
Commit
•
4a7d23e
1
Parent(s):
f7e3c7d
Upload 18 files
Browse files- README.md +71 -8
- img/da_grad_norm.png +0 -0
- img/da_learning_rate.png +0 -0
- img/da_loss.png +0 -0
- img/sft_grad_norm.png +0 -0
- img/sft_learning_rate.png +0 -0
- img/sft_loss.png +0 -0
- model-00001-of-00006.safetensors +1 -1
- model-00002-of-00006.safetensors +1 -1
- model-00003-of-00006.safetensors +1 -1
- model-00004-of-00006.safetensors +1 -1
- model-00005-of-00006.safetensors +1 -1
- model-00006-of-00006.safetensors +1 -1
README.md
CHANGED
|
@@ -12,15 +12,15 @@ tags:
|
|
| 12 |
base_model: KoboldAI/LLaMA2-13B-Psyfighter2
|
| 13 |
model_type: llama
|
| 14 |
prompt_template: >
|
|
|
|
|
|
|
| 15 |
Below is an instruction that describes a task. Write a response that
|
| 16 |
appropriately completes the request.
|
| 17 |
|
| 18 |
-
|
| 19 |
-
### Instruction:
|
| 20 |
|
| 21 |
{prompt}
|
| 22 |
|
| 23 |
-
|
| 24 |
### Response:
|
| 25 |
---
|
| 26 |
|
|
@@ -28,7 +28,7 @@ prompt_template: >
|
|
| 28 |
|
| 29 |
This model is a version of [KoboldAI/LLaMA2-13B-Psyfighter2](https://huggingface.co/KoboldAI/LLaMA2-13B-Psyfighter2) finetuned to better understand vore context. The primary purpose of this model is to be a storywriting assistant, a conversational model in a chat, and an interactive choose-your-own-adventure text game.
|
| 30 |
|
| 31 |
-
The Adventure Mode is still work in progress
|
| 32 |
|
| 33 |
This is the FP16-precision version of the model for merging and fine-tuning. **For using the model, please see the quantized version and the instructions here: [SnakyMcSnekFace/Psyfighter2-13B-vore-GGUF](https://huggingface.co/SnakyMcSnekFace/Psyfighter2-13B-vore-GGUF)**
|
| 34 |
|
|
@@ -38,6 +38,7 @@ The model behaves similarly to `KoboldAI/LLaMA2-13B-Psyfighter2`, which it was d
|
|
| 38 |
|
| 39 |
### Updates
|
| 40 |
|
|
|
|
| 41 |
- 06/02/2024 - fixed errors in training and merging, significantly improving the overall prose quality
|
| 42 |
- 05/25/2024 - updated training process, making the model more coherent and improving the writing quality
|
| 43 |
- 04/13/2024 - uploaded the first version of the model
|
|
@@ -59,7 +60,7 @@ The quantized version of the model was prepared using [llama.cpp](https://github
|
|
| 59 |
|
| 60 |
### LoRa adapter configuration
|
| 61 |
|
| 62 |
-
- Rank:
|
| 63 |
- Alpha: 16
|
| 64 |
- Dropout rate: 0.1
|
| 65 |
- Target weights: `["q_proj", "k_proj", "o_proj", "gate_proj", "up_proj"]`,
|
|
@@ -68,7 +69,7 @@ The quantized version of the model was prepared using [llama.cpp](https://github
|
|
| 68 |
|
| 69 |
### Domain adaptation
|
| 70 |
|
| 71 |
-
The initial training phase consists of fine-tuning the adapter on ~55 MiB of free-form text that containing stories focused around the vore theme. The text is broken into paragraphs, which are aggregated into training samples of 4096 tokens or less, without crossing the document boundary. Each sample starts with BOS token (with its `
|
| 72 |
|
| 73 |
#### Dataset pre-processing
|
| 74 |
|
|
@@ -86,14 +87,76 @@ The raw-text stories in dataset were edited as follows:
|
|
| 86 |
- Number of epochs: 2
|
| 87 |
- Learning rate: 1e-4
|
| 88 |
- Warmup: 64 steps
|
| 89 |
-
- LR Schedule:
|
| 90 |
- Batch size: 1
|
| 91 |
- Gradient accumulation steps: 1
|
| 92 |
|
| 93 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 94 |
### Adventure mode SFT
|
| 95 |
|
| 96 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 97 |
|
| 98 |
### Adventure mode KTO
|
| 99 |
|
|
|
|
| 12 |
base_model: KoboldAI/LLaMA2-13B-Psyfighter2
|
| 13 |
model_type: llama
|
| 14 |
prompt_template: >
|
| 15 |
+
### Instruction:
|
| 16 |
+
|
| 17 |
Below is an instruction that describes a task. Write a response that
|
| 18 |
appropriately completes the request.
|
| 19 |
|
| 20 |
+
### Input:
|
|
|
|
| 21 |
|
| 22 |
{prompt}
|
| 23 |
|
|
|
|
| 24 |
### Response:
|
| 25 |
---
|
| 26 |
|
|
|
|
| 28 |
|
| 29 |
This model is a version of [KoboldAI/LLaMA2-13B-Psyfighter2](https://huggingface.co/KoboldAI/LLaMA2-13B-Psyfighter2) finetuned to better understand vore context. The primary purpose of this model is to be a storywriting assistant, a conversational model in a chat, and an interactive choose-your-own-adventure text game.
|
| 30 |
|
| 31 |
+
The preliminary support for Adventure Mode has been added, but it is still work in progress.
|
| 32 |
|
| 33 |
This is the FP16-precision version of the model for merging and fine-tuning. **For using the model, please see the quantized version and the instructions here: [SnakyMcSnekFace/Psyfighter2-13B-vore-GGUF](https://huggingface.co/SnakyMcSnekFace/Psyfighter2-13B-vore-GGUF)**
|
| 34 |
|
|
|
|
| 38 |
|
| 39 |
### Updates
|
| 40 |
|
| 41 |
+
- 09/02/2024 - fine-tuned the model to follow Kobold AI Adventure Mode format
|
| 42 |
- 06/02/2024 - fixed errors in training and merging, significantly improving the overall prose quality
|
| 43 |
- 05/25/2024 - updated training process, making the model more coherent and improving the writing quality
|
| 44 |
- 04/13/2024 - uploaded the first version of the model
|
|
|
|
| 60 |
|
| 61 |
### LoRa adapter configuration
|
| 62 |
|
| 63 |
+
- Rank: 64
|
| 64 |
- Alpha: 16
|
| 65 |
- Dropout rate: 0.1
|
| 66 |
- Target weights: `["q_proj", "k_proj", "o_proj", "gate_proj", "up_proj"]`,
|
|
|
|
| 69 |
|
| 70 |
### Domain adaptation
|
| 71 |
|
| 72 |
+
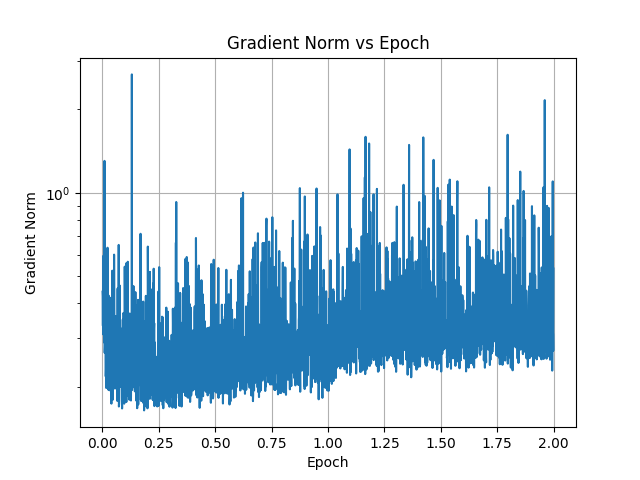
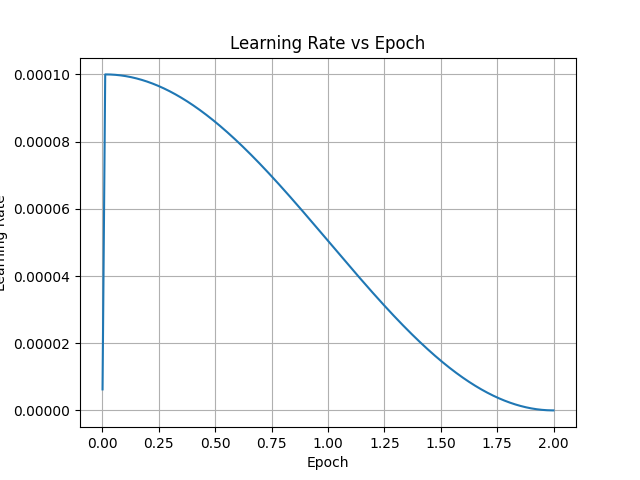
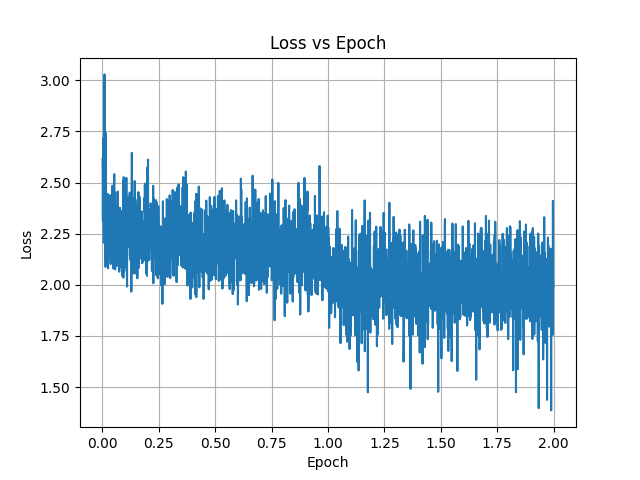
The initial training phase consists of fine-tuning the adapter on ~55 MiB of free-form text that containing stories focused around the vore theme. The text is broken into paragraphs, which are aggregated into training samples of 4096 tokens or less, without crossing the document boundary. Each sample starts with BOS token (with its `label` set to `-100`), and ends in EOS token. The paragraph breaks are normalized to always consist of two line breaks.
|
| 73 |
|
| 74 |
#### Dataset pre-processing
|
| 75 |
|
|
|
|
| 87 |
- Number of epochs: 2
|
| 88 |
- Learning rate: 1e-4
|
| 89 |
- Warmup: 64 steps
|
| 90 |
+
- LR Schedule: cosine
|
| 91 |
- Batch size: 1
|
| 92 |
- Gradient accumulation steps: 1
|
| 93 |
|
| 94 |
|
| 95 |
+
#### Plots
|
| 96 |
+
|
| 97 |
+

|
| 98 |
+

|
| 99 |
+

|
| 100 |
+
|
| 101 |
+
|
| 102 |
### Adventure mode SFT
|
| 103 |
|
| 104 |
+
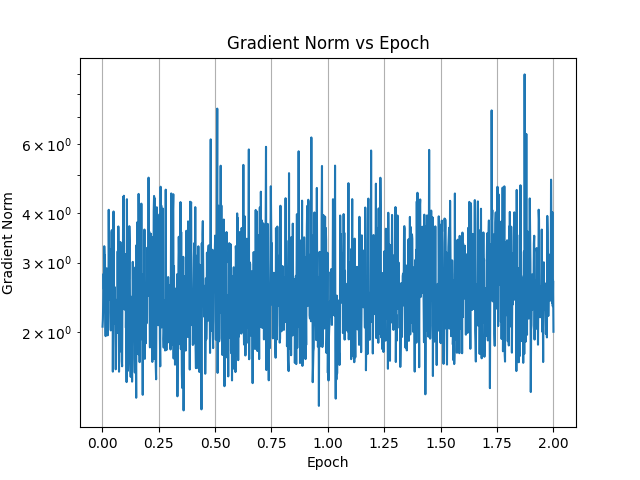
The model is further trained on a private dataset of the adventure transcripts in Kobold AI adventure format, i.e:
|
| 105 |
+
|
| 106 |
+
```
|
| 107 |
+
As you venture deeper into the damp cave, you come across a lone goblin. The vile creature mumbles something to itself as it stares at the glowing text on a cave wall. It doesn't notice your approach.
|
| 108 |
+
|
| 109 |
+
> You sneak behind the goblin and hit it with the sword.
|
| 110 |
+
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
The dataset is generated by running adventure playthoughts with the model, and editing its output as necessary to create a cohesive evocative narrative. There are total of 657 player turns in the dataset.
|
| 114 |
+
|
| 115 |
+
The model is trained on completions only; the loss for the user input tokens is ignored by setting their `label` to `-100`. The prompt is truncated on the left with the maximum length of 2048 tokens.
|
| 116 |
+
|
| 117 |
+
#### Training parameters
|
| 118 |
+
|
| 119 |
+
- Max. sequence length: 4096 tokens
|
| 120 |
+
- Samples per epoch: 657
|
| 121 |
+
- Number of epochs: 2
|
| 122 |
+
- Learning rate: 1e-5
|
| 123 |
+
- Warmup: 32 steps
|
| 124 |
+
- LR Schedule: cosine
|
| 125 |
+
- Batch size: 1
|
| 126 |
+
- Gradient accumulation steps: 1
|
| 127 |
+
|
| 128 |
+
The training takes ~150 minutes on NVIDIA GeForce RTX 4060 Ti.
|
| 129 |
+
|
| 130 |
+
#### Results
|
| 131 |
+
|
| 132 |
+
The fine-tuned model is able to understand the Kobold AI Adventure Format. It no longer attempts to generate the player's inputs starting with ">", and instead emits the EOS token, allowing the player to take turn.
|
| 133 |
+
|
| 134 |
+
Without the context, the model tends to produce very short responses, 1-2 paragraphs at most. The non-player characters are passive and the model does not advance the narrative. This behavior is easily corrected by setting up the context in the instruct format:
|
| 135 |
+
|
| 136 |
+
```
|
| 137 |
+
### Instruction:
|
| 138 |
+
|
| 139 |
+
Text transcript of a never-ending adventure story, written by the AI assistant. AI assistant uses vivid and evocative language to create a well-written novel. Characters are proactive and take initiative. Think about what goals the characters of the story have and write what they do to achieve those goals.
|
| 140 |
+
|
| 141 |
+
### Input:
|
| 142 |
+
|
| 143 |
+
<< transcript of the adventure + player's next turn >>
|
| 144 |
+
|
| 145 |
+
Write a few paragraphs that advance the plot of the story.
|
| 146 |
+
|
| 147 |
+
### Response:
|
| 148 |
+
|
| 149 |
+
```
|
| 150 |
+
|
| 151 |
+
(See instructions in [SnakyMcSnekFace/Psyfighter2-13B-vore-GGUF](https://huggingface.co/SnakyMcSnekFace/Psyfighter2-13B-vore-GGUF) for formatting the context in `koboldcpp`.)
|
| 152 |
+
|
| 153 |
+
Setting or removing the instructions allows the model to generate accepted/rejected synthetic data samples for KTO. This data can then be used to further steer the model towards better storytelling in the Adventure Mode without the need for the specially-crafted context.
|
| 154 |
+
|
| 155 |
+
#### Plots
|
| 156 |
+
|
| 157 |
+

|
| 158 |
+

|
| 159 |
+

|
| 160 |
|
| 161 |
### Adventure mode KTO
|
| 162 |
|
img/da_grad_norm.png
ADDED
|
img/da_learning_rate.png
ADDED
|
img/da_loss.png
ADDED
|
img/sft_grad_norm.png
ADDED
|
img/sft_learning_rate.png
ADDED
|
img/sft_loss.png
ADDED
|
model-00001-of-00006.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4978265728
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:899684315684bc1e86b9493697244d53984f7b6a4d5fb59f2548e6e2c6bdb4bc
|
| 3 |
size 4978265728
|
model-00002-of-00006.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4970422160
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7ed32a3422d944542c174f4e6309f4d73476d50f7156090dcbfbee0c9b2508ca
|
| 3 |
size 4970422160
|
model-00003-of-00006.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4970422184
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4f226876c9cf080978ea5741e79b14efc51e6e78ec1083defc6aa33355b12b88
|
| 3 |
size 4970422184
|
model-00004-of-00006.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4933701432
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d618f98e38c59e56b0e0e547c315ecb14cefbde7aa5ef5592ba9c5baf7cc772e
|
| 3 |
size 4933701432
|
model-00005-of-00006.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4933722144
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:411c4db646c7108407a2452586852e0e3a3696acb0db1e16eeda3b826ae7f71a
|
| 3 |
size 4933722144
|
model-00006-of-00006.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 1245236904
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e0a650c32055713abaab4b59813d9a8d5503d11fc74023a526c4c15f180a7260
|
| 3 |
size 1245236904
|