
zR
commited on
Commit
•
2978dc0
1
Parent(s):
3187e63
init
Browse files- README.md +39 -17
- README_zh.md +38 -17
README.md
CHANGED
|
@@ -13,20 +13,41 @@ tags:
|
|
| 13 |
|
| 14 |
inference: false
|
| 15 |
---
|
| 16 |
-
|
|
|
|
| 17 |
|
| 18 |
[中文版本README](README_zh.md)
|
| 19 |
|
| 20 |
-
|
| 21 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 22 |
the [MVBench](https://github.com/OpenGVLab/Ask-Anything), [VideoChatGPT-Bench](https://github.com/mbzuai-oryx/Video-ChatGPT)
|
| 23 |
and Zero-shot VideoQA datasets (MSVD-QA, MSRVTT-QA, ActivityNet-QA). Where VCG-* refers to the VideoChatGPTBench, ZS-*
|
| 24 |
refers to Zero-Shot VideoQA datasets and MV-* refers to main categories in the MVBench.
|
| 25 |
|
| 26 |

|
| 27 |
|
| 28 |
-
## Detailed performance
|
| 29 |
-
|
| 30 |
Performance on VideoChatGPT-Bench and Zero-shot VideoQA dataset:
|
| 31 |
|
| 32 |
| Models | VCG-AVG | VCG-CI | VCG-DO | VCG-CU | VCG-TU | VCG-CO | ZS-AVG |
|
|
@@ -41,15 +62,15 @@ Performance on VideoChatGPT-Bench and Zero-shot VideoQA dataset:
|
|
| 41 |
|
| 42 |
Performance on MVBench dataset:
|
| 43 |
|
| 44 |
-
|
|
| 45 |
-
|
| 46 |
-
| IG-VLM GPT4V | 43.7 | 72.0 | 39.0 | 40.5 |
|
| 47 |
-
| ST-LLM | 54.9 | 84.0 | 36.5 | 31.0 | 53.5 | 66.0 | 46.5 | 58.5 | 34.5
|
| 48 |
-
| ShareGPT4Video | 51.2 | 79.5 | 35.5 | 41.5 | 39.5 | 49.5 | 46.5 | 51.5 | 28.5
|
| 49 |
-
| VideoGPT+ | 58.7 | 83.0 | 39.5 | 34.0 | 60.0 |
|
| 50 |
-
| VideoChat2_HD_mistral | 62.3
|
| 51 |
-
| PLLaVA-34B | 58.1 | 82.0 | 40.5 | 49.5 | 53.0 | 67.5 | 66.5 | 59.0 |
|
| 52 |
-
| CogVLM2-Video | **62.3** | **85.5** | 41.5 | 31.5 | 65.5
|
| 53 |
|
| 54 |
## Evaluation details
|
| 55 |
|
|
@@ -77,10 +98,11 @@ our [github](https://github.com/THUDM/CogVLM2/tree/main/video_demo).
|
|
| 77 |
|
| 78 |
## License
|
| 79 |
|
| 80 |
-
This model is released under the
|
| 81 |
-
|
|
|
|
|
|
|
| 82 |
|
| 83 |
## Training details
|
| 84 |
|
| 85 |
Pleaser refer to our technical report for training formula and hyperparameters.
|
| 86 |
-
|
|
|
|
| 13 |
|
| 14 |
inference: false
|
| 15 |
---
|
| 16 |
+
|
| 17 |
+
# CogVLM2-Video-Llama3-Base
|
| 18 |
|
| 19 |
[中文版本README](README_zh.md)
|
| 20 |
|
| 21 |
+
## Introduction
|
| 22 |
+
|
| 23 |
+
CogVLM2-Video achieves state-of-the-art performance on multiple video question answering tasks. It can achieve video
|
| 24 |
+
understanding within one minute. We provide two example videos to demonstrate CogVLM2-Video's video understanding and
|
| 25 |
+
video temporal grounding capabilities.
|
| 26 |
+
|
| 27 |
+
<table>
|
| 28 |
+
<tr>
|
| 29 |
+
<td>
|
| 30 |
+
<video width="100%" controls>
|
| 31 |
+
<source src="https://github.com/THUDM/CogVLM2/raw/main/resources/videos/lion.mp4" type="video/mp4">
|
| 32 |
+
</video>
|
| 33 |
+
</td>
|
| 34 |
+
<td>
|
| 35 |
+
<video width="100%" controls>
|
| 36 |
+
<source src="https://github.com/THUDM/CogVLM2/raw/main/resources/videos/basketball.mp4" type="video/mp4">
|
| 37 |
+
</video>
|
| 38 |
+
</td>
|
| 39 |
+
</tr>
|
| 40 |
+
</table>
|
| 41 |
+
|
| 42 |
+
## BenchMark
|
| 43 |
+
|
| 44 |
+
The following diagram shows the performance of CogVLM2-Video on
|
| 45 |
the [MVBench](https://github.com/OpenGVLab/Ask-Anything), [VideoChatGPT-Bench](https://github.com/mbzuai-oryx/Video-ChatGPT)
|
| 46 |
and Zero-shot VideoQA datasets (MSVD-QA, MSRVTT-QA, ActivityNet-QA). Where VCG-* refers to the VideoChatGPTBench, ZS-*
|
| 47 |
refers to Zero-Shot VideoQA datasets and MV-* refers to main categories in the MVBench.
|
| 48 |
|
| 49 |

|
| 50 |
|
|
|
|
|
|
|
| 51 |
Performance on VideoChatGPT-Bench and Zero-shot VideoQA dataset:
|
| 52 |
|
| 53 |
| Models | VCG-AVG | VCG-CI | VCG-DO | VCG-CU | VCG-TU | VCG-CO | ZS-AVG |
|
|
|
|
| 62 |
|
| 63 |
Performance on MVBench dataset:
|
| 64 |
|
| 65 |
+
| Models | AVG | AA | AC | AL | AP | AS | CO | CI | EN | ER | FA | FP | MA | MC | MD | OE | OI | OS | ST | SC | UA |
|
| 66 |
+
|-----------------------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|
|
| 67 |
+
| IG-VLM GPT4V | 43.7 | 72.0 | 39.0 | 40.5 | 63.5 | 55.5 | 52.0 | 11.0 | 31.0 | 59.0 | 46.5 | 47.5 | 22.5 | 12.0 | 12.0 | 18.5 | 59.0 | 29.5 | 83.5 | 45.0 | 73.5 |
|
| 68 |
+
| ST-LLM | 54.9 | 84.0 | 36.5 | 31.0 | 53.5 | 66.0 | 46.5 | 58.5 | 34.5 | 41.5 | 44.0 | 44.5 | 78.5 | 56.5 | 42.5 | 80.5 | 73.5 | 38.5 | 86.5 | 43.0 | 58.5 |
|
| 69 |
+
| ShareGPT4Video | 51.2 | 79.5 | 35.5 | 41.5 | 39.5 | 49.5 | 46.5 | 51.5 | 28.5 | 39.0 | 40.0 | 25.5 | 75.0 | 62.5 | 50.5 | 82.5 | 54.5 | 32.5 | 84.5 | 51.0 | 54.5 |
|
| 70 |
+
| VideoGPT+ | 58.7 | 83.0 | 39.5 | 34.0 | 60.0 | 69.0 | 50.0 | 60.0 | 29.5 | 44.0 | 48.5 | 53.0 | 90.5 | 71.0 | 44.0 | 85.5 | 75.5 | 36.0 | 89.5 | 45.0 | 66.5 |
|
| 71 |
+
| VideoChat2_HD_mistral | **62.3** | 79.5 | **60.0** | **87.5** | 50.0 | 68.5 | **93.5** | 71.5 | 36.5 | 45.0 | 49.5 | **87.0** | 40.0 | **76.0** | **92.0** | 53.0 | 62.0 | **45.5** | 36.0 | 44.0 | 69.5 |
|
| 72 |
+
| PLLaVA-34B | 58.1 | 82.0 | 40.5 | 49.5 | 53.0 | 67.5 | 66.5 | 59.0 | **39.5** | **63.5** | 47.0 | 50.0 | 70.0 | 43.0 | 37.5 | 68.5 | 67.5 | 36.5 | 91.0 | 51.5 | **79.0** |
|
| 73 |
+
| CogVLM2-Video | **62.3** | **85.5** | 41.5 | 31.5 | **65.5** | **79.5** | 58.5 | **77.0** | 28.5 | 42.5 | **54.0** | 57.0 | **91.5** | 73.0 | 48.0 | **91.0** | **78.0** | 36.0 | **91.5** | **47.0** | 68.5 |
|
| 74 |
|
| 75 |
## Evaluation details
|
| 76 |
|
|
|
|
| 98 |
|
| 99 |
## License
|
| 100 |
|
| 101 |
+
This model is released under the
|
| 102 |
+
CogVLM2 [LICENSE](https://modelscope.cn/models/ZhipuAI/cogvlm2-video-llama3-base/file/view/master?fileName=LICENSE&status=0).
|
| 103 |
+
For models built with Meta Llama 3, please also adhere to
|
| 104 |
+
the [LLAMA3_LICENSE](https://modelscope.cn/models/ZhipuAI/cogvlm2-video-llama3-base/file/view/master?fileName=LLAMA3_LICENSE&status=0).
|
| 105 |
|
| 106 |
## Training details
|
| 107 |
|
| 108 |
Pleaser refer to our technical report for training formula and hyperparameters.
|
|
|
README_zh.md
CHANGED
|
@@ -1,15 +1,34 @@
|
|
| 1 |
-
# CogVLM2-Video
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4 |
在 [MVBench](https://github.com/OpenGVLab/Ask-Anything)、[VideoChatGPT-Bench](https://github.com/mbzuai-oryx/Video-ChatGPT)
|
| 5 |
和 Zero-shot VideoQA 数据集 (MSVD-QA、MSRVTT-QA、ActivityNet-QA) 上的性能。
|
| 6 |
|
| 7 |
-
、[VideoChatGPT-Bench](https://github.com/mbzuai-oryx/Video-ChatGPT)
|
| 26 |
和 Zero-shot VideoQA 数据集 (MSVD-QA、MSRVTT-QA、ActivityNet-QA) 上的性能。
|
| 27 |
|
| 28 |
+
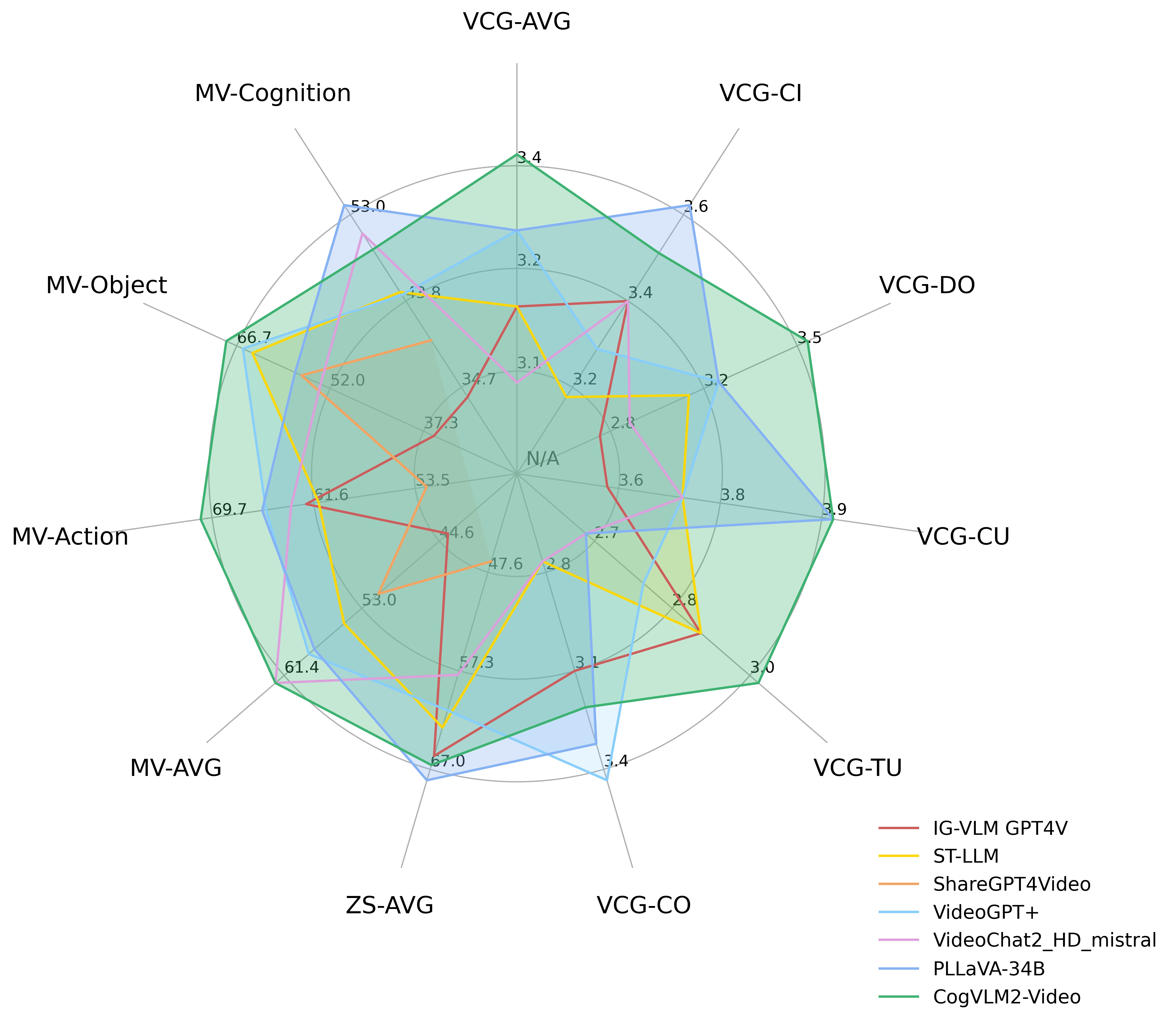
|
| 29 |
|
| 30 |
其中 VCG 指的是 VideoChatGPTBench,ZS 指的是零样本 VideoQA 数据集,MV-* 指的是 MVBench 中的主要类别。
|
| 31 |
|
|
|
|
|
|
|
| 32 |
具体榜单测试数据如下:
|
| 33 |
|
| 34 |
| Models | VCG-AVG | VCG-CI | VCG-DO | VCG-CU | VCG-TU | VCG-CO | ZS-AVG |
|
|
|
|
| 43 |
|
| 44 |
CogVLM2-Video 在 MVBench 数据集上的表现
|
| 45 |
|
| 46 |
+
| Models | AVG | AA | AC | AL | AP | AS | CO | CI | EN | ER | FA | FP | MA | MC | MD | OE | OI | OS | ST | SC | UA |
|
| 47 |
+
|-----------------------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|
|
| 48 |
+
| IG-VLM GPT4V | 43.7 | 72.0 | 39.0 | 40.5 | 63.5 | 55.5 | 52.0 | 11.0 | 31.0 | 59.0 | 46.5 | 47.5 | 22.5 | 12.0 | 12.0 | 18.5 | 59.0 | 29.5 | 83.5 | 45.0 | 73.5 |
|
| 49 |
+
| ST-LLM | 54.9 | 84.0 | 36.5 | 31.0 | 53.5 | 66.0 | 46.5 | 58.5 | 34.5 | 41.5 | 44.0 | 44.5 | 78.5 | 56.5 | 42.5 | 80.5 | 73.5 | 38.5 | 86.5 | 43.0 | 58.5 |
|
| 50 |
+
| ShareGPT4Video | 51.2 | 79.5 | 35.5 | 41.5 | 39.5 | 49.5 | 46.5 | 51.5 | 28.5 | 39.0 | 40.0 | 25.5 | 75.0 | 62.5 | 50.5 | 82.5 | 54.5 | 32.5 | 84.5 | 51.0 | 54.5 |
|
| 51 |
+
| VideoGPT+ | 58.7 | 83.0 | 39.5 | 34.0 | 60.0 | 69.0 | 50.0 | 60.0 | 29.5 | 44.0 | 48.5 | 53.0 | 90.5 | 71.0 | 44.0 | 85.5 | 75.5 | 36.0 | 89.5 | 45.0 | 66.5 |
|
| 52 |
+
| VideoChat2_HD_mistral | **62.3** | 79.5 | **60.0** | **87.5** | 50.0 | 68.5 | **93.5** | 71.5 | 36.5 | 45.0 | 49.5 | **87.0** | 40.0 | **76.0** | **92.0** | 53.0 | 62.0 | **45.5** | 36.0 | 44.0 | 69.5 |
|
| 53 |
+
| PLLaVA-34B | 58.1 | 82.0 | 40.5 | 49.5 | 53.0 | 67.5 | 66.5 | 59.0 | **39.5** | **63.5** | 47.0 | 50.0 | 70.0 | 43.0 | 37.5 | 68.5 | 67.5 | 36.5 | 91.0 | 51.5 | **79.0** |
|
| 54 |
+
| CogVLM2-Video | **62.3** | **85.5** | 41.5 | 31.5 | **65.5** | **79.5** | 58.5 | **77.0** | 28.5 | 42.5 | **54.0** | 57.0 | **91.5** | 73.0 | 48.0 | **91.0** | **78.0** | 36.0 | **91.5** | **47.0** | 68.5 |
|
| 55 |
|
| 56 |
## 评估和复现
|
| 57 |
|
|
|
|
| 76 |
|
| 77 |
## 模型协议
|
| 78 |
|
| 79 |
+
此模型根据
|
| 80 |
+
CogVLM2 [LICENSE](https://modelscope.cn/models/ZhipuAI/cogvlm2-video-llama3-base/file/view/master?fileName=LICENSE&status=0)
|
| 81 |
+
发布。对于使用 Meta Llama 3 构建的模型,还请遵守
|
| 82 |
+
[LLAMA3_LICENSE](https://modelscope.cn/models/ZhipuAI/cogvlm2-video-llama3-base/file/view/master?fileName=LLAMA3_LICENSE&status=0)。
|
| 83 |
|
| 84 |
## 引用
|
| 85 |
|