
|
| 139 |
+
"transformer.h.23.ln_2.weight": "model-00002-of-00002.safetensors",
|
| 140 |
+
"transformer.h.23.mlp.c_proj.weight": "model-00002-of-00002.safetensors",
|
| 141 |
+
"transformer.h.23.mlp.w1.weight": "model-00002-of-00002.safetensors",
|
| 142 |
+
"transformer.h.23.mlp.w2.weight": "model-00002-of-00002.safetensors",
|
| 143 |
+
"transformer.h.3.attn.c_attn.bias": "model-00001-of-00002.safetensors",
|
| 144 |
+
"transformer.h.3.attn.c_attn.weight": "model-00001-of-00002.safetensors",
|
| 145 |
+
"transformer.h.3.attn.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 146 |
+
"transformer.h.3.ln_1.weight": "model-00001-of-00002.safetensors",
|
| 147 |
+
"transformer.h.3.ln_2.weight": "model-00001-of-00002.safetensors",
|
| 148 |
+
"transformer.h.3.mlp.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 149 |
+
"transformer.h.3.mlp.w1.weight": "model-00001-of-00002.safetensors",
|
| 150 |
+
"transformer.h.3.mlp.w2.weight": "model-00001-of-00002.safetensors",
|
| 151 |
+
"transformer.h.4.attn.c_attn.bias": "model-00001-of-00002.safetensors",
|
| 152 |
+
"transformer.h.4.attn.c_attn.weight": "model-00001-of-00002.safetensors",
|
| 153 |
+
"transformer.h.4.attn.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 154 |
+
"transformer.h.4.ln_1.weight": "model-00001-of-00002.safetensors",
|
| 155 |
+
"transformer.h.4.ln_2.weight": "model-00001-of-00002.safetensors",
|
| 156 |
+
"transformer.h.4.mlp.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 157 |
+
"transformer.h.4.mlp.w1.weight": "model-00001-of-00002.safetensors",
|
| 158 |
+
"transformer.h.4.mlp.w2.weight": "model-00001-of-00002.safetensors",
|
| 159 |
+
"transformer.h.5.attn.c_attn.bias": "model-00001-of-00002.safetensors",
|
| 160 |
+
"transformer.h.5.attn.c_attn.weight": "model-00001-of-00002.safetensors",
|
| 161 |
+
"transformer.h.5.attn.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 162 |
+
"transformer.h.5.ln_1.weight": "model-00001-of-00002.safetensors",
|
| 163 |
+
"transformer.h.5.ln_2.weight": "model-00001-of-00002.safetensors",
|
| 164 |
+
"transformer.h.5.mlp.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 165 |
+
"transformer.h.5.mlp.w1.weight": "model-00001-of-00002.safetensors",
|
| 166 |
+
"transformer.h.5.mlp.w2.weight": "model-00001-of-00002.safetensors",
|
| 167 |
+
"transformer.h.6.attn.c_attn.bias": "model-00001-of-00002.safetensors",
|
| 168 |
+
"transformer.h.6.attn.c_attn.weight": "model-00001-of-00002.safetensors",
|
| 169 |
+
"transformer.h.6.attn.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 170 |
+
"transformer.h.6.ln_1.weight": "model-00001-of-00002.safetensors",
|
| 171 |
+
"transformer.h.6.ln_2.weight": "model-00001-of-00002.safetensors",
|
| 172 |
+
"transformer.h.6.mlp.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 173 |
+
"transformer.h.6.mlp.w1.weight": "model-00001-of-00002.safetensors",
|
| 174 |
+
"transformer.h.6.mlp.w2.weight": "model-00001-of-00002.safetensors",
|
| 175 |
+
"transformer.h.7.attn.c_attn.bias": "model-00001-of-00002.safetensors",
|
| 176 |
+
"transformer.h.7.attn.c_attn.weight": "model-00001-of-00002.safetensors",
|
| 177 |
+
"transformer.h.7.attn.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 178 |
+
"transformer.h.7.ln_1.weight": "model-00001-of-00002.safetensors",
|
| 179 |
+
"transformer.h.7.ln_2.weight": "model-00001-of-00002.safetensors",
|
| 180 |
+
"transformer.h.7.mlp.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 181 |
+
"transformer.h.7.mlp.w1.weight": "model-00001-of-00002.safetensors",
|
| 182 |
+
"transformer.h.7.mlp.w2.weight": "model-00001-of-00002.safetensors",
|
| 183 |
+
"transformer.h.8.attn.c_attn.bias": "model-00001-of-00002.safetensors",
|
| 184 |
+
"transformer.h.8.attn.c_attn.weight": "model-00001-of-00002.safetensors",
|
| 185 |
+
"transformer.h.8.attn.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 186 |
+
"transformer.h.8.ln_1.weight": "model-00001-of-00002.safetensors",
|
| 187 |
+
"transformer.h.8.ln_2.weight": "model-00001-of-00002.safetensors",
|
| 188 |
+
"transformer.h.8.mlp.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 189 |
+
"transformer.h.8.mlp.w1.weight": "model-00001-of-00002.safetensors",
|
| 190 |
+
"transformer.h.8.mlp.w2.weight": "model-00001-of-00002.safetensors",
|
| 191 |
+
"transformer.h.9.attn.c_attn.bias": "model-00001-of-00002.safetensors",
|
| 192 |
+
"transformer.h.9.attn.c_attn.weight": "model-00001-of-00002.safetensors",
|
| 193 |
+
"transformer.h.9.attn.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 194 |
+
"transformer.h.9.ln_1.weight": "model-00001-of-00002.safetensors",
|
| 195 |
+
"transformer.h.9.ln_2.weight": "model-00001-of-00002.safetensors",
|
| 196 |
+
"transformer.h.9.mlp.c_proj.weight": "model-00001-of-00002.safetensors",
|
| 197 |
+
"transformer.h.9.mlp.w1.weight": "model-00001-of-00002.safetensors",
|
| 198 |
+
"transformer.h.9.mlp.w2.weight": "model-00001-of-00002.safetensors",
|
| 199 |
+
"transformer.ln_f.weight": "model-00002-of-00002.safetensors",
|
| 200 |
+
"transformer.wte.weight": "model-00001-of-00002.safetensors"
|
| 201 |
+
}
|
| 202 |
+
}
|
modeling_qwen.py
ADDED
|
@@ -0,0 +1,1363 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Alibaba Cloud.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
import copy
|
| 7 |
+
import importlib
|
| 8 |
+
import math
|
| 9 |
+
import pathlib
|
| 10 |
+
from typing import TYPE_CHECKING, Optional, Tuple, Union, Callable, List, Any, Generator
|
| 11 |
+
|
| 12 |
+
import torch
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
import torch.utils.checkpoint
|
| 15 |
+
import warnings
|
| 16 |
+
|
| 17 |
+
from torch.nn import CrossEntropyLoss
|
| 18 |
+
from transformers import PreTrainedTokenizer, GenerationConfig, StoppingCriteriaList
|
| 19 |
+
from transformers.generation.logits_process import LogitsProcessorList
|
| 20 |
+
|
| 21 |
+
if TYPE_CHECKING:
|
| 22 |
+
from transformers.generation.streamers import BaseStreamer
|
| 23 |
+
from transformers.generation.utils import GenerateOutput
|
| 24 |
+
from transformers.modeling_outputs import (
|
| 25 |
+
BaseModelOutputWithPast,
|
| 26 |
+
CausalLMOutputWithPast,
|
| 27 |
+
)
|
| 28 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 29 |
+
from transformers.utils import logging
|
| 30 |
+
|
| 31 |
+
try:
|
| 32 |
+
from einops import rearrange
|
| 33 |
+
except ImportError:
|
| 34 |
+
rearrange = None
|
| 35 |
+
from torch import nn
|
| 36 |
+
|
| 37 |
+
SUPPORT_CUDA = torch.cuda.is_available()
|
| 38 |
+
SUPPORT_BF16 = SUPPORT_CUDA and torch.cuda.is_bf16_supported()
|
| 39 |
+
SUPPORT_FP16 = SUPPORT_CUDA and torch.cuda.get_device_capability(0)[0] >= 7
|
| 40 |
+
SUPPORT_TORCH2 = hasattr(torch, '__version__') and int(torch.__version__.split(".")[0]) >= 2
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
from .configuration_qwen import QWenConfig
|
| 44 |
+
from .qwen_generation_utils import (
|
| 45 |
+
HistoryType,
|
| 46 |
+
make_context,
|
| 47 |
+
decode_tokens,
|
| 48 |
+
get_stop_words_ids,
|
| 49 |
+
StopWordsLogitsProcessor,
|
| 50 |
+
)
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
logger = logging.get_logger(__name__)
|
| 54 |
+
|
| 55 |
+
_CHECKPOINT_FOR_DOC = "qwen"
|
| 56 |
+
_CONFIG_FOR_DOC = "QWenConfig"
|
| 57 |
+
|
| 58 |
+
QWen_PRETRAINED_MODEL_ARCHIVE_LIST = ["qwen-7b"]
|
| 59 |
+
|
| 60 |
+
_ERROR_BAD_CHAT_FORMAT = """\
|
| 61 |
+
We detect you are probably using the pretrained model (rather than chat model) for chatting, since the chat_format in generation_config is not "chatml".
|
| 62 |
+
If you are directly using the model downloaded from Huggingface, please make sure you are using our "Qwen/Qwen-7B-Chat" Huggingface model (rather than "Qwen/Qwen-7B") when you call model.chat().
|
| 63 |
+
我们检测到您可能在使用预训练模型(而非chat模型)进行多轮chat,因为您当前在generation_config指定的chat_format,并未设置为我们在对话中所支持的"chatml"格式。
|
| 64 |
+
如果您在直接使用我们从Huggingface提供的模型,请确保您在调用model.chat()时,使用的是"Qwen/Qwen-7B-Chat"模型(而非"Qwen/Qwen-7B"预训练模型)。
|
| 65 |
+
"""
|
| 66 |
+
|
| 67 |
+
_SENTINEL = object()
|
| 68 |
+
_ERROR_STREAM_IN_CHAT = """\
|
| 69 |
+
Pass argument `stream` to model.chat() is buggy, deprecated, and marked for removal. Please use model.chat_stream(...) instead of model.chat(..., stream=True).
|
| 70 |
+
向model.chat()传入参数stream的用法可能存在Bug,该用法已被废弃,将在未来被移除。请使用model.chat_stream(...)代替model.chat(..., stream=True)。
|
| 71 |
+
"""
|
| 72 |
+
|
| 73 |
+
_ERROR_INPUT_CPU_QUERY_WITH_FLASH_ATTN_ACTIVATED = """\
|
| 74 |
+
We detect you have activated flash attention support, but running model computation on CPU. Please make sure that your input data has been placed on GPU. If you actually want to run CPU computation, please following the readme and set device_map="cpu" to disable flash attention when loading the model (calling AutoModelForCausalLM.from_pretrained).
|
| 75 |
+
检测到您的模型已激活了flash attention支持,但正在执行CPU运算任务。如使用flash attention,请您确认模型输入已经传到GPU上。如果您确认要执行CPU运算,请您在载入模型(调用AutoModelForCausalLM.from_pretrained)时,按照readme说法,指定device_map="cpu"以禁用flash attention。
|
| 76 |
+
"""
|
| 77 |
+
|
| 78 |
+
apply_rotary_emb_func = None
|
| 79 |
+
rms_norm = None
|
| 80 |
+
flash_attn_unpadded_func = None
|
| 81 |
+
flash_attn_func = None
|
| 82 |
+
|
| 83 |
+
def _import_flash_attn():
|
| 84 |
+
global apply_rotary_emb_func, rms_norm, flash_attn_unpadded_func, flash_attn_func
|
| 85 |
+
try:
|
| 86 |
+
from flash_attn.layers.rotary import apply_rotary_emb_func as __apply_rotary_emb_func
|
| 87 |
+
apply_rotary_emb_func = __apply_rotary_emb_func
|
| 88 |
+
except ImportError:
|
| 89 |
+
logger.warn(
|
| 90 |
+
"Warning: import flash_attn rotary fail, please install FlashAttention rotary to get higher efficiency "
|
| 91 |
+
"https://github.com/Dao-AILab/flash-attention/tree/main/csrc/rotary"
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
try:
|
| 95 |
+
from flash_attn.ops.rms_norm import rms_norm as __rms_norm
|
| 96 |
+
rms_norm = __rms_norm
|
| 97 |
+
except ImportError:
|
| 98 |
+
logger.warn(
|
| 99 |
+
"Warning: import flash_attn rms_norm fail, please install FlashAttention layer_norm to get higher efficiency "
|
| 100 |
+
"https://github.com/Dao-AILab/flash-attention/tree/main/csrc/layer_norm"
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
try:
|
| 104 |
+
import flash_attn
|
| 105 |
+
_flash_attn_func = None
|
| 106 |
+
if not hasattr(flash_attn, '__version__'):
|
| 107 |
+
from flash_attn.flash_attn_interface import flash_attn_unpadded_func as __flash_attn_unpadded_func
|
| 108 |
+
else:
|
| 109 |
+
if int(flash_attn.__version__.split(".")[0]) >= 2:
|
| 110 |
+
if int(flash_attn.__version__.split(".")[1]) >= 1:
|
| 111 |
+
from flash_attn.flash_attn_interface import flash_attn_func as _flash_attn_func
|
| 112 |
+
from flash_attn.flash_attn_interface import flash_attn_varlen_func as __flash_attn_unpadded_func
|
| 113 |
+
else:
|
| 114 |
+
from flash_attn.flash_attn_interface import flash_attn_unpadded_func as __flash_attn_unpadded_func
|
| 115 |
+
flash_attn_unpadded_func = __flash_attn_unpadded_func
|
| 116 |
+
flash_attn_func = _flash_attn_func
|
| 117 |
+
except ImportError:
|
| 118 |
+
logger.warn(
|
| 119 |
+
"Warning: import flash_attn fail, please install FlashAttention to get higher efficiency "
|
| 120 |
+
"https://github.com/Dao-AILab/flash-attention"
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
def quantize_cache_v(fdata, bits, qmax, qmin):
|
| 124 |
+
# b, s, head, h-dim->b, head, s, h-dim
|
| 125 |
+
qtype = torch.uint8
|
| 126 |
+
device = fdata.device
|
| 127 |
+
shape = fdata.shape
|
| 128 |
+
|
| 129 |
+
fdata_cal = torch.flatten(fdata, 2)
|
| 130 |
+
fmax = torch.amax(fdata_cal, dim=-1, keepdim=True)
|
| 131 |
+
fmin = torch.amin(fdata_cal, dim=-1, keepdim=True)
|
| 132 |
+
# Compute params
|
| 133 |
+
if qmax.device != fmax.device:
|
| 134 |
+
qmax = qmax.to(device)
|
| 135 |
+
qmin = qmin.to(device)
|
| 136 |
+
scale = (fmax - fmin) / (qmax - qmin)
|
| 137 |
+
zero = qmin - fmin / scale
|
| 138 |
+
scale = scale.unsqueeze(-1).repeat(1,1,shape[2],1).contiguous()
|
| 139 |
+
zero = zero.unsqueeze(-1).repeat(1,1,shape[2],1).contiguous()
|
| 140 |
+
# Quantize
|
| 141 |
+
res_data = fdata / scale + zero
|
| 142 |
+
qdata = torch.clamp(res_data, qmin, qmax).to(qtype)
|
| 143 |
+
return qdata.contiguous(), scale, zero
|
| 144 |
+
|
| 145 |
+
def dequantize_cache_torch(qdata, scale, zero):
|
| 146 |
+
data = scale * (qdata - zero)
|
| 147 |
+
return data
|
| 148 |
+
|
| 149 |
+
class FlashSelfAttention(torch.nn.Module):
|
| 150 |
+
def __init__(
|
| 151 |
+
self,
|
| 152 |
+
causal=False,
|
| 153 |
+
softmax_scale=None,
|
| 154 |
+
attention_dropout=0.0,
|
| 155 |
+
):
|
| 156 |
+
super().__init__()
|
| 157 |
+
assert flash_attn_unpadded_func is not None, (
|
| 158 |
+
"Please install FlashAttention first, " "e.g., with pip install flash-attn"
|
| 159 |
+
)
|
| 160 |
+
assert (
|
| 161 |
+
rearrange is not None
|
| 162 |
+
), "Please install einops first, e.g., with pip install einops"
|
| 163 |
+
self.causal = causal
|
| 164 |
+
self.softmax_scale = softmax_scale
|
| 165 |
+
self.dropout_p = attention_dropout
|
| 166 |
+
|
| 167 |
+
def unpad_input(self, hidden_states, attention_mask):
|
| 168 |
+
valid_mask = attention_mask.squeeze(1).squeeze(1).eq(0)
|
| 169 |
+
seqlens_in_batch = valid_mask.sum(dim=-1, dtype=torch.int32)
|
| 170 |
+
indices = torch.nonzero(valid_mask.flatten(), as_tuple=False).flatten()
|
| 171 |
+
max_seqlen_in_batch = seqlens_in_batch.max().item()
|
| 172 |
+
cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
|
| 173 |
+
hidden_states = hidden_states[indices]
|
| 174 |
+
return hidden_states, indices, cu_seqlens, max_seqlen_in_batch
|
| 175 |
+
|
| 176 |
+
def pad_input(self, hidden_states, indices, batch, seqlen):
|
| 177 |
+
output = torch.zeros(batch * seqlen, *hidden_states.shape[1:], device=hidden_states.device,
|
| 178 |
+
dtype=hidden_states.dtype)
|
| 179 |
+
output[indices] = hidden_states
|
| 180 |
+
return rearrange(output, '(b s) ... -> b s ...', b=batch)
|
| 181 |
+
|
| 182 |
+
def forward(self, q, k, v, attention_mask=None):
|
| 183 |
+
assert all((i.dtype in [torch.float16, torch.bfloat16] for i in (q, k, v)))
|
| 184 |
+
assert all((i.is_cuda for i in (q, k, v)))
|
| 185 |
+
batch_size, seqlen_q = q.shape[0], q.shape[1]
|
| 186 |
+
seqlen_k = k.shape[1]
|
| 187 |
+
seqlen_out = seqlen_q
|
| 188 |
+
|
| 189 |
+
if flash_attn_func is not None and batch_size == 1:
|
| 190 |
+
dropout_p = self.dropout_p if self.training else 0
|
| 191 |
+
output = flash_attn_func(q, k, v, dropout_p, softmax_scale=self.softmax_scale, causal=self.causal)
|
| 192 |
+
return output
|
| 193 |
+
|
| 194 |
+
q, k, v = [rearrange(x, "b s ... -> (b s) ...") for x in [q, k, v]]
|
| 195 |
+
cu_seqlens_q = torch.arange(
|
| 196 |
+
0,
|
| 197 |
+
(batch_size + 1) * seqlen_q,
|
| 198 |
+
step=seqlen_q,
|
| 199 |
+
dtype=torch.int32,
|
| 200 |
+
device=q.device,
|
| 201 |
+
)
|
| 202 |
+
|
| 203 |
+
if batch_size > 1 and attention_mask is not None:
|
| 204 |
+
k, indices_k, cu_seqlens_k, seqlen_k = self.unpad_input(k, attention_mask)
|
| 205 |
+
if q.size(0) == v.size(0):
|
| 206 |
+
q = q[indices_k]
|
| 207 |
+
cu_seqlens_q = cu_seqlens_k
|
| 208 |
+
seqlen_q = seqlen_k
|
| 209 |
+
v = v[indices_k]
|
| 210 |
+
else:
|
| 211 |
+
cu_seqlens_k = torch.arange(
|
| 212 |
+
0,
|
| 213 |
+
(batch_size + 1) * seqlen_k,
|
| 214 |
+
step=seqlen_k,
|
| 215 |
+
dtype=torch.int32,
|
| 216 |
+
device=q.device,
|
| 217 |
+
)
|
| 218 |
+
|
| 219 |
+
if self.training:
|
| 220 |
+
assert seqlen_k == seqlen_q
|
| 221 |
+
is_causal = self.causal
|
| 222 |
+
dropout_p = self.dropout_p
|
| 223 |
+
else:
|
| 224 |
+
is_causal = seqlen_q == seqlen_k
|
| 225 |
+
dropout_p = 0
|
| 226 |
+
|
| 227 |
+
output = flash_attn_unpadded_func(
|
| 228 |
+
q,
|
| 229 |
+
k,
|
| 230 |
+
v,
|
| 231 |
+
cu_seqlens_q,
|
| 232 |
+
cu_seqlens_k,
|
| 233 |
+
seqlen_q,
|
| 234 |
+
seqlen_k,
|
| 235 |
+
dropout_p,
|
| 236 |
+
softmax_scale=self.softmax_scale,
|
| 237 |
+
causal=is_causal,
|
| 238 |
+
)
|
| 239 |
+
if batch_size > 1 and attention_mask is not None and seqlen_q == seqlen_k:
|
| 240 |
+
output = self.pad_input(output, indices_k, batch_size, seqlen_out)
|
| 241 |
+
else:
|
| 242 |
+
new_shape = (batch_size, output.shape[0] // batch_size) + output.shape[1:]
|
| 243 |
+
output = output.view(new_shape)
|
| 244 |
+
return output
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
class QWenAttention(nn.Module):
|
| 248 |
+
def __init__(self, config):
|
| 249 |
+
super().__init__()
|
| 250 |
+
|
| 251 |
+
self.register_buffer("masked_bias", torch.tensor(-1e4), persistent=False)
|
| 252 |
+
self.seq_length = config.seq_length
|
| 253 |
+
|
| 254 |
+
self.hidden_size = config.hidden_size
|
| 255 |
+
self.split_size = config.hidden_size
|
| 256 |
+
self.num_heads = config.num_attention_heads
|
| 257 |
+
self.head_dim = self.hidden_size // self.num_heads
|
| 258 |
+
|
| 259 |
+
self.use_flash_attn = config.use_flash_attn
|
| 260 |
+
self.scale_attn_weights = True
|
| 261 |
+
|
| 262 |
+
self.projection_size = config.kv_channels * config.num_attention_heads
|
| 263 |
+
|
| 264 |
+
assert self.projection_size % config.num_attention_heads == 0
|
| 265 |
+
self.hidden_size_per_attention_head = (
|
| 266 |
+
self.projection_size // config.num_attention_heads
|
| 267 |
+
)
|
| 268 |
+
|
| 269 |
+
self.c_attn = nn.Linear(config.hidden_size, 3 * self.projection_size)
|
| 270 |
+
|
| 271 |
+
self.c_proj = nn.Linear(
|
| 272 |
+
config.hidden_size, self.projection_size, bias=not config.no_bias
|
| 273 |
+
)
|
| 274 |
+
|
| 275 |
+
self.is_fp32 = not (config.bf16 or config.fp16)
|
| 276 |
+
if (
|
| 277 |
+
self.use_flash_attn
|
| 278 |
+
and flash_attn_unpadded_func is not None
|
| 279 |
+
and not self.is_fp32
|
| 280 |
+
):
|
| 281 |
+
self.core_attention_flash = FlashSelfAttention(
|
| 282 |
+
causal=True, attention_dropout=config.attn_dropout_prob
|
| 283 |
+
)
|
| 284 |
+
self.bf16 = config.bf16
|
| 285 |
+
|
| 286 |
+
self.use_dynamic_ntk = config.use_dynamic_ntk
|
| 287 |
+
self.use_logn_attn = config.use_logn_attn
|
| 288 |
+
|
| 289 |
+
logn_list = [
|
| 290 |
+
math.log(i, self.seq_length) if i > self.seq_length else 1
|
| 291 |
+
for i in range(1, 32768)
|
| 292 |
+
]
|
| 293 |
+
logn_tensor = torch.tensor(logn_list)[None, :, None, None]
|
| 294 |
+
self.register_buffer("logn_tensor", logn_tensor, persistent=False)
|
| 295 |
+
|
| 296 |
+
self.attn_dropout = nn.Dropout(config.attn_dropout_prob)
|
| 297 |
+
self.softmax_in_fp32 = config.softmax_in_fp32 if hasattr(config, 'softmax_in_fp32') else False
|
| 298 |
+
self.use_cache_quantization = config.use_cache_quantization if hasattr(config, 'use_cache_quantization') else False
|
| 299 |
+
self.use_cache_kernel = config.use_cache_kernel if hasattr(config,'use_cache_kernel') else False
|
| 300 |
+
cache_dtype = torch.float
|
| 301 |
+
if self.bf16:
|
| 302 |
+
cache_dtype=torch.bfloat16
|
| 303 |
+
elif config.fp16:
|
| 304 |
+
cache_dtype = torch.float16
|
| 305 |
+
self.cache_qmax = torch.tensor(torch.iinfo(torch.uint8).max, dtype=cache_dtype)
|
| 306 |
+
self.cache_qmin = torch.tensor(torch.iinfo(torch.uint8).min, dtype=cache_dtype)
|
| 307 |
+
|
| 308 |
+
if config.use_cache_quantization and config.use_cache_kernel:
|
| 309 |
+
# pre check if the support files existing
|
| 310 |
+
module_root = pathlib.Path(__file__).parent
|
| 311 |
+
src_files = ("cache_autogptq_cuda_256.cpp", "cache_autogptq_cuda_kernel_256.cu")
|
| 312 |
+
if any(not (module_root/src).is_file() for src in src_files):
|
| 313 |
+
warnings.warn("KV cache kernel source files (.cpp and .cu) not found.")
|
| 314 |
+
self.cache_kernels = None
|
| 315 |
+
else:
|
| 316 |
+
try:
|
| 317 |
+
from .cpp_kernels import cache_autogptq_cuda_256
|
| 318 |
+
self.cache_kernels = cache_autogptq_cuda_256
|
| 319 |
+
except ImportError:
|
| 320 |
+
warnings.warn("Failed to import KV cache kernels.")
|
| 321 |
+
self.cache_kernels = None
|
| 322 |
+
|
| 323 |
+
def _attn(self, query, key, value, causal_mask=None, attention_mask=None, head_mask=None):
|
| 324 |
+
device = query.device
|
| 325 |
+
if self.use_cache_quantization:
|
| 326 |
+
qk, qk_scale, qk_zero = key
|
| 327 |
+
if self.use_cache_kernel and self.cache_kernels is not None:
|
| 328 |
+
shape = query.shape[:-1] + (qk.shape[-2],)
|
| 329 |
+
attn_weights = torch.zeros(shape, dtype=torch.float16, device=device)
|
| 330 |
+
self.cache_kernels.vecquant8matmul_batched_faster_old(
|
| 331 |
+
query.contiguous() if query.dtype == torch.float16 else query.to(torch.float16).contiguous(),
|
| 332 |
+
qk.transpose(-1, -2).contiguous(),
|
| 333 |
+
attn_weights,
|
| 334 |
+
qk_scale.contiguous() if qk_scale.dtype == torch.float16 else qk_scale.to(torch.float16).contiguous(),
|
| 335 |
+
qk_zero.contiguous()if qk_zero.dtype == torch.float16 else qk_zero.to(torch.float16).contiguous())
|
| 336 |
+
# attn_weights = attn_weights.to(query.dtype).contiguous()
|
| 337 |
+
else:
|
| 338 |
+
key = dequantize_cache_torch(qk, qk_scale, qk_zero)
|
| 339 |
+
attn_weights = torch.matmul(query, key.transpose(-1, -2))
|
| 340 |
+
else:
|
| 341 |
+
attn_weights = torch.matmul(query, key.transpose(-1, -2))
|
| 342 |
+
|
| 343 |
+
if self.scale_attn_weights:
|
| 344 |
+
if self.use_cache_quantization:
|
| 345 |
+
size_temp = value[0].size(-1)
|
| 346 |
+
else:
|
| 347 |
+
size_temp = value.size(-1)
|
| 348 |
+
attn_weights = attn_weights / (size_temp ** 0.5)
|
| 349 |
+
|
| 350 |
+
mask_value = torch.finfo(attn_weights.dtype).min
|
| 351 |
+
if causal_mask is not None:
|
| 352 |
+
attn_weights = torch.where(
|
| 353 |
+
causal_mask, attn_weights.to(attn_weights.dtype), mask_value
|
| 354 |
+
)
|
| 355 |
+
|
| 356 |
+
if attention_mask is not None:
|
| 357 |
+
attn_weights = attn_weights + attention_mask
|
| 358 |
+
|
| 359 |
+
if self.softmax_in_fp32:
|
| 360 |
+
attn_weights = nn.functional.softmax(attn_weights.float(), dim=-1)
|
| 361 |
+
else:
|
| 362 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
|
| 363 |
+
|
| 364 |
+
attn_weights = attn_weights.type(query.dtype)
|
| 365 |
+
attn_weights = self.attn_dropout(attn_weights)
|
| 366 |
+
|
| 367 |
+
if head_mask is not None:
|
| 368 |
+
attn_weights = attn_weights * head_mask
|
| 369 |
+
|
| 370 |
+
if self.use_cache_quantization:
|
| 371 |
+
qv, qv_scale, qv_zero = value
|
| 372 |
+
if self.use_cache_kernel and self.cache_kernels is not None:
|
| 373 |
+
shape = attn_weights.shape[:-1] + (query.shape[-1],)
|
| 374 |
+
attn_output = torch.zeros(shape, dtype=torch.float16, device=device)
|
| 375 |
+
self.cache_kernels.vecquant8matmul_batched_column_compression_faster_old(
|
| 376 |
+
attn_weights.contiguous() if attn_weights.dtype == torch.float16 else attn_weights.to(torch.float16).contiguous(),
|
| 377 |
+
qv.contiguous(), # dtype: int32
|
| 378 |
+
attn_output,
|
| 379 |
+
qv_scale.contiguous() if qv_scale.dtype == torch.float16 else qv_scale.to(torch.float16).contiguous(),
|
| 380 |
+
qv_zero.contiguous() if qv_zero.dtype == torch.float16 else qv_zero.to(torch.float16).contiguous())
|
| 381 |
+
if attn_output.dtype != query.dtype:
|
| 382 |
+
attn_output = attn_output.to(query.dtype)
|
| 383 |
+
attn_weights = attn_weights.to(query.dtype)
|
| 384 |
+
else:
|
| 385 |
+
value = dequantize_cache_torch(qv, qv_scale, qv_zero)
|
| 386 |
+
attn_output = torch.matmul(attn_weights, value)
|
| 387 |
+
else:
|
| 388 |
+
attn_output = torch.matmul(attn_weights, value)
|
| 389 |
+
|
| 390 |
+
attn_output = attn_output.transpose(1, 2)
|
| 391 |
+
|
| 392 |
+
return attn_output, attn_weights
|
| 393 |
+
|
| 394 |
+
def _split_heads(self, tensor, num_heads, attn_head_size):
|
| 395 |
+
new_shape = tensor.size()[:-1] + (num_heads, attn_head_size)
|
| 396 |
+
tensor = tensor.view(new_shape)
|
| 397 |
+
return tensor
|
| 398 |
+
|
| 399 |
+
def _merge_heads(self, tensor, num_heads, attn_head_size):
|
| 400 |
+
tensor = tensor.contiguous()
|
| 401 |
+
new_shape = tensor.size()[:-2] + (num_heads * attn_head_size,)
|
| 402 |
+
return tensor.view(new_shape)
|
| 403 |
+
|
| 404 |
+
def forward(
|
| 405 |
+
self,
|
| 406 |
+
hidden_states: Optional[Tuple[torch.FloatTensor]],
|
| 407 |
+
rotary_pos_emb_list: Optional[List[List[torch.Tensor]]] = None,
|
| 408 |
+
layer_past: Optional[Tuple[torch.Tensor]] = None,
|
| 409 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 410 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 411 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 412 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 413 |
+
output_attentions: Optional[bool] = False,
|
| 414 |
+
use_cache: Optional[bool] = False,
|
| 415 |
+
):
|
| 416 |
+
mixed_x_layer = self.c_attn(hidden_states)
|
| 417 |
+
|
| 418 |
+
query, key, value = mixed_x_layer.split(self.split_size, dim=2)
|
| 419 |
+
|
| 420 |
+
query = self._split_heads(query, self.num_heads, self.head_dim)
|
| 421 |
+
key = self._split_heads(key, self.num_heads, self.head_dim)
|
| 422 |
+
value = self._split_heads(value, self.num_heads, self.head_dim)
|
| 423 |
+
|
| 424 |
+
if rotary_pos_emb_list is not None:
|
| 425 |
+
cur_len = query.shape[1]
|
| 426 |
+
if len(rotary_pos_emb_list) == 1:
|
| 427 |
+
rotary_pos_emb = rotary_pos_emb_list[0]
|
| 428 |
+
rotary_pos_emb = [i[:, -cur_len:, :, :] for i in rotary_pos_emb]
|
| 429 |
+
rotary_pos_emb = (rotary_pos_emb,) * 2
|
| 430 |
+
q_pos_emb, k_pos_emb = rotary_pos_emb
|
| 431 |
+
# Slice the pos emb for current inference
|
| 432 |
+
query = apply_rotary_pos_emb(query, q_pos_emb)
|
| 433 |
+
key = apply_rotary_pos_emb(key, k_pos_emb)
|
| 434 |
+
else:
|
| 435 |
+
query_list = []
|
| 436 |
+
key_list = []
|
| 437 |
+
for i, rotary_pos_emb in enumerate(rotary_pos_emb_list):
|
| 438 |
+
rotary_pos_emb = [i[:, -cur_len:, :, :] for i in rotary_pos_emb]
|
| 439 |
+
rotary_pos_emb = (rotary_pos_emb,) * 2
|
| 440 |
+
q_pos_emb, k_pos_emb = rotary_pos_emb
|
| 441 |
+
# Slice the pos emb for current inference
|
| 442 |
+
query_list += [apply_rotary_pos_emb(query[i:i+1, :, :], q_pos_emb)]
|
| 443 |
+
key_list += [apply_rotary_pos_emb(key[i:i+1, :, :], k_pos_emb)]
|
| 444 |
+
query = torch.cat(query_list, dim=0)
|
| 445 |
+
key = torch.cat(key_list, dim=0)
|
| 446 |
+
|
| 447 |
+
if self.use_cache_quantization:
|
| 448 |
+
key = quantize_cache_v(key.permute(0, 2, 1, 3),
|
| 449 |
+
bits=8,
|
| 450 |
+
qmin=self.cache_qmin,
|
| 451 |
+
qmax=self.cache_qmax)
|
| 452 |
+
value = quantize_cache_v(value.permute(0, 2, 1, 3),
|
| 453 |
+
bits=8,
|
| 454 |
+
qmin=self.cache_qmin,
|
| 455 |
+
qmax=self.cache_qmax)
|
| 456 |
+
|
| 457 |
+
|
| 458 |
+
if layer_past is not None:
|
| 459 |
+
past_key, past_value = layer_past[0], layer_past[1]
|
| 460 |
+
if self.use_cache_quantization:
|
| 461 |
+
# use_cache_quantization:
|
| 462 |
+
# present=((q_key,key_scale,key_zero_point),
|
| 463 |
+
# (q_value,value_scale,value_zero_point))
|
| 464 |
+
key = (torch.cat((past_key[0], key[0]), dim=2),
|
| 465 |
+
torch.cat((past_key[1], key[1]), dim=2),
|
| 466 |
+
torch.cat((past_key[2], key[2]), dim=2))
|
| 467 |
+
value = (torch.cat((past_value[0], value[0]), dim=2),
|
| 468 |
+
torch.cat((past_value[1], value[1]), dim=2),
|
| 469 |
+
torch.cat((past_value[2], value[2]), dim=2))
|
| 470 |
+
else:
|
| 471 |
+
# not use_cache_quantization:
|
| 472 |
+
# present=(key,value)
|
| 473 |
+
key = torch.cat((past_key, key), dim=1)
|
| 474 |
+
value = torch.cat((past_value, value), dim=1)
|
| 475 |
+
|
| 476 |
+
if use_cache:
|
| 477 |
+
present = (key, value)
|
| 478 |
+
else:
|
| 479 |
+
present = None
|
| 480 |
+
|
| 481 |
+
key_size = key[0].size(2) if self.use_cache_quantization else key.size(1)
|
| 482 |
+
if key_size > self.seq_length and self.use_logn_attn and not self.training:
|
| 483 |
+
if self.use_cache_quantization:
|
| 484 |
+
seq_start = key[0].size(2) - query.size(1)
|
| 485 |
+
seq_end = key[0].size(2)
|
| 486 |
+
else:
|
| 487 |
+
seq_start = key.size(1) - query.size(1)
|
| 488 |
+
seq_end = key.size(1)
|
| 489 |
+
logn_tensor = self.logn_tensor[:, seq_start:seq_end, :, :].type_as(query)
|
| 490 |
+
query = query * logn_tensor.expand_as(query)
|
| 491 |
+
|
| 492 |
+
if (
|
| 493 |
+
self.use_flash_attn
|
| 494 |
+
and flash_attn_unpadded_func is not None
|
| 495 |
+
and not self.is_fp32
|
| 496 |
+
and query.is_cuda
|
| 497 |
+
):
|
| 498 |
+
q, k, v = query, key, value
|
| 499 |
+
attn_output = self.core_attention_flash(q, k, v, attention_mask=attention_mask)
|
| 500 |
+
else:
|
| 501 |
+
key_size = key[0].size(2) if self.use_cache_quantization else key.size(1)
|
| 502 |
+
if query.size(1) == key_size:
|
| 503 |
+
causal_mask = torch.tril(
|
| 504 |
+
torch.ones((key_size, key_size), dtype=torch.bool, device=query.device)
|
| 505 |
+
).view(1, 1, key_size, key_size)
|
| 506 |
+
else:
|
| 507 |
+
causal_mask = None
|
| 508 |
+
query = query.permute(0, 2, 1, 3)
|
| 509 |
+
if not self.use_cache_quantization:
|
| 510 |
+
key = key.permute(0, 2, 1, 3)
|
| 511 |
+
value = value.permute(0, 2, 1, 3)
|
| 512 |
+
if (
|
| 513 |
+
causal_mask is None
|
| 514 |
+
and self.use_flash_attn
|
| 515 |
+
and flash_attn_unpadded_func is not None
|
| 516 |
+
and not self.is_fp32
|
| 517 |
+
and not query.is_cuda
|
| 518 |
+
):
|
| 519 |
+
raise Exception(_ERROR_INPUT_CPU_QUERY_WITH_FLASH_ATTN_ACTIVATED)
|
| 520 |
+
|
| 521 |
+
if not self.use_cache_quantization and SUPPORT_TORCH2:
|
| 522 |
+
if attention_mask is not None:
|
| 523 |
+
attention_mask = attention_mask.expand(-1, -1, query.size(2), -1)
|
| 524 |
+
if causal_mask is not None:
|
| 525 |
+
attention_mask = attention_mask.masked_fill(~causal_mask, torch.finfo(query.dtype).min)
|
| 526 |
+
else:
|
| 527 |
+
attention_mask = causal_mask
|
| 528 |
+
attn_output = F.scaled_dot_product_attention(
|
| 529 |
+
query, key, value, attn_mask=attention_mask
|
| 530 |
+
).transpose(1, 2)
|
| 531 |
+
attn_weight = None
|
| 532 |
+
else:
|
| 533 |
+
attn_output, attn_weight = self._attn(
|
| 534 |
+
query, key, value, causal_mask, attention_mask, head_mask
|
| 535 |
+
)
|
| 536 |
+
context_layer = self._merge_heads(
|
| 537 |
+
attn_output, self.num_heads, self.head_dim
|
| 538 |
+
)
|
| 539 |
+
|
| 540 |
+
attn_output = self.c_proj(context_layer)
|
| 541 |
+
|
| 542 |
+
outputs = (attn_output, present)
|
| 543 |
+
if output_attentions:
|
| 544 |
+
if (
|
| 545 |
+
self.use_flash_attn
|
| 546 |
+
and flash_attn_unpadded_func is not None
|
| 547 |
+
and not self.is_fp32
|
| 548 |
+
):
|
| 549 |
+
raise ValueError("Cannot output attentions while using flash-attn")
|
| 550 |
+
elif not self.use_cache_quantization and SUPPORT_TORCH2:
|
| 551 |
+
raise ValueError("Cannot output attentions while using scaled_dot_product_attention")
|
| 552 |
+
else:
|
| 553 |
+
outputs += (attn_weight,)
|
| 554 |
+
|
| 555 |
+
return outputs
|
| 556 |
+
|
| 557 |
+
|
| 558 |
+
class QWenMLP(nn.Module):
|
| 559 |
+
def __init__(self, config):
|
| 560 |
+
super().__init__()
|
| 561 |
+
self.w1 = nn.Linear(
|
| 562 |
+
config.hidden_size, config.intermediate_size // 2, bias=not config.no_bias
|
| 563 |
+
)
|
| 564 |
+
self.w2 = nn.Linear(
|
| 565 |
+
config.hidden_size, config.intermediate_size // 2, bias=not config.no_bias
|
| 566 |
+
)
|
| 567 |
+
ff_dim_in = config.intermediate_size // 2
|
| 568 |
+
self.c_proj = nn.Linear(ff_dim_in, config.hidden_size, bias=not config.no_bias)
|
| 569 |
+
|
| 570 |
+
def forward(self, hidden_states):
|
| 571 |
+
a1 = self.w1(hidden_states)
|
| 572 |
+
a2 = self.w2(hidden_states)
|
| 573 |
+
intermediate_parallel = a1 * F.silu(a2)
|
| 574 |
+
output = self.c_proj(intermediate_parallel)
|
| 575 |
+
return output
|
| 576 |
+
|
| 577 |
+
|
| 578 |
+
class QWenBlock(nn.Module):
|
| 579 |
+
def __init__(self, config):
|
| 580 |
+
super().__init__()
|
| 581 |
+
hidden_size = config.hidden_size
|
| 582 |
+
self.bf16 = config.bf16
|
| 583 |
+
|
| 584 |
+
self.ln_1 = RMSNorm(
|
| 585 |
+
hidden_size,
|
| 586 |
+
eps=config.layer_norm_epsilon,
|
| 587 |
+
)
|
| 588 |
+
self.attn = QWenAttention(config)
|
| 589 |
+
self.ln_2 = RMSNorm(
|
| 590 |
+
hidden_size,
|
| 591 |
+
eps=config.layer_norm_epsilon,
|
| 592 |
+
)
|
| 593 |
+
|
| 594 |
+
self.mlp = QWenMLP(config)
|
| 595 |
+
|
| 596 |
+
def forward(
|
| 597 |
+
self,
|
| 598 |
+
hidden_states: Optional[Tuple[torch.FloatTensor]],
|
| 599 |
+
rotary_pos_emb_list: Optional[List[List[torch.Tensor]]] = None,
|
| 600 |
+
layer_past: Optional[Tuple[torch.Tensor]] = None,
|
| 601 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 602 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 603 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 604 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 605 |
+
use_cache: Optional[bool] = False,
|
| 606 |
+
output_attentions: Optional[bool] = False,
|
| 607 |
+
):
|
| 608 |
+
layernorm_output = self.ln_1(hidden_states)
|
| 609 |
+
|
| 610 |
+
attn_outputs = self.attn(
|
| 611 |
+
layernorm_output,
|
| 612 |
+
rotary_pos_emb_list,
|
| 613 |
+
layer_past=layer_past,
|
| 614 |
+
attention_mask=attention_mask,
|
| 615 |
+
head_mask=head_mask,
|
| 616 |
+
use_cache=use_cache,
|
| 617 |
+
output_attentions=output_attentions,
|
| 618 |
+
)
|
| 619 |
+
attn_output = attn_outputs[0]
|
| 620 |
+
|
| 621 |
+
outputs = attn_outputs[1:]
|
| 622 |
+
|
| 623 |
+
residual = hidden_states
|
| 624 |
+
layernorm_input = attn_output + residual
|
| 625 |
+
|
| 626 |
+
layernorm_output = self.ln_2(layernorm_input)
|
| 627 |
+
|
| 628 |
+
residual = layernorm_input
|
| 629 |
+
mlp_output = self.mlp(layernorm_output)
|
| 630 |
+
hidden_states = residual + mlp_output
|
| 631 |
+
|
| 632 |
+
if use_cache:
|
| 633 |
+
outputs = (hidden_states,) + outputs
|
| 634 |
+
else:
|
| 635 |
+
outputs = (hidden_states,) + outputs[1:]
|
| 636 |
+
|
| 637 |
+
return outputs
|
| 638 |
+
|
| 639 |
+
|
| 640 |
+
class QWenPreTrainedModel(PreTrainedModel):
|
| 641 |
+
config_class = QWenConfig
|
| 642 |
+
base_model_prefix = "transformer"
|
| 643 |
+
is_parallelizable = False
|
| 644 |
+
supports_gradient_checkpointing = True
|
| 645 |
+
_no_split_modules = ["QWenBlock"]
|
| 646 |
+
_skip_keys_device_placement = "past_key_values"
|
| 647 |
+
|
| 648 |
+
def __init__(self, *inputs, **kwargs):
|
| 649 |
+
super().__init__(*inputs, **kwargs)
|
| 650 |
+
|
| 651 |
+
def _init_weights(self, module):
|
| 652 |
+
"""Initialize the weights."""
|
| 653 |
+
if isinstance(module, nn.Linear):
|
| 654 |
+
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 655 |
+
if module.bias is not None:
|
| 656 |
+
module.bias.data.zero_()
|
| 657 |
+
elif isinstance(module, nn.Embedding):
|
| 658 |
+
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 659 |
+
if module.padding_idx is not None:
|
| 660 |
+
module.weight.data[module.padding_idx].zero_()
|
| 661 |
+
elif isinstance(module, RMSNorm):
|
| 662 |
+
module.weight.data.fill_(1.0)
|
| 663 |
+
|
| 664 |
+
for name, p in module.named_parameters():
|
| 665 |
+
if name == "c_proj.weight":
|
| 666 |
+
p.data.normal_(
|
| 667 |
+
mean=0.0,
|
| 668 |
+
std=(
|
| 669 |
+
self.config.initializer_range
|
| 670 |
+
/ math.sqrt(2 * self.config.num_hidden_layers)
|
| 671 |
+
),
|
| 672 |
+
)
|
| 673 |
+
|
| 674 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 675 |
+
if isinstance(module, QWenModel):
|
| 676 |
+
module.gradient_checkpointing = value
|
| 677 |
+
|
| 678 |
+
|
| 679 |
+
class QWenModel(QWenPreTrainedModel):
|
| 680 |
+
_keys_to_ignore_on_load_missing = ["attn.masked_bias"]
|
| 681 |
+
|
| 682 |
+
def __init__(self, config):
|
| 683 |
+
super().__init__(config)
|
| 684 |
+
self.vocab_size = config.vocab_size
|
| 685 |
+
self.num_hidden_layers = config.num_hidden_layers
|
| 686 |
+
self.embed_dim = config.hidden_size
|
| 687 |
+
self.use_cache_quantization = self.config.use_cache_quantization if hasattr(self.config, 'use_cache_quantization') else False
|
| 688 |
+
|
| 689 |
+
self.gradient_checkpointing = False
|
| 690 |
+
self.use_dynamic_ntk = config.use_dynamic_ntk
|
| 691 |
+
self.seq_length = config.seq_length
|
| 692 |
+
|
| 693 |
+
self.wte = nn.Embedding(self.vocab_size, self.embed_dim)
|
| 694 |
+
|
| 695 |
+
self.drop = nn.Dropout(config.emb_dropout_prob)
|
| 696 |
+
|
| 697 |
+
if config.rotary_pct == 1.0:
|
| 698 |
+
self.rotary_ndims = None
|
| 699 |
+
else:
|
| 700 |
+
assert config.rotary_pct < 1
|
| 701 |
+
self.rotary_ndims = int(
|
| 702 |
+
config.kv_channels * config.rotary_pct
|
| 703 |
+
)
|
| 704 |
+
dim = (
|
| 705 |
+
self.rotary_ndims
|
| 706 |
+
if self.rotary_ndims is not None
|
| 707 |
+
else config.kv_channels
|
| 708 |
+
)
|
| 709 |
+
self.rotary_emb = RotaryEmbedding(dim, base=config.rotary_emb_base)
|
| 710 |
+
|
| 711 |
+
self.use_flash_attn = config.use_flash_attn
|
| 712 |
+
self.is_fp32 = not (config.bf16 or config.fp16)
|
| 713 |
+
|
| 714 |
+
self.h = nn.ModuleList(
|
| 715 |
+
[
|
| 716 |
+
QWenBlock(
|
| 717 |
+
config
|
| 718 |
+
)
|
| 719 |
+
for i in range(config.num_hidden_layers)
|
| 720 |
+
]
|
| 721 |
+
)
|
| 722 |
+
self.ln_f = RMSNorm(
|
| 723 |
+
self.embed_dim,
|
| 724 |
+
eps=config.layer_norm_epsilon,
|
| 725 |
+
)
|
| 726 |
+
|
| 727 |
+
self.post_init()
|
| 728 |
+
|
| 729 |
+
def get_input_embeddings(self):
|
| 730 |
+
return self.wte
|
| 731 |
+
|
| 732 |
+
def set_input_embeddings(self, new_embeddings):
|
| 733 |
+
self.wte = new_embeddings
|
| 734 |
+
|
| 735 |
+
def get_ntk_alpha(self, true_seq_len):
|
| 736 |
+
context_value = math.log(true_seq_len / self.seq_length, 2) + 1
|
| 737 |
+
ntk_alpha = 2 ** math.ceil(context_value) - 1
|
| 738 |
+
ntk_alpha = max(ntk_alpha, 1)
|
| 739 |
+
return ntk_alpha
|
| 740 |
+
|
| 741 |
+
def forward(
|
| 742 |
+
self,
|
| 743 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 744 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
|
| 745 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 746 |
+
token_type_ids: Optional[torch.LongTensor] = None,
|
| 747 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 748 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 749 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 750 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 751 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 752 |
+
use_cache: Optional[bool] = None,
|
| 753 |
+
output_attentions: Optional[bool] = None,
|
| 754 |
+
output_hidden_states: Optional[bool] = None,
|
| 755 |
+
return_dict: Optional[bool] = None,
|
| 756 |
+
):
|
| 757 |
+
output_attentions = (
|
| 758 |
+
output_attentions
|
| 759 |
+
if output_attentions is not None
|
| 760 |
+
else self.config.output_attentions
|
| 761 |
+
)
|
| 762 |
+
output_hidden_states = (
|
| 763 |
+
output_hidden_states
|
| 764 |
+
if output_hidden_states is not None
|
| 765 |
+
else self.config.output_hidden_states
|
| 766 |
+
)
|
| 767 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 768 |
+
return_dict = (
|
| 769 |
+
return_dict if return_dict is not None else self.config.use_return_dict
|
| 770 |
+
)
|
| 771 |
+
|
| 772 |
+
if input_ids is not None and inputs_embeds is not None:
|
| 773 |
+
raise ValueError(
|
| 774 |
+
"You cannot specify both input_ids and inputs_embeds at the same time"
|
| 775 |
+
)
|
| 776 |
+
elif input_ids is not None:
|
| 777 |
+
input_shape = input_ids.size()
|
| 778 |
+
input_ids = input_ids.view(-1, input_shape[-1])
|
| 779 |
+
batch_size = input_ids.shape[0]
|
| 780 |
+
elif inputs_embeds is not None:
|
| 781 |
+
input_shape = inputs_embeds.size()[:-1]
|
| 782 |
+
batch_size = inputs_embeds.shape[0]
|
| 783 |
+
else:
|
| 784 |
+
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
| 785 |
+
|
| 786 |
+
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
| 787 |
+
|
| 788 |
+
if token_type_ids is not None:
|
| 789 |
+
token_type_ids = token_type_ids.view(-1, input_shape[-1])
|
| 790 |
+
if position_ids is not None:
|
| 791 |
+
position_ids = position_ids.view(-1, input_shape[-1])
|
| 792 |
+
|
| 793 |
+
if past_key_values is None:
|
| 794 |
+
past_length = 0
|
| 795 |
+
past_key_values = tuple([None] * len(self.h))
|
| 796 |
+
else:
|
| 797 |
+
if self.use_cache_quantization:
|
| 798 |
+
past_length = past_key_values[0][0][0].size(2)
|
| 799 |
+
else:
|
| 800 |
+
past_length = past_key_values[0][0].size(-2)
|
| 801 |
+
if position_ids is None:
|
| 802 |
+
position_ids = torch.arange(
|
| 803 |
+
past_length,
|
| 804 |
+
input_shape[-1] + past_length,
|
| 805 |
+
dtype=torch.long,
|
| 806 |
+
device=device,
|
| 807 |
+
)
|
| 808 |
+
position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
|
| 809 |
+
|
| 810 |
+
if attention_mask is not None:
|
| 811 |
+
if batch_size <= 0:
|
| 812 |
+
raise ValueError("batch_size has to be defined and > 0")
|
| 813 |
+
attention_mask = attention_mask.view(batch_size, -1)
|
| 814 |
+
attention_mask = attention_mask[:, None, None, :]
|
| 815 |
+
attention_mask = attention_mask.to(dtype=self.dtype)
|
| 816 |
+
attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min
|
| 817 |
+
|
| 818 |
+
encoder_attention_mask = None
|
| 819 |
+
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
|
| 820 |
+
|
| 821 |
+
if inputs_embeds is None:
|
| 822 |
+
inputs_embeds = self.wte(input_ids)
|
| 823 |
+
hidden_states = inputs_embeds
|
| 824 |
+
|
| 825 |
+
kv_seq_len = hidden_states.size()[1]
|
| 826 |
+
if past_key_values[0] is not None:
|
| 827 |
+
# past key values[0][0] shape: bs * seq_len * head_num * dim
|
| 828 |
+
if self.use_cache_quantization:
|
| 829 |
+
kv_seq_len += past_key_values[0][0][0].shape[2]
|
| 830 |
+
else:
|
| 831 |
+
kv_seq_len += past_key_values[0][0].shape[1]
|
| 832 |
+
|
| 833 |
+
if self.training or not self.use_dynamic_ntk:
|
| 834 |
+
ntk_alpha_list = [1.0]
|
| 835 |
+
elif kv_seq_len != hidden_states.size()[1]:
|
| 836 |
+
ntk_alpha_list = self.rotary_emb._ntk_alpha_cached_list
|
| 837 |
+
else:
|
| 838 |
+
ntk_alpha_list = []
|
| 839 |
+
if attention_mask is not None and kv_seq_len > self.seq_length:
|
| 840 |
+
true_seq_lens = attention_mask.squeeze(1).squeeze(1).eq(0).sum(dim=-1, dtype=torch.int32)
|
| 841 |
+
for i in range(hidden_states.size()[0]):
|
| 842 |
+
true_seq_len = true_seq_lens[i].item()
|
| 843 |
+
ntk_alpha = self.get_ntk_alpha(true_seq_len)
|
| 844 |
+
ntk_alpha_list.append(ntk_alpha)
|
| 845 |
+
else:
|
| 846 |
+
ntk_alpha = self.get_ntk_alpha(kv_seq_len)
|
| 847 |
+
ntk_alpha_list.append(ntk_alpha)
|
| 848 |
+
self.rotary_emb._ntk_alpha_cached_list = ntk_alpha_list
|
| 849 |
+
rotary_pos_emb_list = [
|
| 850 |
+
self.rotary_emb(kv_seq_len, ntk_alpha=ntk_alpha) for ntk_alpha in ntk_alpha_list
|
| 851 |
+
]
|
| 852 |
+
|
| 853 |
+
hidden_states = self.drop(hidden_states)
|
| 854 |
+
output_shape = input_shape + (hidden_states.size(-1),)
|
| 855 |
+
|
| 856 |
+
if self.gradient_checkpointing and self.training:
|
| 857 |
+
if use_cache:
|
| 858 |
+
logger.warning_once(
|
| 859 |
+
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
| 860 |
+
)
|
| 861 |
+
use_cache = False
|
| 862 |
+
|
| 863 |
+
presents = () if use_cache else None
|
| 864 |
+
all_self_attentions = () if output_attentions else None
|
| 865 |
+
all_hidden_states = () if output_hidden_states else None
|
| 866 |
+
for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
|
| 867 |
+
|
| 868 |
+
if output_hidden_states:
|
| 869 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 870 |
+
|
| 871 |
+
if self.gradient_checkpointing and self.training:
|
| 872 |
+
|
| 873 |
+
def create_custom_forward(module):
|
| 874 |
+
def custom_forward(*inputs):
|
| 875 |
+
# None for past_key_value
|
| 876 |
+
return module(*inputs, use_cache, output_attentions)
|
| 877 |
+
|
| 878 |
+
return custom_forward
|
| 879 |
+
|
| 880 |
+
outputs = torch.utils.checkpoint.checkpoint(
|
| 881 |
+
create_custom_forward(block),
|
| 882 |
+
hidden_states,
|
| 883 |
+
rotary_pos_emb_list,
|
| 884 |
+
None,
|
| 885 |
+
attention_mask,
|
| 886 |
+
head_mask[i],
|
| 887 |
+
encoder_hidden_states,
|
| 888 |
+
encoder_attention_mask,
|
| 889 |
+
)
|
| 890 |
+
else:
|
| 891 |
+
outputs = block(
|
| 892 |
+
hidden_states,
|
| 893 |
+
layer_past=layer_past,
|
| 894 |
+
rotary_pos_emb_list=rotary_pos_emb_list,
|
| 895 |
+
attention_mask=attention_mask,
|
| 896 |
+
head_mask=head_mask[i],
|
| 897 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 898 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 899 |
+
use_cache=use_cache,
|
| 900 |
+
output_attentions=output_attentions,
|
| 901 |
+
)
|
| 902 |
+
|
| 903 |
+
hidden_states = outputs[0]
|
| 904 |
+
if use_cache is True:
|
| 905 |
+
presents = presents + (outputs[1],)
|
| 906 |
+
|
| 907 |
+
if output_attentions:
|
| 908 |
+
all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
|
| 909 |
+
|
| 910 |
+
hidden_states = self.ln_f(hidden_states)
|
| 911 |
+
hidden_states = hidden_states.view(output_shape)
|
| 912 |
+
# Add last hidden state
|
| 913 |
+
if output_hidden_states:
|
| 914 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 915 |
+
|
| 916 |
+
if not return_dict:
|
| 917 |
+
return tuple(
|
| 918 |
+
v for v in [hidden_states, presents, all_hidden_states] if v is not None
|
| 919 |
+
)
|
| 920 |
+
|
| 921 |
+
return BaseModelOutputWithPast(
|
| 922 |
+
last_hidden_state=hidden_states,
|
| 923 |
+
past_key_values=presents,
|
| 924 |
+
hidden_states=all_hidden_states,
|
| 925 |
+
attentions=all_self_attentions,
|
| 926 |
+
)
|
| 927 |
+
|
| 928 |
+
|
| 929 |
+
class QWenLMHeadModel(QWenPreTrainedModel):
|
| 930 |
+
_keys_to_ignore_on_load_missing = [r"h\.\d+\.attn\.rotary_emb\.inv_freq"]
|
| 931 |
+
_keys_to_ignore_on_load_unexpected = [r"h\.\d+\.attn\.masked_bias"]
|
| 932 |
+
|
| 933 |
+
def __init__(self, config):
|
| 934 |
+
super().__init__(config)
|
| 935 |
+
assert (
|
| 936 |
+
config.bf16 + config.fp16 + config.fp32 <= 1
|
| 937 |
+
), "Only one of \"bf16\", \"fp16\", \"fp32\" can be true"
|
| 938 |
+
|
| 939 |
+
autoset_precision = config.bf16 + config.fp16 + config.fp32 == 0
|
| 940 |
+
|
| 941 |
+
if autoset_precision:
|
| 942 |
+
if SUPPORT_BF16:
|
| 943 |
+
logger.warn(
|
| 944 |
+
"The model is automatically converting to bf16 for faster inference. "
|
| 945 |
+
"If you want to disable the automatic precision, please manually add bf16/fp16/fp32=True to \"AutoModelForCausalLM.from_pretrained\"."
|
| 946 |
+
)
|
| 947 |
+
config.bf16 = True
|
| 948 |
+
elif SUPPORT_FP16:
|
| 949 |
+
logger.warn(
|
| 950 |
+
"The model is automatically converting to fp16 for faster inference. "
|
| 951 |
+
"If you want to disable the automatic precision, please manually add bf16/fp16/fp32=True to \"AutoModelForCausalLM.from_pretrained\"."
|
| 952 |
+
)
|
| 953 |
+
config.fp16 = True
|
| 954 |
+
else:
|
| 955 |
+
config.fp32 = True
|
| 956 |
+
|
| 957 |
+
if config.bf16 and SUPPORT_CUDA and not SUPPORT_BF16:
|
| 958 |
+
logger.warn("Your device does NOT seem to support bf16, you can switch to fp16 or fp32 by by passing fp16/fp32=True in \"AutoModelForCausalLM.from_pretrained\".")
|
| 959 |
+
if config.fp16 and SUPPORT_CUDA and not SUPPORT_FP16:
|
| 960 |
+
logger.warn("Your device does NOT support faster inference with fp16, please switch to fp32 which is likely to be faster")
|
| 961 |
+
if config.fp32:
|
| 962 |
+
if SUPPORT_BF16:
|
| 963 |
+
logger.warn("Your device support faster inference by passing bf16=True in \"AutoModelForCausalLM.from_pretrained\".")
|
| 964 |
+
elif SUPPORT_FP16:
|
| 965 |
+
logger.warn("Your device support faster inference by passing fp16=True in \"AutoModelForCausalLM.from_pretrained\".")
|
| 966 |
+
|
| 967 |
+
if config.use_flash_attn == "auto":
|
| 968 |
+
if config.bf16 or config.fp16:
|
| 969 |
+
logger.warn("Try importing flash-attention for faster inference...")
|
| 970 |
+
config.use_flash_attn = True
|
| 971 |
+
else:
|
| 972 |
+
config.use_flash_attn = False
|
| 973 |
+
if config.use_flash_attn and config.fp32:
|
| 974 |
+
logger.warn("Flash attention will be disabled because it does NOT support fp32.")
|
| 975 |
+
|
| 976 |
+
if config.use_flash_attn:
|
| 977 |
+
_import_flash_attn()
|
| 978 |
+
|
| 979 |
+
self.transformer = QWenModel(config)
|
| 980 |
+
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
| 981 |
+
|
| 982 |
+
if config.bf16:
|
| 983 |
+
self.transformer.bfloat16()
|
| 984 |
+
self.lm_head.bfloat16()
|
| 985 |
+
if config.fp16:
|
| 986 |
+
self.transformer.half()
|
| 987 |
+
self.lm_head.half()
|
| 988 |
+
self.post_init()
|
| 989 |
+
|
| 990 |
+
def get_output_embeddings(self):
|
| 991 |
+
return self.lm_head
|
| 992 |
+
|
| 993 |
+
def set_output_embeddings(self, new_embeddings):
|
| 994 |
+
self.lm_head = new_embeddings
|
| 995 |
+
|
| 996 |
+
def prepare_inputs_for_generation(
|
| 997 |
+
self, input_ids, past_key_values=None, inputs_embeds=None, **kwargs
|
| 998 |
+
):
|
| 999 |
+
if past_key_values:
|
| 1000 |
+
input_ids = input_ids[:, -1].unsqueeze(-1)
|
| 1001 |
+
|
| 1002 |
+
if input_ids.size(0) == 1:
|
| 1003 |
+
attention_mask = None
|
| 1004 |
+
else:
|
| 1005 |
+
attention_mask = kwargs.get("attention_mask", None)
|
| 1006 |
+
|
| 1007 |
+
if inputs_embeds is not None and past_key_values is None:
|
| 1008 |
+
model_inputs = {"inputs_embeds": inputs_embeds}
|
| 1009 |
+
else:
|
| 1010 |
+
model_inputs = {"input_ids": input_ids}
|
| 1011 |
+
|
| 1012 |
+
model_inputs.update(
|
| 1013 |
+
{
|
| 1014 |
+
"past_key_values": past_key_values,
|
| 1015 |
+
"use_cache": kwargs.get("use_cache"),
|
| 1016 |
+
"attention_mask": attention_mask,
|
| 1017 |
+
}
|
| 1018 |
+
)
|
| 1019 |
+
return model_inputs
|
| 1020 |
+
|
| 1021 |
+
def forward(
|
| 1022 |
+
self,
|
| 1023 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 1024 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
|
| 1025 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 1026 |
+
token_type_ids: Optional[torch.LongTensor] = None,
|
| 1027 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1028 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 1029 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1030 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 1031 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 1032 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1033 |
+
use_cache: Optional[bool] = None,
|
| 1034 |
+
output_attentions: Optional[bool] = None,
|
| 1035 |
+
output_hidden_states: Optional[bool] = None,
|
| 1036 |
+
return_dict: Optional[bool] = None,
|
| 1037 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 1038 |
+
|
| 1039 |
+
return_dict = (
|
| 1040 |
+
return_dict if return_dict is not None else self.config.use_return_dict
|
| 1041 |
+
)
|
| 1042 |
+
|
| 1043 |
+
transformer_outputs = self.transformer(
|
| 1044 |
+
input_ids,
|
| 1045 |
+
past_key_values=past_key_values,
|
| 1046 |
+
attention_mask=attention_mask,
|
| 1047 |
+
token_type_ids=token_type_ids,
|
| 1048 |
+
position_ids=position_ids,
|
| 1049 |
+
head_mask=head_mask,
|
| 1050 |
+
inputs_embeds=inputs_embeds,
|
| 1051 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1052 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1053 |
+
use_cache=use_cache,
|
| 1054 |
+
output_attentions=output_attentions,
|
| 1055 |
+
output_hidden_states=output_hidden_states,
|
| 1056 |
+
return_dict=return_dict,
|
| 1057 |
+
)
|
| 1058 |
+
hidden_states = transformer_outputs[0]
|
| 1059 |
+
|
| 1060 |
+
lm_logits = self.lm_head(hidden_states)
|
| 1061 |
+
|
| 1062 |
+
loss = None
|
| 1063 |
+
if labels is not None:
|
| 1064 |
+
labels = labels.to(lm_logits.device)
|
| 1065 |
+
shift_logits = lm_logits[..., :-1, :].contiguous()
|
| 1066 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 1067 |
+
loss_fct = CrossEntropyLoss()
|
| 1068 |
+
loss = loss_fct(
|
| 1069 |
+
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)
|
| 1070 |
+
)
|
| 1071 |
+
|
| 1072 |
+
if not return_dict:
|
| 1073 |
+
output = (lm_logits,) + transformer_outputs[1:]
|
| 1074 |
+
return ((loss,) + output) if loss is not None else output
|
| 1075 |
+
|
| 1076 |
+
return CausalLMOutputWithPast(
|
| 1077 |
+
loss=loss,
|
| 1078 |
+
logits=lm_logits,
|
| 1079 |
+
past_key_values=transformer_outputs.past_key_values,
|
| 1080 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 1081 |
+
attentions=transformer_outputs.attentions,
|
| 1082 |
+
)
|
| 1083 |
+
|
| 1084 |
+
@staticmethod
|
| 1085 |
+
def _reorder_cache(
|
| 1086 |
+
past_key_values: Tuple[Tuple[torch.Tensor]], beam_idx: torch.Tensor
|
| 1087 |
+
) -> Tuple[Tuple[torch.Tensor]]:
|
| 1088 |
+
|
| 1089 |
+
return tuple(
|
| 1090 |
+
tuple(
|
| 1091 |
+
past_state.index_select(0, beam_idx.to(past_state.device))
|
| 1092 |
+
for past_state in layer_past
|
| 1093 |
+
)
|
| 1094 |
+
for layer_past in past_key_values
|
| 1095 |
+
)
|
| 1096 |
+
|
| 1097 |
+
def chat(
|
| 1098 |
+
self,
|
| 1099 |
+
tokenizer: PreTrainedTokenizer,
|
| 1100 |
+
query: str,
|
| 1101 |
+
history: Optional[HistoryType],
|
| 1102 |
+
system: str = "You are a helpful assistant.",
|
| 1103 |
+
stream: Optional[bool] = _SENTINEL,
|
| 1104 |
+
stop_words_ids: Optional[List[List[int]]] = None,
|
| 1105 |
+
generation_config: Optional[GenerationConfig] = None,
|
| 1106 |
+
**kwargs,
|
| 1107 |
+
) -> Tuple[str, HistoryType]:
|
| 1108 |
+
generation_config = generation_config if generation_config is not None else self.generation_config
|
| 1109 |
+
|
| 1110 |
+
assert stream is _SENTINEL, _ERROR_STREAM_IN_CHAT
|
| 1111 |
+
assert generation_config.chat_format == 'chatml', _ERROR_BAD_CHAT_FORMAT
|
| 1112 |
+
if history is None:
|
| 1113 |
+
history = []
|
| 1114 |
+
else:
|
| 1115 |
+
# make a copy of the user's input such that is is left untouched
|
| 1116 |
+
history = copy.deepcopy(history)
|
| 1117 |
+
|
| 1118 |
+
if stop_words_ids is None:
|
| 1119 |
+
stop_words_ids = []
|
| 1120 |
+
|
| 1121 |
+
max_window_size = kwargs.get('max_window_size', None)
|
| 1122 |
+
if max_window_size is None:
|
| 1123 |
+
max_window_size = generation_config.max_window_size
|
| 1124 |
+
raw_text, context_tokens = make_context(
|
| 1125 |
+
tokenizer,
|
| 1126 |
+
query,
|
| 1127 |
+
history=history,
|
| 1128 |
+
system=system,
|
| 1129 |
+
max_window_size=max_window_size,
|
| 1130 |
+
chat_format=generation_config.chat_format,
|
| 1131 |
+
)
|
| 1132 |
+
|
| 1133 |
+
stop_words_ids.extend(get_stop_words_ids(
|
| 1134 |
+
generation_config.chat_format, tokenizer
|
| 1135 |
+
))
|
| 1136 |
+
input_ids = torch.tensor([context_tokens]).to(self.device)
|
| 1137 |
+
outputs = self.generate(
|
| 1138 |
+
input_ids,
|
| 1139 |
+
stop_words_ids=stop_words_ids,
|
| 1140 |
+
return_dict_in_generate=False,
|
| 1141 |
+
generation_config=generation_config,
|
| 1142 |
+
**kwargs,
|
| 1143 |
+
)
|
| 1144 |
+
|
| 1145 |
+
response = decode_tokens(
|
| 1146 |
+
outputs[0],
|
| 1147 |
+
tokenizer,
|
| 1148 |
+
raw_text_len=len(raw_text),
|
| 1149 |
+
context_length=len(context_tokens),
|
| 1150 |
+
chat_format=generation_config.chat_format,
|
| 1151 |
+
verbose=False,
|
| 1152 |
+
errors='replace'
|
| 1153 |
+
)
|
| 1154 |
+
|
| 1155 |
+
# as history is a copy of the user inputs,
|
| 1156 |
+
# we can always return the new turn to the user.
|
| 1157 |
+
# separating input history and output history also enables the user
|
| 1158 |
+
# to implement more complex history management
|
| 1159 |
+
history.append((query, response))
|
| 1160 |
+
|
| 1161 |
+
return response, history
|
| 1162 |
+
|
| 1163 |
+
def chat_stream(
|
| 1164 |
+
self,
|
| 1165 |
+
tokenizer: PreTrainedTokenizer,
|
| 1166 |
+
query: str,
|
| 1167 |
+
history: Optional[HistoryType],
|
| 1168 |
+
system: str = "You are a helpful assistant.",
|
| 1169 |
+
stop_words_ids: Optional[List[List[int]]] = None,
|
| 1170 |
+
logits_processor: Optional[LogitsProcessorList] = None,
|
| 1171 |
+
generation_config: Optional[GenerationConfig] = None,
|
| 1172 |
+
**kwargs,
|
| 1173 |
+
) -> Generator[str, Any, None]:
|
| 1174 |
+
generation_config = generation_config if generation_config is not None else self.generation_config
|
| 1175 |
+
assert generation_config.chat_format == 'chatml', _ERROR_BAD_CHAT_FORMAT
|
| 1176 |
+
if history is None:
|
| 1177 |
+
history = []
|
| 1178 |
+
if stop_words_ids is None:
|
| 1179 |
+
stop_words_ids = []
|
| 1180 |
+
|
| 1181 |
+
max_window_size = kwargs.get('max_window_size', None)
|
| 1182 |
+
if max_window_size is None:
|
| 1183 |
+
max_window_size = generation_config.max_window_size
|
| 1184 |
+
raw_text, context_tokens = make_context(
|
| 1185 |
+
tokenizer,
|
| 1186 |
+
query,
|
| 1187 |
+
history=history,
|
| 1188 |
+
system=system,
|
| 1189 |
+
max_window_size=max_window_size,
|
| 1190 |
+
chat_format=generation_config.chat_format,
|
| 1191 |
+
)
|
| 1192 |
+
|
| 1193 |
+
stop_words_ids.extend(get_stop_words_ids(
|
| 1194 |
+
generation_config.chat_format, tokenizer
|
| 1195 |
+
))
|
| 1196 |
+
if stop_words_ids is not None:
|
| 1197 |
+
stop_words_logits_processor = StopWordsLogitsProcessor(
|
| 1198 |
+
stop_words_ids=stop_words_ids,
|
| 1199 |
+
eos_token_id=generation_config.eos_token_id,
|
| 1200 |
+
)
|
| 1201 |
+
if logits_processor is None:
|
| 1202 |
+
logits_processor = LogitsProcessorList([stop_words_logits_processor])
|
| 1203 |
+
else:
|
| 1204 |
+
logits_processor.append(stop_words_logits_processor)
|
| 1205 |
+
input_ids = torch.tensor([context_tokens]).to(self.device)
|
| 1206 |
+
|
| 1207 |
+
from transformers_stream_generator.main import NewGenerationMixin, StreamGenerationConfig
|
| 1208 |
+
self.__class__.generate_stream = NewGenerationMixin.generate
|
| 1209 |
+
self.__class__.sample_stream = NewGenerationMixin.sample_stream
|
| 1210 |
+
stream_config = StreamGenerationConfig(**generation_config.to_dict(), do_stream=True)
|
| 1211 |
+
|
| 1212 |
+
def stream_generator():
|
| 1213 |
+
outputs = []
|
| 1214 |
+
for token in self.generate_stream(
|
| 1215 |
+
input_ids,
|
| 1216 |
+
return_dict_in_generate=False,
|
| 1217 |
+
generation_config=stream_config,
|
| 1218 |
+
logits_processor=logits_processor,
|
| 1219 |
+
seed=-1,
|
| 1220 |
+
**kwargs):
|
| 1221 |
+
outputs.append(token.item())
|
| 1222 |
+
yield tokenizer.decode(outputs, skip_special_tokens=True, errors='ignore')
|
| 1223 |
+
|
| 1224 |
+
return stream_generator()
|
| 1225 |
+
|
| 1226 |
+
def generate(
|
| 1227 |
+
self,
|
| 1228 |
+
inputs: Optional[torch.Tensor] = None,
|
| 1229 |
+
generation_config: Optional[GenerationConfig] = None,
|
| 1230 |
+
logits_processor: Optional[LogitsProcessorList] = None,
|
| 1231 |
+
stopping_criteria: Optional[StoppingCriteriaList] = None,
|
| 1232 |
+
prefix_allowed_tokens_fn: Optional[
|
| 1233 |
+
Callable[[int, torch.Tensor], List[int]]
|
| 1234 |
+
] = None,
|
| 1235 |
+
synced_gpus: Optional[bool] = None,
|
| 1236 |
+
assistant_model: Optional["PreTrainedModel"] = None,
|
| 1237 |
+
streamer: Optional["BaseStreamer"] = None,
|
| 1238 |
+
**kwargs,
|
| 1239 |
+
) -> Union[GenerateOutput, torch.LongTensor]:
|
| 1240 |
+
generation_config = generation_config if generation_config is not None else self.generation_config
|
| 1241 |
+
|
| 1242 |
+
# Process stop_words_ids.
|
| 1243 |
+
stop_words_ids = kwargs.pop("stop_words_ids", None)
|
| 1244 |
+
if stop_words_ids is None and generation_config is not None:
|
| 1245 |
+
stop_words_ids = getattr(generation_config, "stop_words_ids", None)
|
| 1246 |
+
if stop_words_ids is None:
|
| 1247 |
+
stop_words_ids = getattr(generation_config, "stop_words_ids", None)
|
| 1248 |
+
|
| 1249 |
+
if stop_words_ids is not None:
|
| 1250 |
+
stop_words_logits_processor = StopWordsLogitsProcessor(
|
| 1251 |
+
stop_words_ids=stop_words_ids,
|
| 1252 |
+
eos_token_id=generation_config.eos_token_id,
|
| 1253 |
+
)
|
| 1254 |
+
if logits_processor is None:
|
| 1255 |
+
logits_processor = LogitsProcessorList([stop_words_logits_processor])
|
| 1256 |
+
else:
|
| 1257 |
+
logits_processor.append(stop_words_logits_processor)
|
| 1258 |
+
|
| 1259 |
+
return super().generate(
|
| 1260 |
+
inputs,
|
| 1261 |
+
generation_config=generation_config,
|
| 1262 |
+
logits_processor=logits_processor,
|
| 1263 |
+
stopping_criteria=stopping_criteria,
|
| 1264 |
+
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
|
| 1265 |
+
synced_gpus=synced_gpus,
|
| 1266 |
+
assistant_model=assistant_model,
|
| 1267 |
+
streamer=streamer,
|
| 1268 |
+
**kwargs,
|
| 1269 |
+
)
|
| 1270 |
+
|
| 1271 |
+
|
| 1272 |
+
class RotaryEmbedding(torch.nn.Module):
|
| 1273 |
+
def __init__(self, dim, base=10000):
|
| 1274 |
+
super().__init__()
|
| 1275 |
+
self.dim = dim
|
| 1276 |
+
self.base = base
|
| 1277 |
+
inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float() / dim))
|
| 1278 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
| 1279 |
+
if importlib.util.find_spec("einops") is None:
|
| 1280 |
+
raise RuntimeError("einops is required for Rotary Embedding")
|
| 1281 |
+
|
| 1282 |
+
self._rotary_pos_emb_cache = None
|
| 1283 |
+
self._seq_len_cached = 0
|
| 1284 |
+
self._ntk_alpha_cached = 1.0
|
| 1285 |
+
self._ntk_alpha_cached_list = [1.0]
|
| 1286 |
+
|
| 1287 |
+
def update_rotary_pos_emb_cache(self, seqlen, ntk_alpha=1.0):
|
| 1288 |
+
if seqlen > self._seq_len_cached or ntk_alpha != self._ntk_alpha_cached:
|
| 1289 |
+
base = self.base * ntk_alpha ** (self.dim / (self.dim - 2))
|
| 1290 |
+
self.inv_freq = 1.0 / (
|
| 1291 |
+
base
|
| 1292 |
+
** (
|
| 1293 |
+
torch.arange(0, self.dim, 2, device=self.inv_freq.device).float()
|
| 1294 |
+
/ self.dim
|
| 1295 |
+
)
|
| 1296 |
+
)
|
| 1297 |
+
self._seq_len_cached = max(2 * seqlen, 16)
|
| 1298 |
+
self._ntk_alpha_cached = ntk_alpha
|
| 1299 |
+
seq = torch.arange(self._seq_len_cached, device=self.inv_freq.device)
|
| 1300 |
+
freqs = torch.outer(seq.type_as(self.inv_freq), self.inv_freq)
|
| 1301 |
+
|
| 1302 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 1303 |
+
from einops import rearrange
|
| 1304 |
+
|
| 1305 |
+
emb = rearrange(emb, "n d -> 1 n 1 d")
|
| 1306 |
+
|
| 1307 |
+
cos, sin = emb.cos(), emb.sin()
|
| 1308 |
+
self._rotary_pos_emb_cache = [cos, sin]
|
| 1309 |
+
|
| 1310 |
+
def forward(self, max_seq_len, ntk_alpha=1.0):
|
| 1311 |
+
self.update_rotary_pos_emb_cache(max_seq_len, ntk_alpha)
|
| 1312 |
+
cos, sin = self._rotary_pos_emb_cache
|
| 1313 |
+
return [cos[:, :max_seq_len], sin[:, :max_seq_len]]
|
| 1314 |
+
|
| 1315 |
+
|
| 1316 |
+
def _rotate_half(x):
|
| 1317 |
+
from einops import rearrange
|
| 1318 |
+
|
| 1319 |
+
x = rearrange(x, "... (j d) -> ... j d", j=2)
|
| 1320 |
+
x1, x2 = x.unbind(dim=-2)
|
| 1321 |
+
return torch.cat((-x2, x1), dim=-1)
|
| 1322 |
+
|
| 1323 |
+
|
| 1324 |
+
def apply_rotary_pos_emb(t, freqs):
|
| 1325 |
+
""" Apply rotary embedding to the first rotary_dim of the iput
|
| 1326 |
+
|
| 1327 |
+
Arguments:
|
| 1328 |
+
t (tensor(batch_size, seq_len, n_head, head_dim)):
|
| 1329 |
+
the input embedding/hidden states
|
| 1330 |
+
freqs (list[tensor(1, seq_len, 1, rotary_dim), tensor(1, seq_len, 1, rotary_dim)]):
|
| 1331 |
+
the cached cos/sin position embeddings
|
| 1332 |
+
"""
|
| 1333 |
+
rot_dim = freqs[0].shape[-1]
|
| 1334 |
+
cos, sin = freqs
|
| 1335 |
+
t_float = t.float()
|
| 1336 |
+
if apply_rotary_emb_func is not None and t.is_cuda:
|
| 1337 |
+
# apply_rotary_emb in flash_attn requires cos/sin to be of
|
| 1338 |
+
# shape (seqlen, rotary_dim / 2) and apply rotary embedding
|
| 1339 |
+
# to the first rotary_dim of the input
|
| 1340 |
+
cos = cos.squeeze(0).squeeze(1)[:, : rot_dim // 2]
|
| 1341 |
+
sin = sin.squeeze(0).squeeze(1)[:, : rot_dim // 2]
|
| 1342 |
+
return apply_rotary_emb_func(t_float, cos, sin).type_as(t)
|
| 1343 |
+
else:
|
| 1344 |
+
t_rot, t_pass = t_float[..., :rot_dim], t_float[..., rot_dim:]
|
| 1345 |
+
t_rot = (t_rot * cos) + (_rotate_half(t_rot) * sin)
|
| 1346 |
+
return torch.cat((t_rot, t_pass), dim=-1).type_as(t)
|
| 1347 |
+
|
| 1348 |
+
|
| 1349 |
+
class RMSNorm(torch.nn.Module):
|
| 1350 |
+
def __init__(self, dim: int, eps: float = 1e-6):
|
| 1351 |
+
super().__init__()
|
| 1352 |
+
self.eps = eps
|
| 1353 |
+
self.weight = nn.Parameter(torch.ones(dim))
|
| 1354 |
+
|
| 1355 |
+
def _norm(self, x):
|
| 1356 |
+
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
|
| 1357 |
+
|
| 1358 |
+
def forward(self, x):
|
| 1359 |
+
if rms_norm is not None and x.is_cuda:
|
| 1360 |
+
return rms_norm(x, self.weight, self.eps)
|
| 1361 |
+
else:
|
| 1362 |
+
output = self._norm(x.float()).type_as(x)
|
| 1363 |
+
return output * self.weight
|
qwen.tiktoken
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
qwen_generation_utils.py
ADDED
|
@@ -0,0 +1,416 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Alibaba Cloud.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
"""Generation support."""
|
| 7 |
+
|
| 8 |
+
from typing import Tuple, List, Union, Iterable
|
| 9 |
+
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
from transformers import PreTrainedTokenizer
|
| 14 |
+
from transformers import logging
|
| 15 |
+
from transformers.generation import LogitsProcessor
|
| 16 |
+
|
| 17 |
+
logger = logging.get_logger(__name__)
|
| 18 |
+
|
| 19 |
+
# Types.
|
| 20 |
+
HistoryType = List[Tuple[str, str]]
|
| 21 |
+
TokensType = List[int]
|
| 22 |
+
BatchTokensType = List[List[int]]
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def pad_batch(batch: BatchTokensType, pad_id: int, seq_length: int) -> BatchTokensType:
|
| 26 |
+
for tokens in batch:
|
| 27 |
+
context_length = len(tokens)
|
| 28 |
+
if context_length < seq_length:
|
| 29 |
+
tokens.extend([pad_id] * (seq_length - context_length))
|
| 30 |
+
return batch
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def get_ltor_masks_and_position_ids(
|
| 34 |
+
data,
|
| 35 |
+
eod_token,
|
| 36 |
+
reset_position_ids,
|
| 37 |
+
reset_attention_mask,
|
| 38 |
+
eod_mask_loss,
|
| 39 |
+
):
|
| 40 |
+
"""Build masks and position id for left to right model."""
|
| 41 |
+
|
| 42 |
+
# Extract batch size and sequence length.
|
| 43 |
+
micro_batch_size, seq_length = data.size()
|
| 44 |
+
|
| 45 |
+
# Attention mask (lower triangular).
|
| 46 |
+
if reset_attention_mask:
|
| 47 |
+
att_mask_batch = micro_batch_size
|
| 48 |
+
else:
|
| 49 |
+
att_mask_batch = 1
|
| 50 |
+
attention_mask = torch.tril(
|
| 51 |
+
torch.ones((att_mask_batch, seq_length, seq_length), device=data.device)
|
| 52 |
+
).view(att_mask_batch, 1, seq_length, seq_length)
|
| 53 |
+
|
| 54 |
+
# Loss mask.
|
| 55 |
+
loss_mask = torch.ones(data.size(), dtype=torch.float, device=data.device)
|
| 56 |
+
if eod_mask_loss:
|
| 57 |
+
loss_mask[data == eod_token] = 0.0
|
| 58 |
+
|
| 59 |
+
# Position ids.
|
| 60 |
+
position_ids = torch.arange(seq_length, dtype=torch.long, device=data.device)
|
| 61 |
+
position_ids = position_ids.unsqueeze(0).expand_as(data)
|
| 62 |
+
# We need to clone as the ids will be modifed based on batch index.
|
| 63 |
+
if reset_position_ids:
|
| 64 |
+
position_ids = position_ids.clone()
|
| 65 |
+
|
| 66 |
+
if reset_position_ids or reset_attention_mask:
|
| 67 |
+
# Loop through the batches:
|
| 68 |
+
for b in range(micro_batch_size):
|
| 69 |
+
|
| 70 |
+
# Find indecies where EOD token is.
|
| 71 |
+
eod_index = position_ids[b, data[b] == eod_token]
|
| 72 |
+
# Detach indecies from positions if going to modify positions.
|
| 73 |
+
if reset_position_ids:
|
| 74 |
+
eod_index = eod_index.clone()
|
| 75 |
+
|
| 76 |
+
# Loop through EOD indecies:
|
| 77 |
+
prev_index = 0
|
| 78 |
+
for j in range(eod_index.size()[0]):
|
| 79 |
+
i = eod_index[j]
|
| 80 |
+
# Mask attention loss.
|
| 81 |
+
if reset_attention_mask:
|
| 82 |
+
attention_mask[b, 0, (i + 1) :, : (i + 1)] = 0
|
| 83 |
+
# Reset positions.
|
| 84 |
+
if reset_position_ids:
|
| 85 |
+
position_ids[b, (i + 1) :] -= i + 1 - prev_index
|
| 86 |
+
prev_index = i + 1
|
| 87 |
+
|
| 88 |
+
# Convert attention mask to binary:
|
| 89 |
+
attention_mask = attention_mask < 0.5
|
| 90 |
+
|
| 91 |
+
return attention_mask, loss_mask, position_ids
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def get_batch(context_tokens: torch.LongTensor, eod_id: int):
|
| 95 |
+
"""Generate batch from context tokens."""
|
| 96 |
+
# Move to GPU.
|
| 97 |
+
tokens = context_tokens.contiguous().to(context_tokens.device)
|
| 98 |
+
# Get the attention mask and postition ids.
|
| 99 |
+
attention_mask, _, position_ids = get_ltor_masks_and_position_ids(
|
| 100 |
+
tokens,
|
| 101 |
+
eod_id,
|
| 102 |
+
reset_position_ids=False,
|
| 103 |
+
reset_attention_mask=False,
|
| 104 |
+
eod_mask_loss=False,
|
| 105 |
+
)
|
| 106 |
+
return tokens, attention_mask, position_ids
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def get_stop_words_ids(chat_format, tokenizer):
|
| 110 |
+
if chat_format == "raw":
|
| 111 |
+
stop_words_ids = [tokenizer.encode("Human:"), [tokenizer.eod_id]]
|
| 112 |
+
elif chat_format == "chatml":
|
| 113 |
+
stop_words_ids = [[tokenizer.im_end_id], [tokenizer.im_start_id]]
|
| 114 |
+
else:
|
| 115 |
+
raise NotImplementedError(f"Unknown chat format {chat_format!r}")
|
| 116 |
+
return stop_words_ids
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
def make_context(
|
| 120 |
+
tokenizer: PreTrainedTokenizer,
|
| 121 |
+
query: str,
|
| 122 |
+
history: List[Tuple[str, str]] = None,
|
| 123 |
+
system: str = "",
|
| 124 |
+
max_window_size: int = 6144,
|
| 125 |
+
chat_format: str = "chatml",
|
| 126 |
+
):
|
| 127 |
+
if history is None:
|
| 128 |
+
history = []
|
| 129 |
+
|
| 130 |
+
if chat_format == "chatml":
|
| 131 |
+
im_start, im_end = "<|im_start|>", "<|im_end|>"
|
| 132 |
+
im_start_tokens = [tokenizer.im_start_id]
|
| 133 |
+
im_end_tokens = [tokenizer.im_end_id]
|
| 134 |
+
nl_tokens = tokenizer.encode("\n")
|
| 135 |
+
|
| 136 |
+
def _tokenize_str(role, content):
|
| 137 |
+
return f"{role}\n{content}", tokenizer.encode(
|
| 138 |
+
role, allowed_special=set()
|
| 139 |
+
) + nl_tokens + tokenizer.encode(content, allowed_special=set())
|
| 140 |
+
|
| 141 |
+
system_text, system_tokens_part = _tokenize_str("system", system)
|
| 142 |
+
system_tokens = im_start_tokens + system_tokens_part + im_end_tokens
|
| 143 |
+
|
| 144 |
+
raw_text = ""
|
| 145 |
+
context_tokens = []
|
| 146 |
+
|
| 147 |
+
for turn_query, turn_response in reversed(history):
|
| 148 |
+
query_text, query_tokens_part = _tokenize_str("user", turn_query)
|
| 149 |
+
query_tokens = im_start_tokens + query_tokens_part + im_end_tokens
|
| 150 |
+
response_text, response_tokens_part = _tokenize_str(
|
| 151 |
+
"assistant", turn_response
|
| 152 |
+
)
|
| 153 |
+
response_tokens = im_start_tokens + response_tokens_part + im_end_tokens
|
| 154 |
+
|
| 155 |
+
next_context_tokens = nl_tokens + query_tokens + nl_tokens + response_tokens
|
| 156 |
+
prev_chat = (
|
| 157 |
+
f"\n{im_start}{query_text}{im_end}\n{im_start}{response_text}{im_end}"
|
| 158 |
+
)
|
| 159 |
+
|
| 160 |
+
current_context_size = (
|
| 161 |
+
len(system_tokens) + len(next_context_tokens) + len(context_tokens)
|
| 162 |
+
)
|
| 163 |
+
if current_context_size < max_window_size:
|
| 164 |
+
context_tokens = next_context_tokens + context_tokens
|
| 165 |
+
raw_text = prev_chat + raw_text
|
| 166 |
+
else:
|
| 167 |
+
break
|
| 168 |
+
|
| 169 |
+
context_tokens = system_tokens + context_tokens
|
| 170 |
+
raw_text = f"{im_start}{system_text}{im_end}" + raw_text
|
| 171 |
+
context_tokens += (
|
| 172 |
+
nl_tokens
|
| 173 |
+
+ im_start_tokens
|
| 174 |
+
+ _tokenize_str("user", query)[1]
|
| 175 |
+
+ im_end_tokens
|
| 176 |
+
+ nl_tokens
|
| 177 |
+
+ im_start_tokens
|
| 178 |
+
+ tokenizer.encode("assistant")
|
| 179 |
+
+ nl_tokens
|
| 180 |
+
)
|
| 181 |
+
raw_text += f"\n{im_start}user\n{query}{im_end}\n{im_start}assistant\n"
|
| 182 |
+
|
| 183 |
+
elif chat_format == "raw":
|
| 184 |
+
raw_text = query
|
| 185 |
+
context_tokens = tokenizer.encode(raw_text)
|
| 186 |
+
else:
|
| 187 |
+
raise NotImplementedError(f"Unknown chat format {chat_format!r}")
|
| 188 |
+
|
| 189 |
+
return raw_text, context_tokens
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
def _decode_default(
|
| 193 |
+
tokens: List[int],
|
| 194 |
+
*,
|
| 195 |
+
stop_words: List[str],
|
| 196 |
+
eod_words: List[str],
|
| 197 |
+
tokenizer: PreTrainedTokenizer,
|
| 198 |
+
raw_text_len: int,
|
| 199 |
+
verbose: bool = False,
|
| 200 |
+
return_end_reason: bool = False,
|
| 201 |
+
errors: str='replace',
|
| 202 |
+
):
|
| 203 |
+
trim_decode_tokens = tokenizer.decode(tokens, errors=errors)[raw_text_len:]
|
| 204 |
+
if verbose:
|
| 205 |
+
print("\nRaw Generate: ", trim_decode_tokens)
|
| 206 |
+
|
| 207 |
+
end_reason = f"Gen length {len(tokens)}"
|
| 208 |
+
for stop_word in stop_words:
|
| 209 |
+
trim_decode_tokens = trim_decode_tokens.replace(stop_word, "").strip()
|
| 210 |
+
for eod_word in eod_words:
|
| 211 |
+
if eod_word in trim_decode_tokens:
|
| 212 |
+
end_reason = f"Gen {eod_word!r}"
|
| 213 |
+
trim_decode_tokens = trim_decode_tokens.split(eod_word)[0]
|
| 214 |
+
trim_decode_tokens = trim_decode_tokens.strip()
|
| 215 |
+
if verbose:
|
| 216 |
+
print("\nEnd Reason:", end_reason)
|
| 217 |
+
print("\nGenerate: ", trim_decode_tokens)
|
| 218 |
+
|
| 219 |
+
if return_end_reason:
|
| 220 |
+
return trim_decode_tokens, end_reason
|
| 221 |
+
else:
|
| 222 |
+
return trim_decode_tokens
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
def _decode_chatml(
|
| 226 |
+
tokens: List[int],
|
| 227 |
+
*,
|
| 228 |
+
stop_words: List[str],
|
| 229 |
+
eod_token_ids: List[int],
|
| 230 |
+
tokenizer: PreTrainedTokenizer,
|
| 231 |
+
raw_text_len: int,
|
| 232 |
+
context_length: int,
|
| 233 |
+
verbose: bool = False,
|
| 234 |
+
return_end_reason: bool = False,
|
| 235 |
+
errors: str='replace'
|
| 236 |
+
):
|
| 237 |
+
end_reason = f"Gen length {len(tokens)}"
|
| 238 |
+
eod_token_idx = context_length
|
| 239 |
+
for eod_token_idx in range(context_length, len(tokens)):
|
| 240 |
+
if tokens[eod_token_idx] in eod_token_ids:
|
| 241 |
+
end_reason = f"Gen {tokenizer.decode([tokens[eod_token_idx]])!r}"
|
| 242 |
+
break
|
| 243 |
+
|
| 244 |
+
trim_decode_tokens = tokenizer.decode(tokens[:eod_token_idx], errors=errors)[raw_text_len:]
|
| 245 |
+
if verbose:
|
| 246 |
+
print("\nRaw Generate w/o EOD:", tokenizer.decode(tokens, errors=errors)[raw_text_len:])
|
| 247 |
+
print("\nRaw Generate:", trim_decode_tokens)
|
| 248 |
+
print("\nEnd Reason:", end_reason)
|
| 249 |
+
for stop_word in stop_words:
|
| 250 |
+
trim_decode_tokens = trim_decode_tokens.replace(stop_word, "").strip()
|
| 251 |
+
trim_decode_tokens = trim_decode_tokens.strip()
|
| 252 |
+
if verbose:
|
| 253 |
+
print("\nGenerate:", trim_decode_tokens)
|
| 254 |
+
|
| 255 |
+
if return_end_reason:
|
| 256 |
+
return trim_decode_tokens, end_reason
|
| 257 |
+
else:
|
| 258 |
+
return trim_decode_tokens
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
def decode_tokens(
|
| 262 |
+
tokens: Union[torch.LongTensor, TokensType],
|
| 263 |
+
tokenizer: PreTrainedTokenizer,
|
| 264 |
+
raw_text_len: int,
|
| 265 |
+
context_length: int,
|
| 266 |
+
chat_format: str,
|
| 267 |
+
verbose: bool = False,
|
| 268 |
+
return_end_reason: bool = False,
|
| 269 |
+
errors: str="replace",
|
| 270 |
+
) -> str:
|
| 271 |
+
if torch.is_tensor(tokens):
|
| 272 |
+
tokens = tokens.cpu().numpy().tolist()
|
| 273 |
+
|
| 274 |
+
if chat_format == "chatml":
|
| 275 |
+
return _decode_chatml(
|
| 276 |
+
tokens,
|
| 277 |
+
stop_words=[],
|
| 278 |
+
eod_token_ids=[tokenizer.im_start_id, tokenizer.im_end_id],
|
| 279 |
+
tokenizer=tokenizer,
|
| 280 |
+
raw_text_len=raw_text_len,
|
| 281 |
+
context_length=context_length,
|
| 282 |
+
verbose=verbose,
|
| 283 |
+
return_end_reason=return_end_reason,
|
| 284 |
+
errors=errors,
|
| 285 |
+
)
|
| 286 |
+
elif chat_format == "raw":
|
| 287 |
+
return _decode_default(
|
| 288 |
+
tokens,
|
| 289 |
+
stop_words=["<|endoftext|>"],
|
| 290 |
+
eod_words=["<|endoftext|>"],
|
| 291 |
+
tokenizer=tokenizer,
|
| 292 |
+
raw_text_len=raw_text_len,
|
| 293 |
+
verbose=verbose,
|
| 294 |
+
return_end_reason=return_end_reason,
|
| 295 |
+
errors=errors,
|
| 296 |
+
)
|
| 297 |
+
else:
|
| 298 |
+
raise NotImplementedError(f"Unknown chat format {chat_format!r}")
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
class StopWordsLogitsProcessor(LogitsProcessor):
|
| 302 |
+
"""
|
| 303 |
+
:class:`transformers.LogitsProcessor` that enforces that when specified sequences appear, stop geration.
|
| 304 |
+
|
| 305 |
+
Args:
|
| 306 |
+
stop_words_ids (:obj:`List[List[int]]`):
|
| 307 |
+
List of list of token ids of stop ids. In order to get the tokens of the words
|
| 308 |
+
that should not appear in the generated text, use :obj:`tokenizer(bad_word,
|
| 309 |
+
add_prefix_space=True).input_ids`.
|
| 310 |
+
eos_token_id (:obj:`int`):
|
| 311 |
+
The id of the `end-of-sequence` token.
|
| 312 |
+
"""
|
| 313 |
+
|
| 314 |
+
def __init__(self, stop_words_ids: Iterable[Iterable[int]], eos_token_id: int):
|
| 315 |
+
|
| 316 |
+
if not isinstance(stop_words_ids, List) or len(stop_words_ids) == 0:
|
| 317 |
+
raise ValueError(
|
| 318 |
+
f"`stop_words_ids` has to be a non-emtpy list, but is {stop_words_ids}."
|
| 319 |
+
)
|
| 320 |
+
if any(not isinstance(bad_word_ids, list) for bad_word_ids in stop_words_ids):
|
| 321 |
+
raise ValueError(
|
| 322 |
+
f"`stop_words_ids` has to be a list of lists, but is {stop_words_ids}."
|
| 323 |
+
)
|
| 324 |
+
if any(
|
| 325 |
+
any(
|
| 326 |
+
(not isinstance(token_id, (int, np.integer)) or token_id < 0)
|
| 327 |
+
for token_id in stop_word_ids
|
| 328 |
+
)
|
| 329 |
+
for stop_word_ids in stop_words_ids
|
| 330 |
+
):
|
| 331 |
+
raise ValueError(
|
| 332 |
+
f"Each list in `stop_words_ids` has to be a list of positive integers, but is {stop_words_ids}."
|
| 333 |
+
)
|
| 334 |
+
|
| 335 |
+
self.stop_words_ids = list(
|
| 336 |
+
filter(
|
| 337 |
+
lambda bad_token_seq: bad_token_seq != [eos_token_id], stop_words_ids
|
| 338 |
+
)
|
| 339 |
+
)
|
| 340 |
+
self.eos_token_id = eos_token_id
|
| 341 |
+
for stop_token_seq in self.stop_words_ids:
|
| 342 |
+
assert (
|
| 343 |
+
len(stop_token_seq) > 0
|
| 344 |
+
), "Stop words token sequences {} cannot have an empty list".format(
|
| 345 |
+
stop_words_ids
|
| 346 |
+
)
|
| 347 |
+
|
| 348 |
+
def __call__(
|
| 349 |
+
self, input_ids: torch.LongTensor, scores: torch.FloatTensor
|
| 350 |
+
) -> torch.FloatTensor:
|
| 351 |
+
stopped_samples = self._calc_stopped_samples(input_ids)
|
| 352 |
+
for i, should_stop in enumerate(stopped_samples):
|
| 353 |
+
if should_stop:
|
| 354 |
+
scores[i, self.eos_token_id] = float(2**15)
|
| 355 |
+
return scores
|
| 356 |
+
|
| 357 |
+
def _tokens_match(self, prev_tokens: torch.LongTensor, tokens: List[int]) -> bool:
|
| 358 |
+
if len(tokens) == 0:
|
| 359 |
+
# if bad word tokens is just one token always ban it
|
| 360 |
+
return True
|
| 361 |
+
elif len(tokens) > len(prev_tokens):
|
| 362 |
+
# if bad word tokens are longer then prev input_ids they can't be equal
|
| 363 |
+
return False
|
| 364 |
+
elif prev_tokens[-len(tokens) :].tolist() == tokens:
|
| 365 |
+
# if tokens match
|
| 366 |
+
return True
|
| 367 |
+
else:
|
| 368 |
+
return False
|
| 369 |
+
|
| 370 |
+
def _calc_stopped_samples(self, prev_input_ids: Iterable[int]) -> Iterable[int]:
|
| 371 |
+
stopped_samples = []
|
| 372 |
+
for prev_input_ids_slice in prev_input_ids:
|
| 373 |
+
match = False
|
| 374 |
+
for stop_token_seq in self.stop_words_ids:
|
| 375 |
+
if self._tokens_match(prev_input_ids_slice, stop_token_seq):
|
| 376 |
+
# if tokens do not match continue
|
| 377 |
+
match = True
|
| 378 |
+
break
|
| 379 |
+
stopped_samples.append(match)
|
| 380 |
+
|
| 381 |
+
return stopped_samples
|
| 382 |
+
|
| 383 |
+
|
| 384 |
+
def top_k_logits(logits, top_k=0, top_p=0.0, filter_value=-float("Inf")):
|
| 385 |
+
"""This function has been mostly taken from huggingface conversational
|
| 386 |
+
ai code at
|
| 387 |
+
https://medium.com/huggingface/how-to-build-a-state-of-the-art-
|
| 388 |
+
conversational-ai-with-transfer-learning-2d818ac26313"""
|
| 389 |
+
|
| 390 |
+
if top_k > 0:
|
| 391 |
+
# Remove all tokens with a probability less than the
|
| 392 |
+
# last token of the top-k
|
| 393 |
+
indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None]
|
| 394 |
+
logits[indices_to_remove] = filter_value
|
| 395 |
+
|
| 396 |
+
if top_p > 0.0:
|
| 397 |
+
# Cconvert to 1D
|
| 398 |
+
sorted_logits, sorted_indices = torch.sort(logits, descending=True, dim=-1)
|
| 399 |
+
cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
|
| 400 |
+
|
| 401 |
+
# Remove tokens with cumulative probability above the threshold
|
| 402 |
+
sorted_indices_to_remove = cumulative_probs > top_p
|
| 403 |
+
# Shift the indices to the right to keep also the first token
|
| 404 |
+
# above the threshold
|
| 405 |
+
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
|
| 406 |
+
sorted_indices_to_remove[..., 0] = 0
|
| 407 |
+
for i in range(sorted_indices.size(0)):
|
| 408 |
+
indices_to_remove = sorted_indices[i][sorted_indices_to_remove[i]]
|
| 409 |
+
logits[i][indices_to_remove] = filter_value
|
| 410 |
+
|
| 411 |
+
return logits
|
| 412 |
+
|
| 413 |
+
|
| 414 |
+
def switch(val1, val2, boolean):
|
| 415 |
+
boolean = boolean.type_as(val1)
|
| 416 |
+
return (1 - boolean) * val1 + boolean * val2
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
{
|
| 4 |
+
"content": "<|im_end|>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false
|
| 9 |
+
}
|
| 10 |
+
],
|
| 11 |
+
"eos_token": "<|endoftext|>",
|
| 12 |
+
"pad_token": "<|endoftext|>"
|
| 13 |
+
}
|
tokenization_qwen.py
ADDED
|
@@ -0,0 +1,276 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Alibaba Cloud.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
"""Tokenization classes for QWen."""
|
| 7 |
+
|
| 8 |
+
import base64
|
| 9 |
+
import logging
|
| 10 |
+
import os
|
| 11 |
+
import unicodedata
|
| 12 |
+
from typing import Collection, Dict, List, Set, Tuple, Union
|
| 13 |
+
|
| 14 |
+
import tiktoken
|
| 15 |
+
from transformers import PreTrainedTokenizer, AddedToken
|
| 16 |
+
|
| 17 |
+
logger = logging.getLogger(__name__)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
VOCAB_FILES_NAMES = {"vocab_file": "qwen.tiktoken"}
|
| 21 |
+
|
| 22 |
+
PAT_STR = r"""(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+"""
|
| 23 |
+
ENDOFTEXT = "<|endoftext|>"
|
| 24 |
+
IMSTART = "<|im_start|>"
|
| 25 |
+
IMEND = "<|im_end|>"
|
| 26 |
+
# as the default behavior is changed to allow special tokens in
|
| 27 |
+
# regular texts, the surface forms of special tokens need to be
|
| 28 |
+
# as different as possible to minimize the impact
|
| 29 |
+
EXTRAS = tuple((f"<|extra_{i}|>" for i in range(205)))
|
| 30 |
+
# changed to use actual index to avoid misconfiguration with vocabulary expansion
|
| 31 |
+
SPECIAL_START_ID = 151643
|
| 32 |
+
SPECIAL_TOKENS = tuple(
|
| 33 |
+
enumerate(
|
| 34 |
+
(
|
| 35 |
+
(
|
| 36 |
+
ENDOFTEXT,
|
| 37 |
+
IMSTART,
|
| 38 |
+
IMEND,
|
| 39 |
+
)
|
| 40 |
+
+ EXTRAS
|
| 41 |
+
),
|
| 42 |
+
start=SPECIAL_START_ID,
|
| 43 |
+
)
|
| 44 |
+
)
|
| 45 |
+
SPECIAL_TOKENS_SET = set(t for i, t in SPECIAL_TOKENS)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def _load_tiktoken_bpe(tiktoken_bpe_file: str) -> Dict[bytes, int]:
|
| 49 |
+
with open(tiktoken_bpe_file, "rb") as f:
|
| 50 |
+
contents = f.read()
|
| 51 |
+
return {
|
| 52 |
+
base64.b64decode(token): int(rank)
|
| 53 |
+
for token, rank in (line.split() for line in contents.splitlines() if line)
|
| 54 |
+
}
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class QWenTokenizer(PreTrainedTokenizer):
|
| 58 |
+
"""QWen tokenizer."""
|
| 59 |
+
|
| 60 |
+
vocab_files_names = VOCAB_FILES_NAMES
|
| 61 |
+
|
| 62 |
+
def __init__(
|
| 63 |
+
self,
|
| 64 |
+
vocab_file,
|
| 65 |
+
errors="replace",
|
| 66 |
+
extra_vocab_file=None,
|
| 67 |
+
**kwargs,
|
| 68 |
+
):
|
| 69 |
+
super().__init__(**kwargs)
|
| 70 |
+
|
| 71 |
+
# how to handle errors in decoding UTF-8 byte sequences
|
| 72 |
+
# use ignore if you are in streaming inference
|
| 73 |
+
self.errors = errors
|
| 74 |
+
|
| 75 |
+
self.mergeable_ranks = _load_tiktoken_bpe(vocab_file) # type: Dict[bytes, int]
|
| 76 |
+
self.special_tokens = {
|
| 77 |
+
token: index
|
| 78 |
+
for index, token in SPECIAL_TOKENS
|
| 79 |
+
}
|
| 80 |
+
|
| 81 |
+
# try load extra vocab from file
|
| 82 |
+
if extra_vocab_file is not None:
|
| 83 |
+
used_ids = set(self.mergeable_ranks.values()) | set(self.special_tokens.values())
|
| 84 |
+
extra_mergeable_ranks = _load_tiktoken_bpe(extra_vocab_file)
|
| 85 |
+
for token, index in extra_mergeable_ranks.items():
|
| 86 |
+
if token in self.mergeable_ranks:
|
| 87 |
+
logger.info(f"extra token {token} exists, skipping")
|
| 88 |
+
continue
|
| 89 |
+
if index in used_ids:
|
| 90 |
+
logger.info(f'the index {index} for extra token {token} exists, skipping')
|
| 91 |
+
continue
|
| 92 |
+
self.mergeable_ranks[token] = index
|
| 93 |
+
# the index may be sparse after this, but don't worry tiktoken.Encoding will handle this
|
| 94 |
+
|
| 95 |
+
enc = tiktoken.Encoding(
|
| 96 |
+
"Qwen",
|
| 97 |
+
pat_str=PAT_STR,
|
| 98 |
+
mergeable_ranks=self.mergeable_ranks,
|
| 99 |
+
special_tokens=self.special_tokens,
|
| 100 |
+
)
|
| 101 |
+
assert (
|
| 102 |
+
len(self.mergeable_ranks) + len(self.special_tokens) == enc.n_vocab
|
| 103 |
+
), f"{len(self.mergeable_ranks) + len(self.special_tokens)} != {enc.n_vocab} in encoding"
|
| 104 |
+
|
| 105 |
+
self.decoder = {
|
| 106 |
+
v: k for k, v in self.mergeable_ranks.items()
|
| 107 |
+
} # type: dict[int, bytes|str]
|
| 108 |
+
self.decoder.update({v: k for k, v in self.special_tokens.items()})
|
| 109 |
+
|
| 110 |
+
self.tokenizer = enc # type: tiktoken.Encoding
|
| 111 |
+
|
| 112 |
+
self.eod_id = self.tokenizer.eot_token
|
| 113 |
+
self.im_start_id = self.special_tokens[IMSTART]
|
| 114 |
+
self.im_end_id = self.special_tokens[IMEND]
|
| 115 |
+
|
| 116 |
+
def __getstate__(self):
|
| 117 |
+
# for pickle lovers
|
| 118 |
+
state = self.__dict__.copy()
|
| 119 |
+
del state["tokenizer"]
|
| 120 |
+
return state
|
| 121 |
+
|
| 122 |
+
def __setstate__(self, state):
|
| 123 |
+
# tokenizer is not python native; don't pass it; rebuild it
|
| 124 |
+
self.__dict__.update(state)
|
| 125 |
+
enc = tiktoken.Encoding(
|
| 126 |
+
"Qwen",
|
| 127 |
+
pat_str=PAT_STR,
|
| 128 |
+
mergeable_ranks=self.mergeable_ranks,
|
| 129 |
+
special_tokens=self.special_tokens,
|
| 130 |
+
)
|
| 131 |
+
self.tokenizer = enc
|
| 132 |
+
|
| 133 |
+
def __len__(self) -> int:
|
| 134 |
+
return self.tokenizer.n_vocab
|
| 135 |
+
|
| 136 |
+
def get_vocab(self) -> Dict[bytes, int]:
|
| 137 |
+
return self.mergeable_ranks
|
| 138 |
+
|
| 139 |
+
def convert_tokens_to_ids(
|
| 140 |
+
self, tokens: Union[bytes, str, List[Union[bytes, str]]]
|
| 141 |
+
) -> List[int]:
|
| 142 |
+
ids = []
|
| 143 |
+
if isinstance(tokens, (str, bytes)):
|
| 144 |
+
if tokens in self.special_tokens:
|
| 145 |
+
return self.special_tokens[tokens]
|
| 146 |
+
else:
|
| 147 |
+
return self.mergeable_ranks.get(tokens)
|
| 148 |
+
for token in tokens:
|
| 149 |
+
if token in self.special_tokens:
|
| 150 |
+
ids.append(self.special_tokens[token])
|
| 151 |
+
else:
|
| 152 |
+
ids.append(self.mergeable_ranks.get(token))
|
| 153 |
+
return ids
|
| 154 |
+
|
| 155 |
+
def _add_tokens(
|
| 156 |
+
self,
|
| 157 |
+
new_tokens: Union[List[str], List[AddedToken]],
|
| 158 |
+
special_tokens: bool = False,
|
| 159 |
+
) -> int:
|
| 160 |
+
if not special_tokens and new_tokens:
|
| 161 |
+
raise ValueError("Adding regular tokens is not supported")
|
| 162 |
+
for token in new_tokens:
|
| 163 |
+
surface_form = token.content if isinstance(token, AddedToken) else token
|
| 164 |
+
if surface_form not in SPECIAL_TOKENS_SET:
|
| 165 |
+
raise ValueError("Adding unknown special tokens is not supported")
|
| 166 |
+
return 0
|
| 167 |
+
|
| 168 |
+
def save_vocabulary(self, save_directory: str, **kwargs) -> Tuple[str]:
|
| 169 |
+
"""
|
| 170 |
+
Save only the vocabulary of the tokenizer (vocabulary).
|
| 171 |
+
|
| 172 |
+
Returns:
|
| 173 |
+
`Tuple(str)`: Paths to the files saved.
|
| 174 |
+
"""
|
| 175 |
+
file_path = os.path.join(save_directory, "qwen.tiktoken")
|
| 176 |
+
with open(file_path, "w", encoding="utf8") as w:
|
| 177 |
+
for k, v in self.mergeable_ranks.items():
|
| 178 |
+
line = base64.b64encode(k).decode("utf8") + " " + str(v) + "\n"
|
| 179 |
+
w.write(line)
|
| 180 |
+
return (file_path,)
|
| 181 |
+
|
| 182 |
+
def tokenize(
|
| 183 |
+
self,
|
| 184 |
+
text: str,
|
| 185 |
+
allowed_special: Union[Set, str] = "all",
|
| 186 |
+
disallowed_special: Union[Collection, str] = (),
|
| 187 |
+
**kwargs,
|
| 188 |
+
) -> List[Union[bytes, str]]:
|
| 189 |
+
"""
|
| 190 |
+
Converts a string in a sequence of tokens.
|
| 191 |
+
|
| 192 |
+
Args:
|
| 193 |
+
text (`str`):
|
| 194 |
+
The sequence to be encoded.
|
| 195 |
+
allowed_special (`Literal["all"]` or `set`):
|
| 196 |
+
The surface forms of the tokens to be encoded as special tokens in regular texts.
|
| 197 |
+
Default to "all".
|
| 198 |
+
disallowed_special (`Literal["all"]` or `Collection`):
|
| 199 |
+
The surface forms of the tokens that should not be in regular texts and trigger errors.
|
| 200 |
+
Default to an empty tuple.
|
| 201 |
+
|
| 202 |
+
kwargs (additional keyword arguments, *optional*):
|
| 203 |
+
Will be passed to the underlying model specific encode method.
|
| 204 |
+
|
| 205 |
+
Returns:
|
| 206 |
+
`List[bytes|str]`: The list of tokens.
|
| 207 |
+
"""
|
| 208 |
+
tokens = []
|
| 209 |
+
text = unicodedata.normalize("NFC", text)
|
| 210 |
+
|
| 211 |
+
# this implementation takes a detour: text -> token id -> token surface forms
|
| 212 |
+
for t in self.tokenizer.encode(
|
| 213 |
+
text, allowed_special=allowed_special, disallowed_special=disallowed_special
|
| 214 |
+
):
|
| 215 |
+
tokens.append(self.decoder[t])
|
| 216 |
+
return tokens
|
| 217 |
+
|
| 218 |
+
def convert_tokens_to_string(self, tokens: List[Union[bytes, str]]) -> str:
|
| 219 |
+
"""
|
| 220 |
+
Converts a sequence of tokens in a single string.
|
| 221 |
+
"""
|
| 222 |
+
text = ""
|
| 223 |
+
temp = b""
|
| 224 |
+
for t in tokens:
|
| 225 |
+
if isinstance(t, str):
|
| 226 |
+
if temp:
|
| 227 |
+
text += temp.decode("utf-8", errors=self.errors)
|
| 228 |
+
temp = b""
|
| 229 |
+
text += t
|
| 230 |
+
elif isinstance(t, bytes):
|
| 231 |
+
temp += t
|
| 232 |
+
else:
|
| 233 |
+
raise TypeError("token should only be of type types or str")
|
| 234 |
+
if temp:
|
| 235 |
+
text += temp.decode("utf-8", errors=self.errors)
|
| 236 |
+
return text
|
| 237 |
+
|
| 238 |
+
@property
|
| 239 |
+
def vocab_size(self):
|
| 240 |
+
return self.tokenizer.n_vocab
|
| 241 |
+
|
| 242 |
+
def _convert_id_to_token(self, index: int) -> Union[bytes, str]:
|
| 243 |
+
"""Converts an id to a token, special tokens included"""
|
| 244 |
+
if index in self.decoder:
|
| 245 |
+
return self.decoder[index]
|
| 246 |
+
raise ValueError("unknown ids")
|
| 247 |
+
|
| 248 |
+
def _convert_token_to_id(self, token: Union[bytes, str]) -> int:
|
| 249 |
+
"""Converts a token to an id using the vocab, special tokens included"""
|
| 250 |
+
if token in self.special_tokens:
|
| 251 |
+
return self.special_tokens[token]
|
| 252 |
+
if token in self.mergeable_ranks:
|
| 253 |
+
return self.mergeable_ranks[token]
|
| 254 |
+
raise ValueError("unknown token")
|
| 255 |
+
|
| 256 |
+
def _tokenize(self, text: str, **kwargs):
|
| 257 |
+
"""
|
| 258 |
+
Converts a string in a sequence of tokens (string), using the tokenizer. Split in words for word-based
|
| 259 |
+
vocabulary or sub-words for sub-word-based vocabularies (BPE/SentencePieces/WordPieces).
|
| 260 |
+
|
| 261 |
+
Do NOT take care of added tokens.
|
| 262 |
+
"""
|
| 263 |
+
raise NotImplementedError
|
| 264 |
+
|
| 265 |
+
def _decode(
|
| 266 |
+
self,
|
| 267 |
+
token_ids: Union[int, List[int]],
|
| 268 |
+
skip_special_tokens: bool = False,
|
| 269 |
+
errors: str = None,
|
| 270 |
+
**kwargs,
|
| 271 |
+
) -> str:
|
| 272 |
+
if isinstance(token_ids, int):
|
| 273 |
+
token_ids = [token_ids]
|
| 274 |
+
if skip_special_tokens:
|
| 275 |
+
token_ids = [i for i in token_ids if i < self.eod_id]
|
| 276 |
+
return self.tokenizer.decode(token_ids, errors=errors or self.errors)
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {},
|
| 3 |
+
"additional_special_tokens": [
|
| 4 |
+
"<|im_end|>"
|
| 5 |
+
],
|
| 6 |
+
"auto_map": {
|
| 7 |
+
"AutoTokenizer": [
|
| 8 |
+
"tokenization_qwen.QWenTokenizer",
|
| 9 |
+
null
|
| 10 |
+
]
|
| 11 |
+
},
|
| 12 |
+
"clean_up_tokenization_spaces": true,
|
| 13 |
+
"eos_token": "<|endoftext|>",
|
| 14 |
+
"model_max_length": 8192,
|
| 15 |
+
"pad_token": "<|endoftext|>",
|
| 16 |
+
"padding_side": "right",
|
| 17 |
+
"split_special_tokens": false,
|
| 18 |
+
"tokenizer_class": "QWenTokenizer"
|
| 19 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"train_loss": 1.4494417681873177,
|
| 4 |
+
"train_runtime": 7393.5069,
|
| 5 |
+
"train_samples_per_second": 10.831,
|
| 6 |
+
"train_steps_per_second": 0.169
|
| 7 |
+
}
|
trainer_log.jsonl
ADDED
|
@@ -0,0 +1,126 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"current_steps": 10, "total_steps": 1251, "loss": 2.3263, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.9992117348705316e-05, "epoch": 0.01, "percentage": 0.8, "elapsed_time": "0:01:00", "remaining_time": "2:05:49"}
|
| 2 |
+
{"current_steps": 20, "total_steps": 1251, "loss": 1.9238, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.9968474365716575e-05, "epoch": 0.02, "percentage": 1.6, "elapsed_time": "0:02:01", "remaining_time": "2:04:46"}
|
| 3 |
+
{"current_steps": 30, "total_steps": 1251, "loss": 1.8386, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.992908596058501e-05, "epoch": 0.02, "percentage": 2.4, "elapsed_time": "0:03:03", "remaining_time": "2:04:08"}
|
| 4 |
+
{"current_steps": 40, "total_steps": 1251, "loss": 1.7599, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.9873976972115636e-05, "epoch": 0.03, "percentage": 3.2, "elapsed_time": "0:04:02", "remaining_time": "2:02:25"}
|
| 5 |
+
{"current_steps": 50, "total_steps": 1251, "loss": 1.7486, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.980318215270361e-05, "epoch": 0.04, "percentage": 4.0, "elapsed_time": "0:05:04", "remaining_time": "2:01:45"}
|
| 6 |
+
{"current_steps": 60, "total_steps": 1251, "loss": 1.7243, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.9716746146418905e-05, "epoch": 0.05, "percentage": 4.8, "elapsed_time": "0:06:03", "remaining_time": "2:00:11"}
|
| 7 |
+
{"current_steps": 70, "total_steps": 1251, "loss": 1.684, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.9614723460853294e-05, "epoch": 0.06, "percentage": 5.6, "elapsed_time": "0:07:01", "remaining_time": "1:58:30"}
|
| 8 |
+
{"current_steps": 80, "total_steps": 1251, "loss": 1.7019, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.949717843274711e-05, "epoch": 0.06, "percentage": 6.39, "elapsed_time": "0:07:55", "remaining_time": "1:56:00"}
|
| 9 |
+
{"current_steps": 90, "total_steps": 1251, "loss": 1.6845, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.93641851874178e-05, "epoch": 0.07, "percentage": 7.19, "elapsed_time": "0:08:59", "remaining_time": "1:55:54"}
|
| 10 |
+
{"current_steps": 100, "total_steps": 1251, "loss": 1.6427, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.921582759201557e-05, "epoch": 0.08, "percentage": 7.99, "elapsed_time": "0:09:59", "remaining_time": "1:54:56"}
|
| 11 |
+
{"current_steps": 110, "total_steps": 1251, "loss": 1.6465, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.905219920263573e-05, "epoch": 0.09, "percentage": 8.79, "elapsed_time": "0:10:57", "remaining_time": "1:53:37"}
|
| 12 |
+
{"current_steps": 120, "total_steps": 1251, "loss": 1.6448, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.887340320532111e-05, "epoch": 0.1, "percentage": 9.59, "elapsed_time": "0:11:56", "remaining_time": "1:52:29"}
|
| 13 |
+
{"current_steps": 130, "total_steps": 1251, "loss": 1.6385, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.86795523509917e-05, "epoch": 0.1, "percentage": 10.39, "elapsed_time": "0:12:57", "remaining_time": "1:51:48"}
|
| 14 |
+
{"current_steps": 140, "total_steps": 1251, "loss": 1.6059, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.847076888434251e-05, "epoch": 0.11, "percentage": 11.19, "elapsed_time": "0:13:58", "remaining_time": "1:50:54"}
|
| 15 |
+
{"current_steps": 150, "total_steps": 1251, "loss": 1.6419, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.824718446675464e-05, "epoch": 0.12, "percentage": 11.99, "elapsed_time": "0:14:54", "remaining_time": "1:49:24"}
|
| 16 |
+
{"current_steps": 160, "total_steps": 1251, "loss": 1.6043, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.800894009326801e-05, "epoch": 0.13, "percentage": 12.79, "elapsed_time": "0:15:50", "remaining_time": "1:47:59"}
|
| 17 |
+
{"current_steps": 170, "total_steps": 1251, "loss": 1.5975, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.775618600366812e-05, "epoch": 0.14, "percentage": 13.59, "elapsed_time": "0:16:49", "remaining_time": "1:46:56"}
|
| 18 |
+
{"current_steps": 180, "total_steps": 1251, "loss": 1.5865, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.7489081587743125e-05, "epoch": 0.14, "percentage": 14.39, "elapsed_time": "0:17:49", "remaining_time": "1:46:02"}
|
| 19 |
+
{"current_steps": 190, "total_steps": 1251, "loss": 1.5931, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.7207795284770605e-05, "epoch": 0.15, "percentage": 15.19, "elapsed_time": "0:18:52", "remaining_time": "1:45:23"}
|
| 20 |
+
{"current_steps": 200, "total_steps": 1251, "loss": 1.5763, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.69125044772978e-05, "epoch": 0.16, "percentage": 15.99, "elapsed_time": "0:19:52", "remaining_time": "1:44:28"}
|
| 21 |
+
{"current_steps": 210, "total_steps": 1251, "loss": 1.5786, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.6603395379281975e-05, "epoch": 0.17, "percentage": 16.79, "elapsed_time": "0:20:53", "remaining_time": "1:43:33"}
|
| 22 |
+
{"current_steps": 220, "total_steps": 1251, "loss": 1.5494, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.628066291866166e-05, "epoch": 0.18, "percentage": 17.59, "elapsed_time": "0:21:53", "remaining_time": "1:42:33"}
|
| 23 |
+
{"current_steps": 230, "total_steps": 1251, "loss": 1.5663, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.5944510614432734e-05, "epoch": 0.18, "percentage": 18.39, "elapsed_time": "0:22:50", "remaining_time": "1:41:22"}
|
| 24 |
+
{"current_steps": 240, "total_steps": 1251, "loss": 1.5687, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.55951504483069e-05, "epoch": 0.19, "percentage": 19.18, "elapsed_time": "0:23:48", "remaining_time": "1:40:15"}
|
| 25 |
+
{"current_steps": 250, "total_steps": 1251, "loss": 1.5446, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.523280273103342e-05, "epoch": 0.2, "percentage": 19.98, "elapsed_time": "0:24:48", "remaining_time": "1:39:19"}
|
| 26 |
+
{"current_steps": 260, "total_steps": 1251, "loss": 1.5486, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.485769596346849e-05, "epoch": 0.21, "percentage": 20.78, "elapsed_time": "0:25:46", "remaining_time": "1:38:15"}
|
| 27 |
+
{"current_steps": 270, "total_steps": 1251, "loss": 1.5278, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.447006669247991e-05, "epoch": 0.22, "percentage": 21.58, "elapsed_time": "0:26:45", "remaining_time": "1:37:14"}
|
| 28 |
+
{"current_steps": 280, "total_steps": 1251, "loss": 1.5244, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.407015936177762e-05, "epoch": 0.22, "percentage": 22.38, "elapsed_time": "0:27:44", "remaining_time": "1:36:12"}
|
| 29 |
+
{"current_steps": 290, "total_steps": 1251, "loss": 1.5223, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.3658226157764704e-05, "epoch": 0.23, "percentage": 23.18, "elapsed_time": "0:28:45", "remaining_time": "1:35:17"}
|
| 30 |
+
{"current_steps": 300, "total_steps": 1251, "loss": 1.5536, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.3234526850505456e-05, "epoch": 0.24, "percentage": 23.98, "elapsed_time": "0:29:45", "remaining_time": "1:34:21"}
|
| 31 |
+
{"current_steps": 310, "total_steps": 1251, "loss": 1.5282, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.2799328629911323e-05, "epoch": 0.25, "percentage": 24.78, "elapsed_time": "0:30:41", "remaining_time": "1:33:10"}
|
| 32 |
+
{"current_steps": 320, "total_steps": 1251, "loss": 1.5201, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.2352905937247654e-05, "epoch": 0.26, "percentage": 25.58, "elapsed_time": "0:31:34", "remaining_time": "1:31:51"}
|
| 33 |
+
{"current_steps": 330, "total_steps": 1251, "loss": 1.495, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.189554029206776e-05, "epoch": 0.26, "percentage": 26.38, "elapsed_time": "0:32:32", "remaining_time": "1:30:48"}
|
| 34 |
+
{"current_steps": 340, "total_steps": 1251, "loss": 1.5137, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.142752011468326e-05, "epoch": 0.27, "percentage": 27.18, "elapsed_time": "0:33:33", "remaining_time": "1:29:55"}
|
| 35 |
+
{"current_steps": 350, "total_steps": 1251, "loss": 1.4861, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.094914054428272e-05, "epoch": 0.28, "percentage": 27.98, "elapsed_time": "0:34:32", "remaining_time": "1:28:56"}
|
| 36 |
+
{"current_steps": 360, "total_steps": 1251, "loss": 1.5195, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.0460703252813326e-05, "epoch": 0.29, "percentage": 28.78, "elapsed_time": "0:35:34", "remaining_time": "1:28:02"}
|
| 37 |
+
{"current_steps": 370, "total_steps": 1251, "loss": 1.4974, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.996251625474293e-05, "epoch": 0.3, "percentage": 29.58, "elapsed_time": "0:36:32", "remaining_time": "1:27:01"}
|
| 38 |
+
{"current_steps": 380, "total_steps": 1251, "loss": 1.5008, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.945489371282237e-05, "epoch": 0.3, "percentage": 30.38, "elapsed_time": "0:37:30", "remaining_time": "1:25:57"}
|
| 39 |
+
{"current_steps": 390, "total_steps": 1251, "loss": 1.5005, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.89381557399706e-05, "epoch": 0.31, "percentage": 31.18, "elapsed_time": "0:38:28", "remaining_time": "1:24:55"}
|
| 40 |
+
{"current_steps": 400, "total_steps": 1251, "loss": 1.4808, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.84126281974077e-05, "epoch": 0.32, "percentage": 31.97, "elapsed_time": "0:39:22", "remaining_time": "1:23:46"}
|
| 41 |
+
{"current_steps": 410, "total_steps": 1251, "loss": 1.4921, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.787864248916276e-05, "epoch": 0.33, "percentage": 32.77, "elapsed_time": "0:40:23", "remaining_time": "1:22:51"}
|
| 42 |
+
{"current_steps": 420, "total_steps": 1251, "loss": 1.4761, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.7336535353086544e-05, "epoch": 0.34, "percentage": 33.57, "elapsed_time": "0:41:24", "remaining_time": "1:21:55"}
|
| 43 |
+
{"current_steps": 430, "total_steps": 1251, "loss": 1.4805, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.6786648648500495e-05, "epoch": 0.34, "percentage": 34.37, "elapsed_time": "0:42:24", "remaining_time": "1:20:57"}
|
| 44 |
+
{"current_steps": 440, "total_steps": 1251, "loss": 1.4614, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.622932914061611e-05, "epoch": 0.35, "percentage": 35.17, "elapsed_time": "0:43:22", "remaining_time": "1:19:57"}
|
| 45 |
+
{"current_steps": 450, "total_steps": 1251, "loss": 1.4709, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.566492828186063e-05, "epoch": 0.36, "percentage": 35.97, "elapsed_time": "0:44:21", "remaining_time": "1:18:57"}
|
| 46 |
+
{"current_steps": 460, "total_steps": 1251, "loss": 1.497, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.509380199024684e-05, "epoch": 0.37, "percentage": 36.77, "elapsed_time": "0:45:20", "remaining_time": "1:17:57"}
|
| 47 |
+
{"current_steps": 470, "total_steps": 1251, "loss": 1.4642, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.451631042492693e-05, "epoch": 0.38, "percentage": 37.57, "elapsed_time": "0:46:17", "remaining_time": "1:16:56"}
|
| 48 |
+
{"current_steps": 480, "total_steps": 1251, "loss": 1.4579, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.393281775907167e-05, "epoch": 0.38, "percentage": 38.37, "elapsed_time": "0:47:13", "remaining_time": "1:15:51"}
|
| 49 |
+
{"current_steps": 490, "total_steps": 1251, "loss": 1.4586, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.3343691950218514e-05, "epoch": 0.39, "percentage": 39.17, "elapsed_time": "0:48:12", "remaining_time": "1:14:52"}
|
| 50 |
+
{"current_steps": 500, "total_steps": 1251, "loss": 1.4664, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.2749304508233056e-05, "epoch": 0.4, "percentage": 39.97, "elapsed_time": "0:49:12", "remaining_time": "1:13:54"}
|
| 51 |
+
{"current_steps": 510, "total_steps": 1251, "loss": 1.4452, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.215003026103041e-05, "epoch": 0.41, "percentage": 40.77, "elapsed_time": "0:50:10", "remaining_time": "1:12:53"}
|
| 52 |
+
{"current_steps": 520, "total_steps": 1251, "loss": 1.4393, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.1546247118204235e-05, "epoch": 0.42, "percentage": 41.57, "elapsed_time": "0:51:11", "remaining_time": "1:11:57"}
|
| 53 |
+
{"current_steps": 530, "total_steps": 1251, "loss": 1.4462, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.093833583271233e-05, "epoch": 0.42, "percentage": 42.37, "elapsed_time": "0:52:10", "remaining_time": "1:10:58"}
|
| 54 |
+
{"current_steps": 540, "total_steps": 1251, "loss": 1.4334, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.0326679760769226e-05, "epoch": 0.43, "percentage": 43.17, "elapsed_time": "0:53:08", "remaining_time": "1:09:58"}
|
| 55 |
+
{"current_steps": 550, "total_steps": 1251, "loss": 1.4495, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.9711664620097107e-05, "epoch": 0.44, "percentage": 43.96, "elapsed_time": "0:54:02", "remaining_time": "1:08:53"}
|
| 56 |
+
{"current_steps": 560, "total_steps": 1251, "loss": 1.4096, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.9093678246687574e-05, "epoch": 0.45, "percentage": 44.76, "elapsed_time": "0:54:59", "remaining_time": "1:07:50"}
|
| 57 |
+
{"current_steps": 570, "total_steps": 1251, "loss": 1.4371, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.847311035022753e-05, "epoch": 0.46, "percentage": 45.56, "elapsed_time": "0:55:58", "remaining_time": "1:06:52"}
|
| 58 |
+
{"current_steps": 580, "total_steps": 1251, "loss": 1.425, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.7850352268343594e-05, "epoch": 0.46, "percentage": 46.36, "elapsed_time": "0:56:58", "remaining_time": "1:05:54"}
|
| 59 |
+
{"current_steps": 590, "total_steps": 1251, "loss": 1.4343, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.7225796719819778e-05, "epoch": 0.47, "percentage": 47.16, "elapsed_time": "0:57:58", "remaining_time": "1:04:56"}
|
| 60 |
+
{"current_steps": 600, "total_steps": 1251, "loss": 1.4293, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.6599837556944353e-05, "epoch": 0.48, "percentage": 47.96, "elapsed_time": "0:58:58", "remaining_time": "1:03:59"}
|
| 61 |
+
{"current_steps": 610, "total_steps": 1251, "loss": 1.4137, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.597286951714176e-05, "epoch": 0.49, "percentage": 48.76, "elapsed_time": "0:59:56", "remaining_time": "1:02:58"}
|
| 62 |
+
{"current_steps": 620, "total_steps": 1251, "loss": 1.4065, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.534528797404646e-05, "epoch": 0.5, "percentage": 49.56, "elapsed_time": "1:00:55", "remaining_time": "1:02:00"}
|
| 63 |
+
{"current_steps": 630, "total_steps": 1251, "loss": 1.4444, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.4717488688175512e-05, "epoch": 0.5, "percentage": 50.36, "elapsed_time": "1:01:50", "remaining_time": "1:00:57"}
|
| 64 |
+
{"current_steps": 640, "total_steps": 1251, "loss": 1.4088, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.408986755735719e-05, "epoch": 0.51, "percentage": 51.16, "elapsed_time": "1:02:48", "remaining_time": "0:59:57"}
|
| 65 |
+
{"current_steps": 650, "total_steps": 1251, "loss": 1.3999, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.3462820367073057e-05, "epoch": 0.52, "percentage": 51.96, "elapsed_time": "1:03:48", "remaining_time": "0:58:59"}
|
| 66 |
+
{"current_steps": 660, "total_steps": 1251, "loss": 1.4124, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.2836742540870818e-05, "epoch": 0.53, "percentage": 52.76, "elapsed_time": "1:04:48", "remaining_time": "0:58:01"}
|
| 67 |
+
{"current_steps": 670, "total_steps": 1251, "loss": 1.3908, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.2212028891005457e-05, "epoch": 0.54, "percentage": 53.56, "elapsed_time": "1:05:46", "remaining_time": "0:57:02"}
|
| 68 |
+
{"current_steps": 680, "total_steps": 1251, "loss": 1.4017, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.1589073369465844e-05, "epoch": 0.54, "percentage": 54.36, "elapsed_time": "1:06:47", "remaining_time": "0:56:05"}
|
| 69 |
+
{"current_steps": 690, "total_steps": 1251, "loss": 1.3934, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.0968268819543848e-05, "epoch": 0.55, "percentage": 55.16, "elapsed_time": "1:07:46", "remaining_time": "0:55:05"}
|
| 70 |
+
{"current_steps": 700, "total_steps": 1251, "loss": 1.3971, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.035000672810261e-05, "epoch": 0.56, "percentage": 55.96, "elapsed_time": "1:08:46", "remaining_time": "0:54:08"}
|
| 71 |
+
{"current_steps": 710, "total_steps": 1251, "loss": 1.3923, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.9734676978700177e-05, "epoch": 0.57, "percentage": 56.75, "elapsed_time": "1:09:40", "remaining_time": "0:53:05"}
|
| 72 |
+
{"current_steps": 720, "total_steps": 1251, "loss": 1.3962, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.91226676057242e-05, "epoch": 0.58, "percentage": 57.55, "elapsed_time": "1:10:37", "remaining_time": "0:52:05"}
|
| 73 |
+
{"current_steps": 730, "total_steps": 1251, "loss": 1.37, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.8514364549692794e-05, "epoch": 0.58, "percentage": 58.35, "elapsed_time": "1:11:38", "remaining_time": "0:51:07"}
|
| 74 |
+
{"current_steps": 740, "total_steps": 1251, "loss": 1.3808, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.7910151413875717e-05, "epoch": 0.59, "percentage": 59.15, "elapsed_time": "1:12:35", "remaining_time": "0:50:07"}
|
| 75 |
+
{"current_steps": 750, "total_steps": 1251, "loss": 1.3868, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.731040922238956e-05, "epoch": 0.6, "percentage": 59.95, "elapsed_time": "1:13:36", "remaining_time": "0:49:09"}
|
| 76 |
+
{"current_steps": 760, "total_steps": 1251, "loss": 1.3889, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.6715516179919322e-05, "epoch": 0.61, "percentage": 60.75, "elapsed_time": "1:14:35", "remaining_time": "0:48:11"}
|
| 77 |
+
{"current_steps": 770, "total_steps": 1251, "loss": 1.378, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.6125847433217883e-05, "epoch": 0.62, "percentage": 61.55, "elapsed_time": "1:15:36", "remaining_time": "0:47:13"}
|
| 78 |
+
{"current_steps": 780, "total_steps": 1251, "loss": 1.3709, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.5541774834534024e-05, "epoch": 0.62, "percentage": 62.35, "elapsed_time": "1:16:35", "remaining_time": "0:46:14"}
|
| 79 |
+
{"current_steps": 790, "total_steps": 1251, "loss": 1.3563, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.4963666707117852e-05, "epoch": 0.63, "percentage": 63.15, "elapsed_time": "1:17:27", "remaining_time": "0:45:12"}
|
| 80 |
+
{"current_steps": 800, "total_steps": 1251, "loss": 1.3687, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.4391887612951685e-05, "epoch": 0.64, "percentage": 63.95, "elapsed_time": "1:18:25", "remaining_time": "0:44:12"}
|
| 81 |
+
{"current_steps": 810, "total_steps": 1251, "loss": 1.3729, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.3826798122852868e-05, "epoch": 0.65, "percentage": 64.75, "elapsed_time": "1:19:26", "remaining_time": "0:43:15"}
|
| 82 |
+
{"current_steps": 820, "total_steps": 1251, "loss": 1.3498, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.3268754589093468e-05, "epoch": 0.66, "percentage": 65.55, "elapsed_time": "1:20:25", "remaining_time": "0:42:16"}
|
| 83 |
+
{"current_steps": 830, "total_steps": 1251, "loss": 1.3399, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.2718108920680193e-05, "epoch": 0.66, "percentage": 66.35, "elapsed_time": "1:21:27", "remaining_time": "0:41:19"}
|
| 84 |
+
{"current_steps": 840, "total_steps": 1251, "loss": 1.3618, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.2175208361436328e-05, "epoch": 0.67, "percentage": 67.15, "elapsed_time": "1:22:29", "remaining_time": "0:40:21"}
|
| 85 |
+
{"current_steps": 850, "total_steps": 1251, "loss": 1.3448, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.1640395271025572e-05, "epoch": 0.68, "percentage": 67.95, "elapsed_time": "1:23:28", "remaining_time": "0:39:22"}
|
| 86 |
+
{"current_steps": 860, "total_steps": 1251, "loss": 1.3443, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.1114006909055876e-05, "epoch": 0.69, "percentage": 68.75, "elapsed_time": "1:24:26", "remaining_time": "0:38:23"}
|
| 87 |
+
{"current_steps": 870, "total_steps": 1251, "loss": 1.3523, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.059637522239949e-05, "epoch": 0.7, "percentage": 69.54, "elapsed_time": "1:25:24", "remaining_time": "0:37:24"}
|
| 88 |
+
{"current_steps": 880, "total_steps": 1251, "loss": 1.3462, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.0087826635863198e-05, "epoch": 0.7, "percentage": 70.34, "elapsed_time": "1:26:18", "remaining_time": "0:36:23"}
|
| 89 |
+
{"current_steps": 890, "total_steps": 1251, "loss": 1.3398, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 9.58868184634095e-06, "epoch": 0.71, "percentage": 71.14, "elapsed_time": "1:27:16", "remaining_time": "0:35:23"}
|
| 90 |
+
{"current_steps": 900, "total_steps": 1251, "loss": 1.3426, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 9.099255620578451e-06, "epoch": 0.72, "percentage": 71.94, "elapsed_time": "1:28:17", "remaining_time": "0:34:25"}
|
| 91 |
+
{"current_steps": 910, "total_steps": 1251, "loss": 1.3455, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 8.619856596677459e-06, "epoch": 0.73, "percentage": 72.74, "elapsed_time": "1:29:17", "remaining_time": "0:33:27"}
|
| 92 |
+
{"current_steps": 920, "total_steps": 1251, "loss": 1.3317, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 8.150787089464893e-06, "epoch": 0.74, "percentage": 73.54, "elapsed_time": "1:30:20", "remaining_time": "0:32:30"}
|
| 93 |
+
{"current_steps": 930, "total_steps": 1251, "loss": 1.3206, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 7.69234289984942e-06, "epoch": 0.74, "percentage": 74.34, "elapsed_time": "1:31:20", "remaining_time": "0:31:31"}
|
| 94 |
+
{"current_steps": 940, "total_steps": 1251, "loss": 1.3388, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 7.244813128285835e-06, "epoch": 0.75, "percentage": 75.14, "elapsed_time": "1:32:23", "remaining_time": "0:30:34"}
|
| 95 |
+
{"current_steps": 950, "total_steps": 1251, "loss": 1.349, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 6.8084799924647724e-06, "epoch": 0.76, "percentage": 75.94, "elapsed_time": "1:33:21", "remaining_time": "0:29:34"}
|
| 96 |
+
{"current_steps": 960, "total_steps": 1251, "loss": 1.3558, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 6.383618649342893e-06, "epoch": 0.77, "percentage": 76.74, "elapsed_time": "1:34:15", "remaining_time": "0:28:34"}
|
| 97 |
+
{"current_steps": 970, "total_steps": 1251, "loss": 1.3238, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 5.970497021625507e-06, "epoch": 0.78, "percentage": 77.54, "elapsed_time": "1:35:14", "remaining_time": "0:27:35"}
|
| 98 |
+
{"current_steps": 980, "total_steps": 1251, "loss": 1.3243, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 5.569375628811296e-06, "epoch": 0.78, "percentage": 78.34, "elapsed_time": "1:36:14", "remaining_time": "0:26:36"}
|
| 99 |
+
{"current_steps": 990, "total_steps": 1251, "loss": 1.3033, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 5.180507422905584e-06, "epoch": 0.79, "percentage": 79.14, "elapsed_time": "1:37:14", "remaining_time": "0:25:38"}
|
| 100 |
+
{"current_steps": 1000, "total_steps": 1251, "loss": 1.3483, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.804137628905692e-06, "epoch": 0.8, "percentage": 79.94, "elapsed_time": "1:38:13", "remaining_time": "0:24:39"}
|
| 101 |
+
{"current_steps": 1010, "total_steps": 1251, "loss": 1.3327, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.440503590159145e-06, "epoch": 0.81, "percentage": 80.74, "elapsed_time": "1:39:36", "remaining_time": "0:23:46"}
|
| 102 |
+
{"current_steps": 1020, "total_steps": 1251, "loss": 1.3165, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 4.089834618692048e-06, "epoch": 0.82, "percentage": 81.53, "elapsed_time": "1:40:38", "remaining_time": "0:22:47"}
|
| 103 |
+
{"current_steps": 1030, "total_steps": 1251, "loss": 1.3148, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.7523518506021594e-06, "epoch": 0.82, "percentage": 82.33, "elapsed_time": "1:41:37", "remaining_time": "0:21:48"}
|
| 104 |
+
{"current_steps": 1040, "total_steps": 1251, "loss": 1.3136, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.428268106607782e-06, "epoch": 0.83, "percentage": 83.13, "elapsed_time": "1:42:31", "remaining_time": "0:20:47"}
|
| 105 |
+
{"current_steps": 1050, "total_steps": 1251, "loss": 1.3285, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.1177877578404485e-06, "epoch": 0.84, "percentage": 83.93, "elapsed_time": "1:43:32", "remaining_time": "0:19:49"}
|
| 106 |
+
{"current_steps": 1060, "total_steps": 1251, "loss": 1.3074, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.8211065969660167e-06, "epoch": 0.85, "percentage": 84.73, "elapsed_time": "1:44:32", "remaining_time": "0:18:50"}
|
| 107 |
+
{"current_steps": 1070, "total_steps": 1251, "loss": 1.3004, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.5384117147154384e-06, "epoch": 0.86, "percentage": 85.53, "elapsed_time": "1:45:31", "remaining_time": "0:17:50"}
|
| 108 |
+
{"current_steps": 1080, "total_steps": 1251, "loss": 1.3128, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.26988138190308e-06, "epoch": 0.86, "percentage": 86.33, "elapsed_time": "1:46:30", "remaining_time": "0:16:51"}
|
| 109 |
+
{"current_steps": 1090, "total_steps": 1251, "loss": 1.31, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.015684937006981e-06, "epoch": 0.87, "percentage": 87.13, "elapsed_time": "1:47:31", "remaining_time": "0:15:52"}
|
| 110 |
+
{"current_steps": 1100, "total_steps": 1251, "loss": 1.3127, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.775982679381985e-06, "epoch": 0.88, "percentage": 87.93, "elapsed_time": "1:48:30", "remaining_time": "0:14:53"}
|
| 111 |
+
{"current_steps": 1110, "total_steps": 1251, "loss": 1.3108, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.5509257681730032e-06, "epoch": 0.89, "percentage": 88.73, "elapsed_time": "1:49:26", "remaining_time": "0:13:54"}
|
| 112 |
+
{"current_steps": 1120, "total_steps": 1251, "loss": 1.2913, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.340656126992243e-06, "epoch": 0.9, "percentage": 89.53, "elapsed_time": "1:50:20", "remaining_time": "0:12:54"}
|
| 113 |
+
{"current_steps": 1130, "total_steps": 1251, "loss": 1.3126, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.145306354420439e-06, "epoch": 0.9, "percentage": 90.33, "elapsed_time": "1:51:17", "remaining_time": "0:11:55"}
|
| 114 |
+
{"current_steps": 1140, "total_steps": 1251, "loss": 1.3001, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 9.649996403886086e-07, "epoch": 0.91, "percentage": 91.13, "elapsed_time": "1:52:17", "remaining_time": "0:10:56"}
|
| 115 |
+
{"current_steps": 1150, "total_steps": 1251, "loss": 1.3104, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 7.99849688492979e-07, "epoch": 0.92, "percentage": 91.93, "elapsed_time": "1:53:19", "remaining_time": "0:09:57"}
|
| 116 |
+
{"current_steps": 1160, "total_steps": 1251, "loss": 1.3257, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 6.499606442921163e-07, "epoch": 0.93, "percentage": 92.73, "elapsed_time": "1:54:20", "remaining_time": "0:08:58"}
|
| 117 |
+
{"current_steps": 1170, "total_steps": 1251, "loss": 1.296, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 5.154270296314878e-07, "epoch": 0.94, "percentage": 93.53, "elapsed_time": "1:55:20", "remaining_time": "0:07:59"}
|
| 118 |
+
{"current_steps": 1180, "total_steps": 1251, "loss": 1.3004, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.9633368303683696e-07, "epoch": 0.94, "percentage": 94.32, "elapsed_time": "1:56:18", "remaining_time": "0:06:59"}
|
| 119 |
+
{"current_steps": 1190, "total_steps": 1251, "loss": 1.2962, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.9275570621398463e-07, "epoch": 0.95, "percentage": 95.12, "elapsed_time": "1:57:16", "remaining_time": "0:06:00"}
|
| 120 |
+
{"current_steps": 1200, "total_steps": 1251, "loss": 1.311, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 2.047584166887717e-07, "epoch": 0.96, "percentage": 95.92, "elapsed_time": "1:58:11", "remaining_time": "0:05:01"}
|
| 121 |
+
{"current_steps": 1210, "total_steps": 1251, "loss": 1.3142, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 1.3239730661706307e-07, "epoch": 0.97, "percentage": 96.72, "elapsed_time": "1:59:11", "remaining_time": "0:04:02"}
|
| 122 |
+
{"current_steps": 1220, "total_steps": 1251, "loss": 1.3046, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 7.571800779069271e-08, "epoch": 0.98, "percentage": 97.52, "elapsed_time": "2:00:11", "remaining_time": "0:03:03"}
|
| 123 |
+
{"current_steps": 1230, "total_steps": 1251, "loss": 1.2985, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 3.4756262861521116e-08, "epoch": 0.98, "percentage": 98.32, "elapsed_time": "2:01:10", "remaining_time": "0:02:04"}
|
| 124 |
+
{"current_steps": 1240, "total_steps": 1251, "loss": 1.313, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 9.53790280169009e-09, "epoch": 0.99, "percentage": 99.12, "elapsed_time": "2:02:08", "remaining_time": "0:01:05"}
|
| 125 |
+
{"current_steps": 1250, "total_steps": 1251, "loss": 1.306, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": 7.883061428071159e-11, "epoch": 1.0, "percentage": 99.92, "elapsed_time": "2:03:08", "remaining_time": "0:00:05"}
|
| 126 |
+
{"current_steps": 1251, "total_steps": 1251, "loss": null, "eval_loss": null, "predict_loss": null, "reward": null, "learning_rate": null, "epoch": 1.0, "percentage": 100.0, "elapsed_time": "2:03:13", "remaining_time": "0:00:00"}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,780 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 0.9998001998001999,
|
| 5 |
+
"eval_steps": 500,
|
| 6 |
+
"global_step": 1251,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 0.01,
|
| 13 |
+
"learning_rate": 4.9992117348705316e-05,
|
| 14 |
+
"loss": 2.3263,
|
| 15 |
+
"step": 10
|
| 16 |
+
},
|
| 17 |
+
{
|
| 18 |
+
"epoch": 0.02,
|
| 19 |
+
"learning_rate": 4.9968474365716575e-05,
|
| 20 |
+
"loss": 1.9238,
|
| 21 |
+
"step": 20
|
| 22 |
+
},
|
| 23 |
+
{
|
| 24 |
+
"epoch": 0.02,
|
| 25 |
+
"learning_rate": 4.992908596058501e-05,
|
| 26 |
+
"loss": 1.8386,
|
| 27 |
+
"step": 30
|
| 28 |
+
},
|
| 29 |
+
{
|
| 30 |
+
"epoch": 0.03,
|
| 31 |
+
"learning_rate": 4.9873976972115636e-05,
|
| 32 |
+
"loss": 1.7599,
|
| 33 |
+
"step": 40
|
| 34 |
+
},
|
| 35 |
+
{
|
| 36 |
+
"epoch": 0.04,
|
| 37 |
+
"learning_rate": 4.980318215270361e-05,
|
| 38 |
+
"loss": 1.7486,
|
| 39 |
+
"step": 50
|
| 40 |
+
},
|
| 41 |
+
{
|
| 42 |
+
"epoch": 0.05,
|
| 43 |
+
"learning_rate": 4.9716746146418905e-05,
|
| 44 |
+
"loss": 1.7243,
|
| 45 |
+
"step": 60
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"epoch": 0.06,
|
| 49 |
+
"learning_rate": 4.9614723460853294e-05,
|
| 50 |
+
"loss": 1.684,
|
| 51 |
+
"step": 70
|
| 52 |
+
},
|
| 53 |
+
{
|
| 54 |
+
"epoch": 0.06,
|
| 55 |
+
"learning_rate": 4.949717843274711e-05,
|
| 56 |
+
"loss": 1.7019,
|
| 57 |
+
"step": 80
|
| 58 |
+
},
|
| 59 |
+
{
|
| 60 |
+
"epoch": 0.07,
|
| 61 |
+
"learning_rate": 4.93641851874178e-05,
|
| 62 |
+
"loss": 1.6845,
|
| 63 |
+
"step": 90
|
| 64 |
+
},
|
| 65 |
+
{
|
| 66 |
+
"epoch": 0.08,
|
| 67 |
+
"learning_rate": 4.921582759201557e-05,
|
| 68 |
+
"loss": 1.6427,
|
| 69 |
+
"step": 100
|
| 70 |
+
},
|
| 71 |
+
{
|
| 72 |
+
"epoch": 0.09,
|
| 73 |
+
"learning_rate": 4.905219920263573e-05,
|
| 74 |
+
"loss": 1.6465,
|
| 75 |
+
"step": 110
|
| 76 |
+
},
|
| 77 |
+
{
|
| 78 |
+
"epoch": 0.1,
|
| 79 |
+
"learning_rate": 4.887340320532111e-05,
|
| 80 |
+
"loss": 1.6448,
|
| 81 |
+
"step": 120
|
| 82 |
+
},
|
| 83 |
+
{
|
| 84 |
+
"epoch": 0.1,
|
| 85 |
+
"learning_rate": 4.86795523509917e-05,
|
| 86 |
+
"loss": 1.6385,
|
| 87 |
+
"step": 130
|
| 88 |
+
},
|
| 89 |
+
{
|
| 90 |
+
"epoch": 0.11,
|
| 91 |
+
"learning_rate": 4.847076888434251e-05,
|
| 92 |
+
"loss": 1.6059,
|
| 93 |
+
"step": 140
|
| 94 |
+
},
|
| 95 |
+
{
|
| 96 |
+
"epoch": 0.12,
|
| 97 |
+
"learning_rate": 4.824718446675464e-05,
|
| 98 |
+
"loss": 1.6419,
|
| 99 |
+
"step": 150
|
| 100 |
+
},
|
| 101 |
+
{
|
| 102 |
+
"epoch": 0.13,
|
| 103 |
+
"learning_rate": 4.800894009326801e-05,
|
| 104 |
+
"loss": 1.6043,
|
| 105 |
+
"step": 160
|
| 106 |
+
},
|
| 107 |
+
{
|
| 108 |
+
"epoch": 0.14,
|
| 109 |
+
"learning_rate": 4.775618600366812e-05,
|
| 110 |
+
"loss": 1.5975,
|
| 111 |
+
"step": 170
|
| 112 |
+
},
|
| 113 |
+
{
|
| 114 |
+
"epoch": 0.14,
|
| 115 |
+
"learning_rate": 4.7489081587743125e-05,
|
| 116 |
+
"loss": 1.5865,
|
| 117 |
+
"step": 180
|
| 118 |
+
},
|
| 119 |
+
{
|
| 120 |
+
"epoch": 0.15,
|
| 121 |
+
"learning_rate": 4.7207795284770605e-05,
|
| 122 |
+
"loss": 1.5931,
|
| 123 |
+
"step": 190
|
| 124 |
+
},
|
| 125 |
+
{
|
| 126 |
+
"epoch": 0.16,
|
| 127 |
+
"learning_rate": 4.69125044772978e-05,
|
| 128 |
+
"loss": 1.5763,
|
| 129 |
+
"step": 200
|
| 130 |
+
},
|
| 131 |
+
{
|
| 132 |
+
"epoch": 0.17,
|
| 133 |
+
"learning_rate": 4.6603395379281975e-05,
|
| 134 |
+
"loss": 1.5786,
|
| 135 |
+
"step": 210
|
| 136 |
+
},
|
| 137 |
+
{
|
| 138 |
+
"epoch": 0.18,
|
| 139 |
+
"learning_rate": 4.628066291866166e-05,
|
| 140 |
+
"loss": 1.5494,
|
| 141 |
+
"step": 220
|
| 142 |
+
},
|
| 143 |
+
{
|
| 144 |
+
"epoch": 0.18,
|
| 145 |
+
"learning_rate": 4.5944510614432734e-05,
|
| 146 |
+
"loss": 1.5663,
|
| 147 |
+
"step": 230
|
| 148 |
+
},
|
| 149 |
+
{
|
| 150 |
+
"epoch": 0.19,
|
| 151 |
+
"learning_rate": 4.55951504483069e-05,
|
| 152 |
+
"loss": 1.5687,
|
| 153 |
+
"step": 240
|
| 154 |
+
},
|
| 155 |
+
{
|
| 156 |
+
"epoch": 0.2,
|
| 157 |
+
"learning_rate": 4.523280273103342e-05,
|
| 158 |
+
"loss": 1.5446,
|
| 159 |
+
"step": 250
|
| 160 |
+
},
|
| 161 |
+
{
|
| 162 |
+
"epoch": 0.21,
|
| 163 |
+
"learning_rate": 4.485769596346849e-05,
|
| 164 |
+
"loss": 1.5486,
|
| 165 |
+
"step": 260
|
| 166 |
+
},
|
| 167 |
+
{
|
| 168 |
+
"epoch": 0.22,
|
| 169 |
+
"learning_rate": 4.447006669247991e-05,
|
| 170 |
+
"loss": 1.5278,
|
| 171 |
+
"step": 270
|
| 172 |
+
},
|
| 173 |
+
{
|
| 174 |
+
"epoch": 0.22,
|
| 175 |
+
"learning_rate": 4.407015936177762e-05,
|
| 176 |
+
"loss": 1.5244,
|
| 177 |
+
"step": 280
|
| 178 |
+
},
|
| 179 |
+
{
|
| 180 |
+
"epoch": 0.23,
|
| 181 |
+
"learning_rate": 4.3658226157764704e-05,
|
| 182 |
+
"loss": 1.5223,
|
| 183 |
+
"step": 290
|
| 184 |
+
},
|
| 185 |
+
{
|
| 186 |
+
"epoch": 0.24,
|
| 187 |
+
"learning_rate": 4.3234526850505456e-05,
|
| 188 |
+
"loss": 1.5536,
|
| 189 |
+
"step": 300
|
| 190 |
+
},
|
| 191 |
+
{
|
| 192 |
+
"epoch": 0.25,
|
| 193 |
+
"learning_rate": 4.2799328629911323e-05,
|
| 194 |
+
"loss": 1.5282,
|
| 195 |
+
"step": 310
|
| 196 |
+
},
|
| 197 |
+
{
|
| 198 |
+
"epoch": 0.26,
|
| 199 |
+
"learning_rate": 4.2352905937247654e-05,
|
| 200 |
+
"loss": 1.5201,
|
| 201 |
+
"step": 320
|
| 202 |
+
},
|
| 203 |
+
{
|
| 204 |
+
"epoch": 0.26,
|
| 205 |
+
"learning_rate": 4.189554029206776e-05,
|
| 206 |
+
"loss": 1.495,
|
| 207 |
+
"step": 330
|
| 208 |
+
},
|
| 209 |
+
{
|
| 210 |
+
"epoch": 0.27,
|
| 211 |
+
"learning_rate": 4.142752011468326e-05,
|
| 212 |
+
"loss": 1.5137,
|
| 213 |
+
"step": 340
|
| 214 |
+
},
|
| 215 |
+
{
|
| 216 |
+
"epoch": 0.28,
|
| 217 |
+
"learning_rate": 4.094914054428272e-05,
|
| 218 |
+
"loss": 1.4861,
|
| 219 |
+
"step": 350
|
| 220 |
+
},
|
| 221 |
+
{
|
| 222 |
+
"epoch": 0.29,
|
| 223 |
+
"learning_rate": 4.0460703252813326e-05,
|
| 224 |
+
"loss": 1.5195,
|
| 225 |
+
"step": 360
|
| 226 |
+
},
|
| 227 |
+
{
|
| 228 |
+
"epoch": 0.3,
|
| 229 |
+
"learning_rate": 3.996251625474293e-05,
|
| 230 |
+
"loss": 1.4974,
|
| 231 |
+
"step": 370
|
| 232 |
+
},
|
| 233 |
+
{
|
| 234 |
+
"epoch": 0.3,
|
| 235 |
+
"learning_rate": 3.945489371282237e-05,
|
| 236 |
+
"loss": 1.5008,
|
| 237 |
+
"step": 380
|
| 238 |
+
},
|
| 239 |
+
{
|
| 240 |
+
"epoch": 0.31,
|
| 241 |
+
"learning_rate": 3.89381557399706e-05,
|
| 242 |
+
"loss": 1.5005,
|
| 243 |
+
"step": 390
|
| 244 |
+
},
|
| 245 |
+
{
|
| 246 |
+
"epoch": 0.32,
|
| 247 |
+
"learning_rate": 3.84126281974077e-05,
|
| 248 |
+
"loss": 1.4808,
|
| 249 |
+
"step": 400
|
| 250 |
+
},
|
| 251 |
+
{
|
| 252 |
+
"epoch": 0.33,
|
| 253 |
+
"learning_rate": 3.787864248916276e-05,
|
| 254 |
+
"loss": 1.4921,
|
| 255 |
+
"step": 410
|
| 256 |
+
},
|
| 257 |
+
{
|
| 258 |
+
"epoch": 0.34,
|
| 259 |
+
"learning_rate": 3.7336535353086544e-05,
|
| 260 |
+
"loss": 1.4761,
|
| 261 |
+
"step": 420
|
| 262 |
+
},
|
| 263 |
+
{
|
| 264 |
+
"epoch": 0.34,
|
| 265 |
+
"learning_rate": 3.6786648648500495e-05,
|
| 266 |
+
"loss": 1.4805,
|
| 267 |
+
"step": 430
|
| 268 |
+
},
|
| 269 |
+
{
|
| 270 |
+
"epoch": 0.35,
|
| 271 |
+
"learning_rate": 3.622932914061611e-05,
|
| 272 |
+
"loss": 1.4614,
|
| 273 |
+
"step": 440
|
| 274 |
+
},
|
| 275 |
+
{
|
| 276 |
+
"epoch": 0.36,
|
| 277 |
+
"learning_rate": 3.566492828186063e-05,
|
| 278 |
+
"loss": 1.4709,
|
| 279 |
+
"step": 450
|
| 280 |
+
},
|
| 281 |
+
{
|
| 282 |
+
"epoch": 0.37,
|
| 283 |
+
"learning_rate": 3.509380199024684e-05,
|
| 284 |
+
"loss": 1.497,
|
| 285 |
+
"step": 460
|
| 286 |
+
},
|
| 287 |
+
{
|
| 288 |
+
"epoch": 0.38,
|
| 289 |
+
"learning_rate": 3.451631042492693e-05,
|
| 290 |
+
"loss": 1.4642,
|
| 291 |
+
"step": 470
|
| 292 |
+
},
|
| 293 |
+
{
|
| 294 |
+
"epoch": 0.38,
|
| 295 |
+
"learning_rate": 3.393281775907167e-05,
|
| 296 |
+
"loss": 1.4579,
|
| 297 |
+
"step": 480
|
| 298 |
+
},
|
| 299 |
+
{
|
| 300 |
+
"epoch": 0.39,
|
| 301 |
+
"learning_rate": 3.3343691950218514e-05,
|
| 302 |
+
"loss": 1.4586,
|
| 303 |
+
"step": 490
|
| 304 |
+
},
|
| 305 |
+
{
|
| 306 |
+
"epoch": 0.4,
|
| 307 |
+
"learning_rate": 3.2749304508233056e-05,
|
| 308 |
+
"loss": 1.4664,
|
| 309 |
+
"step": 500
|
| 310 |
+
},
|
| 311 |
+
{
|
| 312 |
+
"epoch": 0.41,
|
| 313 |
+
"learning_rate": 3.215003026103041e-05,
|
| 314 |
+
"loss": 1.4452,
|
| 315 |
+
"step": 510
|
| 316 |
+
},
|
| 317 |
+
{
|
| 318 |
+
"epoch": 0.42,
|
| 319 |
+
"learning_rate": 3.1546247118204235e-05,
|
| 320 |
+
"loss": 1.4393,
|
| 321 |
+
"step": 520
|
| 322 |
+
},
|
| 323 |
+
{
|
| 324 |
+
"epoch": 0.42,
|
| 325 |
+
"learning_rate": 3.093833583271233e-05,
|
| 326 |
+
"loss": 1.4462,
|
| 327 |
+
"step": 530
|
| 328 |
+
},
|
| 329 |
+
{
|
| 330 |
+
"epoch": 0.43,
|
| 331 |
+
"learning_rate": 3.0326679760769226e-05,
|
| 332 |
+
"loss": 1.4334,
|
| 333 |
+
"step": 540
|
| 334 |
+
},
|
| 335 |
+
{
|
| 336 |
+
"epoch": 0.44,
|
| 337 |
+
"learning_rate": 2.9711664620097107e-05,
|
| 338 |
+
"loss": 1.4495,
|
| 339 |
+
"step": 550
|
| 340 |
+
},
|
| 341 |
+
{
|
| 342 |
+
"epoch": 0.45,
|
| 343 |
+
"learning_rate": 2.9093678246687574e-05,
|
| 344 |
+
"loss": 1.4096,
|
| 345 |
+
"step": 560
|
| 346 |
+
},
|
| 347 |
+
{
|
| 348 |
+
"epoch": 0.46,
|
| 349 |
+
"learning_rate": 2.847311035022753e-05,
|
| 350 |
+
"loss": 1.4371,
|
| 351 |
+
"step": 570
|
| 352 |
+
},
|
| 353 |
+
{
|
| 354 |
+
"epoch": 0.46,
|
| 355 |
+
"learning_rate": 2.7850352268343594e-05,
|
| 356 |
+
"loss": 1.425,
|
| 357 |
+
"step": 580
|
| 358 |
+
},
|
| 359 |
+
{
|
| 360 |
+
"epoch": 0.47,
|
| 361 |
+
"learning_rate": 2.7225796719819778e-05,
|
| 362 |
+
"loss": 1.4343,
|
| 363 |
+
"step": 590
|
| 364 |
+
},
|
| 365 |
+
{
|
| 366 |
+
"epoch": 0.48,
|
| 367 |
+
"learning_rate": 2.6599837556944353e-05,
|
| 368 |
+
"loss": 1.4293,
|
| 369 |
+
"step": 600
|
| 370 |
+
},
|
| 371 |
+
{
|
| 372 |
+
"epoch": 0.49,
|
| 373 |
+
"learning_rate": 2.597286951714176e-05,
|
| 374 |
+
"loss": 1.4137,
|
| 375 |
+
"step": 610
|
| 376 |
+
},
|
| 377 |
+
{
|
| 378 |
+
"epoch": 0.5,
|
| 379 |
+
"learning_rate": 2.534528797404646e-05,
|
| 380 |
+
"loss": 1.4065,
|
| 381 |
+
"step": 620
|
| 382 |
+
},
|
| 383 |
+
{
|
| 384 |
+
"epoch": 0.5,
|
| 385 |
+
"learning_rate": 2.4717488688175512e-05,
|
| 386 |
+
"loss": 1.4444,
|
| 387 |
+
"step": 630
|
| 388 |
+
},
|
| 389 |
+
{
|
| 390 |
+
"epoch": 0.51,
|
| 391 |
+
"learning_rate": 2.408986755735719e-05,
|
| 392 |
+
"loss": 1.4088,
|
| 393 |
+
"step": 640
|
| 394 |
+
},
|
| 395 |
+
{
|
| 396 |
+
"epoch": 0.52,
|
| 397 |
+
"learning_rate": 2.3462820367073057e-05,
|
| 398 |
+
"loss": 1.3999,
|
| 399 |
+
"step": 650
|
| 400 |
+
},
|
| 401 |
+
{
|
| 402 |
+
"epoch": 0.53,
|
| 403 |
+
"learning_rate": 2.2836742540870818e-05,
|
| 404 |
+
"loss": 1.4124,
|
| 405 |
+
"step": 660
|
| 406 |
+
},
|
| 407 |
+
{
|
| 408 |
+
"epoch": 0.54,
|
| 409 |
+
"learning_rate": 2.2212028891005457e-05,
|
| 410 |
+
"loss": 1.3908,
|
| 411 |
+
"step": 670
|
| 412 |
+
},
|
| 413 |
+
{
|
| 414 |
+
"epoch": 0.54,
|
| 415 |
+
"learning_rate": 2.1589073369465844e-05,
|
| 416 |
+
"loss": 1.4017,
|
| 417 |
+
"step": 680
|
| 418 |
+
},
|
| 419 |
+
{
|
| 420 |
+
"epoch": 0.55,
|
| 421 |
+
"learning_rate": 2.0968268819543848e-05,
|
| 422 |
+
"loss": 1.3934,
|
| 423 |
+
"step": 690
|
| 424 |
+
},
|
| 425 |
+
{
|
| 426 |
+
"epoch": 0.56,
|
| 427 |
+
"learning_rate": 2.035000672810261e-05,
|
| 428 |
+
"loss": 1.3971,
|
| 429 |
+
"step": 700
|
| 430 |
+
},
|
| 431 |
+
{
|
| 432 |
+
"epoch": 0.57,
|
| 433 |
+
"learning_rate": 1.9734676978700177e-05,
|
| 434 |
+
"loss": 1.3923,
|
| 435 |
+
"step": 710
|
| 436 |
+
},
|
| 437 |
+
{
|
| 438 |
+
"epoch": 0.58,
|
| 439 |
+
"learning_rate": 1.91226676057242e-05,
|
| 440 |
+
"loss": 1.3962,
|
| 441 |
+
"step": 720
|
| 442 |
+
},
|
| 443 |
+
{
|
| 444 |
+
"epoch": 0.58,
|
| 445 |
+
"learning_rate": 1.8514364549692794e-05,
|
| 446 |
+
"loss": 1.37,
|
| 447 |
+
"step": 730
|
| 448 |
+
},
|
| 449 |
+
{
|
| 450 |
+
"epoch": 0.59,
|
| 451 |
+
"learning_rate": 1.7910151413875717e-05,
|
| 452 |
+
"loss": 1.3808,
|
| 453 |
+
"step": 740
|
| 454 |
+
},
|
| 455 |
+
{
|
| 456 |
+
"epoch": 0.6,
|
| 457 |
+
"learning_rate": 1.731040922238956e-05,
|
| 458 |
+
"loss": 1.3868,
|
| 459 |
+
"step": 750
|
| 460 |
+
},
|
| 461 |
+
{
|
| 462 |
+
"epoch": 0.61,
|
| 463 |
+
"learning_rate": 1.6715516179919322e-05,
|
| 464 |
+
"loss": 1.3889,
|
| 465 |
+
"step": 760
|
| 466 |
+
},
|
| 467 |
+
{
|
| 468 |
+
"epoch": 0.62,
|
| 469 |
+
"learning_rate": 1.6125847433217883e-05,
|
| 470 |
+
"loss": 1.378,
|
| 471 |
+
"step": 770
|
| 472 |
+
},
|
| 473 |
+
{
|
| 474 |
+
"epoch": 0.62,
|
| 475 |
+
"learning_rate": 1.5541774834534024e-05,
|
| 476 |
+
"loss": 1.3709,
|
| 477 |
+
"step": 780
|
| 478 |
+
},
|
| 479 |
+
{
|
| 480 |
+
"epoch": 0.63,
|
| 481 |
+
"learning_rate": 1.4963666707117852e-05,
|
| 482 |
+
"loss": 1.3563,
|
| 483 |
+
"step": 790
|
| 484 |
+
},
|
| 485 |
+
{
|
| 486 |
+
"epoch": 0.64,
|
| 487 |
+
"learning_rate": 1.4391887612951685e-05,
|
| 488 |
+
"loss": 1.3687,
|
| 489 |
+
"step": 800
|
| 490 |
+
},
|
| 491 |
+
{
|
| 492 |
+
"epoch": 0.65,
|
| 493 |
+
"learning_rate": 1.3826798122852868e-05,
|
| 494 |
+
"loss": 1.3729,
|
| 495 |
+
"step": 810
|
| 496 |
+
},
|
| 497 |
+
{
|
| 498 |
+
"epoch": 0.66,
|
| 499 |
+
"learning_rate": 1.3268754589093468e-05,
|
| 500 |
+
"loss": 1.3498,
|
| 501 |
+
"step": 820
|
| 502 |
+
},
|
| 503 |
+
{
|
| 504 |
+
"epoch": 0.66,
|
| 505 |
+
"learning_rate": 1.2718108920680193e-05,
|
| 506 |
+
"loss": 1.3399,
|
| 507 |
+
"step": 830
|
| 508 |
+
},
|
| 509 |
+
{
|
| 510 |
+
"epoch": 0.67,
|
| 511 |
+
"learning_rate": 1.2175208361436328e-05,
|
| 512 |
+
"loss": 1.3618,
|
| 513 |
+
"step": 840
|
| 514 |
+
},
|
| 515 |
+
{
|
| 516 |
+
"epoch": 0.68,
|
| 517 |
+
"learning_rate": 1.1640395271025572e-05,
|
| 518 |
+
"loss": 1.3448,
|
| 519 |
+
"step": 850
|
| 520 |
+
},
|
| 521 |
+
{
|
| 522 |
+
"epoch": 0.69,
|
| 523 |
+
"learning_rate": 1.1114006909055876e-05,
|
| 524 |
+
"loss": 1.3443,
|
| 525 |
+
"step": 860
|
| 526 |
+
},
|
| 527 |
+
{
|
| 528 |
+
"epoch": 0.7,
|
| 529 |
+
"learning_rate": 1.059637522239949e-05,
|
| 530 |
+
"loss": 1.3523,
|
| 531 |
+
"step": 870
|
| 532 |
+
},
|
| 533 |
+
{
|
| 534 |
+
"epoch": 0.7,
|
| 535 |
+
"learning_rate": 1.0087826635863198e-05,
|
| 536 |
+
"loss": 1.3462,
|
| 537 |
+
"step": 880
|
| 538 |
+
},
|
| 539 |
+
{
|
| 540 |
+
"epoch": 0.71,
|
| 541 |
+
"learning_rate": 9.58868184634095e-06,
|
| 542 |
+
"loss": 1.3398,
|
| 543 |
+
"step": 890
|
| 544 |
+
},
|
| 545 |
+
{
|
| 546 |
+
"epoch": 0.72,
|
| 547 |
+
"learning_rate": 9.099255620578451e-06,
|
| 548 |
+
"loss": 1.3426,
|
| 549 |
+
"step": 900
|
| 550 |
+
},
|
| 551 |
+
{
|
| 552 |
+
"epoch": 0.73,
|
| 553 |
+
"learning_rate": 8.619856596677459e-06,
|
| 554 |
+
"loss": 1.3455,
|
| 555 |
+
"step": 910
|
| 556 |
+
},
|
| 557 |
+
{
|
| 558 |
+
"epoch": 0.74,
|
| 559 |
+
"learning_rate": 8.150787089464893e-06,
|
| 560 |
+
"loss": 1.3317,
|
| 561 |
+
"step": 920
|
| 562 |
+
},
|
| 563 |
+
{
|
| 564 |
+
"epoch": 0.74,
|
| 565 |
+
"learning_rate": 7.69234289984942e-06,
|
| 566 |
+
"loss": 1.3206,
|
| 567 |
+
"step": 930
|
| 568 |
+
},
|
| 569 |
+
{
|
| 570 |
+
"epoch": 0.75,
|
| 571 |
+
"learning_rate": 7.244813128285835e-06,
|
| 572 |
+
"loss": 1.3388,
|
| 573 |
+
"step": 940
|
| 574 |
+
},
|
| 575 |
+
{
|
| 576 |
+
"epoch": 0.76,
|
| 577 |
+
"learning_rate": 6.8084799924647724e-06,
|
| 578 |
+
"loss": 1.349,
|
| 579 |
+
"step": 950
|
| 580 |
+
},
|
| 581 |
+
{
|
| 582 |
+
"epoch": 0.77,
|
| 583 |
+
"learning_rate": 6.383618649342893e-06,
|
| 584 |
+
"loss": 1.3558,
|
| 585 |
+
"step": 960
|
| 586 |
+
},
|
| 587 |
+
{
|
| 588 |
+
"epoch": 0.78,
|
| 589 |
+
"learning_rate": 5.970497021625507e-06,
|
| 590 |
+
"loss": 1.3238,
|
| 591 |
+
"step": 970
|
| 592 |
+
},
|
| 593 |
+
{
|
| 594 |
+
"epoch": 0.78,
|
| 595 |
+
"learning_rate": 5.569375628811296e-06,
|
| 596 |
+
"loss": 1.3243,
|
| 597 |
+
"step": 980
|
| 598 |
+
},
|
| 599 |
+
{
|
| 600 |
+
"epoch": 0.79,
|
| 601 |
+
"learning_rate": 5.180507422905584e-06,
|
| 602 |
+
"loss": 1.3033,
|
| 603 |
+
"step": 990
|
| 604 |
+
},
|
| 605 |
+
{
|
| 606 |
+
"epoch": 0.8,
|
| 607 |
+
"learning_rate": 4.804137628905692e-06,
|
| 608 |
+
"loss": 1.3483,
|
| 609 |
+
"step": 1000
|
| 610 |
+
},
|
| 611 |
+
{
|
| 612 |
+
"epoch": 0.81,
|
| 613 |
+
"learning_rate": 4.440503590159145e-06,
|
| 614 |
+
"loss": 1.3327,
|
| 615 |
+
"step": 1010
|
| 616 |
+
},
|
| 617 |
+
{
|
| 618 |
+
"epoch": 0.82,
|
| 619 |
+
"learning_rate": 4.089834618692048e-06,
|
| 620 |
+
"loss": 1.3165,
|
| 621 |
+
"step": 1020
|
| 622 |
+
},
|
| 623 |
+
{
|
| 624 |
+
"epoch": 0.82,
|
| 625 |
+
"learning_rate": 3.7523518506021594e-06,
|
| 626 |
+
"loss": 1.3148,
|
| 627 |
+
"step": 1030
|
| 628 |
+
},
|
| 629 |
+
{
|
| 630 |
+
"epoch": 0.83,
|
| 631 |
+
"learning_rate": 3.428268106607782e-06,
|
| 632 |
+
"loss": 1.3136,
|
| 633 |
+
"step": 1040
|
| 634 |
+
},
|
| 635 |
+
{
|
| 636 |
+
"epoch": 0.84,
|
| 637 |
+
"learning_rate": 3.1177877578404485e-06,
|
| 638 |
+
"loss": 1.3285,
|
| 639 |
+
"step": 1050
|
| 640 |
+
},
|
| 641 |
+
{
|
| 642 |
+
"epoch": 0.85,
|
| 643 |
+
"learning_rate": 2.8211065969660167e-06,
|
| 644 |
+
"loss": 1.3074,
|
| 645 |
+
"step": 1060
|
| 646 |
+
},
|
| 647 |
+
{
|
| 648 |
+
"epoch": 0.86,
|
| 649 |
+
"learning_rate": 2.5384117147154384e-06,
|
| 650 |
+
"loss": 1.3004,
|
| 651 |
+
"step": 1070
|
| 652 |
+
},
|
| 653 |
+
{
|
| 654 |
+
"epoch": 0.86,
|
| 655 |
+
"learning_rate": 2.26988138190308e-06,
|
| 656 |
+
"loss": 1.3128,
|
| 657 |
+
"step": 1080
|
| 658 |
+
},
|
| 659 |
+
{
|
| 660 |
+
"epoch": 0.87,
|
| 661 |
+
"learning_rate": 2.015684937006981e-06,
|
| 662 |
+
"loss": 1.31,
|
| 663 |
+
"step": 1090
|
| 664 |
+
},
|
| 665 |
+
{
|
| 666 |
+
"epoch": 0.88,
|
| 667 |
+
"learning_rate": 1.775982679381985e-06,
|
| 668 |
+
"loss": 1.3127,
|
| 669 |
+
"step": 1100
|
| 670 |
+
},
|
| 671 |
+
{
|
| 672 |
+
"epoch": 0.89,
|
| 673 |
+
"learning_rate": 1.5509257681730032e-06,
|
| 674 |
+
"loss": 1.3108,
|
| 675 |
+
"step": 1110
|
| 676 |
+
},
|
| 677 |
+
{
|
| 678 |
+
"epoch": 0.9,
|
| 679 |
+
"learning_rate": 1.340656126992243e-06,
|
| 680 |
+
"loss": 1.2913,
|
| 681 |
+
"step": 1120
|
| 682 |
+
},
|
| 683 |
+
{
|
| 684 |
+
"epoch": 0.9,
|
| 685 |
+
"learning_rate": 1.145306354420439e-06,
|
| 686 |
+
"loss": 1.3126,
|
| 687 |
+
"step": 1130
|
| 688 |
+
},
|
| 689 |
+
{
|
| 690 |
+
"epoch": 0.91,
|
| 691 |
+
"learning_rate": 9.649996403886086e-07,
|
| 692 |
+
"loss": 1.3001,
|
| 693 |
+
"step": 1140
|
| 694 |
+
},
|
| 695 |
+
{
|
| 696 |
+
"epoch": 0.92,
|
| 697 |
+
"learning_rate": 7.99849688492979e-07,
|
| 698 |
+
"loss": 1.3104,
|
| 699 |
+
"step": 1150
|
| 700 |
+
},
|
| 701 |
+
{
|
| 702 |
+
"epoch": 0.93,
|
| 703 |
+
"learning_rate": 6.499606442921163e-07,
|
| 704 |
+
"loss": 1.3257,
|
| 705 |
+
"step": 1160
|
| 706 |
+
},
|
| 707 |
+
{
|
| 708 |
+
"epoch": 0.94,
|
| 709 |
+
"learning_rate": 5.154270296314878e-07,
|
| 710 |
+
"loss": 1.296,
|
| 711 |
+
"step": 1170
|
| 712 |
+
},
|
| 713 |
+
{
|
| 714 |
+
"epoch": 0.94,
|
| 715 |
+
"learning_rate": 3.9633368303683696e-07,
|
| 716 |
+
"loss": 1.3004,
|
| 717 |
+
"step": 1180
|
| 718 |
+
},
|
| 719 |
+
{
|
| 720 |
+
"epoch": 0.95,
|
| 721 |
+
"learning_rate": 2.9275570621398463e-07,
|
| 722 |
+
"loss": 1.2962,
|
| 723 |
+
"step": 1190
|
| 724 |
+
},
|
| 725 |
+
{
|
| 726 |
+
"epoch": 0.96,
|
| 727 |
+
"learning_rate": 2.047584166887717e-07,
|
| 728 |
+
"loss": 1.311,
|
| 729 |
+
"step": 1200
|
| 730 |
+
},
|
| 731 |
+
{
|
| 732 |
+
"epoch": 0.97,
|
| 733 |
+
"learning_rate": 1.3239730661706307e-07,
|
| 734 |
+
"loss": 1.3142,
|
| 735 |
+
"step": 1210
|
| 736 |
+
},
|
| 737 |
+
{
|
| 738 |
+
"epoch": 0.98,
|
| 739 |
+
"learning_rate": 7.571800779069271e-08,
|
| 740 |
+
"loss": 1.3046,
|
| 741 |
+
"step": 1220
|
| 742 |
+
},
|
| 743 |
+
{
|
| 744 |
+
"epoch": 0.98,
|
| 745 |
+
"learning_rate": 3.4756262861521116e-08,
|
| 746 |
+
"loss": 1.2985,
|
| 747 |
+
"step": 1230
|
| 748 |
+
},
|
| 749 |
+
{
|
| 750 |
+
"epoch": 0.99,
|
| 751 |
+
"learning_rate": 9.53790280169009e-09,
|
| 752 |
+
"loss": 1.313,
|
| 753 |
+
"step": 1240
|
| 754 |
+
},
|
| 755 |
+
{
|
| 756 |
+
"epoch": 1.0,
|
| 757 |
+
"learning_rate": 7.883061428071159e-11,
|
| 758 |
+
"loss": 1.306,
|
| 759 |
+
"step": 1250
|
| 760 |
+
},
|
| 761 |
+
{
|
| 762 |
+
"epoch": 1.0,
|
| 763 |
+
"step": 1251,
|
| 764 |
+
"total_flos": 5.24659992301142e+17,
|
| 765 |
+
"train_loss": 1.4494417681873177,
|
| 766 |
+
"train_runtime": 7393.5069,
|
| 767 |
+
"train_samples_per_second": 10.831,
|
| 768 |
+
"train_steps_per_second": 0.169
|
| 769 |
+
}
|
| 770 |
+
],
|
| 771 |
+
"logging_steps": 10,
|
| 772 |
+
"max_steps": 1251,
|
| 773 |
+
"num_input_tokens_seen": 0,
|
| 774 |
+
"num_train_epochs": 1,
|
| 775 |
+
"save_steps": 1000,
|
| 776 |
+
"total_flos": 5.24659992301142e+17,
|
| 777 |
+
"train_batch_size": 16,
|
| 778 |
+
"trial_name": null,
|
| 779 |
+
"trial_params": null
|
| 780 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:73f87e95eda5f92d56295806124c482635e490859595ab78190b6caab61836e0
|
| 3 |
+
size 4920
|
training_loss.png
ADDED
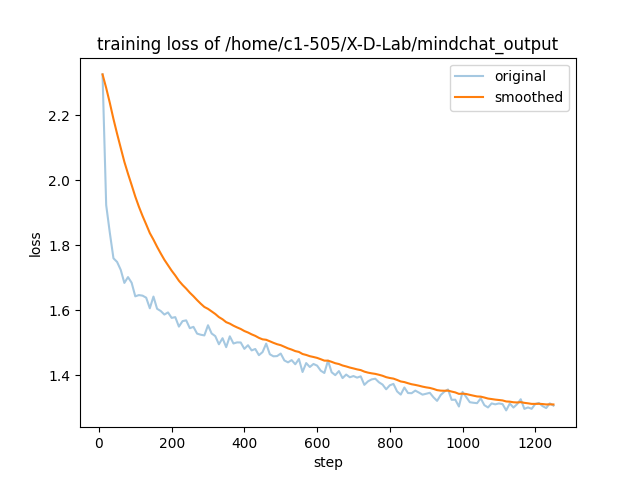
|